
Red Hat Training
A Red Hat training course is available for RHEL 8
Configuração e gerenciamento de clusters de alta disponibilidade
Configuração e gerenciamento do Red Hat High Availability Add-On
Resumo
Tornando o código aberto mais inclusivo
A Red Hat tem o compromisso de substituir a linguagem problemática em nosso código, documentação e propriedades da web. Estamos começando com estes quatro termos: master, slave, blacklist e whitelist. Por causa da enormidade deste esforço, estas mudanças serão implementadas gradualmente ao longo de vários lançamentos futuros. Para mais detalhes, veja a mensagem de nosso CTO Chris Wright.
Fornecendo feedback sobre a documentação da Red Hat
Agradecemos sua contribuição em nossa documentação. Por favor, diga-nos como podemos melhorá-la. Para fazer isso:
Para comentários simples sobre passagens específicas:
- Certifique-se de que você está visualizando a documentação no formato Multi-page HTML. Além disso, certifique-se de ver o botão Feedback no canto superior direito do documento.
- Use o cursor do mouse para destacar a parte do texto que você deseja comentar.
- Clique no pop-up Add Feedback que aparece abaixo do texto destacado.
- Siga as instruções apresentadas.
Para enviar comentários mais complexos, crie um bilhete Bugzilla:
- Ir para o site da Bugzilla.
- Como Componente, use Documentation.
- Preencha o campo Description com sua sugestão de melhoria. Inclua um link para a(s) parte(s) relevante(s) da documentação.
- Clique em Submit Bug.
Capítulo 1. Visão geral do Add-On de Alta Disponibilidade
O Add-On de Alta Disponibilidade é um sistema agrupado que proporciona confiabilidade, escalabilidade e disponibilidade para serviços críticos de produção.
Um cluster são dois ou mais computadores (chamados nodes ou members) que trabalham juntos para realizar uma tarefa. Os clusters podem ser usados para fornecer serviços ou recursos altamente disponíveis. A redundância de múltiplas máquinas é usada para proteger contra falhas de muitos tipos.
Os clusters de alta disponibilidade oferecem serviços altamente disponíveis, eliminando pontos únicos de falha e falhando nos serviços de um nó de cluster para outro caso um nó se torne inoperante. Tipicamente, os serviços em um cluster de alta disponibilidade lêem e escrevem dados (por meio de sistemas de arquivos montados de leitura-escrita). Portanto, um cluster de alta disponibilidade deve manter a integridade dos dados quando um nó de cluster assume o controle de um serviço de outro nó de cluster. As falhas de um nó em um cluster de alta disponibilidade não são visíveis de clientes fora do cluster. (Os clusters de alta disponibilidade são às vezes chamados de clusters de failover.) O Add-On de Alta Disponibilidade fornece clustering de alta disponibilidade através de seu componente de gerenciamento de serviços de alta disponibilidade, Pacemaker.
1.1. Componentes adicionais de alta disponibilidade
O Add-On de Alta Disponibilidade consiste nos seguintes componentes principais:
- Infra-estrutura do cluster
- Gestão de serviços de alta disponibilidade
- Ferramentas de administração de clusters
Você pode complementar o Add-On de Alta Disponibilidade com os seguintes componentes:
- Red Hat GFS2 (Global File System 2)
-
LVM Locking Daemon (
lvmlockd) - Balanceador de carga
1.2. Visão geral do marcapasso
Pacemaker é um gerente de recursos de cluster. Ele alcança a máxima disponibilidade para seus serviços e recursos de cluster fazendo uso das capacidades de mensagens e membros da infra-estrutura de cluster para dissuadir e recuperar de falhas nos nós e nos recursos.
1.2.1. Componentes da arquitetura do marcapasso
Um cluster configurado com Pacemaker é composto de daemons componentes separados que monitoram os membros do cluster, scripts que gerenciam os serviços, e subsistemas de gerenciamento de recursos que monitoram os recursos díspares.
Os seguintes componentes formam a arquitetura do Pacemaker:
- Base de Informações do Cluster (CIB)
- O daemon de informação do Pacemaker, que usa XML internamente para distribuir e sincronizar a configuração atual e informações de status do Coordenador Designado (DC)
- Daemon de Gerenciamento de Recursos de Cluster (CRMd)
As ações de recursos de agrupamento de marcapassos são encaminhadas através deste daemon. Os recursos gerenciados pelo CRMd podem ser consultados pelos sistemas do cliente, movidos, instanciados e alterados quando necessário.
Cada nó de cluster também inclui um daemon (LRMd) gerente de recursos local que atua como uma interface entre CRMd e recursos. O LRMd passa os comandos do CRMd para os agentes, tais como iniciar e parar e retransmitir informações de status.
- Atire no Outro Nó da Cabeça (STONITH)
- STONITH é a implementação da esgrima do Pacemaker. Ela atua como um recurso de cluster no Pacemaker que processa pedidos de cercas, fechando forçosamente os nós e removendo-os do cluster para garantir a integridade dos dados. STONITH é configurado na CIB e pode ser monitorado como um recurso normal de cluster. Para uma visão geral das cercas, veja Seção 1.3, “Visão geral da vedação”.
- corosync
corosyncé o componente - e um daemon com o mesmo nome - que atende às principais necessidades de adesão e de comunicação dos membros para os clusters de alta disponibilidade. Ele é necessário para que o Add-On de Alta Disponibilidade funcione.Além dessas funções de afiliação e de envio de mensagens,
corosynctambém:- Gerencia as regras de quorum e determinação.
- Fornece recursos de mensagens para aplicações que coordenam ou operam em múltiplos membros do cluster e, portanto, devem comunicar informações estatais ou outras informações entre as instâncias.
-
Utiliza a biblioteca
kronosnetcomo seu transporte de rede para fornecer múltiplos links redundantes e failover automático.
1.2.2. Ferramentas de configuração e gerenciamento
O Add-On de Alta Disponibilidade apresenta duas ferramentas de configuração para implantação, monitoramento e gerenciamento de clusters.
pcsA interface de linha de comando
pcscontrola e configura o Pacemaker e o daemon de batimento cardíacocorosync. Um programa baseado em linha de comando,pcspode realizar as seguintes tarefas de gerenciamento de clusters:- Criar e configurar um cluster Pacemaker/Corosync
- Modificar a configuração do cluster enquanto ele está funcionando
- Configurar remotamente tanto Pacemaker e Corosync, quanto iniciar, parar e exibir informações de status do cluster
pcsdWeb UI- Uma interface gráfica do usuário para criar e configurar clusters Pacemaker/Corosync.
1.2.3. Os arquivos de configuração do cluster e do marcapasso
Os arquivos de configuração para o Red Hat High Availability Add-On são corosync.conf e cib.xml.
O arquivo corosync.conf fornece os parâmetros de cluster usados pelo corosync, o gerenciador de cluster em que a Pacemaker é construída. Em geral, você não deve editar o corosync.conf diretamente, mas, em vez disso, usar a interface pcs ou pcsd.
O arquivo cib.xml é um arquivo XML que representa tanto a configuração do cluster quanto o estado atual de todos os recursos no cluster. Este arquivo é utilizado pela Pacemaker's Cluster Information Base (CIB). O conteúdo da CIB é mantido automaticamente em sincronia em todo o cluster. Não edite o arquivo cib.xml diretamente; use a interface pcs ou pcsd em seu lugar.
1.3. Visão geral da vedação
Se a comunicação com um único nó do cluster falhar, então outros nós do cluster devem ser capazes de restringir ou liberar o acesso a recursos aos quais o nó de cluster falhado possa ter acesso. Isto não pode ser feito contatando o próprio nó de cluster, pois o nó de cluster pode não ser responsivo. Ao invés disso, deve-se fornecer um método externo, que é chamado de vedação com um agente de vedação. Um dispositivo de cerca é um dispositivo externo que pode ser usado pelo cluster para restringir o acesso a recursos compartilhados por um nó errante, ou para emitir uma reinicialização dura no nó de cluster.
Sem um dispositivo de cerca configurado, você não tem como saber que os recursos usados anteriormente pelo nó de cluster desconectado foram liberados, e isso poderia impedir que os serviços funcionassem em qualquer um dos outros nós de cluster. Por outro lado, o sistema pode assumir erroneamente que o nó de cluster liberou seus recursos e isto pode levar à corrupção e perda de dados. Sem um dispositivo de cerca, a integridade dos dados configurados não pode ser garantida e a configuração do cluster não será suportada.
Quando a vedação está em andamento, nenhuma outra operação de agrupamento é permitida. A operação normal do aglomerado não pode ser retomada até que a vedação tenha sido concluída ou o nó de aglomerado volte a juntar-se ao aglomerado depois que o nó de aglomerado tiver sido reinicializado.
Para mais informações sobre esgrima, consulte Esgrima em um Aglomerado de Alta Disponibilidade da Red Hat.
1.4. Visão geral do Quorum
A fim de manter a integridade e disponibilidade do cluster, os sistemas de cluster utilizam um conceito conhecido como quorum para evitar a corrupção e perda de dados. Um cluster tem quorum quando mais da metade dos nós do cluster estão on-line. Para mitigar a chance de corrupção de dados devido a falhas, o Pacemaker por padrão pára todos os recursos se o cluster não tiver quorum.
O Quorum é estabelecido usando um sistema de votação. Quando um nó de agrupamento não funciona como deveria ou perde a comunicação com o resto do agrupamento, os nós de trabalho da maioria podem votar para isolar e, se necessário, cercar o nó para manutenção.
Por exemplo, em um cluster de 6 nós, o quorum é estabelecido quando pelo menos 4 nós de cluster estão funcionando. Se a maioria dos nós ficar offline ou indisponível, o aglomerado não tem mais quórum e o Pacemaker pára os serviços de aglomeração.
As características do quorum em Pacemaker impedem o que também é conhecido como split-brain, um fenômeno onde o cluster é separado da comunicação, mas cada parte continua trabalhando como clusters separados, potencialmente escrevendo para os mesmos dados e possivelmente causando corrupção ou perda. Para mais informações sobre o que significa estar em um estado de cérebro dividido, e sobre conceitos de quórum em geral, veja Exploring Concepts of RHEL High Availability Clusters - Quorum.
Um cluster do Red Hat Enterprise Linux High Availability Add-On usa o serviço votequorum, em conjunto com a esgrima, para evitar situações de cérebro dividido. Um número de votos é atribuído a cada sistema no cluster, e as operações de cluster são permitidas somente quando uma maioria de votos está presente.
1.5. Visão geral dos recursos
A cluster resource é uma instância de programa, dados ou aplicação a ser gerenciada pelo serviço de cluster. Estes recursos são abstraídos por agents que fornecem uma interface padrão para gerenciar o recurso em um ambiente de cluster.
Para garantir que os recursos permaneçam saudáveis, você pode acrescentar uma operação de monitoramento à definição de um recurso. Se você não especificar uma operação de monitoramento para um recurso, uma é adicionada por padrão.
Você pode determinar o comportamento de um recurso em um cluster configurando constraints. Você pode configurar as seguintes categorias de restrições:
- restrições de localização
- restrições de pedidos
- restrições de colocação
Um dos elementos mais comuns de um agrupamento é um conjunto de recursos que precisam ser localizados juntos, começar sequencialmente e parar na ordem inversa. Para simplificar esta configuração, o Pacemaker apóia o conceito de groups.
Capítulo 2. Começando com Pacemaker
Os seguintes procedimentos fornecem uma introdução às ferramentas e processos que você utiliza para criar um cluster Pacemaker. Eles são destinados aos usuários que estão interessados em ver como é o software do cluster e como ele é administrado, sem a necessidade de configurar um cluster funcional.
Estes procedimentos não criam um cluster Red Hat suportado, que requer pelo menos dois nós e a configuração de um dispositivo de esgrima.
2.1. Aprendendo a usar o Pacemaker
Este exemplo requer um único nó rodando RHEL 8 e requer um endereço IP flutuante que reside na mesma rede que um dos endereços IP atribuídos estaticamente a um dos nós.
-
O nó utilizado neste exemplo é
z1.example.com. - O endereço IP flutuante usado neste exemplo é 192.168.122.120.
Certifique-se de que o nome do nó em que você está rodando esteja em seu arquivo /etc/hosts.
Trabalhando através deste procedimento, você aprenderá como usar o Pacemaker para configurar um cluster, como exibir o status do cluster, e como configurar um serviço de cluster. Este exemplo cria um servidor HTTP Apache como um recurso de cluster e mostra como o cluster responde quando o recurso falha.
Instale os pacotes de software Red Hat High Availability Add-On a partir do canal High Availability, e inicie e habilite o serviço
pcsd.#
yum install pcs pacemaker fence-agents-all... #systemctl start pcsd.service#systemctl enable pcsd.serviceSe você estiver rodando o daemon
firewalld, habilite os portos que são exigidos pelo suplemento de alta disponibilidade da Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadDefina uma senha para o usuário
haclusterem cada nó do cluster e autentique o usuáriohaclusterpara cada nó do cluster no nó a partir do qual você executará os comandospcs. Este exemplo está usando apenas um único nó, o nó a partir do qual você está executando os comandos, mas esta etapa está incluída aqui uma vez que é uma etapa necessária na configuração de um cluster multi-nó de alta disponibilidade compatível com a Red Hat High Availability.#
passwd hacluster... #pcs host auth z1.example.comCriar um agrupamento chamado
my_clustercom um membro e verificar o status do agrupamento. Este comando cria e inicia o agrupamento em uma única etapa.#
pcs cluster setup my_cluster --start z1.example.com... #pcs cluster statusCluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 1 node configured 0 resources configured PCSD Status: z1.example.com: OnlineUm aglomerado Red Hat High Availability requer que você configure a vedação para o aglomerado. As razões para esta exigência estão descritas em Esgrima em um Aglomerado de Alta Disponibilidade da Red Hat. Para esta introdução, entretanto, que se destina a mostrar apenas como usar os comandos básicos do Marcapasso, desabilite o cercado definindo a opção de cercado do
stonith-enabledparafalse.AtençãoO uso do
stonith-enabled=falseé completamente inadequado para um cluster de produção. Ele diz ao aglomerado para simplesmente fingir que os nós falhados estão cercados com segurança.#
pcs property set stonith-enabled=falseConfigure um navegador web em seu sistema e crie uma página web para exibir uma simples mensagem de texto. Se você estiver executando o daemon
firewalld, habilite as portas que são exigidas porhttpd.NotaNão utilize
systemctl enablepara permitir que quaisquer serviços que serão gerenciados pelo cluster comecem na inicialização do sistema.#
yum install -y httpd wget... #firewall-cmd --permanent --add-service=http#firewall-cmd --reload#cat <<-END >/var/www/html/index.html<html><body>My Test Site - $(hostname)</body></html>ENDPara que o agente de recursos Apache obtenha o status do Apache, crie a seguinte adição à configuração existente para habilitar a URL do servidor de status.
#
cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusOrder deny,allowDeny from allAllow from 127.0.0.1Allow from ::1</Location>ENDCrie recursos para o cluster
IPaddr2eapachepara gerenciá-lo. O recurso 'IPaddr2' é um endereço IP flutuante que não deve ser um já associado a um nó físico. Se o dispositivo NIC do recurso 'IPaddr2' não for especificado, o IP flutuante deve residir na mesma rede que o endereço IP estaticamente atribuído usado pelo nó.Você pode exibir uma lista de todos os tipos de recursos disponíveis com o comando
pcs resource list. Você pode usar o comandopcs resource describe resourcetypepara exibir os parâmetros que você pode definir para o tipo de recurso especificado. Por exemplo, o seguinte comando exibe os parâmetros que você pode definir para um recurso do tipoapache:#
pcs resource describe apache...Neste exemplo, o recurso de endereço IP e o recurso apache são ambos configurados como parte de um grupo chamado
apachegroup, o que garante que os recursos sejam mantidos juntos para funcionar no mesmo nó quando você estiver configurando um cluster de vários nós em funcionamento.#
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup#pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup#pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 1 node configured 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online ...Após ter configurado um recurso de cluster, você pode usar o comando
pcs resource configpara exibir as opções que estão configuradas para aquele recurso.#
pcs resource config WebSiteResource: WebSite (class=ocf provider=heartbeat type=apache) Attributes: configfile=/etc/httpd/conf/httpd.conf statusurl=http://localhost/server-status Operations: start interval=0s timeout=40s (WebSite-start-interval-0s) stop interval=0s timeout=60s (WebSite-stop-interval-0s) monitor interval=1min (WebSite-monitor-interval-1min)- Aponte seu navegador para o site que você criou usando o endereço IP flutuante que você configurou. Isto deve exibir a mensagem de texto que você definiu.
Pare o serviço web apache e verifique o status do cluster. O uso do
killall -9simula uma falha em nível de aplicação.#
killall -9 httpdVerifique o status do agrupamento. Você deve ver que parar o serviço web causou uma ação fracassada, mas que o software de cluster reiniciou o serviço e você ainda deve ser capaz de acessar o site.
#
pcs statusCluster name: my_cluster ... Current DC: z1.example.com (version 1.1.13-10.el7-44eb2dd) - partition with quorum 1 node and 2 resources configured Online: [ z1.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=13, status=complete, exitreason='none', last-rc-change='Thu Oct 11 23:45:50 2016', queued=0ms, exec=0ms PCSD Status: z1.example.com: OnlineVocê pode limpar o status de falha no recurso que falhou uma vez que o serviço esteja funcionando novamente e o aviso de falha de ação não aparecerá mais quando você visualizar o status do cluster.
#
pcs resource cleanup WebSiteQuando terminar de olhar o agrupamento e o status do agrupamento, pare os serviços de agrupamento no nó. Embora você só tenha iniciado os serviços em um nó para esta introdução, o parâmetro
--allestá incluído, pois pararia os serviços de cluster em todos os nós de um cluster real de vários nós.#
pcs cluster stop --all
2.2. Aprendendo a configurar o failover
Este procedimento fornece uma introdução à criação de um agrupamento de Pacemaker executando um serviço que irá falhar de um nó para outro quando o nó no qual o serviço está sendo executado se tornar indisponível. Trabalhando através deste procedimento, você pode aprender como criar um serviço em um cluster de dois nós e então você pode observar o que acontece com esse serviço quando ele falha no nó em que está rodando.
Este procedimento de exemplo configura um cluster de dois nós Pacemaker rodando um servidor Apache HTTP. Você pode então parar o serviço Apache em um nó para ver como o serviço permanece disponível.
Este procedimento requer como pré-requisito que você tenha dois nós rodando o Red Hat Enterprise Linux 8 que possam se comunicar um com o outro, e requer um endereço IP flutuante que resida na mesma rede que um dos endereços IP atribuídos estaticamente a um dos nós.
-
Os nós utilizados neste exemplo são
z1.example.comez2.example.com. - O endereço IP flutuante usado neste exemplo é 192.168.122.120.
Certifique-se de que os nomes dos nós que você está usando estão no arquivo /etc/hosts em cada nó.
Em ambos os nós, instalar os pacotes de software Red Hat High Availability Add-On do canal High Availability, e iniciar e habilitar o serviço
pcsd.#
yum install pcs pacemaker fence-agents-all... #systemctl start pcsd.service#systemctl enable pcsd.serviceSe você estiver rodando o daemon
firewalld, em ambos os nós habilite as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadEm ambos os nós do cluster, defina uma senha para o usuário
hacluster.#
passwd haclusterAutentique o usuário
haclusterpara cada nó do cluster no nó a partir do qual você estará executando os comandospcs.#
pcs host auth z1.example.com z2.example.comCriar um cluster chamado
my_clustercom ambos os nós como membros do cluster. Este comando cria e inicia o agrupamento em uma única etapa. Você só precisa executar isto a partir de um nó no cluster porque os comandos de configuraçãopcsentram em vigor para o cluster inteiro.Em um nó em cluster, execute o seguinte comando.
#
pcs cluster setup my_cluster --start z1.example.com z2.example.comUm aglomerado Red Hat High Availability requer que você configure a vedação para o aglomerado. As razões para esta exigência estão descritas em Esgrima em um Aglomerado de Alta Disponibilidade da Red Hat. Para esta introdução, porém, para mostrar apenas como funciona o failover nesta configuração, desabilite a vedação definindo a opção de cluster
stonith-enabledparafalseAtençãoO uso do
stonith-enabled=falseé completamente inadequado para um cluster de produção. Ele diz ao aglomerado para simplesmente fingir que os nós falhados estão cercados com segurança.#
pcs property set stonith-enabled=falseApós criar um agrupamento e desativar a vedação, verifique o status do agrupamento.
NotaQuando você executa o comando
pcs cluster status, ele pode mostrar uma saída que difere temporariamente dos exemplos à medida que os componentes do sistema são iniciados.#
pcs cluster statusCluster Status: Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Thu Oct 11 16:11:18 2018 Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z1.example.com 2 nodes configured 0 resources configured PCSD Status: z1.example.com: Online z2.example.com: OnlineEm ambos os nós, configure um navegador web e crie uma página web para exibir uma mensagem de texto simples. Se você estiver executando o daemon
firewalld, habilite as portas que são exigidas porhttpd.NotaNão utilize
systemctl enablepara permitir que quaisquer serviços que serão gerenciados pelo cluster comecem na inicialização do sistema.#
yum install -y httpd wget... #firewall-cmd --permanent --add-service=http#firewall-cmd --reload#cat <<-END >/var/www/html/index.html<html><body>My Test Site - $(hostname)</body></html>ENDPara que o agente de recursos Apache obtenha o status do Apache, em cada nó do cluster crie a seguinte adição à configuração existente para habilitar a URL do servidor de status.
#
cat <<-END > /etc/httpd/conf.d/status.conf<Location /server-status>SetHandler server-statusOrder deny,allowDeny from allAllow from 127.0.0.1Allow from ::1</Location>ENDCrie recursos para o cluster
IPaddr2eapachepara gerenciá-lo. O recurso 'IPaddr2' é um endereço IP flutuante que não deve ser um já associado a um nó físico. Se o dispositivo NIC do recurso 'IPaddr2' não for especificado, o IP flutuante deve residir na mesma rede que o endereço IP estaticamente atribuído usado pelo nó.Você pode exibir uma lista de todos os tipos de recursos disponíveis com o comando
pcs resource list. Você pode usar o comandopcs resource describe resourcetypepara exibir os parâmetros que você pode definir para o tipo de recurso especificado. Por exemplo, o seguinte comando exibe os parâmetros que você pode definir para um recurso do tipoapache:#
pcs resource describe apache...Neste exemplo, o recurso de endereço IP e o recurso apache são ambos configurados como parte de um grupo chamado
apachegroup, o que garante que os recursos sejam mantidos juntos para funcionar no mesmo nó.Execute os seguintes comandos a partir de um nó no aglomerado:
#
pcs resource create ClusterIP ocf:heartbeat:IPaddr2 ip=192.168.122.120 --group apachegroup#pcs resource create WebSite ocf:heartbeat:apache configfile=/etc/httpd/conf/httpd.conf statusurl="http://localhost/server-status" --group apachegroup#pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online ...Note que, neste caso, o serviço
apachegroupestá rodando no nó z1.example.com.Acesse o site que você criou, pare o serviço no nó em que ele está funcionando e observe como o serviço falha até o segundo nó.
- Aponte um navegador para o site que você criou usando o endereço IP flutuante que você configurou. Isto deve exibir a mensagem de texto que você definiu, exibindo o nome do nó no qual o site está rodando.
Pare o serviço web apache. O uso do
killall -9simula uma falha no nível de aplicação.#
killall -9 httpdVerifique o status do agrupamento. Você deve ver que parar o serviço web causou uma ação falhada, mas que o software de cluster reiniciou o serviço no nó no qual ele estava rodando e você ainda deve ser capaz de acessar o navegador web.
#
pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z1.example.com WebSite (ocf::heartbeat:apache): Started z1.example.com Failed Resource Actions: * WebSite_monitor_60000 on z1.example.com 'not running' (7): call=31, status=complete, exitreason='none', last-rc-change='Fri Feb 5 21:01:41 2016', queued=0ms, exec=0msLimpar o status de falha uma vez que o serviço esteja funcionando novamente.
#
pcs resource cleanup WebSiteColoque o nó sobre o qual o serviço está funcionando em modo de espera. Observe que, como desativamos a vedação, não podemos efetivamente simular uma falha no nível do aceno (como puxar um cabo de força) porque a vedação é necessária para que o aglomerado se recupere de tais situações.
#
pcs node standby z1.example.comVerifique o status do grupo e anote onde o serviço está funcionando agora.
#
pcs statusCluster name: my_cluster Stack: corosync Current DC: z1.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum Last updated: Fri Oct 12 09:54:33 2018 Last change: Fri Oct 12 09:54:30 2018 by root via cibadmin on z1.example.com 2 nodes configured 2 resources configured Node z1.example.com: standby Online: [ z2.example.com ] Full list of resources: Resource Group: apachegroup ClusterIP (ocf::heartbeat:IPaddr2): Started z2.example.com WebSite (ocf::heartbeat:apache): Started z2.example.com- Acesse o site. Não deve haver perda de serviço, embora a mensagem de exibição deva indicar o nó em que o serviço está agora em execução.
Para restaurar os serviços de agrupamento para o primeiro nó, tire o nó do modo de espera. Isto não irá necessariamente mover o serviço de volta para aquele nó.
#
pcs node unstandby z1.example.comPara a limpeza final, pare os serviços de agrupamento em ambos os nós.
#
pcs cluster stop --all
Capítulo 3. A interface de linha de comando pcs
A interface de linha de comando pcs controla e configura serviços de cluster como corosync, pacemaker,booth, e sbd, fornecendo uma interface mais fácil para seus arquivos de configuração.
Note que você não deve editar o arquivo de configuração cib.xml diretamente. Na maioria dos casos, o Pacemaker rejeitará um arquivo cib.xml diretamente modificado.
3.1. pcs ajudam a exibir
Você pode usar a opção -h de pcs para exibir os parâmetros de um comando pcs e uma descrição desses parâmetros. Por exemplo, o comando a seguir exibe os parâmetros do comando pcs resource. Apenas uma parte da saída é mostrada.
# pcs resource -h3.2. Visualizando a configuração do cluster bruto
Embora você não deva editar o arquivo de configuração de cluster diretamente, você pode visualizar a configuração de cluster em bruto com o comando pcs cluster cib.
Você pode salvar a configuração do cluster bruto em um arquivo especificado com o pcs cluster cib filename comando. Se você tiver configurado previamente um cluster e já houver um CIB ativo, você usa o seguinte comando para salvar o arquivo xml bruto.
pcs cluster cib filename
Por exemplo, o seguinte comando salva o xml bruto da CIB em um arquivo chamado testfile.
pcs cluster cib test file
3.3. Salvando uma mudança de configuração para um arquivo de trabalho
Ao configurar um cluster, você pode salvar as alterações de configuração em um arquivo especificado sem afetar a CIB ativa. Isto permite que você especifique atualizações de configuração sem atualizar imediatamente a configuração de cluster em execução no momento com cada atualização individual.
Para informações sobre como salvar o CIB em um arquivo, consulte Visualização da configuração do cluster bruto. Uma vez criado esse arquivo, você pode salvar as alterações de configuração nesse arquivo em vez de na CIB ativa, usando a opção -f do comando pcs. Quando você tiver concluído as mudanças e estiver pronto para atualizar o arquivo CIB ativo, você pode empurrar essas atualizações de arquivo com o comando pcs cluster cib-push.
A seguir, o procedimento recomendado para empurrar mudanças no arquivo CIB. Este procedimento cria uma cópia do arquivo CIB original gravado e faz alterações nessa cópia. Ao empurrar essas alterações para o arquivo CIB ativo, este procedimento especifica a opção diff-against do comando pcs cluster cib-push para que somente as alterações entre o arquivo original e o arquivo atualizado sejam empurradas para o CIB. Isto permite que os usuários façam alterações em paralelo que não se sobrepõem e reduz a carga no Pacemaker que não precisa analisar o arquivo de configuração inteiro.
Salvar a CIB ativa em um arquivo. Este exemplo salva a CIB em um arquivo chamado
original.xml.#
pcs cluster cib original.xmlCopie o arquivo salvo para o arquivo de trabalho que você estará usando para as atualizações de configuração.
#
cp original.xml updated.xmlAtualize sua configuração conforme necessário. O seguinte comando cria um recurso no arquivo
updated.xml, mas não adiciona esse recurso à configuração de cluster atualmente em execução.#
pcs -f updated.xml resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 op monitor interval=30sEmpurre o arquivo atualizado para a CIB ativa, especificando que você está empurrando apenas as mudanças que fez no arquivo original.
#
pcs cluster cib-push updated.xml diff-against=original.xml
Alternativamente, você pode empurrar todo o conteúdo atual de um arquivo CIB com o seguinte comando.
pcs cluster cib-push filename
Ao empurrar o arquivo CIB inteiro, o Pacemaker verifica a versão e não permite que você empurre um arquivo CIB que seja mais antigo do que aquele já em um cluster. Se você precisar atualizar o arquivo CIB inteiro com uma versão mais antiga que a que está atualmente no cluster, você pode usar a opção --config do comando pcs cluster cib-push.
pcs cluster cib-push --config filename3.4. Exibição do status do cluster
Você pode exibir o status do agrupamento e os recursos do agrupamento com o seguinte comando.
status pcs
Você pode exibir o status de um determinado componente de cluster com o parâmetro commands do comando pcs status, especificando resources, cluster, nodes, ou pcsd.
status pcs commandsPor exemplo, o seguinte comando exibe o status dos recursos do cluster.
recursos de status pcs
O seguinte comando exibe o status do agrupamento, mas não os recursos do agrupamento.
pcs status de cluster
3.5. Exibição da configuração completa do cluster
Use o seguinte comando para exibir a configuração atual completa do cluster.
pcs config
Capítulo 4. Criando um cluster de Alta Disponibilidade Red Hat com Pacemaker
O seguinte procedimento cria um cluster de dois nós Red Hat High Availability usando pcs.
A configuração do cluster neste exemplo requer que seu sistema inclua os seguintes componentes:
-
2 nós, que serão usados para criar o agrupamento. Neste exemplo, os nós utilizados são
z1.example.comez2.example.com. - Comutadores de rede para a rede privada. Recomendamos, mas não exigimos uma rede privada para a comunicação entre os nós de cluster e outros equipamentos de cluster, tais como comutadores de energia de rede e comutadores de canal de fibra óptica.
-
Um dispositivo de vedação para cada nó do aglomerado. Este exemplo usa duas portas do interruptor de energia APC com um nome de host
zapc.example.com.
4.1. Instalação de software de cluster
O seguinte procedimento instala o software de cluster e configura seu sistema para a criação de clusters.
Em cada nó do cluster, instale os pacotes de software Red Hat High Availability Add-On junto com todos os agentes de vedação disponíveis no canal High Availability.
#
yum install pcs pacemaker fence-agents-allAlternativamente, você pode instalar os pacotes de software Red Hat High Availability Add-On junto com apenas o agente de vedação que você necessita com o seguinte comando.
#
yum install pcs pacemaker fence-agents-modelO comando a seguir exibe uma lista dos agentes de vedação disponíveis.
#
rpm -q -a | grep fencefence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...AtençãoApós instalar os pacotes Red Hat High Availability Add-On, você deve assegurar-se de que suas preferências de atualização de software estejam definidas para que nada seja instalado automaticamente. A instalação em um cluster em execução pode causar comportamentos inesperados. Para mais informações, consulte Práticas recomendadas para a aplicação de atualizações de software em um cluster de armazenamento RHEL de alta disponibilidade ou resiliente.
Se você estiver executando o daemon
firewalld, execute os seguintes comandos para habilitar as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.NotaVocê pode determinar se o daemon
firewalldestá instalado em seu sistema com o comandorpm -q firewalld. Se ele estiver instalado, você pode determinar se ele está rodando com o comandofirewall-cmd --state.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityNotaA configuração ideal de firewall para componentes de cluster depende do ambiente local, onde talvez seja necessário levar em conta considerações como, por exemplo, se os nós têm múltiplas interfaces de rede ou se há firewalls fora do host. O exemplo aqui, que abre as portas que são geralmente exigidas por um cluster Pacemaker, deve ser modificado para se adequar às condições locais. A habilitação de portas para o Add-On de Alta Disponibilidade mostra as portas para habilitar para o Add-On de Alta Disponibilidade da Red Hat e fornece uma explicação para o que cada porta é usada.
Para usar
pcspara configurar o cluster e se comunicar entre os nós, você deve definir uma senha em cada nó para o ID do usuáriohacluster, que é a conta de administraçãopcs. É recomendado que a senha para o usuáriohaclusterseja a mesma em cada nó.#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Antes que o cluster possa ser configurado, o daemon
pcsddeve ser iniciado e habilitado para iniciar na inicialização em cada nó. Este daemon trabalha com o comandopcspara gerenciar a configuração através dos nós do cluster.Em cada nó do cluster, execute os seguintes comandos para iniciar o serviço
pcsde para habilitarpcsdno início do sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
4.2. Instalação do pacote pcp-zeroconf (recomendado)
Ao configurar seu cluster, é recomendável instalar o pacote pcp-zeroconf para a ferramenta Performance Co-Pilot (PCP). O PCP é a ferramenta de monitoramento de recursos recomendada pela Red Hat para os sistemas RHEL. A instalação do pacote pcp-zeroconf permite que você tenha o PCP rodando e coletando dados de monitoramento de desempenho para o benefício de investigações sobre esgrima, falhas de recursos e outros eventos que perturbam o cluster.
As implantações de clusters onde o PCP é ativado precisarão de espaço suficiente disponível para os dados capturados do PCP no sistema de arquivos que contém /var/log/pcp/. O uso típico de espaço pelo PCP varia entre as implantações, mas 10Gb é normalmente suficiente quando se utiliza as configurações padrão pcp-zeroconf, e alguns ambientes podem requerer menos. O monitoramento do uso neste diretório durante um período de 14 dias de atividade típica pode fornecer uma expectativa de uso mais precisa.
Para instalar o pacote pcp-zeroconf, execute o seguinte comando.
# yum install pcp-zeroconf
Este pacote permite pmcd e estabelece a captura de dados em um intervalo de 10 segundos.
Para informações sobre a revisão de dados PCP, veja Por que um nó de cluster RHEL de alta disponibilidade foi reinicializado - e como posso evitar que isso aconteça novamente? no Portal do Cliente da Red Hat.
4.3. Criação de um cluster de alta disponibilidade
Este procedimento cria um cluster de Red Hat High Availability Add-On que consiste nos nós z1.example.com e z2.example.com.
Autentique o usuário
pcshaclusterpara cada nó do cluster no nó a partir do qual você estará rodandopcs.O seguinte comando autentica o usuário
haclusteremz1.example.compara os dois nós em um cluster de dois nós que consistirá dez1.example.comez2.example.com.[root@z1 ~]#
pcs host auth z1.example.com z2.example.comUsername:haclusterPassword: z1.example.com: Authorized z2.example.com: AuthorizedExecute o seguinte comando de
z1.example.compara criar o cluster de dois nósmy_clusterque consiste de nósz1.example.comez2.example.com. Isto propagará os arquivos de configuração do cluster para ambos os nós do cluster. Este comando inclui a opção--start, que iniciará os serviços de cluster em ambos os nós do cluster.[root@z1 ~]#
pcs cluster setup my_cluster --startz1.example.com z2.example.comPermitir que os serviços de cluster funcionem em cada nó do cluster quando o nó for inicializado.
NotaPara seu ambiente particular, você pode optar por deixar os serviços de cluster desativados, pulando esta etapa. Isto lhe permite assegurar que se um nó cair, quaisquer problemas com seu agrupamento ou seus recursos serão resolvidos antes que o nó se reintegre ao agrupamento. Se você deixar os serviços do cluster desativados, você precisará iniciar manualmente os serviços quando reiniciar um nó executando o comando
pcs cluster startnaquele nó.[root@z1 ~]#
pcs cluster enable --all
Você pode exibir o status atual do cluster com o comando pcs cluster status. Como pode haver um pequeno atraso antes que o cluster esteja pronto e funcionando quando você iniciar os serviços de cluster com a opção --start do comando pcs cluster setup, você deve assegurar que o cluster esteja pronto e funcionando antes de executar qualquer ação subseqüente sobre o cluster e sua configuração.
[root@z1 ~]# pcs cluster status
Cluster Status:
Stack: corosync
Current DC: z2.example.com (version 2.0.0-10.el8-b67d8d0de9) - partition with quorum
Last updated: Thu Oct 11 16:11:18 2018
Last change: Thu Oct 11 16:11:00 2018 by hacluster via crmd on z2.example.com
2 Nodes configured
0 Resources configured
...4.4. Criação de um cluster de alta disponibilidade com múltiplos links
Você pode usar o comando pcs cluster setup para criar um cluster Red Hat High Availability com múltiplos links, especificando todos os links para cada nó.
O formato do comando para criar um cluster de dois nós com dois links é o seguinte.
pcs cluster setup cluster_name node1_name addr=node1_link0_address addr=node1_link1_address node2_name addr=node2_link0_address addr=node2_link1_address
Ao criar um cluster com múltiplos links, você deve levar em conta o seguinte.
-
A ordem do
addr=addressparâmetros é importante. O primeiro endereço especificado após o nome de um nó é paralink0, o segundo paralink1, e assim por diante. - É possível especificar até oito ligações usando o protocolo de transporte de nós, que é o protocolo de transporte padrão.
-
Todos os nós devem ter o mesmo número de parâmetros
addr=. -
A partir do RHEL 8.1, é possível adicionar, remover e alterar links em um cluster existente usando os comandos
pcs cluster link add, opcs cluster link remove, opcs cluster link deletee opcs cluster link update. - Assim como nos clusters de link único, não misture endereços IPv4 e IPv6 em um link, embora você possa ter um link rodando IPv4 e o outro rodando IPv6.
- Como nos clusters de link único, você pode especificar endereços como endereços IP ou como nomes desde que os nomes resolvam para endereços IPv4 ou IPv6 para os quais endereços IPv4 e IPv6 não estejam misturados em um link.
O exemplo seguinte cria um cluster de dois nós chamado my_twolink_cluster com dois nós, rh80-node1 e rh80-node2. rh80-node1 tem duas interfaces, endereço IP 192.168.122.201 como link0 e 192.168.123.201 como link1. rh80-node2 tem duas interfaces, endereço IP 192.168.122.202 como link0 e 192.168.123.202 como link1.
# pcs cluster setup my_twolink_cluster rh80-node1 addr=192.168.122.201 addr=192.168.123.201 rh80-node2 addr=192.168.122.202 addr=192.168.123.202Para informações sobre como adicionar nós a um cluster existente com múltiplos links, consulte Adicionando um nó a um cluster com múltiplos links.
Para informações sobre como alterar os links em um cluster existente com múltiplos links, veja Adicionar e modificar links em um cluster existente.
4.5. Configuração de cercas
Você deve configurar um dispositivo de vedação para cada nó do aglomerado. Para informações sobre os comandos e opções de configuração da cerca, veja Configurando a cerca em um cluster de Alta Disponibilidade da Red Hat.
Para informações gerais sobre cercas e sua importância em um aglomerado de Red Hat High Availability, veja Fencing in a Red Hat High Availability Cluster.
Ao configurar um dispositivo de vedação, deve ser dada atenção se esse dispositivo compartilha energia com quaisquer nós ou dispositivos do cluster. Se um nó e seu dispositivo de cerca compartilham energia, então o aglomerado pode estar em risco de não poder cercar esse nó se a energia para ele e seu dispositivo de cerca forem perdidos. Tal aglomerado deve ter fontes de alimentação redundantes para os dispositivos e nós do cercado, ou dispositivos de cercado redundantes que não compartilham a energia. Métodos alternativos de vedação como SBD ou vedação de armazenamento também podem trazer redundância no caso de perdas isoladas de energia.
Este exemplo usa o interruptor de energia APC com um nome de host zapc.example.com para cercar os nós, e usa o agente de cercas fence_apc_snmp. Como ambos os nós serão vedados pelo mesmo agente de vedação, você pode configurar ambos os dispositivos de vedação como um único recurso, usando a opção pcmk_host_map.
Você cria um dispositivo de esgrima configurando o dispositivo como um recurso stonith com o comando pcs stonith create. O seguinte comando configura um recurso stonith chamado myapc que usa o agente de esgrima fence_apc_snmp para os nós z1.example.com e z2.example.com. A opção pcmk_host_map mapeia z1.example.com para a porta 1, e z2.example.com para a porta 2. O valor de login e a senha para o dispositivo APC são ambos apc. Por padrão, este dispositivo usará um intervalo de monitor de sessenta segundos para cada nó.
Observe que você pode usar um endereço IP ao especificar o nome do host para os nós.
[root@z1 ~]#pcs stonith create myapc fence_apc_snmp\ipaddr="zapc.example.com"\pcmk_host_map="z1.example.com:1;z2.example.com:2"\login="apc" passwd="apc"
O seguinte comando exibe os parâmetros de um dispositivo STONITH existente.
[root@rh7-1 ~]# pcs stonith config myapc
Resource: myapc (class=stonith type=fence_apc_snmp)
Attributes: ipaddr=zapc.example.com pcmk_host_map=z1.example.com:1;z2.example.com:2 login=apc passwd=apc
Operations: monitor interval=60s (myapc-monitor-interval-60s)Após configurar seu dispositivo de cerca, você deve testar o dispositivo. Para informações sobre como testar um dispositivo de cerca, veja Testar um dispositivo de cerca.
Não teste seu dispositivo de cercas desativando a interface de rede, pois isso não testará corretamente as cercas.
Uma vez configurada a vedação e iniciado um cluster, um reinício da rede acionará a vedação para o nó que reinicia a rede, mesmo quando o tempo limite não for ultrapassado. Por este motivo, não reinicie o serviço de rede enquanto o serviço de cluster estiver em funcionamento, pois ele acionará uma vedação não intencional no nó.
4.6. Apoio e restauração de uma configuração de cluster
Você pode fazer o backup da configuração do cluster em uma tarball com o seguinte comando. Se você não especificar um nome de arquivo, será usada a saída padrão.
pcs config backup filename
O comando pcs config backup faz backup apenas da própria configuração do cluster conforme configurado no CIB; a configuração dos daemons de recursos está fora do escopo deste comando. Por exemplo, se você tiver configurado um recurso Apache no cluster, as configurações do recurso (que estão na CIB) serão copiadas, enquanto as configurações do daemon Apache (como definido em`/etc/httpd`) e os arquivos que ele serve não serão copiados. Da mesma forma, se houver um recurso de banco de dados configurado no cluster, o banco de dados em si não será feito o backup, enquanto a configuração do recurso de banco de dados (CIB) será feita.
Use o seguinte comando para restaurar os arquivos de configuração de cluster em todos os nós a partir do backup. Se você não especificar um nome de arquivo, será usada a entrada padrão. Especificar a opção --local restaura somente os arquivos no nó atual.
pcs config restore [--local] [filename]4.7. Habilitação de portas para o Add-On de Alta Disponibilidade
A configuração ideal de firewall para componentes de cluster depende do ambiente local, onde talvez seja necessário levar em conta considerações como, por exemplo, se os nós têm múltiplas interfaces de rede ou se há firewalls fora do host.
Se você estiver executando o daemon firewalld, execute os seguintes comandos para habilitar as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.
#firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availability
Talvez seja necessário modificar quais portos estão abertos para atender às condições locais.
Você pode determinar se o daemon firewalld está instalado em seu sistema com o comando rpm -q firewalld. Se o daemon firewalld estiver instalado, você pode determinar se ele está rodando com o comando firewall-cmd --state.
Tabela 4.1, “Portos que possibilitam um suplemento de alta disponibilidade” mostra os portos a serem habilitados para o Red Hat High Availability Add-On e fornece uma explicação para o que o porto é usado.
Tabela 4.1. Portos que possibilitam um suplemento de alta disponibilidade
| Porto | Quando necessário |
|---|---|
| TCP 2224 |
Padrão
É crucial abrir a porta 2224 de tal forma que |
| TCP 3121 | Necessário em todos os nós se o agrupamento tiver algum nó de Pacemaker Remote
O daemon do Pacemaker |
| TCP 5403 |
Necessário no quorum quando se utiliza um dispositivo de quorum com |
| UDP 5404-5412 |
Necessário nos nós corosync para facilitar a comunicação entre os nós. É crucial abrir as portas 5404-5412 de tal forma que |
| TCP 21064 |
Necessário em todos os nós se o cluster contiver algum recurso que requeira DLM (como |
| TCP 9929, UDP 9929 | É necessário estar aberto em todos os nós de cluster e nós árbitros de estande para conexões de qualquer um desses mesmos nós quando o gerente de bilhetes do estande é usado para estabelecer um cluster com vários locais. |
Capítulo 5. Configuração de um servidor HTTP Apache ativo/passivo em um cluster Red Hat High Availability
O seguinte procedimento configura um servidor Apache HTTP ativo/passivo em um cluster de dois nós Red Hat Enterprise Linux High Availability Add-On usando pcs para configurar recursos de cluster. Neste caso de uso, os clientes acessam o servidor Apache HTTP através de um endereço IP flutuante. O servidor web roda em um dos dois nós do cluster. Se o nó no qual o servidor web está rodando ficar inoperante, o servidor web inicia novamente no segundo nó do cluster com interrupção mínima do serviço.
Figura 5.1, “Apache em um grupo de dois nós de alta disponibilidade de chapéu vermelho” mostra uma visão geral de alto nível do cluster no qual O cluster é um cluster de dois nós Red Hat High Availability configurado com um switch de energia de rede e com armazenamento compartilhado. Os nós do cluster são conectados a uma rede pública, para acesso do cliente ao servidor HTTP Apache através de um IP virtual. O servidor Apache roda no Nó 1 ou no Nó 2, cada um dos quais tem acesso ao armazenamento no qual os dados do Apache são mantidos. Nesta ilustração, o servidor web está rodando no Nó 1, enquanto o Nó 2 está disponível para rodar o servidor caso o Nó 1 se torne inoperante.
Figura 5.1. Apache em um grupo de dois nós de alta disponibilidade de chapéu vermelho
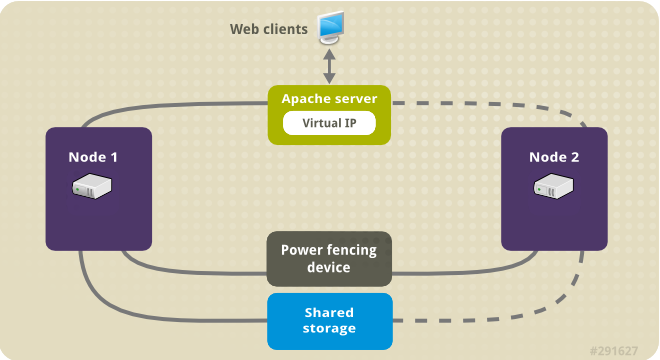
Este caso de uso requer que seu sistema inclua os seguintes componentes:
- Um cluster de dois nós Red Hat High Availability com vedação de energia configurada para cada nó. Recomendamos, mas não exigimos uma rede privada. Este procedimento utiliza o exemplo de cluster fornecido em Criar um cluster Red Hat High-Availability com Pacemaker.
- Um endereço IP virtual público, necessário para o Apache.
- Armazenamento compartilhado para os nós do cluster, utilizando iSCSI, Fibre Channel ou outro dispositivo de bloco de rede compartilhado.
O cluster é configurado com um grupo de recursos Apache, que contém os componentes do cluster que o servidor web requer: um recurso LVM, um recurso de sistema de arquivos, um recurso de endereço IP e um recurso de servidor web. Este grupo de recursos pode falhar de um nó do cluster para o outro, permitindo que qualquer um dos nós execute o servidor web. Antes de criar o grupo de recursos para este cluster, você estará executando os seguintes procedimentos:
-
Configurar um sistema de arquivo
ext4no volume lógicomy_lv. - Configurar um servidor web.
Depois de executar estas etapas, você cria o grupo de recursos e os recursos que ele contém.
5.1. Configuração de um volume LVM com um sistema de arquivo ext4 em um cluster Pacemaker
Este caso de uso requer a criação de um volume lógico LVM no armazenamento que é compartilhado entre os nós do cluster.
Os volumes LVM e as partições e dispositivos correspondentes usados pelos nós de cluster devem ser conectados somente aos nós de cluster.
O procedimento seguinte cria um volume lógico LVM e depois cria um sistema de arquivo ext4 nesse volume para uso em um cluster de Pacemaker. Neste exemplo, a partição compartilhada /dev/sdb1 é usada para armazenar o volume físico LVM a partir do qual o volume lógico LVM será criado.
Em ambos os nós do cluster, executar os seguintes passos para definir o valor para o ID do sistema LVM para o valor do identificador
unamepara o sistema. O ID do sistema LVM será usado para garantir que somente o cluster seja capaz de ativar o grupo de volume.Defina a opção de configuração
system_id_sourceno arquivo de configuração/etc/lvm/lvm.confparauname.# Configuration option global/system_id_source. system_id_source = "uname"
Verificar se o ID do sistema LVM no nó corresponde ao
unamepara o nó.#
lvm systemidsystem ID: z1.example.com #uname -nz1.example.com
Criar o volume LVM e criar um sistema de arquivo ext4 sobre esse volume. Uma vez que a partição
/dev/sdb1é o armazenamento compartilhado, esta parte do procedimento é realizada em apenas um nó.Criar um volume físico LVM na partição
/dev/sdb1.#
pvcreate /dev/sdb1Physical volume "/dev/sdb1" successfully createdCriar o grupo de volume
my_vgque consiste no volume físico/dev/sdb1.#
vgcreate my_vg /dev/sdb1Volume group "my_vg" successfully createdVerifique se o novo grupo de volume tem a identificação do sistema do nó no qual você está rodando e a partir do qual você criou o grupo de volume.
#
vgs -o+systemidVG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCriar um volume lógico utilizando o grupo de volume
my_vg.#
lvcreate -L450 -n my_lv my_vgRounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdVocê pode usar o comando
lvspara exibir o volume lógico.#
lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Criar um sistema de arquivo ext4 no volume lógico
my_lv.#
mkfs.ext4 /dev/my_vg/my_lvmke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
5.2. Configuração de um Servidor HTTP Apache
O seguinte procedimento configura um Servidor HTTP Apache.
Garantir que o Servidor HTTP Apache esteja instalado em cada nó do cluster. Você também precisa da ferramenta
wgetinstalada no cluster para poder verificar o status do Servidor HTTP Apache.Em cada nó, executar o seguinte comando.
#
yum install -y httpd wgetSe você estiver rodando o daemon
firewalld, em cada nó do cluster habilite as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --reloadPara que o agente de recursos Apache obtenha o status do Servidor HTTP Apache, certifique-se de que o seguinte texto esteja presente no arquivo
/etc/httpd/conf/httpd.confem cada nó do cluster, e certifique-se de que ele não tenha sido comentado. Se este texto ainda não estiver presente, adicione o texto ao final do arquivo.<Location /server-status> SetHandler server-status Require local </Location>Quando você usa o agente de recursos
apachepara gerenciar o Apache, ele não usasystemd. Por causa disso, você deve editar o scriptlogrotatefornecido com o Apache para que ele não utilizesystemctlpara recarregar o Apache.Remova a seguinte linha no arquivo
/etc/logrotate.d/httpdem cada nó do cluster./bin/systemctl reload httpd.service > /dev/null 2>/dev/null || true
Substitua a linha que você removeu pelas três linhas a seguir.
/usr/bin/test -f /run/httpd.pid >/dev/null 2>/dev/null && /usr/bin/ps -q $(/usr/bin/cat /run/httpd.pid) >/dev/null 2>/dev/null && /usr/sbin/httpd -f /etc/httpd/conf/httpd.conf \ -c "PidFile /run/httpd.pid" -k graceful > /dev/null 2>/dev/null || true
Criar uma página web para que o Apache possa servir. Em um nó do cluster, monte o sistema de arquivo que você criou em Configurando um volume LVM com um sistema de arquivo ext4, crie o arquivo
index.htmlnesse sistema de arquivo, e depois desmonte o sistema de arquivo.#
mount /dev/my_vg/my_lv /var/www/#mkdir /var/www/html#mkdir /var/www/cgi-bin#mkdir /var/www/error#restorecon -R /var/www#cat <<-END >/var/www/html/index.html<html><body>Hello</body></html>END#umount /var/www
5.3. Criação dos recursos e grupos de recursos
Este caso de uso requer que você crie quatro recursos de cluster. Para garantir que todos esses recursos funcionem no mesmo nó, eles são configurados como parte do grupo de recursos apachegroup. Os recursos a serem criados são os seguintes, listados na ordem em que serão iniciados.
-
Um recurso
LVMchamadomy_lvmque usa o grupo de volume LVM que você criou em Configurar um volume LVM com um sistema de arquivo ext4. -
Um recurso
Filesystemchamadomy_fs, que usa o dispositivo de sistema de arquivo/dev/my_vg/my_lvque você criou em Configurando um volume LVM com um sistema de arquivo ext4. -
Um recurso
IPaddr2, que é um endereço IP flutuante para o grupo de recursosapachegroup. O endereço IP não deve ser um endereço já associado a um nó físico. Se o dispositivo NIC do recursoIPaddr2não for especificado, o IP flutuante deve residir na mesma rede que um dos endereços IP do nó estaticamente atribuído, caso contrário o dispositivo NIC para atribuir o endereço IP flutuante não poderá ser detectado corretamente. -
Um recurso
apachechamadoWebsiteque usa o arquivoindex.htmle a configuração do Apache que você definiu em Configurando um servidor Apache HTTP.
O seguinte procedimento cria o grupo de recursos apachegroup e os recursos que o grupo contém. Os recursos começarão na ordem em que são adicionados ao grupo, e pararão na ordem inversa em que são adicionados ao grupo. Execute este procedimento a partir de um único nó do grupo.
O seguinte comando cria o recurso
LVM-activatemy_lvm. Como o grupo de recursosapachegroupainda não existe, este comando cria o grupo de recursos.NotaNão configure mais de um recurso
LVM-activateque utiliza o mesmo grupo de volume LVM em uma configuração HA ativa/passiva, pois isso poderia causar corrupção de dados. Além disso, não configure um recursoLVM-activatecomo um recurso clone em uma configuração de HA ativa/passiva.[root@z1 ~]#
pcs resource create my_lvm ocf:heartbeat:LVM-activatevgname=my_vgvg_access_mode=system_id --group apachegroupQuando você cria um recurso, o recurso é iniciado automaticamente. Você pode usar o seguinte comando para confirmar que o recurso foi criado e foi iniciado.
#
pcs resource statusResource Group: apachegroup my_lvm (ocf::heartbeat:LVM-activate): StartedVocê pode parar e iniciar manualmente um recurso individual com os comandos
pcs resource disableepcs resource enable.Os seguintes comandos criam os recursos restantes para a configuração, adicionando-os ao grupo de recursos existentes
apachegroup.[root@z1 ~]#
pcs resource create my_fs Filesystem\device="/dev/my_vg/my_lv" directory="/var/www" fstype="ext4"\--group apachegroup[root@z1 ~]#pcs resource create VirtualIP IPaddr2 ip=198.51.100.3\cidr_netmask=24 --group apachegroup[root@z1 ~]#pcs resource create Website apache\configfile="/etc/httpd/conf/httpd.conf"\statusurl="http://127.0.0.1/server-status" --group apachegroupDepois de criar os recursos e o grupo de recursos que os contém, você pode verificar o status do agrupamento. Observe que todos os quatro recursos estão funcionando no mesmo nó.
[root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Wed Jul 31 16:38:51 2013 Last change: Wed Jul 31 16:42:14 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com my_fs (ocf::heartbeat:Filesystem): Started z1.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z1.example.com Website (ocf::heartbeat:apache): Started z1.example.comObserve que se você não tiver configurado um dispositivo de esgrima para seu cluster, por padrão os recursos não começam.
Uma vez que o cluster esteja instalado e funcionando, você pode apontar um navegador para o endereço IP que você definiu como o recurso
IPaddr2para visualizar a exibição da amostra, que consiste na simples palavra "Olá".Olá
Se você descobrir que os recursos que você configurou não estão funcionando, você pode executar o
pcs resource debug-start resourcecomando para testar a configuração do recurso.
5.4. Teste da configuração dos recursos
Na exibição do status do cluster mostrada em Criando os recursos e grupos de recursos, todos os recursos estão rodando no nó z1.example.com. Você pode testar se o grupo de recursos falha no nó z2.example.com usando o seguinte procedimento para colocar o primeiro nó no modo standby, após o qual o nó não será mais capaz de hospedar recursos.
O seguinte comando coloca o nó
z1.example.comno modostandby.[root@z1 ~]#
pcs node standby z1.example.comApós colocar o nó
z1no modostandby, verifique o status do agrupamento. Observe que agora todos os recursos devem estar funcionando emz2.[root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Wed Jul 31 17:16:17 2013 Last change: Wed Jul 31 17:18:34 2013 via crm_attribute on z1.example.com Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.10-5.el7-9abe687 2 Nodes configured 6 Resources configured Node z1.example.com (1): standby Online: [ z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: apachegroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com my_fs (ocf::heartbeat:Filesystem): Started z2.example.com VirtualIP (ocf::heartbeat:IPaddr2): Started z2.example.com Website (ocf::heartbeat:apache): Started z2.example.comO site no endereço IP definido ainda deve ser exibido, sem interrupção.
Para remover
z1do modostandby, digite o seguinte comando.[root@z1 ~]#
pcs node unstandby z1.example.comNotaA remoção de um nó do modo
standbynão faz com que os recursos, por si só, falhem de volta a esse nó. Isto dependerá do valorresource-stickinesspara os recursos. Para informações sobre o meta atributoresource-stickiness, consulte Configurando um recurso para preferir seu nó atual.
Capítulo 6. Configuração de um servidor NFS ativo/passivo em um cluster Red Hat High Availability
O procedimento a seguir configura um servidor NFS ativo/passivo altamente disponível em um cluster de dois nós Red Hat Enterprise Linux High Availability Add-On usando armazenamento compartilhado. O procedimento usa pcs para configurar os recursos de cluster do Pacemaker. Neste caso de uso, os clientes acessam o sistema de arquivo NFS através de um endereço IP flutuante. O servidor NFS roda em um dos dois nós do cluster. Se o nó no qual o servidor NFS está rodando se torna inoperante, o servidor NFS inicia novamente no segundo nó do cluster com interrupção mínima do serviço.
6.1. Pré-requisitos
Este caso de uso requer que seu sistema inclua os seguintes componentes:
- Um cluster de dois nós Red Hat High Availability com vedação de energia configurada para cada nó. Recomendamos, mas não exigimos uma rede privada. Este procedimento utiliza o exemplo de cluster fornecido em Criar um cluster Red Hat High-Availability com Pacemaker.
- Um endereço IP virtual público, necessário para o servidor NFS.
- Armazenamento compartilhado para os nós do cluster, utilizando iSCSI, Fibre Channel ou outro dispositivo de bloco de rede compartilhado.
6.2. Visão geral dos procedimentos
A configuração de um servidor NFS ativo/passivo altamente disponível em um cluster Red Hat Enterprise Linux High Availability de dois nós já existente requer que você execute os seguintes passos:
-
Configurar um sistema de arquivo
ext4no volume lógico do LVMmy_lvsobre o armazenamento compartilhado para os nós no cluster. - Configurar um compartilhamento NFS sobre o armazenamento compartilhado no volume lógico LVM.
- Criar os recursos do cluster.
- Teste o servidor NFS que você configurou.
6.3. Configuração de um volume LVM com um sistema de arquivo ext4 em um cluster Pacemaker
Este caso de uso requer a criação de um volume lógico LVM no armazenamento que é compartilhado entre os nós do cluster.
Os volumes LVM e as partições e dispositivos correspondentes usados pelos nós de cluster devem ser conectados somente aos nós de cluster.
O procedimento seguinte cria um volume lógico LVM e depois cria um sistema de arquivo ext4 nesse volume para uso em um cluster de Pacemaker. Neste exemplo, a partição compartilhada /dev/sdb1 é usada para armazenar o volume físico LVM a partir do qual o volume lógico LVM será criado.
Em ambos os nós do cluster, executar os seguintes passos para definir o valor para o ID do sistema LVM para o valor do identificador
unamepara o sistema. O ID do sistema LVM será usado para garantir que somente o cluster seja capaz de ativar o grupo de volume.Defina a opção de configuração
system_id_sourceno arquivo de configuração/etc/lvm/lvm.confparauname.# Configuration option global/system_id_source. system_id_source = "uname"
Verificar se o ID do sistema LVM no nó corresponde ao
unamepara o nó.#
lvm systemidsystem ID: z1.example.com #uname -nz1.example.com
Criar o volume LVM e criar um sistema de arquivo ext4 sobre esse volume. Uma vez que a partição
/dev/sdb1é o armazenamento compartilhado, esta parte do procedimento é realizada em apenas um nó.Criar um volume físico LVM na partição
/dev/sdb1.#
pvcreate /dev/sdb1Physical volume "/dev/sdb1" successfully createdCriar o grupo de volume
my_vgque consiste no volume físico/dev/sdb1.#
vgcreate my_vg /dev/sdb1Volume group "my_vg" successfully createdVerifique se o novo grupo de volume tem a identificação do sistema do nó no qual você está rodando e a partir do qual você criou o grupo de volume.
#
vgs -o+systemidVG #PV #LV #SN Attr VSize VFree System ID my_vg 1 0 0 wz--n- <1.82t <1.82t z1.example.comCriar um volume lógico utilizando o grupo de volume
my_vg.#
lvcreate -L450 -n my_lv my_vgRounding up size to full physical extent 452.00 MiB Logical volume "my_lv" createdVocê pode usar o comando
lvspara exibir o volume lógico.#
lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convert my_lv my_vg -wi-a---- 452.00m ...Criar um sistema de arquivo ext4 no volume lógico
my_lv.#
mkfs.ext4 /dev/my_vg/my_lvmke2fs 1.44.3 (10-July-2018) Creating filesystem with 462848 1k blocks and 115824 inodes ...
6.5. Configuração dos recursos e grupo de recursos para um servidor NFS em um cluster
Esta seção fornece o procedimento para configurar os recursos do cluster para este caso de uso.
Se você não tiver configurado um dispositivo de esgrima para seu cluster, por padrão os recursos não começam.
Se você descobrir que os recursos que você configurou não estão funcionando, você pode executar o pcs resource debug-start resource comando para testar a configuração do recurso. Isto inicia o serviço fora do controle e do conhecimento do cluster. No ponto em que os recursos configurados estão rodando novamente, executar pcs resource cleanup resource para que o grupo tome conhecimento das atualizações.
O procedimento a seguir configura os recursos do sistema. Para garantir que todos estes recursos funcionem no mesmo nó, eles são configurados como parte do grupo de recursos nfsgroup. Os recursos começarão na ordem em que são adicionados ao grupo, e pararão na ordem inversa em que são adicionados ao grupo. Execute este procedimento a partir de um único nó do grupo.
Criar o recurso LVM-activate chamado
my_lvm. Como o grupo de recursosnfsgroupainda não existe, este comando cria o grupo de recursos.AtençãoNão configure mais de um recurso
LVM-activateque utiliza o mesmo grupo de volume LVM em uma configuração HA ativa/passiva, pois isso corre o risco de corrupção de dados. Além disso, não configure um recursoLVM-activatecomo um recurso clone em uma configuração de HA ativa/passiva.[root@z1 ~]#
pcs resource create my_lvm ocf:heartbeat:LVM-activatevgname=my_vgvg_access_mode=system_id --group nfsgroupVerifique o status do agrupamento para verificar se o recurso está funcionando.
root@z1 ~]#
pcs statusCluster name: my_cluster Last updated: Thu Jan 8 11:13:17 2015 Last change: Thu Jan 8 11:13:08 2015 Stack: corosync Current DC: z2.example.com (2) - partition with quorum Version: 1.1.12-a14efad 2 Nodes configured 3 Resources configured Online: [ z1.example.com z2.example.com ] Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com PCSD Status: z1.example.com: Online z2.example.com: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabledConfigurar um recurso
Filesystempara o cluster.O seguinte comando configura um recurso ext4
Filesystemchamadonfssharecomo parte do grupo de recursosnfsgroup. Este sistema de arquivo usa o grupo de volume LVM e o sistema de arquivo ext4 que você criou em Configuring an LVM volume with an ext4 file system e será montado no diretório/nfsshareque você criou em Configuring an NFS share.[root@z1 ~]#
pcs resource create nfsshare Filesystem\device=/dev/my_vg/my_lv directory=/nfsshare\fstype=ext4 --group nfsgroupVocê pode especificar opções de montagem como parte da configuração do recurso para um recurso
Filesystemcom ooptions=optionsparâmetro. Execute o comandopcs resource describe Filesystempara opções de configuração completa.Verifique se os recursos
my_lvmenfsshareestão funcionando.[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com ...Criar o recurso
nfsserverchamadonfs-daemoncomo parte do grupo de recursosnfsgroup.NotaO recurso
nfsserverpermite especificar um parâmetronfs_shared_infodir, que é um diretório que os servidores NFS usam para armazenar informações de estado relacionadas ao NFS.Recomenda-se que este atributo seja definido em um subdiretório de um dos recursos
Filesystemque você criou nesta coleção de exportações. Isto garante que os servidores NFS estejam armazenando suas informações de estado em um dispositivo que ficará disponível para outro nó se este grupo de recursos precisar se relocalizar. Neste exemplo;-
/nfsshareé o diretório de armazéns compartilhados gerenciado pelo recursoFilesystem -
/nfsshare/exports/export1e/nfsshare/exports/export2são os diretórios de exportação -
/nfsshare/nfsinfoé o diretório de informações compartilhadas para o recursonfsserver
[root@z1 ~]#
pcs resource create nfs-daemon nfsserver\nfs_shared_infodir=/nfsshare/nfsinfo nfs_no_notify=true\--group nfsgroup[root@z1 ~]#pcs status...-
Adicione os recursos de
exportfspara exportar o diretório/nfsshare/exports. Estes recursos fazem parte do grupo de recursosnfsgroup. Isto constrói um diretório virtual para clientes do NFSv4. Os clientes do NFSv3 também podem acessar estas exportações.NotaA opção
fsid=0é necessária somente se você quiser criar um diretório virtual para clientes do NFSv4. Para mais informações, veja Como configurar a opção fsid no arquivo /etc/exports de um servidor NFS?[root@z1 ~]#
pcs resource create nfs-root exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash\directory=/nfsshare/exports\fsid=0 --group nfsgroup[root@z1 ~]# #pcs resource create nfs-export1 exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash directory=/nfsshare/exports/export1\fsid=1 --group nfsgroup[root@z1 ~]# #pcs resource create nfs-export2 exportfs\clientspec=192.168.122.0/255.255.255.0\options=rw,sync,no_root_squash directory=/nfsshare/exports/export2\fsid=2 --group nfsgroupAdicione o recurso de endereço IP flutuante que os clientes NFS usarão para acessar o compartilhamento NFS. Este recurso faz parte do grupo de recursos
nfsgroup. Para este exemplo de implantação, estamos usando 192.168.122.200 como o endereço IP flutuante.[root@z1 ~]#
pcs resource create nfs_ip IPaddr2\ip=192.168.122.200 cidr_netmask=24 --group nfsgroupAdicione um recurso
nfsnotifypara enviar notificações de reinicialização do NFSv3 quando toda a implantação do NFS tiver sido iniciada. Este recurso faz parte do grupo de recursosnfsgroup.NotaPara que a notificação NFS seja processada corretamente, o endereço IP flutuante deve ter associado um nome de host que seja consistente tanto nos servidores NFS quanto no cliente NFS.
[root@z1 ~]#
pcs resource create nfs-notify nfsnotify\source_host=192.168.122.200 --group nfsgroupDepois de criar os recursos e as restrições de recursos, você pode verificar o status do agrupamento. Observe que todos os recursos estão funcionando no mesmo nó.
[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...
6.6. Teste da configuração do recurso NFS
Você pode validar a configuração de seu sistema com os seguintes procedimentos. Você deve ser capaz de montar o sistema de arquivo exportado com NFSv3 ou NFSv4.
6.6.1. Teste da exportação do NFS
Em um nó fora do agrupamento, residindo na mesma rede que a instalação, verifique se o compartilhamento NFS pode ser visto através da montagem do compartilhamento NFS. Para este exemplo, estamos utilizando a rede 192.168.122.0/24.
#
showmount -e 192.168.122.200Export list for 192.168.122.200: /nfsshare/exports/export1 192.168.122.0/255.255.255.0 /nfsshare/exports 192.168.122.0/255.255.255.0 /nfsshare/exports/export2 192.168.122.0/255.255.255.0Para verificar se você pode montar o compartilhamento NFS com o NFSv4, monte o compartilhamento NFS em um diretório no nó do cliente. Após a montagem, verifique se o conteúdo dos diretórios de exportação está visível. Desmonte o compartilhamento após o teste.
#
mkdir nfsshare#mount -o "vers=4" 192.168.122.200:export1 nfsshare#ls nfsshareclientdatafile1 #umount nfsshareVerifique se você pode montar o compartilhamento do NFS com o NFSv3. Após a montagem, verifique se o arquivo de teste
clientdatafile1está visível. Ao contrário do NFSv4, como o NFSv3 não utiliza o sistema de arquivo virtual, você deve montar uma exportação específica. Desmonte o compartilhamento após o teste.#
mkdir nfsshare#mount -o "vers=3" 192.168.122.200:/nfsshare/exports/export2 nfsshare#ls nfsshareclientdatafile2 #umount nfsshare
6.6.2. Teste de failover
Em um nó fora do cluster, montar o compartilhamento NFS e verificar o acesso ao
clientdatafile1que criamos em Configuring an NFS share#
mkdir nfsshare#mount -o "vers=4" 192.168.122.200:export1 nfsshare#ls nfsshareclientdatafile1A partir de um nó dentro do agrupamento, determinar qual nó do agrupamento está funcionando
nfsgroup. Neste exemplo,nfsgroupestá rodando emz1.example.com.[root@z1 ~]#
pcs status... Full list of resources: myapc (stonith:fence_apc_snmp): Started z1.example.com Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z1.example.com nfsshare (ocf::heartbeat:Filesystem): Started z1.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z1.example.com nfs-root (ocf::heartbeat:exportfs): Started z1.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z1.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z1.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z1.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z1.example.com ...A partir de um nó dentro do agrupamento, coloque o nó que está rodando
nfsgroupem modo de espera.[root@z1 ~]#
pcs node standby z1.example.comVerifique se
nfsgroupcomeça com sucesso no outro nó de agrupamento.[root@z1 ~]#
pcs status... Full list of resources: Resource Group: nfsgroup my_lvm (ocf::heartbeat:LVM): Started z2.example.com nfsshare (ocf::heartbeat:Filesystem): Started z2.example.com nfs-daemon (ocf::heartbeat:nfsserver): Started z2.example.com nfs-root (ocf::heartbeat:exportfs): Started z2.example.com nfs-export1 (ocf::heartbeat:exportfs): Started z2.example.com nfs-export2 (ocf::heartbeat:exportfs): Started z2.example.com nfs_ip (ocf::heartbeat:IPaddr2): Started z2.example.com nfs-notify (ocf::heartbeat:nfsnotify): Started z2.example.com ...A partir do nó fora do agrupamento no qual você montou a parte NFS, verifique se este nó externo ainda continua a ter acesso ao arquivo de teste dentro da montagem NFS.
#
ls nfsshareclientdatafile1O serviço será perdido brevemente para o cliente durante o failover, mas o cliente deverá recuperá-lo sem intervenção do usuário. Por padrão, os clientes que utilizam o NFSv4 podem levar até 90 segundos para recuperar a montagem; estes 90 segundos representam o período de graça do NFSv4 observado pelo servidor na inicialização. Os clientes do NFSv3 devem recuperar o acesso à montagem em questão de poucos segundos.
De um nó dentro do agrupamento, remova o nó que estava inicialmente rodando
nfsgroupdo modo de espera.NotaA remoção de um nó do modo
standbynão faz com que os recursos, por si só, falhem de volta a esse nó. Isto dependerá do valorresource-stickinesspara os recursos. Para informações sobre o meta atributoresource-stickiness, consulte Configurando um recurso para preferir seu nó atual.[root@z1 ~]#
pcs node unstandby z1.example.com
Capítulo 7. Sistemas de arquivo GFS2 em um cluster
Esta seção fornece:
- Um procedimento para criar um cluster de Pacemaker que inclui sistemas de arquivo GFS2
- Um procedimento para migrar os volumes lógicos RHEL 7 que contêm sistemas de arquivo GFS2 para um cluster RHEL 8
7.1. Configuração de um sistema de arquivo GFS2 em um cluster
Este procedimento é um esboço dos passos necessários para a criação de um cluster Pacemaker que inclui sistemas de arquivos GFS2. Este exemplo cria três sistemas de arquivos GFS2 em três volumes lógicos.
Como pré-requisito para este procedimento, você deve instalar e iniciar o software de cluster em todos os nós e criar um cluster básico de dois nós. Você também deve configurar a vedação para o cluster. Para informações sobre como criar um cluster Pacemaker e configurar a vedação para o cluster, veja Criar um cluster Red Hat High-Availability com Pacemaker.
Procedimento
Em ambos os nós do cluster, instalar os pacotes
lvm2-lockd,gfs2-utils, edlm. O pacotelvm2-lockdfaz parte do canal AppStream e os pacotesgfs2-utilsedlmfazem parte do canal de Armazenamento Resiliente.#
yum install lvm2-lockd gfs2-utils dlmDefinir o parâmetro global Pacemaker
no_quorum_policyparafreeze.NotaPor padrão, o valor de
no-quorum-policyestá definido parastop, indicando que uma vez perdido o quorum, todos os recursos na partição restante serão imediatamente parados. Normalmente este padrão é a opção mais segura e ótima, mas ao contrário da maioria dos recursos, o GFS2 requer quorum para funcionar. Quando o quorum é perdido, tanto as aplicações que utilizam os suportes GFS2 como o próprio suporte GFS2 não podem ser parados corretamente. Qualquer tentativa de parar estes recursos sem quorum falhará, o que resultará no final em todo o aglomerado ser cercado toda vez que o quorum for perdido.Para resolver esta situação, defina
no-quorum-policyparafreezequando o GFS2 estiver em uso. Isto significa que quando o quorum for perdido, a partição restante não fará nada até que o quorum seja recuperado.#
pcs property set no-quorum-policy=freezeConfigurar um recurso em
dlm. Esta é uma dependência necessária para configurar um sistema de arquivos GFS2 em um cluster. Este exemplo cria o recursodlmcomo parte de um grupo de recursos chamadolocking.[root@z1 ~]#
pcs resource create dlm --group locking ocf:pacemaker:controld op monitor interval=30s on-fail=fenceClonar o grupo de recursos
lockingpara que o grupo de recursos possa estar ativo nos dois nós do cluster.[root@z1 ~]#
pcs resource clone locking interleave=trueEstabelecer um recurso
lvmlockdcomo parte do grupolocking.[root@z1 ~]#
pcs resource create lvmlockd --group locking ocf:heartbeat:lvmlockd op monitor interval=30s on-fail=fenceVerifique o status do agrupamento para garantir que o grupo de recursos
lockingtenha começado em ambos os nós do agrupamento.[root@z1 ~]#
pcs status --fullCluster name: my_cluster [...] Online: [ z1.example.com (1) z2.example.com (2) ] Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Started: [ z1.example.com z2.example.com ]Verifique se o daemon
lvmlockdestá rodando nos dois nós do cluster.[root@z1 ~]#
ps -ef | grep lvmlockdroot 12257 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlm [root@z2 ~]#ps -ef | grep lvmlockdroot 12270 1 0 17:45 ? 00:00:00 lvmlockd -p /run/lvmlockd.pid -A 1 -g dlmEm um nó do agrupamento, criar dois grupos de volume compartilhado. Um grupo de volume conterá dois sistemas de arquivos GFS2 e o outro grupo de volume conterá um sistema de arquivos GFS2.
O seguinte comando cria o grupo de volume compartilhado
shared_vg1em/dev/vdb.[root@z1 ~]#
vgcreate --shared shared_vg1 /dev/vdbPhysical volume "/dev/vdb" successfully created. Volume group "shared_vg1" successfully created VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready...O seguinte comando cria o grupo de volume compartilhado
shared_vg2em/dev/vdc.[root@z1 ~]#
vgcreate --shared shared_vg2 /dev/vdcPhysical volume "/dev/vdc" successfully created. Volume group "shared_vg2" successfully created VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...No segundo nó do agrupamento, inicie o gerenciador de fechaduras para cada um dos grupos de volume compartilhado.
[root@z2 ~]#
vgchange --lock-start shared_vg1VG shared_vg1 starting dlm lockspace Starting locking. Waiting until locks are ready... [root@z2 ~]#vgchange --lock-start shared_vg2VG shared_vg2 starting dlm lockspace Starting locking. Waiting until locks are ready...Em um nó do cluster, criar os volumes lógicos compartilhados e formatar os volumes com um sistema de arquivos GFS2. É necessário um diário para cada nó que monta o sistema de arquivo. Certifique-se de criar periódicos suficientes para cada um dos nós de seu cluster.
[root@z1 ~]#
lvcreate --activate sy -L5G -n shared_lv1 shared_vg1Logical volume "shared_lv1" created. [root@z1 ~]#lvcreate --activate sy -L5G -n shared_lv2 shared_vg1Logical volume "shared_lv2" created. [root@z1 ~]#lvcreate --activate sy -L5G -n shared_lv1 shared_vg2Logical volume "shared_lv1" created. [root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo1 /dev/shared_vg1/shared_lv1[root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo2 /dev/shared_vg1/shared_lv2[root@z1 ~]#mkfs.gfs2 -j2 -p lock_dlm -t my_cluster:gfs2-demo3 /dev/shared_vg2/shared_lv1Crie um recurso
LVM-activatepara cada volume lógico para ativar automaticamente esse volume lógico em todos os nós.Criar um recurso
LVM-activatechamadosharedlv1para o volume lógicoshared_lv1no grupo de volumeshared_vg1. Este comando também cria o grupo de recursosshared_vg1que inclui o recurso. Neste exemplo, o grupo de recursos tem o mesmo nome do grupo de volume compartilhado que inclui o volume lógico.[root@z1 ~]#
pcs resource create sharedlv1 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCriar um recurso
LVM-activatechamadosharedlv2para o volume lógicoshared_lv2no grupo de volumeshared_vg1. Este recurso também fará parte do grupo de recursosshared_vg1.[root@z1 ~]#
pcs resource create sharedlv2 --group shared_vg1 ocf:heartbeat:LVM-activate lvname=shared_lv2 vgname=shared_vg1 activation_mode=shared vg_access_mode=lvmlockdCriar um recurso
LVM-activatechamadosharedlv3para o volume lógicoshared_lv1no grupo de volumeshared_vg2. Este comando também cria o grupo de recursosshared_vg2que inclui o recurso.[root@z1 ~]#
pcs resource create sharedlv3 --group shared_vg2 ocf:heartbeat:LVM-activate lvname=shared_lv1 vgname=shared_vg2 activation_mode=shared vg_access_mode=lvmlockd
Clonar os dois novos grupos de recursos.
[root@z1 ~]#
pcs resource clone shared_vg1 interleave=true[root@z1 ~]#pcs resource clone shared_vg2 interleave=trueConfigurar as restrições de pedidos para garantir que o grupo de recursos
lockingque inclui os recursosdlmelvmlockdcomece primeiro.[root@z1 ~]#
pcs constraint order start locking-clone then shared_vg1-cloneAdding locking-clone shared_vg1-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@z1 ~]#pcs constraint order start locking-clone then shared_vg2-cloneAdding locking-clone shared_vg2-clone (kind: Mandatory) (Options: first-action=start then-action=start)Configurar as restrições de colocação para garantir que os grupos de recursos
vg1evg2comecem no mesmo nó que o grupo de recursoslocking.[root@z1 ~]#
pcs constraint colocation add shared_vg1-clone with locking-clone[root@z1 ~]#pcs constraint colocation add shared_vg2-clone with locking-cloneEm ambos os nós do agrupamento, verificar se os volumes lógicos estão ativos. Pode haver um atraso de alguns segundos.
[root@z1 ~]#
lvsLV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00g [root@z2 ~]#lvsLV VG Attr LSize shared_lv1 shared_vg1 -wi-a----- 5.00g shared_lv2 shared_vg1 -wi-a----- 5.00g shared_lv1 shared_vg2 -wi-a----- 5.00gCriar um recurso de sistema de arquivo para montar automaticamente cada sistema de arquivo GFS2 em todos os nós.
Você não deve adicionar o sistema de arquivo ao arquivo
/etc/fstabporque ele será gerenciado como um recurso de cluster Pacemaker. As opções de montagem podem ser especificadas como parte da configuração do recurso comoptions=options. Execute o comandopcs resource describe Filesystempara opções de configuração completa.Os seguintes comandos criam os recursos do sistema de arquivos. Estes comandos adicionam cada recurso ao grupo de recursos que inclui o recurso de volume lógico para aquele sistema de arquivo.
[root@z1 ~]#
pcs resource create sharedfs1 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv1" directory="/mnt/gfs1" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence[root@z1 ~]#pcs resource create sharedfs2 --group shared_vg1 ocf:heartbeat:Filesystem device="/dev/shared_vg1/shared_lv2" directory="/mnt/gfs2" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fence[root@z1 ~]#pcs resource create sharedfs3 --group shared_vg2 ocf:heartbeat:Filesystem device="/dev/shared_vg2/shared_lv1" directory="/mnt/gfs3" fstype="gfs2" options=noatime op monitor interval=10s on-fail=fenceVerificar se os sistemas de arquivo GFS2 estão montados em ambos os nós do cluster.
[root@z1 ~]#
mount | grep gfs2/dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel) [root@z2 ~]#mount | grep gfs2/dev/mapper/shared_vg1-shared_lv1 on /mnt/gfs1 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg1-shared_lv2 on /mnt/gfs2 type gfs2 (rw,noatime,seclabel) /dev/mapper/shared_vg2-shared_lv1 on /mnt/gfs3 type gfs2 (rw,noatime,seclabel)Verifique o status do agrupamento.
[root@z1 ~]#
pcs status --fullCluster name: my_cluster [...1 Full list of resources: smoke-apc (stonith:fence_apc): Started z1.example.com Clone Set: locking-clone [locking] Resource Group: locking:0 dlm (ocf::pacemaker:controld): Started z2.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z2.example.com Resource Group: locking:1 dlm (ocf::pacemaker:controld): Started z1.example.com lvmlockd (ocf::heartbeat:lvmlockd): Started z1.example.com Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg1-clone [shared_vg1] Resource Group: shared_vg1:0 sharedlv1 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z2.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg1:1 sharedlv1 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedlv2 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs1 (ocf::heartbeat:Filesystem): Started z1.example.com sharedfs2 (ocf::heartbeat:Filesystem): Started example.co Started: [ z1.example.com z2.example.com ] Clone Set: shared_vg2-clone [shared_vg2] Resource Group: shared_vg2:0 sharedlv3 (ocf::heartbeat:LVM-activate): Started z2.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z2.example.com Resource Group: shared_vg2:1 sharedlv3 (ocf::heartbeat:LVM-activate): Started z1.example.com sharedfs3 (ocf::heartbeat:Filesystem): Started z1.example.com Started: [ z1.example.com z2.example.com ] ...
Recursos adicionais
- Para informações sobre a configuração do armazenamento em bloco compartilhado para um cluster Red Hat High Availability com discos compartilhados Microsoft Azure, consulte Configuração do armazenamento em bloco compartilhado.
- Para informações sobre a configuração do armazenamento em bloco compartilhado para um cluster Red Hat High Availability com volumes Amazon EBS Multi-Attach, consulte Configuração do armazenamento em bloco compartilhado.
- Para informações sobre como configurar o armazenamento em blocos compartilhados para um cluster de alta disponibilidade da Red Hat em Alibaba Cloud, veja Configurando o armazenamento em blocos compartilhados para um cluster de alta disponibilidade da Red Hat em Alibaba Cloud.
7.2. Migração de um sistema de arquivos GFS2 de RHEL7 para RHEL8
No Red Hat Enterprise Linux 8, o LVM usa o daemon LVM lock lvmlockd ao invés de clvmd para gerenciar dispositivos de armazenamento compartilhado em um cluster ativo/ativo. Isto requer que você configure os volumes lógicos que seu cluster ativo/ativo irá requerer como volumes lógicos compartilhados. Além disso, isto requer que você use o recurso LVM-activate para gerenciar um volume LVM e que você use o agente de recursos lvmlockd para gerenciar o daemon lvmlockd. Veja Configurando um sistema de arquivos GFS2 em um cluster para um procedimento completo de configuração de um cluster Pacemaker que inclui sistemas de arquivos GFS2 usando volumes lógicos compartilhados.
Para usar seus volumes lógicos existentes do Red Hat Enterprise Linux 7 ao configurar um cluster RHEL8 que inclui sistemas de arquivo GFS2, execute o seguinte procedimento a partir do cluster RHEL8. Neste exemplo, o volume lógico do cluster RHEL 7 faz parte do grupo de volume upgrade_gfs_vg.
O cluster RHEL8 deve ter o mesmo nome que o cluster RHEL7 que inclui o sistema de arquivos GFS2 para que o sistema de arquivos existente seja válido.
- Certifique-se de que os volumes lógicos contendo os sistemas de arquivo GFS2 estejam atualmente inativos. Este procedimento é seguro somente se todos os nós tiverem parado de usar o grupo de volume.
A partir de um nó no aglomerado, mudar forçadamente o grupo de volume para ser local.
[root@rhel8-01 ~]#
vgchange --lock-type none --lock-opt force upgrade_gfs_vgForcibly change VG lock type to none? [y/n]: y Volume group "upgrade_gfs_vg" successfully changedDe um nó no agrupamento, mude o grupo de volume local para um grupo de volume compartilhado
[root@rhel8-01 ~]#
vgchange --lock-type dlm upgrade_gfs_vgVolume group "upgrade_gfs_vg" successfully changedEm cada nó do aglomerado, comece a travar para o grupo de volume.
[root@rhel8-01 ~]#
vgchange --lock-start upgrade_gfs_vgVG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready... [root@rhel8-02 ~]#vgchange --lock-start upgrade_gfs_vgVG upgrade_gfs_vg starting dlm lockspace Starting locking. Waiting until locks are ready...
Após realizar este procedimento, você pode criar um recurso LVM-activate para cada volume lógico.
Capítulo 8. Começando com o pcsd Web UI
A pcsd Web UI é uma interface gráfica do usuário para criar e configurar clusters Pacemaker/Corosync.
8.1. Instalação de software de cluster
O seguinte procedimento instala o software de cluster e configura seu sistema para a criação de clusters.
Em cada nó do cluster, instale os pacotes de software Red Hat High Availability Add-On junto com todos os agentes de vedação disponíveis no canal High Availability.
#
yum install pcs pacemaker fence-agents-allAlternativamente, você pode instalar os pacotes de software Red Hat High Availability Add-On junto com apenas o agente de vedação que você necessita com o seguinte comando.
#
yum install pcs pacemaker fence-agents-modelO comando a seguir exibe uma lista dos agentes de vedação disponíveis.
#
rpm -q -a | grep fencefence-agents-rhevm-4.0.2-3.el7.x86_64 fence-agents-ilo-mp-4.0.2-3.el7.x86_64 fence-agents-ipmilan-4.0.2-3.el7.x86_64 ...AtençãoApós instalar os pacotes Red Hat High Availability Add-On, você deve assegurar-se de que suas preferências de atualização de software estejam definidas para que nada seja instalado automaticamente. A instalação em um cluster em execução pode causar comportamentos inesperados. Para mais informações, consulte Práticas recomendadas para a aplicação de atualizações de software em um cluster de armazenamento RHEL de alta disponibilidade ou resiliente.
Se você estiver executando o daemon
firewalld, execute os seguintes comandos para habilitar as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.NotaVocê pode determinar se o daemon
firewalldestá instalado em seu sistema com o comandorpm -q firewalld. Se ele estiver instalado, você pode determinar se ele está rodando com o comandofirewall-cmd --state.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityNotaA configuração ideal de firewall para componentes de cluster depende do ambiente local, onde talvez seja necessário levar em conta considerações como, por exemplo, se os nós têm múltiplas interfaces de rede ou se há firewalls fora do host. O exemplo aqui, que abre as portas que são geralmente exigidas por um cluster Pacemaker, deve ser modificado para se adequar às condições locais. A habilitação de portas para o Add-On de Alta Disponibilidade mostra as portas para habilitar para o Add-On de Alta Disponibilidade da Red Hat e fornece uma explicação para o que cada porta é usada.
Para usar
pcspara configurar o cluster e se comunicar entre os nós, você deve definir uma senha em cada nó para o ID do usuáriohacluster, que é a conta de administraçãopcs. É recomendado que a senha para o usuáriohaclusterseja a mesma em cada nó.#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Antes que o cluster possa ser configurado, o daemon
pcsddeve ser iniciado e habilitado para iniciar na inicialização em cada nó. Este daemon trabalha com o comandopcspara gerenciar a configuração através dos nós do cluster.Em cada nó do cluster, execute os seguintes comandos para iniciar o serviço
pcsde para habilitarpcsdno início do sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
8.2. Criação da interface Web do pcsd
Após ter instalado as ferramentas de configuração do Pacemaker e configurado seu sistema para configuração de cluster, use o seguinte procedimento para configurar seu sistema para usar a interface web pcsd para configurar um cluster.
Em qualquer sistema, abra um navegador para o seguinte URL, especificando um dos nós do cluster (note que este usa o protocolo
https). Isto faz surgir a tela de loginpcsdWeb UI.https://nodename:2224Faça o login como usuário
hacluster. Isto traz à tona a páginaManage Clusterscomo mostrado em Figura 8.1, “Página Gerenciar Clusters”.Figura 8.1. Página Gerenciar Clusters
8.3. Criando um cluster com o pcsd Web UI
A partir da página Gerenciar clusters, você pode criar um novo cluster, adicionar um cluster existente à interface web, ou remover um cluster da interface web.
-
Para criar um cluster, clique em
Create New. Digite o nome do agrupamento a ser criado e os nós que constituem o agrupamento. Se você não tiver autenticado previamente o usuáriohaclusterpara cada nó do cluster, será solicitado que você autentique os nós do cluster. -
Ao criar o cluster, você pode configurar opções avançadas de cluster, clicando em
Go to advanced settingsnesta tela. As configurações avançadas de cluster que você pode configurar são descritas em Configuração de opções avançadas de configuração de cluster com a interface Web do pcsd. -
Para adicionar um cluster existente à interface web, clique em
Add Existinge digite o nome do host ou endereço IP de um nó no cluster que você gostaria de gerenciar com a interface web.
Uma vez criado ou adicionado um agrupamento, o nome do agrupamento é exibido na página Gerenciar Agrupamento. Selecionando o agrupamento, são exibidas informações sobre o agrupamento.
Ao usar a interface pcsd para configurar um cluster, você pode mover o mouse sobre o texto descrevendo muitas das opções para ver descrições mais longas dessas opções como um display tooltip.
8.3.1. Configuração de opções avançadas de configuração de clusters com a interface Web do pcsd
Ao criar um cluster, você pode configurar opções adicionais de cluster clicando em na tela Criar cluster. Isto permite modificar as configurações configuráveis dos seguintes componentes do cluster:
- Configurações de transporte: Valores para o mecanismo de transporte utilizado para a comunicação em cluster
-
Ajustes do quorum: Valores para as opções de quorum do serviço
votequorum - Ajustes do Totem: Valores para o protocolo Totem usado pela Corosync
Selecionando essas opções, são exibidas as configurações que você pode configurar. Para obter informações sobre cada uma das configurações, coloque o ponteiro do mouse sobre a opção em particular.
8.3.2. Definição de permissões de gerenciamento de clusters
Há dois conjuntos de permissões de agrupamento que você pode conceder aos usuários:
-
Permissões para gerenciar o cluster com a interface Web, que também concede permissões para executar comandos
pcsque se conectam aos nós através de uma rede. Esta seção descreve como configurar essas permissões com a interface Web. - Permissões para usuários locais para permitir o acesso somente leitura ou leitura-escrita à configuração do cluster, usando ACLs. A configuração de ACLs com a interface Web é descrita em Configuração de componentes de cluster com a interface Web pcsd.
Você pode conceder permissão para usuários específicos que não o usuário hacluster para gerenciar o cluster através da interface Web e executar comandos pcs que se conectam aos nós através de uma rede, adicionando-os ao grupo haclient. Você pode então configurar as permissões definidas para um membro individual do grupo haclient, clicando na guia Permissões na página Gerenciar clusters e definindo as permissões na tela resultante. A partir desta tela, você também pode configurar as permissões para os grupos.
Você pode conceder as seguintes permissões:
- Leia as permissões, para ver as configurações do cluster
- Escrever permissões, para modificar as configurações do cluster (exceto permissões e ACLs)
- Conceder permissões, para modificar as permissões de agrupamento e ACLs
- Permissões completas, para acesso irrestrito a um cluster, incluindo adição e remoção de nós, com acesso a chaves e certificados
8.4. Configuração de componentes de cluster com o pcsd Web UI
Para configurar os componentes e atributos de um cluster, clique no nome do cluster exibido na tela Manage Clusters. Isto faz surgir a página Nodes, conforme descrito em Seção 8.4.1, “Configuração de nós de cluster com a interface Web do pcsd”. Esta página exibe um menu na parte superior da página com as seguintes entradas:
- Nós, como descrito em Seção 8.4.1, “Configuração de nós de cluster com a interface Web do pcsd”
- Recursos, conforme descritos em Seção 8.4.2, “Configuração de recursos de cluster com o pcsd Web UI”
- Dispositivos de vedação, como descrito em Seção 8.4.3, “Configuração de dispositivos de vedação com a interface Web do pcsd”
- ACLs, como descrito em Seção 8.4.4, “Configuração de ACLs com a interface web pcsd”
- Propriedades do Cluster, como descrito em Seção 8.4.5, “Configuração das propriedades do cluster com a interface Web do pcsd”
8.4.1. Configuração de nós de cluster com a interface Web do pcsd
Selecionando a opção Nodes no menu ao longo da parte superior da página de gerenciamento de cluster exibe os nós atualmente configurados e o status do nó atualmente selecionado, incluindo quais recursos estão rodando no nó e as preferências de localização de recursos. Esta é a página padrão que é exibida quando você seleciona um cluster na tela Manage Clusters.
Forme esta página, Você pode adicionar ou remover nós. Você também pode iniciar, parar, reiniciar ou colocar um nó em modo de espera ou de manutenção. Para informações sobre o modo standby, consulte Colocando um nó em modo standby. Para informações sobre o modo de manutenção, consulte Colocando um nó em modo de manutenção.
Você também pode configurar os dispositivos de vedação diretamente desta página, como descrito na seleção Configure Fencing. A configuração dos dispositivos de cercas é descrita em Seção 8.4.3, “Configuração de dispositivos de vedação com a interface Web do pcsd”.
8.4.2. Configuração de recursos de cluster com o pcsd Web UI
Selecionando a opção Resources no menu ao longo da parte superior da página de gerenciamento de cluster exibe os recursos atualmente configurados para o cluster, organizados de acordo com grupos de recursos. A seleção de um grupo ou recurso exibe os atributos desse grupo ou recurso.
A partir desta tela, você pode adicionar ou remover recursos, pode editar a configuração dos recursos existentes e pode criar um grupo de recursos.
Acrescentar um novo recurso ao agrupamento:
-
Clique em
Add. Isto faz surgir a telaAdd Resource. -
Quando você seleciona um tipo de recurso no menu suspenso
Type, os argumentos que você deve especificar para esse recurso aparecem no menu. -
Você pode clicar em
Optional Argumentspara exibir argumentos adicionais que você pode especificar para o recurso que você está definindo. -
Após inserir os parâmetros para o recurso que você está criando, clique em
Create Resource.
Ao configurar os argumentos para um recurso, uma breve descrição do argumento aparece no menu. Se você mover o cursor para o campo, é exibida uma descrição mais longa da ajuda desse argumento.
Você pode definir um recurso como um recurso clonado, ou como um recurso clonado promocional. Para informações sobre estes tipos de recursos, consulte Criando recursos de cluster que estão ativos em vários nós (recursos clonados).
Uma vez criado pelo menos um recurso, você pode criar um grupo de recursos. Para obter informações gerais sobre grupos de recursos, consulte Configuração de grupos de recursos.
Para criar um grupo de recursos:
-
Selecione os recursos que farão parte do grupo na tela
Resourcese, em seguida, clique emCreate Group. Isto exibe a telaCreate Group. -
A partir da tela
Create Group, você pode reorganizar a ordem dos recursos em um grupo de recursos usando o recurso de arrastar e soltar para mover a lista dos recursos de um lugar para outro. -
Digite um nome de grupo e clique em
Create Group. Isto o retorna à telaResources, que agora exibe o nome do grupo e os recursos dentro desse grupo.
Após ter criado um grupo de recursos, você pode indicar o nome desse grupo como parâmetro de recurso ao criar ou modificar recursos adicionais.
8.4.3. Configuração de dispositivos de vedação com a interface Web do pcsd
Selecionando a opção Fence Devices no menu ao longo da parte superior da página de gerenciamento de agrupamento exibe a tela Fence Devices, mostrando os dispositivos de vedação atualmente configurados.
Para adicionar um novo dispositivo de cerca ao conjunto:
-
Clique em
Add. Isto faz surgir a telaAdd Fence Device. -
Quando você seleciona um tipo de dispositivo de cerca no menu suspenso
Type, os argumentos que você deve especificar para aquele dispositivo de cerca aparecem no menu. -
Você pode clicar em
Optional Argumentspara exibir argumentos adicionais que você pode especificar para o dispositivo de cerca que você está definindo. -
Após inserir os parâmetros para o novo dispositivo de vedação, clique em
Create Fence Instance.
Para configurar um dispositivo de esgrima SBD, clique em SBD na tela Fence Devices. Isto chama uma tela que lhe permite ativar ou desativar a SBD no cluster.
Para mais informações sobre dispositivos de cercas, consulte Configuração de cercas em um cluster de Alta Disponibilidade da Red Hat.
8.4.4. Configuração de ACLs com a interface web pcsd
Selecionando a opção ACLS no menu ao longo do topo da página de gerenciamento de cluster exibe uma tela a partir da qual você pode definir permissões para usuários locais, permitindo acesso somente leitura ou leitura-escrita à configuração do cluster usando listas de controle de acesso (ACLs).
Para atribuir permissões ACL, você cria uma função e define as permissões de acesso para essa função. Cada função pode ter um número ilimitado de permissões (leitura/escrita/denúncia) aplicadas a uma consulta XPath ou à identificação de um elemento específico. Após definir a função, você pode atribuí-la a um usuário ou grupo existente.
Para mais informações sobre a atribuição de permissões usando ACLs, consulte Definindo permissões locais usando ACLs.
8.4.5. Configuração das propriedades do cluster com a interface Web do pcsd
Selecionando a opção Cluster Properties no menu ao longo do topo da página de gerenciamento de cluster exibe as propriedades do cluster e permite modificar estas propriedades a partir de seus valores padrão. Para obter informações sobre as propriedades de agrupamento do Pacemaker, consulte Propriedades de agrupamento do Pacemaker.
8.5. Configuração de uma interface Web pcsd de alta disponibilidade
Quando você usa a interface pcsd, você se conecta a um dos nós do cluster para exibir as páginas de gerenciamento do cluster. Se o nó ao qual você está se conectando cair ou ficar indisponível, você pode reconectar-se ao cluster abrindo seu navegador para uma URL que especifique um nó diferente do cluster.
É possível, no entanto, configurar a própria interface pcsd para alta disponibilidade, caso em que você pode continuar a gerenciar o cluster sem entrar em uma nova URL.
Para configurar a interface web pcsd para alta disponibilidade, execute os seguintes passos.
-
Certifique-se de que os certificados
pcsdestejam sincronizados entre os nós do cluster, definindoPCSD_SSL_CERT_SYNC_ENABLEDparatrueno arquivo de configuração/etc/sysconfig/pcsd. A habilitação da sincronização de certificados faz com quepcsdsincronize os certificados para a configuração do cluster e os comandos de adição de nós. No RHEL 8,PCSD_SSL_CERT_SYNC_ENABLEDé definido comofalsepor padrão. -
Crie um recurso de cluster
IPaddr2, que é um endereço IP flutuante que você usará para se conectar àpcsdWeb UI. O endereço IP não deve ser um endereço já associado a um nó físico. Se o dispositivo NIC do recursoIPaddr2não for especificado, o IP flutuante deve residir na mesma rede que um dos endereços IP do nó estaticamente atribuído, caso contrário o dispositivo NIC para atribuir o endereço IP flutuante não poderá ser detectado adequadamente. Criar certificados SSL personalizados para uso com
pcsde garantir que eles sejam válidos para os endereços dos nós usados para conexão com a IU da Webpcsd.- Para criar certificados SSL personalizados, você pode usar certificados wildcard ou pode usar a extensão do certificado Subject Alternative Name. Para informações sobre o Sistema de Certificados Red Hat, consulte o Guia de Administração do Sistema de Certificados Red Hat.
-
Instale os certificados personalizados para
pcsdcom o comandopcs pcsd certkey. -
Sincronize os certificados
pcsdpara todos os nós do cluster com o comandopcs pcsd sync-certificates.
-
Conecte-se à
pcsdWeb UI usando o endereço IP flutuante que você configurou como um recurso de cluster.
Mesmo quando você configurar a interface pcsd para alta disponibilidade, você será solicitado a entrar novamente quando o nó ao qual você está se conectando for desligado.
Capítulo 9. Configuração de cercas em um cluster de alta disponibilidade de chapéu vermelho
Um nó que não responde ainda pode estar acessando dados. A única maneira de ter certeza de que seus dados estão seguros é cercando o nó usando STONITH. STONITH é um acrônimo para "Shoot The Other Node In The Head" e protege seus dados de serem corrompidos por nós desonestos ou acessos simultâneos. Usando STONITH, você pode ter certeza de que um nó está verdadeiramente offline antes de permitir que os dados sejam acessados de outro nó.
A STONITH também tem um papel a desempenhar no caso de um serviço agrupado não poder ser interrompido. Neste caso, o cluster utiliza STONITH para forçar o nó inteiro a ficar offline, tornando assim seguro iniciar o serviço em outro lugar.
Para informações gerais mais completas sobre cercas e sua importância em um cluster da Red Hat High Availability, veja Fencing in a Red Hat High Availability Cluster.
Você implementa STONITH em um aglomerado de Pacemaker, configurando dispositivos de vedação para os nós do aglomerado.
9.1. Exibição dos agentes de vedação disponíveis e suas opções
Use o seguinte comando para visualizar a lista de todos os agentes STONITH disponíveis. Quando você especifica um filtro, este comando exibe apenas os agentes STONITH que correspondem ao filtro.
pcs stonith list [filter]Use o seguinte comando para visualizar as opções para o agente STONITH especificado.
pcs stonith descrevem stonith_agentPor exemplo, o seguinte comando exibe as opções para o agente de vedação para APC sobre telnet/SSH.
# pcs stonith describe fence_apc
Stonith options for: fence_apc
ipaddr (required): IP Address or Hostname
login (required): Login Name
passwd: Login password or passphrase
passwd_script: Script to retrieve password
cmd_prompt: Force command prompt
secure: SSH connection
port (required): Physical plug number or name of virtual machine
identity_file: Identity file for ssh
switch: Physical switch number on device
inet4_only: Forces agent to use IPv4 addresses only
inet6_only: Forces agent to use IPv6 addresses only
ipport: TCP port to use for connection with device
action (required): Fencing Action
verbose: Verbose mode
debug: Write debug information to given file
version: Display version information and exit
help: Display help and exit
separator: Separator for CSV created by operation list
power_timeout: Test X seconds for status change after ON/OFF
shell_timeout: Wait X seconds for cmd prompt after issuing command
login_timeout: Wait X seconds for cmd prompt after login
power_wait: Wait X seconds after issuing ON/OFF
delay: Wait X seconds before fencing is started
retry_on: Count of attempts to retry power on
Para agentes de cercas que fornecem uma opção method, um valor de cycle não é apoiado e não deve ser especificado, pois pode causar corrupção de dados.
9.2. Criando um dispositivo de cerca
O formato para o comando para criar um dispositivo de pedra é o seguinte. Para uma listagem das opções de criação de pedra disponíveis, consulte a tela pcs stonith -h.
pcs stonith create stonith_id stonith_device_type [stonith_device_options] [op operation_action operation_options]
O seguinte comando cria um único dispositivo de esgrima para um único nó.
# pcs stonith create MyStonith fence_virt pcmk_host_list=f1 op monitor interval=30sAlguns dispositivos de cerca podem cercar apenas um único nó, enquanto outros dispositivos podem cercar vários nós. Os parâmetros que você especifica ao criar um dispositivo de cerca dependem do que seu dispositivo de cerca suporta e requer.
- Alguns dispositivos de cercas podem determinar automaticamente quais nós podem cercar.
-
Você pode usar o parâmetro
pcmk_host_listao criar um dispositivo de esgrima para especificar todas as máquinas que são controladas por esse dispositivo de esgrima. -
Alguns dispositivos de cercas exigem um mapeamento dos nomes dos hospedeiros de acordo com as especificações que o dispositivo de cerca compreende. Você pode mapear os nomes dos anfitriões com o parâmetro
pcmk_host_mapao criar um dispositivo de cercas.
Para informações sobre os parâmetros pcmk_host_list e pcmk_host_map, consulte Propriedades Gerais dos Dispositivos de Esgrima.
Após configurar um dispositivo de cerca, é imperativo que você teste o dispositivo para garantir que ele esteja funcionando corretamente. Para informações sobre como testar um dispositivo de cerca, consulte Testando um dispositivo de cerca.
9.3. Propriedades gerais dos dispositivos de esgrima
Qualquer nó de cluster pode cercar qualquer outro nó de cluster com qualquer dispositivo de cerca, independentemente de o recurso de cerca ser iniciado ou parado. Se o recurso é iniciado controla apenas o monitor periódico do dispositivo, não se ele pode ser usado, com as seguintes exceções:
-
Você pode desativar um dispositivo de esgrima ao executar o
pcs stonith disable stonith_idcomando. Isto impedirá qualquer nó de usar aquele dispositivo. -
Para evitar que um nó específico utilize um dispositivo de esgrima, você pode configurar restrições de localização para o recurso de esgrima com o comando
pcs constraint location … avoids. -
A configuração do
stonith-enabled=falseirá desativar totalmente a vedação. Note, entretanto, que a Red Hat não suporta aglomerados quando a vedação é desativada, pois não é adequada para um ambiente de produção.
Tabela 9.1, “Propriedades Gerais dos Dispositivos de Esgrima” descreve as propriedades gerais que você pode definir para dispositivos de esgrima.
Tabela 9.1. Propriedades Gerais dos Dispositivos de Esgrima
| Campo | Tipo | Padrão | Descrição |
|---|---|---|---|
|
| corda |
Um mapeamento de nomes de host para números de porta para dispositivos que não suportam nomes de host. Por exemplo: | |
|
| corda |
Uma lista das máquinas controladas por este dispositivo (Opcional, a menos que | |
|
| corda |
*
* Caso contrário,
* Caso contrário,
*Caso contrário, |
Como determinar quais máquinas são controladas pelo dispositivo. Valores permitidos: |
9.4. Opções avançadas de configuração de cercas
Tabela 9.2, “Propriedades Avançadas dos Dispositivos de Esgrima” resume as propriedades adicionais que você pode definir para dispositivos de esgrima. Note que estas propriedades são apenas para uso avançado.
Tabela 9.2. Propriedades Avançadas dos Dispositivos de Esgrima
| Campo | Tipo | Padrão | Descrição |
|---|---|---|---|
|
| corda | porto |
Um parâmetro alternativo para fornecer em vez de porto. Alguns dispositivos não suportam o parâmetro padrão de porta ou podem fornecer parâmetros adicionais. Use isto para especificar um parâmetro alternativo, específico do dispositivo, que deve indicar a máquina a ser vedada. Um valor de |
|
| corda | reinicialização |
Um comando alternativo para executar ao invés de |
|
| tempo | 60s |
Especifique um tempo limite alternativo a ser usado para ações de reinicialização em vez de |
|
| inteiro | 2 |
O número máximo de vezes para tentar novamente o comando |
|
| corda | off |
Um comando alternativo para executar ao invés de |
|
| tempo | 60s |
Especifique um tempo limite alternativo a ser usado para ações fora do ar em vez de |
|
| inteiro | 2 | O número máximo de vezes para tentar novamente o comando off dentro do tempo limite. Alguns dispositivos não suportam conexões múltiplas. As operações podem falhar se o dispositivo estiver ocupado com outra tarefa, então o Pacemaker irá automaticamente tentar de novo a operação, se houver tempo restante. Use esta opção para alterar o número de vezes em que o Pacemaker tenta novamente desligar as ações antes de desistir. |
|
| corda | lista |
Um comando alternativo para executar ao invés de |
|
| tempo | 60s | Especifique um tempo limite alternativo a ser usado para ações de lista. Alguns dispositivos precisam de muito mais ou muito menos tempo para serem completados do que o normal. Use isto para especificar um tempo limite alternativo, específico do dispositivo, para as ações da lista. |
|
| inteiro | 2 |
O número máximo de vezes para tentar novamente o comando |
|
| corda | monitor |
Um comando alternativo para executar ao invés de |
|
| tempo | 60s |
Especifique um tempo limite alternativo a ser usado para ações de monitoramento em vez de |
|
| inteiro | 2 |
O número máximo de vezes para tentar novamente o comando |
|
| corda | status |
Um comando alternativo para executar ao invés de |
|
| tempo | 60s |
Especifique um tempo limite alternativo a ser usado para ações de status em vez de |
|
| inteiro | 2 | O número máximo de vezes para tentar novamente o comando de status dentro do período de tempo limite. Alguns dispositivos não suportam conexões múltiplas. As operações podem falhar se o dispositivo estiver ocupado com outra tarefa, então o Pacemaker irá automaticamente tentar de novo a operação, se houver tempo restante. Use esta opção para alterar o número de vezes em que o Pacemaker tenta novamente as ações de status antes de desistir. |
|
| tempo | 0s |
Habilitar um atraso de base para ações de pedra e especificar um valor de atraso de base. Em um cluster com um número par de nós, configurar um atraso pode ajudar a evitar que os nós se cerquem uns aos outros ao mesmo tempo em uma divisão uniforme. Um atraso aleatório pode ser útil quando o mesmo dispositivo de cerca é usado para todos os nós, e diferentes atrasos estáticos podem ser úteis em cada dispositivo de cerca quando um dispositivo separado é usado para cada nó. O atraso geral é derivado de um valor de atraso aleatório adicionando este atraso estático para que a soma seja mantida abaixo do atraso máximo. Se você definir
Alguns agentes individuais de cercas implementam um parâmetro de "atraso", que é independente de atrasos configurados com uma propriedade |
|
| tempo | 0s |
Permitir um atraso aleatório para ações pedregosas e especificar o máximo de atraso aleatório. Em um cluster com um número par de nós, configurar um atraso pode ajudar a evitar que os nós se cerquem uns aos outros ao mesmo tempo em uma divisão uniforme. Um atraso aleatório pode ser útil quando o mesmo dispositivo de cerca é usado para todos os nós, e diferentes atrasos estáticos podem ser úteis em cada dispositivo de cerca quando um dispositivo separado é usado para cada nó. O atraso geral é derivado deste valor de atraso aleatório adicionando um atraso estático para que a soma seja mantida abaixo do atraso máximo. Se você definir
Alguns agentes individuais de cercas implementam um parâmetro de "atraso", que é independente de atrasos configurados com uma propriedade |
|
| inteiro | 1 |
O número máximo de ações que podem ser realizadas em paralelo neste dispositivo. A propriedade do cluster |
|
| corda | em |
Apenas para uso avançado: Um comando alternativo para executar em vez de |
|
| tempo | 60s |
Apenas para uso avançado: Especifique um tempo limite alternativo para usar para ações em |
|
| inteiro | 2 |
Apenas para uso avançado: O número máximo de vezes para tentar novamente o comando |
Além das propriedades que você pode definir para cada dispositivo de cerca, há também propriedades de agrupamento que você pode definir que determinam o comportamento da cerca, como descrito em Tabela 9.3, “Propriedades de aglomeração que determinam o comportamento das vedações”.
Tabela 9.3. Propriedades de aglomeração que determinam o comportamento das vedações
| Opção | Padrão | Descrição |
|---|---|---|
|
| verdadeiro |
Indica que os nós que falharam e os nós com recursos que não podem ser parados devem ser cercados. A proteção de seus dados requer que você defina isto
Se
A Red Hat só suporta clusters com este valor definido para |
|
| reinicialização |
Ação para enviar ao dispositivo STONITH. Valores permitidos: |
|
| 60s | Quanto tempo esperar para que uma ação de STONITH seja concluída. |
|
| 10 | Quantas vezes a esgrima pode falhar para um alvo antes que o agrupamento não o volte a tentar imediatamente. |
|
| O tempo máximo de espera até que um nó possa ser assumido como tendo sido morto pelo cão de guarda de hardware. Recomenda-se que este valor seja ajustado para o dobro do valor do timeout do cão de guarda de hardware. Esta opção só é necessária se a SBD baseada em Watchdog for usada para esgrima. | |
|
| verdadeiro (RHEL 8.1 e posteriores) | Permitir que as operações de esgrima sejam realizadas em paralelo. |
|
| parar |
(Red Hat Enterprise Linux 8.2 e posteriores) Determina como um nó de cluster deve reagir se notificado de sua própria vedação. Um nó de cluster pode receber notificação de seu próprio cercado se o cercado estiver mal configurado, ou se estiver em uso um cercado de tecido que não corte a comunicação de cluster. Os valores permitidos são
Embora o valor padrão para esta propriedade seja |
Para informações sobre a definição das propriedades de agrupamento, consulte Definição e remoção das propriedades de agrupamento.
9.5. Teste de um dispositivo de cerca
A vedação é uma parte fundamental da infra-estrutura do Red Hat Cluster e, portanto, é importante validar ou testar se a vedação está funcionando corretamente.
Use o seguinte procedimento para testar um dispositivo de cerca.
Use ssh, telnet, HTTP, ou qualquer protocolo remoto que for usado para conectar ao dispositivo para fazer o login e testar manualmente o dispositivo de cerca ou ver qual saída é dada. Por exemplo, se você estiver configurando uma cerca para um dispositivo habilitado para IPMI, então tente fazer o log in remotamente com
ipmitool. Tome nota das opções usadas ao fazer o login manualmente, pois essas opções podem ser necessárias ao usar o agente de vedação.Se você não conseguir entrar no dispositivo de cerca, verifique se o dispositivo é "pingável", não há nada como uma configuração de firewall que esteja impedindo o acesso ao dispositivo de cerca, o acesso remoto está habilitado no dispositivo de cerca e as credenciais estão corretas.
Executar o agente de vedação manualmente, usando o roteiro do agente de vedação. Isto não requer que os serviços de cercado estejam sendo executados, portanto, você pode executar esta etapa antes que o dispositivo seja configurado no cercado. Isto pode garantir que o dispositivo de cerca esteja respondendo corretamente antes de prosseguir.
NotaOs exemplos nesta seção utilizam o script
fence_ipmilanfence agent para um dispositivo iLO. O verdadeiro agente de cerca que você usará e o comando que chama esse agente dependerá do hardware de seu servidor. Você deve consultar a página de manual do agente de cerca que você está usando para determinar quais opções especificar. Você normalmente precisará saber o login e a senha do dispositivo de cerca e outras informações relacionadas ao dispositivo de cerca.O exemplo a seguir mostra o formato que você usaria para executar o script
fence_ipmilanfence agent com o parâmetro-o statuspara verificar o status da interface do dispositivo de cerca em outro nó sem realmente cercar o mesmo. Isto permite que você teste o dispositivo e o faça funcionar antes de tentar reiniciar o nó. Ao executar este comando, você especifica o nome e a senha de um usuário iLO que tem permissão para ligar e desligar o dispositivo iLO.#
fence_ipmilan -a ipaddress -l username -p password -o statusO exemplo a seguir mostra o formato que você usaria para executar o script
fence_ipmilanfence agent com o parâmetro-o reboot. A execução deste comando em um nó reinicia o nó gerenciado por este dispositivo iLO.#
fence_ipmilan -a ipaddress -l username -p password -o rebootSe o agente da cerca falhou em fazer uma ação de status, desligado, ligado ou reinicialização, você deve verificar o hardware, a configuração do dispositivo da cerca e a sintaxe de seus comandos. Além disso, você pode executar o script do agente de cerca com a saída de debug habilitada. A saída de depuração é útil para alguns agentes de cercas para ver onde na seqüência de eventos o script do agente de cercas está falhando ao efetuar login no dispositivo de cercas.
#
fence_ipmilan -a ipaddress -l username -p password -o status -D /tmp/$(hostname)-fence_agent.debugAo diagnosticar uma falha que tenha ocorrido, você deve se certificar de que as opções especificadas ao fazer o login manualmente no dispositivo de cerca são idênticas ao que você passou para o agente de cerca com o roteiro do agente de cerca.
Para agentes de cerca que suportam uma conexão criptografada, você pode ver um erro devido à falha na validação do certificado, exigindo que você confie no host ou que você use o parâmetro
ssl-insecuredo agente de cerca. Da mesma forma, se o SSL/TLS estiver desabilitado no dispositivo alvo, você pode precisar prestar contas disso ao definir os parâmetros SSL para o agente de cerca.NotaSe o agente de vedação que está sendo testado é um
fence_drac,fence_ilo, ou algum outro agente de vedação para um dispositivo de gerenciamento de sistemas que continua a falhar, então volte a tentarfence_ipmilan. A maioria dos cartões de gerenciamento de sistemas suporta o login remoto IPMI e o único agente de vedação suportado éfence_ipmilan.Uma vez que o dispositivo de cerca tenha sido configurado no aglomerado com as mesmas opções que funcionaram manualmente e o aglomerado tenha sido iniciado, teste a cerca com o comando
pcs stonith fencede qualquer nó (ou mesmo várias vezes de diferentes nós), como no exemplo a seguir. O comandopcs stonith fencelê a configuração do cluster a partir do CIB e chama o agente de cerca como configurado para executar a ação de cerca. Isto verifica se a configuração do aglomerado está correta.#
pcs stonith fence node_nameSe o comando
pcs stonith fencefuncionar corretamente, isso significa que a configuração da cerca para o conjunto deve funcionar quando ocorrer um evento de cerca. Se o comando falhar, isso significa que o gerenciamento do cercado não pode invocar o dispositivo de cercado através da configuração que ele recuperou. Verifique as seguintes questões e atualize sua configuração de cercas conforme necessário.- Verifique a configuração de sua cerca. Por exemplo, se você tiver usado um mapa do host, você deve assegurar-se de que o sistema possa encontrar o nó usando o nome do host que você forneceu.
- Verifique se a senha e o nome de usuário do dispositivo incluem algum caractere especial que possa ser mal interpretado pela concha do bash. Certifique-se de digitar senhas e nomes de usuário rodeados de aspas que possam resolver este problema.
-
Verifique se você pode se conectar ao dispositivo usando o endereço IP exato ou o nome do host que você especificou no comando
pcs stonith. Por exemplo, se você der o nome do host no comando stonith mas testar usando o endereço IP, este não é um teste válido. Se o protocolo que seu dispositivo de cerca usa for acessível a você, use esse protocolo para tentar se conectar ao dispositivo. Por exemplo, muitos agentes usam ssh ou telnet. Você deve tentar conectar-se ao dispositivo com as credenciais que você forneceu ao configurar o dispositivo, para ver se você recebe um prompt válido e pode fazer o login no dispositivo.
Se você determinar que todos os seus parâmetros são apropriados, mas ainda tiver problemas de conexão com seu dispositivo de cerca, você pode verificar o registro no próprio dispositivo de cerca, se o dispositivo fornece isso, o que mostrará se o usuário se conectou e qual comando o usuário emitiu. Você também pode procurar no arquivo
/var/log/messagespor casos de pedraria e erro, o que poderia dar alguma idéia do que está acontecendo, mas alguns agentes podem fornecer informações adicionais.
Uma vez que os testes do dispositivo de vedação estejam funcionando e o conjunto esteja em funcionamento, teste uma falha real. Para isso, tomar uma ação no aglomerado que deve iniciar uma perda simbólica.
Desmontar uma rede. A maneira como você toma uma rede depende de sua configuração específica. Em muitos casos, você pode fisicamente puxar a rede ou os cabos de energia para fora do host. Para informações sobre como simular uma falha de rede, veja Qual é a maneira adequada de simular uma falha de rede em um Cluster RHEL?
NotaDesabilitar a interface de rede no host local em vez de desconectar fisicamente a rede ou os cabos de energia não é recomendado como um teste de vedação, pois não simula com precisão uma falha típica do mundo real.
Bloquear o tráfego corosync tanto na entrada quanto na saída usando o firewall local.
O seguinte exemplo bloqueia a corosync, assumindo que a porta padrão corosync é usada,
firewalldé usado como firewall local, e a interface de rede usada pela corosync está na zona padrão do firewall:#
firewall-cmd --direct --add-rule ipv4 filter OUTPUT 2 -p udp --dport=5405 -j DROP#firewall-cmd --add-rich-rule='rule family="ipv4" port port="5405" protocol="udp" drop'Simule um acidente e entre em pânico com sua máquina com
sysrq-trigger. Note, entretanto, que desencadear um pânico no núcleo pode causar perda de dados; é recomendável que você desative seus recursos de cluster primeiro.#
echo c > /proc/sysrq-trigger
9.6. Configuração dos níveis de vedação
O pacemaker suporta nós de vedação com múltiplos dispositivos através de uma característica chamada topologias de vedação. Para implementar topologias, crie os dispositivos individuais como você normalmente faria e então defina um ou mais níveis de vedação na seção de topologia de vedação na configuração.
- Cada nível é tentado em ordem numérica ascendente, começando em 1.
- Se um dispositivo falhar, o processamento termina para o nível atual. Nenhum outro dispositivo nesse nível é exercido e o próximo nível é tentado em seu lugar.
- Se todos os dispositivos forem vedados com sucesso, então esse nível foi bem sucedido e nenhum outro nível é tentado.
- A operação é concluída quando um nível tiver passado (sucesso), ou quando todos os níveis tiverem sido tentados (fracassados).
Use o seguinte comando para adicionar um nível de esgrima a um nó. Os dispositivos são dados como uma lista separada por vírgula de ids de pedra, que são tentadas para o nó nesse nível.
pcs nível de pedra adicionar level node devices
O seguinte comando lista todos os níveis de vedação que estão configurados atualmente.
pcs nível de pedra
No exemplo a seguir, há dois dispositivos de cerca configurados para o nó rh7-2: um dispositivo de cerca ilo chamado my_ilo e um dispositivo de cerca apc chamado my_apc. Estes comandos configuram os níveis de cerca de modo que, se o dispositivo my_ilo falhar e não conseguir cercar o nó, então o Pacemaker tentará usar o dispositivo my_apc. Este exemplo também mostra a saída do comando pcs stonith level depois que os níveis são configurados.
#pcs stonith level add 1 rh7-2 my_ilo#pcs stonith level add 2 rh7-2 my_apc#pcs stonith levelNode: rh7-2 Level 1 - my_ilo Level 2 - my_apc
O seguinte comando remove o nível da cerca para o nó e dispositivos especificados. Se nenhum nó ou dispositivo for especificado, então o nível de cerca especificado será removido de todos os nós.
pcs stonith nível remover level [node_id] [stonith_id] ... [stonith_id]
O comando a seguir limpa os níveis da cerca no nó especificado ou na identificação da pedra. Se você não especificar um nó ou id de pedra, todos os níveis da cerca são limpos.
pcs stonith level clear [node|stonith_id(s)]
Se você especificar mais de uma identificação de pedra, elas devem ser separadas por uma vírgula e sem espaços, como no exemplo a seguir.
# pcs stonith level clear dev_a,dev_bO seguinte comando verifica que todos os dispositivos e nós especificados nos níveis das cercas existem.
pcs verificação de nível de pedra
Você pode especificar os nós na topologia da cerca por uma expressão regular aplicada sobre o nome de um nó e por um atributo de nó e seu valor. Por exemplo, os seguintes comandos configuram os nós node1, node2, e `node3 para usar dispositivos de cerca apc1 e `apc2, e os nós `node4, node5, e `node6 para usar dispositivos de cerca apc3 e `apc4.
pcs stonith level add 1 "regexp%node[1-3]" apc1,apc2 pcs stonith level add 1 "regexp%node[4-6]" apc3,apc4
Os seguintes comandos produzem os mesmos resultados usando a correspondência de atributos de nós.
pcs node attribute node1 rack=1 pcs node attribute node2 rack=1 pcs node attribute node3 rack=1 pcs node attribute node4 rack=2 pcs node attribute node5 rack=2 pcs node attribute node6 rack=2 pcs stonith level add 1 attrib%rack=1 apc1,apc2 pcs stonith level add 1 attrib%rack=2 apc3,apc4
9.7. Configuração de cercas para fontes de alimentação redundantes
Ao configurar a vedação para fontes de alimentação redundantes, o cluster deve assegurar que ao tentar reiniciar um host, ambas as fontes de alimentação sejam desligadas antes que qualquer uma delas seja ligada novamente.
Se o nó nunca perder completamente a energia, o nó pode não liberar seus recursos. Isto abre a possibilidade de os nós acessarem esses recursos simultaneamente e corrompê-los.
Você precisa definir cada dispositivo apenas uma vez e especificar que ambos são necessários para cercar o nó, como no exemplo a seguir.
#pcs stonith create apc1 fence_apc_snmp ipaddr=apc1.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"#pcs stonith create apc2 fence_apc_snmp ipaddr=apc2.example.com login=user passwd='7a4D#1j!pz864' pcmk_host_map="node1.example.com:1;node2.example.com:2"#pcs stonith level add 1 node1.example.com apc1,apc2#pcs stonith level add 1 node2.example.com apc1,apc2
9.8. Exibição de dispositivos de cercas configurados
O comando a seguir mostra todos os dispositivos de vedação atualmente configurados. Se for especificado um stonith_id, o comando mostra as opções apenas para aquele dispositivo de pedra configurado. Se a opção --full for especificada, todas as opções de pedra configuradas são exibidas.
pcs stonith config [stonith_id] [--full] [--full] [--full] [--full] [--full9.9. Modificação e eliminação de dispositivos de cercas
Use o seguinte comando para modificar ou adicionar opções a um dispositivo de esgrima configurado atualmente.
pcs stonith update stonith_id [stonith_device_options]
Use o seguinte comando para remover um dispositivo de esgrima da configuração atual.
pcs stonith apagar stonith_id9.10. Esgrima manual de um nó de cluster
Você pode cercar um nó manualmente com o seguinte comando. Se você especificar --off, isto usará a chamada API off para o Stonith, que desligará o nó em vez de reiniciá-lo.
pcs stonith fence node [--off]Em uma situação em que nenhum dispositivo de pedra é capaz de cercar um nó mesmo que ele não esteja mais ativo, o aglomerado pode não ser capaz de recuperar os recursos do nó. Se isto ocorrer, após assegurar manualmente que o nó está desligado, você pode entrar com o seguinte comando para confirmar ao aglomerado que o nó está desligado e liberar seus recursos para recuperação.
Se o nó especificado não estiver realmente desligado, mas executando o software ou serviços normalmente controlados pelo cluster, ocorrerá corrupção/falha de cluster de dados.
pcs stonith confirmam node9.11. Desativação de um dispositivo de cerca
Para desativar um dispositivo/recurso de esgrima, você executa o comando pcs stonith disable.
O seguinte comando desabilita o dispositivo de vedação myapc.
# pcs stonith disable myapc9.12. Impedir que um nó utilize um dispositivo de vedação
Para evitar que um nó específico utilize um dispositivo de vedação, você pode configurar restrições de localização para o recurso de vedação.
O seguinte exemplo impede que o dispositivo de vedação node1-ipmi funcione em node1.
# pcs constraint location node1-ipmi avoids node19.13. Configuração do ACPI para uso com dispositivos de cercas integradas
Se seu agrupamento utiliza dispositivos de vedação integrados, você deve configurar o ACPI (Advanced Configuration and Power Interface) para garantir a vedação imediata e completa.
Se um nó de cluster for configurado para ser cercado por um dispositivo de cerca integrado, desabilite o ACPI Soft-Off para esse nó. A desativação do ACPI Soft-Off permite que um dispositivo de cerca integrado desligue um nó imediata e completamente ao invés de tentar um desligamento limpo (por exemplo, shutdown -h now). Caso contrário, se o ACPI Soft-Off for ativado, um dispositivo de cerca integrado pode levar quatro ou mais segundos para desligar um nó (veja a nota que se segue). Além disso, se o ACPI Soft-Off estiver ativado e um nó entrar em pânico ou congelar durante o desligamento, um dispositivo de cerca integrado pode não ser capaz de desligar o nó. Nessas circunstâncias, a vedação é atrasada ou não tem êxito. Consequentemente, quando um nó é cercado com um dispositivo de cerca integrado e o ACPI Soft-Off é habilitado, um aglomerado se recupera lentamente ou requer intervenção administrativa para se recuperar.
A quantidade de tempo necessária para cercar um nó depende do dispositivo de cerca integrado utilizado. Alguns dispositivos de cerca integrados realizam o equivalente a pressionar e segurar o botão de energia; portanto, o dispositivo de cerca desliga o nó em quatro a cinco segundos. Outros dispositivos de cercas integradas executam o equivalente a pressionar o botão de energia momentaneamente, contando com o sistema operacional para desligar o nó; portanto, o dispositivo de cercas desliga o nó em um período de tempo muito maior do que quatro a cinco segundos.
- A maneira preferida de desativar o ACPI Soft-Off é alterar a configuração da BIOS para "instant-off" ou uma configuração equivalente que desligue o nó sem demora, como descrito em Seção 9.13.1, “Desabilitando o ACPI Soft-Off com o BIOS”.
A desativação do ACPI Soft-Off com o BIOS pode não ser possível com alguns sistemas. Se a desativação do ACPI Soft-Off com o BIOS não for satisfatória para seu cluster, você pode desativar o ACPI Soft-Off com um dos seguintes métodos alternativos:
-
Configurando
HandlePowerKey=ignoreno arquivo/etc/systemd/logind.confe verificando que o nó do nó se desliga imediatamente quando cercado, como descrito em Seção 9.13.2, “Desabilitando o ACPI Soft-Off no arquivo logind.conf”. Este é o primeiro método alternativo de desativação do ACPI Soft-Off. Anexando
acpi=offà linha de comando de inicialização do kernel, conforme descrito em Seção 9.13.3, “Desabilitando completamente o ACPI no arquivo GRUB 2”. Este é o segundo método alternativo de desativação do ACPI Soft-Off, se o método preferido ou o primeiro método alternativo não estiver disponível.ImportanteEste método desabilita completamente o ACPI; alguns computadores não inicializam corretamente se o ACPI estiver completamente desabilitado. Use este método only se os outros métodos não forem eficazes para seu cluster.
9.13.1. Desabilitando o ACPI Soft-Off com o BIOS
Você pode desativar o ACPI Soft-Off configurando a BIOS de cada nó de cluster com o seguinte procedimento.
O procedimento para desativar o ACPI Soft-Off com o BIOS pode ser diferente entre os sistemas de servidores. Você deve verificar este procedimento com sua documentação de hardware.
-
Reiniciar o nó e iniciar o programa
BIOS CMOS Setup Utility. - Navegue até o menu Poder (ou menu de gerenciamento de energia equivalente).
No menu Power, defina a função
Soft-Off by PWR-BTTN(ou equivalente) paraInstant-Off(ou a configuração equivalente que desliga o nó por meio do botão Power sem demora).BIOS CMOS Setup Utility: mostra um menu Power comACPI Functiondefina paraEnabledeSoft-Off by PWR-BTTNdefina paraInstant-Off.NotaOs equivalentes a
ACPI Function,Soft-Off by PWR-BTTN, eInstant-Offpodem variar entre computadores. Entretanto, o objetivo deste procedimento é configurar a BIOS para que o computador seja desligado sem demora por meio do botão de ligar/desligar.-
Sair do programa
BIOS CMOS Setup Utility, salvando a configuração da BIOS. - Verificar se o nó se desliga imediatamente quando cercado. Para informações sobre como testar um dispositivo de cerca, veja Testar um dispositivo de cerca.
BIOS CMOS Setup Utility:
`Soft-Off by PWR-BTTN` set to `Instant-Off`
+---------------------------------------------|-------------------+ | ACPI Function [Enabled] | Item Help | | ACPI Suspend Type [S1(POS)] |-------------------| | x Run VGABIOS if S3 Resume Auto | Menu Level * | | Suspend Mode [Disabled] | | | HDD Power Down [Disabled] | | | Soft-Off by PWR-BTTN [Instant-Off | | | CPU THRM-Throttling [50.0%] | | | Wake-Up by PCI card [Enabled] | | | Power On by Ring [Enabled] | | | Wake Up On LAN [Enabled] | | | x USB KB Wake-Up From S3 Disabled | | | Resume by Alarm [Disabled] | | | x Date(of Month) Alarm 0 | | | x Time(hh:mm:ss) Alarm 0 : 0 : | | | POWER ON Function [BUTTON ONLY | | | x KB Power ON Password Enter | | | x Hot Key Power ON Ctrl-F1 | | | | | | | | +---------------------------------------------|-------------------+
Este exemplo mostra ACPI Function set to Enabled, e Soft-Off by PWR-BTTN set to Instant-Off.
9.13.2. Desabilitando o ACPI Soft-Off no arquivo logind.conf
Para desativar a entrega da chave de alimentação no arquivo /etc/systemd/logind.conf, use o seguinte procedimento.
Defina a seguinte configuração no arquivo
/etc/systemd/logind.conf:HandlePowerKey=ignore
Reinicie o serviço
systemd-logind:#
systemctl restart systemd-logind.service- Verificar se o nó se desliga imediatamente quando cercado. Para informações sobre como testar um dispositivo de cerca, veja Testar um dispositivo de cerca.
9.13.3. Desabilitando completamente o ACPI no arquivo GRUB 2
Você pode desativar o ACPI Soft-Off anexando acpi=off à entrada do menu GRUB para um kernel.
Este método desabilita completamente o ACPI; alguns computadores não inicializam corretamente se o ACPI estiver completamente desabilitado. Use este método only se os outros métodos não forem eficazes para seu cluster.
Use o seguinte procedimento para desativar o ACPI no arquivo GRUB 2:
Use a opção
--argsem combinação com a opção--update-kernelda ferramentagrubbypara alterar o arquivogrub.cfgde cada nó de cluster da seguinte forma:#
grubby --args=acpi=off --update-kernel=ALL- Reiniciar o nó.
- Verificar se o nó se desliga imediatamente quando cercado. Para informações sobre como testar um dispositivo de cerca, veja Testar um dispositivo de cerca.
Capítulo 10. Configuração de recursos de cluster
O formato do comando para criar um recurso de cluster é o seguinte:
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options [operation_action operation options ]...] [meta meta_options...] [clone [clone_options] | master [master_options] | --group group_name [--before resource_id | --after resource_id] | [bundle bundle_id] [--disabled] [--wait[=n]] [--wait[= ]]
As principais opções de criação de recursos de cluster incluem o seguinte:
-
Quando você especifica a opção
--group, o recurso é adicionado ao grupo de recursos nomeado. Se o grupo não existir, isto cria o grupo e adiciona este recurso ao grupo.
-
As opções
--beforee--afterespecificam a posição do recurso adicionado em relação a um recurso que já existe em um grupo de recursos. -
A especificação da opção
--disabledindica que o recurso não é iniciado automaticamente.
Você pode determinar o comportamento de um recurso em um cluster, configurando restrições para esse recurso.
Exemplos de criação de recursos
O seguinte comando cria um recurso com o nome VirtualIP da norma ocf, provedor heartbeat, e tipo IPaddr2. O endereço flutuante deste recurso é 192.168.0.120, e o sistema verificará se o recurso está funcionando a cada 30 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30s
Alternativamente, você pode omitir os campos standard e provider e usar o seguinte comando. Isto será padrão para um padrão de ocf e um provedor de heartbeat.
# pcs resource create VirtualIP IPaddr2 ip=192.168.0.120 cidr_netmask=24 op monitor interval=30sEliminação de um recurso configurado
Use o seguinte comando para excluir um recurso configurado.
pcs resource delete resource_id
Por exemplo, o seguinte comando apaga um recurso existente com um ID de recurso de VirtualIP.
# pcs resource delete VirtualIP10.1. Identificadores do agente de recursos
Os identificadores que você define para um recurso dizem ao agrupamento qual agente usar para o recurso, onde encontrar esse agente e quais padrões ele está em conformidade. Tabela 10.1, “Agente de Identificação de Recursos”, descreve estas propriedades.
Tabela 10.1. Agente de Identificação de Recursos
| Campo | Descrição |
|---|---|
| padrão | O padrão ao qual o agente está em conformidade. Os valores permitidos e seu significado:
*
*
*
*
* |
| tipo |
O nome do agente de recursos que você deseja utilizar, por exemplo |
| fornecedor |
A especificação OCF permite que vários fornecedores forneçam o mesmo agente de recursos. A maioria dos agentes enviados pela Red Hat usa |
Tabela 10.2, “Comandos para exibir as propriedades dos recursos” resume os comandos que exibem as propriedades dos recursos disponíveis.
Tabela 10.2. Comandos para exibir as propriedades dos recursos
| pcs Display Command | Saída |
|---|---|
|
| Exibe uma lista de todos os recursos disponíveis. |
|
| Exibe uma lista de padrões de agentes de recursos disponíveis. |
|
| Exibe uma lista de fornecedores de agentes de recursos disponíveis. |
|
| Exibe uma lista dos recursos disponíveis filtrados pela seqüência especificada. Você pode usar este comando para exibir recursos filtrados pelo nome de um padrão, de um provedor ou de um tipo. |
10.2. Exibição de parâmetros específicos de recursos
Para qualquer recurso individual, você pode usar o seguinte comando para exibir uma descrição do recurso, os parâmetros que você pode definir para aquele recurso e os valores padrão que são definidos para o recurso.
pcs resource describe [standard:[provider:]]type
Por exemplo, o seguinte comando exibe informações para um recurso do tipo apache.
# pcs resource describe ocf:heartbeat:apache
This is the resource agent for the Apache Web server.
This resource agent operates both version 1.x and version 2.x Apache
servers.
...10.3. Configurando as meta opções de recursos
Além dos parâmetros específicos do recurso, você pode configurar opções adicionais de recursos para qualquer recurso. Estas opções são usadas pelo cluster para decidir como seu recurso deve se comportar.
Tabela 10.3, “Meta Opções de Recursos” descreve as meta opções de recursos.
Tabela 10.3. Meta Opções de Recursos
| Campo | Padrão | Descrição |
|---|---|---|
|
|
| Se nem todos os recursos puderem estar ativos, o agrupamento parará os recursos de prioridade mais baixa para manter os de prioridade mais alta ativos. |
|
|
| Em que estado o agrupamento deve tentar manter este recurso? Valores permitidos: * Stopped - Forçar o recurso a ser parado * Started - Permitir que o recurso seja iniciado (e no caso de clones promovíveis, promovidos para dominar o papel, se apropriado) * Master - Permitir que o recurso seja iniciado e, se apropriado, promovido * Slave - Permitir que o recurso seja iniciado, mas somente no modo Escravo, se o recurso for promocional |
|
|
|
É permitido que o agrupamento comece e pare o recurso? Valores permitidos: |
|
| 0 | Valor para indicar o quanto o recurso prefere ficar onde está. |
|
| Calculado | Indica sob quais condições o recurso pode ser iniciado.
O padrão é
*
*
*
* |
|
|
|
Quantas falhas podem ocorrer para este recurso em um nó, antes que este nó seja marcado como inelegível para hospedar este recurso. Um valor de 0 indica que este recurso está desabilitado (o nó nunca será marcado como inelegível); em contraste, o cluster trata |
|
|
|
Usado em conjunto com a opção |
|
|
| O que o agrupamento deve fazer se alguma vez encontrar o recurso ativo em mais de um nó. Valores permitidos:
*
*
* |
10.3.1. Alterando o valor padrão de uma opção de recurso
A partir do Red Hat Enterprise Linux 8.3, você pode alterar o valor default de uma opção de recurso para todos os recursos com o comando pcs resource defaults update. O seguinte comando redefine o valor default de resource-stickiness para 100.
# pcs resource defaults update resource-stickiness=100
O original pcs resource defaults name=value que define os padrões para todos os recursos em versões anteriores do RHEL 8, continua sendo suportado, a menos que haja mais de um conjunto de padrões configurado. Entretanto, pcs resource defaults update é agora a versão preferida do comando.
10.3.2. Alteração do valor padrão de uma opção de recurso para conjuntos de recursos (RHEL 8.3 e posteriores)
A partir do Red Hat Enterprise Linux 8.3, você pode criar múltiplos conjuntos de padrões de recursos com o comando pcs resource defaults set create, o que lhe permite especificar uma regra que contém expressões resource. Apenas as expressões resource, incluindo and, or e parênteses, são permitidas nas regras que você especificar com este comando.
Com o comando pcs resource defaults set create, você pode configurar um valor de recurso padrão para todos os recursos de um determinado tipo. Se, por exemplo, você estiver rodando bancos de dados que levam muito tempo para parar, você pode aumentar o valor padrão resource-stickiness para todos os recursos do tipo banco de dados para evitar que esses recursos se movam para outros nós com mais freqüência do que você deseja.
O seguinte comando define o valor padrão de resource-stickiness para 100 para todos os recursos do tipo pqsql.
-
A opção
id, que nomeia o conjunto de padrões de recursos, não é obrigatória. Se você não definir esta opçãopcsirá gerar uma identificação automaticamente. A definição deste valor permite que você forneça um nome mais descritivo. Neste exemplo,
::pgsqlsignifica um recurso de qualquer classe, de qualquer fornecedor, do tipopgsql.-
Especificar
ocf:heartbeat:pgsqlindicaria a classeocf, fornecedorheartbeat, tipopgsql, -
Especificar
ocf:pacemaker:indicaria todos os recursos da classeocf, fornecedorpacemaker, de qualquer tipo.
-
Especificar
# pcs resource defaults set create id=pgsql-stickiness meta resource-stickiness=100 rule resource ::pgsql
Para alterar os valores padrão em um conjunto existente, use o comando pcs resource defaults set update.
10.3.3. Exibição dos padrões de recursos configurados atualmente
O comando pcs resource defaults exibe uma lista de valores padrão configurados atualmente para opções de recursos, incluindo quaisquer regras que você especificou.
O exemplo a seguir mostra a saída deste comando após você ter redefinido o valor padrão de resource-stickiness para 100.
# pcs resource defaults
Meta Attrs: rsc_defaults-meta_attributes
resource-stickiness=100
O exemplo a seguir mostra a saída deste comando após ter redefinido o valor padrão de resource-stickiness para 100 para todos os recursos do tipo pqsql e ajustado a opção id para id=pgsql-stickiness.
# pcs resource defaults
Meta Attrs: pgsql-stickiness
resource-stickiness=100
Rule: boolean-op=and score=INFINITY
Expression: resource ::pgsql10.3.4. Definição de meta opções na criação de recursos
Quer você tenha redefinido ou não o valor padrão de uma meta opção de recurso, você pode definir uma opção de recurso para um determinado recurso para um valor diferente do padrão quando você criar o recurso. O seguinte mostra o formato do comando pcs resource create que você usa ao especificar um valor para uma meta opção de recurso.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta meta_options...]
Por exemplo, o seguinte comando cria um recurso com um valor resource-stickiness de 50.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.120 meta resource-stickiness=50Você também pode definir o valor de uma meta opção de recurso para um recurso existente, grupo, ou recurso clonado com o seguinte comando.
pcs resource meta resource_id | group_id | clone_id meta_options
No exemplo a seguir, há um recurso existente chamado dummy_resource. Este comando coloca a meta opção failure-timeout em 20 segundos, para que o recurso possa tentar reiniciar no mesmo nó em 20 segundos.
# pcs resource meta dummy_resource failure-timeout=20s
Após executar este comando, você pode exibir os valores do recurso para verificar se failure-timeout=20s está configurado.
# pcs resource config dummy_resource
Resource: dummy_resource (class=ocf provider=heartbeat type=Dummy)
Meta Attrs: failure-timeout=20s
...10.4. Configuração de grupos de recursos
Um dos elementos mais comuns de um agrupamento é um conjunto de recursos que precisam ser localizados juntos, começar sequencialmente e parar na ordem inversa. Para simplificar esta configuração, o Pacemaker apóia o conceito de grupos de recursos.
10.4.1. Criação de um grupo de recursos
Você cria um grupo de recursos com o seguinte comando, especificando os recursos a serem incluídos no grupo. Se o grupo não existir, este comando cria o grupo. Se o grupo existir, este comando adiciona recursos adicionais ao grupo. Os recursos começarão na ordem que você os especificar com este comando, e pararão na ordem inversa de sua ordem inicial.
pcs resource group acrescentar group_name resource_id [resource_id] ... [resource_id] [- antes resource_id | - depois resource_id]
Você pode usar as opções --before e --after deste comando para especificar a posição dos recursos adicionados em relação a um recurso que já existe no grupo.
Você também pode adicionar um novo recurso a um grupo existente quando você criar o recurso, usando o seguinte comando. O recurso que você cria é adicionado ao grupo chamado group_name. Se o grupo group_name não existir, ele será criado.
pcs resource create resource_id [standard:[provider:]]type [resource_options] [op operation_action operation_options ] --group group_name
Não há limite para o número de recursos que um grupo pode conter. As propriedades fundamentais de um grupo são as seguintes.
- Os recursos são agrupados dentro de um grupo.
- Os recursos são iniciados na ordem em que você os especifica. Se um recurso do grupo não puder funcionar em nenhum lugar, então nenhum recurso especificado após esse recurso é permitido para funcionar.
- Os recursos são interrompidos na ordem inversa na qual você os especifica.
O exemplo seguinte cria um grupo de recursos chamado shortcut que contém os recursos existentes IPaddr e Email.
# pcs resource group add shortcut IPaddr EmailNeste exemplo:
-
O
IPaddré iniciado primeiro, depoisEmail. -
O recurso
Emailé interrompido primeiro, depoisIPAddr. -
Se
IPaddrnão pode funcionar em qualquer lugar, também não podeEmail. -
Se
Emailnão puder funcionar em nenhum lugar, no entanto, isso não afeta de forma algumaIPaddr.
10.4.2. Remoção de um grupo de recursos
Você remove um recurso de um grupo com o seguinte comando. Se não houver recursos restantes no grupo, este comando remove o próprio grupo.
pcs resource group remove group_name resource_id ...
10.4.3. Exibição de grupos de recursos
O seguinte comando lista todos os grupos de recursos atualmente configurados.
lista de grupos de recursos pcs
10.4.4. Opções de grupo
Você pode definir as seguintes opções para um grupo de recursos e elas mantêm o mesmo significado que quando são definidas para um único recurso: priority, target-role, is-managed. Para obter informações sobre as meta opções de recursos, consulte Configurando as meta opções de recursos.
10.4.5. Adesividade do grupo
A viscosidade, a medida de quanto um recurso quer ficar onde está, é aditiva em grupos. Cada recurso ativo do grupo contribuirá com seu valor de pegajosidade para o total do grupo. Portanto, se o padrão resource-stickiness é 100, e um grupo tem sete membros, dos quais cinco são ativos, então o grupo como um todo preferirá sua localização atual com uma pontuação de 500.
10.5. Determinando o comportamento dos recursos
Você pode determinar o comportamento de um recurso em um cluster, configurando restrições para esse recurso. Você pode configurar as seguintes categorias de restrições:
-
locationrestrições -
orderrestrições -
colocationrestrições
Como abreviação para configurar um conjunto de restrições que irá localizar um conjunto de recursos em conjunto e garantir que os recursos comecem sequencialmente e parem em ordem inversa, a Pacemaker apóia o conceito de grupos de recursos. Após ter criado um grupo de recursos, você pode configurar restrições no próprio grupo, assim como configurar restrições para recursos individuais. Para obter informações sobre grupos de recursos, consulte Configuração de grupos de recursos.
Capítulo 11. Determinação dos nós em que um recurso pode funcionar
As restrições de localização determinam em quais nós um recurso pode funcionar. Você pode configurar as restrições de localização para determinar se um recurso preferirá ou evitará um nó especificado.
Além das restrições de localização, o nó em que um recurso funciona é influenciado pelo valor resource-stickiness para esse recurso, que determina até que ponto um recurso prefere permanecer no nó em que está funcionando atualmente. Para informações sobre como definir o valor resource-stickiness, consulte Configurando um recurso para preferir seu nó atual.
11.1. Configuração das restrições de localização
Você pode configurar uma restrição básica de localização para especificar se um recurso prefere ou evita um nó, com um valor opcional score para indicar o grau relativo de preferência pela restrição.
O seguinte comando cria uma restrição de localização para que um recurso prefira o nó ou nós especificados. Note que é possível criar restrições em um determinado recurso para mais de um nó com um único comando.
pcs constraint location rsc prefere node[=score] [node[=score]] ...
O seguinte comando cria uma restrição de localização para um recurso para evitar o nó ou nós especificados.
pcs constraint location rsc evita node[=score] [node[=score]] ...
Tabela 11.1, “Opções de restrição de localização” resume os significados das opções básicas para a configuração das restrições de localização.
Tabela 11.1. Opções de restrição de localização
| Campo | Descrição |
|---|---|
|
| Um nome de recurso |
|
| O nome de um nó |
|
|
Valor inteiro positivo para indicar o grau de preferência para se o recurso dado deve preferir ou evitar o nó dado.
Um valor de
Um valor de
Uma pontuação numérica (ou seja, não |
O seguinte comando cria uma restrição de localização para especificar que o recurso Webserver prefere o nó node1.
pcs constraint location Webserver prefere o nó1
pcs suporta expressões regulares em restrições de localização na linha de comando. Estas restrições se aplicam a múltiplos recursos com base na expressão regular que corresponde ao nome do recurso. Isto permite que você configure contrações de múltiplas localizações com uma única linha de comando.
O seguinte comando cria uma restrição de localização para especificar que os recursos dummy0 a dummy9 preferem node1.
pcs constraint location 'regexpmmy[0-9]' prefere o nó1
Como a Pacemaker usa expressões regulares estendidas POSIX, conforme documentado em http://pubs.opengroup.org/onlinepubs/9699919799/basedefs/V1_chap09.html#tag_09_04você pode especificar a mesma restrição com o seguinte comando.
pcs constraint location 'regexpmmy[[:digit:]]' prefere o nó1
11.2. Limitando a descoberta de recursos a um subconjunto de nós
Antes que o Pacemaker inicie um recurso em qualquer lugar, ele primeiro executa uma única operação de monitoramento (freqüentemente chamada de "sonda") em cada nó, para saber se o recurso já está funcionando. Este processo de descoberta de recursos pode resultar em erros nos nós que são incapazes de executar o monitor.
Ao configurar uma restrição de localização em um nó, você pode usar a opção resource-discovery do comando pcs constraint location para indicar se a Pacemaker deve realizar a descoberta de recursos neste nó para o recurso especificado. Limitar a descoberta de recursos a um subconjunto de nós em que o recurso é fisicamente capaz de funcionar pode aumentar significativamente o desempenho quando um grande conjunto de nós está presente. Quando pacemaker_remote estiver em uso para expandir a contagem do nó para a faixa de centenas de nós, esta opção deve ser considerada.
O seguinte comando mostra o formato para especificar a opção resource-discovery do comando pcs constraint location. Neste comando, um valor positivo para score corresponde a uma restrição de localização básica que configura um recurso para preferir um nó, enquanto um valor negativo para score corresponde a uma restrição de localização básica`constraint que configura um recurso para evitar um nó. Assim como as restrições básicas de localização, você pode usar expressões regulares para recursos com estas restrições também.
pcs constraint location add id rsc node score [resource-discovery=option]
Tabela 11.2, “Parâmetros de Restrição de Descoberta de Recursos” resume os significados dos parâmetros básicos para a configuração de restrições para a descoberta de recursos.
Tabela 11.2. Parâmetros de Restrição de Descoberta de Recursos
| Campo | Descrição |
|
| Um nome escolhido pelo usuário para a restrição em si. |
|
| Um nome de recurso |
|
| O nome de um nó |
|
| Valor inteiro para indicar o grau de preferência para se o recurso dado deve preferir ou evitar o nó dado. Um valor positivo para pontuação corresponde a uma restrição básica de localização que configura um recurso para preferir um nó, enquanto um valor negativo para pontuação corresponde a uma restrição básica de localização que configura um recurso para evitar um nó.
Um valor de
Uma pontuação numérica (ou seja, não |
|
|
*
*
* |
O ajuste resource-discovery para never ou exclusive remove a capacidade da Pacemaker de detectar e parar instâncias indesejadas de um serviço em execução onde ele não deveria estar. Cabe ao administrador do sistema certificar-se de que o serviço nunca poderá estar ativo em nós sem a descoberta de recursos (por exemplo, deixando o software relevante desinstalado).
11.3. Configuração de uma estratégia de restrição de localização
Ao utilizar restrições de localização, você pode configurar uma estratégia geral para especificar em quais nós um recurso pode funcionar:
- Aglomerados de Opt-In
- Aglomerados de Opt-Out
A escolha de configurar seu cluster como um cluster opt-in ou opt-out depende tanto de sua preferência pessoal quanto da composição de seu cluster. Se a maioria de seus recursos puder funcionar na maioria dos nós, então uma configuração opt-out provavelmente resultará em uma configuração mais simples. Por outro lado, se a maioria dos recursos só pode funcionar em um pequeno subconjunto de nós, uma configuração opt-in pode ser mais simples.
11.3.1. Configuração de um Cluster "Opt-In
Para criar um cluster opt-in, defina a propriedade do cluster symmetric-cluster para false para evitar que os recursos funcionem em qualquer lugar por padrão.
# pcs property set symmetric-cluster=false
Habilitar os nós para os recursos individuais. Os seguintes comandos configuram restrições de localização para que o recurso Webserver prefira o nó example-1, o recurso Database prefira o nó example-2, e ambos os recursos podem falhar em relação ao nó example-3 se seu nó preferido falhar. Ao configurar as restrições de localização para um cluster opt-in, definir uma pontuação zero permite que um recurso seja executado em um nó sem indicar qualquer preferência para preferir ou evitar o nó.
#pcs constraint location Webserver prefers example-1=200#pcs constraint location Webserver prefers example-3=0#pcs constraint location Database prefers example-2=200#pcs constraint location Database prefers example-3=0
11.3.2. Configuração de um Cluster "Opt-Out"
Para criar um cluster opt-out, defina a propriedade do cluster symmetric-cluster para true para permitir que os recursos funcionem em todos os lugares por padrão. Esta é a configuração padrão se symmetric-cluster não for definido explicitamente.
# pcs property set symmetric-cluster=true
Os seguintes comandos produzirão então uma configuração que é equivalente ao exemplo em Seção 11.3.1, “Configuração de um Cluster "Opt-In”. Ambos os recursos podem falhar no nó example-3 se seu nó preferido falhar, uma vez que cada nó tem uma pontuação implícita de 0.
#pcs constraint location Webserver prefers example-1=200#pcs constraint location Webserver avoids example-2=INFINITY#pcs constraint location Database avoids example-1=INFINITY#pcs constraint location Database prefers example-2=200
Note que não é necessário especificar uma pontuação de INFINIDADE nestes comandos, já que esse é o valor padrão para a pontuação.
11.4. Configuração de um recurso para preferir seu nó atual
Os recursos têm um valor resource-stickiness que você pode definir como meta atributo ao criar o recurso, conforme descrito em Configurando as meta opções de recursos. O valor resource-stickiness determina o quanto um recurso quer permanecer no nó onde está rodando atualmente. O Pacemaker considera o valor resource-stickiness em conjunto com outras configurações (por exemplo, os valores de pontuação das restrições de localização) para determinar se um recurso deve ser movido para outro nó ou se deve ser deixado no lugar.
Por padrão, um recurso é criado com um valor resource-stickiness de 0. O comportamento padrão do Pacemaker quando resource-stickiness é definido como 0 e não há restrições de localização é mover os recursos de forma que eles sejam distribuídos uniformemente entre os nós de cluster. Isto pode resultar na movimentação de recursos saudáveis com mais freqüência do que se deseja. Para evitar este comportamento, você pode definir o valor padrão resource-stickiness como 1. Este padrão se aplicará a todos os recursos no cluster. Este pequeno valor pode ser facilmente superado por outras restrições que você cria, mas é suficiente para evitar que o Pacemaker movimente desnecessariamente recursos saudáveis em torno do cluster.
O seguinte comando define o valor padrão resource-stickiness como 1.
# pcs resource defaults resource-stickiness=1
Se o valor resource-stickiness for definido, então nenhum recurso será movido para um nó recém-adicionado. Se o equilíbrio de recursos for desejado nesse ponto, você pode definir temporariamente o valor resource-stickiness de volta para 0.
Observe que se uma pontuação de restrição de localização for maior que o valor resource-stickiness, o agrupamento ainda pode mover um recurso saudável para o nó onde a restrição de localização aponta.
Para maiores informações sobre como o Pacemaker determina onde colocar um recurso, veja Configurando uma estratégia de colocação de nó.
Capítulo 12. Determinação da ordem na qual os recursos de agrupamento são executados
Para determinar a ordem na qual os recursos funcionam, você configura uma restrição de pedidos.
O seguinte mostra o formato do comando para configurar uma restrição de ordenação.
pedido de restrição pcs [action] resource_id e depois [action] resource_id [options]
Tabela 12.1, “Propriedades de uma restrição de ordem”, resume as propriedades e opções para configurar as restrições de pedidos.
Tabela 12.1. Propriedades de uma restrição de ordem
| Campo | Descrição |
|---|---|
| resource_id | O nome de um recurso sobre o qual uma ação é executada. |
| ação | A ação a ser realizada sobre um recurso. Os valores possíveis da propriedade action são os seguintes:
*
*
*
*
Se nenhuma ação for especificada, a ação padrão é |
|
|
Como fazer cumprir a restrição. Os valores possíveis da opção
*
*
* |
|
|
Se for verdade, o contrário da restrição se aplica à ação oposta (por exemplo, se B começa após A começa, então B pára antes de Ordenar restrições para as quais |
Use o seguinte comando para remover recursos de qualquer restrição de pedidos.
ordem de restrição de pcs remover resource1 [resourceN]...
12.1. Configuração de pedidos obrigatórios
Uma restrição de pedido obrigatória indica que a segunda ação não deve ser iniciada para o segundo recurso a menos que e até que a primeira ação seja concluída com sucesso para o primeiro recurso. As ações que podem ser encomendadas são stop, start, e, adicionalmente, para clones promocionais, demote e promote. Por exemplo, "A e depois B" (que é equivalente a "iniciar A e depois iniciar B") significa que B não será iniciado a menos que e até que A comece com sucesso. Uma restrição de pedido é obrigatória se a opção kind para a restrição for definida para Mandatory ou deixada como padrão.
Se a opção symmetrical for definida para true ou deixada para o padrão, as ações opostas serão ordenadas em reverso. As ações start e stop são opostas, e demote e promote são opostas. Por exemplo, uma ordem simétrica de "promover A e depois iniciar B" implica em "parar B e depois rebaixar A", o que significa que A não pode ser rebaixado até e a menos que B pare com sucesso. Uma ordenação simétrica significa que mudanças no estado de A podem fazer com que ações sejam programadas para B. Por exemplo, dado "A então B", se A reinicia devido a falha, B será parado primeiro, depois A será parado, depois A será iniciado, depois B será iniciado.
Observe que o agrupamento reage a cada mudança de estado. Se o primeiro recurso for reiniciado e estiver num estado inicial novamente antes do segundo recurso iniciar uma operação de parada, o segundo recurso não precisará ser reiniciado.
12.2. Configuração de pedidos de consultoria
Quando a opção kind=Optional é especificada para uma restrição de pedido, a restrição é considerada opcional e só se aplica se ambos os recursos estiverem executando as ações especificadas. Qualquer mudança no estado pelo primeiro recurso especificado não terá efeito sobre o segundo recurso especificado.
O seguinte comando configura uma restrição de ordenação consultiva para os recursos denominados VirtualIP e dummy_resource.
# pcs constraint order VirtualIP then dummy_resource kind=Optional12.3. Configuração de conjuntos de recursos encomendados
Uma situação comum é que um administrador crie uma cadeia de recursos ordenados, onde, por exemplo, o recurso A começa antes do recurso B que começa antes do recurso C. Se sua configuração exigir que você crie um conjunto de recursos que seja colocado e iniciado em ordem, você pode configurar um grupo de recursos que contenha esses recursos, conforme descrito em Configuração de grupos de recursos.
Há algumas situações, entretanto, onde a configuração dos recursos que precisam começar em uma ordem específica como um grupo de recursos não é apropriada:
- Talvez seja necessário configurar os recursos para começar em ordem e os recursos não são necessariamente colocados.
- Você pode ter um recurso C que deve começar depois que o recurso A ou B tiver começado, mas não há nenhuma relação entre A e B.
- Você pode ter recursos C e D que devem começar depois que ambos os recursos A e B tiverem começado, mas não há relação entre A e B ou entre C e D.
Nestas situações, você pode criar uma restrição de pedidos em um conjunto ou conjuntos de recursos com o comando pcs constraint order set.
Você pode definir as seguintes opções para um conjunto de recursos com o comando pcs constraint order set.
sequential, que pode ser ajustado paratrueoufalsepara indicar se o conjunto de recursos deve ser ordenado em relação um ao outro. O valor padrão étrue.A configuração
sequentialparafalsepermite que um conjunto seja ordenado em relação a outros conjuntos na restrição de ordenação, sem que seus membros sejam ordenados em relação uns aos outros. Portanto, esta opção só faz sentido se vários conjuntos estiverem listados na restrição; caso contrário, a restrição não tem efeito.-
require-all, que pode ser ajustado paratrueoufalsepara indicar se todos os recursos do conjunto devem estar ativos antes de continuar. Definirrequire-allparafalsesignifica que apenas um recurso do conjunto precisa ser iniciado antes de continuar para o próximo conjunto. A configuraçãorequire-allafalsenão tem efeito, a menos que seja usada em conjunto com conjuntos não ordenados, que são conjuntos para os quaissequentialestá configurado parafalse. O valor padrão étrue. -
action, que pode ser ajustado parastart,promote,demoteoustop, conforme descrito em Propriedades de uma Restrição de Ordem. -
role, que pode ser ajustado paraStopped,Started,Master, ouSlave.
Você pode definir as seguintes opções de restrição para um conjunto de recursos seguindo o parâmetro setoptions do comando pcs constraint order set.
-
id, para fornecer um nome para a restrição que você está definindo. -
kind, que indica como aplicar a restrição, conforme descrito em Propriedades de uma Restrição de Ordem. -
symmetrical, para definir se o inverso da restrição se aplica à ação oposta, conforme descrito em Propriedades de uma Restrição de Ordem.
pcs constraint order set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]]] [set [setoptions [constraint_options]]]
Se você tiver três recursos chamados D1, D2, e D3, o seguinte comando os configura como um conjunto de recursos ordenados.
# pcs constraint order set D1 D2 D3
Se você tiver seis recursos denominados A, B, C, D, E, e F, este exemplo configura uma restrição de pedido para o conjunto de recursos que começará como a seguir:
-
AeBcomeçam independentemente um do outro -
Ccomeça uma vez queAouBjá começou -
Dcomeça quandoCjá começou -
EeFcomeçam independentemente um do outro uma vez queDjá começou
A interrupção dos recursos não é influenciada por esta restrição, uma vez que o site symmetrical=false está definido.
# pcs constraint order set A B sequential=false require-all=false set C D set E F sequential=false setoptions symmetrical=false12.4. Configuração de ordem de partida para dependências de recursos não gerenciadas pela Pacemaker
É possível que um agrupamento inclua recursos com dependências que não são gerenciadas pelo próprio agrupamento. Neste caso, é preciso garantir que essas dependências sejam iniciadas antes de o Pacemaker ser iniciado e parado depois que o Pacemaker for parado.
Você pode configurar sua ordem de partida para responder por esta situação por meio da meta systemd resource-agents-deps . Você pode criar uma unidade drop-in systemd para este alvo e o Pacemaker se encarregará de fazer o pedido de forma apropriada em relação a este alvo.
Por exemplo, se um cluster inclui um recurso que depende do serviço externo foo que não é gerenciado pelo cluster, execute o seguinte procedimento.
Crie a unidade drop-in
/etc/systemd/system/resource-agents-deps.target.d/foo.confque contém o seguinte:[Unit] Requires=foo.service After=foo.service
-
Execute o comando
systemctl daemon-reload.
Uma dependência de cluster especificada desta forma pode ser algo diferente de um serviço. Por exemplo, você pode ter uma dependência na montagem de um sistema de arquivo em /srv, caso em que você executaria o seguinte procedimento:
-
Assegure-se de que
/srvesteja listado no arquivo/etc/fstab. Isto será convertido automaticamente para o arquivosystemdsrv.mountna inicialização, quando a configuração do gerenciador do sistema for recarregada. Para mais informações, consulte as páginas de manualsystemd.mount(5) esystemd-fstab-generator(8). Para ter certeza de que o Pacemaker inicia após a montagem do disco, crie a unidade drop-in
/etc/systemd/system/resource-agents-deps.target.d/srv.confque contém o seguinte.[Unit] Requires=srv.mount After=srv.mount
-
Execute o comando
systemctl daemon-reload.
Capítulo 13. Colocando recursos de cluster
Para especificar que a localização de um recurso depende da localização de outro recurso, você configura uma restrição de colocação.
Há um importante efeito colateral de criar uma restrição de colocação entre dois recursos: ela afeta a ordem na qual os recursos são atribuídos a um nó. Isto porque não se pode colocar o recurso A em relação ao recurso B, a menos que se saiba onde está o recurso B. Portanto, quando você estiver criando restrições de colocação, é importante considerar se você deve colocar o recurso A com o recurso B ou o recurso B com o recurso A.
Outra coisa a ter em mente ao criar restrições de colocação é que, supondo que o recurso A esteja colocado com o recurso B, o agrupamento também levará em conta as preferências do recurso A ao decidir qual nó escolher para o recurso B.
O seguinte comando cria uma restrição de colocação.
pcs constraint colocation add [master|slave] source_resource com [master|slave] target_resource [score] [options]
Tabela 13.1, “Propriedades de uma Restrição de Colocação”, resume as propriedades e opções para a configuração de restrições de colocação.
Tabela 13.1. Propriedades de uma Restrição de Colocação
| Campo | Descrição |
|---|---|
| fonte_resource | A fonte de colocação. Se a restrição não puder ser satisfeita, o agrupamento pode decidir não permitir que o recurso funcione de forma alguma. |
| target_resource | O alvo da colocação. O agrupamento decidirá onde colocar este recurso em primeiro lugar e depois decidirá onde colocar o recurso fonte. |
| pontuação |
Os valores positivos indicam que o recurso deve funcionar no mesmo nó. Os valores negativos indicam que os recursos não devem ser executados no mesmo nó. Um valor de |
13.1. Especificar a colocação obrigatória de recursos
A colocação obrigatória ocorre sempre que a pontuação da restrição é INFINITY ou -INFINITY. Nesses casos, se a restrição não puder ser satisfeita, então o source_resource não tem permissão para funcionar. Para score=INFINITY, isto inclui casos em que o target_resource não está ativo.
Se você precisar que myresource1 funcione sempre na mesma máquina que myresource2, você acrescentaria a seguinte restrição:
# pcs constraint colocation add myresource1 with myresource2 score=INFINITY
Como INFINITY foi utilizado, se myresource2 não puder funcionar em nenhum dos nós de cluster (por qualquer razão), então myresource1 não será permitido funcionar.
Alternativamente, você pode querer configurar o oposto, um cluster no qual myresource1 não pode funcionar na mesma máquina que myresource2. Neste caso, use score=-INFINITY
# pcs constraint colocation add myresource1 with myresource2 score=-INFINITY
Mais uma vez, especificando -INFINITY, a restrição é vinculativa. Portanto, se o único lugar que resta para correr é onde já está myresource2, então myresource1 não pode correr em nenhum lugar.
13.2. Especificar a colocação de recursos consultivos
Se a colocação obrigatória é sobre "deve" e "não deve", então a colocação consultiva é a alternativa "eu preferiria se". Para restrições com pontuação maior que -INFINITY e menor que INFINITY, o agrupamento tentará acomodar seus desejos, mas poderá ignorá-los se a alternativa for parar alguns dos recursos do agrupamento.
13.3. Colocando conjuntos de recursos
Se sua configuração exigir que você crie um conjunto de recursos que são colocados e iniciados em ordem, você pode configurar um grupo de recursos que contenha esses recursos, conforme descrito em Configuração de grupos de recursos. Há algumas situações, no entanto, onde configurar os recursos que precisam ser colocados como um grupo de recursos não é apropriado:
- Você pode precisar colocar um conjunto de recursos, mas os recursos não precisam necessariamente começar em ordem.
- Você pode ter um recurso C que deve ser colocado com o recurso A ou B, mas não há nenhuma relação entre A e B.
- Você pode ter recursos C e D que devem ser colocados com ambos os recursos A e B, mas não há relação entre A e B ou entre C e D.
Nestas situações, você pode criar uma restrição de colocação sobre um conjunto ou conjuntos de recursos com o comando pcs constraint colocation set.
Você pode definir as seguintes opções para um conjunto de recursos com o comando pcs constraint colocation set.
sequential, que pode ser ajustado paratrueoufalsepara indicar se os membros do conjunto devem ser colocados uns com os outros.A configuração
sequentialparafalsepermite que os membros deste conjunto sejam colocados com outro conjunto listado posteriormente na restrição, independentemente de quais membros deste conjunto estejam ativos. Portanto, esta opção só faz sentido se outro conjunto for listado depois deste na restrição; caso contrário, a restrição não tem efeito.-
role, que pode ser ajustado paraStopped,Started,Master, ouSlave.
Você pode definir a seguinte opção de restrição para um conjunto de recursos seguindo o parâmetro setoptions do comando pcs constraint colocation set.
-
id, para fornecer um nome para a restrição que você está definindo. -
score, para indicar o grau de preferência por esta restrição. Para informações sobre esta opção, consulte Opções de Restrição de Localização.
Ao listar os membros de um conjunto, cada membro é colocado com aquele que o precedeu. Por exemplo, "conjunto A B" significa "B é colocado com A". No entanto, ao listar vários conjuntos, cada conjunto é colocado com o que está depois dele. Por exemplo, "conjunto C D seqüencial=conjunto falso A B" significa "conjunto C D (onde C e D não têm relação entre si) é colocado com o conjunto A B (onde B é colocado com A)".
O seguinte comando cria uma restrição de colocação sobre um conjunto ou conjuntos de recursos.
pcs constraint colocation set resource1 resource2 [resourceN]... [options] [set resourceX resourceY ... [options]]] [set [setoptions [constraint_options]]]
13.4. Remoção de Restrições de Colocação
Use o seguinte comando para remover as restrições de colocação com source_resource.
pcs constraint colocation remover source_resource target_resource
Capítulo 14. Exibindo restrições de recursos
Há vários comandos que você pode usar para exibir as restrições que foram configuradas.
14.1. Exibindo todas as restrições configuradas
O seguinte comando lista todas as restrições atuais de localização, ordem e colocação. Se a opção --full for especificada, mostrar as identificações de restrições internas.
pcs constraint [list|show] [--full] [--full] [--full] [--full
A partir do RHEL 8.2, a listagem das restrições de recursos não mais, por padrão, exibe as restrições expiradas. Para incluir os consignamentos expirados, use a opção --all do comando pcs constraint. Isto listará as restrições expiradas, anotando as restrições e suas regras associadas como (expired) no display.
14.2. Exibição das restrições de localização
O comando a seguir lista todas as restrições de localização atuais.
-
Se
resourcesfor especificado, as restrições de localização são exibidas por recurso. Este é o comportamento padrão. -
Se
nodesfor especificado, as restrições de localização são exibidas por nó. - Se forem especificados recursos ou nós específicos, então somente informações sobre esses recursos ou nós serão exibidas.
pcs constraint location [mostrar [recursos [resource...]] | [nós [node...]] [--cheio]
14.3. Exibir restrições de pedidos
O seguinte comando lista todas as restrições de pedidos atuais.
pcs ordem de restrição [mostrar]
14.4. Exibição de restrições de colocação
O seguinte comando lista todas as restrições de colocação atuais.
pcs constraint colocation [mostrar]
14.5. Exibindo restrições específicas de recursos
O seguinte comando lista as restrições que fazem referência a recursos específicos.
pcs constraint ref resource...14.6. Exibição das dependências de recursos (Red Hat Enterprise Linux 8.2 e posteriores)
O comando seguinte mostra as relações entre os recursos de agrupamento em uma estrutura em árvore.
pcs resource relations resource [--full]
Se a opção --full for utilizada, o comando exibe informações adicionais, incluindo as identificações de restrição e os tipos de recursos.
No exemplo a seguir, há 3 recursos configurados: C, D, e E.
#pcs constraint order start C then start DAdding C D (kind: Mandatory) (Options: first-action=start then-action=start) #pcs constraint order start D then start EAdding D E (kind: Mandatory) (Options: first-action=start then-action=start) #pcs resource relations CC `- order | start C then start D `- D `- order | start D then start E `- E #pcs resource relations DD |- order | | start C then start D | `- C `- order | start D then start E `- E # pcsresource relations EE `- order | start D then start E `- D `- order | start C then start D `- C
No exemplo a seguir, há 2 recursos configurados: A e B. Os recursos A e B são parte do grupo de recursos G.
#pcs resource relations AA `- outer resource `- G `- inner resource(s) | members: A B `- B #pcs resource relations BB `- outer resource `- G `- inner resource(s) | members: A B `- A #pcs resource relations GG `- inner resource(s) | members: A B |- A `- B
Capítulo 15. Determinação da localização dos recursos com regras
Para restrições de localização mais complicadas, você pode usar as regras do Pacemaker para determinar a localização de um recurso.
15.1. Regras do marcapasso
As regras podem ser usadas para tornar sua configuração mais dinâmica. Um uso de regras pode ser o de atribuir máquinas a diferentes grupos de processamento (usando um atributo de nó) com base no tempo e depois usar esse atributo ao criar restrições de localização.
Cada regra pode conter uma série de expressões, expressões de datas e até mesmo outras regras. Os resultados das expressões são combinados com base no campo da regra boolean-op para determinar se a regra finalmente avalia para true ou false. O que acontece em seguida depende do contexto em que a regra está sendo usada.
Tabela 15.1. Propriedades de uma regra
| Campo | Descrição |
|---|---|
|
|
Limita a regra a ser aplicada somente quando o recurso está nessa função. Valores permitidos: |
|
|
A pontuação a aplicar se a regra for avaliada para |
|
|
O atributo do nó a ser procurado e usado como pontuação se a regra for avaliada para |
|
|
Como combinar o resultado de objetos de expressão múltipla. Valores permitidos: |
15.1.1. Expressões de atributos de nós
As expressões de atributos de nós são utilizadas para controlar um recurso com base nos atributos definidos por um ou mais nós.
Tabela 15.2. Propriedades de uma Expressão
| Campo | Descrição |
|---|---|
|
| O atributo do nó a ser testado |
|
|
Determina como o(s) valor(es) deve(m) ser testado(s). Valores permitidos: |
|
| A comparação a ser feita. Os valores permitidos:
*
*
*
*
*
*
*
* |
|
|
Valor fornecido pelo usuário para comparação (necessário, a menos que |
Além de quaisquer atributos adicionados pelo administrador, o cluster define atributos de nó especiais e integrados para cada nó que também podem ser usados, como descrito em Tabela 15.3, “Atributos dos nós embutidos”.
Tabela 15.3. Atributos dos nós embutidos
| Nome | Descrição |
|---|---|
|
| Nome do nó |
|
| Identificação do nó |
|
|
Tipo de nó. Os valores possíveis são |
|
|
|
|
|
O valor da propriedade do cluster |
|
|
O valor do atributo do nó |
|
| O papel que o clone promocional relevante tem sobre este nó. Válido somente dentro de uma regra para uma restrição de localização para um clone promocional. |
15.1.2. Expressões baseadas em tempo/data
As expressões de data são usadas para controlar um recurso ou opção de cluster com base na data/hora atual. Elas podem conter uma especificação de data opcional.
Tabela 15.4. Propriedades de uma expressão de data
| Campo | Descrição |
|---|---|
|
| Uma data/hora em conformidade com a especificação ISO8601. |
|
| Uma data/hora em conformidade com a especificação ISO8601. |
|
| Compara a data/hora atual com a data inicial ou final ou ambas as datas, dependendo do contexto. Valores permitidos:
*
*
*
* |
15.1.3. Especificações de data
As especificações de data são usadas para criar expressões semelhantes a cron cron cronômetro relacionadas ao tempo. Cada campo pode conter um único número ou um único intervalo. Em vez de ser padrão a zero, qualquer campo não fornecido é ignorado.
Por exemplo, monthdays="1" corresponde ao primeiro dia de cada mês e hours="09-17" corresponde ao horário entre 9h e 17h (inclusive). Entretanto, não é possível especificar weekdays="1,2" ou weekdays="1-2,5-6", uma vez que eles contêm múltiplos intervalos.
Tabela 15.5. Propriedades de uma especificação de data
| Campo | Descrição |
|---|---|
|
| Um nome único para a data |
|
| Valores permitidos: 0-23 |
|
| Valores permitidos: 0-31 (dependendo do mês e do ano) |
|
| Valores permitidos: 1-7 (1=Domingo, 7=Domingo) |
|
| Valores permitidos: 1-366 (dependendo do ano) |
|
| Valores permitidos: 1-12 |
|
|
Valores permitidos: 1-53 (dependendo de |
|
| Ano de acordo com o calendário gregoriano |
|
|
Pode diferir dos anos gregorianos; por exemplo, |
|
| Valores permitidos: 0-7 (0 é novo, 4 é lua cheia). |
15.2. Configuração de uma restrição de localização de marcapasso usando regras
Use o seguinte comando para configurar uma restrição do Pacemaker que usa regras. Se score for omitido, o padrão é INFINIDADE. Se resource-discovery for omitido, o valor padrão é always.
Para informações sobre a opção resource-discovery, consulte Limitando a descoberta de recursos a um subconjunto de nós.
Assim como com as restrições básicas de localização, você pode usar expressões regulares para recursos com estas restrições também.
Ao utilizar regras para configurar restrições de localização, o valor de score pode ser positivo ou negativo, com um valor positivo indicando "prefere" e um valor negativo indicando "evita".
pcs constraint location rsc rule [resource-discovery=option] [role=master|slave] [score=score | score-attribute=attribute] expression
A opção expression pode ser uma das seguintes onde duration_options e date_spec_options são: horas, dias do mês, dias da semana, dias da semana, dias do ano, meses, semanas, anos, anos da semana, lua, conforme descrito em Propriedades de uma Especificação de Data.
-
defined|not_defined attribute -
attribute lt|gt|lte|gte|eq|ne [string|integer|version] value -
date gt|lt date -
date in_range date to date -
date in_range date to duration duration_options … -
date-spec date_spec_options -
expression and|or expression -
(expression)
Observe que as durações são uma forma alternativa de especificar um fim para as operações do in_range por meio de cálculos. Por exemplo, você pode especificar uma duração de 19 meses.
A seguinte restrição de localização configura uma expressão que é verdadeira se agora for em qualquer época do ano de 2018.
# pcs constraint location Webserver rule score=INFINITY date-spec years=2018O seguinte comando configura uma expressão que é verdadeira das 9h às 17h, de segunda a sexta-feira. Observe que o valor de 16 horas corresponde até 16:59:59, pois o valor numérico (hora) ainda corresponde.
# pcs constraint location Webserver rule score=INFINITY date-spec hours="9-16" weekdays="1-5"O comando seguinte configura uma expressão que é verdadeira quando há lua cheia na sexta-feira, dia treze.
# pcs constraint location Webserver rule date-spec weekdays=5 monthdays=13 moon=4Para remover uma regra, use o seguinte comando. Se a regra que você está removendo é a última regra em sua restrição, a restrição será removida.
regra de restrição de pcs remover rule_idCapítulo 16. Gerenciamento de recursos de cluster
Esta seção descreve vários comandos que você pode usar para gerenciar recursos de cluster.
16.1. Exibição de recursos configurados
Para exibir uma lista de todos os recursos configurados, use o seguinte comando.
pcs status dos recursos
Por exemplo, se seu sistema for configurado com um recurso chamado VirtualIP e um recurso chamado WebSite, o comando pcs resource show produz o seguinte resultado.
# pcs resource status
VirtualIP (ocf::heartbeat:IPaddr2): Started
WebSite (ocf::heartbeat:apache): Started
Para exibir uma lista de todos os recursos configurados e os parâmetros configurados para esses recursos, use a opção --full do comando pcs resource config, como no exemplo a seguir.
# pcs resource config
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s
Resource: WebSite (type=apache class=ocf provider=heartbeat)
Attributes: statusurl=http://localhost/server-status configfile=/etc/httpd/conf/httpd.conf
Operations: monitor interval=1minPara exibir os parâmetros configurados para um recurso, use o seguinte comando.
pcs resource config resource_id
Por exemplo, o seguinte comando exibe os parâmetros atualmente configurados para o recurso VirtualIP.
# pcs resource config VirtualIP
Resource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat)
Attributes: ip=192.168.0.120 cidr_netmask=24
Operations: monitor interval=30s16.2. Modificação dos parâmetros dos recursos
Para modificar os parâmetros de um recurso configurado, use o seguinte comando.
atualização de recursos pcs resource_id [resource_options]
A seguinte seqüência de comandos mostra os valores iniciais dos parâmetros configurados para o recurso VirtualIP, o comando para alterar o valor do parâmetro ip, e os valores após o comando de atualização.
#pcs resource config VirtualIPResource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat) Attributes: ip=192.168.0.120 cidr_netmask=24 Operations: monitor interval=30s #pcs resource update VirtualIP ip=192.169.0.120#pcs resource config VirtualIPResource: VirtualIP (type=IPaddr2 class=ocf provider=heartbeat) Attributes: ip=192.169.0.120 cidr_netmask=24 Operations: monitor interval=30s
Quando você atualiza a operação de um recurso com o comando pcs resource update, quaisquer opções que você não chamar especificamente são redefinidas para seus valores padrão.
16.3. Status de falhas de compensação de recursos de cluster
Se um recurso falhou, uma mensagem de falha aparece quando você exibe o status do cluster. Se você resolver esse recurso, você pode limpar esse status de falha com o comando pcs resource cleanup. Este comando restabelece o status do recurso e failcount, dizendo ao cluster para esquecer o histórico de operação de um recurso e re-detectar seu estado atual.
O seguinte comando limpa o recurso especificado por resource_id.
pcs limpeza de recursos resource_id
Se você não especificar um resource_id, este comando restabelece o status do recurso e failcountpara todos os recursos.
O comando pcs resource cleanup sonda apenas os recursos que se apresentam como uma ação fracassada. Para sondar todos os recursos em todos os nós, você pode digitar o seguinte comando:
atualização de recursos pcs
Por padrão, o comando pcs resource refresh sonda apenas os nós onde o estado de um recurso é conhecido. Para sondar todos os recursos, mesmo que o estado não seja conhecido, digite o seguinte comando:
atualização de recursos pcs --cheio
16.4. Movimentação de recursos em um cluster
Pacemaker fornece uma variedade de mecanismos para configurar um recurso para mover de um nó para outro e para mover manualmente um recurso quando necessário.
Você pode mover recursos manualmente em um cluster com os comandos pcs resource move e pcs resource relocate, conforme descrito em Movimentação manual de recursos de cluster.
Além destes comandos, você também pode controlar o comportamento dos recursos de cluster, ativando, desativando e proibindo recursos, conforme descrito em Habilitação, desativação e proibição de recursos de cluster.
Você pode configurar um recurso para que ele se mova para um novo nó após um número definido de falhas, e você pode configurar um cluster para mover recursos quando a conectividade externa for perdida.
16.4.1. Movimentação de recursos devido a falhas
Quando você cria um recurso, você pode configurar o recurso para que ele se mova para um novo nó após um número definido de falhas, definindo a opção migration-threshold para esse recurso. Uma vez atingido o limite, este nó não terá mais permissão para executar o recurso falhado até que seja atingido:
-
O administrador redefine manualmente o recurso
failcountusando o comandopcs resource cleanup. -
O valor do recurso
failure-timeouté alcançado.
O valor de migration-threshold é definido como INFINITY por padrão. INFINITY é definido internamente como um número muito grande, mas finito. Um valor de 0 desativa o recurso migration-threshold.
Configurar um migration-threshold para um recurso não é o mesmo que configurar um recurso para migração, no qual o recurso se move para outro local sem perda de estado.
O exemplo seguinte acrescenta um limiar de migração de 10 ao recurso denominado dummy_resource, o que indica que o recurso se moverá para um novo nó após 10 falhas.
# pcs resource meta dummy_resource migration-threshold=10Você pode adicionar um limiar de migração aos padrões para todo o cluster com o seguinte comando.
# pcs resource defaults migration-threshold=10
Para determinar o estado atual de falhas e limites do recurso, use o comando pcs resource failcount show.
Há duas exceções ao conceito de limite de migração; elas ocorrem quando um recurso não inicia ou não pára. Se a propriedade do cluster start-failure-is-fatal estiver definida para true (que é o padrão), as falhas de partida fazem com que o failcount seja definido para INFINITY e, assim, sempre faz com que o recurso se mova imediatamente.
As falhas de parada são ligeiramente diferentes e cruciais. Se um recurso não parar e o STONITH for ativado, então o agrupamento cercará o nó a fim de poder iniciar o recurso em outro lugar. Se o STONITH não estiver ativado, então o aglomerado não tem como continuar e não tentará iniciar o recurso em outro lugar, mas tentará pará-lo novamente após o timeout de falhas.
16.4.2. Movimentação de recursos devido a mudanças na conectividade
A configuração do cluster para mover recursos quando a conectividade externa é perdida é um processo de duas etapas.
-
Adicione um recurso
pingao agrupamento. O recursopingusa a utilidade do sistema com o mesmo nome para testar se uma lista de máquinas (especificada pelo nome do host DNS ou endereço IPv4/IPv6) é alcançável e usa os resultados para manter um atributo de nó chamadopingd. - Configurar uma restrição de localização para o recurso que irá mover o recurso para um nó diferente quando a conectividade for perdida.
Tabela 10.1, “Agente de Identificação de Recursos” descreve as propriedades que você pode definir para um recurso ping.
Tabela 16.1. Propriedades de um recurso de ping
| Campo | Descrição |
|---|---|
|
| O tempo de espera (amortecimento) para que ocorram mais mudanças. Isto evita que um recurso salte ao redor do cluster quando os nós do cluster percebem a perda de conectividade em momentos ligeiramente diferentes. |
|
| O número de nós de ping conectados é multiplicado por este valor para obter uma pontuação. Útil quando há múltiplos nós ping configurados. |
|
| As máquinas a serem contatadas a fim de determinar o estado atual da conectividade. Os valores permitidos incluem nomes de hosts DNS resolvíveis, endereços IPv4 e IPv6. As entradas na lista de hosts são separadas por espaço. |
O seguinte exemplo de comando cria um recurso ping que verifica a conectividade para gateway.example.com. Na prática, você verificaria a conectividade com seu gateway/router de rede. Você configura o recurso ping como um clone para que o recurso seja executado em todos os nós de cluster.
# pcs resource create ping ocf:pacemaker:ping dampen=5s multiplier=1000 host_list=gateway.example.com clone
O exemplo a seguir configura uma regra de restrição de localização para o recurso existente denominado Webserver. Isso fará com que o recurso Webserver se mude para um host capaz de ping gateway.example.com se o host em que ele está atualmente funcionando não puder pingar gateway.example.com.
# pcs constraint location Webserver rule score=-INFINITY pingd lt 1 or not_defined pingdModule included in the following assemblies: // // <List assemblies here, each on a new line> // rhel-8-docs/enterprise/assemblies/assembly_managing-cluster-resources.adoc
16.5. Desabilitando uma operação de monitor
A maneira mais fácil de parar um monitor recorrente é apagá-lo. No entanto, pode haver momentos em que você deseja desativá-lo apenas temporariamente. Nesses casos, adicione enabled="false" à definição da operação. Quando você quiser restabelecer a operação de monitoramento, defina enabled="true" para a definição da operação.
Quando você atualiza a operação de um recurso com o comando pcs resource update, quaisquer opções que você não chamar especificamente são redefinidas para seus valores padrão. Por exemplo, se você tiver configurado uma operação de monitoramento com um valor de timeout personalizado de 600, a execução dos seguintes comandos redefinirá o valor de timeout para o valor padrão de 20 (ou o que quer que você tenha configurado o valor padrão com o comando pcs resource ops default ).
#pcs resource update resourceXZY op monitor enabled=false#pcs resource update resourceXZY op monitor enabled=true
A fim de manter o valor original de 600 para esta opção, quando você restabelece a operação de monitoramento você deve especificar este valor, como no exemplo a seguir.
# pcs resource update resourceXZY op monitor timeout=600 enabled=true16.6. Configuração e gerenciamento de etiquetas de recursos de cluster (RHEL 8.3 e posteriores)
A partir do Red Hat Enterprise Linux 8.3, você pode usar o comando pcs para marcar os recursos do cluster. Isto permite que você habilite, desabilite, gerencie ou não gerencie um conjunto específico de recursos com um único comando.
16.6.1. Marcação de recursos de cluster para administração por categoria
O seguinte procedimento marca dois recursos com uma etiqueta de recurso e desativa os recursos marcados. Neste exemplo, os recursos existentes a serem etiquetados são denominados d-01 e d-02.
Criar uma tag chamada
special-resourcespara os recursosd-01ed-02.[root@node-01]#
pcs tag create special-resources d-01 d-02Exibir a configuração da etiqueta de recurso.
[root@node-01]#
pcs tag configspecial-resources d-01 d-02Desabilite todos os recursos que estão marcados com a tag
special-resources.[root@node-01]#
pcs resource disable special-resourcesMostrar o status dos recursos para confirmar que os recursos
d-01ed-02estão desativados.[root@node-01]#
pcs resource* d-01 (ocf::pacemaker:Dummy): Stopped (disabled) * d-02 (ocf::pacemaker:Dummy): Stopped (disabled)
Além do comando pcs resource disable, os comandos pcs resource enable, pcs resource manage, e pcs resource unmanage apóiam a administração de recursos marcados.
Depois de ter criado uma etiqueta de recurso:
-
Você pode excluir uma etiqueta de recurso com o comando
pcs tag delete. -
Você pode modificar a configuração da tag de recurso para uma tag de recurso existente com o comando
pcs tag update.
16.6.2. Eliminação de um recurso de cluster etiquetado
Você não pode excluir um recurso de cluster marcado com o comando pcs. Para excluir um recurso etiquetado, use o seguinte procedimento.
Remover a etiqueta do recurso.
O seguinte comando remove a tag de recurso
special-resourcesde todos os recursos com essa tag,[root@node-01]#
pcs tag remove special-resources[root@node-01]#pcs tagNo tags definedO seguinte comando remove a etiqueta do recurso
special-resourcesdo recursod-01apenas.[root@node-01]#
pcs tag update special-resources remove d-01
Eliminar o recurso.
[root@node-01]#
pcs resource delete d-01Attempting to stop: d-01... Stopped
Capítulo 17. Criação de recursos de cluster que estão ativos em múltiplos nós (recursos clonados)
Você pode clonar um recurso de cluster para que o recurso possa estar ativo em vários nós. Por exemplo, você pode utilizar recursos clonados para configurar múltiplas instâncias de um recurso IP para distribuir em todo um cluster para balanceamento de nós. Você pode clonar qualquer recurso, desde que o agente de recursos o suporte. Um clone consiste em um recurso ou um grupo de recursos.
Somente os recursos que podem estar ativos em vários nós ao mesmo tempo são adequados para clonagem. Por exemplo, um recurso Filesystem que monta um sistema de arquivo não exclusivo como ext4 a partir de um dispositivo de memória compartilhada não deve ser clonado. Como a partição ext4 não está ciente do cluster, este sistema de arquivo não é adequado para operações de leitura/gravação que ocorrem a partir de múltiplos nós ao mesmo tempo.
17.1. Criação e remoção de um recurso clonado
Você pode criar um recurso e um clone desse recurso ao mesmo tempo com o seguinte comando.
pcs resource create resource_id [standard:[provider:]]type [resource options] [meta resource meta options] clone [clone options]
O nome do clone será resource_id-clone.
Não se pode criar um grupo de recursos e um clone desse grupo de recursos em um único comando.
Alternativamente, você pode criar um clone de um recurso ou grupo de recursos previamente criado com o seguinte comando.
pcs resource clone resource_id | group_name [clone options]...
O nome do clone será resource_id-clone ou group_name-clone.
Você precisa configurar as mudanças de configuração de recursos em apenas um nó.
Ao configurar as restrições, use sempre o nome do grupo ou clone.
Quando você cria um clone de um recurso, o clone assume o nome do recurso com -clone anexado ao nome. Os seguintes comandos criam um recurso do tipo apache chamado webfarm e um clone desse recurso chamado webfarm-clone.
# pcs resource create webfarm apache clone
Quando você cria um recurso ou clone de grupo de recursos que será encomendado após outro clone, você deve quase sempre definir a opção interleave=true. Isto garante que as cópias do clone dependente possam parar ou começar quando o clone do qual depende tiver parado ou começado no mesmo nó. Se você não definir esta opção, se um recurso clonado B depender de um recurso clonado A e um nó sair do cluster, quando o nó retornar ao cluster e o recurso A começar naquele nó, então todas as cópias do recurso B em todos os nós serão reiniciadas. Isto porque quando um recurso clonado dependente não tem a opção interleave definida, todas as instâncias desse recurso dependem de qualquer instância em execução do recurso do qual ele depende.
Use o seguinte comando para remover um clone de um recurso ou de um grupo de recursos. Isto não remove o recurso ou o próprio grupo de recursos.
pcs resource unclone resource_id | group_name
Tabela 17.1, “Opções de Clonagem de Recursos” descreve as opções que você pode especificar para um recurso clonado.
Tabela 17.1. Opções de Clonagem de Recursos
| Campo | Descrição |
|---|---|
|
| Opções herdadas do recurso que está sendo clonado, conforme descrito em Tabela 10.3, “Meta Opções de Recursos”. |
|
| Quantas cópias do recurso para começar. O número de nós no agrupamento é o padrão. |
|
|
Quantas cópias do recurso podem ser iniciadas em um único nó; o valor padrão é |
|
|
Ao parar ou iniciar uma cópia do clone, informe todas as outras cópias com antecedência e quando a ação foi bem sucedida. Valores permitidos: |
|
|
Cada cópia do clone desempenha uma função diferente? Valores permitidos:
Se o valor desta opção é
Se o valor desta opção for |
|
|
Caso as cópias sejam iniciadas em série (ao invés de em paralelo). Valores permitidos: |
|
|
Muda o comportamento das restrições de pedidos (entre clones) para que as cópias do primeiro clone possam começar ou parar assim que a cópia no mesmo nó do segundo clone tenha começado ou parado (em vez de esperar até que cada instância do segundo clone tenha começado ou parado). Valores permitidos: |
|
|
Se um valor for especificado, quaisquer clones que forem pedidos após este clone não poderão começar até que o número especificado de instâncias do clone original esteja em execução, mesmo que a opção |
Para alcançar um padrão de alocação estável, os clones são ligeiramente pegajosos por padrão, o que indica que eles têm uma ligeira preferência por permanecer no nó em que estão correndo. Se não for fornecido um valor para resource-stickiness, o clone usará um valor de 1. Sendo um valor pequeno, ele causa uma perturbação mínima nos cálculos de pontuação de outros recursos, mas é suficiente para evitar que o Pacemaker movimente desnecessariamente cópias em torno do agrupamento. Para informações sobre a configuração da meta-opção de recursos resource-stickiness, consulte Configurando as meta-opções de recursos.
17.2. Configuração de restrições de recursos clonais
Na maioria dos casos, um clone terá uma única cópia em cada nó ativo de cluster. Você pode, no entanto, definir clone-max para o recurso clone para um valor menor do que o número total de nós no cluster. Se este for o caso, você pode indicar a quais nós o cluster deve, preferencialmente, atribuir cópias com restrições de localização de recursos. Estas restrições não são escritas de maneira diferente daquelas para recursos regulares, exceto que a identificação do clone deve ser usada.
O seguinte comando cria uma restrição de localização para que o cluster atribua preferencialmente o clone de recursos webfarm-clone para node1.
# pcs constraint location webfarm-clone prefers node1
As restrições de pedidos comportam-se de forma ligeiramente diferente para os clones. No exemplo abaixo, porque a opção de clonagem interleave é deixada por padrão como false, nenhuma instância de webfarm-stats começará até que todas as instâncias de webfarm-clone que precisam ser iniciadas o tenham feito. Somente se nenhuma cópia de webfarm-clone puder ser iniciada, então webfarm-stats será impedida de ser ativada. Além disso, webfarm-clone aguardará que webfarm-stats seja interrompido antes de parar por si mesmo.
# pcs constraint order start webfarm-clone then webfarm-statsA colocação de um recurso regular (ou de grupo) com um clone significa que o recurso pode funcionar em qualquer máquina com uma cópia ativa do clone. O grupo escolherá uma cópia com base no local onde o clone está rodando e nas preferências de localização do próprio recurso.
A recolocação entre clones também é possível. Nesses casos, o conjunto de locais permitidos para o clone é limitado aos nós nos quais o clone está (ou estará) ativo. A alocação é então realizada como normalmente.
O seguinte comando cria uma restrição de colocação para garantir que o recurso webfarm-stats funcione no mesmo nó que uma cópia ativa de webfarm-clone.
# pcs constraint colocation add webfarm-stats with webfarm-clone17.3. Criação de recursos de clonagem promocionais
Os recursos de clonagem promocionais são recursos de clonagem com o meta atributo promotable definido para true. Eles permitem que as instâncias estejam em um dos dois modos operacionais; estes são chamados Master e Slave. Os nomes dos modos não têm significados específicos, exceto pela limitação de que quando uma instância é iniciada, ela deve aparecer no estado Slave.
17.3.1. Criando um recurso promocional
Você pode criar um recurso como um clone promocional com o seguinte comando único.
pcs resource create resource_id [standard:[provider:]]type [resource options] promocional [clone options]
O nome do clone promocional será resource_id-clone.
Alternativamente, você pode criar um recurso promocional a partir de um recurso ou grupo de recursos previamente criado com o seguinte comando. O nome do clone promocional será resource_id-clone ou group_name-clone.
recursos pcs promocionais resource_id [clone options]
Tabela 17.2, “Opções extras de clones disponíveis para clones promocionais” descreve as opções de clonagem extra que você pode especificar para um recurso promocional.
Tabela 17.2. Opções extras de clones disponíveis para clones promocionais
| Campo | Descrição |
|---|---|
|
| Quantas cópias do recurso podem ser promovidas; padrão 1. |
|
| Quantas cópias do recurso podem ser promovidas em um único nó; padrão 1. |
17.3.2. Configuração de restrições de recursos promocionais
Na maioria dos casos, um recurso promocional terá uma única cópia em cada nó ativo de cluster. Se este não for o caso, você pode indicar a quais nós o agrupamento deve, preferencialmente, atribuir cópias com restrições de localização de recursos. Estas restrições não são escritas de maneira diferente daquelas para os recursos regulares.
Você pode criar uma restrição de colocação que especifica se os recursos estão operando em um papel de mestre ou de escravo. O seguinte comando cria uma restrição de colocação de recursos.
pcs constraint colocation add [master|slave] source_resource com [master|slave] target_resource [score] [options]
Para informações sobre restrições de colocação, consulte Colocando recursos de agrupamento.
Ao configurar uma restrição de pedido que inclui recursos promocionais, uma das ações que você pode especificar para os recursos é promote, indicando que o recurso seja promovido do papel de escravo para o papel de mestre. Além disso, você pode especificar uma ação de demote, indicando que o recurso deve ser rebaixado do papel de mestre para o papel de escravo.
O comando para configurar uma restrição de ordem é o seguinte.
pedido de restrição pcs [action] resource_id e depois [action] resource_id [options]
Para informações sobre restrições de pedidos de recursos, ver ifdef:: Determinar a ordem em que os recursos de agrupamento são executados.
17.4. Demonstrando um recurso promovido sobre o fracasso (RHEL 8.3 e posteriores)
Você pode configurar um recurso promocional para que quando uma ação promote ou monitor falhar para esse recurso, ou a partição na qual o recurso está rodando perder quorum, o recurso será rebaixado mas não será totalmente interrompido. Isto pode evitar a necessidade de intervenção manual em situações em que a parada total do recurso o exigiria.
Para configurar um recurso promocional a ser rebaixado quando uma ação
promotefalhar, defina a meta-opção da operaçãoon-failparademote, como no exemplo a seguir.#
pcs resource op add my-rsc promote on-fail="demote"Para configurar um recurso promocional a ser rebaixado quando uma ação
monitorfalhar, definaintervalpara um valor não zero, defina a meta-opção de operaçãoon-failparademote, e definaroleparaMaster, como no exemplo a seguir.#
pcs resource op add my-rsc monitor interval="10s" on-fail="demote" role="Master"-
Para configurar um cluster para que, quando uma partição de cluster perder quorum, quaisquer recursos promovidos sejam despromovidos mas deixados em funcionamento e todos os outros recursos sejam interrompidos, defina a propriedade do cluster
no-quorum-policyparademote
Especificar um meta-atributo demote para uma operação não afeta como a promoção de um recurso é determinada. Se o nó afetado ainda tiver a maior pontuação de promoção, ele será selecionado para ser promovido novamente.
Capítulo 18. Gerenciando nós de cluster
As seções seguintes descrevem os comandos usados para gerenciar os nós de cluster, incluindo comandos para iniciar e parar serviços de cluster e para adicionar e remover nós de cluster.
18.1. Parar os serviços de cluster
O seguinte comando pára os serviços de agrupamento no nó ou nós especificados. Como com o pcs cluster start, a opção --all interrompe os serviços de cluster em todos os nós e se você não especificar nenhum nó, os serviços de cluster são interrompidos somente no nó local.
pcs cluster stop [--tudo | node] [...] [..
Você pode forçar uma parada dos serviços de cluster no nó local com o seguinte comando, que executa um comando kill -9.
pcs cluster kill
18.2. Habilitação e desativação de serviços de cluster
Use o seguinte comando para habilitar os serviços de cluster, que configura os serviços de cluster para serem executados na inicialização no nó ou nós especificados. A ativação permite que os nós se juntem novamente ao cluster automaticamente após terem sido cercados, minimizando o tempo em que o cluster está com menos de força total. Se os serviços de cluster não forem habilitados, um administrador pode investigar manualmente o que deu errado antes de iniciar os serviços de cluster manualmente, de modo que, por exemplo, um nó com problemas de hardware não possa voltar ao cluster quando for provável que falhe novamente.
-
Se você especificar a opção
--all, o comando permite serviços de cluster em todos os nós. - Se você não especificar nenhum nó, os serviços de cluster são habilitados somente no nó local.
pcs cluster enable [--all | node] [...] [..Use o seguinte comando para configurar os serviços de cluster para não serem executados na inicialização no nó ou nós especificados.
-
Se você especificar a opção
--all, o comando desabilita os serviços de cluster em todos os nós. - Se você não especificar nenhum nó, os serviços de cluster são desativados somente no nó local.
pcs cluster disable [--all | node] [...] [..18.3. Adição de nós de cluster
É altamente recomendável que você adicione nós aos agrupamentos existentes somente durante uma janela de manutenção da produção. Isto permite que você realize os testes apropriados de recursos e implantação para o novo nó e sua configuração de cercas.
Use o seguinte procedimento para adicionar um novo nó a um agrupamento existente. Este procedimento adiciona nós de clusters padrão rodando corosync. Para informações sobre a integração de nós não-corossincronos em um cluster, consulte Integração de nós não-corossincronos em um cluster: o serviço pacemaker_remote.
Neste exemplo, os nós de agrupamento existentes são clusternode-01.example.com, clusternode-02.example.com, e clusternode-03.example.com. O novo nó é newnode.example.com.
No novo nó a ser adicionado ao agrupamento, execute as seguintes tarefas.
Instalar os pacotes de cluster. Se o cluster utiliza a SBD, o gerente de tickets do estande ou um dispositivo de quorum, você deve instalar manualmente os respectivos pacotes (
sbd,booth-site,corosync-qdevice) no novo nó também.[root@newnode ~]#
yum install -y pcs fence-agents-allAlém dos pacotes de cluster, você também precisará instalar e configurar todos os serviços que você está executando no cluster, os quais você instalou nos nós de cluster existentes. Por exemplo, se você estiver rodando um servidor Apache HTTP em um cluster de alta disponibilidade da Red Hat, você precisará instalar o servidor no nó que está adicionando, assim como a ferramenta
wgetque verifica o status do servidor.Se você estiver executando o daemon
firewalld, execute os seguintes comandos para habilitar as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.#
firewall-cmd --permanent --add-service=high-availability#firewall-cmd --add-service=high-availabilityDefina uma senha para o ID do usuário
hacluster. Recomenda-se utilizar a mesma senha para cada nó do cluster.[root@newnode ~]#
passwd haclusterChanging password for user hacluster. New password: Retype new password: passwd: all authentication tokens updated successfully.Execute os seguintes comandos para iniciar o serviço
pcsde para habilitarpcsdno início do sistema.#
systemctl start pcsd.service#systemctl enable pcsd.service
Em um nó do agrupamento existente, executar as seguintes tarefas.
Autenticar o usuário
haclusterno novo nó de cluster.[root@clusternode-01 ~]#
pcs host auth newnode.example.comUsername: hacluster Password: newnode.example.com: AuthorizedAdicionar o novo nó ao agrupamento existente. Este comando também sincroniza o arquivo de configuração do cluster
corosync.confcom todos os nós do cluster, incluindo o novo nó que você está adicionando.[root@clusternode-01 ~]#
pcs cluster node add newnode.example.com
No novo nó a ser adicionado ao agrupamento, execute as seguintes tarefas.
Iniciar e habilitar serviços de cluster no novo nó.
[root@newnode ~]#
pcs cluster startStarting Cluster... [root@newnode ~]#pcs cluster enable- Certifique-se de configurar e testar um dispositivo de esgrima para o novo nó de cluster.
18.4. Remoção de nós de cluster
O seguinte comando desliga o nó especificado e o remove do arquivo de configuração do cluster, corosync.conf, em todos os outros nós do cluster.
pcs remover nó de cluster node18.5. Adicionando um nó a um agrupamento com múltiplos links
Ao adicionar um nó a um agrupamento com múltiplos links, você deve especificar endereços para todos os links. O exemplo seguinte adiciona o nó rh80-node3 a um cluster, especificando o endereço IP 192.168.122.203 para o primeiro link e 192.168.123.203 como o segundo link.
# pcs cluster node add rh80-node3 addr=192.168.122.203 addr=192.168.123.20318.6. Adição e modificação de links em um cluster existente (RHEL 8.1 e posteriores)
Na maioria dos casos, você pode adicionar ou modificar os links em um cluster existente sem reiniciar o cluster.
18.6.1. Adicionar e remover links em um cluster existente
Para adicionar um novo link para um cluster em execução, use o comando pcs cluster link add.
- Ao adicionar um link, você deve especificar um endereço para cada nó.
- Adicionar e remover um link só é possível quando se está usando o protocolo de transporte de nós.
- Pelo menos um link no agrupamento deve ser definido a qualquer momento.
- O número máximo de links em um agrupamento é 8, numerados de 0 a 7. Não importa quais links são definidos, assim, por exemplo, você pode definir apenas os links 3, 6 e 7.
-
Quando você adiciona um link sem especificar seu número de link,
pcsusa o link mais baixo disponível. -
Os números dos links atualmente configurados estão contidos no arquivo
corosync.conf. Para exibir o arquivocorosync.conf, execute o comandopcs cluster corosync.
O seguinte comando adiciona o link número 5 a um agrupamento de três nós.
[root@node1 ~] # pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=5
Para remover um link existente, use o comando pcs cluster link delete ou pcs cluster link remove. Qualquer um dos comandos a seguir removerá o link número 5 do agrupamento.
[root@node1 ~] #pcs cluster link delete 5[root@node1 ~] #pcs cluster link remove 5
18.6.2. Modificação de um link em um cluster com múltiplos links
Se houver vários links no agrupamento e você quiser mudar um deles, execute o procedimento a seguir.
Remova o link que você deseja mudar.
[root@node1 ~] #
pcs cluster link remove 2Adicione o link de volta ao cluster com os endereços e opções atualizados.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2
18.6.3. Modificando os endereços dos links em um cluster com um único link
Se seu agrupamento utiliza apenas um link e você deseja modificar esse link para utilizar endereços diferentes, execute o procedimento a seguir. Neste exemplo, o link original é o link 1.
Adicione um novo link com os novos endereços e opções.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 node3=10.0.5.31 options linknumber=2Remover o link original.
[root@node1 ~] #
pcs cluster link remove 1
Observe que você não pode especificar endereços que estão em uso no momento ao adicionar links a um cluster. Isto significa, por exemplo, que se você tiver um cluster de dois nós com um link e quiser alterar o endereço de apenas um nó, você não pode usar o procedimento acima para adicionar um novo link que especifique um novo endereço e um endereço existente. Ao invés disso, você pode adicionar um link temporário antes de remover o link existente e adicioná-lo de volta com o endereço atualizado, como no exemplo a seguir.
Neste exemplo:
- O link para o agrupamento existente é o link 1, que usa o endereço 10.0.5.11 para o nó 1 e o endereço 10.0.5.12 para o nó 2.
- Você gostaria de mudar o endereço do nó 2 para 10.0.5.31.
Para atualizar apenas um dos endereços de um cluster de dois nós com um único link, use o seguinte procedimento.
Adicionar um novo link temporário ao cluster existente, utilizando endereços que não estão em uso atualmente.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Remover o link original.
[root@node1 ~] #
pcs cluster link remove 1Adicione o novo e modificado link.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.31 options linknumber=1Remova o vínculo temporário que você criou
[root@node1 ~] #
pcs cluster link remove 2
18.6.4. Modificando as opções de link para um link em um cluster com um único link
Se seu agrupamento utiliza apenas um link e você deseja modificar as opções para esse link mas não deseja modificar o endereço a ser utilizado, você pode adicionar um link temporário antes de remover e atualizar o link para modificar.
Neste exemplo:
- O link para o agrupamento existente é o link 1, que usa o endereço 10.0.5.11 para o nó 1 e o endereço 10.0.5.12 para o nó 2.
-
Você gostaria de mudar a opção de link
link_prioritypara 11.
Use o seguinte procedimento para modificar a opção de link em um cluster com um único link.
Adicionar um novo link temporário ao cluster existente, utilizando endereços que não estão em uso atualmente.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.13 node2=10.0.5.14 options linknumber=2Remover o link original.
[root@node1 ~] #
pcs cluster link remove 1Adicione de volta o link original com as opções atualizadas.
[root@node1 ~] #
pcs cluster link add node1=10.0.5.11 node2=10.0.5.12 options linknumber=1 link_priority=11Remover o vínculo temporário.
[root@node1 ~] #
pcs cluster link remove 2
18.6.5. Modificar um link ao adicionar um novo link não é possível
Se por algum motivo não for possível adicionar um novo link em sua configuração e sua única opção for modificar um único link existente, você pode usar o seguinte procedimento, o que requer que você feche seu cluster.
O seguinte procedimento de exemplo atualiza o link número 1 no agrupamento e estabelece a opção link_priority para o link 11.
Pare os serviços de agrupamento para o agrupamento.
[root@node1 ~] #
pcs cluster stop --allAtualizar os endereços e opções do link.
O comando
pcs cluster link updatenão exige que você especifique todos os endereços e opções dos nós. Ao invés disso, você pode especificar apenas os endereços a serem alterados. Este exemplo modifica os endereços paranode1enode3e a opçãolink_priorityapenas.[root@node1 ~] #
pcs cluster link update 1 node1=10.0.5.11 node3=10.0.5.31 options link_priority=11Para remover uma opção, você pode definir a opção para um valor nulo com o
option=formato.Reiniciar o conjunto
[root@node1 ~] #
pcs cluster start --all
18.7. Configuração de um grande cluster com muitos recursos
Se o cluster que você está implantando consiste de um grande número de nós e muitos recursos, você pode precisar modificar os valores padrão dos seguintes parâmetros para seu cluster.
- A propriedade do cluster
cluster-ipc-limit A propriedade de cluster
cluster-ipc-limité o backlog máximo de mensagens IPC antes que um daemon de cluster desconecte outro. Quando um grande número de recursos é limpo ou modificado simultaneamente em um grande aglomerado, um grande número de atualizações CIB chega de uma só vez. Isto pode fazer com que clientes mais lentos sejam despejados se o serviço Pacemaker não tiver tempo para processar todas as atualizações de configuração antes que o limite da fila de eventos CIB seja atingido.O valor recomendado de
cluster-ipc-limitpara uso em grandes clusters é o número de recursos no cluster multiplicado pelo número de nós. Este valor pode ser aumentado se você vir mensagens de "Evicting client" para PIDs de clusters nos logs.Você pode aumentar o valor de
cluster-ipc-limita partir de seu valor padrão de 500 com o comandopcs property set. Por exemplo, para um cluster de dez nós com 200 recursos, você pode definir o valor decluster-ipc-limitpara 2000 com o seguinte comando.#
pcs property set cluster-ipc-limit=2000- O parâmetro
PCMK_ipc_bufferPacemaker Em implantações muito grandes, as mensagens internas do marca-passo podem exceder o tamanho do buffer de mensagens. Quando isto ocorrer, você verá uma mensagem nos logs do sistema no seguinte formato:
Compressed message exceeds X% of configured IPC limit (X bytes); consider setting PCMK_ipc_buffer to X or higherAo ver esta mensagem, você pode aumentar o valor de
PCMK_ipc_bufferno arquivo de configuração/etc/sysconfig/pacemakerem cada nó. Por exemplo, para aumentar o valor dePCMK_ipc_bufferde seu valor padrão para 13396332 bytes, altere o campo não comentadoPCMK_ipc_bufferno arquivo/etc/sysconfig/pacemakerem cada nó do cluster da seguinte forma.PCMK_ipc_buffer=13396332Para aplicar esta mudança, execute o seguinte comando.
#
systemctl restart pacemaker
Capítulo 19. Definir permissões de usuário para um cluster de Pacemaker
Você pode conceder permissão para outros usuários específicos além do usuário hacluster para gerenciar um cluster Pacemaker. Há dois conjuntos de permissões que você pode conceder a usuários individuais:
-
Permissões que permitem aos usuários individuais gerenciar o cluster através da interface Web e executar comandos
pcsque se conectam aos nós através de uma rede. Os comandos que se conectam aos nós através de uma rede incluem comandos para configurar um cluster, ou para adicionar ou remover nós de um cluster. - Permissões para usuários locais para permitir o acesso somente leitura ou leitura-escrita à configuração do cluster. Os comandos que não requerem conexão através de uma rede incluem comandos que editam a configuração do cluster, tais como os que criam recursos e configuram restrições.
Em situações onde ambos os conjuntos de permissões foram atribuídos, as permissões para comandos que se conectam através de uma rede são aplicadas primeiro, e depois as permissões para editar a configuração do cluster no nó local são aplicadas. A maioria dos comandos pcs não exige acesso à rede e, nesses casos, as permissões de rede não serão aplicadas.
19.1. Definir permissões para o acesso dos nós através de uma rede
Para conceder permissão a usuários específicos para gerenciar o cluster através da interface Web e executar comandos pcs que se conectam aos nós através de uma rede, adicione esses usuários ao grupo haclient. Isto deve ser feito em todos os nós do cluster.
19.2. Definir permissões locais usando ACLs
Você pode usar o comando pcs acl para definir permissões para usuários locais para permitir acesso somente leitura ou leitura-escrita à configuração do cluster, usando listas de controle de acesso (ACLs).
Por padrão, as ACLs não são habilitadas. Quando as ACLs não são ativadas, o usuário root e qualquer usuário que seja membro do grupo haclient em todos os nós tem acesso local completo à configuração do cluster enquanto os usuários que não são membros do haclient não têm acesso. Quando as ACLs são ativadas, entretanto, mesmo os usuários que são membros do grupo haclient têm acesso apenas ao que foi concedido a esse usuário pelas ACLs.
A definição de permissões para usuários locais é um processo em duas etapas:
-
Executar o comando
pcs acl role create…para criar um role que define as permissões para essa função. -
Atribua a função que você criou a um usuário com o comando
pcs acl user create. Se você atribuir várias funções ao mesmo usuário, qualquer permissãodenytem precedência, entãowrite, entãoread.
O seguinte procedimento de exemplo fornece acesso somente leitura para uma configuração de cluster a um usuário local chamado rouser. Note que também é possível restringir o acesso apenas a certas partes da configuração.
É importante realizar este procedimento como raiz ou salvar todas as atualizações de configuração em um arquivo de trabalho que você pode então empurrar para a CIB ativa quando estiver terminado. Caso contrário, você pode se bloquear de fazer qualquer outra alteração. Para informações sobre como salvar atualizações de configuração em um arquivo de trabalho, consulte Salvando uma mudança de configuração em um arquivo de trabalho.
Este procedimento exige que o usuário
rouserexista no sistema local e que o usuáriorouserseja um membro do grupohaclient.#
adduser rouser#usermod -a -G haclient rouserHabilite as ACLs do Pacemaker com o comando
pcs acl enable.#
pcs acl enableCriar uma função chamada
read-onlycom permissões somente de leitura para a cib.#
pcs acl role create read-only description="Read access to cluster" read xpath /cibCriar o usuário
rouserno sistema ACL da pcs e atribuir a esse usuário a funçãoread-only.#
pcs acl user create rouser read-onlyVeja as ACLs atuais.
#
pcs aclUser: rouser Roles: read-only Role: read-only Description: Read access to cluster Permission: read xpath /cib (read-only-read)
Capítulo 20. Operações de monitoramento de recursos
Para garantir que os recursos permaneçam saudáveis, você pode acrescentar uma operação de monitoramento à definição de um recurso. Se você não especificar uma operação de monitoramento para um recurso, por padrão o comando pcs criará uma operação de monitoramento, com um intervalo que é determinado pelo agente do recurso. Se o agente de recursos não fornecer um intervalo de monitoramento padrão, o comando pcs criará uma operação de monitoramento com um intervalo de 60 segundos.
Tabela 20.1, “Propriedades de uma operação” resume as propriedades de uma operação de monitoramento de recursos.
Tabela 20.1. Propriedades de uma operação
| Campo | Descrição |
|---|---|
|
| Nome único para a ação. O sistema atribui isto quando você configura uma operação. |
|
|
A ação a realizar. Valores comuns: |
|
|
Se definido para um valor diferente de zero, é criada uma operação recorrente que se repete nesta freqüência, em segundos. Um valor diferente de zero só faz sentido quando a ação
Se definido como zero, que é o valor padrão, este parâmetro permite fornecer valores a serem usados para operações criadas pelo cluster. Por exemplo, se o |
|
|
Se a operação não for concluída no tempo definido por este parâmetro, abortar a operação e considerá-la fracassada. O valor padrão é o valor de
O valor |
|
| A ação a ser tomada se esta ação falhar. Os valores permitidos:
*
*
*
*
*
*
*
O padrão para a operação |
|
|
Se |
20.1. Configuração de operações de monitoramento de recursos
Você pode configurar as operações de monitoramento ao criar um recurso, usando o seguinte comando.
pcs resource create resource_id standard:provider:type|type [resource_options] [op operation_action operation_options [operation_type operation_options ]...]
Por exemplo, o seguinte comando cria um recurso IPaddr2 com uma operação de monitoramento. O novo recurso é chamado VirtualIP com um endereço IP de 192.168.0.99 e uma máscara de rede de 24 em eth2. Uma operação de monitoramento será realizada a cada 30 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2 op monitor interval=30sAlternativamente, você pode adicionar uma operação de monitoramento a um recurso existente com o seguinte comando.
pcs resource op adicionar resource_id operation_action [operation_properties]
Use o seguinte comando para excluir uma operação de recurso configurado.
pcs resource op remove resource_id operation_name operation_properties
Você deve especificar as propriedades exatas da operação para remover corretamente uma operação existente.
Para alterar os valores de uma opção de monitoramento, você pode atualizar o recurso. Por exemplo, você pode criar um VirtualIP com o seguinte comando.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2Por padrão, este comando cria estas operações.
Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s)
stop interval=0s timeout=20s (VirtualIP-stop-timeout-20s)
monitor interval=10s timeout=20s (VirtualIP-monitor-interval-10s)Para alterar a operação de parada, execute o seguinte comando.
#pcs resource update VirtualIP op stop interval=0s timeout=40s#pcs resource show VirtualIPResource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2) Attributes: ip=192.168.0.99 cidr_netmask=24 nic=eth2 Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s) monitor interval=10s timeout=20s (VirtualIP-monitor-interval-10s) stop interval=0s timeout=40s (VirtualIP-name-stop-interval-0s-timeout-40s)
20.2. Configuração de padrões de operação de recursos globais
A partir do Red Hat Enterprise Linux 8.3, você pode alterar o valor default de uma operação de recurso para todos os recursos com o comando pcs resource op defaults update. O seguinte comando define o valor default global de um timeout de 240 segundos para todas as operações de monitoramento.
# pcs resource op defaults update timeout=240s
O original pcs resource op defaults name=value que define os padrões de operação de recursos para todos os recursos em versões anteriores do RHEL 8, continua sendo suportado, a menos que haja mais de um conjunto de padrões configurado. Entretanto, pcs resource op defaults update é agora a versão preferida do comando.
20.2.1. Valores de operação superiores aos recursos específicos
Observe que um recurso de cluster usará o padrão global somente quando a opção não estiver especificada na definição do recurso de cluster. Por padrão, os agentes de recursos definem a opção timeout para todas as operações. Para que o valor de timeout global da operação seja honrado, você deve criar o recurso de cluster sem a opção timeout explicitamente ou deve remover a opção timeout atualizando o recurso de cluster, como no seguinte comando.
# pcs resource update VirtualIP op monitor interval=10s
Por exemplo, após definir um valor padrão global de 240 segundos para timeout para todas as operações de monitoramento e atualizar o recurso de cluster VirtualIP para remover o valor de timeout para a operação monitor, o recurso VirtualIP terá então valores de timeout para start, stop e monitor operações de 20s, 40s e 240s, respectivamente. O valor padrão global para operações de timeout é aplicado aqui apenas na operação monitor, onde a opção padrão timeout foi removida pelo comando anterior.
# pcs resource show VirtualIP
Resource: VirtualIP (class=ocf provider=heartbeat type=IPaddr2)
Attributes: ip=192.168.0.99 cidr_netmask=24 nic=eth2
Operations: start interval=0s timeout=20s (VirtualIP-start-timeout-20s)
monitor interval=10s (VirtualIP-monitor-interval-10s)
stop interval=0s timeout=40s (VirtualIP-name-stop-interval-0s-timeout-40s)20.2.2. Alteração do valor padrão de uma operação de recurso para conjuntos de recursos (RHEL 8.3 e posteriores)
A partir do Red Hat Enterprise Linux 8.3, você pode criar múltiplos conjuntos de padrões de operação de recursos com o comando pcs resource op defaults set create, que lhe permite especificar uma regra que contém resource e expressões de operação. Somente resource e expressões de operação, incluindo and, or e parênteses, são permitidas nas regras que você especificar com este comando.
Com este comando, você pode configurar um valor padrão de operação de recursos para todos os recursos de um determinado tipo. Por exemplo, agora é possível configurar os recursos implícitos podman criados pela Pacemaker quando os pacotes estão em uso.
O seguinte comando estabelece um valor de tempo limite padrão de 90s para todas as operações para todos os recursos podman. Neste exemplo, ::podman significa um recurso de qualquer classe, de qualquer fornecedor, do tipo podman.
A opção id, que nomeia o conjunto de recursos padrão de operação, não é obrigatória. Se você não definir esta opção, pcs irá gerar uma identificação automaticamente. A definição deste valor permite que você forneça um nome mais descritivo.
# pcs resource op defaults set create id=podman-timeout meta timeout=90s rule resource ::podman
O seguinte comando estabelece um valor padrão de tempo limite de 120s para a operação stop para todos os recursos.
# pcs resource op defaults set create id=stop-timeout meta timeout=120s rule op stop
É possível definir o valor padrão de timeout para uma operação específica para todos os recursos de um determinado tipo. O exemplo a seguir define um valor de timeout padrão de 120s para a operação stop para todos os recursos podman.
# pcs resource op defaults set create id=podman-stop-timeout meta timeout=120s rule resource ::podman and op stop20.2.3. Exibição dos valores padrão de operação dos recursos atualmente configurados
O comando pcs resource op defaults exibe uma lista de valores padrão configurados atualmente para operações de recursos, incluindo quaisquer regras que você especificou.
O seguinte comando exibe os valores padrão de operação para um cluster que foi configurado com um valor de timeout padrão de 90s para todas as operações de todos os recursos podman, e para o qual foi definido um ID para o conjunto de padrões de operação de recursos como podman-timeout.
# pcs resource op defaults
Meta Attrs: podman-timeout
timeout=90s
Rule: boolean-op=and score=INFINITY
Expression: resource ::podman
O seguinte comando exibe os valores padrão de operação para um cluster que foi configurado com um valor de timeout padrão de 120s para a operação stop para todos os recursos podman, e para o qual foi definido um ID para o conjunto de recursos padrão de operação como podman-stop-timeout.
# pcs resource op defaults
Meta Attrs: podman-stop-timeout
timeout=120s
Rule: boolean-op=and score=INFINITY
Expression: resource ::podman
Expression: op stop20.3. Configuração de múltiplas operações de monitoramento
Você pode configurar um único recurso com tantas operações de monitoramento quanto um agente de recursos suporta. Desta forma, você pode fazer um exame de saúde superficial a cada minuto e progressivamente mais intenso em intervalos maiores.
Ao configurar várias operações de monitoramento, você deve garantir que não sejam realizadas duas operações no mesmo intervalo.
Para configurar operações de monitoramento adicionais para um recurso que suporte verificações mais profundas em diferentes níveis, você adiciona um OCF_CHECK_LEVEL=n opção.
Por exemplo, se você configurar o seguinte recurso IPaddr2, por padrão isto cria uma operação de monitoramento com um intervalo de 10 segundos e um valor de timeout de 20 segundos.
# pcs resource create VirtualIP ocf:heartbeat:IPaddr2 ip=192.168.0.99 cidr_netmask=24 nic=eth2Se o IP Virtual suporta uma verificação diferente com uma profundidade de 10, o seguinte comando faz com que o Pacemaker realize a verificação de monitoramento mais avançada a cada 60 segundos, além da verificação IP Virtual normal a cada 10 segundos. (Como observado, não se deve configurar a operação de monitoramento adicional com um intervalo de 10 segundos também)
# pcs resource op add VirtualIP monitor interval=60s OCF_CHECK_LEVEL=10Capítulo 21. Propriedades do conjunto do marcapasso
As propriedades do agrupamento controlam como o agrupamento se comporta quando confrontado com situações que podem ocorrer durante a operação de agrupamento.
21.1. Resumo das propriedades e opções do cluster
Tabela 21.1, “Propriedades do Cluster” resume as propriedades do Pacemaker cluster, mostrando os valores padrão das propriedades e os possíveis valores que você pode definir para essas propriedades.
Há propriedades de agrupamento adicionais que determinam o comportamento das vedações. Para informações sobre essas propriedades, consulte Opções avançadas de configuração de cercas.
Além das propriedades descritas nesta tabela, há propriedades adicionais de cluster que são expostas pelo software de cluster. Para estas propriedades, é recomendável não alterar seus valores em relação a seus padrões.
Tabela 21.1. Propriedades do Cluster
| Opção | Padrão | Descrição |
|---|---|---|
|
| 0 | O número de ações de recursos que o agrupamento é permitido executar em paralelo. O valor "correto" dependerá da velocidade e da carga de sua rede e dos nós de cluster. O valor padrão de 0 significa que o cluster irá impor dinamicamente um limite quando qualquer nó tiver uma carga alta de CPU. |
|
| -1 (ilimitado) | O número de trabalhos de migração que o agrupamento é permitido executar em paralelo em um nó. |
|
| parar | O que fazer quando o conjunto não tem quorum. Valores permitidos: * ignorar - continuar toda a gestão de recursos * congelar - continuar o gerenciamento de recursos, mas não recuperar recursos de nós que não estejam na partição afetada * parar - parar todos os recursos na partição do cluster afetado * suicídio - cercar todos os nós na divisória de cluster afetada * demote - se uma partição de cluster perder quorum, demote quaisquer recursos promovidos e pare todos os outros recursos |
|
| verdadeiro | Indica se os recursos podem ser executados em qualquer nó por padrão. |
|
| 60s | Atraso de ida e volta sobre a rede (excluindo a execução da ação). O valor "correto" dependerá da velocidade e da carga de sua rede e dos nós de cluster. |
|
| verdadeiro | Indica se os recursos eliminados devem ser suspensos. |
|
| verdadeiro | Indica se as ações eliminadas devem ser canceladas. |
|
| verdadeiro |
Indica se a falha em iniciar um recurso em um determinado nó impede novas tentativas de iniciar esse nó. Quando ajustado para
Ajustando |
|
| -1 (todos) | O número de entradas do programador resultando em ERRORs para economizar. Usado ao relatar problemas. |
|
| -1 (todos) | O número de entradas do programador resultando em ADVERTÊNCIAS a serem salvas. Usado ao relatar problemas. |
|
| -1 (todos) | O número de entradas "normais" do agendador para economizar. Usado ao relatar problemas. |
|
| A pilha de mensagens sobre a qual a Pacemaker está atualmente funcionando. Utilizada para fins de informação e diagnóstico; não é configurável pelo usuário. | |
|
| Versão do Pacemaker no Controlador Designado (DC) do cluster. Utilizado para fins de diagnóstico; não configurável pelo usuário. | |
|
| 15 minutos | Intervalo de votação para mudanças baseadas no tempo para opções, parâmetros de recursos e restrições. Valores permitidos: Zero desativa a votação, os valores positivos são um intervalo em segundos (a menos que outras unidades SI sejam especificadas, tais como 5min). Observe que este valor é o tempo máximo entre verificações; se um evento de cluster ocorrer mais cedo do que o tempo especificado por este valor, a verificação será feita mais cedo. |
|
| falso | O modo de manutenção diz ao grupo para ir para um modo "mãos desligadas", e não iniciar ou parar qualquer serviço até que seja dito o contrário. Quando o modo de manutenção é concluído, o cluster faz uma verificação de sanidade do estado atual de qualquer serviço, e então pára ou inicia qualquer serviço que precise dele. |
|
| 20min | O tempo depois do qual desistir de tentar fechar graciosamente e simplesmente sair. Somente para uso avançado. |
|
| falso | Caso o agrupamento interrompa todos os recursos. |
|
| falso |
Indica se o cluster pode utilizar listas de controle de acesso, conforme definido com o comando |
|
|
| Indica se e como o agrupamento levará em conta os atributos de utilização ao determinar a colocação de recursos nos nós do agrupamento. |
|
| 0 (inválido) | (RHEL 8.3 e posteriores) Permite configurar um agrupamento de dois nós de modo que, em uma situação de cérebro dividido, o nó com menos recursos em funcionamento seja o nó que é cercado.
A propriedade
Por exemplo, se você definir O nó que executa o papel principal de um clone promocional recebe um ponto extra se uma prioridade tiver sido configurada para aquele clone.
Qualquer atraso definido com a propriedade
Somente esgrima programada pela própria Pacemaker irá observar |
21.2. Ajuste e remoção das propriedades de agrupamento
Para definir o valor de uma propriedade de cluster, use o seguinte pcs comando.
pcs conjunto de propriedade property=value
Por exemplo, para definir o valor de symmetric-cluster para false, use o seguinte comando.
# pcs property set symmetric-cluster=falseVocê pode remover uma propriedade de cluster da configuração com o seguinte comando.
pcs propriedade não definida property
Alternativamente, você pode remover uma propriedade de cluster de uma configuração, deixando o campo de valor do comando pcs property set em branco. Isto restaura essa propriedade a seu valor padrão. Por exemplo, se você definiu previamente a propriedade symmetric-cluster para false, o seguinte comando remove o valor definido da configuração e restaura o valor de symmetric-cluster para true, que é seu valor padrão.
# pcs property set symmetic-cluster=21.3. Consulta de configurações de propriedade de clusters
Na maioria dos casos, quando você usa o comando pcs para exibir valores dos vários componentes do cluster, você pode usar pcs list ou pcs show intercambiavelmente. Nos exemplos seguintes, pcs list é o formato usado para exibir uma lista completa de todas as configurações para mais de uma propriedade, enquanto pcs show é o formato usado para exibir os valores de uma propriedade específica.
Para exibir os valores dos ajustes de propriedade que foram definidos para o conjunto, use o seguinte pcs comando.
pcs lista de propriedades
Para exibir todos os valores das configurações de propriedade para o conjunto, incluindo os valores padrão das configurações de propriedade que não foram explicitamente definidas, use o seguinte comando.
pcs lista de propriedades -- todas
Para exibir o valor atual de uma propriedade de cluster específica, use o seguinte comando.
pcs property show property
Por exemplo, para exibir o valor atual do imóvel cluster-infrastructure, execute o seguinte comando:
# pcs property show cluster-infrastructure
Cluster Properties:
cluster-infrastructure: cmanPara fins informativos, você pode exibir uma lista de todos os valores padrão para as propriedades, quer tenham sido definidos para um valor diferente do padrão ou não, usando o seguinte comando.
pcs propriedade [lista|show] -defaults
Capítulo 22. Configuração de recursos para permanecer parado no desligamento do nó limpo (RHEL 8.2 e posteriores)
Quando um nó de cluster se desliga, a resposta padrão do Pacemaker é parar todos os recursos que estão correndo naquele nó e recuperá-los em outro lugar, mesmo que o desligamento seja um desligamento limpo. A partir do RHEL 8.2, você pode configurar o Pacemaker para que quando um nó for desligado de forma limpa, os recursos anexados ao nó serão bloqueados ao nó e não poderão ser iniciados em outro lugar até que comecem novamente quando o nó que foi desligado se juntar novamente ao cluster. Isto permite que você desligue os nós durante as janelas de manutenção quando as interrupções de serviço forem aceitáveis, sem fazer com que os recursos desse nó falhem para outros nós do aglomerado.
22.1. Propriedades do cluster para configurar recursos para permanecer parado no desligamento do nó limpo
A capacidade de evitar que os recursos falhem em um desligamento de nó limpo é implementada por meio das seguintes propriedades de agrupamento.
shutdown-lockQuando esta propriedade de agrupamento é definida para o valor padrão de
false, o agrupamento recuperará recursos que estão ativos nos nós que estão sendo limpos. Quando esta propriedade é definida paratrue, os recursos que estão ativos nos nós que estão sendo limpos não podem começar em outro lugar até que eles comecem no nó novamente depois que ele se juntar ao cluster.A propriedade
shutdown-lockfuncionará tanto para nós de cluster quanto para nós remotos, mas não para nós convidados.Se
shutdown-lockestiver configurado paratrue, você pode remover a trava em um recurso de cluster quando um nó estiver em baixo para que o recurso possa começar em outro lugar, executando uma atualização manual no nó com o seguinte comando.pcs resource refresh resource node=nodenameNote que uma vez que os recursos sejam desbloqueados, o agrupamento é livre para mover os recursos para outro lugar. Você pode controlar a probabilidade de isto ocorrer usando valores de aderência ou preferências de localização para o recurso.
NotaUma atualização manual só funcionará com nós remotos se você executar primeiro os seguintes comandos:
-
Execute o comando
systemctl stop pacemaker_remoteno nó remoto para parar o nó. -
Execute o
pcs resource disable remote-connection-resourcecomando.
Você pode então realizar uma atualização manual no nó remoto.
-
Execute o comando
shutdown-lock-limitQuando esta propriedade de agrupamento for definida para um tempo diferente do valor padrão de 0, os recursos estarão disponíveis para recuperação em outros nós se o nó não voltar dentro do tempo especificado desde que o desligamento foi iniciado.
NotaA propriedade
shutdown-lock-limitsó funcionará com nós remotos se você executar primeiro os seguintes comandos:-
Execute o comando
systemctl stop pacemaker_remoteno nó remoto para parar o nó. -
Execute o
pcs resource disable remote-connection-resourcecomando.
Após executar estes comandos, os recursos que estavam sendo executados no nó remoto estarão disponíveis para recuperação em outros nós quando o tempo especificado como o
shutdown-lock-limittiver passado.-
Execute o comando
22.2. Configurando a propriedade de bloqueio de fechamento
O exemplo a seguir define a propriedade do cluster shutdown-lock como true em um cluster de exemplo e mostra o efeito que isso tem quando o nó é desligado e iniciado novamente. Este exemplo de cluster consiste em três nós: z1.example.com, z2.example.com, e z3.example.com.
Defina o imóvel
shutdown-lockparatruee verifique seu valor. Neste exemplo, o imóvelshutdown-lock-limitmantém seu valor padrão de 0.[root@z3.example.com ~]#
pcs property set shutdown-lock=true[root@z3.example.com ~]#pcs property list --all | grep shutdown-lockshutdown-lock: true shutdown-lock-limit: 0Verifique o status do agrupamento. Neste exemplo, os recursos
thirdefifthestão funcionando emz1.example.com.[root@z3.example.com ~]#
pcs status... Full List of Resources: ... * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Started z1.example.com * fourth (ocf::pacemaker:Dummy): Started z2.example.com * fifth (ocf::pacemaker:Dummy): Started z1.example.com ...Encerrar
z1.example.com, o que irá parar os recursos que estão funcionando naquele nó.[root@z3.example.com ~]
# pcs cluster stop z1.example.comStopping Cluster (pacemaker)... Stopping Cluster (corosync)...A execução do comando
pcs statusmostra que o nóz1.example.comestá offline e que os recursos que estavam rodando noz1.example.comsãoLOCKEDenquanto o nó está em baixo.[root@z3.example.com ~]#
pcs status... Node List: * Online: [ z2.example.com z3.example.com ] * OFFLINE: [ z1.example.com ] Full List of Resources: ... * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Stopped z1.example.com (LOCKED) * fourth (ocf::pacemaker:Dummy): Started z3.example.com * fifth (ocf::pacemaker:Dummy): Stopped z1.example.com (LOCKED) ...Comece novamente os serviços de cluster em
z1.example.compara que ele se reintegre ao cluster. Os recursos bloqueados devem começar naquele nó, embora uma vez iniciados não necessariamente permaneçam no mesmo nó.[root@z3.example.com ~]#
pcs cluster start z1.example.comStarting Cluster...Neste exemplo, os recursos
thirdefifthsão recuperados no nóz1.example.com.[root@z3.example.com ~]#
pcs status... Node List: * Online: [ z1.example.com z2.example.com z3.example.com ] Full List of Resources: .. * first (ocf::pacemaker:Dummy): Started z3.example.com * second (ocf::pacemaker:Dummy): Started z2.example.com * third (ocf::pacemaker:Dummy): Started z1.example.com * fourth (ocf::pacemaker:Dummy): Started z3.example.com * fifth (ocf::pacemaker:Dummy): Started z1.example.com ...
Capítulo 23. Configuração de uma estratégia de posicionamento do nó
O pacemaker decide onde colocar um recurso de acordo com as pontuações de alocação de recursos em cada nó. O recurso será alocado ao nó onde o recurso tiver a pontuação mais alta. Esta pontuação de alocação é derivada de uma combinação de fatores, incluindo restrições de recursos, configurações resource-stickiness, histórico anterior de falhas de um recurso em cada nó, e utilização de cada nó.
Se as pontuações de alocação de recursos em todos os nós forem iguais, pela estratégia de colocação padrão o Pacemaker escolherá um nó com o menor número de recursos alocados para equilibrar a carga. Se o número de recursos em cada nó for igual, o primeiro nó elegível listado na CIB será escolhido para executar o recurso.
Muitas vezes, porém, recursos diferentes utilizam proporções significativamente diferentes das capacidades de um nó (como memória ou E/S). Nem sempre é possível equilibrar a carga de forma ideal levando em conta apenas o número de recursos alocados a um nó. Além disso, se os recursos forem colocados de forma que suas necessidades combinadas excedam a capacidade fornecida, eles podem não conseguir iniciar completamente ou podem funcionar com desempenho degradado. Para levar estes fatores em consideração, o Pacemaker permite configurar os seguintes componentes:
- a capacidade que um determinado nó proporciona
- a capacidade que um determinado recurso requer
- uma estratégia global para a colocação de recursos
23.1. Atributos de utilização e estratégia de colocação
Para configurar a capacidade que um nó fornece ou um recurso requer, você pode usar utilization attributes para nós e recursos. Você faz isso definindo uma variável de utilização para um recurso e atribuindo um valor a essa variável para indicar o que o recurso requer, e então definindo essa mesma variável de utilização para um nó e atribuindo um valor a essa variável para indicar o que o nó fornece.
Você pode nomear atributos de utilização de acordo com suas preferências e definir tantos pares de nomes e valores quanto suas necessidades de configuração. Os valores dos atributos de utilização devem ser números inteiros.
23.1.1. Configuração do nó e da capacidade de recursos
O exemplo a seguir configura um atributo de utilização da capacidade da CPU para dois nós, definindo este atributo como a variável cpu. Ele também configura um atributo de utilização da capacidade de RAM, definindo este atributo como a variável memory. Neste exemplo:
- O Nó 1 é definido como fornecendo uma capacidade de CPU de dois e uma capacidade de RAM de 2048
- O Nó 2 é definido como fornecendo uma capacidade de CPU de quatro e uma capacidade de RAM de 2048
#pcs node utilization node1 cpu=2 memory=2048#pcs node utilization node2 cpu=4 memory=2048
O exemplo a seguir especifica os mesmos atributos de utilização que três recursos diferentes exigem. Neste exemplo:
-
recurso
dummy-smallrequer uma capacidade de CPU de 1 e uma capacidade de RAM de 1024 -
recurso
dummy-mediumrequer uma capacidade de CPU de 2 e uma capacidade de RAM de 2048 -
recurso
dummy-largerequer uma capacidade de CPU de 1 e uma capacidade de RAM de 3072
#pcs resource utilization dummy-small cpu=1 memory=1024#pcs resource utilization dummy-medium cpu=2 memory=2048#pcs resource utilization dummy-large cpu=3 memory=3072
Um nó é considerado elegível para um recurso se tiver capacidade livre suficiente para satisfazer as necessidades do recurso, conforme definido pelos atributos de utilização.
23.1.2. Configuração da estratégia de colocação
Após ter configurado as capacidades que seus nós fornecem e as capacidades que seus recursos requerem, você precisa definir a propriedade do cluster placement-strategy, caso contrário, as configurações de capacidade não terão efeito.
Quatro valores estão disponíveis para a propriedade do cluster placement-strategy:
-
default -
utilization -
balanced -
minimal
O seguinte exemplo de comando estabelece o valor de placement-strategy para balanced. Após executar este comando, Pacemaker assegurará que a carga de seus recursos será distribuída uniformemente por todo o cluster, sem a necessidade de complicados conjuntos de restrições de colocação.
# pcs property set placement-strategy=balanced23.2. Alocação de recursos do marcapasso
As subseções a seguir resumem como a Pacemaker aloca os recursos.
23.2.1. Preferência de Nó
O marcapasso determina qual nó é preferido ao alocar recursos de acordo com a seguinte estratégia.
- O nó com o maior peso do nó é consumido primeiro. O peso do nó é uma pontuação mantida pelo agrupamento para representar a saúde do nó.
Se vários nós tiverem o mesmo peso de nó:
Se a propriedade do cluster
placement-strategyédefaultouutilization:- O nó que tem o menor número de recursos alocados é consumido primeiro.
- Se os números de recursos alocados forem iguais, o primeiro nó elegível listado na CIB é consumido primeiro.
Se a propriedade do cluster
placement-strategyébalanced:- O nó que tem a capacidade mais livre é consumido primeiro.
- Se as capacidades livres dos nós forem iguais, o nó que tiver o menor número de recursos alocados é consumido primeiro.
- Se as capacidades livres dos nós forem iguais e o número de recursos alocados for igual, o primeiro nó elegível listado na CIB é consumido primeiro.
-
Se a propriedade do cluster
placement-strategyéminimal, o primeiro nó elegível listado na CIB é consumido primeiro.
23.2.2. Capacidade do Nó
O marcapasso determina qual nó tem a capacidade mais livre, de acordo com a seguinte estratégia.
- Se apenas um tipo de atributo de utilização tiver sido definido, a capacidade livre é uma simples comparação numérica.
Se vários tipos de atributos de utilização tiverem sido definidos, então o nó que é numericamente mais alto na maioria dos tipos de atributos tem a capacidade mais livre. Por exemplo, o nó que tem a capacidade mais livre:
- Se NodeA tem mais CPUs livres, e NodeB tem mais memória livre, então suas capacidades livres são iguais.
- Se NodeA tem mais CPUs livres, enquanto NodeB tem mais memória e armazenamento livres, então NodeB tem mais capacidade livre.
23.2.3. Preferência de Alocação de Recursos
Pacemaker determina qual recurso é alocado primeiro de acordo com a seguinte estratégia.
- O recurso que tem a maior prioridade é alocado primeiro. Você pode definir a prioridade de um recurso ao criar o recurso.
- Se as prioridades dos recursos forem iguais, o recurso que tiver a pontuação mais alta no nó onde ele está funcionando é alocado primeiro, para evitar o embaralhamento de recursos.
- Se as pontuações dos recursos nos nós onde os recursos estão funcionando forem iguais ou se os recursos não estiverem funcionando, o recurso que tiver a pontuação mais alta no nó preferido é alocado primeiro. Se as pontuações dos recursos no nó preferido forem iguais neste caso, o primeiro recurso executável listado na CIB é alocado em primeiro lugar.
23.3. Diretrizes de estratégia de colocação de recursos
Para garantir que a estratégia de colocação de recursos da Pacemaker funcione de forma mais eficaz, você deve levar em conta as seguintes considerações ao configurar seu sistema.
Certifique-se de que você tenha capacidade física suficiente.
Se a capacidade física de seus nós estiver sendo utilizada ao máximo em condições normais, então poderão ocorrer problemas durante o failover. Mesmo sem o recurso de utilização, você pode começar a experimentar timeouts e falhas secundárias.
Construa algum buffer nas capacidades que você configura para os nós.
Anuncie um pouco mais de recursos de nós do que você fisicamente tem, no pressuposto de que um recurso Pacemaker não utilizará 100% da quantidade configurada de CPU, memória, e assim por diante o tempo todo. Esta prática às vezes é chamada de overcommit.
Especifique as prioridades de recursos.
Se o grupo vai sacrificar serviços, devem ser aqueles com os quais você menos se importa. Assegure-se de que as prioridades de recursos estejam devidamente definidas para que seus recursos mais importantes sejam agendados em primeiro lugar.
23.4. O agente de recursos NodeUtilization
O agente NodeUtilization pode detectar os parâmetros do sistema de CPU disponível, disponibilidade de memória host e disponibilidade de memória hypervisor e adicionar estes parâmetros ao CIB. Você pode executar o agente como um recurso clone para que ele preencha automaticamente estes parâmetros em cada nó.
Para obter informações sobre o agente de recursos NodeUtilization e as opções de recursos para este agente, execute o comando pcs resource describe NodeUtilization.
Capítulo 24. Configuração de um domínio virtual como um recurso
Você pode configurar um domínio virtual que é gerenciado pela estrutura de virtualização libvirt como um recurso de cluster com o comando pcs resource create, especificando VirtualDomain como o tipo de recurso.
Ao configurar um domínio virtual como um recurso, leve em conta as seguintes considerações:
- Um domínio virtual deve ser interrompido antes de ser configurado como um recurso de cluster.
- Uma vez que um domínio virtual é um recurso de cluster, ele não deve ser iniciado, parado ou migrado, exceto através das ferramentas de cluster.
- Não configure um domínio virtual que você tenha configurado como um recurso de cluster para começar quando seu host boots.
- Todos os nós autorizados a executar um domínio virtual devem ter acesso aos arquivos de configuração e dispositivos de armazenamento necessários para esse domínio virtual.
Se você quiser que o cluster gerencie serviços dentro do próprio domínio virtual, você pode configurar o domínio virtual como um nó convidado.
24.1. Opções de recursos de domínio virtual
Tabela 24.1, “Opções de Recursos para Recursos de Domínio Virtual” descreve as opções de recursos que você pode configurar para um recurso VirtualDomain.
Tabela 24.1. Opções de Recursos para Recursos de Domínio Virtual
| Campo | Padrão | Descrição |
|---|---|---|
|
|
(requerido) Caminho absoluto para o arquivo de configuração | |
|
| Dependente do sistema |
Hypervisor URI para conectar. Você pode determinar o URI padrão do sistema executando o comando |
|
|
|
Sempre desligue à força ("destruir") o domínio em parada. O comportamento padrão é recorrer a um desligamento forçado somente após uma tentativa de desligamento gracioso ter falhado. Você deve definir isto para |
|
| Dependente do sistema |
Transporte usado para conectar ao hipervisor remoto enquanto migrava. Se este parâmetro for omitido, o recurso usará o transporte padrão do |
|
| Utilizar uma rede de migração dedicada. A URI de migração é composta pela adição do valor deste parâmetro ao final do nome do nó. Se o nome do nó for um nome de domínio totalmente qualificado (FQDN), inserir o sufixo imediatamente antes do primeiro período (.) no FQDN. Certifique-se de que este nome de host composto seja resolúvel localmente e o endereço IP associado seja acessível através da rede favorecida. | |
|
|
Para monitorar serviços dentro do domínio virtual, adicione este parâmetro com uma lista de scripts para monitorar. Note: Quando os scripts de monitoramento forem usados, as operações de | |
|
|
|
Se ajustado para |
|
|
|
Se for definido como verdadeiro, o agente detectará o número de |
|
| porto alto aleatório |
Este porto será utilizado no |
|
|
Caminho para o diretório de instantâneos onde a imagem da máquina virtual será armazenada. Quando este parâmetro for definido, o estado de RAM da máquina virtual será salvo em um arquivo no diretório de instantâneos quando parado. Se ao iniciar um arquivo de estado estiver presente para o domínio, o domínio será restaurado para o mesmo estado em que estava antes de ter parado por último. Esta opção é incompatível com a opção |
Além das opções de recursos VirtualDomain, você pode configurar a opção allow-migrate metadados para permitir a migração ao vivo do recurso para outro nó. Quando esta opção é configurada para true, o recurso pode ser migrado sem perda de estado. Quando esta opção for definida para false, que é o estado padrão, o domínio virtual será desligado no primeiro nó e então reiniciado no segundo nó quando ele for movido de um nó para o outro.
24.2. Criando o recurso de domínio virtual
Use o seguinte procedimento para criar um recurso VirtualDomain em um cluster para uma máquina virtual que você tenha criado anteriormente:
Para criar o agente de recursos
VirtualDomainpara o gerenciamento da máquina virtual, a Pacemaker requer que o arquivo de configuraçãoxmlda máquina virtual seja despejado em um arquivo em disco. Por exemplo, se você criou uma máquina virtual chamadaguest1, descarte o arquivoxmlpara um arquivo em algum lugar em um dos nós do cluster que será permitido executar o convidado. Você pode usar um nome de arquivo de sua escolha; este exemplo usa/etc/pacemaker/guest1.xml.#
virsh dumpxml guest1 > /etc/pacemaker/guest1.xml-
Copie o arquivo de configuração da máquina virtual
xmlpara todos os outros nós de cluster que poderão executar o convidado, no mesmo local em cada nó. - Assegurar que todos os nós autorizados a executar o domínio virtual tenham acesso aos dispositivos de armazenamento necessários para esse domínio virtual.
- Testar separadamente que o domínio virtual pode iniciar e parar em cada nó que irá executar o domínio virtual.
- Se estiver funcionando, desligue o nó convidado. O marcapasso iniciará o nó quando ele estiver configurado no cluster. A máquina virtual não deve ser configurada para iniciar automaticamente quando o host iniciar.
Configure o recurso
VirtualDomaincom o comandopcs resource create. Por exemplo, o seguinte comando configura um recursoVirtualDomainchamadoVM. Como a opçãoallow-migrateestá configurada paratrueapcs move VM nodeXseria feito como uma migração ao vivo.Neste exemplo
migration_transportestá configurado parassh. Observe que para que a migração SSH funcione corretamente, o registro sem chave deve funcionar entre nós.#
pcs resource create VM VirtualDomain config=/etc/pacemaker/guest1.xml migration_transport=ssh meta allow-migrate=true
Capítulo 25. Quórum de Cluster
Um cluster do Red Hat Enterprise Linux High Availability Add-On usa o serviço votequorum, em conjunto com a esgrima, para evitar situações de cérebro dividido. Um número de votos é atribuído a cada sistema no cluster, e as operações de cluster são permitidas somente quando uma maioria de votos está presente. O serviço deve ser carregado em todos os nós ou em nenhum; se for carregado em um subconjunto de nós de cluster, os resultados serão imprevisíveis. Para informações sobre a configuração e operação do serviço votequorum, consulte a página de manual votequorum(5).
25.1. Configuração das opções do quorum
Há algumas características especiais de configuração de quorum que você pode definir ao criar um cluster com o comando pcs cluster setup. Tabela 25.1, “Opções do Quorum” resume estas opções.
Tabela 25.1. Opções do Quorum
| Opção | Descrição |
|---|---|
|
|
Quando ativado, o aglomerado pode sofrer até 50% de falhas nos nós ao mesmo tempo, de forma determinista. A partição do cluster, ou o conjunto de nós que ainda estão em contato com o
A opção
A opção |
|
| Quando ativado, o agrupamento será quorato pela primeira vez somente após todos os nós terem sido visíveis pelo menos uma vez ao mesmo tempo.
A opção
A opção |
|
|
Quando ativado, o agrupamento pode recalcular dinamicamente |
|
|
O tempo, em milissegundos, para esperar antes de recalcular |
Para maiores informações sobre a configuração e utilização destas opções, consulte a página de manual votequorum(5).
25.2. Modificação das opções do quorum
Você pode modificar as opções gerais de quorum para seu agrupamento com o comando pcs quorum update. A execução deste comando exige que o agrupamento seja interrompido. Para informações sobre as opções de quorum, consulte a página de manual votequorum(5).
O formato do comando pcs quorum update é o seguinte.
pcs quorum update [auto_tie_breaker=[0|1]] [last_man_standing=[0|1]] [last_man_standing_window=[time-in-ms] [wait_for_all=[0|1]]
A série de comandos a seguir modifica a opção do quorum wait_for_all e exibe o status atualizado da opção. Note que o sistema não permite executar este comando enquanto o cluster estiver em execução.
[root@node1:~]#pcs quorum update wait_for_all=1Checking corosync is not running on nodes... Error: node1: corosync is running Error: node2: corosync is running [root@node1:~]#pcs cluster stop --allnode2: Stopping Cluster (pacemaker)... node1: Stopping Cluster (pacemaker)... node1: Stopping Cluster (corosync)... node2: Stopping Cluster (corosync)... [root@node1:~]#pcs quorum update wait_for_all=1Checking corosync is not running on nodes... node2: corosync is not running node1: corosync is not running Sending updated corosync.conf to nodes... node1: Succeeded node2: Succeeded [root@node1:~]#pcs quorum configOptions: wait_for_all: 1
25.3. Exibição da configuração e status do quorum
Uma vez que um agrupamento esteja em execução, você pode entrar nos seguintes comandos de quorum de agrupamento.
O seguinte comando mostra a configuração do quorum.
pcs quorum [config]
O seguinte comando mostra o status do quorum runtime.
status de quorum pcs
25.4. Execução de clusters de inquéritos
Se você retirar nós de um agrupamento por um longo período de tempo e a perda desses nós causar perda de quórum, você pode alterar o valor do parâmetro expected_votes para o agrupamento ao vivo com o comando pcs quorum expected-votes. Isto permite que o aglomerado continue operando quando não tiver quorum.
A mudança dos votos esperados em um grupo vivo deve ser feita com extrema cautela. Se menos de 50% do agrupamento estiver funcionando porque você mudou manualmente os votos esperados, então os outros nós do agrupamento podem ser iniciados separadamente e executar serviços de agrupamento, causando corrupção de dados e outros resultados inesperados. Se você alterar este valor, você deve garantir que o parâmetro wait_for_all esteja ativado.
O seguinte comando define os votos esperados no conjunto vivo para o valor especificado. Isto afeta apenas o live cluster e não altera o arquivo de configuração; o valor de expected_votes é redefinido para o valor no arquivo de configuração no caso de uma recarga.
quorum esperado de votos pcs votes
Em uma situação em que você sabe que o agrupamento é inquirido, mas quer que o agrupamento prossiga com o gerenciamento de recursos, você pode usar o comando pcs quorum unblock para evitar que o agrupamento espere por todos os nós ao estabelecer o quorum.
Este comando deve ser usado com extrema cautela. Antes de emitir este comando, é imperativo garantir que os nós que não estão atualmente no cluster sejam desligados e não tenham acesso a recursos compartilhados.
# pcs quorum unblock25.5. Dispositivos do quorum
Você pode permitir que um agrupamento mantenha mais falhas nos nós do que as regras de quórum padrão permitem, configurando um dispositivo de quórum separado que atua como um dispositivo de arbitragem de terceiros para o agrupamento. Um dispositivo de quorum é recomendado para clusters com um número par de nós. Com clusters de dois nós, o uso de um dispositivo de quórum pode determinar melhor qual o nó que sobrevive em uma situação de cérebro dividido.
Deve-se levar em conta o seguinte ao configurar um dispositivo de quorum.
- Recomenda-se que um dispositivo de quorum seja executado em uma rede física diferente no mesmo local que o aglomerado que utiliza o dispositivo de quorum. O ideal é que o host do dispositivo de quorum esteja em um rack separado do cluster principal, ou pelo menos em uma PSU separada e não no mesmo segmento de rede que o anel ou anéis corosync.
- Não é possível usar mais de um dispositivo de quorum em um conjunto ao mesmo tempo.
-
Embora não se possa usar mais de um dispositivo de quorum em um agrupamento ao mesmo tempo, um único dispositivo de quorum pode ser usado por vários agrupamentos ao mesmo tempo. Cada agrupamento usando esse dispositivo de quorum pode usar diferentes algoritmos e opções de quorum, já que estes são armazenados nos próprios nós do agrupamento. Por exemplo, um único dispositivo de quorum pode ser usado por um cluster com um algoritmo
ffsplit(fifty/fifty split) e por um segundo cluster com um algoritmolms(last man standing). - Um dispositivo de quorum não deve ser executado em um nó de cluster existente.
25.5.1. Instalação de pacotes de dispositivos de quorum
A configuração de um dispositivo de quorum para um cluster requer que você instale os seguintes pacotes
Instale
corosync-qdevicenos nós de um cluster existente.[root@node1:~]#
yum install corosync-qdevice[root@node2:~]#yum install corosync-qdeviceInstale
pcsecorosync-qnetdno host do dispositivo quorum.[root@qdevice:~]#
yum install pcs corosync-qnetdIniciar o serviço
pcsde habilitarpcsdno início do sistema no host do dispositivo quorum.[root@qdevice:~]#
systemctl start pcsd.service[root@qdevice:~]#systemctl enable pcsd.service
25.5.2. Configuração de um dispositivo de quorum
O procedimento seguinte configura um dispositivo de quorum e o adiciona ao conjunto. Neste exemplo:
-
O nó utilizado para um dispositivo de quorum é
qdevice. O modelo do dispositivo de quorum é
net, que é atualmente o único modelo suportado. O modelonetsuporta os seguintes algoritmos:-
ffsplit: fifty-fifty split. Isto proporciona exatamente um voto para a partição com o maior número de nós ativos. lms: último homem de pé. Se o nó é o único que resta no cluster que pode ver o servidorqnetd, então ele retorna uma votação.AtençãoO algoritmo LMS permite que o cluster permaneça quorado mesmo com apenas um nó restante, mas também significa que o poder de voto do dispositivo de quorum é grande, pois é o mesmo que o número_de_nós - 1. Perder a conexão com o dispositivo de quorum significa perder número_de_nós - 1 voto, o que significa que apenas um cluster com todos os nós ativos pode permanecer quorado (através da votação excessiva do dispositivo de quorum); qualquer outro cluster se torna inquieto.
Para informações mais detalhadas sobre a implementação destes algoritmos, consulte a página de manual
corosync-qdevice(8).
-
-
Os nós de agrupamento são
node1enode2.
O procedimento seguinte configura um dispositivo de quorum e adiciona esse dispositivo de quorum a um conjunto.
No nó que você usará para hospedar seu dispositivo de quórum, configure o dispositivo de quórum com o seguinte comando. Este comando configura e inicia o dispositivo de quorum modelo
nete configura o dispositivo para iniciar na inicialização.[root@qdevice:~]#
pcs qdevice setup model net --enable --startQuorum device 'net' initialized quorum device enabled Starting quorum device... quorum device startedApós configurar o dispositivo do quorum, você pode verificar seu status. Isto deve mostrar que o daemon
corosync-qnetdestá funcionando e, neste ponto, não há clientes conectados a ele. A opção de comando--fullfornece uma saída detalhada.[root@qdevice:~]#
pcs qdevice status net --fullQNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytesHabilite as portas no firewall necessárias ao daemon
pcsde ao dispositivo de quorumnethabilitando o serviçohigh-availabilityemfirewalldcom os seguintes comandos.[root@qdevice:~]#
firewall-cmd --permanent --add-service=high-availability[root@qdevice:~]#firewall-cmd --add-service=high-availabilityDe um dos nós do cluster existente, autentique o usuário
haclusterno nó que está hospedando o dispositivo de quorum. Isto permite quepcsno cluster se conecte apcsno hostqdevice, mas não permite quepcsno hostqdevicese conecte apcsno cluster.[root@node1:~] #
pcs host auth qdeviceUsername: hacluster Password: qdevice: AuthorizedAdicione o dispositivo de quorum ao conjunto.
Antes de adicionar o dispositivo de quorum, você pode verificar a configuração atual e o status do dispositivo de quorum para comparação posterior. A saída para estes comandos indica que o agrupamento ainda não está usando um dispositivo de quorum, e o status de membro
Qdevicepara cada nó éNR(Não registrado).[root@node1:~]#
pcs quorum configOptions:[root@node1:~]#
pcs quorum statusQuorum information ------------------ Date: Wed Jun 29 13:15:36 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 2 Highest expected: 2 Total votes: 2 Quorum: 1 Flags: 2Node Quorate Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 NR node1 (local) 2 1 NR node2O seguinte comando acrescenta o dispositivo de quorum que você criou anteriormente ao agrupamento. Você não pode usar mais de um dispositivo de quorum em um agrupamento ao mesmo tempo. Entretanto, um dispositivo de quorum pode ser usado por vários aglomerados ao mesmo tempo. Este comando de exemplo configura o dispositivo de quorum para usar o algoritmo
ffsplit. Para informações sobre as opções de configuração do dispositivo de quorum, consulte a página de manualcorosync-qdevice(8).[root@node1:~]#
pcs quorum device add model net host=qdevice\algorithm=ffsplitSetting up qdevice certificates on nodes... node2: Succeeded node1: Succeeded Enabling corosync-qdevice... node1: corosync-qdevice enabled node2: corosync-qdevice enabled Sending updated corosync.conf to nodes... node1: Succeeded node2: Succeeded Corosync configuration reloaded Starting corosync-qdevice... node1: corosync-qdevice started node2: corosync-qdevice startedVerificar o status de configuração do dispositivo de quorum.
Do lado do cluster, você pode executar os seguintes comandos para ver como a configuração mudou.
O
pcs quorum configmostra o dispositivo do quorum que foi configurado.[root@node1:~]#
pcs quorum configOptions: Device: Model: net algorithm: ffsplit host: qdeviceO comando
pcs quorum statusmostra o status de tempo de execução do quorum, indicando que o dispositivo do quorum está em uso. Os significados dos valores de status das informações de associação doQdevicepara cada nó de agrupamento são os seguintes:-
A/NA -
V/NV MW/NMW[root@node1:~]#
pcs quorum statusQuorum information ------------------ Date: Wed Jun 29 13:17:02 2016 Quorum provider: corosync_votequorum Nodes: 2 Node ID: 1 Ring ID: 1/8272 Quorate: Yes Votequorum information ---------------------- Expected votes: 3 Highest expected: 3 Total votes: 3 Quorum: 2 Flags: Quorate Qdevice Membership information ---------------------- Nodeid Votes Qdevice Name 1 1 A,V,NMW node1 (local) 2 1 A,V,NMW node2 0 1 QdeviceO
pcs quorum device statusmostra o status de tempo de execução do dispositivo de quorum.[root@node1:~]#
pcs quorum device statusQdevice information ------------------- Model: Net Node ID: 1 Configured node list: 0 Node ID = 1 1 Node ID = 2 Membership node list: 1, 2 Qdevice-net information ---------------------- Cluster name: mycluster QNetd host: qdevice:5403 Algorithm: ffsplit Tie-breaker: Node with lowest node ID State: ConnectedDo lado do dispositivo do quorum, você pode executar o seguinte comando de status, que mostra o status do daemon
corosync-qnetd.[root@qdevice:~]#
pcs qdevice status net --fullQNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 2 Connected clusters: 1 Maximum send/receive size: 32768/32768 bytes Cluster "mycluster": Algorithm: ffsplit Tie-breaker: Node with lowest node ID Node ID 2: Client address: ::ffff:192.168.122.122:50028 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK) Node ID 1: Client address: ::ffff:192.168.122.121:48786 HB interval: 8000ms Configured node list: 1, 2 Ring ID: 1.2050 Membership node list: 1, 2 TLS active: Yes (client certificate verified) Vote: ACK (ACK)
-
25.5.3. Gerenciando o Serviço de Dispositivos Quorum
O PCS fornece a capacidade de gerenciar o serviço de dispositivo de quorum no host local (corosync-qnetd), como mostrado nos comandos do exemplo a seguir. Observe que estes comandos afetam apenas o serviço corosync-qnetd.
[root@qdevice:~]#pcs qdevice start net[root@qdevice:~]#pcs qdevice stop net[root@qdevice:~]#pcs qdevice enable net[root@qdevice:~]#pcs qdevice disable net[root@qdevice:~]#pcs qdevice kill net
25.5.4. Gerenciamento das configurações do dispositivo de quorum em um cluster
As seções seguintes descrevem os comandos PCS que você pode usar para gerenciar as configurações do dispositivo de quorum em um cluster.
25.5.4.1. Mudança das configurações do dispositivo de quorum
Você pode alterar a configuração de um dispositivo de quorum com o comando pcs quorum device update.
Para mudar a opção host do modelo net do dispositivo quorum, use os comandos pcs quorum device remove e pcs quorum device add para configurar corretamente a configuração, a menos que o antigo e o novo host sejam a mesma máquina.
O seguinte comando muda o algoritmo do dispositivo de quorum para lms.
[root@node1:~]# pcs quorum device update model algorithm=lms
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Reloading qdevice configuration on nodes...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
node1: corosync-qdevice started
node2: corosync-qdevice started25.5.4.2. Remoção de um dispositivo de quorum
Use o seguinte comando para remover um dispositivo de quorum configurado em um nó de cluster.
[root@node1:~]# pcs quorum device remove
Sending updated corosync.conf to nodes...
node1: Succeeded
node2: Succeeded
Corosync configuration reloaded
Disabling corosync-qdevice...
node1: corosync-qdevice disabled
node2: corosync-qdevice disabled
Stopping corosync-qdevice...
node1: corosync-qdevice stopped
node2: corosync-qdevice stopped
Removing qdevice certificates from nodes...
node1: Succeeded
node2: SucceededDepois de remover um dispositivo de quórum, você deve ver a seguinte mensagem de erro ao exibir o status do dispositivo de quórum.
[root@node1:~]# pcs quorum device status
Error: Unable to get quorum status: corosync-qdevice-tool: Can't connect to QDevice socket (is QDevice running?): No such file or directory25.5.4.3. Destruindo um dispositivo de quorum
Para desativar e parar um dispositivo de quorum no host do dispositivo de quorum e excluir todos os seus arquivos de configuração, use o seguinte comando.
[root@qdevice:~]# pcs qdevice destroy net
Stopping quorum device...
quorum device stopped
quorum device disabled
Quorum device 'net' configuration files removedCapítulo 26. Acionamento de scripts para eventos de cluster
Um cluster Pacemaker é um sistema acionado por eventos, onde um evento pode ser uma falha de recurso ou nó, uma mudança de configuração, ou um recurso iniciando ou parando. Você pode configurar os alertas de cluster do Pacemaker para tomar alguma ação externa quando um evento de cluster ocorre por meio de agentes de alerta, que são programas externos que o cluster chama da mesma forma que o cluster chama os agentes de recursos para lidar com a configuração e operação dos recursos.
O cluster passa informações sobre o evento para o agente por meio de variáveis ambientais. Os agentes podem fazer qualquer coisa com estas informações, como enviar uma mensagem de e-mail ou log para um arquivo ou atualizar um sistema de monitoramento.
-
Pacemaker fornece vários agentes de alerta de amostra, que são instalados em
/usr/share/pacemaker/alertspor padrão. Estes exemplos de scripts podem ser copiados e usados como estão, ou podem ser usados como modelos a serem editados de acordo com seus propósitos. Consulte o código fonte dos agentes de amostra para o conjunto completo de atributos que eles suportam. - Se as amostras de agentes de alerta não atenderem às suas necessidades, você pode escrever seus próprios agentes de alerta para que um alerta de Pacemaker seja chamado.
26.1. Instalação e configuração de amostras de agentes de alerta
Ao utilizar um dos agentes de alerta de amostra, você deve revisar o roteiro para garantir que ele se adapte às suas necessidades. Estes agentes de amostra são fornecidos como ponto de partida para scripts personalizados para ambientes de cluster específicos. Note que enquanto a Red Hat suporta as interfaces que os scripts de agentes de alerta usam para se comunicar com o Pacemaker, a Red Hat não fornece suporte para os agentes personalizados em si.
Para utilizar um dos agentes de alerta de amostra, você deve instalar o agente em cada nó do aglomerado. Por exemplo, o seguinte comando instala o script alert_file.sh.sample como alert_file.sh.
# install --mode=0755 /usr/share/pacemaker/alerts/alert_file.sh.sample /var/lib/pacemaker/alert_file.shApós ter instalado o roteiro, você pode criar um alerta que utiliza o roteiro.
O exemplo a seguir configura um alerta que utiliza o agente de alerta alert_file.sh instalado para registrar eventos em um arquivo. Os agentes de alerta funcionam como o usuário hacluster, que tem um conjunto mínimo de permissões.
Este exemplo cria o arquivo de registro pcmk_alert_file.log que será usado para registrar os eventos. Ele então cria o agente de alerta e adiciona o caminho para o arquivo de registro como seu destinatário.
#touch /var/log/pcmk_alert_file.log#chown hacluster:haclient /var/log/pcmk_alert_file.log#chmod 600 /var/log/pcmk_alert_file.log#pcs alert create id=alert_file description="Log events to a file." path=/var/lib/pacemaker/alert_file.sh#pcs alert recipient add alert_file id=my-alert_logfile value=/var/log/pcmk_alert_file.log
O seguinte exemplo instala o script alert_snmp.sh.sample como alert_snmp.sh e configura um alerta que usa o agente de alerta alert_snmp.sh instalado para enviar eventos de cluster como armadilhas SNMP. Por padrão, o script enviará todos os eventos, exceto as chamadas de monitoramento bem sucedidas para o servidor SNMP. Este exemplo configura o formato de timestamp como uma meta opção. Após configurar o alerta, este exemplo configura um destinatário para o alerta e exibe a configuração do alerta.
#install --mode=0755 /usr/share/pacemaker/alerts/alert_snmp.sh.sample /var/lib/pacemaker/alert_snmp.sh#pcs alert create id=snmp_alert path=/var/lib/pacemaker/alert_snmp.sh meta timestamp-format="%Y-%m-%d,%H:%M:%S.%01N"#pcs alert recipient add snmp_alert value=192.168.1.2#pcs alertAlerts: Alert: snmp_alert (path=/var/lib/pacemaker/alert_snmp.sh) Meta options: timestamp-format=%Y-%m-%d,%H:%M:%S.%01N. Recipients: Recipient: snmp_alert-recipient (value=192.168.1.2)
O exemplo seguinte instala o agente alert_smtp.sh e depois configura um alerta que usa o agente de alerta instalado para enviar eventos de cluster como mensagens de e-mail. Após configurar o alerta, este exemplo configura um destinatário e exibe a configuração do alerta.
#install --mode=0755 /usr/share/pacemaker/alerts/alert_smtp.sh.sample /var/lib/pacemaker/alert_smtp.sh#pcs alert create id=smtp_alert path=/var/lib/pacemaker/alert_smtp.sh options email_sender=donotreply@example.com#pcs alert recipient add smtp_alert value=admin@example.com#pcs alertAlerts: Alert: smtp_alert (path=/var/lib/pacemaker/alert_smtp.sh) Options: email_sender=donotreply@example.com Recipients: Recipient: smtp_alert-recipient (value=admin@example.com)
26.2. Criando um alerta de agrupamento
O seguinte comando cria um alerta de agrupamento. As opções que você configura são valores de configuração específicos do agente que são passados para o script do agente de alerta no caminho especificado como variáveis adicionais de ambiente. Se você não especificar um valor para id, será gerado um.
pcs alert create path=path [id=alert-id] [description=description] [options [option=value]...] [meta [meta-option=value]...]
Múltiplos agentes de alerta podem ser configurados; o grupo chamará todos eles para cada evento. Os agentes de alerta serão chamados apenas nos nós de agrupamento. Eles serão chamados para eventos envolvendo nós Remotos de Pacemaker, mas nunca serão chamados sobre esses nós.
O exemplo a seguir cria um alerta simples que ligará para myscript.sh para cada evento.
# pcs alert create id=my_alert path=/path/to/myscript.sh26.3. Exibição, modificação e remoção de alertas de agrupamento
O seguinte comando mostra todos os alertas configurados juntamente com os valores das opções configuradas.
pcs alert [config|show]
O seguinte comando atualiza um alerta existente com o valor alert-id especificado.
pcs alert update alert-id [path=path] [description=description] [options [option=value]...] [meta [meta-option=value]...]
O seguinte comando remove um alerta com o valor alert-id especificado.
pcs alert remover alert-id
Alternativamente, você pode executar o comando pcs alert delete, que é idêntico ao comando pcs alert remove. Tanto o comando pcs alert delete quanto o pcs alert remove permitem especificar mais de um alerta a ser excluído.
26.4. Configuração dos destinatários de alerta
Normalmente os alertas são direcionados para um destinatário. Assim, cada alerta pode ser configurado adicionalmente com um ou mais destinatários. O grupo chamará o agente separadamente para cada destinatário.
O destinatário pode ser qualquer coisa que o agente de alerta possa reconhecer: an Endereço IP, um endereço de e-mail, um nome de arquivo, ou qualquer coisa que o agente em particular suporte.
O seguinte comando adiciona um novo destinatário ao alerta especificado.
pcs alert receptor adicionar alert-id value=recipient-value [id=recipient-id] [description=description] [options [option=value]...] [meta [meta-option=value]...]
O seguinte comando atualiza um receptor de alerta existente.
pcs alertam o destinatário recipient-id [valor=recipient-value] [descrição=description] [opções [option=value]...] [meta [meta-option=value]...]
O seguinte comando remove o receptor de alerta especificado.
pcs alertar o destinatário remover recipient-id
Alternativamente, você pode executar o comando pcs alert recipient delete, que é idêntico ao comando pcs alert recipient remove. Tanto o comando pcs alert recipient remove como o pcs alert recipient delete permitem remover mais de um receptor de alerta.
O seguinte exemplo de comando adiciona o destinatário do alerta my-alert-recipient com uma identificação do destinatário de my-recipient-id ao alerta my-alert. Isto irá configurar o cluster para chamar o script de alerta que foi configurado para my-alert para cada evento, passando o destinatário some-address como uma variável de ambiente.
# pcs alert recipient add my-alert value=my-alert-recipient id=my-recipient-id options value=some-address26.5. Meta opções de alerta
Assim como os agentes de recursos, as meta opções podem ser configuradas para que os agentes de alerta possam afetar a forma como a Pacemaker os chama. Tabela 26.1, “Alertar Meta Opções” descreve as meta opções de alerta. As meta opções podem ser configuradas por agente de alerta, assim como por destinatário.
Tabela 26.1. Alertar Meta Opções
| Meta-Atributo | Padrão | Descrição |
|---|---|---|
|
| %H:%M:%S.N |
O formato que o grupo usará ao enviar o carimbo de horário do evento para o agente. Esta é uma string como usada com o comando |
|
| 30s | Se o agente de alerta não concluir dentro deste período de tempo, ele será encerrado. |
O exemplo seguinte configura um alerta que chama o script myscript.sh e depois adiciona dois destinatários ao alerta. O primeiro destinatário tem uma identificação de my-alert-recipient1 e o segundo destinatário tem uma identificação de my-alert-recipient2. O script será chamado duas vezes para cada evento, com cada chamada usando um timeout de 15 segundos. Uma chamada será passada ao destinatário someuser@example.com com um timestamp no formato %H:%M, enquanto a outra chamada será passada ao destinatário otheruser@example.com com um timestamp no formato
#pcs alert create id=my-alert path=/path/to/myscript.sh meta timeout=15s#pcs alert recipient add my-alert value=someuser@example.com id=my-alert-recipient1 meta timestamp-format="%D %H:%M"#pcs alert recipient add my-alert value=otheruser@example.com id=my-alert-recipient2 meta timestamp-format="%c"
26.6. Exemplos de comandos de configuração de alertas
Os exemplos seqüenciais a seguir mostram alguns comandos básicos de configuração de alerta para mostrar o formato a ser usado para criar alertas, adicionar destinatários e exibir os alertas configurados.
Observe que enquanto você deve instalar os próprios agentes de alerta em cada nó de um cluster, você precisa executar os comandos pcs apenas uma vez.
Os seguintes comandos criam um alerta simples, adicionam dois destinatários ao alerta e exibem os valores configurados.
-
Como nenhum valor de identificação de alerta é especificado, o sistema cria um valor de identificação de alerta de
alert. -
O primeiro comando de criação de destinatários especifica um destinatário de
rec_value. Como este comando não especifica um ID de destinatário, o valor dealert-recipienté usado como o ID de destinatário. -
O segundo comando de criação de destinatários especifica um destinatário de
rec_value2. Este comando especifica um ID de destinatário demy-recipientpara o destinatário.
#pcs alert create path=/my/path#pcs alert recipient add alert value=rec_value#pcs alert recipient add alert value=rec_value2 id=my-recipient#pcs alert configAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2)
Estes comandos seguintes acrescentam um segundo alerta e um destinatário para esse alerta. O ID do alerta para o segundo alerta é my-alert e o valor do destinatário é my-other-recipient. Como nenhuma identificação do destinatário é especificada, o sistema fornece uma identificação do destinatário de my-alert-recipient.
#pcs alert create id=my-alert path=/path/to/script description=alert_description options option1=value1 opt=val meta timeout=50s timestamp-format="%H%B%S"#pcs alert recipient add my-alert value=my-other-recipient#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=value1 Meta options: timestamp-format=%H%B%S timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient)
Os seguintes comandos modificam os valores de alerta para o alerta my-alert e para o destinatário my-alert-recipient.
#pcs alert update my-alert options option1=newvalue1 meta timestamp-format="%H%M%S"#pcs alert recipient update my-alert-recipient options option1=new meta timeout=60s#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Recipient: my-recipient (value=rec_value2) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=newvalue1 Meta options: timestamp-format=%H%M%S timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient) Options: option1=new Meta options: timeout=60s
O seguinte comando remove o destinatário my-alert-recipient de alert.
#pcs alert recipient remove my-recipient#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value) Alert: my-alert (path=/path/to/script) Description: alert_description Options: opt=val option1=newvalue1 Meta options: timestamp-format="%M%B%S" timeout=50s Recipients: Recipient: my-alert-recipient (value=my-other-recipient) Options: option1=new Meta options: timeout=60s
O seguinte comando remove myalert da configuração.
#pcs alert remove myalert#pcs alertAlerts: Alert: alert (path=/my/path) Recipients: Recipient: alert-recipient (value=rec_value)
26.7. Escrever um agente de alerta
Há três tipos de alertas de Pacemaker: alertas de nós, alertas de cercas e alertas de recursos. As variáveis de ambiente que são passadas aos agentes de alerta podem ser diferentes, dependendo do tipo de alerta. Tabela 26.2, “Variáveis Ambientais Passadas aos Agentes de Alerta” descreve as variáveis de ambiente que são passadas aos agentes de alerta e especifica quando a variável de ambiente é associada a um tipo de alerta específico.
Tabela 26.2. Variáveis Ambientais Passadas aos Agentes de Alerta
| Variável Ambiental | Descrição |
|---|---|
|
| O tipo de alerta (nó, vedação, ou recurso) |
|
| A versão do Pacemaker enviando o alerta |
|
| O destinatário configurado |
|
| Um número seqüencial aumentado sempre que um alerta é emitido no nó local, que pode ser usado para referenciar a ordem na qual os alertas foram emitidos pela Pacemaker. Um alerta para um evento que aconteceu mais tarde de forma confiável tem um número seqüencial maior do que os alertas para eventos anteriores. Esteja ciente de que este número não tem um significado de agrupamento. |
|
|
Um carimbo de tempo criado antes da execução do agente, no formato especificado pela meta opção |
|
| Nome do nó afetado |
|
|
Detalhe do evento. Para alertas de nó, este é o estado atual do nó (membro ou perdido). Para alertas de esgrima, este é um resumo da operação de esgrima solicitada, incluindo origem, alvo e código de erro da operação de esgrima, se houver. Para alertas de recursos, este é um equivalente de string legível de |
|
| Identificação do nó cujo status mudou (fornecido apenas com alertas de nó) |
|
| A operação de esgrima ou recurso solicitada (apenas com alertas de esgrima e recursos) |
|
| O código numérico de retorno da operação de cercado ou recurso (fornecido apenas com alertas de cercado e recurso) |
|
| O nome do recurso afetado (somente alertas de recursos) |
|
| O intervalo da operação do recurso (somente alertas de recurso) |
|
| O código numérico de retorno esperado da operação (somente alertas de recursos) |
|
| Um código numérico utilizado pela Pacemaker para representar o resultado da operação (apenas alertas de recursos) |
Ao escrever um agente de alerta, você deve levar em conta as seguintes preocupações.
- Agentes de alerta podem ser chamados sem destinatário (se nenhum estiver configurado), portanto, o agente deve ser capaz de lidar com esta situação, mesmo que só saia nesse caso. Os usuários podem modificar a configuração em etapas, e adicionar um destinatário mais tarde.
- Se mais de um destinatário estiver configurado para um alerta, o agente de alerta será chamado uma vez por destinatário. Se um agente não for capaz de operar simultaneamente, ele deverá ser configurado com apenas um único destinatário. O agente é livre, entretanto, para interpretar o destinatário como uma lista.
- Quando ocorre um evento de cluster, todos os alertas são disparados ao mesmo tempo em que os processos são separados. Dependendo de quantos alertas e destinatários são configurados e do que é feito dentro dos agentes de alerta, pode ocorrer uma explosão de carga significativa. O agente pode ser escrito para levar isto em consideração, por exemplo, enfileirando ações de recursos intensivos em alguma outra instância, em vez de executá-las diretamente.
-
Os agentes de alerta são executados como o usuário
hacluster, que tem um conjunto mínimo de permissões. Se um agente requer privilégios adicionais, recomenda-se configurarsudopara permitir que o agente execute os comandos necessários como outro usuário com os privilégios apropriados. -
Tenha o cuidado de validar e higienizar parâmetros configurados pelo usuário, tais como
CRM_alert_timestamp(cujo conteúdo é especificado pelo usuário-configuradotimestamp-format),CRM_alert_recipient, e todas as opções de alerta. Isto é necessário para proteger contra erros de configuração. Além disso, se algum usuário pode modificar a CIB sem ter acesso aos nós de cluster emhacluster, esta é uma preocupação potencial de segurança também, e o usuário deve evitar a possibilidade de injeção de código. -
Se um cluster contém recursos com operações para as quais o parâmetro
on-failestá definido parafence, haverá múltiplas notificações de falha da cerca, uma para cada recurso para o qual este parâmetro está definido mais uma notificação adicional. Tanto opacemaker-fencedcomo opacemaker-controldenviarão notificações. O marcapasso realiza apenas uma operação de cerca real neste caso, entretanto, não importa quantas notificações sejam enviadas.
A interface de alertas é projetada para ser retrocompatível com a interface de scripts externos utilizada pelo recurso ocf:pacemaker:ClusterMon. Para preservar esta compatibilidade, as variáveis de ambiente passadas aos agentes de alerta estão disponíveis com CRM_notify_ bem como CRM_alert_. Uma quebra na compatibilidade é que o recurso ClusterMon executou scripts externos como usuário root, enquanto os agentes de alerta são executados como usuário hacluster.
Capítulo 27. Configuração de clusters de múltiplos locais com Pacemaker
Quando um cluster abrange mais de um site, os problemas de conectividade de rede entre os sites podem levar a situações de cérebro dividido. Quando a conectividade cai, não há maneira de um nó em um site determinar se um nó em outro site falhou ou ainda está funcionando com uma interligação de site falhada. Além disso, pode ser problemático fornecer serviços de alta disponibilidade em dois sites que estão muito distantes para manter a sincronia.
Para resolver estes problemas, a Pacemaker oferece suporte total para a capacidade de configurar clusters de alta disponibilidade que abrangem vários locais através do uso de um gerente de ingressos para clusters de estande.
27.1. Visão geral do gerente de bilheteria de estandes
O estande ticket manager é um serviço distribuído que deve ser executado em uma rede física diferente das redes que conectam os nós de cluster em determinados locais. Ele produz outro cluster solto, um Booth formation, que fica em cima dos clusters regulares nos sites. Esta camada de comunicação agregada facilita os processos de decisão baseados em consenso para os bilhetes individuais dos estandes.
Um estande ticket é um singleton na formação do estande e representa uma unidade de autorização móvel e sensível ao tempo. Os recursos podem ser configurados para exigir um determinado bilhete para rodar. Isto pode garantir que os recursos sejam executados em apenas um local de cada vez, para o qual um bilhete ou bilhetes foram concedidos.
Você pode pensar na formação de um estande como um aglomerado sobreposto que consiste em clusters funcionando em locais diferentes, onde todos os clusters originais são independentes uns dos outros. É o serviço de estande que comunica aos aglomerados se foi concedido um bilhete, e é o Pacemaker que determina se os recursos devem ser administrados em um aglomerado com base em uma restrição de bilhetes do Pacemaker. Isto significa que ao utilizar o gerenciador de bilhetes, cada um dos clusters pode administrar seus próprios recursos, bem como os recursos compartilhados. Por exemplo, pode haver recursos A, B e C rodando apenas em um cluster, recursos D, E e F rodando apenas no outro cluster, e recursos G e H rodando em qualquer um dos dois clusters conforme determinado por um ticket. Também é possível ter um recurso adicional J que poderia funcionar em qualquer um dos dois aglomerados, conforme determinado por um bilhete separado.
27.2. Configuração de clusters de múltiplos locais com Pacemaker
O procedimento a seguir fornece um esboço dos passos a seguir para configurar uma configuração em vários locais que utiliza o gerente de bilhetes do estande.
Estes comandos de exemplo utilizam a seguinte disposição:
-
O Cluster 1 é composto pelos nós
cluster1-node1ecluster1-node2 - O Cluster 1 tem um endereço IP flutuante atribuído a ele de 192.168.11.100
-
O Cluster 2 consiste em
cluster2-node1ecluster2-node2 - O Cluster 2 tem um endereço IP flutuante atribuído a ele de 192.168.22.100
-
O nó árbitro é
arbitrator-nodecom um endereço ip de 192.168.99.100 -
O nome do bilhete do estande que esta configuração utiliza é
apacheticket
Estes comandos de exemplo assumem que os recursos de cluster para um serviço Apache foram configurados como parte do grupo de recursos apachegroup para cada cluster. Não é necessário que os recursos e grupos de recursos sejam os mesmos em cada cluster para configurar uma restrição de ingressos para esses recursos, já que a instância Pacemaker para cada cluster é independente, mas isso é um cenário de failover comum.
Observe que a qualquer momento no procedimento de configuração você pode entrar no comando pcs booth config para exibir a configuração do estande para o nó ou cluster atual ou o comando pcs booth status para exibir o status atual do estande no nó local.
Instale o pacote
booth-siteBooth ticket manager em cada nó de ambos os clusters.[root@cluster1-node1 ~]#
yum install -y booth-site[root@cluster1-node2 ~]#yum install -y booth-site[root@cluster2-node1 ~]#yum install -y booth-site[root@cluster2-node2 ~]#yum install -y booth-siteInstale os pacotes
pcs,booth-core, ebooth-arbitratorno nó árbitro.[root@arbitrator-node ~]#
yum install -y pcs booth-core booth-arbitratorSe você estiver executando o daemon
firewalld, execute os seguintes comandos em todos os nós em ambos os clusters, bem como no nó árbitro para habilitar as portas que são exigidas pelo Add-On de Alta Disponibilidade da Red Hat.#
firewall-cmd --permanent --add-service=high-availability` #firewall-cmd --add-service=high-availability`Talvez seja necessário modificar quais portos estão abertos para atender às condições locais. Para mais informações sobre as portas que são exigidas pelo suplemento de alta disponibilidade da Red Hat, veja Habilitação de portas para o suplemento de alta disponibilidade.
Criar uma configuração de estande em um nó de um cluster. Os endereços especificados para cada cluster e para o árbitro devem ser endereços IP. Para cada cluster, você especifica um endereço IP flutuante.
[cluster1-node1 ~] #
pcs booth setup sites 192.168.11.100 192.168.22.100 arbitrators 192.168.99.100Este comando cria os arquivos de configuração
/etc/booth/booth.confe/etc/booth/booth.keyno nó a partir do qual é executado.Criar um bilhete para a configuração do estande. Este é o bilhete que será usado para definir a restrição de recursos que permitirá que os recursos funcionem somente quando este bilhete tiver sido concedido ao conjunto.
Este procedimento básico de configuração de failover utiliza apenas um ticket, mas você pode criar tickets adicionais para cenários mais complicados onde cada ticket está associado a um recurso ou recursos diferentes.
[cluster1-node1 ~] #
pcs booth ticket add apacheticketSincronizar a configuração do estande com todos os nós do cluster atual.
[cluster1-node1 ~] #
pcs booth syncDo nó do árbitro, puxe a configuração do estande para o árbitro. Se você não o tiver feito anteriormente, deve primeiro autenticar
pcspara o nó do qual você está puxando a configuração.[arbitrator-node ~] #
pcs host auth cluster1-node1[arbitrator-node ~] #pcs booth pull cluster1-node1Puxe a configuração da cabine para o outro conjunto e sincronize com todos os nós desse conjunto. Como no caso do nó árbitro, se você não o fez anteriormente, deve primeiro autenticar
pcspara o nó do qual você está puxando a configuração.[cluster2-node1 ~] #
pcs host auth cluster1-node1[cluster2-node1 ~] #pcs booth pull cluster1-node1[cluster2-node1 ~] #pcs booth syncComece e habilite Booth no árbitro.
NotaVocê não deve iniciar ou ativar manualmente Booth em nenhum dos nós dos agrupamentos, uma vez que Booth funciona como um recurso de Pacemaker nesses agrupamentos.
[arbitrator-node ~] #
pcs booth start[arbitrator-node ~] #pcs booth enableConfigure Booth para funcionar como um recurso de cluster em ambos os locais de cluster. Isto cria um grupo de recursos com
booth-ipebooth-servicecomo membros desse grupo.[cluster1-node1 ~] #
pcs booth create ip 192.168.11.100[cluster2-node1 ~] #pcs booth create ip 192.168.22.100Adicione uma restrição de bilhetes ao grupo de recursos que você definiu para cada grupo.
[cluster1-node1 ~] #
pcs constraint ticket add apacheticket apachegroup[cluster2-node1 ~] #pcs constraint ticket add apacheticket apachegroupVocê pode digitar o seguinte comando para exibir as restrições de bilhetes atualmente configuradas.
pcs constraint ticket [show]
Conceda o bilhete que você criou para esta configuração ao primeiro grupo.
Note que não é necessário ter restrições de ingressos definidas antes de conceder um bilhete. Uma vez que você tenha inicialmente concedido um bilhete para um agrupamento, então Booth assume o gerenciamento de bilhetes, a menos que você anule isto manualmente com o comando
pcs booth ticket revoke. Para obter informações sobre os comandos de administraçãopcs booth, consulte a tela de ajuda do PCS para o comandopcs booth.[cluster1-node1 ~] #
pcs booth ticket grant apacheticket
É possível adicionar ou remover bilhetes a qualquer momento, mesmo após a conclusão deste procedimento. Após adicionar ou remover um bilhete, entretanto, deve-se sincronizar os arquivos de configuração com os outros nós e clusters, bem como com o árbitro e conceder o bilhete, como é mostrado neste procedimento.
Para informações sobre comandos adicionais de administração de estandes que você pode usar para limpar e remover arquivos de configuração de estandes, ingressos e recursos, consulte a tela de ajuda do PCS para o comando pcs booth.
Capítulo 28. Integração de nós não-coroasync em um cluster: o serviço pacemaker_remote
O serviço pacemaker_remote permite que os nós que não funcionam corosync se integrem ao cluster e façam com que o cluster gerencie seus recursos como se fossem verdadeiros nós de cluster.
Entre as capacidades que o serviço pacemaker_remote oferece estão as seguintes:
-
O serviço
pacemaker_remotepermite escalar além do limite de 32 nós de suporte da Red Hat para o RHEL 8.1. -
O serviço
pacemaker_remotepermite gerenciar um ambiente virtual como um recurso de cluster e também gerenciar serviços individuais dentro do ambiente virtual como recursos de cluster.
Os seguintes termos são usados para descrever o serviço pacemaker_remote.
- cluster node
- remote node
- guest node
- pacemaker_remote
Um cluster Pacemaker executando o serviço pacemaker_remote tem as seguintes características.
-
Os nós remotos e os nós convidados executam o serviço
pacemaker_remote(com muito pouca configuração necessária no lado da máquina virtual). -
A pilha de cluster (
pacemakerecorosync), rodando nos nós do cluster, conecta-se ao serviçopacemaker_remotenos nós remotos, permitindo que eles se integrem ao cluster. -
A pilha de cluster (
pacemakerecorosync), rodando nos nós de cluster, lança os nós convidados e se conecta imediatamente ao serviçopacemaker_remotenos nós convidados, permitindo que eles se integrem ao cluster.
A principal diferença entre os nós de cluster e os nós remoto e de convidado que os nós de cluster gerenciam é que os nós remoto e de convidado não estão rodando a pilha de cluster. Isto significa que os nós remoto e de convidado têm as seguintes limitações:
- não se realizam em quorum
- eles não executam ações de dispositivos de esgrima
- não são elegíveis para ser o Controlador Designado (DC) do cluster
-
eles mesmos não executam a gama completa de comandos
pcs
Por outro lado, os nós remotos e os nós convidados não estão vinculados aos limites de escalabilidade associados com a pilha de agregados.
Além dessas limitações observadas, os nós remotos e convidados comportam-se como nós de cluster no que diz respeito ao gerenciamento de recursos, e os nós remotos e convidados podem eles mesmos ser cercados. O cluster é totalmente capaz de gerenciar e monitorar recursos em cada nó remoto e convidado: Você pode criar restrições contra eles, colocá-los em espera ou executar qualquer outra ação nos nós de cluster com os comandos pcs. Os nós remoto e de convidado aparecem na saída de status do cluster exatamente como os nós de cluster aparecem.
28.1. Autenticação do hospedeiro e do convidado dos nós de pacemaker_remote
A conexão entre os nós de cluster e o pacemaker_remote é protegida usando a Camada de Segurança de Transporte (TLS) com criptografia de chave pré-compartilhada (PSK) e autenticação sobre TCP (usando a porta 3121 por padrão). Isto significa que tanto o nó de cluster quanto o nó rodando pacemaker_remote devem compartilhar a mesma chave privada. Por padrão, esta chave deve ser colocada em /etc/pacemaker/authkey nos dois nós de cluster e nos nós remotos.
O comando pcs cluster node add-guest estabelece o authkey para nós convidados e o pcs cluster node add-remote estabelece o authkey para nós remotos.
28.2. Configuração dos nós convidados da KVM
Um nó convidado da Pacemaker é um nó convidado virtual que executa o serviço pacemaker_remote. O nó hóspede virtual é gerenciado pelo cluster.
28.2.1. Opções de recursos de nós de hóspedes
Ao configurar uma máquina virtual para atuar como um nó convidado, você cria um recurso VirtualDomain, que gerencia a máquina virtual. Para descrições das opções que você pode definir para um recurso VirtualDomain, veja Tabela 24.1, “Opções de Recursos para Recursos de Domínio Virtual”.
Além das opções de recursos VirtualDomain, as opções de metadados definem o recurso como um nó convidado e definem os parâmetros de conexão. Você define estas opções de recurso com o comando pcs cluster node add-guest. Tabela 28.1, “Opções de Metadados para Configuração de Recursos KVM como Nós Remotos” descreve estas opções de metadados.
Tabela 28.1. Opções de Metadados para Configuração de Recursos KVM como Nós Remotos
| Campo | Padrão | Descrição |
|---|---|---|
|
| <none> | O nome do nó convidado que este recurso define. Isto tanto permite o recurso como um nó convidado e define o nome único usado para identificar o nó convidado. WARNING: Este valor não pode se sobrepor a nenhum recurso ou ID de nó. |
|
| 3121 |
Configura uma porta personalizada a ser utilizada para a conexão do hóspede para |
|
|
O endereço fornecido no comando | O endereço IP ou nome do host para se conectar a |
|
| 60s | O tempo antes de uma conexão de convidado pendente será expirado |
28.2.2. Integrando uma máquina virtual como um nó convidado
O procedimento a seguir é um resumo de alto nível dos passos a serem executados para que a Pacemaker lance uma máquina virtual e para integrar essa máquina como um nó convidado, usando libvirt e convidados virtuais da KVM.
-
Configure os recursos do
VirtualDomain. Insira os seguintes comandos em cada máquina virtual para instalar pacotes
pacemaker_remote, inicie o serviçopcsde habilite-o a funcionar na inicialização, e permita a porta TCP 3121 através do firewall.#
yum install pacemaker-remote resource-agents pcs#systemctl start pcsd.service#systemctl enable pcsd.service#firewall-cmd --add-port 3121/tcp --permanent#firewall-cmd --add-port 2224/tcp --permanent#firewall-cmd --reload- Dê a cada máquina virtual um endereço de rede estático e um nome de host único, que deve ser conhecido por todos os nós. Para informações sobre como definir um endereço IP estático para a máquina virtual convidada, consulte o Virtualization Deployment and Administration Guide.
Se você ainda não o fez, autentique
pcsao nó que você estará integrando como um nó de busca.#
pcs host auth nodenameUse o seguinte comando para converter um recurso
VirtualDomainexistente em um nó convidado. Este comando deve ser executado em um nó de cluster e não no nó convidado que está sendo adicionado. Além de converter o recurso, este comando copia o/etc/pacemaker/authkeypara o nó convidado e inicia e habilita o daemonpacemaker_remoteno nó convidado. O nome do nó para o nó convidado, que você pode definir arbitrariamente, pode diferir do nome do host para o nó.#
pcs cluster node add-guest nodename resource_id[options]Depois de criar o recurso
VirtualDomain, você pode tratar o nó convidado da mesma forma que trataria qualquer outro nó do agrupamento. Por exemplo, você pode criar um recurso e colocar uma restrição de recursos no recurso a ser executado no nó convidado como nos comandos a seguir, que são executados a partir de um nó de cluster. Você pode incluir nós convidados em grupos, o que permite agrupar um dispositivo de armazenamento, sistema de arquivos e VM.#
pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s#pcs constraint location webserver prefersnodename
28.3. Configuração dos nós remotos do Pacemaker
Um nó remoto é definido como um recurso de cluster com ocf:pacemaker:remote como o agente de recurso. Você cria este recurso com o comando pcs cluster node add-remote.
28.3.1. Opções de recursos de nós remotos
Tabela 28.2, “Opções de recursos para nós remotos” descreve as opções de recursos que você pode configurar para um recurso remote.
Tabela 28.2. Opções de recursos para nós remotos
| Campo | Padrão | Descrição |
|---|---|---|
|
| 0 | Tempo em segundos para esperar antes de tentar religar a um nó remoto após uma conexão ativa com o nó remoto ter sido cortada. Esta espera é recorrente. Se a reconexão falhar após o período de espera, uma nova tentativa de reconexão será feita após a observação do tempo de espera. Quando esta opção estiver em uso, o Pacemaker continuará tentando alcançar e conectar-se ao nó remoto indefinidamente após cada intervalo de espera. |
|
|
Endereço especificado com o comando | Servidor a que se conectar. Este pode ser um endereço IP ou um nome de host. |
|
| Porta TCP para conexão. |
28.3.2. Visão geral da configuração do nó remoto
Esta seção fornece um resumo de alto nível dos passos a serem executados para configurar um nó Pacemaker Remote e para integrar esse nó em um ambiente de cluster Pacemaker existente.
No nó que você estará configurando como um nó remoto, permita serviços relacionados ao cluster através do firewall local.
#
firewall-cmd --permanent --add-service=high-availabilitysuccess #firewall-cmd --reloadsuccessNotaSe você estiver usando diretamente
iptables, ou alguma outra solução de firewall além defirewalld, basta abrir as seguintes portas: Portas TCP 2224 e 3121.Instale o daemon
pacemaker_remoteno nó remoto.#
yum install -y pacemaker-remote resource-agents pcsIniciar e ativar
pcsdno nó remoto.#
systemctl start pcsd.service#systemctl enable pcsd.serviceSe você ainda não o fez, autentique
pcsno nó que você estará adicionando como um nó remoto.#
pcs host auth remote1Adicione o recurso do nó remoto ao agrupamento com o seguinte comando. Este comando também sincroniza todos os arquivos de configuração relevantes para o novo nó, inicia o nó e o configura para iniciar
pacemaker_remotena inicialização. Este comando deve ser executado em um nó de cluster e não no nó remoto que está sendo adicionado.#
pcs cluster node add-remote remote1Depois de adicionar o recurso
remoteao agrupamento, você pode tratar o nó remoto da mesma forma que trataria qualquer outro nó no agrupamento. Por exemplo, você pode criar um recurso e colocar uma restrição de recursos sobre o recurso a ser executado no nó remoto como nos comandos a seguir, que são executados a partir de um nó de cluster.#
pcs resource create webserver apache configfile=/etc/httpd/conf/httpd.conf op monitor interval=30s#pcs constraint location webserver prefers remote1AtençãoNunca envolva um recurso de conexão de nó remoto em um grupo de recursos, restrição de colocação, ou restrição de ordem.
- Configurar recursos de esgrima para o nó remoto. Os nós remotos são cercados da mesma forma que os nós de cluster. Configurar os recursos de cercas para uso com nós remotos da mesma forma que você faria com os nós de cluster. Observe, entretanto, que os nós remotos nunca podem iniciar uma ação de vedação. Somente os nós de cluster são capazes de realmente executar uma operação de cerca contra outro nó.
28.4. Mudando a localização padrão da porta
Se você precisar alterar a localização padrão da porta para Pacemaker ou pacemaker_remote, você pode definir a variável de ambiente PCMK_remote_port que afeta estes dois daemons. Esta variável de ambiente pode ser ativada colocando-a no arquivo /etc/sysconfig/pacemaker da seguinte forma.
====# Pacemaker Remote
...
#
# Specify a custom port for Pacemaker Remote connections
PCMK_remote_port=3121
Ao alterar a porta padrão usada por um determinado nó convidado ou remoto, a variável PCMK_remote_port deve ser definida no arquivo /etc/sysconfig/pacemaker desse nó, e o recurso de cluster que cria a conexão do nó convidado ou do nó remoto também deve ser configurado com o mesmo número de porta (usando a opção remote-port metadados para nós convidados, ou a opção port para nós remotos).
28.5. Atualização de sistemas com nós de pacemaker_remote
Se o serviço pacemaker_remote for interrompido em um nó Pacemaker Remote ativo, o cluster migrará graciosamente os recursos para fora do nó antes de interromper o nó. Isto permite que você realize atualizações de software e outros procedimentos de manutenção de rotina sem remover o nó do cluster. Uma vez que o pacemaker_remote for desligado, no entanto, o cluster tentará imediatamente reconectar-se. Se pacemaker_remote não for reiniciado dentro do tempo limite do monitor do recurso, o cluster considerará a operação do monitor como falhada.
Se você deseja evitar falhas de monitoramento quando o serviço pacemaker_remote é interrompido em um nó remoto do Pacemaker ativo, você pode usar o seguinte procedimento para retirar o nó do cluster antes de realizar qualquer administração de sistema que possa parar pacemaker_remote
-
Parar o recurso de conexão do nó com o
pcs resource disable resourcenameque tirará todos os serviços do nó. Para nós convidados, isto também irá parar o VM, portanto o VM deve ser iniciado fora do cluster (por exemplo, usandovirsh) para realizar qualquer manutenção. - Realizar a manutenção necessária.
-
Quando estiver pronto para retornar o nó ao agrupamento, reative o recurso com o
pcs resource enable.
Capítulo 29. Execução de manutenção de clusters
A fim de realizar a manutenção nos nós de seu cluster, você pode precisar parar ou mover os recursos e serviços em execução naquele cluster. Ou você pode precisar parar o software do cluster enquanto deixa os serviços intocados. Pacemaker oferece uma variedade de métodos para realizar a manutenção do sistema.
- Se você precisar parar um nó em um aglomerado enquanto continua a fornecer os serviços funcionando nesse aglomerado em outro nó, você pode colocar o nó do aglomerado em modo de espera. Um nó que está em modo de espera não é mais capaz de hospedar recursos. Qualquer recurso atualmente ativo no nó será movido para outro nó, ou parado se nenhum outro nó for elegível para executar o recurso. Para informações sobre o modo de espera, consulte Colocando um nó em modo de espera.
Se você precisar mover um recurso individual para fora do nó no qual ele está atualmente rodando sem parar esse recurso, você pode usar o comando
pcs resource movepara mover o recurso para um nó diferente. Para obter informações sobre o comandopcs resource move, consulte Movimentação manual de recursos em cluster.Quando você executa o comando
pcs resource move, isto acrescenta uma restrição ao recurso para impedi-lo de rodar no nó no qual ele está rodando atualmente. Quando você estiver pronto para mover o recurso de volta, poderá executar o comandopcs resource clearoupcs constraint deletepara remover a restrição. Isto não necessariamente move os recursos de volta para o nó original, no entanto, já que onde os recursos podem ser executados naquele ponto depende de como você configurou seus recursos inicialmente. Você pode realocar um recurso para seu nó preferido com o comandopcs resource relocate run, como descrito em Movendo um recurso para seu nó preferido.-
Se você precisar parar completamente um recurso em execução e impedir que o cluster o inicie novamente, você pode usar o comando
pcs resource disable. Para informações sobre o comandopcs resource disable, consulte Habilitação, desativação e proibição de recursos de cluster. -
Se você quiser impedir que o Pacemaker tome qualquer ação para um recurso (por exemplo, se você quiser desativar ações de recuperação enquanto realiza a manutenção no recurso, ou se você precisar recarregar as configurações
/etc/sysconfig/pacemaker), use o comandopcs resource unmanage, conforme descrito em Configurando um recurso para o modo não gerenciado. Os recursos de conexão remota do pacemaker nunca devem ser não gerenciados. -
Se você precisar colocar o cluster em um estado onde nenhum serviço será iniciado ou interrompido, você pode definir a propriedade do cluster
maintenance-mode. Colocando o cluster em modo de manutenção, todos os recursos são automaticamente desmanchados. Para informações sobre como colocar o cluster em modo de manutenção, consulte Colocando um cluster em modo de manutenção. - Se você precisar atualizar os pacotes que compõem os Add-Ons RHEL de Alta Disponibilidade e Armazenamento Resiliente, você pode atualizar os pacotes em um nó de cada vez ou em todo o cluster como um todo, conforme resumido em Atualizando um cluster de alta disponibilidade do Red Hat Enterprise Linux.
- Se você precisar fazer manutenção em um nó remoto do Pacemaker, você pode remover esse nó do cluster desativando o recurso do nó remoto, como descrito em Atualização de nós remotos e nós convidados.
29.1. Colocando um nó em modo de espera
Quando um nó de cluster está em modo de espera, o nó não é mais capaz de hospedar recursos. Quaisquer recursos atualmente ativos no nó serão movidos para outro nó.
O comando a seguir coloca o nó especificado em modo de espera. Se você especificar o --all, este comando coloca todos os nós em modo de espera.
Você pode usar este comando ao atualizar os pacotes de um recurso. Você também pode usar este comando ao testar uma configuração, para simular a recuperação sem realmente desligar um nó.
pcs node standby node | -- todos
O seguinte comando remove o nó especificado do modo de espera. Após executar este comando, o nó especificado é então capaz de hospedar recursos. Se você especificar o --all, este comando remove todos os nós do modo standby.
pcs node unstandby node | -- tudo
Note que ao executar o comando pcs node standby, isto impede que os recursos sejam executados no nó indicado. Quando você executa o comando pcs node unstandby, isto permite que os recursos sejam executados no nó indicado. Isto não necessariamente move os recursos de volta para o nó indicado; onde os recursos podem ser executados naquele ponto depende de como você configurou seus recursos inicialmente.
29.2. Movimentação manual dos recursos do cluster
Você pode anular o agrupamento e forçar os recursos a se moverem a partir de sua localização atual. Há duas ocasiões em que você gostaria de fazer isso:
- Quando um nó está em manutenção, e você precisa mover todos os recursos funcionando nesse nó para um nó diferente
- Quando recursos individualmente especificados precisam ser movimentados
Para mover todos os recursos funcionando em um nó para um nó diferente, você coloca o nó em modo de espera.
Você pode mover recursos individualmente especificados de uma das seguintes maneiras.
-
Você pode usar o comando
pcs resource movepara mover um recurso de um nó no qual ele está rodando atualmente. -
Você pode usar o comando
pcs resource relocate runpara mover um recurso para seu nó preferido, conforme determinado pelo status atual do cluster, restrições, localização dos recursos e outras configurações.
29.2.1. Movendo um recurso de seu nó atual
Para mover um recurso para fora do nó no qual ele está rodando atualmente, use o seguinte comando, especificando o resource_id do recurso, conforme definido. Especifique o destination_node se você quiser indicar em qual nó rodar o recurso que você está movendo.
pcs resource move resource_id [destination_node] [--master] [--master] [lifetime=lifetime]
Quando você executa o comando pcs resource move, isto acrescenta uma restrição ao recurso para impedi-lo de rodar no nó no qual ele está rodando atualmente. Você pode executar o comando pcs resource clear ou o comando pcs constraint delete para remover a restrição. Isto não necessariamente move os recursos de volta para o nó original; onde os recursos podem ser executados naquele ponto depende de como você configurou seus recursos inicialmente.
Se você especificar o parâmetro --master do comando pcs resource move, o escopo da restrição é limitado ao papel principal e você deve especificar master_id em vez de resource_id.
Opcionalmente, você pode configurar um parâmetro lifetime para o comando pcs resource move para indicar um período de tempo em que a restrição deve permanecer. Você especifica as unidades de um parâmetro lifetime de acordo com o formato definido na ISO 8601, o que requer que você especifique a unidade como uma letra maiúscula como Y (para anos), M (para meses), W (para semanas), D (para dias), H (para horas), M (para minutos), e S (para segundos).
Para distinguir uma unidade de minutos(M) de uma unidade de meses(M), é necessário especificar o PT antes de indicar o valor em minutos. Por exemplo, um parâmetro lifetime de 5M indica um intervalo de cinco meses, enquanto um parâmetro lifetime de PT5M indica um intervalo de cinco minutos.
O parâmetro lifetime é verificado em intervalos definidos pela propriedade do cluster cluster-recheck-interval. Por padrão, este valor é de 15 minutos. Se sua configuração exigir que você verifique este parâmetro com mais freqüência, você pode redefinir este valor com o seguinte comando.
pcs conjunto de propriedade cluster-recheck-interval=value
Opcionalmente, você pode configurar um --wait[=n] para o comando pcs resource move para indicar o número de segundos de espera para que o recurso comece no nó de destino antes de retornar 0 se o recurso for iniciado ou 1 se o recurso ainda não tiver começado. Se você não especificar n, será usado o tempo limite padrão do recurso.
O seguinte comando move o recurso resource1 para o nó example-node2 e evita que ele volte ao nó no qual estava originalmente rodando por uma hora e trinta minutos.
pcs resource move resource1 exemplo-node2 vida útil=PT1H30M
O seguinte comando move o recurso resource1 para o nó example-node2 e impede que ele volte ao nó no qual estava originalmente rodando por trinta minutos.
pcs resource move resource1 exemplo-node2 lifetime=PT30M
29.2.2. Movendo um recurso para seu nó de preferência
Após um recurso ter se movido, seja devido a um failover ou a um administrador movendo manualmente o nó, ele não necessariamente voltará a seu nó original, mesmo depois que as circunstâncias que causaram o failover tenham sido corrigidas. Para deslocar os recursos para seu nó de preferência, use o seguinte comando. Um nó preferencial é determinado pelo status atual do cluster, restrições, localização dos recursos e outras configurações e pode mudar com o tempo.
pcs resource relocate run [resource1] [resource2] ...
Se você não especificar nenhum recurso, todos os recursos são realocados para seus nós preferidos.
Este comando calcula o nó preferido para cada recurso, ignorando a aderência do recurso. Após calcular o nó preferido, ele cria restrições de localização que farão com que os recursos se movam para seus nós preferidos. Uma vez que os recursos tenham sido movidos, as restrições são apagadas automaticamente. Para remover todas as restrições criadas pelo comando pcs resource relocate run, você pode digitar o comando pcs resource relocate clear. Para exibir o status atual dos recursos e seu nó ótimo ignorando a aderência dos recursos, digite o comando pcs resource relocate show.
29.3. Desativação, habilitação e proibição de recursos de cluster
Além dos comandos pcs resource move e pcs resource relocate, há uma variedade de outros comandos que você pode usar para controlar o comportamento dos recursos do cluster.
Desabilitando um recurso de cluster
Você pode parar manualmente um recurso em execução e impedir que o cluster o inicie novamente com o seguinte comando. Dependendo do resto da configuração (restrições, opções, falhas, etc.), o recurso pode permanecer iniciado. Se você especificar a opção --wait, pcs esperará até 'n' segundos para o recurso parar e então retornará 0 se o recurso estiver parado ou 1 se o recurso não tiver parado. Se 'n' não for especificado, o tempo padrão é de 60 minutos.
pcs resource disable resource_id [--wait[=n]]]
A partir do Red Hat Enterprise Linux 8.2, você pode especificar que um recurso seja desativado somente se a desativação do recurso não tiver um efeito sobre outros recursos. Assegurar que este seria o caso pode ser impossível de fazer à mão quando relações complexas de recursos são estabelecidas.
-
O comando
pcs resource disable --simulatemostra os efeitos da desativação de um recurso sem alterar a configuração do cluster. -
O comando
pcs resource disable --safedesabilita um recurso somente se nenhum outro recurso for afetado de alguma forma, como por exemplo, ser migrado de um nó para outro. O comandopcs resource safe-disableé um pseudônimo para o comandopcs resource disable --safe. -
O comando
pcs resource disable --safe --no-strictdesabilita um recurso somente se nenhum outro recurso for interrompido ou rebaixado
Permitindo um recurso de cluster
Use o seguinte comando para permitir que o agrupamento inicie um recurso. Dependendo do resto da configuração, o recurso pode permanecer parado. Se você especificar a opção --wait, pcs esperará até 'n' segundos para que o recurso comece e então retornará 0 se o recurso for iniciado ou 1 se o recurso não tiver começado. Se 'n' não for especificado, o tempo padrão é de 60 minutos.
pcs resource enable resource_id [--wait[=n]]]
Impedir que um recurso funcione em um determinado nó
Use o seguinte comando para evitar que um recurso seja executado em um nó especificado, ou no nó atual, se nenhum nó for especificado.
pcs resource ban resource_id [node] [--master] [--master] [lifetime=lifetime] [--wait[=n]]
Note que quando você executa o comando pcs resource ban, isto adiciona uma restrição de localização -INFINITY ao recurso para impedir que ele funcione no nó indicado. Você pode executar o comando pcs resource clear ou o comando pcs constraint delete para remover a restrição. Isto não necessariamente move os recursos de volta para o nó indicado; onde os recursos podem rodar naquele ponto depende de como você configurou seus recursos inicialmente.
Se você especificar o parâmetro --master do comando pcs resource ban, o escopo da restrição é limitado ao papel principal e você deve especificar master_id em vez de resource_id.
Opcionalmente, você pode configurar um parâmetro lifetime para o comando pcs resource ban para indicar um período de tempo em que a restrição deve permanecer.
Opcionalmente, você pode configurar um --wait[=n] para o comando pcs resource ban para indicar o número de segundos de espera para que o recurso comece no nó de destino antes de retornar 0 se o recurso for iniciado ou 1 se o recurso ainda não tiver começado. Se você não especificar n, será usado o tempo limite padrão do recurso.
Forçando um recurso a começar no nó atual
Use o parâmetro debug-start do comando pcs resource para forçar um recurso especificado a iniciar no nó atual, ignorando as recomendações do cluster e imprimindo a saída a partir do início do recurso. Isto é usado principalmente para depuração de recursos; a partida de recursos em um cluster é (quase) sempre feita pelo Pacemaker e não diretamente com um comando pcs. Se seu recurso não está iniciando, geralmente é devido ou a uma má configuração do recurso (que você depura no log do sistema), a restrições que impedem o início do recurso ou a desativação do recurso. Você pode usar este comando para testar a configuração do recurso, mas ele normalmente não deve ser usado para iniciar recursos em um cluster.
O formato do comando debug-start é o seguinte.
pcs resource debug-start resource_id29.4. Colocando um recurso em modo não gerenciado
Quando um recurso está no modo unmanaged, o recurso ainda está na configuração, mas o Pacemaker não gerencia o recurso.
O comando a seguir define os recursos indicados para o modo unmanaged.
pcs resource unmanage resource1 [resource2] ...
O seguinte comando define os recursos para o modo managed, que é o estado padrão.
pcs resource manage resource1 [resource2] ...
Você pode especificar o nome de um grupo de recursos com o comando pcs resource manage ou pcs resource unmanage. O comando atuará sobre todos os recursos do grupo, de modo que você possa definir todos os recursos de um grupo para o modo managed ou unmanaged com um único comando e, em seguida, gerenciar os recursos contidos individualmente.
29.5. Colocando um cluster em modo de manutenção
Quando um cluster está em modo de manutenção, o cluster não inicia ou pára qualquer serviço até que se diga o contrário. Quando o modo de manutenção é concluído, o cluster faz uma verificação de sanidade do estado atual de qualquer serviço, e então pára ou inicia qualquer serviço que precise dele.
Para colocar um cluster em modo de manutenção, use o seguinte comando para definir a propriedade do cluster maintenance-mode para true.
# pcs property set maintenance-mode=true
Para remover um cluster do modo de manutenção, use o seguinte comando para definir a propriedade do cluster maintenance-mode para false.
# pcs property set maintenance-mode=falseVocê pode remover uma propriedade de cluster da configuração com o seguinte comando.
pcs propriedade não definida property
Alternativamente, você pode remover uma propriedade de cluster de uma configuração, deixando o campo de valor do comando pcs property set em branco. Isto restaura essa propriedade a seu valor padrão. Por exemplo, se você definiu previamente a propriedade symmetric-cluster para false, o seguinte comando remove o valor definido da configuração e restaura o valor de symmetric-cluster para true, que é seu valor padrão.
# pcs property set symmetric-cluster=29.6. Atualização de um cluster de alta disponibilidade RHEL
A atualização dos pacotes que compõem os Add-Ons RHEL High Availability e Resilient Storage Add-Ons, seja individualmente ou como um todo, pode ser feita de uma de duas maneiras gerais:
- Rolling Updates: Remover um nó de cada vez do serviço, atualizar seu software e depois integrá-lo de volta ao cluster. Isto permite que o cluster continue fornecendo serviços e gerenciando recursos enquanto cada nó é atualizado.
- Entire Cluster Update: Pare todo o agrupamento, aplique atualizações em todos os nós e, em seguida, inicie o backup do agrupamento.
É fundamental que ao realizar procedimentos de atualização de software para os clusters Red Hat Enterprise LInux de Alta Disponibilidade e Armazenamento Resiliente, você garanta que qualquer nó que será submetido a atualizações não seja um membro ativo do cluster antes que essas atualizações sejam iniciadas.
Para uma descrição completa de cada um desses métodos e os procedimentos a seguir para as atualizações, consulte Práticas recomendadas para a aplicação de atualizações de software em um Cluster RHEL de alta disponibilidade ou de armazenamento resiliente.
29.7. Atualização de nós remotos e nós de convidados
Se o serviço pacemaker_remote for interrompido em um nó remoto ativo ou em um nó convidado, o cluster migrará graciosamente os recursos para fora do nó antes de parar o nó. Isto permite que você realize atualizações de software e outros procedimentos de manutenção de rotina sem remover o nó do cluster. Uma vez que pacemaker_remote seja desligado, no entanto, o cluster tentará imediatamente reconectar-se. Se pacemaker_remote não for reiniciado dentro do tempo limite do monitor do recurso, o cluster considerará a operação do monitor como falhada.
Se você deseja evitar falhas de monitoramento quando o serviço pacemaker_remote é interrompido em um nó remoto do Pacemaker ativo, você pode usar o seguinte procedimento para retirar o nó do cluster antes de realizar qualquer administração de sistema que possa parar pacemaker_remote
-
Parar o recurso de conexão do nó com o
pcs resource disable resourcenameque tirará todos os serviços do nó. Para nós convidados, isto também irá parar o VM, portanto o VM deve ser iniciado fora do cluster (por exemplo, usandovirsh) para realizar qualquer manutenção. - Realizar a manutenção necessária.
-
Quando estiver pronto para retornar o nó ao agrupamento, reative o recurso com o
pcs resource enable.
29.8. Migração de VMs em um cluster RHEL
Informações sobre políticas de suporte para clusters de alta disponibilidade da RHEL com membros de clusters virtualizados podem ser encontradas em Políticas de suporte para clusters de alta disponibilidade da RHEL - Condições Gerais com Membros de Clusters Virtualizados. Como observado, a Red Hat não suporta a migração ao vivo de nós de cluster ativos através de hipervisores ou hosts. Se você precisar realizar uma migração ao vivo, primeiro você precisará parar os serviços de cluster na VM para remover o nó do cluster, e então iniciar o backup do cluster após realizar a migração. Os passos seguintes descrevem o procedimento para remover uma VM de um cluster, migrando a VM, e restaurando a VM para o cluster.
Este procedimento se aplica às VMs que são usadas como nós de cluster completos, não às VMs gerenciadas como recursos de cluster (incluindo as VMs usadas como nós convidados) que podem ser migradas ao vivo sem precauções especiais. Para informações gerais sobre o procedimento mais completo necessário para atualizar os pacotes que compõem os Add-Ons de Alta Disponibilidade e Armazenamento Resiliente da RHEL, seja individualmente ou como um todo, consulte Práticas Recomendadas para Aplicação de Atualizações de Software a um Cluster de Alta Disponibilidade ou Armazenamento Resiliente da RHEL.
Antes de realizar este procedimento, considere o efeito sobre o quorum de aglomeração da remoção de um nó de aglomeração. Por exemplo, se você tiver um agrupamento de três nós e remover um nó, seu agrupamento pode suportar apenas mais uma falha de nó. Se um nó de um aglomerado de três nós já estiver em baixo, a remoção de um segundo nó perderá o quorum.
- Se alguma preparação precisar ser feita antes de parar ou mover os recursos ou software em execução na VM para migrar, execute essas etapas.
Execute o seguinte comando na VM para parar o software de cluster na VM.
#
pcs cluster stop- Realizar a migração ao vivo do VM.
Iniciar serviços de cluster na VM.
#
pcs cluster start
Capítulo 30. Configuração de clusters de recuperação de desastres
Um método de recuperação de desastres para um cluster de alta disponibilidade é a configuração de dois clusters. Você pode então configurar um cluster como seu cluster principal de site, e o segundo cluster como seu cluster de recuperação de desastres.
Em circunstâncias normais, o aglomerado primário está operando recursos no modo de produção. O cluster de recuperação de desastres também tem todos os recursos configurados e está executando-os em modo despromoção ou não está funcionando em modo de produção. Por exemplo, pode haver um banco de dados rodando no cluster primário em modo promovido e rodando no cluster de recuperação de desastres em modo despromovido. O banco de dados nesta configuração seria configurado para que os dados sejam sincronizados do local primário para o local de recuperação de desastres. Isto é feito através da própria configuração do banco de dados e não através da interface de comando pcs.
Quando o cluster primário cair, os usuários podem usar a interface de comando pcs para falhar manualmente os recursos para o site de recuperação de desastres. Eles podem então entrar no site do desastre e promover e iniciar os recursos lá. Uma vez recuperado o cluster primário, os usuários podem usar a interface de comando pcs para mover manualmente os recursos de volta para o site primário.
A partir do Red Hat Enterprise Linux 8.2, você pode usar o comando pcs para exibir o status do cluster do site principal e do site de recuperação de desastres a partir de um único nó em ambos os sites.
30.1. Considerações sobre clusters de recuperação de desastres
Ao planejar e configurar um site de recuperação de desastres que você irá gerenciar e monitorar com a interface de comando pcs, observe as seguintes considerações.
- O local de recuperação de desastres deve ser um aglomerado. Isto torna possível configurá-lo com as mesmas ferramentas e procedimentos similares ao local principal.
-
Os clusters primários e de recuperação de desastres são criados por comandos independentes do
pcs cluster setup. - Os clusters e seus recursos devem ser configurados para que os dados sejam sincronizados e o failover seja possível.
- Os nós de agrupamento no local de recuperação não podem ter os mesmos nomes que os nós no local primário.
-
O usuário do pcs
haclusterdeve ser autenticado para cada nó em ambos os clusters no nó a partir do qual você estará executando os comandospcs.
30.2. Exibição do status dos clusters de recuperação (RHEL 8.2 e posteriores)
Para configurar um cluster primário e um cluster de recuperação de desastres para que você possa exibir o status de ambos os clusters, execute o seguinte procedimento.
A criação de um cluster de recuperação de desastres não configura automaticamente os recursos nem reproduz os dados. Esses itens devem ser configurados manualmente pelo usuário.
Neste exemplo:
-
O cluster primário será denominado
PrimarySitee consistirá dos nósz1.example.com. ez2.example.com. -
O cluster do site de recuperação de desastres será denominado
DRsitee será composto pelos nósz3.example.comez4.example.com.
Este exemplo estabelece um cluster básico sem recursos ou cercas configuradas.
Autenticar todos os nós que serão utilizados para ambos os agrupamentos.
[root@z1 ~]#
pcs host auth z1.example.com z2.example.com z3.example.com z4.example.com -u hacluster -p passwordz1.example.com: Authorized z2.example.com: Authorized z3.example.com: Authorized z4.example.com: AuthorizedCriar o cluster que será usado como cluster primário e iniciar os serviços de cluster para o cluster.
[root@z1 ~]#
pcs cluster setup PrimarySite z1.example.com z2.example.com --start{...} Cluster has been successfully set up. Starting cluster on hosts: 'z1.example.com', 'z2.example.com'...Criar o cluster que será usado como o cluster de recuperação de desastres e iniciar os serviços de cluster para o cluster.
[root@z1 ~]#
pcs cluster setup DRSite z3.example.com z4.example.com --start{...} Cluster has been successfully set up. Starting cluster on hosts: 'z3.example.com', 'z4.example.com'...A partir de um nó no aglomerado primário, montar o segundo aglomerado como o local de recuperação. O local de recuperação é definido por um nome de um de seus nós.
[root@z1 ~]#
pcs dr set-recovery-site z3.example.comSending 'disaster-recovery config' to 'z3.example.com', 'z4.example.com' z3.example.com: successful distribution of the file 'disaster-recovery config' z4.example.com: successful distribution of the file 'disaster-recovery config' Sending 'disaster-recovery config' to 'z1.example.com', 'z2.example.com' z1.example.com: successful distribution of the file 'disaster-recovery config' z2.example.com: successful distribution of the file 'disaster-recovery config'Verifique a configuração de recuperação de desastres.
[root@z1 ~]#
pcs dr configLocal site: Role: Primary Remote site: Role: Recovery Nodes: z1.example.com z2.example.comVerificar o status do aglomerado primário e do aglomerado de recuperação de desastres de um nó no aglomerado primário.
[root@z1 ~]#
pcs dr status--- Local cluster - Primary site --- Cluster name: PrimarySite WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: z2.example.com (version 2.0.3-2.el8-2c9cea563e) - partition with quorum * Last updated: Mon Dec 9 04:10:31 2019 * Last change: Mon Dec 9 04:06:10 2019 by hacluster via crmd on z2.example.com * 2 nodes configured * 0 resource instances configured Node List: * Online: [ z1.example.com z2.example.com ] Full List of Resources: * No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled --- Remote cluster - Recovery site --- Cluster name: DRSite WARNINGS: No stonith devices and stonith-enabled is not false Cluster Summary: * Stack: corosync * Current DC: z4.example.com (version 2.0.3-2.el8-2c9cea563e) - partition with quorum * Last updated: Mon Dec 9 04:10:34 2019 * Last change: Mon Dec 9 04:09:55 2019 by hacluster via crmd on z4.example.com * 2 nodes configured * 0 resource instances configured Node List: * Online: [ z3.example.com z4.example.com ] Full List of Resources: * No resources Daemon Status: corosync: active/disabled pacemaker: active/disabled pcsd: active/enabled
Para opções de exibição adicionais para uma configuração de recuperação de desastres, consulte a tela de ajuda para o comando pcs dr.