로깅, 모니터링 및 문제 해결 가이드
OpenStack 로깅, 모니터링 및 문제 해결을 위한 심화 가이드
초록
보다 포괄적 수용을 위한 오픈 소스 용어 교체
Red Hat은 코드, 문서, 웹 속성에서 문제가 있는 용어를 교체하기 위해 최선을 다하고 있습니다. 먼저 마스터(master), 슬레이브(slave), 블랙리스트(blacklist), 화이트리스트(whitelist) 등 네 가지 용어를 교체하고 있습니다. 이러한 변경 작업은 작업 범위가 크므로 향후 여러 릴리스에 걸쳐 점차 구현할 예정입니다. 자세한 내용은 CTO Chris Wright의 메시지를 참조하십시오.
Red Hat 문서에 관한 피드백 제공
문서 개선을 위한 의견을 보내 주십시오. Red Hat이 어떻게 이를 개선하는지 알려주십시오.
DDF(직접 문서 피드백) 기능 사용
특정 문장, 단락 또는 코드 블록에 대한 직접 주석은 피드백 추가 DDF 기능을 사용하십시오.
- 다중 페이지 HTML 형식으로 설명서를 봅니다.
- 문서 오른쪽 상단에 Feedback (피드백) 버튼이 표시되는지 확인합니다.
- 주석 처리하려는 텍스트 부분을 강조 표시합니다.
- 피드백 추가를 클릭합니다.
- 주석을 사용하여 Add Feedback (피드백 추가) 필드를 작성합니다.
- 선택 사항: 설명서 팀이 문제에 대한 자세한 내용을 문의할 수 있도록 이메일 주소를 추가하십시오.
- Submit(제출)을 클릭합니다.
1장. 이 가이드 정보
Red Hat은 현재 이 릴리스에 대한 본 가이드에서 제공하는 정보 및 절차를 검토하고 있습니다.
이 문서는 Red Hat OpenStack Platform 12 문서를 기반으로 하며 로깅, 모니터링 및 문제 해결 가이드에서 확인할 수 있습니다.
현재 Red Hat OpenStack Platform 릴리스에 대한 지원이 필요한 경우 Red Hat 지원팀에 문의하십시오.
2장. 로그 서비스 설치 및 구성
RHOSP(Red Hat OpenStack Platform)는 특정 로그 파일에 정보 메시지를 작성합니다. 이러한 메시지를 사용하여 시스템 이벤트 문제를 해결하고 모니터링할 수 있습니다. 로그 수집 에이전트 Rsyslog는 클라이언트 측에서 로그를 수집하고 이러한 로그를 서버 측에서 실행 중인 Rsyslog 인스턴스로 전송합니다. 서버 측 Rsyslog 인스턴스는 스토리지를 위해 로그 레코드를 Elasticsearch로 리디렉션합니다.
개별 로그 파일을 지원 사례에 수동으로 연결할 필요는 없습니다. sosreport 유틸리티는 필요한 로그를 자동으로 수집합니다.
2.1. 중앙 집중식 로그 시스템 아키텍처 및 구성 요소
모니터링 툴은 RHOSP(Red Hat OpenStack Platform) Overcloud 노드에 배포된 클라이언트와 함께 클라이언트-서버 모델을 사용합니다. Rsyslog 서비스는 클라이언트 쪽 중앙 집중식 로깅(CL)을 제공합니다.
모든 RHOSP 서비스는 로그 파일을 생성하고 업데이트합니다. 이러한 로그 파일은 작업, 오류, 경고 및 기타 이벤트를 기록합니다. OpenStack과 같은 분산 환경에서는 중앙 위치에서 이러한 로그를 수집하면 디버깅 및 관리를 단순화합니다.
중앙 집중식 로깅을 사용하면 전체 RHOSP 환경에서 로그를 볼 수 있는 중앙 지점 하나가 있습니다. 이러한 로그는 syslog 및 감사 로그 파일, 인프라 구성 요소(예: RabbitMQ 및 MariaDB) 및 ID, 계산 등의 OpenStack 서비스와 같은 운영 체제에서 가져옵니다. 중앙 집중식 로깅 툴체인은 다음 구성 요소로 구성됩니다.
- 로그 컬렉션 에이전트(Rsyslog)
- 데이터 저장소(ElasticSearch)
- API/Presentation Layer(Grafana)
Red Hat OpenStack Platform director는 중앙 집중식 로깅을 위한 서버 측 구성 요소를 배포하지 않습니다. Red Hat은 Elasticsearch 데이터베이스 및 Grafana를 포함한 서버 측 구성 요소를 지원하지 않습니다.
2.2. Elasticsearch를 사용하여 중앙 집중식 로깅 활성화
중앙 집중식 로깅을 사용하려면 OS::TripleO::Services::Rsyslog 구성 가능 서비스의 구현을 지정해야 합니다.
Rsyslog 서비스는 중앙 집중식 로깅을 위해 데이터 저장소로 Elasticsearch만 사용합니다.
사전 요구 사항
- Elasticsearch는 서버측에 설치되어 있습니다.
절차
다음 예와 같이 사용자 환경 및
배포와 관련된 다른 환경 파일과 함께 오버클라우드배포 명령에 로깅 환경 파일의 파일 경로를 추가합니다.openstack overcloud deploy \ <existing_overcloud_environment_files> \ -e /usr/share/openstack-tripleo-heat-templates/environments/logging-environment-rsyslog.yaml
<existing_overcloud_environment_files>를 기존 배포의 일부인 환경 파일 목록으로 바꿉니다.
2.3. 로깅 기능 구성
로깅 기능을 구성하려면 logging-environment-rsyslog.yaml 파일에서 RsyslogElasticsearchSetting 매개변수를 수정합니다.
절차
-
tripleo-heat-templates/environments/logging-environment-rsyslog.yaml파일을 홈 디렉터리에 복사합니다. 환경에 맞게
RsyslogElasticsearchSetting매개변수에 항목을 생성합니다. 다음 스니펫은RsyslogElasticsearchSetting매개변수 구성의 예입니다.parameter_defaults: RsyslogElasticsearchSetting: uid: "elastic" pwd: "yourownpassword" skipverifyhost: "on" allowunsignedcerts: "on" server: "https://log-store-service-telemetry.apps.stfcloudops1.lab.upshift.rdu2.redhat.com" serverport: 443
추가 리소스
- 구성 가능한 매개변수에 대한 자세한 내용은 2.3.1절. “구성 가능한 로깅 매개변수” 을 참조하십시오.
2.3.1. 구성 가능한 로깅 매개변수
이 표에는 RHOSP(Red Hat OpenStack Platform)에서 로깅 기능을 구성하는 데 사용하는 로깅 매개변수에 대한 설명이 포함되어 있습니다. 이러한 매개변수는 tripleo-heat-templates/deployment/logging/rsyslog-container-puppet.yaml 파일에서 찾을 수 있습니다.
표 2.1. 구성 가능한 로깅 매개변수
| 매개변수 | 설명 |
|---|---|
|
|
|
|
| Elasticsearch 서버 인증서를 발급한 CA의 CA 인증서 내용을 포함합니다. |
|
| Elasticsearch에 대해 클라이언트 인증서 인증을 수행하기 위한 클라이언트 인증서의 내용을 포함합니다. |
|
|
인증서 |
2.4. 로그 파일의 기본 경로 재정의
기본 컨테이너를 수정하고 수정 사항에 서비스 로그 파일의 경로가 포함된 경우 기본 로그 파일 경로도 수정해야 합니다. 구성 가능한 모든 서비스에는 <service_name>LoggingSource 매개변수가 있습니다. 예를 들어 nova-compute 서비스의 경우 매개 변수는 NovaComputeLoggingSource 입니다.
절차
nova-compute 서비스의 기본 경로를 재정의하려면 구성 파일의
NovaComputeLoggingSource매개변수에 대한 경로를 추가합니다.NovaComputeLoggingSource: tag: openstack.nova.compute file: /some/other/path/nova-compute.log참고각 서비스에 대해
태그와파일을정의합니다. 다른 값은 기본적으로 파생됩니다.특정 서비스의 형식을 수정할 수 있습니다. 이는 Rsyslog 구성에 직접 전달됩니다.
LoggingDefaultFormat매개변수의 기본 형식은 /(?<time>\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}입니다.\d+) (?< PID>\d+) (?<priority>\S+) (?<message>.*)$/다음 구문을 사용하십시오.<service_name>LoggingSource: tag: <service_name>.tag path: <service_name>.path format: <service_name>.format다음 코드 조각은 더 복잡한 변환의 예입니다.
ServiceLoggingSource: tag: openstack.Service path: /var/log/containers/service/service.log format: multiline format_firstline: '/^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}.\d{3} \d+ \S+ \S+ \[(req-\S+ \S+ \S+ \S+ \S+ \S+|-)\]/' format1: '/^(?<Timestamp>\S+ \S+) (?<Pid>\d+) (?<log_level>\S+) (?<python_module>\S+) (\[(req-(?<request_id>\S+) (?<user_id>\S+) (?<tenant_id>\S+) (?<domain_id>\S+) (?<user_domain>\S+) (?<project_domain>\S+)|-)\])? (?<Payload>.*)?$/'
2.5. 로그 레코드 형식 수정
특정 서비스의 로그 레코드 시작 형식을 수정할 수 있습니다. 이는 Rsyslog 구성에 직접 전달됩니다.
RHOSP(Red Hat OpenStack Platform) 로그 레코드의 기본 형식은 ('^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ [0-9]+)? (DEBUG|INFO|WARNING|ERROR) ').
절차
로그 레코드 시작을 구문 분석하기 위해 다른 정규 표현식을 추가하려면 구성에
startmsg.regex를 추가합니다.NovaComputeLoggingSource: tag: openstack.nova.compute file: /some/other/path/nova-compute.log startmsg.regex: "^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ \\+[0-9]+)? [A-Z]+ \\([a-z]+\\)
2.6. Rsyslog와 Elasticsearch 간 연결 테스트
클라이언트 측에서 Rsyslog와 Elasticsearch 간의 통신을 확인할 수 있습니다.
절차
-
Rsyslog 컨테이너의 Elasticsearch 연결 로그 파일
/var/log/rsyslog/omelasticsearch.log또는 호스트의/var/log/containers/rsyslog/omelasticsearch.log로 이동합니다. 이 로그 파일이 없거나 로그 파일이 있지만 로그가 포함되지 않은 경우 연결 문제가 없습니다. 로그 파일이 있고 로그를 포함하는 경우 Rsyslog가 성공적으로 연결되지 않았습니다.
서버 측에서 연결을 테스트하려면 Elasticsearch 로그를 확인하여 연결 문제를 확인합니다.
2.7. 서버 측 로깅
Elasticsearch 클러스터가 실행 중인 경우, 오버클라우드 노드에서 실행 중인 Rsysloglog를 연결하려면 매개변수를 구성해야 합니다. logging-environment-rsyslog.yaml 파일에서 RsyslogElasticsearchSettingRsyslogElasticsearchSetting 매개변수를 구성하려면 https://www.rsyslog.com/doc/v8-stable/configuration/modules/omelasticsearch.html을 참조하십시오.
2.8. tracebacks
문제가 발생하고 문제를 해결하기 시작하면 역추적 로그를 사용하여 문제를 진단할 수 있습니다. 로그 파일에서 역추적에는 일반적으로 여러 줄의 정보가 있으며 모두 동일한 문제와 관련이 있습니다.
rsyslog는 로그 레코드가 시작되는 방식을 정의하는 정규 표현식을 제공합니다. 각 로그 레코드는 일반적으로 타임스탬프로 시작하며, 추적의 첫 번째 행은 이 정보가 포함된 유일한 행입니다. rsyslog는 들여쓰기된 레코드를 첫 번째 행과 함께 번들로 전송하며 하나의 로그 레코드로 전송합니다.
이 동작의 경우 <Service>LoggingSource의 startmsg.regex 가 사용됩니다. 다음 정규 표현식은 director의 모든 <service>LoggingSource 매개변수의 기본값입니다.
startmsg.regex='^[0-9]{4}-[0-9]{2}-[0-9]{2} [0-9]{2}:[0-9]{2}:[0-9]{2}(.[0-9]+ [0-9]+)? (DEBUG|INFO|WARNING|ERROR) '
이 기본값이 추가되거나 수정된 LoggingSource 의 로그 레코드와 일치하지 않는 경우 startmsg.regex 를 적절하게 변경해야 합니다.
2.9. OpenStack 서비스의 로그 파일 위치
각 OpenStack 구성 요소에는 실행 중인 서비스와 관련된 파일이 들어 있는 별도의 로깅 디렉터리가 있습니다.
2.9.1. 베어 메탈 프로비저닝(ironic) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Ironic API | openstack-ironic-api.service | /var/log/containers/ironic/ironic-api.log |
| OpenStack Ironic Conductor | openstack-ironic-conductor.service | /var/log/containers/ironic/ironic-conductor.log |
2.9.2. Block Storage(cinder) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 블록 스토리지 API | openstack-cinder-api.service | /var/log/containers/cinder-api.log |
| 블록 스토리지 백업 | openstack-cinder-backup.service | /var/log/containers/cinder/backup.log |
| 정보 메시지 | cinder-manage 명령 | /var/log/containers/cinder/cinder-manage.log |
| 블록 스토리지 스케줄러 | openstack-cinder-scheduler.service | /var/log/containers/cinder/scheduler.log |
| 블록 스토리지 볼륨 | openstack-cinder-volume.service | /var/log/containers/cinder/volume.log |
2.9.3. Compute(nova) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Compute API 서비스 | openstack-nova-api.service | /var/log/containers/nova/nova-api.log |
| OpenStack Compute 인증서 서버 | openstack-nova-cert.service | /var/log/containers/nova/nova-cert.log |
| OpenStack Compute 서비스 | openstack-nova-compute.service | /var/log/containers/nova/nova-compute.log |
| OpenStack Compute Conductor 서비스 | openstack-nova-conductor.service | /var/log/containers/nova/nova-conductor.log |
| OpenStack Compute VNC 콘솔 인증 서버 | openstack-nova-consoleauth.service | /var/log/containers/nova/nova-consoleauth.log |
| 정보 메시지 | nova-manage 명령 | /var/log/containers/nova/nova-manage.log |
| OpenStack Compute NoVNC Proxy 서비스 | openstack-nova-novncproxy.service | /var/log/containers/nova/nova-novncproxy.log |
| OpenStack Compute Scheduler 서비스 | openstack-nova-scheduler.service | /var/log/containers/nova/nova-scheduler.log |
2.9.4. 대시보드(horizon) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 특정 사용자 상호 작용 로그 | 대시보드 인터페이스 | /var/log/containers/horizon/horizon.log |
Apache HTTP 서버는 웹 브라우저 또는 명령줄 클라이언트(예: keystone 및 nova)를 사용하여 액세스할 수 있는 대시보드 웹 인터페이스에 몇 가지 추가 로그 파일을 사용합니다. 다음 표의 로그 파일은 대시보드 사용을 추적하고 오류를 진단하는 데 유용할 수 있습니다.
| 목적 | 로그 경로 |
|---|---|
| 처리된 모든 HTTP 요청 | /var/log/containers/httpd/horizon_access.log |
| HTTP 오류 | /var/log/containers/httpd/horizon_error.log |
| admin-role API 요청 | /var/log/containers/httpd/keystone_wsgi_admin_access.log |
| 관리자 역할 API 오류 | /var/log/containers/httpd/keystone_wsgi_admin_error.log |
| 멤버 역할 API 요청 | /var/log/containers/httpd/keystone_wsgi_main_access.log |
| 멤버 역할 API 오류 | /var/log/containers/httpd/keystone_wsgi_main_error.log |
동일한 호스트에서 실행 중인 다른 웹 서비스에서 보고한 오류를 저장하는 /var/log/containers/httpd/default_error.log 도 있습니다.
2.9.5. ID 서비스(keystone) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Identity Service | openstack-keystone.service | /var/log/containers/keystone/keystone.log |
2.9.6. Image 서비스(glance) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Image Service API 서버 | openstack-glance-api.service | /var/log/containers/glance/api.log |
| OpenStack 이미지 서비스 레지스트리 서버 | openstack-glance-registry.service | /var/log/containers/glance/registry.log |
2.9.7. 네트워킹(neutron) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Neutron DHCP 에이전트 | neutron-dhcp-agent.service | /var/log/containers/neutron/dhcp-agent.log |
| OpenStack Networking Layer 3 에이전트 | neutron-l3-agent.service | /var/log/containers/neutron/l3-agent.log |
| 메타데이터 에이전트 서비스 | neutron-metadata-agent.service | /var/log/containers/neutron/metadata-agent.log |
| 메타데이터 네임스페이스 프록시 | 해당 없음 | /var/log/containers/neutron/neutron-ns-metadata-proxy-UUID.log |
| Open vSwitch 에이전트 | neutron-openvswitch-agent.service | /var/log/containers/neutron/openvswitch-agent.log |
| OpenStack Networking 서비스 | neutron-server.service | /var/log/containers/neutron/server.log |
2.9.8. Object Storage(swift) 로그 파일
OpenStack 오브젝트 스토리지는 로그를 시스템 로깅 기능으로만 전송합니다.
기본적으로 모든 오브젝트 스토리지 로그 파일은 local0, local1 및 local2 syslog 기능을 사용하여 /var/log/containers/swift/swift.log 로 이동합니다.
오브젝트 스토리지의 로그 메시지는 REST API 서비스별 두 가지 범주와 백그라운드 데몬별로 분류됩니다. API 서비스 메시지에는 널리 사용되는 HTTP 서버와 유사한 방식으로 API 요청당 한 줄이 포함되어 있습니다. 프론트엔드(Proxy) 및 백엔드(Account, Container, Object) 서비스는 이러한 메시지를 게시합니다. 데몬 메시지는 덜 구조화되지 않으며 일반적으로 정기적인 작업을 수행하는 데몬에 대한 사람이 읽을 수 있는 정보가 포함됩니다. 그러나 메시지를 생성하는 오브젝트 스토리지의 일부에 관계없이 소스 ID는 항상 행의 시작 부분에 있습니다.
프록시 메시지의 예는 다음과 같습니다.
Apr 20 15:20:34 rhev-a24c-01 proxy-server: 127.0.0.1 127.0.0.1 20/Apr/2015/19/20/34 GET /v1/AUTH_zaitcev%3Fformat%3Djson%26marker%3Dtestcont HTTP/1.0 200 - python-swiftclient-2.1.0 AUTH_tk737d6... - 2 - txc454fa8ea4844d909820a-0055355182 - 0.0162 - - 1429557634.806570053 1429557634.822791100
다음은 백그라운드 데몬의 애드혹 메시지의 예입니다.
Apr 27 17:08:15 rhev-a24c-02 object-auditor: Object audit (ZBF). Since Mon Apr 27 21:08:15 2015: Locally: 1 passed, 0 quarantined, 0 errors files/sec: 4.34 , bytes/sec: 0.00, Total time: 0.23, Auditing time: 0.00, Rate: 0.00 Apr 27 17:08:16 rhev-a24c-02 object-auditor: Object audit (ZBF) "forever" mode completed: 0.56s. Total quarantined: 0, Total errors: 0, Total files/sec: 14.31, Total bytes/sec: 0.00, Auditing time: 0.02, Rate: 0.04 Apr 27 17:08:16 rhev-a24c-02 account-replicator: Beginning replication run Apr 27 17:08:16 rhev-a24c-02 account-replicator: Replication run OVER Apr 27 17:08:16 rhev-a24c-02 account-replicator: Attempted to replicate 5 dbs in 0.12589 seconds (39.71876/s) Apr 27 17:08:16 rhev-a24c-02 account-replicator: Removed 0 dbs Apr 27 17:08:16 rhev-a24c-02 account-replicator: 10 successes, 0 failures
2.9.9. 오케스트레이션(heat) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack Heat API 서비스 | openstack-heat-api.service | /var/log/containers/heat/heat-api.log |
| OpenStack Heat Engine Service | openstack-heat-engine.service | /var/log/containers/heat/heat-engine.log |
| 오케스트레이션 서비스 이벤트 | 해당 없음 | /var/log/containers/heat/heat-manage.log |
2.9.11. Telemetry(ceilometer) 로그 파일
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| OpenStack ceilometer 알림 에이전트 | ceilometer_agent_notification | /var/log/containers/ceilometer/agent-notification.log |
| OpenStack ceilometer 중앙 에이전트 | ceilometer_agent_central | /var/log/containers/ceilometer/central.log |
| openstack ceilometer 수집 | openstack-ceilometer-collector.service | /var/log/containers/ceilometer/collector.log |
| OpenStack ceilometer 컴퓨팅 에이전트 | ceilometer_agent_compute | /var/log/containers/ceilometer/compute.log |
2.9.12. 서비스 지원용 로그 파일
다음 서비스는 핵심 OpenStack 구성 요소에서 사용하며 자체 로그 디렉터리 및 파일이 있습니다.
| Service | 서비스 이름 | 로그 경로 |
|---|---|---|
| 메시지 브로커 (RabbitMQ) | rabbitmq-server.service |
/var/log/rabbitmq/rabbit@short_hostname.log |
| 데이터베이스 서버(MariaDB) | mariadb.service | /var/log/mariadb/mariadb.log |
| 가상 네트워크 스위치(Open vSwitch) | openvswitch-nonetwork.service |
/var/log/openvswitch/ovsdb-server.log |
2.9.13. Aodh (alarming service) 로그 파일
| Service | 컨테이너 이름 | 로그 경로 |
|---|---|---|
| 알람 API | aodh_api | /var/log/containers/httpd/aodh-api/aodh_wsgi_access.log |
| 알람 평가자 로그 | aodh_evaluator | /var/log/containers/aodh/aodh-evaluator.log |
| 알람 리스너 | aodh_listener | /var/log/containers/aodh/aodh-listener.log |
| 알람 알림 | aodh_notifier | /var/log/containers/aodh/aodh-notifier.log |
2.9.14. gnocchi(지표 스토리지) 로그 파일
| Service | 컨테이너 이름 | 로그 경로 |
|---|---|---|
| Gnocchi API | gnocchi_api | /var/log/containers/httpd/gnocchi-api/gnocchi_wsgi_access.log |
| Gnocchi 지표 | gnocchi_metricd | /var/log/containers/gnocchi/gnocchi-metricd.log |
| Gnocchi statsd | gnocchi_statsd | /var/log/containers/gnocchi/gnocchi-statsd.log |
3장. Telemetry용 시계열 데이터베이스(Gnocchi) 구성
시계열 데이터베이스(Gnocchi)는 다중 프로젝트, 지표 및 리소스 데이터베이스입니다. 이는 운영자와 사용자에게 지표와 리소스 정보에 대한 액세스를 제공하는 동시에 대규모로 지표를 저장하도록 설계되었습니다.
3.1. 시계열 데이터베이스 이해
이 섹션에서는 시계열 데이터베이스(Gnocchi) 기능에 대해 일반적으로 사용되는 용어를 정의합니다.
- 집계 방법
-
여러 측정값을 집계하는 데 사용되는 함수입니다. 예를 들어
min집계 방법은 다양한 측정값의 값을 시간 범위의 모든 측정값의 최소 값으로 집계합니다. - 집계
- 보관 정책에 따라 여러 측정값에서 생성된 데이터 지점. 집계는 타임스탬프와 값으로 구성됩니다.
- 보관 정책
- 지표에 연결된 집계 스토리지 정책입니다. 보관 정책은 집계가 지표에 보관되는 기간 및 집계가 집계되는 방식(통합 방법)을 결정합니다.
- 단위
- 지표의 집계 시계열에서 두 집계 사이의 시간입니다.
- 측정
- API에서 시계열 데이터베이스로 전송되는 들어오는 데이터 지점입니다. 측정값은 타임스탬프와 값으로 구성됩니다.
- 메트릭
- UUID로 식별된 집계를 저장하는 엔터티입니다. 지표는 이름을 사용하여 리소스에 연결할 수 있습니다. 지표에서 집계를 저장하는 방법은 지표가 연결된 보관 정책에 의해 정의됩니다.
- 리소스
- 지표를 과 연결할 수 있는 인프라의 모든 항목을 나타내는 엔터티입니다. 리소스는 고유한 ID로 식별되며 속성을 포함할 수 있습니다.
- 시계열
- 시간순으로 주문된 집계 목록입니다.
- timespan
- 지표가 집계를 유지하는 시간입니다. 이는 보관 정책의 컨텍스트에서 사용됩니다.
3.2. 메트릭
시계열 데이터베이스(Gnocchi)는 원격 분석에서 측정할 수 있는 모든 항목을 지정하는 메트릭 을 저장합니다(예: 서버의 CPU 사용량, 공간 온도 또는 네트워크 인터페이스에서 전송한 바이트 수).
메트릭에는 다음 속성이 있습니다.
- 지표를 식별하기 위한 UUID
- 메트릭 이름
- 측정값을 저장하고 집계하는 데 사용되는 보관 정책
시계열 데이터베이스는 etc/ceilometer/polling.yaml 파일에 정의된 대로 기본적으로 다음 지표를 저장합니다.
[root@controller-0 ~]# podman exec -ti ceilometer_agent_central cat /etc/ceilometer/polling.yaml
---
sources:
- name: some_pollsters
interval: 300
meters:
- cpu
- memory.usage
- network.incoming.bytes
- network.incoming.packets
- network.outgoing.bytes
- network.outgoing.packets
- disk.read.bytes
- disk.read.requests
- disk.write.bytes
- disk.write.requests
- hardware.cpu.util
- hardware.memory.used
- hardware.memory.total
- hardware.memory.buffer
- hardware.memory.cached
- hardware.memory.swap.avail
- hardware.memory.swap.total
- hardware.system_stats.io.outgoing.blocks
- hardware.system_stats.io.incoming.blocks
- hardware.network.ip.incoming.datagrams
- hardware.network.ip.outgoing.datagrams
또한 polling.yaml 파일은 기본 폴링 간격을 300초(5분)로 지정합니다.
3.3. 시계열 데이터베이스 구성 요소
현재 Gnocchi는 인증에 ID 서비스를 사용하고, Redis는 들어오는 측정값 스토리지에 사용합니다. 집계된 측정값을 저장하기 위해 Gnocchi는 Swift 또는 Ceph(Object Storage)를 사용합니다. Gnocchi는 MySQL을 활용하여 리소스 및 지표의 색인도 저장합니다.
시계열 데이터베이스는 statsd 프로토콜과 호환되며 네트워크를 통해 전송된 지표를 수신 대기할 수 있는 statsd deamon(gnocchi-statsd)을 제공합니다. Gnocchi에서 enable statsd 지원을 사용하려면 구성 파일에서 [statsd] 옵션을 구성합니다. 리소스 ID 매개 변수는 모든 지표가 연결된 기본 일반 리소스, 리소스 및 지표와 연결된 사용자 및 프로젝트 ID, 지표를 생성하는 데 사용되는 보관 정책 이름으로 사용됩니다.
지표가 gnocchi-statsd 로 전송되고 제공된 이름과 함께 구성한 리소스 ID에 연결되므로 모든 지표가 동적으로 생성됩니다.
3.4. 시계열 데이터베이스 실행
HTTP 서버 및 지표 데몬을 실행하여 시계열 데이터베이스를 실행합니다.
# gnocchi-api # gnocchi-metricd
3.5. WSGI 애플리케이션으로 실행
mod_wsgi 또는 기타 WSGI 애플리케이션과 같은 WSGI 서비스를 통해 Gnocchi를 실행할 수 있습니다. Gnocchi와 함께 제공되는 gnocchi/rest/app.wsgi 파일을 사용하여 Gnocchi를 WSGI 애플리케이션으로 활성화할 수 있습니다.
Gnocchi API 계층은 WSGI를 사용하여 실행됩니다. 즉, Apache httpd 및 mod_wsgi 또는 와 같은 다른 HTTP 데몬을 사용하여 실행할 수 있습니다. 있는 CPU 수에 따라 프로세스 및 스레드 수를 구성합니다(일반적으로 약 uwsgi 1.5개의 CPU 수 ). 하나의 서버가 충분하지 않은 경우 여러 개의 새 API 서버를 생성하여 여러 다른 시스템에서도 Gnocchi를 확장할 수 있습니다.
3.6. 측정된 작업자
기본적으로 gnocchi-metricd 데몬은 컴퓨팅 메트릭 집계 시 CPU 사용률을 극대화하기 위해 모든 CPU 성능을 확장합니다. gnocchi status 명령을 사용하여 HTTP API를 쿼리하고 지표 처리를 위해 클러스터 상태를 가져올 수 있습니다. 이 명령은 처리할 지표 수(gnocchi -metricd의 처리 백로그) 를 표시합니다. 이 백로그가 지속적으로 늘어나지 않는 한, gnocchi-metricd는 전송되는 메트릭의 양을 처리할 수 있음을 의미합니다. 프로세스에 대한 측정값 수가 지속적으로 증가하는 경우 일시적으로 gnocchi-metricd 데몬 수를 늘려야 할 수 있습니다. 원하는 수의 서버에서 원하는 수의 지표 데몬을 실행할 수 있습니다.
director 기반 배포의 경우 환경 파일에서 특정 메트릭 처리 매개변수를 조정할 수 있습니다.
-
MetricProcessingDelay- 지표 처리 사이의 지연 기간을 조정합니다. -
GnocchiMetricdWorkers-메트릭된작업자 수를 구성합니다.
3.7. 시계열 데이터베이스 모니터링
HTTP API의 /v1/status 엔드포인트는 쉽게 모니터링할 수 있는 프로세스 측정값(백로그 측정)과 같은 다양한 정보를 반환합니다. 전체 시스템의 상태를 확인하려면 HTTP 서버 및 gnocchi-metricd 데몬이 실행 중이며 로그 파일에 오류를 쓰지 않는지 확인합니다.
3.8. 시계열 데이터베이스 백업 및 복원
예기치 않은 이벤트에서 복구하려면 인덱스와 스토리지를 둘 다 백업합니다. 데이터베이스 덤프(PostgreSQL 또는 MySQL)를 만들고 데이터 스토리지(Ceph, Swift 또는 파일 시스템)의 스냅샷 또는 복사본을 만들어야 합니다. 복원 절차는 인덱스 및 스토리지 백업을 복원하고, 필요한 경우 Gnocchi를 다시 설치하고, 다시 시작하는 것입니다.
3.9. Gnocchi에서 이전 리소스를 삭제하는 배치
오래된 측정값을 제거하려면 요구 사항에 맞게 보관 정책을 만듭니다. 리소스, 지표 및 측정값을 일괄 삭제하려면 CLI 또는 REST API를 사용합니다. 예를 들어 30일 전에 종료된 리소스 및 관련 지표를 모두 삭제하려면 다음 명령을 실행합니다.
openstack metric resource batch delete "ended_at < '-30days'"
3.10. 원격 분석 서비스를 사용한 용량 미터링
OpenStack 원격 분석 서비스에서는 청구, 차지백 및 표시 목적으로 사용할 수 있는 사용량 지표를 제공합니다. 또한 타사 애플리케이션에서 이러한 지표 데이터를 사용하여 클러스터에서 용량을 계획할 수 있으며 OpenStack Heat을 사용하여 가상 인스턴스 자동 확장에도 활용할 수 있습니다. 자세한 내용은 인스턴스의 자동 확장을 참조하십시오.
모니터링 및 알람을 위해 Ceilometer와 Gnocchi의 조합을 사용할 수 있습니다. 이는 소규모 클러스터와 알려진 제한사항에서 지원됩니다. 실시간 모니터링을 위해 Red Hat OpenStack Platform에는 지표 데이터를 제공하는 에이전트가 포함되어 있으며 별도의 모니터링 인프라 및 애플리케이션에서 사용할 수 있습니다. 자세한 내용은 Monitoring Tools Configuration을 참조하십시오.
3.10.1. 측정값 보기
특정 리소스에 대한 모든 측정값을 나열합니다.
# openstack metric measures show --resource-id UUID METER_NAME
타임스탬프 범위 내에서 특정 리소스에 대한 측정값만 나열합니다.
# openstack metric measures show --aggregation mean --start <START_TIME> --stop <STOP_TIME> --resource-id UUID METER_NAME
타임스탬프 변수 <startT_TIME> 및 <STOP_TIME>은 iso-dateThh:mm:ss 형식을 사용합니다.
3.10.2. 새 측정값 생성
측정값을 사용하여 원격 분석 서비스로 데이터를 전송할 수 있으며 이전에 정의한 미터에 해당하지 않아도 됩니다. 예를 들면 다음과 같습니다.
# openstack metrics measures add -m 2015-01-12T17:56:23@42 --resource-id UUID METER_NAME
3.10.3. 예제: 클라우드 사용량 측정값 보기
이 예에서는 각 프로젝트의 모든 인스턴스의 평균 메모리 사용량을 보여줍니다.
# openstack metric measures aggregation --resource-type instance --groupby project_id -m memory
3.10.4. 기존 알람 보기
기존 원격 분석 알람을 나열하려면 aodh 명령을 사용합니다. 예를 들면 다음과 같습니다.
# aodh alarm list +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+ | alarm_id | type | name | state | severity | enabled | +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+ | 922f899c-27c8-4c7d-a2cf-107be51ca90a | gnocchi_aggregation_by_resources_threshold | iops-monitor-read-requests | insufficient data | low | True | +--------------------------------------+--------------------------------------------+----------------------------+-------------------+----------+---------+
리소스에 할당된 미터를 나열하려면 리소스의 UUID (인스턴스, 이미지 또는 볼륨)를 지정합니다. 예를 들면 다음과 같습니다.
# gnocchi resource show 5e3fcbe2-7aab-475d-b42c-a440aa42e5ad
3.10.5. 알람 만들기
aodh 를 사용하여 임계값에 도달하면 활성화되는 알람을 만들 수 있습니다. 이 예에서 알람은 개별 인스턴스의 평균 CPU 사용률이 80%를 초과할 때 로그 항목을 활성화하고 추가합니다. 쿼리는 모니터링 목적으로 특정 인스턴스의 ID(94619081-abf5-4f1f-81c7-9cedaa872403)를격리하는 데 사용됩니다.
# aodh alarm create --type gnocchi_aggregation_by_resources_threshold --name cpu_usage_high --metric cpu_util --threshold 80 --aggregation-method sum --resource-type instance --query '{"=": {"id": "94619081-abf5-4f1f-81c7-9cedaa872403"}}' --alarm-action 'log://'
+---------------------------+-------------------------------------------------------+
| Field | Value |
+---------------------------+-------------------------------------------------------+
| aggregation_method | sum |
| alarm_actions | [u'log://'] |
| alarm_id | b794adc7-ed4f-4edb-ace4-88cbe4674a94 |
| comparison_operator | eq |
| description | gnocchi_aggregation_by_resources_threshold alarm rule |
| enabled | True |
| evaluation_periods | 1 |
| granularity | 60 |
| insufficient_data_actions | [] |
| metric | cpu_util |
| name | cpu_usage_high |
| ok_actions | [] |
| project_id | 13c52c41e0e543d9841a3e761f981c20 |
| query | {"=": {"id": "94619081-abf5-4f1f-81c7-9cedaa872403"}} |
| repeat_actions | False |
| resource_type | instance |
| severity | low |
| state | insufficient data |
| state_timestamp | 2016-12-09T05:18:53.326000 |
| threshold | 80.0 |
| time_constraints | [] |
| timestamp | 2016-12-09T05:18:53.326000 |
| type | gnocchi_aggregation_by_resources_threshold |
| user_id | 32d3f2c9a234423cb52fb69d3741dbbc |
+---------------------------+-------------------------------------------------------+
기존 임계값 알람을 편집하려면 aodh alarm update 명령을 사용합니다. 예를 들어 알람 임계값을 75%로 늘리려면 다음을 수행합니다.
# aodh alarm update --name cpu_usage_high --threshold 75
3.10.6. 알람 비활성화 또는 삭제
알람을 비활성화하려면 다음을 수행합니다.
# aodh alarm update --name cpu_usage_high --enabled=false
알람을 삭제하려면 다음을 수행합니다.
# aodh alarm delete --name cpu_usage_high
3.10.7. 예제: 인스턴스의 디스크 활동 모니터링
다음 예제에서는 Aodh 알람을 사용하여 특정 프로젝트에 포함된 모든 인스턴스의 누적 디스크 활동을 모니터링하는 방법을 보여줍니다.
1. 기존 프로젝트를 검토하고 모니터링해야 하는 프로젝트의 적절한 UUID를 선택합니다. 이 예에서는 admin 프로젝트를 사용합니다.
$ openstack project list +----------------------------------+----------+ | ID | Name | +----------------------------------+----------+ | 745d33000ac74d30a77539f8920555e7 | admin | | 983739bb834a42ddb48124a38def8538 | services | | be9e767afd4c4b7ead1417c6dfedde2b | demo | +----------------------------------+----------+
2. 프로젝트의 UUID를 사용하여 admin 프로젝트에서 인스턴스에서 생성한 모든 읽기 요청의 sum() 을 분석하는 알람을 생성합니다( --query 매개 변수로 쿼리를 좀 더 제한할 수 있음).
# aodh alarm create --type gnocchi_aggregation_by_resources_threshold --name iops-monitor-read-requests --metric disk.read.requests.rate --threshold 42000 --aggregation-method sum --resource-type instance --query '{"=": {"project_id": "745d33000ac74d30a77539f8920555e7"}}'
+---------------------------+-----------------------------------------------------------+
| Field | Value |
+---------------------------+-----------------------------------------------------------+
| aggregation_method | sum |
| alarm_actions | [] |
| alarm_id | 192aba27-d823-4ede-a404-7f6b3cc12469 |
| comparison_operator | eq |
| description | gnocchi_aggregation_by_resources_threshold alarm rule |
| enabled | True |
| evaluation_periods | 1 |
| granularity | 60 |
| insufficient_data_actions | [] |
| metric | disk.read.requests.rate |
| name | iops-monitor-read-requests |
| ok_actions | [] |
| project_id | 745d33000ac74d30a77539f8920555e7 |
| query | {"=": {"project_id": "745d33000ac74d30a77539f8920555e7"}} |
| repeat_actions | False |
| resource_type | instance |
| severity | low |
| state | insufficient data |
| state_timestamp | 2016-11-08T23:41:22.919000 |
| threshold | 42000.0 |
| time_constraints | [] |
| timestamp | 2016-11-08T23:41:22.919000 |
| type | gnocchi_aggregation_by_resources_threshold |
| user_id | 8c4aea738d774967b4ef388eb41fef5e |
+---------------------------+-----------------------------------------------------------+3.10.8. 예제: CPU 사용량 모니터링
인스턴스의 성능을 모니터링하려면 먼저 gnocchi 데이터베이스를 검사하여 메모리 또는 CPU 사용량과 같은 모니터링할 수 있는 지표를 식별합니다. 예를 들어, gnocchi 리소스를 인스턴스에 표시하여 모니터링할 수 있는 지표를 확인합니다.
특정 인스턴스 UUID에 사용할 수 있는 지표를 쿼리합니다.
$ gnocchi resource show --type instance d71cdf9a-51dc-4bba-8170-9cd95edd3f66
--------------------------------------------------------------------------------------------+ | Field | Value |--------------------------------------------------------------------------------------------+ | created_by_project_id | 44adccdc32614688ae765ed4e484f389 | | created_by_user_id | c24fa60e46d14f8d847fca90531b43db | | creator | c24fa60e46d14f8d847fca90531b43db:44adccdc32614688ae765ed4e484f389 | | display_name | test-instance | | ended_at | None | | flavor_id | 14c7c918-df24-481c-b498-0d3ec57d2e51 | | flavor_name | m1.tiny | | host | overcloud-compute-0 | | id | d71cdf9a-51dc-4bba-8170-9cd95edd3f66 | | image_ref | e75dff7b-3408-45c2-9a02-61fbfbf054d7 | | metrics | compute.instance.booting.time: c739a70d-2d1e-45c1-8c1b-4d28ff2403ac | | | cpu.delta: 700ceb7c-4cff-4d92-be2f-6526321548d6 | | | cpu: 716d6128-1ea6-430d-aa9c-ceaff2a6bf32 | | | cpu_l3_cache: 3410955e-c724-48a5-ab77-c3050b8cbe6e | | | cpu_util: b148c392-37d6-4c8f-8609-e15fc15a4728 | | | disk.allocation: 9dd464a3-acf8-40fe-bd7e-3cb5fb12d7cc | | | disk.capacity: c183d0da-e5eb-4223-a42e-855675dd1ec6 | | | disk.ephemeral.size: 15d1d828-fbb4-4448-b0f2-2392dcfed5b6 | | | disk.iops: b8009e70-daee-403f-94ed-73853359a087 | | | disk.latency: 1c648176-18a6-4198-ac7f-33ee628b82a9 | | | disk.read.bytes.rate: eb35828f-312f-41ce-b0bc-cb6505e14ab7 | | | disk.read.bytes: de463be7-769b-433d-9f22-f3265e146ec8 | | | disk.read.requests.rate: 588ca440-bd73-4fa9-a00c-8af67262f4fd | | | disk.read.requests: 53e5d599-6cad-47de-b814-5cb23e8aaf24 | | | disk.root.size: cee9d8b1-181e-4974-9427-aa7adb3b96d9 | | | disk.usage: 4d724c99-7947-4c6d-9816-abbbc166f6f3 | | | disk.write.bytes.rate: 45b8da6e-0c89-4a6c-9cce-c95d49d9cc8b | | | disk.write.bytes: c7734f1b-b43a-48ee-8fe4-8a31b641b565 | | | disk.write.requests.rate: 96ba2f22-8dd6-4b89-b313-1e0882c4d0d6 | | | disk.write.requests: 553b7254-be2d-481b-9d31-b04c93dbb168 | | | memory.bandwidth.local: 187f29d4-7c70-4ae2-86d1-191d11490aad | | | memory.bandwidth.total: eb09a4fc-c202-4bc3-8c94-aa2076df7e39 | | | memory.resident: 97cfb849-2316-45a6-9545-21b1d48b0052 | | | memory.swap.in: f0378d8f-6927-4b76-8d34-a5931799a301 | | | memory.swap.out: c5fba193-1a1b-44c8-82e3-9fdc9ef21f69 | | | memory.usage: 7958d06d-7894-4ca1-8c7e-72ba572c1260 | | | memory: a35c7eab-f714-4582-aa6f-48c92d4b79cd | | | perf.cache.misses: da69636d-d210-4b7b-bea5-18d4959e95c1 | | | perf.cache.references: e1955a37-d7e4-4b12-8a2a-51de4ec59efd | | | perf.cpu.cycles: 5d325d44-b297-407a-b7db-cc9105549193 | | | perf.instructions: 973d6c6b-bbeb-4a13-96c2-390a63596bfc | | | vcpus: 646b53d0-0168-4851-b297-05d96cc03ab2 | | original_resource_id | d71cdf9a-51dc-4bba-8170-9cd95edd3f66 | | project_id | 3cee262b907b4040b26b678d7180566b | | revision_end | None | | revision_start | 2017-11-16T04:00:27.081865+00:00 | | server_group | None | | started_at | 2017-11-16T01:09:20.668344+00:00 | | type | instance | | user_id | 1dbf5787b2ee46cf9fa6a1dfea9c9996 |--------------------------------------------------------------------------------------------+이 결과
지표값은 Aodh 알람(예:cpu_util)을 사용하여 모니터링할 수 있는 구성 요소를 나열합니다.CPU 사용량을 모니터링하려면
cpu_util지표가 필요합니다. 이 메트릭에 대한 자세한 내용을 보려면 다음을 수행합니다.$ gnocchi metric show --resource d71cdf9a-51dc-4bba-8170-9cd95edd3f66 cpu_util
-------------------------------------------------------------------------------------------------------+ | Field | Value |-------------------------------------------------------------------------------------------------------+ | archive_policy/aggregation_methods | std, count, min, max, sum, mean | | archive_policy/back_window | 0 | | archive_policy/definition | - points: 8640, granularity: 0:05:00, timespan: 30 days, 0:00:00 | | archive_policy/name | low | | created_by_project_id | 44adccdc32614688ae765ed4e484f389 | | created_by_user_id | c24fa60e46d14f8d847fca90531b43db | | creator | c24fa60e46d14f8d847fca90531b43db:44adccdc32614688ae765ed4e484f389 | | id | b148c392-37d6-4c8f-8609-e15fc15a4728 | | name | cpu_util | | resource/created_by_project_id | 44adccdc32614688ae765ed4e484f389 | | resource/created_by_user_id | c24fa60e46d14f8d847fca90531b43db | | resource/creator | c24fa60e46d14f8d847fca90531b43db:44adccdc32614688ae765ed4e484f389 | | resource/ended_at | None | | resource/id | d71cdf9a-51dc-4bba-8170-9cd95edd3f66 | | resource/original_resource_id | d71cdf9a-51dc-4bba-8170-9cd95edd3f66 | | resource/project_id | 3cee262b907b4040b26b678d7180566b | | resource/revision_end | None | | resource/revision_start | 2017-11-17T00:05:27.516421+00:00 | | resource/started_at | 2017-11-16T01:09:20.668344+00:00 | | resource/type | instance | | resource/user_id | 1dbf5787b2ee46cf9fa6a1dfea9c9996 | | unit | None |-------------------------------------------------------------------------------------------------------+-
archive_policy-std, count, min, max, sum, mean값을 계산하기 위해 집계 간격을 정의합니다.
-
Aodh를 사용하여
cpu_util을 쿼리하는 모니터링 작업을 생성합니다. 이 작업은 지정한 설정에 따라 이벤트를 트리거합니다. 예를 들어 인스턴스의 CPU가 연장된 기간 동안 80%를 초과할 때 로그 항목을 늘리려면 다음을 수행합니다.aodh alarm create \ --project-id 3cee262b907b4040b26b678d7180566b \ --name high-cpu \ --type gnocchi_resources_threshold \ --description 'High CPU usage' \ --metric cpu_util \ --threshold 80.0 \ --comparison-operator ge \ --aggregation-method mean \ --granularity 300 \ --evaluation-periods 1 \ --alarm-action 'log://' \ --ok-action 'log://' \ --resource-type instance \ --resource-id d71cdf9a-51dc-4bba-8170-9cd95edd3f66 +---------------------------+--------------------------------------+ | Field | Value | +---------------------------+--------------------------------------+ | aggregation_method | mean | | alarm_actions | [u'log://'] | | alarm_id | 1625015c-49b8-4e3f-9427-3c312a8615dd | | comparison_operator | ge | | description | High CPU usage | | enabled | True | | evaluation_periods | 1 | | granularity | 300 | | insufficient_data_actions | [] | | metric | cpu_util | | name | high-cpu | | ok_actions | [u'log://'] | | project_id | 3cee262b907b4040b26b678d7180566b | | repeat_actions | False | | resource_id | d71cdf9a-51dc-4bba-8170-9cd95edd3f66 | | resource_type | instance | | severity | low | | state | insufficient data | | state_reason | Not evaluated yet | | state_timestamp | 2017-11-16T05:20:48.891365 | | threshold | 80.0 | | time_constraints | [] | | timestamp | 2017-11-16T05:20:48.891365 | | type | gnocchi_resources_threshold | | user_id | 1dbf5787b2ee46cf9fa6a1dfea9c9996 | +---------------------------+--------------------------------------+
-
comparison-operator-ge연산자는 CPU 사용량이 80%보다 크거나 같은 경우 알람이 트리거되도록 정의합니다. -
세분성 - 측정값에는 연결된 보관 정책이 있습니다. 정책에는 다양한 단위(예: 1시간 + 1시간 동안 5분 집계)가 있을 수 있습니다.granularity값은 보관 정책에 설명된 기간과 일치해야 합니다. -
evaluation-periods- 알람이 트리거되기 전에 통과해야 하는세분성 기간 수입니다. 예를 들어 이 값을2로 설정하면 알람이 트리거되기 전에 두 폴링 기간 동안 CPU 사용량이 80%를 초과해야 합니다. [U'log://']- 이 값은 이벤트를 Aodh 로그 파일에 기록합니다.참고알람이 트리거될 때( alarm
_actions) 및 웹 후크 URL과 같은 일반 상태(ok_actions)로 반환되는 경우 실행되도록 다양한 작업을 정의할 수 있습니다.
-
알람이 트리거되었는지 확인하려면 알람의 기록을 쿼리합니다.
aodh alarm-history show 1625015c-49b8-4e3f-9427-3c312a8615dd --fit-width +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+ | timestamp | type | detail | event_id | +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+ | 2017-11-16T05:21:47.850094 | state transition | {"transition_reason": "Transition to ok due to 1 samples inside threshold, most recent: 0.0366665763", "state": "ok"} | 3b51f09d-ded1-4807-b6bb-65fdc87669e4 | +----------------------------+------------------+---------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------+
3.10.9. 리소스 유형 관리
이전에 하드 코딩되었던 원격 분석 리소스 유형은 이제 gnocchi 클라이언트에서 관리할 수 있습니다. gnocchi 클라이언트를 사용하여 리소스 유형을 생성, 보기 및 삭제할 수 있으며 gnocchi API를 사용하여 속성을 업데이트하거나 삭제할 수 있습니다.
1. 새 리소스 유형을 생성합니다.
$ gnocchi resource-type create testResource01 -a bla:string:True:min_length=123 +----------------+------------------------------------------------------------+ | Field | Value | +----------------+------------------------------------------------------------+ | attributes/bla | max_length=255, min_length=123, required=True, type=string | | name | testResource01 | | state | active | +----------------+------------------------------------------------------------+
2. resource-type 의 구성을 검토합니다.
$ gnocchi resource-type show testResource01 +----------------+------------------------------------------------------------+ | Field | Value | +----------------+------------------------------------------------------------+ | attributes/bla | max_length=255, min_length=123, required=True, type=string | | name | testResource01 | | state | active | +----------------+------------------------------------------------------------+
3. resource-type 을 삭제합니다.
$ gnocchi resource-type delete testResource01
리소스를 사용하는 경우 리소스 유형을 삭제할 수 없습니다.
4장. 문제 해결
이 장에서는 Red Hat OpenStack Platform 배포 문제 해결을 지원하기 위한 로깅 및 지원 정보를 설명합니다.
4.1. 지원
클라이언트 명령이 실패하거나 다른 문제가 발생한 경우 Red Hat 기술 지원 센터에 제공된 내용, 전체 콘솔 출력, 콘솔 출력에서 참조되는 모든 로그 파일, 문제가 발생한 노드의 sosreport 에 문의하십시오. 예를 들어 컴퓨팅 수준에 문제가 발생하면 Nova 노드에서 sosreport 를 실행하거나 네트워킹 문제인 경우 Neutron 노드에서 유틸리티를 실행합니다. 일반적인 배포 문제의 경우 클라우드 컨트롤러에서 sosreport 를 실행하는 것이 좋습니다.
sosreport 명령(sos 패키지)에 대한 자세한 내용은 What is a sosreport 및 Red Hat Enterprise Linux 4.6 이상에서 하나를 생성하는 방법을 참조하십시오.
힌트가 있는지 /var/log/messages 파일도 확인하십시오.
4.2. ID 클라이언트 (keystone) 연결 문제 해결
ID 클라이언트(keystone)가 ID 서비스에 연결할 수 없는 경우 오류를 반환합니다.
Unable to communicate with identity service: [Errno 113] No route to host. (HTTP 400)
문제를 디버깅하려면 다음과 같은 일반적인 원인을 확인하십시오.
- ID 서비스가 다운되었습니다
이제 ID 서비스가 httpd.service 내에서 실행됩니다. ID 서비스를 호스팅하는 시스템에서 서비스 상태를 확인합니다.
# systemctl status httpd.service
서비스가 활성 상태가 아닌 경우 root 사용자로 로그인하여 시작합니다.
# systemctl start httpd.service
- 방화벽이 제대로 구성되지 않았습니다.
-
포트
5000및35357의 TCP 트래픽을 허용하도록 방화벽이 구성되지 않을 수 있습니다. 이 경우 방화벽 설정을 확인하고 사용자 지정 규칙 정의에 대한 지침은 Advanced Overcloud Customization 가이드의 Overcloud 방화벽 관리 가이드를 참조하십시오. - 서비스 엔드 포인트가 올바르게 정의되지 않았습니다.
ID 서비스를 호스팅하는 시스템에서 엔드포인트가 올바르게 정의되어 있는지 확인합니다.
관리 토큰을 가져옵니다.
# grep admin_token /etc/keystone/keystone.conf admin_token = 91f0866234a64fc299db8f26f8729488
ID 서비스에 대한 올바른 관리 끝점을 확인합니다.
http://IP:35357/VERSION
IP 를 ID 서비스를 호스팅하는 시스템의 IP 주소 또는 호스트 이름으로 바꿉니다. VERSION 을 사용 중인 API 버전(v
2.0또는v3)으로바꿉니다.사전 정의된 ID 서비스 관련 환경 변수를 설정 해제합니다.
# unset OS_USERNAME OS_TENANT_NAME OS_PASSWORD OS_AUTH_URL
관리 토큰 및 엔드포인트를 사용하여 ID 서비스로 인증합니다. ID 서비스 엔드포인트가 올바른지 확인합니다. 예를 들면 다음과 같습니다.
# openstack endpoint list --os-token=91f0556234a64fc299db8f26f8729488 --os-url=https://osp.lab.local:35357/v3/ --os-identity-api-version 3
ID 서비스에 대해 나열된
publicurl, internalurl 및 adminurl이 올바른지 확인합니다. 특히 각 엔드포인트 내에 나열된 IP 주소와 포트 번호는 네트워크를 통해 올바르고 연결할 수 있는지 확인합니다.이러한 값이 올바르지 않은 경우 올바른 엔드포인트를 추가하고
openstack명령의엔드포인트 삭제작업을 사용하여 잘못된 엔드포인트를 제거합니다. 예를 들면 다음과 같습니다.# openstack endpoint delete 2d32fa6feecc49aab5de538bdf7aa018 --os-token=91f0866234a64fc299db8f26f8729488 --os-url=https://osp.lab.local:35357/v3/ --os-identity-api-version 3
TOKEN 및 ENDPOINT 를 이전에 식별된 값으로 바꿉니다. endpoint
-list 작업에서 나열한 대로 제거할 ID 를 엔드포인트의 ID로 교체합니다.
4.3. OpenStack Networking 문제 해결
이 섹션에서는 사용할 수 있는 다양한 명령과 OpenStack Networking 서비스 문제를 해결하기 위해 수행할 수 있는 절차에 대해 설명합니다.
- 네트워킹 장치 디버깅
-
ip a명령을 사용하여 모든 실제 및 가상 장치를 표시합니다. -
ovs-vsctl show명령을 사용하여 가상 스위치의 인터페이스와 브리지를 표시합니다. -
스위치의 datapaths를 표시하려면
ovs-dpctl show명령을 사용합니다.
-
- 네트워킹 패킷 추적
tcpdump명령을 사용하여 패킷이 통과하지 않는 위치를 확인합니다.# tcpdump -n -i INTERFACE -e -w FILENAME
INTERFACE 를 네트워크 인터페이스의 이름으로 교체하여 패킷이 통과하지 않는 위치를 확인합니다. 인터페이스 이름은 브리지 또는 호스트 이더넷 장치의 이름이 될 수 있습니다.
e
플래그를사용하면 링크 수준 헤더가 덤프되었는지 확인합니다(vlan태그가 나타납니다).-w플래그는 선택 사항입니다. 출력을 파일에 쓰고자 하는 경우에만 사용할 수 있습니다. 그렇지 않으면 출력이 표준 출력(stdout)에 작성됩니다.tcpdump에 대한 자세한 내용은를 실행하여 도움말 페이지를 참조하십시오.man tcpdump
- 네트워크 네임스페이스 디버깅
-
ip netns list명령을 사용하여 알려진 모든 네트워크 네임스페이스를 나열합니다. ip netns exec명령을 사용하여 특정 네임스페이스 내부의 라우팅 테이블을 표시합니다.# ip netns exec NAMESPACE_ID bash # route -nip netns exec명령 없이 후속 명령을 호출할 수 있도록 bash 쉘에서ip netns exec명령을 시작합니다.
-
4.4. 대시보드에서 네트워크 및 경로 탭 표시 문제 해결
Networks(네트워크) 및 Routers(라우터 ) 탭은 환경이 OpenStack Networking을 사용하도록 구성된 경우에만 대시보드에 표시됩니다. 특히 PackStack 유틸리티는 현재 Nova 네트워킹을 배포하고 이러한 방식으로 배포된 환경에는 탭이 표시되지 않습니다.
OpenStack 네트워킹이 환경에 배포되었지만 탭이 여전히 ID 서비스에 서비스 엔드포인트가 올바르게 정의되어 있지 않은 경우, 방화벽에서 엔드포인트에 대한 액세스를 허용하고 서비스가 실행 중인지 확인합니다.
4.5. 대시보드에서 인스턴스 시작 오류 문제 해결
대시보드를 사용하여 작업이 실패하면 인스턴스를 시작하면 일반 오류 메시지가 표시됩니다. 오류의 실제 원인을 확인하려면 명령줄 도구를 사용해야 합니다.
nova list 명령을 사용하여 인스턴스의 고유 식별자를 찾습니다. 그런 다음 이 식별자를 nova show 명령에 대한 인수로 사용합니다. 반환된 항목 중 하나는 오류 조건이 됩니다. 가장 일반적인 값은 NoValidHost 입니다.
이 오류는 인스턴스를 호스트하는 데 충분한 사용 가능한 리소스가 있는 유효한 호스트를 찾을 수 없음을 나타냅니다. 이 문제를 해결하려면 인스턴스 크기를 더 작게 선택하거나 환경에 대한 과다 할당 허용치를 늘리는 것이 좋습니다.
지정된 인스턴스를 호스팅하려면 계산 노드에 사용 가능한 CPU 및 RAM 리소스뿐만 아니라 인스턴스와 연결된 임시 스토리지에 충분한 디스크 공간이 있어야 합니다.
4.6. Keystone v3 대시보드 인증 문제 해결
django_openstack_auth는 Django의 contrib.auth 프레임워크와 함께 작동하는 플러그형 Django 인증 백엔드로, OpenStack ID 서비스 API에 대해 사용자를 인증합니다. Django_openstack_auth는 토큰 오브젝트를 사용하여 사용자 및 Keystone 관련 정보를 캡슐화합니다. 대시보드는 토큰 오브젝트를 사용하여 Django 사용자 오브젝트를 다시 빌드합니다.
토큰 오브젝트는 현재 저장되어 있습니다.
- Keystone 토큰
- 사용자 정보
- 범위
- 역할
- 서비스 카탈로그
대시보드는 사용자 세션 데이터를 처리하는 데 Django의 세션 프레임워크를 사용합니다. 다음은 local_settings.py 파일의 SESSION_ENGINE 설정을 통해 제어되는 수많은 세션 백엔드 목록입니다.
- 로컬 메모리 캐시
- Memcached
- 데이터베이스
- 캐시된 데이터베이스
- 쿠키
서명된 쿠키 세션 백엔드를 사용하고 한 번에 또는 모든 서비스를 동시에 활성화하는 경우 쿠키 크기가 제한에 도달할 수 있으며 대시보드는 로그인에 실패할 수 있습니다. 쿠키 크기가 증가하는 이유 중 하나는 서비스 카탈로그입니다. 더 많은 서비스가 등록되면 서비스 카탈로그 크기가 커집니다.
이러한 시나리오에서 세션 토큰 관리를 개선하려면 특히 Keystone v3 인증을 사용하는 경우 대시보드에 로그인하기 위한 다음 구성 설정을 포함합니다.
/usr/share/openstack-dashboard/openstack_dashboard/settings.py에서 다음 구성을 추가합니다.
DATABASES = { default: { ENGINE: django.db.backends.mysql, NAME: horizondb, USER: User Name, PASSWORD: Password, HOST: localhost, } }동일한 파일에서 SESSION_ENGINE를 다음으로 변경합니다.
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db'
mysql 명령을 사용하여 데이터베이스 서비스에 연결하고 연결할 사용자 이름으로 USER를 바꿉니다. USER는 root 사용자(또는 올바른 권한인 사용자 create db)여야 합니다.
# mysql -u USER -p
Horizon 데이터베이스를 만듭니다.
mysql > create database horizondb;
mysql 클라이언트를 종료합니다.
mysql > exit
openstack_dashboard 디렉터리로 변경하고 다음을 사용하여 데이터베이스를 동기화합니다.
# cd /usr/share/openstack-dashboard/openstack_dashboard $ ./manage.py syncdb
수퍼유저를 생성할 필요가 없으므로 질문에 n 으로 답하십시오.
Apache http 서버를 다시 시작합니다. Red Hat Enterprise Linux의 경우:
# systemctl restart httpd
4.6.1. OpenStack Dashboard - Red Hat Access Tab
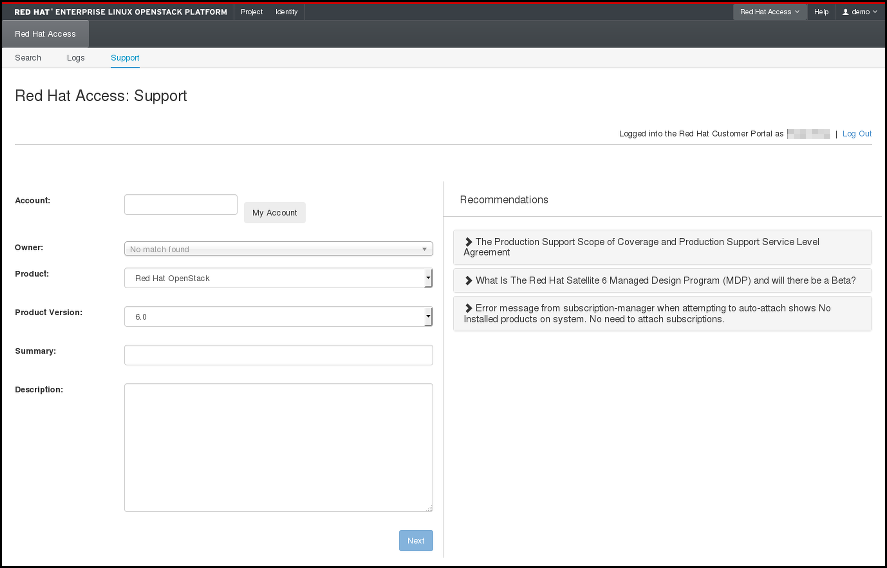
OpenStack 대시보드의 일부인 Red Hat Access(Red Hat 액세스 ) 탭에서는 Red Hat 고객 포털에서 문서 또는 솔루션을 검색 및 읽고, 인스턴스에서 로그를 보고 진단하고, 고객 지원 사례를 사용할 수 있습니다.
그림 4.1. Red Hat 액세스 탭.
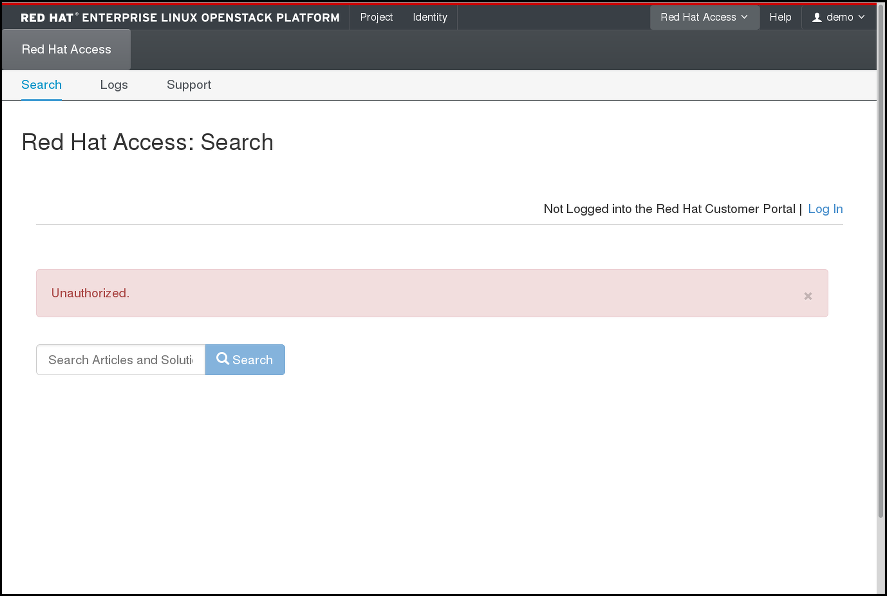
Red Hat Access 탭에서 제공하는 기능을 사용하려면 브라우저에서 Red Hat 고객 포털에 로그인해야 합니다.
로그인하지 않은 경우 지금 다음을 수행할 수 있습니다.
- Log In (로그인)을 클릭합니다.
- Red Hat 로그인 정보를 입력합니다.
- Red Hat 암호를 입력합니다.
- Sign in (로그인)을 클릭합니다.
양식은 다음과 같은 방식입니다.
그림 4.2. Red Hat 고객 포털 로그인.
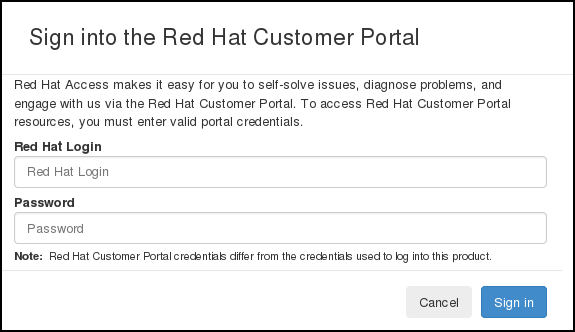
지금 로그인하지 않으면 인증이 필요한 기능 중 하나를 사용할 때 Red Hat 로그인 및 암호를 입력하라는 메시지가 표시됩니다.
4.6.1.1. 검색
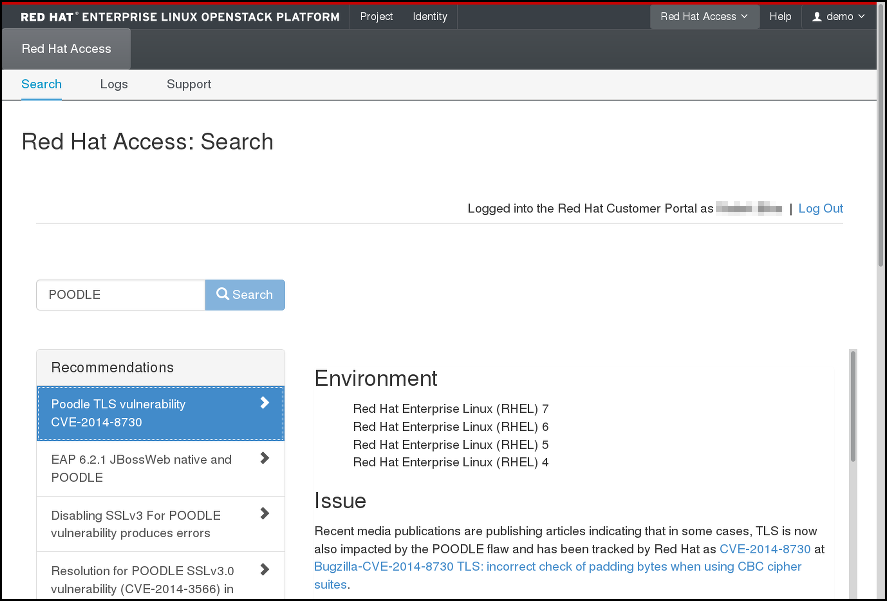
하나 이상의 검색 키워드를 입력하여 Red Hat 고객 포털에서 기사와 솔루션을 검색할 수 있습니다. 관련 기사 및 솔루션 제목이 표시됩니다. 주어진 문서 또는 솔루션을 보려면 제목을 클릭하십시오.
그림 4.3. Red Hat 액세스 탭의 검색 결과 예.
4.6.1.2. 로그
여기에서 OpenStack 인스턴스에서 로그를 읽을 수 있습니다.
그림 4.4. Red Hat 액세스 탭의 인스턴스 로그.
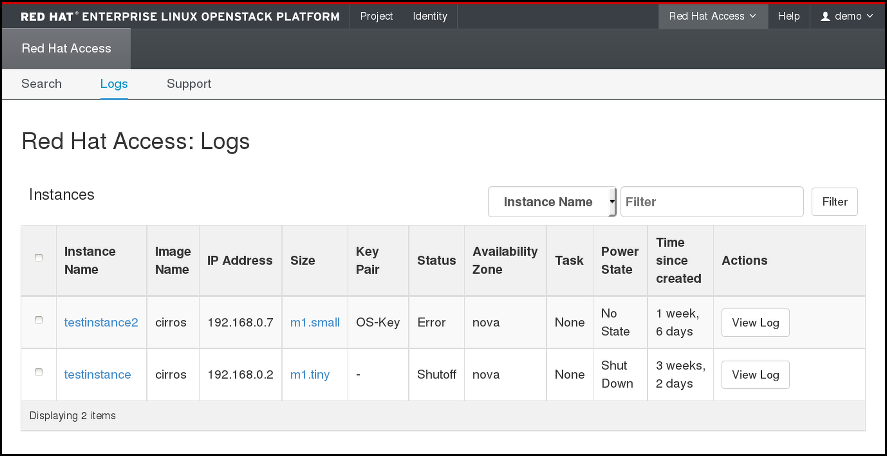
표에서 선택한 인스턴스를 찾습니다. 많은 인스턴스가 있는 경우 이름, 상태, 이미지 ID 또는 플레이버 ID로 필터링할 수 있습니다. 확인할 인스턴스의 Actions(작업) 열에서 View Log (로그 보기)를 클릭합니다.
인스턴스 로그가 표시되면 Red Hat 진단을 클릭하여 해당 콘텐츠에 대한 권장 사항을 얻을 수 있습니다.
그림 4.5. Red Hat 액세스 탭의 인스턴스 로그.
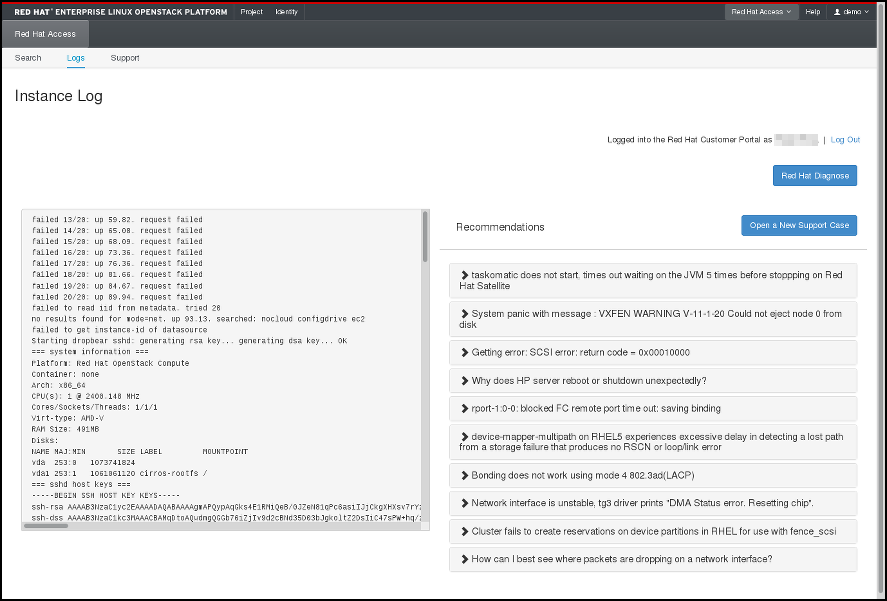
유용한 권장 사항이 없거나 심각한 문제가 기록된 경우 Open a New Support Case (새 지원 사례 열기)를 클릭하여 문제를 Red Hat 지원에 보고합니다.
4.6.1.3. 지원
Red Hat 액세스 탭의 마지막 옵션을 사용하면 Red Hat 고객 포털에서 지원 케이스를 검색할 수 있습니다.
그림 4.6. 지원 사례 검색.
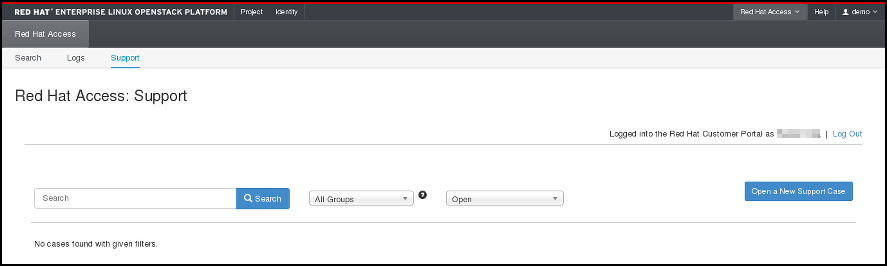
다음 페이지에서 해당 버튼을 클릭하고 양식을 작성하여 새 지원 케이스를 열 수도 있습니다.
그림 4.7. 새 지원 사례 열기.