
운영 측정
물리적 및 가상 리소스 추적 및 지표 수집
초록
보다 포괄적 수용을 위한 오픈 소스 용어 교체
Red Hat은 코드, 문서, 웹 속성에서 문제가 있는 용어를 교체하기 위해 최선을 다하고 있습니다. 먼저 마스터(master), 슬레이브(slave), 블랙리스트(blacklist), 화이트리스트(whitelist) 등 네 가지 용어를 교체하고 있습니다. 이러한 변경 작업은 작업 범위가 크므로 향후 여러 릴리스에 걸쳐 점차 구현할 예정입니다. 자세한 내용은 CTO Chris Wright의 메시지를 참조하십시오.
Red Hat 문서에 관한 피드백 제공
문서 개선을 위한 의견을 보내 주십시오. Red Hat이 어떻게 이를 개선하는지 알려주십시오.
DDF(직접 문서 피드백) 기능 사용
특정 문장, 단락 또는 코드 블록에 대한 직접 주석은 피드백 추가 DDF 기능을 사용하십시오.
- 다중 페이지 HTML 형식으로 설명서를 봅니다.
- 문서 오른쪽 상단에 Feedback (피드백) 버튼이 표시되는지 확인합니다.
- 주석 처리하려는 텍스트 부분을 강조 표시합니다.
- 피드백 추가를 클릭합니다.
- 주석을 사용하여 Add Feedback (피드백 추가) 필드를 작성합니다.
- 선택 사항: 설명서 팀이 문제에 대한 자세한 내용을 문의할 수 있도록 이메일 주소를 추가하십시오.
- Submit(제출)을 클릭합니다.
1장. 운영 측정 소개
RHOSP(Red Hat OpenStack Platform) 환경에서 원격 분석 서비스의 구성 요소를 사용하여 물리적 및 가상 리소스를 추적하고, Gnocchi 백엔드에 집계를 저장하는 데이터 수집 데몬을 사용하여 배포의 CPU 사용 및 리소스 가용성과 같은 지표를 수집할 수 있습니다.
가용성 및 성능 모니터링 툴을 사용하여 RHOSP 환경을 측정 및 유지 관리할 수 있습니다. 이러한 도구는 다음 기능을 수행합니다.
- 가용성 모니터링
- RHOSP 환경의 모든 구성 요소를 모니터링하고 현재 중단이 발생하거나 작동하지 않는 구성 요소가 있는지 확인합니다. 문제가 식별될 때 경고를 표시하도록 시스템을 구성할 수도 있습니다.
- 성능 모니터링
- 데이터 수집 데몬을 사용하여 시스템 정보를 정기적으로 수집하고 값을 저장 및 모니터링하는 메커니즘을 제공합니다. 이 데몬은 수집하는 데이터(예: 운영 체제 및 로그 파일)를 저장합니다. 또한 네트워크를 통해 데이터를 사용할 수 있게 합니다. 데이터에서 수집한 통계를 사용하여 시스템을 모니터링하고, 성능 장애물을 찾고, 향후 시스템 로드를 예측할 수 있습니다.
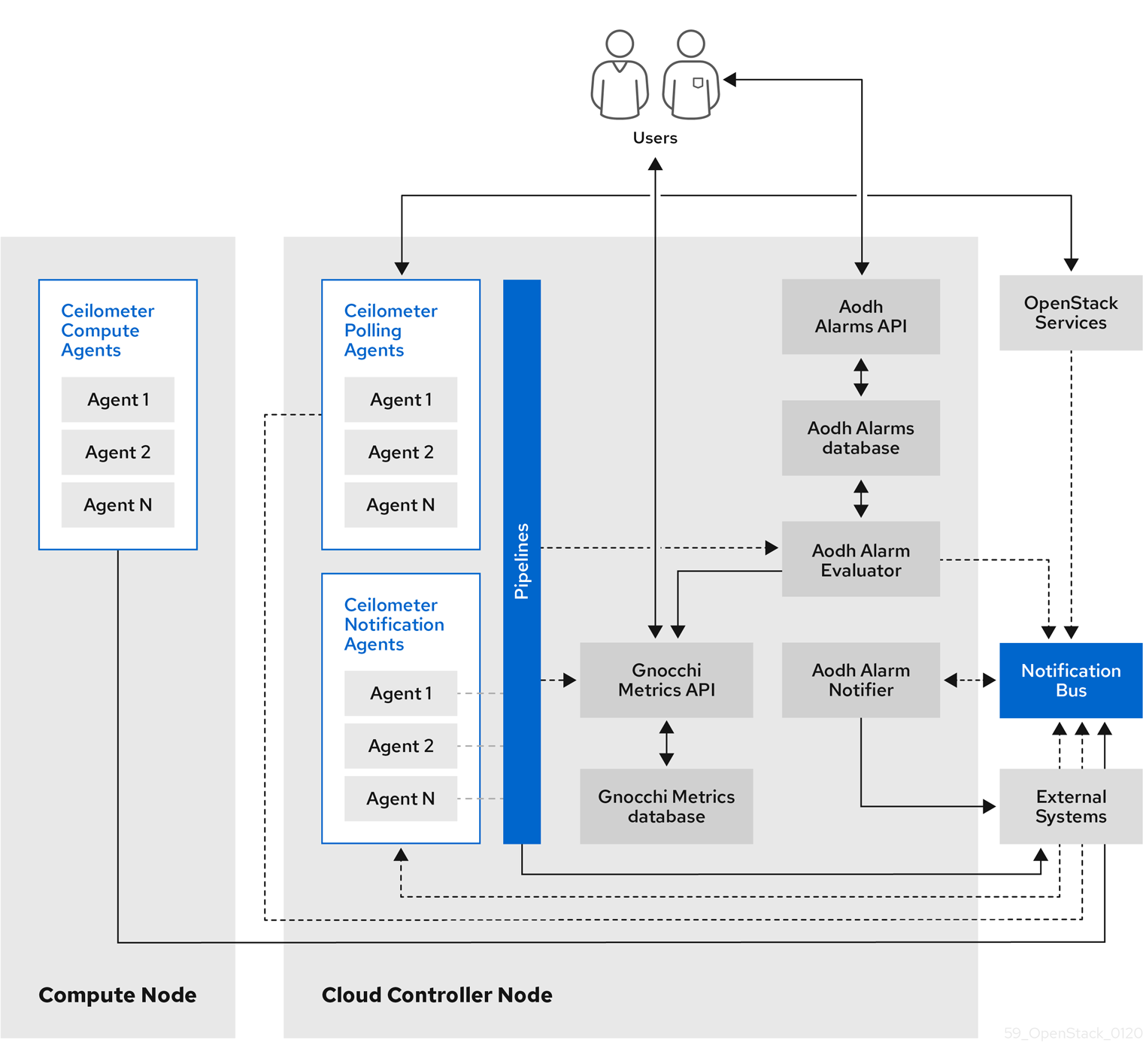
1.1. 원격 분석 아키텍처
RHOSP(Red Hat OpenStack Platform) Telemetry는 OpenStack 기반 클라우드를 위한 사용자 수준의 사용 데이터를 제공합니다. 고객 청구, 시스템 모니터링 또는 알림에 데이터를 사용할 수 있습니다. 계산 사용 이벤트와 같은 기존 RHOSP 구성 요소에서 전송하거나 libvirt와 같은 RHOSP 인프라 리소스를 폴링하여 데이터를 수집하도록 원격 분석 구성 요소를 구성할 수 있습니다. Telemetry는 수집된 데이터를 데이터 저장소 및 메시지 대기열을 포함하여 다양한 타겟에 게시합니다.
Telemetry는 다음 구성 요소로 구성됩니다.
- 데이터 수집: 원격 분석에서는 Ceilometer를 사용하여 지표 및 이벤트 데이터를 수집합니다. 자세한 내용은 1.2.1절. “Ceilometer”의 내용을 참조하십시오.
- 스토리지: 원격 분석에서는 지표 데이터를 Panko에 Gnocchi 및 이벤트 데이터를 저장합니다. 자세한 내용은 1.3절. “Gnocchi를 사용한 스토리지”의 내용을 참조하십시오.
- 알람 서비스: 원격 분석에서는 알람 서비스(Aodh)를 사용하여 Ceilometer에서 수집한 지표 또는 이벤트 데이터에 대해 정의된 규칙에 따라 작업을 트리거합니다.
데이터를 수집한 후에는 타사 툴을 사용하여 지표 데이터를 표시하고 분석할 수 있으며 알람 서비스를 사용하여 이벤트 알람을 구성할 수 있습니다.
그림 1.1. 원격 분석 아키텍처
1.1.1. 모니터링 구성 요소의 상태 지원
이 표를 사용하여 Red Hat OpenStack Platform에서 구성 요소 모니터링의 지원 상태를 확인하십시오.
표 1.1. 지원 상태
| 구성 요소 | 이후 완전하게 지원됨 | 더 이상 사용되지 않음 | 이후 삭제 | 참고 |
|---|---|---|---|---|
| Aodh | RHOSP 9 | RHOSP 15 | 자동 스케일링 사용 사례에 대해 지원됩니다. | |
| Ceilometer | RHOSP 4 | 자동 스케일링 및 STF(Service Telemetry Framework) 사용 사례에서 RHOSP의 메트릭 및 이벤트 수집에 지원됩니다. | ||
| collectd | RHOSP 11 | RHOSP 17.1 | STF에 대한 인프라 메트릭 컬렉션에 대해 지원됩니다. | |
| Gnocchi | RHOSP 9 | RHOSP 15 | 자동 스케일링 사용 사례에 대한 메트릭 스토리지에 지원됩니다. | |
| Panko | RHOSP 11 | RHOSP 12에서는 RHOSP 14 이후 기본적으로 설치되지 않음 | RHOSP 17.0 | |
| QDR | RHOSP 13 | RHOSP 17.1 | RHOSP에서 STF로 메트릭 및 이벤트 데이터 전송을 지원합니다. |
1.2. Red Hat OpenStack Platform의 데이터 수집
RHOSP(Red Hat OpenStack Platform)는 다음 두 가지 유형의 데이터 수집을 지원합니다.
- OpenStack 구성 요소 수준 모니터링용 Ceilometer. 자세한 내용은 1.2.1절. “Ceilometer”의 내용을 참조하십시오.
- 인프라 모니터링을 위한 collectd. 자세한 내용은 1.2.2절. “collectd”의 내용을 참조하십시오.
1.2.1. Ceilometer
Ceilometer는 현재의 모든 OpenStack 핵심 구성 요소에서 데이터를 표준화하고 변환하는 기능을 제공하는 OpenStack 원격 분석 서비스의 기본 데이터 수집 구성 요소입니다. Ceilometer는 OpenStack 서비스와 관련된 미터링 및 이벤트 데이터를 수집합니다. 수집된 데이터는 배포 구성에 따라 사용자가 액세스할 수 있습니다.
Ceilometer 서비스는 세 개의 에이전트를 사용하여 RHOSP(Red Hat OpenStack Platform) 구성 요소에서 데이터를 수집합니다.
-
컴퓨팅 에이전트(ceilometer-agent-compute): 각 Compute 노드에서 실행되며 리소스 사용률 통계에 대해 폴링합니다. 이 에이전트는
--과 동일합니다.polling namespace-compute 매개 변수를 사용하여 실행 중인 폴링 에이전트 ceilometer-polling -
중앙 에이전트(ceilometer-agent-central): 중앙 관리 서버에서 를 실행하여 인스턴스 또는 컴퓨팅 노드에 연결되지 않은 리소스의 리소스 사용률 통계를 폴링합니다. 여러 에이전트를 시작하여 서비스를 수평으로 확장할 수 있습니다.
--과 동일합니다.polling namespace-central 매개변수를 사용하여 작동하는 폴링 에이전트 ceilometer-polling - 알림 에이전트 (ceilometer-agent-notification): 중앙 관리 서버에서 실행되며 메시지 큐의 메시지를 사용하여 이벤트 및 미터링 데이터를 빌드합니다. 정의된 대상에 데이터 게시. Gnocchi가 기본 대상입니다. 이러한 서비스는 RHOSP 알림 버스를 사용하여 통신합니다.
Ceilometer 에이전트는 게시자를 사용하여 해당 엔드포인트(예: Gnocchi)로 데이터를 보냅니다. 이 정보는 pipeline.yaml 파일에서 구성할 수 있습니다.
추가 리소스
- Publisher에 대한 자세한 내용은 1.2.1.1절. “게시자” 의 내용을 참조하십시오.
1.2.1.1. 게시자
원격 분석 서비스는 수집된 데이터를 외부 시스템으로 전송하는 여러 전송 방법을 제공합니다. 이 데이터의 소비자는 데이터 손실을 허용할 수 있는 시스템 모니터링 및 안정적인 데이터 이동이 필요한 청구 시스템 등 다릅니다. 원격 분석에서는 두 시스템 유형의 요구 사항을 충족하는 방법을 제공합니다. 서비스의 Publisher 구성 요소를 사용하여 메시지 버스를 통해 영구 스토리지에 데이터를 저장하거나 하나 이상의 외부 소비자에게 보낼 수 있습니다. 하나의 체인에는 여러 게시자가 포함될 수 있습니다.
지원되는 게시자 유형은 다음과 같습니다.
- Gnocchi (기본값): Gnocchi 게시자가 활성화되면 시계열에 최적화된 스토리지를 위해 측정 및 리소스 정보가 Gnocchi로 푸시됩니다. Ceilometer로 ID 서비스에 Gnocchi를 등록하여 ID 서비스를 통해 정확한 경로를 검색해야 합니다.
- Panko: Ceilometer의 이벤트 데이터를 Red Hat OpenStack Platform의 시스템 이벤트를 쿼리하는 HTTP REST 인터페이스를 제공하는 Panko에 저장할 수 있습니다. Panko는 더 이상 사용되지 않습니다.
게시자 매개변수 구성
원격 분석 서비스 내의 각 데이터 지점에 대해 다중 게시자를 구성하여 동일한 기술 미터 또는 이벤트를 여러 대상에 여러 번 게시할 수 있으며 각각 다른 전송 방법을 사용할 수 있습니다.
절차
YAML 파일을 만들어 가능한 게시자 매개 변수 및 기본값(예:
ceilometer-publisher.yaml)을 설명합니다. parameter_defaults에 다음 매개 변수를삽입합니다.parameter_defaults: ManagePipeline: true ManageEventPipeline: true EventPipelinePublishers: - gnocchi://?archive_policy=high PipelinePublishers: - gnocchi://?archive_policy=high
Overcloud를 배포합니다.
openstack overcloud deploy명령에 수정된 YAML 파일을 포함합니다. 다음 예제에서는<environment_files>를 배포에 포함하려는 다른 YAML 파일로 바꿉니다.$ openstack overcloud deploy --templates \ -e /home/custom/ceilometer-publisher.yaml -e <environment_files>
추가 리소스
- 매개변수에 대한 자세한 내용은 Advanced Overcloud Customization 가이드의 Overcloud Parameters 가이드 및 Parameters 의 Telemetry 매개변수를 참조하십시오.
1.2.2. collectd
성능 모니터링은 시스템 정보를 정기적으로 수집하고 데이터 수집 에이전트를 사용하여 다양한 방식으로 값을 저장하고 모니터링하는 메커니즘을 제공합니다. Red Hat은 데이터 수집 에이전트로 collectd 데몬을 지원합니다. 이 데몬은 시계열 데이터베이스에 데이터를 저장합니다. Red Hat 지원 데이터베이스 중 하나를 Gnocchi라고 합니다. 이 저장된 데이터를 사용하여 시스템을 모니터링하고, 성능 병목을 찾고, 향후 시스템 로드를 예측할 수 있습니다.
추가 리소스
- Gnocchi에 대한 자세한 내용은 1.3절. “Gnocchi를 사용한 스토리지” 을 참조하십시오.
1.3. Gnocchi를 사용한 스토리지
Gnocchi는 오픈 소스 시계열 데이터베이스입니다. 매우 큰 규모로 메트릭을 저장하고, 운영자와 사용자에게 지표와 리소스에 대한 액세스를 제공합니다. Gnocchi는 보관 정책을 사용하여 계산할 집계 수 및 유지할 집계 수를 정의합니다. 인덱서 드라이버는 모든 리소스, 보관 정책 및 지표의 색인을 저장합니다.
1.3.1. 보관 정책: 짧은 및 장기 데이터를 시계열 데이터베이스에 저장
보관 정책은 계산할 집계와 유지할 집계 수를 정의합니다. Gnocchi는 최소, 최대, 평균, N번째 백분율 및 표준 편차와 같은 다양한 집계 방법을 지원합니다. 이러한 집계는 세분성라는 기간 동안 계산되며 특정 시간 동안 유지됩니다.
보관 정책은 지표를 집계하는 방법과 해당 메트릭이 저장되는 기간을 정의합니다. 각 보관 정책은 시간 간격의 지점 수로 정의됩니다.
예를 들어, 보관 정책에서 단위가 1초인 10개 지점의 정책을 정의하면 시계열 아카이브가 최대 10초 동안 유지되며 각각 1초 이상의 집계를 나타냅니다. 이는 시계열이 가장 최근 지점과 이전 지점 사이에 10초 동안 유지됨을 의미합니다.
보관 정책은 사용되는 집계 방법도 정의합니다. 기본값은 기본적으로 mean, min, max. sum, std, count로 설정된 default_aggregation_methods 매개 변수로 설정됩니다. 따라서 사용 사례에 따라 보관 정책과 세분성은 다양합니다.
추가 리소스
- 보관 정책에 대한 자세한 내용은 보관 정책 계획 및 관리를 참조하십시오.
1.3.2. 인덱서 드라이버
인덱서는 정의, 유형 및 속성과 함께 모든 리소스, 보관 정책 및 지표의 인덱스 저장을 담당합니다. 또한 리소스를 지표와 연결하는 역할을 담당합니다. Red Hat OpenStack Platform director는 기본적으로 인덱서 드라이버를 설치합니다. Gnocchi에서 처리하는 모든 리소스와 지표를 인덱싱하려면 데이터베이스가 필요합니다. 지원되는 드라이버는 MySQL입니다.
1.3.3. Gnocchi Metric-as-a-Service 용어
이 테이블에는 Metric-as-a-Service 기능에 대해 일반적으로 사용되는 용어의 정의가 포함되어 있습니다.
표 1.2. metric-as-a-Service 용어
| 용어 | 정의 |
|---|---|
| 집계 방법 | 여러 측정값을 집계하는 데 사용되는 함수입니다. 예를 들어 min 집계 방법은 다양한 측정값의 값을 시간 범위의 모든 측정값의 최소 값으로 집계합니다. |
| 집계 | 보관 정책에 따라 여러 측정값에서 생성된 데이터 지점. 집계는 타임스탬프 및 값으로 구성됩니다. |
| 보관 정책 | 지표에 연결된 집계 스토리지 정책입니다. 보관 정책은 집계가 지표에 보관되는 기간 및 집계가 집계되는 방식(통합 방법)을 결정합니다. |
| 단위 | 지표의 집계 시계열에서 두 집계 사이의 시간입니다. |
| 측정 | API에서 시계열 데이터베이스로 전송되는 들어오는 데이터 지점입니다. 측정값은 타임스탬프와 값으로 구성됩니다. |
| 메트릭 | UUID로 식별된 집계를 저장하는 엔터티입니다. 지표는 이름을 사용하여 리소스에 연결할 수 있습니다. 지표에서 집계를 저장하는 방법은 지표가 연결된 보관 정책에 의해 정의됩니다. |
| 리소스 | 지표를 과 연결할 수 있는 인프라의 모든 항목을 나타내는 엔터티입니다. 리소스는 고유한 ID로 식별되며 속성을 포함할 수 있습니다. |
| 시계열 | 시간순으로 주문된 집계 목록입니다. |
| timespan | 지표가 집계를 유지하는 시간입니다. 이는 보관 정책의 컨텍스트에서 사용됩니다. |
1.4. 메트릭 데이터 표시
다음 도구를 사용하여 지표 데이터를 표시하고 분석할 수 있습니다.
- Grafana: 오픈 소스 지표 분석 및 시각화 제품군. Grafana는 인프라 및 애플리케이션 분석을 위해 시계열 데이터를 시각화하는 데 가장 일반적으로 사용됩니다.
- Red Hat CloudForms: IT 부서가 가상 시스템과 사설 클라우드 전반에 걸쳐 프로비저닝, 관리 및 규정 준수를 보장하는 사용자의 셀프 서비스 기능을 제어하는 데 사용하는 인프라 관리 플랫폼입니다.
추가 리소스
- Grafana에 대한 자세한 내용은 1.4.1절. “Grafana를 사용하여 데이터 표시” 을 참조하십시오.
- Red Hat Cloudforms에 대한 자세한 내용은 제품 설명서 를 참조하십시오.
1.4.1. Grafana를 사용하여 데이터 표시
타사 소프트웨어(예: Grafana)를 사용하여 수집 및 저장된 지표의 그래픽 표시를 볼 수 있습니다.
Grafana는 오픈 소스 지표 분석, 모니터링 및 시각화 제품군입니다. Grafana를 설치하고 구성하려면 공식 Grafana 문서를 참조하십시오.
2장. 작동 측정 계획
모니터링하는 리소스는 비즈니스 요구 사항에 따라 다릅니다. Ceilometer 또는 collectd를 사용하여 리소스를 모니터링할 수 있습니다.
- collectd 측정에 대한 자세한 내용은 2.2절. “collectd 측정” 을 참조하십시오.
- Ceilometer 측정에 대한 자세한 내용은 2.1절. “Ceilometer 측정” 을 참조하십시오.
2.1. Ceilometer 측정
전체 Ceilometer 조치 목록은 https://docs.openstack.org/ceilometer/train/admin/telemetry-measurements.html를 참조하십시오.
2.2. collectd 측정
다음 측정은 가장 일반적으로 사용되는 collectd 지표입니다.
- disk
- 인터페이스
- load
- memory
- 프로세스
- tcpconns
전체 측정 목록은 collectd 지표 및 이벤트를 참조하십시오.
2.3. 데이터 스토리지 계획
Gnocchi는 각 데이터 포인트가 집계되는 데이터 요소의 컬렉션을 저장합니다. 스토리지 형식은 다른 기술을 사용하여 압축됩니다. 따라서 시계열 데이터베이스의 크기를 계산하려면 가장 어려운 시나리오를 기반으로 크기를 추정해야 합니다.
절차
데이터 요소 수를 계산합니다.
포인트 수 = timespan / granularity
예를 들어 1 년의 데이터를 1 분 해상도로 유지하려면 공식을 사용하십시오.
데이터 포인트 수 = (365일 X 24 시간 X 60 분) / 1 분 데이터 포인트 = 525600
시계열 데이터베이스의 크기를 계산합니다.
크기(바이트) = 데이터 점 수 X 8 바이트
이 수식을 예제에 적용하면 결과는 4.1MB입니다.
바이트 단위 = 525600 포인트 X 8 바이트 = 4204800 바이트 = 4.1MB
이 값은 집계된 단일 시계열 데이터베이스에 대한 예상 스토리지 요구 사항입니다. 아카이브 정책에서 여러 집계 방법(최소, max, mean, sum, std, count)을 사용하는 경우 이 값을 사용하는 집계 방법 수로 곱합니다.
2.4. 보관 정책 계획 및 관리
보관 정책은 메트릭을 집계하는 방법과 시계열 데이터베이스에 지표를 저장하는 기간을 정의합니다. 보관 정책은 timespan에 걸쳐 포인트 수로 정의됩니다.
보관 정책에서 10초 단위로 정책을 정의하는 경우 시계열 아카이브는 최대 10초 동안 유지되며 각각 1초 이상의 집계를 나타냅니다. 즉, 시계열은 가장 최근 지점과 이전 지점 간에 최대 10초의 데이터를 유지합니다. 보관 정책에서는 사용할 집계 방법도 정의합니다. 기본값은 매개 변수 default_aggregation_methods 로 설정됩니다. 기본값은 ,min,max.sum,count 입니다. 따라서 사용 사례에 따라 보관 정책 및 세분성이 다를 수 있습니다.
보관 정책을 계획하려면 다음 개념을 잘 알고 있어야 합니다.
- 지표. 자세한 내용은 2.4.1절. “메트릭”의 내용을 참조하십시오.
- 측정. 자세한 내용은 2.4.2절. “사용자 정의 조치 생성”의 내용을 참조하십시오.
- 집계. 자세한 내용은 2.4.4절. “시계열 집계의 크기 계산”의 내용을 참조하십시오.
- 측정된 작업자입니다. 자세한 내용은 2.4.5절. “측정된 작업자”의 내용을 참조하십시오.
보관 정책을 생성하고 관리하려면 다음 작업을 완료합니다.
- 아카이브 정책을 생성합니다. 자세한 내용은 2.4.6절. “보관 정책 생성”의 내용을 참조하십시오.
- 보관 정책을 관리합니다. 자세한 내용은 2.4.7절. “아카이브 정책 관리”의 내용을 참조하십시오.
- 아카이브 정책 규칙을 생성합니다. 자세한 내용은 2.4.8절. “아카이브 정책 규칙 생성”의 내용을 참조하십시오.
2.4.1. 메트릭
Gnocchi는 지표 라는 오브젝트 유형을 제공합니다. 메트릭은 서버의 CPU 사용량, 방의 온도 또는 네트워크 인터페이스에서 보낸 바이트 수를 측정할 수 있는 모든 것입니다. 메트릭에는 다음과 같은 속성이 있습니다.
- 식별할 UUID입니다.
- 이름
- 측정값을 저장하고 집계하는 데 사용되는 보관 정책
추가 리소스
- 용어 정의는 Gnocchi Metric-as-a-Service 용어를 참조하십시오.
2.4.1.1. 메트릭 생성
절차
리소스를 생성합니다. <resource_name>을 리소스 이름으로 교체합니다.
$ openstack metric resource create <resource_name>
지표를 생성합니다. <resource_name>을 리소스 이름으로 바꾸고 <metric_name>을 메트릭 이름으로 바꿉니다.
$ openstack metric metric create -r <resource_name> <metric_name>
지표를 생성할 때 보관 정책 속성이 수정되어 변경할 수 없습니다.
archive_policy엔드포인트를 통해 보관 정책의 정의를 변경할 수 있습니다.
2.4.2. 사용자 정의 조치 생성
측정값은 API가 Gnocchi에 보내는 들어오는 데이터 포인트 tuple입니다. 타임스탬프와 값으로 구성됩니다. 고유한 사용자 지정 조치를 만들 수 있습니다.
절차
사용자 정의 측정을 생성합니다.
$ openstack metric measures add -m <MEASURE1> -m <MEASURE2> .. -r <RESOURCE_NAME> <METRIC_NAME>
2.4.3. 기본 보관 정책
기본적으로 Gnocchi에는 다음과 같은 보관 정책이 있습니다.
low
- 30일 동안 5분 단위
-
사용되는 집계 방법:
default_aggregation_methods - 메트릭당 최대 예상 크기: 406 KiB
medium
- 7일 동안의 1분 단위
- 1시간 단위로 365일 이상 단위
-
사용되는 집계 방법:
default_aggregation_methods - 메트릭당 최대 예상 크기: 887 KiB
high
- 1시간 동안 1초 단위
- 1주일에 1분 단위
- 1년 동안의 1시간 단위
-
사용되는 집계 방법:
default_aggregation_methods - 메트릭당 최대 예상 크기: 1 057 KiB
bool
- 1년 동안의 1초 단위
- 사용된 집계 방법: 마지막
- 메트릭당 최대 최적화 크기: 1539 KiB
- 메트릭당 최대 pessimistic 크기: 277 172 KiB
2.4.4. 시계열 집계의 크기 계산
Gnocchi는 데이터 요소 컬렉션을 저장합니다. 여기서 각 지점이 집계됩니다. 스토리지 형식은 다른 기술을 사용하여 압축됩니다. 결과적으로 다음 예제와 같이 시계열의 크기를 계산하는 것은 가장 나쁜 시나리오를 기반으로 추정됩니다.
절차
이 공식을 사용하여 포인트 수를 계산합니다.
포인트 수 = timespan / granularity
예를 들어 1년 간의 해결 방법을 사용하여 데이터를 유지하려면 다음을 수행하십시오.
포인트 수 = (365일 X 24 시간 X 60 분) / 1 분
포인트 수 = 525600
바이트 단위를 계산하려면 다음 수식을 사용합니다.
크기(바이트) = 포인트 X 8 바이트
바이트 단위 = 525600 포인트 X 8 바이트 = 4204800 바이트 = 4.1MB
이 값은 집계된 단일 시계열에 대한 예상 스토리지 요구 사항입니다. 아카이브 정책에서 min, max, mean, sum, std, count - 이 값을 사용하는 집계 방법 수로 곱한 집계 방법을 사용합니다.
2.4.5. 측정된 작업자
지표 데몬을 사용하면 집계를 처리하고, 집계를 생성하고, 집계를 저장하고, 지표를 삭제할 수 있습니다. 지표 데몬에서는 Gnocchi의 대부분의 CPU 사용량 및 I/O 작업을 담당합니다. 각 지표의 아카이브 정책에 따라 지표 데몬이 수행하는 속도가 결정됩니다. 지표는 들어오는 스토리지에 주기적으로 새 조치가 있는지 확인합니다. 각 점검 간의 지연 시간을 구성하려면 [metricd]metric_processing_delay 구성 옵션을 사용할 수 있습니다.
2.4.6. 보관 정책 생성
절차
아카이브 정책을 생성합니다. <archive-policy-name>을 정책 이름으로 바꾸고 <aggregation-method>를 집계 방법으로 바꿉니다.
# openstack metric archive policy create <archive-policy-name> --definition <definition> \ --aggregation-method <aggregation-method>
참고<definition>은 정책 정의입니다. 여러 특성을 쉼표(,)로 구분합니다. 아카이브 정책 정의의 이름과 값을 콜론(:)으로 구분합니다.
2.4.7. 아카이브 정책 관리
보관 정책을 삭제하려면 다음을 수행합니다.
openstack metric archive policy delete <archive-policy-name>
모든 보관 정책을 보려면 다음을 수행합니다.
# openstack metric archive policy list
보관 정책의 세부 정보를 보려면 다음을 수행합니다.
# openstack metric archive-policy show <archive-policy-name>
2.4.8. 아카이브 정책 규칙 생성
보관 정책 규칙은 지표와 보관 정책 간의 매핑을 정의합니다. 이를 통해 사용자에게 규칙을 사전 정의할 수 있으므로 보관 정책이 일치하는 패턴에 따라 지표에 할당됩니다.
절차
아카이브 정책 규칙을 생성합니다. <rule-name>을 규칙 이름으로 바꾸고 <archive-policy-name>을 보관 정책 이름으로 바꿉니다.
# openstack metric archive-policy-rule create <rule-name> / --archive-policy-name <archive-policy-name>
2.5. Red Hat OpenStack Platform 배포 확인
openstack metric 명령을 사용하여 성공적인 배포를 확인할 수 있습니다.
절차
배포를 확인합니다.
(overcloud) [stack@undercloud-0 ~]$ openstack metric status +-----------------------------------------------------+-------+ | Field | Value | +-----------------------------------------------------+-------+ | storage/number of metric having measures to process | 0 | | storage/total number of measures to process | 0 | +-----------------------------------------------------+-------+
3장. 알람 관리
Telemetry Alarming 서비스(aodh)를 사용하여 Ceilometer 또는 Gnocchi에서 수집한 지표 또는 이벤트 데이터에 대해 정의된 규칙에 따라 작업을 트리거할 수 있습니다.
알람은 다음 상태 중 하나일 수 있습니다.
- 확인
- 지표 또는 이벤트가 허용 가능 상태입니다.
- 실행
- 지표 또는 이벤트가 정의된 ok 상태가 아닙니다.
- 데이터가 충분하지 않음
- 알람 상태는 알 수 없습니다. 예를 들어, 요청된 세분화에 대한 데이터가 없고 검사가 아직 실행되지 않은 등의 여러 가지 이유로 발생할 수 있습니다.
3.1. 기존 알람 보기
기존 원격 분석 알람 정보를 보고 리소스에 할당된 미터를 나열하여 지표의 현재 상태를 확인할 수 있습니다.
절차
기존 Telemetry 알람을 나열합니다.
# openstack alarm list +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+ | alarm_id | type | name | state | severity | enabled | +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+ | 922f899c-27c8-4c7d-a2cf-107be51ca90a | gnocchi_aggregation_by_resources_threshold | iops-monitor-read-requests | insufficient data | low | True | +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+
리소스에 할당된 미터를 나열하려면 리소스의 UUID를 지정합니다. 예를 들면 다음과 같습니다.
# openstack metric resource show 22592ae1-922a-4f51-b935-20c938f48753 | Field | Value | +-----------------------+-------------------------------------------------------------------+ | created_by_project_id | 1adaed3aaa7f454c83307688c0825978 | | created_by_user_id | d8429405a2764c3bb5184d29bd32c46a | | creator | d8429405a2764c3bb5184d29bd32c46a:1adaed3aaa7f454c83307688c0825978 | | ended_at | None | | id | 22592ae1-922a-4f51-b935-20c938f48753 | | metrics | cpu: a0375b0e-f799-47ea-b4ba-f494cf562ad8 | | | disk.ephemeral.size: cd082824-dfd6-49c3-afdf-6bfc8c12bd2a | | | disk.root.size: cd88dc61-ba85-45eb-a7b9-4686a6a0787b | | | memory.usage: 7a1e787c-5fa7-4ac3-a2c6-4c3821eaf80a | | | memory: ebd38ef7-cdc1-49f1-87c1-0b627d7c189e | | | vcpus: cc9353f1-bb24-4d37-ab8f-d3e887ca8856 | | original_resource_id | 22592ae1-922a-4f51-b935-20c938f48753 | | project_id | cdda46e0b5be4782bc0480dac280832a | | revision_end | None | | revision_start | 2021-09-16T17:00:41.227453+00:00 | | started_at | 2021-09-16T16:17:08.444032+00:00 | | type | instance | | user_id | f00de1d74408428cadf483ea7dbb2a83 | +-----------------------+-------------------------------------------------------------------+
3.2. 알람 생성
원격 분석 알람 서비스(aodh)를 사용하여 임계값에 도달한 경우와 같이 특정 조건이 충족될 때 트리거되는 알람을 만듭니다. 이 예에서 알람은 개별 인스턴스의 평균 CPU 사용률이 80%를 초과할 때 로그 항목을 활성화하고 추가합니다.
절차
보관 정책은 배포 프로세스 중에 미리 채워지며 새 보관 정책을 생성할 필요가 거의 없습니다. 그러나 구성된 보관 정책이 없는 경우 파일을 만들어야 합니다. 5s * 86400 포인트 5일(5일)에 대한 지표를 생성하는 보관 정책을 생성하려면 다음 명령을 사용합니다.
# openstack archive-policy create <name> \ -d granularity:5s,points:86400 \ -b 3 -m mean -m rate:mean+ <name> 을 보관 정책 이름으로 바꿉니다.
참고원격 분석 알람 서비스의 평가 기간 값을 60보다 큰 정수로 설정해야 합니다. Ceilometer 폴링 간격은 평가 기간에 연결됩니다. Ceilometer 폴링 간격 값을 60~600 사이의 숫자로 설정하고 해당 값이 원격 분석 알람 서비스의 평가 기간 값보다 큰지 확인합니다. Ceilometer 폴링 간격이 너무 낮은 경우 시스템 로드에 심각한 영향을 줄 수 있습니다.
알람을 생성하고 쿼리를 사용하여 모니터링을 위해 인스턴스의 특정 ID를 격리합니다. 다음 예에 있는 인스턴스 ID는 94619081-abf5-4f1f-81c7-9cedaa872403입니다.
참고임계값을 계산하려면 다음 공식을 사용합니다. ✓,000 x {granularity} x {percentage_in_decimal}
# openstack alarm create \ --type gnocchi_aggregation_by_resources_threshold \ --name cpu_usage_high \ --granularity 5 --metric cpu \ --threshold 48000000000 \ --aggregation-method rate:mean \ --resource-type instance \ --query '{"=": {"id": "94619081-abf5-4f1f-81c7-9cedaa872403"}}' --alarm-action 'log://' +---------------------------+-------------------------------------------------------+ | Field | Value | +---------------------------+-------------------------------------------------------+ | aggregation_method | rate:mean | | alarm_actions | [u'log://'] | | alarm_id | b794adc7-ed4f-4edb-ace4-88cbe4674a94 | | comparison_operator | eq | | description | gnocchi_aggregation_by_resources_threshold alarm rule | | enabled | True | | evaluation_periods | 1 | | granularity | 5 | | insufficient_data_actions | [] | | metric | cpu | | name | cpu_usage_high | | ok_actions | [] | | project_id | 13c52c41e0e543d9841a3e761f981c20 | | query | {"=": {"id": "94619081-abf5-4f1f-81c7-9cedaa872403"}} | | repeat_actions | False | | resource_type | instance | | severity | low | | state | insufficient data | | state_timestamp | 2016-12-09T05:18:53.326000 | | threshold | 48000000000.0 | | time_constraints | [] | | timestamp | 2016-12-09T05:18:53.326000 | | type | gnocchi_aggregation_by_resources_threshold | | user_id | 32d3f2c9a234423cb52fb69d3741dbbc | +---------------------------+-------------------------------------------------------+
3.3. 알람 편집
알람을 편집하면 알람의 값 임계값을 늘리거나 줄입니다.
절차
임계값을 업데이트하려면
openstack alarm update명령을 사용합니다. 예를 들어 알람 임계값을 75%로 늘리려면 다음 명령을 사용합니다.# openstack alarm update --name cpu_usage_high --threshold 75
3.4. 알람 비활성화
알람을 비활성화하고 활성화할 수 있습니다.
절차
알람을 비활성화합니다.
# openstack alarm update --name cpu_usage_high --enabled=false
3.5. 알람 삭제
openstack alarm delete 명령을 사용하여 알람을 삭제합니다.
절차
알람을 삭제하려면 다음 명령을 입력합니다.
# openstack alarm delete --name cpu_usage_high
3.6. 예제: 인스턴스의 디스크 활동 모니터링
이 예제에서는 원격 분석 알람 서비스의 일부인 알람을 사용하여 특정 프로젝트에 포함된 모든 인스턴스의 누적 디스크 활동을 모니터링하는 방법을 보여줍니다.
절차
기존 프로젝트를 검토하고 모니터링할 프로젝트의 적절한 UUID를 선택합니다. 이 예에서는
admin테넌트를 사용합니다.$ openstack project list +----------------------------------+----------+ | ID | Name | +----------------------------------+----------+ | 745d33000ac74d30a77539f8920555e7 | admin | | 983739bb834a42ddb48124a38def8538 | services | | be9e767afd4c4b7ead1417c6dfedde2b | demo | +----------------------------------+----------+
프로젝트 UUID를 사용하여
admin테넌트의 인스턴스에서 생성한 모든 읽기 요청의sum()을 분석하는 알람을 만듭니다.--query매개변수를 사용하여 쿼리를 추가로 제한할 수 있습니다.# openstack alarm create \ --type gnocchi_aggregation_by_resources_threshold \ --name iops-monitor-read-requests \ --metric disk.read.requests.rate \ --threshold 42000 \ --aggregation-method sum \ --resource-type instance \ --query '{"=": {"project_id": "745d33000ac74d30a77539f8920555e7"}}' +---------------------------+-----------------------------------------------------------+ | Field | Value | +---------------------------+-----------------------------------------------------------+ | aggregation_method | sum | | alarm_actions | [] | | alarm_id | 192aba27-d823-4ede-a404-7f6b3cc12469 | | comparison_operator | eq | | description | gnocchi_aggregation_by_resources_threshold alarm rule | | enabled | True | | evaluation_periods | 1 | | granularity | 60 | | insufficient_data_actions | [] | | metric | disk.read.requests.rate | | name | iops-monitor-read-requests | | ok_actions | [] | | project_id | 745d33000ac74d30a77539f8920555e7 | | query | {"=": {"project_id": "745d33000ac74d30a77539f8920555e7"}} | | repeat_actions | False | | resource_type | instance | | severity | low | | state | insufficient data | | state_timestamp | 2016-11-08T23:41:22.919000 | | threshold | 42000.0 | | time_constraints | [] | | timestamp | 2016-11-08T23:41:22.919000 | | type | gnocchi_aggregation_by_resources_threshold | | user_id | 8c4aea738d774967b4ef388eb41fef5e | +---------------------------+-----------------------------------------------------------+
3.7. 예제: CPU 사용 모니터링
인스턴스의 성능을 모니터링하려면 Gnocchi 데이터베이스를 검사하여 모니터링할 수 있는 지표(예: 메모리 또는 CPU 사용량)를 확인합니다.
절차
모니터링할 수 있는 지표를 식별하려면 인스턴스 UUID를 사용하여
openstack metric resource show명령을 입력합니다.$ openstack metric resource show --type instance 22592ae1-922a-4f51-b935-20c938f48753 +-----------------------+-------------------------------------------------------------------+ | Field | Value | +-----------------------+-------------------------------------------------------------------+ | availability_zone | nova | | created_at | 2021-09-16T16:16:24+00:00 | | created_by_project_id | 1adaed3aaa7f454c83307688c0825978 | | created_by_user_id | d8429405a2764c3bb5184d29bd32c46a | | creator | d8429405a2764c3bb5184d29bd32c46a:1adaed3aaa7f454c83307688c0825978 | | deleted_at | None | | display_name | foo-2 | | ended_at | None | | flavor_id | 0e5bae38-a949-4509-9868-82b353ef7ffb | | flavor_name | workload_flavor_0 | | host | compute-0.redhat.local | | id | 22592ae1-922a-4f51-b935-20c938f48753 | | image_ref | 3cde20b4-7620-49f3-8622-eeacbdc43d49 | | launched_at | 2021-09-16T16:17:03+00:00 | | metrics | cpu: a0375b0e-f799-47ea-b4ba-f494cf562ad8 | | | disk.ephemeral.size: cd082824-dfd6-49c3-afdf-6bfc8c12bd2a | | | disk.root.size: cd88dc61-ba85-45eb-a7b9-4686a6a0787b | | | memory.usage: 7a1e787c-5fa7-4ac3-a2c6-4c3821eaf80a | | | memory: ebd38ef7-cdc1-49f1-87c1-0b627d7c189e | | | vcpus: cc9353f1-bb24-4d37-ab8f-d3e887ca8856 | | original_resource_id | 22592ae1-922a-4f51-b935-20c938f48753 | | project_id | cdda46e0b5be4782bc0480dac280832a | | revision_end | None | | revision_start | 2021-09-16T17:00:41.227453+00:00 | | server_group | None | | started_at | 2021-09-16T16:17:08.444032+00:00 | | type | instance | | user_id | f00de1d74408428cadf483ea7dbb2a83 | +-----------------------+-------------------------------------------------------------------+
이 결과 지표 값은 알람 서비스로 모니터링할 수 있는 구성 요소를 나열합니다(예:
cpu).CPU 사용량을 모니터링하려면
cpu지표를 사용합니다.$ openstack metric show --resource-id 22592ae1-922a-4f51-b935-20c938f48753 cpu +--------------------------------+-------------------------------------------------------------------+ | Field | Value | +--------------------------------+-------------------------------------------------------------------+ | archive_policy/name | ceilometer-high-rate | | creator | d8429405a2764c3bb5184d29bd32c46a:1adaed3aaa7f454c83307688c0825978 | | id | a0375b0e-f799-47ea-b4ba-f494cf562ad8 | | name | cpu | | resource/created_by_project_id | 1adaed3aaa7f454c83307688c0825978 | | resource/created_by_user_id | d8429405a2764c3bb5184d29bd32c46a | | resource/creator | d8429405a2764c3bb5184d29bd32c46a:1adaed3aaa7f454c83307688c0825978 | | resource/ended_at | None | | resource/id | 22592ae1-922a-4f51-b935-20c938f48753 | | resource/original_resource_id | 22592ae1-922a-4f51-b935-20c938f48753 | | resource/project_id | cdda46e0b5be4782bc0480dac280832a | | resource/revision_end | None | | resource/revision_start | 2021-09-16T17:00:41.227453+00:00 | | resource/started_at | 2021-09-16T16:17:08.444032+00:00 | | resource/type | instance | | resource/user_id | f00de1d74408428cadf483ea7dbb2a83 | | unit | ns | +--------------------------------+-------------------------------------------------------------------+
archive_policy는 std, count, min, max, sum, mean 값을 계산하기 위한 집계 간격을 정의합니다.
cpu지표에 대해 현재 선택한 보관 정책을 검사합니다.$ openstack metric archive-policy show ceilometer-high-rate +---------------------+-------------------------------------------------------------------+ | Field | Value | +---------------------+-------------------------------------------------------------------+ | aggregation_methods | rate:mean, mean | | back_window | 0 | | definition | - timespan: 1:00:00, granularity: 0:00:01, points: 3600 | | | - timespan: 1 day, 0:00:00, granularity: 0:01:00, points: 1440 | | | - timespan: 365 days, 0:00:00, granularity: 1:00:00, points: 8760 | | name | ceilometer-high-rate | +---------------------+-------------------------------------------------------------------+
알람 서비스를 사용하여
cpu를 쿼리하는 모니터링 작업을 생성합니다. 이 작업은 지정한 설정에 따라 이벤트를 트리거합니다. 예를 들어 인스턴스의 CPU가 연장 기간 동안 80%를 초과하면 로그 항목을 늘리려면 다음 명령을 사용합니다.$ openstack alarm create \ --project-id 3cee262b907b4040b26b678d7180566b \ --name high-cpu \ --type gnocchi_resources_threshold \ --description 'High CPU usage' \ --metric cpu \ --threshold 800,000,000.0 \ --comparison-operator ge \ --aggregation-method mean \ --granularity 300 \ --evaluation-periods 1 \ --alarm-action 'log://' \ --ok-action 'log://' \ --resource-type instance \ --resource-id 22592ae1-922a-4f51-b935-20c938f48753 +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | aggregation_method | rate:mean | | alarm_actions | ['log:'] | | alarm_id | c7b326bd-a68c-4247-9d2b-56d9fb18bf38 | | comparison_operator | ge | | description | High CPU usage | | enabled | True | | evaluation_periods | 1 | | granularity | 300 | | insufficient_data_actions | [] | | metric | cpu | | name | high-cpu | | ok_actions | ['log:'] | | project_id | cdda46e0b5be4782bc0480dac280832a | | repeat_actions | False | | resource_id | 22592ae1-922a-4f51-b935-20c938f48753 | | resource_type | instance | | severity | low | | state | insufficient data | | state_reason | Not evaluated yet | | state_timestamp | 2021-09-21T08:02:57.090592 | | threshold | 800000000.0 | | time_constraints | [] | | timestamp | 2021-09-21T08:02:57.090592 | | type | gnocchi_resources_threshold | | user_id | f00de1d74408428cadf483ea7dbb2a83 | +---------------------------+--------------------------------------+
- comparison-operator: ge 운영자는 CPU 사용량이 80%보다 크거나 같은 경우 알람이 트리거되도록 정의합니다.
- 세분화: 지표에는 보관 정책이 연결되어 있습니다. 정책에는 다양한 단위가 있을 수 있습니다. 예를 들어 한 달 동안 1시간 + 1시간 동안 5분 집계를 수행합니다. granularity 값은 보관 정책에 설명된 기간과 일치해야 합니다.
- 평가-periods: 알람이 트리거되기 전에 통과해야 하는 세분성 기간 수입니다. 예를 들어 이 값을 2로 설정하면 알람이 트리거되기 전에 두 폴링 기간 동안 CPU 사용량이 80% 이상 있어야 합니다.
[U'log://']:
alarm_actions또는ok_actions를[u'log://']로 설정하면 이벤트가 트리거되거나 정상 상태로 돌아가며 aodh 로그 파일에 기록됩니다.참고알람이 트리거될 때(alarm_actions) 및 웹 후크 URL과 같은 일반 상태(ok_actions)로 반환되는 경우 실행되도록 다양한 작업을 정의할 수 있습니다.
3.8. 알람 내역 보기
특정 알람이 트리거되었는지 확인하려면 알람 기록을 쿼리하고 이벤트 정보를 볼 수 있습니다.
절차
openstack alarm-history show명령을 사용합니다.$ openstack alarm-history show 1625015c-49b8-4e3f-9427-3c312a8615dd --fit-width +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+ | timestamp | type | detail | event_id | +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+ | 2017-11-16T05:21:47.850094 | state transition | {"transition_reason": "Transition to ok due to 1 samples inside threshold, most recent: 0.0366665763", "state": "ok"} | 3b51f09d-ded1-4807-b6bb-65fdc87669e4 | +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+
4장. 로그 서비스 설치 및 구성
RHOSP(Red Hat OpenStack Platform)는 특정 로그 파일에 정보 메시지를 작성합니다. 이러한 메시지를 사용하여 시스템 이벤트 문제를 해결하고 모니터링할 수 있습니다. 로그 수집 에이전트 Rsyslog는 클라이언트 측에서 로그를 수집하고 이러한 로그를 서버 측에서 실행 중인 Rsyslog 인스턴스로 전송합니다. 서버 측 Rsyslog 인스턴스는 스토리지를 위해 로그 레코드를 Elasticsearch로 리디렉션합니다.
개별 로그 파일을 지원 사례에 수동으로 연결할 필요는 없습니다. sosreport 유틸리티는 필요한 로그를 자동으로 수집합니다.
4.1. 중앙 집중식 로그 시스템 아키텍처 및 구성 요소
모니터링 툴은 RHOSP(Red Hat OpenStack Platform) Overcloud 노드에 배포된 클라이언트와 함께 클라이언트-서버 모델을 사용합니다. Rsyslog 서비스는 클라이언트 쪽 중앙 집중식 로깅(CL)을 제공합니다.
모든 RHOSP 서비스는 로그 파일을 생성하고 업데이트합니다. 이러한 로그 파일은 작업, 오류, 경고 및 기타 이벤트를 기록합니다. OpenStack과 같은 분산 환경에서는 중앙 위치에서 이러한 로그를 수집하면 디버깅 및 관리를 단순화합니다.
중앙 집중식 로깅을 사용하면 전체 RHOSP 환경에서 로그를 볼 수 있는 중앙 지점 하나가 있습니다. 이러한 로그는 syslog 및 감사 로그 파일, 인프라 구성 요소(예: RabbitMQ 및 MariaDB) 및 ID, 계산 등의 OpenStack 서비스와 같은 운영 체제에서 가져옵니다. 중앙 집중식 로깅 툴체인은 다음 구성 요소로 구성됩니다.
- 로그 컬렉션 에이전트(Rsyslog)
- 데이터 저장소(ElasticSearch)
- API/Presentation Layer(Grafana)
Red Hat OpenStack Platform director는 중앙 집중식 로깅을 위한 서버 측 구성 요소를 배포하지 않습니다. Red Hat은 Elasticsearch 데이터베이스 및 Grafana를 포함한 서버 측 구성 요소를 지원하지 않습니다.
4.2. Elasticsearch를 사용하여 중앙 집중식 로깅 활성화
중앙 집중식 로깅을 사용하려면 OS::TripleO::Services::Rsyslog 구성 가능 서비스의 구현을 지정해야 합니다.
Rsyslog 서비스는 중앙 집중식 로깅을 위해 데이터 저장소로 Elasticsearch만 사용합니다.
사전 요구 사항
- Elasticsearch는 서버측에 설치되어 있습니다.
절차
다음 예와 같이 사용자 환경 및
배포와 관련된 다른 환경 파일과 함께 오버클라우드배포 명령에 로깅 환경 파일의 파일 경로를 추가합니다.openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e /usr/share/openstack-tripleo-heat-templates/environments/logging-environment-rsyslog.yaml
<existing_overcloud_environment_files>를 기존 배포의 일부인 환경 파일 목록으로 바꿉니다.
4.3. 로깅 기능 구성
로깅 기능을 구성하려면 logging-environment-rsyslog.yaml 파일에서 RsyslogElasticsearchSetting 매개변수를 수정합니다.
절차
-
tripleo-heat-templates/environments/logging-environment-rsyslog.yaml파일을 홈 디렉터리에 복사합니다. 환경에 맞게
RsyslogElasticsearchSetting매개변수에 항목을 생성합니다. 다음 스니펫은RsyslogElasticsearchSetting매개변수 구성의 예입니다.parameter_defaults: RsyslogElasticsearchSetting: uid: "elastic" pwd: "yourownpassword" skipverifyhost: "on" allowunsignedcerts: "on" server: "https://log-store-service-telemetry.apps.stfcloudops1.lab.upshift.rdu2.redhat.com" serverport: 443
추가 리소스
- 구성 가능한 매개변수에 대한 자세한 내용은 4.3.1절. “구성 가능한 로깅 매개변수” 을 참조하십시오.
4.3.1. 구성 가능한 로깅 매개변수
이 표에는 RHOSP(Red Hat OpenStack Platform)에서 로깅 기능을 구성하는 데 사용하는 로깅 매개변수에 대한 설명이 포함되어 있습니다. 이러한 매개변수는 tripleo-heat-templates/deployment/logging/rsyslog-container-puppet.yaml 파일에서 찾을 수 있습니다.
표 4.1. 구성 가능한 로깅 매개변수
| 매개변수 | 설명 |
|---|---|
|
|
|
|
| Elasticsearch 서버 인증서를 발급한 CA의 CA 인증서 내용을 포함합니다. |
|
| Elasticsearch에 대해 클라이언트 인증서 인증을 수행하기 위한 클라이언트 인증서의 내용을 포함합니다. |
|
|
인증서 |
4.4. 로그 관리
컨테이너화된 서비스 로그 파일은 /var/log/containers/<service >에 저장됩니다(예: /var/log/containers/cinder ). 컨테이너 내에서 실행 중인 서비스의 로그 파일은 로컬에 저장됩니다. 사용 가능한 로그는 활성화된 서비스 및 비활성화된 서비스에 따라 다를 수 있습니다.
다음 예제에서는 p olkit 작업이 10 MB에 도달할 때 새 로그 파일을 생성하고 14 일 동안 로그 파일을 유지합니다.
parameter_defaults LogrotateRotate: '14' LogrotatePurgeAfterDays: '14' LogrotateMaxsize: '10M'
로그 회전 매개변수를 사용자 지정하려면 환경 템플릿에 이러한 parameter_defaults 를 입력한 다음 오버클라우드를 배포합니다.
openstack overcloud deploy \ --timeout 100 \ --templates /usr/share/openstack-tripleo-heat-templates \ ... \ -e /home/stack/templates/rotate.yaml \ --log-file overcloud_deployment_90.log
검증: 모든 오버클라우드 노드에서 NFD _crond 가 업데이트되었는지 확인합니다.
[root@compute0 ~]# podman exec -it logrotate_crond cat /etc/logrotate-crond.conf
/var/log/containers/*/*log /var/log/containers/*/*/*log /var/log/containers/*/*err {
daily
rotate 14
maxage 14
# minsize 1 is required for GDPR compliance, all files in
# /var/log/containers not managed with logrotate will be purged!
minsize 1
# Do not use size as it's not compatible with time-based rotation rules
# required for GDPR compliance.
maxsize 10M
missingok
notifempty
copytruncate
delaycompress
compress
}
다음 예에서는 nova-compute.log 파일이 한 번 순환되었습니다.
[root@compute0 ~]# ls -lah /var/log/containers/nova/ total 48K drwxr-x---. 2 42436 42436 79 May 12 09:01 . drwxr-x---. 7 root root 82 Jan 21 2021 .. -rw-r--r--. 1 42436 42436 12K May 12 14:00 nova-compute.log -rw-r--r--. 1 42436 42436 33K May 12 09:01 nova-compute.log.1 -rw-r--r--. 1 42436 42436 0 Jan 21 2021 nova-manage.log
로그 파일 순환 프로세스는 VDDK _crond 컨테이너에서 수행됩니다. /var/spool/cron/root 구성 파일이 읽고 프로세스로 전송된 구성을 읽습니다.
검증: 구성이 모든 컨트롤러 노드에 있는지 확인합니다.
[root@controller0 ~]# podman exec -it logrotate_crond /bin/sh
()[root@9410925fded9 /]$ cat /var/spool/cron/root
# HEADER: This file was autogenerated at 2021-01-21 16:47:27 +0000 by puppet.
# HEADER: While it can still be managed manually, it is definitely not recommended.
# HEADER: Note particularly that the comments starting with 'Puppet Name' should
# HEADER: not be deleted, as doing so could cause duplicate cron jobs.
# Puppet Name: logrotate-crond
PATH=/bin:/usr/bin:/usr/sbin SHELL=/bin/sh
0 * * * * sleep `expr ${RANDOM} \% 90`; /usr/sbin/logrotate -s /var/lib/logrotate/logrotate-crond.status /etc/logrotate-crond.conf 2>&1|logger -t logrotate-crond
/var/lib/config-data/puppet-generated/crond/etc/logrotate-crond.conf 파일은 Bugzilla _ crond 컨테이너 내부의 /etc/logrotate-crond.conf 에 바인딩됩니다.
이전 구성 파일은 과거의 이유로 남아 있지만 사용되지 않습니다.
4.5. 로그 파일의 기본 경로 재정의
기본 컨테이너를 수정하고 수정 사항에 서비스 로그 파일의 경로가 포함된 경우 기본 로그 파일 경로도 수정해야 합니다. 구성 가능한 모든 서비스에는 <service_name>LoggingSource 매개변수가 있습니다. 예를 들어 nova-compute 서비스의 경우 매개 변수는 NovaComputeLoggingSource 입니다.
절차
nova-compute 서비스의 기본 경로를 재정의하려면 구성 파일의
NovaComputeLoggingSource매개변수에 대한 경로를 추가합니다.NovaComputeLoggingSource: tag: openstack.nova.compute file: /some/other/path/nova-compute.log참고각 서비스에 대해
태그와파일을정의합니다. 다른 값은 기본적으로 파생됩니다.특정 서비스의 형식을 수정할 수 있습니다. 이는 Rsyslog 구성에 직접 전달됩니다.
LoggingDefaultFormat매개변수의 기본 형식은 /(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}입니다.\d+) (?< PID>\d+) (?<priority>\S+) (?<message>.*)$/다음 구문을 사용하십시오.<service_name>LoggingSource: tag: <service_name>.tag path: <service_name>.path format: <service_name>.format다음 코드 조각은 더 복잡한 변환의 예입니다.
ServiceLoggingSource: tag: openstack.Service path: /var/log/containers/service/service.log format: multiline format_firstline: '/^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3} \d+ \S+ \S+ \[(req-\S+ \S+ \S+ \S+ \S+ \S+|-)\]/' format1: '/^(?<Timestamp>\S+ \S+) (?<Pid>\d+) (?<log_level>\S+) (?<python_module>\S+) (\[(req-(?<request_id>\S+) (?<user_id>\S+) (?<tenant_id>\S+) (?<domain_id>\S+) (?<user_domain>\S+) (?<project_domain>\S+)|-)\])? (?<Payload>.*)?$/'
4.6. 로그 레코드 형식 수정
특정 서비스의 로그 레코드 시작 형식을 수정할 수 있습니다. 이는 Rsyslog 구성에 직접 전달됩니다.
RHOSP(Red Hat OpenStack Platform) 로그 레코드의 기본 형식은 ('^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ [0-9]+)? (DEBUG|INFO|WARNING|ERROR) ').
절차
로그 레코드 시작을 구문 분석하기 위해 다른 정규 표현식을 추가하려면 구성에
startmsg.regex를 추가합니다.NovaComputeLoggingSource: tag: openstack.nova.compute file: /some/other/path/nova-compute.log startmsg.regex: "^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ \\+[0-9]+)? [A-Z]+ \\([a-z]+\\)
4.7. Rsyslog와 Elasticsearch 간 연결 테스트
클라이언트 측에서 Rsyslog와 Elasticsearch 간의 통신을 확인할 수 있습니다.
절차
-
Rsyslog 컨테이너의 Elasticsearch 연결 로그 파일
/var/log/rsyslog/omelasticsearch.log또는 호스트의/var/log/containers/rsyslog/omelasticsearch.log로 이동합니다. 이 로그 파일이 없거나 로그 파일이 있지만 로그가 포함되지 않은 경우 연결 문제가 없습니다. 로그 파일이 있고 로그를 포함하는 경우 Rsyslog가 성공적으로 연결되지 않았습니다.
서버 측에서 연결을 테스트하려면 Elasticsearch 로그를 확인하여 연결 문제를 확인합니다.
4.8. 서버 측 로깅
Elasticsearch 클러스터가 실행 중인 경우, 오버클라우드 노드에서 실행 중인 Rsysloglog를 연결하려면 매개변수를 구성해야 합니다. logging-environment-rsyslog.yaml 파일에서 RsyslogElasticsearchSettingRsyslogElasticsearchSetting 매개변수를 구성하려면 https://www.rsyslog.com/doc/v8-stable/configuration/modules/omelasticsearch.html을 참조하십시오.
4.9. tracebacks
문제가 발생하고 문제를 해결하기 시작하면 역추적 로그를 사용하여 문제를 진단할 수 있습니다. 로그 파일에서 역추적에는 일반적으로 여러 줄의 정보가 있으며 모두 동일한 문제와 관련이 있습니다.
rsyslog는 로그 레코드가 시작되는 방식을 정의하는 정규 표현식을 제공합니다. 각 로그 레코드는 일반적으로 타임스탬프로 시작하며, 추적의 첫 번째 행은 이 정보가 포함된 유일한 행입니다. rsyslog는 들여쓰기된 레코드를 첫 번째 행과 함께 번들로 전송하며 하나의 로그 레코드로 전송합니다.
이 동작의 경우 <Service>LoggingSource의 startmsg.regex 가 사용됩니다. 다음 정규 표현식은 director의 모든 <service>LoggingSource 매개변수의 기본값입니다.
startmsg.regex='^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ [0-9]+)? (DEBUG|INFO|WARNING|ERROR) '
이 기본값이 추가되거나 수정된 LoggingSource 의 로그 레코드와 일치하지 않는 경우 startmsg.regex 를 적절하게 변경해야 합니다.
4.10. OpenStack 서비스의 로그 파일 위치
각 OpenStack 구성 요소에는 실행 중인 서비스와 관련된 파일이 들어 있는 별도의 로깅 디렉터리가 있습니다.
4.10.1. 베어 메탈 프로비저닝(ironic) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Ironic API | openstack-ironic-api.service | /var/log/containers/ironic/ironic-api.log |
| OpenStack Ironic Conductor | openstack-ironic-conductor.service | /var/log/containers/ironic/ironic-conductor.log |
4.10.2. Block Storage(cinder) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 블록 스토리지 API | openstack-cinder-api.service | /var/log/containers/cinder-api.log |
| 블록 스토리지 백업 | openstack-cinder-backup.service | /var/log/containers/cinder/backup.log |
| 정보 메시지 | cinder-manage 명령 | /var/log/containers/cinder/cinder-manage.log |
| 블록 스토리지 스케줄러 | openstack-cinder-scheduler.service | /var/log/containers/cinder/scheduler.log |
| 블록 스토리지 볼륨 | openstack-cinder-volume.service | /var/log/containers/cinder/volume.log |
4.10.3. Compute(nova) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Compute API 서비스 | openstack-nova-api.service | /var/log/containers/nova/nova-api.log |
| OpenStack Compute 인증서 서버 | openstack-nova-cert.service | /var/log/containers/nova/nova-cert.log |
| OpenStack Compute 서비스 | openstack-nova-compute.service | /var/log/containers/nova/nova-compute.log |
| OpenStack Compute Conductor 서비스 | openstack-nova-conductor.service | /var/log/containers/nova/nova-conductor.log |
| OpenStack Compute VNC 콘솔 인증 서버 | openstack-nova-consoleauth.service | /var/log/containers/nova/nova-consoleauth.log |
| 정보 메시지 | nova-manage 명령 | /var/log/containers/nova/nova-manage.log |
| OpenStack Compute NoVNC Proxy 서비스 | openstack-nova-novncproxy.service | /var/log/containers/nova/nova-novncproxy.log |
| OpenStack Compute Scheduler 서비스 | openstack-nova-scheduler.service | /var/log/containers/nova/nova-scheduler.log |
4.10.4. 대시보드(horizon) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 특정 사용자 상호 작용 로그 | 대시보드 인터페이스 | /var/log/containers/horizon/horizon.log |
Apache HTTP 서버는 웹 브라우저 또는 명령줄 클라이언트(예: keystone 및 nova)를 사용하여 액세스할 수 있는 대시보드 웹 인터페이스에 몇 가지 추가 로그 파일을 사용합니다. 다음 표의 로그 파일은 대시보드 사용을 추적하고 오류를 진단하는 데 유용할 수 있습니다.
| 목적 | 로그 경로 |
|---|---|
| 처리된 모든 HTTP 요청 | /var/log/containers/httpd/horizon_access.log |
| HTTP 오류 | /var/log/containers/httpd/horizon_error.log |
| admin-role API 요청 | /var/log/containers/httpd/keystone_wsgi_admin_access.log |
| 관리자 역할 API 오류 | /var/log/containers/httpd/keystone_wsgi_admin_error.log |
| 멤버 역할 API 요청 | /var/log/containers/httpd/keystone_wsgi_main_access.log |
| 멤버 역할 API 오류 | /var/log/containers/httpd/keystone_wsgi_main_error.log |
동일한 호스트에서 실행 중인 다른 웹 서비스에서 보고한 오류를 저장하는 /var/log/containers/httpd/default_error.log 도 있습니다.
4.10.5. ID 서비스(keystone) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Identity Service | openstack-keystone.service | /var/log/containers/keystone/keystone.log |
4.10.6. Image 서비스(glance) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Image Service API 서버 | openstack-glance-api.service | /var/log/containers/glance/api.log |
| OpenStack 이미지 서비스 레지스트리 서버 | openstack-glance-registry.service | /var/log/containers/glance/registry.log |
4.10.7. 네트워킹(neutron) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Neutron DHCP 에이전트 | neutron-dhcp-agent.service | /var/log/containers/neutron/dhcp-agent.log |
| OpenStack Networking Layer 3 에이전트 | neutron-l3-agent.service | /var/log/containers/neutron/l3-agent.log |
| 메타데이터 에이전트 서비스 | neutron-metadata-agent.service | /var/log/containers/neutron/metadata-agent.log |
| 메타데이터 네임스페이스 프록시 | 해당 없음 | /var/log/containers/neutron/neutron-ns-metadata-proxy-UUID.log |
| Open vSwitch 에이전트 | neutron-openvswitch-agent.service | /var/log/containers/neutron/openvswitch-agent.log |
| OpenStack Networking 서비스 | neutron-server.service | /var/log/containers/neutron/server.log |
4.10.8. Object Storage(swift) 로그 파일
OpenStack 오브젝트 스토리지는 로그를 시스템 로깅 기능으로만 전송합니다.
기본적으로 모든 오브젝트 스토리지 로그 파일은 local0, local1 및 local2 syslog 기능을 사용하여 /var/log/containers/swift/swift.log 로 이동합니다.
오브젝트 스토리지의 로그 메시지는 REST API 서비스별 두 가지 범주와 백그라운드 데몬별로 분류됩니다. API 서비스 메시지에는 널리 사용되는 HTTP 서버와 유사한 방식으로 API 요청당 한 줄이 포함되어 있습니다. 프론트엔드(Proxy) 및 백엔드(Account, Container, Object) 서비스는 이러한 메시지를 게시합니다. 데몬 메시지는 덜 구조화되지 않으며 일반적으로 정기적인 작업을 수행하는 데몬에 대한 사람이 읽을 수 있는 정보가 포함됩니다. 그러나 메시지를 생성하는 오브젝트 스토리지의 일부에 관계없이 소스 ID는 항상 행의 시작 부분에 있습니다.
프록시 메시지의 예는 다음과 같습니다.
Apr 20 15:20:34 rhev-a24c-01 proxy-server: 127.0.0.1 127.0.0.1 20/Apr/2015/19/20/34 GET /v1/AUTH_zaitcev%3Fformat%3Djson%26marker%3Dtestcont HTTP/1.0 200 - python-swiftclient-2.1.0 AUTH_tk737d6... - 2 - txc454fa8ea4844d909820a-0055355182 - 0.0162 - - 1429557634.806570053 1429557634.822791100
다음은 백그라운드 데몬의 애드혹 메시지의 예입니다.
Apr 27 17:08:15 rhev-a24c-02 object-auditor: Object audit (ZBF). Since Mon Apr 27 21:08:15 2015: Locally: 1 passed, 0 quarantined, 0 errors files/sec: 4.34 , bytes/sec: 0.00, Total time: 0.23, Auditing time: 0.00, Rate: 0.00 Apr 27 17:08:16 rhev-a24c-02 object-auditor: Object audit (ZBF) "forever" mode completed: 0.56s. Total quarantined: 0, Total errors: 0, Total files/sec: 14.31, Total bytes/sec: 0.00, Auditing time: 0.02, Rate: 0.04 Apr 27 17:08:16 rhev-a24c-02 account-replicator: Beginning replication run Apr 27 17:08:16 rhev-a24c-02 account-replicator: Replication run OVER Apr 27 17:08:16 rhev-a24c-02 account-replicator: Attempted to replicate 5 dbs in 0.12589 seconds (39.71876/s) Apr 27 17:08:16 rhev-a24c-02 account-replicator: Removed 0 dbs Apr 27 17:08:16 rhev-a24c-02 account-replicator: 10 successes, 0 failures
4.10.9. 오케스트레이션(heat) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Heat API 서비스 | openstack-heat-api.service | /var/log/containers/heat/heat-api.log |
| OpenStack Heat Engine Service | openstack-heat-engine.service | /var/log/containers/heat/heat-engine.log |
| 오케스트레이션 서비스 이벤트 | 해당 없음 | /var/log/containers/heat/heat-manage.log |
4.10.11. Telemetry(ceilometer) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack ceilometer 알림 에이전트 | ceilometer_agent_notification | /var/log/containers/ceilometer/agent-notification.log |
| OpenStack ceilometer 중앙 에이전트 | ceilometer_agent_central | /var/log/containers/ceilometer/central.log |
| openstack ceilometer 수집 | openstack-ceilometer-collector.service | /var/log/containers/ceilometer/collector.log |
| OpenStack ceilometer 컴퓨팅 에이전트 | ceilometer_agent_compute | /var/log/containers/ceilometer/compute.log |
4.10.12. 서비스 지원용 로그 파일
다음 서비스는 핵심 OpenStack 구성 요소에서 사용하며 자체 로그 디렉터리 및 파일이 있습니다.
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 메시지 브로커 (RabbitMQ) | rabbitmq-server.service |
/var/log/rabbitmq/rabbit@short_hostname.log |
| 데이터베이스 서버(MariaDB) | mariadb.service | /var/log/mariadb/mariadb.log |
| 가상 네트워크 스위치(Open vSwitch) | openvswitch-nonetwork.service |
/var/log/openvswitch/ovsdb-server.log |
4.10.13. Aodh (alarming service) 로그 파일
| Service | 컨테이너 이름 | 로그 경로 |
|---|---|---|
| 알람 API | aodh_api | /var/log/containers/httpd/aodh-api/aodh_wsgi_access.log |
| 알람 평가자 로그 | aodh_evaluator | /var/log/containers/aodh/aodh-evaluator.log |
| 알람 리스너 | aodh_listener | /var/log/containers/aodh/aodh-listener.log |
| 알람 알림 | aodh_notifier | /var/log/containers/aodh/aodh-notifier.log |
4.10.14. gnocchi(지표 스토리지) 로그 파일
| Service | 컨테이너 이름 | 로그 경로 |
|---|---|---|
| Gnocchi API | gnocchi_api | /var/log/containers/httpd/gnocchi-api/gnocchi_wsgi_access.log |
| Gnocchi 지표 | gnocchi_metricd | /var/log/containers/gnocchi/gnocchi-metricd.log |
| Gnocchi statsd | gnocchi_statsd | /var/log/containers/gnocchi/gnocchi-statsd.log |
5장. collectd 플러그인
RHOSP(Red Hat OpenStack Platform) 16.1 환경에 따라 여러 collectd 플러그인을 구성할 수 있습니다.
다음 플러그인 목록은 기본값을 재정의하도록 설정할 수 있는 사용 가능한 heat 템플릿 ExtraConfig 매개변수를 보여줍니다. 각 섹션에는 ExtraConfig 옵션의 일반 구성 이름이 있습니다. 예를 들어 example_plugin 이라는 collectd 플러그인이 있는 경우 플러그인 제목의 형식은 collectd::plugin::example_plugin 입니다.
다음 예와 같이 특정 플러그인에 대한 사용 가능한 매개변수 테이블을 참조합니다.
ExtraConfig: collectd::plugin::example_plugin::<parameter>: <value>
Prometheus 또는 Grafana 쿼리에 대한 특정 플러그인의 지표 테이블을 참조합니다.
collectd::plugin::aggregation
집계 플러그인을 사용하여 여러 값을 하나로 집계 할 수 있습니다. sum,average,min, max 와 같은 집계 함수를 사용하여 평균 및 총 CPU 통계와 같은 메트릭을 계산합니다.
표 5.1. 집계 매개변수
| 매개변수 | 유형 |
|---|---|
| 호스트 | 문자열 |
| plugin | 문자열 |
| plugininstance | 정수 |
| agg_type | 문자열 |
| typeinstance | 문자열 |
| sethost | 문자열 |
| setplugin | 문자열 |
| setplugininstance | 정수 |
| settypeinstance | 문자열 |
| groupby | 문자열 배열 |
| calculatesum | 부울 |
| calculatenum | 부울 |
| calculateaverage | 부울 |
| calculateminimum | 부울 |
| calculatemaximum | 부울 |
| calculatestddev | 부울 |
설정 예:
세 개의 집계 구성을 배포하여 다음 파일을 생성합니다.
-
aggregator-calcCpuLoadAvg.conf: 호스트 및 상태별로 그룹화된 모든 CPU 코어의 평균 CPU 부하 -
aggregator-calcCpuLoadMinMax.conf: 호스트 및 상태별로 최소 및 최대 CPU 로드 그룹 -
aggregator-calcMemoryTotalMaxAvg.conf: 유형별로 그룹화된 메모리의 최대, 평균, 합계
집계 구성에서는 기본 CPU 및 메모리 플러그인 구성을 사용합니다.
parameter_defaults:
CollectdExtraPlugins:
- aggregation
ExtraConfig:
collectd::plugin::aggregation::aggregators:
calcCpuLoadAvg:
plugin: "cpu"
agg_type: "cpu"
groupby:
- "Host"
- "TypeInstance"
calculateaverage: True
calcCpuLoadMinMax:
plugin: "cpu"
agg_type: "cpu"
groupby:
- "Host"
- "TypeInstance"
calculatemaximum: True
calculateminimum: True
calcMemoryTotalMaxAvg:
plugin: "memory"
agg_type: "memory"
groupby:
- "TypeInstance"
calculatemaximum: True
calculateaverage: True
calculatesum: Truecollectd::plugin::amqp1
amqp1 플러그인을 사용하여 amqp1 메시지 버스(예: AMQ Interconnect)에 값을 작성합니다.
표 5.2. amqp1 매개변수
| 매개변수 | 유형 |
|---|---|
| manage_package | 부울 |
| 전송 | 문자열 |
| 호스트 | 문자열 |
| port | 정수 |
| user | 문자열 |
| 암호 | 문자열 |
| address | 문자열 |
| instances | hash |
| retry_delay | 정수 |
| send_queue_limit | 정수 |
| 간격 | 정수 |
send_queue_limit 매개변수를 사용하여 발신 지표 대기열의 길이를 제한합니다.
AMQP1 연결이 없는 경우 플러그인은 계속 메시지를 보내 보내며 이로 인해 바인딩되지 않은 메모리 소비가 발생할 수 있습니다. 기본값은 0이며, 발신 지표 대기열을 비활성화합니다.
메트릭이 누락된 경우 send_queue_limit 매개변수 값을 늘립니다.
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- amqp1
ExtraConfig:
collectd::plugin::amqp1::send_queue_limit: 5000
collectd::plugin::apache
apache 플러그인을 사용하여 Apache 웹 서버에서 제공하는 mod_status 플러그인에서 Apache 데이터를 수집합니다. 제공된 각 인스턴스에는 초 단위로지정된 간격 값이 있습니다. 인스턴스에 대한 시간 제한 간격 매개 변수를 제공하는 경우 값은 밀리초 단위입니다.
표 5.3. Apache 매개변수
| 매개변수 | 유형 |
|---|---|
| instances | hash |
| 간격 | 정수 |
| manage-package | 부울 |
| package_install_options | list |
표 5.4. Apache 인스턴스 매개변수
| 매개변수 | 유형 |
|---|---|
| url | HTTP URL |
| user | 문자열 |
| 암호 | 문자열 |
| verifypeer | 부울 |
| verifyhost | 부울 |
| cacert | AbsolutePath |
| sslciphers | 문자열 |
| timeout | 정수 |
설정 예:
이 예에서 인스턴스 이름은 localhost 이며, http://10.0.0.111/mod_status?auto 에서 Apache 웹 서버에 연결합니다. 상태 페이지가 플러그인과 호환되지 않는 유형으로 반환되지 않도록 URL 끝에 ?auto 를 추가해야 합니다.
parameter_defaults:
CollectdExtraPlugins:
- apache
ExtraConfig:
collectd::plugin::apache::instances:
localhost:
url: "http://10.0.0.111/mod_status?auto"추가 리소스
apache 플러그인 구성에 대한 자세한 내용은 apache 를 참조하십시오 .
collectd::plugin::battery
건전지 플러그인을 사용하여 랩톱의 나머지 용량, 전원 또는 대전기를 보고할 수 있습니다.
표 5.5. 브러시 매개변수
| 매개변수 | 유형 |
|---|---|
| values_percentage | 부울 |
| report_degraded | 부울 |
| query_state_fs | 부울 |
| 간격 | 정수 |
추가 리소스
건전지 플러그인 구성에 대한 자세한 내용은 건전지를 참조하십시오.
collectd::plugin::bind
bind 플러그인을 사용하여 DNS 서버에서 쿼리 및 응답에 대한 인코딩된 통계를 검색합니다. 플러그인은 collectd에 값을 제출합니다.
표 5.6. 매개변수 바인딩
| 매개변수 | 유형 |
|---|---|
| url | HTTP URL |
| memorystats | 부울 |
| opcodes | 부울 |
| parsetime | 부울 |
| qtypes | 부울 |
| resolverstats | 부울 |
| serverstats | 부울 |
| zonemaintstats | 부울 |
| views | array |
| 간격 | 정수 |
표 5.7. 바인딩 보기 매개변수
| 매개변수 | 유형 |
|---|---|
| name | 문자열 |
| qtypes | 부울 |
| resolverstats | 부울 |
| cacherrsets | 부울 |
| zones | 문자열 목록 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- bind
ExtraConfig:
collectd::plugins::bind:
url: http://localhost:8053/
memorystats: true
opcodes: true
parsetime: false
qtypes: true
resolverstats: true
serverstats: true
zonemaintstats: true
views:
- name: internal
qtypes: true
resolverstats: true
cacherrsets: true
- name: external
qtypes: true
resolverstats: true
cacherrsets: true
zones:
- "example.com/IN"
collectd::plugin::ceph
ceph 플러그인을 사용하여 ceph 데몬에서 데이터를 수집합니다.
표 5.8. Ceph 매개변수
| 매개변수 | 유형 |
|---|---|
| 데몬 | array |
| longrunavglatency | 부울 |
| 변환적 인디언트 유형 | 부울 |
| package_name | 문자열 |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::ceph::daemons:
- ceph-osd.0
- ceph-osd.1
- ceph-osd.2
- ceph-osd.3
- ceph-osd.4
OSD(오브젝트 스토리지 데몬)가 모든 노드에 없는 경우 OSD를 나열해야 합니다.
collectd를 배포하면 ceph 플러그인이 Ceph 노드에 추가됩니다. 배포에 실패하므로 Ceph 노드에 ceph 플러그인을 CollectdExtraPlugins 에 추가하지 마십시오.
추가 리소스
ceph 플러그인 구성에 대한 자세한 내용은 ceph 를 참조하십시오 .
collectd::plugins::cgroups
cgroups 플러그인을 사용하여 cgroup의 프로세스 정보를 수집합니다.
표 5.9. cgroups 매개변수
| 매개변수 | 유형 |
|---|---|
| ignore_selected | 부울 |
| 간격 | 정수 |
| cGroup | list |
추가 리소스
cgroups 플러그인 구성에 대한 자세한 내용은 cgroups 를 참조하십시오 .
collectd::plugin::connectivity
연결 플러그인을 사용하여 네트워크 인터페이스의 상태를 모니터링합니다.
나열된 인터페이스가 없는 경우 모든 인터페이스는 기본적으로 모니터링됩니다.
표 5.10. 연결 매개변수
| 매개변수 | 유형 |
|---|---|
| 인터페이스 | array |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::connectivity::interfaces:
- eth0
- eth1
추가 리소스
연결 플러그인 구성에 대한 자세한 내용은 연결을 참조하십시오.
collectd::plugin::conntrack
conntrack 플러그인을 사용하여 Linux connection-tracking 테이블의 항목 수를 추적합니다. 이 플러그인에 대한 매개 변수는 없습니다.
collectd::plugin::contextswitch
ContextSwitch 플러그인을 사용하여 시스템이 처리하는 컨텍스트 스위치 수를 수집합니다. 사용 가능한 유일한 매개 변수는 간격 이며, 이는 초 단위로 정의된 폴링 간격입니다.
추가 리소스
contextswitch 플러그인 구성에 대한 자세한 내용은 contextswitch 를 참조하십시오.
collectd::plugin::cpu
cpu 플러그인을 사용하여 CPU가 다양한 상태(예: 유휴, 사용자 코드 실행, 시스템 코드 실행, IO 작동 대기) 및 기타 상태를 모니터링하는 시간을 모니터링합니다.
cpu 플러그인은 백분율 값이 아닌 jiffies 를 수집합니다. jiffy 값은 하드웨어 플랫폼의 클럭 빈도에 따라 달라지므로 절대 시간 간격 단위가 아닙니다.
백분율 값을 보고하려면 부울 매개변수 reportbycpu 및 reportbystate 를 true 로 설정한 다음 부울 매개변수 값을 true로 설정합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.11. CPU 메트릭
| 이름 | 설명 | query |
|---|---|---|
| idle | 유휴 시간 초과 |
|
| 인터럽트 | 인터럽트에 의해 차단된 CPU |
|
| nice | 우선순위가 낮은 프로세스 실행 시간 |
|
| softirq | 인터럽트 요청을 처리하는 데 사용되는 사이클의 양 |
|
| steal | 하이퍼바이저가 다른 가상 프로세서를 서비스하는 동안 가상 CPU가 실제 CPU를 대기하는 시간의 백분율입니다. |
|
| 시스템 | 시스템 수준에서 사용된 시간(커널) |
|
| user | 사용자 프로세스에서 사용하는 예 |
|
| wait | 미결한 I/O 요청에서 대기 중인 CPU |
|
표 5.12. CPU 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| reportbystate | 부울 | true |
| 값 Percentage | 부울 | true |
| reportbycpu | 부울 | true |
| reportnumcpu | 부울 | false |
| reportgueststate | 부울 | false |
| subtractgueststate | 부울 | true |
| 간격 | 정수 | 120 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- cpu
ExtraConfig:
collectd::plugin::cpu::reportbystate: true
추가 리소스
cpu 플러그인 구성에 대한 자세한 내용은 cpu 를 참조하십시오 .
collectd::plugin::cpufreq
cpufreq 플러그인을 사용하여 현재 CPU 빈도를 수집합니다. 이 플러그인에 대한 매개 변수는 없습니다.
collectd::plugin::csv
csv 플러그인을 사용하여 CSV 형식으로 로컬 파일에 값을 씁니다.
표 5.13. CSV 매개변수
| 매개변수 | 유형 |
|---|---|
| datadir | 문자열 |
| storerates | 부울 |
| 간격 | 정수 |
collectd::plugin::df
df 플러그인을 사용하여 파일 시스템의 디스크 공간 사용 정보를 수집합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.14. DF 지표
| 이름 | 설명 | query |
|---|---|---|
| free | 디스크 여유 공간 크기 |
|
| reserved | 예약된 디스크 공간 |
|
| 사용됨 | 사용된 디스크 공간의 양 |
|
표 5.15. DF 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| devices | array |
|
| fstypes | array |
|
| ignoreselected | 부울 | true |
| 마운트 지점 | array |
|
| reportbydevice | 부울 | true |
| reportinodes | 부울 | true |
| reportreserved | 부울 | true |
| valuesabsolute | 부울 | true |
| 값 Percentage | 부울 | false |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::df::fstypes: ['tmpfs','xfs']
추가 리소스
df 플러그인 구성에 대한 자세한 내용은 df 를 참조하십시오 .
collectd::plugin::disk
디스크 플러그인을 사용하여 하드 디스크 및 지원되는 파티션의 성능 통계를 수집합니다.
모든 디스크는 기본적으로 모니터링됩니다. ignoreselected 매개변수를 사용하여 디스크 목록을 무시할 수 있습니다. 예제 구성에서는 sda,sdb 및 sdc 디스크를 무시하고 목록에 포함되지 않은 모든 디스크를 모니터링합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.16. disk 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| 디스크 | array |
|
| ignoreselected | 부울 | false |
| udevnameattr | 문자열 | <undefined> |
표 5.17. 디스크 메트릭
| 이름 | 설명 |
|---|---|
| merged | 함께 병합할 수 있는 대기 중인 작업 수(예: 하나의 물리적 디스크 액세스에서 두 개 이상의 논리 작업 제공) |
| time | I/O 작업을 완료하는 데 걸리는 평균 시간입니다. 값이 정확하지 않을 수 있습니다. |
| io_time | I/O(ms)를 수행하는 데 소요되는 시간. 이 메트릭을 장치 부하 백분율로 사용할 수 있습니다. 1초의 값은 부하의 100%와 일치합니다. |
| weighted_io_time | I/O 완료 시간과 누적될 수 있는 백로그를 모두 측정합니다. |
| pending_operations | 보류 중인 I/O 작업의 대기열 크기를 표시합니다. |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::disk::disks: ['sda', 'sdb', 'sdc']
collectd::plugin::disk::ignoreselected: true
추가 리소스
디스크 플러그인 구성에 대한 자세한 내용은 디스크를 참조하십시오.
collectd::plugin::hugepages
hugepages 플러그인을 사용하여 hugepages 정보를 수집합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.18. hugepages 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| report_per_node_hp | 부울 | true |
| report_root_hp | 부울 | true |
| values_pages | 부울 | true |
| values_bytes | 부울 | false |
| values_percentage | 부울 | false |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::hugepages::values_percentage: true
추가 리소스
-
hugepages 플러그인 구성에 대한 자세한 내용은 hugepages를 참조하십시오.
collectd::plugin::interface
인터페이스 플러그인을 사용하여 octets의 인터페이스 트래픽, 초당 패킷, 초당 오류 속도를 측정합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.19. 인터페이스 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| 인터페이스 | array |
|
| ignoreselected | 부울 | false |
| reportinactive | 부울 | true |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::interface::interfaces:
- lo
collectd::plugin::interface::ignoreselected: true
추가 리소스
-
인터페이스플러그인 구성에 대한 자세한 내용은 인터페이스를 참조하십시오.
collectd::plugin::load
load 플러그인을 사용하여 시스템 로드와 시스템 사용 개요를 수집합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.20. 플러그인 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| report_relative | 부울 | true |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::load::report_relative: false
추가 리소스
-
load 플러그인 구성에 대한 자세한 내용은 load를 참조하십시오.
collectd::plugin::mcelog
mcelog 플러그인을 사용하여 시스템 검사 예외가 발생할 때 발생하는 알림 및 통계를 보냅니다. 데몬 모드에서 실행되도록 mcelog 를 구성하고 로깅 기능을 활성화합니다.
표 5.21. mcelog 매개변수
| 매개변수 | 유형 |
|---|---|
| Mcelogfile | 문자열 |
| 메모리 |
hash |
설정 예:
parameter_defaults:
CollectdExtraPlugins: mcelog
CollectdEnableMcelog: true
추가 리소스
-
mcelog플러그인 구성에 대한 자세한 내용은 mcelog 를 참조하십시오.
collectd::plugin::memcached
memcached 플러그인을 사용하여 memcached 캐시 사용량, 메모리 및 기타 관련 정보에 대한 정보를 검색합니다.
표 5.22. Memcached 매개변수
| 매개변수 | 유형 |
|---|---|
| instances | hash |
| 간격 | 정수 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- memcached
ExtraConfig:
collectd::plugin::memcached::instances:
local:
host: "%{hiera('fqdn_canonical')}"
port: 11211
추가 리소스
-
memcached플러그인 구성에 대한 자세한 내용은 memcached 를 참조하십시오.
collectd::plugin::memory
메모리 플러그인을 사용하여 시스템의 메모리 정보를 검색합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.23. 메모리 매개변수
| 매개변수 | 유형 |
|---|---|
| 기본값 | valuesabsolute |
| 부울 | true |
| 값 Percentage | 부울 |
설정 예:
parameter_defaults:
ExtraConfig:
collectd::plugin::memory::valuesabsolute: true
collectd::plugin::memory::valuespercentage: false
추가 리소스
-
메모리플러그인 구성에 대한 자세한 내용은 메모리를 참조하십시오.
collectd::plugin::ntpd
statistical 플러그인 을 사용하여 통계에 대한 액세스를 허용하고 구성된 매개 변수 및 시간 동기화 상태에 대한 정보를 검색하도록 구성된 로컬 NTP 서버를 쿼리합니다.
표 5.24. NoExecute 매개변수
| 매개변수 | 유형 |
|---|---|
| 호스트 | 호스트 이름 |
| port | 포트 번호(정수) |
| reverselookups | 부울 |
| includeunitid | 부울 |
| 간격 | 정수 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- ntpd
ExtraConfig:
collectd::plugin::ntpd::host: localhost
collectd::plugin::ntpd::port: 123
collectd::plugin::ntpd::reverselookups: false
collectd::plugin::ntpd::includeunitid: false
추가 리소스
-
dotnet 플러그인 구성에 대한 자세한 내용은
pxe;을 참조하십시오.
collectd::plugin::ovs_stats
ovs_stats 플러그인을 사용하여 OVS 연결 인터페이스의 통계를 수집합니다. ovs_stats 플러그인은 OVSDB 관리 프로토콜(RFC7047) 모니터 메커니즘을 사용하여 OVSDB에서 통계를 가져옵니다.
표 5.25. ovs_stats parameters
| 매개변수 | 유형 |
|---|---|
| address | 문자열 |
| bridge | list |
| port | 정수 |
| socket | 문자열 |
설정 예:
다음 예제에서는 ovs_stats 플러그인을 활성화하는 방법을 보여줍니다. OVS를 사용하여 오버클라우드를 배포하는 경우 ovs_stats 플러그인을 활성화할 필요가 없습니다.
parameter_defaults:
CollectdExtraPlugins:
- ovs_stats
ExtraConfig:
collectd::plugin::ovs_stats::socket: '/run/openvswitch/db.sock'추가 리소스
-
ovs_stats플러그인 구성에 대한 자세한 내용은 ovs_stats 를 참조하십시오.
collectd::plugin::processes
프로세스 플러그인은 시스템 프로세스에 대한 정보를 제공합니다. 프로세스 일치를 지정하지 않으면 플러그인은 프로세스 수와 프로세스 포크 비율만 수집합니다.
특정 프로세스에 대한 자세한 정보를 수집하려면 process 매개변수를 사용하여 프로세스 이름 또는 process_match 옵션을 사용하여 정규 표현식과 일치하는 프로세스 이름을 지정할 수 있습니다. process_match 출력에 대한 통계는 프로세스 이름으로 그룹화됩니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.26. 플러그인 매개변수
| 매개변수 | 유형 | 기본값 |
|---|---|---|
| 프로세스 | array | <undefined> |
| process_matches | array | <undefined> |
| collect_context_switch | 부울 | <undefined> |
| collect_file_descriptor | 부울 | <undefined> |
| collect_memory_maps | 부울 | <undefined> |
추가 리소스
-
프로세스 플러그인 구성에 대한 자세한 내용은 프로세스를 참조하십시오.
collectd::plugin::smart
스마트 플러그인을 사용하여 노드의 물리적 디스크에서 SMART 정보를 수집합니다. 스마트 플러그인이 SMART Telemetry를 읽을 수 있도록 매개 변수 CollectdContainerTotalCapAdd 를 CAP_SYS_RAWIO 에 설정해야 합니다. CollectdContaineradditionalCapAdd 매개변수를 설정하지 않으면 collectd 오류 로그에 다음 메시지가 기록됩니다.
스마트 플러그인: collectd를 root로 실행했지만 CAP_SYS_RAWIO 기능이 없습니다. 플러그인의 읽기 기능은 실패할 수 있습니다. init 시스템이 기능을 삭제합니까?.
표 5.27. 스마트 매개변수
| 매개변수 | 유형 |
|---|---|
| 디스크 | array |
| ignoreselected | 부울 |
| 간격 | 정수 |
설정 예:
parameter_defaults: CollectdExtraPlugins: - smart CollectdContainerAdditionalCapAdd: "CAP_SYS_RAWIO"
추가 정보
-
스마트 플러그인 구성에 대한 자세한 내용은
스마트플러그인을 참조하십시오. https://collectd.org/documentation/manpages/collectd.conf.5.shtml#plugin_smart
collectd::plugin::swap
스왑 플러그인을 사용하여 사용 가능하고 사용된 스왑 공간에 대한 정보를 수집합니다.
표 5.28. 스왑 매개변수
| 매개변수 | 유형 |
|---|---|
| reportbydevice | 부울 |
| reportbytes | 부울 |
| valuesabsolute | 부울 |
| 값 Percentage | 부울 |
| reportio | 부울 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- swap
ExtraConfig:
collectd::plugin::swap::reportbydevice: false
collectd::plugin::swap::reportbytes: true
collectd::plugin::swap::valuesabsolute: true
collectd::plugin::swap::valuespercentage: false
collectd::plugin::swap::reportio: true
collectd::plugin::tcpconns
tcpconns 플러그인을 사용하여 구성된 포트에서 인바운드 또는 아웃바운드 연결 수에 대한 정보를 수집합니다. 로컬 포트 구성은 포트에 대한 인바운드 연결을 나타냅니다. 원격 포트 구성은 포트의 아웃바운드 연결을 나타냅니다.
표 5.29. tcpconns 매개변수
| 매개변수 | 유형 |
|---|---|
| localports | 포트(Array) |
| remoteports | 포트(Array) |
| 수신 대기 | 부울 |
| allportssummary | 부울 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- tcpconns
ExtraConfig:
collectd::plugin::tcpconns::listening: false
collectd::plugin::tcpconns::localports:
- 22
collectd::plugin::tcpconns::remoteports:
- 22
collectd::plugin::thermal
rmal 플러그인을 사용하여 ACPI thermal 영역 정보를 검색합니다.
표 5.30. 열 매개변수
| 매개변수 | 유형 |
|---|---|
| devices | array |
| ignoreselected | 부울 |
| 간격 | 정수 |
설정 예:
parameter_defaults: CollectdExtraPlugins: - thermal
collectd::plugin::uptime
uptime 플러그인을 사용하여 시스템 가동 시간에 대한 정보를 수집합니다.
이 플러그인은 기본적으로 활성화되어 있습니다.
표 5.31. uptime 매개변수
| 매개변수 | 유형 |
|---|---|
| 간격 | 정수 |
collectd::plugin::virt
virt 플러그인을 사용하여 호스트의 가상 시스템의 libvirt API를 통해 CPU, 디스크, 네트워크 로드 및 기타 지표를 수집합니다.
이 플러그인은 컴퓨팅 호스트에서 기본적으로 활성화되어 있습니다.
표 5.32. virt 매개변수
| 매개변수 | 유형 |
|---|---|
| 연결 | 문자열 |
| refresh_interval | hash |
| domain | 문자열 |
| block_device | 문자열 |
| interface_device | 문자열 |
| ignore_selected | 부울 |
| plugin_instance_format | 문자열 |
| hostname_format | 문자열 |
| interface_format | 문자열 |
| extra_stats | 문자열 |
설정 예:
ExtraConfig: collectd::plugin::virt::hostname_format: "name uuid hostname" collectd::plugin::virt::plugin_instance_format: metadata
추가 리소스
virt 플러그인 구성에 대한 자세한 내용은 virt 을 참조하십시오 .
collectd::plugin::vmem
vmem 플러그인을 사용하여 커널 하위 시스템에서 가상 메모리에 대한 정보를 수집합니다.
표 5.33. vmem 매개변수
| 매개변수 | 유형 |
|---|---|
| verbose | 부울 |
| 간격 | 정수 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- vmem
ExtraConfig:
collectd::plugin::vmem::verbose: true
collectd::plugin::write_http
write_http 출력 플러그인을 사용하여 POST 요청 및 JSON으로 지표를 인코딩하거나 PUTVAL 명령을 사용하여 HTTP 서버에 값을 제출합니다.
표 5.34. write_http 매개변수
| 매개변수 | 유형 |
|---|---|
| 확인 | enum[present,absent] |
| 노드 | hash[String, Hash[String, Scalar]] |
| URL | hash[String, Hash[String, Scalar]] |
| manage_package | 부울 |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- write_http
ExtraConfig:
collectd::plugin::write_http::nodes:
collectd:
url: “http://collectd.tld.org/collectd”
metrics: true
header: “X-Custom-Header: custom_value"
추가 리소스
-
write_http플러그인 구성에 대한 자세한 내용은 write_http 를 참조하십시오.
collectd::plugin::write_kafka
write_kafka 플러그인을 사용하여 값을 Kafka 항목에 보냅니다. 하나 이상의 주제 블록을 사용하여 write_kafka 플러그인을 구성합니다. 각 topic 블록에 대해 고유한 이름과 하나의 Kafka 생산자를 지정해야 합니다. topic 블록 내에서 다음 항목별 매개변수를 사용할 수 있습니다.
표 5.35. write_kafka parameters
| 매개변수 | 유형 |
|---|---|
| kafka_hosts | array[String] |
| 주제 | hash |
| 속성 | hash |
| meta | hash |
설정 예:
parameter_defaults:
CollectdExtraPlugins:
- write_kafka
ExtraConfig:
collectd::plugin::write_kafka::kafka_hosts:
- remote.tld:9092
collectd::plugin::write_kafka::topics:
mytopic:
format: JSON
추가 리소스:
write_kafka 플러그인을 구성하는 방법에 대한 자세한 내용은 write_kafka 를 참조하십시오.