
第 6 章 调度 NUMA 感知工作负载
了解 NUMA 感知调度以及如何使用它来在 OpenShift Container Platform 集群中部署高性能工作负载。
NUMA 感知调度是 OpenShift Container Platform 版本 4.12.0 到 4.12.23 中的技术预览功能。它在 OpenShift Container Platform 版本 4.12.24 及更高版本中是正式发布版本(GA)。技术预览功能不受红帽产品服务等级协议(SLA)支持,且功能可能并不完整。红帽不推荐在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
有关红帽技术预览功能支持范围的更多信息,请参阅技术预览功能支持范围。
NUMA Resources Operator 允许您在相同的 NUMA 区域中调度高性能工作负载。它部署一个节点资源导出代理,该代理在可用的集群节点 NUMA 资源以及管理工作负载的辅助调度程序上报告。
6.1. 关于 NUMA 感知调度
非统一内存访问 (NUMA) 是一个计算平台架构,允许不同的 CPU 以不同速度访问不同区域。NUMA 资源拓扑引用与计算节点上相互相对的 CPU、内存和 PCI 设备的位置。在一起的资源表示在同一 NUMA 区域中。对于高性能应用程序,集群需要处理单个 NUMA 区域中的 pod 工作负载。
NUMA 架构允许有多个内存控制器的 CPU 在 CPU 复杂间使用任何可用内存,无论内存所处的位置。这可以以牺牲性能为代价来增加灵活性。使用位于 NUMA 区域以外的内存的 CPU 处理工作负载的速度比单个 NUMA 区域处理的工作负载要慢。另外,对于对 I/O 有限制的工作负载,在远程的 NUMA 区域中的网络接口会减慢访问应用程序的速度。高性能工作负载(如电信工作负载)无法在这些条件下达到操作要求。NUMA 感知调度会调整同一 NUMA 区域中请求的集群计算资源(CPU、内存、设备),以有效地处理对延迟敏感的工作负责或高性能工作负载。NUMA 感知调度还提高了每个计算节点的 pod 密度,以提高资源效率。
默认的 OpenShift Container Platform pod 调度程序调度逻辑考虑整个计算节点的可用资源,而不是单个 NUMA 区域。如果在 kubelet 拓扑管理器中请求最严格的资源协调,则会在将 pod 传递给节点时出现错误条件。相反,如果没有请求限制性最严格的资源协调,则 pod 可以在没有正确的资源协调的情况下被节点接受,从而导致性能更差或无法达到预期。例如,当 pod 调度程序通过不知道 pod 请求的资源可用而导致做出非最佳的调度决定时,pod 创建可能会出现 Topology Affinity Error 状态。调度不匹配决策可能会导致 pod 启动延迟。另外,根据集群状态和资源分配,pod 调度决策可能会因为启动失败而对集群造成额外的负载。
NUMA Resources Operator 部署了一个自定义 NUMA 资源辅助调度程序和其他资源,以缓解默认 OpenShift Container Platform pod 调度程序的缩写。下图显示了 NUMA 感知 pod 调度的高级概述。
图 6.1. NUMA 感知调度概述
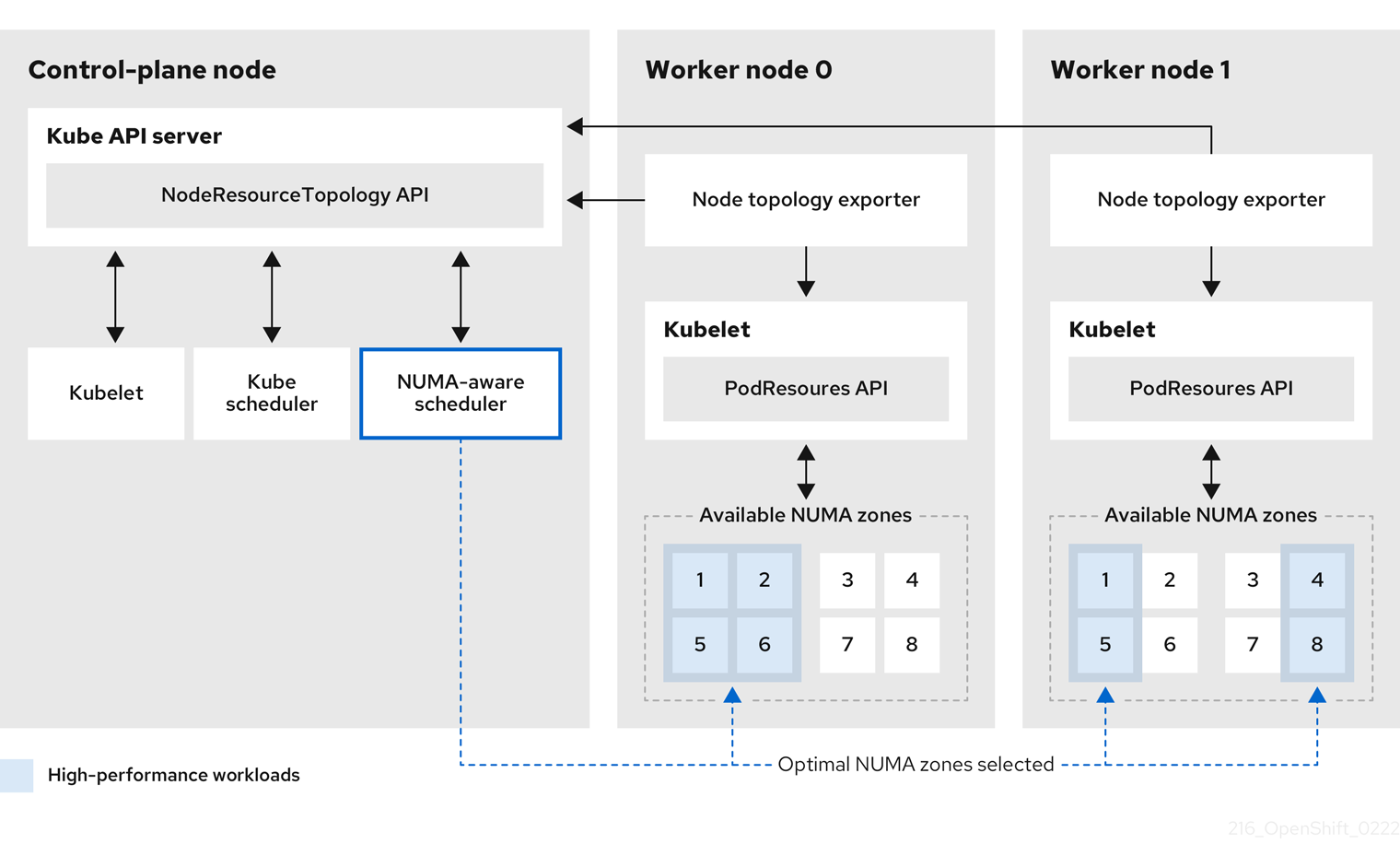
- NodeResourceTopology API
-
NodeResourceTopologyAPI 描述了每个计算节点上可用的 NUMA 区资源。 - NUMA 感知调度程序
-
NUMA 感知辅助调度程序从
NodeResourceTopologyAPI 接收有关可用 NUMA 区域的信息,并在可以最佳处理的节点上调度高性能工作负载。 - 节点拓扑 exporter
-
节点拓扑 exporter 会公开每个计算节点的可用 NUMA 区资源到
NodeResourceTopologyAPI。节点拓扑 exporter 守护进程使用PodResourcesAPI 跟踪来自 kubelet 的资源分配。 - PodResources API
-
对于每个节点,
PodResourcesAPI 是本地的,并向 kubelet 公开资源拓扑和可用资源。
其他资源
- 有关在集群中运行二级 pod 调度程序以及如何使用二级 pod 调度程序部署 pod 的更多信息,请参阅使用二级调度程序调度 pod。