
Red Hat Training
A Red Hat training course is available for OpenShift Container Platform
集群管理
OpenShift Container Platform 3.11 集群管理
摘要
第 1 章 概述
这些群集管理主题涵盖管理 OpenShift Container Platform 集群的日常任务和其他高级配置主题。
第 2 章 管理节点
2.1. 概述
在执行节点管理操作时,CLI 与代表实际节点主机的节点对象进行交互。master 使用来自节点对象的信息通过健康检查来验证节点。
2.2. 列出节点
列出 master 已知的所有节点:
$ oc get nodes
输出示例
NAME STATUS ROLES AGE VERSION master.example.com Ready master 7h v1.9.1+a0ce1bc657 node1.example.com Ready compute 7h v1.9.1+a0ce1bc657 node2.example.com Ready compute 7h v1.9.1+a0ce1bc657
使用节点信息,列出包含项目 pod 部署信息的所有节点:
$ oc get nodes -o wide
输出示例
NAME STATUS ROLES AGE VERSION EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME ip-172-18-0-39.ec2.internal Ready infra 1d v1.10.0+b81c8f8 54.172.185.130 Red Hat Enterprise Linux Server 7.5 (Maipo) 3.10.0-862.el7.x86_64 docker://1.13.1 ip-172-18-10-95.ec2.internal Ready master 1d v1.10.0+b81c8f8 54.88.22.81 Red Hat Enterprise Linux Server 7.5 (Maipo) 3.10.0-862.el7.x86_64 docker://1.13.1 ip-172-18-8-35.ec2.internal Ready compute 1d v1.10.0+b81c8f8 34.230.50.57 Red Hat Enterprise Linux Server 7.5 (Maipo) 3.10.0-862.el7.x86_64 docker://1.13.1
要只列出单个节点的信息,使用完整节点名称替换 <node>:
$ oc get node <node>
这些命令输出中的 STATUS 列可显示节点的以下状况:
表 2.1. 节点状况
| 状况 | 描述 |
|---|---|
|
|
节点通过返回 |
|
| 节点没有从 master 传递执行的健康检查。 |
|
| 无法调度放置到节点上的 pod。 |
如果 CLI 无法找到任何节点状况,则节点的 STATUS 可能还会显示 Unknown。
要获取有关特定节点的详细信息,包括造成当前状况的原因:
$ oc describe node <node>
例如:
$ oc describe node node1.example.com
输出示例
Name: node1.example.com 1 Roles: compute 2 Labels: beta.kubernetes.io/arch=amd64 3 beta.kubernetes.io/os=linux kubernetes.io/hostname=m01.example.com node-role.kubernetes.io/compute=true node-role.kubernetes.io/infra=true node-role.kubernetes.io/master=true zone=default Annotations: volumes.kubernetes.io/controller-managed-attach-detach=true 4 CreationTimestamp: Thu, 24 May 2018 11:46:56 -0400 Taints: <none> 5 Unschedulable: false Conditions: 6 Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- OutOfDisk False Tue, 17 Jul 2018 11:47:30 -0400 Tue, 10 Jul 2018 15:45:16 -0400 KubeletHasSufficientDisk kubelet has sufficient disk space available MemoryPressure False Tue, 17 Jul 2018 11:47:30 -0400 Tue, 10 Jul 2018 15:45:16 -0400 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Tue, 17 Jul 2018 11:47:30 -0400 Tue, 10 Jul 2018 16:03:54 -0400 KubeletHasNoDiskPressure kubelet has no disk pressure Ready True Tue, 17 Jul 2018 11:47:30 -0400 Mon, 16 Jul 2018 15:10:25 -0400 KubeletReady kubelet is posting ready status PIDPressure False Tue, 17 Jul 2018 11:47:30 -0400 Thu, 05 Jul 2018 10:06:51 -0400 KubeletHasSufficientPID kubelet has sufficient PID available Addresses: 7 InternalIP: 192.168.122.248 Hostname: node1.example.com Capacity: 8 cpu: 2 hugepages-2Mi: 0 memory: 8010336Ki pods: 40 Allocatable: cpu: 2 hugepages-2Mi: 0 memory: 7907936Ki pods: 40 System Info: 9 Machine ID: b3adb9acbc49fc1f9a7d6 System UUID: B3ADB9A-B0CB-C49FC1F9A7D6 Boot ID: 9359d15aec9-81a20aef5876 Kernel Version: 3.10.0-693.21.1.el7.x86_64 OS Image: OpenShift Enterprise Operating System: linux Architecture: amd64 Container Runtime Version: docker://1.13.1 Kubelet Version: v1.10.0+b81c8f8 Kube-Proxy Version: v1.10.0+b81c8f8 ExternalID: node1.example.com Non-terminated Pods: (14 in total) 10 Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits --------- ---- ------------ ---------- --------------- ------------- default docker-registry-2-w252l 100m (5%) 0 (0%) 256Mi (3%) 0 (0%) default registry-console-2-dpnc9 0 (0%) 0 (0%) 0 (0%) 0 (0%) default router-2-5snb2 100m (5%) 0 (0%) 256Mi (3%) 0 (0%) kube-service-catalog apiserver-jh6gt 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-service-catalog controller-manager-z4t5j 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-system master-api-m01.example.com 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-system master-controllers-m01.example.com 0 (0%) 0 (0%) 0 (0%) 0 (0%) kube-system master-etcd-m01.example.com 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-ansible-service-broker asb-1-hnn5t 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-node sync-dvhvs 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-sdn ovs-zjs5k 100m (5%) 200m (10%) 300Mi (3%) 400Mi (5%) openshift-sdn sdn-zr4cb 100m (5%) 0 (0%) 200Mi (2%) 0 (0%) openshift-template-service-broker apiserver-s9n7t 0 (0%) 0 (0%) 0 (0%) 0 (0%) openshift-web-console webconsole-785689b664-q7s9j 100m (5%) 0 (0%) 100Mi (1%) 0 (0%) Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) CPU Requests CPU Limits Memory Requests Memory Limits ------------ ---------- --------------- ------------- 500m (25%) 200m (10%) 1112Mi (14%) 400Mi (5%) Events: 11 Type Reason Age From Message ---- ------ ---- ---- ------- Normal NodeHasSufficientPID 6d (x5 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 6d kubelet, m01.example.com Updated Node Allocatable limit across pods Normal NodeHasSufficientMemory 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasNoDiskPressure Normal NodeHasSufficientDisk 6d (x6 over 6d) kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientDisk Normal NodeHasSufficientPID 6d kubelet, m01.example.com Node m01.example.com status is now: NodeHasSufficientPID Normal Starting 6d kubelet, m01.example.com Starting kubelet. ...
2.3. 查看节点
您可以显示节点的用量统计,这些统计信息为容器提供了运行时环境。这些用量统计包括 CPU、内存和存储的消耗。
查看用量统计:
$ oc adm top nodes
输出示例
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% node-1 297m 29% 4263Mi 55% node-0 55m 5% 1201Mi 15% infra-1 85m 8% 1319Mi 17% infra-0 182m 18% 2524Mi 32% master-0 178m 8% 2584Mi 16%
查看具有标签的节点的用量统计信息:
$ oc adm top node --selector=''
您必须选择过滤所基于的选择器(标签查询)。支持 =、== 和 !=。
您必须有 cluster-reader 权限才能查看用量统计。
必须安装 metrics-server 才能查看用量统计。请参阅使用 Horizontal Pod Autoscalers 的要求。
2.4. 添加主机
您可以通过运行 scaleup.yml playbook 添加新主机到集群。此 playbook 查询 master,为新主机生成和发布新证书,然后仅在新主机上运行配置 playbook。在运行 scaleup.yml playbook 之前,请完成所有必备的主机准备步骤。
scaleup.yml playbook 仅配置新主机。它不会更新 master 服务的 NO_PROXY,也不会重启 master 服务。
您必须有一个现有的清单文件,如 /etc/ansible/hosts,它代表当前集群配置,才能运行 scaleup.yml playbook。如果您之前使用 atomic-openshift-installer 命令来运行安装,您可以检查 ~/.config/openshift/hosts 查找安装程序生成的最后一个清单文件,并将该文件用作清单文件。您可以根据需要修改此文件。然后,在运行 ansible-playbook 时,您必须使用 -i 指定文件位置。
有关推荐的最大节点数,请参阅集群最大值部分。
流程
通过更新 openshift-ansible 软件包来确保您有最新的 playbook:
# yum update openshift-ansible
编辑 /etc/ansible/hosts 文件,并将 new_<host_type> 添加到 [OSEv3:children] 部分。例如,要添加新节点主机,请添加 new_nodes :
[OSEv3:children] masters nodes new_nodes
若要添加新的 master 主机,可添加 new_masters。
创建一个 [new_<host_type>] 部分来为新主机指定主机信息。将此部分格式化为现有部分,如下例所示:
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] node3.example.com openshift_node_group_name='node-config-infra'
如需了解更多选项,请参阅配置主机变量。
在添加新 master 时,将主机添加到 [new_masters] 部分和 [new_nodes] 部分,以确保新 master 主机是 OpenShift SDN 的一部分:
[masters] master[1:2].example.com [new_masters] master3.example.com [nodes] master[1:2].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] master3.example.com
重要如果您使用
node-role.kubernetes.io/infra=true标签标记 master 主机,且没有其他专用基础架构节点,还必须通过向条目中添加openshift_schedulable=true明确将该主机标记为可以调度。否则,registry 和路由器 Pod 将无法放置到任何节点。更改到 playbook 目录,再运行 openshift_node_group.yml playbook。如果您的清单文件位于 /etc/ansible/hosts 默认以外的位置,请使用
-i选项指定位置:$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/openshift_node_group.yml
这会为新节点组创建 ConfigMap,并最终为主机上的节点配置文件。
注意运行 openshift_node_group.yaml playbook 只会更新新节点。无法运行它来更新集群中的现有节点。
运行 scaleup.yml playbook。如果您的清单文件位于默认 /etc/ansible/hosts 以外的位置,请使用
-i选项指定位置。对于额外的节点:
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-node/scaleup.yml对于额外的 master:
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/scaleup.yml
如果您在集群中部署了 EFK 堆栈,请将节点标签设置为
logging-infra-fluentd=true:# oc label node/new-node.example.com logging-infra-fluentd=true
- 在 playbook 运行后,验证安装。
将您在 [new_<host_type>] 部分定义的任何主机移动到它们的相应部分。通过移动这些主机,后续的 playbook 运行使用此清单文件正确处理节点。您可以保留空 [new_<host_type>] 部分。例如,添加新节点时:
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' node3.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes]
2.5. 删除节点
当您使用 CLI 删除节点时,节点对象会从 Kubernetes 中删除,但节点本身上存在的 pod 不会被删除。任何未由复制控制器支持的裸机 pod 都无法被 OpenShift Container Platform 访问,由复制控制器支持的 pod 将被重新调度到其他可用的节点,并且需要手动删除本地清单 pod。
从 OpenShift Container Platform 集群中删除节点:
2.6. 更新节点上的标签
在节点上添加或更新标签 :
$ oc label node <node> <key_1>=<value_1> ... <key_n>=<value_n>
查看更详细的用法:
$ oc label -h
2.7. 列出节点上的 pod
列出一个或多个节点上的所有或选定 pod:
$ oc adm manage-node <node1> <node2> \
--list-pods [--pod-selector=<pod_selector>] [-o json|yaml]列出选定节点上的所有或选定 pod:
$ oc adm manage-node --selector=<node_selector> \
--list-pods [--pod-selector=<pod_selector>] [-o json|yaml]2.8. 将节点标记为不可调度或可以调度
默认情况下,具有 Ready 状态的健康节点被标记为可以调度,即允许在该节点上放置新的 pod。如果手动将节点标记为不可调度,则会阻止在该节点上调度任何新的 pod。节点上的现有 pod 不受影响。
将一个或多个节点标记为不可调度:
$ oc adm manage-node <node1> <node2> --schedulable=false
例如:
$ oc adm manage-node node1.example.com --schedulable=false
输出示例
NAME LABELS STATUS node1.example.com kubernetes.io/hostname=node1.example.com Ready,SchedulingDisabled
将当前不可调度的一个或多个节点标记为可以调度:
$ oc adm manage-node <node1> <node2> --schedulable
另外,您也可以使用 --selector=<node_selector> 选项将选定的节点标记为可以调度或不可调度,而不指定具体的节点名称(如 <node1> <node2>)。
2.9. 撤离节点上的 pod
通过撤离 pod,您可以迁移给定节点中的所有或选定 pod。节点必须首先标记为不可调度(unschedulable),才能执行 pod 撤离。
只有由复制控制器支持的 pod 可以撤离;复制控制器在其他节点上创建新 pod,并从指定节点移除现有的 pod。裸机 pod(即不由复制控制器支持的 pod)默认情况下不受影响。您可以通过指定 pod 选择器来撤离一小部分 pod。pod 选择器基于标签,因此具有指定标签的所有 pod 将被撤离。
撤离节点上的所有或选定 pod:
$ oc adm drain <node> [--pod-selector=<pod_selector>]
您可以使用 --force 选项强制删除裸机 pod。设为 true 时,即使存在不由复制控制器、ReplicaSet、作业、daemonset 或 StatefulSet 管理的 pod,也会继续执行删除:
$ oc adm drain <node> --force=true
您可以使用 --grace-period 设置一个期限(以秒为单位),以便每个 pod 能够安全终止。如果为负,则使用 pod 中指定的默认值:
$ oc adm drain <node> --grace-period=-1
您可以使用 --ignore-daemonset 并将其设置为 true 以忽略 daemonset-managed pod:
$ oc adm drain <node> --ignore-daemonsets=true
您可以使用 --timeout 来设置放弃前要等待的时长。值为 0 时设定无限时长:
$ oc adm drain <node> --timeout=5s
您可以使用 --delete-local-data 并将其设置为 true 以继续删除,即使存在使用 emptyDir 的 pod(在节点排空时会删除本地数据):
$ oc adm drain <node> --delete-local-data=true
要列出将要迁移的对象而不实际执行撤离,请使用 --dry-run 选项并将其设置为 true :
$ oc adm drain <node> --dry-run=true
您可以使用 --selector=<node_selector> 选项将 pod 撤离与选择器匹配的节点上,而不是指定具体的节点名称。
2.10. 重新引导节点
要重新引导节点而不导致平台上运行的应用的中断,务必要先 撤离 pod。对于由路由层提供高可用性的 pod,不需要执行其他操作。对于需要存储的其他 pod(通常是数据库),务必要确保它们能够在一个 pod 临时下线时仍然保持运作。尽管为有状态 pod 实现可持续运行的方法会视不同应用程序而异,但在所有情形中,都要将调度程序配置为使用节点反关联性,从而确保 pod 在可用节点之间合理分布。
另一个挑战是如何处理运行关键基础架构的节点,比如路由器或 registry。相同的节点撤离过程同样适用于这类节点,但必须要了解某些边缘情况。
2.10.1. 基础架构节点
基础架构节点是标记为运行 OpenShift Container Platform 环境组成部分的节点。目前,管理节点重新引导的最简单方法是确保至少有三个节点可用于运行基础架构。以下情景演示了一个常见的错误,只有两个节点可用时,它可能会导致 OpenShift Container Platform 上运行的应用程序发生服务中断。
- 节点 A 标记为不可调度,所有 pod 都被撤离。
- 该节点上运行的 registry pod 现在重新部署到节点 B 上。也就是说,节点 B 现在同时运行两个 registry pod。
- 节点 B 现在标记为不可调度,并且被撤离。
- 在节点 B 上公开两个 pod 端点的服务在短时间内失去所有端点,直到它们被重新部署到节点 A。
使用三个基础架构节点的同一流程不会导致服务中断。但由于 pod 调度的原因,最后一个节点在撤离并返回到轮转后,会保留为运行零个 registry。其他两个节点将分别运行两个 registry 和一个 registry。最好的解决方法是借助 pod 反关联性。Kubernetes 中有一个 alpha 功能,现在可用于测试,但尚不支持用于生产环境工作负载。
2.10.2. 使用 pod 反关联性
Pod 反关联性 与 节点反关联性 稍有不同。如果没有其他适当的位置来部署 pod,则可以违反节点反关联性。Pod 反关联性可以设置为必要的或偏好的。
apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
affinity:
podAntiAffinity: 1
preferredDuringSchedulingIgnoredDuringExecution: 2
- weight: 100 3
podAffinityTerm:
labelSelector:
matchExpressions:
- key: docker-registry 4
operator: In 5
values:
- default
topologyKey: kubernetes.io/hostname
本例假定容器镜像 registry pod 具有标签 docker-registry=default。Pod 反关联性可以使用任何 Kubernetes 匹配表达式。
最后一步是在 /etc/origin/master/scheduler.json 中启用 MatchInterPodAffinity 调度程序 predicate。进行了这样的设置后,如果只有两个基础架构节点可用,并且一个节点发生重新引导,容器镜像 registry pod 会被禁止在另一节点上运行。oc get pods 会报告 pod 未就绪,直到有合适的节点可用为止。一旦某个节点可用,并且所有 pod 恢复到就绪状态,下一个节点就可以重启。
2.10.3. 处理运行路由器的节点
在大多数情况下,运行 OpenShift Container Platform 路由器的 pod 将公开主机端口。PodFitsPorts 调度程序 predicate 确保没有使用相同端口的其他路由器 pod 在同一节点上运行,并且达成 pod 反关联性。如果路由器依赖于 IP 故障转移来实现高可用性,则不需要任何其他操作。如果路由器 pod 依赖 AWS Elastic Load Balancing 等外部服务来实现高可用性,则由该服务负责响应路由器 pod 重启。
在个别情况下,路由器 pod 可能没有配置主机端口。在这些情况下,务必要遵循推荐的基础架构节点的重启流程。
2.11. 修改节点
在安装过程中,OpenShift Container Platform 为每类节点组在 openshift-node 项目中创建一个 configmap:
- node-config-master
- node-config-infra
- node-config-compute
- node-config-all-in-one
- node-config-master-infra
若要对现有节点进行配置更改,请编辑相应的配置映射。各个节点上的 同步 pod 监视配置映射的变化。在安装过程中,使用 sync Daemonsets 和一个 /etc/origin/node/node-config.yaml 文件(节点的配置参数所在的文件)创建的同步 pod 被添加到每个节点。当同步 pod 检测到配置映射更改时,它会在该节点组的所有节点上更新 node-config.yaml,并在适当的节点上重启 atomic-openshift-node.service。
$ oc get cm -n openshift-node
输出示例
NAME DATA AGE node-config-all-in-one 1 1d node-config-compute 1 1d node-config-infra 1 1d node-config-master 1 1d node-config-master-infra 1 1d
node-config-compute 组的配置映射示例
apiVersion: v1 authConfig: 1 authenticationCacheSize: 1000 authenticationCacheTTL: 5m authorizationCacheSize: 1000 authorizationCacheTTL: 5m dnsBindAddress: 127.0.0.1:53 dnsDomain: cluster.local dnsIP: 0.0.0.0 2 dnsNameservers: null dnsRecursiveResolvConf: /etc/origin/node/resolv.conf dockerConfig: dockerShimRootDirectory: /var/lib/dockershim dockerShimSocket: /var/run/dockershim.sock execHandlerName: native enableUnidling: true imageConfig: format: registry.reg-aws.openshift.com/openshift3/ose-${component}:${version} latest: false iptablesSyncPeriod: 30s kind: NodeConfig kubeletArguments: 3 bootstrap-kubeconfig: - /etc/origin/node/bootstrap.kubeconfig cert-dir: - /etc/origin/node/certificates cloud-config: - /etc/origin/cloudprovider/aws.conf cloud-provider: - aws enable-controller-attach-detach: - 'true' feature-gates: - RotateKubeletClientCertificate=true,RotateKubeletServerCertificate=true node-labels: - node-role.kubernetes.io/compute=true pod-manifest-path: - /etc/origin/node/pods 4 rotate-certificates: - 'true' masterClientConnectionOverrides: acceptContentTypes: application/vnd.kubernetes.protobuf,application/json burst: 40 contentType: application/vnd.kubernetes.protobuf qps: 20 masterKubeConfig: node.kubeconfig networkConfig: 5 mtu: 8951 networkPluginName: redhat/openshift-ovs-subnet 6 servingInfo: 7 bindAddress: 0.0.0.0:10250 bindNetwork: tcp4 clientCA: client-ca.crt 8 volumeConfig: localQuota: perFSGroup: null volumeDirectory: /var/lib/origin/openshift.local.volumes
- 1
- 身份验证和授权配置选项.
- 2
- 附加到 pod 的 /etc/resolv.conf 的 IP 地址。
- 3
- 直接传递给与 Kubelet 命令行参数匹配的 Kubelet 的键值对。
- 4
- pod 清单文件或目录的路径。目录必须包含一个或多个清单文件。OpenShift 容器平台使用清单文件在节点上创建 pod。
- 5
- 节点上的 pod 网络设置。
- 6
- 软件定义型网络(SDN)插件.为 ovs-subnet 插件设置为
redhat/openshift-ovs-subnet,为 ovs-multitenant 插件设置为redhat/openshift-ovs-multitenant,为 ovs-networkpolicy 插件设置为redhat/openshift-ovs-networkpolicy。 - 7
- 节点的证书信息。
- 8
- 可选:PEM 编码的证书捆绑包。如果设置,则必须根据指定文件中的证书颁发机构显示并验证有效的客户端证书,然后才能检查请求标头中的用户名。
不要手动修改 /etc/origin/node/node-config.yaml 文件。
2.11.1. 配置节点资源
您可以通过在节点配置映射中添加 kubelet 参数来配置节点资源。
编辑配置映射:
$ oc edit cm node-config-compute -n openshift-node
添加
kubeletArguments部分并指定您的选项:kubeletArguments: max-pods: 1 - "40" resolv-conf: 2 - "/etc/resolv.conf" image-gc-high-threshold: 3 - "90" image-gc-low-threshold: 4 - "80" kube-api-qps: 5 - "20" kube-api-burst: 6 - "40"
查看所有可用 kubelet 选项:
$ hyperkube kubelet -h
2.11.2. 每个节点设置最大 pod
如需了解每个 OpenShift Container Platform 版本的最大支持限制,请参阅集群最大限制。
在 /etc/origin/node/node-config.yaml 文件中,一个参数控制可调度到节点的 pod 的最大数量: max-pods。当使用 max-pods 选项时,它会限制节点上的 pod 数量。超过这个值可能会导致:
- OpenShift Container Platform 和 Docker 的 CPU 使用率增加。
- 减慢 pod 调度的速度。
- 潜在的内存不足情况(取决于节点中的内存量)。
- 耗尽 IP 地址池。
- 资源过量使用,导致用户应用程序性能变差。
在 Kubernetes 中,包含单个容器的 pod 实际使用两个容器。第二个容器用来在实际容器启动前设置联网。因此,运行 10 个 pod 的系统实际上会运行 20 个容器。
max-pods 把节点可以运行的 pod 数量设置为一个固定值,而不需要考虑节点的属性。集群限制 记录 max-pods 的最大支持值。
kubeletArguments:
max-pods:
- "250"
使用上例,max-pods 的默认值为 250。
2.12. 重置 Docker 存储
当您下载容器镜像并运行和删除容器时,Docker 并不总是释放映射的磁盘空间。因此,随着时间推移,节点上可能会耗尽空间,这可能会阻止 OpenShift Container Platform 创建新 pod,或者导致 pod 创建需要几分钟。
例如,下面显示了 6 分钟后仍然处于 ContainerCreating 状态的容器集,事件日志会显示一个 FailedSync 事件。
$ oc get pod
输出示例
NAME READY STATUS RESTARTS AGE cakephp-mysql-persistent-1-build 0/1 ContainerCreating 0 6m mysql-1-9767d 0/1 ContainerCreating 0 2m mysql-1-deploy 0/1 ContainerCreating 0 6m
$ oc get events
输出示例
LASTSEEN FIRSTSEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE 6m 6m 1 cakephp-mysql-persistent-1-build Pod Normal Scheduled default-scheduler Successfully assigned cakephp-mysql-persistent-1-build to ip-172-31-71-195.us-east-2.compute.internal 2m 5m 4 cakephp-mysql-persistent-1-build Pod Warning FailedSync kubelet, ip-172-31-71-195.us-east-2.compute.internal Error syncing pod 2m 4m 4 cakephp-mysql-persistent-1-build Pod Normal SandboxChanged kubelet, ip-172-31-71-195.us-east-2.compute.internal Pod sandbox changed, it will be killed and re-created.
解决这个问题的一种方法是重置 Docker 存储,以移除 Docker 不需要的构件。
在您要重启 Docker 存储的节点中:
运行以下命令将节点标记为不可调度:
$ oc adm manage-node <node> --schedulable=false
运行以下命令关闭 Docker 和 atomic-openshift-node 服务:
$ systemctl stop docker atomic-openshift-node
运行以下命令删除本地卷目录:
$ rm -rf /var/lib/origin/openshift.local.volumes
此命令会清除本地镜像缓存。因此,镜像(包括
ose-*镜像)需要重新拉取。这会导致镜像存储恢复时 pod 启动时间较慢。删除 /var/lib/docker 目录:
$ rm -rf /var/lib/docker
运行以下命令来重置 Docker 存储:
$ docker-storage-setup --reset
运行以下命令重新创建 Docker 存储:
$ docker-storage-setup
重新创建 /var/lib/docker 目录:
$ mkdir /var/lib/docker
运行以下命令来重启 Docker 和 atomic-openshift-node 服务:
$ systemctl start docker atomic-openshift-node
通过重启主机来重启节点服务:
# systemctl restart atomic-openshift-node.service
运行以下命令将节点标记为可以调度:
$ oc adm manage-node <node> --schedulable=true
第 3 章 恢复 OpenShift Container Platform 组件
3.1. 概述
在 OpenShift Container Platform 中,您可以通过从单独的存储重新创建集群元素(包括节点和应用程序)来恢复集群及其组件。
要恢复集群,您必须首先 备份它。
以下过程描述了恢复应用程序和 OpenShift Container Platform 集群的通用方法。它不能考虑自定义要求。您可能需要采取额外的操作来恢复集群。
3.2. 恢复集群
要恢复集群,首先重新安装 OpenShift Container Platform。
流程
- 按照您原先安装 OpenShift Container Platform 的相同方式重新安装 OpenShift Container Platform。
- 运行所有自定义安装后步骤,例如更改 OpenShift Container Platform 控制之外的服务或安装额外的服务,如监控代理。
3.3. 恢复 master 主机备份
在创建了重要 master 主机文件的备份后,如果它们被破坏或意外删除,您可以通过将文件复制到 master,确保文件包含正确的内容并重新启动受影响的服务来恢复文件。
流程
恢复
/etc/origin/master/master-config.yaml文件:# MYBACKUPDIR=*/backup/$(hostname)/$(date +%Y%m%d)* # cp /etc/origin/master/master-config.yaml /etc/origin/master/master-config.yaml.old # cp /backup/$(hostname)/$(date +%Y%m%d)/origin/master/master-config.yaml /etc/origin/master/master-config.yaml # master-restart api # master-restart controllers
警告重新启动主控服务可能会导致停机。但是,您可以从高可用性负载均衡器池中移除 master 主机,然后执行恢复操作。正确恢复该服务后,您可以将 master 主机重新添加到负载均衡器池中。
注意对受影响的实例执行完全重启,以恢复
iptables配置。如果因为缺少软件包而无法重启 OpenShift Container Platform,请重新安装软件包。
获取当前安装的软件包列表:
$ rpm -qa | sort > /tmp/current_packages.txt
查看软件包列表之间的区别:
$ diff /tmp/current_packages.txt ${MYBACKUPDIR}/packages.txt > ansible-2.4.0.0-5.el7.noarch重新安装缺少的软件包:
# yum reinstall -y <packages> 1- 1
- 将
<packages>替换为软件包列表之间不同的软件包。
通过将证书复制到
/etc/pki/ca-trust/source/anchors/目录并执行update-ca-trust来恢复系统证书:$ MYBACKUPDIR=*/backup/$(hostname)/$(date +%Y%m%d)* $ sudo cp ${MYBACKUPDIR}/etc/pki/ca-trust/source/anchors/<certificate> /etc/pki/ca-trust/source/anchors/ 1 $ sudo update-ca-trust- 1
- 将
<certificate>替换为要恢复的系统证书的文件名。
注意始终确保返回文件时恢复用户 ID 和组 ID,以及
SELinux上下文。
3.4. 恢复节点主机备份
创建重要节点主机文件的备份后,如果它们被破坏或意外删除,您可以通过复制 文件来恢复文件,确保该文件包含正确的内容并重新启动受影响的服务。
流程
恢复
/etc/origin/node/node-config.yaml文件:# MYBACKUPDIR=/backup/$(hostname)/$(date +%Y%m%d) # cp /etc/origin/node/node-config.yaml /etc/origin/node/node-config.yaml.old # cp /backup/$(hostname)/$(date +%Y%m%d)/etc/origin/node/node-config.yaml /etc/origin/node/node-config.yaml # reboot
重新启动服务可能会导致停机。如需有关如何简化流程的提示,请参阅节点维护。
对受影响的实例执行完全重启,以恢复 iptables 配置。
如果因为缺少软件包而无法重启 OpenShift Container Platform,请重新安装软件包。
获取当前安装的软件包列表:
$ rpm -qa | sort > /tmp/current_packages.txt
查看软件包列表之间的区别:
$ diff /tmp/current_packages.txt ${MYBACKUPDIR}/packages.txt > ansible-2.4.0.0-5.el7.noarch重新安装缺少的软件包:
# yum reinstall -y <packages> 1- 1
- 将
<packages>替换为软件包列表之间不同的软件包。
通过将证书复制到
/etc/pki/ca-trust/source/anchors/目录并执行update-ca-trust来恢复系统证书:$ MYBACKUPDIR=*/backup/$(hostname)/$(date +%Y%m%d)* $ sudo cp ${MYBACKUPDIR}/etc/pki/ca-trust/source/anchors/<certificate> /etc/pki/ca-trust/source/anchors/ $ sudo update-ca-trust- 将
<certificate>替换为要恢复的系统证书的文件名。
注意始终确保在文件返回时恢复正确的用户 ID 和组 ID,以及
SELinux上下文。
3.5. 恢复 etcd
3.5.1. 恢复 etcd 配置文件
如果 etcd 主机已损坏,并且 /etc/etcd/etcd.conf 文件丢失,请按照以下步骤恢复该文件:
访问 etcd 主机:
$ ssh master-0 1- 1
- 将
master-0替换为 etcd 主机的名称。
将备份
etcd.conf文件复制到/etc/etcd/中:# cp /backup/etcd-config-<timestamp>/etcd/etcd.conf /etc/etcd/etcd.conf
在文件中设置所需的权限和 selinux 上下文:
# restorecon -RvF /etc/etcd/etcd.conf
在本例中,备份文件存储在 /backup/etcd-config-<timestamp>/etcd/etcd.conf 路径中,其中可用作外部 NFS 共享、S3 存储桶或其他存储解决方案。
恢复 etcd 配置文件后,您必须重启静态 pod。这是在恢复 etcd 数据后完成的。
3.5.2. 恢复 etcd 数据
在静态 pod 中恢复 etcd 前:
etcdctl二进制文件必须可用,或者在容器化安装中,rhel7/etcd容器必须可用。您可以运行以下命令,使用 etcd 软件包安装
etcdctl二进制文件:# yum install etcd
该软件包还会安装 systemd 服务。禁用并屏蔽该服务,使其在 etcd 在静态 pod 中运行时不会作为 systemd 服务运行。通过禁用并屏蔽该服务,确保您不会意外启动该服务,并防止它在重启系统时自动重启该服务。
# systemctl disable etcd.service
# systemctl mask etcd.service
在静态 pod 上恢复 etcd:
如果 pod 正在运行,通过将 pod 清单 YAML 文件移到另一个目录中来停止 etcd pod:
# mkdir -p /etc/origin/node/pods-stopped
# mv /etc/origin/node/pods/etcd.yaml /etc/origin/node/pods-stopped
移动所有旧数据:
# mv /var/lib/etcd /var/lib/etcd.old
您可以使用 etcdctl 在恢复 pod 的节点中重新创建数据。
将 etcd 快照恢复到 etcd pod 的挂载路径:
# export ETCDCTL_API=3
# etcdctl snapshot restore /etc/etcd/backup/etcd/snapshot.db \ --data-dir /var/lib/etcd/ \ --name ip-172-18-3-48.ec2.internal \ --initial-cluster "ip-172-18-3-48.ec2.internal=https://172.18.3.48:2380" \ --initial-cluster-token "etcd-cluster-1" \ --initial-advertise-peer-urls https://172.18.3.48:2380 \ --skip-hash-check=true
从 etcd.conf 文件获取集群的适当值。
在数据目录中设置所需的权限和 selinux 上下文:
# restorecon -RvF /var/lib/etcd/
通过将 pod 清单 YAML 文件移到所需目录中来重启 etcd pod:
# mv /etc/origin/node/pods-stopped/etcd.yaml /etc/origin/node/pods/
3.6. 添加 etcd 节点
恢复 etcd 后,您可以在集群中添加更多 etcd 节点。您可以使用 Ansible playbook 或手动步骤添加 etcd 主机。
3.6.1. 使用 Ansible 添加新 etcd 主机
流程
在 Ansible 清单文件中,创建一个名为
[new_etcd]的新组,再添加新主机。然后,将new_etcd组添加为[OSEv3]组的子组:[OSEv3:children] masters nodes etcd new_etcd 1 ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com [new_etcd] 2 etcd0.example.com 3
注意将旧的
etcd 主机条目替换为清单文件中的新etcd主机条目。在替换旧的etcd 主机时,必须创建一个/etc/etcd/ca/目录的副本。另外,您可以在扩展etcd 主机前重新部署 etcd ca 和 certs。在安装 OpenShift Container Platform 并托管 Ansible 清单文件的主机中,切换到 playbook 目录并运行 etcd
scaleupplaybook:$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-etcd/scaleup.yml
在 playbook 运行后,通过将新 etcd 主机从
[new_etcd]组移到[etcd]组来修改清单文件,使其反映当前的状态:[OSEv3:children] masters nodes etcd new_etcd ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com etcd0.example.com
如果使用 Flannel,修改位于
/etc/sysconfig/flanneld主机上的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
3.6.2. 手动添加新 etcd 主机
如果您没有以静态 pod 用户身份在 master 节点上运行 etcd,您可能需要添加另一个 etcd 主机。
流程
修改当前的 etcd 集群
要创建 etcd 证书,请运行 openssl 命令,将值替换为您环境中的值。
创建一些环境变量:
export NEW_ETCD_HOSTNAME="*etcd0.example.com*" export NEW_ETCD_IP="192.168.55.21" export CN=$NEW_ETCD_HOSTNAME export SAN="IP:${NEW_ETCD_IP}, DNS:${NEW_ETCD_HOSTNAME}" export PREFIX="/etc/etcd/generated_certs/etcd-$CN/" export OPENSSLCFG="/etc/etcd/ca/openssl.cnf"注意用作
etcd_v3_ca_*的自定义openssl扩展包括 $SAN 环境变量作为subjectAltName。如需更多信息,请参阅/etc/etcd/ca/openssl.cnf。创建用于存储配置和证书的目录:
# mkdir -p ${PREFIX}创建服务器证书请求并为其签名:(server.csr 和 server.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}server.key \ -out ${PREFIX}server.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}server.crt \ -in ${PREFIX}server.csr \ -extensions etcd_v3_ca_server -batch创建对等证书请求并将其签名:(peer.csr 和 peer.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}peer.key \ -out ${PREFIX}peer.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}peer.crt \ -in ${PREFIX}peer.csr \ -extensions etcd_v3_ca_peer -batch从当前节点复制当前的 etcd 配置和
ca.crt文件,作为稍后修改的示例:# cp /etc/etcd/etcd.conf ${PREFIX} # cp /etc/etcd/ca.crt ${PREFIX}当仍处于存活的 etcd 主机上时,将新主机添加到集群中。要在集群中添加额外的 etcd 成员,您必须首先调整第一个成员的
peerURLs值中的默认 localhost peer:使用
member list命令获取第一个成员的成员 ID:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ 1 member list- 1
- 请确定在
--peers参数值中只指定活跃的 etcd 成员的 URL。
获取 etcd 侦听集群对等点的 IP 地址:
$ ss -l4n | grep 2380
通过传递从上一步中获取的成员 ID 和 IP 地址,使用
etcdctl member update命令更新peerURLs的值:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ member update 511b7fb6cc0001 https://172.18.1.18:2380-
重新运行
member list命令,并确保对等 URL 不再包含 localhost。
将新主机添加到 etcd 集群。请注意,新主机尚未配置,因此在您配置新主机之前,状态将保持为
未启动。警告您必须添加每个成员,并一次性使他们在线。将每个额外成员添加到集群时,您必须调整当前对等点的
peerURLs列表。peerURLs列表会针对每个添加的成员增长一个。etcdctl member add命令输出在 etcd.conf 文件中设置的值,以添加每个成员,如下说明所述。# etcdctl -C https://${CURRENT_ETCD_HOST}:2379 \ --ca-file=/etc/etcd/ca.crt \ --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key member add ${NEW_ETCD_HOSTNAME} https://${NEW_ETCD_IP}:2380 1 Added member named 10.3.9.222 with ID 4e1db163a21d7651 to cluster ETCD_NAME="<NEW_ETCD_HOSTNAME>" ETCD_INITIAL_CLUSTER="<NEW_ETCD_HOSTNAME>=https://<NEW_HOST_IP>:2380,<CLUSTERMEMBER1_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER2_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER3_NAME>=https:/<CLUSTERMEMBER3_IP>:2380" ETCD_INITIAL_CLUSTER_STATE="existing"- 1
- 在这一行中,
10.3.9.222是 etcd 成员的标签。您可以指定主机名、IP 地址或简单名称。
更新示例
${PREFIX}/etcd.conf文件。将以下值替换为上一步中生成的值:
- ETCD_NAME
- ETCD_INITIAL_CLUSTER
- ETCD_INITIAL_CLUSTER_STATE
使用上一步中输出中的新主机 IP 修改以下变量:您可以使用
${NEW_ETCD_IP}作为值。ETCD_LISTEN_PEER_URLS ETCD_LISTEN_CLIENT_URLS ETCD_INITIAL_ADVERTISE_PEER_URLS ETCD_ADVERTISE_CLIENT_URLS
- 如果您之前使用 member 系统作为 etcd 节点,您必须覆盖 /etc/etcd/etcd.conf 文件中的当前值。
检查文件中的语法错误或缺少 IP 地址,否则 etcd 服务可能会失败:
# vi ${PREFIX}/etcd.conf
-
在托管安装文件的节点上,更新 /etc/ansible/hosts 清单文件中的
[etcd]主机组。删除旧的 etcd 主机并添加新主机。 创建一个包含证书、示例配置文件和
ca的tgz文件,并将其复制到新主机上:# tar -czvf /etc/etcd/generated_certs/${CN}.tgz -C ${PREFIX} . # scp /etc/etcd/generated_certs/${CN}.tgz ${CN}:/tmp/
修改新的 etcd 主机
安装
iptables-services以提供 iptables 工具为 etcd 打开所需的端口:# yum install -y iptables-services
创建
OS_FIREWALL_ALLOW防火墙规则以允许 etcd 进行通信:- 客户端的端口 2379/tcp
端口 2380/tcp 用于对等通信
# systemctl enable iptables.service --now # iptables -N OS_FIREWALL_ALLOW # iptables -t filter -I INPUT -j OS_FIREWALL_ALLOW # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2379 -j ACCEPT # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2380 -j ACCEPT # iptables-save | tee /etc/sysconfig/iptables
注意在本例中,创建了一个新的链
OS_FIREWALL_ALLOW,这是 OpenShift Container Platform 安装程序用于防火墙规则的标准命名。警告如果环境托管在 IaaS 环境中,请修改实例的安全组,以允许传入到这些端口的流量。
安装 etcd:
# yum install -y etcd
确保安装了
etcd-2.3.7-4.el7.x86_64或更高的版本,通过删除 etcd pod 定义来确保 etcd 服务没有运行:
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/
删除所有 etcd 配置和数据:
# rm -Rf /etc/etcd/* # rm -Rf /var/lib/etcd/*
提取证书和配置文件:
# tar xzvf /tmp/etcd0.example.com.tgz -C /etc/etcd/
在新主机上启动 etcd:
# systemctl enable etcd --now
验证主机是否是集群的一部分以及当前的集群健康状况:
如果使用 v2 etcd api,请运行以下命令:
# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ cluster-health member 5ee217d19001 is healthy: got healthy result from https://192.168.55.12:2379 member 2a529ba1840722c0 is healthy: got healthy result from https://192.168.55.8:2379 member 8b8904727bf526a5 is healthy: got healthy result from https://192.168.55.21:2379 member ed4f0efd277d7599 is healthy: got healthy result from https://192.168.55.13:2379 cluster is healthy如果使用 v3 etcd api,请运行以下命令:
# ETCDCTL_API=3 etcdctl --cert="/etc/etcd/peer.crt" \ --key=/etc/etcd/peer.key \ --cacert="/etc/etcd/ca.crt" \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ endpoint health https://master-0.example.com:2379 is healthy: successfully committed proposal: took = 5.011358ms https://master-1.example.com:2379 is healthy: successfully committed proposal: took = 1.305173ms https://master-2.example.com:2379 is healthy: successfully committed proposal: took = 1.388772ms https://etcd0.example.com:2379 is healthy: successfully committed proposal: took = 1.498829ms
修改每个 OpenShift Container Platform master
修改每个 master 上
/etc/origin/master/master-config.yaml文件的etcClientInfo部分中的 master 配置。将新的 etcd 主机添加到 OpenShift Container Platform 用来存储数据的 etcd 服务器列表中,并删除所有失败的 etcd 主机:etcdClientInfo: ca: master.etcd-ca.crt certFile: master.etcd-client.crt keyFile: master.etcd-client.key urls: - https://master-0.example.com:2379 - https://master-1.example.com:2379 - https://master-2.example.com:2379 - https://etcd0.example.com:2379重启 master API 服务:
在每个 master 上:
# master-restart api # master-restart controllers
警告etcd 节点的数量必须是奇数,因此您必须至少添加两个主机。
如果使用 Flannel,修改每个 OpenShift Container Platform 主机的
/etc/sysconfig/flanneld服务的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
3.7. 使 OpenShift Container Platform 服务恢复在线
完成更改后,重新在线 OpenShift Container Platform。
流程
在每个 OpenShift Container Platform master 上,从备份中恢复 master 和节点配置,并启用并重启所有相关服务:
# cp ${MYBACKUPDIR}/etc/origin/node/pods/* /etc/origin/node/pods/ # cp ${MYBACKUPDIR}/etc/origin/master/master.env /etc/origin/master/master.env # cp ${MYBACKUPDIR}/etc/origin/master/master-config.yaml.<timestamp> /etc/origin/master/master-config.yaml # cp ${MYBACKUPDIR}/etc/origin/node/node-config.yaml.<timestamp> /etc/origin/node/node-config.yaml # cp ${MYBACKUPDIR}/etc/origin/master/scheduler.json.<timestamp> /etc/origin/master/scheduler.json # master-restart api # master-restart controllers在每个 OpenShift Container Platform 节点上,根据需要更新节点配置映射,然后启用并重启 atomic-openshift-node 服务:
# cp /etc/origin/node/node-config.yaml.<timestamp> /etc/origin/node/node-config.yaml # systemctl enable atomic-openshift-node # systemctl start atomic-openshift-node
3.8. 恢复项目
要恢复项目,请创建新项目,然后运行 oc create -f <file_name> 来恢复所有导出的文件。
流程
创建项目:
$ oc new-project <project_name> 1- 1
- 此
<project_name>值必须与备份的项目的名称匹配。
导入项目对象:
$ oc create -f project.yaml
导入您在备份项目时导出的任何其他资源,如角色绑定、secret、服务帐户和持久性卷声明:
$ oc create -f <object>.yaml
如果某些资源需要存在另一个对象,则可能无法导入。如果发生了这种情况,请查看错误消息以确定必须首先导入哪些资源。
某些资源(如 pod 和默认服务帐户)可能无法创建。
3.9. 恢复应用程序数据
假设容器镜像中安装了 rsync,您可以使用 oc rsync 命令恢复应用程序数据。Red Hat rhel7 基础镜像包含 rsync.因此,所有基于 rhel7 的镜像也都包含它。请参阅 对 CLI 操作进行故障排除和调试 - rsync。
这是应用程序数据的一种 通用 恢复,没有考虑特定于应用程序的备份程序,例如数据库系统的特殊导出和导入程序。
可能存在其他恢复方式,具体取决于您使用的持久卷类型,如 Cinder、NFS 或 Gluster。
流程
恢复 Jenkins 部署的应用数据示例
验证备份:
$ ls -la /tmp/jenkins-backup/ total 8 drwxrwxr-x. 3 user user 20 Sep 6 11:14 . drwxrwxrwt. 17 root root 4096 Sep 6 11:16 .. drwxrwsrwx. 12 user user 4096 Sep 6 11:14 jenkins
使用
oc rsync工具将数据复制到正在运行的 pod 中:$ oc rsync /tmp/jenkins-backup/jenkins jenkins-1-37nux:/var/lib
注意根据应用程序,您可能需要重新启动应用程序。
另外,还可使用新数据重启应用程序:
$ oc delete pod jenkins-1-37nux
另外,您可以将部署缩减为 0,然后再次向上扩展:
$ oc scale --replicas=0 dc/jenkins $ oc scale --replicas=1 dc/jenkins
3.10. 恢复持久性卷声明
本主题描述了两种恢复数据的方法。第一个步骤涉及删除 文件,然后将文件重新放到预期位置。第二个示例演示了迁移持久卷声明。当后端存储不再存在时,迁移会在需要移动的存储或灾难场景中发生。
检查特定应用程序的恢复程序,了解将数据恢复到应用程序所需的任何步骤。
3.10.1. 将文件恢复到现有 PVC
流程
删除该文件:
$ oc rsh demo-2-fxx6d sh-4.2$ ls */opt/app-root/src/uploaded/* lost+found ocp_sop.txt sh-4.2$ *rm -rf /opt/app-root/src/uploaded/ocp_sop.txt* sh-4.2$ *ls /opt/app-root/src/uploaded/* lost+found
替换包含 pvc 中文件的 rsync 备份的服务器中的文件:
$ oc rsync uploaded demo-2-fxx6d:/opt/app-root/src/
使用
oc rsh连接到 pod 并查看目录的内容,验证该文件是否在 pod 上恢复:$ oc rsh demo-2-fxx6d sh-4.2$ *ls /opt/app-root/src/uploaded/* lost+found ocp_sop.txt
3.10.2. 将数据恢复到新 PVC
下列步骤假定已创建新的 pvc。
流程
覆盖当前定义的
claim-name:$ oc set volume dc/demo --add --name=persistent-volume \ --type=persistentVolumeClaim --claim-name=filestore \ --mount-path=/opt/app-root/src/uploaded --overwrite
验证 pod 是否在使用新 PVC:
$ oc describe dc/demo Name: demo Namespace: test Created: 3 hours ago Labels: app=demo Annotations: openshift.io/generated-by=OpenShiftNewApp Latest Version: 3 Selector: app=demo,deploymentconfig=demo Replicas: 1 Triggers: Config, Image(demo@latest, auto=true) Strategy: Rolling Template: Labels: app=demo deploymentconfig=demo Annotations: openshift.io/container.demo.image.entrypoint=["container-entrypoint","/bin/sh","-c","$STI_SCRIPTS_PATH/usage"] openshift.io/generated-by=OpenShiftNewApp Containers: demo: Image: docker-registry.default.svc:5000/test/demo@sha256:0a9f2487a0d95d51511e49d20dc9ff6f350436f935968b0c83fcb98a7a8c381a Port: 8080/TCP Volume Mounts: /opt/app-root/src/uploaded from persistent-volume (rw) Environment Variables: <none> Volumes: persistent-volume: Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace) *ClaimName: filestore* ReadOnly: false ...omitted...现在,部署配置使用新的
pvc,运行oc rsync将文件放在新的pvc中:$ oc rsync uploaded demo-3-2b8gs:/opt/app-root/src/ sending incremental file list uploaded/ uploaded/ocp_sop.txt uploaded/lost+found/ sent 181 bytes received 39 bytes 146.67 bytes/sec total size is 32 speedup is 0.15
使用
oc rsh连接到 pod 并查看目录的内容,验证该文件是否在 pod 上恢复:$ oc rsh demo-3-2b8gs sh-4.2$ ls /opt/app-root/src/uploaded/ lost+found ocp_sop.txt
第 4 章 替换 master 主机
您可以替换失败的 master 主机。
首先,从集群中删除失败的 master 主机,然后添加替换的 master 主机。如果失败的 master 主机运行 etcd,请通过在新的 master 主机上添加 etcd 来扩展 etcd。
您必须完成本主题的所有部分。
4.1. 弃用 master 主机
Master 主机运行重要的服务,如 OpenShift Container Platform API 和控制器服务。为了弃用 master 主机,必须停止这些服务。
OpenShift Container Platform API 服务是一个主动/主动服务,因此只要请求发送到单独的 master 服务器,停止该服务不会影响环境。但是,OpenShift Container Platform 控制器服务是一个主动/被动服务,服务使用 etcd 来决定活跃的 master。
在多主控机架构中弃用 master 主机包括从负载均衡器池中移除 master,以避免尝试使用该 master 的新连接。这个过程很大程度上依赖于使用的负载均衡器。以下步骤显示从 haproxy 中删除 master 的详细信息。如果 OpenShift Container Platform 在云供应商上运行或使用 F5 设备,请查看特定的产品文档来从轮转中删除 master。
流程
删除
/etc/haproxy/haproxy.cfg配置文件中的backend部分。例如,如果使用haproxy弃用名为master-0.example.com的 master,请确保从以下内容中删除主机名:backend mgmt8443 balance source mode tcp # MASTERS 8443 server master-1.example.com 192.168.55.12:8443 check server master-2.example.com 192.168.55.13:8443 check然后,重新启动
haproxy服务。$ sudo systemctl restart haproxy
从负载均衡器中删除 master 后,通过将定义文件移出静态 pod dir /etc/origin/node/pods 来禁用 API 和控制器服务:
# mkdir -p /etc/origin/node/pods/disabled # mv /etc/origin/node/pods/controller.yaml /etc/origin/node/pods/disabled/: +
- 由于 master 主机是一个可调度的 OpenShift Container Platform 节点,因此请按照 弃用节点主机 部分中的步骤进行操作。
从
/etc/ansible/hostsAnsible 清单文件中的[masters]和[nodes]组移除 master 主机,以避免在使用该清单文件运行任何 Ansible 任务时出现问题。警告弃用 Ansible 清单中列出的第一个 master 主机需要额外的举措。
/etc/origin/master/ca.serial.txt文件仅对 Ansible 主机清单中列出的第一个 master 生成。如果您弃用了第一个 master 主机,请在进程前将/etc/origin/master/ca.serial.txt文件复制到其余 master 主机中。重要在运行多个 master 的 OpenShift Container Platform 3.11 集群中,其中一个 master 节点会包括额外的 CA 证书(
/etc/origin/master,/etc/etcd/ca, 和/etc/etcd/generated_certs)。这些是应用程序节点和 etcd 节点扩展操作所必需的,如果 CA 主机 master 已被弃用,则必须在另一个 master 节点上恢复。kubernetes服务将 master 主机 IP 作为端点包含在内。要验证 master 已被正确弃用,请查看kubernetes服务输出并查看已弃用的 master 是否已被删除:$ oc describe svc kubernetes -n default Name: kubernetes Namespace: default Labels: component=apiserver provider=kubernetes Annotations: <none> Selector: <none> Type: ClusterIP IP: 10.111.0.1 Port: https 443/TCP Endpoints: 192.168.55.12:8443,192.168.55.13:8443 Port: dns 53/UDP Endpoints: 192.168.55.12:8053,192.168.55.13:8053 Port: dns-tcp 53/TCP Endpoints: 192.168.55.12:8053,192.168.55.13:8053 Session Affinity: ClientIP Events: <none>
主机成功弃用后,可以安全地删除之前运行主控机的主机。
4.2. 添加主机
您可以通过运行 scaleup.yml playbook 添加新主机到集群。此 playbook 查询 master,为新主机生成和发布新证书,然后仅在新主机上运行配置 playbook。在运行 scaleup.yml playbook 之前,请完成所有必备的主机准备步骤。
scaleup.yml playbook 仅配置新主机。它不会更新 master 服务的 NO_PROXY,也不会重启 master 服务。
您必须有一个现有的清单文件,如 /etc/ansible/hosts,它代表当前集群配置,才能运行 scaleup.yml playbook。如果您之前使用 atomic-openshift-installer 命令来运行安装,您可以检查 ~/.config/openshift/hosts 查找安装程序生成的最后一个清单文件,并将该文件用作清单文件。您可以根据需要修改此文件。然后,在运行 ansible-playbook 时,您必须使用 -i 指定文件位置。
有关推荐的最大节点数,请参阅集群最大值部分。
流程
通过更新 openshift-ansible 软件包来确保您有最新的 playbook:
# yum update openshift-ansible
编辑 /etc/ansible/hosts 文件,并将 new_<host_type> 添加到 [OSEv3:children] 部分。例如,要添加新节点主机,请添加 new_nodes :
[OSEv3:children] masters nodes new_nodes
若要添加新的 master 主机,可添加 new_masters。
创建一个 [new_<host_type>] 部分来为新主机指定主机信息。将此部分格式化为现有部分,如下例所示:
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] node3.example.com openshift_node_group_name='node-config-infra'
如需了解更多选项,请参阅配置主机变量。
在添加新 master 时,将主机添加到 [new_masters] 部分和 [new_nodes] 部分,以确保新 master 主机是 OpenShift SDN 的一部分:
[masters] master[1:2].example.com [new_masters] master3.example.com [nodes] master[1:2].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes] master3.example.com
重要如果您使用
node-role.kubernetes.io/infra=true标签标记 master 主机,且没有其他专用基础架构节点,还必须通过向条目中添加openshift_schedulable=true明确将该主机标记为可以调度。否则,registry 和路由器 Pod 将无法放置到任何节点。更改到 playbook 目录,再运行 openshift_node_group.yml playbook。如果您的清单文件位于 /etc/ansible/hosts 默认以外的位置,请使用
-i选项指定位置:$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/openshift_node_group.yml
这会为新节点组创建 ConfigMap,并最终为主机上的节点配置文件。
注意运行 openshift_node_group.yaml playbook 只会更新新节点。无法运行它来更新集群中的现有节点。
运行 scaleup.yml playbook。如果您的清单文件位于默认 /etc/ansible/hosts 以外的位置,请使用
-i选项指定位置。对于额外的节点:
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-node/scaleup.yml对于额外的 master:
$ ansible-playbook [-i /path/to/file] \ playbooks/openshift-master/scaleup.yml
如果您在集群中部署了 EFK 堆栈,请将节点标签设置为
logging-infra-fluentd=true:# oc label node/new-node.example.com logging-infra-fluentd=true
- 在 playbook 运行后,验证安装。
将您在 [new_<host_type>] 部分定义的任何主机移动到它们的相应部分。通过移动这些主机,后续的 playbook 运行使用此清单文件正确处理节点。您可以保留空 [new_<host_type>] 部分。例如,添加新节点时:
[nodes] master[1:3].example.com node1.example.com openshift_node_group_name='node-config-compute' node2.example.com openshift_node_group_name='node-config-compute' node3.example.com openshift_node_group_name='node-config-compute' infra-node1.example.com openshift_node_group_name='node-config-infra' infra-node2.example.com openshift_node_group_name='node-config-infra' [new_nodes]
4.3. 扩展 etcd
您可以通过在 etcd 主机中添加更多资源或通过添加更多 etcd 主机来纵向扩展 etcd 集群。
由于 etcd 使用的投票系统,集群必须始终包含奇数个成员数。
拥有奇数 etcd 主机的集群可考虑容错。etcd 主机数量为奇数不会改变仲裁所需的数量,但会增加故障的容错能力。例如,对于包含三个成员的群集,仲裁为 2,保留一个失败容错能力。这可确保集群在两个成员健康时继续运行。
建议具有三个 etcd 主机的生产环境级别的集群。
新主机需要一个全新的 Red Hat Enterprise Linux 7 专用主机。etcd 存储应位于 SSD 磁盘上,以实现最佳性能和在 /var/lib/etcd 中挂载的专用磁盘上。
先决条件
- 在添加新的 etcd 主机前,备份 etcd 配置和数据以防止数据丢失。
检查当前的 etcd 集群状态,以避免添加新主机到不健康的集群。运行这个命令:
# ETCDCTL_API=3 etcdctl --cert="/etc/etcd/peer.crt" \ --key=/etc/etcd/peer.key \ --cacert="/etc/etcd/ca.crt" \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379" endpoint health https://master-0.example.com:2379 is healthy: successfully committed proposal: took = 5.011358ms https://master-1.example.com:2379 is healthy: successfully committed proposal: took = 1.305173ms https://master-2.example.com:2379 is healthy: successfully committed proposal: took = 1.388772ms在运行
scaleupplaybook 前,请确保新主机已注册到正确的红帽软件频道:# subscription-manager register \ --username=*<username>* --password=*<password>* # subscription-manager attach --pool=*<poolid>* # subscription-manager repos --disable="*" # subscription-manager repos \ --enable=rhel-7-server-rpms \ --enable=rhel-7-server-extras-rpmsetcd 托管在
rhel-7-server-extras-rpms软件频道中。确保从 etcd 集群中删除所有未使用的 etcd 成员。这必须在运行
scaleupplaybook 之前完成。列出 etcd 成员:
# etcdctl --cert="/etc/etcd/peer.crt" --key="/etc/etcd/peer.key" \ --cacert="/etc/etcd/ca.crt" --endpoints=ETCD_LISTEN_CLIENT_URLS member list -w table
复制未使用的 etcd 成员 ID(如果适用)。
通过使用以下命令指定其 ID 来删除未使用的成员:
# etcdctl --cert="/etc/etcd/peer.crt" --key="/etc/etcd/peer.key" \ --cacert="/etc/etcd/ca.crt" --endpoints=ETCD_LISTEN_CLIENT_URL member remove UNUSED_ETCD_MEMBER_ID
在当前 etcd 节点上升级 etcd 和 iptables:
# yum update etcd iptables-services
- 为 etcd 主机备份 /etc/etcd 配置。
- 如果新的 etcd 成员也是 OpenShift Container Platform 节点,将所需的主机数量添加到集群中。
- 此流程的其余部分假定您添加了一台主机,但是如果您添加多个主机,请在每个主机上执行所有步骤。
4.3.1. 使用 Ansible 添加新 etcd 主机
流程
在 Ansible 清单文件中,创建一个名为
[new_etcd]的新组,再添加新主机。然后,将new_etcd组添加为[OSEv3]组的子组:[OSEv3:children] masters nodes etcd new_etcd 1 ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com [new_etcd] 2 etcd0.example.com 3
注意将旧的
etcd 主机条目替换为清单文件中的新etcd主机条目。在替换旧的etcd 主机时,必须创建一个/etc/etcd/ca/目录的副本。另外,您可以在扩展etcd 主机前重新部署 etcd ca 和 certs。在安装 OpenShift Container Platform 并托管 Ansible 清单文件的主机中,切换到 playbook 目录并运行 etcd
scaleupplaybook:$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-etcd/scaleup.yml
在 playbook 运行后,通过将新 etcd 主机从
[new_etcd]组移到[etcd]组来修改清单文件,使其反映当前的状态:[OSEv3:children] masters nodes etcd new_etcd ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com etcd0.example.com
如果使用 Flannel,修改位于
/etc/sysconfig/flanneld主机上的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
4.3.2. 手动添加新 etcd 主机
如果您没有以静态 pod 用户身份在 master 节点上运行 etcd,您可能需要添加另一个 etcd 主机。
流程
修改当前的 etcd 集群
要创建 etcd 证书,请运行 openssl 命令,将值替换为您环境中的值。
创建一些环境变量:
export NEW_ETCD_HOSTNAME="*etcd0.example.com*" export NEW_ETCD_IP="192.168.55.21" export CN=$NEW_ETCD_HOSTNAME export SAN="IP:${NEW_ETCD_IP}, DNS:${NEW_ETCD_HOSTNAME}" export PREFIX="/etc/etcd/generated_certs/etcd-$CN/" export OPENSSLCFG="/etc/etcd/ca/openssl.cnf"注意用作
etcd_v3_ca_*的自定义openssl扩展包括 $SAN 环境变量作为subjectAltName。如需更多信息,请参阅/etc/etcd/ca/openssl.cnf。创建用于存储配置和证书的目录:
# mkdir -p ${PREFIX}创建服务器证书请求并为其签名:(server.csr 和 server.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}server.key \ -out ${PREFIX}server.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}server.crt \ -in ${PREFIX}server.csr \ -extensions etcd_v3_ca_server -batch创建对等证书请求并将其签名:(peer.csr 和 peer.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}peer.key \ -out ${PREFIX}peer.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}peer.crt \ -in ${PREFIX}peer.csr \ -extensions etcd_v3_ca_peer -batch从当前节点复制当前的 etcd 配置和
ca.crt文件,作为稍后修改的示例:# cp /etc/etcd/etcd.conf ${PREFIX} # cp /etc/etcd/ca.crt ${PREFIX}当仍处于存活的 etcd 主机上时,将新主机添加到集群中。要在集群中添加额外的 etcd 成员,您必须首先调整第一个成员的
peerURLs值中的默认 localhost peer:使用
member list命令获取第一个成员的成员 ID:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ 1 member list- 1
- 请确定在
--peers参数值中只指定活跃的 etcd 成员的 URL。
获取 etcd 侦听集群对等点的 IP 地址:
$ ss -l4n | grep 2380
通过传递从上一步中获取的成员 ID 和 IP 地址,使用
etcdctl member update命令更新peerURLs的值:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ member update 511b7fb6cc0001 https://172.18.1.18:2380-
重新运行
member list命令,并确保对等 URL 不再包含 localhost。
将新主机添加到 etcd 集群。请注意,新主机尚未配置,因此在您配置新主机之前,状态将保持为
未启动。警告您必须添加每个成员,并一次性使他们在线。将每个额外成员添加到集群时,您必须调整当前对等点的
peerURLs列表。peerURLs列表会针对每个添加的成员增长一个。etcdctl member add命令输出在 etcd.conf 文件中设置的值,以添加每个成员,如下说明所述。# etcdctl -C https://${CURRENT_ETCD_HOST}:2379 \ --ca-file=/etc/etcd/ca.crt \ --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key member add ${NEW_ETCD_HOSTNAME} https://${NEW_ETCD_IP}:2380 1 Added member named 10.3.9.222 with ID 4e1db163a21d7651 to cluster ETCD_NAME="<NEW_ETCD_HOSTNAME>" ETCD_INITIAL_CLUSTER="<NEW_ETCD_HOSTNAME>=https://<NEW_HOST_IP>:2380,<CLUSTERMEMBER1_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER2_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER3_NAME>=https:/<CLUSTERMEMBER3_IP>:2380" ETCD_INITIAL_CLUSTER_STATE="existing"- 1
- 在这一行中,
10.3.9.222是 etcd 成员的标签。您可以指定主机名、IP 地址或简单名称。
更新示例
${PREFIX}/etcd.conf文件。将以下值替换为上一步中生成的值:
- ETCD_NAME
- ETCD_INITIAL_CLUSTER
- ETCD_INITIAL_CLUSTER_STATE
使用上一步中输出中的新主机 IP 修改以下变量:您可以使用
${NEW_ETCD_IP}作为值。ETCD_LISTEN_PEER_URLS ETCD_LISTEN_CLIENT_URLS ETCD_INITIAL_ADVERTISE_PEER_URLS ETCD_ADVERTISE_CLIENT_URLS
- 如果您之前使用 member 系统作为 etcd 节点,您必须覆盖 /etc/etcd/etcd.conf 文件中的当前值。
检查文件中的语法错误或缺少 IP 地址,否则 etcd 服务可能会失败:
# vi ${PREFIX}/etcd.conf
-
在托管安装文件的节点上,更新 /etc/ansible/hosts 清单文件中的
[etcd]主机组。删除旧的 etcd 主机并添加新主机。 创建一个包含证书、示例配置文件和
ca的tgz文件,并将其复制到新主机上:# tar -czvf /etc/etcd/generated_certs/${CN}.tgz -C ${PREFIX} . # scp /etc/etcd/generated_certs/${CN}.tgz ${CN}:/tmp/
修改新的 etcd 主机
安装
iptables-services以提供 iptables 工具为 etcd 打开所需的端口:# yum install -y iptables-services
创建
OS_FIREWALL_ALLOW防火墙规则以允许 etcd 进行通信:- 客户端的端口 2379/tcp
端口 2380/tcp 用于对等通信
# systemctl enable iptables.service --now # iptables -N OS_FIREWALL_ALLOW # iptables -t filter -I INPUT -j OS_FIREWALL_ALLOW # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2379 -j ACCEPT # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2380 -j ACCEPT # iptables-save | tee /etc/sysconfig/iptables
注意在本例中,创建了一个新的链
OS_FIREWALL_ALLOW,这是 OpenShift Container Platform 安装程序用于防火墙规则的标准命名。警告如果环境托管在 IaaS 环境中,请修改实例的安全组,以允许传入到这些端口的流量。
安装 etcd:
# yum install -y etcd
确保安装了
etcd-2.3.7-4.el7.x86_64或更高的版本,通过删除 etcd pod 定义来确保 etcd 服务没有运行:
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/
删除所有 etcd 配置和数据:
# rm -Rf /etc/etcd/* # rm -Rf /var/lib/etcd/*
提取证书和配置文件:
# tar xzvf /tmp/etcd0.example.com.tgz -C /etc/etcd/
在新主机上启动 etcd:
# systemctl enable etcd --now
验证主机是否是集群的一部分以及当前的集群健康状况:
如果使用 v2 etcd api,请运行以下命令:
# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ cluster-health member 5ee217d19001 is healthy: got healthy result from https://192.168.55.12:2379 member 2a529ba1840722c0 is healthy: got healthy result from https://192.168.55.8:2379 member 8b8904727bf526a5 is healthy: got healthy result from https://192.168.55.21:2379 member ed4f0efd277d7599 is healthy: got healthy result from https://192.168.55.13:2379 cluster is healthy如果使用 v3 etcd api,请运行以下命令:
# ETCDCTL_API=3 etcdctl --cert="/etc/etcd/peer.crt" \ --key=/etc/etcd/peer.key \ --cacert="/etc/etcd/ca.crt" \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ endpoint health https://master-0.example.com:2379 is healthy: successfully committed proposal: took = 5.011358ms https://master-1.example.com:2379 is healthy: successfully committed proposal: took = 1.305173ms https://master-2.example.com:2379 is healthy: successfully committed proposal: took = 1.388772ms https://etcd0.example.com:2379 is healthy: successfully committed proposal: took = 1.498829ms
修改每个 OpenShift Container Platform master
修改每个 master 上
/etc/origin/master/master-config.yaml文件的etcClientInfo部分中的 master 配置。将新的 etcd 主机添加到 OpenShift Container Platform 用来存储数据的 etcd 服务器列表中,并删除所有失败的 etcd 主机:etcdClientInfo: ca: master.etcd-ca.crt certFile: master.etcd-client.crt keyFile: master.etcd-client.key urls: - https://master-0.example.com:2379 - https://master-1.example.com:2379 - https://master-2.example.com:2379 - https://etcd0.example.com:2379重启 master API 服务:
在每个 master 上:
# master-restart api # master-restart controllers
警告etcd 节点的数量必须是奇数,因此您必须至少添加两个主机。
如果使用 Flannel,修改每个 OpenShift Container Platform 主机的
/etc/sysconfig/flanneld服务的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
第 5 章 管理用户
5.1. 概述
用户是与 OpenShift 容器平台 API 交互的实体。这些可以是用于开发应用的开发人员,也可以是用于管理集群的管理员。可以将用户分配到组,这样可设置应用到组所有成员的权限。例如,您可以为组提供 API 访问权限,授予组 API 的所有成员访问权限。
本节介绍用户帐户的管理,包括如何在 OpenShift Container Platform 中创建新用户帐户以及如何删除它们。
5.2. 创建用户
创建用户的过程取决于配置的身份提供程序。默认情况下,OpenShift Container Platform 使用 DenyAll 身份提供程序,该供应商拒绝访问所有用户名和密码。
以下过程创建新用户,然后为用户添加一个角色:
-
根据您的身份提供程序,创建用户帐户。这可能取决于用作 身份提供程序配置的
mappingmethod。 为新用户指定所需的角色:
# oc create clusterrolebinding <clusterrolebinding_name> \ --clusterrole=<role> --user=<user>
其中
--clusterrole选项是所需的集群角色。例如,要授予新用户cluster-admin权限,用户可以访问集群中的所有内容:# oc create clusterrolebinding registry-controller \ --clusterrole=cluster-admin --user=admin
有关角色的说明和列表,请参阅 架构指南中的集群角色和本地角色部分。
作为集群管理员,您还可以 管理每个用户的访问级别。
根据身份提供商和定义的组结构,某些角色可能会自动提供给用户。如需更多信息,请参阅使用 LDAP 同步组部分。
5.3. 查看用户和身份列表
OpenShift Container Platform 用户配置存储在 OpenShift Container Platform 中的多个位置。无论身份提供程序如何,OpenShift Container Platform 都会在内部存储诸如基于角色的访问控制(RBAC)信息和组成员资格等详情。要完全删除用户信息,除用户帐户外,还必须删除此数据。
在 OpenShift Container Platform 中,两种对象类型包含身份提供商之外的用户数据:用户和身份。
获取当前用户列表:
$ oc get user NAME UID FULL NAME IDENTITIES demo 75e4b80c-dbf1-11e5-8dc6-0e81e52cc949 htpasswd_auth:demo
获取当前的身份列表:
$ oc get identity NAME IDP NAME IDP USER NAME USER NAME USER UID htpasswd_auth:demo htpasswd_auth demo demo 75e4b80c-dbf1-11e5-8dc6-0e81e52cc949
请注意两个对象类型之间匹配的 UID。如果在开始使用 OpenShift Container Platform 后尝试更改身份验证供应商,重叠的用户名将无法工作,因为身份列表中的条目仍会指向旧的身份验证方法。
5.4. 创建组
用户是向 OpenShift 容器平台发出请求的实体,但可以将用户组织到由一组用户组成的一个或多个组中。组可用于一次性管理许多用户,如授权策略或一次性向多个用户授予权限。
如果您的机构使用 LDAP,您可以将任何 LDAP 记录同步到 OpenShift Container Platform,以便您可以在一个位置配置组。这假设有关您的用户的信息位于 LDAP 服务器中。如需更多信息,请参阅使用 LDAP 同步组部分。
如果未使用 LDAP,您可以使用以下步骤手动创建组。
要创建新组,请执行以下操作:
# oc adm groups new <group_name> <user1> <user2>
例如,要创建 west 组,并放置 john 和 betty 用户:
# oc adm groups new west john betty
要验证组是否已创建并列出与该组关联的用户,请运行以下命令:
# oc get groups NAME USERS west john, betty
后续步骤:
5.5. 管理用户和组标签
为用户或组群添加标签:
$ oc label user/<user_name> <label_name>=<label_value>
例如,如果用户名是 theuser 且标签是 level=gold :
$ oc label user/theuser level=gold
删除标签:
$ oc label user/<user_name> <label_name>-
显示用户或组群的标签:
$ oc describe user/<user_name>
5.6. 删除用户
删除用户:
删除用户记录:
$ oc delete user demo user "demo" deleted
删除用户身份。
用户的身份与您所使用的身份供应商相关。在
oc get user中从用户记录中获取供应商名称。在本例中,身份提供程序名称为 htpasswd_auth。该命令为:
# oc delete identity htpasswd_auth:demo identity "htpasswd_auth:demo" deleted
如果您跳过这一步,该用户将无法再次登录。
完成这些步骤后,当用户再次登录时,OpenShift Container Platform 中会创建一个新帐户。
如果您的用意是阻止用户再次登录(例如,如果员工已离开公司并且想要永久删除帐户),您也可以将用户从您配置的身份供应商的身份验证后端(如 htpasswd、kerberos 或其他)中删除。
例如,如果您使用 htpasswd,请使用用户名和密码删除为 OpenShift Container Platform 配置的 htpasswd 文件中的条目。
对于诸如轻量级目录访问协议(LDAP)或红帽身份管理(IdM)等外部识别管理,请使用用户管理工具来删除用户条目。
第 6 章 管理项目
6.1. 概述
在 OpenShift Container Platform 中,项目用于分组和隔离相关的对象。作为管理员,您可以为开发人员授予某些项目的访问权限,让他们能够自行创建项目,并授予他们个别项目内的管理权限。
6.2. 自助配置项目
您可以允许开发人员创建自己的项目。有一个端点将根据 模板 调配项目。当开发人员 创建一个新项目,Web 控制台和 oc new-project 命令会使用此端点。
6.2.1. 为新项目修改模板
API 服务器根据由 master-config.yaml 文件的 projectRequestTemplate 参数标识的模板自动置备项目。如果没有定义该参数,API 服务器会创建一个默认模板,该模板将以请求的名称创建项目,并将请求用户分配至该项目的 admin 角色。
创建自己的自定义项目模板:
从当前的默认项目模板开始:
$ oc adm create-bootstrap-project-template -o yaml > template.yaml
- 使用文本编辑器通过添加对象或修改现有对象来修改 template.yaml 文件。
加载模板:
$ oc create -f template.yaml -n default
修改 master-config.yaml 文件以引用载入的模板:
... projectConfig: projectRequestTemplate: "default/project-request" ...
提交项目请求时,API 会替换模板中的以下参数:
| 参数 | 描述 |
|---|---|
| PROJECT_NAME | 项目的名称。必需。 |
| PROJECT_DISPLAYNAME | 项目的显示名称。可以为空。 |
| PROJECT_DESCRIPTION | 项目的描述。可以为空。 |
| PROJECT_ADMIN_USER | 管理用户的用户名。 |
| PROJECT_REQUESTING_USER | 请求用户的用户名。 |
API 访问权限授予具有 self-provisioner 角色和 self-provisioners 集群角色绑定的开发人员。默认情况下,所有通过身份验证的开发人员都可获得此角色。
6.2.2. 禁用自助置备
您可以防止经过身份验证的用户组自助置备新项目。
- 以具有 cluster-admin 权限的用户身份登录。
检查
self-provisionersclusterrolebinding usage。运行以下命令,然后检查self-provisioners部分中的主题。$ oc describe clusterrolebinding.rbac self-provisioners Name: self-provisioners Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: self-provisioner Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated:oauth
从
system:authenticated:oauth组中移除self-provisioner集群角色。如果
self-provisioners集群角色绑定仅将self-provisioner角色绑定至system:authenticated:oauth组,请运行以下命令:$ oc patch clusterrolebinding.rbac self-provisioners -p '{"subjects": null}'如果
self-provisionersclusterrolebinding 将self-provisioner角色绑定到system:authenticated:oauth组以外的更多用户、组或 serviceaccounts,请运行以下命令:$ oc adm policy remove-cluster-role-from-group self-provisioner system:authenticated:oauth
设置 master-config.yaml 文件中的
projectRequestMessage参数值,以指示开发人员如何请求新项目。此参数值是一个字符串,当用户尝试自助置备项目时,该字符串将在 Web 控制台中显示给用户。您可以使用以下信息之一:-
To request a project, contact your system administrator at
projectname@example.com. -
To request a new project, fill out the project request form located at
https://internal.example.com/openshift-project-request.
YAML 文件示例
... projectConfig: ProjectRequestMessage: "message" ...
-
To request a project, contact your system administrator at
编辑
self-provisioners集群角色绑定,以防止自动更新角色。自动更新会使集群角色重置为默认状态。从命令行更新角色绑定:
运行以下命令:
$ oc edit clusterrolebinding.rbac self-provisioners
在显示的角色绑定中,将
rbac.authorization.kubernetes.io/autoupdate参数值设置为false,如下例所示:apiVersion: authorization.openshift.io/v1 kind: ClusterRoleBinding metadata: annotations: rbac.authorization.kubernetes.io/autoupdate: "false" ...
使用单个命令更新角色绑定:
$ oc patch clusterrolebinding.rbac self-provisioners -p '{ "metadata": { "annotations": { "rbac.authorization.kubernetes.io/autoupdate": "false" } } }'
6.3. 使用 Node Selectors
节点选择器与带标签的节点搭配使用,以控制 pod 的放置。
6.3.1. 设置集群范围的默认 Node Selector
作为集群管理员,您可以设置集群范围的默认节点选择器来限制 pod 放置到特定的节点。
编辑 /etc/origin/master/master-config.yaml 中的 master 配置文件,并为默认节点选择器添加一个值。这应用到没有指定 nodeSelector 值的所有项目中创建的 pod:
... projectConfig: defaultNodeSelector: "type=user-node,region=east" ...
重启 OpenShift 服务以使更改生效:
# master-restart api # master-restart controllers
6.3.2. 设置项目范围的 Node Selector
要使用节点选择器创建单个项目,请在创建项目时使用 --node-selector 选项。例如,如果您有一个带有多个区域的 OpenShift Container Platform 拓扑,您可以使用节点选择器限制特定的 OpenShift Container Platform 项目,仅将 pod 部署到特定区域的节点。
以下命令创建一个名为 myproject 的新项目,它规定 pod 部署到标有 user-node 和 east 的节点上:
$ oc adm new-project myproject \
--node-selector='type=user-node,region=east'运行此命令后,这便成为指定项目中包含的所有容器集的管理员设置节点选择器。
new-project 子命令分别可用于 oc adm 和 oc,而集群管理员和 developer 命令则分别可用于使用节点选择器创建新项目,但仅可使用 oc adm 命令使用。在自调配项目时,new-project 子命令不可供项目开发人员使用。
使用 oc adm new-project 命令,为项目添加 注解 部分。您可以编辑项目,并更改 openshift.io/node-selector 值来覆盖默认值:
...
metadata:
annotations:
openshift.io/node-selector: type=user-node,region=east
...您还可以使用以下命令覆盖现有项目命名空间的默认值:
# oc patch namespace myproject -p \
'{"metadata":{"annotations":{"openshift.io/node-selector":"node-role.kubernetes.io/infra=true"}}}'
如果 openshift.io/node-selector 设置为空字符串(oc adm new-project --node-selector=""),则项目将无法具有管理员设置的节点选择器,即使已经设置了集群范围的默认值。这意味着,作为集群管理员,您可以设置默认值,将开发人员项目限制为节点的子集,并且仍然启用基础架构或其他项目来调度整个集群。
6.3.3. 开发人员指定的 Node Selectors
如果 OpenShift Container Platform 开发人员希望进一步限制节点,则可以在其 pod 配置上设置节点选择器。这将是项目节点选择器的补充,这意味着您仍然可以为具有节点选择器值的所有项目指定节点选择器值。
例如,如果使用上述注解创建了一个项目(openshift.io/node-selector: type=user-node,region=east),并且开发人员在该项目中的 pod 上设置了另一个节点选择器(例如 disable=classified),pod 只会调度到具有所有三个标签(type=user-node、region=east 和 working=classified) 的节点上。如果容器集上设置了 region=west,则其容器集将要求具有标签 region=east 和 region=west 的节点,它们无法工作。pod 不会被调度,因为标签只能设置为一个值。
6.4. 每个用户限制自助项目数量
给定用户请求的自助置备项目数量可使用 ProjectRequestLimit admission control plug-in来限制。
如果在 OpenShift Container Platform 3.1 或更早版本中使用 修改新项目模板中所述的流程创建了项目请求模板,则生成的模板不包括注解 openshift.io/requester: ${PROJECT_REQUESTING_USER},它用于 ProjectRequestLimitConfig。您必须添加注解。
要为用户指定限值,必须在 /etc/origin/master/master-config.yaml 的 master 配置文件内为插件指定配置。插件配置取用户标签选择器和关联的最大项目请求的列表作为值。
选择器按顺序评估。第一个与当前用户匹配的将用于确定项目的最大数量。如果没有指定选择器,则限制适用于所有用户。如果没有指定最多的项目数,则允许特定选择器有无限数量的项目。
以下配置为每个用户设置 2 个项目的全局限制,同时为带有 level=advanced 和无限制项目的用户使用 10 个项目 。
admissionConfig:
pluginConfig:
ProjectRequestLimit:
configuration:
apiVersion: v1
kind: ProjectRequestLimitConfig
limits:
- selector:
level: admin 1
- selector:
level: advanced 2
maxProjects: 10
- maxProjects: 2 3管理用户和组标签 提供了有关如何为用户和组添加、删除或显示标签的进一步指导。
更改完成后,重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
6.5. 针对每个服务帐户,启用和限制自提供的项目
默认情况下,服务帐户无法创建项目。但是,管理员可以为每个服务帐户启用此功能,任何给定服务帐户请求的自置备项目数量则可使用 ProjectRequestLimit 准入控制插件 限制。
如果服务帐户被允许创建项目,则您无法信任上放置的任何标签,因为项目编辑器可以操作这些标签。
如果服务帐户不存在,在项目中创建服务帐户:
$ oc create sa <sa_name>
以具有
cluster-admin权限的用户身份,将self-provisioner集群角色添加到服务帐户:$ oc adm policy \ add-cluster-role-to-user self-provisioner \ system:serviceaccount:<project>:<sa_name>编辑 /etc/origin/master/master-config.yaml 中的 master 配置文件,并将
ProjectRequestLimit部分中的maxProjectsForServiceAccounts参数值设置为任何给定 self-provisioner-enabled 服务帐户可以创建的最大项目数。例如,以下配置为每个服务帐户设置三个项目的全局限值:
admissionConfig: pluginConfig: ProjectRequestLimit: configuration: apiVersion: v1 kind: ProjectRequestLimitConfig maxProjectsForServiceAccounts: 3保存更改后,重启 OpenShift Container Platform 以使更改生效:
# master-restart api # master-restart controllers
以服务帐户身份登录并创建新项目,验证是否已应用您的更改。
使用其令牌作为服务帐户登录:
$ oc login --token <token>
创建一个新项目
$ oc new-project <project_name>
第 7 章 管理 Pod
7.1. 概述
本主题描述了 pod 的管理,包括限制其运行一次的持续时间,以及它们可以使用的带宽量。
7.2. 查看 Pod
您可以显示 pod 的用量统计,这些统计信息为容器提供了运行时环境。这些用量统计包括 CPU、内存和存储的消耗。
查看用量统计:
$ oc adm top pods NAME CPU(cores) MEMORY(bytes) hawkular-cassandra-1-pqx6l 219m 1240Mi hawkular-metrics-rddnv 20m 1765Mi heapster-n94r4 3m 37Mi
查看带有标签的 pod 的用量统计:
$ oc adm top pod --selector=''
您必须选择过滤所基于的选择器(标签查询)。支持 =、== 和 !=。
您必须有 cluster-reader 权限才能查看用量统计。
必须安装 metrics-server 才能查看用量统计。请参阅使用 Horizontal Pod Autoscalers 的要求。
7.3. 限制 Pod 运行时
OpenShift Container Platform 依赖于运行一次 pod 来执行诸如部署 pod 或执行构建等任务。Run-once pod 是带有 RestartPolicy 为 Never 或 OnFailure 的 pod。
集群管理员可以使用 RunOnceDuration 准入控制插件来强制限制这些运行时间,因为 pod 可以处于活跃状态。时间限制过期后,集群将尝试主动终止这些 pod。具有此类限制的主要原因是防止构建等任务运行过长的时间。
7.3.1. 配置 RunOnceDuration 插件
插件配置应包含运行后 pod 的默认活跃截止时间。此截止时间在全局范围内执行,但可以根据每个项目替代。
admissionConfig:
pluginConfig:
RunOnceDuration:
configuration:
apiVersion: v1
kind: RunOnceDurationConfig
activeDeadlineSecondsOverride: 3600 1
....- 1
- 以秒为单位为 run-once pod 指定全局默认值。
7.3.2. 指定每个项目自定义持续时间
除了为运行一次 pod 指定全局最长持续时间外,管理员还可以向特定项目添加注解(openshift.io/active-deadline-seconds-override),以覆盖全局默认值。
对于新项目,在项目 specification .yaml 文件中定义注解。
apiVersion: v1 kind: Project metadata: annotations: openshift.io/active-deadline-seconds-override: "1000" 1 name: myproject- 1
- 将运行一次 pod 的默认活跃期限秒数覆盖为 1000 秒。请注意,覆盖的值必须以字符串形式指定。
对于现有项目,
运行
oc edit并添加openshift.io/active-deadline-seconds-override:1000注解。$ oc edit namespace <project-name>
或者
使用
oc patch命令:$ oc patch namespace <project_name> -p '{"metadata":{"annotations":{"openshift.io/active-deadline-seconds-override":"1000"}}}'
7.3.2.1. 部署 Egress Router Pod
例 7.1. Egress 路由器的 Pod 定义示例
apiVersion: v1
kind: Pod
metadata:
name: egress-1
labels:
name: egress-1
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
containers:
- name: egress-router
image: openshift3/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE 1
value: 192.168.12.99
- name: EGRESS_GATEWAY 2
value: 192.168.12.1
- name: EGRESS_DESTINATION 3
value: 203.0.113.25
nodeSelector:
site: springfield-1 4
pod.network.openshift.io/assign-macvlan 注释 在主网络接口上创建一个 Macvlan 网络接口,然后在启动 egress-router 容器前将它移到 pod 的网络命名空间中。
保留 "true" 上的引号。省略它们将导致错误。
pod 包含一个容器,它使用 openshift3/ose-egress-router 镜像,该容器会特权运行,以便它可以配置 Macvlan 接口并设置 iptables 规则。
环境变量告知 egress-router 镜像要使用的地址;它将配置 Macvlan 接口,以将 EGRESS_SOURCE 用作 其 IP 地址,并将 EGRESS_GATEWAY 作为其网关。
设置 NAT 规则,以便将到 Pod 集群 IP 地址上的任何 TCP 或 UDP 端口的连接重定向到 EGRESS_DESTINATION 上的相同端口。
如果集群中只有部分节点能够声明指定的源 IP 地址并使用指定的网关,您可以指定一个 nodeName 或 nodeSelector 来表示哪些节点可以接受。
7.3.2.2. 部署 Egress 路由器服务
虽然严格来说并不是必需的,但您通常希望创建指向出口路由器的服务:
apiVersion: v1
kind: Service
metadata:
name: egress-1
spec:
ports:
- name: http
port: 80
- name: https
port: 443
type: ClusterIP
selector:
name: egress-1您的 pod 现在可以连接到此服务。使用保留的出口 IP 地址将其连接重新指向外部服务器的对应端口。
7.3.3. 使用 Egress Firewall 限制 Pod 访问
作为 OpenShift Container Platform 集群管理员,您可以使用出口策略限制集群中有些或所有 pod 可以访问的外部地址,以便:
pod 只能与内部主机通信,且无法启动到公共互联网的连接。
或者,
pod 只能与公共互联网通信,且无法(在集群外)启动与内部主机的连接。
或者,
- pod 无法访问不应该联系的特定内部子网/主机。
例如,您可以使用不同的出口策略配置项目,允许 <project A> 访问指定的 IP 范围,但拒绝对 <project B> 相同的访问。
您必须启用 ovs-multitenant 插件, 以便限制通过出口策略的 pod 访问。
项目管理员既不能创建 EgressNetworkPolicy 对象,也不能编辑您在项目中创建的对象。另外还有一些其他限制可以创建 EgressNetworkPolicy :
-
default项目(以及通过oc adm pod-network make-projects-global使全局化的任何其他项目)不能具有出口策略。 -
如果您将两个项目合并在一起(通过
oc adm pod-network join-projects),则无法 在任何 合并的项目中使用出口策略。 - 项目不能有多个出口策略对象。
违反这些限制将导致项目的出口策略中断,并可能导致所有外部网络流量被丢弃。
7.3.3.1. 配置 Pod 访问限制
要配置 pod 访问限制,您必须使用 oc 命令或 REST API。您可以使用 oc [create|replace|delete] 来操作 EgressNetworkPolicy 对象。api/swagger-spec/oapi-v1.json 文件包含对象的实际工作方式的 API 级别详情。
配置 pod 访问限制:
- 导航到您要影响的项目。
为 pod 限制策略创建 JSON 文件:
# oc create -f <policy>.json
使用策略详情配置 JSON 文件。例如:
{ "kind": "EgressNetworkPolicy", "apiVersion": "v1", "metadata": { "name": "default" }, "spec": { "egress": [ { "type": "Allow", "to": { "cidrSelector": "1.2.3.0/24" } }, { "type": "Allow", "to": { "dnsName": "www.foo.com" } }, { "type": "Deny", "to": { "cidrSelector": "0.0.0.0/0" } } ] } }当上例添加到项目中时,它允许到 IP 范围
1.2.3.0/24的流量和域名www.foo.com,但拒绝访问所有其他外部 IP 地址。(流量到其他 pod 不会受到影响,因为策略仅适用于 外部 流量。)EgressNetworkPolicy中的规则按顺序检查,第一个匹配的规则会生效。如果上面示例中的三个规则被颠倒,则不允许流量到1.2.3.0/24和www.foo.com,因为首先要检查0.0.0.0/0规则,它将匹配和拒绝所有流量。域名更新在 30 分钟内有所反映。在上面的示例中,假设
www.foo.com解析为10.11.12.13,但之后被更改为20.21.22.23。然后,OpenShift Container Platform 最多需要 30 分钟时间来适应这些 DNS 更新。
7.4. 限制 Pod 可用的带宽
您可以对 pod 应用服务质量流量控制,有效限制其可用带宽。出口流量(从 pod 传出)按照策略来处理,仅在超出配置的速率时丢弃数据包。入口流量(传入 pod 中)通过控制已排队数据包进行处理,以便有效地处理数据。您对 pod 应用的限制不会影响其他 pod 的带宽。
限制 pod 的带宽:
编写对象定义 JSON 文件,并使用
kubernetes.io/ingress-bandwidth和kubernetes.io/egress-bandwidth注解指定数据流量速度。例如,将 pod 出口和入口带宽限制为 10M/s:受限 Pod 对象定义
{ "kind": "Pod", "spec": { "containers": [ { "image": "openshift/hello-openshift", "name": "hello-openshift" } ] }, "apiVersion": "v1", "metadata": { "name": "iperf-slow", "annotations": { "kubernetes.io/ingress-bandwidth": "10M", "kubernetes.io/egress-bandwidth": "10M" } } }使用对象定义创建 pod:
$ oc create -f <file_or_dir_path>
7.5. 设置 Pod Disruption 预算
pod 中断预算是 Kubernetes API 的一部分,可以像其他对象类型一样通过 oc 命令进行管理。它们允许在操作过程中指定 pod 的安全约束,比如为维护而清空节点。
PodDisruptionBudget 是一个 API 对象,用于指定在某一时间必须保持在线的副本的最小数量或百分比。在项目中进行这些设置对节点维护(比如缩减集群或升级集群)有益,而且仅在自愿驱除(而非节点失败)时遵从这些设置。
PodDisruptionBudget 对象的配置由以下关键部分组成:
- 标签选择器,即一组 pod 的标签查询。
- 可用性级别,指定必须同时可用的最小 pod 数量。
以下是 PodDisruptionBudget 资源示例:
apiVersion: policy/v1beta1 1 kind: PodDisruptionBudget metadata: name: my-pdb spec: selector: 2 matchLabels: foo: bar minAvailable: 2 3
如果您使用上述对象定义创建 YAML 文件,您可以使用以下内容将其添加到项目中:
$ oc create -f </path/to/file> -n <project_name>
您可以使用以下命令来检查所有项目的 pod 中断预算:
$ oc get poddisruptionbudget --all-namespaces NAMESPACE NAME MIN-AVAILABLE SELECTOR another-project another-pdb 4 bar=foo test-project my-pdb 2 foo=bar
如果系统中至少有 minAvailable 个 pod 正在运行,则 PodDisruptionBudget 被视为是健康的。超过该限制的每个 pod 都可被 驱除。
根据 pod 优先级和抢占 设置,可能会即使 pod 中断预算要求而移除较低优先级 pod。
7.6. 配置关键 Pod
有许多核心组件(如 DNS)对于集群完全正常工作至关重要,但它们在常规集群节点而不是主节点上运行。如果一个关键附加组件被驱除,集群可能会停止正常工作。您可以通过在 pod 规格中添加 scheduler.alpha.kubernetes.io/critical-pod 注解以使 pod 成为关键 pod,以便 descheduler 不会删除这些 pod。
spec:
template:
metadata:
name: critical-pod
annotations:
scheduler.alpha.kubernetes.io/critical-pod: "true"第 8 章 管理网络
8.1. 概述
本主题描述了整个 集群网络 的管理,包括项目隔离和出站流量控制。
在 管理 Pod 中,会讨论 Pod 级别的网络功能,如每个 pod 带宽限制。
8.2. 管理 Pod 网络
当集群配置为使用 ovs-multitenant SDN 插件 时,您可以使用管理员 CLI 为项目管理单独的 pod 覆盖网络。如有必要,请参阅配置 SDN 部分以了解插件配置步骤。
8.2.1. 加入项目网络
将项目加入现有项目网络:
$ oc adm pod-network join-projects --to=<project1> <project2> <project3>
在上例中,<project2> 和 <project3> 中的所有 pod 和服务现在可以访问 <project1> 中的任何 pod 和服务,反之亦然。服务可以通过 IP 或完全限定 DNS 名称(<service>.<pod_namespace>.svc.cluster.local)访问。例如,若要访问 myproject 项目中名为 db 的服务,可使用 db.myproject.svc.cluster.local。
另外,您也可以使用 --selector=<project_selector> 选项,而不指定具体的项目名称。
验证您接合的网络:
$ oc get netnamespaces
然后查看 NETID 列。同一 pod-network 中的项目将具有相同的 NetID。
8.3. 隔离项目网络
要在集群中隔离项目网络,反之亦然,请运行:
$ oc adm pod-network isolate-projects <project1> <project2>
在上例中,<project1> 和 <project2> 中的所有 pod 和服务都无法从集群中的其他非全局项目访问任何 pod 和服务,反之亦然。
另外,您也可以使用 --selector=<project_selector> 选项,而不指定具体的项目名称。
8.3.1. 使项目网络全局化
允许项目访问集群中的所有 pod 和服务,反之亦然:
$ oc adm pod-network make-projects-global <project1> <project2>
在上例中,<project1> 和 <project2> 中的所有 pod 和服务现在可以访问集群中的任何 pod 和服务,反之亦然。
另外,您也可以使用 --selector=<project_selector> 选项,而不指定具体的项目名称。
8.4. 为路由和入口对象禁用主机名集合
在 OpenShift Container Platform 中,路由和入口对象的主机名冲突攻击会被默认启用。这意味着没有 cluster-admin 角色的用户只能在创建时在路由或入口对象中设置主机名,之后无法更改它。但是,您可以为部分或所有用户放松对路由和入口对象的限制。
由于 OpenShift Container Platform 使用对象创建时间戳来确定给定主机名的最旧的路由或入口对象,如果旧的路由更改了主机名,或者使用了 ingress 对象,则路由或入口对象可能会劫持较新路由的主机名。
作为 OpenShift Container Platform 集群管理员,您可以在创建后编辑路由中的主机名。您还可以创建一个角色来允许特定用户这样做:
$ oc create clusterrole route-editor --verb=update --resource=routes.route.openshift.io/custom-host
然后您可以将新角色绑定到用户:
$ oc adm policy add-cluster-role-to-user route-editor user
您还可以对入口对象禁用主机名冲突检测。这样,没有 cluster-admin 角色的用户可在创建后编辑 ingress 对象的主机名。这对依赖于 Kubernetes 行为的 OpenShift Container Platform 安装很有用,包括允许编辑 ingress 对象中的主机名。
将以下内容添加到
master.yaml文件中:admissionConfig: pluginConfig: openshift.io/IngressAdmission: configuration: apiVersion: v1 allowHostnameChanges: true kind: IngressAdmissionConfig location: ""重启 master 服务以使更改生效:
$ master-restart api $ master-restart controllers
8.5. 控制出口流量
作为集群管理员,您可以在主机级别上为特定节点分配多个静态 IP 地址。如果应用开发人员需要其应用服务的专用 IP 地址,可以在他们用于询问防火墙访问的过程中请求一个 IP 地址。然后,他们可以从开发人员的项目部署出口路由器,在部署配置中使用 nodeSelector 来确保 pod 驻留在带有预分配的静态 IP 地址的主机上。
egress pod 的部署声明了其中一个源 IP、受保护服务的目标 IP,以及用于到达目的地的网关 IP。部署 pod 后,您可以创建一个服务来访问出口路由器 pod,然后将该源 IP 添加到公司防火墙中。然后,开发人员具有访问在其项目中创建的出口路由器服务的信息,如 service.project.cluster.domainname.com。
当开发人员需要访问外部的防火墙化服务时,他们可以调用其应用(例如 JDBC 连接信息)中的出口路由器 pod服务(service.project.cluster.domainname.com),而不是实际受保护的服务 URL。
您还可以为项目分配静态 IP 地址,确保来自指定项目的所有传出外部连接都具有可识别的来源。这与默认出口路由器不同,后者用于将流量发送到特定目的地。
如需更多信息,请参阅 为外部项目流量启用修复 IP 部分。
作为 OpenShift Container Platform 集群管理员,您可以使用以下方法控制出口流量:
- firewall
- 通过利用出口防火墙,您可以强制执行可接受的出站流量策略,以便特定端点或 IP 范围(子网)成为 OpenShift Container Platform 中可以与之通信的动态端点(pod)的唯一可接受目标。
- 路由器
- 通过使用出口路由器,您可以创建可识别的服务将流量发送到某些目的地,确保流量被视为来自已知来源的流量。这有助于提高安全性,因为它允许您保护外部数据库,以便只有命名空间中的特定 pod 可以与将流量代理到数据库的服务(出口路由器)进行通信。
- iptables
- 除了上述 OpenShift Container Platform 内部解决方案外,还可以创建应用于传出流量的 iptables 规则。这些规则允许比出口防火墙更多的可能性,但不能限制为特定的项目。
8.6. 使用 Egress Firewall 来限制对外部资源的访问
作为 OpenShift Container Platform 集群管理员,您可以使用出口防火墙策略限制集群内的部分或所有 Pod 可以访问的外部 IP 地址。出口防火墙策略支持以下情况:
- pod 只能连接到内部主机,且无法启动到公共互联网的连接。
- pod 只能连接到公共互联网,且无法启动到 OpenShift Container Platform 集群外的内部主机的连接。
- pod 无法访问指定的内部子网或主机。
可通过以 CIDR 格式或指定 DNS 名称指定 IP 地址范围来设置出口策略。例如,您可以允许 <project_A> 访问指定 IP 范围,但拒绝对 <project_B> 相同的访问。或者,您可以限制应用程序开发人员从(Python)pip 镜像进行更新,并强制更新仅来自批准的源。
您必须 启用了ovs-multitenant 或 ovs-networkpolicy 插件,才能通过出口策略限制 pod 访问。
如果您使用 ovs-multitenant 插件,egress 策略仅与每个项目的一个策略兼容,且无法用于共享网络的项目,如全局项目。
项目管理员既不能创建 EgressNetworkPolicy 对象,也不能编辑您在项目中创建的对象。另外还有一些其他限制可以创建 EgressNetworkPolicy :
-
default项目(以及通过oc adm pod-network make-projects-global使全局化的任何其他项目)不能具有出口策略。 -
如果您将两个项目合并在一起(通过
oc adm pod-network join-projects),则无法 在任何 合并的项目中使用出口策略。 - 项目不能有多个出口策略对象。
违反这些限制会导致项目的出口策略出现问题,并可能导致所有外部网络流量被丢弃。
使用 oc 命令或 REST API 配置出口策略。您可以使用 oc [create|replace|delete] 来操作 EgressNetworkPolicy 对象。api/swagger-spec/oapi-v1.json 文件包含对象的实际工作方式的 API 级别详情。
配置出口策略:
- 导航到您要影响的项目。
使用您要使用的策略配置创建一个 JSON 文件,如下例所示:
{ "kind": "EgressNetworkPolicy", "apiVersion": "v1", "metadata": { "name": "default" }, "spec": { "egress": [ { "type": "Allow", "to": { "cidrSelector": "1.2.3.0/24" } }, { "type": "Allow", "to": { "dnsName": "www.foo.com" } }, { "type": "Deny", "to": { "cidrSelector": "0.0.0.0/0" } } ] } }当上例添加到项目中时,它允许到 IP 范围
1.2.3.0/24的流量和域名www.foo.com,但拒绝访问所有其他外部 IP 地址。流量到其他 pod 的流量不受影响,因为策略仅适用于 外部 流量。EgressNetworkPolicy中的规则按顺序检查,第一个匹配的规则会生效。如果上面示例中的三个规则被颠倒,则不允许流量到1.2.3.0/24和www.foo.com,因为首先要检查0.0.0.0/0规则,它将匹配和拒绝所有流量。域名更新根据本地非授权服务器返回的域的 TTL(time to live)值进行轮询。pod 也应该在必要时从同一本地名称服务器解析域,否则出口网络策略控制器和 pod 感知的域的 IP 地址会有所不同,出口网络策略可能无法按预期强制执行。由于出口网络策略控制器和 pod 会异步轮询相同的本地名称服务器,因此可能会有一个竞争条件,pod 在出口控制器前可能会获取更新的 IP。由于此限制,仅建议在
EgressNetworkPolicy中使用域名来更改 IP 地址的域。注意出口防火墙始终允许 pod 访问 pod 所在的用于 DNS 解析的节点的外部接口。如果您的 DNS 解析不是由本地节点上的某个内容处理,那么如果您在 pod 中使用域名,则需要添加出口防火墙规则,以允许访问 DNS 服务器的 IP 地址。
使用 JSON 文件创建 EgressNetworkPolicy 对象:
$ oc create -f <policy>.json
通过创建 路由 来公开服务将忽略 EgressNetworkPolicy。出口网络策略服务端点过滤在节点 kubeproxy 上完成。当涉及路由器时,kubeproxy 被绕过,且不会应用出口网络策略强制。管理员可以通过限制对创建路由的访问来防止此缺陷。
8.6.1. 使用 Egress 路由器允许外部资源识别 Pod 流量
OpenShift Container Platform 出口路由器使用一个私有源 IP 地址运行一项服务,该服务将流量重定向到指定的远程服务器。服务允许容器集与设置为仅允许从白名单 IP 地址访问的服务器进行通信。
出口路由器并不适用于每个传出的连接。创建大量出口路由器可以推送网络硬件的限制。例如,为每个项目或应用创建出口路由器可能会超出网络接口可以处理的本地 MAC 地址数,然后再回退到软件中的 MAC 地址过滤。
目前,出口路由器与 Amazon AWS、Azure Cloud 或其他不支持第 2 层操作的云平台不兼容,因为它们与 macvlan 流量不兼容。
部署注意事项
Egress 路由器向节点的主网络接口添加第二个 IP 地址和 MAC 地址。如果您没有在裸机上运行 OpenShift Container Platform,您可能需要配置虚拟机监控程序或云供应商来允许额外的地址。
- Red Hat OpenStack Platform
如果要在 Red Hat OpenStack Platform 上部署 OpenShift Container Platform,则需要将 OpenStack 环境中的 IP 和 MAC 地址列入白名单,否则 通信将失败 :
neutron port-update $neutron_port_uuid \ --allowed_address_pairs list=true \ type=dict mac_address=<mac_address>,ip_address=<ip_address>
- Red Hat Enterprise Virtualization
-
如果您使用 Red Hat Enterprise Virtualization,您应该将
EnableMACAntiSpoofingFilterRules设置为false。 - VMware vSphere
- 如果您使用 VMware vSphere,请参阅 VMWare 文档来保证 vSphere 标准交换器的安全。通过从 vSphere Web 客户端中选择主机的虚拟交换机来查看和更改 VMWare vSphere 默认设置。
具体来说,请确保启用了以下功能:
出口路由器模式
出口路由器可以三种不同的模式运行: 重定向模式、HTTP 代理模式和 DNS 代理模式。重定向模式可用于除 HTTP 和 HTTPS 以外的所有服务。对于 HTTP 和 HTTPS 服务,请使用 HTTP 代理模式。对于使用 IP 地址或域名的基于 TCP 的服务,请使用 DNS 代理模式。
8.6.1.1. 以重定向模式部署 Egress Router Pod
在重定向模式中,出口路由器设置 iptables 规则,将流量从其自身 IP 地址重定向到一个或多个目标 IP 地址。希望使用保留源 IP 地址的客户端 pod 必须修改来连接到出口路由器,而不是直接连接到目标 IP。
使用以下内容创建 pod 配置:
apiVersion: v1 kind: Pod metadata: name: egress-1 labels: name: egress-1 annotations: pod.network.openshift.io/assign-macvlan: "true" 1 spec: initContainers: - name: egress-router image: registry.redhat.io/openshift3/ose-egress-router securityContext: privileged: true env: - name: EGRESS_SOURCE 2 value: 192.168.12.99/24 - name: EGRESS_GATEWAY 3 value: 192.168.12.1 - name: EGRESS_DESTINATION 4 value: 203.0.113.25 - name: EGRESS_ROUTER_MODE 5 value: init containers: - name: egress-router-wait image: registry.redhat.io/openshift3/ose-pod nodeSelector: site: springfield-1 6- 1
- 在主网络接口上创建一个 Macvlan 网络接口,并将它移到 pod 的网络项目中,然后再启动 egress-router 容器。保留
"true"上的引号。省略它们会导致错误。要在主接口以外的网络接口上创建 Macvlan 接口,请将注解值设置为该接口的名称。例如:eth1。 - 2
- 节点所在的物理网络中的 IP 地址,由集群管理员保留给此 pod 使用。(可选)您可以包含子网长度和
/24后缀,以便能够设置指向本地子网的正确路由。如果没有指定子网长度,则出口路由器只能访问使用EGRESS_GATEWAY变量指定的主机,且子网上没有其他主机。 - 3
- 值与节点使用的默认网关相同。
- 4
- 用于将流量定向到的外部服务器。使用这个示例,到 pod 的连接会被重定向到 203.0.113.25,源 IP 地址为 192.168.12.99。
- 5
- 这将告知出口路由器镜像,它被部署为"init 容器"。以前的 OpenShift Container Platform 版本(和出口路由器镜像)不支持这个模式,它必须作为普通容器运行。
- 6
- pod 仅部署到带有标签
site=springfield-1的节点。
使用上述定义创建 pod:
$ oc create -f <pod_name>.json
检查 pod 是否已创建:
$ oc get pod <pod_name>
通过创建服务指向出口路由器,确保其他 pod 可以找到 pod 的 IP 地址:
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http port: 80 - name: https port: 443 type: ClusterIP selector: name: egress-1您的 pod 现在可以连接到此服务。使用保留的出口 IP 地址将其连接重新指向外部服务器的对应端口。
出口路由器设置由从 openshift3/ose-egress-router 镜像创建的"init 容器"执行,该容器则特权运行,以便它配置 Macvlan 接口并设置 iptables 规则。设置 iptables 规则后,它会退出,openshift 3/ose-pod 容器将运行(什么都不运行),直到 pod 被终止为止。
环境变量告知 egress-router 镜像要使用的地址;它将配置 Macvlan 接口,以将 EGRESS_SOURCE 用作 其 IP 地址,并将 EGRESS_GATEWAY 作为其网关。
设置 NAT 规则,以便将到 Pod 集群 IP 地址上的任何 TCP 或 UDP 端口的连接重定向到 EGRESS_DESTINATION 上的相同端口。
如果集群中只有部分节点能够声明指定的源 IP 地址并使用指定的网关,您可以指定一个 nodeName 或 nodeSelector 来表示哪些节点可以接受。
8.6.1.2. 重定向至多个目标
在上例中,任何端口上的出口 pod(或其对应服务)的连接都会重定向到单个目标 IP。您还可以根据端口配置不同的目标 IP:
apiVersion: v1
kind: Pod
metadata:
name: egress-multi
labels:
name: egress-multi
annotations:
pod.network.openshift.io/assign-macvlan: "true"
spec:
initContainers:
- name: egress-router
image: registry.redhat.io/openshift3/ose-egress-router
securityContext:
privileged: true
env:
- name: EGRESS_SOURCE 1
value: 192.168.12.99/24
- name: EGRESS_GATEWAY
value: 192.168.12.1
- name: EGRESS_DESTINATION 2
value: |
80 tcp 203.0.113.25
8080 tcp 203.0.113.26 80
8443 tcp 203.0.113.26 443
203.0.113.27
- name: EGRESS_ROUTER_MODE
value: init
containers:
- name: egress-router-wait
image: registry.redhat.io/openshift3/ose-pod
EGRESS_DESTINATION 每行可以是三种类型之一:
-
<port> <protocol> <IP_address>- 这表示到给定<port>的传入连接应该被重新定向到给定<IP_address>上的同一端口。<protocol>是tcp或udp。在上例中,第一行将流量从本地端口 80 重定向到 203.0.113.25 上的端口 80。 -
<port> <protocol> <IP_address> <remote_port>- 如上所示,除了连接被重新定向到<IP_address>上的一个不同的<remote_port>中。在上例中,第二行和第三行将本地端口 8080 和 8443 重定向到 203.0.113.26 上的远程端口 80 和 443。 -
<fallback_IP_address>- 如果EGRESS_DESTINATION的最后一行是一个 IP 地址,那么任何其他端口上的任何连接都将重定向到该 IP 地址上的对应端口(例如,上例中的 203.0.113.27)。如果没有回退 IP 地址,则其他端口上的连接将直接被拒绝。)
8.6.1.3. 使用 ConfigMap 指定 EGRESS_DESTINATION
对于大量或经常更改的目标映射集合,您可以使用 ConfigMap 外部维护列表,并让出口路由器 pod 从那里读取它。这将具有项目管理员能够编辑 ConfigMap 的优点,而他们可能无法直接编辑 Pod 定义,因为它包含特权容器。
创建一个包含
EGRESS_DESTINATION数据的文件:$ cat my-egress-destination.txt # Egress routes for Project "Test", version 3 80 tcp 203.0.113.25 8080 tcp 203.0.113.26 80 8443 tcp 203.0.113.26 443 # Fallback 203.0.113.27
请注意,您可以将空行和注释放在此文件中
从文件创建 ConfigMap 对象:
$ oc delete configmap egress-routes --ignore-not-found $ oc create configmap egress-routes \ --from-file=destination=my-egress-destination.txt
此处
egress-routes是所创建的 ConfigMap 对象的名称,my-egress-destination.txt是正在从中读取数据的文件名。如上所示,创建一个出口路由器 pod 定义,但在 environment 部分为
EGRESS_DESTINATION指定 ConfigMap:... env: - name: EGRESS_SOURCE 1 value: 192.168.12.99/24 - name: EGRESS_GATEWAY value: 192.168.12.1 - name: EGRESS_DESTINATION valueFrom: configMapKeyRef: name: egress-routes key: destination - name: EGRESS_ROUTER_MODE value: init ...- 1
- 节点所在的物理网络中的 IP 地址,由集群管理员保留给此 pod 使用。(可选)您可以包含子网长度和
/24后缀,以便能够设置指向本地子网的正确路由。如果没有指定子网长度,则出口路由器只能访问使用EGRESS_GATEWAY变量指定的主机,且子网上没有其他主机。
当 ConfigMap 更改时,出口路由器不会自动更新。重新启动容器集以获取更新。
8.6.1.4. 部署 Egress Router HTTP 代理 Pod
在 HTTP 代理模式中,出口路由器作为 HTTP 代理在端口 8080 上运行。这只适用于与基于 HTTP 或基于 HTTPS 的服务进行通信的客户端,但通常需要较少的更改才能使客户端容器集正常工作。通过设置环境变量,可以告知程序使用 HTTP 代理。
使用以下示例创建 pod:
apiVersion: v1 kind: Pod metadata: name: egress-http-proxy labels: name: egress-http-proxy annotations: pod.network.openshift.io/assign-macvlan: "true" 1 spec: initContainers: - name: egress-router-setup image: registry.redhat.io/openshift3/ose-egress-router securityContext: privileged: true env: - name: EGRESS_SOURCE 2 value: 192.168.12.99/24 - name: EGRESS_GATEWAY 3 value: 192.168.12.1 - name: EGRESS_ROUTER_MODE 4 value: http-proxy containers: - name: egress-router-proxy image: registry.redhat.io/openshift3/ose-egress-http-proxy env: - name: EGRESS_HTTP_PROXY_DESTINATION 5 value: | !*.example.com !192.168.1.0/24 *- 1
- 在主网络接口上创建一个 Macvlan 网络接口,然后将它移到 pod 的网络项目中,然后再启动 egress-router 容器。保留
"true"上的引号。省略它们会导致错误。 - 2
- 节点所在的物理网络中的 IP 地址,由集群管理员保留给此 pod 使用。(可选)您可以包含子网长度和
/24后缀,以便能够设置指向本地子网的正确路由。如果没有指定子网长度,则出口路由器只能访问使用EGRESS_GATEWAY变量指定的主机,且子网上没有其他主机。 - 3
- 值与节点本身使用的默认网关相同。
- 4
- 这会告知出口路由器镜像,它被部署为 HTTP 代理的一部分,因此不应设置 iptables 重定向规则。
- 5
- 一个字符串或 YAML 多行字符串指定如何配置代理。请注意,这作为 HTTP 代理容器中的环境变量指定,而不是与 init 容器中的其他环境变量指定。
您可以为
EGRESS_HTTP_PROXY_DESTINATION值指定以下任意一项:您还可以使用*,这表示"允许连接到所有远程目的地"。配置中的每行都指定允许或者拒绝的连接组:-
IP 地址(如
192.168.1.1)允许连接到该 IP 地址。 -
CIDR 范围(如
192.168.1.0/24)允许连接到那个 CIDR 范围。 -
主机名(如
www.example.com)允许代理到该主机。 -
前面带有
*.(例如,*.example.com)的域名允许代理到那个域及其所有子域。 -
一个
!后跟上述任意一个项会拒绝连接,而不是允许连接 -
如果最后一行是
*,则允许任何未被拒绝的任何内容。否则,未被允许的任何内容都将被拒绝。
通过创建服务指向出口路由器,确保其他 pod 可以找到 pod 的 IP 地址:
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: http-proxy port: 8080 1 type: ClusterIP selector: name: egress-1- 1
- 确保
http端口始终设置为8080。
通过设置
http_proxy或https_proxy变量,将客户端 pod(而不是出口代理 pod)配置为使用 HTTP 代理:... env: - name: http_proxy value: http://egress-1:8080/ 1 - name: https_proxy value: http://egress-1:8080/ ...- 1
- 第 2 步中创建的服务。
注意不需要在所有设置中使用
http环境变量。如果以上内容没有创建可以正常工作设置,请查阅 pod 中运行的工具或软件的文档。_proxy和 https_proxy
您还可以使用 ConfigMap 指定 EGRESS_HTTP_PROXY_DESTINATION,类似于 上面的重定向出口路由器示例。
8.6.1.5. 部署 Egress Router DNS 代理 Pod
在 DNS 代理模式中,出口路由器作为基于 TCP 服务的 DNS 代理运行,从其自身 IP 地址到一个或多个目标 IP 地址。希望使用保留的客户端 pod,必须修改源 IP 地址以连接到出口路由器,而不是直接连接到目标 IP。这样可确保外部目的地将流量视为来自已知来源的流量。
使用以下示例创建 pod:
apiVersion: v1 kind: Pod metadata: name: egress-dns-proxy labels: name: egress-dns-proxy annotations: pod.network.openshift.io/assign-macvlan: "true" 1 spec: initContainers: - name: egress-router-setup image: registry.redhat.io/openshift3/ose-egress-router securityContext: privileged: true env: - name: EGRESS_SOURCE 2 value: 192.168.12.99/24 - name: EGRESS_GATEWAY 3 value: 192.168.12.1 - name: EGRESS_ROUTER_MODE 4 value: dns-proxy containers: - name: egress-dns-proxy image: registry.redhat.io/openshift3/ose-egress-dns-proxy env: - name: EGRESS_DNS_PROXY_DEBUG 5 value: "1" - name: EGRESS_DNS_PROXY_DESTINATION 6 value: | # Egress routes for Project "Foo", version 5 80 203.0.113.25 100 example.com 8080 203.0.113.26 80 8443 foobar.com 443- 1
- 使用
pod.network.openshift.io/assign-macvlan 注释在主网络接口上创建一个 Macvlan 网络接口,然后在启动 egress-router-setup 容器前将它移到 pod 的网络命名空间。保留"true"上的引号。省略它们会导致错误。 - 2
- 节点所在的物理网络中的 IP 地址,由集群管理员保留给此 pod 使用。(可选)您可以包含子网长度和
/24后缀,以便能够设置指向本地子网的正确路由。如果没有指定子网长度,则出口路由器只能访问使用EGRESS_GATEWAY变量指定的主机,且子网上没有其他主机。 - 3
- 值与节点本身使用的默认网关相同。
- 4
- 这会告知出口路由器镜像,它被部署为 DNS 代理的一部分,因此不应设置 iptables 重定向规则。
- 5
- 可选。设置此变量将在 stdout 上显示 DNS 代理日志输出。
- 6
- 这会将 YAML 语法用于多行字符串。详情请查看以下。
注意EGRESS_DNS_PROXY_DESTINATION的每一行可以通过以下两种方式之一设置:-
<port> <remote_address>- 这表示到给定<port>的传入连接应该代理到给定<remote_address>上的相同 TCP 端口,<remote_address>可以是 IP 地址或 DNS 名称。如果是 DNS 名称,DNS 解析会在运行时进行。在上例中,第一行将 TCP 流量代理从本地端口 80 到 203.0.113.25 上的端口 80。第二行将 TCP 流量代理从本地端口 100 至 example.com 上的端口 100。 -
<port> <remote_address> <remote_port>- 如上所示,除了连接代理到<remote_address>上的不同<remote_port>。在上例中,第三行代理本地端口 8080 到 203.0.113.26 上的远程端口 80,第四行将本地端口 8443 代理到 foobar.com 上的远程端口 443。
通过创建服务指向出口路由器,确保其他 pod 可以找到 pod 的 IP 地址:
apiVersion: v1 kind: Service metadata: name: egress-dns-svc spec: ports: - name: con1 protocol: TCP port: 80 targetPort: 80 - name: con2 protocol: TCP port: 100 targetPort: 100 - name: con3 protocol: TCP port: 8080 targetPort: 8080 - name: con4 protocol: TCP port: 8443 targetPort: 8443 type: ClusterIP selector: name: egress-dns-proxyPod 现在可以连接至此服务。使用保留的出口 IP 地址将其连接代理到外部服务器的对应端口。
您还可以使用 ConfigMap 指定 EGRESS_DNS_PROXY_DESTINATION,类似于 上面的重定向出口路由器示例。
8.6.1.6. 为 Egress Router Pod 启用故障切换
通过使用复制控制器,您可以确保始终有一个出口路由器 pod 副本以防止停机。
使用以下方法创建复制控制器配置文件:
apiVersion: v1 kind: ReplicationController metadata: name: egress-demo-controller spec: replicas: 1 1 selector: name: egress-demo template: metadata: name: egress-demo labels: name: egress-demo annotations: pod.network.openshift.io/assign-macvlan: "true" spec: initContainers: - name: egress-demo-init image: registry.redhat.io/openshift3/ose-egress-router env: - name: EGRESS_SOURCE 2 value: 192.168.12.99/24 - name: EGRESS_GATEWAY value: 192.168.12.1 - name: EGRESS_DESTINATION value: 203.0.113.25 - name: EGRESS_ROUTER_MODE value: init securityContext: privileged: true containers: - name: egress-demo-wait image: registry.redhat.io/openshift3/ose-pod nodeSelector: site: springfield-1
使用定义创建 pod:
$ oc create -f <replication_controller>.json
要验证,请检查是否创建了复制控制器 pod:
$ oc describe rc <replication_controller>
8.6.2. 使用 iptables 规则限制对外部资源的访问
有些集群管理员可能希望对传出流量执行操作,这些流量不适合 EgressNetworkPolicy 或出口路由器的模型。在某些情况下,这可以通过直接创建 iptables 规则来完成。
例如,您可以创建记录到特定目的地的流量的规则,或者防止每秒超过特定数量的传出连接。
OpenShift Container Platform 不提供自动添加自定义 iptables 规则的方法,但它提供了一个可供管理员手动添加此类规则的位置。在启动时,每个节点都会在 过滤器 表中创建一个名为 OPENSHIFT-ADMIN-OUTPUT-RULES 的空链(假设链尚不存在)。管理员添加至该链的任何规则都将应用到从 pod 到集群外目的地的所有流量(而不是任何其他流量)。
使用此功能时需要注意以下几点:
- 您需要确保在每个节点上创建规则 ; OpenShift Container Platform 不提供自动实现该操作的任何方法。
-
规则不适用于通过出口路由器退出集群的网络流量,并在应用
EgressNetworkPolicy规则后运行(因此不会看到EgressNetworkPolicy拒绝的流量)。 - 处理从 pod 到节点或 pod 到 master 的连接非常复杂,因为节点同时具有"外部"IP 地址和"内部"SDN IP 地址。因此,一些 pod 到节点/master 流量可能会通过此链,但其他 pod 到节点/master 流量可能会绕过它。
8.7. 为外部项目流量启用静态 IP
作为集群管理员,您可以为项目分配特定的静态 IP 地址,以便流量可在外部轻松识别。这与默认出口路由器不同,后者用于将流量发送到特定目的地。
可识别的 IP 流量通过确保原始数据可见来提高集群安全性。启用后,来自指定项目的所有传出外部连接将共享相同的固定源 IP,这意味着任何外部资源都可以识别流量。
与出口路由器不同,这可能受 EgressNetworkPolicy 防火墙规则的约束。
为集群中的项目分配静态 IP 地址需要 SDN 使用 ovs-networkpolicy 或 ovs-multitenant 网络插件。
如果您以多租户模式使用 OpenShift SDN,则无法将出口 IP 地址与与其关联的项目附加到另一个命名空间的任何命名空间一起使用。例如,如果 project1 和 project2 通过运行 oc adm pod-network join-projects --to=project1 project2 命令被连接,则这两个项目都不能使用出口 IP 地址。如需更多信息,请参阅 BZ#1645577。
启用静态源 IP:
使用所需 IP 更新
NetNamespace:$ oc patch netnamespace <project_name> -p '{"egressIPs": ["<IP_address>"]}'例如,将
MyProject项目分配给 IP 地址 192.168.1.100:$ oc patch netnamespace MyProject -p '{"egressIPs": ["192.168.1.100"]}'egressIPs字段是一个数组。您可以将egressIPs设置为位于不同节点上的两个或多个 IP 地址,以提供高可用性。如果设置了多个出口 IP 地址,Pod 会将列表中的第一个 IP 用于出口,但如果托管该 IP 地址的节点失败,Pod 会在短暂的延迟后切换到使用列表中的下一个 IP。手动将出口 IP 分配给所需的节点主机。在节点主机上的
HostSubnet对象中设置egressIPs字段。包含尽可能多的 IP 地址,以便分配给该节点主机:$ oc patch hostsubnet <node_name> -p \ '{"egressIPs": ["<IP_address_1>", "<IP_address_2>"]}'例如,假设
node1应具有出口 IP 192.168.1.100、192.168.1.101 和 192.168.1.102:$ oc patch hostsubnet node1 -p \ '{"egressIPs": ["192.168.1.100", "192.168.1.101", "192.168.1.102"]}'重要出口 IP 是作为额外 IP 地址在主网络接口中实现的,且必须与节点的主 IP 位于同一个子网中。此外,不应在任何 Linux 网络配置文件中配置任何外部 IP,如 ifcfg-eth0。
在主网络接口上允许额外 IP 地址可能需要在使用某些云或虚拟机解决方案时进行额外的配置。
如果为项目启用了上述内容,则该项目的所有出口流量都将路由到托管该出口 IP 的节点,然后(使用 NAT)连接到该 IP 地址。如果在 NetNamespace 中设置 egressIPs,但没有节点托管该出口 IP,则会丢弃来自该命名空间的出口流量。
8.8. 启用自动 Egress IP
与 为外部项目流量启用静态 IP 类似,作为集群管理员,您可以通过将 egressIPs 参数设置为 NetNamespace 资源,将出口 IP 地址分配给命名空间。您只能将单个 IP 地址与一个项目关联。
如果您以多租户模式使用 OpenShift SDN,则无法将出口 IP 地址与与其关联的项目附加到另一个命名空间的任何命名空间一起使用。例如,如果 project1 和 project2 通过运行 oc adm pod-network join-projects --to=project1 project2 命令被连接,则这两个项目都不能使用出口 IP 地址。如需更多信息,请参阅 BZ#1645577。
使用完全自动出口 IP,您可以设置每个节点的 HostSubnet 资源的 egressCIDRs 参数,以指示可以托管的出口 IP 地址范围。请求出口 IP 地址的命名空间与可以托管那些出口 IP 地址的节点匹配,然后将出口 IP 地址分配给这些节点。
高可用性是自动的。如果托管出口 IP 地址的节点停机,并且根据 HostSubnet 资源的 egressCIDR 值托管这些出口 IP 地址的节点,则出口 IP 地址将移到一个新节点。当原始出口 IP 地址节点恢复在线后,出口 IP 地址会自动移动,以在节点之间均衡出口 IP 地址。
您不能在同一节点上使用手动分配和自动分配的出口 IP 地址,或者 IP 地址范围相同。
使用出口 IP 地址更新
NetNamespace:$ oc patch netnamespace <project_name> -p '{"egressIPs": ["<IP_address>"]}'您只能为
egressIPs参数指定一个 IP 地址。不支持使用多 IP 地址。例如,将
project1分配给 IP 地址 192.168.1.100,将project2分配给 IP 地址 192.168.1.101:$ oc patch netnamespace project1 -p '{"egressIPs": ["192.168.1.100"]}' $ oc patch netnamespace project2 -p '{"egressIPs": ["192.168.1.101"]}''通过设置哪些节点的
egressCIDRs字段来指示哪些节点可以托管出口 IP 地址:$ oc patch hostsubnet <node_name> -p \ '{"egressCIDRs": ["<IP_address_range_1>", "<IP_address_range_2>"]}'例如,将
node1和node2设置为托管范围为 192.168.1.0 到 192.168.1.255 的出口 IP 地址:$ oc patch hostsubnet node1 -p '{"egressCIDRs": ["192.168.1.0/24"]}' $ oc patch hostsubnet node2 -p '{"egressCIDRs": ["192.168.1.0/24"]}'-
OpenShift Container Platform 会自动以均衡的方式将特定的出口 IP 地址分配给可用的节点。在本例中,它会将出口 IP 地址 192.168.1.100 分配给
node1,并将出口 IP 地址 192.168.1.101 分配给node2,或反之。
8.9. 启用多播
目前,多播最适用于低带宽协调或服务发现,而不是高带宽解决方案。
默认情况下,OpenShift Container Platform pod 之间多播流量被禁用。如果使用 ovs-multitenant 或 ovs-networkpolicy 插件,您可以通过在项目对应的 netnamespace 对象上设置注解来启用每个项目的多播:
$ oc annotate netnamespace <namespace> \
netnamespace.network.openshift.io/multicast-enabled=true通过删除注解来禁用多播:
$ oc annotate netnamespace <namespace> \
netnamespace.network.openshift.io/multicast-enabled-使用 ovs-multitenant 插件时:
- 在隔离的项目中,容器集发送的多播数据包将传送到项目中的所有其他 pod。
-
如果将 网络连接在一起,则需要在每个项目的
netnamespace中启用多播,以便它在任何项目中生效。接合网络中的 pod 发送的多播数据包将传送到所有接合网络中的所有 pod。 -
要在
default项目中启用多播,还必须在kube-service-catalog项目和所有其他 已全局 的项目中启用它。全局项目不是多播的"全局";全局项目中的 pod 发送的多播数据包将仅传送到其他全局项目中的 pod,而非所有项目中的所有容器集。同样,全局项目中的 pod 将仅接收从其他全局项目中的 pod 发送的多播数据包,而不接收来自所有项目中所有容器集的多播数据包。
使用 ovs-networkpolicy 插件时:
-
pod 发送的多播数据包将传送到项目中的所有其他 pod,而无需考虑
NetworkPolicy对象。(pod 或许能通过多播进行通信,即使它们无法通过单播进行通信。) -
一个项目中的 pod 发送的多播数据包不会传送到任何其他项目中的 pod,即使存在允许项目间通信的
NetworkPolicy 对象。
8.10. 启用 NetworkPolicy
ovs-subnet 和 ovs-multitenant 插件具有自己的传统网络隔离模型,不支持 Kubernetes NetworkPolicy。但是,NetworkPolicy 支持可以通过 ovs-networkpolicy 插件获得。
Egress 策略类型、ipBlock 参数以及 OpenShift Container Platform 中无法组合 podSelector 和 namespaceSelector 参数的能力。
不要在默认的 OpenShift Container Platform 项目中应用 NetworkPolicy 功能,因为它们可能会破坏与集群的通信。
NetworkPolicy 规则不适用于主机网络命名空间。启用主机网络的 Pod 不受 NetworkPolicy 规则的影响 。
在 配置为使用 ovs-networkpolicy 插件的 集群中,网络隔离完全由 NetworkPolicy 对象 控制。默认情况下,项目中的所有 pod 都可被其他 pod 和网络端点访问。要在一个项目中隔离一个或多个 Pod,您可以在该项目中创建 NetworkPolicy 对象来指示允许的入站连接。项目管理员可以在自己的项目中创建和删除 NetworkPolicy 对象。
没有指向它们的 NetworkPolicy 对象的 Pod 可以完全访问,而具有一个或多个指向它们的 NetworkPolicy 对象的 pod 会被隔离。这些隔离的 pod 只接受至少被其中一个 NetworkPolicy 对象接受的连接。
以下是一些支持不同场景的 NetworkPolicy 对象定义示例:
拒绝所有流量
要使项目"默认为拒绝"添加匹配所有 pod 但不接受任何流量的
NetworkPolicy对象。kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: deny-by-default spec: podSelector: ingress: []
仅接受项目中 pod 的连接
要使 pod 接受同一项目中其他 pod 的连接,但拒绝其他项目中所有 pod 的连接:
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-same-namespace spec: podSelector: ingress: - from: - podSelector: {}只允许基于 pod 标签的 HTTP 和 HTTPS 流量
要对带有特定标签的 Pod 仅启用 HTTP 和 HTTPS 访问(以下示例中
role=frontend),请添加类似如下的NetworkPolicy对象:kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-http-and-https spec: podSelector: matchLabels: role: frontend ingress: - ports: - protocol: TCP port: 80 - protocol: TCP port: 443
NetworkPolicy 对象是可添加的;也就是说,您可以组合多个 NetworkPolicy 对象来满足复杂的网络要求。
例如,对于以上示例中定义的 NetworkPolicy 对象,您可以在同一个项目中定义 allow-same-namespace 和 allow-http-and-https 策略。因此,允许带有标签 role=frontend 的 pod 接受每一策略所允许的任何连接。也就是说,任何端口上来自同一 命名空间中的 pod 的连接,以及端口 80 和 443 上的来自 任意 命名空间中 pod 的连接。
8.10.1. 高效地使用 NetworkPolicy
NetworkPolicy 对象允许您在命名空间中通过标签来相互隔离不同的 pod。
将 NetworkPolicy 对象应用到单一命名空间中的大量 pod 时,效率较低。pod 标签不存在于 IP 级别上,因此 NetworkPolicy 对象会为使用 pod Selector 选择的每个 pod 之间生成单独的 OVS 流规则。
例如,在一个 NetworkPolicy 对象中如果 spec podSelector 和 ingress podSelector 每个都匹配 200 个 pod,则会产生 40,000 (200*200) 个 OVS 流规则。这可能会减慢机器的速度。
若要减少 OVS 流规则的数量,可使用命名空间来包含需要隔离的 pod 组。
使用 namespaceSelectors 或空 podSelectors 选择整个命名空间的 NetworkPolicy 对象只会生成与命名空间的 VXLAN VNID 匹配的 OVS 流规则。
保留不需要在原始命名空间中隔离的 pod,并将需要隔离的 pod 移到一个或多个不同的命名空间中。
创建额外的目标跨命名空间策略,以允许来自隔离 pod 的特定流量。
8.10.2. NetworkPolicy 和路由器
使用 ovs-multitenant 插件时,所有命名空间中会自动允许来自路由器的流量。这是因为路由器通常位于 default 命名空间中,所有命名空间都允许来自该命名空间中的 pod 的连接。使用 ovs-networkpolicy 插件时,这不会自动发生。因此,如果您有一个默认隔离命名空间的策略,则需要执行额外的步骤来允许路由器访问命名空间。
一种选择是为每个服务创建一个策略,允许从所有来源访问。例如:
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: allow-to-database-service
spec:
podSelector:
matchLabels:
role: database
ingress:
- ports:
- protocol: TCP
port: 5432这允许路由器访问该服务,但也允许其他用户命名空间中的容器集访问该服务。这不应造成任何问题,因为这些容器集通常可以使用公共路由器访问服务。
另外,您可以创建一个允许从默认命名空间中完全访问的策略,如 ovs-multitenant 插件中所示:
向 default 命名空间添加标签。
重要如果您使用上一步中的默认标签标记了
default项目,则跳过这一步。集群管理员角色需要向命名空间添加标签。$ oc label namespace default name=default
创建允许从该命名空间进行连接的策略。
注意对您要允许连接的每个命名空间执行此步骤。具有 Project Administrator 角色的用户可以创建策略。
kind: NetworkPolicy apiVersion: networking.k8s.io/v1 metadata: name: allow-from-default-namespace spec: podSelector: ingress: - from: - namespaceSelector: matchLabels: name: default
8.10.3. 为新项目设置默认 NetworkPolicy
集群管理员可修改默认项目模板,以便在创建新项目时自动创建默认 NetworkPolicy 对象 (一个或多个)。要做到这一点:
- 创建自定义项目模板,并将主模板配置为使用它。
使用
default标签标记default项目:重要如果您使用上一步中的默认标签标记了
default项目,则跳过这一步。集群管理员角色需要向命名空间添加标签。$ oc label namespace default name=default
编辑模板以包含所需的
NetworkPolicy对象:$ oc edit template project-request -n default
注意要将
NetworkPolicy对象包含在现有模板中,请使用oc edit命令。目前,无法使用oc patch将对象添加到Template资源中。在
objects数组中添加每个默认策略作为元素:objects: ... - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-same-namespace spec: podSelector: ingress: - from: - podSelector: {} - apiVersion: networking.k8s.io/v1 kind: NetworkPolicy metadata: name: allow-from-default-namespace spec: podSelector: ingress: - from: - namespaceSelector: matchLabels: name: default ...
8.11. 启用 HTTP 严格传输安全性
HTTP 严格传输安全性 (HSTS) 策略是一种安全增强,可确保主机上只允许 HTTPS 流量。所有 HTTP 请求都会默认丢弃。这可用于确保与网站安全交互,或提供安全应用程序让用户受益。
当 HSTS 启用时,HSTS 会添加一个 Strict Transport Security 标头到站点的 HTTPS 响应。您可以在要重定向的路由中使用 insecureEdgeTerminationPolicy 值,以将 HTTP 发送到 HTTPS。但是,当启用 HSTS 时,客户端会在发送请求前将所有来自 HTTP URL 的请求更改为 HTTPS,从而消除对重定向的需求。客户端不需要支持此功能,而且也可通过设置 max-age=0 来禁用。
HSTS 仅适用于安全路由(边缘终止或重新加密)。其配置在 HTTP 或传递路由上无效。
要将 HSTS 启用到路由,请将 haproxy.router.openshift.io/hsts_header 值添加到边缘终止或重新加密路由:
apiVersion: v1
kind: Route
metadata:
annotations:
haproxy.router.openshift.io/hsts_header: max-age=31536000;includeSubDomains;preload
确保 haproxy.router.openshift.io/hsts_header 值的参数中没有空格,且没有其他值。仅需要 max-age。
所需的 max-age 参数指示时间长度(以秒为单位),HSTS 策略生效。每当从主机收到含有 HSTS 标头的响应时,客户端会更新 max-age。如果 max-age 超时,客户端会丢弃该策略。
可选 includeSubDomains 参数告知客户端主机的所有子域与主机相同。
如果 max-age 大于 0,可选的 preload 参数允许外部服务将此站点包含在 HSTS 预加载列表中。例如,Google 等站点可以构造设有 preload 的站点的列表。浏览器可以使用这些列表来确定哪些站点仅通过 HTTPS 与 通信,即使在哪些站点与站点交互之前也是如此。如果不设置 preload,他们需要通过 HTTPS 与站点通信以获取标头。
8.12. 吞吐量问题故障排除
有时,通过 OpenShift Container Platform 部署的应用程序可能会导致网络吞吐量问题,如特定服务间的延迟异常高。
如果 pod 日志未能揭示造成问题的原因,请使用以下方法分析性能问题:
使用 ping 或 tcpdump 等数据包分析器,分析 pod 与其节点之间的流量。
例如,在每个 pod 上运行 tcpdump 工具,同时重现导致问题的行为。检查两端的捕获信息,以便比较发送和接收时间戳来分析与 pod 往来的流量的延迟。如果节点接口被其他 pod、存储设备或者数据平面的流量过载,则 OpenShift Container Platform 中可能会出现延迟。
$ tcpdump -s 0 -i any -w /tmp/dump.pcap host <podip 1> && host <podip 2> 1- 1
podip是 pod 的 IP 地址。运行以下命令以获取 pod 的 IP 地址:
# oc get pod <podname> -o wide
tcpdump 在 /tmp/dump.pcap 中生成一个包含这两个 pod 间所有流量的文件。最好在运行分析器后立即重现问题,并在问题重现完成后马上停止分析器,从而尽量减小文件的大小。您还可以通过以下命令,在节点之间运行数据包分析器(从考量范围中剔除 SDN):
# tcpdump -s 0 -i any -w /tmp/dump.pcap port 4789
- 使用 iperf 等带宽测量工具来测量数据流吞吐量和 UDP 吞吐量。先从 pod 运行该工具,然后从节点运行,以尝试查找瓶颈。iperf3 工具是 RHEL 7 的一部分。
有关安装和使用 iperf3 的详情,请参考这个 红帽解决方案。
第 9 章 配置服务帐户
9.1. 概述
当用户使用 OpenShift Container Platform CLI 或 Web 控制台时,他们的 API 令牌会通过 OpenShift Container Platform API 进行身份验证。但是,当普通用户的凭据不可用时,组件通常会单独进行 API 调用。例如:
- 复制控制器进行 API 调用来创建或删除容器集。
- 容器内的应用可以发出 API 调用来进行发现。
- 外部应用程序可以发出 API 调用来监控或集成。
服务帐户为控制 API 访问提供了灵活的方式,不需要共享常规用户的凭证。
9.2. 用户名和组
每个服务帐户都有一个关联的用户名,可以像普通用户一样被授予角色。用户名派生自其项目和名称:
system:serviceaccount:<project>:<name>
例如,将 view 角色添加到 top-secret 项目中的 robot 服务帐户:
$ oc policy add-role-to-user view system:serviceaccount:top-secret:robot
如果要向项目中的特定服务帐户授予访问权限,您可以使用 -z 标志。在服务帐户所属的项目中,使用 -z 标志并指定 <serviceaccount_name>。强烈建议您这样做,因为它有助于防止拼写错误,并确保只为指定的服务帐户授予访问权限。例如:
$ oc policy add-role-to-user <role_name> -z <serviceaccount_name>
如果没有在项目中,请使用 -n 选项来指示它应用到的项目命名空间,如下例所示。
每一服务帐户也是以下两个组的成员:
- system:serviceaccounts
- 包含系统中的所有服务帐户。
- system:serviceaccounts:<project>
- 包含指定项目中的所有服务帐户。
例如,允许所有项目中的所有服务帐户查看 top-secret 项目中的资源:
$ oc policy add-role-to-group view system:serviceaccounts -n top-secret
允许 managers 项目中的所有服务帐户编辑 top-secret 项目中的资源:
$ oc policy add-role-to-group edit system:serviceaccounts:managers -n top-secret
9.3. 管理服务帐户
服务帐户是各个项目中存在的 API 对象。要管理服务帐户,您可以使用 oc 命令和 sa 或 serviceaccount 对象类型,或者使用 Web 控制台。
获取当前项目中现有服务帐户的列表:
$ oc get sa NAME SECRETS AGE builder 2 2d default 2 2d deployer 2 2d
要创建新服务帐户,请执行以下操作:
$ oc create sa robot serviceaccount "robot" created
一旦创建了服务帐户,会自动向其中添加两个 secret:
- API 令牌
- OpenShift Container Registry 的凭证
可以通过描述服务帐户来查看它们:
$ oc describe sa robot
Name: robot
Namespace: project1
Labels: <none>
Annotations: <none>
Image pull secrets: robot-dockercfg-qzbhb
Mountable secrets: robot-token-f4khf
robot-dockercfg-qzbhb
Tokens: robot-token-f4khf
robot-token-z8h44系统确保服务帐户始终具有 API 令牌和 registry 凭据。
生成的 API 令牌和 registry 凭据不会过期,但可通过删除 secret 来撤销。删除 secret 时,会自动生成一个新 secret 来代替它。
9.4. 启用服务帐户身份验证
服务帐户使用由 RSA 私钥签名的令牌向 API 进行身份验证。身份验证层使用匹配的公共 RSA 密钥验证签名。
要启用服务帐户令牌生成,更新 master 上的 /etc/origin/master/master-config.yml 文件中的 serviceAccountConfig 小节,以指定 privateKeyFile (用于签名)以及 publicKeyFiles 列表中匹配的公钥文件:
9.5. 受管服务帐户
每个项目都需要服务帐户来运行构建、部署和其他容器集。master 控制哪些服务帐户在每个项目中自动创建的 /etc/origin/master/master-config.yml 文件中的 managedNames 设置:
serviceAccountConfig: ... managedNames: 1 - builder 2 - deployer 3 - default 4 - ...
项目中的所有服务帐户都会被授予 system:image-puller 角色,允许使用内部容器镜像 registry 从项目中的任何镜像流拉取镜像。
9.6. 基础架构服务帐户
几个基础架构控制器使用服务帐户凭证运行。服务器启动时在 OpenShift Container Platform 基础架构项目 (openshift-infra) 中创建以下服务帐户,并授予其如下集群范围角色:
| 服务帐户 | 描述 |
|---|---|
| replication-controller | 分配 system:replication-controller 角色 |
| deployment-controller | 分配 system:deployment-controller 角色。 |
| build-controller | 分配 system:build-controller 角色。另外,build-controller 服务帐户也包含在特权安全上下文约束中,以便创建特权构建 Pod。 |
要配置创建这些服务帐户的项目,请在 master 上的 /etc/origin/master/master-config.yml 文件中设置 openshiftInfrastructureNamespace 字段:
policyConfig: ... openshiftInfrastructureNamespace: openshift-infra
9.7. 服务帐户和 Secrets
将 master 上的 /etc/origin/master/master-config.yml 文件中的 limitSecretReferences 字段设置为 true,要求其服务帐户将 pod secret 引用列入白名单。将它的值设为 false,以允许容器集引用项目中的任何机密。
serviceAccountConfig: ... limitSecretReferences: false
第 10 章 管理基于角色的访问控制 (RBAC)
10.1. 概述
10.2. 查看角色和绑定
角色 可用于授予 集群范围 和 项目范围内的各种访问级别。用户和组可以同时关联或绑定到多个角色。您可以使用 oc describe 命令查看角色及其绑定的详细信息。
在集群范围内绑定了 cluster-admin 默认集群角色的用户可以对任何资源执行任何操作。本地绑定了 admin 默认集群角色的用户可以管理该项目中的角色和绑定。
检查 Evaluating Authorization 部分中的操作动词的完整列表。
10.2.1. 查看集群角色
查看集群角色及其关联的规则集:
$ oc describe clusterrole.rbac Name: admin Labels: <none> Annotations: openshift.io/description=A user that has edit rights within the project and can change the project's membership. rbac.authorization.kubernetes.io/autoupdate=true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- appliedclusterresourcequotas [] [] [get list watch] appliedclusterresourcequotas.quota.openshift.io [] [] [get list watch] bindings [] [] [get list watch] buildconfigs [] [] [create delete deletecollection get list patch update watch] buildconfigs.build.openshift.io [] [] [create delete deletecollection get list patch update watch] buildconfigs/instantiate [] [] [create] buildconfigs.build.openshift.io/instantiate [] [] [create] buildconfigs/instantiatebinary [] [] [create] buildconfigs.build.openshift.io/instantiatebinary [] [] [create] buildconfigs/webhooks [] [] [create delete deletecollection get list patch update watch] buildconfigs.build.openshift.io/webhooks [] [] [create delete deletecollection get list patch update watch] buildlogs [] [] [create delete deletecollection get list patch update watch] buildlogs.build.openshift.io [] [] [create delete deletecollection get list patch update watch] builds [] [] [create delete deletecollection get list patch update watch] builds.build.openshift.io [] [] [create delete deletecollection get list patch update watch] builds/clone [] [] [create] builds.build.openshift.io/clone [] [] [create] builds/details [] [] [update] builds.build.openshift.io/details [] [] [update] builds/log [] [] [get list watch] builds.build.openshift.io/log [] [] [get list watch] configmaps [] [] [create delete deletecollection get list patch update watch] cronjobs.batch [] [] [create delete deletecollection get list patch update watch] daemonsets.extensions [] [] [get list watch] deploymentconfigrollbacks [] [] [create] deploymentconfigrollbacks.apps.openshift.io [] [] [create] deploymentconfigs [] [] [create delete deletecollection get list patch update watch] deploymentconfigs.apps.openshift.io [] [] [create delete deletecollection get list patch update watch] deploymentconfigs/instantiate [] [] [create] deploymentconfigs.apps.openshift.io/instantiate [] [] [create] deploymentconfigs/log [] [] [get list watch] deploymentconfigs.apps.openshift.io/log [] [] [get list watch] deploymentconfigs/rollback [] [] [create] deploymentconfigs.apps.openshift.io/rollback [] [] [create] deploymentconfigs/scale [] [] [create delete deletecollection get list patch update watch] deploymentconfigs.apps.openshift.io/scale [] [] [create delete deletecollection get list patch update watch] deploymentconfigs/status [] [] [get list watch] deploymentconfigs.apps.openshift.io/status [] [] [get list watch] deployments.apps [] [] [create delete deletecollection get list patch update watch] deployments.extensions [] [] [create delete deletecollection get list patch update watch] deployments.extensions/rollback [] [] [create delete deletecollection get list patch update watch] deployments.apps/scale [] [] [create delete deletecollection get list patch update watch] deployments.extensions/scale [] [] [create delete deletecollection get list patch update watch] deployments.apps/status [] [] [create delete deletecollection get list patch update watch] endpoints [] [] [create delete deletecollection get list patch update watch] events [] [] [get list watch] horizontalpodautoscalers.autoscaling [] [] [create delete deletecollection get list patch update watch] horizontalpodautoscalers.extensions [] [] [create delete deletecollection get list patch update watch] imagestreamimages [] [] [create delete deletecollection get list patch update watch] imagestreamimages.image.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreamimports [] [] [create] imagestreamimports.image.openshift.io [] [] [create] imagestreammappings [] [] [create delete deletecollection get list patch update watch] imagestreammappings.image.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io [] [] [create delete deletecollection get list patch update watch] imagestreams/layers [] [] [get update] imagestreams.image.openshift.io/layers [] [] [get update] imagestreams/secrets [] [] [create delete deletecollection get list patch update watch] imagestreams.image.openshift.io/secrets [] [] [create delete deletecollection get list patch update watch] imagestreams/status [] [] [get list watch] imagestreams.image.openshift.io/status [] [] [get list watch] imagestreamtags [] [] [create delete deletecollection get list patch update watch] imagestreamtags.image.openshift.io [] [] [create delete deletecollection get list patch update watch] jenkins.build.openshift.io [] [] [admin edit view] jobs.batch [] [] [create delete deletecollection get list patch update watch] limitranges [] [] [get list watch] localresourceaccessreviews [] [] [create] localresourceaccessreviews.authorization.openshift.io [] [] [create] localsubjectaccessreviews [] [] [create] localsubjectaccessreviews.authorization.k8s.io [] [] [create] localsubjectaccessreviews.authorization.openshift.io [] [] [create] namespaces [] [] [get list watch] namespaces/status [] [] [get list watch] networkpolicies.extensions [] [] [create delete deletecollection get list patch update watch] persistentvolumeclaims [] [] [create delete deletecollection get list patch update watch] pods [] [] [create delete deletecollection get list patch update watch] pods/attach [] [] [create delete deletecollection get list patch update watch] pods/exec [] [] [create delete deletecollection get list patch update watch] pods/log [] [] [get list watch] pods/portforward [] [] [create delete deletecollection get list patch update watch] pods/proxy [] [] [create delete deletecollection get list patch update watch] pods/status [] [] [get list watch] podsecuritypolicyreviews [] [] [create] podsecuritypolicyreviews.security.openshift.io [] [] [create] podsecuritypolicyselfsubjectreviews [] [] [create] podsecuritypolicyselfsubjectreviews.security.openshift.io [] [] [create] podsecuritypolicysubjectreviews [] [] [create] podsecuritypolicysubjectreviews.security.openshift.io [] [] [create] processedtemplates [] [] [create delete deletecollection get list patch update watch] processedtemplates.template.openshift.io [] [] [create delete deletecollection get list patch update watch] projects [] [] [delete get patch update] projects.project.openshift.io [] [] [delete get patch update] replicasets.extensions [] [] [create delete deletecollection get list patch update watch] replicasets.extensions/scale [] [] [create delete deletecollection get list patch update watch] replicationcontrollers [] [] [create delete deletecollection get list patch update watch] replicationcontrollers/scale [] [] [create delete deletecollection get list patch update watch] replicationcontrollers.extensions/scale [] [] [create delete deletecollection get list patch update watch] replicationcontrollers/status [] [] [get list watch] resourceaccessreviews [] [] [create] resourceaccessreviews.authorization.openshift.io [] [] [create] resourcequotas [] [] [get list watch] resourcequotas/status [] [] [get list watch] resourcequotausages [] [] [get list watch] rolebindingrestrictions [] [] [get list watch] rolebindingrestrictions.authorization.openshift.io [] [] [get list watch] rolebindings [] [] [create delete deletecollection get list patch update watch] rolebindings.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] rolebindings.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] roles [] [] [create delete deletecollection get list patch update watch] roles.authorization.openshift.io [] [] [create delete deletecollection get list patch update watch] roles.rbac.authorization.k8s.io [] [] [create delete deletecollection get list patch update watch] routes [] [] [create delete deletecollection get list patch update watch] routes.route.openshift.io [] [] [create delete deletecollection get list patch update watch] routes/custom-host [] [] [create] routes.route.openshift.io/custom-host [] [] [create] routes/status [] [] [get list watch update] routes.route.openshift.io/status [] [] [get list watch update] scheduledjobs.batch [] [] [create delete deletecollection get list patch update watch] secrets [] [] [create delete deletecollection get list patch update watch] serviceaccounts [] [] [create delete deletecollection get list patch update watch impersonate] services [] [] [create delete deletecollection get list patch update watch] services/proxy [] [] [create delete deletecollection get list patch update watch] statefulsets.apps [] [] [create delete deletecollection get list patch update watch] subjectaccessreviews [] [] [create] subjectaccessreviews.authorization.openshift.io [] [] [create] subjectrulesreviews [] [] [create] subjectrulesreviews.authorization.openshift.io [] [] [create] templateconfigs [] [] [create delete deletecollection get list patch update watch] templateconfigs.template.openshift.io [] [] [create delete deletecollection get list patch update watch] templateinstances [] [] [create delete deletecollection get list patch update watch] templateinstances.template.openshift.io [] [] [create delete deletecollection get list patch update watch] templates [] [] [create delete deletecollection get list patch update watch] templates.template.openshift.io [] [] [create delete deletecollection get list patch update watch] Name: basic-user Labels: <none> Annotations: openshift.io/description=A user that can get basic information about projects. rbac.authorization.kubernetes.io/autoupdate=true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- clusterroles [] [] [get list] clusterroles.authorization.openshift.io [] [] [get list] clusterroles.rbac.authorization.k8s.io [] [] [get list watch] projectrequests [] [] [list] projectrequests.project.openshift.io [] [] [list] projects [] [] [list watch] projects.project.openshift.io [] [] [list watch] selfsubjectaccessreviews.authorization.k8s.io [] [] [create] selfsubjectrulesreviews [] [] [create] selfsubjectrulesreviews.authorization.openshift.io [] [] [create] storageclasses.storage.k8s.io [] [] [get list] users [] [~] [get] users.user.openshift.io [] [~] [get] Name: cluster-admin Labels: <none> Annotations: authorization.openshift.io/system-only=true openshift.io/description=A super-user that can perform any action in the cluster. When granted to a user within a project, they have full control over quota and membership and can perform every action... rbac.authorization.kubernetes.io/autoupdate=true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- [*] [] [*] *.* [] [] [*] Name: cluster-debugger Labels: <none> Annotations: authorization.openshift.io/system-only=true rbac.authorization.kubernetes.io/autoupdate=true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- [/debug/pprof] [] [get] [/debug/pprof/*] [] [get] [/metrics] [] [get] Name: cluster-reader Labels: <none> Annotations: authorization.openshift.io/system-only=true rbac.authorization.kubernetes.io/autoupdate=true PolicyRule: Resources Non-Resource URLs Resource Names Verbs --------- ----------------- -------------- ----- [*] [] [get] apiservices.apiregistration.k8s.io [] [] [get list watch] apiservices.apiregistration.k8s.io/status [] [] [get list watch] appliedclusterresourcequotas [] [] [get list watch] ...
10.2.2. 查看集群角色绑定
查看当前的集群角色绑定集合,这显示绑定到各种角色的用户和组:
$ oc describe clusterrolebinding.rbac Name: admin Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount template-instance-controller openshift-infra Name: basic-users Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: cluster-admin Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount pvinstaller default Group system:masters Name: cluster-admins Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: cluster-admin Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-admins User system:admin Name: cluster-readers Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: cluster-reader Subjects: Kind Name Namespace ---- ---- --------- Group system:cluster-readers Name: cluster-status-binding Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: cluster-status Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Group system:unauthenticated Name: registry-registry-role Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:registry Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount registry default Name: router-router-role Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:router Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount router default Name: self-access-reviewers Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: self-access-reviewer Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Group system:unauthenticated Name: self-provisioners Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: self-provisioner Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated:oauth Name: system:basic-user Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:basic-user Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Group system:unauthenticated Name: system:build-strategy-docker-binding Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:build-strategy-docker Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: system:build-strategy-jenkinspipeline-binding Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:build-strategy-jenkinspipeline Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: system:build-strategy-source-binding Labels: <none> Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:build-strategy-source Subjects: Kind Name Namespace ---- ---- --------- Group system:authenticated Name: system:controller:attachdetach-controller Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:controller:attachdetach-controller Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount attachdetach-controller kube-system Name: system:controller:certificate-controller Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate=true Role: Kind: ClusterRole Name: system:controller:certificate-controller Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount certificate-controller kube-system Name: system:controller:cronjob-controller Labels: kubernetes.io/bootstrapping=rbac-defaults Annotations: rbac.authorization.kubernetes.io/autoupdate=true ...
10.2.3. 查看本地角色和绑定
所有默认集群角色都可以在本地绑定到用户或组。
可以创建自定义本地角色。
本地角色绑定也可以查看。
查看当前的本地角色绑定集合,这显示绑定到各种角色的用户和组:
$ oc describe rolebinding.rbac
默认情况下,在查看本地角色绑定时使用当前项目。此外,也可通过 -n 标志指定项目。如果用户已经拥有 admin 默认集群角色,这可用于查看另一个项目的本地角色绑定。
$ oc describe rolebinding.rbac -n joe-project Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User joe Name: system:deployers Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
10.3. 管理角色绑定
向用户或组添加或 绑定 角色 可让用户或组获得该角色授予的相关访问权限。您可以使用 oc adm policy 命令向用户和组添加和移除角色。
在使用以下操作为本地角色绑定管理用户或组的关联角色时,可以通过 -n 标志来指定项目:如果未指定,则使用当前项目。
表 10.1. 本地角色绑定操作
| 命令 | 描述 |
|---|---|
|
| 指出哪些用户可以对某一资源执行某种操作。 |
|
| 将给定角色绑定到当前项目中的指定用户。 |
|
| 从当前项目中的指定用户移除指定角色。 |
|
| 移除当前项目中的指定用户及其所有角色。 |
|
| 将给定角色绑定到当前项目中的指定组。 |
|
| 从当前项目中的指定组移除给定角色。 |
|
| 移除当前项目中的指定组及其所有角色。 |
|
|
可以与 |
您也可以使用以下操作管理集群角色绑定。因为集群角色绑定使用没有命名空间的资源,所以这些操作不使用 -n 标志。
表 10.2. 集群角色绑定操作
| 命令 | 描述 |
|---|---|
|
| 将给定角色绑定到集群中所有项目的指定用户。 |
|
| 从集群中所有项目的指定用户移除给定角色。 |
|
| 将给定角色绑定到集群中所有项目的指定组。 |
|
| 从集群中所有项目的指定组移除给定角色。 |
|
|
可以与 |
例如,您可以运行以下命令,将 admin 角色添加到 joe-project 中的 alice 用户:
$ oc adm policy add-role-to-user admin alice -n joe-project
然后您可以查看本地角色绑定,并在输出中验证添加情况:
$ oc describe rolebinding.rbac -n joe-project Name: admin Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User joe Name: admin-0 1 Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: admin Subjects: Kind Name Namespace ---- ---- --------- User alice 2 Name: system:deployers Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:deployer Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount deployer joe-project Name: system:image-builders Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:image-builder Subjects: Kind Name Namespace ---- ---- --------- ServiceAccount builder joe-project Name: system:image-pullers Labels: <none> Annotations: <none> Role: Kind: ClusterRole Name: system:image-puller Subjects: Kind Name Namespace ---- ---- --------- Group system:serviceaccounts:joe-project
10.4. 创建本地角色
您可以为项目创建本地角色,然后将其绑定到用户。
要为项目创建本地角色,请运行以下命令:
$ oc create role <name> --verb=<verb> --resource=<resource> -n <project>
在这个命令中,指定: *
<name>,即本地角色的名称 *<verb>,这是以逗号分隔的动词列表,应用到角色 *<resource>,即项目名称 *<project>+ 例如,要创建一个本地角色来允许用户查看
blue项目中的 Pod,请运行以下命令:+
$ oc create role podview --verb=get --resource=pod -n blue
- 要将新角色绑定到用户,运行以下命令:
$ oc adm policy add-role-to-user podview user2 --role-namespace=blue -n blue
10.5. 创建集群角色
要创建集群角色,请运行以下命令:
$ oc create clusterrole <name> --verb=<verb> --resource=<resource>
在此命令中,指定:
-
<name>,本地角色的名称 -
<verb>,以逗号分隔的、应用到角色的操作动词列表 -
<resource>,角色应用到的资源
例如,要创建一个集群角色来允许用户查看 Pod,请运行以下命令:
$ oc create clusterrole podviewonly --verb=get --resource=pod
10.6. 集群和本地角色绑定
集群角色绑定是存在于集群级别的绑定。角色绑定存在于项目级别。集群角色 view 必须使用本地角色绑定来绑定到用户,以便该用户能够查看项目。只有集群角色不提供特定情形所需的权限集合时才应创建本地角色。
有些集群角色名称最初可能会造成困惑。您可以使用本地角色绑定将 cluster-admin 绑定到用户,使它似乎具有集群管理员的特权。事实并非如此。将 cluster-admin 绑定到某一项目更像是该项目的超级管理员,授予集群角色 admin 的权限,以及一些额外的权限,如编辑速率限值的能力。这可能会产生混淆,特别是通过 Web 控制台 UI,它不会列出绑定到真正集群管理员的集群角色绑定。然而,它会列出可用来本地绑定 cluster-admin 的本地角色绑定。
10.7. 更新策略定义
在集群升级过程中,在所有 master 重启时,会自动协调 默认集群角色 来恢复任何缺少的权限。
如果您自定义默认集群角色并希望确保角色协调不会修改它们:
保护每个角色免受协调:
$ oc annotate clusterrole.rbac <role_name> --overwrite rbac.authorization.kubernetes.io/autoupdate=false
警告您必须手动更新包含此设置的角色,以便在升级后包含任何新的或所需的权限。
生成默认 bootstrap 策略模板文件:
$ oc adm create-bootstrap-policy-file --filename=policy.json
注意文件的内容因 OpenShift Container Platform 版本而异,但文件仅包含默认策略。
- 更新 policy.json 文件,使其包含任何集群角色自定义。
使用策略文件自动协调不受协调保护的角色和角色绑定:
$ oc auth reconcile -f policy.json
协调安全性上下文约束:
# oc adm policy reconcile-sccs \ --additive-only=true \ --confirm
第 11 章 镜像策略
11.1. 概述
您可以控制在集群中导入、标记并运行哪些镜像。为此,有两个设施:
允许导入的 Registry 是一种镜像策略配置,允许您将镜像来源限制为特定的外部 registry 集合。这组规则应用到要导入或标记到任何镜像流的任何镜像。因此,任何与规则集不匹配的引用 registry 的镜像都将被拒绝。
ImagePolicy 准入插件 可让您指定允许在集群中运行哪些镜像。这目前被视为 beta。它允许您控制:
- 镜像源 :可以使用哪些 registry 来拉取镜像
- 镜像解析 :强制 pod 使用不可变摘要运行,以确保镜像不会因为重新标签而改变
- 容器镜像标签限制 :限制或需要镜像上的标签
- 镜像注解限制 :限制或需要集成容器镜像 registry 中的镜像的注解
11.2. 配置 registry 允许导入
您可以在 imagePolicyConfig:allowedRegistriesForImport 部分下配置允许导入 master-config.yaml 中的 registry,如下例所示。如果没有设置,则允许所有镜像,这是默认设置。
例 11.1. Registries 允许导入的配置示例
每个规则由以下属性组成:
-
domainName:主机名是可选用:<port>后缀终止的,该后缀可以识别特殊通配符 (?,*)。前者匹配包含任何长度的字符序列,而后面的字符恰好匹配一个字符。通配符字符可以在前后都存在:分隔符。通配符仅适用于分隔符之前或之后的部分,而不考虑分隔符的存在。 -
insecure: 是一个布尔值,用于决定在domainName中缺少:<port>部分时匹配哪些端口。如果为 true,domainName将会匹配带有:80后缀或未指定端口的 registry,只要导入过程中使用了不安全的标志。如果为 false,则匹配带有:443后缀或未指定端口的 registry。
如果规则应当同时与同一域的安全和不安全端口匹配,则必须列出规则两次(安装后为 insecure=true,一次具有 insecure=false )。
在进行任何规则评估之前,非限定镜像引用是 docker.io 限定的。要将它们列入白名单,请使用 domainName: docker.io。
domainname:* 规则与任何 registry 主机名匹配,但端口仍限制为 443。要在任意端口上匹配任意 registry 服务,请使用 domainName: *:*。
根据 Registries 配置示例中为导入而 创建的规则:
-
oc tag --insecure reg.mydomain.com/app:v1 app:v1会因为mydomain.com规则而列入白名单 -
oc import-image --from reg1.mydomain.com:80/foo foo:latest也会列入白名单 -
oc tag local.registry.corp/bar bar:latest将被拒绝,因为端口与第三个规则中的5000不匹配
被拒绝的镜像导入将生成类似以下文本的错误消息:
The ImageStream "bar" is invalid: * spec.tags[latest].from.name: Forbidden: registry "local.registry.corp" not allowed by whitelist: "local.registry.corp:5000", "*.mydomain.com:80", "registry.redhat.io:443" * status.tags[latest].items[0].dockerImageReference: Forbidden: registry "local.registry.corp" not allowed by whitelist: "local.registry.corp:5000", "*.mydomain.com:80", "registry.redhat.io:443"
11.3. 配置 ImagePolicy Admission 插件
要配置可以在集群中运行的镜像,请在 master-config.yaml 文件中配置 ImagePolicy Admission 插件。您可以根据需要设置一个或多个规则。
使用特定注解拒绝镜像 :
使用此规则拒绝在其上设置特定注解的所有镜像。以下使用
images.openshift.io/deny-execution注解拒绝所有镜像:- name: execution-denied onResources: - resource: pods - resource: builds reject: true matchImageAnnotations: - key: images.openshift.io/deny-execution 1 value: "true" skipOnResolutionFailure: true- 1
- 如果特定镜像被视为是恶意的,管理员可以设置此注解来标记这些镜像。
允许用户从 Docker Hub 运行镜像 :
使用此规则允许用户使用 Docker Hub 中的镜像:
- name: allow-images-from-dockerhub onResources: - resource: pods - resource: builds matchRegistries: - docker.io
以下是在 master-config.yaml 文件中设置多个 ImagePolicy addmission 插件规则的示例配置:
注解的文件示例
admissionConfig:
pluginConfig:
openshift.io/ImagePolicy:
configuration:
kind: ImagePolicyConfig
apiVersion: v1
resolveImages: AttemptRewrite 1
executionRules: 2
- name: execution-denied
# Reject all images that have the annotation images.openshift.io/deny-execution set to true.
# This annotation may be set by infrastructure that wishes to flag particular images as dangerous
onResources: 3
- resource: pods
- resource: builds
reject: true 4
matchImageAnnotations: 5
- key: images.openshift.io/deny-execution
value: "true"
skipOnResolutionFailure: true 6
- name: allow-images-from-internal-registry
# allows images from the internal registry and tries to resolve them
onResources:
- resource: pods
- resource: builds
matchIntegratedRegistry: true
- name: allow-images-from-dockerhub
onResources:
- resource: pods
- resource: builds
matchRegistries:
- docker.io
resolutionRules: 7
- targetResource:
resource: pods
localNames: true
policy: AttemptRewrite
- targetResource: 8
group: batch
resource: jobs
localNames: true 9
policy: AttemptRewrite
- 1
- 尝试将镜像解析到不可变镜像摘要中,并更新 pod 中的镜像拉取规格。
- 2
- 针对传入资源进行评估的规则数组。如果您只有
reject: true规则,则默认为 允许所有。如果您有任何接受规则,则在任何规则中都reject: false,ImagePolicy 的默认行为 deny-all。 - 3
- 指示要强制执行规则的资源。如果未指定任何内容,则默认为 pod。
- 4
- 表示如果此规则匹配,则 Pod 应该被拒绝。
- 5
- 镜像对象的元数据匹配的注解列表。
- 6
- 如果您无法解析镜像,请不要失败 pod。
- 7
- 允许在 Kubernetes 资源中使用镜像流的规则数组。默认配置允许 pod、复制控制器、replicaset、有状态集、daemonset、Deployment 和作业在镜像字段中使用相同的项目镜像流标签引用。
- 8
- 标识规则应用到的组和资源。如果资源是
*,则此规则将应用到该组中的所有资源。 - 9
如果您通常依赖使用默认 registry 前缀(如 docker.io 或 registry.redhat.io)拉取的基础架构镜像,则这些镜像与任何 matchRegistries 值不匹配,因为它们没有 registry 前缀。为确保基础架构镜像具有与镜像策略匹配的 registry 前缀,请在 master-config.yaml 文件中设置 imageConfig.format 值。
11.4. 使用 Admission Controller 来始终拉取镜像
镜像拉取到某个节点后,来自任何用户在该节点上的任何 Pod 都可以使用该镜像,而无需对镜像进行授权检查。为确保 Pod 不使用它们没有凭证的镜像,请使用 AlwaysPullImages 准入控制器。
此 准入控制器 会修改每个新 Pod 来强制镜像拉取(pull)策略为 Always,确保私有镜像只能由拥有凭证的用户使用,即使 Pod 规格使用 Never 镜像拉取策略。
启用 AlwaysPullImages 准入控制器:
11.5. 测试 ImagePolicy Admission 插件
使用
openshift/image-policy-check来测试您的配置。例如,使用以上信息,然后测试如下:
$ oc import-image openshift/image-policy-check:latest --confirm
使用此 YAML 创建 pod。应当创建 pod。
apiVersion: v1 kind: Pod metadata: generateName: test-pod spec: containers: - image: docker.io/openshift/image-policy-check:latest name: first创建指向其他 Registry 的另一个 pod。pod 应该被拒绝。
apiVersion: v1 kind: Pod metadata: generateName: test-pod spec: containers: - image: different-registry/openshift/image-policy-check:latest name: first使用导入的镜像创建指向内部 Registry 的 pod。pod 应该被创建,如果您查看镜像规格,您应该会看到一个摘要来代替标签。
apiVersion: v1 kind: Pod metadata: generateName: test-pod spec: containers: - image: <internal registry IP>:5000/<namespace>/image-policy-check:latest name: first使用导入的镜像创建指向内部 Registry 的 pod。pod 应该被创建,如果您查看镜像规格,您应该会看到该标签未修改。
apiVersion: v1 kind: Pod metadata: generateName: test-pod spec: containers: - image: <internal registry IP>:5000/<namespace>/image-policy-check:v1 name: first从
oc get istag/image-policy-check:latest获取摘要,并将其用于oc annotate images/<digest> images.openshift.io/deny-execution=true。例如:$ oc annotate images/sha256:09ce3d8b5b63595ffca6636c7daefb1a615a7c0e3f8ea68e5db044a9340d6ba8 images.openshift.io/deny-execution=true
再次创建此 pod,您应该会看到 pod 被拒绝:
apiVersion: v1 kind: Pod metadata: generateName: test-pod spec: containers: - image: <internal registry IP>:5000/<namespace>/image-policy-check:latest name: first
第 12 章 镜像签名
12.1. 概述
在 Red Hat Enterprise Linux(RHEL)系统上的容器镜像签名提供了一种方法:
- 验证容器镜像来自的位置,
- 检查镜像是否未被篡改,
- 设置策略,以确定哪些经过验证的镜像可以拉取到主机。
如需更完整地了解 RHEL 系统上的容器镜像签名架构,请参阅 容器镜像签名集成指南。
OpenShift Container Registry 允许通过 REST API 存储签名。oc CLI 可用于验证镜像签名,其验证显示在 Web 控制台或 CLI 中。
12.2. 使用 Atomic CLI 签署镜像
OpenShift Container Platform 不自动执行镜像签名。签名需要开发人员的专用 GPG 密钥,通常存储在工作站上。本文档描述了该工作流。
atomic 命令行界面(CLI)版本 1.12.5 或更高版本提供用于签名容器镜像的命令,这些镜像可以推送到 OpenShift 容器 Registry。基于红帽的发布中提供了 atomic CLI:RHEL、Centos 和 Fedora.在 RHEL Atomic Host 系统中预先安装 atomic CLI。有关在 RHEL 主机上安装 atomic 软件包的详情,请参考启用镜像签名支持。
atomic CLI 使用来自 oc login 的身份验证凭据。务必在同一主机上对 atomic 和 oc 命令使用相同的用户。例如,如果您以 sudo 身份执行 atomic CLI,请确保使用 sudo oc login 登录 OpenShift Container Platform。
要将签名附加到镜像,用户必须具有 image-signer 集群角色。集群管理员可使用以下方法添加此项:
$ oc adm policy add-cluster-role-to-user system:image-signer <user_name>
镜像可以在推送时签名:
$ atomic push [--sign-by <gpg_key_id>] --type atomic <image>
当指定 atomic 传输类型参数时,签名存储在 OpenShift Container Platform 中。如需更多信息,请参阅 签名传输。
有关如何使用 atomic CLI 设置和执行镜像签名的详情,请查看 RHEL Atomic 主机管理容器:签署容器镜像 文档或 atomic push --help 输出以获取参数详细信息。
容器镜像签名集成指南中介绍了使用 atomic CLI 和 OpenShift 容器注册表的具体示例工作流。
12.3. 使用 OpenShift CLI 验证镜像签名
您可以使用 oc adm verify-image-signature 命令验证导入到 OpenShift Container Registry 的镜像的签名。此命令通过利用公共 GPG 密钥验证签名本身,验证镜像签名中包含的镜像身份是否可以被信任,然后将所提供的预期身份与给定镜像的身份( pull spec)匹配。
默认情况下,该命令使用位于 $GNUPGHOME/pubring.gpg 中的公共 GPG 密钥环,通常位于路径 ~/.gnupg 中。默认情况下,这个命令不会将验证结果保存到镜像对象。要做到这一点,您必须指定 --save 标志,如下所示。
要验证镜像的签名,用户必须具有 image-auditor 集群角色。集群管理员可使用以下方法添加此项:
$ oc adm policy add-cluster-role-to-user system:image-auditor <user_name>
在已验证的镜像上使用 --save 标志以及无效的 GPG 密钥或无效的预期身份,会导致保存的验证状态并移除所有签名,并且镜像将不再验证。
为了避免错误地删除所有签名,您可以先运行不带 --save 标志的命令,并检查日志中是否有潜在的问题。
要验证镜像签名,请使用以下格式:
$ oc adm verify-image-signature <image> --expected-identity=<pull_spec> [--save] [options]
<pull_spec> 可以通过描述镜像流来找到。<image> 可以通过描述镜像流标签来找到。请参见以下示例命令输出。
镜像签名验证示例
$ oc describe is nodejs -n openshift
Name: nodejs
Namespace: openshift
Created: 2 weeks ago
Labels: <none>
Annotations: openshift.io/display-name=Node.js
openshift.io/image.dockerRepositoryCheck=2017-07-05T18:24:01Z
Docker Pull Spec: 172.30.1.1:5000/openshift/nodejs
...
$ oc describe istag nodejs:latest -n openshift
Image Name: sha256:2bba968aedb7dd2aafe5fa8c7453f5ac36a0b9639f1bf5b03f95de325238b288
...
$ oc adm verify-image-signature \
sha256:2bba968aedb7dd2aafe5fa8c7453f5ac36a0b9639f1bf5b03f95de325238b288 \
--expected-identity 172.30.1.1:5000/openshift/nodejs:latest \
--public-key /etc/pki/rpm-gpg/RPM-GPG-KEY-redhat-release \
--save
如果 oc adm verify-image-signature 命令返回 x509: certificate signed by unknown authority 错误,您可能需要将 registry 的证书颁发机构(CA)添加到系统中信任的 CA 列表中。您可以执行以下步骤来实现:
将 CA 证书从集群传输到客户端机器。
例如,要为 docker-registry.default.svc 添加 CA,传输位于 /etc/docker/certs.d/docker-registry.default.svc\:5000/node-client-ca.crt 的文件。
将 CA 证书复制到 /etc/pki/ca-trust/source/anchors/ 目录中。例如:
# cp </path_to_file>/node-client-ca.crt \ /etc/pki/ca-trust/source/anchors/执行
update-ca-trust以更新可信 CA 列表:# update-ca-trust
12.4. 使用 Registry API 访问镜像签名
OpenShift Container Registry 提供了一个 extensions 端点,供您编写和读取镜像签名。镜像签名通过容器镜像 registry API 存储在 OpenShift Container Platform 键值存储中。
此端点是实验性的,不受上游容器镜像 registry 项目的支持。有关容器镜像 registry API 的常规信息,请参阅上游 API 文档。
12.4.1. 通过 API 编写镜像签名
要向镜像添加新签名,您可以使用 HTTP PUT 方法将 JSON 有效负载发送到 extensions 端点:
PUT /extensions/v2/<namespace>/<name>/signatures/<digest>
$ curl -X PUT --data @signature.json http://<user>:<token>@<registry_endpoint>:5000/extensions/v2/<namespace>/<name>/signatures/sha256:<digest>
带有签名内容的 JSON 有效负载应具有以下结构:
{
"version": 2,
"type": "atomic",
"name": "sha256:4028782c08eae4a8c9a28bf661c0a8d1c2fc8e19dbaae2b018b21011197e1484@cddeb7006d914716e2728000746a0b23",
"content": "<cryptographic_signature>"
}
name 字段包含镜像签名的名称,该名称必须是唯一的,格式为 <digest>@<name>。<digest> 代表镜像名称,<name> 是签名的名称。签名名称长度必须为 32 个字符。<cryptgraph_signature> 必须遵循 容器/镜像库 中记录的规格。
12.4.2. 通过 API 读取镜像签名
假设已签名的镜像已被推送到 OpenShift Container Registry 中,您可以使用以下命令读取签名:
GET /extensions/v2/<namespace>/<name>/signatures/<digest>
$ curl http://<user>:<token>@<registry_endpoint>:5000/extensions/v2/<namespace>/<name>/signatures/sha256:<digest>
<namespace> 代表 OpenShift Container Platform 项目名称或 registry 存储库名称,<name> 代表镜像存储库的名称。摘要(digest)代表镜像的 SHA-256 校验和。
如果给定镜像包含签名数据,则上述命令的输出应生成以下 JSON 响应:
{
"signatures": [
{
"version": 2,
"type": "atomic",
"name": "sha256:4028782c08eae4a8c9a28bf661c0a8d1c2fc8e19dbaae2b018b21011197e1484@cddeb7006d914716e2728000746a0b23",
"content": "<cryptographic_signature>"
}
]
}
name 字段包含镜像签名的名称,该名称必须是唯一的,格式为 <digest>@<name>。<digest> 代表镜像名称,<name> 是签名的名称。签名名称长度必须为 32 个字符。<cryptgraph_signature> 必须遵循 容器/镜像库 中记录的规格。
12.4.3. 从签名存储中自动导入镜像签名
如果在所有 OpenShift Container Platform master 节点上通过 registry 配置目录配置了签名存储,OpenShift Container Platform 可以自动导入镜像签名。
registry 配置目录包含各种 registry(存储远程容器镜像)和其中存储的内容的配置。单个目录确保不必在每一个命令的命令行选项中提供配置,以便容器/镜像的所有用户可以共享该配置。
默认 registry 配置目录位于 /etc/containers/registries.d/default.yaml 文件中。
导致所有红帽镜像自动导入镜像签名的示例配置示例:
docker:
registry.redhat.io:
sigstore: https://registry.redhat.io/containers/sigstore 1- 1
- 定义签名存储的 URL。此 URL 用于读取现有签名。
默认情况下,OpenShift Container Platform 自动导入的签名将被认为是未验证,必须由镜像管理员验证。
有关 registry 配置目录的详情,请参阅 registry 配置目录。
第 13 章 有作用域的令牌
13.1. 概述
用户可能希望为另一个实体赋予其作为自己的权限,但只能以有限的方式授予权限。例如,项目管理员可能希望委派创建 pod 的权限。执行此操作的一种方法是创建有作用域令牌。
有作用域令牌是一种令牌,它标识为给定用户,但仅限于其范围中的某些操作。目前,只有 cluster-admin 可以创建有范围的令牌。
13.2. 评估
通过将令牌的范围集合转换为 PolicyRule 集合来评估其范围。然后,请求会与这些规则进行匹配。请求属性必须至少匹配其中一条范围规则,才能传递给 "normal" 授权程序进行进一步授权检查。
13.3. 用户范围
用户范围主要用于获取给定用户的信息。它们是基于意图的,因此会自动为您创建规则:
-
user:full- 允许使用用户的所有权限对 API 进行完全的读/写访问。 -
user:info- 允许只读访问 user: name、group 等信息。 -
user:check-access- 允许访问 self-localsubjectaccessreviews 和 self-subjectaccessreviews。这些是在请求对象中传递空用户和组的变量。 -
user:list-projects- 允许只读访问,可以列出用户可访问的项目。
13.4. 角色范围
角色范围允许您具有与给定角色相同等级的访问权限,该角色通过命名空间过滤。
role:<cluster-role name>:<namespace or * for all>- 将范围限定为集群角色指定的规则,但仅在指定的命名空间中。注意注意:这可以防止升级访问权限。即使角色允许访问 secret、角色绑定和角色等资源,但此范围会拒绝访问这些资源。这有助于防止意外升级。许多人认为 edit 等角色并不是升级角色,但对于访问 secret 而言,这的确是升级角色。
-
role:<cluster-role name>:<namespace or * for all>:!- 这与上例相似,但因为包含感叹号而使得此范围允许升级访问权限。
第 14 章 监控镜像
14.1. 概述
14.2. 查看镜像统计信息
您可以显示 OpenShift Container Platform 管理的所有镜像的用量统计。换句话说,所有镜像都会直接或通过 构建推送到内部 Registry。
查看用量统计:
$ oc adm top images NAME IMAGESTREAMTAG PARENTS USAGE METADATA STORAGE sha256:80c985739a78b openshift/python (3.5) yes 303.12MiB sha256:64461b5111fc7 openshift/ruby (2.2) yes 234.33MiB sha256:0e19a0290ddc1 test/ruby-ex (latest) sha256:64461b5111fc71ec Deployment: ruby-ex-1/test yes 150.65MiB sha256:a968c61adad58 test/django-ex (latest) sha256:80c985739a78b760 Deployment: django-ex-1/test yes 186.07MiB
该命令显示以下信息:
- 镜像 ID
-
附带的
ImageStreamTag的项目、名称和标签 - 镜像的潜在父级,按 ID 列出
- 有关镜像使用位置的信息
- 标志通知镜像是否包含正确的 Docker 元数据信息
- 镜像大小
14.3. 查看 ImageStreams 统计信息
您可以显示 ImageStreams 的用量统计。
查看用量统计:
$ oc adm top imagestreams NAME STORAGE IMAGES LAYERS openshift/python 1.21GiB 4 36 openshift/ruby 717.76MiB 3 27 test/ruby-ex 150.65MiB 1 10 test/django-ex 186.07MiB 1 10
该命令显示以下信息:
-
ImageStream的项目和名称 -
存储在 Red Hat Container Registry内部的
ImageStream的大小 -
此特定
ImageStream指向的镜像数量 -
ImageStream层数包括
14.4. 修剪镜像
从以上命令返回的信息有助于执行镜像修剪。
第 15 章 管理安全性上下文约束
15.1. 概述
通过安全性上下文约束,管理员可以控制容器集的权限。要了解更多有关此 API 类型的信息,请参阅 安全性上下文约束 (SCC)架构文档。您可以使用 CLI,以普通 API 对象 的形式管理实例中的 SCC。
您必须具有 cluster-admin 特权才能 管理 SCC。
不要修改默认 SCC。自定义默认 SCC 会导致升级时出现问题。而是 创建新的 SCC。
15.2. 列出安全性上下文约束
获取当前的 SCC 列表:
$ oc get scc NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES anyuid false [] MustRunAs RunAsAny RunAsAny RunAsAny 10 false [configMap downwardAPI emptyDir persistentVolumeClaim secret] hostaccess false [] MustRunAs MustRunAsRange MustRunAs RunAsAny <none> false [configMap downwardAPI emptyDir hostPath persistentVolumeClaim secret] hostmount-anyuid false [] MustRunAs RunAsAny RunAsAny RunAsAny <none> false [configMap downwardAPI emptyDir hostPath nfs persistentVolumeClaim secret] hostnetwork false [] MustRunAs MustRunAsRange MustRunAs MustRunAs <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret] nonroot false [] MustRunAs MustRunAsNonRoot RunAsAny RunAsAny <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret] privileged true [*] RunAsAny RunAsAny RunAsAny RunAsAny <none> false [*] restricted false [] MustRunAs MustRunAsRange MustRunAs RunAsAny <none> false [configMap downwardAPI emptyDir persistentVolumeClaim secret]
15.3. 检查安全性上下文约束对象
您可以查看特定 SCC 的信息,包括这个 SCC 应用到哪些用户、服务帐户和组。
例如,检查 restricted SCC:
$ oc describe scc restricted Name: restricted Priority: <none> Access: Users: <none> 1 Groups: system:authenticated 2 Settings: Allow Privileged: false Default Add Capabilities: <none> Required Drop Capabilities: KILL,MKNOD,SYS_CHROOT,SETUID,SETGID Allowed Capabilities: <none> Allowed Seccomp Profiles: <none> Allowed Volume Types: configMap,downwardAPI,emptyDir,persistentVolumeClaim,projected,secret Allow Host Network: false Allow Host Ports: false Allow Host PID: false Allow Host IPC: false Read Only Root Filesystem: false Run As User Strategy: MustRunAsRange UID: <none> UID Range Min: <none> UID Range Max: <none> SELinux Context Strategy: MustRunAs User: <none> Role: <none> Type: <none> Level: <none> FSGroup Strategy: MustRunAs Ranges: <none> Supplemental Groups Strategy: RunAsAny Ranges: <none>
要在升级过程中保留自定义 SCC,请不要编辑优先级、用户、组、标签和注解以外的默认 SCC 的设置。
15.4. 创建新安全性上下文约束
创建新 SCC:
在 JSON 或 YAML 文件中定义 SCC:
安全性上下文约束对象定义
kind: SecurityContextConstraints apiVersion: v1 metadata: name: scc-admin allowPrivilegedContainer: true runAsUser: type: RunAsAny seLinuxContext: type: RunAsAny fsGroup: type: RunAsAny supplementalGroups: type: RunAsAny users: - my-admin-user groups: - my-admin-group
此外,您可以通过将
requiredDropCapabilities字段设为所需的值,向 SCC 添加丢弃功能。所有指定的功能都将从容器中丢弃。例如,若要创建具有KILL、MKNOD和SYS_CHROOT所需丢弃功能的 SCC,请将以下内容添加到 SCC 对象中:requiredDropCapabilities: - KILL - MKNOD - SYS_CHROOT
您可以在 Docker 文档中查看可能值的列表。
提示由于功能会传递到 Docker,您可以使用特殊值
ALL来丢弃所有可能的功能。然后,运行
oc create并传递文件来创建:$ oc create -f scc_admin.yaml securitycontextconstraints "scc-admin" created
验证 SCC 已创建好:
$ oc get scc scc-admin NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP PRIORITY READONLYROOTFS VOLUMES scc-admin true [] RunAsAny RunAsAny RunAsAny RunAsAny <none> false [awsElasticBlockStore azureDisk azureFile cephFS cinder configMap downwardAPI emptyDir fc flexVolume flocker gcePersistentDisk glusterfs iscsi nfs persistentVolumeClaim photonPersistentDisk quobyte rbd secret vsphere]
15.5. 删除安全性上下文约束
删除 SCC:
$ oc delete scc <scc_name>
如果删除了默认 SCC,重启后会重新生成它。
15.6. 更新安全性上下文约束
更新现有的 SCC:
$ oc edit scc <scc_name>
要在升级过程中保留自定义 SCC,请不要编辑优先级、用户和组以外的默认 SCC 的设置。
15.6.1. 安全性上下文约束设置示例
但没有清除 runAsUser 设置
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext: 1
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0
- 1
- 当容器或 Pod 没有指定应运行它的用户 ID 时,则生效的 UID 由发出此 Pod 的 SCC 决定。由于在默认情况下,受限 SCC 会授权给所有经过身份验证的用户,所以它可供所有用户和服务帐户使用,并在大多数情形中使用。受限 SCC 使用
MustRunAsRange策略来约束并默认设定securityContext.runAsUser字段的可能值。准入插件会在当前项目上查找openshift.io/sa.scc.uid-range注解来填充范围字段,因为它不提供这一范围。最后,容器的runAsUser值等于这一范围中的第一个值,而这难以预测,因为每个项目都有不同的范围。如需更多信息,请参阅 了解预分配值和安全上下文约束。
使用 Explicit runAsUser 设置
apiVersion: v1
kind: Pod
metadata:
name: security-context-demo
spec:
securityContext:
runAsUser: 1000 1
containers:
- name: sec-ctx-demo
image: gcr.io/google-samples/node-hello:1.0
- 1
- 只有服务帐户或用户被授予对允许某一用户 ID 的 SCC 访问权限时,OpenShift Container Platform 才会接受请求该用户 ID 的容器或 Pod。SCC 允许任意 ID、属于某一范围的 ID,或特定于请求的确切用户 ID。
这可与 SELinux、fsGroup 和补充组配合使用。如需更多信息,请参阅卷安全性。
15.7. 更新默认安全性上下文约束
如果缺少默认 SCC,则在主控机启动时创建默认 SCC。要将 SCC 重置为默认值,或者在升级后将现有 SCC 更新为新的默认定义:
- 删除您要重置的任何 SCC,并通过重启 master 来重新创建它
-
使用
oc adm policy reconcile-sccs命令
oc adm policy reconcile-sccs 命令将所有 SCC 策略设置为默认值,但保留任何其他用户、组、标签和注解,以及您可能已设置的优先级。要查看要更改哪些 SCC,您可以不带选项运行该命令,或者通过 -o <format> 选项指定您首选的输出。
在检查完现有 SCC 后,建议您备份现有的 SCC,然后使用 --confirm 选项来持久保存数据。
如果要重置优先级并授予,请使用 --additive-only=false 选项。
如果您在 SCC 中有除优先级、用户、组、标签或注解以外的自定义设置,则协调时会丢失这些设置。
15.8. 我怎么样?
以下介绍了使用 SCC 的常见场景和程序。
15.8.1. 授予对 Privileged SCC 的访问权限
在某些情况下,管理员可能希望允许管理员组以外的用户或组创建更多 特权 pod。为此,您可以:
确定您要具有 SCC 访问权限的用户或组。
警告只有用户直接创建容器集时,才能授予用户访问权限。对于代表用户创建的容器集,在大多数情况下,系统本身 应授予对其执行相关控制器的服务帐户的访问权限。代表用户创建 pod 的资源示例有 Deployments、StatefulSet、DaemonSet 等。
运行:
$ oc adm policy add-scc-to-user <scc_name> <user_name> $ oc adm policy add-scc-to-group <scc_name> <group_name>
例如,要允许 e2e-user 访问 特权 SCC,请运行:
$ oc adm policy add-scc-to-user privileged e2e-user
-
修改容器的
SecurityContext,以请求特权模式。
15.8.2. 为服务帐户授予 Privileged SCC 访问权限
首先,创建一个 服务帐户。例如,要在 myproject 项目中创建服务帐户 mysvcacct :
$ oc create serviceaccount mysvcacct -n myproject
然后,将服务帐户添加到 特权 SCC。
$ oc adm policy add-scc-to-user privileged system:serviceaccount:myproject:mysvcacct
然后,确保为服务帐户创建资源。为此,请将 spec.serviceAccountName 字段设置为服务帐户名称。将服务帐户名称留空将导致使用 default 服务帐户。
然后,确保至少有一个 pod 的容器在安全上下文中请求特权模式。
15.8.3. 在 Dockerfile 中启用镜像以使用 USER 运行
放松集群中的安全性,以便镜像不会强制以预分配的 UID 运行,而不授予每个人都对 特权 SCC 的访问权限:
授予所有经过身份验证的用户对 anyuid SCC 的访问权限:
$ oc adm policy add-scc-to-group anyuid system:authenticated
如果 Dockerfile 中没有指定 USER,这允许镜像作为 root UID 运行。
15.8.4. 启用需要 Root 的容器镜像
某些容器镜像(示例: postgres 和 redis)需要 root 访问权限,并且对卷的拥有方式有一定期望。对于这些镜像,将服务帐户添加到 anyuid SCC。
$ oc adm policy add-scc-to-user anyuid system:serviceaccount:myproject:mysvcacct
15.8.5. 在 Registry 上使用 --mount-host
推荐持久性存储使用PersistentVolume,PersistentVolumeClaim对象可用于 registry 部署。如果您要测试并且希望将 oc adm registry 命令与 --mount-host 选项搭配使用,您必须首先为 Registry 创建一个新 服务帐户,并将它添加到 特权 SCC。有关完整说明,请参阅 管理员指南 。
15.8.6. 提供额外的功能
在某些情况下,镜像可能会需要一些功能,它们没有包括在开箱即用的 Docker 中。您可以在 Pod 规格中请求其他功能,这些功能将针对 SCC 进行验证。
这样,镜像就可以使用提升的功能运行,并且仅在需要时才使用。您不应该编辑默认 受限 SCC 来启用额外的功能。
与非 root 用户结合使用时,还必须确保使用 setcap 命令赋予需要额外权限的文件。例如,在镜像的 Dockerfile 中:
setcap cap_net_raw,cap_net_admin+p /usr/bin/ping
此外,如果 Docker 中默认提供了一项功能,则您无需修改 pod 规格即可请求该功能。例如,默认情况下会提供 NET_RAW,并且应该已在 ping 上设置功能,因此无需执行特殊步骤来运行 ping。
提供额外的功能:
- 创建新 SCC
-
使用
allowedCapabilities字段添加允许的能力。 -
在创建 pod 时,请求
securityContext.capabilities.add字段中的功能。
15.8.7. 修改集群默认行为
当您为每个人授予对 anyuid SCC 的访问权限时,您的集群:
- 不预先分配 UID
- 允许容器以任意用户身份运行
- 防止特权容器
$ oc adm policy add-scc-to-group anyuid system:authenticated
要修改集群,使其不预先分配 UID,且不允许容器以 root 用户身份运行,请为每个人授予 nonroot SCC 的访问权限:
$ oc adm policy add-scc-to-group nonroot system:authenticated
对于对集群范围有影响的任何修改,请非常小心。当您向所有经过身份验证的用户(如上例中所示)授予 SCC 时,或者修改应用于 受限 SCC 等所有用户的 SCC,它也会影响 Kubernetes 和 OpenShift Container Platform 组件,包括 Web 控制台和集成的容器镜像 registry。使用这些 SCC 进行的更改可能会导致这些组件停止正常运行。
相反,创建自定义 SCC 并将其仅指向特定的用户或组。这样,潜在的问题仅限于受影响的用户或组,不会影响到关键集群组件。
15.8.8. 使用 hostPath 卷插件
要缓解集群中的安全性,以便允许 pod 使用 hostPath 卷插件,而不授予每个人都对更多特权 SCC(如 特权、hostaccess 或 hostmount-anyuid )的访问权限,请执行以下操作:
-
创建名为
hostpath的新 SCC 将新 SCC 的
allowHostDirVolumePlugin参数设置为true:$ oc patch scc hostpath -p '{"allowHostDirVolumePlugin": true}'为所有用户授予对此 SCC 的访问权限:
$ oc adm policy add-scc-to-group hostpath system:authenticated
现在,hostPath 卷的所有 pod 都被 hostpath SCC 接受。
15.8.9. 确保 Admission 会首先尝试使用特定 SCC
您可以通过设置 SCC 的 Priority 字段来控制准入中的 SCC 排序。有关排序的更多信息,请参阅 SCC 优先级部分。
15.8.10. 将 SCC 添加到用户、组或项目
在添加 SCC 到用户或组之前,您可以先使用 scc-review 选项来检查用户或组是否可以创建容器集。如需更多信息,请参阅 授权 主题。
SCC 不直接授予项目。相反,您要将服务帐户添加到 SCC 中,并指定 Pod 上的服务帐户名称,或者在未指定的情况下作为 default 服务帐户运行。
将 SCC 添加到用户:
$ oc adm policy add-scc-to-user <scc_name> <user_name>
将 SCC 添加到服务帐户:
$ oc adm policy add-scc-to-user <scc_name> \
system:serviceaccount:<serviceaccount_namespace>:<serviceaccount_name>
如果您当前处于服务帐户所属的项目中,您可以使用 -z 标志,只需指定 <serviceaccount_name>。
$ oc adm policy add-scc-to-user <scc_name> -z <serviceaccount_name>
强烈建议您使用 -z 标志,因为它有助于防止拼写错误,并确保只为指定的服务帐户授予访问权限。如果没有在项目中,请使用 -n 选项来指示它应用到的项目命名空间。
将 SCC 添加到组中:
$ oc adm policy add-scc-to-group <scc_name> <group_name>
将 SCC 添加到命名空间中的所有服务帐户:
$ oc adm policy add-scc-to-group <scc_name> \
system:serviceaccounts:<serviceaccount_namespace>第 16 章 调度
16.1. 概述
16.1.1. 概述
Pod 调度是一个内部过程,决定新 pod 如何放置到集群内的节点上。
调度程度代码具有明确隔离,会监测创建的新 pod 并确定最适合托管它们的节点。然后,它会利用主 API 为 pod 创建 pod 至节点的绑定。
16.1.2. 默认调度
OpenShift Container Platform 附带一个满足大多数用户需求的默认调度程序。默认调度程序同时使用内置和可自定义的工具来确定最适合 pod 的工具。
有关默认调度程序如何决定 pod 放置和可用可自定义参数的详情,请参考 默认调度。
16.1.3. 高级调度
如果您想要更多地控制新 pod 的放置位置,可以利用 OpenShift Container Platform 高级调度功能来配置 pod,从而使 pod 能够根据要求或偏好在特定的节点上运行,或者与特定的 pod 一起运行。通过高级调度,您还可以防止 pod 放置到某个节点上或放置到另一个 pod 中。
有关高级调度的详情,请查看 高级调度。
16.1.4. 自定义调度
OpenShift Container Platform 还允许您通过编辑 pod 规格来使用自己的或第三方调度程序。
如需更多信息,请参阅 自定义调度程序。
16.2. 默认调度
16.2.1. 概述
OpenShift Container Platform 的默认 pod 调度程序负责确定在集群的节点中放置新的 pod。它从 pod 读取数据,并尝试根据配置的策略寻找最适合的节点。它完全独立存在,作为单机或可插拔的解决方案。它不会修改 pod,只是为 pod 创建将 pod 与特定节点衔接起来的绑定。
16.2.2. 通用调度程序
现有的通用调度程序是平台默认提供的调度程序引擎,它可通过三步操作来选择托管 pod 的节点:
- 调度程序 使用 predicates 过滤出不正确的节点。
- 调度程序 优先选择过滤后的节点列表。
- 调度程序 为 pod 选择最高优先级的节点。
16.2.3. 过滤节点
根据指定的约束或要求过滤可用的节点。这可以通过称为 predicates 的过滤器函数列表运行每个节点。
16.2.3.1. 排列过滤后节点列表的优先顺序
这可以通过一系列 priority 函数来实现,这些函数为其分配分数介于 0 到 10 之间,0 表示不适合,10 则表示最适合托管该 pod。调度程序配置还可以为每个优先级函数使用简单的权重(正数值)。每个优先级函数提供的节点分数乘以权重(大多数优先级的默认权重为 1),然后将每个节点从所有优先级获得的分数相加。管理员可以使用这个权重属性,为一些优先级赋予更高的重要性。
16.2.3.2. 选择最适合的节点
节点按照分数排序,系统选择分数最高的节点来托管该 pod。如果多个节点的分数相同,则随机选择其中一个。
16.2.4. 调度程序策略
选择 predicate 和 priorities 定义调度程序的策略。
调度程序配置文件是一个 JSON 文件,指定调度程序将考虑的 predicates 和 priorities。
如果没有调度程序策略文件,则会应用默认配置文件 /etc/origin/master/scheduler.json。
调度程序配置文件中定义的 predicates 和 priorities 会完全覆盖默认的调度程序策略。如果需要任何默认的 predicates 和 priorities,您必须在调度程序配置文件中明确指定函数。
默认调度程序配置文件
{
"apiVersion": "v1",
"kind": "Policy",
"predicates": [
{
"name": "NoVolumeZoneConflict"
},
{
"name": "MaxEBSVolumeCount"
},
{
"name": "MaxGCEPDVolumeCount"
},
{
"name": "MaxAzureDiskVolumeCount"
},
{
"name": "MatchInterPodAffinity"
},
{
"name": "NoDiskConflict"
},
{
"name": "GeneralPredicates"
},
{
"name": "PodToleratesNodeTaints"
},
{
"argument": {
"serviceAffinity": {
"labels": [
"region"
]
}
},
"name": "Region"
}
],
"priorities": [
{
"name": "SelectorSpreadPriority",
"weight": 1
},
{
"name": "InterPodAffinityPriority",
"weight": 1
},
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "BalancedResourceAllocation",
"weight": 1
},
{
"name": "NodePreferAvoidPodsPriority",
"weight": 10000
},
{
"name": "NodeAffinityPriority",
"weight": 1
},
{
"name": "TaintTolerationPriority",
"weight": 1
},
{
"argument": {
"serviceAntiAffinity": {
"label": "zone"
}
},
"name": "Zone",
"weight": 2
}
]
}
16.2.4.1. 修改调度程序策略
调度器策略默认在 master 的名为 /etc/origin/master/scheduler.json 的文件中定义,除非被 master 配置文件中的 kubernetesMasterConfig.schedulerConfigFile 项覆盖。
修改的调度程序配置文件示例
kind: "Policy"
version: "v1"
"predicates": [
{
"name": "PodFitsResources"
},
{
"name": "NoDiskConflict"
},
{
"name": "MatchNodeSelector"
},
{
"name": "HostName"
},
{
"argument": {
"serviceAffinity": {
"labels": [
"region"
]
}
},
"name": "Region"
}
],
"priorities": [
{
"name": "LeastRequestedPriority",
"weight": 1
},
{
"name": "BalancedResourceAllocation",
"weight": 1
},
{
"name": "ServiceSpreadingPriority",
"weight": 1
},
{
"argument": {
"serviceAntiAffinity": {
"label": "zone"
}
},
"name": "Zone",
"weight": 2
}
]
修改调度程序策略:
- 编辑调度程序配置文件,以配置所需的 默认 predicates 和 priorities。您可以创建自定义配置,或使用和修改其中一个 示例策略配置。
- 添加任何可配置的 predicates 和您需要的 可配置优先级。
重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
16.2.5. 可用 predicates
predicates 是用于过滤掉不合格节点的规则。
OpenShift Container Platform 中默认提供一些 predicates。其中的一些 predicates 可以通过提供特定参数来自定义。可以组合多个 predicates 来提供更多节点过滤。
16.2.5.1. 静态 predicates
此类 predicates 不接受任何来自于用户的配置参数或输入。它们通过其确切的名称在调度程序配置中指定。
16.2.5.1.1. 默认 predicates
默认的调度程序策略包括以下 predicates:
NoVolumeZoneConflict 检查区中是否有 pod 请求的卷。
{"name" : "NoVolumeZoneConflict"}MaxEBSVolumeCount 检查可附加到 AWS 实例的最大卷数。
{"name" : "MaxEBSVolumeCount"}MaxGCEPDVolumeCount 检查 Google Compute Engine(GCE)持久磁盘(PD)的最大数量。
{"name" : "MaxGCEPDVolumeCount"}MatchInterPodAffinity 检查 pod 关联性/反关联性规则是否允许该 pod。
{"name" : "MatchInterPodAffinity"}NoDiskConflict 检查 pod 请求的卷是否可用。
{"name" : "NoDiskConflict"}PodToleratesNodeTaints 检查 pod 是否可以容忍节点污点。
{"name" : "PodToleratesNodeTaints"}16.2.5.1.2. 其他静态 predicates
OpenShift Container Platform 还支持下列 predicates:
CheckVolumeBinding 根据 pod 请求的卷,评估 pod 是否同时适合绑定和未绑定 PVC。* 对于绑定的 PVC,该 predicate 检查给定节点是否满足对应 PV 的节点关联性。* 对于未绑定 PVC,该 predicate 会搜索可满足 PVC 要求的可用 PV,并且检查给定节点是否满足 PV 的节点关联性。
如果所有绑定 PVC 都有与节点兼容的 PV,且所有未绑定 PVC 都可与可用并兼容节点的 PV 匹配,该 predicate 会返回 true。
{"name" : "CheckVolumeBinding"}
CheckVolumeBinding predicate 必须在非默认调度程序中启用。
CheckNodeCondition 检查 pod 是否可以调度到报告 磁盘不足、网络不可用或未就绪状况的节点。
{"name" : "CheckNodeCondition"}PodToleratesNodeNoExecuteTaints 检查 pod 容限是否容忍节点的 NoExecute 污点。
{"name" : "PodToleratesNodeNoExecuteTaints"}CheckNodeLabelPresence 检查节点上是否存在所有指定的标签,而不考虑它们的值。
{"name" : "CheckNodeLabelPresence"}checkServiceAffinity 检查 ServiceAffinity 标签是否对于节点上调度的 pod 来说是相同的。
{"name" : "checkServiceAffinity"}MaxAzureDiskVolumeCount 检查 Azure 磁盘卷的最大数量。
{"name" : "MaxAzureDiskVolumeCount"}16.2.5.2. 常规 predicates
下列常规 predicates 检查是否通过非关键 predicates 和必要 predicates 的检查。非关键 predicates 是只有非关键 pod 需要通过的 predicates,而必要 predicates 则是所有 pod 都需要通过的 predicates。
默认调度程序策略包含常规 predicates。
非关键常规 predicates
PodFitsResources 根据资源可用性(CPU、内存、GPU 等)来确定适合性。节点可以声明其资源容量,然后 pod 可以指定它们所需要的资源。适合性基于请求的资源,而非使用的资源。
{"name" : "PodFitsResources"}必要常规 predicates
PodFitsHostPorts 确定节点是否有空闲端口可用于请求的 pod 端口(不存在端口冲突)。
{"name" : "PodFitsHostPorts"}HostName 基于存在 Host 参数以及与主机名称匹配的字符串来确定适合性。
{"name" : "HostName"}MatchNodeSelector 根据 pod 中定义的 节点选择器(nodeSelector) 查询来确定适合性。
{"name" : "MatchNodeSelector"}16.2.5.3. 可配置 predicates
您可以在调度程序配置中配置这些 predicates,默认为 /etc/origin/master/scheduler.json,添加可影响 predicate 函数的标签。
由于它们是可配置的,因此可以组合相同类型的多个谓词(但配置参数不同),只要其用户定义的名称不同。
有关使用这些优先级的详情,请参考修改调度程序策略。
serviceAffinity 根据该 pod 上运行的服务将 pod 放置到节点上。将同一服务的 pod 放置到相同或共同定位的节点上可提高效率。
此 predicate 会尝试在其 节点选择器 中将带有特定标签的 pod 放置到具有相同标签的节点。
如果 pod 没有在其节点选择器中指定标签,则第一个 pod 会根据可用性放置到任何节点上,服务的所有后续 pod 都会调度到具有与该节点相同标签值的节点上。
"predicates":[
{
"name":"<name>", 1
"argument":{
"serviceAffinity":{
"labels":[
"<label>" 2
]
}
}
}
],例如:
"name":"ZoneAffinity",
"argument":{
"serviceAffinity":{
"labels":[
"rack"
]
}
}
例如,如果服务的第一个 pod 具有节点选择器 rack 被调度到一个带有 region=rack 标签的节点,则属于同一服务的所有其他后续 pod 都将被调度到具有相同 region=rack 标签的节点。如需更多信息,请参阅 控制 Pod 放置。
也支持多级标签。用户也可以指定服务要调度到同一地区内、同一区域(位于区域下)的所有 pod。
labelsPresence 参数检查特定节点是否具有特定的标签。标签创建 LabelPreference 优先级使用的节点 组。例如,通过标签匹配非常有用,其中节点具有按标签定义的物理位置或状态。
"predicates":[
{
"name":"<name>", 1
"argument":{
"labelsPresence":{
"labels":[
"<label>" 2
],
"presence": true 3
}
}
}
],例如:
"name":"RackPreferred",
"argument":{
"labelsPresence":{
"labels":[
"rack",
"region"
],
"presence": true
}
}16.2.6. 可用优先级
优先级是根据偏好排列剩余节点等级的规则。
可以指定一组自定义优先级来配置调度程序。OpenShift Container Platform 中默认提供一些优先级。也可通过提供某些参数来自定义其他优先级。可将多个优先级合并,并为每个优先级赋予不同的权重来影响优先顺序。
16.2.6.1. 静态优先级
静态优先级不使用用户提供的配置参数,但权重除外。权重必须指定,且不能为 0 或负数。
这些是在调度程序配置中指定的,默认为 /etc/origin/master/scheduler.json。
16.2.6.1.1. 默认优先级
默认调度程序策略包括以下优先级。每个优先级函数的权重为 1,但 NodePreferAvoidPodsPriority 除外,它的权重是 10000。
SelectorSpreadPriority 查找与 pod 匹配的服务、复制控制器 (RC)、复制集 (RS) 和有状态集,然后查找与这些选择器匹配的现有 pod。调度程序优先选择具有较少现有匹配 pod 的节点。然后,它会将 pod 调度到具有与所调度 pod 的选择器匹配的 pod 数量最少的节点上。
{"name" : "SelectorSpreadPriority", "weight" : 1}
InterPodAffinityPriority 通过迭代 weightedPodAffinityTerm 的元素并在节点满足对应的 PodAffinityTerm 时加上权重来计算总和。总和最高的节点是优先级最高的节点。
{"name" : "InterPodAffinityPriority", "weight" : 1}LeastRequestedPriority 优先选择请求资源较少的节点。它计算节点上调度的 pod 所请求的内存和 CPU 百分比,并优先选择可用/剩余容量最高的节点。
{"name" : "LeastRequestedPriority", "weight" : 1}
BalancedResourceAllocation 优先选择资源使用率均衡的节点。它以占容量比形式计算 CPU 和内存已使用量的差值,并基于两个指标相互接近的程度来优先选择节点。这应该始终与 LeastRequestedPriority 一同使用。
{"name" : "BalancedResourceAllocation", "weight" : 1}NodePreferAvoidPodsPriority 忽略除复制控制器以外的控制器拥有的 pod。
{"name" : "NodePreferAvoidPodsPriority", "weight" : 10000}NodeAffinityPriority 根据节点关联性调度偏好来排列节点的优先顺序
{"name" : "NodeAffinityPriority", "weight" : 1}
TaintTolerationPriority 为 pod 优先考虑那些具有较少不可容忍的污点的节点。不可容忍的污点是具有 PreferNoSchedule 键的污点。
{"name" : "TaintTolerationPriority", "weight" : 1}16.2.6.1.2. 其他静态优先级
OpenShift Container Platform 还支持下列优先级:
若不提供任何优先级配置,则 EqualPriority 为所有节点赋予相等的权重 1。建议您仅在测试环境中使用此优先级。
{"name" : "EqualPriority", "weight" : 1}MostRequestedPriority 优先选择具有最多所请求资源的节点。它计算节点上调度的 pod 所请求的内存与 CPU 百分比,并根据请求量对容量的平均占比的最大值来排列优先级。
{"name" : "MostRequestedPriority", "weight" : 1}ImageLocalityPriority 优先选择已请求了 pod 容器镜像的节点。
{"name" : "ImageLocalityPriority", "weight" : 1}ServiceSpreadingPriority 通过尽量减少将属于同一服务的 pod 分配到同一台机器的数量来分散 pod。
{"name" : "ServiceSpreadingPriority", "weight" : 1}16.2.6.2. 可配置优先级
您可以在调度程序配置中配置这些优先级(默认为 /etc/origin/master/scheduler.json ),以添加可影响优先级的标签。
优先级函数的类型由它们所使用的参数来标识。由于它们是可配置的,因此可以组合类型相同(但配置参数不同)的多个优先级,但前提是它们的用户定义名称不同。
有关使用这些优先级的详情,请参考修改调度程序策略。
ServiceAntiAffinity 接受一个标签,确保将属于同一服务的 pod 正常地分散到基于标签值的一组节点。它为指定标签值相同的所有节点赋予相同的分数。它将较高的分数给予组内 pod 密度最低的节点。
"priorities":[
{
"name":"<name>", 1
"weight" : 1 2
"argument":{
"serviceAntiAffinity":{
"label":[
"<label>" 3
]
}
}
}
]例如:
"name":"RackSpread", 1 "weight" : 1 2 "argument":{ "serviceAntiAffinity":{ "label": "rack" 3 } }
在某些情况下,基于自定义标签的 ServiceAntiAffinity 不能按预期分散 pod。请参考此红帽解决方案。
* labelPreference 参数根据指定的标签赋予优先级。如果节点上存在该标签,则该节点被赋予优先级。如果未指定标签,则为没有标签的节点赋予优先级。
"priorities":[
{
"name":"<name>", 1
"weight" : 1, 2
"argument":{
"labelPreference":{
"label": "<label>", 3
"presence": true 4
}
}
}
]16.2.7. 使用案例
在 OpenShift Container Platform 中调度的一个重要用例是支持灵活的关联性和反关联性策略。
16.2.7.1. 基础架构拓扑级别
管理员可以通过在节点上指定标签 (如 region=r1, zone=z1, rack=s1) 来为自己的基础架构定义多拓扑级别。
这些标签名称没有特别含义,管理员可以自由地命名其基础架构级别的任何级别(例如,城市/建筑/房间)。另外,管理员可以为其基础架构拓扑定义任意数量的级别,通常三个级别比较适当(例如:regions → zone → racks)。管理员可以在各个级别上以任何组合指定关联性和反关联性规则。
16.2.7.2. 关联性
管理员应能够配置调度程序,在任何一个甚至多个拓扑级别上指定关联性。特定级别上的关联性指示所有属于同一服务的 pod 调度到属于同一级别的节点。这会让管理员确保对等 pod 在地理上不会过于分散,以此处理应用程序对延迟的要求。如果同一关联性组中没有节点可用于托管 pod,则不调度该 pod。
如果需要更多地控制 pod 的调度位置,请参阅使用节点关联性和使用 Pod 关联性和反关联性。管理员可以利用这些高级调度功能,来指定 pod 可以调度到哪些节点,并且相对于其他 pod 来强制或拒绝调度。
16.2.7.3. 反关联性
管理员应能够配置调度程序,在任何一个甚至多个拓扑级别上指定反关联性。特定级别上的反关联性(或分散)指示属于同一服务的所有 pod 分散到属于该级别的不同节点上。这样可确保应用程序合理分布,以实现高可用性目的。调度程序尝试在所有适用的节点之间尽可能均匀地平衡服务 pod。
如果需要更多地控制 pod 的调度位置,请参阅使用节点关联性和使用 Pod 关联性和反关联性。管理员可以利用这些高级调度功能,来指定 pod 可以调度到哪些节点,并且相对于其他 pod 来强制或拒绝调度。
16.2.8. 策略配置示例
以下配置如果通过调度程序策略文件指定,则指定默认的调度程序配置。
kind: "Policy" version: "v1" predicates: ... - name: "RegionZoneAffinity" 1 argument: serviceAffinity: 2 labels: 3 - "region" - "zone" priorities: ... - name: "RackSpread" 4 weight: 1 argument: serviceAntiAffinity: 5 label: "rack" 6
在下方的所有示例配置中,predicates 和 priorities 函数的列表都已截断,仅包含与指定用例相关的内容。在实践中,完整/有意义的调度程序策略应当包含前文所述的大部分(若非全部)默认 predicates 和 priorities。
以下示例定义了三个拓扑级别,即 region(关联性)-> zone(关联性)-> rack(反关联性):
kind: "Policy"
version: "v1"
predicates:
...
- name: "RegionZoneAffinity"
argument:
serviceAffinity:
labels:
- "region"
- "zone"
priorities:
...
- name: "RackSpread"
weight: 1
argument:
serviceAntiAffinity:
label: "rack"以下示例定义了三个拓扑级别,即 city(关联性)-> building(反关联性)-> room(反关联性):
kind: "Policy"
version: "v1"
predicates:
...
- name: "CityAffinity"
argument:
serviceAffinity:
labels:
- "city"
priorities:
...
- name: "BuildingSpread"
weight: 1
argument:
serviceAntiAffinity:
label: "building"
- name: "RoomSpread"
weight: 1
argument:
serviceAntiAffinity:
label: "room"以下示例定义了一个策略,以仅使用定义了“region”标签的节点,并且优先选择定义有“zone”标签的节点:
kind: "Policy"
version: "v1"
predicates:
...
- name: "RequireRegion"
argument:
labelsPresence:
labels:
- "region"
presence: true
priorities:
...
- name: "ZonePreferred"
weight: 1
argument:
labelPreference:
label: "zone"
presence: true以下示例组合使用静态和可配置的 predicates 和 priorities:
kind: "Policy"
version: "v1"
predicates:
...
- name: "RegionAffinity"
argument:
serviceAffinity:
labels:
- "region"
- name: "RequireRegion"
argument:
labelsPresence:
labels:
- "region"
presence: true
- name: "BuildingNodesAvoid"
argument:
labelsPresence:
labels:
- "building"
presence: false
- name: "PodFitsPorts"
- name: "MatchNodeSelector"
priorities:
...
- name: "ZoneSpread"
weight: 2
argument:
serviceAntiAffinity:
label: "zone"
- name: "ZonePreferred"
weight: 1
argument:
labelPreference:
label: "zone"
presence: true
- name: "ServiceSpreadingPriority"
weight: 116.3. 取消调度
16.3.1. 概述
分离涉及根据 特定的策略 驱除 pod,以便可将 pod 重新调度到更合适的节点上。
集群可以从取消调度和重新调度已在运行的 pod 中受益,原因如下:
- 节点使用不足或过度使用。
- Pod 和节点关联性要求(如污点或标签)已更改,并且原始的调度不再适合于某些节点。
- 节点失败需要移动 pod。
- 集群中添加了新节点。
descheduler 不调度被驱除的 pod。调度程序 自动为被驱除的 pod 执行此任务。
务必要注意,有许多核心组件(如 DNS)对于集群全面运行至关重要,但在常规集群节点而非 master 上运行。如果组件被驱除,集群可能会停止正常工作。要防止 descheduler 删除这些 pod,请将 pod 配置为 关键 pod,方法是将 scheduler.alpha.kubernetes.io/critical-pod 注解添加到 pod 规格中。
descheduler 作业被视为关键 pod,可防止 descheduler pod 被 descheduler 驱除。
descheduler 作业和 descheduler pod 在 kube-system 项目中创建,默认创建。
descheduler 只是一个技术预览功能。技术预览功能不包括在红帽生产服务级别协议(SLA)中,且其功能可能并不完善。因此,红帽不建议在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需红帽技术预览功能支持范围的更多信息,请参阅 https://access.redhat.com/support/offerings/techpreview/。
descheduler 不会驱除以下类型的 pod:
-
关键 pod(带有
scheduler.alpha.kubernetes.io/critical-pod注解)。 - Pod(静态和镜像 pod 或独立模式的 pod)与 Replica Set、Replication Controller、Deployment 或 Job 没有关联(因为这些 pod 不会被重新创建)。
- 与 DaemonSet 关联的 Pod。
- 具有本地存储的 Pod。
- 如果取消调度违反了 PDB,受 Pod Disruption Budget (PDB) 限制的 Pod 不会被驱除。可以使用一个驱除策略来驱除 pod。
在 Burstable 和 Guaranteed pod 之前,pod 会被驱除。
以下小节描述了配置和运行 descheduler 的流程:
- 创建角色。
- 在策略文件中定义取消调度行为。
- 创建配置映射以引用策略文件。
- 创建 descheduler 作业配置。
- 运行 descheduler 作业。
16.3.2. 创建集群角色
配置 descheduler 在 pod 中正常工作所需的权限:
使用以下规则创建 集群角色 :
kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: descheduler-cluster-role rules: - apiGroups: [""] resources: ["nodes"] verbs: ["get", "watch", "list"] 1 - apiGroups: [""] resources: ["pods"] verbs: ["get", "watch", "list", "delete"] 2 - apiGroups: [""] resources: ["pods/eviction"] 3 verbs: ["create"]
创建用于运行作业的服务帐户 :
# oc create sa <file-name>.yaml -n kube-system
例如:
# oc create sa descheduler-sa.yaml -n kube-system
将集群角色绑定到服务帐户:
# oc create clusterrolebinding descheduler-cluster-role-binding \ --clusterrole=<cluster-role-name> \ --serviceaccount=kube-system:<service-account-name>例如:
# oc create clusterrolebinding descheduler-cluster-role-binding \ --clusterrole=descheduler-cluster-role \ --serviceaccount=kube-system:descheduler-sa
16.3.3. 创建 Descheduler 策略
您可以将 descheduler 配置为从违反了 YAML 策略文件中 策略 定义的规则的节点中删除 pod。然后,您可以创建一个 包含策略文件路径的配置映射 以及使用该配置映射应用特定取消调度策略的作业规格。
descheduler 策略文件示例
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: false
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds:
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds:
"cpu" : 50
"memory": 50
"pods": 50
numberOfNodes: 3
"RemovePodsViolatingInterPodAntiAffinity":
enabled: true
"RemovePodsViolatingNodeAffinity":
enabled: true
params:
nodeAffinityType:
- "requiredDuringSchedulingIgnoredDuringExecution"
有三个可与 descheduler 一起使用的默认策略:
您可以根据需要配置和禁用与策略关联的参数。
16.3.3.1. 删除重复的 Pod
RemoveDuplicates 策略确保了在运行的同一个节点上只有一个 pod 与 Replica Set, Replication Controller, Deployment Configuration, 或 Job 相关联。如果存在与这些对象关联的其他 pod,则重复的 pod 会被驱除。删除重复的 pod 会导致在集群中更好地分散 pod。
例如,如果某个节点失败并且节点上的 pod 移到另一个节点,导致多个与 Replica Set 或 Replication Controller 关联的 pod,在同一节点上运行,可能会出现重复的 pod。当出现故障的节点再次就绪后,此策略可用于驱除这些重复的 pod。
没有与此策略关联的参数。
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemoveDuplicates":
enabled: false 1- 1
- 将此值设为
enabled: true以使用此策略。设置为false以禁用此策略。
16.3.3.2. 创建低节点利用率策略
LowNodeUtilization 策略查找使用率不足的节点,并从其他节点驱除 pod,以便能够在这些使用率不足的节点上调度被驱除的 pod。
节点使用率不足通过 CPU、内存或 pod 数量(基于百分比)的可配置的 阈值、阈值决定。如果节点用量低于所有这些阈值,则该节点会被视为使用率不足,descheduler 可以从其他节点驱除 pod。计算节点资源利用率时会考虑 Pod 请求资源要求。
高阈值 targetThresholds 用于确定正确使用的节点。阈值 和 targetThresholds 之间的任何节点都将被正确使用,不考虑驱除。阈值( targetThresholds )可以配置为 CPU、内存和 pod 数量(基于百分比)。
可以针对集群的要求调整这些阈值。
numberOfNodes 参数可以配置为仅在使用率不足的节点超过配置的值时激活策略。如果一些节点利用率不足,则设置这个参数。默认情况下,numberOfNodes 被设置为零。
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"LowNodeUtilization":
enabled: true
params:
nodeResourceUtilizationThresholds:
thresholds: 1
"cpu" : 20
"memory": 20
"pods": 20
targetThresholds: 2
"cpu" : 50
"memory": 50
"pods": 50
numberOfNodes: 3 316.3.3.3. 移除 Pod 冲突间的关联性
RemovePodsViolatingInterPodAntiAffinity 策略确保违反了 pod 间的反关联性的 pod 被从节点中驱除。
例如,Node1 具有 podA、podB 和 podC。podB 和 podC 具有反关联性规则,阻止它们在与 podA 相同的节点上运行。podA 将被从该节点上运行,以便 podB 和 podC 可以在该节点上运行。当 podB 和 podC 在节点上运行时,会出现这种情况。
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingInterPodAntiAffinity": 1
enabled: true- 1
- 将此值设为
enabled: true以使用此策略。设置为false以禁用此策略。
16.3.3.4. 删除 Pod 冲突节点关联性
RemovePodsViolatingNodeAffinity 策略确保违反了节点关联性的所有 pod 都从节点中驱除。当节点不再满足 pod 的关联性规则,会出现这种情况。如果存在另外一个节点来满足关联性规则,则 pod 会被驱除。
例如,podA 被调度到 nodeA 上,因为节点满足调度时所需的 DuringSchedulingIgnoredDuringExecution 节点关联性规则。如果 nodeA 停止满足规则,并且有另外一个节点满足节点关联性规则,则策略会从 nodeA 驱除 podA 并将其移到其他节点。
apiVersion: "descheduler/v1alpha1" kind: "DeschedulerPolicy" strategies: "RemovePodsViolatingNodeAffinity": 1 enabled: true params: nodeAffinityType: - "requiredDuringSchedulingIgnoredDuringExecution" 2
16.3.4. 为 Descheduler 策略创建配置映射
为 kube-system 项目中 descheduler 策略文件创建 配置映射,以便 descheduler 作业可以引用它。
# oc create configmap descheduler-policy-configmap \
-n kube-system --from-file=<path-to-policy-dir/policy.yaml> 1- 1
- 您创建的策略文件的路径。
16.3.5. 创建作业规格
为 descheduler 创建 作业配置。
apiVersion: batch/v1
kind: Job
metadata:
name: descheduler-job
namespace: kube-system
spec:
parallelism: 1
completions: 1
template:
metadata:
name: descheduler-pod 1
annotations:
scheduler.alpha.kubernetes.io/critical-pod: "true" 2
spec:
containers:
- name: descheduler
image: registry.access.redhat.com/openshift3/ose-descheduler
volumeMounts: 3
- mountPath: /policy-dir
name: policy-volume
command:
- "/bin/sh"
- "-ec"
- |
/bin/descheduler --policy-config-file /policy-dir/policy.yaml 4
restartPolicy: "Never"
serviceAccountName: descheduler-sa 5
volumes:
- name: policy-volume
configMap:
name: descheduler-policy-configmap策略文件作为卷从配置映射中挂载。
16.3.6. 运行 Descheduler
以 pod 中作业的形式运行 descheduler:
# oc create -f <file-name>.yaml
例如:
# oc create -f descheduler-job.yaml
16.4. 自定义调度
16.4.1. 概述
您可以运行多个自定义调度程序以及默认调度程序,并配置要用于各个 pod 的调度程序。
要使用特定的调度程序调度给定 pod,在 Pod 的规格中指定调度程序的名称。
有关如何创建调度程序二进制文件的信息超出了本文档的讨论范围。例如,请参阅 Kubernetes 文档中的配置多个调度程序。
16.4.2. 打包调度程序
在集群中包含自定义调度程序的常规流程涉及创建镜像,并将该镜像包含在部署中。
- 将调度程序二进制文件打包到容器镜像中。
创建包含调度程序二进制文件的容器镜像。
例如:
FROM <source-image> ADD <path-to-binary> /usr/local/bin/kube-scheduler
将文件保存为 Dockerfile,构建镜像并将其推送到 Registry。
例如:
docker build -t <dest_env_registry_ip>:<port>/<namespace>/<image name>:<tag> docker push <dest_env_registry_ip>:<port>/<namespace>/<image name>:<tag>
在 OpenShift Container Platform 中,为自定义调度程序创建一个部署。
apiVersion: v1 kind: ServiceAccount metadata: name: custom-scheduler namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: custom-scheduler subjects: - kind: ServiceAccount name: custom-scheduler namespace: kube-system roleRef: kind: ClusterRole name: system:kube-scheduler apiGroup: rbac.authorization.k8s.io --- apiVersion: apps/v1 kind: Deployment metadata: name: custom-scheduler namespace: kube-system labels: app: custom-scheduler spec: replicas: 1 selector: matchLabels: app: custom-scheduler template: metadata: labels: app: custom-scheduler spec: serviceAccount: custom-scheduler containers: - name: custom-scheduler image: "<namespace>/<image name>:<tag>" 1 imagePullPolicy: Always- 1
- 指定您为自定义调度程序创建的容器镜像。
16.4.3. 使用自定义调度程序部署 Pod
在集群中部署自定义调度程序后,您可以将 pod 配置为使用该调度程序,而不是默认调度程序。
创建或编辑 pod 配置,并使用
schedulerName参数指定调度程序的名称。名称必须是唯一的。使用调度程序的 pod 规格示例
apiVersion: v1 kind: Pod metadata: name: custom-scheduler-example labels: name: custom-scheduler-example spec: schedulerName: custom-scheduler 1 containers: - name: pod-with-second-annotation-container image: docker.io/ocpqe/hello-pod- 1
- 要使用的调度程序的名称。如果没有提供调度程序名称,pod 会自动使用默认调度程序来调度。
运行以下命令来创建 pod:
$ oc create -f <file-name>.yaml
例如:
$ oc create -f custom-scheduler-example.yaml
运行以下命令来检查 pod 是否已创建:
$ oc get pod <file-name>
例如:
$ oc get pod custom-scheduler-example NAME READY STATUS RESTARTS AGE custom-scheduler-example 1/1 Running 0 4m
运行以下命令来检查自定义调度程序是否调度了 pod:
$ oc describe pod <pod-name>
例如:
$ oc describe pod custom-scheduler-example
列出了调度程序的名称,如以下截断的输出所示:
... Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 custom-scheduler Normal Scheduled Successfully assigned custom-scheduler to <$node1> ...
16.5. 控制 Pod 放置
16.5.1. 概述
作为集群管理员,您可以设置策略,以防止具有特定角色的应用开发人员在调度 pod 时定位特定的节点。
Pod 节点 Constraints 准入控制器确保 pod 只使用标签部署到指定的节点主机上,并防止没有特定角色的用户使用 nodeSelector 字段来调度 pod。
16.5.2. 使用节点名称限制 Pod 放置
使用 Pod 节点 Constraints 准入控制器,通过为其分配标签并在 pod 配置中的 nodeName 设置中指定 pod,以确保 pod 只部署到指定节点主机上。
确保您有所需的标签(请参阅 在节点上更新标签)和节点选择器设置。
例如,请确保您的 pod 配置具有指示所需标签的
nodeName值:apiVersion: v1 kind: Pod spec: nodeName: <value>
修改 master 配置文件 /etc/origin/master/master-config.yaml,将
PodNodeConstraints添加到admissionConfig部分:... admissionConfig: pluginConfig: PodNodeConstraints: configuration: apiversion: v1 kind: PodNodeConstraintsConfig ...重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
16.5.3. 使用 Node Selector 约束 Pod 放置
使用 节点选择器,您可以确保 pod 只放置到具有特定标签的节点上。作为集群管理员,您可以使用 Pod 节点约束准入控制器来设置一个策略,防止没有 pod/绑定 权限的用户使用节点选择器来调度 pod。
master 配置文件的 nodeSelectorLabelBlacklist 字段可让您控制 pod 配置的 nodeSelector 字段中特定角色可以指定的标签。具有 pod/binding 权限 角色 的用户、服务帐户和组可以指定任何节点选择器。没有 pods/binding 权限的组群会被禁止为 nodeSelectorLabelBlacklist 中出现的任何标签设置 nodeSelector。
例如,OpenShift Container Platform 集群可能包含五个数据中心,分布在两个区域。U.S.:us-east, us-central, 和 us-west; Asia-Pacific region (APAC), apac-east 和 apac-west。每个地理区域中的每个节点都会进行相应的标记。例如 region: us-east。
有关分配标签的详情,请参阅在节点上更新标签。
作为集群管理员,您可以创建一个基础架构,应用程序开发人员应在最接近其地理位置的节点上部署 pod。您可以创建节点选择器,将美国数据中心分组到 superregion: us,APAC 数据中心到 superregion: apac。
要维护每个数据中心的资源甚至加载,您可以将所需的 区域 添加到 master 配置的 nodeSelectorLabelBlacklist 部分。然后,每当位于美国的开发人员创建 pod 时,它将部署到具有 superregion: us 标签的其中一个区域的节点。如果开发人员尝试将其容器集的特定区域作为目标(如 region: us-east),则他们会收到错误。如果他们再次尝试,其 pod 上没有节点选择器,它仍然可以部署到他们尝试的目标区域,因为 superregion: us 被设置为项目级别节点选择器,节点被标记为 region: us-east 的节点也被标记为 superregion: us。
确保您有所需的标签(请参阅 在节点上更新标签)和节点选择器设置。
例如,请确保您的 pod 配置具有指明所需标签的
nodeSelector值:apiVersion: v1 kind: Pod spec: nodeSelector: <key>: <value> ...修改 master 配置文件 /etc/origin/master/master-config.yaml,将
nodeSelectorLabelBlacklist添加到admissionConfig部分,带有分配给您要拒绝 pod 放置的节点主机的标签:... admissionConfig: pluginConfig: PodNodeConstraints: configuration: apiversion: v1 kind: PodNodeConstraintsConfig nodeSelectorLabelBlacklist: - kubernetes.io/hostname - <label> ...重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
16.5.4. 控制 Pod 放置到项目
Pod Node Selector 准入控制器允许您将 pod 强制到与特定项目关联的节点上,并防止 pod 调度到这些节点上。
Pod Node Selector 准入控制器使用项目中的标签和在 pod 中指定的节点选择器决定 pod 放置的位置。只有 pod 中的节点选择器与项目中的标签匹配时,才会将新 pod 放置到与项目关联的节点上。
在 pod 创建后,节点选择器合并到 pod 中,以便 pod 规格包括最初包含在规格中的标签以及节点选择器中的任何新标签。以下示例说明了合并效果。
Pod Node Selector 准入控制器还允许您创建在特定项目中允许的标签列表。此列表充当 白名单,使开发人员能够知道可在项目中使用哪些标签,并让管理员更好地控制集群中的标签。
激活 Pod Node Selector 准入控制器:
使用以下方法之一配置 Pod Node Selector 准入控制器和白名单:
将以下内容添加到 master 配置文件 /etc/origin/master/master-config.yaml 中:
admissionConfig: pluginConfig: PodNodeSelector: configuration: podNodeSelectorPluginConfig: 1 clusterDefaultNodeSelector: "k3=v3" 2 ns1: region=west,env=test,infra=fedora,os=fedora 3创建包含准入控制器信息的文件:
podNodeSelectorPluginConfig: clusterDefaultNodeSelector: "k3=v3" ns1: region=west,env=test,infra=fedora,os=fedora然后,在 master 配置中引用该文件:
admissionConfig: pluginConfig: PodNodeSelector: location: <path-to-file>注意如果项目没有指定节点选择器,则与该项目关联的 pod 将使用默认节点选择器(
clusterDefaultNodeSelector)进行合并。
重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
创建包含
scheduler.alpha.kubernetes.io/node-selector注解和标签的项目对象。apiVersion: v1 kind: Namespace metadata name: ns1 annotations: scheduler.alpha.kubernetes.io/node-selector: env=test,infra=fedora 1 spec: {}, status: {}- 1
- 创建标签以匹配项目标签选择器的注释。此处的键/值标签是
env=test和infra=fedora。
注意使用 Pod Node Selector 准入控制器时,您无法使用
oc adm new-project <project-name>来设置项目节点选择器。当您使用oc adm new-project myproject --node-selector='type=user-node,region=<region>命令设置项目节点选择器时,OpenShift Container Platform 会设置openshift.io/node-selector注解,该注解由 NodeEnv 准入插件处理。创建在节点选择器中包含标签的 pod 规格,例如:
apiVersion: v1 kind: Pod metadata: labels: name: hello-pod name: hello-pod spec: containers: - image: "docker.io/ocpqe/hello-pod:latest" imagePullPolicy: IfNotPresent name: hello-pod ports: - containerPort: 8080 protocol: TCP resources: {} securityContext: capabilities: {} privileged: false terminationMessagePath: /dev/termination-log dnsPolicy: ClusterFirst restartPolicy: Always nodeSelector: 1 env: test os: fedora serviceAccount: "" status: {}- 1
- 与项目标签匹配的节点选择器。
在项目中创建 pod:
# oc create -f pod.yaml --namespace=ns1
检查节点选择器标签是否已添加到 pod 配置中:
get pod pod1 --namespace=ns1 -o json nodeSelector": { "env": "test", "infra": "fedora", "os": "fedora" }节点选择器合并到 pod 中,容器集应当调度到适当的项目中。
如果您创建了一个没有在项目规格中指定的标签的 pod,则 pod 不会被调度到该节点上。
例如,这里的标签 env: production 不在任何项目规格中:
nodeSelector: "env: production" "infra": "fedora", "os": "fedora"
如果有一个没有节点选择器注解的节点,则 pod 会在该处调度。
16.6. Pod 优先级和抢占功能
16.6.1. 应用 pod 优先级和抢占
您可以在集群中启用 pod 优先级与抢占功能。Pod 优先级指明 pod 相对于其他 pod 的重要程度,并根据这个优先级对 pod 进行排队。Pod 抢占则允许集群驱除低优先级 pod 或与之争抢,从而在合适的节点上没有可用空间时能够调度优先级较高的 pod。pod 优先级也会影响 pod 的调度顺序以及节点上资源不足驱除顺序。
要使用优先级和抢占功能,您需要创建优先级类来定义 pod 的相对权重。然后,在 pod 规格中引用优先级类,以应用这个权重来进行调度。
抢占通过调度程序配置文件中的 disablePreemption 参数来进行控制,该参数默认设置为 false。
16.6.2. 关于 pod 优先级
当启用 Pod 优先级和抢占功能时,调度程序会按照优先级调度待处理 pod,并将待处理 pod 放在调度队列中优先级较低的其他待处理 pod 的前面。因此,如果达到调度要求,较高优先级的 pod 可能比低优先级的 pod 更早调度。如果 pod 无法调度,调度程序会继续调度其他较低优先级 pod。
16.6.2.1. Pod 优先级类
您可以为 pod 分配一个优先级类,它是一种非命名空间的对象,用于定义从名称到优先级整数值的映射。数值越大,优先级越高。
优先级类对象可以取小于或等于 1000000000(十亿)的 32 位整数值。对于不应被抢占或驱除的关键 pod,可保留大于十亿的数值。默认情况下,OpenShift Container Platform 有两个保留优先级类,用于需要保证调度的关键系统 pod。
- system-node-critical - 此优先级类的值为 2000001000,用于不应从节点驱除的所有 pod。具有此优先级类的 pod 示例有 sdn-ovs 和 sdn 等。
-
system-cluster-critical - 此优先级类的值为 2000000000(二十亿),用于对集群而言很重要的 pod。在某些情况下,具有此优先级类的 Pod 可以从节点中驱除。例如,配置了
system-node-critical优先级类的 pod 可以拥有优先权。不过,此优先级类确实能够保证调度。具有此优先级类的 pod 示例有 fluentd 以及 descheduler 这样的附加组件等。
如果升级现有的集群,则现有 pod 的优先级相当于为零。不过,带有 scheduler.alpha.kubernetes.io/critical-pod 注解的现有 pod 会自动转换为 system-cluster-critical 类。
16.6.2.2. Pod 优先级名称
拥有一个或多个优先级类后,您可以创建 pod,并在 pod 规格中指定优先级类名称。优先准入控制器使用优先级类名称字段来填充优先级的整数值。如果没有找到给定名称的优先级类,pod 将被拒绝。
以下 YAML 是使用上例中创建的优先级类的 pod 配置示例:优先级准入控制器检查规格,并将 pod 的优先级解析为 1000000。
16.6.3. 关于 pod 抢占
当开发人员创建 pod 时,pod 会排入某一队列。当启用 Pod 优先级和抢占功能时,调度程序会从队列中选择一个 pod,并尝试将 pod 调度到节点上。如果调度程序无法在满足 pod 的所有指定要求的适当节点上找到空间,则会为待处理 pod 触发抢占逻辑。
当调度程序在节点上抢占一个或多个节点时,较高优先级 pod 规格的 nominatedNodeName 字段将设为该节点的名称,nodename 字段同样如此。调度程序使用 nominatedNodeName 字段来跟踪为 pod 保留的资源,同时也向用户提供与集群中抢占相关的信息。
在调度程序抢占了某一较低优先级 pod 后,调度程序会尊重该 pod 的安全终止期限。如果在调度程序等待较低优先级 pod 终止过程中另一节点变为可用,调度程序会将较高优先级 pod 调度到该节点上。因此,pod 规格的 nominatedNodeName 字段和 nodeName 字段可能会不同。
另外,如果调度程序在某一节点上抢占 pod 并正在等待终止,这时又有优先级比待处理 pod 高的 pod 需要调度,那么调度程序可以改为调度这个优先级更高的 pod。在这种情况下,调度程序会清除待处理 pod 的 nominatedNodeName,使该 pod 有资格调度到其他节点上。
抢占不一定从节点中移除所有较低优先级 pod。调度程序可以通过移除一部分较低优先级 pod 调度待处理 pod。
只有待处理 pod 能够调度到节点时,调度程序才会对这个节点考虑 pod 抢占。
16.6.3.1. Pod 抢占和其他调度程序设置
如果启用 pod 优先级与抢占功能,请考虑其他的调度程序设置:
- pod 优先级和 pod 中断预算
- pod 中断预算指定某一时间必须保持在线的副本的最小数量或百分比。如果您指定了 pod 中断预算,OpenShift Container Platform 会在抢占 pod 时尽力尊重这些预算。调度程序会尝试在不违反 pod 中断预算的前提下抢占 pod。如果找不到这样的 pod,则可能会无视 pod 中断预算要求而抢占较低优先级 pod。
- pod 优先级和 pod 关联性
- pod 关联性要求将新 pod 调度到与具有同样标签的其他 pod 相同的节点上。
如果待处理 pod 与节点上的一个或多个低优先级 pod 具有 pod 间关联性,调度程序就不能在不违反关联要求的前提下抢占较低优先级 pod。这时,调度程序会寻找其他节点来调度待处理 pod。但是,不能保证调度程序能够找到合适的节点,因此可能无法调度待处理 pod。
要防止这种情况,请仔细配置优先级相同的 pod 的 pod 关联性。
16.6.3.2. 安全终止被抢占的 pod
在抢占 pod 时,调度程序会等待 pod 安全终止期限 过期,允许 pod 完成工作并退出。如果 pod 在到期后没有退出,调度程序会终止该 pod。此安全终止期限会在调度程序抢占该 pod 的时间和待处理 pod 调度到节点的时间之间造成一个时间差。
要尽量缩短这个时间差,可以为较低优先级 pod 配置较短的安全终止期限。
16.6.4. Pod 优先级示例场景
Pod 优先级和抢占为 pod 分配优先级,以进行调度。调度程序将抢占(驱除)较低优先级 pod,从而调度优先级较高的 pod。
- 典型的抢占场景
Pod P 是一个待处理 pod。
- 调度程序会找到 Node N,删除一个或多个 pod 会导致 Pod P 调度到该节点上。
- 调度程序从 Node N 中删除较低优先级 pod,并将 Pod P 调度到该节点上。
-
Pod P 的
nominatedNodeName字段被设置为 Node N 的名称。
Pod P 不一定调度到已提名节点。
- 抢占和终止期限
抢占的 pod 具有较长的终止期限。
- 调度程序在 Node N 上抢占了一个较低优先级 pod。
- 调度程序会等待 pod 正常终止。
- 出于其他调度原因,节点 M 变为可用。
- 然后调度程序可以在 节点 M 上调度 Pod P。
16.6.5. 配置优先级和抢占
通过创建优先级类对象并使用 pod 规格中的 priorityClassName 将 pod 与优先级关联,可以应用 pod 优先级与抢占。
优先级类对象示例
apiVersion: scheduling.k8s.io/v1beta1 kind: PriorityClass metadata: name: high-priority 1 value: 1000000 2 globalDefault: false 3 description: "This priority class should be used for XYZ service pods only." 4
带有优先级类名称的 pod 规格示例
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority 1
- 1
- 指定要用于此 pod 的优先级类。
配置集群以使用优先级与抢占功能:
创建一个或多个优先级类:
- 指定优先级的名称和值。
-
(可选)指定优先级类的
globalDefault字段和描述。
- 创建 pod 或编辑现有的 pod 以包含优先级类的名称。您可以将优先级名称直接添加到 pod 配置或 pod 模板中:
16.6.6. 禁用优先级与抢占
您可以禁用 pod 优先级与抢占功能。
禁用该功能后,现有 pod 会保留其优先级字段,但会禁用抢占功能,而且也会忽略优先级字段。如果禁用该功能,您便无法在新 pod 中设置优先级类名称。
在集群面临资源压力时,关键 pod 依赖于调度程序抢占功能来进行调度。因此,红帽建议您不要禁用抢占。DaemonSet pod 由 DaemonSet 控制器调度,不受禁用抢占的影响。
为集群禁用抢占:
修改
master-config.yaml,将schedulerArgs部分中的disablePreemption参数设置为false。disablePreemption=false
重启 OpenShift Container Platform master 服务和调度程序以应用更改。
# master-restart api # master-restart scheduler
16.7. 高级调度
16.7.1. 概述
高级调度涉及配置 pod,以便 pod 需要在特定节点上运行,或者优先在特定节点上运行。
通常,不需要高级调度,因为 OpenShift Container Platform 会自动以合理的方式放置 pod。例如,默认调度程序会尝试在节点间平均分配 pod,并考虑节点中的可用资源。但是,您可能需要更多地控制 pod 的放置位置。
如果 pod 需要位于具有更快磁盘速度(或阻止放置于该计算机上)或来自两个不同服务的 pod 以便它们进行通信的机器上,您可以使用高级调度来实现这一点。
为确保将适当的新 pod 调度到专用的一组节点上,并防止将其他新 pod 调度到这些节点上,您可以根据需要组合这些方法。
16.7.2. 使用高级调度
在集群中调用高级调度的方法有几种:
- Pod 关联性和反关联性
容器集关联性允许 pod 向一组 容器集 指定关联性(或反关联性),这表示应用的延迟要求,因为安全性等原因。节点对放置没有控制权。
容器集关联性使用节点上的标签和 pod 上的标签选择器来创建 pod 放置规则。规则可以是强制(必需)或est-effort(首选)。
请参阅使用 Pod 关联性和反关联性。
- 节点关联性
节点关联性允许 pod 向一组 节点 (因为其特殊硬件、位置、高可用性要求等)指定关联性(或反关联性)。节点对放置没有控制权。
节点关联性使用节点上的标签和 pod 上的标签选择器来创建 pod 放置规则。规则可以是强制(必需)或est-effort(首选)。
请参阅使用节点关联性。
- 节点选择器
节点选择器是最简单的高级调度形式。与节点关联性一样,节点选择器也使用节点上的标签和 pod 上的标签选择器,以允许 pod 控制它可以放置的节点。但是,节点选择器没有节点关联性具有的必要和偏好规则。
- 污点和容限
污点和容限(taint/Tolerations) 允许 节点 控制哪些 pod 应该(或不应该)调度到节点上。污点是节点上的标签,容限是 pod 上的标签。pod 上的标签必须匹配(或容许)节点上的标签(taint)才能调度。
与关联性相比,污点/容限有一个优势。例如,如果您添加到集群中,一组具有不同标签的新节点,则需要更新您要访问该节点的每个 pod 上的关联性,以及您不想使用新节点的所有其他 pod。使用污点/容限时,您只需要更新置入这些新节点上的 pod,因为会出现其他 pod。
16.8. 高级调度和节点关联性
16.8.1. 概述
节点关联性 是由调度程序用来确定 pod 的可放置位置的一组规则。规则使用 节点上的自定义标签和 pod 中指定的选择器来定义。节点关联性允许 pod 为其可放置的一组 节点 指定关联性(或反关联性)。节点对放置没有控制权。
例如,您可以将 pod 配置为仅在具有特定 CPU 或位于特定可用区的节点上运行。
节点关联性规则有两种,即必要规则和偏好规则。
必须满足必要规则,pod 才能调度到节点上。偏好规则指定在满足规则时调度程序会尝试强制执行规则,但不保证一定能强制执行成功。
如果节点标签在运行时改变,使得不再满足 pod 上的节点关联性规则,该 pod 将继续在这个节点上运行。
16.8.2. 配置节点关联性
您可以通过 pod 规格文件配置节点关联性。您可以指定 必要规则(required rule)或 偏好规则(preferred rule) ,或同时指定两者。如果您同时指定,节点必须首先满足必要规则,然后尝试满足偏好规则。
下例中的 pod 规格包含一条规则,要求 pod 放置到具有某一标签(键为 e2e-az-NorthSouth 且值为 e2e-az-North 或 e2e-az-South)的节点上:
具有节点关联性必要规则的 pod 配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity: 1
requiredDuringSchedulingIgnoredDuringExecution: 2
nodeSelectorTerms:
- matchExpressions:
- key: e2e-az-NorthSouth 3
operator: In 4
values:
- e2e-az-North 5
- e2e-az-South 6
containers:
- name: with-node-affinity
image: docker.io/ocpqe/hello-pod
下例中的节点规格包含一条偏好规则,其规定优先为 pod 选择具有键为 e2e-az-EastWest 且值为 e2e-az-East 或 e2e-az-West 的节点:
具有节点关联性偏好规则的 pod 配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity: 1
preferredDuringSchedulingIgnoredDuringExecution: 2
- weight: 1 3
preference:
matchExpressions:
- key: e2e-az-EastWest 4
operator: In 5
values:
- e2e-az-East 6
- e2e-az-West 7
containers:
- name: with-node-affinity
image: docker.io/ocpqe/hello-pod
没有明确的节点反关联性概念,但使用 NotIn 或 DoesNotExist 运算符就能实现这种行为。
如果您在同一 pod 配置中使用节点关联性和 节点选择器,请注意以下几点:
-
如果同时配置了
nodeSelector和nodeAffinity,则必须满足这两个条件时 pod 才能调度到候选节点。 -
如果您指定了多个与
nodeAffinity类型关联的nodeSelectorTerms,那么其中一个nodeSelectorTerms满足时 pod 就能调度到节点上。 -
如果您指定了多个与
nodeSelectorTerms关联的matchExpressions,那么只有所有matchExpressions都满足时 pod 才能调度到节点上。
16.8.2.1. 配置所需的节点关联性规则
必须满足必要规则,pod 才能调度到节点上。
以下步骤演示了一个简单的配置,此配置会创建一个节点,以及调度程序要放置到该节点上的 pod。
通过编辑节点配置或使用
oc label node命令向节点添加标签:$ oc label node node1 e2e-az-name=e2e-az1
注意要修改集群中的节点,请根据需要更新节点配置映射。不要手动编辑
node-config.yaml文件。在 pod 规格中,使用
nodeAffinity小节来配置requiredDuringSchedulingIgnoredDuringExecution参数:-
指定必须满足的键和值。如果希望新 pod 调度到您编辑的节点上,请使用与节点中标签相同的
key和value参数。 指定一个
operator。运算符可以是In、NotIn、Exists或DoesNotExist、Lt或Gt。例如,使用运算符In来要求节点上存在该标签:spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: e2e-az-name operator: In values: - e2e-az1 - e2e-az2
-
指定必须满足的键和值。如果希望新 pod 调度到您编辑的节点上,请使用与节点中标签相同的
创建 pod:
$ oc create -f e2e-az2.yaml
16.8.2.2. 配置节点关联性偏好规则
偏好规则指定在满足规则时调度程序会尝试强制执行规则,但不保证一定能强制执行成功。
以下步骤演示了一个简单的配置,此配置会创建一个节点,以及调度程序尝试放置到该节点上的 pod。
通过编辑节点配置或执行
oc label node命令,为节点添加标签:$ oc label node node1 e2e-az-name=e2e-az3
注意要修改集群中的节点,请根据需要更新节点配置映射。不要手动编辑
node-config.yaml文件。在 pod 规格中,使用
nodeAffinity小节来配置preferredDuringSchedulingIgnoredDuringExecution参数:- 为节点指定一个权重,值为 1 到 100 的数字。优先选择权重最高的节点。
指定必须满足的键和值。如果希望新 pod 调度到您编辑的节点上,请使用与节点中标签相同的
key和value参数:preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: e2e-az-name operator: In values: - e2e-az3
-
指定一个
operator。运算符可以是In、NotIn、Exists或DoesNotExist、Lt或Gt。例如,使用运算符In来要求节点上存在该标签。 创建 pod。
$ oc create -f e2e-az3.yaml
16.8.3. 示例
以下示例演示了节点关联性。
16.8.3.1. 具有匹配标签的节点关联性
以下示例演示了具有匹配标签的节点与 pod 的节点关联性:
Node1 节点具有标签
zone:us:$ oc label node node1 zone=us
pod pod-s1 在节点关联性必要规则下具有
zone和us键/值对:$ cat pod-s1.yaml apiVersion: v1 kind: Pod metadata: name: pod-s1 spec: containers: - image: "docker.io/ocpqe/hello-pod" name: hello-pod affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: "zone" operator: In values: - us使用标准命令创建 pod:
$ oc create -f pod-s1.yaml pod "pod-s1" created
pod pod-s1 可以调度到 Node1 上:
$ oc get pod -o wide NAME READY STATUS RESTARTS AGE IP NODE pod-s1 1/1 Running 0 4m IP1 node1
16.8.3.2. 无匹配标签的节点关联性
以下示例演示了无匹配标签的节点与 pod 的节点关联性:
Node1 节点有标签
zone:emea:$ oc label node node1 zone=emea
pod pod-s1 在节点关联性必要规则下具有
zone和us键/值对:$ cat pod-s1.yaml apiVersion: v1 kind: Pod metadata: name: pod-s1 spec: containers: - image: "docker.io/ocpqe/hello-pod" name: hello-pod affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: "zone" operator: In values: - uspod pod-s1 无法调度到 Node1 上:
$ oc describe pod pod-s1 ... Events: FirstSeen LastSeen Count From SubObjectPath Type Reason --------- -------- ----- ---- ------------- -------- ------ 1m 33s 8 default-scheduler Warning FailedScheduling No nodes are available that match all of the following predicates:: MatchNodeSelector (1).
16.9. 高级调度和 Pod 关联性和反关联性
16.9.1. 概述
通过 pod 关联性和 pod 反关联性,您可以指定有关如何将 pod 放置到其他 pod 的规则。规则使用 节点上的自定义标签和 pod 中指定的选择器来定义。pod 关联性/反关联性允许 pod 为其可以放置的一组 pod 指定关联性(或反关联性)。节点对放置没有控制权。
例如,您可以使用关联性规则,在服务内或相对于其他服务中的 pod 来分散或聚拢 pod。如果特定服务的 pod 的性能已知会受到另一服务的 pod 影响,那么您可以利用反关联性规则,防止前一服务的 pod 调度到与后一服务的 pod 相同的节点上。或者,您可以将服务的 pod 分散到不同的节点或可用区间,以减少关联的故障。
pod 关联性/反关联性允许您根据其他 pod 上的标签限制 pod 有资格调度到哪些节点。标签 是一个键/值对。
- 如果新 pod 上的标签选择器与当前 pod 上的标签匹配,pod 关联性可以命令调度程序将新 pod 放置到与其他 pod 相同的节点上。
- 如果新 pod 上的标签选择器与当前 pod 上的标签匹配,pod 反关联性可以阻止调度程序将新 pod 放置到与具有相同标签的 pod 相同的节点上。
pod 关联性规则有两种,即必要规则和偏好规则。
必须满足必要规则,pod 才能调度到节点上。偏好规则指定在满足规则时调度程序会尝试强制执行规则,但不保证一定能强制执行成功。
根据 pod 优先级和抢占 设置,调度程序可能无法在不违反关联性要求的情况下为 pod 查找适当的节点。若是如此,pod 可能不会被调度。
要防止这种情况,请仔细配置优先级相同的 pod 的 pod 关联性。
16.9.2. 配置 Pod 关联性和反关联性
您可以通过 pod 规格文件来配置 pod 的关联性/反关联性。您可以指定 必要规则(required rule)或 偏好规则(preferred rule) ,或同时指定两者。如果您同时指定,节点必须首先满足必要规则,然后尝试满足偏好规则。
以下示例显示配置了 pod 关联性和反关联性的 pod 规格。
在本例中,pod 关联性规则指明,只有当节点至少有一个已在运行且具有键 security 和值 S1 的标签的 pod 时,pod 才可以调度到这个节点上。pod 反关联性则表示,如果节点已在运行带有键 security 和值 S2.的标签的 pod,则 pod 将偏向于不调度到该节点上。
设有 pod 关联性的 pod 配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: with-pod-affinity
spec:
affinity:
podAffinity: 1
requiredDuringSchedulingIgnoredDuringExecution: 2
- labelSelector:
matchExpressions:
- key: security 3
operator: In 4
values:
- S1 5
topologyKey: failure-domain.beta.kubernetes.io/zone
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
设有 pod 反关联性的 pod 配置文件示例
apiVersion: v1
kind: Pod
metadata:
name: with-pod-antiaffinity
spec:
affinity:
podAntiAffinity: 1
preferredDuringSchedulingIgnoredDuringExecution: 2
- weight: 100 3
podAffinityTerm:
labelSelector:
matchExpressions:
- key: security 4
operator: In 5
values:
- S2
topologyKey: kubernetes.io/hostname
containers:
- name: with-pod-affinity
image: docker.io/ocpqe/hello-pod
如果节点标签在运行时改变,使得不再满足 pod 上的关联性规则,pod 会继续在该节点上运行。
16.9.2.1. 配置关联性规则
以下步骤演示了一个简单的双 pod 配置,它创建一个带有某标签的 pod,以及一个使用关联性来允许随着该 pod 一起调度的 pod。
创建 pod 规格中具有特定标签的 pod:
$ cat team4.yaml apiVersion: v1 kind: Pod metadata: name: security-s1 labels: security: S1 spec: containers: - name: security-s1 image: docker.io/ocpqe/hello-pod在创建其他 pod 时,请按下方所示编辑 pod 规格:
-
使用
podAffinity小节配置requiredDuringSchedulingIgnoredDuringExecution参数或preferredDuringSchedulingIgnoredDuringExecution参数: 指定必须满足的键和值。如果您希望新 pod 与另一个 pod 一起调度,请使用与第一个 pod 上标签相同的
key和value参数。podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - S1 topologyKey: failure-domain.beta.kubernetes.io/zone-
指定一个
operator。运算符可以是In、NotIn、Exists或DoesNotExist。例如,使用运算符In来要求节点上存在该标签。 -
指定
topologyKey,这是一个预填充的 Kubernetes 标签,供系统用于表示这样的拓扑域。
-
使用
创建 pod。
$ oc create -f <pod-spec>.yaml
16.9.2.2. 配置反关联性规则
以下步骤演示了一个简单的双 pod 配置,它创建一个带有某标签的 pod,以及一个使用反关联性偏好规则来尝试阻止随着该 pod 一起调度的 pod。
创建 pod 规格中具有特定标签的 pod:
$ cat team4.yaml apiVersion: v1 kind: Pod metadata: name: security-s2 labels: security: S2 spec: containers: - name: security-s2 image: docker.io/ocpqe/hello-pod- 在创建其他 pod 时,请编辑 pod 规格来设置以下参数:
使用
podAffinity小节配置requiredDuringSchedulingIgnoredDuringExecution参数或preferredDuringSchedulingIgnoredDuringExecution参数:- 为节点指定一个 1 到 100 的权重。优先选择权重最高的节点。
指定必须满足的键和值。如果您希望新 pod 不与另一个 pod 一起调度,请使用与第一个 pod 上标签相同的
key和value参数。podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 100 podAffinityTerm: labelSelector: matchExpressions: - key: security operator: In values: - S2 topologyKey: kubernetes.io/hostname- 为偏好规则指定一个 1 到 100 的权重。
-
指定一个
operator。运算符可以是In、NotIn、Exists或DoesNotExist。例如,使用运算符In来要求节点上存在该标签。
-
指定
topologyKey,这是一个预填充的 Kubernetes 标签,供系统用于表示这样的拓扑域。 创建 pod。
$ oc create -f <pod-spec>.yaml
16.9.3. 示例
以下示例演示了 pod 关联性和 pod 反关联性。
16.9.3.1. Pod 关联性
以下示例演示了具有匹配标签和标签选择器的 pod 的 pod 关联性。
pod team4 具有标签
team:4。$ cat team4.yaml apiVersion: v1 kind: Pod metadata: name: team4 labels: team: "4" spec: containers: - name: ocp image: docker.io/ocpqe/hello-podpod team4a 在
podAffinity下具有标签选择器team:4。$ cat pod-team4a.yaml apiVersion: v1 kind: Pod metadata: name: team4a spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: team operator: In values: - "4" topologyKey: kubernetes.io/hostname containers: - name: pod-affinity image: docker.io/ocpqe/hello-pod- team4a pod 调度到与 team4 pod 相同的节点上。
16.9.3.2. Pod 反关联性
以下示例演示了具有匹配标签和标签选择器的 pod 的 pod 反关联性。
pod pod-s1 具有标签
security:s1。$ cat pod-s1.yaml apiVersion: v1 kind: Pod metadata: name: pod-s1 labels: security: s1 spec: containers: - name: ocp image: docker.io/ocpqe/hello-podpod pod-s2 在
podAntiAffinity下具有标签选择器security:s1。$ cat pod-s2.yaml apiVersion: v1 kind: Pod metadata: name: pod-s2 spec: affinity: podAntiAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - s1 topologyKey: kubernetes.io/hostname containers: - name: pod-antiaffinity image: docker.io/ocpqe/hello-pod-
pod pod-s2 无法调度到与
pod-s1相同的节点上。
16.9.3.3. 无匹配标签的 Pod 反关联性
以下示例演示了在没有匹配标签和标签选择器时的 pod 的 pod 关联性。
pod pod-s1 具有标签
security:s1。$ cat pod-s1.yaml apiVersion: v1 kind: Pod metadata: name: pod-s1 labels: security: s1 spec: containers: - name: ocp image: docker.io/ocpqe/hello-podpod pod-s2 具有标签选择器
security:s2。$ cat pod-s2.yaml apiVersion: v1 kind: Pod metadata: name: pod-s2 spec: affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: security operator: In values: - s2 topologyKey: kubernetes.io/hostname containers: - name: pod-affinity image: docker.io/ocpqe/hello-pod除非节点上具有带
security:s2标签的 pod,否则不会调度 pod-s2。如果没有具有该标签的其他 pod,新 pod 会保持在待处理状态:NAME READY STATUS RESTARTS AGE IP NODE pod-s2 0/1 Pending 0 32s <none>
16.10. 高级调度和 Node Selectors
16.10.1. 概述
节点选择器指定一个键值对映射。使用节点中的自定义标签和 pod 中指定的选择器来定义规则。
若要使 pod 有资格在某一节点上运行,pod 必须具有指定为该节点上标签的键值对。
16.10.2. 配置 Node Selectors
在 pod 配置中使用 nodeSelector,您可以确保 pod 只放置到带有特定标签的节点上。
确保您有所需的标签(请参阅 在节点上更新标签)和节点选择器设置。
例如,请确保您的 pod 配置具有指明所需标签的
nodeSelector值:apiVersion: v1 kind: Pod spec: nodeSelector: <key>: <value> ...修改 master 配置文件 /etc/origin/master/master-config.yaml,将
nodeSelectorLabelBlacklist添加到admissionConfig部分,带有分配给您要拒绝 pod 放置的节点主机的标签:... admissionConfig: pluginConfig: PodNodeConstraints: configuration: apiversion: v1 kind: PodNodeConstraintsConfig nodeSelectorLabelBlacklist: - kubernetes.io/hostname - <label> ...重启 OpenShift Container Platform 以使更改生效。
# master-restart api # master-restart controllers
如果您在同一 pod 配置中同时使用节点选择器和节点关联性,请注意:
-
如果同时配置了
nodeSelector和nodeAffinity,则必须满足这两个条件时 pod 才能调度到候选节点。 -
如果您指定了多个与
nodeAffinity类型关联的nodeSelectorTerms,那么其中一个nodeSelectorTerms满足时 pod 就能调度到节点上。 -
如果您指定了多个与
nodeSelectorTerms关联的matchExpressions,那么只有所有matchExpressions都满足时 pod 才能调度到节点上。
16.11. 高级调度、污点和忍限
16.11.1. 概述
通过污点和容限,节点 可以控制哪些 pod 应该(或不应该)调度到节点上。
16.11.2. 污点和容限
通过使用污点(taint),节点可以拒绝调度 pod,除非 pod 具有匹配的容限(toleration)。
您可以通过节点规格 (NodeSpec) 将污点应用到节点,并通过 pod 规格 (PodSpec) 将容限应用到 pod。节点上的污点指示节点排斥所有不容许该污点的 pod。
污点与容限由 key、value 和 effect 组成。运算符允许您将其中一个参数留空。
表 16.1. 污点和容限组件
| 参数 | 描述 | ||||||
|---|---|---|---|---|---|---|---|
|
|
| ||||||
|
|
| ||||||
|
| effect 的值包括:
| ||||||
|
|
|
容限与污点匹配:
如果
operator参数设为Equal:-
key参数相同; -
value参数相同; -
effect参数相同。
-
如果
operator参数设为Exists:-
key参数相同; -
effect参数相同。
-
16.11.2.1. 使用多个污点
您可以在同一个节点中放入多个污点,并在同一 pod 中放入多个容限。OpenShift Container Platform 按照如下所述处理多个污点和容限:
- 处理 pod 具有匹配容限的污点。
其余的不匹配污点在 pod 上有指示的 effect:
-
如果至少有一个不匹配污点具有
NoScheduleeffect,则 OpenShift Container Platform 无法将 pod 调度到该节点上。 -
如果没有不匹配污点具有
NoScheduleeffect,但至少有一个不匹配污点具有PreferNoScheduleeffect,则 OpenShift Container Platform 尝试不将 pod 调度到该节点上。 如果至少有一个未匹配污点具有
NoExecuteeffect,OpenShift Container Platform 会将 pod 从该节点驱除(如果它已在该节点上运行),或者不将 pod 调度到该节点上(如果还没有在该节点上运行)。- 不容许污点的 Pod 会立即被驱除。
-
如果 Pod 容许污点,且没有在容限规格中指定
tolerationSeconds,则会永久保持绑定。 -
如果 Pod 容许污点,且指定了
tolerationSeconds,则会在指定的时间里保持绑定。
-
如果至少有一个不匹配污点具有
例如:
节点具有以下污点:
$ oc adm taint nodes node1 key1=value1:NoSchedule $ oc adm taint nodes node1 key1=value1:NoExecute $ oc adm taint nodes node1 key2=value2:NoSchedule
pod 具有以下容限:
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoSchedule" - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute"
在本例中,pod 无法调度到节点上,因为没有与第三个污点匹配的容限。如果在添加污点时 pod 已在节点上运行,pod 会继续运行,因为第三个污点是三个污点中 pod 唯一不容许的污点。
16.11.3. 将 Taint 添加到现有节点
您可以使用 oc adm taint 命令为节点添加污点,以及 Taint 和 toleration 组件 表中描述的参数:
$ oc adm taint nodes <node-name> <key>=<value>:<effect>
例如:
$ oc adm taint nodes node1 key1=value1:NoExecute
该示例在 node1 上放置一个键为 key1 且值为 value1 的污点,污点效果是 NoExecute。
16.11.4. 在 Pod 中添加容限
要为 pod 添加容限,请编辑 pod 规格使其包含 tolerations 部分:
使用 Equal 运算符的 pod 配置文件示例
tolerations: - key: "key1" 1 operator: "Equal" 2 value: "value1" 3 effect: "NoExecute" 4 tolerationSeconds: 3600 5
- 1 2 3 4
- 容限参数,如 Taint 和 toleration 组件表中所述。
- 5
tolerationSeconds参数指定 pod 在被驱除前可以保持与节点绑定的时长。请参阅以下 使用 Toleration seconds to Delay Pod 驱除。
使用 Exists 运算符的 pod 配置文件示例
tolerations: - key: "key1" operator: "Exists" effect: "NoExecute" tolerationSeconds: 3600
这两个容限都与 以上 oc adm taint 命令创建 的污点匹配。具有任一容限的 pod 可以调度到 node1。
16.11.4.1. 使用 Toleration Seconds 延迟 Pod 驱除
您可以通过在 pod 规格中指定 tolerationSeconds 参数,指定 pod 在被驱除前可以保持与节点绑定的时长。如果将具有 NoExecute effect 的污点添加到某个节点,则所有不容许该污点的 pod 都被立即驱除(容许该污点的 pod 不会被驱除)。但是,如果要被驱除的 pod 具有 tolerationSeconds 参数,则只有该时限到期后 pod 才会被驱除。
例如:
tolerations: - key: "key1" operator: "Equal" value: "value1" effect: "NoExecute" tolerationSeconds: 3600
在这里,如果此 pod 正在运行但没有匹配的污点,pod 保持与节点绑定 3600 秒,然后被驱除。如果污点在这个时间之前移除,pod 就不会被驱除。
16.11.4.1.1. 为 Toleration second 设置默认值
此插件为 pod 设置默认的强制容限,以容忍 node.kubernetes.io/not-ready:NoExecute 和 node.kubernetes.io/unreachable:NoExecute 污点为五分钟。
如果用户提供的 pod 配置已具有任一容限,则不会添加默认值。
启用 Default Toleration seconds:
将 master 配置文件(/etc/origin/master/master-config.yaml)修改为将
DefaultTolerationSeconds添加到 admissionConfig 部分:admissionConfig: pluginConfig: DefaultTolerationSeconds: configuration: kind: DefaultAdmissionConfig apiVersion: v1 disable: false重启 OpenShift 以使更改生效:
# master-restart api # master-restart controllers
验证是否已添加默认值:
创建 pod:
$ oc create -f </path/to/file>
例如:
$ oc create -f hello-pod.yaml pod "hello-pod" created
检查 pod 容限:
$ oc describe pod <pod-name> |grep -i toleration
例如:
$ oc describe pod hello-pod |grep -i toleration Tolerations: node.kubernetes.io/not-ready=:Exists:NoExecute for 300s
16.11.5. 节点问题的 Pod 驱除
OpenShift Container Platform 可以配置为用污点来代表节点不可访问和节点未就绪状况。这样,就可以对每个 pod 设置在节点变得不可访问或未就绪时保持与节点绑定的时长,而不是使用默认的五分钟。
当启用 Taint Based Evictions 功能时,节点控制器会自动添加污点,并且禁用从 Ready 节点驱除 pod 的一般逻辑。
-
如果节点进入未就绪状态,则添加
node.kubernetes.io/not-ready:NoExecute污点,并且无法将 pod 调度到该节点上。现有 pod 在容限秒数期限内保留。 -
如果节点进入不可访问状态,则添加
node.kubernetes.io/unreachable:NoExecute污点,并且无法将 pod 调度到该节点上。现有 pod 在容限秒数期限内保留。
启用基于污点的驱除:
修改 master 配置文件(/etc/origin/master/master-config.yaml),将以下内容添加到
kubernetesMasterConfig部分:kubernetesMasterConfig: controllerArguments: feature-gates: - TaintBasedEvictions=true检查污点是否已添加到节点:
$ oc describe node $node | grep -i taint Taints: node.kubernetes.io/not-ready:NoExecute
重启 OpenShift 以使更改生效:
# master-restart api # master-restart controllers
为 pod 添加容限:
tolerations: - key: "node.kubernetes.io/unreachable" operator: "Exists" effect: "NoExecute" tolerationSeconds: 6000
或者
tolerations: - key: "node.kubernetes.io/not-ready" operator: "Exists" effect: "NoExecute" tolerationSeconds: 6000
为了保持由于节点问题而导致 pod 驱除的现有 速率限制 行为,系统以限速方式添加污点。这可防止在主控机从节点分区等情形中发生大量 pod 驱除。
16.11.6. DaemonSet 和 Tolerations
DaemonSet pod 创建时带有 node.kubernetes.io/unreachable 和 node.kubernetes.io/not-ready 的 NoExecute 容限,且没有 tolerationSeconds,以确保 DaemonSet pod 不会被驱除,即使禁用了 Default Toleration Seconds 功能。
16.11.7. 例子
污点和容限是一种灵活的方式,可以禁止 pod 离开节点或驱除不应在节点上运行的 pod。一些典型的使用场景是:
16.11.7.1. 为用户指定节点
您可以指定一组节点供一组特定用户独占使用。
指定专用节点:
给这些节点添加污点:
例如:
$ oc adm taint nodes node1 dedicated=groupName:NoSchedule
通过编写自定义准入 控制器,为 pod 添加对应的容限。
只有具有这些容限的 pod 才可以使用专用节点。
16.11.7.2. 将用户绑定到节点
您可以配置节点,使特定用户只能使用专用节点。
配置节点以使用户只能使用该节点:
给这些节点添加污点:
例如:
$ oc adm taint nodes node1 dedicated=groupName:NoSchedule
通过编写自定义准入 控制器,为 pod 添加对应的容限。
准入控制器应该添加一个节点关联性,使得 pod 只能调度到具有
key:value标签 (dedicated=groupName) 的节点。-
给专用节点添加与污点类似的标签(如
key:value标签)。
16.11.7.3. 具有特殊硬件的节点
如果集群中有少量节点具有特殊的硬件(如 GPU),您可以使用污点和容限让不需要特殊硬件的 pod 与这些节点保持距离,从而将这些节点保留给那些确实需要特殊硬件的 pod。您还可以要求需要特殊硬件的 pod 使用特定的节点。
确保 pod 被禁止使用特殊硬件:
使用以下命令之一,给拥有特殊硬件的节点添加污点:
$ oc adm taint nodes <node-name> disktype=ssd:NoSchedule $ oc adm taint nodes <node-name> disktype=ssd:PreferNoSchedule
- 为使用准入 控制器 使用特殊硬件的 pod 添加对应的容限。
例如,准入控制器可以使用 pod 的一些特征来决定是否应该允许 pod 通过添加容限来使用特殊节点。
要确保 pod 只能使用特殊硬件,您需要一些额外的机制。例如,您可以给具有特殊硬件的节点打上标签,并在需要该硬件的 pod 上使用节点关联性。
第 17 章 设置配额
17.1. 概述
资源配额 由 ResourceQuota 对象定义,提供约束来限制各个项目的聚合资源消耗。它可根据类型限制项目中创建的对象数量,以及该项目中资源可以消耗的计算资源和存储的总和。
有关计算资源的更多信息,请参阅 开发人员指南。
17.2. 由配额管理的资源
下文描述了可能通过配额管理的计算资源和对象类型的集合。
如果 status.phase in (Failed, Succeeded) 为 true,则 Pod 处于终端状态。
表 17.1. 由配额管理的计算资源
| 资源名称 | 描述 |
|---|---|
|
|
非终端状态的所有 Pod 的 CPU 请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的内存请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的本地临时存储请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的 CPU 请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的内存请求总和不能超过这个值。 |
|
|
非终端状态的所有 Pod 的临时存储请求总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的 CPU 限值总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的内存限值总和不能超过这个值。 |
|
| 非终端状态的所有 Pod 的临时存储限值总和不能超过这个值。只有在您启用了临时存储技术预览时,此资源才可用。此功能默认为禁用。 |
表 17.2. 由配额管理的存储资源
| 资源名称 | 描述 |
|---|---|
|
| 处于任何状态的所有持久性卷声明的存储请求总和不能超过这个值。 |
|
| 项目中可以存在的持久性卷声明的总数。 |
|
| 在处于任何状态且具有匹配存储类的所有持久性卷声明中,存储请求总和不能超过这个值。 |
|
| 项目中可以存在的具有匹配存储类的持久性卷声明的总数。 |
表 17.3. 由配额管理的对象计数
| 资源名称 | 描述 |
|---|---|
|
| 项目中可以存在的处于非终端状态的 Pod 总数。 |
|
| 项目中可以存在的复制控制器的总数。 |
|
| 项目中可以存在的资源配额总数。 |
|
| 项目中可以存在的服务总数。 |
|
| 项目中可以存在的 secret 的总数。 |
|
|
项目中可以存在的 |
|
| 项目中可以存在的持久性卷声明的总数。 |
|
| 项目中可以存在的镜像流的总数。 |
您可以在创建配额时使用 count/<resource>.<group> 语法为这些标准命名空间资源类型配置对象数配额。
$ oc create quota <name> --hard=count/<resource>.<group>=<quota> 1- 1
<resource>是资源名称,<group>则是 API 组(若适用)。使用oc api-resources命令可以列出资源及其关联的 API 组。
17.2.1. 为扩展资源设置资源配额
扩展资源不允许过量使用资源,因此您必须在配额中为相同扩展资源指定 requests 和 limits。目前,扩展资源仅允许使用前缀 requests. 的配额项。以下是如何为 GPU 资源 nvidia.com/gpu 设置资源配额的示例场景。
流程
确定集群中某个节点中有多少 GPU 可用。例如:
# oc describe node ip-172-31-27-209.us-west-2.compute.internal | egrep 'Capacity|Allocatable|gpu' openshift.com/gpu-accelerator=true Capacity: nvidia.com/gpu: 2 Allocatable: nvidia.com/gpu: 2 nvidia.com/gpu 0 0本例中有 2 个 GPU 可用。
在命名空间
nvidia中设置配额。本例中配额为1:# cat gpu-quota.yaml apiVersion: v1 kind: ResourceQuota metadata: name: gpu-quota namespace: nvidia spec: hard: requests.nvidia.com/gpu: 1创建配额:
# oc create -f gpu-quota.yaml resourcequota/gpu-quota created
验证命名空间是否设置了正确的配额:
# oc describe quota gpu-quota -n nvidia Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 0 1
运行一个请求单个 GPU 的 Pod:
# oc create pod gpu-pod.yaml
apiVersion: v1 kind: Pod metadata: generateName: gpu-pod- namespace: nvidia spec: restartPolicy: OnFailure containers: - name: rhel7-gpu-pod image: rhel7 env: - name: NVIDIA_VISIBLE_DEVICES value: all - name: NVIDIA_DRIVER_CAPABILITIES value: "compute,utility" - name: NVIDIA_REQUIRE_CUDA value: "cuda>=5.0" command: ["sleep"] args: ["infinity"] resources: limits: nvidia.com/gpu: 1验证 Pod 是否在运行:
# oc get pods NAME READY STATUS RESTARTS AGE gpu-pod-s46h7 1/1 Running 0 1m
验证配额计数器
Used是否正确:# oc describe quota gpu-quota -n nvidia Name: gpu-quota Namespace: nvidia Resource Used Hard -------- ---- ---- requests.nvidia.com/gpu 1 1
尝试在
nvidia命名空间中创建第二个 GPU Pod。从技术上讲,该节点支持 2 个 GPU,因为它有 2 个 GPU:# oc create -f gpu-pod.yaml Error from server (Forbidden): error when creating "gpu-pod.yaml": pods "gpu-pod-f7z2w" is forbidden: exceeded quota: gpu-quota, requested: requests.nvidia.com/gpu=1, used: requests.nvidia.com/gpu=1, limited: requests.nvidia.com/gpu=1
应该会显示此 Forbidden 错误消息,因为您有设为 1 个 GPU 的配额,但这一 Pod 试图分配第二个 GPU,而这超过了配额。
17.3. 配额范围
每个配额都有一组关联的范围。配额仅在与枚举的范围交集匹配时才会测量资源的使用量。
为配额添加范围会限制该配额可应用的资源集合。指定允许的集合之外的资源会导致验证错误。
| 影响范围 | 描述 |
|---|---|
| Terminating |
匹配 |
| NotTerminating |
匹配 |
| BestEffort |
匹配带有最佳服务质量的 |
| NotBestEffort |
匹配 |
BestEffort 范围将配额仅限为限制以下资源:
-
pods
Terminating、NotTerminating 和 NotBestEffort 范围将配额仅限为跟踪以下资源:
-
pods -
memory -
requests.memory -
limits.memory -
cpu -
requests.cpu -
limits.cpu -
ephemeral-storage -
requests.ephemeral-storage -
limits.ephemeral-storage
只有在启用了临时存储技术预览功能时,才会应用临时存储请求和限值。此功能默认为禁用。
17.4. 配额强制
在项目中首次创建资源配额后,项目会限制您创建可能会违反配额约束的新资源,直到它计算了更新后的使用量统计。
在创建了配额并且更新了使用量统计后,项目会接受创建新的内容。当您创建或修改资源时,配额使用量会在请求创建或修改资源时立即递增。
在您删除资源时,配额使用量在下一次完整重新计算项目的配额统计时才会递减。可配置的时间量决定了将配额使用量统计降低到其当前观察到的系统值所需的时间。
如果项目修改超过配额使用量限值,服务器将拒绝该操作,并将相应的错误消息返回给用户,说明违反了配额约束,以及它们当前观察到的系统中使用量统计。
17.5. 请求与限制
在分配计算资源时,每个容器可能会为 CPU、内存和临时存储各自指定请求和限制值。配额可以限制任何这些值。
如果配额具有为 requests.cpu 或 requests.memory 指定的值,那么它要求每个传入的容器都明确请求这些资源。如果配额具有为 limits.cpu 或 limits.memory 的值,那么它要求每个传入的容器为那些资源指定一个显式限值。
17.6. 资源配额定义示例
core-object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: core-object-counts
spec:
hard:
configmaps: "10" 1
persistentvolumeclaims: "4" 2
replicationcontrollers: "20" 3
secrets: "10" 4
services: "10" 5
openshift-object-counts.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: openshift-object-counts
spec:
hard:
openshift.io/imagestreams: "10" 1
- 1
- 项目中可以存在的镜像流的总数。
compute-resources.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4" 1
requests.cpu: "1" 2
requests.memory: 1Gi 3
requests.ephemeral-storage: 2Gi 4
limits.cpu: "2" 5
limits.memory: 2Gi 6
limits.ephemeral-storage: 4Gi 7
besteffort.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort
spec:
hard:
pods: "1" 1
scopes:
- BestEffort 2
compute-resources-long-running.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-long-running
spec:
hard:
pods: "4" 1
limits.cpu: "4" 2
limits.memory: "2Gi" 3
limits.ephemeral-storage: "4Gi" 4
scopes:
- NotTerminating 5
compute-resources-time-bound.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources-time-bound
spec:
hard:
pods: "2" 1
limits.cpu: "1" 2
limits.memory: "1Gi" 3
limits.ephemeral-storage: "1Gi" 4
scopes:
- Terminating 5
storage-consumption.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage-consumption
spec:
hard:
persistentvolumeclaims: "10" 1
requests.storage: "50Gi" 2
gold.storageclass.storage.k8s.io/requests.storage: "10Gi" 3
silver.storageclass.storage.k8s.io/requests.storage: "20Gi" 4
silver.storageclass.storage.k8s.io/persistentvolumeclaims: "5" 5
bronze.storageclass.storage.k8s.io/requests.storage: "0" 6
bronze.storageclass.storage.k8s.io/persistentvolumeclaims: "0" 7
17.7. 创建配额
要创建配额,首先在文件中定义配额,如 Sample Resource Quota Definitions 中的示例。然后,使用该文件将其应用到项目:
$ oc create -f <resource_quota_definition> [-n <project_name>]
例如:
$ oc create -f core-object-counts.yaml -n demoproject
17.7.1. 创建对象数配额
您可以针对所有 OpenShift Container Platform 标准命名空间资源类型创建对象数配额,如 BuildConfig 和 DeploymentConfig。对象配额数将定义的配额施加于所有标准命名空间资源类型。
在使用资源配额时,如果服务器存储中存在某一对象,则从其配额中扣减。这些类型的配额对防止耗尽存储资源很有用处。
要为资源配置对象数配额,请运行以下命令:
$ oc create quota <name> --hard=count/<resource>.<group>=<quota>,count/<resource>.<group>=<quota>
例如:
$ oc create quota test --hard=count/deployments.extensions=2,count/replicasets.extensions=4,count/pods=3,count/secrets=4 resourcequota "test" created $ oc describe quota test Name: test Namespace: quota Resource Used Hard -------- ---- ---- count/deployments.extensions 0 2 count/pods 0 3 count/replicasets.extensions 0 4 count/secrets 0 4
本例将列出的资源限制为集群中各个项目的硬限值。
17.8. 查看配额
您可以在 Web 控制台导航到项目的 Quota 页面,查看与项目配额中定义的硬限值相关的使用量统计。
您还可以使用 CLI 查看配额详情:
首先,获取项目中定义的配额列表。例如,对于名为 demoproject 的项目:
$ oc get quota -n demoproject NAME AGE besteffort 11m compute-resources 2m core-object-counts 29m
然后,描述您需要的配额,如 core-object-counts 配额:
$ oc describe quota core-object-counts -n demoproject Name: core-object-counts Namespace: demoproject Resource Used Hard -------- ---- ---- configmaps 3 10 persistentvolumeclaims 0 4 replicationcontrollers 3 20 secrets 9 10 services 2 10
17.9. 配置配额同步周期
删除一组资源时,资源的同步时间由 /etc/origin/master/master -config.yaml 文件中的 resource-quota-sync- period 设置决定。
在恢复配额使用量之前,用户在尝试重用资源时可能会遇到问题。您可以更改 resource-quota-sync-period 设置,使其在所需时间(以秒为单位)重新生成一组资源,并使资源再次可用:
kubernetesMasterConfig:
apiLevels:
- v1beta3
- v1
apiServerArguments: null
controllerArguments:
resource-quota-sync-period:
- "10s"进行任何更改后,重启主服务以应用它们。
# master-restart api # master-restart controllers
在使用自动化时,调整重新生成时间对创建资源和决定资源使用量很有帮助。
resource-quota-sync-period 设置旨在平衡系统性能。缩短同步周期可能会导致 master 遭遇重度负载。
17.10. 部署配置中的配额核算
如果为项目定义了配额,请参阅 Deployment Resources 了解任何部署配置的注意事项。
17.11. 要求显式配额来消耗资源
如果资源不受配额管理,用户可以消耗的资源量就不会有限制。例如,如果没有与金级存储类相关的存储配额,则项目可以创建的金级存储量没有限制。
对于高成本计算或存储资源,管理员可能需要授予显式配额才能消耗资源。譬如,如果某个项目没有显式赋予与金级存储类有关的存储配额,则该项目的用户将无法创建该类型的存储。
要要求显式配额来消耗特定资源,应该将以下小节添加到 master-config.yaml 中。
admissionConfig:
pluginConfig:
ResourceQuota:
configuration:
apiVersion: resourcequota.admission.k8s.io/v1alpha1
kind: Configuration
limitedResources:
- resource: persistentvolumeclaims 1
matchContains:
- gold.storageclass.storage.k8s.io/requests.storage 2
在上例中,配额系统将拦截创建或更新 PersistentVolumeClaim 的每个操作。它会检查将要消耗的配额理解哪些资源,如果项目中没有配额涵盖这些资源,则请求会被拒绝。在本例中,如果用户创建的 PersistentVolumeClaim 使用与金级存储类关联的存储,并且项目中没有匹配的配额,请求会被拒绝。
17.12. 已知问题
- 无效的对象可能会导致项目的配额资源耗尽。在验证资源之前,配额会在准入中递增。因此,即使 pod 最终没有持久保留,也可以递增配额。这将在以后的发行版本中解决。(BZ1485375)
第 18 章 设置多项目配额
18.1. 概述
多项目配额由 ClusterResourceQuota 对象定义,允许在多个项目之间共享 配额。将聚合每个选定项目中使用的资源,并将使用此聚合来限制所有选定项目中的资源。
18.2. 选择项目
您可以根据注解选择和/或标签选择来选择项目。例如,要根据注解选择项目,请运行以下命令:
$ oc create clusterquota for-user \
--project-annotation-selector openshift.io/requester=<user-name> \
--hard pods=10 \
--hard secrets=20
它创建以下 ClusterResourceQuota 对象:
apiVersion: v1 kind: ClusterResourceQuota metadata: name: for-user spec: quota: 1 hard: pods: "10" secrets: "20" selector: annotations: 2 openshift.io/requester: <user-name> labels: null 3 status: namespaces: 4 - namespace: ns-one status: hard: pods: "10" secrets: "20" used: pods: "1" secrets: "9" total: 5 hard: pods: "10" secrets: "20" used: pods: "1" secrets: "9"
此多项目配额文档使用默认的项目请求端点控制 <user-name> 请求的所有项目。您需要有 10 个 Pod 和 20 个 secret 的限制。
同样,若要根据标签选择项目,请运行以下命令:
$ oc create clusterresourcequota for-name \ 1 --project-label-selector=name=frontend \ 2 --hard=pods=10 --hard=secrets=20
它创建以下 ClusterResourceQuota 对象定义:
apiVersion: v1
kind: ClusterResourceQuota
metadata:
creationTimestamp: null
name: for-name
spec:
quota:
hard:
pods: "10"
secrets: "20"
selector:
annotations: null
labels:
matchLabels:
name: frontend18.3. 查看适用的 ClusterResourceQuotas
项目管理员无法创建或修改多项目配额来限制自己的项目,但管理员可以查看应用到自己项目的多项目配额文档。项目管理员可以通过 AppliedClusterResourceQuota 资源执行此操作。
$ oc describe AppliedClusterResourceQuota
生成:
Name: for-user Namespace: <none> Created: 19 hours ago Labels: <none> Annotations: <none> Label Selector: <null> AnnotationSelector: map[openshift.io/requester:<user-name>] Resource Used Hard -------- ---- ---- pods 1 10 secrets 9 20
18.4. 选择图形性
由于在声明配额分配时会考虑锁定,因此通过多项目配额选择的活跃项目数量是一个重要因素。在单个多项目配额下选择 100 多个项目可能会对这些项目中的 API 服务器响应产生影响。
第 19 章 修剪对象
19.1. 概述
随着时间推移,OpenShift Container Platform 中创建的 API 对象 可以通过常规用户操作(如构建和部署应用程序)积累到 etcd 数据存储 中。
作为管理员,您可以定期从 OpenShift Container Platform 实例中修剪不再需要的旧版本对象。例如,您可以通过修剪镜像来删除不再使用但仍然占用磁盘空间的旧镜像和旧层。
19.2. 基本修剪操作
CLI 将修剪操作分组到一个通用的父命令下。
$ oc adm prune <object_type> <options>
这将指定:
-
要对其执行操作的
<object_type>,如groups、builds、deployments或images。 -
修剪该对象类型所支持的
<options>。
19.3. 修剪组
要修剪来自外部提供程序的组记录,管理员可以运行以下命令:
$ oc adm prune groups --sync-config=path/to/sync/config [<options>]
表 19.1. 修剪组 CLI 配置选项
| 选项 | 描述 |
|---|---|
|
| 指明应该执行修剪,而不是空运行。 |
|
| 指向组黑名单文件的路径。有关黑名单文件结构,请参阅使用 LDAP 同步组。 |
|
| 指向组白名单文件的路径。有关白名单文件结构,请参阅使用 LDAP 同步组。 |
|
| 指向同步配置文件的路径。有关此文件的结构,请参阅配置 LDAP 同步。 |
查看 prune 命令删除的组:
$ oc adm prune groups --sync-config=ldap-sync-config.yaml
执行修剪操作:
$ oc adm prune groups --sync-config=ldap-sync-config.yaml --confirm
19.4. 修剪部署
要修剪因为时间和状态而不再需要的部署,管理员可运行以下命令:
$ oc adm prune deployments [<options>]
表 19.2. 修剪部署 CLI 配置选项
| 选项 | 描述 |
|---|---|
|
| 指明应该执行修剪,而不是空运行。 |
|
| 修剪所有不再存在部署配置、状态为 complete 或 failed 且副本数为零的部署。 |
|
|
对于每个部署配置,保留状态为 Complete 且副本数为零的最后 N 个部署。(默认值 |
|
|
对于每个部署配置,保留状态为失败且副本数为零的最后 N 个部署。(默认值 |
|
|
不修剪相对于当前时间年龄不到 |
查看修剪操作要删除的对象:
$ oc adm prune deployments --orphans --keep-complete=5 --keep-failed=1 \
--keep-younger-than=60m真正执行修剪操作:
$ oc adm prune deployments --orphans --keep-complete=5 --keep-failed=1 \
--keep-younger-than=60m --confirm19.5. 修剪构建
要修剪系统因为年龄和状态而不再需要的构建,管理员可运行以下命令:
$ oc adm prune builds [<options>]
表 19.3. 修剪构建 CLI 配置选项
| 选项 | 描述 |
|---|---|
|
| 指明应该执行修剪,而不是空运行。 |
|
| 修剪不再有构建配置且状态为 Complete、Failed、Error 或 Canceled 的构建。 |
|
|
对于每个构建配置,保留状态为 Complete 的最后 N 个构建。(默认值 |
|
|
对于每个构建配置,保留状态为 failed、error 或 Canceled 的最后 N 个构建(默认值 |
|
|
不修剪相对于当前时间年龄不到 |
查看修剪操作要删除的对象:
$ oc adm prune builds --orphans --keep-complete=5 --keep-failed=1 \
--keep-younger-than=60m真正执行修剪操作:
$ oc adm prune builds --orphans --keep-complete=5 --keep-failed=1 \
--keep-younger-than=60m --confirm开发人员可以通过 修改其构建配置来启用自动修剪 构建。
19.6. 修剪镜像
要修剪系统因为年龄、状态或超过限值而不再需要的镜像,管理员可运行以下命令:
$ oc adm prune images [<options>]
除非使用了 --prune-registry=false,否则修剪镜像会从集成 registry 中移除数据。要使此操作正常工作,请确保 registry 配置了 storage:delete:enabled 设置为 true。
使用 --namespace 标志修剪镜像时不移除镜像,只移除镜像流。镜像是没有命名空间的资源。因此,将修剪限制到特定的命名空间会导致无法计算其当前使用量。
默认情况下,集成 registry 会缓存 blob 元数据来减少对存储的请求数量,并提高处理请求的速度。修剪不会更新集成 registry 缓存。在修剪后推送的镜像如果含有修剪的层,它们会被破坏,因为不会推送在缓存中有元数据的已修剪层。因此,修剪之后需要清除缓存。这可以通过重新部署 registry 来完成:
$ oc rollout latest dc/docker-registry
如果集成 registry 使用 redis 缓存,则需要手动清理数据库。
如果无法在修剪后重新部署 registry,则必须永久禁用缓存。
表 19.4. 修剪镜像 CLI 配置选项
| 选项 | 描述 |
|---|---|
|
|
包括没有推送到 registry 但已通过 pullthrough 镜像的镜像。默认为开启。要将修剪限制为已被推送到集成 registry 的镜像,请传递 |
|
| 与 OpenShift Container Platform 管理的 registry 通信时使用的证书颁发机构文件的路径。默认为来自当前用户配置文件的证书颁发机构数据。如果提供,将启动安全连接。 |
|
|
指明应该执行修剪,而不是空运行。这需要具有指向集成容器镜像 registry 的有效路由。如果此命令在集群网络外运行,则需要使用 |
|
| 谨慎使用这个选项。允许与通过 HTTP 托管或具有无效 HTTPS 证书的 Docker 注册表进行不安全连接。如需更多信息 ,请参阅使用安全连接或 不安全连接。 |
|
|
对于每个镜像流,每个标签最多保留 N 个镜像修订。(默认值 |
|
|
不修剪相对于当前时间年龄不到 |
|
|
修剪超过同一项目中定义的最小 限值 的每个镜像。此标志不能与 |
|
|
联系 registry 时使用的地址。命令将尝试使用由受管镜像和镜像流决定的集群内部 URL。如果失败(registry 无法解析或访问),则需要使用此标志提供一个替代路由。registry 主机名可以加上前缀 |
|
| 此选项与其他选项规定的条件一起使用,用于控制是否修剪 registry 中与 OpenShift Container Platform 镜像 API 对象对应的数据。默认情况下,镜像修剪同时处理镜像 API 对象和 registry 中的对应数据。当您只关注移除 etcd 内容时(可能要减少镜像对象的数量,但并不关心清理 registry)或要通过 硬化 Pruning Registry 来单独进行此操作(可能在 registry 的适当维护窗口期间),此选项很有用处。 |
19.6.1. 镜像修剪条件
删除"由 OpenShift Container Platform 管理"的镜像(带有注解
openshift.io/image.managed的镜像),该镜像至少在--keep-younger-than 分钟前创建,且目前没有被以下对象引用:-
在
--keep-younger-than指定的分钟内创建的所有 pod。 -
任何
--keep-younger-than 分钟前之后创建的镜像流。 - 任何正在运行的容器集。
- 任何待处理的 pod。
- 任何复制控制器。
- 任何部署配置。
- 任何构建配置。
- 任何构建。
-
stream.status.tags-revisions 个最新项。[].items 中的 --keep-tag
-
在
对于"由 OpenShift Container Platform 管理"的镜像(带有注解
openshift.io/image.managed的镜像),请删除超过同一项目中定义的最小 限值 且目前没有被以下对象引用的镜像:- 任何正在运行的容器集。
- 任何待处理的 pod。
- 任何复制控制器。
- 任何部署配置。
- 任何构建配置。
- 任何构建。
- 不支持从外部 registry 进行修剪。
-
镜像被修剪后,会从在
status.tags中引用镜像的所有镜像流中移除对该镜像的所有引用。 - 也移除不再被任何镜像引用的镜像层。
--prune-over-size-limit 无法与 --keep-tag-revisions 或 --keep-younger-than 标志结合使用。这样做将返回不允许执行此操作的信息。
分离 OpenShift Container Platform 镜像 API 对象和 registry 中的镜像数据,方法是使用 --prune-registry=false,然后再通过 硬修剪注册表 来缩小一些计时窗口,与尝试通过一个命令同时修剪这两者相比更为安全。但是,计时窗口不会完全剔除。
例如,您仍然可以创建一个引用镜像的 Pod,因为修剪会标识该镜像进行修剪。您仍然应该跟踪修剪操作期间创建的 API 对象,该对象可能会引用镜像,从而避免引用已删除的内容。
此外,请注意,如果重新执行修剪时不使用 --prune-registry 选项或 --prune-registry=true 选项,则不会修剪之前通过 --prune-registry=false 修剪的镜像的镜像 registry 中关联的存储。使用 --prune-registry=false 修剪的任何镜像只能通过 硬化 Pruning 从 registry 存储中删除。
查看修剪操作要删除的对象:
最多保留三个标签修订,并且保留年龄不足 60 分钟的资源(镜像、镜像流和 pod):
$ oc adm prune images --keep-tag-revisions=3 --keep-younger-than=60m
修剪超过定义的限值的所有镜像:
$ oc adm prune images --prune-over-size-limit
实际对上述选项执行修剪操作:
$ oc adm prune images --keep-tag-revisions=3 --keep-younger-than=60m --confirm $ oc adm prune images --prune-over-size-limit --confirm
19.6.2. 使用安全或不安全连接
安全连接是首选和推荐的方法。它通过 HTTPS 协议来进行,并且会强制验证证书。若有可能,prune 命令始终会尝试使用这种连接。如果不可能,在某些情况下可能会回退到不安全连接,而这很危险。这时,会跳过证书验证或使用普通 HTTP 协议。
除非指定了 --certificate-authority,否则以下情形中允许回退到不安全连接:
-
使用
--force-insecure选项运行prune命令。 -
提供的
registry-url带有http://架构前缀。 -
提供的
registry-url是本地链接地址或 localhost。 -
当前用户的配置允许不安全连接。这可能是由用户使用
--insecure-skip-tls-verify登录或在提示时选择不安全连接造成的。
如果 registry 是由不同于 OpenShift Container Platform 使用的证书颁发机构保护的,则需要使用 --certificate-authority 标志来指定。否则,prune 命令将失败,并显示与使用 Wrong 证书颁发机构 中列出的类似的错误 或者使用不安全连接 Against 安全注册表的错误。
19.6.3. 镜像修剪问题
镜像没有被修剪
如果您的镜像不断积累,并且 prune 命令只删除了您期望的一小部分,请确保了解镜像被视为修剪候选者 的条件。
请尤其确保您要删除的镜像在每个 标签历史记录 中的位置高于您所选的标签修订阈值。例如,有一个名为 sha:abz 的陈旧镜像。在标记镜像的命名空间 N 中运行以下命令,您将看到该镜像在一个名为 myapp 的镜像流中被标记三次:
$ image_name="sha:abz"
$ oc get is -n openshift -o go-template='{{range $isi, $is := .items}}{{range $ti, $tag := $is.status.tags}}{{range $ii, $item := $tag.items}}{{if eq $item.image "'$image_name'"}}{{$is.metadata.name}}:{{$tag.tag}} at position {{$ii}} out of {{len $tag.items}}
{{end}}{{end}}{{end}}{{end}}' # Before this place {{end}}{{end}}{{end}}{{end}}, use new line
myapp:v2 at position 4 out of 5
myapp:v2.1 at position 2 out of 2
myapp:v2.1-may-2016 at position 0 out of 1
使用默认选项时,不会修剪镜像,因为它出现在 myapp:v2.1-may-2016 标签历史记录中的位置 0 上。要将镜像视为需要修剪,管理员必须:
在运行
oc adm prune images命令时指定--keep-tag-revisions=0。小心此操作将从所有含有基础镜像的命名空间中有效移除所有标签,除非它们比指定阈值年轻,或者有比指定阈值年轻的对象引用它们。
-
删除所有位置低于修订阈值的 is tag,即
myapp:v2.1和myapp:v2.1-may-2016。 - 在历史记录中进一步移动镜像,可以通过运行新构建并推送到同一 istag,或者标记其他镜像。遗憾的是,这对旧版标签可能并不始终适合。
应该避免在标签的名称中包含特定镜像的构建日期或时间,除非镜像需要保留不定的时长。这样的标签通常在历史记录中只有一个镜像,实际上会永久阻止它们被修剪。了解有关 istag 命名的更多信息.
对不安全 registry 使用安全连接
如果您在 oc adm prune images 的输出中看到类似于如下的消息,则您的 registry 未受保护,并且 oc adm prune images 客户端将尝试使用安全连接:
error: error communicating with registry: Get https://172.30.30.30:5000/healthz: http: server gave HTTP response to HTTPS client
-
重新连接的解决方案是保护 注册表的安全。如果不需要,您可以在命令后附加
--force-insecure来强制客户端使用不安全连接(不推荐)。
19.6.3.1. 对受保护 registry 使用不安全连接
如果您在 oc adm prune images 命令的输出中看到以下错误之一,这意味着您的 registry 已设有保护,而不是使用由 oc adm prune images 客户端用于连接验证的证书。
error: error communicating with registry: Get http://172.30.30.30:5000/healthz: malformed HTTP response "\x15\x03\x01\x00\x02\x02" error: error communicating with registry: [Get https://172.30.30.30:5000/healthz: x509: certificate signed by unknown authority, Get http://172.30.30.30:5000/healthz: malformed HTTP response "\x15\x03\x01\x00\x02\x02"]
默认情况下,存储在用户配置文件中的证书颁发机构数据用于与主 API 通信。
使用 --certificate-authority 选项为容器镜像 registry 服务器提供正确的证书颁发机构。
使用错误的证书颁发机构
以下错误表示用于为受保护容器镜像 registry 的证书签名的证书颁发机构与客户端使用的不同。
error: error communicating with registry: Get https://172.30.30.30:5000/: x509: certificate signed by unknown authority
务必通过 --certificate-authority 提供正确的证书颁发机构。
作为临时解决方案,可以添加 --force-insecure 标志(不推荐)。
19.7. 硬修剪 registry
OpenShift Container Registry 可能会积累未被 OpenShift Container Platform 集群的 etcd 引用的 Blob。因此,基本镜像修剪过程对它们无法操作。它们称为孤立的 Blob。
以下情形中可能会出现孤立的 Blob:
-
使用
oc delete image <sha256:image-id>命令手动删除镜像,该命令仅从 etcd 中移除镜像,而不从 registry 存储中移除。 - docker 守护进程失败发起了推送到 registry,这会造成只上传一些 Blob,但不上传其镜像清单(这作为最后一个组件上传)。所有唯一镜像 Blob 变成孤立的 Blob。
- OpenShift Container Platform 因为配额限制而拒绝某一镜像。
- 标准镜像修剪器删除镜像清单,但在删除相关 Blob 前中断。
- registry 修剪器中有一个程序错误,无法移除预定的 Blob,从而导致引用它们的镜像对象被移除,并且 Blob 变成孤立的 Blob。
硬修剪 registry,这是独立于基本镜像修剪的过程,允许您删除孤立的 Blob。如果 OpenShift Container registry 的存储空间不足,并且您认为有孤立的 Blob,则应该执行硬修剪。
这应该是罕见的操作,只有在有证据表明创建了大量新的孤立项时才需要。否则,您可以定期执行标准镜像修剪,例如一天一次(取决于要创建的镜像数量)。
从 registry 中硬修剪孤立的 Blob:
- 登录 :以具有访问令牌的用户身份使用 CLI 登录。
运行基本镜像修剪 :基本镜像修剪会移除了不再需要的额外镜像。硬修剪不移除自己的镜像,只移除保存在 registry 存储中的 Blob。因此,您应该在硬修剪之前运行此操作。
如需了解步骤,请参阅修剪镜像。
将 registry 切换为只读模式 :如果 registry 不以只读模式运行,任何在修剪的同时发生的推送将会:
- 失败,并导致出现新的孤立项;或者
- 成功,尽管镜像不可拉取(因为删除了一些引用的 Blob)。
只有 registry 切回到读写模式后,推送才会成功。因此,必须仔细地调度硬修剪。
将 registry 切换成只读模式:
设置以下环境变量:
$ oc set env -n default \ dc/docker-registry \ 'REGISTRY_STORAGE_MAINTENANCE_READONLY={"enabled":true}'默认情况下,上一步骤完成后,registry 应自动重新部署;等待重新部署完成后再继续。然而,如果您禁用了这些触发器,则必须手动重新部署 registry,以便获取新的环境变量:
$ oc rollout -n default \ latest dc/docker-registry
添加 system:image-pruner 角色 :用来运行 registry 实例的服务帐户需要额外的权限才能列出某些资源。
获取服务帐户名称:
$ service_account=$(oc get -n default \ -o jsonpath=$'system:serviceaccount:{.metadata.namespace}:{.spec.template.spec.serviceAccountName}\n' \ dc/docker-registry)将 system:image-pruner 集群角色添加到服务帐户:
$ oc adm policy add-cluster-role-to-user \ system:image-pruner \ ${service_account}
(可选)在空运行模式下运行修剪器 :若要查看会移除多少 Blob,请以空运行模式运行硬修剪器。不会实际进行任何更改:
$ oc -n default \ exec -i -t "$(oc -n default get pods -l deploymentconfig=docker-registry \ -o jsonpath=$'{.items[0].metadata.name}\n')" \ -- /usr/bin/dockerregistry -prune=check另外,若要获得修剪候选者的准确路径,可提高日志级别:
$ oc -n default \ exec "$(oc -n default get pods -l deploymentconfig=docker-registry \ -o jsonpath=$'{.items[0].metadata.name}\n')" \ -- /bin/sh \ -c 'REGISTRY_LOG_LEVEL=info /usr/bin/dockerregistry -prune=check'已截断的输出示例
$ oc exec docker-registry-3-vhndw \ -- /bin/sh -c 'REGISTRY_LOG_LEVEL=info /usr/bin/dockerregistry -prune=check' time="2017-06-22T11:50:25.066156047Z" level=info msg="start prune (dry-run mode)" distribution_version="v2.4.1+unknown" kubernetes_version=v1.6.1+$Format:%h$ openshift_version=unknown time="2017-06-22T11:50:25.092257421Z" level=info msg="Would delete blob: sha256:00043a2a5e384f6b59ab17e2c3d3a3d0a7de01b2cabeb606243e468acc663fa5" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:25.092395621Z" level=info msg="Would delete blob: sha256:0022d49612807cb348cabc562c072ef34d756adfe0100a61952cbcb87ee6578a" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:25.092492183Z" level=info msg="Would delete blob: sha256:0029dd4228961086707e53b881e25eba0564fa80033fbbb2e27847a28d16a37c" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.673946639Z" level=info msg="Would delete blob: sha256:ff7664dfc213d6cc60fd5c5f5bb00a7bf4a687e18e1df12d349a1d07b2cf7663" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.674024531Z" level=info msg="Would delete blob: sha256:ff7a933178ccd931f4b5f40f9f19a65be5eeeec207e4fad2a5bafd28afbef57e" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 time="2017-06-22T11:50:26.674675469Z" level=info msg="Would delete blob: sha256:ff9b8956794b426cc80bb49a604a0b24a1553aae96b930c6919a6675db3d5e06" go.version=go1.7.5 instance.id=b097121c-a864-4e0c-ad6c-cc25f8fdf5a6 ... Would delete 13374 blobs Would free up 2.835 GiB of disk space Use -prune=delete to actually delete the data运行硬修剪 :在 docker-registry pod 的一个正在运行的实例中执行以下命令进行硬修剪:
$ oc -n default \ exec -i -t "$(oc -n default get pods -l deploymentconfig=docker-registry -o jsonpath=$'{.items[0].metadata.name}\n')" \ -- /usr/bin/dockerregistry -prune=delete输出示例
$ oc exec docker-registry-3-vhndw \ -- /usr/bin/dockerregistry -prune=delete Deleted 13374 blobs Freed up 2.835 GiB of disk space将 registry 切回到读写模式 :在修剪完成后,可以执行以下命令将 registry 切回到读写模式:
$ oc set env -n default dc/docker-registry REGISTRY_STORAGE_MAINTENANCE_READONLY-
19.8. 修剪 Cron 任务
Cron Jobs 只是一个技术预览功能。技术预览功能不包括在红帽生产服务级别协议(SLA)中,且其功能可能并不完善。因此,红帽不建议在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需红帽技术预览功能支持范围的更多信息,请参阅 https://access.redhat.com/support/offerings/techpreview/。
Cron 任务可以修剪成功的任务,但可能无法正确处理失败的作业。因此,集群管理员应定期手动清理作业。我们还建议将对 cron 作业 的访问 限制为一小组值得信任的用户,并设置适当的 配额 以防止 cron 作业创建太多的作业和 pod。
第 20 章 使用自定义资源扩展 Kubernetes API
20.1. Kubernetes 自定义资源定义
在 Kubernetes API 中,资源是存储某一类 API 对象集合的端点。例如,内置 pod 资源包含一组 Pod 对象。
自定义资源 是一个扩展 Kubernetes API 的对象,或允许您在项目或集群中引入自己的 API。
自定义资源定义 (CRD)文件定义了自己的对象类型,并允许 API 服务器处理整个生命周期。将 CRD 部署到集群中会导致 Kubernetes API 服务器开始提供指定的自定义资源。
当您创建新的自定义资源定义(CRD)时,Kubernetes API 服务器会通过创建新的 RESTful 资源路径来做出反应,该路径可由整个集群或单个项目(命名空间)访问。与现有的内置对象一样,删除项目会删除该项目中的所有自定义对象。
如果要向用户授予 CRD 访问权限,请使用集群角色聚合为用户授予 admin、edit 或 view 默认集群角色的访问权限。集群角色聚合支持将自定义策略规则插入到这些集群角色中。这一行为会将新资源整合至集群的 RBAC 策略中,就像内置资源一样。
虽然只有集群管理员可创建 CRD,但如果您具有读写权限,则可以从 CRD 创建对象。
20.2. 创建自定义资源定义
要创建自定义对象,您必须首先创建一个自定义资源定义(CRD)。
只有集群管理员才能创建 CRD。
流程
要创建 CRD:
创建一个包含以下示例字段的 YAML 文件:
自定义资源定义的 YAML 文件示例
apiVersion: apiextensions.k8s.io/v1beta1 1 kind: CustomResourceDefinition metadata: name: crontabs.stable.example.com 2 spec: group: stable.example.com 3 version: v1 4 scope: Namespaced 5 names: plural: crontabs 6 singular: crontab 7 kind: CronTab 8 shortNames: - ct 9
- 1
- 使用
apiextensions.k8s.io/v1beta1API。 - 2
- 为定义指定名称。这必须采用 <plural-name><group> 格式,并使用来自
group和plural字段的值。 - 3
- 为 API 指定组名。API 组是一个逻辑上相关的对象集。例如,
Job或ScheduledJob等所有批处理对象,均可添加至批处理 API 组 (如 batch.api.example.com) 中。最好使用组织的完全限定域名。 - 4
- 指定 URL 中要用的版本名称。每个 API 组均可能存在于多个版本中。例如:
v1alpha、v1beta、v1。 - 5
- 指定自定义对象可用于某一个项目 (
Namespaced) 还是集群中的所有项目 (Cluster)。 - 6
- 指定 URL 中要用的复数名称。
plural字段与 API URL 网址中的资源相同。 - 7
- 指定将在 CLI 上用作别名并用于显示的单数名称。
- 8
- 指定可创建的对象类型。类型可以采用 CamelCase。
- 9
- 指定与 CLI 中的资源相匹配的较短字符串。
注意默认情况下,自定义资源定义是全集群范围的,适用于所有项目。
创建对象:
oc create -f <file-name>.yaml
在以下位置新建一个 RESTful API 端点:
/apis/<spec:group>/<spec:version>/<scope>/*/<names-plural>/...
例如,以下端点便是通过示例文件创建的:
/apis/stable.example.com/v1/namespaces/*/crontabs/...
您可以使用此端点 URL 来创建和管理自定义对象。对象类型基于您创建的自定义资源定义对象的
spec.kind字段。
20.3. 为自定义资源定义创建集群角色
创建集群范围的自定义资源定义(CRD)后,您可以为其授予权限。如果使用 admin、edit 和 view 默认集群角色,请利用集群角色聚合来制定规则。
您必须为每个角色明确分配权限。权限更多的角色不会继承权限较少角色的规则。如果要为某个角色分配规则,还必须将该操作动词分配给具有更多权限的角色。例如,如果您将"get crontabs"权限授予 view 角色,则还必须将其授予 edit 和 admin 角色。admin 或 edit 角色通常分配给通过项目 模板创建项目 的用户。
先决条件
- 创建 CRD。
流程
为 CRD 创建集群角色定义文件。集群角色定义是一个 YAML 文件,其中包含适用于各个集群角色的规则。OpenShift Container Platform 控制器会将您指定的规则添加至默认集群角色中。
集群角色定义的 YAML 文件示例
apiVersion: rbac.authorization.k8s.io/v1 1 kind: ClusterRole items: - metadata: name: aggregate-cron-tabs-admin-edit 2 labels: rbac.authorization.k8s.io/aggregate-to-admin: "true" 3 rbac.authorization.k8s.io/aggregate-to-edit: "true" 4 rules: - apiGroups: ["stable.example.com"] 5 resources: ["crontabs"] 6 verbs: ["get", "list", "watch", "create", "update", "patch", "delete", "deletecollection"] 7 - metadata: name: aggregate-cron-tabs-view 8 labels: # Add these permissions to the "view" default role. rbac.authorization.k8s.io/aggregate-to-view: "true" 9 rbac.authorization.k8s.io/aggregate-to-cluster-reader: "true" 10 rules: - apiGroups: ["stable.example.com"] 11 resources: ["crontabs"] 12 verbs: ["get", "list", "watch"] 13
创建集群角色:
oc create -f <file-name>.yaml
20.4. 从 CRD 创建自定义对象
创建自定义资源定义(CRD)对象后,您可以创建自定义对象来使用其规格。
自定义对象可以包含包含任意 JSON 代码的自定义字段。
先决条件
- 创建 CRD。
流程
为自定义对象创建 YAML 定义。在以下示例中,
cronSpec和镜像自定义字段在类型为CronTab的自定义对象中设置。kind 来自自定义资源定义对象的spec.kind字段。自定义对象的 YAML 文件示例
apiVersion: "stable.example.com/v1" 1 kind: CronTab 2 metadata: name: my-new-cron-object 3 finalizers: 4 - finalizer.stable.example.com spec: 5 cronSpec: "* * * * /5" image: my-awesome-cron-image
创建对象文件后,创建对象:
oc create -f <file-name>.yaml
20.5. 管理自定义对象
创建对象后,您可以管理自定义资源。
先决条件
- 创建自定义资源定义(CRD)。
- 从 CRD 创建对象。
流程
要获取有关特定类型的自定义资源的信息,请输入:
oc get <kind>
例如:
oc get crontab NAME KIND my-new-cron-object CronTab.v1.stable.example.com
请注意,资源名称不区分大小写,您可以使用 CRD 中定义的单数或复数形式,以及任何短名称。例如:
oc get crontabs oc get crontab oc get ct
您还可以查看自定义资源的原始 YAML 数据:
oc get <kind> -o yaml
oc get ct -o yaml apiVersion: v1 items: - apiVersion: stable.example.com/v1 kind: CronTab metadata: clusterName: "" creationTimestamp: 2017-05-31T12:56:35Z deletionGracePeriodSeconds: null deletionTimestamp: null name: my-new-cron-object namespace: default resourceVersion: "285" selfLink: /apis/stable.example.com/v1/namespaces/default/crontabs/my-new-cron-object uid: 9423255b-4600-11e7-af6a-28d2447dc82b spec: cronSpec: '* * * * /5' 1 image: my-awesome-cron-image 2
第 21 章 垃圾收集器
21.1. 概述
OpenShift Container Platform 节点执行两种类型的垃圾回收:
21.2. Container Garbage Collection
容器垃圾回收默认是启用的,并会在响应达到驱除阈值时自动发生。节点会尝试为任何可从 API 访问的 pod 保留容器。如果 pod 已被删除,则容器也会被删除。只要 pod 没有被删除且没有达到驱除阈值,容器就会保留。如果节点面临磁盘压力,它将移除容器,它们的日志将不再能通过 oc logs 访问。
容器垃圾收集策略基于三个节点设置:
| 设置 | 描述 |
|---|---|
|
| 容器符合垃圾回收条件的最低期限。默认值为 0。0 代表没有限制。此设置的值可以使用单位后缀指定,例如 h 表示小时,m 表示 分钟,s 代表秒。 |
|
| 每个容器要保留的旧实例数量。默认值为 1。 |
|
| 节点中死容器的最大数量。默认值为 -1,即无限制。 |
在发生冲突时,max-dead-containers 设置优先于 maximum-dead-containers-per-container 设置。例如,如果保留 max -dead-containers-per-container 的数量,则会导致容器总数大于 maximum-dead-containers,则会移除最旧的容器来满足 最大dead-containers 限值。
当节点移除死容器时,这些容器内的所有文件也会被删除。只有节点创建的容器才会收集垃圾回收。
如果您不想使用默认设置,您可以在适当的 节点配置映射 的 kubeletArguments 部分中指定这些设置的值。如果尚未存在,请添加 部分。
如果节点配置映射中没有这些参数,则容器垃圾回收使用默认值执行。
容器垃圾收集设置
kubeletArguments:
minimum-container-ttl-duration:
- "10s"
maximum-dead-containers-per-container:
- "2"
maximum-dead-containers:
- "240"
21.2.1. 检测容器进行删除
垃圾收集器循环的每个旋转都执行以下步骤:
- 检索可用容器的列表。
-
过滤掉所有运行或未超过
minimum-container-ttl-duration参数的容器。未处于活动状态的容器可能处于退出、死机或已终止状态。 - 根据 pod 和镜像名称成员资格,将所有剩余容器分类为等类。
- 删除所有未经识别的容器(由 kubelet 管理但名称不正确的容器)。
-
对于包含比
maximum-dead-containers-per-container参数更多的容器,根据创建时间在类中对容器进行排序。 -
首先从最旧的容器移除容器,直到达到
maximum-dead-containers-per-container参数。 -
如果列表中的容器数量仍然超过
maximum-dead-containers参数,收集器开始从每个类中删除容器,因此每个类中的容器数量不会大于每个类的容器数量,或者<all_remaining_containers>/<number_of_classes>。 -
如果这仍然不够,收集器对列表中的所有容器进行排序,首先开始从最旧的容器移除容器,直到满足
最大dead-containers条件为止。
更新默认设置以满足您的需要。
垃圾回收仅移除没有与其关联的 pod 的容器。
21.3. Image Garbage Collection
镜像垃圾回收依靠节点上 cAdvisor 报告的磁盘用量来决定从节点中移除哪些镜像。它考虑以下设置:
| 设置 | 描述 |
|---|---|
|
| 触发镜像垃圾回收的磁盘用量百分比(以整数表示)。 |
|
| 镜像垃圾回收试尝试释放的磁盘用量百分比(以整数表示)。 |
要启用镜像垃圾回收,请在适当的 节点配置映射 的 kubeletArguments 部分中指定这些设置的值。如果尚未存在,请添加 部分。
如果节点配置映射中没有这些参数,则镜像垃圾回收将使用默认值来执行。
镜像垃圾收集设置
kubeletArguments:
image-gc-high-threshold:
- "85"
image-gc-low-threshold:
- "80"
21.3.1. 检测镜像以进行删除
每次运行垃圾收集器都会检索两个镜像列表:
- 当前在至少一个 pod 中运行的镜像列表
- 主机上可用镜像的列表
随着新容器运行,新镜像即会出现。所有镜像都标有时间戳。如果镜像正在运行(上方第一个列表)或者刚被检测到(上方第二个列表),它将标上当前的时间。其余镜像的标记来自于以前的运行。然后,所有镜像都根据时间戳进行排序。
一旦开始回收,首先删除最旧的镜像,直到满足停止条件。
第 22 章 分配节点资源
22.1. 分配节点资源的目的
为提供更可靠的调度并最大程度减少节点资源过量使用,请保留一部分 CPU 和内存资源供底层 节点组件 (如 kubelet、kube-proxy 和容器引擎)使用。您保留的资源也供 sshd、NetworkManager 等其余系统组件使用。指定要保留的资源可为调度程序提供有关节点可用于 pod 使用的剩余内存和 CPU 资源的更多信息。
22.2. 为分配的资源配置节点
通过配置 system-reserved 节点设置,为 OpenShift Container Platform 中的节点组件和系统组件保留资源。
OpenShift Container Platform 不使用 kube-reserved 设置。有关 Kubernetes 和一些提供 Kubernetes 环境的云供应商的文档可能建议配置 kube-reserved。该信息不适用于 OpenShift Container Platform 集群。
当您根据资源限制调整集群并使用驱除强制实施限制时,请小心。在内存资源运行不足时,强制实施 system-reserved 限制可防止关键系统服务接收 CPU 时间或终止关键系统服务。
在大多数情况下,调优资源分配是通过调整调整,然后使用类生产工作负载监控集群性能来进行的。这个过程会重复,直到集群稳定并符合服务级别协议。
有关这些设置的影响的更多信息,请参阅计算分配资源。
| 设置 | 描述 |
|---|---|
|
|
此设置不会用于 OpenShift Container Platform。将您要保留的 CPU 和内存资源添加到 |
|
| 为节点组件和系统组件保留的资源。默认为 none。 |
运行以下命令,查看由 system-reserved( 使用 lscgroup 等工具)控制的服务:
# yum install libcgroup-tools
$ lscgroup memory:/system.slice
通过添加一组 <resource_type>=<resource_quantity> 对来保留节点配置映射的 kubeletArguments 部分中的资源。例如,cpu=500m,memory=1Gi 保留 500 毫秒的 CPU 和 1GB 内存。
例 22.1. Node-Allocatable 资源设置
kubeletArguments:
system-reserved:
- "cpu=500m,memory=1Gi"
如果 system-reserved 字段不存在,请添加该字段。
不要直接编辑 node-config.yaml 文件。
要确定这些设置的适当值,请使用节点概述 API 查看节点的资源使用情况。如需更多信息,请参阅 由节点报告的系统资源。
设置 system-reserved 后:
监控节点的高水位标记的内存使用情况:
$ ps aux | grep <service-name>
例如:
$ ps aux | grep atomic-openshift-node USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 11089 11.5 0.3 112712 996 pts/1 R+ 16:23 0:00 grep --color=auto atomic-openshift-node
如果这个值与
system-reserved标记接近,您可以增加system-reserved值。运行以下命令,使用
cgget等工具监控系统服务的内存使用情况:# yum install libcgroup-tools
$ cgget -g memory /system.slice | grep memory.usage_in_bytes
如果这个值与
system-reserved标记接近,您可以增加system-reserved值。- 使用 OpenShift Container Platform 集群加载程序来测量处于各种集群状态的部署的性能指标。
22.3. 计算分配的资源
分配的资源数量根据以下公式来计算:
[Allocatable] = [Node Capacity] - [system-reserved] - [Hard-Eviction-Thresholds]
来自可分配的 Hard-Eviction-Thresholds 可提高系统可靠性,因为可分配的值在节点级别强制实施。用户可使用 experimental-allocatable-ignore-eviction 设置来保留传统的行为,但这个设置会在未来发行版中弃用。
如果 [Allocatable] 为负,它会被设为 0。
22.4. 查看 Node-Allocatable 资源和容量
要查看节点的当前容量和可分配的资源,请运行以下命令:
$ oc get node/<node_name> -o yaml
在以下部分输出中,可分配的值小于容量。差异是正常的,与 system-reserved 的 cpu=500m,memory=1Gi 资源分配匹配。
status:
...
allocatable:
cpu: "3500m"
memory: 6857952Ki
pods: "110"
capacity:
cpu: "4"
memory: 8010948Ki
pods: "110"
...
调度程序使用 可分配量 的值来决定节点是否为 pod 调度候选者。
22.5. 节点报告的系统资源
每个节点报告容器运行时和 kubelet 使用的系统资源。要简化 system-reserved 的配置,请使用节点概述 API 查看节点的资源使用情况。节点概述位于 <master>/api/v1/nodes/<node>/proxy/stats/summary。
例如,要从 cluster.node22 节点访问资源,请运行以下命令:
$ curl <certificate details> https://<master>/api/v1/nodes/cluster.node22/proxy/stats/summary
响应中包括类似如下的信息:
{
"node": {
"nodeName": "cluster.node22",
"systemContainers": [
{
"cpu": {
"usageCoreNanoSeconds": 929684480915,
"usageNanoCores": 190998084
},
"memory": {
"rssBytes": 176726016,
"usageBytes": 1397895168,
"workingSetBytes": 1050509312
},
"name": "kubelet"
},
{
"cpu": {
"usageCoreNanoSeconds": 128521955903,
"usageNanoCores": 5928600
},
"memory": {
"rssBytes": 35958784,
"usageBytes": 129671168,
"workingSetBytes": 102416384
},
"name": "runtime"
}
]
}
}有关证书详情的详情,请参阅 REST API 概述。
22.6. 节点强制
节点可以根据配置的可分配值限制 pod 可消耗的资源总量。此功能可以防止 pod 使用系统服务(如容器运行时和节点代理)所需的 CPU 和内存资源,从而显著提高节点可靠性。为提高节点可靠性,管理员应该根据目标保留资源使用。
节点使用一个新的 cgroup 分级结构来强制实施资源限制,它强制实现服务质量。所有 pod 都在专用的 cgroup 层次结构中启动,与系统守护进程隔离。
要配置节点强制,请在适当的 节点配置映射 中使用以下参数:
例 22.2. 节点 Cgroup 设置
kubeletArguments:
cgroups-per-qos:
- "true" 1
cgroup-driver:
- "systemd" 2
enforce-node-allocatable:
- "pods" 3
管理员应该像对待具有保证服务质量的 pod 一样对待系统守护进程。系统守护进程可能会在其限定控制组中爆发,此行为需要作为集群部署的一个部分进行管理。通过在 system-reserved 中指定资源来为系统守护进程保留 CPU 和内存资源,如为 分配资源配置节点一节所示。
要查看设置的 cgroup 驱动程序,请运行以下命令:
$ systemctl status atomic-openshift-node -l | grep cgroup-driver=
输出包括类似如下的响应:
--cgroup-driver=systemd
有关管理和故障排除 cgroup 驱动程序的更多信息,请参阅 控制组(Cgroups)简介。
22.7. 驱除阈值
如果某个节点面临内存压力,这可能会影响整个节点以及该节点上运行的所有 pod。如果系统守护进程使用的内存超过保留的内存量,则可能会出现内存不足事件,从而影响整个节点和节点上运行的所有 pod。为避免系统内存不足事件或降低内存不足事件的可能性,节点提供 资源不足处理。
第 23 章 过量使用
23.1. 概述
容器可以指定 计算资源请求和限值。请求用于调度容器,以提供最低服务保证。限制约束节点上可以消耗的计算资源数量。
调度程序 会尝试优化集群中所有节点的计算资源使用。它将 pod 放置到特定的节点上,同时考虑 pod 的计算资源请求和节点的可用容量。
请求和限制使管理员能够允许和管理节点上资源的过量使用,这在可以接受以保证性能换取容量的开发环境中是理想的。
23.2. 请求和限制
对于每个计算资源,容器可以指定一个资源请求和限制。根据确保节点有足够可用容量以满足请求值的请求来做出调度决策。如果容器指定了限制,但忽略了请求,则请求会默认采用这些限制。容器无法超过节点上指定的限制。
限制的强制实施取决于计算资源类型。如果容器没有请求或限制,容器会调度到没有资源保障的节点。在实践中,容器可以在最低本地优先级适用的范围内消耗指定的资源。在资源较少的情况下,不指定资源请求的容器将获得最低的服务质量。
23.2.1. 调整缓冲区块限制
如果 Fluentd 日志记录器无法跟上大量日志,则需要切换到文件缓冲来降低内存用量并防止数据丢失。
Fluentd buffer_chunk_limit 由环境变量 BUFFER_SIZE_LIMIT 决定,其默认值为 8m。每个输出的文件缓冲区大小由环境变量 FILE_BUFFER_LIMIT 决定,其默认值为 256Mi。持久性卷大小必须大于 FILE_BUFFER_LIMIT 与输出相乘的结果。
例如,在 Fluentd 和 Mux pod 上,持久性卷 /var/lib/fluentd 应该由 PVC 或 hostmount 准备。然后,将该区域用作文件缓冲区。
buffer_type 和 buffer_path 在 Fluentd 配置文件中进行配置,如下所示:
$ egrep "buffer_type|buffer_path" *.conf output-es-config.conf: buffer_type file buffer_path `/var/lib/fluentd/buffer-output-es-config` output-es-ops-config.conf: buffer_type file buffer_path `/var/lib/fluentd/buffer-output-es-ops-config` filter-pre-mux-client.conf: buffer_type file buffer_path `/var/lib/fluentd/buffer-mux-client`
Fluentd buffer_queue_limit 是变量 BUFFER_QUEUE_LIMIT 的值。默认值为 32。
环境变量 BUFFER_QUEUE_LIMIT 计算为 (FILE_BUFFER_LIMIT / (number_of_outputs * BUFFER_SIZE_LIMIT))。
如果 BUFFER_QUEUE_LIMIT 变量具有默认值:
-
FILE_BUFFER_LIMIT = 256Mi -
number_of_outputs = 1 -
BUFFER_SIZE_LIMIT = 8Mi
buffer_queue_limit 的值为 32。要更改 buffer_queue_limit,您需要更改 FILE_BUFFER_LIMIT 的值。
在这个公式中,如果所有日志都发送到单个资源,则 number_of_outputs 为 1,否则每多一个资源就会递增 1。例如,number_of_outputs 的值为:
-
1- 如果所有日志都发送到单个 ElasticSearch pod -
2- 如果应用程序日志发送到 ElasticSearch pod,并且 ops 日志发送到另一个 ElasticSearch pod -
4- 如果应用程序日志发送到一个 ElasticSearch pod,ops 日志发送到另一个 ElasticSearch pod,并且这两者都转发到其他 Fluentd 实例
23.3. 计算资源
计算资源的节点强制行为特定于资源类型。
23.3.1. CPU
容器可以保证获得其请求的 CPU 量,还可额外消耗节点上提供的超额 CPU,但不会超过容器指定的限制。如果多个容器试图使用超额 CPU,则会根据每个容器请求的 CPU 数量来分配 CPU 时间。
例如,如果一个容器请求了 500m CPU 时间,另一个容器请求了 250m CPU 时间,那么该节点上提供的额外 CPU 时间以 2:1 比例在这两个容器之间分配。如果容器指定了一个限制,它将被限速,无法使用超过指定限制的 CPU。
使用 Linux 内核中的 CFS 共享支持强制实施 CPU 请求。默认情况下,使用 Linux 内核中的 CFS 配额支持以 100ms 测量间隔强制实施 CPU 限制,但 这可以被禁用。
23.3.2. 内存
容器可以保证获得其请求的内存量。容器可以使用高于请求量的内存,但一旦超过请求量,就有可能在节点上遇到内存不足情形时被终止。
如果容器使用的内存少于请求量,它不会被终止,除非系统任务或守护进程需要的内存量超过了节点资源保留考虑在内的内存量。如果容器指定了内存限制,则超过限制数量时会立即被终止。
23.3.3. 临时存储
只有在您启用了临时存储技术预览功能时,才会应用这个主题。此功能默认为禁用。如果启用,OpenShift Container Platform 集群将使用临时存储来存储在集群销毁后不需要保留的信息。要启用此功能,请参阅为临时存储配置。
容器可以保证它请求的临时存储量。容器可以使用超过请求的临时存储,但超过请求量后,如果可用临时磁盘磁盘空间太小,可以终止它。
如果容器使用不请求的临时存储,它不会被终止,除非系统任务或守护进程需要比在节点资源保留中考虑的更多本地临时存储。如果容器指定了临时存储的限值,则超过限制数量时会立即被终止。
23.4. 服务质量类
当节点上调度了没有发出请求的 pod,或者节点上所有 pod 的限制总和超过了机器可用容量时,该节点处于过量使用状态。
在过量使用环境中,节点上的 pod 可能会在任意给定时间点尝试使用超过可用量的计算资源。发生这种情况时,节点必须为 pod 赋予不同的优先级。有助于做出此决策的工具称为服务质量 (QoS) 类。
对于每个计算资源,容器划分到三个 QoS 类中的一个,它们按照优先级降序排列:
表 23.1. 服务质量类
| 优先级 | 类名称 | 描述 |
|---|---|---|
| 1(最高) | Guaranteed | 如果为所有资源设置了限制和可选请求(不等于 0)并且它们相等,则容器被归类为 Guaranteed。 |
| 2 | Burstable | 如果为所有资源设置了请求和可选限制(不等于 0)并且它们不相等,则容器被归类为 Burstable。 |
| 3(最低) | BestEffort | 如果没有为任何资源设置请求和限制,则容器被归类为 BestEffort。 |
内存是一种不可压缩的资源,因此在内存量较低的情况下,优先级最低的容器首先被终止:
- Guaranteed 容器优先级最高,并且保证只有在它们超过限制或者系统遇到内存压力且没有优先级更低的容器可被驱除时,才会被终止。
- 在遇到系统内存压力时,Burstable 容器如果超过其请求量并且不存在其他 BestEffort 容器,则有较大的可能会被终止。
- BestEffort 容器被视为优先级最低。系统内存不足时,这些容器中的进程最先被终止。
23.5. 为 Overcommitment 配置 Master
调度基于请求的资源,而配额和硬限制指的是资源限制,它们可以设置为高于请求的资源。请求和限制的差值决定了过量使用程度;例如,如果为容器赋予 1Gi 内存请求和 2Gi 内存限制,则根据 1Gi 请求将容器调度到节点上,但最多可使用 2Gi;因此过量使用为 200%。
如果 OpenShift Container Platform 管理员想要控制过量使用的程度并管理节点上的容器密度,则可以配置 master 来覆盖开发人员容器上设置的请求和限制之间的比例。与针对项目的 LimitRange 一起使用指定限制和默认,可以调整容器限制和请求以达到所需的过量使用程度。
这需要在 master-config.yaml 中配置 ClusterResourceOverride 准入控制器,如下例所示(如果存在现有配置树,或根据需要引入缺少的元素):
admissionConfig:
pluginConfig:
ClusterResourceOverride: 1
configuration:
apiVersion: v1
kind: ClusterResourceOverrideConfig
memoryRequestToLimitPercent: 25 2
cpuRequestToLimitPercent: 25 3
limitCPUToMemoryPercent: 200 4在更改 master 配置后,需要一个 master 重启。
请注意,如果没有在容器中设置任何限制,这些覆盖无效。创建一个带有默认限制(每个独立的项目或在 项目模板)的 LimitRange 对象,以确保能够应用覆盖。
另请注意,在覆盖后,容器限制和请求必须仍需要满足项目中的 LimitRange 对象的要求。这可能会导致 pod 被禁止的情况。例如,开发人员指定了一个接近最小限制的限制,然后其请求被覆盖为低于最小限制。这个问题在以后会加以解决,但目前而言,请小心地配置此功能和 LimitRange。
配置后,可通过编辑项目并添加以下注解来禁用每个项目覆盖的覆盖范围(例如,允许独立于覆盖配置基础架构组件):
quota.openshift.io/cluster-resource-override-enabled: "false"
23.6. 为 Overcommitment 配置节点
在过量使用的环境中,务必要正确配置节点,以提供最佳的系统行为。
23.6.1. 为不同的服务质量等级保留内存
您可以使用 experimental-qos-reserved 参数指定在特定 QoS 级别上 pod 保留的内存百分比。此功能尝试保留请求的资源,阻止较低 QoS 类中的 pod 使用较高 QoS 类中 pod 所请求的资源。
通过为更高的 QOS 级别保留资源,没有资源限制的 pod 被禁止对 pod 在较高的 QoS 级别请求的资源进行规范化。
要配置 experimental-qos-reserved 参数,请编辑适当的节点 配置映射。
kubeletArguments:
cgroups-per-qos:
- true
cgroup-driver:
- 'systemd'
cgroup-root:
- '/'
experimental-qos-reserved: 1
- 'memory=50%'- 1
- 指定 pod 资源请求在 QoS 级别保留的方式。
OpenShift Container Platform 使用 experimental-qos-reserved 参数,如下所示:
-
experimental-qos-reserved=memory=100%的值将阻止Burstable和BestEffortQOS 类消耗较高 QoS 类所请求的内存。这会增加BestEffort和Burstable工作负载上为了提高Guaranteed和Burstable工作负载的内存资源保障而遭遇 OOM 的风险。 -
值为
experimental-qos-reserved=memory=50%时,允许Burstable和BestEffortQoS 类消耗较高 QoS 类所请求的内存的一半。 -
值为
experimental-qos-reserved=memory=0%时,允许Burstable和BestEffortQoS 类最多消耗完整节点可分配量(如果可用),但会增加Guaranteed工作负载无法访问请求内存的风险。此条件等同于禁用这项功能。
23.6.2. 强制 CPU 限制
默认情况下,节点使用 Linux 内核中的 CPU CFS 配额支持强制实施指定的 CPU 限制。如果您不想在节点上强制实施 CPU 限制,您可以通过修改适当的节点 配置映射 来禁用其执行,使其包含以下参数:
kubeletArguments:
cpu-cfs-quota:
- "false"如果需要禁用 CPU 限制强制实施,则务必要了解其对您的节点可能造成的影响:
- 如果容器发出 CPU 请求,它将继续由 Linux 内核中的 CFS 份额来实施。
- 如果容器没有明确发出 CPU 请求,但它确实指定了限制,则请求将默认为指定的限制,并且由 Linux 内核中的 CFS 份额来实施。
- 如果容器同时指定 CPU 请求和限制,则由 Linux 内核中的 CFS 份额来实施请求,并且限制不会对节点产生影响。
23.6.3. 为系统进程保留资源
调度程序 确保根据 pod 请求,节点上所有 pod 有足够的资源。它验证节点上容器请求总和不能超过节点容量。它包括由节点启动的所有容器,但不包括容器,或在集群知识之外启动的容器。
建议您保留节点容量的某些部分,以便集群在节点上运行所需的系统守护进程(sshd、docker 等等)。特别是,建议您为内存等不可压缩的资源保留资源。
如果要显式为非 pod 进程保留资源,可以通过两种方式来:
- 首选方法是通过指定可用于调度的资源来分配节点资源。如需了解更多详细信息 ,请参阅分配 节点资源。
另外,您可以创建一个不执行任何操作的 resource-reserver pod,但保留容量是否被集群调度到节点上。例如:
例 23.1. resource-reserver Pod 定义
您可以将定义保存到文件中,如 resource-reserver.yaml,然后将该文件放到节点配置目录中,例如 /etc/origin/node/ 或
--config=<dir> 位置。另外,通过在适当的节点 配置映射中 指定 目录,将节点
服务器配置为从节点配置目录读取定义:kubeletArguments: config: - "/etc/origin/node" 1- 1
- 如果指定了
--config=<dir>,请在此处使用<dir>。
使用 resource-reserver.yaml 文件,启动节点服务器也会启动 sleep-forever 容器。调度程序考虑节点的剩余容量,调整相应地放置集群 pod 的位置。
要删除 resource-reserver pod,您可以从节点配置目录中删除或移动 resource-reserver.yaml 文件。
23.6.4. 内核可调项
当节点启动时,它会确保为内存管理正确设置内核可微调标识。除非物理内存不足,否则内核应该永不会在内存分配时失败。
为确保此行为,节点会指示内核始终过量使用内存:
$ sysctl -w vm.overcommit_memory=1
节点还会指示内核在内存不足时不会崩溃。相反,内核 OOM 终止程序应该根据优先级终止进程:
$ sysctl -w vm.panic_on_oom=0
节点上应该已设置了上述标记,不需要进一步操作。
23.6.5. 禁用交换内存
自 OpenShift 容器平台 3.9 起,swap 作为 Ansible 节点安装的一部分被禁用。启用 swap 不再被支持,但在评估将来的版本下,对 swap 的支持会被正确支持。
在启用了交换的情况下运行会出现意想不到的后果。如果启用了交换,则对于可用内存的资源不足处理驱除阈值将无法正常发挥作用。利用资源处理不足,允许在遇到内存压力时从节点驱除 pod,并重新调度到没有此类压力的备选节点上。
第 24 章 处理资源错误
24.1. 概述
本节讨论防止 OpenShift Container Platform 内存不足(OOM)和无磁盘空间状况的最佳尝试。
当可用的计算资源较低时,节点必须保持稳定性。这在处理内存或磁盘等不压缩的资源时尤为重要。如果任一资源用尽,节点就变得不稳定。
管理员可以主动监控节点,防止节点使用可配置 驱除策略 从计算和内存资源不足的情况。
本主题还提供有关 OpenShift Container Platform 如何处理资源不足条件的信息,并提供 示例场景 和 推荐做法 :
如果为节点启用了交换内存,则该节点无法检测到它面临内存压力。
要利用基于内存的驱除,操作员必须 禁用交换。
24.2. 配置驱除策略
当节点在可用资源上运行较低时,驱除策略 允许节点失败一个或多个 pod。pod 失败,节点可以回收所需资源。
驱除策略是 驱除触发器信号 以及节点配置文件或者 命令行 中设置的特定 驱除阈值 的组合。驱除可以是 硬 的,其中节点可以对超过阈值的 pod 执行操作,或 软 操作,其中节点允许在执行操作前允许宽限期。
要修改集群中的节点,请根据需要更新节点配置映射。不要手动编辑 node-config.yaml 文件。
通过使用配置良好的驱除策略,节点可以主动监控并阻止计算资源的总资源消耗。
当节点出现故障时,节点将终止 pod 中的所有容器,并且 PodPhase 过渡到 Failed。
在检测磁盘压力时,节点支持 nodefs 和 imagefs 文件系统分区。
nodefs 或 rootfs 是节点用于本地磁盘卷、守护进程日志、emptyDir 和其他本地存储的文件系统。例如,rootfs 是提供 / 的文件系统。rootfs 包含 openshift.local.volumes,默认为 /var/lib/origin/openshift.local.volumes。
imagefs 是容器运行时用来存储镜像和个别容器可写层的文件系统。对于 imagefs,驱除阈值达到 85% 满。imagefs 文件系统取决于运行时,如果 Docker,容器使用的存储驱动程序。
对于 Docker:
如果您使用
devicemapper存储驱动程序,imagefs是精简池。您可以通过在 Docker 守护进程中设置
--storage-opt dm.basesize标志来限制容器的读写层。$ sudo dockerd --storage-opt dm.basesize=50G
-
如果您使用
overlay2存储驱动程序,imagefs是包含 /var/lib/docker/overlay2 的文件系统。
-
对于使用 overlay 驱动程序的 CRI-O,
imagefs默认是 /var/lib/containers/storage。
如果不使用本地存储隔离(临时存储),并且不使用 XFS 配额(volumeConfig),则不能限制 pod 的本地磁盘用量。
24.2.1. 使用节点配置来创建策略
要配置驱除策略,请编辑适当的节点 配置映射,在 eviction-hard 或 eviction-soft 参数下指定驱除阈值。
以下示例演示了驱除阈值:
用于硬盘的节点配置文件示例
kubeletArguments: eviction-hard: 1 - memory.available<100Mi 2 - nodefs.available<10% - nodefs.inodesFree<5% - imagefs.available<15% - imagefs.inodesFree<10%
您必须为 inodesFree 参数提供百分比值。您可以为其他参数提供百分比或数字值。
Soft Eviction 的节点配置文件示例
kubeletArguments: eviction-soft: 1 - memory.available<100Mi 2 - nodefs.available<10% - nodefs.inodesFree<5% - imagefs.available<15% - imagefs.inodesFree<10% eviction-soft-grace-period:3 - memory.available=1m30s - nodefs.available=1m30s - nodefs.inodesFree=1m30s - imagefs.available=1m30s - imagefs.inodesFree=1m30s
重启 OpenShift Container Platform 服务以使更改生效:
# systemctl restart atomic-openshift-node
24.2.2. 了解驱除信号
您可以在下表中描述的任何信号上配置节点来触发驱除决策。您可以为驱除阈值添加 驱除 信号,以及一个阈值。
查看信号:
curl <certificate details> \ https://<master>/api/v1/nodes/<node>/proxy/stats/summary
表 24.1. 支持的 Eviction Signals
| 节点条件 | 驱除信号 | 值 | 描述 |
|---|---|---|---|
|
|
|
| 节点上的可用内存已超过驱除阈值。 |
|
|
|
| 节点根文件系统或镜像文件系统上的可用磁盘空间已超过驱除阈值。 |
|
|
| ||
|
|
| ||
|
|
|
上表中的每个信号都支持字面或百分比的值,但 内节点Free。inodesFree 信号需要以百分比的形式指定。基于百分比的值相对于与每个信号关联的总容量计算。
脚本使用 kubelet 执行的相同步骤集从 cgroup 驱动程序中获取 内存 的值。该脚本从其计算中排除不活动文件内存(即非活动 LRU 列表中的字节数),因为它假定不活动文件内存在压力下被回收。
不要使用 free -m 等工具,因为 free -m 无法在容器中工作。
OpenShift Container Platform 每 10 秒监控这些文件系统。
如果您将卷和日志存储在专用文件系统中,则该节点不会监控该文件系统。
节点支持根据磁盘压力触发驱除决策。由于磁盘压力导致 pod 驱除前,节点还会执行容器和镜像垃圾回收。
24.2.3. 了解驱除阈值
您可以配置节点来指定驱除阈值。达到阈值会触发节点重新声明资源。您可以在节点配置文件 中配置 阈值。
如果达到驱除阈值,则独立于其关联的宽限期,节点会报告一个条件以指示节点处于内存或磁盘压力下。报告压力可防止调度程序在节点上调度任何其他 pod,同时尝试重新声明资源。
节点将继续根据 node-status-update-frequency 参数指定的频率报告节点状态更新。默认频率为 10s (秒)。
驱除阈值可能是 硬 的,当您在重新声明资源前允许宽限期时,节点会在达到阈值时立即采取操作,或 软 操作。
以特定级别利用率为目标时,软驱除用量更为常见,但可以容忍临时高峰。我们推荐设置软驱除阈值低于硬驱除阈值,但时间周期可以特定于 operator。系统保留应同时覆盖软驱除阈值。
软驱除阈值是高级功能。您应该在尝试使用软驱除阈值前配置硬驱除阈值。
阈值使用以下格式进行配置:
<eviction_signal><operator><quantity>
例如,如果 Operator 有一个具有 10Gi 内存的节点,且如果可用内存低于 1Gi,则操作员希望避免驱除,则内存的驱除阈值可以指定为以下之一:
memory.available<1Gi memory.available<10%
节点每 10 秒评估和监控驱除阈值,且无法修改值。这是内务处理间隔。
24.2.3.1. 了解 Hard Eviction Thresholds
硬驱除阈值没有宽限期。当达到硬驱除阈值时,节点会立即采取操作来重新声明关联的资源。例如,节点可以在不安全终止的情况下立即终止一个或多个 pod。
要配置硬驱除阈值,请在 eviction-hard 下为节点配置文件添加驱除阈值,如使用 节点配置来创建策略。
带有硬驱除的节点配置文件示例
kubeletArguments: eviction-hard: - memory.available<500Mi - nodefs.available<500Mi - nodefs.inodesFree<5% - imagefs.available<100Mi - imagefs.inodesFree<10%
这个示例是常规的指南,我们不推荐的设置。
24.2.3.1.1. 默认硬驱除阈值
OpenShift Container Platform 使用以下默认配置进行 eviction-hard。
... kubeletArguments: eviction-hard: - memory.available<100Mi - nodefs.available<10% - nodefs.inodesFree<5% - imagefs.available<15% ...
24.2.3.2. 了解 Soft Eviction Thresholds
软驱除阈值将一个驱除阈值与所需的管理员指定宽限期相关联。在超过该宽限期前,该节点不会回收与驱除信号关联的资源。如果节点配置中没有提供宽限期,节点会在启动时出现错误。
另外,如果达到软驱除阈值,Operator 可以指定最高允许的 pod 终止宽限期,以便在从节点驱除 pod 时使用。如果指定了 eviction-max-pod-grace-period,则节点使用 pod.Spec.TerminationGracePeriodSeconds 和 maximum-allowed grace period 之间的 lesser 值。如果没有指定,节点将立即终止 pod,且不正常终止。
对于软驱除阈值,支持以下标记:
-
eviction-soft:一组驱除阈值,如memory.available<1.5Gi。如果在对应的宽限期中达到阈值,则阈值会触发 pod 驱除。 -
eviction-soft-grace-period:一组驱除宽限期,如memory.available=1m30s。宽限期与触发 pod 驱除阈值前的软驱除阈值需要保留的时长。 -
eviction-max-pod-grace-period:终止 pod 时允许的最大宽限期(以秒为单位)用于响应所满足软驱除阈值。
要配置软驱除阈值,请在 eviction-soft 下为 节点配置文件添加驱除阈值,如使用 节点配置来创建策略。
带有软驱除阈值的节点配置文件示例
kubeletArguments: eviction-soft: - memory.available<500Mi - nodefs.available<500Mi - nodefs.inodesFree<5% - imagefs.available<100Mi - imagefs.inodesFree<10% eviction-soft-grace-period: - memory.available=1m30s - nodefs.available=1m30s - nodefs.inodesFree=1m30s - imagefs.available=1m30s - imagefs.inodesFree=1m30s
这个示例是常规的指南,我们不推荐的设置。
24.3. 为调度配置资源挂载
您可以控制可用于调度的节点资源的数量,以便调度程序能够完全分配节点并防止驱除。
设置 system-reserved 等于您要供调度程序用于部署 pod 和 system-daemon 的资源量。system-reserved 资源用于操作系统守护进程,如 sshd 和 NetworkManager。只有在 pod 使用超过其可分配量的可分配资源时,才会发生驱除。
节点报告两个值:
-
容量:机器上的资源量。 -
可分配量:为调度提供了多少资源。
要配置可分配量的资源量,请编辑适当的节点 配置映射以添加或修改 system-reserved 参数,以用于 eviction-hard 或 eviction-soft。
kubeletArguments:
eviction-hard: 1
- "memory.available<500Mi"
system-reserved:
- "memory=1.5Gi"- 1
- 此阈值可以是
eviction-hard或eviction-soft。
要确定 system-reserved 设置的适当值,请使用节点概述 API 确定节点的资源使用情况。如需更多信息,请参阅为分配资源配置节点。
重启 OpenShift Container Platform 服务以使更改生效:
# systemctl restart atomic-openshift-node
24.4. 控制节点条件 Oscillation
如果节点在软驱除阈值上和低于软驱除阈值,但没有超过关联的宽限期,则 oscillation 可能会导致调度程序出现问题。
要防止 oscillation,设置 eviction-pressure-transition-period 参数,以控制节点在摆脱压力状况前必须等待的时间。
使用一组 <
resource_type>=<resource_quantity> 对,编辑参数到适当 节点配置映射的kubeletArguments部分。kubeletArguments: eviction-pressure-transition-period: - 5m
当节点在指定时间段内未能满足指定压力状况时,节点会将条件重新切换为 false。
注意在进行任何调整前,请使用默认值 5 分钟。默认值旨在让系统稳定并阻止调度程序在设置新 pod 之前将新 pod 调度到节点。
重启 OpenShift Container Platform 服务以使更改生效:
# systemctl restart atomic-openshift-node
24.5. 重新声明节点级别资源
如果满足驱除条件,节点会启动重新声明压力资源的过程,直到信号低于定义的阈值。在此期间,节点不支持调度任何新 pod。
根据主机系统是否为容器运行时配置了专用 imagefs,节点会在节点驱除最终用户 pod 之前尝试重新声明节点级别资源。
使用 Imagefs
如果主机系统有 imagefs :
如果
nodefs文件系统满足驱除阈值,节点会按照以下顺序释放磁盘空间:- 删除死 pod 和容器。
如果
imagefs文件系统满足驱除阈值,节点会按照以下顺序释放磁盘空间:- 删除所有未使用的镜像。
没有 Imagefs
如果主机系统没有 imagefs :
如果
nodefs文件系统满足驱除阈值,节点会按照以下顺序释放磁盘空间:- 删除死 pod 和容器。
- 删除所有未使用的镜像。
24.6. 了解 Pod 驱除
如果达到驱除阈值并且传递宽限期,节点会启动驱除 pod 过程,直到信号低于定义的阈值。
节点通过其 服务质量 对 pod 进行驱除。在具有相同服务质量的 pod 中,节点会相对于 pod 的调度请求,消耗计算资源的消耗来扩展 pod。
每个服务质量级别都有内存不足分数。Linux 内存不足工具(OOM 终止程序)使用分数来确定要结束的 pod。如需更多信息,请参阅了解服务质量和内存不足 Killer。
下表列出了每个服务质量级别,以及内存分数的相关等级。
表 24.2. 服务级别质量
| 服务质量 | 描述 |
|---|---|
|
| 相对于请求消耗最多的资源的 Pod 首先失败。如果没有 pod 超过其请求,策略会以资源的最大使用者为目标。 |
|
| 相对于该资源请求的请求,消耗最多的资源的 Pod 会首先失败。如果没有 pod 超过其请求,策略会以资源的最大使用者为目标。 |
|
| 消耗最多资源数量的 Pod 首先失败。 |
除非系统守护进程(如节点或容器引擎)消耗资源,或保证服务质量 pod 不会因为其他 pod 消耗而被驱除,超过使用 system-reserved 分配的资源消耗的资源,或者节点仅保证服务质量 pod 的剩余质量。
如果节点仅保证剩余的服务质量 pod,节点会驱除影响节点稳定性的 pod,并将意外消耗的影响限制到其他保证的服务 pod。
本地磁盘是服务资源的最优质量。如果需要,节点会一次驱除 pod,以便在遇到磁盘压力时回收磁盘空间。节点根据服务质量对 pod 进行排序。如果节点正在响应缺少可用内节点,则节点会首先驱除具有最低服务质量的 pod,从而回收内节点。如果节点正在响应缺少可用磁盘,则该节点会将 pod 在服务质量中排入使用最多的本地磁盘,然后首先驱除这些 pod。
24.6.1. 了解服务质量和内存不足 Killer
如果节点在能够重新声明内存前出现系统内存不足(OOM)事件,则该节点会依赖于 OOM 终止程序来响应。
节点根据 pod 的服务质量,为每个容器设置一个 oom_score_adj 值。
表 24.3. 服务级别质量
| 服务质量 | oom_score_adj 值 |
|---|---|
|
| -998 |
|
| min(max(2, 1000 - (1000 * memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
|
| 1000 |
如果节点在节点遇到系统 OOM 事件前无法重新声明内存,则 OOM 终止程序进程会计算 OOM 分数:
% of node memory a container is using + oom_score_adj = oom_score
然后,节点将以最高分数结束容器。
首先,具有最低服务质量的容器,可以消耗最大数量的内存(相对于调度请求)。
与 pod 驱除不同,如果 pod 容器因为 OOM 终止,节点可以根据节点重启策略重启容器。
24.7. 了解 Pod 调度程序和 OOR 条件
当调度程序将额外 pod 放置到节点上时,调度程序会查看节点状况。例如,如果节点有类似以下的驱除阈值:
eviction-hard is "memory.available<500Mi"
如果可用内存低于 500Mi,节点会在 Node.Status.Conditions 中报告为 MemoryPressure 的值。
表 24.4. 节点条件和调度程序行为
| 节点条件 | 调度程序行为 |
|---|---|
|
|
如果节点报告此状况,调度程序不会将 |
|
| 如果节点报告此状况,调度程序不会将任何额外 pod 放置到该节点上。 |
24.8. Scenario 示例
一个 Operator:
- 具有内存容量为 10Gi 的节点。
- 希望为系统守护进程(如内核、节点和其他守护进程)保留 10% 内存容量。
- 希望以 95% 内存利用率驱除 pod,以减少系统的 OOM 出现和推移。
此配置中隐式理解 system-reserved 应该包括驱除阈值所涵盖的内存量。
要达到这个容量,一些 pod 都使用它的请求,或者系统正在使用 1Gi。
如果节点有 10 Gi 容量,且您想要为系统守护进程保留 system-reserved 设置的 10%,请执行以下计算:
capacity = 10 Gi system-reserved = 10 Gi * .1 = 1 Gi
可分配的资源量成为:
allocatable = capacity - system-reserved = 9 Gi
这意味着调度程序将调度为该节点请求 9 Gi 内存的 pod。
如果要启用驱除,以便在节点发现可用内存低于 10% 30 秒时,或低于 5% 容量时立即触发驱除,您需要调度程序将可分配内存评估为 8Gi。因此,请确定您的系统保留涵盖了您的驱除阈值。
capacity = 10 Gi eviction-threshold = 10 Gi * .1 = 1 Gi system-reserved = (10Gi * .1) + eviction-threshold = 2 Gi allocatable = capacity - system-reserved = 8 Gi
将以下内容添加到适当的节点 配置映射 :
kubeletArguments: system-reserved: - "memory=2Gi" eviction-hard: - "memory.available<.5Gi" eviction-soft: - "memory.available<1Gi" eviction-soft-grace-period: - "memory.available=30s"
此配置可确保调度程序不会将 pod 放置到节点上,并立即引发内存压力并触发驱除。此配置假定这些 pod 使用小于配置的请求。
24.9. 推荐的实践
24.9.1. 守护进程集和资源处理
如果节点驱除由守护进程集创建的 pod,则 pod 会立即重新创建并重新调度到同一节点。调度程序以这种方式运行,因为节点无法区分守护进程集和任何其他对象创建的 pod。
通常,守护进程集不应创建最佳工作 pod,以避免被识别为驱除的候选 pod。相反,守护进程集应启动 pod,并使用保证的服务质量进行配置。
第 25 章 设置限制范围
25.1. 限制范围的目的
一个限制范围,由 LimitRange 对象定义,在 pod、容器、镜像、镜像流和持久性卷声明一级的一个 项目中枚举的计算资源约束,并指定 pod、容器、镜像、镜像流和持久性卷声明一级可以消耗的资源数量。
要创建和修改资源的所有请求都会针对项目中的每个 LimitRange 对象进行评估。如果资源违反了任何限制,则会拒绝该资源。如果资源没有设置显式值,如果约束支持默认值,则默认值将应用到资源。
对于 CPU 和内存限值,如果您指定一个最大值,但没有指定最小限制,资源会消耗超过最大值的 CPU 和内存资源。
您可以使用临时存储技术预览功能指定临时存储的限值和请求。此功能默认为禁用。要启用此功能,请参阅为临时存储配置。
核心限制范围对象定义
apiVersion: "v1" kind: "LimitRange" metadata: name: "core-resource-limits" 1 spec: limits: - type: "Pod" max: cpu: "2" 2 memory: "1Gi" 3 min: cpu: "200m" 4 memory: "6Mi" 5 - type: "Container" max: cpu: "2" 6 memory: "1Gi" 7 min: cpu: "100m" 8 memory: "4Mi" 9 default: cpu: "300m" 10 memory: "200Mi" 11 defaultRequest: cpu: "200m" 12 memory: "100Mi" 13 maxLimitRequestRatio: cpu: "10" 14
- 1
- 限制范围对象的名称。
- 2
- pod 可在所有容器间请求的最大 CPU 量。
- 3
- pod 可在所有容器间请求的最大内存量。
- 4
- pod 可在所有容器间请求的最小 CPU 量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过maxCPU 值。 - 5
- pod 可在所有容器间请求的最小内存量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过max内存的值。 - 6
- pod 中单个容器可以请求的最大 CPU 量。
- 7
- pod 中单个容器可以请求的最大内存量。
- 8
- pod 中单个容器可以请求的最小 CPU 量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过maxCPU 值。 - 9
- pod 中单个容器可以请求的最小内存量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过max内存的值。 - 10
- 如果没有在 pod 规格中指定限制,则容器的默认 CPU 限值。
- 11
- 如果没有在 pod 规格中指定限制,则容器的默认内存限值。
- 12
- 如果您没有在 pod 规格中指定请求,则容器的默认 CPU 请求。
- 13
- 如果您没有在 pod 规格中指定请求,则容器的默认内存请求。
- 14
- 容器最大的限制与请求的比率。
如需有关如何测量 CPU 和内存的更多信息,请参阅 Compute Resources。
OpenShift Container Platform 限制范围对象定义
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "openshift-resource-limits"
spec:
limits:
- type: openshift.io/Image
max:
storage: 1Gi 1
- type: openshift.io/ImageStream
max:
openshift.io/image-tags: 20 2
openshift.io/images: 30 3
- type: "Pod"
max:
cpu: "2" 4
memory: "1Gi" 5
ephemeral-storage: "1Gi" 6
max:
cpu: "1" 7
memory: "1Gi" 8
- 1
- 可以推送到内部 registry 的最大镜像大小。
- 2
- 镜像流规格中定义的唯一镜像标签的最大数量。
- 3
- 镜像流状态规格中定义的唯一镜像引用的最大数量。
- 4
- pod 可在所有容器间请求的最大 CPU 量。
- 5
- pod 可在所有容器间请求的最大内存量。
- 6
- 如果启用了临时存储,则 pod 可在所有容器间请求节点的最大临时存储量。
- 7
- pod 可在所有容器间请求的最小 CPU 量。如果确实设置了
min值,或者将min设置为0,则结果为 no limit,pod 可以消耗超过maxCPU 的值。 - 8
- pod 可在所有容器间请求的最小内存量。如果没有设置
min值,或者将min设置为0,则结果为没有限制,pod 消耗的消耗可能会超过max内存的值。
您可以在一个限制范围对象中指定 core 和 OpenShift Container Platform 资源。它们在两个示例中单独显示。
25.1.1. 容器限制
支持的资源:
- CPU
- 内存
支持的限制:
根据容器,如果指定,则必须满足以下条件:
表 25.1. Container
| 约束 | 行为 |
|---|---|
|
|
如果配置定义了 |
|
|
如果配置定义了 |
|
|
如果限制范围定义了
例如,如果容器有 |
支持的默认值:
Default[resource]-
如果无,则默认为
container.resources.limit[resource]作为指定的值。 默认请求[资源]-
如果无,则默认为
container.resources.requests[resource]作为指定的值。
25.1.2. Pod 限制
支持的资源:
- CPU
- 内存
支持的限制:
在 pod 中的所有容器中,需要满足以下条件:
表 25.2. Pod
| 约束 | 强制行为 |
|---|---|
|
|
|
|
|
|
|
|
|
25.1.3. 镜像限制
支持的资源:
- 存储
资源类型名称:
-
openshift.io/Image
对于每个镜像,如果指定,则必须满足以下条件:
表 25.3. Image
| 约束 | 行为 |
|---|---|
|
|
|
要防止超过限制的 Blob 上传到 registry,则必须将 registry 配置为强制实施配额。REGISTRY_MIDDLEWARE_REPOSITORY_OPENSHIFT_ENFORCEQUOTA 环境变量必须设置为 true。默认情况下,新部署的环境变量设为 true。
在上传的镜像清单中,镜像大小并非始终可用。这对使用 Docker 1.10 或更高版本构建并推送到 v2 registry 的镜像来说尤为如此。如果这样的镜像使用旧的 Docker 守护进程拉取,镜像清单将由 registry 转换为 schema v1,且不包含所有大小信息。镜像未设置存储限制将阻止镜像被上传。
这个问题正在被决。
25.1.4. 镜像流限值
支持的资源:
-
openshift.io/image-tags -
openshift.io/images
资源类型名称:
-
openshift.io/ImageStream
对于每个镜像流,如果指定,则必须满足以下条件:
表 25.4. ImageStream
| 约束 | 行为 |
|---|---|
|
|
|
|
|
|
25.1.4.1. 镜像参考的计数
openshift.io/image-tags 资源代表唯一镜像引用。可能的引用是 ImageStreamTag、ImageStreamImage 或 DockerImage。可以使用 oc tag 和 oc import-image 命令或使用标签跟踪来创建标签。内部和外部引用之间没有区别。但是,镜像流规格中标记的每个唯一引用仅计算一次。它不以任何方式限制推送到内部容器镜像 registry,但对标签限制很有用。
openshift.io/images 资源代表镜像流状态中记录的唯一镜像名称。它允许对可以推送到内部 registry 的大量镜像进行限制。内部和外部引用无法区分。
25.1.5. PersistentVolumeClaim Limits
支持的资源:
- 存储
支持的限制:
在一个项目中的所有持久性卷声明中,必须满足以下条件:
表 25.5. Pod
| 约束 | 强制行为 |
|---|---|
|
| Min[resource] <= claim.spec.resources.requests[resource] (required) |
|
| claim.spec.resources.requests[resource] (required) <= Max[resource] |
限制范围对象定义
{
"apiVersion": "v1",
"kind": "LimitRange",
"metadata": {
"name": "pvcs" 1
},
"spec": {
"limits": [{
"type": "PersistentVolumeClaim",
"min": {
"storage": "2Gi" 2
},
"max": {
"storage": "50Gi" 3
}
}
]
}
}
25.2. 创建限制范围
将限制范围应用到一个项目:
- 使用您的所需规格创建限制范围对象定义。
创建对象:
$ oc create -f <limit_range_file> -n <project>
25.3. 查看限制
您可以通过在 Web 控制台中导航到项目的 Quota 页面来查看项目中定义的任何限值范围。
您还可以通过执行以下步骤来使用 CLI 查看限制范围详情:
获取项目中定义的限值范围对象列表。例如,对于名为 demoproject 的项目:
$ oc get limits -n demoproject
输出示例
NAME AGE resource-limits 6d
描述限值范围。例如,对于名为 resource-limits 的限制范围:
$ oc describe limits resource-limits -n demoproject
输出示例
Name: resource-limits Namespace: demoproject Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Pod cpu 200m 2 - - - Pod memory 6Mi 1Gi - - - Container cpu 100m 2 200m 300m 10 Container memory 4Mi 1Gi 100Mi 200Mi - openshift.io/Image storage - 1Gi - - - openshift.io/ImageStream openshift.io/image - 12 - - - openshift.io/ImageStream openshift.io/image-tags - 10 - - -
25.4. 删除限制范围
要删除限制范围,不再强制实施项目的限制:
运行以下命令:
$ oc delete limits <limit_name>
第 26 章 节点问题检测程序
26.1. 概述
节点问题检测程序(Node Problem Detector)通过发现某些问题并向 API 服务器报告这些问题,来监控节点的健康状况。detector 在每个节点上作为 daemonset 运行。
节点问题检测程序只是一个技术预览功能。技术预览功能不包括在红帽生产服务级别协议(SLA)中,且其功能可能并不完善。因此,红帽不建议在生产环境中使用它们。这些技术预览功能可以使用户提早试用新的功能,并有机会在开发阶段提供反馈意见。
如需红帽技术预览功能支持范围的更多信息,请参阅 https://access.redhat.com/support/offerings/techpreview/。
Node Problem Detector 读取系统日志并监视特定条目,并使 control plane 可以看到这些问题,您可以使用 OpenShift Container Platform 命令(如 oc get node 和 oc get event )来查看。然后,您可以使用您选择的工具(如 OpenShift Container Platform 日志监控 )采取措施以纠正这些问题。检测到的问题可能位于以下类别之一:
-
NodeCondition:使节点对 pod 不可用的持久性问题。在主机重启前,节点条件不会被清除。 -
事件:对节点有限制影响的临时问题,但会信息。
节点问题检测程序可以检测到:
容器运行时问题:
- 无响应的运行时守护进程
硬件问题:
- 错误 CPU
- 错误内存
- 错误磁盘
内核问题:
- 内核死锁条件
- 损坏的文件系统
- 无响应的运行时守护进程
基础架构守护进程问题:
- NTP 服务中断
26.2. 节点问题检测程序输出示例
以下示例显示了节点问题检测程序监视特定节点上的内核死锁节点情况的输出。命令使用 oc get node 监视日志中 KernelDeadlock 条目的特定节点过滤。
# oc get node <node> -o yaml | grep -B5 KernelDeadlock
没有问题的节点问题检测程序输出示例
message: kernel has no deadlock reason: KernelHasNoDeadlock status: false type: KernelDeadLock
KernelDeadLock 条件的输出示例
message: task docker:1234 blocked for more than 120 seconds reason: DockerHung status: true type: KernelDeadLock
本例显示了节点问题检测程序监视节点上的事件的输出。以下命令使用 oc get event 监视 default 项目中的、在 Node Problem Detector configuration map 的 kernel-monitor.json 部分中列出的事件。
# oc get event -n default --field-selector=source=kernel-monitor --watch
显示节点上的事件的输出示例
LAST SEEN FIRST SEEN COUNT NAME KIND SUBOBJECT TYPE REASON SOURCE MESSAGE 2018-06-27 09:08:27 -0400 EDT 2018-06-27 09:08:27 -0400 EDT 1 my-node1 node Warning TaskHunk kernel-monitor.my-node1 docker:1234 blocked for more than 300 seconds 2018-06-27 09:08:27 -0400 EDT 2018-06-27 09:08:27 -0400 EDT 3 my-node2 node Warning KernelOops kernel-monitor.my-node2 BUG: unable to handle kernel NULL pointer deference at nowhere 2018-06-27 09:08:27 -0400 EDT 2018-06-27 09:08:27 -0400 EDT 1 my-node1 node Warning KernelOops kernel-monitor.my-node2 divide error 0000 [#0] SMP
节点问题检测程序消耗资源。如果使用节点问题检测程序,请确保有足够的节点来平衡集群性能。
26.3. 安装节点问题检测程序
如果在 /etc/ansible/hosts 清单文件中将 openshift_node_problem_detector_install 设置为 true,则安装 会默认创建一个 Node Problem Detector daemonset,并为 detector 创建一个项目,称为 openshift-node-problem-detector。
因为节点问题检测程序只是一个技术预览,所以 openshift_node_problem_detector_install 被默认设置为 false。安装节点问题检测程序时,您必须手动将参数改为 true。
如果没有安装 Node Problem Detector,请切换到 playbook 目录并运行 openshift-node-problem-detector/config.yml playbook 来安装 Node Problem Detector:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-node-problem-detector/config.yml
26.4. 自定义依赖条件
您可以通过编辑 Node Problem Detector 配置映射来配置 Node Problem Detector 来监控任何日志字符串。
节点问题检测程序配置映射示例
apiVersion: v1 kind: ConfigMap metadata: name: node-problem-detector data: docker-monitor.json: | 1 { "plugin": "journald", 2 "pluginConfig": { "source": "docker" }, "logPath": "/host/log/journal", 3 "lookback": "5m", "bufferSize": 10, "source": "docker-monitor", "conditions": [], "rules": [ 4 { "type": "temporary", 5 "reason": "CorruptDockerImage", 6 "pattern": "Error trying v2 registry: failed to register layer: rename /var/lib/docker/image/(.+) /var/lib/docker/image/(.+): directory not empty.*" 7 } ] } kernel-monitor.json: | 8 { "plugin": "journald", 9 "pluginConfig": { "source": "kernel" }, "logPath": "/host/log/journal", 10 "lookback": "5m", "bufferSize": 10, "source": "kernel-monitor", "conditions": [ 11 { "type": "KernelDeadlock", 12 "reason": "KernelHasNoDeadlock", 13 "message": "kernel has no deadlock" 14 } ], "rules": [ { "type": "temporary", "reason": "OOMKilling", "pattern": "Kill process \\d+ (.+) score \\d+ or sacrifice child\\nKilled process \\d+ (.+) total-vm:\\d+kB, anon-rss:\\d+kB, file-rss:\\d+kB" }, { "type": "temporary", "reason": "TaskHung", "pattern": "task \\S+:\\w+ blocked for more than \\w+ seconds\\." }, { "type": "temporary", "reason": "UnregisterNetDevice", "pattern": "unregister_netdevice: waiting for \\w+ to become free. Usage count = \\d+" }, { "type": "temporary", "reason": "KernelOops", "pattern": "BUG: unable to handle kernel NULL pointer dereference at .*" }, { "type": "temporary", "reason": "KernelOops", "pattern": "divide error: 0000 \\[#\\d+\\] SMP" }, { "type": "permanent", "condition": "KernelDeadlock", "reason": "AUFSUmountHung", "pattern": "task umount\\.aufs:\\w+ blocked for more than \\w+ seconds\\." }, { "type": "permanent", "condition": "KernelDeadlock", "reason": "DockerHung", "pattern": "task docker:\\w+ blocked for more than \\w+ seconds\\." } ] }
要配置节点问题检测程序,添加或删除问题条件和事件。
使用文本编辑器编辑 Node Problem Detector 配置映射。
$ oc edit configmap -n openshift-node-problem-detector node-problem-detector
根据需要删除、添加或编辑任何节点状况或事件。
{ "type": <`temporary` or `permanent`>, "reason": <free-form text describing the error>, "pattern": <log message to watch for> },例如:
{ "type": "temporary", "reason": "UnregisterNetDevice", "pattern": "unregister_netdevice: waiting for \\w+ to become free. Usage count = \\d+" },重启正在运行的 pod 以应用更改。要重启 pod,您可以删除所有现有的 pod:
# oc delete pods -n openshift-node-problem-detector -l name=node-problem-detector
要将节点问题检测程序输出显示到标准输出(stdout)和标准错误(stderr),请在 Node Problem Detector 的 DaemonSet 中添加以下内容:
spec: template: spec: containers: - name: node-problem-detector command: - node-problem-detector - --alsologtostderr=true 1 - --log_dir="/tmp" 2 - --system-log-monitors=/etc/npd/kernel-monitor.json,/etc/npd/docker-monitor.json 3
26.5. 验证节点问题检测程序正在运行
验证节点问题检测程序是否活跃:
运行以下命令来获取 Problem Node Detector pod 的名称:
# oc get pods -n openshift-node-problem-detector NAME READY STATUS RESTARTS AGE node-problem-detector-8z8r8 1/1 Running 0 1h node-problem-detector-nggjv 1/1 Running 0 1h
运行以下命令,以查看 Problem Node Detector pod 的日志信息:
# oc logs -n openshift-node-problem-detector <pod_name>
输出结果应类似于以下内容:
# oc logs -n openshift-node-problem-detector node-problem-detector-c6kng I0416 23:22:00.641354 1 log_monitor.go:63] Finish parsing log monitor config file: {WatcherConfig:{Plugin:journald PluginConfig:map[source:kernel] LogPath:/host/log/journal Lookback:5m} BufferSize:10 Source:kernel-monitor DefaultConditions:[{Type:KernelDeadlock Status:false Transition:0001-01-01 00:00:00 +0000 UTC Reason:KernelHasNoDeadlock Message:kernel has no deadlock}]通过模拟节点上的事件来测试节点问题检测程序:
# echo "kernel: divide error: 0000 [#0] SMP." >> /dev/kmsg
通过模拟节点上的条件来测试节点问题检测程序:
# echo "kernel: task docker:7 blocked for more than 300 seconds." >> /dev/kmsg
26.6. 卸载节点问题检测程序
卸载节点问题检测程序:
在 Ansible 清单文件中添加以下选项:
[OSEv3:vars] openshift_node_problem_detector_state=absent
进入 playbook 目录并运行 config.yml Ansible playbook:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-node-problem-detector/config.yml
第 27 章 为入站流量分配唯一外部 IP
27.1. 概述
将外部流量进入集群的一种方法是使用 ExternalIP 或 IngressIP 地址。
这个功能只在非云部署中被支持。对于云(GCE、AWS 和 OpenStack)部署,使用 Load Balancer 服务自动部署云负载均衡器,以针对服务的端点为目标。
OpenShift Container Platform 支持两个 IP 地址池:
- 在为服务选择外部 IP 地址时,Loadbalancer 使用 ingressIP。
- 当用户从配置的池中选择特定 IP 时,会使用 ExternalIP。
两者都必须配置为要使用的 OpenShift Container Platform 主机上的设备,无论是网络接口控制器(NIC)还是虚拟以太网,以及外部路由。建议使用 ipfailover,因为它选择主机并配置 NIC。
ingressIP 和 ExternalIP 都允许外部流量访问集群,如果路由正确,外部流量可以通过服务公开的任何 TCP/UDP 端口访问该服务的端点。当手动为服务分配外部 IP 地址时,这比管理有限共享 IP 地址的端口空间更简单。另外,在配置高可用性时,这些地址也可以用作虚拟 IP(VIP)。
OpenShift Container Platform 支持自动和手动分配 IP 地址,并且保证每个地址都被分配到最多一个服务。这样可保证,无论由其他服务公开的端口是什么,每个服务都可以公开选择的端口。
27.2. 限制
要使用 ExternalIP,您可以:
-
从
externalIPNetworkCIDRs范围内选择一个 IP 地址。 在 master 配置文件中,具有从
ingressIPNetworkCIDR池分配的 IP 地址。在本例中,OpenShift Container Platform 实现了负载均衡器服务类型的非云版本,并为服务分配 IP 地址。小心您必须确保分配的 IP 地址池在集群中的一个或多个节点上终止。您可以使用现有的
oc adm ipfailover来确保外部 IP 具有高可用性。
对于手动配置的外部 IP,潜在的端口冲突将由首次提供服务。如果您请求了端口,则仅在尚未为该 IP 地址分配端口时才可用。例如:
用于手动配置外部 IP 的端口冲突示例
有两个服务手动配置为 172.7.7.7 的同一外部 IP 地址。
MongoDB 服务 A 请求端口 27017,然后 MongoDB 服务 B 请求同一端口;第一个请求获取端口。
但是,端口冲突不是入口控制器分配的外部 IP 的问题,因为控制器会为每个服务分配一个唯一地址。
27.3. 配置集群以使用唯一外部 IP
在非云集群中,ingressIPNetworkCIDR 被默认设置为 172.29.0.0/16。如果您的集群环境还没有使用这个私有范围,您可以使用默认值。但是,如果要使用不同的范围,则必须在分配入口 IP 前在 /etc/origin/master/master-config.yaml 文件中设置 ingressIPNetworkCIDR。然后,重启 master 服务。
分配给 LoadBalancer 类型的服务的外部 IP 将始终在 ingressIPNetworkCIDR 范围内。如果更改了 ingressIPNetworkCIDR,则分配的外部 IP 不再范围内,受影响的服务将被分配与新范围兼容的新外部 IP。
如果您使用高可用性,则此范围必须小于 255 个 IP 地址。
Sample /etc/origin/master/master-config.yaml
networkConfig: ingressIPNetworkCIDR: 172.29.0.0/16
27.3.1. 为服务配置 Ingress IP
分配入口 IP:
为 LoadBalancer 服务创建一个 YAML 文件,通过
loadBalancerIP设置请求特定 IP:LoadBalancer 配置示例
apiVersion: v1 kind: Service metadata: name: egress-1 spec: ports: - name: db port: 3306 loadBalancerIP: 172.29.0.1 type: LoadBalancer selector: name: my-db-selector在 pod 上创建 LoadBalancer 服务:
$ oc create -f loadbalancer.yaml
检查服务是否有外部 IP。例如,对于名为
myservice的服务:$ oc get svc myservice
当您的 LoadBalancer-type 服务分配了外部 IP 时,输出会显示 IP:
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE myservice 172.30.74.106 172.29.0.1 3306/TCP 30s
27.4. 路由用于开发或测试的 Ingress CIDR
添加将入口 CIDR 流量定向到集群中的节点的静态路由。例如:
# route add -net 172.29.0.0/16 gw 10.66.140.17 eth0
在上例中,172.29 .0.0/16 是 ingressIPNetworkCIDR,10.66.140.17 是节点 IP。
27.4.1. Service externalIPs
除了集群的内部 IP 地址外,应用程序开发人员还可以配置集群外部的 IP 地址。作为 OpenShift Container Platform 管理员,您负责确保流量通过此 IP 到达节点。
管理员必须从 master-config.yaml 文件中配置的 externalIPNetworkCIDRs 范围内选择 externalIPs。当 master-config.yaml 发生变化时,必须重启 master 服务。
# master-restart api # master-restart controllers
externalIPNetworkCIDR /etc/origin/master/master-config.yaml 示例
networkConfig: externalIPNetworkCIDR: 172.47.0.0/24
服务 externalIPs 定义(JSON)
{
"kind": "Service",
"apiVersion": "v1",
"metadata": {
"name": "my-service"
},
"spec": {
"selector": {
"app": "MyApp"
},
"ports": [
{
"name": "http",
"protocol": "TCP",
"port": 80,
"targetPort": 9376
}
],
"externalIPs" : [
"80.11.12.10" 1
]
}
}
- 1
- 在其上公开端口的外部 IP 地址列表。除了内部 IP 地址外)
第 28 章 监控和调试路由器
28.1. 概述
根据底层的实现,您可以以多种方式 监控正在运行的路由器。本节讨论 HAProxy 模板路由器和要检查的组件以确保其健康状况。
28.2. 查看统计
HAProxy 路由器为 HAProxy 统计公开一个 web 侦听器。输入路由器的公共 IP 地址以及正确配置的端口(默认为1936 ),以查看统计信息页面,并在系统提示时输入管理员密码。此密码和端口在路由器安装期间配置,但可以通过查看容器上的 haproxy.config 文件找到它们。
要以 Prometheus 格式提取原始统计,请运行以下命令:
$ curl -u <user>:<password> -kv <router_IP>:<STATS_PORT>/metrics
有关获取此命令所需的信息,请参阅 公开路由器指标。
28.3. 禁用统计视图
默认情况下,HAProxy 统计在端口 1936 上公开(具有受密码保护的帐户)。要禁用公开 HAProxy 统计,请指定 0 作为统计端口号。
$ oc adm router hap --service-account=router --stats-port=0
备注:HAProxy 仍将收集和存储统计信息,而不只是通过 web 侦听器公开它们。您仍然可以通过向 HAProxy 路由器容器内 HAProxy AF_UNIX 套接字发送请求来获取统计信息的访问权限。
$ cmd="echo 'show stat' | socat - UNIX-CONNECT:/var/lib/haproxy/run/haproxy.sock"
$ routerPod=$(oc get pods --selector="router=router" \
--template="{{with index .items 0}}{{.metadata.name}}{{end}}")
$ oc exec $routerPod -- bash -c "$cmd"
为了安全起见,oc exec 命令在访问特权容器时无法工作。相反,您可以 SSH 到节点主机,然后在所需容器上使用 docker exec 命令。
28.4. 查看日志
要查看路由器日志,请在 pod 上运行 oc logs 命令。由于路由器作为用于管理底层实施的插件进程运行,因此日志用于插件,而非实际的 HAProxy 日志。
要查看 HAProxy 生成的日志,启动 syslog 服务器并使用以下环境变量将位置传递给路由器 pod。
表 28.1. 路由器 Syslog 变量
| 环境变量 | 描述 |
|---|---|
|
| syslog 服务器的 IP 地址。如果未指定端口,端口 514 是默认值。 |
|
| 可选。设置以更改 HAProxy 日志级别。如果没有设置,则默认的日志级别为 warning。这可以改为 HAProxy 支持的任何日志级别。 |
|
| 可选。设置以定义自定义的 HAProxy 日志格式。这可以改为 HAProxy 接受的任何日志格式字符串。 |
设置正在运行的路由器 pod 以发送消息到 syslog 服务器:
$ oc set env dc/router ROUTER_SYSLOG_ADDRESS=<dest_ip:dest_port> ROUTER_LOG_LEVEL=<level>
例如,以下将 HAProxy 设置为使用默认端口 514 将日志发送到 127.0.0.1,并将日志级别更改为 debug。
$ oc set env dc/router ROUTER_SYSLOG_ADDRESS=127.0.0.1 ROUTER_LOG_LEVEL=debug
28.5. 查看路由器内部
routes.json
路由由 HAProxy 路由器处理,它们同时存储在磁盘和 HAProxy 配置文件中的内存。内部路由表示(传递给模板来生成 HAProxy 配置文件)位于 /var/lib/haproxy/router/routes.json 文件中。在对路由问题进行故障排除时,请查看此文件以查看用于驱动器配置的数据。
HAProxy 配置
您可以在 /var/lib/haproxy/conf/haproxy.config 文件中找到为特定路由创建的 HAProxy 配置和后端。映射文件在同一目录中。当将传入请求映射到后端时,帮助程序前端和后端会使用映射文件。
证书
证书存储在两个位置:
- 边缘终止和重新加密终止路由的证书保存在 /var/lib/haproxy/router/certs 目录中。
- 用于连接到重新加密已终止路由的后端的证书保存在 /var/lib/haproxy/router/cacerts 目录中。
文件由路由的命名空间和名称进行密钥。密钥、证书和 CA 证书串联为单个文件。您可以使用 OpenSSL 查看这些文件的内容。
第 29 章 高可用性
29.1. 概述
本节介绍了为 OpenShift Container Platform 集群中的 pod 和服务设置高可用性。
IP 故障转移(IP failover)在一组节点上管理一个虚拟 IP(VIP)地址池。集合中的每个 VIP 都由从集合中选择的节点提供服务。只要单个节点可用,就会提供 VIP。无法将 VIP 显式分发到节点上。因此可能存在没有 VIP 的节点和具有多个 VIP 的节点。如果只有一个节点,则所有 VIP 将位于其中。
VIP 必须可以从集群外部路由。
IP 故障转移会监控每个 VIP 上的端口,以确定该端口能否在节点上访问。如果端口无法访问,则不会向节点分配 VIP。如果端口设为 0,则会禁止此检查。check脚本执行所需的测试。
IP 故障转移使用 Keepalived 在一组主机上托管一组外部访问的 VIP 地址。在一个时间点上,每个 VIP 仅由一个主机提供服务。 keepalived 使用 VRRP 协议来确定哪个主机(来自主机集合)将为哪个主机提供 VIP 服务。如果主机不可用,或者 Keepalived 正在监视的服务没有响应,则 VIP 会切换到来自集合的另一个主机。因此,只要主机可用,就会始终为 VIP 服务。
当运行 Keepalived 的主机通过 check 脚本时,主机可以根据其优先级和当前 MASTER 的优先级,由 抢占策略决定的 MASTER 状态。
管理员可以通过 --notify-script= 选项提供脚本,该选项会在状态发生变化时调用。keepalived 在为 VIP 提供时处于 MASTER 状态,当另一个节点提供 VIP 服务时,处于 BACKUP 状态,或者在 检查 脚本失败时处于 FAULT' 状态。每当状态更改时,notify 脚本 都会被调用,并显示新的状态。
OpenShift Container Platform 支持通过运行 oc adm ipfailover 命令来创建 IP 故障转移部署配置。IP 故障转移部署配置指定 VIP 地址的集合,以及服务它们的一组节点。一个集群可以具有多个 IP 故障转移部署配置,各自管理自己的一组唯一的 VIP 地址。IP 故障转移配置中的每个节点运行 IP 故障转移 pod,此 pod 运行 Keepalived。
当使用 VIP 访问具有主机网络(如路由器)的 pod 时,应用程序 pod 应该在运行 ipfailover pod 的所有节点上运行。这可让任何 ipfailover 节点成为 master,并在需要时为 VIP 服务。如果应用程序 pod 没有在使用 ipfailover 的节点上运行,某些 ipfailover 节点永远不会为 VIP 服务,或者一些应用程序 pod 不会接收任何流量。对 ipfailover 和应用 pod 都使用相同的选择器和复制数,以避免这种不匹配。
在使用 VIP 访问服务时,任何节点都可以位于一组节点的 ipfailover 部分,因为该服务可在所有节点(无论应用程序 pod 在哪里运行)访问该服务。任何 ipfailover 节点都可以随时变为 master。该服务可以使用外部 IP 和服务端口,或者可以使用 nodePort。
当在服务中使用外部 IP 时,VIP 被设置为外部 IP,ipfailover 监控端口被设置为服务端口。一个 nodePort 在集群的每个节点中打开,该服务将与当前支持 VIP 的任何节点中负载平衡流量。在本例中,ipfailover 监控端口在服务定义中被设置为 nodePort。
设置 nodePort 是一个特权操作。
即使一个服务 VIP 具有高可用性,但性能仍会受到影响。keepalived 确保每个 VIP 都由配置中的某个节点提供服务,即使其他节点没有,也会在同一节点上出现多个 VIP。当 ipfailover 在同一节点上放置多个 VIP 时,在一组 VIP 之间进行外部负载均衡的策略可能会被破解。
当使用 ingressIP 时,您可以将 ipfailover 设置为与 ingressIP 范围相同的 VIP 范围。您还可以禁用监控端口。在这种情况下,所有 VIP 都出现在集群的同一节点上。任何用户都可以使用 ingressIP 设置服务,并使其具有高可用性。
集群中最多有 255 个 VIP。
29.2. 配置 IP 故障切换
使用带有 适当选项 的 oc adm ipfailover 命令,创建 ipfailover 部署配置。
目前,ipfailover 与云基础架构不兼容。对于 AWS,可使用 AWS 控制台使用 Elastic Load Balancer(ELB)使 OpenShift Container Platform 具有高可用性。
作为管理员,您可以在整个集群中或节点子集中配置 ipfailover,如标签选择器定义。您还可以在集群中配置多个 IP 故障转移部署配置,每个配置都独立于其他配置。oc adm ipfailover - 命令会创建一个 ipfailover 部署配置,以确保故障转移 pod 在与约束或使用的标签匹配的每个节点上运行。此 pod 在所有 Keepalived 守护进程中使用 VRRP(虚拟路由器冗余协议)运行 Keepalived,以确保监视端口上的服务可用,如果不可用,Keepalived 会自动浮点虚拟 IP(VIP)。
对于生产环境,请确保使用至少两个节点的 --selector=<label > 来选择节点。另外,设置 --replicas=<n> 值,该值与给定标签选择器的节点数量匹配。
oc adm ipfailover 命令包含命令行选项,用于设置控制 Keepalived 的环境变量。环境变量 从 OPENSHIFT_HA_* 开始,它们可以根据需要进行更改。
例如,下面的命令将在选择标记为 router=us-west-ha 的节点(在 4 个带有 7 个虚拟 IP 监控服务侦听端口 80 的节点上)创建 IP 故障转移配置。
$ oc adm ipfailover --selector="router=us-west-ha" \
--virtual-ips="1.2.3.4,10.1.1.100-104,5.6.7.8" \
--watch-port=80 --replicas=4 --create29.2.1. 虚拟 IP 地址
keepalived 管理一组虚拟 IP 地址(VIP)。管理员必须确保所有这些地址:
- 可在集群外部配置的主机上访问。
- 不可用于集群中的任何其他目的。
每个节点上的 keepalived 确定所需服务是否在运行。如果是,则支持 VIP,Keepalived 参与协商来确定哪个节点将提供 VIP。对于要参与的节点,服务必须侦听 VIP 上的观察端口,或者必须禁用检查。
集合中的每个 VIP 最终都可能由不同的节点提供。
29.2.2. 检查和通知脚本
Keepalived 通过定期运行可选用户提供的检查脚本来监控应用程序的健康状况。例如,该脚本可以通过发出请求并验证响应来测试 Web 服务器。
该脚本通过 oc adm ipfailover 命令的 --check-script=<script> 选项提供。对于 PASS 或 1,该脚本必须以 0 退出。
默认情况下,检查每两秒完成一次,但可以使用 --check-interval=<seconds> 选项进行更改。
不提供检查脚本时,将运行一个简单的默认脚本来测试 TCP 连接。当监控端口为 0 时,禁止此默认测试。
对于每个虚拟 IP(VIP),keepalived 保留节点的状态。节点上的 VIP 可能处于 MASTER、BACKUP 或 FAULT 状态。所有不在 FAULT 状态的节点上的 VIP 均参与协商来决定是否哪个是 VIP 的 MASTER。所有丢失者都进入 BACKUP 状态。当 MASTER 上的 检查 脚本失败时,VIP 会进入 FAULT 状态,并触发重新协商。当 BACKUP 失败时,VIP 会进入 FAULT 状态。当 check 脚本再次在 FAULT 状态的 VIP 上再次传递时,它会退出 FAULT 并协商 MASTER。生成的状态为 MASTER 或 BACKUP。
管理员可以提供可选的 notify 脚本,该脚本会在状态更改时调用。keepalived 将以下三个参数传递给脚本:
-
$1- "GROUP"|"INSTANCE" -
$2- 组或实例的名称 -
$3- 新状态("MASTER"|"BACKUP"|"FAULT")
这些脚本在 IP 故障转移 pod 中运行,并使用 pod 的文件系统,而不是主机文件系统。选项需要脚本的完整路径。管理员必须使容器集中的 脚本从运行 notify 脚本提取结果。提供脚本的建议方法是使用 ConfigMap。
检查 和通知 脚本的完整路径名称添加到 keepalived 配置文件 /etc/keepalived/keepalived.conf 中,该文件会在 keepalived 启动时加载。脚本可以通过 ConfigMap 添加到 pod,如下所示。
创建所需脚本,并创建 ConfigMap 来容纳它。脚本没有输入参数,并且必须返回
0(OK )和1(表示 FAIL )。检查脚本,mycheckscript.sh:
#!/bin/bash # Whatever tests are needed # E.g., send request and verify response exit 0创建 ConfigMap:
$ oc create configmap mycustomcheck --from-file=mycheckscript.sh
可以通过两种方式将脚本添加到 pod:使用
oc命令或编辑部署配置。在这两种情况下,所挂载的configMap文件的defaultMode必须允许执行。值通常为0755(493十进制)。使用
oc命令:$ oc env dc/ipf-ha-router \ OPENSHIFT_HA_CHECK_SCRIPT=/etc/keepalive/mycheckscript.sh $ oc set volume dc/ipf-ha-router --add --overwrite \ --name=config-volume \ --mount-path=/etc/keepalive \ --source='{"configMap": { "name": "mycustomcheck", "defaultMode": 493}}'编辑 ipf-ha-router 部署配置:
使用
oc edit dc ipf-ha-router使用文本编辑器编辑路由器部署配置。... spec: containers: - env: - name: OPENSHIFT_HA_CHECK_SCRIPT 1 value: /etc/keepalive/mycheckscript.sh ... volumeMounts: 2 - mountPath: /etc/keepalive name: config-volume dnsPolicy: ClusterFirst ... volumes: 3 - configMap: defaultMode: 0755 4 name: customrouter name: config-volume ...- 保存更改并退出编辑器。这会重启 ipf-ha-router。
29.2.3. VRRP 抢占
当主机通过传递检查脚本保持 FAULT 状态时,如果新主机的优先级低于当前处于 MASTER 状态的主机,则主机将变为 BACKUP。但是,如果它具有更高的优先级,则抢占策略会决定它在集群中的角色。
nopreempt 策略不会将 MASTER 从较低优先级主机移到优先级更高的主机。使用 preempt 300 时,Keepalived 会等待指定的 300 秒,并将 MASTER 移到优先级更高的主机。
指定抢占:
使用
preemption-strategy创建 ipfailover 时:$ oc adm ipfailover --preempt-strategy=nopreempt \ ...
使用
oc set env命令设置变量:$ oc set env dc/ipf-ha-router \ --overwrite=true \ OPENSHIFT_HA_PREEMPTION=nopreempt使用
oc edit dc ipf-ha-router编辑路由器部署配置:... spec: containers: - env: - name: OPENSHIFT_HA_PREEMPTION 1 value: nopreempt ...
29.2.4. keepalived 多播
OpenShift Container Platform 的 IP 故障转移内部使用 keepalived。
确保在上方标记的节点上启用了 多播,它可以接受 224.0.0.18(VRRP VRRP 多播 IP 地址)的网络流量。
在启动 keepalived 守护进程前,启动脚本会验证允许多播流量流的 iptables 规则。如果没有这样的规则,启动脚本会创建一个新的规则,并将其添加到 IP 表配置中。其中此新规则添加到 IP 表配置取决于 --iptables-chain= 选项。如果指定了 --iptables-chain= 选项,规则会添加到 选项中指定的链中。否则,该规则将添加到 INPUT 链中。
每当节点上运行一个或多个 keepalived 守护进程时,iptables 规则都必须存在。
可以在最后一个 keepalived 守护进程终止后删除 iptables 规则。该规则不会自动删除。
您可以手动管理每个节点上的 iptables 规则。它仅在不存在时创建(只要 ipfailover 没有使用 -iptable-chain="" 选项创建 )。
您必须确保系统重启后手动添加规则会保留。
请注意,因为每个 keepalived 守护进程都使用 VRRP 协议在多播 224.0.0.18 间与对等点进行协商。每个 VIP 都必须有不同的 VRRP-id(范围 0..255))。
$ for node in openshift-node-{5,6,7,8,9}; do ssh $node <<EOF
export interface=${interface:-"eth0"}
echo "Check multicast enabled ... ";
ip addr show $interface | grep -i MULTICAST
echo "Check multicast groups ... "
ip maddr show $interface | grep 224.0.0
EOF
done;29.2.5. 命令行选项和环境变量
表 29.1. 命令行选项和环境变量
| 选项 | 变量名称 | 默认 | 备注 |
|---|---|---|---|
|
|
| 80 | ipfailover pod 会尝试在每个 VIP 上打开到此端口的 TCP 连接。如果建立连接,则服务将被视为正在运行。如果此端口设为 0,则测试始终通过。 |
|
|
|
要使用的 ipfailover 的接口名称,用于发送 VRRP 流量。默认情况下使用 | |
|
|
| 2 |
要创建的副本数。这必须与 ipfailover 部署配置中的 |
|
|
| 要复制的 IP 地址范围列表。必须提供.(例如,1.2.3.4-6,1.2.3.9.) 请参见 此讨论 以了解更多详细信息。 | |
|
|
| 0 | 如需了解更多详细信息,请参阅 VRRP ID Offset 中的内容。 |
|
|
|
为 VRRP 创建的组数量。如果没有设置,则会为每个使用 | |
|
|
| 输入 |
iptables 链的名称,用于自动添加允许 VRRP 流量的 |
|
|
| 定期运行的脚本的 pod 文件系统中的完整路径名称,以验证应用程序是否正在运行。请参见 此讨论 以了解更多详细信息。 | |
|
|
| 2 | 检查脚本运行的期间(以秒为单位)。 |
|
|
| 当状态发生变化时运行的脚本的 pod 文件系统中的完整路径名称。请参见 此讨论 以了解更多详细信息。 | |
|
|
| preempt 300 | 处理新的更高优先级主机的策略。详情请查看 VRRP 抢占部分。 |
29.2.6. VRRP ID Offset
每个 ipfailover pod 由 ipfailover 部署配置(每个节点 1 个 pod)管理的 ipfailover pod 都运行一个 keepalived 守护进程。配置了更多 ipfailover 部署配置时,会创建更多 pod,并将更多守护进程加入到通用的 VRRP 协商中。这个协商由所有 keepalived 守护进程完成,它决定哪些节点将服务哪些虚拟 IP(VIP)。
keepalived 在内部分配一个唯一的 vrrp-id 到每个 VIP。协商使用这一组 vrrp-ids,在做出决策时,胜出的 vrrp-id 对应的 VIP 将在胜出的节点上服务。
因此,对于 ipfailover 部署配置中定义的每个 VIP,ipfailover pod 必须分配一个对应的 vrrp-id。这可以通过从 --vrrp-id-offset 开始,并按顺序将 vrrp-ids 分配给 VIP 列表来实现。vrrp-ids 的值在 1...255 之间。
当有多个 ipfailover 部署配置时,必须指定 --vrrp-id-offset,以便在部署配置中增加 VIPS 的数量,并且没有 vrrp-id 范围重叠。
29.2.7. 为超过 254 地址配置 IP 故障转移
IP 故障转移管理仅限于 254 个 VIP 地址组。默认情况下,OpenShift Container Platform 会为每个组分配一个 IP 地址。您可以使用 virtual-ip-groups 选项进行更改,因此每个组中有多个 IP 地址,并在配置 IP 故障转移 时为每个 VRRP 实例定义可用 VIP 组的数量。
在 VRRP 故障转移事件中,对 VIP 进行分组会为每个 VRRP 创建更广泛的 VIP 分配范围,并在集群中的所有主机都能够从本地访问服务时很有用。例如,当服务通过 ExternalIP 公开时。
使用故障转移的一个规则是,请勿将路由等服务限制到一个特定的主机。相反,服务应复制到每一主机上,以便在 IP 故障转移时,不必在新主机上重新创建服务。
如果使用 OpenShift Container Platform 健康检查,IP 故障转移和组的性质意味着不会检查组中的所有实例。因此,必须使用 Kubernetes 健康检查来确保服务处于活动状态。
# oc adm ipfailover <ipfailover_name> --create \
...
--virtual-ip-groups=<number_of_ipfailover_groups>
例如,如果在有 7 个 VIP 的环境中,--virtual-ip-groups 被设置为 3,它会创建三个组,为第一个组分配三个 VIP,并为剩余的两个组分配两个 VIP。
如果 --virtual-ip-groups 选项设置的组数量少于设置为失败的 IP 地址数,则组将包含多个 IP 地址,且所有地址都将作为一个单元移动。
29.2.8. 配置高可用性服务
以下示例描述了如何在一组节点上设置具有 IP 故障切换的高可用性 路由器和 geo-cache 网络服务。
标记将用于服务的节点。如果您在 OpenShift Container Platform 集群的所有节点上运行服务,且将使用集群中所有节点的 VIP,则此步骤可以是可选。
以下示例定义了在 US west geography ha-svc-nodes=geo-us-west 中为流量提供服务的节点的标签:
$ oc label nodes openshift-node-{5,6,7,8,9} "ha-svc-nodes=geo-us-west"创建服务帐户。您可以使用 ipfailover 或在使用路由器(取决于环境策略)时,您可以重复利用之前创建的 router 服务帐户或新的 ipfailover 服务帐户。
以下示例在 default 命名空间中创建一个名为 ipfailover 的新服务帐户:
$ oc create serviceaccount ipfailover -n default
将 default 命名空间中的 ipfailover 服务帐户添加到 特权 SCC:
$ oc adm policy add-scc-to-user privileged system:serviceaccount:default:ipfailover
启动 路由器和 geo-cache 服务。
重要由于 ipfailover 在第 1 步中的所有节点上运行,因此建议在所有第 1 步中运行路由器/服务。
使用与第一步中使用的标签匹配的节点启动路由器。以下示例使用 ipfailover 服务帐户运行五个实例:
$ oc adm router ha-router-us-west --replicas=5 \ --selector="ha-svc-nodes=geo-us-west" \ --labels="ha-svc-nodes=geo-us-west" \ --service-account=ipfailover使用每个节点上的副本运行 geo-cache 服务。对于运行 geo-cache 服务的信息,请参阅示例配置。
重要确保将文件中引用的 myimages/geo-cache 容器镜像替换为您的预期镜像。将副本数改为 geo-cache 标签的节点数量。检查标签是否与第一步中使用的标签匹配。
$ oc create -n <namespace> -f ./examples/geo-cache.json
为路由器和 geo-cache 服务配置 ipfailover。每个 VIP 都有自己的 VIP,它们都使用标记为第一步中的 ha-svc-nodes=geo-us-west 的节点。确保副本数量与标签设置中列出的节点数匹配第一步。
重要路由器、geo-cache 和 ipfailover 所有创建部署配置,且所有这些配置都必须具有不同的名称。
指定 ipfailover 应该在所需实例上监控的 VIP 和端口号。
路由器的 ipfailover 命令:
$ oc adm ipfailover ipf-ha-router-us-west \ --replicas=5 --watch-port=80 \ --selector="ha-svc-nodes=geo-us-west" \ --virtual-ips="10.245.2.101-105" \ --iptables-chain="INPUT" \ --service-account=ipfailover --create以下是正在侦听端口 9736 的 geo-cache 服务的
oc adm ipfailover命令。由于有两种ipfailover部署配置,必须设置--vrrp-id-offset,以便每个 VIP 都获得自己的偏移值。在本例中,设置值为10表示ipf-ha-router-us-west最多可有 10 个 VIPs(0-9),因为ipf-ha-geo-cache从 10 开始。$ oc adm ipfailover ipf-ha-geo-cache \ --replicas=5 --watch-port=9736 \ --selector="ha-svc-nodes=geo-us-west" \ --virtual-ips=10.245.3.101-105 \ --vrrp-id-offset=10 \ --service-account=ipfailover --create在上面的命令中,每个节点上都有 ipfailover, router, 和 geo-cache pod。每个 ipfailover 配置的 VIP 集合不得重叠,且不能在外部或云环境中的其他位置使用。每个示例中的五个 VIP 地址
10.245.{2,3}.101-105由两个 ipfailover 部署配置提供。IP 故障转移动态选择在其上提供哪个地址。管理员设置外部 DNS 以指向 VIP 地址,知道所有 路由器 VIP 都指向同一 路由器,所有 geo-cache VIP 都指向相同的 geo-cache 服务。只要一个节点保持运行,就会提供所有 VIP 地址。
29.2.8.1. 部署 IP 故障切换 Pod
部署 ipfailover 路由器以监控在节点端口 32439 和外部 IP 地址(如 postgresql-ingress 服务中定义的)的 postgresql 侦听节点:
29.2.9. 为高可用性服务动态更新虚拟 IP
IP 故障转移服务的默认部署策略是重新创建部署。要为高可用性路由服务动态更新 VIP,且不需要停机,您必须:
- 更新 IP 故障转移服务部署配置以使用滚动更新策略,以及
-
使用更新列表或虚拟 IP 地址集合更新
OPENSHIFT_HA_VIRTUAL_IPS环境变量。
以下示例演示了如何动态更新部署策略和虚拟 IP 地址:
考虑使用以下命令创建的 IP 故障转移配置:
$ oc adm ipfailover ipf-ha-router-us-west \ --replicas=5 --watch-port=80 \ --selector="ha-svc-nodes=geo-us-west" \ --virtual-ips="10.245.2.101-105" \ --service-account=ipfailover --create编辑部署配置:
$ oc edit dc/ipf-ha-router-us-west
将
spec.strategy.type字段从Recreate更新为Rolling:spec: replicas: 5 selector: ha-svc-nodes: geo-us-west strategy: resources: {} rollingParams: maxSurge: 0 type: Rolling 1- 1
- 设置为
Rolling。
更新
OPENSHIFT_HA_VIRTUAL_IPS环境变量,使其包含额外的虚拟 IP 地址:- name: OPENSHIFT_HA_VIRTUAL_IPS value: 10.245.2.101-105,10.245.2.110,10.245.2.201-205 1- 1
10.245.2.110,10.245.2.201-205已添加到列表中。
- 更新外部 DNS,使其与 VIP 集合匹配。
29.3. 配置服务 ExternalIP 和 NodePort
用户可以在服务中分配 VIP 作为 ExternalIP。keepalived 确保每个 VIP 都在 ipfailover 配置中的某个节点上提供。当请求到达节点时,在集群中的所有节点上运行的服务会在服务的端点之间平衡请求。
NodePorts 可以设置为 ipfailover 监控端口,以便 keepalived 能够检查应用是否正在运行。NodePort 在集群中的所有节点上公开,因此所有 ipfailover 节点上可由 keepalived 使用。
29.4. IngressIP 的高可用性
在非云集群中,可以将 ipfailover 和 ingressIP 合并到服务。对于使用 ingressIP 创建服务的用户,结果是高可用性服务。
方法是指定一个 ingressIPNetworkCIDR 范围,然后在创建 ipfailover 配置时使用相同的范围。
因为 ipfailover 可以支持整个集群最多 255 个 VIP,ingressIPNetworkCIDR 需要为 /24 或更少。
第 30 章 iptables
30.1. 概述
有许多系统组件,包括 OpenShift Container Platform、容器和软件,它们管理本地防火墙策略,这些策略依赖于内核 iptables 配置才能进行正确的网络操作。另外,集群中所有节点的 iptables 配置必须正确才能正常工作。
所有组件均与 iptables 独立使用,无需了解其他组件如何使用它们。这使得一个组件很容易破坏另一组件配置。另外,OpenShift Container Platform 和 Docker 服务会假定 iptables 仍然与其设置一样。它们可能无法检测其他组件引入的更改,如果这些组件可能有一些布局,则它们可能会发生修复。特别是,OpenShift Container Platform 会监控并修复问题。但是,Docker 服务没有。
确保节点上对 iptables 配置所做的任何更改不会影响 OpenShift Container Platform 和 Docker 服务的操作。另外,更改通常需要在集群中的所有节点上进行。请小心使用,因为 iptables 没有设计为多个并发用户,而且很容易破坏 OpenShift Container Platform 和 Docker 网络。
OpenShift Container Platform 提供多个链,其中一个链供管理员用于自己的目的:OPENSHIFT-ADMIN-OUTPUT-RULES。
如需更多信息,请参阅使用 iptables 规则的讨论来限制对外部资源的访问。
必须在集群中的每个节点上正确设置了链、链顺序以及内核 iptables 规则,才能使 OpenShift Container Platform 和 Docker 网络正常工作。系统中常用的一些工具和服务与内核 iptables 交互,并可能会意外影响 OpenShift Container Platform 和 Docker 服务。
30.2. iptables
iptables 工具可用于设置、维护和检查 Linux 内核中的 IPv4 数据包过滤规则表。
独立于其他用途,如防火墙、OpenShift Container Platform 和 Docker 服务在某些表中管理链。链按特定顺序插入,规则特定于其需求。
iptables --flush [chain] 可以删除所需的密钥配置。不要执行此命令。
30.3. iptables.service
iptables 服务支持本地网络防火墙。它假设 iptables 配置的总控制。当它启动时,它会清除并恢复完整的 iptables 配置。恢复的规则来自其配置文件 /etc/sysconfig/iptables。配置文件在操作期间不会保持最新,因此动态添加的规则会在每次重启后丢失。
停止并启动 iptables.service 将销毁 OpenShift Container Platform 和 Docker 所需的配置。OpenShift Container Platform 和 Docker 不会获得更改通知。
# systemctl disable iptables.service # systemctl mask iptables.service
如果您需要运行 iptables.service,在配置文件中保留有限的配置,并依赖 OpenShift Container Platform 和 Docker 来安装其所需的规则。
iptables.service 配置从中加载:
/etc/sysconfig/iptables
要进行永久规则更改,请在此文件中编辑更改。不要包含 Docker 或 OpenShift Container Platform 规则。
在节点上启动或重启 iptables.service 后,必须重启 Docker 服务和 atomic-openshift-node.service 来重建所需的 iptables 配置。
重启 Docker 服务将导致节点上运行的所有容器停止并重新启动。
# systemctl restart iptables.service # systemctl restart docker # systemctl restart atomic-openshift-node.service
第 31 章 通过策略保护构建
31.1. 概述
OpenShift Container Platform 中的构建在有权访问 Docker 守护进程套接字的特权容器中运行。作为一种安全措施,建议限制可以运行构建的人员以及用于这些构建的策略。自定义构建 本质上不如 Source 构建安全,因为他们可以在构建中执行任何代码,并有可能对节点的 Docker 套接字具有完全访问权限,因此默认禁用。另外,还应谨慎授予 Docker 构建 权限,因为 Docker 构建逻辑中的漏洞可能会导致在主机节点上授予特权。
在 Docker 和自定义构建过程中,Docker 守护进程执行的操作是特权的,并在主机网络命名空间中发生。这样的操作会绕过配置的联网规则,包括 EgressNetworkPolicy 对象和静态出口 IP 地址定义的规则。
默认情况下,所有能够创建构建的用户都被授予相应的权限,可以使用 Docker 和 Source-to-Image 构建策略。具有 cluster-admin 特权的用户可以启用 Custom 构建策略,如 将构建策略限制在本页的 User Globally 部分中所述。
您可以使用 授权策略 控制谁可以使用哪个构建策略进行构建。每个构建策略都有一个对应的构建子资源。用户必须具有创建构建的权限以及创建构建策略子资源的权限,才能使用该策略创建构建。提供的默认角色用于授予构建策略子资源的 create 权限。
表 31.1. 构建策略子资源和角色
| 策略 | 子资源 | 角色 |
|---|---|---|
| Docker | builds/docker | system:build-strategy-docker |
| Source-to-Image | builds/source | system:build-strategy-source |
| Custom | builds/custom | system:build-strategy-custom |
| JenkinsPipeline | builds/jenkinspipeline | system:build-strategy-jenkinspipeline |
31.2. 全局禁用构建策略
要在全局范围内阻止对特定构建策略的访问,请以具有 cluster-admin 特权的用户身份登录,从 system:authenticated 组中移除对应的角色,再应用注解 openshift.io/reconcile-protect: "true" 以防止它们在 API 重启后更改。以下示例演示了如何禁用 Docker 构建策略。
应用
openshift.io/reconcile-protect注解$ oc edit clusterrolebinding system:build-strategy-docker-binding apiVersion: v1 groupNames: - system:authenticated kind: ClusterRoleBinding metadata: annotations: openshift.io/reconcile-protect: "true" 1 creationTimestamp: 2018-08-10T01:24:14Z name: system:build-strategy-docker-binding resourceVersion: "225" selfLink: /oapi/v1/clusterrolebindings/system%3Abuild-strategy-docker-binding uid: 17b1f3d4-9c3c-11e8-be62-0800277d20bf roleRef: name: system:build-strategy-docker subjects: - kind: SystemGroup name: system:authenticated userNames: - system:serviceaccount:management-infra:management-admin- 1
- 将
openshift.io/reconcile-protect注解的值更改为"true"。默认情况下,它被设置为"false"。
移除角色:
$ oc adm policy remove-cluster-role-from-group system:build-strategy-docker system:authenticated
在 3.2 之前的版本中,构建策略子资源包含在 admin 和 edit 角色中。
确保也从这些角色中移除构建策略子资源:
$ oc edit clusterrole admin $ oc edit clusterrole edit
对于每个角色,移除与要禁用的策略资源对应的行。
为 admin 禁用 Docker 构建策略
kind: ClusterRole
metadata:
name: admin
...
rules:
- resources:
- builds/custom
- builds/docker 1
- builds/source
...
...
- 1
- 删除此行,以在全局范围内禁止具有 admin 角色的用户进行 Docker 构建。
31.3. 将构建策略限制为用户全局
只允许一组特定用户使用特定策略创建构建:
- 禁用构建策略 的全局访问。
将与构建策略对应的角色分配给特定用户。例如,将 system:build-strategy-docker 集群角色添加到用户 devuser:
$ oc adm policy add-cluster-role-to-user system:build-strategy-docker devuser
在集群级别授予用户对 builds/docker 子资源的访问权限,那么该用户将能够在他们可以创建构建的任何项目中使用 Docker 策略来创建构建。
31.4. 在项目中限制用户使用构建策略
与在全局范围内向用户授予构建策略角色类似,仅允许项目中的一组特定用户使用特定策略来创建构建:
- 禁用构建策略 的全局访问。
将与构建策略对应的角色分配给项目中的特定用户。例如,将 devproject 项目中的 system:build-strategy-docker 角色添加到用户 devuser:
$ oc adm policy add-role-to-user system:build-strategy-docker devuser -n devproject
第 32 章 使用Seccomp 限制应用程序功能
32.1. 概述
seccomp(安全计算模式)用于限制系统调用应用集合,允许集群管理员更好地控制在 OpenShift Container Platform 中运行的工作负载的安全性。
seccomp 支持通过 pod 配置中的两个注解来实现:
- seccomp.security.alpha.kubernetes.io/pod: 配置集应用到没有覆盖的 pod 中的所有容器
- container.seccomp.security.alpha.kubernetes.io/<container_name> : 容器特定的配置集覆盖
容器默认使用 unconfined seccomp 设置运行。
如需详细信息,请参阅 seccomp 设计文档。
32.2. 启用Seccomp
seccomp 是 Linux 内核的一个功能。要确定在您的系统中启用了 seccomp,请运行:
$ cat /boot/config-`uname -r` | grep CONFIG_SECCOMP= CONFIG_SECCOMP=y
32.3. 为 Seccomp 配置 OpenShift Container Platform
seccomp 配置集是一个 json 文件,提供 syscalls 以及调用 syscall 时要采取的适当操作。
创建 seccomp 配置集。
在很多情况下,默认配置集 已经足够了,但集群管理员必须定义单个系统的安全限制。
要创建自己的自定义配置集,请在
seccomp-profile-root目录中的每个节点创建一个文件。如果您使用默认的 docker/default 配置集,则不需要创建一个。
将节点配置为使用 seccomp-profile-root 目录,在适当的节点 配置映射中 使用 kubeletArguments 存储您的配置集:
kubeletArguments: seccomp-profile-root: - "/your/path"重启节点服务以应用更改:
# systemctl restart atomic-openshift-node
为了控制可以使用了哪些配置集以及设置默认配置集,请通过 seccompProfiles 字段配置您的 SCC。第一个配置集将用作默认值。
seccompProfiles 字段的允许格式包括:
- docker/default :容器运行时的默认配置文件(不需要配置集)
- unconfined: unconfined 配置集,禁用 seccomp
localhost/<profile-name > :安装到节点的本地 seccomp 配置集根目录
例如,如果您使用默认的 docker/default 配置集,请将 SCC 配置为:
seccompProfiles: - docker/default
32.4. 为自定义Seccomp 配置集配置 OpenShift Container Platform
确保集群中的 pod 使用自定义配置集运行:
- 在 seccomp-profile-root 中创建 seccomp 配置集。
配置 seccomp-profile-root :
kubeletArguments: seccomp-profile-root: - "/your/path"重启节点服务以应用更改:
# systemctl restart atomic-openshift-node
配置 SCC:
seccompProfiles: - localhost/<profile-name>
第 33 章 Sysctls
33.1. 概述
Sysctl 设置可以通过 Kubernetes 来公开,允许用户在运行时为容器内的命名空间修改某些内核参数。只有拥有命名空间的 sysctl 才能独立于 pod 进行设置。如果 sysctl 没有命名空间,则称为节点级别,无法在 OpenShift Container Platform 中设置。此外,只有被认为是安全的 sysctl 才会默认列在白名单中;您可以在节点上手动启用其他不安全 sysctl 来供用户使用。
33.2. 了解 sysctl
在 Linux 中,管理员可通过 sysctl 接口在运行时修改内核参数。参数可通过 /proc/sys/ 虚拟进程文件系统提供。这些参数涵盖了各种不同的子系统,例如:
- 内核(通用前缀:kernel.)
- 网络(通用前缀:net.)
- 虚拟内存(通用前缀:vm.)
- MDADM(通用前缀:dev.)
如需了解更多子系统,请参阅 Kernel 文档。要获取所有参数的列表,您可以运行:
$ sudo sysctl -a
33.3. 命名空间和节点级 sysctl
多个 sysctl 在当今的 Linux 内核中是拥有命名空间的。这意味着您可以针对节点上的每个 pod 单独设置它们。sysctl 必须拥有命名空间,才能在 Kubernetes 内的 pod 上下文中访问它们。
以下 sysctl 已知是拥有命名空间的:
- kernel.shm*
- kernel.msg*
- kernel.sem
- fs.mqueue.*
另外,net.* 组中的大多数 sysctl 都已知是拥有命名空间的。其命名空间的采用根据内核版本和发行方而有所不同。
要检查您的系统中哪个 net.* sysctls 有命名空间,请运行以下命令:
$ podman run --rm -ti docker.io/fedora \
/bin/sh -c "dnf install -y findutils && find /proc/sys/ \
| grep -e /proc/sys/net"无命名空间的 sysctl 被视为节点级别,且必须由集群管理员手动设置,或者通过使用节点的底层 Linux 发行版,如修改 /etc/sysctls.conf 文件,或者通过使用带有特权容器的 DaemonSet。
可以考虑将带有特殊 sysctl 节点标记为污点。仅将 pod 调度到需要这些 sysctl 设置的节点。使用污点和容限功能来 标记节点。
33.4. 安全与不安全 sysctl
sysctl 划分为安全和不安全 sysctl。除了正确的名称外,还必须在同一节点上的 pod 之间正确隔离一个安全 sysctl。这意味着,如果您将一个 sysctl 设置为安全的一个 pod,则不能:
- 影响节点上的其他任何 pod
- 危害节点的健康
- 获取超过 pod 资源限制的 CPU 或内存资源
目前,大多数命名空间的 sysctl 都不一定被视为安全。
目前,OpenShift Container Platform 支持或列入白名单,安全集合中的以下 sysctl:
- kernel.shm_rmid_forced
- net.ipv4.ip_local_port_range
- net.ipv4.tcp_syncookies
当 kubelet 支持更好的隔离机制时,这个列表可能会在以后的版本中扩展。
所有安全 sysctl 都默认启用。所有不安全 sysctl 都默认禁用,集群管理员必须逐个节点手动启用它们。禁用不安全 sysctl 的 Pod 将会调度,但无法启动。
33.5. 启用不安全 sysctl
集群管理员可在非常特殊的情况下允许某些不安全 sysctl,比如高性能或实时应用程序性能优化。
如果要使用不安全 sysctl,集群管理员必须在节点上单独启用它们。它们只能启用命名空间 sysctl。
您可以通过在 forbiddenSysctls 和 allowedUnsafeSysctls 字段中指定 Security Context Constraints 字段中的 sysctl 模式列表来控制 pod 中可以设置哪些 sysctl。
-
forbiddenSysctls选项用来排除特定 sysctls。 -
allowedUnsafeSysctls选项用来控制特定的需求,如高性能或实时应用程序调整。
由于其不安全特性,使用不安全 sysctl 的风险是自带的,可能会导致严重问题,如容器、资源短缺或完全节点中断等严重问题。
在适当的节点配置映射文件的
kubeletArguments参数中添加不安全 sysctl,如 配置节点资源 所述:例如:
$ oc edit cm node-config-compute -n openshift-node ... kubeletArguments: allowed-unsafe-sysctls: 1 - "net.ipv4.tcp_keepalive_time" - "net.ipv4.tcp_keepalive_intvl" - "net.ipv4.tcp_keepalive_probes"- 1
- 添加您要使用的不安全 sysctl。
创建一个新的使用 restricted SCC 的内容并添加不安全 sysctl 的 SCC:
... allowHostDirVolumePlugin: false allowHostIPC: false allowHostNetwork: false allowHostPID: false allowHostPorts: false allowPrivilegeEscalation: true allowPrivilegedContainer: false allowedCapabilities: null allowedUnsafeSysctls: 1 - net.ipv4.tcp_keepalive_time - net.ipv4.tcp_keepalive_intvl - net.ipv4.tcp_keepalive_probes ... metadata: name: restricted-sysctls 2 ...
授予 pod ServiceAccount 的新 SCC 访问权限:
$ oc adm policy add-scc-to-user restricted-sysctls -z default -n your_project_name
将不安全 sysctl 添加到 pod 的 DeploymentConfig 中。
kind: DeploymentConfig ... template: ... spec: containers: ... securityContext: sysctls: - name: net.ipv4.tcp_keepalive_time value: "300" - name: net.ipv4.tcp_keepalive_intvl value: "20" - name: net.ipv4.tcp_keepalive_probes value: "3"重启节点服务以应用更改:
# systemctl restart atomic-openshift-node
33.6. 为 pod 设置 sysctl
sysctl 使用 pod 的 securityContext 在 pod 上设置。securityContext 适用于同一 pod 中的所有容器。
以下示例使用 pod securityContext 设置一个安全 sysctl kernel.shm_rmid_forced,以及两个不安全 sysctl net.ipv4.route.min_pmtu 和 kernel.msgmax。在规格中,安全和不安全 sysctl 并无区别。
为了避免让操作系统变得不稳定,只有在了解了参数的作用后才修改 sysctl 参数。
修改定义 pod 的 YAML 文件并添加 securityContext 规格,如下例所示:
apiVersion: v1
kind: Pod
metadata:
name: sysctl-example
spec:
securityContext:
sysctls:
- name: kernel.shm_rmid_forced
value: "0"
- name: net.ipv4.route.min_pmtu
value: "552"
- name: kernel.msgmax
value: "65536"
...第 34 章 在数据存储层加密数据
34.1. 概述
本节介绍了如何在数据存储层中启用和配置 secret 数据加密。虽然示例使用 secret 资源,但任何资源都可以加密,如 configmaps。
要使用这个功能,需要 etcd v3 或更高版本。
34.2. 配置并确定是否启用了加密
要激活数据加密,请将 --experimental-encryption-provider-config 参数传递给 Kubernetes API 服务器:
master-config.yaml摘录
kubernetesMasterConfig:
apiServerArguments:
experimental-encryption-provider-config:
- /path/to/encryption-config.yaml
有关 master-config.yaml 及其格式的更多信息,请参阅 主配置文件 主题。
34.3. 了解加密配置
使用所有可用供应商的加密配置文件
kind: EncryptionConfig apiVersion: v1 resources: 1 - resources: 2 - secrets providers: 3 - aescbc: 4 keys: - name: key1 5 secret: c2VjcmV0IGlzIHNlY3VyZQ== 6 - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - secretbox: keys: - name: key1 secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY= - aesgcm: keys: - name: key1 secret: c2VjcmV0IGlzIHNlY3VyZQ== - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - identity: {}
从存储中读取资源时,与存储的数据匹配的每个提供程序都会尝试按顺序解密数据。如果没有因为格式或 secret 密钥不匹配而导致存储的数据读取存储的数据,则会返回一个错误,这可以防止客户端访问该资源。
如果任何资源无法通过加密配置读取(因为键已更改),则唯一恢复是从底层的 etcd 中直接删除该密钥。调用尝试读取该资源将会失败,直到它被删除或有效解密密钥。
34.3.1. 可用供应商
| 名称 | Encryption | 强度 | 速度 | 键长度 | 其他注意事项 |
|---|---|---|---|---|---|
| 身份 | 无 | N/A | N/A | N/A | 在不加密的情况下写为即用的资源。当设置为第一个提供程序时,资源将作为新值进行解密。 |
| aescbc | AES-CBC,带有 PKCS#7 padding | 强大 | 速度快 | 32 字节 | 推荐的加密选择,但可能比 secretbox 稍慢。 |
| secretbox | XSalsa20 and Poly1305 | 强 | 速度更快 | 32 字节 | 较新的标准,在需要高审核级别的环境中不被视为可以接受。 |
| aesgcm | AES-GCM,带有随机初始化向量(IV) | 必须对每 200,000 个写入进行轮转 | 十快 | 16、24 或 32 字节 | 不建议使用,除非采用自动密钥轮转方案。 |
每个供应商支持多个密钥。为解密而尝试密钥。如果该提供程序是第一个提供程序,则使用第一个密钥进行加密。
Kubernetes 没有正确的非生成器,并使用随机 IV 作为 AES-GCM 的非。由于 AES-GCM 需要正确非安全,因此不推荐使用 AES-GCM。200,000 个写入限制只会将致命非滥用的可能性限制为合理的低利润。
34.4. 加密数据
创建新的加密配置文件。
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {}要创建新 secret,请执行以下操作:
生成 32 字节随机密钥和 base64 编码。例如,在 Linux 和 macOS 中使用:
$ head -c 32 /dev/urandom | base64
重要加密密钥必须使用 /dev/urandom 等适当加密安全随机数生成器生成。例如,来自 Golang 或
random.random的math/random不适用。-
将该值放在
secret字段中。 重启 API 服务器:
# master-restart api # master-restart controllers
加密供应商配置文件包含可以在 etcd 中解密内容的键,因此您必须在 master 上正确限制权限,以便只有运行 master API 服务器的用户才能读取它。
34.5. 验证数据是否加密
在写入 etcd 时数据会被加密。在重启 API 服务器后,任何新创建或更新的 secret 都应在存储时加密。要检查,您可以使用 etcdctl 命令行程序检索您的 secret 的内容。
在
default命名空间中创建一个名为secret1的新 secret:$ oc create secret generic secret1 -n default --from-literal=mykey=mydata
使用
etcdctl命令行,从 etcd 中读取该 secret:$ ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 -w fields [...] | grep Value
[…]必须是连接到 etcd 服务器的附加参数。最终的命令类似如下:
$ ETCDCTL_API=3 etcdctl get /kubernetes.io/secrets/default/secret1 -w fields \ --cacert=/var/lib/origin/openshift.local.config/master/ca.crt \ --key=/var/lib/origin/openshift.local.config/master/master.etcd-client.key \ --cert=/var/lib/origin/openshift.local.config/master/master.etcd-client.crt \ --endpoints 'https://127.0.0.1:4001' | grep Value
- 验证以上命令的输出是否为前缀 k8s:enc:aescbc:v1:,它表示 aescbc 供应商已加密生成的数据。
通过 API 检索时验证 secret 是否已正确解密:
$ oc get secret secret1 -n default -o yaml | grep mykey
这应与 mykey: bXlkYXRh 匹配。
34.6. 确定所有 secret 都被加密
由于 secret 在编写时加密,对 secret 执行更新将加密该内容。
$ oc adm migrate storage --include=secrets --confirm
此命令读取所有 secret,然后更新它们以应用服务器端加密。如果因写入冲突而发生错误,请重试 命令。
对于较大的集群,您可以通过命名空间或脚本更新来划分 secret。
34.7. 轮转解密密钥
在不发生停机的情况下更改机密需要执行多步骤操作,特别是在有多个 API 服务器运行的高可用性部署中。
- 生成新密钥并将其添加到所有服务器中当前提供程序的第二个密钥条目。
重启所有 API 服务器,以确保每个服务器都可以使用新密钥进行解密。
注意如果使用单一 API 服务器,您可以跳过这一步。
# master-restart api # master-restart controllers
-
将新的密钥放置到
keys数组中的第一个条目,以便它用于配置中进行加密。 重启所有 API 服务器,以确保每个服务器现在都使用新密钥加密。
# master-restart api # master-restart controllers
运行以下命令使用新密钥加密所有现有 secret:
$ oc adm migrate storage --include=secrets --confirm
- 在使用新密钥备份 etcd 并更新所有 secret 后,从配置中删除旧的解密密钥。
34.8. 解密数据
在数据存储层禁用加密:
- 将身份提供程序作为配置中的第一个条目放置:
kind: EncryptionConfig
apiVersion: v1
resources:
- resources:
- secrets
providers:
- identity: {}
- aescbc:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>重启所有 API 服务器:
# master-restart api # master-restart controllers
运行以下命令来强制解密所有 secret:
$ oc adm migrate storage --include=secrets --confirm
第 35 章 使用 IPsec 加密节点间的流量
35.1. 概述
IPsec 通过加密所有使用互联网协议(IP)通信的 master 和节点主机间的通信来保护 OpenShift Container Platform 集群中的流量。
本节演示了如何确保 OpenShift Container Platform 主机接收来自其 IP 地址(包括所有集群管理和 pod 数据流量)的整个 IP 子网通信。
因为 OpenShift Container Platform 管理流量使用 HTTPS,所以启用 IPsec 会再次加密管理流量。
此过程必须在集群中的每个 master 主机上重复,然后在集群中的节点主机上重复。没有启用 IPsec 的主机将无法与主机通信。
35.2. 加密主机
先决条件
- 确保在集群主机上安装 libreswan 3.15 或更高版本。如果需要 opportunistic 组功能,则需要 libreswan 版本 3.19 或更高版本。
本主题描述了需要
62字节的 IPsec 配置。如果集群在以太网网络上运行,且最大传输单元(MTU)值为1500字节,那么 SDN MTU 值必须改为1388字节,以允许 IPsec 和 SDN 封装的开销。完成以下步骤,更改集群中节点的 MTU:编辑以下每个 ConfigMap:
node-config-master、node-config-infra、node-config-compute。运行以下命令来编辑 ConfigMap。将
<config_map> 替换为要编辑的 ConfigMap 的名称。# oc edit cm <config_map> -n openshift-node
将
mtu参数更新为足够用于 IPsec 开销的 MTU 大小,如1388字节:networkConfig: mtu: 1388
运行以下命令来移除 SDN 接口。将
<ovs_pod_name> 替换为 OVS pod 的名称。# oc exec <ovs_pod_name> -- ovs-vsctl del-br br0
对于集群中的每个节点,完成以下操作:
-
确认更新的 MTU 值已保存到
/etc/origin/node/node-config.yaml文件中。 运行以下命令重启 SDN 和 OVS pod:
# oc delete pod -n openshift-sdn -l=app=ovs # oc delete pod -n openshift-sdn -l=app=sdn
-
确认更新的 MTU 值已保存到
35.2.1. 为 IPsec 配置证书
您可以使用 OpenShift Container Platform 内部证书颁发机构(CA)生成适合 IPsec 的 RSA 密钥。内部 CA 有一个通用名称(CN)值设置为 openshift-signer。
运行以下命令在 master 节点上生成 RSA 证书:
# export CA=/etc/origin/master # oc adm ca create-server-cert \ --signer-cert=$CA/ca.crt --signer-key=$CA/ca.key \ --signer-serial=$CA/ca.serial.txt \ --hostnames='<hostname>' \ 1 --cert=<hostname>.crt \ 2 --key=<hostname>.key 3
使用 openssl 将客户端证书、CA 证书和私钥文件组合到 PKCS#12 文件中,该文件是多个证书和密钥的通用文件格式:
# openssl pkcs12 -export \ -in <hostname>.crt \ 1 -inkey <hostname>.key \ 2 -certfile /etc/origin/master/ca.crt \ -passout pass: \ -out <hostname>.p12 3
对于集群中的每个节点,安全地传输您在上一步中为主机创建的文件,然后将 PKCS#12 文件导入到 libreswan 证书数据库中。
-W选项为空,因为没有为 PKCS#12 文件分配密码,因为它只是临时的。# ipsec initnss # pk12util -i <hostname>.p12 -d sql:/etc/ipsec.d -W "" # rm <hostname>.p12
35.2.2. 创建 libreswan IPsec 策略
确保将必要的证书导入到 libreswan 证书数据库后,创建一个策略来使用它们来保护集群中的不同主机之间的通信。
如果您使用 libreswan 3.19 或更高版本,则建议使用 opportunistic 组配置。否则,需要明确的连接。
35.2.2.1. 配置 opportunistic 组
以下配置创建两个 libreswan 连接。第一个使用 OpenShift Container Platform 证书加密流量,第二个则使用 cluster-external 流量创建异常。
将以下内容放在 /etc/ipsec.d/openshift-cluster.conf 文件中:
conn private left=%defaultroute leftid=%fromcert # our certificate leftcert="NSS Certificate DB:<cert_nickname>" 1 right=%opportunisticgroup rightid=%fromcert # their certificate transmitted via IKE rightca=%same ikev2=insist authby=rsasig failureshunt=drop negotiationshunt=hold auto=ondemand encapsulation=yes 2 conn clear left=%defaultroute right=%group authby=never type=passthrough auto=route priority=100
告诉 libreswan 使用 /etc/ipsec.d/policies/ 中的策略文件应用每个策略,其中每个配置的连接都有对应的策略文件。因此,在上面的示例中,两个连接是
私有和清除的,每个连接在 /etc/ipsec.d/policies/ 中都有一个文件。/etc/ipsec.d/policies/private 必须包含集群的 IP 子网,主机从中接收 IP 地址。默认情况下,如果远程主机的客户端证书针对本地主机的证书颁发机构证书进行身份验证,则会导致集群子网中主机间的所有通信都会被加密。如果远程主机的证书没有身份验证,则这两个主机间的所有流量都会被阻断。
例如,如果所有主机都配置为使用
172.16.0.0/16地址空间中的地址,您的私有策略文件将包含172.16.0.0/16。要加密的任何其他子网数量可能添加到该文件中,这样会导致使用 IPsec 对这些子网的所有流量。在所有主机和子网网关之间取消加密通信,以确保流量进入并退出集群。在 /etc/ipsec.d/policies/clear 文件中添加网关:
172.16.0.1/32
可以在此文件中添加其他主机和子网,这将导致对这些主机和子网的所有流量都未加密。
35.2.2.2. 配置显式连接
在此配置中,每个 IPsec 节点配置都必须明确列出集群中每个节点的配置。建议使用 Ansible 等配置管理工具在每一主机上生成此文件。
不要手动编辑 node-config.yaml 文件。要修改集群中的节点,请根据需要更新节点配置映射。
此配置还需要将每个节点的完整证书主题放在其他节点的配置中。
使用 openssl 从节点的证书中读取此主题:
# openssl x509 \ -in /path/to/client-certificate -text | \ grep "Subject:" | \ sed 's/[[:blank:]]*Subject: //'
将以下行放在集群中的每个节点的 /etc/ipsec.d/openshift-cluster.conf 文件中:
conn <other_node_hostname> left=<this_node_ip> 1 leftid="CN=<this_node_cert_nickname>" 2 leftrsasigkey=%cert leftcert=<this_node_cert_nickname> 3 right=<other_node_ip> 4 rightid="<other_node_cert_full_subject>" 5 rightrsasigkey=%cert auto=start keyingtries=%forever encapsulation=yes 6- 1
- 将 < this_node_ip> 替换为这个节点的集群 IP 地址。
- 2 3
- 将 < this_node_cert_nickname> 替换为步骤 1 中的节点证书别名。
- 4
- 将 <other_node_ip> 替换为其他节点的集群 IP 地址。
- 5
- 将 <other_node_cert_full_subject> 替换为以上节点的证书主题。例如:"O=system:nodes,CN=openshift-node-45.example.com".
- 6
- 如果不使用 NAT,则必须在配置中包含
encapsulation=yes来强制封装。Amazon 和 Azure 内部云网络没有路由 IPsecESP或AH数据包。这些数据包必须封装在UDP中,如果配置了,则 NAT 检测会在UDP封装中配置ESP。如果使用 NAT 或您没有在 Network/Cloud-Provider 的限制下,如前所述,请省略此参数和值。
将以下内容放在每个节点的 /etc/ipsec.d/openshift-cluster.secrets 文件中:
: RSA "<this_node_cert_nickname>" 1- 1
- 将 < this_node_cert_nickname> 替换为步骤 1 中的节点证书别名。
35.3. 配置 IPsec 防火墙
集群中的所有节点都需要允许 IPsec 相关网络流量。这包括 IP 协议编号 50 和 51,以及 UDP 端口 500。
例如,如果集群节点通过接口 eth0 进行通信:
-A OS_FIREWALL_ALLOW -i eth0 -p 50 -j ACCEPT -A OS_FIREWALL_ALLOW -i eth0 -p 51 -j ACCEPT -A OS_FIREWALL_ALLOW -i eth0 -p udp --dport 500 -j ACCEPT
IPsec 还在 NAT 遍历中使用 UDP 端口 4500,但应该不适用于正常的集群部署。
35.4. 启动并启用 IPsec
启动 ipsec 服务以载入新的配置和策略,并开始加密:
# systemctl start ipsec
在引导时启用 ipsec 服务:
# systemctl enable ipsec
35.5. 优化 IPsec
有关使用 IPsec 加密时,请参阅扩展和性能 指南。
35.6. 故障排除
当两个主机之间无法完成身份验证时,您将无法在它们之间 ping 通,因为所有 IP 流量都会被拒绝。如果没有正确配置 清除 策略,您将无法从集群中的另一主机通过 SSH 连接到主机。
您可以使用 ipsec status 命令检查已加载了 clear 和 private 策略。
第 36 章 构建依赖树
36.1. 概述
OpenShift Container Platform 使用 BuildConfig 中的镜像更改触发器 来检测 镜像流标签何时 更新。您可以使用 oc adm build-chain 命令构建依赖项树,通过更新指定 镜像流 中的镜像 来影响哪些镜像。
build-chain 工具可以决定要触发哪些 构建 ;它会分析这些构建的输出,以确定它们是否依次更新另一个 镜像流标签。如果这样做,工具将继续遵循依赖项树。最后,它会输出一个图形,指定镜像流标签,这些标签会受到对顶级标签的更新的影响。此工具的默认输出语法设置为人类可读格式;也支持 DOT 格式。
36.2. 使用方法
下表描述了常见的 构建链 用法和常规语法:
表 36.1. 常见 build-chain 操作
| 描述 | 语法 |
|---|---|
|
在 < |
$ oc adm build-chain <image-stream> |
| 以 DOT 格式构建 v2 标签的依赖项树,并使用 DOT 实用程序视觉化它。 |
$ oc adm build-chain <image-stream>:v2 \
-o dot \
| dot -T svg -o deps.svg
|
| 为找到 test 项目的指定镜像流标签,跨所有项目构建依赖项树。 |
$ oc adm build-chain <image-stream>:v1 \
-n test --all
|
您可能需要安装 graphviz 软件包以使用 dot 命令。
第 37 章 替换失败的 etcd 成员
如果一些 etcd 成员失败,但您仍有 etcd 成员的仲裁,您可以使用剩余的 etcd 成员以及添加更多 etcd 成员的数据,而无需 etcd 或集群停机。
37.1. 删除失败的 etcd 节点
在添加新 etcd 节点前,请删除失败的节点。
流程
在活跃的 etcd 主机中删除失败的 etcd 节点:
# etcdctl -C https://<surviving host IP>:2379 \ --ca-file=/etc/etcd/ca.crt \ --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key cluster-health # etcdctl -C https://<surviving host IP>:2379 \ --ca-file=/etc/etcd/ca.crt \ --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key member remove <failed member identifier>
通过删除 etcd pod 定义来停止失败的 etcd 成员中的 etcd 服务:
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/
删除
etcd目录的内容:重要建议在删除内容前将此目录备份到非集群的位置。您可以在成功恢复后删除此备份。
# rm -rf /var/lib/etcd/*
37.2. 添加 etcd 成员
您可以使用 Ansible playbook 或手动步骤添加 etcd 主机。
37.2.1. 使用 Ansible 添加新 etcd 主机
流程
在 Ansible 清单文件中,创建一个名为
[new_etcd]的新组,再添加新主机。然后,将new_etcd组添加为[OSEv3]组的子组:[OSEv3:children] masters nodes etcd new_etcd 1 ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com [new_etcd] 2 etcd0.example.com 3
注意将旧的
etcd 主机条目替换为清单文件中的新etcd主机条目。在替换旧的etcd 主机时,必须创建一个/etc/etcd/ca/目录的副本。另外,您可以在扩展etcd 主机前重新部署 etcd ca 和 certs。在安装 OpenShift Container Platform 并托管 Ansible 清单文件的主机中,切换到 playbook 目录并运行 etcd
scaleupplaybook:$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook playbooks/openshift-etcd/scaleup.yml
在 playbook 运行后,通过将新 etcd 主机从
[new_etcd]组移到[etcd]组来修改清单文件,使其反映当前的状态:[OSEv3:children] masters nodes etcd new_etcd ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com master-2.example.com etcd0.example.com
如果使用 Flannel,修改位于
/etc/sysconfig/flanneld主机上的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
37.2.2. 手动添加新 etcd 主机
如果您没有以静态 pod 用户身份在 master 节点上运行 etcd,您可能需要添加另一个 etcd 主机。
流程
修改当前的 etcd 集群
要创建 etcd 证书,请运行 openssl 命令,将值替换为您环境中的值。
创建一些环境变量:
export NEW_ETCD_HOSTNAME="*etcd0.example.com*" export NEW_ETCD_IP="192.168.55.21" export CN=$NEW_ETCD_HOSTNAME export SAN="IP:${NEW_ETCD_IP}, DNS:${NEW_ETCD_HOSTNAME}" export PREFIX="/etc/etcd/generated_certs/etcd-$CN/" export OPENSSLCFG="/etc/etcd/ca/openssl.cnf"注意用作
etcd_v3_ca_*的自定义openssl扩展包括 $SAN 环境变量作为subjectAltName。如需更多信息,请参阅/etc/etcd/ca/openssl.cnf。创建用于存储配置和证书的目录:
# mkdir -p ${PREFIX}创建服务器证书请求并为其签名:(server.csr 和 server.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}server.key \ -out ${PREFIX}server.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}server.crt \ -in ${PREFIX}server.csr \ -extensions etcd_v3_ca_server -batch创建对等证书请求并将其签名:(peer.csr 和 peer.crt)
# openssl req -new -config ${OPENSSLCFG} \ -keyout ${PREFIX}peer.key \ -out ${PREFIX}peer.csr \ -reqexts etcd_v3_req -batch -nodes \ -subj /CN=$CN # openssl ca -name etcd_ca -config ${OPENSSLCFG} \ -out ${PREFIX}peer.crt \ -in ${PREFIX}peer.csr \ -extensions etcd_v3_ca_peer -batch从当前节点复制当前的 etcd 配置和
ca.crt文件,作为稍后修改的示例:# cp /etc/etcd/etcd.conf ${PREFIX} # cp /etc/etcd/ca.crt ${PREFIX}当仍处于存活的 etcd 主机上时,将新主机添加到集群中。要在集群中添加额外的 etcd 成员,您必须首先调整第一个成员的
peerURLs值中的默认 localhost peer:使用
member list命令获取第一个成员的成员 ID:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ 1 member list- 1
- 请确定在
--peers参数值中只指定活跃的 etcd 成员的 URL。
获取 etcd 侦听集群对等点的 IP 地址:
$ ss -l4n | grep 2380
通过传递从上一步中获取的成员 ID 和 IP 地址,使用
etcdctl member update命令更新peerURLs的值:# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://172.18.1.18:2379,https://172.18.9.202:2379,https://172.18.0.75:2379" \ member update 511b7fb6cc0001 https://172.18.1.18:2380-
重新运行
member list命令,并确保对等 URL 不再包含 localhost。
将新主机添加到 etcd 集群。请注意,新主机尚未配置,因此在您配置新主机之前,状态将保持为
未启动。警告您必须添加每个成员,并一次性使他们在线。将每个额外成员添加到集群时,您必须调整当前对等点的
peerURLs列表。peerURLs列表会针对每个添加的成员增长一个。etcdctl member add命令输出在 etcd.conf 文件中设置的值,以添加每个成员,如下说明所述。# etcdctl -C https://${CURRENT_ETCD_HOST}:2379 \ --ca-file=/etc/etcd/ca.crt \ --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key member add ${NEW_ETCD_HOSTNAME} https://${NEW_ETCD_IP}:2380 1 Added member named 10.3.9.222 with ID 4e1db163a21d7651 to cluster ETCD_NAME="<NEW_ETCD_HOSTNAME>" ETCD_INITIAL_CLUSTER="<NEW_ETCD_HOSTNAME>=https://<NEW_HOST_IP>:2380,<CLUSTERMEMBER1_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER2_NAME>=https:/<CLUSTERMEMBER2_IP>:2380,<CLUSTERMEMBER3_NAME>=https:/<CLUSTERMEMBER3_IP>:2380" ETCD_INITIAL_CLUSTER_STATE="existing"- 1
- 在这一行中,
10.3.9.222是 etcd 成员的标签。您可以指定主机名、IP 地址或简单名称。
更新示例
${PREFIX}/etcd.conf文件。将以下值替换为上一步中生成的值:
- ETCD_NAME
- ETCD_INITIAL_CLUSTER
- ETCD_INITIAL_CLUSTER_STATE
使用上一步中输出中的新主机 IP 修改以下变量:您可以使用
${NEW_ETCD_IP}作为值。ETCD_LISTEN_PEER_URLS ETCD_LISTEN_CLIENT_URLS ETCD_INITIAL_ADVERTISE_PEER_URLS ETCD_ADVERTISE_CLIENT_URLS
- 如果您之前使用 member 系统作为 etcd 节点,您必须覆盖 /etc/etcd/etcd.conf 文件中的当前值。
检查文件中的语法错误或缺少 IP 地址,否则 etcd 服务可能会失败:
# vi ${PREFIX}/etcd.conf
-
在托管安装文件的节点上,更新 /etc/ansible/hosts 清单文件中的
[etcd]主机组。删除旧的 etcd 主机并添加新主机。 创建一个包含证书、示例配置文件和
ca的tgz文件,并将其复制到新主机上:# tar -czvf /etc/etcd/generated_certs/${CN}.tgz -C ${PREFIX} . # scp /etc/etcd/generated_certs/${CN}.tgz ${CN}:/tmp/
修改新的 etcd 主机
安装
iptables-services以提供 iptables 工具为 etcd 打开所需的端口:# yum install -y iptables-services
创建
OS_FIREWALL_ALLOW防火墙规则以允许 etcd 进行通信:- 客户端的端口 2379/tcp
端口 2380/tcp 用于对等通信
# systemctl enable iptables.service --now # iptables -N OS_FIREWALL_ALLOW # iptables -t filter -I INPUT -j OS_FIREWALL_ALLOW # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2379 -j ACCEPT # iptables -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2380 -j ACCEPT # iptables-save | tee /etc/sysconfig/iptables
注意在本例中,创建了一个新的链
OS_FIREWALL_ALLOW,这是 OpenShift Container Platform 安装程序用于防火墙规则的标准命名。警告如果环境托管在 IaaS 环境中,请修改实例的安全组,以允许传入到这些端口的流量。
安装 etcd:
# yum install -y etcd
确保安装了
etcd-2.3.7-4.el7.x86_64或更高的版本,通过删除 etcd pod 定义来确保 etcd 服务没有运行:
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/* /etc/origin/node/pods-stopped/
删除所有 etcd 配置和数据:
# rm -Rf /etc/etcd/* # rm -Rf /var/lib/etcd/*
提取证书和配置文件:
# tar xzvf /tmp/etcd0.example.com.tgz -C /etc/etcd/
在新主机上启动 etcd:
# systemctl enable etcd --now
验证主机是否是集群的一部分以及当前的集群健康状况:
如果使用 v2 etcd api,请运行以下命令:
# etcdctl --cert-file=/etc/etcd/peer.crt \ --key-file=/etc/etcd/peer.key \ --ca-file=/etc/etcd/ca.crt \ --peers="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ cluster-health member 5ee217d19001 is healthy: got healthy result from https://192.168.55.12:2379 member 2a529ba1840722c0 is healthy: got healthy result from https://192.168.55.8:2379 member 8b8904727bf526a5 is healthy: got healthy result from https://192.168.55.21:2379 member ed4f0efd277d7599 is healthy: got healthy result from https://192.168.55.13:2379 cluster is healthy如果使用 v3 etcd api,请运行以下命令:
# ETCDCTL_API=3 etcdctl --cert="/etc/etcd/peer.crt" \ --key=/etc/etcd/peer.key \ --cacert="/etc/etcd/ca.crt" \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379,\ https://*etcd0.example.com*:2379"\ endpoint health https://master-0.example.com:2379 is healthy: successfully committed proposal: took = 5.011358ms https://master-1.example.com:2379 is healthy: successfully committed proposal: took = 1.305173ms https://master-2.example.com:2379 is healthy: successfully committed proposal: took = 1.388772ms https://etcd0.example.com:2379 is healthy: successfully committed proposal: took = 1.498829ms
修改每个 OpenShift Container Platform master
修改每个 master 上
/etc/origin/master/master-config.yaml文件的etcClientInfo部分中的 master 配置。将新的 etcd 主机添加到 OpenShift Container Platform 用来存储数据的 etcd 服务器列表中,并删除所有失败的 etcd 主机:etcdClientInfo: ca: master.etcd-ca.crt certFile: master.etcd-client.crt keyFile: master.etcd-client.key urls: - https://master-0.example.com:2379 - https://master-1.example.com:2379 - https://master-2.example.com:2379 - https://etcd0.example.com:2379重启 master API 服务:
在每个 master 上:
# master-restart api # master-restart controllers
警告etcd 节点的数量必须是奇数,因此您必须至少添加两个主机。
如果使用 Flannel,修改每个 OpenShift Container Platform 主机的
/etc/sysconfig/flanneld服务的flanneld服务配置,使其包含新的 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379,https://etcd0.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
第 38 章 恢复 etcd 仲裁
如果丢失了 etcd 仲裁,可以恢复它。
- 如果在单独的主机上运行 etcd,您必须备份 etcd,请关闭 etcd 集群,并形成一个新数据。您可以使用一个健康的 etcd 节点来组成新集群,但必须删除所有其他健康节点。
- 如果您在 master 节点上以静态 pod 身份运行 etcd,请停止 etcd pod,创建一个临时集群,然后重启 etcd pod。
在 etcd 仲裁丢失过程中,在 OpenShift Container Platform 上运行的应用程序不受影响。但是,平台功能仅限于只读操作。您无法采取操作,如扩展应用程序、更改部署或运行或修改构建。
要确认 etcd 仲裁丢失,请运行以下命令并确认集群不健康:
如果使用 etcd v2 API,请运行以下命令:
# etcd_ctl=2 etcdctl --cert-file=/etc/origin/master/master.etcd-client.crt \ --key-file /etc/origin/master/master.etcd-client.key \ --ca-file /etc/origin/master/master.etcd-ca.crt \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379"\ cluster-health member 165201190bf7f217 is unhealthy: got unhealthy result from https://master-0.example.com:2379 member b50b8a0acab2fa71 is unreachable: [https://master-1.example.com:2379] are all unreachable member d40307cbca7bc2df is unreachable: [https://master-2.example.com:2379] are all unreachable cluster is unhealthy如果使用 v3 API,请运行以下命令:
# ETCDCTL_API=3 etcdctl --cert=/etc/origin/master/master.etcd-client.crt \ --key=/etc/origin/master/master.etcd-client.key \ --cacert=/etc/origin/masterca.crt \ --endpoints="https://*master-0.example.com*:2379,\ https://*master-1.example.com*:2379,\ https://*master-2.example.com*:2379"\ endpoint health https://master-0.example.com:2379 is unhealthy: failed to connect: context deadline exceeded https://master-1.example.com:2379 is unhealthy: failed to connect: context deadline exceeded https://master-2.example.com:2379 is unhealthy: failed to connect: context deadline exceeded Error: unhealthy cluster
记录主机的成员 ID 和主机名。您可以使用其中一个节点组成新集群。
38.1. 为独立的服务恢复 etcd 仲裁
38.1.1. 备份 etcd
当备份 etcd 时,您必须备份 etcd 配置文件和 etcd 数据。
38.1.1.1. 备份 etcd 配置文件
要保留的 etcd 配置文件都存储在运行 etcd 的实例的 /etc/etcd 目录中。这包括 etcd 配置文件(/etc/etcd/etcd.conf)和集群通信所需的证书。所有这些文件都是在安装时由 Ansible 安装程序生成的。
流程
对于集群的每个 etcd 成员,备份 etcd 配置。
$ ssh master-0 1
# mkdir -p /backup/etcd-config-$(date +%Y%m%d)/
# cp -R /etc/etcd/ /backup/etcd-config-$(date +%Y%m%d)/- 1
- 将
master-0替换为 etcd 成员的名称。
每个 etcd 集群成员上的证书和配置文件是唯一的。
38.1.1.2. 备份 etcd 数据
先决条件
OpenShift Container Platform 安装程序创建别名,以避免为 etcd v2 任务输入名为 etcdctl2 的所有标志,以及用于 etcd v3 任务的 etcdctl3。
但是,etcdctl3 别名不会向 etcdctl 命令提供完整的端点列表,因此您必须指定 --endpoints 选项并列出所有端点。
备份 etcd 之前:
-
etcdctl二进制文件必须可用,或者在容器化安装中,rhel7/etcd容器必须可用。 - 确保 OpenShift Container Platform API 服务正在运行。
- 确保与 etcd 集群的连接(端口 2379/tcp)。
- 确保正确的证书以连接到 etcd 集群。
流程
虽然 etcdctl backup 命令用于执行备份,etcd v3 没有 备份 的概念。您可以使用 etcdctl snapshot save 命令对一个实时成员进行快照,或从 etcd 数据目录中复制 member/snap/db 文件。
etcdctl 备份 命令重写了备份中所含的一些元数据,特别是节点 ID 和集群 ID,这意味着在备份中,节点会丢失它的以前的身份。要从备份重新创建集群,您可以创建一个新的单节点集群,然后将其他节点的其余部分添加到集群中。元数据被重写以防止新节点加入现有集群。
备份 etcd 数据:
从以前的 OpenShift Container Platform 版本升级的集群可能包含 v2 数据存储。备份所有 etcd 数据存储。
从静态 pod 清单获取 etcd 端点 IP 地址:
$ export ETCD_POD_MANIFEST="/etc/origin/node/pods/etcd.yaml"
$ export ETCD_EP=$(grep https ${ETCD_POD_MANIFEST} | cut -d '/' -f3)以管理员身份登录:
$ oc login -u system:admin
获取 etcd pod 名称:
$ export ETCD_POD=$(oc get pods -n kube-system | grep -o -m 1 '^master-etcd\S*')
进入
kube-system项目:$ oc project kube-system
在 pod 中生成 etcd 数据快照并将其保存在本地:
$ oc exec ${ETCD_POD} -c etcd -- /bin/bash -c "ETCDCTL_API=3 etcdctl \ --cert /etc/etcd/peer.crt \ --key /etc/etcd/peer.key \ --cacert /etc/etcd/ca.crt \ --endpoints $ETCD_EP \ snapshot save /var/lib/etcd/snapshot.db" 1- 1
- 您必须将快照写入
/var/lib/etcd/下的目录中。
38.1.2. 删除 etcd 主机
如果 etcd 主机无法恢复,将其从集群中移除。要从 etcd 仲裁丢失中恢复,还必须删除所有健康的 etcd 节点,但从集群中删除。
在所有 master 主机上执行的步骤
流程
从 etcd 集群中删除其他 etcd 主机。为每个 etcd 节点运行以下命令:
# etcdctl3 --endpoints=https://<surviving host IP>:2379 --cacert=/etc/etcd/ca.crt --cert=/etc/etcd/peer.crt --key=/etc/etcd/peer.key member remove <failed member ID>
从每个 master 上的
/etc/origin/master/master-config.yaml+master 配置文件中删除其他 etcd 主机:etcdClientInfo: ca: master.etcd-ca.crt certFile: master.etcd-client.crt keyFile: master.etcd-client.key urls: - https://master-0.example.com:2379 - https://master-1.example.com:2379 1 - https://master-2.example.com:2379 2在每个 master 上重启 master API 服务:
# master-restart api restart-master controller
在当前 etcd 集群中执行的步骤
流程
从集群中删除失败的主机:
# etcdctl2 cluster-health member 5ee217d19001 is healthy: got healthy result from https://192.168.55.12:2379 member 2a529ba1840722c0 is healthy: got healthy result from https://192.168.55.8:2379 failed to check the health of member 8372784203e11288 on https://192.168.55.21:2379: Get https://192.168.55.21:2379/health: dial tcp 192.168.55.21:2379: getsockopt: connection refused member 8372784203e11288 is unreachable: [https://192.168.55.21:2379] are all unreachable member ed4f0efd277d7599 is healthy: got healthy result from https://192.168.55.13:2379 cluster is healthy # etcdctl2 member remove 8372784203e11288 1 Removed member 8372784203e11288 from cluster # etcdctl2 cluster-health member 5ee217d19001 is healthy: got healthy result from https://192.168.55.12:2379 member 2a529ba1840722c0 is healthy: got healthy result from https://192.168.55.8:2379 member ed4f0efd277d7599 is healthy: got healthy result from https://192.168.55.13:2379 cluster is healthy- 1
remove命令需要 etcd ID,而不是主机名。
要确保 etcd 配置在 etcd 服务重启时不使用失败的主机,修改所有剩余的 etcd 主机上的
/etc/etcd/etcd.conf文件,并在ETCD_INITIAL_CLUSTER变量的值中删除失败主机:# vi /etc/etcd/etcd.conf
例如:
ETCD_INITIAL_CLUSTER=master-0.example.com=https://192.168.55.8:2380,master-1.example.com=https://192.168.55.12:2380,master-2.example.com=https://192.168.55.13:2380
成为:
ETCD_INITIAL_CLUSTER=master-0.example.com=https://192.168.55.8:2380,master-1.example.com=https://192.168.55.12:2380
注意不需要重启 etcd 服务,因为失败的主机是使用
etcdctl被删除。修改 Ansible 清单文件,以反映集群的当前状态,并避免在重新运行 playbook 时出现问题:
[OSEv3:children] masters nodes etcd ... [OUTPUT ABBREVIATED] ... [etcd] master-0.example.com master-1.example.com
如果您使用 Flannel,请修改每个主机上
/etc/sysconfig/flanneld的flanneld服务配置并删除 etcd 主机:FLANNEL_ETCD_ENDPOINTS=https://master-0.example.com:2379,https://master-1.example.com:2379,https://master-2.example.com:2379
重启
flanneld服务:# systemctl restart flanneld.service
38.1.3. 创建单节点 etcd 集群
要恢复 OpenShift Container Platform 实例的完整功能,请使 etcd 节点变为独立的 etcd 集群。
流程
在没有从集群中删除的 etcd 节点上,通过删除 etcd pod 定义来停止所有 etcd 服务:
# mkdir -p /etc/origin/node/pods-stopped # mv /etc/origin/node/pods/etcd.yaml /etc/origin/node/pods-stopped/ # systemctl stop atomic-openshift-node # mv /etc/origin/node/pods-stopped/etcd.yaml /etc/origin/node/pods/
在主机上运行 etcd 服务,强制使用新集群。
这些命令为 etcd 服务创建自定义文件,它会在 etcd start 命令中添加
--force-new-cluster选项:# mkdir -p /etc/systemd/system/etcd.service.d/ # echo "[Service]" > /etc/systemd/system/etcd.service.d/temp.conf # echo "ExecStart=" >> /etc/systemd/system/etcd.service.d/temp.conf # sed -n '/ExecStart/s/"$/ --force-new-cluster"/p' \ /usr/lib/systemd/system/etcd.service \ >> /etc/systemd/system/etcd.service.d/temp.conf # systemctl daemon-reload # master-restart etcd列出 etcd 成员,并确认成员列表仅包含您的单个 etcd 主机:
# etcdctl member list 165201190bf7f217: name=192.168.34.20 peerURLs=http://localhost:2380 clientURLs=https://master-0.example.com:2379 isLeader=true
恢复数据并创建新集群后,您必须更新
peerURLs参数值,以使用 etcd 侦听对等通信的 IP 地址:# etcdctl member update 165201190bf7f217 https://192.168.34.20:2380 1- 1
165201190bf7f217是上一命令输出中显示的成员 ID,而https://192.168.34.20:2380是其 IP 地址。
要验证,请检查 IP 是否在成员列表中:
$ etcdctl2 member list 5ee217d17301: name=master-0.example.com peerURLs=https://*192.168.55.8*:2380 clientURLs=https://192.168.55.8:2379 isLeader=true
38.1.4. 恢复后添加 etcd 节点
在第一个实例运行后,您可以在集群中添加多个 etcd 服务器。
流程
在
ETCD_NAME变量中获取实例的 etcd 名称:# grep ETCD_NAME /etc/etcd/etcd.conf
获取 etcd 侦听对等通信的 IP 地址:
# grep ETCD_INITIAL_ADVERTISE_PEER_URLS /etc/etcd/etcd.conf
如果节点之前是 etcd 集群的一部分,请删除之前的 etcd 数据:
# rm -Rf /var/lib/etcd/*
在运行 etcd 的 etcd 主机上,添加新成员:
# etcdctl3 member add *<name>* \ --peer-urls="*<advertise_peer_urls>*"
命令输出一些变量。例如:
ETCD_NAME="master2" ETCD_INITIAL_CLUSTER="master-0.example.com=https://192.168.55.8:2380" ETCD_INITIAL_CLUSTER_STATE="existing"
将上一个命令中的值添加到新主机的
/etc/etcd/etcd.conf文件中:# vi /etc/etcd/etcd.conf
在加入集群的节点中启动 etcd 服务:
# systemctl start etcd.service
检查错误信息:
# master-logs etcd etcd
添加所有节点后,验证集群状态和集群健康状况:
# etcdctl3 endpoint health --endpoints="https://<etcd_host1>:2379,https://<etcd_host2>:2379,https://<etcd_host3>:2379" https://master-0.example.com:2379 is healthy: successfully committed proposal: took = 1.423459ms https://master-1.example.com:2379 is healthy: successfully committed proposal: took = 1.767481ms https://master-2.example.com:2379 is healthy: successfully committed proposal: took = 1.599694ms # etcdctl3 endpoint status --endpoints="https://<etcd_host1>:2379,https://<etcd_host2>:2379,https://<etcd_host3>:2379" https://master-0.example.com:2379, 40bef1f6c79b3163, 3.2.5, 28 MB, true, 9, 2878 https://master-1.example.com:2379, 1ea57201a3ff620a, 3.2.5, 28 MB, false, 9, 2878 https://master-2.example.com:2379, 59229711e4bc65c8, 3.2.5, 28 MB, false, 9, 2878
- 将剩余的同级服务器重新添加到集群中。
38.2. 为静态 pod 恢复 etcd 仲裁
如果您在将静态 pod 用于 etcd 的集群上丢失 etcd 仲裁,请执行以下步骤:
流程
停止 etcd pod:
mv /etc/origin/node/pods/etcd.yaml .
在 etcd 主机上临时强制新集群:
$ cp /etc/etcd/etcd.conf etcd.conf.bak $ echo "ETCD_FORCE_NEW_CLUSTER=true" >> /etc/etcd/etcd.conf
重启 etcd pod:
$ mv etcd.yaml /etc/origin/node/pods/.
停止 etcd pod 并删除
FORCE_NEW_CLUSTER命令:$ mv /etc/origin/node/pods/etcd.yaml . $ rm /etc/etcd/etcd.conf $ mv etcd.conf.bak /etc/etcd/etcd.conf
重启 etcd pod:
$ mv etcd.yaml /etc/origin/node/pods/.
第 39 章 OpenShift SDN 故障排除
39.1. 概述
如 SDN 文档中所述,SDN 文档 创建多个层接口,它们创建的接口可以正确地将流量从一个容器传递到另一个。要调试连接问题,您必须测试堆栈的不同层,以解决问题发生的位置。本指南将帮助您向下浏览层来识别问题以及如何解决问题。
问题的一部分在于,OpenShift Container Platform 可以通过多种方式设置,并且可能会在几个不同的位置上出现网络错误。因此,本文档将在一些情况下进行升级,希望能够涵盖大多数情况。如果未涵盖您的问题,则引入的工具和概念应帮助引导调试工作。
39.2. Nomenclature
- 集群
- 集群中的机器集合 。例如, Masters 和 节点。
- Master
- OpenShift Container Platform 集群的控制器。请注意,masters 可能不是集群中的节点,因此可能没有与 pod 的 IP 连接。
- 节点
- 主机在运行可托管 pod 的 OpenShift Container Platform 中。
- Pod
- 由 OpenShift Container Platform 管理的一个节点上运行的容器组。
- 服务
- 抽象化,它是由一个或多个 pod 支持的统一网络接口。
- 路由器
- 一个 Web 代理,它可以将各种 URL 和路径映射到 OpenShift Container Platform 服务,以便外部流量传输到集群中。
- 节点地址
- 节点的 IP 地址。这由节点所附加到的网络的所有者分配和管理。必须可以从集群中的任何节点(master 和 client)访问。
- Pod 地址
- pod 的 IP 地址。它们由 OpenShift Container Platform 分配和管理。默认情况下,会为它们分配自 10.128.0.0/14 网络(或者在旧版本 10.1.0.0/16 中)。只能从客户端节点访问。
- 服务地址
- 代表服务的 IP 地址,并在内部映射到 pod 地址。它们由 OpenShift Container Platform 分配和管理。默认情况下,它们被从 172.30.0.0/16 网络分配。只能从客户端节点访问。
下图显示了外部访问涉及的所有组件。
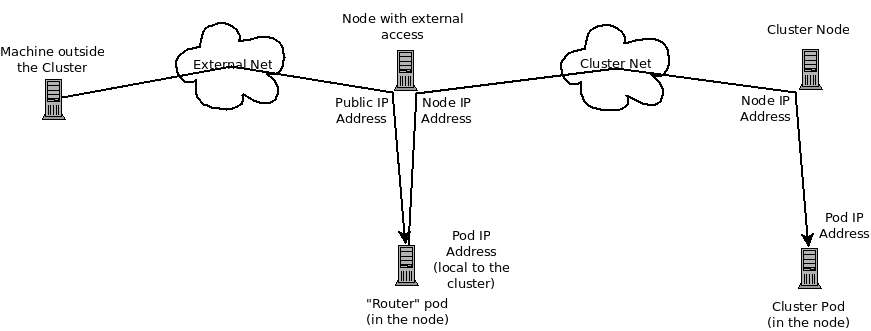
39.3. 调试到 HTTP 服务的外部访问
如果您位于集群外的机器上,并且正在尝试访问集群提供的资源,则需要是一个在 pod 中运行的一种进程,侦听集群中的公共 IP 地址和"路由"该流量。OpenShift Container Platform 路由器 为 HTTP、HTTPS(使用 SNI)、WebSockets 或 TLS(使用 SNI)提供目的。
假设您无法从集群外访问 HTTP 服务,我们首先在有故障的机器的命令行中重现问题。Try:
curl -kv http://foo.example.com:8000/bar # But replace the argument with your URL
如果有效,您是否从正确的位置重现错误?服务也可能会有一些正常工作的 pod,而有些 pod 则不行。因此,请跳至 第 39.4 节 “调试路由器” 部分。
如果失败,则让我们将 DNS 名称解析为 IP 地址(假设它还没有一个地址):
dig +short foo.example.com # But replace the hostname with yours
如果这没有提供 IP 地址,则此时应该对 DNS 进行故障排除,但这超出了本指南的范围。
请确定您返回的 IP 地址是您期望运行该路由器的 IP 地址。如果没有,请修复您的 DNS。
接下来,使用 ping -c address 和 tracepath address 来检查是否可以到达路由器主机。可能无法响应 ICMP 数据包,在这种情况下,这些测试将失败,但路由器计算机可以访问。在这种情况下,尝试使用 telnet 命令直接访问路由器的端口:
telnet 1.2.3.4 8000
您可能会得到:
Trying 1.2.3.4... Connected to 1.2.3.4. Escape character is '^]'.
如果是这样,则会在 IP 地址上侦听端口。这很好。按 ctrl-],然后按 Enter 键,然后键入 close 以退出 telnet。移到 第 39.4 节 “调试路由器” 部分,以检查路由器上的其他内容。
或者可以得到:
Trying 1.2.3.4... telnet: connect to address 1.2.3.4: Connection refused
告知我们路由器没有侦听该端口。有关如何配置路由器的更多指针,请参阅 第 39.4 节 “调试路由器” 部分。
或者看到:
Trying 1.2.3.4... telnet: connect to address 1.2.3.4: Connection timed out
告诉我们您无法与这个 IP 地址的任何通信。检查您的路由、防火墙以及您是否有路由器侦听该 IP 地址。要调试路由器,请查看 第 39.4 节 “调试路由器” 部分。对于 IP 路由和防火墙问题,这已超出本指南的理解情况。
39.4. 调试路由器
现在,您已拥有 IP 地址,我们需要 ssh 到该计算机,并检查该计算机上的路由器软件是否在该计算机上运行并正确配置。因此,我们已有 ssh 来获取 OpenShift Container Platform 凭证。
检查路由器是否正在运行:
# oc get endpoints --namespace=default --selector=router NAMESPACE NAME ENDPOINTS default router 10.128.0.4:80
如果该命令失败,则您的 OpenShift Container Platform 配置出现问题。修复本文档的范围。
您应当会看到列出一个或多个路由器端点,但这不会告诉您是否在带有给定外部 IP 地址的机器中运行,因为端点 IP 地址将是集群内部的 pod 地址之一。要获取路由器主机 IP 地址列表,请运行:
# oc get pods --all-namespaces --selector=router --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{"\n"}}{{end}}'
HostIP: 192.168.122.202 PodIP: 10.128.0.4您应该会看到与外部地址对应的主机 IP。如果没有,请参阅 路由器文档,将路由器 Pod 配置为在正确的节点上运行(通过正确设置关联性)或更新您的 DNS,以匹配路由器运行的 IP 地址。
在本指南中,您应位于节点上运行路由器 Pod 的节点,但您仍然无法获取 HTTP 请求才能工作。首先,我们需要确保路由器将外部 URL 映射到正确的服务,如果有效,我们需要 dig 到该服务,以确保所有端点都可以访问。
让我们列出 OpenShift Container Platform 所知的所有路由:
# oc get route --all-namespaces NAME HOST/PORT PATH SERVICE LABELS TLS TERMINATION route-unsecured www.example.com /test service-name
如果您的 URL 中的主机名和路径与返回路由列表中的任何内容都不匹配,则需要添加路由。请参阅 路由器文档。
如果存在路由,则需要调试对端点的访问。这与您在服务中调试问题时相同,因此继续进行下一 第 39.5 节 “调试服务” 部分。
39.5. 调试服务
如果您无法从集群内部与服务通信(因为您的服务无法直接通信,或者因为您使用路由器,一切工作,直到进入集群)后,您需要执行与服务关联的端点并调试它们。
首先,让我们获得这些服务:
# oc get services --all-namespaces NAMESPACE NAME LABELS SELECTOR IP(S) PORT(S) default docker-registry docker-registry=default docker-registry=default 172.30.243.225 5000/TCP default kubernetes component=apiserver,provider=kubernetes <none> 172.30.0.1 443/TCP default router router=router router=router 172.30.213.8 80/TCP
您应该会在列表中看到您的服务。如果没有,您需要 定义服务。
服务输出中列出的 IP 地址是 Kubernetes 服务 IP 地址,Kubernetes 将映射到支持该服务的其中一个 pod。因此,您应该能够与这个 IP 地址进行通信。但遗憾的是,即使您可以想象的是所有 pod 都可被访问,也意味着可以访问所有 pod;如果无法访问,则并不意味着所有 pod 都无法访问。它只是告诉您 kubeproxy hooked 的一个状态。
让我们一起测试服务。从其中一个节点:
curl -kv http://172.30.243.225:5000/bar # Replace the argument with your service IP address and port
然后,让我们来看看哪些 pod 正在支持我们的服务(将 docker-registry 替换为已损坏的服务的名称替换 docker-registry):
# oc get endpoints --selector=docker-registry NAME ENDPOINTS docker-registry 10.128.2.2:5000
我们可以看到,只有一个端点。因此,如果您的服务测试成功,并且路由器测试成功,那么实际上会发生奇怪。但是,如果有多个端点,或者服务测试失败,请尝试 每个端点的 以下内容:确定端点无法正常工作后,继续执行下一节。
首先,测试每个端点(更改 URL 以获取正确的端点 IP、端口和路径):
curl -kv http://10.128.2.2:5000/bar
如果这不起作用,请尝试下一个操作。如果失败,请记下这部分,我们将在下一节中找出原因。
如果所有这些都失败,则可能本地节点无法正常工作,跳到 第 39.7 节 “调试本地网络” 部分。
如果它们都正常工作,则跳至 第 39.11 节 “调试 Kubernetes” 部分来找出为什么服务 IP 地址无法正常工作。
39.6. 调试节点到节点网络
使用我们的未工作端点列表,我们需要测试与该节点的连接。
确保所有节点都具有预期的 IP 地址:
# oc get hostsubnet NAME HOST HOST IP SUBNET rh71-os1.example.com rh71-os1.example.com 192.168.122.46 10.1.1.0/24 rh71-os2.example.com rh71-os2.example.com 192.168.122.18 10.1.2.0/24 rh71-os3.example.com rh71-os3.example.com 192.168.122.202 10.1.0.0/24
如果您使用的是 DHCP,它们可能会有所变化。确保主机名、IP 地址和子网与您所期望的内容匹配。如果任何节点详细信息已更改,请使用
oc edit hostsubnet更正条目。确保节点地址和主机名正确后,列出端点 IP 和节点 IP:
# oc get pods --selector=docker-registry \ --template='{{range .items}}HostIP: {{.status.hostIP}} PodIP: {{.status.podIP}}{{end}}{{"\n"}}' HostIP: 192.168.122.202 PodIP: 10.128.0.4查找您之前记录的端点 IP 地址,并在
PodIP条目中查找它,并找到对应的HostIP地址。然后,使用HostIP的地址测试节点主机级别的连接:-
ping -c 3 <IP_address>:没有响应可能意味着中间路由器正在破坏 ICMP 流量。 tracepath <IP_address>:如果所有跃点返回了 ICMP 数据包,则显示了指向目标的 IP 路由。如果
tracepath和ping失败,则查找与本地或虚拟网络的连接问题。
-
对于本地网络,检查以下内容:
检查数据包从方框到目标地址的路由:
# ip route get 192.168.122.202 192.168.122.202 dev ens3 src 192.168.122.46 cache在上例中,它会进入名为
ens3的接口,源地址为192.168.122.46,并直接转至目标。如果预期相符,请使用ip 显示 dev ens3来获取接口详情,并确保 是预期的接口。一个备用结果可能是:
# ip route get 192.168.122.202 1.2.3.4 via 192.168.122.1 dev ens3 src 192.168.122.46
它将
通过IP 值传递以适当地路由。确保流量路由正确。调试路由流量超出了本指南的范围。
以下可以解决节点到节点网络的其他调试选项:
-
两端上是否有以太网链接?在
ethtool <network_interface>的输出中查找Link detected: yes -
您的 duplex 设置和以太网速度是否在两端均正确?查看
ethtool <network_interface> 信息的其余部分。 - 电缆是否正确插入?到正确的端口?
- 交换机是否正确配置?
一旦您确定了节点到节点连接,就需要查看两端的 SDN 配置。
39.7. 调试本地网络
此时,我们应该有一个或多个端点列表,您无法与 通信,但具有节点到节点连接。对于每个,我们需要操作错误,但首先需要了解 SDN 如何在不同 pod 上设置网络。
39.7.1. 节点上的接口
OpenShift SDN 创建的接口:
-
br0:容器将附加到的 OVS 网桥设备。OpenShift SDN 还在这个网桥上配置一组特定于非子网的流规则。 -
tun0:OVS 内部端口(br0上的端口 2)。这会分配集群子网网关地址,用于外部网络访问。OpenShift SDN 配置netfilter和路由规则,以启用通过 NAT 从集群子网到外部网络的访问。 -
vxlan_sys_4789:OVS VXLAN 设备(br0上的端口 1),提供对远程节点上容器的访问。在 OVS 规则中称为vxlan0。 -
vethX(在主 netns 中):Docker netns 中eth0的 Linux 虚拟以太网对等点。它将附加到其中一个其他端口上的 OVS 网桥。
39.7.2. 节点内部的 SDN 流

根据您要访问的内容(或从其访问),其路径会有所不同。SDN 连接(在节点旁边)有四种不同的位置。在上图中以红色标记它们。
- Pod:流量从一个 pod 到达同一计算机上的另一个 pod(1 到不同的 1)
- 远程节点(或 Pod):流量来自本地 pod 到同一集群中的远程节点或 pod(1 到 2)
- 外部机器:流量来自集群外的本地 pod(1 到 3)
当然,也可以进行相反的流量流。
39.7.3. 调试步骤
39.7.3.1. IP 转发是否启用?
检查 sysctl net.ipv4.ip_forward 是否已设置为 1(如果是虚拟机,并检查主机)
39.7.3.2. 您的路由是否正确?
使用 ip route 检查路由表:
# ip route default via 192.168.122.1 dev ens3 10.128.0.0/14 dev tun0 proto kernel scope link # This sends all pod traffic into OVS 10.128.2.0/23 dev tun0 proto kernel scope link src 10.128.2.1 # This is traffic going to local pods, overriding the above 169.254.0.0/16 dev ens3 scope link metric 1002 # This is for Zeroconf (may not be present) 172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.42.1 # Docker's private IPs... used only by things directly configured by docker; not OpenShift 192.168.122.0/24 dev ens3 proto kernel scope link src 192.168.122.46 # The physical interface on the local subnet
您应该看到 10.128.x.x 行(假设您将 pod 网络设置为配置中的默认范围)。如果没有,请检查 OpenShift Container Platform 日志(请参阅 第 39.10 节 “读取日志” 部分)
39.7.4. Open vSwitch(OVS)是否正确配置?
您必须在其中一个 OVS pod 上运行 ovs-vsctl 和 ovs-ofctl 命令。
要列出 OVS pod,请输入以下命令:
$ oc get pod -n openshift-sdn -l app=ovs
检查两端的 Open vSwitch 网桥。将 <ovs_pod_name > 替换为其中一个 OVS pod 的名称。
$ oc exec -n openshift-sdn <ovs_pod_name> -- ovs-vsctl list-br br0
上一命令应返回 br0。
您可以列出 OVS 知道的所有端口:
$ oc exec -n openshift-sdn <ovs_pod_name> -- ovs-ofctl -O OpenFlow13 dump-ports-desc br0
OFPST_PORT_DESC reply (OF1.3) (xid=0x2):
1(vxlan0): addr:9e:f1:7d:4d:19:4f
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
2(tun0): addr:6a:ef:90:24:a3:11
config: 0
state: 0
speed: 0 Mbps now, 0 Mbps max
8(vethe19c6ea): addr:1e:79:f3:a0:e8:8c
config: 0
state: 0
current: 10GB-FD COPPER
speed: 10000 Mbps now, 0 Mbps max
LOCAL(br0): addr:0a:7f:b4:33:c2:43
config: PORT_DOWN
state: LINK_DOWN
speed: 0 Mbps now, 0 Mbps max
特别是,所有活跃的 pod 的 vethX 设备应当列为端口。
接下来,列出该网桥中配置的流:
$ oc exec -n openshift-sdn <ovs_pod_name> -- ovs-ofctl -O OpenFlow13 dump-flows br0
根据您使用的 ovs-subnet 或 ovs-multitenant 插件,结果会稍有不同,但您可以查找的一些一般操作:
-
每个远程节点都应该有一个与
tun_src=<node_IP_address>(用于来自该节点的 VXLAN 流量)和另一流(包括操作set_field:<node_IP_address>->tun_dst)匹配的流(用于向该节点传出的 VXLAN 流量)。 -
每个本地 pod 都应该有与
arp_spa=<pod_IP_address> 和arp_tpa=<pod_IP_address>(用于该 pod 的传入和传出 IP 流量)匹配的流,以及与nw_IP_address> 和nw_dst=<pod_IP_address>(用于该 pod 的传入和传出 IP 流量)匹配的流。
如果缺少流,请查看 第 39.10 节 “读取日志” 部分。
39.7.4.1. iptables 配置是否正确?
检查 iptables-save 的输出,确保您未过滤流量。但是,OpenShift Container Platform 在正常操作过程中设置 iptables 规则,因此无法意外地看到相关的条目。
39.7.4.2. 您的外部网络是否正确?
检查外部防火墙(如果有的话)允许到目标地址的流量(这独立于站点,且在本指南的清除之外)。
39.8. 调试虚拟网络
39.8.1. 虚拟网络上的构建是 Failing
如果您使用虚拟网络(如 OpenStack)安装 OpenShift Container Platform,且构建失败,目标节点主机的最大传输单元(MTU)可能无法与主网络接口的 MTU(如 eth0)兼容。
要使构建成功完成,SDN 的 MTU 必须小于 eth0 网络 MTU,才能在节点主机之间传递数据。
运行
ip addr命令检查网络的 MTU:# ip addr --- 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether fa:16:3e:56:4c:11 brd ff:ff:ff:ff:ff:ff inet 172.16.0.0/24 brd 172.16.0.0 scope global dynamic eth0 valid_lft 168sec preferred_lft 168sec inet6 fe80::f816:3eff:fe56:4c11/64 scope link valid_lft forever preferred_lft forever ---以上网络的 MTU 是 1500。
节点配置中的 MTU 必须小于网络值。检查目标节点主机的节点配置中的
mtu:# $ oc describe configmaps node-config-infra ... networkConfig: mtu: 1450 networkPluginName: company/openshift-ovs-subnet ...
在上面的节点配置文件中,
mtu值小于网络 MTU,因此不需要配置。如果mtu值较高,请编辑 文件,并将该值降低为比主网络接口的 MTU 少 50 个单元,然后重新启动节点服务。这将允许较大的数据数据包在节点间传递。注意要修改集群中的节点,请根据需要更新节点配置映射。不要手动编辑
node-config.yaml文件。
39.9. 调试 Pod Egress
如果您要从 pod 访问外部服务,如:
curl -kv github.com
确保 DNS 正确解析:
dig +search +noall +answer github.com
这应该返回 github 服务器的 IP 地址,但检查是否返回正确的地址。如果您返回没有地址,或者其中一个机器的地址,则可以在本地 DNS 服务器中匹配通配符条目。
要修复该问题,您需要确保具有通配符条目的 DNS 服务器没有列为 /etc/resolv.conf 中的 名称服务器,或者您需要确保通配符域不在搜索列表中列出。
如果返回了正确的 IP 地址,请尝试 第 39.7 节 “调试本地网络” 中列出的调试建议。您的流量应该使 Open vSwitch 在端口 2 上离开,从而通过 iptables 规则,然后正常退出路由表。
39.10. 读取日志
run: journalctl -u atomic-openshift-node.service --boot | less
查找 Output of setup script: 行。所有以 '+' 开头的内容都是脚本步骤。仔细检查是否存在明显的错误。
按照脚本所示,您应该会看到带有 Output of adding table=0 的行。这些是 OVS 规则,不应有任何错误。
39.11. 调试 Kubernetes
检查 iptables -t nat -L,以确保服务使用 NAT 为 kubeproxy 指向本地机器上的正确端口。
This is all changing soon… kubeProxy 正在被消除,并替换为只使用 iptables 的解决方案。
39.12. 使用诊断工具查找网络问题
作为集群管理员,运行诊断工具来诊断常见的网络问题:
# oc adm diagnostics NetworkCheck
诊断工具对指定组件的错误条件运行一系列检查。如需更多信息,请参阅 Diagnostics Tool 部分。
目前,诊断工具无法诊断 IP 故障转移问题。作为临时解决方案,您可以在 master 上运行 https://raw.githubusercontent.com/openshift/openshift-sdn/master/hack/ipf-debug.sh 脚本(或从可访问 master 的另一台机器)运行该脚本来生成有用的调试信息。但是,这个脚本不受支持。
默认情况下,oc adm diagnostics NetworkCheck 将错误记录到 /tmp/openshift/ 中。这可以通过 --network-logdir 选项进行配置:
# oc adm diagnostics NetworkCheck --network-logdir=<path/to/directory>
39.13. 其他备注
39.13.1. ingress 的其他冲突
- kube - 将服务声明为 NodePort,它将声明集群中所有计算机上的端口(在什么接口上),然后路由到 kube-proxy,然后路由到后备 pod。请参阅 https://kubernetes.io/docs/concepts/services-networking/service/#type-nodeport (某些节点必须可以被外部访问)
- Kube - 声明为 LoadBalancer,您需要写入的内容才能进行剩余操作
- OS/AE - 都使用路由器
39.13.2. TLS Handshake Timeout
当 pod 部署失败时,检查其 docker 日志是否有 TLS 握手超时:
$ docker log <container_id> ... [...] couldn't get deployment [...] TLS handshake timeout ...
这种情况一般是建立安全连接的错误,可能是由 tun0 和主接口(如 eth0)之间的 MTU 值的大差异导致,如 tun0 MTU 是 1500,而 eth0 MTU 是 9000(巨型帧)。
39.13.3. 其他调试备注
-
可以使用
ethtool -S ifname确定对等接口(Linux 虚拟以太网对) -
Driver type:
ethtool -i ifname
第 40 章 诊断工具
40.1. 概述
oc adm diagnostics 命令对主机或集群中的错误条件运行一系列检查。具体来说,它:
- 验证默认 registry 和路由器是否正在运行并正确配置。
-
检查
ClusterRoleBinding和ClusterRole,以与基本策略保持一致。 - 检查所有客户端配置上下文是否有效且可以连接到。
- 检查 SkyDNS 是否正常工作,并且 pod 具有 SDN 连接。
- 验证主机上的 master 和节点配置。
- 检查节点是否正在运行并可用。
- 分析主机日志以了解已知错误。
- 检查 systemd 单元是否已配置为预期为主机。
40.2. 使用 Diagnostics 工具
您可以通过几种方式部署 OpenShift Container Platform。它们是:
- 从源构建
- 包含在虚拟机镜像中
- 作为容器镜像
- 使用企业 RPM
每种方法适合不同的配置和环境。为尽量减少环境假设,可将诊断工具包含在 openshift 二进制文件中,以在 OpenShift Container Platform 服务器或客户端中提供诊断功能。
要使用诊断工具,最好是在 master 主机和集群管理员上,请运行:
# oc adm diagnostics
它会运行所有可用的诊断,并跳过所有不适用于环境的诊断。
您可以按名称运行特定诊断,或按照名称运行特定的诊断功能来解决问题。例如:
$ oc adm diagnostics
诊断工具的选项需要正常工作的配置文件。例如,除非节点配置可用,否则 NodeConfigCheck 不会运行。
诊断工具默认使用标准配置文件位置:
Client:
-
如
$KUBECONFIG环境变量所示 - ~/.kube/config file
-
如
Master:
- /etc/origin/master/master-config.yaml
节点:
- /etc/origin/node/node-config.yaml
您可以使用 --config、--master-config 和 --node-config 选项指定非标准位置。如果没有指定配置文件,则会跳过相关的诊断。
可用的诊断包括:
| 诊断名称 | 用途 |
|---|---|
|
| 检查聚合的日志记录集成是否正确配置和操作。 |
|
| 检查 systemd 服务日志中的问题。不需要对配置文件进行检查。 |
|
| 检查集群是否有可构建和镜像流的工作容器镜像 registry。 |
|
| 检查默认集群角色绑定是否存在,并根据基本策略包含预期的主题。 |
|
| 检查集群角色是否存在,并根据基本策略包含预期权限。 |
|
| 检查集群中是否正常工作的默认路由器。 |
|
| 检查客户端配置中的每个上下文已完成,并已连接到其 API 服务器。 |
|
| 创建一个从应用程序角度运行诊断的 pod,它检查 pod 中的 DNS 是否正常工作,以及默认服务帐户的凭证是否正确向 master API 进行身份验证。 |
|
| 在一段时间内检查对 etcd 进行写入的卷,并通过操作和密钥对它们进行分类。这个诊断只在特殊请求时运行,因为它不会因为其他诊断而快速运行,并可增加 etcd 的负载。 |
|
| 检查此主机的主配置文件是否有问题。 |
|
| 检查此主机上运行的主服务器也正在运行,以验证其是否为集群 SDN 的成员。 |
|
| 检查可以通过集群 API 代理访问集成的 Heapster 指标。 |
|
| 在多个节点中创建诊断 pod,从应用程序或 pod 的角度诊断常见的网络问题。当 master 可以在节点上调度 pod 时运行此诊断,但 pod 有连接问题。此检查确认 pod 可以连接到服务、其他 pod 和外部网络。
如果有错误,这个诊断将结果保存并检索到本地目录(默认为/tmp/openshift/ )中以便进一步分析。可以使用 |
|
| 检查此主机的节点配置文件是否存在问题。 |
|
| 检查 master API 中定义的节点是否已就绪,并可调度 pod。 |
|
| 检查通过扩展验证可能会被拒绝的那些路由证书的所有路由证书。 |
|
| 检查指定外部 IP 的现有服务,这些服务会被禁止使用 master 配置。 |
|
| 对于与 OpenShift Container Platform 相关的此主机上的单元,检查 systemd 状态。不需要对配置文件进行检查。 |
40.3. 在服务器环境中运行诊断
Ansible 部署的集群为 OpenShift Container Platform 集群中的节点提供额外的诊断功能。它们是:
- Master 和节点配置基于标准位置中的配置文件。
- systemd 单元配置为管理服务器。
- master 和节点配置文件都在标准位置。
- 创建 systemd 单元,并被配置为管理集群中的节点。
- 所有组件都日志记录到 journald。
保留由 Ansible 部署的集群放置的配置文件的默认位置,可确保运行 oc adm diagnostics 可以正常工作。如果没有在配置文件中使用默认位置,则必须使用 --master-config 和 --node-config 选项:
# oc adm diagnostics --master-config=<file_path> --node-config=<file_path>
当前日志诊断逻辑需要 journald 中的 systemd 单元和日志条目。对于其他部署类型,日志可以存储在单个文件中,并存储在组合节点和 master 日志的文件中,或输出到 stdout。如果日志条目不使用 journald,则日志诊断功能无法正常工作且不运行。
40.4. 在客户端环境中运行诊断
您可以以普通用户或 cluster-admin 身份运行诊断工具,它使用授予您从其运行它的帐户的权限级别运行。
具有普通访问权限的客户端可以诊断它与 master 的连接并运行诊断 pod。如果配置了多个用户或 master,则会测试所有连接,但诊断 pod 仅针对当前用户、服务器或项目运行。
具有 cluster-admin 访问权限的客户端可以诊断基础架构的状态,如节点、registry 和路由器。在每个情形中,运行 oc adm diagnostics 会在其标准位置搜索标准客户端配置文件,并在可用的情况下使用它。
40.5. 基于 Ansible 的健康检查
通过用于安装和管理 OpenShift Container Platform 集群的 基于 Ansible 的工具提供了额外的诊断健康检查。它们可以为当前 OpenShift Container Platform 安装报告常见部署问题。
这些检查可以使用 ansible-playbook 命令(集群安装中使用的相同方法)或作为 openshift-ansible 的容器化版本来运行。对于 ansible-playbook 方法,检查由 openshift-ansible RPM 软件包提供。对于容器化方法,openshift3/ose-ansible 容器镜像通过 Red Hat Container Registry 分发。后续小节中提供了每种方法的示例用法。
以下健康检查是一组诊断任务,用于使用提供的 health.yml playbook 为部署的 OpenShift Container Platform 集群的 Ansible 清单文件运行。
由于状况更改健康检查 playbook 可以进行环境,因此您必须对仅 Ansible 部署的集群运行 playbook,并使用用于部署的相同清单文件运行 playbook。更改由安装依赖项组成,以便检查可以收集所需信息。在某些情况下,如果其当前状态与清单文件中的配置不同,额外的系统组件(如 docker 或网络配置)可能会改变。只有在您不期望清单文件对现有集群配置进行任何更改时,才应运行这些健康检查。
表 40.1. 诊断健康检查
| 检查名称 | 用途 |
|---|---|
|
| 此检查可测量 etcd 集群中 OpenShift Container Platform 镜像数据的总大小。如果计算的大小超过用户定义的限制,则检查会失败。如果没有指定限制,如果镜像数据大小达到 50% 或 etcd 集群中当前使用的空间的大小,这个检查会失败。 此检查失败表示 OpenShift Container Platform 镜像数据正在占用大量 etcd,这可能会最终造成 etcd 集群崩溃。
可以通过传递 |
|
|
此检查会检测到 etcd 主机上的高than-normal 流量。如果找到 etcd 同步持续时间警告的 如需有关改进 etcd 性能的更多信息,请参阅 OpenShift Container Platform etcd 主机和 红帽知识库的建议实践。 |
|
|
此检查可确保 etcd 集群的卷使用量低于最大用户指定的阈值。如果没有指定最大阈值值,则默认为总卷大小的
可以通过传递 |
|
| 仅在依赖于 docker 守护进程的主机上运行(节点和容器化安装)。检查 docker 的总用量没有超过用户定义的限制。如果没有设置用户自定义的限制,则 docker 的最大用量阈值默认为可用总大小的 90%。
您可以为总百分比设置阈值限制,清单文件中有一个变量,如 这也检查 docker 的存储是否使用 受支持的配置。 |
|
|
这一组检查验证 Curator、Kibana、Elasticsearch 和 Fluentd Pod 是否已部署并处于 |
|
| 此检查检测到日志记录堆栈部署中 Elasticsearch 创建和日志聚合之间的正常时间延迟。如果在超时内无法通过 Elasticsearch 查询新的日志条目(默认为 30 秒),它会失败。检查仅在启用日志记录时运行。
可以通过传递 |
|
| 此检查对 OpenShift Container Platform SDN 执行以下集群级别的诊断:
如果使用
当 |
在配置 Cluster Pre-install Checks 中,包括了一组类似的检查旨在作为安装过程的一部分运行。关于检查证书过期的信息,请参阅重新部署证书。
40.5.1. 通过 ansible-playbook 运行健康检查
要使用 ansible-playbook 命令运行 openshift-ansible 健康检查,进入 playbook 目录,指定集群的清单文件,并运行 health.yml playbook:
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-checks/health.yml
要在命令行中设置变量,请将 -e 标志包括在 key=value 格式的任何所需变量中。例如:
$ cd /usr/share/ansible/openshift-ansible
$ ansible-playbook -i <inventory_file> \
playbooks/openshift-checks/health.yml \
-e openshift_check_logging_index_timeout_seconds=45 \
-e etcd_max_image_data_size_bytes=40000000000
要禁用特定的检查,请在运行 playbook 前,以逗号分隔的检查名称列表包括 openshift_disable_check 变量。例如:
openshift_disable_check=etcd_traffic,etcd_volume
另外,在运行 ansible-playbook 命令时,使用 -e openshift_disable_check=<check1>,<check2 > 设置为 disable。
40.5.2. 通过 Docker CLI 运行健康检查
您可以在容器中运行 openshift-ansible playbook,以避免在可通过 Docker CLI 运行 ose-ansible 镜像的任何主机上运行 ose-ansible 镜像。
作为具有运行容器权限的非 root 用户运行以下命令:
# docker run -u `id -u` \ 1 -v $HOME/.ssh/id_rsa:/opt/app-root/src/.ssh/id_rsa:Z,ro \ 2 -v /etc/ansible/hosts:/tmp/inventory:ro \ 3 -e INVENTORY_FILE=/tmp/inventory \ -e PLAYBOOK_FILE=playbooks/openshift-checks/health.yml \ 4 -e OPTS="-v -e openshift_check_logging_index_timeout_seconds=45 -e etcd_max_image_data_size_bytes=40000000000" \ 5 openshift3/ose-ansible
- 1
- 这些选项使容器使用与当前用户相同的 UID 运行,权限是必需的,以便可以在容器中读取 SSH 密钥(SSH 私钥应可由其所有者读取)。
- 2
- 以非 root 用户身份运行容器时,将 SSH 密钥作为卷挂载到 /opt/app-root/src/.ssh 下。
- 3
- 如果不同,将 /etc/ansible/hosts 更改为集群清单文件的位置。此文件被绑定挂载到 /tmp/inventory,它供容器中的
INVENTORY_FILE环境变量使用。 - 4
PLAYBOOK_FILE环境变量设置为与容器内的 /usr/share/ansible/openshift-ansible 相关的 health.yml playbook 的位置。- 5
- 使用
-e key=value格式设置单个运行所需的任何变量。
在上一命令中,使用 :Z 选项挂载 SSH 密钥,以便容器可以从其受限 SELinux 上下文读取 SSH 密钥。添加这个选项意味着您的原始 SSH 密钥文件与 system_u:object_r:container_file_t:s0:c113,c247 一样进行重新标记。有关 :Z 的详情,请查看 docker-run(1) man page。
这些卷挂载规格可能会产生意外后果。例如,如果您挂载了 和 protobuf 之后,则 $HOME/.ssh 目录,sshd 将无法访问公钥以允许远程登录。为避免更改原始文件标签,请挂载 SSH 密钥或目录的副本。
挂载整个 .ssh 目录会很有帮助:
- 允许您使用 SSH 配置来匹配主机的密钥或修改其他连接参数。
-
允许用户提供 known_hosts 文件并让 SSH 验证主机密钥。这由默认配置禁用,可以通过在
docker命令行中添加-e ANSIBLE_HOST_KEY_CHECKING=True来使用环境变量重新启用。
第 41 章 闲置应用程序
41.1. 概述
作为 OpenShift Container Platform 管理员,您可以闲置应用程序来减少资源消耗。这在部署到与资源消耗相关的公共云上部署时很有用。
如果任何可扩展的资源没有被使用,OpenShift Container Platform 会发现这些资源,然后把它们扩展为 0 个副本。当网络流量定向到资源时,通过扩展副本来取消闲置这些资源,然后操作继续进行。
应用程序由服务以及其他可扩展的资源组成,如部署配置。闲置应用程序的操作涉及闲置所有关联的资源。
41.2. 闲置应用程序
闲置应用程序包括查找与服务关联的可扩展资源(部署配置和复制控制器等)。闲置应用程序时会查找相关的服务,将其标记为空闲,并将资源缩减为零个副本。
您可以使用 oc idle 命令来闲置单个服务,或使用 --resource-names-file 选项来闲置多个服务。
41.2.1. 闲置单一服务
使用以下命令闲置单个服务:
$ oc idle <service>
41.2.2. 闲置多个服务
通过创建所需服务列表来闲置多个服务,然后使用 oc idle 命令的 --resource-names-file 选项。
如果应用程序横跨一个项目中的一组服务,或者将多个服务与脚本一起闲置多个服务时,这将非常有用。
- 创建一个包含服务列表的文本文件,每个服务各自列于一行。
使用
--resource-names-file选项闲置这些服务:$ oc idle --resource-names-file <filename>
idle 命令仅限于一个项目。若要闲置一个集群中的应用程序,请单独为每个项目运行 idle 命令。
41.3. 取消闲置应用程序
当应用程序服务接收网络流量并会备份之前的状态时,应用程序服务会再次激活。这包括流向服务的流量和通过路由的流量。
可以通过扩展资源来手动取消闲置应用程序。例如,要扩展 deploymentconfig,请运行以下命令:
$ oc scale --replicas=1 dc <deploymentconfig>
目前,只有默认的 HAProxy 路由器支持通过路由器自动取消闲置。
第 42 章 分析集群容量
42.1. 概述
作为集群管理员,您可以使用 hypercc cluster-capacity 工具查看可调度的 pod 数量,以便在资源耗尽前增加当前的资源,并确保将来的 pod 可以被调度。此容量来自于集群中的节点主机,包括 CPU、内存和磁盘空间等。
hypercc cluster-capacity 工具模拟一系列调度决策,以确定在资源耗尽前集群中可以调度多少个输入 pod 实例,以提供更加准确的估算。
因为它不计算节点间分布的所有资源,所以它所显示的剩余可分配容量是粗略估算值。它只分析剩余的资源,并通过估算集群中可以调度多少个具有给定要求的 pod 实例来估测仍可被消耗的可用容量。
另外,根据选择和关联性条件,可能仅支持将 pod 调度到特定的节点集合。因此,可能很难估算集群还能调度多少个 pod。
您可以从命令行运行 hypercc cluster-capacity 分析工具作为独立实用程序,或者在 OpenShift Container Platform 集群中的 pod 中作为一个作业。以 pod 内作业的方式运行时,可以将它运行多次而无需干预。
42.2. 在命令行中运行集群容量分析
安装 openshift-enterprise-cluster-capacity RPM 软件包以获取工具。在命令行中运行该工具:
$ hypercc cluster-capacity --kubeconfig <path-to-kubeconfig> \
--podspec <path-to-pod-spec>
--kubeconfig 选项表示您的 Kubernetes 配置文件,-- podspec 选项表示示例 pod 规格文件,工具将使用该文件来估算资源使用量。podspec 以 limits 或 requests 的形式指定资源要求。hypercc cluster-capacity 工具在估算分析时会考虑 pod 的资源要求。
pod 规格输入的示例如下:
apiVersion: v1
kind: Pod
metadata:
name: small-pod
labels:
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google-samples/gb-frontend:v4
imagePullPolicy: Always
resources:
limits:
cpu: 150m
memory: 100Mi
requests:
cpu: 150m
memory: 100Mi
您还可以添加 --verbose 选项,以输出集群的各个节点上可以调度多少个 pod 的详细描述:
$ hypercc cluster-capacity --kubeconfig <path-to-kubeconfig> \
--podspec <path-to-pod-spec> --verbose输出结果类似如下:
small-pod pod requirements: - CPU: 150m - Memory: 100Mi The cluster can schedule 52 instance(s) of the pod small-pod. Termination reason: Unschedulable: No nodes are available that match all of the following predicates:: Insufficient cpu (2). Pod distribution among nodes: small-pod - 192.168.124.214: 26 instance(s) - 192.168.124.120: 26 instance(s)
在上例中,集群中估计可以调度的 pod 数量是 52。
42.3. 将集群容量作为 Pod 的作业运行
若以 pod 中作业的方式运行集群容量工具,其优点是可以在无需用户干预的前提下多次运行。以作业方式运行集群容量工具需要使用 ConfigMap。
创建集群角色:
$ cat << EOF| oc create -f - kind: ClusterRole apiVersion: v1 metadata: name: cluster-capacity-role rules: - apiGroups: [""] resources: ["pods", "nodes", "persistentvolumeclaims", "persistentvolumes", "services"] verbs: ["get", "watch", "list"] EOF
创建服务帐户:
$ oc create sa cluster-capacity-sa
将角色添加到服务帐户:
$ oc adm policy add-cluster-role-to-user cluster-capacity-role \ system:serviceaccount:default:cluster-capacity-sa 1- 1
- 如果服务帐户不在
default项目中,请将default替换为项目名称。
定义并创建 pod 规格:
apiVersion: v1 kind: Pod metadata: name: small-pod labels: app: guestbook tier: frontend spec: containers: - name: php-redis image: gcr.io/google-samples/gb-frontend:v4 imagePullPolicy: Always resources: limits: cpu: 150m memory: 100Mi requests: cpu: 150m memory: 100Mi集群容量分析使用名为
cluster-capacity-configmap的ConfigMap挂载到卷中,从而将输入 pod 规格文件pod.yaml挂载到卷test-volume的路径/test-pod上。如果还没有创建
ConfigMap,请在创建作业前创建:$ oc create configmap cluster-capacity-configmap \ --from-file=pod.yaml使用以下作业规格文件示例创建作业:
apiVersion: batch/v1 kind: Job metadata: name: cluster-capacity-job spec: parallelism: 1 completions: 1 template: metadata: name: cluster-capacity-pod spec: containers: - name: cluster-capacity image: registry.redhat.io/openshift3/ose-cluster-capacity imagePullPolicy: "Always" volumeMounts: - mountPath: /test-pod name: test-volume env: - name: CC_INCLUSTER 1 value: "true" command: - "/bin/sh" - "-ec" - | /bin/cluster-capacity --podspec=/test-pod/pod.yaml --verbose restartPolicy: "Never" serviceAccountName: cluster-capacity-sa volumes: - name: test-volume configMap: name: cluster-capacity-configmap- 1
- 必要的环境变量,使集群容量工具知道它将作为一个 pod 在集群中运行。
ConfigMap的pod.yaml键与 pod 规格文件相同,但这不是强制要求。如果这样做,输入 pod 规格文件可作为/test-pod/pod.yaml在 pod 中被访问。
以 pod 中作业的方式运行集群容量镜像:
$ oc create -f cluster-capacity-job.yaml
检查作业日志,以查找在集群中可调度的 pod 数量:
$ oc logs jobs/cluster-capacity-job small-pod pod requirements: - CPU: 150m - Memory: 100Mi The cluster can schedule 52 instance(s) of the pod small-pod. Termination reason: Unschedulable: No nodes are available that match all of the following predicates:: Insufficient cpu (2). Pod distribution among nodes: small-pod - 192.168.124.214: 26 instance(s) - 192.168.124.120: 26 instance(s)
第 43 章 在 AWS 中配置集群自动扩展
您可以在 Amazon Web Services(AWS)的 OpenShift Container Platform 集群上配置自动扩展,以便为应用程序工作负载提供弹性。自动扩展可确保有足够的节点活跃来运行 pod,且活跃节点的数量与当前需求成比例。
只能在 AWS 上运行 auto-scaler。
43.1. 关于 OpenShift Container Platform auto-scaler
OpenShift Container Platform 中的自动扩展程序会重复检查以查看 pod 有多少待处理的节点分配。如果 pod 是待处理的分配,且自动扩展没有达到其最大容量,那么会持续置备新节点以适应当前需求。当需求下降和减少节点时,自动扩展器会删除未使用的节点。安装自动扩展后,其行为是自动的。您只需要将所需的副本数添加到部署中。
在 OpenShift Container Platform 版本 3.11 中,您只能在 Amazon Web Services(AWS)上部署 auto-scaler。auto-scaler 使用一些标准 AWS 对象来管理集群大小,包括自动扩展组和启动配置。
auto-scaler 使用以下资产:
- 自动扩展组
- 自动扩展组是一组计算机的逻辑表示。您可以配置自动扩展组,它具有要运行的最少实例数量、可运行的最大实例数,以及要运行的实例数量。自动扩展组首先启动足够的实例来满足您所需的容量。您可以配置自动扩展组,使其以零个实例开头。
- 启动配置
Launch Configuration 是自动扩展组用于启动实例的模板。在创建 Launch Configuration 时,您可以指定如下信息:
- 用作基础镜像的 Amazon Machine Image(AMI)的 ID
- 实例类型,如 m4.large
- 密钥对
- 一个或多个安全组
- 将启动配置应用到的子网
- OpenShift Container Platform primed 镜像
- 当自动扩展组置备新实例时,它启动的镜像必须已经准备好 OpenShift Container Platform。自动扩展组使用此镜像自动引导节点并在集群内注册它,而无需手动干预。
43.2. 创建 primed 镜像
您可以使用 Ansible playbook 自动创建一个 primed 镜像,供自动扩展器使用。您必须从现有 Amazon Web Services(AWS)集群中提供属性。
如果您已经有 primed 镜像,您可以使用它而不是创建新镜像。
流程
在用于创建 OpenShift Container Platform 集群的主机上,创建一个 primed 镜像:
在本地主机上创建一个新的 Ansible 清单文件。此文件需要分配
cloudprovider标志的变量,以便在参与的节点上启用自动扩展。如果没有这些变量,build_ami.ymlplaybook 无法使用openshift_cloud_provider角色:[OSEv3:children] masters nodes etcd [OSEv3:vars] openshift_deployment_type=openshift-enterprise ansible_ssh_user=ec2-user openshift_clusterid=mycluster ansible_become=yes openshift_cloudprovider_kind=aws 1 openshift_cloudprovider_aws_access_key=<aws_access_key> 2 openshift_cloudprovider_aws_secret_key=<aws_secret_key> 3 [masters] [etcd] [nodes]
在本地主机上创建置备文件 build-ami-provisioning-vars.yaml :
openshift_deployment_type: openshift-enterprise openshift_aws_clusterid: mycluster 1 openshift_aws_region: us-east-1 2 openshift_aws_create_vpc: false 3 openshift_aws_vpc_name: production 4 openshift_aws_subnet_az: us-east-1d 5 openshift_aws_create_security_groups: false 6 openshift_aws_ssh_key_name: production-ssh-key 7 openshift_aws_base_ami: ami-12345678 8 openshift_aws_create_s3: False 9 openshift_aws_build_ami_group: default 10 openshift_aws_vpc: 11 name: "{{ openshift_aws_vpc_name }}" cidr: 172.18.0.0/16 subnets: us-east-1: - cidr: 172.18.0.0/20 az: "us-east-1d" container_runtime_docker_storage_type: overlay2 12 container_runtime_docker_storage_setup_device: /dev/xvdb 13 # atomic-openshift-node service requires gquota to be set on the # filesystem that hosts /var/lib/origin/openshift.local.volumes (OCP # emptydir). Often is it not ideal or cost effective to deploy a vol # for emptydir. This pushes emptydir up to the / filesystem. Base ami # often does not ship with gquota enabled for /. Set this bool true to # enable gquota on / filesystem when using Red Hat Cloud Access RHEL7 # AMI or Amazon Market RHEL7 AMI. openshift_aws_ami_build_set_gquota_on_slashfs: true 14 rhsub_user: user@example.com 15 rhsub_pass: password 16 rhsub_pool: pool-id 17
- 1
- 提供现有集群的名称。
- 2
- 提供现有集群正在运行的区域。
- 3
- 指定
False来禁用 VPC 的创建。 - 4
- 提供集群在其中运行的现有 VPC 名称。
- 5
- 提供现有集群在其中运行的子网名称。
- 6
- 指定
False来禁用安全组的创建。 - 7
- 提供要用于 SSH 访问的 AWS 密钥名称。
- 8
- 提供 AMI 镜像 ID,以用作 primed 镜像的基础镜像。请参阅 Red Hat® Cloud Access。
- 9
- 指定
False来禁用 S3 存储桶的创建。 - 10
- 提供安全组名称。
- 11
- 提供现有集群的 VPC 子网。
- 12
- 指定
overlay2作为 Docker 存储类型。 - 13
- 指定 LVM 和 /var/lib/docker 目录的挂载点。
- 14
- 如果使用 Red Hat Cloud,则将此参数设置为
true,使其在文件系统中启用gquota。 - 15
- 为具有有效 OpenShift Container Platform 订阅的红帽帐户指定电子邮件地址。
- 16
- 指定红帽帐户的密码
- 17
- 为 OpenShift Container Platform 订阅指定一个池 ID。您可以使用创建集群时所用的相同池 ID。
运行 build_ami.yml playbook 以生成 primed 镜像:
# ansible-playbook -i </path/to/inventory/file> \ /usr/openshift-ansible/playbooks/aws/openshift-cluster/build_ami.yml \ -e @build-ami-provisioning-vars.yamlplaybook 运行后,您会在其输出中看到新镜像 ID 或 AMI。您可以指定在创建 Launch Configuration 时生成的 AMI。
43.3. 创建启动配置和自动扩展组
在部署集群自动扩展前,您必须创建一个 Amazon Web Services(AWS)启动配置和自动缩放组来引用 primed 镜像。您必须配置启动配置,以便在新节点启动时自动加入现有集群。
先决条件
- 在 AWS 中安装 OpenShift Container Platform 集群。
- 创建 primed 镜像。
-
如果在集群中部署了 EFK 堆栈,请将节点标签设置为
logging-infra-fluentd=true。
流程
通过从 master 节点生成 bootstrap.kubeconfig 文件来创建 bootstrap.kubeconfig 文件:
$ ssh master "sudo oc serviceaccounts create-kubeconfig -n openshift-infra node-bootstrapper" > ~/bootstrap.kubeconfig
从 bootstrap.kubeconfig 文件创建 user-data.txt cloud-init 文件:
$ cat <<EOF > user-data.txt #cloud-config write_files: - path: /root/openshift_bootstrap/openshift_settings.yaml owner: 'root:root' permissions: '0640' content: | openshift_node_config_name: node-config-compute - path: /etc/origin/node/bootstrap.kubeconfig owner: 'root:root' permissions: '0640' encoding: b64 content: | $(base64 ~/bootstrap.kubeconfig | sed '2,$s/^/ /') runcmd: - [ ansible-playbook, /root/openshift_bootstrap/bootstrap.yml] - [ systemctl, restart, systemd-hostnamed] - [ systemctl, restart, NetworkManager] - [ systemctl, enable, atomic-openshift-node] - [ systemctl, start, atomic-openshift-node] EOF- 将启动配置模板上传到 AWS S3 存储桶。
使用 AWS CLI 创建启动配置:
$ aws autoscaling create-launch-configuration \ --launch-configuration-name mycluster-LC \ 1 --region us-east-1 \ 2 --image-id ami-987654321 \ 3 --instance-type m4.large \ 4 --security-groups sg-12345678 \ 5 --template-url https://s3-.amazonaws.com/.../yourtemplate.json \ 6 --key-name production-key \ 7注意如果在对模板进行编码前,如果您的模板少于 16 KB,您可以使用 AWS CLI 将
--template-url替换为--user-data来提供它。使用 AWS CLI 创建自动扩展组:
$ aws autoscaling create-auto-scaling-group \ --auto-scaling-group-name mycluster-ASG \ 1 --launch-configuration-name mycluster-LC \ 2 --min-size 1 \ 3 --max-size 6 \ 4 --vpc-zone-identifier subnet-12345678 \ 5 --tags ResourceId=mycluster-ASG,ResourceType=auto-scaling-group,Key=Name,Value=mycluster-ASG-node,PropagateAtLaunch=true ResourceId=mycluster-ASG,ResourceType=auto-scaling-group,Key=kubernetes.io/cluster/mycluster,Value=true,PropagateAtLaunch=true ResourceId=mycluster-ASG,ResourceType=auto-scaling-group,Key=k8s.io/cluster-autoscaler/node-template/label/node-role.kubernetes.io/compute,Value=true,PropagateAtLaunch=true 6
43.4. 在集群中部署自动扩展组件
在创建 Launch Configuration 和自动扩展组后,您可以将自动扩展组件部署到集群中。
先决条件
- 在 AWS 中安装 OpenShift Container Platform 集群。
- 创建 primed 镜像。
- 创建启动配置和自动扩展组,以引用 primed 镜像。
流程
部署 auto-scaler:
更新集群,以运行 auto-scaler:
默认情况下,将以下参数添加到用于创建集群的清单文件,默认为 /etc/ansible/hosts :
openshift_master_bootstrap_auto_approve=true
要获取自动扩展组件,请切换到 playbook 目录并再次运行 playbook:
$ cd /usr/share/ansible/openshift-ansible $ ansible-playbook -i </path/to/inventory/file> \ playbooks/openshift-master/enable_bootstrap.yml确认
bootstrap-autoapproverpod 正在运行:$ oc get pods --all-namespaces | grep bootstrap-autoapprover NAMESPACE NAME READY STATUS RESTARTS AGE openshift-infra bootstrap-autoapprover-0 1/1 Running 0
为 auto-scaler 创建命名空间:
$ oc apply -f - <<EOF apiVersion: v1 kind: Namespace metadata: name: cluster-autoscaler annotations: openshift.io/node-selector: "" EOF为 auto-scaler 创建服务帐户:
$ oc apply -f - <<EOF apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-addon: cluster-autoscaler.addons.k8s.io k8s-app: cluster-autoscaler name: cluster-autoscaler namespace: cluster-autoscaler EOF创建集群角色,为服务帐户授予所需的权限:
$ oc apply -n cluster-autoscaler -f - <<EOF apiVersion: v1 kind: ClusterRole metadata: name: cluster-autoscaler rules: - apiGroups: 1 - "" resources: - pods/eviction verbs: - create attributeRestrictions: null - apiGroups: - "" resources: - persistentvolumeclaims - persistentvolumes - pods - replicationcontrollers - services verbs: - get - list - watch attributeRestrictions: null - apiGroups: - "" resources: - events verbs: - get - list - watch - patch - create attributeRestrictions: null - apiGroups: - "" resources: - nodes verbs: - get - list - watch - patch - update attributeRestrictions: null - apiGroups: - extensions - apps resources: - daemonsets - replicasets - statefulsets verbs: - get - list - watch attributeRestrictions: null - apiGroups: - policy resources: - poddisruptionbudgets verbs: - get - list - watch attributeRestrictions: null EOF- 1
- 如果存在
cluster-autoscaler对象,请确保在 verb创建时pod/eviction规则存在。
为部署自动扩展创建角色:
$ oc apply -n cluster-autoscaler -f - <<EOF apiVersion: v1 kind: Role metadata: name: cluster-autoscaler rules: - apiGroups: - "" resources: - configmaps resourceNames: - cluster-autoscaler - cluster-autoscaler-status verbs: - create - get - patch - update attributeRestrictions: null - apiGroups: - "" resources: - configmaps verbs: - create attributeRestrictions: null - apiGroups: - "" resources: - events verbs: - create attributeRestrictions: null EOF
创建 creds 文件来存储 auto-scaler 的 AWS 凭证:
$ cat <<EOF > creds [default] aws_access_key_id = your-aws-access-key-id aws_secret_access_key = your-aws-secret-access-key EOF
auto-scaler 使用这些凭证来启动新实例。
创建包含 AWS 凭证的 secret:
$ oc create secret -n cluster-autoscaler generic autoscaler-credentials --from-file=creds
auto-scaler 使用此 secret 在 AWS 中启动实例。
为您创建的
cluster-autoscaler服务帐户创建并授予 cluster-reader 角色:$ oc adm policy add-cluster-role-to-user cluster-autoscaler system:serviceaccount:cluster-autoscaler:cluster-autoscaler -n cluster-autoscaler $ oc adm policy add-role-to-user cluster-autoscaler system:serviceaccount:cluster-autoscaler:cluster-autoscaler --role-namespace cluster-autoscaler -n cluster-autoscaler $ oc adm policy add-cluster-role-to-user cluster-reader system:serviceaccount:cluster-autoscaler:cluster-autoscaler -n cluster-autoscaler
部署集群自动扩展:
$ oc apply -n cluster-autoscaler -f - <<EOF apiVersion: apps/v1 kind: Deployment metadata: labels: app: cluster-autoscaler name: cluster-autoscaler namespace: cluster-autoscaler spec: replicas: 1 selector: matchLabels: app: cluster-autoscaler role: infra template: metadata: labels: app: cluster-autoscaler role: infra spec: containers: - args: - /bin/cluster-autoscaler - --alsologtostderr - --v=4 - --skip-nodes-with-local-storage=False - --leader-elect-resource-lock=configmaps - --namespace=cluster-autoscaler - --cloud-provider=aws - --nodes=0:6:mycluster-ASG env: - name: AWS_REGION value: us-east-1 - name: AWS_SHARED_CREDENTIALS_FILE value: /var/run/secrets/aws-creds/creds image: registry.redhat.io/openshift3/ose-cluster-autoscaler:v3.11 name: autoscaler volumeMounts: - mountPath: /var/run/secrets/aws-creds name: aws-creds readOnly: true dnsPolicy: ClusterFirst nodeSelector: node-role.kubernetes.io/infra: "true" serviceAccountName: cluster-autoscaler terminationGracePeriodSeconds: 30 volumes: - name: aws-creds secret: defaultMode: 420 secretName: autoscaler-credentials EOF
43.5. 测试自动扩展
在 Amazon Web Services(AWS)集群中添加 auto-scaler 后,您可以通过部署超过当前节点可以运行的 pod 来确认 auto-scaler 是否正常工作。
先决条件
- 将 auto-scaler 添加到在 AWS 上运行的 OpenShift Container Platform 集群中。
流程
创建 scale-up.yaml 文件,其中包含用于测试自动扩展的部署配置:
apiVersion: apps/v1 kind: Deployment metadata: name: scale-up labels: app: scale-up spec: replicas: 20 1 selector: matchLabels: app: scale-up template: metadata: labels: app: scale-up spec: containers: - name: origin-base image: openshift/origin-base resources: requests: memory: 2Gi command: - /bin/sh - "-c" - "echo 'this should be in the logs' && sleep 86400" terminationGracePeriodSeconds: 0- 1
- 此部署指定 20 个副本,但集群的初始大小在没有首先增加计算节点数量的情况下无法运行所有 pod。
为部署创建一个命名空间:
$ oc apply -f - <<EOF apiVersion: v1 kind: Namespace metadata: name: autoscaler-demo EOF
部署配置:
$ oc apply -n autoscaler-demo -f scale-up.yaml
查看命名空间中的 pod:
查看在命名空间中运行的 pod:
$ oc get pods -n autoscaler-demo | grep Running cluster-autoscaler-5485644d46-ggvn5 1/1 Running 0 1d scale-up-79684ff956-45sbg 1/1 Running 0 31s scale-up-79684ff956-4kzjv 1/1 Running 0 31s scale-up-79684ff956-859d2 1/1 Running 0 31s scale-up-79684ff956-h47gv 1/1 Running 0 31s scale-up-79684ff956-htjth 1/1 Running 0 31s scale-up-79684ff956-m996k 1/1 Running 0 31s scale-up-79684ff956-pvvrm 1/1 Running 0 31s scale-up-79684ff956-qs9pp 1/1 Running 0 31s scale-up-79684ff956-zwdpr 1/1 Running 0 31s
查看命名空间中的待处理 pod:
$ oc get pods -n autoscaler-demo | grep Pending scale-up-79684ff956-5jdnj 0/1 Pending 0 40s scale-up-79684ff956-794d6 0/1 Pending 0 40s scale-up-79684ff956-7rlm2 0/1 Pending 0 40s scale-up-79684ff956-9m2jc 0/1 Pending 0 40s scale-up-79684ff956-9m5fn 0/1 Pending 0 40s scale-up-79684ff956-fr62m 0/1 Pending 0 40s scale-up-79684ff956-q255w 0/1 Pending 0 40s scale-up-79684ff956-qc2cn 0/1 Pending 0 40s scale-up-79684ff956-qjn7z 0/1 Pending 0 40s scale-up-79684ff956-tdmqt 0/1 Pending 0 40s scale-up-79684ff956-xnjhw 0/1 Pending 0 40s
在集群自动扩展自动置备新计算节点以运行 pod 前,这些待处理的 pod 无法运行。节点可以在几分钟内,处于
Ready状态。
几分钟后,检查节点列表以查看新节点是否就绪:
$ oc get nodes NAME STATUS ROLES AGE VERSION ip-172-31-49-172.ec2.internal Ready infra 1d v1.11.0+d4cacc0 ip-172-31-53-217.ec2.internal Ready compute 7m v1.11.0+d4cacc0 ip-172-31-55-89.ec2.internal Ready compute 9h v1.11.0+d4cacc0 ip-172-31-56-21.ec2.internal Ready compute 7m v1.11.0+d4cacc0 ip-172-31-56-71.ec2.internal Ready compute 7m v1.11.0+d4cacc0 ip-172-31-63-234.ec2.internal Ready master 1d v1.11.0+d4cacc0
当更多节点就绪时,再次查看在命名空间中运行的 pod:
$ oc get pods -n autoscaler-demo NAME READY STATUS RESTARTS AGE cluster-autoscaler-5485644d46-ggvn5 1/1 Running 0 1d scale-up-79684ff956-45sbg 1/1 Running 0 8m scale-up-79684ff956-4kzjv 1/1 Running 0 8m scale-up-79684ff956-5jdnj 1/1 Running 0 8m scale-up-79684ff956-794d6 1/1 Running 0 8m scale-up-79684ff956-7rlm2 1/1 Running 0 8m scale-up-79684ff956-859d2 1/1 Running 0 8m scale-up-79684ff956-9m2jc 1/1 Running 0 8m scale-up-79684ff956-9m5fn 1/1 Running 0 8m scale-up-79684ff956-fr62m 1/1 Running 0 8m scale-up-79684ff956-h47gv 1/1 Running 0 8m scale-up-79684ff956-htjth 1/1 Running 0 8m scale-up-79684ff956-m996k 1/1 Running 0 8m scale-up-79684ff956-pvvrm 1/1 Running 0 8m scale-up-79684ff956-q255w 1/1 Running 0 8m scale-up-79684ff956-qc2cn 1/1 Running 0 8m scale-up-79684ff956-qjn7z 1/1 Running 0 8m scale-up-79684ff956-qs9pp 1/1 Running 0 8m scale-up-79684ff956-tdmqt 1/1 Running 0 8m scale-up-79684ff956-xnjhw 1/1 Running 0 8m scale-up-79684ff956-zwdpr 1/1 Running 0 8m ...
第 44 章 使用功能门禁用功能
作为管理员,您可以使用功能门(feature gates)关闭特定节点或整个平台。
例如,您可以关闭生产集群的新功能,同时为测试集群保留功能,以便完全测试它们。
如果您禁用 web 控制台中出现的功能,您可能会看到该功能,但没有列出对象。如果您试图使用与禁用的功能关联的命令,OpenShift Container Platform 会显示一个错误。
如果您禁用集群中任何应用程序依赖的功能,则应用程序可能无法正常工作,具体取决于功能被禁用以及应用程序如何使用该功能。
功能门使用 master 配置文件中的 key=value 对(/etc/origin/master/master-config.yaml)以及描述您要阻断功能的节点配置文件。
要修改节点配置文件,请根据需要更新 节点配置映射。不要手动编辑 node-config.yaml 文件。
例如,以下代码关闭 Huge Pages 功能:
kubernetesMasterConfig:
apiServerArguments:
feature-gates:
- HugePages=false 1
...
controllerArguments:
feature-gates:
- HugePages=false 2指定一个以逗号分隔的行中的多个功能门:
kubeletArguments: feature-gates: - RotateKubeletClientCertificate=true,RotateKubeletServerCertificate=true,ExpandPersistentVolumes=true,HugePages=false
44.1. 为集群禁用功能
要为整个集群关闭一个功能,请编辑 master 配置文件,默认为 /etc/origin/master/master-config.yaml :
对于您要关闭的功能,在
apiServerArguments和controllerArguments下输入:<feature_name>=false。例如:
kubernetesMasterConfig: apiServerArguments: feature-gates: - HugePages=false controllerArguments: feature-gates: - HugePages=false指定一个以逗号分隔的行中的多个功能门:
kubernetesMasterConfig: apiServerArguments: feature-gates: - RotateKubeletClientCertificate=false,RotateKubeletServerCertificate=false,ExpandPersistentVolumes=true,HugePages=false controllerArguments: feature-gates: - RotateKubeletClientCertificate=false,RotateKubeletServerCertificate=false,ExpandPersistentVolumes=true,HugePages=false重启 OpenShift Container Platform master 服务以应用更改。
# master-restart api # master-restart controllers
要重新启用禁用的功能,请编辑 master 配置文件以删除 <feature_name>=false 并重启 master 服务。
44.2. 为节点禁用功能
要为节点主机关闭某个功能,请编辑适当的节点 配置映射 :
要修改节点配置文件: 根据需要更新 节点配置映射。不要手动编辑 node-config.yaml 文件。
对于您要关闭的功能,在
kubeletArguments下输入:<feature_name>=false。例如:
kubeletArguments: feature-gates: - HugePages=false
指定一个以逗号分隔的行中的多个功能门:
kubeletArguments: feature-gates: - RotateKubeletClientCertificate=false,RotateKubeletServerCertificate=false,ExpandPersistentVolumes=true,HugePages=false
重启 OpenShift Container Platform 服务以使更改生效:
# systemctl restart atomic-openshift-node.service
要重新启用禁用的功能,请编辑节点配置文件以删除 <feature_name>=false 并重启节点服务。
要修改节点配置文件,请根据需要更新 节点配置映射。不要手动编辑 node-config.yaml 文件。
44.2.1. Feature Gates 列表
使用以下列表来决定您要禁用的功能名称:
| 功能门 | 描述 |
|---|---|
| 加速器 | 使用 Docker 时启用 Nvidia GPU 支持。 |
| AdvancedAuditing | 启用 高级审计。 |
| APIListChunking | 允许 API 客户端从 API 服务器以块中检索 LIST 或 GET 资源。 |
| APIResponseCompression | 支持为 LIST 或 GET 请求压缩 API 响应。 |
| AppArmor | 使用 Docker 时,在 Linux 节点上启用基于 AppArmor 的强制访问控制。如需更多信息,请参阅 Kubernetes AppArmor 文档。 |
| BlockVolume | 启用 pod 中原始块设备的定义和消耗。如需更多信息,请参阅 Kubernetes Raw Block Volume 支持。 |
| CPUManager | 启用容器级别的 CPU 关联性支持。如需更多信息,请参阅使用 CPU Manager。 |
| CRIContainerLogRotation | 为 CRI 容器运行时启用容器日志轮转。 |
| CSIPersistentVolume | 通过兼容 CSI(容器存储接口)兼容的卷插件启用发现和挂载卷。如需更多信息,请参阅 Kubernetes 设计文档中的 CSI 卷插件。 |
| CustomPodDNS | 启用使用 dnsConfig 属性自定义 pod 的 DNS 设置。 |
| CustomResourceSubresources | 在通过 CustomResourceDefinition 创建的资源上启用 /status 和 /scale 子资源。请参阅使用自定义资源扩展 Kubernetes API。 |
| CustomResourceValidation | 在从自定义资源定义中创建的资源上启用基于架构的验证。如需更多信息,请参阅使用自定义资源扩展 Kubernetes API。 |
| DebugContainers | 启用在 pod 命名空间中运行调试容器以对正在运行的 Pod 进行故障排除。 |
| DevicePlugins | 在节点上 启用基于设备插件 的资源置备。 |
| DynamicKubeletConfig | 在集群中启用动态配置。 |
| DynamicVolumeProvisioning(deprecated) | 支持将持久性卷的动态置备到 pod。 |
| EnableEquivalenceClassCache | 启用调度程序在调度 Pod 时缓存超过节点的情况。 |
| ExperimentalCriticalPodAnnotation | 允许将特定 pod 标注为关键,以便保证其调度。 |
| ExperimentalHostUserNamespaceDefaultingGate | 启用禁用用户命名空间。这适用于使用其他主机项目、主机挂载或使用特定非项目功能的容器,如 MKNODE、SYS_MODULE 等。这只有在 Docker 守护进程中启用了用户项目重新映射时才启用。 |
| GCERegionalPersistentDisk | 启用 GCE Persistent Disk 功能。 |
| HugePages | 启用预先分配的巨页的分配和消耗。 |
| HyperVContainer | 为 Windows 容器启用 Hyper-V 隔离。 |
| Intializers | 启用 动态准入控制,作为内置准入控制器的扩展。 |
| LocalStorageCapacityIsolation |
启用本地临时存储的消耗以及 emptyDir 卷的 |
| MountContainers | 启用在主机上使用 utility 容器作为卷挂载。 |
| MountPropagation | 启用将一个容器挂载的卷与其他容器或 pod 共享。 |
| PersistentLocalVolumes | 启用 本地卷 pod 的使用。如果请求本地卷,则必须指定 Pod 关联性。 |
| PodPriority | 根据优先级启用 pod 的取消调度与抢占。 |
| ReadOnlyAPIDataVolumes | |
| ResourceLimitsPriorityFunction |
启用 调度程序 优先级函数,将最低的分数 |
| RotateKubeletClientCertificate | 在集群中启用客户端 TLS 证书轮转。 |
| RotateKubeletServerCertificate | 在集群中启用服务器 TLS 证书轮转。 |
| RunAsGroup | 允许控制容器的 init 进程上设置的主组 ID。 |
| ScheduleDaemonSetPods | 启用 DaemonSet pod 由默认调度程序 而不是 DaemonSet 控制器调度。 |
| ServiceNodeExclusion | 支持从云供应商创建的负载均衡器中排除节点。 |
| StorageObjectInUseProtection | 如果 持久性卷或持久性卷声明 对象仍然被使用,请启用删除它们。 |
| StreamingProxyRedirects | 指示 API 服务器拦截,并遵循后端 kubelet 重定向到流传输请求。 |
| SupportIPVSProxyMode | 启用使用 IP 虚拟服务器提供集群服务负载均衡。 |
| SupportPodPidsLimit | 启用对在 pod 中运行的进程(PID)数量进行限制。 |
| TaintBasedEvictions | 启用根据节点上的 污点和 pod 上的容限,从节点驱除 pod。 |
| TaintNodesByCondition | 启用自动根据 节点状况污点节点。 |
| TokenRequest | 在服务帐户资源上启用 TokenRequest 端点。 |
| VolumeScheduling | 启用无处学学调度,并告知持久性卷声明 (PVC)对调度决策的约束。它还启用了与 PersistentLocalVolumes 功能门一起使用的 本地卷类型。 |
第 45 章 Kuryr SDN 管理
45.1. 概述
Kuryr (或 Kuryr-Kubernetes)是 OpenShift Container Platform 的 SDN 选择之一。Kuryr 使用 OpenStack 网络服务 Neutron 将 pod 连接到网络。使用此方法,pod 可以与 OpenStack 虚拟机(VM)互相连接,这对于 OpenStack 虚拟机上部署的 OpenShift Container Platform 集群非常有用。
45.1.1. 孤立的 OpenStack 资源
Kuryr 创建的所有 OpenStack 资源都绑定到 OpenShift Container Platform 资源生命周期。手动删除 Kuryr 创建的资源(如 OpenStack 虚拟机)可能会导致 OpenStack 部署具有孤立资源。这包括,但不限于 Neutron 端口、Octavia、负载均衡器、网络、子网和为 Kuryr 使用而创建的安全组。通过查找 kuryr.conf 文件中找到的资源 ID,可以正确删除孤立的资源。另外,如果 Kuryr 资源由单独的 OpenStack 用户创建,您可以使用关联的用户名查询 OpenStack API。