
Red Hat Training
A Red Hat training course is available for RHEL 8
Endurecimento da segurança
Protegendo o Red Hat Enterprise Linux 8
Resumo
Tornando o código aberto mais inclusivo
A Red Hat tem o compromisso de substituir a linguagem problemática em nosso código, documentação e propriedades da web. Estamos começando com estes quatro termos: master, slave, blacklist e whitelist. Por causa da enormidade deste esforço, estas mudanças serão implementadas gradualmente ao longo de vários lançamentos futuros. Para mais detalhes, veja a mensagem de nosso CTO Chris Wright.
Fornecendo feedback sobre a documentação da Red Hat
Agradecemos sua contribuição em nossa documentação. Por favor, diga-nos como podemos melhorá-la. Para fazer isso:
Para comentários simples sobre passagens específicas:
- Certifique-se de que você está visualizando a documentação no formato Multi-page HTML. Além disso, certifique-se de ver o botão Feedback no canto superior direito do documento.
- Use o cursor do mouse para destacar a parte do texto que você deseja comentar.
- Clique no pop-up Add Feedback que aparece abaixo do texto destacado.
- Siga as instruções apresentadas.
Para enviar comentários mais complexos, crie um bilhete Bugzilla:
- Ir para o site da Bugzilla.
- Como Componente, use Documentation.
- Preencha o campo Description com sua sugestão de melhoria. Inclua um link para a(s) parte(s) relevante(s) da documentação.
- Clique em Submit Bug.
Capítulo 1. Visão geral do endurecimento da segurança na RHEL
Devido ao aumento da dependência de computadores poderosos e em rede para ajudar a administrar os negócios e manter o controle de nossas informações pessoais, setores inteiros foram formados em torno da prática da segurança de redes e computadores. As empresas solicitaram o conhecimento e as habilidades de especialistas em segurança para auditar adequadamente os sistemas e adaptar as soluções para atender às exigências operacionais de sua organização. Como a maioria das organizações é cada vez mais dinâmica por natureza, seus trabalhadores estão acessando recursos críticos de TI da empresa local e remotamente, daí a necessidade de ambientes computacionais seguros ter se tornado mais pronunciada.
Infelizmente, muitas organizações, bem como usuários individuais, consideram a segurança como mais um pensamento posterior, um processo que é negligenciado em favor do aumento de poder, produtividade, conveniência, facilidade de uso e preocupações orçamentárias. A implementação adequada da segurança é muitas vezes promulgada post-mortem - após uma intrusão não autorizada já ter ocorrido. Tomar as medidas corretas antes de conectar um site a uma rede não confiável, como a Internet, é um meio eficaz de frustrar muitas tentativas de intrusão.
1.1. O que é segurança informática?
Segurança informática é um termo geral que cobre uma ampla área de computação e processamento de informações. As indústrias que dependem de sistemas e redes de computadores para realizar transações comerciais diárias e acessar informações críticas consideram seus dados como uma parte importante de seu patrimônio geral. Vários termos e métricas entraram em nosso vocabulário comercial diário, tais como custo total de propriedade (TCO), retorno do investimento (ROI) e qualidade do serviço (QoS). Usando essas métricas, as indústrias podem calcular aspectos como integridade de dados e alta disponibilidade (HA) como parte de seus custos de planejamento e gerenciamento de processos. Em alguns setores, como o comércio eletrônico, a disponibilidade e confiabilidade dos dados pode significar a diferença entre o sucesso e o fracasso.
1.2. Padronizando a segurança
As empresas de todos os setores dependem de regulamentações e regras que são estabelecidas por organismos de normalização como a Associação Médica Americana (AMA) ou o Institute of Electrical and Electronics Engineers (IEEE). Os mesmos conceitos são válidos para a segurança da informação. Muitos consultores e fornecedores de segurança concordam com o modelo de segurança padrão conhecido como CIA, ou Confidentiality, Integrity, and Availability. Este modelo de três níveis é um componente geralmente aceito para avaliar os riscos de informações sensíveis e estabelecer uma política de segurança. A seguir, descrevemos o modelo da CIA em mais detalhes:
- Confidencialidade
- Integridade
- Disponibilidade
1.3. Software criptográfico e certificações
O Red Hat Enterprise Linux passa por várias certificações de segurança, tais como FIPS 140-2 ou Common Criteria (CC), para garantir que as melhores práticas da indústria sejam seguidas.
O RHEL 8 core crypto components O artigo Knowledgebase fornece uma visão geral dos principais componentes criptográficos do Red Hat Enterprise Linux 8, documentando quais são eles, como são selecionados, como são integrados ao sistema operacional, como suportam módulos de segurança de hardware e cartões inteligentes e como as certificações criptográficas se aplicam a eles.
1.4. Controles de segurança
A segurança de computadores é freqüentemente dividida em três categorias principais distintas, comumente referidas como controls:
- Físico
- Técnico
- Administrativo
Essas três grandes categorias definem os principais objetivos de uma implementação adequada da segurança. Dentro destes controles estão subcategorias que detalham ainda mais os controles e como implementá-los.
1.4.1. Controles físicos
O controle físico é a implementação de medidas de segurança em uma estrutura definida utilizada para impedir ou impedir o acesso não autorizado a material sensível. Exemplos de controles físicos são:
- Câmeras de vigilância em circuito fechado
- Sistemas de alarme de movimento ou térmico
- Guardas de segurança
- IDs de fotos
- Portas de aço trancadas e com fechadura de ferro
- Biometria (inclui impressão digital, voz, rosto, íris, caligrafia e outros métodos automatizados usados para reconhecer indivíduos)
1.4.2. Controles técnicos
Os controles técnicos utilizam a tecnologia como base para controlar o acesso e o uso de dados sensíveis através de uma estrutura física e sobre uma rede. Os controles técnicos são de grande alcance e abrangem tecnologias como:
- Criptografia
- Cartões inteligentes
- Autenticação da rede
- Listas de controle de acesso (ACLs)
- Software de auditoria de integridade de arquivos
1.4.3. Controles administrativos
Os controles administrativos definem os fatores humanos de segurança. Eles envolvem todos os níveis de pessoal dentro de uma organização e determinam quais usuários têm acesso a que recursos e informações por tais meios:
- Treinamento e conscientização
- Preparação para desastres e planos de recuperação
- Estratégias de recrutamento e separação de pessoal
- Registro de pessoal e contabilidade
1.5. Avaliação de vulnerabilidades
Com tempo, recursos e motivação, um atacante pode entrar em quase qualquer sistema. Todos os procedimentos e tecnologias de segurança atualmente disponíveis não podem garantir que qualquer sistema esteja completamente a salvo de intrusões. Os roteadores ajudam a proteger os gateways para a Internet. Os firewalls ajudam a proteger a borda da rede. Redes Privadas Virtuais passam dados com segurança em um fluxo criptografado. Os sistemas de detecção de intrusão advertem sobre atividades maliciosas. Entretanto, o sucesso de cada uma destas tecnologias depende de uma série de variáveis, inclusive:
- A experiência do pessoal responsável pela configuração, monitoramento e manutenção das tecnologias.
- A capacidade de remendar e atualizar serviços e kernels de forma rápida e eficiente.
- A capacidade dos responsáveis de manter uma vigilância constante sobre a rede.
Dado o estado dinâmico dos sistemas e tecnologias de dados, a segurança dos recursos corporativos pode ser bastante complexa. Devido a esta complexidade, muitas vezes é difícil encontrar recursos especializados para todos os seus sistemas. Embora seja possível ter pessoal com conhecimento em muitas áreas de segurança da informação de alto nível, é difícil reter pessoal que seja especialista em mais do que algumas áreas temáticas. Isto se deve principalmente porque cada área temática de segurança da informação requer atenção e foco constantes. A segurança da informação não fica parada.
Uma avaliação de vulnerabilidade é uma auditoria interna da segurança de sua rede e sistema; os resultados indicam a confidencialidade, integridade e disponibilidade de sua rede. Tipicamente, a avaliação de vulnerabilidade começa com uma fase de reconhecimento, durante a qual são coletados dados importantes sobre os sistemas e recursos alvo. Esta fase leva à fase de prontidão do sistema, na qual o alvo é essencialmente verificado quanto a todas as vulnerabilidades conhecidas. A fase de prontidão culmina com a fase de relatório, onde os resultados são classificados em categorias de alto, médio e baixo risco; e métodos para melhorar a segurança (ou mitigar o risco de vulnerabilidade) do alvo são discutidos
Se você realizasse uma avaliação de vulnerabilidade de sua casa, você provavelmente verificaria cada porta de sua casa para ver se elas estão fechadas e trancadas. Você também verificaria cada janela, certificando-se de que elas estejam completamente fechadas e trancadas corretamente. Este mesmo conceito se aplica a sistemas, redes e dados eletrônicos. Os usuários maliciosos são os ladrões e vândalos de seus dados. Concentre-se em suas ferramentas, mentalidade e motivações, e você poderá então reagir rapidamente às suas ações.
1.5.1. Definindo a avaliação e os testes
As avaliações de vulnerabilidades podem ser divididas em um de dois tipos: outside looking in e inside looking around.
Ao realizar uma avaliação de vulnerabilidade externa, você está tentando comprometer seus sistemas a partir do exterior. Ser externo à sua empresa lhe fornece o ponto de vista do cracker. Você vê o que um cracker vê
Quando você realiza uma avaliação de vulnerabilidade interna, você está em vantagem, pois é interno e seu status é elevado à confiança. Este é o ponto de vista que você e seus colegas de trabalho já se conectaram aos seus sistemas. Você vê servidores de impressão, servidores de arquivos, bancos de dados e outros recursos.
Há distinções notáveis entre os dois tipos de avaliações de vulnerabilidade. Ser interno de sua empresa lhe dá mais privilégios do que um forasteiro. Na maioria das organizações, a segurança é configurada para manter os intrusos de fora. Muito pouco é feito para proteger os internos da organização (tais como firewalls departamentais, controles de acesso a nível de usuário e procedimentos de autenticação de recursos internos). Normalmente, há muito mais recursos quando se olha por dentro, já que a maioria dos sistemas são internos a uma empresa. Uma vez fora da empresa, seu status não é confiável. Os sistemas e recursos disponíveis para você externamente são normalmente muito limitados.
Considere a diferença entre as avaliações de vulnerabilidade e penetration tests. Pense em uma avaliação de vulnerabilidade como o primeiro passo para um teste de penetração. As informações colhidas da avaliação são utilizadas para testes. Enquanto a avaliação é realizada para verificar a existência de furos e vulnerabilidades potenciais, o teste de penetração realmente tenta explorar os resultados.
Avaliar a infra-estrutura da rede é um processo dinâmico. A segurança, tanto da informação quanto física, é dinâmica. A realização de uma avaliação mostra uma visão geral, que pode gerar falsos positivos e falsos negativos. Um falso positivo é um resultado, onde a ferramenta encontra vulnerabilidades que na realidade não existem. Um falso negativo é quando ele omite as vulnerabilidades reais.
Os administradores de segurança são apenas tão bons quanto as ferramentas que utilizam e os conhecimentos que retêm. Pegue qualquer uma das ferramentas de avaliação atualmente disponíveis, compare-as com seu sistema, e é quase uma garantia de que existem alguns falsos positivos. Seja por falha do programa ou erro do usuário, o resultado é o mesmo. A ferramenta pode encontrar falsos positivos, ou, pior ainda, falsos negativos.
Agora que a diferença entre uma avaliação de vulnerabilidade e um teste de penetração está definida, tome as conclusões da avaliação e as reveja cuidadosamente antes de realizar um teste de penetração como parte de sua nova abordagem de melhores práticas.
Não tente explorar vulnerabilidades nos sistemas de produção. Fazer isso pode ter efeitos adversos sobre a produtividade e eficiência de seus sistemas e rede.
A lista a seguir examina alguns dos benefícios de realizar avaliações de vulnerabilidade.
- Cria um foco pró-ativo na segurança da informação.
- Encontra explorações potenciais antes que os crackers as encontrem.
- O resultado é que os sistemas são mantidos atualizados e remendados.
- Promove o crescimento e ajuda a desenvolver a experiência do pessoal.
- Suprime as perdas financeiras e a publicidade negativa.
1.5.2. Estabelecendo uma metodologia para avaliação de vulnerabilidade
Para ajudar na seleção de ferramentas para uma avaliação de vulnerabilidade, é útil estabelecer uma metodologia de avaliação de vulnerabilidade. Infelizmente, não existe uma metodologia predefinida ou aprovada pela indústria neste momento; no entanto, o bom senso e as melhores práticas podem atuar como um guia suficiente.
What is the target? Are we looking at one server, or are we looking at our entire network and everything within the network? Are we external or internal to the company? As respostas a estas perguntas são importantes, pois ajudam a determinar não apenas quais ferramentas selecionar, mas também a maneira pela qual são utilizadas.
Para saber mais sobre o estabelecimento de metodologias, consulte o seguinte website:
1.5.3. Ferramentas de avaliação de vulnerabilidades
Uma avaliação pode começar usando alguma forma de ferramenta de coleta de informações. Ao avaliar toda a rede, mapeie primeiro o layout para encontrar os hosts que estão em execução. Uma vez localizado, examine cada anfitrião individualmente. O foco nesses hosts requer outro conjunto de ferramentas. Saber quais ferramentas usar pode ser o passo mais crucial para encontrar vulnerabilidades.
As seguintes ferramentas são apenas uma pequena amostra das ferramentas disponíveis:
-
Nmapé uma ferramenta popular que pode ser usada para encontrar sistemas host e portos abertos nesses sistemas. Para instalarNmapa partir do repositórioAppStream, digite o comandoyum install nmapcomo usuárioroot. Veja a página de manualnmap(1)para mais informações. -
As ferramentas da suíte
OpenSCAP, como o utilitário de linha de comandooscape o utilitário gráficoscap-workbench, fornecem uma auditoria de conformidade totalmente automatizada. Veja Scanning the system for security compliance and vulnerabilities para mais informações. -
O Advanced Intrusion Detection Environment (
AIDE) é um utilitário que cria um banco de dados de arquivos no sistema, e depois utiliza esse banco de dados para garantir a integridade dos arquivos e detectar intrusões no sistema. Veja Verificação de integridade com AIDE para mais informações.
1.6. Ameaças à segurança
1.6.1. Ameaças à segurança da rede
As más práticas ao configurar os seguintes aspectos de uma rede podem aumentar o risco de um ataque.
Arquiteturas inseguras
Uma rede mal configurada é um ponto de entrada principal para usuários não autorizados. Deixar uma rede local aberta e baseada na confiança vulnerável à Internet altamente insegura é muito parecido com deixar uma porta entreaberta em um bairro dominado pelo crime
Redes de radiodifusão
Os administradores de sistemas freqüentemente não percebem a importância do hardware de rede em seus esquemas de segurança. Hardware simples, como hubs e roteadores, depende do princípio de transmissão ou não; ou seja, sempre que um nó transmite dados através da rede para um nó receptor, o hub ou roteador envia uma transmissão dos pacotes de dados até que o nó receptor receba e processe os dados. Este método é o mais vulnerável ao protocolo de resolução de endereços (ARP) ou ao controle de acesso à mídia (MAC), tanto por intrusos externos quanto por usuários não autorizados em hosts locais.
Servidores centralizados
Outra armadilha potencial da rede é o uso da computação centralizada. Uma medida comum de corte de custos para muitas empresas é consolidar todos os serviços em uma única máquina poderosa. Isto pode ser conveniente, pois é mais fácil de gerenciar e custa consideravelmente menos do que configurações de múltiplos servidores. Entretanto, um servidor centralizado introduz um único ponto de falha na rede. Se o servidor central for comprometido, ele pode tornar a rede completamente inútil ou pior, propensa à manipulação ou roubo de dados. Nessas situações, um servidor central torna-se uma porta aberta que permite o acesso a toda a rede.
1.6.2. Ameaças à segurança do servidor
A segurança do servidor é tão importante quanto a segurança da rede, pois os servidores muitas vezes contêm uma grande quantidade de informações vitais de uma organização. Se um servidor for comprometido, todo o seu conteúdo pode ficar disponível para o cracker roubar ou manipular à vontade. As seções seguintes detalham algumas das principais questões.
Serviços não utilizados e portos abertos
Uma instalação completa do Red Hat Enterprise Linux 8 contém mais de 1000 aplicações e pacotes de bibliotecas. Entretanto, a maioria dos administradores de servidores não optam por instalar cada pacote na distribuição, preferindo instalar uma instalação base de pacotes, incluindo várias aplicações de servidor.
Uma ocorrência comum entre os administradores de sistemas é instalar o sistema operacional sem prestar atenção a quais programas estão sendo instalados. Isto pode ser problemático porque serviços desnecessários podem ser instalados, configurados com as configurações padrão e possivelmente ativados. Isto pode causar que serviços indesejados, tais como Telnet, DHCP ou DNS, sejam executados em um servidor ou estação de trabalho sem que o administrador perceba, o que por sua vez pode causar tráfego indesejado para o servidor ou mesmo um caminho potencial para o sistema para crackers.
Serviços inigualáveis
A maioria das aplicações de servidor que estão incluídas em uma instalação padrão são peças de software sólidas e exaustivamente testadas. Tendo sido usado em ambientes de produção por muitos anos, seu código foi completamente refinado e muitos dos bugs foram encontrados e corrigidos.
Entretanto, não existe um software perfeito e sempre há espaço para mais refinamento. Além disso, os softwares mais novos muitas vezes não são tão rigorosamente testados quanto se poderia esperar, devido à sua recente chegada aos ambientes de produção ou porque podem não ser tão populares quanto outros softwares de servidor.
Desenvolvedores e administradores de sistemas frequentemente encontram bugs exploráveis em aplicações de servidor e publicam as informações sobre rastreamento de bugs e sites relacionados à segurança, tais como a lista de discussão Bugtraq (http://www.securityfocus.com) ou o site da Equipe de Resposta a Emergências de Computador (CERT) (http://www.cert.org). Embora estes mecanismos sejam uma forma eficaz de alertar a comunidade sobre as vulnerabilidades de segurança, cabe aos administradores de sistemas remendar prontamente seus sistemas. Isto é particularmente verdadeiro porque os crackers têm acesso a estes mesmos serviços de rastreamento de vulnerabilidades e usarão as informações para quebrar sistemas não remendados sempre que puderem. Uma boa administração do sistema requer vigilância, acompanhamento constante de bugs e manutenção adequada do sistema para garantir um ambiente computacional mais seguro.
Administração desatenta
Os administradores que falham em corrigir seus sistemas são uma das maiores ameaças à segurança do servidor. Isto se aplica tanto a administradores inexperientes quanto a administradores superconfiantes ou motivados.
Alguns administradores não corrigem seus servidores e estações de trabalho, enquanto outros não observam as mensagens de registro do kernel do sistema ou o tráfego de rede. Outro erro comum é quando as senhas ou chaves de serviços padrão são deixadas inalteradas. Por exemplo, alguns bancos de dados têm senhas de administração padrão porque os desenvolvedores de bancos de dados assumem que o administrador do sistema muda essas senhas imediatamente após a instalação. Se um administrador de banco de dados não alterar esta senha, mesmo um cracker inexperiente pode usar uma senha padrão amplamente conhecida para obter privilégios administrativos para o banco de dados. Estes são apenas alguns exemplos de como uma administração desatenta pode levar a servidores comprometidos.
Inerentemente inseguros, os serviços
Mesmo a organização mais vigilante pode ser vítima de vulnerabilidades se os serviços de rede que escolherem forem intrinsecamente inseguros. Por exemplo, há muitos serviços desenvolvidos sob a suposição de que são utilizados através de redes confiáveis; no entanto, esta suposição falha assim que o serviço se torna disponível através da Internet
Uma categoria de serviços de rede inseguros são aqueles que requerem nomes de usuário e senhas não criptografados para autenticação. Telnet e FTP são dois desses serviços. Se o software de checagem de pacotes estiver monitorando o tráfego entre o usuário remoto e tal serviço, nomes de usuário e senhas podem ser facilmente interceptados.
Inerentemente, tais serviços também podem cair mais facilmente no que a indústria de segurança denomina o ataque man-in-the-middle. Neste tipo de ataque, um cracker redireciona o tráfego da rede enganando um servidor de nomes craqueado na rede para apontar para sua máquina ao invés do servidor pretendido. Quando alguém abre uma sessão remota para o servidor, a máquina do atacante age como um conduto invisível, sentado em silêncio entre o serviço remoto e o usuário insuspeito que está capturando informações. Desta forma, um cracker pode reunir senhas administrativas e dados brutos sem que o servidor ou o usuário se dê conta.
Outra categoria de serviços inseguros inclui sistemas de arquivos de rede e serviços de informação como NFS ou NIS, que são desenvolvidos explicitamente para uso em LAN mas, infelizmente, são estendidos para incluir WANs (para usuários remotos). O NFS não tem, por padrão, nenhum mecanismo de autenticação ou segurança configurado para impedir que um cracker monte o compartilhamento do NFS e acesse qualquer coisa contida nele. O NIS também possui informações vitais que devem ser conhecidas por todos os computadores em uma rede, incluindo senhas e permissões de arquivos, dentro de um banco de dados de texto simples ASCII ou DBM (derivado do ASCII). Um cracker que obtém acesso a este banco de dados pode então acessar cada conta de usuário em uma rede, incluindo a conta do administrador.
Por default, o Red Hat Enterprise Linux 8 é lançado com todos esses serviços desativados. Entretanto, como os administradores muitas vezes se vêem forçados a usar esses serviços, uma configuração cuidadosa é fundamental.
1.6.3. Ameaças à segurança de estações de trabalho e PCs domésticos
Estações de trabalho e PCs domésticos podem não ser tão propensos a ataques como redes ou servidores, mas como muitas vezes contêm dados sensíveis, tais como informações de cartão de crédito, eles são alvo de crackers de sistema. As estações de trabalho também podem ser cooptadas sem o conhecimento do usuário e usadas por atacantes como máquinas "bot" em ataques coordenados. Por estas razões, conhecer as vulnerabilidades de uma estação de trabalho pode poupar aos usuários a dor de cabeça de reinstalar o sistema operacional, ou pior, de se recuperar do roubo de dados.
Más senhas
Senhas ruins são uma das maneiras mais fáceis para um atacante ter acesso a um sistema.
Aplicações de clientes vulneráveis
Embora um administrador possa ter um servidor totalmente seguro e com patches, isso não significa que os usuários remotos estejam seguros ao acessá-lo. Por exemplo, se o servidor oferece serviços Telnet ou FTP através de uma rede pública, um atacante pode capturar os nomes e senhas dos usuários em texto simples à medida que eles passam pela rede, e então usar as informações da conta para acessar a estação de trabalho do usuário remoto.
Mesmo ao utilizar protocolos seguros, como o SSH, um usuário remoto pode estar vulnerável a certos ataques se não mantiver suas aplicações clientes atualizadas. Por exemplo, clientes do protocolo SSH versão 1 são vulneráveis a um ataque de encaminhamento X de servidores SSH maliciosos. Uma vez conectado ao servidor, o atacante pode capturar silenciosamente quaisquer teclas e cliques de mouse feitos pelo cliente através da rede. Este problema foi corrigido no protocolo SSH versão 2, mas cabe ao usuário acompanhar quais aplicações têm tais vulnerabilidades e atualizá-las conforme necessário.
1.7. Explorações e ataques comuns
Tabela 1.1, “Explorações comuns” detalha algumas das explorações e pontos de entrada mais comuns usados por intrusos para acessar recursos da rede organizacional. A chave para estas explorações comuns são as explicações de como elas são realizadas e como os administradores podem proteger adequadamente sua rede contra tais ataques.
Tabela 1.1. Explorações comuns
| Exploração | Descrição | Notas |
|---|---|---|
| Senhas nulas ou padrão | Deixar senhas administrativas em branco ou usar uma senha padrão definida pelo fornecedor do produto. Isto é mais comum em hardware como roteadores e firewalls, mas alguns serviços que rodam no Linux também podem conter senhas default de administrador (embora o Red Hat Enterprise Linux 8 não seja enviado com elas). | Comumente associado com hardware de rede como roteadores, firewalls, VPNs e dispositivos de armazenamento conectado à rede (NAS). Comum em muitos sistemas operacionais antigos, especialmente aqueles que agrupam serviços (como UNIX e Windows) Os administradores às vezes criam contas de usuários privilegiados com pressa e deixam a senha nula, criando um ponto de entrada perfeito para usuários maliciosos que descobrem a conta. |
| Chaves compartilhadas por padrão | Serviços seguros, às vezes chaves de segurança padrão de pacotes para fins de desenvolvimento ou testes de avaliação. Se essas chaves forem deixadas inalteradas e colocadas em um ambiente de produção na Internet, all usuários com as mesmas chaves padrão têm acesso a esse recurso de chave compartilhada, e a qualquer informação sensível que ela contenha. | Mais comum em pontos de acesso sem fio e aparelhos de servidor seguro pré-configurados. |
| IP spoofing | Uma máquina remota atua como um nó em sua rede local, encontra vulnerabilidades com seus servidores e instala um programa de backdoor ou cavalo de Tróia para ganhar controle sobre os recursos de sua rede. | O spoofing é bastante difícil, pois envolve o atacante prever números de seqüência TCP/IP para coordenar uma conexão com sistemas alvo, mas várias ferramentas estão disponíveis para ajudar os crackers a realizar tal vulnerabilidade.
Depende dos serviços do sistema alvo (tais como |
| Espionagem | Coleta de dados que passam entre dois nós ativos em uma rede através da escuta da conexão entre os dois nós. | Este tipo de ataque funciona principalmente com protocolos de transmissão de texto simples, tais como Telnet, FTP e transferências HTTP. O atacante remoto deve ter acesso a um sistema comprometido em uma LAN para realizar tal ataque; geralmente o cracker usou um ataque ativo (como IP spoofing ou man-in-the-middle) para comprometer um sistema na LAN. Medidas preventivas incluem serviços com troca de chaves criptográficas, senhas únicas ou autenticação criptografada para evitar a bisbilhotice de senhas; uma criptografia forte durante a transmissão também é aconselhada. |
| Vulnerabilidades de serviço | Um atacante encontra uma falha ou lacuna em um serviço executado através da Internet; através desta vulnerabilidade, o atacante compromete todo o sistema e quaisquer dados que ele possa conter, e pode possivelmente comprometer outros sistemas na rede. | Serviços baseados em HTTP, como CGI, são vulneráveis à execução de comandos remotos e até mesmo ao acesso de shell interativo. Mesmo que o serviço HTTP seja executado como um usuário não-privilegiado, como "ninguém", informações como arquivos de configuração e mapas de rede podem ser lidas, ou o atacante pode iniciar um ataque de negação de serviço que drena recursos do sistema ou o torna indisponível para outros usuários. Serviços às vezes podem ter vulnerabilidades que passam despercebidas durante o desenvolvimento e testes; estas vulnerabilidades (tais como buffer overflows, onde atacantes quebram um serviço usando valores arbitrários que enchem o buffer de memória de uma aplicação, dando ao atacante um prompt de comando interativo a partir do qual podem executar comandos arbitrários) podem dar controle administrativo completo a um atacante. Os administradores devem certificar-se de que os serviços não sejam executados como usuário root, e devem ficar atentos às atualizações de correções e erratas para aplicações de fornecedores ou organizações de segurança, tais como CERT e CVE. |
| Vulnerabilidades de aplicação | Os atacantes encontram falhas em aplicações desktop e estações de trabalho (como clientes de e-mail) e executam código arbitrário, implantam cavalos de Tróia para futuros compromissos, ou sistemas de crash. Exploração adicional pode ocorrer se a estação de trabalho comprometida tiver privilégios administrativos sobre o resto da rede. | As estações de trabalho e os desktops são mais propensos à exploração, pois os trabalhadores não têm o conhecimento ou a experiência para evitar ou detectar um comprometimento; é imperativo informar as pessoas sobre os riscos que estão correndo quando instalam software não autorizado ou abrem anexos de e-mail não solicitados. As salvaguardas podem ser implementadas de modo que o software do cliente de e-mail não abra ou execute automaticamente os anexos. Além disso, a atualização automática do software da estação de trabalho usando Red Hat Network; ou outros serviços de gerenciamento de sistemas podem aliviar a carga de implementações de segurança com vários assentos. |
| Ataques de Negação de Serviço (DoS) | O atacante ou grupo de atacantes coordena contra os recursos da rede ou do servidor de uma organização, enviando pacotes não autorizados ao host alvo (seja servidor, roteador ou estação de trabalho). Isto força o recurso a ficar indisponível aos usuários legítimos. | O caso mais relatado de DoS nos EUA ocorreu em 2000. Vários sites comerciais e governamentais altamente traficados foram tornados indisponíveis por um ataque coordenado de inundação ping usando vários sistemas comprometidos com conexões de alta largura de banda agindo como zombies, ou nós de transmissão redirecionados. Os pacotes-fonte são geralmente forjados (assim como retransmitidos), tornando difícil a investigação sobre a verdadeira origem do ataque.
Avanços na filtragem de entrada (IETF rfc2267) usando |
Capítulo 2. Segurança da RHEL durante a instalação
A segurança começa antes mesmo de iniciar a instalação do Red Hat Enterprise Linux. A configuração segura de seu sistema desde o início facilita a implementação de configurações de segurança adicionais posteriormente.
2.1. BIOS e segurança UEFI
A proteção por senha do BIOS (ou equivalente) e do carregador de inicialização pode impedir que usuários não autorizados que tenham acesso físico aos sistemas inicializem usando mídia removível ou obtenham privilégios de raiz através do modo de usuário único. As medidas de segurança que você deve tomar para se proteger contra tais ataques dependem tanto da sensibilidade das informações na estação de trabalho quanto da localização da máquina.
Por exemplo, se uma máquina é utilizada em uma feira e não contém informações sensíveis, então pode não ser crítico para evitar tais ataques. Entretanto, se o laptop de um funcionário com chaves SSH privadas e não criptografadas para a rede corporativa for deixado sem supervisão nessa mesma feira comercial, isso pode levar a uma grande quebra de segurança com ramificações para toda a empresa.
Se a estação de trabalho estiver localizada em um local onde somente pessoas autorizadas ou de confiança tenham acesso, no entanto, a fixação da BIOS ou do carregador de inicialização pode não ser necessária.
2.1.1. Senhas da BIOS
As duas principais razões para proteger a BIOS de um computador por senha são[1]:
- Preventing changes to BIOS settings
- Preventing system booting
Como os métodos para definir uma senha BIOS variam entre os fabricantes de computadores, consulte o manual do computador para obter instruções específicas.
Se você esquecer a senha da BIOS, ela pode ser redefinida com jumpers na placa-mãe ou desligando a bateria CMOS. Por este motivo, é uma boa prática travar a caixa do computador, se possível. Entretanto, consulte o manual do computador ou da placa-mãe antes de tentar desconectar a bateria CMOS.
2.1.1.1. Segurança de sistemas não baseados em BIOS
Outros sistemas e arquiteturas usam programas diferentes para executar tarefas de baixo nível, aproximadamente equivalentes aos da BIOS em sistemas x86. Por exemplo, o shell Unified Extensible Firmware Interface (UEFI).
Para instruções sobre a proteção por senha de programas do tipo BIOS, consulte as instruções do fabricante.
2.2. Particionamento de discos
A Red Hat recomenda a criação de partições separadas para os diretórios /boot, /, /home, /tmp, e /var/tmp/. As razões para cada uma delas são diferentes, e vamos tratar de cada partição.
/boot- Esta partição é a primeira partição que é lida pelo sistema durante o boot up. As imagens do carregador de inicialização e do kernel que são usadas para inicializar seu sistema no Red Hat Enterprise Linux 8 são armazenadas nesta partição. Esta partição não deve ser criptografada. Se esta partição estiver incluída em / e esta partição estiver criptografada ou se tornar indisponível, seu sistema não será capaz de inicializar.
/home-
Quando os dados do usuário (
/home) são armazenados em/ao invés de em uma partição separada, a partição pode encher fazendo com que o sistema operacional se torne instável. Além disso, ao atualizar seu sistema para a próxima versão do Red Hat Enterprise Linux 8 é muito mais fácil quando você pode manter seus dados na partição/home, pois eles não serão sobregravados durante a instalação. Se a partição raiz (/) se corromper, seus dados poderão ser perdidos para sempre. Ao usar uma partição separada, há um pouco mais de proteção contra a perda de dados. Você também pode direcionar esta partição para backups freqüentes. /tmpe/var/tmp/-
Os diretórios
/tmpe/var/tmp/são usados para armazenar dados que não precisam ser armazenados por um longo período de tempo. Entretanto, se muitos dados inundarem um desses diretórios, ele pode consumir todo o seu espaço de armazenamento. Se isto acontecer e estes diretórios forem armazenados em/, então seu sistema pode se tornar instável e falhar. Por esta razão, mover estes diretórios para suas próprias partições é uma boa idéia.
Durante o processo de instalação, você tem a opção de criptografar as divisórias. Você deve fornecer uma frase-senha. Esta frase-chave serve como chave para destravar a chave de criptografia em massa, que é usada para proteger os dados da partição.
2.3. Restringindo a conectividade de rede durante o processo de instalação
Ao instalar o Red Hat Enterprise Linux 8, o meio de instalação representa um instantâneo do sistema em um determinado momento. Devido a isto, ele pode não estar atualizado com as últimas correções de segurança e pode estar vulnerável a certos problemas que foram corrigidos somente após o sistema fornecido pelo meio de instalação ter sido liberado.
Ao instalar um sistema operacional potencialmente vulnerável, sempre limite a exposição somente à zona de rede necessária mais próxima. A escolha mais segura é a zona "sem rede", o que significa deixar sua máquina desconectada durante o processo de instalação. Em alguns casos, uma conexão LAN ou intranet é suficiente enquanto a conexão à Internet é a mais arriscada. Para seguir as melhores práticas de segurança, escolha a zona mais próxima com seu repositório durante a instalação do Red Hat Enterprise Linux 8 a partir de uma rede.
2.4. Instalando a quantidade mínima de pacotes necessários
É a melhor prática instalar somente os pacotes que você usará, pois cada software em seu computador poderia conter uma vulnerabilidade. Se você estiver instalando a partir da mídia DVD, aproveite a oportunidade para selecionar exatamente quais pacotes você deseja instalar durante a instalação. Se você achar que precisa de outro pacote, você pode sempre adicioná-lo ao sistema mais tarde.
2.5. Procedimentos pós-instalação
Os seguintes passos são os procedimentos relacionados à segurança que devem ser realizados imediatamente após a instalação do Red Hat Enterprise Linux 8.
Atualize seu sistema. Digite o seguinte comando como root:
# yum updateMesmo que o serviço de firewall,
firewalld, seja ativado automaticamente com a instalação do Red Hat Enterprise Linux, há cenários onde ele pode ser explicitamente desativado, por exemplo, na configuração do kickstart. Em tal caso, recomenda-se considerar a possibilidade de habilitar novamente o firewall.Para iniciar
firewalld, digite os seguintes comandos como raiz:# systemctl start firewalld # systemctl enable firewalld
Para aumentar a segurança, desabilite os serviços de que você não precisa. Por exemplo, se não houver impressoras instaladas em seu computador, desabilite o serviço
cupsusando o seguinte comando:# systemctl disable cupsPara revisar os serviços ativos, digite o seguinte comando:
$ systemctl list-units | grep service
2.6. Instalação de um sistema RHEL 8 com o modo FIPS habilitado
Para ativar a auto-verificação do módulo criptográfico mandado pelo Federal Information Processing Standard (FIPS) Publication 140-2, você tem que operar o RHEL 8 no modo FIPS. Você pode conseguir isto através de:
- Iniciando a instalação no modo FIPS.
- Mudança do sistema para o modo FIPS após a instalação.
Para evitar a regeneração de material criptográfico chave e a reavaliação da conformidade do sistema resultante associado à conversão de sistemas já implantados, a Red Hat recomenda iniciar a instalação no modo FIPS.
2.6.1. Norma Federal de Processamento de Informações (FIPS)
A publicação Federal Information Processing Standard (FIPS) 140-2 é uma norma de segurança informática desenvolvida pelo governo dos EUA e pelo grupo de trabalho da indústria para validar a qualidade dos módulos criptográficos. Veja as publicações oficiais FIPS no NIST Computer Security Resource Center.
A norma FIPS 140-2 garante que as ferramentas criptográficas implementem seus algoritmos corretamente. Um dos mecanismos para isso é a auto-verificação em tempo de execução. Veja a norma FIPS 140-2 completa na FIPS PUB 140-2 para mais detalhes e outras especificações da norma FIPS.
Para saber mais sobre os requisitos de conformidade, consulte a página de Normas Governamentais da Red Hat.
2.6.2. Instalando o sistema com o modo FIPS habilitado
Para habilitar as auto-verificações do módulo criptográfico mandado pelo Federal Information Processing Standard (FIPS) Publication 140-2, habilite o modo FIPS durante a instalação do sistema.
A Red Hat recomenda a instalação do Red Hat Enterprise Linux 8 com o modo FIPS habilitado, ao invés de habilitar o modo FIPS mais tarde. A ativação do modo FIPS durante a instalação assegura que o sistema gere todas as chaves com algoritmos aprovados pelo FIPS e testes de monitoramento contínuo no local.
Procedimento
Adicione a opção
fips=1à linha de comando do kernel durante a instalação do sistema.Durante a etapa de seleção do software, não instale nenhum software de terceiros.
Após a instalação, o sistema inicia automaticamente no modo FIPS.
Etapas de verificação
Após o início do sistema, verifique se o modo FIPS está habilitado:
$ fips-mode-setup --check FIPS mode is enabled.
Recursos adicionais
- Consulte a seção Editando opções de inicialização na seção Executando um documento de instalação avançado da RHEL para obter mais informações sobre diferentes maneiras de editar opções de inicialização.
2.6.3. Recursos adicionais
Capítulo 3. Usando políticas criptográficas de todo o sistema
Políticas criptográficas é um componente do sistema que configura os subsistemas criptográficos centrais, cobrindo os protocolos TLS, IPSec, SSH, DNSSec, e Kerberos. Ele fornece um pequeno conjunto de políticas, que o administrador pode selecionar.
3.1. Políticas criptográficas de todo o sistema
Uma vez estabelecida uma política para todo o sistema, as aplicações na RHEL a seguem e se recusam a usar algoritmos e protocolos que não atendem à política, a menos que você solicite explicitamente a aplicação para fazê-lo. Ou seja, a política se aplica ao comportamento padrão dos aplicativos quando em execução com a configuração fornecida pelo sistema, mas você pode anulá-la se necessário.
O Red Hat Enterprise Linux 8 contém os seguintes níveis de políticas:
|
| O nível padrão da política criptográfica do sistema oferece configurações seguras para os modelos de ameaça atuais. Ele permite os protocolos TLS 1.2 e 1.3, assim como os protocolos IKEv2 e SSH2. As chaves RSA e os parâmetros Diffie-Hellman são aceitos se tiverem pelo menos 2048 bits de comprimento. |
|
|
Esta política assegura a máxima compatibilidade com o Red Hat Enterprise Linux 5 e anteriores; é menos segura devido a uma superfície de ataque maior. Além dos algoritmos e protocolos de nível |
|
| Um nível de segurança conservador que se acredita suportar qualquer ataque futuro a curto prazo. Este nível não permite o uso de SHA-1 em algoritmos de assinatura. As chaves RSA e os parâmetros Diffie-Hellman são aceitos se tiverem pelo menos 3072 bits de comprimento. |
|
|
Um nível de política que esteja em conformidade com os requisitos FIPS 140-2. Isto é usado internamente pela ferramenta |
A Red Hat ajusta continuamente todos os níveis da política de modo que todas as bibliotecas, exceto quando se utiliza a política LEGACY, forneçam padrões de segurança. Mesmo que o perfil LEGACY não forneça padrões seguros, ele não inclui nenhum algoritmo que seja facilmente explorável. Como tal, o conjunto de algoritmos habilitados ou tamanhos de chave aceitáveis em qualquer política fornecida pode mudar durante a vida útil do RHEL 8.
Tais mudanças refletem novos padrões de segurança e novas pesquisas de segurança. Se você deve garantir a interoperabilidade com um sistema específico durante toda a vida útil do RHEL 8, você deve optar por não utilizar políticas criptográficas para componentes que interagem com esse sistema.
Como uma chave criptográfica usada por um certificado no API do Portal do Cliente não atende aos requisitos da política de criptografia do sistema FUTURE, o utilitário redhat-support-tool não funciona com este nível de política no momento.
Para contornar este problema, utilize a política de criptografia DEFAULT enquanto se conecta ao API do Portal do Cliente.
Os algoritmos e cifras específicos descritos nos níveis de política como permitidos estão disponíveis somente se uma aplicação os suportar.
Ferramenta para gerenciar políticas criptográficas
Para visualizar ou alterar a atual política de criptografia do sistema, use a ferramenta update-crypto-policies, por exemplo:
$ update-crypto-policies --show DEFAULT # update-crypto-policies --set FUTURE Setting system policy to FUTURE
Para garantir que a mudança da política criptográfica seja aplicada, reinicie o sistema.
Padrões criptográficos fortes através da remoção de conjuntos e protocolos criptográficos inseguros
A lista a seguir contém conjuntos de cifras e protocolos removidos das bibliotecas criptográficas centrais no RHEL 8. Eles não estão presentes nas fontes, ou seu suporte é desativado durante a construção, de modo que as aplicações não podem usá-los.
- DES (desde RHEL 7)
- Todas as suítes de cifras de grau de exportação (desde RHEL 7)
- MD5 em assinaturas (desde RHEL 7)
- SSLv2 (desde RHEL 7)
- SSLv3 (desde RHEL 8)
- Todas as curvas ECC < 224 bits (desde RHEL 6)
- Todas as curvas ECC de campo binário (desde RHEL 6)
Suítes de cifras e protocolos desabilitados em todos os níveis de políticas
Os seguintes conjuntos de cifras e protocolos são desativados em todos os níveis da política criptográfica. Eles só podem ser habilitados através de uma configuração explícita de aplicações individuais.
- DH com parâmetros < 1024 bits
- RSA com chave de tamanho < 1024 bits
- Camélia
- ARIA
- SEED
- IDEA
- Suítes de cifras somente de integridade
- TLS CBC modo criptográfico usando SHA-384 HMAC
- AES-CCM8
- Todas as curvas ECC incompatíveis com o TLS 1.3, incluindo o secp256k1
- IKEv1 (desde RHEL 8)
Suítes de cifras e protocolos habilitados nos níveis cripto-políticos
A tabela a seguir mostra os conjuntos e protocolos de cifras habilitados em todos os quatro níveis de criptografia.
LEGACY | DEFAULT | FIPS | FUTURE | |
|---|---|---|---|---|
| IKEv1 | não | não | não | não |
| 3DES | sim | não | não | não |
| RC4 | sim | não | não | não |
| DH | min. 1024 bits | min. 2048 bits | min. 2048 bits | min. 3072 bits |
| RSA | min. 1024 bits | min. 2048 bits | min. 2048 bits | min. 3072 bits |
| DSA | sim | não | não | não |
| TLS v1.0 | sim | não | não | não |
| TLS v1.1 | sim | não | não | não |
| SHA-1 in digital signatures | sim | sim | não | não |
| CBC mode ciphers | sim | sim | sim | não |
| Symmetric ciphers with keys < 256 bits | sim | sim | sim | não |
| SHA-1 and SHA-224 signatures in certificates | sim | sim | sim | não |
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
update-crypto-policies(8).
3.2. Mudando a política de criptografia de todo o sistema para o modo compatível com versões anteriores
A política padrão de criptografia de todo o sistema no Red Hat Enterprise Linux 8 não permite a comunicação usando protocolos mais antigos e inseguros. Para ambientes que requerem ser compatíveis com o Red Hat Enterprise Linux 5 e, em alguns casos, também com versões anteriores, o nível menos seguro da política LEGACY está disponível.
A mudança para o nível da política LEGACY resulta em um sistema e aplicações menos seguros.
Procedimento
Para mudar a política de criptografia de todo o sistema para o nível
LEGACY, digite o seguinte comando comoroot:# update-crypto-policies --set LEGACY Setting system policy to LEGACY
Recursos adicionais
-
Para a lista de níveis de políticas criptográficas disponíveis, consulte a página de manual
update-crypto-policies(8).
3.3. Mudando o sistema para o modo FIPS
As políticas criptográficas de todo o sistema contêm um nível de política que permite a auto-verificação dos módulos criptográficos de acordo com os requisitos da Publicação 140-2 do Federal Information Processing Standard (FIPS). A ferramenta fips-mode-setup que habilita ou desabilita o modo FIPS internamente usa o nível de política criptográfica em todo o sistema FIPS.
A Red Hat recomenda a instalação do Red Hat Enterprise Linux 8 com o modo FIPS habilitado, ao invés de habilitar o modo FIPS mais tarde. A ativação do modo FIPS durante a instalação assegura que o sistema gere todas as chaves com algoritmos aprovados pelo FIPS e testes de monitoramento contínuo no local.
Procedimento
Para mudar o sistema para o modo FIPS no RHEL 8:
# fips-mode-setup --enable Setting system policy to FIPS FIPS mode will be enabled. Please reboot the system for the setting to take effect.Reinicie seu sistema para permitir que o kernel mude para o modo FIPS:
# reboot
Etapas de verificação
Após o reinício, você pode verificar o estado atual do modo FIPS:
# fips-mode-setup --check FIPS mode is enabled.
Recursos adicionais
-
A página do homem
fips-mode-setup(8). - Lista de aplicações RHEL 8 que utilizam criptografia que não estão em conformidade com FIPS 140-2
- Para mais detalhes sobre o FIPS 140-2, consulte os Requisitos de Segurança para Módulos Criptográficos no site do National Institute of Standards and Technology (NIST).
3.4. Habilitando o modo FIPS em um contêiner
Para permitir a auto-verificação dos módulos criptográficos de acordo com as exigências do Federal Information Processing Standard (FIPS) Publicação 140-2 em um contêiner:
Pré-requisitos
- O sistema hospedeiro deve ser comutado primeiro no modo FIPS, veja Mudando o sistema para o modo FIPS.
Procedimento
-
Monte o arquivo
/etc/system-fipsno recipiente do anfitrião. Estabelecer o nível da política criptográfica FIPS no contêiner:
$ update-crypto-policies --set FIPS
RHEL 8.2 introduziu um método alternativo para mudar um contêiner para o modo FIPS. Ele requer apenas o uso do seguinte comando no contêiner:
# mount --bind /usr/share/crypto-policies/back-ends/FIPS /etc/crypto-policies/back-ends
No RHEL 8, o comando fips-mode-setup não funciona corretamente em um container e não pode ser usado para habilitar ou verificar o modo FIPS neste cenário.
3.5. Lista de aplicações RHEL usando criptografia que não está em conformidade com FIPS 140-2
A Red Hat recomenda a utilização de bibliotecas do conjunto de componentes criptográficos essenciais, uma vez que é garantido que eles passem todas as certificações criptográficas relevantes, tais como FIPS 140-2, e também sigam as políticas de criptografia do sistema RHEL.
Veja o artigo sobre componentes criptográficos do núcleo RHEL 8 para uma visão geral dos componentes criptográficos do núcleo RHEL 8, as informações sobre como são selecionados, como são integrados ao sistema operacional, como suportam módulos de segurança de hardware e cartões inteligentes, e como as certificações criptográficas se aplicam a eles.
Além da tabela a seguir, em alguns lançamentos da RHEL 8 Z-stream (por exemplo, 8.1.1), os pacotes do navegador Firefox foram atualizados e contêm uma cópia separada da biblioteca de criptografia NSS. Desta forma, a Red Hat quer evitar a interrupção do rebase de um componente de tão baixo nível em um lançamento de patch. Como resultado, estes pacotes Firefox não usam um módulo validado FIPS 140-2.
Tabela 3.1. Lista de aplicações RHEL 8 que utilizam criptografia que não está em conformidade com FIPS 140-2
| Aplicação | Detalhes |
|---|---|
| FreeRADIUS | O protocolo RADIUS utiliza o MD5 |
| ghostscript | Cripto próprio (MD5, RC4, SHA-2, AES) para criptografar e decodificar documentos |
| ipxe | A pilha criptográfica para TLS é compilada em, no entanto, não é utilizada |
| java-1.8.0-openjdk | Empilhamento criptográfico completo[a] |
| libica | Fallbacks de software para vários algoritmos, tais como RSA e ECDH através de instruções CPACF |
| Ovmf (firmware UEFI), Edk2, shim | Pilha criptográfica completa (uma cópia embutida da biblioteca OpenSSL) |
| perl-Digest-HMAC | HMAC, HMAC-SHA1, HMAC-MD5 |
| perl-Digest-SHA | SHA-1, SHA-224, .. |
| pidgin | DES, RC4 |
| samba[b] | AES, DES, RC4 |
| valgrind | AES, hashes[c] |
[a]
No RHEL 8.1, o java-1.8.0-openjdk requer configuração manual adicional para ser compatível com o FIPS.
[b]
A partir do RHEL 8.3, o samba usa criptografia compatível com FIPS.
[c]
Re-implementos em operações de hardware de software, tais como AES-NI.
| |
3.6. Excluindo uma aplicação de seguir as políticas de criptografia de todo o sistema
Você pode personalizar as configurações criptográficas usadas por sua aplicação, de preferência configurando as suítes de cifras suportadas e os protocolos diretamente na aplicação.
Você também pode remover um link simbólico relacionado à sua aplicação do diretório /etc/crypto-policies/back-ends e substituí-lo por suas configurações criptográficas personalizadas. Esta configuração impede o uso de políticas criptográficas de todo o sistema para aplicações que utilizam o back end excluído. Além disso, esta modificação não é suportada pela Red Hat.
3.6.1. Exemplos de exclusão de políticas de criptografia de todo o sistema
wget
Para personalizar as configurações criptográficas usadas pelo downloader da rede wget, use as opções --secure-protocol e --ciphers. Por exemplo:
$ wget --secure-protocol=TLSv1_1 --ciphers="SECURE128" https://example.com
Consulte a seção Opções HTTPS (SSL/TLS) da página de manual wget(1) para mais informações.
enrolar
Para especificar as cifras usadas pela ferramenta curl, use a opção --ciphers e forneça uma lista de cifras separadas por dois pontos como um valor. Por exemplo:
$ curl https://example.com --ciphers '@SECLEVEL=0:DES-CBC3-SHA:RSA-DES-CBC3-SHA'
Consulte a página de manual curl(1) para mais informações.
Firefox
Mesmo que você não possa optar por não participar das políticas de criptografia do sistema no navegador Firefox, você pode restringir ainda mais as cifras suportadas e as versões TLS no Editor de Configuração do Firefox. Digite about:config na barra de endereço e altere o valor da opção security.tls.version.min conforme necessário. Definindo security.tls.version.min como 1 permite TLS 1.0 como o mínimo exigido, security.tls.version.min 2 permite TLS 1.1, e assim por diante.
OpenSSH
Para optar pela exclusão das políticas de criptografia de todo o sistema para seu servidor OpenSSH, descomente a linha com a variável CRYPTO_POLICY= no arquivo /etc/sysconfig/sshd. Após esta mudança, os valores que você especificar nas seções Ciphers, MACs, KexAlgoritms, e GSSAPIKexAlgorithms no arquivo /etc/ssh/sshd_config não serão sobrepostos. Consulte a página de manual sshd_config(5) para maiores informações.
Libreswan
Consulte o documento Configuring IPsec connections that opt out of the system-wide crypto policies no documento Securing networks para obter informações detalhadas.
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
update-crypto-policies(8).
3.7. Personalização de políticas criptográficas em todo o sistema com modificadores de políticas
Use este procedimento para ajustar certos algoritmos ou protocolos de qualquer nível de política criptográfica de todo o sistema ou uma política totalmente personalizada.
A personalização de políticas criptográficas de todo o sistema está disponível na RHEL 8.2.
Procedimento
Checkout para o diretório
/etc/crypto-policies/policies/modules/:# cd /etc/crypto-policies/policies/modules/Crie módulos de políticas para seus ajustes, por exemplo:
# touch MYCRYPTO1.pmod # touch NO-AES128.pmod
ImportanteUse letras maiúsculas nos nomes dos arquivos dos módulos de políticas.
Abra os módulos de política em um editor de texto de sua escolha e insira opções que modificam a política criptográfica de todo o sistema, por exemplo:
# vi MYCRYPTO1.pmodsha1_in_certs = 0 min_rsa_size = 3072
# vi NO-AES128.pmodcipher = -AES-128-GCM -AES-128-CCM -AES-128-CTR -AES-128-CBC
- Salvar as mudanças nos arquivos do módulo.
Aplique seus ajustes de política ao nível da política criptográfica do sistema
DEFAULT:# update-crypto-policies --set DEFAULT:MYCRYPTO1:NO-AES128Para tornar suas configurações criptográficas efetivas para serviços e aplicações já em execução, reinicie o sistema:
# reboot
Recursos adicionais
-
Para mais detalhes, consulte a seção
Custom Policiesna página de manualupdate-crypto-policies(8)e a seçãoCrypto Policy Definition Formatna página de manualcrypto-policies(7). - O artigo Como personalizar políticas criptográficas no RHEL 8.2 fornece exemplos adicionais de personalização de políticas criptográficas em todo o sistema.
3.8. Desabilitando o SHA-1 através da personalização de uma política de criptografia de todo o sistema
A função hash SHA-1 tem um design inerentemente fraco e o avanço da criptanálise a tornou vulnerável a ataques. Por padrão, a RHEL 8 não usa SHA-1, mas algumas aplicações de terceiros, por exemplo, assinaturas públicas, ainda usam SHA-1. Para desativar o uso do SHA-1 em algoritmos de assinatura em seu sistema, você pode usar o módulo de política NO-SHA1.
O módulo para desativação do SHA-1 está disponível na RHEL 8.3. A personalização das políticas criptográficas de todo o sistema está disponível na RHEL 8.2.
Procedimento
Aplique seus ajustes de política ao nível da política criptográfica do sistema
DEFAULT:# update-crypto-policies --set DEFAULT:NO-SHA1Para tornar suas configurações criptográficas efetivas para serviços e aplicações já em execução, reinicie o sistema:
# reboot
Recursos adicionais
-
Para mais detalhes, consulte a seção
Custom Policiesna página de manualupdate-crypto-policies(8)e a seçãoCrypto Policy Definition Formatna página de manualcrypto-policies(7). - O post do blog Como personalizar as políticas de criptografia no RHEL 8.2 fornece exemplos adicionais de personalização de políticas criptográficas em todo o sistema.
3.9. Criação e definição de uma política criptográfica personalizada para todo o sistema
Os passos seguintes demonstram a personalização das políticas criptográficas de todo o sistema através de um arquivo completo de políticas.
A personalização de políticas criptográficas de todo o sistema está disponível na RHEL 8.2.
Procedimento
Crie um arquivo de políticas para suas personalizações:
# cd /etc/crypto-policies/policies/ # touch MYPOLICY.pol
Alternativamente, comece copiando um dos quatro níveis de política pré-definidos:
# cp /usr/share/crypto-policies/policies/DEFAULT.pol /etc/crypto-policies/policies/MYPOLICY.polEdite o arquivo com sua política de criptografia personalizada em um editor de texto de sua escolha para atender às suas exigências, por exemplo:
# vi /etc/crypto-policies/policies/MYPOLICY.polMude a política de criptografia de todo o sistema para seu nível personalizado:
# update-crypto-policies --set MYPOLICYPara tornar suas configurações criptográficas efetivas para serviços e aplicações já em execução, reinicie o sistema:
# reboot
Recursos adicionais
-
Para mais detalhes, consulte a seção
Custom Policiesna página de manualupdate-crypto-policies(8)e a seçãoCrypto Policy Definition Formatna página de manualcrypto-policies(7). - O artigo Como personalizar políticas criptográficas no RHEL 8.2 fornece exemplos adicionais de personalização de políticas criptográficas em todo o sistema.
Capítulo 4. Configuração de aplicações para usar hardware criptográfico através do PKCS #11
A separação de partes de suas informações secretas em dispositivos criptográficos dedicados, tais como cartões inteligentes e fichas criptográficas para autenticação do usuário final e módulos de segurança de hardware (HSM) para aplicações de servidor, proporciona uma camada adicional de segurança. No Red Hat Enterprise Linux 8, o suporte para hardware criptográfico através da API PKCS #11 é consistente entre diferentes aplicações, e o isolamento de segredos em hardware criptográfico não é uma tarefa complicada.
4.1. Suporte de hardware criptográfico através do PKCS #11
O PKCS #11 (Public-Key Cryptography Standard) define uma interface de programação de aplicação (API) para dispositivos criptográficos que contêm informações criptográficas e realizam funções criptográficas. Estes dispositivos são chamados tokens, e podem ser implementados em forma de hardware ou software.
Uma ficha PKCS #11 pode armazenar vários tipos de objetos, incluindo um certificado; um objeto de dados; e uma chave pública, privada ou secreta. Estes objetos são unicamente identificáveis através do esquema PKCS #11 URI.
Um PKCS #11 URI é uma forma padrão de identificar um objeto específico em um módulo PKCS #11 de acordo com os atributos do objeto. Isto permite configurar todas as bibliotecas e aplicações com a mesma cadeia de configuração na forma de um URI.
O Red Hat Enterprise Linux 8 fornece por default o driver OpenSC PKCS #11 para cartões inteligentes. Entretanto, os tokens de hardware e HSMs podem ter seus próprios módulos PKCS #11 que não têm sua contraparte no Red Hat Enterprise Linux. Você pode registrar tais módulos PKCS #11 com a ferramenta p11-kit, que atua como um invólucro sobre os drivers de Cartão Smart Card registrados no sistema.
Para fazer seu próprio módulo PKCS #11 funcionar no sistema, adicione um novo arquivo de texto ao diretório /etc/pkcs11/modules/
Você pode adicionar seu próprio módulo PKCS #11 ao sistema, criando um novo arquivo de texto no diretório /etc/pkcs11/modules/. Por exemplo, o arquivo de configuração do OpenSC em p11-kit tem a seguinte aparência:
$ cat /usr/share/p11-kit/modules/opensc.module
module: opensc-pkcs11.so4.2. Usando chaves SSH armazenadas em um cartão inteligente
O Red Hat Enterprise Linux 8 permite que você use chaves RSA e ECDSA armazenadas em um cartão inteligente em clientes OpenSSH. Use este procedimento para habilitar a autenticação usando um Cartão Smart Card ao invés de usar uma senha.
Pré-requisitos
-
No lado do cliente, o pacote
openscestá instalado e o serviçopcscdestá funcionando.
Procedimento
Liste todas as chaves fornecidas pelo módulo OpenSC PKCS #11 incluindo seus PKCS #11 URIs e salve a saída para o arquivo keys.pub:
$ ssh-keygen -D pkcs11: > keys.pub $ ssh-keygen -D pkcs11: ssh-rsa AAAAB3NzaC1yc2E...KKZMzcQZzx pkcs11:id=%02;object=SIGN%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so ecdsa-sha2-nistp256 AAA...J0hkYnnsM= pkcs11:id=%01;object=PIV%20AUTH%20pubkey;token=SSH%20key;manufacturer=piv_II?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so
Para permitir a autenticação usando um cartão inteligente em um servidor remoto (example.com), transfira a chave pública para o servidor remoto. Use o comando
ssh-copy-idcom keys.pub criado na etapa anterior:$ ssh-copy-id -f -i keys.pub username@example.comPara conectar-se a example.com usando a chave ECDSA da saída do comando
ssh-keygen -Dno passo 1, você pode usar apenas um subconjunto do URI, que faz referência única à sua chave, por exemplo:$ ssh -i "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" example.com Enter PIN for 'SSH key': [example.com] $Você pode usar a mesma cadeia URI no arquivo
~/.ssh/configpara tornar a configuração permanente:$ cat ~/.ssh/config IdentityFile "pkcs11:id=%01?module-path=/usr/lib64/pkcs11/opensc-pkcs11.so" $ ssh example.com Enter PIN for 'SSH key': [example.com] $
Como o OpenSSH usa a embalagem
p11-kit-proxye o módulo OpenSC PKCS #11 está registrado no Kit PKCS #11, você pode simplificar os comandos anteriores:$ ssh -i "pkcs11:id=%01" example.com Enter PIN for 'SSH key': [example.com] $
Se você pular a parte id= de um PKCS #11 URI, o OpenSSH carrega todas as chaves que estão disponíveis no módulo proxy. Isto pode reduzir a quantidade de digitação necessária:
$ ssh -i pkcs11: example.com
Enter PIN for 'SSH key':
[example.com] $Recursos adicionais
- Fedora 28: Melhor suporte a cartões inteligentes no OpenSSH
-
p11-kit(8)página do homem -
ssh(1)página do homem -
ssh-keygen(1)página do homem -
opensc.conf(5)página do homem -
pcscd(8)página do homem
4.3. Usando HSMs protegendo chaves privadas em Apache e Nginx
Os servidores HTTP Apache e Nginx podem trabalhar com chaves privadas armazenadas em módulos de segurança de hardware (HSMs), o que ajuda a evitar a revelação das chaves e ataques "man-in-the-middle". Note que isto normalmente requer HSMs de alto desempenho para servidores ocupados.
Apache Servidor HTTP
Para uma comunicação segura na forma do protocolo HTTPS, o servidor Apache HTTP (httpd) utiliza a biblioteca OpenSSL. A OpenSSL não suporta o PKCS #11 nativamente. Para utilizar HSMs, é necessário instalar o pacote openssl-pkcs11, que fornece acesso aos módulos PKCS #11 através da interface do motor. Você pode usar um URI PKCS #11 em vez de um nome de arquivo comum para especificar uma chave de servidor e um certificado no arquivo de configuração /etc/httpd/conf.d/ssl.conf, por exemplo:
SSLCertificateFile "pkcs11:id=%01;token=softhsm;type=cert" SSLCertificateKeyFile "pkcs11:id=%01;token=softhsm;type=private?pin-value=111111"
Instale o pacote httpd-manual para obter a documentação completa para o Servidor HTTP Apache, incluindo a configuração TLS. As diretrizes disponíveis no arquivo de configuração /etc/httpd/conf.d/ssl.conf são descritas em detalhes em /usr/share/httpd/manual/mod/mod_ssl.html.
Nginx Servidor HTTP e proxy
Como Nginx também usa o OpenSSL para operações criptográficas, o suporte para o PKCS #11 deve passar pelo motor openssl-pkcs11. Nginx atualmente suporta apenas o carregamento de chaves privadas de um HSM, e um certificado deve ser fornecido separadamente como um arquivo regular. Modifique as opções ssl_certificate e ssl_certificate_key na seção server do arquivo de configuração /etc/nginx/nginx.conf:
ssl_certificate /path/to/cert.pem ssl_certificate_key "engine:pkcs11:pkcs11:token=softhsm;id=%01;type=private?pin-value=111111";
Note que o prefixo engine:pkcs11: é necessário para o PKCS #11 URI no arquivo de configuração Nginx. Isto porque o outro prefixo pkcs11 se refere ao nome do motor.
4.4. Configuração de aplicações para autenticar usando certificados de cartões inteligentes
O downloader da rede
wgetpermite especificar PKCS #11 URIs em vez de caminhos para chaves privadas armazenadas localmente, e assim simplifica a criação de scripts para tarefas que requerem chaves privadas e certificados armazenados com segurança. Por exemplo, o PKCS #11 URIs:$ wget --private-key 'pkcs11:token=softhsm;id=;type=private?pin-value=11111111' --certificado 'pkcs11:token=softhsm;id=;type=cert' https://example.com/
Consulte a página de manual
wget(1)para mais informações.A especificação do PKCS #11 URI para uso pela ferramenta
curlé análoga:$ curl --key 'pkcs11:token=softhsm;id=;type=private?pin-value=11111111' --cert 'pkcs11:token=softhsm;id=;type=cert' https://example.com/
Consulte a página de manual
curl(1)para mais informações.-
O navegador web
Firefoxcarrega automaticamente o módulop11-kit-proxy. Isto significa que cada Cartão Smart Card suportado no sistema é detectado automaticamente. Para usar a autenticação do cliente TLS, nenhuma configuração adicional é necessária e as chaves de um Cartão Smart Card são automaticamente usadas quando um servidor as solicita.
Usando o PKCS #11 URIs em aplicações personalizadas
Se sua aplicação utiliza a biblioteca GnuTLS ou NSS, o suporte para o PKCS #11 URIs é garantido por seu suporte integrado ao PKCS #11. Além disso, as aplicações que dependem da biblioteca OpenSSL podem acessar módulos de hardware criptográfico graças ao motor openssl-pkcs11.
Com aplicações que requerem trabalhar com chaves privadas em cartões inteligentes e que não usam NSS, GnuTLS, ou OpenSSL, use p11-kit para implementar o registro dos módulos PKCS #11.
Consulte a página de manual p11-kit(8) para mais informações.
Capítulo 6. Verificação do sistema para conformidade e vulnerabilidades de configuração
Uma auditoria de conformidade é um processo para determinar se um determinado objeto segue todas as regras especificadas em uma política de conformidade. A política de conformidade é definida por profissionais de segurança que especificam as configurações necessárias, muitas vezes na forma de uma lista de verificação, que um ambiente de computação deve utilizar.
As políticas de conformidade podem variar substancialmente entre organizações e até mesmo entre diferentes sistemas dentro de uma mesma organização. As diferenças entre estas políticas são baseadas no propósito de cada sistema e sua importância para a organização. As configurações personalizadas do software e as características de implantação também levantam uma necessidade de listas de verificação de políticas personalizadas.
6.1. Ferramentas de conformidade de configuração na RHEL
O Red Hat Enterprise Linux fornece ferramentas que permitem que você realize uma auditoria de conformidade totalmente automatizada. Estas ferramentas são baseadas no padrão Security Content Automation Protocol (SCAP) e são projetadas para a adaptação automatizada das políticas de conformidade.
-
SCAP Workbench - O utilitário gráfico
scap-workbenché projetado para realizar varreduras de configuração e vulnerabilidade em um único sistema local ou remoto. Você também pode usá-lo para gerar relatórios de segurança com base nestas varreduras e avaliações. -
OpenSCAP - A biblioteca
OpenSCAP, com o utilitário de linha de comandooscap, foi projetada para realizar varreduras de configuração e vulnerabilidade em um sistema local, para validar o conteúdo de conformidade de configuração e para gerar relatórios e guias baseados nessas varreduras e avaliações. -
SCAP Security Guide (SSG) - O pacote
scap-security-guidefornece a mais recente coleção de políticas de segurança para sistemas Linux. A orientação consiste em um catálogo de conselhos práticos de endurecimento, ligados às exigências governamentais, quando aplicável. O projeto faz a ponte entre os requisitos de políticas generalizadas e diretrizes específicas de implementação. -
Script Check Engine (SCE) - O SCE é uma extensão do protocolo SCAP que permite aos administradores escrever seu conteúdo de segurança usando uma linguagem de script, como Bash, Python e Ruby. A extensão SCE é fornecida no pacote
openscap-engine-sce. O SCE em si não faz parte do padrão SCAP.
Para realizar auditorias de conformidade automatizadas em múltiplos sistemas remotamente, você pode usar a solução OpenSCAP para o Red Hat Satellite.
Recursos adicionais
-
oscap(8)- A página do manual do utilitário de linha de comandooscapfornece uma lista completa de opções disponíveis e explicações sobre seu uso. - Demonstrações de segurança da Red Hat: Criando Conteúdo de Política de Segurança Personalizada para Automatizar a Conformidade de Segurança - Um laboratório prático para obter experiência inicial na automatização da conformidade de segurança usando as ferramentas incluídas no Red Hat Enterprise Linux para cumprir tanto as políticas de segurança padrão da indústria quanto as políticas de segurança personalizadas. Se você deseja treinamento ou acesso a estes exercícios de laboratório para sua equipe, contate sua equipe de conta da Red Hat para obter detalhes adicionais.
- Demonstrações de segurança da Red Hat: Defenda-se com as Tecnologias de Segurança RHEL - Um laboratório prático para aprender como implementar segurança em todos os níveis de seu sistema RHEL, usando as principais tecnologias de segurança disponíveis no Red Hat Enterprise Linux, incluindo OpenSCAP. Se você deseja treinamento ou acesso a estes exercícios de laboratório para sua equipe, contate sua equipe de conta da Red Hat para obter detalhes adicionais.
-
scap-workbench(8)- A página do manual da aplicaçãoSCAP Workbenchfornece informações básicas sobre a aplicação, bem como alguns links para fontes potenciais de conteúdo SCAP. -
scap-security-guide(8)- A página do manual do projetoscap-security-guidefornece mais documentação sobre os vários perfis de segurança SCAP disponíveis. São fornecidos também exemplos de como utilizar as referências fornecidas usando o utilitário OpenSCAP. - Para mais detalhes sobre o uso do OpenSCAP com o Red Hat Satellite, veja Gerenciamento de Conformidade de Segurança no Guia de Administração do Red Hat Satellite.
6.2. Varredura de vulnerabilidades
6.2.1. Red Hat Security Advisories Alimentação OVAL
Os recursos de auditoria de segurança do Red Hat Enterprise Linux são baseados no padrão Security Content Automation Protocol (SCAP). O SCAP é uma estrutura multiuso de especificações que suporta configuração automatizada, verificação de vulnerabilidade e patch, atividades de conformidade de controle técnico e medição de segurança.
As especificações SCAP criam um ecossistema onde o formato do conteúdo de segurança é bem conhecido e padronizado, embora a implementação do scanner ou editor de políticas não seja mandatada. Isto permite que as organizações construam sua política de segurança (conteúdo SCAP) uma vez, não importa quantos fornecedores de segurança empreguem.
A linguagem de avaliação de vulnerabilidade aberta (OVAL) é o componente essencial e mais antigo da SCAP. Ao contrário de outras ferramentas e scripts personalizados, a OVAL descreve um estado de recursos necessários de forma declarativa. O código OVAL nunca é executado diretamente, mas usando uma ferramenta de intérprete OVAL chamada scanner. A natureza declarativa do OVAL garante que o estado do sistema avaliado não seja modificado acidentalmente.
Como todos os outros componentes SCAP, OVAL é baseado em XML. A norma SCAP define vários formatos de documentos. Cada um deles inclui um tipo diferente de informação e serve a um propósito diferente.
ASegurança de Produtos Red Hat ajuda os clientes a avaliar e gerenciar riscos, rastreando e investigando todas as questões de segurança que afetam os clientes da Red Hat. Ela fornece correções oportunas e concisas e conselhos de segurança no Portal do Cliente da Red Hat. A Red Hat cria e suporta as definições de patches OVAL, fornecendo versões legíveis por máquina de nossos alertas de segurança.
Devido às diferenças entre plataformas, versões e outros fatores, as classificações qualitativas de severidade de vulnerabilidades da Red Hat Product Security não se alinham diretamente com as classificações de base do Common Vulnerability Scoring System (CVSS) fornecidas por terceiros. Portanto, recomendamos que você utilize as definições do RHSA OVAL em vez daquelas fornecidas por terceiros.
As definições da RHSA OVAL estão disponíveis individualmente e como um pacote completo, e são atualizadas dentro de uma hora após uma nova consultoria de segurança ser disponibilizada no Portal do Cliente da Red Hat.
Cada definição de patch OVAL mapeia um a um para uma Consultoria de Segurança da Red Hat (RHSA). Como uma RHSA pode conter correções para múltiplas vulnerabilidades, cada vulnerabilidade é listada separadamente por seu nome Common Vulnerabilities and Exposures (CVE) e tem um link para sua entrada em nosso banco de dados público de bugs.
As definições da RHSA OVAL são projetadas para verificar as versões vulneráveis dos pacotes RPM instalados em um sistema. É possível estender estas definições para incluir verificações adicionais, por exemplo, para descobrir se os pacotes estão sendo usados em uma configuração vulnerável. Estas definições são projetadas para cobrir software e atualizações enviados pela Red Hat. Definições adicionais são necessárias para detectar o status do patch de software de terceiros.
Para procurar vulnerabilidades de segurança em contêineres ou imagens de contêineres, veja Scanning Containers and Container Images for Vulnerabilities.
6.2.2. Verificação de vulnerabilidades no sistema
O utilitário de linha de comando oscap permite digitalizar sistemas locais, validar o conteúdo de conformidade da configuração e gerar relatórios e guias baseados nestas digitalizações e avaliações. Este utilitário serve como um front end para a biblioteca OpenSCAP e agrupa suas funcionalidades em módulos (subcomandos) com base no tipo de conteúdo SCAP que processa.
Pré-requisitos
-
O repositório
AppStreamestá habilitado.
Procedimento
Instale os pacotes
openscap-scannerebzip2:# yum install openscap-scanner bzip2Faça o download das últimas definições da RHSA OVAL para seu sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlProcure vulnerabilidades no sistema e salve os resultados no arquivo vulnerability.html:
# oscap oval eval --report vulnerability.html rhel-8.oval.xml
Etapas de verificação
Verifique os resultados em um navegador à sua escolha, por exemplo:
$ firefox vulnerability.html &
Recursos adicionais
-
A página do homem
oscap(8). - A lista de definições do Red Hat OVAL.
6.2.3. Varredura de sistemas remotos em busca de vulnerabilidades
Você também pode verificar as vulnerabilidades de sistemas remotos com o scanner OpenSCAP usando a ferramenta oscap-ssh sobre o protocolo SSH.
Pré-requisitos
-
O repositório
AppStreamestá habilitado. -
O pacote
openscap-scannerestá instalado nos sistemas remotos. - O servidor SSH está rodando nos sistemas remotos.
Procedimento
Instale os pacotes
openscap-utilsebzip2:# yum install openscap-utils bzip2Faça o download das últimas definições da RHSA OVAL para seu sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlEscaneie um sistema remoto com o nome do host machine1, SSH rodando na porta 22, e o nome de usuário joesec em busca de vulnerabilidades e salve os resultados no arquivo remote-vulnerability.html:
# oscap-ssh joesec@machine1 22 oval eval --report remote-vulnerability.html rhel-8.oval.xml
Recursos adicionais
-
A página do homem
oscap-ssh(8). - A lista de definições do Red Hat OVAL.
6.3. Verificação da conformidade da configuração
6.3.1. Conformidade de configuração no RHEL 8
Você pode usar a varredura de conformidade de configuração para estar em conformidade com uma linha de base definida por uma organização específica. Por exemplo, se você trabalhar com o governo dos EUA, poderá ter que estar em conformidade com o Perfil de Proteção do Sistema Operacional (OSPP), e se você for um processador de pagamento, poderá ter que estar em conformidade com o Payment Card Industry Data Security Standard (PCI-DSS). Você também pode realizar a verificação de conformidade da configuração para reforçar a segurança de seu sistema.
A Red Hat recomenda que você siga o conteúdo do Protocolo de Automação de Conteúdo de Segurança (SCAP) fornecido no pacote do Guia de Segurança SCAP porque ele está de acordo com as melhores práticas da Red Hat para os componentes afetados.
O pacote do Guia de Segurança SCAP fornece conteúdo em conformidade com as normas SCAP 1.2 e SCAP 1.3. O utilitário openscap scanner é compatível com o conteúdo SCAP 1.2 e SCAP 1.3 fornecido no pacote do Guia de Segurança SCAP.
A realização de uma verificação de conformidade de configuração não garante que o sistema esteja em conformidade.
O conjunto SCAP Security Guide fornece perfis para várias plataformas em uma forma de documentos de fluxo de dados. Um fluxo de dados é um arquivo que contém definições, benchmarks, perfis e regras individuais. Cada regra especifica a aplicabilidade e os requisitos de conformidade. O RHEL 8 fornece vários perfis para a conformidade com as políticas de segurança. Além do padrão do setor, os fluxos de dados da Red Hat também contêm informações para a remediação de regras falhadas.
Estrutura dos recursos de verificação de conformidade
Data stream ├── xccdf | ├── benchmark | ├── profile | ├──rule | ├── xccdf | ├── oval reference ├── oval ├── ocil reference ├── ocil ├── cpe reference └── cpe └── remediation
Um perfil é um conjunto de regras baseadas em uma política de segurança, como o Perfil de Proteção do Sistema Operacional (OSPP) ou a Norma de Segurança de Dados da Indústria de Cartões de Pagamento (PCI-DSS). Isto permite auditar o sistema de forma automatizada para o cumprimento das normas de segurança.
Você pode modificar (adaptar) um perfil para personalizar certas regras, por exemplo, o comprimento da senha. Para mais informações sobre personalização de perfis, consulte Personalizando um Perfil de Segurança com o SCAP Workbench.
Para verificar a conformidade da configuração de recipientes ou imagens de recipientes, consulte Scanning Containers e Imagens de Recipientes para Vulnerabilidades.
6.3.2. Possíveis resultados de uma varredura OpenSCAP
Dependendo das várias propriedades de seu sistema e do fluxo de dados e perfil aplicado a uma varredura OpenSCAP, cada regra pode produzir um resultado específico. Esta é uma lista de resultados possíveis com breves explicações sobre o que significam.
Tabela 6.1. Possíveis resultados de uma varredura OpenSCAP
| Resultado | Explicação |
|---|---|
| Passe | A varredura não encontrou nenhum conflito com esta regra. |
| Falha | A varredura encontrou um conflito com esta regra. |
| Não verificado | O OpenSCAP não realiza uma avaliação automática desta regra. Verifique se seu sistema está em conformidade com esta regra manualmente. |
| Não aplicável | Esta regra não se aplica à configuração atual. |
| Não selecionado | Esta regra não faz parte do perfil. O OpenSCAP não avalia esta regra e não exibe estas regras nos resultados. |
| Erro |
A varredura encontrou um erro. Para informações adicionais, você pode digitar o comando |
| Desconhecido |
A varredura encontrou uma situação inesperada. Para informações adicionais, você pode entrar no comando |
6.3.3. Visualização de perfis para conformidade de configuração
Antes de decidir usar perfis para escaneamento ou correção, você pode listá-los e verificar suas descrições detalhadas usando o sub-comando oscap info.
Pré-requisitos
-
Os pacotes
openscap-scannerescap-security-guideestão instalados.
Procedimento
Liste todos os arquivos disponíveis com perfis de conformidade de segurança fornecidos pelo projeto Guia de Segurança SCAP:
$ ls /usr/share/xml/scap/ssg/content/ ssg-firefox-cpe-dictionary.xml ssg-rhel6-ocil.xml ssg-firefox-cpe-oval.xml ssg-rhel6-oval.xml ... ssg-rhel6-ds-1.2.xml ssg-rhel8-oval.xml ssg-rhel8-ds.xml ssg-rhel8-xccdf.xml ...Exibir informações detalhadas sobre um fluxo de dados selecionado usando o sub-comando
oscap info. Os arquivos XML contendo fluxos de dados são indicados pela cadeia de caracteres-dsem seus nomes. Na seçãoProfiles, você pode encontrar uma lista de perfis disponíveis e seus IDs:$ oscap info /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml ... Profiles: Title: PCI-DSS v3.2.1 Control Baseline for Red Hat Enterprise Linux 8 Id: xccdf_org.ssgproject.content_profile_pci-dss Title: OSPP - Protection Profile for General Purpose Operating Systems Id: xccdf_org.ssgproject.content_profile_ospp ...Selecione um perfil do arquivo de fluxo de dados e exiba detalhes adicionais sobre o perfil selecionado. Para isso, utilize
oscap infocom a opção--profileseguida da última seção do ID exibido na saída do comando anterior. Por exemplo, o ID do perfil do PCI-DSS é:xccdf_org.ssgproject.content_profile_pci-dss, e o valor para a opção--profileépci-dss:$ oscap info --profile pci-dss /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml ... Title: PCI-DSS v3.2.1 Control Baseline for Red Hat Enterprise Linux 8 Id: xccdf_org.ssgproject.content_profile_pci-dss Description: Ensures PCI-DSS v3.2.1 security configuration settings are applied. ...
Recursos adicionais
-
A página do homem
scap-security-guide(8).
6.3.4. Avaliar a conformidade da configuração com uma linha de base específica
Para determinar se seu sistema está em conformidade com uma linha de base específica, siga estes passos.
Pré-requisitos
-
Os pacotes
openscap-scannerescap-security-guideestão instalados - Você conhece a identificação do perfil dentro da linha de base com a qual o sistema deve cumprir. Para encontrar a identificação, consulte Visualizando Perfis para Conformidade de Configuração.
Procedimento
Avaliar a conformidade do sistema com o perfil selecionado e salvar os resultados da varredura no arquivo HTML report.html, por exemplo:
$ sudo oscap xccdf eval --report report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlOpcional: Digitalize um sistema remoto com o nome do host
machine1, SSH rodando na porta22, e o nome do usuáriojoesecpara verificar a conformidade e salvar os resultados no arquivoremote-report.html:$ oscap-ssh joesec@machine1 22 xccdf eval --report remote_report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionais
-
scap-security-guide(8)página do homem -
A documentação
SCAP Security Guideinstalada nofile:///usr/share/doc/scap-security-guide/diretório. -
O Guia para a Configuração Segura do Red Hat Enterprise Linux 8 instalado com o pacote
scap-security-guide-doc.
6.4. Remediação do sistema para alinhar-se a uma linha de base específica
Use este procedimento para remediar o sistema RHEL 8 para se alinhar com uma linha de base específica. Este exemplo usa o Perfil de Proteção para Sistemas Operacionais de Propósito Geral (OSPP).
Se não for usado cuidadosamente, a execução da avaliação do sistema com a opção Remediate habilitada pode tornar o sistema não funcional. A Red Hat não fornece nenhum método automatizado para reverter as mudanças feitas por remediações que dificultem a segurança. As remediações são suportadas nos sistemas RHEL na configuração padrão. Se seu sistema foi alterado após a instalação, a execução de remediações pode não torná-lo em conformidade com o perfil de segurança exigido.
Pré-requisitos
-
O pacote
scap-security-guideestá instalado em seu sistema RHEL 8.
Procedimento
Use o comando
oscapcom a opção--remediate:$ sudo oscap xccdf eval --profile ospp --remediate /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml- Reinicie seu sistema.
Etapa de verificação
Avalie a conformidade do sistema com o perfil OSPP, e salve os resultados da varredura no arquivo
ospp_report.html:$ oscap xccdf eval --report ospp_report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionais
-
scap-security-guide(8)eoscap(8)páginas man
6.5. Remediação do sistema para alinhar-se a uma linha de base específica usando o SSG Ansible playbook
Use este procedimento para remediar seu sistema com uma linha de base específica usando o arquivo Ansible playbook do projeto Guia de Segurança SCAP. Este exemplo utiliza o Perfil de Proteção para Sistemas Operacionais de Propósito Geral (OSPP).
Se não for usado cuidadosamente, a execução da avaliação do sistema com a opção Remediate habilitada pode tornar o sistema não funcional. A Red Hat não fornece nenhum método automatizado para reverter as mudanças feitas por remediações que dificultem a segurança. As remediações são suportadas nos sistemas RHEL na configuração padrão. Se seu sistema foi alterado após a instalação, a execução de remediações pode não torná-lo em conformidade com o perfil de segurança exigido.
Pré-requisitos
-
O pacote
scap-security-guideestá instalado em seu sistema RHEL 8. -
O pacote
ansibleestá instalado. Consulte o Guia de Instalação Possível para mais informações.
Procedimento
Remeta seu sistema para se alinhar com o OSPP usando o Ansible:
# ansible-playbook -i localhost, -c local /usr/share/scap-security-guide/ansible/rhel8-playbook-ospp.yml- Reinicie o sistema.
Etapas de verificação
Avalie a conformidade do sistema com o perfil OSPP, e salve os resultados da varredura no arquivo
ospp_report.html:# oscap xccdf eval --profile ospp --report ospp_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionais
-
scap-security-guide(8)eoscap(8)páginas man - Documentação possível
6.6. Criação de um livro de exercícios para alinhar o sistema com uma linha de base específica
Use este procedimento para criar um livro de jogo possível contendo apenas as remediações necessárias para alinhar seu sistema com uma linha de base específica. Este exemplo utiliza o Perfil de Proteção para Sistemas Operacionais de Propósito Geral (OSPP). Com este procedimento, você cria um playbook menor que não cobre os requisitos já satisfeitos. Seguindo estas etapas, você não modifica seu sistema de forma alguma, você apenas prepara um arquivo para aplicação posterior.
Pré-requisitos
-
O pacote
scap-security-guideestá instalado em seu sistema RHEL 8.
Procedimento
Digitalize o sistema e salve os resultados:
# oscap xccdf eval --profile ospp --results ospp-results.xml /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlGerar um livro de jogo possível com base no arquivo gerado na etapa anterior:
# oscap xccdf generate fix --fix-type ansible --output ospp-remediations.yml ospp-results.xml-
O arquivo
ospp-remediations.ymlcontém remediações possíveis para as regras que falharam durante a varredura realizada na etapa 1. Após revisar este arquivo gerado, você pode aplicá-lo com o comandoansible-playbook ospp-remediations.yml.
Etapas de verificação
-
Em um editor de texto de sua escolha, verifique se o arquivo
ospp-remediations.ymlcontém regras que falharam na varredura realizada na etapa 1.
Recursos adicionais
-
scap-security-guide(8)eoscap(8)páginas man - Documentação possível
6.7. Criação de um roteiro de Bash de remediação para uma aplicação posterior
Use este procedimento para criar um Bash script contendo remediações que alinhem seu sistema com um perfil de segurança como o PCI-DSS. Usando as seguintes etapas, você não faz nenhuma modificação em seu sistema, você só prepara um arquivo para aplicação posterior.
Pré-requisitos
-
O pacote
scap-security-guideestá instalado em seu sistema RHEL 8.
Procedimento
Use o comando
oscappara escanear o sistema e para salvar os resultados em um arquivo XML. No exemplo a seguir,oscapavalia o sistema em relação ao perfilpci-dss:# oscap xccdf eval --profile pci-dss --results pci-dss-results.xml /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlGerar um Bash script com base no arquivo de resultados gerado na etapa anterior:
# oscap xccdf generate fix --profile pci-dss --fix-type bash --output pci-dss-remediations.sh pci-dss-results.xml-
O arquivo
pci-dss-remediations.shcontém remediações de regras que falharam durante a varredura realizada na etapa 1. Após revisar este arquivo gerado, você pode aplicá-lo com o comando./pci-dss-remediations.shquando estiver no mesmo diretório que este arquivo.
Etapas de verificação
-
Em um editor de texto de sua escolha, verifique se o arquivo
pci-dss-remediations.shcontém regras que falharam na varredura realizada na etapa 1.
Recursos adicionais
-
scap-security-guide(8),oscap(8), ebash(1)páginas man
6.8. Digitalização do sistema com um perfil personalizado utilizando o SCAP Workbench
SCAP Workbench, que está contido no pacote scap-workbench, é um utilitário gráfico que permite aos usuários realizar varreduras de configuração e vulnerabilidade em um único sistema local ou remoto, realizar remediação do sistema e gerar relatórios baseados em avaliações de varredura. Note que SCAP Workbench tem funcionalidade limitada em comparação com o utilitário de linha de comando oscap. SCAP Workbench processa o conteúdo de segurança na forma de arquivos de fluxo de dados.
6.8.1. Usando o SCAP Workbench para escanear e remediar o sistema
Para avaliar seu sistema em relação à política de segurança selecionada, use o seguinte procedimento.
Pré-requisitos
-
O pacote
scap-workbenchestá instalado em seu sistema.
Procedimento
Para executar
SCAP Workbenchdo ambiente de trabalhoGNOME Classic, pressione a tecla Super para entrar noActivities Overview, digitescap-workbench, e depois pressione Enter. Alternativamente, use:$ scap-workbench &Selecione uma política de segurança usando uma das seguintes opções:
-
Load Contentbotão na janela inicial -
Open content from SCAP Security Guide Open Other Contentno menuFile, e pesquisar no respectivo XCCDF, SCAP RPM, ou arquivo de fluxo de dados.
-
Você pode permitir a correção automática da configuração do sistema, selecionando a caixa de seleção . Com esta opção ativada,
SCAP Workbenchtenta alterar a configuração do sistema de acordo com as regras de segurança aplicadas pela política. Este processo deve corrigir as verificações relacionadas que falham durante a verificação do sistema.AtençãoSe não for usado cuidadosamente, a execução da avaliação do sistema com a opção
Remediatehabilitada pode tornar o sistema não funcional. A Red Hat não fornece nenhum método automatizado para reverter as mudanças feitas por remediações que dificultem a segurança. As remediações são suportadas nos sistemas RHEL na configuração padrão. Se seu sistema foi alterado após a instalação, a execução de remediações pode não torná-lo em conformidade com o perfil de segurança exigido.Digitalize seu sistema com o perfil selecionado, clicando no botão .
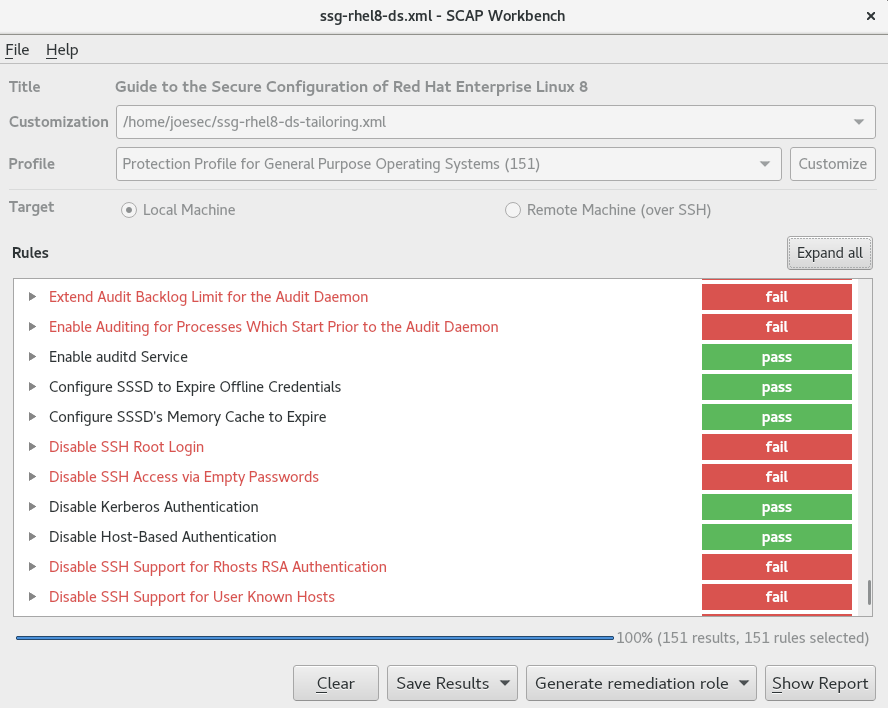
-
Para armazenar os resultados da varredura na forma de um arquivo XCCDF, ARF, ou HTML, clique na caixa de combinação . Escolha a opção
HTML Reportpara gerar o relatório de varredura em formato legível por humanos. Os formatos XCCDF e ARF (data stream) são adequados para processamento automático posterior. Você pode escolher repetidamente todas as três opções. - Para exportar remediações baseadas em resultados para um arquivo, use o menu pop-up .
6.8.2. Personalizando um perfil de segurança com o SCAP Workbench
Você pode personalizar um perfil de segurança alterando parâmetros em certas regras (por exemplo, comprimento mínimo da senha), removendo regras que você cobre de maneira diferente e selecionando regras adicionais, para implementar políticas internas. Você não pode definir novas regras personalizando um perfil.
O procedimento a seguir demonstra o uso do site SCAP Workbench para personalizar (alfaiataria) um perfil. Você também pode salvar o perfil personalizado para uso com o utilitário de linha de comando oscap.
Pré-requisitos
-
O pacote
scap-workbenchestá instalado em seu sistema.
Procedimento
-
Execute
SCAP Workbench, e selecione o perfil a ser personalizado usandoOpen content from SCAP Security GuideouOpen Other Contentno menuFile. Para ajustar o perfil de segurança selecionado de acordo com suas necessidades, clique no botão .
Isto abre a nova janela de personalização que permite modificar o perfil atualmente selecionado sem alterar o arquivo do fluxo de dados original. Escolha um novo ID de perfil.

- Encontre uma regra para modificar usando a estrutura em árvore com regras organizadas em grupos lógicos ou o campo .
Incluir ou excluir regras usando caixas de seleção na estrutura em árvore, ou modificar valores nas regras, quando aplicável.

- Confirme as mudanças clicando no botão .
Para armazenar suas mudanças permanentemente, use uma das seguintes opções:
-
Salve um arquivo de personalização separadamente, usando
Save Customization Onlyno menuFile. Salve todo o conteúdo de segurança de uma vez por
Save Allno menuFile.Se você selecionar a opção
Into a directory,SCAP Workbenchsalva tanto o arquivo de fluxo de dados quanto o arquivo de personalização para o local especificado. Você pode usar isto como uma solução de backup.Ao selecionar a opção
As RPM, você pode instruirSCAP Workbencha criar um pacote RPM contendo o arquivo de fluxo de dados e o arquivo de personalização. Isto é útil para distribuir o conteúdo de segurança para sistemas que não podem ser escaneados remotamente, e para entregar o conteúdo para processamento posterior.
-
Salve um arquivo de personalização separadamente, usando
Como SCAP Workbench não suporta remediações baseadas em resultados para perfis personalizados, use as remediações exportadas com o utilitário de linha de comando oscap.
6.9. Implantação de sistemas que estejam em conformidade com um perfil de segurança imediatamente após uma instalação
Você pode usar o conjunto OpenSCAP para implantar sistemas RHEL que estejam em conformidade com um perfil de segurança, como OSPP ou PCI-DSS, imediatamente após o processo de instalação. Usando este método de implantação, você pode aplicar regras específicas que não podem ser aplicadas posteriormente usando scripts de correção, por exemplo, uma regra para a força da senha e particionamento.
6.9.1. Implantação de sistemas RHEL em conformidade com a basiléia, utilizando a instalação gráfica
Use este procedimento para implantar um sistema RHEL que esteja alinhado com uma linha de base específica. Este exemplo utiliza o Perfil de Proteção para Sistema Operacional de Propósito Geral (OSPP).
Pré-requisitos
-
Você iniciou no programa de instalação
graphical. Note que o OSCAP Anaconda Add-on não suporta instalação somente de texto. -
Você acessou a janela
Installation Summary.
Procedimento
-
A partir da janela
Installation Summary, clique emSoftware Selection. A janelaSoftware Selectionse abre. A partir do painel
Base Environment, selecione o ambienteServer. Você pode selecionar apenas um ambiente de base.AtençãoNão utilize o ambiente base
Server with GUIse você quiser implantar um sistema compatível. Os perfis de segurança fornecidos como parte do SCAP Security Guide podem não ser compatíveis com o conjunto de pacotes estendidos deServer with GUI. Para maiores informações, veja, por exemplo, BZ#1648162, BZ#1787156, ou BZ#1816199.-
Clique em
Donepara aplicar a configuração e retornar à janelaInstallation Summary. -
Clique em
Security Policy. A janelaSecurity Policyse abre. -
Para permitir políticas de segurança no sistema, mude a chave
Apply security policyparaON. -
Selecione
Protection Profile for General Purpose Operating Systemsno painel de perfil. -
Clique em
Select Profilepara confirmar a seleção. -
Confirme as mudanças no painel
Changes that were done or need to be doneque é exibido na parte inferior da janela. Completar quaisquer alterações manuais restantes. -
Como o OSPP tem requisitos rigorosos de particionamento que devem ser cumpridos, crie partições separadas para
/boot,/home,/var,/var/log,/var/tmp, e/var/log/audit. Completar o processo de instalação gráfica.
NotaO programa de instalação gráfica cria automaticamente um arquivo Kickstart correspondente após uma instalação bem sucedida. Você pode usar o arquivo
/root/anaconda-ks.cfgpara instalar automaticamente sistemas compatíveis com OSPP.
Etapas de verificação
Para verificar o status atual do sistema após a conclusão da instalação, reinicialize o sistema e inicie uma nova varredura:
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionais
- Para mais detalhes sobre particionamento, consulte Configuração de particionamento manual.
6.9.2. Implantação de sistemas RHEL em conformidade com a Baseline-compliant usando Kickstart
Use este procedimento para implantar sistemas RHEL que estejam alinhados com uma linha de base específica. Este exemplo utiliza o Perfil de Proteção para Sistema Operacional de Propósito Geral (OSPP).
Pré-requisitos
-
O pacote
scap-security-guideestá instalado em seu sistema RHEL 8.
Procedimento
-
Abra o arquivo
/usr/share/scap-security-guide/kickstart/ssg-rhel8-ospp-ks.cfgKickstart em um editor de sua escolha. Atualize o esquema de partição para adequá-lo às suas necessidades de configuração. Para conformidade com o OSPP, as partições separadas para
/boot,/home,/var,/var/log,/var/tmp, e/var/log/auditdevem ser preservadas, e você só pode alterar o tamanho das partições.AtençãoComo o plugin
OSCAP Anaconda Addonnão suporta instalação apenas de texto, não utilize a opçãotextem seu arquivo Kickstart. Para mais informações, consulte RHBZ#1674001.- Iniciar uma instalação Kickstart como descrito em Execução de uma instalação automatizada usando Kickstart.
As senhas no formulário hash não podem ser verificadas para os requisitos do OSPP.
Etapas de verificação
Para verificar o status atual do sistema após a conclusão da instalação, reinicialize o sistema e inicie uma nova varredura:
# oscap xccdf eval --profile ospp --report eval_postinstall_report.html /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xml
Recursos adicionais
- Para mais detalhes, consulte a página do projeto OSCAP Anaconda Addon.
6.10. Digitalização de imagens de contêineres e recipientes em busca de vulnerabilidades
Use este procedimento para encontrar vulnerabilidades de segurança em um contêiner ou em uma imagem de contêiner.
O comando oscap-podman está disponível em RHEL 8.2. Para o RHEL 8.1 e 8.0, use a alternativa descrita no artigo Usando OpenSCAP para escanear recipientes no artigo da Base de Conhecimento RHEL 8.
Pré-requisitos
-
O pacote
openscap-utilsestá instalado.
Procedimento
Faça o download das últimas definições da RHSA OVAL para seu sistema:
# wget -O - https://www.redhat.com/security/data/oval/v2/RHEL8/rhel-8.oval.xml.bz2 | bzip2 --decompress > rhel-8.oval.xmlObter a identificação de um recipiente ou uma imagem de um recipiente, por exemplo:
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBDigitalize o recipiente ou a imagem do recipiente em busca de vulnerabilidades e salve os resultados no arquivo vulnerability.html:
# oscap-podman 096cae65a207 oval eval --report vulnerability.html rhel-8.oval.xmlNote que o comando
oscap-podmanrequer privilégios de raiz, e a identificação de um recipiente é o primeiro argumento.
Etapas de verificação
Verifique os resultados em um navegador à sua escolha, por exemplo:
$ firefox vulnerability.html &
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
oscap-podman(8)eoscap(8).
6.11. Avaliar a conformidade de segurança de um recipiente ou de uma imagem de recipiente com uma linha de base específica
Siga estas etapas para avaliar a conformidade de seu container ou de uma imagem de container com uma linha de base de segurança específica, como o Perfil de Proteção do Sistema Operacional (OSPP) ou a Norma de Segurança de Dados da Indústria de Cartões de Pagamento (PCI-DSS).
O comando oscap-podman está disponível em RHEL 8.2. Para o RHEL 8.1 e 8.0, use a alternativa descrita no artigo Usando OpenSCAP para escanear recipientes no artigo da Base de Conhecimento RHEL 8.
Pré-requisitos
-
Os pacotes
openscap-utilsescap-security-guideestão instalados.
Procedimento
Obter a identificação de um recipiente ou uma imagem de um recipiente, por exemplo:
# podman images REPOSITORY TAG IMAGE ID CREATED SIZE registry.access.redhat.com/ubi8/ubi latest 096cae65a207 7 weeks ago 239 MBAvalie a conformidade da imagem do recipiente com o perfil OSPP e salve os resultados da varredura no arquivo HTML report.html
# oscap-podman 096cae65a207 xccdf eval --report report.html --profile ospp /usr/share/xml/scap/ssg/content/ssg-rhel8-ds.xmlSubstitua 096cae65a207 pela ID de sua imagem do contêiner e o valor ospp por pci-dss se você avaliar a conformidade de segurança com a linha de base PCI-DSS. Observe que o comando
oscap-podmanrequer privilégios de root.
Etapas de verificação
Verifique os resultados em um navegador à sua escolha, por exemplo:
$ firefox report.html &
As regras marcadas como notapplicable são regras que não se aplicam a sistemas em contêineres. Estas regras se aplicam somente a sistemas de metal nulo e virtualizados.
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
oscap-podman(8)escap-security-guide(8). -
A documentação
SCAP Security Guideinstalada nofile:///usr/share/doc/scap-security-guide/diretório.
6.12. Versões suportadas do Guia de Segurança SCAP em RHEL
As versões oficialmente suportadas do Guia de Segurança SCAP são versões fornecidas na versão menor relacionada do RHEL ou na atualização de lote relacionada do RHEL.
Tabela 6.2. Versões suportadas do Guia de Segurança SCAP em RHEL
| Versão Red Hat Enterprise Linux | Versão do Guia de Segurança SCAP |
|---|---|
| RHEL 6.6 | scap-security-guide-0.1.18-3.el6 |
| RHEL 6.9 | scap-security-guide-0.1.28-3.el6 |
| RHEL 6.10 | scap-security-guide-0.1.28-4.el6 |
| RHEL 7.2 AUS | scap-security-guide-0.1.25-3.el7 |
| RHEL 7.3 AUS | scap-security-guide-0.1.30-5.el7_3 |
| RHEL 7.4 AUS, E4S | scap-security-guide-0.1.33-6.el7_4 |
| RHEL 7.5 (atualização do lote) | scap-security-guide-0.1.36-10.el7_5 |
| RHEL 7.6 EUS | scap-security-guide-0.1.40-13.el7_6 |
| RHEL 7.7 EUS | scap-security-guide-0.1.43-13.el7 |
| RHEL 7.8 (atualização do lote) | scap-security-guide-0.1.46-11.el7 |
| RHEL 7.9 | scap-security-guide-0.1.52-2.el7_9 |
| RHEL 8.0 SAP | scap-security-guide-0.1.42-11.el8 |
| RHEL 8.1 EUS | scap-security-guide-0.1.47-8.el8_1 |
| RHEL 8.2 (atualização do lote) | scap-security-guide-0.1.48-10.el8_2 |
| RHEL 8.3 | scap-security-guide-0.1.50-16.el8_3 |
6.13. Perfis do Guia de Segurança SCAP suportados no RHEL 8
Use somente o conteúdo SCAP fornecido na versão menor em particular da RHEL. Isto ocorre porque os componentes que participam do endurecimento são às vezes atualizados com novas capacidades. O conteúdo SCAP muda para refletir essas atualizações, mas nem sempre é compatível com versões anteriores.
Nas tabelas a seguir, você pode encontrar os perfis fornecidos em cada versão menor da RHEL, juntamente com a versão da política com a qual o perfil se alinha.
Tabela 6.3. Perfis do Guia de Segurança SCAP suportados no RHEL 8.3
| Nome do perfil | Identificação do perfil | Versão da política |
|---|---|---|
| CIS Red Hat Enterprise Linux 8 Benchmark |
| 1.0.0 |
| Informações não classificadas em Sistemas e Organizações de Informação Não-Federais (NIST 800-171) |
| r1 |
| Centro Australiano de Segurança Cibernética (ACSC) Essential Eight |
| não versionado |
| Lei de Portabilidade e Responsabilização de Seguros de Saúde (HIPAA) |
| não versionado |
| Perfil de Proteção para Sistemas Operacionais de Propósito Geral |
| 4.2.1 |
| PCI-DSS v3.2.1 Linha de base de controle para o Red Hat Enterprise Linux 8 |
| 3.2.1 |
| [PROJETO] O Guia de Implementação Técnica de Segurança da Agência de Sistemas de Informação de Defesa (DISA STIG) para o Red Hat Enterprise Linux 8 |
| rascunho |
Tabela 6.4. Perfis do Guia de Segurança SCAP suportados no RHEL 8.2
| Nome do perfil | Identificação do perfil | Versão da política |
|---|---|---|
| Centro Australiano de Segurança Cibernética (ACSC) Essential Eight |
| não versionado |
| Perfil de Proteção para Sistemas Operacionais de Propósito Geral |
| 4.2.1 |
| PCI-DSS v3.2.1 Linha de base de controle para o Red Hat Enterprise Linux 8 |
| 3.2.1 |
| [PROJETO] DISA STIG para Red Hat Enterprise Linux 8 |
| rascunho |
Tabela 6.5. Perfis do Guia de Segurança SCAP suportados no RHEL 8.1
| Nome do perfil | Identificação do perfil | Versão da política |
|---|---|---|
| Perfil de Proteção para Sistemas Operacionais de Propósito Geral |
| 4.2.1 |
| PCI-DSS v3.2.1 Linha de base de controle para o Red Hat Enterprise Linux 8 |
| 3.2.1 |
Tabela 6.6. Perfis do Guia de Segurança SCAP suportados no RHEL 8.0
| Nome do perfil | Identificação do perfil | Versão da política |
|---|---|---|
| OSPP - Perfil de Proteção para Sistemas Operacionais de Propósito Geral |
| rascunho |
| PCI-DSS v3.2.1 Linha de base de controle para o Red Hat Enterprise Linux 8 |
| 3.2.1 |
Recursos adicionais
- Para informações sobre perfis na RHEL 7, consulte os perfis do Guia de Segurança SCAP suportados na RHEL 7
Capítulo 7. Verificação de integridade com AIDE
O Advanced Intrusion Detection Environment (AIDE) é um utilitário que cria um banco de dados de arquivos no sistema, e depois utiliza esse banco de dados para garantir a integridade dos arquivos e detectar intrusões no sistema.
7.1. Instalando o AIDE
Os seguintes passos são necessários para instalar AIDE e iniciar seu banco de dados.
Pré-requisitos
-
O repositório
AppStreamestá habilitado.
Procedimento
Para instalar o pacote aide:
# yum instale um assistente
Para gerar um banco de dados inicial:
# assistente --init
NotaNa configuração padrão, o comando
aide --initverifica apenas um conjunto de diretórios e arquivos definidos no arquivo/etc/aide.conf. Para incluir diretórios ou arquivos adicionais no banco de dadosAIDE, e para alterar seus parâmetros vigiados, edite/etc/aide.confde acordo.Para começar a usar o banco de dados, remova o substrato
.newdo nome do arquivo inicial do banco de dados:# mv /var/lib/aide/aide.db.new.gz /var/lib/aide/aide.db.gz
-
Para alterar a localização do banco de dados
AIDE, edite o arquivo/etc/aide.confe modifique o valorDBDIR. Para segurança adicional, armazenar o banco de dados, a configuração e o arquivo binário/usr/sbin/aideem um local seguro, como uma mídia somente de leitura.
7.2. Execução de verificações de integridade com AIDE
Pré-requisitos
-
AIDEestá devidamente instalado e seu banco de dados é inicializado. Ver Seção 7.1, “Instalando o AIDE”
Procedimento
Para iniciar uma verificação manual:
# aide --check Start timestamp: 2018-07-11 12:41:20 +0200 (AIDE 0.16) AIDE found differences between database and filesystem!! ... [trimmed for clarity]
No mínimo,
AIDEdeve ser configurado para executar uma varredura semanal. No máximo,AIDEdeve ser executado diariamente. Por exemplo, para agendar uma execução diária deAIDEem 04:05 a.m. usando o comandocron, adicione a seguinte linha ao arquivo/etc/crontab:05 4 * * * root /usr/sbin/aide --check
7.3. Atualização de um banco de dados AIDE
Após verificar as mudanças de seu sistema, tais como, atualizações de pacotes ou ajustes de arquivos de configuração, é recomendável atualizar seu banco de dados de base AIDE.
Pré-requisitos
-
AIDEestá devidamente instalado e seu banco de dados é inicializado. Ver Seção 7.1, “Instalando o AIDE”
Procedimento
Atualize sua base de dados AIDE:
# aide --update
O comando aide --update cria o arquivo de banco de dados
/var/lib/aide/aide.db.new.gz.-
Para começar a usar o banco de dados atualizado para verificações de integridade, remova o sub-material
.newdo nome do arquivo.
Capítulo 8. Criptografando dispositivos de blocos usando LUKS
A criptografia de disco protege os dados em um dispositivo de bloco ao criptografá-los. Para acessar o conteúdo descriptografado do dispositivo, o usuário deve fornecer uma frase-chave ou senha como autenticação. Isto é particularmente importante quando se trata de computadores móveis e mídias removíveis: ajuda a proteger o conteúdo do dispositivo mesmo que ele tenha sido fisicamente removido do sistema. O formato LUKS é uma implementação padrão de criptografia de dispositivo de bloqueio no RHEL.
8.1. Criptografia de disco LUKS
O Linux Unified Key Setup-on-disk-format (LUKS) permite criptografar dispositivos de bloco e fornece um conjunto de ferramentas que simplifica o gerenciamento dos dispositivos criptografados. O LUKS permite que múltiplas chaves de usuário descriptografem uma chave mestra, que é usada para a criptografia em massa da partição.
A RHEL utiliza o LUKS para realizar a criptografia do dispositivo de bloqueio. Por padrão, a opção para criptografar o dispositivo de bloco é desmarcada durante a instalação. Se você selecionar a opção para criptografar seu disco, o sistema solicita uma senha toda vez que você inicia o computador. Esta frase-chave “desbloqueia” a chave de criptografia em bloco que descriptografa sua partição. Se você escolher modificar a tabela de partições padrão, você pode escolher quais partições deseja criptografar. Isto é definido nas configurações da tabela de partição.
O que a LUKS faz
- A LUKS criptografa dispositivos de bloco inteiro e, portanto, é bem adequada para proteger o conteúdo de dispositivos móveis, tais como mídias de armazenamento removíveis ou unidades de disco de laptop.
- O conteúdo subjacente do dispositivo de bloco criptografado é arbitrário, o que o torna útil para a criptografia de dispositivos de troca. Isto também pode ser útil com certos bancos de dados que utilizam dispositivos de bloco especialmente formatados para armazenamento de dados.
- A LUKS utiliza o subsistema de mapeamento do núcleo do dispositivo existente.
- A LUKS fornece um reforço de senha que protege contra ataques de dicionários.
- Os dispositivos LUKS contêm vários slots de chave, permitindo aos usuários adicionar chaves de backup ou frases-passe.
O que a LUKS faz not
- Soluções de criptografia de disco como o LUKS protegem os dados somente quando seu sistema está desligado. Assim que o sistema estiver ligado e a LUKS descriptografar o disco, os arquivos nesse disco estarão disponíveis para qualquer pessoa que normalmente teria acesso a eles.
- A LUKS não é adequada para cenários que exigem que muitos usuários tenham chaves de acesso distintas para o mesmo dispositivo. O formato LUKS1 fornece oito slots de chave, LUKS2 até 32 slots de chave.
- O LUKS não é adequado para aplicações que exigem criptografia em nível de arquivo.
Cifras
A cifra padrão utilizada para LUKS é aes-xts-plain64. O tamanho padrão da chave para o LUKS é de 512 bits. O tamanho padrão da chave para LUKS com Anaconda (modo XTS) é de 512 bits. As cifras que estão disponíveis são:
- AES - Norma Avançada de Criptografia - FIPS PUB 197
- Dois peixes (uma cifra de bloco de 128 bits)
- Serpente
Recursos adicionais
8.2. Versões LUKS em RHEL 8
No RHEL 8, o formato padrão para criptografia LUKS é LUKS2. O formato antigo LUKS1 permanece totalmente suportado e é fornecido como um formato compatível com os lançamentos anteriores da RHEL.
O formato LUKS2 é projetado para permitir futuras atualizações de várias partes sem a necessidade de modificar estruturas binárias. O LUKS2 usa internamente o formato de texto JSON para metadados, fornece redundância de metadados, detecta corrupção de metadados e permite reparos automáticos a partir de uma cópia de metadados.
Não use LUKS2 em sistemas que precisam ser compatíveis com sistemas legados que suportam apenas LUKS1. Note que a RHEL 7 suporta o formato LUKS2 desde a versão 7.6.
LUKS2 e LUKS1 usam comandos diferentes para criptografar o disco. O uso do comando errado para uma versão LUKS pode causar perda de dados.
| Versão LUKS | Comando de encriptação |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
Reencriptação on-line
O formato LUKS2 suporta a re-encriptação de dispositivos criptografados enquanto os dispositivos estão em uso. Por exemplo, não é necessário desmontar o sistema de arquivo no dispositivo para realizar as seguintes tarefas:
- Alterar a chave de volume
- Alterar o algoritmo de criptografia
Ao criptografar um dispositivo não criptografado, você ainda deve desmontar o sistema de arquivo. Você pode montar novamente o sistema de arquivo após uma breve inicialização da criptografia.
O formato LUKS1 não suporta a reencriptação on-line.
Conversão
O formato LUKS2 é inspirado no LUKS1. Em certas situações, você pode converter LUKS1 para LUKS2. A conversão não é possível especificamente nos seguintes cenários:
-
Um dispositivo LUKS1 é marcado como sendo usado por uma solução de decriptação baseada em políticas (PBD - Clevis). A ferramenta
cryptsetupse recusa a converter o dispositivo quando alguns metadadosluksmetasão detectados. - Um dispositivo está ativo. O dispositivo deve estar no estado inativo antes que qualquer conversão seja possível.
8.3. Opções para proteção de dados durante a re-encriptação LUKS2
LUKS2 fornece várias opções que priorizam o desempenho ou a proteção de dados durante o processo de reencriptação:
checksumEste é o modo padrão. Ele equilibra a proteção de dados e o desempenho.
Este modo armazena checksums individuais dos setores na área de reencriptação, para que o processo de recuperação possa detectar quais setores LUKS2 já foram reencriptados. Este modo exige que a gravação do setor do dispositivo de bloco seja atômica.
journal- Esse é o modo mais seguro, mas também o mais lento. Esta modalidade registra a área de reencriptação na área binária, portanto LUKS2 escreve os dados duas vezes.
none-
Este modo prioriza o desempenho e não oferece proteção de dados. Ele protege os dados somente contra o término seguro do processo, como o sinal
SIGTERMou a pressão do usuário Ctrl+C. Qualquer falha inesperada do sistema ou falha de aplicação pode resultar em corrupção de dados.
Você pode selecionar o modo usando a opção --resilience de cryptsetup.
Se um processo de reencriptação LUKS2 termina inesperadamente pela força, a LUKS2 pode realizar a recuperação de uma das seguintes formas:
-
Automaticamente, durante a próxima ação aberta do dispositivo LUKS2. Esta ação é acionada ou pelo comando
cryptsetup openou anexando o dispositivo comsystemd-cryptsetup. -
Manualmente, usando o comando
cryptsetup repairno dispositivo LUKS2.
8.4. Criptografia de dados existentes em um dispositivo de bloco usando LUKS2
Este procedimento criptografa os dados existentes em um dispositivo ainda não criptografado usando o formato LUKS2. Um novo cabeçalho LUKS é armazenado na cabeça do dispositivo.
Pré-requisitos
- O dispositivo de bloco contém um sistema de arquivo.
Você fez backup de seus dados.
AtençãoVocê pode perder seus dados durante o processo de criptografia: devido a um hardware, kernel, ou falha humana. Certifique-se de que você tenha um backup confiável antes de começar a criptografar os dados.
Procedimento
Desmonte todos os sistemas de arquivo no dispositivo que você planeja criptografar. Por exemplo:
# umount /dev/sdb1Criar espaço livre para o armazenamento de um cabeçalho LUKS. Escolha uma das seguintes opções que se adapte ao seu cenário:
No caso de encriptar um volume lógico, você pode estender o volume lógico sem redimensionar o sistema de arquivo. Por exemplo, o volume lógico pode ser aumentado:
# lvextend -L 32M vg00/lv00
-
Ampliar a divisória utilizando ferramentas de gerenciamento de divisórias, tais como
parted. -
Encolha o sistema de arquivo no dispositivo. Você pode usar o utilitário
resize2fspara os sistemas de arquivo ext2, ext3, ou ext4. Note que você não pode encolher o sistema de arquivo XFS.
Inicializar a criptografia. Por exemplo:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --reduce-device-size 32M \ /dev/sdb1 sdb1_encryptedO comando lhe pede uma senha e inicia o processo de criptografia.
Monte o dispositivo:
# montar /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Iniciar a criptografia online:
# criptasetup recriar -resumir apenas /dev/sdb1
Recursos adicionais
-
Para mais detalhes, consulte as páginas de manual
cryptsetup(8),lvextend(8),resize2fs(8), eparted(8).
8.5. Encriptação de dados existentes em um dispositivo de bloco usando LUKS2 com um cabeçalho destacado
Este procedimento codifica os dados existentes em um dispositivo de bloco sem criar espaço livre para o armazenamento de um cabeçalho LUKS. O cabeçalho é armazenado em um local separado, o que também serve como uma camada adicional de segurança. O procedimento utiliza o formato de criptografia LUKS2.
Pré-requisitos
- O dispositivo de bloco contém um sistema de arquivo.
Você fez backup de seus dados.
AtençãoVocê pode perder seus dados durante o processo de criptografia: devido a um hardware, kernel, ou falha humana. Certifique-se de que você tenha um backup confiável antes de começar a criptografar os dados.
Procedimento
Desmontar todos os sistemas de arquivo no dispositivo. Por exemplo:
# umount /dev/sdb1Inicializar a criptografia:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --header /path/to/header \ /dev/sdb1 sdb1_encryptedSubstituir /path/to/header por um caminho para o arquivo com um cabeçalho LUKS destacado. O cabeçalho LUKS destacado tem que ser acessível para que o dispositivo criptografado possa ser desbloqueado posteriormente.
O comando lhe pede uma senha e inicia o processo de criptografia.
Monte o dispositivo:
# montar /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Iniciar a criptografia online:
# cryptsetup reencrypt --resume-only --header /path/to/header /dev/sdb1
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
cryptsetup(8).
8.6. Criptografia de um dispositivo de bloco em branco usando LUKS2
Este procedimento fornece informações sobre a criptografia de um dispositivo de bloco em branco usando o formato LUKS2.
Pré-requisitos
- Um dispositivo de bloco em branco.
Procedimento
Configurar uma partição como uma partição LUKS criptografada:
# cryptsetup luksFormat /dev/sdb1Abra uma partição LUKS criptografada:
# Criptsetup aberto /dev/sdb1 sdb1_encryptedIsto desbloqueia a partição e a mapeia para um novo dispositivo usando o mapeador de dispositivos. Isto alerta o kernel que
deviceé um dispositivo criptografado e deve ser endereçado através do LUKS usando o/dev/mapper/device_mapped_namepara não sobregravar os dados criptografados.Para escrever dados criptografados na partição, eles devem ser acessados através do nome mapeado do dispositivo. Para isso, é necessário criar um sistema de arquivos. Por exemplo, um sistema de arquivos:
# mkfs -t ext4 /dev/mapper/sdb1_encryptedMonte o dispositivo:
# montar /dev/mapper/sdb1_encrypted
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
cryptsetup(8).
8.7. Criação de um volume codificado LUKS usando a função de armazenamento
Você pode usar o papel storage para criar e configurar um volume criptografado com LUKS, executando um livro de brincadeiras Ansible playbook.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja criar o volume.
-
Você tem o pacote
rhel-system-rolesinstalado no controlador Ansible. - Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja implantar um volume codificado LUKS usando a função de sistema de armazenamento.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar a sintaxe do playbook:
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
- Para mais informações sobre a LUKS, veja 17. Criptografando dispositivos de blocos usando LUKS...
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
Capítulo 9. Configuração do desbloqueio automático de volumes criptografados utilizando decriptação baseada em políticas
A Decriptação Baseada em Políticas (PBD) é um conjunto de tecnologias que permitem desbloquear volumes codificados de raiz e secundários de discos rígidos em máquinas físicas e virtuais. O PBD usa uma variedade de métodos de desbloqueio, tais como senhas de usuário, um dispositivo TPM (Trusted Platform Module), um dispositivo PKCS #11 conectado a um sistema, por exemplo, um smart card, ou um servidor de rede especial.
O PBD permite combinar diferentes métodos de desbloqueio em uma política, o que torna possível desbloquear o mesmo volume de maneiras diferentes. A implementação atual do PBD no Red Hat Enterprise Linux consiste na estrutura Clevis e plug-ins chamados pins. Cada pino fornece uma capacidade de destravamento separada. Atualmente, os seguintes pinos estão disponíveis:
-
tang- permite o desbloqueio de volumes usando um servidor de rede -
tpm2- permite desbloquear volumes usando uma política TPM2
O Network Bound Disc Encryption (NBDE) é uma subcategoria de PBD que permite ligar volumes criptografados a um servidor de rede especial. A implementação atual do NBDE inclui um pin Clevis para o servidor Tang e para o próprio servidor Tang.
9.1. Criptografia de disco em rede
No Red Hat Enterprise Linux, a NBDE é implementada através dos seguintes componentes e tecnologias:
Figura 9.1. Esquema NBDE ao utilizar um volume encriptado de LUKS1. A embalagem luksmeta não é utilizada para volumes LUKS2.

Tang é um servidor para vincular dados à presença na rede. Ele torna um sistema contendo seus dados disponível quando o sistema está vinculado a uma determinada rede segura. Tang é stateless e não requer TLS ou autenticação. Ao contrário das soluções baseadas em escrow, onde o servidor armazena todas as chaves de criptografia e tem conhecimento de cada chave já utilizada, Tang nunca interage com nenhuma chave do cliente, portanto, nunca obtém nenhuma informação de identificação do cliente.
Clevis é uma estrutura plugável para a decriptação automatizada. No NBDE, Clevis fornece o desbloqueio automatizado de volumes LUKS. O clevis fornece o lado do cliente do recurso.
A Clevis pin é um plug-in para a estrutura Clevis. Um desses pinos é um plug-in que implementa as interações com o servidor NBDE
Clevis e Tang são componentes genéricos de cliente e servidor que fornecem criptografia vinculada à rede. No Red Hat Enterprise Linux, eles são usados em conjunto com o LUKS para criptografar e decodificar volumes de armazenamento raiz e não-raiz para realizar a criptografia de discos vinculados à rede.
Tanto os componentes do lado do cliente quanto do lado do servidor utilizam a biblioteca José para realizar operações de criptografia e decriptação.
Quando você começa a provisionar NBDE, o pin Clevis para o servidor Tang recebe uma lista das chaves assimétricas anunciadas do servidor Tang. Alternativamente, como as chaves são assimétricas, uma lista das chaves públicas Tang pode ser distribuída fora da banda para que os clientes possam operar sem acesso ao servidor Tang. Este modo é chamado offline provisioning.
O pino Clevis para Tang usa uma das chaves públicas para gerar uma chave de criptografia única e forte em termos criptográficos. Uma vez que os dados são criptografados usando esta chave, a chave é descartada. O cliente Clevis deve armazenar o estado produzido por esta operação de provisionamento em um local conveniente. Este processo de encriptação de dados é o provisioning step.
O LUKS versão 2 (LUKS2) é o formato padrão no Red Hat Enterprise Linux 8, portanto, o estado de provisionamento para NBDE é armazenado como um token em um cabeçalho LUKS2. A alavancagem do estado de provisionamento para NBDE pelo luksmeta é usado somente para volumes criptografados com LUKS1. O pino Clevis para Tang suporta tanto LUKS1 quanto LUKS2 sem necessidade de especificação.
Quando o cliente está pronto para acessar seus dados, ele carrega os metadados produzidos na etapa de provisionamento e responde para recuperar a chave de criptografia. Este processo é o recovery step.
Em NBDE, Clevis liga um volume LUKS usando um pino para que ele possa ser automaticamente desbloqueado. Após a conclusão bem sucedida do processo de encadernação, o disco pode ser desbloqueado usando o desbloqueador Dracut fornecido.
9.2. Instalando um cliente de criptografia - Clevis
Use este procedimento para implantar e começar a usar a estrutura plugável Clevis em seu sistema.
Procedimento
Para instalar Clevis e seus pinos em um sistema com um volume criptografado:
# yum install clevisPara decodificar dados, use um comando
clevis decrypte forneça um texto cifrado no formato JSON Web Encryption (JWE), por exemplo:$ clevis decrypt < secret.jwe
Recursos adicionais
Para uma referência rápida, veja a ajuda CLI embutida:
$ clevis Usage: clevis COMMAND [OPTIONS] clevis decrypt Decrypts using the policy defined at encryption time clevis encrypt sss Encrypts using a Shamir's Secret Sharing policy clevis encrypt tang Encrypts using a Tang binding server policy clevis encrypt tpm2 Encrypts using a TPM2.0 chip binding policy clevis luks bind Binds a LUKS device using the specified policy clevis luks list Lists pins bound to a LUKSv1 or LUKSv2 device clevis luks pass Returns the LUKS passphrase used for binding a particular slot. clevis luks regen Regenerate LUKS metadata clevis luks report Report any key rotation on the server side clevis luks unbind Unbinds a pin bound to a LUKS volume clevis luks unlock Unlocks a LUKS volume-
Para mais informações, consulte a página de manual
clevis(1).
9.3. Implantação de um servidor Tang com SELinux em modo de aplicação
Use este procedimento para implantar um servidor Tang rodando em uma porta personalizada como um serviço confinado no modo de aplicação do SELinux.
Pré-requisitos
-
O pacote
policycoreutils-python-utilse suas dependências estão instalados.
Procedimento
Para instalar o pacote
tange suas dependências, digite o seguinte comando comoroot:# yum install tangEscolha um porto desocupado, por exemplo, 7500/tcp, e permita que o serviço
tangdse ligue a esse porto:# semanage port -a -t tangd_port_t -p tcp 7500Note que uma porta só pode ser usada por um serviço de cada vez e, portanto, uma tentativa de usar uma porta já ocupada implica na mensagem de erro
ValueError: Port already defined.Abra a porta no firewall:
# firewall-cmd --add-port=7500/tcp # firewall-cmd --runtime-to-permanent
Habilite o serviço
tangd:# systemctl enable tangd.socketCriar um arquivo de substituição:
# systemctl edit tangd.socketNa seguinte tela do editor, que abre um arquivo
override.confvazio localizado no diretório/etc/systemd/system/tangd.socket.d/, altere a porta padrão para o servidor Tang de 80 para o número escolhido anteriormente, adicionando as seguintes linhas:[Socket] ListenStream= ListenStream=7500Salvar o arquivo e sair do editor.
Recarregar a configuração alterada:
# systemctl daemon-reloadVerifique se sua configuração está funcionando:
# systemctl show tangd.socket -p Listen Listen=[::]:7500 (Stream)Iniciar o serviço
tangd:# systemctl start tangd.socketComo
tangdusa o mecanismo de ativação do soquetesystemd, o servidor inicia assim que a primeira conexão chega. Um novo conjunto de chaves criptográficas é gerado automaticamente no primeiro início. Para realizar operações criptográficas como a geração manual de chaves, use o utilitáriojose.
Recursos adicionais
-
tang(8)página do homem -
semanage(8)página do homem -
firewall-cmd(1)página do homem -
systemd.unit(5)esystemd.socket(5)páginas man -
jose(1)página do homem
9.4. Chaves de servidor Tang rotativas e atualização de ligações em clientes
Use as seguintes etapas para girar suas chaves de servidor Tang e atualizar as ligações existentes nos clientes. O intervalo preciso no qual você deve rotacioná-las depende de sua aplicação, tamanho das chaves e política institucional.
Pré-requisitos
- Um servidor Tang está funcionando.
-
Os pacotes
cleviseclevis-luksestão instalados em seus clientes. -
Note que
clevis luks list,clevis luks report, eclevis luks regenforam introduzidos na RHEL 8.2.
Procedimento
Para girar as chaves, gerar novas chaves usando o comando
/usr/libexec/tangd-keygenno diretório/var/db/tangdo banco de dados de chaves no servidor Tang:# ls /var/db/tang UV6dqXSwe1bRKG3KbJmdiR020hY.jwk y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk # /usr/libexec/tangd-keygen /var/db/tang # ls /var/db/tang UV6dqXSwe1bRKG3KbJmdiR020hY.jwk y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk zyLuX6hijUy_PSeUEFDi7hi38.jwk
Verifique se o seu servidor Tang anuncia a chave de assinatura do novo par de chaves, por exemplo:
# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54Renomeie as antigas chaves para ter um líder
.para escondê-las da publicidade. Observe que os nomes dos arquivos no exemplo a seguir diferem dos nomes de arquivos únicos no diretório de banco de dados de chaves de seu servidor Tang:# cd /var/db/tang # ls -l -rw-r--r--. 1 root tang 354 Sep 23 16:08 3ZWS6-cDrCG61UPJS2BMmPU4I54.jwk -rw-r--r--. 1 root tang 349 Sep 23 16:08 I-zyLuX6hijUy_PSeUEFDi7hi38.jwk -rw-r--r--. 1 root root 349 Feb 7 14:55 UV6dqXSwe1bRKG3KbJmdiR020hY.jwk -rw-r--r--. 1 root root 354 Feb 7 14:55 y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk # mv UV6dqXSwe1bRKG3KbJmdiR020hY.jwk .UV6dqXSwe1bRKG3KbJmdiR020hY.jwk # mv y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk .y9hxLTQSiSB5jSEGWnjhY8fDTJU.jwk
Tang pega imediatamente todas as mudanças. Não é necessário reiniciar. Neste ponto, os novos clientes que ligam as novas chaves e os antigos clientes podem continuar a utilizar as chaves antigas.
Em seus clientes NBDE, use o comando
clevis luks reportpara verificar se as chaves anunciadas pelo servidor Tang permanecem as mesmas. Você pode identificar os slots com a vinculação relevante usando o comandoclevis luks list, por exemplo:# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv"}' # clevis luks report -d /dev/sda2 -s 1 ... Report detected that some keys were rotated. Do you want to regenerate luks metadata with "clevis luks regen -d /dev/sda2 -s 1"? [ynYN]
Para regenerar os metadados LUKS para as novas teclas, pressione
ypara o prompt do comando anterior, ou use o comandoclevis luks regen:# clevis luks regen -d /dev/sda2 -s 1Quando você tem certeza de que todos os clientes antigos usam as novas chaves, você pode remover as chaves antigas do servidor Tang, por exemplo:
# cd /var/db/tang # rm .*.jwk
A remoção das chaves antigas enquanto os clientes ainda estão usando-as pode resultar em perda de dados. Se você remover acidentalmente tais chaves, use o comando clevis luks regen nos clientes, e forneça sua senha LUKS manualmente.
Recursos adicionais
-
tang-show-keys(1),clevis-luks-list(1),clevis-luks-report(1), eclevis-luks-regen(1)páginas man
9.5. Configuração do desbloqueio automático usando uma chave Tang no console web
Configurar o desbloqueio automático de um dispositivo de armazenamento criptografado LUKS usando uma chave fornecida por um servidor Tang.
Pré-requisitos
O console web RHEL 8 foi instalado.
Para detalhes, consulte Instalando o console web.
-
O pacote
cockpit-storagedestá instalado em seu sistema. -
O serviço
cockpit.socketestá funcionando no porto 9090. -
Os pacotes
clevis,tang, eclevis-dracutestão instalados. - Um servidor Tang está funcionando.
Procedimento
Abra o console web RHEL digitando o seguinte endereço em um navegador web:
https://localhost:9090Substitua a parte localhost pelo nome do host ou endereço IP do servidor remoto quando você se conectar a um sistema remoto.
- Forneça suas credenciais e clique em . Selecione um dispositivo criptografado e clique em na parte Content:
Clique em na seção Keys para adicionar uma chave Tang:

Forneça o endereço de seu servidor Tang e uma senha que destrave o dispositivo criptografado LUKS. Clique em para confirmar:
A janela de diálogo a seguir fornece um comando para verificar se o hash chave corresponde. RHEL 8.2
# tang-show-keys 7500 3ZWS6-cDrCG61UPJS2BMmPU4I54No RHEL 8.1 e anteriores, obtenha o hash chave usando o seguinte comando:
# curl -s localhost:7500/adv | jose fmt -j- -g payload -y -o- | jose jwk use -i- -r -u verify -o- | jose jwk thp -i- 3ZWS6-cDrCG61UPJS2BMmPU4I54Clique em quando os hashes da chave no console web e na saída dos comandos listados anteriormente são os mesmos:
Para ativar o sistema de inicialização antecipada para processar a encadernação do disco, clique em na parte inferior da barra de navegação esquerda e digite os seguintes comandos:
# yum install clevis-dracut # dracut -fv --regenerate-all
Etapas de verificação
Verifique se a chave Tang recentemente adicionada está agora listada na seção Keys com o tipo
Keyserver:
Verificar se as amarrações estão disponíveis para a inicialização antecipada, por exemplo:
# lsinitrd | grep clevis clevis clevis-pin-sss clevis-pin-tang clevis-pin-tpm2 -rwxr-xr-x 1 root root 1600 Feb 11 16:30 usr/bin/clevis -rwxr-xr-x 1 root root 1654 Feb 11 16:30 usr/bin/clevis-decrypt ... -rwxr-xr-x 2 root root 45 Feb 11 16:30 usr/lib/dracut/hooks/initqueue/settled/60-clevis-hook.sh -rwxr-xr-x 1 root root 2257 Feb 11 16:30 usr/libexec/clevis-luks-askpass
Recursos adicionais
- Para mais detalhes sobre a instalação e login no console web RHEL, consulte o capítulo Introdução ao uso do console web RHEL.
9.6. Implementação de um cliente de criptografia para um sistema NBDE com Tang
O procedimento seguinte contém passos para configurar o desbloqueio automático de um volume criptografado com um servidor de rede Tang.
Pré-requisitos
- A estrutura Clevis está instalada.
- Um servidor Tang está disponível.
Procedimento
Para vincular um cliente de criptografia Clevis a um servidor Tang, use o sub-comando
clevis encrypt tang:$ clevis encrypt tang '{"url":"http://tang.srv:port"}' < input-plain.txt > secret.jwe The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] yAlterar a URL http://tang.srv:port no exemplo anterior para corresponder à URL do servidor onde
tangestá instalado. O arquivo de saída secret.jwe contém seu texto criptografado em cifra no formato JSON Web Encryption. Este texto de cifra é lido do arquivo de entrada input-plain.txt.Alternativamente, se sua configuração requer uma comunicação não interativa com um servidor Tang sem acesso SSH, você pode baixar um anúncio e salvá-lo em um arquivo:
$ curl -sfg http://tang.srv:port/adv -o adv.jwsUse o anúncio no arquivo adv.jws para qualquer tarefa seguinte, como a criptografia de arquivos ou mensagens:
$ echo 'hello' | clevis encrypt tang '{"url":"http://tang.srv:port","adv":"adv.jws"}'Para decifrar dados, use o comando
clevis decrypte forneça o texto cifrado (JWE):$ clevis decrypt < secret.jwe > output-plain.txt
Recursos adicionais
Para uma referência rápida, veja a página de manual
clevis-encrypt-tang(1)ou use a ajuda CLI embutida:$ clevis $ clevis decrypt $ clevis encrypt tang Usage: clevis encrypt tang CONFIG < PLAINTEXT > JWE ...
Para mais informações, consulte as seguintes páginas de homem:
-
clevis(1) -
clevis-luks-unlockers(7)
-
9.7. Remoção manual de um pino Clevis de um volume codificado em LUKS
Use o seguinte procedimento para remover manualmente os metadados criados pelo comando clevis luks bind e também para limpar um rasgo de chave que contém a senha adicionada por Clevis.
A maneira recomendada para remover um pino Clevis de um volume codificado em LUKS é através do comando clevis luks unbind. O procedimento de remoção usando clevis luks unbind consiste de apenas um passo e funciona tanto para os volumes LUKS1 como para LUKS2. O seguinte comando de exemplo remove os metadados criados pela etapa de encadernação e limpa o slot de chave 1 no dispositivo /dev/sda2:
# clevis luks unbind -d /dev/sda2 -s 1Pré-requisitos
- Um volume encriptado LUKS com uma encadernação Clevis.
Procedimento
Verifique em qual versão LUKS o volume, por exemplo /dev/sda2, está codificado e identifique um slot e um token que está vinculado a Clevis:
# cryptsetup luksDump /dev/sda2 LUKS header information Version: 2 ... Keyslots: 0: luks2 ... 1: luks2 Key: 512 bits Priority: normal Cipher: aes-xts-plain64 ... Tokens: 0: clevis Keyslot: 1 ...No exemplo anterior, o token Clevis é identificado por 0 e o espaço chave associado é 1.
No caso de criptografia LUKS2, remova o token:
# cryptsetup token remove --token-id 0 /dev/sda2Se seu dispositivo for criptografado por LUKS1, que é indicado pela string
Version: 1na saída do comandocryptsetup luksDump, execute este passo adicional com o comandoluksmeta wipe:# luksmeta wipe -d /dev/sda2 -s 1Limpe a ranhura da chave que contém a frase-chave Clevis:
# cryptsetup luksKillSlot /dev/sda2 1
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
clevis-luks-unbind(1),cryptsetup(8)eluksmeta(8).
9.8. Implementando um cliente de criptografia com uma política TPM 2.0
O seguinte procedimento contém passos para configurar o desbloqueio automático de um volume criptografado com uma política do Trusted Platform Module 2.0 (TPM 2.0).
Pré-requisitos
- A estrutura Clevis está instalada. Ver Instalação de um cliente de criptografia - Clevis
- Um sistema com a arquitetura Intel de 64 bits ou AMD de 64 bits
Procedimento
Para implantar um cliente que codifica usando um chip TPM 2.0, use o sub-comando
clevis encrypt tpm2com o único argumento na forma do objeto de configuração JSON:$ clevis encrypt tpm2 '{}' < input-plain.txt > secret.jwePara escolher uma hierarquia diferente, hash e algoritmos chave, especificar as propriedades de configuração, por exemplo:
$ clevis encrypt tpm2 '{"hash":"sha1","key":"rsa"}' < input-plain.txt > secret.jwePara decodificar os dados, forneça o texto cifrado no formato JSON Web Encryption (JWE):
$ clevis decrypt < secret.jwe > output-plain.txt
O pino também suporta dados de vedação para um estado de Registros de Configuração de Plataforma (PCR). Dessa forma, os dados só podem ser des selados se os valores dos PCRs corresponderem à política usada na selagem.
Por exemplo, para selar os dados para o PCR com índices 0 e 1 para o banco SHA-1:
$ clevis encrypt tpm2 '{"pcr_bank":"sha1","pcr_ids":"0,1"}' < input-plain.txt > secret.jweRecursos adicionais
-
Para mais informações e a lista de possíveis propriedades de configuração, consulte a página de manual
clevis-encrypt-tpm2(1).
9.9. Configuração da inscrição manual de volumes criptografados LUKS
Use os seguintes passos para configurar o desbloqueio de volumes codificados com LUKS com NBDE.
Pré-requisito
- Um servidor Tang está funcionando e disponível.
Procedimento
Para desbloquear automaticamente um volume encriptado de LUKS existente, instale o subpacote
clevis-luks:# yum install clevis-luksIdentificar o volume criptografado LUKS para PBD. No exemplo a seguir, o dispositivo de bloco é referido como /dev/sda2:
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 12G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 11G 0 part └─luks-40e20552-2ade-4954-9d56-565aa7994fb6 253:0 0 11G 0 crypt ├─rhel-root 253:0 0 9.8G 0 lvm / └─rhel-swap 253:1 0 1.2G 0 lvm [SWAP]Ligar o volume a um servidor Tang usando o comando
clevis luks bind:# clevis luks bind -d /dev/sda2 tang '{"url":"http://tang.srv"}' The advertisement contains the following signing keys: _OsIk0T-E2l6qjfdDiwVmidoZjA Do you wish to trust these keys? [ynYN] y You are about to initialize a LUKS device for metadata storage. Attempting to initialize it may result in data loss if data was already written into the LUKS header gap in a different format. A backup is advised before initialization is performed. Do you wish to initialize /dev/sda2? [yn] y Enter existing LUKS password:Este comando executa quatro etapas:
- Cria uma nova chave com a mesma entropia que a chave mestra LUKS.
- Criptografa a nova chave com Clevis.
- Armazena o objeto Clevis JWE no símbolo de cabeçalho LUKS2 ou usa LUKSMeta se for usado o cabeçalho LUKS1 sem defeito.
Permite a nova chave para uso com LUKS.
NotaO procedimento de encadernação pressupõe que haja pelo menos um slot de senha LUKS livre. O comando
clevis luks bindpega um dos slots.
- O volume agora pode ser desbloqueado com sua senha existente, assim como com a política Clevis.
Para habilitar o sistema de inicialização antecipada para processar a encadernação do disco, digite os seguintes comandos em um sistema já instalado:
# yum install clevis-dracut # dracut -fv --regenerate-all
Etapas de verificação
Para verificar se o objeto Clevis JWE é colocado com sucesso em um cabeçalho LUKS, use o comando
clevis luks list:# clevis luks list -d /dev/sda2 1: tang '{"url":"http://tang.srv:port"}'
Para utilizar NBDE para clientes com configuração IP estática (sem DHCP), passe sua configuração de rede para a ferramenta dracut manualmente, por exemplo:
# dracut -fv --regenerate-all --kernel-cmdline "ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none:192.0.2.45"
Alternativamente, crie um arquivo .conf no diretório /etc/dracut.conf.d/ com as informações estáticas da rede. Por exemplo, um arquivo .conf:
# cat /etc/dracut.conf.d/static_ip.conf
kernel_cmdline="ip=192.0.2.10::192.0.2.1:255.255.255.0::ens3:none:192.0.2.45"Regenerar a imagem inicial do disco RAM:
# dracut -fv --regenerate-allRecursos adicionais
Para mais informações, consulte as seguintes páginas de homem:
-
clevis-luks-bind(1) -
dracut.cmdline(7)
9.10. Configuração da inscrição automatizada de volumes codificados com LUKS usando Kickstart
Siga as etapas deste procedimento para configurar um processo de instalação automatizado que utiliza Clevis para a inscrição de volumes criptografados LUKS.
Procedimento
Instrua o Kickstart a particionar o disco de forma que a criptografia LUKS tenha habilitado para todos os pontos de montagem, exceto
/boot, com uma senha temporária. A senha é temporária para esta etapa do processo de inscrição.part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --grow --encrypted --passphrase=temppass
Observe que os sistemas de reclamação OSPP requerem uma configuração mais complexa, por exemplo:
part /boot --fstype="xfs" --ondisk=vda --size=256 part / --fstype="xfs" --ondisk=vda --size=2048 --encrypted --passphrase=temppass part /var --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /tmp --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /home --fstype="xfs" --ondisk=vda --size=2048 --grow --encrypted --passphrase=temppass part /var/log --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass part /var/log/audit --fstype="xfs" --ondisk=vda --size=1024 --encrypted --passphrase=temppass
Instale os pacotes Clevis relacionados, listando-os na seção
%packages:%packages clevis-dracut %end
Ligue para
clevis luks bindpara realizar a encadernação na seção%post. Em seguida, remova a senha temporária:%post curl -sfg http://tang.srv/adv -o adv.jws clevis luks bind -f -k- -d /dev/vda2 \ tang '{"url":"http://tang.srv","adv":"adv.jws"}' \ <<< "temppass" cryptsetup luksRemoveKey /dev/vda2 <<< "temppass" %endNo exemplo anterior, observe que baixamos o anúncio do servidor Tang como parte de nossa configuração de encadernação, permitindo que a encadernação seja completamente não-interativa.
AtençãoO comando
cryptsetup luksRemoveKeyimpede qualquer administração posterior de um dispositivo LUKS2 no qual você o aplica. Você pode recuperar uma chave mestra removida usando o comandodmsetupsomente para dispositivos LUKS1.
Você pode usar um procedimento análogo ao usar uma política TPM 2.0 ao invés de um servidor Tang.
Recursos adicionais
-
clevis(1),clevis-luks-bind(1),cryptsetup(8), edmsetup(8)páginas man - Instalando o Red Hat Enterprise Linux 8 usando o Kickstart
9.11. Configuração do desbloqueio automático de um dispositivo de armazenamento removível criptografado LUKS
Use este procedimento para configurar um processo de desbloqueio automático de um dispositivo de armazenamento USB criptografado LUKS.
Procedimento
Para desbloquear automaticamente um dispositivo de armazenamento removível encriptado LUKS, como uma unidade USB, instale o pacote
clevis-udisks2:# yum install clevis-udisks2Reinicie o sistema e depois execute a etapa de encadernação usando o comando
clevis luks bind, como descrito em Configurando a inscrição manual de volumes criptografados LUKS, por exemplo:# clevis luks bind -d /dev/sdb1 tang '{"url":"http://tang.srv"}'O dispositivo removível criptografado LUKS pode agora ser desbloqueado automaticamente em sua sessão desktop GNOME. O dispositivo vinculado a uma política Clevis também pode ser desbloqueado pelo comando
clevis luks unlock:# clevis luks unlock -d /dev/sdb1
Você pode usar um procedimento análogo ao usar uma política TPM 2.0 ao invés de um servidor Tang.
Recursos adicionais
Para mais informações, consulte a seguinte página de manual:
-
clevis-luks-unlockers(7)
9.12. Implantação de sistemas NBDE de alta disponibilidade
A Tang fornece dois métodos para a construção de uma implantação de alta disponibilidade:
- Redundância de clientes (recomendado)
-
Os clientes devem ser configurados com a capacidade de se ligar a múltiplos servidores Tang. Nesta configuração, cada servidor Tang tem suas próprias chaves e os clientes podem decodificar entrando em contato com um subconjunto destes servidores. A Clevis já suporta este fluxo de trabalho através de seu plug-in
sss. A Red Hat recomenda este método para uma implantação de alta disponibilidade. - Compartilhamento de chaves
-
Para fins de redundância, mais de uma instância de Tang pode ser implantada. Para criar uma segunda instância ou qualquer outra posterior, instale os pacotes
tange copie o diretório de chaves para o novo host usandorsyncsobreSSH. Note que a Red Hat não recomenda este método porque compartilhar chaves aumenta o risco de comprometimento de chaves e requer uma infra-estrutura de automação adicional.
9.12.1. NBDE de alta disponibilidade usando o compartilhamento secreto da Shamir
Shamir's Secret Sharing (SSS) é um esquema criptográfico que divide um segredo em várias partes únicas. Para reconstruir o segredo, é necessária uma série de partes. O número é chamado de limiar e o SSS também é referido como um esquema de limiar.
Clevis fornece uma implementação do SSS. Ele cria uma chave e a divide em uma série de peças. Cada peça é criptografada usando outro pino, incluindo até mesmo o SSS recursivamente. Além disso, você define o limite t. Se uma implementação NBDE descriptografa pelo menos t peças, então recupera a chave de criptografia e o processo de descriptografia é bem sucedido. Quando Clevis detecta um número menor de peças do que o especificado no limiar, ele imprime uma mensagem de erro.
9.12.1.1. Exemplo 1: Redundância com dois servidores Tang
O seguinte comando decripta um dispositivo criptografado LUKS quando pelo menos um dos dois servidores Tang está disponível:
# clevis luks bind -d /dev/sda1 sss "t":1,"pins":"tang":[url":http://tang1.srv",{\i1}"url":http://tang2.srv"]{\i1}O comando anterior utilizava o seguinte esquema de configuração:
{
"t":1,
"pins":{
"tang":[
{
"url":"http://tang1.srv"
},
{
"url":"http://tang2.srv"
}
]
}
}
Nesta configuração, o limiar do SSS t está definido para 1 e o comando clevis luks bind reconstrói com sucesso o segredo se pelo menos um de dois servidores tang listados estiver disponível.
9.13. Implantação de máquinas virtuais em uma rede NBDE
O comando clevis luks bind não altera a chave mestra LUKS. Isto implica que se você criar uma imagem encriptada LUKS para uso em uma máquina virtual ou ambiente de nuvem, todas as instâncias que executam esta imagem compartilharão uma chave mestra. Isto é extremamente inseguro e deve ser evitado em todos os momentos.
Isto não é uma limitação de Clevis, mas um princípio de projeto da LUKS. Se você deseja ter volumes raiz criptografados em uma nuvem, você precisa ter certeza de que você realiza o processo de instalação (geralmente usando Kickstart) para cada instância do Red Hat Enterprise Linux em uma nuvem também. As imagens não podem ser compartilhadas sem também compartilhar uma chave mestra LUKS.
Se você pretende implementar o desbloqueio automatizado em um ambiente virtualizado, a Red Hat recomenda fortemente que você use sistemas como lorax ou virt-install juntamente com um arquivo Kickstart (veja Configurando o registro automatizado de volumes criptografados LUKS usando Kickstart) ou outra ferramenta de provisionamento automatizado para garantir que cada VM criptografada tenha uma chave mestra única.
O desbloqueio automatizado com uma política TPM 2.0 não é suportado em uma máquina virtual.
Recursos adicionais
Para mais informações, consulte a seguinte página de manual:
-
clevis-luks-bind(1)
9.14. Construindo imagens de VM automaticamente para ambientes em nuvem usando NBDE
A implantação de imagens criptografadas automaticamente registráveis em um ambiente de nuvem pode proporcionar um conjunto único de desafios. Como outros ambientes de virtualização, é recomendado reduzir o número de instâncias iniciadas a partir de uma única imagem para evitar o compartilhamento da chave mestra LUKS.
Portanto, a melhor prática é criar imagens personalizadas que não sejam compartilhadas em nenhum repositório público e que forneçam uma base para a implantação de uma quantidade limitada de instâncias. O número exato de instâncias a serem criadas deve ser definido pelas políticas de segurança da implantação e baseado na tolerância ao risco associado ao vetor de ataque da chave mestra LUKS.
Para construir implantações automatizadas habilitadas para LUKS, sistemas como o Lorax ou virt-install juntamente com um arquivo Kickstart devem ser usados para garantir a exclusividade da chave mestra durante o processo de construção da imagem.
Os ambientes em nuvem permitem duas opções de implementação de servidores Tang que consideramos aqui. Primeiro, o servidor Tang pode ser implantado dentro do próprio ambiente de nuvem. Segundo, o servidor Tang pode ser implantado fora da nuvem em infra-estrutura independente com um link VPN entre as duas infra-estruturas.
A implantação de Tang nativamente na nuvem permite uma implantação fácil. Entretanto, dado que ele compartilha a infra-estrutura com a camada de persistência de dados do texto cifrado de outros sistemas, pode ser possível que tanto a chave privada do servidor Tang quanto os metadados Clevis sejam armazenados no mesmo disco físico. O acesso a este disco físico permite um comprometimento total dos dados do texto criptografado.
Por este motivo, a Red Hat recomenda fortemente a manutenção de uma separação física entre o local onde os dados são armazenados e o sistema onde o Tang está rodando. Esta separação entre a nuvem e o servidor Tang garante que a chave privada do servidor Tang não possa ser combinada acidentalmente com os metadados do Clevis. Ela também fornece controle local do servidor Tang se a infraestrutura da nuvem estiver em risco.
9.15. Introdução às funções do sistema Clevis e Tang
As funções do sistema RHEL são uma coleção de funções e módulos possíveis que fornecem uma interface de configuração consistente para gerenciar remotamente vários sistemas RHEL.
A RHEL 8.3 introduziu funções possíveis para implantações automatizadas de soluções de decriptação baseada em políticas (PBD) usando Clevis e Tang. O pacote rhel-system-roles contém estas funções do sistema, os exemplos relacionados, e também a documentação de referência.
A função do sistema nbde_client permite que você implante vários clientes Clevis de forma automatizada. Note que a função nbde_client suporta apenas as ligações Tang, e você não pode utilizá-la para ligações TPM2 no momento.
A função nbde_client requer volumes que já estão criptografados usando LUKS. Esta função suporta ligar um volume criptografado pelo LUKS a um ou mais servidores Network-Bound (NBDE) - servidores Tang. Você pode preservar a criptografia de volume existente com uma frase-senha ou removê-la. Após remover a frase-senha, você pode desbloquear o volume somente usando NBDE. Isto é útil quando um volume é inicialmente criptografado usando uma chave temporária ou senha que você deve remover após o sistema que você fornece o sistema.
Se você fornecer tanto uma senha como um arquivo chave, a função usa primeiro o que você forneceu. Se não encontrar nenhuma delas válida, tenta recuperar uma frase-chave a partir de uma ligação existente.
PBD define uma ligação como um mapeamento de um dispositivo para um slot. Isto significa que você pode ter várias encadernações para o mesmo dispositivo. O slot padrão é o slot 1.
A função nbde_client fornece também a variável state. Use o valor present para criar uma nova ligação ou atualizar uma já existente. Ao contrário de um comando clevis luks bind, você pode usar state: present também para sobrescrever uma encadernação existente em seu slot de dispositivo. O valor absent remove uma encadernação especificada.
Usando a função nbde_server, você pode implantar e gerenciar um servidor Tang como parte de uma solução automatizada de criptografia de disco. Esta função suporta as seguintes características:
- Chaves Tang rotativas
- Implantação e backup de chaves Tang
Recursos adicionais
-
Para uma referência detalhada sobre as variáveis de funções de Criptografia de Disco Ligado à Rede (NBDE), instale o pacote
rhel-system-rolese consulte os arquivosREADME.mdeREADME.htmlnos diretórios/usr/share/doc/rhel-system-roles/nbde_client/e/usr/share/doc/rhel-system-roles/nbde_server/. -
Por exemplo, livros-rolos do sistema, instalar o pacote
rhel-system-roles, e ver os diretórios/usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/. - Para mais informações sobre os papéis do Sistema RHEL, veja Introdução aos papéis do Sistema RHEL
9.16. Usando a função do sistema nbde_server para a criação de múltiplos servidores Tang
Siga os passos para preparar e aplicar um livro de jogo possível contendo as configurações do seu servidor Tang.
Pré-requisitos
- Sua assinatura do Red Hat Ansible Engine está anexada ao sistema. Veja o artigo Como faço o download e instalação do Red Hat Ansible Engine para mais informações.
Procedimento
Habilite o repositório RHEL Ansible, por exemplo:
# subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpmsInstalar Motor Possível:
# yum install ansibleInstalar as funções do sistema RHEL:
# yum install rhel-system-rolesPrepare seu playbook contendo configurações para os servidores Tang. Você pode começar do zero, ou usar um dos exemplos de playbooks do diretório
/usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/.# cp /usr/share/ansible/roles/rhel-system-roles.nbde_server/examples/simple_deploy.yml ./my-tang-playbook.ymlEdite o playbook em um editor de texto de sua escolha, por exemplo:
# vi my-tang-playbook.ymlAdicione os parâmetros necessários. O seguinte exemplo de playbook garante a implantação de seu servidor Tang e uma rotação de chaves:
--- - hosts: all vars: nbde_server_rotate_keys: yes roles: - linux-system-roles.nbde_serverAplique o livro de jogo acabado:
# ansible-playbook -i host1,host2,host3 my-tang-playbook.yml
Recursos adicionais
-
Para mais informações, instale o pacote
rhel-system-roles, e consulte os diretórios/usr/share/doc/rhel-system-roles/nbde_server/eusr/share/ansible/roles/rhel-system-roles.nbde_server/.
9.17. Usando a função do sistema nbde_client para a criação de vários clientes Clevis
Siga os passos para preparar e aplicar um livro de jogo possível contendo suas configurações Clevis-cliente.
A função do sistema nbde_client suporta apenas as amarrações Tang. Isto significa que não é possível utilizá-lo para as amarrações TPM2 no momento.
Pré-requisitos
- Sua assinatura do Red Hat Ansible Engine está anexada ao sistema. Veja o artigo Como faço o download e instalação do Red Hat Ansible Engine para mais informações.
- Seus volumes já estão criptografados pela LUKS.
Procedimento
Habilite o repositório RHEL Ansible, por exemplo:
# subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpmsInstalar Motor Possível:
# yum install ansibleInstalar as funções do sistema RHEL:
# yum install rhel-system-rolesPrepare seu playbook contendo configurações para os clientes Clevis. Você pode começar do zero, ou usar um dos exemplos de playbooks do diretório
/usr/share/ansible/roles/rhel-system-roles.nbde_client/examples/.# cp /usr/share/ansible/roles/rhel-system-roles.nbde_client/examples/high_availability.yml ./my-clevis-playbook.ymlEdite o playbook em um editor de texto de sua escolha, por exemplo:
# vi my-clevis-playbook.ymlAdicione os parâmetros necessários. O seguinte exemplo de playbook configura os clientes Clevis para desbloqueio automatizado de dois volumes codificados por LUKS quando pelo menos um dos dois servidores Tang estiver disponível:
--- - hosts: all vars: nbde_client_bindings: - device: /dev/rhel/root encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com - device: /dev/rhel/swap encryption_key_src: /etc/luks/keyfile servers: - http://server1.example.com - http://server2.example.com roles: - linux-system-roles.nbde_clientAplique o livro de jogo acabado:
# ansible-playbook -i host1,host2,host3 my-clevis-playbook.yml
Recursos adicionais
-
Para detalhes sobre os parâmetros e informações adicionais sobre a função
nbde_client, instale o pacoterhel-system-roles, e consulte os diretórios/usr/share/doc/rhel-system-roles/nbde_client/e/usr/share/ansible/roles/rhel-system-roles.nbde_client/.
9.18. Recursos adicionais
-
As páginas
tang(8),clevis(1),jose(1), eclevis-luks-unlockers(7)man. - O artigo Como configurar a criptografia de disco em rede com múltiplos dispositivos LUKS (Clevis Tang unlocking) Knowledgebase.
Capítulo 10. Auditoria do sistema
A auditoria não fornece segurança adicional ao seu sistema; ao contrário, ela pode ser usada para descobrir violações das políticas de segurança usadas em seu sistema. Essas violações podem ainda ser evitadas por medidas de segurança adicionais, como a SELinux.
10.1. Auditoria Linux
O sistema de Auditoria Linux fornece uma maneira de rastrear informações relevantes para a segurança em seu sistema. Baseado em regras pré-configuradas, o Audit gera entradas de registro para registrar o máximo de informações sobre os eventos que estão acontecendo em seu sistema. Estas informações são cruciais para ambientes de missão crítica para determinar o infrator da política de segurança e as ações que ele executou.
A seguinte lista resume algumas das informações que a Audit é capaz de registrar em seus arquivos de registro:
- Data e hora, tipo e resultado de um evento.
- Etiquetas de sensibilidade de sujeitos e objetos.
- Associação de um evento com a identidade do usuário que acionou o evento.
- Todas as modificações na configuração de Auditoria e tentativas de acesso aos arquivos de log de Auditoria.
- Todos os usos de mecanismos de autenticação, tais como SSH, Kerberos e outros.
-
Mudanças em qualquer banco de dados confiável, tais como
/etc/passwd. - Tentativas de importar ou exportar informações de ou para o sistema.
- Incluir ou excluir eventos baseados na identidade do usuário, etiquetas de assunto e objeto, e outros atributos.
O uso do sistema de Auditoria também é um requisito para uma série de certificações relacionadas à segurança. A auditoria é projetada para atender ou exceder as exigências das seguintes certificações ou guias de conformidade:
- Perfil de Proteção de Acesso Controlado (CAPP)
- Perfil de Proteção de Segurança Rotulado (LSPP)
- Controle de Acesso à Base do Conjunto de Regras (RSBAC)
- Manual de Operação do Programa Nacional de Segurança Industrial (NISPOM)
- Federal Information Security Management Act (FISMA)
- Indústria de cartões de pagamento
- Guias de Implementação Técnica de Segurança (STIG)
A auditoria também tem sido:
- Avaliado pela National Information Assurance Partnership (NIAP) e Best Security Industries (BSI).
- Certificado para LSPP/CAPP/RSBAC/EAL4 no Red Hat Enterprise Linux 5.
- Certificado ao Perfil de Proteção do Sistema Operacional / Garantia de Avaliação Nível 4 (OSPP/EAL4 ) no Red Hat Enterprise Linux 6.
Casos de uso
- Acesso ao arquivo de observação
- A auditoria pode rastrear se um arquivo ou um diretório foi acessado, modificado, executado ou se os atributos do arquivo foram alterados. Isto é útil, por exemplo, para detectar o acesso a arquivos importantes e ter uma pista de Auditoria disponível no caso de um destes arquivos ser corrompido.
- Chamadas ao sistema de monitoramento
-
A auditoria pode ser configurada para gerar uma entrada de registro cada vez que uma determinada chamada de sistema é utilizada. Isto pode ser usado, por exemplo, para rastrear mudanças no tempo do sistema monitorando o
settimeofday,clock_adjtime, e outras chamadas de sistema relacionadas ao tempo. - Comandos de gravação executados por um usuário
-
A auditoria pode rastrear se um arquivo foi executado, de modo que podem ser definidas regras para registrar cada execução de um determinado comando. Por exemplo, uma regra pode ser definida para cada executável no diretório
/bin. As entradas de registro resultantes podem então ser pesquisadas por ID de usuário para gerar uma trilha de auditoria de comandos executados por usuário. - Gravação da execução dos patamares do sistema
- Além de observar o acesso ao arquivo que traduz um caminho para um inode na invocação de regras, a Audit pode agora observar a execução de um caminho mesmo que ele não exista na invocação de regras, ou se o arquivo for substituído após a invocação de regras. Isto permite que as regras continuem a funcionar após a atualização de um programa executável ou antes mesmo que ele seja instalado.
- Gravação de eventos de segurança
-
O módulo de autenticação
pam_faillocké capaz de registrar tentativas de login falhadas. A auditoria também pode ser configurada para registrar tentativas de login falhadas e fornece informações adicionais sobre o usuário que tentou fazer o login. - Busca de eventos
-
A auditoria fornece o utilitário
ausearch, que pode ser usado para filtrar as entradas dos registros e fornecer uma trilha de auditoria completa com base em várias condições. - Execução de relatórios resumidos
-
A utilidade
aureportpode ser usada para gerar, entre outras coisas, relatórios diários de eventos registrados. Um administrador de sistema pode então analisar esses relatórios e investigar mais a fundo as atividades suspeitas. - Monitoramento do acesso à rede
-
Os utilitários
iptableseebtablespodem ser configurados para acionar eventos de Auditoria, permitindo que os administradores do sistema monitorem o acesso à rede.
O desempenho do sistema pode ser afetado dependendo da quantidade de informação que é coletada pela Auditoria.
10.2. Arquitetura do sistema de auditoria
O sistema de Auditoria consiste em duas partes principais: as aplicações e utilitários de espaço do usuário, e o processamento de chamadas do sistema do lado do kernel. O componente kernel recebe chamadas de sistema de aplicações de espaço do usuário e as filtra através de um dos seguintes filtros: user, task, fstype, ou exit.
Uma vez que uma chamada de sistema passa pelo filtro exclude, ele é enviado através de um dos filtros acima mencionados, que, com base na configuração da regra de Auditoria, o envia para o daemon de Auditoria para processamento posterior.
O daemon de Auditoria do espaço do usuário coleta as informações do kernel e cria entradas em um arquivo de log. Outras utilidades do espaço do usuário de Auditoria interagem com o daemon de Auditoria, o componente Audit do kernel ou os arquivos de log de Auditoria:
-
auditctl -
Os demais utilitários de Auditoria tomam o conteúdo dos arquivos de log de Auditoria como entrada e geram saída com base nas necessidades do usuário. Por exemplo, o utilitário
aureportgera um relatório de todos os eventos registrados.
No RHEL 8, a funcionalidade do daemon de Auditoria (audisp) está integrada no daemon de Auditoria (auditd). Os arquivos de configuração dos plugins para a interação de programas analíticos em tempo real com eventos de Auditoria estão localizados no diretório /etc/audit/plugins.d/ por padrão.
10.3. Configurando a auditoria para um ambiente seguro
A configuração padrão auditd deve ser adequada para a maioria dos ambientes. Entretanto, se seu ambiente tiver que atender a rígidas políticas de segurança, as seguintes configurações são sugeridas para a configuração do daemon de Auditoria no arquivo /etc/audit/auditd.conf:
- log_file
-
O diretório que contém os arquivos de log de auditoria (geralmente
/var/log/audit/) deve residir em um ponto de montagem separado. Isto evita que outros processos consumam espaço neste diretório e fornece uma detecção precisa do espaço restante para o daemon de Auditoria. - max_log_file
- Especifica o tamanho máximo de um único arquivo de log de Auditoria, deve ser definido para fazer pleno uso do espaço disponível na partição que contém os arquivos de log de Auditoria.
- max_log_file_action
-
Decide qual ação é tomada uma vez atingido o limite estabelecido em
max_log_file, deve ser definido parakeep_logspara evitar que os arquivos de log de Auditoria sejam sobrescritos. - space_left
-
Especifica a quantidade de espaço livre restante no disco para o qual uma ação que está definida no parâmetro
space_left_actioné acionada. Deve ser definido para um número que dê ao administrador tempo suficiente para responder e liberar espaço livre no disco. O valorspace_leftdepende da taxa na qual os arquivos de log de auditoria são gerados. - space_left_action
-
Recomenda-se definir o parâmetro
space_left_actionparaemailouexeccom um método de notificação apropriado. - admin_esquerda_esquerda_espacial
-
Especifica a quantidade mínima absoluta de espaço livre para o qual uma ação definida no parâmetro
admin_space_left_actiondeve ser definida para um valor que deixe espaço suficiente para registrar as ações executadas pelo administrador. - admin_space_left_action
-
Deve ser ajustado para
singlepara colocar o sistema no modo de usuário único e permitir que o administrador liberte algum espaço em disco. - disk_full_action
-
Especifica uma ação que é acionada quando não há espaço livre disponível na partição que contém os arquivos de log de auditoria, deve ser definida para
haltousingle. Isto assegura que o sistema esteja desligado ou operando em modo de usuário único quando a Auditoria não puder mais registrar eventos. - disk_error_action
-
Especifica uma ação que é acionada caso seja detectado um erro na partição que contém os arquivos de log de auditoria, deve ser definida para
syslog,single, ouhalt, dependendo de suas políticas locais de segurança em relação ao tratamento de falhas de hardware. - descarga
-
Deve ser ajustado para
incremental_async. Funciona em combinação com o parâmetrofreq, que determina quantos registros podem ser enviados ao disco antes de forçar uma sincronização rígida com o disco rígido. O parâmetrofreqdeve ser definido para100. Estes parâmetros asseguram que os dados de eventos de Auditoria sejam sincronizados com os arquivos de registro no disco, mantendo um bom desempenho para explosões de atividade.
As demais opções de configuração devem ser definidas de acordo com sua política de segurança local.
10.4. Iniciando e controlando a auditoria
Uma vez configurado auditd, iniciar o serviço para coletar informações de Auditoria e armazená-las nos arquivos de registro. Use o seguinte comando como usuário root para iniciar auditd:
# service auditd start
Para configurar auditd para começar no momento da inicialização:
# systemctl enable auditd
Uma série de outras ações podem ser realizadas no site auditd usando o service auditd action onde action pode ser um dos seguintes:
stop-
Pára
auditd. restart-
Reinicia
auditd. reloadouforce-reload-
Recarrega a configuração de
auditda partir do arquivo/etc/audit/auditd.conf. rotate-
Gira os arquivos de log no diretório
/var/log/audit/. resume- Retoma o registro dos eventos de Auditoria após ter sido suspenso anteriormente, por exemplo, quando não há espaço livre suficiente na partição do disco que contém os arquivos de registro de Auditoria.
condrestartoutry-restart-
Reinicia
auditdsomente se já estiver em funcionamento. status-
Exibe o status de funcionamento do
auditd.
O comando service é a única maneira de interagir corretamente com o daemon auditd. Você precisa usar o comando service para que o valor auid seja devidamente registrado. Você pode usar o comando systemctl somente para duas ações: enable e status.
10.5. Entendendo os arquivos de log de auditoria
Por padrão, o sistema de Auditoria armazena entradas de log no arquivo /var/log/audit/audit.log; se a rotação de log estiver ativada, os arquivos audit.log rodados são armazenados no mesmo diretório.
Adicione a seguinte regra de Auditoria para registrar cada tentativa de ler ou modificar o arquivo /etc/ssh/sshd_config:
# auditctl -w /etc/ssh/sshd_config -p warx -k sshd_config
Se o daemon auditd estiver em execução, por exemplo, usando o seguinte comando, cria-se um novo evento no arquivo de log de Auditoria:
$ cat /etc/ssh/sshd_config
Este evento no arquivo audit.log tem a seguinte aparência:
type=SYSCALL msg=audit(1364481363.243:24287): arch=c000003e syscall=2 success=no exit=-13 a0=7fffd19c5592 a1=0 a2=7fffd19c4b50 a3=a items=1 ppid=2686 pid=3538 auid=1000 uid=1000 gid=1000 euid=1000 suid=1000 fsuid=1000 egid=1000 sgid=1000 fsgid=1000 tty=pts0 ses=1 comm="cat" exe="/bin/cat" subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 key="sshd_config" type=CWD msg=audit(1364481363.243:24287): cwd="/home/shadowman" type=PATH msg=audit(1364481363.243:24287): item=0 name="/etc/ssh/sshd_config" inode=409248 dev=fd:00 mode=0100600 ouid=0 ogid=0 rdev=00:00 obj=system_u:object_r:etc_t:s0 nametype=NORMAL cap_fp=none cap_fi=none cap_fe=0 cap_fver=0 type=PROCTITLE msg=audit(1364481363.243:24287) : proctitle=636174002F6574632F7373682F737368645F636F6E666967
O evento acima consiste em quatro registros, que compartilham o mesmo carimbo de tempo e número de série. Os registros sempre começam com a palavra-chave type=. Cada registro consiste de vários name=value pares separados por um espaço branco ou por uma vírgula. Segue-se uma análise detalhada do evento acima:
Primeiro Registro
type=SYSCALL-
O campo
typecontém o tipo de registro. Neste exemplo, o valorSYSCALLespecifica que este registro foi acionado por uma chamada do sistema ao kernel.
msg=audit(1364481363.243:24287):Os registros de campo
msg:-
um carimbo de tempo e uma identificação única do registro no formulário
audit(time_stamp:ID). Vários registros podem compartilhar o mesmo carimbo de tempo e identificação se foram gerados como parte de um mesmo evento de Auditoria. O carimbo de horário está usando o formato de horário Unix - segundos desde 00:00:00 UTC em 1 de janeiro de 1970. -
vários eventos específicos
name=valuepares fornecidos pelo kernel ou por aplicações de espaço do usuário.
-
um carimbo de tempo e uma identificação única do registro no formulário
arch=c000003e-
O campo
archcontém informações sobre a arquitetura da CPU do sistema. O valor,c000003e, é codificado em notação hexadecimal. Ao procurar registros de auditoria com o comandoausearch, use a opção-iou--interpretpara converter automaticamente valores hexadecimais em seus equivalentes legíveis por humanos. O valorc000003eé interpretado comox86_64. syscall=2-
O campo
syscallregistra o tipo de chamada do sistema que foi enviada ao kernel. O valor,2, pode ser correspondido com seu equivalente legível em humanos no arquivo/usr/include/asm/unistd_64.h. Neste caso,2é a chamada de sistemaopen. Note que o utilitárioausyscallpermite converter os números de chamada do sistema para seus equivalentes legíveis por humanos. Use o comandoausyscall --dumppara exibir uma lista de todas as chamadas de sistema junto com seus números. Para mais informações, consulte a página de manualausyscall(8). success=no-
O campo
successregistra se a chamada ao sistema registrada nesse evento em particular foi bem sucedida ou falhou. Neste caso, a chamada não foi bem sucedida. exit=-13O campo
exitcontém um valor que especifica o código de saída retornado pela chamada ao sistema. Este valor varia para uma chamada de sistema diferente. Você pode interpretar o valor para seu equivalente legível por humanos com o seguinte comando:# ausearch --interpret --exit -13Note que o exemplo anterior assume que seu log de Auditoria contém um evento que falhou com o código de saída
-13.a0=7fffd19c5592,a1=0,a2=7fffd19c5592,a3=a-
Os campos
a0aa3registram os quatro primeiros argumentos, codificados em notação hexadecimal, da chamada ao sistema neste evento. Estes argumentos dependem da chamada de sistema que é utilizada; eles podem ser interpretados pelo utilitárioausearch. items=1-
O campo
itemscontém o número de registros auxiliares PATH que seguem o registro da syscall. ppid=2686-
O campo
ppidregistra o ID do Processo dos Pais (PPID). Neste caso,2686era o PPID do processo de pais, comobash. pid=3538-
O campo
pidregistra o ID do processo (PID). Neste caso,3538foi o PID do processocat. auid=1000-
O campo
auidregistra o ID do usuário de Auditoria, ou seja, o loginuid. Este ID é atribuído a um usuário no momento do login e é herdado por cada processo mesmo quando a identidade do usuário muda, por exemplo, trocando as contas de usuário com o comandosu - john. uid=1000-
O campo
uidregistra o ID do usuário que iniciou o processo analisado. O ID do usuário pode ser interpretado em nomes de usuário com o seguinte comandoausearch -i --uid UID. gid=1000-
O campo
gidregistra o ID do grupo do usuário que iniciou o processo analisado. euid=1000-
O campo
euidregistra o ID de usuário efetivo do usuário que iniciou o processo analisado. suid=1000-
O campo
suidregistra o ID de usuário definido do usuário que iniciou o processo analisado. fsuid=1000-
O campo
fsuidregistra o ID do usuário do sistema de arquivos do usuário que iniciou o processo analisado. egid=1000-
O campo
egidregistra a identificação do grupo efetivo do usuário que iniciou o processo analisado. sgid=1000-
O campo
sgidregistra o ID do grupo definido do usuário que iniciou o processo analisado. fsgid=1000-
O campo
fsgidregistra o ID do grupo do sistema de arquivos do usuário que iniciou o processo analisado. tty=pts0-
O campo
ttyregistra o terminal a partir do qual o processo analisado foi invocado. ses=1-
O campo
sesregistra o ID da sessão a partir da qual o processo analisado foi invocado. comm="cat"-
O campo
commregistra o nome da linha de comando do comando que foi usado para invocar o processo analisado. Neste caso, o comandocatfoi usado para acionar este evento de Auditoria. exe="/bin/cat"-
O campo
exeregistra o caminho para o executável que foi usado para invocar o processo analisado. subj=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023-
O campo
subjregistra o contexto SELinux com o qual o processo analisado foi rotulado no momento da execução. key="sshd_config"-
O campo
keyregistra a seqüência definida pelo administrador associada à regra que gerou este evento no log de Auditoria.
Segundo registro
type=CWDNo segundo registro, o valor do campo
typeéCWDO objetivo deste registro é registrar a localização do processo atual no caso de um caminho relativo acabar sendo capturado no registro PATH associado. Desta forma, o caminho absoluto pode ser reconstruído.
msg=audit(1364481363.243:24287)-
O campo
msgpossui o mesmo carimbo de tempo e valor de identificação que o valor do primeiro registro. O carimbo de hora está usando o formato Unix time - segundos desde 00:00:00 UTC em 1 de janeiro de 1970. cwd="/home/user_name"-
O campo
cwdcontém o caminho para o diretório no qual a chamada ao sistema foi invocada.
Terceiro registro
type=PATH-
No terceiro registro, o valor do campo
typeéPATH. Um evento de Auditoria contém um registro do tipoPATHpara cada caminho que é passado para a chamada ao sistema como argumento. Neste evento de Auditoria, apenas um caminho (/etc/ssh/sshd_config) foi usado como argumento. msg=audit(1364481363.243:24287):-
O campo
msgpossui o mesmo carimbo de tempo e valor de identificação do primeiro e segundo registros. item=0-
O campo
itemindica qual item, do número total de itens referenciados no registro do tipoSYSCALL, é o registro atual. Este número é baseado em zero; um valor de0significa que ele é o primeiro item. name="/etc/ssh/sshd_config"-
O campo
nameregistra o caminho do arquivo ou diretório que foi passado para a chamada ao sistema como um argumento. Neste caso, foi o arquivo/etc/ssh/sshd_config. inode=409248O campo
inodecontém o número do inode associado ao arquivo ou diretório gravado neste evento. O seguinte comando exibe o arquivo ou diretório que está associado ao número do inode409248:# find / -inum 409248 -print /etc/ssh/sshd_configdev=fd:00-
O campo
devespecifica a identificação menor e maior do dispositivo que contém o arquivo ou diretório gravado neste evento. Neste caso, o valor representa o dispositivo/dev/fd/0. mode=0100600-
O campo
moderegistra as permissões do arquivo ou diretório, codificadas em notação numérica, conforme retornado pelo comandostatno campost_mode. Consulte a página de manualstat(2)para maiores informações. Neste caso,0100600pode ser interpretado como-rw-------, significando que somente o usuário root tem permissões de leitura e escrita para o arquivo/etc/ssh/sshd_config. ouid=0-
O campo
ouidregistra o ID de usuário do proprietário do objeto. ogid=0-
O campo
ogidregistra a identificação do grupo do proprietário do objeto. rdev=00:00-
O campo
rdevcontém um identificador de dispositivo registrado somente para arquivos especiais. Neste caso, ele não é utilizado, pois o arquivo gravado é um arquivo normal. obj=system_u:object_r:etc_t:s0-
O campo
objregistra o contexto SELinux com o qual o arquivo ou diretório gravado foi rotulado no momento da execução. nametype=NORMAL-
O campo
nametyperegistra a intenção da operação de cada registro de caminho no contexto de uma determinada chamada de sistema. cap_fp=none-
O campo
cap_fpregistra dados relacionados à configuração de um sistema de arquivo permitido baseado na capacidade do arquivo ou objeto de diretório. cap_fi=none-
O campo
cap_firegistra dados relacionados à configuração de um sistema de arquivo herdado baseado na capacidade do arquivo ou objeto de diretório. cap_fe=0-
O campo
cap_feregistra a configuração do bit efetivo da capacidade baseada no sistema de arquivos do arquivo ou objeto de diretório. cap_fver=0-
O campo
cap_fverregistra a versão do sistema de arquivo baseado na capacidade do arquivo ou objeto de diretório.
Quarto Registro
type=PROCTITLE-
O campo
typecontém o tipo de registro. Neste exemplo, o valorPROCTITLEespecifica que este registro dá a linha de comando completa que acionou este evento de Auditoria, acionado por uma chamada do sistema ao kernel. proctitle=636174002F6574632F7373682F737368645F636F6E666967-
O campo
proctitleregistra a linha de comando completa do comando que foi usado para invocar o processo analisado. O campo é codificado em notação hexadecimal para não permitir que o usuário influencie o analisador de logs de auditoria. O texto decodifica para o comando que acionou este evento de Auditoria. Ao pesquisar registros de Auditoria com o comandoausearch, use a opção-iou--interpretpara converter automaticamente valores hexadecimais em seus equivalentes legíveis por humanos. O valor636174002F6574632F7373682F737368645F636F6E666967é interpretado comocat /etc/ssh/sshd_config.
10.6. Utilização de Auditctl para definir e executar Regras de Auditoria
O sistema de Auditoria opera sobre um conjunto de regras que definem o que é capturado nos arquivos de registro. As regras de auditoria podem ser definidas tanto na linha de comando usando o utilitário auditctl ou no diretório /etc/audit/rules.d/.
O comando auditctl permite controlar a funcionalidade básica do sistema de Auditoria e definir regras que decidem quais eventos de Auditoria são registrados.
Exemplos de regras do sistema de arquivos
Para definir uma regra que registra todos os acessos de escrita e cada mudança de atributo do arquivo
/etc/passwd:# auditctl -w /etc/passwd -p wa -k passwd_changesDefinir uma regra que registra todos os acessos de escrita e todas as mudanças de atributos de todos os arquivos no diretório
/etc/selinux/:# auditctl -w /etc/selinux/ -p wa -k selinux_changes
Exemplos de regras de chamada de sistema
Para definir uma regra que cria uma entrada de registro cada vez que as chamadas ao sistema
adjtimexousettimeofdaysão usadas por um programa, e o sistema usa a arquitetura de 64 bits:# auditctl -a always,exit -F arch=b64 -S adjtimex -S settimeofday -k time_changeDefinir uma regra que cria uma entrada de registro cada vez que um arquivo é excluído ou renomeado por um usuário do sistema cuja ID é 1000 ou maior:
# auditctl -a always,exit -S unlink -S unlinkat -S rename -S renameat -F auid>=1000 -F auid!=4294967295 -k deleteNote que a opção
-F auid!=4294967295é usada para excluir usuários cujo login UID não está definido.
Regras de arquivo executável
Para definir uma regra que registra toda a execução do programa /bin/id, execute o seguinte comando:
# auditctl -a always,exit -F exe=/bin/id -F arch=b64 -S execve -k execution_bin_idRecursos adicionais
-
Consulte a página de manual
audictl(8)para mais informações, dicas de desempenho e exemplos adicionais de uso.
10.7. Definindo regras de Auditoria persistente
Para definir as regras de Auditoria que são persistentes nas reinicializações, você deve incluí-las diretamente no arquivo /etc/audit/rules.d/audit.rules ou usar o programa augenrules que lê as regras localizadas no diretório /etc/audit/rules.d/.
Note que o arquivo /etc/audit/audit.rules é gerado sempre que o serviço auditd é iniciado. Os arquivos em /etc/audit/rules.d/ utilizam a mesma sintaxe de linha de comando auditctl para especificar as regras. Linhas vazias e texto seguindo um sinal de hash (#) são ignoradas.
Além disso, você pode usar o comando auditctl para ler regras de um arquivo específico usando a opção -R, por exemplo:
# auditctl -R /usr/share/audit/sample-rules/30-stig.rules10.8. Usando arquivos de regras pré-configuradas
No diretório /usr/share/audit/sample-rules, o pacote audit fornece um conjunto de arquivos de regras pré-configuradas de acordo com vários padrões de certificação:
- 30-nispom.rules
- Configuração de regras de auditoria que satisfaçam os requisitos especificados no capítulo Segurança do Sistema de Informação do Manual de Operações do Programa Nacional de Segurança Industrial.
- 30-ospp-v42*.rules
- Configuração de regras de auditoria que satisfaçam os requisitos definidos no perfil OSPP (Protection Profile for General Purpose Operating Systems) versão 4.2.
- 30-pci-dss-v31.rules
- Configuração de regras de auditoria que satisfaçam os requisitos estabelecidos pela Norma de Segurança de Dados da Indústria de Cartões de Pagamento (PCI DSS) v3.1.
- 30-stig.rules
- Configuração de regras de auditoria que satisfaçam os requisitos estabelecidos pelos Guias de Implementação Técnica de Segurança (STIG).
Para utilizar estes arquivos de configuração, copie-os para o diretório /usr/share/audit/sample-rules e use o comando augenrules --load, por exemplo:
# cd /usr/share/audit/sample-rules/ # cp 10-base-config.rules 30-stig.rules 31-privileged.rules 99-finalize.rules /etc/audit/rules.d/ # augenrules --load
Recursos adicionais
-
Você pode encomendar regras de Auditoria usando um esquema de numeração. Consulte o arquivo
/usr/share/audit/sample-rules/README-rulespara obter mais informações. -
Consulte a página de manual
audit.rules(7)para mais informações, solução de problemas e exemplos adicionais de uso.
10.9. Usando as regras de augenrices para definir regras persistentes
O script augenrules lê regras localizadas no diretório /etc/audit/rules.d/ e as compila em um arquivo audit.rules. Este script processa todos os arquivos que terminam com .rules em uma ordem específica com base em sua ordem natural de classificação. Os arquivos neste diretório estão organizados em grupos com os seguintes significados:
- 10 - Configuração do kernel e auditctl
- 20 - Regras que poderiam corresponder às regras gerais, mas você quer uma correspondência diferente
- 30 - Principais regras
- 40 - Regras opcionais
- 50 - Regras específicas do servidor
- 70 - Regras locais do sistema
- 90 - Finalizar (imutável)
As regras não devem ser usadas de uma só vez. Elas são partes de uma política que deve ser pensada e arquivos individuais copiados para /etc/audit/rules.d/. Por exemplo, para configurar um sistema na configuração STIG, copiar as regras 10-base-config, 30-stig, 31-privileged, e 99-finalize.
Uma vez que você tenha as regras no diretório /etc/audit/rules.d/, carregue-as executando o script augenrules com a diretiva --load:
# augenrules --load
/sbin/augenrules: No change
No rules
enabled 1
failure 1
pid 742
rate_limit 0
...Recursos adicionais
-
Para mais informações sobre as regras de Auditoria e o roteiro
augenrules, consulte as páginas de manualaudit.rules(8)eaugenrules(8).
10.10. Desabilitando as regras de augenia
Use os seguintes passos para desativar o utilitário augenrules. Isto muda a Auditoria para usar as regras definidas no arquivo /etc/audit/audit.rules.
Procedimento
Copie o arquivo
/usr/lib/systemd/system/auditd.servicepara o diretório/etc/systemd/system/:# cp -f /usr/lib/systemd/system/auditd.service /etc/systemd/system/Edite o arquivo
/etc/systemd/system/auditd.serviceem um editor de texto de sua escolha, por exemplo:# vi /etc/systemd/system/auditd.serviceComente a linha contendo
augenrules, e descomente a linha contendo o comandoauditctl -R:#ExecStartPost=-/sbin/augenrules --load ExecStartPost=-/sbin/auditctl -R /etc/audit/audit.rules
Recarregue o daemon
systemdpara ir buscar as mudanças no arquivoauditd.service:# systemctl daemon-reloadReinicie o serviço
auditd:# service auditd restart
Recursos adicionais
-
As páginas de manual
augenrules(8)eaudit.rules(8). - O reinício do serviço Auditd anula as alterações feitas no artigo /etc/audit/audit.rules.
Capítulo 11. Bloqueio e permissão de aplicações usando fapolicyd
Estabelecer e aplicar uma política que permite ou nega a execução de aplicativos com base em um conjunto de regras impede eficientemente a execução de software desconhecido e potencialmente malicioso.
11.1. Introdução ao fapolicida
A estrutura de software fapolicyd controla a execução de aplicações com base em uma política definida pelo usuário. Esta é uma das formas mais eficientes de impedir a execução de aplicações não confiáveis e possivelmente maliciosas no sistema.
A estrutura fapolicyd fornece os seguintes componentes:
-
fapolicydserviço -
fapolicydutilidades de linha de comando -
fapolicydPlug-in YUM -
fapolicydidioma das regras
O administrador pode definir as regras de execução allow e deny para qualquer aplicação com a possibilidade de auditoria baseada em um caminho, hash, tipo MIME, ou trust.
A estrutura fapolicyd introduz o conceito de confiança. Uma aplicação é confiável quando devidamente instalada pelo gerente de pacotes do sistema e, portanto, é registrada no banco de dados RPM do sistema. O daemon fapolicyd usa o banco de dados RPM como uma lista de binários e scripts confiáveis. O plugin fapolicyd do YUM registra qualquer atualização do sistema que é gerenciada pelo gerenciador de pacotes YUM. O plugin notifica o daemon fapolicyd sobre mudanças neste banco de dados.
Uma instalação usando o utilitário rpm requer uma atualização manual do banco de dados, e outras formas de adicionar aplicações requerem a criação de regras personalizadas e o reinício do serviço fapolicyd.
A configuração do serviço fapolicyd está localizada no diretório /etc/fapolicyd/ com a seguinte estrutura:
-
O arquivo
fapolicyd.rulescontémallowedenyregras de execução. -
O arquivo
fapolicyd.confcontém as opções de configuração do daemon. Este arquivo é útil principalmente para fins de ajuste de desempenho.
Recursos adicionais
-
Consulte as páginas de manual
fapolicyd(8),fapolicyd.rules(5), efapolicyd.conf(5)para mais informações.
11.2. Implantação de fapolicida
Para implantar a estrutura fapolicyd na RHEL:
Procedimento
Instale o pacote
fapolicyd:# yum install fapolicydHabilite e inicie o serviço
fapolicyd:# systemctl enable --now fapolicyd
Etapas de verificação
Verifique se o serviço
fapolicydestá funcionando corretamente:# systemctl status fapolicyd ● fapolicyd.service - File Access Policy Daemon Loaded: loaded (/usr/lib/systemd/system/fapolicyd.service; enabled; vendor p> Active: active (running) since Tue 2019-10-15 18:02:35 CEST; 55s ago Process: 8818 ExecStart=/usr/sbin/fapolicyd (code=exited, status=0/SUCCESS) Main PID: 8819 (fapolicyd) Tasks: 4 (limit: 11500) Memory: 78.2M CGroup: /system.slice/fapolicyd.service └─8819 /usr/sbin/fapolicyd Oct 15 18:02:35 localhost.localdomain systemd[1]: Starting File Access Policy D> Oct 15 18:02:35 localhost.localdomain fapolicyd[8819]: Initialization of the da> Oct 15 18:02:35 localhost.localdomain fapolicyd[8819]: Reading RPMDB into memory Oct 15 18:02:35 localhost.localdomain systemd[1]: Started File Access Policy Da> Oct 15 18:02:36 localhost.localdomain fapolicyd[8819]: Creating databaseEntre como um usuário sem privilégios de raiz e verifique se
fapolicydestá funcionando, por exemplo:$ cp /bin/ls /tmp $ /tmp/ls bash: /tmp/ls: Operation not permitted
11.3. Marcação de arquivos como confiáveis usando uma fonte adicional de confiança
Você pode usar este procedimento para utilizar uma fonte adicional de confiança para fapolicyd. Antes da RHEL 8.3, fapolicyd confiava apenas nos arquivos contidos no banco de dados RPM. A estrutura fapolicyd agora suporta também o uso do arquivo de texto simples /etc/fapolicyd/fapolicyd.trust como fonte de confiança. Você pode modificar fapolicyd.trust diretamente com um editor de texto ou através dos comandos do fapolicyd CLI.
Prefira marcar arquivos como confiáveis usando fapolicyd.trust em vez de escrever regras personalizadas fapolicyd.
Pré-requisitos
-
A estrutura
fapolicydestá implantada em seu sistema.
Procedimento
Copie seu binário personalizado para o diretório necessário, por exemplo:
$ cp /bin/ls /tmp $ /tmp/ls bash: /tmp/ls: Operation not permitted
Marque seu binário personalizado como confiável:
# fapolicyd-cli --file add /tmp/lsNote que o comando anterior adiciona a linha correspondente a
/etc/fapolicyd/fapolicyd.trust.Reinicie
fapolicyd:# systemctl restart fapolicyd
Etapas de verificação
Verifique se seu binário personalizado já pode ser executado, por exemplo:
$ /tmp/ls ls
Recursos adicionais
-
Consulte a página de manual
fapolicyd.trust(5)para mais informações.
11.4. Adicionar regras de permissão e negação de fapolicida
O conjunto padrão de regras do pacote fapolicyd não afeta as funções do sistema. Para cenários personalizados, como armazenar binários e scripts em um diretório não-padrão ou adicionar aplicações sem os instaladores yum ou rpm, é necessário modificar as regras existentes ou adicionar novas regras. Os passos seguintes demonstram a adição de uma nova regra para permitir um binário personalizado.
Pré-requisitos
-
A estrutura
fapolicydestá implantada em seu sistema.
Procedimento
Copie seu binário personalizado para o diretório necessário, por exemplo:
$ cp /bin/ls /tmp $ /tmp/ls bash: /tmp/ls: Operation not permitted
Pare o serviço
fapolicyd:# systemctl stop fapolicydUse o modo de depuração para identificar uma regra correspondente. Porque a saída do comando
fapolicyd --debugé verbosa e você só pode pará-la pressionando Ctrl+C ou matar o processo correspondente, redirecionar a saída de erro para um arquivo:# fapolicyd --debug 2> fapolicy.output & [1] 51341
Alternativamente, você pode executar o modo de depuração
fapolicydem outro terminal.Repita o comando que não foi permitido:
$ /tmp/ls bash: /tmp/ls: Operation not permittedParar o modo de depuração, retomando-o em primeiro plano e pressionando Ctrl+C:
# fg fapolicyd --debug ^Cshutting down... Inter-thread max queue depth 1 Allowed accesses: 2 Denied accesses: 1 [...]Alternativamente, mate o processo do modo de depuração
fapolicyd:# kill 51341Encontre uma regra que negue a execução de seu pedido:
# cat fapolicy.output [...] rule:9 dec=deny_audit perm=execute auid=1000 pid=51362 exe=/usr/bin/bash : file=/tmp/ls ftype=application/x-executable [...]Adicione uma nova regra
allowbefore a regra que negou a execução de seu binário personalizado no arquivo/etc/fapolicyd/fapolicyd.rules. A saída do comando anterior indicava que a regra é a regra número 9 neste exemplo:allow perm=execute exe=/usr/bin/bash trust=1 : path=/tmp/ls ftype=application/x-executable trust=0
Alternativamente, você pode permitir a execução de todos os binários no diretório
/tmp, adicionando a seguinte regra no arquivo/etc/fapolicyd/fapolicyd.rules:permitir perm=execute exe=/usr/bin/bash trust=1 : dir=/tmp/ all trust=0
Para evitar mudanças no conteúdo de seu binário personalizado, defina a regra necessária usando um checksum SHA-256:
$ sha256sum /tmp/ls 780b75c90b2d41ea41679fcb358c892b1251b68d1927c80fbc0d9d148b25e836 lsMude a regra para a seguinte definição:
allow perm=execute exe=/usr/bin/bash trust=1 : sha256hash=780b75c90b2d41ea41679fcb358c892b1251b68d1927c80fbc0d9d148b25e836Iniciar o serviço
fapolicyd:# systemctl start fapolicyd
Etapas de verificação
Verifique se seu binário personalizado já pode ser executado, por exemplo:
$ /tmp/ls ls
Recursos adicionais
-
Consulte a página de manual
fapolicyd.trust(5)para mais informações.
11.6. Recursos adicionais
-
Veja as páginas de homem relacionadas a
fapolicyd- listadas usando o comandoman -k fapolicydpara mais informações. -
A apresentação da FOSDEM 2020 fapolicyd fornece vários exemplos de adição de regras personalizadas
fapolicyd.
Capítulo 12. Protegendo sistemas contra dispositivos USB intrusivos
Os dispositivos USB podem ser carregados com spyware, malware ou Trojans, que podem roubar seus dados ou danificar seu sistema. Como administrador do Red Hat Enterprise Linux, você pode evitar tais ataques USB com USBGuard.
12.1. USBGuard
Com a estrutura do software USBGuard, você pode proteger seus sistemas contra dispositivos USB intrusivos usando listas básicas de dispositivos permitidos e proibidos com base no recurso de autorização de dispositivos USB no kernel.
A estrutura do USBGuard fornece os seguintes componentes:
- O componente de serviço do sistema com uma interface de comunicação inter-processo (IPC) para interação dinâmica e aplicação de políticas
-
A interface de linha de comando para interagir com um serviço de sistema
usbguardem execução - A linguagem de regra para escrever políticas de autorização de dispositivos USB
- O API C para interagir com o componente de serviço do sistema implementado em uma biblioteca compartilhada
O arquivo de configuração do serviço do sistema usbguard (/etc/usbguard/usbguard-daemon.conf) inclui as opções para autorizar os usuários e grupos a usar a interface IPC.
O serviço do sistema fornece a interface pública IPC USBGuard. No Red Hat Enterprise Linux, o acesso a esta interface é limitado ao usuário root apenas por default.
Considere definir a opção IPCAccessControlFiles (recomendada) ou as opções IPCAllowedUsers e IPCAllowedGroups para limitar o acesso à interface IPC.
Certifique-se de não deixar a Lista de Controle de Acesso (ACL) desconfigurada, pois isso expõe a interface IPC a todos os usuários locais e lhes permite manipular o estado de autorização dos dispositivos USB e modificar a política do USBGuard.
12.2. Instalando o USBGuard
Use este procedimento para instalar e iniciar a estrutura USBGuard.
Procedimento
Instale o pacote
usbguard:# yum install usbguardCriar um conjunto inicial de regras:
# usbguard generate-policy > /etc/usbguard/rules.confInicie o daemon
usbguarde assegure-se de que ele comece automaticamente na inicialização:# systemctl enable --now usbguard
Etapas de verificação
Verifique se o serviço
usbguardestá funcionando:# systemctl status usbguard ● usbguard.service - USBGuard daemon Loaded: loaded (/usr/lib/systemd/system/usbguard.service; enabled; vendor preset: disabled) Active: active (running) since Thu 2019-11-07 09:44:07 CET; 3min 16s ago Docs: man:usbguard-daemon(8) Main PID: 6122 (usbguard-daemon) Tasks: 3 (limit: 11493) Memory: 1.2M CGroup: /system.slice/usbguard.service └─6122 /usr/sbin/usbguard-daemon -f -s -c /etc/usbguard/usbguard-daemon.conf Nov 07 09:44:06 localhost.localdomain systemd[1]: Starting USBGuard daemon... Nov 07 09:44:07 localhost.localdomain systemd[1]: Started USBGuard daemon.Liste os dispositivos USB reconhecidos por
USBGuard:# usbguard list-devices 4: allow id 1d6b:0002 serial "0000:02:00.0" name "xHCI Host Controller" hash...
Recursos adicionais
-
usbguard(1)eusbguard-daemon.conf(5)páginas man
12.3. Bloqueio e autorização de um dispositivo USB usando CLI
Este procedimento delineia como autorizar e bloquear um dispositivo USB usando o comando usbguard.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando.
Procedimento
Liste os dispositivos USB reconhecidos por
USBGuard:# usbguard list-devices 1: allow id 1d6b:0002 serial "0000:00:06.7" name "EHCI Host Controller" hash "JDOb0BiktYs2ct3mSQKopnOOV2h9MGYADwhT+oUtF2s=" parent-hash "4PHGcaDKWtPjKDwYpIRG722cB9SlGz9l9Iea93+Gt9c=" via-port "usb1" with-interface 09:00:00 ... 6: block id 1b1c:1ab1 serial "000024937962" name "Voyager" hash "CrXgiaWIf2bZAU+5WkzOE7y0rdSO82XMzubn7HDb95Q=" parent-hash "JDOb0BiktYs2ct3mSQKopnOOV2h9MGYADwhT+oUtF2s=" via-port "1-3" with-interface 08:06:50
Autorizar o dispositivo 6 a interagir com o sistema:
# usbguard allow-device 6Desautorizar e remover o dispositivo 6:
# usbguard reject-device 6Desautorize e retenha o dispositivo 6:
# usbguard block-device 6
USBGuard utiliza os termos block e reject com os seguintes significados:
- block: não interaja com este dispositivo por enquanto.
- reject: ignorar este dispositivo como se ele não existisse.
Recursos adicionais
Liste todas as opções do comando
usbguard:$ usbguard --help-
usbguard(1)página do homem
12.4. Bloqueio permanente e autorização de um dispositivo USB
Você pode bloquear e autorizar permanentemente um dispositivo USB usando a opção -p. Isto acrescenta uma regra específica do dispositivo à política atual.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando.
Procedimento
Configurar o SELinux para permitir que o daemon
usbguardescreva regras.Mostrar o
semanageBooleans relevante parausbguard.# semanage boolean -l | grep usbguard usbguard_daemon_write_conf (off , off) Allow usbguard to daemon write conf usbguard_daemon_write_rules (on , on) Allow usbguard to daemon write rulesOpcional: Se o
usbguard_daemon_write_rulesBoolean estiver desligado, ligue-o.# semanage boolean -m --on usbguard_daemon_write_rules
Liste os dispositivos USB reconhecidos por USBGuard:
# usbguard list-devices 1: allow id 1d6b:0002 serial "0000:00:06.7" name "EHCI Host Controller" hash "JDOb0BiktYs2ct3mSQKopnOOV2h9MGYADwhT+oUtF2s=" parent-hash "4PHGcaDKWtPjKDwYpIRG722cB9SlGz9l9Iea93+Gt9c=" via-port "usb1" with-interface 09:00:00 ... 6: block id 1b1c:1ab1 serial "000024937962" name "Voyager" hash "CrXgiaWIf2bZAU+5WkzOE7y0rdSO82XMzubn7HDb95Q=" parent-hash "JDOb0BiktYs2ct3mSQKopnOOV2h9MGYADwhT+oUtF2s=" via-port "1-3" with-interface 08:06:50
Autorizar permanentemente o dispositivo 6 para interagir com o sistema:
# usbguard allow-device 6 -pDesautorizar e remover permanentemente o dispositivo 6:
# usbguard reject-device 6 -pDesautorizar e manter permanentemente o dispositivo 6:
# usbguard block-device 6 -p
USBGuard utiliza os termos block e reject com os seguintes significados:
- block: não interaja com este dispositivo por enquanto.
- reject: ignorar este dispositivo como se ele não existisse.
Verificação
Verifique se as regras do
USBGuardincluem as mudanças que você fez.# usbguard list-rules
Recursos adicionais
Liste todas as opções do comando
usbguard:$ usbguard --help-
usbguard(1)página do homem
12.5. Criando uma política personalizada para dispositivos USB
O procedimento a seguir contém passos para criar um conjunto de regras para dispositivos USB que reflita as exigências de seu cenário.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando. -
O arquivo
/etc/usbguard/rules.confcontém um conjunto inicial de regras geradas pelo comandousbguard generate-policy.
Procedimento
Criar uma política que autorize os dispositivos USB atualmente conectados e armazenar as regras geradas no arquivo
rules.conf:# usbguard generate-policy --no-hashes > ./rules.confA opção
--no-hashesnão gera atributos de hash para dispositivos. Evite atributos de hash em suas configurações, pois eles podem não ser persistentes.Edite o arquivo
rules.confcom um editor de texto de sua escolha, por exemplo:# vi ./rules.confAdicionar, remover ou editar as regras, conforme necessário. Por exemplo, a regra a seguir permite que somente dispositivos com uma única interface de armazenamento em massa interajam com o sistema:
permitir com -interface é igual a { 08:*:* }Consulte a página de manual
usbguard-rules.conf(5)para uma descrição detalhada das regras e mais exemplos.Instalar a política atualizada:
# install -m 0600 -o root -g root rules.conf /etc/usbguard/rules.confReinicie o daemon
usbguardpara aplicar suas mudanças:# systemctl restart usbguard
Etapas de verificação
Verifique se suas regras personalizadas estão na política ativa, por exemplo:
# usbguard list-rules ... 4: allow with-interface 08:*:* ...
Recursos adicionais
-
usbguard-rules.conf(5)página do homem
12.6. Criação de uma política personalizada estruturada para dispositivos USB
Você pode organizar sua política personalizada USBGuard em vários arquivos .conf dentro do diretório /etc/usbguard/rules.d/. O usbguard-daemon combina então o arquivo principal rules.conf com os arquivos .conf dentro do diretório, em ordem alfabética.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando.
Procedimento
Criar uma política que autorize os dispositivos USB atualmente conectados e armazenar as regras geradas em um novo arquivo
.conf, por exemplo,policy.conf.# usbguard generate-policy --no-hashes > ./policy.confA opção
--no-hashesnão gera atributos de hash para dispositivos. Evite atributos de hash em suas configurações, pois eles podem não ser persistentes.Mostrar o
policy.confarquivo com um editor de texto de sua escolha, por exemplo:# vi ./policy.conf ... allow id 04f2:0833 serial "" name "USB Keyboard" via-port "7-2" with-interface { 03:01:01 03:00:00 } with-connect-type "unknown" ...Mova as linhas selecionadas para um arquivo
.confseparado.NotaOs dois dígitos no início do nome do arquivo especificam a ordem na qual o daemon lê os arquivos de configuração.
Por exemplo, copie as regras para seus teclados em um novo arquivo
.conf.# grep "USB Keyboard" ./policy.conf > ./10keyboards.confInstale a nova política no diretório
/etc/usbguard/rules.d/.# install -m 0600 -o root -g root 10keyboards.conf /etc/usbguard/rules.d/10keyboards.confMova o restante das linhas para um arquivo principal em
rules.conf.# grep -v "USB Keyboard" ./policy.conf > ./rules.confInstale as demais regras.
# install -m 0600 -o root -g root rules.conf /etc/usbguard/rules.confReinicie o daemon
usbguardpara aplicar suas mudanças.# systemctl restart usbguard
Etapas de verificação
Exibir todas as regras ativas USBGuard.
# usbguard list-rules ... 15: allow id 04f2:0833 serial "" name "USB Keyboard" hash "kxM/iddRe/WSCocgiuQlVs6Dn0VEza7KiHoDeTz0fyg=" parent-hash "2i6ZBJfTl5BakXF7Gba84/Cp1gslnNc1DM6vWQpie3s=" via-port "7-2" with-interface { 03:01:01 03:00:00 } with-connect-type "unknown" ...Exibir o conteúdo do arquivo
rules.confe todos os arquivos.confno diretório/etc/usbguard/rules.d/.# cat /etc/usbguard/rules.conf /etc/usbguard/rules.d/*.conf- Verificar se as regras ativas contêm todas as regras dos arquivos e se estão na ordem correta.
Recursos adicionais
-
usbguard-rules.conf(5)página do homem
12.7. Autorizar usuários e grupos a usar a interface USBGuard IPC
Use este procedimento para autorizar um usuário específico ou um grupo a usar a interface pública IPC do USBGuard. Por padrão, somente o usuário root pode usar esta interface.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando. -
O arquivo
/etc/usbguard/rules.confcontém um conjunto inicial de regras geradas pelo comandousbguard generate-policy.
Procedimento
Edite o arquivo
/etc/usbguard/usbguard-daemon.confcom um editor de texto de sua escolha:# vi /etc/usbguard/usbguard-daemon.confPor exemplo, adicionar uma linha com uma regra que permite a todos os usuários do grupo
wheelusar a interface IPC, e salvar o arquivo:IPCAllowGroups=roda
Você pode adicionar usuários ou grupos também com o comando
usbguard. Por exemplo, o seguinte comando permite que o usuário joesec tenha acesso total às seçõesDeviceseExceptions. Além disso, joesec pode listar a política atual e ouvir os sinais de política.# usbguard add-user joesec --devices ALL --policy list,listen --exceptions ALLPara remover as permissões concedidas para o usuário joesec, use o comando
usbguard remove-user joesec.Reinicie o daemon
usbguardpara aplicar suas mudanças:# systemctl restart usbguard
Recursos adicionais
-
usbguard(1)eusbguard-rules.conf(5)páginas man
12.8. Registro de eventos de autorização do USBguard no registro de auditoria do Linux
Use os seguintes passos para integrar o registro de eventos de autorização do USBguard ao registro de auditoria padrão do Linux. Por padrão, o daemon usbguard registra os eventos no arquivo /var/log/usbguard/usbguard-audit.log.
Pré-requisitos
-
O serviço
usbguardestá instalado e funcionando. -
O serviço
auditdestá funcionando.
Procedimento
Edite o arquivo
usbguard-daemon.confcom um editor de texto de sua escolha:# vi /etc/usbguard/usbguard-daemon.confMude a opção
AuditBackenddeFileAuditparaLinuxAudit:AuditBackend=LinuxAudit
Reinicie o daemon
usbguardpara aplicar a mudança de configuração:# systemctl restart usbguard
Etapas de verificação
Consulte o log
auditdaemon para um evento de autorização USB, por exemplo:# ausearch -ts recent -m USER_DEVICE
Recursos adicionais
-
usbguard-daemon.conf(5)página do homem
12.9. Recursos adicionais
-
usbguard(1),usbguard-rules.conf(5),usbguard-daemon(8), eusbguard-daemon.conf(5)páginas man - Página inicial do USBGuard