
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
Visão Geral do Cluster Suite
Red Hat Cluster Suite para o Red Hat Enterprise Linux 5
Edição 3
Resumo
Introdução
- Red Hat Enterprise Linux Guia de instalação — Fornece informação sobre a instalação da Red Hat Enterprise Linux 5.
- Red Hat Enterprise Linux Guia de implantação — Fornece informação sobre a implantação, configuração e administração da Red Hat Enterprise Linux 5.
- Configurando e Gerenciando o Red Hat Cluster — Fornece informação sobre instalação, configuração e gerenciamento dos componentes do Red Hat Cluster.
- LVM Administrator's Guide: Configuration and Administration — Provides a description of the Logical Volume Manager (LVM), including information on running LVM in a clustered environment.
- Sistema de Arquivo Global: Configuração e Administração — Fornece informação sobre instalação, configuração e manutenção do Red Hat GSF - Red Hat Global File System ( Sistema de Arquivo Global Red Hat ).
- Sistema de Arquivo Global 2: Configuração e Administração — Fornece informação sobre instalação, configuração e manutenção do Red Hat GFS2 (Red Hat Global File System 2 - Sistema de Arquivo Global 2 da Red Hat ).
- Usando o Disparador Mapper de Caminhos Diversos — Fornece informação sobre o uso do Disparador Mapper de Caminhos Diversos da Red Hat Enterprise Linux 5.
- Usando GNBD com o Sistema de Arquivo Global — Fornece uma visão geral de como se utilizar o Global Network Block Device ( GNBD, Dispositivo de Bloqueio da Rede Global ), com o Red Hat GFS.
- Administração do Servidor Virtual Linux — Fornece informação na configuração de sistemas de alta execução e serviços com o Linux Virtual Server ( LVS, Servidor Virtual Linux ).
- Notas da Versão do Red Hat Cluster Suite — Fornece informação sobre a atual versão do Red Hat Cluster Suite.
1. Feedback
Cluster_Suite_Overview(EN)-5 (2008-12-11T15:49)
Capítulo 1. Red Hat Cluster Suite Visão geral
1.1. Clusters Básicos
- Armazenamento
- Alta disponibilidade
- Balanceamento de carga
- Alto desempenho
Nota
1.2. Red Hat Cluster Suite Introduction
- Infraestrutura de cluster — Fornece funções fundamentais para os nós, trabalhando juntamente com um cluster: gerenciamento de configuração de arquivo, gerenciamento de associados e delimitação.
- Gerenciamento de Serviço de Alta disponibilidade — Fornece os serviços de falha de um nó de cluster para outro, caso um nó se torne inoperante.
- Ferramentas de administração de cluster — Ferramentas de configuração e gerenciamento para configurar e gerenciar um cluster Red Hat. As ferramentas são usadas com os componentes de Infraestrutura de Cluster, alta disponibilidade e componentes de Gerenciamento de Serviço, e armazenamento.
- Linux Virtual Server (LVS) — software de rotação que fornece o balanceamento de carga IP. O LVS executa em pares os servidores de redundância e distribui igualmente as solicitações dos clientes para servidores reais, que estão atrás de servidores do LVS.
- Red Hat GFS ( Global File System ) Sistema de Arquivo Global — Fornece um sistema de arquivo de cluster para uso com o Red Hat Cluster Suite. O GFS permite que os nós múltiplos compartilharem o armazenamento, num nível de bloqueio, como se o armazenamento fosse conectado localmente com cada nó de cluster.
- Cluster Logical Volume Manager (CLVM) Gerenciador de Volume Lógico de Cluster — Fornece o gerenciamento do volume de armazenamento de cluster.
Nota
When you create or modify a CLVM volume for a clustered environment, you must ensure that you are running theclvmddaemon. For further information, refer to Seção 1.6, “Gerenciador de Volume Lógico de Cluster”. - Global Network Block Device (GNBD) Dispositivo de Bloqueio da Rede Global — Um componente auxiliar do GFS que exporta o armazenamento de nível de bloqueio para Ethernet. Esta é uma maneira econômica de se fazer disponível o armazenamento de nível de bloqueio no Red Hat GFS.

Figura 1.1. Red Hat Cluster Suite Introduction
Nota
1.3. Cluster Infrastructure
- Gerenciamento de Cluster
- Gerenciamento de bloqueio
- Fencing
- Gerenciamento de configuração de cluster
1.3.1. Gerenciamento de cluster
Nota

Figura 1.2. CMAN/DLM Overview
1.3.2. Gerenciamento de bloqueio
1.3.3. Fencing
fenced.
Fenced, quando for notificada a falha, o fence atua no nó falhado. Os outros componentes de infra-estrutura de cluster determinam quais ações a serem tomadas — eles atuam em qualquer recuperação que necessita ser feita. Por exemplo, quando um nó de falha for notificado pelo DLM e GFS, a atividade será suspensa até eles detectarem que o fenced tenha completado o fencing no nó de falha. O DLM e GFS executam a recuperação, sob confirmação de que o nó sofreu fencing. O DLM libera bloqueios de nó de falhas, enquanto que o GFS recupera o relatório de um nó de falha.
- Força fencing — Um método fencing que usa uma força controladora para desligar um nó inoperante.
- Alternador fencing de Canal de Fibra — Um método fencing do qual desativa a porta do Canal de Fibra que conecta o armazenamento a um nó inoperante.
- GNBD fencing — A fencing method that disables an inoperable node's access to a GNBD server.
- Outros fencing — Diversos métodos fencing que desativam o I/O ou força de um nó inoperante, incluindo bladecentres IBM, PAP, DRAC/MC, HP ILO, IPMI, IBM RSA II, e outros.

Figura 1.3. Power Fencing Example

Figura 1.4. Fibre Channel Switch Fencing Example

Figura 1.5. Fencing a Node with Dual Power Supplies

Figura 1.6. Fencing a Node with Dual Fibre Channel Connections
1.3.4. Sistema de Configuração de Cluster

Figura 1.7. CCS Overview

Figura 1.8. Accessing Configuration Information
/etc/cluster/cluster.conf ) é um arquivo XML que descreve as seguintes características de cluster:
- O nome do cluster — Exibe o nome do cluster, o nível de revisão do arquivo de configuração de cluster, e propriedades básicas de tempo de fence usadas quando um nó une-se a um cluster, ou é limitado por um cluster.
- Cluster — Exibe cada nó de um cluster, especificando o nome do nó, a Id do nó, o número de votos do quórum, e o método fencing para aquele nó.
- Dispositivo de fence — Exibe os dispositivos de fence num cluster. Os parâmetros variam de acordo com o tipo de dispositivo de fence. Por exemplo, para um controlador de energia usado como um dispositivo de fence, a configuração de cluster define o nome do controlador de energia, seu endereço IP, logon e senha.
- Recursos Gerenciados — Exibe os recursos requeridos para criação de serviços de cluster. Os recursos gerenciados englobam a definição de domínios de falha, recursos ( por exemplo um endereço IP ) e serviços. Com isto, os recursos gerenciados definem os serviços de cluster e comportamento de falha dos serviços cluster.
1.4. Gerenciamento de Serviço de Alta Disponibilidade
rgmanager, implementa a falha fria para aplicações off-the-shelf ( fora da prateleira ). Em um cluster Red Hat, a aplicação é configurada com outros recursos para formar um serviço de cluster de alta disponibilidade. Um serviço de cluster de alta disponibilidade pode falhar de um para outro nó de cluster sem nenhuma interrupção aparente para clientes de cluster. A falha do serviço de cluster pode ocorrer caso um nó de cluster falhar, ou se um administrador de sistema de cluster mover o serviço de cluster de um para outro nó de cluster. ( por exemplo, para uma interrupção planejada de um nó de cluster ).
Nota

Figura 1.9. Domínios de Falha
- Recurso do endereço IP — endereço IP 10.10.10.201.
- An application resource named "httpd-content" — a web server application init script
/etc/init.d/httpd(specifyinghttpd). - A file system resource — Red Hat GFS named "gfs-content-webserver".

Figura 1.10. Web Server Cluster Service Example
1.5. Red Hat GFS
- Simplificar a sua infraestrutura de dados
- Instalar e patch as aplicações de uma única vez para todo o cluster.
- Eliminar a necessidade de cópias redundantes dos dados de aplicação ( duplicação ).
- Permitir o acesso ler/escrever coexistente para dados de diversos clientes.
- Simplificar o backup e recuperação de desastre ( apenas um sistema de arquivo para backup ou recuperação ).
- Aumentar o uso de recursos de armazenamento; diminuindo os custos de administração do armazenamento.
- Gerenciar o armazenamento como um todo, ao contrário de apenas por partição.
- Diminuir, de uma maneira geral, as necessidades do armazenamento eliminando as replicações de dados.
- Escalar o cluster sem interrupção adicionando servidores ou armazenamento no fly.
- A partição de armazenamento através de técnicas complicadas não é existente.
- Adicionar servidores para o cluster num fly, montando-os ao sistema de arquivo comum.
Nota
1.5.1. Desempenho Superior e Escalabilidade

Figura 1.11. GFS with a SAN
1.5.2. Desempenho, Escalabilidade e Preço Moderado

Figura 1.12. GFS and GNBD with a SAN
1.5.3. Economia e desempenho

Figura 1.13. GFS e GNBD com Armazenamento Conectado Diretamente
1.6. Gerenciador de Volume Lógico de Cluster
clvmd. clvmd is a daemon that provides clustering extensions to the standard LVM2 tool set and allows LVM2 commands to manage shared storage. clvmd runs in each cluster node and distributes LVM metadata updates in a cluster, thereby presenting each cluster node with the same view of the logical volumes (refer to Figura 1.14, “CLVM Overview”). Logical volumes created with CLVM on shared storage are visible to all nodes that have access to the shared storage. CLVM allows a user to configure logical volumes on shared storage by locking access to physical storage while a logical volume is being configured. CLVM uses the lock-management service provided by the cluster infrastructure (refer to Seção 1.3, “Cluster Infrastructure”).
Nota
clvmd) ou os agentes do Gerenciamento de Volume Lógico de Alta Disponibilidade (HA-LVM). Se você não conseguir usar o daemon do clvmd ou o HA-LVM por motivos operacionais ou porque você não possui os direitos corretos, não use o single-instance LVM no disco compartilhado, pois isto pode danificar os dados. Caso tenha qualquer dúvida, entre em contato com o representante de serviços da Red Hat.
Nota
/etc/lvm/lvm.conf para bloqueamento de um cluster amplo.

Figura 1.14. CLVM Overview

Figura 1.15. LVM Graphical User Interface

Figura 1.16. Conga LVM Graphical User Interface

Figura 1.17. Creating Logical Volumes
1.7. Dispositivo de Bloqueio da Rede Global

Figura 1.18. Visualização GNBD
1.8. Servidor Virtual Linux
- Balancear a carga através de servidores reais.
- Checar a integridade de serviços em cada servidor real.
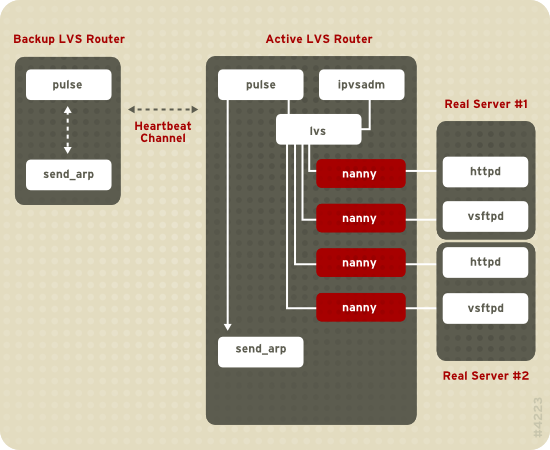
Figura 1.19. Components of a Running LVS Cluster
pulse daemon atua nos roteadores LVS ativos e passivos. Em um roteador LVS de backup, o pulse envia um heartbeat para a interface pública de um roteador ativo para garantir que o roteador LVS esteja funcionando propriamente. Num roteador LVS ativo, o pulse inicia o lvs daemon e responde ao heartbeat as perguntas do roteador LVS de backup.
lvs daemon chama a utilidade ipvsadm para configurar e manter o IPVS ( Servidor Virtual IP ) de tabela ampla no kernel, e inicia um processo nanny para cada servidor virtual configurado em cada servidor real. Cada processo nanny verifica o estado de um serviço configurado em um servidor real, e informa o daemon lvs, caso o serviço daquele servidor real possuir mal funcionamento. Se o mal funcionamento for detectado, o daemon lvs induz o ipvsadm a remover aquele servidor real de uma tabela ampla IPVS.
send_arp para reinstalar todos os endereços IP virtuais nos endereços de hardware NIC ( endereços MAC ) de roteador LVS de backup. Isto enviará um comando para o roteador LVS ativo por meio das interfaces da rede pública e privada, desativando o daemon lvs num roteador LVS ativo e iniciando o daemon lvs, no roteador LVS de backup, para aceitação das solicitações de servidores virtuais configurados.
- Sincronizar os dados através de servidores reais.
- Adicionar a terceira camada da topologia para acesso de dados compartilhados.
rsync para replicar a mudança de dados através de todos os nós em um intervalo definido. No entanto, a sincronização de dados não funciona de maneira otimista para os ambientes onde os usuários freqüentemente fazem o carregamento do arquivo ou têm problemas em transações de datadados, usando o script ou o comando rsync. Portanto, para os servidores reais com um alto número de carregamento, transações de datadados, ou tráfico similar, a topologia de três camadas é a mais apropriada para a sincronização de dados.
1.8.1. Two-Tier LVS Topology
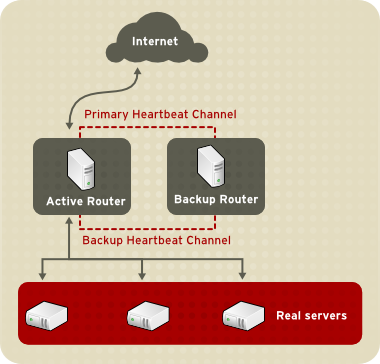
Figura 1.20. Two-Tier LVS Topology
eth0:1. Alternativamente, cada servidor virtual pode ser associado com o dispositivo separado por serviço. Por exemplo, o tráfico HTTP pode ser tratado em eth0:1, e o tráfico FTP pode ser tratado em eth0:2.
- Round-Robin Scheduling — Distribui cada solicitação seqüencial em volta de um pool de servidores reais. Usando este algoritmo, todos os servidores reais são tratados como equivalentes sem considerar a capacidade ou carga.
- Weighted Round-Robin Scheduling — Distribui cada solicitação seqüencial em volta do pool de servidores reais, mas gera mais trabalho para servidores de grande capacidade. A capacidade é indicada por um usuário determinado pelo fator peso, que então é ajustado acima e abaixo por informação de carga dinâmica. Esta é a escolha preferida se houver diferenças significantes entre a capacidade de servidores reais em um pool de servidor. No entanto, se a solicitação de carga variar dramaticamente, um servidor de carga mais pesada, poderá responder além de sua própria repartição de solicitações.
- Least-Connection — Distribui mais solicitações de servidores reais com poucas conexões ativas. Essa conexão é um algoritmo de agendamento dinâmico, executando uma melhor escolha em caso de existir um alto grau de variação nesta carga solicitada. É, também, a conexão mais adequada para um pool de servidor real, onde cada nó de servidor possui aproximadamente a mesma capacidade. Em caso de servidores reais possuírem capacidades variáveis, o agendamento de conexão mínima carregada será a melhor escolha.
- Weighted Least-Connections ( padrão ) — Distribui mais solicitações para servidores com poucas conexões ativas relativas às suas capacidades. A capacidade é indicada pela carga determinada pelo usuário, o que é então ajustada para acima ou para baixo por uma informação de carga dinâmica. A adição de carregamento faz com que este algoritmo seja perfeito, quando o pool de servidor real conter o hardware de capacidade variável.
- Locality-Based Least-Connection Scheduling — Distribui mais solicitações aos servidores com poucas conexões ativas relativas as suas destinações IPs. Esse algoritmo é para uso de um cluster de servidor proxy-cache. Ele roteia os pacotes dos endereços IP para o servidor daquele endereço, a não ser que este servidor esteja acima da capacidade e possua um servidor de baixa carga. Neste caso, isto determinará o endereço IP do servidor real de carregamento mínimo.
- Locality-Based Least-Connection Scheduling with Replication Scheduling — Distribui mais solicitações aos servidores com poucas conexões ativas relativas as suas destinações IPs. Esse algoritmo é também para o uso de um cluster de servidor proxy-cache. Isto diferencia um Locality-Based Least-Connection Scheduling pelo mapeamento do endereço alvo IP ao subset do servidor real.
- Source Hash Scheduling — Distribui solicitações ao pool de servidores reais, checando o recurso IP numa mesa hash estática. Este algoritmo é para os roteadores LVS com múltiplos firewalls.
1.8.2. Three-Tier LVS Topology
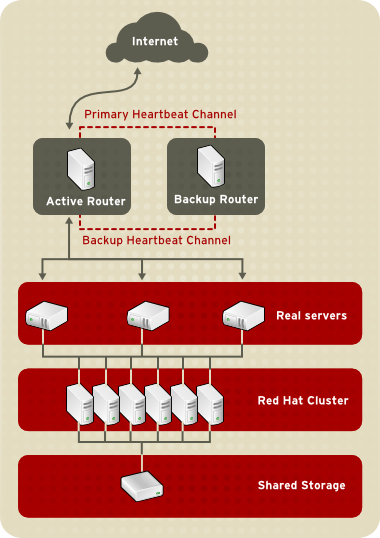
Figura 1.21. Three-Tier LVS Topology
1.8.3. Métodos Encaminhados
1.8.3.1. Roteamento NAT
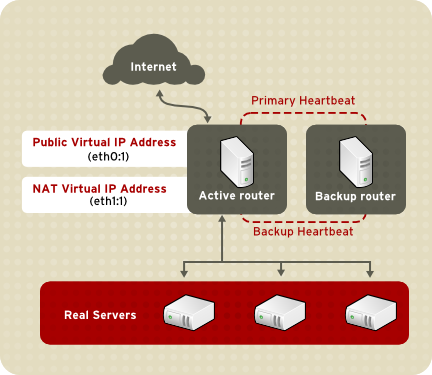
Figura 1.22. LVS Implemented with NAT Routing
1.8.3.2. Roteamento direto
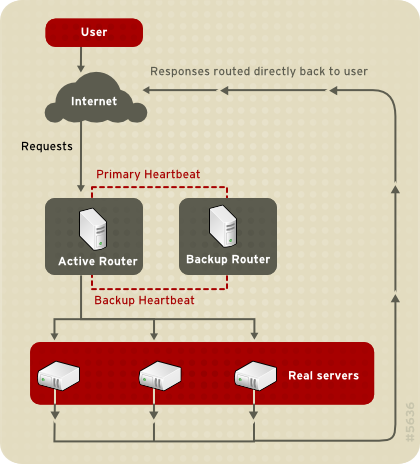
Figura 1.23. LVS Implemented with Direct Routing
arptables.
1.8.4. Marcas de Firewall e Persistência
1.8.4.1. Persistence
1.8.4.2. Marcas Firewall
1.9. Ferramentas de Administração de Cluster
1.9.1. Conga
- Uma interface da Web para gerenciamento e armazenamento de cluster
- Implantação Automática de dados de Cluster e Pacotes de Apoio
- Fácil Integração com Clusters Existentes
- Não Necessita da Re-Autenticação
- Integração de Status de Clusters e Logs
- Controle Fino-Granulado sobre Permissão do Usuário
- — fornece ferramentas para a adição e deletação de computadores, adição e deletação de usuários, e configuração de usuários privilegiados. Apenas um sistema administrador é permitido a acessar esta tab.
- — Fornece ferramentas para a criação e configuração de clusters. Cada instância das listas de clusters luci das quais foram montadas com o luci. Um administrador de sistemas pode administrar todos os clusters listados nesta tab. Outros usuários podem administrar apenas os clusters em que o usuário possui permissão para gerenciar. ( concedido por um administrador ).
- — Fornece ferramentas para uma administração remota de armazenamento. Com as ferramentas desta tab, você pode gerenciar o armazenamento em computadores, sendo estes pertencentes a um cluster ou não.

Figura 1.24. luci Tab

Figura 1.25. luci Tab

Figura 1.26. luci Tab
1.9.2. GUI Administração de Cluster
system-config-cluster cluster administration graphical user interface (GUI) available with Red Hat Cluster Suite. The GUI is for use with the cluster infrastructure and the high-availability service management components (refer to Seção 1.3, “Cluster Infrastructure” and Seção 1.4, “Gerenciamento de Serviço de Alta Disponibilidade”). The GUI consists of two major functions: the Cluster Configuration Tool and the Cluster Status Tool. The Cluster Configuration Tool provides the capability to create, edit, and propagate the cluster configuration file (/etc/cluster/cluster.conf). The Cluster Status Tool provides the capability to manage high-availability services. The following sections summarize those functions.
1.9.2.1. Cluster Configuration Tool

Figura 1.27. Cluster Configuration Tool
/etc/cluster/cluster.conf ), com um gráfico hierárquico exibido à esquerda do painel. Um ícone no formato de um triângulo à esquerda do nome de um componente, indica que o componente possui um ou mais componentes subordinados designados para isto. Clicando no ícone de triângulo, a porção de árvore abaixo de um componente se expande e colapsa. Os componentes exibidos no GUI são resumidos como a seguir:
- Nós de Cluster — Exibe os nós de cluster. Os nós são representados pelo nome assim como os elementos subordinados sob os Nós de Cluster. Usando os botões de configuração no botão direito do quadro ( abaixo das Propriedades ), você pode adicionar nós, deletar nós, editar propriedades de nós e configurar os métodos de fencing para cada nó.
- Dispositivos de Fence — Exibe dispositivos de fence. Os dispositivos de fence são representados como elementos subordinados sob os Dispositivos de Fence. Usando os botões de configuração no canto direito abaixo do quadro ( abaixo das Propriedades ), você pode adicionar os dispositivos de fence, deletar os dispositivos de fence e editar as propriedades de dispositivos de fence. Os dispositivos de fence devem ser definidos antes de você configurar o fencing ( com o botão ) para cada nó.
- Recursos Gerenciados — exibe as falhas dominantes, os recursos e os serviços.
- Domínios de Falha — Para configurar um ou mais subconjuntos de nós de cluster usados para executar um serviço de alta disponibilidade, num evento de uma falha de nó. Os domínios de falhas são representados como elementos subordinados sob os Domínios de Falhas. Usando botões de configuração no botão ao lado direito do quadro ( abaixo de Propriedades ), você pode criar as falhas dominantes ( quando forem selecionados os Domínios de Falha ) ou editar propriedades de domínio de falha ( quando um domínio de falha for selecionado ).
- Recursos — Para configurar os recursos compartilhados a serem usados por serviços de alta disponibilidade. Os recursos compartilhados consistem nos sistemas de arquivos, endereços IP, montagem e exportação NFS e scripts de criação do usuário dos quais estão disponíveis a um serviço de alta disponibilidade num cluster. Os recursos são representados como elementos subordinados sob os Recursos. Usando os botões de configuração no canto direito do quadro ( abaixo das Propriedades ), você pode criar recursos ( quando forem selecionados os Recursos ) ou editar propriedades de recursos ( quando um recurso é selecionado ).
Nota
A Cluster Configuration Tool também fornece a capacidade de configurar os recursos privados. O recurso privado é um recurso do qual é configurado para o uso de apenas um serviço. Você pode configurar um recurso privado com um componente Service em GUI. - Serviços — Para criar e configurar serviços de alta disponibilidade. Um serviço é configurado apenas determinando recursos ( compartilhados e privados ), determinando o domínio de falha, e definindo uma política de recuperação para o serviço. Os serviços são representados como elementos subordinados sob os Serviços. Usando botões de configuração do lado direito do quadro ( abaixo de Propriedades ), você pode criar serviços ( quando forem selecionados os Serviços ) ou editar propriedades de serviço ( quando um serviço for selecionado )
1.9.2.2. Cluster Status Tool

Figura 1.28. Cluster Status Tool
/etc/cluster/cluster.conf ). Você pode usar a Cluster Status Tool para ativar, desativar, reiniciar ou redirecionar o serviço de alta disponibilidade.
1.9.3. Ferramentas de Administração de Linha de Comando
system-config-cluster Cluster Administration GUI, command line tools are available for administering the cluster infrastructure and the high-availability service management components. The command line tools are used by the Cluster Administration GUI and init scripts supplied by Red Hat. Tabela 1.1, “Ferramentas de Linha de Comando” summarizes the command line tools.
Tabela 1.1. Ferramentas de Linha de Comando
| Ferramenta de Linha de Comando | Usado com | Propósito |
|---|---|---|
ccs_tool — Ferramenta de Sistema de Configuração de Cluster | Cluster Infrastructure | ccs_tool é um programa para realizar atualizações on-line do arquivo de configuração de cluster. Isto fornece a capacidade de criar e modificar os componentes de infraestrutura de cluster ( por exemplo, criação do cluster, adição e remoção do nó ). Para maiores informações sobre esta ferramenta, refira-se à página man ccs_tool(8). |
cman_tool — Ferramenta de Gerenciamento de Cluster | Cluster Infrastructure | cman_tool é o programa que administra o gerenciador de cluster CMAN. Isto fornece a capacidade de unir-se ao cluster, abandonar o cluster, cancelar o nó, ou mudar os votos de quórum esperados de um nó num cluster. Para maiores informações sobre esta ferramenta, refira-se à pagina man cman_tool(8). |
fence_tool( — Ferramenta de Fence | Cluster Infrastructure | fence_tool é um programa usado para unir ou abandonar o domínio de fence padrão. Especificamente, isto inicia o fence daemon (fenced) para juntar-se ao domínio e eliminar o fenced para abandonar o domínio. Para maiores informações sobre esta ferramenta, refira-se à página man fence_tool(8). |
clustat — Utilidade de Status de Cluster | Componentes de Gerenciamento de Serviço de Alta Disponibilidade | O comando clustat exibe o status do cluster. Isto apresenta a informação de associação, verificação do quórum e estado de todos os serviços de usuários configurados. Para maiores informações sobre esta ferramenta, refira-se a página man clustat(8). |
clusvcadm — Utilidade de Administração de Serviço do Usuário de Cluster | Componentes de Gerenciamento de Serviço de Alta Disponibilidade | O comando clusvcadm permite que você ative, desative, redirecione e reinicie os serviços de alta disponibilidade num cluster. Para maiores informações sobre esta ferramenta, refira-se à página man clusvcadm(8). |
1.10. GUI Administrador de Serviço Virtual Linux
/etc/sysconfig/ha/lvs.cf.
piranha-gui seja executado no roteador LVS ativo. Você pode acessar a Piranha Configuration Tool localmente ou remotamente com o navegador da Web. É possível acessar isto localmente com o URL: http://localhost:3636. Como também, é possível acessar isto remotamente, tanto com o nome do anfitrião como o endereço IP real seguido pelo :3636. Caso você esteja acessando a Piranha Configuration Tool remotamente, você precisará de uma conexão ssh para ativar o roteador LVS ativo como o usuário de root.
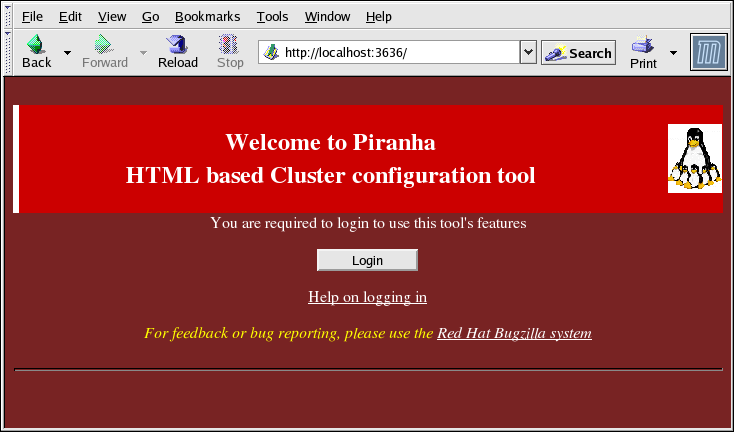
Figura 1.29. The Welcome Panel
1.10.1. CONTROL/MONITORING
pulse, a tabela de roteamento LVS e os processos nanny LVS gerados.
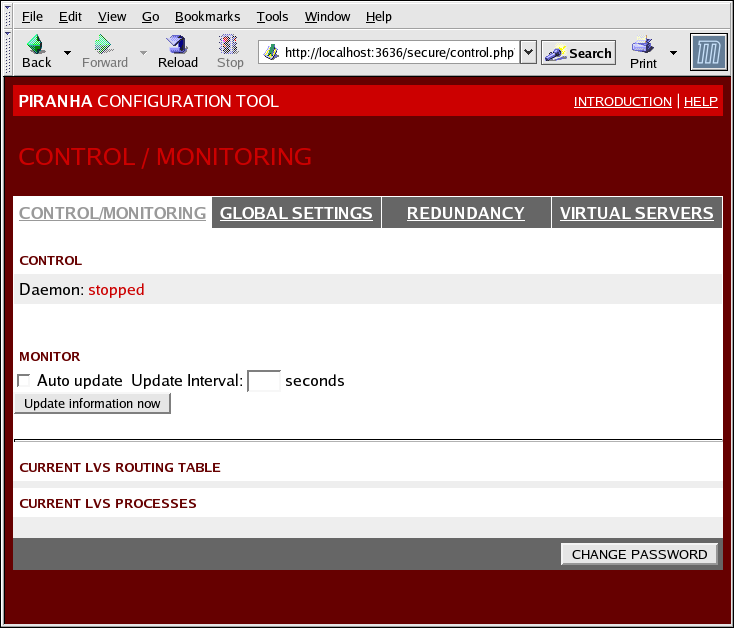
Figura 1.30. The CONTROL/MONITORING Panel
- Auto update
- Ativa o status exibido para ser automaticamente atualizado no intervalo configurável do usuário definido na caixa de texto de freqüência de atualização em segundos ( o valor do padrão é de 10 segundos ).Não é recomendável que você defina a atualização automática a um intervalo menor que 10 segundos. Do contrário, será difícil reconfigurar o intervalo Auto atualização, pois a página irá atualizar-se com uma freqüência muito grande. Caso você se depare com este problema, apenas clique num outro painel e então retorne ao CONTROLE/MONITORAMENTO.
- Fornece a atualização do manual de status de informação
- Clicando neste botão você encontrará uma tela de ajuda com a informação de como mudar a senha administrativa para a Piranha Configuration Tool.
1.10.2. GLOBAL SETTINGS
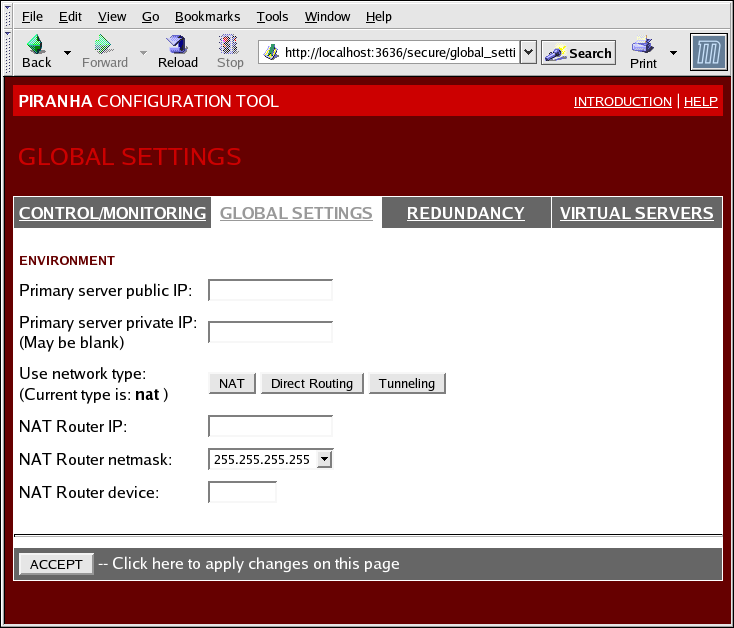
Figura 1.31. The GLOBAL SETTINGS Panel
- Primary server public IP
- O endereço IP real de roteamento em comum para o nó LVS primário
- Primary server private IP
- O endereço IP real para uma interface da rede alternativa no nó LVS primário. Este endereço é somente usado como uma alternativa do canal de heartbeat para o roteador de backup.
- Use network type
- Seleciona o roteamento NAT de seleção.
- NAT Router IP
- O IP flutuante privado no campo do texto. O IP flutuante deve ser usado como porta de comunicação para os servidores reais.
- NAT Router netmask
- If the NAT router's floating IP needs a particular netmask, select it from drop-down list.
- NAT Router device
- Fornece o nome do dispositivo da interface da rede para o endereço IP flutuante, como
eth1:1.
1.10.3. REDUNDANCY
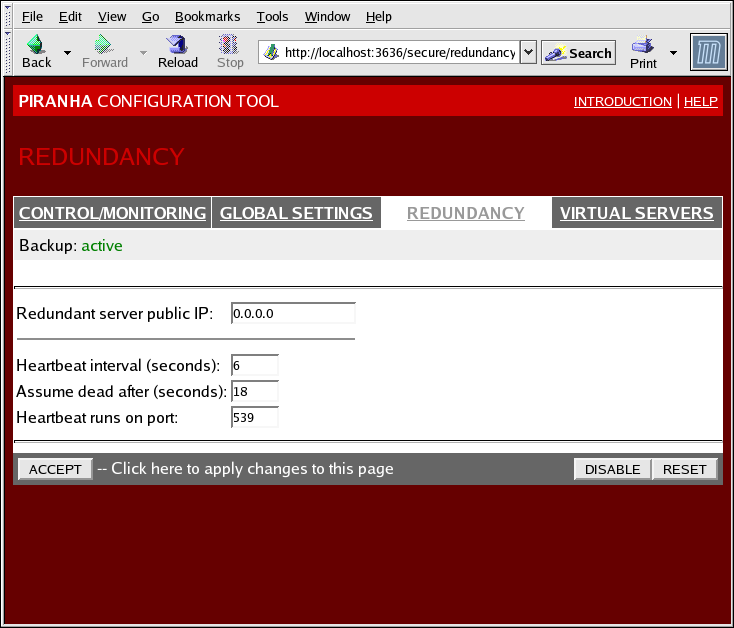
Figura 1.32. The REDUNDANCY Panel
- Redundant server public IP
- O endereço IP real público para o roteador de backup.
- Redundant server private IP
- The backup router's private real IP address.
- Heartbeat Interval (seconds)
- Marca o número de segundos entre heartbeats — o intervalo em que o nó de backup irá checar o status funcional do nó primário LVS.
- Assume dead after (seconds)
- Caso o nó LVS primário não responda após este número de segundos, então o nó de roteador LVS de backup iniciará a falha.
- Heartbeat runs on port
- Prepara o portal do qual o heartbeat se comunica com o nó LVS primário. O padrão é programado para 539 se o campo estiver em branco.
1.10.4. VIRTUAL SERVERS

Figura 1.33. The VIRTUAL SERVERS Panel
1.10.4.1. A Subseção do SERVIDOR VIRTUAL
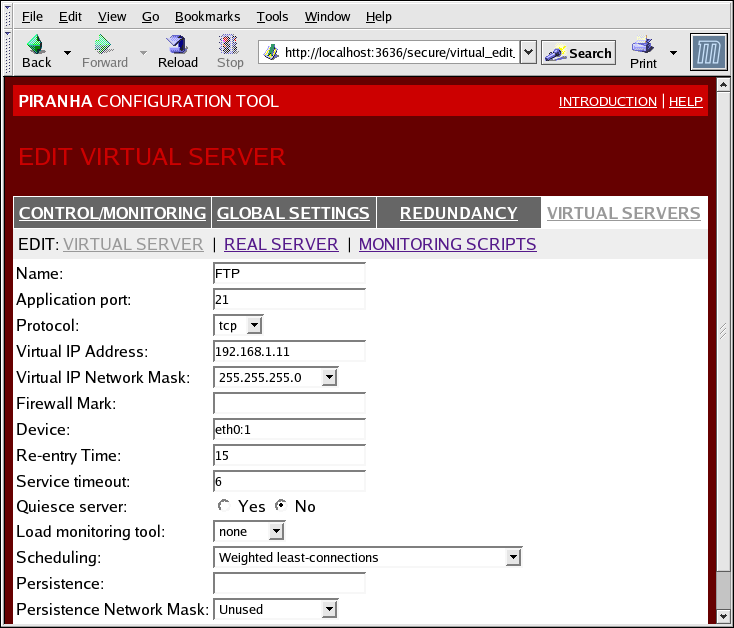
Figura 1.34. The VIRTUAL SERVERS Subsection
- Name
- O nome descritivo para identificar o servidor virtual. Este nome não é o nome do anfitrião para a máquina, sendo então descritivo e facilmente identificável. Você pode também referenciar o protocolo usado pelo servidor virtual, como por exemplo o HTTP.
- Application port
- O número do portal através do qual o aplicativo do serviço irá escutá-lo.
- Fornece uma escolha de UDP ou TCP, num menu suspenso.
- Virtual IP Address
- The virtual server's floating IP address.
- A netmask para este servidor virtual, num menu suspenso.
- Firewall Mark
- A entrada do valor integral da marca do firewall, quando construindo os protocolos de portais múltiplos ou criando os servidores virtuais de portal múltiplo de separação, no entanto os protocolos relatados.
- Device
- O nome do dispositivo de rede, do qual você queira o endereço IP flutuante definido no campo do Endereço IP Virtual, para a vinculação.Você pode alias o endereço IP flutuante a uma interface Ethernet conectada à rede pública.
- Re-entry Time
- Um valor integral que define o número de segundos antes do roteador LVS ativo tentar usar o servidor real, após a falha do servidor real.
- Service Timeout
- Um valor integral que define o número de segundos antes de um servidor real ser considerado inativo e não disponível.
- Quiesce server
- Quando o botão de rádio do servidor Quiesce for selecionado, um novo nó do servidor real aparecerá on-line a qualquer instante. A tabela mínima de conexão é regulada para zero, assim o roteador LVS ativo encaminha as solicitações como se todos os servidores reais fossem adicionados recentemente ao cluster. Esta opção evita um novo servidor começar a atolar-se com o alto número de conexões pela entrada do cluster.
- Load monitoring tool
- O roteador LVS pode monitorar a carga em vários servidores reais usando tanto o
rupouruptime. Se você selecionar orupdo menu suspenso, cada servidor real deverá executar o serviçorstatd. Se você selecionar oruptime, cada servidor real deverá executar o serviçorwhod. - Scheduling
- O algoritmo de agendamento preferido do menu suspenso. O padrão é de
Weighted least-connection. - Persistência
- Utilizado caso você precise de conexões persistentes para o servidor virtual durante as transações dos clientes. Especifica o número de segundos da inatividade permitida para o lapso, antes do tempo limite neste campo do texto.
- Para limitar a persistência de um subnet particular, selecione a máscara da rede apropriada para o menu suspenso.
1.10.4.2. Subseção do SERVIDOR REAL
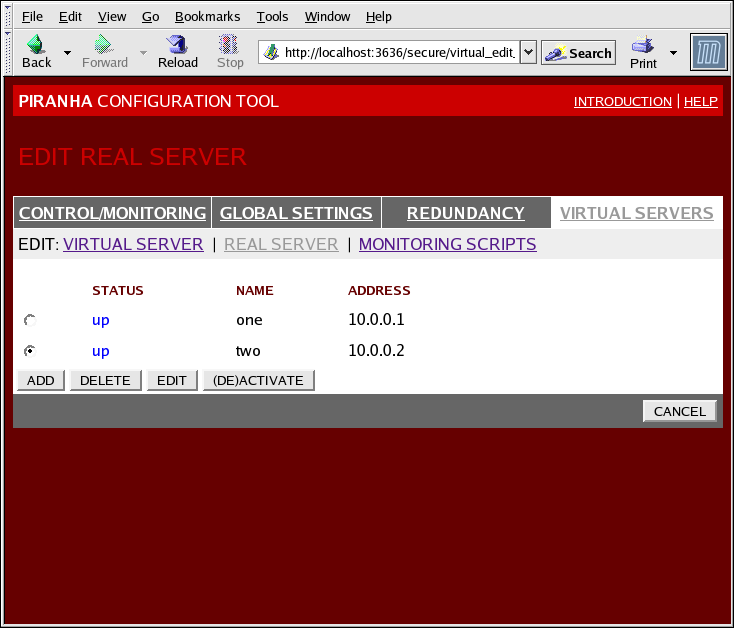
Figura 1.35. The REAL SERVER Subsection
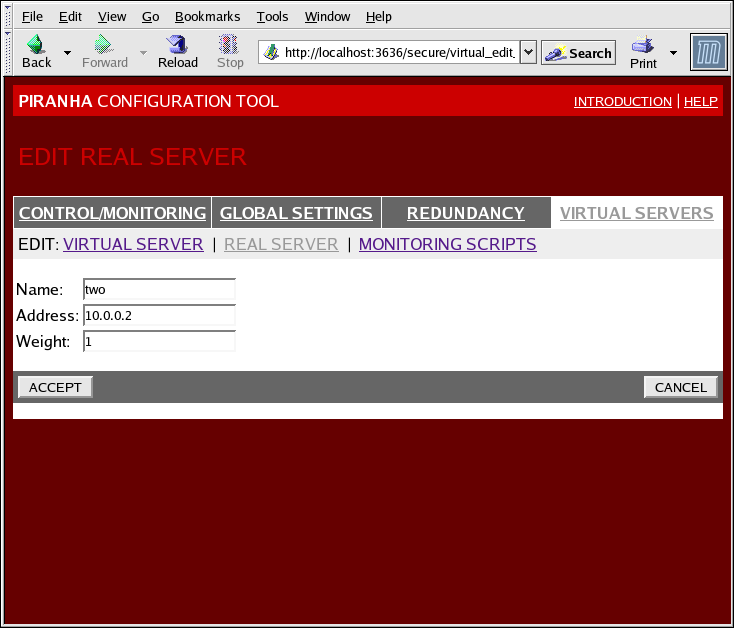
Figura 1.36. The REAL SERVER Configuration Panel
- Name
- O nome descritivo para o servidor real.
Nota
Este nome não é o nome anfitrião para a máquina, então faça com que ele seja descritivo e facilmente identificado. - Address
- The real server's IP address. Since the listening port is already specified for the associated virtual server, do not add a port number.
- Weight
- An integer value indicating this host's capacity relative to that of other hosts in the pool. The value can be arbitrary, but treat it as a ratio in relation to other real servers.
1.10.4.3. EDIT MONITORING SCRIPTS Subsection
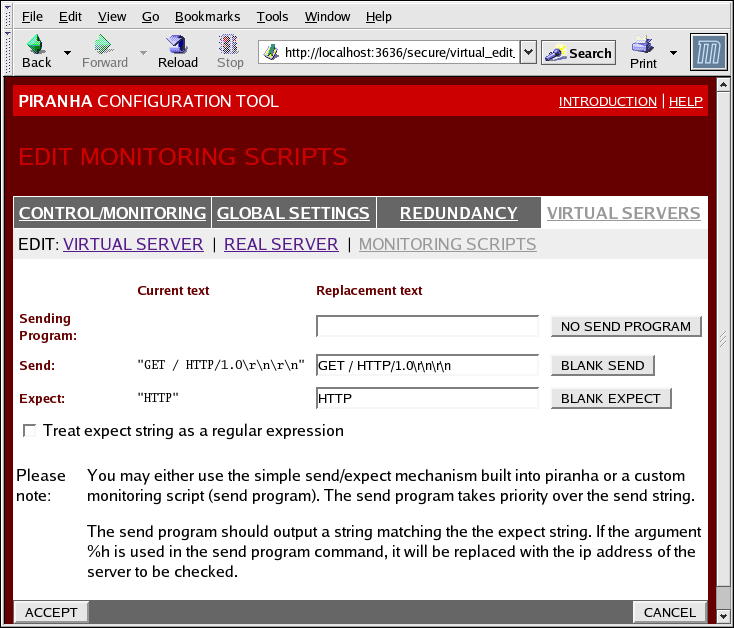
Figura 1.37. The EDIT MONITORING SCRIPTS Subsection
- Sending Program
- Para uma verificação de serviço avançado, você pode usar este campo para especificar o caminho ao script de serviço de checagem. Esta função é de grande auxílio aos serviços que requerem dinamicamente os dados de mudança, como por exemplo os HTTPS or SSL.Para uso desta função, você deve escrever um script que retorna a uma resposta de texto, preparar isto para ser executado e digitar o caminho dele no campo Programa de Envio.
Nota
Caso um programa externo seja inserido no campo Programa de Envio, o campo Enviar será ignorado. - Send
- Uma seqüência do daemon
nannya ser enviada a cada servidor real deste campo. Por padrão, o campo enviado é completado pelo HTTP. Você pode alterar este valor dependendo de suas necessidades. Caso, você deixe este campo em branco, o daemonnannytentará abrir o portal e assumirá o serviço executado, caso isto se suceda.Apenas uma seqüência enviada é permitida neste campo, e pode apenas conter imprimíveis caracteres ASCII como também os seguintes caracteres de fuga:- \n para uma nova linha
- \r para o retorno do carro.
- \t para tab.
- \ para escapar para o próximo capítulo.
- Expect
- A resposta de texto ao servidor deve retornar, se isto estiver funcionando propriamente. Caso você escreva seu próprio programa de envio, entre a resposta que você elaborou para envio no caso desta ser bem sucedida.
Capítulo 2. Sumário do Componente do Red Hat Cluster Suite
2.1. Componentes de Cluster
Tabela 2.1. Red Hat Cluster Suite Software Subsystem Components ( Componentes de Subsistema de Software )
| Função | Componentes | Descrição |
|---|---|---|
| Conga | luci | Sistema de Gerenciamento Remoto - Estação de Gerenciamento |
ricci | Sistema de Gerenciamento Remoto - Estação de Gerenciamento | |
| Cluster Configuration Tool | system-config-cluster | Comando usado para gerenciar uma configuração de cluster numa configuração gráfica. |
| Cluster Logical Volume Manager ( CLVM, Gerenciador de Volume Lógico de Cluster ) | clvmd | O daemon distribui as atualizações do LVM de metadados em volta de um cluster. Isto deve ser executado em todos os nós de um cluster e pode gerar erro, caso um nó de um cluster não possua a execução daemon. |
lvm | Ferramentas LVM2. Fornece as ferramentas de linha de comando do LVM2. | |
system-config-lvm | Fornece a interface gráfica do usuário para o LVM2. | |
lvm.conf | O arquivo da configuração do LVM. O caminho direto é o seguinte: /etc/lvm/lvm.conf. | |
| Cluster Configuration System (CCS, Sistema de Configuração de Cluster ). | ccs_tool | ccs_tool faz parte do Cluster Configuration System (CCS). Isto é utilizado para fazer atualizações on-line de arquivos de configuração CCS. Além disso, isto pode ser usado para atualizar os arquivos de configuração de cluster de arquivos CCS criados com GFS 6.0 ( e anteriormente ) à configuração de formato XML, formato usado com esta liberação de Red Hat Cluster Suite. |
ccs_test | Diagnóstico e comando testados dos quais são utilizados para resgatar informação dos arquivos de configuração através do ccsd. | |
ccsd | O CCS daemon que atua em todos os nós de cluster e fornece dados do arquivo de configuração a um software de cluster. | |
cluster.conf | Este é um arquivo de configuração de cluster. O caminho direto é /etc/cluster/cluster.conf. | |
| Cluster Manager (CMAN) - Gerenciador de Cluster (CMAN) | cman.ko | O módulo Kernel para o CMAN. |
cman_tool | Este é o fim da frente administrativa para o CMAN. Inicia e interrompe o CMAN, podendo mudar alguns parâmetros internos como os votos. | |
dlm_controld | Daemon iniciado pelo cman script de iniciação para gerenciar o dlm em kernel, não é utilizado pelo usuário. | |
gfs_controld | Daemon iniciado pelo cman script de iniciação para gerenciar o gfs em kernel, não é usado pelo usuário. | |
group_tool | Usado para gerar uma lista de grupos relacionada ao ferncing, DLM, GFS, e adquirindo informação do depurador. Inclui os cman_tool services fornecido em RHEL 4. | |
groupd | Daemon iniciado por cman script de iniciação para a interface entre openais/cman e dlm_controld/gfs_controld/fenced; não é usado pelo usuário. | |
libcman.so.<version number> | Biblioteca para programas que precisam interagir com o cman.ko. | |
| Resource Group Manager (rgmanager) - Gerenciador de Grupo de Recurso - (rgmanager) | clusvcadm | Comando usado para manualmente capacitar, desativar, relocar e restaurar os serviços do usuário num cluster. |
clustat | Comando usado para exibir o status de um cluster, incluindo o nó associado e serviços de execução. | |
clurgmgrd | Daemon usado para manusear as solicitações de serviço do usuário incluindo o serviço iniciado, serviço desativado, serviço realocado e serviço restaurado. | |
clurmtabd | Daemon usado para manusear as tabelas de elevação NFS Clustered. | |
| Fence | fence_apc | Agente fence para a tomada elétrica APC. |
fence_bladecenter | Agente fence para o IBM Bladecenters com interface Telnet. | |
fence_bullpap | Agente fence para a Interface Bull NovaScale Plataform Administration Processor ( PAP ). | |
fence_drac | Agente fencing para o Cartão de Acesso Remoto Dell. | |
fence_ipmilan | Agente fence para máquinas controladas pela IPMI - Intelligent Platform Management Interface ( Interface de Gerenciamento da Plataforma Inteligente ) sobre LAN. | |
fence_wti | Agente fence para a tomada eletrônica WTI. | |
fence_brocade | Agente fence para a tomada de Canal de Fibra Brocada. | |
fence_mcdata | Agente fence para a tomada de Canal de Fibra McData. | |
fence_vixel | Agente fence para a tomada de Canal de Fibra Vixel. | |
fence_sanbox2 | Agente fence para a tomada de Canal de Fibra SANBox2. | |
fence_ilo | Agente fence para as interfaces HP ILO ( anteriormente fence_rib ). | |
fence_rsa | Agente fence I/O para o IBM RSA II. | |
fence_gnbd | Agente fence usado com o armazenamento GNBD. | |
fence_scsi | Agente fencing I/O para as reservas de persistência SCSI. | |
fence_egenera | Agente fence usado para o sistema Egenera BladeFrame. | |
fence_manual | Agente fence de interação manual. NOTA Este componente não é suportado para ambientes de produção. | |
fence_ack_manual | Interface do usuário para o agente fence_manual. | |
fence_node | Um programa que apresenta o fence I/O num único nó. | |
fence_xvm | Agente fence I/O para as máquinas virtuais Xen | |
fence_xvmd | Agente fence I/O hospedeiro para as máquinas virtuais Xen. | |
fence_tool | Um programa para unir-se e sair do domínio fence. | |
fenced | O fence I/O daemon. | |
| DLM | libdlm.so.<version number> | Biblioteca para o suporte de Distributed Lock Manager ( DLM, Gerenciador de Bloqueio Distribuído ). |
| GFS | gfs.ko | Módulo Kernel que implementa o sistema de arquivo GFS, e é carregado nos nós de cluster GFS. |
gfs_fsck | Comando que repara um sistema de arquivo GFS desmontado | |
gfs_grow | Comanda o que cresce no sistema de arquivo GFS montado. | |
gfs_jadd | Comando que adiciona diários a um sistema de arquivo GFS montado. | |
gfs_mkfs | Comando que cria um sistema de arquivo GFS num dispositivo armazenado. | |
gfs_quota | Comando que gerencia as cotas num sistema de arquivo GFS montado. | |
gfs_tool | Comando que configura ou forma um sistema de arquivo GFS. Este comando pode também concentrar uma variedade de informações sobre o sistema de arquivo. | |
mount.gfs | Auxílio de montagem chamado por mount(8); não é usado pelo usuário. | |
| GNBD | gnbd.ko | Módulo Kernel que implementa o driver de dispositivo GNBD nos clientes. |
gnbd_export | Comando para criação, exportação e gerenciamento GNBDs num servidor GNBD. | |
gnbd_import | Comando para importar e gerenciar os GNBDs num cliente GNBD. | |
gnbd_serv | Um servidor daemon que permite um nó exportar o armazenamento local na rede. | |
| LVS | pulse | This is the controlling process which starts all other daemons related to LVS routers. At boot time, the daemon is started by the /etc/rc.d/init.d/pulse script. It then reads the configuration file /etc/sysconfig/ha/lvs.cf. On the active LVS router, pulse starts the LVS daemon. On the backup router, pulse determines the health of the active router by executing a simple heartbeat at a user-configurable interval. If the active LVS router fails to respond after a user-configurable interval, it initiates failover. During failover, pulse on the backup LVS router instructs the pulse daemon on the active LVS router to shut down all LVS services, starts the send_arp program to reassign the floating IP addresses to the backup LVS router's MAC address, and starts the lvs daemon. |
lvsd | O daemon lvs executa o roteador LVS ativo, uma vez chamado pelo pulse. Ele lê o arquivo de configuração /etc/sysconfig/ha/lvs.cf, chamando a utilidade ipvsadm para construir e manter a tabela de roteamento IPVS, e atribuir um processo nanny para cada serviço LVS configurado. Se o nanny reportar que o servidor real está fora de operação, o lvs instrui a utilidade ipvsadm para remover o servidor real de uma tabela de roteamento IPVS. | |
ipvsadm | Este serviço atualiza a tabela de roteamento IPVS no kernel. O daemon lvs configura e administra o LVS pela chamada ipvsadm para adicionar, mudar, ou deletar as entradas numa tabela de roteamento IPVS. | |
nanny | O monitoramento daemon nanny executa o roteador LVS ativo. Através deste deamon, o roteador LVS ativo determina o health de cada servidor e, opcionalmente, monitora esta carga de trabalho. Um processo separado atua em cada servidor definido para cada servidor real. | |
lvs.cf | Este é o arquivo de configuração LVS. O caminho completo para este arquivo é o seguinte: /0etc/sysconfig/ha/lvs.cf. Todos os daemons adquirem a informação de configuração por este arquivo diretamente ou indiretamente. | |
| Piranha Configuration Tool | Esta é a ferramenta baseada na web para monitoramento, configuração e administração do LVS. Esta é a ferramenta padrão para manter o arquivo /etc/sysconfig/ha/lvs.cf de configuração LVS. | |
send_arp | Este programa envia difusões seletivas quando o endereço IP flutuante muda de um nó para outro durante a falha. | |
| Disco Quórum | qdisk | Um disco baseado em quórum deamon para o CMAN / Linux-Cluster. |
mkqdisk | Utilidade de Disco Quórum de Cluster | |
qdiskd | Disco Quórum de Cluster Daemon |
2.2. Páginas Man
- Infraestrutura de Cluster
- ccs_tool (8) - A ferramenta usada para realizar atualizações on-line de arquivos de configuração CCS;
- ccs_test (8) - A ferramenta de diagnóstico para a execução de Sistema de Configuração de Cluster;
- ccsd (8) - O daemon usado para acessar os arquivos de configuração de cluster;
- ccs (7) - Sistema de Configuração Cluster;
- cman_tool (8) - Ferramenta de Gerenciamento de Cluster;
- cluster.conf [cluster] (5) - O arquivo de configuração para produtos de cluster;
- qdisk (5) - um daemon baseado no disco quórum para o CMAN / Linux-Cluster;
- mkqdisk (8) - Utilidade de Disco Quórum de Cluster;
- qdiskd (8) - Disco Quórum de Cluster Daemon;
- fence_ack_manual (8) - programa executado por um operador como parte do manual de fence I/O;
- fence_apc (8) - Agente fence para o APC MasterSwitch;
- fence_bladecenter (8) - Agente fence I/O para o IBM Bladecenter;
- fence_brocade (8) - Agente fence I/O para as tomadas Brocade FC;
- fence_bullpap (8) - Agente fence I/O para a arquitetura controlado por um console gerenciado PAP;
- fence_drac (8) - Agente fence para o Cartão de Acesso Remoto Dell;
- fence_egenera (8) - Agente fence I/O para a Egenera BladeFrame;
- fence_gnbd (8) - Agente fence I/O para o GNBD baseado em clusters GFS;
- fence_ilo (8) - Agente fence I/O para o HP Integrated Lights Out card;
- fence_ipmilan (8) - Agente fence I/O para as máquinas controladas por IPMI sobre LAN;
- fence_manual (8) - programa executado pelo fence como parte do manual de fence I/O;
- fence_mcdata (8) - Agente fence I/O para as tomadas McData FC;
- fence_node (8) - Um programa que atua no fence I/O para um único nó;
- fence_rib (8) - Agente fence I/O para o Compaq Remote Insight Lights Out card;
- fence_rsa (8) - Agente fence I/O para o IBM RSA II;
- fence_sanbox2 (8) - Agente fence I/O para as tomadas QLogic SANBox2 FC;
- fence_scsi (8) - Agente fence I/O para as reservas de persistência SCSI;
- fence_tool (8) - Um programa para unir e sair do domínio fence;
- fence_vixel (8) - Agente fence I/O para as tomadas Vixel FC;
- fence_wti (8) - Agente fence I/O para o WTI Network Power Switch;
- fence_xvm (8) - Agente fence I/O para as máquinas virtuais Xen;
- fence_xvmd (8) - Agente fence I/O anfitrião para as máquinas virtuais Xen;
- fenced (8) - o fence I/O daemon.
- Gerenciador de Serviço de Alta Disponibilidade
- clusvcadm (8) - Utilidade de Administração do Serviço de Usuário de Cluster;
- clustat (8) - Utilidade de Status de Cluster;
- Clurgmgrd [clurgmgrd] (8) - Grupo de Recurso Gerenciador ( Serviço de Cluster ) Daemon;
- clurmtabd (8) - Tabela de Montagem Remota NFS de Cluster Daemon.
- GFS
- gfs_fsck (8) - Sistema de checagem do arquivo GFS off-line;
- gfs_grow (8) - Expande o sistema de arquivo GFS;
- gfs_jadd (8)- Adiciona relatórios ao sistema de arquivo GFS;
- gfs_mount (8) - opções de montagem GFS;
- gfs_quota (8)- Manipula as cotas de disco GFS;
- gfs_tool (8) - interface para as chamadas gfs ioctl;
- Gerenciador de Volume Lógico de Cluster
- clvmd (8) - o LVM de cluster daemon;
- lvm (8) - ferramentas LVM2;
- lvm.conf [lvm] (5) - Arquivo de configuração para o LVM2;
- lvmchange (8) - muda as características do gerenciador de volume lógico;
- pvcreate (8) - inicia um disco ou partição para ser usado pelo LVM;
- lvs (8) - relata informação sobre os volumes lógicos.
- Dispositivo de Bloqueio da Rede Global
- gnbd_export (8) - a interface para exportar os GNBDs;
- gnbd_import (8) - manipula os dispositivos de bloqueio de um cliente;
- gnbd_serv (8) - servidor gnbd daemon.
- LVS
- pulse (8) - heartbeating daemon para monitoração do health de nós de cluster;
- lvs.cf [lvs] (5) - arquivo de configuração para o lvs;
- lvscan (8) - rastreia ( todos os discos ) de volumes lógicos;
- lvsd (8) - daemon para o controle dos serviços de clustering Red Hat;
- ipvsadm (8) - administração do Servidor Virtual Linux;
- ipvsadm-restore (8) - restaura a tabela IPVS do stdin;
- ipvsadm-save (8) - salva a tabela IPVS para stdout;
- nanny (8) - ferramenta para monitar o status do serviço num cluster;
- send_arp (8) - ferramenta para notificar a rede sobre um novo endereço IP / endereço de mapeamento MAC;
2.3. Hardware ( disco rígido ) compatível
Apêndice A. Histórico de Revisão
| Histórico de Revisões | |||
|---|---|---|---|
| Revisão 3-7.400 | 2013-10-31 | ||
| |||
| Revisão 3-7 | 2012-07-18 | ||
| |||
| Revisão 1.0-0 | Tue Jan 20 2008 | ||
| |||
Índice Remissivo
C
- cluster
- displaying status, Cluster Status Tool
- cluster administration
- displaying cluster and service status, Cluster Status Tool
- cluster component compatible hardware, Hardware ( disco rígido ) compatível
- cluster component man pages, Páginas Man
- cluster components table, Componentes de Cluster
- Cluster Configuration Tool
- accessing, Cluster Configuration Tool
- cluster service
- displaying status, Cluster Status Tool
- command line tools table, Ferramentas de Administração de Linha de Comando
- compatible hardware
- cluster components, Hardware ( disco rígido ) compatível
- Conga
- overview, Conga
- Conga overview, Conga
F
- feedback, Feedback
I
- introduction, Introdução
- other Red Hat Enterprise Linux documents, Introdução
L
- LVS
- direct routing
- requirements, hardware, Roteamento direto
- requirements, network, Roteamento direto
- requirements, software, Roteamento direto
- routing methods
- NAT, Métodos Encaminhados
- three tiered
- high-availability cluster, Three-Tier LVS Topology
M
- man pages
- cluster components, Páginas Man
N
- NAT
- routing methods, LVS, Métodos Encaminhados
- network address translation (ver NAT)
O
- overview
- economy, Red Hat GFS
- performance, Red Hat GFS
- scalability, Red Hat GFS
P
- Piranha Configuration Tool
- CONTROL/MONITORING, CONTROL/MONITORING
- EDIT MONITORING SCRIPTS Subsection, EDIT MONITORING SCRIPTS Subsection
- GLOBAL SETTINGS, GLOBAL SETTINGS
- login panel, GUI Administrador de Serviço Virtual Linux
- necessary software, GUI Administrador de Serviço Virtual Linux
- REAL SERVER subsection, Subseção do SERVIDOR REAL
- REDUNDANCY, REDUNDANCY
- VIRTUAL SERVER subsection, VIRTUAL SERVERS
- Firewall Mark , A Subseção do SERVIDOR VIRTUAL
- Persistence , A Subseção do SERVIDOR VIRTUAL
- Scheduling , A Subseção do SERVIDOR VIRTUAL
- Virtual IP Address , A Subseção do SERVIDOR VIRTUAL
- VIRTUAL SERVERS, VIRTUAL SERVERS
R
- Red Hat Cluster Suite
- components, Componentes de Cluster
T
- table
- cluster components, Componentes de Cluster
- command line tools, Ferramentas de Administração de Linha de Comando