
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Обзор Cluster Suite
Red Hat Cluster Suite для Red Hat Enterprise Linux 5
Редакция 3
Аннотация
Введение
- Руководство по установке Red Hat Enterprise Linux предоставляет информацию о процессе установки Red Hat Enterprise Linux 5.
- Руководство по развертыванию Red Hat Enterprise Linux предоставляет информацию по развертыванию, конфигурации и администрированию Red Hat Enterprise Linux 5.
- Конфигурация и администрирование Red Hat Cluster предоставляет информацию об установке, конфигурации и управлению компонентами Red Hat Cluster.
- LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Глобальная файловая система: Конфигурация и администрирование предоставляет информацию по установке, настройке и обеспечении поддержки GFS Red Hat.
- Глобальная файловая система 2: Конфигурация и администрирование предоставляет информацию по установке, конфигурации и обеспечении поддержки GFS2 Red Hat.
- Использование Device-Mapper Multipath содержит описание возможности Device-Mapper Multipath в Red Hat Enterprise Linux 5.
- Использование GNBD с GFS содержит обзорную информацию о работе GNBD (Global Network Block Device) с GFS Red Hat.
- Администрирование виртуального сервера Linux содержит информацию о конфигурации высокопроизводительных систем и служб с помощью виртуального сервера Linux (LVS, Linux Virtual Server).
- Замечания к выпуску Red Hat Cluster Suite содержат краткие сведения о выпуске.
1. Обратная связь
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Глава 1. Обзор Red Hat Cluster Suite
1.1. Основы кластера
- Хранилище
- Высокая доступность
- Распределение нагрузки
- Высокая производительность
Примечание
1.2. Red Hat Cluster Suite Introduction
- Инфраструктура кластера — предоставляет основные функции узлам, которые позволяют их объединять в кластер. Эти функции включают управление файлами конфигурации, участниками, блокировкой, а также функции изолирования узлов.
- Управление службами высокой доступности — обеспечивает перенос работы служб с проблемного узла на функционирующий.
- Утилиты администрирования кластера — утилиты конфигурации и управления кластером Red Hat используются вместе с компонентами инфраструктуры кластера, компонентами высокой доступности, управления службами и хранилищами.
- Виртуальный сервер Linux (LVS, Linux Virtual Server) — программное обеспечение маршрутизации, осуществляющее распределение нагрузки IP. LVS выполняется на двух избыточных серверах, которые равномерно распределяют запросы клиентов между рабочими серверами, на основе которых и созданы виртуальные сервера.
- Red Hat GFS (Global File System) — кластерная файловая система для Red Hat Cluster Suite. GFS допускает совместное использование хранилища несколькими узлами на уровне блоков так, как будто оно подключено локально к каждому узлу.
- Менеджер логических томов кластера (CLVM, Cluster Logical Volume Manager) — обеспечивает управление кластерным хранилищем.
Примечание
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Раздел 1.6, «Менеджер логических томов кластера». - Устройство GNBD (Global Network Block Device) — дополнительный компонент GFS, экспортирующий блочное хранилище для Ethernet. GNBD представляет собой экономичное решение для обеспечения доступа Red Hat GFS к хранилищу.

Рисунок 1.1. Red Hat Cluster Suite Introduction
Примечание
1.3. Cluster Infrastructure
- Управление кластерами
- Управление блокировками
- Fencing
- Управление конфигурацией кластера
1.3.1. Управление кластером
Примечание

Рисунок 1.2. CMAN/DLM Overview
1.3.2. Управление блокировкой
1.3.3. Fencing
fenced.
fenced, который тут же изолирует проблемный узел. Другие компоненты будут выполнять действия в соответствии с ситуацией, к примеру, начнут операции восстановления. Получив информацию о сбое узла, DLM и GFS прекращают все действия, до тех пор пока fenced не завершит его изолирование.
- Изолирование с помощью питания: использует контроллер питания для отключения проблемного узла.
- Изолирование с помощью переключателя Fibre Channel: отключает порт Fibre Channel, соединяющий хранилище с проблемным узлом.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Прочие виды: отключение ввода/ вывода или питания проблемного узла, включая IBM Bladecenters, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II и пр.

Рисунок 1.3. Power Fencing Example

Рисунок 1.4. Fibre Channel Switch Fencing Example

Рисунок 1.5. Fencing a Node with Dual Power Supplies

Рисунок 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Система конфигурации кластера

Рисунок 1.7. CCS Overview

Рисунок 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf) представляет собой XML-файл, содержащий определения следующих характеристрик:
- Имя кластера: Отображает имя кластера, версию его файла конфигурации, основные временные параметры изоляции, назначаемые узлу при его включении в кластер.
- Кластер: Отображает все узлы кластера с указанием их имен, идентификаторов, число соответствующих пунктов кворума и изолирующий метод.
- Изолирующее устройство: Отображает соответствующие кластеру устройства. Параметры могут отличаться для разных типов устройств. Например, если в качестве ограничивающего устройства используется контроллер питания, то настройки будут включать его имя, IP-адрес, имя входа и пароль.
- Управляемые ресурсы: Отображают необходимые для создания кластерных служб ресурсы, что включает определения доменов восстановления, ресурсов (IP-адреса и др.), а также службы. Комбинация управляемых ресурсов позволяет определить кластерные службы и их поведение в случае сбоя.
1.4. Управление службами высокой доступности
rgmanager, обеспечивающий восстановление приложений. В кластере Red Hat для организации службы с высоким доступом осуществляется настройка приложения с другими кластерными ресурсами. Такие службы могут быть перенесены с одного кластерного узла на другой без видимого клиенту прерывания работы. Перенос обычно выполняется при сбое узла или в случае необходимости (например, плановой профилактики).
Примечание

Рисунок 1.9. Домены восстановления
- Ресурс IP-адреса: 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Рисунок 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Упрощение инфраструктуры данных
- Установка приложений и их исправлений один раз для всего кластера.
- Нет необходимости в избыточных копиях данных приложений (дублировании).
- Активируется одновременный доступ чтения/ записи данных для клиентов.
- Упрощение резервного копирования и восстановления после аварийного сбоя (для одной файловой системы).
- Максимальная утилизация ресурсов хранения, минимизация издержек их администрирования.
- Управление хранилищем как единым целым, а не на уровне разделов.
- Снижение потребностей хранилища в ресурсах за счет исключения дублирования данных.
- Прозрачное масштабирование кластера за счет добавления серверов или хранилища «на лету».
- Упрощено разбиение хранилища на разделы.
- Добавление серверов в кластер «на лету» путем их монтирования в общую файловую систему.
Примечание
1.5.1. Повышение производительности и масштабируемости

Рисунок 1.11. GFS with a SAN
1.5.2. Производительность, масштабируемость, экономичность

Рисунок 1.12. GFS and GNBD with a SAN
1.5.3. Экономичность и производительность

Рисунок 1.13. GFS и GNBD с напрямую подключенным хранилищем
1.6. Менеджер логических томов кластера
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Рисунок 1.14, «CLVM Overview»). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Раздел 1.3, «Cluster Infrastructure»).
Примечание
clvmd или агенты управления высокодоступными логическими томами HA-LVM (High Availability Logical Volume Management). Если по какой-то причине вы не можете их запустить, например, у вас нет достаточных полномочий, то не используйте LVM на диске с совместным доступом, так как это может повредить данные. Если у вас есть вопросы, обратитесь за помощью к торговому представителю Red Hat.
Примечание
/etc/lvm/lvm.conf.

Рисунок 1.14. CLVM Overview

Рисунок 1.15. LVM Graphical User Interface

Рисунок 1.16. Conga LVM Graphical User Interface

Рисунок 1.17. Creating Logical Volumes
1.7. Устройство GNBD

Рисунок 1.18. Обзор GNBD
1.8. Виртуальный сервер Linux
- Обеспечивать баланс загрузки между настоящими серверами.
- Выполнять проверку целостности служб на каждом реальном сервере.
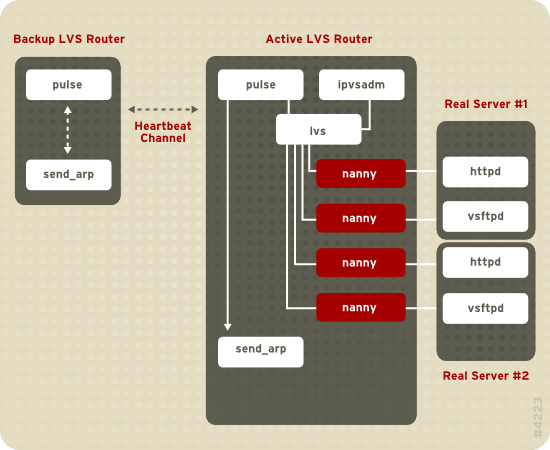
Рисунок 1.19. Components of a Running LVS Cluster
pulse. На резервном маршрутизаторе LVS pulse отправляет тактовый импульс общему интерфейсу активного маршрутизатора, чтобы проверить корректность его работы. На активном маршрутизаторе pulse запустит демон lvs и ответит на полученные от резервного маршрутизатора LVS запросы тактового импульса.
lvs вызывает утилиту ipvsadm для выполнения конфигурации и обеспечения поддержки работы таблицы маршрутизации сервера IPVS (IP Virtual Server) в ядре, а также на каждом реальном сервере запускает процесс nanny для каждого настроенного виртуального сервера. Процесс nanny проверяет состояние одной службы для каждого настоящего сервера и сообщает демону lvs о неполадках. Если обнаружены проблемы, lvs укажет ipvsadm удалить соответствующий настоящий сервер из таблицы маршрутизации IPVS.
send_arp, что позволит переназначить все виртуальные адреса IP аппаратным адресам NIC (MAC) резервного маршрутизатора LVS. Затем активному маршрутизатору будет направлена команда завершения работы демона lvs и через общий, и через частный сетевые интерфейсы, а на резервном маршрутизаторе будет запущен демон lvs, для того чтобы получать запросы от настроенных виртуальных серверов.
- Синхронизировать данные между серверами.
- Добавить третий слой топологии для доступа к разделяемым данным.
rsync для периодической синхронизации измененных данных на всех серверах. Но в окружениях, где пользователи часто закачивают файлы на сервер или обращаются к базе данных, вместо rsync или сценариев оболочки для синхронизации данных больше подходит применение трехуровневой топологии.
1.8.1. Two-Tier LVS Topology
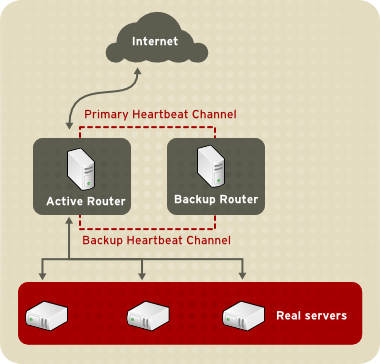
Рисунок 1.20. Two-Tier LVS Topology
eth0:1. Или же каждый виртуальный сервер может быть сопоставлен отдельному устройству для каждой службы. К примеру, обработка HTTP-трафика будет осуществляться на eth0:1, а FTP-трафика -- на eth0:2.
- Последовательный (RR, Round-Robin): распределяет каждый запрос последовательно между серверами в предопределенном наборе. В этом случае предпочтение не отдается никаким серверам, независимо от их емкости или загрузки.
- Последовательный с коэффициентом (WRR, Weighted Round-Robin): распределяет каждый запрос последовательно между серверами в предопределенном наборе, но назначает серверам с большей емкостью больше задач. Емкость определяется заданным пользователем коэффициентом, который изменяется в зависимости от информации о загрузке. Такой метод является предпочтительным, если емкости серверов значительно отличаются. Но если загрузка запросов сильно изменяется, сервер с бóльшим коэффициентом может обработать большее число запросов.
- Минимальное число соединений: распределяет больше запросов между серверами с меньшим числом активных соединений. Такой алгоритм динамического распределения предпочтителен в случаях, когда загрузка запросов значительно изменяется, и лучше всего подходит для набора реальных серверов, в котором все сервера обладают приблизительно одинаковой емкостью. Если же их емкость отличается, можно использовать следующий алгоритм.
- Минимальное число соединений с коэффициентом (используется по умолчанию): распределяет больше запросов между серверами с меньшим числом активных соединений, которые зависят от емкости, которой соответствует определенный пользователем коэффициент. Коэффициент изменяется в зависимости от информации загрузки. Добавление коэффициента делает этот алгоритм идеальным выбором, если набор настоящих серверов содержит оборудование с различной емкостью.
- Минимальное число соединений в зависимости от расположения: распределяет больше запросов между серверами с меньшим числом активных соединений, которые зависят от целевого IP-адреса. Такой алгоритм используется для кластеров сервера прокси-кэша. При этом пакеты, предназначенные IP-адресу на сервере, направляются этому серверу, если только емкость сервера не превышена, а загрузка сервера не достигла половины, в случае чего IP-адрес будет присвоен наименее загруженному настоящему серверу.
- Минимальное число соединений в зависимости от расположения с дублированием: распределяет больше запросов между серверами с меньшим числом активных соединений, которые зависят от целевого IP-адреса. Такой алгоритм используется для кластеров сервера прокси-кэша. Он отличается от предыдущего алгоритма тем, что целевой IP-адрес сопоставляется набору настоящих серверов. Затем запросы направляются тому серверу, которому соответствует наименьшее число соединений. Если же емкость всех узлов для заданного IP-адреса превышена, будет выполнено дублирование нового сервера путем добавления настоящего сервера с минимальным числом подключений из общего набора в подмножество серверов для целевого IP-адреса. Максимально загруженный узел будет исключен из набора, что позволит избежать излишнего дублирования.
- Хеш источника: распределяет запросы между реальными серверами в наборе, определяя IP-адрес источника из статической таблицы хеша. Этот алгоритм обычно применяется для маршрутизаторов LVS c несколькими межсетевыми экранами.
1.8.2. Three-Tier LVS Topology
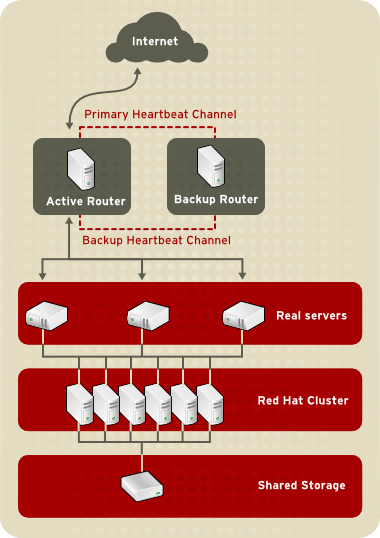
Рисунок 1.21. Three-Tier LVS Topology
1.8.3. Методы маршрутизации
1.8.3.1. Маршрутизация NAT
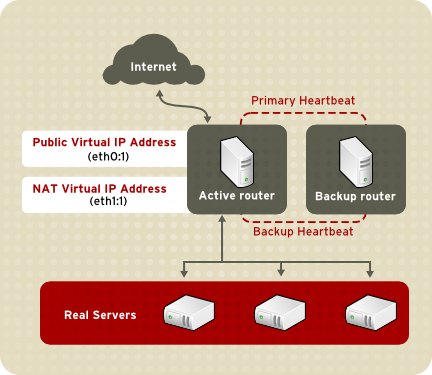
Рисунок 1.22. LVS Implemented with NAT Routing
1.8.3.2. Прямая маршрутизация
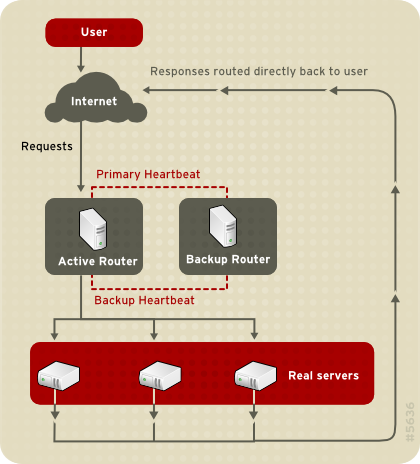
Рисунок 1.23. LVS Implemented with Direct Routing
arptables.
1.8.4. Постоянство и метки межсетевого экрана
1.8.4.1. Persistence
1.8.4.2. Метки межсетевого экрана
1.9. Средства администрирования кластера
1.9.1. Conga
- Управление кластером и хранилищем осуществляется с помощью одного интерфейса.
- Автоматическое развертывание данных кластера и пакетов поддержки.
- Легкость интеграции с существующими кластерами.
- Отсутствие необходимости в повторной аутентификации.
- Объединение информации состояния кластера и журналов.
- Контроль за разрешениями пользователей.
- : добавление и удаление компьютеров, пользователей и настройка пользовательских привилегий. Доступ к данной вкладке разрешен только системному администратору.
- : создание и конфигурация кластеров. Каждая версия luci отображает настроенные с ее помощью кластеры. На этой вкладке системный администратор может управлять кластерами; другие пользователи могут управлять только теми кластерами, разрешения на управление которыми им предоставлены администратором.
- : удаленное управление хранилищем на компьютерах независимо от того, входят ли они в состав кластера или нет.

Рисунок 1.24. luci : Вкладка

Рисунок 1.25. luci : Вкладка

Рисунок 1.26. luci : Вкладка
1.9.2. Интерфейс утилиты администрирования кластера
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Раздел 1.3, «Cluster Infrastructure» and Раздел 1.4, «Управление службами высокой доступности»). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Рисунок 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf). Треугольник слева от имени компонента обозначает, что данному компоненту соответствует несколько подчиненных компонентов. Нажав на этот значок, можно развернуть или свернуть поддерево. Отображаемые компоненты сгруппированы следующим образом:
- Cluster Nodes: Узлы кластера, каждый из которых представлен именем. С помощью кнопок настройки, расположенных внизу экрана, можно добавлять, удалять узлы, изменять их свойства и настраивать методы ограничения для каждого узла.
- Fence Devices: Отображает изолирующие устройства. С помощью кнопок настройки, расположенных внизу экрана, можно добавлять, удалять устройства и изменять их свойства. Изолирующие устройства должны быть определены заранее для каждого узла (нажмите кнопку ), прежде чем вы сможете настроить ограничения.
- Managed Resources: Отображает домены восстановления, ресурсы и службы.
- Failover Domains: Используется для конфигурации доменов, на которые будут переноситься службы высокого доступа в случае сбоя узлов, на которых они выполняются. С помощью кнопок настройки, расположенных внизу экрана, можно создавать домены восстановления (строка Failover Domains при этом должна быть выделена) или изменять их свойства (предварительно выбрав домен для модификации).
- Resources: Настройка разделяемых ресурсов служб высокой доступности. Разделяемые ресурсы включают файловые системы, IP-адреса, монтируемые и экспортируемые по NFS ресурсы, пользовательские сценарии, доступные всем службам высокой доступности кластера. С помощью кнопок настройки, расположенных внизу экрана, можно создавать ресурсы (строка Resources при этом должна быть выделена) или изменять их свойства (предварительно выбрав ресурс для модификации).
Примечание
Утилита конфигурации также позволяет выполнить настройку частных ресурсов, которые могут использоваться лишь одной службой. Настройка таких ресурсов осуществляется с помощью компонента Services. - Services: Создание и конфигурация служб высокой доступности. Настройка служб включает назначение ресурсов (общих или частных), назначение домена восстановления, определение политики восстановления. С помощью кнопок настройки, расположенных внизу экрана, можно создавать службы (строка Services при этом должна быть выделена) или изменять их свойства (предварительно выбрав службу для модификации).
1.9.2.2. Cluster Status Tool

Рисунок 1.28. Cluster Status Tool
/etc/cluster/cluster.conf), и позволяет включить, отключить, перезапустить или переместить службы высокой доступности.
1.9.3. Текстовые утилиты администрирования
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Таблица 1.1, «Утилиты командной строки» summarizes the command line tools.
Таблица 1.1. Утилиты командной строки
| Утилита командной строки | Используется в комплекте | Назначение |
|---|---|---|
ccs_tool: системная утилита конфигурации кластера | Cluster Infrastructure | ccs_tool: программа онлайн-обновления файла конфигурации кластера. Обеспечивает возможность создания и изменения компонентов инфраструктуры кластера (к примеру, создание, добавление и удаление узла). Подробная информация может быть найдена на странице помощи ccs_tool(8). |
cman_tool: утилита администрирования кластера | Cluster Infrastructure | cman_tool: программа администрирования менеджера кластера CMAN. Обеспечивает возможность включения в кластер, исключения из него, немедленного удаления узла и пр. Подробная информация может быть найдена на странице помощи ccs_tool(8). |
fence_tool: утилита изолирования | Cluster Infrastructure | fence_tool: программа, отвечающая за включение узла в заданный изолирующий домен и за его исключение. Иначе говоря, эта программа запускает демон fenced (при подключении узла к домену) или останавливает fenced (kill) (при исключении из домена). Более подробная информация может быть найдена на странице помощи fence_tool(8). |
clustat: утилита статуса кластера | Компоненты управления службами высокой доступности | clustat отображает статус кластера, что включает информацию об участниках, кворуме и состоянии настроенных пользовательских служб. Подробная информация может быть найдена на странице помощи clustat(8). |
clusvcadm: утилита администрирования пользовательских служб кластера | Компоненты управления службами высокой доступности | clusvcadm позволяет включить, выключить, переместить и перезапустить службы высокой доступности на кластере. Подробная информация может быть найдена на странице помощи clusvcadm(8). |
1.10. Графический интерфейс администрирования виртуального сервера Linux
/etc/sysconfig/ha/lvs.cf.
piranha-gui. Эту утилиту можно открыть локально или удаленно в веб-браузере. Для локального доступа используйте адрес http://localhost:3636. Для удаленного доступа используйте действительный IP-адрес с последующим указанием :3636, плюс вам понадобится установить соединение ssh к активному маршрутизатору LVS в качестве пользователя root.
Рисунок 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
pulse, таблицы маршрутизации LVS и процессов nanny.

Рисунок 1.30. The CONTROL/MONITORING Panel
- Auto update
- Активирует автоматическое обновление экрана состояния каждые 10 секунд (по умолчанию). Интервал времени может быть изменен в поле Update frequency in seconds.Не рекомендуется задавать интервал менее 10 секунд, так как при этом будет сложнее модифицировать интервал Auto update вследствие частого обновления страницы. Если вы столкнулись с такой проблемой, щелкните на любой другой панели, затем вернитесь на панель CONTROL/MONITORING.
- Ручное обновление статуса.
- При нажатии этой кнопки будет отображен экран помощи с информацией о том, как изменить административный пароль Piranha.
1.10.2. GLOBAL SETTINGS
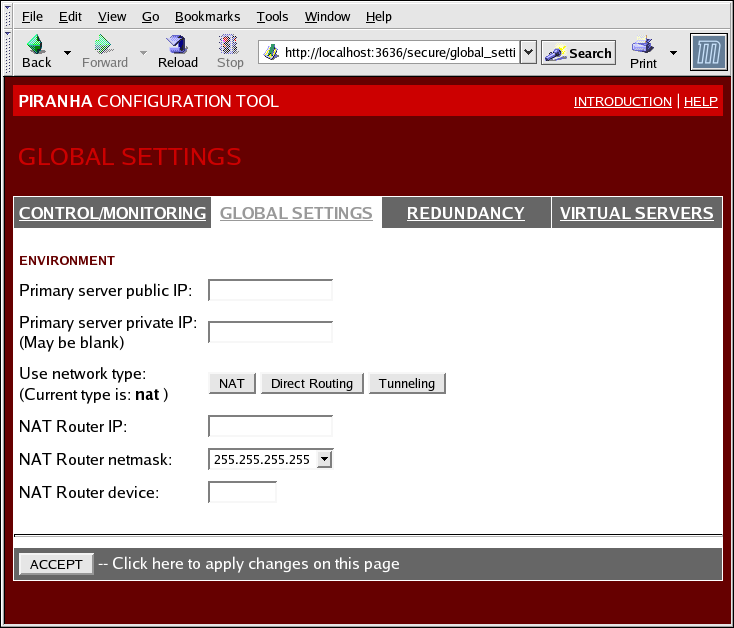
Рисунок 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- Действительный IP-адрес основного узла LVS, доступный извне.
- Primary server private IP
- Действительный IP-адрес альтернативного сетевого интерфейса основного узла LVS. Этот адрес используется лишь как дополнительный канал обмена тактовыми импульсами с резервным маршрутизатором.
- Use network type
- Тип маршрутизации. По умолчанию используется NAT.
- NAT Router IP
- Частный «плавающий» IP-адрес, который используется в качестве шлюза для настоящих серверов.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Имя устройства сетевого интерфейса для «плавающего» IP-адреса (например,
eth1:1).
1.10.3. REDUNDANCY
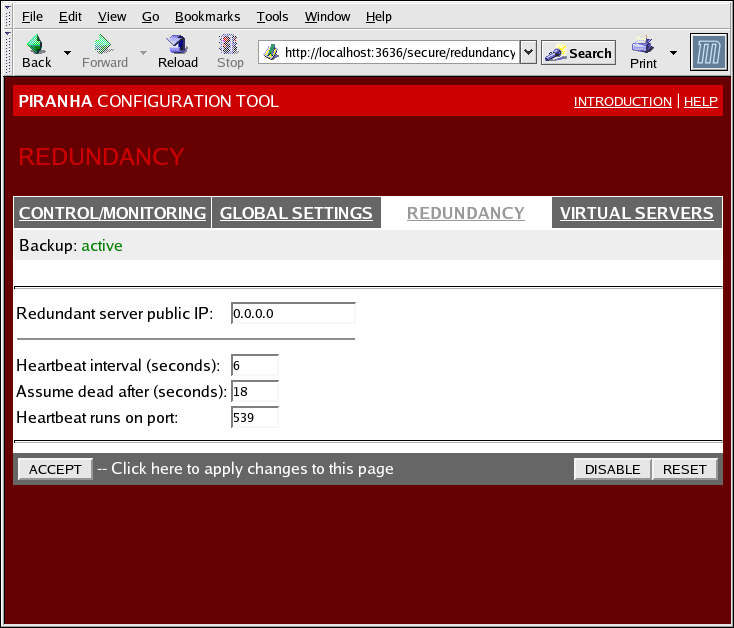
Рисунок 1.32. The REDUNDANCY Panel
- Redundant server public IP
- Открытый, действительный IP-адрес резервного маршрутизатора LVS.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Задает интервал (в секундах) между тактовыми импульсами, целью которых является проверка работы основного узла LVS.
- Assume dead after (seconds)
- Если главный узел LVS не отвечает в течение заданного интервала (в секундах), то резервный узел LVS инициирует процесс восстановления.
- Heartbeat runs on port
- Определяет порт, используемый для взаимодействия с главным узлом LVS. Если поле оставлено пустым, используется порт 539.
1.10.4. VIRTUAL SERVERS

Рисунок 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. Подсекция VIRTUAL SERVER

Рисунок 1.34. The VIRTUAL SERVERS Subsection
- Name
- Имя, идентифицирующее виртуальный сервер. Это имя НЕ является именем узла машины, поэтому рекомендуется сделать его как можно более наглядным. Даже можно включить имя протокола (например, HTTP), используемого виртуальным сервером.
- Application port
- Номер прослушиваемого службой порта.
- Позволяет выбрать протокол (UDP или TCP) из выпадающего списка.
- Virtual IP Address
- The virtual server's floating IP address.
- Выпадающее меню для выбора маски сети виртуального сервера.
- Firewall Mark
- Целое значение метки межсетевого экрана при объединении протоколов с несколькими портами или при создании виртуального сервера с различными, но связанными каналами.
- Device
- Имя сетевого устройства, к которому будет привязан «плавающий» IP-адрес, заданный в поле Virtual IP Address.Следует связать открытый «плавающий» адрес с интерфейсом Ethernet, подключенным к открытой сети.
- Re-entry Time
- Целое значение, которое определяет интервал времени (в секундах), до того как активный маршрутизатор LVS попытается использовать реальный сервер после сбоя сервера.
- Service Timeout
- Целое значение, которое определяет интервал времени (в секундах), по истечению которого реальный сервер будет считаться недоступным.
- Quiesce server
- При выборе опции Quiesce server, если реальный сервер переходит в онлайн, содержимое таблицы least-connections будет сброшено в ноль, при этом активный маршрутизатор LVS обрабатывает запросы, как будто все действительные серверы были заново добавлены в кластер. Эта опция позволяет избежать перегрузки нового сервера большим количеством соединений при его включении в кластер.
- Load monitoring tool
- Маршрутизатор LVS может наблюдать за нагрузкой на различных серверах с помощью
rupилиruptime. При выбореrupкаждый реальный сервер будет выполнять службуrstatd. Если же вы выберетеruptime, то будет выполняться службаrwhod. - Scheduling
- Выберите предпочитаемый алгоритм из выпадающего меню. По умолчанию используется метод
Weighted least-connection. - Persistence
- Используется, если необходимо сохранять постоянство подключений к виртуальному серверу при его взаимодействии с клиентом. Введите интервал времени (в секундах), по истечению которого соединение будет остановлено.
- Из выпадающего меню выберите маску сети, чтобы ограничить сохранение постоянства подключений пределами конкретной подсети.
1.10.4.2. Подсекция REAL SERVER
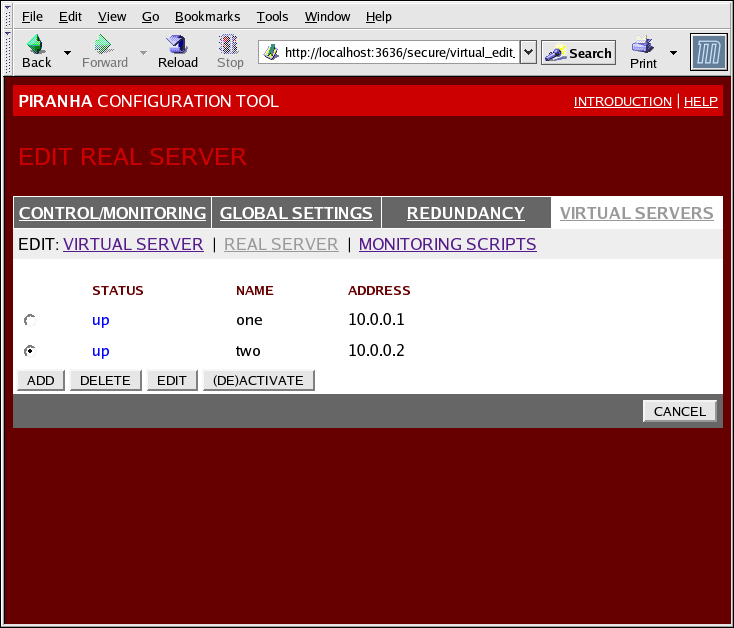
Рисунок 1.35. The REAL SERVER Subsection
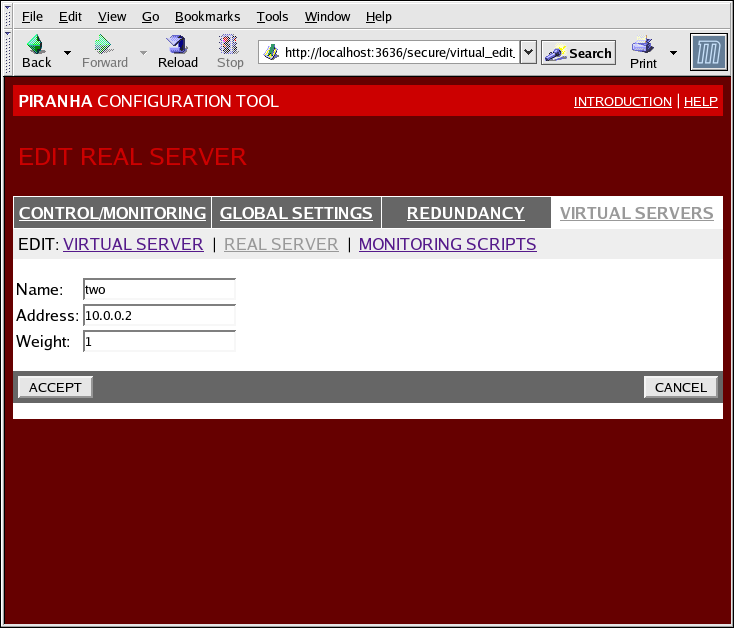
Рисунок 1.36. The REAL SERVER Configuration Panel
- Name
- Описательное имя реального сервера.
Примечание
Это имя НЕ является именем узла машины, поэтому рекомендуется сделать его как можно более наглядным. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection
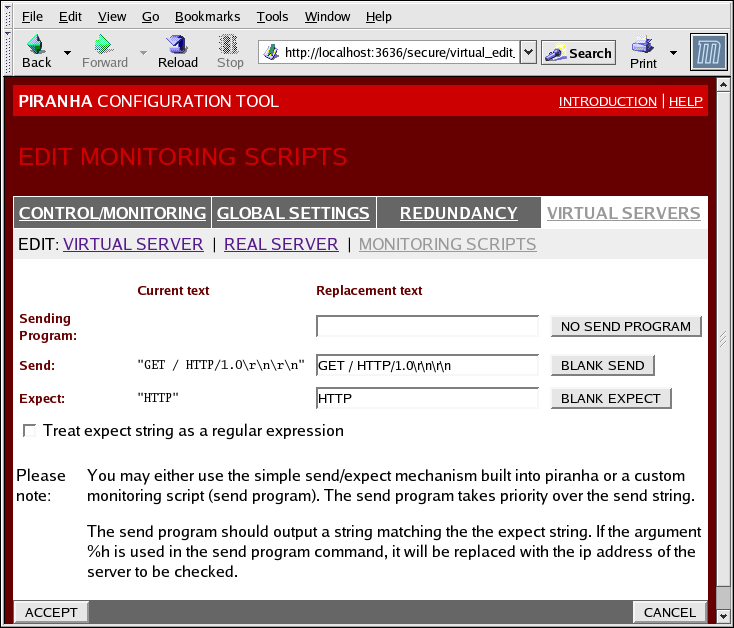
Рисунок 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Введите путь к сценарию проверки службы, чтобы обеспечить возможность более детальной проверки. Эта функция особенно важна для служб, работающих с динамически изменяемыми данными (например, HTTPS, SSL).Чтобы иметь возможность использования этой функции, необходимо написать сценарий, который в результате исполнения вернет текст, и ввести путь к нему в поле Sending Program.
Примечание
Если поле содержит указание внешней программы, то поле Send будет проигнорировано. - Send
- Строка, которую демон
nannyбудет отправлять каждому реальному серверу. По умолчанию его содержимое настроено для HTTP. Если вы оставите поле пустым,nannyпопытается открыть порт и решит, что служба выполняется, если порт открыт успешно.Поле может содержать только одну отправляемую последовательность, которая, в свою очередь, может содержать Escape-последовательности и ASCII:- \n — новая строка.
- \r — возврат каретки.
- \t — символ табуляции.
- \ — конвертирует последующий символ в Escape-последовательность.
- Expect
- Текст ответа, которые ожидается получить от сервера. Если вы написали собственную программу для отправки, введите соответствующий вариант ответа, который она отправит в случае успеха.
Глава 2. Обзор компонентов Red Hat Cluster Suite
2.1. Компоненты кластера
Таблица 2.1. Компоненты программных подсистем Red Hat Cluster Suite
| Назначение | Компоненты | Описание |
|---|---|---|
| Conga | luci | Удаленное управление системой — Управляющая станция. |
ricci | Удаленное управление системой — Управляемая станция. | |
| Cluster Configuration Tool | system-config-cluster | Графическая утилита управления настройками кластера. |
| Менеджер логических томов кластера (CLVM, Cluster Logical Volume Manager) | clvmd | Этот демон передает обновления метаданных LVS участникам кластера. Он должен выполняться на всех узлах кластера, в противном случае будет отображена ошибка. |
lvm | Утилиты командной строки для работы с LVM2. | |
system-config-lvm | Графический интерфейс для LVM2. | |
lvm.conf | Файл конфигурации LVM (/etc/lvm/lvm.conf.). | |
| Система конфигурации кластера (CSS, Cluster Configuration System) | ccs_tool | ccs_tool является частью системы конфигурации кластера (CCS, Cluster Configuration System). Кроме того, ccs_tool может использоваться для выполнения онлайн-обновлений файлов конфигурации из архивов CCS, созданных в GFS 6.0 (или более ранних версиях) в формат XML, использующийся в данном выпуске Red Hat Cluster Suite. |
ccs_test | Команда диагностики и тестирования, используемая для получения информации из файлов конфигурации с помощью ccsd. | |
ccsd | Демон CCS исполняется на всех кластерных узлах и предоставляет данные файла конфигурации программному обеспечению кластера. | |
cluster.conf | Файл конфигурации кластера (/etc/cluster/cluster.conf). | |
| Менеджер кластера (CMAN, Cluster Manager) | cman.ko | Модуль ядра для CMAN. |
cman_tool | Административный интерфейс CMAN, с помощью которого можно запускать и останавливать CMAN, а также изменять некоторые внутренние параметры. | |
dlm_controld | Демон, запускаемый сценарием инициализации cman. Предназначен для управления dlm и не используется напрямую пользователем. | |
gfs_controld | Демон, запускаемый сценарием инициализации cman. Предназначен для управления gfs и не используется напрямую пользователем. | |
group_tool | Используется для получения списка групп (изолирование, DLM, GFS), а также отладочной информации. Включает функции, которые в RHEL4 исполняли службы cman_tool. | |
groupd | Демон, запускаемый сценарием инициализации cman. Предназначен для взаимодействия openais/cman и dlm_controld/gfs_controld/fenced и не используется напрямую пользователем. | |
libcman.so.<version number> | Библиотека для приложений, взаимодействующих с cman.ko. | |
| Менеджер группы ресурсов (rgmanager) | clusvcadm | Команда, которая позволяет вручную активировать, деактивировать, переместить и перезапустить пользовательские службы на кластере. |
clustat | Команда отображения состояния кластера, включая информацию об участвующих узлах и выполняющихся службах. | |
clurgmgrd | Демон, управляющий пользовательскими запросами запуска, остановки, перемещения и перезапуска служб. | |
clurmtabd | Демон для работы с таблицами монтирования кластерной NFS. | |
| Изолирование | fence_apc | Изолирующий агент для блоков питания APC. |
fence_bladecenter | Изолирующий агент для IBM Bladecenters с интерфейсом Telnet. | |
fence_bullpap | Изолирующий агент для интерфейса Bull Novascale Platform Administration Processor (PAP). | |
fence_drac | Изолирующий агент для карт удаленного доступа Dell. | |
fence_ipmilan | Изолирующий агент для интерфейса IPMI (Bull Novascale Intelligent Platform Management Interface), подключаемого в LAN. | |
fence_wti | Изолирующий агент для для переключателя питания WTI. | |
fence_brocade | Изолирующий агент для переключателя Brocade Fibre Channel. | |
fence_mcdata | Изолирующий агент для переключателя McData Fibre Channel. | |
fence_vixel | Изолирующий агент для переключателя Vixel Fibre Channel. | |
fence_sanbox2 | Изолирующий агент для переключателя SANBox2 Fibre Channel. | |
fence_ilo | Изолирующий агент для интерфейсов HP ILO (раньше назывался fence_rib). | |
fence_rsa | Агент ограничения ввода/ вывода для IBM RSA II. | |
fence_gnbd | Изолирующий агент, используемый с хранилищем GNBD. | |
fence_scsi | Изолирующий ввод/ вывод агент для SCSI. | |
fence_egenera | Изолирующий агент, используемый с системой Egenera BladeFrame. | |
fence_manual | Изолирующий агент, используемый для ручной настройки. Замечание: Этот компонент не поддерживается в критических окружениях. | |
fence_ack_manual | Интерфейс пользователя для работы с агентом fence_manual. | |
fence_node | Программа, осуществляющая ограничение ввода/ вывода для одного узла. | |
fence_xvm | Агент ограничения ввода/ вывода для виртуальных машин Xen. | |
fence_xvmd | Узел ограничивающего ввод/ вывод агента для виртуальных машин Xen. | |
fence_tool | Программа для входа и выхода из изолируемого домена. | |
fenced | Демон, ограничивающий ввод/ вывод. | |
| DLM | libdlm.so.<version number> | Библиотека для поддержки менеджера DLM (Distributed Lock Manager). |
| GFS | gfs.ko | Модуль ядра для работы с файловой системой GFS. Загружается на GFS-узлы кластера. |
gfs_fsck | Команда проверки несмонтированной GFS. | |
gfs_grow | Команда, с помощью которой можно увеличивать размер смонтированной файловой системы GFS. | |
gfs_jadd | Команда добавления журналов к смонтированной файловой системе GFS. | |
gfs_mkfs | Команда создания на накопителе файловой системы GFS. | |
gfs_quota | Команда управления квотами в смонтированной файловой системе GFS. | |
gfs_tool | Команда конфигурации файловой системы GFS. С ее помощью также можно осуществлять сбор информации о файловой системе. | |
mount.gfs | Помощник монтирования, вызываемый командой mount(8); не используется пользователем напрямую. | |
| GNBD | gnbd.ko | Модуль ядра, который позволяет активировать драйвер устройств GNBD на клиентах. |
gnbd_export | Команда для создания, экспорта и управления GNBD на сервере GNBD. | |
gnbd_import | Команда импортирования и управления GNBD на клиенте GNBD. | |
gnbd_serv | Демон сервера, позволяющий экспорт локального хранилища узла по сети. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | Демон lvs будет запущен на активном маршрутизаторе LVS процессом pulse. lvs считывает файл конфигурации /etc/sysconfig/ha/lvs.cf, вызывает утилиту ipvsadm для создания и поддержки таблицы маршрутизации IPVS и сопоставляет каждой настроенной службе LVS процесс nanny. Если nanny сообщает, что действительный сервер не работает, то по указанию lvs утилита ipvsadm удалит этот сервер из таблицы маршрутизации IPVS. | |
ipvsadm | Эта служба обновляет в ядре таблицу маршрутизации IPVS. Демон lvs осуществляет настройку и управление LVS посредством вызова ipvsadm для добавления, изменения или удаления записей в таблице маршрутизации IPVS. | |
nanny | Демон мониторинга nanny выполняется на активном маршрутизаторе LVS. С его помощью определяется текущее состояние всех действительных серверов и их нагрузка. Для каждой службы на отдельном сервере исполняется отдельный процесс. | |
lvs.cf | Файл конфигурации LVS (/etc/sysconfig/ha/lvs.cf). Все демоны получают информацию конфигурации из этого файла, напрямую или косвенно. | |
| Piranha Configuration Tool | Веб-утилита наблюдения, конфигурации и администрирования LVS, используемая по умолчанию для поддержки файла конфигурации /etc/sysconfig/ha/lvs.cf. | |
send_arp | Эта программа отправляет широковещательные сообщения ARP, если «плавающий» IP-адрес в процессе восстановления переносится с одного узла на другой. | |
| Кворум диска | qdisk | Демон кворума диска для CMAN/ Linux-Cluster. |
mkqdisk | Утилита кворума диска. | |
qdiskd | Демон кворума диска. |
2.2. Страницы помощи
- Инфраструктура кластера
- ccs_tool (8): Используется для онлайн-обновлений файлов конфигурации CCS
- ccs_test (8): Утилита диагностики для работающей системы CCS (Cluster Configuration System)
- ccsd (8): Демон доступа к файлам конфигурации кластера CCS
- ccs (7): Система конфигурации кластера
- cman_tool (8): Утилита администрирования кластера
- cluster.conf [cluster] (5): Файл конфигурации продуктов кластера
- qdisk (5): Демон кворума (на диске) для CMAN / Linux-Cluster
- mkqdisk (8): Утилита кворума диска
- qdiskd (8): Демон кворума диска
- fence_ack_manual (8): Программа, исполняемая оператором как часть ручного ограничения ввода/ вывода
- fence_apc (8): Агент ограничения ввода/ вывода для APC MasterSwitch
- fence_bladecenter (8): Агент ограничения ввода/ вывода для IBM Bladecenter
- fence_brocade (8): Агент ограничения ввода/ вывода для переключателей Brocade FC
- fence_bullpap (8): Агент ограничения ввода/ вывода для архитектуры Bull FAME, управляемой с помощью консоли PAP
- fence_drac (8): Изолирующий агент для карт удаленного доступа Dell
- fence_egenera (8): Агент ограничения ввода/ вывода для Egenera BladeFrame
- fence_gnbd (8): Агент ограничения ввода/ вывода для GFS-кластеров на основе GNBD
- fence_ilo (8): Агент ограничения ввода/ вывода для карт HP Integrated Lights Out
- fence_ipmilan (8): Агент ограничения ввода/ вывода для машин, которые находятся под управлением IPMI по LAN.
- fence_manual (8): Программа, которую исполняет демон fenced в процессе ручного ограничения ввода/ вывода
- fence_mcdata (8): Агент ограничения ввода/ вывода для переключателей McData FC
- fence_node (8): Программа ограничения ввода/ вывода на одном узле
- fence_rib (8): Агент ограничения ввода/ вывода для карт Compaq Remote Insight Lights Out
- fence_rsa (8): Агент ограничения ввода/ вывода для IBM RSA II
- fence_sanbox2 (8): Агент ограничения ввода/ вывода для переключателей QLogic SANBox2 FC
- fence_scsi (8): Агент ограничения ввода/ вывода для сохраняемых соответствий SCSI
- fence_tool (8): Программа подключения и отключения от изолированного домена
- fence_vixel (8): Агент ограничения ввода/ вывода для переключателей Vixel FC
- fence_wti (8): Агент ограничения ввода/ вывода для сетевого переключателя питания WTI
- fence_xvm (8): Агент ограничения ввода/ вывода для виртуальных машин Xen
- fence_xvmd (8): Агент ограничения ввода/ вывода для виртуальных машин Xen
- fenced (8): Демон ограничения ввода/ вывода
- Управление службами высокого доступа
- clusvcadm (8): Утилита администрирования пользовательских служб кластера
- clustat (8): Утилита состояния кластера
- Clurgmgrd [clurgmgrd] (8): Демон менеджера группы ресурсов
- clurmtabd (8): Демон таблицы удаленного монтирования по NFS
- GFS
- gfs_fsck (8): Оффлайн-проверка файловой системы GFS
- gfs_grow (8): Расширение файловой системы GFS
- gfs_jadd (8): Добавление журналов в файловую систему GFS
- gfs_mount (8): Опции монтирования GFS
- gfs_quota (8): Работа с дисковыми квотами GFS
- gfs_tool (8): Интерфейс к вызовам gfs ioctl
- Менеджер логических томов кластера
- clvmd (8): Демон LVM
- lvm (8): Утилиты LVM2
- lvm.conf [lvm] (5): Файл конфигурации LVM2
- lvmchange (8): Изменение атрибутов менеджера логических томов
- pvcreate (8): Инициализация диска или раздела для LVM
- lvs (8): Вывод сведений о логических томах
- GNBD (Global Network Block Device)
- gnbd_export (8): Интерфейс для экспорта устройств GNBD
- gnbd_import (8): Манипулирование блочными устройствами GNBD на клиенте
- gnbd_serv (8): Демон gnbd для сервера
- LVS
- pulse (8): Демон обмена тестовыми сообщениями для контроля состояния кластерных узлов
- lvs.cf [lvs] (5): Файл конфигурации для LVS
- lvscan (8): Сканирование всех дисков
- lvsd (8): Демон контроля кластерных служб Red Hat
- ipvsadm (8): Администрирование виртуального сервера Linux
- ipvsadm-restore (8): Восстанавливает таблицу IPVS из stdin
- ipvsadm-save (8): Сохраняет таблицу IPVS в stdout
- nanny (8): Утилита для наблюдения за состоянием служб кластера
- send_arp (8): Утилита для оповещения сети о новом соответствии IP-адреса и MAC-адреса
2.3. Совместимое оборудование
Приложение A. Revision History
| История переиздания | |||
|---|---|---|---|
| Издание 3-7.400 | 2013-10-31 | ||
| |||
| Издание 3-7 | 2012-07-18 | ||
| |||
| Издание 1.0-0 | Tue Jan 20 2008 | ||
| |||
Предметный указатель
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Совместимое оборудование
- cluster component man pages, Страницы помощи
- cluster components table, Компоненты кластера
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Текстовые утилиты администрирования
- compatible hardware
- cluster components, Совместимое оборудование
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Обратная связь
L
- LVS
- direct routing
- requirements, hardware, Прямая маршрутизация
- requirements, network, Прямая маршрутизация
- requirements, software, Прямая маршрутизация
- routing methods
- NAT, Методы маршрутизации
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Страницы помощи
N
- NAT
- routing methods, LVS, Методы маршрутизации
- network address translation (см. NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, Графический интерфейс администрирования виртуального сервера Linux
- necessary software, Графический интерфейс администрирования виртуального сервера Linux
- REAL SERVER subsection, Подсекция REAL SERVER
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , Подсекция VIRTUAL SERVER
- Persistence , Подсекция VIRTUAL SERVER
- Scheduling , Подсекция VIRTUAL SERVER
- Virtual IP Address , Подсекция VIRTUAL SERVER
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Компоненты кластера
T
- table
- cluster components, Компоненты кластера
- command line tools, Текстовые утилиты администрирования