
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
스토리지 관리 가이드
RHEL 7에서 단일 노드 스토리지 배포 및 구성
초록
1장. 개요
1.1. Red Hat Enterprise Linux 7의 새로운 기능 및 기능 개선
1.1.1. ecryptfs가 포함되지 않음
1.1.2. 시스템 스토리지 관리자
1.1.3. XFS는 기본 파일 시스템입니다.
1.1.4. 파일 시스템 재구성
/bin,/sbin,/lib, /lib64 디렉토리가 이제 /usr 아래에 중첩됩니다.
1.1.5. snapper
1.1.6. 1.8.0 (기술 프리뷰)
1.1.7. NFSv2 더 이상 지원되지 않음
I 부. 파일 시스템
2장. 파일 시스템 구조 및 유지 관리
- 편집할 수 있고 이해할 수 없는 파일
- 공유할 수 있는 파일은 로컬 및 원격 호스트에서 액세스할 수 있습니다. Unsharable 파일은 로컬에만 사용할 수 있습니다.
- 변수 및 정적 파일
- 문서와 같은 변수 파일은 언제든지 변경할 수 있습니다. 바이너리와 같은 정적 파일은 시스템 관리자의 작업 없이 변경되지 않습니다.
2.1. 파일 시스템 계층 구조 표준(FHS) 개요
- 다른 FHS 호환 시스템과의 호환성
/usr/파티션을 읽기 전용으로 마운트하는 기능. 이는/usr/에 공통 실행 파일이 포함되어 있으므로 사용자가 변경할 수 없기 때문에 중요합니다. 또한/usr/가 읽기 전용으로 마운트되므로 CD-ROM 드라이브 또는 읽기 전용 NFS 마운트를 통해 다른 시스템에서 마운트할 수 있어야 합니다.
2.1.1. FHS Organization
2.1.1.1. 파일 시스템 정보 수집
2.1.1.1.1. DF 명령
예 2.1. DF 명령 출력
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
11675568 6272120 4810348 57% / /dev/sda1
100691 9281 86211 10% /boot
none 322856 0 322856 0% /dev/shm
예 2.2. df -h Command Output
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
12G 6.0G 4.6G 57% / /dev/sda1
99M 9.1M 85M 10% /boot
none 316M 0 316M 0% /dev/shm
/dev/shm 은 시스템의 가상 메모리 파일 시스템을 나타냅니다.
2.1.1.1.2. du Command
2.1.1.1.3. GNOME 시스템 모니터
그림 2.1. GNOME 시스템 모니터의 파일 시스템 탭
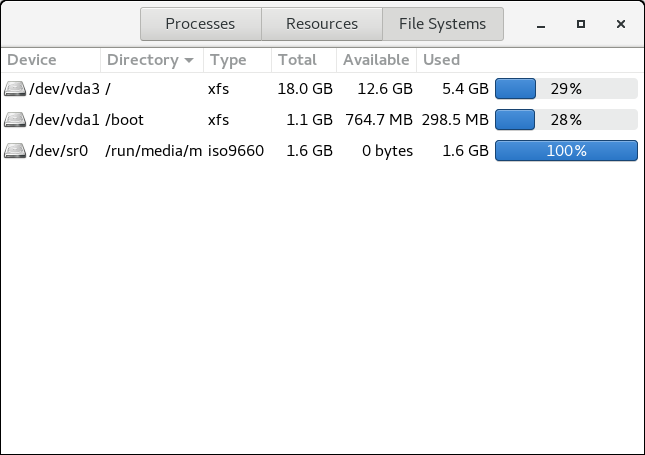
[D]
2.1.1.2. /boot/ 디렉토리
/boot/ 디렉터리에는 시스템을 부팅하는 데 필요한 정적 파일(예: Linux 커널)이 포함되어 있습니다. 이러한 파일은 시스템이 올바르게 부팅되는 데 필수적입니다.
/boot/ 디렉토리를 제거하지 마십시오. 이렇게 하면 시스템을 부팅할 수 없게 됩니다.
2.1.1.3. /dev/ Directory
/dev/ 디렉터리에는 다음 장치 유형을 나타내는 장치 노드가 포함되어 있습니다.
- 시스템에 연결된 장치;
- 커널에서 제공하는 가상 장치.
/dev/ 에서 장치 노드를 생성하고 제거합니다.
/dev/ 디렉토리 및 하위 디렉토리에 있는 장치는 문자 (입력 및 출력의 직렬 스트림만 제공) 또는 블록 (예: 하드 드라이브 또는 플로피 드라이브와 같은 무작위로 액세스할 수 있음)으로 정의됩니다. GNOME 또는 KDE가 설치되면 일부 스토리지 장치가 자동으로 감지되거나 (예: USB) 또는 삽입(예: CD 또는 DVD 드라이브)이 표시되고 콘텐츠를 표시하는 팝업 창이 표시됩니다.
표 2.1. /dev 디렉터리에 있는 공통 파일의 예
| 파일 | 설명 |
|---|---|
/dev/hda | 기본 IDE 채널의 마스터 장치입니다. |
/dev/hdb | 기본 IDE 채널의 슬레이브 장치입니다. |
/dev/tty0 | 첫 번째 가상 콘솔. |
/dev/tty1 | 두 번째 가상 콘솔. |
/dev/sda | 기본 SCSI 또는 SATA 채널의 첫 번째 장치입니다. |
/dev/lp0 | 첫 번째 병렬 포트. |
- 매핑된 장치
- 볼륨 그룹의 논리 볼륨(예:
/dev/mapper/VolGroup00-LogVol02). - 고정 장치
- 기존 스토리지 볼륨(예: /dev/ sdb X )은 스토리지 장치 이름이며 X 는 파티션 번호입니다.
/dev/sdbX는/dev/disk/by-id/WWID또는/dev/disk/by-uuid/UUID일 수도 있습니다. 자세한 내용은 25.8절. “영구 이름 지정” 에서 참조하십시오.
2.1.1.4. /etc/ 디렉터리
/etc/ 디렉토리는 시스템에 로컬인 구성 파일에 대해 예약되어 있습니다. 바이너리가 포함되어 있지 않아야 합니다. 바이너리가 있는 경우 /usr/bin/ 또는 /usr/sbin/ 로 이동합니다.
/etc/skel/ 디렉터리는 사용자를 처음 생성할 때 홈 디렉터리를 채우는 데 사용되는 "스케일론" 사용자 파일을 저장합니다. 애플리케이션은 또한 구성 파일을 이 디렉터리에 저장하고 실행할 때 참조할 수 있습니다. /etc/exports 파일은 원격 호스트로 내보내는 파일 시스템을 제어합니다.
2.1.1.5. /mnt/ 디렉터리
/mnt/ 디렉터리는 NFS 파일 시스템 마운트와 같이 임시 마운트된 파일 시스템을 위해 예약되어 있습니다. 이동식 모든 스토리지 미디어에 대해 /media/ 디렉터리를 사용합니다. 감지된 이동식 미디어가 /media 디렉터리에 자동으로 마운트됩니다.
/mnt 디렉토리는 설치 프로그램에서 사용해서는 안 됩니다.
2.1.1.6. /opt/ Directory
/opt/ 디렉토리는 일반적으로 기본 설치의 일부가 아닌 소프트웨어 및 애드온 패키지용으로 예약되어 있습니다. /opt/ 에 설치하는 패키지는 해당 이름이 포함된 디렉토리를 만듭니다(예: /opt/packagename/ ). 대부분의 경우 이러한 패키지는 예측 가능한 하위 디렉토리 구조를 따릅니다. 대부분의 경우 바이너리를 /opt/packagename/bin/ 에 저장하고 해당 도움말 페이지를 /opt/패키지 이름/ man / 에 저장합니다.
2.1.1.7. /proc/ 디렉토리
/proc/ 디렉토리에는 커널에서 정보를 추출하거나 정보를 전송하는 특수 파일이 포함되어 있습니다. 이러한 정보의 예로는 시스템 메모리, CPU 정보 및 하드웨어 구성이 있습니다. /proc/ 에 대한 자세한 내용은 2.3절. “/proc 가상 파일 시스템” 을 참조하십시오.
2.1.1.8. /srv/ 디렉터리
/srv/ 디렉터리에는 Red Hat Enterprise Linux 시스템에서 제공하는 사이트별 데이터가 포함되어 있습니다. 이 디렉토리는 사용자에게 FTP, WWW 또는 CVS와 같은 특정 서비스에 대한 데이터 파일의 위치를 제공합니다. 특정 사용자와 관련된 데이터만 /home/ 디렉토리에 있어야 합니다.
2.1.1.9. /sys/ 디렉터리
/sys/ 디렉터리는 커널과 관련된 새로운 sysfs 가상 파일 시스템을 사용합니다. 커널의 핫 플러그 하드웨어 장치에 대한 지원이 늘어남에 따라 /sys/ 디렉터리에는 /proc/ 에서 유지하는 것과 유사한 정보가 포함되어 있지만 핫 플러그 장치와 관련된 장치 정보의 계층적 보기가 표시됩니다.
2.1.1.10. /usr/ Directory
/usr/ 디렉토리는 여러 시스템에서 공유할 수 있는 파일용입니다. /usr/ 디렉토리는 종종 자체 파티션에 있으며 읽기 전용으로 마운트됩니다. 최소한 /usr/ 에는 다음 하위 디렉터리가 포함되어야 합니다.
/usr/bin- 이 디렉터리는 바이너리에 사용됩니다.
/usr/etc- 이 디렉터리는 시스템 전체 구성 파일에 사용됩니다.
/usr/ games- 이 디렉토리는 게임을 저장합니다.
/usr/include- 이 디렉토리는 C 헤더 파일에 사용됩니다.
/usr/kerberos- 이 디렉터리는 Kerberos 관련 바이너리 및 파일에 사용됩니다.
/usr/lib- 이 디렉토리는 쉘 스크립트 또는 사용자가 직접 사용하도록 설계되지 않은 오브젝트 파일 및 라이브러리에 사용됩니다.Red Hat Enterprise Linux 7.0부터
/lib/디렉터리가/usr/lib과 병합되었습니다. 이제/usr/bin/및/usr/sbin/에서 바이너리를 실행하는 데 필요한 라이브러리도 포함됩니다. 이러한 공유 라이브러리 이미지는 시스템을 부팅하거나 루트 파일 시스템 내에서 명령을 실행하는 데 사용됩니다. /usr/libexec- 이 디렉토리에는 다른 프로그램에서 호출되는 작은 도우미 프로그램이 포함되어 있습니다.
/usr/sbin- Red Hat Enterprise Linux 7.0부터
/sbin이/usr/sbin으로 변경되었습니다. 즉, 시스템 부팅, 복원, 복구 또는 복구에 필요한 시스템 관리 바이너리를 포함하여 모든 시스템 관리 바이너리가 포함됩니다./usr/sbin/의 바이너리에는 사용할 수 있는 root 권한이 필요합니다. /usr/share- 이 디렉터리는 아키텍처별로 차별화되지 않은 파일을 저장합니다.
/usr/src- 이 디렉터리는 소스 코드를 저장합니다.
/usr/tmp가/var/tmp에 연결됩니다.- 이 디렉터리는 임시 파일을 저장합니다.
/usr/ 디렉토리에는 /local/ 하위 디렉터리도 포함되어야 합니다. FHS에 따라 이 하위 디렉터리는 시스템 관리자가 로컬로 소프트웨어를 설치할 때 사용되며 시스템 업데이트 중에 안전하게 덮어쓰지 않아야 합니다. /usr/ local 디렉터리에는 /usr/ 과 유사한 구조가 있으며 다음 하위 디렉터리를 포함합니다.
/usr/local/bin/usr/local/etc/usr/local/plays/usr/local/include/usr/local/lib/usr/local/libexec/usr/local/sbin/usr/local/share/usr/local/src
/usr/local/ 사용은 FHS와 약간 다릅니다. FHS는 시스템 소프트웨어 업그레이드로부터 안전해야 하는 소프트웨어를 저장하는 데 /usr/local/ 를 사용해야 한다고 명시되어 있습니다. RPM 패키지 관리자는 소프트웨어 업그레이드를 안전하게 수행할 수 있으므로 /usr/local/ 에 파일을 저장하여 파일을 보호할 필요가 없습니다.
/usr/local/ 를 사용합니다. 예를 들어 /usr/ 디렉토리가 원격 호스트의 읽기 전용 NFS 공유로 마운트된 경우에도 /usr/local/ 디렉터리에 패키지 또는 프로그램을 설치할 수 있습니다.
2.1.1.11. /var/ 디렉터리
/usr/ 를 읽기 전용으로 마운트해야 하므로 로그 파일을 쓰거나 spool/ 또는 lock/ 디렉터리가 필요한 모든 프로그램을 /var/ 디렉토리에 써야 합니다. FHS는 /var/ 가 변수 데이터로, 스풀 디렉토리 및 파일, 로깅 데이터, 임시 파일을 포함합니다.
/var/ 디렉터리에 있는 일부 디렉터리입니다.
/var/account//var/arpwatch//var/cache//var/crash//var/db//var/empty//var/ftp//var/gdm//var/kerberos//var/lib//var/local//var/lock//var/log//var/spool/mail/에 연결된/var/mail/var/mailman//var/named//var/nis//var/opt//var/preserve//var/run//var/spool//var/tmp//var/tux//var/www//var/yp/
/var/run/media/사용자 디렉터리에는 USB 스토리지 미디어, DVD, CD-ROM, Zip 디스크와 같은 이동식 미디어의 마운트 지점으로 사용되는 하위 디렉터리가 포함되어 있습니다. 이전에는 /media/ 디렉터리가 이 용도로 사용되었습니다.
메시지 및 lastlog 와 같은 시스템 로그 파일은 /var/log/ 디렉토리에 있습니다. /var/lib/rpm/ 디렉터리에는 RPM 시스템 데이터베이스가 포함되어 있습니다. 잠금은 /var/lock/ 디렉토리에 파일을 사용하는 프로그램의 디렉토리에 있습니다. /var/spool/ 디렉터리에는 일부 프로그램의 데이터 파일을 저장하는 하위 디렉터리가 있습니다. 이러한 하위 디렉터리에는 다음이 포함됩니다.
/var/spool/at//var/spool/clientmqueue//var/spool/cron//var/spool/cups//var/spool/exim//var/spool/lpd//var/spool/mail//var/spool/mailman//var/spool/mqueue//var/spool/news//var/spool/postfix//var/spool/repackage//var/spool/rwho//var/spool/samba//var/spool/squid//var/spool/squirrelmail//var/spool/up2date//var/spool/uucp//var/spool/uucppublic//var/spool/vbox/
2.2. 특수 Red Hat Enterprise Linux 파일 위치
/var/lib/rpm/ 디렉토리에 보관됩니다. RPM에 대한 자세한 내용은 man rpm 을 참조하십시오.
/var/cache/yum/ 디렉터리에는 시스템의 RPM 헤더 정보를 포함하여 패키지 업데이트 관리자에서 사용하는 파일이 포함되어 있습니다. 이 위치는 시스템을 업데이트하는 동안 다운로드한 RPM을 임시로 저장하는 데도 사용할 수 있습니다. Red Hat Network에 대한 자세한 내용은 https://rhn.redhat.com/ 을 참조하십시오.
/etc/sysconfig/ 디렉터리입니다. 이 디렉터리는 다양한 구성 정보를 저장합니다. 부팅 시 실행되는 많은 스크립트는 이 디렉터리의 파일을 사용합니다.
2.3. /proc 가상 파일 시스템
/proc 에는 텍스트 또는 바이너리 파일이 포함되어 있지 않습니다. 가상 파일이 포함되어 있기 때문에 /proc 는 가상 파일 시스템이라고 합니다. 이러한 가상 파일은 많은 양의 정보가 포함되어 있어도 일반적으로 크기가 0바이트입니다.
/proc 파일 시스템은 스토리지에 사용되지 않습니다. 주요 목적은 하드웨어, 메모리, 실행 중인 프로세스 및 기타 시스템 구성 요소에 파일 기반 인터페이스를 제공하는 것입니다. 해당 /proc 파일을 확인하여 많은 시스템 구성 요소에서 실시간 정보를 검색할 수 있습니다. /proc 내의 일부 파일은 (사용자 및 애플리케이션 모두) 커널을 구성하기 위해 조작할 수도 있습니다.
/proc 파일은 시스템 스토리지를 관리하고 모니터링하는 것과 관련이 있습니다.
- /proc/devices
- 현재 구성된 다양한 문자 및 블록 장치를 표시합니다.
- /proc/filesystems
- 커널은 현재 지원하는 모든 파일 시스템 유형을 나열합니다.
- /proc/mdstat
- 시스템의 여러 디스크 또는 RAID 구성(있는 경우)에 대한 현재 정보를 포함합니다.
- /proc/mounts
- 시스템에서 현재 사용하는 모든 마운트를 나열합니다.
- /proc/partitions
- 파티션 블록 할당 정보가 포함되어 있습니다.
/proc 파일 시스템에 대한 자세한 내용은 Red Hat Enterprise Linux 7 배포 가이드를 참조하십시오.
2.4. 사용되지 않는 블록 삭제
- 일괄 삭제 작업은 fstrim 명령을 사용하여 사용자가 명시적으로 실행합니다. 이 명령은 사용자 기준과 일치하는 파일 시스템에서 사용되지 않은 모든 블록을 삭제합니다.
- 온라인 삭제 작업은 마운트 명령의 일부로
-o discard옵션을 사용하거나/etc/fstab파일의discard옵션을 사용하여 마운트 시 지정됩니다. 사용자 개입 없이 실시간으로 실행됩니다. 온라인 삭제 작업에서는 사용 가능한 블록만 삭제합니다.
/sys/block/device/queue/discard_max_bytes 파일에 저장된 값이 0이 아닌 경우 물리적 삭제 작업이 지원됩니다.
- 삭제 작업을 지원하지 않는 장치 또는
- 장치 중 하나가 삭제 작업을 지원하지 않는 여러 장치로 구성된 논리 장치(LVM 또는 MD)
fstrim -v /mnt/non_discard
fstrim: /mnt/non_discard: the discard operation is not supported
3장. XFS 파일 시스템
- XFS의 주요 기능
- XFS는 더 빠른 충돌 복구를 용이하게 하는 메타데이터 저널링 을 지원합니다.
- XFS 파일 시스템은 마운트된 활성 상태에서 조각 모음 및 확대될 수 있습니다.
- 또한 Red Hat Enterprise Linux 7은 XFS와 관련된 백업 및 복원 유틸리티를 지원합니다.
- 할당 기능
- XFS에는 다음과 같은 할당 체계가 있습니다.
- 범위 기반 할당
- 스트라이프 인식 할당 정책
- 할당량 지연
- 공간 사전 할당
지연된 할당 및 기타 성능 최적화는 XFS에 ext4와 동일한 방식으로 영향을 미칩니다. 즉, 프로그램이 나중에 fsync() 호출을 발행하지 않는 한, XFS 파일 시스템에 대한 프로그램의 쓰기는 디스크상의 것이 보장되지 않습니다.파일 시스템에서 지연된 할당의 영향에 대한 자세한 내용은 할당 기능 의 5장. ext4 파일 시스템 를 참조하십시오.참고디스크 공간이 충분한 것처럼 보이는 경우에도 예기치 않은 ENOSPC 쓰기 실패와 함께 파일을 만들거나 확장하는 데 실패하는 경우가 있습니다. 이는 XFS의 성능 지향 설계 때문입니다. 실제로는 나머지 공간이 몇 블록일 경우에만 발생하기 때문에 문제가 되지 않습니다. - 기타 XFS 기능
- XFS 파일 시스템은 다음과 같은 기능도 지원합니다.
- 확장 속성 (
xattr) - 이를 통해 시스템은 파일마다 여러 개의 추가 이름/값 쌍을 연결할 수 있습니다. 기본적으로 활성화되어 있습니다.
- 할당량 저널링
- 이렇게 하면 충돌 후 긴 할당량 일관성 검사가 필요하지 않습니다.
- 프로젝트/디렉터리 할당량
- 이렇게 하면 디렉터리 트리에 대한 할당량 제한이 허용됩니다.
- 서브초 타임스탬프
- 이렇게 하면 타임 스탬프가 하위초로 이동할 수 있습니다.
- 확장 속성 (
- 기본 atime 동작은 relatime입니다.
- relatime 은 기본적으로 XFS에 대해 입니다. sane atime 값을 유지하면서 noatime 에 비해 오버헤드가 거의 없습니다.
3.1. XFS 파일 시스템 생성
- XFS 파일 시스템을 생성하려면 다음 명령을 사용합니다.
#mkfs.xfs block_device- block_device 를 블록 장치의 경로로 교체합니다. 예를 들어
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-59453ceb2a,/dev/my-volgroup/my-lv. - 일반적으로 기본 옵션은 일반적인 용도로 최적입니다.
- 기존 파일 시스템이 포함된 블록 장치에서 mkfs.xfs 를 사용하는 경우
-f옵션을 추가하여 해당 파일 시스템을 덮어씁니다.
예 3.1. mkfs.xfs 명령 출력
meta-data=/dev/device isize=256 agcount=4, agsize=3277258 blks
= sectsz=512 attr=2
data = bsize=4096 blocks=13109032, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=6400, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
사용되지 않는 블록 장치
mkfs 유틸리티( ext3, ext4 및 xfs의 경우)는 이 지오메트리를 자동으로 사용합니다. 스트라이프 지오메트리는 mkfs 유틸리티에 의해 감지되지 않으며 실제로 스토리지에서 스트라이프 지오메트리가 있더라도 다음 옵션을 사용하여 파일 시스템을 만들 때 수동으로 지정할 수 있습니다.
- su=value
- 스트라이프 단위 또는 RAID 청크 크기를 지정합니다. 값은
k,m또는g접미사를 사용하여 바이트 단위로 지정해야 합니다. - sw=value
- RAID 장치의 데이터 디스크 수 또는 스트라이프의 스트라이프 단위 수를 지정합니다.
# mkfs.xfs -d su=64k,sw=4 /dev/block_device추가 리소스
- mkfs.xfs(8) 도움말 페이지
3.2. XFS 파일 시스템 마운트
# mount /dev/device /mount/pointmke2fs 와 달리mkfs.xfs 는 구성 파일을 사용하지 않으며 모두 명령줄에 지정됩니다.
3.2.1. 쓰기 Barriers
# mount -o nobarrier /dev/device /mount/point3.2.2. 직접 액세스 기술 프리뷰
Direct Access (DAX)는 ext4 및 XFS 파일 시스템에서 기술 프리뷰로 사용할 수 있습니다. 이는 애플리케이션이 영구 메모리를 주소 공간에 직접 매핑하는 수단입니다. DAX를 사용하려면 시스템에서 일부 형태의 영구 메모리를 사용할 수 있어야 합니다. 일반적으로 비 VDIMM(Non-Volatile Dual Inline Memory Modules)과 DAX를 지원하는 파일 시스템을 NVDIMM(s)에서 생성해야 합니다. 또한 dax 마운트 옵션을 사용하여 파일 시스템을 마운트해야 합니다. 그런 다음 dax-mounted 파일 시스템에 있는 파일의 mmap 을 애플리케이션 주소 공간에 직접 매핑합니다.
3.3. XFS 할당량 관리
- uquota/uqnoenforce: 사용자 할당량
- gquota/gqnoenforce: 그룹 할당량
- pquota/pqnoenforce: 프로젝트 할당량
- quota username/userID
- 지정된 사용자 이름 또는 숫자 userID의 사용량 및 제한 표시
- df
- 블록 및 inode에 대해 무료이고 사용되는 수를 표시합니다.
# xfs_quota -x- 보고서 /path
- 특정 파일 시스템에 대한 할당량 정보를 보고합니다.
- limit
- 할당량 제한을 수정합니다.
예 3.2. 샘플 할당량 보고서 표시
/home ( /dev/blockdevice에서)에 대한 샘플 할당량 보고서를 표시하려면 xfs_quota -x -c 'report -h' /home 명령을 사용합니다. 그러면 다음과 유사한 출력이 표시됩니다.
User quota on /home (/dev/blockdevice) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 0 0 0 00 [------] testuser 103.4G 0 0 00 [------] ...
/home/john 인 사용자 john 에 대해 소프트 및 하드 inode 수 제한을 각각 설정하려면 다음 명령을 사용합니다.
# xfs_quota -x -c 'limit isoft=500 ihard=700 john' /home/예 3.3. 소프트 및 하드 블록 제한 설정
/target/path 파일 시스템에서 accounting 그룹으로 설정하려면 다음 명령을 사용합니다.
# xfs_quota -x -c 'limit -g bsoft=1000m bhard=1200m accounting' /target/path3.3.1. 프로젝트 제한 설정
- 프로젝트 제어 디렉토리를
/etc/projects에 추가합니다. 예를 들어 다음은 고유 ID가 11인/var/log경로를/etc/projects에 추가합니다. 프로젝트 ID는 프로젝트에 매핑된 모든 숫자 값일 수 있습니다.#echo 11:/var/log >> /etc/projects /etc/projid에 프로젝트 이름을 추가하여 프로젝트 ID를 프로젝트 이름에 매핑합니다. 예를 들어 다음에서는 Logs라는 프로젝트를 이전 단계에서 정의한 대로 프로젝트 ID 11과 연결합니다.#echo Logs:11 >> /etc/projid- 프로젝트 디렉터리를 초기화합니다. 예를 들어 다음은 프로젝트 디렉토리
/var:를 초기화합니다.#xfs_quota -x -c 'project -s logfiles' /var - 초기화된 디렉터리를 사용하여 프로젝트의 할당량을 구성합니다.
#xfs_quota -x -c 'limit -p bhard=lg logfiles' /var
3.4. XFS 파일 시스템의 크기 늘리기
# xfs_growfs /mount/point -D size3.5. XFS 파일 시스템 복구
# xfs_repair /dev/device3.6. XFS 파일 시스템 일시 중단
# xfs_freeze mount-pointxfsprogs 패키지에서 제공하며 x86_64에서만 사용할 수 있습니다.
# xfs_freeze -f /mount/point
# xfs_freeze -u /mount/point3.7. XFS 파일 시스템 백업 및 복원
- 백업 생성을 위한 xfsdump
- 백업에서 복원하는 xfsrestore
3.7.1. XFS 백업 및 복원 기능
3.7.1.1. Backup
xfsdump 유틸리티를 사용하여 다음을 수행할 수 있습니다.
- 일반 파일 이미지에 대한 백업을 수행합니다.일반 파일에 하나의 백업만 쓸 수 있습니다.
- 테이프 드라이브에 백업을 수행합니다.
xfsdump유틸리티를 사용하면 동일한 테이프에 여러 백업을 쓸 수도 있습니다. 백업은 여러 개의 테이프에 걸쳐 있을 수 있습니다.여러 파일 시스템을 단일 테이프 장치에 백업하려면 이미 XFS 백업이 포함된 테이프에 백업을 작성합니다. 그러면 이전 백업에 새 백업이 추가됩니다. 기본적으로xfsdump는 기존 백업을 덮어쓰지 않습니다. - 증분 백업을 생성합니다.
xfsdump유틸리티는 덤프 수준을 사용하여 다른 백업이 상대적인 기본 백업을 결정합니다.0에서9까지의 숫자는 덤프 수준 증가를 나타냅니다. 증분 백업은 낮은 수준의 마지막 덤프 이후 변경된 파일만 백업합니다.- 전체 백업을 수행하려면 파일 시스템에서 수준 0 덤프를 수행합니다.
- 수준 1 덤프는 전체 백업 후 첫 번째 증분 백업입니다. 다음 증분 백업은 레벨 2로, 마지막 레벨 1 덤프 이후 변경된 파일만 최대 레벨 9로 백업합니다.
- size, subtree 또는 inode 플래그를 사용하여 백업에서 파일을 제외하여 필터링합니다.
3.7.1.2. 복원
xfsrestore 대화형 모드를 입력합니다. 대화형 모드는 백업 파일을 조작하는 명령 집합을 제공합니다.
3.7.2. XFS 파일 시스템 백업
절차 3.1. XFS 파일 시스템 백업
- 다음 명령을 사용하여 XFS 파일 시스템을 백업합니다.
#xfsdump -l level [-L label] -f backup-destination path-to-xfs-filesystem- level 을 백업의 덤프 수준으로 바꿉니다.
0을 사용하여 누적 증분 백업을 수행하려면 전체 백업 또는1~9 - backup-destination 을 백업을 저장할 경로로 교체합니다. 대상은 일반 파일, 테이프 드라이브 또는 원격 테이프 장치일 수 있습니다. 예를 들어, 파일
/backup-files/Data.xfsdump또는 테이프 드라이브의 경우/dev/st0입니다. - path-to-xfs-filesystem 을 백업하려는 XFS 파일 시스템의 마운트 지점으로 바꿉니다. 예를 들면
/mnt/data/입니다. 파일 시스템이 마운트되어야 합니다. - 여러 파일 시스템을 백업하고 단일 테이프 장치에 저장할 때
-L 라벨 옵션을 사용하여 각 백업에 세션 레이블을 추가하여 복원할 때 보다 쉽게 식별할 수 있습니다. 레이블을 백업의 이름으로 바꿉니다(예:backup_data).
예 3.4. 여러 XFS 파일 시스템 백업
/boot/및/data/디렉토리에 마운트된 XFS 파일 시스템의 내용을 백업하고/backup-files/디렉토리에 파일로 저장합니다.#xfsdump -l 0 -f /backup-files/boot.xfsdump /boot#xfsdump -l 0 -f /backup-files/data.xfsdump /data- 단일 테이프 장치에서 여러 파일 시스템을 백업하려면
-L 라벨 옵션을 사용하여 각 백업에 세션 레이블을추가합니다.#xfsdump -l 0 -L "backup_boot" -f /dev/st0 /boot#xfsdump -l 0 -L "backup_data" -f /dev/st0 /data
추가 리소스
- XFS 파일 시스템 백업에 대한 자세한 내용은 xfsdump(8) 도움말 페이지를 참조하십시오.
3.7.3. 백업에서 XFS 파일 시스템 복원
사전 요구 사항
- 3.7.2절. “XFS 파일 시스템 백업” 에 설명된 대로 XFS 파일 시스템의 파일 또는 테이프 백업이 필요합니다.
절차 3.2. 백업에서 XFS 파일 시스템 복원
- 백업 복원 명령은 전체 백업 또는 증분 백업에서 복원하는지에 따라 달라집니다.The command to restore the backup vary depending on whether you are restoring from a full backup or an incremental one, or are restoring multiple backups from a single tape device:
#xfsrestore [-r] [-S session-id] [-L session-label] [-i]-f backup-locationrestoration-path- 백업 위치를 백업 위치로 교체합니다. 이는 일반 파일, 테이프 드라이브 또는 원격 테이프 장치일 수 있습니다.This can be a regular file, a tape drive, or a remote tape device. 예를 들어, 파일
/backup-files/Data.xfsdump또는 테이프 드라이브의 경우/dev/st0입니다. - restoration-path 를 파일 시스템을 복원할 디렉터리의 경로로 바꿉니다. 예를 들면
/mnt/data/입니다. - 증분(레벨 1에서 레벨 9) 백업에서 파일 시스템을 복원하려면
-r옵션을 추가합니다. - 여러 백업이 포함된 테이프 장치에서 백업을 복원하려면
-S또는-L옵션을 사용하여 백업을 지정합니다.S를 사용하면 세션 ID로 백업을 선택할 수 있지만-L을 사용하면 세션 라벨에 따라 선택할 수 있습니다. 세션 ID 및 세션 레이블을 가져오려면 xfsrestore -I 명령을 사용합니다.session-id 를 백업의 세션 ID로 교체합니다. 예를 들어b74a3586-e52e-4a4a-8775-c3334fa8ea2c. session-label 을 백업의 세션 레이블로 바꿉니다. 예를 들면my_backup_session_label입니다. - 대화형으로
xfsrestore를 사용하려면-i옵션을 사용합니다.대화형 대화 상자는xfsrestore가 지정된 장치를 읽은 후에 시작됩니다. 대화형xfsrestore쉘에서 사용 가능한 명령에는 cd,ls,add,delete, extract; 명령 전체 목록은 help 명령을 사용합니다.
예 3.5. 여러 XFS 파일 시스템 복원
/mnt/ 아래의 디렉터리에 저장하려면 다음을 수행합니다.
#xfsrestore -f /backup-files/boot.xfsdump /mnt/boot/#xfsrestore -f /backup-files/data.xfsdump /mnt/data/
#xfsrestore -f /dev/st0 -L "backup_boot" /mnt/boot/#xfsrestore -f /dev/st0 -S "45e9af35-efd2-4244-87bc-4762e476cbab" /mnt/data/
Tape에서 백업을 복원 할 때 정보 메시지
xfsrestore 유틸리티에서 메시지를 발행할 수 있습니다. 이 메시지는 xfsrestore 가 순서대로 테이프에서 각 백업을 검사할 때 요청된 백업이 있는지 여부를 알려줍니다. 예를 들어 다음과 같습니다.
xfsrestore: preparing drive xfsrestore: examining media file 0 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) xfsrestore: examining media file 1 xfsrestore: inventory session uuid (8590224e-3c93-469c-a311-fc8f23029b2a) does not match the media header's session uuid (7eda9f86-f1e9-4dfd-b1d4-c50467912408) [...]
추가 리소스
- XFS 파일 시스템을 복원하는 방법에 대한 자세한 내용은 xfsrestore(8) 도움말 페이지를 참조하십시오.
3.8. 오류 동작 구성
- 다음 중 하나로 다시 시도합니다.
- I/O 작업이 성공 또는
- I/O 작업 재시도 횟수 또는 제한 시간이 초과되었습니다.
- 오류가 영구적으로 고려되고 시스템을 중단합니다.
EIO: 장치에 쓰기를 시도하는 동안 오류가 발생했습니다.ENOSPC: 장치에 남아 있는 공간이 없습니다.ENODEV: 장치를 찾을 수 없습니다.
3.8.1. 특정 조건 및 정의되지 않은 조건에 대한 구성 파일
/sys/fs/xfs/device/error/ 디렉토리에 있습니다.
/sys/fs/xfs/장치/error/metadata/ 디렉터리에는 각 특정 오류 조건에 대한 하위 디렉터리가 포함되어 있습니다.
EIO 오류 조건의 경우 /sys/fs/xfs/장치/error/metadata/EIO/ENODEV 오류 조건의 경우 /sys/fs/xfs/장치/error/metadata/ENODEV/ENOSPC 오류 조건의 경우 /sys/fs/xfs/장치/error/metadata/ENOSPC/
/sys/fs/xfs/장치/error/metadata/조건/max_retries: XFS가 작업을 다시 시도하는 최대 횟수를 제어합니다./sys/fs/xfs/장치/error/metadata/condition/retry_timeout_seconds: XFS가 작업 재시도를 중지하는 시간 제한(초)
/sys/fs/xfs/장치/error/metadata/default/max_retries: 최대 재시도 횟수를 제어합니다./sys/fs/xfs/장치/error/metadata/default/retry_timeout_seconds: 재시도 시간 제한을 제어합니다.
3.8.2. 특정 및 정의되지 않은 조건에 대해 파일 시스템 동작 설정
max_retries 파일에 씁니다.
- 특정 조건의 경우:
#echo value > /sys/fs/xfs/device/error/metadata/condition/max_retries - 정의되지 않은 조건의 경우:
#echo value > /sys/fs/xfs/device/error/metadata/default/max_retries
-1 과 가능한 최대 값 int, C 부호 있는 정수 유형 사이의 숫자입니다. 64비트 Linux에서 2147483647 입니다.
retry_timeout_seconds 파일에 씁니다.
- 특정 조건의 경우:
#echo value > /sys/fs/xfs/device/error/metadata/condition/retry_timeout_seconds - 정의되지 않은 조건의 경우:
#echo value > /sys/fs/xfs/device/error/metadata/default/retry_timeout_seconds
-1 과 86400 사이의 숫자이며 하루 중 초 수입니다.
max_retries 및 retry_timeout_seconds 옵션 모두에서 -1 은 영원히 재시도 하여 즉시 중지합니다.
/dev/ 디렉토리에 있는 것처럼 장치 이름입니다(예: sda ).
ENODEV 와 같은 일부 오류는 재시도 횟수에 관계없이 치명적 및 복구 가능으로 간주되므로 기본값은 0 입니다.
3.8.3. 마운트 해제 동작 설정
fail_at_unmount 옵션이 설정되면 파일 시스템은 마운트 해제 중에 다른 모든 오류 구성을 재정의하고 I/O 작업을 다시 시도하지 않고 즉시 파일 시스템을 제거합니다. 이를 통해 영구 오류 발생 경우에도 마운트 해제 작업이 성공할 수 있습니다.
# echo value > /sys/fs/xfs/device/error/fail_at_unmount1 또는 0 입니다.
1오류가 발견되면 즉시 재시도를 취소하는 것을 의미합니다.0은max_retries및retry_timeout_seconds옵션을 존중하는 것을 의미합니다.
/dev/ 디렉토리에 있는 것처럼 장치 이름입니다(예: sda ).
fail_at_unmount 옵션을 원하는 대로 설정해야 합니다. 마운트 해제 작업이 시작되면 구성 파일 및 디렉터리를 사용할 수 없습니다.
3.9. 기타 XFS 파일 시스템 유틸리티
- xfs_fsr
- 마운트된 XFS 파일 시스템을 조각 모음하는 데 사용됩니다. 인수 없이 호출할 때 xfs_fsr 는 마운트된 모든 XFS 파일 시스템의 모든 일반 파일을 조각 모음합니다. 이 유틸리티를 사용하면 사용자가 지정된 시간에 조각 모음을 중단하고 나중에 중단한 위치에서 다시 시작할 수 있습니다.또한 xfs_fsr 는 xfs_fsr /path/to/file 과 같이 하나의 파일의 조각 모음만 허용합니다. Red Hat은 XFS가 기본적으로 조각화를 방지하기 때문에 전체 파일 시스템을 주기적으로 축소하지 않도록 권장합니다. 시스템의 다양한 조각 모음으로 인해 여유 공간에서 조각화의 부작용을 초래할 수 있습니다.
- xfs_bmap
- XFS 파일 시스템의 파일에서 사용하는 디스크 블록 맵을 출력합니다. 이 맵은 지정된 파일에서 사용하는 각 범위와 해당 블록(즉, 홀더)이 없는 파일의 영역을 나열합니다.
- xfs_info
- XFS 파일 시스템 정보를 출력합니다.
- xfs_admin
- XFS 파일 시스템의 매개변수를 변경합니다. xfs_admin 유틸리티는 마운트 해제된 장치 또는 파일 시스템의 매개변수만 수정할 수 있습니다.
- xfs_copy
- 전체 XFS 파일 시스템의 콘텐츠를 병렬로 하나 이상의 대상에 복사합니다.
- xfs_metadump
- XFS 파일 시스템 메타데이터를 파일에 복사합니다. Red Hat은 마운트 해제된 파일 시스템 또는 읽기 전용 파일 시스템을 복사하는 데 xfs_metadump 유틸리티만 지원합니다. 그러지 않으면 생성되는 덤프가 손상되거나 일치하지 않을 수 있습니다.
- xfs_mdrestore
- XFS metadump 이미지( xfs_metadump를 사용하여 생성)를 파일 시스템 이미지로 복원합니다.
- xfs_db
- XFS 파일 시스템을 디버깅합니다.
3.10. ext4에서 XFS로 마이그레이션
3.10.1. Ext3/4 및 XFS 간 차이점
- 파일 시스템 복구
- Ext3/4는 필요에 따라 저널을 복구하기 위해 부팅 시 사용자 공간에서 e2fsck 를 실행합니다. XFS는 마운트 시 커널 공간에서 저널 복구를 수행합니다.
fsck.xfs쉘 스크립트는 제공되지만 initscript 요구 사항을 충족하기 위해서만 있으므로 유용한 작업을 수행하지 않습니다.XFS 파일 시스템을 복구하거나 확인할 때 xfs_repair 명령을 사용합니다. 읽기 전용 검사에는 -n 옵션을 사용합니다.xfs_repair 명령은 더티 로그가 있는 파일 시스템에서 작동하지 않습니다. 이러한 파일 시스템을 복구하고 마운트 해제 하려면 먼저 로그를 재생해야합니다. 로그가 손상되어 재생할 수 없는 경우 로그에서 -L 옵션을 사용하여 로그아웃할 수 있습니다.파일 시스템 복구에 대한 자세한 내용은 XFS 파일 시스템을 참조하십시오. 12.2.2절. “XFS” - 메타데이터 오류 동작
- 메타데이터 오류가 발생할 때 ext3/4 파일 시스템의 구성 가능한 동작이 있어 기본 동작은 계속 수행됩니다. XFS가 복구할 수 없는 메타데이터 오류가 발생하면 파일 시스템을 종료하고
EFSCORRUPTED오류를 반환합니다. 시스템 로그에 발생한 오류에 대한 세부 정보가 포함되어 있으며 필요한 경우 xfs_repair 를 실행하는 것이 좋습니다. - 할당량
- XFS 할당량은 다시 마운트할 수 없는 옵션입니다. 할당량을 적용하려면 초기 마운트에 -o 할당량 옵션을 지정해야 합니다.할당량 패키지의 표준 툴은 기본 할당량 관리 작업(예: setquota 및 repquota)을 수행할 수 있지만 xfs_quota 툴은 프로젝트 할당량 관리와 같은 XFS별 기능에 사용할 수 있습니다.quotacheck 명령은 XFS 파일 시스템에 영향을 미치지 않습니다. 할당량 회계가 XFS를 처음 켜는 경우 내부적으로 자동 할당량 검사를 수행합니다. XFS 할당량 메타데이터는 최상위, 저널링 메타데이터 오브젝트이므로 할당량이 수동으로 해제될 때까지 할당량 시스템은 항상 일관되게 유지됩니다.
- 파일 시스템 크기 조정
- XFS 파일 시스템에는 파일 시스템을 축소하는 유틸리티가 없습니다. XFS 파일 시스템은 xfs_growfs 명령을 통해 온라인으로 확장할 수 있습니다.
- inode 번호
- 256바이트 inode가 있거나 512바이트 inode가 있는 2TB보다 큰 파일 시스템의 경우 XFS inode 번호는 2^32를 초과할 수 있습니다. 이러한 대규모 inode 번호로 인해 EOVERFLOW 반환 값과 함께 32비트 stat 호출이 실패합니다. 기본 Red Hat Enterprise Linux 7 구성을 사용할 때 설명된 문제가 발생할 수 있습니다: 4개의 할당 그룹으로 정리되지 않은 문제가 발생할 수 있습니다. 사용자 지정 구성(예: 파일 시스템 확장 또는 XFS 파일 시스템 매개변수 변경)은 다른 동작이 발생할 수 있습니다.애플리케이션은 일반적으로 이러한 대규모 inode 번호를 올바르게 처리합니다. 필요한 경우 -o inode32 매개변수로 XFS 파일 시스템을 마운트하여 2^32 미만의 inode 번호를 적용합니다.
inode32는 64비트 숫자로 이미 할당된 inode에는 영향을 미치지 않습니다.중요특정 환경에 필요하지 않은 경우inode32옵션을 사용하지 마십시오.inode32옵션은 할당 동작을 변경합니다. 결과적으로 하위 디스크 블록에서 inode를 할당할 수 있는 공간이 없는 경우 ENOSPC 오류가 발생할 수 있습니다. - 사양 사전 할당
- XFS는 사양 사전 할당 을 사용하여 파일이 작성된 대로 이전 EOF 블록을 할당합니다. 따라서 NFS 서버에서 동시 스트리밍 쓰기 워크로드로 인해 파일 조각화가 발생하지 않습니다. 기본적으로 이 사전 할당은 파일 크기와 함께 증가하며 "du" 출력에 표시됩니다. 사양 사전 할당이 있는 파일이 5분 동안 처리되지 않은 경우 사전 할당이 삭제됩니다. 해당 시간 이전에 inode가 캐시에서 순환되면 inode가 회수될 때 사전 할당이 삭제됩니다.투기 사전 할당으로 인해 premature ENOSPC 문제가 표시되는 경우 -o allocsize=amount 마운트 옵션으로 고정된 사전 할당 양을 지정할 수 있습니다.
- 조각화 관련 툴
- 조각화는 지연된 할당 및 예상 사전 할당과 같은 heuristics 및 동작으로 인해 XFS 파일 시스템에서 심각한 문제가 거의 없습니다. 그러나 파일 시스템 조각화 측정 및 파일 시스템 조각 모음을 위한 도구가 있습니다. 사용하는 것은 권장되지 않습니다.xfs_db frag 명령은 모든 파일 시스템 할당을 백분율로 표시되는 단일 조각화 번호로 중단하려고 합니다. 명령의 출력은 의미를 이해하기 위해 상당한 전문 지식이 필요합니다. 예를 들어 조각화 요인 75%는 파일당 평균 4개의 확장 영역만 의미합니다. 이러한 이유로 xfs_db의 frag의 출력은 유용하지 않으며 조각화 문제에 대한 보다 신중하게 분석하는 것이 좋습니다.주의xfs_fsr 명령을 사용하여 개별 파일 또는 파일 시스템의 모든 파일을 조각 모음할 수 있습니다. 나중에 파일의 로컬성을 제거하고 여유 공간을 조각 모음할 수 있으므로 특히 권장되지 않습니다.
3.10.1.1. ext3 및 ext4와 함께 사용되는 명령 XFS와 비교
표 3.1. ext3 및 ext4의 일반적인 명령 XFS와 비교
| Task | ext3/4 | XFS |
|---|---|---|
| 파일 시스템 생성 | mkfs.ext4 or mkfs.ext3 | mkfs.xfs |
| 파일 시스템 검사 | e2fsck | xfs_repair |
| 파일 시스템 크기 조정 | resize2fs | xfs_growfs |
| 파일 시스템 이미지 저장 | e2image | xfs_metadump and xfs_mdrestore |
| 파일 시스템에 레이블을 지정하거나 튜닝 | tune2fs | xfs_admin |
| 파일 시스템 백업 | 덤프 및 복원 | xfsdump 및 xfsrestore |
표 3.2. ext4 및 XFS용 일반 툴
| Task | ext4 | XFS |
|---|---|---|
| 할당량 | quota | xfs_quota |
| 파일 매핑 | filefrag | xfs_bmap |
4장. ext3 파일 시스템
- 가용성
- 예기치 않은 정전 또는 시스템 충돌(정확되지 않은 시스템 종료라고도 함) 후 시스템의 각 마운트된 ext2 파일 시스템은 e2fsck 프로그램에서 일관성을 확인해야 합니다. 이 프로세스는 특히 많은 수의 파일이 포함된 대용량의 경우 시스템 부팅 시간을 크게 지연시킬 수 있는 시간이 많이 걸리는 프로세스입니다. 이 시간 동안 볼륨의 모든 데이터에 연결할 수 없습니다.라이브 파일 시스템에서 fsck -n 을 실행할 수 있습니다. 그러나 이러한 변경 사항은 변경되지 않으며 부분적으로 작성된 메타데이터가 발생하는 경우 잘못된 결과를 초래할 수 있습니다.스택에서 LVM을 사용하는 경우 또 다른 옵션은 파일 시스템의 LVM 스냅샷을 찍고 대신 fsck 를 실행하는 것입니다.마지막으로 파일 시스템을 읽기 전용으로 다시 마운트할 수 있는 옵션이 있습니다. 그런 다음 모든 보류 중인 메타데이터 업데이트(및 쓰기)는 다시 마운트하기 전에 디스크에 강제 적용됩니다. 이렇게 하면 이전 손상이 없으므로 파일 시스템이 일관되게 유지됩니다. 이제 fsck -n 을 실행할 수 있습니다.ext3 파일 시스템에서 제공하는 저널링은 불명확한 시스템 종료 후 이러한 종류의 파일 시스템 점검이 더 이상 필요하지 않음을 의미합니다. ext3를 사용하여 일관성 검사가 발생하는 유일한 경우는 하드 드라이브 실패와 같은 드문 하드웨어 오류입니다. 불명확한 시스템 종료 후 ext3 파일 시스템을 복구하는 시간은 파일 시스템의 크기 또는 파일 수에 의존하지 않습니다. 오히려 일관성을 유지하는 데 사용되는 저널 의 크기에 따라 다릅니다. 기본 저널 크기는 하드웨어 속도에 따라 복구하는 데 약 1초가 걸립니다.참고Red Hat에서 지원하는 ext3에서 지원하는 유일한 저널링 모드는 data=ordered (기본값)입니다.
- 데이터 무결성
- ext3 파일 시스템은 불명확한 시스템 종료가 발생하는 경우 데이터 무결성의 손실을 방지합니다. ext3 파일 시스템을 사용하면 데이터를 수신하는 보호 유형 및 수준을 선택할 수 있습니다. 파일 시스템의 상태와 관련하여 ext3 볼륨은 기본적으로 높은 수준의 데이터 일관성을 유지하도록 구성됩니다.
- 속도
- 일부 데이터를 두 번 이상 작성하더라도 ext3은 ext3의 저널링을 하드 드라이브 헤드 동작을 최적화하기 때문에 대부분의 경우 ext2보다 처리량이 높습니다. 세 가지 저널링 모드 중에서 선택하여 속도를 최적화할 수 있지만 시스템이 실패하는 경우 데이터 무결성과 관련하여 절충을 의미합니다.참고Red Hat에서 지원하는 ext3에서 지원하는 유일한 저널링 모드는 data=ordered (기본값)입니다.
- 간편한 전환
- ext2에서 ext3로 쉽게 마이그레이션할 수 있으며, 다시 포맷하지 않고도 강력한 저널링 파일 시스템의 이점을 얻을 수 있습니다. 이 작업을 수행하는 방법에 대한 자세한 내용은 4.2절. “ext3 파일 시스템으로 변환” 을 참조하십시오.
ext4.ko 를 사용합니다. 즉, 커널 메시지는 사용된 ext 파일 시스템에 관계없이 항상 ext4를 참조합니다.
4.1. ext3 파일 시스템 생성
mkfs.ext3유틸리티를 사용하여 파티션 또는 LVM 볼륨을 ext3 파일 시스템으로 포맷합니다.#mkfs.ext3 block_device- block_device 를 블록 장치의 경로로 교체합니다. 예를 들어
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-59453ceb2a,/dev/my-volgroup/my-lv.
e2label유틸리티를 사용하여 파일 시스템에 레이블을 지정합니다.#e2label block_device volume_label
UUID 구성
-U 옵션을 사용합니다.
# mkfs.ext3 -U UUID device- UUID 를 설정할 UUID로 바꿉니다(예:
7cd65de3-e0be-41d9-b66d-96d749c02da7). - UUID를 추가할 수 있도록 device 를 ext3 파일 시스템의 경로로 바꿉니다(예:
/dev/sda8).
추가 리소스
- mkfs.ext3(8) 도움말 페이지
- e2label(8) 도움말 페이지
4.2. ext3 파일 시스템으로 변환
ext2 파일 시스템을 ext3 로 변환합니다.
ext2 파일 시스템을 ext3 로 변환하려면 root로 로그인하고 터미널에 다음 명령을 입력합니다.
# tune2fs -j block_device4.3. Ext2 파일 시스템으로 되돌리기
/dev/mapper/VolGroup00-LogVol02
절차 4.1. ext3에서 ext2로 되돌리기
- root로 로그인하고 다음을 입력하여 파티션을 마운트 해제합니다.
# umount /dev/mapper/VolGroup00-LogVol02 - 다음 명령을 입력하여 파일 시스템 유형을 ext2로 변경합니다.
# tune2fs -O ^has_journal /dev/mapper/VolGroup00-LogVol02 - 다음 명령을 입력하여 파티션에 오류를 확인합니다.
# e2fsck -y /dev/mapper/VolGroup00-LogVol02 - 그런 다음 다음을 입력하여 파티션을 ext2 파일 시스템으로 다시 마운트합니다.
# mount -t ext2 /dev/mapper/VolGroup00-LogVol02 /mount/point/mount/point 를 파티션의 마운트 지점으로 바꿉니다.참고파티션의 루트 수준에.journal파일이 있는 경우 삭제합니다.
/etc/fstab 파일을 업데이트해야 합니다. 그렇지 않으면 부팅 후 다시 되돌아갑니다.
5장. ext4 파일 시스템
- 주요 기능
- ext4 파일 시스템은 ext2 및 ext3에서 사용하는 기존 블록 매핑 체계와는 반대로 확장 기능을 사용하므로 대용량 파일을 사용할 때 성능이 향상되고 대용량 파일의 메타데이터 오버헤드가 감소합니다. 또한 ext4는 할당되지 않은 블록 그룹 및 inode 테이블 섹션에 레이블을 지정하여 파일 시스템 검사 중에 건너뛸 수 있습니다. 이렇게 하면 파일 시스템의 크기가 증가함에 따라 파일 시스템 점검이 빨라집니다.
- 할당 기능
- ext4 파일 시스템에는 다음과 같은 할당 체계가 있습니다.
- 영구 사전 할당
- 할당량 지연
- 다중 블록 할당
- 스트라이프 인식 할당
지연된 할당 및 기타 성능 최적화로 인해 ext4의 디스크에 파일 작성 동작이 ext3과 다릅니다. ext4에서는 프로그램이 파일 시스템에 쓸 때 프로그램이 나중에 fsync() 호출을 발행하지 않는 한 디스크상의 것이 보장되지 않습니다.기본적으로 ext3는 fsync() 를 사용하지 않고도 새로 생성된 파일을 즉시 디스크에 적용합니다. 이 동작은 fsync() 를 사용하지 않은 프로그램의 버그로 인해 기록된 데이터가 디스크에 있는지 확인합니다. 반면 ext4 파일 시스템은 종종 몇 초 동안 디스크에 변경 사항을 쓸 때까지 대기하여 ext3보다 더 나은 디스크 성능을 위해 쓰기를 결합하고 재정렬할 수 있습니다.주의ext3과 달리 ext4 파일 시스템은 트랜잭션 커밋 시 데이터를 디스크에 강제 적용하지 않습니다. 따라서 버퍼링된 쓰기가 디스크에 플러시되는 데 시간이 더 오래 걸립니다. 모든 파일 시스템과 마찬가지로 fsync() 와 같은 데이터 무결성 호출을 사용하여 데이터가 영구 스토리지에 작성되었는지 확인합니다. - 기타 ext4 기능
- ext4 파일 시스템은 다음과 같은 기능도 지원합니다.
- 확장 속성 (
xattr) - 이를 통해 시스템은 파일당 여러 개의 추가 이름 및 값 쌍을 연결할 수 있습니다. - 할당량 저널링 - 충돌 후 긴 할당량 일관성 검사가 필요하지 않습니다.참고ext4에서 지원되는 유일한 저널링 모드는 data=ordered (기본값)입니다.
- 하위 시간 타임스탬프 - 이 명령은 타임스탬프를 서브초에 제공합니다.
5.1. ext4 파일 시스템 생성
- ext4 파일 시스템을 생성하려면 다음 명령을 사용합니다.
#mkfs.ext4 block_device- block_device 를 블록 장치의 경로로 교체합니다. 예를 들어
/dev/sdb1,/dev/disk/by-uuid/05e99ec8-def1-4a5e-8a9d-59453ceb2a,/dev/my-volgroup/my-lv. - 일반적으로 기본 옵션은 대부분의 사용 시나리오에 적합합니다.
예 5.1. mkfs.ext4 명령 출력
~]# mkfs.ext4 /dev/sdb1
mke2fs 1.41.12 (17-May-2010)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
245280 inodes, 979456 blocks
48972 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=1006632960
30 block groups
32768 blocks per group, 32768 fragments per group
8176 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736
Writing inode tables: done
Creating journal (16384 blocks): done
Writing superblocks and filesystem accounting information: done
사용되지 않는 블록 장치
- stride=value
- RAID 청크 크기를 지정합니다.
- stripe-width=value
- RAID 장치의 데이터 디스크 수 또는 스트라이프의 스트라이프 단위 수를 지정합니다.
# mkfs.ext4 -E stride=16,stripe-width=64 /dev/block_deviceUUID 구성
-U 옵션을 사용합니다.
# mkfs.ext4 -U UUID device- UUID 를 설정할 UUID로 바꿉니다(예:
7cd65de3-e0be-41d9-b66d-96d749c02da7). - UUID를 추가할 수 있도록 device 를 ext4 파일 시스템의 경로로 바꿉니다(예:
/dev/sda8).
추가 리소스
- mkfs.ext4(8) 도움말 페이지
5.2. ext4 파일 시스템 마운트
# mount /dev/device /mount/point
# mount -o acl,user_xattr /dev/device /mount/point
# mount -o data_err=abort /dev/device /mount/point5.2.1. 쓰기 Barriers
# mount -o nobarrier /dev/device /mount/point5.2.2. 직접 액세스 기술 프리뷰
직접 액세스 )는 ext4 및 XFS 파일 시스템에서 기술 프리뷰로 제공합니다. 즉 애플리케이션이 영구 메모리를 주소 공간에 직접 매핑하는 수단입니다. DAX를 사용하려면 일반적으로 하나 이상의 비접근 다각형 메모리 모듈(NVDIMM) 및 DAX를 지원하는 파일 시스템을 NVDIMM(NVDIMM)에서 시스템에서 사용할 수 있는 일종의 영구 메모리가 있어야 합니다. 또한 dax 마운트 옵션을 사용하여 파일 시스템을 마운트해야 합니다. 그런 다음 dax-mounted 파일 시스템에 있는 파일의 mmap 을 애플리케이션 주소 공간에 직접 매핑합니다.
5.3. ext4 파일 시스템 크기 조정
# resize2fs /mount/device size
# resize2fs /dev/device size- s - 512바이트 섹터
- K — kilobytes
- m - 메가바이트
- g - 기가바이트
5.4. ext2, ext3 또는 ext4 파일 시스템 백업
사전 요구 사항
- 시스템이 오랫동안 실행 중인 경우 백업 전에 파티션에서
e2fsck유틸리티를 실행합니다.#e2fsck /dev/device
절차 5.1. ext2, ext3 또는 ext4 파일 시스템 백업
/etc/fstab파일의 내용 및 metadata -l 명령의 출력을 포함한 구성 정보를 백업합니다. 이는 파티션을 복원하는 데 유용합니다.이 정보를 캡처하려면sosreport또는sysreport유틸리티를 실행합니다.sosreport에 대한 자세한 내용은 What is a sosreport and how to create one in Red Hat Enterprise Linux 4.6 이상에서참조하십시오. Kdowledgebase 문서.- 파티션 역할에 따라:
- 백업 중인 파티션이 운영 체제 파티션인 경우 시스템을 복구 모드로 부팅합니다. 시스템 관리자 가이드의 Booting to Rescue Mode 섹션을 참조하십시오.
- 정규 데이터 파티션을 백업할 때 마운트 해제합니다.데이터 파티션이 마운트되는 동안 데이터 파티션을 백업할 수는 있지만 마운트된 데이터 파티션을 백업한 결과를 예측할 수 없습니다.
dump유틸리티를 사용하여 마운트된 파일 시스템을 백업해야 하는 경우 파일 시스템이 과도하게 로드되지 않을 때 이 작업을 수행합니다. 백업 시 파일 시스템에서 작업이 많을수록 백업 손상 위험이 높아집니다.
덤프유틸리티를 사용하여 파티션의 내용을 백업합니다.#dump -0uf backup-file /dev/devicebackup-file 을 백업을 저장할 파일의 경로로 바꿉니다. 장치를 백업하려는 ext4 파티션의 이름으로 바꿉니다. 백업 중인 파티션과 다른 파티션에 마운트된 디렉터리에 백업을 저장해야 합니다.예 5.2. 여러 ext4 파티션 백업
/dev/sda1,/dev/sda2파티션의 내용을/backup-files/#dump -0uf /backup-files/sda1.dump /dev/sda1#dump -0uf /backup-files/sda2.dump /dev/sda2#dump -0uf /backup-files/sda3.dump /dev/sda3원격 백업을 수행하려면ssh유틸리티를 사용하거나 암호 없는ssh로그인을 설정합니다.ssh및 암호 없는 로그인에 대한 자세한 내용은 시스템 관리자 가이드 의 ssh 유틸리티 사용 및 키 기반 인증 사용 섹션을 참조하십시오.예를 들어ssh를 사용하는 경우 다음을 수행합니다.예 5.3.
ssh를 사용하여 원격 백업 수행#dump -0u -f - /dev/device | ssh root@remoteserver.example.com dd of=backup-file표준 리디렉션을 사용하는 경우-f옵션을 별도로 전달해야 합니다.
5.4.1. 추가 리소스
- 자세한 내용은 dump(8) 도움말 페이지를 참조하십시오.
5.5. ext2, ext3 또는 ext4 파일 시스템 복원
사전 요구 사항
- 5.4절. “ext2, ext3 또는 ext4 파일 시스템 백업” 에 설명된 대로 파티션 및 해당 메타데이터 백업이 필요합니다.
절차 5.2. ext2, ext3 또는 ext4 파일 시스템 복원
- 운영 체제 파티션을 복원하는 경우 시스템을 복구 모드로 부팅합니다. 시스템 관리자 가이드의 Booting to Rescue Mode 섹션을 참조하십시오.이 단계는 일반 데이터 파티션에 필요하지 않습니다.
fdisk또는partedutilites를 사용하여 복원할 파티션을 다시 빌드합니다.파티션이 더 이상 존재하지 않으면 다시 생성합니다. 새 파티션은 복원된 데이터를 포함할 수 있을 만큼 충분히 커야 합니다. 시작 및 끝 번호를 올바르게 얻는 것이 중요합니다. 이는 백업 시 metadata 유틸리티에서 얻은 파티션의 시작 및 끝 번호입니다.파티션 수정에 대한 자세한 내용은 다음을 참조하십시오. 13장. 파티션mkfs유틸리티를 사용하여 대상 파티션을 포맷합니다.#mkfs.ext4 /dev/device중요백업 파일을 저장하는 파티션을 포맷 하지 마십시오.- 새 파티션을 생성한 경우 모든 파티션을 다시 레이블이
/etc/fstab파일의 해당 항목과 일치하도록 합니다.#e2label /dev/device label - 임시 마운트 지점을 생성하고 여기에 파티션을 마운트합니다.
#mkdir /mnt/device#mount -t ext4 /dev/device /mnt/device - 마운트된 파티션의 백업에서 데이터를 복원합니다.
#cd /mnt/device#restore -rf device-backup-file원격 시스템에 복원하거나 원격 호스트에 저장된 백업 파일에서 복원하려면ssh유틸리티를 사용할 수 있습니다.ssh에 대한 자세한 내용은 시스템 관리자 가이드 의 ssh 유틸리티 사용 섹션을 참조하십시오.다음 명령에 대해 암호 없이 로그인을 구성해야 합니다. 암호가 없는ssh로그인을 설정하는 방법에 대한 자세한 내용은 시스템 관리자 가이드의 키 기반 인증 사용 섹션을 참조하십시오.- 동일한 머신에 저장된 백업 파일에서 원격 머신의 파티션을 복원하려면 다음을 수행합니다.
#ssh remote-address "cd /mnt/device && cat backup-file | /usr/sbin/restore -r -f -" - 다른 원격 머신에 저장된 백업 파일에서 원격 머신의 파티션을 복원하려면 다음을 수행합니다.
#ssh remote-machine-1 "cd /mnt/device && RSH=/usr/bin/ssh /usr/sbin/restore -rf remote-machine-2:backup-file"
- reboot:
#systemctl reboot
예 5.4. 여러 ext4 파티션 복원
- fdisk 명령을 사용하여 복원할 파티션을 다시 작성합니다.
- 대상 파티션을 포맷합니다.
#mkfs.ext4 /dev/sda1#mkfs.ext4 /dev/sda2#mkfs.ext4 /dev/sda3 /etc/fstab파일과 일치하도록 모든 파티션에 레이블을 다시 지정합니다.#e2label /dev/sda1 Boot1#e2label /dev/sda2 Root#e2label /dev/sda3 Data- 작업 디렉터리를 준비합니다.새 파티션을 마운트합니다.
#mkdir /mnt/sda1#mount -t ext4 /dev/sda1 /mnt/sda1#mkdir /mnt/sda2#mount -t ext4 /dev/sda2 /mnt/sda2#mkdir /mnt/sda3#mount -t ext4 /dev/sda3 /mnt/sda3백업 파일이 포함된 파티션을 마운트합니다.#mkdir /backup-files#mount -t ext4 /dev/sda6 /backup-files - 백업에서 마운트된 파티션으로 데이터를 복원합니다.
#cd /mnt/sda1#restore -rf /backup-files/sda1.dump#cd /mnt/sda2#restore -rf /backup-files/sda2.dump#cd /mnt/sda3#restore -rf /backup-files/sda3.dump - reboot:
#systemctl reboot
추가 리소스
- 자세한 내용은 restore(8) 도움말 페이지를 참조하십시오.
5.6. 기타 ext4 파일 시스템 유틸리티
- e2fsck
- ext4 파일 시스템을 복구하는 데 사용됩니다. 이 툴은 ext4 디스크 구조의 업데이트 때문에 ext3보다 더 효율적으로 ext4 파일 시스템을 점검하고 복구합니다.
- e2label
- ext4 파일 시스템에서 레이블을 변경합니다. 이 도구는 ext2 및 ext3 파일 시스템에서도 작동합니다.
- 할당량
- ext4 파일 시스템에서 사용자와 그룹이 디스크 공간(블록) 및 파일(inode) 사용을 제어하고 보고합니다. 할당량 사용에 대한 자세한 내용은 man 할당량 및 17.1절. “디스크 할당량 구성” 을 참조하십시오.
- fsfreeze
- 파일 시스템에 대한 액세스를 일시 중지하려면 # fsfreeze -f 마운트 지점 을 사용하여 정지하고 # fsfreeze -u 마운트 -u 마운트 지점 을 해제하십시오. 이렇게 하면 파일 시스템에 대한 액세스가 중단되고 디스크에 안정적인 이미지가 생성됩니다.참고장치 매퍼 드라이브에 fsfreeze 를 사용하는 것은 불필요합니다.자세한 내용은 fsfreeze(8) 매뉴얼 페이지를 참조하십시오.
- debugfs
- ext2, ext3 또는 ext4 파일 시스템을 디버깅합니다.
- e2image
- 중요한 ext2, ext3 또는 ext4 파일 시스템 메타데이터를 파일에 저장합니다.
6장. 1.8.0 (기술 프리뷰)
6.1. btrfs 파일 시스템 생성
# mkfs.btrfs /dev/device6.2. btrfs 파일 시스템 마운트
# mount /dev/device /mount-point
- device=/dev/name
- mount 명령에 이 옵션을 추가하면 btrfs 볼륨에 대해 이름이 지정된 장치를 검사하도록 btrfs가 지시합니다. btrfs가 아닌 장치를 마운트하려고 하면 마운트가 실패하는 것을 확인하는 데 사용됩니다.참고따라서 모든 장치가 파일 시스템에 추가되는 것은 아니며 파일 시스템에만 스캔합니다.
- max_inline=number
- 메타데이터 B-트리 리프 내에서 인라인 데이터에 사용할 수 있는 최대 공간(바이트 단위)을 설정하려면 이 옵션을 사용합니다. 기본값은 8192바이트입니다. 4k 페이지의 경우 리프에 적합해야 하는 추가 헤더로 인해 3900바이트로 제한됩니다.
- alloc_start=number
- 디스크 할당이 시작되는 위치를 설정하려면 이 옵션을 사용합니다.
- thread_pool=number
- 할당된 작업자 스레드 수를 할당하려면 이 옵션을 사용합니다.
- 삭제
- 여유 블록에서 discard/TRIM을 활성화하려면 이 옵션을 사용합니다.
- noacl
- 이 옵션을 사용하여 ACL의 사용을 비활성화합니다.
- space_cache
- 블록 그룹을 더 빠르게 캐싱하려면 이 옵션을 사용하여 사용 가능한 공간 데이터를 디스크에 저장합니다. 이는 영구적 변경 사항이며 이전 커널로 부팅하는 것이 안전합니다.
- nospace_cache
- 위의 space_cache 를 비활성화하려면 이 옵션을 사용합니다.
- clear_cache
- 마운트 중에 사용 가능한 모든 공간 캐시를 지우려면 이 옵션을 사용합니다. 이 옵션은 안전한 옵션이지만 공간 캐시를 다시 빌드하도록 트리거합니다. 따라서 다시 빌드 프로세스를 완료할 수 있도록 파일 시스템을 마운트된 상태로 둡니다. 이 마운트 옵션은 한 번만 사용되며 사용 가능한 공간에 문제가 표시된 후에만 사용됩니다.
- enospc_debug
- 이 옵션은 "공간이 남아 있지 않음"과 관련된 문제를 디버그하는 데 사용됩니다.
- 복구
- 마운트 시 자동 복구 기능을 사용하려면 이 옵션을 사용합니다.
6.3. btrfs 파일 시스템 크기 조정
6.3.1. btrfs 파일 시스템 등록
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize +200M /btrfssingle Resize '/btrfssingle' of '+200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 를 확인한 후 다음 명령을 사용합니다.
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:+200M /btrfstest Resize '/btrfstest/' of '2:+200M'
6.3.2. btrfs 파일 시스템 축소
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize -200M /btrfssingle Resize '/btrfssingle' of '-200M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 524.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 를 확인한 후 다음 명령을 사용합니다.
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:-200M /btrfstest Resize '/btrfstest' of '2:-200M'
6.3.3. 파일 시스템 크기 설정
# btrfs filesystem resize amount /mount-point
# btrfs filesystem resize 700M /btrfssingle Resize '/btrfssingle' of '700M'
# btrfs filesystem show /mount-point
# btrfs filesystem show /btrfstest Label: none uuid: 755b41b7-7a20-4a24-abb3-45fdbed1ab39 Total devices 4 FS bytes used 192.00KiB devid 1 size 1.00GiB used 224.75MiB path /dev/vdc devid 2 size 724.00MiB used 204.75MiB path /dev/vdd devid 3 size 1.00GiB used 8.00MiB path /dev/vde devid 4 size 1.00GiB used 8.00MiB path /dev/vdf Btrfs v3.16.2
devid 를 확인한 후 다음 명령을 사용합니다.
# btrfs filesystem resize devid:amount /mount-point
# btrfs filesystem resize 2:300M /btrfstest Resize '/btrfstest' of '2:300M'
6.4. 여러 장치에 대한 통합 볼륨 관리
6.4.1. 여러 장치가 있는 파일 시스템 생성
- raid0
- raid1
- raid10
- DUP
- single
예 6.1. RAID 10 btrfs 파일 시스템 생성
# mkfs.btrfs /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m raid0 /dev/device1 /dev/device2
# mkfs.btrfs -m raid10 -d raid10 /dev/device1 /dev/device2 /dev/device3 /dev/device4
# mkfs.btrfs -m single /dev/device
# mkfs.btrfs -d single /dev/device1 /dev/device2 /dev/device3
# btrfs device add /dev/device1 /mount-point
6.4.2. btrfs 장치 검색
/dev 에서 모든 블록 장치를 검사하고 btrfs 볼륨을 검색합니다. 파일 시스템에서 둘 이상의 장치로 실행하는 경우 btrfs 모듈을 로드한 후 수행해야 합니다.
# btrfs device scan
# btrfs device scan /dev/device
6.4.3. btrfs 파일 시스템에 새 장치 추가
예 6.2. btrfs 파일 시스템에 새 장치 추가
# mkfs.btrfs /dev/device1 # mount /dev/device1
# btrfs device add /dev/device2 /mount-point
/dev/device1 에만 저장됩니다. 이제 모든 장치에 분산되도록 균형을 조정해야 합니다.
# btrfs filesystem balance /mount-point
6.4.4. btrfs 파일 시스템 변환
예 6.3. btrfs 파일 시스템 변환
/dev/sdb1 을 단일 디스크 장애로부터 보호하기 위해 raid1 시스템이 두 개의 장치로 변환하려면 다음 명령을 사용합니다.
# mount /dev/sdb1 /mnt # btrfs device add /dev/sdc1 /mnt # btrfs balance start -dconvert=raid1 -mconvert=raid1 /mnt
6.4.5. btrfs 장치 제거
예 6.4. btrfs 파일 시스템에서 장치 제거
# mkfs.btrfs /dev/sdb /dev/sdc /dev/sdd /dev/sde # mount /dev/sdb /mnt
# btrfs device delete /dev/sdc /mnt
6.4.6. btrfs 파일 시스템에서 실패한 장치 교체
# mkfs.btrfs -m raid1 /dev/sdb /dev/sdc /dev/sdd /dev/sde ssd is destroyed or removed, use -o degraded to force the mount to ignore missing devices # mount -o degraded /dev/sdb /mnt 'missing' is a special device name # btrfs device delete missing /mnt
- 성능 저하 모드에서 마운트
- 새 장치를 추가하고,
- 및 누락된 장치를 제거합니다.
6.4.7. /etc/fstab에 btrfs 파일 시스템 등록
initrd 가 없거나 btrfs 장치 검사를 수행하지 않은 경우 파일 시스템의 모든 장치를 마운트 명령에 명시적으로 전달하여 다중 볼륨 btrfs 파일 시스템을 마운트 할 수 있습니다.
예 6.5. /etc/fstab Entry의 예
/etc/fstab 항목의 예는 다음과 같습니다.
/dev/sdb /mnt btrfs device=/dev/sdb,device=/dev/sdc,device=/dev/sdd,device=/dev/sde 0
6.5. SSD 최적화
mkfs.btrfs 가 단일 장치에서 메타데이터 중복을 끄는 것입니다. /sys/block/device/queue/rotational 이 지정된 단일 장치의 경우 0입니다. 명령줄에서 -m single 을 지정하는 것과 동일합니다. m dup 옵션을 제공하여 강제된 메타데이터와 중복 메타데이터를 재정의할 수 있습니다. 두 복사본을 손실 할 수있는 SSD 펌웨어로 인해 중복이 필요하지 않습니다. 이로 인해 공간을 소비하고 성능 비용이 절약됩니다.
- 이를 통해 더 큰 메타데이터 클러스터 할당이 가능합니다.
- 가능한 경우 데이터를 더 순차적으로 할당합니다.
- 키 및 블록 순서와 일치하도록 btree leaf rewriting을 비활성화합니다.
- 여러 프로세스를 배치하지 않고 로그 조각을 커밋합니다.
6.6. tested 참고 사항
- 스냅샷을 관리하기 위한 모든 subvolume 명령.
장치관리를 위한 장치 명령입니다.- scrub,balance 및 fragment 명령
7장. 글로벌 파일 시스템 2
gfs2.ko 커널 모듈은 GFS2 파일 시스템을 구현하고, GFS2 클러스터 노드에 로드됩니다.
8장. 네트워크 파일 시스템(NFS)
8.1. NFS 소개
- NFS 버전 3(NFSv3)은 안전한 비동기 쓰기를 지원하며 이전 NFSv2보다 오류 처리에서 더 강력합니다. 또한 64비트 파일 크기 및 오프셋을 지원하므로 클라이언트가 2GB 이상의 파일 데이터에 액세스할 수 있습니다.
- NFS 버전 4(NFSv4)는 방화벽과 인터넷에서 작동하므로 더 이상 alice bind 서비스가 필요하지 않으며 ACL을 지원하며 상태 저장 작업을 사용할 수 있습니다.
- 스파스 파일: 파일의 공간 효율성을 확인하고 자리 표시자를 사용하여 스토리지 효율성을 개선할 수 있습니다. 하나 이상의 홀이 있는 파일이며, 허자는 할당되지 않았거나 초기화되지 않은 데이터 블록은 0으로만 구성됩니다.
lseek()NFSv4.2의 작업은seek_hole()및seek_data()을 지원하므로 애플리케이션이 스파스 파일에 있는 허위의 위치를 매핑할 수 있습니다. - 공간 예약: 스토리지 서버가 여유 공간을 예약하여 서버가 공간을 비우는 것을 방지할 수 있습니다. NFSv4.2에서는
allocate()작업을 통해 예약할 수 있는deallocate()작업, 예약되지 않은 공간 및fallocate()작업을 통해 파일에 공간을 사전 할당하거나 할당 해제할 수 있습니다. - 레이블이 지정된 NFS: 데이터 액세스 권한을 적용하고 NFS 파일 시스템의 개별 파일에 대해 클라이언트와 서버 간에 SELinux 레이블을 활성화합니다.
- 레이아웃 기능 향상: NFSv4.2는 클라이언트가 레이아웃과의 통신에 대해 메타데이터 서버에 알리는 데 사용할 수 있는 새로운 작업인
layoutstats()를 제공합니다.
- 네트워크의 성능 및 보안을 강화하고 PNFS(Parallel NFS)에 대한 클라이언트 측 지원도 포함됩니다.
- 더 이상 콜백에 대한 별도의 TCP 연결이 필요하지 않으므로, NFS 서버에서 클라이언트에 연결할 수 없는 경우에도 위임을 부여할 수 있습니다. 예를 들어 NAT 또는 방화벽이 간섭하는 경우입니다.
- 이는 정확히 한 번 의미 체계(재부팅 작업 제외)를 제공하여 응답이 손실되고 작업이 두 번 전송되는 경우 특정 작업에서 부정확한 결과를 반환할 수 있는 이전 문제를 방지합니다.
/etc/exports 구성 파일을 참조하여 클라이언트가 내보낸 파일 시스템에 액세스할 수 있는지 여부를 확인합니다. 확인되면 모든 파일 및 디렉터리 작업을 사용자가 사용할 수 있습니다.
8.1.1. 필수 서비스
- nfs
- systemctl start nfs 는 NFS 서버를 시작하고 적절한 RPC 프로세스는 공유 NFS 파일 시스템에 대한 요청을 서비스합니다.
- nfslock
- systemctl start nfs-lock 은 NFS 클라이언트가 서버에 파일을 잠글 수 있도록 적절한 RPC 프로세스를 시작하는 필수 서비스를 활성화합니다.
- rpcbind
- Diffiebind 는 로컬 RPC 서비스의 포트 예약을 허용합니다. 그런 다음 이러한 포트를 사용할 수 있도록 (또는 광고)하여 해당 원격 RPC 서비스에서 액세스할 수 있습니다. INPUTbind 는 RPC 서비스 요청에 응답하고 요청된 RPC 서비스에 대한 연결을 설정합니다. NFSv4에서는 사용되지 않습니다.
- rpc.mountd
- 이 프로세스는 NFS 서버에서 NFSv3 클라이언트의 MOUNT 요청을 처리하는 데 사용됩니다. 요청된 NFS 공유가 현재 NFS 서버에서 내보내고 클라이언트가 액세스할 수 있는지 확인합니다. 마운트 요청이 허용되면 EgressIP.mountd 서버는
Success상태로 응답하고 이 NFS 공유에 대한File-Handle을 NFS 클라이언트에 다시 제공합니다. - rpc.nfsd
- RPC.nfsd 를 사용하면 명시적 NFS 버전 및 서버에서 알리는 프로토콜을 정의할 수 있습니다. NFS 클라이언트가 연결할 때마다 서버 스레드를 제공하는 등 NFS 클라이언트의 동적 요구사항을 충족하기 위해 Linux 커널과 함께 작동합니다. 이 프로세스는 nfs 서비스에 해당합니다.
- lockd
- lockd 는 클라이언트와 서버에서 모두 실행되는 커널 스레드입니다. NFSv3 클라이언트가 서버에 파일을 잠글 수 있도록 하는 NLM( Network Lock Manager ) 프로토콜을 구현합니다. NFS 서버가 실행될 때마다 NFS 파일 시스템이 마운트될 때마다 자동으로 시작됩니다.
- rpc.statd
- 이 프로세스에서는 NSM( Network Status Monitor ) RPC 프로토콜을 구현하므로 NFS 서버가 정상적으로 시작되지 않을 때 NFS 서버를 다시 시작할 때 NFS 클라이언트에 알립니다. RPC.statd 는 nfslock 서비스에 의해 자동으로 시작되며 사용자 구성이 필요하지 않습니다. NFSv4에서는 사용되지 않습니다.
- rpc.rquotad
- 이 프로세스는 원격 사용자에 대한 사용자 할당량 정보를 제공합니다. RPC.rquotad 는 nfs 서비스에서 자동으로 시작하며 사용자 구성이 필요하지 않습니다.
- rpc.idmapd
- RPC .idmapd 는 NFSv4 클라이언트와 서버 upcalls를 제공합니다. 이 호출은 유선 NFSv4 이름(
user@domain형식의 문자열)과 로컬 UID 및 GID 간에 매핑됩니다. idmapd 가 NFSv4에서 작동하려면/etc/idmapd.conf파일을 구성해야 합니다. 최소한 NFSv4 매핑 도메인을 정의하는 "Domain" 매개변수를 지정해야 합니다. NFSv4 매핑 도메인이 DNS 도메인 이름과 동일한 경우 이 매개 변수를 건너뛸 수 있습니다. ID가 올바르게 작동하려면 클라이언트와 서버는 NFSv4 매핑 도메인에 동의해야 합니다.참고Red Hat Enterprise Linux 7에서 NFSv4 서버만 INPUT .idmapd 를 사용합니다. NFSv4 클라이언트는 인증 키 기반 idmapper nfsidmap 을 사용합니다. nfsidmap 은 ID 매핑을 수행하기 위해 커널 온-요청에 의해 호출되는 독립형 프로그램입니다. 이는 데몬이 아닙니다. nfsidmap 에 문제가 있는 경우 클라이언트가 EgressIP .idmapd를 사용하여 대체합니다. nfsidmap 에 대한 자세한 내용은 nfsidmap 매뉴얼 페이지에서 확인할 수 있습니다.
8.2. NFS 클라이언트 구성
# mount -t nfs -o options server:/remote/export /local/directory- options
- 쉼표로 구분된 마운트 옵션 목록. 유효한 NFS 마운트 옵션에 대한 자세한 내용은 8.4절. “일반적인 NFS 마운트 옵션” 의 내용을 참조하십시오.
- server
- 마운트하려는 파일 시스템을 내보내는 서버의 호스트 이름, IP 주소 또는 정규화된 도메인 이름
- /remote/export
- 서버에서 내보낼 파일 시스템 또는 디렉터리, 즉 마운트하려는 디렉터리입니다.
- /local/directory
- /remote/export 가 마운트된 클라이언트 위치
/etc/fstab 파일과 autofs 서비스를 제공합니다. 자세한 내용은 8.2.1절. “/etc/fstab을 사용하여 NFS 파일 시스템 마운트” 및 8.3절. “flexs” 을 참조하십시오.
8.2.1. /etc/fstab을 사용하여 NFS 파일 시스템 마운트
/etc/fstab 파일에 행을 추가하는 것입니다. 행은 NFS 서버의 호스트 이름, 내보낼 서버의 디렉터리 및 NFS 공유를 마운트할 로컬 시스템의 디렉터리를 지정해야 합니다. /etc/fstab 파일을 수정하려면 root여야 합니다.
예 8.1. 구문 예
/etc/fstab 행의 일반적인 구문은 다음과 같습니다.
server:/usr/local/pub /pub nfs defaults 0 0
/pub 가 클라이언트 시스템에 있어야 합니다. 클라이언트 시스템의 /etc/fstab 에 이 행을 추가한 후 mount /pub 명령을 사용하고 /pub 마운트 지점 /pub 는 서버에서 마운트됩니다.
/etc/fstab 항목에 다음 정보가 포함되어야 합니다.
server:/remote/export /local/directory nfs options 0 0
/etc/fstab 를 읽기 전에 클라이언트에 있어야 합니다. 그렇지 않으면 마운트가 실패합니다.
/etc/fstab 을 편집한 후 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
# systemctl daemon-reload추가 리소스
/etc/fstab에 대한 자세한 내용은 man fstab 을 참조하십시오.
8.3. flexs
/etc/fstab 를 사용하는 한 가지 단점은 마운트된 파일 시스템을 유지하기 위해 리소스를 전용으로 지정해야 한다는 것입니다. 이는 하나 또는 두 개의 마운트에 문제가 아니지만 한 번에 여러 시스템에 마운트를 유지하는 경우 전체 시스템 성능에 영향을 줄 수 있습니다. /etc/fstab 대신 커널 기반 자동 마운트 유틸리티를 사용하는 것입니다. 자동 마운터는 다음 두 가지 구성 요소로 구성됩니다.
- 파일 시스템을 구현하는 커널 모듈, 및
- 기타 모든 기능을 수행하는 사용자 공간 데몬.
/etc/auto.master (마스터 맵)를 기본 기본 설정 파일로 사용합니다. Name Service Switch(NSS) 메커니즘과 함께 autofs 구성( /etc/sysconfig/autofs)을 사용하여 지원되는 다른 네트워크 소스와 이름을 사용하도록 변경할 수 있습니다. autofs 버전 4 데몬의 인스턴스는 마스터 맵에 구성된 각 마운트 지점에 대해 실행되었으며 지정된 마운트 지점에 대해 명령줄에서 수동으로 실행할 수 있습니다. autofs 버전 5에서는 단일 데몬을 사용하여 구성된 모든 마운트 지점을 관리하기 때문에 이 작업을 수행할 수 없습니다. 따라서 모든 자동 마운트를 마스터 맵에서 구성해야 합니다. 이는 다른 업계 표준 자동 마운터의 일반적인 요구 사항과 일치합니다. 마운트 지점, 호스트 이름, 내보낸 디렉터리 및 옵션은 각 호스트에 대해 수동으로 구성하는 대신 파일 집합(또는 기타 지원되는 네트워크 소스)에서 모두 지정할 수 있습니다.
8.3.1. 버전 4를 통한 autofs 버전 5 개선 사항
- 직접 맵 지원
- autofs 의 직접 맵은 파일 시스템 계층 구조의 임의의 지점에서 파일 시스템을 자동으로 마운트하는 메커니즘을 제공합니다. 직접 맵은 마스터 맵의 마운트 지점
/-로 표시됩니다. 직접 맵의 항목에는 절대 경로 이름이 키로 포함됩니다(직모 맵에서 사용되는 상대 경로 이름 대신). - 지연 마운트 및 마운트 해제 지원
- 다중 마운트 맵 항목은 단일 키 아래의 마운트 지점 계층을 설명합니다. 이에 대한 좋은 예는
-hosts맵이며, 일반적으로/net/에 있는 호스트의 모든 내보내기를 다중 마운트 맵 항목으로 자동 마운트하는 데 사용됩니다.-hosts맵을 사용하는 경우 ls of /net/host는 호스트 에서 각 내보내기에 대해 autofs 트리거 마운트를 마운트합니다. 그러면 액세스 시 마운트 및 만료됩니다. 이렇게 하면 대량의 내보내기가 있는 서버에 액세스하는 경우 필요한 활성 마운트 수를 크게 줄일 수 있습니다. - LDAP 지원 강화
- autofs 설정 파일(
/etc/sysconfig/autofs)은 사이트에서 구현하는 autofs 스키마를 지정하는 메커니즘을 제공하므로 애플리케이션 자체의 평가판 및 오류를 통해 이를 결정해야 합니다. 또한 공통 LDAP 서버 구현에서 지원하는 대부분의 메커니즘을 사용하여 LDAP 서버에 인증된 바인딩이 지원됩니다. 이러한 지원을 위해 새로운 설정 파일이 추가되었습니다./etc/autofs_ldap_auth.conf. 기본 구성 파일은 자체 문서화되며 XML 형식을 사용합니다. - Name Service Switch(nsswitch) 구성을 올바르게 사용합니다.
- Name Service Switch 구성 파일은 특정 구성 데이터가 제공되는 위치를 결정하는 수단을 제공하기 위해 존재합니다. 이 구성의 이유는 관리자가 선택한 백엔드 데이터베이스를 사용하는 동시에 데이터에 액세스할 수 있는 균일한 소프트웨어 인터페이스를 유지하는 유연성을 제공하기 위한 것입니다. NSS 설정을 처리할 때 버전 4 자동 마운터가 점점 더 높아지고 있지만 아직 완료되지 않았습니다. 반면, Libv 버전 5는 완전한 구현입니다.이 파일의 지원되는 구문에 대한 자세한 내용은 man nsswitch.conf 를 참조하십시오. 모든 NSS 데이터베이스가 유효한 맵 소스는 아니며, 구문 분석기에서 유효하지 않은 맵을 거부합니다. 유효한 소스는 파일, yp,nis,nisplus,ldap, hesiod 입니다.
- autofs 마운트 지점당 여러 마스터 맵 항목
- 자주 사용되지만 아직 언급되지 않은 한 가지는 직접 마운트 지점(
/-)에 대해 여러 개의 마스터 맵 항목을 처리하는 것입니다. 각 항목의 맵 키는 병합되고 하나의 맵으로 작동합니다.예 8.2. autofs 마운트 지점당 다중 마스터 맵 항목
다음은 직접 마운트를 위한 connectathon 테스트 맵의 예입니다./- /tmp/auto_dcthon /- /tmp/auto_test3_direct /- /tmp/auto_test4_direct
8.3.2. autofs 설정
/etc/auto.master 이며, 8.3.1절. “버전 4를 통한 autofs 버전 5 개선 사항” 에 설명된 대로 변경될 수 있는 마스터 맵이라고도 합니다. 마스터 맵은 시스템의 autofs- controlled 마운트 지점과 자동 마운트 맵이라는 해당 구성 파일 또는 네트워크 소스를 나열합니다. 마스터 맵 형식은 다음과 같습니다.
mount-point map-name options
- mount-point
- autofs 마운트 지점(예:
/home)입니다. - map-name
- 마운트 지점 목록이 포함된 맵 소스의 이름과 해당 마운트 지점을 마운트해야 하는 파일 시스템 위치입니다.
- options
- 제공된 경우 지정된 맵의 모든 항목에 적용되지만 자체적으로 옵션이 지정되지 않습니다. 이 동작은 옵션이 누적된 autofs 버전 4와 다릅니다. 이는 혼합된 환경 호환성을 구현하도록 변경되었습니다.
예 8.3. /etc/auto.master File
/etc/auto.master 파일의 샘플 행입니다( cat /etc/auto.master와 함께 표시됨).
/home /etc/auto.misc
mount-point [options] location
- mount-point
- 이는 autofs 마운트 지점을 나타냅니다. 간접 마운트를 위한 단일 디렉터리 이름 또는 직접 마운트를 위한 마운트 지점의 전체 경로일 수 있습니다. 각 직접 및 간접 맵 항목 키(마운트 지점) 뒤에는 여러 마운트 항목으로 알려진 오프셋 디렉토리(각 디렉터리 이름)가
/로 시작하는 오프셋 디렉토리 목록이 올 수 있습니다. - options
- 제공할 때마다 자체 옵션을 지정하지 않는 맵 항목의 마운트 옵션입니다.
- 위치
- 이는 로컬 파일 시스템 경로( Sun map format escape 문자 ":"로 시작하는 맵 이름), NFS 파일 시스템 또는 기타 유효한 파일 시스템 위치와 같은 파일 시스템 위치를 나타냅니다.
/etc/auto.misc).
payroll -fstype=nfs personnel:/dev/hda3 sales -fstype=ext3 :/dev/hda4
직원이라는 서버의 판매 /home/payroll 및 / home/ale 입니다. -fstype= 옵션은 종종 생략되며, 일반적으로 올바른 작업에 필요하지 않습니다.
# systemctl start autofs# systemctl restart autofs/home/ payroll/2006/July.sxc 와 같은 autofs 마운트 해제된 디렉토리에 액세스해야 하는 경우 자동 마운트 데몬에서 자동으로 디렉터리를 마운트합니다. 시간 초과를 지정하면 시간 제한 기간 동안 디렉터리에 액세스하지 않으면 디렉터리가 자동으로 마운트 해제됩니다.
# systemctl status autofs8.3.3. 사이트 구성 파일 덮어쓰기 또는 수정
- 자동 마운터 맵은 NIS에 저장되고
/etc/nsswitch.conf파일에는 다음 지시문이 있습니다.automount: files nis
auto.master파일에는 다음이 포함됩니다.+auto.master
- NIS
auto.master맵 파일에는 다음이 포함됩니다./home auto.home
- NIS
auto.home맵에는 다음이 포함됩니다.beth fileserver.example.com:/export/home/beth joe fileserver.example.com:/export/home/joe * fileserver.example.com:/export/home/&
- 파일 맵
/etc/auto.home이 없습니다.
auto.home 을 재정의하고 다른 서버의 홈 디렉터리를 마운트해야 한다고 가정하겠습니다. 이 경우 클라이언트는 다음 /etc/auto.master 맵을 사용해야 합니다.
/home /etc/auto.home +auto.master
/etc/auto.home 맵에는 항목이 포함되어 있습니다.
* labserver.example.com:/export/home/&
/home 에는 NIS auto.home 맵 대신 /etc/auto.home 내용이 포함됩니다.
auto.home 맵을 보강하려면 /etc/auto.home 파일 맵을 만들고 새 항목이 배치됩니다. 끝에 NIS auto.home 맵을 포함합니다. 그런 다음 /etc/auto.home 파일 맵은 다음과 유사합니다.
mydir someserver:/export/mydir +auto.home
auto.home 맵 조건을 사용하면 ls /home 명령이 출력됩니다.
beth joe mydir
8.3.4. LDAP를 사용하여 자동 마운터 맵 저장
openldap 패키지는 Manila의 종속성으로 자동 설치되어야 합니다. LDAP 액세스를 구성하려면 /etc/openldap/ldap.conf 를 수정합니다. BASE, URI 및 스키마가 사이트에 적절히 설정되어 있는지 확인합니다.
rfc2307bis 에 설명되어 있습니다. 이 스키마를 사용하려면 스키마 정의에서 주석 문자를 제거하여 autofs 구성(/etc/sysconfig/autofs)에서 설정해야 합니다. 예를 들어 다음과 같습니다.
예 8.4. autofs 설정
DEFAULT_MAP_OBJECT_CLASS="automountMap" DEFAULT_ENTRY_OBJECT_CLASS="automount" DEFAULT_MAP_ATTRIBUTE="automountMapName" DEFAULT_ENTRY_ATTRIBUTE="automountKey" DEFAULT_VALUE_ATTRIBUTE="automountInformation"
rfc2307bis 스키마의 cn 속성을 대체합니다. 다음은 LDAP 데이터 상호 변경 형식(LDIF) 구성의 예입니다.
예 8.5. LDF 설정
# extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.master)) # requesting: ALL # # auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: top objectClass: automountMap automountMapName: auto.master # extended LDIF # # LDAPv3 # base <automountMapName=auto.master,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # /home, auto.master, example.com dn: automountMapName=auto.master,dc=example,dc=com objectClass: automount cn: /home automountKey: /home automountInformation: auto.home # extended LDIF # # LDAPv3 # base <> with scope subtree # filter: (&(objectclass=automountMap)(automountMapName=auto.home)) # requesting: ALL # # auto.home, example.com dn: automountMapName=auto.home,dc=example,dc=com objectClass: automountMap automountMapName: auto.home # extended LDIF # # LDAPv3 # base <automountMapName=auto.home,dc=example,dc=com> with scope subtree # filter: (objectclass=automount) # requesting: ALL # # foo, auto.home, example.com dn: automountKey=foo,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: foo automountInformation: filer.example.com:/export/foo # /, auto.home, example.com dn: automountKey=/,automountMapName=auto.home,dc=example,dc=com objectClass: automount automountKey: / automountInformation: filer.example.com:/export/&
8.4. 일반적인 NFS 마운트 옵션
/etc/fstab 설정 및 autofs 와 함께 사용할 수 있습니다.
- lookupcache=mode
- 커널이 지정된 마운트 지점의 디렉터리 항목 캐시를 관리하는 방법을 지정합니다. mode 에 유효한 인수는
all,none또는pos/positive입니다. - nfsvers=version
- 사용할 NFS 프로토콜의 버전을 지정합니다. 여기서 version 은 3 또는 4입니다. 이 기능은 여러 NFS 서버를 실행하는 호스트에 유용합니다. 버전을 지정하지 않으면 NFS는 kernel에서 지원하는 가장 높은 버전과 mount 명령을 사용합니다.옵션 vers 는 nfsvers 와 동일하며 호환성을 이유로 이 릴리스에 포함됩니다.
- noacl
- ACL 처리를 모두 해제합니다. 최신 ACL 기술이 이전 시스템과 호환되지 않기 때문에 이전 버전의 Red Hat Enterprise Linux, Red Hat Linux 또는 Solaris와 상호 작용해야 할 수 있습니다.
- NOLOCK
- 파일 잠금을 비활성화합니다. 이 설정은 매우 오래된 NFS 서버에 연결할 때 필요한 경우가 있습니다.
- noexec
- 마운트된 파일 시스템에서 바이너리 실행을 방지합니다. 이는 시스템이 호환되지 않는 바이너리가 포함된 비 Linux 파일 시스템을 마운트하는 경우에 유용합니다.
- nosuid
set-user-identifier또는set-group-identifier비트를 비활성화합니다. 이렇게 하면 원격 사용자가 setuid 프로그램을 실행하여 더 높은 권한을 얻지 못합니다.- port=num
- NFS 서버 포트의 숫자 값을 지정합니다. num 이 0 (기본값)이면 사용할 포트 번호에 대해 원격 호스트의 CHAP bind 서비스를 쿼리합니다. 원격 호스트의 NFS 데몬이 changed bind 서비스에 등록되지 않은 경우 표준 NFS 포트 번호 TCP 2049가 대신 사용됩니다.
- rsize=num 및 wsize=num
- 이러한 옵션은 단일 NFS 읽기 또는 쓰기 작업에서 전송할 최대 바이트 수를 설정합니다.
rsize및wsize에 대한 고정 기본값은 없습니다. 기본적으로 NFS는 서버와 클라이언트 모두 지원하는 가장 큰 값을 사용합니다. Red Hat Enterprise Linux 7에서 클라이언트 및 서버 최대값은 1,048,576 바이트입니다. 자세한 내용은 NFS 마운트를 사용한 rsize 및 wsize의 기본값과 최대값을 참조하십시오. Kbase 문서. - sec=flavors
- 마운트된 내보내기의 파일에 액세스하는 데 사용할 보안 플레이버입니다. flavor 값은 하나 이상의 보안 플레이버 로 구성된 콜론으로 구분된 목록입니다.기본적으로 클라이언트는 클라이언트와 서버 지원 보안 플레이버를 찾습니다. 서버가 선택한 플레이버를 지원하지 않으면 마운트 작업이 실패합니다.
sec=sys는 로컬 UNIX UID와 GID를 사용합니다. 이러한 작업은AUTH_SYS를 사용하여 NFS 작업을 인증합니다.sec=krb5는 로컬 UNIX UID 및 GID 대신 Kerberos V5를 사용하여 사용자를 인증합니다.sec=krb5i는 사용자 인증에 Kerberos V5를 사용하고 데이터 변조를 방지하기 위해 보안 체크섬을 사용하여 NFS 작업을 무결성 검사를 수행합니다.sec=krb5p는 사용자 인증, 무결성 검사 및 NFS 트래픽을 암호화하여 트래픽 스니핑을 방지하기 위해 Kerberos V5를 사용합니다. 이는 가장 안전한 설정이지만 성능 오버헤드가 가장 많습니다. - tcp
- NFS 마운트에 TCP 프로토콜을 사용하도록 지시합니다.
- udp
- NFS 마운트에 UDP 프로토콜을 사용하도록 지시합니다.
8.5. NFS 서버 시작 및 중지
사전 요구 사항
- NFSv2 또는 NFSv3 연결을 지원하는 서버의 경우 INPUT
bind[1]서비스가 실행 중이어야 합니다.rpcbind가 활성 상태인지 확인하려면 다음 명령을 사용합니다.$systemctl status rpcbindNFSv4 전용 서버를 구성하는 데 필요한 NFSv4 전용 서버를 구성하려면 8.6.7절. “NFSv4 전용 서버 구성” 을 참조하십시오. - Red Hat Enterprise Linux 7.0에서 NFS 서버가 NFSv3를 내보내고 부팅 시 시작되도록 활성화된 경우
nfs-lock서비스를 수동으로 시작하고 활성화해야 합니다.#systemctl start nfs-lock#systemctl enable nfs-lockRed Hat Enterprise Linux 7.1 이상에서는 필요한 경우nfs-lock이 자동으로 시작되고 수동으로 활성화하려고 합니다.
절차
- NFS 서버를 시작하려면 다음 명령을 사용하십시오.
# systemctl start nfs - 부팅 시 시작되도록 NFS를 활성화하려면 다음 명령을 사용합니다.
# systemctl enable nfs - 서버를 중지하려면 다음을 사용합니다.
# systemctl stop nfs 다시 시작옵션은 NFS를 중지한 다음 시작할 수 있는 간단한 방법입니다. 이 방법은 NFS 구성 파일을 편집한 후 구성 변경을 적용하는 가장 효율적인 방법입니다. 서버 유형을 다시 시작하려면 다음을 수행합니다.# systemctl restart nfs/etc/sysconfig/nfs파일을 편집한 후 새 값이 적용되도록 다음 명령을 실행하여 nfs-config 서비스를 다시 시작합니다.# systemctl restart nfs-configtry-restart명령은 현재 실행 중인 경우에만 nfs 를 시작합니다. 이 명령은 Red Hat init 스크립트의 condrestart( 조건부 재시작 )와 동일하며 NFS가 실행되고 있지 않은 경우 데몬을 시작하지 않기 때문에 유용합니다.서버를 조건부로 다시 시작하려면 다음을 입력합니다.# systemctl try-restart nfs- 서비스 유형을 다시 시작하지 않고 NFS 서버 구성 파일을 다시 로드하려면 다음을 수행합니다.
# systemctl reload nfs
8.6. NFS 서버 구성
- NFS 구성 파일 즉,
/etc/exports를 수동으로 편집할 수 있습니다. - 명령행을 통해, 즉 exportfs명령을 사용하여
8.6.1. /etc/exports 구성 파일
/etc/exports 파일은 원격 호스트로 내보낼 파일 시스템을 제어하고 옵션을 지정합니다. 다음 구문 규칙을 따릅니다.
- 빈 줄은 무시됩니다.
- 주석을 추가하려면 해시 표시(#)로 행을 시작합니다.
- 긴 줄을 백슬래시(\)로 래핑할 수 있습니다.
- 내보낸 각 파일 시스템은 고유한 개별 행에 있어야 합니다.
- 내보낸 파일 시스템 뒤에 배치된 권한 있는 호스트 목록은 공백 문자로 구분해야 합니다.
- 각 호스트에 대한 옵션은 호스트와 첫 번째 괄호를 구분하여 호스트 식별자 뒤에 직접 배치해야 합니다.
export host(options)
- export
- 내보낼 디렉토리
- host
- 내보내기를 공유할 호스트 또는 네트워크
- options
- 호스트에사용할 옵션
export host1(options1) host2(options2) host3(options3)
/etc/exports 파일은 내보낸 디렉토리와 다음 예와 같이 액세스하도록 허용된 호스트만 지정합니다.
예 8.6. /etc/exports 파일
/exported/directory bob.example.com
bob.example.com 는 NFS 서버에서 /exported/directory/ 를 마운트할 수 있습니다. 이 예에서는 옵션이 지정되지 않으므로 NFS는 기본 설정을 사용합니다.
- ro
- 내보낸 파일 시스템은 읽기 전용입니다. 원격 호스트는 파일 시스템에서 공유하는 데이터를 변경할 수 없습니다. 호스트가 파일 시스템(즉, 읽기 및 쓰기)을 변경할 수 있도록 허용하려면
rw옵션을 지정합니다. - sync
- 이전 요청의 변경 전에 NFS 서버는 요청에 응답하지 않습니다. 대신 비동기 쓰기를 활성화하려면
async옵션을 지정합니다. - wdelay
- 다른 쓰기 요청이 무미한 것으로 의심되는 경우 NFS 서버는 디스크에 쓰기를 지연합니다. 이렇게 하면 별도의 쓰기 명령으로 디스크에 액세스해야 하는 횟수가 줄어들어 쓰기 오버헤드가 줄어들어 성능을 향상시킬 수 있습니다. 이를 비활성화하려면
no_wdelay를 지정합니다.no_wdelay는 기본동기화옵션도 지정된 경우에만 사용할 수 있습니다. - root_squash
- 이렇게 하면 루트 사용자가 root 권한을 원격으로 연결할 수 없습니다. 대신, NFS 서버에서 사용자 ID
nfsnobody를 할당합니다. 이를 통해 원격 루트 사용자의 권한을 가장 낮은 로컬 사용자에게 효과적으로 "스쿼리"하여 원격 서버에 무단 쓰기를 방지할 수 있습니다. 루트 스쿼시를 비활성화하려면no_root_squash를 지정합니다.
all_squash 를 사용합니다. NFS 서버가 특정 호스트의 원격 사용자에게 할당해야 하는 사용자 및 그룹 ID를 지정하려면 다음과 같이 anonuid 및 anongid 옵션을 각각 사용합니다.
export host(anonuid=uid,anongid=gid)
anonuid 및 anongid 옵션을 사용하면 원격 NFS 사용자가 공유할 수 있는 특수 사용자 및 그룹 계정을 만들 수 있습니다.
rw 옵션을 지정하지 않으면 내보낸 파일 시스템이 읽기 전용으로 공유됩니다. 다음은 두 가지 기본 옵션을 재정의하는 /etc/exports 의 샘플 행입니다.
/another/exported/directory/ 읽기 및 쓰기를 마운트할 수 있으며 디스크에 대한 모든 쓰기는 비동기입니다. 옵션 내보내기에 대한 자세한 내용은 man exportfs 를 참조하십시오.
/etc/exports 파일의 형식은 특히 공백 문자를 사용하는 것과 관련하여 매우 정확합니다. 내보낸 파일 시스템을 항상 공백 문자를 사용하여 호스트 및 호스트와 서로 분리해야 합니다. 주석 행을 제외하고 파일에는 다른 공백 문자가 없어야 합니다.
/home bob.example.com(rw) /home bob.example.com (rw)
bob.example.com 의 사용자만 /home 디렉터리에 대한 읽기 및 쓰기 액세스 권한을 허용합니다. 두 번째 행을 사용하면 bob.example.com 의 사용자가 디렉터리를 읽기 전용(기본값)으로 마운트할 수 있으며 나머지 사용자는 읽기/쓰기로 마운트할 수 있습니다.
8.6.2. exportfs 명령
/etc/exports 파일에 나열됩니다. nfs 서비스가 시작되면 /usr/sbin/exportfs 명령이 이 파일을 시작하고 읽고 이 파일을 읽고, 실제 마운트 프로세스의 경우 CHAP .mountd (if NFSv3)에 제어를 전달한 다음, 원격 사용자가 파일 시스템을 사용할 수 있는 locations .nfsd 에 대한 제어를 전달합니다.
/var/lib/nfs/xtab 에 씁니다. file 시스템에 대한 액세스 권한을 결정할 때 xtab.mountd 는 xtab 파일을 참조하므로 내보낸 파일 시스템 목록의 변경 사항이 즉시 적용됩니다.
- -r
/var/lib/nfs/etab에 새 내보내기 목록을 구성하여/etc/exports에 나열된 모든 디렉토리를 내보내도록 합니다. 이 옵션은/etc/exports를 변경하여 내보내기 목록을 효과적으로 새로 고칩니다.- -a
- /usr/sbin/exportfs 에 전달되는 다른 옵션에 따라 모든 디렉토리를 내보내거나 내보내기 해제하도록 합니다. 다른 옵션이 지정되지 않은 경우 /usr/sbin/exportfs 는
/etc/exports에 지정된 모든 파일 시스템을 내보냅니다. - -o file-systems
/etc/exports에 나열되지 않은 내보낼 디렉토리를 지정합니다. 파일 시스템을 내보낼 추가 파일 시스템으로 교체합니다. 이러한 파일 시스템은/etc/exports에 지정된 방식과 동일하게 포맷해야 합니다. 이 옵션은 내보낼 파일 시스템 목록에 영구적으로 추가하기 전에 내보낸 파일 시스템을 테스트하는 데 자주 사용됩니다./etc/exports구문에 대한 자세한 내용은 8.6.1절. “/etc/exports구성 파일” 을 참조하십시오.- -i
/etc/exports는 무시합니다. 명령줄에 제공된 옵션만 내보낸 파일 시스템을 정의하는 데 사용됩니다.- -u
- 모든 공유 디렉토리를 연결을 해제합니다. /usr/sbin/exportfs -ua 명령은 모든 NFS 데몬을 유지하면서 NFS 파일 공유를 일시 중지합니다. NFS 공유를 다시 활성화하려면 exportfs -r 을 사용합니다.
- -v
- exportfs 명령을 실행할 때 내보내거나 내보내지 않은 파일 시스템이 더 자세히 표시되는 상세 작업입니다.
8.6.2.1. NFSv4에서 exportfs 사용
/etc/sysconfig/nfs 에서 RPCNFSDARGS= -N 4 를 설정하여 전원을 끕니다.
8.6.3. NFS 실행 방화벽
/etc/sysconfig/nfs 파일을 편집하여 RPC 서비스가 실행되는 포트를 설정합니다. 방화벽을 통해 클라이언트가 RPC 할당량에 액세스할 수 있도록 허용하려면 8.6.4절. “방화벽을 통해 RPC 할당량에 액세스” 을 참조하십시오.
/etc/sysconfig/nfs 파일은 기본적으로 모든 시스템에 존재하지 않습니다. /etc/sysconfig/nfs 가 없는 경우 이를 생성하고 다음을 지정합니다.
- RPCMOUNTDOPTS="-p port"
- 이를 통해 "-p 포트"-p 포트 ".pc.mount 명령 행:authorization .mount -p 포트 가 추가됩니다.
nlockmgr 서비스에서 사용할 포트를 지정하려면 /etc/modprobe.d/lockd.conf 파일의 nlm_tcpport 및 nlm_udpport 옵션에 대한 포트 번호를 설정합니다.
/var/log/messages 를 확인합니다. 일반적으로 이미 사용 중인 포트 번호를 지정하면 NFS가 시작되지 않습니다. /etc/sysconfig/nfs 를 편집한 후 새 값이 Red Hat Enterprise Linux 7.2 및 실행 전에 적용되도록 nfs-config 서비스를 다시 시작해야 합니다.
# systemctl restart nfs-config
그런 다음 NFS 서버를 다시 시작하십시오.
# systemctl restart nfs-server
alice info -p 를 실행하여 변경 사항이 적용되었는지 확인합니다.
/proc/sys/fs/nfs_callback_tcpport 를 설정하고 서버가 클라이언트의 해당 포트에 연결할 수 있습니다.
mountd,statd, lockd 를 위한 다른 포트는 순수 NFSv4 환경에 필요하지 않습니다.
8.6.3.1. NFS 내보내기 검색
- NFSv3를 지원하는 모든 서버에서 showmount 명령을 사용합니다.
$showmount -e myserver Export list for mysever /exports/foo /exports/bar - NFSv4를 지원하는 모든 서버에서 루트 디렉터리를 마운트하고 살펴봅니다.
#mount myserver:/ /mnt/#cd /mnt/ exports#ls exports foo bar
8.6.4. 방화벽을 통해 RPC 할당량에 액세스
절차 8.1. RPC 할당량 액세스 가능으로 방화벽 설정
- EgressIP
-rquotad 서비스를활성화하려면 다음 명령을 사용합니다.#systemctl enable rpc-rquotad - EgressIP
-rquotad서비스를 시작하려면 다음 명령을 사용합니다.
g#systemctl start rpc-rquotadRPC-rquotad는 활성화된 경우nfs-server서비스를 시작한 후 자동으로 시작됩니다. - 방화벽 뒤에서 할당량 RPC 서비스에 액세스할 수 있도록 하려면 UDP 또는 TCP 포트
875를 열어야 합니다. 기본 포트 번호는/etc/services파일에 정의됩니다./etc/sysconfig/rpc를 추가하여 기본 포트 번호를 덮어쓸 수 있습니다.-rquotad파일의RPCRQUOTADOPTS변수에 -p port-number /etc/sysconfig/파일의 변경 사항을 적용하려면 INPUT-rquotad를 다시 시작하십시오.rpc-rquotad#systemctl restart rpc-rquotad
원격 호스트에서 할당량 설정
/etc/sysconfig/rpc-rquotad 파일의 RPCRQUOTADOPTS 변수에 -S 옵션을 추가합니다.
/etc/sysconfig/ rpc-rquotad 파일의 변경 사항을 적용하려면 INPUT-rquotad를 다시 시작하십시오.
# systemctl restart rpc-rquotad
8.6.5. 호스트 이름 형식
- 단일 머신
- 정규화된 도메인 이름(서버로 해결할 수 있음), 호스트 이름(서버로 확인할 수 있음) 또는 IP 주소입니다.
- 와일드카드로 지정된 일련의 머신
*또는?문자를 사용하여 일치하는 문자열을 지정합니다. IP 주소와 함께 와일드카드를 사용할 수 없지만 역방향 DNS 조회가 실패하는 경우 실수로 작동하지 않을 수 있습니다. 정규화된 도메인 이름에 와일드 카드를 지정할 때 점(.)은 와일드카드에 포함되지 않습니다. 예를 들어*.example.com에는one.example.com이 포함되지만include one.two.example.com은 포함되지 않습니다.- IP 네트워크
- a.b.c.d/z 를 사용합니다. 여기서 a.b.c.d 는 네트워크이며 z 는 넷마스크의 비트 수입니다(예:httpd). 또 다른 허용 가능한 형식은 a.b.c.d입니다. 여기서 a.b.c.d 는 네트워크 및 넷마스크 입니다(예: 192.168.100.8/255.255.0).
- netgroups
- @group-name 포맷을 사용합니다. 여기서 group-name 은 NIS netgroup 이름입니다.
8.6.6. RDMA(NFSORDMA)를 통한 NFS 활성화
- rdma 및 rdma-core 패키지를 설치합니다.
/etc/rdma/rdma.conf파일에는 기본적으로XPRTRDMA_LOAD=yes를 설정하는 행이 포함되어 있으며, 이 행은rdma서비스가 NFSoRDMA 클라이언트 모듈을 로드하도록 요청합니다. - NFSoRDMA 서버 모듈의 자동 로드를 활성화하려면
/etc/rdma/rdma.conf의 새 줄에SVCRDMA_LOAD=yes을 추가합니다.RPCNFSDARGS="--rdma=20049"/etc/sysconfig/nfs파일에서 NFSoRDMA 서비스가 클라이언트를 수신 대기하는 포트 번호를 지정합니다. RFC 5667 은 RDMA를 통해 NFSv4 서비스를 제공할 때 서버가 포트20049에서 수신 대기해야 함을 지정합니다. /etc/rdma/rdma.conf파일을 편집한 후nfs서비스를 다시 시작하십시오.#systemctl restart nfs이전 커널 버전에서는 변경 사항이 적용되려면/etc/rdma/rdma.conf를 편집한 후 시스템 재부팅이 필요합니다.
8.6.7. NFSv4 전용 서버 구성
수 와 시스템에서 서비스를 실행하면 됩니다.
Requested NFS version or transport protocol is not supported.
절차 8.2. NFSv4 전용 서버 구성
/etc/sysconfig/nfs구성 파일에 다음 행을 추가하여 NFSv2, NFSv3 및 UDP를 비활성화합니다.RPCNFSDARGS="-N 2 -N 3 -U"
- 필요한 경우 NFSv4 전용 경우 필요하지 않은
RPCBIND,MOUNT,NSM프로토콜 호출에 대한 수신 대기를 비활성화합니다.이러한 옵션을 비활성화하는 방법은 다음과 같습니다.- NFSv2 또는 NFSv3를 사용하여 서버의 공유를 마운트하려고 시도하는 클라이언트가 응답하지 않습니다.
- NFS 서버 자체는 NFSv2 및 NFSv3 파일 시스템을 마운트할 수 없습니다.
이러한 옵션을 비활성화하려면 다음을 수행합니다.- 다음을
/etc/sysconfig/nfs파일에 추가합니다.RPCMOUNTDOPTS="-N 2 -N 3"
- 관련 서비스를 비활성화합니다.
#systemctl mask --now rpc-statd.service rpcbind.service rpcbind.socket
- NFS 서버를 다시 시작합니다.
#systemctl restart nfs변경 사항은 NFS 서버를 시작하거나 다시 시작하는 즉시 적용됩니다.
8.6.7.1. NFSv4 전용 설정 확인
netstat 유틸리티를 사용하여 NFS 서버가 NFSv4 전용 모드로 구성되었는지 확인할 수 있습니다.
- 다음은 NFSv4 전용 서버의
netstat출력 예입니다.RPCBIND,MOUNT및NSM수신 대기도 비활성화됩니다.nfs는 유일한 수신 대기 NFS 서비스입니다.#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* - 반면 NFSv4 전용 서버를 구성하기 전에
netstat출력에는sunrpc및mountd서비스가 포함되어 있습니다.#netstat -ltu Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 0.0.0.0:nfs 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:36069 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:52364 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:sunrpc 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:mountd 0.0.0.0:* LISTEN tcp 0 0 0.0.0.0:ssh 0.0.0.0:* LISTEN tcp 0 0 localhost:smtp 0.0.0.0:* LISTEN tcp6 0 0 [::]:34941 [::]:* LISTEN tcp6 0 0 [::]:nfs [::]:* LISTEN tcp6 0 0 [::]:sunrpc [::]:* LISTEN tcp6 0 0 [::]:mountd [::]:* LISTEN tcp6 0 0 [::]:12432 [::]:* LISTEN tcp6 0 0 [::]:56881 [::]:* LISTEN tcp6 0 0 [::]:12434 [::]:* LISTEN tcp6 0 0 localhost:7092 [::]:* LISTEN tcp6 0 0 [::]:ssh [::]:* LISTEN udp 0 0 localhost:323 0.0.0.0:* udp 0 0 0.0.0.0:37190 0.0.0.0:* udp 0 0 0.0.0.0:876 0.0.0.0:* udp 0 0 localhost:877 0.0.0.0:* udp 0 0 0.0.0.0:mountd 0.0.0.0:* udp 0 0 0.0.0.0:38588 0.0.0.0:* udp 0 0 0.0.0.0:nfs 0.0.0.0:* udp 0 0 0.0.0.0:bootpc 0.0.0.0:* udp 0 0 0.0.0.0:sunrpc 0.0.0.0:* udp6 0 0 localhost:323 [::]:* udp6 0 0 [::]:57683 [::]:* udp6 0 0 [::]:876 [::]:* udp6 0 0 [::]:mountd [::]:* udp6 0 0 [::]:40874 [::]:* udp6 0 0 [::]:nfs [::]:* udp6 0 0 [::]:sunrpc [::]:*
8.7. NFS 보안
8.7.1. AUTH_SYS 및 Export Controls를 사용한 NFS 보안
AUTH_SYS ( AUTH_UNIX라고도 함)를 사용합니다. 즉, 악성 또는 잘못 구성된 클라이언트가 쉽게이 잘못된 얻을 수 있으며 사용자가 사용하지 않아야하는 파일에 대한 액세스를 허용 할 수 있습니다.
8.7.2. AUTH_GSS를 사용한 NFS 보안
Kerberos 구성
절차 8.3. RPCSEC_GSS를 사용하도록 IdM용 NFS 서버 및 클라이언트 구성
- NFS 서버 측에서
nfs/hostname.domain@REALM주체를 생성합니다. - server 및 client side 둘 다에
host/hostname.domain@REALM주체를 생성합니다. - 클라이언트 및 서버의 키탭에 해당 키를 추가합니다.
자세한 내용은 Red Hat Enterprise Linux 7 Linux 도메인 ID, 인증 및 정책 가이드 의 Kerberos 인식 NFS 서버 섹션 추가 및 편집 서비스 항목을 참조하십시오.- 서버 측에서
sec=옵션을 사용하여 원하는 보안 플레이버를 활성화합니다. 모든 보안 플레이버 및 비 암호화 마운트를 활성화하려면 다음을 수행합니다./export *(sec=sys:krb5:krb5i:krb5p)
sec=옵션과 함께 사용할 유효한 보안 플레이버는 다음과 같습니다.sys: 암호화 보호 없음, 기본값krb5: 인증 전용krb5i: 무결성 보호krb5p: 개인 정보 보호
- 클라이언트 측에서 마운트 옵션에
sec=krb5(또는sec=krb5i,sec=krb5p, sec=krb5p )를 추가합니다.# mount -o sec=krb5 server:/export /mnt
NFS 클라이언트를 구성하는 방법에 대한 자세한 내용은 Red Hat Enterprise Linux 7 Linux 도메인 ID, 인증 및 정책 가이드의 Kerberos 인식 NFS 클라이언트 설정 섹션을 참조하십시오.
추가 리소스
- Red Hat은 IdM 사용을 권장하지만 AD(Active Directory) Kerberos 서버도 지원됩니다. 자세한 내용은 SSSD 및 Active Directory를 사용하여 RHEL 7에서 Kerberos 인증을 사용하여 NFS를 설정하는 방법을 참조하십시오.
- Kerberos 보안 NFS 공유에 root로 파일을 쓰고 이러한 파일에 대해 루트 소유권을 유지해야 하는 경우 의 내용을 참조하십시오 https://access.redhat.com/articles/4040141. 이 구성은 권장되지 않습니다.
8.7.2.1. NFSv4를 통한 NFS 보안
MOUNT 프로토콜 사용을 제거하는 것입니다. MOUNT 프로토콜은 프로토콜에서 파일을 처리하는 방식 때문에 보안 위험이 발생했습니다.
8.7.3. 파일 권한
nobody 로 설정됩니다. root squashing은 기본 옵션 root_squash 에 의해 제어됩니다. 이 옵션에 대한 자세한 내용은 8.6.1절. “/etc/exports 구성 파일” 을 참조하십시오. 가능한 경우 루트 스쿼시를 비활성화하지 마십시오.
all_squash 옵션을 사용하는 것이 좋습니다. 이 옵션을 사용하면 내보낸 파일 시스템에 액세스하는 모든 사용자가 nfsnobody 사용자의 사용자 ID를 가져옵니다.
8.8. NFS 및 authorizationbind
bind 서비스가 필요한 NFSv3 구현에만 적용됩니다.
bind 가 필요하지 않은 NFSv4 전용 서버를 구성하는 방법에 대한 자세한 내용은 8.6.7절. “NFSv4 전용 서버 구성” 을 참조하십시오.
8.8.1. NFS 및authorization bind 문제해결
# rpcinfo -p예 8.7. Diffieinfo -p 명령 출력
program vers proto port service
100021 1 udp 32774 nlockmgr
100021 3 udp 32774 nlockmgr
100021 4 udp 32774 nlockmgr
100021 1 tcp 34437 nlockmgr
100021 3 tcp 34437 nlockmgr
100021 4 tcp 34437 nlockmgr
100011 1 udp 819 rquotad
100011 2 udp 819 rquotad
100011 1 tcp 822 rquotad
100011 2 tcp 822 rquotad
100003 2 udp 2049 nfs
100003 3 udp 2049 nfs
100003 2 tcp 2049 nfs
100003 3 tcp 2049 nfs
100005 1 udp 836 mountd
100005 1 tcp 839 mountd
100005 2 udp 836 mountd
100005 2 tcp 839 mountd
100005 3 udp 836 mountd
100005 3 tcp 839 mountd8.9. pNFS
pNFS Flex Files
PNFS 공유 마운트
- pNFS 기능을 활성화하려면 NFS 버전 4.1 이상에서 pNFS 사용 서버의 공유를 마운트합니다.
#mount -t nfs -o v4.1 server:/remote-export /local-directory서버가 pNFS를 사용하면 첫 번째 마운트에nfs_layout_nfsv41_files커널이 자동으로 로드됩니다. 출력의 mount 항목에minorversion=1이 포함되어야 합니다. 다음 명령을 사용하여 모듈이 로드되었는지 확인합니다.$ lsmod | grep nfs_layout_nfsv41_files - flex Files를 지원하는 서버의 flex Files 기능으로 NFS 공유를 마운트하려면 NFS 버전 4.2 이상을 사용합니다.
#mount -t nfs -o v4.2 server:/remote-export /local-directorynfs_layout_flexfiles모듈이 로드되었는지 확인합니다.$lsmod | grep nfs_layout_flexfiles
추가 리소스
8.10. NFS에서 pNFS SCSI 레이아웃 활성화
사전 요구 사항
- 클라이언트와 서버 모두 동일한 블록 장치에 SCSI 명령을 보낼 수 있어야 합니다. 즉, 블록 장치는 공유 SCSI 버스에 있어야 합니다.
- 블록 장치에는 XFS 파일 시스템이 포함되어야 합니다.
- SCSI 장치는 SCSI-3 기본 명령 사양에 설명된 대로 SCSI 영구 예약을 지원해야 합니다.
8.10.1. pNFS SCSI 레이아웃
클라이언트와 서버 간 작업
LAYOUTGET 작업을 수행합니다. 서버는 SCSI 장치에 있는 파일의 위치로 응답합니다. 클라이언트는 GETDEVICEINFO 의 추가 작업을 수행하여 사용할 SCSI 장치를 결정해야 할 수 있습니다. 이러한 작업이 올바르게 작동하는 경우 클라이언트는 READ 및 WRITE 작업을 서버로 보내는 대신 I/O 요청을 SCSI 장치로 직접 실행할 수 있습니다.
READ 및 WRITE 작업을 서버에 실행하기 위해 대체됩니다.
장치 예약
8.10.2. pNFS에서 SCSI 장치 호환성 확인
사전 요구 사항
- sg3_utils 패키지를 설치합니다.
# yum install sg3_utils
절차 8.4. pNFS에서 SCSI 장치 호환성 확인
- 서버와 클라이언트 모두에서 적절한 SCSI 장치 지원이 있는지 확인합니다.
# sg_persist --in --report-capabilities --verbose path-to-scsi-device
Persist through Power losts Active(PTPL_A) 비트가 설정되었는지 확인합니다.예 8.8. pNFS SCSI를 지원하는 SCSI 장치
다음은 pNFS SCSI를 지원하는 SCSI 장치의sg_persist출력 예입니다. POSTPL_A비트는1을 보고합니다.inquiry cdb: 12 00 00 00 24 00 Persistent Reservation In cmd: 5e 02 00 00 00 00 00 20 00 00 LIO-ORG block11 4.0 Peripheral device type: disk Report capabilities response: Compatible Reservation Handling(CRH): 1 Specify Initiator Ports Capable(SIP_C): 1 All Target Ports Capable(ATP_C): 1 Persist Through Power Loss Capable(PTPL_C): 1 Type Mask Valid(TMV): 1 Allow Commands: 1 Persist Through Power Loss Active(PTPL_A): 1 Support indicated in Type mask: Write Exclusive, all registrants: 1 Exclusive Access, registrants only: 1 Write Exclusive, registrants only: 1 Exclusive Access: 1 Write Exclusive: 1 Exclusive Access, all registrants: 1
추가 리소스
- sg_persist(8) 도움말 페이지
8.10.3. 서버에서 pNFS SCSI 설정
절차 8.5. 서버에서 pNFS SCSI 설정
- 서버에서 SCSI 장치에 생성된 XFS 파일 시스템을 마운트합니다.
- NFS 버전 4.1 이상을 내보내도록 NFS 서버를 구성합니다.
/etc/nfs.conf파일의[nfsd]섹션에서 다음 옵션을 설정합니다.[nfsd] vers4.1=y
pnfs옵션을 사용하여 NFS를 통해 XFS 파일 시스템을 내보내도록 NFS 서버를 구성합니다.예 8.9. pNFS SCSI 내보내기의 /etc/exports의 항목
/etc/exports구성 파일의 다음 항목은/exported/directory/에 마운트된 파일 시스템을 pNFS SCSI 레이아웃으로allowed.example.com클라이언트에 내보냅니다./exported/directory allowed.example.com(pnfs)
추가 리소스
- NFS 서버 구성에 대한 자세한 내용은 8.6절. “NFS 서버 구성” 을 참조하십시오.
8.10.4. 클라이언트에서 pNFS SCSI 설정
사전 요구 사항
- NFS 서버는 pNFS SCSI를 통해 XFS 파일 시스템을 내보내도록 구성됩니다. 8.10.3절. “서버에서 pNFS SCSI 설정” 을 참조하십시오.
절차 8.6. 클라이언트에서 pNFS SCSI 설정
- 클라이언트에서 NFS 버전 4.1 이상을 사용하여 내보낸 XFS 파일 시스템을 마운트합니다.
# mount -t nfs -o nfsvers=4.1 host:/remote/export /local/directory
NFS 없이 직접 XFS 파일 시스템을 마운트하지 마십시오.
추가 리소스
- NFS 공유 마운트에 대한 자세한 내용은 8.2절. “NFS 클라이언트 구성” 을 참조하십시오.
8.10.5. 서버에서 pNFS SCSI 예약 해제
사전 요구 사항
- sg3_utils 패키지를 설치합니다.
# yum install sg3_utils
절차 8.7. 서버에서 pNFS SCSI 예약 해제
- 서버에서 기존 예약을 쿼리합니다.
# sg_persist --read-reservation path-to-scsi-device
예 8.10. /dev/sda에서 예약 쿼리
# sg_persist --read-reservation /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk PR generation=0x8, Reservation follows: Key=0x100000000000000 scope: LU_SCOPE, type: Exclusive Access, registrants only - 서버에서 기존 등록을 제거합니다.
# sg_persist --out \ --release \ --param-rk=reservation-key \ --prout-type=6 \ path-to-scsi-device예 8.11. /dev/sda에 예약 삭제
# sg_persist --out \ --release \ --param-rk=0x100000000000000 \ --prout-type=6 \ /dev/sda LIO-ORG block_1 4.0 Peripheral device type: disk
추가 리소스
- sg_persist(8) 도움말 페이지
8.10.6. pNFS SCSI 레이아웃 기능 모니터링
사전 요구 사항
- pNFS SCSI 클라이언트와 서버가 구성되어 있습니다.
8.10.6.1. nfsstat를 사용하여 서버에서 pNFS SCSI 작업 확인
nfsstat 유틸리티를 사용하여 서버에서 pNFS SCSI 작업을 모니터링합니다.
절차 8.8. nfsstat를 사용하여 서버에서 pNFS SCSI 작업 확인
- 서버에서 서비스되는 작업을 모니터링합니다.
# watch --differences \ "nfsstat --server | egrep --after-context=1 read\|write\|layout" Every 2.0s: nfsstat --server | egrep --after-context=1 read\|write\|layout putrootfh read readdir readlink remove rename 2 0% 0 0% 1 0% 0 0% 0 0% 0 0% -- setcltidconf verify write rellockowner bc_ctl bind_conn 0 0% 0 0% 0 0% 0 0% 0 0% 0 0% -- getdevlist layoutcommit layoutget layoutreturn secinfononam sequence 0 0% 29 1% 49 1% 5 0% 0 0% 2435 86% - 다음과 같은 경우 클라이언트 및 서버는 pNFS SCSI 작업을 사용합니다.
레이아웃get,layoutreturn,layoutcommit카운터 증가 즉, 서버가 레이아웃을 제공하고 있습니다.- 서버
읽기및쓰기카운터는 증가하지 않습니다. 즉 클라이언트가 SCSI 장치에 직접 I/O 요청을 수행하고 있습니다.
8.10.6.2. mountstats를 사용하여 클라이언트에서 pNFS SCSI 작업 확인
/proc/self/mountstats 파일을 사용하여 클라이언트에서 pNFS SCSI 작업을 모니터링합니다.
절차 8.9. mountstats를 사용하여 클라이언트에서 pNFS SCSI 작업 확인
- 마운트당 작업 카운터를 나열합니다.
# cat /proc/self/mountstats \ | awk /scsi_lun_0/,/^$/ \ | egrep device\|READ\|WRITE\|LAYOUT device 192.168.122.73:/exports/scsi_lun_0 mounted on /mnt/rhel7/scsi_lun_0 with fstype nfs4 statvers=1.1 nfsv4: bm0=0xfdffbfff,bm1=0x40f9be3e,bm2=0x803,acl=0x3,sessions,pnfs=LAYOUT_SCSI READ: 0 0 0 0 0 0 0 0 WRITE: 0 0 0 0 0 0 0 0 READLINK: 0 0 0 0 0 0 0 0 READDIR: 0 0 0 0 0 0 0 0 LAYOUTGET: 49 49 0 11172 9604 2 19448 19454 LAYOUTCOMMIT: 28 28 0 7776 4808 0 24719 24722 LAYOUTRETURN: 0 0 0 0 0 0 0 0 LAYOUTSTATS: 0 0 0 0 0 0 0 0 - 결과에서 다음을 수행합니다.
LAYOUT통계는 클라이언트와 서버가 pNFS SCSI 작업을 사용하는 요청을 나타냅니다.READ및WRITE통계는 클라이언트와 서버가 NFS 작업으로 대체되는 요청을 나타냅니다.
8.11. NFS 참조
8.11.1. 설치된 문서
- man mount - NFS 서버 및 클라이언트 구성을 위한 마운트 옵션을 포괄적으로 포함합니다.
- man fstab - 부팅 시 파일 시스템을 마운트하는 데 사용되는
/etc/fstab파일 형식에 대한 세부 정보를 제공합니다. - man nfs - NFS 관련 파일 시스템 내보내기 및 마운트 옵션에 대한 세부 정보를 제공합니다.
- man export - NFS 파일 시스템을 내보낼 때
/etc/exports파일에 사용되는 일반적인 옵션을 표시합니다.
8.11.2. 유용한 웹 사이트
- http://linux-nfs.org - 프로젝트 상태 업데이트를 볼 수 있는 개발자의 현재 사이트입니다.
- http://nfs.sourceforge.net/ - 여전히 유용한 정보가 많이 들어 있는 개발자의 오래된 홈입니다.
- http://www.citi.umich.edu/projects/nfsv4/linux/ - Linux 2.6 커널 리소스의 NFSv4
- http://citeseer.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.4086 - NFS 버전 4 프로토콜의 기능 및 개선 사항에 대한 우수한 백서입니다.
9장. 서버 메시지 블록(SMB)
cifs-utils 유틸리티를 사용하여 원격 서버에서 SMB 공유를 마운트합니다.
cifs 라는 이름을 사용합니다.
10장. FS-Cache
그림 10.1. FS-Cache 개요
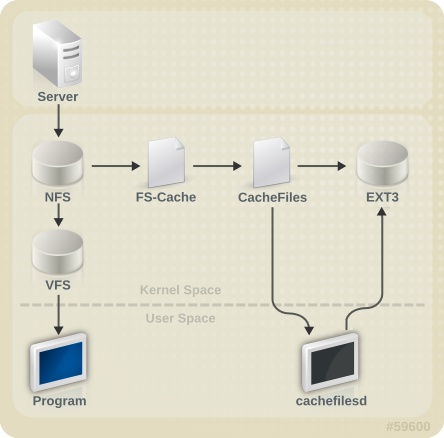
[D]
10.1. 성능 보장
10.2. 캐시 설정
/etc/cachefilesd.conf 파일은 cachefiles 이 캐싱 서비스를 제공하는 방법을 제어합니다.
$ dir /path/to/cache/etc/cachefilesd.conf 에 다음과 같이 /var/cache/fscache 로 설정됩니다.
$ dir /var/cache/fscache
/var/cache/fscache 와 동일해야 합니다.
#semanage fcontext -a -e /var/cache/fscache /path/to/cache#restorecon -Rv /path/to/cache
#semanage permissive -a cachefilesd_t#semanage permissive -a cachefiles_kernel_t
/)을 사용하는 것이 좋지만 데스크탑 시스템의 경우 캐시용 디스크 파티션을 구체적으로 마운트하는 것이 좋습니다.
- ext3 (Extended attributes enabled)
- ext4
- gtv
- XFS
# tune2fs -o user_xattr /dev/device
# mount /dev/device /path/to/cache -o user_xattrcachefilesd 서비스를 시작합니다.
# systemctl start cachefilesd
# systemctl enable cachefilesd10.3. NFS에서 캐시 사용
# mount nfs-share:/ /mount/point -o fsc10.3.1. 캐시 공유
- 수준 1: 서버 세부 정보
- 수준 2: 일부 마운트 옵션, 보안 유형, FSID, uniquifier
- 수준 3: 파일 처리
- 수준 4: 파일의 페이지 번호
예 10.1. 캐시 공유
/home/fred 및 /home/jim 은 특히 NFS 서버의 볼륨/파티션이 동일한 옵션인 것처럼 수퍼 블록을 공유할 수있습니다. 이제 다음 두 가지 마운트 명령을 고려하십시오.
/home/fred 및 /home/jim 은 고급 2 키의 일부인 네트워크 액세스 매개 변수가 다르기 때문에 수퍼 블록을 공유하지 않습니다. 다음과 같은 마운트 시퀀스에 대해 동일한 작업이 수행됩니다.
/home/fred1 및 /home/fred2)의 콘텐츠가 두 번 캐시됩니다.
home0:/disk0/fred 및 home0:/disk0/jim 의 수준 2 키를 구분할 필요가 없으므로 수퍼 블록 중 하나만 캐시를 사용할 수 있습니다. 이 문제를 해결하려면 마운트 중 하나 이상의 고유 식별자 (예: fsc=unique-identifier )를 추가합니다. 예를 들어 다음과 같습니다.
/home/jim 에 대한 캐시에 사용된 수준 2 키에 추가됩니다.
10.3.2. NFS를 사용한 캐시 제한
- 직접 I/O를 위해 공유 파일 시스템에서 파일을 열면 캐시가 자동으로 무시됩니다. 이러한 유형의 액세스 권한이 서버에 직접 있어야 하기 때문입니다.
- 쓰기 위해 공유 파일 시스템에서 파일을 여는 것은 NFS 버전 2 및 3에서 작동하지 않습니다. 이러한 버전의 프로토콜은 클라이언트가 다른 클라이언트의 동일한 파일에 동시 쓰기를 감지할 수 있도록 충분한 일관성 관리 정보를 제공하지 않습니다.
- 직접 I/O에 대해 공유 파일 시스템에서 파일을 열거나 파일의 캐시된 복사본을 쓰는 경우 파일을 엽니다.Opens a file from a shared file system for either direct I/O or writing flushes the cached copy of the file. FS-Cache는 더 이상 직접 I/O 또는 쓰기용으로 열 때까지 파일을 다시 캐시하지 않습니다.
- 또한 이 FS-Cache 릴리스는 일반 NFS 파일만 캐시합니다. FS-Cache는 디렉토리, 심볼릭 링크, 장치 파일, FIFOs 및 소켓을 캐시 하지 않습니다.
10.4. 캐시 캐시 제한 설정
/etc/cachefilesd.conf 의 설정으로 제어되는 6개의 제한이 있습니다.
- Brun N% (블록 백분율) , frun N% (파일의 백분율)
- 사용 가능한 공간의 양과 캐시의 사용 가능한 파일 수가 두 제한 이상으로 증가하면 조각이 꺼집니다.
- Bcull N% (블록의 백분율), fcull N% (파일의 백분율)
- 사용 가능한 공간의 크기 또는 캐시의 파일 수가 이러한 제한 중 하나에 속하는 경우 조각이 시작됩니다.
- bstop N% (블록 백분율), FSTOP N% (파일의 백분율)
- 사용 가능한 공간의 양 또는 캐시의 사용 가능한 파일 수가 이러한 제한 중 하나보다 아래로 떨어지면 조각이 이러한 제한을 초과할 때까지 디스크 공간이나 파일을 더 이상 할당하지 않아도 됩니다.
N 기본값은 다음과 같습니다.
- brun/frun - 10%
- bcull/fcull - 7%
- bstop/fstop - 3%
- 0 ࣘ bstop < bcull < brun < 100
- 0 ࣘ fstop < fcull < frun < 100
10.5. 통계 정보
# cat /proc/fs/fscache/stats/usr/share/doc/kernel-doc-version/Documentation/filesystems/caching/fscache.txt
10.6. FS-Cache 참조
/usr/share/doc/cachefilesd-version-number/README/usr/share/man/man5/cachefilesd.conf.5.gz/usr/share/man/man8/cachefilesd.8.gz
/usr/share/doc/kernel-doc-버전/Documentation/filesystems/caching/fscache.txt를 참조하십시오.
II 부. 스토리지 관리
11장. 설치 중 스토리지 고려 사항
11.1. 특수 고려 사항
11.1.1. /home, /opt, /usr/local에 대한 개별 파티션
/home,/opt, /usr/local 을 별도의 장치에 업그레이드합니다. 이를 통해 사용자 및 애플리케이션 데이터를 유지하면서 운영 체제가 포함된 장치 또는 파일 시스템을 다시 포맷할 수 있습니다.
11.1.2. IBM System Z의 DASD 및 zFCP 장치
DASD= 매개 변수로 장치 번호(또는 장치 번호 범위)를 나열합니다.
FCP_x= 줄을 사용하면 설치 프로그램에 대해 이 정보를 지정할 수 있습니다.
11.1.3. LUKS를 사용하여 블록 장치 암호화
11.1.4. 오래된 BIOS RAID 메타데이터
# dmraid -r -E /device/11.1.5. iSCSI 탐지 및 설정
11.1.6. FCoE Detection and Configuration
11.1.7. DASD
11.1.8. DIF/DIX가 활성화된 블록 장치
12장. 파일 시스템 확인
/etc/fstab 에 나열된 각 파일 시스템에서 실행됩니다. 저널링 파일 시스템의 경우 파일 시스템의 메타데이터 저널링을 통해 충돌 후에도 일관성을 보장하기 때문에 일반적으로 매우 짧은 작업입니다.
/etc/fstab 의 여섯 번째 필드를 0 으로 설정하여 파일 시스템 검사를 비활성화할 수 있습니다.
12.1. fsck 모범 사례
- 시험 실행
- 대부분의 파일 시스템 검사기에는 확인하지만 파일 시스템을 복구하지 않는 작동 모드가 있습니다. 이 모드에서 검사기는 실제로 파일 시스템을 수정하지 않고 발견한 오류와 작업을 출력합니다.참고일관성 검사의 이후 단계는 복구 모드에서 실행되는 경우 초기 단계에서 수정되는 불일치를 발견하므로 추가 오류를 출력할 수 있습니다.
- 파일 시스템 이미지에서 먼저 작동
- 대부분의 파일 시스템은 메타데이터만 포함된 파일 시스템의 스파스 복사본인 메타데이터 이미지 생성을 지원합니다. 파일 시스템 검사기는 메타데이터에서만 작동하기 때문에 이러한 이미지를 사용하여 실제 파일 시스템 복구 예행 실행을 수행하여 실제로 수행할 변경 사항을 평가할 수 있습니다. 변경 사항이 허용되는 경우 파일 시스템 자체에서 복구를 수행할 수 있습니다.참고심각하게 손상된 파일 시스템은 메타데이터 이미지 생성에 문제가 있을 수 있습니다.
- 지원 조사를 위해 파일 시스템 이미지 저장
- 파일 시스템 메타데이터 이미지는 소프트웨어 버그로 인해 손상이 발생할 가능성이 있는 경우 지원 조사에 유용한 경우가 많습니다. 사전 쌍 이미지 손상 패턴으로 인해 근본 원인 분석이 도움이 될 수 있습니다.
- 마운트 해제된 파일 시스템에서만 작동
- 파일 시스템 복구는 마운트 해제된 파일 시스템에서만 실행해야 합니다. 툴은 파일 시스템에 단독으로 액세스할 수 있어야 하거나 추가 손상으로 인해 발생할 수 있습니다. 대부분의 파일 시스템 도구는 이 요구 사항을 복구 모드로 적용하지만 일부는 마운트된 파일 시스템에서 확인 전용 모드만 지원합니다. 마운트된 파일 시스템에서 검사 전용 모드가 실행되는 경우 마운트 해제된 파일 시스템에서 실행할 때 발견되지 않는 심각한 오류를 찾을 수 있습니다.
- 디스크 오류
- 파일 시스템 검사 도구는 하드웨어 문제를 복구할 수 없습니다. 복구가 성공적으로 작동하는 경우 파일 시스템을 완전히 읽고 쓸 수 있어야 합니다. 하드웨어 오류로 인해 파일 시스템이 손상된 경우 먼저 파일 시스템을 양호한 디스크로 이동해야 합니다(예: dd(8) 유틸리티 사용).
12.2. fsck에 대한 파일 시스템별 정보
12.2.1. ext2, ext3 및 ext4
e2fsck 바이너리를 사용하여 파일 시스템 검사 및 복구를 수행합니다. 파일 이름 fsck.ext2,fsck.ext3, fsck.ext4 는 이 동일한 바이너리로 하드링크됩니다. 이러한 바이너리는 부팅 시 자동으로 실행되며 해당 동작은 확인 중인 파일 시스템과 파일 시스템의 상태에 따라 달라집니다.
- -n
- no-modify 모드입니다. 확인 전용 작업입니다.
- - B 수퍼 블록
- 기본 키가 손상된 경우 대체 suprerblock의 블록 번호를 지정합니다.
- -f
- 수퍼 블록에 기록된 오류가 없는 경우에도 강제 전체 검사를 수행합니다.
- -j journal-dev
- 해당하는 경우 외부 저널 장치를 지정합니다.
- -p
- 사용자 입력 없이 파일 시스템을 자동으로 복구하거나 "사전"합니다.
- -y
- 모든 질문에 대해 "예"에 대한 답변을 가정합니다.
- inode, 블록 및 크기 점검.
- 디렉터리 구조 확인.
- 디렉터리 연결 확인.
- 참조 수 확인.
- 그룹 요약 정보 검사.
12.2.2. XFS
fsck.xfs 바이너리는 xfsprogs 패키지에 있지만 부팅 시 fsck.파일 시스템 바이너리를 찾는 initscripts를 충족하기 위해서만 제공됩니다. fsck.xfs 는 종료 코드 0으로 즉시 종료됩니다.
- -n
- 수정 모드 없음 확인 전용 작업입니다.
- -L
- 메타데이터 로그가 0입니다. 마운트로 로그를 재생할 수 없는 경우에만 사용합니다.
- -m maxmem
- 실행 중에 사용되는 메모리를 maxmemMB로 제한합니다. 필요한 최소 메모리의 대략적인 추정을 얻기 위해 0을 지정할 수 있습니다.
- - L logdev
- 있는 경우 외부 로그 장치를 지정합니다.
- inode 및 inode 블록 맵(addressing) 검사를 수행합니다.
- inode 할당 맵입니다.
- inode 크기 확인
- 디렉터리 확인.
- 경로 이름 확인.
- 링크 수 검사.
- Freemap 확인입니다.
- 슈퍼 블록 검사.
12.2.3. gtv
- 범위 점검.
- 파일 시스템 루트 검사.
- 루트 참조 수 확인.
13장. 파티션
- 기존 파티션 테이블을 봅니다.
- 기존 파티션의 크기를 변경합니다.
- 여유 공간 또는 추가 하드 드라이브에서 파티션을 추가합니다.
# parted /dev/sda사용 중인 장치에서 파티션 조작
파티션 테이블 수정
# partx --update --nr partition-number disk
- 디스크 파티션(예: 시스템 디스크의 경우)을 마운트 해제할 수 없는 경우 복구 모드로 시스템을 부팅합니다.
- 파일 시스템을 마운트하라는 메시지가 표시되면 를 선택합니다.
표 13.1. parted 명령
| 명령 | 설명 |
|---|---|
| help | 사용 가능한 명령 목록 표시 |
| mklabel label | 파티션 테이블의 디스크 레이블 만들기 |
| mkpart part-type [fs-type] start-mb end-mb | 새 파일 시스템을 만들지 않고 파티션을 만듭니다. |
| name minor-num name | Mac 및 PC98 disklabels의 파티션 이름만 |
| 파티션 테이블 표시 | |
| 종료 | parted를 종료 |
| rescue start-mb end-mb | start-mb 에서 end-mb까지 손실된 파티션을 복구 |
| rm minor-num | 파티션 제거 |
| 장치선택 | 구성할 다른 장치 선택 |
| set minor-num flag state | 파티션에서 플래그를 설정합니다. 상태는 on 또는 off입니다. |
| 전환 [NUMBER [FAG] | 파티션 NUMBER에서 FLAG 의 상태를 전환 |
| unit UNIT | 기본 단위를 UNIT으로 설정합니다. |
13.1. 파티션 테이블 보기
- parted 를 시작합니다.
- 파티션 테이블을 보려면 다음 명령을 사용하십시오.
(parted)print
예 13.1. 파티션 테이블
Model: ATA ST3160812AS (scsi) Disk /dev/sda: 160GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 32.3kB 107MB 107MB primary ext3 boot 2 107MB 105GB 105GB primary ext3 3 105GB 107GB 2147MB primary linux-swap 4 107GB 160GB 52.9GB extended root 5 107GB 133GB 26.2GB logical ext3 6 133GB 133GB 107MB logical ext3 7 133GB 160GB 26.6GB logical lvm
- 모델: ATA ST3160812AS(scsi): 디스크 유형, 제조업체, 모델 번호 및 인터페이스를 설명합니다.
- Disk /dev/sda: 160GB: 블록 장치의 파일 경로와 스토리지 용량을 표시합니다.
- 파티션 테이블: msdos: 디스크 레이블 유형을 표시합니다.
- 파티션 테이블에서
Number는 파티션 번호입니다. 예를 들어, 마이너 번호 1이 있는 파티션은/dev/sda1에 해당합니다.Start및End값은 메가바이트 단위입니다. 유효한Types은 metadata, free, primary, extended 또는 logical입니다.File system는 파일 시스템 유형입니다. Flags 열에는 파티션에 설정된 플래그가 나열됩니다. 사용 가능한 플래그는 boot, root, swap, hidden, raid, lvm 또는 lba입니다.
File system 는 다음 중 하나일 수 있습니다.
- ext2
- ext3
- fat16
- fat32
- irsw
- jfs
- linux-swap
- ntfs
- reiserfs
- hp-ufs
- sun-ufs
- xfs
File system 에 값이 표시되지 않으면 해당 파일 시스템 유형을 알 수 없습니다.
13.2. 파티션 만들기
절차 13.1. 파티션 만들기
- 파티션을 만들기 전에 복구 모드로 부팅하거나 장치의 파티션을 마운트 해제하고 장치의 스왑 공간을 끕니다.
- parted 를 시작합니다.
# parted /dev/sda/dev/sda 를 파티션을 생성할 장치 이름으로 교체합니다. - 현재 파티션 테이블을 보고 사용 가능한 공간이 충분한지 확인합니다.
(parted)print여유 공간이 충분하지 않은 경우 기존 파티션의 크기를 조정할 수 있습니다. 자세한 내용은 13.5절. “fdisk를 사용하여 파티션 크기 조정” 에서 참조하십시오.파티션 테이블에서 새 파티션의 시작 및 끝점과 해당 파티션 유형을 결정합니다. 장치에는 확장 파티션이 없는 네 개의 기본 파티션만 사용할 수 있습니다. 4개 이상의 파티션이 필요한 경우 3개의 기본 파티션, 하나의 확장 파티션, 확장 파티션 내에 여러 개의 논리 파티션이 있을 수 있습니다. 디스크 파티션에 대한 개요는 Red Hat Enterprise Linux 7 설치 가이드의 디스크 파티션 소개 부록을 참조하십시오. - 파티션을 만들려면 다음을 수행합니다.
(parted)mkpart part-type name fs-type start endpart-type 을 primary, logical 또는 requirement에 따라 확장합니다.name 을 partition-name으로 바꿉니다. GPT 파티션 테이블에는 이름이 필요합니다.fs-type 을 btrfs, ext2, ext3, ext4, fat16, fat32, hfs, hfs+, linux-swap, ntfs, reiserfs 또는 xfs 중 하나로 바꿉니다. fs-type은 선택 사항입니다.시작 끝을 요구 사항에 따라 메가바이트 단위로 바꿉니다.예를 들어 하드 드라이브에 2048 메가바이트까지 ext3 파일 시스템이 있는 기본 파티션을 만들려면 다음 명령을 입력합니다.(parted)mkpart primary 1024 2048참고대신 mkpartfs 명령을 사용하면 파티션이 생성된 후 파일 시스템이 생성됩니다. 그러나 parted 는 ext3 파일 시스템 생성을 지원하지 않습니다. 따라서 ext3 파일 시스템을 생성하려면 mkpart 를 사용하고 나중에 설명된 대로 mkfs 명령으로 파일 시스템을 만듭니다.Enter 를 누르면 즉시 변경 사항이 이루어지므로 실행 전에 명령을 검토합니다. - 파티션 테이블을 보고 생성된 파티션이 올바른 파티션 유형, 파일 시스템 유형 및 다음 명령을 사용하여 파티션 테이블에 있는지 확인합니다.
(parted)print또한 모든 파일 시스템에 레이블을 지정할 수 있도록 새 파티션의 마이너 번호를 기록해 둡니다. - parted 쉘을 종료합니다.
(parted)quit - parted가 종료된 후 다음 명령을 사용하여 커널이 새 파티션을 인식할 수 있습니다.
#cat /proc/partitions
13.2.1. 파티션 포맷 및 레이블 지정
절차 13.2. 파티션 형식 및 레이블 지정
- 파티션에는 파일 시스템이 없습니다.
ext4파일 시스템을 생성하려면 다음을 사용합니다.#mkfs.ext4 /dev/sda6경고파티션을 포맷하면 현재 파티션에 존재하는 모든 데이터가 영구적으로 제거됩니다. - 파티션의 파일 시스템에 레이블을 지정합니다. 예를 들어 새 파티션의 파일 시스템이
/dev/sda6이고 작업에 레이블을 지정한 경우 다음을 사용합니다.#e2label /dev/sda6 "Work"기본적으로 설치 프로그램은 파티션의 마운트 지점을 레이블로 사용하여 레이블이 고유한지 확인합니다. 원하는 레이블을 사용할 수 있습니다. - 루트로 마운트 지점(예:
/work)을 만듭니다.
13.2.2. /etc/fstab에 파티션 추가
- 루트 사용자로
/etc/fstab파일을 편집하여 파티션의 UUID를 사용하여 새 파티션을 포함합니다.파티션의 UUID 전체 목록을 보려면 blkid -o 목록을 사용하거나 개별 장치 세부 정보는 blkid 장치를 사용합니다./etc/fstab에서 다음을 수행합니다.- 첫 번째 열에는
UUID=뒤에 파일 시스템의 UUID가 포함되어야 합니다. - 두 번째 열에는 새 파티션의 마운트 지점이 포함되어야 합니다.
- 세 번째 열은 파일 시스템 유형이어야 합니다(예:
ext4또는swap). - 네 번째 열에는 파일 시스템의 마운트 옵션이 나열됩니다. 여기서
default라는 단어는 기본 옵션을 사용하여 부팅 시 파티션이 마운트됨을 의미합니다. - 다섯 번째 및 여섯 번째 필드는 backup 및 check 옵션을 지정합니다. 루트가 아닌 파티션의 예제 값은
0 2입니다.
- 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
#systemctl daemon-reload - 파일 시스템을 마운트하여 구성이 작동하는지 확인합니다.
# mount /work
추가 정보
/etc/fstab형식에 대한 자세한 정보가 필요한 경우 fstab(5) 도움말 페이지를 참조하십시오.
13.3. 파티션 제거
절차 13.3. 파티션 제거
- 파티션을 제거하기 전에 다음 중 하나를 수행합니다.
- 복구 모드로 부팅하거나
- 장치의 파티션을 마운트 해제하고 장치의 스왑 공간을 끕니다.
parted유틸리티를 시작합니다.# parted device장치를 파티션을 제거할 장치로 교체합니다(예:/dev/sda).- 현재 파티션 테이블을 보고 제거할 파티션의 마이너 번호를 확인합니다.
(parted) print - rm 명령으로 파티션을 제거합니다. 예를 들어, 마이너 번호가 3인 파티션을 제거하려면 다음을 수행합니다.
(parted) rm 3Enter 키를 누르면 즉시 변경 사항이 수행되므로 커밋하기 전에 명령을 검토합니다. - 파티션을 제거한 후 출력 명령을 사용하여 파티션 테이블에서 제거되었는지 확인합니다.
(parted) print partedshell을 종료합니다.(parted) quit/proc/partitions파일의 내용을 검사하여 커널이 파티션이 제거되었는지 확인합니다.# cat /proc/partitions/etc/fstab파일에서 파티션을 제거합니다. 삭제된 파티션을 선언하는 행을 찾아 파일에서 제거합니다.- 시스템에서 새
/etc/fstab구성을 등록하도록 마운트 장치를 다시 생성합니다.#systemctl daemon-reload
13.4. 파티션 유형 설정
systemd-gpt-auto-generator 와 같이 자동 장치 식별 및 마운트와 같은 온-the-fly 생성기에 중요합니다.
fdisk 유틸리티를 시작하고 t 명령을 사용하여 파티션 유형을 설정할 수 있습니다. 다음 예제에서는 첫 번째 파티션의 파티션 유형을 Linux에서 기본값인 0x83으로 변경하는 방법을 보여줍니다.
#fdisk /dev/sdc Command (m for help): t Selected partition1Partition type (type L to list all types):83Changed type of partition 'Linux LVM' to 'Linux'.
parted 유틸리티는 파티션 유형을 'flags'에 매핑하려고 시도하여 파티션 유형에 대한 제어를 제공하며, 이는 최종 사용자에게 편리하지 않습니다. parted 유틸리티는 특정 파티션 유형(예: LVM 또는 RAID)만 처리할 수 있습니다. 예를 들어 parted 가 있는 첫 번째 파티션에서 lvm 플래그를 제거하려면 다음을 사용합니다.
# parted /dev/sdc 'set 1 lvm off'
13.5. fdisk를 사용하여 파티션 크기 조정
fdisk 유틸리티를 사용하면 GPT, MBR, Sun, SGI 및 BSD 파티션 테이블을 만들고 조작할 수 있습니다. GPG(GUID 파티션 테이블)가 있는 디스크의 경우 parted 유틸리티를 사용하는 것이 좋습니다.절차 GPT 지원이 실험 단계에 있기 때문입니다. 절차 13.4. 파티션 크기 조정
fdisk 를 사용하여 파티션의 크기를 조정하려면 다음을 수행합니다.
- 장치를 마운트 해제합니다.
#umount /dev/vda - fdisk disk_name 을 실행합니다. 예를 들어 다음과 같습니다.
#fdisk /dev/vda Welcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Command (m for help): - 삭제할 파티션의 행 번호를 확인하려면
p옵션을 사용합니다.Command (m for help): p Disk /dev/vda: 16.1 GB, 16106127360 bytes, 31457280 sectors Units = sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disk label type: dos Disk identifier: 0x0006d09a Device Boot Start End Blocks Id System /dev/vda1 * 2048 1026047 512000 83 Linux /dev/vda2 1026048 31457279 15215616 8e Linux LVM
- 파티션을 삭제하려면 d 옵션을 사용합니다. 둘 이상의 파티션을 사용할 수 있는 경우 fdisk 에서 삭제할 파티션 수를 입력하라는 메시지를 표시합니다.
Command (m for help): d Partition number (1,2, default 2): 2 Partition 2 is deleted
n옵션을 사용하여 파티션을 생성하고 프롬프트를 따릅니다. 향후 크기 조정을 위한 충분한 공간을 허용합니다. fdisk 기본 동작(Enter키를 누름)은 장치의 모든 공간을 사용하는 것입니다. 파티션의 끝을 섹터별로 지정하거나 + <size> < suffix> (예: +500M 또는 +10G)을 사용하여 사람이 읽을 수 있는크기를 지정할 수 있습니다.모든 여유 공간을 사용하지 않으려면 fdisk 에서 파티션의 끝을 물리 섹터에 맞추기 때문에 사람이 읽을 수 있는 크기 사양을 사용하는 것이 좋습니다. 정확한 수( 섹터)를 제공하여 크기를 지정하는 경우, fdisk 는 파티션의 끝을 정렬하지 않습니다.Command (m for help): n Partition type: p primary (1 primary, 0 extended, 3 free) e extended Select (default p): *Enter* Using default response p Partition number (2-4, default 2): *Enter* First sector (1026048-31457279, default 1026048): *Enter* Using default value 1026048 Last sector, +sectors or +size{K,M,G} (1026048-31457279, default 31457279): +500M Partition 2 of type Linux and of size 500 MiB is set- 파티션 유형을 LVM으로 설정합니다.
Command (m for help): t Partition number (1,2, default 2): *Enter* Hex code (type L to list all codes): 8e Changed type of partition 'Linux' to 'Linux LVM'
- 변경 사항이 올바른지 확인하는 경우 w 옵션으로 변경 사항을 작성하십시오. 오류로 인해 선택한 파티션에 불안정할 수 있습니다.
- 장치에서 e2fsck 를 실행하여 일관성을 확인합니다.
#e2fsck /dev/vda e2fsck 1.41.12 (17-May-2010) Pass 1:Checking inodes, blocks, and sizes Pass 2:Checking directory structure Pass 3:Checking directory connectivity Pass 4:Checking reference counts Pass 5:Checking group summary information ext4-1:11/131072 files (0.0% non-contiguous),27050/524128 blocks - 장치를 마운트합니다.
#mount /dev/vda
14장. snapper를 사용하여 스냅샷 생성 및 유지 관리
14.1. 초기 스냅퍼 구성 생성
절차 14.1. snapper 구성 파일 생성
- 다음 중 하나를 만들거나 선택합니다.
- Red Hat 지원 파일 시스템이 있는 씬 프로비저닝된 논리 볼륨 또는
- vGPU 하위 볼륨.
- 파일 시스템을 마운트합니다.
- 이 볼륨을 정의하는 구성 파일을 생성합니다.LVM2의 경우
#snapper -c config_name create-config -f "lvm(fs_type)" /mount-point예를 들어 /lvm_mount에 마운트된 ext4 파일 시스템이 있는 LVM2 하위 볼륨에 lvm_config라는 구성 파일을 생성하려면 다음을 사용합니다.#snapper -c lvm_config create-config -f "lvm(ext4)" /lvm_mounttested의 경우:#snapper -c config_name create-config -f btrfs /mount-point- -c config_name 옵션은 구성 파일의 이름을 지정합니다.
- create-config 는 스냅퍼에게 구성 파일을 만들도록 지시합니다.
- f file_system 은 사용할 파일 시스템을 스냅퍼합니다. 이 경우 스냅퍼는 파일 시스템을 검색하려고 시도합니다.
- /mount-point 는 하위 볼륨 또는 씬 프로비저닝된 LVM2 파일 시스템이 마운트된 위치입니다.
또는/btrfs_mount에 마운트된 vGPU 하위 볼륨에btrfs_config라는 구성 파일을 만들려면 다음을 사용합니다.#snapper -c btrfs_config create-config -f btrfs /btrfs_mount
/etc/snapper/configs/ 디렉토리에 저장됩니다.
14.2. snapper 스냅샷 생성
- 사전 스냅샷
- 사전 스냅샷은 post snapshot의 원본 지점 역할을 합니다. 이 두 가지 요소는 밀접하게 연관되어 있으며 두 지점 간의 파일 시스템 변경을 추적하도록 설계되었습니다. 스냅샷 게시 전에 사전 스냅샷을 만들어야 합니다.
- 스냅샷 후
- post snapshot은 사전 스냅샷의 끝점 역할을 합니다. 결합된 사전 및 사후 스냅샷은 비교를 위한 범위를 정의합니다. 기본적으로 모든 새 스냅퍼 볼륨은 관련 post snapshot이 성공적으로 생성된 후 백그라운드 비교를 생성하도록 구성됩니다.
- Single Snapshot
- 단일 스냅샷은 특정 시점에 생성된 독립 실행형 스냅샷입니다. 이러한 수정의 타임라인을 추적하는 데 사용할 수 있으며 나중에 반환하는 일반적인 지점을 가질 수 있습니다.
14.2.1. Pre 및 Post Snapshot pair 만들기
14.2.1.1. 스냅퍼를 사용하여 사전 스냅샷 생성
# snapper -c config_name create -t prepre,post, 또는 single 입니다.
lvm_config 구성 파일을 사용하여 사전 스냅샷을 생성하려면 다음을 사용합니다.
# snapper -c SnapperExample create -t pre -p
1
p 옵션은 생성된 스냅샷의 수를 출력하고 선택 사항입니다.
14.2.1.2. snapper를 사용하여 게시 후 스냅샷 생성
절차 14.2. 스냅샷 생성
- 사전 스냅샷 수를 확인합니다.
#snapper -c config_name list예를 들어 설정 파일lvm_config를 사용하여 생성된 스냅샷 목록을 표시하려면 다음을 사용합니다.#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | |이 출력은 사전 스냅샷이 숫자 1임을 보여줍니다. - 이전에 생성된 사전 스냅샷에 연결된 후 스냅샷을 생성합니다.
#snapper -c config_file create -t post --pre-num pre_snapshot_number- t post 옵션은 스냅샷 생성을 지정합니다.
- --pre-num 옵션은 해당 사전 스냅샷을 지정합니다.
예를 들어lvm_config구성 파일을 사용하여 게시 스냅샷을 만들고 사전 스냅샷 번호 1에 연결된 경우 다음을 사용합니다.#snapper -c lvm_config create -t post --pre-num 1 -p 2p옵션은 생성된 스냅샷의 수를 출력하고 선택 사항입니다. - 사전 및 게시 스냅샷 1 및 2가 이제 생성되어 쌍으로 생성됩니다. list 명령으로 이를 확인합니다.
#snapper -c lvm_config list Type | # | Pre # | Date | User | Cleanup | Description | Userdata -------+---+-------+-------------------+------+----------+-------------+--------- single | 0 | | | root | | current | pre | 1 | | Mon 06<...> | root | | | post | 2 | 1 | Mon 06<...> | root | | |
14.2.1.3. Pre and Post Snapshots에서 명령 래핑
- snapper create pre snapshot 명령을 실행합니다.
- 명령 또는 명령 목록을 실행하여 파일 시스템 콘텐츠에 잠재적으로 영향을 미치는 작업을 수행합니다.
- snapper create post snapshot 명령을 실행합니다.
절차 14.3. Pre and Post Snapshots에서 명령 래핑
- 명령을 사전 및 사후 스냅샷으로 래핑하려면 다음을 수행합니다.
#snapper -c lvm_config create --command "command_to_be_tracked"예를 들어/lvm_mount/hello_file파일의 생성을 추적하려면 다음을 수행합니다.#snapper -c lvm_config create --command "echo Hello > /lvm_mount/hello_file" - 이를 확인하려면 status 명령을 사용합니다.
#snapper -c config_file status first_snapshot_number..second_snapshot_number예를 들어 첫 번째 단계에서 변경한 내용을 추적하려면 다음을 수행합니다.#snapper -c lvm_config status 3..4 +..... /lvm_mount/hello_file필요한 경우 list 명령을 사용하여 스냅샷 수를 확인합니다.status 명령에 대한 자세한 내용은 14.3절. “스냅 샷 스냅샷 간 변경 사항 추적” 을 참조하십시오.
14.2.2. 단일 스냅퍼 스냅샷 생성
-t 옵션만 single을 지정합니다. 단일 스냅샷은 다른 스냅샷과 관련이 없는 시간에 단일 스냅샷을 생성하는 데 사용됩니다. 그러나 비교를 자동으로 생성하거나 추가 정보를 나열할 필요 없이 LVM2 씬 볼륨의 스냅샷을 간단하게 만드는 데 관심이 있는 경우 16.2.6절. “스냅샷” 에 설명된 대로 이 목적을 위해 snapper 대신 시스템 스토리지 관리자를 사용하는 것이 좋습니다.
# snapper -c config_name create -t singlelvm_config 구성 파일을 사용하여 단일 스냅샷을 만듭니다.
# snapper -c lvm_config create -t single14.2.3. 스냅퍼를 자동 스냅샷으로 구성
- 매시간 스냅샷 10개, 최종 시간별 스냅샷은 "바이ly" 스냅샷으로 저장됩니다.
- 매일 10개의 스냅샷과 한 달의 최종 일일 스냅샷은 "monthly" 스냅샷으로 저장됩니다.
- 매월 10개의 스냅샷과 최종 월간 스냅샷은 "년" 스냅샷으로 저장됩니다.
- 10년 스냅샷입니다.
/etc/snapper/config-templates/default 파일에 지정됩니다. snapper create-config 명령을 사용하여 구성을 생성할 때 지정되지 않은 값은 기본 구성에 따라 설정됩니다. /etc/snapper/configs/config_name 파일에서 정의된 볼륨에 대한 구성을 편집할 수 있습니다.
14.3. 스냅 샷 스냅샷 간 변경 사항 추적
- status
- status 명령은 두 개의 스냅샷 간에 생성, 수정 또는 삭제된 파일 및 디렉터리 목록을 표시합니다. 이 목록은 두 개의 스냅샷 사이의 포괄적인 변경 목록입니다. 이 명령을 사용하면 과도한 세부 정보 없이 변경 사항에 대한 개요를 얻을 수 있습니다.자세한 내용은 14.3.1절. “상태 명령과 변경 사항 비교” 에서 참조하십시오.
- diff
- diff 명령은 하나 이상의 수정이 감지된 경우 status 명령에서 수신한 두 스냅샷 간에 수정된 파일과 디렉토리를 표시합니다.자세한 내용은 14.3.2절. “diff 명령과 변경 사항 비교” 에서 참조하십시오.
- Xadiff
- xadiff 명령은 파일 또는 디렉터리의 확장된 속성이 두 스냅샷 간에 변경되는 방법을 비교합니다.자세한 내용은 14.3.3절. “xadiff 명령과 변경 사항 비교” 에서 참조하십시오.
14.3.1. 상태 명령과 변경 사항 비교
# snapper -c config_file status first_snapshot_number..second_snapshot_numberlvm_config 를 사용하여 스냅샷 1과 2 간의 변경 사항을 표시합니다.
#snapper -c lvm_config status 1..2
tp.... /lvm_mount/dir1
-..... /lvm_mount/dir1/file_a
c.ug.. /lvm_mount/file2
+..... /lvm_mount/file3
....x. /lvm_mount/file4
cp..xa /lvm_mount/file5
+..... /lvm_mount/file3 |||||| 123456
| 출력 결과 | 의미 |
|---|---|
| . | 아무것도 변경되지 않았습니다. |
| + | 파일이 생성되었습니다. |
| - | 파일이 삭제되었습니다. |
| c | 콘텐츠가 변경되었습니다. |
| t | 디렉터리 항목의 유형이 변경되었습니다. 예를 들어 이전 심볼릭 링크가 동일한 파일 이름을 가진 일반 파일로 변경되었습니다. |
| 출력 결과 | 의미 |
|---|---|
| . | 권한이 변경되지 않았습니다. |
| p | 권한이 변경되었습니다. |
| 출력 결과 | 의미 |
|---|---|
| . | 사용자 소유권이 변경되지 않았습니다. |
| u | 사용자 소유권이 변경되었습니다. |
| 출력 결과 | 의미 |
|---|---|
| . | 그룹 소유권이 변경되지 않았습니다. |
| g | 그룹 소유권이 변경되었습니다. |
| 출력 결과 | 의미 |
|---|---|
| . | 확장된 속성이 변경되지 않았습니다. |
| x | 확장 속성이 변경되었습니다. |
| 출력 결과 | 의미 |
|---|---|
| . | ACL이 변경되지 않았습니다. |
| a | ACL이 변경되었습니다. |
14.3.2. diff 명령과 변경 사항 비교
# snapper -c config_name diff first_snapshot_number..second_snapshot_numberlvm_config 설정 파일을 사용하여 비교하려면 다음을 사용합니다.
# snapper -c lvm_config diff 1..2
--- /lvm_mount/.snapshots/13/snapshot/file4 19<...>
+++ /lvm_mount/.snapshots/14/snapshot/file4 20<...>
@@ -0,0 +1 @@
+words
file4 가 파일에 "words"를 추가하도록 수정되었음을 보여줍니다.
14.3.3. xadiff 명령과 변경 사항 비교
# snapper -c config_name xadiff first_snapshot_number..second_snapshot_numberlvm_config 구성 파일을 사용하여 만든 스냅샷 번호 1과 스냅샷 번호 2 간의 xadiff 출력을 표시하려면 다음을 사용합니다.
# snapper -c lvm_config xadiff 1..214.4. 스냅샷 간 변경 사항 취소
1 은 첫 번째 스냅샷이고 2 는 두 번째 스냅샷입니다.
snapper -c config_name undochange 1..2
그림 14.1. Time over Time 상태
[D]
snapshot_1 이 생성되는 시점, file_a 가 생성된 다음 file_b 가 삭제됩니다. 그러면 Snapshot_2 가 생성되고 file_a 가 편집되고 file_c 가 생성됩니다. 이는 현재 시스템의 현재 상태입니다. 현재 시스템에는 file_a, file_b 및 새로 생성된 file_c 가 편집되어 있습니다.
file_a 가 생성됨, file_b 는 삭제됨) 현재 시스템에 적용합니다. 따라서 다음을 수행합니다.
snapshot_1을 생성할 때 아직 생성되지 않았으므로 현재 시스템에는file_a가 없습니다.file_b가 존재하며snapshot_1에서 현재 시스템으로 복사되었습니다.file_c는 지정된 시간 이외에 생성되었기 때문에 존재합니다.
file_b 및 file_c 충돌이 발생하면 시스템이 손상될 수 있습니다.
file_a 의 편집 버전을 snapshot_1 에서 복사한 버전으로 교체하여 snapshot_2 를 생성한 후 해당 파일의 편집을 취소합니다.
마운트 및 마운트 해제 명령을 사용하여 변경 사항
/etc/snapper/configs/config_name 파일에는 사용자와 그룹을 추가할 수 있는 ALLOW_USERS= 및 ALLOW_GROUPS= 변수가 포함되어 있습니다. 그런 다음 snapperd 를 사용하면 추가된 사용자 및 그룹에 대해 마운트 작업을 수행할 수 있습니다.
14.5. snapper 스냅샷 삭제
# snapper -c config_name delete snapshot_number15장. Swap Space
표 15.1. 시스템 스왑 공간 권장
| 시스템의 RAM 크기 | 권장되는 스왑 공간 | 최대 절전을 허용하는 경우 권장 스왑 공간 |
|---|---|---|
| 2GB | RAM의 두 배 크기 | 3배 RAM 용량 |
| > 2GB - 8GB | RAM의 양과 같습니다. | RAM의 두 배 크기 |
| > 8GB - 64GB | 최소 4GB | 1.5배 RAM 용량 |
| > 64GB | 최소 4GB | Hibernation이 권장되지 않음 |
복구 모드에서 부팅되는 동안 스왑 공간을 수정해야 합니다. Red Hat Enterprise Linux 7 설치 가이드에서 복구 모드에서 컴퓨터 부팅 을 참조하십시오. 파일 시스템을 마운트하라는 메시지가 표시되면 를 선택합니다.
15.1. 스왑 공간 추가
15.1.1. LVM2 논리 볼륨에서swap 확장
/dev/VolGroup00/LogVol01 을 2GB로 확장하려는 볼륨이라고 가정하여 다음 절차를 수행하십시오.
절차 15.1. LVM2 논리 볼륨에서swap 확장
- 연결된 논리 볼륨에 대한 스왑을 비활성화합니다.
# swapoff -v /dev/VolGroup00/LogVol01 - LVM2 논리 볼륨의 크기를 2GB로 조정합니다.
# lvresize /dev/VolGroup00/LogVol01 -L +2G - 새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol01 - 확장 논리 볼륨을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol01 - 스왑 논리 볼륨이 확장 및 활성화되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
15.1.2. swap을 위한 LVM2 논리 볼륨 만들기
/dev/VolGroup00/LogVol02 가 추가하려는 스왑 볼륨이라고 가정합니다.
- 2GB 크기의 LVM2 논리 볼륨을 생성합니다.
# lvcreate VolGroup00 -n LogVol02 -L 2G - 새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol02 /etc/fstab파일에 다음 항목을 추가합니다./dev/VolGroup00/LogVol02 swap swap defaults 0 0
- 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
#systemctl daemon-reload - 논리 볼륨에서 스왑을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol02 - 스왑 논리 볼륨이 성공적으로 생성되고 활성화되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
15.1.3. 스왑 파일 생성
절차 15.2. 스왑 파일 추가
- 새 스왑 파일의 크기를 메가바이트 단위로 결정하고 1024를 곱하여 블록 수를 결정합니다. 예를 들어 64MB 스왑 파일의 블록 크기는 65536입니다.
- 빈 파일을 생성합니다.
# dd if=/dev/zero of=/swapfile bs=1024 count=65536count 를 원하는 블록 크기와 동일한 값으로 바꿉니다. - 명령을 사용하여 스왑 파일을 설정합니다.
# mkswap /swapfile - 읽을 수 없도록 스왑 파일의 보안을 변경합니다.
# chmod 0600 /swapfile - 부팅 시 스왑 파일을 활성화하려면
/etc/fstab를 root로 편집하여 다음 항목을 포함합니다./swapfile swap swap defaults 0 0
다음에 시스템을 부팅할 때 새 스왑 파일을 활성화합니다. - 시스템에서 새
/etc/fstab구성을 등록하도록 마운트 장치를 다시 생성합니다.#systemctl daemon-reload - 스왑 파일을 즉시 활성화하려면 다음을 수행하십시오.
# swapon /swapfile - 새 스왑 파일이 성공적으로 생성되고 활성화되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
15.2. 스왑 공간 제거
15.2.1. LVM2 논리 볼륨에서 스왑 감소
/dev/VolGroup00/LogVol01 을 줄이려는 볼륨이라고 가정)
절차 15.3. LVM2 swap 논리 볼륨 감소
- 연결된 논리 볼륨에 대한 스왑을 비활성화합니다.
# swapoff -v /dev/VolGroup00/LogVol01 - LVM2 논리 볼륨을 512MB로 줄입니다.
# lvreduce /dev/VolGroup00/LogVol01 -L -512M - 새 스왑 공간을 포맷합니다.
# mkswap /dev/VolGroup00/LogVol01 - 논리 볼륨에서 스왑을 활성화합니다.
# swapon -v /dev/VolGroup00/LogVol01 - 스왑 논리 볼륨이 성공적으로 감소되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
15.2.2. swap용 LVM2 논리 볼륨 제거
/dev/VolGroup00/LogVol02 를 제거하려는 스왑 볼륨이라고 가정함)
절차 15.4. 스왑 볼륨 그룹 제거
- 연결된 논리 볼륨에 대한 스왑을 비활성화합니다.
#swapoff -v /dev/VolGroup00/LogVol02 - LVM2 논리 볼륨 제거:
#lvremove /dev/VolGroup00/LogVol02 /etc/fstab파일에서 다음 관련 항목을 제거합니다./dev/VolGroup00/LogVol02 swap swap defaults 0 0
- 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
#systemctl daemon-reload /etc/default/grub파일에서 삭제된 스왑 스토리지에 대한 모든 참조를 제거합니다.#vi /etc/default/grub- grub 설정을 다시 빌드합니다.
- BIOS 기반 시스템에서 다음을 실행합니다.
#grub2-mkconfig -o /boot/grub2/grub.cfg - UEFI 기반 시스템에서 다음을 실행합니다.
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 논리 볼륨이 제거되었는지 테스트하려면 활성 스왑 공간을 검사합니다.
$ cat /proc/swaps $ free -h
15.2.3. 스왑 파일 제거
절차 15.5. 스왑 파일 제거
- 쉘 프롬프트에서 다음 명령을 실행하여 스왑 파일을 비활성화합니다(여기서
/swapfile은 스왑 파일임).# swapoff -v /swapfile /etc/fstab파일에서 해당 항목을 제거합니다.- 시스템에서 새 구성을 등록하도록 마운트 장치를 다시 생성합니다.
#systemctl daemon-reload - 실제 파일을 제거합니다.
# rm /swapfile
15.3. 스왑 공간 이동
- 스왑 공간 제거 15.2절. “스왑 공간 제거”.
- 스왑 공간 15.1절. “스왑 공간 추가” 추가
16장. 시스템 스토리지 관리자(SSM)
16.1. SSM 백엔드
ssmlib/main.py 의 핵심 추상화 계층을 사용합니다. 백엔드는 ssmlib/main.py 에 등록하여 ,스냅샷 생성 또는 볼륨 및 풀 제거와 같은 특정 스토리지 기술 방법을 처리할 수 있습니다.
16.1.1. rfc Back End
16.1.1.1. Btrfs Pool
btrfs_pool 입니다.
btrfs_device_base_name의 형식으로 내부에서 사용할 이름을 생성합니다.
16.1.1.2. rfc 볼륨
/dev/lvm_pool/lvol001 로 표시됩니다. 볼륨을 생성하려면 이 경로의 모든 오브젝트가 있어야 합니다. 볼륨은 마운트 지점을 사용하여 참조할 수도 있습니다.
16.1.1.3. rfc Snapshot
16.1.1.4. vGPU 장치
16.1.2. LVM 백엔드
16.1.2.1. LVM Pool
lvm_pool 입니다.
16.1.2.2. LVM 볼륨
16.1.2.3. LVM Snapshot
스냅샷 볼륨이 생성됩니다. vGPU와 달리 LVM은 스냅샷을 일반 볼륨과 구분할 수 있으므로 특정 패턴과 일치하도록 스냅샷 이름이 필요하지 않습니다.
16.1.2.4. LVM Device
16.1.3. Crypt 백엔드
16.1.3.1. Crypt 볼륨
16.1.3.2. Crypt Snapshot
16.1.4. 여러 장치 (md) 백엔드
16.2. 일반 SSM 작업
16.2.1. SSM 설치
# yum install system-storage-manager
- LVM 백엔드에는
lvm2패키지가 필요합니다. - vGPU 백엔드에는
btrfs-progs패키지가 필요합니다. - Crypt 백엔드에는
device-mapper및cryptsetup패키지가 필요합니다.
16.2.2. 모든 탐지된 장치에 대한 정보 표시
# ssm list
----------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------
/dev/sda 2.00 GB PARTITIONED
/dev/sda1 47.83 MB /test
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
----------------------------------------------------------
------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------
---------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
---------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/sda1 47.83 MB xfs 44.50 MB 44.41 MB part /test
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
---------------------------------------------------------------------------------
- devices 또는 dev 인수를 실행하면 일부 장치가 생략됩니다. 예를 들어 CDRoms 및 DM/MD 장치는 볼륨으로 나열되는 대로 의도적으로 숨겨집니다.
- 일부 백엔드에서는 스냅샷을 지원하지 않으며 스냅샷과 일반 볼륨을 구분할 수 없습니다. 이러한 백엔드 중 하나에서 스냅샷 인수를 실행하면 SSM에서 스냅샷 이름을 식별하기 위해 볼륨 이름을 인식하려고 합니다. SSM 정규식이 스냅샷 패턴과 일치하지 않으면 스냅샷이 인식되지 않습니다.
- 기본 vGPU 볼륨(파일 시스템 자체)을 제외하고 마운트 해제된 모든 vGPU 볼륨이 표시되지 않습니다.
16.2.3. 새 풀, 논리 볼륨 및 파일 시스템 생성
/dev/vdb 및 /dev/vdc, 논리 볼륨 1G 및 XFS 파일 시스템이 있는 기본 이름으로 새 풀을 생성합니다.
- f s 옵션은 필요한 파일 시스템 유형을 지정합니다. 현재 지원되는 파일 시스템 유형은 다음과 같습니다.
- ext3
- ext4
- xfs
- btrfs
- s는 논리 볼륨의 크기를 지정합니다. 단위를 정의하는 데 지원되는 접미사는 다음과 같습니다.
k또는 k for kilobytes- 메가바이트의
M또는m - gigabytes의 경우
g또는 gigabytes t또는 t for terabytesP또는 페타바이트의 경우p- 엑사바이트의 경우
e또는 e
- 나열된 두 장치인
/dev/vdb및/dev/vdc는 생성하려는 두 장치입니다.
# ssm create --fs xfs -s 1G /dev/vdb /dev/vdc
Physical volume "/dev/vdb" successfully created
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully created
Logical volume "lvol001" created
lvm_pool 을 사용하게 되었습니다. 그러나 기존 명명 규칙에 맞게 특정 이름을 사용하려면 -p 옵션을 사용해야 합니다.
# ssm create --fs xfs -p new_pool -n XFS_Volume /dev/vdd
Volume group "new_pool" successfully created
Logical volume "XFS_Volume" created
16.2.4. 파일 시스템의 일관성 확인
lvol001 볼륨의 모든 장치를 확인하려면 ssm 명령을 실행하여 /dev/lvm_pool/lvol001.
# ssm check /dev/lvm_pool/lvol001
Checking xfs file system on '/dev/mapper/lvm_pool-lvol001'.
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- agno = 4
- agno = 5
- agno = 6
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
16.2.5. 볼륨 크기 증가
/dev/vdb 에 lvol001 이라는 900MB인 논리 볼륨이 한 개 있습니다.
# ssm list
-----------------------------------------------------------------
Device Free Used Total Pool Mount point
-----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 120.00 MB 900.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
-----------------------------------------------------------------
---------------------------------------------------------
Pool Type Devices Free Used Total
---------------------------------------------------------
lvm_pool lvm 1 120.00 MB 900.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
---------------------------------------------------------
--------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
--------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
--------------------------------------------------------------------------------------------
~]# ssm resize -s +500M /dev/lvm_pool/lvol001 /dev/vdc
Physical volume "/dev/vdc" successfully created
Volume group "lvm_pool" successfully extended
Phase 1 - find and verify superblock...
Phase 2 - using internal log
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
Extending logical volume lvol001 to 1.37 GiB
Logical volume lvol001 successfully resized
meta-data=/dev/mapper/lvm_pool-lvol001 isize=256 agcount=4, agsize=57600 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=230400, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal bsize=4096 blocks=853, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 230400 to 358400
# ssm list
------------------------------------------------------------------
Device Free Used Total Pool Mount point
------------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 640.00 MB 380.00 MB 1.00 GB lvm_pool
------------------------------------------------------------------
------------------------------------------------------
Pool Type Devices Free Used Total
------------------------------------------------------
lvm_pool lvm 2 640.00 MB 1.37 GB 1.99 GB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 1.37 GB xfs 1.36 GB 1.36 GB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
# ssm resize -s-50M /dev/lvm_pool/lvol002
Rounding size to boundary between physical extents: 972.00 MiB
WARNING: Reducing active logical volume to 972.00 MiB
THIS MAY DESTROY YOUR DATA (filesystem etc.)
Do you really want to reduce lvol002? [y/n]: y
Reducing logical volume lvol002 to 972.00 MiB
Logical volume lvol002 successfully resized
16.2.6. 스냅샷
lvol001 의 스냅샷을 생성하려면 다음 명령을 사용합니다.
# ssm snapshot /dev/lvm_pool/lvol001
Logical volume "snap20150519T130900" created
# ssm list
----------------------------------------------------------------
Device Free Used Total Pool Mount point
----------------------------------------------------------------
/dev/vda 15.00 GB PARTITIONED
/dev/vda1 500.00 MB /boot
/dev/vda2 0.00 KB 14.51 GB 14.51 GB rhel
/dev/vdb 0.00 KB 1020.00 MB 1.00 GB lvm_pool
/dev/vdc 1.00 GB
----------------------------------------------------------------
--------------------------------------------------------
Pool Type Devices Free Used Total
--------------------------------------------------------
lvm_pool lvm 1 0.00 KB 1020.00 MB 1020.00 MB
rhel lvm 1 0.00 KB 14.51 GB 14.51 GB
--------------------------------------------------------
----------------------------------------------------------------------------------------------
Volume Pool Volume size FS FS size Free Type Mount point
----------------------------------------------------------------------------------------------
/dev/rhel/root rhel 13.53 GB xfs 13.52 GB 9.64 GB linear /
/dev/rhel/swap rhel 1000.00 MB linear
/dev/lvm_pool/lvol001 lvm_pool 900.00 MB xfs 896.67 MB 896.54 MB linear
/dev/vda1 500.00 MB xfs 496.67 MB 403.56 MB part /boot
----------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------
Snapshot Origin Pool Volume size Size Type
----------------------------------------------------------------------------------
/dev/lvm_pool/snap20150519T130900 lvol001 lvm_pool 120.00 MB 0.00 KB linear
----------------------------------------------------------------------------------
16.2.7. 항목 제거
# ssm remove lvm_pool
Do you really want to remove volume group "lvm_pool" containing 2 logical volumes? [y/n]: y
Do you really want to remove active logical volume snap20150519T130900? [y/n]: y
Logical volume "snap20150519T130900" successfully removed
Do you really want to remove active logical volume lvol001? [y/n]: y
Logical volume "lvol001" successfully removed
Volume group "lvm_pool" successfully removed
16.3. SSM 리소스
- man ssm 페이지는 좋은 설명과 예제뿐만 아니라 여기에 문서화할 수 있는 모든 명령과 옵션에 대한 세부 정보를 제공합니다.
- SSM의 로컬 문서는
doc/디렉터리에 저장됩니다. - SSM wiki는 에서 http://storagemanager.sourceforge.net/index.html 액세스할 수 있습니다.
- 메일링 리스트는 의 메일링 리스트 아카이브 및 메일링 리스트 아카이브에서 https://lists.sourceforge.net/lists/listinfo/storagemanager-devel http://sourceforge.net/mailarchive/forum.php?forum_name=storagemanager-devel 구독할 수 있습니다. 2016년 5월 23일 오후 5시 08분 The mailing list is where developers communicate. 현재 사용자 메일링 리스트가 없으므로 언제든지 질문을 게시할 수 있습니다.
17장. 디스크 할당량
17.1. 디스크 할당량 구성
/etc/fstab파일을 수정하여 파일 시스템당 할당량을 활성화합니다.- 파일 시스템을 다시 마운트합니다.
- 할당량 데이터베이스 파일을 생성하고 디스크 사용량 테이블을 생성합니다.
- 할당량 정책을 할당합니다.
17.1.1. 할당량 활성화
절차 17.1. 할당량 활성화
- root로 로그인합니다.
/etc/fstab파일을 편집합니다.- quotas가 필요한 파일 시스템에 usrquota 또는 grpquota 또는 두 옵션을 모두 추가합니다.
예 17.1. /etc/fstab편집
vim 유형을 사용하려면 다음을 수행합니다.
# vim /etc/fstab예 17.2. 할당량 추가
/dev/VolGroup00/LogVol00 / ext3 defaults 1 1 LABEL=/boot /boot ext3 defaults 1 2 none /dev/pts devpts gid=5,mode=620 0 0 none /dev/shm tmpfs defaults 0 0 none /proc proc defaults 0 0 none /sys sysfs defaults 0 0 /dev/VolGroup00/LogVol02 /home ext3 defaults,usrquota,grpquota 1 2 /dev/VolGroup00/LogVol01 swap swap defaults 0 0 . . .
/home 파일 시스템에는 사용자 및 그룹 할당량이 모두 활성화되어 있습니다.
/etc/fstab 파일에서 할당량 정책을 설정할 수 있습니다.
17.1.2. 파일 시스템 다시 마운트
fstab 항목이 수정된 각 파일 시스템을 다시 마운트합니다. 어떤 프로세스에서 파일 시스템을 사용하지 않는 경우 다음 방법 중 하나를 사용합니다.
- unmount 명령 다음에 mount 명령을 실행하여 파일 시스템을 다시 마운트합니다. 다양한 파일 시스템 유형을 마운트 및 마운트 해제 하기 위한 특정 구문에 대해서는 NoExecute 및 mount 에 대한 도움말 페이지를 참조하십시오.
- mount -o remount file-system 명령(여기서 file-system 은 파일 시스템의 이름)을 실행하여 파일 시스템을 다시 마운트합니다. 예를 들어
/home파일 시스템을 다시 마운트하려면 mount -o remount /home 명령을 실행합니다.
17.1.3. 할당량 데이터베이스 파일 생성
절차 17.2. 할당량 데이터베이스 파일 생성
- 다음 명령을 사용하여 파일 시스템에 할당량 파일을 생성합니다.
#quotacheck -cug /file system - 다음 명령을 사용하여 파일 시스템당 현재 디스크 사용량의 테이블을 생성합니다.
#quotacheck -avug
- c
- 할당량을 활성화한 각 파일 시스템에 대해 할당량 파일을 생성해야 함을 지정합니다.
- u
- 사용자 할당량을 확인합니다.
- g
- 그룹 할당량을 확인합니다.
g만 지정하면 그룹 할당량 파일만 생성됩니다.
-u 또는 -g 옵션이 모두 지정되지 않은 경우 사용자 할당량 파일만 생성됩니다.
- a
- 로컬에서 마운트된 모든 할당량 활성화 파일 시스템을 확인합니다.
- v
- 할당량 검사가 진행되는 동안 상세 상태 정보를 표시합니다.
- u
- 사용자 디스크 할당량 정보 확인
- g
- 그룹 디스크 할당량 정보 확인
/home 과 같은 로컬에서 활성화된 로컬에서 마운트된 파일 시스템에 대한 데이터로 채워집니다.
17.1.4. 사용자당 할당량 할당
- 사용자 할당량을 설정하기 전에 사용자가 있어야 합니다.
절차 17.3. 사용자당 할당량 할당
- 사용자 할당량을 할당하려면 다음 명령을 사용합니다.
#edquota username사용자 이름을 할당량을 할당할 사용자로 교체합니다. - 사용자 할당량이 설정되었는지 확인하려면 다음 명령을 사용합니다.
#quota username
예 17.3. 사용자에게 할당량 할당
/home 파티션에 대해 /etc/fstab 에서 할당량이 활성화되고(다음 예제의/dev/VolGroup00/LogVol02 ) 명령이 실행되고 edquota testuser 명령이 실행되는 경우 시스템에 기본적으로 구성된 편집기에 다음이 표시됩니다.
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 0 0 37418 0 0
EDITOR 환경 변수에서 정의한 텍스트 편집기는 edquota 에서 사용됩니다. 편집기를 변경하려면 ~/.bash_profile 파일의 EDITOR 환경 변수를 선택한 편집기의 전체 경로로 설정합니다.
inodes 열에는 현재 사용자가 사용 중인 inode 수가 표시됩니다. 마지막 두 개의 열은 파일 시스템에서 사용자에 대한 소프트 및 하드 inode 제한을 설정하는 데 사용됩니다.
예 17.4. Desired Limits
Disk quotas for user testuser (uid 501): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440436 500000 550000 37418 0 0
# quota testuser
Disk quotas for user username (uid 501):
Filesystem blocks quota limit grace files quota limit grace
/dev/sdb 1000* 1000 1000 0 0 0
17.1.5. 그룹당 할당량 할당
- 그룹 할당량을 설정하기 전에 그룹이 존재해야 합니다.
절차 17.4. 그룹당 할당량 할당
- 그룹 할당량을 설정하려면 다음 명령을 사용합니다.
#edquota -g groupname - 그룹 할당량이 설정되었는지 확인하려면 다음 명령을 사용합니다.
#quota -g groupname
예 17.5. 그룹에 할당량 할당
devel 그룹에 대한 그룹 할당량을 설정하려면 명령을 사용합니다.
# edquota -g develDisk quotas for group devel (gid 505): Filesystem blocks soft hard inodes soft hard /dev/VolGroup00/LogVol02 440400 0 0 37418 0 0
# quota -g devel17.1.6. 소프트 제한에 대한 Grace Period 설정
# edquota -t17.2. 디스크 할당량 관리
17.2.1. 활성화 및 비활성화
# quotaoff -vaug-u 또는 -g 옵션이 모두 지정되지 않은 경우 사용자 할당량만 비활성화됩니다. -g 만 지정된 경우 그룹 할당량만 비활성화됩니다. -v 스위치를 사용하면 명령이 실행될 때 상세 상태 정보가 표시됩니다.
# quotaon# quotaon -vaug-u 또는 -g 옵션이 모두 지정되지 않은 경우 사용자 할당량만 활성화됩니다. -g 만 지정된 경우 그룹 할당량만 활성화됩니다.
/home 과 같은 특정 파일 시스템에 대한 할당량을 활성화하려면 다음 명령을 사용합니다.
# quotaon -vug /home17.2.2. 디스크 할당량에 대한 보고
예 17.6. repquota 명령의 출력
*** Report for user quotas on device /dev/mapper/VolGroup00-LogVol02 Block grace time: 7days; Inode grace time: 7days Block limits File limits User used soft hard grace used soft hard grace ---------------------------------------------------------------------- root -- 36 0 0 4 0 0 kristin -- 540 0 0 125 0 0 testuser -- 440400 500000 550000 37418 0 0
-a) 할당량 사용 파일 시스템에 대한 디스크 사용량 보고서를 보려면 명령을 사용합니다.
# repquota -a-- 은 블록 또는 inode 제한이 초과되었는지 여부를 빠르게 확인하는 방법입니다. 소프트 제한이 초과되면 해당 - 대신 + 가 표시됩니다. 첫 번째 - 는 블록 제한을 나타내고 두 번째는 inode 제한을 나타냅니다.
grace 열은 일반적으로 비어 있습니다. 소프트 제한을 초과한 경우 열에는 유예 기간에 남아 있는 시간 사양과 동일한 시간 사양이 포함됩니다. 유예 기간이 만료된 경우 none 이 대신 표시됩니다.
17.2.3. 할당량 적용 유지
# quotacheck- 다음 재부팅 시 quotacheck 실행 확인
- 대부분의 시스템에 가장 적합한 방법이 방법은 주기적으로 재부팅되는 (busy) 다중 사용자 시스템에 가장 적합합니다.
/etc/cron.daily/또는/etc/cron.weekly/디렉터리에 쉘 스크립트를 저장하거나 다음 명령을 사용하여 한 번만 예약합니다.#crontab -ecrontab -e 명령에는 touch /forcequotacheck 명령이 포함되어 있습니다. 이렇게 하면 루트 디렉터리에 빈forcequotacheck파일이 생성되며, 시스템 init 스크립트는 부팅 시 찾습니다. 이 항목이 발견되면 init 스크립트는 quotacheck 을 실행합니다. 이후 init 스크립트는/forcequotacheck파일을 제거합니다. 따라서cron을 사용하여 정기적으로 생성할 이 파일을 예약하면 다음 재부팅 중에 quotacheck 가 실행됩니다.cron 에 대한 자세한 내용은 man cron 을 참조하십시오. - 단일 사용자 모드에서 할당량 확인 실행
- 할당량 확인을 안전하게 실행하는 다른 방법은 시스템을 단일 사용자 모드로 부팅하여 할당량 파일에서 데이터 손상 가능성을 방지하고 다음 명령을 실행하는 것입니다.
#quotaoff -vug /file_system#quotacheck -vug /file_system#quotaon -vug /file_system - 실행 중인 시스템에서 할당량 확인 실행
- 필요한 경우 사용자가 로그인하지 않은 동안 시스템에서 quotacheck 를 실행할 수 있으므로 검사 중인 파일 시스템에 열려 있는 파일이 없습니다. quotacheck -vug file_system 명령을 실행합니다. quotacheck 에서 지정된 file_system 을 읽기 전용으로 다시 마운트할 수 없는 경우 이 명령이 실패합니다. 확인 후에는 파일 시스템이 읽기-쓰기로 다시 마운트됩니다.주의할당량 파일 손상 가능성 때문에 읽기-쓰기로 마운트된 라이브 파일 시스템에서 quotacheck 를 실행하는 것은 권장되지 않습니다.
17.3. 디스크 할당량 참조
- quotacheck
- edquota
- repquota
- quota
- quotaon
- quotaoff
18장. 중복 개별 디스크(RAID)
- 속도 향상
- 단일 가상 디스크를 사용하여 스토리지 용량 증가
- 디스크 장애로 인한 데이터 손실 최소화
18.1. RAID 유형
18.1.1. 펌웨어 RAID
18.1.2. 하드웨어 RAID
18.1.3. 소프트웨어 RAID
- 다중 스레드 설계
- 재구성 없이 Linux 시스템 간 배열의 이식성
- 유휴 시스템 리소스를 사용한 백그라운드 배열 재구성
- Hot-swappable 드라이브 지원
- streaming SIMD 지원과 같은 특정 CPU 기능을 활용하기 위한 자동 CPU 탐지
- 배열의 디스크에서 잘못된 섹터 자동 수정
- 배열의 상태를 보장하기 위해 RAID 데이터의 정규 일관성 검사
- 중요한 이벤트에서 지정된 이메일 주소로 전송된 이메일 알림을 통해 배열의 사전 모니터링
- 커널이 전체 배열을 다시 동기화하지 않고 다시 동기화해야 하는 디스크 부분을 정확하게 파악할 수 있도록 하여 이벤트 재동기화 속도가 크게 증가했습니다.
- 다시 동기화 중 컴퓨터를 재부팅하는 경우 다시 동기화를 시작할 때 다시 동기화가 꺼지고 다시 시작되지 않도록 하기 위해 검사점을 다시 동기화합니다.Resyncing so that if you reboot your computer during a resync, at startup the resync will pick up where it left off and not start all over again
- 설치 후 배열의 매개 변수를 변경하는 기능. 예를 들어 추가할 새 디스크가 있는 경우 4 디스크 RAID5 배열을 5 디스크 RAID5 배열로 확장할 수 있습니다. 이 증가 작업은 라이브로 수행되며 새 배열을 다시 설치할 필요가 없습니다.
18.2. RAID 수준 및 선형 지원
- 수준 0
- RAID 수준 0은 종종 "striping"이라고 하는 성능 지향형 데이터 매핑 기술입니다. 즉, 배열에 기록되는 데이터는 배열의 멤버 디스크에 대부분과 기록되어 낮은 비용으로 높은 I/O 성능을 허용하지만 중복을 제공하지 않습니다.많은 RAID 수준 0 구현에서는 배열에서 가장 작은 장치의 크기까지 멤버 장치에서만 데이터를 스트라이프합니다. 즉, 크기가 약간 다른 여러 장치가 있는 경우 각 장치는 가장 작은 드라이브와 크기가 동일한 것처럼 취급됩니다. 따라서 수준 0 배열의 일반적인 스토리지 용량은 하드웨어 RAID에서 가장 작은 멤버 디스크 용량 또는 소프트웨어 RAID의 최소 멤버 파티션 용량과 동일하므로 소프트웨어 RAID에서 디스크 또는 파티션 수를 곱한 것입니다.
- 수준 1
- RAID 레벨 1 또는 "미러링"은 다른 RAID 형식보다 오래 사용되었습니다. 수준 1은 배열의 각 멤버 디스크에 동일한 데이터를 작성하여 중복성을 제공하여 각 디스크에 "미러된" 복사본을 유지합니다. 미러링은 단순성과 높은 수준의 데이터 가용성으로 인해 널리 사용되고 있습니다. 수준 1은 두 개 이상의 디스크로 작동하며 매우 우수한 데이터 안정성과 읽기 집약적 애플리케이션의 성능을 개선하지만 비용이 비교적 높습니다. [3]레벨 1 배열의 스토리지 용량은 소프트웨어 RAID에서 하드웨어 RAID에서 미러링된 최소 하드 디스크 용량 또는 소프트웨어 RAID에서 가장 작은 미러링된 파티션의 용량과 동일합니다. 레벨 1 중복은 모든 RAID 유형 중에서 가능한 최고 수준이며 배열은 단일 디스크에서만 작동할 수 있습니다.
- 수준 4
- 수준 4의 패리티 사용 [4] 데이터를 보호하기 위해 단일 디스크 드라이브에 집중했습니다. 전용 패리티 디스크는 RAID 어레이에 대한 쓰기 트랜잭션의 고유한 병목 현상을 나타내므로, 수준 4는 나중 쓰기 캐싱과 같은 기술 없이 사용되지 않거나 시스템 관리자가 의도적으로 이 성능 장애를 염두에 두고 소프트웨어 RAID 장치를 설계하는 경우(예: 배열이 데이터로 채워지면 쓰기 트랜잭션이 거의 없음) 특정 상황에서 사용되지 않습니다. RAID 레벨 4는 너무 드물게 Anaconda에서 옵션으로 사용할 수 없습니다. 그러나 실제로 필요한 경우 사용자가 수동으로 만들 수 있습니다.하드웨어 RAID 레벨 4의 스토리지 용량은 가장 작은 멤버 파티션의 용량과 같으며 파티션 수를 1 로 곱한 것입니다. RAID 레벨 4 배열의 성능은 항상 symmetrical이 됩니다. 즉 읽기가 더 이상 쓰기가 불가능해집니다. 쓰기는 패리티를 생성할 때 추가 CPU 및 기본 메모리 대역폭을 사용한 다음 데이터뿐만 아니라 패리티뿐만 아니라 패리티를 작성하기 때문에 실제 데이터를 디스크에 작성할 때 추가 버스 대역폭을 사용하기 때문입니다. 읽기는 배열이 성능 저하된 상태에 있지 않는 한 패리티가 아닌 데이터를 읽어야 합니다.Reads need only read the data and not the 패리티 unless the array is in a degraded state. 결과적으로 읽기는 정상 작동 조건에서 동일한 양의 데이터 전송에 대해 드라이브 및 컴퓨터의 버스에서 적은 트래픽을 생성합니다.
- 수준 5
- 이것이 RAID의 가장 일반적인 유형입니다. 모든 배열의 멤버 디스크 드라이브에 패리티를 배포함으로써 RAID 레벨 5는 수준 4에 고유한 쓰기 병목 현상을 제거합니다. 성능 장애는 패리티 계산 프로세스 자체입니다. 최신 CPU 및 소프트웨어 RAID를 사용하면 최신 CPU가 매우 빠르게 패리티를 생성할 수 있기 때문에 일반적으로 병목 현상이 아닙니다. 그러나 소프트웨어 RAID5 어레이에 충분히 많은 멤버 장치가 있는 경우 모든 장치에서 결합된 집계 데이터 전송 속도가 충분히 길면 이러한 성능 장애가 발생하기 시작할 수 있습니다.4단계와 마찬가지로 레벨 5에는 측정된 성능이 크게 저하되어 있으며 성능이 크게 저하됩니다. RAID 레벨 5의 스토리지 용량은 수준 4와 동일한 방식으로 계산됩니다.
- 수준 6
- 이는 데이터 중복성 및 보존 시 일반적인 RAID 수준이며 성능이 아닌 가장 중요한 문제이지만 수준 1의 공간 비효율은 허용되지 않습니다. 수준 6은 복잡한 패리티 체계를 사용하여 배열의 두 드라이브의 손실에서 복구할 수 있습니다. 이러한 복잡한 패리티 체계는 소프트웨어 RAID 장치에 상당한 CPU 부담을 발생시키고 쓰기 트랜잭션 중에 더 많은 부담을 초래합니다. 따라서 수준 6은 4 및 5 수준보다 성능이 훨씬 더 큽니다.RAID 레벨 6 배열의 총 용량은 RAID 레벨 5 및 4와 유사하게 계산됩니다. 단, 1은 추가 패리티 스토리지 공간의 장치 수에서 2개의 장치를 제거해야 합니다.
- 수준 10
- 이 RAID 레벨은 수준 0의 성능 이점과 수준 1의 중복을 결합합니다. 또한 2개 이상의 장치를 사용하여 수준 1 어레이에서 낭비되는 일부 공간을 완화하는 데 도움이 됩니다. 레벨 10에서는 각 데이터의 2개 사본만 저장하도록 구성된 3-드라이브 배열을 생성할 수 있으며, 그러면 전체 배열 크기가 가장 작은 장치와 같은 1.5배가 될 수 있습니다(예: 3-device, 수준 1 배열).레벨 10 배열을 생성할 때 사용할 수 있는 옵션 수와 특정 사용 사례에 대한 올바른 옵션을 선택하는 복잡성으로 인해 설치 중에 만드는 것이 비현실적입니다. 명령줄 mdadm 도구를 사용하여 수동으로 하나를 생성할 수 있습니다. 옵션 및 해당 성능 장단점에 대한 자세한 내용은 man md 를 참조하십시오.
- 선형 RAID
- 선형 RAID는 더 큰 가상 드라이브를 만드는 드라이브의 그룹입니다. 선형 RAID에서는 한 멤버 드라이브에서 순차적으로 청크가 할당되어 첫 번째 드라이브가 완전히 채워질 때만 다음 드라이브로 이동합니다. 이 그룹화는 멤버 드라이브 간에 I/O 작업이 분할될 가능성이 낮기 때문에 성능상의 이점이 없습니다. Linear RAID는 중복성을 제공하지 않으며 안정성을 줄입니다. 하나의 멤버 드라이브가 실패하면 전체 배열을 사용할 수 없습니다. capacity는 모든 멤버 디스크의 총값입니다.
18.3. Linux RAID Subsystems
18.3.1. Linux 하드웨어 RAID 컨트롤러 드라이버
18.3.2. mdraid
18.3.3. dmraid
18.4. Anaconda 설치 프로그램의 RAID 지원
18.5. 설치 후 루트 디스크를 RAID1로 변환
- PReP(PowerPC 참조 플랫폼) 부팅 파티션 내용을
/dev/sda1에서/dev/sdb1로 복사합니다.#dd if=/dev/sda1 of=/dev/sdb1 - 두 디스크의 첫 번째 파티션에서 Prep 및 boot 플래그를 업데이트하십시오.
$parted /dev/sda set 1 prep on$parted /dev/sda set 1 boot on$parted /dev/sdb set 1 prep on$parted /dev/sdb set 1 boot on
18.6. RAID 세트 구성
18.6.1. mdadm
18.6.2. dmraid
18.7. 고급 RAID 장치 생성
/boot 또는 root 파일 시스템 어레이를 설정하는 것을 의미합니다. 이 경우 Anaconda 에서 지원하지 않는 배열 옵션을 사용해야 할 수 있습니다. 이 문제를 해결하려면 다음 절차를 수행하십시오.
절차 18.1. 고급 RAID 장치 생성
- 설치 디스크를 삽입합니다.
- 초기 부팅 중 또는 선택합니다. 시스템이 Rescue 모드로 완전히 부팅되면 사용자에게 명령줄 터미널이 표시됩니다.
- 이 터미널에서 parted 를 사용하여 대상 하드 드라이브에 RAID 파티션을 생성합니다. 그런 다음 mdadm 을 사용하여 사용 가능한 모든 설정 및 옵션을 사용하여 해당 파티션에서 raid 배열을 수동으로 생성합니다. 이 작업을 수행하는 방법에 대한 자세한 내용은 13장. 파티션, man parted, man mdadm 을 참조하십시오.
- 배열을 만든 후에는 필요에 따라 배열에서도 파일 시스템을 만들 수 있습니다.Once the arrays are created, you can optionally create file systems on the arrays as well.
- 컴퓨터를 재부팅하고 이번에는 . Anaconda 가 시스템에서 디스크를 검색하므로 기존 RAID 장치를 찾을 수 있습니다.
- 시스템에서 디스크를 사용하는 방법에 대해 묻는 메시지가 표시되면 을 선택하고 를 클릭합니다. 장치 목록에 기존 MD RAID 장치가 나열됩니다.
- RAID 장치를 선택하고 을 클릭하고 마운트 지점을 구성하고(선택적으로) 사용해야 하는 파일 시스템 유형(이전을 생성하지 않은 경우)을 클릭한 다음 (완료)을 클릭합니다. Anaconda 는 이러한 기존 RAID 장치에 설치를 수행하여 Rescue 모드에서 생성할 때 선택한 사용자 지정 옵션을 유지합니다.
19장. 마운트 명령 사용
19.1. 현재 마운트되어 있는 파일 시스템 나열
$ mount디렉터리 유형 (옵션)의 장치
$ findmnt19.1.1. 파일 시스템 유형 지정
sysfs 및 tmpfs 와 같은 다양한 가상 파일 시스템이 포함됩니다. 특정 파일 시스템 유형의 장치만 표시하려면 -t 옵션을 입력합니다.
$ mount -t type$ findmnt -t typeext4 파일 시스템 나열” 에서 참조하십시오.
예 19.1. 현재 마운트된 ext4 파일 시스템 나열
/ 및 /boot 파티션 모두 ext4 를 사용하도록 포맷됩니다. 이 파일 시스템을 사용하는 마운트 지점만 표시하려면 다음 명령을 사용합니다.
$ mount -t ext4
/dev/sda2 on / type ext4 (rw)
/dev/sda1 on /boot type ext4 (rw)
$ findmnt -t ext4
TARGET SOURCE FSTYPE OPTIONS
/ /dev/sda2 ext4 rw,realtime,seclabel,barrier=1,data=ordered
/boot /dev/sda1 ext4 rw,realtime,seclabel,barrier=1,data=ordered
19.2. 파일 시스템 마운트
$ mount [option…] device directory- 블록 장치의 전체 경로 : 예를 들면
/dev/sda3 - UUID( Universally unique identifier ): 예를 들면
UUID=34795a28-ca6d-4fd8-a347-73671d0c19cb - 볼륨 레이블: (예:
LABEL=home)
findmnt directory; echo $?1 을 반환합니다.
/etc/fstab 파일의 내용을 읽고 지정된 파일 시스템이 나열되어 있는지 확인합니다. /etc/fstab 파일에는 장치 이름 및 선택한 파일 시스템이 마운트되도록 설정된 디렉터리와 파일 시스템 유형 및 마운트 옵션이 포함되어 있습니다. 따라서 /etc/fstab 에 지정된 파일 시스템을 마운트할 때 다음 옵션 중 하나를 선택할 수 있습니다.
mount [option…] directory mount [option…] device
root 로 실행하지 않는 한 파일 시스템을 마운트하는 데 권한이 필요합니다( 19.2.2절. “마운트 옵션 지정”참조).
blkid device/dev/sda3 에 대한 정보를 표시하려면 다음을 수행합니다.
# blkid /dev/sda3
/dev/sda3: LABEL="home" UUID="34795a28-ca6d-4fd8-a347-73671d0c19cb" TYPE="ext3"
19.2.1. 파일 시스템 유형 지정
NFS (Network File System) 또는 CIFS (Common Internet File System)와 같은 특정 파일 시스템이 있으며 수동으로 지정해야 합니다. 파일 시스템 유형을 지정하려면 다음 형식으로 mount 명령을 사용하십시오.
$ mount -t type device directory표 19.1. 일반적인 파일 시스템 유형
| 유형 | 설명 |
|---|---|
ext2 | ext2 파일 시스템. |
ext3 | ext3 파일 시스템. |
ext4 | ext4 파일 시스템. |
btrfs | btrfs 파일 시스템 |
xfs | xfs 파일 시스템입니다. |
iso9660 | ISO 9660 파일 시스템입니다. 이는 일반적으로 광 미디어, 일반적으로 CD에 의해 사용됩니다. |
nfs | NFS 파일 시스템. 일반적으로 네트워크를 통해 파일에 액세스하는 데 사용됩니다. |
nfs4 | NFSv4 파일 시스템. 일반적으로 네트워크를 통해 파일에 액세스하는 데 사용됩니다. |
udf | UDF 파일 시스템 이는 일반적으로 광 미디어, 일반적으로 DVD에 의해 사용됩니다. |
vfat | FAT 파일 시스템입니다. Windows 운영 체제를 실행하는 머신과 USB 플로피 드라이브 또는 플로피 디스크와 같은 특정 디지털 미디어에서 일반적으로 사용됩니다. |
예 19.2. USB 플래쉬 드라이브 마운트
/dev/sdc1 장치를 사용하고 /media/flashdisk/ 디렉터리가 있다고 가정하면 쉘 프롬프트에서 root 로 다음을 입력하여 이 디렉토리에 마운트합니다.
~]# mount -t vfat /dev/sdc1 /media/flashdisk19.2.2. 마운트 옵션 지정
mount -o options device directory표 19.2. 일반적인 마운트 옵션
| 옵션 | 설명 |
|---|---|
async | 파일 시스템에서 비동기 입력/출력 작업을 허용합니다. |
auto | mount -a 명령을 사용하여 파일 시스템을 자동으로 마운트할 수 있습니다. |
defaults | async,auto,dev,exec,nouser,rw,suid 의 별칭을 제공합니다. |
exec | 특정 파일 시스템에서 바이너리 파일을 실행할 수 있습니다. |
loop | 이미지를 루프 장치로 마운트합니다. |
noauto | 기본 동작은 mount -a 명령을 사용하여 파일 시스템의 자동 마운트를 허용하지 않습니다. |
noexec | 특정 파일 시스템에서 바이너리 파일의 실행을 허용하지 않습니다. |
nouser | 파일 시스템을 마운트 및 마운트 해제하기 위해 일반 사용자(즉, 루트가 아닌)를 허용하지 않습니다. |
다시 마운트 | 이미 마운트된 경우 파일 시스템을 다시 마운트합니다. |
ro | 읽기 전용으로 파일 시스템을 마운트합니다. |
rw | 읽고 쓰기 위해 파일 시스템을 마운트합니다. |
user | 일반 사용자(즉, 루트가 아닌)를 사용하여 파일 시스템을 마운트 및 마운트 해제할 수 있습니다. |
예 19.3. ISO 이미지 마운트
/media/cdrom/ 디렉터리가 있다고 가정하면 다음 명령을 실행하여 이미지를 이 디렉터리에 마운트합니다.
# mount -o ro,loop Fedora-14-x86_64-Live-Desktop.iso /media/cdrom19.2.3. 마운트 공유
--bind 옵션을 구현합니다. 사용법은 다음과 같습니다.
$ mount --bind old_directory new_directory$ mount --rbind old_directory new_directory- 공유 마운트
- 공유 마운트를 사용하면 지정된 마운트 지점의 정확한 복제본을 만들 수 있습니다. 마운트 지점이 공유 마운트로 표시되면 원래 마운트 지점 내의 모든 마운트가 여기에 반영되며 그 반대의 경우도 마찬가지입니다. 마운트 지점 유형을 공유 마운트로 변경하려면 쉘 프롬프트에 다음을 입력합니다.
$mount --make-shared mount_point또는 선택한 마운트 지점 및 그 아래에 있는 모든 마운트 지점의 마운트 유형을 변경하려면 다음을 수행합니다.$mount --make-rshared mount_point예제 사용 예는 예 19.4. “공유 마운트 지점 생성” 를 참조하십시오. - 슬레이브 마운트
- 슬레이브 마운트를 사용하면 지정된 마운트 지점을 제한된 중복을 생성할 수 있습니다. 마운트 지점이 슬레이브 마운트로 표시되면 원래 마운트 지점 내의 모든 마운트가 반영되지만 슬레이브 마운트 내의 마운트는 원본에 반영되지 않습니다. 마운트 지점 유형을 슬레이브 마운트로 변경하려면 쉘 프롬프트에 다음을 입력합니다.
mount
--make-slavemount_point또는 다음을 입력하여 선택한 마운트 지점 및 모든 마운트 지점의 마운트 유형을 변경할 수 있습니다.mount
--make-rslavemount_point예제 사용 예는 예 19.5. “Slave Mount Point 생성” 를 참조하십시오.예 19.5. Slave Mount Point 생성
이 예에서는/media/디렉터리의 내용을/mnt/에도 표시할 수 있지만/media/에 반영할/mnt/디렉터리에 마운트가 없는 방법을 보여줍니다.root로, 먼저/media/디렉토리를 공유로 표시합니다.~]# mount --bind /media /media ~]# mount --make-shared /media
그런 다음/mnt/에 중복을 생성하되 "slave"로 표시합니다.~]# mount --bind /media /mnt ~]# mount --make-slave /mnt
이제/media/내의 마운트도/mnt/에 표시되는지 확인합니다. 예를 들어 CD-ROM 드라이브에 비어 있지 않은 미디어가 포함되어 있고/media/cdrom/디렉터리가 있는 경우 다음 명령을 실행합니다.~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom EFI GPL isolinux LiveOS
또한/mnt/디렉터리에 마운트된 파일 시스템이/media/에 반영되지 않았는지도 확인합니다. 예를 들어/dev/sdc1장치를 사용하는 비어 있지 않은 USB 플래시 드라이브가 연결되어 있고/mnt/flashdisk/디렉터리가 있는 경우 다음을 입력합니다.~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- 프라이빗 마운트
- 개인 마운트는 기본 마운트 유형이며 공유 또는 슬레이브 마운트와 달리 전파 이벤트를 수신하거나 전달할 수 없습니다. 마운트 지점을 개인 마운트로 명시적으로 표시하려면 쉘 프롬프트에 다음을 입력합니다.
mount
--make-privatemount_point또는 선택한 마운트 지점 및 모든 마운트 지점의 마운트 유형을 변경할 수 있습니다.mount
--make-rprivatemount_point예제 사용 예는 예 19.6. “개인 마운트 지점 생성” 를 참조하십시오.예 19.6. 개인 마운트 지점 생성
예 19.4. “공유 마운트 지점 생성” 의 시나리오를 고려하여 다음 명령을root로 사용하여 공유 마운트 지점이 이전에 생성되었다고 가정합니다.~]# mount --bind /media /media ~]# mount --make-shared /media ~]# mount --bind /media /mnt
/mnt/디렉토리를 비공개로 표시하려면 다음을 입력합니다.~]# mount --make-private /mnt이제/media/내에 있는 마운트가/mnt/에 표시되지 않는지 확인할 수 있습니다. 예를 들어 CD-ROM 드라이브에 비어 있지 않은 미디어가 포함되어 있고/media/cdrom/디렉터리가 있는 경우 다음 명령을 실행합니다.~]# mount /dev/cdrom /media/cdrom ~]# ls /media/cdrom EFI GPL isolinux LiveOS ~]# ls /mnt/cdrom ~]#
/mnt/디렉터리에 마운트된 파일 시스템이/media/에 반영되지 않았는지도 확인할 수 있습니다. 예를 들어/dev/sdc1장치를 사용하는 비어 있지 않은 USB 플래시 드라이브가 연결되어 있고/mnt/flashdisk/디렉터리가 있는 경우 다음을 입력합니다.~]# mount /dev/sdc1 /mnt/flashdisk ~]# ls /media/flashdisk ~]# ls /mnt/flashdisk en-US publican.cfg
- 바인딩할 수 없는 마운트
- 지정된 마운트 지점이 중복되지 않도록하기 위해 바인딩할 수 없는 마운트가 사용됩니다. 마운트 지점 유형을 바인딩할 수 없는 마운트로 변경하려면 쉘 프롬프트에 다음을 입력합니다.
mount
--make-unbindablemount_point또는 선택한 마운트 지점 및 모든 마운트 지점의 마운트 유형을 변경할 수 있습니다.mount
--make-runbindablemount_point예제 사용 예는 예 19.7. “바인딩할 수 없는 마운트 지점 생성” 를 참조하십시오.예 19.7. 바인딩할 수 없는 마운트 지점 생성
/media/디렉토리가 공유되지 않도록 하려면root로 다음을 수행합니다.#mount --bind /media /media#mount --make-unbindable /media이렇게 하면 이후에 이 마운트를 복제하려고 하면 오류가 발생하고 실패합니다.#mount --bind /media /mnt mount: wrong fs type, bad option, bad superblock on /media, missing codepage or helper program, or other error In some cases useful info is found in syslog - try dmesg | tail or so
19.2.4. 마운트 지점 이동
# mount --move old_directory new_directory예 19.8. 기존 NFS 마운트 지점 이동
/mnt/userdirs/ 에 마운트되어 있습니다. 다음 명령을 사용하여 root 로 이 마운트 지점을 /home 으로 이동합니다.
# mount --move /mnt/userdirs /home#ls /mnt/userdirs#ls /home jill joe
19.2.5. root에 대한 읽기 전용 권한 설정
19.2.5.1. 부팅에 읽기 전용 권한으로 마운트하도록 루트 구성
/etc/sysconfig/readonly-root파일에서READONLY를yes로 변경합니다.# Set to 'yes' to mount the file systems as read-only. READONLY=yes [output truncated]/etc/fstab파일의 루트 항목(/)에기본값을 변경합니다./dev/mapper/luks-c376919e... / ext4 ro,x-systemd.device-timeout=0 1 1/etc/default/grub파일에서GRUB_CMDLINE_LINUX지시문에ro를 추가하고rw가 없는지 확인합니다.GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet ro"- GRUB2 설정 파일을 다시 생성합니다.
#grub2-mkconfig -o /boot/grub2/grub.cfg tmpfs파일 시스템에서 쓰기 권한으로 파일 및 디렉토리를 추가해야 하는 경우/etc/rwtab.d/디렉터리에 텍스트 파일을 생성하고 여기에 설정을 저장하십시오. 예를 들어 쓰기 권한이 있는/etc/example/file을 마운트하려면 /etc/rwtab.d/예제파일에 다음 행을 추가합니다.files /etc/example/file
중요tmpfs의 파일 및 디렉터리 변경 사항은 부팅 시 지속되지 않습니다.이 단계에 대한 자세한 내용은 19.2.5.3절. “쓰기 권한을 보존하는 파일 및 디렉터리” 를 참조하십시오.- 시스템을 재부팅합니다.
19.2.5.2. 루트 를 즉시 다시 마운트
/)가 시스템 부팅에 대한 읽기 전용 권한으로 마운트된 경우 쓰기 권한으로 다시 마운트할 수 있습니다.
# mount -o remount,rw // 가 읽기 전용 권한으로 잘못 마운트되었을 때 특히 유용할 수 있습니다.
/ 를 다시 마운트하려면 다음을 실행합니다.
# mount -o remount,ro // 를 마운트합니다. 더 나은 접근 방식은 19.2.5.1절. “부팅에 읽기 전용 권한으로 마운트하도록 루트 구성” 에 설명된 대로 특정 파일 및 디렉터리에 대한 쓰기 권한을 RAM에 복사하여 유지하는 것입니다.
19.2.5.3. 쓰기 권한을 보존하는 파일 및 디렉터리
tmpfs 임시 파일 시스템의 RAM에 마운트됩니다. 이러한 파일 및 디렉터리의 기본 세트는 다음을 포함하는 /etc/rwtab 파일에서 읽습니다.
dirs /var/cache/man dirs /var/gdm [output truncated] empty /tmp empty /var/cache/foomatic [output truncated] files /etc/adjtime files /etc/ntp.conf [output truncated]
/etc/rwtab 파일의 항목은 다음 형식을 따릅니다.
how the file or directory is copied to tmpfs path to the file or directory
tmpfs 에 복사할 수 있습니다.
빈 경로: 빈 경로가tmpfs에 복사됩니다. 예:비어 있는 /tmpdirs path: 디렉터리 트리가tmpfs로 복사되며 비어 있습니다. 예:dirs /var/run파일 경로: 파일 또는 디렉터리 트리가 그대로tmpfs로 복사됩니다. 예:/etc/resolv.conf 파일
/etc/rwtab.d/ 에 사용자 지정 경로를 추가할 때 동일한 형식이 적용됩니다.
19.3. 파일 시스템 마운트 해제
$umount directory$umount device
root 로 로그인하는 동안 이 작업을 수행하지 않으면 파일 시스템을 마운트 해제하려면 올바른 권한을 사용할 수 있어야 합니다. 자세한 내용은 19.2.2절. “마운트 옵션 지정” 에서 참조하십시오. 예제 사용 예는 예 19.9. “CD 마운트 해제” 를 참조하십시오.
$fuser-mdirectory
/media/cdrom/ 디렉터리에 마운트된 파일 시스템에 액세스하는 프로세스를 나열하려면 다음을 수행합니다.
$ fuser -m /media/cdrom
/media/cdrom: 1793 2013 2022 2435 10532c 10672c
예 19.9. CD 마운트 해제
/media/cdrom/ 디렉터리에 마운트된 CD를 마운트 해제하려면 다음 명령을 사용합니다.
$ umount /media/cdrom19.4. 마운트 명령 참조
19.4.1. 수동 페이지 문서
- man 8 mount: 사용에 대한 전체 문서를 제공하는 mount 명령의 매뉴얼 페이지.
- man 8 unmount: 사용법에 대한 전체 문서를 제공하는 unmount 명령의 도움말 페이지입니다.
- man 8 findmnt: 사용법에 대한 전체 문서를 제공하는 findmnt 명령의 도움말 페이지.
- man 5fstab:
/etc/fstab파일 형식에 대한 철저한 설명을 제공하는 도움말 페이지입니다.
19.4.2. 유용한 웹 사이트
- 공유 하위 트리 - 공유 하위 트리의 개념을 다루는 LWN 문서입니다.
20장. volume_key 함수
20.1. volume_key 명령
volume_key [OPTION]... OPERAND- --save
- 이 명령은 피연산자 볼륨 [packet ]을 예상합니다. 패킷 이 제공되면 volume_key 에서 키와 암호를 추출합니다. 패킷 이 제공되지 않으면 volume_key 가 볼륨에서 키와 암호를 추출하고 필요한 경우 사용자에게 메시지를 표시합니다. 그러면 이러한 키와 암호가 하나 이상의 출력 패킷에 저장됩니다.
- --restore
- 이 명령은 피연산자 볼륨 패킷 을 예상합니다. 그런 다음 볼륨을 열고 패킷 에서 키와 암호를 사용하여 볼륨에 다시 액세스할 수 있도록 하여 필요한 경우 사용자에게 새 암호를 입력할 수 있도록 합니다. 예를 들면 다음과 같습니다.
- --setup-volume
- 이 명령은 피연산자 볼륨 패킷 이름을 예상합니다. 그런 다음 볼륨을 열고 패킷 에 있는 키와 암호를 사용하여 암호가 해독된 데이터를 이름으로 사용할 볼륨을 설정합니다.name 은 dm-crypt 볼륨의 이름입니다. 이 작업을 수행하면 암호 해독된 볼륨을
/dev/mapper/이름으로사용할 수 있습니다.이 작업은 예를 들어 새 암호를 추가하여 볼륨을 영구적으로 변경하지 않습니다. 사용자는 암호 해독된 볼륨에 액세스하여 수정하여 프로세스에서 볼륨을 수정할 수 있습니다. - --reencrypt,--secrets, --dump
- 이 세 가지 명령은 다양한 출력 방법을 사용하여 유사한 기능을 수행합니다. 각각 피연산자 패킷 이 필요하며 각각 패킷 을 열어 필요한 경우 암호를 해독합니다. 그런 다음 --reencrypt 는 정보를 하나 이상의 새 출력 패킷에 저장합니다. --secrets 는 패킷 에 포함된 키와 암호를 출력합니다. --dump 는 패킷 내용을 출력하지만, 키와 암호는 기본적으로 출력되지 않습니다. 명령에 --with-secrets 를 추가하여 변경할 수 있습니다. 또한 --unencrypted 명령을 사용하여 패킷의 암호화되지 않은 부분만 덤프할 수 있습니다. 암호 또는 개인 키 액세스 권한이 필요하지 않습니다.
- -o, --output packet
- 이 명령은 기본 키 또는 암호를 패킷 에 씁니다. 기본 키 또는 암호는 볼륨 형식에 따라 다릅니다. 만료 가능성이 없고 --restore 가 볼륨에 대한 액세스를 복원할 수 있도록 합니다.
- --output-format format
- 이 명령은 모든 출력 패킷에 지정된 형식 을 사용합니다. 형식은 다음 중 하나일 수 있습니다. format can be one of the following:
- identity: CMS를 사용하여 전체 패킷을 암호화하며, 인증서가 필요합니다.
- asymmetric_wrap_secret_only: 시크릿 또는 키 및 암호만 래핑하고 인증서가 필요합니다.
- passphrase: GPG를 사용하여 전체 패킷을 암호화하며 암호가 필요합니다.
- --create-random-passphrase packet
- 이 명령은 임의의 영숫자 암호를 생성하고(다른 암호에 영향을 미치지 않음) 볼륨에 추가한 다음, 이 임의 암호를 패킷 에 저장합니다.
20.2. volume_key 를 개별 사용자로 사용
/path/to/volume 은 내에 포함된 일반 텍스트 장치가 아닌 LUKS 장치입니다. blkid -s 유형 /path/to/volume 은 type="crypto_LUKS" 보고해야 합니다.
절차 20.1. volume_key Stand-alone 사용
- 다음을 실행합니다.
volume_key --save그런 다음 키를 보호하기 위해 에스크로 패킷 암호가 필요한 프롬프트가 나타납니다./path/to/volume-o escrow-packet - 생성된
escrow-packet파일을 저장하여 암호를 잊어버렸습니다.
절차 20.2. Escrow 패킷을 사용하여 데이터에 액세스 복원
- volume_key 를 실행할 수 있고 escrow 패킷을 사용할 수 있는 환경에서 시스템을 부팅합니다(예: 복구 모드).
- 다음을 실행합니다.
volume_key --restore에스크로 패킷을 만들 때 사용된 escrow 패킷 암호와 볼륨에 대한 새 암호에 대한 프롬프트가 표시됩니다./path/to/volumeescrow-packet - 선택한 암호를 사용하여 볼륨을 마운트합니다.
20.3. 대규모 조직에서 volume_key 사용
20.3.1. 암호화 키 저장 준비
절차 20.3. 준비
- X509 인증서/개인 쌍을 만듭니다.
- 개인 키를 손상시키지 않을 신뢰할 수 있는 사용자를 지정합니다. 이러한 사용자는 에스크로 패킷의 암호를 해독할 수 있습니다.
- 에스크로 패킷을 해독하는 데 사용할 시스템을 선택합니다. 이러한 시스템에서 개인 키가 포함된 NSS 데이터베이스를 설정합니다.개인 키가 NSS 데이터베이스에 생성되지 않은 경우 다음 단계를 따르십시오.
PKCS#12파일에 인증서 및 개인 키를 저장합니다.- 다음을 실행합니다.
certutil -d/the/nss/directory-N이 시점에서 NSS 데이터베이스 암호를 선택할 수 있습니다. NSS 데이터베이스는 각각 다른 암호를 가질 수 있으므로 지정된 사용자가 각 사용자가 별도의 NSS 데이터베이스를 사용하는 경우 단일 암호를 공유할 필요가 없습니다. - 다음을 실행합니다.
pk12util -d/the/nss/directory-ithe-pkcs12-file
- 시스템을 설치하거나 기존 시스템에 키를 저장하는 모든 사람에게 인증서를 배포합니다.
- 저장된 개인 키의 경우 머신 및 볼륨에서 조회할 수 있는 스토리지를 준비합니다. 예를 들어 시스템당 하나의 하위 디렉터리가 있는 간단한 디렉터리이거나 다른 시스템 관리 작업에 사용되는 데이터베이스도 될 수 있습니다.
20.3.2. 암호화 키 저장
/path/to/volume 은 포함된 일반 텍스트 장치가 아닌 LUKS 장치입니다. blkid -s 유형 /path/to/volume 은 type="crypto_LUKS" 을 보고해야 합니다.
절차 20.4. 암호화 키 저장
- 다음을 실행합니다.
volume_key --save/path/to/volume-c/path/to/certescrow-packet - 생성된
escrow-packet파일을 준비된 스토리지에 저장하여 시스템 및 볼륨과 연결합니다.
20.3.3. 볼륨에 액세스 복원
절차 20.5. 볼륨에 액세스 복원
- 패킷 스토리지에서 볼륨의 escrow 패킷을 가져와서 암호 해독을 위해 지정된 사용자 중 하나로 전송합니다.
- 지정된 사용자는 다음을 실행합니다.
volume_key --reencrypt -d/the/nss/directoryescrow-packet-in -o escrow-packet-outNSS 데이터베이스 암호를 제공한 후 지정된 사용자는 escrow-packet-out 을 암호화하기 위한 암호를 선택합니다. 이 암호는 매번 다를 수 있으며 지정된 사용자로부터 대상 시스템으로 이동하는 동안 암호화 키만 보호합니다. - 지정된 사용자로부터
escrow-packet-out파일과 암호를 가져옵니다. - volume_key 를 실행할 수 있고 복구 모드와 같은
escrow-packet-out파일을 사용할 수 있는 환경에서 대상 시스템을 부팅합니다. - 다음을 실행합니다.
volume_key --restore/path/to/volumeescrow-packet-out지정된 사용자가 선택한 패킷 암호와 볼륨에 대한 새 암호에 대한 프롬프트가 표시됩니다. - 선택한 볼륨 암호를 사용하여 볼륨을 마운트합니다.
20.3.4. Emergency Passphrases 설정
volume_key --save /path/to/volume -c /path/to/ert --create-random-passphrase passphrase-packet암호 모음에 저장합니다. 또한 --create-random-passphrase 및 -o 옵션을 결합하여 두 패킷을 동시에 생성할 수도 있습니다.
volume_key --secrets -d /your/nss/directory passphrase-packet20.4. volume_key 참조
/usr/share/doc/volume_key-*/README에 있는 readme 파일에서- volume_key 에서 man volume_key를 사용한 manpage
21장. 솔리드 스테이트 디스크 배포 지침
- 파일 시스템에서 사용 가능한 공간을 계속 사용할 수 있습니다.
- 기본 스토리지 장치의 대부분의 논리 블록은 에 이미 작성됩니다.
/sys/block/sda/queue/discard_granularity 를 확인합니다.
배포 고려 사항
- 비 결정적 TRIM
- DRAT(Deterministic TRIM )
- TRIM (RZAT) 이후 결정적 읽기 제로
# hdparm -I /dev/sda | grep TRIM
Data Set Management TRIM supported (limit 8 block)
Deterministic read data after TRIM
삭제 작업을 처리하지 않으면 성능이 저하됩니다. raid456.conf 파일 또는 GRUB2 설정에서 discard를 설정할 수 있습니다. 지침은 다음 절차를 참조하십시오.
절차 21.1. raid456.conf에서 삭제 설정
devices_handle_discard_safely 모듈 매개변수는 raid456 모듈에 설정됩니다. raid456.conf 파일에서 삭제 기능을 활성화하려면 다음을 수행합니다.
- 하드웨어에서 삭제 기능을 지원하는지 확인합니다.
#cat /sys/block/disk-name/queue/discard_zeroes_data반환된 값이1인 경우 삭제가 지원됩니다. 명령이0을 반환하면 RAID 코드가 디스크 아웃이 0이어야 하며 시간이 더 걸립니다. /etc/modprobe.d/raid456.conf파일을 만들고 다음 행을 포함합니다.options raid456 devices_handle_discard_safely=Y
- dracut -f 명령을 사용하여 초기 램디스크(Initrd)를 다시 빌드
합니다. - 변경 사항을 적용하려면 시스템을 재부팅합니다.
절차 21.2. GRUB2 설정에서 discard 설정
devices_handle_discard_safely 모듈 매개변수는 raid456 모듈에 설정됩니다. GRUB2 설정에서 삭제를 활성화하려면 다음을 수행합니다.
- 하드웨어에서 삭제 기능을 지원하는지 확인합니다.
#cat /sys/block/disk-name/queue/discard_zeroes_data반환된 값이1인 경우 삭제가 지원됩니다. 명령이0을 반환하면 RAID 코드가 디스크 아웃이 0이어야 하며 시간이 더 걸립니다. /etc/default/grub파일에 다음 행을 추가합니다.raid456.devices_handle_discard_safely=Y
- GRUB2 설정 파일의 위치는 BIOS 펌웨어가 있는 시스템 및 UEFI가 있는 시스템에서 다릅니다. 다음 명령 중 하나를 사용하여 GRUB2 설정 파일을 다시 생성합니다.
- BIOS 펌웨어가 있는 시스템에서는 다음을 사용합니다.
#grub2-mkconfig -o /boot/grub2/grub.cfg - UEFI 펌웨어가 있는 시스템에서는 다음을 사용합니다.
#grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 변경 사항을 적용하려면 시스템을 재부팅합니다.
/dev/sda2 를 discard가 활성화된 /mnt 에 마운트하려면 다음을 사용합니다.
# mount -t ext4 -o discard /dev/sda2 /mnt성능 튜닝 고려 사항
22장. 쓰기 Barriers
22.1. 이메일 주소
- 파일 시스템은 트랜잭션의 본문을 스토리지 장치로 전송합니다.
- 파일 시스템은 커밋 블록을 보냅니다.
- 트랜잭션과 해당 커밋 블록이 디스크에 기록되면 파일 시스템은 트랜잭션이 전원 실패로 유지되는 것으로 가정합니다.
22.1.1. Barriers의 작업 방법
- 디스크에는 모든 데이터가 포함됩니다.
- 재주문이 발생하지 않았습니다.
22.2. 쓰기 바리커 활성화 및 비활성화
/var/log/messages 에 오류 메시지를 기록합니다. 자세한 내용은 표 22.1. “파일 시스템당 Barrier 오류 메시지” 에서 참조하십시오.
표 22.1. 파일 시스템당 Barrier 오류 메시지
| 파일 시스템 | 오류 메시지 |
|---|---|
| ext3/ext4 | JBD: barrier-based sync failed on device - disabling barriers |
| XFS | Filesystem device - Disabling barriers, trial barrier write failed |
| btrfs | btrfs: disabling barriers on dev device |
22.3. 설문 조사 작성
22.3.1. 쓰기 캐시 비활성화
# hdparm -W0 /device/22.3.2. 기록-Backed 쓰기 캐시
# MegaCli64 -LDGetProp -DskCache -LAll -aALL# MegaCli64 -LDSetProp -DisDskCache -Lall -aALL22.3.3. 하이 엔드 배열
22.3.4. NFS
23장. 스토리지 I/O 정렬 및 크기
23.1. 스토리지 액세스를 위한 매개변수
- physical_block_size
- 장치가 작동할 수 있는 최소 내부 단위
- logical_block_size
- 장치의 위치를 해결하기 위해 외부에서 사용
- alignment_offset
- Linux 블록 장치(partition/MD/LVM 장치)의 시작 부분이 기본 물리적 정렬에서 오프셋하는 바이트 수
- minimum_io_size
- 임의의 I/O에 대해 장치의 기본 최소 단위
- optimal_io_size
- I/O 스트리밍을 위한 장치의 기본 단위
23.2. 사용자 공간 액세스
libblkid-devel 패키지에서 제공합니다.
23.2.1. sysfs 인터페이스
- /sys/block/
disk/alignment_offset또는/sys/block/disk/partition/alignment_offset참고파일 위치는 디스크가 물리적 디스크인지(로컬 디스크, 로컬 RAID 또는 다중 경로 LUN)인지에 따라 다릅니다. 첫 번째 파일 위치는 물리 디스크에 적용되고 두 번째 파일 위치는 가상 디스크에 적용됩니다. 그 이유는 virtio-blk가 항상 파티션의 정렬 값을 보고하기 때문입니다. 물리 디스크는 정렬 값을 보고하거나 보고하지 않을 수 있습니다. - /sys/block/
disk/queue/physical_block_size - /sys/block/
disk/queue/logical_block_size - /sys/block/
disk/queue/minimum_io_size - /sys/block/
disk/queue/optimal_io_size
예 23.1. sysfs 인터페이스
alignment_offset: 0 physical_block_size: 512 logical_block_size: 512 minimum_io_size: 512 optimal_io_size: 0
23.2.2. 블록 장치 ioctls
- BLKALIGNOFF:
alignment_offset - BLKPBSZGET:
physical_block_size - BLKSSZGET:
logical_block_size - BLKIOMIN:
minimum_io_size - BLKIOOPT:
optimal_io_size
23.3. I/O 표준
23.3.1. ATA
23.3.2. SCSI
BLOCK LIMITS VPD 페이지에 대한 액세스 권한과 READ CAPACITY(16) 명령만 SPC-3을 준수하는 장치에만 전송합니다.
LOGICAL BLOCK LENGTH IN BYTES/sys/block/디스크/queue/physical_block_size를 파생하는데 사용됩니다.LOGICAL BLOCKS PER PHYSICAL BLOCK EXPONENT/sys/block/disk/queue/logical_block_size를 파생시키는 데 사용됩니다.LOWEST ALIGNED LOGICAL BLOCK ADDRESS파생하는데 사용됩니다./sys/block/disk/alignment_offset/sys/block/disk/partition/alignment_offset
BLOCK LIMITS VPD 페이지(0xb0)는 I/O 힌트를 제공합니다. 또한 OPTIMAL TRANSFER LENGTH GRANULARITY 및 OPTIMAL TRANSFER LENGTH 을 사용하여 파생됩니다.
/sys/block/disk/queue/minimum_io_size/sys/block/disk/queue/optimal_io_size
sg3_utils 패키지는 BLOCK LIMITS VPD 페이지에 액세스하는 데 사용할 수 있는 sg_inq 유틸리티를 제공합니다. 이렇게 하려면 다음을 실행합니다.
# sg_inq -p 0xb0 disk23.4. stacking I/O Parameters
- I/O 스택에서 하나의 레이어만 0이 아닌 alignment_offset 에 맞게 조정되어야 합니다. 레이어가 그에 따라 조정되면 alignment_offset 이 0인 장치를 내보냅니다.
- LVM으로 생성된 스트립 장치 매퍼(DM) 장치는 스트라이프 수(디스크 수) 및 사용자 제공 청크 크기를 기준으로 minimum_io_size 및 optimal_io_size 를 내보내야 합니다.
23.5. 논리 볼륨 관리자
/etc/lvm/lvm.conf 에서 data_alignment_offset_detection 을 0 로 설정하여 이 동작을 비활성화할 수 있습니다. 이를 비활성화하는 것은 권장되지 않습니다.
/etc/lvm/lvm.conf 에서 data_alignment_detection 을 0 로 설정하여 이 동작을 비활성화할 수 있습니다. 이를 비활성화하는 것은 권장되지 않습니다.
23.6. 파티션 및 파일 시스템 도구
23.6.1. util-linux-ng의 libblkid 및 metadata
util-linux-ng 패키지와 함께 제공되는 libblkid 라이브러리에는 장치의 I/O 매개 변수에 액세스하기 위한 프로그램 API가 포함되어 있습니다. libblkid 는 특히 Direct I/O를 사용하는 애플리케이션이 I/O 요청의 크기를 적절하게 조정할 수 있도록 합니다. util-linux-ng 의 fdisk 유틸리티는 libblkid 를 사용하여 모든 파티션을 최적으로 배치하기 위해 장치의 I/O 매개 변수를 결정합니다. fdisk 유틸리티는 1MB 경계의 모든 파티션을 정렬합니다.
23.6.2. Parted 및 libparted
libparted 라이브러리도 libblkid 의 I/O 매개 변수 API를 사용합니다. Red Hat Enterprise Linux 7 설치 프로그램인 Anaconda 는 libparted 를 사용하므로 설치 또는 parted 가 생성한 모든 파티션이 올바르게 정렬됩니다. I/O 매개 변수를 제공하지 않는 장치에서 생성된 모든 파티션의 경우 기본 정렬은 1MB가 됩니다.
- 항상 보고된 alignment_offset 을 첫 번째 기본 파티션 시작의 오프셋으로 사용합니다.
- optimal_io_size 가 정의된 경우 (즉, 0이 아닌) optimal_io_size 경계의 모든 파티션을 정렬합니다.
- optimal_io_size 가 정의되지 않은 경우(즉, 0), alignment_offset 은 0 이고, minimum_io_size 는 2의 power인 경우 1MB의 기본 정렬을 사용합니다.I/O 힌트를 제공하지 않는 "레거시" 장치용 범용입니다. 따라서 기본적으로 모든 파티션은 1MB 경계에 정렬됩니다.참고Red Hat Enterprise Linux 7은 I/O 힌트를 제공하지 않는 장치와 alignment_offset=0 및 optimal_io_size=0 을 구분할 수 없습니다. 이러한 장치는 단일 SAS 4K 장치일 수 있습니다. 따라서 디스크를 시작할 때 최악의 1MB의 공간이 손실됩니다.
23.6.3. 파일 시스템 도구
24장. 원격 디스크 없는 시스템 설정
tftp-serverxinetddhcpsyslinuxdracut-network참고dracut-network패키지를 설치한 후/etc/dracut.conf에 다음 행을 추가합니다.add_dracutmodules+="nfs"
tftp -server에서 제공하는 tftp 서비스와 DHCP 서비스( dhcp에서 제공)가 필요합니다. tftp 서비스는 PXE 로더를 통해 네트워크에서 커널 이미지 및 initrd 를 검색하는 데 사용됩니다.
/etc/sysconfig/nfs 에서 NFS를 명시적으로 활성화해야 합니다.
/var/lib/tftpboot/pxelinux.cfg/default 에서 root=nfs:server-ip:/exported/root-ip :/ exported/root-ip:/exported/root/directory,vers=4.2.
24.1. 디스크 없는 클라이언트를 위한 tftp 서비스 구성
사전 요구 사항
- 필요한 패키지를 설치합니다. 참조 24장. 원격 디스크 없는 시스템 설정
절차
절차 24.1. tftp를 구성하려면
- 네트워크를 통해 PXE 부팅을 활성화합니다.
#systemctl enable --now tftp - tftp root 디렉토리(chroot)는
/var/lib/tftpboot에 있습니다./usr/share/syslinux/pxelinux.0을/var/lib/tftpboot/로 복사합니다.#cp /usr/share/syslinux/pxelinux.0 /var/lib/tftpboot/ - tftp 루트 디렉터리 내에
pxelinux.cfg디렉터리를 생성합니다.#mkdir -p /var/lib/tftpboot/pxelinux.cfg/ - tftp 트래픽을 허용하도록 방화벽 규칙을 구성합니다.tftp 가 TCP 래퍼를 지원하면
/etc/hosts.allow구성 파일에서 tftp 에 대한 호스트 액세스를 구성할 수 있습니다. TCP 래퍼 및/etc/hosts.allow구성 파일을 구성하는 방법에 대한 자세한 내용은 Red Hat Enterprise Linux 7 보안 가이드를 참조하십시오. hosts_access(5) 은(는)/etc/hosts.allow에 대한 정보도 제공합니다.
다음 단계
24.2. 디스크 없는 클라이언트에 대한 DHCP 구성
사전 요구 사항
- 필요한 패키지를 설치합니다. 참조 24장. 원격 디스크 없는 시스템 설정
tftp서비스를 구성합니다. 24.1절. “디스크 없는 클라이언트를 위한 tftp 서비스 구성” 을 참조하십시오.
절차
- tftp 서버를 구성한 후 동일한 호스트 시스템에 DHCP 서비스를 설정해야 합니다. DHCP 서버 설정에 대한 지침은 DHCP 서버 구성을 참조하십시오.
/etc/dhcp/dhcpd.conf에 다음 구성을 추가하여 DHCP 서버에서 PXE 부팅을 활성화합니다.allow booting; allow bootp; class "pxeclients" { match if substring(option vendor-class-identifier, 0, 9) = "PXEClient"; next-server server-ip; filename "pxelinux.0"; }server-ip를 tftp 및 DHCP 서비스가 상주하는 호스트 머신의 IP 주소로 바꿉니다.
참고libvirt 가 디스크 없는 클라이언트로 사용되는 경우 libvirt 는 DHCP 서비스를 제공하며 스탠드 DHCP 서버는 사용되지 않습니다. 이 경우 libvirt 네트워크 구성에서 bootp file=' 파일이름' 옵션을 사용하여 네트워크 부팅을 활성화해야 합니다. virsh net-edit.
다음 단계
24.3. 디스크 없는 클라이언트를 위해 내보낸 파일 시스템 구성
사전 요구 사항
- 필요한 패키지를 설치합니다. 참조 24장. 원격 디스크 없는 시스템 설정
tftp서비스를 구성합니다. 24.1절. “디스크 없는 클라이언트를 위한 tftp 서비스 구성” 을 참조하십시오.- DHCP를 구성합니다. 24.2절. “디스크 없는 클라이언트에 대한 DHCP 구성” 을 참조하십시오.
절차
- 내보낸 파일 시스템의 루트 디렉터리(네트워크의 디스크 없는 클라이언트에서 사용)는 NFS를 통해 공유됩니다.
/etc/exports에 추가하여 루트 디렉터리를 내보내도록 NFS 서비스를 구성합니다. 이 작업을 수행하는 방법에 대한 지침은 8.6.1절. “/etc/exports구성 파일” 을 참조하십시오. - 완전한 디스크 없는 클라이언트를 수용하려면 루트 디렉터리에 완전한 Red Hat Enterprise Linux 설치가 포함되어야 합니다. 기존 설치를 복제하거나 새 기본 시스템을 설치할 수 있습니다.
- 실행 중인 시스템과 동기화하려면
rsync유틸리티를 사용합니다.#rsync -a -e ssh --exclude='/proc/*' --exclude='/sys/*' \ hostname.com:/exported-root-directory- hostname.com 을
rsync를 통해 동기화할 실행 중인 시스템의 호스트 이름으로 바꿉니다. - exported-root-directory 를 내보낸 파일 시스템의 경로로 바꿉니다.
- 내보낸 위치에 Red Hat Enterprise Linux를 설치하려면
--installroot옵션과 함께yum유틸리티를 사용합니다.#yum install @Base kernel dracut-network nfs-utils \ --installroot=exported-root-directory --releasever=/
절차 24.2. 파일 시스템 구성
- 디스크 없는 클라이언트가 사용할 커널을 선택하고(
vmlinuz-kernel-version)를 tftp 부팅 디렉터리에 복사합니다.#cp /boot/vmlinuz-kernel-version /var/lib/tftpboot/ - NFS 지원을 사용하여
initrd(즉,initramfs-kernel-version.img)를 만듭니다.#dracut --add nfs initramfs-kernel-version.img kernel-version - 다음 명령을 사용하여 initrd의 파일 권한을 644로 변경합니다.
#chmod 644 initramfs-kernel-version.img주의initrd 파일 권한이 변경되지 않으면 pxelinux.0 부트 로더가 "파일을 찾을 수 없음" 오류와 함께 실패합니다. - 결과
initramfs-kernel-version.img를 tftp 부팅 디렉터리에 복사합니다. /var/lib/tftpboot/디렉토리에서initrd및 kernel을 사용하도록 기본 부팅 구성을 편집합니다. 이 구성은 디스크 없는 클라이언트의 루트에 내보낸 파일 시스템(/exported/root/directory)을 읽기-쓰기로 마운트하도록 지시해야 합니다./var/lib/tftpboot/pxelinux.cfg/default파일에 다음 설정을 추가합니다.default rhel7 label rhel7 kernel vmlinuz-kernel-version append initrd=initramfs-kernel-version.img root=nfs:server-ip:/exported/root/directory rw
server-ip를 tftp 및 DHCP 서비스가 상주하는 호스트 머신의 IP 주소로 바꿉니다.
25장. 온라인 스토리지 관리
/usr/share/doc/kernel-doc-버전/Documentation/sysfs-rules.txt 문서를 참조하십시오.
25.1. 대상 설정
#systemctl start target#systemctl enable target
25.1.1. StatefulSet 설치 및 실행
# yum install targetcli대상 서비스를 시작합니다.
# systemctl start target대상을 구성합니다.
# systemctl enable target3260 을 열고 방화벽 구성을 다시 로드합니다.
#firewall-cmd --permanent --add-port=3260/tcp Success#firewall-cmd --reload Success
# targetcli
:
/> ls
o- /........................................[...]
o- backstores.............................[...]
| o- block.................[Storage Objects: 0]
| o- fileio................[Storage Objects: 0]
| o- pscsi.................[Storage Objects: 0]
| o- ramdisk...............[Storage Ojbects: 0]
o- iscsi...........................[Targets: 0]
o- loopback........................[Targets: 0]
25.1.2. Backstore 생성
- FILEIO(Linux 파일 지원 스토리지)
- FILEIO 스토리지 오브젝트는 write_back 또는 write_thru 작업을 지원할 수 있습니다. write_back 을 사용하면 로컬 파일 시스템 캐시가 활성화됩니다. 이로 인해 성능이 향상되지만 데이터 손실 위험이 증가합니다. write_thru 와 함께 write_back=false 를 사용하여 write_back 을 비활성화하는 것이 좋습니다.fileio 스토리지 오브젝트를 생성하려면 /backstores/fileio create file_name file_size write_ back=false 명령을 실행합니다. 예를 들어 다음과 같습니다.
/> /backstores/fileio create file1 /tmp/disk1.img 200M write_back=false Created fileio file1 with size 209715200
- BLOCK(Linux BLOCK 장치)
- 블록 드라이버를 사용하면
/sys/block에 표시되는 모든 블록 장치를 LIO와 함께 사용할 수 있습니다. 여기에는 물리 장치(예: HDD, SSD, CD, DVD) 및 논리 장치(예: 소프트웨어 또는 하드웨어 RAID 볼륨 또는 LVM 볼륨)가 포함됩니다.참고BLOCK 백 저장소는 일반적으로 최상의 성능을 제공합니다.블록 장치를 사용하여 BLOCK backstore를 생성하려면 다음 명령을 사용합니다.#fdisk/dev/vdbWelcome to fdisk (util-linux 2.23.2). Changes will remain in memory only, until you decide to write them. Be careful before using the write command. Device does not contain a recognized partition table Building a new DOS disklabel with disk identifier 0x39dc48fb. Command (m for help): n Partition type: p primary (0 primary, 0 extended, 4 free) e extended Select (default p): *Enter* Using default response p Partition number (1-4, default 1): *Enter* First sector (2048-2097151, default 2048): *Enter* Using default value 2048 Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +250M Partition 1 of type Linux and of size 250 MiB is set Command (m for help): w The partition table has been altered! Calling ioctl() to re-read partition table. Syncing disks./> /backstores/block create name=block_backend dev=/dev/vdb Generating a wwn serial. Created block storage object block_backend using /dev/vdb.
참고논리 볼륨에 BLOCK backstore를 생성할 수도 있습니다. - PSCSI(Linux 패스스루 SCSI 장치)
- SCSI 에뮬레이션 없이 SCSI 명령을 직접 통과하고,
/proc/scsi/scsi(예: SAS 하드 드라이브)에서 lsscsi와 함께 표시되는 기본 SCSI 장치가 포함된 스토리지 오브젝트를 보조 저장소로 구성할 수 있습니다. SCSI-3 이상은 이 하위 시스템에서 지원됩니다.주의PSCSI는 고급 사용자만 사용해야 합니다. Aysmmetric Logical Unit Assignment(ALUA) 또는 영구 예약 할당(예: VMware ESX 및 vSphere에서 사용하는 것과 같은 고급 SCSI 명령)은 일반적으로 장치 펌웨어에서 구현되지 않으며 오작동 또는 충돌을 일으킬 수 있습니다. 의심할 때, 대신 프로덕션 설정에 대한 BLOCK을 사용하십시오.물리적 SCSI 장치에 대한 PSCSI 백 저장소를 생성하려면 이 예제에서/dev/sr0을 사용하는 TYPE_ROM 장치는 다음을 사용합니다./> backstores/pscsi/ create name=pscsi_backend dev=/dev/sr0 Generating a wwn serial. Created pscsi storage object pscsi_backend using /dev/sr0
- 메모리 복사 RAM 디스크(Linux RAMDISK_MCP)
- 메모리 복사 RAM 디스크(램디스크)는 이니시에이터의 메모리 사본을 사용하여 전체 SCSI 에뮬레이션 및 개별 메모리 매핑이 있는 RAM 디스크를 제공합니다. 이는 멀티 세션 기능을 제공하며 프로덕션 목적으로 빠르고 휘발성 대용량 스토리지에 특히 유용합니다.1GB RAM 디스크 백스토어를 생성하려면 다음 명령을 사용하십시오.
/> backstores/ramdisk/ create name=rd_backend size=1GB Generating a wwn serial. Created rd_mcp ramdisk rd_backend with size 1GB.
25.1.3. iSCSI 대상 생성
절차 25.1. iSCSI 대상 생성
- 6443 을 실행합니다.
- iSCSI 구성 경로로 이동합니다.
/> iscsi/
참고cd 명령은 디렉토리를 변경하고 이동할 경로를 나열하는 것도 허용됩니다. - 기본 대상 이름을 사용하여 iSCSI 대상을 만듭니다.
/iscsi> create Created target iqn.2003-01.org.linux-iscsi.hostname.x8664:sn.78b473f296ff Created TPG1
또는 지정된 이름을 사용하여 iSCSI 대상을 만듭니다./iscsi > create iqn.2006-04.com.example:444 Created target iqn.2006-04.com.example:444 Created TPG1
- 대상이 ls 로 나열될 때 새로 생성된 대상이 표시되는지 확인합니다.
/iscsi > ls o- iscsi.......................................[1 Target] o- iqn.2006-04.com.example:444................[1 TPG] o- tpg1...........................[enabled, auth] o- acls...............................[0 ACL] o- luns...............................[0 LUN] o- portals.........................[0 Portal]
25.1.4. iSCSI 포털 구성
절차 25.2. iSCSI 포털 생성
- TPG로 이동합니다.
/iscsi> iqn.2006-04.example:444/tpg1/
- 포털을 생성하는 방법에는 기본 포털을 생성하거나 수신 대기할 IP 주소를 지정하는 포털을 생성하는 두 가지가 있습니다.기본 포털을 생성하면 기본 iSCSI 포트 3260을 사용하며 대상이 해당 포트의 모든 IP 주소에서 수신 대기할 수 있습니다.
/iscsi/iqn.20...mple:444/tpg1> portals/ create Using default IP port 3260 Binding to INADDR_Any (0.0.0.0) Created network portal 0.0.0.0:3260
수신 대기할 IP 주소를 지정하는 포털을 생성하려면 다음 명령을 사용합니다./iscsi/iqn.20...mple:444/tpg1> portals/ create 192.168.122.137 Using default IP port 3260 Created network portal 192.168.122.137:3260
- ls 명령을 사용하여 새로 생성된 포털이 표시되는지 확인합니다.
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns ......................................[0 LUN] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
25.1.5. LUN 구성
절차 25.3. LUN 구성
- 이미 생성된 스토리지 오브젝트의 LUN을 만듭니다.
/iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/ramdisk/rd_backend Created LUN 0. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/block/block_backend Created LUN 1. /iscsi/iqn.20...mple:444/tpg1> luns/ create /backstores/fileio/file1 Created LUN 2.
- 변경 사항을 표시합니다.
/iscsi/iqn.20...mple:444/tpg1> ls o- tpg.................................. [enambled, auth] o- acls ......................................[0 ACL] o- luns .....................................[3 LUNs] | o- lun0.........................[ramdisk/ramdisk1] | o- lun1.................[block/block1 (/dev/vdb1)] | o- lun2...................[fileio/file1 (/foo.img)] o- portals ................................[1 Portal] o- 192.168.122.137:3260......................[OK]
참고Red Hat Enterprise Linux 6에서 tgtd 를 사용하는 경우와 마찬가지로 기본 LUN 이름은 0에서 시작합니다. - ACL을 구성합니다. 자세한 내용은 25.1.6절. “ACL 구성” 에서 참조하십시오.
절차 25.4. 읽기 전용 LUN 만들기
- 읽기 전용 권한으로 LUN을 만들려면 먼저 다음 명령을 사용합니다.
/> set global auto_add_mapped_luns=false Parameter auto_add_mapped_luns is now 'false'.
이렇게 하면 LUN을 기존 ACL에 대한 자동 매핑이 금지되므로 LUN을 수동 매핑할 수 있습니다. - 다음으로 iscsi/target_iqn_name/tpg1/acls/initiator_iqn_name/ create mapped_lun=next_sequential_LUN_number tpg_lun_or_backstore= backstore=backstore = backstore=1.
/> iscsi/iqn.2015-06.com.redhat:target/tpg1/acls/iqn.2015-06.com.redhat:initiator/ create mapped_lun=1 tpg_lun_or_backstore=/backstores/block/block2 write_protect=1 Created LUN 1. Created Mapped LUN 1. /> ls o- / ...................................................... [...] o- backstores ........................................... [...] <snip> o- iscsi ......................................... [Targets: 1] | o- iqn.2015-06.com.redhat:target .................. [TPGs: 1] | o- tpg1 ............................ [no-gen-acls, no-auth] | o- acls ....................................... [ACLs: 2] | | o- iqn.2015-06.com.redhat:initiator .. [Mapped LUNs: 2] | | | o- mapped_lun0 .............. [lun0 block/disk1 (rw)] | | | o- mapped_lun1 .............. [lun1 block/disk2 (ro)] | o- luns ....................................... [LUNs: 2] | | o- lun0 ...................... [block/disk1 (/dev/vdb)] | | o- lun1 ...................... [block/disk2 (/dev/vdc)] <snip>
이제 mapped_lun1 행에는 (rw)가 읽기 전용임을 나타내는 끝에 (ro)가 끝에 있습니다(xlun0의 (rw)). - ACL을 구성합니다. 자세한 내용은 25.1.6절. “ACL 구성” 에서 참조하십시오.
25.1.6. ACL 구성
/etc/iscsi/initiatorname.iscsi 에서 확인할 수 있습니다.
절차 25.5. ACL 구성
- acls 디렉터리로 이동합니다.
/iscsi/iqn.20...mple:444/tpg1> acls/
- ACL을 만듭니다. 이니시에이터의
/etc/iscsi/initiatorname.iscsi에 있는 이니시에이터 이름을 사용하거나, 쉽게 이해할 수 있는 이름을 사용하는 경우 ACL이 이니시에이터와 일치하는지 25.2절. “iSCSI 초기자 생성” 를 참조하십시오. 예를 들어 다음과 같습니다./iscsi/iqn.20...444/tpg1/acls> create iqn.2006-04.com.example.foo:888 Created Node ACL for iqn.2006-04.com.example.foo:888 Created mapped LUN 2. Created mapped LUN 1. Created mapped LUN 0.
참고지정된 예제의 동작은 사용된 설정에 따라 다릅니다. 이 경우 전역 설정 auto_add_mapped_luns 가 사용됩니다. 이렇게 하면 생성된 모든 ACL에 LUN이 자동으로 매핑됩니다.대상 서버의 TPG 노드 내에서 사용자가 생성한 ACL을 설정할 수 있습니다./iscsi/iqn.20...scsi:444/tpg1>set attribute generate_node_acls=1 - 변경 사항을 표시합니다.
/iscsi/iqn.20...444/tpg1/acls> ls o- acls .................................................[1 ACL] o- iqn.2006-04.com.example.foo:888 ....[3 Mapped LUNs, auth] o- mapped_lun0 .............[lun0 ramdisk/ramdisk1 (rw)] o- mapped_lun1 .................[lun1 block/block1 (rw)] o- mapped_lun2 .................[lun2 fileio/file1 (rw)]
25.1.7. 파이버 채널 over Ethernet(FCoE) 대상 구성
절차 25.6. FCoE 대상 구성
- FCoE 대상을 설정하려면 dependencies와 함께
targetcli패키지를 설치해야 합니다. Clevis 기본 설정에 대한 자세한 내용은 25.1절. “대상 설정” 를 참조하십시오. - FCoE 인터페이스에서 FCoE 대상 인스턴스를 만듭니다.
/> tcm_fc/ create 00:11:22:33:44:55:66:77FCoE 인터페이스가 시스템에 있는 경우, 생성 후 탭 컴파일은 사용 가능한 인터페이스를 나열합니다. 그렇지 않은 경우fcoeadm -i에 활성 인터페이스가 표시되는지 확인합니다. - 보조 저장소를 대상 인스턴스에 매핑합니다.
예 25.1. Backstore를 대상 인스턴스에 매핑하는 예
/> tcm_fc/00:11:22:33:44:55:66:77/> luns/ create /backstores/fileio/example2 - FCoE 이니시에이터에서 LUN에 대한 액세스를 허용합니다.
/> acls/ create 00:99:88:77:66:55:44:33이제 해당 이니시에이터에서 LUN에 액세스할 수 있어야 합니다. - 재부팅 후에도 변경 사항을 적용하려면 saveconfig 명령을 사용하고 메시지가 표시되면 yes 를 입력합니다. 이 작업이 완료되지 않으면 재부팅 후 구성이 손실됩니다.
- exit 를 입력하거나 ctrl+D 를 입력하여 identity를 종료합니다.
25.1.8. StatefulSet를 사용하여 오브젝트 제거
/> /backstores/backstore-type/backstore-name
/> /iscsi/iqn-name/tpg/acls/ delete iqn-name
/> /iscsi delete iqn-name
25.1.9. 6 443 참조
- man customers
- 6 443 도움말 페이지. 여기에는 간단한 예제가 포함되어 있습니다.
- Linux SCSI 대상 Wiki
- Andy Grover의 screencast
- 참고이 파일은 2012년 2월 28일에 업로드되었습니다. 따라서 서비스 이름이 customers에서 대상으로 변경되었습니다.
25.2. iSCSI 초기자 생성
절차 25.7. iSCSI 초기자 생성
- iscsi-initiator-utils 를 설치합니다.
#yum install iscsi-initiator-utils -y - ACL에 25.1.6절. “ACL 구성” 에 사용자 지정 이름이 제공된 경우 그에 따라
/etc/iscsi/initiatorname.iscsi파일을 수정합니다. 예를 들어 다음과 같습니다.#cat /etc/iscsi/initiatorname.iscsi InitiatorName=iqn.2006-04.com.example.node1#vi /etc/iscsi/initiatorname.iscsi - 대상을 검색합니다.
#iscsiadm -m discovery -t st -p target-ip-address 10.64.24.179:3260,1 iqn.2006-04.com.example:3260 - 3단계에서 검색한 대상 IQN을 사용하여 대상에 로그인합니다.
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -l Logging in to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] (multiple) Login to [iface: default, target: iqn.2006-04.com.example:3260, portal: 10.64.24.179,3260] successful.이 절차는 25.1.6절. “ACL 구성” 에 설명된 대로 특정 이니시에이터 이름을 ACL에 추가하는 한 동일한 LUN에 연결된 수의 초기화기에 대해 따를 수 있습니다. - iSCSI 디스크 이름을 찾아서 이 iSCSI 디스크에서 파일 시스템을 만듭니다.
#grep "Attached SCSI" /var/log/messages#mkfs.ext4/dev/disk_namedisk_name 을/var/log/messages에 표시된 iSCSI 디스크 이름으로 교체합니다. - 파일 시스템을 마운트합니다.
#mkdir /mount/point#mount/dev/disk_name/mount/point/mount/point 를 파티션의 마운트 지점으로 바꿉니다. - 시스템이 부팅될 때 자동으로 파일 시스템을 마운트하도록
/etc/fstab를 편집합니다.#vim /etc/fstab/dev/disk_name/mount/point ext4 _netdev 0 0disk_name 을 iSCSI 디스크 이름으로 교체합니다. - 대상에서 로그아웃합니다.
#iscsiadm -m node -T iqn.2006-04.com.example:3260 -u
25.3. Challenge-Handshake 인증 프로토콜 설정
절차 25.8. 대상에 대한 CHAP 설정
- 특성 인증을 설정합니다.
/iscsi/iqn.20...mple:444/tpg1>set attribute authentication=1 Parameter authentication is now '1'. - userid 및 password를 설정합니다.
/iscsi/iqn.20...mple:444/tpg1>set auth userid=redhat Parameter userid is now 'redhat'./iscsi/iqn.20...mple:444/tpg1>set auth password=redhat_passwd Parameter password is now 'redhat_passwd'.
절차 25.9. 이니시에이터에 대한 CHAP 설정
iscsid.conf파일을 편집합니다.iscsid.conf파일에서 CHAP 인증을 활성화합니다.#vi /etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP기본적으로 node.session.auth.authmethod 옵션은 None 으로 설정됩니다.iscsid.conf파일에 대상 사용자 이름 및 암호를 추가합니다.node.session.auth.username = redhat node.session.auth.password = redhat_passwd
- iscsid 서비스를 다시 시작합니다.
#systemctl restart iscsid.service
25.4. 파이버 채널
25.4.1. 파이버 채널 API
/sys/class/ 디렉터리 목록입니다. 각 항목에서 호스트 번호는 H 에 의해 지정되며, 버스 번호는 B 이고, 대상이 T 이고, 논리 단위 번호(LUN)는 L 이며 원격 포트 번호는 R 입니다.
- 전송:
/sys/class/fc_transport/targetH:B:T/ port_id- 24비트 포트 ID/addressNODE_NAME- 64비트 노드 이름port_name- 64비트 포트 이름
- 원격 포트:
/sys/class/fc_remote_ports/rport-H:B-R/ port_idnode_nameport_namedev_loss_tmo: scsi 장치가 시스템에서 제거될 때 제어합니다.dev_loss_tmo가 트리거되면 scsi 장치가 제거됩니다.multipath.conf에서dev_loss_tmo를무한으로 설정할 수 있습니다. 이 값은 2,147,483,647초 또는 68년이며 최대dev_loss_tmo값입니다.Red Hat Enterprise Linux 7에서fast_io_fail_tmo옵션을 설정하지 않으면dev_loss_tmo가 600초로 제한됩니다. 기본적으로multipathd서비스가 실행되는 경우 Red Hat Enterprise Linux 7에서fast_io_fail_tmo가 5초로 설정됩니다. 그러지 않으면off로 설정됩니다.fast_io_fail_tmo: 링크를 "bad"로 표시하기 전에 대기하는 시간(초)을 지정합니다. 링크가 좋지 않으면 기존 실행 중인 I/O 또는 해당 경로의 새 I/O가 실패합니다.I/O가 차단 큐에 있는 경우dev_loss_tmo가 만료되고 큐가 차단되지 않을 때까지 실패합니다.fast_io_fail_tmo가해제를 제외한 모든 값으로 설정된 경우dev_loss_tmo는 이스케이프되지 않습니다.fast_io_fail_tmo가off로 설정되면 시스템에서 장치를 제거할 때까지 I/O가 실패하지 않습니다.fast_io_fail_tmo가 숫자로 설정되면fast_io_fail_tmo시간 초과가 트리거되면 I/O가 즉시 실패합니다.
- 호스트:
/sys/class/fc_host/hostH/ port_idissue_lip: 드라이버에 원격 포트를 다시 검색하도록 지시합니다.
25.4.2. 네이티브 파이버 채널 드라이버 및 기능
lpfcqla2xxxzfcpbfa
qlini_mode 모듈 매개변수를 사용하여 파이버 채널 대상 모드를 활성화합니다.
/usr/lib/modprobe.d/qla2xxx.conf qla2xxx 모듈 구성 파일에 다음 매개 변수를 추가합니다.
options qla2xxx qlini_mode=disabled
initrd)를 다시 빌드하고 변경 사항을 적용하려면 시스템을 재부팅합니다.
25.5. 이더넷 인터페이스를 통한 파이버 채널 구성
fcoe-utilslldpad
절차 25.10. FCoE를 사용하도록 이더넷 인터페이스 구성
- 새 VLAN을 구성하려면 기존 네트워크 스크립트의 사본을 만듭니다(예:
/etc/fcoe/cfg-eth0), 이름을 FCoE를 지원하는 이더넷 장치로 변경합니다. 구성할 기본 파일이 제공됩니다. FCoE 장치가 ethX 인 경우 다음을 실행합니다.# cp /etc/fcoe/cfg-ethx /etc/fcoe/cfg-ethX
필요에 따라cfg-ethX의 내용을 수정합니다. 특히, hardware Data Center Bridging Exchange (DCBX) 프로토콜 클라이언트를 구현하는 네트워킹 인터페이스의 경우DCB_REQUIRED를no로 설정합니다. - 부팅 시 장치가 자동으로 로드되도록 하려면 해당
/etc/sysconfig/network-scripts/ifcfg-ethX파일에서ONBOOT=yes를 설정합니다. 예를 들어 FCoE 장치가 eth2인 경우 이에 따라/etc/sysconfig/network-scripts/ifcfg-eth2를 편집합니다. - 다음을 실행하여 데이터 센터 브리징 데몬(dcbd)을 시작합니다.
# systemctl start lldpad
- 하드웨어 DCBX 클라이언트를 구현하는 네트워킹 인터페이스의 경우 이 단계를 건너뜁니다.소프트웨어 DCBX 클라이언트가 필요한 인터페이스의 경우 다음을 실행하여 이더넷 인터페이스에서 데이터 센터 브리징을 활성화합니다.
# dcbtool sc ethX dcb on
그런 다음 다음을 실행하여 이더넷 인터페이스에서 FCoE를 활성화합니다.# dcbtool sc ethX app:fcoe e:1
이러한 명령은 이더넷 인터페이스의 dcbd 설정이 변경되지 않은 경우에만 작동합니다. - 이제 다음을 사용하여 FCoE 장치를 로드합니다.
# ip link set dev ethX up
- FCoE를 사용하여 시작:
# systemctl start fcoe
패브릭의 다른 모든 설정이 올바른 경우 FCoE 장치가 곧 표시됩니다. 구성된 FCoE 장치를 보려면 다음을 실행합니다.# fcoeadm -i
lldpad 서비스를 사용하도록 설정하는 것이 좋습니다. 이 작업을 수행하려면 systemctl 유틸리티를 사용합니다.
# systemctl enable lldpad
# systemctl enable fcoe25.6. 부팅 시 자동으로 마운트되도록 FCoE 인터페이스 구성
/usr/share/doc/fcoe-utils-버전/README 에서 확인할 수 있습니다. 마이너 릴리스에서 가능한 변경 사항은 해당 문서를 참조하십시오.
/lib/systemd/system/fcoe.service 입니다.
예 25.2. FCoE 마운트 코드
/etc/fstab 의 와일드카드를 통해 지정된 파일 시스템을 마운트하는 샘플 FCoE 코드입니다.
mount_fcoe_disks_from_fstab()
{
local timeout=20
local done=1
local fcoe_disks=($(egrep 'by-path\/fc-.*_netdev' /etc/fstab | cut -d ' ' -f1))
test -z $fcoe_disks && return 0
echo -n "Waiting for fcoe disks . "
while [ $timeout -gt 0 ]; do
for disk in ${fcoe_disks[*]}; do
if ! test -b $disk; then
done=0
break
fi
done
test $done -eq 1 && break;
sleep 1
echo -n ". "
done=1
let timeout--
done
if test $timeout -eq 0; then
echo "timeout!"
else
echo "done!"
fi
# mount any newly discovered disk
mount -a 2>/dev/null
}/etc/fstab 에 다음 경로로 지정된 FCoE 디스크가 마운트됩니다.
/dev/disk/by-path/fc-0xXX:0xXX /mnt/fcoe-disk1 ext3 defaults,_netdev 0 0 /dev/disk/by-path/fc-0xYY:0xYY /mnt/fcoe-disk2 ext3 defaults,_netdev 0 0
fc- 및 _netdev 하위 문자열이 있는 항목을 사용하면 mount_fcoe_disks_from_fstab 함수에서 FCoE 디스크 마운트 항목을 식별할 수 있습니다. /etc/fstab 항목에 대한 자세한 내용은 man 5fstab을 참조하십시오.
25.7. iSCSI
iscsi-initiator-utils 를 실행하여 iscsi-initiator-utils 패키지를 먼저 설치합니다.
node.startup = automatic 로 표시된 노드가 없는 경우 iscsiadm 또는 iscsi 커널 모듈을 시작하는 데 iscsiadm 명령을 실행할 때까지 iSCSI 서비스가 시작되지 않습니다. 예를 들어 discovery 명령 iscsiadm -m discovery -t st -p ip:port 를 실행하면 iscsiadm 이 iSCSI 서비스를 시작합니다.
25.7.1. iSCSI API
# iscsiadm -m session -P 3
# iscsiadm -m session -P 0
# iscsiadm -m session
driver [sid] target_ip:port,target_portal_group_tag proper_target_name
예 25.3. iscsisadm -m 세션 명령의 출력
# iscsiadm -m session tcp [2] 10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 tcp [3] 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
/usr/share/doc/iscsi-initiator-utils-version/README.
25.8. 영구 이름 지정
25.8.1. 스토리지 장치의 주 및 마이너 수
sd 드라이버에서 관리하는 스토리지 장치는 주요 장치 번호 및 관련 마이너 번호로 내부적으로 식별됩니다. 이 목적에 사용되는 주요 장치 번호는 연속 범위에 포함되지 않습니다. 각 스토리지 장치는 장치 내에서 전체 장치 또는 파티션을 식별하는 데 사용되는 주요 번호와 다양한 마이너 번호로 표시됩니다. sd <s)> 번호 형식으로 장치와 숫자에 할당된 메이저 및 마이너[번호] 사이에 직접 연관이 있습니다. sd 드라이버가 새 장치를 감지할 때마다 사용 가능한 주요 번호와 마이너 번호 범위가 할당됩니다. 운영 체제에서 장치를 제거할 때마다 나중에 재사용할 수 있도록 주요 번호 및 마이너 번호 범위가 확보됩니다.
sd 이름은 감지 시 각 장치에 할당됩니다. 즉, 장치 감지 순서가 변경될 경우 메이저 및 마이너 번호 범위 및 관련 sd 이름 간의 연결이 변경될 수 있습니다. 일부 하드웨어 구성에서는 드문 경우지만(예: 섀시 내의 물리적 위치에 의해 할당된 SCSI 대상 ID가 있는 내부 SCSI 컨트롤러 및 디스크 사용) 여전히 발생할 수 있습니다. 이러한 상황이 발생할 수 있는 예는 다음과 같습니다.
- 디스크의 전원을 켜거나 SCSI 컨트롤러에 응답하지 못할 수 있습니다. 그러면 일반 장치 프로브에서 탐지되지 않습니다. 디스크는 시스템에서 액세스할 수 없으며, 연결된
sd이름이 변경된 것을 포함하여 주요 번호 범위가 있습니다. 예를 들어 일반적으로sdb라고 하는 디스크가 감지되지 않으면 일반적으로sdc라고 하는 디스크는 대신sdb로 표시됩니다. - SCSI 컨트롤러(호스트 버스 어댑터 또는 HBA)가 초기화되지 않아 해당 HBA에 연결된 모든 디스크가 감지되지 않을 수 있습니다. 이후에 검색된 HBA에 연결된 모든 디스크에는 다른 주요 및 마이너 번호 범위가 할당되며 서로 다른 연결된
sd이름이 할당됩니다. - 시스템에 HBA의 다른 유형이 있는 경우 드라이버 초기화 순서가 변경될 수 있습니다. 이로 인해 해당 HBA에 연결된 디스크가 다른 순서로 탐지됩니다. 이는 HBA를 시스템의 다른 PCI 슬롯으로 이동하는 경우에도 발생할 수 있습니다.
- 예를 들어 스토리지 어레이 또는 전원이 꺼진 스위치로 인해 스토리지 장치가 검색되는 시점에 파이버 채널, iSCSI 또는 FCoE 어댑터가 시스템에 연결된 디스크에 액세스할 수 없습니다. 이는 정전 후 시스템을 재부팅할 때 시스템 부팅에 걸리는 스토리지 어레이보다 온라인 상태가 더 오래 걸리는 경우 발생할 수 있습니다. 일부 파이버 채널 드라이버는 WWPN 매핑에 영구 SCSI 대상 ID를 지정하는 메커니즘을 지원하지만, 이로 인해 주요 번호 범위 및 관련
sd이름이 예약되지 않으며 일관된 SCSI 대상 ID 번호만 제공합니다.
/etc/fstab 파일과 같이 장치를 참조할 때 메이저 및 마이너 번호 범위 또는 관련 sd 이름을 사용하지 않도록 합니다. 잘못된 장치가 마운트되고 데이터 손상이 발생할 가능성이 있습니다.
sd 이름을 참조해야 합니다. 이는 Linux 커널이 장치와 관련된 커널 메시지에서 sd 이름(및 SCSI host/channel/target/LUN tuples)을 사용하기 때문입니다.
25.8.2. World Wide Identifier(WWWID)
0x83) 또는 단위 일련 번호 (페이지 0x80)를 검색하기 위한 SCSI 기술서를 발행하여 얻을 수 있습니다. 이러한 WWID의 현재 /dev/sd 이름에 대한 매핑은 /dev/disk/by-id/ 디렉터리에 유지 관리되는 symlink에서 확인할 수 있습니다.
예 25.4. WWID
0x83 식별자가 있는 장치는 다음과 같습니다.
scsi-3600508b400105e210000900000490000 -> ../../sda
0x80 식별자가 있는 장치에는 다음이 포함됩니다.
scsi-SSEAGATE_ST373453LW_3HW1RHM6 -> ../../sda
/dev/sd 이름으로 적절한 매핑을 자동으로 유지합니다. 애플리케이션은 /dev/disk/by-id/ 이름을 사용하여 장치 경로가 변경되거나 다른 시스템의 장치에 액세스하는 경우에도 디스크의 데이터를 참조할 수 있습니다.
/dev/mapper/wwid 디렉터리에 /dev/mapper/3600508b400105df70000e00000ac0000 과 같은 단일 "pseudo-device"를 제공합니다.
Host:Channel:Target:LUN, /dev/sd 이름, major:minor number.
3600508b400105df70000e00000ac0000 dm-2 vendor,product [size=20G][features=1 queue_if_no_path][hwhandler=0][rw] \_ round-robin 0 [prio=0][active] \_ 5:0:1:1 sdc 8:32 [active][undef] \_ 6:0:1:1 sdg 8:96 [active][undef] \_ round-robin 0 [prio=0][enabled] \_ 5:0:0:1 sdb 8:16 [active][undef] \_ 6:0:0:1 sdf 8:80 [active][undef]
/dev/sd 이름에 각 WWID 기반 장치 이름의 적절한 매핑을 자동으로 유지합니다. 이러한 이름은 경로 변경 시 지속되며 다른 시스템의 장치에 액세스할 때 일관되게 유지됩니다.
user_friendly_names 기능( DM Multipath)을 사용하면 WWID가 /dev/mapper/mpathn 형식의 이름에 매핑됩니다. 기본적으로 이 매핑은 /etc/multipath/bindings 파일에서 유지됩니다. 이러한 mpathn 이름은 해당 파일이 유지되는 한 영구적입니다.
user_friendly_names 를 사용하는 경우 클러스터에서 일관된 이름을 얻으려면 추가 단계가 필요합니다. DM Multipath 도서의 클러스터의 Consistent Multipath 장치 이름을 참조하십시오.
udev 규칙을 사용하여 스토리지의 WWID에 매핑된 고유한 영구 이름을 구현할 수도 있습니다.
25.8.3. /dev/disk/by-*의 udev Mechanism에서 관리하는 장치 이름
udev 메커니즘은 다음 세 가지 주요 구성 요소로 구성됩니다.
- 커널
- 장치가 추가, 제거 또는 변경될 때 사용자 공간으로 전송되는 이벤트를 생성합니다.
udevd서비스- 이벤트를 수신합니다.
udev규칙udev서비스가 커널 이벤트를 수신할 때 수행할 작업을 지정합니다.
/dev/disk/ 디렉토리에 심볼릭 링크를 생성하는 udev 규칙이 포함되어 있어 스토리지 장치를 콘텐츠, 고유 식별자, 일련 번호 또는 장치에 액세스하는 데 사용되는 하드웨어 경로에서 참조할 수 있습니다.
/dev/disk/by-label/- 이 디렉터리의 항목은 장치에 저장된 콘텐츠(즉, 데이터)의 레이블로 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다. blkid 유틸리티는 장치에서 데이터를 읽고 장치의 이름(즉, 레이블)을 결정하는 데 사용됩니다. 예를 들어 다음과 같습니다.
/dev/disk/by-label/Boot
참고정보는 장치의 콘텐츠(즉, 데이터)에서 가져오기되므로 콘텐츠가 다른 장치에 복사되면 레이블은 동일하게 유지됩니다.레이블은 다음 구문을 사용하여/etc/fstab에서 장치를 참조하는 데 사용할 수도 있습니다.LABEL=Boot
/dev/disk/by-uuid/- 이 디렉터리의 항목은 장치에 저장된 콘텐츠(즉, 데이터)의 고유 식별자로 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다. blkid 유틸리티는 장치에서 데이터를 읽고 장치에 대한 고유 식별자(즉, UUID)를 가져오는 데 사용됩니다. 예를 들어 다음과 같습니다.
UUID=3e6be9de-8139-11d1-9106-a43f08d823a6
/dev/disk/by-id/- 이 디렉터리의 항목은 고유한 식별자(다른 모든 스토리지 장치와 다름)로 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다. 식별자는 장치의 속성이지만 장치의 콘텐츠(즉, 데이터)에 저장되지 않습니다. 예를 들어 다음과 같습니다.
/dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05
id는 장치의 전역 ID 또는 장치 일련 번호에서 가져옵니다./dev/disk/by-id/항목에는 파티션 번호가 포함될 수 있습니다. 예를 들어 다음과 같습니다./dev/disk/by-id/scsi-3600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-id/wwn-0x600508e000000000ce506dc50ab0ad05-part1
/dev/disk/by-path/- 이 디렉터리의 항목은 PCI 계층에서 스토리지 컨트롤러에 대한 참조로 시작하여 PCI 계층에서 스토리지 컨트롤러에 대한 참조로 시작하여 SCSI 호스트, 채널, 대상 및 LUN 번호, 선택적으로 파티션 번호를 포함하여 장치에 액세스하는 데 사용되는 하드웨어 경로에 의해 스토리지 장치를 참조하는 심볼릭 이름을 제공합니다. 이러한 이름은 크고 작은 숫자 또는
sd이름을 사용하는 것이 바람직하지만, 대상 숫자가 파이버 채널 SAN 환경에서 변경되지 않도록 하고(예: 영구 바인딩을 사용하여) 호스트 어댑터를 다른 PCI 슬롯으로 이동하는 경우 이름 사용을 업데이트해야 합니다. 또한 HBA에서 드라이버를 다른 순서로 로드하거나 시스템에 새 HBA가 설치되어 있는 경우 HBA에서 검색에 실패하는 경우 또는 새 HBA가 시스템에 설치된 경우 SCSI 호스트 번호가 변경될 수 있습니다. 경로별 목록은 다음과 같습니다./dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0
/dev/disk/by-path/항목은 다음과 같은 파티션 번호를 포함할 수 있습니다./dev/disk/by-path/pci-0000:03:00.0-scsi-0:1:0:0-part1
25.8.3.1. udev 장치 이름 지정 규정의 제한 사항
udev 이름 지정 규칙의 몇 가지 제한 사항입니다.
udev메커니즘이udev이벤트를 위해udev를 처리할 때 스토리지 장치를 쿼리하는 기능에 의존할 수 있기 때문에 쿼리가 수행될 때 장치를 액세스할 수 없을 수도 있습니다. 이는 장치가 서버 섀시에 없는 경우 파이버 채널, iSCSI 또는 FCoE 스토리지 장치에서 발생할 가능성이 큽니다.- 커널은 언제든지
udev이벤트를 보낼 수 있으므로 규칙을 처리하여 장치에 액세스할 수 없는 경우/dev/disk/by-*/링크가 제거됩니다. udev이벤트가 생성되는 경우와 많은 수의 장치가 감지되는 경우와 사용자 공간udev서비스가 감지되는 경우와 각 이벤트에 대한 규칙을 처리하는 데 약간의 시간이 걸리는 시간 사이에 지연이 발생할 수 있습니다. 이로 인해 커널이 장치를 탐지할 때와/dev/disk/by-*/이름을 사용할 수 있는 시간 사이에 지연될 수 있습니다.- 규칙에 의해 호출되는 blkid 와 같은 외부 프로그램은 짧은 기간 동안 장치를 열 수 있으므로 다른 용도로 장치에 액세스 할 수 없습니다.
25.8.3.2. 영구 이름 지정 속성 수정
udev 이름 지정 속성은 영구적이지만 시스템 재부팅 시 자체적으로 변경되지 않으며 일부는 구성할 수도 있습니다. 다음 영구 이름 지정 특성에 대한 사용자 지정 값을 설정할 수 있습니다.
UUID: 파일 시스템 UUIDLABEL: 파일 시스템 레이블
UUID 및 LABEL 속성은 파일 시스템과 관련이 있으므로, 사용해야 하는 툴은 해당 파티션의 파일 시스템에 따라 다릅니다.
- XFS 파일 시스템의
UUID또는LABEL속성을 변경하려면 파일 시스템을 마운트 해제한 다음 xfs_admin 유틸리티를 사용하여 속성을 변경합니다.#umount /dev/device#xfs_admin [-U new_uuid] [-L new_label] /dev/device#udevadm settle - ext4, ext3 또는 ext2 파일 시스템의
UUID또는LABEL속성을 변경하려면 tune2fs 유틸리티를 사용합니다.#tune2fs [-U new_uuid] [-L new_label] /dev/device#udevadm settle
1cdfbc07-1c90-4984-b5ec-f61943f5ea50 ). new_label 을 레이블로 바꿉니다(예: backup_data ).
udev 속성 변경은 백그라운드에서 수행되며 시간이 오래 걸릴 수 있습니다. udevadm settle 명령은 변경 사항이 완전히 등록될 때까지 대기하여 다음 명령이 새 속성을 올바르게 사용할 수 있도록 합니다.
PARTUUID 또는 PARTLABEL 속성이 있는 파티션을 만들거나 새 파일 시스템을 만든 후에 사용해야 합니다.
25.9. 스토리지 장치 제거
- 사용 가능한 메모리는 100개당 10개 이상의 샘플에서 총 메모리의 5% 미만입니다(사용 가능한 명령도 총 메모리를 표시하는 데 사용할 수 있음).
- 스와핑이 활성화되었습니다( vmstat 출력의 0이외
si및so열).
절차 25.11. 제거 후 장치 제거 확인
- 필요에 따라 장치의 모든 사용자와 백업 장치 데이터를 닫습니다.
- device가 마운트된 모든 파일 시스템을 마운트 해제 하려면 unmount를 사용합니다.
- 장치를 사용하는 모든 md 및 LVM 볼륨에서 제거합니다. 장치가 LVM 볼륨 그룹의 멤버인 경우 pv passes 명령을 사용하여 장치에서 데이터를 이동한 다음, vgreduce 명령을 사용하여 물리 볼륨을 제거하고 (선택적으로) pvremove 를 디스크에서 제거해야 할 수 있습니다.
- multipath -l 명령을 실행하여 다중 경로 장치로 구성된 장치 목록을 찾습니다. 장치가 다중 경로 장치로 구성된 경우 multipath -f device 명령을 실행하여 적용되지 않은 I/O를 플러시하고 다중 경로 장치를 제거합니다.
- 모든 미해결 I/O를 사용한 경로로 플러시합니다. 이는 I/O 플러시를 유발하기 위해 NoExecute 또는 vgreduce 작업이 없는 원시 장치에 중요합니다. 이 단계는 다음과 같은 경우에만 수행해야 합니다.
- 장치가 다중 경로 장치로 구성되지 않았거나
- 장치는 다중 경로 장치로 구성되며 I/O는 과거의 특정 시점에서 개별 경로에 직접 발행되었습니다.
다음 명령을 사용하여 미해결 I/O를 플러시합니다.#blockdev --flushbufs device - 시스템의 애플리케이션, 스크립트 또는 유틸리티에서
/dev/sd,/dev/disk/by-path또는 major:minor 번호, 시스템의 경로 기반 이름에 대한 참조를 제거합니다. 이는 앞으로 다른 장치가 추가 된 장치를 추가 할 때 현재 장치에 대해 잘못되지 않도록하는 데 중요합니다. - 마지막으로 SCSI 하위 시스템에서 장치로의 각 경로를 제거합니다. 이렇게 하려면 echo 1 > /sys/block/device-name/device/delete 명령을 사용합니다. 여기서 device-name 은
sde일 수 있습니다.이 작업의 또 다른 변형은 echo 1 > /sys/class/scsi_device/h: c :t:l/device/delete 입니다. 여기서 h 는 HBA 번호이며, t 는 SCSI 대상 ID이고, l 은 LUN입니다.참고이러한 명령의 이전 형태인 echo "scsi remove-single-device 0 0 0" > /proc/scsi/scsi 는 더 이상 사용되지 않습니다.
25.10. 스토리지 장치의 경로 제거
절차 25.12. 스토리지 장치의 경로 제거
- 시스템의 애플리케이션, 스크립트 또는 유틸리티에서 /dev/
sd 또는또는 major:minor 번호와 같이 장치의 경로 기반 이름에 대한 참조를 제거합니다. 이는 앞으로 다른 장치가 추가 된 장치를 추가 할 때 현재 장치에 대해 잘못되지 않도록하는 데 중요합니다./dev/disk/by-path - echo offline > /sys/block/sda/device/state를 사용하여 오프라인 경로를 선택합니다.이로 인해 이 경로의 장치로 전송된 후속 I/O가 즉시 실패합니다. device -mapper-multipath 는 장치의 나머지 경로를 계속 사용합니다.
- SCSI 하위 시스템에서 경로를 제거합니다. 이렇게 하려면 echo 1 > /sys/block/device-name/device/delete 명령을 사용합니다. 여기서 장치 이름은
sde(예: 절차 25.11. “제거 후 장치 제거 확인”에 설명됨)입니다.
25.11. 스토리지 장치 또는 경로 추가
/dev/disk/by-path 이름)이 시스템에서 새 장치에 할당한 경우 이전에 제거된 장치에서 사용되었을 수 있습니다. 따라서 경로 기반 장치 이름에 대한 이전 참조가 모두 제거되었는지 확인합니다. 그렇지 않으면 새 장치가 이전 장치에 대해 잘못되었을 수 있습니다.
절차 25.13. 스토리지 장치 또는 경로 추가
- 저장 장치 또는 경로를 추가하는 첫 번째 단계는 새 스토리지 장치에 대한 액세스 또는 기존 장치에 대한 새 경로를 물리적으로 활성화하는 것입니다. 이 작업은 파이버 채널 또는 iSCSI 스토리지 서버에서 벤더별 명령을 사용하여 수행됩니다. 이 작업을 수행할 때 호스트에 제공되는 새 스토리지의 LUN 값을 기록해 둡니다. 스토리지 서버가 파이버 채널인 경우 스토리지 서버의 WWNN(WWNN)을 기록해 두고 스토리지 서버의 모든 포트에 대해 단일 WWNN이 있는지 확인합니다. 그렇지 않은 경우 새 LUN에 액세스하는 데 사용할 각 포트에 대해 WWWN( Wide Wide Port Name )을 기록해 두십시오.
- 다음으로 운영 체제가 새 스토리지 장치 또는 기존 장치 경로를 인식하도록 합니다. 사용할 권장 명령은 다음과 같습니다.
$ echo "c t l" > /sys/class/scsi_host/hosth/scan
이전 명령에서 h 는 HBA 번호, c 는 HBA의 채널이고 t 는 SCSI 대상 ID이고 l 은 LUN입니다.참고이 명령의 이전 형태인 echo "scsi add-single-device 0 0 0" > /proc/scsi/scsi 는 더 이상 사용되지 않습니다.- 일부 파이버 채널 하드웨어에서 RAID 배열에서 새로 생성된 LUN은 루프 초기화 프로토콜 (LIP) 작업이 수행될 때까지 운영 체제에 표시되지 않을 수 있습니다. 이 작업을 수행하는 방법에 대한 지침은 25.12절. “스토리지 상호 연결 스캔” 를 참조하십시오.중요LIP가 필요한 경우 이 작업이 실행되는 동안 I/O를 중지해야 합니다.
- RAID 배열에 새 LUN이 추가되었지만 운영 체제에서 아직 구성되지 않은 경우 sg3_utils 패키지의 일부인 sg_luns 명령을 사용하여 배열에서 내보낸 LUN 목록을 확인합니다. 그러면 SCSI REPORT LUNS 명령이 RAID 배열로 실행되고 있는 LUN 목록을 반환합니다.
모든 포트에 대해 단일 WWNN을 구현하는 파이버 채널 스토리지 서버의 경우 sysfs 에서 WWNN을 검색하여 올바른 h,c 및 t 값(예: HBA 번호, HBA 채널, SCSI 대상 ID)을 확인할 수 있습니다.예 25.5. 수정 h,c, t 값을 확인
예를 들어 스토리지 서버의 WWNN이0x5006016090203181인 경우 다음을 사용합니다.$ grep 5006016090203181 /sys/class/fc_transport/*/node_name
다음과 유사한 출력이 표시됩니다./sys/class/fc_transport/target5:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target5:0:3/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:2/node_name:0x5006016090203181 /sys/class/fc_transport/target6:0:3/node_name:0x5006016090203181
이는 이 대상에 대한 4개의 파이버 채널 경로(각각 두 개의 스토리지 포트 발생)가 있음을 나타냅니다. LUN 값이56이라고 가정하면 다음 명령은 첫 번째 경로를 구성합니다.$ echo "0 2 56" > /sys/class/scsi_host/host5/scan
이 작업은 새 장치의 각 경로에 대해 수행해야 합니다.모든 포트에 대해 단일 WWNN을 구현하지 않는 파이버 채널 스토리지 서버의 경우 sysfs 에서 각 WWPN을 검색하여 올바른 HBA 번호, HBA 채널 및 SCSI 대상 ID를 확인할 수 있습니다.HBA 번호, HBA 채널 및 SCSI 대상 ID를 결정하는 또 다른 방법은 새 장치와 동일한 경로에 이미 구성된 다른 장치를 참조하는 것입니다. 이 작업은 lsscsi,scsi_id,multipath -l, ls -l /dev/disk/by-* 와 같은 다양한 명령으로 수행할 수 있습니다. 이 정보와 새 장치의 LUN 번호를 위에 표시된 대로 사용하여 새 장치에 대한 해당 경로를 조사하고 구성할 수 있습니다. - 장치에 모든 SCSI 경로를 추가한 후 다중 경로 명령을 실행하고 장치가 올바르게 구성되었는지 확인합니다. 이 시점에서 장치를 md, LVM, mkfs 또는 마운트 에 추가할 수 있습니다. 예를 들면 다음과 같습니다.
25.12. 스토리지 상호 연결 스캔
- 영향을 받는 상호 연결의 모든 I/O는 절차를 실행하기 전에 일시 중지하고 플러시해야 I/O가 다시 시작하기 전에 검사 결과가 다시 시작됩니다.
- 장치 제거와 마찬가지로 시스템이 메모리 부족 상태에 있을 때는 상호 연결 스캔이 권장되지 않습니다. 메모리 부족을 확인하려면 vmstat 1 100 명령을 실행합니다. 사용 가능한 메모리가 100개당 10개 이상의 샘플에 있는 총 메모리의 5% 미만이면 상호 연결 스캔이 권장되지 않습니다. 또한 스왑이 활성화되는 경우( vmstat 출력의 0이 아닌
si및so열) 상호 연결 스캔이 권장되지 않습니다. free 명령은 총 메모리를 표시할 수도 있습니다.
- echo "1" > /sys/class/fc_host/hostN/issue_lip
- ( N 을 호스트 번호로 대체합니다.)이 작업은 LIP(LIP) 프로토콜 (LIP)을 수행하고 상호 연결을 검사하고 SCSI 계층을 업데이트하여 버스에 현재 있는 장치를 반영합니다. 기본적으로 LIP는 버스 재설정이며 장치 추가 및 제거가 발생합니다. 이 절차는 파이버 채널 상호 연결에서 새 SCSI 대상을 구성하는 데 필요합니다.issue_lip 은 비동기 작업입니다. 전체 검사가 완료되기 전에 명령을 완료할 수 있습니다. issue_lip 종료 시기를 확인하려면
/var/log/messages를 모니터링해야 합니다.lpfc,qla2xxx,bnx2fc드라이버는 issue_lip 를 지원합니다. Red Hat Enterprise Linux의 각 드라이버에서 지원하는 API 기능에 대한 자세한 내용은 표 25.1. “파이버 채널 API 기능” 을 참조하십시오. /usr/bin/rescan-scsi-bus.sh/usr/bin/rescan-scsi-bus.sh스크립트는 Red Hat Enterprise Linux 5.4에 도입되었습니다. 기본적으로 이 스크립트는 시스템의 모든 SCSI 버스를 검색하고 SCSI 계층을 업데이트하여 버스의 새 장치를 반영합니다. 이 스크립트는 장치 제거 및 LIP 발행을 허용하는 추가 옵션을 제공합니다. 알려진 문제를 포함하여 이 스크립트에 대한 자세한 내용은 25.18절. “논리 단위 추가/제거를 통해 rescan-scsi-bus.sh” 을 참조하십시오.- echo "- - -" > /sys/class/scsi_host/hosth/scan
- 이 명령은 25.11절. “스토리지 장치 또는 경로 추가” 에 설명된 명령과 동일하여 스토리지 장치 또는 경로를 추가합니다. 그러나 이 경우 채널 번호, SCSI 대상 ID, LUN 값은 와일드카드로 교체됩니다. 식별자와 와일드카드의 조합을 허용하므로 필요한 경우 명령을 특정 또는 넓게 만들 수 있습니다. 이 절차에서는 LUN을 추가하지만 제거하지는 않습니다.
- modprobe --remove driver-name, modprobe driver-name
- modprobe --remove driver-name 명령을 실행한 후 modprobe driver-name 명령을 실행하면 드라이버에서 제어하는 모든 상호 연결의 상태가 완전히 다시 초기화됩니다. 다소 극단적인 경우에도 설명된 명령을 사용하면 특정 상황에서 적절할 수 있습니다. 예를 들어 명령을 사용하여 다른 모듈 매개 변수 값으로 드라이버를 다시 시작할 수 있습니다.
25.13. iSCSI 검색 구성
/etc/iscsi/iscsid.conf 입니다. 이 파일에는 iscsid 및 iscsiadm 에서 사용하는 iSCSI 설정이 포함되어 있습니다.
/etc/iscsi/iscsid.conf 의 설정을 사용하여 두 가지 유형의 레코드를 만듭니다.
/var/lib/iscsi/nodes의 노드 레코드- 대상에 로그인할 때 iscsiadm 은 이 파일의 설정을 사용합니다.
/var/lib/iscsi/discovery_type의 검색 레코드- 동일한 대상에 검색을 수행할 때 iscsiadm 은 이 파일의 설정을 사용합니다.
/var/lib/iscsi/discovery_type)를 먼저 삭제합니다. 이 작업을 수행하려면 다음 명령을 사용합니다. [5]
# iscsiadm -m discovery -t discovery_type -p target_IP:port -o deletesendtargets, iss, fw 일 수 있습니다.
- 검색을 수행하기 전에
/etc/iscsi/iscsid.conf파일을 직접 편집합니다. 검색 설정은 접두사검색을사용하며, 이를 보려면 다음을 실행합니다.#iscsiadm -m discovery -t discovery_type -p target_IP:port - 또는 iscsiadm 을 사용하여 검색 레코드 설정을 다음과 같이 직접 변경할 수도 있습니다.
#iscsiadm -m discovery -t discovery_type -p target_IP:port -o update -n setting -v %value사용 가능한 설정 옵션 및 유효한 값 옵션에 대한 자세한 내용은 iscsiadm(8) 도움말 페이지를 참조하십시오.
/etc/iscsi/iscsid.conf 파일에는 적절한 구성 구문에 대한 예제도 포함되어 있습니다.
25.14. iSCSI 오프로드 및 인터페이스 바인딩 구성
$ ping -I ethX target_IP
25.14.1. 사용 가능한 iface 구성 보기
- Software iSCSI
- 이 스택은 세션당 하나의 연결로 iSCSI 호스트 인스턴스(즉, scsi_host)를 세션당 할당합니다. 그 결과
/sys/class_scsi_host및/proc/scsi는 로그인한 각 연결/세션에 대해 scsi_host 를 보고합니다. - 오프로드 iSCSI
- 이 스택은 각 PCI 장치에 scsi_host 를 할당합니다. 따라서 호스트 버스 어댑터의 각 포트는 HBA 포트당 scsi_host 와 다른 PCI 장치로 표시됩니다.
/var/lib/iscsi/ifaces 에 입력해야 합니다.
iface_name transport_name,hardware_address,ip_address,net_ifacename,initiator_name
표 25.2. iface 설정
| 설정 | 설명 |
|---|---|
| iface_name | iface 구성 이름입니다. |
| transport_name | 드라이버의 이름 |
| hardware_address | MAC 주소 |
| ip_address | 이 포트에 사용할 IP 주소 |
| net_iface_name | 소프트웨어 iSCSI 세션의 vlan 또는 alias 바인딩에 사용되는 이름입니다. iSCSI 오프로드의 경우 net_iface_name 은 재부팅 시 이 값이 유지되지 않기 때문에 <empty> 이 됩니다. |
| initiator_name | 이 설정은 /etc/iscsi/initiatorname.iscsi에 정의된 이니시에이터의 기본 이름을 재정의하는 데 사용됩니다. |
예 25.6. iscsiadm -m iface 명령 샘플 출력
iface0 qla4xxx,00:c0:dd:08:63:e8,20.15.0.7,default,iqn.2005-06.com.redhat:madmax iface1 qla4xxx,00:c0:dd:08:63:ea,20.15.0.9,default,iqn.2005-06.com.redhat:madmax
예 25.7. iscsiadm -m iface 출력 및 Chelsio 네트워크 카드
default tcp,<empty>,<empty>,<empty>,<empty> iser iser,<empty>,<empty>,<empty>,<empty> cxgb3i.00:07:43:05:97:07 cxgb3i,00:07:43:05:97:07,<empty>,<empty>,<empty>
iface.setting = value
예 25.8. Chelsio Converged Network Adapter와 함께 iface 설정 사용
# BEGIN RECORD 2.0-871 iface.iscsi_ifacename = cxgb3i.00:07:43:05:97:07 iface.net_ifacename = <empty> iface.ipaddress = <empty> iface.hwaddress = 00:07:43:05:97:07 iface.transport_name = cxgb3i iface.initiatorname = <empty> # END RECORD
25.14.2. 소프트웨어 iSCSI 용 iface 구성
# iscsiadm -m iface -I iface_name --op=new
# iscsiadm -m iface -I iface_name --op=update -n iface.setting -v hw_address
예 25.9. MAC 주소 설정 iface0
iface0 의 MAC 주소(hardware_address)를 00:0F:1F:92:6B:BF 로 설정하려면 다음을 실행합니다.
# iscsiadm -m iface -I iface0 --op=update -n iface.hwaddress -v 00:0F:1F:92:6B:BF
default 또는 iser 를 iface 이름으로 사용하지 마십시오. 두 문자열 모두 이전 버전과의 호환성을 위해 iscsiadm 에서 사용하는 특수 값입니다. default 또는 iser 라는 이름의 ace 구성에서 수동으로 생성한 경우 이전 버전과의 호환성이 비활성화됩니다.
25.14.3. iSCSI 오프로드에 대한 iface 구성
iscsiadm 은 각 포트에 대해 iface 구성을 생성합니다. 사용 가능한 iface 구성을 보려면 소프트웨어 iSCSI: iscsiadm -m iface 에서 동일한 명령을 사용합니다.
iface.ipaddress 값을 인터페이스에서 사용해야 하는 이니시에이터 IP 주소로 설정합니다.
be2iscsi드라이버를 사용하는 장치의 경우 IP 주소는 BIOS 설정 화면에 구성됩니다.- 다른 모든 장치에 대해
iface의 IP 주소를 구성하려면 다음을 사용합니다.# iscsiadm -m iface -I iface_name -o update -n iface.ipaddress -v initiator_ip_address
예 25.10. Chelsio 카드의 iface IP 주소 설정
iface 이름이 cxgb3i.00:07:05:97:07:07:97:07인 카드를 사용하는 경우 iface IP 주소를 20.15.0. 66 으로 설정하려면 다음을 사용합니다.
# iscsiadm -m iface -I cxgb3i.00:07:43:05:97:07 -o update -n iface.ipaddress -v 20.15.0.66
25.14.4. 포털에 iface를 바인딩/연결 해제
/var/lib/iscsi/ifaces 에서 각 iface.transport 설정을 확인합니다. 그런 다음 iscsiadm 유틸리티는 iface.transport 가 tcp 인 모든 iface 에 포털을 바인딩합니다.
# iscsiadm -m discovery -t st -p target_IP:port -I iface_name -P 1 [5]
tcp 로 설정되지 않았기 때문입니다. 따라서 iface 구성을 검색 포털에 수동으로 바인딩해야 합니다.
default 를 iface_name 과 같이 사용합니다.
# iscsiadm -m discovery -t st -p IP:port -I default -P 1
# iscsiadm -m node -targetname proper_target_name -I iface0 --op=delete[6]
# iscsiadm -m node -I iface_name --op=delete
# iscsiadm -m node -p IP:port -I iface_name --op=delete
/var/lib/iscsi/iface 에 정의된 iface 구성이 없고 -I 옵션이 사용되지 않으면 iscsiadm 에서 네트워크 하위 시스템에서 특정 포털에서 사용할 장치를 결정할 수 있습니다.
25.15. iSCSI 상호 연결 스캔
# iscsiadm -m discovery -t sendtargets -p target_IP:port [5]
target_IP:port,target_portal_group_tag proper_target_name
예 25.11. iscsiadm 을 사용하여 sendtargets 명령 발행
iqn.1992-08.com.netapp:sn.33615311 의 proper_target_name 과 target_IP:port 가 10.15.85.19:3260 인 대상의 경우 출력이 다음과 같이 표시될 수 있습니다.
10.15.84.19:3260,2 iqn.1992-08.com.netapp:sn.33615311 10.15.85.19:3260,3 iqn.1992-08.com.netapp:sn.33615311
10.15.84.19:3260 를 사용하는 포털 두 개가 있습니다. 10.15.85.19:3260
Target: proper_target_name
Portal: target_IP:port,target_portal_group_tag
Iface Name: iface_name예 25.12. iface 설정 보기
Target: iqn.1992-08.com.netapp:sn.33615311
Portal: 10.15.84.19:3260,2
Iface Name: iface2
Portal: 10.15.85.19:3260,3
Iface Name: iface2
iqn.1992-08.com.netapp:sn.33615311 에서 iface2 를 iface 구성으로 사용합니다.
# iscsiadm -m session --rescan
# iscsiadm -m session -r SID --rescan[7]
/var/lib/iscsi/nodes 데이터베이스의 콘텐츠를 덮어씁니다. 그러면 이 데이터베이스는 /etc/iscsi/iscsid.conf 의 설정을 사용하여 다시 채워집니다. 그러나 세션이 현재 로그인되어 있고 사용 중인 경우에는 이러한 문제가 발생하지 않습니다.
/var/lib/iscsi/nodes 를 덮어쓰지 않고 새 target/portals를 추가하려면 다음 명령을 사용합니다.
iscsiadm -m discovery -t st -p target_IP -o new
/var/lib/iscsi/nodes 항목을 삭제하려면 다음을 사용합니다.
iscsiadm -m discovery -t st -p target_IP -o delete
iscsiadm -m discovery -t st -p target_IP -o delete -o new
ip:port,target_portal_group_tag proper_target_name
예 25.13. sendtargets 명령의 출력
10.16.41.155:3260,0 iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1
# iscsiadm --mode node --targetname proper_target_name --portal ip:port,target_portal_group_tag \ --login [8]
예 25.14. 전체 iscsiadm 명령
# iscsiadm --mode node --targetname \ iqn.2001-05.com.equallogic:6-8a0900-ac3fe0101-63aff113e344a4a2-dl585-03-1 \ --portal 10.16.41.155:3260,0 --login[8]
25.16. iSCSI 대상에 로그인
# systemctl start iscsiinit 스크립트가 node.startup 설정이 automatic 로 구성된 대상에 자동으로 로그인합니다. 이는 모든 대상의 기본값 node.startup 입니다.
node.startup 을 manual 로 설정합니다. 이 작업을 수행하려면 다음 명령을 실행합니다.
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o update -n node.startup -v manual
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -o delete
/etc/fstab 에 마운트할 파티션 항목을 추가합니다. 예를 들어 시작 중에 iSCSI 장치 sdb 를 /mount/iscsi 에 자동으로 마운트하려면 /etc/fstab 에 다음 행을 추가합니다.
/dev/sdb /mnt/iscsi ext3 _netdev 0 0
# iscsiadm -m node --targetname proper_target_name -p target_IP:port -l
25.17. 온라인 논리 단위 크기 조정
25.17.1. 파이버 채널 논리 단위 크기 조정
$ echo 1 > /sys/block/sdX/device/rescan
25.17.2. iSCSI 논리 단위 크기 조정
# iscsiadm -m node --targetname target_name -R [5]
# iscsiadm -m node -R -I interface
- echo "- -" > /sys/class/scsi_host/host/scan 에서 수행하는 것과 동일한 방식으로 새 장치를 검색합니다( 25.15절. “iSCSI 상호 연결 스캔”참조).
- echo 1 > /sys/block/sdX/rescan 명령을 수행하는 것과 동일한 방식으로 new/modified 논리 단위를 다시 스캔 합니다. 이 명령은 Fibre Channel 논리 단위를 다시 스캔하는 데 사용되는 것과 동일합니다.
25.17.3. Multipath 장치의 크기 업데이트
# multipathd -k"resize map multipath_device"
/dev/mapper 에 있는 장치의 해당 다중 경로 항목입니다. 시스템에 다중 경로를 설정하는 방법에 따라 multipath_device 는 다음 두 가지 형식 중 하나일 수 있습니다.
- mpathX.. 여기서 X 는 장치의 해당 항목입니다(예: mpath0)
- WWID; 예를 들면 3600508b400105e210000900000490000
/etc/multipath.conf)가 "queue" 로 설정되어 있고 장치에 대한 활성 경로가 없는 경우 이 명령을 사용하지 마십시오.
25.17.4. 온라인 논리 단위의 읽기/쓰기 상태 변경
# blockdev --getro /dev/sdXYZ
# cat /sys/block/sdXYZ/ro 1 = read-only 0 = read-write36001438005deb4710000500000640000 dm-8 GZ,GZ500 [size=20G][features=0][hwhandler=0][ro] \_ round-robin 0 [prio=200][active] \_ 6:0:4:1 sdax 67:16 [active][ready] \_ 6:0:5:1 sday 67:32 [active][ready] \_ round-robin 0 [prio=40][enabled] \_ 6:0:6:1 sdaz 67:48 [active][ready] \_ 6:0:7:1 sdba 67:64 [active][ready]
절차 25.14. R/W 상태 변경
- 장치를 RO에서 R/W로 이동하려면 2단계를 참조하십시오.장치를 R/W에서 RO로 이동하려면 추가 쓰기가 발행되지 않도록 합니다. 애플리케이션을 중지하거나 적절한 애플리케이션별 작업을 사용하여 이 작업을 수행합니다.다음 명령을 사용하여 모든 처리되지 않은 쓰기 I/O가 완료되었는지 확인합니다.
# blockdev --flushbufs /dev/device장치를 원하는 설계기로 교체합니다. 장치 매퍼 다중 경로의 경우dev/mapper에서 장치의 항목입니다. 예:/dev/mapper/mpath3. - 스토리지 장치의 관리 인터페이스를 사용하여 논리 단위의 상태를 R/W에서 RO로 또는 RO에서 R/W로 변경합니다. 이 절차는 각 배열과 다릅니다. 자세한 내용은 해당 스토리지 어레이 벤더 설명서를 참조하십시오.
- 장치를 다시 스캔하여 장치의 R/W 상태 운영 체제 보기를 업데이트합니다. 장치 매퍼 다중 경로를 사용하는 경우 다중 경로가 장치 맵을 다시 로드하도록 지시하기 전에 장치의 각 경로에 대해 이 다시 스캔을 수행합니다.이 프로세스는 25.17.4.1절. “논리 단위 다시 스캔” 에서 자세히 설명합니다.
25.17.4.1. 논리 단위 다시 스캔
# echo 1 > /sys/block/sdX/device/rescan예 25.15. multipath -11 명령 사용
# echo 1 > /sys/block/sdax/device/rescan # echo 1 > /sys/block/sday/device/rescan # echo 1 > /sys/block/sdaz/device/rescan # echo 1 > /sys/block/sdba/device/rescan
25.17.4.2. Multipath 장치의 R/W 상태 업데이트
# multipath -r25.17.4.3. 문서
25.18. 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
sg3_utils 패키지는 필요에 따라 호스트의 논리 단위 구성을 자동으로 업데이트할 수 있는 rescan-scsi-bus.sh 스크립트를 제공합니다(장치가 시스템에 추가된 후). rescan-scsi-bus.sh 스크립트는 지원되는 장치에서 issue_lip 를 수행할 수도 있습니다. 이 스크립트를 사용하는 방법에 대한 자세한 내용은 rescan-scsi-bus.sh --help 를 참조하십시오.
sg3_utils 패키지를 설치하려면 yum install sg3_utils 를 실행합니다.
25.18.1. rescan-scsi-bus.sh로 알려진 문제
rescan-scsi-bus.sh 스크립트를 사용하는 경우 다음과 같은 알려진 문제를 기록해 두십시오.
rescan-scsi-bus.sh가 제대로 작동하려면 LUN0 이 첫 번째 논리 단위여야 합니다.rescan-scsi-bus.sh는 LUN0 인 경우에만 첫 번째 매핑된 논리 단위를 감지할 수 있습니다. --nooptscan 옵션을 사용하는 경우에도 첫 번째 매핑된 논리 장치를 감지하지 않는 한rescan-scsi-bus.sh는 다른 논리 장치를 검사할 수 없습니다.- 경쟁 조건을 사용하려면 논리 단위가 처음 매핑된 경우
rescan-scsi-bus.sh를 두 번 실행해야 합니다. 첫 번째 스캔 중에rescan-scsi-bus.sh는 LUN0 만 추가합니다. 다른 모든 논리 단위는 두 번째 검사에 추가됩니다. rescan-scsi-bus.sh스크립트의 버그는 --remove 옵션을 사용할 때 논리 단위 크기의 변경 사항을 인식하는 기능을 잘못 실행합니다.rescan-scsi-bus.sh스크립트에서 ISCSI 논리 장치 제거를 인식하지 않습니다.
25.19. 링크 손실 동작 수정
25.19.1. 파이버 채널
dev_loss_tmo 콜백을 구현하면 전송 문제가 감지되면 링크를 통해 장치에 대한 액세스가 차단됩니다. 장치가 차단되었는지 확인하려면 다음 명령을 실행합니다.
$ cat /sys/block/device/device/state
blocked 를 반환합니다. 장치가 정상적으로 작동하는 경우 이 명령은 running 을 반환합니다.
절차 25.15. 원격 포트의 상태 확인
- 원격 포트의 상태를 확인하려면 다음 명령을 실행합니다.
$ cat /sys/class/fc_remote_port/rport-H:B:R/port_state
- 이 명령은 원격 포트(를 통해 액세스한 장치)가 차단되면
Blocked를 반환합니다. 원격 포트가 정상적으로 작동하는 경우 명령은Online을 반환합니다. dev_loss_tmo초 내에 문제가 해결되지 않으면 rport 및 devices가 차단 해제되고 해당 장치에서 실행되는 모든 I/O(해당 장치로 전송된 새로운 I/O 전송)가 실패합니다.
절차 25.16. dev_loss_tmo변경
dev_loss_tmo값을 변경하려면 원하는 값을 파일에 에코 합니다. 예를 들어dev_loss_tmo를 30초로 설정하려면 다음을 실행합니다.$ echo 30 > /sys/class/fc_remote_port/rport-H:B:R/dev_loss_tmo
dev_loss_tmo 에 대한 자세한 내용은 25.4.1절. “파이버 채널 API” 을 참조하십시오.
dev_loss_tmo 를 초과하면 scsi_device 및 sdN 장치가 제거됩니다. 일반적으로 Fibre Channel 클래스는 장치를 그대로 둡니다. 즉, /dev/sdx 는 /dev/sdx 로 남게 됩니다. 이는 대상 바인딩이 파이버 채널 드라이버에 의해 저장되므로 대상 포트가 반환될 때 SCSI 주소가 실수로 다시 생성되기 때문입니다. 그러나 이 값은 보장할 수 없습니다. LUN의 저장소 내 박스 구성에 대한 추가 변경 사항이 없는 경우에만 sdx 가 복원됩니다.
25.19.2. dm-multipath를 사용한 iSCSI 설정
/etc/multipath.conf 의 장치 { 아래에 다음 행을 중첩합니다.
features "1 queue_if_no_path"
25.19.2.1. NOP-Out Interval/Timeout
5 초입니다. 이를 조정하려면 /etc/iscsi/iscsid.conf 를 열고 다음 행을 편집합니다.
node.conn[0].timeo.noop_out_interval = [interval value]
node.conn[0].timeo.noop_out_timeout = [timeout value]
25.19.2.1.1. SCSI 오류 처리기
# iscsiadm -m session -P 3
25.19.2.2. replacement_timeout
/etc/iscsi/iscsid.conf 를 열고 다음 행을 편집합니다.
node.session.timeo.replacement_timeout = [replacement_timeout]
/etc/multipath.conf 의 1 queue_if_no_path 옵션은 iSCSI 타이머를 설정하여 즉시 다중 경로 계층( 25.19.2절. “dm-multipath를 사용한 iSCSI 설정”참조)으로 명령을 지연하도록 설정합니다. 이 설정은 I/O 오류가 애플리케이션에 전파되지 않도록 합니다. 이로 인해 replacement_timeout 을 15-20초로 설정할 수 있습니다.
/etc/iscsi/iscsid.conf 대신 /etc/multipath.conf 의 설정을 기반으로 다중 경로 및 장치 매퍼 계층이 내부적으로 큐 I/O 대기열 I/O를 수행합니다.
iSCSI 및 DM Multipath 덮어쓰기
recovery_tmo sysfs 옵션은 특정 iSCSI 장치의 시간 제한을 제어합니다. 다음 옵션은 recovery_tmo 값을 전역적으로 덮어씁니다.
replacement_timeout구성 옵션은 모든 iSCSI 장치의recovery_tmo값을 전역적으로 덮어씁니다.- DM Multipath에서 관리하는 모든 iSCSI 장치의 경우 DM Multipath의
fast_io_fail_tmo옵션은recovery_tmo값을 전체적으로 덮어씁니다. DM Multipath의fast_io_fail_tmo옵션은 파이버 채널 장치의fast_io_fail_tmo옵션도 덮어씁니다.DM Multipathfast_io_fail_tmo옵션이replacement_timeout보다 우선합니다. DM Multipath에서 관리하는 장치에서replacement_timeout을 사용하여recovery_tmo를 덮어쓰는 것을 권장하지 않습니다. DM Multipath는다중 경로서비스가 다시 로드될 때 항상recovery_tmo를 재설정하기 때문입니다.
25.19.3. iSCSI Root
/etc/iscsi/iscsid.conf 를 열고 다음과 같이 편집합니다.
node.conn[0].timeo.noop_out_interval = 0 node.conn[0].timeo.noop_out_timeout = 0
/etc/iscsi/iscsid.conf 를 열고 다음 행을 편집합니다.
node.session.timeo.replacement_timeout = replacement_timeout
/etc/iscsi/iscsid.conf 를 구성한 후 영향을 받는 스토리지를 다시 검색해야 합니다. 그러면 시스템이 /etc/iscsi/iscsid.conf 에 새 값을 로드하고 사용할 수 있습니다. iSCSI 장치를 검색하는 방법에 대한 자세한 내용은 25.15절. “iSCSI 상호 연결 스캔” 을 참조하십시오.
25.19.3.1. 특정 세션에 대한 시간 제한 구성
/etc/iscsi/iscsid.conf를 사용하여 대신). 이렇게 하려면 다음 명령을 실행합니다(에 따라 변수 교체).
# iscsiadm -m node -T target_name -p target_IP:port -o update -n node.session.timeo.replacement_timeout -v $timeout_value
25.20. SCSI 명령 타이머 및 장치 상태 제어
- 명령을 중지합니다.
- 장치를 재설정합니다.
- 버스를 재설정합니다.
- 호스트를 재설정합니다.
25.20.1. 장치 상태
$ cat /sys/block/device-name/device/state
# echo running > /sys/block/device-name/device/state
25.20.2. 명령 timer
/sys/block/device-name/device/timeout 파일을 수정합니다.
# echo value > /sys/block/device-name/device/timeout
25.21. 온라인 스토리지 설정 문제 해결
- 논리적 장치 제거 상태가 호스트에 반영되지 않습니다.
- 구성된 파일러에서 논리 유닛이 삭제되면 변경 사항이 호스트에 반영되지 않습니다. 이러한 경우, dm-multipath 를 사용할 때 lvm 명령이 무기한 중지됩니다. 논리 단위가 더 이상 사용되지 않으므로 이 명령이 사용되지 않습니다.이 문제를 해결하려면 다음 절차를 수행하십시오.
절차 25.17. 작업 대일 논리 단위
/etc/lvm/cache/.cache의 mpath 링크 항목이 오래된 논리 단위에 고유한지 확인합니다. 이 작업을 수행하려면 다음 명령을 실행합니다.$ ls -l /dev/mpath | grep stale-logical-unit
예 25.16. 특정 mpath Link Entries 확인
예를 들어 stale-logical-unit 이 3600d0230003414f30000203a7bc41a00인 경우 다음과 같은 결과가 나타날 수 있습니다.lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00 -> ../dm-4 lrwxrwxrwx 1 root root 7 Aug 2 10:33 /3600d0230003414f30000203a7bc41a00p1 -> ../dm-5
즉, 3600d0230003414f30000203a7bc41a00은 두 개의 mpath 링크 dm-4 및 dm-5 에 매핑됩니다.- 다음으로
/etc/lvm/cache/.cache를 엽니다. stale-logical-unit 및 stale-logical-unit 이 매핑되는 mpath 링크를 포함하는 모든 행을 삭제합니다.예 25.17. 관련 줄 삭제
이전 단계에서 동일한 예제를 사용하여 삭제해야 하는 행은 다음과 같습니다./dev/dm-4 /dev/dm-5 /dev/mapper/3600d0230003414f30000203a7bc41a00 /dev/mapper/3600d0230003414f30000203a7bc41a00p1 /dev/mpath/3600d0230003414f30000203a7bc41a00 /dev/mpath/3600d0230003414f30000203a7bc41a00p1
25.22. eh_deadline을 사용하여 오류 복구에 대한 최대 시간 구성
eh_deadline 매개변수를 활성화할 필요가 없습니다. eh_deadline 매개변수를 사용하면 특정 시나리오에서 유용합니다(예: 파이버 채널 스위치와 대상 포트 간에 링크 손실이 발생하고 HBA) 등록 상태 변경 알림(RSCN)이 수신되지 않는 경우입니다. 이러한 경우 오류가 발생하지 않고 항상 I/O 요청 및 오류 복구 명령이 실행됩니다. 이 환경에서 eh_deadline 을 설정하면 복구 시간에 상한이 적용되므로 다중 경로를 통해 실패한 I/O를 다른 사용 가능한 다른 경로에서 다시 시도할 수 있습니다.
eh_deadline 기능을 통해 I/O 및 오류 복구 명령이 즉시 실패하여 다중 경로를 다시 시도할 수 있으므로 추가 이점이 없습니다.
eh_deadline 매개변수를 사용하면 전체 HBA를 중지하고 재설정하기 전에 SCSI 오류 처리 메커니즘에서 오류 복구를 시도하는 최대 시간을 구성할 수 있습니다.
eh_deadline 의 값은 초 단위로 지정됩니다. 기본 설정은 해제 되어 시간 제한을 비활성화하고 모든 오류 복구를 수행할 수 있습니다. sysfs 를 사용하는 것 외에도 scsi_mod.eh_deadline 커널 매개 변수를 사용하여 모든 SCSI HBA에 기본값을 설정할 수 있습니다.
eh_deadline 가 만료되면 HBA가 재설정됩니다. HBA는 해당 HBA의 모든 대상 경로뿐만 아니라 실패한 대상 경로뿐만 아니라 재설정됩니다. 결과적으로 일부 중복 경로를 다른 이유로 사용할 수 없는 경우 I/O 오류가 발생할 수 있습니다. 모든 대상에 완전히 중복된 다중 경로 구성이 있는 경우에만 eh_deadline 을 활성화합니다.
26장. 장치 매퍼 다중 경로(DM Multipath) 및 가상 머신용 스토리지
26.1. 가상 머신용 스토리지
- 파이버 채널
- iSCSI
- NFS
- GFS2
- 로컬 스토리지 풀
- 로컬 스토리지에는 호스트, 로컬 디렉터리, 직접 연결된 디스크, LVM 볼륨 그룹에 직접 연결된 스토리지 장치, 파일 또는 디렉터리가 포함됩니다.
- 네트워크(공유) 스토리지 풀
- 네트워크로 연결된 스토리지는 표준 프로토콜을 사용하여 네트워크를 통해 공유하는 스토리지 장치를 다룹니다. 여기에는 파이버 채널, iSCSI, NFS, GFS2, SCSI RDMA 프로토콜을 사용하는 공유 스토리지 장치가 포함되어 있으며 호스트 간에 가상화된 게스트를 마이그레이션하기 위한 요구 사항입니다.
26.2. DM Multipath
- redundancy
- DM Multipath는 활성/수동 구성에서 장애 조치를 제공할 수 있습니다. 활성/수동 구성에서는 I/O에 대해 경로 절반만 사용됩니다. I/O 경로의 요소가 실패하면 DM Multipath가 대체 경로로 전환됩니다.
- 성능 개선
- DM Multipath는 활성/활성 모드로 구성할 수 있으며, 여기서 I/O는 라운드 로빈 방식으로 경로를 통해 분산됩니다. 일부 구성에서 DM Multipath는 I/O 경로에서 로드를 감지하고 부하를 동적으로 리밸런스할 수 있습니다.
27장. External Array Management (libStorageMgmt)
libStorageMgmt 라는 새로운 외부 어레이 관리 라이브러리가 포함되어 있습니다.
27.1. libStorageMgmt 소개
libStorageMgmt 라이브러리는 스토리지 배열의 API(애플리케이션 프로그래밍 인터페이스)입니다. 개발자는 이 API를 사용하여 다양한 스토리지 어레이를 관리하고 하드웨어 가속 기능을 활용할 수 있습니다.
libStorageMgmt 라이브러리를 사용하면 다음 작업을 수행할 수 있습니다.
- 스토리지 풀, 볼륨, 액세스 그룹 또는 파일 시스템을 나열합니다.
- 볼륨, 액세스 그룹, 파일 시스템 또는 NFS 내보내기를 만들고 삭제합니다.
- 볼륨, 액세스 그룹 또는 이니시에이터에 대한 액세스 권한을 부여 및 제거합니다.
- 스냅샷, 복제 및 복사본으로 볼륨을 복제합니다.
- 액세스 그룹을 만들고 삭제하고 그룹의 멤버를 편집합니다.
- 클라이언트 애플리케이션 및 플러그인 개발자를 위한 안정적인 C 및 Python API.
- 라이브러리를 사용하는 명령줄 인터페이스(
lsmcli). - 플러그인을 실행하는 데몬(
lsmd). - 클라이언트 애플리케이션을 테스트할 수 있는 시뮬레이터 플러그인(Sim
). - 배열과 상호 작용하기 위한 플러그인 아키텍처.
libStorageMgmt 라이브러리는 REPORTED LUNS DATA HAS CHANGED 단위 주의를 처리하는 기본 udev 규칙을 추가합니다.
sysfs 를 사용하여 자동으로 다시 스캔됩니다.
/lib/udev/rules.d/90-scsi-ua.rules 에는 커널이 생성할 수 있는 다른 이벤트를 열거하는 예제 규칙이 포함되어 있습니다.
libStorageMgmt 라이브러리는 플러그인 아키텍처를 사용하여 스토리지 어레이의 차이를 수용합니다. libStorageMgmt 플러그인과 이를 작성하는 방법에 대한 자세한 내용은 Red Hat 개발자 가이드 를 참조하십시오.
27.2. libStorageMgmt Terminology
- 스토리지 배열
- NAS(Network Attached Storage)를 통해 블록 액세스(FC, FCoE, iSCSI) 또는 파일 액세스를 제공하는 스토리지 시스템.
- volume
- SAN(Storage Area Network) 스토리지 배열은 FC, iSCSI 또는 FCoE와 같은 다양한 전송을 통해 볼륨을 HBA(Host Bus Adapter)에 노출할 수 있습니다. 호스트 OS는 이를 블록 장치로 처리합니다.
multipath[2]가 활성화된 경우 하나의 볼륨을 여러 디스크에 노출할 수 있습니다.이를 LUN(Logical Unit Number), SNIA 용어가 있는 StorageVolume 또는 가상 디스크라고도 합니다. - pool
- 스토리지 공간 그룹입니다. 파일 시스템 또는 볼륨은 풀에서 만들 수 있습니다. 풀은 디스크, 볼륨 및 기타 풀에서 만들 수 있습니다. 풀에는 RAID 설정 또는 씬 프로비저닝 설정도 포함될 수 있습니다.이를 SNIA Terminology를 사용한 StoragePool라고도 합니다.
- 스냅샷
- 시간, 읽기 전용, 공간 효율적인 데이터 사본입니다.이 스냅샷은 읽기 전용 스냅샷이라고도 합니다.
- clone
- 특정 시점, 쓰기 가능, 공간 효율적인 데이터 사본입니다.이 스냅샷을 읽을 수 있는 스냅샷이라고도 합니다.
- 복사
- 데이터의 전체 비트 복사본입니다.A full copy of the data. 그것은 전체 공간을 차지합니다.
- mirror
- 지속적으로 업데이트되는 사본(동기 및 비동기)입니다.
- 액세스 그룹
- 하나 이상의 스토리지 볼륨에 대한 액세스 권한이 부여된 iSCSI, FC 및 FCoE 이니시에이터의 컬렉션입니다. 이렇게 하면 지정된 이니시에이터에서 스토리지 볼륨만 액세스할 수 있습니다.이를 이니시에이터 그룹이라고도 합니다.
- 액세스 권한 부여
- 지정된 액세스 그룹 또는 이니시에이터에 볼륨을 노출합니다. 현재
libStorageMgmt라이브러리는 특정 논리 단위 번호를 선택할 수 있는 LUN 매핑을 지원하지 않습니다.libStorageMgmt라이브러리를 사용하면 스토리지 배열에서 할당에 사용할 수 있는 다음 LUN을 선택할 수 있습니다. SAN에서 부팅을 수행하거나 256개 이상의 볼륨을 마스킹하는 경우 OS, Storage Array 또는 HBA 문서를 읽어야 합니다.액세스 권한 부여를 LUN masking이라고도 합니다. - 시스템
- 스토리지 어레이 또는 직접 연결 스토리지 RAID를 나타냅니다.
- 파일 시스템
- NAS(Network Attached Storage) 스토리지 어레이는 NFS 또는 CIFS 프로토콜을 사용하여 IP 네트워크를 통해 OS를 호스팅하는 파일 시스템을 노출할 수 있습니다. 호스트 OS는 클라이언트 운영 체제에 따라 마운트 지점 또는 파일이 포함된 폴더로 처리합니다.
- 디스크
- 데이터를 보관하는 물리 디스크입니다. 이는 일반적으로 RAID 설정이 있는 풀을 생성할 때 사용됩니다.이는 SNIA Terminology를 사용하는 DiskDrive라고도 합니다.
- 이니시에이터
- 파이버 채널(FC) 또는 FFC(Fibre Channel over Ethernet)에서 이니시에이터는 WWWN( World Wide Port Name) 또는 WWNN(WWNN)입니다. iSCSI에서 이니시에이터는 IQN(iSCSI Qualified Name)입니다. NFS 또는 CIFS에서 이니시에이터는 호스트의 호스트 이름 또는 IP 주소입니다.
- 하위 종속성
- 일부 배열은 원본(상위 볼륨 또는 파일 시스템)과 하위 집합(예: 스냅샷 또는 복제본) 간의 암시적 관계가 있습니다. 예를 들어, 하나 이상의 자식이 종속된 경우 부모를 삭제하는 것은 불가능합니다. API는 필요한 블록을 복제하여 이러한 관계가 존재하는지 여부와 종속성을 제거하는 메서드를 제공합니다.
27.3. libStorageMgmt 설치
libStorageMgmt 를 설치하려면 필요한 런타임 라이브러리 및 시뮬레이터 플러그인을 사용합니다.
# yum install libstoragemgmt libstoragemgmt-python
# yum install libstoragemgmt-devellibStorageMgmt 를 설치하려면 다음 명령을 사용하여 하나 이상의 적절한 플러그인 패키지를 선택합니다.
# yum install libstoragemgmt-name-plugin- libstoragemgmt-smis-plugin
- 일반 SMI-S 어레이 지원
- libstoragemgmt-netapp-plugin
- NetApp 파일을 구체적으로 지원합니다.
- libstoragemgmt-nstor-plugin
- NexentaStor에 대한 구체적인 지원
- libstoragemgmt-targetd-plugin
- targetd에 대한 특정 지원
lsmd)은 시스템의 모든 표준 서비스처럼 작동합니다.
# systemctl status libstoragemgmt# systemctl stop libstoragemgmt# systemctl start libstoragemgmt27.4. libStorageMgmt 사용
libStorageMgmt 를 사용하려면 lsmcli 도구를 사용합니다.
- 배열에 연결하는 플러그인을 식별하는 데 사용되는 URI(Uniform Resource Identifier) 및 배열에 필요한 구성 가능한 옵션입니다.
- 배열에 유효한 사용자 이름 및 암호입니다.
plugin+선택적-transport://user-name@host:port/?query-string-parameters
예 27.1. 다양한 플러그인 요구 사항의 예
사용자 이름 또는 암호가 필요하지 않은 Simulator 플러그인
sim://
사용자 이름 루트를 사용한 SSL을 통한 NetApp 플러그인
ontap+ssl://root@filer.company.com/
EMC Array용 SSL을 통한 SMI-S 플러그인
smis+ssl://admin@provider.com:5989/?namespace=root/emc
- URI를 명령의 일부로 전달합니다.
$lsmcli -u sim:// - URI를 환경 변수에 저장합니다.
$export LSMCLI_URI=sim:// ~/.lsmcli파일에 "="로 구분된 이름-값 쌍을 포함하는 URI를 배치합니다. 현재 지원되는 유일한 구성은 'uri'입니다.
-P 옵션을 지정하거나 환경 변수 LSMCLI_PASSWORD 에 배치하여 암호를 제공합니다.
예 27.2. lsmcli의 예
$ lsmcli list --type SYSTEMS
ID | Name | Status
-------+-------------------------------+--------
sim-01 | LSM simulated storage plug-in | OK
$ lsmcli list --type POOLS -H
ID | Name | Total space | Free space | System ID
-----+---------------+----------------------+----------------------+-----------
POO2 | Pool 2 | 18446744073709551616 | 18446744073709551616 | sim-01
POO3 | Pool 3 | 18446744073709551616 | 18446744073709551616 | sim-01
POO1 | Pool 1 | 18446744073709551616 | 18446744073709551616 | sim-01
POO4 | lsm_test_aggr | 18446744073709551616 | 18446744073709551616 | sim-01
$ lsmcli volume-create --name volume_name --size 20G --pool POO1 -H
ID | Name | vpd83 | bs | #blocks | status | ...
-----+-------------+----------------------------------+-----+----------+--------+----
Vol1 | volume_name | F7DDF7CA945C66238F593BC38137BD2F | 512 | 41943040 | OK | ...
$ lsmcli --create-access-group example_ag --id iqn.1994-05.com.domain:01.89bd01 --type ISCSI --system sim-01
ID | Name | Initiator ID |SystemID
---------------------------------+------------+----------------------------------+--------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 |sim-01
$ lsmcli access-group-create --name example_ag --init iqn.1994-05.com.domain:01.89bd01 --init-type ISCSI --sys sim-01
ID | Name | Initiator IDs | System ID
---------------------------------+------------+----------------------------------+-----------
782d00c8ac63819d6cca7069282e03a0 | example_ag | iqn.1994-05.com.domain:01.89bd01 | sim-01$ lsmcli access-group-grant --ag 782d00c8ac63819d6cca7069282e03a0 --vol Vol1 --access RW-b 옵션을 사용할 수 있습니다. 종료 코드가 0이면 명령이 완료됩니다. 종료 코드가 7이면 명령이 진행 중이며 작업 식별자가 표준 출력에 기록됩니다. 그런 다음 사용자 또는 스크립트는 lsmcli --jobstatus JobID를 사용하여 필요에 따라 작업 ID를 사용하고 명령 상태를 쿼리할 수 있습니다. 작업이 이제 완료되면 종료 값이 0이 되고 결과가 표준 출력에 출력됩니다. 명령이 계속 진행 중인 경우 반환 값은 7이 되고 완료 백분율이 표준 출력에 출력됩니다.
예 27.3. 비동기의 예
-b 옵션을 전달하는 볼륨을 생성합니다.
$ lsmcli volume-create --name async_created --size 20G --pool POO1 -b JOB_3$ echo $?
7$ lsmcli job-status --job JOB_3
33$ echo $?
7$ lsmcli job-status --job JOB_3
ID | Name | vpd83 | Block Size | ...
-----+---------------+----------------------------------+-------------+-----
Vol2 | async_created | 855C9BA51991B0CC122A3791996F6B15 | 512 | ...
-t SeparatorCharacters 옵션을 전달합니다. 이렇게 하면 출력을 더 쉽게 구문 분석할 수 있습니다.
예 27.4. 스크립팅 예
$ lsmcli list --type volumes -t#
Vol1#volume_name#049167B5D09EC0A173E92A63F6C3EA2A#512#41943040#21474836480#OK#sim-01#POO1
Vol2#async_created#3E771A2E807F68A32FA5E15C235B60CC#512#41943040#21474836480#OK#sim-01#POO1
$ lsmcli list --type volumes -t " | "
Vol1 | volume_name | 049167B5D09EC0A173E92A63F6C3EA2A | 512 | 41943040 | 21474836480 | OK | 21474836480 | sim-01 | POO1
Vol2 | async_created | 3E771A2E807F68A32FA5E15C235B60CC | 512 | 41943040 | 21474836480 | OK | sim-01 | POO1
$ lsmcli list --type volumes -s
---------------------------------------------
ID | Vol1
Name | volume_name
VPD83 | 049167B5D09EC0A173E92A63F6C3EA2A
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
ID | Vol2
Name | async_created
VPD83 | 3E771A2E807F68A32FA5E15C235B60CC
Block Size | 512
#blocks | 41943040
Size | 21474836480
Status | OK
System ID | sim-01
Pool ID | POO1
---------------------------------------------
28장. 영구 메모리: NVDIMMs
pmem)는 메모리와 스토리지의 조합입니다. PMEM은 스토리지 내구성과 낮은 액세스 대기 시간 및 높은 대역폭의 DRAM(Dynamic RAM)을 결합합니다.
- 영구 메모리는 바이트 주소 지정 가능이므로 CPU 로드 및 저장 지침을 사용하여 액세스할 수 있습니다. 기존 블록 기반 스토리지에 액세스하는 데 필요한
read()또는write()시스템 호출 외에도pmem에서는 직접 로드 및 저장 프로그래밍 모델도 지원합니다. - 영구 메모리의 성능 특성은 일반적으로 10과 수백의 나노초에서 매우 낮은 액세스 대기 시간이 있는 III와 유사합니다.
- 영구 메모리의 콘텐츠는 전원이 꺼져 있을 때 스토리지처럼 보존됩니다.
영구 메모리 사용은 다음과 같은 사용 사례에 유용합니다.
- 신속한 시작: 데이터 세트가 이미 메모리에 있습니다.
- 빠른 시작은 웜 캐시 효과라고도 합니다. 시작 후 파일 서버에 메모리의 파일 콘텐츠가 없습니다. 클라이언트가 데이터를 연결하고 읽을 때 해당 데이터는 페이지 캐시에 캐시됩니다. 결국 캐시에는 주로 핫 데이터가 포함됩니다. 재부팅 후 시스템이 프로세스를 다시 시작해야합니다.영구 메모리를 사용하면 애플리케이션이 제대로 설계된 경우 재부팅 후에도 애플리케이션이 웜 캐시를 유지할 수 있습니다. 이 경우 페이지 캐시가 연결되지 않습니다. 애플리케이션은 영구 메모리에서 직접 데이터를 캐시합니다.
- 빠른 쓰기 캐시
- 파일 서버는 데이터가 내구성 있는 미디어에 있을 때까지 클라이언트의 쓰기 요청을 확인하지 않는 경우가 많습니다. 영구 메모리를 빠른 쓰기 캐시로 사용하면 파일 서버에서
pmem의 짧은 대기 시간으로 인해 쓰기 요청을 신속하게 승인할 수 있습니다.
NVDIMMs Interleaving
- NVDIMM과 마찬가지로 NVDIMM은 interleave 집합으로 구성될 때 성능을 향상시킬 수 있습니다.
- 여러 개의 작은 NVDIMM을 하나의 더 큰 논리 장치로 결합하는 데 사용할 수 있습니다.
- ECDHENVDIMMs에서 라벨을 지원하는 경우 지역 장치를 네임스페이스로 더 세분화할 수 있습니다.
- NVDIMMs에서 라벨을 지원하지 않는 경우 리전 장치에는 단일 네임스페이스만 포함할 수 있습니다. 이 경우 커널은 전체 리전을 다루는 기본 네임스페이스를 생성합니다.
영구 메모리 액세스 모드
섹터,fsdax,devdax (device direct access) 또는 raw 모드에서 영구 메모리 장치를 사용할 수 있습니다.
섹터모드- 스토리지를 빠른 블록 장치로 제공합니다. 섹터 모드를 사용하면 영구 메모리를 사용하도록 수정되지 않은 레거시 애플리케이션 또는 장치 매퍼를 포함하여 전체 I/O 스택을 사용하는 애플리케이션에 유용합니다.
fsdax모드- 이를 통해 영구 메모리 장치는 SNIA(Storage Networking Industry Association) NVMe( Non-Volatile Memory) 프로그래밍 모델 사양에 설명된 대로 직접 액세스 프로그래밍을 지원할 수 있습니다. 이 모드에서는 I/O가 커널의 스토리지 스택을 무시하고 많은 장치 매퍼 드라이버를 사용할 수 없습니다.
devdax모드devdax(device DAX) 모드는 DAX 문자 장치 노드를 사용하여 영구 메모리에 대한 원시 액세스를 제공합니다.devdax장치의 데이터는 CPU 캐시 플러시 및 펜싱 명령을 사용하여 내구성을 유지할 수 있습니다. 특정 데이터베이스 및 가상 머신 하이퍼바이저는devdax모드의 이점을 누릴 수 있습니다. 장치devdax인스턴스에서 파일 시스템을 만들 수 없습니다.원시모드- 원시 모드 네임스페이스에는 몇 가지 제한 사항이 있으며 사용해서는 안 됩니다.
28.1. ndctl을 사용하여 영구 메모리 구성
# yum install ndctl절차 28.1. 라벨을 지원하지 않는 장치에 대한 영구 메모리 구성
- 시스템에서 사용 가능한
pmem리전을 나열합니다. 다음 예에서 명령은 레이블을 지원하지 않는 NVDIMM-N 장치를 나열합니다.#ndctl list --regions [ { "dev":"region1", "size":34359738368, "available_size":0, "type":"pmem" }, { "dev":"region0", "size":34359738368, "available_size":0, "type":"pmem" } ]Red Hat Enterprise Linux는 NVDIMM-N 장치가 레이블을 지원하지 않기 때문에 각 지역에 대해 기본 네임스페이스를 생성합니다. 따라서 사용 가능한 크기는 0바이트입니다. - 시스템의 모든 비활성 네임스페이스를 나열합니다.
#ndctl list --namespaces --idle [ { "dev":"namespace1.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":1 }, { "dev":"namespace0.0", "mode":"raw", "size":34359738368, "state":"disabled", "numa_node":0 } ] - 이 공간을 사용하도록 비활성 네임스페이스를 재구성합니다. 예를 들어 DAX를 지원하는 파일 시스템에 namespace0.0 을 사용하려면 다음 명령을 사용합니다.
#ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem { "dev":"namespace0.0", "mode":"fsdax", "size":"32.00 GiB (34.36 GB)", "uuid":"ab91cc8f-4c3e-482e-a86f-78d177ac655d", "blockdev":"pmem0", "numa_node":0 }
절차 28.2. 레이블을 지원하는 장치에 대한 영구 메모리 구성
- 시스템에서 사용 가능한
pmem리전을 나열합니다. 다음 예에서 명령은 레이블을 지원하는 NVDIMM-N 장치를 나열합니다.#ndctl list --regions [ { "dev":"region5", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-7337419320239190016 }, { "dev":"region4", "size":270582939648, "available_size":270582939648, "type":"pmem", "iset_id":-137289417188962304 } ] - NVDIMM 장치가 라벨을 지원하는 경우 기본 네임스페이스는 생성되지 않으며 --force 또는 --reconfigure 플래그를 사용하지 않고 리전에서 하나 이상의 네임스페이스를 할당할 수 있습니다.
#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.0", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"9c5330b5-dc90-4f7a-bccd-5b558fa881fe", "blockdev":"pmem4", "numa_node":0 }이제 동일한 리전에서 다른 네임스페이스를 생성할 수 있습니다.#ndctl create-namespace --region=region4 --mode=fsdax --map=dev --size=36G { "dev":"namespace4.1", "mode":"fsdax", "size":"35.44 GiB (38.05 GB)", "uuid":"91868e21-830c-4b8f-a472-353bf482a26d", "blockdev":"pmem4.1", "numa_node":0 }다음 명령을 사용하여 동일한 리전에서 다른 유형의 네임스페이스를 생성할 수도 있습니다.#ndctl create-namespace --region=region4 --mode=devdax --align=2M --size=36G { "dev":"namespace4.2", "mode":"devdax", "size":"35.44 GiB (38.05 GB)", "uuid":"a188c847-4153-4477-81bb-7143e32ffc5c", "daxregion": { "id":4, "size":"35.44 GiB (38.05 GB)", "align":2097152, "devices":[ { "chardev":"dax4.2", "size":"35.44 GiB (38.05 GB)" }] }, "numa_node":0 }
28.2. 블록 장치로 사용할 영구 메모리 구성(Legacy Mode)
# ndctl create-namespace --force --reconfig=namespace1.0 --mode=sector
{
"dev":"namespace1.0",
"mode":"sector",
"size":17162027008,
"uuid":"029caa76-7be3-4439-8890-9c2e374bcc76",
"sector_size":4096,
"blockdev":"pmem1s"
}
namespace1.0 은 섹터 모드로 재구성됩니다. 블록 장치 이름이 pmem1에서 pmem1 s 로 변경되었습니다. 이 장치는 시스템의 다른 블록 장치와 동일한 방식으로 사용할 수 있습니다. 예를 들어 장치를 파티셔닝할 수 있으며, 장치에 파일 시스템을 만들고, 장치를 소프트웨어 RAID 세트의 일부로 구성할 수 있으며 장치는 dm-cache 의 캐시 장치일 수 있습니다.
28.3. 파일 시스템 직접 액세스를 위한 영구 메모리 구성
fsdax 모드로 구성해야 합니다. 이 모드는 직접 액세스 프로그래밍 모델을 허용합니다. 장치가 fsdax 모드에서 구성되면 파일 시스템을 위에서 생성한 다음 -o fsdax 마운트 옵션을 사용하여 마운트할 수 있습니다. 그러면 이 파일 시스템의 파일에서 mmap() 작업을 수행하는 모든 애플리케이션이 스토리지에 직접 액세스할 수 있습니다. 다음 예제를 참조하십시오.
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=fsdax --map=mem
{
"dev":"namespace0.0",
"mode":"fsdax",
"size":17177772032,
"uuid":"e6944638-46aa-4e06-a722-0b3f16a5acbf",
"blockdev":"pmem0"
}
namespace0.0 이 네임스페이스 fsdax 모드로 변환됩니다. --map=mem 인수를 사용하면 ndctl 에서 시스템 iLO에서 Direct Memory Access(DMA)에 사용되는 운영 체제 데이터 구조를 배치합니다.
fsdax 모드에서 네임스페이스를 구성한 후 네임스페이스가 파일 시스템에 준비되어 있습니다. Red Hat Enterprise Linux 7.3부터 Ext4 및 XFS 파일 시스템은 모두 영구 메모리를 기술 프리뷰로 사용할 수 있습니다. 파일 시스템 생성에는 특별한 인수가 필요하지 않습니다. DAX 기능을 가져오려면 dax 마운트 옵션을 사용하여 파일 시스템을 마운트합니다. 예를 들어 다음과 같습니다.
#mkfs -t xfs /dev/pmem0#mount -o dax /dev/pmem0 /mnt/pmem/
/mnt/pmem/ 디렉터리에 파일을 생성하고 파일을 열고 mmap 작업을 사용하여 직접 액세스할 수 있도록 파일을 매핑할 수 있습니다.
pmem 장치에 파티션을 생성할 때는 페이지 경계에 파티션을 정렬해야 합니다. Intel 64 및 AMD64 아키텍처에서 파티션의 시작과 끝을 위해 최소 4KiB 정렬이 적용되지만 2MiB는 기본 정렬입니다. 기본적으로 파트된 도구는 파티션을 1MiB 경계로 정렬합니다. 첫 번째 파티션의 경우 파티션 시작으로 2MiB를 지정합니다. 파티션 크기가 2MiB인 경우 다른 모든 파티션도 정렬됩니다.
28.4. 장치 DAX 모드에서 사용할 영구 메모리 구성
(Dedax)는 파일 시스템의 개입 없이 애플리케이션이 스토리지에 직접 액세스할 수 있는 수단을 제공합니다. 장치 DAX의 이점은 ndctl 유틸리티와 함께 --align 옵션을 사용하여 구성할 수 있는 보장된 오류 세분성을 제공한다는 점입니다.
# ndctl create-namespace --force --reconfig=namespace0.0 --mode=devdax --align=2M- 4KiB
- 2MiB
- 1GiB
/dev/daxN.M)는 다음 시스템 호출만 지원합니다.
open()close()mmap()fallocate()
read() 또한 사용 사례가 영구 메모리 프로그래밍에 연결되어 있기 때문에 write() 변형은 지원되지 않습니다.
28.5. NVDIMM 문제 해결
28.5.1. S.M.A.R.T를 사용하여 NVDIMM 상태 모니터링.
사전 요구 사항
- 일부 시스템에서는 acpi_ipmi 드라이버를 로드하여 다음 명령을 사용하여 상태 정보를 검색해야 합니다.
#modprobe acpi_ipmi
절차
- 상태 정보에 액세스하려면 다음 명령을 사용합니다.
#ndctl list --dimms --health ... { "dev":"nmem0", "id":"802c-01-1513-b3009166", "handle":1, "phys_id":22, "health": { "health_state":"ok", "temperature_celsius":25.000000, "spares_percentage":99, "alarm_temperature":false, "alarm_spares":false, "temperature_threshold":50.000000, "spares_threshold":20, "life_used_percentage":1, "shutdown_state":"clean" } } ...
28.5.2. Broken NVDIMM 감지 및 교체
- NVDIMM 장치가 실패하는지 감지합니다.
- 저장된 데이터를 백업하고,
- 물리적으로 장치를 교체하십시오.
절차 28.3. Broken NVDIMM 감지 및 교체
- 손상된 DIMM을 감지하려면 다음 명령을 사용하십시오.
# ndctl list --dimms --regions --health --media-errors --human
badblocks필드에는 NVDIMM이 손상된 것으로 표시됩니다.dev필드에서 해당 이름을 기록해 둡니다. 다음 예에서nmem0이라는 NVDIMM이 손상되었습니다.예 28.1. NVDIMM 장치의 상태
# ndctl list --dimms --regions --health --media-errors --human ... "regions":[ { "dev":"region0", "size":"250.00 GiB (268.44 GB)", "available_size":0, "type":"pmem", "numa_node":0, "iset_id":"0xXXXXXXXXXXXXXXXX", "mappings":[ { "dimm":"nmem1", "offset":"0x10000000", "length":"0x1f40000000", "position":1 }, { "dimm":"nmem0", "offset":"0x10000000", "length":"0x1f40000000", "position":0 } ], "badblock_count":1, "badblocks":[ { "offset":65536, "length":1, "dimms":[ "nmem0" ] } ], "persistence_domain":"memory_controller" } ] } - 다음 명령을 사용하여 손상된 NVDIMM의
phys_id속성을 찾습니다.# ndctl list --dimms --human
이전 예에서nmem0이 손상된 NVDIMM임을 알 수 있습니다. 따라서nmem0의phys_id속성을 찾습니다. 다음 예제에서phys_id는0x10입니다.예 28.2. NVDIMM의 phys_id 속성
# ndctl list --dimms --human [ { "dev":"nmem1", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x120", "phys_id":"0x1c" }, { "dev":"nmem0", "id":"XXXX-XX-XXXX-XXXXXXXX", "handle":"0x20", "phys_id":"0x10", "flag_failed_flush":true, "flag_smart_event":true } ] - 다음 명령을 사용하여 손상된 NVDIMM의 메모리 슬롯을 찾습니다.
# dmidecode
출력에서Handle식별자가 손상된 NVDIMM의phys_id속성과 일치하는 항목을 찾습니다.검색필드에는 손상된 NVDIMM에 사용되는 메모리 슬롯이 나열됩니다. 다음 예에서nmem0장치는0x0010식별자와 일치하며DIMM-XXX-YYYY메모리 슬롯을 사용합니다.예 28.3. NVDIMM 메모리 슬롯 목록
# dmidecode ... Handle 0x0010, DMI type 17, 40 bytes Memory Device Array Handle: 0x0004 Error Information Handle: Not Provided Total Width: 72 bits Data Width: 64 bits Size: 125 GB Form Factor: DIMM Set: 1 Locator: DIMM-XXX-YYYY Bank Locator: Bank0 Type: Other Type Detail: Non-Volatile Registered (Buffered) ... - NVDIMM의 네임스페이스의 모든 데이터를 백업합니다. NVDIMM을 교체하기 전에 데이터를 백업하지 않으면 시스템에서 NVDIMM을 제거할 때 데이터가 손실됩니다.주의NVDIMM이 완전히 손상되는 경우와 같이 경우에 따라 백업이 실패할 수 있습니다.이를 방지하려면 28.5.1절. “S.M.A.R.T를 사용하여 NVDIMM 상태 모니터링.” 에 설명된 대로 S.M.A.R.T를 사용하여 NVDIMM 장치를 정기적으로 모니터링하고 장애가 발생하기 전에 NVDIMM을 교체하십시오.다음 명령을 사용하여 NVDIMM의 네임스페이스를 나열합니다.
# ndctl list --namespaces --dimm=DIMM-ID-number
다음 예에서nmem0장치에는 백업해야 하는namespace0.0및namespace0.2네임스페이스가 포함되어 있습니다.예 28.4. NVDIMM 네임스페이스 목록
# ndctl list --namespaces --dimm=0 [ { "dev":"namespace0.2", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0.2s", "numa_node":0 }, { "dev":"namespace0.0", "mode":"sector", "size":67042312192, "uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "raw_uuid":"XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX", "sector_size":4096, "blockdev":"pmem0s", "numa_node":0 } ] - 손상된 NVDIMM을 물리적으로 교체합니다.
29장. NVMe 패브릭 장치 개요
NVMe 를 구성합니다.
- RDMA(Remote Direct Memory Access)를 사용하는 NVMe over fabric. NVMe/RDMA를 구성하는 방법에 대한 자세한 내용은 29.1절. “RDMA를 사용하는 NVMe over fabric” 을 참조하십시오.
- 파이버 채널(FC)을 사용하는 NVMe/ 패브릭 FC-NVMe을 구성하는 방법에 대한 자세한 내용은 29.2절. “FC를 사용하는 패브릭을 사용하여 NVMe” 을 참조하십시오.
29.1. RDMA를 사용하는 NVMe over fabric
29.1.1. NVMe over RDMA 클라이언트 구성
nvme-cli)를 사용하여 NVMe/RDMA 클라이언트를 구성하려면 이 절차를 사용하십시오.
nvme-cli패키지를 설치합니다.#yum install nvme-cli- 로드되지 않은 경우
nvme-rdma모듈을 로드합니다.#modprobe nvme-rdma - NVMe 대상에서 사용 가능한 하위 시스템을 검색합니다.
#nvme discover -t rdma -a 172.31.0.202 -s 4420 Discovery Log Number of Records 1, Generation counter 2 =====Discovery Log Entry 0====== trtype: rdma adrfam: ipv4 subtype: nvme subsystem treq: not specified, sq flow control disable supported portid: 1 trsvcid: 4420 subnqn: testnqn traddr: 172.31.0.202 rdma_prtype: not specified rdma_qptype: connected rdma_cms: rdma-cm rdma_pkey: 0x0000 - 검색된 하위 시스템에 연결합니다.
#nvme connect -t rdma -n testnqn -a 172.31.0.202 -s 4420#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home nvme0n1#cat /sys/class/nvme/nvme0/transport rdmatestnqn 을 NVMe 하위 시스템 이름으로 교체합니다.172.31.0.202 를 대상 IP 주소로 바꿉니다.4420 을 포트 번호로 바꿉니다. - 현재 연결된 NVMe 장치를 나열합니다.
#nvme list - 선택 사항: 대상에서 연결을 해제합니다.
#nvme disconnect -n testnqn NQN:testnqn disconnected 1 controller(s)#lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 1G 0 part /boot └─sda2 8:2 0 464.8G 0 part ├─rhel_rdma--virt--03-root 253:0 0 50G 0 lvm / ├─rhel_rdma--virt--03-swap 253:1 0 4G 0 lvm [SWAP] └─rhel_rdma--virt--03-home 253:2 0 410.8G 0 lvm /home
추가 리소스
- 자세한 내용은
nvmeman 페이지 및 NVMe-cli Github 리포지토리를 참조하십시오.
29.2. FC를 사용하는 패브릭을 사용하여 NVMe
29.2.1. Broadcom 어댑터에 대한 NVMe 이니시에이터 구성
nvme-cli) 도구를 사용하여 Broadcom 어댑터 클라이언트에 대한 NVMe 이니시에이터를 구성합니다.
nvme-cli툴을 설치합니다.#yum install nvme-cli이렇게 하면/etc/nvme/디렉터리에hostnqn파일이 생성됩니다.hostnqn파일은 NVMe 호스트를 식별합니다. 새hostnqn을 생성하려면 다음을 수행합니다.#nvme gen-hostnqn- 다음 콘텐츠를 사용하여
/etc/modprobe.d/lpfc.conf파일을 생성합니다.options lpfc lpfc_enable_fc4_type=3
initramfs이미지를 다시 빌드합니다.# dracut --force
- 호스트 시스템을 재부팅하여
lpfc드라이버를 재구성합니다.# systemctl reboot
- 로컬 및 원격 포트의 WWNN 및 WWPN을 찾고 출력을 사용하여 하위 시스템 NQN을 찾습니다.
#cat /sys/class/scsi_host/host*/nvme_info NVME Initiator Enabled XRI Dist lpfc0 Total 6144 IO 5894 ELS 250 NVME LPORT lpfc0 WWPN x10000090fae0b5f5 WWNN x20000090fae0b5f5 DID x010f00 ONLINE NVME RPORT WWPN x204700a098cbcac6 WWNN x204600a098cbcac6 DID x01050e TARGET DISCSRVC ONLINE NVME Statistics LS: Xmt 000000000e Cmpl 000000000e Abort 00000000 LS XMIT: Err 00000000 CMPL: xb 00000000 Err 00000000 Total FCP Cmpl 00000000000008ea Issue 00000000000008ec OutIO 0000000000000002 abort 00000000 noxri 00000000 nondlp 00000000 qdepth 00000000 wqerr 00000000 err 00000000 FCP CMPL: xb 00000000 Err 00000000#nvme discover --transport fc \ --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 \ --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1 traddr: nn-0x204600a098cbcac6:pn-0x204700a098cbcac6nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 을traddr으로 교체합니다.nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 를host_traddr으로 교체합니다. nvme-cli를 사용하여 NVMe 대상에 연결합니다.#nvme connect --transport fc --traddr nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 --host-traddr nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 -n nqn.1992-08.com.netapp:sn.e18bfca87d5e11e98c0800a098cbcac6:subsystem.st14_nvme_ss_1_1nn-0x204600a098cbcac6:pn-0x204700a098cbcac6 을traddr으로 교체합니다.nn-0x20000090fae0b5f5:pn-0x10000090fae0b5f5 를host_traddr로 바꿉니다.nqn.1992-08.com.netapp:sn.e18bfca87d5e98c0800a098cbcac6:subsystem.st14_nvme_1_1 을하위qn으로 교체합니다.- NVMe 장치가 현재 연결되어 있는지 확인합니다.
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
추가 리소스
- 자세한 내용은
nvmeman 페이지 및 NVMe-cli Github 리포지토리를 참조하십시오.
29.2.2. QLogic 어댑터에 대한 NVMe 이니시에이터 구성
(nvme-cli) 툴을 사용하여 Qlogic 어댑터 클라이언트에 대한 NVMe 이니시에이터를 구성하려면 이 절차를 사용합니다.
nvme-cli툴을 설치합니다.#yum install nvme-cli이렇게 하면/etc/nvme/디렉터리에hostnqn파일이 생성됩니다.hostnqn파일은 NVMe 호스트를 식별합니다. 새hostnqn을 생성하려면 다음을 수행합니다.#nvme gen-hostnqnqla2xxx모듈을 제거하고 다시 로드합니다.#rmmod qla2xxx#modprobe qla2xxx- 로컬 및 원격 포트의 WWNN 및 WWPN을 찾습니다.
#dmesg |grep traddr [ 6.139862] qla2xxx [0000:04:00.0]-ffff:0: register_localport: host-traddr=nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 on portID:10700 [ 6.241762] qla2xxx [0000:04:00.0]-2102:0: qla_nvme_register_remote: traddr=nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 PortID:01050d이host-traddr및traddr을 사용하여 하위 시스템 NQN을 찾습니다.#nvme discover --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host-traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 Discovery Log Number of Records 2, Generation counter 49530 =====Discovery Log Entry 0====== trtype: fc adrfam: fibre-channel subtype: nvme subsystem treq: not specified portid: 0 trsvcid: none subnqn: nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468 traddr: nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 을traddr으로 교체합니다.nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 를host_traddr으로 교체합니다. nvme-cli도구를 사용하여 NVMe 대상에 연결합니다.#nvme connect --transport fc --traddr nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 --host_traddr nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 -n nqn.1992-08.com.netapp:sn.c9ecc9187b1111e98c0800a098cbcac6:subsystem.vs_nvme_multipath_1_subsystem_468nn-0x203b00a098cbcac6:pn-0x203d00a098cbcac6 을traddr으로 교체합니다.nn-0x20000024ff19bb62:pn-0x21000024ff19bb62 를host_traddr으로 교체합니다.nqn.1992-08.com.netapp:sn.c9ecc9187b11e98c0800a098cbcac6:subsystem.vs_multipath_1_subsystem_468 을subnqn으로 바꿉니다.- NVMe 장치가 현재 연결되어 있는지 확인합니다.
#nvme list Node SN Model Namespace Usage Format FW Rev ---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- -------- /dev/nvme0n1 80BgLFM7xMJbAAAAAAAC NetApp ONTAP Controller 1 107.37 GB / 107.37 GB 4 KiB + 0 B FFFFFFFF#lsblk |grep nvme nvme0n1 259:0 0 100G 0 disk
추가 리소스
- 자세한 내용은
nvmeman 페이지 및 NVMe-cli Github 리포지토리를 참조하십시오.
III 부. Data Dificationplication and Compression with VDO
30장. VDO 통합
30.1. VDO에 대한 기본 개요
- 중복 제거는 중복 블록의 여러 복사본을 제거하여 스토리지 리소스 사용을 줄이는 기술입니다.동일한 데이터를 두 번 이상 작성하는 대신 VDO는 각 중복 블록을 감지하고 이를 원래 블록에 대한 참조로 기록합니다. VDO는 VDO 위의 스토리지 계층에서 물리적 블록 주소로 사용하는 논리 블록 주소에서 VDO의 스토리지 계층에서 사용하는 매핑을 유지합니다.중복 제거 후 여러 개의 논리 블록 주소가 동일한 물리적 블록 주소에 매핑될 수 있습니다. 이러한 블록 주소를 공유 블록 이라고 합니다. 블록 공유는 스토리지 사용자에게 보이지 않으므로 VDO가 존재하지 않는 것처럼 블록을 읽고 씁니다. 공유 블록을 덮어쓰면 공유 물리적 블록에 매핑된 다른 논리 블록 주소가 수정되지 않도록 새 블록 데이터를 저장하기 위해 새 물리 블록이 할당됩니다.
- 압축 은 로그 파일 및 데이터베이스와 같이 블록 수준 중복성을 반드시 표시하지 않는 파일 형식과 함께 작동하는 데이터 가상화 기술입니다. 자세한 내용은 30.4.8절. “압축 사용” 를 참조하십시오.
kvdo- Linux 장치 매퍼 계층에 로드하여 중복되고 압축되고 씬 프로비저닝된 블록 스토리지 볼륨을 제공하는 커널 모듈
uds- 볼륨의 Universal Deduplication Service(UDS) 인덱스와 통신하는 커널 모듈이며 중복을 위해 데이터를 분석합니다.
- 명령줄 툴
- 최적화된 스토리지를 구성하고 관리하는 데 사용됩니다.
30.1.1. UDS 커널 모듈(uds)
uds 커널 모듈로 커널 내부에서 실행됩니다.
30.1.2. VDO 커널 모듈(kvdo)
kvdo Linux 커널 모듈은 Linux 장치 매퍼 계층 내에서 블록 계층 중복 제거 서비스를 제공합니다. Linux 커널에서 장치 매퍼는 블록 스토리지 풀을 관리하기 위한 일반 프레임워크 역할을 하므로 커널 블록 인터페이스와 실제 스토리지 장치 드라이버 사이의 블록 처리 모듈을 스토리지 스택에 삽입할 수 있습니다.
kvdo 모듈은 블록 스토리지에 대해 직접 액세스하거나 XFS 또는 ext4와 같이 사용 가능한 여러 Linux 파일 시스템 중 하나를 통해 제공할 수 있는 블록 장치로 노출됩니다. kvdo 가 VDO 볼륨에서 데이터 블록을 읽기 위한 요청을 수신하면 요청된 논리 블록을 기본 물리적 블록에 매핑한 다음 요청된 데이터를 읽고 반환합니다.
kvdo 가 VDO 볼륨에 데이터 블록을 쓰기 위한 요청을 수신하면 먼저 DISCARD 또는 TRIM 요청인지 또는 데이터가 균일하게 0인지 여부를 확인합니다. 이러한 조건 중 하나가 있는 경우 kvdo 는 블록 맵을 업데이트하고 요청을 승인합니다. 그렇지 않으면 요청에 의해 사용하기 위해 물리적 블록이 할당됩니다.
30.1.2.1. VDO 쓰기 정책 개요
kvdo 모듈이 동기 모드에서 작동하는 경우:
- 요청에 데이터를 일시적으로 기록한 다음 요청을 승인합니다.
- 승인이 완료되면 VDO 인덱스로 전송되는 블록 데이터의 MurmurHash-3 서명을 컴퓨팅하여 블록을 분리하려고 시도합니다.
- VDO 인덱스에 동일한 서명이 있는 블록에 대한 항목이 포함된 경우
kvdo는 표시된 블록을 읽고 두 블록의 바이트 단위로 비교하여 동일한지 확인합니다. - 실제로 동일한 경우
kvdo는 블록 맵을 업데이트하여 논리 블록이 해당 물리적 블록을 가리키고 할당된 물리적 블록을 해제하도록 합니다. - VDO 인덱스에 작성된 블록의 서명에 대한 항목이 포함되어 있지 않거나 표시된 블록에 실제로 동일한 데이터가 포함되지 않은 경우
kvdo는 블록 맵을 업데이트하여 임시 물리적 블록을 영구적으로 만듭니다.
kvdo 가 비동기 모드에서 작동하는 경우:
- 데이터를 작성하지 않고 즉시 요청을 승인합니다.
- 그런 다음 위에서 설명한 것과 동일한 방식으로 블록을 복제하려고 시도합니다.
- 블록이 중복되는 경우
kvdo는 블록 맵을 업데이트하고 할당된 블록을 해제합니다. 그렇지 않으면 할당된 블록에 데이터를 쓰고 블록 맵을 업데이트하여 물리적 블록을 영구적으로 만듭니다.
30.1.3. VDO 볼륨
그림 30.1. VDO 디스크 조직

30.1.3.1. Slabs
표 30.1. 물리 볼륨 크기의 VDO Slab 크기 권장
| 물리 볼륨 크기 | 권장 크기 |
|---|---|
| 10–99 GB | 1GB |
| 100GB - 1TB | 2 GB |
| 2-256 TB | 32GB |
vdo create 명령에
--vdoSlabSize=megabytes
옵션을 제공하여 제어할 수 있습니다.
30.1.3.2. 물리적 크기 및 사용 가능한 물리적 크기
- 물리적 크기는 기본 블록 장치와 크기가 같습니다. VDO는 다음 용도로 이 스토리지를 사용합니다.
- 사용자 데이터가 분할되고 압축될 수 있습니다.
- VDO 메타데이터(예: UDS 인덱스)
- 사용 가능한 물리적 크기는 VDO가 사용자 데이터에 사용할 수 있는 물리적 크기의 일부입니다.물리 크기와 같습니다. 메타데이터의 크기를 뺀 후 나머지 볼륨을 지정된 slab 크기로 slabs로 분할한 후 나머지를 뺀 값입니다.
30.1.3.3. 논리 크기
--vdoLogicalSize 옵션이 지정되지 않은 경우 논리 볼륨 크기는 기본적으로 사용 가능한 물리 볼륨 크기로 설정됩니다. 그림 30.1. “VDO 디스크 조직” 에서 VDO 중복된 스토리지 대상은 블록 장치의 상단에 완전히 있으므로 VDO 볼륨의 실제 크기는 기본 블록 장치와 동일합니다.
30.1.4. 명령줄 툴
30.2. 시스템 요구 사항
프로세서 아키텍처
RAM
- VDO 모듈은 370MB와 1TB의 물리적 스토리지 관리마다 추가 268MB가 필요합니다.
- Universal Deduplication Service (UDS) 인덱스에는 최소 250MB의 iLO가 필요하며, 이는 중복 제거에 사용되는 기본 용량이기도 합니다. UDS의 메모리 사용량에 대한 자세한 내용은 30.2.1절. “UDS 인덱스 메모리 요구 사항” 을 참조하십시오.
스토리지
추가 시스템 소프트웨어
- LVM
- python 2.7
yum 패키지 관리자는 필요한 모든 소프트웨어 종속 항목을 자동으로 설치합니다.
스토리지 스택에 VDO 배치
- VDO의 경우 DM-Multipath, DM-Crypt 및 소프트웨어 RAID(LVM 또는
mdraid)가 있습니다. - VDO: LVM 캐시, LVM 스냅샷, LVM 씬 프로비저닝.
- VDO 볼륨의 맨 위에 있는 VDO: 스토리지 → VDO → LVM → VDO
- LVM Snapshots 위에 있는 VDO
- LVM 캐시 상단에 있는 VDO
- 루프백 장치 위에 있는 VDO
- LVM 씬 프로비저닝 상단에 있는 VDO
- VDO 상단의 암호화된 볼륨: 스토리지 → VDO → DM-Crypt
- VDO 볼륨의 파티션:
fdisk,parted, similar partitions - VDO 볼륨 상단에 RAID(LVM, MD 또는 기타 유형)
동기화와 비동기 동기화 의 두 가지 쓰기 모드를 지원합니다. VDO가 동기화 모드인 경우 VDO 장치에 대한 쓰기는 기본 저장소에서 데이터를 영구적으로 기록하면 승인됩니다. VDO가 async 모드인 경우 영구 스토리지에 쓰기 전에 쓰기를 승인합니다.
auto 옵션으로 설정됩니다.
30.2.1. UDS 인덱스 메모리 요구 사항
- 컴팩트한 표현은 고유한 블록당 최대 하나의 항목을 포함하는 메모리에서 사용됩니다.
- 오류가 발생하면 인덱스에 표시된 관련 블록 이름을 순서대로 기록하는 디스크 구성 요소입니다.
- 밀도가 높은 인덱스의 경우 UDS는 1TB RAM당 1TB의 중복 제거 창을 제공합니다. 1GB 인덱스는 일반적으로 최대 4TB의 스토리지 시스템에 충분합니다.
- 스파스 인덱스의 경우 UDS는 1GB RAM당 10TB의 중복 제거 창을 제공합니다. 1GB 스파스 인덱스는 일반적으로 최대 40TB의 물리적 스토리지에 충분합니다.
30.2.2. VDO 스토리지 공간 요구 사항
- VDO는 두 가지 유형의 메타데이터를 기본 물리적 스토리지에 씁니다.
- 첫 번째 유형은 VDO 볼륨의 물리 크기로 확장되며 4GB의 물리 스토리지에 대해 약 1MB와 slab당 1MB를 추가로 사용합니다.
- 두 번째 유형은 VDO 볼륨의 논리 크기로 확장되며 1GB의 논리 스토리지에 약 1.25MB를 사용하고 가장 가까운 slab으로 반올림됩니다.
slabs에 대한 설명은 30.1.3절. “VDO 볼륨” 을 참조하십시오. - UDS 인덱스는 VDO 볼륨 그룹 내에 저장되며 관련 VDO 인스턴스에서 관리합니다. 필요한 스토리지의 크기는 인덱스 유형과 인덱스에 할당된 RAM 크기에 따라 달라집니다. 1GB의 RAM에 대해 밀도가 높은 UDS 인덱스는 17GB의 스토리지를 사용하며 스파스 UDS 인덱스는17GB의 스토리지를 사용합니다.
30.2.3. 물리 볼륨 크기의 VDO 시스템 요구 사항의 예
30.2.3.1. 기본 스토리지 배포
표 30.2. 기본 스토리지에 대한 VDO 스토리지 및 메모리 요구 사항
| 물리 볼륨 크기 | 10GB - 1TB | 2-10TB | 11-50TB | 51-100 TB | 101-256 TB |
|---|---|---|---|---|---|
| RAM 사용량 | 250MB |
밀도: 1GB
스파스: 250MB
| 2 GB | 3GB | 12GB |
| 디스크 사용량 | 2.5 GB |
밀도: 10GB
스파스: 22GB
| 17GB | 255 GB | 1020GB |
| 인덱스 유형 | 밀도 | 밀도 또는 구문 분석 | 스파스 | 스파스 | 스파스 |
30.2.3.2. 백업 스토리지 배포
표 30.3. 백업 스토리지에 대한 VDO 스토리지 및 메모리 요구 사항
| 물리 볼륨 크기 | 10GB - 1TB | 2-10TB | 11-50TB | 51-100 TB | 101-256 TB |
|---|---|---|---|---|---|
| RAM 사용량 | 250MB | 2 GB | 10GB | 20 GB | 26 GB |
| 디스크 사용량 | 2.5 GB | 17GB | 850 GB | 1700 GB | 3400 GB |
| 인덱스 유형 | 밀도 | 스파스 | 스파스 | 스파스 | 스파스 |
30.3. VDO 시작하기
30.3.1. 소개
- 활성 VM 또는 컨테이너를 호스팅하는 경우, 10:1 논리에서 물리적 비율로 스토리지를 프로비저닝하는 것이 좋습니다. 즉 1TB의 물리 스토리지를 사용하는 경우 10TB의 논리 스토리지로 제공됩니다.
- Ceph에서 제공하는 유형과 같은 개체 스토리지의 경우 3:1 논리적 대 물리적 비율을 사용할 것을 권장합니다. 즉, 1TB의 물리적 스토리지가 3TB 논리적 스토리지로 제공됩니다.
- Red Hat Virtualization을 사용하여 구축된 가상화 서버와 같은 가상화 서버에 직접 연결된 사용 사례
- Ceph Storage를 사용하여 빌드된 오브젝트 기반 분산 스토리지 클러스터의 클라우드 스토리지 사용 사례입니다.참고Ceph를 사용한 VDO 배포는 현재 지원되지 않습니다.
30.3.2. VDO 설치
- vdo
- kmod-kvdo
# yum install vdo kmod-kvdo30.3.3. VDO 볼륨 생성
1 ).
- VDO 관리자를 사용하여 VDO 볼륨을 생성합니다.
#vdo create \--name=vdo_name\--device=block_device\--vdoLogicalSize=logical_size \[--vdoSlabSize=slab_size]- VDO 볼륨을 생성하려는 블록 장치의 영구 이름으로 block_device 를 교체합니다. 예를 들어
/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f입니다.중요영구 장치 이름을 사용합니다. 비영구 장치 이름을 사용하는 경우 장치 이름이 변경되면 VDO가 나중에 제대로 시작되지 않을 수 있습니다.영구 이름에 대한 자세한 내용은 25.8절. “영구 이름 지정” 을 참조하십시오. - logical_size 를 VDO 볼륨이 제공해야 하는 논리 스토리지 양으로 교체합니다.
- 활성 VM 또는 컨테이너 스토리지의 경우 블록 장치의 물리적 크기가 10 배인 논리 크기를 사용합니다. 예를 들어, 블록 장치의 크기가 1TB인 경우 여기에서
10T를 사용하십시오. - 오브젝트 스토리지의 경우 블록 장치의 물리적 크기를 세 배인 논리 크기를 사용합니다. 예를 들어, 블록 장치의 크기가 1TB인 경우 여기에서
3T를 사용하십시오.
- 블록 장치가 16TiB보다 큰 경우
--vdoSlabSize=32G를 추가하여 볼륨의 slab 크기를 32GiB로 늘립니다.16TiB 이상의 블록 장치에서 기본 slab 크기 2GiB를 사용하면 EgressIP create 명령이 다음과 같은 오류로 인해 실패합니다.vdo: ERROR - vdoformat: formatVDO failed on '/dev/device': VDO Status: Exceeds maximum number of slabs supported
자세한 내용은 30.1.3절. “VDO 볼륨” 에서 참조하십시오.
예 30.1. 컨테이너 스토리지용 VDO 생성
예를 들어 1TB 블록 장치에서 컨테이너 스토리지에 대한 VDO 볼륨을 생성하려면 다음을 사용할 수 있습니다.#vdo create \--name=vdo1\--device=/dev/disk/by-id/scsi-3600508b1001c264ad2af21e903ad031f\--vdoLogicalSize=10TVDO 볼륨이 생성되면 VDO는 항목을/etc/vdoconf.yml구성 파일에 추가합니다. 그런 다음 EgressIP.servicesystemd 장치는 항목을 사용하여 기본적으로 볼륨을 시작합니다.중요VDO 볼륨을 만들 때 오류가 발생하면 정리할 볼륨을 제거합니다. 자세한 내용은 30.4.3.1절. “불필요한 Created 볼륨 제거” 를 참조하십시오. - 파일 시스템을 생성합니다.
- XFS 파일 시스템의 경우 다음을 수행합니다.
#mkfs.xfs -K /dev/mapper/vdo_name - ext4 파일 시스템의 경우:
#mkfs.ext4 -E nodiscard /dev/mapper/vdo_name
- 파일 시스템을 마운트합니다.
#mkdir -m 1777 /mnt/vdo_name#mount /dev/mapper/vdo_name /mnt/vdo_name - 자동으로 마운트되도록 파일 시스템을 구성하려면
/etc/fstab파일 또는 systemd 마운트 장치를 사용합니다./etc/fstab구성 파일을 사용하기로 결정한 경우 다음 행 중 하나를 파일에 추가합니다.- XFS 파일 시스템의 경우 다음을 수행합니다.
/dev/mapper/vdo_name /mnt/vdo_name xfs defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- ext4 파일 시스템의 경우:
/dev/mapper/vdo_name /mnt/vdo_name ext4 defaults,_netdev,x-systemd.device-timeout=0,x-systemd.requires=vdo.service 0 0
- 또는 systemd 장치를 사용하기로 결정하는 경우 적절한 파일 이름으로 systemd 마운트 장치 파일을 만듭니다. VDO 볼륨의 마운트 지점의 경우 다음 콘텐츠를 사용하여
/etc/systemd/system/mnt-cabundle_name.mount파일을 생성합니다.[Unit] Description = VDO unit file to mount file system name = vdo_name.mount Requires = vdo.service After = multi-user.target Conflicts = umount.target [Mount] What = /dev/mapper/vdo_name Where = /mnt/vdo_name Type = xfs [Install] WantedBy = multi-user.target
예를 들어 systemd 장치 파일은/usr/share/doc/vdo/examples/systemd/VDO.mount.example에 설치됩니다.
- VDO 장치에서 파일 시스템의
삭제기능을 활성화합니다. VDO에서 배치 및 온라인 작업 모두 작동합니다.삭제기능을 설정하는 방법에 대한 자세한 내용은 2.4절. “사용되지 않는 블록 삭제” 을 참조하십시오.
30.3.4. VDO 모니터링
# vdostats --human-readable
Device 1K-blocks Used Available Use% Space saving%
/dev/mapper/node1osd1 926.5G 21.0G 905.5G 2% 73%
/dev/mapper/node1osd2 926.5G 28.2G 898.3G 3% 64%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool vdo_name. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool vdo_name is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool vdo_name is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool vdo_name is now 96.07% full.
30.3.5. 배포 예
30.3.5.1. KVM을 사용한 VDO 배포
그림 30.2. KVM을 사용한 VDO 배포

30.3.5.2. 추가 배포 시나리오
30.4. VDO 관리
30.4.1. VDO 시작 또는 중지
#vdo start --name=my_vdo#vdo start --all
#vdo stop --name=my_vdo#vdo stop --all
- 볼륨은 항상 UDS 인덱스의 1GiB마다 1GiB 정도를 씁니다.
- 스파스 UDS 인덱스를 사용하는 볼륨은 블록 맵 캐시 크기와 slab당 최대 8MiB와 동일한 데이터 양을 추가로 기록합니다.
- 동기 모드에서 종료하기 전에 VDO에서 승인한 모든 쓰기가 다시 작성됩니다.
- 비동기 모드에서는 마지막으로 승인한 플러시 요청보다 먼저 승인된 모든 쓰기가 다시 빌드됩니다.
30.4.2. VDO 쓰기 모드 선택
동기화,async, auto 를 지원합니다.
- VDO가
동기화모드인 경우 위의 계층에서는 쓰기 명령이 영구 스토리지에 데이터를 쓰는 것으로 가정합니다. 그 결과, 파일 시스템 또는 애플리케이션이 FLUSH 또는 Force Unit Access (FUA) 요청을 발행할 필요가 없어 데이터가 중요한 시점에서 영구적이 될 수 있습니다.VDO는 쓰기 명령이 완료될 때 기본 스토리지로 데이터가 영구 스토리지에 기록되도록만동기화모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 캐시가 없거나 캐시를 통한 쓰기가 있어야 합니다. - VDO가
async모드에 있을 때 쓰기 명령이 승인되면 데이터가 영구 스토리지에 기록될 수 없습니다. 파일 시스템 또는 애플리케이션에는 각 트랜잭션의 중요 시점에 데이터 지속성을 보장하기 위해 FLUSH 또는 FUA 요청을 발행해야 합니다.쓰기 명령이 완료될 때 기본 저장소가 영구 스토리지에 기록된다는 것을 보장하지 않는 경우 VDO는async모드로 설정해야 합니다. 즉, 스토리지에 휘발성 쓰기 백 캐시가 있는 경우입니다.장치가 휘발성 캐시를 사용하는지 확인하는 방법에 대한 자세한 내용은 “볼트일 캐시 확인” 을 참조하십시오.주의VDO가async모드에서 실행되는 경우 Atomicity, Consistency, Isolation, Durability (ACID)와 호환되지 않습니다. VDO 볼륨 상단에 ACID 준수를 가정하는 애플리케이션 또는 파일 시스템이 있는 경우async모드에서 예기치 않은 데이터가 손실될 수 있습니다. 자동모드는 각 장치의 특성에 따라동기화또는async를 자동으로 선택합니다. 이는 기본 옵션입니다.
--writePolicy 옵션을 사용합니다. 이 설정은 30.3.3절. “VDO 볼륨 생성” 에서 VDO 볼륨을 생성할 때 또는 changeWritePolicy 하위 명령으로 기존 VDO 볼륨을 수정할 때 지정할 수 있습니다.
# vdo changeWritePolicy --writePolicy=sync|async|auto --name=vdo_name30.4.2.1. 볼트일 캐시 확인
/sys/block/block_device/scsi_disk/identifier/cache_type sysfs 파일을 참조하십시오. 예를 들어 다음과 같습니다.
- 장치
sda가 쓰기 캐시가 있음을 나타냅니다.$cat '/sys/block/sda/device/scsi_disk/7:0:0:0/cache_type' write back - 장치
sdb는 쓰기 캐시가 없음을 나타냅니다.$cat '/sys/block/sdb/device/scsi_disk/1:2:0:0/cache_type' None
sd 7:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA sd 1:2:0:0: [sdb] Write cache: disabled, read cache: disabled, supports DPO and FUA
sda장치의비동기모드sdb장치의동기화모드
cache_type 값이 없는 경우 동기화 쓰기 정책을 사용하도록 VDO 를 구성해야 합니다.
30.4.3. VDO 볼륨 제거
# vdo remove --name=my_vdo30.4.3.1. 불필요한 Created 볼륨 제거
--force 옵션을 사용하여 실패한 볼륨을 제거합니다.
# vdo remove --force --name=my_vdo--force 옵션이 필요합니다. --force 옵션을 사용하지 않으면 다음 메시지와 함께 EgressIP remove 명령이 실패합니다.
[...] A previous operation failed. Recovery from the failure either failed or was interrupted. Add '--force' to 'remove' to perform the following cleanup. Steps to clean up VDO my_vdo: umount -f /dev/mapper/my_vdo udevadm settle dmsetup remove my_vdo vdo: ERROR - VDO volume my_vdo previous operation (create) is incomplete
30.4.4. UDS 인덱스 구성
--indexMem= size 옵션을 사용하여 인덱스 메모리크기를지정하여 결정됩니다. 사용할 디스크 공간의 양은 자동으로 결정됩니다.
--sparseIndex=enabled --indexMem=0.25 옵션을 지정합니다. 이 설정으로 인해 2.5TB의 중복 제거 창이 생성됩니다(즉, 2.5TB의 이력을 기억함). 대부분의 사용 사례에서 2.5TB의 중복 제거 창은 최대 10TB의 스토리지 풀에 적합합니다.
30.4.5. VDO 볼륨 복구: 불명확한 종료 후
- VDO가 동기 스토리지에서 실행 중이고 쓰기 정책이
동기화로 설정된 경우 볼륨에 기록된 모든 데이터가 완전히 복구됩니다. - 쓰기 정책이
async인 경우 VDO를FLUSH명령을 전송하여 영구하지 않은 경우 일부 쓰기가 복구되지 않거나FUA플래그로 태그된 쓰기 I/O가 (유효한 단위 액세스)되지 않을 수 있습니다. 이 작업은fsync,fdatasync,sync또는umount와 같은 데이터 무결성 작업을 호출하여 사용자 모드에서 수행됩니다.
30.4.5.1. 온라인 복구
사용 중인 블록 과 무료 블록. 다시 빌드가 완료되면 이러한 통계를 사용할 수 있습니다.
30.4.5.2. 강제 작성
ue stats의 운영 모드 속성은 VDO 볼륨이 읽기 전용 모드인지 여부를 나타냅니다.)
# vdo stop --name=my_vdo--forceRebuild 옵션을 사용하여 볼륨을 재시작합니다.
# vdo start --name=my_vdo --forceRebuild30.4.6. 시스템 부팅에서 VDO 볼륨 자동 시작
maintains systemd 장치는 활성화된 대로 구성된 모든 VDO 장치를 자동으로 시작합니다.
- 특정 볼륨을 비활성화하려면 다음을 수행합니다.
#vdo deactivate --name=my_vdo - 모든 볼륨을 비활성화하려면 다음을 수행합니다.
#vdo deactivate --all
- 특정 볼륨을 활성화하려면 다음을 수행합니다.
#vdo activate --name=my_vdo - 모든 볼륨을 활성화하려면 다음을 수행합니다.
#vdo activate --all
--activate=disabled 옵션을 추가하여 자동으로 시작하지 않는 VDO 볼륨을 생성할 수도 있습니다.
- LVM의 하위 계층을 먼저 시작해야 합니다(대부분의 시스템에서 LVM2 패키지를 설치할 때 이 계층을 자동으로 구성).
- 그런
다음maintains systemd 장치를 시작해야 합니다. - 마지막으로 현재 VDO 볼륨이 실행 중인 LVM 볼륨 또는 기타 서비스를 시작하려면 추가 스크립트를 실행해야 합니다.
30.4.7. Deduplication 비활성화 및 다시 활성화
- VDO 볼륨에서 중복 제거를 중지하려면 다음 명령을 사용합니다.
#vdo disableDeduplication --name=my_vdo이렇게 하면 연결된 UDS 인덱스가 중지되고 VDO 볼륨에서 중복 제거가 더 이상 활성화되지 않았음을 알립니다. - VDO 볼륨에서 중복 제거를 다시 시작하려면 다음 명령을 사용합니다.
#vdo enableDeduplication --name=my_vdo이렇게 하면 연결된 UDS 인덱스가 다시 시작되고 VDO 볼륨에서 중복 제거가 다시 활성화되었음을 알립니다.
--deduplication=disabled 옵션을 추가하여 새 VDO 볼륨을 만들 때 중복 제거를 비활성화할 수도 있습니다.
30.4.8. 압축 사용
30.4.8.1. 소개
30.4.8.2. 압축 활성화 및 비활성화
--compression=disabled 옵션을 EgressIP create 명령에 추가하여 압축을 비활성화할 수 있습니다.
- VDO 볼륨에서 압축을 중지하려면 다음 명령을 사용합니다.
#vdo disableCompression --name=my_vdo - 다시 시작하려면 다음 명령을 사용하십시오.
#vdo enableCompression --name=my_vdo
30.4.9. 여유 공간 관리
stats 유틸리티를 사용하여 결정할 수 있습니다. 자세한 내용은 30.7.2절. “vdostats” 을 참조하십시오. 이 유틸리티의 기본 출력에는 Linux df 유틸리티와 유사한 형식으로 실행 중인 모든 VDO 볼륨에 대한 정보가 나열됩니다. 예를 들어 다음과 같습니다.
Device 1K-blocks Used Available Use% /dev/mapper/my_vdo 211812352 105906176 105906176 50%
Oct 2 17:13:39 system lvm[13863]: Monitoring VDO pool my_vdo. Oct 2 17:27:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 80.69% full. Oct 2 17:28:19 system lvm[13863]: WARNING: VDO pool my_vdo is now 85.25% full. Oct 2 17:29:39 system lvm[13863]: WARNING: VDO pool my_vdo is now 90.64% full. Oct 2 17:30:29 system lvm[13863]: WARNING: VDO pool my_vdo is now 96.07% full.
30.4.9.1. 파일 시스템의 공간 회수
DISCARD,TRIM 또는 UNMAP 명령을 사용하여 블록이 자유로우는 것을 통신하지 않는 한 공간을 회수할 수 없습니다. DISCARD,TRIM 또는 UNMAP 를 사용하지 않는 파일 시스템의 경우 여유 공간이 바이너리 0으로 구성된 파일을 저장한 다음 해당 파일을 삭제하여 수동으로 회수할 수 있습니다.
DISCARD 요청을 실행하도록 구성할 수 있습니다.
- 실시간 삭제 (또한 온라인 삭제 또는 삭제)
- 실시간 삭제가 활성화되면 파일 시스템은 사용자가 파일을 삭제하고 공간을 확보할 때마다 블록 계층에
REQ_DISCARD요청을 보냅니다. VDO는 이러한 요청을 수정하고 블록이 공유되지 않은 경우 사용 가능한 풀에 공간을 반환합니다.온라인 삭제 기능을 지원하는 파일 시스템의 경우 마운트 시삭제옵션을 설정하여 활성화할 수 있습니다. - batch 삭제
- 일괄 삭제는 파일 시스템에서 사용되지 않는 블록의 블록 계층(VDO)에 알리는 사용자 시작 작업입니다. 이는 파일 시스템을
FITRIM이라는ioctl요청으로 전송하여 수행됩니다.fstrim유틸리티(예:cron)를 사용하여 이ioctl을 파일 시스템으로 보낼 수 있습니다.
삭제 기능에 대한 자세한 내용은 2.4절. “사용되지 않는 블록 삭제” 을 참조하십시오.
30.4.9.2. 파일 시스템이 없는 공간 회수
REQ_DISCARD 명령을 지원하며 공간을 확보하기 위해 적절한 논리 블록 주소에서 VDO로 요청을 전달합니다. 다른 볼륨 관리자를 사용하는 경우 REQ_DISCARD 를 지원하거나 SCSI 장치의 경우 UNMAP 또는 ATA 장치의 경우 TRIM 을 지원해야 합니다.
30.4.9.3. 파이버 채널 또는 이더넷 네트워크에서 공간 회수
UNMAP 명령을 사용하여 씬 프로비저닝된 스토리지 대상의 공간을 확보할 수 있지만, 이 명령에 대한 지원을 광고하려면 SCSI 대상 프레임워크를 구성해야 합니다. 일반적으로 이러한 볼륨은 씬 프로비저닝 을 활성화하여 수행됩니다. UNMAP 에 대한 지원은 다음 명령을 실행하여 Linux 기반 SCSI 이니시에이터에서 확인할 수 있습니다.
# sg_vpd --page=0xb0 /dev/device30.4.10. 논리 볼륨 크기 증가
# vdo growLogical --name=my_vdo --vdoLogicalSize=new_logical_size
30.4.11. 물리 볼륨 크기 증가
- 기본 장치의 크기를 늘립니다.정확한 절차는 장치 유형에 따라 다릅니다. 예를 들어, MBR 파티션의 크기를 조정하려면 13.5절. “fdisk를 사용하여 파티션 크기 조정” 에 설명된 대로
fdisk유틸리티를 사용합니다. growPhysical옵션을 사용하여 VDO 볼륨에 새 물리 스토리지 공간을 추가합니다.#vdo growPhysical --name=my_vdo
30.4.12. Ansible을 사용하여 VDO 자동화
- Ansible 문서: https://docs.ansible.com/
- VDO Ansible 모듈 설명서: https://docs.ansible.com/ansible/latest/modules/vdo_module.html
30.5. 배포 시나리오
30.5.1. iSCSI 대상
그림 30.3. 중복된 블록 스토리지 대상

30.5.2. 파일 시스템
그림 30.4. Deduplicated NAS

30.5.3. LVM
RPC1 에서 LV4까지)이 deduplicated 스토리지 풀에서 생성됩니다. 이러한 방식으로 VDO는 기본 중복 스토리지 풀에 대한 다중 프로토콜 통합 블록/파일 액세스를 지원할 수 있습니다.
그림 30.5. 중복된 통합 스토리지
30.5.4. 암호화
그림 30.6. 암호화와 함께 VDO 사용
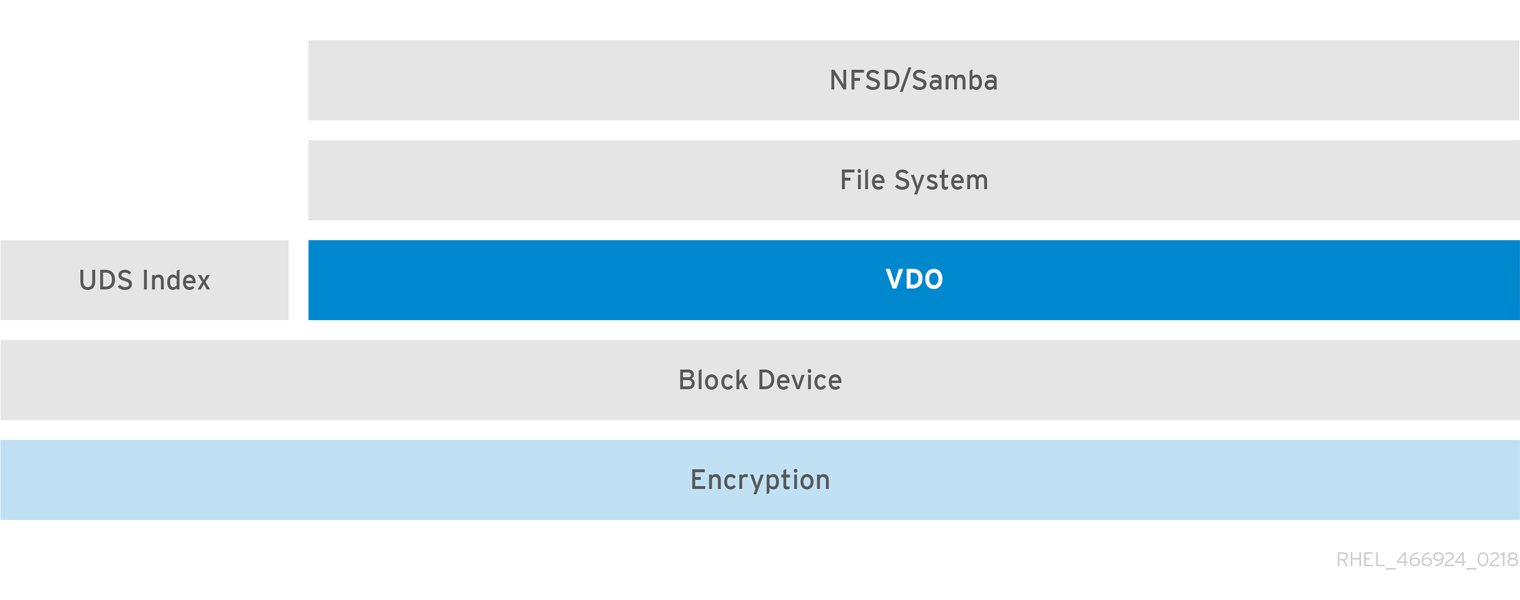
30.6. VDO 튜닝
30.6.1. VDO 튜닝 소개
30.6.2. VDO 아키텍처 배경 정보
- 논리 영역 스레드
- 문자열
kvdo:logQ를 포함한 프로세스 이름이 있는 논리 스레드는 VDO 장치의 사용자에게 제공되는 LBN(Logical Block Number)과 기본 스토리지 시스템의 물리적 블록 번호(PBN) 간의 매핑을 유지합니다. 또한 동일한 블록에 쓰기 위해 두 개의 I/O 작업이 동시에 처리되지 않도록 잠금을 구현합니다. 논리 영역 스레드는 읽기 및 쓰기 작업 중 활성화되어 있습니다.LBN은 청크로 나뉩니다( 블록 맵 페이지에는 3MB 이상의 LBN이 포함되어 있으며 이러한 청크는 스레드 간에 분할되는 영역으로 그룹화됩니다.처리는 스레드 전반에 걸쳐 상당히 균등하게 배포되어야 하지만 일부 의도하지 않은 액세스 패턴은 때때로 하나의 스레드에서 또는 다른 스레드에서 작동하는 데 집중할 수 있습니다. 예를 들어, 지정된 블록 맵 페이지 내에서 LBN에 자주 액세스하는 경우 논리 스레드 중 하나가 이러한 모든 작업을 처리합니다.logical zone 스레드 수를 통해 organization's command의--vdoLogicalThreads=thread count옵션을 사용하여 제어할 수 있습니다. - 물리적 영역 스레드
- 물리적, 또는
kvdo:physQ, 스레드는 데이터 블록 할당을 관리하고 참조 개수를 유지 관리합니다. 쓰기 작업 중에 활성화됩니다.LBN과 마찬가지로 PBN은 slabs 라는 청크로 나뉘며, 이는 추가로 영역으로 나뉘어 처리 부하를 분산하는 작업자 스레드에 할당됩니다.physical zone 스레드의 수는 organization 명령의--vdoPhysicalThreads=thread count옵션을 사용하여 제어할 수 있습니다. - I/O 제출 스레드
kvdo:bioQ스레드는 VDO에서 스토리지 시스템으로 블록 I/O(bio) 작업을 제출합니다. 다른 VDO 스레드에 의해 큐잉된 I/O 요청을 가져와서 기본 장치 드라이버에 전달합니다. 이러한 스레드는 장치와 관련된 데이터 구조와 통신하거나 장치 드라이버의 커널 스레드를 처리할 요청을 설정할 수 있습니다. 기본 장치의 요청 대기열이 가득 차면 I/O 요청을 제출할 수 있으므로 이 작업은 처리 지연을 방지하기 위해 전용 스레드에 의해 수행됩니다.이러한 스레드가ps또는top유틸리티로D상태에 자주 표시되는 경우 VDO는 스토리지 시스템을 I/O 요청과 함께 사용량에 따라 자주 유지합니다. 일부 SSD는 또는 요청 처리가 파이프라인될 수 있으므로 스토리지 시스템이 병렬로 여러 요청을 처리할 수 있는 경우 유용합니다. 이러한 기간 동안 스레드 CPU 사용률이 매우 낮으면 I/O 제출 스레드 수를 줄일 수 있습니다.CPU 사용량 및 메모리 경합은 VDO 아래의 장치 드라이버에 따라 다릅니다. 더 많은 스레드가 추가될 때 I/O 요청당 CPU 사용률이 증가하면 해당 장치 드라이버에서 CPU, 메모리 또는 잠금 경합이 있는지 확인합니다.EgressIP 명령의--vdoBioThreads=thread count옵션을 사용하여 I/O 제출 스레드 수를 제어할 수 있습니다.- CPU 처리 스레드
kvdo:cpuQ스레드는 컴퓨팅 해시 값과 같은 CPU 집약적인 작업을 수행하거나 차단되지 않거나 다른 스레드 유형과 관련된 데이터 구조에 대한 배타적 액세스 권한이 필요한 데이터 블록을 수행하기 위해 존재합니다.maintains 명령의--vdoCpuThreads=thread count옵션을 사용하여 CPU 처리 스레드 수를 제어할 수 있습니다.- I/O 승인 스레드
kvdo:ackQ스레드는 I/O 요청의 완료를 보고하도록 atop VDO(예: 커널 페이지 캐시 또는 애플리케이션 프로그램 스레드)가 있는 모든 항목에 콜백을 발행합니다. CPU 시간 요구 사항 및 메모리 경합은 이 다른 커널 수준 코드에 따라 달라집니다.acknowledgement 스레드 수는 EgressIP 명령의--vdoAckThreads=thread count옵션을 사용하여 제어할 수 있습니다.- 스케일링할 수 없는 VDO 커널 스레드:
- 중복 스레드
kvdo:dedupeQ스레드는 대기 중인 I/O 요청과 UDS 연락처를 사용합니다. 서버가 충분히 빠르게 요청을 처리할 수 없거나 커널 메모리가 다른 시스템 활동에 의해 제한되는 경우 소켓 버퍼를 채울 수 있으므로 이 작업은 별도의 스레드에 의해 수행되므로 스레드가 차단해야 하는 경우 다른 VDO 처리가 계속될 수 있습니다. 지연 후(초) 후에 I/O 요청을 건너뛰는 시간 초과 메커니즘도 있습니다.- journal 스레드
kvdo:journalQ스레드는 복구 저널을 업데이트하고 쓰기를 위해 저널 블록을 예약합니다. VDO 장치는 한 개의 저널만 사용하므로 이 작업은 스레드 간에 분할할 수 없습니다.- Packer 스레드
kvdo:packerQ스레드는 압축이 활성화될 때 쓰기 경로에서 활성화되며, 낭비된 공간을 최소화하기 위해kvdo:cpuQ스레드에 의해 압축된 데이터 블록을 수집합니다. 하나의 패더 데이터 구조가 있어서 VDO 장치당 하나의 패더 스레드가 있습니다.
30.6.3. 튜닝할 값
30.6.3.1. CPU/메모리
30.6.3.1.1. 논리, 물리적, cpu, ack 스레드 수
30.6.3.1.2. CPU 유사성 및 NUMA
taskset 유틸리티를 사용하여 한 노드에서 VDO 스레드를 수집합니다. 다른 VDO 관련 작업을 동일한 노드에서 실행할 수도 있는 경우 경합을 추가로 줄일 수 있습니다. 이 경우 한 노드에 처리 수요를 따라가는 CPU 성능이 부족하면 다른 노드로 이동할 스레드를 선택할 때 메모리 경합을 고려해야 합니다. 예를 들어, 스토리지 장치의 드라이버에 유지 관리해야 하는 상당한 수의 데이터 구조가 있는 경우 장치의 인터럽트 처리 및 VDO의 I/O 제출(장치의 드라이버 코드를 호출하는 BIOS 스레드)을 다른 노드로 이동하는 데 도움이 될 수 있습니다. I/O 승인(ack threads) 및 상위 I/O 제출 스레드(사용자 모드 스레드)(직접 I/O 또는 커널의 페이지 캐시 플러시 스레드)를 연결하는 것도 좋은 방법입니다.
30.6.3.1.3. 빈도 제한
/sys/devices/system/cpu/cpu*/cpufreq/scaling_governor 파일에 문자열 성능을 쓰는 경우 더 나은 결과가 발생할 수 있습니다. 이러한 sysfs 노드가 없으면 Linux 또는 시스템의 BIOS에서 CPU 빈도 관리를 구성하는 다른 옵션을 제공할 수 있습니다.
30.6.3.2. 캐싱
30.6.3.2.1. 블록 맵 캐시
--blockMapCacheSize=megabytes
옵션을 사용하여 늘릴 수 있습니다. 더 큰 캐시를 사용하면 임의의 액세스 워크로드에 상당한 이점이 발생할 수 있습니다.
30.6.3.2.2. 읽기 캐시
--readCache={enabled | disabled}
옵션은 읽기 캐시가 사용되는지 여부를 제어합니다. 활성화하면 캐시의 최소 크기가 8MB지만
--readCacheSize=megabytes
옵션을 사용하여 늘릴 수 있습니다. 읽기 캐시를 관리하면 약간의 오버헤드가 발생하므로 스토리지 시스템이 충분히 빠른 경우 성능이 저하되지 않을 수 있습니다. 읽기 캐시는 기본적으로 비활성화되어 있습니다.
30.6.3.3. 스토리지 시스템 I/O
30.6.3.3.1. Bio Threads
30.6.3.3.2. IRQ 처리
%hi 표시기)에 대한 많은 사이클이 필요할 수 있습니다. 이 경우 IRQ 처리를 특정 코어에 할당하고 해당 코어에서 실행되지 않도록 VDO 커널 스레드의 CPU 선호도를 조정하는 데 도움이 될 수 있습니다.
30.6.3.4. 최대 Discard Sector
/sys/kvdo/max_discard_sectors 를 통해 조정할 수 있습니다. 기본값은 8개 섹터입니다(즉, 1개의 4KB 블록). VDO는 여전히 루프에서 이를 처리할 수 있지만 한 번에 하나의 메타데이터 업데이트가 저널에 기록되고 다음 블록을 시작하기 전에 디스크에 플러시합니다.
30.6.4. Bottlenecks 확인
상단 또는 ps 와 같은 유틸리티에서 볼 수 있듯이 70 % 이상의 스레드 또는 CPU 사용률은 일반적으로 너무 많은 작업이 한 스레드 또는 하나의 CPU에 집중되고 있음을 의미합니다. 그러나 경우에 따라 VDO 스레드가 CPU에서 실행되도록 예약되었지만 실제로 아무 일도 발생하지 않았습니다. 이 시나리오는 과도한 하드웨어 인터럽트 처리기 처리, 코어 또는 NUMA 노드 간의 메모리 경합 또는 회전 잠금에 대한 경합으로 발생할 수 있습니다.
top 유틸리티를 사용하여 시스템 성능을 검사할 때 Red Hat은 top -H 를 실행하여 모든 프로세스 스레드를 별도로 표시하고 1 f j 키를 입력한 다음 Enter/Return 키를 입력하면 top 명령은 개별 CPU 코어에 로드를 표시하고 각 프로세스 또는 스레드가 마지막으로 실행된 CPU를 식별합니다. 이 정보는 다음 통찰력을 제공할 수 있습니다.
- 코어에
%id(idle) 및%wa(waiting-for-I/O) 값이 낮은 경우 일종의 작업에서 계속 사용되고 있습니다. - 코어의
%hi값이 매우 낮으면 해당 코어는 일반 처리 작업을 수행하며 커널 스케줄러로 부하 분산됩니다. 해당 세트에 코어를 추가하면 NUMA 경합이 발생하지 않는 한 부하를 줄일 수 있습니다. - 코어의
%hi가 몇 % 이상이고 해당 코어에 하나의 스레드만 할당되고%id및%wa가 0이면 코어가 오버 커밋되고 스케줄러가 상황을 처리하지 않습니다. 이 경우 커널 스레드 또는 장치 인터럽트 처리를 별도의 코어에 계속 할당해야 합니다.
perf 유틸리티는 많은 CPU의 성능 카운터를 검사할 수 있습니다. Red Hat은 perf top 하위 명령을 스레드 또는 프로세서가 수행하는 작업을 검사하는 시작점으로 사용할 것을 제안합니다. 예를 들어, bioQ 스레드가 회전 잠금을 획득하려는 많은 사이클을 소비하고 있는 경우 VDO 미만의 장치 드라이버에 너무 많은 경합이 있을 수 있으며, bioQ 스레드의 수를 줄이면 상황을 완화할 수 있습니다. CPU를 많이 사용하는 경우(대개 회전 잠금 또는 다른 위치에서) NUMA 노드 간 경합이 다른 노드에서 실행되는 경우(예: bioQ 스레드와 장치 인터럽트 처리기)도 나타낼 수 있습니다. 프로세서가 이를 지원하는 경우 stalled-cycles-backend,cache-misses, node-load-misses 와 같은 카운터가 관심을 가질 수 있습니다.
sar 유틸리티는 여러 시스템 통계에 대한 정기적인 보고서를 제공할 수 있습니다. sar -d 1 명령은 블록 장치 사용률 수준( 진행 중인 I/O 작업이 하나 이상 있음)과 큐 길이(초당 한 번 대기 중인 I/O 요청 수)를 보고합니다. 그러나 모든 블록 장치 드라이버가 이러한 정보를 보고할 수 있는 것은 아니므로 sar usefulness는 사용 중인 장치 드라이버에 따라 달라질 수 있습니다.
30.7. VDO 명령
30.7.1. vdo
kvdo 및 UDS 구성 요소를 모두 관리합니다.
30.7.1.1. 개요
vdo { activate | changeWritePolicy | create | deactivate | disableCompression | disableDeduplication | enableCompression | enableDeduplication | growLogical | growPhysical | list | modify | printConfigFile | remove | start | status | stop }
[ options... ]
30.7.1.2. 하위 명령
표 30.4. VDO 하위 명령
| 하위 명령 | 설명 |
|---|---|
create
|
VDO 볼륨 및 관련 인덱스를 만들고 이를 사용할 수 있도록 합니다.
activate=disabled 가 지정되면 VDO 볼륨이 생성되지만 사용할 수 없습니다. 기존 파일 시스템 또는 포맷된 VDO 볼륨을 덮어쓰지 않는 한, 기존 파일 시스템 또는 포맷의 VDO 볼륨을 덮어쓰 지 않습니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
제거
|
하나 이상의 중지된 VDO 볼륨 및 관련 인덱스를 제거합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
start
|
하나 이상의 중지됨, VDO 볼륨 및 관련 서비스를 활성화합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
중지
|
실행 중인 VDO 볼륨 및 관련 서비스를 하나 이상 중지합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
activate
|
하나 이상의 VDO 볼륨을 활성화합니다.
start
|
deactivate
|
하나 이상의 VDO 볼륨을 비활성화합니다. 비활성화된 볼륨은
start
|
status
|
VDO 시스템 및 볼륨 상태를 YAML 형식으로 보고합니다. 이 명령은 루트 권한이 필요하지 않지만, 를 사용하지 않고 실행하면 정보가 불완전합니다. 적용 가능한 옵션은 다음과 같습니다.
제공된 출력은 표 30.6. “VDO 상태 출력” 를 참조하십시오.
|
list
|
시작된 VDO 볼륨 목록을 표시합니다.
-all이 지정되면 시작된 볼륨 및 시작되지 않은 볼륨을 모두 표시합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
modify
|
하나 또는 모든 VDO 볼륨의 구성 매개 변수를 수정합니다. 변경 사항은 VDO 장치를 다음에 시작할 때 적용됩니다. 이미 실행 중인 장치는 영향을 받지 않습니다. 적용 가능한 옵션은 다음과 같습니다.
|
changeWritePolicy
|
하나 또는 모든 실행 중인 VDO 볼륨의 쓰기 정책을 수정합니다. 이 명령은 root 권한으로 실행해야 합니다.
|
enableDeduplication
|
하나 이상의 VDO 볼륨에서 중복 제거를 활성화합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
disableDeduplication
|
하나 이상의 VDO 볼륨에서 중복 제거를 비활성화합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
enableCompression
|
하나 이상의 VDO 볼륨에서 압축을 활성화합니다. VDO 볼륨이 실행 중인 경우 즉시 적용됩니다. VDO 볼륨이 실행 중이지 않은 경우 다음에 VDO 볼륨이 시작될 때 압축이 활성화됩니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
disableCompression
|
하나 이상의 VDO 볼륨에서 압축을 비활성화합니다. VDO 볼륨이 실행 중인 경우 즉시 적용됩니다. VDO 볼륨이 실행 중이 아닌 경우 다음에 VDO 볼륨이 시작될 때 압축이 비활성화됩니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
growLogical
|
VDO 볼륨에 논리 공간을 추가합니다. 볼륨이 있어야 하며 실행 중이어야 합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
growPhysical
|
VDO 볼륨에 물리적 공간을 추가합니다. 볼륨이 있어야 하며 실행 중이어야 합니다. 이 명령은 root 권한으로 실행해야 합니다. 적용 가능한 옵션은 다음과 같습니다.
|
printConfigFile
|
구성 파일을
stdout 에 출력합니다. 이 명령에는 root 권한이 필요합니다. 적용 가능한 옵션은 다음과 같습니다.
|
30.7.1.3. 옵션
표 30.5. VDO 옵션
| 옵션 | 설명 |
|---|---|
--indexMem=gigabytes
| UDS 서버 메모리의 양을 gigabytes로 지정합니다. 기본 크기는 1GB입니다. 특수 10진수 값 0.25, 0.5, 0.75는 양의 정수로 사용할 수 있습니다. |
--sparseIndex={enabled | disabled}
| 스파스 인덱싱을 활성화하거나 비활성화합니다. 기본값은 disabled 입니다. |
--all
| 명령을 구성된 모든 VDO 볼륨에 적용해야 함을 나타냅니다. name . name 과 함께 사용할 수 없습니다. |
--blockMapCacheSize=megabytes
| 블록 맵 페이지를 캐싱하기 위해 할당된 메모리 양을 지정합니다. 값은 4096의 배수여야 합니다. B(ytes), K(GB), M(egabytes), G(GB), T(erabytes), P(etabytes) 또는 E(xabytes) 접미사로 값을 사용하는 것은 선택 사항입니다. 접미사가 제공되지 않으면 값은 메가바이트로 해석됩니다. 기본값은 128M입니다. 값은 128M이고 16T보다 작아야 합니다. 메모리 오버헤드는 15 %입니다. |
--blockMapPeriod=period
| 캐시된 페이지가 디스크에 플러시되기 전에 누적될 수 있는 블록 맵 업데이트 수를 결정하는 1에서 16380 사이의 값입니다. 값이 클수록 정상적인 작업 중에 성능이 저하되는 비용으로 충돌이 발생한 후 복구 시간이 단축됩니다. 기본값은 16380입니다. 이 매개 변수를 조정하기 전에 Red Hat 담당자와 상의하십시오. |
--compression={enabled | disabled}
| VDO 장치 내에서 압축을 활성화하거나 비활성화합니다. 기본값은 enabled입니다. 성능을 극대화하거나 압축이 불가능한 데이터 처리 속도를 높이기 위해 필요한 경우 압축을 비활성화할 수 있습니다. |
--confFile=file
| 대체 구성 파일을 지정합니다. 기본값은 /etc/vdoconf.yml 입니다. |
--deduplication={enabled | disabled}
| VDO 장치 내에서 중복 제거를 활성화하거나 비활성화합니다. 기본값은 enabled 입니다. 데이터가 제대로 중복 제거 속도를 원하지 않는 경우에는 중복 제거가 비활성화될 수 있지만 압축은 여전히 필요합니다. |
--emulate512={enabled | disabled}
| 512바이트 블록 장치 에뮬레이션 모드를 활성화합니다. 기본값은 disabled 입니다. |
--force
| VDO 볼륨을 중지하기 전에 마운트된 파일 시스템을 마운트 해제합니다. |
--forceRebuild
| 읽기 전용 VDO 볼륨을 시작하기 전에 오프라인 다시 빌드를 강제 적용하여 온라인 상태가 되고 사용 가능하게 만들 수 있습니다. 이 옵션을 사용하면 데이터가 손실되거나 손상될 수 있습니다. |
--help
| EgressIP 유틸리티에 대한 문서 를 표시합니다. |
--logfile=pathname
| 이 스크립트의 로그 메시지를 전달할 파일을 지정합니다. 경고 및 오류 메시지는 항상 syslog에 기록됩니다. |
--name=volume
| 지정된 VDO 볼륨에서 실행됩니다. --all 과 함께 사용할 수 없습니다. |
--device=device
| VDO 스토리지에 사용할 장치의 절대 경로를 지정합니다. |
--activate={enabled | disabled}
| 인수 disabled 는 VDO 볼륨만 생성해야 함을 나타냅니다. 볼륨이 시작되거나 활성화되지 않습니다. 기본값은 enabled 입니다. |
--vdoAckThreads=thread count
| 요청된 VDO I/O 작업의 승인 완료에 사용할 스레드 수를 지정합니다. 기본값은 1입니다. 값은 0 이상이어야 하며 100보다 작거나 같아야 합니다. |
--vdoBioRotationInterval=I/O count
| 작업을 다음으로 보내기 전에 각 bio-submission 스레드에 대해 큐에 추가할 I/O 작업 수를 지정합니다. 기본값은 64입니다. 값은 1024 이상이어야 합니다. |
--vdoBioThreads=thread count
| 스토리지 장치에 I/O 작업을 제출하는 데 사용할 스레드 수를 지정합니다. 최소값은 1이며 최대값은 100입니다. 기본값은 4입니다. 값은 1 이상이어야 하며 100보다 작아야 합니다. |
--vdoCpuThreads=thread count
| 해시 또는 압축과 같은 CPU 집약적 작업에 사용할 스레드 수를 지정합니다. 기본값은 2입니다. 값은 1 이상이어야 하며 100보다 작거나 같아야 합니다. |
--vdoHashZoneThreads=thread count
| 블록 데이터에서 계산된 해시 값에 따라 VDO 처리의 일부를 세분화할 수 있는 스레드 수를 지정합니다. 기본값은 1 입니다. 값은 0 이상이어야 하며 100보다 작거나 같아야 합니다. EgressIPHashZoneThreads, 192.168.LogicalThreads 및 EgressIP PhysicalThreads 는 모두 0 또는 모두 0이 아니어야 합니다. |
--vdoLogicalThreads=thread count
| 블록 데이터에서 계산된 해시 값에 따라 VDO 처리의 일부를 세분화할 수 있는 스레드 수를 지정합니다. 값은 0 이상이어야 하며 100보다 작아야 합니다. 9 이상의 논리 스레드 수를 사용하려면 충분히 큰 블록 맵 캐시 크기를 명시적으로 지정해야 합니다. EgressIPHashZoneThreads, msgLogicalThreads 및 EgressIP PhysicalThreads 는 모두 0이거나 모두 0이 아닌 값이어야 합니다. 기본값은 1입니다. |
--vdoLogLevel=level
| VDO 드라이버 로그 수준을 지정합니다. critical, error, warning, notice, info 또는 debug. 수준은 대소문자를 구분합니다. 기본값은 info 입니다. |
--vdoLogicalSize=megabytes
| 논리 VDO 볼륨 크기를 메가바이트 단위로 지정합니다. S(ectors), B(ytes), M(egabytes), G(GB), T(GB), P(etabytes) 또는 E(xabytes) 접미사로 값을 사용하는 것은 선택 사항입니다. |
--vdoPhysicalThreads=thread count
| 물리적 블록 주소를 기반으로 VDO 처리 부분을 세분화할 수 있는 스레드 수를 지정합니다. 값은 0 이상이어야 하며 16보다 작거나 같아야 합니다. 첫 번째 이후의 각 추가 스레드는 추가 10MB의 RAM을 사용합니다. EgressIPPhysicalThreads, EgressIPHashZoneThreads,${ LogicalThreads 는 모두 0 이거나 모두 0이 아닌 값이어야 합니다. 기본값은 1입니다. |
--readCache={enabled | disabled}
| VDO 장치 내에서 읽기 캐시를 활성화하거나 비활성화합니다. 기본값은 disabled 입니다. 쓰기 워크로드에 높은 수준의 중복 제거가 있거나 고도로 압축 가능한 데이터의 읽기 집약적인 워크로드가 필요한 경우 캐시가 활성화되어야 합니다. |
--readCacheSize=megabytes
| 추가 VDO 장치 읽기 캐시 크기를 메가바이트 단위로 지정합니다. 이 공간은 시스템에 정의된 최소 공간도 추가됩니다. B(ytes), K(GB), M(egabytes), G(GB), T(erabytes), P(etabytes) 또는 E(xabytes) 접미사로 값을 사용하는 것은 선택 사항입니다. 기본값은 0M입니다. BIOS 스레드에 따라 지정된 MB의 읽기 캐시당 1.12MB의 메모리가 사용됩니다. |
--vdoSlabSize=megabytes
| VDO가 증가한 증가의 크기를 지정합니다. 작은 크기를 사용하면 수용할 수 있는 총 최대 물리적 크기가 제한됩니다. 128M에서 32G 사이의 전원이어야 합니다. 기본값은 2G입니다. S(ectors), B(ytes), M(egabytes), G(GB), T(GB), P(etabytes) 또는 E(xabytes) 접미사로 값을 사용하는 것은 선택 사항입니다. |
--verbose
| 명령을 실행하기 전에 출력합니다. |
--writePolicy={ auto | sync | async }
| 쓰기 정책을 지정합니다.
|
status
하위 명령은 다음과 같이 키로 나뉘며 YAML 형식으로 다음 정보를 반환합니다.
표 30.6. VDO 상태 출력
| 키 | 설명 | |
|---|---|---|
| VDO 상태 | 이 키의 정보는 호스트 및 날짜의 이름과 상태 조회가 수행되는 시간을 다룹니다. 이 영역에서 보고된 매개변수는 다음과 같습니다. | |
| 노드 | VDO가 실행 중인 시스템의 호스트 이름입니다. | |
| 날짜 | EgressIP status 명령이 실행되는 날짜 및 시간입니다. | |
| 커널 모듈 | 이 키의 정보는 구성된 커널을 다룹니다. | |
| 로드됨 | 커널 모듈이 로드되었는지 여부(True 또는 False) | |
| 버전 정보 | 구성된 kvdo 버전에 대한 정보입니다. | |
| 설정 | 이 키의 정보는 VDO 구성 파일의 위치와 상태를 다룹니다. | |
| 파일 | VDO 구성 파일의 위치입니다. | |
| 마지막으로 변경된 사항 | VDO 구성 파일의 마지막 수정 날짜입니다. | |
| VDOs | 모든 VDO 볼륨에 대한 구성 정보를 제공합니다. 각 VDO 볼륨에 대해 보고된 매개 변수는 다음과 같습니다. | |
| 블록 크기 | VDO 볼륨의 블록 크기(바이트)입니다. | |
| 512바이트 에뮬레이션 | 볼륨이 512바이트 에뮬레이션 모드에서 실행 중인지 여부를 나타냅니다. | |
| 중복 제거 활성화 | 볼륨에 중복 제거가 활성화되었는지 여부. | |
| 논리 크기 | VDO 볼륨의 논리 크기입니다. | |
| 물리적 크기 | VDO 볼륨의 기본 물리 스토리지의 크기입니다. | |
| 정책 작성 | 쓰기 정책(sync 또는 async)의 구성된 값입니다. | |
| VDO 통계 | EgressIPstats 유틸리티의 출력입니다. | |
30.7.2. vdostats
IPstats 유틸리티는 Linux df 유틸리티와 유사한 형식으로 구성된 각 장치에 대한 통계를 표시합니다.
않으면 EgressIPstats 유틸리티의 출력이 불완전할 수 있습니다.
30.7.2.1. 개요
vdostats [ --verbose | --human-readable | --si | --all ] [ --version ] [ device ...]
30.7.2.2. 옵션
표 30.7. EgressIPstats 옵션
| 옵션 | 설명 |
|---|---|
--verbose
|
하나 이상의 VDO 장치에 대한 사용률 및 블록 I/O(bios) 통계를 표시합니다. 자세한 내용은 표 30.9. “-2021-stats --verbose 출력” 를 참조하십시오.
|
--human-readable
| 블록 값을 읽을 수 있는 형식으로 표시합니다(Base 2: 1 KB = 210 bytes = 1024 bytes). |
--si
| --si 옵션은 SI 단위를 사용하도록 --human-readable 옵션의 출력을 수정합니다(기본 10: 1KB = 10바이트 = 1000바이트). --human-readable 옵션을 제공하지 않으면 --si 옵션이 적용되지 않습니다. |
--all
| 이 옵션은 이전 버전과의 호환성을 위해서만 제공됩니다. 이제 --verbose 옵션과 동일합니다. |
--version
| -2021 -stats 버전을 표시합니다. |
장치..
| 보고할 하나 이상의 특정 볼륨을 지정합니다. 이 인수가 생략된 경우-2021 -stats 는 모든 장치에 대해 보고합니다. |
30.7.2.3. 출력 결과
Device 1K-blocks Used Available Use% Space Saving% /dev/mapper/my_vdo 1932562432 427698104 1504864328 22% 21%
표 30.8. 기본 EgressIPstats 출력
| 항목 | 설명 |
|---|---|
| 장치 | VDO 볼륨의 경로입니다. |
| 1K-블록 | VDO 볼륨용으로 할당된 총 1K 블록 수(= 물리 볼륨 크기 * 블록 크기 / 1024) |
| 사용됨 | VDO 볼륨에 사용되는 총 1K 블록 수 (= 물리적 블록 사용 * 블록 크기 / 1024) |
| Available | VDO 볼륨에서 사용 가능한 총 1K 블록 수 (= 물리적 블록 무료 * 블록 크기 / 1024) |
| % 사용 | VDO 볼륨에 사용되는 물리적 블록의 백분율 (= 사용 블록 / 할당된 블록 * 100) |
| 공간 절약% | VDO 볼륨에 저장된 물리적 블록의 백분율 (= [logical 블록 사용 - 사용된 물리 블록] / 논리 블록) |
--human-readable 옵션은 블록 수를 기존 단위로 변환합니다(1KB = 1024바이트).
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 1.8T 407.9G 1.4T 22% 21%
--human-readable 및 --si 옵션은 블록 수를 SI 단위(1KB = 1000바이트)로 변환합니다.
Device Size Used Available Use% Space Saving% /dev/mapper/my_vdo 2.0T 438G 1.5T 22% 21%
--verbose (표 30.9. “-2021-stats --verbose 출력”) 옵션은 하나의 VDO 장치에 대한 YAML 형식으로 VDO 장치 통계를 표시합니다.
표 30.9. -2021-stats --verbose 출력
| 항목 | 설명 |
|---|---|
| 버전 | 이러한 통계의 버전입니다. |
| 릴리스 버전 | VDO 릴리스 버전입니다. |
| 데이터 블록 사용 | 데이터를 저장하기 위해 VDO 볼륨에서 현재 사용 중인 물리적 블록 수입니다. |
| overhead 블록 사용 | VDO 볼륨에서 현재 사용 중인 물리적 블록 수로 VDO 메타데이터를 저장합니다. |
| 논리 블록 사용 | 현재 매핑된 논리 블록 수입니다. |
| 물리적 블록 | VDO 볼륨에 할당된 총 물리적 블록 수입니다. |
| 논리 블록 | VDO 볼륨에서 매핑할 수 있는 최대 논리 블록 수입니다. |
| 1K-blocks | VDO 볼륨용으로 할당된 총 1K 블록 수(= 물리 볼륨 크기 * 블록 크기 / 1024) |
| 1K 블록 사용 | VDO 볼륨에 사용되는 총 1K 블록 수 (= 물리적 블록 사용 * 블록 크기 / 1024) |
| 1K 블록 사용 가능 | VDO 볼륨에서 사용 가능한 총 1K 블록 수 (= 물리적 블록 무료 * 블록 크기 / 1024) |
| 사용된 백분율 | VDO 볼륨에 사용되는 물리적 블록의 백분율 (= 사용 블록 / 할당된 블록 * 100) |
| 저장 백분율 | VDO 볼륨에 저장된 물리적 블록의 백분율 (= [logical 블록 사용 - 사용된 물리 블록] / 논리 블록) |
| 블록 맵 캐시 크기 | 블록 맵 캐시의 크기(바이트)입니다. |
| 정책 작성 | 활성 쓰기 정책(sync 또는 async)입니다. 이를 통해 chapter changeWritePolicy --writePolicy=auto|sync|async 를 통해 구성됩니다. |
| 블록 크기 | VDO 볼륨의 블록 크기(바이트)입니다. |
| 완료된 복구 수 | VDO 볼륨이 불명확한 종료에서 복구된 횟수입니다. |
| 읽기 전용 복구 수 | VDO 볼륨이 읽기 전용 모드( vdo start --forceRebuild를 통해) 복구된 횟수입니다. |
| 작동 모드 | VDO 볼륨이 정상적으로 작동하는지, 복구 모드인지 또는 읽기 전용 모드인지 여부를 나타냅니다. |
| 복구 진행 상황 (%) | 볼륨이 복구 모드에 없는 경우 온라인 복구 진행 상황 또는 N/A 을 나타냅니다. |
| 작성된 압축된 조각 | VDO 볼륨이 마지막으로 다시 시작된 이후 작성된 압축된 조각의 수입니다. |
| 압축된 블록 | VDO 볼륨이 마지막으로 다시 시작된 이후 작성된 압축된 데이터의 물리적 블록 수입니다. |
| 팩커의 압축된 조각 | 아직 기록되지 않은 처리된 조각의 수입니다. |
| Slab count | 총 slabs 수입니다. |
| Slabs가 열렸습니다. | 블록이 할당된 총 slabs 수입니다. |
| Slabs reopened | slabs 횟수가 VDO가 시작된 이후 다시 열었습니다. |
| journal 디스크 전체 수 | 복구 저널이 가득 차 있었기 때문에 요청에서 복구 저널 항목을 만들 수 없는 횟수입니다. |
| 요청한 저널 커밋 수 | 복구 저널에서 요청한 slab journal 커밋 횟수입니다. |
| 배치된 journal 항목 | 저널 항목 쓰기 수 - 기록된 저널 항목 수입니다. |
| 저널 항목이 시작됨 | 메모리에 생성된 저널 항목의 수입니다. |
| 저널 항목 쓰기 | 제출된 쓰기의 저널 항목 수는 스토리지에 커밋된 저널 항목 수입니다. |
| 작성된 저널 항목 | 쓰기가 실행된 총 저널 항목 수입니다. |
| 커밋된 journal 항목 | 스토리지에 기록된 저널 항목 수입니다. |
| journal 블록 배치 | 저널 블록 쓰기 수 - 작성된 저널 블록 수입니다. |
| journal 블록 시작 | 메모리에 삽입된 저널 블록 수입니다. |
| journal 블록 작성 | 기록된 저널 블록 수(활성 메모리에 metadata타 포함)는 커밋된 저널 블록 수입니다. |
| 작성된 저널 항목 | 쓰기가 실행된 총 저널 블록 수입니다. |
| 커밋된 journal 블록 | 스토리지에 기록된 저널 블록 수입니다. |
| Slab 저널 디스크 전체 수 | 디스크에 있는 slab 저널이 가득 찬 횟수입니다. |
| Slab 저널 플러시 수 | 플러시 임계값을 초과하는 slab 저널에 항목이 추가된 횟수입니다. |
| Slab 저널 차단 수 | 차단 임계값을 초과하는 slab 저널에 항목이 추가된 횟수입니다. |
| Slab 저널 블록 작성 | 발행된 slab 저널 블록 쓰기 수입니다. |
| Slab 저널의 사용량이 많은 수 | slab 저널 쓰기를 기다리는 쓰기 요청이 차단되는 횟수입니다. |
| Slab summary 블록 작성 | slab summary 블록 쓰기 수입니다. |
| 기록된 참조 블록 | 발행된 참조 블록 쓰기 수입니다. |
| 블록 맵 더티 페이지 | 블록 맵 캐시의 더티 페이지 수입니다. |
| 블록 맵 정리 페이지 | 블록 맵 캐시의 정리 페이지 수입니다. |
| 블록 맵 여유 페이지 | 블록 맵 캐시의 사용 가능한 페이지 수입니다. |
| 블록 맵 실패 페이지 | 쓰기 오류가 있는 블록 맵 캐시 페이지의 수입니다. |
| 블록 맵 수신 페이지 | 캐시에서 읽고 있는 블록 맵 캐시 페이지의 수입니다. |
| 블록 맵 발신 페이지 | 작성 중인 블록 맵 캐시 페이지 수입니다. |
| 블록 맵 캐시 부족 | 필요한 경우 무료 페이지를 사용할 수 없는 횟수입니다. |
| 블록 맵 읽기 수 | 총 블록 맵 페이지 수가 표시됩니다. |
| 블록 맵 쓰기 수 | 총 블록 맵 페이지 쓰기 수입니다. |
| 블록 맵 읽기에 실패했습니다. | 총 블록 맵의 읽기 오류 수입니다. |
| 블록 맵이 쓰기에 실패했습니다. | 총 블록 맵 쓰기 오류 수입니다. |
| 블록 맵 회수됨 | 회수된 총 블록 맵 페이지 수입니다. |
| 블록 맵 읽기 발신 | 작성 중인 페이지에 대해 읽은 총 블록 맵 수입니다. |
| 캐시에 있는 블록 맵 | 총 블록 맵 캐시 적중 수입니다. |
| 블록 맵 삭제 필요 | 페이지가 취소되어야 하는 총 블록 맵 요청 수입니다. |
| 블록 맵이 페이지 대기 | 페이지를 기다려야 하는 총 요청 수입니다. |
| 블록 맵 가져오기 필요 | 페이지를 가져오는 데 필요한 총 요청 수입니다. |
| 로드된 블록 맵 페이지 | 가져오는 총 페이지 수입니다. |
| 저장된 블록 맵 페이지 | 저장된 총 페이지 수입니다. |
| 블록 맵 플러시 수 | 블록 맵에서 발행한 총 플러시 수입니다. |
| PBN 수에 대한 잘못된 조언 | 인덱스가 잘못된 조언을 반환한 횟수 |
| 공간 오류 수가 없습니다. | VDO 볼륨이 공간이 부족하여 실패한 쓰기 요청 수입니다. |
| 오류 수만 읽기 | VDO 볼륨이 읽기 전용 모드이므로 실패한 쓰기 요청 수입니다. |
| 인스턴스 | VDO 인스턴스입니다. |
| 512바이트 에뮬레이션 | 볼륨에 대해 512바이트 에뮬레이션이 on 또는 off인지 여부를 나타냅니다. |
| 현재 VDO IO 요청이 진행 중입니다. | VDO가 현재 처리 중인 I/O 요청 수입니다. |
| 진행 중인 최대 VDO IO 요청 | VDO가 처리한 최대 동시 I/O 요청 수입니다. |
| 현재 중복 쿼리 | 현재 비행 중 중복 제거 쿼리 수입니다. |
| 최대 중복 쿼리 | 진행 중인 중복 제거 쿼리의 최대 수입니다. |
| Ddupe 조언을 사용할 수 있습니다. | 중복 제거 조언의 횟수가 잘못되었습니다. |
| 오래된 권장 사항 | 중복 제거 조언의 횟수가 잘못되었습니다. |
| 중복 조언 시간 초과 | 중복 제거가 시간 초과된 횟수입니다. |
| flush out | VDO에서 기본 스토리지에 제출한 플러시 요청 수입니다. |
| BIOS 의 경우.. BIOS 부분.. BIOS가 출력됩니다.. BIOS 메타 데이터.. BIOS 저널.. BIOS 페이지 캐시.. BIOS가 준비되었습니다.. BIOS 메타가 완료되었습니다.. BIOS 저널이 완료되었습니다.. BIOS 페이지 캐시가 완료되었습니다.. BIOS 승인됨.. BIOS는 부분적인 부분을 인정했습니다.. BIOS 진행 중.. |
이러한 통계는 지정된 플래그를 사용하여 각 카테고리의 생체 수를 계산합니다. 카테고리는 다음과 같습니다.
플래그에는 다음 세 가지 유형이 있습니다.
|
| 캐시 액세스 읽기 | VDO가 읽기 캐시를 검색한 횟수입니다. |
| 캐시 적중 읽기 | 읽기 캐시 적중 수입니다. |
30.8. /sys의 통계 파일
/sys/kvdo/volume_name/statistics 디렉터리의 파일에서 읽을 수 있습니다. 여기서 volume_name 은 VDO 볼륨의 이름입니다. 이를 통해 OSP stats 유틸리티에서 생성된 데이터에 대한 대체 인터페이스를 쉘 스크립트 및 관리 소프트웨어의 액세스에 적합한 인터페이스를 제공합니다.
통계 디렉터리에는 아래 표에 나열된 파일 외에도 파일이 있습니다. 이러한 추가 통계 파일은 향후 릴리스에서 지원되지 않을 수 있습니다.
표 30.10. 통계 파일
| 파일 | 설명 |
|---|---|
dataBlocksUsed | 데이터를 저장하기 위해 VDO 볼륨에서 현재 사용 중인 물리적 블록 수입니다. |
logicalBlocksUsed | 현재 매핑된 논리 블록 수입니다. |
physicalBlocks | VDO 볼륨에 할당된 총 물리적 블록 수입니다. |
logicalBlocks | VDO 볼륨에서 매핑할 수 있는 최대 논리 블록 수입니다. |
mode | VDO 볼륨이 정상적으로 작동하는지, 복구 모드인지 또는 읽기 전용 모드인지 여부를 나타냅니다. |
31장. VDO 평가
31.1. 소개
- VDO별 구성 가능한 속성(성능 사용자 애플리케이션 튜닝)
- 기본 4KB 블록 장치가 되는 영향
- 중복 제거 및 압축의 액세스 패턴 및 배포에 대한 응답
- 높은 로드 환경에서의 성능(필수)
- 비용을 분석합니다. 용량과 성능을 기반으로 애플리케이션을 기반으로 합니다.
31.1.1. 예상 및 제공
- 엔지니어가 테스트 장치에서 최적의 응답을 작성하는 구성 설정을 식별하는 데 도움이 됩니다.
- 제품의 잘못된 설정을 방지할 수 있도록 기본 튜닝 매개 변수 이해
- "실제" 애플리케이션 결과와 비교하기 위한 참조로 성능 결과 포트폴리오 생성
- 성능 및 데이터 효율성에 어떤 영향을 미치는지 확인
- VDO 구현을 통한 빠른 출시 시간
31.2. 테스트 환경 준비
31.2.1. 시스템 설정
- 사용 가능한 CPU 코어 수 및 유형입니다. 이는
taskset유틸리티를 사용하여 제어할 수 있습니다. - 사용 가능한 메모리와 총 설치된 메모리.
- 스토리지 장치 구성.
- Linux 커널 버전. Red Hat Enterprise Linux 7은 하나의 Linux 커널 버전만 제공합니다.
- 패키지가 설치됩니다.
31.2.2. VDO 구성
- 파티션 스키마
- VDO 볼륨에서 사용되는 파일 시스템
- VDO 볼륨에 할당된 물리적 스토리지의 크기
- 생성된 논리 VDO 볼륨의 크기
- 스파스 또는 밀도가 높은 인덱싱
- 메모리 크기의 UDS 인덱스
- VDO의 스레드 구성
31.2.3. 워크로드
- 테스트 데이터를 생성하는 데 사용되는 툴 유형
- 동시 클라이언트 수
- 기록된 데이터의 중복 4KB 블록 수
- 읽기 및 쓰기 패턴
- 작업 세트 크기
31.2.4. 지원되는 시스템 구성
- 유연한 I/O Tester 버전 2.08 이상; fio 패키지에서 사용 가능
<= 버전 8.1.2-2 이상; sysstat 패키지에서 사용 가능
31.2.5. 테스트 시스템 준비
- 시스템 설정
- CPU가 최고 성능 설정에서 실행되고 있는지 확인합니다.
- BIOS 구성 또는 Linux
cpupower유틸리티를 사용하여 가능한 경우 빈도 스케일링을 비활성화합니다. - 가능한 경우 터보 모드를 활성화하여 최대 처리량을 달성할 수 있습니다. 터보 모드는 테스트 결과에 몇 가지 변형을 도입하지만 성능은 터보 없이 테스트를 충족하거나 초과합니다.
- Linux Configuration
- 디스크 기반 솔루션의 경우 Linux는 대기 중인 여러 읽기/쓰기 요청을 처리할 수 있는 여러 I/O 스케줄러 알고리즘을 제공합니다. 기본적으로 Red Hat Enterprise Linux는 CFQ(완전한 대기 시간) 스케줄러를 사용하여 여러 상황에서 회전 디스크(하드 디스크) 액세스를 향상시키는 방식으로 요청을 정렬합니다. 대신 Red Hat 랩 테스트에서 더 나은 처리량과 대기 시간을 제공하는 회전 디스크에 Deadline 스케줄러를 사용하는 것이 좋습니다. 다음과 같이 장치 설정을 변경합니다.
# echo "deadline" > /sys/block/device/queue/scheduler
- 플래쉬 기반 솔루션의 경우
noop스케줄러는 Red Hat 랩 테스트에서 뛰어난 랜덤 액세스 처리량 및 대기 시간을 보여줍니다. 다음과 같이 장치 설정을 변경합니다.# echo "noop" > /sys/block/device/queue/scheduler
- 스토리지 장치 구성파일 시스템(ext4, XFS 등)은 성능에 고유한 영향을 미칠 수 있습니다. 종종 성능 측정을 간소화하여 결과에 VDO의 영향을 분리하는 것이 더 어려워집니다. 합리적인 경우 원시 블록 장치에서 성능을 측정하는 것이 좋습니다. 이 기능을 사용할 수 없는 경우 대상 구현에서 사용되는 파일 시스템을 사용하여 장치를 포맷합니다.
31.2.6. VDO 내부 구조
31.2.7. VDO 최적화
31.2.7.1. High Load
31.2.7.2. 동기 vs. 비동기 쓰기 정책
# vdo status --name=my_vdo
31.2.7.3. 메타데이터 캐싱
31.2.7.4. VDO 멀티스레딩 구성
31.2.7.5. 데이터 콘텐츠
31.2.8. 테스트 수행을 위한 특수 고려 사항
- 4KB 블록이 작성된 적이 없는 경우 VDO는 스토리지에 I/O를 수행하지 않고 제로 블록으로 즉시 응답합니다.
- 4KB 블록이 작성되었지만 모든 0이 포함된 경우 VDO는 스토리지에 I/O를 수행하지 않으며 0 블록으로 즉시 응답합니다.
31.2.9. 크로스 토크
31.3. 데이터 효율성 테스트 작업
테스트 환경
- 하나 이상의 Linux 물리적 블록 장치를 사용할 수 있습니다.
- 대상 블록 장치(예:
/dev/sdb)는 512GB보다 큽니다. - 유연한 I/O Tester(
fio) 버전 2.1.1 이상이 설치되어 있습니다. - VDO가 설치되어 있어야 합니다.
- 커널 빌드 번호를 포함하여 사용된 Linux 빌드입니다.
- rpm -qa 명령에서 얻은 전체 설치된 패키지 목록입니다.
- 전체 시스템 사양:
- CPU 유형 및 양(
/proc/cpuinfo에서 사용 가능). - 기본 OS가 실행된 후 사용 가능한 메모리 및 양(
/proc/meminfo에서 사용 가능) - 사용된 드라이브 컨트롤러의 유형입니다.
- 사용된 디스크 유형 및 수량이 있습니다.
- 실행 중인 프로세스( ps aux 또는 유사한 목록)의 전체 목록입니다.
- VDO와 함께 사용하기 위해 생성된 물리 볼륨 이름 및 볼륨 그룹 이름(pvs 및 vgs 목록).
- VDO 볼륨을 포맷할 때 사용되는 파일 시스템(있는 경우).
- 마운트된 디렉토리에 대한 권한입니다.
/etc/vdoconf.yaml콘텐츠.- VDO 파일의 위치입니다.
워크로드
fio 를 테스트 중에 사용하는 것이 좋습니다.
페오를 사용합니다. 인수를 이해하면 성공적인 평가에 중요합니다.
표 31.1. Fio 옵션
| 인수 | 설명 | 값 |
|---|---|---|
--size | 데이터 fio의 수량은 작업당 대상으로 보냅니다(아래 numjobs 참조). | 100GB |
--bs | fio에서 생성된 각 읽기/쓰기 요청의 블록 크기입니다. Red Hat은 VDO의 4KB 기본값과 일치하도록 4KB 블록 크기를 권장합니다. | 4k |
--numjobs |
벤치마크를 실행하기 위해 fio가 생성할 작업 수입니다.
각 작업은
--size 매개변수에서 지정한 데이터 양을 전송합니다.
첫 번째 작업은
--offset 매개변수로 지정된 오프셋의 장치로 데이터를 전송합니다. 후속 작업은 --offset_increment 매개변수를 제공하지 않는 한 동일한 디스크 영역(덮어쓰기)을 작성합니다. 이 매개변수는 이전 작업이 해당 값으로 시작된 각 작업을 오프셋합니다. 적어도 두 개 이상의 작업에서는 플래쉬에서 최대 성능을 달성하는 것이 좋습니다. 한 작업은 일반적으로 회전 디스크(HDD) 처리량을 최소화하기에 충분합니다.
|
1 (HDD)
2 (SSD)
|
--thread | 포크가 아닌 스레드에서 fio 작업을 실행하도록 지시하여 컨텍스트 전환을 제한하여 더 나은 성능을 제공할 수 있습니다. | <N/A> |
--ioengine |
Linux에는 fio를 사용하여 테스트할 수 있는 여러 I/O 엔진을 사용할 수 있습니다. Red Hat 테스트는 버퍼 없는 비동기 엔진(
libaio)을 사용합니다. 다른 엔진에 관심이 있으시면 Red Hat 영업 엔지니어와 상의하십시오.
Linux
libaio 엔진은 하나 이상의 프로세스가 동시에 임의의 요청을 수행하는 워크로드를 평가하는 데 사용됩니다. libaio 여러 요청이 동기 엔진을 통해 여러 스레드에서 제공한 경우 필요한 컨텍스트 스위치 수를 제한하기 전에 단일 스레드에서 비동기적으로 여러 요청을 수행할 수 있습니다.Allows multiple requests to be made asynchronously from a single thread before any data has been retrieved, which limits the number of context switches that would be required if the requests were provided by manythreads via a synchronous engine.
| libaio |
--direct |
설정된 경우 직접 Linux 커널의 페이지 캐시를 바이패스하는 장치에 요청을 전송할 수 있습니다.
libaio Engine:
libaio 는 direct 활성화(=1)와 함께 사용해야 하며 커널이 모든 I/O 요청에 대해 sync API를 사용할 수 있습니다.
| 1 (libaio) |
--iodepth |
언제든지 비행 중 I/O 버퍼 수입니다.
iodepth 가 높으면 특히 임의의 읽기 또는 쓰기의 경우 성능이 향상됩니다. 깊이가 높아 컨트롤러에 항상 배치 요청이 있는지 확인합니다. 그러나 iodepth 너무 높은 (일반적으로 1K 이하)을 설정하면 바람직하지 않은 대기 시간이 발생할 수 있습니다. Red Hat은 iodepth 에서 128~512 사이를 권장하지만 최종 값은 절충 시점이며 애플리케이션이 대기 시간을 허용하는 방법에 따라 다릅니다.
| 128 (최소) |
--iodepth_batch_submit | iodepth 버퍼 풀이 비어 있을 때 생성할 I/O 수입니다. 이 매개변수는 테스트 중 I/O에서 버퍼 생성으로 작업을 제한합니다. | 16 |
--iodepth_batch_complete | 배치를 제출하기 전에 완료해야 하는 I/O 수(iodepth_batch_complete). 이 매개변수는 테스트 중 I/O에서 버퍼 생성으로 작업을 제한합니다. | 16 |
--gtod_reduce | 대기 시간을 계산하는 일별 호출을 비활성화합니다. 이 설정은 활성화된 경우 처리량이 감소하므로 대기 시간 측정이 필요하지 않는 한 (=1) 활성화되어야 합니다. | 1 |
31.3.1. VDO 테스트 볼륨 구성
31.3.1.1. 1. 512GB 물리 볼륨에 논리 크기가 1TB인 VDO 볼륨 만들기
- VDO 볼륨을 생성합니다.
- 동기 스토리지 상단에서 VDO
async모드를 테스트하려면--writePolicy=async옵션을 사용하여 비동기 볼륨을 생성합니다.# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=async --verbose - 동기 스토리지 상단에서 VDO
동기화모드를 테스트하려면--writePolicy=sync옵션을 사용하여 동기 볼륨을 생성합니다.# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=1T --writePolicy=sync --verbose
- XFS 또는 ext4 파일 시스템으로 새 장치를 포맷합니다.
- XFS의 경우:
# mkfs.xfs -K /dev/mapper/vdo0
- ext4의 경우:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- 포맷된 장치를 마운트합니다.
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
31.3.2. VDO Efficiency 테스트
31.3.2.1. 2. VDO 볼륨에 대한 읽기 및 쓰기 테스트
- VDO 볼륨에 32GB의 임의의 데이터를 씁니다.
$ dd if=/dev/urandom of=/mnt/VDOVolume/testfile bs=4096 count=8388608
- VDO 볼륨에서 데이터를 읽고 VDO 볼륨이 아닌 다른 위치에 씁니다.
$ dd if=/mnt/VDOVolume/testfile of=/home/user/testfile bs=4096
diff을(를) 사용하여 두 파일을 비교합니다. 파일이 동일하다는 것을 보고해야 합니다.$ diff -s /mnt/VDOVolume/testfile /home/user/testfile
- 파일을 VDO 볼륨의 두 번째 위치에 복사합니다.
$ dd if=/home/user/testfile of=/mnt/VDOVolume/testfile2 bs=4096
- 세 번째 파일을 두 번째 파일과 비교합니다. 그러면 파일이 동일하다고 보고해야 합니다.
$ diff -s /mnt/VDOVolume/testfile2 /home/user/testfile
31.3.2.2. 3. VDO 볼륨 제거
- VDO 볼륨에서 생성된 파일 시스템을 마운트 해제합니다.
# umount /mnt/VDOVolume
- 명령을 실행하여 시스템에서 VDO 볼륨
cabundle0을 제거합니다.# vdo remove --name=vdo0
- 볼륨이 제거되었는지 확인합니다. VDO 파티션의 Egress IP 목록에 목록이 없어야 합니다.
# vdo list --all | grep vdo
31.3.2.3. 4. D trainingplication 측정
- 31.3.1절. “VDO 테스트 볼륨 구성” 에서 VDO 볼륨을 생성하고 마운트합니다.
- test 데이터 세트의 복사본 10을 보관하기 위해 VDO 볼륨에서 EgressIP
1through step10이라는 10개의 디렉터리를 생성합니다.$ mkdir /mnt/VDOVolume/vdo{01..10} - 파일 시스템에 따라 사용된 디스크 공간의 양을 확인합니다.
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 198M 1.4T 1% /mnt/VDOVolume
결과를 표에 배치하는 것이 좋습니다.통계 베어 파일 시스템 Seed 후 10 복사 후 파일 시스템 사용 크기 198MB VDO 데이터 사용 VDO 논리 사용 - 다음 명령을 실행하여 값을 기록합니다. "데이터 블록"은 VDO에서 실행되는 물리적 장치의 사용자 데이터에 의해 사용되는 블록 수입니다. "논리 블록 사용"은 최적화 전에 사용되는 블록 수입니다. 측정의 시작점으로 사용될 것입니다.
# vdostats --verbose | grep "blocks used" data blocks used : 1090 overhead blocks used : 538846 logical blocks used : 6059434
- VDO 볼륨의 최상위 수준에 데이터 소스 파일 생성
$ dd if=/dev/urandom of=/mnt/VDOVolume/sourcefile bs=4096 count=1048576 4294967296 bytes (4.3 GB) copied, 540.538 s, 7.9 MB/s
- 사용 중인 물리적 디스크 공간의 양을 다시 검사합니다. 방금 작성한 파일에 해당하는 블록 수가 증가해야 합니다.
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 4.2G 1.4T 1% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050093 (increased by 4GB) overhead blocks used : 538846 (Did not change) logical blocks used : 7108036 (increased by 4GB)
- 파일을 10개의 하위 디렉터리 각각에 복사합니다.
$ for i in {01..10}; do cp /mnt/VDOVolume/sourcefile /mnt/VDOVolume/vdo$i done - 다시 한 번, 사용된 물리적 디스크 공간(데이터 블록)을 확인합니다. 이 수는 위의 6단계의 결과와 유사해야 하며 파일 시스템 저널링 및 메타데이터로 인해 약간의 증가만 사용해야 합니다.
$ df -h /mnt/VDOVolume Filesystem Size Used Avail Use% Mounted on /dev/mapper/vdo0 1.5T 45G 1.3T 4% /mnt/VDOVolume
# vdostats --verbose | grep "blocks used" data blocks used : 1050836 (increased by 3M) overhead blocks used : 538846 logical blocks used : 17594127 (increased by 41G)
- 테스트 데이터를 쓰기 전에 찾은 값에서 파일 시스템에서 사용하는 공간의 새 값을 뺀 값입니다. 파일 시스템의 관점에서 이 테스트에서 사용하는 공간의 양입니다.
- 기록된 통계에서 공간 절감을 관찰합니다.참고:다음 표에서 값이 MB/GB로 변환된 경우, "blocks"는 4,096 B입니다.
통계 베어 파일 시스템 Seed 후 10 복사 후 파일 시스템 사용 크기 198MB 4.2GB 45GB VDO 데이터 사용 4MB 4.1GB 4.1GB VDO 논리 사용 23.6 GB* 27.8 GB 68.7 GB * 1.6TB 포맷 드라이브의 파일 시스템 오버헤드
31.3.2.4. 5. 압축 측정
- 최소 10GB의 물리 및 논리 크기의 VDO 볼륨을 생성합니다. 중복 제거를 비활성화하고 압축을 활성화하는 옵션을 추가합니다.
# vdo create --name=vdo0 --device=/dev/sdb \ --vdoLogicalSize=10G --verbose \ --deduplication=disabled --compression=enabled - 전송 전 VDO 통계를 검사합니다. 사용된 데이터 블록과 사용된 논리 블록을 기록해 둡니다( 둘 다 0이 되어야 함).
# vdostats --verbose | grep "blocks used"
- XFS 또는 ext4 파일 시스템으로 새 장치를 포맷합니다.
- XFS의 경우:
# mkfs.xfs -K /dev/mapper/vdo0
- ext4의 경우:
# mkfs.ext4 -E nodiscard /dev/mapper/vdo0
- 포맷된 장치를 마운트합니다.
# mkdir /mnt/VDOVolume # mount /dev/mapper/vdo0 /mnt/VDOVolume && \ chmod a+rwx /mnt/VDOVolume
- VDO 볼륨을 동기화하여 완료되지 않은 압축을 완료합니다.
# sync && dmsetup message vdo0 0 sync-dedupe
- VDO 통계를 다시 검사합니다. 사용된 논리 블록 - 사용되는 데이터 블록은 파일 시스템의 압축으로 저장되는 4KB 블록 수입니다. VDO는 파일 시스템 오버헤드 및 실제 사용자 데이터를 최적화합니다.
# vdostats --verbose | grep "blocks used"
/lib의 콘텐츠를 VDO 볼륨에 복사합니다. 총 크기를 기록합니다.# cp -vR /lib /mnt/VDOVolume ... sent 152508960 bytes received 60448 bytes 61027763.20 bytes/sec total size is 152293104 speedup is 1.00
- Linux 캐시 및 VDO 볼륨을 동기화합니다.
# sync && dmsetup message vdo0 0 sync-dedupe
- VDO 통계를 다시 검사합니다. 사용되는 논리 및 데이터 블록을 확인합니다.
# vdostats --verbose | grep "blocks used"
- 사용된 논리 블록 - 사용되는 데이터 블록은
/lib파일의 사본에 사용되는 공간 크기(4KB 블록 단위로)를 나타냅니다. - “4. D trainingplication 측정”의 표에 있는 전체 크기 - (논리적 블록 used-data 블록은 * 4096) = 압축으로 저장된 바이트를 사용했습니다.
- VDO 볼륨 제거:
# umount /mnt/VDOVolume && vdo remove --name=vdo0
31.3.2.5. 6. test VDO Compression Efficiency
- 31.3.1절. “VDO 테스트 볼륨 구성” 에서 VDO 볼륨을 생성하고 마운트합니다.
- 볼륨을 제거하지 않고 “4. D trainingplication 측정” 및 “5. 압축 측정” 에서 실험을 반복합니다. affect
stats의 공간 절감에 대한 변경사항을 관찰합니다. - 자체 데이터 세트를 실험하십시오.
31.3.2.6. 7. TRIM 및 DISCARD 이해
TRIM 또는 DISCARD 명령을 전송하여 논리 블록이 더 이상 필요하지 않은 경우 스토리지 시스템을 알립니다. 이러한 명령은 삭제 마운트 옵션을 사용하여 블록을 삭제할 때마다 보내거나 파일 시스템에 사용되지 않는 논리 블록을 탐지하고 TRIM 또는 DISCARD 명령 형식으로 스토리지 시스템으로 정보를 전송하도록 파일 시스템에 지시하여 제어된 방식으로 보낼 수 있습니다. - 31.3.1절. “VDO 테스트 볼륨 구성” 에 따라 새 VDO 논리 볼륨을 생성하고 마운트합니다.
- 불필요한 블록을 제거하기 위해 파일 시스템을 Trim합니다(시간이 오래 걸릴 수 있음).
# fstrim /mnt/VDOVolume
- 다음을 입력하여 아래 표에 초기 상태를 기록합니다.
$ df -m /mnt/VDOVolume
파일 시스템에서 용량이 얼마나 많이 사용되는지 확인하고 EgressIPstats를 실행하여 사용 중인 물리 및 논리적 데이터 블록 수를 확인합니다. - VDO에서 실행되는 파일 시스템에 데이터가 아닌 1GB 파일을 생성합니다.
$ dd if=/dev/urandom of=/mnt/VDOVolume/file bs=1M count=1K
그런 다음 동일한 데이터를 수집합니다. 파일 시스템은 1GB를 추가로 사용해야 하며, 사용된 데이터 블록과 논리 블록이 유사하게 증가했습니다. fstrim /mnt/VDOVolume를 실행하고 새 파일을 생성한 후 이 항목에 영향을 미치지 않는지 확인합니다.- 1GB 파일을 삭제합니다.
$ rm /mnt/VDOVolume/file
매개 변수를 확인하고 기록합니다. 파일 시스템은 파일이 삭제되었지만 파일 삭제가 기본 스토리지와 전달되지 않았기 때문에 물리적 또는 논리 블록 수에 대한 변경 사항이 없음을 인지하고 있습니다. fstrim /mnt/VDOVolume를 실행하고 동일한 매개변수를 기록합니다.fstrim은 파일 시스템에서 무료 블록을 찾고 사용하지 않는 주소에 대해 TRIM 명령을 전송하며 VDO는 연관된 논리 블록을 해제하고 VDO는 TRIM을 기본 물리적 블록을 해제하도록 처리합니다.Step 파일 공간 사용(MB) 데이터 블록 사용 논리 블록 사용 initial 1GB 파일 추가 run fstrim1GB 파일 삭제 run fstrim
fstrim 는 효율성을 높이기 위해 여러 블록을 한 번에 분석하는 명령줄 도구입니다. 대체 방법은 마운트 시 파일 시스템 삭제 옵션을 사용하는 것입니다. 삭제 옵션은 각 파일 시스템 블록이 삭제될 때 기본 스토리지를 업데이트하여 처리량이 느려지지만 활용도가 큰 인식을 제공합니다. 또한 TRIM 또는 DISCARD 사용되지 않는 블록이 VDO에 고유하지 않다는 것을 이해하는 것이 중요합니다. 씬 프로비저닝된 스토리지 시스템은 동일한 챌린지가 있습니다.
31.4. 성능 테스트 절차
31.4.1. 1 단계 : I/O Depth의 효과, 수정된 4 KB 블록
- 4KB I/O 및 I/O 깊이 1, 8, 16, 32, 64, 128, 256, 512, 1024의 4 니너 테스트를 수행합니다.
- 순차적 100% 읽기, 고정 4 KB *
- 순차적 100% 쓰기, 고정 4KB
- 100 % 읽기, 고정 4 KB *
- 임의의 100 % 쓰기, 고정 4 KB **
* 쓰기 fio 작업을 먼저 수행하여 읽기 테스트 중에 읽을 수 있는 모든 영역을 미리 채우십시오.** 4KB 임의 쓰기 I/O 실행 후 VDO 볼륨 다시 생성쉘 테스트 입력 stimulus의 예(쓰기):# for depth in 1 2 4 8 16 32 64 128 256 512 1024 2048; do fio --rw=write --bs=4096 --name=vdo --filename=/dev/mapper/vdo0 \ --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300\ --direct=1 --iodepth=$depth --scramble_buffers=1 --offset=0 \ --size=100g done - 각 데이터 지점에서 처리량 및 대기 시간을 기록한 다음 그래프를 표시합니다.
- 테스트를 반복하여 4개의업체 테스트(
--rw=randwrite,--rw=read,--rw=randread)를 완료합니다.
- 이 특정 어플라이언스는 순차적 4 KB I의 깊이 > X입니다. 깊이가 줄어들며 대역폭 대역폭 증가가 감소하고, 평균 요청 대기 시간이 1~1개씩 증가합니다.
- 이 특정 어플라이언스는 4KB I의 깊이 > Z. 깊이를 줄이고, 대역폭 증가가 감소되고, 평균 요청 대기 시간이 1~1개씩 증가합니다.
그림 31.1. I/O Depth Analysis
그림 31.2. Random Writes에 대한 I/O 증가의 대기 시간 응답
31.4.2. 2 단계: I/O 요청 크기의 효과
- 범위 8KB에서 1MB까지 다양한 블록 크기( 2)를 사용하여 고정 I/O 깊이에서 4파티너 테스트를 수행합니다. 모든 영역을 미리 입력하고 테스트 간에 볼륨을 다시 생성합니다.
- I/O Depth를 31.4.1절. “1 단계 : I/O Depth의 효과, 수정된 4 KB 블록” 에 정의된 값으로 설정합니다.테스트 입력 stimulus(쓰기)의 예:
# z=[see previous step] # for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=write --bs=$iosize\k --name=vdo --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread --norandommap --runtime=300 --direct=1 --iodepth=$z --scramble_buffers=1 --offset=0 --size=100g done - 각 데이터 지점에서 처리량 및 대기 시간을 기록한 다음 그래프를 표시합니다.
- 테스트를 반복하여 4개의업체 테스트(
--rw=randwrite,--rw=read,--rw=randread)를 완료합니다.
- 순차적 쓰기는 요청 크기 Y의 최대 처리량에 도달합니다. 이 곡선은 특정 요청 크기에 의해 구성 가능하거나 자연적으로 관리하는 애플리케이션이 성능을 인식할 수 있는 방법을 보여줍니다. 4KB I/O는 병합할 수 있으므로 요청 크기가 더 많은 처리량을 제공하는 경우가 많습니다.
- 순차적 읽기는 Z 포인트에서 유사한 최대 처리량에 도달합니다. I/O가 완료되기 전에 전체 대기 시간은 추가 처리량 없이 증가합니다. 이 크기보다 큰 I/O를 허용하지 않도록 장치를 조정하는 것이 좋습니다.
- 랜덤 읽기는 점 X에서 최대 처리량을 달성합니다. 일부 장치는 대규모 요청 크기 임의 액세스에서 가까운 처리량 속도를 달성하는 반면, 다른 장치는 순차 액세스가 다양할 때 더 많은 페널티를 겪게 됩니다.
- 임의 쓰기는 Y 지점에서 최대 처리량을 달성합니다. Random 쓰기에는 중복 제거 장치의 가장 많은 상호 작용이 포함되며 VDO는 요청 크기 및/또는 I/O 깊이가 큰 경우 고성능을 수행합니다.
그림 31.3. 요청 크기와 크기 비교. throughput Analysis and Key Inflection Points
31.4.3. 3 단계: Read & Write I/Os 혼합의 효과
- 고정 I/O 깊이에서 4파티너 테스트를 수행하고, 8 KB에서 256KB 범위로 다양한 블록 크기(유효력)를 사용하고 0%부터 0%로 부터 10% 증가로 읽기 백분율을 설정합니다. 모든 영역을 미리 입력하고 테스트 간에 볼륨을 다시 생성합니다.
- I/O Depth를 31.4.1절. “1 단계 : I/O Depth의 효과, 수정된 4 KB 블록” 에 정의된 값으로 설정합니다.테스트 입력 stimulus(읽기/쓰기 혼합)의 예:
# z=[see previous step] # for readmix in 0 10 20 30 40 50 60 70 80 90 100; do for iosize in 4 8 16 32 64 128 256 512 1024; do fio --rw=rw --rwmixread=$readmix --bs=$iosize\k --name=vdo \ --filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \ --norandommap --runtime=300 --direct=0 --iodepth=$z --scramble_buffers=1 \ --offset=0 --size=100g done done - 각 데이터 지점에서 처리량 및 대기 시간을 기록한 다음 그래프를 표시합니다.
그림 31.4. Varying Read/Write Mixes의 성능 일관성
31.4.4. 4 단계: 애플리케이션 환경
# for readmix in 20 50 80; do
for iosize in 4 8 16 32 64 128 256 512 1024; do
fio --rw=rw --rwmixread=$readmix --bsrange=4k-256k --name=vdo \
--filename=/dev/mapper/vdo0 --ioengine=libaio --numjobs=1 --thread \
--norandommap --runtime=300 --direct=0 --iodepth=$iosize \
--scramble_buffers=1 --offset=0 --size=100g
done
done
그림 31.5. 혼합 환경 성능
31.5. 문제 보고
- 테스트 환경에 대한 자세한 설명은 “테스트 환경” 에서 구체적인 내용을 참조하십시오.
- VDO 구성
- 문제를 생성한 사용 사례
- 오류 발생 시 수행 중인 작업
- 콘솔 또는 터미널에 있는 오류 메시지의 텍스트
- 커널 로그 파일
- 커널 크래시 덤프(사용 가능한 경우)
sosreport결과에서 전체 Linux 환경을 설명하는 데이터를 캡처합니다.
31.6. conclusion
부록 A. Red Hat Customer Portal Labs Relevant to Storage Administration
SCSI 디코더
/log/* 파일 또는 로그 파일 스니펫에서 SCSI 오류 메시지를 디코딩하도록 설계되었습니다. 이러한 오류 메시지는 사용자가 이해하기 어려울 수 있습니다.
파일 시스템 레이아웃 계산기
root 로 실행하여 필요한 파일 시스템을 만듭니다.
LVM RAID 계산기
root 로 복사하고 실행하여 필요한 LVM을 만듭니다.
iSCSI 도우미
Samba 설정 도우미
- 를 클릭하여 기본 서버 설정을 지정합니다.
- 하려는 디렉터리를 추가하려면 공유를 클릭합니다.
- 를 클릭하여 연결된 프린터를 개별적으로 추가합니다.
다중 경로 도우미
multipath.conf 파일도 제공합니다. 필요한 구성을 달성하면 서버에서 실행할 설치 스크립트를 다운로드합니다.
NFS 도우미
다중 경로 구성 시각화 도구
- 서버 측에 HBA(Host Bus Adapters), 로컬 장치 및 iSCSI 장치를 포함한 호스트 구성 요소
- 스토리지 측의 스토리지 구성 요소
- 서버와 스토리지 간의 패브릭스 또는 이더넷 구성 요소
- 모든 언급 된 구성 요소에 대한 경로
RHEL 백업 및 복원 Assistant
덤프 및 복원: ext2, ext3 및 ext4 파일 시스템 백업용.tar 및 cpio: 특히 테이프 드라이브를 백업할 때 파일 및 폴더를 보관하거나 복원하는 경우.rsync: 백업 작업을 수행하고 위치 간 파일과 디렉토리를 동기화하기 위한 것입니다.DD: 파일 시스템 또는 운영 체제와 관계없이 블록에서 소스에서 대상 블록으로 파일을 복사합니다.
- 재해 복구
- 하드웨어 마이그레이션
- 파티션 테이블 백업
- 중요한 폴더 백업
- 증분 백업
- Differentmin 백업
부록 B. 개정 내역
| 고친 과정 | |||
|---|---|---|---|
| 고침 4-10 | Mon Aug 10 2020 | ||
| |||
| 고침 4-09 | Mon Jan 7 2019 | ||
| |||
| 고침 4-08 | Mon Oct 23 2018 | ||
| |||
| 고침 4-07 | Thu Sep 13 2018 | ||
| |||
| 고침 4-00 | Fri Apr 6 2018 | ||
| |||
| 고침 3-95 | Thu Apr 5 2018 | ||
| |||
| 고침 3-93 | Mon Mar 5 2018 | ||
| |||
| 고침 3-92 | Fri Feb 9 2018 | ||
| |||
| 고침 3-90 | Wed Dec 6 2017 | ||
| |||
| 고침 3-86 | Mon Nov 6 2017 | ||
| |||
| 고침 3-80 | Thu Jul 27 2017 | ||
| |||
| 고침 3-77 | Wed May 24 2017 | ||
| |||
| 고침 3-68 | Fri Oct 21 2016 | ||
| |||
| 고침 3-67 | Fri Jun 17 2016 | ||
| |||
| 고침 3-64 | Wed Nov 11 2015 | ||
| |||
| 고침 3-33 | Wed Feb 18 2015 | ||
| |||
| 고침 3-26 | Wed Jan 21 2015 | ||
| |||
| 고침 3-22 | Thu Dec 4 2014 | ||
| |||
| 고침 3-4 | Thu Jul 17 2014 | ||
| |||
| 고침 3-1 | Tue Jun 3 2014 | ||
| |||
색인
Symbols
- /boot/ 디렉토리, /boot/ 디렉토리
- /dev/shm, DF 명령
- /etc/fstab, ext3 파일 시스템으로 변환, /etc/fstab을 사용하여 NFS 파일 시스템 마운트, 파일 시스템 마운트
- /etc/fstab 파일
- 을 사용하여 디스크 할당량 활성화, 할당량 활성화
- /local/directory(클라이언트 구성, 마운트)
- NFS, NFS 클라이언트 구성
- /proc
- /proc/devices, /proc 가상 파일 시스템
- /proc/filesystems, /proc 가상 파일 시스템
- /proc/mdstat, /proc 가상 파일 시스템
- /proc/mounts, /proc 가상 파일 시스템
- /proc/mounts/, /proc 가상 파일 시스템
- /proc/partitions, /proc 가상 파일 시스템
- /proc/devices
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /proc/filesystems
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /proc/mdstat
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /proc/mounts
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /proc/mounts/
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /proc/partitions
- 가상 파일 시스템(/proc), /proc 가상 파일 시스템
- /remote/export(클라이언트 구성, 마운트)
- NFS, NFS 클라이언트 구성
- 가상 머신용 스토리지, 가상 머신용 스토리지
- 가상 파일 시스템(/proc)
- /proc/devices, /proc 가상 파일 시스템
- /proc/filesystems, /proc 가상 파일 시스템
- /proc/mdstat, /proc 가상 파일 시스템
- /proc/mounts, /proc 가상 파일 시스템
- /proc/mounts/, /proc 가상 파일 시스템
- /proc/partitions, /proc 가상 파일 시스템
- 감사자 쓰기
- enablind/disabling, 쓰기 바리커 활성화 및 비활성화
- ext4, ext4 파일 시스템 마운트
- NFS, NFS
- XFS, 쓰기 Barriers
- 고급 배열, 하이 엔드 배열
- 배터리 지원 쓰기 캐시, 기록-Backed 쓰기 캐시
- 쓰기 캐시 비활성화, 쓰기 캐시 비활성화
- 오류 메시지, 쓰기 바리커 활성화 및 비활성화
- 자주하는 질문, 이메일 주소
- 장애물을 작성하는 방법, Barriers의 작업 방법
- 정의, 쓰기 Barriers
- 개별 사용자
- volume_key, volume_key 를 개별 사용자로 사용
- 개요, 개요
- 온라인 스토리지, 온라인 스토리지 관리
- 개인 마운트, 마운트 공유
- 계층 구조, 파일 시스템, 파일 시스템 계층 구조 표준(FHS) 개요
- 고급 RAID 장치 생성
- RAID, 고급 RAID 장치 생성
- 고급 배열
- 감사자 쓰기, 하이 엔드 배열
- 공유 마운트, 마운트 공유
- 공유 하위 트리, 마운트 공유
- 구성
- discovery
- iSCSI, iSCSI 검색 구성
- 글로벌 파일 시스템 2
- gfs2.ko, 글로벌 파일 시스템 2
- 최대 크기, 글로벌 파일 시스템 2
- 파일 시스템 유형, 글로벌 파일 시스템 2
- 기본 파이버 채널 드라이버, 네이티브 파이버 채널 드라이버 및 기능
- 기타 디렉터리, /etc/ 디렉터리
- 기타 파일 시스템 유틸리티
- ext4, 기타 ext4 파일 시스템 유틸리티
- 내보낸 파일 시스템
- 디스크 없는 시스템, 디스크 없는 클라이언트를 위해 내보낸 파일 시스템 구성
- 네트워크 부팅 서비스
- 디스크 없는 시스템, 원격 디스크 없는 시스템 설정
- 네트워크 파일 시스템 (살펴볼 내용 NFS)
- 논리 단위의 크기 조정, 크기 조정, 온라인 논리 단위 크기 조정
- 누적 모드 (xfsrestore)
- XFS, 복원
- 단순 모드 (xfsrestore)
- XFS, 복원
- 대상
- iSCSI, iSCSI 대상에 로그인
- 대화형 작업 (xfsrestore)
- XFS, 복원
- 더티 로그 ( XFS 파일 시스템 페어링)
- XFS, XFS 파일 시스템 복구
- 더티 로그를 사용하여 XFS 파일 시스템 복구
- XFS, XFS 파일 시스템 복구
- 덤프 수준
- XFS, Backup
- 드라이버(네이티브), 파이버 채널, 네이티브 파이버 채널 드라이버 및 기능
- 디렉터리
- /boot/, /boot/ 디렉토리
- /dev/, /dev/ Directory
- /etc/, /etc/ 디렉터리
- /mnt/, /mnt/ 디렉터리
- /opt/, /opt/ Directory
- /proc/, /proc/ 디렉토리
- /srv/, /srv/ 디렉터리
- /sys/, /sys/ 디렉터리
- /usr/, /usr/ Directory
- /var/, /var/ 디렉터리
- 디렉터리 선택, /opt/ Directory
- 디스크 스토리지 (살펴볼 내용 디스크 할당량)
- parted (살펴볼 내용 parted)
- 디스크 없는 시스템
- DHCP, 구성, 디스크 없는 클라이언트에 대한 DHCP 구성
- TFTP 서비스, 구성, 디스크 없는 클라이언트를 위한 tftp 서비스 구성
- 내보낸 파일 시스템, 디스크 없는 클라이언트를 위해 내보낸 파일 시스템 구성
- 네트워크 부팅 서비스, 원격 디스크 없는 시스템 설정
- 원격 디스크 없는 시스템, 원격 디스크 없는 시스템 설정
- 필수 패키지, 원격 디스크 없는 시스템 설정
- 디스크 없는 클라이언트에 대한 DHCP 구성
- 디스크 없는 시스템, 디스크 없는 클라이언트에 대한 DHCP 구성
- 디스크 없는 클라이언트에 대한 tftp 서비스 구성
- 디스크 없는 시스템, 디스크 없는 클라이언트를 위한 tftp 서비스 구성
- 디스크 할당량, 디스크 할당량
- disabling, 활성화 및 비활성화
- 관리, 디스크 할당량 관리
- 보고, 디스크 할당량에 대한 보고
- 할당량 검사 명령, 을 사용하여 확인, 할당량 적용 유지
- 그룹당 할당, 그룹당 할당량 할당
- 사용자당 할당, 사용자당 할당량 할당
- 소프트 제한, 사용자당 할당량 할당
- 유예 기간, 사용자당 할당량 할당
- 추가 리소스, 디스크 할당량 참조
- 파일 시스템당 할당, 소프트 제한에 대한 Grace Period 설정
- 하드 제한, 사용자당 할당량 할당
- 활성화, 디스크 할당량 구성, 활성화 및 비활성화
- /etc/fstab, 수정, 할당량 활성화
- quotacheck, running, 할당량 데이터베이스 파일 생성
- 할당량 파일 생성, 할당량 데이터베이스 파일 생성
- 레코드 유형
- discovery
- iSCSI, iSCSI 검색 구성
- 로그인
- iSCSI 대상, iSCSI 대상에 로그인
- 링크 손실 동작 수정, 링크 손실 동작 수정
- 파이버 채널, 파이버 채널
- 마운트, 파일 시스템 마운트
- ext4, ext4 파일 시스템 마운트
- XFS, XFS 파일 시스템 마운트
- 마운트 (명령), 마운트 명령 사용
- options, 마운트 옵션 지정
- 공유 하위 트리, 마운트 공유
- 마운트 나열, 현재 마운트되어 있는 파일 시스템 나열
- 마운트 지점 이동, 마운트 지점 이동
- 파일 시스템 마운트, 파일 시스템 마운트
- 마운트 지점 이동, 마운트 지점 이동
- 마운트 해제, 파일 시스템 마운트 해제
- 마운트(클라이언트 구성)
- NFS, NFS 클라이언트 구성
- 명령
- volume_key, volume_key 명령
- 문제 해결
- 온라인 스토리지, 온라인 스토리지 설정 문제 해결
- 미러링
- RAID, RAID 수준 및 선형 지원
- 바인딩할 수 없는 마운트, 마운트 공유
- 배터리 지원 쓰기 캐시
- 감사자 쓰기, 기록-Backed 쓰기 캐시
- 배포 지침
- 솔리드 스테이트 디스크, 솔리드 스테이트 디스크 배포 지침
- 백업 복원
- XFS, 복원
- 백업/교육
- XFS, XFS 파일 시스템 백업 및 복원
- 별도의 파티션 (/home, /opt, /usr/local)
- 설치 중 스토리지 고려 사항, /home, /opt, /usr/local에 대한 개별 파티션
- 병렬 NFS
- pNFS, pNFS
- 블록 장치 ioctls(사용자 공간 액세스)
- I/O 정렬 및 크기, 블록 장치 ioctls
- 사용 가능한 iface 구성 보기
- 오프로드 및 인터페이스 바인딩
- iSCSI, 사용 가능한 iface 구성 보기
- 사용자 공간 API 파일
- 파이버 채널 API, 파이버 채널 API
- 사용자 공간 액세스
- I/O 정렬 및 크기, 사용자 공간 액세스
- 사이트 구성 파일 덮어쓰기/자동fs
- NFS, autofs 설정
- 상호 연결(scanning)
- iSCSI, iSCSI 상호 연결 스캔
- 새로운 기능
- 설치 중 스토리지 고려 사항, 설치 중 스토리지 고려 사항
- 생성
- ext4, ext4 파일 시스템 생성
- XFS, XFS 파일 시스템 생성
- 서버(클라이언트 구성, 마운트)
- NFS, NFS 클라이언트 구성
- 선형 RAID
- RAID, RAID 수준 및 선형 지원
- 설치 스토리지 구성
- DIF/DIX 지원 블록 장치, DIF/DIX가 활성화된 블록 장치
- IBM System z의 DASD 및 zFCP 장치, IBM System Z의 DASD 및 zFCP 장치
- iSCSI 탐지 및 구성, iSCSI 탐지 및 설정
- LUKS/dm-crypt, 을 사용하여 블록 장치 암호화, LUKS를 사용하여 블록 장치 암호화
- 별도의 파티션 (/home, /opt, /usr/local), /home, /opt, /usr/local에 대한 개별 파티션
- 새로운 기능, 설치 중 스토리지 고려 사항
- 업데이트, 설치 중 스토리지 고려 사항
- 오래된 BIOS RAID 메타데이터, 오래된 BIOS RAID 메타데이터
- 채널 명령 단어 (CCW), IBM System Z의 DASD 및 zFCP 장치
- 설치 중 스토리지 고려 사항
- DIF/DIX 지원 블록 장치, DIF/DIX가 활성화된 블록 장치
- IBM System z의 DASD 및 zFCP 장치, IBM System Z의 DASD 및 zFCP 장치
- iSCSI 탐지 및 구성, iSCSI 탐지 및 설정
- LUKS/dm-crypt, 을 사용하여 블록 장치 암호화, LUKS를 사용하여 블록 장치 암호화
- 별도의 파티션 (/home, /opt, /usr/local), /home, /opt, /usr/local에 대한 개별 파티션
- 새로운 기능, 설치 중 스토리지 고려 사항
- 업데이트, 설치 중 스토리지 고려 사항
- 오래된 BIOS RAID 메타데이터, 오래된 BIOS RAID 메타데이터
- 채널 명령 단어 (CCW), IBM System Z의 DASD 및 zFCP 장치
- 설치 프로그램 지원
- 성능 보장
- FS-Cache, 성능 보장
- 소프트웨어 iSCSI용 iface
- 오프로드 및 인터페이스 바인딩
- iSCSI, 소프트웨어 iSCSI 용 iface 구성
- 소프트웨어 RAID (살펴볼 내용 RAID)
- 솔리드 스테이트 디스크
- Deployment, 솔리드 스테이트 디스크 배포 지침
- SSD, 솔리드 스테이트 디스크 배포 지침
- TRIM 명령, 솔리드 스테이트 디스크 배포 지침
- 배포 지침, 솔리드 스테이트 디스크 배포 지침
- 처리량 클래스, 솔리드 스테이트 디스크 배포 지침
- 수준
- RAID, RAID 수준 및 선형 지원
- 스왑 공간, Swap Space
- expanding, 스왑 공간 추가
- file
- LVM2
- extending, LVM2 논리 볼륨에서swap 확장
- 감소, LVM2 논리 볼륨에서 스왑 감소
- 생성, swap을 위한 LVM2 논리 볼륨 만들기
- 제거, swap용 LVM2 논리 볼륨 제거
- 권장 크기, Swap Space
- 생성, 스왑 공간 추가
- 이동, 스왑 공간 이동
- 제거, 스왑 공간 제거
- 스캔 상호 연결
- iSCSI, iSCSI 상호 연결 스캔
- 스택 I/O 매개변수
- I/O 정렬 및 크기, stacking I/O Parameters
- 스토리지 상호 연결 스캔, 스토리지 상호 연결 스캔
- 스토리지 상호 연결, 스캔, 스토리지 상호 연결 스캔
- 스토리지 액세스 매개변수
- I/O 정렬 및 크기, 스토리지 액세스를 위한 매개변수
- 스토리지 액세스를 위한 매개변수
- I/O 정렬 및 크기, 스토리지 액세스를 위한 매개변수
- 스토리지 장치에 경로 추가, 스토리지 장치 또는 경로 추가
- 스토리지 장치에 대한 경로 제거, 스토리지 장치의 경로 제거
- 스토리지 장치의 경로, 제거, 스토리지 장치의 경로 제거
- 스토리지 장치의 경로, 추가, 스토리지 장치 또는 경로 추가
- 스트라이프 너비(스트립 스트라이프 지형 검사)
- ext4, ext4 파일 시스템 생성
- 스트라이프 지오메트리
- ext4, ext4 파일 시스템 생성
- 슬레이브 마운트, 마운트 공유
- 시스템 스토리지 관리자
- SSM, 시스템 스토리지 관리자(SSM)
- 명령 나열, 모든 탐지된 장치에 대한 정보 표시
- 명령 크기 조정, 볼륨 크기 증가
- 백엔드, SSM 백엔드
- 설치, SSM 설치
- 스냅샷 명령, 스냅샷
- 시스템 정보
- 파일 시스템, 파일 시스템 정보 수집
- /dev/shm, DF 명령
- 실행 중 상태
- Linux SCSI 계층, SCSI 명령 타이머 및 장치 상태 제어
- 실행 중인 세션, 정보 검색
- iSCSI API, iSCSI API
- 쓰기 캐시 비활성화
- 감사자 쓰기, 쓰기 캐시 비활성화
- 업데이트
- 설치 중 스토리지 고려 사항, 설치 중 스토리지 고려 사항
- 영구 이름 지정, 영구 이름 지정
- 오래된 BIOS RAID 메타데이터
- 설치 중 스토리지 고려 사항, 오래된 BIOS RAID 메타데이터
- 오류 메시지
- 감사자 쓰기, 쓰기 바리커 활성화 및 비활성화
- 오프라인 상태
- Linux SCSI 계층, SCSI 명령 타이머 및 장치 상태 제어
- 오프로드 및 인터페이스 바인딩
- iSCSI, iSCSI 오프로드 및 인터페이스 바인딩 구성
- 온라인 논리 단위
- 읽기/쓰기 상태 변경, 온라인 논리 단위의 읽기/쓰기 상태 변경
- 온라인 스토리지
- 개요, 온라인 스토리지 관리
- sysfs, 온라인 스토리지 관리
- 문제 해결, 온라인 스토리지 설정 문제 해결
- 파이버 채널, 파이버 채널
- 옵션(클라이언트 구성, 마운트)
- NFS, NFS 클라이언트 구성
- 원격 디스크 없는 시스템
- 디스크 없는 시스템, 원격 디스크 없는 시스템 설정
- 원격 포트
- 파이버 채널 API, 파이버 채널 API
- 원격 포트 상태 확인
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- 원격 포트 상태, 결정
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- 이니시에이터 구현
- 오프로드 및 인터페이스 바인딩
- iSCSI, 사용 가능한 iface 구성 보기
- 이더넷을 통한 파이버 채널
- FCoE, 이더넷 인터페이스를 통한 파이버 채널 구성
- 인덱싱 키
- FS-Cache, FS-Cache
- 일관성 데이터
- FS-Cache, FS-Cache
- 일시 중단
- XFS, XFS 파일 시스템 일시 중단
- 읽기/쓰기 상태 변경
- 온라인 논리 단위, 온라인 논리 단위의 읽기/쓰기 상태 변경
- 자주하는 질문
- 감사자 쓰기, 이메일 주소
- 장애물을 작성하는 방법
- 감사자 쓰기, Barriers의 작업 방법
- 장치 매퍼 다중 경로, DM Multipath
- 장치 상태
- Linux SCSI 계층, 장치 상태
- 장치 제거, 스토리지 장치 제거
- 장치, 제거, 스토리지 장치 제거
- 장치가 차단되었는지 확인
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- 저장할 LDAP를 사용하여 자동 마운터 맵 저장(autofs)
- NFS, 사이트 구성 파일 덮어쓰기 또는 수정
- 적절한 nsswitch 구성(autofs 버전 5), 사용
- 전문가 모드 (xfs_quota)
- XFS, XFS 할당량 관리
- 제한 (xfs_quota 전문가 모드)
- XFS, XFS 할당량 관리
- 주요 기능
- ext4, ext4 파일 시스템
- XFS, XFS 파일 시스템
- 직접 맵 지원(autofs 버전 5)
- 차단된 장치 확인
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- 채널 명령 단어 (CCW)
- 설치 중 스토리지 고려 사항, IBM System Z의 DASD 및 zFCP 장치
- 처리량 클래스
- 솔리드 스테이트 디스크, 솔리드 스테이트 디스크 배포 지침
- 최대 크기
- GFS2, 글로벌 파일 시스템 2
- 최대 크기인 GFS2 파일 시스템, 글로벌 파일 시스템 2
- 캐시 cull 제한
- FS-Cache, 캐시 캐시 제한 설정
- 캐시 공유
- FS-Cache, 캐시 공유
- 캐시 백엔드
- FS-Cache, FS-Cache
- 캐시 설정
- FS-Cache, 캐시 설정
- 캐시 쓰기, 비활성화
- 감사자 쓰기, 쓰기 캐시 비활성화
- 크기 조정
- ext4, ext4 파일 시스템 크기 조정
- 크기가 조정된 논리 단위 크기 조정, 온라인 논리 단위 크기 조정
- 통계 정보 (추적)
- FS-Cache, 통계 정보
- 통계 정보 추적
- FS-Cache, 통계 정보
- 툴(파티션 및 기타 파일 시스템 기능용)
- I/O 정렬 및 크기, 파티션 및 파일 시스템 도구
- 특정 세션 시간 초과, 구성
- iSCSI 구성, 특정 세션에 대한 시간 제한 구성
- 특정 세션의 시간 초과 구성
- iSCSI 구성, 특정 세션에 대한 시간 제한 구성
- 파이버 채널
- 온라인 스토리지, 파이버 채널
- 파이버 채널 API, 파이버 채널 API
- 파이버 채널 드라이버(네이티브), 네이티브 파이버 채널 드라이버 및 기능
- 파일 시스템, 파일 시스템 정보 수집
- ext2 (살펴볼 내용 ext2)
- ext3 (살펴볼 내용 ext3)
- FHS 표준, FHS Organization
- gtv, 1.8.0 (기술 프리뷰)
- 계층 구조, 파일 시스템 계층 구조 표준(FHS) 개요
- 구조, 파일 시스템 구조 및 유지 관리
- 조직, FHS Organization
- 파일 시스템 복구
- XFS, XFS 파일 시스템 복구
- 파일 시스템 유형
- ext4, ext4 파일 시스템
- GFS2, 글로벌 파일 시스템 2
- XFS, XFS 파일 시스템
- 파일 시스템 크기 증가
- XFS, XFS 파일 시스템의 크기 늘리기
- 파티션
- formatting
- mkfs , 파티션 포맷 및 레이블 지정
- 목록 보기, 파티션 테이블 보기
- 생성, 파티션 만들기
- 제거, 파티션 제거
- 크기 조정, fdisk를 사용하여 파티션 크기 조정
- 파티션 테이블
- 보기, 파티션 테이블 보기
- 패리티
- RAID, RAID 수준 및 선형 지원
- 포털에 iface를 바인딩/연결 해제
- 오프로드 및 인터페이스 바인딩
- iSCSI, 포털에 iface를 바인딩/연결 해제
- 포트 상태(원격) 확인
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- 프로젝트 제한(설정)
- XFS, 프로젝트 제한 설정
- 필수 패키지
- adding/removing
- LUN(논리적 단위 번호), 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- FCoE, 이더넷 인터페이스를 통한 파이버 채널 구성
- 디스크 없는 시스템, 원격 디스크 없는 시스템 설정
- 하드웨어 RAID (살펴볼 내용 RAID)
- 하드웨어 RAID 컨트롤러 드라이버
- 할당 기능
- ext4, ext4 파일 시스템
- XFS, XFS 파일 시스템
- 할당량 (다른 ext4 파일 시스템 유틸리티)
- ext4, 기타 ext4 파일 시스템 유틸리티
- 할당량 관리
- XFS, XFS 할당량 관리
- 확인된 문제
- adding/removing
- LUN(논리적 단위 번호), rescan-scsi-bus.sh로 알려진 문제
A
- adding/removing
- LUN(논리적 단위 번호), 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- Anaconda 지원
- API, iSCSI, iSCSI API
- API, 파이버 채널, 파이버 채널 API
- ATA 표준
- I/O 정렬 및 크기, ATA
- autofs 마운트 지점당 다중 마스터 맵 항목(autofs 버전 5)
- autofs 버전 5
B
- bcull (캐릭 제한 설정 캐시)
- FS-Cache, 캐시 캐시 제한 설정
- Brun (cache cull 제한 설정)
- FS-Cache, 캐시 캐시 제한 설정
- bstop (cache cull 제한 설정)
- FS-Cache, 캐시 캐시 제한 설정
C
- cachefiles
- FS-Cache, FS-Cache
- cachefilesd
- FS-Cache, 캐시 설정
- CCW, 채널 명령 단어
- 설치 중 스토리지 고려 사항, IBM System Z의 DASD 및 zFCP 장치
- changing dev_loss_tmo
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- Command timer (SCSI)
- Linux SCSI 계층, 명령 timer
D
- debugfs(다른 ext4 파일 시스템 유틸리티)
- ext4, 기타 ext4 파일 시스템 유틸리티
- Deployment
- 솔리드 스테이트 디스크, 솔리드 스테이트 디스크 배포 지침
- dev 디렉터리, /dev/ Directory
- dev_loss_tmo
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- dev_loss_tmo, changing
- 파이버 채널
- 링크 손실 동작 수정, 파이버 채널
- df, DF 명령
- DHCP, 구성
- 디스크 없는 시스템, 디스크 없는 클라이언트에 대한 DHCP 구성
- DIF/DIX 지원 블록 장치
- 설치 중 스토리지 고려 사항, DIF/DIX가 활성화된 블록 장치
- discovery
- iSCSI, iSCSI 검색 구성
- dm-multipath
- iSCSI 구성, dm-multipath를 사용한 iSCSI 설정
- dmraid
- RAID, dmraid
- dmraid( RAID 세트 구성)
- RAID, dmraid
- du, du Command
E
- e2fsck, Ext2 파일 시스템으로 되돌리기
- e2image(다른 ext4 파일 시스템 유틸리티)
- ext4, 기타 ext4 파일 시스템 유틸리티
- e2label
- ext4, 기타 ext4 파일 시스템 유틸리티
- e2label(다른 ext4 파일 시스템 유틸리티)
- ext4, 기타 ext4 파일 시스템 유틸리티
- enablind/disabling
- 감사자 쓰기, 쓰기 바리커 활성화 및 비활성화
- ext2
- ext3에서 복구, Ext2 파일 시스템으로 되돌리기
- ext3
- ext2에서 변환, ext3 파일 시스템으로 변환
- 기능, ext3 파일 시스템
- 생성, ext3 파일 시스템 생성
- ext4
- debugfs(다른 ext4 파일 시스템 유틸리티), 기타 ext4 파일 시스템 유틸리티
- e2image(다른 ext4 파일 시스템 유틸리티), 기타 ext4 파일 시스템 유틸리티
- e2label, 기타 ext4 파일 시스템 유틸리티
- e2label(다른 ext4 파일 시스템 유틸리티), 기타 ext4 파일 시스템 유틸리티
- fsync(), ext4 파일 시스템
- mkfs.ext4, ext4 파일 시스템 생성
- nobarrier 마운트 옵션, ext4 파일 시스템 마운트
- resize2fs (resizing ext4), ext4 파일 시스템 크기 조정
- stride ( 스트라이프 지오메트리 지정), ext4 파일 시스템 생성
- tune2fs(마운트), ext4 파일 시스템 마운트
- 감사자 쓰기, ext4 파일 시스템 마운트
- 기타 파일 시스템 유틸리티, 기타 ext4 파일 시스템 유틸리티
- 마운트, ext4 파일 시스템 마운트
- 생성, ext4 파일 시스템 생성
- 스트라이프 너비(스트립 스트라이프 지형 검사), ext4 파일 시스템 생성
- 스트라이프 지오메트리, ext4 파일 시스템 생성
- 주요 기능, ext4 파일 시스템
- 크기 조정, ext4 파일 시스템 크기 조정
- 파일 시스템 유형, ext4 파일 시스템
- 할당 기능, ext4 파일 시스템
- 할당량 (다른 ext4 파일 시스템 유틸리티), 기타 ext4 파일 시스템 유틸리티
F
- FCoE
- FCoE를 사용하도록 이더넷 인터페이스 구성, 이더넷 인터페이스를 통한 파이버 채널 구성
- 이더넷을 통한 파이버 채널, 이더넷 인터페이스를 통한 파이버 채널 구성
- 필수 패키지, 이더넷 인터페이스를 통한 파이버 채널 구성
- FCoE를 사용하도록 이더넷 인터페이스 구성
- FCoE, 이더넷 인터페이스를 통한 파이버 채널 구성
- FHS, 파일 시스템 계층 구조 표준(FHS) 개요, FHS Organization
- ([살펴볼 다른 내용] 파일 시스템)
- flexs , flexs, autofs 설정
- ([살펴볼 다른 내용] NFS)
- FS-Cache
- bcull (캐릭 제한 설정 캐시), 캐시 캐시 제한 설정
- Brun (cache cull 제한 설정), 캐시 캐시 제한 설정
- bstop (cache cull 제한 설정), 캐시 캐시 제한 설정
- cachefiles, FS-Cache
- cachefilesd, 캐시 설정
- NFS(로 캐시 제한), NFS를 사용한 캐시 제한
- NFS(와 함께 사용), NFS에서 캐시 사용
- tune2fs(캐시 설정), 캐시 설정
- 성능 보장, 성능 보장
- 인덱싱 키, FS-Cache
- 일관성 데이터, FS-Cache
- 캐시 cull 제한, 캐시 캐시 제한 설정
- 캐시 공유, 캐시 공유
- 캐시 백엔드, FS-Cache
- 캐시 설정, 캐시 설정
- 통계 정보 (추적), 통계 정보
- fsync()
- ext4, ext4 파일 시스템
- XFS, XFS 파일 시스템
G
- GFS2
- gfs2.ko, 글로벌 파일 시스템 2
- 최대 크기, 글로벌 파일 시스템 2
- 파일 시스템 유형, 글로벌 파일 시스템 2
- GFS2 파일 시스템 최대 크기, 글로벌 파일 시스템 2
- gfs2.ko
- GFS2, 글로벌 파일 시스템 2
- gquota/gqnoenforce
- XFS, XFS 할당량 관리
- gtv
- 파일 시스템, 1.8.0 (기술 프리뷰)
H
- host
- 파이버 채널 API, 파이버 채널 API
I
- I/O 매개 변수 스택
- I/O 정렬 및 크기, stacking I/O Parameters
- I/O 정렬 및 크기, 스토리지 I/O 정렬 및 크기
- ATA 표준, ATA
- Linux I/O 스택, 스토리지 I/O 정렬 및 크기
- logical_block_size, 사용자 공간 액세스
- LVM, 논리 볼륨 관리자
- READ CAPACITY(16), SCSI
- SCSI 표준, SCSI
- sysfs 인터페이스(사용자 공간 액세스), sysfs 인터페이스
- 블록 장치 ioctls(사용자 공간 액세스), 블록 장치 ioctls
- 사용자 공간 액세스, 사용자 공간 액세스
- 스택 I/O 매개변수, stacking I/O Parameters
- 스토리지 액세스 매개변수, 스토리지 액세스를 위한 매개변수
- 툴(파티션 및 기타 파일 시스템 기능용), 파티션 및 파일 시스템 도구
- IBM System z의 DASD 및 zFCP 장치
- 설치 중 스토리지 고려 사항, IBM System Z의 DASD 및 zFCP 장치
- iface (iSCSI 오프로드를 위한 구성)
- 오프로드 및 인터페이스 바인딩
- iSCSI, iSCSI 오프로드에 대한 iface 구성
- iface binding/unbinding
- 오프로드 및 인터페이스 바인딩
- iSCSI, 포털에 iface를 바인딩/연결 해제
- iface 구성, 보기
- 오프로드 및 인터페이스 바인딩
- iSCSI, 사용 가능한 iface 구성 보기
- iface 설정
- 오프로드 및 인터페이스 바인딩
- iSCSI, 사용 가능한 iface 구성 보기
- Introduction, 개요
- iSCSI
- discovery, iSCSI 검색 구성
- 구성, iSCSI 검색 구성
- 레코드 유형, iSCSI 검색 구성
- software iSCSI, 소프트웨어 iSCSI 용 iface 구성
- 대상, iSCSI 대상에 로그인
- 로그인, iSCSI 대상에 로그인
- 스캔 상호 연결, iSCSI 상호 연결 스캔
- 오프로드 및 인터페이스 바인딩, iSCSI 오프로드 및 인터페이스 바인딩 구성
- iface (iSCSI 오프로드를 위한 구성), iSCSI 오프로드에 대한 iface 구성
- iface 구성, 보기, 사용 가능한 iface 구성 보기
- iface 설정, 사용 가능한 iface 구성 보기
- software iSCSI, 소프트웨어 iSCSI 용 iface 구성
- 사용 가능한 iface 구성 보기, 사용 가능한 iface 구성 보기
- 소프트웨어 iSCSI용 iface, 소프트웨어 iSCSI 용 iface 구성
- 이니시에이터 구현, 사용 가능한 iface 구성 보기
- 포털에 iface를 바인딩/연결 해제, 포털에 iface를 바인딩/연결 해제
- iSCSI API, iSCSI API
- iSCSI root
- iSCSI 구성, iSCSI Root
- iSCSI 논리 단위 크기 조정, iSCSI 논리 단위 크기 조정
- iSCSI 논리 단위, 크기 조정, iSCSI 논리 단위 크기 조정
- iSCSI 탐지 및 구성
- 설치 중 스토리지 고려 사항, iSCSI 탐지 및 설정
L
- lazy mount/unmount 지원 (autofs 버전 5)
- LDAP 지원 강화 (autofs 버전 5)
- Linux I/O 스택
- I/O 정렬 및 크기, 스토리지 I/O 정렬 및 크기
- logical_block_size
- I/O 정렬 및 크기, 사용자 공간 액세스
- LUKS/dm-crypt, 을 사용하여 블록 장치 암호화
- 설치 중 스토리지 고려 사항, LUKS를 사용하여 블록 장치 암호화
- LUN(논리적 단위 번호)
- adding/removing, 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- rescan-scsi-bus.sh, 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- 필수 패키지, 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- 확인된 문제, rescan-scsi-bus.sh로 알려진 문제
- LVM
- I/O 정렬 및 크기, 논리 볼륨 관리자
M
- mdadm( RAID 세트 구성)
- RAID, mdadm
- mdraid
- RAID, mdraid
- mkfs , 파티션 포맷 및 레이블 지정
- mkfs.ext4
- ext4, ext4 파일 시스템 생성
- mkfs.xfs
- XFS, XFS 파일 시스템 생성
- mnt 디렉터리, /mnt/ 디렉터리
- mnt(명령) 찾기
- 마운트 나열, 현재 마운트되어 있는 파일 시스템 나열
N
- NFS
- /etc/fstab , /etc/fstab을 사용하여 NFS 파일 시스템 마운트
- /local/directory(클라이언트 구성, 마운트), NFS 클라이언트 구성
- /remote/export(클라이언트 구성, 마운트), NFS 클라이언트 구성
- autofs 마운트 지점당 다중 마스터 맵 항목(autofs 버전 5), 버전 4를 통한 autofs 버전 5 개선 사항
- autofs 버전 5, 버전 4를 통한 autofs 버전 5 개선 사항
- condrestart, NFS 서버 시작 및 중지
- flexs
- LDAP, LDAP를 사용하여 자동 마운터 맵 저장
- 구성, autofs 설정
- 보강, 사이트 구성 파일 덮어쓰기 또는 수정
- FS-Cache, NFS에서 캐시 사용
- lazy mount/unmount 지원 (autofs 버전 5), 버전 4를 통한 autofs 버전 5 개선 사항
- LDAP 지원 강화 (autofs 버전 5), 버전 4를 통한 autofs 버전 5 개선 사항
- NFS 및authorizationbind 문제 해결, NFS 및authorization bind 문제해결
- RDMA, RDMA(NFSORDMA)를 통한 NFS 활성화
- rfc2307bis (autofs), LDAP를 사용하여 자동 마운터 맵 저장
- rpcbind , NFS 및 authorizationbind
- Starting, NFS 서버 시작 및 중지
- status, NFS 서버 시작 및 중지
- stopping, NFS 서버 시작 및 중지
- TCP, NFS 소개
- UDP, NFS 소개
- 감사자 쓰기, NFS
- 다시 로드, NFS 서버 시작 및 중지
- 다시 시작, NFS 서버 시작 및 중지
- 도입 부분, 네트워크 파일 시스템(NFS)
- 마운트(클라이언트 구성), NFS 클라이언트 구성
- 방화벽 구성, NFS 실행 방화벽
- 보안, NFS 보안
- NFSv3 호스트 액세스, AUTH_SYS 및 Export Controls를 사용한 NFS 보안
- NFSv4 호스트 액세스, AUTH_GSS를 사용한 NFS 보안
- 파일 권한, 파일 권한
- 사이트 구성 파일 덮어쓰기/자동fs, autofs 설정
- 서버 구성, NFS 서버 구성
- /etc/exports , /etc/exports 구성 파일
- exportfs 명령, exportfs 명령
- NFSv4를 사용한 exportfs 명령, NFSv4에서 exportfs 사용
- 서버(클라이언트 구성, 마운트), NFS 클라이언트 구성
- 옵션(클라이언트 구성, 마운트), NFS 클라이언트 구성
- 작동 방식, NFS 소개
- 저장할 LDAP를 사용하여 자동 마운터 맵 저장(autofs), 사이트 구성 파일 덮어쓰기 또는 수정
- 적절한 nsswitch 구성(autofs 버전 5), 사용, 버전 4를 통한 autofs 버전 5 개선 사항
- 직접 맵 지원(autofs 버전 5), 버전 4를 통한 autofs 버전 5 개선 사항
- 추가 리소스, NFS 참조
- 클라이언트
- flexs , flexs
- 구성, NFS 클라이언트 구성
- 마운트 옵션, 일반적인 NFS 마운트 옵션
- 필수 서비스, 필수 서비스
- 호스트 이름 형식, 호스트 이름 형식
- NFS 및authorizationbind 문제 해결
- NFS(로 캐시 제한)
- FS-Cache, NFS를 사용한 캐시 제한
- NFS(와 함께 사용)
- FS-Cache, NFS에서 캐시 사용
- NFS를 통한 캐시 제한 사항
- FS-Cache, NFS를 사용한 캐시 제한
- nobarrier 마운트 옵션
- ext4, ext4 파일 시스템 마운트
- XFS, 쓰기 Barriers
- NOP-Out (disabling)
- iSCSI 구성, iSCSI Root
- NOP-Out 요청
- 링크 손실 수정
- iSCSI 구성, NOP-Out Interval/Timeout
- NOP-Outs 비활성화
- iSCSI 구성, iSCSI Root
P
- parted , 파티션
- 개요, 파티션
- 명령 테이블, 파티션
- 장치 선택, 파티션 테이블 보기
- 파티션 생성, 파티션 만들기
- 파티션 제거, 파티션 제거
- 파티션 크기 조정, fdisk를 사용하여 파티션 크기 조정
- 파티션 테이블 보기, 파티션 테이블 보기
- pNFS
- 병렬 NFS, pNFS
- pquota/pqnoenforce
- XFS, XFS 할당량 관리
- proc 디렉터리, /proc/ 디렉토리
Q
- queue_if_no_path
- iSCSI 구성, dm-multipath를 사용한 iSCSI 설정
- 링크 손실 수정
- iSCSI 구성, replacement_timeout
- quotacheck , 할당량 데이터베이스 파일 생성
- quotacheck 명령
- 할당량 정확도 확인, 할당량 적용 유지
- quotaoff , 활성화 및 비활성화
- quotaon , 활성화 및 비활성화
R
- RAID
- Anaconda 지원, Anaconda 설치 프로그램의 RAID 지원
- dmraid, dmraid
- dmraid( RAID 세트 구성), dmraid
- mdadm( RAID 세트 구성), mdadm
- mdraid, mdraid
- RAID 세트 구성, RAID 세트 구성
- RAID 하위 시스템, Linux RAID Subsystems
- striping, RAID 수준 및 선형 지원
- 고급 RAID 장치 생성, 고급 RAID 장치 생성
- 미러링, RAID 수준 및 선형 지원
- 사용하는 이유, 중복 개별 디스크(RAID)
- 선형 RAID, RAID 수준 및 선형 지원
- 설치 프로그램 지원, Anaconda 설치 프로그램의 RAID 지원
- 소프트웨어 RAID, RAID 유형
- 수준, RAID 수준 및 선형 지원
- 수준 0, RAID 수준 및 선형 지원
- 수준 1, RAID 수준 및 선형 지원
- 수준 4, RAID 수준 및 선형 지원
- 수준 5, RAID 수준 및 선형 지원
- 패리티, RAID 수준 및 선형 지원
- 하드웨어 RAID, RAID 유형
- 하드웨어 RAID 컨트롤러 드라이버, Linux 하드웨어 RAID 컨트롤러 드라이버
- RAID 세트 구성
- RAID, RAID 세트 구성
- RAID 하위 시스템
- RAID, Linux RAID Subsystems
- RDMA
- READ CAPACITY(16)
- I/O 정렬 및 크기, SCSI
- Red Hat Enterprise Linux 관련 파일 위치
- /etc/sysconfig/, 특수 Red Hat Enterprise Linux 파일 위치
- ([살펴볼 다른 내용] sysconfig 디렉터리)
- /var/cache/yum, 특수 Red Hat Enterprise Linux 파일 위치
- /var/lib/rpm/, 특수 Red Hat Enterprise Linux 파일 위치
- replacement_timeout
- 링크 손실 수정
- iSCSI 구성, SCSI 오류 처리기, replacement_timeout
- replacement_timeoutM
- iSCSI 구성, iSCSI Root
- Report (xfs_quota 전문가 모드)
- XFS, XFS 할당량 관리
- rescan-scsi-bus.sh
- adding/removing
- LUN(논리적 단위 번호), 논리 단위 추가/제거를 통해 rescan-scsi-bus.sh
- resize2fs, Ext2 파일 시스템으로 되돌리기
- resize2fs (resizing ext4)
- ext4, ext4 파일 시스템 크기 조정
- rfc2307bis (autofs)
- rpcbind , NFS 및 authorizationbind
- ([살펴볼 다른 내용] NFS)
- NFS, NFS 및authorization bind 문제해결
- rpcinfo , NFS 및authorization bind 문제해결
- status, NFS 서버 시작 및 중지
- rpcinfo , NFS 및authorization bind 문제해결
S
- SCSI 명령 타이머
- Linux SCSI 계층, 명령 timer
- SCSI 명령 타이머 및 장치 상태 제어
- Linux SCSI 계층, SCSI 명령 타이머 및 장치 상태 제어
- SCSI 오류 처리기
- 링크 손실 수정
- iSCSI 구성, SCSI 오류 처리기
- SCSI 표준
- I/O 정렬 및 크기, SCSI
- SMB (살펴볼 내용 SMB)
- software iSCSI
- iSCSI, 소프트웨어 iSCSI 용 iface 구성
- 오프로드 및 인터페이스 바인딩
- iSCSI, 소프트웨어 iSCSI 용 iface 구성
- srv 디렉토리, /srv/ 디렉터리
- SSD
- 솔리드 스테이트 디스크, 솔리드 스테이트 디스크 배포 지침
- SSM
- 시스템 스토리지 관리자, 시스템 스토리지 관리자(SSM)
- 명령 나열, 모든 탐지된 장치에 대한 정보 표시
- 명령 크기 조정, 볼륨 크기 증가
- 백엔드, SSM 백엔드
- 설치, SSM 설치
- 스냅샷 명령, 스냅샷
- stride ( 스트라이프 지오메트리 지정)
- ext4, ext4 파일 시스템 생성
- striping
- RAID, RAID 수준 및 선형 지원
- RAID 기본 사항, 중복 개별 디스크(RAID)
- Su (mkfs.xfs 하위 옵션)
- XFS, XFS 파일 시스템 생성
- SW(mkfs.xfs 하위 옵션)
- XFS, XFS 파일 시스템 생성
- sys 디렉토리, /sys/ 디렉터리
- sysconfig 디렉터리, 특수 Red Hat Enterprise Linux 파일 위치
- sysfs
- 개요
- 온라인 스토리지, 온라인 스토리지 관리
- sysfs 인터페이스(사용자 공간 액세스)
- I/O 정렬 및 크기, sysfs 인터페이스
T
- TFTP 서비스, 구성
- 디스크 없는 시스템, 디스크 없는 클라이언트를 위한 tftp 서비스 구성
- transport
- 파이버 채널 API, 파이버 채널 API
- TRIM 명령
- 솔리드 스테이트 디스크, 솔리드 스테이트 디스크 배포 지침
- tune2fs
- 를 사용하여 ext2로 되돌리기, Ext2 파일 시스템으로 되돌리기
- 을 사용하여 ext3으로 변환, ext3 파일 시스템으로 변환
- tune2fs(마운트)
- ext4, ext4 파일 시스템 마운트
- tune2fs(캐시 설정)
- FS-Cache, 캐시 설정
U
- udev 규칙(timeout)
- Command timer (SCSI), 명령 timer
- umount, 파일 시스템 마운트 해제
- uquota/uqnoenforce
- XFS, XFS 할당량 관리
- usr 디렉토리, /usr/ Directory
V
- var 디렉터리, /var/ 디렉터리
- var/lib/rpm/ directory, 특수 Red Hat Enterprise Linux 파일 위치
- var/spool/up2date/ 디렉토리, 특수 Red Hat Enterprise Linux 파일 위치
- version
- 새로운 기능
- flexs, 버전 4를 통한 autofs 버전 5 개선 사항
- volume_key
- 개별 사용자, volume_key 를 개별 사용자로 사용
- 명령, volume_key 명령
W
- World Wide Identifier(WWWID)
- 영구 이름 지정, World Wide Identifier(WWWID)
- WWID
- 영구 이름 지정, World Wide Identifier(WWWID)
X
- XFS
- fsync(), XFS 파일 시스템
- gquota/gqnoenforce, XFS 할당량 관리
- mkfs.xfs, XFS 파일 시스템 생성
- nobarrier 마운트 옵션, 쓰기 Barriers
- pquota/pqnoenforce, XFS 할당량 관리
- Report (xfs_quota 전문가 모드), XFS 할당량 관리
- Su (mkfs.xfs 하위 옵션), XFS 파일 시스템 생성
- SW(mkfs.xfs 하위 옵션), XFS 파일 시스템 생성
- uquota/uqnoenforce, XFS 할당량 관리
- xfsdump, Backup
- xfsprogs, XFS 파일 시스템 일시 중단
- xfsrestore, 복원
- xfs_admin, 기타 XFS 파일 시스템 유틸리티
- xfs_bmap, 기타 XFS 파일 시스템 유틸리티
- xfs_copy, 기타 XFS 파일 시스템 유틸리티
- xfs_db, 기타 XFS 파일 시스템 유틸리티
- xfs_freeze, XFS 파일 시스템 일시 중단
- xfs_fsr, 기타 XFS 파일 시스템 유틸리티
- xfs_growfs, XFS 파일 시스템의 크기 늘리기
- xfs_info, 기타 XFS 파일 시스템 유틸리티
- xfs_mdrestore, 기타 XFS 파일 시스템 유틸리티
- xfs_metadump, 기타 XFS 파일 시스템 유틸리티
- xfs_quota, XFS 할당량 관리
- xfs_repair, XFS 파일 시스템 복구
- 감사자 쓰기, 쓰기 Barriers
- 누적 모드 (xfsrestore), 복원
- 단순 모드 (xfsrestore), 복원
- 대화형 작업 (xfsrestore), 복원
- 더티 로그를 사용하여 XFS 파일 시스템 복구, XFS 파일 시스템 복구
- 덤프 수준, Backup
- 마운트, XFS 파일 시스템 마운트
- 백업/교육, XFS 파일 시스템 백업 및 복원
- 생성, XFS 파일 시스템 생성
- 일시 중단, XFS 파일 시스템 일시 중단
- 전문가 모드 (xfs_quota), XFS 할당량 관리
- 제한 (xfs_quota 전문가 모드), XFS 할당량 관리
- 주요 기능, XFS 파일 시스템
- 파일 시스템 복구, XFS 파일 시스템 복구
- 파일 시스템 유형, XFS 파일 시스템
- 파일 시스템 크기 증가, XFS 파일 시스템의 크기 늘리기
- 프로젝트 제한(설정), 프로젝트 제한 설정
- 할당 기능, XFS 파일 시스템
- 할당량 관리, XFS 할당량 관리
- xfsdump
- XFS, Backup
- xfsprogs
- XFS, XFS 파일 시스템 일시 중단
- xfsrestore
- XFS, 복원
- xfs_admin
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_bmap
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_copy
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_db
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_freeze
- XFS, XFS 파일 시스템 일시 중단
- xfs_fsr
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_growfs
- XFS, XFS 파일 시스템의 크기 늘리기
- xfs_info
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_mdrestore
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_metadump
- XFS, 기타 XFS 파일 시스템 유틸리티
- xfs_quota
- XFS, XFS 할당량 관리
- xfs_repair
- XFS, XFS 파일 시스템 복구