
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
1.8. Servidor Virtual Linux
O Servidor Virtual Linux ( LVS - Linux Virtual Server ) é um conjunto de componentes de software integrados para balanceamento da carga IP através de um conjunto de servidores reais. O LVS atua num par de igualdade de computadores configurados: o roteador LVS ativo e o roteador LVS de backup. O roteador LVS ativo apresenta duas funções:
- Balancear a carga através de servidores reais.
- Checar a integridade de serviços em cada servidor real.
O roteador LVS de backup monitora o roteador LVS ativo e se responsabiliza por isto, em caso do roteador LVS ativo falhar.
Figura 1.19, “Components of a Running LVS Cluster” provides an overview of the LVS components and their interrelationship.
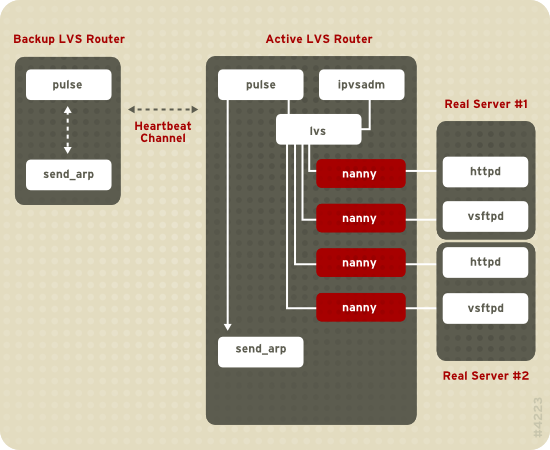
Figura 1.19. Components of a Running LVS Cluster
O
pulse daemon atua nos roteadores LVS ativos e passivos. Em um roteador LVS de backup, o pulse envia um heartbeat para a interface pública de um roteador ativo para garantir que o roteador LVS esteja funcionando propriamente. Num roteador LVS ativo, o pulse inicia o lvs daemon e responde ao heartbeat as perguntas do roteador LVS de backup.
Um vez iniciado, o
lvs daemon chama a utilidade ipvsadm para configurar e manter o IPVS ( Servidor Virtual IP ) de tabela ampla no kernel, e inicia um processo nanny para cada servidor virtual configurado em cada servidor real. Cada processo nanny verifica o estado de um serviço configurado em um servidor real, e informa o daemon lvs, caso o serviço daquele servidor real possuir mal funcionamento. Se o mal funcionamento for detectado, o daemon lvs induz o ipvsadm a remover aquele servidor real de uma tabela ampla IPVS.
Caso um roteador LVS de backup não receber uma resposta de um roteador LVS, ele iniciará a falha chamando o
send_arp para reinstalar todos os endereços IP virtuais nos endereços de hardware NIC ( endereços MAC ) de roteador LVS de backup. Isto enviará um comando para o roteador LVS ativo por meio das interfaces da rede pública e privada, desativando o daemon lvs num roteador LVS ativo e iniciando o daemon lvs, no roteador LVS de backup, para aceitação das solicitações de servidores virtuais configurados.
No caso de um usuário de fora estar acessando um serviço anfitrião ( como um website ou aplicação de banco de dados ), o LVS se apresenta como um servidor. No entanto, o usuário estará acessando os servidores reais por trás dos roteadores LVS.
Devido ao LVS não possuir o componente construído para compartilhamento dos dados entre os servidores reais, você terá duas opções básicas:
- Sincronizar os dados através de servidores reais.
- Adicionar a terceira camada da topologia para acesso de dados compartilhados.
A primeira opção é preferida pelos servidores que não permitem um número grande de usuários para carregar ou mudar os dados em servidores reais. Se um servidor real permitir um número grande de usuários modificar os dados, como um website de e-comércio, é preferível a adição da terceira camada.
Existem diversas maneiras de sincronizar dados de servidores reais. Por exemplo, você pode utilizar os scripts shell para enviar simultaneamente as páginas atualizadas da web de usuários reais. Além disso, você pode usar programas como o
rsync para replicar a mudança de dados através de todos os nós em um intervalo definido. No entanto, a sincronização de dados não funciona de maneira otimista para os ambientes onde os usuários freqüentemente fazem o carregamento do arquivo ou têm problemas em transações de datadados, usando o script ou o comando rsync. Portanto, para os servidores reais com um alto número de carregamento, transações de datadados, ou tráfico similar, a topologia de três camadas é a mais apropriada para a sincronização de dados.
1.8.1. Two-Tier LVS Topology
Figura 1.20, “Two-Tier LVS Topology” shows a simple LVS configuration consisting of two tiers: LVS routers and real servers. The LVS-router tier consists of one active LVS router and one backup LVS router. The real-server tier consists of real servers connected to the private network. Each LVS router has two network interfaces: one connected to a public network (Internet) and one connected to a private network. A network interface connected to each network allows the LVS routers to regulate traffic between clients on the public network and the real servers on the private network. In Figura 1.20, “Two-Tier LVS Topology”, the active LVS router uses Network Address Translation (NAT) to direct traffic from the public network to real servers on the private network, which in turn provide services as requested. The real servers pass all public traffic through the active LVS router. From the perspective of clients on the public network, the LVS router appears as one entity.
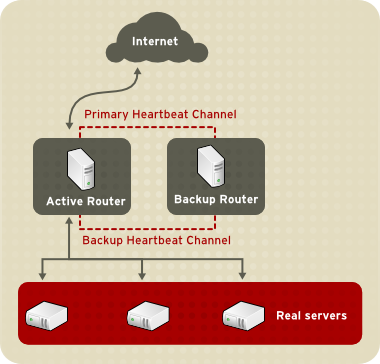
Figura 1.20. Two-Tier LVS Topology
O serviço solicita que a chegada no roteador LVS seja endereçada a um endereço IP virtual ou VIP. Este é um endereço roteado publicamente do administrador do site de associados, com o nome dominante inteiramente qualificado. Por exemplo: www.example.com, que é determinado para um ou mais servidores virtuais[1]. Perceba que um endereço VIP migra de um para outro roteador LVS durante a falha, deste modo mantendo a presença no endereço IP, também conhecido como endereço IP flutuante.
Os endereços VIP podem ser alias no mesmo dispositivo que conecta o roteador LVS à rede pública. Por exemplo, se o eth0 é conectado à Internet, então diversos servidores virtuais podem ser alias ao
eth0:1. Alternativamente, cada servidor virtual pode ser associado com o dispositivo separado por serviço. Por exemplo, o tráfico HTTP pode ser tratado em eth0:1, e o tráfico FTP pode ser tratado em eth0:2.
Apenas o roteador LVS está ativo desta vez. A função do roteador LVS ativo é de redirecionar os serviços solicitados de um endereço virtual IP aos servidores reais. A redireção é baseada em um destes oito algoritmo de carga balanceada:
- Round-Robin Scheduling — Distribui cada solicitação seqüencial em volta de um pool de servidores reais. Usando este algoritmo, todos os servidores reais são tratados como equivalentes sem considerar a capacidade ou carga.
- Weighted Round-Robin Scheduling — Distribui cada solicitação seqüencial em volta do pool de servidores reais, mas gera mais trabalho para servidores de grande capacidade. A capacidade é indicada por um usuário determinado pelo fator peso, que então é ajustado acima e abaixo por informação de carga dinâmica. Esta é a escolha preferida se houver diferenças significantes entre a capacidade de servidores reais em um pool de servidor. No entanto, se a solicitação de carga variar dramaticamente, um servidor de carga mais pesada, poderá responder além de sua própria repartição de solicitações.
- Least-Connection — Distribui mais solicitações de servidores reais com poucas conexões ativas. Essa conexão é um algoritmo de agendamento dinâmico, executando uma melhor escolha em caso de existir um alto grau de variação nesta carga solicitada. É, também, a conexão mais adequada para um pool de servidor real, onde cada nó de servidor possui aproximadamente a mesma capacidade. Em caso de servidores reais possuírem capacidades variáveis, o agendamento de conexão mínima carregada será a melhor escolha.
- Weighted Least-Connections ( padrão ) — Distribui mais solicitações para servidores com poucas conexões ativas relativas às suas capacidades. A capacidade é indicada pela carga determinada pelo usuário, o que é então ajustada para acima ou para baixo por uma informação de carga dinâmica. A adição de carregamento faz com que este algoritmo seja perfeito, quando o pool de servidor real conter o hardware de capacidade variável.
- Locality-Based Least-Connection Scheduling — Distribui mais solicitações aos servidores com poucas conexões ativas relativas as suas destinações IPs. Esse algoritmo é para uso de um cluster de servidor proxy-cache. Ele roteia os pacotes dos endereços IP para o servidor daquele endereço, a não ser que este servidor esteja acima da capacidade e possua um servidor de baixa carga. Neste caso, isto determinará o endereço IP do servidor real de carregamento mínimo.
- Locality-Based Least-Connection Scheduling with Replication Scheduling — Distribui mais solicitações aos servidores com poucas conexões ativas relativas as suas destinações IPs. Esse algoritmo é também para o uso de um cluster de servidor proxy-cache. Isto diferencia um Locality-Based Least-Connection Scheduling pelo mapeamento do endereço alvo IP ao subset do servidor real.
- Source Hash Scheduling — Distribui solicitações ao pool de servidores reais, checando o recurso IP numa mesa hash estática. Este algoritmo é para os roteadores LVS com múltiplos firewalls.
Além disso, o roteador LVS ativo monitora dinamicamente o health, em geral, de serviços específicos nos servidores reais através de um simples script enviado/esperado. Para assistir na detecção do health dos servidores que requerem os dados dinâmicos, como os HTTPS ou SSL, você pode também chamar por execuções externas. Caso um serviço em um servidor real não funcione corretamente, o roteador LVS ativo interrompe o envio de trabalhos para o servidor até que isto retorne à operação normal.
O roteador LVS de backup executa a função de um sistema standby ( estado de prontidão ). Periodicamente, os roteadores LVS mudam as mensagens hearbeat através da interface pública externa primária. No caso do roteador LVS de backup falhar em receber a mensagem heartbeat no intervalo esperado, a falha será iniciada e assumirá a função do roteador LVS ativo. Durante a falha, o roteador LVS de backup é responsável pelos serviços de endereços VIP por um roteador falhado usando uma técnica conhecida como ARP spoofing — onde o roteador LVS de backup anuncia-se como destino dos pacotes endereçados para os nós falhados. Quando os nós falhados retornarem ao serviço ativo, o roteador LVS de backup assumirá sua função de backup novamente.
The simple, two-tier configuration in Figura 1.20, “Two-Tier LVS Topology” is suited best for clusters serving data that does not change very frequently — such as static web pages — because the individual real servers do not automatically synchronize data among themselves.