
Advanced Cluster Management를 사용하여 SriovIBNetwork-DR용 OpenShift Data Foundation 구성
재해 복구 기능을 제공하는 스토리지 인프라를 제공하는 두 가지 지리적 위치 간에 OpenShift Data Foundation을 설정하는 방법.
초록
보다 포괄적 수용을 위한 오픈 소스 용어 교체
Red Hat은 코드, 문서, 웹 속성에서 문제가 있는 용어를 교체하기 위해 최선을 다하고 있습니다. 먼저 마스터(master), 슬레이브(slave), 블랙리스트(blacklist), 화이트리스트(whitelist) 등 네 가지 용어를 교체하고 있습니다. 이러한 변경 작업은 작업 범위가 크므로 향후 여러 릴리스에 걸쳐 점차 구현할 예정입니다. 자세한 내용은 CTO Chris Wright의 메시지를 참조하십시오.
Red Hat 문서에 관한 피드백 제공
문서 개선을 위한 의견을 보내 주십시오. 개선할 내용에 대해 알려주십시오. 피드백을 보내주시려면 다음을 확인하십시오.
특정 문구에 대한 간단한 의견 작성 방법은 다음과 같습니다.
- 문서가 Multi-page HTML 형식으로 표시되는지 확인합니다. 또한 문서 오른쪽 상단에 피드백 버튼이 있는지 확인합니다.
- 마우스 커서를 사용하여 주석 처리하려는 텍스트 부분을 강조 표시합니다.
- 강조 표시된 텍스트 아래에 표시되는 피드백 추가 팝업을 클릭합니다.
- 표시된 지침을 따릅니다.
보다 상세하게 피드백을 제출하려면 다음과 같이 Bugzilla 티켓을 생성하십시오.
- Bugzilla 웹 사이트로 이동하십시오.
- 구성 요소 섹션에서 문서 를 선택합니다.
- 설명 필드에 문서 개선을 위한 제안 사항을 기입하십시오. 관련된 문서의 해당 부분 링크를 알려주십시오.
- 버그 제출을 클릭합니다.
1장. Region-DR 소개
재해 복구는 비즈니스 크리티컬 애플리케이션을 자연 또는 사람이 생성한 재해에서 복구 및 지속할 수 있는 기능입니다. 이는 주요 불리한 이벤트 중 비즈니스 운영의 연속성을 유지하기 위해 설계된 주요 조직의 전반적인 비즈니스 지속적인 전략입니다.
regional-DR 기능은 지리적으로 분산된 사이트 간에 볼륨 영구 데이터 및 메타데이터 복제 기능을 제공합니다. 퍼블릭 클라우드에서 이러한 기능은 지역 실패로부터 보호하는 것과 비슷합니다. 지역-DR은 지리적 지역에 제공되지 않는 동안 비즈니스 연속성을 보장함으로써 예측 가능한 양의 데이터 손실을 허용합니다. 이는 일반적으로 복구 포인트 목표(RPO) 및 복구 시간 목표(RTO)로 표시됩니다.
- RPO는 백업 또는 영구 데이터의 스냅샷을 수행하는 빈도를 나타냅니다. 실제로 RPO는 손실되거나 중단 후 다시 입력해야 하는 데이터의 양을 나타냅니다.
- RTO는 비즈니스에서 허용할 수 있는 다운 타임입니다. RTO는 "비즈니스 중단에 대한 알림을 받은 후 시스템을 복구하는 데 얼마나 오랜 시간이 걸릴 수 있습니까?"
이 가이드의 의도는 재해 복구를 활성화하기 위해 인프라를 구성하는 데 필요한 단계 및 명령을 자세히 설명하는 것입니다.
1.1. Region-DR 솔루션의 구성 요소
regional-DR은 Red Hat Advanced Cluster Management for Kubernetes (RHACM) 및 OpenShift Data Foundation 구성 요소로 구성되어 OpenShift Container Platform 클러스터에서 애플리케이션 및 데이터 이동성을 제공합니다.
Red Hat Advanced Cluster Management for Kubernetes(RHACM)
RHACM은 여러 클러스터 및 애플리케이션 라이프사이클을 관리할 수 있는 기능을 제공합니다. 따라서 다중 클러스터 환경에서 컨트롤 플레인 역할을 합니다.
RHACM은 다음 두 부분으로 나뉩니다.
- RHACM Hub: 멀티 클러스터 컨트롤 플레인에서 실행되는 구성 요소
- 관리형 클러스터: 관리되는 클러스터에서 실행되는 구성 요소
이 제품에 대한 자세한 내용은 RHACM 문서 및 RHACM "Managing Applications" 설명서를 참조하십시오.
OpenShift Data Foundation
OpenShift Data Foundation은 OpenShift Container Platform 클러스터에서 상태 저장 애플리케이션에 대한 스토리지를 프로비저닝하고 관리할 수 있는 기능을 제공합니다.
OpenShift Data Foundation은 OpenShift Data Foundation 구성 요소 스택에서 Rook에 의해 라이프사이클이 관리하는 스토리지 공급자로서 Ceph에서 지원합니다. Ceph-CSI는 상태 저장 애플리케이션을 위한 영구 볼륨 프로비저닝 및 관리를 제공합니다.
OpenShift Data Foundation 스택은 다음과 같은 기능을 통해 향상되었습니다.
- 미러링을 위해 풀 활성화
- RBD 풀의 이미지 자동 미러링
- 영구 볼륨 클레임 미러링별로 관리할 csi-addons 제공
OpenShift DR
OpenShift DR은 RHACM을 사용하여 배포 및 관리하는 피어 OpenShift 클러스터 세트에 대한 상태 저장 애플리케이션의 재해 복구 오케스트레이터이며 영구 볼륨에서 애플리케이션 상태의 라이프사이클을 오케스트레이션하는 클라우드 네이티브 인터페이스를 제공합니다. 여기에는 다음이 포함됩니다.
- OpenShift 클러스터에서 애플리케이션 상태 관계 보호
- 현재 배포된 클러스터를 사용할 수 없는 피어 클러스터로 애플리케이션 상태를 장애 조치
- 애플리케이션 상태를 이전에 배포한 클러스터로 재배치
OpenShift DR은 다음 세 가지 구성 요소로 나뉩니다.
- ODF Multicluster Orchestrator: 다중 클러스터 컨트롤 플레인 (RHACM Hub)에 설치되며 부트스트랩 토큰을 생성하고 관리 클러스터 간에 이 토큰을 교환합니다.
- OpenShift DR Hub Operator: 애플리케이션에 대한 장애 조치 및 재배치를 관리하기 위해 허브 클러스터에 설치되었습니다.
- OpenShift DR Cluster Operator: 애플리케이션의 모든 PVC 라이프사이클을 관리하기 위해 각 관리 클러스터에 설치됨.
1.2. regional-DR 배포 워크플로
이 섹션에서는 OpenShift Data Foundation 버전 4.9 및 RHACM 버전 2.4를 사용하여 OpenShift Data Foundation 버전 4.9 및 RHACM 버전 2.4를 구성하고 배포하는 데 필요한 단계에 대한 개요를 제공합니다. 두 개의 관리형 클러스터 외에도 고급 클러스터 관리 허브 솔루션을 배포하려면 세 번째 OpenShift Container Platform 클러스터가 필요합니다.
인프라를 구성하려면 다음과 같은 순서로 다음 단계를 수행하십시오.
- regional-DR 각 요구 사항을 충족해야 합니다. regional -DR 활성화를 위한 요구 사항을 참조하십시오.
- 두 OpenShift Data Foundation 관리형 클러스터 간의 미러링 관계를 생성하여 다중 사이트 스토리지 복제를 구성합니다. 다중 사이트 스토리지 복제 구성을 참조하십시오.
- 각 관리 클러스터에 VolumeReplicationClass 리소스를 생성하여 복제 일정을 구성합니다(예: 5분마다 피어 간 복제). VolumeReplicationClass 리소스 생성 을 참조하십시오.
-
미러링이 활성화된 블록 볼륨에 대해 새
imageFeatures를 지원하는 각 관리형 클러스터에 미러링 StorageClass 리소스를 만듭니다. 미러링 StorageClass 리소스 생성 을 참조하십시오. - 관리형 클러스터에 OpenShift DR Cluster Operator를 설치하고 필요한 오브젝트 버킷, 시크릿 및 구성 맵을 생성합니다. 관리형 클러스터에 OpenShift DR Cluster Operator 설치를 참조하십시오.
- Hub 클러스터에 OpenShift DR Hub Operator를 설치하고 필요한 오브젝트 버킷, 시크릿 및 구성 맵을 생성합니다. Hub 클러스터에 OpenShift DR Hub Operator 설치를 참조하십시오.
- 관리되는 클러스터에 워크로드를 배포, 장애 조치 및 재배치하는 데 사용되는 허브 클러스터에서 DRPolicy 리소스를 생성합니다. Hub 클러스터에서 재해 복구 정책 생성 을 참조하십시오.
2장. Region-DR을 활성화하기 위한 요구 사항
네트워크 연결이 가능한 세 개의 OpenShift 클러스터가 있어야 합니다.
- Advanced Cluster Management for Kubernetes (RHACM operator), ODF Multicluster Orchestrator 및 OpenShift DR Hub 컨트롤러가 설치된 Hub 클러스터 입니다.
- OpenShift Data Foundation, OpenShift DR 클러스터 컨트롤러 및 애플리케이션이 설치된 기본 관리형 클러스터입니다.
- OpenShift Data Foundation, OpenShift DR 클러스터 컨트롤러 및 애플리케이션이 설치된 보조 관리형 클러스터입니다.
Hub 클러스터에 RHACM Operator 및 MultiClusterResourceOverride를 설치하고 OpenShift 인증 정보를 사용하여 RHACM 콘솔에 로그인했는지 확인합니다. 자세한 내용은 RHACM 설치 가이드 를 참조하십시오.
Advanced Cluster Manager 콘솔에 대해 생성된 경로를 찾습니다.
$ oc get route multicloud-console -n open-cluster-management -o jsonpath --template="https://{.spec.host}/multicloud/clusters{'\n'}"출력 예:
https://multicloud-console.apps.perf3.example.com/multicloud/clusters
OpenShift 인증 정보를 사용하여 로그인하면 로컬 클러스터가 표시됩니다.
RHACM 콘솔을 사용하여 기본 관리 클러스터 와 보조 관리 클러스터를 가져오거나 생성했는지 확인합니다.
Submariner 애드온을 사용하여 관리형 OpenShift 클러스터 및 서비스 네트워크를 연결하려면 각 관리 클러스터에 다음 명령을 실행하여 두 클러스터에 비overlapping 네트워크가 있는지 확인해야 합니다.
$ oc get networks.config.openshift.io cluster -o json | jq .spec
cluster1의 출력 예 (예:ocp4perf1):{ "clusterNetwork": [ { "cidr": "10.5.0.0/16", "hostPrefix": 23 } ], "externalIP": { "policy": {} }, "networkType": "OpenShiftSDN", "serviceNetwork": [ "10.15.0.0/16" ] }cluster2의 출력 예 (예:ocp4perf2):{ "clusterNetwork": [ { "cidr": "10.6.0.0/16", "hostPrefix": 23 } ], "externalIP": { "policy": {} }, "networkType": "OpenShiftSDN", "serviceNetwork": [ "10.16.0.0/16" ] }자세한 내용은 Submariner add-ons 설명서 를 참조하십시오.
-
Managed 클러스터는
Submariner 애드온을 사용하여 연결할 수 있는지 확인합니다. 클러스터 및 서비스 네트워크에 겹치지 않는 범위가 있는지 확인하고 확인한 후 RHACM 콘솔 및 클러스터세트를사용하여 각 관리 클러스터의하위 추가 기능을설치합니다. 자세한 내용은 하위 문서를 참조하십시오. 각 관리형 클러스터에 OpenShift Data Foundation 4.9 이상이 설치되어 있는지 확인합니다.
- OpenShift Data Foundation 배포에 대한 자세한 내용은 인프라별 배포 가이드 (예: AWS, VMware, Bare Metal, Azure)를 참조하십시오.
다음 명령을 사용하여 각 관리 클러스터에서 성공적인 배포를 확인합니다.
$ oc get storagecluster -n openshift-storage ocs-storagecluster -o jsonpath='{.status.phase}{"\n"}'
Primary managed cluster 및 Secondary managed cluster 에서 상태 결과가
Ready인 경우 관리 클러스터에서 미러링을 계속 활성화합니다.
3장. 다중 사이트 스토리지 복제 구성
미러링 또는 복제는 피어 관리 클러스터 내에서 CephBlockPool 별로 활성화되며 풀 내의 특정 이미지 서브 세트에서 구성할 수 있습니다. rbd-mirror 데몬은 로컬 피어 클러스터에서 원격 클러스터의 동일한 이미지로 이미지 업데이트를 복제합니다.
이러한 지침은 두 OpenShift Data Foundation 관리 클러스터 간의 미러링 관계를 생성하는 방법을 자세히 설명합니다.
3.1. 관리형 클러스터에서 OMAP 생성기 및 볼륨 복제 활성화
기본 관리 클러스터 및 보조 관리 클러스터에서 다음 단계를 실행하여 csi-rbdplugin-provisioner Pod에서 OMAP 및 Volume-Replication CSI 사이드카 컨테이너를 활성화합니다.
절차
다음
patch명령을 실행하여rook-ceph-operator-configConfigMap에서CSI_ENABLE_OMAP_GENERATOR의 값을true로 설정합니다.$ oc patch cm rook-ceph-operator-config -n openshift-storage --type json --patch '[{ "op": "add", "path": "/data/CSI_ENABLE_OMAP_GENERATOR", "value": "true" }]'출력 예:
configmap/rook-ceph-operator-config patched
다음
patch명령을 실행하여rook-ceph-operator-configConfigMap에서CSI_ENABLE_VOLUME_REPLICATION의 값을true로 설정합니다.$ oc patch cm rook-ceph-operator-config -n openshift-storage --type json --patch '[{ "op": "add", "path": "/data/CSI_ENABLE_VOLUME_REPLICATION", "value": "true" }]'출력 예:
configmap/rook-ceph-operator-config patched
csi-rbdplugin-provisionerPod당 다음 두 개의 새로운 CSI 사이드카 컨테이너가 추가되었는지 확인합니다.$ for l in $(oc get pods -n openshift-storage -l app=csi-rbdplugin-provisioner -o jsonpath={.items[*].spec.containers[*].name}) ; do echo $l ; done | egrep "csi-omap-generator|volume-replication"출력 예:
csi-omap-generator volume-replication csi-omap-generator volume-replication
참고중복을 위한
csi-rbdplugin-provisionerPod가 두 개 있으므로 새 컨테이너가 반복됩니다.
3.2. OpenShift Data Foundation Multicluster Orchestrator 설치
OpenShift Data Foundation Multicluster Orchestrator는 Hub 클러스터의 OpenShift Container Platform OperatorHub에서 설치된 컨트롤러입니다. 이 멀티 클러스터 오케스트레이터 컨트롤러는 Mirrorexporter 사용자 정의 리소스와 함께 부트스트랩 토큰을 생성하고 관리 클러스터 간에 이 토큰을 교환합니다.
절차
- Hub 클러스터에서 OperatorHub 로 이동하고 키워드 필터를 사용하여 ODF MulticlusterOrchestrator를 검색합니다.
- ODF Multicluster Orchestrator 타일을 클릭합니다.
기본 설정을 모두 유지하고 설치를 클릭합니다.
Operator 리소스는
openshift-operators에 설치되고 모든 네임스페이스에서 사용할 수 있습니다.- ODF MulticlusterOrchest rator에 성공적인 설치를 나타내는 녹색 눈금이 표시되는지 확인합니다.
3.3. hub 클러스터에서 미러 피어 생성
mirror Peer는 피어 투 피어 관계를 가질 관리형 클러스터에 대한 정보를 보유하는 클러스터 범위 리소스입니다.
사전 요구 사항
- ODF Multicluster Orchestrator 가 Hub 클러스터에 설치되어 있는지 확인합니다.
- 미러 피어당 두 개의 클러스터만 있어야 합니다.
-
각 클러스터에
ocp4perf1및ocp4perf2와 같은 고유하게 식별 가능한 클러스터 이름이 있는지 확인합니다.
절차
ODF Multicluster Orchestrator 를 클릭하여 Operator 세부 정보를 확인합니다.
Multicluster Orchestrator가 설치된 후 View Operator 를 클릭할 수도 있습니다.
- Mirror Peer API Create instance 를 클릭한 다음 YAML 보기를 선택합니다.
YAML 보기에서 미러 피어를 만듭니다.
< cluster1> 및 < cluster 2 >를 RHACM 콘솔에서 관리 클러스터의 올바른 이름으로 교체한 후 다음 YAML을
mirror-peer.yaml에 복사합니다.apiVersion: multicluster.odf.openshift.io/v1alpha1 kind: MirrorPeer metadata: name: mirrorpeer-<cluster1>-<cluster2> spec: items: - clusterName: <cluster1> storageClusterRef: name: ocs-storagecluster namespace: openshift-storage - clusterName: <cluster2> storageClusterRef: name: ocs-storagecluster namespace: openshift-storage참고MirrorTiB가 클러스터 범위 리소스이므로 이 리소스를 생성하기 위해 네임스페이스를 지정할 필요가 없습니다.
-
고유한
mirror-peer.yaml파일의 콘텐츠를 YAML 뷰에 복사합니다. 원본 콘텐츠를 완전히 교체해야 합니다. - YAML 보기 화면 하단에 있는 생성 을 클릭합니다.
단계 상태를
ExchangedSecret으로 볼 수 있는지 확인합니다.참고일부 배포에서는 검증 출력도 허용 가능한 결과
인 ExchangeSecret일 수 있습니다.
3.4. 관리 클러스터에서 미러링 활성화
미러링을 활성화하려면 각 관리형 클러스터에 대한 스토리지 클러스터의 미러링 설정을 활성화해야 합니다. CLI 및 oc patch 명령을 사용하는 수동 단계입니다.
스토리지 클러스터가 미러링된 후 기본 관리 클러스터 와 보조 관리 클러스터에서 oc patch storagecluster 명령을 실행해야 합니다.
절차
스토리지 클러스터 이름을 사용하여 클러스터 수준 미러링 플래그를 활성화합니다.
$ oc patch storagecluster $(oc get storagecluster -n openshift-storage -o=jsonpath='{.items[0].metadata.name}') -n openshift-storage --type json --patch '[{ "op": "replace", "path": "/spec/mirroring", "value": {"enabled": true} }]'출력 예:
storagecluster.ocs.openshift.io/ocs-storagecluster patched
미러링이 기본 Ceph 블록 풀에서 활성화되어 있는지 확인합니다.
$ oc get cephblockpool -n openshift-storage -o=jsonpath='{.items[?(@.metadata.ownerReferences[*].kind=="StorageCluster")].spec.mirroring.enabled}{"\n"}'출력 예:
true
rbd-mirror포드가 실행 중인지 확인합니다.$ oc get pods -o name -l app=rook-ceph-rbd-mirror -n openshift-storage
출력 예:
pod/rook-ceph-rbd-mirror-a-6486c7d875-56v2v
데몬상태의 상태를 확인합니다.$ oc get cephblockpool ocs-storagecluster-cephblockpool -n openshift-storage -o jsonpath='{.status.mirroringStatus.summary}{"\n"}'출력 예:
{"daemon_health":"OK","health":"OK","image_health":"OK","states":{}}
데몬 상태 및 상태 필드가 Warning 에서 OK 로 변경되는 데 최대 10분이 걸릴 수 있습니다. 약 10분 내에 상태가 OK 로 변경되지 않으면 RHACM 콘솔을 사용하여 Submariner 애드온 연결이 여전히 정상 상태인지 확인합니다.
4장. VolumeReplicationClass 리소스 생성
VolumeReplicationClass 는 복제할 각 볼륨의 mirroringMode 와 로컬 클러스터에서 원격 클러스터로 볼륨 또는 이미지를 복제하는 빈도(예: 5분마다)를 지정하는 데 사용됩니다.
이 리소스는 기본 관리 클러스터와 보조 관리 클러스터에서 생성해야 합니다.
절차
다음 YAML을
rbd-volumereplicationclass.yaml의 파일 이름에 저장합니다.apiVersion: replication.storage.openshift.io/v1alpha1 kind: VolumeReplicationClass metadata: name: odf-rbd-volumereplicationclass spec: provisioner: openshift-storage.rbd.csi.ceph.com parameters: mirroringMode: snapshot schedulingInterval: "5m" # <-- Must be the same as scheduling interval in the DRPolicy replication.storage.openshift.io/replication-secret-name: rook-csi-rbd-provisioner replication.storage.openshift.io/replication-secret-namespace: openshift-storage두 관리 클러스터에 파일을 생성합니다.
$ oc create -f rbd-volumereplicationclass.yaml
출력 예:
volumereplicationclass.replication.storage.openshift.io/odf-rbd-volumereplicationclass created
5장. 미러링 StorageClass 리소스 생성
미러링이 활성화된 블록 볼륨은 관리형 클러스터 간에 더 빠른 이미지 복제를 활성화하는 데 필요한 추가 imageFeatures 가 있는 새 StorageClass 를 사용하여 생성해야 합니다. 새로운 기능은 배타적 잠금,개체 맵 및 fast-diff 입니다. 기본 OpenShift Data Foundation StorageClass ocs-storagecluster-ceph-rbd 에는 이러한 기능이 포함되어 있지 않습니다.
이 리소스는 기본 관리 클러스터와 보조 관리 클러스터에서 생성해야 합니다.
절차
다음 YAML을 파일 이름
ocs-storagecluster-ceph-rbdmirror.yaml에 저장합니다.allowVolumeExpansion: true apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: ocs-storagecluster-ceph-rbdmirror parameters: clusterID: openshift-storage csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage csi.storage.k8s.io/fstype: ext4 csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage imageFeatures: layering,exclusive-lock,object-map,fast-diff imageFormat: "2" pool: ocs-storagecluster-cephblockpool provisioner: openshift-storage.rbd.csi.ceph.com reclaimPolicy: Delete volumeBindingMode: Immediate
두 관리 클러스터에 파일을 생성합니다.
$ oc create -f ocs-storagecluster-ceph-rbdmirror.yaml
출력 예:
storageclass.storage.k8s.io/ocs-storagecluster-ceph-rbdmirror created
6장. 관리형 클러스터에 OpenShift DR Cluster Operator 설치
절차
- 각 관리형 클러스터에서 OperatorHub로 이동하여 OpenShift DR Cluster Operator 를 필터링합니다.
화면 지침에 따라
openshift-dr-system프로젝트에 Operator를 설치합니다.참고OpenShift DR Cluster Operator는 기본 관리 클러스터와 보조 관리 클러스터에 모두 설치되어 있어야 합니다.보안 전송 프로토콜 및 오브젝트 버킷에 대한 액세스를 검증하기 위해 Hub 클러스터에서 MCG 오브젝트 버킷의 대체 클러스터에 메타데이터를 저장할 수 있도록 s3 끝점 간의 SSL 액세스를 구성합니다.
참고모든 OpenShift 클러스터가 사용자 환경에 대해 서명된 신뢰할 수 있는 인증서 세트를 사용하여 배포된 경우 이 섹션을 건너뛸 수 있습니다.
기본 관리 클러스터 의 수신 인증서를 추출하고 출력을
primary.crt에 저장합니다.$ oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > primary.crtSecondary 관리 클러스터 의 수신 인증서를 추출하고 출력을
secondary.crt에 저장합니다.$ oc get cm default-ingress-cert -n openshift-config-managed -o jsonpath="{['data']['ca-bundle\.crt']}" > secondary.crtPrimary managed cluster,Secondary managed cluster 및 Hub 클러스터에서 파일 이름
cm-clusters-crt.yaml로 원격 클러스터의 인증서 번들을 보관할 새 ConfigMap 을 만듭니다.참고이 예제 파일에 표시된 대로 각 클러스터에 대해 3개 이상의 인증서가 있을 수 있습니다.
apiVersion: v1 data: ca-bundle.crt: | -----BEGIN CERTIFICATE----- <copy contents of cert1 from primary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert2 from primary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert3 primary.crt here> -----END CERTIFICATE---- -----BEGIN CERTIFICATE----- <copy contents of cert1 from secondary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert2 from secondary.crt here> -----END CERTIFICATE----- -----BEGIN CERTIFICATE----- <copy contents of cert3 from secondary.crt here> -----END CERTIFICATE----- kind: ConfigMap metadata: name: user-ca-bundle namespace: openshift-config기본 관리 클러스터,보조 관리 클러스터, Hub 클러스터에서 다음 명령을 실행하여 파일을 만듭니다.
$ oc create -f cm-clusters-crt.yaml
출력 예:
configmap/user-ca-bundle created
중요Hub 클러스터에서 DRPolicy 리소스인 DRPolicy 리소스를 사용하여 오브젝트 버킷에 대한 액세스 권한을 확인하려면 Hub 클러스터에서 동일한 ConfigMap
cm-clusters-crt.yaml을 생성해야 합니다.기본 프록시 클러스터 리소스를 수정합니다.
다음 콘텐츠를 복사하여 새 YAML 파일
proxy-ca.yaml에 저장합니다.apiVersion: config.openshift.io/v1 kind: Proxy metadata: name: cluster spec: trustedCA: name: user-ca-bundle이 새 파일을 기본 관리 클러스터,보조 관리 클러스터, Hub 클러스터 의 기본 프록시 리소스에 적용합니다.
$ oc apply -f proxy-ca.yaml
출력 예:
proxy.config.openshift.io/cluster configured
MCG(Multicloud Object Gateway) 키 및 외부 S3 엔드포인트를 검색합니다.
MCG가 주 관리 클러스터 및 보조 관리 클러스터에 설치되어 있는지 확인하고 단계가
준비되었는지 확인합니다.$ oc get noobaa -n openshift-storage
출력 예:
NAME MGMT-ENDPOINTS S3-ENDPOINTS IMAGE PHASE AGE noobaa ["https://10.70.56.161:30145"] ["https://10.70.56.84:31721"] quay.io/rhceph-dev/mcg-core@sha256:c4b8857ee9832e6efc5a8597a08b81730b774b2c12a31a436e0c3fadff48e73d Ready 27h
다음 YAML 파일을 파일 이름
odrbucket.yaml에 복사합니다.apiVersion: objectbucket.io/v1alpha1 kind: ObjectBucketClaim metadata: name: odrbucket namespace: openshift-dr-system spec: generateBucketName: "odrbucket" storageClassName: openshift-storage.noobaa.io
기본 관리 클러스터와 보조 관리 클러스터 모두에 MCG 버킷
odrbucket을 만듭니다.$ oc create -f odrbucket.yaml
출력 예:
objectbucketclaim.objectbucket.io/odrbucket created
다음 명령을 사용하여 각 관리 클러스터의
odrbucketOBC 액세스 키를 base-64 인코딩 값으로 추출합니다.$ oc get secret odrbucket -n openshift-dr-system -o jsonpath='{.data.AWS_ACCESS_KEY_ID}{"\n"}'출력 예:
cFpIYTZWN1NhemJjbEUyWlpwN1E=
다음 명령을 사용하여 각 관리 클러스터의
odrbucketOBC 시크릿 키를 base-64 인코딩 값으로 추출합니다.$ oc get secret odrbucket -n openshift-dr-system -o jsonpath='{.data.AWS_SECRET_ACCESS_KEY}{"\n"}'출력 예:
V1hUSnMzZUoxMHRRTXdGMU9jQXRmUlAyMmd5bGwwYjNvMHprZVhtNw==
관리형 클러스터에 대한 S3 시크릿을 생성합니다.
이제 필요한 MCG 정보가 추출되었으므로 기본 관리 클러스터와 보조 관리 클러스터에서 생성된 새 시크릿이 추출되어야 합니다. 이러한 새 시크릿은 두 관리 클러스터의 MCG 액세스 및 시크릿 키를 저장합니다.
참고OpenShift DR에는 관리형 클러스터에서 워크로드의 관련 클러스터 데이터를 저장하고 장애 조치 또는 재배치 작업 중에 워크로드 복구를 오케스트레이션하기 위해 하나 이상의 S3 저장소가 필요합니다. 이러한 지침은 MCG(Multicloud Gateway)를 사용하여 필요한 오브젝트 버킷을 생성하는 데 적용할 수 있습니다. MCG는 이미 OpenShift Data Foundation을 설치함으로써 설치되어 있어야 합니다.
기본 관리 클러스터의 다음 S3 시크릿 YAML 형식을
odr-s3secret-hiera.yaml 파일 이름으로 복사합니다.apiVersion: v1 data: AWS_ACCESS_KEY_ID: <primary cluster base-64 encoded access key> AWS_SECRET_ACCESS_KEY: <primary cluster base-64 encoded secret access key> kind: Secret metadata: name: odr-s3secret-primary namespace: openshift-dr-system
< primary cluster base-64 encoded access key > 및 < primary cluster base-64 encoded secret access key >를 이전 단계에서 검색된 실제 값으로 바꿉니다.
기본 관리 클러스터 및 보조 관리 클러스터에 이 시크릿을 생성합니다.
$ oc create -f odr-s3secret-primary.yaml
출력 예:
secret/odr-s3secret-primary created
보조 관리 클러스터의 다음 S3 시크릿 YAML 형식을
odr-s3secret-secondary.yaml파일 이름으로 복사합니다.apiVersion: v1 data: AWS_ACCESS_KEY_ID: <secondary cluster base-64 encoded access key> AWS_SECRET_ACCESS_KEY: <secondary cluster base-64 encoded secret access key> kind: Secret metadata: name: odr-s3secret-secondary namespace: openshift-dr-system
< secondary 클러스터 base-64로 인코딩된 액세스 키 > 및 < secondary cluster base-64 encoded secret access key >를 4단계에서 검색된 실제 값으로 바꿉니다.
기본 관리 클러스터 및 보조 관리 클러스터에 이 시크릿을 생성합니다.
$ oc create -f odr-s3secret-secondary.yaml
출력 예:
secret/odr-s3secret-secondary created
중요액세스 및 시크릿 키의 값은 base-64로 인코딩 되어야 합니다. 키의 인코딩된 값이 이전 단계에서 검색되었습니다.
각 관리형 클러스터에서 OpenShift DR Cluster Operator ConfigMap을 구성합니다.
다음 명령을 사용하여 각 관리 클러스터에서 외부 S 3 endpoint s3 CompatibilityibleEndpoint 또는 route for MCG를 검색합니다.
$ oc get route s3 -n openshift-storage -o jsonpath --template="https://{.spec.host}{'\n'}"출력 예:
https://s3-openshift-storage.apps.perf1.example.com
중요기본 관리 클러스터 및 보조 관리
클러스터 모두에 대해 각각 s3 CompatibilityibleEndpoint 경로 또는 s3-openshift-storage.apps.<baseDomain> 및s3-openshift-storage.apps.<secondary clusterID>.<baseDomain>을 검색해야 합니다.odrbucketOBC 버킷 이름을 검색합니다.$ oc get configmap odrbucket -n openshift-dr-system -o jsonpath='{.data.BUCKET_NAME}{"\n"}'출력 예:
odrbucket-2f2d44e4-59cb-4577-b303-7219be809dcd
중요고유한 s3Bucket 이름 odrbucket-<your value1 > 및 odrbucket-<your value2 >를 각각 기본 관리 클러스터 와 보조 관리 클러스터에서 검색해야 합니다.
ConfigMap
ramen-dr-cluster-operator-config를 수정하여 새 콘텐츠를 추가합니다.$ oc edit configmap ramen-dr-cluster-operator-config -n openshift-dr-system
s3StoreProfiles부터 기본 관리 클러스터의 ConfigMap과 보조 관리 클러스터 의 다음 새 콘텐츠를 추가합니다.[...] data: ramen_manager_config.yaml: | apiVersion: ramendr.openshift.io/v1alpha1 kind: RamenConfig [...] ramenControllerType: "dr-cluster" ### Start of new content to be added s3StoreProfiles: - s3ProfileName: s3-primary s3CompatibleEndpoint: https://s3-openshift-storage.apps.<primary clusterID>.<baseDomain> s3Region: primary s3Bucket: odrbucket-<your value1> s3SecretRef: name: odr-s3secret-primary namespace: openshift-dr-system - s3ProfileName: s3-secondary s3CompatibleEndpoint: https://s3-openshift-storage.apps.<secondary clusterID>.<baseDomain> s3Region: secondary s3Bucket: odrbucket-<your value2> s3SecretRef: name: odr-s3secret-secondary namespace: openshift-dr-system [...]
7장. Hub 클러스터에 OpenShift DR Hub Operator 설치
사전 요구 사항
- access 및 secret 키의 값이 base-64로 인코딩 되었는지 확인합니다. 키의 인코딩된 값은 이전 섹션에서 검색되었으며 결과 보안 은 관리형 클러스터에서 이미 생성된 값과 정확히 동일합니다.
절차
- Hub 클러스터에서 OperatorHub로 이동하여 OpenShift DR Hub Operator 에 대한 검색 필터를 사용합니다.
-
화면 지시에 따라
openshift-dr-system프로젝트에 Operator를 설치합니다. 기본 관리 클러스터에 대해 다음 S3 시크릿 YAML 형식을 사용하여 Hub 클러스터의 S3 시크릿 시크릿을 생성합니다.
apiVersion: v1 data: AWS_ACCESS_KEY_ID: <primary cluster base-64 encoded access key> AWS_SECRET_ACCESS_KEY: <primary cluster base-64 encoded secret access key> kind: Secret metadata: name: odr-s3secret-primary namespace: openshift-dr-system
다음 명령을 실행하여 Hub 클러스터에서 이 시크릿을 생성합니다.
$ oc create -f odr-s3secret-primary.yaml
출력 예:
secret/odr-s3secret-primary created
보조 관리 클러스터에 대해 다음 S3 시크릿 YAML 형식을 사용하여 S3 시크릿을 만듭니다.
apiVersion: v1 data: AWS_ACCESS_KEY_ID: <secondary cluster base-64 encoded access key> AWS_SECRET_ACCESS_KEY: <secondary cluster base-64 encoded secret access key> kind: Secret metadata: name: odr-s3secret-secondary namespace: openshift-dr-system
다음 명령을 실행하여 Hub 클러스터에서 이 시크릿을 생성합니다.
$ oc create -f odr-s3secret-secondary.yaml
출력 예:
secret/odr-s3secret-secondary created
OpenShift DR Hub Operator의 ConfigMap을 구성합니다.
Operator가 성공적으로 생성되면
ramen-hub-operator-config라는 새 ConfigMap이 생성됩니다.다음 명령을 실행하여 파일을 편집합니다.
$ oc edit configmap ramen-hub-operator-config -n openshift-dr-system
s3StoreProfiles부터 Hub 클러스터의 ConfigMap 에 다음과 같은 새 콘텐츠를 추가합니다.[...] apiVersion: v1 data: ramen_manager_config.yaml: | apiVersion: ramendr.openshift.io/v1alpha1 kind: RamenConfig [...] ramenControllerType: "dr-hub" ### Start of new content to be added s3StoreProfiles: - s3ProfileName: s3-primary s3CompatibleEndpoint: https://s3-openshift-storage.apps.<primary clusterID>.<baseDomain> s3Region: primary s3Bucket: odrbucket-<your value1> s3SecretRef: name: odr-s3secret-primary namespace: openshift-dr-system - s3ProfileName: s3-secondary s3CompatibleEndpoint: https://s3-openshift-storage.apps.<secondary clusterID>.<baseDomain> s3Region: secondary s3Bucket: odrbucket-<your value2> s3SecretRef: name: odr-s3secret-secondary namespace: openshift-dr-system [...]참고< primary clusterID > , < secondary clusterID > , baseDomain,odrbucket-<your value1 >, odrbucket-<your value2 > 변수를 관리 클러스터의
ramen-cluster-operator-configConfigMap 에 사용된 것과 정확히 동일한 값으로 교체해야 합니다.
8장. Hub 클러스터에서 재해 복구 정책 생성
OpenShift DR은 RHACM 허브 클러스터에서 Dis broken recovery Policy(DRPolicy) 리소스(클러스터 범위)를 사용하여 관리형 클러스터에 워크로드를 배포, 장애 조치, 재배치합니다.
사전 요구 사항
- 스토리지 수준 복제에 대해 피어링되고 CSI 볼륨 복제가 활성화된 두 개의 클러스터 세트가 있는지 확인합니다.
- DRPolicy를 사용하여 워크로드에 대한 세분화된 복구 포인트 목표(RPO) 역할을 하는 빈도 데이터 복제가 수행되는 빈도를 결정하는 스케줄링 간격이 있는지 확인합니다.
- 정책의 각 클러스터에 OpenShift DR 클러스터 및 허브 Operator의 ConfigMap을 사용하여 구성된 S3 프로필 이름이 할당되어 있는지 확인합니다.
절차
-
Hub 클러스터에서
openshift-dr-system프로젝트에서 Installed Operators로 이동하여 OpenShift DR Hub Operator 를 클릭합니다. 사용 가능한 API 두 개, DRPolicy 및 DRPlacementControl이 표시됩니다. - DRPolicy에 대한 인스턴스 생성 을 클릭하고 YAML 보기를 클릭합니다.
< cluster1> 및 < cluster 2 >를 RHACM의 관리형 클러스터의 올바른 이름으로 교체한 후 파일 이름
drpolicy.yaml에 다음 YAML을 복사하고 저장합니다.apiVersion: ramendr.openshift.io/v1alpha1 kind: DRPolicy metadata: name: odr-policy-5m spec: drClusterSet: - name: <cluster1> s3ProfileName: s3-primary - name: <cluster2> s3ProfileName: s3-secondary schedulingInterval: 5m참고DRPolicy는 클러스터 범위 리소스이므로 이 리소스를 생성하기 위해 네임스페이스를 지정할 필요가 없습니다.
-
고유한
drpolicy.yaml파일의 콘텐츠를 YAML 보기에 복사합니다. 원본 콘텐츠를 완전히 교체해야 합니다. YAML 보기 화면에서 생성 을 클릭합니다.
중요DRPolicy 스케줄링 간격은 Creating VolumeReplicationClass resource 섹션에 구성된 간격과 일치해야 합니다.
명령을 실행하여 DRPolicy 가 생성되었는지 확인합니다.
$ oc get drpolicy odr-policy-5m -n openshift-dr-system -o jsonpath='{.status.conditions[].reason}{"\n"}'출력 예:
Succeeded
9장. 샘플 애플리케이션 생성
기본 관리 클러스터에서 보조 관리 클러스터로 장애 조치를 테스트하고 다시하려면 샘플 애플리케이션이 필요합니다. 예제로 busybox 라는 샘플 애플리케이션을 사용합니다.
절차
busybox샘플 애플리케이션에 사용할 Hub 클러스터에서 네임스페이스 또는 프로젝트를 생성합니다.$ oc new-project busybox-sample
참고busybox-sample이외의 다른 프로젝트 이름을 원하는 경우 사용할 수 있습니다. Advanced Cluster Manager 콘솔을 통해 샘플 애플리케이션을 배포하여 이 단계에서 생성된 것과 동일한 프로젝트 이름을 사용해야 합니다.DRPlacementControl 리소스 생성
DRPlacementControl은 OpenShift DR Hub Operator가 Hub 클러스터에 설치된 후 사용 가능한 API입니다. DRPolicy에 속하는 클러스터 전체의 데이터 가용성에 따라 배치 결정을 오케스트레이션하는 Advanced Cluster Manager PlacementRule 조정기입니다.
-
Hub 클러스터에서
busybox-sample프로젝트에서 Installed Operators로 이동하여 OpenShift DR Hub Operator 를 클릭합니다. 사용 가능한 API 두 개, DRPolicy 및 DRPlacementControl이 표시됩니다. -
DRPlacementControl 에 대한 인스턴스를 생성한 다음 YAML 보기로 이동합니다.
busybox-sample프로젝트가 선택되어 있는지 확인합니다. Advanced Cluster Manager의 관리 클러스터의 < cluster1 >을 올바른 이름으로 교체한 후 파일 이름
busybox-drpc.yaml에 다음 YAML을 복사하고 저장합니다.apiVersion: ramendr.openshift.io/v1alpha1 kind: DRPlacementControl metadata: labels: app: busybox-sample name: busybox-drpc spec: drPolicyRef: name: odr-policy-5m placementRef: kind: PlacementRule name: busybox-placement preferredCluster: <cluster1> pvcSelector: matchLabels: appname: busybox-
고유한
busybox-drpc.yaml파일의 콘텐츠를 YAML 보기(원래 콘텐츠 교체)로 복사합니다. YAML 보기 화면에서 생성 을 클릭합니다.
다음 CLI 명령을 사용하여 이 리소스를 생성할 수도 있습니다.
$ oc create -f busybox-drpc.yaml -n busybox-sample
출력 예:
drplacementcontrol.ramendr.openshift.io/busybox-drpc created
중요이 리소스는
busybox-sample네임 스페이스(또는 이전에 만든 네임스페이스)에서 생성해야 합니다.
-
Hub 클러스터에서
리소스 템플릿을 배포할 수 있는 대상 클러스터를 정의하는 배치 규칙 리소스를 생성합니다. 배치 규칙을 사용하여 애플리케이션의 다중 클러스터 배포를 용이하게 합니다.
다음 YAML을 복사하여 파일 이름
busybox-placementrule.yaml에 저장합니다.apiVersion: apps.open-cluster-management.io/v1 kind: PlacementRule metadata: labels: app: busybox-sample name: busybox-placement spec: clusterConditions: - status: "True" type: ManagedClusterConditionAvailable clusterReplicas: 1 schedulerName: ramenbusybox-sample애플리케이션에 대한 배치 규칙 리소스를 생성합니다.$ oc create -f busybox-placementrule.yaml -n busybox-sample
출력 예:
placementrule.apps.open-cluster-management.io/busybox-placement created
중요이 리소스는
busybox-sample네임 스페이스(또는 이전에 만든 네임스페이스)에서 생성해야 합니다.
RHACM 콘솔을 사용하여 샘플 애플리케이션 생성
아직 로그인하지 않은 경우 OpenShift 인증 정보를 사용하여 RHACM 콘솔에 로그인합니다.
$ oc get route multicloud-console -n open-cluster-management -o jsonpath --template="https://{.spec.host}/multicloud/applications{'\n'}"출력 예:
https://multicloud-console.apps.perf3.example.com/multicloud/applications
- Applications (애플리케이션)로 이동하여 Create application 을 클릭합니다.
- type을 Subscription 으로 선택합니다.
-
애플리케이션 이름 (예:
busybox) 및 네임스페이스 (예:busybox-sample)를 입력합니다. -
Repository location for resources 섹션에서 Repository type
Git을 선택합니다. 샘플 애플리케이션의 Git 리포지토리 URL, github Branch 및 Path 를 입력합니다. 여기서 리소스
busyboxPod 및 PVC가 생성됩니다.Branch 가
main이고 Path 가busybox-odr인 경우 샘플 애플리케이션 리포지토리를https://github.com/RamenDR/ocm-ramen-samples사용합니다.중요진행하기 전에 새 StorageClass
ocs-storagecluster-ceph-rbdmirror가 [Create StorageClass resource] 섹션에 자세히 설명되어 있는지 확인합니다.다음 명령을 사용하여 생성되었는지 확인합니다.
oc get storageclass | grep rbdmirror | awk '{print $1}'출력 예:
ocs-storagecluster-ceph-rbdmirror
- 양식을 아래로 스크롤하여 배포할 클러스터 선택 섹션까지 아래로 스크롤하고 기존 배치 구성 선택을 클릭합니다.
-
드롭다운 목록에서 기존 배치 규칙 (예:
busybox-placement)을 선택합니다. 저장을 클릭합니다.
애플리케이션이 생성되면 애플리케이션 세부 정보 페이지가 표시됩니다. 리소스 토폴로지 섹션으로 스크롤할 수 있습니다. 토폴로지의 요소 및 애플리케이션에 녹색 확인 표시가 있어야 합니다.
참고자세한 내용을 보려면 토폴로지 요소를 클릭하면 토폴로지 보기 오른쪽에 창이 표시됩니다.
샘플 애플리케이션 배포 및 복제를 확인합니다.
이제
busybox애플리케이션이 기본 클러스터(DRPlacementControl에 지정)에 배포되었으므로 배포를 검증할 수 있습니다.RHACM에서
busybox를 배포한 관리형 클러스터에 로그인합니다.$ oc get pods,pvc -n busybox-sample
출력 예:
NAME READY STATUS RESTARTS AGE pod/busybox 1/1 Running 0 6m NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/busybox-pvc Bound pvc-a56c138a-a1a9-4465-927f-af02afbbff37 1Gi RWO ocs-storagecluster-ceph-rbd 6m
busyboxPVC에 대한 복제 리소스도 생성되었는지 확인합니다.$ oc get volumereplication,volumereplicationgroup -n busybox-sample
출력 예:
NAME AGE VOLUMEREPLICATIONCLASS PVCNAME DESIREDSTATE CURRENTSTATE volumereplication.replication.storage.openshift.io/busybox-pvc 6m odf-rbd-volumereplicationclass busybox-pvc primary Primary NAME AGE volumereplicationgroup.ramendr.openshift.io/busybox-drpc 6m
Primary Management 클러스터와 Secondary 관리 클러스터에서 다음 명령을 실행하여
busybox볼륨이 대체 클러스터에 복제되었는지 확인합니다.$ oc get cephblockpool ocs-storagecluster-cephblockpool -n openshift-storage -o jsonpath='{.status.mirroringStatus.summary}{"\n"}'출력 예:
{"daemon_health":"OK","health":"OK","image_health":"OK","states":{"replaying":2}}참고두 관리 클러스터 모두 새 상태가
"states":{"replaying":2}'인 출력이 동일해야 합니다.
9.1. 샘플 애플리케이션 삭제
RHACM 콘솔을 사용하여 샘플 애플리케이션 busybox 를 삭제할 수 있습니다.
절차
- RHACM 콘솔에서 Applications (애플리케이션) .
-
삭제할 샘플 애플리케이션을 검색합니다(예:
busybox). - 삭제하려는 애플리케이션 옆에 있는 Action Menu(작업 메뉴) 를 클릭합니다.
애플리케이션 삭제를 클릭합니다.
Delete application(애플리케이션 삭제)을 선택하면 애플리케이션 관련 리소스도 삭제해야 하는지 묻는 새 화면이 표시됩니다.
- 애플리케이션 관련 리소스 제거 확인란을 선택하여 서브스크립션 및 PlacementRule을 삭제합니다.
- 삭제를 클릭합니다. 이렇게 하면 기본 관리 클러스터(또는 애플리케이션이 실행 중인 클러스터)에서 busybox 애플리케이션이 삭제됩니다.
RHACM 콘솔을 사용하여 삭제된 리소스 외에도
DRPlacementControl도busybox애플리케이션을 삭제한 직후 삭제해야 합니다.-
Hub 클러스터의 OpenShift 웹 콘솔에 로그인하고
busybox-sample프로젝트에 대해 설치된 Operator로 이동합니다. - OpenShift DR Hub Operator 를 클릭한 다음 DRPlacementControl 탭을 클릭합니다.
-
삭제하려는
busybox애플리케이션 DRPlacementControl 옆에 있는 Action Menu(및 작업 메뉴) 를 클릭합니다. - DRPlacementControl 삭제를 클릭합니다.
- 삭제를 클릭합니다.
-
Hub 클러스터의 OpenShift 웹 콘솔에 로그인하고
이 프로세스를 사용하여 DRPlacementControl 리소스가 있는 모든 애플리케이션을 삭제할 수 있습니다. CLI를 사용하여 애플리케이션 네임스페이스에서 DRPlacementControl 리소스를 삭제할 수도 있습니다.
10장. 관리형 클러스터 간 애플리케이션 장애 조치
이 섹션에서는 busybox 샘플 애플리케이션을 장애 조치하는 방법에 대한 지침을 제공합니다. #150-DR에 대한 장애 조치(failover) 방법은 애플리케이션을 기반으로 합니다. 이러한 방식으로 보호되도록 하는 각 애플리케이션은 DR 테스트용 샘플 애플리케이션 생성 섹션에 표시된 대로 애플리케이션 네임스페이스에 생성된 해당 DRPlacementControl 리소스 및 PlacementRule 리소스가 있어야 합니다.
절차
- Hub 클러스터에서 Installed Operators로 이동한 다음 Openshift DR Hub Operator 를 클릭합니다.
- DRPlacementControl 탭을 클릭합니다.
-
DRPC
busybox-drpc를 클릭한 다음 YAML 보기를 클릭합니다. 아래 스크린샷과 같이
작업및 장애 조치 클러스터세부 정보를 추가합니다.장애 조치클러스터는 Secondary 관리 클러스터의 ACM 클러스터 이름입니다.DRPlacementControl 추가 장애 조치
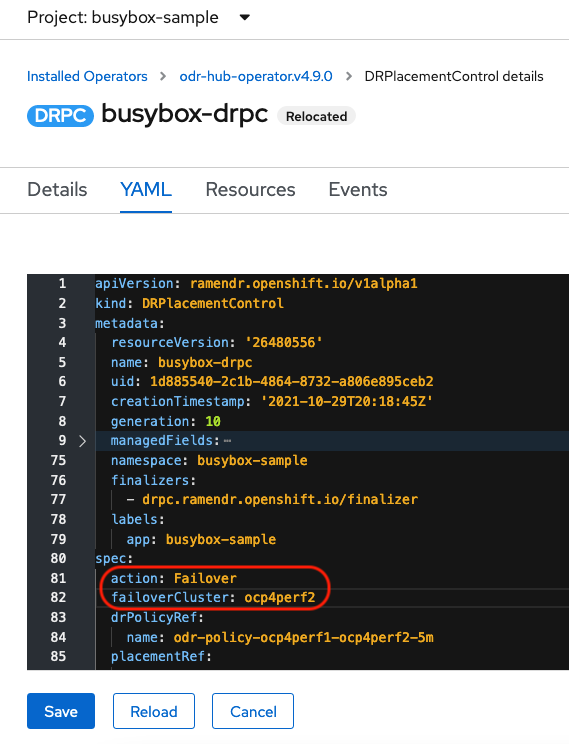
- 저장을 클릭합니다.
이제 애플리케이션이 YAML 파일에 지정된 장애 조치 클러스터
ocp4perf2인 Secondary 관리 클러스터에서 실행 중인지 확인합니다.$ oc get pods,pvc -n busybox-sample
출력 예:
NAME READY STATUS RESTARTS AGE pod/busybox 1/1 Running 0 35s NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/busybox-pvc Bound pvc-79f2a74d-6e2c-48fb-9ed9-666b74cfa1bb 5Gi RWO ocs-storagecluster-ceph-rbd 35s
busybox가 기본 관리 클러스터에서 더 이상 실행되지 않는지 확인합니다.$ oc get pods,pvc -n busybox-sample
출력 예:
No resources found in busybox-sample namespace.
릴리스 노트의 Known issues 섹션에 설명된 알려진 Region-DR 문제에 대해 유의하십시오.
개발자 프리뷰 기능에 대한 지원이 필요한 경우 ocs-devpreview@redhat.com 메일링 목록에 도달하고 Red Hat Development Team의 멤버는 가용성 및 작업 일정에 따라 최대한 빨리 도움을 드릴 것입니다.
11장. 관리 클러스터 간에 애플리케이션 재배치
재배치 작업은 장애 조치와 매우 유사합니다. 재배치는 애플리케이션을 기반으로 하며 DRPlacementControl을 사용하여 재배치를 트리거합니다. 재배치의 주요 차이점은 보조 관리 클러스터에 저장된 새 애플리케이션 데이터가 주 관리 클러스터에 복제된 미러링 일정 간격을 기다리지 않고 즉시 있는지 확인하기 위해 재동기화 가 발행된다는 것입니다.
절차
- Hub 클러스터에서 Installed Operators로 이동한 다음 Openshift DR Hub Operator 를 클릭합니다.
- DRPlacementControl 탭을 클릭합니다.
-
DRPC
busybox-drpc를 클릭한 다음 YAML 보기를 클릭합니다. Relocate작업을 수정DRPlacementControl Relocate에 대한 작업 수정
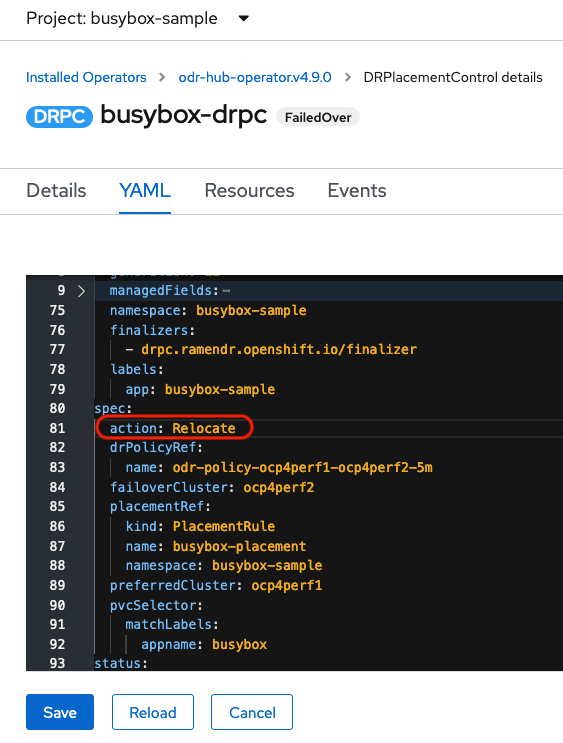
- 저장을 클릭합니다.
이제 애플리케이션이 기본 관리 클러스터에서 실행 중인지 확인합니다. YAML 파일에 지정된 장애 조치 클러스터
ocp4perf2입니다.$ oc get pods,pvc -n busybox-sample
출력 예:
NAME READY STATUS RESTARTS AGE pod/busybox 1/1 Running 0 60s NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE persistentvolumeclaim/busybox-pvc Bound pvc-79f2a74d-6e2c-48fb-9ed9-666b74cfa1bb 5Gi RWO ocs-storagecluster-ceph-rbd 61s
Secondary 관리 클러스터에서
busybox가 실행 중인지 확인합니다. busybox 애플리케이션은 이 관리 클러스터에서 더 이상 실행되지 않아야 합니다.$ oc get pods,pvc -n busybox-sample
출력 예:
No resources found in busybox-sample namespace.
릴리스 노트의 Known issues 섹션에 설명된 알려진 Region-DR 문제에 대해 유의하십시오.
개발자 프리뷰 기능에 대한 지원이 필요한 경우 ocs-devpreview@redhat.com 메일링 목록에 도달하고 Red Hat Development Team의 멤버는 가용성 및 작업 일정에 따라 최대한 빨리 도움을 드릴 것입니다.