
스토리지 장치 관리
Red Hat Enterprise Linux 9에서 단일 노드 스토리지 배포 및 구성
초록
보다 포괄적 수용을 위한 오픈 소스 용어 교체
Red Hat은 코드, 문서, 웹 속성에서 문제가 있는 용어를 교체하기 위해 최선을 다하고 있습니다. 먼저 마스터(master), 슬레이브(slave), 블랙리스트(blacklist), 화이트리스트(whitelist) 등 네 가지 용어를 교체하고 있습니다. 이러한 변경 작업은 작업 범위가 크므로 향후 여러 릴리스에 걸쳐 점차 구현할 예정입니다. 자세한 내용은 CTO Chris Wright의 메시지를 참조하십시오.
Red Hat 문서에 관한 피드백 제공
문서에 대한 피드백에 감사드립니다. 어떻게 개선할 수 있는지 알려주십시오.
특정 문구에 대한 의견 제출
- Multi-page HTML 형식으로 설명서를 보고 페이지가 완전히 로드된 후 오른쪽 상단 모서리에 피드백 버튼이 표시되는지 확인합니다.
- 커서를 사용하여 주석 처리할 텍스트 부분을 강조 표시합니다.
- 강조 표시된 텍스트 옆에 표시되는 피드백 추가 버튼을 클릭합니다.
- 의견을 추가하고 제출 을 클릭합니다.
Bugzilla를 통해 피드백 제출(등록 필요)
- Bugzilla 웹 사이트에 로그인합니다.
- 버전 메뉴에서 올바른 버전을 선택합니다.
- Summary (요약) 필드에 설명 제목을 입력합니다.
- Description (설명) 필드에 개선을 위한 제안을 입력합니다. 문서의 관련 부분에 대한 링크를 포함합니다.
- 버그 제출을 클릭합니다.
1장. 사용 가능한 스토리지 옵션 개요
Red Hat Enterprise Linux 8에는 여러 로컬, 원격 및 클러스터 기반 스토리지 옵션이 있습니다.
로컬 스토리지는 스토리지 장치가 시스템에 설치되거나 시스템에 직접 연결되어 있음을 의미합니다.
원격 스토리지를 사용하면 LAN, 인터넷 또는 파이버 채널 네트워크를 통해 장치에 액세스합니다. 다음과 같은 높은 수준의 Red Hat Enterprise Linux 스토리지 다이어그램은 다양한 스토리지 옵션을 설명합니다.
그림 1.1. 높은 수준의 Red Hat Enterprise Linux 스토리지 다이어그램
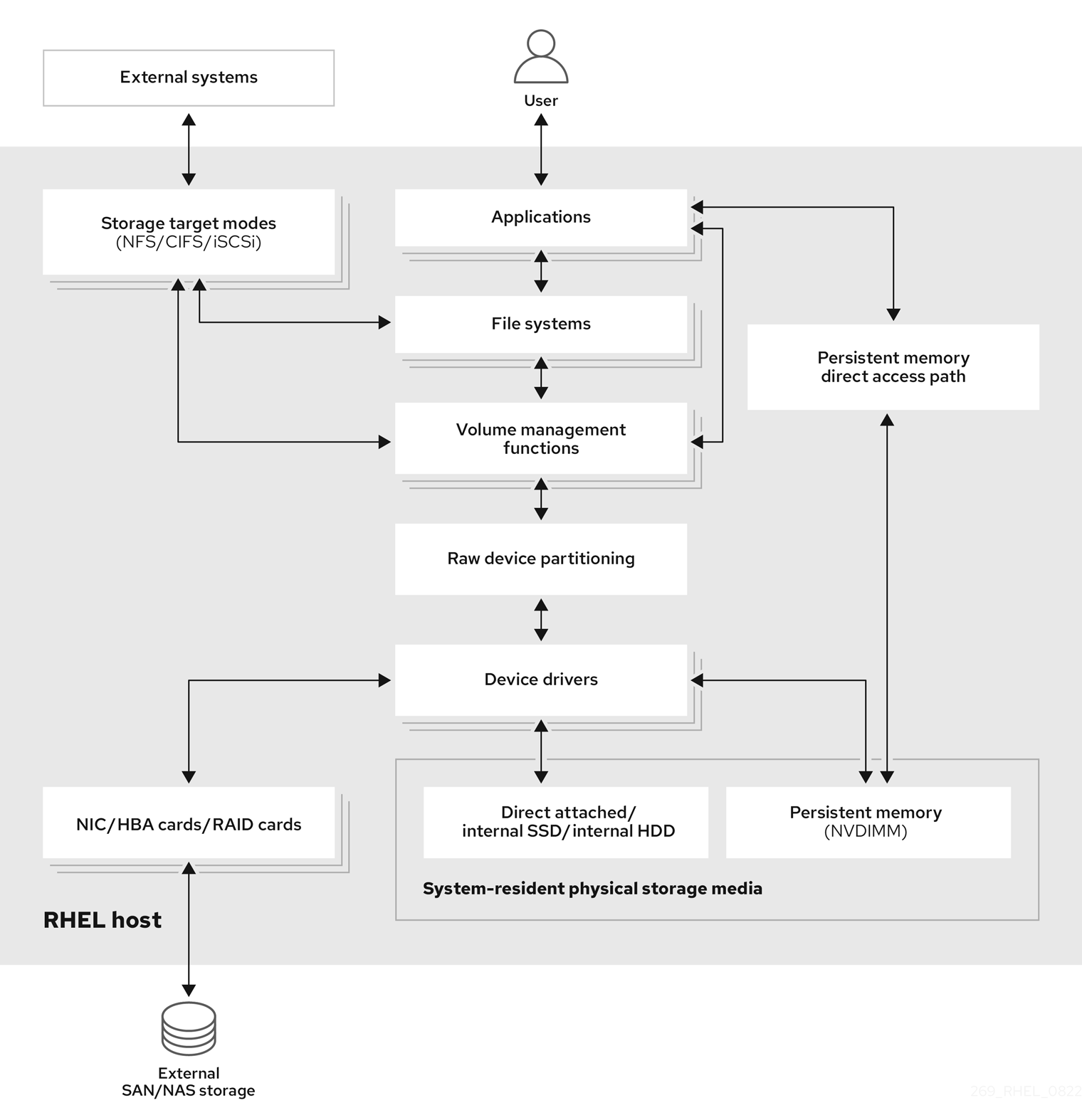
1.1. 로컬 스토리지 개요
Red Hat Enterprise Linux 9는 다양한 로컬 스토리지 옵션을 제공합니다.
- 기본 디스크 관리
parted및fdisk를 사용하여 디스크 파티션을 생성, 수정, 삭제 및 볼 수 있습니다. 다음은 파티션 레이아웃 표준입니다.- 마스터 부팅 레코드 (MBR)
- BIOS 기반 컴퓨터에서 사용됩니다. 기본, 확장 및 논리 파티션을 생성할 수 있습니다.
- GUID 파티션 테이블(GPT)
- GUID(Globally Unique identifier)를 사용하며 고유 디스크 및 파티션 GUID를 제공합니다.
파티션을 암호화하려면 Linux Unified Key Setup-on-disk-format(LUKS)을 사용할 수 있습니다. 파티션을 암호화하려면 설치 중에 옵션을 선택하고 암호를 입력하라는 프롬프트가 표시됩니다. 이 암호는 암호화 키를 잠금 해제합니다.
- 스토리지 사용 옵션
- 비 Volatile Dual In-line Memory Module (NVDIMM) 관리
- 이는 메모리 및 스토리지의 조합입니다. 시스템에 연결된 NVDIMM 장치에서 다양한 유형의 스토리지를 활성화하고 관리할 수 있습니다.
- 블록 스토리지 관리
- 데이터는 각 블록에 고유 식별자를 갖는 블록 형태로 저장됩니다.
- 파일 스토리지
- 데이터는 로컬 시스템의 파일 수준에서 저장됩니다. 이러한 데이터는 NFS 및 SMB를 사용하여 XFS(기본값) 또는 ext4를 사용하여 로컬로 액세스할 수 있으며 네트워크를 통해 로컬로 액세스할 수 있습니다.
- 논리 볼륨
- LVM(Logical Volume Manager)
물리적 장치에서 논리적 장치를 생성합니다. 논리 볼륨(LV)은 물리 볼륨(PV) 및 볼륨 그룹(VG)의 조합입니다. LVM을 구성하는 방법은 다음과 같습니다.
- 하드 드라이브에서 PV 생성.
- PV에서 VG 만들기.
- VG에서 LV에 대한 마운트 지점을 할당하는 LV 만들기.
- VDO(가상 데이터 최적화 도구)
중복 제거, 압축 및 씬 프로비저닝을 사용하여 데이터 감소에 사용됩니다. VDO 아래의 VDO를 사용하면 다음과 같은 이점이 있습니다.
- VDO 볼륨의 확장
- 여러 장치에 걸쳐 VDO 볼륨 확장
- 로컬 파일 시스템
- XFS
- 기본 RHEL 파일 시스템.
- Ext4
- 레거시 파일 시스템.
- Stratis
- 기술 프리뷰로 사용할 수 있습니다. Stratis는 고급 스토리지 기능을 지원하는 하이브리드 사용자 및 커널 로컬 스토리지 관리 시스템입니다.
1.2. 원격 스토리지 개요
다음은 Red Hat Enterprise Linux 8에서 사용할 수 있는 원격 스토리지 옵션입니다.
- 스토리지 연결 옵션
- iSCSI
- RHEL 9는 IdP 툴을 사용하여 iSCSI 스토리지 상호 연결을 추가, 제거, 보기 및 모니터링합니다.
- 파이버 채널(FC)
RHEL 9에서는 다음과 같은 기본 파이버 채널 드라이버를 제공합니다.
-
lpfc -
qla2xxx -
Zfcp
-
- NVMe(Non-volatile Memory Express)
호스트 소프트웨어 유틸리티가 솔리드 스테이트 드라이브와 통신할 수 있는 인터페이스입니다. 다음 유형의 패브릭 전송을 사용하여 패브릭을 통해 NVMe를 구성합니다.
- RDMA(Remote Direct Memory Access)를 사용하는 NVMe over fabric.
- 파이버 채널(FC)을 사용하는 NVMe over fabric
- 장치 매퍼 다중 경로(DM Multipath)
- 서버 노드와 스토리지 어레이 간의 여러 I/O 경로를 단일 장치로 구성할 수 있습니다. 이러한 I/O 경로는 별도의 케이블, 스위치 및 컨트롤러를 포함할 수 있는 물리적 SAN 연결입니다.
- 네트워크 파일 시스템
- NFS
- SMB
1.3. GFS2 파일 시스템 개요
Red Hat Global File System 2(GFS2) 파일 시스템은 공유 이름 공간을 제공하고 공통 블록 장치를 공유하는 여러 노드 간에 일관성을 관리하는 64비트 대칭 클러스터 파일 시스템입니다. GFS2 파일 시스템은 로컬 파일 시스템에 최대한 가까운 기능 세트를 제공하는 반면, 동시에 노드 간에 전체 클러스터 일관성을 적용할 수 있습니다. 이를 위해 노드는 파일 시스템 리소스에 클러스터 전체 잠금 체계를 사용합니다. 이 잠금 방식은 TCP/IP와 같은 통신 프로토콜을 사용하여 잠금 정보를 교환합니다.
어떤 경우에는 Linux 파일 시스템 API에서 GFS2의 클러스터형 특성을 완전히 투명하게 사용할 수 없습니다. 예를 들어, GFS2에서 POSIX 잠금을 사용하는 프로그램은 클러스터형 환경에서 GETLK 함수를 사용하지 않아야 합니다. 그러나 대부분의 경우 GFS2 파일 시스템의 기능은 로컬 파일 시스템의 기능과 동일합니다.
Red Hat Enterprise Linux 복구 스토리지 애드온은 GFS2를 제공하며 Red Hat Enterprise Linux High Availability Add-On을 통해 GFS2에 필요한 클러스터 관리를 제공합니다.
gfs2.ko 커널 모듈은 GFS2 파일 시스템을 구현하고, GFS2 클러스터 노드에 로드됩니다.
GFS2에서 최상의 성능을 얻으려면 기본 설계에서 줄인 성능 고려 사항을 고려해야 합니다. 로컬 파일 시스템과 마찬가지로 GFS2는 자주 사용하는 데이터의 로컬 캐싱으로 성능을 개선하기 위해 페이지 캐시를 사용합니다. 클러스터의 노드에서 일관성을 유지하기 위해 glock 상태 시스템에서 캐시 제어를 제공합니다.
추가 리소스
1.4. Gluster Storage 개요
RHGS(Red Hat Gluster Storage)는 클러스터에 배포할 수 있는 소프트웨어 정의 스토리지 플랫폼입니다. 여러 서버의 디스크 스토리지 리소스를 단일 글로벌 네임스페이스로 집계합니다. GlusterFS는 클라우드 및 하이브리드 솔루션에 적합한 오픈 소스 분산 파일 시스템입니다.
볼륨은 GlusterFS의 기반을 형성하고 다른 요구 사항을 제공합니다. 각 볼륨은 신뢰할 수 있는 스토리지 풀의 서버의 내보내기 디렉터리로 표시되는 기본 스토리지 단위인 brick 컬렉션입니다.
다음 유형의 GlusterFS 볼륨을 사용할 수 있습니다.
- 분산 GlusterFS 볼륨 은 각 파일이 하나의 brick에 저장되는 기본 볼륨이며 파일은 다른 brick 간에 공유할 수 없습니다.
- 복제 GlusterFS 볼륨 유형은 사용자 데이터를 복제하므로 하나의 brick에 오류가 발생하면 데이터에 계속 액세스할 수 있습니다.
- 분산 복제 GlusterFS 볼륨 은 다수의 시스템에 복제본을 배포하는 하이브리드 볼륨입니다. 스토리지 확장성 및 높은 신뢰성이 중요한 환경에 적합합니다.
추가 리소스
1.5. Ceph Storage 개요
RHCS(Red Hat Ceph Storage)는 Ceph 스토리지 시스템의 가장 안정적인 버전을 Ceph 관리 플랫폼, 배포 유틸리티 및 지원 서비스와 결합하는 확장 가능한 오픈 소프트웨어 정의 스토리지 플랫폼입니다.
Red Hat Ceph Storage는 클라우드 인프라 및 웹 스케일 오브젝트 스토리지를 위해 설계되었습니다. Red Hat Ceph Storage 클러스터는 다음과 같은 유형의 노드로 구성됩니다.
- Red Hat Ceph Storage Ansible 관리 노드
이 유형의 노드는 이전 버전의 Red Hat Ceph Storage에서 수행했던 기존 Ceph 관리 노드로 작동합니다. 이 유형의 노드는 다음과 같은 기능을 제공합니다.
- 중앙 집중식 스토리지 클러스터 관리
- Ceph 구성 파일 및 키
- 보안상의 이유로 인터넷에 액세스할 수 없는 노드에 Ceph를 설치하기 위한 로컬 리포지토리(선택 사항)
- 노드 모니터링
각 모니터 노드는 클러스터 맵의 사본을 유지 관리하는 모니터 데몬(
ceph-mon)을 실행합니다. 클러스터 맵에는 클러스터 토폴로지가 포함됩니다. Ceph 클러스터에 연결하는 클라이언트는 모니터에서 클러스터 맵의 현재 사본을 검색하여 클라이언트가 클러스터에 데이터를 읽고 쓸 수 있습니다.중요Ceph는 하나의 모니터를 사용하여 실행할 수 있지만 프로덕션 클러스터에서 고가용성을 보장하기 위해 Red Hat은 최소 3개의 모니터 노드가 있는 배포만 지원합니다. Red Hat은 스토리지 클러스터에 대해 총 5개의 Ceph Monitor를 750 OSD를 초과할 것을 권장합니다.
- OSD 노드
각 OSD(오브젝트 스토리지 장치) 노드는 노드에 연결된 논리 디스크와 상호 작용하는 Ceph OSD 데몬(
ceph-osd)을 실행합니다. Ceph는 이러한 OSD 노드에 데이터를 저장합니다.Ceph는 매우 적은 OSD 노드로 실행할 수 있습니다. 기본값은 3개이지만, 스토리지 클러스터에서는 50개의 OSD(예: 스토리지 클러스터에서 50개의 OSD)를 모드형 확장에서 시작하는 더 나은 성능을 실현할 수 있습니다. Ceph 클러스터에는 CRUSH 맵을 생성하여 격리된 장애 도메인을 허용하는 여러 OSD 노드가 있는 것이 좋습니다.
- MDS 노드
-
각 메타데이터 서버(MDS) 노드는 MDS 데몬(
ceph-mds)을 실행하여 Ceph 파일 시스템(CephFS)에 저장된 파일과 관련된 메타데이터를 관리합니다. MDS 데몬은 공유 클러스터에 대한 액세스도 조정합니다. - 오브젝트 게이트웨이 노드
-
Ceph Object Gateway 노드는 Ceph RADOS Gateway 데몬(
ceph-radosgw)을 실행하고,librados위에 구축된 개체 스토리지 인터페이스로, Ceph Storage 클러스터에 RESTful 게이트웨이를 제공합니다. Ceph Object Gateway는 다음 두 가지 인터페이스를 지원합니다. - S3
- Amazon S3 RESTful API의 대규모 하위 집합과 호환되는 인터페이스가 포함된 오브젝트 스토리지 기능을 제공합니다.
- Swift
- OpenStack Swift API의 대규모 하위 집합과 호환되는 인터페이스가 포함된 오브젝트 스토리지 기능을 제공합니다.
추가 리소스
2장. RHEL 시스템 역할을 사용하여 로컬 스토리지 관리
Ansible을 사용하여 LVM 및 로컬 파일 시스템(FS)을 관리하려면 RHEL 9에서 사용할 수 있는 RHEL 시스템 역할 중 하나인 스토리지 역할을 사용할 수 있습니다.
스토리지 역할을 사용하면 RHEL 7.7부터 여러 시스템의 디스크 및 논리 볼륨 및 모든 버전의 RHEL에서 파일 시스템을 자동으로 관리할 수 있습니다.
RHEL 시스템 역할 및 적용 방법에 대한 자세한 내용은 RHEL 시스템 역할 소개를 참조하십시오.
2.1. 스토리지 RHEL 시스템 역할 소개
스토리지 역할은 다음을 관리할 수 있습니다.
- 분할되지 않은 디스크의 파일 시스템
- 논리 볼륨 및 파일 시스템을 포함한 전체 LVM 볼륨 그룹
- MD RAID 볼륨 및 파일 시스템
스토리지 역할을 사용하면 다음 작업을 수행할 수 있습니다.
- 파일 시스템 생성
- 파일 시스템 제거
- 파일 시스템 마운트
- 파일 시스템 마운트 해제
- LVM 볼륨 그룹 생성
- LVM 볼륨 그룹 제거
- 논리 볼륨 생성
- 논리 볼륨 제거
- RAID 볼륨 생성
- RAID 볼륨 제거
- RAID를 사용하여 LVM 볼륨 그룹 생성
- RAID를 사용하여 LVM 볼륨 그룹 제거
- 암호화된 LVM 볼륨 그룹 만들기
- RAID를 사용하여 LVM 논리 볼륨 생성
2.2. 스토리지 RHEL 시스템 역할에서 스토리지 장치를 식별하는 매개변수
스토리지 역할 구성은 다음 변수에 나열된 파일 시스템, 볼륨 및 풀에만 영향을 미칩니다.
storage_volumes관리할 파티션되지 않은 모든 디스크의 파일 시스템 목록입니다.
storage_volumes에는 잘못된 볼륨도 포함할수 있습니다.파티션은 현재 지원되지 않습니다.
storage_pools관리할 풀 목록입니다.
현재 지원되는 유일한 풀 유형은 LVM입니다. LVM을 사용하면 풀은 볼륨 그룹(VG)을 나타냅니다. 각 풀에는 역할로 관리할 볼륨 목록이 있습니다. LVM에서 각 볼륨은 파일 시스템의 논리 볼륨(LV)에 해당합니다.
2.3. 블록 장치에서 XFS 파일 시스템을 생성하는 Ansible 플레이북 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 기본 매개 변수를 사용하여 블록 장치에 XFS 파일 시스템을 생성하도록 storage 역할을 적용합니다.
스토리지 역할은 분할되지 않은 전체 디스크 또는 논리 볼륨(LV)에서만 파일 시스템을 생성할 수 있습니다. 파티션에 파일 시스템을 만들 수 없습니다.
예 2.1. /dev/sdb에서 XFS를 생성하는 플레이북
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
roles:
- rhel-system-roles.storage-
볼륨 이름(예의
베어fs)은 현재 임의적입니다.스토리지역할은disks:속성 아래에 나열된 디스크 장치에서 볼륨을 식별합니다. -
XFS는 RHEL 9의 기본 파일 시스템이므로
fs_type: xfs행을 생략할 수 있습니다. LV에서 파일 시스템을 만들려면 enclosing 볼륨 그룹을 포함하여
disk:속성 아래에 LVM 설정을 제공합니다. 자세한 내용은 Example Ansible Playbook to manage logical volumes 에서 참조하십시오.LV 장치의 경로를 제공하지 마십시오.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.4. 파일 시스템을 영구적으로 마운트하는 Ansible 플레이북 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 storage 역할을 적용하여 XFS 파일 시스템을 즉시 지속적으로 마운트합니다.
예 2.2. /dev/sdb에 파일 시스템을 /mnt/data에 마운트하는 플레이북
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
이 Playbook은 파일 시스템을
/etc/fstab파일에 추가하고 파일 시스템을 즉시 마운트합니다. -
/dev/sdb장치 또는 마운트 지점 디렉터리의 파일 시스템이 없으면 플레이북이 해당 장치를 생성합니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.5. 논리 볼륨을 관리하는 Ansible 플레이북 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 스토리지 역할을 적용하여 볼륨 그룹에 LVM 논리 볼륨을 생성합니다.
예 2.3. myvg 볼륨 그룹에 mylv 논리 볼륨을 생성하는 플레이북
- hosts: all
vars:
storage_pools:
- name: myvg
disks:
- sda
- sdb
- sdc
volumes:
- name: mylv
size: 2G
fs_type: ext4
mount_point: /mnt/data
roles:
- rhel-system-roles.storagemyvg볼륨 그룹은 다음 디스크로 구성됩니다.-
/dev/sda -
/dev/sdb -
/dev/sdc
-
-
myvg볼륨 그룹이 이미 있는 경우 플레이북에서 논리 볼륨을 볼륨 그룹에 추가합니다. -
myvg볼륨 그룹이 없는 경우 플레이북에서 해당 그룹을 생성합니다. -
Playbook은
mylv논리 볼륨에 Ext4 파일 시스템을 생성하고/mnt에 파일 시스템을 영구적으로 마운트합니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.6. 온라인 블록 삭제 활성화를 활성화하는 Ansible 플레이북의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 Playbook은 온라인 블록 삭제가 활성화된 XFS 파일 시스템을 마운트하는 스토리지 역할을 적용합니다.
예 2.4. /mnt/data/에서 온라인 블록 삭제가 활성화되는 플레이북
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: xfs
mount_point: /mnt/data
mount_options: discard
roles:
- rhel-system-roles.storage추가 리소스
- 파일 시스템을 영구적으로 마운트하는 Ansible 플레이북 예
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.7. Ext4 파일 시스템을 생성하고 마운트하는 Ansible Playbook의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 storage 역할을 적용하여 Ext4 파일 시스템을 생성하고 마운트합니다.
예 2.5. /dev/sdb에서 Ext4를 생성하고 /mnt/data에 마운트하는 플레이북
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext4
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
Playbook은
/dev/sdb디스크에 파일 시스템을 생성합니다. -
플레이북은
/mnt/data디렉터리에 파일 시스템을 영구적으로 마운트합니다. -
파일 시스템의 레이블은
label-name입니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.8. ext3 파일 시스템을 생성하고 마운트하는 Ansible Playbook의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 storage 역할을 적용하여 Ext3 파일 시스템을 생성하고 마운트합니다.
예 2.6. /dev/sdb 에서 Ext3를 생성하고 /mnt/data에 마운트하는 플레이북
---
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- sdb
fs_type: ext3
fs_label: label-name
mount_point: /mnt/data
roles:
- rhel-system-roles.storage-
Playbook은
/dev/sdb디스크에 파일 시스템을 생성합니다. -
플레이북은
/mnt/data디렉터리에 파일 시스템을 영구적으로 마운트합니다. -
파일 시스템의 레이블은
label-name입니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.9. 스토리지 RHEL 시스템 역할을 사용하여 기존 Ext4 또는 Ext3 파일 시스템의 크기를 조정하는 Ansible Playbook의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 Playbook은 스토리지 역할을 적용하여 블록 장치의 기존 Ext4 또는 Ext3 파일 시스템의 크기를 조정합니다.
예 2.7. 디스크에 단일 볼륨을 설정하는 플레이북
---
- name: Create a disk device mounted on /opt/barefs
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- /dev/sdb
size: 12 GiB
fs_type: ext4
mount_point: /opt/barefs
roles:
- rhel-system-roles.storage-
이전 예제의 볼륨이 이미 존재하는 경우, 볼륨의 크기를 조정하려면 매개 변수
크기에대해 다른 값을 사용하여 동일한 플레이북을 실행해야 합니다. 예를 들면 다음과 같습니다.
예 2.8. /dev/sdb에서 ext4 의 크기를 조정하는 플레이북
---
- name: Create a disk device mounted on /opt/barefs
- hosts: all
vars:
storage_volumes:
- name: barefs
type: disk
disks:
- /dev/sdb
size: 10 GiB
fs_type: ext4
mount_point: /opt/barefs
roles:
- rhel-system-roles.storage- 볼륨 이름(예의 약자)은 현재 임의적입니다. 스토리지 역할은 disks: 속성 아래에 나열된 디스크 장치로 볼륨을 식별합니다.
다른 파일 시스템에서 Resizing 작업을 사용하면 작업 중인 장치의 데이터를 삭제할 수 있습니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.10. 스토리지 RHEL 시스템 역할을 사용하여 LVM에서 기존 파일 시스템의 크기를 조정하는 Ansible Playbook의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 스토리지 RHEL 시스템 역할을 적용하여 파일 시스템으로 LVM 논리 볼륨의 크기를 조정합니다.
다른 파일 시스템에서 Resizing 작업을 사용하면 작업 중인 장치의 데이터를 삭제할 수 있습니다.
예 2.9. myvg 볼륨 그룹의 기존 mylv1 및 myvl2 논리 볼륨의 크기를 조정하는 플레이북
---
- hosts: all
vars:
storage_pools:
- name: myvg
disks:
- /dev/sda
- /dev/sdb
- /dev/sdc
volumes:
- name: mylv1
size: 10 GiB
fs_type: ext4
mount_point: /opt/mount1
- name: mylv2
size: 50 GiB
fs_type: ext4
mount_point: /opt/mount2
- name: Create LVM pool over three disks
include_role:
name: rhel-system-roles.storage이 Playbook은 다음과 같은 기존 파일 시스템의 크기를 조정합니다.
-
/opt/mount1에 마운트된mylv1볼륨의 Ext4 파일 시스템은 크기가 10GiB로 조정됩니다. -
/opt/mount2에 마운트된mylv2볼륨의 Ext4 파일 시스템은 크기가 50GiB로 조정됩니다.
-
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.11. 스토리지 RHEL 시스템 역할을 사용하여 스왑 볼륨을 생성하는 Ansible Playbook의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 스토리지 역할을 적용하여 스왑 볼륨이 없는 경우 또는 기본 매개변수를 사용하는 블록 장치에 스왑 볼륨을 수정하거나 스왑 볼륨이 이미 존재하는 경우 수정합니다.
예 2.10. /dev/sdb에서 기존 XFS를 생성하거나 수정하는 플레이북
---
- name: Create a disk device with swap
- hosts: all
vars:
storage_volumes:
- name: swap_fs
type: disk
disks:
- /dev/sdb
size: 15 GiB
fs_type: swap
roles:
- rhel-system-roles.storage-
볼륨 이름(예의
swap_fs)은 현재 임의적입니다.스토리지역할은disks:속성 아래에 나열된 디스크 장치에서 볼륨을 식별합니다.
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.12. 스토리지 시스템 역할을 사용하여 RAID 볼륨 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform 및 Ansible-Core를 사용하여 RHEL에서 RAID 볼륨을 구성할 수 있습니다. 매개변수를 사용하여 Ansible 플레이북을 생성하여 요구 사항에 맞게 RAID 볼륨을 구성합니다.
사전 요구 사항
- Ansible Core 패키지는 컨트롤 시스템에 설치되어 있어야 합니다.
-
플레이북을 실행할 시스템에
rhel-system-roles패키지가 설치되어 있습니다. -
스토리지시스템 역할을 사용하여 RAID 볼륨을 배포하려는 시스템을 자세히 설명하는 인벤토리 파일이 있습니다.
절차
다음 콘텐츠를 사용하여 새 playbook.yml 파일을 생성합니다.
--- - name: Configure the storage hosts: managed-node-01.example.com tasks: - name: Create a RAID on sdd, sde, sdf, and sdg include_role: name: rhel-system-roles.storage vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present주의장치 이름은 예를 들어 시스템에 새 디스크를 추가하는 경우와 같이 특정 상황에서 변경될 수 있습니다. 따라서 데이터 손실을 방지하려면 플레이북에서 특정 디스크 이름을 사용하지 마십시오.
선택 사항: 플레이북 구문을 확인합니다.
# ansible-playbook --syntax-check playbook.yml플레이북을 실행합니다.
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일 - RHEL System Roles를 사용하도록 제어 노드 및 관리형 노드 준비
2.13. 스토리지 RHEL 시스템 역할을 사용하여 RAID로 LVM 풀 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform을 사용하여 RHEL에서 RAID로 LVM 풀을 구성할 수 있습니다. 이 섹션에서는 사용 가능한 매개 변수로 Ansible 플레이북을 설정하여 RAID를 사용하여 LVM 풀을 구성하는 방법을 알아봅니다.
사전 요구 사항
- Ansible Core 패키지는 컨트롤 시스템에 설치되어 있어야 합니다.
-
플레이북을 실행할 시스템에
rhel-system-roles패키지가 설치되어 있습니다. -
스토리지시스템 역할을 사용하여 RAID로 LVM 풀을 구성하려는 시스템을 자세히 설명하는 인벤토리 파일이 있습니다.
절차
다음 내용으로 새
playbook.yml파일을 생성합니다.- hosts: all vars: storage_safe_mode: false storage_pools: - name: my_pool type: lvm disks: [sdh, sdi] raid_level: raid1 volumes: - name: my_pool size: "1 GiB" mount_point: "/mnt/app/shared" fs_type: xfs state: present roles: - name: rhel-system-roles.storage참고RAID를 사용하여 LVM 풀을 생성하려면
raid_level매개변수를 사용하여 RAID 유형을 지정해야 합니다.선택 사항: 플레이북 구문을 확인합니다.
# ansible-playbook --syntax-check playbook.yml인벤토리 파일에서 플레이북을 실행합니다.
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일.
2.14. 스토리지 RHEL 시스템 역할을 사용하여 LVM에서 VDO 볼륨을 압축하고 중복 제거하는 Ansible 플레이북의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 스토리지 RHEL 시스템 역할을 적용하여 VDO(가상 데이터 최적화 도구)를 사용하여 LVM(Logical Volumes) 압축 및 중복 제거를 활성화합니다.
예 2.11. myvg 볼륨 그룹에 mylv1 LVM VDO 볼륨을 생성하는 플레이북
---
- name: Create LVM VDO volume under volume group 'myvg'
hosts: all
roles:
-rhel-system-roles.storage
vars:
storage_pools:
- name: myvg
disks:
- /dev/sdb
volumes:
- name: mylv1
compression: true
deduplication: true
vdo_pool_size: 10 GiB
size: 30 GiB
mount_point: /mnt/app/shared
이 예에서는 압축 및 중복 제거 풀이 true로 설정되어 VDO가 사용되도록 지정합니다. 다음은 이러한 매개변수의 사용법을 설명합니다.
-
중복 제거는
스토리지 볼륨에 저장된중복된 데이터를 복제하는 데 사용됩니다. - 압축은 스토리지 볼륨에 저장된 데이터를 압축하는 데 사용하여 더 많은 스토리지 용량을 만듭니다.
-
vdo_pool_size는 장치에서 사용하는 볼륨의 실제 크기를 지정합니다. VDO 볼륨의 가상 크기는
size매개변수로 설정됩니다. 알림: LVM VDO를 Storage 역할로 사용하므로 풀당 하나의 볼륨만 압축 및 중복 제거를 사용할 수 있습니다.
2.15. 스토리지 RHEL 시스템 역할을 사용하여 LUKS 암호화 볼륨 생성
storage 역할을 사용하여 Ansible 플레이북을 실행하여 LUKS로 암호화된 볼륨을 생성하고 구성할 수 있습니다.
사전 요구 사항
-
crypto_policies시스템 역할로 설정하려는 하나 이상의 관리형 노드에 대한 액세스 및 권한. Red Hat Ansible Core가 기타 시스템을 구성하는 시스템인 제어 노드에 대한 액세스 및 권한.
제어 노드에서 다음을 수행합니다.
-
ansible-core및rhel-system-roles패키지가 설치됩니다.
-
RHEL 8.0-8.5는 Ansible 기반 자동화를 위해 Ansible Engine 2.9가 포함된 별도의 Ansible 리포지토리에 대한 액세스를 제공했습니다. Ansible Engine에는 ansible, ansible-playbook, docker 및 podman과 같은 커넥터, 여러 플러그인 및 모듈과 같은 명령줄 유틸리티가 포함되어 있습니다. Ansible Engine을 확보하고 설치하는 방법에 대한 자세한 내용은 Red Hat Ansible Engine 지식베이스를 다운로드하고 설치하는 방법에 대한 지식베이스 문서를 참조하십시오.
RHEL 8.6 및 9.0에서는 Ansible 명령줄 유틸리티, 명령 및 소규모의 기본 제공 Ansible 플러그인 세트가 포함된 Ansible Core( ansible-core 패키지로 제공)를 도입했습니다. RHEL은 AppStream 리포지토리를 통해 이 패키지를 제공하며 제한된 지원 범위를 제공합니다. 자세한 내용은 RHEL 9 및 RHEL 8.6 이상 AppStream 리포지토리 지식 베이스에 포함된 Ansible Core 패키지에 대한 지원 범위에 대한 지식베이스 문서를 참조하십시오.
- 관리 노드를 나열하는 인벤토리 파일.
절차
다음 내용으로 새
playbook.yml파일을 생성합니다.- hosts: all vars: storage_volumes: - name: barefs type: disk disks: - sdb fs_type: xfs fs_label: label-name mount_point: /mnt/data encryption: true encryption_password: your-password roles: - rhel-system-roles.storage선택 사항: 플레이북 구문을 확인합니다.
# ansible-playbook --syntax-check playbook.yml인벤토리 파일에서 플레이북을 실행합니다.
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일
2.16. 스토리지 RHEL 시스템 역할을 사용하여 백분율로 풀 볼륨 크기를 표시하는 Ansible 플레이북의 예
이 섹션에서는 예제 Ansible 플레이북을 제공합니다. 이 플레이북은 스토리지 시스템 역할을 적용하여 풀의 총 크기의 백분율로 논리 관리자 볼륨(LVM) 볼륨 크기를 표시할 수 있습니다.
예 2.12. 볼륨 크기를 풀의 총 크기의 백분율로 표시하는 플레이북
---
- name: Express volume sizes as a percentage of the pool's total size
hosts: all
roles
- rhel-system-roles.storage
vars:
storage_pools:
- name: myvg
disks:
- /dev/sdb
volumes:
- name: data
size: 60%
mount_point: /opt/mount/data
- name: web
size: 30%
mount_point: /opt/mount/web
- name: cache
size: 10%
mount_point: /opt/cache/mount이 예에서는 LVM 볼륨의 크기를 풀 크기의 백분율로 지정합니다. 예를 들면 다음과 같습니다. "60%". 또한 LVM 볼륨의 크기를 사람이 읽을 수 있는 파일 시스템의 크기(예: "10g" 또는 "50GiB)에서 풀 크기의 백분율로 지정할 수도 있습니다.
2.17. 추가 리소스
-
/usr/share/doc/rhel-system-roles/storage/ -
/usr/share/ansible/roles/rhel-system-roles.storage/
3장. 디스크 파티션
디스크를 하나 이상의 논리 영역으로 분할하려면 디스크 파티션 유틸리티를 사용합니다. 각 파티션을 별도로 관리할 수 있습니다.
3.1. 파티션 개요
하드 디스크는 파티션 테이블의 각 디스크 파티션의 위치와 크기에 대한 정보를 저장합니다. 파티션 테이블의 정보를 사용하여 운영 체제는 각 파티션을 논리 디스크로 처리합니다. 디스크 파티션의 몇 가지 장점은 다음과 같습니다.
- 물리 볼륨의 관리 감독 가능성 감소
- 충분한 백업 확인
- 효율적인 디스크 관리 제공
3.2. 디스크에서 파티션을 수정하기 전에 고려 사항
디스크 파티션을 생성, 제거 또는 크기 조정하기 전에 다음 측면을 고려하십시오.
장치에서 파티션 테이블의 유형에 따라 개별 파티션의 최대 수와 크기가 결정됩니다.
최대 파티션 수:
마스터 부팅 레코드(MBR) 파티션 테이블을 사용하여 포맷된 장치에서 다음을 수행할 수 있습니다.
- 최대 4개의 기본 파티션.
최대 3개의 기본 파티션, 즉 하나의 확장 파티션
- 확장 파티션 내의 여러 논리 파티션
GUID 파티션 테이블(GPT) 으로 포맷된 장치의 경우 다음을 수행할 수 있습니다.
parted유틸리티를 사용하는 경우 최대 128개의 파티션이 있습니다.- GPT 사양은 파티션 테이블의 예약된 크기를 늘려 파티션을 더 허용하지만 parted 유틸리티는 128 파티션에 필요한 영역을 제한합니다.
최대 파티션 크기:
Master Boot Record (MBR) 파티션 테이블로 포맷된 장치의 경우:
- 512b 섹터 드라이브를 사용하는 동안 최대 크기는 2TiB입니다.
- 4k 섹터 드라이브를 사용하는 동안 최대 크기는 16TiB입니다.
GUID 파티션 테이블(GPT) 으로 포맷된 장치의 경우:
- 512b 섹터 드라이브를 사용하는 동안 최대 크기는 8ZiB입니다.
- 4k 섹터 드라이브를 사용하는 동안 최대 크기는 64ZiB입니다.
parted 유틸리티를 사용하여 여러 다른 접미사를 사용하여 파티션 크기를 지정할 수 있습니다.
MiB, GiB 또는 TiB
- 2의 힘으로 표시된 크기입니다.
- 파티션의 출발점은 크기에 따라 지정된 정확한 섹터에 맞춰져 있습니다.
- 마지막 포인트는 지정된 크기 - 1 섹터에 맞춰집니다.
MB, GB 또는 TB:
- 10의 힘으로 표시된 크기입니다.
- 시작점과 종료점은 지정된 유닛의 1/2에 맞춰져 있습니다. 예를 들어 MB 접미사를 사용하는 경우 500KB입니다.
이 섹션에서는 IBM Z 아키텍처에 특정한 DASD 파티션 테이블에는 적용되지 않습니다.
3.3. 파티션 테이블 유형 비교
장치에서 파티션을 활성화하려면 다른 유형의 파티션 테이블로 블록 장치를 포맷합니다. 다음 표에서는 블록 장치에서 만들 수 있는 다양한 유형의 파티션 테이블의 속성을 비교합니다.
표 3.1. 파티션 테이블 유형
| 파티션 테이블 | 최대 파티션 수 | 최대 파티션 크기 |
|---|---|---|
| 마스터 부팅 레코드 (MBR) | 4 기본 또는 3 기본 파티션 및 12 개의 논리 파티션이있는 확장 파티션 | 2TiB |
| GUID 파티션 테이블(GPT) | 128 | 8ZiB |
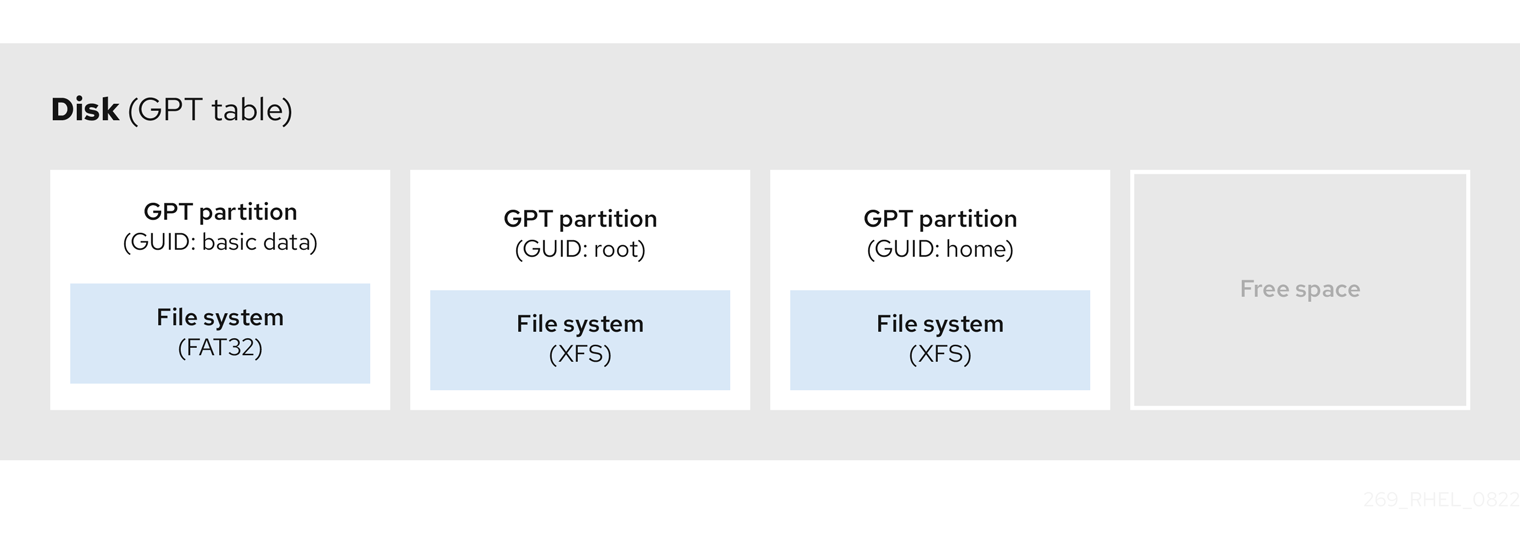
3.4. GPT 디스크 파티션
파티션 테이블은 디스크 시작 부분에 저장된 파일 시스템 또는 사용자 데이터 앞에 저장됩니다. 보다 명확한 예를 들어 다음 다이어그램에서 파티션 테이블이 별도의 것으로 표시됩니다.
그림 3.1. GPT 파티션 테이블이 있는 디스크
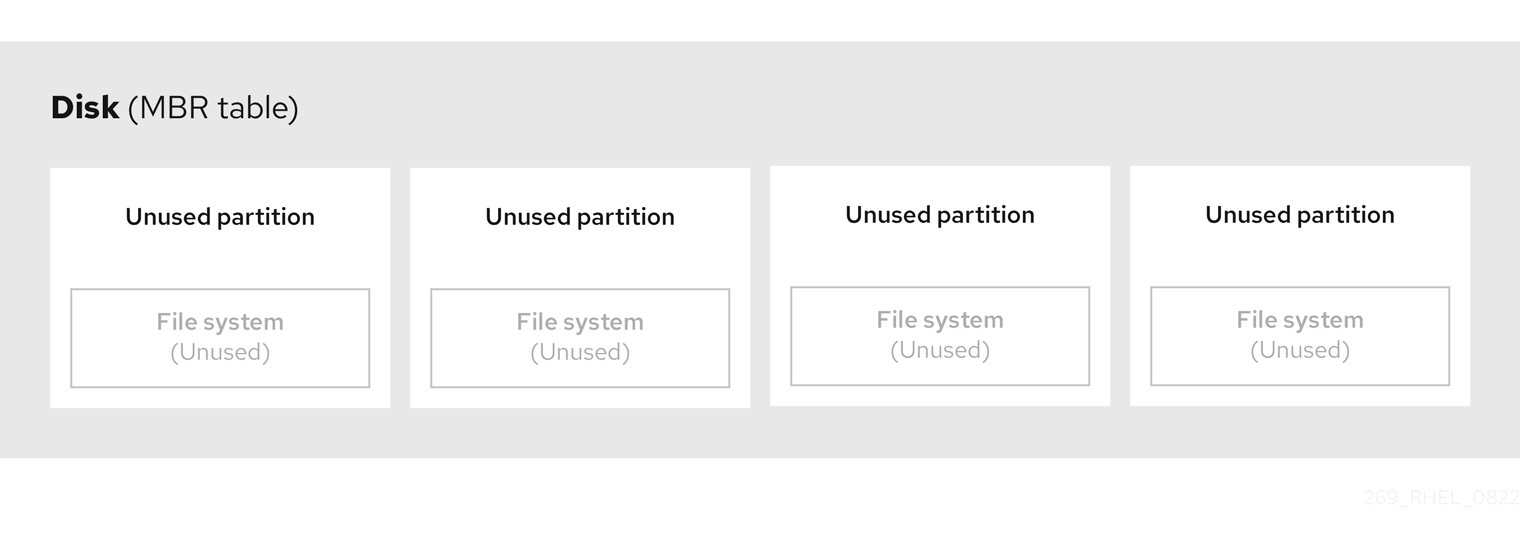
이전 다이어그램에서 볼 수 있듯이 파티션 테이블은 사용되지 않은 4개의 기본 파티션 4개의 섹션으로 나뉩니다. 기본 파티션은 하나의 논리 드라이브(또는 섹션)만 포함하는 하드 드라이브의 파티션입니다. 각 논리 드라이브에는 단일 파티션을 정의하는 데 필요한 정보가 있습니다. 즉 파티션 테이블이 4개 이상의 기본 파티션을 정의할 수 없습니다.
각 파티션 테이블 항목에는 파티션의 중요한 특성이 포함되어 있습니다.
- 파티션이 시작되고 끝나는 디스크 지점
-
파티션의 상태는 하나의 파티션만
active로 플래그를 지정할 수 있으므로 - 파티션 유형입니다.
시작 및 종료 포인트는 디스크의 파티션의 크기와 위치를 정의합니다. 일부 운영 체제 부트 로더는 활성 플래그를 사용합니다. 즉, "활성"으로 표시된 파티션의 운영 체제가 부팅됩니다.
유형은 파티션의 예상 사용을 식별하는 번호입니다. 일부 운영 체제는 다음과 같이 파티션 유형을 사용합니다.
- 특정 파일 시스템 유형을 나타냅니다.
- 파티션을 특정 운영 체제와 관련된 플래그
- 파티션에 부팅 가능한 운영 체제가 포함되어 있음을 나타냅니다.
다음 다이어그램에서는 단일 파티션이 있는 드라이브의 예를 보여줍니다. 이 예에서 첫 번째 파티션은 idrac 파티션 유형으로 레이블이 지정됩니다.
그림 3.2. 단일 파티션이 있는 디스크
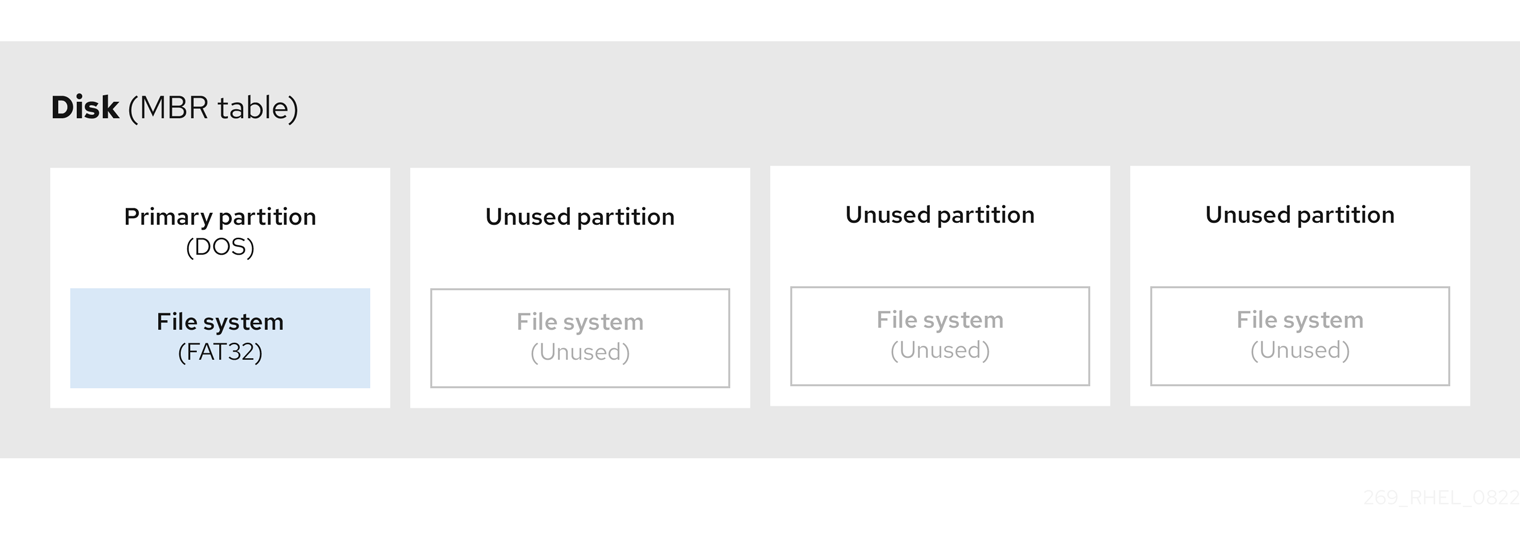
추가 리소스
3.5. 확장된 GPT 파티션
필요한 경우 추가 파티션을 만들려면 유형을 확장 로 설정합니다.
확장 파티션은 디스크 드라이브와 유사합니다. 확장 파티션에 전체적으로 포함된 하나 이상의 논리 파티션을 가리키는 자체 파티션 테이블이 있습니다. 다음 다이어그램에서는 두 개의 기본 파티션이 있는 디스크 드라이브와 파티션되지 않은 여유 공간과 함께 두 개의 논리 파티션을 포함하는 확장 파티션 하나를 보여줍니다.
그림 3.3. 기본 파티션과 확장된 reserved 파티션이 둘 다 있는 디스크
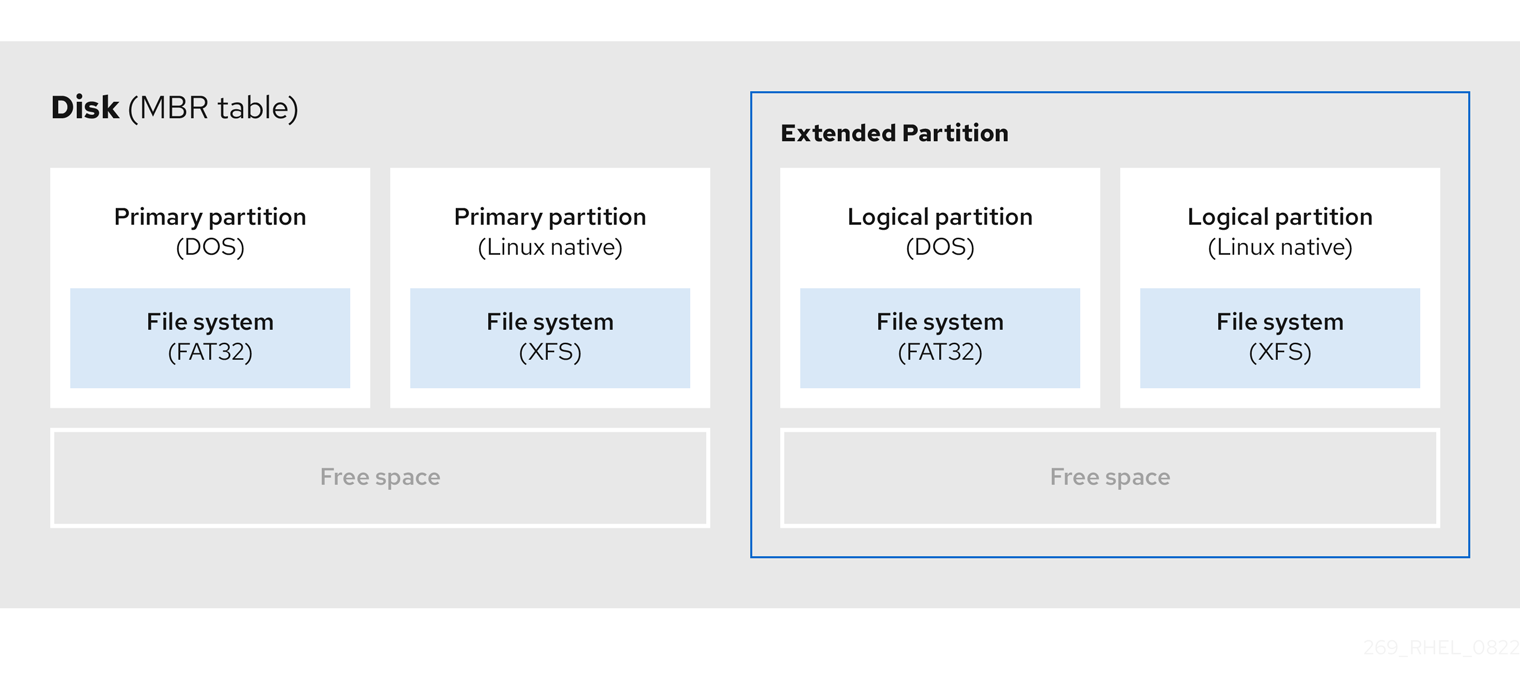
최대 4개의 기본 파티션과 확장 파티션만 보유할 수 있지만 논리 파티션 수에는 고정된 제한이 없습니다. Linux에서 파티션에 액세스하기 위한 제한으로 단일 디스크 드라이브는 최대 15개의 논리 파티션을 허용합니다.
3.6. GPT 파티션 유형
아래 표는 가장 일반적으로 사용되는 STATUS 파티션 유형 및 16진수 숫자 중 일부를 나타내는 목록을 보여줍니다.
표 3.2. GPT 파티션 유형
| iDRAC 파티션 유형 | 값 | iDRAC 파티션 유형 | 값 |
| empty | 00 | 7.7 Netware 386 | 65 |
| idrac 12비트 FAT | 01 | PIC/IX | 75 |
| XENIX 루트 | O2 | 이전 MINIX | 80 |
| XENIXSecurityGroup | O3 | Linux/MINUX | 81 |
| idrac 16-bit databind32M | 04 | Linux swap | 82 |
| 확장 | 05 | Linux 네이티브 | 83 |
| DOS 16-bit >=32 | 06 | Linux 확장 | 85 |
| OS/2 HPFS | 07 | amoeba | 93 |
| AIX | 08 | Amoeba 2.7T | 94 |
| AIX 부팅 가능 | 09 | BSD/386 | a5 |
| OS/2 Boot Manager | 0a | OpenBSD | a6 |
| Win95 FAT32 | 0b | NEXTSTEP | a7 |
| Win95 FAT32 (LBA) | 0c | BSDI fs | b7 |
| Win95 FAT16 (LBA) | 0e | BSDI 스왑 | b8 |
| Win95 Extended (LBA) | 0f | Syrinx | c7 |
| Venix 80286 | 40 | CP/M | db |
| NetNamespace | 51 | idrac 액세스 | e1 |
| Prep Boot | 41 | DOS R/O | e3 |
| GNU HURD | 63 | idrac secondary | f2 |
| controlPlane Netware 286 | 64 | BBT | ff |
3.7. GUID 파티션 테이블
GUID 파티션 테이블(GPT)은 GUID(Globally Unique Identifier)를 기반으로 하는 파티션 구성입니다.
GPT는 Mater Boot Record (MBR) 파티션 테이블의 제한 사항을 다룹니다. MBR 파티션 테이블은 2TiB보다 큰 스토리지를 처리할 수 없으며 약 2.2TB와 동일합니다. 대신 GPT는 용량이 큰 하드 디스크를 지원합니다. 최대 주소 가능한 디스크 크기는 512b 섹터 드라이브를 사용할 때 8ZiB이며 4096b 섹터 드라이브를 사용할 때 64ZiB입니다. 또한 GPT는 기본적으로 최대 128개의 기본 파티션 생성을 지원합니다. 파티션 테이블에 더 많은 공간을 할당하여 기본 파티션의 최대 크기를 확장합니다.
GPT에는 GUID를 기반으로 하는 파티션 유형이 있습니다. 특정 파티션에는 특정 GUID가 필요합니다. 예를 들어 EFI(Extensible Firmware Interface) 부트 로더의 시스템 파티션에는 GUID C12A7328-F81F-11D2-BA4B-00A0C93EC93B 가 필요합니다.
GPT 디스크는 다음과 같이 논리 블록 주소 지정(LBA)과 파티션 레이아웃을 사용합니다.
- MBR 디스크와의 역호환을 위해 시스템은 MBR 데이터에 대해 GPT의 첫 번째 섹터(LBA 0)를 예약하고 "protective MBR"이라는 이름을 적용합니다.
기본 GPT
- 헤더는 장치의 두 번째 논리 블록 (LBA 1)에서 시작됩니다. 헤더에는 디스크 GUID, 기본 파티션 테이블의 위치, 보조 GPT 헤더의 위치, CRC32 체크섬, 기본 파티션 테이블이 포함되어 있습니다. 또한 테이블의 파티션 항목 수를 지정합니다.
- 기본적으로 기본 GPT에는 128개의 파티션 항목이 포함되어 있습니다. 각 파티션에는 128바이트, 파티션 유형 GUID 및 고유한 파티션 GUID의 입력 크기가 있습니다.
secondary GPT
- 복구를 위해 기본 파티션 테이블이 손상된 경우 백업 테이블로 유용합니다.
- 디스크의 마지막 논리 섹터에는 보조 GPT 헤더가 포함되어 있으며 기본 헤더가 손상된 경우 GPT 정보를 복구합니다.
다음이 포함됩니다.
- 디스크 GUID
- 보조 파티션 테이블 및 기본 GPT 헤더의 위치
- CRC32 체크섬s
- 보조 파티션 테이블
- 사용 가능한 파티션 항목 수
그림 3.4. GUID 파티션 테이블이 있는 디스크
GPT 디스크에 부트 로더를 성공적으로 설치하려면 BIOS 부팅 파티션이 있어야 합니다. 디스크에 BIOS 부팅 파티션이 이미 포함된 경우에만 재사용할 수 있습니다. 여기에는 Anaconda 설치 프로그램에서 초기화한 디스크가 포함됩니다.
3.8. 파티션 유형
파티션 유형을 관리하는 방법은 여러 가지가 있습니다.
-
<
;.> 유틸리티는 16진수 코드를 지정하여 파티션 유형의 전체 범위를 지원합니다. -
장치 생성기 유틸리티인
systemd-gpt-auto-generator는 파티션 유형을 사용하여 장치를 자동으로 식별하고 마운트합니다. parted유틸리티는 플래그 와 함께 파티션 유형을 매핑합니다.parted유틸리티는 LVM, 스왑 또는 RAID와 같은 파티션 유형(예: LVM) 파티션 유형만 처리합니다.parted유틸리티는 다음 플래그 설정을 지원합니다.-
boot -
root -
swap -
숨김 -
RAID -
lvm -
lba -
legacy_boot -
irst -
esp -
Palo
-
parted 3.5가 있는 Red Hat Enterprise Linux 9에서는 추가 플래그 Chrome os_kernel 및 를 사용할 수 있습니다.
bls_ boot
parted 유틸리티는 선택적으로 파티션을 생성하는 동안 파일 시스템 유형 인수를 허용합니다. 필수 조건 목록을 보려면 parted로 파티션 생성을 참조하십시오. 다음 값을 사용합니다.
- GPT에 파티션 플래그를 설정합니다.
-
GPT에서 파티션 UUID 유형을 설정합니다. 예를 들어
스왑,fat또는hfs파일 시스템 유형은 다른 GUID를 설정합니다. 기본값은 Linux Data GUID입니다.
인수는 파티션의 파일 시스템을 변경하지 않습니다. 지원되는 플래그와 GUID만 구분합니다.
다음 파일 시스템 유형이 지원됩니다.
-
xfs -
ext2 -
ext3 -
ext4 -
fat16 -
fat32 -
hfs -
hfs+ -
linux-swap -
ntfs -
reiserfs
3.9. 파티션 이름 지정 체계
Red Hat Enterprise Linux는 /dev/xyN 형식의 파일 이름과 함께 파일 기반 이름 지정 체계를 사용합니다.
장치 및 파티션 이름은 다음 구조로 구성됩니다.
/dev/-
모든 장치 파일이 들어 있는 디렉터리의 이름입니다. 하드 디스크에는 파티션이 포함되어 있으므로 가능한 모든 파티션을 나타내는 파일은
/dev에 있습니다. xx- 파티션 이름의 처음 두 문자는 파티션을 포함하는 장치의 유형을 나타냅니다.
y-
이 문자는 파티션을 포함하는 특정 장치를 나타냅니다. 예를 들어 첫 번째 하드 디스크인
/dev/sda와 두 번째 하드 디스크의/dev/sdb입니다. 26개 이상의 드라이브(예:/dev/sdaa1)가 있는 시스템에서 더 많은 문자를 사용할 수 있습니다. N-
마지막 문자는 파티션을 나타내는 숫자를 나타냅니다. 처음 4개(기본값 또는 확장) 파티션은
1에서4까지 번호가 매겨집니다. 논리 파티션은5에서 시작합니다. 예를 들어/dev/sda3은 첫 번째 하드 디스크의 세 번째 기본 또는 확장 파티션이며/dev/sdb6은 두 번째 하드 디스크의 두 번째 논리 파티션입니다. 드라이브 파티션 번호 지정은 GPT 파티션 테이블에만 적용됩니다. N 이 항상 파티션을 의미하지는 않습니다.
Red Hat Enterprise Linux가 모든 유형의 디스크 파티션을 식별하고 참조할 수 있지만 파일 시스템을 읽지 못하므로 모든 파티션 유형에서 저장된 데이터에 액세스하지 못할 수 있습니다. 그러나 대부분의 경우 다른 운영 체제에 전용 파티션의 데이터에 성공적으로 액세스할 수 있습니다.
3.10. 마운트 지점 및 디스크 파티션
Red Hat Enterprise Linux에서 각 파티션은 스토리지의 일부를 형성하며 단일 파일 및 디렉터리를 지원하는 데 필요합니다. 파티션을 마운트하면 마운트 지점 이라는 지정된 디렉터리에서 시작하여 해당 파티션을 스토리지를 사용할 수 있습니다.
예를 들어 파티션 가 /usr/ 에 마운트된 경우 /dev/sda5 /usr/ 아래의 모든 파일 및 디렉터리가 /dev/ sda5에 물리적으로 상주함을 의미합니다. /usr/share/doc/FAQ/txt/Linux-FAQ 파일은 /dev/sda5 에 있지만 /etc/gdm/custom.conf 파일은 그렇지 않습니다.
이 예제를 계속 사용하면 /usr/ 아래의 하나 이상의 디렉터리가 다른 파티션의 마운트 지점이 될 수도 있습니다. 예를 들어 /usr/local/man/whatis 는 /dev/sda5 가 아닌 /dev/sda7 에 있습니다. /usr/local 에 마운트된 /dev/sda7 파티션이 포함된 경우.
4장. 파티션 시작하기
디스크 파티셔닝을 사용하여 각 파티션에서 개별적으로 작업할 수 있는 하나 이상의 논리 영역으로 디스크를 나눕니다. 하드 디스크는 파티션 테이블의 각 디스크 파티션의 위치와 크기에 대한 정보를 저장합니다. 이 테이블을 사용하면 각 파티션이 운영 체제에 대한 논리 디스크로 표시됩니다. 그런 다음 개별 디스크를 읽고 쓸 수 있습니다.
블록 장치에서 파티션을 사용하기 위한 이점과 단점에 대한 개요 는 직접 또는 LVM에 있는 LVM을 통해 LUN에서 파티셔닝을 사용하는 데 따른 장단점 을 참조하십시오.
4.1. parted를 사용하여 디스크에서 파티션 테이블 만들기
parted 유틸리티를 사용하여 파티션 테이블로 블록 장치를 보다 쉽게 포맷합니다.
파티션 테이블을 사용하여 블록 장치를 포맷하면 장치에 저장된 모든 데이터가 삭제됩니다.
절차
대화형
parted쉘을 시작합니다.# parted block-device장치에 이미 파티션 테이블이 있는지 확인합니다.
# (parted) print
장치에 이미 파티션이 포함된 경우 다음 단계에서 삭제됩니다.
새 파티션 테이블을 만듭니다.
# (parted) mklabel table-typetable-type 을 원하는 파티션 테이블 유형으로 바꿉니다.
-
df용MSDOS -
GPT용 GPT
-
예 4.1. GUID 파티션 테이블(GPT) 만들기
디스크에 GPT 테이블을 만들려면 다음을 사용합니다.
# (parted) mklabel gpt
이 명령을 입력한 후 변경 사항이 적용되기 시작합니다.
파티션 테이블을 보고 해당 테이블이 생성되었는지 확인합니다.
# (parted) print
parted쉘을 종료합니다.# (parted) quit
추가 리소스
-
parted(8)도움말 페이지.
4.2. parted로 파티션 테이블 보기
블록 장치의 파티션 테이블을 표시하여 파티션 레이아웃과 개별 파티션에 대한 세부 정보를 확인합니다. parted 유틸리티를 사용하여 블록 장치에서 파티션 테이블을 볼 수 있습니다.
절차
parted유틸리티를 시작합니다. 예를 들어 다음 출력에는/dev/sda가 나열됩니다.# parted /dev/sda
파티션 테이블 보기:
# (parted) print Model: ATA SAMSUNG MZNLN256 (scsi) Disk /dev/sda: 256GB Sector size (logical/physical): 512B/512B Partition Table: msdos Disk Flags: Number Start End Size Type File system Flags 1 1049kB 269MB 268MB primary xfs boot 2 269MB 34.6GB 34.4GB primary 3 34.6GB 45.4GB 10.7GB primary 4 45.4GB 256GB 211GB extended 5 45.4GB 256GB 211GB logical
선택 사항: 다음을 검사하려는 장치로 전환합니다.
# (parted) select block-device
출력 명령 출력에 대한 자세한 설명은 다음을 참조하십시오.
모델: ATASampleSUNG MZNN256 (scsi)- 디스크 유형, 제조업체, 모델 번호, 인터페이스.
디스크 /dev/sda: 256GB- 블록 장치 및 스토리지 용량의 파일 경로입니다.
파티션 테이블: msdos- 디스크 레이블 유형입니다.
숫자-
파티션 번호입니다. 예를 들어, 마이너 번호가 1인 파티션은
/dev/sda1에 해당합니다. 시작및종료- 파티션이 시작되고 끝나는 장치의 위치입니다.
유형- 유효한 유형은 metadata, free, primary, extended 또는 logical입니다.
파일 시스템-
파일 시스템 유형입니다. 장치의
파일 시스템필드에 값이 없음을 나타내는 경우 해당 파일 시스템 유형이 알 수 없음을 의미합니다.parted유틸리티는 암호화된 장치의 파일 시스템을 인식할 수 없습니다. 플래그-
파티션에 설정된 플래그를 나열합니다. 사용 가능한 플래그는
부팅,루트,스왑,숨겨진,raid,lvm또는 ba입니다.
추가 리소스
-
parted(8)도움말 페이지.
4.3. parted로 파티션 생성
시스템 관리자는 parted 유틸리티를 사용하여 디스크에 새 파티션을 만들 수 있습니다.
필요한 파티션은 스왑,/boot/, 및 / (root) 입니다.
사전 요구 사항
- 디스크의 파티션 테이블입니다.
- 생성하려는 파티션이 2TiB보다 크면 GUID 파티션 테이블(GPT) 으로 디스크를 포맷합니다.
절차
parted유틸리티를 시작합니다.# parted block-device사용 가능한 공간이 충분한지 확인하려면 현재 파티션 테이블을 확인합니다.
# (parted) print
- 사용 가능한 공간이 충분하지 않은 경우 파티션의 크기를 조정합니다.
파티션 테이블에서 다음을 확인합니다.
- 새 파티션의 시작 및 끝점입니다.
- GPT에서 파티션 유형은 무엇입니까.
새 파티션을 만듭니다.
# (parted) mkpart part-type name fs-type start end
-
part-type 을
기본,논리또는 확장으로바꿉니다. 이는 reserved 파티션 테이블에만 적용됩니다. - 이름을 임의의 파티션 이름으로 바꿉니다. 이는 GPT 파티션 테이블에 필요합니다.
-
fs-type 을
xfs,ext2,ext3,ext4,fat16,fat32,hfs,hfs+,linux-swap,ntfs또는reiserfs로 바꿉니다. fs-type 매개변수는 선택 사항입니다.parted유틸리티는 파티션에 파일 시스템을 생성하지 않습니다. -
start 및 end 를 파티션의 시작 및 종료 지점을 결정하는 크기로 바꾸고 디스크 시작부터 계산합니다.
512MiB,20GiB또는1.5TiB와 같은 크기 접미사를 사용할 수 있습니다. 기본 크기는 메가바이트입니다.
예 4.2. 작은 기본 파티션 만들기
1024MiB에서 STATUS 테이블의 기본 파티션을 2048MiB까지 만들려면 다음을 사용합니다.
# (parted) mkpart primary 1024MiB 2048MiB
변경 사항은 명령을 입력한 후 적용을 시작합니다.
-
part-type 을
파티션 테이블을 보고 생성된 파티션이 올바른 파티션 유형, 파일 시스템 유형 및 크기가 있는 파티션 테이블에 있는지 확인합니다.
# (parted) print
parted쉘을 종료합니다.# (parted) quit
새 장치 노드를 등록합니다.
# udevadm settle
커널이 새 파티션을 인식하는지 확인합니다.
# cat /proc/partitions
추가 리소스
-
parted(8)도움말 페이지. - parted를 사용하여 디스크에서 파티션 테이블 만들기
- parted로 파티션 크기 조정
4.4. <.>을 사용하여 파티션 유형 설정
<.> 유틸리티를 사용하여 파티션 유형 또는 플래그를 설정할 수 있습니다.
사전 요구 사항
- 디스크의 파티션입니다.
절차
대화형 <.>
;쉘을 시작합니다.# fdisk block-device현재 파티션 테이블을 보고 마이너 파티션 번호를 확인합니다.
Command (m for help): print유형 열에서 현재 파티션
유형과Id열의 해당 유형 ID를 확인할 수 있습니다.파티션 유형 명령을 입력하고 마이너 번호를 사용하여 파티션을 선택합니다.
Command (m for help): type Partition number (1,2,3 default 3): 2
선택 사항: 16진수 코드의 목록을 확인합니다.
Hex code (type L to list all codes): L파티션 유형을 설정합니다.
Hex code (type L to list all codes): 8e변경 사항을 작성하고 <.>
쉘을 종료합니다.Command (m for help): write The partition table has been altered. Syncing disks.변경 사항을 확인합니다.
# fdisk --list block-device
4.5. parted로 파티션 크기 조정
parted 유틸리티를 사용하여 사용되지 않은 디스크 공간을 활용하도록 파티션을 확장하거나 다른 용도로 용량을 사용하도록 파티션을 줄입니다.
사전 요구 사항
- 파티션을 축소하기 전에 데이터를 백업합니다.
- 생성하려는 파티션이 2TiB보다 크면 GUID 파티션 테이블(GPT) 으로 디스크를 포맷합니다.
- 파티션을 축소하려면 먼저 크기가 조정된 파티션보다 크지 않도록 파일 시스템을 축소합니다.
XFS는 축소를 지원하지 않습니다.
절차
parted유틸리티를 시작합니다.# parted block-device현재 파티션 테이블을 확인합니다.
# (parted) print
파티션 테이블에서 다음을 확인합니다.
- 파티션의 마이너 번호입니다.
- 크기 조정 후 기존 파티션 및 해당 새 종료 지점의 위치입니다.
파티션의 크기를 조정합니다.
# (parted) resizepart 1 2GiB
- 1 을 크기 조정 중인 파티션의 마이너 번호로 바꿉니다.
-
2 를 크기가 조정된 파티션의 새 끝 지점을 결정하는 크기로 바꾸고 디스크 처음부터 계산합니다.
512MiB,20GiB또는1.5TiB와 같은 크기 접미사를 사용할 수 있습니다. 기본 크기는 메가바이트입니다.
파티션 테이블을 보고 크기 조정이 올바른 크기의 파티션 테이블에 있는지 확인합니다.
# (parted) print
parted쉘을 종료합니다.# (parted) quit
커널이 새 파티션을 등록하는지 확인합니다.
# cat /proc/partitions
- 선택 사항: 파티션을 확장한 경우 파일 시스템도 확장합니다.
추가 리소스
-
parted(8)도움말 페이지. - parted를 사용하여 디스크에서 파티션 테이블 만들기
- ext3 파일 시스템 크기 조정
- XFS 파일 시스템의 크기 증가
4.6. parted로 파티션 제거
parted 유틸리티를 사용하면 디스크 파티션을 제거하여 디스크 공간을 확보할 수 있습니다.
파티션을 제거하면 파티션에 저장된 모든 데이터가 삭제됩니다.
절차
대화형
parted쉘을 시작합니다.# parted block-device-
블록 장치를 파티션을 제거하려는 장치의 경로로 바꿉니다(예:
/dev/sda).
-
블록 장치를 파티션을 제거하려는 장치의 경로로 바꿉니다(예:
제거할 파티션의 마이너 수를 확인하려면 현재 파티션 테이블을 확인합니다.
(parted) print
파티션을 제거합니다.
(parted) rm minor-number- minor-number 를 제거하려는 파티션의 마이너 번호로 바꿉니다.
변경 사항은 이 명령을 입력하는 즉시 적용을 시작합니다.
파티션 테이블에서 파티션을 제거했는지 확인합니다.
(parted) print
parted쉘을 종료합니다.(parted) quit
커널이 파티션이 제거되었는지 확인합니다.
# cat /proc/partitions
-
/etc/fstab파일이 있는 경우 파티션을 제거합니다. 제거된 파티션을 선언하고 파일에서 제거하는 행을 찾습니다. 시스템이 새
/etc/fstab구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.# systemctl daemon-reload
스왑 파티션을 삭제하거나 LVM을 제거한 경우 커널 명령줄에서 파티션에 대한 모든 참조를 제거하십시오.
활성 커널 옵션을 나열하고 옵션이 제거된 파티션을 참조하는지 확인합니다.
# grubby --info=ALL
삭제된 파티션을 참조하는 커널 옵션을 제거합니다.
# grubby --update-kernel=ALL --remove-args="option"
초기 부팅 시스템에 변경 사항을 등록하려면
initramfs파일 시스템을 다시 빌드합니다.# dracut --force --verbose
추가 리소스
-
parted(8)도움말 페이지
5장. 디스크를 다시 분할하기 위한 전략
디스크를 다시 분할하는 방법은 다양합니다. 여기에는 다음이 포함됩니다.
- 파티션되지 않은 여유 공간을 사용할 수 있습니다.
- 사용되지 않은 파티션을 사용할 수 있습니다.
- 활발하게 사용되는 파티션의 여유 공간을 사용할 수 있습니다.
다음 예제는 명확성을 위해 단순화되며 Red Hat Enterprise Linux를 실제로 설치할 때 정확한 파티션 레이아웃을 반영하지 않습니다.
5.1. 파티션되지 않은 여유 공간 사용
이미 정의되어 있고 전체 하드 디스크에 걸쳐 있지 않은 파티션은 정의된 파티션에 속하지 않는 할당되지 않은 공간을 남겨 둡니다. 다음 다이어그램에서는 이것이 어떻게 보이는지 보여줍니다.
그림 5.1. 파티션 여유 공간이 파티션되지 않은 디스크

첫 번째 다이어그램은 하나의 기본 파티션과 할당되지 않은 공간이 있는 정의되지 않은 파티션이 있는 디스크를 나타냅니다. 두 번째 다이어그램은 공간이 할당된 두 개의 정의된 파티션이 있는 디스크를 나타냅니다.
사용되지 않은 하드 디스크도 이 범주에 속합니다. 유일한 차이점은 모든 공간이 정의된 파티션의 일부가 아니라는 것입니다.
새 디스크에서 사용되지 않는 공간을 통해 필요한 파티션을 만들 수 있습니다. 대부분의 사전 설치된 운영 체제는 디스크 드라이브에서 사용 가능한 모든 공간을 차지하도록 구성됩니다.
5.2. 사용되지 않은 파티션의 공간 사용
다음 예에서 첫 번째 다이어그램은 사용되지 않은 파티션이 있는 디스크를 나타냅니다. 두 번째 다이어그램은 Linux에서 사용되지 않은 파티션을 찾는 것을 나타냅니다.
그림 5.2. 사용되지 않는 파티션이 있는 디스크

사용되지 않은 파티션에 할당된 공간을 사용하려면 파티션을 삭제한 다음 적절한 Linux 파티션을 만듭니다. 또는 설치 프로세스 중에 사용되지 않은 파티션을 삭제하고 새 파티션을 수동으로 만듭니다.
5.3. 활성 파티션의 여유 공간 사용
이 프로세스에는 이미 사용 중인 활성 파티션에 필요한 여유 공간이 포함되어 있으므로 이 프로세스를 관리하기 어려울 수 있습니다. 대부분의 경우 소프트웨어가 사전 설치된 컴퓨터 하드 디스크에는 운영 체제 및 데이터를 보유한 더 큰 파티션이 포함되어 있습니다.
활성 파티션에서 운영 체제(OS)를 사용하려면 OS를 다시 설치해야 합니다. 사전 설치된 소프트웨어를 포함하는 일부 컴퓨터는 원래 OS를 재설치하기 위한 설치 미디어를 포함하지 않습니다. 원래 파티션과 OS 설치를 제거하기 전에 이것이 OS에 적용되는지 확인하십시오.
사용 가능한 여유 공간 사용을 최적화하기 위해, 안전하지 않거나 파괴되지 않은 재파운딩 방법을 사용할 수 있습니다.
5.3.1. 안전하지 않은 재파티션
안전하지 않은 재파티션은 하드 드라이브에서 파티션을 제거하고 대신 작은 여러 파티션을 만듭니다. 이 방법을 사용하면 전체 내용이 삭제되므로 원래 파티션에서 필요한 모든 데이터를 백업하십시오.
기존 운영 체제에 대해 더 작은 파티션을 생성한 후 다음을 수행할 수 있습니다.
- 소프트웨어 재설치.
- 데이터를 복원합니다.
- Red Hat Enterprise Linux 설치를 시작하십시오.
다음 다이어그램은 안전하지 않은 repartitioning 방법 사용에 대한 단순화된 표현입니다.
그림 5.3. 디스크에서 안전하지 않은 재파티션 작업

이 방법은 원래 파티션에 이전에 저장된 모든 데이터를 삭제합니다.
5.3.2. 거부되지 않은 repartitioning
데이터 손실 없이 파티션 재파티브 크기 조정이 지연되지 않습니다. 이 방법은 신뢰할 수 있지만 큰 드라이브에서 처리 시간이 오래 걸립니다.
다음은 거부된 복원을 시작하는 데 도움이 될 수 있는 메서드 목록입니다.
- 기존 데이터 압축
일부 데이터의 저장 위치는 변경할 수 없습니다. 이렇게 하면 파티션이 필요한 크기로 크기를 조정하는 것을 방지할 수 있으며 궁극적으로 안전하지 않은 재파티션 프로세스가 발생할 수 있습니다. 이미 존재하는 파티션의 데이터를 압축하면 필요에 따라 파티션의 크기를 조정하는 데 도움이 될 수 있습니다. 또한 사용 가능한 공간을 최대화하는 데 도움이 될 수 있습니다.
다음 다이어그램은 이 프로세스를 간단하게 나타냅니다.
그림 5.4. 디스크의 데이터 압축

가능한 데이터 손실을 방지하려면 압축 프로세스를 계속하기 전에 백업을 만듭니다.
- 기존 파티션의 크기 조정
기존 파티션의 크기를 조정하면 더 많은 공간을 확보할 수 있습니다. 소프트웨어 크기 조정에 따라 결과가 다를 수 있습니다. 대부분의 경우 원래 파티션과 동일한 유형의 포맷되지 않은 새 파티션을 만들 수 있습니다.
크기 조정 후 수행하는 단계는 사용하는 소프트웨어에 따라 달라질 수 있습니다. 다음 예제에서 가장 좋은 방법은 새 ClusterTask (Disk Operating System) 파티션을 삭제하고 대신 Linux 파티션을 만드는 것입니다. 크기 조정 프로세스를 시작하기 전에 디스크에 가장 적합한 항목을 확인합니다.
그림 5.5. 디스크의 파티션 크기 조정

- 선택 사항: 새 파티션 생성
소프트웨어 크기 조정 중 일부는 Linux 기반 시스템을 지원합니다. 이러한 경우 크기 조정 후 새로 생성된 파티션을 삭제할 필요가 없습니다. 나중에 새 파티션을 만드는 것은 사용하는 소프트웨어에 따라 다릅니다.
다음 다이어그램은 새 파티션을 만들기 전과 후에 디스크 상태를 나타냅니다.
그림 5.6. 최종 파티션 구성이 있는 디스크

6장. iSCSI 대상 구성
Red Hat Enterprise Linux는 targetcli 쉘을 명령줄 인터페이스로 사용하여 다음 작업을 수행합니다.
- iSCSI 하드웨어를 활용하기 위해 iSCSI 스토리지 상호 연결을 추가, 제거, 보기 및 모니터링합니다.
- 파일, 볼륨, 로컬 SCSI 장치 또는 RAM 디스크에서 지원하는 로컬 스토리지 리소스를 원격 시스템으로 내보냅니다.
targetcli 툴에는 기본 제공 탭 완성, 자동 완성 지원 및 인라인 설명서를 포함한 트리 기반 레이아웃이 있습니다.
6.1. targetcli 설치
targetcli 도구를 설치하여 iSCSI 스토리지 상호 연결을 추가, 모니터링 및 제거합니다.
절차
targetcli툴을 설치합니다.# dnf install targetcli
대상 서비스를 시작합니다.
# systemctl start target
부팅 시 시작할 대상을 설정합니다.
# systemctl enable target
방화벽에서 포트
3260을 열고 방화벽 구성을 다시 로드합니다.# firewall-cmd --permanent --add-port=3260/tcp Success # firewall-cmd --reload Success
검증
targetcli레이아웃을 확인합니다.# targetcli /> ls o- /........................................[...] o- backstores.............................[...] | o- block.................[Storage Objects: 0] | o- fileio................[Storage Objects: 0] | o- pscsi.................[Storage Objects: 0] | o- ramdisk...............[Storage Objects: 0] o- iscsi...........................[Targets: 0] o- loopback........................[Targets: 0]
추가 리소스
-
targetcli(8)도움말 페이지
6.2. iSCSI 대상 생성
iSCSI 타겟을 생성하면 클라이언트의 iSCSI 이니시에이터가 서버의 스토리지 장치에 액세스할 수 있습니다. 타겟과 이니시에이터 모두 고유한 식별 이름을 갖습니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오.
절차
iSCSI 디렉토리로 이동합니다.
/> iscsi/
참고cd명령은 디렉터리를 변경하고 로 이동할 경로를 나열하는 데 사용됩니다.다음 옵션 중 하나를 사용하여 iSCSI 대상을 생성합니다.
기본 대상 이름을 사용하여 iSCSI 대상 생성:
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
특정 이름을 사용하여 iSCSI 대상 생성:
/iscsi> create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1 Here
iqn.2006-04.com.example:444is target_iqn_nameiqn.2006-04.com.example:444 를 특정 대상 이름으로 바꿉니다.
새로 생성된 대상을 확인합니다.
/iscsi> ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
추가 리소스
-
targetcli(8)도움말 페이지
6.3. iSCSI 보조 저장소
iSCSI 보조 저장소를 사용하면 내보낸 LUN 데이터를 로컬 시스템에 저장하는 다양한 방법을 지원할 수 있습니다. 스토리지 오브젝트를 생성하면 보조 저장소에서 사용하는 리소스를 정의합니다.
관리자는 LIO(Linux-IO)에서 지원하는 다음 보조 저장소 장치 중 하나를 선택할 수 있습니다.
FileIO보조 저장소-
로컬
파일 시스템에서 일반 파일을 디스크 이미지로 사용하는 경우 fileio스토리지 오브젝트를 생성합니다.fileio백 저장소 생성은 fileio 스토리지 오브젝트 생성을 참조하십시오. 블록보조 저장소-
로컬
블록장치 및 논리적 장치를 사용하는 경우 블록 스토리지 오브젝트를 생성합니다.블록백 저장소 생성은 블록 스토리지 오브젝트 생성을 참조하십시오. pscsibackstore-
스토리지 오브젝트가 SCSI 명령의 직접 패스스루를 지원하는 경우
pscsi스토리지 오브젝트를 만듭니다.pscsibackstore를 생성하려면 pscsi 스토리지 오브젝트 생성을 참조하십시오. ramdisk보조 저장소-
임시 RAM 백업 장치를 생성하려면
ramdisk스토리지 오브젝트를 생성합니다.램디스크백업 저장소 생성은 메모리 복사 RAM 디스크 스토리지 오브젝트 생성을 참조하십시오.
추가 리소스
-
targetcli(8)도움말 페이지
6.4. fileio 스토리지 오브젝트 생성
FileIO 스토리지 오브젝트는 write_back 또는 작업을 지원할 수 있습니다. write_ thruwrite_back 작업을 사용하면 로컬 파일 시스템 캐시가 활성화됩니다. 이렇게 하면 성능이 향상되지만 데이터 손실 위험이 높아집니다.
write_back=false를 사용하여 write_ thru 작업을 위해 write_back 작업을 비활성화하는 것이 좋습니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오.
절차
backstores/디렉토리에서fileio/로 이동합니다./> backstores/fileio
fileio스토리지 오브젝트를 생성합니다./backstores/fileio> create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
검증
생성된
fileio스토리지 오브젝트를 확인합니다./backstores/fileio> ls
추가 리소스
-
targetcli(8)도움말 페이지
6.5. 블록 스토리지 오브젝트 생성
블록 드라이버를 사용하면 /sys/block/ 디렉터리에 나타나는 모든 블록 장치를 LIO(Linux-IO)와 함께 사용할 수 있습니다. 여기에는, DASD, SSD, CD 및 DVD와 같은 물리적 장치, 소프트웨어 또는 하드웨어 RAID 볼륨 또는 LVM 볼륨과 같은 논리 장치가 포함됩니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오.
절차
backstores/디렉터리에서block/로 이동합니다./> backstores/block/
블록보조 저장소를 생성합니다./backstores/block> create name=block_backend dev=/dev/sdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
검증
생성된
블록스토리지 오브젝트를 확인합니다./backstores/block> ls
참고논리 볼륨에
블록 보조 저장소를생성할 수도 있습니다.
추가 리소스
-
targetcli(8)도움말 페이지
6.6. pscsi 스토리지 오브젝트 생성
보조 저장소로 SCSI 에뮬레이션 없이 SCSI 명령의 직접 패스스루를 지원하는 스토리지 오브젝트와 SAS 하드 드라이브와 같은 /proc/scsi/ 와 함께 표시되는 기본 SCSI 장치를 사용할 수 있습니다. 이 하위 시스템에서 SCSI-3 이상이 지원됩니다.
scsi에 l sscsi
pscsi 는 고급 사용자만 사용해야 합니다. ALUA(Asymmetric Logical Unit Assignment) 또는 영구 예약(예: VMware ESX 및 vSphere)과 같은 고급 SCSI 명령은 일반적으로 장치 펌웨어에 구현되지 않으며 오작동 또는 충돌을 일으킬 수 있습니다. 확실하지 않은 경우 대신 block backstore를 프로덕션 설정에 사용합니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오.
절차
backstores/디렉터리에서pscsi/로 이동합니다./> backstores/pscsi/
이 예에서는
/dev/sr0을 사용하여 TYPE_ROM 장치의pscsi백 저장소를 생성합니다./backstores/pscsi> create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0
검증
생성된
pscsi스토리지 오브젝트를 확인합니다./backstores/pscsi> ls
추가 리소스
-
targetcli(8)도움말 페이지
6.7. 메모리 복사 RAM 스토리지 오브젝트 생성
메모리 복사 RAM 디스크(ramdisk)는 RAM 디스크에 전체 SCSI 에뮬레이션 및 이니시에이터의 메모리 복사본을 사용하여 별도의 메모리 매핑을 제공합니다. 이는 멀티 세션에 대한 기능을 제공하며, 특히 생산 용도로 빠르고 휘발성 대량 스토리지에 유용합니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오.
절차
backstores/디렉토리에서ramdisk/로 이동합니다./> backstores/ramdisk/
1GB RAM 디스크 보조 저장소를 생성합니다.
/backstores/ramdisk> create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
검증
생성된
ramdisk스토리지 오브젝트를 확인합니다./backstores/ramdisk> ls
추가 리소스
-
targetcli(8)도움말 페이지
6.8. iSCSI 포털 생성
iSCSI 포털을 만들면 타겟을 계속 활성화하는 대상에 IP 주소와 포트가 추가됩니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오. - TPG(대상 포털 그룹)와 연결된 iSCSI 대상입니다. 자세한 내용은 iSCSI 대상 생성을 참조하십시오.
절차
TPG 디렉토리로 이동합니다.
/iscsi> iqn.2006-04.example:444/tpg1/
다음 옵션 중 하나를 사용하여 iSCSI 포털을 생성합니다.
기본 포털을 생성하면 기본 iSCSI 포트
3260을 사용하며 타겟에서 해당 포트의 모든 IP 주소를 수신 대기할 수 있습니다./iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
참고iSCSI 대상이 생성되면 기본 포털도 생성됩니다. 이 포털은 기본 포트 번호인 모든 IP 주소를 수신 대기하도록 설정되어 있습니다.
0.0.0.0:3260.기본 포털을 제거하려면 다음 명령을 사용합니다.
/iscsi/iqn-name/tpg1/portals delete ip_address=0.0.0.0 ip_port=3260
특정 IP 주소를 사용하여 포털 생성:
/iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
검증
새로 생성된 포털을 확인합니다.
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
추가 리소스
-
targetcli(8)도움말 페이지
6.9. iSCSI LUN 생성
LUN(Logical Unit Number)은 iSCSI 보조 저장소에서 지원하는 물리적 장치입니다. 각 LUN에는 고유한 번호가 있습니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오. - TPG(대상 포털 그룹)와 연결된 iSCSI 대상입니다. 자세한 내용은 iSCSI 대상 생성을 참조하십시오.
- 생성된 스토리지 오브젝트. 자세한 내용은 iSCSI Backstore 를 참조하십시오.
절차
이미 생성된 스토리지 오브젝트의 LUN을 만듭니다.
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
생성된 LUN을 확인합니다.
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]기본 LUN 이름은
0부터 시작됩니다.중요기본적으로 LUN은 읽기-쓰기 권한으로 생성됩니다. ACL이 생성된 후 새 LUN이 추가되면 LUN은 사용 가능한 모든 ACL에 자동으로 매핑되며 보안 위험이 발생할 수 있습니다. 읽기 전용 권한으로 LUN을 만들려면 읽기 전용 iSCSI LUN 만들기 를 참조하십시오.
- ACL 구성. 자세한 내용은 iSCSI ACL 생성을 참조하십시오.
추가 리소스
-
targetcli(8)도움말 페이지
6.10. 읽기 전용 iSCSI LUN 생성
기본적으로 LUN은 읽기-쓰기 권한으로 생성됩니다. 다음 절차에서는 읽기 전용 LUN을 만드는 방법을 설명합니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오. - TPG(대상 포털 그룹)와 연결된 iSCSI 대상입니다. 자세한 내용은 iSCSI 대상 생성을 참조하십시오.
- 생성된 스토리지 오브젝트. 자세한 내용은 iSCSI Backstore 를 참조하십시오.
절차
읽기 전용 권한을 설정합니다.
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
이렇게 하면 LUN을 수동으로 매핑할 수 있도록 하는 기존 ACL과 LUN의 자동 매핑이 금지됩니다.
initiator_iqn_name 디렉터리로 이동합니다.
/> iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/LUN을 생성합니다.
/iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name> create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore=backstore write_protect=1예제:
/iscsi/target_iqn_name/tpg1/acls/2006-04.com.example.foo:888> create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1.
생성된 LUN을 확인합니다.
/iscsi/target_iqn_name/tpg1/acls/2006-04.com.example.foo:888> ls o- 2006-04.com.example.foo:888 .. [Mapped LUNs: 2] | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | o- mapped_lun1 .............. [lun1 block/disk2 (ro)]
이제 mapped_lun1 행의 끝에 (rw
)가 읽기 전용임을 나타내는 mapped_lun0의 (rw)가 있습니다.- ACL 구성. 자세한 내용은 iSCSI ACL 생성을 참조하십시오.
추가 리소스
-
targetcli(8)도움말 페이지
6.11. iSCSI ACL 생성
targetcli 에서 ACL(액세스 제어 목록)은 액세스 규칙을 정의하는 데 사용되며 각 이니시에이터는 LUN에 대한 독점적인 액세스 권한을 갖습니다.
타겟과 이니시에이터 모두 고유한 식별 이름을 갖습니다. ACL을 구성하려면 이니시에이터의 고유 이름을 알아야 합니다. iSCSI 이니시에이터는 /etc/iscsi/initiatorname.iscsi 파일에 있습니다.
사전 요구 사항
-
targetcli설치 및 실행. 자세한 내용은 NFD 설치를 참조하십시오. - TPG(대상 포털 그룹)와 연결된 iSCSI 대상입니다. 자세한 내용은 iSCSI 대상 생성을 참조하십시오.
절차
acls 디렉토리로 이동합니다.
/iscsi/iqn.20...mple:444/tpg1> acls/
다음 옵션 중 하나를 사용하여 ACL을 만듭니다.
-
이니시에이터의
/etc/iscsi/initiatorname.iscsi파일에서 이니시에이터 이름 사용. 쉽게 이해할 수 있는 이름을 사용하는 경우, ACL이 이니시에이터와 일치하는지 확인하는 iSCSI 이니시에이터 생성 섹션을 참조하십시오.
/iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
참고앞의 예제에서 사용되는 글로벌 설정
auto_add_mapped_luns는 생성된 모든 ACL에 LUN을 자동으로 매핑합니다.대상 서버의 TPG 노드 내에 사용자 생성 ACL을 설정할 수 있습니다.
/iscsi/iqn.20...scsi:444/tpg1> set attribute generate_node_acls=1
-
이니시에이터의
검증
생성된 ACL을 확인합니다.
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
추가 리소스
-
targetcli(8)도움말 페이지
6.12. 대상에 대한 Challenge-Handshake Authentication Protocol 설정
CHAP ( Challenge-Handshake Authentication Protocol)를 사용하면 사용자가 암호로 대상을 보호할 수 있습니다. 이니시에이터는 대상에 연결할 수 있으려면 이 암호를 알고 있어야 합니다.
사전 요구 사항
- iSCSI ACL 생성. 자세한 내용은 iSCSI ACL 생성을 참조하십시오.
절차
속성 인증 설정:
/iscsi/iqn.20...mple:444/tpg1> set attribute authentication=1 Parameter authentication is now '1'.
userid및암호설정 :/tpg1> set auth userid=redhat Parameter userid is now 'redhat'. /iscsi/iqn.20...689dcbb3/tpg1> set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
추가 리소스
-
targetcli(8)도움말 페이지
6.13. targetcli 도구를 사용하여 iSCSI 오브젝트 제거
다음 절차에서는 targetcli 툴을 사용하여 iSCSI 오브젝트를 제거하는 방법을 설명합니다.
절차
대상에서 로그아웃합니다.
# iscsiadm -m node -T iqn.2006-04.example:444 -u대상에 로그인하는 방법에 대한 자세한 내용은 iSCSI 이니시에이터 생성을 참조하십시오.
모든 ACL, LUN 및 포털을 포함한 전체 대상을 제거합니다.
/> iscsi/ delete iqn.2006-04.com.example:444iqn.2006-04.com.example:444 를 target_iqn_name으로 바꿉니다.
iSCSI 보조 저장소를 제거하려면 다음을 수행합니다.
/> backstores/backstore-type/ delete block_backend
-
backstore-type 을
fileio,block,pscsi또는ramdisk로 바꿉니다. - block_backend 를 삭제하려는 보조 저장소 이름으로 교체합니다.
-
backstore-type 을
ACL과 같은 iSCSI 대상의 일부를 제거하려면 다음을 수행합니다.
/> /iscsi/iqn-name/tpg/acls/ delete iqn.2006-04.com.example:444
검증
변경 사항을 확인합니다.
/> iscsi/ ls
추가 리소스
-
targetcli(8)도움말 페이지
7장. iSCSI 개시자 구성
iSCSI 이니시에이터는 iSCSI 대상에 연결하기 위한 세션을 형성합니다. 기본적으로 iSCSI 서비스는 지연 시작되며 iscsiadm 명령을 실행한 후에 서비스가 시작됩니다. root가 iSCSI 장치에 없거나 node.startup = 자동으로 표시된 노드가 없는 경우 서비스가 시작되지 않습니다.
iscsid 또는 iscsi 커널 모듈이 필요한 iscsiadm 명령이 실행될 때까지 iSCSI
systemctl start iscsid.service 명령을 root로 실행하여 iscsid 데몬이 실행되고 iSCSI 커널 모듈이 로드되도록 강제 적용합니다.
7.1. iSCSI 개시자 생성
iSCSI 이니시에이터를 생성하여 서버의 스토리지 장치에 액세스하기 위해 iSCSI 대상에 연결합니다.
사전 요구 사항
iSCSI 대상의 호스트 이름과 IP 주소가 있습니다.
- 외부 소프트웨어가 생성한 스토리지 대상에 연결하는 경우 스토리지 관리자의 대상 호스트 이름과 IP 주소를 찾습니다.
- iSCSI 대상을 생성하는 경우 iSCSI 대상 만들기를 참조하십시오.
절차
클라이언트 시스템에
iscsi-initiator-utils를 설치합니다.# dnf install iscsi-initiator-utils
이니시에이터 이름을 확인합니다.
# cat /etc/iscsi/initiatorname.iscsi InitiatorName=2006-04.com.example.foo:888
ACL에 iSCSI ACL 생성에 사용자 지정 이름이 지정된 경우 그에 따라
/etc/iscsi/initiatorname.iscsi파일을 수정합니다.# vi /etc/iscsi/initiatorname.iscsi
대상을 검색하고 표시된 대상 IQN을 사용하여 타겟에 로그인합니다.
# iscsiadm -m discovery -t st -p 10.64.24.179 10.64.24.179:3260,1 iqn.2006-04.example:444 # iscsiadm -m node -T iqn.2006-04.example:444 -l Logging in to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.example:444, portal: 10.64.24.179,3260] successful.
10.64.24.179 를 target-ip-address로 바꿉니다.
iSCSI ACL 생성에 설명된 대로 해당 이니시에이터 이름이 ACL에 추가되는 경우 동일한 대상에 연결된 수의 이니시에이터에 이 절차를 사용할 수 있습니다.
iSCSI 디스크 이름을 찾아서 이 iSCSI 디스크에 파일 시스템을 생성합니다.
# grep "Attached SCSI" /var/log/messages # mkfs.ext4 /dev/disk_namedisk_name 을
/var/log/messages파일에 표시된 iSCSI 디스크 이름으로 바꿉니다.파일 시스템을 마운트합니다.
# mkdir /mount/point # mount /dev/disk_name /mount/point
/mount/point 를 파티션의 마운트 지점으로 바꿉니다.
시스템이 부팅될 때
/etc/fstab파일을 편집하여 파일 시스템을 자동으로 마운트합니다.# vi /etc/fstab /dev/disk_name /mount/point ext4 _netdev 0 0disk_name 을 iSCSI 디스크 이름으로 바꾸고 /mount/point 를 파티션의 마운트 지점으로 바꿉니다.
추가 리소스
-
targetcli(8)및iscsiadm(8)도움말 페이지
7.2. 이니시에이터에 대한 Challenge-Handshake Authentication Protocol 설정
CHAP ( Challenge-Handshake Authentication Protocol)를 사용하면 사용자가 암호로 대상을 보호할 수 있습니다. 이니시에이터는 대상에 연결할 수 있으려면 이 암호를 알고 있어야 합니다.
사전 요구 사항
- iSCSI 이니시에이터 생성. 자세한 내용은 iSCSI 이니시에이터 생성을 참조하십시오.
-
대상에 대한
CHAP를 설정합니다. 자세한 내용은 대상에 대한 Challenge-Handshake Authentication Protocol 설정을 참조하십시오.
절차
iscsid.conf 파일에서 CHAP 인증을 활성화합니다.# vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP
기본적으로
node.session.auth.authmethod는None으로 설정됩니다.iscsid.conf 파일에 대상사용자 이름및암호를추가합니다.node.session.auth.username = redhat node.session.auth.password = redhat_passwd
iscsid데몬을 시작합니다.# systemctl start iscsid.service
추가 리소스
-
iscsiadm(8)도움말 페이지
7.3. iscsiadm 유틸리티를 사용하여 iSCSI 세션 모니터링
다음 절차에서는 iscsi adm 유틸리티를 사용하여 iscsi 세션을 모니터링하는 방법을 설명합니다.
기본적으로 iSCSI 서비스는 지연 시작되며 시작됩니다. root가 iSCSI 장치에 없거나 iscsiadm 명령을 실행한 후에 서비스가node.startup = 자동으로 표시된 노드가 없는 경우 서비스가 시작되지 않습니다.
iscsid 또는 iscsi 커널 모듈이 필요한 iscsiadm 명령이 실행될 때까지 iSCSI
systemctl start iscsid.service 명령을 root로 실행하여 iscsid 데몬이 실행되고 iSCSI 커널 모듈이 로드되도록 강제 적용합니다.
절차
클라이언트 시스템에
iscsi-initiator-utils를 설치합니다.# dnf install iscsi-initiator-utils
실행 중인 세션에 대한 정보를 찾습니다.
# iscsiadm -m session -P 3
이 명령은 세션 또는 장치 상태, 세션 ID(sid), 일부 협상 매개 변수 및 세션을 통해 액세스할 수 있는 SCSI 장치를 표시합니다.
예를 들어 sid
-to-node매핑만 표시하려면 더 짧은 출력을 보려면 다음을 실행합니다.# iscsiadm -m session -P 0 or # iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311이러한 명령은 실행 중인 세션 목록을 다음 형식으로 출력합니다.
driver [sid] target_ip:port,target_group_tag proper_target_target_name.
추가 리소스
-
/usr/share/doc/iscsi-initiator-utils-version/READMEfile -
iscsiadm(8)도움말 페이지
7.4. DM Multipath가 장치 시간 초과를 덮어씁니다
recovery_tmo sysfs 옵션은 특정 iSCSI 장치에 대한 시간 초과를 제어합니다. 다음 옵션은 recovery_tmo 값을 전역적으로 덮어씁니다.
-
replacement_timeout구성 옵션은 모든 iSCSI 장치의recovery_tmo값을 전역적으로 덮어씁니다. DM Multipath에서 관리하는 모든 iSCSI 장치의 경우 DM Multipath의
fast_io_fail_tmo옵션은recovery_tmo값을 전역적으로 덮어씁니다.DM Multipath의
fast_io_fail_tmo옵션은 파이버 채널 장치의fast_io_fail_tmo옵션도 재정의합니다.
DM Multipath fast_io_fail_tmo 옵션이 replacement_timeout 보다 우선합니다. DM Multipath는 multipathd 서비스가 다시 로드될 때 항상 recovery_tmo 를 재설정하므로 replacement_timeout 을 사용하여 DM Multipath에서 관리하는 장치에서 recovery_tmo 를 덮어쓰는 것을 권장하지 않습니다.
8장. 파이버 채널 장치 사용
Red Hat Enterprise Linux 9는 다음과 같은 기본 파이버 채널 드라이버를 제공합니다.
-
lpfc -
qla2xxx -
zfcp
8.1. 파이버 채널 논리 단위 크기 조정
시스템 관리자는 파이버 채널 논리 단위의 크기를 조정할 수 있습니다.
절차
다중경로 논리적 장치의 경로를 결정합니다.multipath -ll
다중 경로를 사용하는 시스템에서 파이버 채널 논리 단위를 다시 스캔합니다.
$ echo 1 > /sys/block/sdX/device/rescan
추가 리소스
-
multipath(8)도움말 페이지
8.2. 파이버 채널을 사용하여 장치의 링크 손실 동작 확인
드라이버가 Transport dev_loss_tmo 콜백을 구현하는 경우, 전송 문제가 감지되면 링크를 통해 장치에 대한 액세스가 차단됩니다.
절차
원격 포트의 상태를 확인합니다.
$ cat /sys/class/fc_remote_port/rport-host:bus:remote-port/port_state
이 명령은 다음 출력 중 하나를 반환합니다.
-
원격 포트가
를 통해 액세스되는 장치와 함께 차단되면 차단됩니다. 원격 포트가 정상적으로 작동하는 경우
온라인dev_loss_tmo초 내에 문제가 해결되지 않으면rport및 장치가 차단 해제됩니다. 해당 장치에 전송된 새로운 I/O와 함께 해당 장치에서 실행되는 모든 I/O가 실패합니다.
-
원격 포트가
링크 손실이 dev_loss_tmo 를 초과하면 scsi_device 및 sd_N_ 장치가 제거됩니다. 일반적으로 파이버 채널 클래스는 /dev/ sdx는 /dev/ sdx는 /dev/sdx 와 같이 해당 장치를 그대로 둡니다 . 이는 대상 바인딩이 파이버 채널 드라이버에 의해 저장되고 대상 포트가 반환되면 SCSI 주소가 다시 생성되기 때문입니다. 그러나 이를 보장할 수는 없으며 LUN의 스토리지 상자 구성이 추가 변경되지 않은 경우에만 sdx 장치가 복원됩니다.
추가 리소스
-
multipath.conf(5) 도움말페이지 - Oracle RAC 클러스터 지식 베이스 문서를 구성하는 동안 scsi,multipath 및 애플리케이션 계층에서 튜닝하는 것이 좋습니다.
8.3. 파이버 채널 구성 파일
다음은 파이버 채널에 사용자 공간 API를 제공하는 /sys/class/ 디렉토리의 구성 파일 목록입니다.
항목은 다음 변수를 사용합니다.
H- 호스트 번호
B- 버스 번호
T- 대상
L- 논리 단위(LUN)
R- 원격 포트 번호
시스템이 다중 경로 소프트웨어를 사용하는 경우 이 섹션에 설명된 값을 변경하기 전에 하드웨어 공급 업체를 참조하십시오.
/sys/class/fc_transport/targetH:B:T/
port_id- 24비트 포트 ID/주소
node_name- 64비트 노드 이름
port_name- 64비트 포트 이름
/sys/class/fc_remote_ports/rport-H:B-R/의 원격 포트 구성
-
port_id -
node_name -
port_name dev_loss_tmoscsi 장치가 시스템에서 제거될 시기를 제어합니다.
dev_loss_tmo가 트리거되면 scsi 장치가 제거됩니다.multipath.conf파일에서dev_loss_tmo를infinity로 설정할 수 있습니다.Red Hat Enterprise Linux 9에서
fast_io_fail_tmo옵션을 설정하지 않으면dev_loss_tmo가600초로 제한됩니다. 기본적으로 Red Hat Enterprise Linux 9에서fast_io_fail_tmo는multipathd서비스가 실행 중인 경우5초로 설정됩니다. 그렇지 않으면off로 설정됩니다.fast_io_fail_tmo링크를 "bad"로 표시하기 전에 대기하는 시간(초)을 지정합니다. 링크가 잘못 표시되면 기존 실행 중인 I/O 또는 해당 경로의 새 I/O가 실패합니다.
I/O가 차단된 큐에 있는 경우
dev_loss_tmo가 만료되고 큐가 차단되지 않을 때까지 실패합니다.fast_io_fail_tmo가 off를 제외한 값으로 설정된 경우dev_loss_tmo는 적용되지 않습니다.fast_io_fail_tmo가 off로 설정된 경우 장치를 시스템에서 제거할 때까지 I/O가 실패하지 않습니다.fast_io_fail_tmo를 숫자로 설정하면fast_io_fail_tmo제한 시간이 트리거되면 즉시 I/O가 실패합니다.
/sys/class/fc_host/hostH에서의 호스트 구성 /
-
port_id -
node_name -
port_name issue_lip는 드라이버에 원격 포트를 다시 검색하도록 지시합니다.
8.4. DM Multipath가 장치 시간 초과를 덮어씁니다
recovery_tmo sysfs 옵션은 특정 iSCSI 장치에 대한 시간 초과를 제어합니다. 다음 옵션은 recovery_tmo 값을 전역적으로 덮어씁니다.
-
replacement_timeout구성 옵션은 모든 iSCSI 장치의recovery_tmo값을 전역적으로 덮어씁니다. DM Multipath에서 관리하는 모든 iSCSI 장치의 경우 DM Multipath의
fast_io_fail_tmo옵션은recovery_tmo값을 전역적으로 덮어씁니다.DM Multipath의
fast_io_fail_tmo옵션은 파이버 채널 장치의fast_io_fail_tmo옵션도 재정의합니다.
DM Multipath fast_io_fail_tmo 옵션이 replacement_timeout 보다 우선합니다. DM Multipath는 multipathd 서비스가 다시 로드될 때 항상 recovery_tmo 를 재설정하므로 replacement_timeout 을 사용하여 DM Multipath에서 관리하는 장치에서 recovery_tmo 를 덮어쓰는 것을 권장하지 않습니다.
9장. NVMe/RDMA를 사용하여 패브릭을 통해 NVMe 구성
RDMA(NVMe/RDMA)를 통한 NVMe(Non-volatile Memory Express) 설정에서 NVMe 컨트롤러 및 NVMe 이니시에이터를 구성합니다.
시스템 관리자로서 다음 작업을 완료하여 NVMe/RDMA 설정을 배포합니다.
9.1. 패브릭 장치를 통한 NVMe 개요
NVMe(Non-volatile Memory Express)는 호스트 소프트웨어 유틸리티가 솔리드 스테이트 드라이브와 통신할 수 있도록 하는 인터페이스입니다.
다음 유형의 패브릭 전송을 사용하여 패브릭 장치로 NVMe를 구성합니다.
- NVMe over Remote Direct Memory Access(NVMe/RDMA)
- NVMe/RDMA를 구성하는 방법에 대한 자세한 내용은 NVMe/RDMA 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- NVMe/FC(NVMe over Fibre Channel)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe/FC 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- TCP를 통한 NVMe(NVMe/TCP)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe /TCP를 사용하여 NVMe over fabric 구성 을 참조하십시오.
NVMe over fabrics를 사용하는 경우 솔리드 스테이트 드라이브는 시스템에 로컬일 필요가 없으며 NVMe over fabrics 장치를 통해 원격으로 구성할 수 있습니다.
9.2. configfs를 사용하여 NVMe/RDMA 컨트롤러 설정
configfs 를 사용하여 NVMe/RDMA 컨트롤러를 구성하려면 다음 절차를 사용하십시오.
사전 요구 사항
-
nvmet하위 시스템에 할당할 블록 장치가 있는지 확인합니다.
절차
nvmet-rdma하위 시스템을 생성합니다.# modprobe nvmet-rdma # mkdir /sys/kernel/config/nvmet/subsystems/testnqn # cd /sys/kernel/config/nvmet/subsystems/testnqn
testnqn 을 하위 시스템 이름으로 교체합니다.
모든 호스트가 이 컨트롤러에 연결할 수 있도록 허용합니다.
# echo 1 > attr_allow_any_host
네임스페이스를 구성합니다.
# mkdir namespaces/10 # cd namespaces/10
10 을 네임 스페이스 번호로 바꿉니다.
NVMe 장치의 경로를 설정합니다.
# echo -n /dev/nvme0n1 > device_path네임스페이스를 활성화합니다.
# echo 1 > enable
NVMe 포트를 사용하여 디렉터리를 생성합니다.
# mkdir /sys/kernel/config/nvmet/ports/1 # cd /sys/kernel/config/nvmet/ports/1
mlx5_ib0 의 IP 주소 표시 :
# ip addr show mlx5_ib0 8: mlx5_ib0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 4092 qdisc mq state UP group default qlen 256 link/infiniband 00:00:06:2f:fe:80:00:00:00:00:00:00:e4:1d:2d:03:00:e7:0f:f6 brd 00:ff:ff:ff:ff:12:40:1b:ff:ff:00:00:00:00:00:00:ff:ff:ff:ff inet 172.31.0.202/24 brd 172.31.0.255 scope global noprefixroute mlx5_ib0 valid_lft forever preferred_lft forever inet6 fe80::e61d:2d03:e7:ff6/64 scope link noprefixroute valid_lft forever preferred_lft forever컨트롤러의 전송 주소를 설정합니다.
# echo -n 172.31.0.202 > addr_traddr
RDMA를 전송 유형으로 설정합니다.
# echo rdma > addr_trtype # echo 4420 > addr_trsvcid
포트의 주소 제품군을 설정합니다.
# echo ipv4 > addr_adrfam
소프트 링크를 생성합니다.
# ln -s /sys/kernel/config/nvmet/subsystems/testnqn /sys/kernel/config/nvmet/ports/1/subsystems/testnqn
검증
NVMe 컨트롤러가 지정된 포트에서 수신하고 연결 요청을 준비했는지 확인합니다.
# dmesg | grep "enabling port" [ 1091.413648] nvmet_rdma: enabling port 1 (172.31.0.202:4420)
추가 리소스
-
nvme(1)man page
9.3. nvmetcli를 사용하여 NVMe/RDMA 컨트롤러 설정
nvmetcli 유틸리티를 사용하여 NVMe 컨트롤러를 편집, 보기, 시작합니다. nvmetcli 유틸리티는 명령줄과 대화형 쉘 옵션을 제공합니다. 다음 절차를 사용하여 nvmetcli 에서 NVMe/RDMA 컨트롤러를 구성합니다.
사전 요구 사항
-
nvmet하위 시스템에 할당할 블록 장치가 있는지 확인합니다. -
다음
nvmetcli작업을 root 사용자로 실행합니다.
절차
nvmetcli패키지를 설치합니다.# dnf install nvmetcli
rdma.json파일을 다운로드합니다.# wget http://git.infradead.org/users/hch/nvmetcli.git/blob_plain/0a6b088db2dc2e5de11e6f23f1e890e4b54fee64:/rdma.json
-
rdma.json파일을 편집하고traddr값을172.31.0.202로 변경합니다. NVMe 컨트롤러 구성 파일을 로드하여 컨트롤러를 설정합니다.
# nvmetcli restore rdma.json
NVMe 컨트롤러 구성 파일 이름이 지정되지 않은 경우 nvmetcli 는 /etc/nvmet/config.json 파일을 사용합니다.
검증
NVMe 컨트롤러가 지정된 포트에서 수신하고 연결 요청을 준비했는지 확인합니다.
# dmesg | tail -1 [ 4797.132647] nvmet_rdma: enabling port 2 (172.31.0.202:4420)
선택 사항: 현재 NVMe 컨트롤러를 지웁니다.
# nvmetcli clear
추가 리소스
-
nvmetcli및nvme(1) 도움말페이지
9.4. NVMe/RDMA 호스트 구성
NVMe 관리 명령줄 인터페이스(nvme-cli) 툴을 사용하여 NVMe/RDMA 호스트를 구성하려면 다음 절차를 사용하십시오.
절차
nvme-cli툴을 설치합니다.# dnf install nvme-cli
로드되지 않은 경우
nvme-rdma모듈을 로드합니다.# modprobe nvme-rdma
NVMe 컨트롤러에서 사용 가능한 하위 시스템을 검색합니다.
# nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000
검색된 하위 시스템에 연결합니다.
# nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420 # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1 # cat /sys/class/nvme/nvme0/transport rdma
testnqn 을 NVMe 하위 시스템 이름으로 교체합니다.
172.31.0.202 를 컨트롤러 IP 주소로 바꿉니다.
4420 을 포트 번호로 바꿉니다.
검증
현재 연결된 NVMe 장치를 나열합니다.
# nvme list
선택 사항: 컨트롤러에서 연결을 끊습니다.
# nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s) # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
추가 리소스
-
nvme(1)man page - NVMe-cli Github 리포지토리
9.5. 다음 단계
10장. NVMe/FC를 사용하여 NVMe over fabric 구성
특정 Broadcom Emulex 및 Marvell Qlogic Fibre Channel 어댑터와 함께 사용할 때 호스트 모드에서 NVMe(Non-volatile Memory Express) over Fibre Channel 전송이 완전히 지원됩니다. 시스템 관리자는 다음 섹션의 작업을 완료하여 NVMe/FC 설정을 배포합니다.
10.1. 패브릭 장치를 통한 NVMe 개요
NVMe(Non-volatile Memory Express)는 호스트 소프트웨어 유틸리티가 솔리드 스테이트 드라이브와 통신할 수 있도록 하는 인터페이스입니다.
다음 유형의 패브릭 전송을 사용하여 패브릭 장치로 NVMe를 구성합니다.
- NVMe over Remote Direct Memory Access(NVMe/RDMA)
- NVMe/RDMA를 구성하는 방법에 대한 자세한 내용은 NVMe/RDMA 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- NVMe/FC(NVMe over Fibre Channel)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe/FC 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- TCP를 통한 NVMe(NVMe/TCP)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe /TCP를 사용하여 NVMe over fabric 구성 을 참조하십시오.
NVMe over fabrics를 사용하는 경우 솔리드 스테이트 드라이브는 시스템에 로컬일 필요가 없으며 NVMe over fabrics 장치를 통해 원격으로 구성할 수 있습니다.
10.2. Broadcom 어댑터를 위한 NVMe 호스트 구성
NVMe 관리 명령줄 인터페이스(nvme-cli) 도구를 사용하여 Broadcom 어댑터 클라이언트용 NVMe 호스트를 구성하려면 이 절차를 사용하십시오.
절차
nvme-cli툴을 설치합니다.# dnf install nvme-cli
그러면
/etc/생성됩니다.nvme/ 디렉터리에 hostnqn 파일이hostnqn파일은 NVMe 호스트를 식별합니다.로컬 포트와 원격 포트의 WWNN 및 WWPN 식별자를 찾고 출력을 사용하여 하위 시스템 NQN을 찾습니다.
# cat /sys/class/scsi_host/host*/nvme_info NVME Host Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000# nvme discover --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 을
traddr로 교체합니다.nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 를
host-traddr로 바꿉니다.nvme-cli를 사용하여 NVMe 컨트롤러에 연결합니다.# nvme connect --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 \ -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 을
traddr로 교체합니다.nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 를
host-traddr로 바꿉니다.nqn.1992-08.com.netapp:sn.e18bfca8d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 을
subnqn으로 바꿉니다.
검증
현재 연결된 NVMe 장치를 나열합니다.
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF
# lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
추가 리소스
-
nvme(1)man page - NVMe-cli Github 리포지토리
10.3. QLogic 어댑터용 NVMe 호스트 구성
NVMe 관리 명령줄 인터페이스(nvme-cli) 도구를 사용하여 Qlogic 어댑터 클라이언트용 NVMe 호스트를 구성하려면 이 절차를 사용하십시오.
절차
nvme-cli툴을 설치합니다.# dnf install nvme-cli
그러면
/etc/생성됩니다.nvme/ 디렉터리에 hostnqn 파일이hostnqn파일은 NVMe 호스트를 식별합니다.qla2xxx모듈을 다시 로드합니다.# rmmod qla2xxx # modprobe qla2xxx
로컬 포트와 원격 포트의 WWNN 및 WWPN 식별자를 찾습니다.
# dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050d
이러한
host-traddr및traddr값을 사용하여 하위 시스템 NQN을 찾습니다.# nvme discover --transport fc \ --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 \ --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 를
traddr로 교체합니다.nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 를
host-traddr로 바꿉니다.nvme-cli도구를 사용하여 NVMe 컨트롤러에 연결합니다.# nvme connect --transport fc \ --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 \ --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 \ -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 를
traddr로 교체합니다.nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 를
host-traddr로 바꿉니다.nqn.1992-08.com.netapp:sn.c9ecc9187b11e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 를
subnqn으로 바꿉니다.
검증
현재 연결된 NVMe 장치를 나열합니다.
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF # lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
추가 리소스
-
nvme(1)man page - NVMe-cli Github 리포지토리
10.4. 다음 단계
11장. NVMe/TCP를 사용하여 패브릭을 통한 NVMe 구성
TCP(NVMe/TCP)를 통한 NVMe(Non-volatile Memory Express) 설정에서 호스트 모드가 완전히 지원되고 컨트롤러 설정이 지원되지 않습니다.
시스템 관리자는 다음 섹션의 작업을 완료하여 NVMe/TCP 설정을 배포합니다.
11.1. 패브릭 장치를 통한 NVMe 개요
NVMe(Non-volatile Memory Express)는 호스트 소프트웨어 유틸리티가 솔리드 스테이트 드라이브와 통신할 수 있도록 하는 인터페이스입니다.
다음 유형의 패브릭 전송을 사용하여 패브릭 장치로 NVMe를 구성합니다.
- NVMe over Remote Direct Memory Access(NVMe/RDMA)
- NVMe/RDMA를 구성하는 방법에 대한 자세한 내용은 NVMe/RDMA 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- NVMe/FC(NVMe over Fibre Channel)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe/FC 를 사용하여 NVMe over fabric 구성 을 참조하십시오.
- TCP를 통한 NVMe(NVMe/TCP)
- NVMe/FC를 구성하는 방법에 대한 자세한 내용은 NVMe /TCP를 사용하여 NVMe over fabric 구성 을 참조하십시오.
NVMe over fabrics를 사용하는 경우 솔리드 스테이트 드라이브는 시스템에 로컬일 필요가 없으며 NVMe over fabrics 장치를 통해 원격으로 구성할 수 있습니다.
11.2. NVMe/TCP 호스트 구성
NVMe(Non-volatile Memory Express) 관리 명령줄 인터페이스(nvme-cli) 도구를 사용하여 NVMe/TCP 호스트를 구성합니다.
절차
nvme-cli툴을 설치합니다.# dnf install nvme-cli
이 툴은
/etc/nvme/디렉터리에hostnqn파일을 생성하여 NVMe 호스트를 식별합니다.nvme
hostid및hostnqn:# cat /etc/nvme/hostnqn nqn.2014-08.org.nvmexpress:uuid:8ae2b12c-3d28-4458-83e3-658e571ed4b8 # cat /etc/nvme/hostid 09e2ce17-ccc9-412d-8dcf-2b0a1d581ee3
hostid및hostnqn값을 사용하여 NVMe/TCP 컨트롤러를 구성합니다.컨트롤러 상태를 확인합니다.
# nmcli device show ens6 GENERAL.DEVICE: ens6 GENERAL.TYPE: ethernet GENERAL.HWADDR: 52:57:02:12:02:02 GENERAL.MTU: 1500 GENERAL.STATE: 30 (disconnected) GENERAL.CONNECTION: -- GENERAL.CON-PATH: -- WIRED-PROPERTIES.CARRIER: on정적 IP 주소를 사용하여 새로 설치된 이더넷 컨트롤러의 호스트 네트워크를 구성합니다.
# nmcli connection add con-name ens6 ifname ens6 type ethernet ip4 192.168.101.154/24 gw4 192.168.101.1
여기서 192.168.101.154 를 호스트 IP 주소로 바꿉니다.
# nmcli connection mod ens6 ipv4.method manual # nmcli connection up ens6
NVMe/TCP 호스트를 NVMe/TCP 컨트롤러에 연결하기 위해 새 네트워크가 생성되므로 컨트롤러에서도 이 단계를 실행합니다.
검증
새로 생성된 호스트 네트워크가 올바르게 작동하는지 확인합니다.
# nmcli device show ens6 GENERAL.DEVICE: ens6 GENERAL.TYPE: ethernet GENERAL.HWADDR: 52:57:02:12:02:02 GENERAL.MTU: 1500 GENERAL.STATE: 100 (connected) GENERAL.CONNECTION: ens6 GENERAL.CON-PATH: /org/freedesktop/NetworkManager/ActiveConnection/5 WIRED-PROPERTIES.CARRIER: on IP4.ADDRESS[1]: 192.168.101.154/24 IP4.GATEWAY: 192.168.101.1 IP4.ROUTE[1]: dst = 192.168.101.0/24, nh = 0.0.0.0, mt = 101 IP4.ROUTE[2]: dst = 192.168.1.1/32, nh = 0.0.0.0, mt = 101 IP4.ROUTE[3]: dst = 0.0.0.0/0, nh = 192.168.1.1, mt = 101 IP6.ADDRESS[1]: fe80::27ce:dde1:620:996c/64 IP6.GATEWAY: -- IP6.ROUTE[1]: dst = fe80::/64, nh = ::, mt = 101
추가 리소스
-
nvme(1)도움말 페이지
11.3. NVMe/TCP 호스트에 NVMe/TCP 컨트롤러 연결
NVMe/TCP 호스트를 NVMe/TCP 컨트롤러 시스템에 연결하여 NVMe/TCP 호스트가 이제 네임스페이스에 액세스할 수 있는지 확인합니다.
NVMe/TCP 컨트롤러(nvmet_tcp) 모듈은 지원되지 않습니다.
사전 요구 사항
- NVMe/TCP 호스트가 구성되어 있습니다. 자세한 내용은 NVMe/TCP 호스트 구성을 참조하십시오.
- 외부 스토리지 소프트웨어를 사용하여 NVMe/TCP 컨트롤러를 구성하고 네트워크는 컨트롤러에 구성되어 있습니다. 이 절차에서 192.168.101.55 는 NVMe/TCP 컨트롤러의 IP 주소입니다.
절차
아직 그렇지 않은 경우
nvme_tcp모듈을 로드합니다.# modprobe nvme_tcp
NVMe 컨트롤러에서 사용 가능한 하위 시스템을 검색합니다.
# nvme discover --transport=tcp --traddr=192.168.101.55 --host-traddr=192.168.101.154 --trsvcid=8009 Discovery Log Number of Records 2, Generation counter 7 =====Discovery Log Entry 0====== trtype: tcp adrfam: ipv4 subtype: current discovery subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 8009 subnqn: nqn.2014-08.org.nvmexpress.discovery traddr: 192.168.101.55 eflags: not specified sectype: none =====Discovery Log Entry 1====== trtype: tcp adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 2 trsvcid: 8009 subnqn: nqn.2014-08.org.nvmexpress:uuid:0c468c4d-a385-47e0-8299-6e95051277db traddr: 192.168.101.55 eflags: not specified sectype: none
여기에서 192.168.101.55 는 NVMe/TCP 컨트롤러 IP 주소이고 192.168.101.154 는 NVMe/TCP 호스트 IP 주소입니다.
nvme discover명령에 사용되는 매개변수를 추가하도록/etc/nvme/discovery.conf파일을 구성합니다.# echo "--transport=tcp --traddr=192.168.101.55 --host-traddr=192.168.101.154 --trsvcid=8009" >> /etc/nvme/discovery.conf
NVMe/TCP 호스트를 컨트롤러 시스템에 연결합니다.
# nvme connect-all
검증
NVMe/TCP 호스트에서 네임스페이스에 액세스할 수 있는지 확인합니다.
# nvme list-subsys nvme-subsys3 - NQN=nqn.2014-08.org.nvmexpress:uuid:0c468c4d-a385-47e0-8299-6e95051277db \ +- nvme3 tcp traddr=192.168.101.55,trsvcid=8009,host_traddr=192.168.101.154 live optimized # nvme list Node Generic SN Model Namespace Usage Format FW Rev --------------------- --------------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme3n1 /dev/ng3n1 d93a63d394d043ab4b74 Linux 1 21.47 GB / 21.47 GB 512 B + 0 B 5.18.5-2
추가 리소스
-
nvme(1)도움말 페이지
11.4. 다음 단계
12장. NVMe 장치에서 멀티패스 활성화
파이버 채널(FC)과 같은 패브릭 전송을 통해 시스템에 연결된 멀티패스 NVMe 장치를 사용할 수 있습니다. 다중 경로 솔루션 중에서 선택할 수 있습니다.
12.1. 네이티브 NVMe 멀티패스 및 DM Multipath
NVMe 장치는 기본 다중 경로 기능을 지원합니다. NVMe에서 멀티패스를 구성할 때 표준 DM Multipath 프레임워크와 기본 NVMe 다중 경로 중에서 선택할 수 있습니다.
DM Multipath 및 네이티브 NVMe 다중 경로 모두 NVMe 장치의 Asymmetric Namespace Access (ANA) 멀티패스 스키마를 지원합니다. ANA는 컨트롤러와 호스트 간의 최적화된 경로를 식별하고 성능을 향상시킵니다.
네이티브 NVMe 멀티패스가 활성화되면 모든 NVMe 장치에 전역적으로 적용됩니다. 이는 더 높은 성능을 제공할 수 있지만 DM Multipath가 제공하는 모든 기능을 포함하지는 않습니다. 예를 들어 기본 NVMe 다중 경로에서는 numa 및 round-robin 경로 선택 방법만 지원합니다.
기본적으로 Red Hat Enterprise Linux 9에서는 NVMe 멀티패스가 활성화되며 권장되는 다중 경로 솔루션입니다.
12.2. 네이티브 NVMe 멀티패스 활성화
이 절차에서는 네이티브 NVMe 다중 경로 솔루션을 사용하여 연결된 NVMe 장치에서 멀티패스를 활성화합니다.
사전 요구 사항
NVMe 장치가 시스템에 연결되어 있습니다.
패브릭 전송을 연결하는 방법에 대한 자세한 내용은 패브 릭 장치 개요를 참조하십시오.
절차
커널에서 네이티브 NVMe 멀티패스가 활성화되어 있는지 확인합니다.
# cat /sys/module/nvme_core/parameters/multipath
명령은 다음 중 하나를 표시합니다.
N- 네이티브 NVMe 멀티패스가 비활성화되어 있습니다.
Y- 네이티브 NVMe 멀티패스가 활성화되어 있습니다.
네이티브 NVMe 멀티패스가 비활성화된 경우 다음 방법 중 하나를 사용하여 활성화합니다.
커널 옵션 사용:
커널 명령줄에
nvme_core.multipath=Y옵션을 추가합니다.# grubby --update-kernel=ALL --args="nvme_core.multipath=Y"
64비트 IBM Z 아키텍처에서 부팅 메뉴를 업데이트합니다.
# zipl
- 시스템을 재부팅합니다.
커널 모듈 구성 파일 사용:
다음 콘텐츠를 사용하여
/etc/modprobe.d/nvme_core.conf구성 파일을 만듭니다.options nvme_core multipath=Y
initramfs파일 시스템을 백업합니다.# cp /boot/initramfs-$(uname -r).img \ /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).imginitramfs파일 시스템을 다시 빌드합니다.# dracut --force --verbose
- 시스템을 재부팅합니다.
선택 사항: 실행 중인 시스템에서 NVMe 장치의 I/O 정책을 변경하여 사용 가능한 모든 경로에 I/O를 배포합니다.
# echo "round-robin" > /sys/class/nvme-subsystem/nvme-subsys0/iopolicy
선택 사항:
udev규칙을 사용하여 I/O 정책을 영구적으로 설정합니다. 다음 콘텐츠를 사용하여/etc/udev/rules.d/71-nvme-io-policy.rules파일을 생성합니다.ACTION=="add|change", SUBSYSTEM=="nvme-subsystem", ATTR{iopolicy}="round-robin"
검증
시스템이 NVMe 장치를 인식하는지 확인합니다.
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 a34c4f3a0d6f5cec Linux 1 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme0n2 a34c4f3a0d6f5cec Linux 2 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2
연결된 모든 NVMe 하위 시스템을 나열합니다.
# nvme list-subsys nvme-subsys0 - NQN=testnqn \ +- nvme0 fc traddr=nn-0x20000090fadd597a:pn-0x10000090fadd597a host_traddr=nn-0x20000090fac7e1dd:pn-0x10000090fac7e1dd live +- nvme1 fc traddr=nn-0x20000090fadd5979:pn-0x10000090fadd5979 host_traddr=nn-0x20000090fac7e1dd:pn-0x10000090fac7e1dd live +- nvme2 fc traddr=nn-0x20000090fadd5979:pn-0x10000090fadd5979 host_traddr=nn-0x20000090fac7e1de:pn-0x10000090fac7e1de live +- nvme3 fc traddr=nn-0x20000090fadd597a:pn-0x10000090fadd597a host_traddr=nn-0x20000090fac7e1de:pn-0x10000090fac7e1de live
활성 전송 유형을 확인합니다. 예를 들어
nvme0 fc는 장치가 파이버 채널 전송을 통해 연결되어 있음을 나타내고nvme tcp는 장치가 TCP를 통해 연결되어 있음을 나타냅니다.커널 옵션을 편집한 경우 커널 명령줄에서 네이티브 NVMe 멀티패스가 활성화되어 있는지 확인합니다.
# cat /proc/cmdline BOOT_IMAGE=[...] nvme_core.multipath=Y
DM Multipath가 NVMe 네임스페이스를
nvme0c3n1에서로 보고하는지 확인합니다(예:nvme0c3n1nvme0n1~nvme3n1:)# multipath -e -ll | grep -i nvme uuid.8ef20f70-f7d3-4f67-8d84-1bb16b2bfe03 [nvme]:nvme0n1 NVMe,Linux,4.18.0-2 | `- 0:0:1 nvme0c0n1 0:0 n/a optimized live | `- 0:1:1 nvme0c1n1 0:0 n/a optimized live | `- 0:2:1 nvme0c2n1 0:0 n/a optimized live `- 0:3:1 nvme0c3n1 0:0 n/a optimized live uuid.44c782b4-4e72-4d9e-bc39-c7be0a409f22 [nvme]:nvme0n2 NVMe,Linux,4.18.0-2 | `- 0:0:1 nvme0c0n1 0:0 n/a optimized live | `- 0:1:1 nvme0c1n1 0:0 n/a optimized live | `- 0:2:1 nvme0c2n1 0:0 n/a optimized live `- 0:3:1 nvme0c3n1 0:0 n/a optimized live
I/O 정책을 변경한 경우 NVMe 장치의
라운드로빈이 활성 I/O 정책인지 확인합니다.# cat /sys/class/nvme-subsystem/nvme-subsys0/iopolicy round-robin
추가 리소스
12.3. NVMe 장치에서 DM Multipath 활성화
이 절차에서는 DM Multipath 솔루션을 사용하여 연결된 NVMe 장치에서 멀티패스를 활성화합니다.
사전 요구 사항
NVMe 장치가 시스템에 연결되어 있습니다.
패브릭 전송을 연결하는 방법에 대한 자세한 내용은 패브 릭 장치 개요를 참조하십시오.
절차
네이티브 NVMe 멀티패스가 비활성화되어 있는지 확인합니다.
# cat /sys/module/nvme_core/parameters/multipath
명령은 다음 중 하나를 표시합니다.
N- 네이티브 NVMe 멀티패스가 비활성화되어 있습니다.
Y- 네이티브 NVMe 멀티패스가 활성화되어 있습니다.
네이티브 NVMe 멀티패스가 활성화된 경우 비활성화합니다.
커널 명령줄에서
nvme_core.multipath=Y옵션을 제거합니다.# grubby --update-kernel=ALL --remove-args="nvme_core.multipath=Y"
64비트 IBM Z 아키텍처에서 부팅 메뉴를 업데이트합니다.
# zipl
-
/etc/modprobe.d/n제거합니다.vme_core.conf파일에서 nvme_core=Y 줄이 있는 경우 해당 옵션을 - 시스템을 재부팅합니다.
DM Multipath가 활성화되어 있는지 확인합니다.
# systemctl enable --now multipathd.service
사용 가능한 모든 경로에 I/O를 분산합니다.
/etc/multipath.conf파일에 다음 내용을 추가합니다.device { vendor "NVME" product ".*" path_grouping_policy group_by_prio }참고DM Multipath가 NVMe 장치를 관리하는 경우
/sys/class/nvme-subsys0/iopolicy구성 파일은 I/O 배포에 영향을 미치지 않습니다.multipathd서비스를 다시 로드하여 구성 변경 사항을 적용합니다.# multipath -r
initramfs파일 시스템을 백업합니다.# cp /boot/initramfs-$(uname -r).img \ /boot/initramfs-$(uname -r).bak.$(date +%m-%d-%H%M%S).imginitramfs파일 시스템을 다시 빌드합니다.# dracut --force --verbose
검증
시스템이 NVMe 장치를 인식하는지 확인합니다.
# nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 a34c4f3a0d6f5cec Linux 1 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme0n2 a34c4f3a0d6f5cec Linux 2 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme1n1 a34c4f3a0d6f5cec Linux 1 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme1n2 a34c4f3a0d6f5cec Linux 2 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme2n1 a34c4f3a0d6f5cec Linux 1 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme2n2 a34c4f3a0d6f5cec Linux 2 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme3n1 a34c4f3a0d6f5cec Linux 1 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2 /dev/nvme3n2 a34c4f3a0d6f5cec Linux 2 250.06 GB / 250.06 GB 512 B + 0 B 4.18.0-2
연결된 NVMe 하위 시스템을 모두 나열합니다. 명령이
nvme0n1에서nvme3n2를 통해 보고하고 있는지 확인합니다(예:nvme0c0n1에서nvme0c3n1) :# nvme list-subsys nvme-subsys0 - NQN=testnqn \ +- nvme0 fc traddr=nn-0x20000090fadd5979:pn-0x10000090fadd5979 host_traddr=nn-0x20000090fac7e1dd:pn-0x10000090fac7e1dd live +- nvme1 fc traddr=nn-0x20000090fadd597a:pn-0x10000090fadd597a host_traddr=nn-0x20000090fac7e1dd:pn-0x10000090fac7e1dd live +- nvme2 fc traddr=nn-0x20000090fadd5979:pn-0x10000090fadd5979 host_traddr=nn-0x20000090fac7e1de:pn-0x10000090fac7e1de live +- nvme3 fc traddr=nn-0x20000090fadd597a:pn-0x10000090fadd597a host_traddr=nn-0x20000090fac7e1de:pn-0x10000090fac7e1de live
# multipath -ll mpathae (uuid.8ef20f70-f7d3-4f67-8d84-1bb16b2bfe03) dm-36 NVME,Linux size=233G features='1 queue_if_no_path' hwhandler='0' wp=rw `-+- policy='service-time 0' prio=50 status=active |- 0:1:1:1 nvme0n1 259:0 active ready running |- 1:2:1:1 nvme1n1 259:2 active ready running |- 2:3:1:1 nvme2n1 259:4 active ready running `- 3:4:1:1 nvme3n1 259:6 active ready running mpathaf (uuid.44c782b4-4e72-4d9e-bc39-c7be0a409f22) dm-39 NVME,Linux size=233G features='1 queue_if_no_path' hwhandler='0' wp=rw `-+- policy='service-time 0' prio=50 status=active |- 0:1:2:2 nvme0n2 259:1 active ready running |- 1:2:2:2 nvme1n2 259:3 active ready running |- 2:3:2:2 nvme2n2 259:5 active ready running `- 3:4:2:2 nvme3n2 259:7 active ready running
추가 리소스
13장. 스왑 시작하기
이 섹션에서는 스왑 공간 및 추가 및 제거하는 방법에 대해 설명합니다.
13.1. 스왑 공간 개요
Linux의 스왑 공간은 실제 메모리(RAM)가 가득 찰 때 사용됩니다. 시스템에 더 많은 메모리 리소스가 필요하고 RAM이 가득 차면 메모리의 비활성 페이지가 스왑 공간으로 이동합니다. 스왑 공간은 RAM이 적은 시스템에 도움이 될 수 있지만 더 많은 RAM을 대체하는 것으로 간주해서는 안 됩니다.
스왑 공간은 실제 메모리보다 느린 액세스 시간이 있는 하드 드라이브에 있습니다. 스왑 공간은 전용 스왑 파티션(권장), 스왑 파일 또는 스왑 파티션과 스왑 파일의 조합일 수 있습니다.
지난 몇 년 동안 권장 스왑 공간은 시스템의 RAM 용량으로 선형적으로 증가했습니다. 그러나 최신 시스템에는 수백 기가 바이트의 RAM이 포함되어 있는 경우가 많습니다. 결과적으로 권장 스왑 공간은 시스템 메모리가 아닌 시스템 메모리 워크로드의 기능으로 간주됩니다.
- 스왑 공간 추가
다음은 스왑 공간을 추가하는 다양한 방법입니다.
- LVM2 논리 볼륨에서 스왑 확장
- 스왑용 LVM2 논리 볼륨 생성
예를 들어 시스템의 RAM 크기를 1GB에서 2GB로 업그레이드할 수 있지만 2GB의 스왑 공간만 있습니다. 메모리 강화 작업을 수행하거나 메모리가 많은 메모리가 필요한 애플리케이션을 실행하는 경우 스왑 공간의 양을 4GB로 늘리는 것이 유용할 수 있습니다.
- 스왑 공간 제거
다음은 스왑 공간을 제거하는 다양한 방법입니다.
- LVM2 논리 볼륨의 스왑 감소
- 스왑용 LVM2 논리 볼륨 제거
예를 들어 시스템의 RAM 크기를 1GB에서 512MB로 다운그레이드했지만 여전히 2GB의 스왑 공간이 할당되어 있습니다. 2GB가 큰 디스크 공간을 낭비할 수 있기 때문에 스왑 공간의 양을 1GB로 줄이는 것이 유용할 수 있습니다.
13.2. 시스템 스왑 공간 권장
이 섹션에서는 시스템의 RAM 용량 및 시스템의 RAM에 따라 스왑 파티션의 권장 크기에 대해 설명합니다. 권장되는 스왑 파티션 크기는 설치 중에 자동으로 설정됩니다. 그러나 간격을 허용하려면 사용자 지정 파티션 영역에서 스왑 공간을 편집해야 합니다.
특히 1GB 이하의 메모리가 부족한 시스템에서 중요한 권장 사항은 다음과 같습니다. 이러한 시스템에 충분한 스왑 공간을 할당하지 않으면 불안정성이나 설치된 시스템을 부팅할 수 없는 문제가 발생할 수 있습니다.
표 13.1. 권장되는 스왑 공간
| 시스템의 RAM 크기 | 권장되는 스왑 공간 | hibernation을 허용하는 경우 권장되는 스왑 공간 |
|---|---|---|
| 2GB | RAM의 양 2배 | RAM의 양 3배 |
| > 2GB - 8GB | RAM의 양과 동일 | RAM의 양 2배 |
| > 8 GB – 64 GB | 최소 4GB | 1.5 배 RAM의 양입니다. |
| > 64 GB | 최소 4GB | 간격은 권장되지 않습니다. |
이 표에 나열된 각 범위 간 테두리 (예: 2GB, 8GB 또는 64GB의 시스템 RAM이 있는 시스템)에서 선택한 스왑 공간 및 수면 지원과 관련하여 재량을 행사할 수 있습니다. 시스템 리소스를 허용하는 경우 스왑 공간을 늘리면 성능이 향상될 수 있습니다.
여러 스토리지 장치에 스왑 공간을 분산하면 특히 빠른 드라이브, 컨트롤러 및 인터페이스가 있는 시스템에서 스왑 공간 성능이 향상됩니다.
스왑 공간으로 할당된 파일 시스템 및 LVM2 볼륨은 수정할 때 사용하지 않아야 합니다. 시스템 프로세스 또는 커널이 스왑 공간을 사용하는 경우 스왑을 수정하려고 합니다. free 및 cat /proc/swaps 명령을 사용하여 스왑 크기 및 사용 위치를 확인합니다.
스왑 공간 크기를 조정하려면 시스템에서 스왑 공간을 일시적으로 제거해야 합니다. 실행 중인 애플리케이션이 추가 스왑 공간을 사용하고 메모리가 부족한 상황에서 실행되는 경우 문제가 발생할 수 있습니다. 바람직하게는 복구 모드에서 스왑 크기 조정을 수행합니다. 고급 RHEL 9 설치 수행 의 부팅 디버그 옵션을 참조하십시오. 파일 시스템을 마운트하라는 메시지가 표시되면 를 선택합니다.
13.3. LVM2 논리 볼륨에서 스왑 확장
이 절차에서는 기존 LVM2 논리 볼륨의 스왑 공간을 확장하는 방법을 설명합니다. /dev/VolGroup00/LogVol01 이 2GB 로 확장할 볼륨이라고 가정합니다.
사전 요구 사항
- 충분한 디스크 공간이 있습니다.
절차
연결된 논리 볼륨의 스왑을 비활성화합니다.
# swapoff -v /dev/VolGroup00/LogVol01LVM2 논리 볼륨의 크기를 2GB 로 조정합니다.
# lvresize /dev/VolGroup00/LogVol01 -L +2G
새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol01확장된 논리 볼륨을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol01
검증
스왑 논리 볼륨이 성공적으로 확장 및 활성화되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
13.4. 스왑을 위한 LVM2 논리 볼륨 생성
이 절차에서는 스왑을 위한 LVM2 논리 볼륨을 만드는 방법을 설명합니다. /dev/VolGroup00/LogVol02 가 추가할 스왑 볼륨이라고 가정합니다.
사전 요구 사항
- 충분한 디스크 공간이 있습니다.
절차
크기가 2GB 인 LVM2 논리 볼륨 만들기:
# lvcreate VolGroup00 -n LogVol02 -L 2G
새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol02/etc/fstab파일에 다음 항목을 추가합니다./dev/VolGroup00/LogVol02 swap swap defaults 0 0시스템이 새 구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.
# systemctl daemon-reload
논리 볼륨에서 스왑을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol02
검증
스왑 논리 볼륨이 성공적으로 생성 및 활성화되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
13.5. 스왑 파일 만들기
이 절차에서는 스왑 파일을 만드는 방법을 설명합니다.
사전 요구 사항
- 충분한 디스크 공간이 있습니다.
절차
- 새 스왑 파일의 크기를 메가바이트로 결정하고 1024로 곱하여 블록 수를 결정합니다. 예를 들어, 64MB 스왑 파일의 블록 크기는 65536입니다.
빈 파일을 생성합니다.
# dd if=/dev/zero of=/swapfile bs=1024 count=6553665536 을 원하는 블록 크기와 동일한 값으로 바꿉니다.
명령으로 스왑 파일을 설정합니다.
# mkswap /swapfile
읽을 수 없도록 스왑 파일의 보안을 변경합니다.
# chmod 0600 /swapfile
부팅 시 스왑 파일을 활성화하려면 다음 항목으로
/etc/fstab파일을 편집합니다./swapfile swap swap defaults 0 0
다음에 시스템을 부팅할 때 새 스왑 파일을 활성화합니다.
시스템이 새
/etc/fstab구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.# systemctl daemon-reload
스왑 파일을 즉시 활성화합니다.
# swapon /swapfile
검증
새 스왑 파일이 성공적으로 생성 및 활성화되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
13.6. LVM2 논리 볼륨에서 스왑 감소
이 절차에서는 LVM2 논리 볼륨의 스왑을 줄이는 방법을 설명합니다. /dev/VolGroup00/LogVol01 이 축소할 볼륨이라고 가정합니다.
절차
연결된 논리 볼륨의 스왑을 비활성화합니다.
# swapoff -v /dev/VolGroup00/LogVol01LVM2 논리 볼륨을 512MB로 줄입니다.
# lvreduce /dev/VolGroup00/LogVol01 -L -512M
새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol01논리 볼륨에서 스왑을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol01
검증
스왑 논리 볼륨이 성공적으로 감소했는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
13.7. 스왑을 위한 LVM2 논리 볼륨 제거
이 절차에서는 스왑을 위한 LVM2 논리 볼륨을 제거하는 방법을 설명합니다. /dev/VolGroup00/LogVol02 가 삭제하려는 스왑 볼륨이라고 가정합니다.
절차
연결된 논리 볼륨의 스왑을 비활성화합니다.
# swapoff -v /dev/VolGroup00/LogVol02LVM2 논리 볼륨을 제거합니다.
# lvremove /dev/VolGroup00/LogVol02/etc/fstab파일에서 다음 관련 항목을 제거하십시오./dev/VolGroup00/LogVol02 swap swap defaults 0 0시스템이 새 구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.
# systemctl daemon-reload
검증
논리 볼륨이 제거되었는지 테스트하려면 다음 명령을 사용하여 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
13.8. 스왑 파일 제거
이 절차에서는 스왑 파일을 제거하는 방법을 설명합니다.
절차
쉘 프롬프트에서 다음 명령을 실행하여 스왑 파일을 비활성화합니다. 여기서
/swapfile은 스왑 파일입니다.# swapoff -v /swapfile
-
그에 따라
/etc/fstab파일에서 해당 항목을 제거합니다. 시스템이 새 구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.
# systemctl daemon-reload
실제 파일을 제거합니다.
# rm /swapfile
14장. 파이버 채널 over 이더넷 구성
IEEE T11 FC-BB-5 표준에 따라 FCoE(Fib over Ethernet)는 이더넷 네트워크를 통해 파이버 채널 프레임을 전송하는 프로토콜입니다. 일반적으로 데이터 센터에는 고유한 구성으로 서로 분리된 전용 LAN 및 SAN(Storage Area Network)이 있습니다. FCoE는 이러한 네트워크를 단일 및 통합 네트워크 구조로 결합합니다. FCoE의 이점은 예를 들어 하드웨어 및 에너지 비용을 절감할 수 있습니다.
14.1. RHEL에서 하드웨어 FCoE HBA 사용
RHEL에서는 다음 드라이버에서 지원되는 하드웨어 Fibre Channel over Ethernet (FCoE) HBA(Host Bus Adapter)를 사용할 수 있습니다.
-
qedf -
bnx2fc -
fnic
이러한 HBA를 사용하는 경우 HBA 설정에서 FCoE 설정을 구성합니다. 자세한 내용은 어댑터 설명서를 참조하십시오.
HBA를 구성한 후 SAN(Storage Area Network)에서 내보낸 LUN(Logical Unit Numbers)을 RHEL에서 /dev/sd* 장치로 자동으로 사용할 수 있습니다. 로컬 스토리지 장치와 유사한 장치를 사용할 수 있습니다.
14.2. 소프트웨어 FCoE 장치 설정
소프트웨어 FCoE 장치를 사용하여 FCoE(Logical Unit Numbers)에 액세스하여 FCoE 오프로드를 부분적으로 지원하는 이더넷 어댑터를 사용하여 사용합니다.
RHEL은 fcoe.ko 커널 모듈이 필요한 소프트웨어 FCoE 장치를 지원하지 않습니다.
이 절차를 완료하면 SAN(Storage Area Network)에서 내보낸 LUN을 RHEL에서 /dev/sd* 장치로 자동으로 사용할 수 있습니다. 이러한 장치를 로컬 스토리지 장치와 유사한 방식으로 사용할 수 있습니다.
사전 요구 사항
- VLAN을 지원하도록 네트워크 스위치를 구성했습니다.
- SAN은 VLAN을 사용하여 스토리지 트래픽을 일반 이더넷 트래픽과 분리합니다.
- BIOS에서 서버의 HBA를 구성했습니다.
- HBA는 네트워크에 연결되어 있으며 링크가 켜집니다. 자세한 내용은 HBA 문서를 참조하십시오.
절차
fcoe-utils패키지를 설치합니다.# dnf install fcoe-utils
/etc/fcoe/cfg-ethx템플릿 파일을/etc/fcoe/cfg-interface_name에 복사합니다. 예를 들어 FCoE를 사용하도록enp1s0인터페이스를 구성하려면 다음 명령을 입력합니다.# cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-enp1s0fcoe서비스를 활성화하고 시작합니다.# systemctl enable --now fcoe
인터페이스
enp1s0에서 FCoE VLAN을 검색하고, 검색된 VLAN에 대한 네트워크 장치를 생성하고, 이니시에이터를 시작합니다.# fipvlan -s -c enp1s0 Created VLAN device enp1s0.200 Starting FCoE on interface enp1s0.200 Fibre Channel Forwarders Discovered interface | VLAN | FCF MAC ------------------------------------------ enp1s0 | 200 | 00:53:00:a7:e7:1b
선택 사항: 검색된 대상, LUN, LUN과 연결된 장치에 대한 세부 정보를 표시합니다.
# fcoeadm -t Interface: enp1s0.200 Roles: FCP Target Node Name: 0x500a0980824acd15 Port Name: 0x500a0982824acd15 Target ID: 0 MaxFrameSize: 2048 bytes OS Device Name: rport-11:0-1 FC-ID (Port ID): 0xba00a0 State: Online LUN ID Device Name Capacity Block Size Description ------ ----------- ---------- ---------- --------------------- 0 sdb 28.38 GiB 512 NETAPP LUN (rev 820a) ...이 예에서는 SAN의 LUN 0이
/dev/sdb장치로 호스트에 연결되었음을 보여줍니다.
검증
모든 활성 FCoE 인터페이스에 대한 정보를 표시합니다.
# fcoeadm -i Description: BCM57840 NetXtreme II 10 Gigabit Ethernet Revision: 11 Manufacturer: Broadcom Inc. and subsidiaries Serial Number: 000AG703A9B7 Driver: bnx2x Unknown Number of Ports: 1 Symbolic Name: bnx2fc (QLogic BCM57840) v2.12.13 over enp1s0.200 OS Device Name: host11 Node Name: 0x2000000af70ae935 Port Name: 0x2001000af70ae935 Fabric Name: 0x20c8002a6aa7e701 Speed: 10 Gbit Supported Speed: 1 Gbit, 10 Gbit MaxFrameSize: 2048 bytes FC-ID (Port ID): 0xba02c0 State: Online
추가 리소스
-
fcoeadm(8)도움말 페이지 -
/usr/share/doc/fcoe-utils/README - 파이버 채널 장치 사용
15장. 테이프 장치 관리
테이프 장치는 데이터를 순차적으로 저장하고 액세스할 수 있는 자기용 테이프입니다. 데이터는 테이프 드라이브의 도움말을 사용하여 이 테이프 장치에 기록됩니다.Data is written to this tape device with the help of a tape drive. 테이프 장치에 데이터를 저장하기 위해 파일 시스템을 만들 필요가 없습니다. 테이프 드라이브는 SCSI, FC, USB, SATA 및 기타 인터페이스와 같은 다양한 인터페이스가 있는 호스트 컴퓨터에 연결할 수 있습니다.
15.1. 테이프 장치 유형
다음은 다양한 유형의 테이프 장치 목록입니다.
-
/dev/st0은 재개된 테이프 장치입니다. -
/dev/nst0은 non-rewinding tape device입니다. 일별 백업에 대해 비rewinding 장치를 사용합니다.
테이핑 장치를 사용할 때 몇 가지 이점이 있습니다. 이는 비용 효율적이고 안정적입니다. 테이프 장치는 데이터 손상에도 탄력적이며 데이터 보존에 적합합니다.
15.2. 테이프 드라이브 관리 도구 설치
mt 명령을 사용하여 데이터를 뒤로 앞뒤로 전환합니다. mt 유틸리티는 자조 용 테이크 드라이브 작업을 제어하고 st 유틸리티는 SCSI tape 드라이버에 사용됩니다. 이 절차에서는 테이프 드라이브 작업을 위한 mt-st 패키지를 설치하는 방법을 설명합니다.
절차
mt-st패키지를 설치합니다.# dnf install mt-st
추가 리소스
-
MT(1)및st(4)도움말 페이지
15.3. 테이프 장치 다시 사용하기 위한 쓰기
테이프 장치가 모든 작업 후에 다시 멈춘다. 데이터를 백업하려면 tar 명령을 사용할 수 있습니다. 기본적으로 테이프 장치에서 블록 크기는 10KB(bs=10k)입니다. export 특성을 사용하여 TAPE 환경 변수를 설정할 수 있습니다. 대신 TAPE =/dev/st0-f 장치 옵션을 사용하여 테이프 장치 파일을 지정합니다. 이 옵션은 두 개 이상의 테이프 장치를 사용할 때 유용합니다.
사전 요구 사항
-
mt-st패키지가 설치되어 있어야 합니다. 자세한 내용은 저하 드라이브 관리 도구 설치를 참조하십시오.For more information, see Installing tape drive management tool. 테이프 드라이브를 로드합니다.
# mt -f /dev/st0 load
절차
테이프 헤드 확인:
# mt -f /dev/st0 status SCSI 2 tape drive: File number=-1, block number=-1, partition=0. Tape block size 0 bytes. Density code 0x0 (default). Soft error count since last status=0 General status bits on (50000): DR_OPEN IM_REP_EN여기:
-
현재
파일 번호는-1입니다. -
블록 번호는 테이크헤드를 정의합니다. 기본적으로 이 값은 -1로 설정됩니다. -
블록 크기0은 테이프 장치에 고정 블록 크기가 없음을 나타냅니다. -
soft error count는 mt status 명령을 실행한 후 발생한 오류 수를 나타냅니다. -
일반 상태 비트는 테이프 장치의 통계를 설명합니다. -
DR_OPEN은 문이 열려 있고 테이프 장치가 비어 있음을 나타냅니다.IM_REP_EN은 즉각적인 보고서 모드입니다.
-
현재
테이프 장치가 비어 있지 않으면 덮어씁니다.If the tape device is not empty, overwrite it:
# tar -czf /dev/st0 _/source/directory이 명령은 테이프 장치의 데이터를
/source/directory의 콘텐츠로 덮어씁니다./source/directory를 테이프 장치로 백업합니다.# tar -czf /dev/st0 _/source/directory tar: Removing leading `/' from member names /source/directory /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
테이프 장치의 상태 보기:
# mt -f /dev/st0 status
검증 단계
테이프 장치의 모든 파일 목록을 확인합니다.
# tar -tzf /dev/st0 /source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
추가 리소스
-
MT(1),st(4)및tar(1)매뉴얼 페이지 - 기록 보호 Red Hat Knowlegebase 문서로 감지된 테이프 드라이브 미디어
- 시스템 Red Hat Knowlegebase에서 테이크 드라이브가 검색되었는지 확인하는 방법
15.4. non-rewinding tape devices에 쓰기
unrewinding tape 장치는 특정 명령의 실행을 완료한 후 현재 상태로 유지됩니다. 예를 들어 백업 후 취소되지 않은 테이프 장치에 더 많은 데이터를 추가할 수 있습니다.For example, after a backup, you could append more data to a non-rewinding tape device. 또한 예기치 않은 재생 목록을 피하기 위해 사용할 수도 있습니다.
사전 요구 사항
-
mt-st패키지가 설치되어 있어야 합니다. 자세한 내용은 저하 드라이브 관리 도구 설치를 참조하십시오.For more information, see Installing tape drive management tool. 테이프 드라이브를 로드합니다.
# mt -f /dev/nst0 load
절차
non-rewinding tape device
/dev/nst0:# mt -f /dev/nst0 status
테이프의 끝 또는 앞쪽에 있는 포인터를 지정합니다.
# mt -f /dev/nst0 rewind
테이프 장치에 데이터를 추가합니다.
# mt -f /dev/nst0 eod # tar -czf /dev/nst0 /source/directory//source/directory/를테이프 장치로 백업합니다.# tar -czf /dev/nst0 /source/directory/ tar: Removing leading `/' from member names /source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
테이프 장치의 상태 보기:
# mt -f /dev/nst0 status
검증 단계
테이프 장치의 모든 파일 목록을 확인합니다.
# tar -tzf /dev/nst0 /source/directory/ /source/directory/man_db.conf /source/directory/DIR_COLORS /source/directory/rsyslog.conf [...]
추가 리소스
-
MT(1),st(4)및tar(1)매뉴얼 페이지 - 기록 보호 Red Hat Knowlegebase 문서로 감지된 테이프 드라이브 미디어
- 시스템 Red Hat Knowlegebase에서 테이크 드라이브가 검색되었는지 확인하는 방법
15.5. 테이프 장치에서 테이크 헤드 전환
다음 절차에 따라 테이프 장치의 테이크 헤드를 전환하십시오.
사전 요구 사항
-
mt-st패키지가 설치되어 있어야 합니다. 자세한 내용은 저하 드라이브 관리 도구 설치를 참조하십시오.For more information, see Installing tape drive management tool. - 데이터는 테이프 장치에 기록됩니다. 자세한 내용은 deleteing tape devices or writes to non-rewinding tape devices 를 참조하십시오.
절차
테이프 포인터의 현재 위치를 보려면 다음을 수행합니다.
# mt -f /dev/nst0 tell테이프 헤드를 전환 하는 동안 테이프 장치에 데이터를 추가 하려면 다음을 수행 합니다.
# mt -f /dev/nst0 eod이전 레코드로 이동하려면 다음을 수행합니다.
# mt -f /dev/nst0 bsfm 1이전 레코드로 이동하려면 다음을 수행합니다.
# mt -f /dev/nst0 fsf 1
추가 리소스
-
MT(1)매뉴얼 페이지
15.6. 테이프 장치에서 데이터 복원
테이프 장치에서 데이터를 복원하려면 tar 명령을 사용합니다.
사전 요구 사항
-
mt-st패키지가 설치되어 있어야 합니다. 자세한 내용은 저하 드라이브 관리 도구 설치를 참조하십시오.For more information, see Installing tape drive management tool. - 데이터는 테이프 장치에 기록됩니다. 자세한 내용은 deleteing tape devices or writes to non-rewinding tape devices 를 참조하십시오.
절차
테이프 장치를 다시 여는 경우
/dev/st0:/source/directory복원:# tar -xzf /dev/st0 /source/directory/
non-rewinding tape devices
/dev/nst0:테이프 장치를 다시 닫습니다.
# mt -f /dev/nst0 rewindetc디렉토리를 복원하십시오.# tar -xzf /dev/nst0 /source/directory/
추가 리소스
-
MT(1)및tar(1)도움말 페이지
15.7. 테이프 장치에서 데이터 삭제
테이프 장치에서 데이터를 지우려면 삭제 옵션을 사용하십시오.
사전 요구 사항
-
mt-st패키지가 설치되어 있어야 합니다. 자세한 내용은 저하 드라이브 관리 도구 설치를 참조하십시오.For more information, see Installing tape drive management tool. - 데이터는 테이프 장치에 기록됩니다. 자세한 내용은 deleteing tape devices or writes to non-rewinding tape devices 를 참조하십시오.
절차
테이프 장치에서 데이터 삭제:
# mt -f /dev/st0 erase테이프 장치를 언로드합니다.
mt -f /dev/st0 offline
추가 리소스
-
MT(1)매뉴얼 페이지
15.8. 보존 명령
다음은 일반적인 mt 명령입니다.
표 15.1. MT 명령
| 명령 | 설명 |
|---|---|
|
| 테이프 장치의 상태를 표시합니다. |
|
| 전체 테이프를 지웁니다. |
|
| 테이프 장치를 다시 닫습니다. |
|
| 테이프 헤드를 forward 레코드로 전환합니다. 여기서 n 은 선택적 파일 수입니다. 파일 수를 지정하면 tape head는 n 레코드를 건너뜁니다. |
|
| 테이프 헤드를 이전 레코드로 전환합니다. |
|
| 테이프 헤드를 데이터 끝으로 전환합니다. |
16장. RAID 관리
RedECDHE Disks(RAID) 배열을 사용하여 여러 드라이브에 데이터를 저장할 수 있습니다. 이는 드라이브가 실패한 경우 데이터 손실을 방지하는 데 도움이 될 수 있습니다.
16.1. RAID 개요
RAID에서 Restic, SSD 또는 NVMe와 같은 여러 장치가 배열로 결합되어 대규모의 고가의 드라이브로는 얻을 수 없는 성능 또는 중복성 목표를 달성할 수 없습니다. 이 장치 배열은 컴퓨터에 단일 논리 저장 장치 또는 드라이브로 나타납니다.
RAID는 레벨 0, 1, 4, 5, 6, 10 및 선형을 포함한 다양한 구성을 지원합니다. RAID는 디스크 스트리핑(RAID Level 0), 디스크 미러링(RAID Level 1) 및 패리티(RAID Levels 4, 5 및 6)와 같은 기술을 사용하여 중복성, 짧은 대기 시간, 대역폭 증가 및 하드 디스크 충돌에서 복구할 수 있는 극대화 기능을 제공합니다.
RAID는 다른 값이 허용되지만 RAID는 연속적으로 크기가 조정되는 청크(일반적으로 256KB 또는 512KB)로 나누어 배열의 각 장치에 데이터를 분산합니다. 이 청크는 사용된 RAID 수준에 따라 RAID 배열의 하드 드라이브에 씁니다. 데이터를 읽는 동안 프로세스는 반전되어 배열의 여러 장치가 실제로 하나의 큰 드라이브임을 알 수 있습니다.
RAID 기술은 대량의 데이터를 관리하는 사용자에게 유용합니다. 다음은 RAID를 배포하는 주요 이유입니다.
- 속도가 향상됩니다.
- 단일 가상 디스크를 사용하여 스토리지 용량이 증가합니다.
- 디스크 장애로 인한 데이터 손실을 최소화
- RAID 레이아웃 및 레벨 온라인 변환
16.2. RAID 유형
다음은 가능한 RAID 유형입니다.
- 펌웨어 RAID
- 펌웨어 RAID(ATARAID)는 펌웨어 기반 메뉴를 사용하여 RAID 세트를 구성할 수 있는 소프트웨어 RAID 유형입니다. 이 유형의 RAID에서 사용하는 펌웨어도 BIOS에 후크를 사용하므로 RAID 세트에서 부팅할 수 있습니다. 다른 공급업체는 RAID 세트 멤버를 표시하기 위해 다양한 디스크 메타데이터 형식을 사용합니다. Intel Matrix RAID는 펌웨어 RAID 시스템의 예입니다.
- 하드웨어 RAID
하드웨어 기반 배열은 호스트와 독립적으로 RAID 하위 시스템을 관리합니다. RAID 배열당 여러 개의 장치를 호스트에 제공할 수 있습니다.
하드웨어 RAID 장치는 시스템의 내부 또는 외부에 있을 수 있습니다. 내부 장치는 일반적으로 운영 체제에 대해 RAID 작업을 투명하게 처리하는 특수 컨트롤러 카드로 구성됩니다. 외부 장치는 일반적으로 SCSI, 파이버 채널, iSCSI, InfiniBand 또는 기타 고속 네트워크 상호 연결 및 시스템에 논리 장치와 같은 현재 볼륨을 통해 시스템에 연결합니다.
RAID 컨트롤러 카드는 운영 체제에 대한 SCSI 컨트롤러처럼 작동하며 모든 실제 드라이브 통신을 처리합니다. 일반 SCSI 컨트롤러와 유사한 RAID 컨트롤러에 드라이브를 연결한 다음 RAID 컨트롤러의 구성에 추가할 수 있습니다. 운영 체제는 차이를 알 수 없습니다.
- Software RAID
소프트웨어 RAID는 커널 블록 장치 코드에서 다양한 RAID 수준을 구현합니다. 비용이 많이 드는 디스크 컨트롤러 카드 또는 핫스 스왑 섀시가 필요하지 않기 때문에 기본 가능한 솔루션을 제공합니다. 핫 스왑 섀시를 사용하면 시스템의 전원을 끄지 않고도 하드 드라이브를 제거할 수 있습니다. 소프트웨어 RAID는 SATA, SCSI 및 NVMe와 같은 Linux 커널에서 지원하는 모든 블록 스토리지에서도 작동합니다. 오늘날의 더 빠른 CPU를 사용하면 소프트웨어 RAID도 일반적으로 고급 스토리지 장치를 사용하지 않는 한 하드웨어 RAID를 아웃소싱합니다.
Linux 커널에는 여러 장치(MD) 드라이버가 포함되어 있으므로 RAID 솔루션이 완전히 독립적이게 됩니다. 소프트웨어 기반 배열의 성능은 서버 CPU 성능 및 로드에 따라 달라집니다.
다음은 Linux 소프트웨어 RAID 스택의 주요 기능입니다.
- 다중 스레드 설계
- 재구성하지 않고 Linux 시스템 간 배열의 이식성
- 유휴 시스템 리소스를 사용하여 백그라운드 배열 재구성
- hot-swap 드라이브 지원
- MCMD(Single Instruction Multiple Data) 지원과 같은 특정 CPU 기능을 활용하는 자동 CPU 탐지.
- 배열의 디스크에서 잘못된 섹터를 자동으로 수정합니다.
- RAID 데이터의 일관성을 점검하여 배열 상태를 확인합니다.
- 중요한 이벤트에서 지정된 이메일 주소로 전송된 이메일 알림을 사용하여 배열을 사전 모니터링합니다.
쓰기 의도(write-intent)는 시스템 충돌 후 전체 배열을 재동기화할 필요 없이 디스크의 일부를 정확하게 동기화할 수 있도록 하여 재동기화 이벤트의 속도를 크게 높입니다.
참고재동기화는 중복성을 달성하기 위해 기존 RAID의 장치를 통해 데이터를 동기화하는 프로세스입니다.
- 다시 동기화하면 다시 동기화하는 동안 컴퓨터를 재부팅할 때 다시 동기화하면 재동기화가 중단된 위치를 재개하고 다시 시작하지 않도록 합니다.
- 설치 후 배열의 매개변수를 변경하는 기능을 reshaping이라고 합니다. 예를 들어 추가할 새 장치가 있으면 4-disk RAID5 배열을 5-disk RAID5 배열로 확장할 수 있습니다. 이 증가 작업은 라이브로 수행되며 새 배열에 다시 설치할 필요가 없습니다.
- reshaping은 장치 수, RAID4, RAID5, RAID6 또는 RAID10과 같은 RAID 배열 유형의 RAID 알고리즘 또는 크기 변경을 지원합니다.
- takeover는 RAID0에서 RAID6으로 같은 RAID 수준 변환을 지원합니다.
- 클러스터의 스토리지 솔루션인 클러스터 MD는 클러스터에 RAID1 미러링의 중복을 제공합니다. 현재는 RAID1만 지원됩니다.
16.3. RAID 수준 및 선형 지원
다음은 레벨 0, 1, 4, 5, 6, 10 및 선형을 포함하여 RAID에서 지원하는 구성입니다.
- 수준 0
RAID 레벨 0은 종종 스트라이핑이라고 하며 성능 지향 스트라이핑 데이터 매핑 기술입니다. 즉, 배열에 쓰는 데이터가 스트라이프로 분리되고 배열의 멤버 디스크에 기록되므로 고유 비용의 높은 I/O 성능이 허용되지만 중복은 제공되지 않습니다.
RAID 레벨 0 구현은 배열에서 가장 작은 장치의 크기까지 멤버 장치에서만 데이터를 스트라이핑합니다. 즉, 크기가 약간 다른 여러 장치가 있는 경우 각 장치는 최소 드라이브와 동일한 크기인 것처럼 취급됩니다. 따라서 수준 0 배열의 일반적인 스토리지 용량이 모든 디스크의 총 용량입니다. 멤버 디스크에 다른 크기가 있는 경우 RAID0은 사용 가능한 영역을 사용하여 해당 디스크의 모든 공간을 사용합니다.
- 수준 1
RAID 수준 1 또는 미러링은 배열의 각 멤버 디스크에 동일한 데이터를 작성하여 각 디스크에 미러링된 복사본을 남겨 두어 중복성을 제공합니다. 미러링은 단순성과 높은 수준의 데이터 가용성으로 인해 널리 사용됩니다. 수준 1은 두 개 이상의 디스크로 작동하며 매우 우수한 데이터 신뢰성을 제공하고 읽기 집약적인 애플리케이션의 성능을 개선하지만 상대적으로 높은 비용으로 작동합니다.
RAID 수준 1은 데이터 신뢰성을 제공하는 어레이의 모든 디스크에 동일한 정보를 쓰므로 비용이 많이 발생하지만 레벨 5와 같은 패리티 기반 RAID 수준보다 훨씬 공간 효율적입니다. 그러나 이 공간의 비효율성은 성능 이점을 제공하며, 이는 패리티를 생성하기 위해 더 많은 CPU 성능을 소비하는 패리티 기반 RAID 레벨인 반면 RAID 레벨 1은 CPU 오버헤드가 거의 없는 여러 RAID 멤버에 한 번 이상 동일한 데이터를 씁니다. 따라서 RAID 레벨 1은 소프트웨어 RAID가 사용되고 머신의 CPU 리소스가 RAID 활동 이외의 작업으로 일관되게 과세되는 머신에서 패리티 기반 RAID 수준을 초과할 수 있습니다.
수준 1 배열의 스토리지 용량은 하드웨어 RAID에서 가장 작은 미러링된 하드 디스크 용량 또는 소프트웨어 RAID에서 가장 작은 미러링된 파티션의 용량과 동일합니다. 수준 1 중복은 모든 RAID 유형 중에서 가능한 가장 높은 것으로, 배열은 단일 디스크로만 작동할 수 있습니다.
- 레벨 4
레벨 4는 데이터를 보호하기 위해 단일 디스크 드라이브에 집중된 패리티를 사용합니다. 패리티 정보는 배열의 나머지 멤버 디스크의 콘텐츠에 따라 계산됩니다. 그런 다음 이 정보를 사용하여 배열의 디스크 하나가 실패할 때 데이터를 재구성할 수 있습니다. 그런 다음 재구성된 데이터를 사용하여 교체하기 전에 실패한 디스크에 대한 I/O 요청을 충족하고 교체된 디스크를 다시 채울 수 있습니다.
전용 패리티 디스크는 RAID 배열에 대한 모든 쓰기 트랜잭션의 고유 성능 장애를 나타내기 때문에 레벨 4는 나중 쓰기 캐싱과 같은 기술을 함께 사용하지 않고 거의 사용되지 않습니다. 또는 시스템 관리자가 데이터가 채워지면 쓰기 트랜잭션이 거의 없는 배열과 같이 이러한 병목 현상이 있는 소프트웨어 RAID 장치를 의도적으로 설계하는 특정 상황에서 사용됩니다. RAID 수준 4는 너무 드물게 사용되므로 Anaconda에서 옵션으로 사용할 수 없습니다. 그러나 필요한 경우 사용자가 수동으로 생성할 수 있습니다.
하드웨어 RAID 수준 4의 스토리지 용량은 가장 작은 멤버 파티션의 용량과 같으며 파티션 수와 1을 곱한 값입니다. RAID 수준 4 배열의 성능은 항상 DestinationRule이며, 이는 outperform 쓰기를 의미합니다. 이는 쓰기 작업에서 패리티를 생성할 때 추가 CPU 리소스와 주요 메모리 대역폭을 소비하기 때문에 데이터를 작성할 뿐만 아니라 패리티를 작성할 때 실제 데이터를 디스크에 쓸 때 추가 버스 대역폭을 사용하기 때문입니다. 읽기 작업은 배열이 성능 저하된 상태에 있지 않는 한 패리티가 아닌 데이터를 읽기만 하면 됩니다.Read operations need only read the data and not the parity unless the array is in a degraded state. 결과적으로 읽기 작업은 정상적인 작동 상태에서 동일한 양의 데이터 전송을 위해 드라이브 및 컴퓨터 전체에 대한 트래픽을 줄일 수 있습니다.
- 수준 5
RAID의 가장 일반적인 유형입니다. 배열의 모든 멤버 디스크 드라이브에 패리티를 배포하면 RAID 레벨 5는 수준 4에 내재된 쓰기 병목 현상이 제거됩니다. 유일한 성능 병목은 패리티 계산 프로세스 자체입니다. 최신 CPU는 패리티를 매우 빠르게 계산할 수 있습니다. 그러나 RAID 5 어레이에 많은 디스크가 있으므로 모든 장치에서 집계 데이터 전송 속도가 충분히 높으면 패리티 계산이 병목 현상이 발생할 수 있습니다.
레벨 5는 성능이 뛰어나고 실제로 성능이 저하되는 쓰기를 읽습니다. RAID 레벨 5의 스토리지 용량은 수준 4와 동일한 방식으로 계산됩니다.
- 수준 6
이는 데이터 중복성 및 보존이 가장 중요한 문제이지만 수준 1의 비효율성을 허용하지 않는 일반적인 RAID 수준입니다. 레벨 6은 복잡한 패리티 체계를 사용하여 배열에서 두 드라이브의 손실에서 복구할 수 있습니다. 이러한 복잡한 패리티 체계는 소프트웨어 RAID 장치에 CPU 부담을 훨씬 높일 수 있으며 쓰기 트랜잭션 중에 부담을 더 많이 적용합니다. 따라서 레벨 6은 레벨 4 및 5보다 성능이 더 높음입니다.
RAID 레벨 6 배열의 총 용량은 추가 패리티 스토리지 공간에 대해 장치 수에서 1개 대신 두 개 대신 두 개의 장치를 뺀 경우를 제외하고 RAID 수준 5 및 4와 유사하게 계산됩니다.
- 수준 10
이 RAID 수준은 수준 0의 성능 이점과 수준 1의 중복성을 결합합니다. 또한 두 개 이상의 장치가 있는 수준 1 배열에서 부족한 공간 중 일부를 줄입니다. 예를 들어 레벨 10을 사용하면 각 데이터의 두 사본만 저장하도록 구성된 3-드 드라이브 어레이를 생성할 수 있으며, 이를 통해 전체 배열 크기가 3 장치 수준 1 어레이와 유사한 소형 장치보다 1.5배나 작은 장치의 크기를 1.5배로 설정할 수 있습니다. 이렇게 하면 RAID 수준 6과 유사한 패리티를 계산하기 위해 CPU 프로세스 사용량이 발생하지 않지만 공간 효율적입니다.
RAID 레벨 10의 생성은 설치 중에 지원되지 않습니다. 설치 후 수동으로 생성할 수 있습니다.
- Linear RAID
Linear RAID는 더 큰 가상 드라이브를 생성하기 위한 드라이브 그룹입니다.
선형 RAID에서 청크는 하나의 멤버 드라이브에서 순차적으로 할당되며 첫 번째가 완전히 채워진 경우에만 다음 드라이브로 이동합니다. 이 그룹화는 멤버 드라이브 간에 분할되는 I/O 작업이 거의 없기 때문에 성능상의 이점을 제공하지 않습니다. 선형 RAID는 중복을 제공하지 않으며 신뢰성을 줄입니다. 하나의 멤버 드라이브가 실패하면 전체 배열을 사용할 수 없으며 데이터가 손실될 수 있습니다. 용량은 모든 멤버 디스크의 합계입니다.
16.4. Linux RAID 하위 시스템
Linux에서 RAID를 구성하는 하위 시스템은 다음과 같습니다.
- Linux 하드웨어 RAID 컨트롤러 드라이버
- 하드웨어 RAID 컨트롤러에는 Linux에서 특정 RAID 하위 시스템이 없습니다. 특수 RAID 칩셋을 사용하므로 하드웨어 RAID 컨트롤러에 자체 드라이버가 제공됩니다. 이러한 드라이버를 사용하면 시스템은 RAID 세트를 일반 디스크로 탐지합니다.
mdraidmdraid하위 시스템은 Linux용 소프트웨어 RAID 솔루션으로 설계되었습니다. 또한 Red Hat Enterprise Linux의 소프트웨어 RAID에 권장되는 솔루션입니다. 이 하위 시스템은 기본 MD 메타데이터라고 하는 자체 메타데이터 형식을 사용합니다.외부 메타데이터라고도 하는 다른 메타데이터 형식도 지원합니다. Red Hat Enterprise Linux 9는
mdraid를 외부 메타데이터와 함께 사용하여 Intel Rapid Storage(ISW) 또는 IMSM(Intel Matrix Storage Manager) 세트 및 SNIA(Storage Networking Industryknative) 디스크 드라이브 형식(DDF)에 액세스합니다.mdraid하위 시스템 세트는mdadm유틸리티를 통해 구성 및 제어됩니다.
16.5. 설치 중 소프트웨어 RAID 생성
RID(Red Hat Storage) 장치의 중복 배열은 성능 향상 및 일부 구성에서 내결함성을 높이기 위해 여러 스토리지 장치에서 구성됩니다.
RAID 장치는 한 단계에서 생성되며 디스크는 필요에 따라 추가 또는 제거됩니다. 시스템의 각 물리 디스크에 대해 하나의 RAID 파티션을 구성하여 설치 프로그램에서 사용할 수 있는 디스크 수가 사용 가능한 RAID 장치 수준을 결정하도록 할 수 있습니다. 예를 들어 시스템에 두 개의 하드 드라이브가 있는 경우 최소 3개의 개별 디스크가 필요하므로 RAID 10 장치를 생성할 수 없습니다.
64비트 IBM Z에서 스토리지 하위 시스템은 RAID를 투명하게 사용합니다. 소프트웨어 RAID를 수동으로 구성할 필요가 없습니다.
사전 요구 사항
- RAID 구성 옵션이 표시되기 전에 설치용으로 두 개 이상의 디스크를 선택했습니다. 생성할 RAID 유형에 따라 두 개 이상의 디스크가 필요합니다.
- 마운트 지점을 생성했습니다. 마운트 지점을 구성하면 RAID 장치를 구성할 수 있습니다.
- Installation Destination (설치 대상) 창에서 (사용자 정의) 라디오 버튼을 선택했습니다.
절차
- 수동 파티션 창의 왼쪽 창에서 필요한 파티션을 선택합니다.
- 장치 섹션에서 을 클릭합니다. 마운트 지점 구성 대화 상자가 열립니다.
- RAID 장치에 포함할 디스크를 클릭합니다.
- 장치 유형 드롭다운 메뉴를 클릭하고 RAID 를 선택합니다.
- 파일 시스템 드롭다운 메뉴를 클릭하고 선호하는 파일 시스템 유형을 선택합니다.
- RAID 수준 드롭다운 메뉴를 클릭하고 원하는 RAID 수준을 선택합니다.
- 클릭하여 변경 사항을 저장합니다.
- 를 클릭하여 설정을 적용하여 설치 요약 창으로 돌아갑니다.
추가 리소스
16.6. 설치된 시스템에 소프트웨어 RAID 생성
mdadm 유틸리티를 사용하여 기존 시스템에 소프트웨어 RRAID(Red- Array of Disks)를 생성할 수 있습니다.
사전 요구 사항
-
mdadm패키지가 설치되어 있습니다. - 시스템에 두 개 이상의 파티션이 있습니다. 자세한 명령은 parted를 사용하여 파티션 생성 을 참조하십시오.
절차
두 블록 장치의 RAID를 생성합니다(예: /dev/sda1 및 /dev/sdc 1).
# mdadm --create /dev/md0 --level=2 --raid-devices=2 /dev/sda1 /dev/sdc1 mdadm: Defaulting to version 1.2 metadata mdadm: array /dev/md0 started.
level_value 옵션은 RAID 수준을 정의합니다.
선택 사항: RAID 상태를 확인합니다.
# mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Thu Oct 13 15:17:39 2022 Raid Level : raid0 Array Size : 18649600 (17.79 GiB 19.10 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Update Time : Thu Oct 13 15:17:39 2022 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 [...]선택 사항: RAID의 각 장치에 대한 자세한 정보를 관찰합니다.
# mdadm --examine /dev/sda1 /dev/sdc1 /dev/sda1: Magic : a92b4efc Version : 1.2 Feature Map : 0x1000 Array UUID : 77ddfb0a:41529b0e:f2c5cde1:1d72ce2c Name : 0 Creation Time : Thu Oct 13 15:17:39 2022 Raid Level : raid0 Raid Devices : 2 [...]RAID 드라이브에 파일 시스템을 생성합니다.
# mkfs -t xfs /dev/md0드라이브를 포맷하도록 선택한 파일 시스템으로 xfs 를 바꿉니다.
RAID 드라이브의 마운트 지점을 생성하고 마운트합니다.
# mkdir /mnt/raid1 # mount /dev/md0 /mnt/raid1
/mnt/raid1 을 마운트 지점으로 바꿉니다.
시스템이 부팅될 때 RHEL이
md0RAID 장치를 자동으로 마운트하려면/etc/fstab 파일에장치 항목을 추가합니다./dev/md0 /mnt/raid1 xfs defaults 0 0
16.7. 스토리지 시스템 역할을 사용하여 RAID 볼륨 구성
스토리지 시스템 역할을 사용하면 Red Hat Ansible Automation Platform 및 Ansible-Core를 사용하여 RHEL에서 RAID 볼륨을 구성할 수 있습니다. 매개변수를 사용하여 Ansible 플레이북을 생성하여 요구 사항에 맞게 RAID 볼륨을 구성합니다.
사전 요구 사항
- Ansible Core 패키지는 컨트롤 시스템에 설치되어 있어야 합니다.
-
플레이북을 실행할 시스템에
rhel-system-roles패키지가 설치되어 있습니다. -
스토리지시스템 역할을 사용하여 RAID 볼륨을 배포하려는 시스템을 자세히 설명하는 인벤토리 파일이 있습니다.
절차
다음 콘텐츠를 사용하여 새 playbook.yml 파일을 생성합니다.
--- - name: Configure the storage hosts: managed-node-01.example.com tasks: - name: Create a RAID on sdd, sde, sdf, and sdg include_role: name: rhel-system-roles.storage vars: storage_safe_mode: false storage_volumes: - name: data type: raid disks: [sdd, sde, sdf, sdg] raid_level: raid0 raid_chunk_size: 32 KiB mount_point: /mnt/data state: present주의장치 이름은 예를 들어 시스템에 새 디스크를 추가하는 경우와 같이 특정 상황에서 변경될 수 있습니다. 따라서 데이터 손실을 방지하려면 플레이북에서 특정 디스크 이름을 사용하지 마십시오.
선택 사항: 플레이북 구문을 확인합니다.
# ansible-playbook --syntax-check playbook.yml플레이북을 실행합니다.
# ansible-playbook -i inventory.file /path/to/file/playbook.yml
추가 리소스
-
/usr/share/ansible/roles/rhel-system-roles.storage/README.md파일 - RHEL System Roles를 사용하도록 제어 노드 및 관리형 노드 준비
16.8. RAID 확장
mdadm 유틸리티의 --grow 옵션을 사용하여 RAID를 확장할 수 있습니다.
사전 요구 사항
- 디스크 공간이 충분합니다.
-
parted패키지가 설치되어 있습니다.
절차
- RAID 파티션 확장. 자세한 내용은 parted로 파티션 크기 조정을 참조하십시오.
RAID를 파티션 용량의 최대로 확장합니다.
# mdadm --grow --size=max /dev/md0
특정 크기를 설정하려면 kB에서
--size매개변수 값을 작성합니다(예:--size=524228).파일 시스템의 크기를 늘립니다. 예를 들어 볼륨이 XFS를 사용하고 /mnt/ 에 마운트된 경우 다음을 입력합니다.
# xfs_growfs /mnt/
추가 리소스
-
mdadm(8)매뉴얼 페이지 - 파일 시스템 관리
16.9. RAID 축소
mdadm 유틸리티의 --grow 옵션을 사용하여 RAID를 축소할 수 있습니다.
XFS 파일 시스템에서는 축소를 지원하지 않습니다.
사전 요구 사항
-
parted패키지가 설치되어 있습니다.
절차
- 파일 시스템을 줄입니다. 자세한 내용은 파일 시스템 관리를 참조하십시오.
RAID를 크기로 줄입니다(예: 512MB ).
# mdadm --grow --size=524228 /dev/md0kB에
--size매개변수를 작성합니다.- 필요한 크기로 파티션을 축소합니다.
추가 리소스
-
mdadm(8)매뉴얼 페이지 - parted로 파티션 크기 조정.
16.10. 지원되는 RAID 변환
하나의 RAID 수준에서 다른 RAID로 변환할 수 있습니다. 예를 들어 RAID5에서 RAID10으로 변환할 수 있지만 RAID10에서 RAID5로 변환할 수는 없습니다. 다음 표에서는 지원되는 RAID 변환을 설명합니다.
| 소스 수준 | 대상 수준 |
|---|---|
| RAID0 | RAID4, RAID5, RAID10 |
| RAID1 | RAID0, RAID5 |
| RAID4 | RAID0, RAID5 |
| RAID5 | RAID0, RAID1, RAID4, RAID6, RAID10 |
| RAID6 | RAID5 |
| RAID10 | RAID0 |
RAID 5를 RAID0으로 변환하고 RAID4는 ALGORITHM_PARITY_N 레이아웃에서만 가능합니다.
추가 리소스.
-
mdadm(8)매뉴얼 페이지
16.11. RAID 수준 변환
RAID를 필요에 따라 다른 RAID 수준으로 변환할 수 있습니다. 다음 예제에서는 수준 0에서 5로 RAID 장치 /dev/md0 을 변환하고 배열에 하나 이상의 디스크 /dev/sdd 를 추가합니다.
사전 요구 사항
- 변환을 위한 디스크가 충분합니다.
-
mdadm패키지가 설치되어 있습니다. - 의도된 변환이 지원되는지 확인합니다. 지원되는 RAID 변환에서 참조하십시오.
절차
RAID /dev/md0을 RAID 레벨 5 로 변환합니다.
# mdadm --grow --level=5 -n 3 /dev/md0 --force배열에 새 디스크를 추가합니다.
# mdadm --manage /dev/md0 --add /dev/sdd
검증
RAID 수준이 변환되었는지 확인합니다.
# mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Thu Oct 13 15:17:39 2022 Raid Level : raid0 Array Size : 18649600 (17.79 GiB 19.10 GB) Raid Devices : 5 [...]
추가 리소스
-
mdadm(8)매뉴얼 페이지
16.12. 설치 후 루트 디스크를 RAID1로 변환
이 섹션에서는 Red Hat Enterprise Linux 9를 설치한 후 비RAID 루트 디스크를 RAID1 미러로 변환하는 방법을 설명합니다.
PPC(PowerPC) 아키텍처에서 다음 추가 단계를 수행합니다.
사전 요구 사항
- 다음 Red Hat 지식베이스 문서의 지침이 완료됩니다. Red Hat Enterprise Linux 7을 설치한 후 루트 디스크를 RAID1로 변환하려면 어떻게 해야 합니까?
절차
/dev/sda1 의 PowerPC 참조 플랫폼(PReP) 부팅 파티션 내용을 /dev/sdb1 로 복사합니다.
# dd if=/dev/sda1 of=/dev/sdb1
두 디스크의 첫 번째 파티션에서
prep및boot플래그를 업데이트합니다.$ parted /dev/sda set 1 prep on $ parted /dev/sda set 1 boot on $ parted /dev/sdb set 1 prep on $ parted /dev/sdb set 1 boot on
grub2-install /dev/sda 명령을 실행하면 PowerPC 시스템에서 작동하지 않고 오류가 반환되지만 시스템이 예상대로 부팅됩니다.
16.13. 고급 RAID 장치 생성
경우에 따라 설치가 완료되기 전에 생성된 배열에 운영 체제를 설치할 수 있습니다. 일반적으로 이는 복잡한 RAID 장치에서 /boot 또는 루트 파일 시스템 배열을 설정하는 것을 의미합니다. 이러한 경우 Anaconda 설치 프로그램에서 지원하지 않는 배열 옵션을 사용해야 할 수 있습니다. 이 문제를 해결하려면 다음 단계를 수행합니다.
설치 프로그램의 제한된 복구 모드에는 man 페이지가 포함되어 있지 않습니다. mdadm 및 md man 페이지에는 사용자 지정 RAID 배열을 생성하는 데 유용한 정보가 포함되어 있으며 해결 방법 전체에서 필요할 수 있습니다.
절차
- 설치 디스크를 삽입합니다.
-
초기 부팅 중에 설치 또는 업그레이드 대신 Rescue Mode 를 선택합니다. 시스템이
Rescue 모드로완전히 부팅되면 명령행 터미널이 표시됩니다. 이 터미널에서 다음 명령을 실행합니다.
-
parted명령을 사용하여 대상 하드 드라이브에 RAID 파티션을 생성합니다. -
사용 가능한 모든 설정과 옵션을 사용하여 해당 파티션의
mdadm명령을 사용하여 raid 배열을 수동으로 생성합니다.
-
- 선택 사항: 배열을 만든 후 배열에 파일 시스템을 생성합니다.
- 컴퓨터를 재부팅하고 설치 또는 업그레이드 를 선택하여 설치할 수 있습니다. Anaconda 설치 프로그램은 시스템의 디스크를 검색하므로 기존 RAID 장치를 찾습니다.
- 시스템에서 디스크를 사용하는 방법에 대해 묻는 경우 사용자 지정 레이아웃 을 선택하고 클릭합니다. 장치 목록에 기존 MD RAID 장치가 나열됩니다.
- RAID 장치를 선택하고 을 클릭합니다.
- 이전에 생성하지 않은 경우 마운트 지점을 구성하고 선택적으로 사용해야 하는 파일 시스템의 유형을 구성한 다음 를 클릭합니다. Anaconda는 기존 RAID 장치에 설치되고 Rescue 모드로 만들 때 선택한 사용자 지정 옵션을 유지합니다.
16.14. RAID를 모니터링하기 위한 이메일 알림 설정
mdadm 툴을 사용하여 RAID를 모니터링하도록 이메일 경고를 설정할 수 있습니다. MAILADDR 변수가 필수 이메일 주소로 설정되면 모니터링 시스템에서 추가된 이메일 주소로 경고를 보냅니다.
사전 요구 사항
-
mdadm패키지가 설치되어 있습니다. - mail 서비스가 설정되었습니다.
절차
RAID 세부 정보를 스캔하여 배열 모니터링을 위해
/etc/mdadm.conf구성 파일을 만듭니다.# mdadm --detail --scan >> /etc/mdadm.conf
ARRAY및MAILADDR은 필수 변수입니다.선택한 텍스트 편집기로
/etc/mdadm.conf구성 파일을 열고 알림에 대한 메일 주소와 함께MAILADDR변수를 추가합니다. 예를 들어 다음과 같이 새 행을 추가합니다.MAILADDR example@example.com>여기에서 example@example.com 는 배열 모니터링에서 경고를 수신하려는 이메일 주소입니다.
-
/etc/mdadm.conf파일에 변경 사항을 저장하고 닫습니다.
추가 리소스
-
mdadm.conf(5)매뉴얼 페이지
16.15. RAID에서 실패한 디스크 교체
나머지 디스크를 사용하여 실패한 디스크에서 데이터를 재구성할 수 있습니다. RAID 수준 및 총 디스크 수는 성공적인 데이터 재구성에 필요한 최소 디스크 양을 결정합니다.
이 절차에서는 /dev/md0 RAID에 4개의 디스크가 포함되어 있습니다. /dev/sdd 디스크가 실패했으므로 /dev/sdf 디스크로 교체해야 합니다.
사전 요구 사항
- 교체할 예비 디스크입니다.
-
mdadm패키지가 설치되어 있습니다.
절차
실패한 디스크를 확인합니다.
커널 로그를 확인합니다.
# journalctl -k -f
다음과 유사한 메시지를 검색합니다.
md/raid:md0: Disk failure on sdd, disabling device. md/raid:md0: Operation continuing on 3 devices.
-
키보드에서 Ctrl+C 눌러
journalctl프로그램을 종료합니다.
실패한 디스크를 결함으로 표시합니다.
# mdadm --manage /dev/md0 --fail /dev/sdd
선택 사항: 오류가 발생한 디스크가 올바르게 표시되었는지 확인합니다.
# mdadm --detail /dev/md0출력 끝에는 /dev/md0 RAID의 디스크 목록이 있으며 여기서 디스크 /dev/sdd 에 결함이 있습니다.
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc - 0 0 2 removed 3 8 64 3 active sync /dev/sde 2 8 48 - faulty /dev/sdd
RAID에서 실패한 디스크를 제거하십시오.
# mdadm --manage /dev/md0 --remove /dev/sdd
주의RAID가 다른 디스크 오류를 유지할 수 없는 경우 새 디스크에 활성 동기화 상태가 될 때까지 디스크를 제거하지 마십시오.
watch cat /proc/mdstat명령을 사용하여 진행 상황을 모니터링할 수 있습니다.새 디스크를 RAID에 추가합니다.
# mdadm --manage /dev/md0 --add /dev/sdf
/dev/md0 RAID에는 새 디스크 /dev/sdf 가 포함되고
mdadm서비스는 다른 디스크에서 데이터 복사를 자동으로 시작합니다.
검증
배열의 세부 정보를 확인합니다.
# mdadm --detail /dev/md0이 명령이 /dev/md0 RAID의 디스크 목록을 표시하는 경우 새 디스크에 출력 마지막에 예비 재구축 상태가 있는 경우 데이터는 여전히 다른 디스크에서 복사되고 있습니다.
Number Major Minor RaidDevice State 0 8 16 0 active sync /dev/sdb 1 8 32 1 active sync /dev/sdc 4 8 80 2 spare rebuilding /dev/sdf 3 8 64 3 active sync /dev/sde
데이터 복사가 완료되면 새 디스크에 활성 동기화 상태가 됩니다.
추가 리소스
16.16. RAID 디스크 복구
다음 절차에서는 RAID 배열의 디스크를 복구하는 방법을 설명합니다.
사전 요구 사항
-
mdadm패키지가 설치되어 있습니다.
절차
실패한 디스크 동작이 있는지 배열을 확인합니다.
# echo check > /sys/block/md0/md/sync_action이렇게 하면 배열과
/sys/block/md0/md/sync_action에 동기화 작업이 표시됩니다.-
선택한 텍스트 편집기를 사용하여
/sys/block/md0/md/sync_action파일을 열고 디스크 동기화 실패에 대한 메시지가 있는지 확인합니다. -
/sys/block/md0/mismatch_cnt파일을 확인합니다.mismatch_cnt매개변수가0이 아닌 경우 RAID 디스크를 복구해야 합니다. 배열의 디스크를 복구합니다.
# echo repair > /sys/block/md0/md/sync_action이렇게 하면 배열의 디스크를 복구하고 결과를
/sys/block/md0/md/sync_action파일에 씁니다.동기화 진행 상황을 확인합니다.
# cat /sys/block/md0/md/sync_action repair # cat /proc/mdstat Personalities : [raid0] [raid6] [raid5] [raid4] [raid1] md0 : active raid1 sdg[1] dm-3[0] 511040 blocks super 1.2 [2/2] [UU] unused devices: <none>
17장. NVDIMM 영구 메모리 스토리지 사용
시스템에 연결된 NVDIMM(Non-Volatile Dual In-line Memory Modules) 장치에서 다양한 유형의 스토리지를 활성화하고 관리할 수 있습니다.
NVDIMM 스토리지에 Red Hat Enterprise Linux 9 를 설치하려면 대신 NVDIMM 장치에 설치를 참조하십시오.
17.1. NVDIMM 영구 메모리 기술
비Volatile Dual In-line Memory Modules (NVDIMM) 영구 메모리 (Storage class memory 또는 pmem )는 메모리와 스토리지의 조합입니다.
NVDIMM은 스토리지의 액세스 대기 시간과 낮은 액세스 대기 시간과 동적 RAM(DRAM)의 높은 대역폭을 결합합니다. NVDIMM을 사용할 때의 다른 이점은 다음과 같습니다.
- NVDIMM 스토리지는 바이트 주소 지정 가능이므로 CPU 로드를 사용하여 액세스할 수 있고 명령을 저장하여 액세스할 수 있습니다. 기존 블록 기반 스토리지에 액세스하는 데 필요한 read() 및 write() 시스템 호출 외에도 NVDIMM은 직접 로드 및 저장소 프로그래밍 모델을 지원합니다.
- NVDIMM의 성능 특성은 매우 낮은 액세스 대기 시간이 있는ECDHE과 유사하며 일반적으로 수십 ~ 수백 나노초입니다.
- NVDIMM에 저장된 데이터는 영구 메모리와 유사하게 전원이 꺼지면 보존됩니다.
- 직접 액세스(DAX) 기술을 사용하면 시스템 페이지 캐시를 통과하지 않고도 메모리 맵 스토리지에 직접 애플리케이션을 사용할 수 있습니다. 이렇게 하면 다른 목적으로 사용할 수 있습니다.
NVDIMM은 다음과 같은 사용 사례에서 유용합니다.
- 데이터베이스
- NVDIMM에서 스토리지 액세스 대기 시간이 감소하면 데이터베이스 성능이 향상됩니다.
- 빠른 재시작
신속한 재시작을 warm 캐시 효과라고도 합니다. 예를 들어, 파일 서버에는 시작 후 메모리에 파일 내용이 없습니다. 클라이언트가 데이터를 연결하고 쓸 때 해당 데이터는 페이지 캐시에 캐시됩니다. 결국 캐시에는 주로 핫 데이터가 포함됩니다. 재부팅 후 시스템은 기존 스토리지에서 프로세스를 다시 시작해야 합니다.
NVDIMM을 사용하면 애플리케이션이 올바르게 설계된 경우 애플리케이션이 재부팅 후에도 웜 캐시를 유지할 수 있습니다. 이 예에서는 관련된 페이지 캐시가 없습니다. 애플리케이션이 영구 메모리에 직접 데이터를 캐시합니다.
- 빠른 쓰기 캐시
- 파일 서버는 데이터가 날카롭게 될 때까지 클라이언트 쓰기 요청을 승인하지 않는 경우가 많습니다. NVDIMM을 빠른 쓰기 캐시로 사용하면 파일 서버에서 쓰기 요청을 신속하게 확인할 수 있으며 대기 시간이 짧습니다.
17.2. NVDIMM 인터리빙 및 리전
비Volatile Dual In-line Memory Modules (NVDIMM) 장치는 인터리브된 리전으로 그룹화를 지원합니다.
NVDIMM 장치는 일반 동적 RAM(DRAM)과 동일한 방식으로 인터리브 세트로 그룹화할 수 있습니다. interleave 세트는 여러 DIMM의 RAID 0 수준(stripe) 구성과 유사합니다. Interleave 세트는 지역이라고도 합니다.
인터리빙에는 다음과 같은 이점이 있습니다.
- NVDIMM 장치는 인터리브 세트로 구성된 경우 성능이 향상됩니다.
- 인터리빙은 여러 개의 작은 NVDIMM 장치를 더 큰 논리 장치로 결합할 수 있습니다.
NVDIMM 인터리브 세트는 시스템 BIOS 또는 UEFI 펌웨어에서 구성됩니다. Red Hat Enterprise Linux는 인터리브 세트마다 하나의 리전 장치를 생성합니다.
17.3. NVDIMM 네임스페이스
비Volatile Dual In-line Memory Modules (NVDIMM) 영역은 라벨 영역 크기에 따라 하나 이상의 네임스페이스로 나눌 수 있습니다. 네임스페이스를 사용하면 섹터,fsdax,devdax 및 raw 와 같은 네임스페이스의 액세스 모드에 따라 다양한 방법을 사용하여 장치에 액세스할 수 있습니다. 자세한 내용은 NVDIMM 액세스 모드 입니다.
일부 NVDIMM 장치는 리전에서 여러 네임스페이스를 지원하지 않습니다.
- ECDHENVDIMM 장치에서 라벨을 지원하는 경우 리전을 네임스페이스로 세분화할 수 있습니다.
- NVDIMM 장치에서 라벨을 지원하지 않는 경우 리전에 단일 네임스페이스만 포함될 수 있습니다. 이 경우 Red Hat Enterprise Linux는 전체 리전을 지원하는 기본 네임스페이스를 생성합니다.
17.4. NVDIMM 액세스 모드
다음 모드 중 하나를 사용하도록 NVDIMM(Non-Volatile Dual In-line Memory Modules) 네임스페이스를 구성할 수 있습니다.
섹터스토리지를 빠른 블록 장치로 제공합니다. 이 모드는 NVDIMM 스토리지를 사용하도록 수정되지 않은 레거시 애플리케이션 또는 장치 매퍼를 포함하여 전체 I/O 스택을 사용하는 애플리케이션에 유용합니다.
섹터장치는 시스템의 다른 블록 장치와 동일한 방식으로 사용할 수 있습니다. 파티션 또는 파일 시스템을 생성하거나 소프트웨어 RAID 세트의 일부로 구성하거나dm-cache의 캐시 장치로 사용할 수 있습니다.이 모드의 장치는
/dev/pmemNs로 사용할 수 있습니다. 네임스페이스를 생성한 후 나열된blockdev값을 참조하십시오.devdax또는 장치 직접 액세스 (DAX)NVDIMM 장치는
devdax를 사용하여 SNIA(Storage Networking IndustryECDHE) NVM(Non-Volatile Memory) programming 모델 사양에 설명된 대로 직접 액세스 프로그래밍을 지원합니다. 이 모드에서 I/O는 커널의 스토리지 스택을 건너뜁니다. 따라서 장치 매퍼 드라이버를 사용할 수 없습니다.장치 DAX는 DAX 문자 장치 노드를 사용하여 NVDIMM 스토리지에 대한 원시 액세스를 제공합니다.
devdax장치의 데이터는 CPU 캐시 플러시 및 펜싱 지침을 사용하여 고정할 수 있습니다. 특정 데이터베이스 및 가상 머신 하이퍼바이저가 이 모드를 사용할 수 있습니다.devdax장치에서는 파일 시스템을 생성할 수 없습니다.이 모드의 장치는
/dev/daxN.M으로 사용할 수 있습니다. 네임스페이스를 생성한 후 나열된ECDHEdev값을 참조하십시오.fsdax또는 파일 시스템 직접 액세스 (DAX)NVDIMM 장치는
fsdax를 사용하여 SNIA(Storage Networking IndustryECDHE) NVM(Non-Volatile Memory) programming 모델 사양에 설명된 대로 직접 액세스 프로그래밍을 지원합니다. 이 모드에서는 I/O가 커널의 스토리지 스택을 무시하고 많은 장치 매퍼 드라이버를 사용할 수 없습니다.파일 시스템 DAX 장치에서 파일 시스템을 만들 수 있습니다.
이 모드의 장치는
/dev/pmemN으로 사용할 수 있습니다. 네임스페이스를 생성한 후 나열된blockdev값을 참조하십시오.중요파일 시스템 DAX 기술은 기술 프리뷰로만 제공되며 Red Hat에서 지원되지 않습니다.
rawDAX를 지원하지 않는 메모리 디스크를 제공합니다. 이 모드에서 네임스페이스에는 몇 가지 제한 사항이 있으며 사용해서는 안 됩니다.
이 모드의 장치는
/dev/pmemN으로 사용할 수 있습니다. 네임스페이스를 생성한 후 나열된blockdev값을 참조하십시오.
17.5. ndctl 설치
ndctl 유틸리티를 설치하여 NVMe(Non-Volatile Dual In-line Memory Modules) 장치를 구성하고 모니터링할 수 있습니다.
절차
ndctl유틸리티를 설치합니다.# dnf install ndctl
17.6. 블록 장치 역할을 할 NVDIMM에 섹터 네임스페이스 생성
기존 블록 기반 스토리지를 지원하기 위해 레거시 모드라고도 하는 섹터 모드에서 NVMe(Non-Volatile Dual In-line Memory Modules) 장치를 구성할 수 있습니다.
다음 중 하나를 수행할 수 있습니다.
- 기존 네임스페이스를 섹터 모드로 재구성
- 사용 가능한 공간이 있는 경우 새 섹터 네임스페이스를 만듭니다.
사전 요구 사항
- NVDIMM 장치가 시스템에 연결되어 있습니다.
17.6.1. 기존 NVDIMM 네임스페이스를 섹터 모드로 재구성
빠른 블록 장치로 사용하기 위해 NVMe(Non-Volatile Dual In-line Memory Modules) 네임스페이스를 섹터 모드로 재구성할 수 있습니다.
네임스페이스를 다시 구성하면 네임스페이스에 이전에 저장된 데이터가 삭제됩니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오.
절차
기존 네임스페이스를 확인합니다.
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ]선택한 네임스페이스를 섹터 모드로 재구성합니다.
# ndctl create-namespace --force --reconfig=namespace-ID --mode=sector예 17.1. 섹터 모드에서 네임스페이스1.0 구성
# ndctl create-namespace --force --reconfig=namespace1.0 --mode=sector { "dev":"namespace1.0", "mode":"sector", "size":"755.26 GiB (810.95 GB)", "uuid":"2509949d-1dc4-4ee0-925a-4542b28aa616", "sector_size":4096, "blockdev":"pmem1s" }재구성된 네임스페이스는 이제
/dev디렉토리에서/dev/pmem1s파일로 사용할 수 있습니다.
검증
시스템의 기존 네임스페이스가 재구성되었는지 확인합니다.
# ndctl list --namespace namespace1.0 [ { "dev":"namespace1.0", "mode":"sector", "size":810954706944, "uuid":"2509949d-1dc4-4ee0-925a-4542b28aa616", "sector_size":4096, "blockdev":"pmem1s" } ]
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.6.2. 섹터 모드에서 새 NVDIMM 네임스페이스 생성
이 리전에 사용 가능한 공간이 있는 경우 빠른 블록 장치로 사용하기 위해 섹터 모드에서 NVMe(Non-Volatile Dual In-line Memory Modules) 네임스페이스를 생성할 수 있습니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오. NVDIMM 장치는 라벨을 지원하여 하나의 리전에 여러 네임스페이스를 생성합니다. 다음 명령을 사용하여 확인할 수 있습니다.
# ndctl read-labels nmem0 >/dev/null read 1 nmem
이는 하나의 NVDIMM 장치의 라벨을 읽을 수 있음을 나타냅니다. 값이
0인 경우 장치에서 레이블을 지원하지 않음을 나타냅니다.
절차
사용 가능한 공간이 있는 시스템의
pmem리전을 나열합니다. 다음 예제에서는 region1 및 region0 리전에서 공간을 사용할 수 있습니다.# ndctl list --regions [ { "dev":"region1", "size":2156073582592, "align":16777216, "available_size":2117418876928, "max_available_extent":2117418876928, "type":"pmem", "iset_id":-9102197055295954944, "badblock_count":1, "persistence_domain":"memory_controller" }, { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2143188680704, "max_available_extent":2143188680704, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller" } ]사용 가능한 리전 중 하나에 하나 이상의 네임스페이스를 할당합니다.
# ndctl create-namespace --mode=sector --region=regionN --size=namespace-size
예 17.2. region0에 36GiB 섹터 네임스페이스 생성
# ndctl create-namespace --mode=sector --region=region0 --size=36G { "dev":"namespace0.1", "mode":"sector", "size":"35.96 GiB (38.62 GB)", "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "sector_size":4096, "blockdev":"pmem0.1s" }새 네임스페이스를
/dev/pmem0.1s로 사용할 수 있습니다.
검증
새 네임스페이스가 섹터 모드에서 생성되었는지 확인합니다.
# ndctl list -RN -n namespace0.1 { "regions":[ { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2104533975040, "max_available_extent":2104533975040, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller", "namespaces":[ { "dev":"namespace0.1", "mode":"sector", "size":38615912448, "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "sector_size":4096, "blockdev":"pmem0.1s" } ] } ] }
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.7. NVDIMM에서 장치 DAX 네임스페이스 생성
Y You can configure an non-Volatile Dual In-line Memory Modules (NVDIMM) device in device DAX mode to support direct access to persistent memory without the use of a file system with direct access capabilities.
다음 중 하나를 수행할 수 있습니다.
- 기존 네임스페이스를 장치 DAX 모드로 재구성하거나
- 사용 가능한 공간이 있는 경우 새 장치 DAX 네임스페이스를 만듭니다.
사전 요구 사항
- NVDIMM 장치가 시스템에 연결되어 있습니다.
17.7.1. 장치 직접 액세스 모드 NVDIMM
장치 직접 액세스(device DAX, devdax)는 애플리케이션이 파일 시스템의 기능 없이 스토리지에 직접 액세스할 수 있는 수단을 제공합니다. 장치 DAX의 이점은 ndctl 유틸리티의 --align 옵션을 사용하여 구성할 수 있는 보장된 내결함성을 제공하는 것입니다.
Intel 64 및 AMD64 아키텍처의 경우 다음과 같은 결함 세분화가 지원됩니다.
- 4 KiB
- 2 MiB
- 1GiB
장치 DAX 노드는 다음 시스템 호출만 지원합니다.
-
open() -
close() -
mmap()
ndctl list --human --capabilities 명령을 사용하여 NVDIMM 장치의 지원되는 정렬을 볼 수 있습니다. 예를 들어 region0 장치에 대해 보려면 ndctl list --human --capabilities -r region0 명령을 사용합니다.
장치 DAX 사용 사례가 SNIA 비Volatile 메모리 프로그래밍 모델에 연결되어 있기 때문에 read() 및 write() 시스템 호출이 지원되지 않습니다.
17.7.2. 기존 NVDIMM 네임스페이스를 장치 DAX 모드로 재구성
기존 NVMe(Non-Volatile Dual In-line Memory Modules) 네임스페이스를 장치 DAX 모드로 재구성할 수 있습니다.
네임스페이스를 다시 구성하면 네임스페이스에 이전에 저장된 데이터가 삭제됩니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오.
절차
시스템의 모든 네임스페이스를 나열합니다.
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "uuid":"ac951312-b312-4e76-9f15-6e00c8f2e6f4" "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":38615912448, "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "state":"disabled", "numa_node":0 } ]네임스페이스를 재구성합니다.
# ndctl create-namespace --force --mode=devdax --reconfig=namespace-ID예 17.3. 장치 DAX로 네임스페이스 구성
다음 명령은 DAX를 지원하는 데이터 저장을 위해
namespace0.1을 재구성합니다. 한 번에 2MiB 페이지에 운영 체제 결함이 있는지 확인하기 위해 2MiB의 내결함성에 맞게 조정됩니다.# ndctl create-namespace --force --mode=devdax --align=2M --reconfig=namespace0.1 { "dev":"namespace0.1", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"426d6a52-df92-43d2-8cc7-046241d6d761", "daxregion":{ "id":0, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax0.1", "size":"35.44 GiB (38.05 GB)", "target_node":4, "mode":"devdax" } ] }, "align":2097152 }이제
/dev/dax0.1경로에서 네임스페이스를 사용할 수 있습니다.
검증
시스템의 기존 네임스페이스가 재구성되었는지 확인합니다.
# ndctl list --namespace namespace0.1 [ { "dev":"namespace0.1", "mode":"devdax", "map":"dev", "size":38048628736, "uuid":"426d6a52-df92-43d2-8cc7-046241d6d761", "chardev":"dax0.1", "align":2097152 } ]
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.7.3. 장치 DAX 모드에서 새 NVDIMM 네임스페이스 생성
이 리전에 사용 가능한 공간이 있는 경우 NVMe(Non-Volatile Dual In-line Memory Modules) 장치에서 새 장치 DAX 네임스페이스를 만들 수 있습니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오. NVDIMM 장치는 라벨을 지원하여 하나의 리전에 여러 네임스페이스를 생성합니다. 다음 명령을 사용하여 확인할 수 있습니다.
# ndctl read-labels nmem0 >/dev/null read 1 nmem
이는 하나의 NVDIMM 장치의 라벨을 읽을 수 있음을 나타냅니다. 값이
0인 경우 장치에서 레이블을 지원하지 않음을 나타냅니다.
절차
사용 가능한 공간이 있는 시스템의
pmem리전을 나열합니다. 다음 예제에서는 region1 및 region0 리전에서 공간을 사용할 수 있습니다.# ndctl list --regions [ { "dev":"region1", "size":2156073582592, "align":16777216, "available_size":2117418876928, "max_available_extent":2117418876928, "type":"pmem", "iset_id":-9102197055295954944, "badblock_count":1, "persistence_domain":"memory_controller" }, { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2143188680704, "max_available_extent":2143188680704, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller" } ]사용 가능한 리전 중 하나에 하나 이상의 네임스페이스를 할당합니다.
# ndctl create-namespace --mode=devdax --region=region_N_ --size=namespace-size예 17.4. 리전에서 네임스페이스 생성
다음 명령은 region0에 36-GiB 장치 DAX 네임스페이스를 생성합니다. 한 번에 2MiB 페이지에 운영 체제 결함이 있는지 확인하기 위해 2MiB의 내결함성에 맞게 조정됩니다.
# ndctl create-namespace --mode=devdax --region=region0 --align=2M --size=36G { "dev":"namespace0.2", "mode":"devdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"89d13f41-be6c-425b-9ec7-1e2a239b5303", "daxregion":{ "id":0, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax0.2", "size":"35.44 GiB (38.05 GB)", "target_node":4, "mode":"devdax" } ] }, "align":2097152 }이제 네임스페이스를
/dev/dax0.2로 사용할 수 있습니다.
검증
새 네임스페이스가 섹터 모드에서 생성되었는지 확인합니다.
# ndctl list -RN -n namespace0.2 { "regions":[ { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2065879269376, "max_available_extent":2065879269376, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller", "namespaces":[ { "dev":"namespace0.2", "mode":"devdax", "map":"dev", "size":38048628736, "uuid":"89d13f41-be6c-425b-9ec7-1e2a239b5303", "chardev":"dax0.2", "align":2097152 } ] } ] }
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.8. NVDIMM에서 파일 시스템 DAX 네임스페이스 생성
직접 액세스 기능을 갖춘 파일 시스템을 지원하도록 파일 시스템 DAX 모드에서 NVMe(Non-Volatile Dual In-line Memory Modules) 장치를 구성할 수 있습니다.
다음 중 하나를 수행할 수 있습니다.
- 기존 네임스페이스를 파일 시스템 DAX 모드로 재구성하거나
- 사용 가능한 공간이 있는 경우 새 파일 시스템 DAX 네임스페이스를 만듭니다.
파일 시스템 DAX 기술은 기술 프리뷰로만 제공되며 Red Hat에서 지원되지 않습니다.
사전 요구 사항
- NVDIMM 장치가 시스템에 연결되어 있습니다.
17.8.1. 파일 시스템의 직접 액세스 모드 NVDIMM
NVDIMM 장치가 파일 시스템 직접 액세스(파일 시스템 DAX, fsdax) 모드로 구성된 경우 파일 시스템을 그 위에 만들 수 있습니다. 이 파일 시스템의 파일에서 mmap() 작업을 수행하는 모든 애플리케이션은 스토리지에 직접 액세스할 수 있습니다. 이를 통해 NVDIMM에서 직접 액세스 프로그래밍 모델을 사용할 수 있습니다.
Red Hat Enterprise Linux 8에서 다음과 같은 새로운 -o dax 옵션을 사용할 수 있으며 필요한 경우 파일 속성을 통해 직접 액세스 동작을 제어할 수 있습니다.
-O dax=inode이는 파일 시스템을 마운트하는 동안 dax 옵션을 지정하지 않는 경우 기본 옵션입니다. 이 옵션을 사용하면 dax 모드를 활성화할 수 있는지 제어하도록 파일에 속성 플래그를 설정할 수 있습니다. 필요한 경우 이 플래그를 개별 파일에 설정할 수 있습니다.
이 플래그를 디렉토리에 설정하고 해당 디렉터리의 모든 파일은 동일한 플래그를 사용하여 생성할 수도 있습니다. 이 속성 플래그는
xfs_io -c 'chattr +x'directory-name 명령을 사용하여 설정할 수 있습니다.-o dax=never-
이 옵션을 사용하면 dax 플래그가
inode모드로 설정된 경우에도 dax 모드가 활성화되지 않습니다. 즉, per-inode dax 특성 플래그가 무시되고 이 플래그를 사용하여 설정된 파일은 직접 액세스할 수 없습니다. -O dax=always이 옵션은 이전
-o dax동작과 동일합니다. 이 옵션을 사용하면 dax 특성 플래그와 관계없이 파일 시스템의 모든 파일에 대해 직접 액세스 모드를 활성화할 수 있습니다.주의추가 릴리스에서는
-o dax가 지원되지 않을 수 있으며 필요한 경우-o dax=always를 대신 사용할 수 있습니다. 이 모드에서는 모든 파일이 직접 액세스 모드에 있을 수 있습니다.- 페이지별 메타데이터 할당
이 모드에서는 시스템ECDHE 또는 NVDIMM 장치 자체에 페이지당 메타데이터를 할당해야 합니다. 이 데이터 구조의 오버헤드는 각 4KiB 페이지당 64바이트입니다.
- 작은 장치에서는 오버헤드의 양이 문제 없이ECDHE에 들어갈 수 있을 만큼 작아집니다. 예를 들어 16GiB 네임스페이스는 페이지 구조에는 256MiB만 있으면 됩니다. NVDIMM 장치는 일반적으로 작고 비용이 많이 들기 때문에ECDHE에 추적 데이터 구조를 저장하는 것이 좋습니다.
크기가 테라바이트 이상인 NVDIMM 장치의 경우 페이지 추적 데이터 구조를 저장하는 데 필요한 메모리 양이 시스템의ECDHE 양을 초과할 수 있습니다. NVDIMM의 TiB 1개에는 페이지 구조에 16GiB가 필요합니다. 결과적으로 이러한 경우 데이터 구조를 NVDIMM 자체에 저장하는 것이 좋습니다.
네임스페이스를 구성할 때
--map옵션을 사용하여 per-page 메타데이터가 저장되는 위치를 구성할 수 있습니다.-
시스템 RAM에 할당하려면
--map=mem을 사용합니다. -
NVDIMM에 할당하려면
--map=dev를 사용합니다.
17.8.2. 기존 NVDIMM 네임스페이스를 파일 시스템 DAX 모드로 재구성
기존 NVMe(Non-Volatile Dual In-line Memory Modules) 네임스페이스를 파일 시스템 DAX 모드로 재구성할 수 있습니다.
네임스페이스를 다시 구성하면 네임스페이스에 이전에 저장된 데이터가 삭제됩니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오.
절차
시스템의 모든 네임스페이스를 나열합니다.
# ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "uuid":"ac951312-b312-4e76-9f15-6e00c8f2e6f4" "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":38615912448, "uuid":"ff5a0a16-3495-4ce8-b86b-f0e3bd9d1817", "state":"disabled", "numa_node":0 } ]네임스페이스를 재구성합니다.
# ndctl create-namespace --force --mode=fsdax --reconfig=namespace-ID예 17.5. 네임스페이스를 파일 시스템 DAX로 재구성
DAX를 지원하는 파일 시스템에
namespace0.0을 사용하려면 다음 명령을 사용합니다.# ndctl create-namespace --force --mode=fsdax --reconfig=namespace0.0 { "dev":"namespace0.0", "mode":"fsdax", "map":"dev", "size":"11.81 GiB (12.68 GB)", "uuid":"f8153ee3-c52d-4c6e-bc1d-197f5be38483", "sector_size":512, "align":2097152, "blockdev":"pmem0" }이제
/dev/pmem0경로에서 네임스페이스를 사용할 수 있습니다.
검증
시스템의 기존 네임스페이스가 재구성되었는지 확인합니다.
# ndctl list --namespace namespace0.0 [ { "dev":"namespace0.0", "mode":"fsdax", "map":"dev", "size":12681478144, "uuid":"f8153ee3-c52d-4c6e-bc1d-197f5be38483", "sector_size":512, "align":2097152, "blockdev":"pmem0" } ]
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.8.3. 파일 시스템 DAX 모드에서 새 NVDIMM 네임스페이스 생성
이 리전에 사용 가능한 공간이 있는 경우 NVMe(Non-Volatile Dual In-line Memory Modules) 장치에서 새 파일 시스템 DAX 네임스페이스를 만들 수 있습니다.
사전 요구 사항
-
ndctl유틸리티가 설치되어 있습니다. 자세한 내용은 Installing ndctl 을 참조하십시오. NVDIMM 장치는 라벨을 지원하여 하나의 리전에 여러 네임스페이스를 생성합니다. 다음 명령을 사용하여 확인할 수 있습니다.
# ndctl read-labels nmem0 >/dev/null read 1 nmem
이는 하나의 NVDIMM 장치의 라벨을 읽을 수 있음을 나타냅니다. 값이
0인 경우 장치에서 레이블을 지원하지 않음을 나타냅니다.
절차
사용 가능한 공간이 있는 시스템의
pmem리전을 나열합니다. 다음 예제에서는 region1 및 region0 리전에서 공간을 사용할 수 있습니다.# ndctl list --regions [ { "dev":"region1", "size":2156073582592, "align":16777216, "available_size":2117418876928, "max_available_extent":2117418876928, "type":"pmem", "iset_id":-9102197055295954944, "badblock_count":1, "persistence_domain":"memory_controller" }, { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2143188680704, "max_available_extent":2143188680704, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller" } ]사용 가능한 리전 중 하나에 하나 이상의 네임스페이스를 할당합니다.
# ndctl create-namespace --mode=fsdax --region=regionN --size=namespace-size
예 17.6. 리전에서 네임스페이스 생성
다음 명령은 region0 에서 36-GiB 파일 시스템 DAX 네임스페이스를 생성합니다.
# ndctl create-namespace --mode=fsdax --region=region0 --size=36G { "dev":"namespace0.3", "mode":"fsdax", "map":"dev", "size":"35.44 GiB (38.05 GB)", "uuid":"99e77865-42eb-4b82-9db6-c6bc9b3959c2", "sector_size":512, "align":2097152, "blockdev":"pmem0.3" }이제 네임스페이스를
/dev/pmem0.3으로 사용할 수 있습니다.
검증
새 네임스페이스가 섹터 모드에서 생성되었는지 확인합니다.
# ndctl list -RN -n namespace0.3 { "regions":[ { "dev":"region0", "size":2156073582592, "align":16777216, "available_size":2027224563712, "max_available_extent":2027224563712, "type":"pmem", "iset_id":736272362787276936, "badblock_count":3, "persistence_domain":"memory_controller", "namespaces":[ { "dev":"namespace0.3", "mode":"fsdax", "map":"dev", "size":38048628736, "uuid":"99e77865-42eb-4b82-9db6-c6bc9b3959c2", "sector_size":512, "align":2097152, "blockdev":"pmem0.3" } ] } ] }
추가 리소스
-
ndctl-create-namespace(1)매뉴얼 페이지
17.8.4. 파일 시스템 DAX 장치에서 파일 시스템 만들기
파일 시스템 DAX 장치에서 파일 시스템을 만들고 파일 시스템을 마운트할 수 있습니다. 파일 시스템을 생성한 후 애플리케이션은 영구 메모리를 사용하고 마운트 지점 디렉터리에 파일을 생성하고, 파일을 열고 mmap 작업을 사용하여 직접 액세스할 수 있도록 파일을 매핑할 수 있습니다.
Red Hat Enterprise Linux 9에서는 NVDIMM에서 XFS 및 ext4 파일 시스템을 기술 프리뷰로 생성할 수 있습니다.
절차
선택 사항: 파일 시스템 DAX 장치에서 파티션을 만듭니다. 자세한 내용은 parted를 사용하여 파티션 생성 을 참조하십시오.
참고fsdax장치에서 파티션을 만들 때 파티션을 페이지 경계에 맞게 조정해야 합니다. Intel 64 및 AMD64 아키텍처에서는 파티션 시작 및 종료 시 최소 4KiB 정렬이 필요합니다. 2MiB는 기본 정렬입니다.기본적으로
parted툴은 파티션을 1MiB 경계로 정렬합니다. 첫 번째 파티션의 경우 파티션 시작으로 2MiB를 지정합니다. 파티션 크기가 2MiB의 다중인 경우 다른 모든 파티션도 정렬됩니다.파티션 또는 NVDIMM 장치에 XFS 또는 ext4 파일 시스템을 생성합니다.
# mkfs.xfs -d su=2m,sw=1 fsdax-partition-or-device참고이제 dax 지원 및 리링크된 파일이 파일 시스템에 공존할 수 있습니다. 그러나 개별 파일의 경우 dax 및 reflink는 함께 사용할 수 없습니다.
XFS의 경우 공유 COW(Copy-On-Write) 데이터 Extent가 dax 마운트 옵션과 호환되지 않으므로 비활성화합니다. 또한 대규모 페이지 매핑 가능성을 높이려면 스트라이프 단위 및 스트라이프 너비를 설정합니다.
파일 시스템을 마운트합니다.
# mount f_sdax-partition-or-device mount-point_
직접 액세스 모드를 활성화하려면 dax 옵션으로 파일 시스템을 마운트할 필요가 없습니다. 마운트하는 동안 dax 옵션을 지정하지 않으면 파일 시스템이
dax=inode모드에 있습니다. 직접 액세스 모드가 활성화되기 전에 파일에 dax 옵션을 설정합니다.
추가 리소스
-
mkfs.xfs(8)매뉴얼 페이지 - 파일 시스템의 직접 액세스 모드 NVDIMM
17.9. S.M.A.R.T를 사용하여 NVDIMM 상태 모니터링.
일부 비Volatile Dual In-line Memory Modules (NVDIMM) 장치는 상태 정보를 검색하기 위해 자체 모니터링, 분석 및 보고 기술(S.M.A.R.T) 인터페이스를 지원합니다.
데이터 손실을 방지하기 위해 NVDIMM 상태를 정기적으로 모니터링합니다. S.M.A.R.T.가 NVDIMM 장치의 상태에 문제를 보고하는 경우 이를 탐지하고 손상된 NVDIMM 장치를 교체하는 데 설명된 대로 교체합니다.
사전 요구 사항
선택 사항: 일부 시스템에서는
acpi_ipmi드라이버를 업로드하여 다음 명령을 사용하여 상태 정보를 검색합니다.# modprobe acpi_ipmi
절차
상태 정보에 액세스합니다.
# ndctl list --dimms --health [ { "dev":"nmem1", "id":"8089-a2-1834-00001f13", "handle":17, "phys_id":32, "security":"disabled", "health":{ "health_state":"ok", "temperature_celsius":36.0, "controller_temperature_celsius":37.0, "spares_percentage":100, "alarm_temperature":false, "alarm_controller_temperature":false, "alarm_spares":false, "alarm_enabled_media_temperature":true, "temperature_threshold":82.0, "alarm_enabled_ctrl_temperature":true, "controller_temperature_threshold":98.0, "alarm_enabled_spares":true, "spares_threshold":50, "shutdown_state":"clean", "shutdown_count":4 } }, [...] ]
추가 리소스
-
ndctl-list(1)매뉴얼 페이지
17.10. 손상된 NVDIMM 장치 탐지 및 교체
시스템 로그 또는 S.M.A.R.T.T.에 의해 보고된 NVDIMM(Non-Volatile Dual In-line Memory Modules)과 관련된 오류 메시지가 발견되면 NVDIMM 장치가 실패할 수 있습니다. 이 경우 다음을 수행해야 합니다.
- 어떤 NVDIMM 장치가 실패하는지 탐지합니다.
- 여기에 저장된 데이터를 백업
- 물리적으로 장치를 교체
절차
손상된 장치를 감지합니다.
# ndctl list --dimms --regions --health { "dimms":[ { "dev":"nmem1", "id":"8089-a2-1834-00001f13", "handle":17, "phys_id":32, "security":"disabled", "health":{ "health_state":"ok", "temperature_celsius":35.0, [...] } [...] }손상된 NVDIMM의 Restics
_id특성을 찾습니다.# ndctl list --dimms --human
이전 예에서
nmem0이 손상된 NVDIMM임을 알 수 있습니다. 따라서nmem0의ECDHEs_id특성을 찾습니다.예 17.7. NVDIMM의 Restics_id 속성
다음 예에서 Restics
_id는0x10입니다.# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ]손상된 NVDIMM의 메모리 슬롯을 찾습니다.
# dmidecode
출력에서 Handle 식별자가 손상된 NVDIMM의 Restics
_id속성과 일치하는 항목을 찾습니다. 이 필드에 는 손상된 NVDIMM에서 사용하는 메모리 슬롯이 나열됩니다.예 17.8. NVDIMM 메모리 슬롯 목록
다음 예에서
nmem0장치는0x0010식별자와 일치하며DIMM-XXX-YYY 메모리 슬롯을 사용합니다.# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ...NVDIMM의 네임스페이스의 모든 데이터를 백업합니다. NVDIMM을 교체하기 전에 데이터를 백업하지 않으면 시스템에서 NVDIMM을 제거할 때 데이터가 손실됩니다.
주의NVDIMM이 완전히 손상될 때와 같이 경우에 따라 백업이 실패할 수 있습니다.
이를 방지하기 위해 S.M.A.R.T. 를 사용하여 NVDIMM 상태 모니터링에 설명된 대로 NVDIMM 장치를 정기적으로 모니터링하고 오류가 발생하기 전에 NVDIMM을 교체합니다.
NVDIMM의 네임스페이스를 나열합니다.
# ndctl list --namespaces --dimm=DIMM-ID-number예 17.9. NVDIMM 네임스페이스 목록
다음 예에서
nmem0장치에는 백업해야 하는namespace0.0및namespace0.2네임스페이스가 포함되어 있습니다.# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ]- 손상된 NVDIMM을 물리적으로 교체하십시오.
추가 리소스
-
ndctl-list(1)및dmidecode(8)매뉴얼 페이지
18장. Stratis 파일 시스템 설정
Stratis는 물리적 스토리지 장치 풀을 관리하기 위해 서비스로 실행되며, 복잡한 스토리지 구성을 설정하고 관리할 수 있도록 쉽게 로컬 스토리지 관리를 단순화합니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 프로덕션 환경에서 사용하는 것은 권장되지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 를 참조하십시오.
18.1. Stratis 정의
Stratis는 Linux를 위한 로컬 스토리지 관리 솔루션입니다. 단순성과 사용 편의성에 중점을 두고 있으며 고급 스토리지 기능에 액세스할 수 있습니다.
Stratis를 사용하면 다음과 같은 작업을 더 쉽게 수행할 수 있습니다.
- 스토리지의 초기 구성
- 나중에 변경
- 고급 스토리지 기능 사용
Stratis는 고급 스토리지 기능을 지원하는 하이브리드 사용자 및 커널 로컬 스토리지 관리 시스템입니다. Stratis의 중심 개념은 스토리지 풀 입니다. 이 풀은 하나 이상의 로컬 디스크 또는 파티션에서 생성되며 풀에서 볼륨이 생성됩니다.
이 풀을 사용하면 다음과 같은 많은 유용한 기능을 사용할 수 있습니다.
- 파일 시스템 스냅샷
- 씬 프로비저닝
- 계층화
추가 리소스
18.2. Stratis 볼륨의 구성 요소
Stratis 볼륨을 구성하는 구성 요소에 대해 알아봅니다.
외부에서 Stratis는 명령줄 인터페이스 및 API에 다음과 같은 볼륨 구성 요소를 제공합니다.
blockdev- 디스크 또는 디스크 파티션과 같은 블록 장치입니다.
pool하나 이상의 블록 장치로 구성됩니다.
풀은 블록 장치의 크기와 같은 고정된 총 크기를 갖습니다.
이 풀에는
dm-cache대상을 사용하는 비volatile 데이터 캐시와 같은 대부분의 Stratis 계층이 포함되어 있습니다.Stratis는 각 풀에 대해
/dev/stratis/my-pool/디렉터리를 생성합니다. 이 디렉터리에는 풀의 Stratis 파일 시스템을 나타내는 장치에 대한 링크가 포함되어 있습니다.
파일 시스템각 풀에는 파일을 저장하는 하나 이상의 파일 시스템이 포함될 수 있습니다.
파일 시스템은 씬 프로비저닝되며 크기가 고정되어 있지 않습니다. 파일 시스템의 실제 크기는 저장된 데이터로 증가합니다. 데이터 크기가 파일 시스템의 가상 크기에 도달하면 Stratis는 thin 볼륨과 파일 시스템을 자동으로 늘립니다.
파일 시스템은 XFS로 포맷됩니다.
중요Stratis는 Stratis를 사용하여 생성된 파일 시스템에 대한 정보를 추적하여 XFS를 인식하지 못하고, XFS를 사용하여 변경한 내용은 Stratis에서 자동으로 업데이트되지 않습니다. 사용자는 Stratis에서 관리하는 XFS 파일 시스템을 다시 포맷하거나 재구성해서는 안 됩니다.
Stratis는
/dev/stratis/my-pool/my-fs경로에 파일 시스템에 대한 링크를 생성합니다.
Stratis는 dmsetup 목록 및 /proc/partitions 파일에 표시되는 많은 장치 매퍼 장치를 사용합니다. 마찬가지로 lsblk 명령 출력은 Stratis의 내부 작업 및 계층을 반영합니다.
18.3. Stratis에서 사용할 수 있는 블록 장치
Stratis와 함께 사용할 수 있는 스토리지 장치입니다.
지원되는 장치
Stratis 풀은 이러한 유형의 블록 장치에서 작동하도록 테스트되었습니다.
- LUKS
- LVM 논리 볼륨
- MD RAID
- DM Multipath
- iSCSI
- Restics 및 SSD
- NVMe 장치
지원되지 않는 장치
Stratis에는 thin-provisioning 계층이 포함되어 있으므로 이미 씬 프로비저닝된 블록 장치에 Stratis 풀을 배치하는 것은 권장되지 않습니다.
18.4. Stratis 설치
Stratis에 필요한 패키지를 설치합니다.
절차
Stratis 서비스 및 명령줄 유틸리티를 제공하는 패키지를 설치합니다.
# dnf install stratisd stratis-cli
stratisd서비스가 활성화되었는지 확인합니다.# systemctl enable --now stratisd
18.5. 암호화되지 않은 Stratis 풀 생성
하나 이상의 블록 장치에서 암호화되지 않은 Stratis 풀을 생성할 수 있습니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀을 생성하는 블록 장치는 사용 중이 아니며 마운트되지 않습니다.
- Stratis 풀을 생성하는 각 블록 장치는 최소 1GB입니다.
-
IBM Z 아키텍처에서
/dev/dasd*블록 장치를 분할해야 합니다. Stratis 풀의 파티션을 사용합니다.
DASD 장치 파티셔닝에 대한 자세한 내용은 IBM Z에서 Linux 인스턴스 구성을 참조하십시오.
암호화되지 않은 Stratis 풀을 암호화할 수 없습니다.
절차
Stratis 풀에 사용하려는 각 블록 장치에 존재하는 파일 시스템, 파티션 테이블 또는 RAID 서명을 해제합니다.
# wipefs --all block-device여기서
block-device는 블록 장치의 경로입니다(예:/dev/sdb).선택한 블록 장치에 암호화되지 않은 새 Stratis 풀을 생성합니다.
# stratis pool create my-pool block-device
여기서
block-device는 빈 또는 초기화된 블록 장치의 경로입니다.참고한 줄에 여러 블록 장치를 지정합니다.
# stratis pool create my-pool block-device-1 block-device-2
새 Stratis 풀이 생성되었는지 확인합니다.
# stratis pool list
18.6. 암호화된 Stratis 풀 생성
데이터를 보호하려면 하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 수 있습니다.
암호화된 Stratis 풀을 생성할 때 커널 키링이 기본 암호화 메커니즘으로 사용됩니다. 후속 시스템을 재부팅한 후 이 커널 키는 암호화된 Stratis 풀의 잠금을 해제하는 데 사용됩니다.
하나 이상의 블록 장치에서 암호화된 Stratis 풀을 생성할 때 다음 사항에 유의하십시오.
-
각 블록 장치는
cryptsetup라이브러리를 사용하여 암호화되며LUKS2형식을 구현합니다. - 각 Stratis 풀은 고유한 키를 보유하거나 다른 풀과 동일한 키를 공유할 수 있습니다. 이러한 키는 커널 키링에 저장됩니다.
- Stratis 풀을 구성하는 블록 장치는 모두 암호화되거나 암호화되지 않아야 합니다. 동일한 Stratis 풀에 암호화되거나 암호화되지 않은 블록 장치를 둘 다 가질 수 없습니다.
- 암호화된 Stratis 풀의 데이터 계층에 추가된 블록 장치는 자동으로 암호화됩니다.
사전 요구 사항
- Stratis v2.1.0 이상이 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀을 생성하는 블록 장치는 사용 중이 아니며 마운트되지 않습니다.
- Stratis 풀을 생성하는 블록 장치는 각각 크기가 최소 1GB입니다.
-
IBM Z 아키텍처에서
/dev/dasd*블록 장치를 분할해야 합니다. Stratis 풀의 파티션을 사용합니다.
DASD 장치 파티셔닝에 대한 자세한 내용은 IBM Z에서 Linux 인스턴스 구성을 참조하십시오.
절차
Stratis 풀에 사용하려는 각 블록 장치에 존재하는 파일 시스템, 파티션 테이블 또는 RAID 서명을 해제합니다.
# wipefs --all block-device여기서
block-device는 블록 장치의 경로입니다(예:/dev/sdb).키 세트를 아직 생성하지 않은 경우 다음 명령을 실행하고 프롬프트에 따라 암호화에 사용할 키 세트를 생성합니다.
# stratis key set --capture-key key-description여기서
key-description은 커널 키링에 생성되는 키에 대한 참조입니다.암호화된 Stratis 풀을 생성하고 암호화에 사용할 키 설명을 지정합니다.
key-description옵션을 사용하는 대신--keyfile-path옵션을 사용하여 키 경로를 지정할 수도 있습니다.# stratis pool create --key-desc key-description my-pool block-device
다음과 같습니다.
key-description- 이전 단계에서 생성한 커널 키링에 있는 키를 참조합니다.
my-pool- 새 Stratis 풀의 이름을 지정합니다.
block-device빈 또는 초기화된 블록 장치의 경로를 지정합니다.
참고한 줄에 여러 블록 장치를 지정합니다.
# stratis pool create --key-desc key-description my-pool block-device-1 block-device-2
새 Stratis 풀이 생성되었는지 확인합니다.
# stratis pool list
18.7. Stratis 파일 시스템에서 씬 프로비저닝 계층 설정
스토리지 스택은 overprovision 상태에 도달할 수 있습니다. 파일 시스템 크기가 지원하는 풀보다 큰 경우 풀이 가득 차게 됩니다. 이를 방지하려면 과도한 프로비저닝을 비활성화하여 풀의 모든 파일 시스템의 크기가 풀에서 제공하는 사용 가능한 물리적 스토리지를 초과하지 않도록 합니다. 중요한 애플리케이션 또는 루트 파일 시스템에 Stratis를 사용하는 경우 이 모드에서는 특정 실패 사례를 방지합니다.
과도한 프로비저닝을 활성화하면 API 신호가 스토리지가 완전히 할당되었을 때 이를 알립니다. 알림은 모든 나머지 풀 공간이 가득 차면 Stratis에 확장할 공간이 없음을 알리는 경고 역할을 합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. 자세한 내용은 Stratis 설치를 참조하십시오.
절차
풀을 올바르게 설정하려면 다음 두 가지 가능성이 있습니다.
하나 이상의 블록 장치에서 풀을 생성합니다.
# stratis pool create --no-overprovision pool-name /dev/sdb
-
no-overprovision옵션을 사용하면 풀에서 실제 사용 가능한 물리적 공간보다 더 많은 논리 공간을 할당할 수 없습니다.
-
기존 풀에서 프로비저닝 모드로 설정합니다.
# stratis pool overprovision pool-name <yes|no>- "yes"로 설정하면 풀에 과다 프로비저닝을 활성화합니다. 즉, Stratis 파일 시스템의 논리 크기 합계는 사용 가능한 데이터 공간 크기를 초과할 수 있습니다.
검증
다음을 실행하여 Stratis 풀의 전체 목록을 확인합니다.
# stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540-
stratis pool list출력에 overprovisioning mode 플래그의 표시가 있는지 확인합니다. " ~"은 "NOT"의 수학 기호이므로~Op는 no-overprovisioning을 의미합니다. 선택 사항: 다음을 실행하여 특정 풀에서 과다 프로비저닝을 확인합니다.
# stratis pool overprovision pool-name yes # stratis pool list Name Total Physical Properties UUID Alerts pool-name 1.42 TiB / 23.96 MiB / 1.42 TiB ~Ca,~Cr,~Op cb7cb4d8-9322-4ac4-a6fd-eb7ae9e1e540
추가 리소스
18.8. Stratis 풀을 NBDE에 바인딩
암호화된 Stratis 풀을NBDE(Network Bound Disk Encryption)에 바인딩하려면 Tang 서버가 필요합니다. Stratis 풀이 포함된 시스템이 재부팅되면 커널 키링 설명을 제공하지 않고도 Tang 서버와 자동으로 암호화된 풀의 잠금을 해제합니다.
Stratis 풀을 Clevis 암호화 메커니즘에 바인딩하면 기본 커널 키링 암호화가 제거되지 않습니다.
사전 요구 사항
- Stratis v2.3.0 이상이 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 암호화된 Stratis 풀을 생성했으며 암호화에 사용된 키의 주요 설명이 있습니다. 자세한 내용은 암호화된 Stratis 풀 생성을 참조하십시오.
- Tang 서버에 연결할 수 있습니다. 자세한 내용은 강제 모드에서 SELinux를 사용하여 Tang 서버배포를 참조하십시오.
절차
암호화된 Stratis 풀을 NBDE에 바인딩합니다.
# stratis pool bind nbde --trust-url my-pool tang-server
다음과 같습니다.
my-pool- 암호화된 Stratis 풀의 이름을 지정합니다.
tang-server- Tang 서버의 IP 주소 또는 URL을 지정합니다.
18.9. Stratis 풀을 TPM에 바인딩
암호화된 Stratis 풀을 신뢰할 수 있는 플랫폼 모듈(TPM) 2.0에 바인딩하면 풀이 재부팅될 때 커널 키링 설명을 제공하지 않아도 풀이 자동으로 잠금 해제됩니다.
사전 요구 사항
- Stratis v2.3.0 이상이 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 암호화된 Stratis 풀을 생성했습니다. 자세한 내용은 암호화된 Stratis 풀 생성을 참조하십시오.
절차
암호화된 Stratis 풀을 TPM에 바인딩합니다.
# stratis pool bind tpm my-pool key-description
다음과 같습니다.
my-pool- 암호화된 Stratis 풀의 이름을 지정합니다.
key-description- 암호화된 Stratis 풀을 생성할 때 생성된 커널 키링에 있는 키를 참조합니다.
18.10. 커널 키링을 사용하여 암호화된 Stratis 풀 잠금 해제
시스템이 재부팅되면 암호화된 Stratis 풀 또는 이를 구성하는 블록 장치가 표시되지 않을 수 있습니다. 풀을 암호화하는 데 사용된 커널 인증 키를 사용하여 풀의 잠금을 해제할 수 있습니다.
사전 요구 사항
- Stratis v2.1.0이 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 암호화된 Stratis 풀을 생성했습니다. 자세한 내용은 암호화된 Stratis 풀 생성을 참조하십시오.
절차
이전에 사용된 것과 동일한 키 설명을 사용하여 키 세트를 다시 생성합니다.
# stratis key set --capture-key key-description여기서 key-description 은 암호화된 Stratis 풀을 생성할 때 생성된 커널 인증 키에 있는 키를 참조합니다.
Stratis 풀 및 이를 구성하는 블록 장치의 잠금을 해제합니다.
# stratis pool unlock keyring
Stratis 풀이 표시되는지 확인합니다.
# stratis pool list
18.11. Clevis를 사용하여 암호화된 Stratis 풀 잠금 해제
시스템이 재부팅되면 암호화된 Stratis 풀 또는 이를 구성하는 블록 장치가 표시되지 않을 수 있습니다. 풀이 바인딩된 암호화 메커니즘을 사용하여 암호화된 Stratis 풀의 잠금을 해제할 수 있습니다.
사전 요구 사항
- Stratis v2.3.0 이상이 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 암호화된 Stratis 풀을 생성했습니다. 자세한 내용은 암호화된 Stratis 풀 생성을 참조하십시오.
- 암호화된 Stratis 풀은 지원되는 제공 암호화 메커니즘에 바인딩됩니다. 자세한 내용은 암호화된 Stratis 풀을 NBDE에 바인딩 하거나 암호화된 Stratis 풀을 TPM에 바인딩을 참조하십시오.
절차
Stratis 풀 및 이를 구성하는 블록 장치의 잠금을 해제합니다.
# stratis pool unlock clevis
Stratis 풀이 표시되는지 확인합니다.
# stratis pool list
18.12. Stratis 풀의 암호화 바인딩 해제
지원되는 제공 암호화 메커니즘에서 암호화된 Stratis 풀을 바인딩 해제하면 기본 커널 키링 암호화가 그대로 유지됩니다.
사전 요구 사항
- Stratis v2.3.0 이상이 시스템에 설치되어 있습니다. 자세한 내용은 Stratis 설치를 참조하십시오.
- 암호화된 Stratis 풀을 생성했습니다. 자세한 내용은 암호화된 Stratis 풀 생성을 참조하십시오.
- 암호화된 Stratis 풀은 지원되는 제공 암호화 메커니즘에 바인딩됩니다.
절차
암호화 메커니즘에서 암호화된 Stratis 풀을 바인딩 해제합니다.
# stratis pool unbind clevis my-pool다음과 같습니다.
my-pool은 바인딩 해제할 Stratis 풀의 이름을 지정합니다.
18.13. Stratis 풀 시작 및 중지
Stratis 풀을 시작하고 중지할 수 있습니다. 이를 통해 파일 시스템, 캐시 장치, 씬 풀 및 암호화된 장치와 같은 풀을 구성하는 데 사용된 모든 개체를 분리하거나 가져올 수 있습니다. 풀이 적극적으로 모든 장치 또는 파일 시스템을 사용하는 경우 경고를 발행하고 중지할 수 없습니다.
중지된 풀은 해당 메타데이터에 중지된 상태를 기록합니다. 이러한 풀은 풀에서 시작 명령을 수신할 때까지 다음 부팅 시 시작되지 않습니다.
암호화되지 않은 경우 이전에 시작된 풀은 부팅 시 자동으로 시작됩니다. 풀 잠금 해제는 이 Stratis 버전에서 은 부팅 시 항상 시작되는 풀 로 교체되므로 암호화된 풀pool start 명령이 필요합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - 암호화되지 않은 또는 암호화된 Stratis 풀 중 하나를 생성했습니다. 암호화되지 않은 Stratis 풀 생성 또는 암호화된 Stratis 풀 생성을 참조하십시오.
절차
다음 명령을 사용하여 Stratis 풀을 시작합니다.
--unlock-method옵션은 암호화된 경우 풀 잠금 해제 방법을 지정합니다.# stratis pool start pool-uuid --unlock-method <keyring|clevis>또는 다음 명령을 사용하여 Stratis 풀을 중지합니다. 이렇게 하면 스토리지 스택이 줄어들지만 모든 메타데이터는 그대로 유지됩니다.
# stratis pool stop pool-name
검증 단계
다음 명령을 사용하여 시스템의 모든 풀을 나열합니다.
# stratis pool list
다음 명령을 사용하여 이전에 시작한 풀을 모두 나열합니다. UUID를 지정하면 명령은 UUID에 해당하는 풀에 대한 세부 정보를 출력합니다.
# stratis pool list --stopped --uuid UUID
18.14. Stratis 파일 시스템 생성
기존 Stratis 풀에 Stratis 파일 시스템을 생성합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀을 생성했습니다. 암호화되지 않은 Stratis 풀 생성 또는 암호화된 Stratis 풀 생성을 참조하십시오.
절차
풀에 Stratis 파일 시스템을 생성하려면 다음을 사용합니다.
# stratis filesystem create --size number-and-unit my-pool my-fs
다음과 같습니다.
number-and-unit- 파일 시스템의 크기를 지정합니다. 사양 형식은 입력의 표준 크기 사양 형식(B, KiB, MiB, GiB, TiB 또는 PiB)을 따라야 합니다.
my-pool- Stratis 풀의 이름을 지정합니다.
my-fs파일 시스템의 임의의 이름을 지정합니다.
예를 들면 다음과 같습니다.
예 18.1. Stratis 파일 시스템 생성
# stratis filesystem create --size 10GiB pool1 filesystem1
검증 단계
풀을 사용하여 파일 시스템을 나열하여 Stratis 파일 시스템이 생성되었는지 확인합니다.
# stratis fs list my-pool
추가 리소스
18.15. Stratis 파일 시스템 마운트
기존 Stratis 파일 시스템을 마운트하여 콘텐츠에 액세스합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. 자세한 내용은 Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 파일 시스템을 생성했습니다. 자세한 내용은 Stratis 파일 시스템 생성을 참조하십시오.
절차
파일 시스템을 마운트하려면 Stratis가
/dev/stratis/디렉터리에 유지보수하는 항목을 사용합니다.# mount /dev/stratis/my-pool/my-fs mount-point
이제 파일 시스템이 마운트 지점 디렉터리에 마운트되어 사용할 준비가 되었습니다.
추가 리소스
18.16. Stratis 파일 시스템 영구적으로 마운트
이 절차에서는 Stratis 파일 시스템을 영구적으로 마운트하므로 시스템을 부팅한 후 자동으로 사용할 수 있습니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 파일 시스템을 생성했습니다. Stratis 파일 시스템 생성을 참조하십시오.
절차
파일 시스템의 UUID 특성을 확인합니다.
$ lsblk --output=UUID /dev/stratis/my-pool/my-fs
예를 들면 다음과 같습니다.
예 18.2. Stratis 파일 시스템의 UUID 보기
$ lsblk --output=UUID /dev/stratis/my-pool/fs1 UUID a1f0b64a-4ebb-4d4e-9543-b1d79f600283
마운트 지점 디렉터리가 없는 경우 다음을 생성합니다.
# mkdir --parents mount-pointroot로
/etc/fstab파일을 편집하고 UUID로 식별되는 파일 시스템에 대한 행을 추가합니다.xfs를 파일 시스템 유형으로 사용하고x-systemd.requires=stratisd.service옵션을 추가합니다.예를 들면 다음과 같습니다.
예 18.3. /etc/fstab의 /fs1 마운트 지점
UUID=a1f0b64a-4ebb-4d4e-9543-b1d79f600283 /fs1 xfs defaults,x-systemd.requires=stratisd.service 0 0
시스템이 새 구성을 등록하도록 다시 마운트 단위를 다시 생성합니다.
# systemctl daemon-reload
파일 시스템을 마운트하여 구성이 작동하는지 확인합니다.
# mount mount-point
추가 리소스
18.17. systemd 서비스를 사용하여 /etc/fstab에서 루트가 아닌 Stratis 파일 시스템 설정
systemd 서비스를 사용하여 /etc/fstab에서 루트가 아닌 파일 시스템 설정을 관리할 수 있습니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 파일 시스템을 생성했습니다. Stratis 파일 시스템 생성을 참조하십시오.
절차
루트가 아닌 모든 Stratis 파일 시스템의 경우 다음을 사용합니다.
# /dev/stratis/[STRATIS_SYMLINK] [MOUNT_POINT] xfs defaults, x-systemd.requires=stratis-fstab-setup@[POOL_UUID].service,x-systemd.after=stratis-stab-setup@[POOL_UUID].service <dump_value> <fsck_value>
추가 리소스
19장. 추가 블록 장치를 사용하여 Stratis 볼륨 확장
Stratis 풀에 추가 블록 장치를 연결하여 Stratis 파일 시스템에 더 많은 스토리지 용량을 제공할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 프로덕션 환경에서 사용하는 것은 권장되지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 를 참조하십시오.
19.1. Stratis 볼륨의 구성 요소
Stratis 볼륨을 구성하는 구성 요소에 대해 알아봅니다.
외부에서 Stratis는 명령줄 인터페이스 및 API에 다음과 같은 볼륨 구성 요소를 제공합니다.
blockdev- 디스크 또는 디스크 파티션과 같은 블록 장치입니다.
pool하나 이상의 블록 장치로 구성됩니다.
풀은 블록 장치의 크기와 같은 고정된 총 크기를 갖습니다.
이 풀에는
dm-cache대상을 사용하는 비volatile 데이터 캐시와 같은 대부분의 Stratis 계층이 포함되어 있습니다.Stratis는 각 풀에 대해
/dev/stratis/my-pool/디렉터리를 생성합니다. 이 디렉터리에는 풀의 Stratis 파일 시스템을 나타내는 장치에 대한 링크가 포함되어 있습니다.
파일 시스템각 풀에는 파일을 저장하는 하나 이상의 파일 시스템이 포함될 수 있습니다.
파일 시스템은 씬 프로비저닝되며 크기가 고정되어 있지 않습니다. 파일 시스템의 실제 크기는 저장된 데이터로 증가합니다. 데이터 크기가 파일 시스템의 가상 크기에 도달하면 Stratis는 thin 볼륨과 파일 시스템을 자동으로 늘립니다.
파일 시스템은 XFS로 포맷됩니다.
중요Stratis는 Stratis를 사용하여 생성된 파일 시스템에 대한 정보를 추적하여 XFS를 인식하지 못하고, XFS를 사용하여 변경한 내용은 Stratis에서 자동으로 업데이트되지 않습니다. 사용자는 Stratis에서 관리하는 XFS 파일 시스템을 다시 포맷하거나 재구성해서는 안 됩니다.
Stratis는
/dev/stratis/my-pool/my-fs경로에 파일 시스템에 대한 링크를 생성합니다.
Stratis는 dmsetup 목록 및 /proc/partitions 파일에 표시되는 많은 장치 매퍼 장치를 사용합니다. 마찬가지로 lsblk 명령 출력은 Stratis의 내부 작업 및 계층을 반영합니다.
19.2. Stratis 풀에 블록 장치 추가
이 절차에서는 Stratis 파일 시스템에서 사용할 수 있도록 Stratis 풀에 하나 이상의 블록 장치를 추가합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 풀에 추가하는 블록 장치는 사용 중이 아니며 마운트되지 않습니다.
- Stratis 풀에 추가하는 블록 장치는 각각 크기가 1GiB 이상입니다.
절차
하나 이상의 블록 장치를 풀에 추가하려면 다음을 사용합니다.
# stratis pool add-data my-pool device-1 device-2 device-n
추가 리소스
-
Stratis(8)매뉴얼 페이지
19.3. 추가 리소스
20장. Stratis 파일 시스템 모니터링
Stratis 사용자는 시스템의 Stratis 볼륨에 대한 정보를 보고 상태 및 여유 공간을 모니터링할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 프로덕션 환경에서 사용하는 것은 권장되지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 를 참조하십시오.
20.1. 다양한 유틸리티에서 보고한 Stratis 크기
이 섹션에서는 df 및 stratis 유틸리티와 같은 표준 유틸리티에서 보고한 Stratis 크기 간의 차이점을 설명합니다.
df 와 같은 표준 Linux 유틸리티는 Stratis의 XFS 파일 시스템 계층 크기를 1TiB로 보고합니다. Stratis의 실제 스토리지 사용량이 씬 프로비저닝으로 인해 줄어들고 XFS 계층이 가득 찼을 때 Stratis가 파일 시스템을 자동으로 확장하기 때문에 유용한 정보가 아닙니다.
Stratis 파일 시스템에 작성된 데이터의 양을 정기적으로 모니터링합니다. 이 값은 총 물리 사용 값으로 보고됩니다. 전체 물리 크기 값을 초과하지 않는지 확인합니다.
추가 리소스
-
Stratis(8)매뉴얼 페이지.
20.2. Stratis 볼륨에 대한 정보 표시
이 절차에서는 Stratis 볼륨에 대한 통계를 나열합니다(예: 풀에 속하는 총, 사용된 크기, 여유 크기 또는 파일 시스템 및 블록 장치).
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다.
절차
시스템에서 Stratis에 사용되는 모든 블록 장치에 대한 정보를 표시하려면 다음을 수행합니다.
# stratis blockdev Pool Name Device Node Physical Size State Tier my-pool /dev/sdb 9.10 TiB In-use Data
시스템의 모든 Stratis 풀에 대한 정보를 표시하려면 다음을 수행합니다.
# stratis pool Name Total Physical Size Total Physical Used my-pool 9.10 TiB 598 MiB
시스템의 모든 Stratis 파일 시스템에 대한 정보를 표시하려면 다음을 수행하십시오.
# stratis filesystem Pool Name Name Used Created Device my-pool my-fs 546 MiB Nov 08 2018 08:03 /dev/stratis/my-pool/my-fs
추가 리소스
-
Stratis(8)매뉴얼 페이지.
20.3. 추가 리소스
21장. Stratis 파일 시스템에서 스냅샷 사용
Stratis 파일 시스템에서 스냅샷을 사용하여 파일 시스템 상태를 임의의 시간에 캡처하고 나중에 복원할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 프로덕션 환경에서 사용하는 것은 권장되지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 를 참조하십시오.
21.1. Stratis 스냅샷의 특성
Stratis에서 스냅샷은 다른 Stratis 파일 시스템의 사본으로 생성된 일반 Stratis 파일 시스템입니다. 처음에는 스냅샷에 원래 파일 시스템과 동일한 파일 내용이 포함되어 있지만 스냅샷이 수정되면 변경될 수 있습니다. 스냅샷을 변경하면 원래 파일 시스템에 반영되지 않습니다.
Stratis의 현재 스냅샷 구현은 다음과 같습니다.
- 파일 시스템의 스냅샷은 다른 파일 시스템입니다.
- 스냅샷과 해당 원본은 수명 동안 연결되지 않습니다. 스냅샷된 파일 시스템은 생성된 파일 시스템보다 오래 유지될 수 있습니다.
- 파일 시스템을 마운트하여 스냅샷을 생성할 필요가 없습니다.
- 각 스냅샷은 XFS 로그에 필요한 약 1GB의 실제 백업 스토리지를 사용합니다.
21.2. Stratis 스냅샷 생성
이 절차에서는 기존 Stratis 파일 시스템의 스냅샷으로 Stratis 파일 시스템을 생성합니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 파일 시스템을 생성했습니다. Stratis 파일 시스템 생성을 참조하십시오.
절차
Stratis 스냅샷을 생성하려면 다음을 사용합니다.
# stratis fs snapshot my-pool my-fs my-fs-snapshot
추가 리소스
-
Stratis(8)매뉴얼 페이지.
21.3. Stratis 스냅샷의 콘텐츠에 액세스
이 절차에서는 Stratis 파일 시스템의 스냅샷을 마운트하여 읽기 및 쓰기 작업에서 액세스할 수 있습니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 스냅샷을 생성했습니다. Stratis 파일 시스템 생성을 참조하십시오.
절차
스냅샷에 액세스하려면
/dev/stratis/my-pool/디렉터리에서 일반 파일 시스템으로 마운트합니다.# mount /dev/stratis/my-pool/my-fs-snapshot mount-point
추가 리소스
- Stratis 파일 시스템 마운트.
-
mount(8)매뉴얼 페이지.
21.4. Stratis 파일 시스템을 이전 스냅샷으로 되돌리기
이 절차에서는 Stratis 파일 시스템의 콘텐츠를 Stratis 스냅샷에 캡처된 상태로 되돌립니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 스냅샷을 생성했습니다. Stratis 스냅샷 생성 을 참조하십시오.
절차
선택적으로 나중에 액세스할 수 있도록 파일 시스템의 현재 상태를 백업하십시오.
# stratis filesystem snapshot my-pool my-fs my-fs-backup
원본 파일 시스템을 마운트 해제하고 제거합니다.
# umount /dev/stratis/my-pool/my-fs # stratis filesystem destroy my-pool my-fs
원래 파일 시스템의 이름 아래에 스냅샷 사본을 생성합니다.
# stratis filesystem snapshot my-pool my-fs-snapshot my-fs
이제 원래 파일 시스템과 동일한 이름으로 액세스할 수 있는 스냅샷을 마운트합니다.
# mount /dev/stratis/my-pool/my-fs mount-point
my-fs 라는 파일 시스템의 내용은 이제 스냅샷 my-fs-snapshot 과 동일합니다.
추가 리소스
-
Stratis(8)매뉴얼 페이지.
21.5. Stratis 스냅샷 제거
이 절차에서는 풀에서 Stratis 스냅샷을 제거합니다. 스냅샷의 데이터가 손실됩니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 스냅샷을 생성했습니다. Stratis 스냅샷 생성 을 참조하십시오.
절차
스냅샷을 마운트 해제합니다.
# umount /dev/stratis/my-pool/my-fs-snapshot
스냅샷을 삭제합니다.
# stratis filesystem destroy my-pool my-fs-snapshot
추가 리소스
-
Stratis(8)매뉴얼 페이지.
21.6. 추가 리소스
22장. Stratis 파일 시스템 제거
기존 Stratis 파일 시스템 또는 Stratis 풀을 제거하여 해당 시스템의 데이터를 제거할 수 있습니다.
Stratis는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 프로덕션 환경에서 사용하는 것은 권장되지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview 를 참조하십시오.
22.1. Stratis 볼륨의 구성 요소
Stratis 볼륨을 구성하는 구성 요소에 대해 알아봅니다.
외부에서 Stratis는 명령줄 인터페이스 및 API에 다음과 같은 볼륨 구성 요소를 제공합니다.
blockdev- 디스크 또는 디스크 파티션과 같은 블록 장치입니다.
pool하나 이상의 블록 장치로 구성됩니다.
풀은 블록 장치의 크기와 같은 고정된 총 크기를 갖습니다.
이 풀에는
dm-cache대상을 사용하는 비volatile 데이터 캐시와 같은 대부분의 Stratis 계층이 포함되어 있습니다.Stratis는 각 풀에 대해
/dev/stratis/my-pool/디렉터리를 생성합니다. 이 디렉터리에는 풀의 Stratis 파일 시스템을 나타내는 장치에 대한 링크가 포함되어 있습니다.
파일 시스템각 풀에는 파일을 저장하는 하나 이상의 파일 시스템이 포함될 수 있습니다.
파일 시스템은 씬 프로비저닝되며 크기가 고정되어 있지 않습니다. 파일 시스템의 실제 크기는 저장된 데이터로 증가합니다. 데이터 크기가 파일 시스템의 가상 크기에 도달하면 Stratis는 thin 볼륨과 파일 시스템을 자동으로 늘립니다.
파일 시스템은 XFS로 포맷됩니다.
중요Stratis는 Stratis를 사용하여 생성된 파일 시스템에 대한 정보를 추적하여 XFS를 인식하지 못하고, XFS를 사용하여 변경한 내용은 Stratis에서 자동으로 업데이트되지 않습니다. 사용자는 Stratis에서 관리하는 XFS 파일 시스템을 다시 포맷하거나 재구성해서는 안 됩니다.
Stratis는
/dev/stratis/my-pool/my-fs경로에 파일 시스템에 대한 링크를 생성합니다.
Stratis는 dmsetup 목록 및 /proc/partitions 파일에 표시되는 많은 장치 매퍼 장치를 사용합니다. 마찬가지로 lsblk 명령 출력은 Stratis의 내부 작업 및 계층을 반영합니다.
22.2. Stratis 파일 시스템 제거
이 절차에서는 기존 Stratis 파일 시스템을 제거합니다. 저장된 데이터는 손실됩니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. - Stratis 파일 시스템을 생성했습니다. Stratis 파일 시스템 생성을 참조하십시오.
절차
파일 시스템을 마운트 해제합니다.
# umount /dev/stratis/my-pool/my-fs
파일 시스템을 삭제합니다.
# stratis filesystem destroy my-pool my-fs
파일 시스템이 더 이상 존재하지 않는지 확인합니다.
# stratis filesystem list my-pool
추가 리소스
-
Stratis(8)매뉴얼 페이지.
22.3. Stratis 풀 제거
이 절차에서는 기존 Stratis 풀을 제거합니다. 저장된 데이터는 손실됩니다.
사전 요구 사항
- Stratis가 설치되어 있어야 합니다. Stratis 설치를 참조하십시오.
-
stratisd서비스가 실행 중입니다. Stratis 풀을 생성했습니다.
- 암호화되지 않은 풀을 생성하려면 암호화되지 않은 Stratis 풀 생성을참조하십시오.
- 암호화된 풀을 생성하려면 암호화된 Stratis 풀 생성을 참조하십시오.
절차
풀의 파일 시스템을 나열합니다.
# stratis filesystem list my-pool풀에서 모든 파일 시스템을 마운트 해제합니다.
# umount /dev/stratis/my-pool/my-fs-1 \ /dev/stratis/my-pool/my-fs-2 \ /dev/stratis/my-pool/my-fs-n
파일 시스템을 삭제합니다.
# stratis filesystem destroy my-pool my-fs-1 my-fs-2
풀을 삭제합니다.
# stratis pool destroy my-pool풀이 더 이상 존재하지 않는지 확인합니다.
# stratis pool list
추가 리소스
-
Stratis(8)매뉴얼 페이지.