
Red Hat Training
A Red Hat training course is available for RHEL 8
Gerenciamento de dispositivos de armazenamento
Implementação e configuração de armazenamento de nó único no Red Hat Enterprise Linux 8
Resumo
Tornando o código aberto mais inclusivo
A Red Hat tem o compromisso de substituir a linguagem problemática em nosso código, documentação e propriedades da web. Estamos começando com estes quatro termos: master, slave, blacklist e whitelist. Por causa da enormidade deste esforço, estas mudanças serão implementadas gradualmente ao longo de vários lançamentos futuros. Para mais detalhes, veja a mensagem de nosso CTO Chris Wright.
Fornecendo feedback sobre a documentação da Red Hat
Agradecemos sua contribuição em nossa documentação. Por favor, diga-nos como podemos melhorá-la. Para fazer isso:
Para comentários simples sobre passagens específicas:
- Certifique-se de que você está visualizando a documentação no formato Multi-page HTML. Além disso, certifique-se de ver o botão Feedback no canto superior direito do documento.
- Use o cursor do mouse para destacar a parte do texto que você deseja comentar.
- Clique no pop-up Add Feedback que aparece abaixo do texto destacado.
- Siga as instruções apresentadas.
Para enviar comentários mais complexos, crie um bilhete Bugzilla:
- Ir para o site da Bugzilla.
- Como Componente, use Documentation.
- Preencha o campo Description com sua sugestão de melhoria. Inclua um link para a(s) parte(s) relevante(s) da documentação.
- Clique em Submit Bug.
Capítulo 1. Visão geral das opções de armazenamento disponíveis
Este capítulo descreve os tipos de armazenamento que estão disponíveis no Red Hat Enterprise Linux 8. O Red Hat Enterprise Linux oferece uma variedade de opções para gerenciar o armazenamento local e para anexar ao armazenamento remoto. Figura 1.1, “Diagrama de armazenamento de alto nível do Red Hat Enterprise Linux” descreve as diferentes opções de armazenamento:
Figura 1.1. Diagrama de armazenamento de alto nível do Red Hat Enterprise Linux
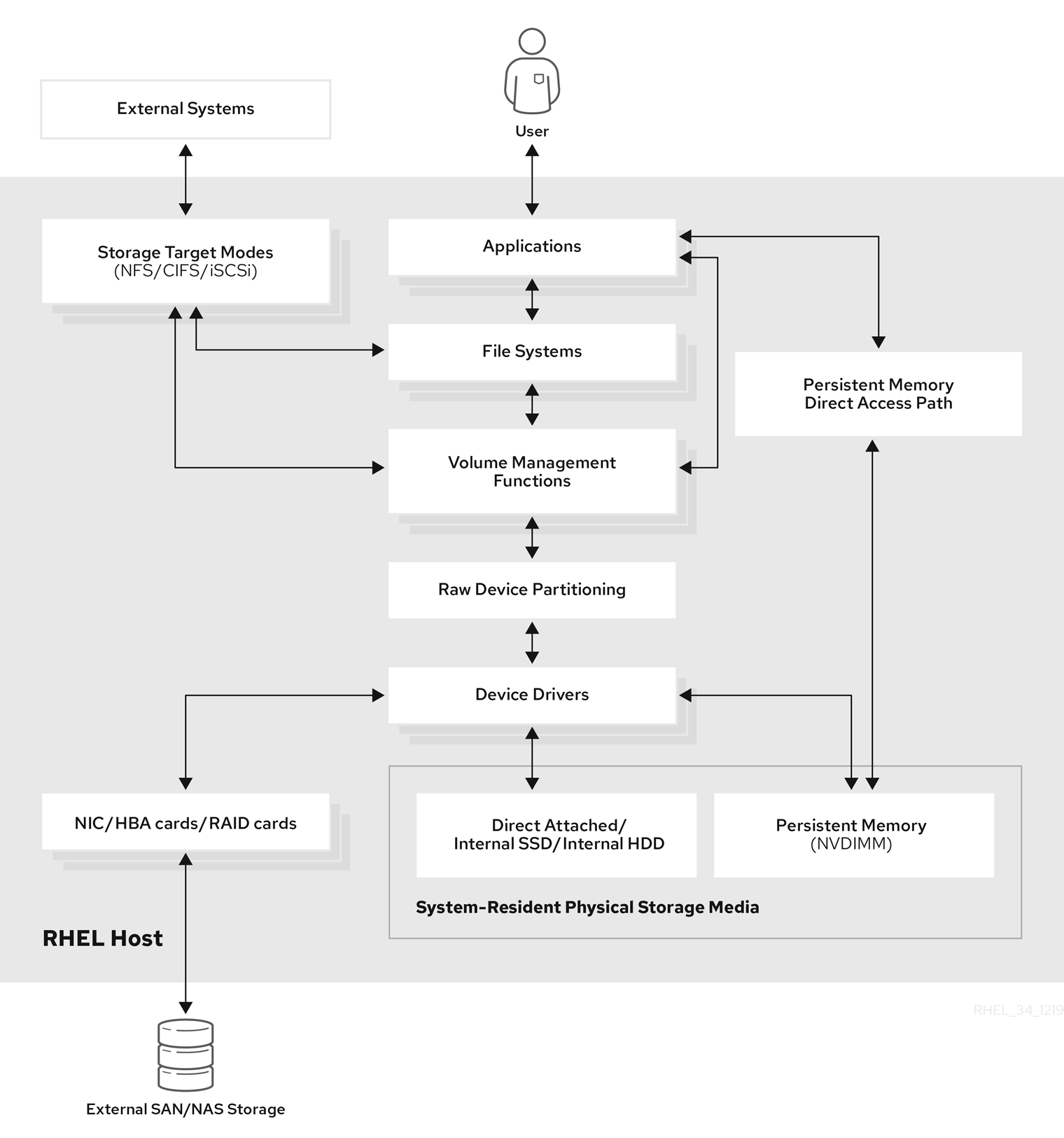
1.1. Opções de armazenamento local
A seguir estão as opções de armazenamento local disponíveis no Red Hat Enterprise Linux 8:
- Administração básica do disco
Usando partições e fdisk, você pode criar, modificar, apagar e visualizar as partições. A seguir estão os padrões de layout das divisórias:
- Registro de Bota Principal (MBR)
- É utilizado com computadores baseados em BIOS. É possível criar partições primárias, ampliadas e lógicas.
- Tabela de partição do GUID (GPT)
- Ele usa um identificador global único (GUID) e fornece um GUID exclusivo de disco e partição.
Para criptografar a partição, você pode usar o Linux Unified Key Setup-on-disk-format (LUKS). Para criptografar a partição, selecione a opção durante a instalação e o prompt de visualização para inserir a frase-chave. Esta frase-chave desbloqueia a chave de criptografia.
- Opções de consumo de armazenamento
- Gestão de Módulos de Memória em Linha Dupla Não-Volátil (NVDIMM)
- É uma combinação de memória e armazenamento. Você pode ativar e gerenciar vários tipos de armazenamento em dispositivos NVDIMM conectados ao seu sistema.
- Gerenciamento de armazenamento em bloco
- Os dados são armazenados sob a forma de blocos onde cada bloco tem um identificador único.
- Armazenamento de arquivos
- Os dados são armazenados em nível de arquivo no sistema local. Estes dados podem ser acessados localmente usando XFS (padrão) ou ext4, e através de uma rede, usando NFS e SMB.
- Volumes lógicos
- Gerenciador de Volume Lógico (LVM)
Ele cria dispositivos lógicos a partir de dispositivos físicos. O volume lógico (LV) é uma combinação dos volumes físicos (PV) e grupos de volume (VG). A configuração de LVM inclui:
- Criando PV a partir dos discos rígidos.
- Criação de VG a partir do PV.
- Criação do LV a partir da VG atribuindo pontos de montagem ao LV.
- Otimizador de Dados Virtual (VDO)
É utilizado para a redução de dados através da deduplicação, compressão e provisionamento fino. O uso do LV abaixo do VDO ajuda a entrar:
- Ampliação do volume VDO
- Abrangendo o volume VDO em múltiplos dispositivos
- Sistemas de arquivo locais
- XFS
- O sistema de arquivos padrão da RHEL.
- Ext4
- Um sistema de arquivo legado.
- Stratis
- Está disponível como uma Pré-visualização Tecnológica. O Stratis é um sistema híbrido de gerenciamento de armazenamento local de usuário e núcleo que suporta recursos avançados de armazenamento.
1.2. Opções de armazenamento remoto
A seguir estão as opções de armazenamento remoto disponíveis no Red Hat Enterprise Linux 8:
- Opções de conectividade de armazenamento
- iSCSI
- A RHEL 8 utiliza a ferramenta targetcli para adicionar, remover, visualizar e monitorar as interconexões de armazenamento iSCSI.
- Canal de Fibra (FC)
O Red Hat Enterprise Linux 8 fornece os seguintes drivers nativos do Fibre Channel:
-
lpfc -
qla2xxx -
Zfcp
-
- Expressão de memória não volátil (NVMe)
Uma interface que permite que o utilitário de software hospedeiro se comunique com acionamentos em estado sólido. Use os seguintes tipos de transporte de tecido para configurar o NVMe sobre tecidos:
- NVMe sobre tecidos usando o Remote Direct Memory Access (RDMA).
- NVMe sobre tecidos usando Fibre Channel (FC)
- Dispositivo Mapper multipathing (DM Multipath)
- Permite configurar múltiplos caminhos de E/S entre nós de servidor e matrizes de armazenamento em um único dispositivo. Estes caminhos de E/S são conexões SAN físicas que podem incluir cabos, interruptores e controladores separados.
- Sistema de arquivo em rede
- NFS
- SMB
1.3. Solução em cluster do sistema de arquivos GFS2
O sistema de arquivo Global File System 2 (GFS2) da Red Hat é um sistema de arquivo de cluster simétrico de 64 bits que fornece um espaço de nome compartilhado e gerencia a coerência entre múltiplos nós que compartilham um dispositivo de bloco comum. Um sistema de arquivo GFS2 destina-se a fornecer um conjunto de recursos que é o mais próximo possível de um sistema de arquivo local, ao mesmo tempo em que reforça a coerência total do cluster entre os nós. Para conseguir isso, os nós empregam um esquema de travamento em cluster para os recursos do sistema de arquivos. Este esquema de travamento utiliza protocolos de comunicação como o TCP/IP para trocar informações de travamento.
Em alguns casos, a API do sistema de arquivos Linux não permite que a natureza de cluster do GFS2 seja totalmente transparente; por exemplo, programas que utilizam bloqueios POSIX no GFS2 devem evitar o uso da função GETLK uma vez que, em um ambiente de cluster, a identificação do processo pode ser para um nó diferente no cluster. Na maioria dos casos, entretanto, a funcionalidade de um sistema de arquivos GFS2 é idêntica à de um sistema de arquivos local.
O Complemento de Armazenamento Resiliente do Red Hat Enterprise Linux (RHEL) fornece o GFS2, e depende do Complemento de Alta Disponibilidade RHEL para fornecer o gerenciamento de cluster exigido pelo GFS2.
O módulo do kernel gfs2.ko implementa o sistema de arquivos GFS2 e é carregado nos nós de cluster GFS2.
Para obter o melhor desempenho do GFS2, é importante levar em conta as considerações de desempenho que decorrem do projeto subjacente. Assim como um sistema de arquivo local, o GFS2 depende do cache de páginas para melhorar o desempenho através do cache local de dados freqüentemente utilizados. Para manter a coerência entre os nós no cluster, o controle do cache é fornecido pela máquina do estado glock.
Recursos adicionais
- Para mais informações sobre os sistemas de arquivo GFS2, consulte a documentação Configurando os sistemas de arquivo GFS2.
1.4. Soluções aglomeradas
Esta seção fornece uma visão geral das opções agrupadas, tais como Red Hat Gluster Storage (RHGS) ou Red Hat Ceph Storage (RHCS).
1.4.1. Opção de armazenamento Red Hat Gluster
O Red Hat Gluster Storage (RHGS) é uma plataforma de armazenamento definida por software. Ela agrega recursos de armazenamento em disco de múltiplos servidores em um único namespace global. O GlusterFS é um sistema de arquivo distribuído de código aberto. Ele é adequado para soluções híbridas e em nuvem.
O GlusterFS consiste em diferentes tipos de volume, que são a base do GlusterFS e fornecem diferentes requisitos. O volume é uma coleção dos tijolos, que são o próprio espaço de armazenamento.
Os tipos de volume GlusterFS são os seguintes:
- Distributed GlusterFS volume é o volume padrão. Neste caso, cada arquivo é armazenado em um único tijolo e não pode ser compartilhado entre tijolos diferentes.
- o tipoReplicated GlusterFS volume mantém as réplicas dos dados. Neste caso, se um tijolo falhar, o usuário ainda poderá acessar os dados.
- Distributed replicated GlusterFS volume é um volume híbrido que distribui réplicas sobre um grande número de sistemas. É adequado para o ambiente onde os requisitos de armazenamento em escala e alta confiabilidade são críticos.
Recursos adicionais
- Para mais informações sobre a RHGS, consulte o guia de administração de armazenamento de gluster da Red Hat.
1.4.2. Opção de armazenamento Red Hat Ceph
A Red Hat Ceph Storage (RHCS) é uma plataforma de armazenamento escalável, aberta e definida por software que combina a versão mais estável do sistema de armazenamento Ceph com uma plataforma de gerenciamento Ceph, utilitários de implantação e serviços de suporte.
O Red Hat Ceph Storage foi projetado para a infra-estrutura de nuvens e armazenamento de objetos em escala web. Os clusters de armazenamento Red Hat Ceph consistem nos seguintes tipos de nós:
- Armazenamento Red Hat Ceph Nó de administração possível
Este tipo de nó atua como o tradicional nó de Administração Ceph para as versões anteriores da Red Hat Ceph Storage. Este tipo de nó fornece as seguintes funções:
- Gerenciamento centralizado do cluster de armazenamento
- Os arquivos e chaves de configuração da Ceph
- Opcionalmente, repositórios locais para instalação do Ceph em nós que não podem acessar a Internet por razões de segurança
- Nós de monitoramento
Cada nó de monitor executa o daemon monitor (
ceph-mon), que mantém uma cópia matriz do mapa de agrupamento. O mapa de agrupamento inclui a topologia do agrupamento. Um cliente conectado ao cluster da Ceph recupera a cópia atual do mapa de cluster do monitor que permite ao cliente ler e escrever dados no cluster.ImportanteA Ceph pode funcionar com um monitor; entretanto, para garantir alta disponibilidade em um cluster de produção, a Red Hat só suportará implantações com pelo menos três nós de monitor. A Red Hat recomenda a implantação de um total de 5 monitores Ceph para clusters de armazenamento que excedam 750 OSDs.
- Nós OSD
Cada nó do Dispositivo de Armazenamento de Objetos (OSD) executa o daemon Ceph OSD (
ceph-osd), que interage com os discos lógicos anexados ao nó. A Ceph armazena dados sobre esses nós OSD.A Ceph pode funcionar com muito poucos nós OSD, que o padrão é três, mas os clusters de produção percebem melhor desempenho a partir de escalas modestas, por exemplo, 50 OSDs em um cluster de armazenamento. Idealmente, um cluster Ceph tem múltiplos nós OSD, permitindo domínios de falha isolados através da criação do mapa CRUSH.
- Nós MDS
-
Cada nó do Metadata Server (MDS) executa o daemon MDS (
ceph-mds), que gerencia os metadados relacionados aos arquivos armazenados no Ceph File System (CephFS). O daemon MDS também coordena o acesso ao cluster compartilhado. - Objeto Nó de porta de entrada
-
O nó Ceph Object Gateway executa o daemon Ceph RADOS Gateway (
ceph-radosgw), e é uma interface de armazenamento de objetos construída em cima delibradospara fornecer aplicações com um gateway RESTful para Ceph Storage Clusters. O gateway Ceph Object Gateway suporta duas interfaces: - S3
- Fornece funcionalidade de armazenamento de objetos com uma interface compatível com um grande subconjunto do Amazon S3 RESTful API.
- Swift
- Fornece funcionalidade de armazenamento de objetos com uma interface compatível com um grande subconjunto do OpenStack Swift API.
Recursos adicionais
- Para mais informações sobre a RHCS, consulte a documentação da Red Hat Ceph Storage.
Capítulo 2. Gerenciamento do armazenamento local usando as funções do sistema RHEL
Para gerenciar LVM e sistemas de arquivos locais (FS) usando o Ansible, você pode usar a função storage, que é uma das funções do Sistema RHEL disponível no RHEL 8.
O uso da função storage permite automatizar a administração de sistemas de arquivos em discos e volumes lógicos em múltiplas máquinas e em todas as versões da RHEL, começando com a RHEL 7.7.
Para mais informações sobre os papéis do Sistema RHEL e como aplicá-los, consulte Introdução aos papéis do Sistema RHEL.
2.1. Introdução à função de armazenamento
A função storage pode administrar:
- Sistemas de arquivos em discos que não foram particionados
- Grupos completos de volumes LVM incluindo seus volumes lógicos e sistemas de arquivo
Com o papel storage você pode realizar as seguintes tarefas:
- Criar um sistema de arquivo
- Remover um sistema de arquivo
- Montar um sistema de arquivo
- Desmontar um sistema de arquivo
- Criar grupos de volume LVM
- Remover grupos de volume LVM
- Criar volumes lógicos
- Remover volumes lógicos
- Criar volumes RAID
- Remover volumes RAID
- Criar pools LVM com RAID
- Remover as piscinas LVM com RAID
2.2. Parâmetros que identificam um dispositivo de armazenamento no papel do sistema de armazenamento
Sua configuração de funções storage afeta apenas os sistemas de arquivos, volumes e pools que você lista nas seguintes variáveis.
storage_volumesLista de sistemas de arquivos em todos os discos não particionados a serem gerenciados.
Atualmente, as partições não têm suporte.
storage_poolsLista de piscinas a serem administradas.
Atualmente, o único tipo de piscina suportada é a LVM. Com LVM, os pools representam grupos de volume (VGs). Sob cada pool há uma lista de volumes a serem gerenciados pela função. Com o LVM, cada volume corresponde a um volume lógico (LV) com um sistema de arquivo.
2.3. Exemplo Livro de reprodução possível para criar um sistema de arquivo XFS em um dispositivo de bloco
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para criar um sistema de arquivos XFS em um dispositivo de bloco usando os parâmetros padrão.
A função storage pode criar um sistema de arquivo somente em um disco não particionado, inteiro ou em um volume lógico (LV). Ele não pode criar o sistema de arquivo em uma partição.
Exemplo 2.1. Um playbook que cria XFS em /dev/sdb
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
roles:
- rhel-system-roles.storage-
O nome do volume (
barefsno exemplo) é atualmente arbitrária. A funçãostorageidentifica o volume pelo dispositivo de disco listado sob o atributodisks:. -
Você pode omitir a linha
fs_type: xfsporque XFS é o sistema de arquivo padrão no RHEL 8. Para criar o sistema de arquivo em um LV, forneça a configuração LVM sob o atributo
disks:, incluindo o grupo de volume envolvente. Para detalhes, veja Exemplo Livro de exemplo para gerenciar volumes lógicos.Não forneça o caminho para o dispositivo LV.
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.4. Exemplo Livro de reprodução possível para montar persistentemente um sistema de arquivo
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para montar imediata e persistentemente um sistema de arquivos XFS.
Exemplo 2.2. Um playbook que monta um sistema de arquivo em /dev/sdb para /mnt/dados
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
Este playbook adiciona o sistema de arquivo ao arquivo
/etc/fstab, e monta o sistema de arquivo imediatamente. -
Se o sistema de arquivo no dispositivo
/dev/sdbou o diretório de pontos de montagem não existir, o playbook os cria.
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.5. Exemplo Livro de exercícios possível para gerenciar volumes lógicos
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para criar um volume lógico LVM em um grupo de volumes.
Exemplo 2.3. Um playbook que cria um volume lógico mylv no grupo de volume myvg
- hosts: all
vars:
storage_pools:
- name: myvg
disks:
- sda
- sdb
- sdc
volumes:
- name: mylv
size: 2G
fs_type: ext4
mount_point: /mnt
roles:
- rhel-system-roles.storageO grupo de volume
myvgé composto pelos seguintes discos:-
/dev/sda -
/dev/sdb -
/dev/sdc
-
-
Se o grupo de volume
myvgjá existe, o playbook adiciona o volume lógico ao grupo de volume. -
Se o grupo de volume
myvgnão existe, o playbook o cria. -
O playbook cria um sistema de arquivo Ext4 no volume lógico
mylve monta persistentemente o sistema de arquivo em/mnt.
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.6. Exemplo Livro de reprodução possível para permitir o descarte em bloco online
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para montar um sistema de arquivo XFS com o descarte de blocos on-line habilitado.
Exemplo 2.4. Um playbook que permite o descarte de blocos online em /mnt/dados/
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storageRecursos adicionais
- Este playbook também realiza todas as operações do exemplo de montagem persistente descrito em Seção 2.4, “Exemplo Livro de reprodução possível para montar persistentemente um sistema de arquivo”.
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.7. Exemplo Livro de reprodução possível para criar e montar um sistema de arquivo Ext4
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para criar e montar um sistema de arquivos Ext4.
Exemplo 2.5. Um playbook que cria Ext4 em /dev/sdb e o monta em /mnt/dados
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext4
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
O playbook cria o sistema de arquivos no disco
/dev/sdb. -
O playbook monta persistentemente o sistema de arquivo no
/mnt/datadiretório. -
A etiqueta do sistema de arquivo é
label-name.
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.8. Exemplo Livro de reprodução possível para criar e montar um sistema de arquivo ext3
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para criar e montar um sistema de arquivos Ext3.
Exemplo 2.6. Um playbook que cria Ext3 em /dev/sdb e o monta em /mnt/dados
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext3
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
O playbook cria o sistema de arquivos no disco
/dev/sdb. -
O playbook monta persistentemente o sistema de arquivo no
/mnt/datadiretório. -
A etiqueta do sistema de arquivo é
label-name.
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.9. Configuração de um volume RAID utilizando a função do sistema de armazenamento
Com o Sistema Função storage, você pode configurar um volume RAID na RHEL usando a Plataforma de Automação Possível Red Hat Ansible Automation. Nesta seção, você aprenderá como configurar um livro de jogo possível com os parâmetros disponíveis para configurar um volume RAID de acordo com suas necessidades.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja implantar a solução
storage.-
Você tem o pacote
rhel-system-rolesinstalado no sistema a partir do qual você deseja executar o playbook. -
Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja implantar um volume RAID usando o sistema
storageFunção do sistema.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present roles: - name: rhel-system-roles.storageAtençãoOs nomes dos dispositivos podem mudar em certas circunstâncias; por exemplo, quando você adiciona um novo disco a um sistema. Portanto, para evitar a perda de dados, não recomendamos o uso de nomes de disco específicos no livro de reprodução.
Opcional. Verificar a sintaxe do playbook.
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
- Para mais informações sobre o RAID, consulte Gerenciando RAID.
-
Para detalhes sobre os parâmetros utilizados na função do sistema de armazenamento, consulte o arquivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.10. Configuração de um pool LVM com RAID utilizando a função de sistema de armazenamento
Com o Sistema Função storage, você pode configurar um pool LVM com RAID na RHEL usando a Plataforma de Automação Possível da Red Hat. Nesta seção você aprenderá como configurar um playbook Ansible com os parâmetros disponíveis para configurar um pool LVM com RAID.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja implantar a solução
storage.-
Você tem o pacote
rhel-system-rolesinstalado no sistema a partir do qual você deseja executar o playbook. -
Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja configurar um pool LVM com RAID usando o sistema
storageFunção do sistema.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_pool size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: present roles: - name: rhel-system-roles.storageNotaPara criar um pool LVM com RAID, você deve especificar o tipo de RAID usando o parâmetro
raid_level.Opcional. Verificar a sintaxe do playbook.
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
- Para mais informações sobre o RAID, consulte Gerenciando RAID.
-
Para detalhes sobre os parâmetros utilizados na função do sistema de armazenamento, consulte o arquivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
2.11. Criação de um volume codificado LUKS usando a função de armazenamento
Você pode usar o papel storage para criar e configurar um volume criptografado com LUKS, executando um livro de brincadeiras Ansible playbook.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja criar o volume.
-
Você tem o pacote
rhel-system-rolesinstalado no controlador Ansible. - Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja implantar um volume codificado LUKS usando a função de sistema de armazenamento.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar a sintaxe do playbook:
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
- Para mais informações sobre a LUKS, veja 17. Criptografando dispositivos de blocos usando LUKS...
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
Recursos adicionais
Para mais informações, instale o pacote
rhel-system-rolese veja os seguintes diretórios:-
/usr/share/doc/rhel-system-roles/storage/ -
/usr/share/ansible/roles/rhel-system-roles.storage/
-
Capítulo 3. Começando com as divisórias
Como administrador do sistema, você pode usar os seguintes procedimentos para criar, excluir e modificar vários tipos de partições de disco.
Para uma visão geral das vantagens e desvantagens de usar divisórias em dispositivos de blocos, consulte o seguinte artigo da KBase: https://access.redhat.com/solutions/163853.
3.1. Visualização da mesa divisória
Como administrador de sistema, você pode exibir a tabela de partição de um dispositivo de bloco para ver o layout da partição e detalhes sobre as partições individuais.
3.1.1. Visualizando a mesa divisória com separação
Este procedimento descreve como visualizar a tabela de partição em um dispositivo de bloco usando o utilitário parted.
Procedimento
Inicie o shell interativo
parted:# Separado block-device-
Substitua block-device com o caminho para o dispositivo que você deseja examinar: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo que você deseja examinar: por exemplo,
Veja a tabela de partição:
(dividido) impressão
Opcionalmente, use o seguinte comando para mudar para outro dispositivo que você queira examinar a seguir:
(separados) selecione block-device
Recursos adicionais
-
A página do homem
parted(8).
3.1.2. Exemplo de saída de parted print
Esta seção fornece um exemplo de saída do comando print na shell parted e descreve os campos na saída.
Exemplo 3.1. Saída do comando print
Model: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logical
A seguir, uma descrição dos campos:
Model: ATA SAMSUNG MZNLN256 (scsi)- O tipo de disco, fabricante, número do modelo e interface.
Disk /dev/sda: 256GB- O caminho do arquivo para o dispositivo do bloco e a capacidade de armazenamento.
Partition Table: msdos- O tipo de etiqueta do disco.
Number-
O número da divisória. Por exemplo, a partição com número menor 1 corresponde a
/dev/sda1. StarteEnd- A localização no dispositivo onde começa e termina a divisória.
Type- Os tipos válidos são metadados, livres, primários, estendidos ou lógicos.
File system-
O tipo de sistema de arquivo. Se o campo
File systemde um dispositivo não mostrar nenhum valor, isto significa que seu tipo de sistema de arquivo é desconhecido. O utilitáriopartednão consegue reconhecer o sistema de arquivo em dispositivos criptografados. Flags-
Relaciona as bandeiras definidas para a divisória. As bandeiras disponíveis são
boot,root,swap,hidden,raid,lvm, oulba.
3.2. Criação de uma tabela de partição em um disco
Como administrador de sistema, você pode formatar um dispositivo de bloco com diferentes tipos de tabelas de partição para permitir o uso de partições no dispositivo.
A formatação de um dispositivo de bloco com uma tabela de partição elimina todos os dados armazenados no dispositivo.
3.2.1. Considerações antes de modificar as partições em um disco
Esta seção lista os pontos-chave a serem considerados antes de criar, remover ou redimensionar as divisórias.
Esta seção não cobre a tabela de partição DASD, que é específica para a arquitetura IBM Z. Para informações sobre o DASD, veja:
- Configuração de uma instância Linux na IBM Z
- O que você deve saber sobre o artigo DASD no Centro de Conhecimento da IBM
O número máximo de divisórias
O número de divisórias em um dispositivo é limitado pelo tipo da tabela de divisórias:
Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), você pode ter qualquer um dos dois:
- Até quatro partições primárias, ou
- Até três divisórias primárias, uma divisória estendida, e múltiplas divisórias lógicas dentro da estendida.
-
Em um dispositivo formatado com o GUID Partition Table (GPT), o número máximo de divisórias é de 128. Enquanto a especificação GPT permite mais partições aumentando a área reservada para a tabela de partição, a prática comum usada pelo utilitário
partedé limitá-la a uma área suficiente para 128 partições.
A Red Hat recomenda que, a menos que você tenha uma razão para fazer o contrário, você deve at least criar as seguintes partições: swap, /boot/, e / (raiz).
O tamanho máximo de uma divisória
O tamanho de uma divisória em um dispositivo é limitado pelo tipo da mesa divisória:
- Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), o tamanho máximo é 2TiB.
- Em um dispositivo formatado com o GUID Partition Table (GPT), o tamanho máximo é 8ZiB.
Se você quiser criar uma partição maior que 2TiB, o disco deve ser formatado com GPT.
Alinhamento de tamanhos
O utilitário parted permite especificar o tamanho da partição usando vários sufixos diferentes:
- MiB, GiB, ou TiB
Tamanho expresso em poderes de 2.
- O ponto de partida da divisória é alinhado ao setor exato especificado por tamanho.
- O ponto final é alinhado com o tamanho especificado menos 1 setor.
- MB, GB, ou TB
Tamanho expresso em poderes de 10.
O ponto inicial e final é alinhado dentro de uma metade da unidade especificada: por exemplo, ±500KB ao utilizar o sufixo MB.
3.2.2. Comparação dos tipos de mesas divisórias
Esta seção compara as propriedades de diferentes tipos de tabelas de partição que você pode criar em um dispositivo de bloco.
Tabela 3.1. Tipos de mesas divisórias
| Mesa divisória | Número máximo de divisórias | Tamanho máximo da divisória |
|---|---|---|
| Registro de Bota Principal (MBR) | 4 primários, ou 3 primários e 12 lógicos dentro de uma partição estendida | 2TiB |
| Tabela de partição do GUID (GPT) | 128 | 8ZiB |
3.2.3. Partições de disco MBR
Os diagramas deste capítulo mostram a tabela de partição como sendo separada do disco real. No entanto, isto não é totalmente exato. Na realidade, a tabela de partição é armazenada logo no início do disco, antes de qualquer sistema de arquivos ou dados do usuário, mas, para maior clareza, eles estão separados nos diagramas a seguir.
Figura 3.1. Disco com mesa divisória MBR
Como mostra o diagrama anterior, a tabela de partições está dividida em quatro seções de quatro partições primárias. Uma partição primária é uma partição em um disco rígido que pode conter apenas um disco lógico (ou seção). Cada seção pode conter as informações necessárias para definir uma única partição, o que significa que a tabela de partição não pode definir mais do que quatro partições.
Cada entrada da tabela de partição contém várias características importantes da partição:
- Os pontos no disco onde começa e termina a partição.
- Se a divisória é active. Apenas uma partição pode ser sinalizada como active.
- O tipo da divisória.
Os pontos inicial e final definem o tamanho e a localização da partição no disco. A bandeira "ativa" é usada por alguns sistemas operacionais carregadores de inicialização. Em outras palavras, o sistema operacional na partição que está marcado como "ativo" é inicializado, neste caso.
O tipo é um número que identifica o uso antecipado da divisória. Alguns sistemas operacionais usam o tipo de partição para denotar um tipo específico de sistema de arquivo, para marcar a partição como sendo associada a um sistema operacional específico, para indicar que a partição contém um sistema operacional inicializável, ou alguma combinação dos três.
O diagrama a seguir mostra um exemplo de uma unidade com uma única partição:
Figura 3.2. Disco com uma única divisória
A partição única neste exemplo está etiquetada como DOS. Esta etiqueta mostra o tipo de partição, sendo DOS uma das mais comuns.
3.2.4. Partições MBR estendidas
Caso quatro divisórias sejam insuficientes para suas necessidades, você pode usar divisórias estendidas para criar divisórias adicionais. Você pode fazer isso definindo o tipo de partição como "Extendida".
Uma partição estendida é como uma unidade de disco em seu próprio direito - ela tem sua própria tabela de partições, que aponta para uma ou mais partições (agora chamadas partições lógicas, ao contrário das quatro partições primárias), contidas inteiramente dentro da própria partição estendida. O diagrama a seguir mostra um drive de disco com uma partição primária e uma partição estendida contendo duas partições lógicas (juntamente com algum espaço livre não particionado):
Figura 3.3. Disco com uma partição MBR primária e uma MBR estendida
Como este número implica, há uma diferença entre as partições primárias e lógicas - só pode haver até quatro partições primárias e estendidas, mas não há um limite fixo para o número de partições lógicas que podem existir. Entretanto, devido à forma como as partições são acessadas no Linux, não podem ser definidas mais de 15 partições lógicas em um único drive de disco.
3.2.5. Tipos de divisórias MBR
A tabela abaixo mostra uma lista de alguns dos tipos de partição MBR comumente usados e números hexadecimais usados para representá-los.
Tabela 3.2. Tipos de divisórias MBR
| MBR partition type | Value | MBR partition type | Value |
| Vazio | 00 | Novell Netware 386 | 65 |
| DOS 12-bit FAT | 01 | PIC/IX | 75 |
| Raiz XENIX | O2 | Velho MINIX | 80 |
| XENIX usr | O3 | Linux/MINUX | 81 |
| DOS 16 bits ⇐32M | 04 | Troca de Linux | 82 |
| Estendido | 05 | Linux nativo | 83 |
| DOS 16-bit >=32 | 06 | Linux estendido | 85 |
| OS/2 HPFS | 07 | Amoeba | 93 |
| AIX | 08 | Amoeba BBT | 94 |
| AIX inicializável | 09 | BSD/386 | a5 |
| Gerenciador de Boot OS/2 | 0a | OpenBSD | a6 |
| Win95 FAT32 | 0b | NEXTSTEP | a7 |
| Win95 FAT32 (LBA) | 0c | BSDI fs | b7 |
| Win95 FAT16 (LBA) | 0e | Troca de BSDI | b8 |
| Win95 Estendido (LBA) | 0f | Syrinx | c7 |
| Venix 80286 | 40 | CP/M | db |
| Novell | 51 | Acesso DOS | e1 |
| Bota PRep | 41 | DOS R/O | e3 |
| GNU HURD | 63 | DOS secundário | f2 |
| Novell Netware 286 | 64 | BBT | ff |
3.2.6. Tabela de partição do GUID
A Tabela de Partição GUID (GPT) é um esquema de partição baseado no uso de um Identificador Único Global (GUID). O GPT foi desenvolvido para lidar com as limitações da tabela de partição MBR, especialmente com o espaço máximo de armazenamento endereçável limitado de um disco. Ao contrário do MBR, que é incapaz de endereçar armazenamento maior que 2 TiB (equivalente a aproximadamente 2,2 TB), o GPT é usado com discos rígidos maiores que este; o tamanho máximo do disco endereçável é 2,2 ZiB. Além disso, o GPT, por padrão, suporta a criação de até 128 partições primárias. Este número poderia ser ampliado alocando mais espaço para a tabela de partições.
Um GPT tem tipos de divisórias baseadas em GUIDs. Note que certas partições requerem um GUID específico. Por exemplo, a partição do sistema para carregadores de inicialização EFI requer o GUID C12A7328-F81F-11D2-BA4B-00A0C93EC93B.
Os discos GPT usam endereçamento lógico de blocos (LBA) e o layout da partição é o seguinte:
- Para preservar a compatibilidade com os discos MBR, o primeiro setor (LBA 0) do GPT é reservado para os dados MBR e é chamado de "MBR de proteção".
- O cabeçalho GPT primário começa no segundo bloco lógico (LBA 1) do dispositivo. O cabeçalho contém o GUID do disco, a localização da tabela de partição primária, a localização do cabeçalho GPT secundário, e os checksums CRC32 de si mesmo, e a tabela de partição primária. Ele também especifica o número de entradas de partição na tabela.
- O GPT primário inclui, por padrão, 128 entradas de partição, cada uma com um tamanho de entrada de 128 bytes, seu tipo de partição GUID e GUID de partição única.
- O GPT secundário é idêntico ao GPT primário. Ele é usado principalmente como uma tabela de reserva para recuperação no caso da tabela de partição primária estar corrompida.
- O cabeçalho secundário GPT está localizado no último setor lógico do disco e pode ser usado para recuperar informações GPT no caso do cabeçalho primário estar corrompido. Ele contém o GUID do disco, a localização da tabela de partição secundária e do cabeçalho GPT primário, os checksums CRC32 de si mesmo e da tabela de partição secundária, e o número de possíveis entradas de partição.
Figura 3.4. Disco com uma tabela de partição GUID
Deve haver uma partição de inicialização BIOS para que o carregador de inicialização seja instalado com sucesso em um disco que contenha uma GPT (GUID Partition Table). Isto inclui discos inicializados por Anaconda. Se o disco já contém uma partição de inicialização da BIOS, ela pode ser reutilizada.
3.2.7. Criação de uma tabela de partição em um disco com partição
Este procedimento descreve como formatar um dispositivo de bloco com uma tabela de partição usando o utilitário parted.
Procedimento
Inicie o shell interativo
parted:# Separado block-device-
Substitua block-device com o caminho para o dispositivo onde você deseja criar uma tabela de partição: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo onde você deseja criar uma tabela de partição: por exemplo,
Determinar se já existe uma tabela de partição no dispositivo:
(dividido) impressão
Se o dispositivo já contém partições, elas serão apagadas nas próximas etapas.
Criar a nova mesa divisória:
(separado) mklabel table-typeSubstitua table-type com o tipo de mesa divisória prevista:
-
msdospara MBR -
gptpara GPT
-
Exemplo 3.2. Criação de uma tabela GPT
Por exemplo, para criar uma tabela GPT sobre o disco, use:
(separado) mklabel gpt
As mudanças começam a acontecer assim que você entra neste comando, portanto, revise-o antes de executá-lo.
Veja a tabela de partição para confirmar que a tabela de partição existe:
(dividido) impressão
Saia da casca
parted:(separado) desistir
Recursos adicionais
-
A página do homem
parted(8).
Próximos passos
- Criar divisórias no dispositivo. Veja Seção 3.3, “Criando uma divisória” para detalhes.
3.3. Criando uma divisória
Como administrador do sistema, você pode criar novas partições em um disco.
3.3.1. Considerações antes de modificar as partições em um disco
Esta seção lista os pontos-chave a serem considerados antes de criar, remover ou redimensionar as divisórias.
Esta seção não cobre a tabela de partição DASD, que é específica para a arquitetura IBM Z. Para informações sobre o DASD, veja:
- Configuração de uma instância Linux na IBM Z
- O que você deve saber sobre o artigo DASD no Centro de Conhecimento da IBM
O número máximo de divisórias
O número de divisórias em um dispositivo é limitado pelo tipo da tabela de divisórias:
Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), você pode ter qualquer um dos dois:
- Até quatro partições primárias, ou
- Até três divisórias primárias, uma divisória estendida, e múltiplas divisórias lógicas dentro da estendida.
-
Em um dispositivo formatado com o GUID Partition Table (GPT), o número máximo de divisórias é de 128. Enquanto a especificação GPT permite mais partições aumentando a área reservada para a tabela de partição, a prática comum usada pelo utilitário
partedé limitá-la a uma área suficiente para 128 partições.
A Red Hat recomenda que, a menos que você tenha uma razão para fazer o contrário, você deve at least criar as seguintes partições: swap, /boot/, e / (raiz).
O tamanho máximo de uma divisória
O tamanho de uma divisória em um dispositivo é limitado pelo tipo da mesa divisória:
- Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), o tamanho máximo é 2TiB.
- Em um dispositivo formatado com o GUID Partition Table (GPT), o tamanho máximo é 8ZiB.
Se você quiser criar uma partição maior que 2TiB, o disco deve ser formatado com GPT.
Alinhamento de tamanhos
O utilitário parted permite especificar o tamanho da partição usando vários sufixos diferentes:
- MiB, GiB, ou TiB
Tamanho expresso em poderes de 2.
- O ponto de partida da divisória é alinhado ao setor exato especificado por tamanho.
- O ponto final é alinhado com o tamanho especificado menos 1 setor.
- MB, GB, ou TB
Tamanho expresso em poderes de 10.
O ponto inicial e final é alinhado dentro de uma metade da unidade especificada: por exemplo, ±500KB ao utilizar o sufixo MB.
3.3.2. Tipos de partição
Esta seção descreve diferentes atributos que especificam o tipo de uma partição.
Tipos de partição ou bandeiras
O tipo de divisória, ou bandeira, é usado por um sistema em funcionamento apenas raramente. Entretanto, o tipo de partição é importante para os geradores em funcionamento, tais como systemd-gpt-auto-generator, que utilizam o tipo de partição para, por exemplo, identificar e montar automaticamente os dispositivos.
-
O utilitário
partedfornece algum controle dos tipos de partição através do mapeamento do tipo de partição para flags. O utilitário parted pode controlar apenas certos tipos de partição: por exemplo LVM, swap, ou RAID. -
O utilitário
fdisksuporta toda a gama de tipos de divisórias especificando códigos hexadecimais.
Tipo de sistema de arquivo de partição
O utilitário parted aceita opcionalmente um argumento de tipo de sistema de arquivo ao criar uma partição. O valor é usado para:
- Coloque as bandeiras de partição no MBR, ou
-
Defina a partição tipo UUID no GPT. Por exemplo, os tipos de sistema de arquivo
swap,fat, ouhfsdefinem diferentes GUIDs. O valor padrão é o GUID de dados Linux.
O argumento não modifica de forma alguma o sistema de arquivo na partição. Ele apenas diferencia entre as bandeiras ou GUIDs suportadas.
Os seguintes tipos de sistemas de arquivo são suportados:
-
xfs -
ext2 -
ext3 -
ext4 -
fat16 -
fat32 -
hfs -
hfs -
linux-swap -
ntfs -
reiserfs
3.3.3. Esquema de nomenclatura das partições
O Red Hat Enterprise Linux usa um esquema de nomes baseado em arquivos, com nomes de arquivos na forma de /dev/xxyN.
Os nomes dos dispositivos e das divisórias consistem na seguinte estrutura:
/dev/-
Este é o nome do diretório no qual estão localizados todos os arquivos do dispositivo. Como as partições são colocadas em discos rígidos, e os discos rígidos são dispositivos, os arquivos que representam todas as partições possíveis estão localizados em
/dev. xx-
As duas primeiras letras do nome das divisórias indicam o tipo de dispositivo em que se encontra a divisória, geralmente
sd. y-
Esta letra indica em qual dispositivo a divisória está ligada. Por exemplo,
/dev/sdapara o primeiro disco rígido,/dev/sdbpara o segundo, e assim por diante. Em sistemas com mais de 26 drives, é possível usar mais letras. Por exemplo,/dev/sdaa1. N-
A letra final indica o número que representa a partição. As quatro primeiras partições (primárias ou ampliadas) são numeradas
1até4. As partições lógicas começam em5. Por exemplo,/dev/sda3é a terceira partição primária ou estendida no primeiro disco rígido, e/dev/sdb6é a segunda partição lógica no segundo disco rígido. A numeração das partições do disco se aplica somente às tabelas de partições MBR. Observe que N nem sempre significa partição.
Mesmo que o Red Hat Enterprise Linux possa identificar e consultar os tipos de partições de disco all, ele pode não ser capaz de ler o sistema de arquivo e, portanto, acessar os dados armazenados em cada tipo de partição. Entretanto, em muitos casos, é possível acessar com sucesso dados em uma partição dedicada a outro sistema operacional.
3.3.4. Pontos de montagem e partições de disco
No Red Hat Enterprise Linux, cada partição é usada para formar parte do armazenamento necessário para suportar um único conjunto de arquivos e diretórios. Isto é feito usando o processo conhecido como mounting, que associa uma partição a um diretório. A montagem de uma partição torna seu armazenamento disponível a partir do diretório especificado, conhecido como mount point.
Por exemplo, se a partição /dev/sda5 estiver montada em /usr/, isso significaria que todos os arquivos e diretórios sob /usr/ residem fisicamente em /dev/sda5. Assim, o arquivo /usr/share/doc/FAQ/txt/Linux-FAQ seria armazenado em /dev/sda5, enquanto o arquivo /etc/gdm/custom.conf não o seria.
Continuando o exemplo, também é possível que um ou mais diretórios abaixo de /usr/ sejam pontos de montagem para outras partições. Por exemplo, uma partição /dev/sda7 poderia ser montada em /usr/local, o que significa que /usr/local/man/whatis residiria então em /dev/sda7 em vez de /dev/sda5.
3.3.5. Criação de uma divisória com separação
Este procedimento descreve como criar uma nova partição em um dispositivo de bloco usando o utilitário parted.
Pré-requisitos
- Há uma tabela de partição no disco. Para detalhes sobre como formatar o disco, veja Seção 3.2, “Criação de uma tabela de partição em um disco”.
- Se a partição que você deseja criar for maior que 2TiB, o disco deve ser formatado com a Tabela de Partição GUID (GPT).
Procedimento
Inicie o shell interativo
parted:# Separado block-device-
Substitua block-device com o caminho para o dispositivo onde você quer criar uma partição: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo onde você quer criar uma partição: por exemplo,
Veja a tabela de partição atual para determinar se há espaço livre suficiente:
(dividido) impressão
- Se não houver espaço livre suficiente, você pode redimensionar uma divisória existente. Para mais informações, consulte Seção 3.5, “Redimensionamento de uma divisória”.
A partir da tabela de partição, determine:
- Os pontos de início e fim da nova divisória
- No MBR, que tipo de partição deve ser.
Criar a nova divisória:
(separado) mkpart part-type name fs-type start end
-
Substitua part-type com
primary,logical, ouextendedcom base no que você decidiu a partir da tabela de partição. Isto se aplica somente à tabela de partição MBR. - Substitua name com um nome de partição arbitrária. Isto é necessário para as tabelas de partição GPT.
-
Substitua fs-type com qualquer um de
xfs,ext2,ext3,ext4,fat16,fat32,hfs,hfs,linux-swap,ntfs, oureiserfs. O fs-type parâmetro é opcional. Note quepartednão cria o sistema de arquivo na partição. -
Substitua start e end com os tamanhos que determinam os pontos inicial e final da partição, contando desde o início do disco. Pode-se usar sufixos de tamanho, como
512MiB,20GiB, ou1.5TiB. Os megabytes de tamanho padrão.
Exemplo 3.3. Criação de uma pequena partição primária
Por exemplo, para criar uma partição primária de 1024MiB até 2048MiB em uma tabela MBR, use:
(dividido) mkpart primário 1024MiB 2048MiB
As mudanças começam a acontecer assim que você entra neste comando, portanto, revise-o antes de executá-lo.
-
Substitua part-type com
Veja a tabela de partição para confirmar que a partição criada está na tabela de partição com o tipo, tipo de sistema de arquivo e tamanho corretos:
(dividido) impressão
Saia da casca
parted:(separado) desistir
Use o seguinte comando para esperar que o sistema registre o novo nó de dispositivo:
# udevadm assentar
Verificar se o núcleo reconhece a nova partição:
# gato /proc/partições
Recursos adicionais
-
A página do homem
parted(8).
3.3.6. Definição de um tipo de divisória com fdisk
Este procedimento descreve como definir um tipo de partição, ou bandeira, usando o utilitário fdisk.
Pré-requisitos
- Há uma partição no disco.
Procedimento
Inicie o shell interativo
fdisk:# fdisk block-device-
Substitua block-device com o caminho para o dispositivo onde você quer definir um tipo de partição: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo onde você quer definir um tipo de partição: por exemplo,
Veja a tabela de partição atual para determinar o número da partição menor:
Comando (m de ajuda) printVocê pode ver o tipo de partição atual na coluna
Typee sua identificação de tipo correspondente na colunaId.Digite o comando tipo de partição e selecione uma partição usando seu número menor:
Command (m for help): type Partition number (1,2,3 default 3): 2
Opcionalmente, liste os códigos hexadecimais disponíveis:
Código hexadecimal (tipo L para listar todos os códigos) LDefina o tipo de divisória:
Código hexadecimal (tipo L para listar todos os códigos) 8eEscreva suas mudanças e saia da casca
fdisk:Command (m for help): write The partition table has been altered. Syncing disks.Verifique suas mudanças:
# fdisk --lista block-device
3.4. Remoção de uma divisória
Como administrador do sistema, você pode remover uma partição de disco que não é mais utilizada para liberar espaço em disco.
A remoção de uma partição apaga todos os dados armazenados na partição.
3.4.1. Considerações antes de modificar as partições em um disco
Esta seção lista os pontos-chave a serem considerados antes de criar, remover ou redimensionar as divisórias.
Esta seção não cobre a tabela de partição DASD, que é específica para a arquitetura IBM Z. Para informações sobre o DASD, veja:
- Configuração de uma instância Linux na IBM Z
- O que você deve saber sobre o artigo DASD no Centro de Conhecimento da IBM
O número máximo de divisórias
O número de divisórias em um dispositivo é limitado pelo tipo da tabela de divisórias:
Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), você pode ter qualquer um dos dois:
- Até quatro partições primárias, ou
- Até três divisórias primárias, uma divisória estendida, e múltiplas divisórias lógicas dentro da estendida.
-
Em um dispositivo formatado com o GUID Partition Table (GPT), o número máximo de divisórias é de 128. Enquanto a especificação GPT permite mais partições aumentando a área reservada para a tabela de partição, a prática comum usada pelo utilitário
partedé limitá-la a uma área suficiente para 128 partições.
A Red Hat recomenda que, a menos que você tenha uma razão para fazer o contrário, você deve at least criar as seguintes partições: swap, /boot/, e / (raiz).
O tamanho máximo de uma divisória
O tamanho de uma divisória em um dispositivo é limitado pelo tipo da mesa divisória:
- Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), o tamanho máximo é 2TiB.
- Em um dispositivo formatado com o GUID Partition Table (GPT), o tamanho máximo é 8ZiB.
Se você quiser criar uma partição maior que 2TiB, o disco deve ser formatado com GPT.
Alinhamento de tamanhos
O utilitário parted permite especificar o tamanho da partição usando vários sufixos diferentes:
- MiB, GiB, ou TiB
Tamanho expresso em poderes de 2.
- O ponto de partida da divisória é alinhado ao setor exato especificado por tamanho.
- O ponto final é alinhado com o tamanho especificado menos 1 setor.
- MB, GB, ou TB
Tamanho expresso em poderes de 10.
O ponto inicial e final é alinhado dentro de uma metade da unidade especificada: por exemplo, ±500KB ao utilizar o sufixo MB.
3.4.2. Remoção de uma divisória com separação
Este procedimento descreve como remover uma partição de disco usando o utilitário parted.
Procedimento
Inicie o shell interativo
parted:# Separado block-device-
Substitua block-device com o caminho para o dispositivo onde você quer remover uma partição: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo onde você quer remover uma partição: por exemplo,
Veja a tabela de partição atual para determinar o número menor da partição a ser removida:
(dividido) impressão
Remover a divisória:
(separados) rm minor-number-
Substitua minor-number com o número menor da partição que você deseja remover: por exemplo,
3.
As mudanças começam a acontecer assim que você entra neste comando, portanto, revise-o antes de executá-lo.
-
Substitua minor-number com o número menor da partição que você deseja remover: por exemplo,
Confirmar que a divisória é removida da mesa divisória:
(dividido) impressão
Saia da casca
parted:(separado) desistir
Verificar se o núcleo sabe que a partição foi removida:
# gato /proc/partições
-
Remova a partição do arquivo
/etc/fstabse ela estiver presente. Encontre a linha que declara a partição removida, e remova-a do arquivo. Regenere as unidades de montagem para que seu sistema registre a nova configuração
/etc/fstab:# systemctl daemon-reload
Se você tiver excluído uma partição swap ou removido pedaços de LVM, remova todas as referências à partição da linha de comando do kernel no arquivo
/etc/default/grube regenere a configuração do GRUB:Em um sistema baseado na BIOS:
# grub2-mkconfig --output=/etc/grub2.cfg
Em um sistema baseado na UEFI:
# grub2-mkconfig --output=/etc/grub2-efi.cfg
Para registrar as mudanças no sistema de inicialização inicial, reconstrua o sistema de arquivos
initramfs:# dracut --force --verbose
Recursos adicionais
-
A página do homem
parted(8)
3.5. Redimensionamento de uma divisória
Como administrador de sistema, você pode estender uma partição para utilizar o espaço não utilizado em disco, ou encolher uma partição para utilizar sua capacidade para diferentes propósitos.
3.5.1. Considerações antes de modificar as partições em um disco
Esta seção lista os pontos-chave a serem considerados antes de criar, remover ou redimensionar as divisórias.
Esta seção não cobre a tabela de partição DASD, que é específica para a arquitetura IBM Z. Para informações sobre o DASD, veja:
- Configuração de uma instância Linux na IBM Z
- O que você deve saber sobre o artigo DASD no Centro de Conhecimento da IBM
O número máximo de divisórias
O número de divisórias em um dispositivo é limitado pelo tipo da tabela de divisórias:
Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), você pode ter qualquer um dos dois:
- Até quatro partições primárias, ou
- Até três divisórias primárias, uma divisória estendida, e múltiplas divisórias lógicas dentro da estendida.
-
Em um dispositivo formatado com o GUID Partition Table (GPT), o número máximo de divisórias é de 128. Enquanto a especificação GPT permite mais partições aumentando a área reservada para a tabela de partição, a prática comum usada pelo utilitário
partedé limitá-la a uma área suficiente para 128 partições.
A Red Hat recomenda que, a menos que você tenha uma razão para fazer o contrário, você deve at least criar as seguintes partições: swap, /boot/, e / (raiz).
O tamanho máximo de uma divisória
O tamanho de uma divisória em um dispositivo é limitado pelo tipo da mesa divisória:
- Em um dispositivo formatado com a tabela de partição Master Boot Record (MBR), o tamanho máximo é 2TiB.
- Em um dispositivo formatado com o GUID Partition Table (GPT), o tamanho máximo é 8ZiB.
Se você quiser criar uma partição maior que 2TiB, o disco deve ser formatado com GPT.
Alinhamento de tamanhos
O utilitário parted permite especificar o tamanho da partição usando vários sufixos diferentes:
- MiB, GiB, ou TiB
Tamanho expresso em poderes de 2.
- O ponto de partida da divisória é alinhado ao setor exato especificado por tamanho.
- O ponto final é alinhado com o tamanho especificado menos 1 setor.
- MB, GB, ou TB
Tamanho expresso em poderes de 10.
O ponto inicial e final é alinhado dentro de uma metade da unidade especificada: por exemplo, ±500KB ao utilizar o sufixo MB.
3.5.2. Redimensionamento de uma divisória com separação
Este procedimento redimensiona uma partição de disco usando o utilitário parted.
Pré-requisitos
Se você quiser encolher uma partição, faça backup dos dados que estão armazenados nela.
AtençãoRetrair uma partição pode resultar em perda de dados na partição.
- Se você quiser redimensionar uma partição para ser maior que 2TiB, o disco deve ser formatado com a Tabela de Partição GUID (GPT). Para obter detalhes sobre como formatar o disco, consulte Seção 3.2, “Criação de uma tabela de partição em um disco”.
Procedimento
- Se você quiser diminuir a partição, encolha primeiro o sistema de arquivo sobre ela para que não seja maior do que a partição redimensionada. Note que o XFS não suporta o encolhimento.
Inicie o shell interativo
parted:# Separado block-device-
Substitua block-device com o caminho para o dispositivo onde você deseja redimensionar uma partição: por exemplo,
/dev/sda.
-
Substitua block-device com o caminho para o dispositivo onde você deseja redimensionar uma partição: por exemplo,
Veja a tabela de partição atual:
(dividido) impressão
A partir da tabela de partição, determine:
- O número menor da divisória
- A localização da divisória existente e seu novo ponto final após o redimensionamento
Redimensionar a divisória:
(dividido) reizepart minor-number new-end
-
Substitua minor-number com o número menor da partição que você está redimensionando: por exemplo,
3. -
Substitua new-end com o tamanho que determina o novo ponto final da partição redimensionada, contando desde o início do disco. Pode-se usar sufixos de tamanho, como
512MiB,20GiB, ou1.5TiB. O tamanho padrão de megabytes.
Exemplo 3.4. Ampliação de uma divisória
Por exemplo, para estender uma partição localizada no início do disco para ser 2GiB em tamanho, use:
(dividido) resizepart 1 2GiB
As mudanças começam a acontecer assim que você entra neste comando, portanto, revise-o antes de executá-lo.
-
Substitua minor-number com o número menor da partição que você está redimensionando: por exemplo,
Veja a tabela de partição para confirmar que a partição redimensionada está na tabela de partição com o tamanho correto:
(dividido) impressão
Saia da casca
parted:(separado) desistir
Verificar se o núcleo reconhece a nova partição:
# gato /proc/partições
- Se você estender a partição, estenda o sistema de arquivo também sobre ela. Veja (referência) para detalhes.
Recursos adicionais
-
A página do homem
parted(8).
3.6. Estratégias para reparticionar um disco
Há várias maneiras diferentes de repartir um disco. Esta seção discute as seguintes abordagens possíveis:
- Espaço livre não repartido está disponível
- Uma divisória não utilizada está disponível
- Espaço livre em uma divisória usada ativamente está disponível
Observe que esta seção discute os conceitos mencionados anteriormente apenas teoricamente e não inclui nenhuma etapa processual sobre como realizar o reparticionamento de discos passo a passo.
As ilustrações a seguir são simplificadas no interesse da clareza e não refletem o layout exato da partição que você encontra ao instalar efetivamente o Red Hat Enterprise Linux.
3.6.1. Utilização de espaço livre não particionado
Nesta situação, as partições já definidas não abrangem todo o disco rígido, deixando espaço não alocado que não faz parte de nenhuma partição definida. O diagrama a seguir mostra o que isto pode parecer:
Figura 3.5. Disco com espaço livre não particionado
No exemplo anterior, o primeiro diagrama representa um disco com uma partição primária e uma partição indefinida com espaço não alocado, e o segundo diagrama representa um disco com duas partições definidas com espaço alocado.
Um disco rígido não utilizado também se enquadra nesta categoria. A única diferença é que all o espaço não é parte de nenhuma partição definida.
Em qualquer caso, você pode criar as partições necessárias a partir do espaço não utilizado. Este cenário é mais provável para um novo disco. A maioria dos sistemas operacionais pré-instalados são configurados para ocupar todo o espaço disponível em um drive de disco.
3.6.2. Usando o espaço de uma divisória não utilizada
Neste caso, você pode ter uma ou mais divisórias que você não usa mais. O diagrama a seguir ilustra tal situação.
Figura 3.6. Disco com uma divisória não utilizada
No exemplo anterior, o primeiro diagrama representa um disco com uma partição não utilizada, e o segundo diagrama representa a realocação de uma partição não utilizada para o Linux.
Nesta situação, você pode utilizar o espaço alocado para a divisória não utilizada. Você deve apagar a partição e depois criar a(s) partição(ões) Linux apropriada(s) em seu lugar. Você pode apagar a partição não utilizada e criar manualmente novas partições durante o processo de instalação.
3.6.3. Usando o espaço livre de uma divisória ativa
Esta é a situação mais comum. É também a mais difícil de lidar, pois mesmo que você tenha espaço livre suficiente, ele está atualmente alocado a uma divisória que já está em uso. Se você adquiriu um computador com software pré-instalado, o disco rígido muito provavelmente tem uma partição maciça que contém o sistema operacional e os dados.
Além de adicionar um novo disco rígido ao seu sistema, você pode escolher entre repartições destrutivas e não-destrutivas.
3.6.3.1. Repartição destrutiva
Isto elimina a divisória e cria várias menores em seu lugar. Você deve fazer um backup completo porque qualquer dado na partição original é destruído. Crie dois backups, use verificação (se disponível em seu software de backup), e tente ler os dados do backup before apagando a partição.
Se um sistema operacional foi instalado nessa partição, ele deve ser reinstalado se você quiser usar esse sistema também. Esteja ciente de que alguns computadores vendidos com sistemas operacionais pré-instalados podem não incluir a mídia de instalação para reinstalar o sistema operacional original. Você deve verificar se isto se aplica a seu sistema before você destrói sua partição original e sua instalação do sistema operacional.
Após criar uma partição menor para seu sistema operacional existente, você pode reinstalar o software, restaurar seus dados e iniciar sua instalação do Red Hat Enterprise Linux.
Figura 3.7. Ação reparticionadora destrutiva em disco
Qualquer dado anteriormente presente na partição original é perdido.
3.6.3.2. Repartição não-destrutiva
Com o reparticionamento não destrutivo você executa um programa que torna uma grande partição menor sem perder nenhum dos arquivos armazenados naquela partição. Este método é geralmente confiável, mas pode ser muito demorado em grandes unidades.
O processo de reparticionamento não destrutivo é simples e consiste em três etapas:
- Comprimir e fazer backup dos dados existentes
- Redimensionar a divisória existente
- Criar nova(s) divisória(s)
Cada passo é descrito com mais detalhes.
3.6.3.2.1. Compressão de dados existentes
O primeiro passo é comprimir os dados em sua partição existente. A razão para fazer isto é reorganizar os dados para maximizar o espaço livre disponível no "fim" da partição.
Figura 3.8. Compressão em disco
No exemplo anterior, o primeiro diagrama representa o disco antes da compressão, e o segundo diagrama após a compressão.
Este passo é crucial. Sem ela, a localização dos dados poderia impedir que a partição fosse redimensionada na medida desejada. Note que alguns dados não podem ser movidos. Neste caso, isso restringe severamente o tamanho de suas novas partições, e você poderá ser forçado a reparticionar seu disco de forma destrutiva.
3.6.3.2.2. Redimensionamento da divisória existente
A figura a seguir mostra o processo real de redimensionamento. Enquanto o resultado real da operação de redimensionamento varia, dependendo do software utilizado, na maioria dos casos o espaço recém-liberado é utilizado para criar uma partição sem formatação do mesmo tipo da partição original.
Figura 3.9. Redimensionamento da partição em disco
No exemplo anterior, o primeiro diagrama representa a partição antes do redimensionamento, e o segundo diagrama após o redimensionamento.
É importante entender o que o software de redimensionamento que você usa faz com o espaço recém-liberado, para que você possa tomar as medidas apropriadas. No caso ilustrado aqui, seria melhor apagar a nova partição DOS e criar a partição ou partições Linux apropriadas.
3.6.3.2.3. Criação de novas divisórias
Como mencionado no exemplo Redimensionando a partição existente, pode ou não ser necessário criar novas partições. Entretanto, a menos que seu software de redimensionamento suporte sistemas com Linux instalado, é provável que você tenha que apagar a partição que foi criada durante o processo de redimensionamento.
Figura 3.10. Disco com configuração final da divisória
No exemplo anterior, o primeiro diagrama representa o disco antes da configuração, e o segundo diagrama após a configuração.
Capítulo 4. Visão geral dos atributos de nomeação persistentes
Como administrador de sistema, você precisa se referir aos volumes de armazenamento usando atributos de nomes persistentes para construir configurações de armazenamento que sejam confiáveis em várias boots de sistema.
4.1. Desvantagens dos atributos de nomenclatura não-persistentes
O Red Hat Enterprise Linux oferece uma série de maneiras de identificar dispositivos de armazenamento. É importante usar a opção correta para identificar cada dispositivo quando usado a fim de evitar o acesso inadvertido ao dispositivo errado, particularmente ao instalar ou reformatar unidades.
Tradicionalmente, nomes não-persistentes na forma de /dev/sd(major number)(minor number) são usados no Linux para se referir a dispositivos de armazenamento. A faixa de números maiores e menores e os nomes associados a sd são alocados para cada dispositivo quando ele é detectado. Isto significa que a associação entre o intervalo de números maior e menor e os nomes associados sd podem mudar se a ordem de detecção do dispositivo mudar.
Tal mudança no ordenamento pode ocorrer nas seguintes situações:
- A paralelização do processo de inicialização do sistema detecta os dispositivos de armazenamento em uma ordem diferente com cada inicialização do sistema.
-
Um disco não consegue ligar ou responder ao controlador SCSI. Isto faz com que ele não seja detectado pela sonda normal do dispositivo. O disco não é acessível ao sistema e os dispositivos subseqüentes terão sua faixa de maior e menor número, incluindo os nomes associados
sddeslocados para baixo. Por exemplo, se um disco normalmente referido comosdbnão for detectado, um disco que normalmente é referido comosdcapareceria comosdb. -
Um controlador SCSI (host bus adapter, ou HBA) não se inicializa, fazendo com que todos os discos conectados a esse HBA não sejam detectados. A quaisquer discos conectados a HBAs subseqüentemente sondados são atribuídas diferentes faixas de números maiores e menores, e diferentes nomes associados a
sd. - A ordem de inicialização do motorista muda se diferentes tipos de HBAs estiverem presentes no sistema. Isto faz com que os discos conectados a esses HBAs sejam detectados em uma ordem diferente. Isto também pode ocorrer se os HBAs forem movidos para diferentes slots PCI no sistema.
-
Os discos conectados ao sistema com adaptadores Fibre Channel, iSCSI ou FCoE podem estar inacessíveis no momento em que os dispositivos de armazenamento são sondados, devido a uma matriz de armazenamento ou interruptor de intervenção sendo desligado, por exemplo. Isto pode ocorrer quando um sistema é reinicializado após uma falha de energia, se a matriz de armazenamento levar mais tempo para ficar on-line do que o sistema leva para arrancar. Embora alguns drivers Fibre Channel suportem um mecanismo para especificar uma identificação de alvo SCSI persistente para o mapeamento WWPN, isto não faz com que as faixas de números maiores e menores, e os nomes associados
sdsejam reservados; ele só fornece números de identificação de alvo SCSI consistentes.
Estas razões tornam indesejável o uso da faixa de números maiores e menores ou dos nomes associados sd ao se referir aos dispositivos, como no arquivo /etc/fstab. Existe a possibilidade de que o dispositivo errado seja montado e a corrupção de dados possa resultar.
Ocasionalmente, porém, ainda é necessário consultar os nomes sd mesmo quando outro mecanismo é utilizado, como quando são relatados erros por um dispositivo. Isto porque o kernel Linux usa os nomes sd (e também os nomes SCSI host/channel/target/LUN tuples) nas mensagens do kernel referentes ao dispositivo.
4.2. Sistema de arquivos e identificadores de dispositivos
Esta seção explica a diferença entre atributos persistentes que identificam sistemas de arquivos e dispositivos de blocos.
Identificadores do sistema de arquivo
Os identificadores do sistema de arquivo são vinculados a um sistema de arquivo particular criado em um dispositivo de bloco. O identificador também é armazenado como parte do sistema de arquivo. Se você copiar o sistema de arquivo para um dispositivo diferente, ele ainda carrega o mesmo identificador de sistema de arquivo. Por outro lado, se você reescrever o dispositivo, por exemplo, formatando-o com o utilitário mkfs, o dispositivo perde o atributo.
Os identificadores do sistema de arquivo incluem:
- Identificador único (UUID)
- Etiqueta
Identificadores de dispositivos
Os identificadores de dispositivos são vinculados a um dispositivo de bloco: por exemplo, um disco ou uma partição. Se você reescrever o dispositivo, por exemplo, formatando-o com o utilitário mkfs, o dispositivo mantém o atributo, pois ele não é armazenado no sistema de arquivos.
Os identificadores de dispositivos incluem:
- World Wide Identifier (WWID)
- Partição UUID
- Número de série
Recomendações
- Alguns sistemas de arquivo, tais como volumes lógicos, abrangem vários dispositivos. A Red Hat recomenda acessar esses sistemas de arquivo usando identificadores de sistemas de arquivo em vez de identificadores de dispositivos.
4.3. Nomes de dispositivos gerenciados pelo mecanismo udev em /dev/disco/
Esta seção lista diferentes tipos de atributos de nomes persistentes que o serviço udev fornece no diretório /dev/disk/.
O mecanismo udev é usado para todos os tipos de dispositivos no Linux, não apenas para dispositivos de armazenamento. No caso de dispositivos de armazenamento, o Red Hat Enterprise Linux contém udev regras que criam links simbólicos no diretório /dev/disk/. Isto permite que você se refira aos dispositivos de armazenamento por:
- Seu conteúdo
- Um identificador único
- Seu número de série.
Embora os atributos de nomenclatura udev sejam persistentes, na medida em que não mudam por si mesmos através de reinicializações do sistema, alguns também são configuráveis.
4.3.1. Identificadores do sistema de arquivo
O atributo UUID em /dev/disco/by-uuid/
As entradas neste diretório fornecem um nome simbólico que se refere ao dispositivo de armazenamento por um unique identifier (UUID) no conteúdo (ou seja, os dados) armazenados no dispositivo. Por exemplo, o nome do dispositivo:
/dev/disco/by-uuid/3e6be9de-8139-11d1-9106-a43f08d823a6
Você pode usar a UUID para consultar o dispositivo no arquivo /etc/fstab usando a seguinte sintaxe:
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6Você pode configurar o atributo UUID ao criar um sistema de arquivo, e também pode alterá-lo mais tarde.
O atributo Label in /dev/disk/by-label/
As entradas neste diretório fornecem um nome simbólico que se refere ao dispositivo de armazenamento por um label no conteúdo (ou seja, os dados) armazenados no dispositivo.
Por exemplo:
/dev/disco/by-label/Boot
Você pode usar a etiqueta para se referir ao dispositivo no arquivo /etc/fstab usando a seguinte sintaxe:
LABEL=BootVocê pode configurar o atributo Label ao criar um sistema de arquivo, e também pode alterá-lo posteriormente.
4.3.2. Identificadores de dispositivos
O atributo WWID em /dev/disco/by-id/
O World Wide Identifier (WWID) é um persistente, system-independent identifier que a norma SCSI exige de todos os dispositivos SCSI. O identificador WWID é garantido como único para cada dispositivo de armazenamento, e independente do caminho que é usado para acessar o dispositivo. O identificador é uma propriedade do dispositivo, mas não é armazenado no conteúdo (ou seja, os dados) dos dispositivos.
Este identificador pode ser obtido emitindo um SCSI Inquiry para recuperar os Dados Vitais de Identificação do Dispositivo (página 0x83) ou o Número de Série da Unidade (página 0x80).
O Red Hat Enterprise Linux mantém automaticamente o mapeamento adequado do nome do dispositivo baseado na WWID para um nome atual /dev/sd naquele sistema. As aplicações podem usar o nome /dev/disk/by-id/ para referenciar os dados no disco, mesmo que o caminho para o dispositivo mude, e mesmo ao acessar o dispositivo a partir de sistemas diferentes.
Exemplo 4.1. Mapas da WWID
| WWID symlink | Dispositivo não-persistente | Nota |
|---|---|---|
|
|
|
Um dispositivo com uma página |
|
|
|
Um dispositivo com uma página |
|
|
| Uma partição de disco |
Além desses nomes persistentes fornecidos pelo sistema, você também pode usar as regras do udev para implementar nomes persistentes próprios, mapeados para a WWID do armazenamento.
O atributo Partição UUID em /dev/disco/by-partuuid
O atributo Partição UUID (PARTUUID) identifica as partições como definidas pela tabela de partição GPT.
Exemplo 4.2. Mapeamentos de partição UUID
| Link simbólico PARTUÍDO | Dispositivo não-persistente |
|---|---|
|
|
|
|
|
|
|
|
|
O atributo Caminho em /dev/disco/by-path/
Este atributo fornece um nome simbólico que se refere ao dispositivo de armazenamento pelo hardware path usado para acessar o dispositivo.
O atributo Path falha se qualquer parte do caminho do hardware (por exemplo, o PCI ID, porta de destino, ou número LUN) mudar. O atributo Caminho não é, portanto, confiável. Entretanto, o atributo Caminho pode ser útil em um dos seguintes cenários:
- Você precisa identificar um disco que está planejando substituir mais tarde.
- Você planeja instalar um serviço de armazenamento em um disco em um local específico.
4.4. O identificador mundial com DM Multipath
Esta seção descreve o mapeamento entre o World Wide Identifier (WWID) e os nomes de dispositivos não persistentes em uma configuração Multipath Mapper Device Mapper.
Se houver múltiplos caminhos de um sistema para um dispositivo, a DM Multipath usa a WWID para detectar isso. A DM Multipath então apresenta um único "pseudo-dispositivo" no diretório /dev/mapper/wwid, tal como /dev/mapper/3600508b400105df70000e00000ac0000.
O comando multipath -l mostra o mapeamento aos identificadores não-persistentes:
-
Host:Channel:Target:LUN -
/dev/sdnome -
major:minornúmero
Exemplo 4.3. Mapas da WWID em uma configuração multipath
Um exemplo de saída do comando multipath -l:
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
DM Multipath mantém automaticamente o mapeamento adequado de cada nome de dispositivo baseado na WWID para seu correspondente nome /dev/sd no sistema. Estes nomes são persistentes nas mudanças de caminho, e são consistentes ao acessar o dispositivo a partir de diferentes sistemas.
Quando o recurso user_friendly_names do DM Multipath é usado, o WWID é mapeado para um nome do formulário /dev/mapper/mpathN. Por padrão, este mapeamento é mantido no arquivo /etc/multipath/bindings. Estes mpathN são persistentes, desde que esse arquivo seja mantido.
Se você usa user_friendly_names, então são necessários passos adicionais para obter nomes consistentes em um cluster.
4.5. Limitações da convenção de nomenclatura de dispositivos udev
A seguir estão algumas limitações da convenção de nomenclatura udev:
-
É possível que o dispositivo não esteja acessível no momento em que a consulta é realizada porque o mecanismo
udevpode confiar na capacidade de consultar o dispositivo de armazenamento quando as regras doudevsão processadas para um eventoudev. Isto é mais provável que ocorra com dispositivos de armazenamento Fibre Channel, iSCSI ou FCoE quando o dispositivo não está localizado no chassi do servidor. -
O kernel pode enviar eventos
udeva qualquer momento, fazendo com que as regras sejam processadas e possivelmente fazendo com que os links/dev/disk/by-*/sejam removidos se o dispositivo não for acessível. -
Pode haver um atraso entre quando o evento
udevé gerado e quando ele é processado, como quando um grande número de dispositivos é detectado e o serviçoudevdde espaço do usuário leva algum tempo para processar as regras para cada um deles. Isto pode causar um atraso entre quando o kernel detecta o dispositivo e quando os nomes/dev/disk/by-*/estão disponíveis. -
Programas externos como o
blkidinvocado pelas regras podem abrir o dispositivo por um breve período de tempo, tornando o dispositivo inacessível para outros usos. -
Os nomes dos dispositivos gerenciados pelo mecanismo
udevem /dev/disco/ podem mudar entre os principais lançamentos, exigindo a atualização dos links.
4.6. Listagem de atributos de nomeação persistentes
Este procedimento descreve como descobrir os atributos persistentes de nomes de dispositivos de armazenamento não persistentes.
Procedimento
Para listar os atributos UUID e Label, use o utilitário
lsblk:$ lsblk --fs storage-devicePor exemplo:
Exemplo 4.4. Visualização da UUID e do rótulo de um sistema de arquivo
$ lsblk --fs /dev/sda1 NAME FSTYPE LABEL UUID MOUNTPOINT sda1 xfs Boot afa5d5e3-9050-48c3-acc1-bb30095f3dc4 /boot
Para listar o atributo PARTUUID, use o utilitário
lsblkcom a opção--output PARTUUID:$ lsblk -- saída PARTUÍDO
Por exemplo:
Exemplo 4.5. Visualização do atributo PARTUUIDO de uma partição
$ lsblk --output +PARTUUID /dev/sda1 NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT PARTUUID sda1 8:1 0 512M 0 part /boot 4cd1448a-01
Para listar o atributo WWID, examine os alvos dos links simbólicos no diretório
/dev/disk/by-id/. Por exemplo:Exemplo 4.6. Visualização da WWID de todos os dispositivos de armazenamento no sistema
$ file /dev/disk/by-id/* /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001 symbolic link to ../../sda /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part1 symbolic link to ../../sda1 /dev/disk/by-id/ata-QEMU_HARDDISK_QM00001-part2 symbolic link to ../../sda2 /dev/disk/by-id/dm-name-rhel_rhel8-root symbolic link to ../../dm-0 /dev/disk/by-id/dm-name-rhel_rhel8-swap symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhP0RMFsNyySVihqEl2cWWbR7MjXJolD6g symbolic link to ../../dm-1 /dev/disk/by-id/dm-uuid-LVM-QIWtEHtXGobe5bewlIUDivKOz5ofkgFhXqH2M45hD2H9nAf2qfWSrlRLhzfMyOKd symbolic link to ../../dm-0 /dev/disk/by-id/lvm-pv-uuid-atlr2Y-vuMo-ueoH-CpMG-4JuH-AhEF-wu4QQm symbolic link to ../../sda2
4.7. Modificação de atributos de nomeação persistentes
Este procedimento descreve como alterar o atributo de nomeação persistente UUID ou Label de um sistema de arquivo.
A mudança dos atributos udev acontece em segundo plano e pode demorar muito tempo. O comando udevadm settle espera até que a mudança seja totalmente registrada, o que garante que seu próximo comando será capaz de utilizar o novo atributo corretamente.
Nos seguintes comandos:
-
Substitua new-uuid com a UUID que você deseja definir; por exemplo,
1cdfbc07-1c90-4984-b5ec-f61943f5ea50. Você pode gerar uma UUID usando o comandouuidgen. -
Substitua new-label com um rótulo; por exemplo,
backup_data.
Pré-requisitos
- Se você estiver modificando os atributos de um sistema de arquivo XFS, desmonte-o primeiro.
Procedimento
Para alterar os atributos UUID ou Label de um sistema de arquivos XFS, use o utilitário
xfs_admin:# xfs_admin -U new-uuid -L new-label storage-device # udevadm settle
Para alterar os atributos UUID ou Label de um sistema de arquivos ext4, ext3, ou ext2, use o utilitário
tune2fs:# tune2fs -U new-uuid -L new-label storage-device # udevadm settle
Para alterar os atributos UUID ou Label de um volume swap, use o utilitário
swaplabel:# swaplabel --uuid new-uuid --label new-label swap-device # udevadm settle
Capítulo 5. Usando o armazenamento de memória persistente NVDIMM
Como administrador do sistema, você pode habilitar e gerenciar vários tipos de armazenamento em dispositivos NVDIMM (Non-Volatile Dual In-line Memory Modules) conectados ao seu sistema.
Para instalar o Red Hat Enterprise Linux 8 no armazenamento NVDIMM, veja Instalando em um dispositivo NVDIMM em vez disso.
5.1. A tecnologia de memória persistente NVDIMM
A memória persistente NVDIMM, também chamada de memória de classe de armazenamento ou pmem, é uma combinação de memória e armazenamento.
O NVDIMM combina a durabilidade do armazenamento com a baixa latência de acesso e a alta largura de banda da RAM dinâmica (DRAM):
-
O armazenamento NVDIMM é endereçável por byte, de modo que pode ser acessado usando as instruções de carga e armazenamento da CPU. Além das chamadas ao sistema
read()ewrite(), que são necessárias para acessar o armazenamento tradicional baseado em blocos, o NVDIMM também suporta carga direta e modelo de programação de armazenamento. - As características de desempenho do NVDIMM são semelhantes às DRAM com latência de acesso muito baixa, normalmente nas dezenas a centenas de nanossegundos.
- Os dados armazenados no NVDIMM são preservados quando a energia está desligada, como no caso do armazenamento.
- A tecnologia de acesso direto (DAX) permite aplicações para o armazenamento de mapas de memória diretamente, sem passar pelo cache de páginas do sistema. Isto libera a DRAM para outros fins.
O NVDIMM é benéfico em casos de uso como, por exemplo
- Bases de dados
- A reduzida latência de acesso ao armazenamento no NVDIMM pode melhorar drasticamente o desempenho do banco de dados.
- Reinício rápido
O reinício rápido também é chamado de efeito de cache quente. Por exemplo, um servidor de arquivos não tem nenhum conteúdo de arquivo na memória após o início. Como os clientes se conectam e lêem ou escrevem dados, esses dados são armazenados em cache no cache da página. Eventualmente, o cache contém, em sua maioria, dados quentes. Após uma reinicialização, o sistema deve iniciar o processo novamente no armazenamento tradicional.
O NVDIMM permite que uma aplicação mantenha o cache quente através de reinicializações se a aplicação for projetada corretamente. Neste exemplo, não haveria cache de página envolvido: a aplicação armazenaria os dados diretamente na memória persistente.
- Cache-escrita rápida
- Os servidores de arquivos geralmente não reconhecem o pedido de escrita de um cliente até que os dados estejam em mídia durável. O uso do NVDIMM como cache de gravação rápida permite que um servidor de arquivos reconheça a solicitação de gravação rapidamente, graças à baixa latência.
5.2. NVDIMM entrelaçamento e regiões
Os dispositivos NVDIMM suportam o agrupamento em regiões intercaladas.
Os dispositivos NVDIMM podem ser agrupados em conjuntos de intercalação da mesma forma que as DRAM normais. Um conjunto de intercalação é semelhante a uma configuração de nível RAID 0 (banda) em vários DIMMs. Um conjunto Interleave também é chamado de region.
A intercalação tem as seguintes vantagens:
- Os dispositivos NVDIMM se beneficiam de um maior desempenho quando são configurados em conjuntos de intercalação.
- Interleaving pode combinar vários dispositivos NVDIMM menores em um dispositivo lógico maior.
Os conjuntos de intercalação NVDIMM são configurados no firmware do sistema BIOS ou UEFI.
O Red Hat Enterprise Linux cria um dispositivo de região para cada conjunto de entrefolhas.
5.3. NVDIMM namespaces
As regiões NVDIMM estão divididas em um ou mais namespaces. Os espaços de nomes permitem o acesso ao dispositivo usando diferentes métodos, com base no tipo de espaço de nomes.
Alguns dispositivos NVDIMM não suportam vários espaços de nomes em uma região:
- Se seu dispositivo NVDIMM suporta etiquetas, você pode subdividir a região em namespaces.
- Se seu dispositivo NVDIMM não suporta etiquetas, a região só pode conter um único espaço de nomes. Nesse caso, o Red Hat Enterprise Linux cria um espaço de nomes padrão que cobre toda a região.
5.4. Modos de acesso NVDIMM
Você pode configurar os espaços de nomes NVDIMM para usar um dos seguintes modos:
sectorApresenta o armazenamento como um dispositivo de bloqueio rápido. Este modo é útil para aplicações legadas que não foram modificadas para usar o armazenamento NVDIMM, ou para aplicações que fazem uso da pilha de E/S completa, incluindo o Device Mapper.
Um dispositivo
sectorpode ser usado da mesma forma que qualquer outro dispositivo de bloco no sistema. Você pode criar partições ou sistemas de arquivo nele, configurá-lo como parte de um conjunto RAID de software ou usá-lo como dispositivo de cache paradm-cache.Os dispositivos neste modo estão disponíveis em
/dev/pmemNs. Veja o valorblockdevlistado após a criação do namespace.devdax, ou acesso direto ao dispositivo (DAX)Permite que os dispositivos NVDIMM suportem a programação de acesso direto, conforme descrito na especificação do Modelo de Programação de Memória Não Volátil (NVM) da Associação da Indústria de Redes de Armazenamento (SNIA). Neste modo, a E/S contorna a pilha de armazenamento do kernel. Portanto, nenhum driver do Device Mapper pode ser usado.
O dispositivo DAX fornece acesso bruto ao armazenamento de NVDIMM usando um nó de dispositivo de caracteres DAX. Os dados em um dispositivo
devdaxpodem ser tornados duráveis usando as instruções de lavagem e vedação do cache da CPU. Alguns bancos de dados e hipervisores de máquinas virtuais podem ser beneficiados por este modo. Os sistemas de arquivos não podem ser criados em dispositivosdevdax.Os dispositivos neste modo estão disponíveis em
/dev/daxN.M. Veja o valorchardevlistado após a criação do namespace.fsdax, ou acesso direto ao sistema de arquivos (DAX)Permite que os dispositivos NVDIMM suportem a programação de acesso direto, conforme descrito na especificação do Modelo de Programação de Memória Não Volátil (NVM) da Associação da Indústria de Redes de Armazenamento (SNIA). Neste modo, a E/S contorna a pilha de armazenamento do kernel, e muitos drivers do Device Mapper, portanto, não podem ser usados.
Você pode criar sistemas de arquivo em dispositivos de sistema de arquivo DAX.
Os dispositivos neste modo estão disponíveis em
/dev/pmemN. Veja o valorblockdevlistado após a criação do namespace.ImportanteA tecnologia DAX do sistema de arquivo é fornecida apenas como uma Pré-visualização Tecnológica, e não é suportada pela Red Hat.
rawApresenta um disco de memória que não suporta DAX. Neste modo, os namespaces têm várias limitações e não devem ser usados.
Os dispositivos neste modo estão disponíveis em
/dev/pmemN. Veja o valorblockdevlistado após a criação do namespace.
5.5. Criar um espaço de nomes de setor em um NVDIMM para atuar como um dispositivo de bloco
Você pode configurar um dispositivo NVDIMM no modo setor, que também é chamado legacy mode, para suportar o armazenamento tradicional, baseado em blocos.
Você pode fazer qualquer um dos dois:
- reconfigurar um espaço de nomes existente para o modo setor, ou
- criar um novo espaço de nomes de setor, se houver espaço disponível.
Pré-requisitos
- Um dispositivo NVDIMM é anexado ao seu sistema.
5.5.1. Instalando o ndctl
Este procedimento instala o utilitário ndctl, que é usado para configurar e monitorar os dispositivos NVDIMM.
Procedimento
Para instalar o utilitário
ndctl, use o seguinte comando:# yum instalar ndctl
5.5.2. Reconfigurando um espaço de nomes NVDIMM existente para o modo setor
Este procedimento reconfigura um espaço de nomes NVDIMM para o modo setor para ser usado como um dispositivo de bloco rápido.
A reconfiguração de um namespace elimina todos os dados previamente armazenados no namespace.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.5.1, “Instalando o ndctl”.
Procedimento
Reconfigurar o espaço de nomes selecionado para o modo setor:
# ndctl create-namespace \ --force \ --reconfig=namespace-ID \ --mode=sectorExemplo 5.1. Reconfigurando o namespace1.0 no modo setor
Para reconfigurar o espaço de nomes
namespace1.0para usar o modosector:# ndctl create-namespace \ --force \ --reconfig=namespace1.0 \ --mode=sector { "dev":"namespace1.0", "mode":"sector", "size":"11.99 GiB (12.87 GB)", "uuid":"5805480e-90e6-407e-96a4-23e1cde2ed78", "raw_uuid":"879d9e9f-fd43-4ed5-b64f-3bcd0781391a", "sector_size":4096, "blockdev":"pmem1s", "numa_node":1 }-
O namespace reconfigurado está agora disponível sob o diretório
/devcomo/dev/pmemNs.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.5.3. Criando um novo espaço de nomes NVDIMM no modo setor
Este procedimento cria um novo espaço de nomes de setor em um dispositivo NVDIMM, permitindo que você o utilize como um dispositivo de bloco tradicional.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.5.1, “Instalando o ndctl”. - O dispositivo NVDIMM suporta etiquetas.
Procedimento
Liste as regiões do
pmemem seu sistema que têm espaço disponível. No exemplo a seguir, o espaço está disponível nas regiõesregion5eregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]Em qualquer uma das regiões disponíveis, alocar um ou mais espaços de nomes:
# ndctl create-namespace \ --mode=sector \ --region=regionN \ --size=namespace-sizeExemplo 5.2. Criando um namespace em uma região
O seguinte comando cria um espaço de nomes setorial de 36 GiB em
region4:# ndctl create-namespace \ --mode=sector \ --region=region4 \ --size=36G-
O novo namespace está agora disponível sob o diretório
/devcomo/dev/pmemNs.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.6. Criação de um espaço de nomes DAX de dispositivo em um NVDIMM
Você pode configurar um dispositivo NVDIMM no modo DAX do dispositivo para suportar o armazenamento de caracteres com capacidades de acesso direto.
Você pode fazer qualquer um dos dois:
- reconfigurar um namespace existente para o modo DAX do dispositivo, ou
- criar um novo espaço de nomes de dispositivos DAX, se houver espaço disponível.
Pré-requisitos
- Um dispositivo NVDIMM é anexado ao seu sistema.
5.6.1. NVDIMM em modo de acesso direto ao dispositivo
O acesso direto ao dispositivo (dispositivo DAX, devdax) fornece um meio de acesso direto ao armazenamento, sem o envolvimento de um sistema de arquivo. O benefício do DAX do dispositivo é que ele fornece uma granularidade de falha garantida, que pode ser configurada usando a opção --align do utilitário ndctl
Para a arquitetura Intel 64 e AMD64, são suportadas as seguintes granularidades de falhas:
- 4 KiB
- 2 MiB
- 1 GiB
Os nós do dispositivo DAX suportam apenas as seguintes chamadas de sistema:
-
open() -
close() -
mmap()
As variantes read() e write() não são suportadas porque a caixa de uso do DAX do dispositivo está ligada à programação de memória persistente.
5.6.2. Instalando o ndctl
Este procedimento instala o utilitário ndctl, que é usado para configurar e monitorar os dispositivos NVDIMM.
Procedimento
Para instalar o utilitário
ndctl, use o seguinte comando:# yum instalar ndctl
5.6.3. Reconfigurando um espaço de nomes NVDIMM existente para o modo DAX do dispositivo
Este procedimento reconfigura um namespace em um dispositivo NVDIMM para o modo DAX do dispositivo, e permite armazenar dados no namespace.
A reconfiguração de um namespace elimina todos os dados previamente armazenados no namespace.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.6.2, “Instalando o ndctl”.
Procedimento
Liste todos os espaços de nomes em seu sistema:
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ]Reconfigurar qualquer espaço de nomes:
# ndctl create-namespace \ --force \ --mode=devdax \ --reconfig=namespace-IDExemplo 5.3. Reconfigurando um namespace como dispositivo DAX
O seguinte comando reconfigura
namespace0.0para armazenamento de dados que suporta DAX. Ele é alinhado a uma granularidade de falha de 2-MiB para garantir que o sistema operacional falhe em páginas de 2-MiB de cada vez:# ndctl create-namespace \ --force \ --mode=devdax \ --align=2M \ --reconfig=namespace0.0-
O namespace está agora disponível no
/dev/daxN.Mcaminho.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.6.4. Criação de um novo espaço de nomes NVDIMM no modo DAX do dispositivo
Este procedimento cria um novo espaço de nomes DAX em um dispositivo NVDIMM, permitindo que você armazene dados no espaço de nomes.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.6.2, “Instalando o ndctl”. - O dispositivo NVDIMM suporta etiquetas.
Procedimento
Liste as regiões do
pmemem seu sistema que têm espaço disponível. No exemplo a seguir, o espaço está disponível nas regiõesregion5eregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]Em qualquer uma das regiões disponíveis, alocar um ou mais espaços de nomes:
# ndctl create-namespace \ --mode=devdax \ --region=regionN \ --size=namespace-sizeExemplo 5.4. Criando um namespace em uma região
O seguinte comando cria um espaço de nomes de dispositivos DAX de 36 GiB em
region4. Ele é alinhado a uma granularidade de falha de 2-MiB para garantir que o sistema operacional falhe em páginas de 2-MiB de cada vez:# ndctl create-namespace \ --mode=devdax \ --region=region4 \ --align=2M \ --size=36G { "dev":"namespace1.2", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"5ae01b9c-1ebf-4fb6-bc0c-6085f73d31ee", "raw_uuid":"4c8be2b0-0842-4bcb-8a26-4bbd3b44add2", "daxregion":{ "id":1, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax1.2", "size":"35.44 GiB (38.05 GB)" } ] }, "numa_node":1 }-
O namespace está agora disponível no
/dev/daxN.Mcaminho.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.7. Criação de um espaço de nomes de sistema de arquivos DAX em um NVDIMM
Você pode configurar um dispositivo NVDIMM no modo DAX do sistema de arquivos para suportar um sistema de arquivos com capacidade de acesso direto.
Você pode fazer qualquer um dos dois:
- reconfigurar um namespace existente para o modo DAX do sistema de arquivo, ou
- criar um novo espaço de nomes do sistema de arquivos DAX, se houver espaço disponível.
A tecnologia DAX do sistema de arquivo é fornecida apenas como uma Pré-visualização Tecnológica, e não é suportada pela Red Hat.
Pré-requisitos
- Um dispositivo NVDIMM é anexado ao seu sistema.
5.7.1. NVDIMM em modo de acesso direto ao sistema de arquivos
Quando um dispositivo NVDIMM é configurado em modo de acesso direto ao sistema de arquivos (file system DAX, fsdax), um sistema de arquivos pode ser criado em cima dele.
Qualquer aplicação que realiza uma operação em mmap() em um arquivo deste sistema de arquivo tem acesso direto ao seu armazenamento. Isto permite o acesso direto ao modelo de programação no NVDIMM. O sistema de arquivo deve ser montado com a opção -o dax para que o mapeamento direto possa acontecer.
Alocação de metadados por página
Este modo requer a alocação de metadados por página no sistema DRAM ou no próprio dispositivo NVDIMM. A sobrecarga desta estrutura de dados é de 64 bytes por cada página de 4 KiB:
- Em dispositivos pequenos, a quantidade de despesas gerais é pequena o suficiente para caber em DRAM sem problemas. Por exemplo, um namespace de 16 GiB requer apenas 256 MiB para estruturas de página. Como os dispositivos NVDIMM são geralmente pequenos e caros, é preferível armazenar as estruturas de dados de rastreamento de página em DRAM.
- Nos dispositivos NVDIMM que são terabytes em tamanho ou maiores, a quantidade de memória necessária para armazenar as estruturas de dados de rastreamento de página pode exceder a quantidade de DRAM no sistema. Um TiB de NVDIMM requer 16 GiB apenas para estruturas de página. Como resultado, o armazenamento das estruturas de dados no próprio NVDIMM é preferível em tais casos.
Você pode configurar onde os metadados por página são armazenados usando a opção --map ao configurar um namespace:
-
Para alocar no sistema RAM, use
--map=mem. -
Para alocar no NVDIMM, use
--map=dev.
Partições e sistemas de arquivo em fsdax
Ao criar divisórias em um dispositivo fsdax, as divisórias devem ser alinhadas nos limites da página. Na arquitetura Intel 64 e AMD64, pelo menos 4 KiB de alinhamento é necessário para o início e fim da partição. 2 MiB é o alinhamento preferido.
No Red Hat Enterprise Linux 8, tanto o sistema de arquivo XFS quanto o ext4 podem ser criados no NVDIMM como uma prévia tecnológica.
5.7.2. Instalando o ndctl
Este procedimento instala o utilitário ndctl, que é usado para configurar e monitorar os dispositivos NVDIMM.
Procedimento
Para instalar o utilitário
ndctl, use o seguinte comando:# yum instalar ndctl
5.7.3. Reconfigurando um espaço de nomes NVDIMM existente para o modo DAX do sistema de arquivo
Este procedimento reconfigura um namespace em um dispositivo NVDIMM para arquivar o modo DAX do sistema e permite que você armazene arquivos no namespace.
A reconfiguração de um namespace elimina todos os dados previamente armazenados no namespace.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.7.2, “Instalando o ndctl”.
Procedimento
Liste todos os espaços de nomes em seu sistema:
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ]Reconfigurar qualquer espaço de nomes:
# ndctl create-namespace \ --force \ --mode=fsdax \ --reconfig=namespace-IDExemplo 5.5. Reconfigurando um namespace como sistema de arquivos DAX
Para usar
namespace0.0para um sistema de arquivo que suporta DAX, use o seguinte comando:# ndctl create-namespace \ --force \ --mode=fsdax \ --reconfig=namespace0.0 { "dev":"namespace0.0", "mode":"fsdax", "size":"32.00 GiB (34.36 GB)", "uuid":"ab91cc8f-4c3e-482e-a86f-78d177ac655d", "blockdev":"pmem0", "numa_node":0 }-
O namespace está agora disponível no
/dev/pmemNcaminho.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.7.4. Criação de um novo espaço de nomes NVDIMM no modo DAX do sistema de arquivos
Este procedimento cria um novo namespace de sistema de arquivos DAX em um dispositivo NVDIMM, permitindo que você armazene arquivos no namespace.
Pré-requisitos
-
O utilitário
ndctlestá instalado. Ver Seção 5.7.2, “Instalando o ndctl”. - O dispositivo NVDIMM suporta etiquetas.
Procedimento
Liste as regiões do
pmemem seu sistema que têm espaço disponível. No exemplo a seguir, o espaço está disponível nas regiõesregion5eregion4:# ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ]Em qualquer uma das regiões disponíveis, alocar um ou mais espaços de nomes:
# ndctl create-namespace \ --mode=fsdax \ --region=regionN \ --size=namespace-sizeExemplo 5.6. Criando um namespace em uma região
O seguinte comando cria um espaço de nomes de arquivo DAX de 36 GiB em
region4:# ndctl create-namespace \ --mode=fsdax \ --region=region4 \ --size=36G { "dev":"namespace4.0", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"9c5330b5-dc90-4f7a-bccd-5b558fa881fe", "blockdev":"pmem4", "numa_node":0 }-
O namespace está agora disponível no
/dev/pmemNcaminho.
Recursos adicionais
-
A página do homem
ndctl-create-namespace(1)
5.7.5. Criação de um sistema de arquivo em um dispositivo DAX de sistema de arquivo
Este procedimento cria um sistema de arquivo em um dispositivo DAX de sistema de arquivo e monta o sistema de arquivo.
Procedimento
Opcionalmente, criar uma partição no dispositivo DAX do sistema de arquivos. Ver Seção 3.3, “Criando uma divisória”.
Por padrão, a ferramenta
partedalinha as partições em limites de 1 MiB. Para a primeira partição, especifique 2 MiB como o início da partição. Se o tamanho da partição for um múltiplo de 2 MiB, todas as outras partições também serão alinhadas.Criar um sistema de arquivo XFS ou ext4 na partição ou no dispositivo NVDIMM.
Para XFS, desabilite a cópia compartilhada de extensões de dados, pois são incompatíveis com a opção de montagem por dax. Adicionalmente, a fim de aumentar a probabilidade de mapeamentos de páginas grandes, defina a unidade de listras e a largura da listra.
# mkfs.xfs -m reflink=0 -d su=2m,sw=1 fsdax-partition-or-deviceMonte o sistema de arquivo com a opção de montagem
-o dax:# montagem -o dax fsdax-partition-or-device mount-point
-
As aplicações podem agora usar memória persistente e criar arquivos no mount-point abrir os arquivos e usar a operação
mmappara mapear os arquivos para acesso direto.
Recursos adicionais
-
A página do homem
mkfs.xfs(8)
5.8. Resolução de problemas de memória persistente NVDIMM
Você pode detectar e corrigir diferentes tipos de erros em dispositivos NVDIMM.
Pré-requisitos
- Um dispositivo NVDIMM é conectado ao seu sistema e configurado.
5.8.1. Instalando o ndctl
Este procedimento instala o utilitário ndctl, que é usado para configurar e monitorar os dispositivos NVDIMM.
Procedimento
Para instalar o utilitário
ndctl, use o seguinte comando:# yum instalar ndctl
5.8.2. Monitoramento da saúde NVDIMM usando S.M.A.R.T.
Alguns dispositivos NVDIMM suportam interfaces de Auto-monitoramento, Análise e Tecnologia de Relatórios (S.M.A.R.T.) para a recuperação de informações sobre saúde.
Monitorar regularmente a saúde do NVDIMM para prevenir a perda de dados. Se a S.M.A.R.T. relatar problemas com o estado de saúde de um dispositivo NVDIMM, substitua-o como descrito em Seção 5.8.3, “Detecção e substituição de um dispositivo NVDIMM quebrado”.
Pré-requisitos
Em alguns sistemas, o motorista do
acpi_ipmideve ser carregado para recuperar informações sobre saúde usando o seguinte comando:# modprobe acpi_ipmi
Procedimento
Para acessar as informações sobre saúde, use o seguinte comando:
# ndctl list --dimms --health ... { "dev":"nmem0", "id":"802c-01-1513-b3009166", "handle":1, "phys_id":22, "health": { "health_state":"ok", "temperature_celsius":25.000000, "spares_percentage":99, "alarm_temperature":false, "alarm_spares":false, "temperature_threshold":50.000000, "spares_threshold":20, "life_used_percentage":1, "shutdown_state":"clean" } } ...
Recursos adicionais
-
A página do homem
ndctl-list(1)
5.8.3. Detecção e substituição de um dispositivo NVDIMM quebrado
Se você encontrar mensagens de erro relacionadas ao NVDIMM relatadas em seu log de sistema ou por S.M.A.R.T., isso pode significar que um dispositivo NVDIMM está falhando. Nesse caso, é necessário:
- Detectar qual dispositivo NVDIMM está falhando
- Cópia de segurança dos dados nele armazenados
- Substituir fisicamente o dispositivo
Procedimento
Para detectar o dispositivo quebrado, use o seguinte comando:
# lista ndctl --dimms --regiões --saúde --mídia-errores --humano
O campo
badblocksmostra qual NVDIMM está quebrado. Anote seu nome no campodev.Exemplo 5.7. Status de saúde dos dispositivos NVDIMM
No exemplo a seguir, o NVDIMM chamado
nmem0está quebrado:# ndctl list --dimms --regions --health --media-errors --human ... "regions":[ { "dev":"region0", "size":"250.00 GiB (268.44 GB)", "available_size":0, "type":"pmem", "numa_node":0, "iset_id":"0xXXXXXXXXXXXXXXXX", "mappings":[ { "dimm":"nmem1", "offset":"0x10000000", "length":"0x1f40000000", "position":1 }, { "dimm":"nmem0", "offset":"0x10000000", "length":"0x1f40000000", "position":0 } ], "badblock_count":1, "badblocks":[ { "offset":65536, "length":1, "dimms":[ "nmem0" ] } ], "persistence_domain":"memory_controller" } ] }Use o seguinte comando para encontrar o atributo
phys_iddo NVDIMM quebrado:# lista ndctl --dimms --humano
Pelo exemplo anterior, você sabe que
nmem0é o NVDIMM quebrado. Portanto, encontre o atributophys_iddenmem0.Exemplo 5.8. The phys_id attributes of NVDIMMs
No exemplo a seguir, o
phys_idé0x10:# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ]Use o seguinte comando para encontrar o slot de memória do NVDIMM quebrado:
# dmidecode
Na saída, encontre a entrada onde o identificador
Handlecorresponde ao atributophys_iddo NVDIMM quebrado. O campoLocatorlista o slot de memória utilizado pelo NVDIMM quebrado.Exemplo 5.9. Lista de Slot de Memória NVDIMM
No exemplo a seguir, o dispositivo
nmem0combina com o identificador0x0010e utiliza o slot de memóriaDIMM-XXX-YYYY:# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ...Faça backup de todos os dados nos namespaces do NVDIMM. Se você não fizer o backup dos dados antes de substituir o NVDIMM, os dados serão perdidos quando você remover o NVDIMM de seu sistema.
AtençãoEm alguns casos, como quando o NVDIMM está completamente quebrado, o backup pode falhar.
Para evitar isso, monitore regularmente seus dispositivos NVDIMM usando S.M.A.R.T. como descrito em Seção 5.8.2, “Monitoramento da saúde NVDIMM usando S.M.A.R.T.” e substitua os NVDIMMs com defeito antes que eles se quebrem.
Use o seguinte comando para listar os espaços de nomes no NVDIMM:
# lista ndctl --namespaces --dimm=DIMM-ID-numberExemplo 5.10. NVDIMM lista de NVDIMM namespaces
No exemplo a seguir, o dispositivo
nmem0contém os namespacesnamespace0.0enamespace0.2, os quais você precisa fazer backup:# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ]- Substituir fisicamente o NVDIMM quebrado.
Recursos adicionais
-
A página do homem
ndctl-list(1) -
A página do homem
dmidecode(8)
Capítulo 6. Descartando blocos não utilizados
Você pode realizar ou programar operações de descarte em dispositivos de bloco que os suportem.
6.1. Operações de descarte em bloco
As operações de descarte de blocos descartam blocos que não estão mais em uso por um sistema de arquivo montado. Eles são úteis:
- Acionamentos em estado sólido (SSDs)
- Armazenagem de provisão fina
Requisitos
O dispositivo de bloco subjacente ao sistema de arquivo deve suportar operações de descarte físico.
As operações de descarte físico são suportadas se o valor no /sys/block/device/queue/discard_max_bytes arquivo não é zero.
6.2. Tipos de operações de descarte em bloco
Você pode executar operações de descarte usando métodos diferentes:
- Lote de descarte
- São administrados explicitamente pelo usuário. Eles descartam todos os blocos não utilizados nos sistemas de arquivo selecionados.
- Descarte on-line
- São especificados no momento da montagem. Funcionam em tempo real, sem a intervenção do usuário. As operações de descarte on-line descartam apenas os blocos que estão passando de usados para livres.
- Descarte periódico
-
São operações em lote que são administradas regularmente por um serviço
systemd.
Todos os tipos são suportados pelos sistemas de arquivo XFS e ext4 e pela VDO.
Recomendações
A Red Hat recomenda que você utilize descarte em lote ou periódico.
Usar o descarte on-line somente se:
- a carga de trabalho do sistema é tal que o descarte de lotes não é viável, ou
- as operações de descarte on-line são necessárias para manter o desempenho.
6.3. Execução de descarte de blocos em lote
Este procedimento realiza uma operação de descarte de blocos em lote para descartar blocos não utilizados em um sistema de arquivo montado.
Pré-requisitos
- O sistema de arquivo é montado.
- O dispositivo de bloco subjacente ao sistema de arquivo suporta operações de descarte físico.
Procedimento
Use o utilitário
fstrim:Para realizar descarte somente em um sistema de arquivo selecionado, use:
# fstrim mount-pointPara realizar descarte em todos os sistemas de arquivos montados, use:
# fstrim -- tudo
Se você executar o comando fstrim em:
- um dispositivo que não suporta operações de descarte, ou
- um dispositivo lógico (LVM ou MD) composto de múltiplos dispositivos, onde qualquer um dos dispositivos não suporta operações de descarte,
a seguinte mensagem é exibida:
# fstrim /mnt/non_discard fstrim: /mnt/non_discard: the discard operation is not supported
Recursos adicionais
-
A página do homem
fstrim(8)
6.4. Permitindo o descarte em bloco online
Este procedimento permite operações de descarte de blocos on-line que descartam automaticamente blocos não utilizados em todos os sistemas de arquivos suportados.
Procedimento
Habilitar o descarte on-line no momento da montagem:
Ao montar um sistema de arquivo manualmente, adicione a opção de montagem
-o discard:# montar -o descartar device mount-point
-
Ao montar um sistema de arquivo de forma persistente, adicione a opção
discardà entrada de montagem no arquivo/etc/fstab.
Recursos adicionais
-
A página do homem
mount(8) -
A página do homem
fstab(5)
6.5. Permitindo o descarte em bloco online usando as funções do sistema RHEL
Esta seção descreve como habilitar o descarte em bloco online usando a função storage.
Pré-requisitos
-
Existe um livro de brincadeiras possível, incluindo o papel
storage.
Para informações sobre como aplicar tal playbook, consulte Aplicando um papel.
6.5.1. Exemplo Livro de reprodução possível para permitir o descarte em bloco online
Esta seção fornece um exemplo de um livro de brincadeiras possível. Este playbook aplica o papel storage para montar um sistema de arquivo XFS com o descarte de blocos on-line habilitado.
Exemplo 6.1. Um playbook que permite o descarte de blocos online em /mnt/dados/
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storageRecursos adicionais
- Este playbook também realiza todas as operações do exemplo de montagem persistente descrito em Seção 2.4, “Exemplo Livro de reprodução possível para montar persistentemente um sistema de arquivo”.
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
6.6. Possibilitando o descarte periódico em bloco
Este procedimento permite um temporizador systemd que descarta regularmente blocos não utilizados em todos os sistemas de arquivo suportados.
Procedimento
Habilitar e iniciar o temporizador
systemd:# systemctl habilita --now fstrim.timer
Capítulo 7. Começando com iSCSI
O Red Hat Enterprise Linux 8 usa a shell targetcli como uma interface de linha de comando para realizar as seguintes operações:
- Adicionar, remover, visualizar e monitorar as interconexões de armazenamento iSCSI para utilizar o hardware iSCSI.
- Exportar recursos de armazenamento local que são apoiados por arquivos, volumes, dispositivos SCSI locais, ou por discos RAM para sistemas remotos.
A ferramenta targetcli tem um layout baseado em árvores, incluindo preenchimento de guias embutidas, suporte de auto-completar e documentação inline.
7.1. Adicionando uma meta iSCSI
Como administrador de sistema, você pode adicionar uma meta iSCSI usando a ferramenta targetcli.
7.1.1. Instalando o targetcli
Instale a ferramenta targetcli para adicionar, monitorar e remover as interconexões de armazenamento iSCSI .
Procedimento
Instale
targetcli:# yum instalar targetcli
Iniciar o serviço alvo:
# alvo de partida systemctl
Configurar o alvo para começar no momento da inicialização:
# systemctl habilita o alvo
Abra a porta
3260no firewall e recarregue a configuração do firewall:# firewall-cmd --permanent --add-port=3260/tcp Success # firewall-cmd --reload Success
Veja o layout
targetcli:# targetcli /> ls o- /........................................[...] o- backstores.............................[...] | o- block.................[Storage Objects: 0] | o- fileio................[Storage Objects: 0] | o- pscsi.................[Storage Objects: 0] | o- ramdisk...............[Storage Objects: 0] o- iscsi...........................[Targets: 0] o- loopback........................[Targets: 0]
Recursos adicionais
-
A página do homem
targetcli.
7.1.2. Criando uma meta iSCSI
A criação de um alvo iSCSI permite ao iniciador iSCSI do cliente acessar os dispositivos de armazenamento no servidor. Tanto os alvos quanto os iniciadores têm nomes de identificação únicos.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”.
Procedimento
Navegue até o diretório iSCSI:
/> iscsi/
NotaO comando
cdé usado para mudar os diretórios, assim como para listar o caminho a ser seguido.Use uma das seguintes opções para criar um alvo iSCSI:
Criação de um alvo iSCSI usando um nome de alvo padrão:
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
Criação de um alvo iSCSI usando um nome específico:
/iscsi> create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1 Here
iqn.2006-04.com.example:444is target_iqn_nameSubstituir iqn.2006-04.com.example:444 pelo nome do alvo específico.
Verificar o alvo recém-criado:
/iscsi> ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
Recursos adicionais
-
A página do homem
targetcli.
7.1.3. backstore iSCSI
Um backstore iSCSI permite suporte para diferentes métodos de armazenamento de dados de um LUN exportado na máquina local. A criação de um objeto de armazenamento define os recursos que o backstore utiliza. Um administrador pode escolher qualquer um dos seguintes dispositivos de backstore que o Linux-IO (LIO) suporta:
-
fileiobackstore: Criar um objeto de armazenamentofileiose você estiver usando arquivos regulares no sistema de arquivos local como imagens de disco. Para criar um backstorefileio, veja Seção 7.1.4, “Criação de um objeto de armazenamento fileio”. -
blockbackstore: Crie um objeto de armazenamentoblockse você estiver usando qualquer dispositivo de bloco local e dispositivo lógico. Para criar um backstoreblock, veja Seção 7.1.5, “Criação de um objeto de armazenamento em bloco”. -
pscsibackstore: Crie um objeto de armazenamentopscsise seu objeto de armazenamento suportar a passagem direta dos comandos SCSI. Para criar um backstorepscsi, veja Seção 7.1.6, “Criação de um objeto de armazenamento pscsi” -
ramdiskbackstore: Crie um objeto de armazenamentoramdiskse você quiser criar um dispositivo temporário com suporte de RAM. Para criar um backstoreramdisk, veja Seção 7.1.7, “Criação de um objeto de armazenamento em disco RAM de cópia de memória”.
Recursos adicionais
-
A página do homem
targetcli.
7.1.4. Criação de um objeto de armazenamento fileio
fileio os objetos de armazenamento podem suportar tanto as operações write_back como write_thru. A operação write_back permite o cache do sistema de arquivo local. Isto melhora o desempenho, mas aumenta o risco de perda de dados. Recomenda-se usar write_back=false para desativar a operação write_back em favor da operação write_thru.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”.
Procedimento
Navegue até o diretório de backstores:
/> backstores/
Criar um objeto de armazenamento em
fileio:/> backstores/fileio create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
Verifique o objeto de armazenamento criado
fileio:/backstores> ls
Recursos adicionais
-
A página do homem
targetcli.
7.1.5. Criação de um objeto de armazenamento em bloco
O driver de bloco permite o uso de qualquer dispositivo de bloco que apareça no diretório /sys/block/ para ser usado com Linux-IO (LIO). Isto inclui dispositivos físicos (por exemplo, HDDs, SSDs, CDs, DVDs) e dispositivos lógicos (por exemplo, volumes RAID de software ou hardware, ou volumes LVM).
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”.
Procedimento
Navegue até o diretório de backstores:
/> backstores/
Criar uma backstore
block:/> backstores/block create name=block_backend dev=/dev/sdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
Verifique o objeto de armazenamento criado
block:/backstores> ls
NotaVocê também pode criar um backstore de blocos em um volume lógico.
Recursos adicionais
-
A página do homem
targetcli.
7.1.6. Criação de um objeto de armazenamento pscsi
Você pode configurar, como backstore, qualquer objeto de armazenamento que suporte a passagem direta dos comandos SCSI sem emulação SCSI e com um dispositivo SCSI subjacente que aparece com lsscsi no /proc/scsi/scsi (tal como um disco rígido SAS) . O SCSI-3 e superiores são suportados com este subsistema.
pscsi deve ser usado somente por usuários avançados. Comandos SCSI avançados, tais como para Asymmetric Logical Unit Assignment (ALUAs) ou Persistent Reservations (por exemplo, aqueles usados pelo VMware ESX, e vSphere) geralmente não são implementados no firmware do dispositivo e podem causar mau funcionamento ou falhas. Em caso de dúvida, utilize o backstore block para configurações de produção.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”.
Procedimento
Navegue até o diretório de backstores:
/> backstores/
Criar um backstore
pscsipara um dispositivo SCSI físico, um dispositivo TYPE_ROM usando/dev/sr0neste exemplo:/> backstores/pscsi/ create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0Verifique o objeto de armazenamento criado
pscsi:/backstores> ls
Recursos adicionais
-
A página do homem
targetcli.
7.1.7. Criação de um objeto de armazenamento em disco RAM de cópia de memória
Os discos RAM de cópia de memória (ramdisk) fornecem discos RAM com emulação SCSI completa e mapeamentos de memória separados usando cópia de memória para iniciadores. Isto fornece capacidade para multi-sessões e é particularmente útil para armazenamento em massa rápido e volátil para fins de produção.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”.
Procedimento
Navegue até o diretório de backstores:
/> backstores/
Criar um backstore de disco de 1GB de RAM:
/> backstores/ramdisk/ create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
Verifique o objeto de armazenamento criado
ramdisk:/backstores> ls
Recursos adicionais
-
A página do homem
targetcli.
7.1.8. Criando um portal iSCSI
A criação de um portal iSCSI adiciona um endereço IP e uma porta ao alvo que mantém o alvo habilitado.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”. - Uma meta iSCSI associada a um Grupo de Portais Alvo (TPG). Para mais informações, veja Seção 7.1.2, “Criando uma meta iSCSI”.
Procedimento
Navegue até o diretório TPG:
/iscsi> iqn.2006-04.example:444/tpg1/
Use uma das seguintes opções para criar um portal iSCSI:
A criação de um portal padrão utiliza a porta padrão iSCSI
3260e permite que o alvo escute todos os endereços IP naquela porta:/iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
NotaQuando um alvo iSCSI é criado, um portal padrão também é criado. Este portal é configurado para ouvir todos os endereços IP com o número de porta padrão que é:
0.0.0.0:3260.Para remover o portal padrão:
/iscsi/iqn-name/tpg1/portals delete ip_address=0.0.0.0 ip_port=3260Criação de um portal usando um endereço IP específico:
/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
Verificar o portal recém-criado:
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
Recursos adicionais
-
A página do homem
targetcli.
7.1.9. Criando um iSCSI LUN
O número da unidade lógica (LUN) é um dispositivo físico que é apoiado pela backstore iSCSI. Cada LUN tem um número único.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”. - Uma meta iSCSI associada a um Grupo de Portais Alvo (TPG). Para mais informações, veja Seção 7.1.2, “Criando uma meta iSCSI”.
- Objetos de armazenamento criados. Para maiores informações, ver Seção 7.1.3, “backstore iSCSI”.
Procedimento
Criar LUNs de objetos de armazenamento já criados:
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
Verificar as LUNs criadas:
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]O nome padrão do LUN começa em
0.ImportantePor padrão, os LUNs são criados com permissões de leitura-escrita. Se um novo LUN é adicionado após a criação de ACLs, o LUN mapeia automaticamente todas as ACLs disponíveis e pode causar um risco de segurança. Para criar um LUN com permissões somente de leitura, veja Seção 7.1.10, “Criando um iSCSI LUN somente de leitura”.
- Configurar ACLs. Para mais informações, veja Seção 7.1.11, “Criação de uma LCA iSCSI”.
Recursos adicionais
-
A página do homem
targetcli.
7.1.10. Criando um iSCSI LUN somente de leitura
Por padrão, os LUNs são criados com permissões de leitura-escrita. Este procedimento descreve como criar um LUN somente de leitura.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”. - Uma meta iSCSI associada a um Grupo de Portais Alvo (TPG). Para mais informações, veja Seção 7.1.2, “Criando uma meta iSCSI”.
- Objetos de armazenamento criados. Para maiores informações, ver Seção 7.1.3, “backstore iSCSI”.
Procedimento
Definir permissões somente leitura:
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
Isto impede o mapeamento automático de LUNs para ACLs existentes, permitindo o mapeamento manual de LUNs.
Crie o LUN:
/> iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/ create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1
Exemplo:
/> iscsi/iqn.2006-04.example:444/tpg1/acls/2006-04.com.example.foo:888/ create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1.
Verificar o LUN criado:
/> ls o- / ...................................................... [...] o- backstores ........................................... [...] <snip> o- iscsi ......................................... [Targets: 1] | o- iqn.2006-04.example:444 .................. [TPGs: 1] | o- tpg1 ............................ [no-gen-acls, no-auth] | o- acls ....................................... [ACLs: 2] | | o- 2006-04.com.example.foo:888 .. [Mapped LUNs: 2] | | | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | | | o- mapped_lun1 .............. [lun1 block/disk2 (ro)] | o- luns ....................................... [LUNs: 2] | | o- lun0 ...................... [block/disk1 (/dev/vdb)] | | o- lun1 ...................... [block/disk2 (/dev/vdc)] <snip>
A linha mapped_lun1 agora tem (
ro) no final (ao contrário dos mapped_lun0's (rw)) afirmando que ela é somente leitura.- Configurar ACLs. Para mais informações, veja Seção 7.1.11, “Criação de uma LCA iSCSI”.
Recursos adicionais
-
A página do homem
targetcli.
7.1.11. Criação de uma LCA iSCSI
Em targetcli, Listas de Controle de Acesso (ACLs) são usadas para definir regras de acesso e cada iniciador tem acesso exclusivo a uma LUN. Tanto os alvos quanto os iniciadores têm nomes de identificação únicos. Você deve saber o nome exclusivo do iniciador para configurar as LCAs. Os iniciadores iSCSI podem ser encontrados no arquivo /etc/iscsi/initiatorname.iscsi.
Pré-requisitos
-
Instalado e funcionando
targetcli. Para mais informações, ver Seção 7.1.1, “Instalando o targetcli”. - Uma meta iSCSI associada a um Grupo de Portais Alvo (TPG). Para mais informações, veja Seção 7.1.2, “Criando uma meta iSCSI”.
Procedimento
Navegue até o diretório acls
/iscsi/iqn.20....mple:444/tpg1> acls/
Use uma das seguintes opções para criar uma ACL :
-
Usando o nome do iniciador a partir do arquivo
/etc/iscsi/initiatorname.iscsino iniciador. Usando um nome que seja mais fácil de lembrar, consulte a seção Seção 7.1.12, “Criando um iniciador iSCSI” para garantir que o ACL corresponda ao iniciador.
/iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
NotaA configuração global
auto_add_mapped_lunsusada no exemplo anterior, mapeia automaticamente os LUNs para qualquer ACL criada.Você pode definir ACLs criadas pelo usuário dentro do nó TPG no servidor de destino:
/iscsi/iqn.20...scsi:444/tpg1> set attribute generate_node_acls=1
-
Usando o nome do iniciador a partir do arquivo
Verificar a ACL criada:
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
Recursos adicionais
-
A página do homem
targetcli.
7.1.12. Criando um iniciador iSCSI
Um iniciador iSCSI forma uma sessão para se conectar com o alvo iSCSI. Para mais informações sobre o alvo iSCSI, veja Seção 7.1.2, “Criando uma meta iSCSI”. Por padrão, um serviço iSCSI é lazily iniciado e o serviço começa após a execução do comando iscsiadm. Se o root não estiver em um dispositivo iSCSI ou não houver nós marcados com node.startup = automatic, então o serviço iSCSI não iniciará até que um comando iscsiadm seja executado, o que requer iscsid ou os módulos do kernel iscsi para ser iniciado.
Forçar o daemon iscsid a rodar e os módulos do kernel iSCSI a carregar:
# systemctl start iscsid.service
Pré-requisitos
-
Instalado e funcionando
targetcliem uma máquina servidora. Para mais informações, veja Seção 7.1.1, “Instalando o targetcli”. - Um alvo iSCSI associado a um Target Portal Groups (TPG) em uma máquina servidora. Para mais informações, veja Seção 7.1.2, “Criando uma meta iSCSI”.
- Criado o iSCSI ACL. Para mais informações, veja Seção 7.1.11, “Criação de uma LCA iSCSI”.
Procedimento
Instalar
iscsi-initiator-utilsna máquina do cliente:# yum instalar iscsi-iniciador-utils
Verifique o nome do iniciador:
# cat /etc/iscsi/initiatorname.iscsi InitiatorName=2006-04.com.example.foo:888
Se a ACL recebeu um nome personalizado em Seção 7.1.11, “Criação de uma LCA iSCSI”, modifique o arquivo
/etc/iscsi/initiatorname.iscside acordo.# vi /etc/iscsi/initiatorname.iscsi
Descubra o alvo e faça login no alvo com o IQN do alvo exibido:
# iscsiadm -m discovery -t st -p 10.64.24.179 10.64.24.179:3260,1 iqn.2006-04.example:444 # iscsiadm -m node -T iqn.2006-04.example:444 -l Logging in to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] successful.
Substituir 10.64.24.179 pelo endereço-ip de destino.
Você pode usar este procedimento para qualquer número de iniciadores conectados ao mesmo alvo se seus respectivos nomes de iniciadores forem adicionados ao ACL, conforme descrito no site Seção 7.1.11, “Criação de uma LCA iSCSI”.
Encontre o nome do disco iSCSI e crie um sistema de arquivo neste disco iSCSI:
# grep "Attached SCSI" /var/log/messages # mkfs.ext4 /dev/disk_nameSubstitua disk_name pelo nome do disco iSCSI exibido no arquivo
/var/log/messages.Montar o sistema de arquivo:
# mkdir /mount/point # mount /dev/disk_name /mount/point
Substituir /mount/point pelo ponto de montagem da divisória.
Edite o arquivo
/etc/fstabpara montar o sistema de arquivo automaticamente quando o sistema for inicializado:# vi /etc/fstab /dev/disk_name /mount/point ext4 _netdev 0 0Substitua disk_name pelo nome do disco iSCSI e /mount/point pelo ponto de montagem da partição.
Recursos adicionais
-
A página do homem
targetcli. -
A página do homem
iscsiadm.
7.1.13. Estabelecendo o Protocolo de Autenticação do Desafio-Amerto de Mãos para o alvo
O Challenge-Handshake Authentication Protocol (CHAP) permite que o usuário proteja o alvo com uma senha. O iniciador deve estar ciente desta senha para poder se conectar com o alvo.
Pré-requisitos
- Criado o iSCSI ACL. Para mais informações, veja Seção 7.1.11, “Criação de uma LCA iSCSI”.
Procedimento
Definir autenticação de atributos:
/iscsi/iqn.20...mple:444/tpg1> set attribute authentication=1 Parameter authentication is now '1'.
Conjunto
useridepassword:/tpg1> set auth userid=redhat Parameter userid is now 'redhat'. /iscsi/iqn.20...689dcbb3/tpg1> set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
Recursos adicionais
-
A página do homem
targetcli.
7.1.14. Estabelecendo o Protocolo de Autenticação do Desafio-Amerto de Mãos para o iniciador
O Challenge-Handshake Authentication Protocol (CHAP) permite que o usuário proteja o alvo com uma senha. O iniciador deve estar ciente desta senha para poder se conectar com o alvo.
Pré-requisitos
- Criado o iniciador iSCSI. Para mais informações, veja Seção 7.1.12, “Criando um iniciador iSCSI”.
-
Defina o
CHAPpara a meta. Para maiores informações, ver Seção 7.1.13, “Estabelecendo o Protocolo de Autenticação do Desafio-Amerto de Mãos para o alvo”.
Procedimento
Habilitar a autenticação CHAP no arquivo
iscsid.conf:# vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP
Por padrão, o site
node.session.auth.authmethodestá configurado paraNoneAdicione o alvo
usernameepasswordno arquivoiscsid.conf:node.session.auth.username = redhat node.session.auth.password = redhat_passwd
Inicie o daemon
iscsid:# systemctl start iscsid.service
Recursos adicionais
-
A página do homem
iscsiadm
7.2. Monitoramento de uma sessão iSCSI
Como administrador do sistema, você pode monitorar a sessão iSCSI usando o utilitário iscsiadm.
7.2.1. Monitoramento de uma sessão iSCSI usando o utilitário iscsiadm
Este procedimento descreve como monitorar a sessão iscsi usando o utilitário iscsiadm.
Por padrão, um serviço iSCSI é lazily iniciado e o serviço começa após a execução do comando iscsiadm. Se o root não estiver em um dispositivo iSCSI ou não houver nós marcados com node.startup = automatic, então o serviço iSCSI não iniciará até que um comando iscsiadm seja executado, o que requer iscsid ou os módulos do kernel iscsi a serem iniciados.
Forçar o daemon iscsid a rodar e os módulos do kernel iSCSI a carregar:
# systemctl start iscsid.service
Pré-requisitos
Instalação de iscsi-iniciador-utils na máquina do cliente:
yum instalar iscsi-iniciador-utils
Procedimento
Encontre informações sobre as sessões em andamento:
# iscsiadm -m sessão -P 3
Este comando exibe o estado da sessão ou dispositivo, o ID da sessão (sid), alguns parâmetros negociados e os dispositivos SCSI acessíveis através da sessão.
Para uma saída mais curta, por exemplo, para exibir apenas o mapeamento
sid-to-node, execute:# iscsiadm -m session -P 0 or # iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311Estes comandos imprimem a lista de sessões em execução no seguinte formato:
driver [sid] target_ip:port,target_portal_group_tag proper_target_name.
Recursos adicionais
-
/usr/share/doc/iscsi-initiator-utils-version/READMEarquivo. -
A página do homem
iscsiadm.
7.3. Removendo um alvo iSCSI
Como administrador do sistema, você pode remover o alvo iSCSI.
7.3.1. Remoção de um objeto iSCSI usando a ferramenta targetcli
Este procedimento descreve como remover os objetos iSCSI usando a ferramenta targetcli.
Procedimento
Faça logoff do alvo:
# iscsiadm -m node -T iqn.2006-04.example:444 -uPara mais informações sobre como acessar o alvo, veja Seção 7.1.12, “Criando um iniciador iSCSI”.
Remover todo o alvo, incluindo todas as ACLs, LUNs e portais:
/> iscsi/ apagar iqn.2006-04.com.example:444Substituir iqn.2006-04.com.example:444 pelo nome_iqn_alvo.
Para remover um backstore iSCSI:
/> backstores/backstore-type/ delete block_backend
-
Substituir backstore-type por
fileio,block,pscsi, ouramdisk. - Substitua block_backend pelo backstore-name que você deseja excluir.
-
Substituir backstore-type por
Para remover partes de um alvo iSCSI, tais como uma LCA:
/> /iscsi/iqn-nome/tpg/acls/ delete iqn.2006-04.com.example:444
Veja as mudanças:
/> iscsi/ ls
Recursos adicionais
-
A página do homem
targetcli.
7.4. DM Multipath overrides do timeout do dispositivo
A opção recovery_tmo sysfs controla o timeout de um determinado dispositivo iSCSI. As opções a seguir substituem globalmente os valores recovery_tmo:
-
A opção de configuração
replacement_timeoutsobrepõe globalmente o valorrecovery_tmopara todos os dispositivos iSCSI. Para todos os dispositivos iSCSI que são gerenciados pela DM Multipath, a opção
fast_io_fail_tmoem DM Multipath sobrepõe globalmente o valorrecovery_tmo.A opção
fast_io_fail_tmoem DM Multipath também anula a opçãofast_io_fail_tmoem dispositivos Fibre Channel.
A opção DM Multipath fast_io_fail_tmo tem precedência sobre replacement_timeout. A Red Hat não recomenda usar replacement_timeout para substituir recovery_tmo em dispositivos gerenciados pela DM Multipath porque a DM Multipath sempre reinicia recovery_tmo quando o serviço multipathd é recarregado.
Capítulo 8. Usando dispositivos Fibre Channel
O RHEL 8 fornece os seguintes condutores nativos de Fibre Channel:
-
lpfc -
qla2xxx -
zfcp
8.1. Redimensionamento de unidades lógicas de canal de fibra
Como administrador do sistema, você pode redimensionar as unidades lógicas Fibre Channel.
Procedimento
Para determinar quais dispositivos são caminhos para uma unidade lógica
multipath:multicaminhos -ll
Para digitalizar novamente as unidades lógicas Fibre Channel em um sistema que utiliza o multicaminho:
$ echo 1 > /sys/block/sdX/device/rescan
Recursos adicionais
-
A página do homem
multipath.
8.2. Determinando o comportamento de perda do link do dispositivo usando o Fibre Channel
Se um motorista implementar o Transport dev_loss_tmo, as tentativas de acesso a um dispositivo através de um link serão bloqueadas quando um problema de transporte for detectado.
Procedimento
Determinar o estado de um porto remoto:
$ gato /sys/class/fc_remote_port/rport-host:bus:remote-port/port_state
Este comando retorna qualquer uma das seguintes saídas:
-
Blockedquando a porta remota juntamente com os dispositivos acessados através dela são bloqueados. -
Onlinese a porta remota estiver operando normalmente
Se o problema não for resolvido em
dev_loss_tmosegundos, orporte os dispositivos serão desbloqueados. Todas as E/S em execução naquele dispositivo juntamente com qualquer nova E/S enviada para aquele dispositivo irão falhar.-
Quando a perda de um link excede dev_loss_tmo, o scsi_device e sdN os dispositivos são removidos. Normalmente, a classe Fibre Channel deixará o dispositivo como está, ou seja /dev/sdx permanecerá /dev/sdx. Isto porque a ligação do alvo é salva pelo condutor do canal de fibra e quando o porto alvo retorna, os endereços SCSI são recriados fielmente. No entanto, isto não pode ser garantido; o sdx só será restaurado se nenhuma mudança adicional na configuração da caixa de armazenagem dos LUNs for feita.
Recursos adicionais
-
A página do homem
multipath.conf Usando
multipath, você pode modificar o comportamento de perda do link do dispositivo. Para maiores informações, veja os seguintes artigos da Base de Conhecimento:
8.3. Arquivos de configuração do Canal de Fibra
A seguir está a lista de arquivos de configuração no diretório /sys/class/ que fornecem a API de espaço do usuário para o Fibre Channel.
Os itens utilizam as seguintes variáveis:
H- Número do anfitrião
B- Número do ônibus
T- Meta
L- Unidade lógica (LUNs)
R- Número da porta remota
Se seu sistema estiver usando software multipath, a Red Hat recomenda que você consulte seu fornecedor de hardware antes de alterar qualquer um dos valores descritos nesta seção.
Configuração do transporte em /sys/class/fc_transport/targetH:B:T/
port_id- ID/endereço de porta de 24 bits
node_name- Nome do nó de 64 bits
port_name- Nome da porta de 64 bits
Configuração de porta remota em /sys/class/fc_remote_ports/rport-H:B-R/
-
port_id -
node_name -
port_name dev_loss_tmoControla quando o dispositivo scsi é removido do sistema. Após o acionamento do
dev_loss_tmo, o dispositivo scsi é removido. No arquivomultipath.conf, você pode configurardev_loss_tmoparainfinity.No Red Hat Enterprise Linux 8, se você não definir a opção
fast_io_fail_tmo,dev_loss_tmoestá limitado a600segundos. Por default,fast_io_fail_tmoestá definido para5segundos no Red Hat Enterprise Linux 8, se o serviçomultipathdestiver rodando; caso contrário, está definido paraoff.fast_io_fail_tmoEspecifica o número de segundos a esperar antes de marcar um link como "ruim". Quando um link é marcado como "ruim", a E/S existente em execução ou qualquer nova E/S em seu caminho correspondente falha.
Se a E/S estiver em uma fila bloqueada, não falhará até que
dev_loss_tmoexpire e a fila seja desbloqueada.Se
fast_io_fail_tmoestiver definido para qualquer valor, exceto desativado,dev_loss_tmoestá desmarcado. Sefast_io_fail_tmoestiver desativado, nenhuma E/S falha até que o dispositivo seja removido do sistema. Sefast_io_fail_tmoestiver definido para um número, a E/S falha imediatamente quando o timeoutfast_io_fail_tmoé acionado.
Configuração do host em /sys/class/fc_host/hostH/
-
port_id -
node_name -
port_name issue_lipInstrui o motorista a redescobrir portos remotos.
8.4. DM Multipath overrides do timeout do dispositivo
A opção recovery_tmo sysfs controla o timeout de um determinado dispositivo iSCSI. As opções a seguir substituem globalmente os valores recovery_tmo:
-
A opção de configuração
replacement_timeoutsobrepõe globalmente o valorrecovery_tmopara todos os dispositivos iSCSI. Para todos os dispositivos iSCSI que são gerenciados pela DM Multipath, a opção
fast_io_fail_tmoem DM Multipath sobrepõe globalmente o valorrecovery_tmo.A opção
fast_io_fail_tmoem DM Multipath também anula a opçãofast_io_fail_tmoem dispositivos Fibre Channel.
A opção DM Multipath fast_io_fail_tmo tem precedência sobre replacement_timeout. A Red Hat não recomenda usar replacement_timeout para substituir recovery_tmo em dispositivos gerenciados pela DM Multipath porque a DM Multipath sempre reinicia recovery_tmo quando o serviço multipathd é recarregado.
Capítulo 9. Configuração do canal de fibra sobre Ethernet
Baseado na norma IEEE T11 FC-BB-5, o Fibre Channel over Ethernet (FCoE) é um protocolo para transmitir quadros de Fibre Channel sobre redes Ethernet. Normalmente, os centros de dados possuem uma rede LAN e uma rede de área de armazenamento (SAN) dedicadas que são separadas umas das outras com sua própria configuração específica. O FCoE combina essas redes em uma estrutura de rede única e convergente. Os benefícios do FCoE são, por exemplo, custos mais baixos de hardware e energia.
9.1. Usando hardware FCoE HBAs em RHEL
No Red Hat Enterprise Linux você pode usar o hardware FCoE Host Bus Adapter (HBA) suportado pelos seguintes drivers:
-
qedf -
bnx2fc -
fnic
Se você usar tal HBA, você configura as configurações do FCoE na configuração do HBA. Para obter detalhes, consulte a documentação do adaptador.
Após configurar o HBA em sua configuração, os Números de Unidade Lógica (LUN) exportados da Rede de Área de Armazenamento (SAN) estão automaticamente disponíveis para a RHEL como dispositivos /dev/sd*. Você pode usar estes dispositivos de forma similar aos dispositivos de armazenamento local.
9.2. Instalação de um dispositivo de software FCoE
Um dispositivo de software FCoE permite acessar os Números de Unidade Lógica (LUN) sobre o FCoE usando um adaptador Ethernet que suporta parcialmente o descarregamento do FCoE.
A RHEL não suporta os dispositivos de software FCoE que requerem o módulo de kernel fcoe.ko. Para detalhes, consulte a remoção do software FCoE na documentação Considerations in adopting RHEL 8.
Após completar este procedimento, os LUNs exportados da Rede de Área de Armazenamento (SAN) estão automaticamente disponíveis para a RHEL como dispositivos /dev/sd*. Você pode usar estes dispositivos de forma similar aos dispositivos de armazenamento locais.
Pré-requisitos
-
O Host Bus Adapter (HBA) usa o driver
qedf,bnx2fc, oufnice não requer o módulo do kernelfcoe.ko. - A SAN usa uma VLAN para separar o tráfego de armazenamento do tráfego Ethernet normal.
- O switch de rede foi configurado para suportar a VLAN.
- O HBA do servidor é configurado em sua BIOS. Para obter detalhes, consulte a documentação de seu HBA.
- A HBA está conectada à rede e o link está pronto.
Procedimento
Instale o pacote
fcoe-utils:#
yum install fcoe-utilsCopie o arquivo modelo
/etc/fcoe/cfg-ethxpara/etc/fcoe/cfg-interface_name. Por exemplo, se você quiser configurar a interfaceenp1s0para usar o FCoE, entre:#
cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-enp1s0Habilite e inicie o serviço
fcoe:#
systemctl enable --now fcoeDescubra o FCoE VLAN ID, inicie o iniciador e crie um dispositivo de rede para a VLAN descoberta:
#
fipvlan -s -c enp1s0Created VLAN device enp1s0.200 Starting FCoE on interface enp1s0.200 Fibre Channel Forwarders Discovered interface | VLAN | FCF MAC ------------------------------------------ enp1s0 | 200 | 00:53:00:a7:e7:1bOpcional: Para exibir detalhes sobre os alvos descobertos, os LUNs, e os dispositivos associados com os LUNs, entre:
#
fcoeadm -tInterface: enp1s0.200 Roles: FCP Target Node Name: 0x500a0980824acd15 Port Name: 0x500a0982824acd15 Target ID: 0 MaxFrameSize: 2048 bytes OS Device Name: rport-11:0-1 FC-ID (Port ID): 0xba00a0 State: Online LUN ID Device Name Capacity Block Size Description ------ ----------- ---------- ---------- --------------------- 0 sdb 28.38 GiB 512 NETAPP LUN (rev 820a) ...Este exemplo mostra que o LUN 0 da SAN foi anexado ao host como o dispositivo
/dev/sdb.
Etapas de verificação
Use o comando
fcoeadm -ipara exibir informações sobre todas as interfaces FCoE ativas:#
fcoeadm -iDescription: BCM57840 NetXtreme II 10 Gigabit Ethernet Revision: 11 Manufacturer: Broadcom Inc. and subsidiaries Serial Number: 000AG703A9B7 Driver: bnx2x Unknown Number of Ports: 1 Symbolic Name: bnx2fc (QLogic BCM57840) v2.12.13 over enp1s0.200 OS Device Name: host11 Node Name: 0x2000000af70ae935 Port Name: 0x2001000af70ae935 Fabric Name: 0x20c8002a6aa7e701 Speed: 10 Gbit Supported Speed: 1 Gbit, 10 Gbit MaxFrameSize: 2048 bytes FC-ID (Port ID): 0xba02c0 State: Online
Recursos adicionais
-
Para mais detalhes sobre a utilidade
fcoeadm, consulte a página de manualfcoeadm(8). -
Para detalhes sobre como montar o armazenamento conectado através de um software FCoE quando o sistema inicia, consulte o arquivo
/usr/share/doc/fcoe-utils/README.
9.3. Recursos adicionais
- Para detalhes sobre o uso de dispositivos Fibre Channel, veja Seção 8.1, “Redimensionamento de unidades lógicas de canal de fibra”
Capítulo 10. Configuração do tempo máximo para recuperação de erros de armazenamento com eh_deadline
Você pode configurar o tempo máximo permitido para recuperar dispositivos SCSI falhos. Esta configuração garante um tempo de resposta de E/S mesmo quando o hardware de armazenamento fica sem resposta devido a uma falha.
10.1. O parâmetro eh_deadline
O mecanismo de tratamento de erros SCSI (EH) tenta realizar a recuperação de erros em dispositivos SCSI falhos. O objeto host SCSI eh_deadline permite configurar a quantidade máxima de tempo para a recuperação. Após o tempo configurado expirar, o SCSI EH pára e restabelece todo o adaptador do barramento host (HBA).
O uso do site eh_deadline pode reduzir o tempo:
- para fechar um caminho fracassado,
- para mudar um caminho, ou
- para desativar uma fatia RAID.
Quando eh_deadline expira, SCSI EH restabelece a HBA, que afeta todos os caminhos alvo dessa HBA, e não apenas o de falha. Se alguns dos caminhos redundantes não estiverem disponíveis por outros motivos, podem ocorrer erros de E/S. Habilite eh_deadline somente se você tiver uma configuração multipath totalmente redundante em todos os alvos.
Cenários quando eh_deadline é útil
Na maioria dos cenários, você não precisa habilitar eh_deadline. Usar eh_deadline pode ser útil em certos cenários específicos, por exemplo, se ocorrer uma perda de link entre uma chave de canal de fibra (FC) e uma porta de destino, e a HBA não receber notificações de mudança de estado registrada (RSCNs). Neste caso, os pedidos de E/S e os comandos de recuperação de erros são sempre enviados ao invés de encontrar um erro. A configuração de eh_deadline neste ambiente coloca um limite superior no tempo de recuperação. Isso permite que as E/S falhadas sejam novamente testadas em outro caminho disponível pela DM Multipath.
Sob as seguintes condições, a funcionalidade eh_deadline não oferece nenhum benefício adicional, pois os comandos de E/S e recuperação de erros falham imediatamente, o que permite que a DM Multipath volte a tentar:
- Se as RSCNs estiverem habilitadas
- Se a HBA não registrar o link ficando indisponível
Possíveis valores
O valor do eh_deadline é especificado em segundos.
A configuração padrão é off, o que desativa o limite de tempo e permite que toda a recuperação do erro ocorra.
10.2. Definição do parâmetro eh_deadline
Este procedimento configura o valor do parâmetro eh_deadline para limitar o tempo máximo de recuperação SCSI.
Procedimento
Você pode configurar
eh_deadlineusando um dos seguintes métodos:sysfs-
Escreva o número de segundos nos arquivos
/sys/class/scsi_host/host*/eh_deadline. - Parâmetro do núcleo
-
Defina um valor padrão para todos os SCSI HBAs usando o parâmetro
scsi_mod.eh_deadlinekernel.
Capítulo 11. Começando com a troca
Esta seção descreve o espaço de troca e como utilizá-lo.
11.1. Trocar o espaço
Swap space no Linux é usado quando a quantidade de memória física (RAM) está cheia. Se o sistema precisar de mais recursos de memória e a RAM estiver cheia, as páginas inativas na memória são movidas para o espaço de troca. Embora o espaço swap possa ajudar máquinas com uma pequena quantidade de RAM, ele não deve ser considerado um substituto para mais RAM. O espaço de troca está localizado em discos rígidos, que têm um tempo de acesso mais lento do que a memória física. O espaço swap pode ser uma partição swap dedicada (recomendada), um arquivo swap ou uma combinação de partições swap e arquivos swap.
Em anos passados, a quantidade recomendada de espaço de troca aumentou linearmente com a quantidade de RAM no sistema. No entanto, os sistemas modernos freqüentemente incluem centenas de gigabytes de RAM. Como conseqüência, o espaço swap recomendado é considerado uma função da carga de trabalho da memória do sistema, e não da memória do sistema.
Seção 11.2, “Espaço de troca recomendado para o sistema” ilustra o tamanho recomendado de uma partição swap, dependendo da quantidade de RAM em seu sistema e se você quer memória suficiente para que seu sistema hibernar. O tamanho recomendado de uma partição swap é estabelecido automaticamente durante a instalação. Para permitir a hibernação, entretanto, você precisa editar o espaço swap na fase de particionamento personalizado.
As recomendações em Seção 11.2, “Espaço de troca recomendado para o sistema” são especialmente importantes em sistemas com pouca memória (1 GB e menos). A falha em alocar espaço de troca suficiente nestes sistemas pode causar problemas como instabilidade ou mesmo tornar o sistema instalado não inicializável.
11.2. Espaço de troca recomendado para o sistema
Esta seção dá recomendações sobre espaço de troca.
| Quantidade de RAM no sistema | Espaço de troca recomendado | Espaço de troca recomendado se permitir a hibernação |
|---|---|---|
| ࣘ 2 GB | 2 vezes a quantidade de RAM | 3 vezes a quantidade de RAM |
| > 2 GB | Igual à quantidade de RAM | 2 vezes a quantidade de RAM |
| > 8 GB | Pelo menos 4 GB | 1.5 vezes a quantidade de RAM |
| > 64 GB | Pelo menos 4 GB | Hibernação não recomendada |
Na fronteira entre cada faixa listada na tabela acima, por exemplo, um sistema com 2 GB, 8 GB, ou 64 GB de RAM do sistema, a discrição pode ser exercida com relação ao espaço swap escolhido e suporte à hibernação. Se os recursos de seu sistema o permitirem, o aumento do espaço de troca pode levar a um melhor desempenho. Um espaço swap de pelo menos 100 GB é recomendado para sistemas com mais de 140 processadores lógicos ou mais de 3 TB de RAM.
Observe que a distribuição de espaço swap em múltiplos dispositivos de armazenamento também melhora o desempenho do espaço swap, particularmente em sistemas com acionamentos rápidos, controladores e interfaces.
Sistemas de arquivo e volumes LVM2 designados como espaço swap should not estejam em uso quando forem modificados. Qualquer tentativa de modificar o swap falha se um processo de sistema ou o kernel estiver usando o espaço swap. Use os comandos free e cat /proc/swaps para verificar quanto e onde o swap está em uso.
Você deve modificar o espaço de troca enquanto o sistema é inicializado no modo rescue, veja as opções de inicialização do Debug no Performing an advanced RHEL installation. Quando for solicitado a montar o sistema de arquivo, selecione .
11.3. Adicionando espaço de troca
Esta seção descreve como adicionar mais espaço de troca após a instalação. Por exemplo, você pode atualizar a quantidade de RAM em seu sistema de 1 GB para 2 GB, mas há apenas 2 GB de espaço swap. Pode ser vantajoso aumentar a quantidade de espaço swap para 4 GB se você realizar operações memorizadas ou executar aplicações que requerem uma grande quantidade de memória.
Há três opções: criar uma nova partição swap, criar um novo arquivo swap ou estender a swap em um volume lógico LVM2 existente. É recomendável estender um volume lógico existente.
11.3.1. Ampliação da troca em um volume lógico LVM2
Este procedimento descreve como ampliar o espaço swap em um volume lógico LVM2 existente. Assumindo que /dev/VolGroup00/LogVol01 é o volume que você deseja ampliar em 2 GB.
Pré-requisitos
- Espaço suficiente em disco.
Procedimento
Desativar a troca para o volume lógico associado:
# swapoff -v /dev/VolGroup00/LogVol01
Redimensionar o volume lógico do LVM2 em 2 GB:
# lvresize /dev/VolGroup00/LogVol01 -L 2G
Formate o novo espaço swap:
# mkswap /dev/VolGroup00/LogVol01
Habilitar o volume lógico ampliado:
# swapon -v /dev/VolGroup00/LogVol01
Para testar se o volume lógico swap foi estendido e ativado com sucesso, inspecionar o espaço swap ativo:
$ cat /proc/swaps $ free -h
11.3.2. Criação de um volume lógico LVM2 para swap
Este procedimento descreve como criar um volume lógico LVM2 para swap. Assumindo que /dev/VolGroup00/LogVol02 é o volume swap que você deseja adicionar.
Pré-requisitos
- Espaço suficiente em disco.
Procedimento
Criar o volume lógico LVM2 de tamanho 2 GB:
# lvcreate VolGroup00 -n LogVol02 -L 2G
Formate o novo espaço swap:
# mkswap /dev/VolGroup00/LogVol02
Adicione a seguinte entrada ao arquivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap defaults 0 0
Regenere unidades de montagem para que seu sistema registre a nova configuração:
# systemctl daemon-reload
Ativar a troca no volume lógico:
# swapon -v /dev/VolGroup00/LogVol02
Para testar se o volume lógico swap foi criado e ativado com sucesso, inspecionar o espaço swap ativo:
$ cat /proc/swaps $ free -h
11.3.3. Criação de um arquivo swap
Este procedimento descreve como criar um arquivo swap.
Pré-requisitos
- Espaço suficiente em disco.
Procedimento
- Determine o tamanho do novo arquivo swap em megabytes e multiplique por 1024 para determinar o número de blocos. Por exemplo, o tamanho do bloco de um arquivo swap de 64 MB é 65536.
Criar um arquivo vazio:
# dd if=/dev/zero of=/swapfile bs=1024 count=65536
Substituir count pelo valor igual ao tamanho do bloco desejado.
Configure o arquivo swap com o comando:
# mkswap /swapfile
Mude a segurança do arquivo swap para que ele não seja legível no mundo.
# chmod 0600 /swapfile
Para ativar o arquivo swap no momento da inicialização, edite
/etc/fstabcomo root para incluir a seguinte entrada:/swapfile swap swap defaults 0 0
Na próxima vez em que o sistema inicia, ele ativa o novo arquivo swap.
Regenere as unidades de montagem para que seu sistema registre a nova configuração
/etc/fstab:# systemctl daemon-reload
Para ativar o arquivo swap imediatamente:
# swapon /swapfile
Para testar se o novo arquivo swap foi criado e ativado com sucesso, inspecione o espaço swap ativo:
$ cat /proc/swaps $ free -h
11.4. Removendo o espaço de troca
Esta seção descreve como reduzir o espaço de troca após a instalação. Por exemplo, você baixou a quantidade de RAM em seu sistema de 1 GB para 512 MB, mas ainda há 2 GB de espaço swap atribuídos. Pode ser vantajoso reduzir a quantidade de espaço swap para 1 GB, já que os 2 GB maiores podem estar desperdiçando espaço em disco.
Dependendo do que você precisa, você pode escolher uma das três opções: reduzir o espaço swap em um volume lógico LVM2 existente, remover um volume lógico LVM2 inteiro usado para swap, ou remover um arquivo swap.
11.4.1. Redução da troca em um volume lógico LVM2
Este procedimento descreve como reduzir a troca em um volume lógico LVM2. Assumindo que /dev/VolGroup00/LogVol01 é o volume que você deseja reduzir.
Procedimento
Desativar a troca para o volume lógico associado:
# swapoff -v /dev/VolGroup00/LogVol01
Reduzir o volume lógico do LVM2 em 512 MB:
# lvreduce /dev/VolGroup00/LogVol01 -L -512M
Formate o novo espaço swap:
# mkswap /dev/VolGroup00/LogVol01
Ativar a troca no volume lógico:
# swapon -v /dev/VolGroup00/LogVol01
Para testar se o volume lógico swap foi reduzido com sucesso, inspecionar o espaço swap ativo:
$ cat /proc/swaps $ free -h
11.4.2. Remoção de um volume lógico LVM2 para troca
Este procedimento descreve como remover um volume lógico LVM2 para troca. Assumindo que /dev/VolGroup00/LogVol02 é o volume swap que você deseja remover.
Procedimento
Desativar a troca para o volume lógico associado:
# swapoff -v /dev/VolGroup00/LogVol02
Remover o volume lógico LVM2:
# lvremove /dev/VolGroup00/LogVol02
Remova a seguinte entrada associada do arquivo
/etc/fstab:/dev/VolGroup00/LogVol02 swap defaults 0 0
Regenere unidades de montagem para que seu sistema registre a nova configuração:
# systemctl daemon-reload
Para testar se o volume lógico foi removido com sucesso, inspecionar o espaço swap ativo:
$ cat /proc/swaps $ free -h
11.4.3. Remoção de um arquivo swap
Este procedimento descreve como remover um arquivo swap.
Procedimento
Em um prompt shell, execute o seguinte comando para desativar o arquivo swap (onde
/swapfileé o arquivo swap):# swapoff -v /swapfile
-
Remova sua entrada do arquivo
/etc/fstabde acordo. Regenere unidades de montagem para que seu sistema registre a nova configuração:
# systemctl daemon-reload
Remover o arquivo real:
# rm /swapfile
Capítulo 12. Gerenciamento de atualizações do sistema com instantâneos
Como administrador de sistemas, você pode realizar atualizações com capacidade de retrocesso dos sistemas Red Hat Enterprise Linux usando o gerenciador de inicialização Boom, o utilitário Leapp e a estrutura de modernização do sistema operacional.
Os procedimentos mencionados neste capítulo não funcionam em múltiplos sistemas de arquivo em sua árvore de sistemas, por exemplo, uma partição separada /var ou /usr.
12.1. Visão geral do processo Boom
Usando Boom, você pode criar entradas de inicialização, que podem então ser acessadas e selecionadas do menu do carregador de inicialização do GRUB 2. Ao criar entradas de inicialização, o processo de preparação para uma atualização com capacidade de retrocesso é agora simplificado.
A seguir estão as diferentes entradas de inicialização, que fazem parte do processo de atualização e rollback:
Upgrade boot entry-
Boots the
Leappambiente de atualização. Use o utilitárioleapppara criar e gerenciar esta entrada de boot. Esta entrada de boot é automaticamente removida durante a atualização deleapp. Red Hat Enterprise Linux 8 boot entry-
Boots o ambiente do sistema atualizado. Use o utilitário
leapppara criar esta entrada de boot após um processo de atualização bem sucedido. Snapshot boot entry-
Boots the snapshot of the original system and can be used to review and test the previous system state after a successful or unsuccessful upgrade attempt. Antes de atualizar o sistema, use o comando
boompara criar esta entrada de inicialização. Rollback boot entry-
Boots o ambiente original do sistema e retrocede qualquer atualização para o estado do sistema anterior. Use o comando
boompara criar esta entrada de inicialização ao iniciar um rollback do procedimento de atualização.
As atualizações com capacidade de Rollback são feitas utilizando o processo a seguir sem edição de nenhum arquivo de configuração:
- Criar um instantâneo ou cópia do sistema de arquivo raiz.
-
Use o comando
boompara criar uma entrada de inicialização para o ambiente atual (mais antigo). - Atualize seu sistema Red Hat Enterprise Linux.
- Reinicie o sistema e selecione a versão que você deseja usar.
O Red Hat Enterprise Linux 8, o instantâneo e as entradas de rollback devem ser limpas no final do procedimento, dependendo do resultado do processo de atualização:
-
Se você quiser manter o sistema Red Hat Enterprise Linux 8 atualizado, remova as entradas de snapshot e rollback criadas usando o comando
boom, e remova os volumes lógicos de snapshot com o comandolvremove. Para mais informações, veja Seção 12.4, “Apagando o instantâneo”. - Se você quiser voltar ao estado original do sistema, fundir a foto e a entrada de boot rollback, e após reiniciar o sistema remover a foto não utilizada e as entradas de boot rollback. Para mais informações, veja Seção 12.5, “Criando a entrada de rollback boot”.
Recursos adicionais
-
A página do homem
boom.
12.2. Atualização para outra versão usando Boom
Além de Boom, os seguintes componentes do Red Hat Enterprise Linux são usados neste processo de atualização:
- Gerenciador de volume lógico (LVM)
- Carregador de porta-bagagens GRUB 2
-
Leappferramenta de atualização
Este procedimento descreve como atualizar do Red Hat Enterprise Linux 7 para o Red Hat Enterprise Linux 8 usando o comando boom.
Pré-requisitos
Instale o pacote
boom:# yum instalar lvm2-python-boom
Certifique-se de que a versão do pacote
lvm2-python-boomseja pelo menosboom-0.9(idealmenteboom-1.2).NotaSe você quiser instalar o pacote
boomno Red Hat Enterprise Linux 8, execute o seguinte comando:# yum instalar boom-boot
O espaço suficiente deve estar disponível para a foto. Use os seguintes comandos para encontrar o espaço livre nos grupos de volume e volumes lógicos:
# vgs VG #PV #LV #SN Attr VSize VFree rhel 4 2 0 wz--n- 103.89g 29.99g # lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root rhel -wi-ao--- 68.88g swap rhel -wi-ao--- 5.98g
Aqui, rhel é o grupo de volume do sistema, e root e swap são os volumes lógicos do sistema.
Encontre todos os volumes lógicos montados:
# mount | grep rhel /dev/mapper/rhel-root on / type xfs (rw,relatime,seclabel,attr2,inode64,noquota)
NotaSe mais de uma entrada estiver presente e os pontos de montagem das entradas adicionais incluírem '/usr' ou '/var', os passos mencionados não podem ser seguidos sem a execução de passos adicionais que estão além do escopo desta história de usuário.
-
O pacote
Leappestá instalado e os repositórios de software estão habilitados. Para mais informações, consulte a seção Preparando um sistema RHEL 7 para a atualização, para baixar os pacotes necessários para a atualização.
Procedimento
Crie um instantâneo de seu volume lógico root:
Se seu sistema de arquivo raiz utiliza thin provisioning, crie uma fina fotografia:
Ao criar uma foto fina, não defina o tamanho da foto. O snapshot é alocado a partir do pool fino.
# lvcreate -s rhel/root -n root_snapshot_before_changesAqui:
-
-sé usado para criar o instantâneo -
rhel/rooté o sistema de arquivo que está sendo copiado no volume lógico -
-nroot_snapshot_before_changes é o nome do instantâneo
-
Se seu sistema de arquivo raiz utiliza provisionamento grosso, crie um instantâneo grosso:
Ao criar um instantâneo grosso, defina o tamanho do instantâneo que é capaz de manter todas as mudanças durante a atualização.
# lvcreate -s rhel/root -n root_snapshot_before_changes -L 25g
Aqui:
-
-sé usado para criar o instantâneo -
rhel/rooté o sistema de arquivo que está sendo copiado -
-nroot_snapshot_before_changes é o nome do instantâneo -L25g é o tamanho do instantâneo. Este instantâneo deve ser capaz de manter todas as mudanças durante a atualizaçãoImportanteApós a criação do instantâneo, quaisquer mudanças adicionais no sistema não são incluídas.
-
Criar o perfil:
# perfil boom criar --from-hosting --uname-padrão el7
NotaSe você quiser criar o perfil
boomno Red Hat Enterprise Linux 8, use oel8como o padrão uname-pattern.Criar uma entrada de inicialização do sistema original, utilizando cópias de segurança das imagens de inicialização originais:
Para a versão
boom-1.2ou posterior:# boom create --backup --title "Root LV snapshot before changes" --rootlv rhel/root_snapshot_before_changes
Aqui:
-
--titleRoot LV snapshot before changes é o nome da entrada de inicialização, que aparece na lista durante a inicialização do sistema -
--rootlvé o volume lógico raiz que corresponde à nova entrada de inicialização
-
Para a versão
boom-1.1ou anterior:# cp /boot/vmlinuz-$(uname r) /boot/vmlinuz$(uname -r).bak # cp /boot/initramfs-$(uname r).img /boot/initramfs$(uname -r).img.bak # boom create -title "Root LV snapshot before changes" --rootlv rhel/root_snapshot_before_changes --linux /boot/vmlinuz$(uname r).bak --initrd /boot/initramfs$(uname -r).img.bak
Se você executar o comando
boom createpela primeira vez, a seguinte mensagem será exibida:WARNING - Boom configuration not found in grub.cfg WARNING - Run 'grub2-mkconfig > /boot/grub2/grub.cfg' to enable
Para habilitar o Boom no GRUB 2:
# grub2-mkconfig > /boot/grub2/grub.cfg
Atualização para o Red Hat Enterprise Linux 8 usando o utilitário
Leapp:# salto de atualização
Rever e endereçar se algum bloqueador indicado no relatório de comando
leapp upgrade.Após resolver os bloqueadores identificados nos relatórios de pré-atualização, executar novamente o comando de atualização com a opção
--reboot:# salto de atualização --reboot
Este comando reinicia na entrada de inicialização atualizada criada pelo utilitário
leappe procede para executar a atualização no local para o Red Hat Enterprise Linux 8. O argumento de reinicialização inicia um reinício automático do sistema após o processo de atualização.Durante a reinicialização, é exibida a tela GRUB 2:
 Nota
NotaSe você estiver no sistema Red Hat Enterprise Linux 8, o sub-menu Snapshots da tela de inicialização do GRUB2 não está disponível.
Etapas de verificação
Selecione a entrada RHEL Upgrade Initramfs e pressione ENTER. A atualização continua e os novos pacotes Red Hat Enterprise Linux 8 RPM são instalados. Após a atualização estar completa, o sistema é automaticamente reinicializado e a tela do GRUB 2 exibe a versão atualizada e a versão mais antiga do sistema disponível. A versão atualizada do sistema é a seleção padrão.

Além disso, o criado Root LV snapshot before changes a entrada de inicialização está presente, o que proporciona um acesso instantâneo ao estado do sistema antes da atualização.
Recursos adicionais
-
A página do homem
boom. - O que é BOOM e como instalá-lo? Artigo de Base de Conhecimento.
- Como criar um artigoBOOM boot entry Knowledgebase.
- Dados requeridos pelo utilitário Leapp para uma atualização no local de um artigo daRHEL 7 para a RHEL 8 Knowledgebase.
12.3. Trocando entre a nova e a antiga versão do Red Hat Enterprise Linux
The Boom boot manager reduces the risks associated with upgrading a system and also helps to reduce hardware downtime. For example, you can upgrade a Red Hat Enterprise Linux 7 system to Red Hat Enterprise Linux 8, while retaining the original Red Hat Enterprise Linux 7 environment. This ability to switch between environments allows you to:
- Comparar rapidamente os dois ambientes de forma lado a lado e alternar entre eles com o mínimo de despesas gerais.
- Recuperar o conteúdo do sistema de arquivos mais antigo.
- Continue acessando o sistema antigo enquanto o host atualizado estiver em funcionamento.
- Pare e reverta o processo de atualização a qualquer momento, mesmo enquanto a atualização em si estiver em execução.
Este procedimento descreve como alternar entre a nova e a antiga versão do Red Hat Enterprise Linux após a atualização estar completa.
Pré-requisitos
- Atualização da versão do Red Hat Enterprise Linux. Para mais informações, veja Seção 12.2, “Atualização para outra versão usando Boom”.
Procedimento
Reinicie o sistema:
# reinicialização
Selecione a entrada de inicialização desejada na tela do carregador de inicialização do GRUB 2.
Etapas de verificação
Verificar se o volume de inicialização selecionado é exibido:
# cat /proc/cmdline root=/dev/rhel/root_snapshot_before_changes ro rd.lvm.lv=rhel/root_snapshot_before_changes rd.lvm.lv=vg_root/swap rhgb quiet
Recursos adicionais
-
A página do homem
boom.
12.4. Apagando o instantâneo
O boot boot boot boot boot boot é o instantâneo do sistema original e pode ser usado para rever e testar o estado do sistema anterior após uma tentativa de atualização bem sucedida ou mal sucedida. Este procedimento descreve os passos para apagar o instantâneo.
Pré-requisitos
- Atualizada para uma nova versão RHEL. Para mais informações, consulte Seção 12.2, “Atualização para outra versão usando Boom”.
Procedimento
Inicie no Red Hat Enterprise Linux 8 a partir da entrada GRUB 2. A saída seguinte confirma que o novo snapshot foi selecionado:
# boom list BootID Version Name RootDevice 6d2ec72 3.10.0-957.21.3.el7.x86_64 Red Hat Enterprise Linux Server /dev/rhel/root_snapshot_before_changes
Excluir a entrada de snapshot usando o valor
BootID:# boom delete --boot-id 6d2ec72Isto elimina a entrada do menu GRUB 2.
Retirar o instantâneo do LV:
# lvremove rhel/root_snapshot_before_changes Do you really want to remove active logical volume rhel/root_snapshot_before_changes? [y/n]: y Logical volume "root_snapshot_before_changes" successfully removed
Recursos adicionais
-
A página do homem
boom.
-
A página do homem
12.5. Criando a entrada de rollback boot
O boot de retorno inicia o ambiente original do sistema e retrocede qualquer atualização para o estado do sistema anterior. A reversão da entrada de inicialização atualizada e de rollback para o ambiente original após sua revisão, agora está disponível através da entrada de inicialização de snapshot.
Uma entrada de rollback pode ser preparada a partir do sistema atualizado ou a partir do ambiente de snapshot.
Pré-requisitos
- Atualizada para uma nova versão RHEL. Para mais informações, consulte Seção 12.2, “Atualização para outra versão usando Boom”.
Procedimento
Fundir o instantâneo:
# lvconvert --merge rhel/root_snapshot_before_changesCriar uma entrada de rollback boot para o snapshot fundido:
Para a versão
boom-1.2ou posterior:boom create --backup --title "RHEL Rollback" --rootlv rhel/rootPara a versão
boom-1.1ou anterior:boom create --title "RHEL Rollback" --rootlv rhel/root --linux /boot/vmlinuz$(uname r).bak --initrd /boot/initramfs$(uname -r).img.bak
Opcional: Ambiente de retrocesso do boot e restauração do estado do sistema:
# reinicialização
Quando o sistema for reinicializado, selecione o RHEL Rollback boot usando as setas do teclado e pressione Enter para iniciar esta entrada.
O sistema inicia automaticamente a operação de fusão de snapshot quando o volume lógico
rooté ativado.NotaUma vez iniciada a operação de fusão, o volume do instantâneo não está mais disponível. Após a inicialização bem sucedida da entrada de inicialização RHEL Rollback, a entrada de inicialização Root LV snapshot before changes não funciona mais porque agora está fundida no volume lógico original. A fusão de um volume lógico de instantâneo, destrói o instantâneo e restaura o estado anterior do volume de origem.
Opcional: Uma vez concluída a operação de fusão, remova as entradas não utilizadas e restaure a entrada de inicialização original:
Remova as entradas de inicialização do Red Hat Enterprise Linux 8 não utilizadas do sistema de arquivo
/boote atualize a configuração doGrub2:# rm -f /boot/el8 # grub2-mkconfig -o /boot/grub2/grub.cfg
Restaurar a entrada de inicialização original do Red Hat Enterprise Linux 7:
# new-kernel-pkg --update $(uname -r)
Após o retorno bem sucedido ao sistema, exclua a entrada de inicialização
boom:# boom list # boom delete boot-id
Recursos adicionais
-
A página do homem
boom.
Capítulo 13. Visão geral da NVMe sobre dispositivos de tecido
Non-volatile Memory Express (NVMe) é uma interface que permite que o utilitário de software hospedeiro se comunique com as unidades de estado sólido.
Use os seguintes tipos de transporte de tecido para configurar NVMe sobre dispositivos de tecido:
-
NVMesobre tecidos usandoRemote Direct Memory Access (RDMA). Para informações sobre como configurar o NVMe/RDMA, ver Seção 13.1, “NVMe sobre tecidos usando RDMA”. -
NVMesobre tecidos usandoFibre Channel (FC). Para informações sobre como configurarFC-NVMe, ver Seção 13.2, “NVMe sobre tecidos usando FC”.
Ao utilizar FC e RDMA, o acionamento em estado sólido não precisa ser local para seu sistema; ele pode ser configurado remotamente através de um controlador FC ou RDMA.
13.1. NVMe sobre tecidos usando RDMA
Em NVMe/RDMA setup, NVMe target e NVMe initiator está configurado.
Como administrador do sistema, complete as tarefas nas seções seguintes para distribuir o NVMe sobre tecidos usando RDMA (NVMe/RDMA):
13.1.1. Estabelecimento de um alvo NVMe/RDMA usando configfs
Use este procedimento para configurar um alvo NVMe/RDMA usando configfs.
Pré-requisitos
-
Verifique se você tem um dispositivo de bloqueio para atribuir ao subsistema
nvmet.
Procedimento
Criar o subsistema
nvmet-rdma:# modprobe nvmet-rdma # mkdir /sys/kernel/config/nvmet/subsystems/testnqn # cd /sys/kernel/config/nvmet/subsystems/testnqn
Substituir testnqn pelo nome do subsistema.
Permitir que qualquer anfitrião se conecte a este alvo:
# echo 1 > attr_allow_any_host
Configurar um
namespace:# mkdir namespaces/10 # cd namespaces/10
Substitua 10 pelo número do namespace
Estabeleça um caminho para o dispositivo
NVMe:#echo -n /dev/nvme0n1 > device_pathHabilite o espaço de nomes:
# echo 1 > habilitar
Criar um diretório com uma porta
NVMe:# mkdir /sys/kernel/config/nvmet/ports/1 # cd /sys/kernel/config/nvmet/ports/1
Mostrar o endereço IP de mlx5_ib0:
# ip addr show mlx5_ib0 8: mlx5_ib0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256 link/infiniband 00:00:06:2f:fe:80:00:00:00:00:00:00:e4:1d:2d:03:00:e7:0f:f6 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff inet 172.31.0.202/24 brd 172.31.0.255 scope global noprefixroute mlx5_ib0 valid_lft forever preferred_lft forever inet6 fe80::e61d:2d03:e7:ff6/64 scope link noprefixroute valid_lft forever preferred_lft foreverDefina o endereço de transporte para a meta:
# echo -n 172.31.0.202 > addr_traddr
Definir
RDMAcomo o tipo de transporte:# echo rdma > addr_trtype # echo 4420 > addr_trsvcid
Defina a família de endereços para o porto:
# echo ipv4 > addr_adrfam
Criar um elo suave:
# ln -s /sys/kernel/config/nvmet/subsystems/testnqn /sys/kernel/config/nvmet/ports/1/subsystems/testnqn
Etapas de verificação
Verifique se o alvo
NVMeestá escutando na porta determinada e pronto para pedidos de conexão:# dmesg | grep "enabling port" [ 1091.413648] nvmet_rdma: enabling port 1 (172.31.0.202:4420)
Recursos adicionais
-
A página do homem
nvme.
13.1.2. Estabelecendo o alvo NVMe/RDMA usando nvmetcli
Use o site nvmetcli para editar, visualizar e iniciar a meta NVMe. O nvmetcli fornece uma linha de comando e uma opção de shell interativa. Use este procedimento para configurar o alvo NVMe/RDMA por nvmetcli.
Pré-requisitos
-
Verifique se você tem um dispositivo de bloqueio para atribuir ao subsistema
nvmet. -
Executar as operações do
nvmetclicomo usuário root.
Procedimento
Instale o pacote
nvmetcli:# yum instalar nvmetcli
Baixe o arquivo
rdma.json# wget http://git.infradead.org/users/hch/nvmetcli.git/blob_plain/0a6b088db2dc2e5de11e6f23f1e890e4b54fee64:/rdma.json
-
Edite o arquivo
rdma.jsone altere o valortraddrpara 172.31.0.202. Configure o alvo carregando o arquivo de configuração do alvo NVMe:
# nvmetcli restore rdma.json
Se o nome do arquivo de configuração do alvo NVMe não for especificado, o nvmetcli usa o arquivo /etc/nvmet/config.json.
Etapas de verificação
Verifique se o alvo
NVMeestá escutando na porta determinada e pronto para pedidos de conexão:#dmesg | tail -1 [ 4797.132647] nvmet_rdma: enabling port 2 (172.31.0.202:4420)
(Opcional) Limpar o alvo atual da NVMe:
# nvmetcli clear
Recursos adicionais
-
A página do homem
nvmetcli. -
A página do homem
nvme.
13.1.3. Configuração de um cliente NVMe/RDMA
Use este procedimento para configurar um cliente NVMe/RDMA usando a ferramenta de linha de comando de gerenciamento NVMe (nvme-cli).
Procedimento
Instale a ferramenta
nvme-cli:# yum instalar nvme-cli
Carregue o módulo
nvme-rdmase não estiver carregado:# modprobe nvme-rdma
Descubra os subsistemas disponíveis na meta
NVMe:# nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000
Conectar com os subsistemas descobertos:
# nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420 # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1 #cat /sys/class/nvme/nvme0/transport rdma
Substituir testnqn pelo nome do sub-sistema
NVMe.Substituir 172.31.0.202 pelo endereço IP de destino.
Substituir 4420 pelo número da porta.
Etapas de verificação
Liste os dispositivos NVMe que estão atualmente conectados:
# lista nvme
(Opcional) Desconectar do alvo:
# nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s) # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
Recursos adicionais
-
A página do homem
nvme. - Nvme-cli Repositório Github
13.2. NVMe sobre tecidos usando FC
O NVMe sobre Fibre Channel (FC-NVMe) é totalmente suportado em modo iniciador quando usado com certos adaptadores Broadcom Emulex e Marvell Qlogic Fibre Channel. Como administrador do sistema, complete as tarefas nas seções seguintes para implantar o FC-NVMe:
13.2.1. Configuração do iniciador NVMe para adaptadores Broadcom
Use este procedimento para configurar o iniciador NVMe para Broadcom adaptadores cliente usando a ferramenta de linha de comando de gerenciamento NVMe (nvme-cli).
Procedimento
Instale a ferramenta
nvme-cli:# yum instalar nvme-cli
Isto cria o arquivo
hostnqnno diretório/etc/nvme/. O arquivohostnqnidentifica o hostNVMe.Para gerar um novo
hostnqn:#nvme gen-hostnqn
Encontre o
WWNNeWWPNdos portos locais e remotos e use a saída para encontrar o subsistemaNQN:# cat /sys/class/scsi_host/host*/nvme_info NVME Initiator Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000# nvme discover --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6
Substitua nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 pelo
traddr.Substitua nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 pelo
host-traddr.Conecte-se ao alvo NVMe usando o
nvme-cli:# nvme connect --transportar fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1
Substitua nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 pelo
traddr.Substitua nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 pelo
host-traddr.Substitua nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 pelo
subnqn.
Etapas de verificação
Liste os dispositivos NVMe que estão atualmente conectados:
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF
# lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
Recursos adicionais
-
A página do homem
nvme. - Nvme-cli Repositório Github
13.2.2. Configuração do iniciador NVMe para os adaptadores QLogic
Use este procedimento para configurar o iniciador NVMe para Qlogic adaptadores cliente usando a ferramenta de linha de comando de gerenciamento NVMe (nvme-cli).
Procedimento
Instale a ferramenta
nvme-cli:# yum instalar nvme-cli
Isto cria o arquivo
hostnqnno diretório/etc/nvme/. O arquivohostnqnidentifica o hostNVMe.Para gerar um novo
hostnqn:#nvme gen-hostnqn
Remova e recarregue o módulo
qla2xxx:# rmmod qla2xxx # modprobe qla2xxx
Encontre os sites
WWNNeWWPNdos portos locais e remotos:# dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050d
Utilizando estes valores
host-traddretraddr, encontre o subsistemaNQN:nvme discover --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6
Substitua nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 pelo
traddr.Substitua nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 pelo
host-traddr.Conecte-se ao alvo NVMe usando a ferramenta
nvme-cli:# nvme connect --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468
Substitua nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 pelo
traddr.Substitua nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 pelo
host-traddr.Substitua nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 pelo
subnqn.
Etapas de verificação
Liste os dispositivos NVMe que estão atualmente conectados:
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF # lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
Recursos adicionais
-
A página do homem
nvme. - Nvme-cli Repositório Github
Capítulo 14. Ajuste do programador de discos
O programador de discos é responsável por encomendar os pedidos de E/S submetidos a um dispositivo de armazenamento.
Você pode configurar o agendador de várias maneiras diferentes:
- Configure o agendador usando Tuned, conforme descrito em Seção 14.6, “Ajuste do programador de discos usando o Tuned”
-
Configure o agendador usando
udev, conforme descrito em Seção 14.7, “Ajuste do programador de discos usando as regras do udev” - Alterar temporariamente o programador em um sistema em funcionamento, como descrito em Seção 14.8, “Programação temporária de um programador para um disco específico”
14.1. Mudanças no agendador de discos no RHEL 8
No RHEL 8, os dispositivos de bloqueio suportam apenas a programação de múltiplas filas. Isto permite que o desempenho da camada de bloco seja bem dimensionado com acionamentos rápidos de estado sólido (SSDs) e sistemas multi-core.
Os programadores tradicionais de fila única, que estavam disponíveis na RHEL 7 e versões anteriores, foram removidos.
14.2. Programadores de disco disponíveis
Os seguintes programadores de discos multi-fila são suportados no RHEL 8:
none- Implemente um algoritmo de programação FIFO (first-in first-out). Ele funde os pedidos na camada de blocos genéricos através de um simples cache de última hora.
mq-deadlineTentativas de fornecer uma latência garantida para os pedidos a partir do momento em que os pedidos chegam ao agendador.
O agendador
mq-deadlineordena as solicitações de E/S em fila de espera em um lote de leitura ou gravação e depois as agende para execução em ordem crescente de endereçamento lógico em bloco (LBA). Por padrão, os lotes de leitura têm precedência sobre os lotes de escrita, porque as aplicações são mais propensas a bloquear nas operações de E/S lidas. Depois demq-deadlineprocessar um lote, ele verifica há quanto tempo as operações de escrita estão sem tempo de processamento e programa o próximo lote de leitura ou escrita, conforme apropriado.Este agendador é adequado para a maioria dos casos de uso, mas particularmente aqueles em que as operações de escrita são em sua maioria assíncronas.
bfqObjetiva sistemas desktop e tarefas interativas.
O programador
bfqgarante que uma única aplicação nunca esteja utilizando toda a largura de banda. Com efeito, o dispositivo de armazenamento é sempre tão responsivo como se estivesse ocioso. Em sua configuração padrão,bfqconcentra-se em fornecer a menor latência em vez de atingir a máxima produtividade.bfqé baseado no códigocfq. Ele não concede o disco a cada processo por uma fatia de tempo fixa, mas atribui um budget medido em número de setores ao processo.Este agendador é adequado enquanto copia arquivos grandes e o sistema não fica sem resposta neste caso.
kyberO programador se afina para atingir um objetivo de latência. Você pode configurar as latências alvo para solicitações de leitura e escrita síncrona.
Este programador é adequado para dispositivos rápidos, por exemplo NVMe, SSD, ou outros dispositivos de baixa latência.
14.3. Diferentes programadores de disco para diferentes casos de uso
Dependendo da tarefa que seu sistema executa, os seguintes programadores de disco são recomendados como uma linha de base antes de qualquer tarefa de análise e ajuste:
Tabela 14.1. Agendadores de discos para diferentes casos de uso
| Estojo de uso | Programador de discos |
|---|---|
| HDD tradicional com uma interface SCSI |
Use |
| SSD de alto desempenho ou um sistema vinculado à CPU com armazenamento rápido |
Use |
| Tarefas de mesa ou interativas |
Use |
| Convidado virtual |
Use |
14.4. O programador de discos padrão
Os dispositivos de bloqueio utilizam o programador de disco padrão, a menos que você especifique outro programador.
Para non-volatile Memory Express (NVMe) especificamente, o programador padrão é none e a Red Hat recomenda não alterar isto.
O kernel seleciona um programador de disco padrão com base no tipo de dispositivo. O programador selecionado automaticamente é tipicamente a configuração ideal. Se você precisar de um agendador diferente, a Red Hat recomenda usar as regras udev ou o aplicativo Tuned para configurá-lo. Combine os dispositivos selecionados e troque o agendador somente para esses dispositivos.
14.5. Determinando o programador de discos ativo
Este procedimento determina qual programador de disco está atualmente ativo em um determinado dispositivo de bloco.
Procedimento
Leia o conteúdo do
/sys/block/device/queue/schedulerarquivo:# cat /sys/block/device/queue/scheduler [mq-deadline] kyber bfq noneNo nome do arquivo, substituir device com o nome do dispositivo do bloco, por exemplo
sdc.O programador ativo está listado entre parênteses rectos (
[ ]).
14.6. Ajuste do programador de discos usando o Tuned
Este procedimento cria e permite um perfil Tuned que define um determinado programador de discos para os dispositivos de bloco selecionados. A configuração persiste através de reinicializações do sistema.
Nos seguintes comandos e configurações, substitua:
-
device com o nome do dispositivo do bloco, por exemplo
sdf -
selected-scheduler com o programador de discos que você deseja definir para o dispositivo, por exemplo
bfq
Pré-requisitos
O serviço
tunedestá instalado e habilitado.
Procedimento
Opcional: Selecione um perfil existente em Tuned no qual seu perfil será baseado. Para obter uma lista dos perfis disponíveis, consulte https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/monitoring_and_managing_system_status_and_performance/getting-started-with-tuned_monitoring-and-managing-system-status-and-performance#tuned-profiles-distributed-with-rhel_getting-started-with-tuned.
Para ver qual perfil está atualmente ativo, use:
$ tuned-adm ativo
Crie um novo diretório para manter seu perfil em Tuned:
# mkdir /etc/tuned/my-profileEncontre o identificador único do sistema do dispositivo de bloco selecionado:
$ udevadm info --query=property --name=/dev/device | grep -E '(WWN|SERIAL)' ID_WWN=0x5002538d00000000 ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 ID_SERIAL_SHORT=20120501030900000
NotaO comando neste exemplo retornará todos os valores identificados como um World Wide Name (WWN) ou número de série associado ao dispositivo de bloco especificado. Embora seja preferível usar um WWN, o WWN nem sempre está disponível para um determinado dispositivo e quaisquer valores retornados pelo comando do exemplo são aceitáveis para uso como o device system unique ID.
Criar o
/etc/tuned/my-profile/tuned.confarquivo de configuração. No arquivo, defina as seguintes opções:Opcional: Incluir um perfil existente:
[main] include=existing-profileDefina o programador de disco selecionado para o dispositivo que corresponda ao identificador da WWN:
[disk] devices_udev_regex=IDNAME=device system unique id elevator=selected-scheduler
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
ID_WWN). -
Substitua device system unique id com o valor do identificador escolhido (por exemplo,
0x5002538d00000000).
Para combinar vários dispositivos na opção
devices_udev_regex, coloque os identificadores entre parênteses e separe-os com barras verticais:-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
devices_udev_regex=(ID_WWN=0x5002538d00000000)|(ID_WWN=0x1234567800000000)
Habilite seu perfil:
# perfil afinado-adm my-profileVerificar se o perfil Sintonizado está ativo e aplicado:
$ tuned-adm active Current active profile: my-profile$ tuned-adm verify Verification succeeded, current system settings match the preset profile. See tuned log file ('/var/log/tuned/tuned.log') for details.
Recursos adicionais
- Para mais informações sobre como criar um perfil em Tuned, veja https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/monitoring_and_managing_system_status_and_performance/customizing-tuned-profiles_monitoring-and-managing-system-status-and-performance.
14.7. Ajuste do programador de discos usando as regras do udev
Este procedimento define um determinado programador de discos para dispositivos de bloco específicos usando as regras do udev. A configuração persiste através de reinicializações do sistema.
Nos seguintes comandos e configurações, substitua:
-
device com o nome do dispositivo do bloco, por exemplo
sdf -
selected-scheduler com o programador de discos que você deseja definir para o dispositivo, por exemplo
bfq
Procedimento
Encontre o identificador único do sistema do dispositivo de bloqueio:
$ udevadm info --name=/dev/device | grep -E '(WWN|SERIAL)' E: ID_WWN=0x5002538d00000000 E: ID_SERIAL=Generic-_SD_MMC_20120501030900000-0:0 E: ID_SERIAL_SHORT=20120501030900000
NotaO comando neste exemplo retornará todos os valores identificados como um World Wide Name (WWN) ou número de série associado ao dispositivo de bloco especificado. Embora seja preferível usar um WWN, o WWN nem sempre está disponível para um determinado dispositivo e quaisquer valores retornados pelo comando do exemplo são aceitáveis para uso como o device system unique ID.
Configurar a regra
udev. Crie o arquivo/etc/udev/rules.d/99-scheduler.rulescom o seguinte conteúdo:ACTION===="add|change==", SUBSYSTEM==="block==="block===="block===="block==", ENVIDNAME}=="device system unique id"\ATTR{queue/scheduler}=="selected-scheduler"
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
ID_WWN). -
Substitua device system unique id com o valor do identificador escolhido (por exemplo,
0x5002538d00000000).
-
Substitua IDNAME com o nome do identificador a ser utilizado (por exemplo,
Recarregar as regras
udev:# controle udevadm --regras de carga
Aplique a configuração do agendador:
# udevadm trigger --type=devices --action=change
Verificar o agendador ativo:
# gato /sys/bloco/device/queue/scheduler
14.8. Programação temporária de um programador para um disco específico
Este procedimento define um determinado programador de discos para dispositivos de blocos específicos. O ajuste não persiste através de reinicializações do sistema.
Procedimento
Escreva o nome do programador selecionado para o
/sys/block/device/queue/schedulerarquivo:# eco selected-scheduler > /sys/block/device/queue/scheduler
No nome do arquivo, substituir device com o nome do dispositivo do bloco, por exemplo
sdc.
Etapas de verificação
Verifique se o programador está ativo no dispositivo:
# gato /sys/bloco/device/queue/scheduler
Capítulo 15. Configuração de um sistema remoto diskless
As seções seguintes descrevem os procedimentos necessários para a implantação de sistemas remotos sem disco em um ambiente de rede. É útil implementar esta solução quando se necessita de vários clientes com configuração idêntica. Além disso, isso economizará o custo de discos rígidos para o número de clientes. Assumindo que o servidor tenha o sistema operacional Red Hat Enterprise Linux 8 instalado.
Figura 15.1. Diagrama de configuração do sistema sem disco remoto

Note que esse gateway pode ser configurado em um servidor separado.
15.1. Preparando um ambiente para o sistema remoto diskless
Este procedimento descreve a preparação do ambiente para o sistema remoto diskless.
A inicialização remota sem disco requer tanto um serviço tftp (fornecido por tftp-server) quanto um serviço DHCP (fornecido por dhcp). O serviço tftp é usado para recuperar a imagem do kernel e initrd pela rede através do carregador PXE.
Pré-requisitos
Instale os seguintes pacotes:
-
tftp-server -
xinetd -
dhcp-server -
syslinux
-
- Estabelecer a conexão de rede.
Procedimento
Instale o pacote
dracut-network:# yum instalar rede de dracut-network
Após a instalação do pacote
dracut-network, adicione a seguinte linha a/etc/dracut.conf:add_dracutmodules =="nfs
Alguns pacotes de RPM começaram a usar capacidades de arquivo (como setcap e getcap). Entretanto, o NFS não os suporta atualmente, portanto a tentativa de instalar ou atualizar quaisquer pacotes que utilizem capacidades de arquivo falhará.
Neste ponto, você tem o servidor pronto para continuar com a implementação remota do sistema diskless.
15.2. Configuração de um serviço tftp para clientes sem diskless
Este procedimento descreve como configurar um serviço tftp para um cliente sem diskless.
Pré-requisitos
- Instalar os pacotes necessários. Veja os pré-requisitos em Seção 15.1, “Preparando um ambiente para o sistema remoto diskless”.
Para Configurar tftp
Habilitar a inicialização do PXE através da rede:
#systemctl enable --now tftpO diretório raiz
tftp(chroot) está localizado em/var/lib/tftpboot. Cópia/usr/share/syslinux/pxelinux.0para/var/lib/tftpboot/:#cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/Criar um diretório
pxelinux.cfgdentro do diretório raiztftp:#mkdir -p /var/lib/tftpboot/pxelinux.cfg/-
Após configurar
tftppara clientes sem disco, configure DHCP, NFS e o sistema de arquivo exportado de acordo.
15.3. Configuração do servidor DHCP para clientes diskless
Este procedimento descreve como configurar o DHCP para um sistema sem disco.
Pré-requisitos
- Instalar os pacotes necessários. Veja os pré-requisitos em Seção 15.1, “Preparando um ambiente para o sistema remoto diskless”.
-
Configurar
tftp. Ver Seção 15.2, “Configuração de um serviço tftp para clientes sem diskless”.
Procedimento
Configure um servidor DHCP e habilite a inicialização PXE adicionando a seguinte configuração a
/etc/dhcp/dhcpd.conf:allow booting; allow bootp; subnet 192.168.205.0 netmask 255.255.255.0 { pool { range 192.168.205.10 192.168.205.25; } option subnet-mask 255.255.255.0; option routers 192.168.205.1; } class "pxeclients" { match if substring(option vendor-class-identifier, 0, 9) = "PXEClient"; next-server server-ip; filename "pxelinux.0"; }Esta configuração não inicializará sobre a UEFI. Para realizar a instalação para a UEFI, siga o procedimento desta documentação: Configuração de um servidor TFTP para clientes baseados em UEFI. Observe também que o
/etc/dhcp/dhcpd.confé um arquivo de exemplo.NotaQuando as máquinas virtuais
libvirtsão utilizadas como cliente diskless,libvirtfornece o serviço DHCP e o servidor DHCP autônomo não é utilizado. Nesta situação, a inicialização em rede deve ser habilitada com obootp file='filename'na configuração da redelibvirt,virsh net-edit.Habilite
dhcpd.servicedigitando o seguinte comando:# systemctl enable --now dhcpd.service
15.4. Configuração de um sistema de arquivo exportado para clientes sem disco
Este procedimento descreve como configurar um sistema de arquivo exportado para um cliente sem disco.
Pré-requisitos
- Instalar os pacotes necessários. Veja os pré-requisitos em Seção 15.1, “Preparando um ambiente para o sistema remoto diskless”.
-
Configurar
tftp. Ver Seção 15.2, “Configuração de um serviço tftp para clientes sem diskless”. - Configure o DHCP. Ver Seção 15.3, “Configuração do servidor DHCP para clientes diskless”.
Procedimento
-
Configure o servidor NFS para exportar o diretório raiz, adicionando-o a
/etc/exports. Para obter as instruções, consulte a configuração do servidor NFS. Para acomodar clientes completamente sem disco, o diretório raiz deve conter uma instalação completa do Red Hat Enterprise Linux. Você pode instalar um novo sistema base ou clonar uma instalação existente:
Para instalar o Red Hat Enterprise Linux no local de exportação, use o utilitário
yumcom a opção--installroot:#yum install @Base kernel dracut-network nfs-utils \ --installroot=exported-root-directory --releasever=/Para sincronizar com um sistema em execução, use o utilitário
rsync:#rsync -a -e ssh --exclude='/proc/' --exclude='/sys/' \ example.com:/exported-root-directory-
Substitua hostname.com pelo nome da máquina do sistema em funcionamento com o qual sincronizar através do utilitário
rsync. Substituir exported-root-directory pelo caminho para o sistema de arquivo exportado.
Note que para esta opção você deve ter um sistema em execução separado, que você clonará para o servidor pelo comando acima.
-
Substitua hostname.com pelo nome da máquina do sistema em funcionamento com o qual sincronizar através do utilitário
O sistema de arquivo a ser exportado ainda precisa ser configurado antes de poder ser utilizado por clientes sem disco. Para fazer isso, execute o seguinte procedimento:
Configurar o sistema de arquivo
Selecione o kernel que os clientes insatisfeitos devem usar (
vmlinuz-kernel-version) e copiá-lo para o diretório de inicializaçãotftp:#cp /exported-root-directory/boot/vmlinuz-kernel-version /var/lib/tftpboot/Crie o
initrd(isto é,initramfs-kernel-version.img) com o apoio da NFS:#dracut --add nfs initramfs-kernel-version.img kernel-versionAlterar as permissões de arquivo para
initrdpara 644 usando o seguinte comando:#chmod 644 /exported-root-directory/boot/initramfs-<kernel-version>.imgAtençãoSe você não alterar as permissões de arquivo do initrd, o carregador de inicialização
pxelinux.0falhará com um erro "file not found".Copie o resultado
initramfs-kernel-version.imgno diretório de inicializaçãotftp:#cp /exported-root-directory/boot/initramfs-kernel-version.img /var/lib/tftpboot/Edite a configuração padrão de inicialização para usar o
initrde o kernel no diretório/var/lib/tftpboot/. Esta configuração deve instruir a raiz do cliente diskless a montar o sistema de arquivos exportado (/exported-root-directory) como leitura-escrita. Adicione a seguinte configuração no arquivo/var/lib/tftpboot/pxelinux.cfg/default:default rhel8 label rhel8 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported-root-directory rw
Substitua
server-ipcom o endereço IP da máquina host na qual residem os serviçostftpe DHCP.Opcionalmente, você pode montar o sistema no formato read-only, usando a seguinte configuração no arquivo
/var/lib/tftpboot/pxelinux.cfg/default:default rhel8 label rhel8 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported-root-directory ro
- Reinicializar o servidor NFS.
A participação da NFS está agora pronta para exportar para clientes sem disco. Estes clientes podem iniciar através da rede via PXE.
15.5. Re-configurando um sistema remoto sem disco
Você precisa reconfigurar o sistema em alguns casos. Os passos abaixo mostram como alterar a senha de um usuário, como instalar software em um sistema e descrever como dividir o sistema em um /usr que está em modo somente leitura e um /var que está em modo leitura-escrita.
Pré-requisitos
-
a opção
no_root_squashestá habilitada no sistema de arquivo exportado.
Procedimento
Para alterar a senha do usuário, siga os passos abaixo:
Mude a linha de comando para /exported/root/directory:
# chroot /exported/root/directory /bin/bashMude a senha para o usuário desejado:
# senha <username>Substitua o <username> por um usuário real para o qual você deseja mudar a senha.
Sair da linha de comando:
# saída
Para instalar o software em um sistema remoto sem disco, use o seguinte comando:
# yum install <package> --installroot=/exported/root/directory --releasever=/ --config /etc/dnf/dnf.conf --setopt=reposdir=/etc/yum.repos.d/Substitua <package> pelo pacote real que você deseja instalar.
- Para dividir um sistema remoto sem disco em um /usr e um /var, é necessário configurar duas exportações separadas. Leia a documentação de configuração do servidor NFS para obter detalhes.
15.6. Os problemas mais comuns com o carregamento de um sistema remoto sem disco
A seção seguinte descreve os problemas durante o carregamento do sistema diskless remoto em um cliente diskless e mostra a solução possível para eles.
15.6.1. O cliente não obtém um endereço IP
Para solucionar esse problema:
Verifique se o serviço DHCP está habilitado no servidor.
Verifique se o site
dhcp.serviceestá funcionando:# status systemctl dhcpd.service
Se o
dhcp.serviceestiver inativo, você deve habilitá-lo e iniciá-lo:# systemctl enable dhcpd.service # systemctl start dhcpd.service
Reinicie o cliente sem disco.
- Se o problema persistir, verifique o arquivo de configuração do DHCP /etc/dhcp/dhcpd.conf em um servidor. Para maiores informações, veja Seção 15.3, “Configuração do servidor DHCP para clientes diskless”.
Verifique se as portas do Firewall estão abertas.
Verifique se o site
tftp.serviceestá listado em serviços ativos:# firewall-cmd --get-active-zones # firewall-cmd --info-zone=public
Se o
tftp.servicenão estiver listado nos serviços ativos, acrescente-o à lista:# firewall-cmd --add-service=tftp
Verifique se o site
nfs.serviceestá listado em serviços ativos:# firewall-cmd --get-active-zones # firewall-cmd --info-zone=public
Se o
nfs.servicenão estiver listado nos serviços ativos, acrescente-o à lista:# firewall-cmd --add-service=nfs
15.6.2. Os arquivos não estão disponíveis durante a inicialização de um sistema sem disco remoto
Para solucionar este problema:
- Verifique se o arquivo está no lugar. A localização em um servidor /var/lib/tftpboot/.
Se o arquivo estiver no local, verifique suas permissões:
# chmod 644 pxelinux.0
- Verifique se as portas do Firewall estão abertas.
15.6.3. O boot do sistema falhou após o carregamento do kernel/initrd
Para solucionar este problema:
Verifique se o serviço NFS está habilitado em um servidor.
Verifique se o site
nfs.serviceestá funcionando:# systemctl status nfs.service
Se o
nfs.serviceestiver inativo, você deve habilitá-lo e iniciá-lo:# systemctl enable nfs.service # systemctl start nfs.service
- Verifique se os parâmetros estão corretos em pxelinux.cfg. Para mais detalhes, ver Seção 15.4, “Configuração de um sistema de arquivo exportado para clientes sem disco”.
- Verifique se as portas do Firewall estão abertas.
Capítulo 16. Gerenciando RAID
Este capítulo descreve a Redundant Array of Independent Disks (RAID). O usuário pode usar RAID para armazenar dados em vários discos. Ele também ajuda a evitar a perda de dados se um drive falhar.
16.1. Matriz redundante de discos independentes (RAID)
A idéia básica por trás do RAID é combinar múltiplos dispositivos, tais como HDD, SSD ou NVMe, em uma matriz para atingir metas de desempenho ou redundância não alcançáveis com um drive grande e caro. Este conjunto de dispositivos aparece ao computador como uma única unidade de armazenamento lógico ou drive.
O RAID permite que as informações sejam espalhadas por vários dispositivos. RAID utiliza técnicas como disk striping (RAID Nível 0), disk mirroring (RAID Nível 1) e disk striping with parity (RAID Níveis 4, 5 e 6) para alcançar redundância, menor latência, maior largura de banda e máxima capacidade de recuperação de falhas no disco rígido.
RAID distribui dados através de cada dispositivo da matriz, dividindo-os em pedaços de tamanho consistente (geralmente 256K ou 512k, embora outros valores sejam aceitáveis). Cada pedaço é então escrito em um disco rígido na matriz RAID de acordo com o nível RAID empregado. Quando os dados são lidos, o processo é revertido, dando a ilusão de que os múltiplos dispositivos na matriz são na verdade um grande disco.
Os administradores de sistemas e outros que gerenciam grandes quantidades de dados se beneficiariam do uso da tecnologia RAID. As principais razões para implantar o RAID incluem:
- Aumenta a velocidade
- Aumenta a capacidade de armazenamento utilizando um único disco virtual
- Minimiza a perda de dados por falha de disco
- Layout RAID e conversão online de nível
16.2. Tipos RAID
Há três possíveis abordagens RAID: RAID por Firmware, RAID por Hardware e RAID por Software.
Firmware RAID
Firmware RAID, também conhecido como ATARAID, é um tipo de RAID de software onde os conjuntos RAID podem ser configurados usando um menu baseado em firmwares. O firmware utilizado por este tipo de RAID também se encaixa no BIOS, permitindo a inicialização a partir de seus conjuntos RAID. Diferentes fornecedores utilizam diferentes formatos de metadados no disco para marcar os membros do conjunto RAID. O RAID Matrix Intel é um bom exemplo de um sistema RAID de firmware.
Hardware RAID
A matriz baseada em hardware gerencia o subsistema RAID independentemente do host. Ele pode apresentar múltiplos dispositivos por matriz RAID para o host.
Os dispositivos RAID de hardware podem ser internos ou externos ao sistema. Os dispositivos internos geralmente consistem de uma placa controladora especializada que lida com as tarefas RAID de forma transparente para o sistema operacional. Os dispositivos externos comumente conectam-se ao sistema via SCSI, Fibre Channel, iSCSI, InfiniBand, ou outras redes de alta velocidade interconectam-se e apresentam volumes como unidades lógicas ao sistema.
As placas controladoras RAID funcionam como uma controladora SCSI para o sistema operacional, e lidam com todas as comunicações de acionamento reais. O usuário pluga os drives no controlador RAID (como um controlador SCSI normal) e depois os adiciona à configuração do controlador RAID. O sistema operacional não será capaz de distinguir a diferença.
Software RAID
O software RAID implementa os vários níveis de RAID no código do dispositivo de bloco do kernel. Ele oferece a solução mais barata possível, como placas controladoras de disco caras ou chassi hot-swap [1] não são necessários. O software RAID também funciona com qualquer armazenamento em bloco que seja suportado pelo kernel Linux, como SATA, SCSI e NVMe. Com as CPUs mais rápidas de hoje em dia, o RAID por software também geralmente supera o RAID por hardware, a menos que você use dispositivos de armazenamento de alta qualidade.
O kernel do Linux contém um driver multiple device (MD) que permite que a solução RAID seja completamente independente do hardware. O desempenho de um array baseado em software depende do desempenho e da carga da CPU do servidor.
Principais características da pilha RAID do software Linux:
- Projeto multifacetado
- Portabilidade de arrays entre máquinas Linux sem reconstrução
- Reconstrução da matriz de fundo utilizando recursos do sistema ocioso
- Suporte de acionamento hot-swappable
- Detecção automática da CPU para tirar proveito de certas características da CPU, tais como o suporte a streaming Single Instruction Multiple Data (SIMD)
- Correção automática de setores ruins em discos de uma matriz
- Verificações regulares de consistência dos dados RAID para garantir a saúde da matriz
- Monitoramento proativo de arrays com alertas de e-mail enviados para um endereço de e-mail designado sobre eventos importantes
Bitmaps escritos-intentados que aumentam drasticamente a velocidade dos eventos de sincronização, permitindo que o núcleo saiba exatamente quais partes de um disco precisam ser sincronizadas em vez de ter que sincronizar toda a matriz após uma falha do sistema
Note que resync é um processo para sincronizar os dados sobre os dispositivos no RAID existente para alcançar redundância
- Resync checkpointing para que se você reiniciar seu computador durante um resync, na inicialização o resync pegará de onde parou e não recomeçará tudo de novo
- A capacidade de alterar os parâmetros da matriz após a instalação, que é chamada reshaping. Por exemplo, você pode fazer crescer uma matriz RAID5 de 4 discos para uma matriz RAID5 de 5 discos quando você tiver um novo dispositivo a ser adicionado. Esta operação de crescimento é feita ao vivo e não requer que você reinstale no novo array
- A reformulação suporta a alteração do número de dispositivos, do algoritmo RAID ou do tamanho do tipo de matriz RAID, como RAID4, RAID5, RAID6 ou RAID10
- A aquisição suporta a conversão de nível RAID, como RAID0 para RAID6
16.3. Níveis RAID e suporte linear
RAID suporta várias configurações, incluindo níveis 0, 1, 4, 5, 6, 10, e linear. Estes tipos de RAID são definidos da seguinte forma:
- Nível 0
RAID nível 0, muitas vezes chamado striping, é uma técnica de mapeamento de dados com faixas orientadas para o desempenho. Isto significa que os dados que estão sendo escritos na matriz são divididos em faixas e escritos nos discos dos membros da matriz, permitindo um alto desempenho de E/S a baixo custo inerente, mas não oferece redundância.
Muitas implementações de nível 0 RAID apenas riscam os dados através dos dispositivos membros até o tamanho do menor dispositivo da matriz. Isto significa que se você tiver vários dispositivos com tamanhos ligeiramente diferentes, cada dispositivo é tratado como se fosse do mesmo tamanho que o menor drive. Portanto, a capacidade de armazenamento comum de uma matriz de nível 0 é igual à capacidade do menor disco membro em um RAID de Hardware ou a capacidade da menor partição membro em um RAID de Software multiplicada pelo número de discos ou partições da matriz.
- Nível 1
RAID nível 1, ou mirroring, fornece redundância ao escrever dados idênticos para cada disco membro da matriz, deixando uma cópia "espelhada" em cada disco. O espelhamento permanece popular devido a sua simplicidade e alto nível de disponibilidade de dados. O nível 1 opera com dois ou mais discos, e oferece muito boa confiabilidade dos dados e melhora o desempenho para aplicações de leitura intensiva, mas a um custo relativamente alto.
O nível RAID 1 tem um custo elevado porque você escreve as mesmas informações em todos os discos da matriz, fornece confiabilidade de dados, mas de uma maneira muito menos eficiente em termos de espaço do que os níveis RAID baseados na paridade, como o nível 5. Entretanto, esta ineficiência de espaço vem com um benefício de desempenho: os níveis RAID baseados em paridade consomem consideravelmente mais energia da CPU para gerar a paridade enquanto o nível RAID 1 simplesmente grava os mesmos dados mais de uma vez para os múltiplos membros RAID com muito pouca sobrecarga de CPU. Como tal, o nível RAID 1 pode superar os níveis RAID baseados na paridade em máquinas onde o RAID por software é empregado e os recursos da CPU na máquina são tributados consistentemente com operações que não sejam atividades RAID.
A capacidade de armazenamento da matriz de nível 1 é igual à capacidade do menor disco rígido espelhado em um RAID de hardware ou a menor partição espelhada em um RAID de software. A redundância de nível 1 é a maior possível entre todos os tipos de RAID, sendo que a matriz pode operar com apenas um único disco presente.
- Nível 4
O nível 4 utiliza a paridade concentrada em um único drive de disco para proteger os dados. A informação da paridade é calculada com base no conteúdo do resto dos discos membros da matriz. Esta informação pode então ser usada para reconstruir os dados quando um disco da matriz falhar. Os dados reconstruídos podem então ser usados para satisfazer as solicitações de E/S para o disco com falha antes de ser substituído e para repovoar o disco com falha após a sua substituição.
Como o disco de paridade dedicado representa um gargalo inerente em todas as transações de gravação no array RAID, o nível 4 raramente é usado sem tecnologias de acompanhamento, como o cache de gravação, ou em circunstâncias específicas onde o administrador do sistema está intencionalmente projetando o dispositivo RAID de software com este gargalo em mente (como um array que terá poucas ou nenhumas transações de gravação uma vez que o array estiver preenchido com dados). O RAID nível 4 é tão raramente usado que não está disponível como opção no Anaconda. Entretanto, ele pode ser criado manualmente pelo usuário, se realmente necessário.
A capacidade de armazenamento do Hardware RAID nível 4 é igual à capacidade da menor partição membro multiplicada pelo número de partições minus one. O desempenho de uma matriz RAID nível 4 é sempre assimétrico, o que significa que a leitura é melhor que a escrita. Isto porque as gravações consomem CPU extra e largura de banda da memória principal ao gerar paridade, e também consomem largura de banda extra do barramento ao escrever os dados reais em discos, porque você está escrevendo não apenas os dados, mas também a paridade. As leituras só precisam ler os dados e não a paridade, a menos que a matriz esteja em um estado degradado. Como resultado, as leituras geram menos tráfego para os discos e através dos ônibus do computador para a mesma quantidade de transferência de dados em condições normais de operação.
- Nível 5
Este é o tipo mais comum de RAID. Ao distribuir a paridade entre todas as unidades de disco de um array, o RAID nível 5 elimina o gargalo de gravação inerente ao nível 4. O único gargalo de desempenho é o próprio processo de cálculo da paridade. Com CPUs e software RAID modernos, isso normalmente não é um gargalo, uma vez que as CPUs modernas podem gerar paridade muito rapidamente. Entretanto, se você tiver um número suficientemente grande de dispositivos membros em uma matriz RAID5 de software, de tal forma que a velocidade de transferência de dados combinados entre todos os dispositivos seja suficientemente alta, então este gargalo pode começar a entrar em jogo.
Assim como no nível 4, o nível 5 tem um desempenho assimétrico e lê textos com um desempenho substancialmente superior ao desempenho. A capacidade de armazenamento do RAID nível 5 é calculada da mesma forma que com o nível 4.
- Nível 6
Este é um nível comum de RAID quando a redundância e preservação de dados, e não o desempenho, são as principais preocupações, mas onde a ineficiência de espaço do nível 1 não é aceitável. O nível 6 utiliza um esquema de paridade complexo para ser capaz de se recuperar da perda de quaisquer dois drives da matriz. Este esquema de paridade complexo cria uma carga de CPU significativamente maior nos dispositivos RAID de software e também impõe uma carga maior durante as transações de gravação. Como tal, o nível 6 é consideravelmente mais assimétrico no desempenho do que os níveis 4 e 5.
A capacidade total de uma matriz RAID nível 6 é calculada de forma semelhante ao RAID nível 5 e 4, exceto que você deve subtrair 2 dispositivos (ao invés de 1) da contagem do dispositivo para o espaço de armazenamento da paridade extra.
- Nível 10
Este nível RAID tenta combinar as vantagens de desempenho do nível 0 com a redundância do nível 1. Ele também ajuda a aliviar parte do espaço desperdiçado em matrizes de nível 1 com mais de 2 dispositivos. Com o nível 10, é possível, por exemplo, criar uma matriz de 3 drives configurada para armazenar apenas 2 cópias de cada pedaço de dados, o que então permite que o tamanho total da matriz seja 1,5 vezes o tamanho dos menores dispositivos em vez de apenas igualar o menor dispositivo (como seria com um array de 3 dispositivos, nível 1). Isto evita o uso do processo de CPU para calcular a paridade como com o RAID nível 6, mas é menos eficiente em termos de espaço.
A criação de RAID nível 10 não é suportada durante a instalação. É possível criar um manualmente após a instalação.
- RAID Linear
O RAID linear é um agrupamento de drives para criar um drive virtual maior.
Em RAID linear, os pedaços são alocados sequencialmente de um drive membro, indo para o próximo drive somente quando o primeiro é completamente preenchido. Este agrupamento não oferece nenhum benefício de desempenho, pois é improvável que qualquer operação de E/S seja dividida entre os drives membros. O RAID linear também não oferece redundância e diminui a confiabilidade. Se qualquer unidade membro falhar, não será possível utilizar todo o conjunto. A capacidade é o total de todos os discos dos membros.
16.4. Subsistemas RAID Linux
Os seguintes subsistemas compõem o RAID em Linux:
16.4.1. Drivers Controladores RAID de Hardware Linux
Os controladores RAID de hardware não possuem um subsistema RAID específico em Linux. Como utilizam chipsets RAID especiais, os controladores RAID de hardware vêm com seus próprios drivers; estes drivers permitem que o sistema detecte os conjuntos RAID como discos regulares.
16.4.2. mdraid
O subsistema mdraid foi projetado como uma solução RAID por software para Linux; ele também é a solução preferida para RAID por software sob Linux. Este subsistema usa seu próprio formato de metadados, geralmente referido como metadados nativos MD.
mdraid também suporta outros formatos de metadados, conhecidos como metadados externos. O Red Hat Enterprise Linux 8 usa mdraid com metadados externos para acessar os conjuntos ISW / IMSM (Intel firmware RAID) e SNIA DDF. mdraid conjuntos são configurados e controlados através do utilitário mdadm.
16.5. Criando software RAID
Siga as etapas deste procedimento para criar um dispositivo RAID (Redundant Arrays of Independent Disks). Os dispositivos RAID são construídos a partir de múltiplos dispositivos de armazenamento que são dispostos para proporcionar maior desempenho e, em algumas configurações, maior tolerância a falhas.
Um dispositivo RAID é criado em uma etapa e os discos são adicionados ou removidos conforme necessário. Você pode configurar uma partição RAID para cada disco físico em seu sistema, assim o número de discos disponíveis para o programa de instalação determina os níveis de dispositivo RAID disponíveis. Por exemplo, se seu sistema tiver dois discos rígidos, você não poderá criar um dispositivo RAID 10, pois ele requer um mínimo de três discos separados.
No IBM Z, o subsistema de armazenamento utiliza RAID de forma transparente. Não é necessário configurar RAID manualmente o software.
Pré-requisitos
- Você selecionou dois ou mais discos para instalação antes que as opções de configuração RAID fiquem visíveis. Pelo menos dois discos são necessários para criar um dispositivo RAID.
- Você criou um ponto de montagem. Ao configurar um ponto de montagem, você configura o dispositivo RAID.
-
Você selecionou o botão de rádio
Customna janelaInstallation Destination.
Procedimento
- A partir do painel esquerdo da janela Manual Partitioning, selecione a divisória desejada.
- Sob a seção Device(s), clique em . A caixa de diálogo Configure Mount Point abre-se.
- Selecione os discos que você deseja incluir no dispositivo RAID e clique em .
- Clique no menu suspenso Device Type e selecione RAID.
- Clique no menu suspenso File System e selecione o tipo de sistema de arquivo de sua preferência.
- Clique no menu suspenso RAID Level e selecione o nível de RAID de sua preferência.
- Clique em para salvar suas alterações.
- Clique em para aplicar as configurações e voltar para a janela Installation Summary.
Uma mensagem é exibida na parte inferior da janela se o nível RAID especificado exigir mais discos.
Para criar e configurar um volume RAID usando o papel do sistema de armazenamento, veja Seção 2.9, “Configuração de um volume RAID utilizando a função do sistema de armazenamento”
16.6. Criação de software RAID após a instalação
Este procedimento descreve como criar um software Redundant Array of Independent Disks (RAID) em um sistema existente usando o utilitário mdadm.
Pré-requisitos
-
O pacote
mdadminstalado. - Existem duas ou mais partições em seu sistema. Para instruções detalhadas, consulte Seção 3.3, “Criando uma divisória”.
Procedimento
Para criar RAID de dois dispositivos de bloco, por exemplo /dev/sda1 e /dev/sdc1, use o seguinte comando:
# mdadm --create /dev/md0 --level=<level_value> --raid-devices=2 /dev/sda1 /dev/sdc1Substituir <level_value> por uma opção de nível RAID. Para mais informações, consulte a página de manual
mdadm(8).Opcionalmente, para verificar o status do RAID, use o seguinte comando:
# mdadm --detail /dev/md0
Opcionalmente, para observar as informações detalhadas sobre cada dispositivo RAID, use o seguinte comando:
# mdadm --examine /dev/sda1 /dev/sdc1
Para criar um sistema de arquivo em um drive RAID, use o seguinte comando:
# mkfs -t <file-system-name> /dev/md0onde <file-system-name> é um sistema de arquivo específico que você escolheu para formatar a unidade. Para mais informações, consulte a página de manual
mkfs.Para criar um ponto de montagem para o drive RAID e montá-lo, use os seguintes comandos:
# mkdir /mnt/raid1 # mount /dev/md0 /mnt/raid1
Depois de terminar as etapas acima, o RAID está pronto para ser usado.
16.7. Configuração de um volume RAID utilizando a função do sistema de armazenamento
Com o Sistema Função storage, você pode configurar um volume RAID na RHEL usando a Plataforma de Automação Possível Red Hat Ansible Automation. Nesta seção, você aprenderá como configurar um livro de jogo possível com os parâmetros disponíveis para configurar um volume RAID de acordo com suas necessidades.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja implantar a solução
storage.-
Você tem o pacote
rhel-system-rolesinstalado no sistema a partir do qual você deseja executar o playbook. -
Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja implantar um volume RAID usando o sistema
storageFunção do sistema.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present roles: - name: rhel-system-roles.storageAtençãoOs nomes dos dispositivos podem mudar em certas circunstâncias; por exemplo, quando você adiciona um novo disco a um sistema. Portanto, para evitar a perda de dados, não recomendamos o uso de nomes de disco específicos no livro de reprodução.
Opcional. Verificar a sintaxe do playbook.
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
-
Para detalhes sobre os parâmetros utilizados na função do sistema de armazenamento, consulte o arquivo
/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
16.8. Reconfigurando o RAID
A seção abaixo descreve como modificar um RAID existente. Para fazer isso, escolha um dos métodos:
- Mudança de atributos RAID (também conhecido como RAID reshape).
- Conversão do nível RAID (também conhecido como RAID takeover).
16.8.1. Redefinindo o RAID
Este capítulo abaixo descreve como reformular o RAID. Você pode escolher um dos métodos de redimensionamento RAID:
- Ampliação (ampliação) RAID.
- RAID encolhido.
16.8.1.1. Redimensionamento RAID (extensão)
Este procedimento descreve como ampliar o RAID. Assumindo que /dev/md0 é RAID, você quer ampliar.
Pré-requisitos
- Espaço suficiente em disco.
-
O pacote
partedestá instalado.
Procedimento
- Ampliar as partições RAID. Para fazer isso, siga as instruções em Redimensionamento da documentação de uma partição.
Para estender o RAID ao máximo da capacidade da partição, use este comando:
# mdadm --grow --size=max /dev/md0
Note que para determinar um tamanho específico, é necessário escrever o parâmetro --size em kB (por exemplo --size=524228).
- Aumentar o tamanho do sistema de arquivo. Para mais informações, consulte a documentação do Sistema de Arquivos de Gerenciamento.
16.8.1.2. Redimensionamento RAID (encolhimento)
Este procedimento descreve como reduzir o RAID. Assumindo que /dev/md0 é o RAID que você quer que encolha para 512 MB.
Pré-requisitos
-
O pacote
partedestá instalado.
Procedimento
Encolher o sistema de arquivo. Para isso, verifique a documentação do sistema de gerenciamento de arquivos.
ImportanteO sistema de arquivos XFS não suporta encolhimento.
Para diminuir o RAID para o tamanho de 512 MB, use este comando:
# mdadm --grow --size=524228 /dev/md0
Nota, você deve escrever o parâmetro --size em kB.
- Encolha a divisória no tamanho que você precisa. Para fazer isso, siga as instruções na documentação do Redimensionamento de uma partição.
16.8.2. Aquisição do RAID
Este capítulo descreve as conversões suportadas em RAID e contém procedimentos para realizar essas conversões.
16.8.2.1. Conversões RAID suportadas
É possível converter de um nível RAID para outro. Esta seção fornece uma tabela que lista as conversões RAID suportadas.
| RAID0 | RAID1 | RAID4 | RAID5 | RAID6 | RAID10 | |
|---|---|---|---|---|---|---|
| RAID0 | ઝ | ઝ | ઙ | ઙ | ઝ | ઙ |
| RAID1 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID4 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID5 | ઙ | ઙ | ઙ | ઝ | ઙ | ઙ |
| RAID6 | ઝ | ઝ | ઝ | ઙ | ઝ | ઝ |
| RAID10 | ઙ | ઝ | ઝ | ઝ | ઝ | ઝ |
Por exemplo, você pode converter RAID nível 0 para RAID nível 4, RAID nível 5 e RAID nível 10
Recursos adicionais
-
Para mais informações sobre conversão de nível RAID, leia a página de manual
mdadm.
16.8.2.2. Conversão do nível RAID
Este procedimento descreve como converter RAID para um nível diferente de RAID. Assumindo, você quer converter RAID /dev/md0 nível 0 para RAID nível 5 e adicionar mais um disco /dev/sdd à matriz.
Pré-requisitos
- Discos suficientes para conversão.
-
O pacote
mdadmestá instalado. - Assegurar que a conversão pretendida seja apoiada. Para verificar se este é o caso, veja a tabela em Seção 16.8.2.1, “Conversões RAID suportadas”.
Procedimento
Para converter o RAID
/dev/md0para o nível RAID 5, use o seguinte comando:# mdadm --grow -- nível=5 -n 3 /dev/md0 --force
Para adicionar um novo disco à matriz, use o seguinte comando:
# mdadm -gerir /dev/md0 --add /dev/sdd
Para verificar novos detalhes da matriz convertida, use o seguinte comando:
# mdadm --detail /dev/md0
Recursos adicionais
-
Para mais informações sobre conversão de nível RAID, leia a página de manual
mdadm.
16.9. Conversão de um disco raiz para RAID1 após a instalação
Esta seção descreve como converter um disco raiz não-RAID para um espelho RAID1 após a instalação do Red Hat Enterprise Linux 8.
Na arquitetura PowerPC (PPC), tome as seguintes medidas adicionais:
Pré-requisitos
- As instruções no seguinte artigo da Red Hat Knowledgebase estão completas: Como posso converter meu disco raiz para RAID1 após a instalação do Red Hat Enterprise Linux 7?
Procedimento
Copie o conteúdo da partição de inicialização da Plataforma de Referência PowerPC (PReP) de
/dev/sda1para/dev/sdb1:#dd if=/dev/sda1 of=/dev/sdb1Atualizar a bandeira de preparação e de inicialização na primeira partição em ambos os discos:
$parted /dev/sda set 1 prep on$parted /dev/sda set 1 boot on$parted /dev/sdb set 1 prep on$parted /dev/sdb set 1 boot on
A execução do comando grub2-install /dev/sda não funciona em uma máquina PowerPC e retorna um erro, mas o sistema inicia como esperado.
16.10. Criação de dispositivos RAID avançados
Em alguns casos, você pode desejar instalar o sistema operacional em uma matriz que não pode ser criada após a conclusão da instalação. Normalmente, isto significa configurar o /boot ou matrizes de sistema de arquivos raiz em um dispositivo RAID complexo; em tais casos, você pode precisar usar opções de matrizes que não são suportadas por Anaconda instalador. Para contornar isto, execute o seguinte procedimento:
Procedimento
- Inserir o disco de instalação.
-
Durante o boot inicial, selecione
Rescue Modeao invés deInstallouUpgrade. Quando o sistema inicializa totalmente em Rescue mode, o usuário receberá um terminal de linha de comando. -
A partir deste terminal, use
partedpara criar partições RAID nos discos rígidos de destino. Em seguida, usemdadmpara criar manualmente matrizes de raid a partir dessas partições usando toda e qualquer configuração e opções disponíveis. Para mais informações sobre como fazer isso, consulteman partedeman mdadm. - Uma vez criadas as matrizes, você pode opcionalmente criar sistemas de arquivo também nas matrizes.
-
Reinicie o computador e selecione
InstallouUpgradepara instalar normalmente. Como Anaconda o instalador procura os discos no sistema, ele encontrará os dispositivos RAID pré-existentes. -
Quando perguntado sobre como usar os discos no sistema, selecione
Custom Layoute clique em . Na listagem de dispositivos, serão listados os dispositivos RAID MD pré-existentes. - Selecione um dispositivo RAID, clique em e configure seu ponto de montagem e (opcionalmente) o tipo de sistema de arquivo que ele deve usar (se você não criou um antes), então clique em Anaconda realizará a instalação neste dispositivo RAID pré-existente, preservando as opções personalizadas que você selecionou quando o criou em Rescue Mode.
O limitado Rescue Mode do instalador não inclui as páginas man. Tanto o man mdadm quanto o man md contêm informações úteis para a criação de matrizes RAID personalizadas, e podem ser necessárias durante todo o processo de trabalho. Como tal, pode ser útil ter acesso a uma máquina com estas páginas man presentes, ou imprimi-las antes de inicializar em Rescue Mode e criar suas matrizes personalizadas.
16.11. Monitoramento RAID
Este módulo descreve como configurar a opção de monitoramento RAID com a ferramenta mdadm.
Pré-requisitos
-
O pacote
mdadmestá instalado - O serviço de correio é criado.
Procedimento
Para criar um arquivo de configuração para monitoramento da matriz, você deve digitalizar os detalhes e encaminhar o resultado para o arquivo
/etc/mdadm.conf. Para fazer isso, use o seguinte comando:# mdadm --detail --scan >> /etc/mdadm.conf
Note-se que ARRAY e MAILADDR são variáveis obrigatórias.
-
Abra o arquivo de configuração
/etc/mdadm.confcom um editor de texto de sua escolha. Adicione a variável MAILADDR com o endereço de correio para a notificação. Por exemplo, adicione uma nova linha:
MAILADDR <example@example.com>
onde example@example.com é um endereço de e-mail para o qual você deseja receber os alertas do monitoramento da matriz.
-
Salve as mudanças no arquivo
/etc/mdadm.confe feche-o.
Após completar as etapas acima, o sistema de monitoramento enviará os alertas para o endereço de e-mail.
Recursos adicionais
-
Para mais informações, leia a página de manual
mdadm.conf 5.
16.12. Mantendo o RAID
Esta seção fornece vários procedimentos para a manutenção do RAID.
16.12.1. Substituição de um disco defeituoso em um RAID
Este procedimento descreve como substituir o disco defeituoso em uma matriz redundante de discos independentes (RAID). Assumindo, você tem /dev/md0 RAID nível 10. Neste cenário, o disco /dev/sdg está defeituoso e você precisa substituí-lo por um novo disco /dev/sdh.
Pré-requisitos
- Disco de reposição adicional.
-
O pacote
mdadmestá instalado. - Uma notificação sobre um disco defeituoso em uma matriz. Para configurar o monitoramento da matriz, ver Seção 16.11, “Monitoramento RAID”.
Procedimento
Certifique-se de qual disco está falhando. Para fazer isso, digite o seguinte comando:
# journalctl -k -f
Você encontrará uma mensagem mostrando-lhe qual disco falhou:
md/raid:md0: Disk failure on sdg, disabling device. md/raid:md0: Operation continuing on 5 devices.
-
Pressione
Ctrl Cem seu teclado para sair do programajournalctl. Adicione um novo disco à matriz. Para fazer isso, digite o seguinte comando:
# mdadm -gerir /dev/md0 --add /dev/sdh
Marcar o disco defeituoso como defeituoso. Para fazer isso, digite o seguinte comando:
# mdadm - gerenciar /dev/md0 --fail /dev/sdg
Verifique se o disco defeituoso foi mascarado corretamente, usando o seguinte comando:
# mdadm --detail /dev/md0
Ao final do último comando de saída você verá informações sobre discos RAID semelhantes a este onde o disco /dev/sdg tem um status faulty:
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh 5 8 96 - faulty /dev/sdgFinalmente, remova o disco defeituoso da matriz. Para fazer isso, digite o seguinte comando:
# mdadm --gerir /dev/md0 --remove /dev/sdg
Verifique os detalhes do RAID usando o seguinte comando:
# mdadm --detail /dev/md0
Ao final da última saída do comando você verá informações sobre discos RAID semelhantes a esta:
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh
Após completar as etapas acima, você terá o RAID /dev/md0 com um novo disco /dev/sdh.
16.12.2. Substituição de um disco quebrado na matriz
Este procedimento descreve como substituir o disco quebrado em uma matriz redundante de discos independentes (RAID). Assumindo, você tem /dev/md0 RAID nível 6. Neste cenário, o disco /dev/sdb tem problema de hardware e não poderia mais ser usado. Você precisa substituí-lo pelo novo disco /dev/sdi.
Pré-requisitos
- Novo disco para substituição.
-
O pacote
mdadmestá instalado.
Procedimento
Verifique a mensagem de registro usando o seguinte comando:
# journalctl -k -f
Você encontrará uma mensagem mostrando-lhe qual disco falhou:
md/raid:md0: Disk failure on sdb, disabling device. md/raid:md0: Operation continuing on 5 devices.
-
Pressione
Ctrl Cem seu teclado para sair do programajournalctl. Adicione o novo disco à matriz como um disco de reposição. Para fazer isso, digite o seguinte comando:
# mdadm -gerir /dev/md0 --add /dev/sdi
Marcar o disco quebrado como faulty. Para fazer isso, digite o seguinte comando:
# mdadm - gerenciar /dev/md0 --fail /dev/sdb
Remova o disco defeituoso da matriz. Para fazer isso, digite o seguinte comando:
# mdadm --gerenciar /dev/md0 --remove /dev/sdb
Verifique o status da matriz usando o seguinte comando:
# mdadm --detail /dev/md0
Ao final da última saída do comando você verá informações sobre discos RAID semelhantes a esta:
Number Major Minor RaidDevice State 7 8 128 0 active sync /dev/sdi 1 8 32 1 active sync /dev/sdc 2 8 48 2 active sync /dev/sdd 3 8 64 3 active sync /dev/sde 4 8 80 4 active sync /dev/sdf 6 8 112 5 active sync /dev/sdh
Após completar as etapas acima, você terá o RAID /dev/md0 com um novo disco /dev/sdi.
16.12.3. Ressincronização de discos RAID
Este procedimento descreve como ressincronizar os discos em uma matriz RAID. Assumindo, você tem /dev/md0 RAID.
Pré-requisitos
-
O pacote
mdadmestá instalado.
Procedimento
Para verificar o comportamento dos discos falhados, digite o seguinte comando:
# echo check > /sys/block/md0/md/sync_action
Essa ação verificará a matriz e escreverá o resultado no arquivo
/sys/block/md0/md/sync_action.-
Abra o arquivo
/sys/block/md0/md/sync_actioncom o editor de texto de sua escolha e veja se há alguma mensagem sobre falhas de sincronização de disco. Para ressincronizar os discos da matriz, digite o seguinte comando:
# reparação echo > /sys/block/md0/md/sync_action
Esta ação irá ressincronizar os discos da matriz e escrever o resultado no arquivo
/sys/block/md0/md/sync_action.Para ver o progresso da sincronização, digite o seguinte comando:
# cat /proc/mdstat
Capítulo 17. Criptografando dispositivos de blocos usando LUKS
A criptografia de disco protege os dados em um dispositivo de bloco ao criptografá-los. Para acessar o conteúdo descriptografado do dispositivo, o usuário deve fornecer uma frase-chave ou senha como autenticação. Isto é particularmente importante quando se trata de computadores móveis e mídias removíveis: ajuda a proteger o conteúdo do dispositivo mesmo que ele tenha sido fisicamente removido do sistema. O formato LUKS é uma implementação padrão de criptografia de dispositivo de bloqueio no RHEL.
17.1. Criptografia de disco LUKS
O Linux Unified Key Setup-on-disk-format (LUKS) permite criptografar dispositivos de bloco e fornece um conjunto de ferramentas que simplifica o gerenciamento dos dispositivos criptografados. O LUKS permite que múltiplas chaves de usuário descriptografem uma chave mestra, que é usada para a criptografia em massa da partição.
A RHEL utiliza o LUKS para realizar a criptografia do dispositivo de bloqueio. Por padrão, a opção para criptografar o dispositivo de bloco é desmarcada durante a instalação. Se você selecionar a opção para criptografar seu disco, o sistema solicita uma senha toda vez que você inicia o computador. Esta frase-chave “desbloqueia” a chave de criptografia em bloco que descriptografa sua partição. Se você escolher modificar a tabela de partições padrão, você pode escolher quais partições deseja criptografar. Isto é definido nas configurações da tabela de partição.
O que a LUKS faz
- A LUKS criptografa dispositivos de bloco inteiro e, portanto, é bem adequada para proteger o conteúdo de dispositivos móveis, tais como mídias de armazenamento removíveis ou unidades de disco de laptop.
- O conteúdo subjacente do dispositivo de bloco criptografado é arbitrário, o que o torna útil para a criptografia de dispositivos de troca. Isto também pode ser útil com certos bancos de dados que utilizam dispositivos de bloco especialmente formatados para armazenamento de dados.
- A LUKS utiliza o subsistema de mapeamento do núcleo do dispositivo existente.
- A LUKS fornece um reforço de senha que protege contra ataques de dicionários.
- Os dispositivos LUKS contêm vários slots de chave, permitindo aos usuários adicionar chaves de backup ou frases-passe.
O que a LUKS faz not
- Soluções de criptografia de disco como o LUKS protegem os dados somente quando seu sistema está desligado. Assim que o sistema estiver ligado e a LUKS descriptografar o disco, os arquivos nesse disco estarão disponíveis para qualquer pessoa que normalmente teria acesso a eles.
- A LUKS não é adequada para cenários que exigem que muitos usuários tenham chaves de acesso distintas para o mesmo dispositivo. O formato LUKS1 fornece oito slots de chave, LUKS2 até 32 slots de chave.
- O LUKS não é adequado para aplicações que exigem criptografia em nível de arquivo.
Cifras
A cifra padrão utilizada para LUKS é aes-xts-plain64. O tamanho padrão da chave para o LUKS é de 512 bits. O tamanho padrão da chave para LUKS com Anaconda (modo XTS) é de 512 bits. As cifras que estão disponíveis são:
- AES - Norma Avançada de Criptografia - FIPS PUB 197
- Dois peixes (uma cifra de bloco de 128 bits)
- Serpente
Recursos adicionais
17.2. Versões LUKS em RHEL 8
No RHEL 8, o formato padrão para criptografia LUKS é LUKS2. O formato antigo LUKS1 permanece totalmente suportado e é fornecido como um formato compatível com os lançamentos anteriores da RHEL.
O formato LUKS2 é projetado para permitir futuras atualizações de várias partes sem a necessidade de modificar estruturas binárias. O LUKS2 usa internamente o formato de texto JSON para metadados, fornece redundância de metadados, detecta corrupção de metadados e permite reparos automáticos a partir de uma cópia de metadados.
Não use LUKS2 em sistemas que precisam ser compatíveis com sistemas legados que suportam apenas LUKS1. Note que a RHEL 7 suporta o formato LUKS2 desde a versão 7.6.
LUKS2 e LUKS1 usam comandos diferentes para criptografar o disco. O uso do comando errado para uma versão LUKS pode causar perda de dados.
| Versão LUKS | Comando de encriptação |
|---|---|
| LUKS2 |
|
| LUKS1 |
|
Reencriptação on-line
O formato LUKS2 suporta a re-encriptação de dispositivos criptografados enquanto os dispositivos estão em uso. Por exemplo, não é necessário desmontar o sistema de arquivo no dispositivo para realizar as seguintes tarefas:
- Alterar a chave de volume
- Alterar o algoritmo de criptografia
Ao criptografar um dispositivo não criptografado, você ainda deve desmontar o sistema de arquivo. Você pode montar novamente o sistema de arquivo após uma breve inicialização da criptografia.
O formato LUKS1 não suporta a reencriptação on-line.
Conversão
O formato LUKS2 é inspirado no LUKS1. Em certas situações, você pode converter LUKS1 para LUKS2. A conversão não é possível especificamente nos seguintes cenários:
-
Um dispositivo LUKS1 é marcado como sendo usado por uma solução de decriptação baseada em políticas (PBD - Clevis). A ferramenta
cryptsetupse recusa a converter o dispositivo quando alguns metadadosluksmetasão detectados. - Um dispositivo está ativo. O dispositivo deve estar no estado inativo antes que qualquer conversão seja possível.
17.3. Opções para proteção de dados durante a re-encriptação LUKS2
LUKS2 fornece várias opções que priorizam o desempenho ou a proteção de dados durante o processo de reencriptação:
checksumEste é o modo padrão. Ele equilibra a proteção de dados e o desempenho.
Este modo armazena checksums individuais dos setores na área de reencriptação, para que o processo de recuperação possa detectar quais setores LUKS2 já foram reencriptados. Este modo exige que a gravação do setor do dispositivo de bloco seja atômica.
journal- Esse é o modo mais seguro, mas também o mais lento. Esta modalidade registra a área de reencriptação na área binária, portanto LUKS2 escreve os dados duas vezes.
none-
Este modo prioriza o desempenho e não oferece proteção de dados. Ele protege os dados somente contra o término seguro do processo, como o sinal
SIGTERMou a pressão do usuário Ctrl+C. Qualquer falha inesperada do sistema ou falha de aplicação pode resultar em corrupção de dados.
Você pode selecionar o modo usando a opção --resilience de cryptsetup.
Se um processo de reencriptação LUKS2 termina inesperadamente pela força, a LUKS2 pode realizar a recuperação de uma das seguintes formas:
-
Automaticamente, durante a próxima ação aberta do dispositivo LUKS2. Esta ação é acionada ou pelo comando
cryptsetup openou anexando o dispositivo comsystemd-cryptsetup. -
Manualmente, usando o comando
cryptsetup repairno dispositivo LUKS2.
17.4. Criptografia de dados existentes em um dispositivo de bloco usando LUKS2
Este procedimento criptografa os dados existentes em um dispositivo ainda não criptografado usando o formato LUKS2. Um novo cabeçalho LUKS é armazenado na cabeça do dispositivo.
Pré-requisitos
- O dispositivo de bloco contém um sistema de arquivo.
Você fez backup de seus dados.
AtençãoVocê pode perder seus dados durante o processo de criptografia: devido a um hardware, kernel, ou falha humana. Certifique-se de que você tenha um backup confiável antes de começar a criptografar os dados.
Procedimento
Desmonte todos os sistemas de arquivo no dispositivo que você planeja criptografar. Por exemplo:
# umount /dev/sdb1Criar espaço livre para o armazenamento de um cabeçalho LUKS. Escolha uma das seguintes opções que se adapte ao seu cenário:
No caso de encriptar um volume lógico, você pode estender o volume lógico sem redimensionar o sistema de arquivo. Por exemplo, o volume lógico pode ser aumentado:
# lvextend -L 32M vg00/lv00
-
Ampliar a divisória utilizando ferramentas de gerenciamento de divisórias, tais como
parted. -
Encolha o sistema de arquivo no dispositivo. Você pode usar o utilitário
resize2fspara os sistemas de arquivo ext2, ext3, ou ext4. Note que você não pode encolher o sistema de arquivo XFS.
Inicializar a criptografia. Por exemplo:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --reduce-device-size 32M \ /dev/sdb1 sdb1_encryptedO comando lhe pede uma senha e inicia o processo de criptografia.
Monte o dispositivo:
# montar /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Iniciar a criptografia online:
# criptasetup recriar -resumir apenas /dev/sdb1
Recursos adicionais
-
Para mais detalhes, consulte as páginas de manual
cryptsetup(8),lvextend(8),resize2fs(8), eparted(8).
17.5. Encriptação de dados existentes em um dispositivo de bloco usando LUKS2 com um cabeçalho destacado
Este procedimento codifica os dados existentes em um dispositivo de bloco sem criar espaço livre para o armazenamento de um cabeçalho LUKS. O cabeçalho é armazenado em um local separado, o que também serve como uma camada adicional de segurança. O procedimento utiliza o formato de criptografia LUKS2.
Pré-requisitos
- O dispositivo de bloco contém um sistema de arquivo.
Você fez backup de seus dados.
AtençãoVocê pode perder seus dados durante o processo de criptografia: devido a um hardware, kernel, ou falha humana. Certifique-se de que você tenha um backup confiável antes de começar a criptografar os dados.
Procedimento
Desmontar todos os sistemas de arquivo no dispositivo. Por exemplo:
# umount /dev/sdb1Inicializar a criptografia:
# cryptsetup reencrypt \ --encrypt \ --init-only \ --header /path/to/header \ /dev/sdb1 sdb1_encryptedSubstituir /path/to/header por um caminho para o arquivo com um cabeçalho LUKS destacado. O cabeçalho LUKS destacado tem que ser acessível para que o dispositivo criptografado possa ser desbloqueado posteriormente.
O comando lhe pede uma senha e inicia o processo de criptografia.
Monte o dispositivo:
# montar /dev/mapper/sdb1_encrypted /mnt/sdb1_encrypted
Iniciar a criptografia online:
# cryptsetup reencrypt --resume-only --header /path/to/header /dev/sdb1
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
cryptsetup(8).
17.6. Criptografia de um dispositivo de bloco em branco usando LUKS2
Este procedimento fornece informações sobre a criptografia de um dispositivo de bloco em branco usando o formato LUKS2.
Pré-requisitos
- Um dispositivo de bloco em branco.
Procedimento
Configurar uma partição como uma partição LUKS criptografada:
# cryptsetup luksFormat /dev/sdb1Abra uma partição LUKS criptografada:
# Criptsetup aberto /dev/sdb1 sdb1_encryptedIsto desbloqueia a partição e a mapeia para um novo dispositivo usando o mapeador de dispositivos. Isto alerta o kernel que
deviceé um dispositivo criptografado e deve ser endereçado através do LUKS usando o/dev/mapper/device_mapped_namepara não sobregravar os dados criptografados.Para escrever dados criptografados na partição, eles devem ser acessados através do nome mapeado do dispositivo. Para isso, é necessário criar um sistema de arquivos. Por exemplo, um sistema de arquivos:
# mkfs -t ext4 /dev/mapper/sdb1_encryptedMonte o dispositivo:
# montar /dev/mapper/sdb1_encrypted
Recursos adicionais
-
Para mais detalhes, consulte a página de manual
cryptsetup(8).
17.7. Criação de um volume codificado LUKS usando a função de armazenamento
Você pode usar o papel storage para criar e configurar um volume criptografado com LUKS, executando um livro de brincadeiras Ansible playbook.
Pré-requisitos
Você tem o Red Hat Ansible Engine instalado no sistema a partir do qual você deseja executar o playbook.
NotaVocê não precisa ter a Plataforma de Automação Possível da Red Hat instalada nos sistemas nos quais você deseja criar o volume.
-
Você tem o pacote
rhel-system-rolesinstalado no controlador Ansible. - Você tem um arquivo de inventário detalhando os sistemas nos quais você deseja implantar um volume codificado LUKS usando a função de sistema de armazenamento.
Procedimento
Criar um novo
playbook.ymlarquivo com o seguinte conteúdo:- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storageOpcional. Verificar a sintaxe do playbook:
# ansible-playbook --syntax-check playbook.ymlExecute o playbook em seu arquivo de inventário:
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
Recursos adicionais
- Para mais informações sobre a LUKS, veja 17. Criptografando dispositivos de blocos usando LUKS...
-
Para detalhes sobre os parâmetros utilizados na função do sistema
storage, consulte o arquivo/usr/share/ansible/roles/rhel-system-roles.storage/README.md.
Capítulo 18. Gerenciamento de dispositivos de fita
Um dispositivo de fita é uma fita magnética onde os dados são armazenados e acessados sequencialmente. Os dados são gravados neste dispositivo de fita com a ajuda de um drive de fita. Não há necessidade de criar um sistema de arquivo para armazenar dados em um dispositivo de fita magnética. Os drives de fita podem ser conectados a um computador host com várias interfaces como, SCSI, FC, USB, SATA e outras interfaces.
A seguir são apresentados os diferentes tipos de dispositivos de fita:
-
/dev/sté um dispositivo de rebobinagem de fita adesiva. -
/dev/nsté um dispositivo de fita não rebobinável. Use dispositivos que não rebobinam para backups diários.
Vantagens dos dispositivos de fita adesiva:
- Econômico
- Resistente contra a corrupção de dados
- Retenção de dados
- Estável
18.1. Instalando a ferramenta de gerenciamento de acionamento de fita
Use o comando mt para enrolar os dados para frente e para trás. O utilitário mt controla as operações de acionamento de fita magnética e o utilitário st é usado para o acionador de fita SCSI. Este procedimento descreve como instalar o pacote mt-st para operações de acionamento de fitas magnéticas.
Procedimento
Instale o pacote
mt-st:# yum instalar mt-st
Recursos adicionais
-
A página do homem
mt. -
A página do homem
st.
18.2. Escrever em dispositivos de fita adesiva
Este procedimento descreve como fazer o backup dos dados usando o comando tar. Por padrão, block size é 10KB (bs=10k) em dispositivos de fita adesiva. A opção de dispositivo -f especifica o arquivo do dispositivo de fita, mas esta opção não é necessária se você tiver configurado a variável de ambiente TAPE usando o comando export TAPE=/dev/st0 atributo.
Pré-requisitos
-
O pacote
mt-stestá instalado. Para mais informações, veja Seção 18.1, “Instalando a ferramenta de gerenciamento de acionamento de fita”. Carregar a unidade de fita adesiva:
# mt -f /dev/st0 load
Procedimento
Verifique a cabeça da fita:
# mt -f /dev/st0 status SCSI 2 tape drive: File number=-1, block number=-1, partition=0. Tape block size 0 bytes. Density code 0x0 (default). Soft error count since last status=0 General status bits on (50000): DR_OPEN IM_REP_ENAqui:
-
o atual
file numberé -1. -
o
block numberdefine a cabeça da fita. Por padrão, ela é definida como -1. -
o
block size0 indica que o dispositivo de fita não tem um tamanho de bloco fixo. -
o
Soft error countindica o número de erros encontrados após a execução do comando de status mt. -
o
General status bitsexplica as estatísticas do dispositivo de fita. -
DR_OPENindica que a porta está aberta e o dispositivo de fita está vazio.IM_REP_ENé o modo de relatório imediato.
-
o atual
Se o dispositivo de fita não estiver vazio, especifique a cabeça da fita:
# mt -f /dev/st0 rewind # tar -czf /dev/st0 /etc
Este comando substitui os dados em um dispositivo de fita com o conteúdo do diretório /etc
Opcional: Para anexar os dados no dispositivo de fita:
# mt -f /dev/st0 eodFaça o backup do diretório /etc para o dispositivo de fita:
# tar -czf /dev/st0 /etc tar: Removing leading `/' from member names /etc/ /etc/man_db.conf /etc/DIR_COLORS /etc/rsyslog.conf [...]Veja o status do dispositivo de fita:
# mt -f /dev/st0 status
Etapas de verificação
Veja a lista de todos os arquivos no dispositivo de fita:
# tar -tzf /dev/st0 /etc/ /etc/man_db.conf /etc/DIR_COLORS /etc/rsyslog.conf [...]
Recursos adicionais
-
A página do homem
mt. -
A página do homem
tar. -
A página do homem
st. - Mídia com fita adesiva detectada como artigo da Red Hat Knowlegebaseprotegido por escrito.
- Como verificar se os drives de fita são detectados no artigo Red Hat Knowlegebase dosistema.
18.3. Cabeça da fita de comutação em dispositivos de fita
Use o seguinte procedimento para mudar o cabeçote da fita no dispositivo de fita. Ao anexar os dados aos dispositivos de fita, use a opção eod para mudar o cabeçote da fita.
Pré-requisitos
-
O pacote
mt-stestá instalado. Para mais informações, veja Seção 18.1, “Instalando a ferramenta de gerenciamento de acionamento de fita”. - Os dados são escritos no dispositivo de fita. Para mais informações, veja Seção 18.2, “Escrever em dispositivos de fita adesiva”.
Procedimento
Para ir até o final dos dados:
# mt -f /dev/st0 eodPara ir para o registro anterior:
# mt -f /dev/st0 bsfm 1Para ir para o registro de avanço:
# mt -f /dev/st0 fsf 1
Recursos adicionais
-
A página do homem
mt.
18.4. Restaurando dados de dispositivos de fita
Para restaurar dados de um dispositivo de fita, use o comando tar.
Pré-requisitos
-
O pacote
mt-stestá instalado. Para mais informações, veja Seção 18.1, “Instalando a ferramenta de gerenciamento de acionamento de fita”. - Os dados são escritos no dispositivo de fita. Para mais informações, veja Seção 18.2, “Escrever em dispositivos de fita adesiva”.
Procedimento
Rebobine o dispositivo de fita:
# mt -f /dev/st0 rebobinarRestaurar o diretório /etc:
# tar -xzf /dev/st0 /etc
Recursos adicionais
-
A página do homem
mt. -
A página do homem
tar.
18.5. Apagamento de dados de dispositivos de fita
Para apagar dados de um dispositivo de fita, use a opção erase.
Pré-requisitos
-
O pacote
mt-stestá instalado. Para mais informações, veja Seção 18.1, “Instalando a ferramenta de gerenciamento de acionamento de fita”. - Os dados são escritos no dispositivo de fita. Para mais informações, veja Seção 18.2, “Escrever em dispositivos de fita adesiva”.
Procedimento
Apagar os dados do dispositivo de fita:
# mt -f /dev/st0 apagarDescarregue o dispositivo de fita:
mt -f /dev/st0 offline
Recursos adicionais
-
A página do homem
mt.
18.6. Comandos de fita adesiva
A seguir estão os comandos comuns do mt:
Tabela 18.1. comandos mt
| Comando | Descrição |
|---|---|
|
| Exibe o status do dispositivo de fita. |
|
| Rebobina o dispositivo de fita. |
|
| Apaga a fita inteira. |
|
| Passa a cabeça da fita para o registro dianteiro. Aqui, n é uma contagem de arquivo opcional. Se uma contagem de arquivo for especificada, a cabeça da fita salta n registros. |
|
| Muda a cabeça da fita para o registro anterior. |
|
| Muda a cabeça da fita para o final dos dados. |
Diretiva não-resolvida em master.adoc - inclui::montagens/montagem_removendo dispositivos de armazenagem.adoc[leveloffset= 1]
Capítulo 19. Gerenciamento de armazenamento local em camadas com o Stratis
Você pode facilmente configurar e gerenciar configurações complexas de armazenamento integradas pelo sistema de alto nível Stratis.
O Stratis está disponível como uma Pré-visualização Tecnológica. Para informações sobre o escopo de suporte das características de Technology Preview da Red Hat, consulte o documento Technology Preview Features Support Scope.
Os clientes que implantam Stratis são encorajados a fornecer feedback à Red Hat.
19.1. Montagem de sistemas de arquivo Stratis
Como administrador do sistema, você pode ativar e configurar o sistema de arquivo de gerenciamento de volume Stratis em seu sistema para gerenciar facilmente o armazenamento em camadas.
19.1.1. O propósito e as características de Stratis
Stratis é uma solução de gerenciamento de armazenamento local para Linux. Ele é focado na simplicidade e facilidade de uso, e dá acesso a recursos avançados de armazenamento.
Stratis facilita as seguintes atividades:
- Configuração inicial de armazenamento
- Fazendo mudanças mais tarde
- Utilização de recursos avançados de armazenamento
O Stratis é um sistema híbrido de gerenciamento de armazenamento local de usuário e núcleo que suporta recursos avançados de armazenamento. O conceito central do Stratis é um sistema de armazenamento pool. Este pool é criado a partir de um ou mais discos ou partições locais, e os volumes são criados a partir do pool.
O pool permite muitas características úteis, como por exemplo:
- Instantâneos do sistema de arquivo
- Provisão fina
- Classificação
19.1.2. Componentes de um volume Stratis
Externamente, Stratis apresenta os seguintes componentes de volume na interface de linha de comando e no API:
blockdev- Dispositivos de bloqueio, tais como uma partição de disco ou uma partição de disco.
poolComposto por um ou mais dispositivos de bloco.
Uma piscina tem um tamanho total fixo, igual ao tamanho dos dispositivos do bloco.
O pool contém a maioria das camadas do Stratis, como o cache de dados não volátil, usando o alvo
dm-cache.Stratis cria um
/stratis/my-pool/para cada pool. Este diretório contém links para dispositivos que representam os sistemas de arquivos Stratis no pool.
filesystemCada pool pode conter um ou mais sistemas de arquivos, que armazenam arquivos.
Os sistemas de arquivo são pouco provisionados e não têm um tamanho total fixo. O tamanho real de um sistema de arquivo cresce com os dados nele armazenados. Se o tamanho dos dados se aproximar do tamanho virtual do sistema de arquivo, o Stratis aumenta o volume fino e o sistema de arquivo automaticamente.
Os sistemas de arquivo são formatados com XFS.
ImportanteStratis rastreia informações sobre sistemas de arquivo criados usando Stratis que o XFS não conhece, e as mudanças feitas usando o XFS não criam automaticamente atualizações no Stratis. Os usuários não devem reformatar ou reconfigurar sistemas de arquivos XFS que são gerenciados pelo Stratis.
Stratis cria links para sistemas de arquivo no
/stratis/my-pool/my-fscaminho.
Stratis usa muitos dispositivos Device Mapper, que aparecem na lista dmsetup e no arquivo /proc/partitions. Da mesma forma, a saída do comando lsblk reflete o funcionamento interno e as camadas do Stratis.
19.1.3. Dispositivos de bloqueio utilizáveis com Stratis
Esta seção lista os dispositivos de armazenamento que você pode usar para o Stratis.
Dispositivos com suporte
As piscinas Stratis foram testadas para trabalhar com estes tipos de dispositivos de blocos:
- LUKS
- LVM volumes lógicos
- MD RAID
- DM Multipath
- iSCSI
- HDDs e SSDs
- Dispositivos NVMe
Na versão atual, o Stratis não lida com falhas em discos rígidos ou outro hardware. Se você criar um pool Stratis sobre múltiplos dispositivos de hardware, você aumenta o risco de perda de dados porque múltiplos dispositivos devem estar operacionais para acessar os dados.
Dispositivos sem suporte
Como o Stratis contém uma camada de provisão fina, a Red Hat não recomenda a colocação de um pool Stratis em dispositivos de blocos que já são fornecidos de forma fina.
Recursos adicionais
-
Para iSCSI e outros dispositivos de bloco que requerem rede, consulte a página de manual
systemd.mount(5)para obter informações sobre a opção de montagem_netdev.
19.1.4. Instalando o Stratis
Este procedimento instala todos os pacotes necessários para o uso do Stratis.
Procedimento
Instalar pacotes que fornecem os serviços e utilitários de linha de comando do Stratis:
# yum instalar stratisd stratis-cli
Certifique-se de que o serviço
stratisdesteja habilitado:# systemctl enable --now stratisd
19.1.5. Criação de um pool Stratis
Este procedimento descreve como criar um pool de Stratis criptografados ou não criptografados a partir de um ou mais dispositivos de bloco.
As seguintes notas se aplicam aos pools de Stratis criptografados:
-
Cada dispositivo de bloco é codificado usando a biblioteca
cryptsetupe implementa o formatoLUKS2. - Cada piscina Stratis pode ter uma chave única ou pode compartilhar a mesma chave com outras piscinas. Estas chaves são armazenadas no chaveiro do kernel.
- Todos os dispositivos de bloco que compõem um pool Stratis são criptografados ou não criptografados. Não é possível ter tanto dispositivos de bloco criptografados quanto não criptografados no mesmo pool do Stratis.
- Os dispositivos de bloqueio adicionados ao nível de dados de um pool de Stratis criptografados são automaticamente criptografados.
Pré-requisitos
- Stratis v2.2.1 está instalado em seu sistema. Veja Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Os dispositivos de blocos nos quais você está criando um pool Stratis não estão em uso e não estão montados.
- Os dispositivos de blocos sobre os quais você está criando um pool Stratis têm pelo menos 1 GiB de tamanho cada um.
Na arquitetura IBM Z, os dispositivos de bloco
/dev/dasd*devem ser particionados. Use a partição no pool do Stratis.Para informações sobre como particionar dispositivos DASD, veja Configurando uma instância Linux na IBM Z.
Procedimento
Se o dispositivo de bloco selecionado contiver sistema de arquivos, tabela de partição ou assinaturas RAID, apague-os usando o seguinte comando:
# limpa-tudo block-deviceonde
block-deviceé o caminho para o dispositivo do bloco; por exemplo,/dev/sdb.Criar o novo pool de Stratis no(s) dispositivo(s) bloco(s) selecionado(s):
NotaEspecifique dispositivos de blocos múltiplos em uma única linha, separados por um espaço:
# criar um pool stratis my-pool block-device-1 block-device-2
Para criar um pool Stratis não criptografado, use o seguinte comando e vá para o passo 3:
# criar um pool stratis my-pool block-device
onde
block-deviceé o caminho para um dispositivo de blocos vazios ou limpos.NotaVocê não pode criptografar um pool Stratis não criptografado depois de criá-lo.
Para criar um pool criptografado de Stratis, complete os seguintes passos:
Se você ainda não tiver criado um conjunto de chaves, execute o seguinte comando e siga as instruções para criar um conjunto de chaves a ser usado para a criptografia:
# conjunto chave stratis --capture-key key-descriptiononde
key-descriptioné a descrição ou o nome do conjunto de chaves.Criar o pool de Stratis criptografados e especificar a descrição da chave a ser usada para a criptografia. Você também pode especificar o caminho da chave usando o parâmetro
--keyfile-path.# stratis pool criar --key-desc key-description my-pool block-device
onde
key-description- Especifica a descrição ou nome do arquivo chave a ser usado para a criptografia.
my-pool- Especifica o nome da nova piscina do Stratis.
block-device- Especifica o caminho para um dispositivo de blocos vazios ou limpos.
Verificar se o novo pool Stratis foi criado:
# lista stratis pool
Solução de problemas
Após um reinício do sistema, às vezes você pode não ver seu pool de Stratis criptografado ou os dispositivos de bloco que o compõem. Se você encontrar este problema, você deve desbloquear o pool do Stratis para torná-lo visível.
Para desbloquear a piscina do Stratis, complete os seguintes passos:
Recriar o conjunto de chaves usando a mesma descrição chave que foi usada anteriormente:
# conjunto chave stratis --capture-key key-descriptionDesbloquear a piscina do Stratis e o(s) dispositivo(s) de bloqueio:
# desbloqueio do pool stratis
Verificar se a piscina do Stratis está visível:
# lista stratis pool
Recursos adicionais
-
A página do homem
stratis(8).
Próximos passos
- Criar um sistema de arquivo Stratis no pool. Para maiores informações, ver Seção 19.1.6, “Criação de um sistema de arquivo Stratis”.
19.1.6. Criação de um sistema de arquivo Stratis
Este procedimento cria um sistema de arquivos Stratis em um pool Stratis existente.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou uma piscina Stratis. Veja Seção 19.1.5, “Criação de um pool Stratis”.
Procedimento
Para criar um sistema de arquivos Stratis em um pool, use:
# stratis fs criam my-pool my-fs
- Substitua my-pool com o nome da sua piscina Stratis existente.
- Substitua my-fs com um nome arbitrário para o sistema de arquivo.
Para verificar, liste os sistemas de arquivos dentro do pool:
# lista stratis fs my-pool
Recursos adicionais
-
A página do homem
stratis(8)
Próximos passos
- Montar o sistema de arquivos Stratis. Ver Seção 19.1.7, “Montagem de um sistema de arquivo Stratis”.
19.1.7. Montagem de um sistema de arquivo Stratis
Este procedimento monta um sistema de arquivo Stratis existente para acessar o conteúdo.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um sistema de arquivo Stratis. Veja Seção 19.1.6, “Criação de um sistema de arquivo Stratis”.
Procedimento
Para montar o sistema de arquivo, use as entradas que Stratis mantém no diretório
/stratis/:# montagem /stratis/my-pool/my-fs mount-point
O sistema de arquivo está agora montado no mount-point e pronto para uso.
Recursos adicionais
-
A página do homem
mount(8)
19.1.8. Montagem persistente de um sistema de arquivo Stratis
Este procedimento monta persistentemente um sistema de arquivo Stratis para que ele esteja disponível automaticamente após a inicialização do sistema.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um sistema de arquivo Stratis. Veja Seção 19.1.6, “Criação de um sistema de arquivo Stratis”.
Procedimento
Determinar o atributo UUID do sistema de arquivo:
$ lsblk --output=UUID /stratis/my-pool/my-fs
Por exemplo:
Exemplo 19.1. Visualizando a UUID do sistema de arquivos Stratis
$ lsblk --output=UUID /stratis/my-pool/fs1 UUID a1f0b64a-4ebb-4d4e-9543-b1d79f600283
Se o diretório de pontos de montagem não existir, crie-o:
# mkdir - pais mount-pointComo root, editar o arquivo
/etc/fstabe adicionar uma linha para o sistema de arquivo, identificado pela UUID. Usexfscomo o tipo de sistema de arquivo e adicione a opçãox-systemd.requires=stratisd.service.Por exemplo:
Exemplo 19.2. O ponto de montagem /fs1 em /etc/fstab
UUID=a1f0b64a-4ebb-4d4e-9543-b1d79f600283 /fs1 xfs default,x-systemd.requires=stratisd.service 0 0
Regenere unidades de montagem para que seu sistema registre a nova configuração:
# systemctl daemon-reload
Tente montar o sistema de arquivo para verificar se a configuração funciona:
# montar mount-point
Recursos adicionais
19.2. Ampliação de um volume Stratis com dispositivos de bloqueio adicionais
Você pode anexar dispositivos de blocos adicionais a um pool Stratis para fornecer mais capacidade de armazenamento para os sistemas de arquivos Stratis.
19.2.1. Componentes de um volume Stratis
Externamente, Stratis apresenta os seguintes componentes de volume na interface de linha de comando e no API:
blockdev- Dispositivos de bloqueio, tais como uma partição de disco ou uma partição de disco.
poolComposto por um ou mais dispositivos de bloco.
Uma piscina tem um tamanho total fixo, igual ao tamanho dos dispositivos do bloco.
O pool contém a maioria das camadas do Stratis, como o cache de dados não volátil, usando o alvo
dm-cache.Stratis cria um
/stratis/my-pool/para cada pool. Este diretório contém links para dispositivos que representam os sistemas de arquivos Stratis no pool.
filesystemCada pool pode conter um ou mais sistemas de arquivos, que armazenam arquivos.
Os sistemas de arquivo são pouco provisionados e não têm um tamanho total fixo. O tamanho real de um sistema de arquivo cresce com os dados nele armazenados. Se o tamanho dos dados se aproximar do tamanho virtual do sistema de arquivo, o Stratis aumenta o volume fino e o sistema de arquivo automaticamente.
Os sistemas de arquivo são formatados com XFS.
ImportanteStratis rastreia informações sobre sistemas de arquivo criados usando Stratis que o XFS não conhece, e as mudanças feitas usando o XFS não criam automaticamente atualizações no Stratis. Os usuários não devem reformatar ou reconfigurar sistemas de arquivos XFS que são gerenciados pelo Stratis.
Stratis cria links para sistemas de arquivo no
/stratis/my-pool/my-fscaminho.
Stratis usa muitos dispositivos Device Mapper, que aparecem na lista dmsetup e no arquivo /proc/partitions. Da mesma forma, a saída do comando lsblk reflete o funcionamento interno e as camadas do Stratis.
19.2.2. Adicionando dispositivos de blocos a uma piscina Stratis
Este procedimento acrescenta um ou mais dispositivos de bloco a um pool Stratis para ser utilizado pelos sistemas de arquivo Stratis.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Os dispositivos de bloco que você está adicionando ao pool Stratis não estão em uso e não estão montados.
- Os dispositivos de bloco que você está adicionando ao pool do Stratis têm pelo menos 1 GiB de tamanho cada um.
Procedimento
Para adicionar um ou mais dispositivos de bloqueio ao pool, use:
# dados adicionais do pool stratis my-pool device-1 device-2 device-n
Recursos adicionais
-
A página do homem
stratis(8)
19.3. Monitoramento dos sistemas de arquivo Stratis
Como um usuário Stratis, você pode visualizar informações sobre volumes Stratis em seu sistema para monitorar seu estado e espaço livre.
19.3.1. Tamanhos Stratis relatados por diferentes utilidades
Esta seção explica a diferença entre os tamanhos do Stratis relatados por utilitários padrão, tais como df e o utilitário stratis.
Utilitários Linux padrão como o df informam o tamanho da camada do sistema de arquivos XFS no Stratis, que é 1 TiB. Esta informação não é útil, porque o uso real de armazenamento do Stratis é menor devido ao provisionamento fino, e também porque o Stratis aumenta automaticamente o sistema de arquivo quando a camada XFS está perto de estar cheia.
Monitore regularmente a quantidade de dados escritos em seus sistemas de arquivos Stratis, que é relatada como o valor Total Physical Used. Certifique-se de que não exceda o valor Total Physical Size.
Recursos adicionais
-
A página do homem
stratis(8)
19.3.2. Exibindo informações sobre os volumes do Stratis
Este procedimento lista estatísticas sobre seus volumes Stratis, tais como o total, usado e tamanho livre ou sistemas de arquivos e dispositivos de blocos pertencentes a um pool.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando.
Procedimento
Para exibir informações sobre todos os block devices utilizados para o Stratis em seu sistema:
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Data
Para exibir informações sobre todos os Stratis pools em seu sistema:
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiB
Para exibir informações sobre todos os Stratis file systems em seu sistema:
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /stratis/my-pool/my-fs
Recursos adicionais
-
A página do homem
stratis(8)
19.4. Usando snapshots em sistemas de arquivo Stratis
Você pode usar instantâneos nos sistemas de arquivo Stratis para capturar o estado do sistema de arquivo em momentos arbitrários e restaurá-lo no futuro.
19.4.1. Características dos snapshots de Stratis
Esta seção descreve as propriedades e limitações dos instantâneos do sistema de arquivo no Stratis.
No Stratis, um instantâneo é um sistema de arquivo Stratis regular criado como uma cópia de outro sistema de arquivo Stratis. O snapshot inicialmente contém o mesmo conteúdo de arquivo do sistema de arquivo original, mas pode mudar à medida que o snapshot é modificado. Quaisquer mudanças que você fizer no instantâneo não serão refletidas no sistema de arquivo original.
A implementação atual no Stratis é caracterizada pelo seguinte:
- Um instantâneo de um sistema de arquivo é outro sistema de arquivo.
- Um instantâneo e sua origem não estão ligados durante toda a vida. Um sistema de arquivo com instantâneo pode viver mais tempo do que o sistema de arquivo a partir do qual foi criado.
- Um sistema de arquivo não precisa ser montado para criar um instantâneo a partir dele.
- Cada snapshot usa cerca de meio gigabyte de armazenamento real, que é necessário para o log XFS.
19.4.2. Criando um instantâneo do Stratis
Este procedimento cria um sistema de arquivo Stratis como um instantâneo de um sistema de arquivo Stratis existente.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um sistema de arquivo Stratis. Veja Seção 19.1.6, “Criação de um sistema de arquivo Stratis”.
Procedimento
Para criar um instantâneo do Stratis, use:
# foto de stratis fs my-pool my-fs my-fs-snapshot
Recursos adicionais
-
A página do homem
stratis(8)
19.4.3. Acesso ao conteúdo de uma foto de Stratis
Este procedimento monta um instantâneo de um sistema de arquivo Stratis para torná-lo acessível para operações de leitura e escrita.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um instantâneo do Stratis. Veja Seção 19.4.2, “Criando um instantâneo do Stratis”.
Procedimento
Para acessar o instantâneo, monte-o como um sistema de arquivo regular a partir do
/stratis/my-pool/diretório:# montagem /stratis/my-pool/my-fs-snapshot mount-point
Recursos adicionais
- Seção 19.1.7, “Montagem de um sistema de arquivo Stratis”
-
A página do homem
mount(8)
19.4.4. Revertendo um sistema de arquivo Stratis para um instantâneo anterior
Este procedimento reverte o conteúdo de um sistema de arquivo Stratis para o estado capturado em um instantâneo Stratis.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um instantâneo do Stratis. Veja Seção 19.4.2, “Criando um instantâneo do Stratis”.
Procedimento
Opcionalmente, faça o backup do estado atual do sistema de arquivos para poder acessá-lo mais tarde:
# foto do sistema de arquivos stratis my-pool my-fs my-fs-backup
Desmontar e remover o sistema de arquivo original:
# umount /stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fs
Criar uma cópia do instantâneo sob o nome do sistema de arquivo original:
# foto do sistema de arquivos stratis my-pool my-fs-snapshot my-fs
Monte o instantâneo, que agora está acessível com o mesmo nome do sistema de arquivo original:
# montagem /stratis/my-pool/my-fs mount-point
O conteúdo do sistema de arquivo chamado my-fs é agora idêntico ao snapshot my-fs-snapshot.
Recursos adicionais
-
A página do homem
stratis(8)
19.4.5. Removendo uma foto do Stratis
Este procedimento remove um instantâneo de Stratis de uma piscina. Os dados do instantâneo são perdidos.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um instantâneo do Stratis. Veja Seção 19.4.2, “Criando um instantâneo do Stratis”.
Procedimento
Desmontar o instantâneo:
# umount /stratis/my-pool/my-fs-snapshot
Destrua o instantâneo:
# sistema de arquivos stratis destruir my-pool my-fs-snapshot
Recursos adicionais
-
A página do homem
stratis(8)
19.5. Remoção dos sistemas de arquivo Stratis
Você pode remover um sistema de arquivos Stratis existente ou um pool Stratis, destruindo os dados sobre eles.
19.5.1. Componentes de um volume Stratis
Externamente, Stratis apresenta os seguintes componentes de volume na interface de linha de comando e no API:
blockdev- Dispositivos de bloqueio, tais como uma partição de disco ou uma partição de disco.
poolComposto por um ou mais dispositivos de bloco.
Uma piscina tem um tamanho total fixo, igual ao tamanho dos dispositivos do bloco.
O pool contém a maioria das camadas do Stratis, como o cache de dados não volátil, usando o alvo
dm-cache.Stratis cria um
/stratis/my-pool/para cada pool. Este diretório contém links para dispositivos que representam os sistemas de arquivos Stratis no pool.
filesystemCada pool pode conter um ou mais sistemas de arquivos, que armazenam arquivos.
Os sistemas de arquivo são pouco provisionados e não têm um tamanho total fixo. O tamanho real de um sistema de arquivo cresce com os dados nele armazenados. Se o tamanho dos dados se aproximar do tamanho virtual do sistema de arquivo, o Stratis aumenta o volume fino e o sistema de arquivo automaticamente.
Os sistemas de arquivo são formatados com XFS.
ImportanteStratis rastreia informações sobre sistemas de arquivo criados usando Stratis que o XFS não conhece, e as mudanças feitas usando o XFS não criam automaticamente atualizações no Stratis. Os usuários não devem reformatar ou reconfigurar sistemas de arquivos XFS que são gerenciados pelo Stratis.
Stratis cria links para sistemas de arquivo no
/stratis/my-pool/my-fscaminho.
Stratis usa muitos dispositivos Device Mapper, que aparecem na lista dmsetup e no arquivo /proc/partitions. Da mesma forma, a saída do comando lsblk reflete o funcionamento interno e as camadas do Stratis.
19.5.2. Remoção de um sistema de arquivo Stratis
Este procedimento remove um sistema de arquivos Stratis existente. Os dados armazenados nele são perdidos.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou um sistema de arquivo Stratis. Veja Seção 19.1.6, “Criação de um sistema de arquivo Stratis”.
Procedimento
Desmontar o sistema de arquivo:
# umount /stratis/my-pool/my-fs
Destruir o sistema de arquivos:
# sistema de arquivos stratis destruir my-pool my-fs
Verificar se o sistema de arquivo não existe mais:
# lista do sistema de arquivos stratis my-pool
Recursos adicionais
-
A página do homem
stratis(8)
19.5.3. Remoção de uma piscina Stratis
Este procedimento remove uma piscina existente do Stratis. Os dados armazenados nele são perdidos.
Pré-requisitos
- O Stratis está instalado. Ver Seção 19.1.4, “Instalando o Stratis”.
-
O serviço
stratisdestá funcionando. - Você criou uma piscina Stratis. Veja Seção 19.1.5, “Criação de um pool Stratis”.
Procedimento
Listar os sistemas de arquivos no pool:
# lista do sistema de arquivos stratis my-poolDesmontar todos os sistemas de arquivos no pool:
# umount /stratis/my-pool/my-fs-1 \ /stratis/my-pool/my-fs-2 \ /stratis/my-pool/my-fs-n
Destruir os sistemas de arquivo:
# sistema de arquivos stratis destruir my-pool my-fs-1 my-fs-2
Destruir a piscina:
# stratis pool destruir my-poolVerificar se o pool não existe mais:
# lista stratis pool
Recursos adicionais
-
A página do homem
stratis(8)