
Monitoring OpenShift Container Storage
스토리지 대시보드를 사용하여 OpenShift Container Storage 모니터링
초록
1장. 클러스터 상태
1.1. OpenShift Container Storage가 정상인지 확인
영구 스토리지 및 오브젝트 서비스 대시보드에 스토리지 상태가 표시됩니다.
절차
- OpenShift 웹 콘솔에 로그인합니다.
다음 위치에서 상태 카드를 확인합니다.
- 홈 → 개요 → 영구 스토리지
홈 → 개요 → 오브젝트 서비스
green Tick 이 상태 카드에 표시되면 클러스터가 정상입니다.
상태가 정상이 아닌 경우 현재 상태 및 표시되는 경고에 대한 자세한 내용은 1.2절. “스토리지 상태 수준 및 클러스터 상태” 을 참조하십시오.
1.2. 스토리지 상태 수준 및 클러스터 상태
OpenShift Container Storage와 관련된 상태 정보 및 경고는 스토리지 대시보드에 표시됩니다.
1.2.1. 영구 스토리지 대시보드 지표
영구 스토리지 대시보드에는 OpenShift Container Storage의 상태뿐만 아니라 영구 볼륨 상태가 표시됩니다.
각 리소스 유형에 대해 가능한 상태는 다음 표에 나열되어 있습니다.
표 1.1. OpenShift Container Storage 상태 수준
| 상태 | icon | 설명 |
|---|---|---|
| 알 수 없음 |
| OpenShift Container Storage는 배포되거나 사용할 수 없습니다. |
| green Tick |
| 클러스터 상태가 좋은 것입니다. |
| 경고 |
| OpenShift Container Storage 클러스터가 경고 상태일 때 내부 모드에서는 문제 세부 정보와 함께 경고가 표시됩니다. 외부 모드의 경우 경고가 표시되지 않습니다. |
| 오류 |
| OpenShift Container Storage 클러스터에 오류가 발생하면 일부 구성 요소가 작동하지 않습니다. 내부 모드에서는 문제 세부 정보와 함께 경고가 표시됩니다. 외부 모드의 경우 경고가 표시되지 않습니다. |
1.2.2. Object Service 대시보드 지표
오브젝트 서비스 대시보드에는 Multicloud Object Gateway의 상태와 클러스터의 모든 오브젝트 클레임이 표시됩니다.
각 리소스 유형에 대해 가능한 상태는 다음 표에 나열되어 있습니다.
표 1.2. 오브젝트 서비스 상태 수준
| 상태 | 설명 |
|---|---|
|
green Tick | 오브젝트 스토리지는 정상입니다. |
| Multicloud Object Gateway가 실행되고 있지 않음 | NooBaa 시스템을 찾을 수 없을 때 표시됩니다. |
| 모든 리소스가 비정상입니다. | 모든 NooBaa 풀이 비정상 상태일 때 표시됩니다. |
| 많은 버킷에 문제가 있습니다. | 버킷의 50%가 오류가 발생하면 표시됩니다. |
| 일부 버킷에 문제가 있습니다. | 버킷의 >= 30%가 오류가 발생하는 경우 표시됩니다. |
| 사용할 수 없음 | 네트워크 문제 및/또는 오류가 존재하는 경우 표시됩니다. |
1.2.3. 경고 패널
클러스터 상태가 정상이 아닌 경우 Alert 패널은 영구 스토리지 대시보드와 오브젝트 서비스 대시보드의 상태 카드 아래에 표시됩니다.
OpenShift Container Storage 문제 해결 에서 특정 경고 및 응답 방법에 대한 정보를 확인할 수 있습니다.
2장. 지표
2.1. 영구 스토리지 대시보드의 지표
영구 스토리지 대시보드를 보려면 OpenShift 웹 콘솔에서 홈 → 개요 → 영구 스토리지를 클릭합니다.
그림 2.1. 내부 모드의 영구 스토리지 개요 대시보드 예
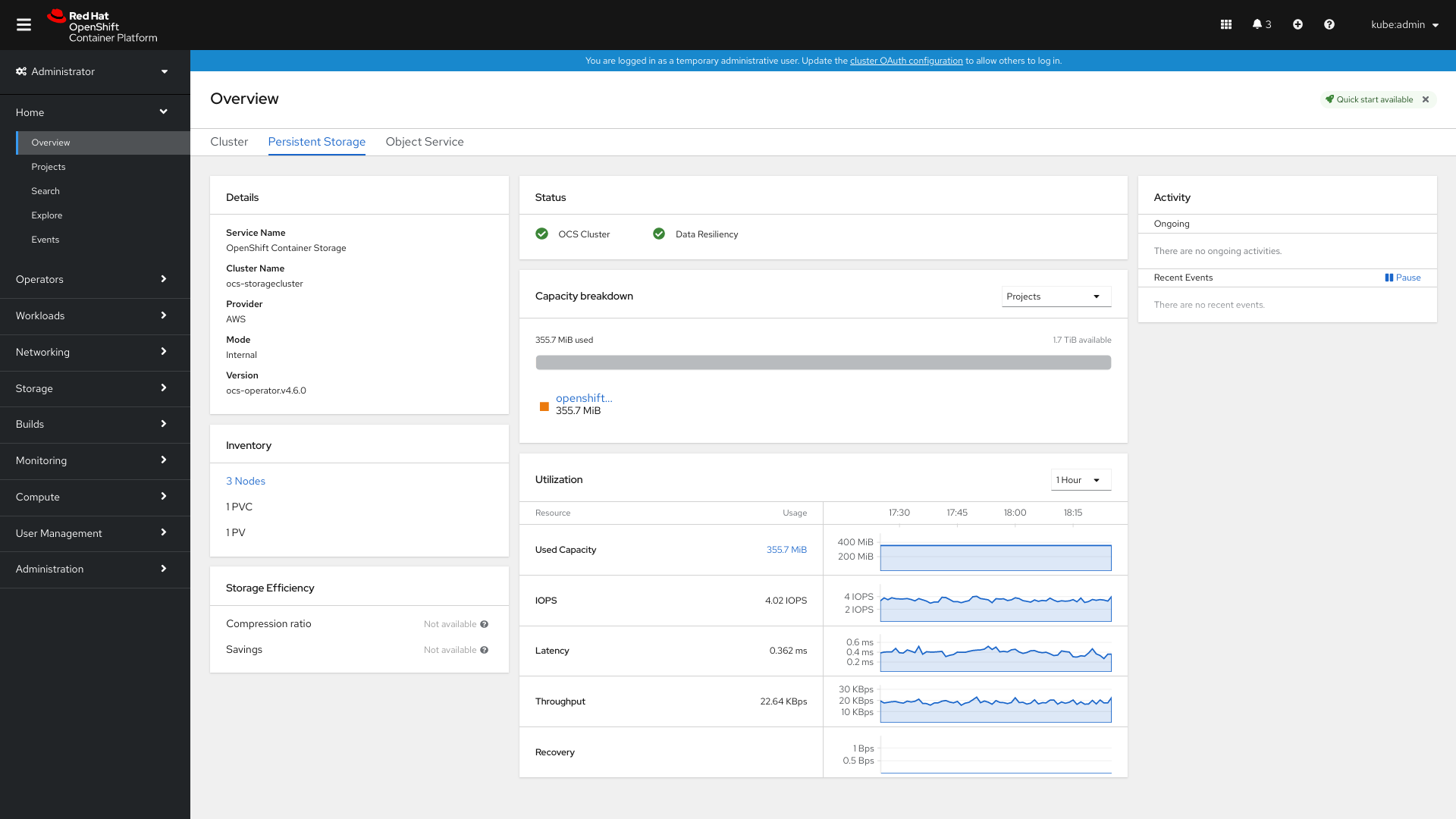
영구 스토리지 대시보드의 다음 카드는 배포 모드(내부 또는 외부)를 기반으로 메트릭을 제공합니다.
- 세부 정보 카드
세부 정보 카드에는 다음이 표시됩니다.
- 서비스 이름
- 클러스터 이름
- 시스템을 실행하는 공급자의 이름(예: AWS, VSphere, 'None' for Bare metal)
- 모드(내부 또는 외부로 배포 모드)
- OpenShift Container Storage Operator 버전.
- 인벤토리 카드
- 인벤토리 카드에는 OpenShift Container Storage 프로비저너에서 지원하는 활성 노드, PVC 및 PV 수가 표시됩니다. 카드 왼쪽에는 스토리지 노드, PVC 및 PV의 총 수가 표시됩니다. 카드의 오른쪽에는 준비 안 됨 상태의 스토리지 노드 수가 표시되지만 Pending 상태의 PVC 수와 Released 상태의 PV가 표시됩니다.
외부 모드의 경우 OpenShift Container Storage 전용 노드가 없기 때문에 기본적으로 노드 수는 0이 됩니다.
- 상태 카드
이 카드는 클러스터가 오류 없이 실행 중인지 또는 몇 가지 문제가 발생하는지를 표시합니다.
내부 모드의 경우 데이터 복원은 복제본에서 Ceph에서 데이터 재조정 상태를 나타냅니다. 내부 모드 클러스터가 경고 또는 오류 상태에 있으면 경고 섹션이 관련 경고와 함께 표시됩니다.
외부 모드의 경우 데이터 복원 및 경고가 표시되지 않습니다.
- 용량 분류 카드
이 카드에서는 프로젝트, 스토리지 클래스 및 Pod당 용량의 그래픽 분석을 볼 수 있습니다. 카드 상단에 있는 드롭다운 메뉴에서 프로젝트, 스토리지 클래스 및 Pod 중에서 선택할 수 있습니다. 이러한 옵션은 그래프에 표시된 데이터를 필터링하는 것입니다.
옵션 Display 프로젝트
OpenShift Container 스토리지를 사용하고 있는 각 프로젝트의 용량과 사용되는 용량입니다.
스토리지 클래스
는 OpenShift Container Storage 기반 스토리지 클래스를 기반으로 하는 집계 용량을 표시합니다.
pods
OpenShift Container Storage 프로비저너에서 지원하는 PVC를 사용하려고 하는 모든 pod
외부 모드의 경우 이 그래프는 사용된 용량 세부 정보만 표시합니다.
- 사용률 카드
카드는 사용 용량, 초당 입력/출력 작업, 대기 시간, 처리량 및 내부 모드 클러스터에 대한 복구 정보를 보여줍니다.
외부 모드의 경우 이 카드는 해당 클러스터에 사용된 용량 세부 사항만 표시합니다.
- 스토리지 효율성 카드
- 이 카드는 압축이 포함된 스토리지 클래스를 사용하여 시스템 전체 압축 비율과 영구 볼륨 클레임용으로 저장된 공간의 양을 보여줍니다.
2.2. 오브젝트 서비스 대시보드의 지표
오브젝트 서비스 대시보드를 보려면 OpenShift 웹 콘솔에서 홈 → 개요 → 오브젝트 서비스를 클릭합니다.
OpenShift Container Storage 4.6 후 업그레이드의 오브젝트 서비스 대시보드에서 Object Gateway(RGW) 지표를 보려면 모니터링을 활성화해야 합니다. RGW에 대한 모니터링을 활성화하려면 오브젝트 서비스 대시보드에 대한 모니터링 활성화를 참조하십시오.
그림 2.2. 오브젝트 서비스 개요 대시보드의 예
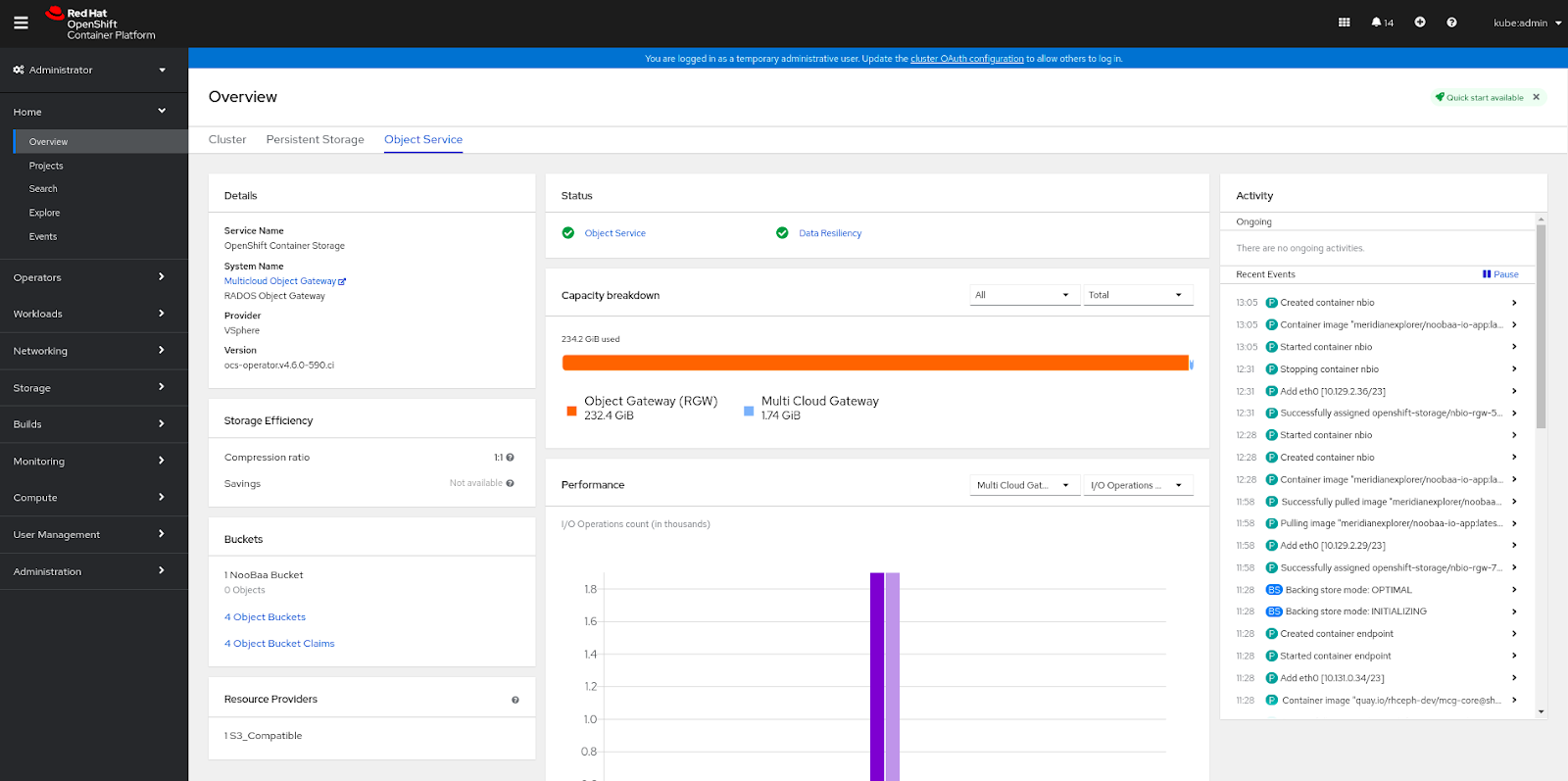
오브젝트 서비스 대시보드에서는 다음 메트릭을 사용할 수 있습니다.
- 세부 정보 카드
이 카드는 다음 정보를 보여줍니다.
- 서비스 이름: MCG(Multicloud Object Gateway) 서비스 이름입니다.
- System Name: Multicloud Object Gateway 및 RADOS Object Gateway 시스템 이름입니다. Multicloud Object Gateway 시스템 이름은 MCG 관리 사용자 인터페이스에 대한 하이퍼링크이기도 합니다.
- 공급자: 시스템이 실행되는 공급자의 이름(예: AWS, VSphere, 'None' for Baremetal)
- 버전: OpenShift Container Storage Operator 버전.
- 스토리지 효율성 카드
- 이 카드에서는 MCG가 중복 제거 및 압축을 통해 스토리지 백엔드 리소스의 사용을 최적화하는 방법을 볼 수 있으며 계산된 효율성 비율(애플리케이션 데이터 vs 논리 데이터)과 예상 비용 절감 수치(최대 바이트 수)를 통해 베어 메탈 및 클라우드 기반 스토리지의 용량에 따라 클라우드 기반 스토리지 및 송신 기능을 제공할 수 있습니다.
- 버킷 카드
버킷은 애플리케이션을 대신하여 데이터를 저장하기 위해 MCG 및 RADOS 오브젝트 게이트웨이에서 유지보수하는 컨테이너입니다. 이러한 버킷은 OBC(오브젝트 버킷 클레임)를 통해 생성되고 액세스할 수 있습니다. 버킷에 특정 정책을 적용하여 데이터 배치, 데이터 분산, 용량 할당량 등을 사용자 지정할 수 있습니다.
이 카드에는 OB(오브젝트 버킷) 및 개체 버킷 클레임(OBC)에 대한 정보가 별도로 표시됩니다. OB에는 S3 또는 사용자 인터페이스(UI)를 사용하여 생성된 모든 버킷이 포함되어 있으며 OBC에는 YAML 또는 CLI(명령줄 인터페이스)를 사용하여 생성된 모든 버킷이 포함됩니다. 버킷 유형 왼쪽에 표시되는 숫자는 OB 또는 OBC의 총 수입니다. 오른쪽에 표시된 숫자에는 오류 수가 표시되며 오류 수가 0보다 큰 경우에만 표시됩니다. 번호를 클릭하면 경고 또는 오류 상태가 있는 버킷 목록을 확인할 수 있습니다.
- 리소스 공급자 카드
- 이 카드에는 현재 사용 중인 모든 Multicloud Object Gateway 및 RADOS Object Gateway 리소스 목록이 표시됩니다. 이러한 리소스는 버킷 정책에 따라 데이터를 저장하는 데 사용되며 클라우드 기반 리소스 또는 베어 메탈 리소스입니다.
- 상태 카드
이 카드는 시스템과 서비스가 문제 없이 실행되고 있는지 여부를 보여줍니다. 시스템이 경고 또는 오류 상태에 있으면 alerts 섹션이 표시되고 관련 경고가 표시됩니다. 문제에 대한 자세한 내용은 각 경고 옆에 있는 경고 링크를 클릭합니다. 상태 점검에 대한 자세한 내용은 클러스터 상태를 참조하십시오.
클러스터에서 여러 오브젝트 스토리지 서비스를 사용할 수 있는 경우 서비스 유형(예: Object Service 또는 Data Resiliency)을 클릭하여 개별 서비스의 상태를 확인합니다.
상태 카드의 데이터 복원력은 Multicloud Object Gateway 및 RADOS Object Gateway를 통해 저장된 데이터에 대한 복원력 문제가 있는지 여부를 나타냅니다.
- 용량 분류 카드
- 이 카드에서는 애플리케이션이 Multicloud Object Gateway 및 RADOS Object Gateway를 통해 오브젝트 스토리지를 사용하는 방법을 시각화할 수 있습니다. 서비스 유형 드롭다운을 사용하여 Multicloud Gateway 및 Object Gateway의 용량 분석을 별도로 확인할 수 있습니다. Multicloud Object Gateway를 볼 때 Break By 드롭다운을 사용하여 프로젝트 또는 버킷 클래스 를 통해 그래프에서 결과를 필터링할 수 있습니다.
- 성능 카드
이 카드에서는 Multicloud Object Gateway 또는 RADOS 오브젝트 게이트웨이의 성능을 볼 수 있습니다. 서비스 유형 드롭다운을 사용하여 보려는 항목을 선택합니다.
Multicloud Object Gateway 계정의 경우 I/O 작업 및 사용된 논리적 용량을 볼 수 있습니다. 공급자의 경우 I/O 작업, 물리적 및 논리 사용량 및 송신을 볼 수 있습니다.
다음 표에서는 카드 상단에 있는 드롭다운 메뉴에서 선택한 항목에 따라 볼 수 있는 다양한 메트릭을 설명합니다.
표 2.1. Multicloud Object Gateway 지표
소비자 유형 지표 차트 표시 accounts
I/O 작업
상위 5명의 소비자에 대한 읽기 및 쓰기 I/O 작업을 표시합니다. 모든 소비자의 전체 읽기 및 쓰기가 맨 아래에 표시됩니다. 이 정보는 애플리케이션 또는 계정당 IOPS( 처리량 수요)를 모니터링할 수 있습니다.
accounts
논리적 사용 용량
상위 5명의 소비자에 대한 각 계정의 총 논리적 사용량을 표시합니다. 이를 통해 애플리케이션 또는 계정별 처리량 수요를 모니터링할 수 있습니다.
공급자
I/O 작업
공급자가 호스팅하는 스토리지 백엔드에 액세스할 때 MCG에서 생성한 I/O 작업 수를 표시합니다. 이를 통해 I/O 패턴에 따라 리소스 할당을 개선하여 비용을 최적화할 수 있도록 클라우드의 트래픽을 이해하는 데 도움이 됩니다.
공급자
물리적 및 논리 사용
실제 사용량을 공급자당 논리 사용량과 비교하여 시스템의 데이터 사용량을 표시합니다. 이를 통해 스토리지 리소스를 제어하고 사용 특성과 성능 요구 사항에 따라 배치 전략을 고안하고 비용을 잠재적으로 최적화할 수 있습니다.
공급자
Egress
MCG가 각 공급자에서 검색하는 데이터 양(Read bandwidth)은 애플리케이션과 함께 시작됩니다. 이를 통해 송신 패턴에 따라 리소스 할당을 개선하기 위해 클라우드의 트래픽을 파악하여 비용을 최적화할 수 있습니다.
accounts
I/O 작업
상위 5명의 소비자에 대한 읽기 및 쓰기 I/O 작업을 표시합니다. 모든 소비자의 전체 읽기 및 쓰기가 맨 아래에 표시됩니다. 이 정보는 애플리케이션 또는 계정당 IOPS( 처리량 수요)를 모니터링할 수 있습니다.
accounts
논리적 사용 용량
상위 5명의 소비자에 대한 각 계정의 총 논리적 사용량을 표시합니다. 이를 통해 애플리케이션 또는 계정별 처리량 수요를 모니터링할 수 있습니다.
RADOS 개체 게이트웨이의 경우 Metric 드롭다운을 사용하여 대기 시간 또는 대역폭 을 볼 수 있습니다.
- latency: RADOS Object Gateway 인스턴스의 평균 GET/PUT 대기 시간 불균형을 나타냅니다.
- 대역폭: RADOS 오브젝트 게이트웨이 인스턴스의 GET/PUT 대역폭 합계를 시각적으로 표시합니다.
- 활동 카드
이 카드는 OpenShift Container Storage 클러스터에서 발생했거나 최근 발생한 활동을 표시합니다. 카드는 두 부분으로 분리되어 있습니다.
- ongoing: 데이터 복원력 재구축 및 OpenShift Container Storage Operator 업그레이드와 관련된 지속적인 활동 진행 상황을 표시합니다.
-
최근 이벤트:
openshift-storage네임스페이스에서 발생한 이벤트 목록을 표시합니다.
3장. 경고
3.1. 경고 설정
내부 모드 클러스터의 경우 스토리지 지표 서비스, 스토리지 클러스터, 디스크 장치, 클러스터 상태, 클러스터 용량 등과 관련된 다양한 경고가 영구 스토리지 및 오브젝트 서비스 대시보드에 표시됩니다. 이러한 경고는 외부 모드에서 사용할 수 없습니다.
이 패널에는 실행 경고만 표시되므로 경고 패널에 경고가 표시되는 데 몇 분이 걸릴 수 있습니다.
추가 세부 정보를 사용하여 경고를 보고 OpenShift Container Platform에서 경고 표시를 사용자 지정할 수도 있습니다.
자세한 내용은 경고 관리를 참조하십시오.
4장. 원격 상태 모니터링
OpenShift Container Storage는 클러스터의 상태, 사용량 및 크기에 대한 익명화된 집계 정보를 수집하여 Telemetry라는 통합 구성 요소를 통해 Red Hat에 보고합니다. 이 정보를 통해 Red Hat은 OpenShift Container Storage를 개선하고 고객에게 영향을 미치는 문제에 보다 신속하게 대응할 수 있습니다.
Telemetry를 통해 Red Hat에 데이터를 보고하는 클러스터는 연결된 클러스터 로 간주됩니다.
4.1. Telemetry 정보
Telemetry는 엄선된 클러스터 모니터링 지표의 일부를 Red Hat으로 보냅니다. 이러한 지표는 지속적으로 전송되며 다음에 대해 설명합니다.
- OpenShift Container Storage 클러스터의 크기
- OpenShift Container Storage 구성 요소의 상태 및 상태
- 수행 중인 업그레이드의 상태
- OpenShift Container Storage 구성 요소 및 기능에 대한 제한된 사용 정보
- 클러스터 모니터링 구성 요소에서 보고한 경보에 대한 요약 정보
Red Hat은 지속적인 데이터 스트림을 사용하여 클러스터의 상태를 실시간으로 모니터링하고 필요에 따라 고객에게 영향을 미치는 문제에 대응합니다. 또한 Red Hat은 OpenShift Container Storage 업그레이드를 고객에게 제공하여 서비스 영향을 최소화하고 지속적으로 업그레이드 환경을 개선할 수 있습니다.
이러한 디버깅 정보는 지원 사례를 통해 보고된 데이터에 액세스하는 것과 동일한 제한 사항이 있는 Red Hat 지원 및 엔지니어링 팀에게 제공됩니다. Red Hat은 연결된 모든 클러스터 정보를 사용하여 OpenShift Container Storage를 더 효율적이고 직관적으로 사용할 수 있습니다. 이 모든 정보는 타사와 공유하지 않습니다.
4.2. Telemetry에서 수집하는 정보
Telemetry에서 수집하는 기본 정보는 다음과 같습니다.
-
ceph 클러스터 크기(바이트) :
"ceph_cluster_total_bytes", -
바이트 단위에 사용된 ceph 클러스터 스토리지 양:
"ceph_cluster_total_used_raw_bytes", -
Ceph 클러스터 상태:
"ceph_health_status", -
osds :
"job:ceph_osd_metadata:count"의 총 수 -
RuntimeClass 클러스터에 있는 총 영구 볼륨 수:
"job:kube_pv:count", -
ceph 클러스터의 모든 풀에 대한 총 iops(reads+writes) 값 :
"job:ceph_pools_iops:total", -
ceph 클러스터의 모든 풀에 대해 총 iops (reads+writes) 값 (바이트 단위) :
"job:ceph_pools_iops_bytes:total", -
실행 중인 ceph 클러스터 버전의 총 수:
"job:ceph_versions_running:count" -
비정상적인 noobaa 버킷의 총 수 :
"job:noobaa_total_unhealthy_buckets:sum" -
총 noobaa 버킷 수 :
"job:noobaa_bucket_count:sum" -
총 noobaa 오브젝트 수 :
"job:noobaa_total_object_count:sum" -
noobaa의 계정 수 :
"noobaa_accounts_num", -
noobaa 스토리지의 총 바이트 수:
"noobaa_total_usage", -
특정 스토리지 프로비저너에서
"cluster:kube_persistentvolumeclaim_resource_requests_storage_bytes:provisioner:sum"의 PVC에서 요청하는 총 스토리지 양 -
특정 스토리지 프로비저너의 PVC에서 사용하는 총 스토리지 크기(바이트
:kubelet_volume_stats_used_bytes:provisioner:sum").
Telemetry에서는 사용자 이름, 암호, 사용자 리소스의 이름 또는 주소와 같은 식별 정보를 수집하지 않습니다. 위에 명시된 Telemetry 정보 외에도 NooBaa는 계정, 버킷, 오브젝트, 용량, 노드, phonehome.nooba.com에 대한 통계 정보를 보냅니다.