
Red Hat Training
A Red Hat training course is available for RHEL 8
Monitoramento e gerenciamento do status e desempenho do sistema
Otimização do rendimento, da latência e do consumo de energia do sistema
Resumo
Tornando o código aberto mais inclusivo
A Red Hat tem o compromisso de substituir a linguagem problemática em nosso código, documentação e propriedades da web. Estamos começando com estes quatro termos: master, slave, blacklist e whitelist. Por causa da enormidade deste esforço, estas mudanças serão implementadas gradualmente ao longo de vários lançamentos futuros. Para mais detalhes, veja a mensagem de nosso CTO Chris Wright.
Fornecendo feedback sobre a documentação da Red Hat
Agradecemos sua contribuição em nossa documentação. Por favor, diga-nos como podemos melhorá-la. Para fazer isso:
Para comentários simples sobre passagens específicas:
- Certifique-se de que você está visualizando a documentação no formato Multi-page HTML. Além disso, certifique-se de ver o botão Feedback no canto superior direito do documento.
- Use o cursor do mouse para destacar a parte do texto que você deseja comentar.
- Clique no pop-up Add Feedback que aparece abaixo do texto destacado.
- Siga as instruções apresentadas.
Para enviar comentários mais complexos, crie um bilhete Bugzilla:
- Ir para o site da Bugzilla.
- Como Componente, use Documentation.
- Preencha o campo Description com sua sugestão de melhoria. Inclua um link para a(s) parte(s) relevante(s) da documentação.
- Clique em Submit Bug.
Capítulo 1. Visão geral das opções de monitoramento de desempenho
A seguir estão algumas das ferramentas de monitoramento e configuração de desempenho disponíveis no Red Hat Enterprise Linux 8:
-
O Performance Co-Pilot (
pcp) é usado para monitorar, visualizar, armazenar e analisar as medições de desempenho em nível de sistema. Ele permite o monitoramento e gerenciamento de dados em tempo real, e o registro e recuperação de dados históricos. O Red Hat Enterprise Linux 8 fornece várias ferramentas que podem ser usadas da linha de comando para monitorar um sistema fora do nível de execução 5. A seguir estão as ferramentas da linha de comando embutidas:
-
topé fornecido pelo pacoteprocps-ng. Ele dá uma visão dinâmica dos processos em um sistema em execução. Ele exibe uma variedade de informações, incluindo um resumo do sistema e uma lista de tarefas atualmente sendo gerenciadas pelo kernel do Linux. -
psé fornecido pelo pacoteprocps-ng. Ele captura um instantâneo de um seleto grupo de processos ativos. Por padrão, o grupo examinado é limitado aos processos que são de propriedade do usuário atual e associados ao terminal onde o comandopsé executado. -
As estatísticas da memória virtual (
vmstat) são fornecidas pelo pacoteprocps-ng. Ele fornece relatórios instantâneos dos processos de seu sistema, memória, paginação, entrada/saída de blocos, interrupções e atividade da CPU. -
O relatório de atividades do sistema (
sar) é fornecido pelo pacotesysstat. Ele coleta e relata informações sobre a atividade do sistema que ocorreu até o momento no dia atual.
-
-
perfusa contadores de desempenho de hardware e pontos de rastreamento de kernel para rastrear o impacto de outros comandos e aplicações em um sistema. -
bcc-toolsé usado para a Coleção de Compiladores BPF (BCC). Ele fornece mais de 100 scriptseBPFque monitoram as atividades do kernel. Para mais informações sobre cada uma destas ferramentas, veja a página de manual descrevendo como utilizá-la e quais funções ela executa. -
turbostaté fornecido pelo pacotekernel-tools. Ele relata a topologia do processador, freqüência, estatísticas do estado de inatividade, temperatura e uso de energia nos processadores Intel 64. -
iostaté fornecido pelo pacotesysstat. Ele monitora e relata a carga do dispositivo de entrada/saída do sistema para ajudar os administradores a tomarem decisões sobre como equilibrar a carga de entrada/saída entre os discos físicos. -
irqbalancedistribui interrupções de hardware entre processadores para melhorar o desempenho do sistema. -
ssimprime informações estatísticas sobre soquetes, permitindo aos administradores avaliar o desempenho do dispositivo ao longo do tempo. A Red Hat recomenda o uso desssobrenetstatno Red Hat Enterprise Linux 8. -
numastaté fornecido pelo pacotenumactl. Por padrão,numastatexibe as estatísticas por nó NUMA de um sistema de falhas do alocador de memória do kernel. O desempenho ideal é indicado pelos valores altosnuma_hite baixosnuma_miss. -
numadé um daemon automático de gestão de afinidade NUMA. Ele monitora a topologia NUMA e o uso de recursos dentro de um sistema que melhora dinamicamente a alocação de recursos NUMA, o gerenciamento e, portanto, o desempenho do sistema. -
SystemTapmonitora e analisa as atividades do sistema operacional, especialmente as atividades do kernel. -
valgrindanalisa as aplicações executando-o em uma CPU sintética e instrumentando o código de aplicação existente à medida que é executado. Em seguida, imprime comentários que identificam claramente cada processo envolvido na execução da aplicação para um arquivo especificado pelo usuário, descritor de arquivo ou soquete de rede. Também é útil para encontrar vazamentos de memória. -
pqosé fornecido pelo pacoteintel-cmt-cat. Ele monitora e controla o cache da CPU e a largura de banda de memória em processadores Intel recentes.
Recursos adicionais
-
Para mais informações, consulte as páginas de homens de
pcp,top,ps,vmstat,sar,perf,iostat,irqbalance,ss,numastat,numad,valgrind, epqos. -
Para maiores informações em
pcp, veja a documentação no diretório/usr/share/doc/. -
Para mais informações sobre o valor
awaite o que pode fazer com que seus valores sejam altos, veja o artigo da Red Hat Knowledgebase: Qual é exatamente o significado do valor "esperar" relatado pelo iostat?
Capítulo 2. Começando com Tuned
Como administrador do sistema, você pode usar o aplicativo Tuned para otimizar o perfil de desempenho de seu sistema para uma variedade de casos de uso.
2.1. O propósito de Tuned
Tuned é um serviço que monitora seu sistema e otimiza o desempenho sob certas cargas de trabalho. O núcleo do Tuned é profiles, que afina seu sistema para diferentes casos de uso.
Tuned é distribuído com uma série de perfis pré-definidos para casos de uso, como por exemplo:
- Alto rendimento
- Baixa latência
- Economia de energia
É possível modificar as regras definidas para cada perfil e personalizar a afinação de um determinado dispositivo. Ao mudar para outro perfil ou desativar Tuned, todas as mudanças feitas nas configurações do sistema pelo perfil anterior retornam ao seu estado original.
Você também pode configurar Tuned para reagir às mudanças no uso do dispositivo e ajustar as configurações para melhorar o desempenho dos dispositivos ativos e reduzir o consumo de energia dos dispositivos inativos.
2.2. Perfis afinados
Uma análise detalhada de um sistema pode ser muito demorada. Tuned fornece uma série de perfis pré-definidos para casos de uso típico. Você também pode criar, modificar e excluir perfis.
Os perfis fornecidos com Tuned estão divididos nas seguintes categorias:
- Perfis de economia de energia
- Perfis de aumento de desempenho
Os perfis de aumento de desempenho incluem perfis que se concentram nos seguintes aspectos:
- Baixa latência para armazenamento e rede
- Alto rendimento para armazenamento e rede
- Desempenho da máquina virtual
- Desempenho do host de virtualização
O perfil padrão
Durante a instalação, o melhor perfil para seu sistema é selecionado automaticamente. Atualmente, o perfil padrão é selecionado de acordo com as seguintes regras personalizáveis:
| Meio Ambiente | Perfil padrão | Objetivo |
|---|---|---|
| Nós de cálculo |
| O melhor desempenho em termos de rendimento |
| Máquinas virtuais |
|
O melhor desempenho. Se você não estiver interessado no melhor desempenho, você pode mudá-lo para o perfil |
| Outros casos |
| Desempenho equilibrado e consumo de energia |
Perfis fundidos
Como uma característica experimental, é possível selecionar mais perfis de uma vez. Tuned tentará fundi-los durante a carga.
Se houver conflitos, as configurações do último perfil especificado têm precedência.
Exemplo 2.1. Baixo consumo de energia em um convidado virtual
O exemplo a seguir otimiza o sistema para funcionar em uma máquina virtual para o melhor desempenho e, ao mesmo tempo, sintoniza-o para baixo consumo de energia, enquanto o baixo consumo de energia é a prioridade:
# Perfil do convidado virtual de perfil afinado powersave
A fusão é feita automaticamente sem verificar se a combinação de parâmetros resultante faz sentido. Conseqüentemente, a característica pode afinar alguns parâmetros da maneira oposta, o que pode ser contraproducente: por exemplo, ajustando o disco para alta produção usando o perfil throughput-performance e, simultaneamente, ajustando o spindown do disco para o valor baixo pelo perfil spindown-disk.
A localização dos perfis
Tuned armazena perfis nos seguintes diretórios:
/usr/lib/tuned/-
Os perfis específicos de distribuição são armazenados no diretório. Cada perfil tem seu próprio diretório. O perfil consiste no arquivo principal de configuração chamado
tuned.conf, e opcionalmente outros arquivos, por exemplo, scripts de ajuda. /etc/tuned/-
Se você precisar personalizar um perfil, copie o diretório de perfis para o diretório, que é usado para perfis personalizados. Se houver dois perfis com o mesmo nome, é usado o perfil personalizado localizado em
/etc/tuned/.
A sintaxe da configuração do perfil
O arquivo tuned.conf pode conter uma seção [main] e outras seções para a configuração de instâncias de plug-in. Entretanto, todas as seções são opcionais.
As linhas que começam com o sinal de hash (#) são comentários.
Recursos adicionais
-
A página do homem
tuned.conf(5).
2.3. Perfis afinados distribuídos com a RHEL
A seguir está uma lista de perfis que estão instalados com Tuned no Red Hat Enterprise Linux.
Pode haver mais perfis de produtos específicos ou de terceiros Tuned disponíveis. Tais perfis são normalmente fornecidos por pacotes de RPM separados.
balanced-
O perfil padrão de economia de energia. Pretende-se que seja um compromisso entre desempenho e consumo de energia. Utiliza o autoescalonamento e o autoajuste sempre que possível. O único inconveniente é o aumento da latência. No atual lançamento Tuned, ele habilita a CPU, disco, áudio e plugins de vídeo, e ativa o governador da CPU
conservative. A opçãoradeon_powersaveusa o valordpm-balancedse for suportado, caso contrário, está configurada paraauto. powersaveUm perfil para o máximo desempenho de economia de energia. Ele pode acelerar o desempenho a fim de minimizar o consumo real de energia. No atual lançamento Tuned, ele permite autosuspendência USB, economia de energia WiFi e economia de energia de Link Power Management (ALPM) agressivo para adaptadores host SATA. Ele também programa economia de energia para sistemas com uma baixa taxa de despertar e ativa o regulador
ondemand. Ele permite economia de energia de áudio AC97 ou, dependendo de seu sistema, economia de energia HDA-Intel com um timeout de 10 segundos. Se seu sistema contém uma placa gráfica Radeon suportada com KMS habilitado, o perfil a configura para economia automática de energia. Nos PCs ASUS Eee, um Motor Super Híbrido dinâmico é habilitado.NotaEm certos casos, o perfil
balancedé mais eficiente em comparação com o perfilpowersave.Considere que há uma quantidade definida de trabalho que precisa ser feita, por exemplo, um arquivo de vídeo que precisa ser transcodificado. Sua máquina pode consumir menos energia se a transcodificação for feita na potência total, porque a tarefa é concluída rapidamente, a máquina começa a ficar ociosa, e pode automaticamente descer para modos de economia de energia muito eficientes. Por outro lado, se você transcodificar o arquivo com uma máquina estrangulada, a máquina consome menos energia durante a transcodificação, mas o processo leva mais tempo e a energia total consumida pode ser maior.
É por isso que o perfil
balancedpode ser geralmente uma opção melhor.throughput-performance-
Um perfil de servidor otimizado para alta taxa de transferência. Ele desabilita mecanismos de economia de energia e permite configurações do
sysctlque melhoram o desempenho de rendimento do disco e do IO da rede. O regulador de CPU está configurado paraperformance. latency-performance-
Um perfil de servidor otimizado para baixa latência. Ele desativa os mecanismos de economia de energia e permite a configuração do
sysctlque melhora a latência. O governador da CPU está configurado paraperformancee a CPU está bloqueada para os estados de baixa C (por PM QoS). network-latency-
Um perfil para ajuste de rede de baixa latência. Ele se baseia no perfil
latency-performance. Além disso, desativa o balanceamento de páginas enormes transparentes e NUMA, e ajusta vários outros parâmetrossysctlrelacionados à rede. network-throughput-
Um perfil para a sintonia da rede de produção. Ele se baseia no perfil
throughput-performance. Além disso, aumenta os buffers de rede do kernel. virtual-guest-
Um perfil projetado para máquinas virtuais Red Hat Enterprise Linux 8 e convidados VMWare com base no perfil
throughput-performanceque, entre outras tarefas, diminui a troca de memória virtual e aumenta os valores de readahead de disco. Ele não desabilita as barreiras de disco. virtual-host-
Um perfil projetado para hosts virtuais com base no perfil
throughput-performanceque, entre outras tarefas, diminui a troca de memória virtual, aumenta os valores de readahead de disco e permite um valor mais agressivo de writeback de páginas sujas. oracle-
Um perfil otimizado para cargas de bancos de dados Oracle baseado no perfil
throughput-performance. Além disso, ele desativa páginas enormes transparentes e modifica outros parâmetros do kernel relacionados ao desempenho. Este perfil é fornecido pelo pacotetuned-profiles-oracle. desktop-
Um perfil otimizado para desktops, com base no perfil
balanced. Além disso, permite a criação de autogrupos programados para uma melhor resposta das aplicações interativas. cpu-partitioningO perfil
cpu-partitioningsepara as CPUs do sistema em CPUs isoladas e domésticas. Para reduzir o jitter e as interrupções em uma CPU isolada, o perfil limpa a CPU isolada dos processos de espaço do usuário, dos fios móveis do kernel, dos manipuladores de interrupção e dos temporizadores do kernel.Uma CPU de manutenção doméstica pode executar todos os serviços, processos shell e fios de kernel.
Você pode configurar o perfil
cpu-partitioningno arquivo/etc/tuned/cpu-partitioning-variables.conf. As opções de configuração são:isolated_cores=cpu-list-
Lista CPUs a serem isoladas. A lista de CPUs isoladas é separada por vírgulas ou o usuário pode especificar o intervalo. É possível especificar um intervalo usando um traço, como por exemplo
3-5. Esta opção é obrigatória. Qualquer CPU em falta nesta lista é automaticamente considerada uma CPU doméstica. no_balance_cores=cpu-list-
Lista as CPUs que não são consideradas pelo núcleo durante o balanceamento de carga do processo em todo o sistema. Esta opção é opcional. Esta é normalmente a mesma lista que a
isolated_cores.
Para mais informações em
cpu-partitioning, consulte a página de manualtuned-profiles-cpu-partitioning(7).postgresql-
Um perfil otimizado para cargas de bancos de dados PostgreSQL baseado no perfil
throughput-performance. Além disso, ele desativa páginas enormes transparentes e modifica outros parâmetros do kernel relacionados ao desempenho. Este perfil é fornecido pelo pacotetuned-profiles-postgresql.
Perfis em tempo real
Os perfis em tempo real são destinados a sistemas que executam o núcleo em tempo real. Sem uma construção especial do kernel, eles não configuram o sistema para ser em tempo real. Na RHEL, os perfis estão disponíveis a partir de repositórios adicionais.
Os seguintes perfis em tempo real estão disponíveis:
realtimeUtilização em sistemas de tempo real de metais nulos.
Fornecido pelo pacote
tuned-profiles-realtime, que está disponível a partir dos repositórios RT ou NFV.realtime-virtual-hostUtilização em um host de virtualização configurado para tempo real.
Fornecido pelo pacote
tuned-profiles-nfv-host, que está disponível no repositório da NFV.realtime-virtual-guestUtilização em um convidado de virtualização configurado para tempo real.
Fornecido pelo pacote
tuned-profiles-nfv-guest, que está disponível no repositório da NFV.
2.4. Sintonia estática e dinâmica em Tuned
Esta seção explica a diferença entre as duas categorias de ajuste de sistemas que se aplicam a Tuned: static e dynamic.
- Sintonia estática
-
Consiste principalmente na aplicação de configurações predefinidas de
sysctlesysfse na ativação de várias ferramentas de configuração, comoethtool. - Sintonia dinâmica
Observa como vários componentes do sistema são usados durante o tempo de funcionamento de seu sistema. Tuned ajusta as configurações do sistema dinamicamente com base nessas informações de monitoramento.
Por exemplo, o disco rígido é muito usado durante a inicialização e o login, mas mal é usado mais tarde quando o usuário pode trabalhar principalmente com aplicações como navegadores web ou clientes de e-mail. Da mesma forma, a CPU e os dispositivos de rede são usados de forma diferente em momentos diferentes. Tuned monitora a atividade destes componentes e reage às mudanças em seu uso.
Por padrão, a sintonia dinâmica está desativada. Para ativá-la, edite o arquivo
/etc/tuned/tuned-main.confe mude a opçãodynamic_tuningpara1. Tuned então periodicamente analisa as estatísticas do sistema e as utiliza para atualizar suas configurações de ajuste do sistema. Para configurar o intervalo de tempo em segundos entre estas atualizações, use a opçãoupdate_interval.Os algoritmos de ajuste dinâmico atualmente implementados tentam equilibrar o desempenho e o poder de corte, e por isso são desativados nos perfis de desempenho. O ajuste dinâmico para plug-ins individuais pode ser habilitado ou desabilitado nos perfis Tuned.
Exemplo 2.2. Sintonia estática e dinâmica em uma estação de trabalho
Em uma estação de trabalho típica do escritório, a interface de rede Ethernet está inativa a maior parte do tempo. Apenas alguns poucos e-mails entram e saem ou algumas páginas da web podem ser carregadas.
Para esses tipos de cargas, a interface de rede não precisa funcionar a toda velocidade o tempo todo, como faz por padrão. Tuned tem um plug-in de monitoramento e ajuste para dispositivos de rede que podem detectar essa baixa atividade e depois baixar automaticamente a velocidade dessa interface, resultando normalmente em um menor consumo de energia.
Se a atividade na interface aumenta por um período de tempo maior, por exemplo, porque uma imagem de DVD está sendo baixada ou um e-mail com um anexo grande é aberto, Tuned detecta isso e define a velocidade máxima da interface para oferecer o melhor desempenho enquanto o nível de atividade é alto.
Este princípio é usado para outros plug-ins para CPU e discos também.
2.5. Modo sintonizado sem demônio
Você pode rodar Tuned no modo no-daemon, que não requer nenhuma memória residente. Neste modo, Tuned aplica as configurações e as saídas.
Por padrão, o modo no-daemon está desativado porque falta muita funcionalidade Tuned neste modo, inclusive:
- Apoio D-Bus
- Suporte a hot-plug
- Suporte Rollback para configurações
Para ativar o modo no-daemon, inclua a seguinte linha no arquivo /etc/tuned/tuned-main.conf:
daemon = 0
2.6. Instalando e habilitando o Tuned
Este procedimento instala e habilita o aplicativo Tuned, instala perfis Tuned e pré-define um perfil padrão Tuned para seu sistema.
Procedimento
Instale o pacote
tuned:# yum instalar afinado
Habilite e inicie o serviço
tuned:# systemctl habilitado --agora sintonizado
Opcionalmente, instale os perfis Tuned para sistemas em tempo real:
# yum instalar perfis sintonizados - perfis sintonizados em tempo real-nfv
Verificar se um perfil Tuned está ativo e aplicado:
$ tuned-adm active Current active profile: balanced$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
2.7. Listagem de perfis afinados disponíveis
Este procedimento lista todos os perfis Tuned que estão atualmente disponíveis em seu sistema.
Procedimento
Para listar todos os perfis disponíveis Tuned em seu sistema, use:
$ tuned-adm list Available profiles: - balanced - General non-specialized tuned profile - desktop - Optimize for the desktop use-case - latency-performance - Optimize for deterministic performance at the cost of increased power consumption - network-latency - Optimize for deterministic performance at the cost of increased power consumption, focused on low latency network performance - network-throughput - Optimize for streaming network throughput, generally only necessary on older CPUs or 40G+ networks - powersave - Optimize for low power consumption - throughput-performance - Broadly applicable tuning that provides excellent performance across a variety of common server workloads - virtual-guest - Optimize for running inside a virtual guest - virtual-host - Optimize for running KVM guests Current active profile: balanced
Para exibir apenas o perfil atualmente ativo, use:
$ tuned-adm active Current active profile: balanced
Recursos adicionais
-
A página do homem
tuned-adm(8).
2.8. Definição de um perfil afinado
Este procedimento ativa um perfil Tuned selecionado em seu sistema.
Pré-requisitos
-
O serviço
tunedestá funcionando. Veja Seção 2.6, “Instalando e habilitando o Tuned” para detalhes.
Procedimento
Opcionalmente, você pode deixar Tuned recomendar o perfil mais adequado para seu sistema:
# tuned-adm recommend balancedAtivar um perfil:
# perfil afinado-adm selected-profileAlternativamente, você pode ativar uma combinação de vários perfis:
# perfil afinado-adm profile1 profile2
Exemplo 2.3. Uma máquina virtual otimizada para baixo consumo de energia
O exemplo a seguir otimiza o sistema para funcionar em uma máquina virtual com o melhor desempenho e, ao mesmo tempo, o afina para um baixo consumo de energia, enquanto o baixo consumo de energia é a prioridade:
# Perfil do convidado virtual de perfil afinado powersave
Veja o perfil atual ativo Tuned em seu sistema:
# tuned-adm active Current active profile: selected-profileReinicie o sistema:
# reinicialização
Etapas de verificação
Verifique se o perfil Tuned está ativo e aplicado:
$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
-
A página do homem
tuned-adm(8)
2.9. Desabilitando Tuned
Este procedimento desativa Tuned e redefine todas as configurações do sistema afetado para seu estado original antes de Tuned modificá-las.
Procedimento
Para desativar todas as afinações temporariamente:
# tuned-adm off
As afinações são aplicadas novamente após o reinício do serviço
tuned.Alternativamente, para parar e desativar o serviço
tunedpermanentemente:# systemctl desativar --agora sintonizado
Recursos adicionais
-
A página do homem
tuned-adm(8).
Capítulo 3. Personalização de perfis afinados
Você pode criar ou modificar os perfis Tuned para otimizar o desempenho do sistema para seu caso de uso pretendido.
Pré-requisitos
- Instalar e habilitar Tuned como descrito em Seção 2.6, “Instalando e habilitando o Tuned”.
3.1. Perfis afinados
Uma análise detalhada de um sistema pode ser muito demorada. Tuned fornece uma série de perfis pré-definidos para casos de uso típico. Você também pode criar, modificar e excluir perfis.
Os perfis fornecidos com Tuned estão divididos nas seguintes categorias:
- Perfis de economia de energia
- Perfis de aumento de desempenho
Os perfis de aumento de desempenho incluem perfis que se concentram nos seguintes aspectos:
- Baixa latência para armazenamento e rede
- Alto rendimento para armazenamento e rede
- Desempenho da máquina virtual
- Desempenho do host de virtualização
O perfil padrão
Durante a instalação, o melhor perfil para seu sistema é selecionado automaticamente. Atualmente, o perfil padrão é selecionado de acordo com as seguintes regras personalizáveis:
| Meio Ambiente | Perfil padrão | Objetivo |
|---|---|---|
| Nós de cálculo |
| O melhor desempenho em termos de rendimento |
| Máquinas virtuais |
|
O melhor desempenho. Se você não estiver interessado no melhor desempenho, você pode mudá-lo para o perfil |
| Outros casos |
| Desempenho equilibrado e consumo de energia |
Perfis fundidos
Como uma característica experimental, é possível selecionar mais perfis de uma vez. Tuned tentará fundi-los durante a carga.
Se houver conflitos, as configurações do último perfil especificado têm precedência.
Exemplo 3.1. Baixo consumo de energia em um convidado virtual
O exemplo a seguir otimiza o sistema para funcionar em uma máquina virtual para o melhor desempenho e, ao mesmo tempo, sintoniza-o para baixo consumo de energia, enquanto o baixo consumo de energia é a prioridade:
# Perfil do convidado virtual de perfil afinado powersave
A fusão é feita automaticamente sem verificar se a combinação de parâmetros resultante faz sentido. Conseqüentemente, a característica pode afinar alguns parâmetros da maneira oposta, o que pode ser contraproducente: por exemplo, ajustando o disco para alta produção usando o perfil throughput-performance e, simultaneamente, ajustando o spindown do disco para o valor baixo pelo perfil spindown-disk.
A localização dos perfis
Tuned armazena perfis nos seguintes diretórios:
/usr/lib/tuned/-
Os perfis específicos de distribuição são armazenados no diretório. Cada perfil tem seu próprio diretório. O perfil consiste no arquivo principal de configuração chamado
tuned.conf, e opcionalmente outros arquivos, por exemplo, scripts de ajuda. /etc/tuned/-
Se você precisar personalizar um perfil, copie o diretório de perfis para o diretório, que é usado para perfis personalizados. Se houver dois perfis com o mesmo nome, é usado o perfil personalizado localizado em
/etc/tuned/.
A sintaxe da configuração do perfil
O arquivo tuned.conf pode conter uma seção [main] e outras seções para a configuração de instâncias de plug-in. Entretanto, todas as seções são opcionais.
As linhas que começam com o sinal de hash (#) são comentários.
Recursos adicionais
-
A página do homem
tuned.conf(5).
3.2. Herança entre perfis afinados
Tuned os perfis podem ser baseados em outros perfis e modificar apenas certos aspectos de seu perfil pai.
A seção [main] de Tuned perfis reconhece a opção include:
[main]
include=parentTodas as configurações do parent são carregados neste perfil child. Nas seções seguintes, o perfil child pode substituir certas configurações herdadas do parent perfil ou adicionar novas configurações não presentes no parent perfil.
Você pode criar seu próprio perfil child no diretório /etc/tuned/ com base em um perfil pré-instalado em /usr/lib/tuned/ com apenas alguns parâmetros ajustados.
Se o parent perfil é atualizado, tal como após uma atualização em Tuned, as mudanças são refletidas no perfil child.
Exemplo 3.2. Um perfil de economia de energia baseado em
A seguir, um exemplo de um perfil personalizado que estende o perfil balanced e define o Aggressive Link Power Management (ALPM) para todos os dispositivos até a máxima economia de energia.
[main] include=balanced [scsi_host] alpm=min_power
Recursos adicionais
-
A página do homem
tuned.conf(5)
3.3. Sintonia estática e dinâmica em Tuned
Esta seção explica a diferença entre as duas categorias de ajuste de sistemas que se aplicam a Tuned: static e dynamic.
- Sintonia estática
-
Consiste principalmente na aplicação de configurações predefinidas de
sysctlesysfse na ativação de várias ferramentas de configuração, comoethtool. - Sintonia dinâmica
Observa como vários componentes do sistema são usados durante o tempo de funcionamento de seu sistema. Tuned ajusta as configurações do sistema dinamicamente com base nessas informações de monitoramento.
Por exemplo, o disco rígido é muito usado durante a inicialização e o login, mas mal é usado mais tarde quando o usuário pode trabalhar principalmente com aplicações como navegadores web ou clientes de e-mail. Da mesma forma, a CPU e os dispositivos de rede são usados de forma diferente em momentos diferentes. Tuned monitora a atividade destes componentes e reage às mudanças em seu uso.
Por padrão, a sintonia dinâmica está desativada. Para ativá-la, edite o arquivo
/etc/tuned/tuned-main.confe mude a opçãodynamic_tuningpara1. Tuned então periodicamente analisa as estatísticas do sistema e as utiliza para atualizar suas configurações de ajuste do sistema. Para configurar o intervalo de tempo em segundos entre estas atualizações, use a opçãoupdate_interval.Os algoritmos de ajuste dinâmico atualmente implementados tentam equilibrar o desempenho e o poder de corte, e por isso são desativados nos perfis de desempenho. O ajuste dinâmico para plug-ins individuais pode ser habilitado ou desabilitado nos perfis Tuned.
Exemplo 3.3. Sintonia estática e dinâmica em uma estação de trabalho
Em uma estação de trabalho típica do escritório, a interface de rede Ethernet está inativa a maior parte do tempo. Apenas alguns poucos e-mails entram e saem ou algumas páginas da web podem ser carregadas.
Para esses tipos de cargas, a interface de rede não precisa funcionar a toda velocidade o tempo todo, como faz por padrão. Tuned tem um plug-in de monitoramento e ajuste para dispositivos de rede que podem detectar essa baixa atividade e depois baixar automaticamente a velocidade dessa interface, resultando normalmente em um menor consumo de energia.
Se a atividade na interface aumenta por um período de tempo maior, por exemplo, porque uma imagem de DVD está sendo baixada ou um e-mail com um anexo grande é aberto, Tuned detecta isso e define a velocidade máxima da interface para oferecer o melhor desempenho enquanto o nível de atividade é alto.
Este princípio é usado para outros plug-ins para CPU e discos também.
3.4. Plug-ins afinados
Os plug-ins são módulos em perfis Tuned que Tuned usa para monitorar ou otimizar diferentes dispositivos no sistema.
Tuned utiliza dois tipos de plug-ins:
- plug-ins de monitoramento
- plug-ins de afinação
Plug-ins de monitoramento
Os plug-ins de monitoramento são usados para obter informações de um sistema em funcionamento. A saída dos plug-ins de monitoramento pode ser usada sintonizando os plug-ins para o ajuste dinâmico.
Os plug-ins de monitoramento são automaticamente instanciados sempre que suas métricas são necessárias por qualquer um dos plug-ins de ajuste habilitados. Se dois plug-ins de ajuste requerem os mesmos dados, apenas uma instância do plug-in de monitoramento é criada e os dados são compartilhados.
Plug-ins de afinação
Cada plug-in de sintonia sintoniza um subsistema individual e toma vários parâmetros que são povoados a partir dos perfis sintonizados. Cada subsistema pode ter vários dispositivos, tais como CPUs múltiplas ou placas de rede, que são tratados por instâncias individuais dos plug-ins de sintonização. Configurações específicas para dispositivos individuais também são suportadas.
Sintaxe para plug-ins em perfis afinados
As seções que descrevem as instâncias de plug-in são formatadas da seguinte forma:
[NAME] type=TYPE devices=DEVICES
- NOME
- é o nome da instância de plug-in como é usada nos logs. Pode ser uma cadeia arbitrária.
- TIPO
- é o tipo do plug-in de sintonia.
- DISPOSITIVOS
é a lista de dispositivos que esta instância de plug-in manipula.
A linha
devicespode conter uma lista, um wildcard (*), e negação (!). Se não houver uma linhadevices, todos os dispositivos presentes ou posteriormente anexados no sistema do TYPE são tratados pela instância de plug-in. Isto é o mesmo que usar a opçãodevices=*.Exemplo 3.4. Dispositivos de blocos de encaixe com um plug-in
O exemplo a seguir corresponde a todos os dispositivos de bloco que começam com
sd, comosdaousdb, e não desabilita as barreiras sobre eles:[data_disk] type=disk devices=sd* disable_barriers=false
O exemplo a seguir corresponde a todos os dispositivos de bloco, exceto
sda1esda2:[data_disk] type=disk devices=!sda1, !sda2 disable_barriers=false
Se nenhuma instância de um plug-in for especificada, o plug-in não é ativado.
Se o plug-in suportar mais opções, elas também podem ser especificadas na seção plug-in. Se a opção não for especificada e não tiver sido previamente especificada no plug-in incluído, o valor padrão é usado.
Sintaxe curta do plug-in
Se você não precisar de nomes personalizados para a instância plug-in e houver apenas uma definição da instância em seu arquivo de configuração, Tuned suporta a seguinte sintaxe curta:
[TYPE] devices=DEVICES
Neste caso, é possível omitir a linha type. A instância é então referenciada com um nome, igual ao tipo. O exemplo anterior poderia então ser reescrito:
Exemplo 3.5. Dispositivos de blocos de correspondência usando a sintaxe curta
[disk] devices=sdb* disable_barriers=false
Definições conflitantes de plug-in em um perfil
Se a mesma seção for especificada mais de uma vez usando a opção include, as configurações são fundidas. Se não puderem ser fundidas devido a um conflito, a última definição conflitante se sobrepõe às definições anteriores. Se você não souber o que foi definido anteriormente, você pode usar a opção replace Boolean e defini-la para true. Isto faz com que todas as definições anteriores com o mesmo nome sejam sobrescritas e a fusão não acontece.
Você também pode desativar o plug-in especificando a opção enabled=false. Isto tem o mesmo efeito como se a instância nunca tivesse sido definida. Desativar o plug-in é útil se você estiver redefinindo a definição anterior a partir da opção include e não quiser que o plug-in esteja ativo em seu perfil personalizado.
Funcionalidade não implementada em nenhum plug-in
Tuned inclui a capacidade de executar qualquer comando de shell como parte da habilitação ou desativação de um perfil de ajuste. Isto permite estender os perfis Tuned com funcionalidades que ainda não foram integradas no Tuned.
Você pode especificar comandos de shell arbitrários usando o plug-in script.
Recursos adicionais
-
A página do homem
tuned.conf(5)
3.5. Plug-ins afinados disponíveis
Esta seção lista todos os plug-ins de monitoramento e sintonia atualmente disponíveis em Tuned.
Plug-ins de monitoramento
Atualmente, são implementados os seguintes plug-ins de monitoramento:
disk- Obtém carga em disco (número de operações IO) por dispositivo e intervalo de medição.
net- Obtém carga de rede (número de pacotes transferidos) por placa de rede e intervalo de medição.
load- Obtém carga de CPU por CPU e intervalo de medição.
Plug-ins de afinação
Atualmente, são implementados os seguintes plug-ins de ajuste. Apenas alguns desses plug-ins implementam o ajuste dinâmico. As opções suportadas pelos plug-ins também são listadas:
cpuDefine o regulador da CPU para o valor especificado pela opção
governore muda dinamicamente a latência de Acesso Direto à Memória da CPU (DMA) da Qualidade de Serviço (PM QoS) de acordo com a carga da CPU.Se a carga da CPU for inferior ao valor especificado pela opção
load_threshold, a latência é definida para o valor especificado pela opçãolatency_high, caso contrário, é definida para o valor especificado porlatency_low.Você também pode forçar a latência a um valor específico e impedi-la de mudar dinamicamente ainda mais. Para fazer isso, defina a opção
force_latencypara o valor de latência necessário.eeepc_sheDefine dinamicamente a velocidade do barramento frontal (FSB) de acordo com a carga da CPU.
Esta característica pode ser encontrada em alguns netbooks e também é conhecida como o ASUS Super Hybrid Engine (SHE).
Se a carga da CPU for menor ou igual ao valor especificado pela opção
load_threshold_powersave, o plug-in define a velocidade da FSB para o valor especificado pela opçãoshe_powersave. Se a carga da CPU for maior ou igual ao valor especificado pela opçãoload_threshold_normal, ela define a velocidade FSB para o valor especificado pela opçãoshe_normal.O ajuste estático não é suportado e o plug-in é desabilitado de forma transparente se Tuned não detectar o suporte de hardware para este recurso.
net-
Configura a funcionalidade Wake-on-LAN para os valores especificados pela opção
wake_on_lan. Utiliza a mesma sintaxe que o utilitárioethtool. Também muda dinamicamente a velocidade da interface de acordo com a utilização da interface. sysctlDefine várias configurações
sysctlespecificadas pelas opções de plug-in.A sintaxe é
name=valueonde name é o mesmo que o nome fornecido pela concessionáriasysctl.Use o plug-in
sysctlse você precisar alterar as configurações do sistema que não são cobertas por outros plug-ins disponíveis em Tuned. Se as configurações forem cobertas por alguns plug-ins específicos, prefira estes plug-ins.usbDefine o timeout automático dos dispositivos USB para o valor especificado pelo parâmetro
autosuspend.O valor
0significa que o autosuspend é desativado.vmPermite ou desativa páginas enormes transparentes, dependendo do valor da opção
transparent_hugepages.Os valores válidos da opção
transparent_hugepagessão:- "sempre"..
- "nunca"..
- "madvise"
audioDefine o tempo limite autosuspendido para os codecs de áudio para o valor especificado pela opção
timeout.Atualmente, os codecs
snd_hda_intelesnd_ac97_codecsão suportados. O valor0significa que o autosuspend está desativado. Você também pode fazer com que o controlador seja reinicializado configurando a opção booleanareset_controllerparatrue.diskDefine o elevador de discos para o valor especificado pela opção
elevator.Também se define:
-
APM para o valor especificado pela opção
apm -
Escalonador quantum para o valor especificado pela opção
scheduler_quantum -
Tempo limite de spindown do disco para o valor especificado pela opção
spindown -
Disco readahead para o valor especificado pelo parâmetro
readahead -
O disco atual readahead a um valor multiplicado pela constante especificada pela opção
readahead_multiply
Além disso, este plug-in muda dinamicamente o gerenciamento avançado de energia e a configuração de spindown timeout para o acionamento de acordo com a utilização atual do acionamento. O ajuste dinâmico pode ser controlado pela opção Booleana
dynamice é ativado por padrão.-
APM para o valor especificado pela opção
scsi_hostOpções de sintonia para os anfitriões SCSI.
Estabelece o Aggressive Link Power Management (ALPM) para o valor especificado pela opção
alpm.mounts-
Ativa ou desativa barreiras para montagens de acordo com o valor booleano da opção
disable_barriers. scriptExecuta um script externo ou binário quando o perfil é carregado ou descarregado. Você pode escolher um executável arbitrário.
ImportanteO plug-in
scripté fornecido principalmente para compatibilidade com versões anteriores. Prefira outros plug-ins Tuned se eles cobrirem a funcionalidade necessária.Tuned chama o executável com um dos seguintes argumentos:
-
startao carregar o perfil -
stopao descarregar o perfil
Você precisa implementar corretamente a ação
stopem seu executável e reverter todas as configurações que você alterou durante a açãostart. Caso contrário, o passo de retrocesso após a mudança de seu perfil Tuned não funcionará.Os scripts Bash podem importar a biblioteca
/usr/lib/tuned/functionsBash e utilizar as funções aí definidas. Use estas funções somente para funcionalidades que não são fornecidas nativamente por Tuned. Se o nome de uma função começa com um sublinhado, como_wifi_set_power_level, considere a função privada e não a utilize em seus scripts, pois ela pode mudar no futuro.Especifique o caminho para o executável usando o parâmetro
scriptna configuração do plug-in.Exemplo 3.6. Executando um Bash script a partir de um perfil
Para executar um script Bash chamado
script.shque está localizado no diretório de perfis, use:[script] script=${i:PROFILE_DIR}/script.sh-
sysfsDefine várias configurações
sysfsespecificadas pelas opções de plug-in.A sintaxe é
name=valueonde name é o caminhosysfsa ser utilizado.Use este plug-in caso precise alterar algumas configurações que não são cobertas por outros plug-ins. Prefira plug-ins específicos se eles cobrirem as configurações necessárias.
videoEstabelece vários níveis de segurança de energia em placas de vídeo. Atualmente, somente os cartões Radeon são suportados.
O nível de powersave pode ser especificado usando a opção
radeon_powersave. Os valores suportados são:-
default -
auto -
low -
mid -
high -
dynpm -
dpm-battery -
dpm-balanced -
dpm-perfomance
Para obter detalhes, consulte www.x.org. Observe que este plug-in é experimental e a opção pode mudar em lançamentos futuros.
-
bootloaderAdiciona opções à linha de comando do kernel. Este plug-in suporta apenas o carregador de inicialização GRUB 2.
A localização personalizada não padrão do arquivo de configuração do GRUB 2 pode ser especificada pela opção
grub2_cfg_file.As opções do kernel são adicionadas à configuração atual do GRUB e seus modelos. O sistema precisa ser reinicializado para que as opções do kernel entrem em vigor.
A mudança para outro perfil ou a parada manual do serviço
tunedremove as opções adicionais. Se você desligar ou reinicializar o sistema, as opções do kernel persistem no arquivogrub.cfg.As opções de kernel podem ser especificadas pela seguinte sintaxe:
cmdline=arg1 arg2 .. argN
Exemplo 3.7. Modificando a linha de comando do kernel
Por exemplo, para adicionar a opção
quieta um perfil Tuned, inclua as seguintes linhas no arquivotuned.conf:[bootloader] cmdline=quiet
A seguir, um exemplo de um perfil personalizado que adiciona a opção
isolcpus=2à linha de comando do kernel:[bootloader] cmdline=isolcpus=2
3.6. Variáveis e funções incorporadas em perfis sintonizados
Variáveis e funções incorporadas se expandem em tempo de execução quando um perfil Tuned é ativado.
O uso das variáveis Tuned reduz a quantidade de digitação necessária nos perfis Tuned. Você também pode:
- Usar várias funções embutidas junto com variáveis Tuned
- Criar funções personalizadas em Python e adicioná-las a Tuned sob a forma de plug-ins
Variáveis
Não há variáveis pré-definidas nos perfis Tuned. Você pode definir suas próprias variáveis, criando a seção [variables] em um perfil e usando a seguinte sintaxe:
[variables] variable_name=value
Para expandir o valor de uma variável em um perfil, use a seguinte sintaxe:
${variable_name}Exemplo 3.8. Isolamento de núcleos de CPU usando variáveis
No exemplo a seguir, a variável ${isolated_cores} se expande para 1,2; daí as botas do kernel com a opção isolcpus=1,2:
[variables]
isolated_cores=1,2
[bootloader]
cmdline=isolcpus=${isolated_cores}
As variáveis podem ser especificadas em um arquivo separado. Por exemplo, você pode adicionar as seguintes linhas a tuned.conf:
[variables]
include=/etc/tuned/my-variables.conf
[bootloader]
cmdline=isolcpus=${isolated_cores}
Se você adicionar a opção isolated_cores=1,2 ao arquivo /etc/tuned/my-variables.conf, o kernel boots com a opção isolcpus=1,2.
Funções
Para chamar uma função, use a seguinte sintaxe:
${f:function_name:argument_1:argument_2}
Para expandir o caminho do diretório onde o perfil e o arquivo tuned.conf estão localizados, use a função PROFILE_DIR, que requer uma sintaxe especial:
${i:PROFILE_DIR}Exemplo 3.9. Isolamento de núcleos de CPU usando variáveis e funções incorporadas
No exemplo a seguir, a variável ${non_isolated_cores} se expande para 0,3-5, e a função embutida cpulist_invert é chamada com o argumento 0,3-5:
[variables]
non_isolated_cores=0,3-5
[bootloader]
cmdline=isolcpus=${f:cpulist_invert:${non_isolated_cores}}
A função cpulist_invert inverte a lista de CPUs. Para uma máquina com 6 CPUs, a inversão é 1,2, e a inicialização do kernel com a opção de linha de comando isolcpus=1,2.
Recursos adicionais
-
A página do homem
tuned.conf(5)
3.7. Funções incorporadas disponíveis em perfis afinados
As seguintes funções embutidas estão disponíveis em todos os perfis Tuned:
PROFILE_DIR-
Retorna o caminho do diretório onde o perfil e o arquivo
tuned.confestão localizados. exec- Executa um processo e devolve sua produção.
assertion- Compara dois argumentos. Se eles do not match, a função registra o texto do primeiro argumento e aborta o carregamento do perfil.
assertion_non_equal- Compara dois argumentos. Se eles match, a função registra o texto do primeiro argumento e aborta o carregamento do perfil.
kb2s- Converte kilobytes em setores de disco.
s2kb- Converte setores de disco em quilobytes.
strip- Cria um cordão a partir de todos os argumentos passados e elimina tanto o espaço branco de chumbo quanto o branco de fuga.
virt_checkVerifica se Tuned está funcionando dentro de uma máquina virtual (VM) ou em metal nu:
- Dentro de uma VM, a função retorna o primeiro argumento.
- No metal nu, a função retorna o segundo argumento, mesmo no caso de um erro.
cpulist_invert-
Inverte uma lista de CPUs para fazer seu complemento. Por exemplo, em um sistema com 4 CPUs, numeradas de 0 a 3, a inversão da lista
0,2,3é1. cpulist2hex- Converte uma lista de CPU para uma máscara de CPU hexadecimal.
cpulist2hex_invert- Converte uma lista de CPU para uma máscara de CPU hexadecimal e a inverte.
hex2cpulist- Converte uma máscara hexadecimal de CPU em uma lista de CPU.
cpulist_online- Verifica se as CPUs da lista estão online. Retorna a lista contendo apenas CPUs online.
cpulist_present- Verifica se as CPUs da lista estão presentes. Retorna a lista contendo apenas as CPUs presentes.
cpulist_unpack-
Desempacote uma lista de CPU na forma de
1-3,4para1,2,3,4. cpulist_pack-
Pacote uma lista de CPU na forma de
1,2,3,5para1-3,5.
3.8. Criação de novos perfis sintonizados
Este procedimento cria um novo perfil Tuned com regras de desempenho personalizadas.
Pré-requisitos
-
O serviço
tunedestá instalado e funcionando. Veja Seção 2.6, “Instalando e habilitando o Tuned” para detalhes.
Procedimento
No diretório
/etc/tuned/, crie um novo diretório com o mesmo nome que o perfil que você deseja criar:# mkdir /etc/tuned/my-profileNo novo diretório, crie um arquivo chamado
tuned.conf. Adicione uma seção[main]e definições de plug-in nela, de acordo com suas exigências.Por exemplo, veja a configuração do perfil
balanced:[main] summary=General non-specialized tuned profile [cpu] governor=conservative energy_perf_bias=normal [audio] timeout=10 [video] radeon_powersave=dpm-balanced, auto [scsi_host] alpm=medium_power
Para ativar o perfil, use:
# perfil afinado-adm my-profileVerificar se o perfil Tuned está ativo e se as configurações do sistema estão aplicadas:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
-
A página do homem
tuned.conf(5)
3.9. Modificação de perfis sintonizados existentes
Este procedimento cria um perfil infantil modificado com base em um perfil Tuned existente.
Pré-requisitos
-
O serviço
tunedestá instalado e funcionando. Veja Seção 2.6, “Instalando e habilitando o Tuned” para detalhes.
Procedimento
No diretório
/etc/tuned/, crie um novo diretório com o mesmo nome que o perfil que você deseja criar:# mkdir /etc/tuned/modified-profileNo novo diretório, crie um arquivo chamado
tuned.conf, e defina a seção[main]como segue:[main] include=parent-profileSubstitua parent-profile com o nome do perfil que você está modificando.
Inclua suas modificações de perfil.
Exemplo 3.10. Diminuindo a troca no perfil de desempenho de produção
Para usar as configurações do perfil
throughput-performancee alterar o valor devm.swappinesspara 5, em vez do valor padrão 10, use:[main] include=throughput-performance [sysctl] vm.swappiness=5
Para ativar o perfil, use:
# perfil afinado-adm modified-profileVerificar se o perfil Tuned está ativo e se as configurações do sistema estão aplicadas:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verfication succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
-
A página do homem
tuned.conf(5)
3.10. Ajuste do programador de discos usando o Tuned
Este procedimento cria e permite um perfil Tuned que define um determinado programador de discos para os dispositivos de bloco selecionados. A configuração persiste através de reinicializações do sistema.
Nos seguintes comandos e configurações, substitua:
-
device com o nome do dispositivo do bloco, por exemplo
sdf -
selected-scheduler com o programador de discos que você deseja definir para o dispositivo, por exemplo
bfq
Pré-requisitos
O serviço
tunedestá instalado e habilitado.Para maiores detalhes, ver Seção 2.6, “Instalando e habilitando o Tuned”.
Procedimento
Opcional: Selecione um perfil existente em Tuned no qual seu perfil será baseado. Para uma lista dos perfis disponíveis, veja Seção 2.3, “Perfis afinados distribuídos com a RHEL”.
Para ver qual perfil está atualmente ativo, use:
$ tuned-adm ativo
Crie um novo diretório para manter seu perfil em Tuned:
# mkdir /etc/tuned/my-profileEncontre o identificador único do sistema do dispositivo de bloco selecionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaO comando neste exemplo retornará todos os valores identificados como um World Wide Name (WWN) ou número de série associado ao dispositivo de bloco especificado. Embora seja preferível usar um WWN, o WWN nem sempre está disponível para um determinado dispositivo e quaisquer valores retornados pelo comando do exemplo são aceitáveis para uso como o device system unique ID.
Criar o
/etc/tuned/my-profile/tuned.confarquivo de configuração. No arquivo, defina as seguintes opções:Opcional: Incluir um perfil existente:
[main] include=existing-profileDefina o programador de disco selecionado para o dispositivo que corresponda ao identificador da WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
ID_WWN). -
Substitua device system unique id com o valor do identificador escolhido (por exemplo,
0x5002538d00000000).
Para combinar vários dispositivos na opção
devices_udev_regex, coloque os identificadores entre parênteses e separe-os com barras verticais:-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilite seu perfil:
# perfil afinado-adm my-profileVerificar se o perfil Sintonizado está ativo e aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
- Para mais informações sobre como criar um perfil em Tuned, veja Capítulo 3, Personalização de perfis afinados.
Capítulo 4. Revisão de um sistema usando interface de atum
Use a ferramenta tuna para ajustar as sintonizações do programador, ajustar a prioridade da rosca, os manipuladores IRQ e isolar os núcleos e soquetes da CPU. O atum reduz a complexidade de executar tarefas de sintonização.
4.1. Instalando a ferramenta atum
A ferramenta tuna foi projetada para ser usada em um sistema em funcionamento. Isto permite que ferramentas de medição específicas da aplicação vejam e analisem o desempenho do sistema imediatamente após as mudanças terem sido feitas.
A ferramenta tuna realiza as seguintes operações:
- Lista as CPUs em um sistema
- Lista os pedidos de interrupção (IRQs) atualmente em funcionamento em um sistema
- Altera a política e as informações prioritárias sobre os tópicos
- Exibe as políticas e prioridades atuais de um sistema
Procedimento
Para instalar a ferramenta
tuna:# yum instalar atum
Para exibir as opções disponíveis do
tunaCLI:# atum -h
Recursos adicionais
-
A página do homem
tuna.
4.2. Visualização do status do sistema usando a ferramenta atum
Este procedimento descreve como visualizar o status do sistema usando a ferramenta de interface de linha de comando (CLI) tuna.
Pré-requisitos
- A ferramenta atum está instalada. Para maiores informações, veja Seção 4.1, “Instalando a ferramenta atum”.
Procedimento
Para ver as políticas e prioridades atuais:
# tuna --show_threads thread pid SCHED_ rtpri affinity cmd 1 OTHER 0 0,1 init 2 FIFO 99 0 migration/0 3 OTHER 0 0 ksoftirqd/0 4 FIFO 99 0 watchdog/0Para visualizar uma linha específica correspondente a um PID ou que corresponda a um nome de comando:
# Atum --threads=pid_or_cmd_list --show_threadsO argumento pid_or_cmd_list é uma lista de PIDs separados por vírgula ou padrões de nomes de comando.
-
Para sintonizar as CPUs usando a
tunaCLI, ver Seção 4.3, “Sintonia de CPUs usando a ferramenta atum”. -
Para sintonizar os IRQs usando a ferramenta
tuna, ver Seção 4.4, “Ajuste de IRQs usando ferramenta de atum”. Para salvar a configuração alterada:
# Atum --guardar= nome do arquivo
Este comando salva atualmente apenas os fios do kernel em execução. Os processos que não estão em execução não são salvos.
Recursos adicionais
-
A página do homem
tuna. -
O comando
tuna -hexibe as opções CLI disponíveis.
4.3. Sintonia de CPUs usando a ferramenta atum
Os comandos da ferramenta tuna podem ter como alvo CPUs individuais. Usando a ferramenta atum, você pode:
Isolate CPUs- Todas as tarefas executadas na CPU especificada passam para a próxima CPU disponível. O isolamento de uma CPU a torna indisponível, removendo-a da máscara de afinidade de todas as roscas.
Include CPUs- Permite que as tarefas sejam executadas na CPU especificada
Restore CPUs- Restaura a CPU especificada para sua configuração anterior.
Este procedimento descreve como sintonizar as CPUs usando o tuna CLI.
Pré-requisitos
- A ferramenta atum está instalada. Para maiores informações, veja Seção 4.1, “Instalando a ferramenta atum”.
Procedimento
Para especificar a lista de CPUs a serem afetadas por um comando:
# atum --cpus=cpu_list [command]
O argumento cpu_list é uma lista de números de CPU separados por vírgula. Por exemplo,
--cpus=0,2. As listas de CPU também podem ser especificadas em uma série, por exemplo--cpus=”1-3”que selecionaria as CPUs 1, 2, e 3.Para adicionar uma CPU específica ao atual cpu_list, por exemplo, use
--cpus= 0.Substituir [command] por, por exemplo,
--isolate.Para isolar uma CPU:
# tuna --cpus=cpu_list --isolate
Para incluir uma CPU:
# atum --cpus=cpu_list --inclua
Para usar um sistema com quatro ou mais processadores, mostrar como fazer todos os threads ssh rodarem na CPU 0 e 1, e todos os threads
httpna CPU 2 e 3:# tuna --cpus=0,1 --threads=ssh\* \ --move --cpus=2,3 --threads=http\* --move
Este comando executa as seguintes operações sequencialmente:
- Seleciona as CPUs 0 e 1.
-
Seleciona todos os tópicos que começam com
ssh. - Movimenta os fios selecionados para as CPUs selecionadas. Atum define a máscara de afinidade dos fios, começando com ssh para as CPUs apropriadas. As CPUs podem ser expressas numericamente como 0 e 1, em máscara hexagonal como 0x3, ou em binário como 11.
- Redefine a lista de CPU para 2 e 3.
-
Seleciona todos os tópicos que começam com
http. -
Movimenta os fios selecionados para as CPUs especificadas. Tuna define a máscara de afinidade dos fios começando com
httppara as CPUs especificadas. As CPUs podem ser expressas numericamente como 2 e 3, em máscara hexadecimal como 0xC, ou em binário como 1100.
Etapas de verificação
Para exibir a configuração atual e verificar se as mudanças foram realizadas como esperado:
# tuna --threads=gnome-sc\* --show_threads \ --cpus=0 --move --show_threads --cpus=1 \ --move --show_threads --cpus=+0 --move --show_threads thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav
Este comando executa as seguintes operações sequencialmente:
-
Seleciona todas as roscas que começam com as roscas
gnome-sc. - Exibe os fios selecionados para permitir que o usuário verifique sua máscara de afinidade e prioridade RT.
- Seleciona CPU 0.
-
Movimenta os fios
gnome-scpara a CPU especificada, CPU 0. - Mostra o resultado da mudança.
- Redefine a lista de CPU para CPU 1.
-
Movimenta os fios
gnome-scpara a CPU especificada, CPU 1. - Exibe o resultado da mudança.
- Adiciona a CPU 0 à lista de CPU.
-
Move os tópicos
gnome-scpara as CPUs especificadas, CPUs 0 e 1. - Exibe o resultado da mudança.
-
Seleciona todas as roscas que começam com as roscas
Recursos adicionais
-
O arquivo
/proc/cpuinfo. -
A página do homem
tuna. -
O comando
tuna -hexibe as opções CLI disponíveis.
4.4. Ajuste de IRQs usando ferramenta de atum
O arquivo /proc/interrupts registra o número de interrupções por IRQ, o tipo de interrupção, e o nome do dispositivo que está localizado nesse IRQ. Este procedimento descreve como afinar os IRQs usando a ferramenta tuna.
Pré-requisitos
- A ferramenta atum está instalada. Para maiores informações, veja Seção 4.1, “Instalando a ferramenta atum”.
Procedimento
Para ver os IRQs atuais e sua afinidade:
# tuna --show_irqs # users affinity 0 timer 0 1 i8042 0 7 parport0 0
Para especificar a lista de IRQs a serem afetados por um comando:
# atum --irqs=irq_list [command]
O argumento irq_list é uma lista de números IRQ separados por vírgula ou padrões de nomes de usuários.
Substituir [command] por, por exemplo,
--isolate.Para mover uma interrupção para uma CPU especificada:
# tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 0,1,2,3 # tuna --irqs=128 --cpus=3 --move
Substituir 128 pelo argumento irq_list e 3 pelo argumento cpu_list.
O argumento cpu_list é uma lista de números de CPU separados por vírgula, por exemplo,
--cpus=0,2. Para mais informações, ver Seção 4.3, “Sintonia de CPUs usando a ferramenta atum”.
Etapas de verificação
Compare o estado dos IRQs selecionados antes e depois de mover qualquer interrupção para uma CPU especificada:
# tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 3
Recursos adicionais
-
O arquivo
/procs/interrupts. -
A página do homem
tuna. -
O comando
tuna -hexibe as opções CLI disponíveis.
Capítulo 5. Monitoramento do desempenho usando os papéis do Sistema RHEL
5.1. Introdução aos papéis do sistema RHEL
O Sistema RHEL Roles é um conjunto de funções e módulos possíveis. As funções do sistema RHEL fornecem uma interface de configuração para gerenciar remotamente vários sistemas RHEL. A interface permite gerenciar configurações de sistema através de múltiplas versões do RHEL, bem como adotar novas versões principais.
No Red Hat Enterprise Linux 8, a interface atualmente consiste nas seguintes funções:
- kdump
- rede
- selinux
- armazenagem
- certificado
- kernel_settings
- madeireiro
- métricas
- nbde_client e nbde_server
- timesync
- tlog
Todas essas funções são fornecidas pelo pacote rhel-system-roles disponível no repositório AppStream.
Recursos adicionais
- Para uma visão geral dos Papéis do Sistema RHEL, veja o artigo do Red Hat Enterprise Linux (RHEL) System Roles Red Hat Knowledgebase.
-
Para informações sobre uma função específica, consulte a documentação sob o diretório
/usr/share/doc/rhel-system-roles. Esta documentação é instalada automaticamente com o pacoterhel-system-roles.
5.2. Terminologia dos papéis do Sistema RHEL
Você pode encontrar os seguintes termos ao longo desta documentação:
Terminologia dos papéis do sistema
- Livro de jogo possível
- Os playbooks são a linguagem de configuração, implantação e orquestração do Ansible. Eles podem descrever uma política que você quer que seus sistemas remotos apliquem, ou um conjunto de passos em um processo geral de TI.
- Nó de controle
- Qualquer máquina com Ansible instalado. Você pode executar comandos e playbooks, invocando /usr/bin/ansible ou /usr/bin/ansible-playbook, a partir de qualquer nó de controle. Você pode usar qualquer computador que tenha o Python instalado nele como um nó de controle - laptops, desktops compartilhados e servidores podem todos rodar o Ansible. Entretanto, você não pode usar uma máquina Windows como nó de controle. Você pode ter múltiplos nós de controle.
- Inventário
- Uma lista de nós administrados. Um arquivo de inventário também é às vezes chamado de "arquivo hospedeiro". Seu inventário pode especificar informações como endereço IP para cada nó gerenciado. Um inventário também pode organizar nós administrados, criando e aninhando grupos para facilitar o escalonamento. Para saber mais sobre o inventário, consulte a seção Trabalhando com o inventário.
- Nós administrados
- Os dispositivos de rede, servidores, ou ambos que você administra com Ansible. Os nós gerenciados também são às vezes chamados de "hosts". O Ansible não é instalado em nós gerenciados.
5.3. Instalação de funções do sistema RHEL em seu sistema
Este parágrafo é a introdução do módulo de procedimento: uma breve descrição do procedimento.
Pré-requisitos
- Você tem uma assinatura de Red Hat Ansible Engine. Veja o procedimento Como faço para baixar e instalar o Red Hat Ansible Engine?
- Você tem os pacotes Ansíveis instalados no sistema que você deseja usar como nó de controle:
Procedimento
Instale o pacote
rhel-system-rolesno sistema que você deseja usar como nó de controle:# yum instalar rhel-system-roles
Se você não tiver uma assinatura do Red Hat Ansible Engine, você pode usar uma versão suportada limitada do Red Hat Ansible Engine fornecida com sua assinatura do Red Hat Enterprise Linux. Neste caso, siga estes passos:
Habilitar o repositório RHEL Ansible Engine:
# subscription-manager refresh # subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpms
Instalar Motor Possível:
# yum instalar possível
Como resultado, você é capaz de criar um livro de brincadeiras possível.
Recursos adicionais
- Para visão geral dos papéis do sistema RHEL, veja os papéis do sistema Red Hat Enterprise Linux (RHEL)
- Para informações mais detalhadas sobre o uso do comando ansible-playbook, consulte a página de manual ansible-playbook.
5.4. Aplicando um papel
O procedimento a seguir descreve como aplicar uma função específica.
Pré-requisitos
O pacote
rhel-system-rolesestá instalado no sistema que você deseja usar como um nó de controle:# yum install rhel-system-rolesO repositório Ansible Engine está habilitado, e o pacote
ansibleestá instalado no sistema que você deseja usar como um nó de controle. Você precisa do pacoteansiblepara executar playbooks que usam os papéis do sistema RHEL.Se você não tiver uma assinatura do Red Hat Ansible Engine, você pode usar uma versão suportada limitada do Red Hat Ansible Engine fornecida com sua assinatura do Red Hat Enterprise Linux. Neste caso, siga estes passos:
Habilitar o repositório RHEL Ansible Engine:
# subscription-manager refresh # subscription-manager repos --enable ansible-2-for-rhel-8-x86_64-rpms
Instalar Motor Possível:
# yum install ansible
- Se você tem uma assinatura de Red Hat Ansible Engine, siga o procedimento descrito em Como faço para baixar e instalar o Red Hat Ansible Engine?
Você é capaz de criar um livro de brincadeiras possível.
Os playbooks representam a linguagem de configuração, implantação e orquestração do Ansible. Usando playbooks, você pode declarar e gerenciar configurações de máquinas remotas, implantar várias máquinas remotas ou etapas de orquestração de qualquer processo encomendado manualmente.
Um playbook é uma lista de um ou mais
plays. Cadaplaypode incluir variáveis, tarefas ou papéis possíveis.Os livros didáticos são legíveis por humanos e são expressos no formato
YAML.Para mais informações sobre livros didáticos, consulte Documentação possível.
Procedimento
Crie um caderno de atividades, incluindo o papel necessário.
O exemplo a seguir mostra como usar os papéis através da opção
roles:para um determinadoplay:--- - hosts: webservers roles: - rhel-system-roles.network - rhel-system-roles.timesyncPara mais informações sobre o uso de papéis em livros didáticos, consulte Documentação possível.
Veja Exemplos possíveis, por exemplo, livros didáticos.
NotaCada função inclui um arquivo README, que documenta como utilizar a função e os valores dos parâmetros suportados. Você também pode encontrar um exemplo de playbook para um determinado papel sob o diretório de documentação do papel. Tal diretório de documentação é fornecido por padrão com o pacote
rhel-system-roles, e pode ser encontrado no local a seguir:/usr/share/doc/rhel-system-roles/SUBSYSTEM/Substituir SUBSYSTEM pelo nome da função requerida, como
selinux,kdump,network,timesync, oustorage.Verificar a sintaxe do playbook:
#
ansible-playbook --syntax-check name.of.the.playbookO comando
ansible-playbookoferece uma opção--syntax-checkque você pode usar para verificar a sintaxe de um playbook.Executar o playbook nos anfitriões-alvo executando o comando
ansible-playbook:#
ansible-playbook -i name.of.the.inventory name.of.the.playbookUm inventário é uma lista de sistemas contra os quais o Ansible funciona. Para mais informações sobre como criar e inventariar, e como trabalhar com ele, consulte a documentação do Ansible.
Se você não tiver um inventário, você pode criá-lo no momento da execução
ansible-playbook:Se você tiver apenas um anfitrião específico contra o qual você deseja executar o playbook, use:
# ansible-playbook -i host1, name.of.the.playbookSe você tiver vários anfitriões alvo contra os quais você deseja executar o livro de jogo, use:
# ansible-playbook -i host1,host2,....,hostn name.of.the.playbook
Recursos adicionais
-
Para obter informações mais detalhadas sobre o uso do comando
ansible-playbook, consulte a página de manualansible-playbook.
5.5. Introdução ao sistema métrico Papel do sistema
As funções do sistema RHEL são um conjunto de funções e módulos possíveis que fornecem uma interface de configuração consistente para gerenciar remotamente vários sistemas RHEL. A função do sistema de métricas configura serviços de análise de desempenho para o sistema local e, opcionalmente, inclui uma lista de sistemas remotos a serem monitorados pelo sistema local. O sistema de métricas System Role permite que você use pcp para monitorar o desempenho de seus sistemas sem ter que configurar pcp separadamente, já que a configuração e implantação de pcp é tratada pelo playbook.
Tabela 5.1. Variáveis de papel do sistema métrico
| Função variável | Descrição | Exemplo de uso |
|---|---|---|
| métricas_monitoradas_hosts |
Lista de hospedeiros remotos a serem analisados pelo hospedeiro alvo. Estes anfitriões terão métricas registradas no anfitrião alvo, portanto, certifique-se de que existe espaço suficiente em disco abaixo de |
|
| dias_de_retenção_métrica | Configura o número de dias para retenção de dados de desempenho antes da exclusão. |
|
| metrics_graph_service |
Uma bandeira booleana que permite a instalação do host com serviços de visualização de dados de desempenho via |
|
| métrica_consulta_serviço |
Uma bandeira booleana que permite configurar o host com serviços de consulta de séries temporais para consulta de métricas registradas |
|
| metrics_provider |
Especifica qual métrica coletor a ser usada para fornecer métricas. Atualmente, |
|
Recursos adicionais
-
para detalhes sobre os parâmetros usados em
metrics_connectionse informações adicionais sobre a função do sistema métrico, veja o arquivo/usr/share/ansible/roles/rhel-system-roles.metrics/README.md.
5.6. Usando o sistema métrico Função do sistema para monitorar seu sistema local com visualização
Este procedimento descreve como usar a métrica RHEL System Role para monitorar seu sistema local enquanto simultaneamente fornece a visualização de dados via grafana.
Pré-requisitos
- Você tem o Red Hat Ansible Engine instalado na máquina que você deseja monitorar.
-
Você tem o pacote
rhel-system-rolesinstalado na máquina que você deseja monitorar.
Procedimento
Configurar
localhostno site/etc/ansible/hostsInventário possível, adicionando o seguinte conteúdo ao inventário:localhost ansible_connection=local
Crie um livro de jogo possível com o seguinte conteúdo:
--- - hosts: localhost vars: metrics_graph_service: yes roles: - rhel-system-roles.metricsExecute o livro de jogo Ansible playbook:
# ansible-playbook name_of_your_playbook.ymlNotaComo o
metrics_graph_serviceboolean está configurado para value="yes",grafanaé automaticamente instalado e provisionado compcpadicionado como fonte de dados.-
Para visualizar a visualização das métricas que estão sendo coletadas em sua máquina, acesse a interface web
grafanacomo descrito em Accessing the Grafana web UI.
5.7. Usando o sistema métrico Função do sistema para configurar uma frota de sistemas individuais para monitorar a si mesmos
Este procedimento descreve como usar o sistema métrico Papel do sistema para montar uma frota de máquinas para monitorar a si mesmos.
Pré-requisitos
- Você tem o Red Hat Ansible Engine instalado na máquina que você deseja usar para executar o playbook.
-
Você tem o pacote
rhel-system-rolesinstalado na máquina que você deseja usar para executar o playbook.
Procedimento
Adicione o nome ou IP das máquinas que você deseja monitorar através do playbook ao arquivo
/etc/ansible/hosts. Um possível arquivo de inventário com um nome de grupo identificador entre parênteses:[remotes] webserver.example.com database.example.com
Crie um livro de jogo possível com o seguinte conteúdo:
--- - hosts: remotes vars: metrics_retention_days: 0 roles: - rhel-system-roles.metricsExecute o livro de jogo Ansible playbook:
# ansible-playbook name_of_your_playbook.yml
5.8. Usando o sistema métrico Papel do sistema para monitorar uma frota de máquinas de forma centralizada através de sua máquina local
Este procedimento descreve como usar o sistema de métricas Função do sistema para configurar sua máquina local para monitorar centralmente uma frota de máquinas, ao mesmo tempo em que fornece a visualização dos dados via grafana e consulta dos dados via redis.
Pré-requisitos
- Você tem o Red Hat Ansible Engine instalado na máquina que você deseja usar para executar o playbook.
-
Você tem o pacote
rhel-system-rolesinstalado na máquina que você deseja usar para executar o playbook.
Procedimento
Crie um livro de jogo possível com o seguinte conteúdo:
--- - hosts: localhost vars: metrics_graph_service: yes metrics_query_service: yes metrics_retention_days: 10 metrics_monitored_hosts: ["database.example.com", "webserver.example.com"] roles: - rhel-system-roles.metricsExecute o livro de jogo Ansible playbook:
# ansible-playbook name_of_your_playbook.ymlNotaComo as booleans
metrics_graph_serviceemetrics_query_serviceestão configuradas para value="yes",grafanaé automaticamente instalado e provisionado compcpadicionado como fonte de dados com o registro de dadospcpindexado emredis, permitindo que a linguagem de consultapcpseja usada para consulta complexa dos dados.-
Para visualizar a representação gráfica das métricas que estão sendo coletadas centralmente por sua máquina e para consultar os dados, acesse a interface web
grafanaconforme descrito em Accessing the Grafana web UI.
Capítulo 6. Monitorando o desempenho com o Co-Piloto de Desempenho
Como administrador de sistemas, você pode monitorar o desempenho do sistema usando o aplicativo Performance Co-Pilot (PCP) no Red Hat Enterprise Linux 8.
6.1. Visão geral do PCP
O PCP é um conjunto de ferramentas, serviços e bibliotecas para monitoramento, visualização, armazenamento e análise de medidas de desempenho em nível de sistema.
Características do PCP:
- Arquitetura distribuída leve, que é útil durante a análise centralizada de sistemas complexos.
- Ele permite o monitoramento e o gerenciamento de dados em tempo real.
- Ele permite o registro e a recuperação de dados históricos.
Você pode adicionar métricas de desempenho usando interfaces Python, Perl, C , e C. Ferramentas de análise podem usar as APIs clientes Python, C , C diretamente, e aplicações web ricas podem explorar todos os dados de desempenho disponíveis usando uma interface JSON.
Você pode analisar padrões de dados comparando resultados ao vivo com dados arquivados.
O PCP tem os seguintes componentes:
-
O Performance Metric Collector Daemon (
pmcd) coleta dados de desempenho dos Agentes do Domínio Performance Metric instalados (pmda). PMDAs pode ser carregado ou descarregado individualmente no sistema e são controlados pelo PMCD no mesmo host. -
Várias ferramentas do cliente, tais como
pminfooupmstat, podem recuperar, exibir, arquivar e processar esses dados no mesmo host ou através da rede. -
O pacote
pcpfornece as ferramentas de linha de comando e a funcionalidade subjacente. -
O pacote
pcp-guifornece a aplicação gráfica. Instale o pacotepcp-guiexecutando o comandoyum install pcp-gui. Para maiores informações, veja Seção 6.6, “Rastreamento visual dos arquivos de log do PCP com a aplicação PCP Charts ”.
Recursos adicionais
-
O diretório
/usr/share/doc/pcp-doc/. - Seção 6.9, “Ferramentas distribuídas com PCP”.
- Os artigos, soluções, tutoriais e white papers do Index of Performance Co-Pilot (PCP ) no Portal do Cliente da Red Hat.
- O artigo Side-by-side comparison of PCP tools with legacy tools Red Hat Knowledgebase.
- A documentação do PCP a montante.
6.2. Instalando e habilitando o PCP
Para começar a usar o PCP, instale todos os pacotes necessários e habilite os serviços de monitoramento do PCP.
Procedimento
Instalar o pacote PCP:
# yum instalar pcp
Habilite e inicie o serviço
pmcdna máquina host:# systemctl enable pmcd # systemctl start pmcd
Verifique se o processo
pmcdestá rodando no host e se o XFS PMDA está listado como habilitado na configuração:# pcp Performance Co-Pilot configuration on workstation: platform: Linux workstation 4.18.0-80.el8.x86_64 #1 SMP Wed Mar 13 12:02:46 UTC 2019 x86_64 hardware: 12 cpus, 2 disks, 1 node, 36023MB RAM timezone: CEST-2 services: pmcd pmcd: Version 4.3.0-1, 8 agents pmda: root pmcd proc xfs linux mmv kvm jbd2
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”.
- A página do homem pmcd.
6.3. Implantação de uma configuração mínima de PCP
A configuração mínima do PCP coleta estatísticas de desempenho no Red Hat Enterprise Linux. A configuração envolve a adição do número mínimo de pacotes em um sistema de produção necessário para coletar dados para análise posterior. Você pode analisar o arquivo tar.gz resultante e o arquivo da saída do pmlogger usando várias ferramentas PCP e compará-los com outras fontes de informação de desempenho.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Atualizar a configuração do
pmlogger:# pmlogconf -r /var/lib/pcp/config/pmlogger/config.default
Iniciar os serviços
pmcdepmlogger:# systemctl start pmcd.service # systemctl start pmlogger.service
- Executar as operações necessárias para registrar os dados de desempenho.
Pare os serviços
pmcdepmlogger:# systemctl stop pmcd.service # systemctl stop pmlogger.service
Salve a saída e salve-a em um arquivo
tar.gznomeado com base no nome do host e na data e hora atuais:# cd /var/log/pcp/pmlogger/ # tar -czf $(hostname).$(date +%F-%Hh%M).pcp.tar.gz $(hostname)
Extraia este arquivo e analise os dados usando ferramentas PCP.
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.8, “Serviços de sistema distribuídos com PCP”
- A página de manual pmlogconf.
- A página de homem do pmlogger.
- A página do homem pmcd.
6.4. Registro de dados de desempenho com o pmlogger
Com a ferramenta PCP, você pode registrar os valores métricos de desempenho e reproduzi-los posteriormente. Isto permite que você faça uma análise retrospectiva do desempenho.
Usando a ferramenta pmlogger, você pode:
- Criar os logs arquivados de métricas selecionadas no sistema
- Especifique quais métricas são registradas no sistema e com que freqüência
6.4.1. Modificando o arquivo de configuração do pmlogger com pmlogconf
Quando o serviço pmlogger está em execução, o PCP registra um conjunto padrão de métricas no host. Use o utilitário pmlogconf para verificar a configuração padrão. Se o arquivo de configuração pmlogger não existir, pmlogconf o cria com um valor de métrica padrão.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Criar ou modificar o arquivo de configuração
pmlogger:# pmlogconf -r /var/lib/pcp/config/pmlogger/config.default
-
Siga as instruções do
pmlogconfpara ativar ou desativar grupos de métricas de desempenho relacionadas e para controlar o intervalo de registro para cada grupo ativado.
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.8, “Serviços de sistema distribuídos com PCP”
- A página de manual pmlogconf.
- A página de homem do pmlogger.
6.4.2. Edição manual do arquivo de configuração do pmlogger
Para criar uma configuração de registro personalizada com métricas específicas e determinados intervalos, edite o arquivo de configuração pmlogger manualmente.
Na configuração manual, você pode:
- Registrar métricas que não estão listadas na configuração automática.
- Escolha freqüências de registro personalizadas.
- Adicione PMDA com a métrica de aplicação.
O arquivo de configuração padrão pmlogger é /var/lib/pcp/config/pmlogger/config.default. O arquivo de configuração especifica quais métricas são registradas pela instância de registro principal.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Abra e edite o arquivo
/var/lib/pcp/config/pmlogger/config.defaultpara adicionar métricas específicas:# It is safe to make additions from here on ... # log mandatory on every 5 seconds { xfs.write xfs.write_bytes xfs.read xfs.read_bytes } log mandatory on every 10 seconds { xfs.allocs xfs.block_map xfs.transactions xfs.log } [access] disallow * : all; allow localhost : enquire;
Recursos adicionais
6.4.3. Permitindo o serviço de pmlogger
O serviço pmlogger deve ser iniciado e habilitado para registrar os valores métricos na máquina local.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Inicie e habilite o serviço
pmlogger:# systemctl start pmlogger # systemctl enable pmlogger
Verifique se o site
pmloggerestá habilitado:# pcp Performance Co-Pilot configuration on workstation: platform: Linux workstation 4.18.0-80.el8.x86_64 #1 SMP Wed Mar 13 12:02:46 UTC 2019 x86_64 hardware: 12 cpus, 2 disks, 1 node, 36023MB RAM timezone: CEST-2 services: pmcd pmcd: Version 4.3.0-1, 8 agents, 1 client pmda: root pmcd proc xfs linux mmv kvm jbd2 pmlogger: primary logger: /var/log/pcp/pmlogger/workstation/20190827.15.54
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.8, “Serviços de sistema distribuídos com PCP”
-
O arquivo
/var/lib/pcp/config/pmlogger/config.default. - A página de homem do pmlogger.
6.4.4. Criação de um sistema cliente para coleta de métricas
Este procedimento descreve como configurar um sistema de cliente para que um servidor central possa coletar métricas de clientes executando PCP.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Instale o pacote
pcp-system-tools:# yum instalar as ferramentas do sistema pcp
Configurar um endereço IP para
pmcd:# echo "-i 192.168.4.62" >/etc/pcp/pmcd/pmcd.optionsSubstituir 192.168.4.62 pelo endereço IP, o cliente deve ouvir.
Por padrão,
pmcdestá escutando no local.Configurar o firewall para adicionar o público
zonepermanentemente:# firewall-cmd --permanent --zone=public --add-port=44321/tcp success # firewall-cmd --reload success
Preparar um booleano SELinux:
# setsebool -P pcp_bind_all_unreserved_ports on
Habilitar os serviços
pmcdepmlogger:# systemctl enable pmcd pmlogger # systemctl restart pmcd pmlogger
Etapas de verificação
Verifique se o
pmcdestá escutando corretamente o endereço IP configurado:# ss -tlp | grep 44321 LISTEN 0 5 127.0.0.1:44321 0.0.0.0:* users:(("pmcd",pid=151595,fd=6)) LISTEN 0 5 192.168.4.62:44321 0.0.0.0:* users:(("pmcd",pid=151595,fd=0)) LISTEN 0 5 [::1]:44321 [::]:* users:(("pmcd",pid=151595,fd=7))
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”.
- Seção 6.8, “Serviços de sistema distribuídos com PCP”.
-
O arquivo
/var/lib/pcp/config/pmlogger/config.default. - A página de homem do pmlogger.
-
A página do homem
firewall-cmd. -
A página do homem
setsebool. -
A página do homem
ss.
6.4.5. Criação de um servidor central para a coleta de dados
Este procedimento descreve como criar um servidor central para coletar métricas de clientes executando PCP.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
- O cliente é configurado para a coleta de métricas. Para maiores informações, veja Seção 6.4.4, “Criação de um sistema cliente para coleta de métricas”.
Procedimento
Instale o pacote
pcp-system-tools:# yum instalar as ferramentas do sistema pcp
Adicionar clientes para monitoramento:
# echo "192.168.4.13 n n PCP_LOG_DIR/pmlogger/rhel7u4a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote # echo "192.168.4.14 n n PCP_LOG_DIR/pmlogger/rhel6u10a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote # echo "192.168.4.62 n n PCP_LOG_DIR/pmlogger/rhel8u1a -r -T24h10m \ -c config.remote" >> /etc/pcp/pmlogger/control.d/remote
Substituir 192.168.4.13, 192.168.4.14, e 192.168.4.62 pelos endereços IP do cliente.
Habilitar os serviços
pmcdepmlogger:# systemctl enable pmcd pmlogger # systemctl restart pmcd pmlogger
Etapas de verificação
Certifique-se de que você possa acessar o arquivo mais recente de cada diretório:
# for i in /var/log/pcp/pmlogger/rhel*/*.0; do pmdumplog -L $i; done Log Label (Log Format Version 2) Performance metrics from host rhel6u10a.local commencing Mon Nov 25 21:55:04.851 2019 ending Mon Nov 25 22:06:04.874 2019 Archive timezone: JST-9 PID for pmlogger: 24002 Log Label (Log Format Version 2) Performance metrics from host rhel7u4a commencing Tue Nov 26 06:49:24.954 2019 ending Tue Nov 26 07:06:24.979 2019 Archive timezone: CET-1 PID for pmlogger: 10941 [..]
Os arquivos do diretório
/var/log/pcp/pmlogger/podem ser usados para análises e gráficos adicionais.
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”.
- Seção 6.8, “Serviços de sistema distribuídos com PCP”.
-
O arquivo
/var/lib/pcp/config/pmlogger/config.default. - A página de homem do pmlogger.
6.4.6. Reprodução dos arquivos de log do PCP com o pmdumptext
Depois de gravar os dados métricos, você pode reproduzir novamente os arquivos de registro do PCP. Para exportar os logs para arquivos de texto e importá-los para planilhas, use utilitários PCP como pmdumptext, pmrep, ou pmlogsummary.
Usando a ferramenta pmdumptext, você pode:
- Ver os arquivos de log
- Analisar o arquivo de log PCP selecionado e exportar os valores para uma tabela ASCII
- Extrair todo o log de arquivo ou apenas selecionar valores métricos do log especificando métricas individuais na linha de comando
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
-
O serviço
pmloggerestá habilitado. Para mais informações, veja Seção 6.4.3, “Permitindo o serviço de pmlogger”. Instale o pacote
pcp-gui:# yum instalar pcp-gui
Procedimento
Exibir os dados no sistema métrico:
$ pmdumptext -t 5seconds -H -a 20170605 xfs.perdev.log.writes Time local::xfs.perdev.log.writes["/dev/mapper/fedora-home"] local::xfs.perdev.log.writes["/dev/mapper/fedora-root"] ? 0.000 0.000 none count / second count / second Mon Jun 5 12:28:45 ? ? Mon Jun 5 12:28:50 0.000 0.000 Mon Jun 5 12:28:55 0.200 0.200 Mon Jun 5 12:29:00 6.800 1.000O exemplo mencionado exibe os dados da métrica
xfs.perdev.logcoletados em um arquivo em um intervalo de 5 second e exibe todos os cabeçalhos.
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.8, “Serviços de sistema distribuídos com PCP”
- A página de homem pmdumptext.
- A página de manual do pmrep.
- A página do pmlogsummary man.
- A página de homem do pmlogger.
6.5. Monitoramento de pós fixado com pmda-postfix
Este procedimento descreve como monitorar as métricas de desempenho do servidor de e-mail postfix com pmda-postfix. Ele ajuda a verificar quantos e-mails são recebidos por segundo.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
-
O serviço
pmloggerestá habilitado. Para mais informações, veja Seção 6.4.3, “Permitindo o serviço de pmlogger”.
Procedimento
Instale os seguintes pacotes:
Instale o
pcp-system-tools:# yum instalar as ferramentas do sistema pcp
Instale o pacote
pmda-postfixpara monitorarpostfix:# yum instalar pcp-pmda-postfix postfix
Instalar o daemon de extração:
# yum instalar rsyslog
Instalar o cliente de correio para testes:
# yum instalar mutt
Habilitar os serviços
postfixersyslog:# systemctl enable postfix rsyslog # systemctl restart postfix rsyslog
Habilite o booleano SELinux, para que
pmda-postfixpossa acessar os arquivos de registro necessários:# setsebool -P pcp_read_generic_logs=on
Instale o
PMDA:# cd /var/lib/pcp/pmdas/postfix/ # ./Install Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Waiting for pmcd to terminate ... Starting pmcd ... Check postfix metrics have appeared ... 7 metrics and 58 values
Etapas de verificação
Verifique a operação
pmda-postfix:echo testmail | raiz mutt
Verificar as métricas disponíveis:
# pminfo postfix postfix.received postfix.sent postfix.queues.incoming postfix.queues.maildrop postfix.queues.hold postfix.queues.deferred postfix.queues.active
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.8, “Serviços de sistema distribuídos com PCP”
-
O arquivo
/var/lib/pcp/config/pmlogger/config.default. - A página de homem do pmlogger.
-
A página do homem
rsyslog. -
A página do homem
postfix. -
A página do homem
setsebool.
6.6. Rastreamento visual dos arquivos de log do PCP com a aplicação PCP Charts
Após gravar os dados métricos, você pode reproduzir novamente os arquivos de registro do PCP como gráficos.
Usando o aplicativo PCP Charts, você pode:
- Reproduza os dados na aplicação PCP Charts e use gráficos para visualizar os dados retrospectivos junto com os dados ao vivo do sistema.
- Traçar os valores métricos de desempenho em gráficos.
- Exibir vários gráficos simultaneamente.
As métricas são obtidas de um ou mais hosts vivos com opções alternativas para usar os dados métricos dos arquivos de log do PCP como fonte de dados históricos.
A seguir estão as diversas maneiras de personalizar a interface do aplicativo PCP Charts para exibir os dados da métrica de desempenho:
- gráfico da linha
- gráficos de barra
- gráficos de utilização
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
-
Dados de desempenho registrados com o
pmlogger. Para mais informações, ver Seção 6.4, “Registro de dados de desempenho com o pmlogger”. Instale o pacote
pcp-gui:# yum instalar pcp-gui
Procedimento
Iniciar o aplicativo PCP Charts a partir da linha de comando:
# pmchart
As configurações do servidor
pmtimeestão localizadas na parte inferior. O botão start e pause permite o controle:- O intervalo no qual o PCP faz o levantamento dos dados métricos
- A data e a hora para a métrica dos dados históricos
- Acesse File → New Chart para selecionar a métrica tanto da máquina local quanto das máquinas remotas, especificando o nome ou endereço de seu host. As opções de configuração avançada incluem a capacidade de definir manualmente os valores dos eixos para o gráfico, e escolher manualmente a cor dos gráficos.
Registre as opiniões criadas na aplicação PCP Charts:
A seguir estão as opções para tirar imagens ou gravar as vistas criadas no aplicativo PCP Charts:
- Clique em File → Export para salvar uma imagem da vista atual.
- Clique em Record → Start para iniciar uma gravação. Clique em Record → Stop para interromper a gravação. Após a interrupção da gravação, as métricas gravadas são arquivadas para serem vistas mais tarde.
Opcional: No aplicativo PCP Charts, o arquivo principal de configuração, conhecido como view, permite salvar os metadados associados a um ou mais gráficos. Estes metadados descrevem todos os aspectos dos gráficos, incluindo as métricas utilizadas e as colunas dos gráficos. Salve a configuração personalizada view clicando em File → Save View, e carregue a configuração view posteriormente. O seguinte exemplo do arquivo de configuração da visualização da aplicação PCP Charts descreve um gráfico de empilhamento mostrando o número total de bytes lidos e escritos no determinado sistema de arquivos XFS
loop1:#kmchart version 1 chart title "Filesystem Throughput /loop1" style stacking antialiasing off plot legend "Read rate" metric xfs.read_bytes instance "loop1" plot legend "Write rate" metric xfs.write_bytes instance "loop1"
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- A página de homens do pmchart.
- A página do homem do pmtime.
6.7. Análise de desempenho do sistema de arquivos XFS com PCP
O XFS PMDA é enviado como parte do pacote pcp e é habilitado por padrão durante a instalação. Ele é usado para reunir dados métricos de desempenho dos sistemas de arquivos XFS em PCP.
6.7.1. Instalação manual do XFS PMDA
Se o XFS PMDA não estiver listado na leitura de configuração do PCP, instale o agente PMDA manualmente.
Procedimento
Navegue até o diretório xfs:
# cd /var/lib/pcp/pmdas/xfs/
Instalar o XFS PMDA manualmente:
xfs]# ./Install You will need to choose an appropriate configuration for install of the “xfs” Performance Metrics Domain Agent (PMDA). collector collect performance statistics on this system monitor allow this system to monitor local and/or remote systems both collector and monitor configuration for this system Please enter c(ollector) or m(onitor) or (both) [b] Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Waiting for pmcd to terminate ... Starting pmcd ... Check xfs metrics have appeared ... 149 metrics and 149 values
Selecione a função PMDA pretendida entrando em
cpara coletor,mpara monitor, oubpara ambos. O roteiro de instalação do PMDA solicita que você especifique uma das seguintes funções do PMDA:-
A função
collectorpermite a coleta de métricas de desempenho no sistema atual A função
monitorpermite ao sistema monitorar sistemas locais, sistemas remotos, ou ambosA opção padrão é tanto
collectorquantomonitor, o que permite que o XFS PMDA funcione corretamente na maioria dos cenários.
-
A função
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- A página do homem pmcd.
6.7.2. Examinando as métricas de desempenho XFS com pminfo
A ferramenta pminfo exibe informações sobre as métricas de desempenho disponíveis. Este procedimento exibe uma lista de todas as métricas disponíveis fornecidas pelo XFS PMDA.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Exibir a lista de todas as métricas disponíveis fornecidas pelo XFS PMDA:
# pminfo xfs
Exibir informações para as métricas individuais. Os exemplos a seguir examinam as métricas específicas do XFS
readewriteusando a ferramentapminfo:Mostrar uma breve descrição da métrica
xfs.write_bytes:# pminfo --oneline xfs.write_bytes xfs.write_bytes [number of bytes written in XFS file system write operations]
Mostrar uma longa descrição da métrica
xfs.read_bytes:# pminfo --helptext xfs.read_bytes xfs.read_bytes Help: This is the number of bytes read via read(2) system calls to files in XFS file systems. It can be used in conjunction with the read_calls count to calculate the average size of the read operations to file in XFS file systems.
Obter o valor de desempenho atual da métrica
xfs.read_bytes:# pminfo --fetch xfs.read_bytes xfs.read_bytes value 4891346238
Recursos adicionais
- Seção 6.10, “Grupos métricos PCP para XFS”.
- A página do pminfo man.
6.7.3. Reinicialização das métricas de desempenho XFS com a loja pm
Com o PCP, você pode modificar os valores de certas métricas, especialmente se a métrica atuar como uma variável de controle, como a métrica xfs.control.reset. Para modificar um valor de métrica, use a ferramenta pmstore.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Mostrar o valor de uma métrica:
$ pminfo -f xfs.write xfs.write value 325262Redefinir todas as métricas do XFS:
# pmstore xfs.control.reset 1 xfs.control.reset old value=0 new value=1
Veja as informações após redefinir o sistema métrico:
$ pminfo --fetch xfs.write xfs.write value 0
Recursos adicionais
- Seção 6.9, “Ferramentas distribuídas com PCP”
- Seção 6.10, “Grupos métricos PCP para XFS”.
- A página do homem da loja da pmstore.
- A página do pminfo man.
6.7.4. Examinando as métricas XFS disponíveis por sistema de arquivo
O PCP permite que o XFS PMDA permita o relatório de certas métricas XFS por cada um dos sistemas de arquivo XFS montados. Isto facilita a identificação de problemas específicos do sistema de arquivo montado e a avaliação do desempenho. O comando pminfo fornece métricas XFS por dispositivo para cada sistema de arquivo XFS montado.
Pré-requisitos
- O PCP está instalado. Para mais informações, veja Seção 6.2, “Instalando e habilitando o PCP”.
Procedimento
Obter métricas por dispositivo XFS com
pminfo:# pminfo --fetch --oneline xfs.perdev.read xfs.perdev.write xfs.perdev.read [number of XFS file system read operations] inst [0 or "loop1"] value 0 inst [0 or "loop2"] value 0 xfs.perdev.write [number of XFS file system write operations] inst [0 or "loop1"] value 86 inst [0 or "loop2"] value 0
Recursos adicionais
- Seção 6.11, “Grupos métricos PCP por dispositivo para XFS”.
- A página do pminfo man.
6.8. Serviços de sistema distribuídos com PCP
| Nome | Descrição |
|
| O Coletor Métrico de Desempenho Daemon (PMCD). |
|
| O Motor de Inferência de Métricas de Desempenho. |
|
| O registrador de métricas de desempenho. |
|
| Gerencia uma coleção de daemons PCP para um conjunto de hospedeiros locais e remotos descobertos executando o Performance Metric Collector Daemon (PMCD) de acordo com zero ou mais diretórios de configuração. |
|
| O servidor proxy PMCD (Performance Metric Collector Daemon). |
6.9. Ferramentas distribuídas com PCP
| Nome | Descrição |
|
| Exibe o status atual de uma instalação do Co-Piloto de Desempenho. |
|
| Mostra a ocupação em nível de sistema dos recursos de hardware mais críticos do ponto de vista de desempenho: CPU, memória, disco e rede. |
|
|
Exibe as métricas de um sistema de cada vez. Para exibir métricas de vários sistemas, use a opção |
|
| Gráficos de valores métricos de desempenho disponíveis através das instalações do Co-Piloto de Desempenho. |
|
| Exibe métricas de desempenho de alto nível do sistema usando a Interface de Programação de Aplicação de Métricas de Desempenho (PMAPI). |
|
| Coleta e exibe dados em nível de sistema, seja de um sistema ao vivo ou de um arquivo de Co-piloto de Desempenho. |
|
| Exibe os valores dos parâmetros de configuração. |
|
| Exibe as bandeiras de controle de depuração do Co-Piloto de Desempenho disponíveis e seus valores. |
|
| Compara os valores médios para cada métrica em um ou dois arquivos, em uma determinada janela de tempo, para mudanças que provavelmente serão de interesse quando se procura por regressões de desempenho. |
|
| Exibe informações de controle, metadados, índice e estado de um arquivo do Co-Piloto de Desempenho. |
|
| Produz os valores de métricas de desempenho coletados ao vivo ou de um arquivo de Co-Pilotos de Desempenho. |
|
| Exibe os códigos de erro disponíveis do Co-Piloto de Desempenho e suas mensagens de erro correspondentes. |
|
| Encontra serviços de PCP na rede. |
|
| Um mecanismo de inferência que periodicamente avalia um conjunto de expressões aritméticas, lógicas e de regras. As métricas são coletadas ou de um sistema ao vivo, ou de um arquivo de arquivo de Co-piloto de Desempenho. |
|
| Exibe ou define variáveis pmie configuráveis. |
|
| Exibe informações sobre métricas de desempenho. As métricas são coletadas ou de um sistema ao vivo, ou de um arquivo do Co-Piloto de Desempenho. |
|
| Relata estatísticas de E/S para dispositivos SCSI (por padrão) ou dispositivos de fabricação de dispositivos (com a opção -x dm). |
|
| Configura interativamente as instâncias ativas do pmlogger. |
|
| Identifica dados inválidos em um arquivo do Co-Piloto de Desempenho. |
|
| Cria e modifica um arquivo de configuração do pmlogger. |
|
| Verifica, modifica ou repara o rótulo de um arquivo do Co-Piloto de Desempenho. |
|
| Calcula informações estatísticas sobre métricas de desempenho armazenadas em um arquivo do Co-Piloto de Desempenho. |
|
| Determina a disponibilidade de métricas de desempenho. |
|
| Relatórios sobre valores selecionados, facilmente personalizáveis, de métricas de desempenho. |
|
| Permite o acesso a um anfitrião de Co-Piloto de Desempenho através de um firewall. |
|
| Periodicamente, exibe um breve resumo do desempenho do sistema. |
|
| Modifica os valores da métrica de desempenho. |
|
| Fornece uma interface de linha de comando para o trace Performance Metrics Domain Agent (PMDA). |
|
| Exibe o valor atual de uma métrica de desempenho. |
6.10. Grupos métricos PCP para XFS
| Grupo Métrico | Métricas fornecidas |
|
| As métricas gerais XFS, incluindo a contagem da operação de leitura e escrita, contagem de bytes de leitura e escrita. Junto com os contadores para o número de vezes que os inodes são enxaguados, agrupados e o número de falhas no agrupamento. |
|
| Gama de métricas relativas à alocação de objetos no sistema de arquivo, estas incluem número de extensões e criação de blocos/árvores. A árvore de alocação procura e compara juntamente com a criação e exclusão de registros de extensão do btree. |
|
| As métricas incluem o número de apagamentos de leitura/escrita de mapas de blocos, operações de lista de extensão para inserção, apagamentos e buscas. Também contadores de operações para comparações, buscas, inserções e operações de exclusão do mapa de blocos. |
|
| Contadores para operações de diretório em sistemas de arquivos XFS para criação, eliminação de entradas, contagem de operações de "getdent". |
|
| Contadores para o número de transações de meta-dados, estes incluem a contagem do número de transações síncronas e assíncronas, juntamente com o número de transações vazias. |
|
| Contadores para o número de vezes que o sistema operacional procurou por um inode XFS no cache inode com resultados diferentes. Essas contagens de acertos, falhas de cache e assim por diante. |
|
| Os contadores para o número de buffer de logs escritos sobre os sistemas de arquivos XFS incluem o número de blocos escritos em disco. Métricas também para o número de fluxos de log e pinagem. |
|
| Conta para o número de bytes de dados de arquivo descarregados pelo deamon de descarga XFS junto com os contadores para o número de buffers descarregados para espaço contíguo e não contíguo em disco. |
|
| Conta para o número de atributo obter, definir, remover e listar operações sobre todos os sistemas de arquivos XFS. |
|
| Métricas para operação de cota sobre sistemas de arquivos XFS, estas incluem contadores para número de recuperações de cota, falhas de cache de cota, acertos de cache e recuperações de dados de cota. |
|
| Gama de métricas relativas a objetos de amortecedores XFS. Os contadores incluem o número de chamadas de buffer solicitadas, bloqueios de buffer bem sucedidos, bloqueios de buffer aguardados, bloqueios de miss_locks, miss_retries e acertos de buffer ao consultar as páginas. |
|
| Métricas relativas às operações da árvore XFS. |
|
| Métricas de configuração que são usadas para reiniciar os contadores métricos para as estatísticas do XFS. As métricas de controle são alternadas por meio da ferramenta pmstore. |
6.11. Grupos métricos PCP por dispositivo para XFS
| Grupo Métrico | Métricas fornecidas |
|
| As métricas gerais XFS, incluindo a contagem da operação de leitura e escrita, contagem de bytes de leitura e escrita. Junto com os contadores para o número de vezes que os inodes são enxaguados, agrupados e o número de falhas no agrupamento. |
|
| Gama de métricas relativas à alocação de objetos no sistema de arquivo, estas incluem número de extensões e criação de blocos/árvores. A árvore de alocação procura e compara juntamente com a criação e exclusão de registros de extensão do btree. |
|
| As métricas incluem o número de apagamentos de leitura/escrita de mapas de blocos, operações de lista de extensão para inserção, apagamentos e buscas. Também contadores de operações para comparações, buscas, inserções e operações de exclusão do mapa de blocos. |
|
| Contadores para operações de diretório de sistemas de arquivos XFS para criação, apagamento de entradas, contagem de operações de "getdent". |
|
| Contadores para o número de transações de meta-dados, estes incluem a contagem do número de transações síncronas e assíncronas, juntamente com o número de transações vazias. |
|
| Contadores para o número de vezes que o sistema operacional procurou por um inode XFS no cache inode com resultados diferentes. Essas contagens de acertos, falhas de cache e assim por diante. |
|
| Os contadores para o número de buffer de logs escritos sobre os filesytems XFS incluem o número de blocos escritos em disco. Métricas também para o número de fluxos de log e pinagem. |
|
| Conta para o número de bytes de dados de arquivo descarregados pelo deamon de descarga XFS junto com os contadores para o número de buffers descarregados para espaço contíguo e não contíguo em disco. |
|
| Conta para o número de atributo obter, definir, remover e listar operações sobre todos os sistemas de arquivos XFS. |
|
| Métricas para operação de cota sobre sistemas de arquivos XFS, estas incluem contadores para número de recuperações de cota, falhas de cache de cota, acertos de cache e recuperações de dados de cota. |
|
| Gama de métricas relativas a objetos de amortecedores XFS. Os contadores incluem o número de chamadas de buffer solicitadas, bloqueios de buffer bem sucedidos, bloqueios de buffer aguardados, bloqueios de miss_locks, miss_retries e acertos de buffer ao consultar as páginas. |
|
| Métricas relativas às operações da árvore XFS. |
Capítulo 7. Criação de representação gráfica da métrica PCP
Usando uma combinação de redis, pcp, bpftrace, vector e grafana fornece gráficos, baseados nos dados ao vivo ou dados coletados pelo Performance Co-Pilot (PCP). Ele permite acessar gráficos de métricas de PCP usando um navegador da web.
- O PCP é uma estrutura genérica que coleta, monitora, analisa e armazena métricas relacionadas ao desempenho. Para mais informações sobre o PCP e seus componentes, consulte Monitorando o desempenho com o Co-Piloto de Desempenho.
-
Redis é um
in-memory-database. Ele é usado para armazenar dados dos arquivos arquivados que são facilmente acessíveis para a geração de gráficos pelo aplicativo Grafana. -
A Bpftrace permite o acesso aos dados ao vivo de fontes que não estão disponíveis como dados normais do
pmloggerou arquivos. - Vector fornece acesso aos dados ao vivo, mas não fornece acesso aos dados do passado.
-
Grafana gera gráficos que são acessíveis através de um navegador. O
grafana-serveré um componente que escuta, por padrão, em todas as interfaces, e fornece serviços web acessados através do navegador web. O plugingrafana-pcpinterage com o protocolopmproxyno backend.
7.1. Configurando o PCP em um sistema
Este procedimento descreve como configurar o PCP em um sistema com o pacote pcp-zeroconf. Uma vez instalado o pacote pcp-zeroconf, o sistema registra o conjunto padrão de métricas em arquivos arquivados.
Procedimento
Instale o pacote
pcp-zeroconf:# yum instalar pcp-zeroconf
Etapas de verificação
Certifique-se de que o serviço
pmloggeresteja ativo, e comece a arquivar as métricas:# pcp | grep pmlogger pmlogger: primary logger: /var/log/pcp/pmlogger/localhost.localdomain/20200401.00.12
Recursos adicionais
-
A página do homem
pmlogger. - Para mais informações sobre o PCP e seus componentes, consulte Monitoramento do desempenho com o Co-Piloto de Desempenho.
7.2. Criação de um servidor de grafana-servidor
Este procedimento descreve como criar um grafana-server. Trata-se de um servidor back-end para o Grafana dashbaord. O componente grafana-server ouve na interface, e fornece serviços web que são acessados via navegador.
Pré-requisitos
-
O pacote
pcp-zeroconfestá instalado. Para mais informações, veja Seção 7.1, “Configurando o PCP em um sistema”.
Procedimento
Instale os seguintes pacotes:
# yum instalar redis grafana grafana-pcp
Reinicie e habilite os seguintes componentes:
# systemctl restart redis pmproxy grafana-server # systemctl enable redis pmproxy grafana-server
Etapas de verificação
Certifique-se de que o
grafana-serverestá escutando e respondendo às solicitações:# ss -ntlp | grep 3000 LISTEN 0 128 *:3000 *:* users:(("grafana-server",pid=19522,fd=7))
Recursos adicionais
-
A página do homem
pmproxy. -
A página do homem
grafana-server.
7.3. Acesso à Grafana web UI
Este procedimento descreve como acessar a interface web do Grafana e gerar gráficos usando diferentes tipos de fontes de dados.
Pré-requisitos
-
O pacote
pcp-zeroconfestá instalado. Para mais informações, veja Seção 7.1, “Configurando o PCP em um sistema”. -
O
grafana-serverestá configurado. Para maiores informações, veja Seção 7.2, “Criação de um servidor de grafana-servidor”.
Procedimento
No sistema do cliente, abra um navegador e acesse o site
grafana-serverna porta3000, usando http://192.0.2.0:3000 link.Substitua 192.0.2.0 pelo IP de sua máquina.
Para o primeiro login, digite admin nos campos username e password.
Figura 7.1. Página de login da Grafana

- Para criar uma conta segura, Grafana solicita a criação de uma nova conta password.
In the pane, hover on the
 configuration icon > click Plugins > in the Filter by name or type, type performance co-pilot > click Performance Co-Pilot plugin and > click Enable to enable the
configuration icon > click Plugins > in the Filter by name or type, type performance co-pilot > click Performance Co-Pilot plugin and > click Enable to enable the grafana-pcpplugin.Figura 7.2. Painel de controle doméstico
 Nota
NotaThe top corner of the screen has a similar
 icon, but it controls the general Dashboard settings.
icon, but it controls the general Dashboard settings.
-
Click the
 icon to view the Home Dashboard.
icon to view the Home Dashboard.
No site Home Dashboard, clique Add data source para adicionar fontes de dados PCP Redis, PCP bpftrace, e PCP Vector.
Para mais informações sobre como adicionar PCP Redis, PCP bpftrace e fontes de dados PCP Vector, veja:
-
Optional: In the pane, hover on the
 icon to change the Preferences or to Sign out.
icon to change the Preferences or to Sign out.
Etapas de verificação
Certifique-se de que o plug-in Performance Co-Pilot esteja habilitado:
# grafana-cli plugins ls | grep performancecopilot-pcp-app performancecopilot-pcp-app @ 1.0.5
Recursos adicionais
-
A página do homem
grafana-cli. -
A página do homem
grafana-server.
7.4. Adicionando PCP Redis como fonte de dados
A fonte de dados PCP Redis visualiza tudo o que o arquivo contém e consulta a capacidade das séries temporais fornecidas pela linguagem pmseries. Ele analisa os dados em vários hosts. Este procedimento descreve como adicionar o PCP Redis como fonte de dados e como visualizar o painel de controle com uma visão geral das métricas úteis.
Pré-requisitos
-
O site
grafana-serverestá acessível. Para maiores informações, veja Seção 7.3, “Acesso à Grafana web UI”.
Procedimento
Click the
icon > click Add data source > in the Filter by name or type, type redis > and click PCP Redis > in the URL field, accept the given suggestion http://localhost:44322 and > click Save & Test.
Figura 7.3. Adicionando PCP Redis na fonte de dados
In the pane, hover on the
 filter icon > click Manage > in the Filter Dashboard by name, type pcp redis > select PCP Redis Host Overview to see a dashboard with an overview of any useful metrics.
filter icon > click Manage > in the Filter Dashboard by name, type pcp redis > select PCP Redis Host Overview to see a dashboard with an overview of any useful metrics.
Figura 7.4. Visão geral do PCP Redis Host
In the pane, hover on the
 icon > click Dashboard option > click Add Query > from the Query list, select the PCP Redis and > in the text field of A, enter metric, for example,
icon > click Dashboard option > click Add Query > from the Query list, select the PCP Redis and > in the text field of A, enter metric, for example, kernel.all.loadto visualize the kernel load graph.Figura 7.5. Consulta PCP Redis
Recursos adicionais
-
A página do homem
pmseries.
7.5. Estabelecimento de autenticação entre componentes PCP
O PCP suporta o mecanismo de autenticação scram-sha-256 através da estrutura SASL (Simple Authentication Security Layer). Este procedimento descreve como configurar a autenticação usando o mecanismo de autenticação scram-sha-256.
A partir do Red Hat Enterprise Linux 8.3, o PCP suporta o mecanismo de autenticação scram-sha-256.
Pré-requisitos
Instalar a estrutura
saslpara o mecanismo de autenticaçãoscram-sha-256:# yum instalar cyrus-sasl-scram cyrus-sasl-lib
Procedimento
Especifique o mecanismo de autenticação suportado e o caminho do banco de dados do usuário no arquivo
pmcd.conf:# vi /etc/sasl2/pmcd.conf mech_list: scram-sha-256 sasldb_path: /etc/pcp/passwd.db
Criar um novo usuário:
# useradd -r metricsSubstitua metrics pelo seu nome de usuário.
Adicione o usuário criado no banco de dados do usuário:
# saslpasswd2 -a pmcd metrics Password: Again (for verification):Defina as permissões do banco de dados do usuário:
# chown root:pcp /etc/pcp/passwd.db # chmod 640 /etc/pcp/passwd.db
Reinicie o serviço
pmcd:# systemctl restart pmcd
Etapas de verificação
Verifique a configuração do
sasl:# pminfo -f -h "pcp://127.0.0.1?username=metrics" disk.dev.read Password: disk.dev.read inst [0 or "sda"] value 19540
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
saslauthd,pminfoesha256. - Para mais informações sobre como configurar a autenticação entre componentes PCP no RHEL 8.2, veja Como posso configurar a autenticação entre componentes PCP, como PMDAs e pmcd? knowledgebase article.
7.6. Adicionando PCP bpftrace como uma fonte de dados
O agente bpftrace permite a introspecção do sistema usando os scripts bpftrace, que usa o Filtro de Pacotes Berkeley melhorado (eBPF) para reunir métricas do kernel e pontos de rastreamento do espaço do usuário. Este procedimento descreve como adicionar o PCP bpftrace como fonte de dados e como visualizar o painel de controle com uma visão geral de quaisquer métricas úteis.
Pré-requisitos
-
O site
grafana-serverestá acessível. Para maiores informações, veja Seção 7.3, “Acesso à Grafana web UI”. -
O mecanismo de autenticação
scram-sha-256está configurado. Para maiores informações, ver Seção 7.5, “Estabelecimento de autenticação entre componentes PCP”.
Pré-requisitos
Instale o pacote
pcp-pmda-bpftrace:# yum instalar pcp-pmda-bpftrace
Procedimento
Edite o arquivo
bpftrace.confe adicione seu usuário, que você criou no site Seção 7.5, “Estabelecimento de autenticação entre componentes PCP”:# vi /var/lib/pcp/pmdas/bpftrace/bpftrace.conf [dynamic_scripts] enabled = true auth_enabled = true allowed_users = root,metricsSubstitua metrics pelo seu nome de usuário.
Instale o
bpftracePMDA:# cd /var/lib/pcp/pmdas/bpftrace/ # ./Install Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Check bpftrace metrics have appeared ... 7 metrics and 6 values
O
pmda-bpftraceestá agora instalado, e só pode ser usado após autenticar seu usuário.- Faça o login na Grafana web UI. Para mais informações, veja Seção 7.3, “Acesso à Grafana web UI”.
Click the
icon > click Add data source > in the Filter by name or type, type bpftrace > and click PCP bpftrace > in the URL field, accept the given suggestion http://localhost:44322.
Selecione a opção > acrescente as credenciais de usuário criadas no campo User e Password e > clique em Save & Test.
Figura 7.6. Adicionando PCP bpftrace na fonte de dados

In the pane, hover on the
filter icon > click Manage > in the Filter Dashboard by name, type pcp bpftrace > select PCP bpftrace System Analysis to see a dashboard with an overview of useful metrics.
Figura 7.7. Análise do Sistema PCP bpftrace
Recursos adicionais
-
A página do homem
pmdabpftrace. -
A página do homem
bpftrace.
7.7. Adicionando o PCP Vector como fonte de dados
A fonte de dados do PCP Vector exibe métricas ao vivo e utiliza a métrica pcp. Ela analisa dados para hosts individuais. Este procedimento descreve como adicionar um PCP Vector como fonte de dados e como visualizar o painel de controle com uma visão geral de quaisquer métricas úteis.
Pré-requisitos
-
O site
grafana-serverestá acessível. Para maiores informações, veja Seção 7.3, “Acesso à Grafana web UI”.
Procedimento
Instale o pacote
pcp-pmda-bcc:# yum instalar pcp-pmda-bcc
Instale o
bccPMDA:# cd /var/lib/pcp/pmdas/bcc # ./Install [Wed Apr 1 00:27:48] pmdabcc(22341) Info: Initializing, currently in 'notready' state. [Wed Apr 1 00:27:48] pmdabcc(22341) Info: Enabled modules: [Wed Apr 1 00:27:48] pmdabcc(22341) Info: ['biolatency', 'sysfork', [...] Updating the Performance Metrics Name Space (PMNS) ... Terminate PMDA if already installed ... Updating the PMCD control file, and notifying PMCD ... Check bcc metrics have appeared ... 1 warnings, 1 metrics and 0 values
- Faça o login na Grafana web UI. Para mais informações, veja Seção 7.3, “Acesso à Grafana web UI”.
Click the
icon > click Add data source > in the Filter by name or type, type vector > and click PCP Vector > in the URL field, accept the given suggestion http://localhost:44322 and > click Save & Test.
Figura 7.8. Adicionando o PCP Vector na fonte de dados
In the pane, hover on the
icon > click Manage > in the Filter Dashboard by name, type pcp vector > select PCP Vector Host Overview to see a dashboard with an overview of useful metrics.
Figura 7.9. Visão geral do PCP Vector Host
Recursos adicionais
-
A página do homem
pmdabcc.
Capítulo 8. Otimizando o desempenho do sistema usando o console web
Saiba como definir um perfil de desempenho no console web RHEL 8 para otimizar o desempenho do sistema para uma tarefa selecionada.
8.1. Opções de ajuste de desempenho no console web
O Red Hat Enterprise Linux 8 fornece vários perfis de desempenho que otimizam o sistema para as seguintes tarefas:
- Sistemas que utilizam a área de trabalho
- Desempenho de produção
- Desempenho na latência
- Desempenho da rede
- Baixo consumo de energia
- Máquinas virtuais
O serviço tuned otimiza as opções do sistema para corresponder ao perfil selecionado.
No console web, você pode definir o perfil de desempenho que seu sistema utiliza.
Recursos adicionais
-
Para obter detalhes sobre o serviço
tuned, consulte Monitoramento e gerenciamento do status e desempenho do sistema.
8.2. Definição de um perfil de desempenho no console web
Este procedimento utiliza o console web para otimizar o desempenho do sistema para uma tarefa selecionada.
Pré-requisitos
O console web é instalado e acessível.
Para detalhes, consulte Instalando o console web.
Procedimento
Acesse o console web RHEL 8.
Para obter detalhes, consulte Login no console web.
- Clique em Overview.
No campo Performance Profile, clique no perfil de desempenho atual.
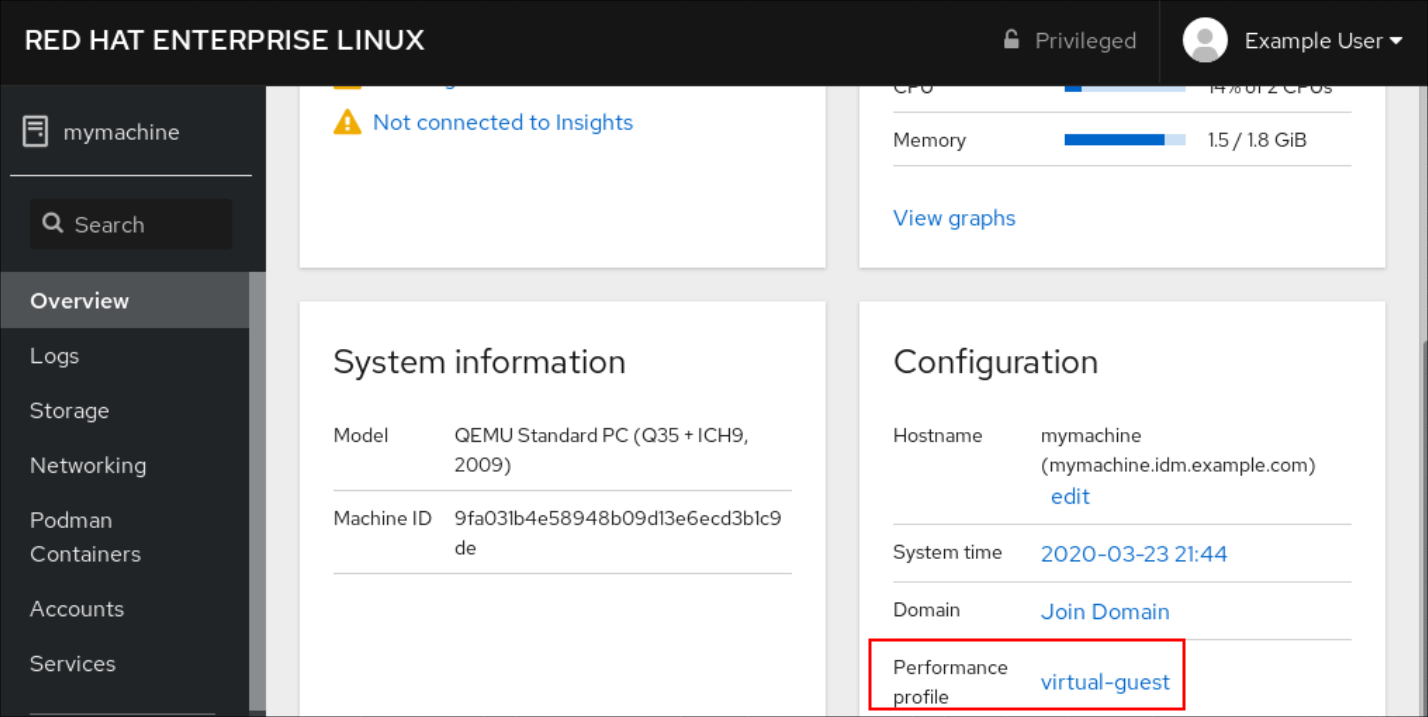
- Na caixa de diálogo Change Performance Profile, altere o perfil, se necessário.
Clique em Change Profile.
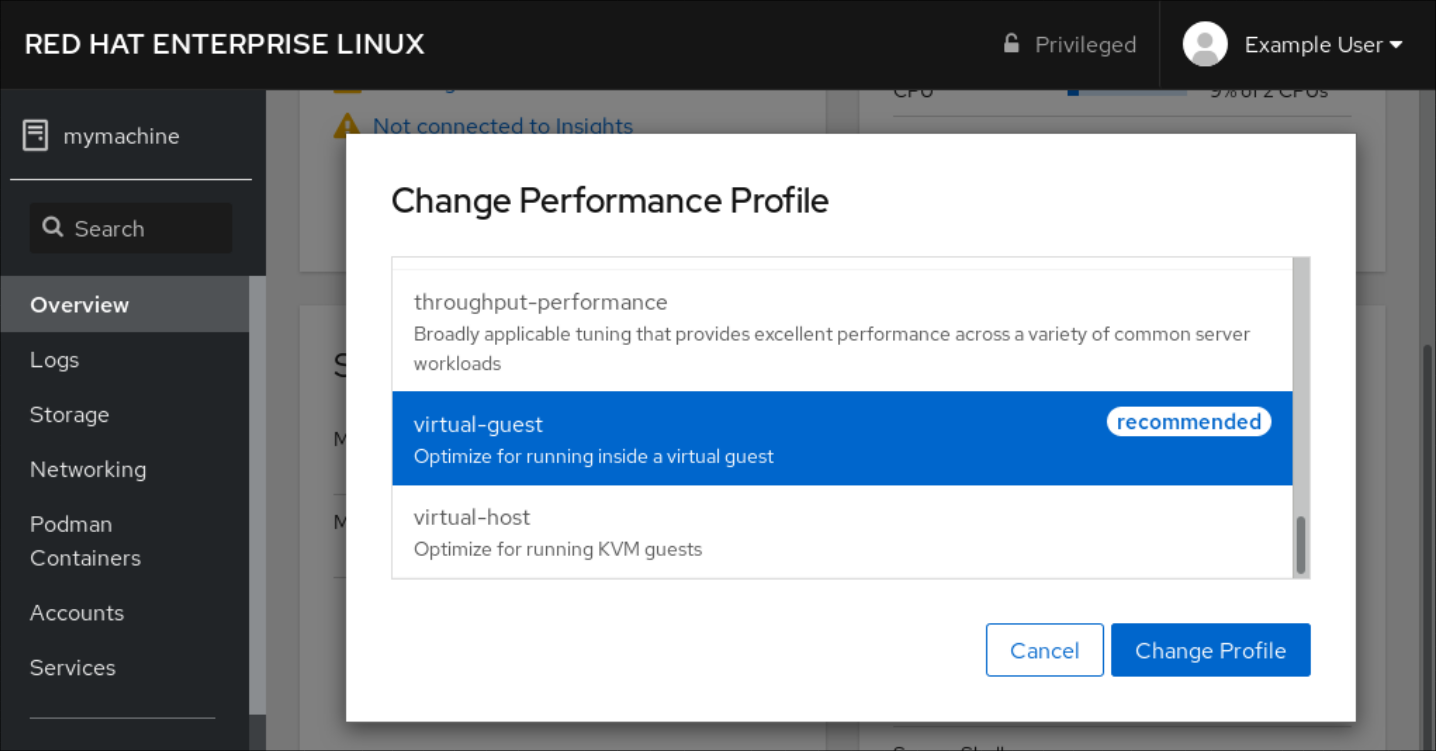
Etapas de verificação
- A aba Overview agora mostra o perfil de desempenho selecionado.
Capítulo 9. Ajuste do programador de discos
O programador de discos é responsável por encomendar os pedidos de E/S submetidos a um dispositivo de armazenamento.
Você pode configurar o agendador de várias maneiras diferentes:
- Configure o agendador usando Tuned, conforme descrito em Seção 9.6, “Ajuste do programador de discos usando o Tuned”
-
Configure o agendador usando
udev, conforme descrito em Seção 9.7, “Ajuste do programador de discos usando as regras do udev” - Alterar temporariamente o programador em um sistema em funcionamento, como descrito em Seção 9.8, “Programação temporária de um programador para um disco específico”
9.1. Mudanças no agendador de discos no RHEL 8
No RHEL 8, os dispositivos de bloqueio suportam apenas a programação de múltiplas filas. Isto permite que o desempenho da camada de bloco seja bem dimensionado com acionamentos rápidos de estado sólido (SSDs) e sistemas multi-core.
Os programadores tradicionais de fila única, que estavam disponíveis na RHEL 7 e versões anteriores, foram removidos.
9.2. Programadores de disco disponíveis
Os seguintes programadores de discos multi-fila são suportados no RHEL 8:
none- Implemente um algoritmo de programação FIFO (first-in first-out). Ele funde os pedidos na camada de blocos genéricos através de um simples cache de última hora.
mq-deadlineTentativas de proporcionar uma latência garantida para os pedidos a partir do momento em que os pedidos chegam ao agendador.
O agendador
mq-deadlineordena as solicitações de E/S em fila de espera em um lote de leitura ou gravação e depois as agende para execução em ordem crescente de endereçamento lógico em bloco (LBA). Por padrão, os lotes de leitura têm precedência sobre os lotes de escrita, porque as aplicações são mais propensas a bloquear nas operações de E/S lidas. Depois demq-deadlineprocessar um lote, ele verifica há quanto tempo as operações de escrita estão sem tempo de processamento e programa o próximo lote de leitura ou escrita, conforme apropriado.Este agendador é adequado para a maioria dos casos de uso, mas particularmente aqueles em que as operações de escrita são em sua maioria assíncronas.
bfqObjetiva sistemas desktop e tarefas interativas.
O programador
bfqgarante que uma única aplicação nunca esteja utilizando toda a largura de banda. Com efeito, o dispositivo de armazenamento é sempre tão responsivo como se estivesse ocioso. Em sua configuração padrão,bfqconcentra-se em fornecer a menor latência em vez de atingir a máxima produtividade.bfqé baseado no códigocfq. Ele não concede o disco a cada processo por uma fatia de tempo fixa, mas atribui um budget medido em número de setores ao processo.Este agendador é adequado enquanto copia arquivos grandes e o sistema não fica sem resposta neste caso.
kyberO programador se afina para atingir um objetivo de latência. Você pode configurar as latências alvo para solicitações de leitura e escrita síncrona.
Este programador é adequado para dispositivos rápidos, por exemplo NVMe, SSD, ou outros dispositivos de baixa latência.
9.3. Diferentes programadores de disco para diferentes casos de uso
Dependendo da tarefa que seu sistema executa, os seguintes programadores de disco são recomendados como uma linha de base antes de qualquer tarefa de análise e ajuste:
Tabela 9.1. Agendadores de discos para diferentes casos de uso
| Estojo de uso | Programador de discos |
|---|---|
| HDD tradicional com uma interface SCSI |
Use |
| SSD de alto desempenho ou um sistema vinculado à CPU com armazenamento rápido |
Use |
| Tarefas de mesa ou interativas |
Use |
| Convidado virtual |
Use |
9.4. O programador de discos padrão
Os dispositivos de bloqueio utilizam o programador de disco padrão, a menos que você especifique outro programador.
Para non-volatile Memory Express (NVMe) especificamente, o programador padrão é none e a Red Hat recomenda não alterar isto.
O kernel seleciona um programador de disco padrão com base no tipo de dispositivo. O programador selecionado automaticamente é tipicamente a configuração ideal. Se você precisar de um agendador diferente, a Red Hat recomenda usar as regras udev ou o aplicativo Tuned para configurá-lo. Combine os dispositivos selecionados e troque o agendador somente para esses dispositivos.
9.5. Determinando o programador de discos ativo
Este procedimento determina qual programador de disco está atualmente ativo em um determinado dispositivo de bloco.
Procedimento
Leia o conteúdo do
/sys/block/device/queue/schedulerarquivo:# cat /sys/block/device/queue/scheduler [mq-deadline] kyber bfq noneNo nome do arquivo, substituir device com o nome do dispositivo do bloco, por exemplo
sdc.O programador ativo está listado entre parênteses rectos (
[ ]).
9.6. Ajuste do programador de discos usando o Tuned
Este procedimento cria e permite um perfil Tuned que define um determinado programador de discos para os dispositivos de bloco selecionados. A configuração persiste através de reinicializações do sistema.
Nos seguintes comandos e configurações, substitua:
-
device com o nome do dispositivo do bloco, por exemplo
sdf -
selected-scheduler com o programador de discos que você deseja definir para o dispositivo, por exemplo
bfq
Pré-requisitos
O serviço
tunedestá instalado e habilitado.Para maiores detalhes, ver Seção 2.6, “Instalando e habilitando o Tuned”.
Procedimento
Opcional: Selecione um perfil existente em Tuned no qual seu perfil será baseado. Para uma lista dos perfis disponíveis, veja Seção 2.3, “Perfis afinados distribuídos com a RHEL”.
Para ver qual perfil está atualmente ativo, use:
$ tuned-adm ativo
Crie um novo diretório para manter seu perfil em Tuned:
# mkdir /etc/tuned/my-profileEncontre o identificador único do sistema do dispositivo de bloco selecionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaO comando neste exemplo retornará todos os valores identificados como um World Wide Name (WWN) ou número de série associado ao dispositivo de bloco especificado. Embora seja preferível usar um WWN, o WWN nem sempre está disponível para um determinado dispositivo e quaisquer valores retornados pelo comando do exemplo são aceitáveis para uso como o device system unique ID.
Criar o
/etc/tuned/my-profile/tuned.confarquivo de configuração. No arquivo, defina as seguintes opções:Opcional: Incluir um perfil existente:
[main] include=existing-profileDefina o programador de disco selecionado para o dispositivo que corresponda ao identificador da WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
ID_WWN). -
Substitua device system unique id com o valor do identificador escolhido (por exemplo,
0x5002538d00000000).
Para combinar vários dispositivos na opção
devices_udev_regex, coloque os identificadores entre parênteses e separe-os com barras verticais:-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilite seu perfil:
# perfil afinado-adm my-profileVerificar se o perfil Sintonizado está ativo e aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
- Para mais informações sobre como criar um perfil em Tuned, veja Capítulo 3, Personalização de perfis afinados.
9.7. Ajuste do programador de discos usando as regras do udev
Este procedimento define um determinado programador de discos para dispositivos de bloco específicos usando as regras do udev. A configuração persiste através de reinicializações do sistema.
Nos seguintes comandos e configurações, substitua:
-
device com o nome do dispositivo do bloco, por exemplo
sdf -
selected-scheduler com o programador de discos que você deseja definir para o dispositivo, por exemplo
bfq
Procedimento
Encontre o identificador único do sistema do dispositivo de bloqueio:
$ udevadm info --name=/dev/device | grep -E '(WWN|SERIAL)' E: ID_WWN=0x5002538d00000000 E: ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 E: ID_SERIAL_SHORT=20120501030900000
NotaO comando neste exemplo retornará todos os valores identificados como um World Wide Name (WWN) ou número de série associado ao dispositivo de bloco especificado. Embora seja preferível usar um WWN, o WWN nem sempre está disponível para um determinado dispositivo e quaisquer valores retornados pelo comando do exemplo são aceitáveis para uso como o device system unique ID.
Configurar a regra
udev. Crie o arquivo/etc/udev/rules.d/99-scheduler.rulescom o seguinte conteúdo:ACTION===="add|change==", SUBSYSTEM==="block===="block===="block===="block==", ENVIDNAME}=="device system unique id"\ATTR{queue/scheduler}=="selected-scheduler"
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
ID_WWN). -
Substitua device system unique id com o valor do identificador escolhido (por exemplo,
0x5002538d00000000).
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
Recarregar as regras
udev:# controle udevadm --regras de carga
Aplique a configuração do agendador:
# udevadm trigger --type=devices --action=change
Verificar o agendador ativo:
# gato /sys/bloco/device/queue/scheduler
9.8. Programação temporária de um programador para um disco específico
Este procedimento define um determinado programador de discos para dispositivos de blocos específicos. O ajuste não persiste através de reinicializações do sistema.
Procedimento
Escreva o nome do programador selecionado para o
/sys/block/device/queue/schedulerarquivo:# eco selected-scheduler > /sys/block/device/queue/scheduler
No nome do arquivo, substituir device com o nome do dispositivo do bloco, por exemplo
sdc.
Etapas de verificação
Verifique se o programador está ativo no dispositivo:
# gato /sys/bloco/device/queue/scheduler
Capítulo 10. Ajustando o desempenho de um servidor de Samba
Este capítulo descreve que configurações podem melhorar o desempenho do Samba em determinadas situações, e que configurações podem ter um impacto negativo no desempenho.
Partes desta seção foram adotadas a partir da documentação Performance Tuning publicada no Samba Wiki. Licença: CC BY 4.0. Autores e colaboradores: Veja a guia Histórico na página Wiki.
Pré-requisitos
O Samba é configurado como um servidor de arquivos ou de impressão
10.1. Definição da versão do protocolo SMB
Cada nova versão SMB acrescenta características e melhora o desempenho do protocolo. Os recentes sistemas operacionais Windows e Windows Server sempre suportam a última versão do protocolo. Se o Samba também usa a versão mais recente do protocolo, os clientes Windows conectados ao Samba se beneficiam das melhorias de desempenho. No Samba, o valor padrão do protocolo máximo do servidor é definido para a última versão estável do protocolo SMB suportada.
Para ter sempre a última versão estável do protocolo SMB habilitada, não defina o parâmetro server max protocol. Se você definir o parâmetro manualmente, será necessário modificar a configuração com cada nova versão do protocolo SMB, para ter a última versão do protocolo ativada.
O procedimento seguinte explica como utilizar o valor padrão no parâmetro server max protocol.
Procedimento
-
Remover o parâmetro
server max protocolda seção[global]no arquivo/etc/samba/smb.conf. Recarregar a configuração do Samba
#
smbcontrol all reload-config
10.3. Configurações que podem ter um impacto negativo no desempenho
Por default, o kernel do Red Hat Enterprise Linux está sintonizado para alto desempenho da rede. Por exemplo, o kernel usa um mecanismo de sintonia automática para tamanhos de buffer. A configuração do parâmetro socket options no arquivo /etc/samba/smb.conf substitui estas configurações do kernel. Como resultado, a configuração deste parâmetro diminui o desempenho da rede Samba na maioria dos casos.
Para utilizar as configurações otimizadas do Kernel, remova o parâmetro socket options da seção [global] no site /etc/samba/smb.conf.
Capítulo 11. Otimizando o desempenho da máquina virtual
As máquinas virtuais (VMs) sempre experimentam algum grau de deterioração de desempenho em comparação com o host. As seções seguintes explicam as razões para esta deterioração e fornecem instruções sobre como minimizar o impacto de desempenho da virtualização no RHEL 8, para que seus recursos de infra-estrutura de hardware possam ser utilizados da forma mais eficiente possível.
11.1. O que influencia o desempenho da máquina virtual
Os VMs são executados como processos de espaço do usuário no host. O hipervisor, portanto, precisa converter os recursos do sistema host para que as VMs possam utilizá-los. Como consequência, uma parte dos recursos é consumida pela conversão, e a VM, portanto, não pode alcançar a mesma eficiência de desempenho que o host.
O impacto da virtualização no desempenho do sistema
Razões mais específicas para a perda de desempenho da VM incluem:
- As CPUs virtuais (vCPUs) são implementadas como threads no host, gerenciadas pelo agendador Linux.
- As VMs não herdam automaticamente recursos de otimização, tais como NUMA ou páginas enormes, do núcleo do host.
- As configurações de E/S do disco e da rede do host podem ter um impacto significativo no desempenho da VM.
- O tráfego de rede normalmente viaja para uma VM através de uma ponte baseada em software.
- Dependendo dos dispositivos host e de seus modelos, pode haver uma sobrecarga significativa devido à emulação de hardware específico.
A severidade do impacto da virtualização no desempenho da VM é influenciada por uma variedade de fatores, que incluem
- O número de VMs em funcionamento concomitante.
- A quantidade de dispositivos virtuais utilizados por cada VM.
- Os tipos de dispositivos utilizados pelas VMs.
Reduzindo a perda de desempenho da VM
O RHEL 8 oferece uma série de recursos que você pode usar para reduzir os efeitos negativos da virtualização. Destacadamente:
-
O serviço
tunedpode otimizar automaticamente a distribuição de recursos e o desempenho de suas VMs. - Oajuste de E/S do bloco pode melhorar o desempenho dos dispositivos de bloco da VM, tais como discos.
- A sintonia NUMA pode aumentar o desempenho da vCPU.
- Asredes virtuais podem ser otimizadas de várias maneiras.
O ajuste do desempenho da VM pode ter efeitos adversos sobre outras funções de virtualização. Por exemplo, pode tornar mais difícil a migração da VM modificada.
11.2. Otimizando o desempenho da máquina virtual usando o tuned
O utilitário tuned é um mecanismo de ajuste de perfil de entrega que adapta a RHEL para certas características de carga de trabalho, tais como requisitos para tarefas de CPU-intensiva ou de armazenamento-rede de resposta em termos de produtividade. Ele fornece uma série de perfis de ajuste que são pré-configurados para melhorar o desempenho e reduzir o consumo de energia em uma série de casos específicos de uso. Você pode editar esses perfis ou criar novos perfis para criar soluções de desempenho adaptadas ao seu ambiente, incluindo ambientes virtualizados.
A Red Hat recomenda o uso dos seguintes perfis ao usar a virtualização no RHEL 8:
-
Para as máquinas virtuais RHEL 8, utilize o perfil virtual-guest. Baseia-se no perfil geralmente aplicável
throughput-performancemas também diminui a permuta da memória virtual. - Para os anfitriões de virtualização RHEL 8, use o perfil virtual-host. Isto permite a gravação mais agressiva de páginas de memória suja, o que beneficia o desempenho do host.
Pré-requisitos
-
O serviço
tunedestá instalado e habilitado.
Procedimento
Para permitir um perfil específico em tuned:
Liste os perfis disponíveis em
tuned.# tuned-adm list Available profiles: - balanced - General non-specialized tuned profile - desktop - Optimize for the desktop use-case [...] - virtual-guest - Optimize for running inside a virtual guest - virtual-host - Optimize for running KVM guests Current active profile: balanced
Optional: Criar um novo perfil
tunedou editar um perfiltunedjá existente.Para mais informações, consulte Perfis ajustados de customização.
Ativar um perfil em
tuned.# tuned-adm profile selected-profilePara otimizar um host de virtualização, utilize o perfil virtual-host.
# tuned-adm profile virtual-hostEm um sistema operacional convidado da RHEL, use o perfil virtual-guest.
# tuned-adm profile virtual-guest
Recursos adicionais
-
Para mais informações sobre os perfis
tunedetuned, consulte Monitoramento e gerenciamento do status e desempenho do sistema.
11.3. Configuração da memória da máquina virtual
Para melhorar o desempenho de uma máquina virtual (VM), você pode atribuir RAM de host adicional para a VM. Da mesma forma, você pode diminuir a quantidade de memória alocada a uma VM para que a memória do host possa ser alocada a outras VMs ou tarefas.
Para realizar estas ações, você pode usar o console web ou a interface de linha de comando.
11.3.1. Adicionar e remover memória de máquina virtual usando o console web
Para melhorar o desempenho de uma máquina virtual (VM) ou para liberar os recursos do host que ela está usando, você pode usar o console web para ajustar a quantidade de memória alocada para a VM.
Pré-requisitos
O sistema operacional convidado está executando os drivers do balão de memória. Para verificar este é o caso:
Garantir que a configuração da VM inclua o dispositivo
memballoon:# virsh dumpxml testguest | grep memballoon <memballoon model='virtio'> </memballoon>Se este comando exibir qualquer saída e o modelo não estiver configurado para
none, o dispositivomemballoonestá presente.Certifique-se de que os condutores de balões estejam funcionando no sistema operacional convidado.
- No Windows, os drivers são instalados como parte do pacote de drivers virtio-win. Para instruções, consulte Instalação de drivers KVM paravirtualizados para máquinas virtuais Windows.
-
Nos convidados Linux, os drivers são geralmente incluídos por padrão e ativados quando o dispositivo
memballoonestá presente.
- Para usar o console web para gerenciar as VMs, instale o plug-in de VM do console web.
Procedimento
Optional: Obter as informações sobre a memória máxima e a memória atualmente utilizada para uma VM. Isto servirá como uma base para suas mudanças, e também para verificação.
# virsh dominfo testguest Max memory: 2097152 KiB Used memory: 2097152 KiBNa interface das , clique em uma linha com o nome das VMs para as quais você deseja visualizar e ajuste a memória alocada.
A linha se expande para revelar o painel de Visão Geral com informações básicas sobre os VMs selecionados.
Clique no valor da linha
Memoryno painel de Visão Geral.Aparece o diálogo
Memory Adjustment.
Configurar as CPUs virtuais para o VM selecionado.
Maximum allocation - Define a quantidade máxima de memória do host que a VM pode usar para seus processos. Aumentar este valor melhora o potencial de desempenho da VM, e reduzir o valor diminui a pegada de desempenho que a VM tem em seu host.
O ajuste da alocação máxima de memória só é possível em uma VM desligada.
- Current allocation - Define a quantidade real de memória alocada para o VM. Você pode ajustar o valor para regular a memória disponível para a VM para seus processos. Este valor não pode exceder o valor máximo de alocação.
Clique em .
A alocação da memória da VM é ajustada.
Recursos adicionais
- Para instruções de ajuste de memória VM usando a interface de linha de comando, veja Seção 11.3.2, “Adicionar e remover memória de máquina virtual usando a interface de linha de comando”.
- Para otimizar como a VM utiliza a memória alocada, você pode modificar sua configuração de vCPU. Para mais informações, veja Seção 11.5, “Otimizando o desempenho da CPU da máquina virtual”.
11.3.2. Adicionar e remover memória de máquina virtual usando a interface de linha de comando
Para melhorar o desempenho de uma máquina virtual (VM) ou para liberar os recursos do host que ela está usando, você pode usar a CLI para ajustar a quantidade de memória alocada para a VM.
Pré-requisitos
O sistema operacional convidado está executando os drivers do balão de memória. Para verificar este é o caso:
Garantir que a configuração da VM inclua o dispositivo
memballoon:# virsh dumpxml testguest | grep memballoon <memballoon model='virtio'> </memballoon>Se este comando exibir qualquer saída e o modelo não estiver configurado para
none, o dispositivomemballoonestá presente.Certifique-se de que os condutores de balões estejam funcionando no sistema operacional convidado.
- No Windows, os drivers são instalados como parte do pacote de drivers virtio-win. Para instruções, consulte Instalação de drivers KVM paravirtualizados para máquinas virtuais Windows.
-
Nos convidados Linux, os drivers são geralmente incluídos por padrão e ativados quando o dispositivo
memballoonestá presente.
Procedimento
Optional: Obter as informações sobre a memória máxima e a memória atualmente utilizada para uma VM. Isto servirá como uma base para suas mudanças, e também para verificação.
# virsh dominfo testguest Max memory: 2097152 KiB Used memory: 2097152 KiBAjuste a memória máxima alocada a uma VM. Aumentar este valor melhora o potencial de desempenho da VM, e reduzir o valor diminui a pegada de desempenho que a VM tem em seu host. Note que esta mudança só pode ser realizada em uma VM desligada, portanto, o ajuste de uma VM em funcionamento requer uma reinicialização para ter efeito.
Por exemplo, para mudar a memória máxima que o testguest VM pode usar para 4096 MiB:
# virt-xml testguest --edit --memory memory=4096,currentMemory=4096 Domain 'testguest' defined successfully. Changes will take effect after the domain is fully powered off.
Optional: Você também pode ajustar a memória atualmente utilizada pela VM, até a alocação máxima. Isto regula a carga de memória que a VM tem no host até a próxima reinicialização, sem alterar a alocação máxima da VM.
# virsh setmem testguest --current 2048
Verificação
Confirmar que a memória utilizada pela VM foi atualizada:
# virsh dominfo testguest Max memory: 4194304 KiB Used memory: 2097152 KiBOptional: Se você ajustar a memória atual da VM, você pode obter as estatísticas do balão de memória da VM para avaliar o quão efetivamente ela regula seu uso de memória.
# virsh domstats --balloon testguest Domain: 'testguest' balloon.current=365624 balloon.maximum=4194304 balloon.swap_in=0 balloon.swap_out=0 balloon.major_fault=306 balloon.minor_fault=156117 balloon.unused=3834448 balloon.available=4035008 balloon.usable=3746340 balloon.last-update=1587971682 balloon.disk_caches=75444 balloon.hugetlb_pgalloc=0 balloon.hugetlb_pgfail=0 balloon.rss=1005456
Recursos adicionais
- Para instruções de ajuste de memória VM usando o console web, veja Seção 11.3.1, “Adicionar e remover memória de máquina virtual usando o console web”.
- Para otimizar como a VM utiliza a memória alocada, você pode modificar sua configuração de vCPU. Para mais informações, veja Seção 11.5, “Otimizando o desempenho da CPU da máquina virtual”.
11.3.3. Recursos adicionais
Para aumentar a memória máxima de uma VM em funcionamento, você pode anexar um dispositivo de memória à VM. Isto também é referido como memory hot plug. Para detalhes, consulte Anexando dispositivos a máquinas virtuais.
Note que remover um dispositivo de memória de um VM, também conhecido como memory hot unplug, não é suportado no RHEL 8, e a Red Hat desencoraja muito seu uso.
11.4. Otimização do desempenho de E/S da máquina virtual
As capacidades de entrada e saída (E/S) de uma máquina virtual (VM) podem limitar significativamente a eficiência geral da VM. Para resolver isso, você pode otimizar a E/S de uma VM configurando os parâmetros de E/S de bloco.
11.4.1. E/S do bloco de sintonia em máquinas virtuais
Quando múltiplos dispositivos de bloco estão sendo usados por uma ou mais VMs, pode ser importante ajustar a prioridade de E/S de dispositivos virtuais específicos, modificando seu I/O weights.
Aumentar o peso de E/S de um dispositivo aumenta sua prioridade para a largura de banda de E/S e, portanto, proporciona mais recursos para o host. Da mesma forma, a redução do peso de um dispositivo faz com que ele consuma menos recursos do host.
O valor de cada dispositivo weight deve estar dentro da faixa 100 a 1000. Alternativamente, o valor pode ser 0, o que retira esse dispositivo das listas por dispositivo.
Procedimento
Para exibir e definir os parâmetros de E/S de um bloco VM:
Exibir os parâmetros atuais
<blkio>para uma VM:# virsh dumpxml VM-name<domain> [...] <blkiotune> <weight>800</weight> <device> <path>/dev/sda</path> <weight>1000</weight> </device> <device> <path>/dev/sdb</path> <weight>500</weight> </device> </blkiotune> [...] </domain>Edite o peso de E/S de um dispositivo especificado:
# virsh blkiotune VM-name --device-weights device, I/O-weightPor exemplo, o seguinte muda o peso do dispositivo /dev/sda no site liftrul VM para 500.
# virsh blkiotune liftbrul --device-weights /dev/sda, 500
11.4.2. Estrangulamento de E/S de disco em máquinas virtuais
Quando várias VMs estão funcionando simultaneamente, elas podem interferir com o desempenho do sistema, utilizando uma E/S em disco excessiva. A aceleração da E/S do disco na virtualização KVM proporciona a capacidade de definir um limite nas solicitações de E/S do disco enviadas pelas VMs para a máquina host. Isto pode evitar que uma VM utilize em excesso recursos compartilhados e tenha impacto no desempenho de outras VMs.
Para ativar a aceleração de E/S de disco, defina um limite para as solicitações de E/S de disco enviadas de cada dispositivo de bloco anexado às VMs para a máquina host.
Procedimento
Use o comando
virsh domblklistpara listar os nomes de todos os dispositivos de disco em uma VM especificada.# virsh domblklist rollin-coal Target Source ------------------------------------------------ vda /var/lib/libvirt/images/rollin-coal.qcow2 sda - sdb /home/horridly-demanding-processes.isoEncontre o dispositivo de bloco hospedeiro onde o disco virtual que você deseja acionar o acelerador está montado.
Por exemplo, se você quiser acionar o disco virtual
sdbda etapa anterior, a saída a seguir mostra que o disco está montado na partição/dev/nvme0n1p3.$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT zram0 252:0 0 4G 0 disk [SWAP] nvme0n1 259:0 0 238.5G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 236.9G 0 part └─luks-a1123911-6f37-463c-b4eb-fxzy1ac12fea 253:0 0 236.9G 0 crypt /homeEstabelecer limites de E/S para o dispositivo de bloco usando o comando
virsh blkiotune.# virsh blkiotune VM-name --parameter device,limitO seguinte exemplo aciona o disco
sdbnorollin-coalVM para 1000 operações de leitura e gravação de E/S por segundo e para 50 MB por segundo de leitura e gravação de rendimento.# virsh blkiotune rollin-coal --device-read-iops-sec /dev/nvme0n1p3,1000 --device-write-iops-sec /dev/nvme0n1p3,1000 --device-write-bytes-sec /dev/nvme0n1p3,52428800 --device-read-bytes-sec /dev/nvme0n1p3,52428800
Informações adicionais
- O estrangulamento de E/S em disco pode ser útil em várias situações, por exemplo, quando VMs pertencentes a diferentes clientes estão funcionando no mesmo host, ou quando são dadas garantias de qualidade de serviço para diferentes VMs. O estrangulamento de E/S de disco também pode ser usado para simular discos mais lentos.
- O estrangulamento de E/S pode ser aplicado independentemente a cada dispositivo de bloco acoplado a uma VM e suporta limites de rendimento e operações de E/S.
-
A Red Hat não suporta o uso do comando
virsh blkdeviotunepara configurar a estrangulamento de E/S em VMs. Para mais informações sobre recursos não suportados ao usar o RHEL 8 como um host VM, consulte Recursos não suportados na virtualização do RHEL 8.
11.4.3. Possibilitando o virtio-scsi de múltiplas filas
Ao utilizar virtio-scsi dispositivos de armazenamento em suas máquinas virtuais (VMs), o recurso multi-queue virtio-scsi oferece melhor desempenho de armazenamento e escalabilidade. Ele permite que cada CPU virtual (vCPU) tenha uma fila separada e interrompa a utilização sem afetar outras vCPUs.
Procedimento
Para habilitar o suporte de virtio-scsi de várias filas para uma VM específica, adicione o seguinte à configuração XML da VM, onde N é o número total de filas de vCPU:
<controller type='scsi' index='0' model='virtio-scsi'> <driver queues='N' /> </controller>
11.5. Otimizando o desempenho da CPU da máquina virtual
Assim como as CPUs físicas em máquinas host, as vCPUs são fundamentais para o desempenho da máquina virtual (VM). Como resultado, a otimização das vCPUs pode ter um impacto significativo na eficiência de recursos de suas VMs. Para otimizar sua vCPU:
- Ajuste quantos CPUs de host são designados para o VM. Você pode fazer isso usando o CLI ou o console web.
Certifique-se de que o modelo vCPU esteja alinhado com o modelo de CPU do host. Por exemplo, configurar o VM testguest1 para usar o modelo de CPU do host:
# virt-xml testguest1 --edit --cpu host-model- Desativar a fusão da mesma página do núcleo (KSM).
Se sua máquina host utiliza Acesso de Memória Não-Uniforme (NUMA), você também pode configure NUMA para suas VMs. Isto mapeia a CPU do host e os processos de memória na CPU e processos de memória da VM o mais próximo possível. Com efeito, o NUMA tuning fornece à vCPU um acesso mais simplificado à memória do sistema alocada à VM, o que pode melhorar a eficácia do processamento da vCPU.
Para maiores detalhes, ver Seção 11.5.3, “Configuração do NUMA em uma máquina virtual” e Seção 11.5.4, “Exemplo de cenário de ajuste de desempenho da vCPU”.
11.5.1. Adicionar e remover CPUs virtuais usando a interface de linha de comando
Para aumentar ou otimizar o desempenho da CPU de uma máquina virtual (VM), você pode adicionar ou remover as CPUs virtuais (vCPUs) atribuídas à VM.
Quando realizado em uma VM em funcionamento, isto também é chamado de vCPU hot plugging e hot unplugging. Entretanto, observe que o hot unplug vCPU não é suportado no RHEL 8, e a Red Hat desencoraja muito seu uso.
Pré-requisitos
Optional: Veja o estado atual das vCPUs na VM visada. Por exemplo, para exibir o número de vCPUs no site testguest VM:
# virsh vcpucount testguest maximum config 4 maximum live 2 current config 2 current live 1Esta saída indica que testguest está usando atualmente 1 vCPU, e mais 1 vCPu pode ser conectado a ele para aumentar o desempenho da VM. Entretanto, após a reinicialização, o número de vCPUs testguest usadas mudará para 2, e será possível fazer hot plug em mais 2 vCPUs.
Procedimento
Ajuste o número máximo de vCPUs que podem ser anexadas a uma VM, o que entra em vigor na próxima inicialização da VM.
Por exemplo, para aumentar a contagem máxima de vCPU para a VM testguest para 8:
# virsh setvcpus testguest 8 --maximum --configObserve que o máximo pode ser limitado pela topologia da CPU, hardware do host, o hipervisor e outros fatores.
Ajuste o número atual de vCPUs acopladas a uma VM, até o máximo configurado na etapa anterior. Por exemplo, o número de vCPUs:
Para aumentar o número de vCPUs anexadas à VM em execução testguest para 4:
# virsh setvcpus testguest 4 --liveIsto aumenta o desempenho da VM e a pegada de carga do host do testguest até a próxima inicialização da VM.
Diminuir permanentemente o número de vCPUs anexadas à testguest VM para 1:
# virsh setvcpus testguest 1 --configIsto diminui o desempenho da VM e a pegada de carga do host do testguest após a próxima inicialização da VM. Entretanto, se necessário, vCPUs adicionais podem ser conectados a quente à VM para aumentar temporariamente seu desempenho.
Verificação
Confirme que o estado atual da vCPU para a VM reflete suas mudanças.
# virsh vcpucount testguest maximum config 8 maximum live 4 current config 1 current live 4
Recursos adicionais
- Para informações sobre como adicionar e remover vCPUs usando o console web, veja Seção 11.5.2, “Gerenciamento de CPUs virtuais usando o console web”.
11.5.2. Gerenciamento de CPUs virtuais usando o console web
Usando o console web RHEL 8, você pode rever e configurar CPUs virtuais usadas pelas máquinas virtuais (VMs) às quais o console web está conectado.
Pré-requisitos
- Para usar o console web para gerenciar as VMs, instale o plug-in de VM do console web.
Procedimento
Na interface das , clique em uma linha com o nome das VMs para as quais você deseja visualizar e configurar os parâmetros da CPU virtual.
A linha se expande para revelar o painel Visão Geral com informações básicas sobre as VMs selecionadas, incluindo o número de CPUs virtuais, e controles para desligar e excluir a VM.
Clique no número de vCPUs no painel de Visão Geral.
Aparece o diálogo de detalhes da vCPU.
 Nota
NotaO aviso no diálogo de detalhes do vCPU só aparece após as configurações da CPU virtual serem alteradas.
Configurar as CPUs virtuais para o VM selecionado.
vCPU Count - O número de vCPUs atualmente em uso.
NotaA contagem da vCPU não pode ser maior do que a vCPU Máxima.
- vCPU Maximum - O número máximo de CPUs virtuais que podem ser configuradas para a VM. Se este valor for maior que o vCPU Count, vCPUs adicionais podem ser anexadas à VM.
- Sockets - O número de tomadas a serem expostas ao VM.
- Cores per socket - O número de núcleos para cada soquete a ser exposto ao VM.
Threads per core - O número de fios para cada núcleo a ser exposto ao VM.
Note que as opções Sockets, Cores per socket, e Threads per core ajustam a topologia da CPU da VM. Isto pode ser benéfico para o desempenho da vCPU e pode impactar a funcionalidade de certos softwares no sistema operacional convidado. Se uma configuração diferente não for exigida por sua implementação, a Red Hat recomenda manter os valores padrão.
Clique em .
As CPUs virtuais para a VM são configuradas.
NotaAs alterações nas configurações da CPU virtual só entram em vigor após o reinício da VM.
Recursos adicionais:
- Para informações sobre como gerenciar suas vCPUs usando a interface de linha de comando, veja Seção 11.5.1, “Adicionar e remover CPUs virtuais usando a interface de linha de comando”.
11.5.3. Configuração do NUMA em uma máquina virtual
Os seguintes métodos podem ser usados para configurar as configurações de Acesso Não-Uniforme de Memória (NUMA) de uma máquina virtual (VM) em um host RHEL 8.
Pré-requisitos
O host é uma máquina compatível com NUMA. Para detectar se este é o caso, use o comando
virsh nodeinfoe veja a linhaNUMA cell(s):# virsh nodeinfo CPU model: x86_64 CPU(s): 48 CPU frequency: 1200 MHz CPU socket(s): 1 Core(s) per socket: 12 Thread(s) per core: 2 NUMA cell(s): 2 Memory size: 67012964 KiB
Se o valor da linha for 2 ou maior, o host é compatível com NUMA.
Procedimento
Para facilidade de uso, você pode configurar uma configuração NUMA da VM usando utilidades e serviços automatizados. Entretanto, é mais provável que a configuração manual do NUMA produza uma melhoria significativa no desempenho.
Automatic methods
Defina a política NUMA da VM para
Preferred. Por exemplo, para fazer isso para o testguest5 VM:# virt-xml testguest5 --edit --vcpus placement=auto # virt-xml testguest5 --edit --numatune mode=preferred
Habilitar o balanceamento automático NUMA no host:
# echo 1 > /proc/sys/kernel/numa_balancingUse o comando
numadpara alinhar automaticamente a CPU da VM com os recursos de memória.# numad
Manual methods
Roscas de vCPU específicas de pinos para uma CPU hospedeira específica ou uma gama de CPUs. Isto também é possível em hosts e VMs não-NUMA, e é recomendado como um método seguro de melhoria do desempenho da vCPU.
Por exemplo, os seguintes comandos pino vCPU fios 0 a 5 do testguest6 VM para hospedar CPUs 1, 3, 5, 7, 9, e 11, respectivamente:
# virsh vcpupin testguest6 0 1 # virsh vcpupin testguest6 1 3 # virsh vcpupin testguest6 2 5 # virsh vcpupin testguest6 3 7 # virsh vcpupin testguest6 4 9 # virsh vcpupin testguest6 5 11
Em seguida, você pode verificar se isto foi bem sucedido:
# virsh vcpupin testguest6 VCPU CPU Affinity ---------------------- 0 1 1 3 2 5 3 7 4 9 5 11Depois de afixar os fios do vCPU, você também pode afixar os fios do processo QEMU associados a uma VM específica para uma CPU host específica ou uma gama de CPUs. Por exemplo, os seguintes comandos fixam a rosca de processo QEMU de testguest6 para CPUs 13 e 15, e verificam se isto foi bem sucedido:
# virsh emulatorpin testguest6 13,15 # virsh emulatorpin testguest6 emulator: CPU Affinity ---------------------------------- *: 13,15
Finalmente, você também pode especificar quais nós do NUMA hospedeiro serão atribuídos especificamente a um determinado VM. Isto pode melhorar o uso da memória do host pelo vCPU da VM. Por exemplo, os comandos a seguir definem testguest6 para usar os nós de host NUMA 3 a 5, e verificar se isto foi bem sucedido:
# virsh numatune testguest6 --nodeset 3-5 # virsh numatune testguest6
Recursos adicionais
- Observe que para melhores resultados de desempenho, é recomendado o uso de todos os métodos de sintonia manual listados acima. Para um exemplo de tal configuração, veja Seção 11.5.4, “Exemplo de cenário de ajuste de desempenho da vCPU”.
-
Para ver a configuração atual do NUMA de seu sistema, você pode usar o utilitário
numastat. Para detalhes sobre o uso denumastat, veja Seção 11.7, “Ferramentas de monitoramento de desempenho de máquinas virtuais”. - Atualmente não é possível realizar a sintonia NUMA em hosts IBM Z. Para maiores informações, veja Como a virtualização no IBM Z difere da AMD64 e Intel 64.
11.5.4. Exemplo de cenário de ajuste de desempenho da vCPU
Para obter o melhor desempenho possível da vCPU, a Red Hat recomenda o uso do manual vcpupin, emulatorpin e numatune, por exemplo, como no cenário a seguir.
Cenário inicial
Seu anfitrião tem as seguintes especificações de hardware:
- 2 nós NUMA
- 3 núcleos de CPU em cada nó
- 2 roscas em cada núcleo
A saída de
virsh nodeinfode uma máquina desse tipo seria semelhante:# virsh nodeinfo CPU model: x86_64 CPU(s): 12 CPU frequency: 3661 MHz CPU socket(s): 2 Core(s) per socket: 3 Thread(s) per core: 2 NUMA cell(s): 2 Memory size: 31248692 KiBVocê pretende modificar uma VM existente para ter 8 vCPUs, o que significa que ela não caberá em um único nó NUMA.
Portanto, você deve distribuir 4 vCPUs em cada nó NUMA e fazer com que a topologia da vCPU se pareça o mais próximo possível da topologia do hospedeiro. Isto significa que as vCPUs que funcionam como filamentos irmãos de uma determinada CPU física devem ser fixadas para hospedar filamentos no mesmo núcleo. Para obter detalhes, veja o site Solution abaixo:
Solução
Obter as informações sobre a topologia do hospedeiro:
# virsh capabilitiesA saída deve incluir uma seção que se pareça com a seguinte:
<topology> <cells num="2"> <cell id="0"> <memory unit="KiB">15624346</memory> <pages unit="KiB" size="4">3906086</pages> <pages unit="KiB" size="2048">0</pages> <pages unit="KiB" size="1048576">0</pages> <distances> <sibling id="0" value="10" /> <sibling id="1" value="21" /> </distances> <cpus num="6"> <cpu id="0" socket_id="0" core_id="0" siblings="0,3" /> <cpu id="1" socket_id="0" core_id="1" siblings="1,4" /> <cpu id="2" socket_id="0" core_id="2" siblings="2,5" /> <cpu id="3" socket_id="0" core_id="0" siblings="0,3" /> <cpu id="4" socket_id="0" core_id="1" siblings="1,4" /> <cpu id="5" socket_id="0" core_id="2" siblings="2,5" /> </cpus> </cell> <cell id="1"> <memory unit="KiB">15624346</memory> <pages unit="KiB" size="4">3906086</pages> <pages unit="KiB" size="2048">0</pages> <pages unit="KiB" size="1048576">0</pages> <distances> <sibling id="0" value="21" /> <sibling id="1" value="10" /> </distances> <cpus num="6"> <cpu id="6" socket_id="1" core_id="3" siblings="6,9" /> <cpu id="7" socket_id="1" core_id="4" siblings="7,10" /> <cpu id="8" socket_id="1" core_id="5" siblings="8,11" /> <cpu id="9" socket_id="1" core_id="3" siblings="6,9" /> <cpu id="10" socket_id="1" core_id="4" siblings="7,10" /> <cpu id="11" socket_id="1" core_id="5" siblings="8,11" /> </cpus> </cell> </cells> </topology>- Optional: Teste o desempenho da VM usando as ferramentas e utilitários aplicáveis.
Montar e montar 1 GiB páginas enormes no host:
Adicione a seguinte linha à linha de comando do kernel do host:
padrão_hugepagesz=1G hugepagesz=1G
Crie o arquivo
/etc/systemd/system/hugetlb-gigantic-pages.servicecom o seguinte conteúdo:[Unit] Description=HugeTLB Gigantic Pages Reservation DefaultDependencies=no Before=dev-hugepages.mount ConditionPathExists=/sys/devices/system/node ConditionKernelCommandLine=hugepagesz=1G [Service] Type=oneshot RemainAfterExit=yes ExecStart=/etc/systemd/hugetlb-reserve-pages.sh [Install] WantedBy=sysinit.target
Crie o arquivo
/etc/systemd/hugetlb-reserve-pages.shcom o seguinte conteúdo:#!/bin/sh nodes_path=/sys/devices/system/node/ if [ ! -d $nodes_path ]; then echo "ERROR: $nodes_path does not exist" exit 1 fi reserve_pages() { echo $1 > $nodes_path/$2/hugepages/hugepages-1048576kB/nr_hugepages } reserve_pages 4 node1 reserve_pages 4 node2Isto reserva quatro páginas enormes da 1GiB de node1 e quatro páginas enormes da 1GiB de node2.
Tornar executável o roteiro criado na etapa anterior:
# chmod x /etc/systemd/hugetlb-reserve-pages.shPermitir a reserva de páginas enormes na inicialização:
# systemctl enable hugetlb-gigantic-pages
Use o comando
virsh editpara editar a configuração XML da VM que você deseja otimizar, neste exemplo super-VM:# virsh edit super-vmAjuste a configuração XML da VM da seguinte maneira:
-
Configure a VM para usar 8 vCPUs estáticas. Use o elemento
<vcpu/>para fazer isso. Fixe cada uma das roscas da vCPU nas roscas correspondentes da CPU hospedeira que ela espelha na topologia. Para fazer isso, use os elementos
<vcpupin/>na seção<cputune>.Observe que, como mostrado pelo utilitário
virsh capabilitiesacima, os fios da CPU do host não são ordenados seqüencialmente em seus respectivos núcleos. Além disso, as roscas vCPU devem ser fixadas ao conjunto mais alto disponível de núcleos hospedeiros no mesmo nó NUMA. Para uma ilustração da tabela, veja a seção Additional Resources abaixo.A configuração XML para as etapas a. e b. pode parecer semelhante a:
<cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='7'/> <vcpupin vcpu='5' cpuset='10'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='11'/> <emulatorpin cpuset='6,9'/> </cputune>
Configure o VM para usar 1 página gigantesca GiB:
<memoryBacking> <hugepages> <page size='1' unit='GiB'/> </hugepages> </memoryBacking>Configurar os nós NUMA da VM para usar a memória dos nós NUMA correspondentes no host. Para fazer isso, use os elementos
<memnode/>na seção<numatune/>:<numatune> <memory mode="preferred" nodeset="1"/> <memnode cellid="0" mode="strict" nodeset="0"/> <memnode cellid="1" mode="strict" nodeset="1"/> </numatune>
Certifique-se de que o modo CPU esteja configurado para
host-passthrough, e que a CPU utilize o cache no modopassthrough:<cpu mode="host-passthrough"> <topology sockets="2" cores="2" threads="2"/> <cache mode="passthrough"/>
-
Configure a VM para usar 8 vCPUs estáticas. Use o elemento
A configuração XML resultante da VM deve incluir uma seção similar à seguinte:
[...] <memoryBacking> <hugepages> <page size='1' unit='GiB'/> </hugepages> </memoryBacking> <vcpu placement='static'>8</vcpu> <cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/> <vcpupin vcpu='4' cpuset='7'/> <vcpupin vcpu='5' cpuset='10'/> <vcpupin vcpu='6' cpuset='8'/> <vcpupin vcpu='7' cpuset='11'/> <emulatorpin cpuset='6,9'/> </cputune> <numatune> <memory mode="preferred" nodeset="1"/> <memnode cellid="0" mode="strict" nodeset="0"/> <memnode cellid="1" mode="strict" nodeset="1"/> </numatune> <cpu mode="host-passthrough"> <topology sockets="2" cores="2" threads="2"/> <cache mode="passthrough"/> <numa> <cell id="0" cpus="0-3" memory="2" unit="GiB"> <distances> <sibling id="0" value="10"/> <sibling id="1" value="21"/> </distances> </cell> <cell id="1" cpus="4-7" memory="2" unit="GiB"> <distances> <sibling id="0" value="21"/> <sibling id="1" value="10"/> </distances> </cell> </numa> </cpu> </domain>- Optional: Teste o desempenho da VM usando as ferramentas e utilitários aplicáveis para avaliar o impacto da otimização da VM.
Recursos adicionais
As tabelas a seguir ilustram as conexões entre as vCPUs e as CPUs anfitriãs às quais elas devem ser fixadas:
Tabela 11.1. Topologia do hospedeiro
CPU threads
0
3
1
4
2
5
6
9
7
10
8
11
Cores
0
1
2
3
4
5
Sockets
0
1
NUMA nodes
0
1
Tabela 11.2. Topologia VM
vCPU threads
0
1
2
3
4
5
6
7
Cores
0
1
2
3
Sockets
0
1
NUMA nodes
0
1
Tabela 11.3. Topologia combinada de host e VM
vCPU threads
0
1
2
3
4
5
6
7
Host CPU threads
0
3
1
4
2
5
6
9
7
10
8
11
Cores
0
1
2
3
4
5
Sockets
0
1
NUMA nodes
0
1
Neste cenário, existem 2 nós NUMA e 8 vCPUs. Portanto, 4 fios de vCPU devem ser fixados a cada nó.
Além disso, a Red Hat recomenda deixar pelo menos uma única linha de CPU disponível em cada nó para as operações do sistema hospedeiro.
Como neste exemplo, cada nó NUMA abriga 3 núcleos, cada um com 2 fios de CPU hospedeira, o conjunto para o nó 0 se traduz como segue:
<vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='4'/> <vcpupin vcpu='2' cpuset='2'/> <vcpupin vcpu='3' cpuset='5'/>
11.5.5. Desativação da fusão do kernel na mesma página
Embora a fusão da mesma página do kernel (KSM) melhore a densidade da memória, ela aumenta a utilização da CPU e pode afetar adversamente o desempenho geral, dependendo da carga de trabalho. Nestes casos, você pode melhorar o desempenho da máquina virtual (VM) desativando o KSM.
Dependendo de suas necessidades, você pode tanto desativar o KSM para uma única sessão ou persistentemente.
Procedimento
Para desativar o KSM para uma única sessão, use o utilitário
systemctlpara pararksmeksmtunedserviços.# systemctl stop ksm # systemctl stop ksmtuned
Para desativar o KSM persistentemente, use o utilitário
systemctlpara desativarksmeksmtunedserviços.# systemctl disable ksm Removed /etc/systemd/system/multi-user.target.wants/ksm.service. # systemctl disable ksmtuned Removed /etc/systemd/system/multi-user.target.wants/ksmtuned.service.
As páginas de memória compartilhadas entre os VMs antes de desativar o KSM continuarão a ser compartilhadas. Para parar de compartilhar, exclua todas as páginas de PageKSM no sistema usando o seguinte comando:
# echo 2 > /sys/kernel/mm/ksm/run
Depois de páginas anônimas substituírem as páginas do KSM, o serviço do kernel khugepaged reconstruirá hugepages transparentes na memória física da VM.
11.6. Otimizando o desempenho da rede de máquinas virtuais
Devido à natureza virtual da placa de interface de rede (NIC) de uma VM, a VM perde uma parte de sua largura de banda de rede alocada ao host, o que pode reduzir a eficiência geral da carga de trabalho da VM. As seguintes dicas podem minimizar o impacto negativo da virtualização no rendimento virtual da placa de interface de rede (vNIC).
Procedimento
Use qualquer um dos métodos a seguir e observe se tem um efeito benéfico no desempenho de sua rede VM:
- Habilitar o módulo vhost_net
No host, certifique-se de que o recurso do kernel
vhost_netesteja habilitado:# lsmod | grep vhost vhost_net 32768 1 vhost 53248 1 vhost_net tap 24576 1 vhost_net tun 57344 6 vhost_netSe a saída deste comando estiver em branco, ative o módulo do kernel
vhost_net:# modprobe vhost_net- Criar uma rede virtio-multi-frequência
Para configurar o recurso multi-queue virtio-net para uma VM, use o comando
virsh editpara editar para a configuração XML da VM. No XML, adicione o seguinte na seção<devices>, e substituaNpelo número de vCPUs na VM, até 16:<interface type='network'> <source network='default'/> <model type='virtio'/> <driver name='vhost' queues='N'/> </interface>Se o VM estiver funcionando, reinicie-o para que as mudanças entrem em vigor.
- Pacotes de rede em lotes
Nas configurações Linux VM com um longo caminho de transmissão, a dosagem de pacotes antes de submetê-los ao kernel pode melhorar a utilização do cache. Para configurar o agrupamento de pacotes, use o seguinte comando no host, e substitua tap0 pelo nome da interface de rede que as VMs usam:
# ethtool -C tap0 rx-frames 128- SR-IOV
- Se seu NIC hospedeiro suporta SR-IOV, use a designação do dispositivo SR-IOV para seus vNICs. Para mais informações, consulte Gerenciando os dispositivos SR-IOV.
Recursos adicionais
- Para informações adicionais sobre tipos de conexão de rede virtual e dicas de uso, consulte Entendendo a rede virtual.
11.7. Ferramentas de monitoramento de desempenho de máquinas virtuais
Para identificar o que consome mais recursos de VM e qual aspecto do desempenho da VM necessita de otimização, podem ser utilizadas ferramentas de diagnóstico de desempenho, tanto gerais quanto específicas de VM.
Ferramentas de monitoramento de desempenho padrão do SO
Para avaliação de desempenho padrão, você pode usar as utilidades fornecidas por padrão por seus sistemas operacionais host e guest:
Em seu host RHEL 8, como root, use o utilitário
topou o aplicativo system monitor, e procureqemuevirtna saída. Isto mostra a quantidade de recursos do sistema host que seus VMs estão consumindo.-
Se a ferramenta de monitoramento mostrar que qualquer um dos processos
qemuouvirtconsome uma grande parte da CPU ou da capacidade de memória do host, use o utilitárioperfpara investigar. Para obter detalhes, veja abaixo. -
Além disso, se um processo de thread
vhost_net, chamado por exemplo vhost_net-1234, for exibido como consumindo uma quantidade excessiva de capacidade de CPU do host, considere o uso de recursos de otimização de rede virtual, tais comomulti-queue virtio-net.
-
Se a ferramenta de monitoramento mostrar que qualquer um dos processos
No sistema operacional convidado, use utilitários e aplicações de desempenho disponíveis no sistema para avaliar quais processos consomem mais recursos do sistema.
-
Em sistemas Linux, você pode usar o utilitário
top. - Em sistemas Windows, você pode usar o aplicativo Task Manager.
-
Em sistemas Linux, você pode usar o utilitário
perf kvm
Você pode usar o utilitário perf para coletar e analisar estatísticas específicas de virtualização sobre o desempenho de seu host RHEL 8. Para fazer isso:
No host, instale o pacote perf:
# yum install perfUse o comando
perf kvm statpara exibir as estatísticas do seu host de virtualização:-
Para o monitoramento em tempo real de seu hipervisor, use o comando
perf kvm stat live. -
Para registrar os dados do seu hipervisor durante um período de tempo, ative o registro usando o comando
perf kvm stat record. Após o comando ser cancelado ou interrompido, os dados são salvos no arquivoperf.data.guest, que pode ser analisado usando o comandoperf kvm stat report.
-
Para o monitoramento em tempo real de seu hipervisor, use o comando
Analisar a saída de
perfpara os tipos de eventosVM-EXITe sua distribuição. Por exemplo, os eventosPAUSE_INSTRUCTIONdevem ser pouco freqüentes, mas na saída seguinte, a alta ocorrência deste evento sugere que as CPUs anfitriãs não estão lidando bem com as vCPUs em funcionamento. Em tal cenário, considere desligar algumas de suas VMs ativas, remover as vCPUs dessas VMs, ou ajustar o desempenho das vCPUs.# perf kvm stat report Analyze events for all VMs, all VCPUs: VM-EXIT Samples Samples% Time% Min Time Max Time Avg time EXTERNAL_INTERRUPT 365634 31.59% 18.04% 0.42us 58780.59us 204.08us ( +- 0.99% ) MSR_WRITE 293428 25.35% 0.13% 0.59us 17873.02us 1.80us ( +- 4.63% ) PREEMPTION_TIMER 276162 23.86% 0.23% 0.51us 21396.03us 3.38us ( +- 5.19% ) PAUSE_INSTRUCTION 189375 16.36% 11.75% 0.72us 29655.25us 256.77us ( +- 0.70% ) HLT 20440 1.77% 69.83% 0.62us 79319.41us 14134.56us ( +- 0.79% ) VMCALL 12426 1.07% 0.03% 1.02us 5416.25us 8.77us ( +- 7.36% ) EXCEPTION_NMI 27 0.00% 0.00% 0.69us 1.34us 0.98us ( +- 3.50% ) EPT_MISCONFIG 5 0.00% 0.00% 5.15us 10.85us 7.88us ( +- 11.67% ) Total Samples:1157497, Total events handled time:413728274.66us.Outros tipos de eventos que podem sinalizar problemas na saída do
perf kvm statincluem:-
INSN_EMULATION- sugere uma configuração de E/S da VM subótima.
-
Para mais informações sobre o uso de perf para monitorar o desempenho da virtualização, consulte a página de manual perf-kvm.
numastat
Para ver a configuração atual de seu sistema NUMA, você pode usar o utilitário numastat, que é fornecido através da instalação do pacote numactl.
O seguinte mostra um host com 4 VMs rodando, cada um obtendo memória de múltiplos nós NUMA. Isto não é ideal para o desempenho do vCPU, e garante o ajuste:
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51722 (qemu-kvm) 68 16 357 6936 2 3 147 598 8128
51747 (qemu-kvm) 245 11 5 18 5172 2532 1 92 8076
53736 (qemu-kvm) 62 432 1661 506 4851 136 22 445 8116
53773 (qemu-kvm) 1393 3 1 2 12 0 0 6702 8114
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 1769 463 2024 7462 10037 2672 169 7837 32434Em contraste, o que se segue mostra a memória sendo fornecida a cada VM por um único nó, o que é significativamente mais eficiente.
# numastat -c qemu-kvm
Per-node process memory usage (in MBs)
PID Node 0 Node 1 Node 2 Node 3 Node 4 Node 5 Node 6 Node 7 Total
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
51747 (qemu-kvm) 0 0 7 0 8072 0 1 0 8080
53736 (qemu-kvm) 0 0 7 0 0 0 8113 0 8120
53773 (qemu-kvm) 0 0 7 0 0 0 1 8110 8118
59065 (qemu-kvm) 0 0 8050 0 0 0 0 0 8051
--------------- ------ ------ ------ ------ ------ ------ ------ ------ -----
Total 0 0 8072 0 8072 0 8114 8110 32368Capítulo 12. Gerenciando o consumo de energia com PowerTOP
Como administrador do sistema, você pode usar o PowerTOP ferramenta para analisar e gerenciar o consumo de energia.
12.1. O propósito do PowerTOP
PowerTOP é um programa que diagnostica questões relacionadas ao consumo de energia e fornece sugestões sobre como prolongar a vida útil da bateria.
O PowerTOP pode fornecer uma estimativa do uso total de energia do sistema e também do uso de energia individual para cada processo, dispositivo, trabalhador do kernel, temporizador e manipulador de interrupções. A ferramenta também pode identificar componentes específicos do kernel e aplicações de espaço do usuário que freqüentemente despertam a CPU.
O Red Hat Enterprise Linux 8 usa a versão 2.x do PowerTOP.
12.2. Usando o PowerTOP
Pré-requisitos
Para poder usar PowerTOPCertifique-se de que o pacote
powertoptenha sido instalado em seu sistema:# yum instalar powertop
12.2.1. Partida PowerTOP
Procedimento
Para correr PowerTOPUse o seguinte comando:
# powertop
Os laptops devem funcionar com energia de bateria ao executar o comando powertop.
12.2.2. Calibrating PowerTOP
Procedimento
Em um laptop, você pode calibrar o motor de estimativa de potência executando o seguinte comando:
# powertop --calibrar
Deixe a calibração terminar sem interagir com a máquina durante o processo.
A calibração leva tempo, pois o processo realiza vários testes, faz ciclos através dos níveis de brilho e liga e desliga os dispositivos.
Quando o processo de calibração estiver concluído, PowerTOP começa como normal. Deixe funcionar por aproximadamente uma hora para coletar dados.
Quando forem coletados dados suficientes, os valores da estimativa de potência serão exibidos na primeira coluna da tabela de saída.
Note que powertop --calibrate só pode ser usado em laptops.
12.2.3. Ajuste do intervalo de medição
Por padrão, PowerTOP faz medições em intervalos de 20 segundos.
Se você quiser mudar esta freqüência de medição, use o seguinte procedimento:
Procedimento
Execute o comando
powertopcom a opção--time:# powertop --time=time in seconds
12.3. Estatísticas PowerTOP
Enquanto funciona, PowerTOP reúne as estatísticas do sistema.
PowerTOPA saída do produto fornece múltiplas abas:
-
Overview -
Idle stats -
Frequency stats -
Device stats -
Tunables
Você pode usar as teclas Tab e Shift Tab para percorrer estas abas.
12.3.1. A aba Visão Geral
Na aba Overview, você pode ver uma lista dos componentes que mais freqüentemente enviam despertadores para a CPU ou que consomem mais energia. Os itens na aba Overview, incluindo processos, interrupções, dispositivos e outros recursos, são classificados de acordo com sua utilização.
As colunas adjacentes dentro da guia Overview fornecem as seguintes informações:
- Utilização
- Estimativa de potência de como o recurso está sendo utilizado.
- Eventos/s
- Acordos por segundo. O número de despertadores por segundo indica a eficiência do desempenho dos serviços ou dos dispositivos e drivers do kernel. Menos despertadores significa que se consome menos energia. Os componentes são ordenados por quanto mais seu uso de energia pode ser otimizado.
- Categoria
- Classificação do componente; tal como processo, dispositivo ou temporizador.
- Descrição
- Descrição do componente.
Se calibrado corretamente, é mostrada também uma estimativa de consumo de energia para cada item listado na primeira coluna.
Além disso, a guia Overview inclui a linha com estatísticas resumidas, como por exemplo:
- Consumo total de energia
- Duração restante da bateria (somente se aplicável)
- Resumo do despertar total por segundo, operações de GPU por segundo, e operações de sistema de arquivo virtual por segundo
12.3.2. A aba de estatísticas de ociosidade
A aba Idle stats mostra o uso dos estados C para todos os processadores e núcleos, enquanto a aba Frequency stats mostra o uso dos estados P incluindo o modo Turbo, se aplicável, para todos os processadores e núcleos. A duração dos estados C ou P é uma indicação de quão bem o uso da CPU foi otimizado. Quanto mais tempo a CPU permanecer nos estados C ou P mais altos (por exemplo, C4 é maior que C3), melhor será a otimização do uso da CPU. O ideal é que a residência seja 90% ou mais no estado C ou P mais alto quando o sistema estiver ocioso.
12.3.3. A aba Estatísticas do dispositivo
A guia Device stats fornece informações semelhantes à guia Overview, mas somente para dispositivos.
12.3.4. A aba Tunables
A guia Tunables contém PowerTOPs sugestões para otimizar o sistema para um menor consumo de energia.
Use as teclas up e down para passar as sugestões, e a tecla enter para ativar ou desativar a sugestão.
Figura 12.1. Saída PowerTOP

Recursos adicionais
Para mais detalhes sobre PowerTOPver a página inicial do PowerTOP.
12.4. Gerando uma saída HTML
Além da saída powertop’s no terminal, você também pode gerar um relatório HTML.
Procedimento
Execute o comando
powertopcom a opção--html:# powertop --html=htmlfile.html
Substituir o parâmetro
htmlfile.htmlpelo nome necessário para o arquivo de saída.
12.5. Otimizando o consumo de energia
Para otimizar o consumo de energia, você pode usar o serviço powertop ou o utilitário powertop2tuned.
12.5.1. Otimização do consumo de energia utilizando o serviço powertop
Você pode usar o serviço powertop para habilitar automaticamente todos PowerTOPsugestões da guia Tunables no porta-malas:
Procedimento
Habilite o serviço
powertop:# systemctl habilita o powertop
12.5.2. O utilitário powertop2tuned
O utilitário powertop2tuned permite que você crie personalizadas Tuned perfis de PowerTOP sugestões.
Por padrão, powertop2tuned cria perfis no diretório /etc/tuned/, e baseia o perfil personalizado no perfil atualmente selecionado Tuned perfil. Por razões de segurança, todos PowerTOP as sintonizações são inicialmente desativadas no novo perfil.
Para habilitar as afinações, você pode:
-
Descomente-os no site
/etc/tuned/profile_name/tuned.conf file. Use a opção
--enableou-epara gerar um novo perfil que permita a maioria das sintonizações sugeridas por PowerTOP.Alguns ajustes potencialmente problemáticos, como o auto-uspend USB, são desativados por padrão e precisam ser descomentados manualmente.
12.5.3. Otimização do consumo de energia usando o powertop2tuned utility
Pré-requisitos
O utilitário
powertop2tunedestá instalado no sistema:# yum instalar tuned-utils
Procedimento
Criar um perfil personalizado:
# powertop2tuned novo_nome_do_perfil
Ativar o novo perfil:
# perfil ajustado_nome_novo_do_perfil
Informações adicionais
Para uma lista completa de opções que
powertop2tunedsuporta, use:$ powertop2tuned --ajuda
12.5.4. Comparação de powertop.service e powertop2tuned
A otimização do consumo de energia com powertop2tuned é preferida em relação a powertop.service pelas seguintes razões:
-
A utilidade
powertop2tunedrepresenta a integração de PowerTOP em Tunedque permite beneficiar das vantagens de ambas as ferramentas. -
O utilitário
powertop2tunedpermite o controle fino da sintonia habilitada. -
Com
powertop2tuned, a sintonia potencialmente perigosa não é ativada automaticamente. -
Com
powertop2tuned, o rollback é possível sem reinicialização.
Capítulo 13. Começando com o perfume
Como administrador do sistema, você pode usar a ferramenta perf para coletar e analisar os dados de desempenho de seu sistema.
13.1. Introdução ao perfume
A ferramenta de espaço do usuário perf faz interface com o subsistema baseado no kernel Performance Counters for Linux (PCL). perf é uma ferramenta poderosa que usa a Unidade de Monitoramento de Desempenho (PMU) para medir, registrar e monitorar uma variedade de eventos de hardware e software. perf também suporta tracepoints, kprobes e uprobes.
13.2. Instalando o perf
Este procedimento instala a ferramenta de espaço do usuário perf.
Procedimento
Instale a ferramenta
perf:# yum instalar perf
13.3. Comandos comuns de desempenho
Esta seção fornece uma visão geral dos comandos comumente usados no perf.
Comandos de perf comumente usados
perf stat- Este comando fornece estatísticas gerais para eventos de desempenho comuns, incluindo instruções executadas e ciclos de relógio consumidos. As opções permitem a seleção de eventos que não sejam os eventos de medição padrão.
perf record-
Este comando registra os dados de desempenho em um arquivo,
perf.data, que pode ser analisado posteriormente usando o comandoperf report. perf report-
Este comando lê e exibe os dados de desempenho do arquivo
perf.datacriado porperf record. perf list- Este comando lista os eventos disponíveis em uma determinada máquina. Estes eventos variam com base na configuração de hardware e software de monitoramento de desempenho do sistema.
perf top-
Este comando executa uma função similar à utilidade
top. Ele gera e exibe um perfil de contador de desempenho em tempo real. perf trace-
Este comando executa uma função similar à da ferramenta
strace. Ele monitora as chamadas do sistema usadas por uma thread ou processo especificado e todos os sinais recebidos por aquela aplicação. perf help-
Este comando exibe uma lista completa dos comandos
perf.
Recursos adicionais
-
Para listar opções adicionais de subcomandos e suas descrições, adicione a opção
-hao comando alvo.
13.4. Perfilamento em tempo real do uso da CPU com perftop
Você pode usar o comando perf top para medir o uso da CPU de diferentes funções em tempo real.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
13.4.1. O propósito do topo perfurado
O comando perf top é usado para o perfil do sistema em tempo real e funciona de forma semelhante ao utilitário top. Entretanto, onde o utilitário top geralmente mostra quanto tempo de CPU um determinado processo ou thread está usando, perf top mostra quanto tempo de CPU cada função específica usa. Em seu estado padrão, perf top lhe informa sobre funções sendo usadas em todas as CPUs, tanto no espaço do usuário quanto no espaço do kernel. Para usar perf top, você precisa de acesso root.
13.4.2. Perfilar o uso de CPU com perf top
Este procedimento ativa perf top e faz o perfil de utilização da CPU em tempo real.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf. - Você tem acesso à raiz
Procedimento
Iniciar a interface de monitoramento
perf top:# perf top
Exemplo 13.1. Desempenho de topo
-------------------------------------------------------------------- PerfTop: 20806 irqs/sec kernel:57.3% exact: 100.0% lost: 0/0 drop: 0/0 [4000Hz cycles], (all, 8 CPUs) --------------------------------------------------------------------- Overhead Shared Object Symbol 2.20% [kernel] [k] do_syscall_64 2.17% [kernel] [k] module_get_kallsym 1.49% [kernel] [k] copy_user_enhanced_fast_string 1.37% libpthread-2.29.so [.] __pthread_mutex_lock 1.31% [unknown] [.] 0000000000000000 1.07% [kernel] [k] psi_task_change 1.04% [kernel] [k] switch_mm_irqs_off 0.94% [kernel] [k] __fget 0.74% [kernel] [k] entry_SYSCALL_64 0.69% [kernel] [k] syscall_return_via_sysret 0.69% libxul.so [.] 0x000000000113f9b0 0.67% [kernel] [k] kallsyms_expand_symbol.constprop.0 0.65% firefox [.] moz_xmalloc 0.65% libpthread-2.29.so [.] __pthread_mutex_unlock_usercnt 0.60% firefox [.] free 0.60% libxul.so [.] 0x000000000241d1cd 0.60% [kernel] [k] do_sys_poll 0.58% [kernel] [k] menu_select 0.56% [kernel] [k] _raw_spin_lock_irqsave 0.55% perf [.] 0x00000000002ae0f3
No exemplo anterior, a função do kernel
do_syscall_64está usando o maior tempo de CPU.
Recursos adicionais
-
A página do homem
perf-top(1).
13.4.3. Interpretação da produção do topo do perf
- A coluna "Adiantamento"
- Exibe a porcentagem de CPU que uma determinada função está usando.
- A coluna "Objeto Compartilhado
- Exibe o nome do programa ou biblioteca que está usando a função.
- A coluna "Símbolo
-
Exibe o nome ou símbolo da função. As funções executadas no kernel-space são identificadas por
[k]e as funções executadas no espaço do usuário são identificadas por[.].
13.4.4. Por que perf exibe alguns nomes de funções como endereços de funções em bruto
Para funções do núcleo, perf usa as informações do arquivo /proc/kallsyms para mapear as amostras para seus respectivos nomes de funções ou símbolos. Para funções executadas no espaço do usuário, entretanto, é possível ver endereços de funções em bruto, pois o binário é despojado.
O pacote debuginfo do executável deve ser instalado ou, se o executável for uma aplicação desenvolvida localmente, a aplicação deve ser compilada com informações de depuração ativadas (a opção -g no GCC) para exibir os nomes ou símbolos das funções em tal situação.
Recursos adicionais
13.4.5. Habilitação de depuração e repositórios de fonte
Uma instalação padrão do Red Hat Enterprise Linux não habilita os repositórios de depuração e fonte. Estes repositórios contêm informações necessárias para depurar os componentes do sistema e medir seu desempenho.
Procedimento
Habilitar os canais do pacote de informações de origem e de depuração:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
A parte
$(uname -i)é automaticamente substituída por um valor correspondente para a arquitetura de seu sistema:Nome da arquitetura Valor Intel e AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
13.4.6. Obtendo pacotes de debuginfo para uma aplicação ou biblioteca usando GDB
As informações de depuração são necessárias para depurar o código. Para o código que é instalado a partir de um pacote, o GNU Debugger (GDB) reconhece automaticamente as informações de depuração faltantes, resolve o nome do pacote e fornece conselhos concretos sobre como obter o pacote.
Pré-requisitos
- A aplicação ou biblioteca que você deseja depurar deve ser instalada no sistema.
-
A GDB e a ferramenta
debuginfo-installdevem ser instaladas no sistema. Para detalhes, veja Configurando para aplicações de depuração. -
Os canais que fornecem os pacotes
debuginfoedebugsourcedevem ser configurados e habilitados no sistema.
Procedimento
Inicie a GDB anexada à aplicação ou biblioteca que você deseja depurar. A GDB reconhece automaticamente as informações de depuração em falta e sugere um comando para executar.
$ gdb -q /bin/ls Reading symbols from /bin/ls...Reading symbols from .gnu_debugdata for /usr/bin/ls...(no debugging symbols found)...done. (no debugging symbols found)...done. Missing separate debuginfos, use: dnf debuginfo-install coreutils-8.30-6.el8.x86_64 (gdb)Sair da GDB: digite q e confirme com Enter.
(gdb) q
Execute o comando sugerido pela GDB para instalar os pacotes necessários
debuginfo:# dnf debuginfo-install coreutils-8.30-6.el8.x86_64
A ferramenta de gerenciamento de pacotes
dnffornece um resumo das mudanças, pede confirmação e, uma vez confirmada, baixa e instala todos os arquivos necessários.-
Caso a GDB não seja capaz de sugerir o pacote
debuginfo, siga o procedimento descrito em Obtendo pacotes de debuginfo para uma aplicação ou biblioteca manualmente.
13.5. Contagem de eventos durante a execução do processo
Você pode usar o comando perf stat para contar eventos de hardware e software durante a execução do processo.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
13.5.1. O objetivo do estatuto de perf
O comando perf stat executa um comando especificado, mantém uma contagem contínua das ocorrências de eventos de hardware e software durante a execução dos comandos e gera estatísticas dessas contagens. Se você não especificar nenhum evento, então perf stat conta um conjunto de eventos comuns de hardware e software.
13.5.2. Contando eventos com o perf stat
Você pode usar perf stat para contar ocorrências de eventos de hardware e software durante a execução do comando e gerar estatísticas destas contagens. Por padrão, perf stat opera em modo por linha.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
Procedimento
Conte os eventos.
A execução do comando
perf statsem acesso root contará apenas os eventos que ocorrem no espaço do usuário:$ por stat ls
Exemplo 13.2. Saída de perf stat sem acesso à raiz
Desktop Documents Downloads Music Pictures Public Templates Videos Performance counter stats for 'ls': 1.28 msec task-clock:u # 0.165 CPUs utilized 0 context-switches:u # 0.000 M/sec 0 cpu-migrations:u # 0.000 K/sec 104 page-faults:u # 0.081 M/sec 1,054,302 cycles:u # 0.823 GHz 1,136,989 instructions:u # 1.08 insn per cycle 228,531 branches:u # 178.447 M/sec 11,331 branch-misses:u # 4.96% of all branches 0.007754312 seconds time elapsed 0.000000000 seconds user 0.007717000 seconds sysComo você pode ver no exemplo anterior, quando
perf statcorre sem acesso root, os nomes dos eventos são seguidos por:u, indicando que estes eventos foram contados apenas no espaço do usuário.Para contar tanto os eventos de espaço do usuário quanto do kernel-space, você deve ter acesso à raiz ao rodar
perf stat:# perf stat ls
Exemplo 13.3. Saída de perf stat executado com acesso à raiz
Desktop Documents Downloads Music Pictures Public Templates Videos Performance counter stats for 'ls': 3.09 msec task-clock # 0.119 CPUs utilized 18 context-switches # 0.006 M/sec 3 cpu-migrations # 0.969 K/sec 108 page-faults # 0.035 M/sec 6,576,004 cycles # 2.125 GHz 5,694,223 instructions # 0.87 insn per cycle 1,092,372 branches # 352.960 M/sec 31,515 branch-misses # 2.89% of all branches 0.026020043 seconds time elapsed 0.000000000 seconds user 0.014061000 seconds sysPor padrão,
perf statopera em modo por fio. Para mudar para a contagem de eventos em toda a CPU, passe a opção-aparaperf stat. Para contar eventos em toda a CPU, você precisa de acesso root:# perf stat -a ls
Recursos adicionais
-
A página do homem
perf-stat(1).
13.5.3. Interpretação da produção estatística do perf
perf stat executa um comando especificado e conta as ocorrências de eventos durante a execução dos comandos e exibe as estatísticas dessas contagens em três colunas:
- O número de ocorrências contadas para um determinado evento
- O nome do evento que foi contado
Quando métricas relacionadas estão disponíveis, uma relação ou porcentagem é exibida após o sinal de hash (
#) na coluna mais à direita.-
Por exemplo, ao executar no modo padrão,
perf statconta tanto os ciclos quanto as instruções e, portanto, calcula e exibe as instruções por ciclo na coluna mais à direita. Você pode ver um comportamento semelhante com relação às falhas de ramos como um percentual de todos os ramos, uma vez que ambos os eventos são contados por default.
-
Por exemplo, ao executar no modo padrão,
13.5.4. Anexando o estatuto de perf a um processo em andamento
Você pode anexar perf stat a um processo em andamento. Isto instruirá perf stat a contar ocorrências de eventos somente nos processos especificados durante a execução de um comando.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
Procedimento
Anexar
perf stata um processo em andamento:US$ stat -p ID1,ID2 sleep seconds
O exemplo anterior conta os eventos nos processos com os IDs de
ID1eID2por um período de tempo desecondssegundos, conforme ditado usando o comandosleep.
Recursos adicionais
-
A página do homem
perf-stat(1).
13.6. Gravação e análise de perfis de desempenho com perf
A ferramenta perf permite que você registre dados de desempenho e os analise posteriormente.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
13.6.1. O propósito do registro de desempenho
O comando perf record mostra os dados de desempenho e os armazena em um arquivo, perf.data, que pode ser lido e visualizado com outros comandos perf. perf.data é gerado no diretório atual e pode ser acessado posteriormente, possivelmente em uma máquina diferente.
Se você não especificar um comando para perf record para gravar durante, ele irá gravar até que você pare o processo manualmente, pressionando Ctrl C. Você pode anexar perf record a processos específicos, passando a opção -p seguida de uma ou mais identificações de processo. Você pode rodar perf record sem acesso root, no entanto, fazendo isso, você só irá samplear os dados de desempenho no espaço do usuário. No modo padrão, perf record usa ciclos de CPU como evento de amostragem e opera no modo por linha com o modo de herança habilitado.
13.6.2. Gravação de um perfil de desempenho sem acesso à raiz
Você pode usar perf record sem acesso root a amostras e registros de dados de desempenho apenas no espaço do usuário.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
Procedimento
Amostragem e registro dos dados de desempenho:
Registro de desempenho de US$ commandSubstitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C.
Recursos adicionais
-
A página do homem
perf-record(1).
13.6.3. Gravação de um perfil de desempenho com acesso à raiz
Você pode usar perf record com acesso root a dados de desempenho de amostra e registro tanto no espaço do usuário quanto no espaço do kernel simultaneamente.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf. - Você tem acesso à raiz.
Procedimento
Amostragem e registro dos dados de desempenho:
# registro de desempenho commandSubstitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C.
Recursos adicionais
-
A página do homem
perf-record(1).
13.6.4. Gravação de um perfil de desempenho em modo por UCP
Você pode usar perf record no modo por CPU para amostrar e registrar dados de desempenho tanto no espaço do usuário como no espaço do kernel simultaneamente em todos os threads de uma CPU monitorada. Por padrão, o modo por UCP monitora todas as CPUs online.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostragem e registro dos dados de desempenho:
# registro perf -a commandSubstitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C.
Recursos adicionais
-
A página do homem
perf-record(1).
13.6.5. Captura de dados gráficos de chamada com registro de desempenho
Você pode configurar a ferramenta perf record para que ela registre qual função está chamando outras funções no perfil de desempenho. Isto ajuda a identificar um gargalo se vários processos estiverem chamando a mesma função.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostra e registro de dados de desempenho com a opção
--call-graph:Registro de desempenho --call-graph method command
-
Substitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C. Substitua method por um dos seguintes métodos de desenrolamento:
fp-
Utiliza o método do ponteiro da moldura. Dependendo da otimização do compilador, como com os binários construídos com a opção GCC
--fomit-frame-pointer, isto pode não ser capaz de desenrolar a pilha. dwarf- Utiliza as informações do DWARF Call Frame Information para desenrolar a pilha.
lbr- Utiliza o último hardware de registro de filial em processadores Intel.
-
Substitua
Recursos adicionais
-
A página do homem
perf-record(1).
13.6.6. Análise de dados perf.com relatório perf
Você pode usar perf report para exibir e analisar um arquivo perf.data.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Há um arquivo
perf.datano diretório atual. -
Se o arquivo
perf.datafoi criado com acesso root, você precisa rodarperf reportcom acesso root também.
Procedimento
Mostrar o conteúdo do arquivo
perf.datapara análise posterior:# relatório perf
Exemplo 13.4. Exemplo de saída
Samples: 2K of event 'cycles', Event count (approx.): 235462960 Overhead Command Shared Object Symbol 2.36% kswapd0 [kernel.kallsyms] [k] page_vma_mapped_walk 2.13% sssd_kcm libc-2.28.so [.] __memset_avx2_erms 2.13% perf [kernel.kallsyms] [k] smp_call_function_single 1.53% gnome-shell libc-2.28.so [.] __strcmp_avx2 1.17% gnome-shell libglib-2.0.so.0.5600.4 [.] g_hash_table_lookup 0.93% Xorg libc-2.28.so [.] __memmove_avx_unaligned_erms 0.89% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_object_unref 0.87% kswapd0 [kernel.kallsyms] [k] page_referenced_one 0.86% gnome-shell libc-2.28.so [.] __memmove_avx_unaligned_erms 0.83% Xorg [kernel.kallsyms] [k] alloc_vmap_area 0.63% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_alloc 0.53% gnome-shell libgirepository-1.0.so.1.0.0 [.] g_base_info_unref 0.53% gnome-shell ld-2.28.so [.] _dl_find_dso_for_object 0.49% kswapd0 [kernel.kallsyms] [k] vma_interval_tree_iter_next 0.48% gnome-shell libpthread-2.28.so [.] __pthread_getspecific 0.47% gnome-shell libgirepository-1.0.so.1.0.0 [.] 0x0000000000013b1d 0.45% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_free1 0.45% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_type_check_instance_is_fundamentally_a 0.44% gnome-shell libc-2.28.so [.] malloc 0.41% swapper [kernel.kallsyms] [k] apic_timer_interrupt 0.40% gnome-shell ld-2.28.so [.] _dl_lookup_symbol_x 0.39% kswapd0 [kernel.kallsyms] [k] __raw_callee_save___pv_queued_spin_unlock
Recursos adicionais
-
A página do homem
perf-report(1).
13.6.7. Interpretação da saída do relatório do perf
A tabela exibida ao executar o comando perf report ordena os dados em várias colunas:
- A coluna "Custos indiretos
- Indica que porcentagem das amostras globais foram coletadas nessa função específica.
- A coluna 'Comando'
- Diz a você de qual processo as amostras foram coletadas.
- A coluna "Objeto Compartilhado
- Mostra o nome da imagem ELF de onde vêm as amostras (o nome [kernel.kallsyms] é usado quando as amostras vêm do kernel).
- A coluna "Símbolo
- Exibe o nome ou símbolo da função.
No modo padrão, as funções são ordenadas em ordem decrescente com aquelas com a maior sobrecarga exibida primeiro.
13.6.8. Por que perf exibe alguns nomes de funções como endereços de funções em bruto
Para funções do núcleo, perf usa as informações do arquivo /proc/kallsyms para mapear as amostras para seus respectivos nomes de funções ou símbolos. Para funções executadas no espaço do usuário, entretanto, é possível ver endereços de funções em bruto, pois o binário é despojado.
O pacote debuginfo do executável deve ser instalado ou, se o executável for uma aplicação desenvolvida localmente, a aplicação deve ser compilada com informações de depuração ativadas (a opção -g no GCC) para exibir os nomes ou símbolos das funções em tal situação.
Recursos adicionais
Não é necessário executar novamente perf record após a instalação do debuginfo associado a um executável. Basta executar de novo perf report.
13.6.9. Habilitação de depuração e repositórios de fonte
Uma instalação padrão do Red Hat Enterprise Linux não habilita os repositórios de depuração e fonte. Estes repositórios contêm informações necessárias para depurar os componentes do sistema e medir seu desempenho.
Procedimento
Habilitar os canais do pacote de informações de origem e de depuração:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
A parte
$(uname -i)é automaticamente substituída por um valor correspondente para a arquitetura de seu sistema:Nome da arquitetura Valor Intel e AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
13.6.10. Obtendo pacotes de debuginfo para uma aplicação ou biblioteca usando GDB
As informações de depuração são necessárias para depurar o código. Para o código que é instalado a partir de um pacote, o GNU Debugger (GDB) reconhece automaticamente as informações de depuração faltantes, resolve o nome do pacote e fornece conselhos concretos sobre como obter o pacote.
Pré-requisitos
- A aplicação ou biblioteca que você deseja depurar deve ser instalada no sistema.
-
A GDB e a ferramenta
debuginfo-installdevem ser instaladas no sistema. Para detalhes, veja Configurando para aplicações de depuração. -
Os canais que fornecem os pacotes
debuginfoedebugsourcedevem ser configurados e habilitados no sistema.
Procedimento
Inicie a GDB anexada à aplicação ou biblioteca que você deseja depurar. A GDB reconhece automaticamente as informações de depuração em falta e sugere um comando para executar.
$ gdb -q /bin/ls Reading symbols from /bin/ls...Reading symbols from .gnu_debugdata for /usr/bin/ls...(no debugging symbols found)...done. (no debugging symbols found)...done. Missing separate debuginfos, use: dnf debuginfo-install coreutils-8.30-6.el8.x86_64 (gdb)Sair da GDB: digite q e confirme com Enter.
(gdb) q
Execute o comando sugerido pela GDB para instalar os pacotes necessários
debuginfo:# dnf debuginfo-install coreutils-8.30-6.el8.x86_64
A ferramenta de gerenciamento de pacotes
dnffornece um resumo das mudanças, pede confirmação e, uma vez confirmada, baixa e instala todos os arquivos necessários.-
Caso a GDB não seja capaz de sugerir o pacote
debuginfo, siga o procedimento descrito em Obtendo pacotes de debuginfo para uma aplicação ou biblioteca manualmente.
Capítulo 14. Monitoramento do desempenho do sistema com perf
Como administrador de sistema você pode usar a ferramenta perf para coletar e analisar os dados de desempenho de seu sistema.
14.1. Gravação de um perfil de desempenho em modo por UCP
Você pode usar perf record no modo por CPU para amostrar e registrar dados de desempenho tanto no espaço do usuário como no espaço do kernel simultaneamente em todos os threads de uma CPU monitorada. Por padrão, o modo por UCP monitora todas as CPUs online.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostragem e registro dos dados de desempenho:
# registro perf -a commandSubstitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C.
Recursos adicionais
-
A página do homem
perf-record(1).
14.2. Captura de dados gráficos de chamada com registro de desempenho
Você pode configurar a ferramenta perf record para que ela registre qual função está chamando outras funções no perfil de desempenho. Isto ajuda a identificar um gargalo se vários processos estiverem chamando a mesma função.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostra e registro de dados de desempenho com a opção
--call-graph:Registro de desempenho --call-graph method command
-
Substitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C. Substitua method por um dos seguintes métodos de desenrolamento:
fp-
Utiliza o método do ponteiro da moldura. Dependendo da otimização do compilador, como com os binários construídos com a opção GCC
--fomit-frame-pointer, isto pode não ser capaz de desenrolar a pilha. dwarf- Utiliza as informações do DWARF Call Frame Information para desenrolar a pilha.
lbr- Utiliza o último hardware de registro de filial em processadores Intel.
-
Substitua
Recursos adicionais
-
A página do homem
perf-record(1).
14.3. Identificação de CPUs ocupadas com perf
Ao investigar problemas de desempenho em um sistema, você pode usar a ferramenta perf para identificar as CPUs mais ocupadas, a fim de concentrar seus esforços.
14.3.1. Exibição de quais eventos de CPU foram contados com a estatística de perf
Você pode usar perf stat para exibir quais eventos de CPU foram contados, desativando a agregação de contagem de CPU. Você deve contar os eventos no modo de todo o sistema usando a bandeira -a para usar esta funcionalidade.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Conte os eventos com a agregação de contagem de CPU desativada:
# perf stat -a -A dormir secondsO exemplo anterior mostra a contagem de um conjunto padrão de eventos comuns de hardware e software registrados durante um período de tempo de
secondssegundos, como ditado pelo comandosleep, sobre cada CPU individual em ordem ascendente, começando porCPU0. Como tal, pode ser útil especificar um evento como os ciclos:# perf stat -a -A -e ciclos de sono seconds
14.3.2. Mostrando quais amostras de CPU foram coletadas com relatório de perf
O comando perf record mostra dados de desempenho e armazena esses dados em um arquivo perf.data que pode ser lido com o comando perf report. O comando perf record sempre registra quais amostras de CPU foram coletadas. Você pode configurar perf report para exibir estas informações.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Há um arquivo
perf.datacriado comperf recordno diretório atual. Se o arquivoperf.datafoi criado com acesso root, você precisa rodarperf reporttambém com acesso root.
Procedimento
Mostrar o conteúdo do arquivo
perf.datapara uma análise mais detalhada durante a ordenação por CPU:# relatório do perf --classificar cpu
Você pode ordenar por CPU e comando para exibir informações mais detalhadas sobre onde o tempo da CPU está sendo gasto:
# relatório perf --sort cpu,comm
Este exemplo listará os comandos de todas as CPUs monitoradas por total overhead em ordem decrescente de uso overhead e identificará a CPU na qual o comando foi executado.
Recursos adicionais
-
Para mais informações sobre a gravação de um arquivo
perf.data, consulte Gravação e análise de perfis de desempenho com perf.
14.3.3. Exibição de CPUs específicas durante a elaboração do perfil com perf top
Você pode configurar perf top para exibir CPUs específicas e seu uso relativo enquanto traça o perfil de seu sistema em tempo real.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Inicie a interface
perf topenquanto ordena por CPU:# perf top --sort cpu
Este exemplo listará as CPUs e suas respectivas despesas gerais em ordem decrescente de uso em tempo real.
Você pode classificar por CPU e comando para obter informações mais detalhadas sobre onde o tempo da CPU está sendo gasto:
# perf top --sort cpu,comm
Este exemplo listará os comandos por ordem decrescente de uso total e identificará a CPU na qual o comando foi executado em tempo real.
14.4. Monitoramento de CPUs específicas com perf
Você pode configurar a ferramenta perf para monitorar apenas CPUs específicas de interesse.
14.4.1. Monitoramento de CPUs específicas com registro de perf e relatório de perf
Você pode configurar perf record para apenas uma amostra específica de CPUs de interesse e analisar o arquivo perf.data gerado com perf report para análise posterior.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostra e registra os dados de desempenho nas CPU's específicas, gerando um arquivo
perf.data:Usando uma lista separada por vírgulas de CPUs:
# registro perf -C 0,1 sleep seconds
O exemplo anterior mostra amostras e registra dados em CPUs 0 e 1 por um período de
secondssegundos, conforme ditado pelo uso do comandosleep.Usando uma gama de CPUs:
# registro perf -C 0-2 sleep seconds
O exemplo anterior mostra e registra dados em todas as CPUs de CPU 0 a 2 por um período de
secondssegundos, conforme ditado pelo uso do comandosleep.
Mostrar o conteúdo do arquivo
perf.datapara análise posterior:# relatório perf
Este exemplo mostrará o conteúdo de
perf.data. Se você estiver monitorando várias CPUs e quiser saber quais dados de CPU foram amostrados, veja Mostrando quais amostras de CPU foram coletadas com o relatório perf.
14.4.2. Exibição de CPUs específicas durante a elaboração do perfil com perf top
Você pode configurar perf top para exibir CPUs específicas e seu uso relativo enquanto traça o perfil de seu sistema em tempo real.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Inicie a interface
perf topenquanto ordena por CPU:# perf top --sort cpu
Este exemplo listará as CPUs e suas respectivas despesas gerais em ordem decrescente de uso em tempo real.
Você pode classificar por CPU e comando para obter informações mais detalhadas sobre onde o tempo da CPU está sendo gasto:
# perf top --sort cpu,comm
Este exemplo listará os comandos por ordem decrescente de uso total e identificará a CPU na qual o comando foi executado em tempo real.
14.5. Gerar um arquivo de dados perf.data que seja legível em um dispositivo diferente
Você pode usar a ferramenta perf para registrar dados de desempenho em um arquivo perf.data para ser analisado em um dispositivo diferente.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
O pacote do kernel
debuginfoestá instalado. Para mais informações, consulte Obtendo pacotes de debuginfo para uma aplicação ou biblioteca usando o GDB.
Procedimento
Capture dados de desempenho que você esteja interessado em investigar mais a fundo:
# registro perf -a --call-graph fp sono secondsEste exemplo geraria um
perf.datasobre todo o sistema por um período desecondssegundos, conforme ditado pelo uso do comandosleep. Ele também capturaria dados de gráficos de chamada usando o método do ponteiro de frame.Gerar um arquivo contendo os símbolos de depuração dos dados registrados:
# arquivo perf
Etapas de verificação
Verifique se o arquivo foi gerado em seu diretório ativo atual:
# ls perf.data*
A saída exibirá cada arquivo em seu diretório atual que começa com
perf.data. O arquivo será nomeado também:perf.data.tar.gzou
perf data.tar.bz2
Recursos adicionais
-
Para mais informações sobre a gravação de um arquivo
perf.data, consulte Gravação e análise de perfis de desempenho com perf. -
Para mais informações sobre a captura de dados de gráficos de chamada com
perf record, consulte Capturar dados de gráficos de chamada com registro de desempenho.
14.6. Análise de um arquivo de dados perf.data que foi criado em um dispositivo diferente
Você pode usar a ferramenta perf para analisar um arquivo perf.data que foi gerado em um dispositivo diferente.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Um arquivo
perf.datae um arquivo associado gerado em um dispositivo diferente estão presentes no dispositivo atual que está sendo utilizado.
Procedimento
-
Copie tanto o arquivo
perf.datacomo o arquivo de arquivo em seu diretório ativo atual. Extraia o arquivo em
~/.debug:# mkdir -p ~/.debug # tar xf perf.data.tar.bz2 -C ~/.debugNotaO arquivo também pode ser nomeado
perf.data.tar.gz.Abra o arquivo
perf.datapara uma análise mais detalhada:# relatório perf
Capítulo 15. Monitoramento do desempenho da aplicação com perf
Esta seção descreve como usar a ferramenta perf para monitorar o desempenho da aplicação.
15.1. Anexar registro de desempenho a um processo em andamento
Pré-requisitos
Você pode anexar perf record a um processo em andamento. Isto instruirá perf record a apenas amostrar e registrar dados de desempenho nos processos especificados.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Anexar
perf recorda um processo em andamento:Registro de $per -p ID1,ID2 sleep seconds
O exemplo anterior mostra e registra os dados de desempenho dos processos com as identificações do processo
ID1eID2por um período de tempo desecondssegundos, conforme ditado usando o comandosleep. Você também pode configurarperfpara registrar eventos em threads específicos:Registro de $per -t ID1,ID2 sleep seconds
NotaAo usar a bandeira
-te estipular os identificadores de linha,perfdesabilita a herança por padrão. Você pode ativar a herança adicionando a opção--inherit.
15.2. Captura de dados gráficos de chamada com registro de desempenho
Você pode configurar a ferramenta perf record para que ela registre qual função está chamando outras funções no perfil de desempenho. Isto ajuda a identificar um gargalo se vários processos estiverem chamando a mesma função.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Amostra e registro de dados de desempenho com a opção
--call-graph:Registro de desempenho --call-graph method command
-
Substitua
commandcom o comando que você quer testar os dados durante. Se você não especificar um comando, entãoperf recordfará uma amostragem dos dados até que você os interrompa manualmente, pressionando Ctrl+C. Substitua method por um dos seguintes métodos de desenrolamento:
fp-
Utiliza o método do ponteiro da moldura. Dependendo da otimização do compilador, como com os binários construídos com a opção GCC
--fomit-frame-pointer, isto pode não ser capaz de desenrolar a pilha. dwarf- Utiliza as informações do DWARF Call Frame Information para desenrolar a pilha.
lbr- Utiliza o último hardware de registro de filial em processadores Intel.
-
Substitua
Recursos adicionais
-
A página do homem
perf-record(1).
15.3. Análise de dados perf.com relatório perf
Você pode usar perf report para exibir e analisar um arquivo perf.data.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Há um arquivo
perf.datano diretório atual. -
Se o arquivo
perf.datafoi criado com acesso root, você precisa rodarperf reportcom acesso root também.
Procedimento
Mostrar o conteúdo do arquivo
perf.datapara análise posterior:# relatório perf
Exemplo 15.1. Exemplo de saída
Samples: 2K of event 'cycles', Event count (approx.): 235462960 Overhead Command Shared Object Symbol 2.36% kswapd0 [kernel.kallsyms] [k] page_vma_mapped_walk 2.13% sssd_kcm libc-2.28.so [.] __memset_avx2_erms 2.13% perf [kernel.kallsyms] [k] smp_call_function_single 1.53% gnome-shell libc-2.28.so [.] __strcmp_avx2 1.17% gnome-shell libglib-2.0.so.0.5600.4 [.] g_hash_table_lookup 0.93% Xorg libc-2.28.so [.] __memmove_avx_unaligned_erms 0.89% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_object_unref 0.87% kswapd0 [kernel.kallsyms] [k] page_referenced_one 0.86% gnome-shell libc-2.28.so [.] __memmove_avx_unaligned_erms 0.83% Xorg [kernel.kallsyms] [k] alloc_vmap_area 0.63% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_alloc 0.53% gnome-shell libgirepository-1.0.so.1.0.0 [.] g_base_info_unref 0.53% gnome-shell ld-2.28.so [.] _dl_find_dso_for_object 0.49% kswapd0 [kernel.kallsyms] [k] vma_interval_tree_iter_next 0.48% gnome-shell libpthread-2.28.so [.] __pthread_getspecific 0.47% gnome-shell libgirepository-1.0.so.1.0.0 [.] 0x0000000000013b1d 0.45% gnome-shell libglib-2.0.so.0.5600.4 [.] g_slice_free1 0.45% gnome-shell libgobject-2.0.so.0.5600.4 [.] g_type_check_instance_is_fundamentally_a 0.44% gnome-shell libc-2.28.so [.] malloc 0.41% swapper [kernel.kallsyms] [k] apic_timer_interrupt 0.40% gnome-shell ld-2.28.so [.] _dl_lookup_symbol_x 0.39% kswapd0 [kernel.kallsyms] [k] __raw_callee_save___pv_queued_spin_unlock
Recursos adicionais
-
A página do homem
perf-report(1).
Capítulo 16. Acesso à memória de perfil com perf mem
16.1. O propósito do perf mem
O sub-comando mem da ferramenta perf permite a amostragem dos acessos à memória (cargas e armazéns). O comando perf mem fornece informações sobre a latência da memória, tipos de acessos à memória, funções que causam acertos e erros no cache e, através do registro do símbolo de dados, os locais da memória onde esses acertos e erros ocorrem.
16.2. Acesso à memória de amostragem com perf mem
Você pode usar o site perf mem para experimentar acessos de memória em seu sistema. O comando toma as mesmas opções que perf record e perf report, assim como algumas opções exclusivas do subcomando mem. Os dados gravados são armazenados em um arquivo perf.data no diretório atual para análise posterior.
Pré-requisitos
-
Você tem a ferramenta de espaço do usuário
perfinstalada como descrito em Instalando o perf.
Procedimento
Amostra os acessos à memória:
# per mem record - um sono secondsEste exemplo mostra os acessos à memória em todas as CPUs por um período de seconds segundos, como ditado pelo comando
sleep. Você pode substituir o comandosleeppor qualquer comando durante o qual você queira amostrar os dados de acesso à memória. Por padrão,perf memmostra tanto as cargas de memória quanto os armazéns. Você pode selecionar apenas uma operação de memória usando a opção-te especificando ou "carregar" ou "armazenar" entreperf memerecord. Para cargas, são capturadas informações sobre o nível hierárquico da memória, acessos à memória TLB, bus snoops e bloqueios de memória.Abra o arquivo
perf.datapara análise:# relatório perf mem
Se você tiver usado os comandos de exemplo, a saída é:
Available samples 35k cpu/mem-loads,ldlat=30/P 54k cpu/mem-stores/P
A linha
cpu/mem-loads,ldlat=30/Pdenota os dados coletados sobre as cargas de memória e a linhacpu/mem-stores/Pdenota os dados coletados sobre os depósitos de memória. Destaque a categoria de interesse e pressione Enter para visualizar os dados:Samples: 35K of event 'cpu/mem-loads,ldlat=30/P', Event count (approx.): 4067062 Overhead Samples Local Weight Memory access Symbol Shared Object Data Symbol Data Object Snoop TLB access Locked 0.07% 29 98 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 26 97 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 25 96 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.06% 1 2325 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e9084 [kernel.kallsyms] None L1 or L2 hit No 0.06% 1 2247 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e8164 [kernel.kallsyms] None L1 or L2 hit No 0.05% 1 2166 L1 or L1 hit [.] 0x00000000038140d6 libxul.so [.] 0x00007ffd7b84b4a8 [stack] None L1 or L2 hit No 0.05% 1 2117 Uncached or N/A hit [k] check_for_unclaimed_mmio [kernel.kallsyms] [k] 0xffffb092c1842300 [kernel.kallsyms] None L1 or L2 hit No 0.05% 22 95 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.05% 1 1898 L1 or L1 hit [.] 0x0000000002a30e07 libxul.so [.] 0x00007f610422e0e0 anon None L1 or L2 hit No 0.05% 1 1878 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e8164 [kernel.kallsyms] None L2 miss No 0.04% 18 94 L1 or L1 hit [.] 0x000000000000a255 libspeexdsp.so.1.5.0 [.] 0x00007f697a3cd0f0 anon None L1 or L2 hit No 0.04% 1 1593 Local RAM or RAM hit [.] 0x00000000026f907d libxul.so [.] 0x00007f3336d50a80 anon Hit L2 miss No 0.03% 1 1399 L1 or L1 hit [.] 0x00000000037cb5f1 libxul.so [.] 0x00007fbe81ef5d78 libxul.so None L1 or L2 hit No 0.03% 1 1229 LFB or LFB hit [.] 0x0000000002962aad libxul.so [.] 0x00007fb6f1be2b28 anon None L2 miss No 0.03% 1 1202 LFB or LFB hit [.] __pthread_mutex_lock libpthread-2.29.so [.] 0x00007fb75583ef20 anon None L1 or L2 hit No 0.03% 1 1193 Uncached or N/A hit [k] pci_azx_readl [kernel.kallsyms] [k] 0xffffb092c06e9164 [kernel.kallsyms] None L2 miss No 0.03% 1 1191 L1 or L1 hit [k] azx_get_delay_from_lpib [kernel.kallsyms] [k] 0xffffb092ca7efcf0 [kernel.kallsyms] None L1 or L2 hit No
Alternativamente, você pode classificar seus resultados para investigar diferentes aspectos de interesse ao exibir os dados. Por exemplo, para classificar os dados sobre as cargas de memória por tipo de acessos de memória que ocorrem durante o período de amostragem, em ordem decrescente de despesas gerais que eles contabilizam:
# perf mem -t load report --sort=mem
Por exemplo, a saída pode ser:
Samples: 35K of event 'cpu/mem-loads,ldlat=30/P', Event count (approx.): 40670 Overhead Samples Memory access 31.53% 9725 LFB or LFB hit 29.70% 12201 L1 or L1 hit 23.03% 9725 L3 or L3 hit 12.91% 2316 Local RAM or RAM hit 2.37% 743 L2 or L2 hit 0.34% 9 Uncached or N/A hit 0.10% 69 I/O or N/A hit 0.02% 825 L3 miss
Recursos adicionais
-
Para uma explicação das opções de comando específicas para o subcomando
mem, consulte a página de manualperf-mem(1).
16.3. Interpretação da saída do relatório perf mem
A tabela exibida executando o comando perf mem report sem nenhum modificador ordena os dados em várias colunas:
- A coluna "Custos indiretos
- Indica a porcentagem de amostras totais coletadas nessa função específica.
- A coluna "Amostras
- Exibe o número de amostras contabilizadas por essa linha.
- A coluna "Peso local
- Exibe a latência de acesso nos ciclos centrais do processador.
- A coluna 'Acesso à Memória'
- Exibe o tipo de acesso à memória que ocorreu.
- A coluna "Símbolo
- Exibe o nome ou símbolo da função.
- A coluna "Objeto Compartilhado
- Mostra o nome da imagem ELF de onde vêm as amostras (o nome [kernel.kallsyms] é usado quando as amostras vêm do kernel).
- A coluna 'Símbolo de dados
- Exibe o endereço do local da memória que a fila estava alvejando.
Muitas vezes, devido à alocação dinâmica da memória ou da memória em pilha sendo acessada, a coluna 'Símbolo de Dados' exibirá um endereço bruto.
- A coluna "Snoop
- Exibe as transações de ônibus.
- A coluna "Acesso TLB"
- Exibe acessos à memória TLB.
- A coluna "Trancado
- Indica se uma função estava ou não bloqueada na memória.
No modo padrão, as funções são ordenadas em ordem decrescente com aquelas com a maior sobrecarga exibida primeiro.
Capítulo 17. Detecção de compartilhamento falso com o perf c2c
17.1. O objetivo do perf c2c
O subcomando c2c da ferramenta perf permite a análise Cache-to-Cache (C2C) de dados compartilhados. Você pode usar o comando perf c2c para inspecionar a contenção da linha de cache para detectar tanto o compartilhamento verdadeiro quanto o falso.
A contenção da linha de cache ocorre quando um núcleo de processador em um sistema de multiprocessamento simétrico (SMP) modifica os itens de dados na mesma linha de cache que está em uso por outros processadores. Todos os outros processadores que usam esta linha de cache devem então invalidar sua cópia e solicitar uma atualizada. Isto pode levar a um desempenho degradado.
The perf c2c command provides the following information: * Cache lines where contention has been detected * Processes reading and writing the data * Instructions causing the contention * The Non-Uniform Memory Access (NUMA) nodes involved in the contention
17.2. Falso compartilhamento
O compartilhamento falso ocorre quando um núcleo de processador em um sistema de multiprocessamento simétrico (SMP) modifica os itens de dados na mesma linha de cache que está em uso por outros processadores para acessar outros itens de dados que não estão sendo compartilhados entre os processadores. Esta modificação inicial exige que os outros processadores que usam a linha de cache invalidem sua cópia e solicitem uma atualizada, apesar dos processadores não precisarem, ou mesmo necessariamente terem acesso a, uma versão atualizada do item de dados modificado.
17.3. Detecção de contenção de linha de cache com o perf c2c
Use o comando perf c2c para detectar a contenção da linha de cache em um sistema. O comando perf c2c suporta as mesmas opções que perf record, assim como algumas opções exclusivas do subcomando c2c. Os dados registrados são armazenados em um arquivo perf.data no diretório atual para análise posterior.
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf.
Procedimento
Use
perf c2cpara detectar a contenção da linha de cache:# registro perf c2c -a sleep seconds
Este exemplo mostra e registra dados de contenção de linha de cache em todas as CPU's por um período de
secondscomo ditado pelo comandosleep. Você pode substituir o comandosleeppor qualquer comando sobre o qual você queira coletar dados de contenção da linha de cache.
Recursos adicionais
-
Para uma explicação das opções de comando específicas para o subcomando
c2c, consulte a página de manualperf-c2c(1).
17.4. Visualizando um arquivo de dados perf.data gravado com o registro perf c2c
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Um arquivo
perf.datagravado usando o comandoperf c2cestá disponível no diretório atual. Para mais informações, consulte Detectando contenção de linha de cache com o perf c2c.
Procedimento
Abra o arquivo
perf.datapara uma análise mais detalhada:# relatório perf c2c --stdio
Este comando visualiza o arquivo
perf.dataem vários gráficos dentro do terminal:================================================= Trace Event Information ================================================= Total records : 329219 Locked Load/Store Operations : 14654 Load Operations : 69679 Loads - uncacheable : 0 Loads - IO : 0 Loads - Miss : 3972 Loads - no mapping : 0 Load Fill Buffer Hit : 11958 Load L1D hit : 17235 Load L2D hit : 21 Load LLC hit : 14219 Load Local HITM : 3402 Load Remote HITM : 12757 Load Remote HIT : 5295 Load Local DRAM : 976 Load Remote DRAM : 3246 Load MESI State Exclusive : 4222 Load MESI State Shared : 0 Load LLC Misses : 22274 LLC Misses to Local DRAM : 4.4% LLC Misses to Remote DRAM : 14.6% LLC Misses to Remote cache (HIT) : 23.8% LLC Misses to Remote cache (HITM) : 57.3% Store Operations : 259539 Store - uncacheable : 0 Store - no mapping : 11 Store L1D Hit : 256696 Store L1D Miss : 2832 No Page Map Rejects : 2376 Unable to parse data source : 1 ================================================= Global Shared Cache Line Event Information ================================================= Total Shared Cache Lines : 55 Load HITs on shared lines : 55454 Fill Buffer Hits on shared lines : 10635 L1D hits on shared lines : 16415 L2D hits on shared lines : 0 LLC hits on shared lines : 8501 Locked Access on shared lines : 14351 Store HITs on shared lines : 109953 Store L1D hits on shared lines : 109449 Total Merged records : 126112 ================================================= c2c details ================================================= Events : cpu/mem-loads,ldlat=30/P : cpu/mem-stores/P Cachelines sort on : Remote HITMs Cacheline data groupping : offset,pid,iaddr ================================================= Shared Data Cache Line Table ================================================= # # Total Rmt ----- LLC Load Hitm ----- ---- Store Reference ---- --- Load Dram ---- LLC Total ----- Core Load Hit ----- -- LLC Load Hit -- # Index Cacheline records Hitm Total Lcl Rmt Total L1Hit L1Miss Lcl Rmt Ld Miss Loads FB L1 L2 Llc Rmt # ..... .................. ....... ....... ....... ....... ....... ....... ....... ....... ........ ........ ....... ....... ....... ....... ....... ........ ........ # 0 0x602180 149904 77.09% 12103 2269 9834 109504 109036 468 727 2657 13747 40400 5355 16154 0 2875 529 1 0x602100 12128 22.20% 3951 1119 2832 0 0 0 65 200 3749 12128 5096 108 0 2056 652 2 0xffff883ffb6a7e80 260 0.09% 15 3 12 161 161 0 1 1 15 99 25 50 0 6 1 3 0xffffffff81aec000 157 0.07% 9 0 9 1 0 1 0 7 20 156 50 59 0 27 4 4 0xffffffff81e3f540 179 0.06% 9 1 8 117 97 20 0 10 25 62 11 1 0 24 7 ================================================= Shared Cache Line Distribution Pareto ================================================= # # ----- HITM ----- -- Store Refs -- Data address ---------- cycles ---------- cpu Shared # Num Rmt Lcl L1 Hit L1 Miss Offset Pid Code address rmt hitm lcl hitm load cnt Symbol Object Source:Line Node{cpu list} # ..... ....... ....... ....... ....... .................. ....... .................. ........ ........ ........ ........ ................... .................... ........................... .... # ------------------------------------------------------------- 0 9834 2269 109036 468 0x602180 ------------------------------------------------------------- 65.51% 55.88% 75.20% 0.00% 0x0 14604 0x400b4f 27161 26039 26017 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:144 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 0.41% 0.35% 0.00% 0.00% 0x0 14604 0x400b56 18088 12601 26671 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:145 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 0.00% 0.00% 24.80% 100.00% 0x0 14604 0x400b61 0 0 0 9 [.] read_write_func no_false_sharing.exe false_sharing_example.c:145 0{0-1,4} 1{24-25,120} 2{48,54} 3{169} 7.50% 9.92% 0.00% 0.00% 0x20 14604 0x400ba7 2470 1729 1897 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:154 1{122} 2{144} 17.61% 20.89% 0.00% 0.00% 0x28 14604 0x400bc1 2294 1575 1649 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:158 2{53} 3{170} 8.97% 12.96% 0.00% 0.00% 0x30 14604 0x400bdb 2325 1897 1828 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:162 0{96} 3{171} ------------------------------------------------------------- 1 2832 1119 0 0 0x602100 ------------------------------------------------------------- 29.13% 36.19% 0.00% 0.00% 0x20 14604 0x400bb3 1964 1230 1788 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:155 1{122} 2{144} 43.68% 34.41% 0.00% 0.00% 0x28 14604 0x400bcd 2274 1566 1793 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:159 2{53} 3{170} 27.19% 29.40% 0.00% 0.00% 0x30 14604 0x400be7 2045 1247 2011 2 [.] read_write_func no_false_sharing.exe false_sharing_example.c:163 0{96} 3{171}
17.5. Interpretação da saída do relatório perf c2c
A visualização exibida ao executar o comando perf c2c report --stdio ordena os dados em várias tabelas:
- Informações sobre eventos de rastreamento
-
Esta tabela fornece um resumo de alto nível de todas as amostras de carga e armazenamento, que são coletadas pelo comando
perf c2c record. - Informações sobre eventos da Linha Global Shared Cache
- Esta tabela fornece estatísticas sobre as linhas de cache compartilhadas.
- c2c Detalhes
-
Esta tabela fornece informações sobre quais eventos foram amostrados e como os dados do
perf c2c reportsão organizados dentro da visualização. - Tabela de Linha de Cache de Dados Compartilhados
- Esta tabela fornece um resumo de uma linha para as linhas de cache mais quentes onde o compartilhamento falso é detectado e é classificado em ordem decrescente pela quantidade de HITMs remotos detectados por linha de cache por padrão.
- Distribuição de Linha de Cache compartilhada Pareto
Estas tabelas fornecem uma variedade de informações sobre cada linha de cache com contendas:
- As linhas do cache estão numeradas na coluna "NUM", começando em 0.
- O endereço virtual de cada linha de cache está contido na coluna "Offset do endereço de dados" e seguido posteriormente pelo offset na linha de cache onde ocorreram diferentes acessos.
- A coluna "Pid" contém a identificação do processo.
- A coluna "Endereço do código" contém o endereço do código do ponteiro de instruções.
- As colunas sob a etiqueta "ciclos" mostram as latências médias de carga.
- A coluna "cpu cnt" mostra quantas amostras diferentes de CPUs vieram (essencialmente, quantas CPUs diferentes estavam esperando pelos dados indexados naquele determinado local).
- A coluna "Símbolo" exibe o nome ou símbolo da função.
- A coluna "Shared Object" mostra o nome da imagem ELF de onde vêm as amostras (o nome [kernel.kallsyms] é usado quando as amostras vêm do kernel).
- A coluna "Fonte:Linha" exibe o arquivo fonte e o número da linha.
- A coluna "Lista de Nó" mostra de quais CPUs específicas vieram amostras para cada nó.
17.6. Detecção de compartilhamento falso com o perf c2c
Pré-requisitos
-
A ferramenta de espaço do usuário
perfestá instalada. Para mais informações, consulte Instalando o perf. -
Um arquivo
perf.datagravado usando o comandoperf c2cestá disponível no diretório atual. Para mais informações, consulte Detectando contenção de linha de cache com o perf c2c.
Procedimento
Abra o arquivo
perf.datapara uma análise mais detalhada:# relatório perf c2c --stdio
Isto abre o arquivo
perf.datano terminal.Na tabela "Trace Event Information", localize a linha contendo os valores para "LLC Misses to Remote Cache (HITM)":
================================================= Trace Event Information ================================================= Total records : 329219 Locked Load/Store Operations : 14654 Load Operations : 69679 Loads - uncacheable : 0 Loads - IO : 0 Loads - Miss : 3972 Loads - no mapping : 0 Load Fill Buffer Hit : 11958 Load L1D hit : 17235 Load L2D hit : 21 Load LLC hit : 14219 Load Local HITM : 3402 Load Remote HITM : 12757 Load Remote HIT : 5295 Load Local DRAM : 976 Load Remote DRAM : 3246 Load MESI State Exclusive : 4222 Load MESI State Shared : 0 Load LLC Misses : 22274 LLC Misses to Local DRAM : 4.4% LLC Misses to Remote DRAM : 14.6% LLC Misses to Remote cache (HIT) : 23.8% LLC Misses to Remote cache (HITM) : 57.3% Store Operations : 259539 Store - uncacheable : 0 Store - no mapping : 11 Store L1D Hit : 256696 Store L1D Miss : 2832 No Page Map Rejects : 2376 Unable to parse data source : 1A porcentagem na coluna de valores da linha "LLC Misses to Remote Cache (HITM)" representa a porcentagem de LLC misses que estavam ocorrendo através dos nós NUMA em linhas de cache modificadas e é um indicador chave de que ocorreu falso compartilhamento.
Inspecione a coluna "Rmt" do campo "LLC Load Hitm" do campo "Shared Data Cache Line Table":
================================================= Shared Data Cache Line Table ================================================= # # Total Rmt ----- LLC Load Hitm ----- ---- Store Reference ---- --- Load Dram ---- LLC Total ----- Core Load Hit ----- -- LLC Load Hit -- # Index Cacheline records Hitm Total Lcl Rmt Total L1Hit L1Miss Lcl Rmt Ld Miss Loads FB L1 L2 Llc Rmt # ..... .................. ....... ....... ....... ....... ....... ....... ....... ....... ........ ........ ....... ....... ....... ....... ....... ........ ........ # 0 0x602180 149904 77.09% 12103 2269 9834 109504 109036 468 727 2657 13747 40400 5355 16154 0 2875 529 1 0x602100 12128 22.20% 3951 1119 2832 0 0 0 65 200 3749 12128 5096 108 0 2056 652 2 0xffff883ffb6a7e80 260 0.09% 15 3 12 161 161 0 1 1 15 99 25 50 0 6 1 3 0xffffffff81aec000 157 0.07% 9 0 9 1 0 1 0 7 20 156 50 59 0 27 4 4 0xffffffff81e3f540 179 0.06% 9 1 8 117 97 20 0 10 25 62 11 1 0 24 7Esta tabela é classificada em ordem decrescente pela quantidade de HITMs remotos detectados por linha de cache. Um número alto na coluna "Rmt" da seção "LLC Load Hitm" indica falso compartilhamento e requer uma inspeção adicional da linha de cache na qual ocorreu a depuração da atividade de falso compartilhamento.
Capítulo 18. Começando com flamegraphs
Como administrador do sistema, você pode usar flamegraphs para criar visualizações dos dados de desempenho do sistema registrados com a ferramenta perf. Como desenvolvedor de software, você pode usar flamegraphs para criar visualizações de dados de desempenho de aplicativos gravados com a ferramenta perf.
A amostragem de traços de pilha é uma técnica comum para traçar o desempenho da CPU com a ferramenta perf. Infelizmente, os resultados dos traços da pilha de perfis com perf podem ser extremamente verbosos e trabalhosos de análise. flamegraphs são visualizações criadas a partir de dados gravados com perf para tornar a identificação de hot code-paths mais rápida e fácil.
18.1. Instalação de flamegrafos
Para começar a utilizar flamegraphs, instale o pacote necessário:
Procedimento
Instale o pacote
flamegraphs:# yum instalar js-d3-flame-graph
18.2. Criação de flamegrafos em todo o sistema
Este procedimento descreve como visualizar os dados de desempenho registrados em todo um sistema usando flamegraphs.
Pré-requisitos
-
flamegraphssão instalados como descrito na instalação de flamegraphs. -
A ferramenta
perfé instalada conforme descrito na instalação do perf.
Procedimento
Registrar os dados e criar a visualização:
# perf script flamegraph -a -F 99 sono 60
Este comando mostra e registra dados de desempenho sobre todo o sistema por 60 segundos, conforme estipulado pelo uso do comando
sleep, e então constrói a visualização que será armazenada no diretório ativo atual comoflamegraph.html. O comando irá amostrar por padrão os dados de chamada de dados e toma os mesmos argumentos que a ferramentaperf, neste caso particular:-a- Estipula para registrar dados sobre todo o sistema.
-F- Para definir a freqüência de amostragem por segundo.
Etapas de verificação
Para análise, veja o flamegraph gerado:
# xdg-open flamegraph.html
Este comando abre o flamegraph no navegador padrão:
18.3. Criação de flamegrafos sobre processos específicos
Você pode usar flamegraphs para visualizar os dados de desempenho registrados em processos específicos de execução.
Pré-requisitos
-
flamegraphssão instalados como descrito na instalação de flamegraphs. -
A ferramenta
perfé instalada conforme descrito na instalação do perf.
Procedimento
Registrar os dados e criar a visualização:
# perf script flamegraph -a -F 99 -p
ID1,ID2dormir 60Este comando registra amostras e dados de desempenho dos processos com os ID's do processo
ID1eID2por 60 segundos, conforme estipulado pelo uso do comandosleep, e depois constrói a visualização que será armazenada no diretório ativo atual comoflamegraph.html. O comando irá amostrar por padrão os dados de chamadas de autógrafos e leva os mesmos argumentos que a ferramentaperf, neste caso particular:-a- Estipula para registrar dados sobre todo o sistema.
-F- Para definir a freqüência de amostragem por segundo.
-p- Estipular identificações de processo específicas para amostragem e registro de dados.
Etapas de verificação
Para análise, veja o flamegraph gerado:
# xdg-open flamegraph.html
Este comando anterior abre o flamegraph no navegador padrão:
18.4. Interpretação de flamegrafos
Cada caixa no flamegraph representa uma função diferente na pilha. O eixo y mostra a profundidade da pilha com a caixa mais alta em cada pilha sendo a função que estava realmente na UCP e tudo abaixo dela sendo ancestral. O eixo x mostra a população da amostra dos dados do gráfico de chamada. Os filhos de uma pilha em uma determinada fila são exibidos com base no número de amostras coletadas de cada função respectiva em ordem decrescente ao longo do eixo x; o eixo x does not representa a passagem do tempo. Quanto mais ampla for uma caixa individual, mais freqüente ela estava na UCP ou parte de um ancestral da UCP no momento em que os dados estavam sendo amostrados.
- IMPORTANTE
-
As caixas que representam funções de espaço do usuário podem ser etiquetadas como Unknown em
flamegraphsporque o binário da função é despojado. O pacotedebuginfodo executável deve ser instalado ou, se o executável for uma aplicação desenvolvida localmente, a aplicação deve ser compilada com informações de depuração, a opção-gno GCC, para exibir os nomes ou símbolos da função em tal situação.
Procedimento
- Para revelar os nomes das funções que podem não ter sido exibidas anteriormente e investigar melhor os dados, clique em uma caixa dentro do flamegraph para ampliar a pilha naquele determinado local:
- Para retornar à visualização padrão do flamegraph, clique no botão
Capítulo 19. Alocação de memória de perfil com numastat
Com a ferramenta numastat, você pode exibir estatísticas sobre a alocação de memória em um sistema. A ferramenta numastat exibe os dados para cada nó NUMA separadamente. Você pode usar estas informações para investigar o desempenho da memória de seu sistema ou a eficácia de diferentes políticas de memória em seu sistema.
19.1. Estatísticas numastat por padrão
Por padrão, a ferramenta numastat exibe estatísticas sobre essas categorias de dados para cada nó NUMA:
numa_hit- O número de páginas que foram alocadas com sucesso a este nó.
numa_miss-
O número de páginas que foram alocadas neste nó por causa da baixa memória no nó pretendido. Cada evento
numa_misstem um evento correspondentenuma_foreignem outro nó. numa_foreign-
O número de páginas inicialmente destinadas a este nó que foram atribuídas a outro nó em seu lugar. Cada evento
numa_foreigntem um evento correspondentenuma_missem outro nó. interleave_hit- O número de páginas de política de intercalação atribuídas com sucesso a este nó.
local_node- O número de páginas alocadas com sucesso neste nó por um processo neste nó.
other_node- O número de páginas alocadas neste nó por um processo em outro nó.
Os valores altos numa_hit e baixos numa_miss (relativos uns aos outros) indicam um ótimo desempenho.
19.2. Alocação de memória de perfil com numastat
Perfilar a alocação de memória do sistema usando a ferramenta numastat.
Pré-requisitos
-
Você tem o pacote
numactlinstalado.
Procedimento
Faça o perfil da alocação de memória do seu sistema:
$ numastat node0 node1 numa_hit 76557759 92126519 numa_miss 30772308 30827638 numa_foreign 30827638 30772308 interleave_hit 106507 103832 local_node 76502227 92086995 other_node 30827840 30867162
Recursos adicionais
-
A página do homem
numastat(8).
Capítulo 20. Configuração de um sistema operacional para otimizar a utilização da CPU
Esta seção descreve como configurar o sistema operacional para otimizar a utilização da CPU através de suas cargas de trabalho.
20.1. Ferramentas para monitoramento e diagnóstico de problemas do processador
A seguir estão as ferramentas disponíveis no Red Hat Enterprise Linux 8 para monitorar e diagnosticar problemas de desempenho relacionados ao processador:
-
turbostatimprime resultados de contador em intervalos especificados para ajudar os administradores a identificar comportamentos inesperados nos servidores, tais como uso excessivo de energia, falha em entrar em estados de sono profundo ou interrupções de gerenciamento do sistema (SMIs) sendo criadas desnecessariamente. -
numactloferece uma série de opções para gerenciar a afinidade entre processador e memória. O pacotenumactlinclui a bibliotecalibnumaque oferece uma interface de programação simples para a política NUMA suportada pelo kernel, e pode ser usado para sintonia mais fina do que a aplicaçãonumactl. -
a ferramenta
numastatexibe estatísticas de memória por nó do sistema operacional e seus processos, e mostra aos administradores se a memória do processo está espalhada por um sistema ou se está centralizada em nós específicos. Esta ferramenta é fornecida pelo pacotenumactl. -
numadé um daemon automático de gestão de afinidade NUMA. Ele monitora a topologia NUMA e o uso de recursos dentro de um sistema, a fim de melhorar dinamicamente a alocação e o gerenciamento de recursos NUMA. -
/proc/interruptsexibe o número da solicitação de interrupção (IRQ), o número de solicitações de interrupção similares tratadas por cada processador no sistema, o tipo de interrupção enviada e uma lista separada por vírgula dos dispositivos que respondem à solicitação de interrupção listada. pqosestá disponível no pacoteintel-cmt-cat. Ele monitora o cache da CPU e a largura de banda de memória em processadores Intel recentes. Ele monitora:- As instruções por ciclo (IPC).
- A contagem do cache de último nível MISSES.
- O tamanho em kilobytes que o programa executando em uma determinada CPU ocupa na LLC.
- A largura de banda para a memória local (MBL).
- A largura de banda para memória remota (MBR).
-
a ferramenta
x86_energy_perf_policypermite aos administradores definir a importância relativa do desempenho e da eficiência energética. Estas informações podem então ser usadas para influenciar os processadores que suportam esta característica quando selecionam opções que se alternam entre desempenho e eficiência energética. -
a ferramenta
taskseté fornecida pelo pacoteutil-linux. Ela permite aos administradores recuperar e definir a afinidade do processador de um processo em execução, ou lançar um processo com uma afinidade de processador especificada.
Recursos adicionais
-
Para mais informações, consulte as páginas de homens de
turbostat,numactl,numastat,numa,numad,pqos,x86_energy_perf_policy, etaskset.
20.2. Determinação da topologia do sistema
Na computação moderna, a idéia de uma CPU é enganosa, pois a maioria dos sistemas modernos tem vários processadores. A topologia do sistema é a forma como esses processadores estão conectados uns aos outros e a outros recursos do sistema. Isto pode afetar o desempenho do sistema e das aplicações, e as considerações de ajuste de um sistema.
20.2.1. Tipos de topologia de sistema
A seguir estão os dois tipos primários de topologia utilizados na computação moderna:
- Topologia Simétrica Multi-Processador (SMP)
- A topologia SMP permite que todos os processadores tenham acesso à memória no mesmo período de tempo. Entretanto, como o acesso à memória compartilhada e igualitária força inerentemente o acesso à memória em série de todas as CPUs, as restrições de escala do sistema SMP são agora geralmente vistas como inaceitáveis. Por esta razão, praticamente todos os sistemas de servidores modernos são máquinas NUMA.
- Topologia de Acesso à Memória Não-Uniforme (NUMA)
A topologia NUMA foi desenvolvida mais recentemente do que a topologia SMP. Em um sistema NUMA, múltiplos processadores são agrupados fisicamente em um soquete. Cada soquete tem uma área dedicada de memória e processadores que têm acesso local a essa memória, estes são referidos coletivamente como um nó. Os processadores no mesmo nó têm acesso de alta velocidade ao banco de memória desse nó, e acesso mais lento aos bancos de memória que não estão em seu nó.
Portanto, há uma penalidade de desempenho ao acessar a memória não-local. Assim, aplicações sensíveis ao desempenho em um sistema com topologia NUMA devem acessar memória que esteja no mesmo nó que o processador que executa a aplicação, e devem evitar acessar memória remota sempre que possível.
Aplicações com múltiplas roscas sensíveis ao desempenho podem se beneficiar de serem configuradas para executar em um nó NUMA específico em vez de em um processador específico. Se isto é adequado depende de seu sistema e dos requisitos de sua aplicação. Se vários threads de aplicação acessarem os mesmos dados em cache, então a configuração desses threads para execução no mesmo processador pode ser adequada. Entretanto, se várias threads que acessam e armazenam dados diferentes executam no mesmo processador, cada thread pode despejar os dados em cache acessados por uma thread anterior. Isto significa que cada thread 'falha' o cache e desperdiça tempo de execução, recuperando os dados da memória e substituindo-os no cache. Use a ferramenta
perfpara verificar se há um número excessivo de falhas no cache.
20.2.2. Exibição de topologias de sistemas
Há uma série de comandos que ajudam a entender a topologia de um sistema. Este procedimento descreve como determinar a topologia de um sistema.
Procedimento
Para exibir uma visão geral da topologia de seu sistema:
$ numactl --hardware available: 4 nodes (0-3) node 0 cpus: 0 4 8 12 16 20 24 28 32 36 node 0 size: 65415 MB node 0 free: 43971 MB [...]
Reunir as informações sobre a arquitetura da CPU, tais como o número de CPUs, fios, núcleos, soquetes e nós NUMA:
$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 40 On-line CPU(s) list: 0-39 Thread(s) per core: 1 Core(s) per socket: 10 Socket(s): 4 NUMA node(s): 4 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Model name: Intel(R) Xeon(R) CPU E7- 4870 @ 2.40GHz Stepping: 2 CPU MHz: 2394.204 BogoMIPS: 4787.85 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36 NUMA node1 CPU(s): 2,6,10,14,18,22,26,30,34,38 NUMA node2 CPU(s): 1,5,9,13,17,21,25,29,33,37 NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39
Para ver uma representação gráfica de seu sistema:
# yum install hwloc-gui # lstopo
Figura 20.1. A saída
lstopo
Para ver a saída textual detalhada:
# yum install hwloc # lstopo-no-graphics Machine (15GB) Package L#0 + L3 L#0 (8192KB) L2 L#0 (256KB) + L1d L#0 (32KB) + L1i L#0 (32KB) + Core L#0 PU L#0 (P#0) PU L#1 (P#4) HostBridge L#0 PCI 8086:5917 GPU L#0 "renderD128" GPU L#1 "controlD64" GPU L#2 "card0" PCIBridge PCI 8086:24fd Net L#3 "wlp61s0" PCIBridge PCI 8086:f1a6 PCI 8086:15d7 Net L#4 "enp0s31f6"
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
numactl,lscpuelstopo.
20.3. Política de programação de sintonia
No Red Hat Enterprise Linux, a menor unidade de execução de processo é chamada de thread. O programador do sistema determina qual processador executa uma thread, e por quanto tempo a thread funciona. Entretanto, como a principal preocupação do agendador é manter o sistema ocupado, ele pode não agendar threads de maneira ideal para o desempenho da aplicação.
Por exemplo, digamos que uma aplicação em um sistema NUMA está rodando no Nó A quando um processador no Nó B se torna disponível. Para manter o processador no Nó B ocupado, o programador move uma das threads da aplicação para o Nó B. Entretanto, a thread da aplicação ainda requer acesso à memória no Nó A. Mas, esta memória levará mais tempo para ser acessada porque a thread agora está rodando no Nó B e a memória do Nó A não é mais local para a thread. Assim, pode levar mais tempo para que a thread termine de rodar no nó B do que levaria para esperar que um processador no nó A ficasse disponível, e então executar a thread no nó original com acesso à memória local.
As aplicações sensíveis ao desempenho muitas vezes se beneficiam do designer ou administrador que determina onde os fios são executados. O programador Linux implementa uma série de políticas de programação que determinam onde e por quanto tempo um thread é executado. A seguir estão as duas principais categorias de políticas de agendamento:
- Políticas normais: Os fios normais são usados para tarefas de prioridade normal.
- Políticas em tempo real: As políticas em tempo real são utilizadas para tarefas sensíveis ao tempo que devem ser concluídas sem interrupções. Os fios em tempo real não estão sujeitos a cortes de tempo. Isto significa que a rosca corre até que bloqueie, saia, ceda voluntariamente, ou seja, é preterida por uma rosca de maior prioridade. A rosca de prioridade mais baixa em tempo real é programada antes de qualquer rosca com uma política normal. Para mais informações, consulte Seção 20.3.1, “Programação estática de prioridades com SCHED_FIFO” e Seção 20.3.2, “Agendamento prioritário redondo com SCHED_RR”.
20.3.1. Programação estática de prioridades com SCHED_FIFO
O SCHED_FIFO, também chamado de programação estática de prioridades, é uma política em tempo real que define uma prioridade fixa para cada linha. Esta política permite que os administradores melhorem o tempo de resposta de eventos e reduzam a latência. É recomendável não executar esta política por um período de tempo prolongado para tarefas sensíveis ao tempo.
Quando SCHED_FIFO estiver em uso, o agendador escaneia a lista de todos os tópicos SCHED_FIFO em ordem de prioridade e agenda o tópico de prioridade mais alta que está pronto para rodar. O nível de prioridade de um tópico SCHED_FIFO pode ser qualquer número inteiro de 1 a 99, onde 99 é tratado como a prioridade mais alta. A Red Hat recomenda começar com um número mais baixo e aumentar a prioridade somente quando você identificar problemas de latência.
Como as roscas em tempo real não estão sujeitas ao corte do tempo, a Red Hat não recomenda estabelecer uma prioridade como 99. Isto mantém seu processo no mesmo nível de prioridade que as roscas de migração e de vigilância; se sua rosca entrar em um loop computacional e estas roscas estiverem bloqueadas, elas não poderão funcionar. Os sistemas com um único processador acabarão ficando pendurados nesta situação.
Os administradores podem limitar a largura de banda SCHED_FIFO para impedir que programadores de aplicações em tempo real iniciem tarefas em tempo real que monopolizam o processador.
A seguir estão alguns dos parâmetros utilizados nesta política:
/proc/sys/kernel/sched_rt_period_us-
Este parâmetro define o período de tempo, em microssegundos, que é considerado como cem por cento da largura de banda do processador. O valor padrão é
1000000 μs, ou1 second. /proc/sys/kernel/sched_rt_runtime_us-
Este parâmetro define o período de tempo, em microssegundos, que é dedicado à execução de roscas em tempo real. O valor padrão é
950000 μs, ou0.95 seconds.
20.3.2. Agendamento prioritário redondo com SCHED_RR
O SCHED_RR é uma variante de roupão redondo do site SCHED_FIFO. Esta política é útil quando vários fios precisam ser executados no mesmo nível de prioridade.
Como SCHED_FIFO, SCHED_RR é uma política em tempo real que define uma prioridade fixa para cada linha. O programador escaneia a lista de todos os tópicos SCHED_RR em ordem de prioridade e programa o tópico de prioridade mais alta que está pronto para rodar. Entretanto, ao contrário de SCHED_FIFO, as roscas que têm a mesma prioridade são programadas em estilo round-robin dentro de uma determinada faixa de tempo.
Você pode definir o valor desta fatia de tempo em milissegundos com o parâmetro sched_rr_timeslice_ms kernel no arquivo /proc/sys/kernel/sched_rr_timeslice_ms. O valor mais baixo é 1 millisecond.
20.3.3. Programação normal com SCHED_OTHER
O SCHED_OTHER é a política padrão de agendamento no Red Hat Enterprise Linux 8. Esta política usa o Programador Completamente Justo (CFS) para permitir o acesso justo do processador a todos os threads agendados com esta política. Esta política é mais útil quando há um grande número de threads ou quando o fluxo de dados é uma prioridade, pois permite o agendamento mais eficiente de threads ao longo do tempo.
Quando esta política está em uso, o programador cria uma lista de prioridades dinâmica baseada em parte no valor de simpatia de cada linha de processo. Os administradores podem alterar o valor de agradabilidade de um processo, mas não podem alterar diretamente a lista de prioridades dinâmicas do agendador.
20.3.4. Definição de políticas de agendamento
Verifique e ajuste as políticas e prioridades do programador usando a ferramenta de linha de comando chrt. Ela pode iniciar novos processos com as propriedades desejadas, ou alterar as propriedades de um processo em execução. Também pode ser usado para definir a política em tempo de execução.
Procedimento
Veja o ID do processo (PID) dos processos ativos:
# ps
Use a opção
--pidou-pcom o comandopspara visualizar os detalhes do PID em particular.Verifique a política de programação, PID, e prioridade de um processo em particular:
# chrt -p 468 pid 468's current scheduling policy: SCHED_FIFO pid 468's current scheduling priority: 85 # chrt -p 476 pid 476's current scheduling policy: SCHED_OTHER pid 476's current scheduling priority: 0
Aqui, 468 e 476 são PID de um processo.
Estabelecer a política de programação de um processo:
Por exemplo, para definir o processo com o PID 1000 para SCHED_FIFO, com prioridade para 50:
# chrt -f -p 50 1000Por exemplo, para definir o processo com o PID 1000 para SCHED_OTHER, com prioridade para 0:
# chrt -o -p 0 1000Por exemplo, para definir o processo com o PID 1000 para SCHED_RR, com prioridade para 10:
# chrt -r -p 10 1000Para iniciar um novo pedido com uma política e prioridade particular, especifique o nome do pedido:
# chrt -f 36 /bin/my-app
Recursos adicionais
-
A página do homem
chrt. - Para mais informações sobre as opções de política, consulte Opções de política para o comando chrt.
- Para informações sobre como definir a política de forma persistente, ver Seção 20.3.6, “Mudando a prioridade dos serviços durante o processo de inicialização”.
20.3.5. Opções de política para o comando chrt
Para definir a política de agendamento de um processo, use a opção de comando apropriada:
Tabela 20.1. Opções de política para o Comando chrt
| Opção curta | Opção longa | Descrição |
|---|---|---|
|
|
|
Estabelecer cronograma para |
|
|
|
Estabelecer cronograma para |
|
|
|
Estabelecer cronograma para |
20.3.6. Mudando a prioridade dos serviços durante o processo de inicialização
Usando o serviço systemd, é possível estabelecer prioridades em tempo real para os serviços lançados durante o processo de inicialização. O unit configuration directives é usado para alterar a prioridade de um serviço durante o processo de inicialização.
A mudança de prioridade do processo de inicialização é feita utilizando as seguintes diretrizes na seção de serviços:
CPUSchedulingPolicy=-
Define a política de programação da CPU para os processos executados. É utilizada para definir as políticas
other,fifoerr. CPUSchedulingPriority=-
Define a prioridade de programação da CPU para os processos executados. A faixa de prioridade disponível depende da política de agendamento de CPU selecionada. Para políticas de programação em tempo real, um número inteiro entre
1(prioridade mais baixa) e99(prioridade mais alta) pode ser usado.
O procedimento seguinte descreve como alterar a prioridade de um serviço, durante o processo de inicialização, utilizando o serviço mcelog.
Pré-requisitos
Instale o pacote sintonizado:
# yum instalar afinado
Habilitar e iniciar o serviço sintonizado:
# systemctl habilitado --agora sintonizado
Procedimento
Veja as prioridades de agendamento dos fios em execução:
# tuna --show_threads thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 1 OTHER 0 0xff 3181 292 systemd 2 OTHER 0 0xff 254 0 kthreadd 3 OTHER 0 0xff 2 0 rcu_gp 4 OTHER 0 0xff 2 0 rcu_par_gp 6 OTHER 0 0 9 0 kworker/0:0H-kblockd 7 OTHER 0 0xff 1301 1 kworker/u16:0-events_unbound 8 OTHER 0 0xff 2 0 mm_percpu_wq 9 OTHER 0 0 266 0 ksoftirqd/0 [...]Criar um arquivo de diretório de configuração de serviços suplementar
mceloge inserir o nome e a prioridade da política neste arquivo:# cat <<-EOF > /etc/systemd/system/mcelog.system.d/priority.conf > [SERVICE] CPUSchedulingPolicy=_fifo_ CPUSchedulingPriority=_20_ EOF
Recarregar a configuração dos scripts do sistema:
# systemctl daemon-reload
Reinicie o serviço de mcelog:
# systemctl restart mcelog
Etapas de verificação
Exibir a prioridade
mcelogdefinida pela ediçãosystemd:# tuna -t mcelog -P thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 826 FIFO 20 0,1,2,3 13 0 mcelog
Recursos adicionais
-
Para mais informações, consulte as páginas de homem de
systemdetuna. - Para obter mais informações sobre a faixa de prioridade, consulte Descrição da faixa de prioridade.
20.3.7. Mapa prioritário
As prioridades são definidas em grupos, com alguns grupos dedicados a certas funções do núcleo.
Tabela 20.2. Descrição da faixa de prioridade
| Prioridade | Tópicos | Descrição |
|---|---|---|
| 1 | Roscas de núcleo de baixa prioridade | Esta prioridade é geralmente reservada para as tarefas que precisam estar logo acima do SCHED_OTHER. |
| 2 - 49 | Disponível para uso | A gama utilizada para as prioridades de aplicação típicas. |
| 50 | Valor padrão do HardIRQ | |
| 51 - 98 | Tópicos de alta prioridade | Use esta faixa para roscas que são executadas periodicamente e devem ter tempos de resposta rápidos. Não utilize esta faixa para roscas vinculadas à CPU, pois você morrerá de fome ao interromper. |
| 99 | Cães de guarda e migração | Linhas do sistema que devem funcionar com a maior prioridade. |
20.3.8. perfil de partição da cpu
O perfil cpu-partitioning é usado para isolar as CPUs das interrupções no nível do sistema. Uma vez isoladas essas CPUs, é possível alocá-las para aplicações específicas. Isto é muito útil em ambientes de baixa latência ou em ambientes onde você deseja extrair o máximo desempenho do seu hardware.
Este perfil também permite designar CPUs domésticas. Uma CPU doméstica é usada para executar todos os serviços, daemons, processos shell e fios do kernel.
Você pode configurar o perfil cpu-partitioning no arquivo /etc/tuned/cpu-partitioning-variables.conf usando as seguintes opções de configuração:
isolated_cores=cpu-list- Lista CPUs a serem isoladas. A lista de CPUs isoladas é separada por vírgula ou você pode especificar um intervalo usando um traço, como 3-5. Esta opção é obrigatória. Qualquer CPU em falta nesta lista é automaticamente considerada uma CPU doméstica.
no_balance_cores=cpu-list-
Lista as CPUs que não são consideradas pelo núcleo durante o balanceamento de carga do processo em todo o sistema. Esta opção é opcional. Esta é normalmente a mesma lista que a
isolated_cores.
20.3.9. Recursos adicionais
-
Para mais informações, consulte as páginas de homens de
sched,sched_setaffinity,sched_getaffinity,sched_setscheduler,sched_getscheduler,cpuset,tuna,chrt,systemd, etuned-profiles-cpu-partitioning.
20.4. Configurando o tempo de tick kernel
Por default, o Red Hat Enterprise Linux 8 usa um kernel sem tickless, que não interrompe CPUs ociosas a fim de reduzir o uso de energia e permitir que novos processadores tirem vantagem dos estados de sono profundo.
O Red Hat Enterprise Linux 8 também oferece uma opção dinâmica sem tickless, que é útil para cargas de trabalho sensíveis à latência, tais como computação de alto desempenho ou computação em tempo real. Por default, a opção dinâmica sem tickless está desativada. Este procedimento descreve como ativar de forma persistente o comportamento dinâmico sem tickless.
Procedimento
Para permitir um comportamento dinâmico sem tickless em certos núcleos, especifique esses núcleos na linha de comando do kernel com o parâmetro
nohz_full. Em um sistema de 16 núcleos, anexar este parâmetro no arquivo/etc/default/grub:nohz_full=1-15
Isto permite um comportamento dinâmico sem cócegas nos núcleos 1 a 15, movendo-se todo o tempo para o único núcleo não especificado (núcleo 0).
Para ativar persistentemente o comportamento dinâmico sem cócegas, regenerar a configuração do GRUB2 usando o arquivo padrão editado. Em sistemas com firmware BIOS, executar o seguinte comando:
# grub2-mkconfig -o /etc/grub2.cfg
Em sistemas com firmware UEFI, executar o seguinte comando:
# grub2-mkconfig -o /etc/grub2-efi.cfg
Quando o sistema inicia, mova manualmente os fios
rcupara o núcleo não sensível à latência, neste caso, o núcleo 0:# for i in `pgrep rcu[^c]` ; do taskset -pc 0 $i ; done
-
Opcional: Use o parâmetro
isolcpusna linha de comando do kernel para isolar certos núcleos das tarefas de espaço do usuário. Opcional: Ajuste a afinidade da CPU para os fios do kernel
write-back bdi-flushpara o núcleo de manutenção da casa:echo 1 > /sys/bus/workqueue/devices/writeback/cpumask
Etapas de verificação
Quando o sistema for reinicializado, verifique se
dynticksestá habilitado:# grep dynticks var/log/dmesg [ 0.000000] NO_HZ: Full dynticks CPUs: 2-5,8-11
Verificar se a configuração dinâmica sem tickless está funcionando corretamente:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1
Aqui,
stressé um programa que gira sobre a CPU para1 second.Um possível substituto para
stressé um roteiro que executa:while :; do d=1; done
A configuração padrão do temporizador do kernel mostra 1000 ticks em uma CPU ocupada:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1000 irq_vectors:local_timer_entry
Com o núcleo dinâmico sem tickless configurado, você deve ver 1 tick em seu lugar:
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1 irq_vectors:local_timer_entry
Recursos adicionais
-
Para mais informações, consulte as páginas de homem de
perfecpuset. - Tudo sobre nohz_full kernel parâmetro Red Hat Knowledgebase artigo.
- Como verificar a lista de "isolados" e "nohz_full" Informações da CPU do sysfs? Artigo da Red Hat Knowledgebase.
20.5. Ajuste de sistemas de afinidade de interrupção
Um pedido de interrupção ou IRQ é um sinal para atenção imediata enviado de uma peça de hardware para um processador. A cada dispositivo de um sistema é atribuído um ou mais números IRQ que permitem que ele envie interrupções únicas. Quando as interrupções são ativadas, um processador que recebe uma solicitação de interrupção pausa imediatamente a execução do tópico de aplicação atual, a fim de atender à solicitação de interrupção.
Como a interrupção interrompe a operação normal, altas taxas de interrupção podem degradar severamente o desempenho do sistema. É possível reduzir o tempo de interrupção configurando a afinidade da interrupção ou enviando uma série de interrupções de menor prioridade em um lote (coalescendo uma série de interrupções).
Os pedidos de interrupção têm uma propriedade de afinidade associada, smp_affinity, que define os processadores que tratam do pedido de interrupção. Para melhorar o desempenho da aplicação, atribuir afinidade de interrupção e afinidade de processo ao mesmo processador, ou processadores no mesmo núcleo. Isto permite que as linhas de interrupção e de aplicação especificadas compartilhem as linhas de cache.
Em sistemas que suportam a direção de interrupção, modificando a propriedade smp_affinity de um pedido de interrupção configura o hardware para que a decisão de fazer uma interrupção com um determinado processador seja tomada no nível do hardware sem intervenção do kernel.
20.5.1. O balanceamento é interrompido manualmente
Se sua BIOS exporta sua topologia NUMA, o serviço irqbalance pode servir automaticamente as solicitações de interrupção no nó que é local para o serviço de solicitação de hardware.
Procedimento
- Verifique quais dispositivos correspondem às solicitações de interrupção que você deseja configurar.
Encontre a especificação de hardware para sua plataforma. Verifique se o chipset em seu sistema suporta interrupções de distribuição.
- Se isso acontecer, você pode configurar a interrupção da entrega como descrito nos passos seguintes. Além disso, verifique qual algoritmo seu chipset usa para equilibrar as interrupções. Algumas BIOSes têm opções para configurar a interrupção da entrega.
- Caso contrário, seu chipset sempre roteia todas as interrupções para uma única CPU estática. Você não pode configurar qual CPU é utilizada.
Verifique qual modo de Controlador de Interrupção Programável Avançado (APIC) está em uso em seu sistema:
$ journalctl --dmesg | grep APIC
Aqui,
-
Se seu sistema usa um modo diferente de
flat, você pode ver uma linha similar aSetting APIC routing to physical flat. Se você não puder ver tal mensagem, seu sistema usa o modo
flat.Se seu sistema usa o modo
x2apic, você pode desativá-lo adicionando a opçãonox2apicà linha de comando do kernel na configuraçãobootloader.Somente o modo flat não-físico (
flat) suporta a distribuição de interrupções para várias CPUs. Este modo está disponível somente para sistemas que tenham até 8 CPUs.
-
Se seu sistema usa um modo diferente de
-
Calcule o
smp_affinity mask. Para mais informações sobre como calcular osmp_affinity mask, ver Seção 20.5.2, “Colocando a máscara smp_affinity”.
20.5.2. Colocando a máscara smp_affinity
O valor smp_affinity é armazenado como uma máscara de bit hexadecimal representando todos os processadores do sistema. Cada bit configura uma CPU diferente. O bit menos significativo é a CPU 0. O valor padrão da máscara é f, o que significa que uma solicitação de interrupção pode ser tratada em qualquer processador do sistema. Ajustar este valor para 1 significa que apenas o processador 0 pode lidar com a interrupção.
Procedimento
Em binário, use o valor 1 para CPUs que lidam com as interrupções. Por exemplo, para definir CPU 0 e CPU 7 para lidar com as interrupções, use
0000000010000001como o código binário:Tabela 20.3. Bits binários para CPUs
CPU 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 Binário
0
0
0
0
0
0
0
0
1
0
0
0
0
0
0
1
Converter o código binário em hexadecimal:
Por exemplo, para converter o código binário usando Python:
>>> hex(int('0000000010000001', 2)) '0x81'Em sistemas com mais de 32 processadores, você deve delimitar os valores
smp_affinitypara grupos discretos de 32 bits. Por exemplo, se você quiser apenas os primeiros 32 processadores de um sistema com 64 processadores para atender a uma solicitação de interrupção, use0xffffffff,00000000.O valor da afinidade de interrupção para uma determinada solicitação de interrupção é armazenado no arquivo
/proc/irq/irq_number/smp_affinityassociado. Coloque a máscarasmp_affinityneste arquivo:# máscara echo > /proc/irq/irq_number/smp_affinity
20.5.3. Recursos adicionais
-
Para mais informações, consulte as páginas de homens de
irqbalance,journalctletaskset.
Capítulo 21. Configuração da RHEL para otimizar o acesso aos recursos da rede
Esta seção descreve como configurar a RHEL para apresentar o acesso otimizado aos recursos da rede através de suas cargas de trabalho. Os problemas de desempenho da rede às vezes são resultado de mau funcionamento do hardware ou de infra-estrutura defeituosa. A resolução destes problemas está além do escopo deste documento. O serviço Tuned fornece vários perfis diferentes para melhorar o desempenho em vários casos específicos de uso:
-
latency-performance -
network-latency -
network-throughput
21.1. Ferramentas para monitoramento e diagnóstico de problemas de desempenho
A seguir estão as ferramentas disponíveis no Red Hat Enterprise Linux 8, que são usadas para monitorar o desempenho do sistema e diagnosticar problemas de desempenho relacionados com o subsistema de rede:
-
ssé um utilitário de linha de comando. Ele imprime informações estatísticas sobre soquetes, permite aos administradores avaliar o desempenho do dispositivo ao longo do tempo. Por padrão,ssexibe soquetes TCP abertos que não escutam e que têm conexões estabelecidas. Usando opções de linha de comando, os administradores podem filtrar estatísticas sobre soquetes específicos. A Red Hat recomendasssobre o depreciadonetstatno Red Hat Enterprise Linux -
ippermite aos administradores gerenciar e monitorar rotas, dispositivos, políticas de roteamento e túneis. O comando de monitoramentoippode monitorar continuamente o estado dos dispositivos, endereços e rotas. Use a opção-jpara exibir a saída no formato JSON, que pode ser fornecida a outras utilidades para automatizar o processamento de informações. -
dropwatché uma ferramenta interativa, fornecida pelo pacotedropwatch. Ela monitora e registra os pacotes que são descartados pelo kernel. -
ethtoolé um utilitário que permite aos administradores visualizar e editar as configurações da placa de interface de rede. Use esta ferramenta para observar as estatísticas, tais como o número de pacotes descartados por aquele dispositivo, de certos dispositivos. Usando oethtool -S device namecomando, veja o status dos contadores de um dispositivo especificado do dispositivo que você deseja monitorar. -
O arquivo
/proc/net/snmpexibe dados que o agentesnmputiliza para monitoramento e gerenciamento de IP, ICMP, TCP e UDP. O exame regular deste arquivo ajuda os administradores a identificar valores incomuns e assim identificar potenciais problemas de desempenho. Por exemplo, um aumento nos erros de entrada do UDP (InErrors) no arquivo/proc/net/snmppode indicar um gargalo em uma fila de recebimento de soquetes. -
nstaté uma ferramenta de linha de comando, que monitora o SNMP do kernel e as estatísticas da interface de rede. Esta ferramenta lê dados do arquivo/proc/net/snmpe imprime as informações em um formato legível por humanos. Por padrão, os scripts
SystemTap, fornecidos pelo pacote systemtap-cliente, estão instalados no diretório/usr/share/systemtap/examples/network:-
nettop.stp: a cada 5 segundos, o script exibe uma lista de processos (identificador e comando do processo) com o número de pacotes enviados e recebidos e a quantidade de dados enviados e recebidos pelo processo durante esse intervalo. -
socket-trace.stp: Instrumenta cada uma das funções do arquivonet/socket.cdo kernel Linux, e exibe dados de rastreamento. -
dropwatch.stp: a cada 5 segundos, o script exibe o número de buffers de soquete liberados em locais no núcleo. Use a opção--all-modulespara ver nomes simbólicos. -
latencytap.stp: Este roteiro registra o efeito que diferentes tipos de latência têm sobre um ou mais processos. Ele imprime uma lista de tipos de latência a cada 30 segundos, ordenados em ordem decrescente pelo tempo total que o processo ou processos passaram esperando. Isto pode ser útil para identificar a causa tanto do armazenamento quanto da latência da rede.
A Red Hat recomenda o uso da opção
--all-modulescom este script para melhor habilitar o mapeamento de eventos de latência. Por padrão, este script é instalado no diretório/usr/share/systemtap/examples/profiling.-
-
BPF Compiler Collection (BCC) é uma biblioteca, que facilita a criação dos programas ampliados Berkeley Packet Filter (
eBPF). A principal utilidade dos programaseBPFé analisar o desempenho do sistema operacional e o desempenho da rede sem ter problemas de overhead ou de segurança.
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
ss,ethtool,nettop,ip,dropwatch, eSystemTap. -
O diretório
/usr/share/systemtap/examples/network. -
Para mais informações sobre BCC, veja o arquivo
/usr/share/doc/bcc/README.md, que é fornecido pelo sitebcc package. - Como escrever um roteiro do NetworkManager para aplicar os comandos ethtool? Solução Red Hat Knowlegebase.
- Configuração de recursos de descarga de etool usando a seçãoNetworkManager.
21.2. Gargalos em uma recepção de pacotes
Embora a pilha de rede seja em grande parte auto-optimizadora, há uma série de pontos durante o processamento de pacotes de rede que podem se tornar gargalos e reduzir o desempenho. A seguir estão as questões que podem causar gargalos:
The buffer or ring buffer of the network card-
O buffer de hardware pode ser um gargalo se o kernel deixar cair um grande número de pacotes. Use o utilitário
ethtoolpara monitorar um sistema para pacotes descartados. The hardware or software interrupt queues- As interrupções podem aumentar a latência e a contenção do processador. Para informações sobre como o processador lida com as interrupções, consulte Ajuste de sistemas de Afinidade de Interrupção.
The socket receive queue of the application-
Um grande número de pacotes que não são copiados ou por um aumento nos erros de entrada do UDP (
InErrors) no arquivo/proc/net/snmp, indica um gargalo na fila de recepção de uma aplicação.
Se um buffer de hardware deixar cair um grande número de pacotes, as poucas soluções potenciais são as seguintes:
Slow the input traffic- Filtrar o tráfego de entrada, reduzir o número de grupos multicast unidos, ou reduzir a quantidade de tráfego de transmissão para diminuir a taxa a que a fila preenche.
Resize the hardware buffer queueRedimensionar a fila de amortecedores de hardware: Reduzir o número de pacotes que estão sendo descartados, aumentando o tamanho da fila para que ela não transborde tão facilmente. Você pode modificar os parâmetros
rx/txdo dispositivo de rede com o comandoethtool:ethtool --set-ring device-name valueChange the drain rate of the queueDiminuir a taxa de enchimento da fila filtrando ou soltando pacotes antes que eles cheguem à fila, ou baixando o peso do dispositivo. Filtrar o tráfego de entrada ou baixar o peso do dispositivo da placa de interface de rede para diminuir o tráfego de entrada.
O peso do dispositivo se refere ao número de pacotes que um dispositivo pode receber de uma vez em um único acesso programado do processador. Você pode aumentar a taxa de drenagem de uma fila aumentando o peso de seu dispositivo que é controlado pela configuração do kernel
dev_weight. Para alterar temporariamente este parâmetro, altere o conteúdo do arquivo/proc/sys/net/core/dev_weight, ou para alterar permanentemente, use o comandosysctl, que é fornecido pelo pacoteprocps-ng.Aumentar o comprimento da fila de soquetes da aplicação: Esta é normalmente a maneira mais fácil de melhorar a taxa de drenagem de uma fila de soquetes, mas é pouco provável que seja uma solução a longo prazo. Se uma fila de soquetes receber uma quantidade limitada de tráfego em rajadas, o aumento da profundidade da fila de soquetes para corresponder ao tamanho das rajadas de tráfego pode impedir que os pacotes sejam descartados. Para aumentar a profundidade de uma fila, aumente o tamanho do buffer de recepção do soquete fazendo uma das seguintes mudanças:
-
Aumentar o valor do parâmetro
/proc/sys/net/core/rmem_default: Este parâmetro controla o tamanho padrão do buffer de recepção utilizado pelos soquetes. Este valor deve ser menor ou igual ao valor do parâmetroproc/sys/net/core/rmem_max. -
Use o
setsockoptpara configurar um valor maiorSO_RCVBUF: Este parâmetro controla o tamanho máximo em bytes do buffer de recepção de um soquete. Use a chamada ao sistemagetsockoptpara determinar o valor atual do buffer.
-
Aumentar o valor do parâmetro
Alterar a taxa de drenagem de uma fila é geralmente a maneira mais simples de mitigar o mau desempenho da rede. Entretanto, o aumento do número de pacotes que um dispositivo pode receber de uma vez utiliza o tempo adicional do processador, durante o qual nenhum outro processo pode ser programado, o que pode causar outros problemas de desempenho.
Recursos adicionais
-
Para mais informações, consulte as páginas de manual
ss,socketeethtool. -
O arquivo
/proc/net/snmp.
21.3. Configuração de pesquisas de opinião pública ocupadas
Se a análise revelar alta latência, seu sistema pode se beneficiar do recebimento de pacotes baseado em pesquisas e não em interrupções.
A pesquisa ocupada ajuda a reduzir a latência no caminho de recepção da rede, permitindo que o código da camada do soquete faça a pesquisa da fila de recepção de um dispositivo de rede, e desativa as interrupções da rede. Isto elimina os atrasos causados pela interrupção e a mudança de contexto resultante. Entretanto, também aumenta a utilização da CPU. A pesquisa ocupada também impede a CPU de dormir, o que pode acarretar consumo adicional de energia. O comportamento de pesquisas ocupadas é suportado por todos os drivers do dispositivo.
21.3.1. Possibilitando pesquisas de opinião pública ocupadas
Por padrão, a votação ocupada está desativada. Este procedimento descreve como habilitar as pesquisas de opinião pública ocupadas.
Procedimento
Certifique-se de que a opção de compilação CONFIG_NET_RX_BUSY_POLL esteja habilitada:
# cat /boot/config-$(uname -r) | grep CONFIG_NET_RX_BUSY_POLL CONFIG_NET_RX_BUSY_POLL=y
Possibilitar pesquisas de opinião pública ocupadas
Para permitir uma votação ocupada em tomadas específicas, defina o valor do kernel
sysctl.net.core.busy_pollpara um valor diferente de0:# echo "net.core.busy_poll=50" > /etc/sysctl.d/95-enable-busy-polling-for-sockets.conf # sysctl -p /etc/sysctl.d/95-enable-busy-polling-for-sockets.conf
Este parâmetro controla o número de microssegundos para esperar por pacotes na sondagem do soquete e selecionar
syscalls. A Red Hat recomenda um valor de50.-
Adicione a opção de soquete
SO_BUSY_POLLao soquete. Para permitir pesquisas de opinião em todo o mundo, defina o
sysctl.net.core.busy_readpara um valor diferente de0:# echo "net.core.busy_read=50" > /etc/sysctl.d/95-enable-busy-polling-globally.conf # sysctl -p /etc/sysctl.d/95-enable-busy-polling-globally.conf
O parâmetro
net.core.busy_readcontrola o número de microssegundos para esperar por pacotes na fila do dispositivo para leituras de soquetes. Ele também define o valor padrão doSO_BUSY_POLL option. A Red Hat recomenda um valor de50para um pequeno número de soquetes, e um valor de100para um grande número de soquetes. Para números extremamente grandes de soquetes, por exemplo, mais de várias centenas, use ao invés disso a chamada ao sistemaepoll.
Etapas de verificação
Verificar se a pesquisa está habilitada
# ethtool -k device | grep "busy-poll" busy-poll: on [fixed] # cat /proc/sys/net/core/busy_read 50
Recursos adicionais
-
Para mais informações, consulte as páginas man
ethtool,socket,sysctl, esysctl.conf. - Configuração de recursos de descarga de etool usando a seçãoNetworkManager.
21.4. Escala do lado da recepção
Receive-Side Scaling (RSS), também conhecido como recepção em várias filas, distribui o processamento de recepção da rede por várias filas de recepção baseadas em hardware, permitindo que o tráfego de entrada da rede seja processado por várias CPUs. RSS pode ser usado para aliviar gargalos no processamento de interrupção de recepção causados pela sobrecarga de uma única CPU e para reduzir a latência da rede. Por padrão, o RSS é ativado.
O número de filas ou CPUs que devem processar a atividade de rede para RSS são configuradas no driver do dispositivo de rede apropriado:
-
Para o motorista
bnx2x, ele está configurado no parâmetronum_queues. -
Para o motorista
sfc, ele está configurado no parâmetrorss_cpus.
Independentemente disso, ela é tipicamente configurada no /sys/class/net/device/queues/rx-queue/ onde device é o nome do dispositivo de rede (como enp1s0) e rx-queue é o nome da fila de recepção apropriada.
O daemon irqbalance pode ser usado em conjunto com RSS para reduzir a probabilidade de transferência de memória entre nós e de salto de linha de cache. Isto reduz a latência do processamento de pacotes de rede.
21.4.1. Visualizando as filas de pedidos de interrupção
Ao configurar o RSS, a Red Hat recomenda limitar o número de filas a uma por núcleo físico da CPU. Hiperfilas são freqüentemente representadas como núcleos separados em ferramentas de análise, mas a configuração de filas para todos os núcleos, incluindo núcleos lógicos, tais como hiperfilas, não se mostrou benéfica para o desempenho da rede.
Quando ativado, o RSS distribui o processamento da rede igualmente entre as CPUs disponíveis com base na quantidade de processamento que cada CPU tem em fila de espera. Entretanto, use os parâmetros --show-rxfh-indir e --set-rxfh-indir do utilitário ethtool, para modificar como a RHEL distribui a atividade da rede, e pesar certos tipos de atividade de rede como mais importantes do que outros.
Este procedimento descreve como visualizar as filas de pedidos de interrupção.
Procedimento
Para determinar se sua placa de interface de rede suporta RSS, verifique se as filas de pedidos de interrupção múltipla estão associadas à interface em
/proc/interrupts:# egrep 'CPU|p1p1' /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 89: 40187 0 0 0 0 0 IR-PCI-MSI-edge p1p1-0 90: 0 790 0 0 0 0 IR-PCI-MSI-edge p1p1-1 91: 0 0 959 0 0 0 IR-PCI-MSI-edge p1p1-2 92: 0 0 0 3310 0 0 IR-PCI-MSI-edge p1p1-3 93: 0 0 0 0 622 0 IR-PCI-MSI-edge p1p1-4 94: 0 0 0 0 0 2475 IR-PCI-MSI-edge p1p1-5
A saída mostra que o driver NIC criou 6 filas de recepção para a interface
p1p1(p1p1-0atép1p1-5). Também mostra quantas interrupções foram processadas por cada fila, e qual CPU atendeu a interrupção. Neste caso, há 6 filas porque, por padrão, este driver NIC específico cria uma fila por CPU, e este sistema tem 6 CPUs. Este é um padrão bastante comum entre os drivers de DNIs.Para listar a fila de pedidos de interrupção para um dispositivo PCI com o endereço
0000:01:00.0:# ls -1 /sys/devices/*/*/0000:01:00.0/msi_irqs 101 102 103 104 105 106 107 108 109
21.5. Receber a direção de pacotes
O RPS (Receive Packet Steering) é similar ao RSS, pois é usado para direcionar pacotes para CPUs específicas para processamento. Entretanto, o RPS é implementado no nível de software e ajuda a evitar que a fila de hardware de uma única placa de interface de rede se torne um gargalo no tráfego da rede. O RPS tem várias vantagens em relação ao RSS baseado em hardware:
- O RPS pode ser usado com qualquer placa de interface de rede.
- É fácil adicionar filtros de software ao RPS para lidar com novos protocolos.
- O RPS não aumenta a taxa de interrupção do hardware do dispositivo de rede. No entanto, ele introduz interrupções inter-processador.
O RPS é configurado por dispositivo de rede e recebe fila, na /sys/class/net/device/queues/rx-queue/rps_cpus onde device é o nome do dispositivo de rede, como enp1s0 e rx-queue é o nome da fila de recepção apropriada, como rx-0.
O valor padrão do arquivo rps_cpus é 0. Isso desativa o RPS, e a CPU lida com a interrupção da rede e também processa o pacote. Para ativar o RPS, configure o arquivo rps_cpus apropriado com as CPUs que devem processar os pacotes a partir do dispositivo de rede especificado e receber a fila.
Os arquivos rps_cpus utilizam bitmaps de CPU delimitados por vírgulas. Portanto, para permitir que uma CPU possa lidar com interrupções para a fila de recepção em uma interface, defina o valor de suas posições no bitmap para 1. Por exemplo, para lidar com interrupções com CPUs 0, 1, 2, e 3, defina o valor do rps_cpus para f, que é o valor hexadecimal para 15. Em representação binária, 15 é 00001111 (1 2 4 8).
Para dispositivos de rede com filas de transmissão únicas, o melhor desempenho pode ser alcançado configurando o RPS para usar CPUs no mesmo domínio de memória. Em sistemas que não sejam do tipoNUMA, isto significa que todas as CPUs disponíveis podem ser utilizadas. Se a taxa de interrupção da rede for extremamente alta, excluindo a CPU que lida com as interrupções da rede também pode melhorar o desempenho.
Para dispositivos de rede com múltiplas filas, normalmente não há benefício em configurar tanto RPS quanto RSS, já que o RSS é configurado para mapear uma CPU para cada fila de recepção por padrão. Entretanto, o RPS ainda pode ser benéfico se houver menos filas de hardware do que CPUs, e o RPS é configurado para usar CPUs no mesmo domínio de memória.
21.6. Receber a direção do fluxo
A Direção de Fluxo de Recepção (RFS) estende o comportamento RPS para aumentar a taxa de acerto do cache da CPU e assim reduzir a latência da rede. Onde o RPS encaminha os pacotes com base unicamente no comprimento da fila, o RFS usa o RPS back end para calcular a CPU mais apropriada, depois encaminha os pacotes com base na localização da aplicação que consome o pacote. Isto aumenta a eficiência do cache da CPU.
Os dados recebidos de um único remetente não são enviados a mais de uma CPU. Se a quantidade de dados recebidos de um único remetente for maior do que uma única CPU pode lidar, configure um tamanho de estrutura maior para reduzir o número de interrupções e, portanto, a quantidade de trabalho de processamento para a CPU. Alternativamente, considere as opções de descarregar NIC ou CPUs mais rápidas.
Considere o uso de numactl ou taskset em conjunto com RFS para fixar aplicações em núcleos específicos, soquetes ou nós NUMA. Isto pode ajudar a evitar que os pacotes sejam processados fora de ordem.
21.6.1. Habilitando a Direção do Fluxo de Recepção
Por padrão, a Direção de Fluxo de Recepção (RFS) está desativada. Este procedimento descreve como ativar a RFS.
Procedimento
Ajuste o valor do kernel
net.core.rps_sock_flow_entriespara o número máximo esperado de conexões ativas concomitantemente:# echo \i1"net.core.rps_sock_flow_entries=32768\i1 > /etc/sysctl.d/95-enable-rps.conf
A Red Hat recomenda um valor de
32768para cargas moderadas do servidor. Todos os valores inseridos são arredondados para a potência mais próxima de2na prática.Fixar persistentemente o valor do
net.core.rps_sock_flow_entries:# sysctl -p /etc/sysctl.d/95-enable-rps.conf
Para definir temporariamente o valor do
sys/class/net/device/queues/rx-queue/rps_flow_cntarquivo ao valor do (rps_sock_flow_entries/N), onde N é o número de filas de recebimento em um dispositivo:# echo 2048 > /sys/class/net/device/queues/rx-queue/rps_flow_cnt
Substitua device pelo nome do dispositivo de rede que você deseja configurar (por exemplo, enp1s0), e rx-queue pela fila de recepção que você deseja configurar (por exemplo, rx-0). _ Substitua N pelo número de filas de recepção configuradas. Por exemplo, se o
rps_flow_entriesestiver configurado em32768e houver16configurado com filas de recepção, orps_flow_cnt = 32786/16= 2048(ou seja, o número de filas de recepção configuradas),rps_flow_cnt = rps_flow_enties/N).Para dispositivos de fila única, o valor de
rps_flow_cnté o mesmo que o valor derps_sock_flow_entries.Habilitar constantemente a RFS em todos os dispositivos de rede, criar o arquivo
/etc/udev/rules.d/99-persistent-net.rulese adicionar o seguinte conteúdo:SUBSYSTEM=="net", ACTION=="add", RUN{program}+="/bin/bash -c 'for x in /sys/$DEVPATH/queues/rx-*; do echo 2048 > $x/rps_flow_cnt; done'"Opcional: Para habilitar o RPS em um dispositivo de rede específico:
SUBSYSTEM==="net", ACTION===="move", NAME=="device name{program} =="/bin/bash -c 'for x in /sys/$DEVPATH/queues/rx-*; do echo 2048 > $x/rps_flow_cnt; done'"Substituir device name pelo nome real do dispositivo de rede.
Etapas de verificação
Verificar se a RFS está habilitada:
# cat /proc/sys/net/core/rps_sock_flow_entries 32768 # cat /sys/class/net/device/queues/rx-queue/rps_flow_cnt 2048
Recursos adicionais
-
Para mais informações, consulte a página de manual
sysctl.
21.7. RFS Acelerado
A RFS acelerada aumenta a velocidade da RFS ao acrescentar assistência de hardware. Como RFS, os pacotes são encaminhados com base na localização da aplicação que consome o pacote. Ao contrário das RFS tradicionais, no entanto, os pacotes são enviados diretamente para uma CPU que é local para o thread que consome os dados:
- ou a CPU que está executando a aplicação
- ou uma CPU local para essa CPU na hierarquia do cache
A RFS acelerada só está disponível se as seguintes condições forem atendidas:
-
O NIC deve apoiar o RFS acelerado. A RFS acelerada é suportada por cartões que exportam a função
ndo_rx_flow_steer()net_device. Verifique a folha de dados da DNI para assegurar-se de que esta função é suportada. -
ntuplea filtragem deve ser habilitada. Para informações sobre como habilitar esses filtros, consulte Seção 21.7.1, “Habilitação dos filtros de ntuplo”.
Uma vez satisfeitas estas condições, o mapeamento da CPU para fila é deduzido automaticamente com base na configuração RFS tradicional. Ou seja, o mapeamento CPU para fila é deduzido com base nas afinidades IRQ configuradas pelo motorista para cada fila de recepção. Para maiores informações sobre a habilitação das RFS tradicionais, veja Seção 21.6.1, “Habilitando a Direção do Fluxo de Recepção”.
21.7.1. Habilitação dos filtros de ntuplo
Use o comando ethtool -k para verificar se os filtros ntuple estão habilitados.
Procedimento
Mostrar o status atual do filtro
ntuple:# ethtool -k enp1s0 | grep ntuple-filters ntuple-filters: offHabilite os filtros
ntuple:# ethtool -k enp1s0 ntuple on
Se a saída é ntuple-filters: off [fixed], então a filtragem ntuple está desativada e não é possível configurá-la:
# ethtool -k enp1s0 | grep ntuple-filters
ntuple-filters: off [fixed]Etapas de verificação
Certifique-se de que os filtros
ntupleestejam habilitados:# ethtool -k enp1s0 | grep ntuple-filters ntuple-filters: on
Recursos adicionais
-
Para mais informações, consulte a página de manual
ethtool.
Capítulo 22. Configuração de um sistema operacional para otimizar o acesso à memória
Esta seção descreve como configurar o sistema operacional para otimizar o acesso à memória através de cargas de trabalho, e as ferramentas que você pode usar para fazê-lo.
22.1. Ferramentas para monitoramento e diagnóstico de problemas de memória do sistema
As seguintes ferramentas estão disponíveis no Red Hat Enterprise Linux 8 para monitorar o desempenho do sistema e diagnosticar problemas de desempenho relacionados à memória do sistema:
-
vmstat, fornecido pelo pacoteprocps-ng, exibe relatórios dos processos de um sistema, memória, paginação, bloqueio de E/S, armadilhas, discos e atividade da CPU. Fornece um relatório instantâneo da média desses eventos desde que a máquina foi ligada pela última vez, ou desde o relatório anterior. valgrindé uma estrutura que fornece instrumentação para os binários de espaço do usuário. Instale esta ferramenta, usando o comandoyum install valgrind. Ela inclui uma série de ferramentas, que você pode usar para traçar o perfil e analisar o desempenho do programa, como por exemplo:a opção
memchecké a ferramenta padrãovalgrind. Ela detecta e relata uma série de erros de memória que podem ser difíceis de detectar e diagnosticar, como por exemplo:- Acesso à memória que não deve ocorrer
- Uso de valor indefinido ou não-inicializado
- Memória de pilha incorretamente liberada
- Sobreposição de ponteiros
Vazamentos de memória
NotaA Memcheck só pode comunicar estes erros, não pode evitar que eles ocorram. Entretanto,
memcheckregistra uma mensagem de erro imediatamente antes que o erro ocorra.
-
a opção
cachegrindsimula a interação da aplicação com a hierarquia de cache de um sistema e o preditor de filiais. Ela reúne estatísticas para a duração da execução da aplicação e fornece um resumo para o console. -
a opção
massifmede o espaço de pilha utilizado por uma aplicação específica. Ela mede tanto o espaço útil quanto qualquer espaço adicional alocado para fins de escrituração e alinhamento.
Recursos adicionais
-
Para mais informações, consulte a página de manual
vmstatevalgrind. -
Para mais informações sobre a estrutura
valgrind, consulte o arquivo/usr/share/doc/valgrind-version/valgrind_manual.pdf.
22.2. Visão geral da memória de um sistema
O Kernel Linux é projetado para maximizar a utilização dos recursos de memória de um sistema (RAM). Devido a estas características de projeto, e dependendo dos requisitos de memória da carga de trabalho, parte da memória do sistema está em uso dentro do kernel em nome da carga de trabalho, enquanto que uma pequena parte da memória é livre. Esta memória livre é reservada para alocações especiais do sistema, e para outros serviços de sistema de baixa ou alta prioridade. O restante da memória do sistema é dedicado à própria carga de trabalho, e dividido nas duas categorias a seguir:
File memoryAs páginas adicionadas nesta categoria representam partes de arquivos em armazenamento permanente. Estas páginas, a partir do cache de páginas, podem ser mapeadas ou não mapeadas nos espaços de endereço de uma aplicação. Você pode usar aplicativos para mapear arquivos em seus espaços de endereços usando as chamadas do sistema
mmap, ou para operar em arquivos através das chamadas do sistema de leitura ou gravação em buffer de E/S.Chamadas de sistema I/O em buffer, assim como aplicações que mapeiam páginas diretamente, podem reaproveitar páginas não mapeadas. Como resultado, estas páginas são armazenadas no cache pelo kernel, especialmente quando o sistema não está executando nenhuma tarefa intensiva de memória, para evitar a reemissão de dispendiosas operações de E/S sobre o mesmo conjunto de páginas.
Anonymous memory- As páginas nesta categoria estão em uso por um processo alocado dinamicamente, ou não estão relacionadas a arquivos em armazenamento permanente. Este conjunto de páginas faz backup das estruturas de controle na memória de cada tarefa, tais como a pilha de aplicações e as áreas de pilha.
Figura 22.1. Padrões de uso de memória
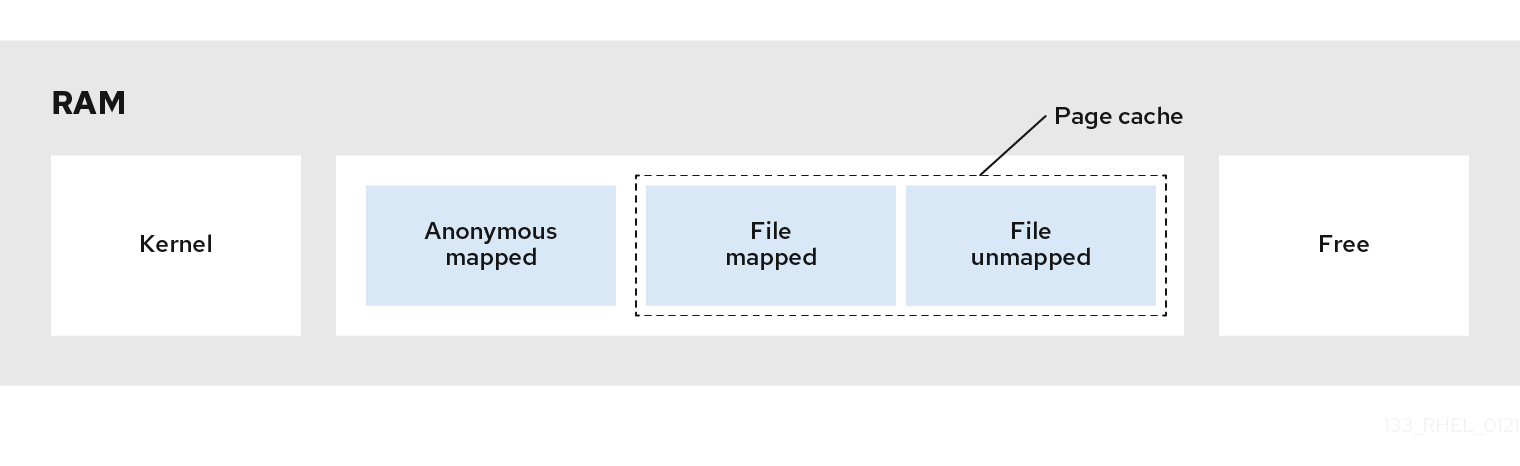
22.3. Otimizando a utilização da memória de um sistema
Esta seção fornece informações sobre parâmetros do kernel relacionados à memória e como usá-los para melhorar a utilização da memória de um sistema. A seguir estão os parâmetros do kernel relacionados à memória disponíveis no Red Hat Enterprise Linux 8:
- Parâmetro de memória virtual. Para mais informações, consulte Seção 22.3.1, “Parâmetros de memória virtual”.
- Parâmetro do sistema de arquivo. Para maiores informações, ver Seção 22.3.2, “Parâmetros do sistema de arquivo”.
- Parâmetro do núcleo. Para mais informações, veja Seção 22.3.3, “Parâmetros do núcleo”.
22.3.1. Parâmetros de memória virtual
Os parâmetros da memória virtual estão listados no diretório /proc/sys/vm, a menos que indicado o contrário.
Os parâmetros de memória virtual disponíveis são os seguintes:
vm.dirty_ratio-
É um valor percentual. Quando esta porcentagem da memória total do sistema é modificada, o sistema começa a gravar as modificações no disco com a operação
pdflush. O valor padrão é 20 por cento. vm.dirty_background_ratio- Um valor percentual. Quando esta porcentagem da memória total do sistema é modificada, o sistema começa a gravar as modificações no disco em segundo plano. O valor padrão é 10 por cento.
vm.overcommit_memoryDefine as condições que determinam se um pedido de memória grande é aceito ou negado. O valor padrão é 0.
Por padrão, o kernel executa um tratamento heurístico de excesso de memória através da estimativa da quantidade de memória disponível e de pedidos falhos que são muito grandes. Entretanto, como a memória é alocada usando um algoritmo heurístico em vez de um algoritmo preciso, a sobrecarga de memória é possível com esta configuração.
Definindo o valor do parâmetro
overcommit_memory:- Quando este parâmetro é ajustado para 1, o kernel não executa nenhuma manipulação de excesso de memória. Isto aumenta a possibilidade de sobrecarga de memória, mas melhora o desempenho para tarefas que exigem muita memória.
-
Quando este parâmetro é ajustado para 2, o kernel nega pedidos de memória iguais ou maiores que a soma do espaço swap total disponível e a porcentagem de RAM física especificada no
overcommit_ratio. Isto reduz o risco de excesso de memória, mas é recomendado apenas para sistemas com áreas de swap maiores do que sua memória física.
vm.overcommit_ratio-
Especifica a porcentagem de RAM física considerada quando
overcommit_memoryé definido como 2. O valor padrão é 50. vm.max_map_count- Define o número máximo de áreas do mapa de memória que um processo pode utilizar. O valor padrão é 65530. Aumente este valor se sua aplicação precisar de mais áreas do mapa de memória.
vm.min_free_kbytesDefine o tamanho do pool de páginas livres reservadas. É também responsável pela definição dos limites
min_page,low_pageehigh_pageque regem o comportamento dos algoritmos de recuperação de páginas do kernel do Linux. Também especifica o número mínimo de kilobytes a serem mantidos livres em todo o sistema. Isto calcula um valor específico para cada zona de pouca memória, a cada uma das quais é atribuído um número de páginas livres reservadas em proporção ao seu tamanho.Definindo o valor do parâmetro
vm.min_free_kbytes:- Aumentar o valor do parâmetro reduz efetivamente a memória utilizável do conjunto de trabalho da aplicação. Portanto, você pode querer usá-la apenas para cargas de trabalho orientadas pelo kernel, onde os buffers de driver precisam ser alocados em contextos atômicos.
A diminuição do valor do parâmetro pode tornar o kernel incapaz de atender as solicitações do sistema, se a memória ficar muito contendida no sistema.
AtençãoOs valores extremos podem ser prejudiciais ao desempenho do sistema. Ajustar o
vm.min_free_kbytespara um valor extremamente baixo impede que o sistema recupere a memória efetivamente, o que pode resultar em falhas no sistema e interrupções no serviço ou outros serviços do kernel. No entanto, o ajuste dovm.min_free_kbytespara um valor muito alto aumenta consideravelmente a atividade de recuperação do sistema, causando latência de alocação devido a um falso estado de recuperação direta. Isto pode fazer com que o sistema entre imediatamente em um estado fora de memória.O parâmetro
vm.min_free_kbytestambém define uma página de recuperação de marca d'água, chamadamin_pages. Esta marca d'água é usada como um fator ao determinar as duas outras marcas d'água de memória,low_pages, ehigh_pages, que governam os algoritmos de recuperação de páginas.
/proc/PID/oom_adjNo caso de um sistema ficar sem memória e o parâmetro
panic_on_oomfor definido como 0, a funçãooom_killermata processos, começando com o processo que tem o mais altooom_score, até que o sistema se recupere.O parâmetro
oom_adjdetermina ooom_scorede um processo. Este parâmetro é definido por identificador de processo. Um valor de -17 desabilita ooom_killerpara esse processo. Outros valores válidos variam de -16 a 15.
Os processos criados por um processo ajustado herdam o oom_score desse processo.
vm.swappinessO valor de swappiness, que varia de 0 a 100, controla o grau em que o sistema favorece a recuperação de memória do pool de memória anônimo, ou do pool de memória cache de páginas.
Definindo o valor do parâmetro
swappiness:- Os valores mais altos favorecem as cargas de trabalho de arquivos mapeados e, ao mesmo tempo, a troca da memória mapeada anônima de RAM dos processos de acesso menos ativo. Isto é útil para servidores de arquivos ou aplicações de streaming que dependem de dados, de arquivos no armazenamento, para residir na memória a fim de reduzir a latência de E/S para as solicitações de serviço.
Valores baixos favorecem cargas de trabalho anônimas enquanto se recupera o cache da página (memória mapeada por arquivo). Esta configuração é útil para aplicações que não dependem muito das informações do sistema de arquivos e utilizam muito a memória privada e dinamicamente alocada, tais como aplicações matemáticas e de números, e poucos supervisores de virtualização de hardware como o QEMU.
O valor padrão do parâmetro
vm.swappinessé 30.AtençãoA configuração do
vm.swappinesspara0evita agressivamente a troca de memória anônima para um disco, o que aumenta o risco de processos serem mortos pela funçãooom_killerquando sob carga de trabalho intensiva de memória ou E/S.
Recursos adicionais
-
Para mais informações, consulte a página de manual
sysctl. - Para mais informações sobre como definir esses parâmetros de forma temporária e persistente, consulte Seção 22.3.4, “Definição de parâmetros de kernel relacionados à memória”.
22.3.2. Parâmetros do sistema de arquivo
Os parâmetros do sistema de arquivos estão listados no diretório /proc/sys/fs. A seguir estão os parâmetros de sistema de arquivo disponíveis:
aio-max-nr- Define o número máximo permitido de eventos em todos os contextos de entrada/saída assíncronos ativos. O valor padrão é 65536, e modificar este valor não pré-aloca nem redimensiona nenhuma estrutura de dados do kernel.
file-maxDetermina o número máximo de alças de arquivo para todo o sistema. O valor padrão no Red Hat Enterprise Linux 8 é 8192 ou um décimo das páginas de memória livre disponíveis no momento em que o kernel inicia, o que for maior.
A elevação deste valor pode resolver erros causados pela falta de arquivos disponíveis.
Recursos adicionais
-
Para mais informações, consulte a página de manual
sysctl.
22.3.3. Parâmetros do núcleo
Os valores padrão para os parâmetros do kernel estão localizados no diretório /proc/sys/kernel/. Estes valores são calculados pelo kernel no momento da inicialização, dependendo dos recursos disponíveis no sistema.
A seguir estão os parâmetros de kernel disponíveis usados para estabelecer limites para as chamadas ao sistema msg* e shm* Sistema V IPC (sysvipc):
msgmax-
Define o tamanho máximo permitido em bytes de qualquer mensagem em uma única fila de mensagens. Este valor não deve exceder o tamanho da fila (
msgmnb). Use o comandosysctl msgmaxpara determinar o valor atualmsgmaxem seu sistema. msgmnb-
Define o tamanho máximo em bytes de uma única fila de mensagens. Use o comando
sysctl msgmnbpara determinar o valor atualmsgmnbem seu sistema. msgmni-
Define o número máximo de identificadores de filas de mensagens e, portanto, o número máximo de filas. Use o comando
sysctl msgmnipara determinar o valor atualmsgmniem seu sistema. shmall-
Define a quantidade total de páginas de memória compartilhada que podem ser usadas no sistema de uma só vez. Por exemplo, uma página é 4096 bytes na arquitetura AMD64 e Intel 64. Use o comando
sysctl shmallpara determinar o valor atualshmallem seu sistema. shmmax-
Define o tamanho máximo em bytes de um único segmento de memória compartilhada permitido pelo kernel. Use o comando
sysctl shmmaxpara determinar o valor atualshmmaxem seu sistema. shmmni- Define o número máximo de segmentos de memória compartilhada em todo o sistema. O valor padrão é 4096 em todos os sistemas.
Recursos adicionais
-
Para mais informações, consulte a página de manual
sysvipcesysctl.
Capítulo 23. Configuração de páginas enormes
A memória física é gerenciada em pedaços de tamanho fixo chamados páginas. Na arquitetura x86_64, suportada pelo Red Hat Enterprise Linux 8, o tamanho padrão de uma página de memória é 4 KB. Este tamanho de página default provou ser adequado para sistemas operacionais de propósito geral, como o Red Hat Enterprise Linux, que suporta muitos tipos diferentes de cargas de trabalho.
Entretanto, aplicações específicas podem se beneficiar do uso de páginas maiores em certos casos. Por exemplo, uma aplicação que funciona com um conjunto de dados grande e relativamente fixo de centenas de megabytes ou mesmo dezenas de gigabytes pode ter problemas de desempenho ao utilizar 4 páginas KB. Tais conjuntos de dados podem exigir uma enorme quantidade de 4 páginas KB, o que pode levar a sobrecarga no sistema operacional e na CPU.
Esta seção fornece informações sobre enormes páginas disponíveis no Red Hat Enterprise Linux 8 e como você pode configurá-las.
23.1. Características de páginas enormes disponíveis
Com o Red Hat Enterprise Linux 8, você pode usar páginas enormes para aplicações que funcionam com grandes conjuntos de dados, e melhorar o desempenho de tais aplicações.
A seguir estão os enormes métodos de página, que são suportados no Red Hat Enterprise Linux 8:
HugeTLB pagesAs páginas HugeTLB também são chamadas de páginas enormes estáticas. Há duas maneiras de reservar as páginas HugeTLB:
- No momento da inicialização: Aumenta a possibilidade de sucesso porque a memória ainda não foi significativamente fragmentada. Entretanto, nas máquinas NUMA, o número de páginas é automaticamente dividido entre os nós NUMA. Para mais informações sobre parâmetros que influenciam o comportamento das páginas do HugeTLB no momento do boot, veja Seção 23.2, “Parâmetros para reservar páginas HugeTLB no momento da inicialização” e como usar esses parâmetros para configurar as páginas do HugeTLB no momento do boot, veja Seção 23.4, “Configuração do HugeTLB no momento da inicialização”.
- Em tempo de execução: Permite reservar as enormes páginas por nó NUMA. Se a reserva de tempo de execução for feita o mais cedo possível no processo de inicialização, a probabilidade de fragmentação da memória é menor. Para mais informações sobre parâmetros que influenciam o comportamento das páginas do HugeTLB em tempo de execução, veja Seção 23.3, “Parâmetros para reservar páginas HugeTLB em tempo de execução” e como usar esses parâmetros para configurar as páginas do HugeTLB em tempo de execução, veja Seção 23.5, “Configuração do HugeTLB em tempo de execução”.
Transparent HugePages (THP)Com THP, o núcleo atribui automaticamente páginas enormes a processos, e portanto não há necessidade de reservar manualmente as páginas enormes estáticas. Os dois modos de operação no THP são os seguintes:
-
system-wide: Aqui, o núcleo tenta atribuir páginas enormes a um processo sempre que é possível alocar as páginas enormes e o processo está usando uma grande área de memória virtual contígua. per-process: Aqui, o kernel só atribui páginas enormes às áreas de memória de processos individuais que você pode especificar usando a chamada de sistemamadvise().NotaA característica THP suporta apenas 2 MB de páginas.
Para informações sobre como ativar e desativar o THP, consulte Seção 23.6, “Possibilitando abraços transparentes” e Seção 23.7, “Desabilitando as páginas de abraços transparentes”.
-
23.2. Parâmetros para reservar páginas HugeTLB no momento da inicialização
Use os seguintes parâmetros para influenciar o comportamento da página HugeTLB no momento da inicialização:
Tabela 23.1. Parâmetros usados para configurar páginas HugeTLB no momento da inicialização
| Parâmetro | Descrição | Valor padrão |
|---|---|---|
|
| Define o número de páginas enormes e persistentes configuradas no kernel no momento da inicialização. Em um sistema NUMA, páginas enormes, que têm este parâmetro definido, são divididas igualmente entre os nós.
Você pode atribuir páginas enormes a nós específicos em tempo de execução, alterando o valor dos nós no arquivo | O valor padrão é 0.
Para atualizar este valor na inicialização, altere o valor deste parâmetro no arquivo |
|
| Define o tamanho de páginas enormes e persistentes configuradas no kernel no momento da inicialização. | Os valores válidos são 2 MB e 1 GB. O valor padrão é 2 MB. |
|
| Define o tamanho padrão de páginas enormes e persistentes configuradas no kernel no momento da inicialização. | Os valores válidos são 2 MB e 1 GB. O valor padrão é 2 MB. |
23.3. Parâmetros para reservar páginas HugeTLB em tempo de execução
Use os seguintes parâmetros para influenciar o comportamento da página HugeTLB em tempo de execução:
Tabela 23.2. Parâmetros usados para configurar páginas HugeTLB em tempo de execução
| Parâmetro | Descrição | Nome do arquivo |
|---|---|---|
|
| Define o número de páginas enormes de um tamanho especificado atribuído a um nó NUMA especificado. |
|
|
| Define o número máximo de páginas enormes adicionais que podem ser criadas e utilizadas pelo sistema através de uma memória de compromisso excessivo. Escrever qualquer valor diferente de zero neste arquivo indica que o sistema obtém esse número de páginas enormes do pool de páginas normal do kernel se o pool de páginas enorme e persistente estiver esgotado. Como estas páginas enormes excedentes ficam sem uso, elas são então liberadas e retornam ao pool normal de páginas do kernel. |
|
23.4. Configuração do HugeTLB no momento da inicialização
O tamanho da página, que o subsistema HugeTLB suporta, depende da arquitetura. A arquitetura x86_64 suporta 2 MB de páginas enormes e 1 GB de páginas gigantescas.
Este procedimento descreve como reservar uma página de 1 GB no momento da inicialização.
Procedimento
Criar um pool HugeTLB para 1 GB de páginas, anexando a seguinte linha às opções de linha de comando do kernel no arquivo
/etc/default/grubcomo root:padrão_hugepagesz=1G hugepagesz=1G
Regenerar a configuração
GRUB2usando o arquivo padrão editado:Se seu sistema utiliza firmware BIOS, execute o seguinte comando:
# grub2-mkconfig -o /boot/grub2/grub.cfg
Se seu sistema utiliza a estrutura UEFI, execute o seguinte comando:
# grub2-mkconfig -o /boot/efi/efi/EFI/redhat/grub.cfg
Crie um novo arquivo chamado
hugetlb-gigantic-pages.serviceno diretório/usr/lib/systemd/system/e adicione o seguinte conteúdo:[Unit] Description=HugeTLB Gigantic Pages Reservation DefaultDependencies=no Before=dev-hugepages.mount ConditionPathExists=/sys/devices/system/node ConditionKernelCommandLine=hugepagesz=1G [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/lib/systemd/hugetlb-reserve-pages.sh [Install] WantedBy=sysinit.target
Crie um novo arquivo chamado
hugetlb-reserve-pages.shno diretório/usr/lib/systemd/e adicione o seguinte conteúdo:Ao adicionar o seguinte conteúdo, substitua number_of_pages pelo número de páginas de 1GB que você deseja reservar, e node pelo nome do nó no qual reservar estas páginas.
#!/bin/sh nodes_path=/sys/devices/system/node/ if [ ! -d $nodes_path ]; then echo "ERROR: $nodes_path does not exist" exit 1 fi reserve_pages() { echo $1 > $nodes_path/$2/hugepages/hugepages-1048576kB/nr_hugepages } reserve_pages number_of_pages nodePor exemplo, para reservar duas páginas de 1GB em node0 e uma página de 1GB em node1, substituir o number_of_pages por 2 para node0 e 1 para node1:
reserve_pages 2 node0 reserve_pages 1 node1
Criar um roteiro executável:
# chmod x /usr/lib/systemd/hugetlb-reserve-pages.sh
Habilitar a reserva antecipada da bota:
# systemctl permite páginas hugetlb-gigantic-pages
-
Você pode tentar reservar mais páginas de 1GB em tempo de execução, escrevendo para
nr_hugepagesa qualquer momento. Entretanto, tais reservas podem falhar devido à fragmentação da memória. A maneira mais confiável de reservar páginas de 1GB é usando este scripthugetlb-reserve-pages.sh, que roda cedo durante a inicialização. - Reservar páginas enormes estáticas pode efetivamente reduzir a quantidade de memória disponível para o sistema e impedi-lo de utilizar adequadamente toda a sua capacidade de memória. Embora um pool de páginas enormes reservadas possa ser benéfico para aplicações que o utilizam, um pool de páginas enormes reservadas ou não utilizadas eventualmente será prejudicial ao desempenho geral do sistema. Ao definir um grande pool de páginas reservadas, certifique-se de que o sistema possa utilizar adequadamente toda a sua capacidade de memória.
Recursos adicionais
-
Para mais informações, consulte a documentação pertinente do kernel, que está instalada no arquivo
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt. -
Para mais informações, consulte a página de manual
systemd.service.
23.5. Configuração do HugeTLB em tempo de execução
Este procedimento descreve como adicionar vinte 2048 kB páginas enormes a node2.
Procedimento
Exibir as estatísticas da memória:
# numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total add AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 0 0 0 HugePages_Free 0 0 0 0 0 HugePages_Surp 0 0 0 0 0Adicione o número de páginas enormes de um tamanho especificado ao nó:
# echo 20 > /sys/devices/system/node/node2/hugepages/hugepages-2048kB/nr_hugepages
Para reservar páginas com base em suas exigências, substitua:
- 20 com o número de páginas enormes que você deseja reservar,
- 2048kB com o tamanho das enormes páginas,
- node2 com o nó no qual você deseja reservar as páginas.
Etapas de verificação
Certifique-se de que o número de páginas enormes seja adicionado:
# numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 40 0 40 HugePages_Free 0 0 40 0 40 HugePages_Surp 0 0 0 0 0
Recursos adicionais
-
Para mais informações, consulte a página de manual
numastat.
23.6. Possibilitando abraços transparentes
O THP é habilitado por default no Red Hat Enterprise Linux 8. No entanto, você pode habilitar ou desabilitar o THP. Este procedimento descreve como habilitar o THP.
Procedimento
Verifique o status atual do THP:
# cat /sys/kernel/mm/transparent_hugepage/enabled
Habilite o THP:
# echo sempre > /sys/kernel/mm/transparent_hugepage/enabled
Para evitar que as aplicações destinem mais recursos de memória do que o necessário, desabilite as enormes páginas transparentes em todo o sistema e habilite-as apenas para as aplicações que o solicitem explicitamente através do site
madvise:# echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
S vezes, fornecer baixa latência para alocações de curta duração tem maior prioridade do que obter imediatamente o melhor desempenho com alocações de longa duração. Nesses casos, você pode desativar a compactação direta, deixando o THP ativado.
A compactação direta é uma compactação síncrona de memória durante a enorme alocação de páginas. A desativação da compactação direta não oferece garantia de economia de memória, mas pode diminuir o risco de latências mais altas durante falhas freqüentes de página. Observe que se a carga de trabalho se beneficia significativamente do THP, o desempenho diminui. Desativar a compactação direta:
# echo madvise > /sys/kernel/mm/transparent_hugepage/defrag
Recursos adicionais
-
Para mais informações, consulte a página de manual
madvise.
23.7. Desabilitando as páginas de abraços transparentes
O THP é habilitado por default no Red Hat Enterprise Linux 8. No entanto, você pode habilitar ou desabilitar o THP. Este procedimento descreve como desabilitar o THP.
Procedimento
Verifique o status atual do THP:
# cat /sys/kernel/mm/transparent_hugepage/enabled
Desativar o THP:
# echo nunca > /sys/kernel/mm/transparent_hugepage/enabled
23.8. Impacto do tamanho da página no tamanho do buffer da tradução
A leitura de mapeamentos de endereços da tabela de páginas é demorada e barata, por isso as CPUs são construídas com um cache para endereços recém-utilizados, chamado de "Translation Lookaside Buffer" (TLB). Entretanto, a TLB padrão só pode armazenar em cache um certo número de mapeamentos de endereços.
Se um mapeamento de endereço solicitado não estiver na TLB, chamado de TLB miss, o sistema ainda precisa ler a tabela de páginas para determinar o mapeamento de endereço físico para virtual. Devido à relação entre os requisitos de memória da aplicação e o tamanho das páginas usadas para o mapeamento de endereços em cache, as aplicações com requisitos de memória grandes têm mais probabilidade de sofrer degradação de desempenho por falhas na TLB do que as aplicações com requisitos mínimos de memória. Portanto, é importante evitar falhas de TLB sempre que possível.
Tanto as características HugeTLB como as Transparent Huge Page permitem que as aplicações utilizem páginas maiores do que 4 KB. Isto permite que endereços armazenados na TLB referenciem mais memória, o que reduz as falhas na TLB e melhora o desempenho da aplicação.
Capítulo 24. Começando com SystemTap
Como administrador de sistema, você pode usar o SystemTap para identificar as causas subjacentes de um bug ou problema de desempenho em um sistema Linux em execução.
Como desenvolvedor de aplicações, você pode usar o SystemTap para monitorar em detalhes como sua aplicação se comporta dentro do sistema Linux.
24.1. O propósito do SystemTap
SystemTap é uma ferramenta de rastreamento e sondagem que você pode usar para estudar e monitorar as atividades de seu sistema operacional (particularmente, o núcleo) com detalhes finos. O SystemTap fornece informações semelhantes à saída de ferramentas como netstat, ps, top, e iostat. Entretanto, o SystemTap fornece mais opções de filtragem e análise para as informações coletadas. Nos scripts do SystemTap, você especifica as informações que o SystemTap reúne.
O SystemTap visa complementar o conjunto existente de ferramentas de monitoramento Linux, fornecendo aos usuários a infra-estrutura para rastrear a atividade do kernel e combinando esta capacidade com dois atributos:
- Flexibility
- a estrutura SystemTap permite desenvolver scripts simples para investigar e monitorar uma grande variedade de funções do kernel, chamadas de sistema e outros eventos que ocorrem no espaço do kernel. Com isso, o SystemTap não é tanto uma ferramenta, mas um sistema que permite desenvolver suas próprias ferramentas forenses e de monitoramento específicas do kernel.
- Ease-of-Use
- SystemTap permite monitorar a atividade do kernel sem ter que recompilar o kernel ou reiniciar o sistema.
24.2. Implementando o SystemTap
Para usar o SystemTap, você deve instalar os pacotes associados do SystemTap e do kernel.
24.2.1. Habilitação de depuração e repositórios de fonte
Uma instalação padrão do Red Hat Enterprise Linux não habilita os repositórios de depuração e fonte. Estes repositórios contêm informações necessárias para depurar os componentes do sistema e medir seu desempenho.
Procedimento
Habilitar os canais do pacote de informações de origem e de depuração:
# subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-baseos-source-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-debug-rpms # subscription-manager repos --enable rhel-8-for-$(uname -i)-appstream-source-rpms
A parte
$(uname -i)é automaticamente substituída por um valor correspondente para a arquitetura de seu sistema:Nome da arquitetura Valor Intel e AMD de 64 bits
x86_64
ARM de 64 bits
aarch64
IBM POWER
ppc64le
IBM Z
s390x
24.2.2. Instalando o SystemTap
Para começar a usar o SystemTap, instale os pacotes necessários. Para usar o SystemTap em mais de um kernel onde um sistema tem múltiplos kernels instalados, instale os pacotes de kernel necessários correspondentes para a versão each do kernel.
Pré-requisitos
- Você habilitou os repositórios de depuração como descrito em Habilitação de repositórios de depuração e de origem.
Procedimento
Instale os pacotes SystemTap necessários:
# yum instalar systemtap
Instalar os pacotes de kernel necessários:
Usando
stap-prep:# stap-prep-prep
Se
stap-prepnão funcionar, instale os pacotes de kernel necessários manualmente:# yum install kernel-debuginfo-$(uname -r) kernel-debuginfo-common-$(uname -i)-$(uname -r) kernel-devel-$(uname -r)
$(uname -i)é automaticamente substituído com a plataforma de hardware de seu sistema e$(uname -r)é automaticamente substituído com a versão de seu kernel em execução.
Etapas de verificação
Se o kernel a ser sondado com SystemTap estiver em uso atualmente, teste se sua instalação foi bem sucedida:
# stap -v -e 'probe kernel.function(vfs_read') {printf({"read performed"); exit()}Uma implementação bem sucedida do SystemTap resulta em um resultado semelhante ao seguinte:
Pass 1: parsed user script and 45 library script(s) in 340usr/0sys/358real ms. Pass 2: analyzed script: 1 probe(s), 1 function(s), 0 embed(s), 0 global(s) in 290usr/260sys/568real ms. Pass 3: translated to C into "/tmp/stapiArgLX/stap_e5886fa50499994e6a87aacdc43cd392_399.c" in 490usr/430sys/938real ms. Pass 4: compiled C into "stap_e5886fa50499994e6a87aacdc43cd392_399.ko" in 3310usr/430sys/3714real ms. Pass 5: starting run. 1 read performed 2 Pass 5: run completed in 10usr/40sys/73real ms. 3
As últimas três linhas de saída (começando com
Pass 5) indicam que:
24.3. Cross-instrumentação do SystemTap
24.3.1. SystemTap de instrumentação cruzada
Quando você executa um script SystemTap, um módulo do kernel é construído a partir desse script. O SystemTap então carrega o módulo para o kernel.
Normalmente, os scripts do SystemTap só podem ser executados em sistemas onde o SystemTap é implantado. Para executar o SystemTap em dez sistemas, o SystemTap precisa ser implantado em todos esses sistemas. Em alguns casos, isto pode não ser viável nem desejado. Por exemplo, a política corporativa pode proibir a instalação de pacotes que forneçam compiladores ou informações de depuração em máquinas específicas, o que impedirá a implantação do SystemTap.
Para contornar este problema, use cross-instrumentation. A instrumentação cruzada é o processo de geração de módulos de instrumentação SystemTap a partir de um script SystemTap em um sistema para ser usado em outro sistema. Este processo oferece os seguintes benefícios:
- Os pacotes de informação do núcleo para várias máquinas podem ser instalados em uma única máquina host.
Os bugs de embalagem do grão podem impedir isso. Nesses casos, os pacotes kernel-debuginfo e kernel-devel para os pacotes host system e target system devem corresponder. Caso isso ocorra, informe o erro em https://bugzilla.redhat.com/.
-
Cada target machine necessita apenas de um pacote a ser instalado para utilizar o módulo de instrumentação SystemTap gerado:
systemtap-runtime.
O host system deve ser a mesma arquitetura e rodar a mesma distribuição de Linux que o target system, para que o instrumentation module construído funcione.
- instrumentation module
- O módulo do kernel construído a partir de um script SystemTap; o módulo SystemTap é construído no host system, e será carregado no target kernel do site target system.
- host system
- O sistema no qual os módulos de instrumentação (dos scripts SystemTap) são compilados, para serem carregados em target systems.
- target system
- O sistema no qual o instrumentation module está sendo construído (a partir dos scripts do SystemTap).
- target kernel
- O núcleo do target system. Este é o kernel que carrega e executa o instrumentation module.
24.3.2. Inicializando a instrumentação cruzada do SystemTap
Inicializar a instrumentação cruzada do SystemTap para construir módulos de instrumentação SystemTap a partir de um script SystemTap em um sistema e usá-los em outro sistema que não tenha o SystemTap totalmente implantado.
Pré-requisitos
- O SystemTap está instalado no site host system como descrito em Instalando o SystemTap.
- Tanto o host system quanto o target system são a mesma arquitetura.
- Tanto o host system quanto o target system estão rodando a mesma versão principal do Red Hat Enterprise Linux (como o Red Hat Enterprise Linux 8), eles can estão rodando diferentes versões menores (como 8.1 e 8.2).
Os bugs de embalagem do kernel podem impedir que vários pacotes kernel-debuginfo e kernel-devel sejam instalados em um sistema. Nesses casos, a versão menor para os pacotes host system e target system deve coincidir. Caso isso ocorra, informe o bug em https://bugzilla.redhat.com/.
Procedimento
Determinar o kernel rodando em cada target system:
$ uname -r
Repita esta etapa para cada um target system.
Instale o pacote necessário para executar módulos pré-compilados em cada um target system:
# yum instalar systemtap-runtime
- No site host system, instale o target kernel e pacotes relacionados para cada target system pelo método descrito na instalação do SystemTap.
Construa um módulo de instrumentação no host system, copie para e execute no target system também:
Usando implementação remota:
# stap --remote target_system script
Este comando implementa remotamente o script especificado no site target system. Você deve garantir que uma conexão SSH possa ser feita ao target system a partir do host system para que isto seja bem sucedido.
Manualmente:
Construa o módulo de instrumentação no site host system:
# stap -r kernel_version script -m module_name -p 4
Aqui, kernel_version refere-se à versão do target kernel determinada no passo 1, script refere-se ao roteiro a ser convertido em instrumentation module, e module_name é o nome desejado do instrumentation module. A opção
-p4diz ao SystemTap para não carregar e executar o módulo compilado.Uma vez compilado o instrumentation module, copie-o para o sistema de destino e carregue-o usando o seguinte comando:
# staprun module_name.koNotaA execução de um módulo pré-compilado requer apenas o pacote
systemtap-runtime.
24.4. Sistema em execuçãoRoteiros de mapas
24.4.1. Privilégios para executar o SystemTap
A execução de scripts SystemTap requer privilégios elevados do sistema mas, em alguns casos, os usuários não privilegiados podem precisar executar a instrumentação SystemTap em sua máquina.
Para permitir que os usuários executem o SystemTap sem acesso root, adicione usuários a both destes grupos de usuários:
stapdevOs membros deste grupo podem usar
stappara executar scripts SystemTap, oustaprunpara executar módulos de instrumentação SystemTap.A execução do
stapenvolve a compilação de scripts SystemTap em módulos do kernel e o seu carregamento no kernel. Isto requer privilégios elevados ao sistema, que são concedidos aos membros dostapdev. Infelizmente, tais privilégios também concedem acesso efetivo à raiz aos membros dostapdev. Como tal, somente concedem astapdevmembros do grupo aos usuários que podem ser confiados com acesso à raiz.stapusr-
Os membros deste grupo só podem usar
staprunpara executar os módulos de instrumentação do SystemTap. Além disso, eles só podem rodar esses módulos a partir do/lib/modules/kernel_version/systemtap/diretório. Este diretório deve ser de propriedade apenas do usuário root, e deve poder ser escrito apenas pelo usuário root.
24.4.2. Sistema em execuçãoRoteiros de mapas
Você pode executar scripts SystemTap a partir de entradas padrão ou a partir de um arquivo.
Os exemplos de scripts que são distribuídos com a instalação do SystemTap podem ser encontrados no diretório /usr/share/systemtap/examples.
Pré-requisitos
- O SystemTap e os pacotes de kernel necessários associados são instalados como descrito na instalação do SystemTap.
Para executar os scripts SystemTap como um usuário normal, adicione o usuário aos grupos SystemTap:
# usermod --append --groups stapdev,stapusr user-name
Procedimento
Execute o script SystemTap:
A partir da entrada padrão:
# echo "probe timer.s(1) {exit()}" | stap -Este comando instrui
stapa executar o script passado porechopara a entrada padrão. Para adicionar as opçõesstap, insira-as antes do caracter-. Por exemplo, para tornar os resultados deste comando mais verbosos, o comando é:# echo "probe timer.s(1) {exit()}" | stap -v -A partir de um arquivo:
# stap file_name
Capítulo 25. Analisando o desempenho do sistema com a Coleção de Compiladores BPF
Como administrador de sistemas, use a biblioteca BPF Compiler Collection (BCC) para criar ferramentas para analisar o desempenho de seu sistema operacional Linux e coletar informações, que podem ser difíceis de obter através de outras interfaces.
25.1. Uma introdução ao BCC
BPF Compiler Collection (BCC) é uma biblioteca, que facilita a criação dos programas ampliados de Filtro de Pacotes Berkeley (eBPF). A principal utilidade dos programas eBPF é analisar o desempenho do sistema operacional e o desempenho da rede sem ter problemas de overhead ou de segurança.
BCC elimina a necessidade de os usuários conhecerem detalhes técnicos profundos do eBPF, e fornece muitos pontos de partida prontos para uso, tais como o pacote bcc-tools com programas eBPF pré-criados.
Os programas eBPF são acionados em eventos, tais como E/S de disco, conexões TCP e criações de processo. É improvável que os programas causem o colapso, loop ou tornem-se insensíveis por funcionarem em uma máquina virtual segura no kernel.
25.2. Instalando o pacote bcc-tools
Esta seção descreve como instalar o pacote bcc-tools, que também instala a biblioteca BPF Compiler Collection (BCC) como uma dependência.
Pré-requisitos
- Um ativo Red Hat Enterprise Linux subscription
-
Um enabled repository contendo o pacote
bcc-tools - Kernel atualizado
- Permissões de raiz.
Procedimento
Instale
bcc-tools:#yum install bcc-toolsAs ferramentas BCC estão instaladas no diretório
/usr/share/bcc/tools/.Opcionalmente, inspecionar as ferramentas:
#ll /usr/share/bcc/tools/... -rwxr-xr-x. 1 root root 4198 Dec 14 17:53 dcsnoop -rwxr-xr-x. 1 root root 3931 Dec 14 17:53 dcstat -rwxr-xr-x. 1 root root 20040 Dec 14 17:53 deadlock_detector -rw-r--r--. 1 root root 7105 Dec 14 17:53 deadlock_detector.c drwxr-xr-x. 3 root root 8192 Mar 11 10:28 doc -rwxr-xr-x. 1 root root 7588 Dec 14 17:53 execsnoop -rwxr-xr-x. 1 root root 6373 Dec 14 17:53 ext4dist -rwxr-xr-x. 1 root root 10401 Dec 14 17:53 ext4slower ...O diretório
docna lista acima contém documentação para cada ferramenta.
25.3. Utilização de ferramentas bcc selecionadas para análises de desempenho
Esta seção descreve como usar certos programas pré-criados da biblioteca da BPF Compiler Collection (BCC) para analisar de forma eficiente e segura o desempenho do sistema em cada evento. O conjunto de programas pré-criados na biblioteca do BCC pode servir como exemplos para a criação de programas adicionais.
Pré-requisitos
- Biblioteca BCC instalada
- Permissões de raiz
Usando o execsnoop para examinar os processos do sistema
Executar o programa
execsnoopem um terminal:# /usr/share/bcc/tools/execsnoopEm outro terminal executar, por exemplo:
$ ls /usr/share/bcc/tools/doc/O acima exposto cria um processo de curta duração do comando
ls.O terminal rodando
execsnoopmostra a saída semelhante ao seguinte:PCOMM PID PPID RET ARGS ls 8382 8287 0 /usr/bin/ls --color=auto /usr/share/bcc/tools/doc/ sed 8385 8383 0 /usr/bin/sed s/^ *[0-9]\+ *// ...
O programa
execsnoopimprime uma linha de saída para cada novo processo, o que consome recursos do sistema. Ele até detecta processos de programas que rodam muito em breve, tais comols, e a maioria das ferramentas de monitoramento não os registrariam.A saída
execsnoopexibe os seguintes campos:-
PCOMM - O nome do processo pai. (
ls) -
PID - A identificação do processo. (
8382) -
PPID - O ID do processo pai. (
8287) -
RET - O valor de retorno da chamada ao sistema
exec()(0), que carrega o código do programa em novos processos. - ARGS - A localização do programa iniciado com argumentos.
-
PCOMM - O nome do processo pai. (
Para ver mais detalhes, exemplos e opções para execsnoop, consulte o arquivo /usr/share/bcc/tools/doc/execsnoop_example.txt.
Para mais informações sobre exec(), consulte as páginas do manual exec(3).
Usando o opensnoop para rastrear quais arquivos um comando abre
Executar o programa
opensnoopem um terminal:# /usr/share/bcc/tools/opensnoop -n unameA saída de impressões acima para arquivos, que são abertos somente pelo processo do comando
uname.Em outro terminal executar:
$ unameO comando acima abre certos arquivos, que são capturados na próxima etapa.
O terminal rodando
opensnoopmostra a saída semelhante ao seguinte:PID COMM FD ERR PATH 8596 uname 3 0 /etc/ld.so.cache 8596 uname 3 0 /lib64/libc.so.6 8596 uname 3 0 /usr/lib/locale/locale-archive ...
O programa
opensnoopobserva a chamada do sistemaopen()em todo o sistema, e imprime uma linha de saída para cada arquivo queunametentou abrir pelo caminho.A saída
opensnoopexibe os seguintes campos:-
PID - A identificação do processo. (
8596) -
COMM - O nome do processo. (
uname) -
FD - O descritor de arquivo - um valor que
open()retorna para se referir ao arquivo aberto. (3) - ERR - Qualquer erro.
PATH - A localização dos arquivos que
open()tentou abrir.Se um comando tentar ler um arquivo inexistente, então a coluna
FDretorna-1e a colunaERRimprime um valor correspondente ao erro relevante. Como resultado,opensnooppode ajudá-lo a identificar uma aplicação que não se comporta corretamente.
-
PID - A identificação do processo. (
Para ver mais detalhes, exemplos e opções para opensnoop, consulte o arquivo /usr/share/bcc/tools/doc/opensnoop_example.txt.
Para mais informações sobre open(), consulte as páginas do manual open(2).
Utilização de biotop para examinar as operações de E/S no disco
Executar o programa
biotopem um terminal:# /usr/share/bcc/tools/biotop 30O comando permite monitorar os processos superiores, que realizam operações de E/S no disco. O argumento garante que o comando produzirá um resumo de 30 segundos.
NotaQuando nenhum argumento é fornecido, a tela de saída, por padrão, é atualizada a cada 1 segundo.
Em outro terminal executar, por exemplo :
# dd if=/dev/vda of=/dev/zeroO comando acima lê o conteúdo do dispositivo de disco rígido local e grava a saída para o arquivo
/dev/zero. Esta etapa gera certo tráfego de E/S para ilustrarbiotop.O terminal rodando
biotopmostra a saída semelhante ao seguinte:PID COMM D MAJ MIN DISK I/O Kbytes AVGms 9568 dd R 252 0 vda 16294 14440636.0 3.69 48 kswapd0 W 252 0 vda 1763 120696.0 1.65 7571 gnome-shell R 252 0 vda 834 83612.0 0.33 1891 gnome-shell R 252 0 vda 1379 19792.0 0.15 7515 Xorg R 252 0 vda 280 9940.0 0.28 7579 llvmpipe-1 R 252 0 vda 228 6928.0 0.19 9515 gnome-control-c R 252 0 vda 62 6444.0 0.43 8112 gnome-terminal- R 252 0 vda 67 2572.0 1.54 7807 gnome-software R 252 0 vda 31 2336.0 0.73 9578 awk R 252 0 vda 17 2228.0 0.66 7578 llvmpipe-0 R 252 0 vda 156 2204.0 0.07 9581 pgrep R 252 0 vda 58 1748.0 0.42 7531 InputThread R 252 0 vda 30 1200.0 0.48 7504 gdbus R 252 0 vda 3 1164.0 0.30 1983 llvmpipe-1 R 252 0 vda 39 724.0 0.08 1982 llvmpipe-0 R 252 0 vda 36 652.0 0.06 ...
A saída
biotopexibe os seguintes campos:-
PID - A identificação do processo. (
9568) -
COMM - O nome do processo. (
dd) -
DISK - O disco que realiza as operações lidas. (
vda) - I/O - O número de operações lidas realizadas. (16294)
- Kbytes - A quantidade de Kbytes alcançados pelas operações lidas. (14,440,636)
- AVGms - O tempo médio de E/S das operações lidas. (3.69)
-
PID - A identificação do processo. (
Para ver mais detalhes, exemplos e opções para biotop, consulte o arquivo /usr/share/bcc/tools/doc/biotop_example.txt.
Para mais informações sobre dd, consulte as páginas do manual dd(1).
Usando xfsslower para expor operações de sistema de arquivo inesperadamente lentas
Executar o programa
xfsslowerem um terminal:# /usr/share/bcc/tools/xfsslower 1O comando acima mede o tempo que o sistema de arquivos XFS gasta em operações de leitura, escrita, abertura ou sincronização (
fsync). O argumento1garante que o programa mostra apenas as operações que são mais lentas do que 1 ms.NotaQuando nenhum argumento é fornecido,
xfsslowerpor padrão exibe operações mais lentas do que 10 ms.Em outro terminal executar, por exemplo, o seguinte:
$ vim textO comando acima cria um arquivo de texto no editor
vimpara iniciar certa interação com o sistema de arquivos XFS.O terminal rodando
xfsslowermostra algo semelhante ao salvar o arquivo da etapa anterior:TIME COMM PID T BYTES OFF_KB LAT(ms) FILENAME 13:07:14 b'bash' 4754 R 256 0 7.11 b'vim' 13:07:14 b'vim' 4754 R 832 0 4.03 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 32 20 1.04 b'libgpm.so.2.1.0' 13:07:14 b'vim' 4754 R 1982 0 2.30 b'vimrc' 13:07:14 b'vim' 4754 R 1393 0 2.52 b'getscriptPlugin.vim' 13:07:45 b'vim' 4754 S 0 0 6.71 b'text' 13:07:45 b'pool' 2588 R 16 0 5.58 b'text' ...
Cada linha acima representa uma operação no sistema de arquivo, que levou mais tempo do que um determinado limite.
xfssloweré bom em expor possíveis problemas no sistema de arquivo, que podem tomar a forma de operações inesperadamente lentas.A saída
xfsslowerexibe os seguintes campos:-
COMM - O nome do processo. (
b’bash') T - O tipo de operação. (
R)- Read
- Writo
- Sync
- OFF_KB - O arquivo compensado em KB. (0)
- FILENAME - O arquivo sendo lido, escrito, ou sincronizado.
-
COMM - O nome do processo. (
Para ver mais detalhes, exemplos e opções para xfsslower, consulte o arquivo /usr/share/bcc/tools/doc/xfsslower_example.txt.
Para mais informações sobre fsync, consulte as páginas do manual fsync(2).