
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
성능 튜닝 가이드
RHEL 7에서 하위 시스템 처리량 모니터링 및 최적화
초록
1장. 소개
- 구성하기 전에 백업
- Red Hat Enterprise Linux 7의 기본 설정은 중간 로드에서 실행되는 대부분의 서비스에 적합합니다. 특정 하위 시스템의 성능을 개선하면 다른 시스템에 부정적인 영향을 미칠 수 있습니다. 시스템 튜닝을 시작하기 전에 모든 데이터 및 구성 정보를 백업하십시오.
- 프로덕션 환경에서 설정 테스트
- 성능 튜닝 가이드에 설명된 절차는 랩과 현장 모두에서 Red Hat 엔지니어가 광범위하게 테스트합니다. Red Hat은 이러한 구성을 프로덕션 시스템에 적용하기 전에 보안 테스트 환경에서 계획된 모든 구성을 테스트할 것을 권장합니다.
이 문서를 읽을 수 있는 사람
- 시스템 관리자
- 성능 튜닝 가이드에서는 시스템 관리자가 특정 목적을 위해 Red Hat Enterprise Linux 7을 최적화할 수 있도록 각 구성 옵션의 영향을 자세히 설명합니다. 이 가이드의 절차는 Red Hat Certified Engineer( Cryostat) 인증을 보유한 시스템 관리자 또는 동등한 양의 경험(Linux 기반 시스템 배포 및 관리 경험)에 적합합니다.
- 시스템 및 비즈니스 애널리스트
- 이 가이드에서는 Red Hat Enterprise Linux 7 성능 기능을 높은 수준으로 설명합니다. 이는 특정 워크로드에서 하위 시스템을 수행하는 방법에 대한 정보를 제공하여, 감사자는 Red Hat Enterprise Linux 7이 사용 사례에 적합한지 여부를 결정할 수 있습니다.가능한 경우 성능 튜닝 가이드에서는 리더에게 보다 자세한 기능 문서를 나타냅니다. 이를 통해 독자는 인프라 및 배포 제안에 필요한 자세한 배포 및 최적화 전략을 수립하는 데 필요한 심층적인 지식을 개발할 수 있습니다.
2장. 성능 모니터링 툴
2.1. /proc
/proc "file system"은 Linux 커널의 현재 상태를 나타내는 파일 계층 구조를 포함하는 디렉터리입니다. 사용자와 애플리케이션에서 시스템의 커널 보기를 볼 수 있습니다.
/proc 디렉터리에는 시스템 하드웨어 및 현재 실행 중인 프로세스에 대한 정보도 포함되어 있습니다. /proc 파일 시스템의 대부분의 파일은 읽기 전용이지만 일부 파일(일반적으로 /proc/sys의 파일)은 사용자와 애플리케이션에서 커널에 구성 변경 사항을 통신할 수 있습니다.
/proc 디렉토리에서 파일 보기 및 편집에 대한 자세한 내용은 Red Hat Enterprise Linux 7 시스템 관리자 가이드를 참조하십시오.
2.2. GNOME 시스템 모니터
- 시스템
- 이 탭에는 시스템의 하드웨어 및 소프트웨어에 대한 기본 정보가 표시됩니다.
- 프로세스
- 이 탭에는 활성 프로세스 및 해당 프로세스 간의 관계에 대한 자세한 정보가 표시됩니다. 표시되는 프로세스를 필터링하여 특정 프로세스를 더 쉽게 찾을 수 있습니다. 이 탭에서는 start, stop, kill 및 change 우선 순위와 같은 표시된 프로세스에 대해 일부 작업을 수행할 수 있습니다.
- Resources
- 이 탭에는 현재 CPU 시간 사용량, 메모리 및 스왑 공간 사용량, 네트워크 사용량이 표시됩니다.
- 파일 시스템
- 이 탭에는 마운트된 모든 파일 시스템이 나열되고 파일 시스템 유형, 마운트 지점, 메모리 사용량과 같은 각 시스템에 대한 몇 가지 기본 정보가 제공됩니다.
2.3. 기본 제공 명령줄 도구
2.3.1. top
$ man top
2.3.2. ps
$ man ps
2.3.3. 가상 메모리 통계(vmstat)
$ man vmstat
2.3.4. 시스템 활동 보고자(sar)
-i 옵션을 사용하여 간격 시간을 초 단위로 설정할 수 있습니다(예: sar -i 60 ).
$ man sar
2.4. perf
2.5. Turbostat
- 고정 타임스탬프 카운터
- APERF 모델별 레지스터
- MPERF 모델별 레지스터
$ man turbostat
2.6. iostat
await 값과 그 값이 높은 이유는 무엇입니까? 다음 Red Hat 지식베이스 문서를 참조하십시오. iostat에서 보고한 값 "await"의 의미는 무엇입니까?
2.7. irqbalance
$ man irqbalance
2.8. SS
$ man ss
2.9. numastat
numa_hit 값과 낮은 numa_miss 값으로 표시됩니다. Numastat 는 시스템의 NUMA 노드에 시스템 및 프로세스 메모리를 배포하는 방법을 표시할 수 있는 여러 명령줄 옵션도 제공합니다.
$ man numastat
2.10. numad
/proc 파일 시스템의 정보에 정기적으로 액세스하여 노드별로 사용 가능한 시스템 리소스를 모니터링합니다. 지정된 리소스 사용 수준을 유지 관리하고, NUMA 노드 간에 프로세스를 이동하여 필요한 경우 리소스 할당을 재조정합니다. 시스템의 NUMA 노드의 하위 집합에서 중요한 프로세스를 지역화하고 격리하여 최적의 NUMA 성능을 달성하려고 합니다.
$ man numad
2.11. SystemTap
2.12. OProfile
- 성능 모니터링 샘플은 정확하지 않을 수 있습니다. 프로세서가 순서가 부족할 수 있기 때문에 인터럽트를 트리거한 명령 대신 샘플이 가까운 명령에서 기록될 수 있습니다.
- OProfile은 프로세스를 여러 번 시작하고 중지할 것으로 예상합니다. 따라서 여러 실행의 샘플이 누적될 수 있습니다. 이전 실행에서 샘플 데이터를 지워야 할 수도 있습니다.
- OProfile은 CPU 액세스로 제한된 프로세스의 문제를 식별하는 데 중점을 둡니다. 따라서 다른 이벤트의 잠금을 기다리는 동안 자고 있는 프로세스를 식별하는 데 유용하지 않습니다.
/usr/share/doc/oprofile-버전에 있는 시스템에 대한 설명서를 참조하십시오.
2.13. valgrind
$ man valgrind
/usr/share/doc/valgrind-버전에서 찾을 수 있습니다.
2.14. pqos
- 모니터링
- 캐시 모니터링 기술(CMT)을 사용한 LLC(Last Level Cache) 사용 및 경합 모니터링
- Memory Bandwidth Monitoring (MBM) 기술을 사용한 스레드별 메모리 대역폭 모니터링
- 할당
- 캐시 할당 기술(CAT)을 사용하여 특정 스레드 및 프로세스에 사용할 수 있는 LLC 공간의 제어
- Code and Data Prioritization (CDP) 기술을 사용하여 LLC의 코드 및 데이터 배치 제어
# pqos --show --verbose추가 리소스
- pqos 사용에 대한 자세한 내용은 pqos(8) 도움말 페이지를 참조하십시오.
- CMT, MBM, CAT, CDP 프로세서 기능에 대한 자세한 내용은 Intel 공식 문서인 Intel® Resource Director Technology(Intel® RDT) 를 참조하십시오.
3장. tuned
3.1. tuned 개요
udev 를 사용하여 연결된 장치와 정적으로 모니터링하고 선택한 프로필에 따라 시스템 설정을 동적으로 조정하는 데몬입니다. tuned 는 높은 처리량, 짧은 대기 시간 또는 powersave와 같은 일반적인 사용 사례에 대해 사전 정의된 여러 프로필과 함께 배포됩니다. 각 프로필에 대해 정의된 규칙을 수정하고 특정 장치를 조정하는 방법을 사용자 지정할 수 있습니다. 특정 프로필에 의한 시스템 설정의 모든 변경 사항을 되돌리려면 다른 프로필로 전환하거나 tuned 서비스를 비활성화할 수 있습니다.
no-daemon 모드에서 Tuned 를 실행할 수 있습니다. 이 모드에서 tuned 는 설정을 적용하고 종료합니다. D -Bus 지원, 핫플러그 지원 또는 설정에 대한 롤백 지원을 포함하여 이 모드에서 많은 tuned 기능이 없기 때문에 no-daemon 모드는 기본적으로 비활성화되어 있습니다. no-daemon 모드를 활성화하려면 /etc/tuned/tuned-main.conf 파일에서 다음을 설정합니다. daemon = 0.
sysctl 및 sysfs 설정 적용과 ethtool 과 같은 여러 구성 툴의 일회성 활성화로 구성됩니다. 또한 tuned 는 시스템 구성 요소 사용을 모니터링하고 해당 모니터링 정보를 기반으로 시스템 설정을 동적으로 조정합니다.
/etc/tuned/tuned-main.conf 파일을 편집하고 dynamic_tuning 플래그를 1 로 변경하여 활성화할 수 있습니다.
3.1.1. 플러그인
disk- 장치 및 측정 간격당 디스크 로드(IO 작업 수)를 가져옵니다.
net- 네트워크 카드 및 측정 간격당 네트워크 로드(전송된 패킷 수)를 가져옵니다.
load- CPU 및 측정 간격당 CPU 부하를 가져옵니다.
cpu- CPU governor를
governor매개변수에 의해 지정된 값으로 설정하고 CPU 로드에 따라 PM QoS CPU>-< 대기 시간을 동적으로 변경합니다. CPU 로드가load_threshold매개변수에서 지정한 값보다 작으면 대기 시간이latency_high매개변수에 의해 지정된 값으로 설정됩니다. 그러지 않으면latency_low에서 지정한 값으로 설정됩니다. 또한 대기 시간을 동적으로 변경하지 않고 특정 값으로 강제 적용할 수 있습니다. 이 작업은force_latency매개변수를 필요한 대기 시간 값으로 설정하여 수행할 수 있습니다. eeepc_she- CPU 로드에 따라 FSB 속도를 동적으로 설정합니다. 이 기능은 일부 netbooks에서 찾을 수 있으며 Asus Super Hybrid Engine이라고도 합니다. CPU 로드가
load_threshold_powersave매개변수에서 지정한 값과 같거나 같은 경우 플러그인은she_powersave매개변수에 지정된 값으로 FSB 속도를 설정합니다. FSB 빈도 및 해당 값에 대한 자세한 내용은 커널 설명서를 참조하십시오. 제공된 기본값은 대부분의 사용자에 대해 작동해야 합니다. CPU 로드가load_threshold_normal매개변수에서 지정한 값과 같으면 FSB 속도를she_normal매개변수에서 지정한 값으로 설정합니다. 정적 튜닝은 지원되지 않으며 이 기능에 대한 하드웨어 지원이 탐지되지 않으면 플러그인이 투명하게 비활성화됩니다. netwake_on_lan매개변수에서 지정한 값에 wake-on-lan을 구성합니다( ethtool 유틸리티와 동일한 구문 사용). 또한 인터페이스 사용률에 따라 인터페이스 속도를 동적으로 변경합니다.sysctl- plugin 매개변수에서 지정하는 다양한
sysctl설정을 설정합니다. 구문은name=value입니다. 여기서name은 sysctl 도구에서 제공하는 이름과 동일합니다. 다른 플러그인에서 다루지 않는 설정을 변경해야 하는 경우 이 플러그인을 사용하십시오(설정이 적용되는 경우 특정 플러그인을 선호). usb- USB 장치의 자동 종료 시간 제한을
autosuspend매개변수에서 지정한 값으로 설정합니다. 값 0은 autosuspend가 비활성화되어 있음을 의미합니다. vmtransparent_hugepages매개변수의 부울 값에 따라 투명한 대규모 페이지를 활성화하거나 비활성화합니다.audio- 오디오 인크의 자동 종료 시간 제한을
timeout매개변수에서 지정한 값으로 설정합니다. 현재snd_hda_intel및snd_ac97_codec가 지원됩니다. 값0은 autosuspend가 비활성화됨을 의미합니다. 부울 매개변수reset_controller를true로 설정하여 컨트롤러 재설정을 적용할 수도 있습니다. diskelevator매개변수에 지정된 값으로 에레이터를 설정합니다. 또한 ALPM을alpm매개변수 에 의해 지정된 값으로 설정하고, WWWM을aspm매개변수에 의해 지정된 값으로, 스케줄러는scheduler_quantum매개변수에 의해 지정된 값에, 디스크 회전 시간 초과를spindown매개변수에 의해 지정된 값에 추가하고, 디스크 readahead를readahead매개변수에 의해 지정된 값에 곱하고,readahead_multiply매개변수에 의해 지정된 상수에 따라 현재 디스크 readahead 값을 곱할 수 있습니다. 또한 이 플러그인은 현재 드라이브 사용률에 따라 드라이브의 고급 전원 관리 및 회전 시간 제한 설정을 동적으로 변경합니다. 동적 튜닝은 부울 매개변수dynamic에서 제어할 수 있으며 기본적으로 활성화되어 있습니다.참고다른 디스크 readahead 값을 지정하는 tuned 프로필을 적용하면udev규칙을 사용하여 구성된 경우 디스크 readahead 값 설정이 재정의됩니다. Red Hat은 tuned 툴을 사용하여 디스크 readahead 값을 조정하는 것이 좋습니다.mountsdisable_barriers매개변수의 부울 값에 따라 마운트의 장벽을 활성화하거나 비활성화합니다.script- 이 플러그인은 프로필이 로드되거나 언로드될 때 실행되는 외부 스크립트를 실행하는 데 사용할 수 있습니다. 이 스크립트는
시작또는중지할 수 있는 하나의 인수로 호출됩니다(프로파일 로드 또는 언로드 중 스크립트 호출 여부에 따라 다름). 스크립트 파일 이름은script매개변수로 지정할 수 있습니다. 스크립트에서 중지 작업을 올바르게 구현하고 시작 작업 중에 변경된 모든 설정을 되돌려야 합니다. 그렇지 않으면 롤백이 작동하지 않습니다. 편의를 위해 Bash 도우미 스크립트가 기본적으로 설치되고 이 스크립트에 정의된 다양한 기능을 가져와서 사용할 수 있습니다.이 기능은 주로 이전 버전과의 호환성을 위해 제공되며 마지막 수단으로 사용하고 필요한 설정을 포함하는 경우 다른 플러그인을 선호하는 것이 좋습니다. sysfs- plugin 매개변수에서 지정하는 다양한
sysfs설정을 설정합니다. 구문은name=value입니다. 여기서name은 사용할sysfs경로입니다. 다른 플러그인에서 다루지 않는 일부 설정을 변경해야 하는 경우 이 플러그인을 사용하십시오(필요한 설정을 포함하는 경우 특정 플러그인을 선호). video- 비디오 카드에 다양한 전원 저장 수준을 설정합니다 (현재 Radeon 카드만 지원됨). 전원 세이프 수준은
radeon_powersave매개변수를 사용하여 지정할 수 있습니다. 지원되는 값은default,auto,low,mid,high,dynpm입니다. 자세한 내용은 을 http://www.x.org/wiki/RadeonFeature#KMS_Power_Management_Options 참조하십시오. 이 플러그인은 실험적이며 매개 변수는 향후 릴리스에서 변경될 수 있습니다. bootloader- 커널 부팅 명령줄에 매개 변수를 추가합니다. 이 플러그인은 레거시 GRUB 1, GRUB 2를 지원하며 EFI(Extensible Firmware Interface)가 있는 GRUB도 지원합니다. 사용자 지정된 grub2 구성 파일의 비표준 위치는
grub2_cfg_file옵션으로 지정할 수 있습니다. 매개변수는 현재 grub 구성 및 해당 템플릿에 추가됩니다. 커널 매개 변수를 적용하려면 시스템을 재부팅해야 합니다.매개변수는 다음 구문으로 지정할 수 있습니다.cmdline=arg1 arg2 ... argn.
3.1.2. 설치 및 사용
yum install tunedthroughput-performance- 이는 컴퓨팅 노드 역할을 하는 Red Hat Enterprise Linux 7 운영 체제에서 미리 선택됩니다. 이러한 시스템의 목표는 최상의 처리량 성능입니다.
virtual-guest- 가상 머신에서 미리 선택됩니다. 목표는 최상의 성능입니다. 최상의 성능에 관심이 없는 경우
balanced또는powersave프로필로 변경하고 싶습니다(벨로우 참조). balanced- 이는 다른 모든 경우에 미리 선택됩니다. 목표는 균형 잡힌 성능과 전력 소비입니다.
systemctl start tunedsystemctl enable tunedtuned-adm
tuned-adm listtuned-adm activetuned-adm profile profiletuned-adm profile powersavethroughput-performance 프로필을 사용하고 스파다운 디스크 프로필에 의해 디스크 스핀다운을 낮은 값으로 설정하여 처리량이 높은 디스크 를 설정하는 것이 있습니다. 다음 예제에서는 최상의 성능을 위해 가상 머신에서 실행되도록 시스템을 최적화하고 낮은 전력 소비를 위해 동시에 튜닝하는 반면 낮은 전력 소비는 우선 순위입니다.
tuned-adm profile virtual-guest powersavetuned-adm recommendtuned --help3.1.3. 사용자 정의 프로필
/usr/lib/tuned/ 디렉터리에 저장됩니다. 각 프로필에는 자체 디렉터리가 있습니다. 프로필은 tuned.conf 라는 기본 구성 파일과 선택적으로 다른 파일(예: 도우미 스크립트)으로 구성됩니다.
/etc/tuned/ 디렉터리에 복사합니다. 동일한 이름의 프로필이 두 개 있는 경우 /etc/tuned/ 에 포함된 프로필이 사용됩니다.
/usr/lib/tuned/ 에 포함된 프로필을 사용할 수도 있습니다.
tuned.conf 파일에는 여러 섹션이 포함되어 있습니다. 한 가지 [main] 섹션이 있습니다. 다른 섹션은 플러그인 인스턴스의 구성입니다. [main] 섹션을 포함한 모든 섹션은 선택 사항입니다. 해시 기호(#)로 시작하는 행은 주석입니다.
[main] 섹션에는 다음과 같은 옵션이 있습니다.
include=profile- 지정된 프로파일이 포함됩니다. 예를 들어
include=powersave에는powersave프로필이 포함됩니다.
[NAME] type=TYPE devices=DEVICES
devices 행에는 목록, 와일드카드(*), 부정(!)이 포함될 수 있습니다. 규칙을 결합할 수도 있습니다. TYPE 시스템에 연결된 장치 라인이 없거나 나중에 있는 모든 장치가 플러그인 인스턴스에서 처리됩니다. 이는 devices=* 를 사용하는 것과 동일합니다. 플러그인의 인스턴스가 지정되지 않은 경우 플러그인이 활성화되지 않습니다. 플러그인이 더 많은 옵션을 지원하는 경우 plugin 섹션에서 지정할 수도 있습니다. 옵션을 지정하지 않으면 기본값이 사용됩니다(포함된 플러그인에 이전에 지정되지 않은 경우). 플러그인 옵션 목록은 3.1.1절. “플러그인”을 참조하십시오.
예 3.1. 플러그인 인스턴스 설명
sd 로 시작하는 모든 항목(예: sda 또는 sdb )과 일치하며 문제 발생을 비활성화하지 않습니다.
[data_disk] type=disk devices=sd* disable_barriers=false
sda1 및 sda2 를 제외한 모든 것과 일치합니다.
[data_disk] type=disk devices=!sda1, !sda2 disable_barriers=false
[TYPE] devices=DEVICES
type 행을 생략할 수 있습니다. 그러면 인스턴스를 유형과 동일한 이름으로 참조합니다. 그런 다음 이전 예제를 다음과 같이 다시 작성할 수 있습니다.
[disk] devices=sdb* disable_barriers=false
include 옵션을 사용하여 두 번 이상 지정되면 설정이 병합됩니다. 충돌로 인해 병합할 수 없는 경우 마지막으로 충돌하는 정의가 충돌의 이전 설정을 재정의합니다. 경우에 따라 이전에 정의된 사항을 알 수 없습니다. 이러한 경우 replace 부울 옵션을 사용하여 true 로 설정할 수 있습니다. 이렇게 하면 이름이 동일한 이전 정의를 모두 덮어쓰고 병합이 수행되지 않습니다.
enabled=false 옵션을 지정하여 플러그인을 비활성화할 수도 있습니다. 인스턴스가 정의되지 않은 경우와 동일한 효과가 있습니다. include 옵션에서 이전 정의를 재정의하고 사용자 지정 프로필에서 플러그인이 활성화되지 않도록 하려면 플러그인을 비활성화하면 유용할 수 있습니다.
균형 잡힌 프로필을 기반으로 하는 사용자 지정 프로필의 예입니다. 모든 장치에 대해 ALPM이 최대 전원으로 설정된 방식으로 확장됩니다.
[main] include=balanced [disk] alpm=min_power
isolcpus=2 를 커널 부팅 명령줄에 추가하는 사용자 지정 프로필의 예입니다.
[bootloader] cmdline=isolcpus=2
3.1.4. tuned-adm
tuned-adm listtuned-adm activetuned-adm profile profile_nametuned-adm profile latency-performancetuned-adm offtuned-adm listyum search tuned-profilesyum install tuned-profiles-profile-namebalanced- 기본 전원 프로필입니다. 성능과 전력 소비 간의 절충이 되는 것입니다. 가능한 경우 자동 확장 및 자동 튜닝을 시도합니다. 대부분의 로드에 대한 좋은 결과가 있습니다. 유일한 단점은 대기 시간이 증가하는 것입니다. 현재 tuned 릴리스에서는 CPU, 디스크, 오디오 및 비디오 플러그인을 활성화하고 보수적인 관리자를 활성화합니다.
radeon_powersave는auto로 설정되어 있습니다. powersave- 최대 절전 성능을 위한 프로필입니다. 실제 전력 소비를 최소화하기 위해 성능을 제한 할 수 있습니다. 현재 tuned 릴리스에서는 SATA 호스트 어댑터에 대해 USB 자동 일시 중지, Bluetooth 전원 저장 및 ALPM 전원을 절약할 수 있습니다. 또한 대기율이 낮은 시스템에 대한 멀티 코어 전원 절감을 예약하고 온디맨드 관리자를 활성화합니다. AC97 오디오 절전을 활성화하거나 시스템에 따라 10초의 시간 초과로HDA-Intel 전력 절감을 가능하게 합니다. 시스템에 지원되는 Radeon 그래픽 카드가 활성화된 KMS가 포함된 경우 자동 절전으로 구성합니다. Asus Eee PC에서 동적 슈퍼 하이브리드 엔진을 사용할 수 있습니다.참고
Powersave프로파일이 항상 가장 효율적인 것은 아닙니다. 예를 들어 트랜스코딩해야 하는 비디오 파일 등 작업을 수행해야 하는 정의된 작업이 있다고 가정합니다. 시스템은 트랜스코딩이 전체 전원으로 수행되면 더 적은 에너지를 소비할 수 있습니다. 작업이 빠르게 완료되므로 시스템은 유휴 상태가 되기 시작하고 매우 효율적인 전원 저장 모드로 자동으로 단계 다운될 수 있습니다. 반면, 제한 된 머신으로 파일을 인코딩하는 경우 시스템은 트랜스코딩 중에 더 적은 전력을 소비하지만 프로세스는 더 오래 걸릴 것이며 전체 소비 에너지가 높을 수 있습니다. 따라서균형 잡힌프로파일은 일반적으로 더 나은 옵션 일 수 있습니다. throughput-performance- 처리량이 높은 서버 프로필입니다. 전원 절약 메커니즘을 비활성화하고 sysctl 설정을 활성화하여 디스크, 네트워크 IO 및
데드라인스케줄러로 전환한 처리량 성능을 향상시킵니다. CPU governor는performance로 설정됩니다. latency-performance- 짧은 대기 시간에 최적화된 서버 프로필입니다. 전원 절약 메커니즘을 비활성화하고 대기 시간을 개선하는 sysctl 설정을 활성화합니다. CPU governor는
performance로 설정되고 CPU는 낮은 C 상태(PM QoS)에 잠겨 있습니다. network-latency- 대기 시간이 짧은 네트워크 튜닝을 위한 프로필입니다.
latency-performance프로필을 기반으로 합니다. 또한 투명한 hugepages, NUMA 밸런싱을 비활성화하고 다른 여러 네트워크 관련 sysctl 매개변수를 조정합니다. network-throughput- 처리량 네트워크 튜닝을 위한 프로필입니다.
throughput-performance프로필을 기반으로 합니다. 커널 네트워크 버퍼도 늘어납니다. virtual-guest- Red Hat Enterprise Linux 7 가상 머신과 엔터프라이즈 스토리지 프로필을 기반으로 하는 VMware 게스트용으로 설계된 프로필로, 다른 작업 중에서도 가상 메모리 스왑을 줄이고 디스크 readahead 값을 늘립니다. 디스크 장애를 비활성화하지 않습니다.
virtual-host엔터프라이즈 스토리지프로필을 기반으로 하는 가상 호스트에 대해 설계된 프로필로, 특히 가상 메모리 스왑성을 줄이고, 디스크 readahead 값을 증가시키고, 더 공격적인 더티 페이지 값을 활성화합니다.Oracle- Oracle 데이터베이스에 최적화된 프로필은
throughput-performance프로필을 기반으로 로드됩니다. 또한 투명한 대규모 페이지를 비활성화하고 다른 성능 관련 커널 매개변수를 수정합니다. 이 프로필은 tuned-profiles-oracle 패키지에서 제공합니다. Red Hat Enterprise Linux 6.8 이상에서 사용할 수 있습니다. 데스크탑- 분산 프로필을 기반으로 하는 데스크탑에 최적화된 프로필입니다.
또한 대화형 애플리케이션의 더 나은 응답을 위해 스케줄러 자동 그룹을 사용할 수 있습니다. cpu-partitioningcpu-partitioning프로필은 시스템 CPU를 분리 및 하우스키핑 CPU로 분할합니다. 격리된 CPU에서 지터 및 중단을 줄이기 위해 프로필은 사용자 공간 프로세스, 이동 가능한 커널 스레드, 인터럽트 처리기 및 커널 타이머에서 격리된 CPU를 지웁니다.하우스키핑 CPU는 모든 서비스, 쉘 프로세스 및 커널 스레드를 실행할 수 있습니다./etc/tuned/파일에서 cpu-partitioning 프로필을 구성할 수 있습니다. 구성 옵션은 다음과 같습니다.cpu-partitioning-variables.confisolated_cores=cpu-list- 격리할 CPU를 나열합니다. 분리된 CPU 목록은 쉼표로 구분되거나 사용자가 범위를 지정할 수 있습니다. 대시를 사용하여
3-5와 같은 범위를 지정할 수 있습니다. 이 옵션은 필수입니다. 이 목록에서 누락된 CPU는 자동으로 하우스키핑 CPU로 간주됩니다. no_balance_cores=cpu-list- 시스템 전체 프로세스 로드 밸런싱 중에 커널에서 고려하지 않는 CPU를 나열합니다. 이 옵션은 선택 사항입니다. 일반적으로
isolated_cores와 동일한 목록입니다.
cpu-partitioning에 대한 자세한 내용은 tuned-profiles-cpu-partitioning(7) 도움말 페이지를 참조하십시오.
선택적 채널에서 사용 가능한 tuned-profiles-compat 패키지를 사용하여 사전 정의된 추가 프로필을 설치할 수 있습니다. 이러한 프로필은 이전 버전과의 호환성을 위해 고안되었으며 더 이상 개발되지 않습니다. 기본 패키지의 일반화된 프로필은 대부분 동일하거나 더 잘 수행합니다. 사용할 특정 이유가 없는 경우 기본 패키지에서 위에서 언급한 프로필을 선호합니다. 호환성 프로필은 다음과 같습니다.
default- 이는 사용 가능한 프로필의 전원 저장에 가장 낮은 영향을 미치고 tuned 의 CPU 및 디스크 플러그인만 활성화합니다.
desktop-powersave- 데스크탑 시스템에서 전달되는 전원 프로필입니다. tuned 의 CPU, 이더넷, 디스크 플러그인뿐만 아니라 SATA 호스트 어댑터에 대한 ALPM 전원 저장 기능을 활성화합니다.
laptop-ac-powersave- AC에서 실행되는 랩탑을 대상으로 하는 중간 수준의 전원 프로필입니다. tuned 의 CPU, 이더넷 및 디스크 플러그인에 대한 SATA 호스트 어댑터, Wi-Fi 절전 및 디스크 플러그인에 대해 ALPM 전원을 활성화합니다.
laptop- neartery-powersave- 배터리에서 실행되는 랩탑에서 제공되는 높은 효과의 전원 프로필입니다. 현재 tuned 구현에서
powersave프로필의 별칭입니다. spindown-disk- 회전 시간을 최대화하기 위해 클래식 HDD가 있는 머신의 전원 연결 프로필입니다. 튜닝된 전원 절약 메커니즘을 비활성화하고, USB 자동 일시 중지를 비활성화하고, Bluetooth를 비활성화하고, Wi-Fi 절전을 활성화하고, 로그 동기화를 비활성화하고, 디스크 쓰기 시간을 늘리고, 디스크 스왑성을 줄입니다.
noatime옵션을 사용하여 모든 파티션을 다시 마운트합니다. enterprise-storage- 엔터프라이즈급 스토리지로 제공되는 서버 프로파일로, I/O 처리량을 극대화합니다.
throughput-performance프로필, multiplies readahead 설정과 동일한 설정을 활성화하고, 루트 이외의 파티션 및 비 부팅 파티션의 장애를 비활성화합니다.
atomic-host 프로필과 가상 머신의 atomic-guest 프로필을 사용합니다.
yum install tuned-profiles-atomicatomic-host- throughput-performance 프로필을 사용하여 베어 메탈 서버에서 호스트 시스템으로 사용되는 경우 Red Hat Enterprise Linux Atomic Host에 최적화된 프로필입니다. 또한 SELinux AVC 캐시, PID 제한 및 netfilter 연결 추적을 조정합니다.
atomic-guest- virtual-guest 프로필을 기반으로 게스트 시스템으로 사용되는 경우 Red Hat Enterprise Linux Atomic Host에 최적화된 프로필입니다. 또한 SELinux AVC 캐시, PID 제한 및 netfilter 연결 추적을 조정합니다.
realtime -virtual-host 및 realtime-virtual- guest 라는 커널 명령줄을 편집할 수 있는 세 가지 tuned 프로필을 사용할 수 있습니다.
실시간 프로필을 활성화하려면 tuned-profiles-realtime 패키지를 설치합니다. root로 다음 명령을 실행합니다.
yum install tuned-profiles-realtimerealtime-virtual-host 및 realtime-virtual-guest 프로필을 활성화하려면 tuned-profiles-nfv 패키지를 설치합니다. root로 다음 명령을 실행합니다.
yum install tuned-profiles-nfv3.1.5. powertop2tuned
yum install tuned-utilspowertop2tuned new_profile_name/etc/tuned 디렉터리에 프로필을 생성하고 현재 선택한 tuned 프로필을 기반으로 합니다. 보안상의 이유로 모든 PowerTOP 튜닝이 처음에 새 프로필에서 비활성화됩니다. 이를 활성화하려면 /etc/tuned/프로필/tuned.conf 에 대한 관심의 튜닝의 주석을 제거합니다. PowerTOP 가 활성화된 대부분의 튜닝을 사용하여 새 프로필을 생성하는 --enable 또는 -e 옵션을 사용할 수 있습니다. USB 자동 일시 중지와 같은 일부 위험한 튜닝은 계속 비활성화됩니다. 실제로 필요한 경우 수동으로 주석 처리를 해제해야 합니다. 기본적으로 새 프로필은 활성화되지 않습니다. 이를 활성화하려면 다음 명령을 실행합니다.
tuned-adm profile new_profile_namepowertop2tuned --help3.2. tuned 및 tuned-adm을 통한 성능 튜닝
tuned 프로필 개요
throughput-performance 입니다.
- 스토리지 및 네트워크에 대한 짧은 대기 시간
- 스토리지 및 네트워크에 대한 높은 처리량
- 가상 머신 성능
- 가상화 호스트 성능
tuned Boot Loader 플러그인
tuned Bootloader 플러그인 을 사용하여 커널(boot 또는 dracut) 명령줄에 매개변수를 추가할 수 있습니다. GRUB 2 부트 로더만 지원되며 프로필 변경 사항을 적용하려면 재부팅이 필요합니다. 예를 들어, quiet 매개변수를 tuned 프로필에 추가하려면 tuned.conf 파일에 다음 행을 포함합니다.
[bootloader] cmdline=quiet다른 프로필로 전환하거나 tuned 서비스를 수동으로 중지하면 추가 매개변수가 제거됩니다. 시스템을 종료하거나 재부팅하면 kernel 매개변수가
grub.cfg 파일에 유지됩니다.
환경 변수 및 조정된 기본 제공 함수 확장
nfsroot=/root 로 확장됩니다.
[bootloader] cmdline="nfsroot=$HOME"
tuned 변수를 환경 변수의 대안으로 사용할 수 있습니다. 다음 예에서 ${isolated_cores} 는 1,2 로 확장되므로 isolcpus=1,2 매개변수로 커널이 부팅됩니다.
[variables]
isolated_cores=1,2
[bootloader]
cmdline=isolcpus=${isolated_cores}
${non_isolated_cores} 는 0,3-5 로 확장되고 cpulist_invert 기본 제공 함수는 0,3-5 인수를 사용하여 호출됩니다.
[variables]
non_isolated_cores=0,3-5
[bootloader]
cmdline=isolcpus=${f:cpulist_invert:${non_isolated_cores}}
cpulist_invert 함수는 CPU 목록을 반전합니다. 6-CPU 머신의 경우 inversion은 1,2 이며 커널은 isolcpus=1,2 명령줄 매개변수로 부팅됩니다.
tuned.conf 에 다음 행을 추가할 수 있습니다.
[variables]
include=/etc/tuned/my-variables.conf
[bootloader]
cmdline=isolcpus=${isolated_cores}
isolated_cores=1,2 를 /etc/tuned/my-variables.conf 파일에 추가하는 경우 커널은 isolcpus=1,2 매개변수로 부팅됩니다.
기본 시스템 조정 프로필 수정
절차 3.1. 새 Tuned 프로필 디렉터리 생성
/etc/tuned/에서 만들려는 프로필과 동일한 이름의 새 디렉토리를/etc/tuned/my_profile_name/로 만듭니다.- 새 디렉터리에서
tuned.conf라는 파일을 생성하고 맨 위에 다음 행을 포함합니다.[main] include=profile_name
- 프로필 수정 사항을 포함합니다. 예를 들어, 기본값 10 대신
vm.swappiness값을 5로 설정하여throughput-performance프로필의 설정을 사용하려면 다음 행을 포함합니다.[main] include=throughput-performance [sysctl] vm.swappiness=5
- 프로필을 활성화하려면 다음을 실행합니다.
# tuned-adm profile my_profile_name
tuned.conf 파일을 사용하여 디렉터리를 생성하면 시스템 tuned 프로필이 업데이트된 후 모든 프로필 수정을 유지할 수 있습니다.
/user/lib/tuned/ 에서 /etc/tuned/ 로 시스템 프로필이 있는 디렉터리를 복사합니다. 예를 들면 다음과 같습니다.
# cp -r /usr/lib/tuned/throughput-performance /etc/tuned
/etc/tuned 의 프로필을 편집합니다. 동일한 이름의 프로필이 두 개 있는 경우 /etc/tuned/ 에 있는 프로필이 로드됩니다. 이 방법의 단점은 조정된 업그레이드 후 시스템 프로필이 업데이트되면 현재 릴리스된 수정된 버전에 변경 사항이 반영되지 않는다는 것입니다.
Resources
4장. tuna
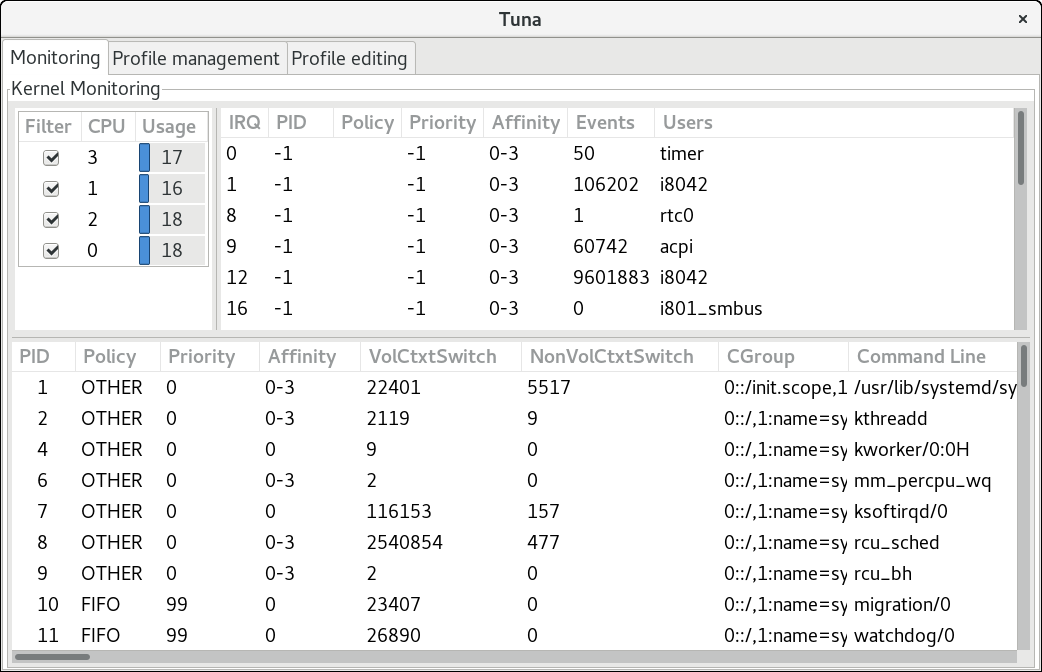
4.1. Tuna를 사용하여 시스템 검토
# tuna --show_threads
thread
pid SCHED_ rtpri affinity cmd
1 OTHER 0 0,1 init
2 FIFO 99 0 migration/0
3 OTHER 0 0 ksoftirqd/0
4 FIFO 99 0 watchdog/0
--show_threads 앞에 --threads 옵션을 추가합니다.
# tuna --threads=pid_or_cmd_list --show_threads#tuna --show_irqs# users affinity 0 timer 0 1 i8042 0 7 parport0 0
--show_irqs 앞에 --irqs 옵션을 추가합니다.
# tuna --irqs=number_or_user_list --show_irqs4.2. Tuna를 사용하여 CPU 튜닝
/proc/cpuinfo 파일의 모니터링 탭을 참조하십시오.
# tuna --cpus=cpu_list --run=COMMAND
# tuna --cpus=cpu_list --isolate
# tuna --cpus=cpu_list --include4.3. Tuna를 사용하여 IRQ 조정
/proc/interrpupts 파일을 참조하십시오. tuna --show_irqs 명령을 사용할 수도 있습니다.
--irqs 매개변수를 사용합니다.
# tuna --irqs=irq_list --run=COMMAND--move 매개변수를 사용합니다.
# tuna --irqs=irq_list --cpus=cpu_list --movesfc1 로 시작하고 두 개의 CPU에 분배되는 모든 인터럽트를 대상으로 지정하려면 다음을 수행합니다.
# tuna --irqs=sfc1\* --cpus=7,8 --move --spread--move 매개변수를 사용하여 IRQ를 수정하기 전과 후에 --show_irqs 매개변수를 사용합니다.
#tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 0,1,2,3#tuna --irqs=128 --cpus=3 --move#tuna --irqs=128 --show_irqs # users affinity 128 iwlwifi 3
4.4. Tuna를 사용하여 작업 튜닝
--priority 매개변수를 사용합니다.
# tuna --threads=pid_or_cmd_list --priority=[policy:]rt_priority- pid_or_cmd_list 인수는 쉼표로 구분된 PID 또는 명령 이름 패턴 목록입니다.
- 기본 정책의 경우 먼저 라운드 로빈,
FIFO또는OTHER에 대해 정책을RR으로 설정합니다.스케줄링 정책 개요는 6.3.6절. “스케줄링 정책 튜닝” 을 참조하십시오. - 1-99 범위에서 rt_priority 를 설정합니다. 1은 우선순위가 가장 낮고 99가 가장 높은 우선순위입니다.
# tuna --threads=7861 --priority=RR:40--priority 매개변수 전후에 --show_threads 매개변수를 사용합니다.
# tuna --threads=sshd --show_threads --priority=RR:40 --show_threads
thread ctxt_switches
pid SCHED_ rtpri affinity voluntary nonvoluntary cmd
1034 OTHER 0 0,1,2,3 12 17 sshd
thread ctxt_switches
pid SCHED_ rtpri affinity voluntary nonvoluntary cmd
1034 RR 40 0,1,2,3 12 17 sshd
4.5. Tuna 사용 예
예 4.1. 특정 CPU에 작업 할당
ssh 스레드와 CPU 2 및 3의 모든 http 스레드에서 실행되는 방법을 보여줍니다.
# tuna --cpus=0,1 --threads=ssh\* --move --cpus=2,3 --threads=http\* --move- CPU 0 및 1을 선택합니다.
ssh로 시작하는 모든 스레드를 선택합니다.- 선택한 스레드를 선택한 CPU로 이동합니다. tuna는
ssh로 시작하는 스레드의 선호도 마스크를 적절한 CPU로 설정합니다. CPU는 숫자 0과 1로 표현될 수 있습니다. 16진수 마스크에서는0x3또는 바이너리에서11로 나타낼 수 있습니다. - CPU 목록을 2 및 3으로 재설정합니다.
http로 시작하는 모든 스레드를 선택합니다.- 선택한 스레드를 선택한 CPU로 이동합니다. tuna는
http로 시작하는 스레드의 선호도 마스크를 적절한 CPU로 설정합니다. CPU는 숫자 2와 3, 16x 마스크는0xC, 또는1100으로 표현될 수 있습니다.
예 4.2. 현재 설정 보기
--show_threads (-P) 매개변수를 사용하여 현재 구성을 표시한 다음 요청된 변경이 예상대로 수행되었는지 테스트합니다.
#tuna--threads=gnome-sc\*\--show_threads\--cpus=0\--move\--show_threads\--cpus=1\--move\--show_threads\--cpus=+0\--move\--show_threadsthread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 1 33997 58 gnome-screensav thread ctxt_switches pid SCHED_ rtpri affinity voluntary nonvoluntary cmd 3861 OTHER 0 0,1 33997 58 gnome-screensav
gnome-sc로 시작하는 모든 스레드를 선택합니다.- 사용자가 선호도 마스크 및 RT 우선 순위를 확인할 수 있도록 선택한 스레드를 표시합니다.
- CPU 0을 선택합니다.
gnome-sc스레드를 선택한 CPU(CPU 0)로 이동합니다.- 이동 결과를 표시합니다.
- CPU 목록을 CPU 1로 재설정합니다.
gnome-sc스레드를 선택한 CPU(CPU 1)로 이동합니다.- 이동 결과를 표시합니다.
- CPU 0을 CPU 목록에 추가합니다.
gnome-sc스레드를 선택한 CPU(CPU 0 및 1)로 이동합니다.- 이동 결과를 표시합니다.
5장. Performance Co- Cryostat (PCP)
5.1. PCP 개요 및 리소스
- 실시간 데이터의 모니터링 및 관리
- 기록 데이터의 로깅 및 검색
pmcd(Performance Metric Collection Daemon)는 호스트 시스템의 성능 데이터와 pminfo 또는 pmstat 와 같은 다양한 클라이언트 툴을 사용하여 동일한 호스트 또는 네트워크를 통해 이 데이터를 검색, 표시, 아카이브, 처리할 수 있습니다. pcp 패키지는 명령줄 툴 및 기본 기능을 제공합니다. 그래픽 툴에는 pcp-gui 패키지가 필요합니다.
Resources
- PCPIntro 라는 수동 페이지는 Performance Co- Cryostat를 도입하는 역할을 합니다. 사용 가능한 툴 목록과 사용 가능한 구성 옵션 및 관련 도움말 페이지 목록을 제공합니다. 기본적으로 포괄적인 문서는
/usr/share/doc/pcp-doc/디렉터리에 설치됩니다. 특히 Performance Co- Cryostat 사용자 및 관리자 가이드 및 성능 Co- Cryostat의 가이드. - PCP에 대한 자세한 내용은 Red Hat 고객 포털의 PCP( Index of Performance Co- Cryostat) 문서, 솔루션, 튜토리얼 및 백서에서 참조하십시오.
- 이미 익숙한 이전 툴의 기능이 있는 PCP 툴을 확인해야 하는 경우 PCP 툴과 레거시 툴을 비교하여 Red Hat 지식베이스 문서를 참조하십시오.
- Performance Co- Cryostat에 대한 자세한 설명과 사용법은 공식 PCP 설명서 를 참조하십시오. Red Hat Enterprise Linux에서 PCP를 빠르게 사용하려면 PCP 빠른 참조 가이드를 참조하십시오. 공식 PCP 웹 사이트에는 자주 묻는 질문 목록이 포함되어 있습니다.
5.2. Performance Co- Cryostat를 사용한 XFS 파일 시스템 성능 분석
5.2.1. PCP를 사용하여 XFS 데이터 수집을 위해 XFS PMDA 설치
# yum install pcp
# systemctl enable pmcd.service
# systemctl start pmcd.service
# pcp
Performance Co-Pilot configuration on workstation:
platform: Linux workstation 3.10.0-123.20.1.el7.x86_64 #1 SMP Thu Jan
29 18:05:33 UTC 2015 x86_64
hardware: 2 cpus, 2 disks, 1 node, 2048MB RAM
timezone: BST-1
services pmcd
pmcd: Version 3.10.6-1, 7 agents
pmda: root pmcd proc xfs linux mmv jbd2
수동으로 XFS PMDA 설치
수집기역할을 사용하면 현재 시스템에서 성능 메트릭을 수집할 수 있습니다.
모니터역할을 사용하면 시스템이 로컬 시스템, 원격 시스템 또는 둘 다를 모니터링할 수 있습니다.
모두 사용하므로 대부분의 시나리오에서 XFS PMDA가 올바르게 작동할 수 있습니다.
# cd /var/lib/pcp/pmdas/xfs/
xfs 디렉터리에 다음을 입력합니다.
xfs]# ./Install
You will need to choose an appropriate configuration for install of
the “xfs” Performance Metrics Domain Agent (PMDA).
collector collect performance statistics on this system
monitor allow this system to monitor local and/or remote systems
both collector and monitor configuration for this system
Please enter c(ollector) or m(onitor) or (both) [b]
Updating the Performance Metrics Name Space (PMNS) ...
Terminate PMDA if already installed ...
Updating the PMCD control file, and notifying PMCD ...
Waiting for pmcd to terminate ...
Starting pmcd ...
Check xfs metrics have appeared ... 149 metrics and 149 values
5.2.2. XFS 성능 지표 구성 및 테스트
5.2.2.1. pminfo를 사용하여 메트릭 검사
pminfo 툴을 사용하는 것입니다. 명령은 XFS PMDA에서 제공하는 사용 가능한 모든 메트릭 목록을 표시합니다.
# pminfo xfs-t metric- 선택한 메트릭을 설명하는 한 줄 도움말 정보를 표시합니다.
-T metric- 선택한 메트릭을 설명하는 더 자세한 도움말 텍스트를 표시합니다.
-f metric- 지표에 해당하는 성능 값의 현재 읽기를 표시합니다.
-t,-T 및 -f 옵션을 사용할 수 있습니다. 대부분의 지표 데이터는 프로빙 시 시스템에 마운트된 각 XFS 파일 시스템에 대해 제공됩니다.
.)을 구분 기호로 사용합니다. 리프 노드 의미 체계( 점)는 모든 PCP 메트릭에 적용됩니다. 각 그룹에서 사용할 수 있는 메트릭 유형에 대한 개요는 표 A.3. “XFS용 PCP 지표 그룹” 를 참조하십시오.
예 5.1. pminfo 툴을 사용하여 XFS 읽기 및 쓰기 지표 검사
xfs.write_bytes 메트릭을 설명하는 한 줄 도움말 정보를 표시하려면 다음을 수행합니다.
# pminfo -t xfs.write_bytes
xfs.write_bytes [number of bytes written in XFS file system write operations]
xfs.read_bytes 메트릭을 설명하는 더 자세한 도움말 텍스트를 표시하려면 다음을 수행합니다.
# pminfo -T xfs.read_bytes
xfs.read_bytes
Help:
This is the number of bytes read via read(2) system calls to files in
XFS file systems. It can be used in conjunction with the read_calls
count to calculate the average size of the read operations to file in
XFS file systems.
xfs.read_bytes 지표에 해당하는 성능 값의 현재 읽기를 얻으려면 다음을 수행합니다.
# pminfo -f xfs.read_bytes
xfs.read_bytes
value 4891346238
5.2.2.2. pmstore를 사용하여 메트릭 구성
xfs.control.reset 메트릭)로 작동하는 경우 특정 메트릭의 값을 수정할 수 있습니다. 지표 값을 수정하려면 pmstore 툴을 사용합니다.
예 5.2. pmstore를 사용하여 xfs.control.reset Metric 재설정
pmstore 를 xfs.control.reset 지표와 함께 사용하여 기록된 카운터 값을 다시 0으로 재설정하는 방법을 보여줍니다.
$ pminfo -f xfs.write
xfs.write
value 325262
# pmstore xfs.control.reset 1
xfs.control.reset old value=0 new value=1
$ pminfo -f xfs.write
xfs.write
value 0
5.2.3. 파일 시스템당 사용 가능한 XFS 지표 검사
예 5.3. pminfo를 사용하여 장치별 XFS 메트릭 가져오기
# pminfo -f -t xfs.perdev.read xfs.perdev.write
xfs.perdev.read [number of XFS file system read operations]
inst [0 or "loop1"] value 0
inst [0 or "loop2"] value 0
xfs.perdev.write [number of XFS file system write operations]
inst [0 or "loop1"] value 86
inst [0 or "loop2"] value 0
5.2.4. pmlogger를 사용하여 성능 데이터 로깅
pmlogger 툴을 사용하여 시스템에서 선택한 지표의 보관된 로그를 생성합니다.
/var/lib/pcp/config/pmlogger/config.default 입니다. 구성 파일은 기본 로깅 인스턴스에서 로깅하는 메트릭을 지정합니다.
pmlogger 를 사용하여 로컬 시스템에서 메트릭 값을 기록하려면 기본 로깅 인스턴스를 시작합니다.
# systemctl start pmlogger.service
# systemctl enable pmlogger.servicepmlogger 가 활성화되어 있고 기본 구성 파일이 설정되면 pmlogger 행이 PCP 구성에 포함됩니다.
# pcp
Performance Co-Pilot configuration on workstation:
platform: Linux workstation 3.10.0-123.20.1.el7.x86_64 #1 SMP Thu Jan
[...]
pmlogger: primary logger:/var/log/pcp/pmlogger/workstation/20160820.10.15
pmlogconf를 사용하여 pmlogger 설정 파일 수정
pmlogger 서비스가 실행 중이면 PCP는 호스트의 기본 메트릭 세트를 기록합니다. pmlogconf 유틸리티를 사용하여 기본 구성을 확인하고 필요에 따라 XFS 로깅 그룹을 활성화할 수 있습니다. 활성화하는 중요한 XFS 그룹에는 XFS 정보,XFS 데이터, 로그 I/O 트래픽 그룹이 포함됩니다.
pmlogconf 프롬프트에 따라 관련 성능 지표 그룹을 활성화하거나 비활성화하고 각 활성화된 그룹의 로깅 간격을 제어합니다. 프롬프트에 대한 응답으로 y (예) 또는 n (아니오)을 눌러 그룹 선택을 수행합니다. pmlogconf를 사용하여 일반 PCP 아카이브 로거 구성 파일을 생성하거나 수정하려면 다음을 입력합니다.
# pmlogconf -r /var/lib/pcp/config/pmlogger/config.default
pmlogger 설정 파일 수동 수정
pmlogger 구성 파일을 수동으로 편집하고 지정된 간격으로 특정 메트릭을 추가하여 맞춤형 로깅 구성을 생성할 수 있습니다.
예 5.4. pmlogger 설정 파일( XFS Metrics 포함)
pmlogger config.default 파일의 추출을 보여줍니다.
# It is safe to make additions from here on ...
#
log mandatory on every 5 seconds {
xfs.write
xfs.write_bytes
xfs.read
xfs.read_bytes
}
log mandatory on every 10 seconds {
xfs.allocs
xfs.block_map
xfs.transactions
xfs.log
}
[access]
disallow * : all;
allow localhost : enquire;
PCP 로그 아카이브 재생
pmdumptext,pmrep또는pmlogsummary와 같은 PCP 유틸리티를 사용하여 로그를 텍스트 파일로 내보내서 조각으로 가져올 수 있습니다.- PCP 차트 애플리케이션에서 데이터를 재생하고 그래프를 사용하여 시스템의 라이브 데이터와 함께 세부 정보를 시각화할 수 있습니다. 5.2.5절. “PCP 차트를 사용한 시각적 추적”을 참조하십시오.
pmdumptext 툴을 사용하여 로그 파일을 볼 수 있습니다. pmdumptext를 사용하면 선택한 PCP 로그 아카이브를 구문 분석하고 값을 ASCII 테이블로 내보낼 수 있습니다. pmdumptext 툴을 사용하면 전체 아카이브 로그를 덤프하거나 명령줄에서 개별 메트릭을 지정하여 로그에서 지표 값만 선택할 수 있습니다.
예 5.5. 특정 XFS 메트릭 로그 정보 표시
xfs.perdev.log 메트릭에 데이터를 표시하려면 모든 헤더를 표시합니다.
$ pmdumptext -t 5seconds -H -a 20170605 xfs.perdev.log.writes
Time local::xfs.perdev.log.writes["/dev/mapper/fedora-home"] local::xfs.perdev.log.writes["/dev/mapper/fedora-root"]
? 0.000 0.000
none count / second count / second
Mon Jun 5 12:28:45 ? ?
Mon Jun 5 12:28:50 0.000 0.000
Mon Jun 5 12:28:55 0.200 0.200
Mon Jun 5 12:29:00 6.800 1.000
5.2.5. PCP 차트를 사용한 시각적 추적
# yum install pcp-gui
pmtime 서버 설정은 하단에 있습니다. 및 버튼을 사용하면 다음을 제어할 수 있습니다.
- PCP가 메트릭 데이터를 폴링하는 간격
- 기록 데이터 메트릭의 날짜 및 시간
- → 를 클릭하여 현재 뷰의 이미지를 저장합니다.
- → 클릭하여 레코딩을 시작합니다. → 를 클릭하여 레코딩을 중지합니다. 기록을 중지한 후에는 기록된 메트릭을 나중에 볼 수 있도록 보관합니다.
- 줄 플롯
- 막대 그래프
- 사용률 그래프
뷰 라고 하는 기본 구성 파일을 사용하면 하나 이상의 차트와 연결된 메타데이터를 저장할 수 있습니다. 이 메타데이터는 사용된 메트릭과 차트 열을 포함하여 모든 차트 측면을 설명합니다. 사용자 지정 보기 구성을 생성하고 → 구성을 로드할 수 있습니다. 보기에 대한 자세한 내용은 pmchart(1) 매뉴얼 페이지를 참조하십시오.
예 5.6. PCP 차트의 누적 차트 그래프 보기 구성
loop1 에서 읽고 쓰는 총 바이트 수를 보여주는 스택 차트 그래프를 설명합니다.
#kmchart
version 1
chart title "Filesystem Throughput /loop1" style stacking antialiasing off
plot legend "Read rate" metric xfs.read_bytes instance "loop1"
plot legend "Write rate" metric xfs.write_bytes instance "loop1"
5.3. 파일 시스템 데이터를 수집하기 위해 최소 PCP 설정 수행
pmlogger 출력의 결과 tar.gz 아카이브는 PCP 차트와 같은 다양한 PCP 툴을 사용하고 다른 성능 정보 소스와 비교하여 분석할 수 있습니다.
- pcp 패키지를 설치합니다.
#yum install pcp pmcd서비스를 시작합니다.#systemctl start pmcd.servicepmlogconf유틸리티를 실행하여pmlogger구성을 업데이트하고 XFS 정보, XFS 데이터, 로그 I/O 트래픽 그룹을 활성화합니다.#pmlogconf -r/var/lib/pcp/config/pmlogger/config.defaultpmlogger서비스를 시작합니다.#systemctl start pmlogger.service- XFS 파일 시스템에서 작업을 수행합니다.
pmlogger서비스를 중지합니다.#systemctl stop pmcd.service#systemctl stop pmlogger.service- 출력을 수집하여 호스트 이름과 현재 날짜와 시간에 따라 이름이 지정된
tar.gz파일에 저장합니다.#cd /var/log/pcp/pmlogger/#tar -czf $(hostname).$(date +%F-%Hh%M).pcp.tar.gz $(hostname)
6장. CPU
6.1. 고려 사항
- 프로세서가 서로 연결되고 메모리와 같은 관련 리소스에 연결되는 방법.
- 프로세서에서 실행을 위해 스레드를 예약하는 방법
- Red Hat Enterprise Linux 7의 인터럽트를 처리하는 프로세서 방법.
6.1.1. 시스템 토폴로지
- 대칭 SMP(Multi-Processor) 토폴로지
- SMP 토폴로지를 사용하면 모든 프로세서가 동일한 시간 내에 메모리에 액세스할 수 있습니다. 그러나 공유 및 동일한 메모리 액세스가 본질적으로 모든 CPU에서 직렬화된 메모리 액세스를 강제 적용하므로 이제 SMP 시스템 확장 제약 조건이 일반적으로 허용되지 않는 것으로 간주됩니다. 이러한 이유로, 거의 모든 최신 서버 시스템은 NUMA 시스템입니다.
- NUMA(Non-Uniform Memory Access) 토폴로지
- NUMA 토폴로지는 최근 SMP 토폴로지보다 더 최근에 개발되었습니다. NUMA 시스템에서 여러 프로세서는 물리적으로 소켓에 그룹화됩니다. 각 소켓에는 전용 메모리 영역이 있으며, 해당 메모리에 대한 로컬 액세스 권한이 있는 프로세서를 노드라고 합니다.동일한 노드의 프로세서는 해당 노드의 메모리 뱅크에 빠르게 액세스할 수 있으며 노드에 없는 메모리 뱅크에 대한 액세스 속도가 느려집니다. 따라서 로컬이 아닌 메모리에 액세스하는 경우 성능이 저하됩니다.이러한 성능 저하를 고려하여 NUMA 토폴로지가 있는 시스템의 성능에 민감한 애플리케이션은 애플리케이션을 실행하는 프로세서와 동일한 노드에 있는 메모리에 액세스해야 하며 가능한 경우 원격 메모리에 액세스하지 않아야 합니다.따라서 NUMA 토폴로지를 사용하여 시스템에서 애플리케이션 성능을 튜닝할 때 애플리케이션이 실행되는 위치와 실행 지점에 가장 가까운 메모리 은행을 고려하는 것이 중요합니다.NUMA 토폴로지가 있는 시스템에서
/sys파일 시스템에는 프로세서, 메모리 및 주변 장치가 연결된 방법에 대한 정보가 포함되어 있습니다./sys/devices/system/cpu디렉터리에는 시스템의 프로세서가 서로 연결되는 방법에 대한 세부 정보가 포함되어 있습니다./sys/devices/system/node디렉터리에는 시스템의 NUMA 노드와 해당 노드 간의 상대 거리에 대한 정보가 포함되어 있습니다.
6.1.1.1. 시스템 토폴로지 확인
$ numactl --hardware available: 4 nodes (0-3) node 0 cpus: 0 4 8 12 16 20 24 28 32 36 node 0 size: 65415 MB node 0 free: 43971 MB node 1 cpus: 2 6 10 14 18 22 26 30 34 38 node 1 size: 65536 MB node 1 free: 44321 MB node 2 cpus: 1 5 9 13 17 21 25 29 33 37 node 2 size: 65536 MB node 2 free: 44304 MB node 3 cpus: 3 7 11 15 19 23 27 31 35 39 node 3 size: 65536 MB node 3 free: 44329 MB node distances: node 0 1 2 3 0: 10 21 21 21 1: 21 10 21 21 2: 21 21 10 21 3: 21 21 21 10
$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 40 On-line CPU(s) list: 0-39 Thread(s) per core: 1 Core(s) per socket: 10 Socket(s): 4 NUMA node(s): 4 Vendor ID: GenuineIntel CPU family: 6 Model: 47 Model name: Intel(R) Xeon(R) CPU E7- 4870 @ 2.40GHz Stepping: 2 CPU MHz: 2394.204 BogoMIPS: 4787.85 Virtualization: VT-x L1d cache: 32K L1i cache: 32K L2 cache: 256K L3 cache: 30720K NUMA node0 CPU(s): 0,4,8,12,16,20,24,28,32,36 NUMA node1 CPU(s): 2,6,10,14,18,22,26,30,34,38 NUMA node2 CPU(s): 1,5,9,13,17,21,25,29,33,37 NUMA node3 CPU(s): 3,7,11,15,19,23,27,31,35,39

6.1.2. 스케줄링
6.1.2.1. Kernel Ticks
nohz_full)을 제공합니다. 이 옵션은 nohz_full 커널 매개변수를 사용하여 지정된 코어에서 활성화할 수 있습니다. 이 옵션을 코어에서 활성화하면 모든 시간 유지 활동이 대기 시간에 민감한 코어로 이동합니다. 이는 사용자 공간 작업이 커널 타이머 틱과 관련된 마이크로초 수준의 대기 시간에 특히 민감한 고성능 컴퓨팅 및 실시간 컴퓨팅 워크로드에 유용할 수 있습니다.
6.1.3. 인터럽트 요청(IRQ) 처리
6.2. 성능 문제 모니터링 및 진단
6.2.1. Turbostat
$ man turbostat
6.2.2. numastat
$ man numastat
6.2.3. /proc/interrupts
/proc/interrupts 파일은 특정 I/O 장치에서 각 프로세서로 전송되는 인터럽트 수를 나열합니다. 인터럽트 요청(IRQ) 번호, 시스템의 각 프로세서에서 처리하는 인터럽트 요청의 수, 전송된 인터럽트 유형 및 나열된 인터럽트 요청에 응답하는 쉼표로 구분된 장치 목록을 표시합니다.
6.2.4. pqos를 사용한 캐시 및 메모리 대역폭 모니터링
- 사이클당 지침(IPC)입니다.
- 마지막 수준 캐시의 개수입니다.
- LLC에서 프로그램이 지정된 CPU에서 실행하는 크기(KB)입니다.
- 로컬 메모리(MBL) 대역폭입니다.
- 원격 메모리(MBR) 대역폭입니다.
# pqos --mon-top추가 리소스
- pqos 유틸리티 및 관련 프로세서 기능에 대한 일반적인 개요는 2.14절. “pqos” 에서 참조하십시오.
- CAT를 사용하는 방법의 예는 DPDK(Data Plane Development Kit)의 네트워크 성능에 대한 시끄러운 주변 가상 머신의 영향을 최소화할 수 있는 방법은 데이터 플레인 개발 키트 Intel 백서 용 플랫폼 품질과 플랫폼 품질을 향상시키는 것을 참조하십시오.
6.3. 구성 제안
6.3.1. 커널 틱 시간 구성
nohz_full 매개변수를 사용하여 커널 명령줄에 해당 코어를 지정합니다. 16코어 시스템에서 nohz_full=1-15 를 지정하면 코어 1에서 15까지 동적 틱리스 동작을 활성화할 수 있습니다. 모든 시간키를 지정되지 않은 코어(코어 0)로 이동합니다. 이 동작은 부팅 시 일시적으로 또는 /etc/default/grub 파일의 GRUB_CMDLINE_LINUX 옵션을 통해 영구적으로 활성화할 수 있습니다. 영구 동작의 경우 grub2-mkconfig -o /boot/grub2/grub.cfg 명령을 실행하여 구성을 저장합니다.
- 시스템이 부팅될 때 rcu 스레드를 수동으로 대기 시간에 민감한 코어(이 경우 core 0)로 이동해야 합니다.
# for i in `pgrep rcu[^c]` ; do taskset -pc 0 $i ; done
- 커널 명령줄의
isolcpus매개변수를 사용하여 사용자 공간 작업에서 특정 코어를 분리합니다. - 선택적으로 커널의 write-back bdi-flush 스레드의 CPU 선호도를 하우스키핑 코어로 설정합니다.
echo 1 > /sys/bus/workqueue/devices/writeback/cpumask
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1
while :; do d=1; done 과 같은 것을 실행하는 스크립트입니다.
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1000 irq_vectors:local_timer_entry
# perf stat -C 1 -e irq_vectors:local_timer_entry taskset -c 1 stress -t 1 -c 1 1 irq_vectors:local_timer_entry
6.3.2. 하드웨어 성능 정책 설정 (x86_energy_perf_policy)
성능 모드의 모든 프로세서에서 작동합니다. CPUID.06H.ECX.bit3 이므로 루트 권한으로 실행해야 하는 프로세서 지원이 필요합니다.
$ man x86_energy_perf_policy
6.3.3. 작업 세트를 사용하여 프로세스 유사성 설정
$ man taskset
6.3.4. numactl을 사용하여 NUMA 유사성 관리
$ man numactl
libnuma 라이브러리가 포함되어 있습니다. 이 라이브러리는 커널에서 지원하는 NUMA 정책에 간단한 프로그래밍 인터페이스를 제공하며 numactl 애플리케이션보다 세분화된 튜닝에 사용할 수 있습니다. 자세한 내용은 도움말 페이지를 참조하십시오.
$ man numa
6.3.5. numad를 사용한 자동 NUMA 선호도 관리
numad 는 자동 NUMA 선호도 관리 데몬입니다. NUMA 리소스 할당 및 관리를 동적으로 개선하기 위해 시스템 내에서 NUMA 토폴로지 및 리소스 사용량을 모니터링합니다.
$ man numad
6.3.6. 스케줄링 정책 튜닝
6.3.6.1. 스케줄링 정책
6.3.6.1.1. Cryostat_FIFO를 사용한 정적 우선 순위 스케줄링
Cryostat_FIFO (정정 우선 순위 스케줄링이라고도 함)는 각 스레드에 고정된 우선 순위를 정의하는 실시간 정책입니다. 관리자는 이 정책을 통해 이벤트 응답 시간을 개선하고 대기 시간을 줄일 수 있으며 장기간 실행되지 않는 시간에 민감한 작업에 권장됩니다.
_FIFO 를 사용 중인 경우 스케줄러는 모든 all Cryostat _FIFO 스레드 목록을 우선 순위순으로 검색하고 실행할 준비가 된 가장 높은 우선 순위 스레드를 예약합니다. priority 수준은 1에서 99까지의 모든 정수일 수 있으며 99는 가장 높은 우선 순위로 취급됩니다. _FIFO 대역폭을 제한할 수 있습니다.
- /proc/sys/kernel/sched_rt_period_us
- 이 매개 변수는 프로세서 대역폭의 100 %로 간주되는 마이크로초 단위로 기간을 정의합니다. 기본값은
1000000Cryostats 또는 1초입니다. - /proc/sys/kernel/sched_rt_runtime_us
- 이 매개 변수는 실시간 스레드를 실행하는 데 사용되는 마이크로초 단위로 기간을 정의합니다. 기본값은
950000Cryostats 또는 0.95초입니다.
6.3.6.1.2. round Robin Priority Scheduling with Cryostat_RR
Cryostat_RR 은 round-robin variant of Cryo stat_FIFO 입니다. 이 정책은 여러 스레드가 동일한 우선 순위 수준에서 실행되어야 하는 경우에 유용합니다.
stat_FIFO 와마찬가지로 Cryostat_RR 은 각 스레드에 대한 고정된 우선 순위를 정의하는 실시간 정책입니다. 스케줄러는 모든 Cryostat _RR 스레드 목록을 우선 순위순으로 스캔하고 실행할 준비가 된 가장 높은 우선 순위 스레드를 예약합니다. 그러나 Cryo stat_FIFO 와 달리 우선 순위가 동일한 스레드는 특정 시간 슬라이스 내에서 라운드 로빈 스타일을 예약합니다.
sched_rr_timeslice_ms 커널 매개변수(/proc/sys/kernel/sched_rr_timeslice_ms)를 사용하여 이 시간 슬라이스의 값을 밀리초 단위로 설정할 수 있습니다. 가장 낮은 값은 1밀리초입니다.
6.3.6.1.3. normal Scheduling with Cryostat_OTHER
Cryostat_OTHER 는 Red Hat Enterprise Linux 7의 기본 스케줄링 정책입니다. 이 정책은 CFS(Completely Fair Scheduler)를 사용하여 이 정책과 함께 예약된 모든 스레드에 대한 공정하게 프로세서 액세스를 허용합니다. 이 정책은 시간이 지남에 따라 스레드를 더 효율적으로 예약할 수 있으므로 많은 스레드 또는 데이터 처리량이 우선 순위입니다.
6.3.6.2. CPU 격리
isolcpus boot 매개변수를 사용하여 스케줄러에서 하나 이상의 CPU를 분리할 수 있습니다. 이렇게 하면 스케줄러에서 이 CPU의 사용자 공간 스레드를 예약할 수 없습니다.
isolcpus=2,5-7
isolcpus 매개변수와 크게 다르며 현재 isolcpus 와 관련된 성능 향상을 달성하지 못합니다. 이 툴에 대한 자세한 내용은 6.3.8절. “Tuna를 사용하여 CPU, Thread 및 Interrupt Affinity 구성” 을 참조하십시오.
6.3.7. AMD64 및 Intel 64에서 Interrupt Affinity 설정
smp_affinity 속성 smp_affinity가 있습니다. 애플리케이션 성능을 개선하기 위해 동일한 프로세서 또는 동일한 코어의 프로세서에 인터럽트 선호도 및 프로세스 선호도를 할당합니다. 이를 통해 지정된 인터럽트 및 애플리케이션 스레드가 캐시 라인을 공유할 수 있습니다.
절차 6.1. 자동으로 인터럽트 밸런싱
- BIOS가 NUMA 토폴로지를 내보내는 경우
irqbalance서비스는 하드웨어 요청 서비스에 로컬인 노드에서 인터럽트 요청을 자동으로 제공할 수 있습니다.irqbalance구성에 대한 자세한 내용은 A.1절. “irqbalance” 을 참조하십시오.
절차 6.2. Interrupts 수동 밸런싱
- 구성할 인터럽트 요청에 해당하는 장치를 확인합니다.Red Hat Enterprise Linux 7.5부터 시스템은 특정 장치와 해당 드라이버에 대한 최적의 인터럽트 선호도를 자동으로 구성합니다. 더 이상 선호도를 수동으로 구성할 수 없습니다. 이는 다음 장치에 적용됩니다.
be2iscsi드라이버를 사용하는 장치- NVMe PCI 장치
- 플랫폼의 하드웨어 사양을 찾습니다. 시스템의 칩셋이 인터럽트 배포를 지원하는지 확인합니다.
- 이 경우 다음 단계에 설명된 대로 인터럽트 전달을 구성할 수 있습니다.또한 칩셋이 인터럽트의 균형을 조정하는 데 사용하는 알고리즘을 확인합니다. 일부 BIOS에는 인터럽트 전달을 구성할 수 있는 옵션이 있습니다.
- 그렇지 않은 경우, 칩셋은 항상 모든 인터럽트를 단일 정적 CPU로 라우팅합니다. 사용 중인 CPU를 구성할 수 없습니다.
- 시스템에서 사용 중인 Advanced Programmable Interrupt Controller (APIC) 모드를 확인합니다.물리적이 아닌 플랫 모드(
flat)만 인터럽트를 여러 CPU에 분산할 수 있습니다. 이 모드는 CPU가 최대 8개인 시스템에만 사용할 수 있습니다.$journalctl --dmesg | grep APIC명령 출력에서 다음을 수행합니다.- 시스템이
flat이외의 모드를 사용하는 경우APIC 라우팅 설정과 유사한 행을 물리적 플랫으로 볼 수 있습니다. - 이러한 메시지가 표시되지 않으면 시스템은
플랫모드를 사용합니다.
시스템에서x2apic모드를 사용하는 경우 부트로더 구성에서nox2apic옵션을 커널 명령줄에 추가하여 비활성화할 수 있습니다. smp_affinitymask를 계산합니다.smp_affinity값은 시스템의 모든 프로세서를 나타내는 16진수 비트 마스크로 저장됩니다. 각 비트는 다른 CPU를 구성합니다. 최소 유효 비트는 CPU 0입니다.마스크의 기본값은f이며, 이는 인터럽트 요청이 시스템의 모든 프로세서에서 처리될 수 있음을 의미합니다. 이 값을1로 설정하면 프로세서 0만 인터럽트를 처리할 수 있습니다.절차 6.3. 영업 및 지원
- 바이너리에서 인터럽트를 처리할 CPU에
1값을 사용합니다.예를 들어 CPU 0 및 CPU 7로 인터럽트를 처리하려면0000000010000001을 바이너리 코드로 사용합니다.표 6.1. CPU용 바이너리 비트
CPU 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0 바이너리 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 - 바이너리 코드를 16진수로 변환합니다.예를 들어 Python을 사용하여 바이너리 코드를 변환하려면 다음을 수행합니다.
>>>hex(int('0000000010000001', 2)) '0x81'
32개 이상의 프로세서가 있는 시스템에서는 개별 32비트 그룹에 대해smp_affinity값을 분리해야 합니다. 예를 들어 64 프로세서 시스템의 처음 32 프로세서만 인터럽트 요청을 서비스하려면0xffffffffffffff 0000 을 사용합니다.smp_affinitymask를 설정합니다.특정 인터럽트 요청에 대한 인터럽트 선호도 값은 연결된/proc/irq/irq_number/smp_affinity파일에 저장됩니다.계산된 마스크를 연결된 파일에 씁니다.# echo mask > /proc/irq/irq_number/smp_affinity
추가 리소스
- 인터럽트를 지원하는 시스템에서 인터럽트 요청의
smp_affinity속성을 수정하면 하드웨어를 설정하여 특정 프로세서와의 인터럽트를 서비스하는 결정이 커널의 개입 없이 하드웨어 수준에서 이루어집니다.인터럽트 운영에 대한 자세한 내용은 9장. 네트워킹 을 참조하십시오.
6.3.8. Tuna를 사용하여 CPU, Thread 및 Interrupt Affinity 구성
7장. 메모리
7.1. 고려 사항
7.1.1. 페이지 크기
정적 대규모 페이지 라고도 하는 HugeTLB 기능과 Transparent Huge Page 기능을 사용할 수 있습니다.
7.1.2. Translation Lookaside Buffer Size
7.2. 성능 문제 모니터링 및 진단
7.2.1. vmstat를 사용하여 메모리 사용량 모니터링
$ vmstat -s
$ man vmstat
7.2.2. Valgrind를 사용하여 애플리케이션 메모리 사용량 프로파일링
# yum install valgrind
7.2.2.1. Memcheck를 사용하여 메모리 사용량 프로파일링
- 발생하지 않아야 하는 메모리 액세스
- 정의되지 않았거나 초기화되지 않은 값 사용
- 잘못 해제된 힙 메모리
- 포인터 중복
- 메모리 누수
# valgrind --tool=memcheck application
- --leak-check
- 애플리케이션 실행이 완료되면 memcheck 에서 메모리 누수를 검색합니다. 기본값은 --leak-check=summary 로 발견된 메모리 누수를 출력합니다. --leak-check=yes 또는 --leak-check=full 을 지정하여 각 개별 누출의 세부 정보를 출력할 수 있습니다. 비활성화하려면 --leak-check=no 를 지정합니다.
- --undef-value-errors
- 기본값은 정의되지 않은 값을 사용할 때 오류를 보고하는 --undef-value-errors=yes 입니다. 또한 --undef-value-errors=no 를 지정하여 이 보고서를 비활성화하고 Memcheck 속도를 약간 높일 수 있습니다.
- --ignore-ranges
- 메모리 주소성을 확인할 때 memcheck 가 무시해야 하는 하나 이상의 범위를 지정합니다(예:
--ignore-ranges=0xPP-0xQ,0xRR-0xSS).
/usr/share/doc/valgrind-version/valgrind_manual.pdf 에 포함된 문서를 참조하십시오.
7.2.2.2. Cachegrind를 사용하여 캐시 사용량 프로파일링
# valgrind --tool=cachegrind application
- --I1
- 다음과 같이 첫 번째 수준 명령 캐시의 크기, 연관성 및 행 크기를 지정합니다(예: --I1=size,associativity ).
- --D1
- 첫 번째 수준 데이터 캐시의 크기, 연결성 및 행 크기를 지정합니다(예: --D1=size,associativity ).
- --LL
- 다음과 같이 마지막 수준 캐시의 크기, 연결성 및 행 크기를 지정합니다. --LL=size,associativity,line_size.
- --cache-sim
- 캐시 액세스 및 누락 개수를 활성화하거나 비활성화합니다. 이는 기본적으로 활성화되어 있습니다(--cache-sim=yes). 이 및 --branch-sim 을 비활성화하면 수집할 정보 없이 cachegrind 가 남습니다.
- --branch-sim
- 분기 명령 및 잘못된 예측 횟수를 활성화하거나 비활성화합니다. 이는 기본적으로 활성화되어 있습니다(--branch-sim=yes). 이 및 --cache-sim 을 비활성화하면 수집할 정보 없이 cachegrind 가 남게 됩니다.cachegrind 는 프로세스별
cachegrind.out.pid파일에 자세한 프로파일링 정보를 작성합니다.여기서 pid 는 프로세스 식별자입니다. 이러한 자세한 정보는 다음과 같이 cg_annotate 툴에서 추가로 처리할 수 있습니다.# cg_annotate cachegrind.out.pid
# cg_diff first second
/usr/share/doc/valgrind-version/valgrind_manual.pdf 에 포함된 문서를 참조하십시오.
7.2.2.3. if를 사용하여 힙 및 스택 공간 프로파일링
# valgrind --tool=massif application
- --heap
- heap을 위한피 규모 프로필의 값을 지정합니다. 기본값은 --heap=yes 입니다. 힙 프로파일링을 --heap=no 로 설정하여 비활성화할 수 있습니다.
- --heap-admin
- 힙 프로파일링을 사용할 때 블록당 바이트 수를 지정합니다. 기본값은
8바이트입니다. - --stacks
- topology if 가 스택을 프로파일링하는지 여부를 지정합니다. 스택 프로파일링이 훨씬 느려질 수 있으므로 기본값은 --stack=no 입니다. 스택 프로파일링을 활성화하려면 이 옵션을 --stack=yes 로 설정합니다. 루트 스택이 프로파일된 애플리케이션과 관련된 스택 크기 변경 사항을 더 잘 나타내기 위해 주 스택이 0으로 시작한다고 가정합니다.
- --time-unit
- chunk if 가 프로파일링 데이터를 수집하는 간격을 지정합니다. 기본값은
i(실행됨)입니다.ms(밀리초 또는 realtime) 및B( heap 및 스택에 할당되거나 할당됨)를 지정할 수도 있습니다. 할당된 바이트를 검사하는 것은 짧은 실행 애플리케이션 및 테스트용으로 여러 하드웨어에서 가장 재현 가능하므로 유용합니다.
if.out.pid 파일로 출력합니다. 여기서 pid 는 지정된 애플리케이션의 프로세스 식별자입니다. ms_print 툴은 이 프로파일링 데이터를 그래프로 표시하여 애플리케이션 실행에 대한 메모리 소비를 표시하고 최대 메모리 할당 지점에서 할당을 담당하는 사이트에 대한 자세한 정보를 표시합니다. volume if.out.pid 파일의 데이터를 그래프로 표시하려면 다음 명령을 실행합니다.
# ms_print massif.out.pid
/usr/share/doc/valgrind-version/valgrind_manual.pdf 에 포함된 문서를 참조하십시오.
7.3. HugeTLB Huge Pages 구성
부팅 시와 런타임 시 대규모 페이지를 예약하는 두 가지 방법이 있습니다. 부팅 시 예약은 메모리가 아직 많이 조각화되어 있지 않으므로 성공할 가능성이 높습니다. 그러나 NUMA 시스템에서 페이지 수는 NUMA 노드 간에 자동으로 분할됩니다. 런타임 방법을 사용하면 NUMA 노드당 대규모 페이지를 예약할 수 있습니다. 부팅 프로세스에서 런타임 예약이 가능한 한 빨리 수행되면 메모리 조각화 가능성이 낮습니다.
7.3.1. 부팅 시 대규모 페이지 구성
- hugepages
- 부팅 시 커널에 구성된 영구 대규모 페이지 수를 정의합니다. 기본값은 0입니다. 시스템에 물리적으로 연속된 무료 페이지가 충분한 경우에만 대규모 페이지를 할당할 수 있습니다. 이 매개변수로 예약된 페이지는 다른 용도로 사용할 수 없습니다.이 값은 부팅 후
/proc/sys/vm/nr_hugepages파일의 값을 변경하여 조정할 수 있습니다.NUMA 시스템에서 이 매개변수로 할당된 대규모 페이지는 노드 간에 동일하게 나뉩니다. 노드의/sys/devices/node/node/node_id/hugepages-1048576kB/nr_hugepages파일의 값을 변경하여 런타임 시 대규모 페이지를 할당할 수 있습니다.자세한 내용은 기본적으로/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/hugetlbpage.txt에 설치된 관련 커널 문서를 참조하십시오. - hugepagesz
- 부팅 시 커널에 구성된 영구 대규모 페이지의 크기를 정의합니다. 유효한 값은 2MB 및 1GB입니다. 기본값은 2MB입니다.
- default_hugepagesz
- 부팅 시 커널에 구성된 영구 대규모 페이지의 기본 크기를 정의합니다. 유효한 값은 2MB 및 1GB입니다. 기본값은 2MB입니다.
절차 7.1. 조기 부팅 중 1GB 페이지 예약
/etc/default/grub파일의 커널 명령줄 옵션에 다음 행을 추가하여 1GB 페이지용 HugeTLB 풀을 root로 생성합니다.default_hugepagesz=1G hugepagesz=1G
- 편집된 기본 파일을 사용하여 GRUB2 설정을 다시 생성합니다. 시스템에서 BIOS 펌웨어를 사용하는 경우 다음 명령을 실행합니다.
# grub2-mkconfig -o /boot/grub2/grub.cfg
UEFI 펌웨어가 있는 시스템에서 다음 명령을 실행합니다.# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
- 다음 콘텐츠를 사용하여
/usr/lib/systemd/system/hugetlb-gigantic-pages.service라는 파일을 만듭니다.[Unit] Description=HugeTLB Gigantic Pages Reservation DefaultDependencies=no Before=dev-hugepages.mount ConditionPathExists=/sys/devices/system/node ConditionKernelCommandLine=hugepagesz=1G [Service] Type=oneshot RemainAfterExit=yes ExecStart=/usr/lib/systemd/hugetlb-reserve-pages.sh [Install] WantedBy=sysinit.target
- 다음 콘텐츠를 사용하여
/usr/lib/systemd/hugetlb-reserve-pages.sh파일을 만듭니다.#!/bin/sh nodes_path=/sys/devices/system/node/ if [ ! -d $nodes_path ]; then echo "ERROR: $nodes_path does not exist" exit 1 fi reserve_pages() { echo $1 > $nodes_path/$2/hugepages/hugepages-1048576kB/nr_hugepages } reserve_pages number_of_pages node마지막 줄에서 number_of_pages 를 예약할 1GB 페이지 수와 node 를 해당 페이지를 예약할 노드 이름으로 바꿉니다.예 7.1.
node0및node1에 페이지 예약예를 들어node0에 1GB페이지를 2개 예약하고 1GB페이지를node1에 예약하려면 마지막 행을 다음 코드로 교체합니다.reserve_pages 2 node0 reserve_pages 1 node1
필요에 따라 수정하거나 다른 노드에서 메모리를 예약하기 위해 더 많은 행을 추가할 수 있습니다. - 스크립트를 실행 가능하게 만듭니다.
# chmod +x /usr/lib/systemd/hugetlb-reserve-pages.sh
- 초기 부팅 예약을 활성화합니다.
# systemctl enable hugetlb-gigantic-pages
nr_hugepages 에 작성하여 런타임 시 더 많은 1GB 페이지를 예약할 수 있습니다. 그러나 메모리 조각화로 인한 실패를 방지하려면 부팅 프로세스 중에 초기에 1GB 페이지를 예약하십시오.
7.3.2. 실행 시 대규모 페이지 구성
- /sys/devices/system/node/node_id/hugepages/hugepages-size/nr_hugepages
- 지정된 NUMA 노드에 할당된 지정된 크기의 대규모 페이지 수를 정의합니다. 이는 Red Hat Enterprise Linux 7.1에서 지원됩니다. 다음 예제는 20개의 2048 kB 대규모 페이지를
node2에 추가합니다.# numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total add AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 0 0 0 HugePages_Free 0 0 0 0 0 HugePages_Surp 0 0 0 0 0 # echo 20 > /sys/devices/system/node/node2/hugepages/hugepages-2048kB/nr_hugepages # numastat -cm | egrep 'Node|Huge' Node 0 Node 1 Node 2 Node 3 Total AnonHugePages 0 2 0 8 10 HugePages_Total 0 0 40 0 40 HugePages_Free 0 0 40 0 40 HugePages_Surp 0 0 0 0 0 - /proc/sys/vm/nr_overcommit_hugepages
- 메모리 과다 할당을 통해 시스템에서 생성하고 사용할 수 있는 최대 대규모 페이지 수를 정의합니다. 이 파일에 0이 아닌 값을 작성하면 영구적인 대규모 페이지 풀이 소진되면 시스템이 커널의 일반 페이지 풀에서 대규모 페이지 수를 얻을 수 있음을 나타냅니다. 이 서한 대규모 페이지가 사용되지 않으면 해제되고 커널의 일반 페이지 풀로 돌아갑니다.
7.4. Transparent Huge Pages 설정
madvise() 시스템 호출로 지정된 개별 프로세스의 메모리 영역에만 대규모 페이지를 할당합니다.
# cat /sys/kernel/mm/transparent_hugepage/enabled
# echo always > /sys/kernel/mm/transparent_hugepage/enabled
# echo madvise > /sys/kernel/mm/transparent_hugepage/enabled
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
직접 압축 을 비활성화 할 수 있습니다.
# echo madvise > /sys/kernel/mm/transparent_hugepage/defrag
/usr/share/doc/kernel-doc-kernel_version/Documentation/vm/transhuge.txt 파일을 참조하십시오.
7.5. 시스템 메모리 용량 구성
/proc 파일 시스템에서 해당 파일의 값을 변경하여 테스트 목적으로 일시적으로 설정할 수 있습니다. 사용 사례에 최적의 성능을 생성하는 값을 확인한 후 sysctl 명령을 사용하여 영구적으로 설정할 수 있습니다.
# echo 1 > /proc/sys/vm/overcommit_memory
/etc/sysctl.conf 에 sysctl vm.overcommit_memory=1 을 추가한 다음 다음 명령을 실행합니다.
# sysctl -p
7.5.1. 가상 메모리 매개변수
/proc/sys/vm 에 있습니다.
- dirty_ratio
- 백분율 값입니다. 총 시스템 메모리의 이 백분율이 수정되면 시스템은
pdflush작업을 사용하여 디스크에 수정 사항을 쓰기 시작합니다. 기본값은20%입니다. - dirty_background_ratio
- 백분율 값입니다. 전체 시스템 메모리의 이 백분율이 수정되면 시스템은 백그라운드에서 디스크에 수정 사항을 쓰기 시작합니다. 기본값은
10%입니다. - overcommit_memory
- 대규모 메모리 요청이 수락 또는 거부되는지 여부를 결정하는 조건을 정의합니다.기본값은
0입니다. 기본적으로 커널은 사용 가능한 메모리 양과 너무 큰 요청 실패를 추정하여 메모리 과다 할당 처리를 수행합니다. 그러나 메모리는 정확한 알고리즘이 아닌 추론을 사용하여 할당되므로 이 설정으로 메모리를 과부하할 수 있습니다.이 매개변수를1로 설정하면 커널에서 메모리 과다 할당 처리를 수행하지 않습니다. 이렇게 하면 메모리 과부하 가능성이 높지만 메모리 집약적인 작업의 성능이 향상됩니다.이 매개변수가2로 설정되면 커널은 사용 가능한 총 스왑 공간 합계 및overcommit_ratio에 지정된 물리적 RAM의 백분율보다 크거나 같은 메모리 요청을 거부합니다. 이렇게 하면 메모리 과다 할당 위험이 줄어들지만 스왑 영역이 실제 메모리보다 큰 시스템에만 권장됩니다. - overcommit_ratio
overcommit_memory가2로 설정될 때 고려되는 물리적 RAM의 백분율을 지정합니다. 기본값은50입니다.- max_map_count
- 프로세스에서 사용할 수 있는 최대 메모리 맵 영역 수를 정의합니다. 기본값은 대부분의 경우
65530입니다. 애플리케이션이 이 파일 수 이상을 매핑해야 하는 경우 이 값을 늘립니다. - min_free_kbytes
- 시스템 전체에서 사용할 수 있는 최소 킬로바이트 수를 지정합니다. 이는 각 낮은 메모리 영역에 적절한 값을 결정하는 데 사용되며, 각 영역에는 해당 크기와 비례하여 여러 개의 예약된 사용 가능한 페이지가 할당됩니다.주의극단적인 값은 시스템을 손상시킬 수 있습니다.
min_free_kbytes를 매우 낮은 값으로 설정하면 시스템이 메모리를 회수할 수 없으므로 시스템 중단 및 OOM 종료 프로세스가 발생할 수 있습니다. 그러나min_free_kbytes를 너무 높게 설정하면 (예: 전체 시스템 메모리의 5-10%)로 인해 시스템이 메모리 부족 상태가 즉시 입력되어 시스템이 메모리를 회수하는 데 시간이 너무 많이 소비됩니다. - oom_adj
- 시스템이 메모리 부족하고
panic_on_oom매개변수가0으로 설정된 경우oom_killer기능은oom_score가 가장 높은 프로세스에서 시스템을 복구할 때까지 프로세스를 종료합니다.oom_adj매개변수는 프로세스의oom_score를 결정하는 데 도움이 됩니다. 이 매개변수는 프로세스 ID별로 설정됩니다. 값-17은 해당 프로세스의oom_killer를 비활성화합니다. 기타 유효한 값은-16에서15사이입니다.참고조정된 프로세스에서 생성한 프로세스는 프로세스의oom_score를 상속합니다. - swappiness
0에서100까지의 swappiness 값은 시스템이 익명 메모리 또는 페이지 캐시를 선호하는 정도를 제어합니다. 값이 높은 경우 파일 시스템 성능이 향상되고 활성 프로세스가 RAM에서 덜 자주 교체됩니다. 값이 낮으면 메모리가 부족하지 않으므로 일반적으로 I/O 성능으로 인해 대기 시간이 줄어듭니다. 기본값은60입니다.주의swappiness==0을 설정하면 매우 공격적으로 스와핑되지 않으므로 강력한 메모리 및 I/O 부족으로 OOM이 종료될 위험이 증가합니다.
7.5.2. 파일 시스템 매개변수
/proc/sys/fs 에 있습니다.
- aio-max-nr
- 모든 활성 비동기 입력/출력 컨텍스트에서 허용되는 최대 이벤트 수를 정의합니다. 기본값은
65536입니다. 이 값을 수정해도 커널 데이터 구조의 크기를 사전 할당하거나 조정하지 않습니다. - file-max
- 전체 시스템에 대한 최대 파일 처리 수를 결정합니다. Red Hat Enterprise Linux 7의 기본값은 커널이 시작될 때 사용할 수 있는 사용 가능한 메모리 페이지의 최대
8192또는 10분의 1입니다.이 값을 늘리면 사용 가능한 파일 처리 부족으로 인한 오류를 해결할 수 있습니다.
7.5.3. 커널 매개변수
/proc/sys/kernel/ 디렉터리에 있는 다음 매개 변수의 기본값은 사용 가능한 시스템 리소스에 따라 부팅 시 커널에서 계산할 수 있습니다.
- msgmax
- 메시지 큐에서 단일 메시지의 최대 허용 크기(바이트)를 정의합니다. 이 값은 큐(
msgmnb)의 크기를 초과해서는 안 됩니다. 시스템의 현재msgmax값을 확인하려면 다음을 사용합니다.# sysctl kernel.msgmax
- msgmnb
- 단일 메시지 큐의 최대 크기(바이트)를 정의합니다. 시스템의 현재
msgmnb값을 확인하려면 다음을 사용합니다.# sysctl kernel.msgmnb
- msgmni
- 최대 메시지 큐 식별자 수를 정의하므로 최대 대기열 수를 정의합니다. 시스템의 현재
msgmni값을 확인하려면 다음을 사용합니다.# sysctl kernel.msgmni
- Shmall
- 시스템에서 동시에 사용할 수 있는 공유 메모리 페이지의 총 양을 정의합니다. 예를 들어, 페이지는 AMD64 및 Intel 64 아키텍처의 4096바이트입니다.시스템의 현재
shmall값을 확인하려면 다음을 사용합니다.# sysctl kernel.shmall
- shmmax
- 커널에서 허용하는 단일 공유 메모리 세그먼트의 최대 크기(바이트)를 정의합니다. 시스템의 현재
shmmax값을 확인하려면 다음을 사용합니다.# sysctl kernel.shmmax
- shmmni
- 시스템 전체 공유 메모리 세그먼트 수를 정의합니다. 기본값은 모든 시스템에서
4096입니다. - threads-max
- 커널에서 사용할 수 있는 시스템 전체 최대 스레드 수를 한 번에 정의합니다. 시스템의 현재
threads-max값을 확인하려면 다음을 사용합니다.# sysctl kernel.threads-max
기본값은 다음과 같습니다.mempages / (8 * THREAD_SIZE / PAGE SIZE )
최소 값은20입니다.
8장. 스토리지 및 파일 시스템
8.1. 고려 사항
- 데이터 쓰기 또는 읽기 패턴
- 기본 데이터 정렬
- 블록 크기
- 파일 시스템 크기
- 저널 크기 및 위치
- 액세스 시간 기록
- 데이터 안정성 보장
- 사전 가져오기 데이터
- 디스크 공간 사전 할당
- 파일 조각화
- 리소스 경합
8.1.1. I/O 스케줄러
- 데드라인
- SATA 디스크를 제외한 모든 블록 장치의 기본 I/O 스케줄러입니다.
데드라인은 요청이 I/O 스케줄러에 도달하는 시점부터 요청에 대해 보장된 대기 시간을 제공하려고 합니다. 이 스케줄러는 대부분의 사용 사례에 적합하지만 읽기 작업이 쓰기 작업보다 더 자주 발생하는 경우가 많습니다.대기 중인 I/O 요청은 읽기 또는 쓰기 일괄 처리로 정렬된 다음 LBA 순서를 늘리도록 스케줄링됩니다. 애플리케이션이 읽기 I/O에서 차단될 가능성이 높기 때문에 읽기 배치는 기본적으로 쓰기 배치보다 우선합니다. 배치가 처리된 후데드라인은 프로세서 시간 쓰기 시간이 얼마나 오래되었는지 확인하고 필요에 따라 다음 읽기 또는 쓰기 배치를 예약합니다. 배치당 처리할 요청 수, 쓰기 배치당 발행할 읽기 배치 수, 요청이 만료되기 전의 시간은 모두 구성할 수 있습니다. 자세한 내용은 8.4.4절. “데드라인 스케줄러 튜닝” 을 참조하십시오. - cfq
- SATA 디스크로 식별되는 장치에 대해서만 기본 스케줄러입니다. Completely Fair Queueing scheduler,
cfq에서는 프로세스를 실시간, 최상의 노력, 유휴 상태의 세 가지 클래스로 나눕니다. 실시간 클래스의 프로세스는 항상 최상의 작업 클래스의 프로세스보다 먼저 수행되며, 이 프로세스는 항상 유휴 클래스의 프로세스보다 먼저 수행됩니다. 즉, 실시간 클래스의 프로세스는 프로세서 시간의 최상의 노력과 유휴 프로세스를 유지할 수 있습니다. 프로세스는 기본적으로 최상의 작업 클래스에 할당됩니다.cfq는 기록 데이터를 사용하여 애플리케이션이 가까운 시일 내에 더 많은 I/O 요청을 발행할지 여부를 예측합니다. 추가 I/O가 예상되는 경우, 다른 프로세스의 I/O가 처리되기를 기다리는 경우에도cfq유휴 상태가 새 I/O를 기다립니다.유휴 상태로 유지되기 때문에 cfq 스케줄러는 이러한 목적으로 튜닝되지 않는 한 큰 검색 페널티를 발생하지 않는 하드웨어와 함께 사용해서는 안 됩니다. 또한 이러한 스케줄러를 스택링하면 많은 대기 시간을 유발하기 때문에 호스트 기반 하드웨어 RAID 컨트롤러와 같은 다른 비작업 사용 스케줄러와 함께 사용해서는 안 됩니다.cfq동작은 구성할 수 있습니다. 자세한 내용은 8.4.5절. “CFQ 스케줄러 튜닝” 에서 참조하십시오. - noop
noopI/O 스케줄러는 간단한 FIFO(first-in first-out) 스케줄링 알고리즘을 구현합니다. 요청은 간단한 마지막 캐시를 통해 일반 블록 계층에서 병합됩니다. 이는 빠른 스토리지를 사용하는 CPU 바인딩된 시스템에 가장 적합한 스케줄러일 수 있습니다.
8.1.2. 파일 시스템
8.1.2.1. XFS
8.1.2.2. Ext4
8.1.2.3. Btrfs (기술 프리뷰)
- 전체 파일 시스템이 아닌 특정 파일, 볼륨 또는 하위 볼륨의 스냅샷을 생성하는 기능
- 저렴한 디스크 (RAID)의 중복 배열의 여러 버전 지원
- 맵 I/O 오류를 파일 시스템 오브젝트에 역참조
- 투명한 압축(파티션의 모든 파일이 자동으로 압축됨)
- 데이터 및 메타 데이터에 대한 체크섬입니다.
8.1.2.4. GFS2
8.1.3. 파일 시스템의 일반 튜닝 고려 사항
8.1.3.1. 형식 시 고려 사항
- 크기
- 워크로드에 맞게 적절하게 크기의 파일 시스템을 생성합니다. 소규모 파일 시스템은 백업 시간이 비례적으로 단축되며 파일 시스템 검사를 위해 더 적은 시간과 메모리가 필요합니다. 그러나 파일 시스템이 너무 작으면 성능이 저하됩니다.
- 블록 크기
- 블록은 파일 시스템의 작업 단위입니다. 블록 크기는 단일 블록에 저장할 수 있는 데이터의 양을 결정하므로 한 번에 쓰거나 읽는 최소 데이터 양을 결정합니다.기본 블록 크기는 대부분의 사용 사례에 적합합니다. 그러나 블록 크기(또는 여러 블록의 크기)가 일반적으로 읽거나 쓰는 데이터 양보다 크거나 같으면 파일 시스템이 더 효율적으로 데이터를 저장합니다. 작은 파일은 여전히 전체 블록을 사용합니다. 파일이 여러 블록에 분산될 수 있지만 이로 인해 추가 런타임 오버헤드가 발생할 수 있습니다. 또한 일부 파일 시스템은 특정 수의 블록으로 제한되며, 이는 파일 시스템의 최대 크기를 제한합니다.블록 크기는 mkfs 명령을 사용하여 장치를 포맷할 때 파일 시스템 옵션의 일부로 지정됩니다. 블록 크기를 지정하는 매개 변수는 파일 시스템에 따라 다릅니다. 자세한 내용은 파일 시스템의 mkfs 도움말 페이지를 참조하십시오. 예를 들어 XFS 파일 시스템을 포맷할 때 사용 가능한 옵션을 보려면 다음 명령을 실행합니다.
$ man mkfs.xfs
- Cryostat
- 파일 시스템은 파일 시스템에서 데이터를 배포하는 것과 관련이 있습니다. 시스템에서 RAID와 같이 스트라이핑된 스토리지를 사용하는 경우 장치를 포맷할 때 데이터 및 메타데이터를 기본 스토리지와 조정하여 성능을 향상시킬 수 있습니다.많은 장치는 특정 파일 시스템으로 장치를 포맷할 때 자동으로 설정하는 것이 좋습니다. 장치가 이러한 권장 사항을 내보내지 않거나 권장 설정을 변경하려면 mkfs 를 사용하여 장치를 포맷할 때 수동으로 지정해야 합니다.파일 시스템을 지정하는 매개변수는 파일 시스템에 따라 다릅니다. 자세한 내용은 파일 시스템의 mkfs 도움말 페이지를 참조하십시오. 예를 들어 ext4 파일 시스템을 포맷할 때 사용 가능한 옵션을 보려면 다음 명령을 실행합니다.
$ man mkfs.ext4
- 외부 저널
- 저널링 파일 시스템은 작업이 실행되기 전에 저널 파일에서 쓰기 작업 중에 수행할 변경 사항을 설명합니다. 이렇게 하면 시스템 충돌 또는 정전 시 스토리지 장치가 손상될 가능성이 줄어들고 복구 프로세스의 속도가 빨라집니다.메타데이터 집약적인 워크로드는 저널에 매우 자주 업데이트됩니다. 더 큰 저널은 더 많은 메모리를 사용하지만 쓰기 작업의 빈도를 줄입니다. 또한 기본 스토리지만큼 빠르거나 더 빠른 전용 스토리지에 저널을 배치하여 메타데이터 집약적인 워크로드가 있는 장치의 검색 시간을 개선할 수 있습니다.주의외부 저널이 신뢰할 수 있는지 확인합니다. 외부 저널 장치를 손실하면 파일 시스템이 손상됩니다.마운트 시 저널 장치를 지정하고 형식 시 외부 저널을 생성해야 합니다. 자세한 내용은 mkfs 및 mount 도움말 페이지를 참조하십시오.
$ man mkfs
$ man mount
8.1.3.2. 마운트 시 고려 사항
- 장애 발생
- 파일 시스템 부족을 통해 파일 시스템 메타데이터를 영구 스토리지에 올바르게 작성하고 정렬할 수 있도록 하며
fsync로 전송된 데이터는 정전 시 유지됩니다. 이전 버전의 Red Hat Enterprise Linux에서 파일 시스템 부족을 사용하면fsync에 크게 의존하는 애플리케이션의 속도가 크게 느려지거나 많은 작은 파일을 생성 및 삭제할 수 있습니다.Red Hat Enterprise Linux 7에서 파일 시스템 장벽 성능을 개선하여 파일 시스템 장애를 비활성화함으로써 성능상의 영향은 무시할 수 없습니다(3% 미만). - 액세스 시간
- 파일을 읽을 때마다 액세스가 발생한 시간(시간)으로 메타데이터
가업데이트됩니다. 추가 쓰기 I/O가 포함됩니다. 대부분의 경우 이 오버헤드는 기본적으로 Red Hat Enterprise Linux 7에서 마지막 수정 시간(mtime) 또는 상태 변경 시간보다 이전 액세스 시간이 지난 경우에만a필드를 업데이트합니다.time그러나 이 메타데이터를 업데이트하는 데 시간이 오래 걸리는 경우, 정확한 액세스 시간 데이터가 필요하지 않은 경우noatime마운트 옵션을 사용하여 파일 시스템을 마운트할 수 있습니다. 이렇게 하면 파일을 읽을 때 메타데이터에 대한 업데이트가 비활성화됩니다. 또한 디렉터리를 읽을 때 메타데이터에 대한 업데이트를 비활성화하는nodiratime동작을 활성화합니다. - Read-ahead
- 미리 읽기 동작은 곧 필요할 가능성이 있는 데이터를 미리 가져와서 페이지 캐시에 로드하여 파일 액세스 속도를 높이며 디스크에 있는 경우보다 빠르게 검색할 수 있습니다. read-ahead 값이 높을수록 시스템이 데이터를 미리 가져옵니다.Red Hat Enterprise Linux는 파일 시스템에 대해 감지한 내용에 따라 적절한 read-ahead 값을 설정하려고 합니다. 그러나 정확한 탐지가 항상 가능한 것은 아닙니다. 예를 들어 스토리지 배열이 단일 LUN으로 시스템에 표시되는 경우 시스템은 단일 LUN을 감지하고 배열에 대한 적절한 읽기-마운드 값을 설정하지 않습니다.순차적 I/O를 많이 스트리밍하는 워크로드는 종종 높은 읽기-ahead 값의 이점을 얻을 수 있습니다. Red Hat Enterprise Linux 7에서 제공되는 스토리지 관련 tuned 프로필은 LVM 스트라이핑을 사용하는 것처럼 read-ahead 값을 높이지만 이러한 조정은 모든 워크로드에 항상 충분하지는 않습니다.미리 읽기 동작을 정의하는 매개변수는 파일 시스템에 따라 다릅니다. 자세한 내용은 마운트 도움말 페이지를 참조하십시오.
$ man mount
8.1.3.3. 유지 관리
- 배치 삭제
- 이러한 유형의 삭제는 fstrim 명령의 일부입니다. 파일 시스템에서 사용되지 않는 모든 블록을 관리자가 지정한 기준과 일치시킵니다.Red Hat Enterprise Linux 7은 물리적 삭제 작업을 지원하는 XFS 및 ext4 형식 장치에서 배치 삭제 기능을 지원합니다(즉,
/sys/block/devname/queue/discard_max_bytes의 값이 0이 아닌 HDD 장치,/sys/block/devname/queue/discard_granularity값이0이 아닌 SSD 장치). - 온라인 삭제
- 이 유형의 삭제 작업은 마운트 시
삭제옵션을 사용하여 구성되며 사용자 개입 없이 실시간으로 실행됩니다. 그러나 온라인 삭제는 사용에서 무료로 전환되는 블록만 삭제합니다. Red Hat Enterprise Linux 7은 XFS 및 ext4 형식의 장치에서 온라인 삭제 기능을 지원합니다.성능을 유지하기 위해 온라인 삭제가 필요한 경우 또는 시스템 워크로드에 배치 삭제가 불가능한 경우를 제외하고 배치 삭제가 권장됩니다. - 사전 할당
- 사전 할당은 해당 공간에 데이터를 쓰지 않고 파일에 디스크 공간을 할당한 것으로 표시합니다. 이는 데이터 조각화 및 잘못된 읽기 성능을 제한하는 데 유용할 수 있습니다. Red Hat Enterprise Linux 7은 마운트 시 XFS, ext4 및 Cryostat2 장치의 사전 위치 공간을 지원합니다. 파일 시스템의 적절한 매개 변수에 대한 마운트 도움말 페이지를 참조하십시오. 애플리케이션은
fallocate(2)glibc호출을 사용하여 사전 위치 지정 공간을 활용할 수도 있습니다.
8.2. 성능 문제 모니터링 및 진단
8.2.1. vmstat를 사용하여 시스템 성능 모니터링
- si
- 의 스왑 또는 스왑 공간(KB)에서 읽습니다.
- so
- 스왑 공간(KB)에 씁니다.
- bi
- KB의 블록 또는 쓰기 작업 블록입니다.
- bo
- KB에서 읽기 작업을 차단하거나 차단합니다.
- wa
- I/O 작업이 완료될 때까지 대기 중인 대기열의 일부입니다.
$ man vmstat
8.2.2. iostat를 사용하여 I/O 성능 모니터링
$ man iostat
8.2.2.1. blktrace를 사용한 자세한 I/O 분석
$ man blktrace
$ man blkparse
8.2.2.2. btt를 사용하여 blktrace 출력 분석
blktrace 메커니즘에서 추적하고 btt 에서 분석한 중요한 이벤트 중 일부는 다음과 같습니다.
- I/O 이벤트 Queuing (
Q) - 드라이버 이벤트(
D)에 I/O의 디스패치 - I/O 이벤트 완료 (
C)
blktrace 이벤트 사이의 타이밍을 확인합니다. 예를 들어 다음 명령은 대기 시간 아래의 평균으로 스케줄러, 드라이버 및 하드웨어 계층을 포함하는Q2C(커널 I/O 스택)의 하위 부분에서 보낸 총 시간을 보고합니다.
$ iostat -x
[...]
Device: await r_await w_await
vda 16.75 0.97 162.05
dm-0 30.18 1.13 223.45
dm-1 0.14 0.14 0.00
[...]D2C)을 서비스하는 데 시간이 오래 걸리는 경우 장치를 과부하하거나 장치로 전송된 워크로드는 하위 최적일 수 있습니다. Q2G(Q2G)로 디스패치되기 전에 블록 I/O가 오랜 시간 대기 중인 경우 사용 중인 스토리지가 I/O 로드를 제공할 수 없음을 나타낼 수 있습니다. 예를 들어 LUN 큐 전체 조건에 도달하여 I/O가 스토리지 장치로 디스패치되지 않습니다.
Q2Q)으로 전송되는 요청 사이의 시간 간격이 블록 계층(Q2C)에서 사용된 총 시간보다 크면 I/O 요청과 I/O 하위 시스템 간에 유휴 시간이 성능 문제가 발생하지 않음을 나타냅니다.
Q2C 값을 비교하면 스토리지 서비스 시간의 변동성이 표시될 수 있습니다. 값은 다음 중 하나일 수 있습니다.
- 작은 범위와 상당히 일치하거나
- 배포 범위에서 높은 변수이며 가능한 스토리지 장치 측 혼잡 문제를 나타냅니다.
$ man btt8.2.2.3. iowatcher를 사용하여 blktrace 출력 분석
8.2.3. SystemTap을 사용한 스토리지 모니터링
/usr/share/doc/systemtap-client/examples/io 디렉터리에 설치됩니다.
disktop.stp- 5초마다 디스크 읽기/쓰기 상태를 확인하고 해당 기간 동안 상위 10개의 항목을 출력합니다.
iotime.stp- 읽기 및 쓰기 작업에 소요되는 시간 및 읽기 및 쓰기 바이트 수를 출력합니다.
traceio.stp- 1초마다 관찰되는 누적 I/O 트래픽을 기반으로 상위 10개의 실행 파일을 출력합니다.
traceio2.stp- 실행 가능한 이름과 프로세스 ID를 지정된 장치에 읽기 및 쓰기로 출력합니다.
inodewatch.stp- 지정된 메이저/마이너 장치의 지정된 inode에 읽기 또는 쓰기가 발생할 때마다 실행 가능한 이름과 프로세스 ID를 출력합니다.
inodewatch2.stp- 속성이 지정된 메이저/마이너 장치의 지정된 inode에서 변경될 때마다 실행 가능한 이름, 프로세스 식별자 및 속성을 출력합니다.
8.3. Solid-State 디스크
SSD 튜닝 고려 사항
usr/share/doc/kernel-버전/Documentation/block/switching-sched.txt 파일을 참조하십시오.
vm_dirty_background_ratio 및 vm_dirty_ratio 설정을 낮춥니다. 쓰기 작업이 증가해도 일반적으로 디스크에 대한 다른 작업의 대기 시간에 부정적인 영향을 미치지 않습니다. 그러나 이 튜닝은 전체 I/O 를 생성할 수 있으므로 일반적으로 워크로드별 테스트 없이 권장되지 않습니다.
8.4. 구성 툴
8.4.1. 스토리지 성능을 위한 튜닝 프로필 구성
- latency-performance
- throughput-performance(기본값)
$ tuned-adm profile name
8.4.2. 기본 I/O 스케줄러 설정
cfq 스케줄러가 사용되며 데드라인 스케줄러는 다른 모든 드라이브에 사용됩니다. 이 섹션의 지침에 따라 기본 스케줄러를 지정하면 기본 스케줄러가 모든 장치에 적용됩니다.
/etc/default/grub 파일을 수동으로 수정할 수 있습니다.
elevator 매개변수를 설정하려면 디스크 플러그인을 활성화합니다. 디스크 플러그인에 대한 자세한 내용은 Tuned 장의 3.1.1절. “플러그인” 를 참조하십시오.
elevator 매개변수를 추가합니다. 절차 8.1. “GRUB 2를 사용하여 기본 I/O 스케줄러 설정” 에 설명된 대로 Tuned 툴을 사용하거나 /etc/default/grub 파일을 수동으로 수정할 수 있습니다.
절차 8.1. GRUB 2를 사용하여 기본 I/O 스케줄러 설정
/etc/default/grub파일의GRUB_CMDLINE_LINUX행에elevator매개변수를 추가합니다.#cat /etc/default/grub ... GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=vg00/lvroot rd.lvm.lv=vg00/lvswap elevator=noop" ...Red Hat Enterprise Linux 7에서 사용 가능한 스케줄러는데드라인,noop및cfq입니다. 자세한 내용은 kernel-doc 패키지를 설치한 후 사용 가능한 커널 설명서의cfq-iosched.txt및deadline-iosched.txt파일을 참조하십시오.elevator매개변수가 추가되어 새 구성을 생성합니다.GRUB 2 설정 파일의 위치는 BIOS 펌웨어가 있는 시스템과 UEFI 시스템이 있는 시스템에서 다릅니다. 다음 명령 중 하나를 사용하여 GRUB 2 설정 파일을 다시 생성합니다.- BIOS 펌웨어가 있는 시스템에서 다음을 사용합니다.
#grub2-mkconfig -o /etc/grub2.cfg - UEFI 펌웨어가 있는 시스템에서 다음을 사용합니다.
#grub2-mkconfig -o /etc/grub2-efi.cfg
- 변경 사항을 적용하려면 시스템을 재부팅합니다.GNU GRand Unified Bootloader(GRUB) 버전 2에 대한 자세한 내용은 Red Hat Enterprise Linux 7 시스템 관리자 가이드의 GRUB 2 부팅 로더 장을 참조하십시오.
8.4.3. 일반 블록 장치 튜닝 매개변수
/sys/block/sdX/queue/ 디렉터리 내에서 사용할 수 있습니다. 나열된 튜닝 매개변수는 I/O 스케줄러 튜닝과 분리되어 있으며 모든 I/O 스케줄러에 적용됩니다.
- add_random
- 일부 I/O 이벤트는
/dev/random의 엔트로피 풀에 기여합니다. 이러한 기여에 따른 오버헤드가 측정 가능한 경우 이 매개변수를0으로 설정할 수 있습니다. - iostats
- 기본값은
1(enabled)입니다.iostats를0으로 설정하면 장치의 I/O 통계 수집이 비활성화됩니다. 이 통계는 I/O 경로로 적은 양의 오버헤드를 제거합니다.iostats를0으로 설정하면 특정 NVMe 솔리드 스테이트 스토리지 장치와 같은 매우 높은 성능 장치의 성능이 약간 향상될 수 있습니다. 벤더가 지정된 스토리지 모델에 달리 지정하지 않는 한iostats를 활성화 상태로 두는 것이 좋습니다.iostats를 비활성화하면 장치의 I/O 통계가/proc/diskstats파일에 더 이상 존재하지 않습니다./sys/diskstats의 콘텐츠는sar또는iostats과 같이 I/O 툴을 모니터링하기 위한 I/O 정보의 소스입니다. 따라서 장치에 대한iostats매개변수를 비활성화하면 장치가 더 이상 I/O 모니터링 툴 출력에 표시되지 않습니다. - max_sectors_kb
- I/O 요청의 최대 크기를 킬로바이트 단위로 지정합니다. 기본값은
512KB입니다. 이 매개 변수의 최소값은 스토리지 장치의 논리 블록 크기에 따라 결정됩니다. 이 매개변수의 최대값은max_hw_sectors_kb값에 따라 결정됩니다.I/O 요청이 내부 삭제 블록 크기보다 크면 특정 솔리드 스테이트 디스크가 제대로 작동하지 않습니다. 시스템에 연결된 솔리드 스테이트 디스크 모델의 경우 이를 확인하려면 하드웨어 공급 업체에 문의하여 권장 사항을 따르십시오. Red Hat은max_sectors_kb에서 항상 최적의 I/O 크기와 내부 삭제 블록 크기 중 여러 개일 것을 권장합니다. 스토리지 장치에서 0이거나 지정하지 않은 경우 매개변수에logical_block_size값을 사용합니다. - nomerges
- 대부분의 워크로드는 요청 병합의 이점을 제공합니다. 그러나 병합을 비활성화하는 것은 디버깅 목적에 유용할 수 있습니다. 기본적으로
nomerges매개변수는0으로 설정되어 병합을 활성화합니다. 간단한 일회성 병합을 비활성화하려면nomerges를1로 설정합니다. 모든 유형의 병합을 비활성화하려면nomerges를2로 설정합니다. - nr_requests
- 한 번에 대기열에 추가할 수 있는 최대 읽기 및 쓰기 요청 수를 지정합니다. 기본값은
128입니다. 즉, 읽기 또는 쓰기를 요청하기 전에 128개의 읽기 요청 및 128개의 쓰기 요청을 대기열에 추가할 수 있습니다.대기 시간에 민감한 애플리케이션의 경우 이 매개변수의 값을 줄이고 스토리지에 대한 명령 대기열 깊이를 제한하여 쓰기 요청으로 장치 큐를 채울 수 없도록 합니다. 장치 큐가 채워지면 대기열 공간을 사용할 수 있을 때까지 I/O 작업을 수행하려는 다른 프로세스가 유휴 상태가 됩니다. 그런 다음 하나의 프로세스가 큐의 모든 지점을 지속적으로 사용하지 못하도록 라운드 로빈 방식으로 요청이 할당됩니다.I/O 스케줄러 내의 최대 I/O 작업 수는nr_requests*2입니다. 언급된 대로nr_requests는 읽기 및 쓰기에 별도로 적용됩니다.nr_requests는 I/O 스케줄러 내의 I/O 작업에만 적용되며 이미 기본 장치에 디스패치된 I/O 작업에는 적용되지 않습니다. 따라서 장치에 대한 I/O 작업의 최대 미해결 제한은(nr_requests*2)+(queue_depth)입니다. 여기서queue_depth는/sys/block/sdN/device/queue_depth이며, LUN 대기열 깊이라고도 합니다. 예를 들어avgqu-sz열에서iostat의 출력과 같은 총 I/O 작업 수를 확인할 수 있습니다. - optimal_io_size
- 일부 스토리지 장치는 이 매개변수를 통해 최적의 I/O 크기를 보고합니다. 이 값이 보고되는 경우 Red Hat은 애플리케이션이 가능한 경우 최적의 I/O 크기에 맞게 I/O를 발행하는 것이 좋습니다.
- read_ahead_kb
- 순차적 읽기 작업 중에 운영 체제가 미리 읽을 수 있는 최대 킬로바이트 수를 정의합니다. 결과적으로 다음 순차적 읽기의 커널 페이지 캐시에 필요한 정보가 이미 있으므로 읽기 I/O 성능이 향상됩니다.장치 매퍼는 종종 높은
read_ahead_kb값의 이점을 제공합니다. 각 장치를 매핑할 수 있는 128KB는 좋은 시작점이지만read_ahead_kb값을 4-8MB까지 늘리면 대용량 파일을 순차적으로 읽는 애플리케이션 환경에서 성능이 향상될 수 있습니다. - rotational
- 일부 솔리드 스테이트 디스크는 솔리드 스테이트 상태를 올바르게 알리지 않으며 기존 회전 디스크로 마운트됩니다. 솔리드 스테이트 장치가 이 값을 자동으로
0으로 설정하지 않으면 스케줄러에서 불필요한 검색 허용 논리를 비활성화하도록 수동으로 설정합니다. - rq_affinity
- 기본적으로 I/O 완료는 I/O 요청을 발행한 프로세서와 다른 프로세서에서 처리될 수 있습니다. 이 기능을 비활성화하고 I/O 요청을 발행한 프로세서에서만 완료를 수행하려면
rq_affinity를1로 설정합니다. 이렇게 하면 프로세서 데이터 캐싱의 효율성을 향상시킬 수 있습니다. - scheduler
- 특정 스토리지 장치에 대한 스케줄러 또는 스케줄러 기본 설정 순서를 설정하려면
/sys/block/devname/queue/scheduler파일을 편집합니다. 여기서 devname 은 구성할 장치의 이름입니다.# echo cfq > /sys/block/hda/queue/scheduler
8.4.4. 데드라인 스케줄러 튜닝
데드라인 이 사용 중인 경우 대기 중인 I/O 요청이 읽기 또는 쓰기 일괄 처리로 정렬된 다음 LBA 순서를 늘리도록 스케줄링됩니다. 애플리케이션이 읽기 I/O에서 차단될 가능성이 높기 때문에 읽기 배치는 기본적으로 쓰기 배치보다 우선합니다. 배치가 처리된 후 데드라인 은 프로세서 시간 쓰기 시간이 얼마나 오래되었는지 확인하고 필요에 따라 다음 읽기 또는 쓰기 배치를 예약합니다.
데드라인 스케줄러의 동작에 영향을 미칩니다.
- fifo_batch
- 단일 일괄 처리로 실행할 읽기 또는 쓰기 작업 수입니다. 기본값은
16입니다. 값이 클수록 처리량이 증가할 수 있지만 대기 시간이 늘어납니다. - front_merges
- 워크로드가 프론트 병합을 생성하지 않으면 이 튜닝 가능 항목을
0으로 설정할 수 있습니다. 그러나 이 검사의 오버헤드를 측정하지 않는 한 Red Hat은 기본값1을 권장합니다. - read_expire
- 읽기 요청을 서비스에 예약해야 하는 시간(밀리초)입니다. 기본값은
500(0.5초)입니다. - write_expire
- 서비스에 대한 쓰기 요청을 예약해야 하는 시간(밀리초)입니다. 기본값은
5000(5초)입니다. - writes_starved
- 쓰기 일괄 처리를 처리하기 전에 처리할 수 있는 읽기 배치 수입니다. 이 값이 높을수록 배치를 읽기 위해 지정된 기본 설정이 커집니다.
8.4.5. CFQ 스케줄러 튜닝
/sys/block/devname/queue/iosched 디렉토리에서 지정된 파일을 변경하여 장치별로 설정됩니다.
- back_seek_max
- CFQ에서 이전 검색을 수행할 최대 거리(KB)입니다. 기본값은
16KB입니다. 역추적 검색은 일반적으로 성능이 손상되므로 큰 값은 권장되지 않습니다. - back_seek_penalty
- 디스크 헤드가 앞으로 또는 뒤로 이동할지 여부를 결정할 때 역추적에 적용된 승수입니다. 기본값은
2입니다. 디스크 헤드 위치가 1024KB이고 시스템(1008KB 및 1040KB)에 적절한 요청이 있는 경우back_seek_penalty는 이전 검색 거리에 적용되며 디스크가 앞으로 이동합니다. - fifo_expire_async
- 비동기(buffered write) 요청이 서비스되지 않은 상태로 유지될 수 있는 시간(밀리초)입니다. 이 시간이 만료되면 중단된 단일 비동기 요청이 디스패치 목록으로 이동합니다. 기본값은
250밀리초입니다. - fifo_expire_sync
- 동기(읽기 또는
O_DIRECT쓰기) 요청이 처리되지 않은 상태로 유지될 수 있는 시간(밀리초)입니다. 이 시간이 만료되면 중단된 단일 동기 요청이 디스패치 목록으로 이동합니다. 기본값은125밀리초입니다. - group_idle
- 이 매개변수는 기본적으로
0(비활성화)으로 설정됩니다.1(enabled)로 설정하면 제어 그룹에서 I/O를 발행하는 마지막 프로세스의cfq스케줄러 유휴 상태가 됩니다. 이는 비례 가중치 I/O 제어 그룹을 사용하고slice_idle가0(빠른 스토리지에서)으로 설정된 경우 유용합니다. - group_isolation
- 이 매개변수는 기본적으로
0(비활성화)으로 설정됩니다.1(enabled)로 설정하면 그룹 간에 더 강력한 격리를 제공하지만 임의의 워크로드와 순차적 워크로드에 공정성이 적용되므로 처리량이 줄어듭니다.group_isolation이 비활성화된 경우(0으로 설정) 순차 워크로드에만 공정성이 제공됩니다. 자세한 내용은/usr/share/doc/kernel-doc-version/Documentation/cgroups/blkio-controller.txt에서 설치된 문서를 참조하십시오. - low_latency
- 이 매개변수는 기본적으로
1(활성화)으로 설정됩니다. 활성화하면cfq는 장치에서 I/O를 발행하는 각 프로세스에 대해 최대 대기 시간을 제공하여 처리량에 대한 공정성을 제공합니다.이 매개변수가0으로 설정되면(비활성화됨) 대상 대기 시간이 무시되고 각 프로세스는 전체 시간 슬라이스를 수신합니다. - Quomom
- 이 매개 변수는
cfq가 한 번에 하나의 장치로 전송하는 I/O 요청 수를 정의합니다. 이 매개변수는 기본적으로 대기열 깊이를 제한합니다. 기본값은8개의 요청입니다. 사용되는 장치는 더 큰 대기열 깊이를 지원할 수 있지만, 특히 순차적 쓰기 작업 부하의 경우 레이턴시 값을 늘리면 레이턴시가 증가합니다. - slice_async
- 이 매개변수는 비동기 I/O 요청을 발행하는 각 프로세스에 할당된 시간 슬라이스(밀리초)를 정의합니다. 기본값은
40밀리초입니다. - slice_idle
- 이 매개변수는 추가 요청을 기다리는 동안 cfq 유휴 상태로 유지되는 시간(밀리초)을 지정합니다. 기본값은
0입니다(Queue 또는 서비스 트리 수준에서 유휴 상태 없음). 기본값은 외부 RAID 스토리지의 처리량에 적합하지만 전체 검색 작업 수가 증가함에 따라 내부 비RAID 스토리지에서 처리량을 저하시킬 수 있습니다. - slice_sync
- 이 매개변수는 동기 I/O 요청을 발행하는 각 프로세스에 할당된 시간 슬라이스(밀리초)를 정의합니다. 기본값은
100ms입니다.
8.4.5.1. Fast Storage를 위한 CFQ 튜닝
cfq 스케줄러를 사용하지 않는 것이 좋습니다. 사용 사례에 이 스토리지에 cfq 를 사용해야 하는 경우 다음 구성 파일을 편집해야 합니다.
/sys/block/devname/queue/iosched/slice_idle을0으로 설정합니다./sys/block/devname/queue/iosched/quantum을64로 설정합니다./sys/block/devname/queue/iosched/group_idle을1로 설정합니다.
8.4.6. noop Scheduler 조정
noop I/O 스케줄러는 주로 빠른 스토리지를 사용하는 CPU 바인딩 시스템에 유용합니다. 또한 noop I/O 스케줄러는 일반적으로 가상 디스크에 대한 I/O 작업을 수행할 때 가상 머신에서 독점적으로 사용되는 것은 아닙니다.
noop I/O 스케줄러와 관련된 조정 가능한 매개변수는 없습니다.
8.4.7. 성능을 위해 파일 시스템 구성
8.4.7.1. XFS 튜닝
8.4.7.1.1. 포맷 옵션
$ man mkfs.xfs
- 디렉터리 블록 크기
- 디렉터리 블록 크기는 I/O 작업별로 검색하거나 수정할 수 있는 디렉터리 정보의 양에 영향을 미칩니다. 디렉터리 블록 크기의 최소값은 파일 시스템 블록 크기(4KB)입니다. 디렉터리 블록 크기의 최대값은
64KB입니다.지정된 디렉터리 블록 크기에서 큰 디렉터리에는 작은 디렉터리보다 더 많은 I/O가 필요합니다. 디렉터리 블록 크기가 큰 시스템은 디렉터리 블록 크기가 작은 시스템보다 I/O 작업당 더 많은 처리 성능을 사용합니다. 따라서 워크로드에 대해 가능한 한 작은 디렉터리 및 디렉터리 블록 크기를 사용하는 것이 좋습니다.Red Hat은 표 8.1. “디렉터리 블록 크기에 권장되는 최대 디렉터리 항목” 에 나열된 쓰기 및 읽기 복구 워크로드에 대해 나열된 항목 수를 초과하는 파일 시스템에 대해 에 나열된 디렉터리 블록 크기를 권장합니다.표 8.1. 디렉터리 블록 크기에 권장되는 최대 디렉터리 항목
디렉터리 블록 크기 max. 항목(읽기하이) 최대 항목(쓰기 복구) 4KB 100,000–200,000 1,000,000–2,000,000 16KB 100,000–1,000,000 1,000,000–10,000,000 64 KB >1,000,000 >10,000,000 다양한 크기의 파일 시스템에서 디렉터리 블록 크기가 읽기 및 쓰기 워크로드에 미치는 영향에 대한 자세한 내용은 XFS 설명서를 참조하십시오.디렉터리 블록 크기를 구성하려면 mkfs.xfs -l 옵션을 사용합니다. 자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오. - 할당 그룹
- 할당 그룹은 파일 시스템의 섹션에서 사용 가능한 공간을 인덱스하고 할당된 inode를 인덱싱하는 독립적인 구조입니다. 각 할당 그룹은 독립적으로 수정할 수 있으므로 동시 작업이 다른 할당 그룹에 영향을 미치는 한 XFS는 할당 및 할당 작업을 동시에 수행할 수 있습니다. 따라서 파일 시스템에서 수행할 수 있는 동시 작업 수는 할당 그룹 수와 동일합니다. 그러나 동시 작업을 수행하는 기능도 작업을 수행할 수 있는 프로세서 수로 제한되므로 할당 그룹 수가 시스템의 프로세서 수보다 크거나 같을 것을 권장합니다.단일 디렉터리는 여러 할당 그룹에서 동시에 수정할 수 없습니다. 따라서 Red Hat은 많은 수의 파일을 생성하고 제거하는 애플리케이션에서 모든 파일을 단일 디렉터리에 저장하지 않는 것이 좋습니다.할당 그룹을 구성하려면 mkfs.xfs -d 옵션을 사용합니다. 자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.
- 성장 제한 조건
- 포맷 시간 후에 파일 시스템의 크기를 늘려야 하는 경우(하드웨어를 추가하거나 씬 프로비저닝을 통해) 포맷이 완료된 후 할당 그룹 크기를 변경할 수 없으므로 초기 파일 레이아웃을 신중하게 고려해야 합니다.할당 그룹은 초기 용량이 아닌 파일 시스템의 최종 용량에 따라 크기를 조정해야 합니다. 할당 그룹이 최대 크기(1TB)를 초과하지 않는 한 완전히 성장하고 있는 파일 시스템의 할당 그룹 수는 백을 초과해서는 안 됩니다. 따라서 대부분의 파일 시스템에서 파일 시스템을 허용하는 권장 최대 증가는 초기 크기보다 10배입니다.새 할당 그룹 헤더가 새로 추가된 스토리지에 올바르게 정렬되도록 장치 크기를 할당 그룹 크기의 정확한 배수에 정렬해야 하므로 RAID 배열에서 파일 시스템을 확장할 때 추가 주의를 수행해야 합니다. 또한 새 스토리지에는 포맷 시간 후에 변경할 수 없으므로 기존 스토리지와 동일한 스토리지가 있어야 하므로 동일한 블록 장치에서 다른 Cryostat의 스토리지에 최적화될 수 없습니다.
- inode 크기 및 인라인 속성
- inode에 사용 가능한 공간이 충분한 경우 XFS는 속성 이름과 값을 inode에 직접 작성할 수 있습니다. 이러한 인라인 속성은 추가 I/O가 필요하지 않으므로 별도의 속성 블록을 검색하는 것보다 빠른 순서로 검색 및 수정할 수 있습니다.기본 inode 크기는 256바이트입니다. 이 중 약 100바이트만 inode에 저장된 데이터 범위 포인터의 수에 따라 속성 스토리지에 사용할 수 있습니다. 파일 시스템을 포맷하면 inode 크기를 늘리면 특성을 저장하는 데 사용할 수 있는 공간을 늘릴 수 있습니다.특성 이름과 속성 값은 모두 254바이트의 최대 크기로 제한됩니다. 이름 또는 값이 길이에서 254바이트를 초과하는 경우, 속성은 인라인으로 저장되는 대신 별도의 특성 블록으로 푸시됩니다.inode 매개 변수를 구성하려면 mkfs.xfs -i 옵션을 사용합니다. 자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.
- RAID
- 소프트웨어 RAID를 사용 중인 경우 mkfs.xfs 는 적절한 스트라이프 단위 및 너비를 사용하여 기본 하드웨어를 자동으로 구성합니다. 그러나 일부 하드웨어 RAID 장치가 이 정보를 내보내는 것은 아니므로 하드웨어 RAID가 사용 중인 경우 스트라이프 단위와 너비를 수동으로 구성해야 할 수 있습니다. 스트라이프 단위 및 너비를 구성하려면 mkfs.xfs -d 옵션을 사용합니다. 자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.
- 로그 크기
- 동기화 이벤트가 트리거될 때까지 보류 중인 변경 사항은 해당 시점에 로그에 기록됩니다. 로그 크기는 한 번에 진행 중일 수 있는 동시 수정 수를 결정합니다. 또한 메모리에 집계할 수 있는 최대 변경 양과 로그 데이터가 디스크에 기록되는 빈도를 결정합니다. 작은 로그는 데이터가 더 큰 로그보다 더 자주 디스크에 기록되도록 합니다. 그러나 더 큰 로그는 더 많은 메모리를 사용하여 보류 중인 수정 사항을 기록하므로 메모리가 제한된 시스템은 더 큰 로그의 이점을 얻을 수 없습니다.로그는 기본 스트라이프 단위에 정렬될 때 더 잘 수행됩니다. 즉, 스트라이프 단위가 스트라이프 단위 경계에서 시작하고 끝납니다. 스트라이프 단위에 로그를 정렬하려면 mkfs.xfs -d 옵션을 사용합니다. 자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.로그 크기를 구성하려면 다음 mkfs.xfs 옵션을 사용하여 logsize 를 로그 크기로 교체합니다.
# mkfs.xfs -l size=logsize
자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.$ man mkfs.xfs
- 로그 스트라이프 단위
- RAID5 또는 RAID6 레이아웃을 사용하는 스토리지 장치에 대한 로그 쓰기는 스트라이프 단위 경계를 시작하고 종료할 때 더 잘 수행할 수 있습니다(기본 스트라이프 단위에 맞게 조정됨). mkfs.xfs 는 적절한 로그 스트라이프 장치를 자동으로 설정하려고 하지만 이 정보를 내보내는 RAID 장치에 따라 다릅니다.큰 로그 스트라이프 장치를 설정하면 로그 스트라이프 단위의 크기에 작은 쓰기를 채워야 하므로 워크로드가 동기화 이벤트를 트리거하는 경우 성능이 저하될 수 있습니다. 워크로드가 로그 쓰기 대기 시간에 바인딩되는 경우 가능한 한 정렬되지 않은 로그 쓰기가 트리거되도록 로그 스트라이프 단위를 1 블록으로 설정하는 것이 좋습니다.지원되는 최대 로그 스트라이프 단위는 최대 로그 버퍼 크기(256KB)의 크기입니다. 따라서 기본 스토리지에 로그에 구성할 수 있는 것보다 큰 스트라이프 단위가 있을 수 있습니다. 이 경우 mkfs.xfs 는 경고를 발행하고 32KB의 로그 스트라이프 단위를 설정합니다.로그 스트라이프 장치를 구성하려면 다음 옵션 중 하나를 사용합니다. 여기서 N 은 스트라이프 단위로 사용할 블록 수이며 크기는 KB의 스트라이프 단위 크기입니다.
mkfs.xfs -l sunit=Nb mkfs.xfs -l su=size
자세한 내용은 mkfs.xfs 도움말 페이지를 참조하십시오.$ man mkfs.xfs
8.4.7.1.2. Mount Options
- inode 할당
- 크기가 1TB보다 큰 파일 시스템에 권장됩니다.
inode64매개변수는 전체 파일 시스템에서 inode 및 데이터를 할당하도록 XFS를 구성합니다. 이렇게 하면 inode가 파일 시스템 시작 부분에 많이 할당되지 않고 파일 시스템 끝에 데이터가 크게 할당되지 않아 대용량 파일 시스템의 성능이 향상됩니다. - 로그 버퍼 크기 및 번호
- 로그 버퍼가 클수록 로그에 모든 변경 사항을 쓰는 데 필요한 I/O 작업이 줄어듭니다. 더 큰 로그 버퍼는 비휘발성 쓰기 캐시가 없는 I/O 집약적인 워크로드가 있는 시스템의 성능을 향상시킬 수 있습니다.로그 버퍼 크기는
logbsize마운트 옵션으로 구성되며 로그 버퍼에 저장할 수 있는 최대 정보 양을 정의합니다. 로그 스트라이프 단위가 설정되지 않은 경우 버퍼 쓰기가 최대값보다 짧을 수 있으므로 동기화가 많은 워크로드에 대한 로그 버퍼 크기를 줄일 필요가 없습니다. 로그 버퍼의 기본 크기는 32KB입니다. 최대 크기는 256KB이고 기타 지원되는 크기는 32KB에서 256KB 사이의 로그 스트라이프 단위의 2KB, 128KB 또는 전원 2개입니다.로그 버퍼 수는logbufs마운트 옵션으로 정의됩니다. 기본값은 8개의 로그 버퍼(최대)이지만 최소 두 개의 로그 버퍼를 구성할 수 있습니다. 일반적으로 추가 로그 버퍼에 메모리를 할당할 수 없는 메모리 바인딩된 시스템을 제외하고 로그 버퍼의 수를 줄일 필요가 없습니다. 로그 버퍼 수를 줄이면 로그 I/O 대기 시간에 민감한 워크로드에서 로그 성능을 줄이는 경향이 있습니다. - 변경 로깅 지연
- XFS에는 로그에 쓰기 전에 메모리에 변경 사항을 집계할 수 있는 옵션이 있습니다.
delaylog매개변수를 사용하면 변경될 때마다 정기적으로 로그에 메타데이터를 쓸 수 있습니다. 이 옵션은 충돌에서 손실될 가능성이 있는 작업 수를 늘리고 메타데이터를 추적하는 데 사용되는 메모리 양을 늘립니다. 그러나 데이터 및 메타데이터를 디스크에 쓰는 데 사용되는 경우 메타데이터 수정 속도와 확장성을 순서대로 늘릴 수 있으며fsync,fdatasync또는sync을 사용하여 데이터 또는 메타데이터 무결성을 줄일 수 없습니다.
8.4.7.2. ext4 튜닝
8.4.7.2.1. 포맷 옵션
- inode 테이블 초기화
- 파일 시스템의 모든 inode를 초기화하는 것은 매우 큰 파일 시스템에서 매우 오랜 시간이 걸릴 수 있습니다. 기본적으로 초기화 프로세스는 지연됩니다(lazy inode 테이블 초기화가 활성화됨). 그러나 시스템에 ext4 드라이버가 없는 경우 lazy inode 테이블 초기화는 기본적으로 비활성화되어 있습니다. lazy_itable_init 를 1)로 설정하여 활성화할 수 있습니다. 이 경우 커널 프로세스는 마운트된 후에도 파일 시스템을 계속 초기화합니다.
$ man mkfs.ext4
8.4.7.2.2. Mount Options
- inode 테이블 초기화 속도
- lazy inode 테이블 초기화가 활성화되면
init_itable매개변수의 값을 지정하여 초기화가 수행되는 속도를 제어할 수 있습니다. 백그라운드 초기화를 수행하는 데 소비되는 시간은 대략 1의 값을 이 매개 변수의 값으로 나눈 것과 같습니다. 기본값은10입니다. - 자동 파일 동기화
- 일부 애플리케이션은 기존 파일 이름 변경 후 또는 작성 후
fsync를 올바르게 수행하지 않습니다. 기본적으로 ext4는 이러한 각 작업 후에 파일을 자동으로 동기화합니다. 그러나 시간이 많이 걸릴 수 있습니다.이 수준의 동기화가 필요하지 않은 경우 마운트 시noauto_da_alloc옵션을 지정하여 이 동작을 비활성화할 수 있습니다.noauto_da_alloc이 설정된 경우 애플리케이션에서 fsync를 명시적으로 사용하여 데이터 지속성을 확인해야 합니다. - 저널 I/O 우선순위
- 기본적으로 저널 I/O의 우선 순위는
3이며 일반 I/O의 우선 순위보다 약간 높습니다. 마운트 시journal_ioprio매개변수를 사용하여 저널 I/O의 우선 순위를 제어할 수 있습니다.journal_ioprio의 유효한 값은0에서7사이이며,0은 가장 높은 우선 순위 I/O입니다.
$ man mount
8.4.7.3. Btrfs 튜닝
데이터 압축
compress=zlib- 압축 비율이 높은 기본 옵션으로 이전 커널에 안전합니다.compress=lzo- zlib보다 압축 속도가 빠르지만 낮습니다.compress=no- 압축을 비활성화합니다.compress-force=방법- 비디오 및 디스크 이미지와 같이 잘 압축하지 않는 파일에도 압축을 활성화합니다. 사용 가능한 방법은zlib및lzo입니다.
zlib 또는 lzo 로 교체한 후 다음 명령을 실행하십시오.
$ btrfs filesystem defragment -cmethod
lzo 를 사용하여 파일을 다시 압축하려면 다음을 실행합니다.
$ btrfs filesystem defragment -r -v -clzo /
8.4.7.4. collectd2 튜닝
- 디렉터리 간격
- OVA2 마운트 지점의 최상위 디렉터리에 생성된 모든 디렉터리는 자동으로 조각화를 줄이고 해당 디렉터리의 쓰기 속도를 높이기 위해 배치됩니다. 최상위 디렉터리와 같은 다른 디렉터리를 배치하려면 표시된 대로 해당 디렉터리를
T속성으로 표시하고 dirname 을 공백 디렉터리의 경로로 바꿉니다.# chattr +T dirname
chattr 은 e2fsprogs 패키지의 일부로 제공됩니다. - 경합 감소
- polkit2는 클러스터 노드 간에 통신이 필요할 수 있는 글로벌 잠금 메커니즘을 사용합니다. 여러 노드 간 파일 및 디렉터리에 대한 경합으로 인해 성능이 저하됩니다. 여러 노드 간에 공유되는 파일 시스템의 영역을 최소화하여 교차 캐시 무효화 위험을 최소화할 수 있습니다.
9장. 네트워킹
9.1. 고려 사항
/proc/sys/net/core/dev_weight)이 전송될 때까지 계속됩니다.
netdev budget), 조정된 튜닝 데몬, numad NUMA 데몬, CPU 전원 상태, 인터럽트 밸런싱, 일시 중지 프레임, 인터럽트 병합, 어댑터 RX 및 TX 버퍼, 어댑터 TX 큐, 모듈 매개 변수, 어댑터 오프로드, Jumbo Frames, TCP 및 UDP 프로토콜 튜닝 및 NUMA 지역화.
9.1.1. Tune하기 전에
9.1.2. 패킷 수신의 병목 현상
- NIC 하드웨어 버퍼 또는 링 버퍼
- 많은 수의 패킷이 삭제되는 경우 하드웨어 버퍼가 병목일 수 있습니다. 삭제된 패킷에 대한 시스템 모니터링에 대한 자세한 내용은 9.2.4절. “ethtool” 을 참조하십시오.
- 하드웨어 또는 소프트웨어 인터럽트 대기열
- 인터럽트는 대기 시간 및 프로세서 경합을 증가시킬 수 있습니다. 프로세서에서 인터럽트를 처리하는 방법에 대한 자세한 내용은 6.1.3절. “인터럽트 요청(IRQ) 처리” 을 참조하십시오. 시스템에서 인터럽트 처리를 모니터링하는 방법에 대한 자세한 내용은 6.2.3절. “/proc/interrupts” 을 참조하십시오. 인터럽트 처리에 영향을 미치는 구성 옵션은 6.3.7절. “AMD64 및 Intel 64에서 Interrupt Affinity 설정” 를 참조하십시오.
- 애플리케이션의 소켓 수신 대기열
- 애플리케이션 수신 대기열의 병목 오류는 요청 애플리케이션에 복사되지 않는 다수의 패킷 또는
/proc/net/snmp의 UDP 입력 오류(Errors) 증가로 표시됩니다. 이러한 오류에 대한 시스템 모니터링에 대한 자세한 내용은 9.2.1절. “SS” 및 9.2.5절. “/proc/net/snmp” 을 참조하십시오.
9.2. 성능 문제 모니터링 및 진단
9.2.1. SS
$ man ss
9.2.2. ip
$ man ip
9.2.3. dropwatch
$ man dropwatch
9.2.4. ethtool
$ ethtool -S devname
$ man ethtool
9.2.5. /proc/net/snmp
/proc/net/snmp 파일은 snmp 에이전트가 IP, ICMP, TCP 및 UDP 모니터링 및 관리에 사용하는 데이터를 표시합니다. 이 파일을 정기적으로 검사하면 관리자가 비정상적인 값을 식별하고 잠재적인 성능 문제를 식별하는 데 도움이 될 수 있습니다. 예를 들어 /proc/net/snmp 의 UDP 입력 오류(InErrors)의 증가는 소켓 수신 대기열의 병목 현상을 나타낼 수 있습니다.
9.2.6. SystemTap을 사용한 네트워크 모니터링
/usr/share/doc/systemtap-client/examples/network 디렉터리에 설치됩니다.
nettop.stp- 5초마다 전송 및 수신한 패킷 수와 해당 간격 동안 프로세스에서 전송 및 수신한 데이터 양으로 프로세스 목록(프로세스 ID 및 명령)을 출력합니다.
socket-trace.stp- Linux 커널의
net/socket.c파일의 각 기능을 완성하고 추적 데이터를 출력합니다. dropwatch.stp- 5초마다 커널의 위치에서 사용 가능한 소켓 버퍼 수를 출력합니다.
all-modules옵션을 사용하여 심볼릭 이름을 확인합니다.
latencytap.stp 스크립트는 다른 대기 시간 유형이 하나 이상의 프로세스에 미치는 영향을 기록합니다. 30초마다 대기 시간 유형 목록을 출력하고 프로세스 또는 프로세스가 대기 중인 총 시간에 따라 내림차순으로 정렬됩니다. 이는 스토리지와 네트워크 대기 시간 둘 다의 원인을 식별하는 데 유용할 수 있습니다. Red Hat은 대기 시간 이벤트의 매핑을 더 잘 활성화하려면 이 스크립트와 함께 --all-modules 옵션을 사용하는 것이 좋습니다. 기본적으로 이 스크립트는 /usr/share/doc/systemtap-client-버전/examples/profiling 디렉터리에 설치됩니다.
9.3. 구성 툴
9.3.1. 네트워크 성능을 위한 튜닝된 프로필
- latency-performance
- network-latency
- Network-throughput
9.3.2. 하드웨어 버퍼 구성
- 입력 트래픽 속도 저하
- 들어오는 트래픽을 필터링하거나, 결합된 멀티 캐스트 그룹의 수를 줄이거나, 브로드캐스트 트래픽 양을 줄여 큐가 채우는 속도를 줄입니다. 들어오는 트래픽을 필터링하는 방법에 대한 자세한 내용은 Red Hat Enterprise Linux 7 보안 가이드를 참조하십시오. 멀티 캐스트 그룹에 대한 자세한 내용은 Red Hat Enterprise Linux 7 Cryostat 설명서를 참조하십시오. 브로드캐스트 트래픽에 대한 자세한 내용은 Red Hat Enterprise Linux 7 시스템 관리자 가이드 또는 구성하려는 장치와 관련된 설명서를 참조하십시오.
- 하드웨어 버퍼 큐 크기 조정
- 큐의 크기를 늘림으로써 삭제되는 패킷 수를 줄임으로써 오버플로우가 쉽게 발생하지 않도록 합니다. ethtool 명령을 사용하여 네트워크 장치의 rx/tx 매개변수를 수정할 수 있습니다.
# ethtool --set-ring devname value
- 큐의 드레이닝 속도 변경
- 장치 가중치는 장치가 한 번에 수신할 수 있는 패킷 수(단일 예약된 프로세서 액세스)를 나타냅니다. 장치 가중치를 늘리면 큐가 드레이닝되는 속도를 늘릴 수 있으며, 이는
dev_weight매개변수에 의해 제어됩니다. 이 매개변수는/proc/sys/net/core/dev_weight파일의 내용을 변경하거나 procps-ng 패키지에서 제공하는 sysctl 을 사용하여 영구적으로 변경되어 일시적으로 변경할 수 있습니다.
9.3.3. 인터럽트 대기열 구성
9.3.3.1. Busy Polling 구성
sysctl.net.core.busy_poll을0이 아닌 값으로 설정합니다. 이 매개 변수는 소켓 폴링에 대해 장치 대기열의 패킷을 대기하고 선택하도록 대기하는 마이크로초의 수를 제어합니다. Red Hat은 값50을 권장합니다.SO_BUSY_POLL소켓 옵션을 소켓에 추가합니다.
sysctl.net.core.busy_read 를 0 이외의 값으로 설정해야 합니다. 이 매개 변수는 소켓 읽기를 위해 장치 대기열의 패킷을 대기하는 마이크로초의 수를 제어합니다. 또한 SO_BUSY_POLL 옵션의 기본값을 설정합니다. Red Hat은 적은 수의 소켓에 대해 값 50 을 권장하고 많은 소켓에 대해 값 100 을 권장합니다. 매우 많은 수의 소켓(백개 이상)의 경우 대신 epoll 를 사용합니다.
- bnx2x
- be2net
- ixgbe
- mlx4
- myri10ge
# ethtool -k device | grep "busy-poll"
[fixed]에서 busy-poll: on 를 반환하는 경우 장치에서 사용 가능한 폴링을 사용할 수 있습니다.
9.3.4. 소켓 수신 대기열 구성
- 들어오는 트래픽의 속도 감소
- 패킷이 큐에 도달하기 전에 패킷을 필터링하거나 삭제하거나 장치의 가중치를 낮추어 큐가 채우는 속도를 줄입니다.
- 애플리케이션 소켓 대기열의 깊이 증가
- 버스트에서 제한된 양의 트래픽을 수신하는 소켓 대기열의 경우 트래픽 버스트 크기와 일치하도록 소켓 대기열의 깊이를 늘리면 패킷이 삭제되지 않을 수 있습니다.
9.3.4.1. 들어오는 트래픽의 속도 감소
dev_weight 매개변수에 의해 제어됩니다. 이 매개변수는 /proc/sys/net/core/dev_weight 파일의 내용을 변경하거나 procps-ng 패키지에서 제공하는 sysctl 을 사용하여 영구적으로 변경되어 일시적으로 변경할 수 있습니다.
9.3.4.2. 대기열 삭제 증가
- /proc/sys/net/core/rmem_default 값을 늘립니다.
- 이 매개 변수는 소켓에서 사용하는 수신 버퍼의 기본 크기를 제어합니다. 이 값은
/proc/sys/net/core/rmem_max값보다 작거나 같아야 합니다. - setsockopt를 사용하여 더 큰 SO_RCVBUF 값 구성
- 이 매개변수는 소켓 수신 버퍼의 최대 크기(바이트)를 제어합니다.
getsockopt시스템 호출을 사용하여 버퍼의 현재 값을 확인합니다. 자세한 내용은 socket(7) 매뉴얼 페이지를 참조하십시오.
9.3.5. RSS(Receive-Side Scaling) 구성
/proc/interrupts 의 인터페이스와 연결되어 있는지 확인합니다. 예를 들어 p1p1 인터페이스에 관심이 있는 경우 다음을 수행합니다.
# egrep 'CPU|p1p1' /proc/interrupts CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 89: 40187 0 0 0 0 0 IR-PCI-MSI-edge p1p1-0 90: 0 790 0 0 0 0 IR-PCI-MSI-edge p1p1-1 91: 0 0 959 0 0 0 IR-PCI-MSI-edge p1p1-2 92: 0 0 0 3310 0 0 IR-PCI-MSI-edge p1p1-3 93: 0 0 0 0 622 0 IR-PCI-MSI-edge p1p1-4 94: 0 0 0 0 0 2475 IR-PCI-MSI-edge p1p1-5
p1p1 인터페이스(p1p1-0 ~ p1p1-5)의 대기열을 수신함을 보여줍니다. 또한 각 대기열에서 처리된 인터럽트 수와 인터럽트를 서비스한 CPU도 보여줍니다. 이 경우 기본적으로 6개의 대기열이 있습니다. 이 특정 NIC 드라이버는 CPU당 하나의 큐를 생성하고 이 시스템에는 6개의 CPU가 있습니다. 이는 NIC 드라이버 중 상당히 일반적인 패턴입니다.
0000:01:00.0 인 장치에 관심이 있는 경우 다음 명령을 사용하여 해당 장치의 인터럽트 요청 대기열을 나열할 수 있습니다.
# ls -1 /sys/devices/*/*/0000:01:00.0/msi_irqs 101 102 103 104 105 106 107 108 109
bnx2x 드라이버의 경우 num_queues 에 구성됩니다. sfc 드라이버의 경우 rss_cpus 매개변수에 구성됩니다. 상관 없이 일반적으로 /sys/class/net/장치/queues/rx-queue/ 에서 구성됩니다. 여기서 장치는 네트워크 장치의 이름(예: eth1) 및 rx-queue 는 적절한 수신 대기열의 이름입니다.
--show-rxfh-indir 및 --set-rxfh-indir 매개변수를 사용하여 네트워크 활동이 배포되는 방식을 수정하고 특정 유형의 네트워크 활동 가중치를 다른 유형보다 더 중요하게 지정할 수 있습니다.
irqbalance 데몬은 RSS와 함께 사용하여 교차 노드 메모리 전송 및 캐시 라인이 발생할 가능성을 줄일 수 있습니다. 이렇게 하면 네트워크 패킷 처리 대기 시간이 단축됩니다.
9.3.6. 수신 패킷 테더링 구성(RPS)
- RPS는 모든 네트워크 인터페이스 카드와 함께 사용할 수 있습니다.
- 새로운 프로토콜을 처리하기 위해 RPS에 소프트웨어 필터를 추가하기 쉽습니다.
- RPS는 네트워크 장치의 하드웨어 인터럽트 속도를 증가시키지 않습니다. 그러나 프로세서 간 인터럽트를 도입합니다.
/sys/class/net/장치/queues/rx-queue/rps_cpus 파일에서 여기서 장치는 네트워크 장치의 이름(예: eth0) 및 rx-queue 는 적절한 수신 대기열의 이름입니다(예: rx-0).
rps_cpus 파일의 기본값은 0 입니다. 이렇게 하면 RPS가 비활성화되므로 네트워크 인터럽트를 처리하는 CPU도 패킷을 처리합니다.
rps_cpus 파일을 구성합니다.
rps_cpus 파일은 쉼표로 구분된 CPU 비트맵을 사용합니다. 따라서 CPU가 인터페이스에서 수신 대기열에 대한 인터럽트를 처리할 수 있도록 하려면 비트맵의 위치 값을 1로 설정합니다. 예를 들어 CPU 0, 1, 2, 3의 인터럽트를 처리하려면 rps_cpus 값을 f 로 설정합니다. 이 값은 15의 16진수 값입니다. 바이너리 표현에서 15는 00001111 (1+2+4+8)입니다.
9.3.7. RFS(Receive Flow Steering) 구성
/proc/sys/net/core/rps_sock_flow_entries- 이 파일의 값을 동시에 활성 연결의 최대 예상 수로 설정합니다. 중간 서버 로드를 위해
32768값을 사용하는 것이 좋습니다. 입력된 모든 값은 실제로 가장 가까운 2로 반올림됩니다. /sys/class/net/device/queues/rx-queue/rps_flow_cnt- 장치를 구성하려는 네트워크 장치의 이름으로 바꾸고(예:
eth0) rx-queue 는 구성할 수신 대기열(예:rx-0)으로 바꿉니다.이 파일의 값을N으로 나눈rps_sock_flow_entries값으로 설정합니다. 여기서N은 장치의 수신 대기열 수입니다. 예를 들어rps_flow_entries가32768로 설정되어 있고 16개의 수신 대기열이 구성된 경우rps_flow_cnt를2048로 설정해야 합니다. 단일 큐 장치의 경우rps_flow_cnt값은rps_sock_flow_entries값과 동일합니다.
9.3.8. 가속 RFS 구성
- 가속화 RFS는 네트워크 인터페이스 카드에서 지원해야 합니다. 가속화 RFS는
ndo_rx_flow_steer()netdevice기능을 내보내는 카드에서 지원됩니다. n튜플필터링을 활성화해야 합니다.
부록 A. 툴 참조
A.1. irqbalance
--oneshot 옵션을 사용하여 한 번만 실행할 수 있습니다.
- --powerthresh
- CPU가 powersave 모드에 배치되기 전에 유휴 상태로 설정할 수 있는 CPU 수를 설정합니다. 임계값보다 많은 CPU가 평균
softirq워크로드보다 낮은 1개 이상의 표준 편차와 CPU가 평균보다 두 개 이상의 표준 편차가 없고irq가 두 개 이상 할당되면 CPU가 powersave 모드로 배치됩니다. powersave 모드에서 CPU는irq밸런싱의 일부가 아니므로 불필요하게 발생하지 않습니다. - --hintpolicy
irq커널 선호도 힌트를 처리하는 방법을 결정합니다. 유효한 값은정확(irqaffinity hint is always applied),subset(irqis balanced, but the assigned object is a subset of the affinity hint) 또는ignore(irqaffinity hint is ignored completely).- --policyscript
- 장치 경로와 irqbalance 에서 예상되는 0개의 종료 코드를 사용하여 각 인터럽트 요청에 대해 실행할 스크립트의 위치를 정의합니다.
정의된 스크립트는 0개 이상의 키 값 쌍을 지정하여 전달된irq.q 관리에 irqbalance 를 안내할 수 있습니다.다음은 유효한 키 값 쌍으로 인식됩니다.- 금지
- 유효한 값은
true(이irq에서 전달된 irq를 제외) 또는false(이irq에 대한 균형 조정 방지)입니다. - balance_level
- 전달된
irq의 밸런스 수준의 사용자 덮어쓰기를 허용합니다. 기본적으로 균형 수준은irq를 보유한 장치의 PCI 장치 클래스를 기반으로 합니다. 유효한 값은none,package,cache또는core입니다. - numa_node
- 전달된
irq에 로컬로 간주되는 NUMA 노드의 사용자 덮어쓰기를 허용합니다. 로컬 노드에 대한 정보가 ACPI에 지정되지 않은 경우 장치는 모든 노드에서 동등한 것으로 간주됩니다. 유효한 값은 특정 NUMA 노드를 식별하는 정수(0부터 시작)와irq가 모든 노드에서 동등한 것으로 간주되어야 함을 지정하는-1입니다.
- --banirq
- 인터럽트 요청 번호가 지정된 인터럽트가 금지된 인터럽트 목록에 추가됩니다.
IRQBALANCE_BANNED_CPUS 환경 변수를 사용하여 irqbalance 에서 무시하는 CPU의 마스크를 지정할 수도 있습니다.
$ man irqbalance
A.2. ethtool
$ man ethtool
A.3. SS
t, 내부 TCP 정보(i), 소켓 메모리 사용량(m), 소켓(p) 및 세부 소켓 정보(i)를 표시합니다.
$ man ss
A.4. tuned
/etc/tuned/tuned-main.conf 파일에서 dynamic_tuning 매개변수를 편집합니다. 그런 다음 tuned 는 시스템 통계를 주기적으로 분석하고 이를 사용하여 시스템 튜닝 설정을 업데이트합니다. update_interval 매개변수를 사용하여 이러한 업데이트 사이에 시간 간격을 초 단위로 구성할 수 있습니다.
$ man tuned
A.5. tuned-adm
include 매개변수를 제공하여 기존 프로필에서 고유한 Tuned 프로필을 기반으로 할 수 있습니다.
- throughput-performance
- 처리량 개선에 중점을 둔 서버 프로필입니다. 이는 기본 프로필이며 대부분의 시스템에 권장됩니다.이 프로필은
intel_pstate및min_perf_pct=100을 설정하여 전력 절감에 대한 성능을 선호합니다. 투명한 대규모 페이지를 활성화하고 cpupower 를 사용하여 cpufreq governor를 설정합니다.또한kernel.sched_min_granularity_ns를10Cryostats로,kernel.sched_wakeup_granularity_ns를15Cryostats로,vm.dirty_ratio을40%로 설정합니다. - latency-performance
- 대기 시간을 줄이는 데 중점을 둔 서버 프로필입니다. 이 프로필은 c-state tuning 및 투명한 대규모 페이지의 TLB 효율성 향상의 이점을 받는 대기 시간에 민감한 워크로드에 권장됩니다.이 프로필은
intel_pstate및max_perf_pct=100을 설정하여 전력 절감보다 성능을 향상시킵니다. 투명한 대규모 페이지를 활성화하고 cpupower 를 사용하여 cpufreq governor를 설정하고,cpu_dma_latency값을1로 요청합니다. - network-latency
- 네트워크 대기 시간을 줄이는 데 중점을 둔 서버 프로필입니다.이 프로필은
intel_pstate및min_perf_pct=100을 설정하여 전력 절감에 대한 성능을 선호합니다. 투명한 대규모 페이지 및 자동 NUMA 분산을 비활성화합니다. 또한 cpupower 를 사용하여performancecpufreq governor를 설정하고cpu_dma_latency값을1로 요청합니다. 또한busy_read및busy_poll시간을50Cryostat로 설정하고tcp_fastopen을3으로 설정합니다. - Network-throughput
- 네트워크 처리량 개선에 중점을 둔 서버 프로필입니다.이 프로필은
intel_pstate및max_perf_pct=100을 설정하고 커널 네트워크 버퍼 크기를 늘림으로써 전력 절감에 비해 성능을 향상시킵니다. 투명한 대규모 페이지를 활성화하고 cpupower 를 사용하여 cpufreq governor를 설정합니다.또한kernel.sched_min_granularity_ns를10Cryostats로,kernel.sched_wakeup_granularity_ns를 15 Cryostats로,vm.dirty_ratio을40%로 설정합니다. - virtual-guest
- Red Hat Enterprise Linux 7 가상 머신과 VMware 게스트의 성능 최적화에 중점을 둔 프로필입니다.이 프로필은
intel_pstate및max_perf_pct=100을 설정하여 전력 절감보다 성능을 향상시킵니다. 또한 가상 메모리의 스왑성을 줄입니다. 투명한 대규모 페이지를 활성화하고 cpupower 를 사용하여 cpufreq governor를 설정합니다.또한kernel.sched_min_granularity_ns를10Cryostats로,kernel.sched_wakeup_granularity_ns를 15 Cryostats로,vm.dirty_ratio을40%로 설정합니다. - virtual-host
- Red Hat Enterprise Linux 7 가상화 호스트의 성능 최적화에 중점을 둔 프로필입니다.이 프로필은
intel_pstate및max_perf_pct=100을 설정하여 전력 절감보다 성능을 향상시킵니다. 또한 가상 메모리의 스왑성을 줄입니다. 이 프로필을 사용하면 투명한 대규모 페이지를 사용할 수 있으며 더 자주 더티 페이지를 디스크에 쓸 수 있습니다. cpupower 를 사용하여 cpufreq governor를 설정합니다.또한kernel.sched_min_granularity_ns를10Cryostats로,kernel.sched_wakeup_granularity_ns를 15 Cryostat로,kernel.sched_migration_cost을5Cryostats로,vm.dirty_ratio에서40%로 설정합니다. cpu-partitioningcpu-partitioning프로필은 시스템 CPU를 분리 및 하우스키핑 CPU로 분할합니다. 격리된 CPU에서 지터 및 중단을 줄이기 위해 프로필은 사용자 공간 프로세스, 이동 가능한 커널 스레드, 인터럽트 처리기 및 커널 타이머에서 격리된 CPU를 지웁니다.하우스키핑 CPU는 모든 서비스, 쉘 프로세스 및 커널 스레드를 실행할 수 있습니다./etc/tuned/파일에서 cpu-partitioning 프로필을 구성할 수 있습니다. 구성 옵션은 다음과 같습니다.cpu-partitioning-variables.confisolated_cores=cpu-list- 격리할 CPU를 나열합니다. 분리된 CPU 목록은 쉼표로 구분되거나 사용자가 범위를 지정할 수 있습니다. 대시를 사용하여
3-5와 같은 범위를 지정할 수 있습니다. 이 옵션은 필수입니다. 이 목록에서 누락된 CPU는 자동으로 하우스키핑 CPU로 간주됩니다. no_balance_cores=cpu-list- 시스템 전체 프로세스 로드 밸런싱 중에 커널에서 고려하지 않는 CPU를 나열합니다. 이 옵션은 선택 사항입니다. 일반적으로
isolated_cores와 동일한 목록입니다.
cpu-partitioning에 대한 자세한 내용은 tuned-profiles-cpu-partitioning(7) 도움말 페이지를 참조하십시오.
tuned-adm 과 함께 제공되는 절전 프로파일에 대한 자세한 내용은 Red Hat Enterprise Linux 7 Power Management Guide 를 참조하십시오.
tuned-adm 사용에 대한 자세한 내용은 도움말 페이지를 참조하십시오.
$ man tuned-adm
A.6. perf
- perf stat
- 이 명령은 실행된 명령 및 사용된 클럭 사이클을 포함하여 일반적인 성능 이벤트에 대한 전체 통계를 제공합니다. 옵션 플래그를 사용하여 기본 측정 이벤트 이외의 이벤트에 대한 통계를 수집할 수 있습니다. Red Hat Enterprise Linux 6.4부터 perf 통계를 사용하여 하나 이상의 지정된 제어 그룹(cgroups)에 따라 모니터링을 필터링할 수 있습니다.자세한 내용은 도움말 페이지를 참조하십시오.
$ man perf-stat
- perf 레코드
- 이 명령은 성능 데이터를 파일에 기록하며 나중에 perf 보고서를 사용하여 분석할 수 있습니다. 자세한 내용은 도움말 페이지를 참조하십시오.
$ man perf-record
- perf 보고서
- 이 명령은 파일에서 성능 데이터를 읽고 기록된 데이터를 분석합니다. 자세한 내용은 도움말 페이지를 참조하십시오.
$ man perf-report
- perf 목록
- 이 명령은 특정 시스템에서 사용 가능한 이벤트를 나열합니다. 이러한 이벤트는 시스템의 성능 모니터링 하드웨어 및 소프트웨어 구성에 따라 달라집니다. 자세한 내용은 도움말 페이지를 참조하십시오.
$ man perf-list
- perf top
- 이 명령은 top 툴과 유사한 기능을 수행합니다. 실시간으로 성능 카운터 프로필을 생성하고 표시합니다. 자세한 내용은 도움말 페이지를 참조하십시오.
$ man perf-top
- perf 추적
- 이 명령은 strace 툴과 유사한 기능을 수행합니다. 지정된 스레드 또는 프로세스에서 사용하는 시스템 호출과 해당 애플리케이션에서 수신한 모든 신호를 모니터링합니다. 추가 추적 대상을 사용할 수 있습니다. 전체 목록은 도움말 페이지를 참조하십시오.
$ man perf-trace
A.7. Performance Co- Cryostat (PCP)
표 A.1. System Services Distributed with Performance Co- Cryostat in Red Hat Enterprise Linux 7
표 A.2. Red Hat Enterprise Linux 7에서 Performance Co- Cryostat를 사용하여 분산되는 툴
표 A.3. XFS용 PCP 지표 그룹
| 메트릭 그룹 | 제공된 지표 |
|---|---|
| xfs.* | 읽기 및 쓰기 작업 수, 읽기 및 쓰기 바이트 수를 포함한 일반 XFS 메트릭입니다. inode가 플러시되는 횟수, 클러스터형 및 클러스터 실패 횟수에 대한 카운터와 함께 |
|
xfs.allocs.*
xfs.alloc_btree.*
| 파일 시스템에서 오브젝트 할당에 대한 메트릭 범위, 범위 및 블록 생성/해제 수를 포함합니다. 할당 트리 조회 및 btree에서 레코드 생성 및 삭제 확장과 비교합니다. |
|
xfs.block_map.*
xfs.bmap_tree.*
| 메트릭에는 블록 맵 읽기/쓰기 및 블록 삭제 수, 삽입, 삭제 및 조회에 대한 범위 목록 작업이 포함됩니다. 또한 작업 카운터는 블록맵에서 비교, 조회, 삽입 및 삭제 작업을 수행합니다. |
| xfs.dir_ops.* | XFS 파일 시스템의 디렉터리 작업을 대상으로 생성, 항목 삭제, "getdent" 작업 수에 대한 카운터입니다. |
| xfs.transactions.* | 메타 데이터 트랜잭션 수에 대한 카운터에는 빈 트랜잭션 수와 함께 동기 및 비동기 트랜잭션 수에 대한 수가 포함됩니다. |
| xfs.inode_ops.* | 운영 체제가 inode 캐시에서 XFS inode를 찾는 횟수와 다른 결과를 나타내는 카운터입니다. 이러한 개수 캐시 적중, 캐시 누락 등입니다. |
|
xfs.log.*
xfs.log_tail.*
| XFS 파일 sytems를 통한 로그 버퍼 쓰기 수에 대한 카운터에는 디스크에 기록된 블록 수가 포함됩니다. 로그 플러시 및 고정 횟수도 메트릭입니다. |
| xfs.xstrat.* | XFS 플러시 deamon에서 플러시한 파일 데이터의 바이트 수와 연속 및 디스크의 연속되지 않은 공간에 플러시된 버퍼 수에 대한 카운터를 계산합니다. |
| xfs.attr.* | 모든 XFS 파일 시스템에 대한 속성 get, set, remove, list 작업의 수를 계산합니다. |
| xfs.quota.* | XFS 파일 시스템에 대한 할당량 작업에 대한 지표에는 할당량 회수 수, 할당량 캐시 누락, 캐시 적중 및 할당량 데이터 회수에 대한 카운터가 포함됩니다. |
| xfs.buffer.* | XFS 버퍼 오브젝트에 대한 지표 범위. 카운터에는 페이지를 조회할 때 요청된 버퍼 호출 수, 성공적인 버퍼 잠금, 대기 버퍼 잠금, miss_locks, miss_retries 및 버퍼 적중이 포함됩니다. |
| xfs.btree.* | XFS btree 작업과 관련된 지표입니다. |
| xfs.control.reset | XFS 통계에 대한 지표 카운터를 재설정하는 데 사용되는 구성 지표입니다. 제어 메트릭은 pmstore 툴을 통해 전환됩니다. |
표 A.4. 장치당 XFS의 PCP 지표 그룹
| 메트릭 그룹 | 제공된 지표 |
|---|---|
| xfs.perdev.* | 읽기 및 쓰기 작업 수, 읽기 및 쓰기 바이트 수를 포함한 일반 XFS 메트릭입니다. inode가 플러시되는 횟수, 클러스터형 및 클러스터 실패 횟수에 대한 카운터와 함께 |
|
xfs.perdev.allocs.*
xfs.perdev.alloc_btree.*
| 파일 시스템에서 오브젝트 할당에 대한 메트릭 범위, 범위 및 블록 생성/해제 수를 포함합니다. 할당 트리 조회 및 btree에서 레코드 생성 및 삭제 확장과 비교합니다. |
|
xfs.perdev.block_map.*
xfs.perdev.bmap_tree.*
| 메트릭에는 블록 맵 읽기/쓰기 및 블록 삭제 수, 삽입, 삭제 및 조회에 대한 범위 목록 작업이 포함됩니다. 또한 작업 카운터는 블록맵에서 비교, 조회, 삽입 및 삭제 작업을 수행합니다. |
| xfs.perdev.dir_ops.* | 생성, 항목 삭제, "getdent" 작업 수를 위한 XFS 파일 시스템의 디렉터리 작업에 대한 카운터입니다. |
| xfs.perdev.transactions.* | 메타 데이터 트랜잭션 수에 대한 카운터에는 빈 트랜잭션 수와 함께 동기 및 비동기 트랜잭션 수에 대한 수가 포함됩니다. |
| xfs.perdev.inode_ops.* | 운영 체제가 inode 캐시에서 XFS inode를 찾는 횟수와 다른 결과를 나타내는 카운터입니다. 이러한 개수 캐시 적중, 캐시 누락 등입니다. |
|
xfs.perdev.log.*
xfs.perdev.log_tail.*
| XFS filesytems를 통해 로그 버퍼 쓰기 수에 대한 카운터에는 디스크에 기록된 블록 수가 포함됩니다. 로그 플러시 및 고정 횟수도 메트릭입니다. |
| xfs.perdev.xstrat.* | XFS 플러시 deamon에서 플러시한 파일 데이터의 바이트 수와 연속 및 디스크의 연속되지 않은 공간에 플러시된 버퍼 수에 대한 카운터를 계산합니다. |
| xfs.perdev.attr.* | 모든 XFS 파일 시스템에 대한 속성 get, set, remove, list 작업의 수를 계산합니다. |
| xfs.perdev.quota.* | XFS 파일 시스템에 대한 할당량 작업에 대한 지표에는 할당량 회수 수, 할당량 캐시 누락, 캐시 적중 및 할당량 데이터 회수에 대한 카운터가 포함됩니다. |
| xfs.perdev.buffer.* | XFS 버퍼 오브젝트에 대한 지표 범위. 카운터에는 페이지를 조회할 때 요청된 버퍼 호출 수, 성공적인 버퍼 잠금, 대기 버퍼 잠금, miss_locks, miss_retries 및 버퍼 적중이 포함됩니다. |
| xfs.perdev.btree.* | XFS btree 작업과 관련된 지표입니다. |
A.8. vmstat
- -a
- 활성 및 비활성 메모리를 표시합니다.
- -f
- 부팅 이후 포크 수를 표시합니다. 여기에는
fork,vfork,clone시스템 호출이 포함되며 생성된 총 작업 수와 동일합니다. 각 프로세스는 스레드 사용량에 따라 하나 이상의 작업으로 표시됩니다. 이 표시는 반복되지 않습니다. - -m
- slab 정보를 표시합니다.
- -n
- 헤더가 주기적으로 표시되지 않고 한 번 표시되도록 지정합니다.
- -s
- 다양한 이벤트 카운터 및 메모리 통계 테이블을 표시합니다. 이 표시는 반복되지 않습니다.
- delay
- 보고서 간 지연 시간(초)입니다. 지연이 지정되지 않은 경우 시스템이 마지막으로 부팅된 이후 평균 값이 있는 하나의 보고서만 출력됩니다.
- count
- 시스템에서 보고하는 횟수입니다. 개수를 지정하지 않고 지연이 정의되면 vmstat 는 무기한 보고됩니다.
- -d
- 디스크 통계를 표시합니다.
- -p
- 파티션 이름을 값으로 사용하고 해당 파티션에 대한 자세한 통계를 보고합니다.
- -S
- 보고서의 단위 출력을 정의합니다. 유효한 값은
k(1000바이트),K(1024바이트),m(1,000,000바이트) 또는M(1,048,576바이트)입니다. - -D
- 디스크 활동에 대한 요약 통계를 보고합니다.
$ man vmstat
A.9. x86_energy_perf_policy
# x86_energy_perf_policy -r
# x86_energy_perf_policy profile_name
- performance
- 프로세서는 에너지 절약을 위해 성능을 희생하지 않습니다. 이는 기본값입니다.
- normal
- 프로세서는 약간의 성능 저하를 허용하여 잠재적으로 상당한 에너지 절약을 허용합니다. 이는 대부분의 서버 및 데스크탑에 대해 합리적인 비용 절감입니다.
- powersave
- 프로세서는 에너지 효율성을 극대화하기 위해 잠재적으로 상당한 성능 저하를 허용합니다.
$ man x86_energy_perf_policy
A.10. Turbostat
- pkg
- 프로세서 패키지 번호입니다.
- 코어
- 프로세서 코어 번호입니다.
- CPU
- Linux CPU(논리 프로세서) 번호입니다.
- %c0
- CPU가 명령을 종료한 간격의 백분율입니다.
- GHz
- 이 숫자가 TSC의 값보다 크면 CPU는 turbo 모드입니다.
- TSC
- 전체 간격 동안의 평균 클럭 속도입니다.
- %c1, %c3 및 %c6
- 프로세서가 c1, c3 또는 c6 상태에 있는 간격의 백분율입니다.
- %pc3 또는 %pc6
- 프로세서가 각각 pc3 또는 pc6 상태에 있는 간격의 백분율입니다.
-i 10 을 실행하여 10초마다 결과를 출력합니다.
A.11. numastat
- numa_hit
- 이 노드에 성공적으로 할당된 페이지 수입니다.
- numa_miss
- 의도한 노드의 메모리 부족으로 인해 이 노드에 할당된 페이지 수입니다. 각
numa_miss이벤트에는 다른 노드에서 해당numa_foreign이벤트가 있습니다. - numa_foreign
- 대신 다른 노드에 할당된 이 노드에 대해 처음 사용되는 페이지 수입니다. 각
numa_foreign이벤트에는 다른 노드에 해당numa_miss이벤트가 있습니다. - interleave_hit
- 이 노드에 성공적으로 할당된 임시 정책 페이지 수입니다.
- local_node
- 이 노드의 프로세스에 의해 이 노드에 성공적으로 할당된 페이지 수입니다.
- other_node
- 다른 노드의 프로세스에 의해 이 노드에 할당된 페이지 수입니다.
- -c
- 표시된 정보 테이블을 수평으로 축소합니다. 이 기능은 NUMA 노드가 많은 시스템에서 사용되지만 열 너비와 열 간 간격은 다소 예측할 수 없습니다. 이 옵션을 사용하면 메모리 양이 가장 가까운 메가바이트로 반올림됩니다.
- -m
/proc/meminfo에 있는 정보와 유사하게 노드별로 시스템 전체 메모리 사용량 정보를 표시합니다.- -n
- 원래 numastat 명령과 동일한 정보 (
numa_hit,numa_miss,numa_foreign, numa_foreign ,interleave_hit,local_node및other_node)와 동일한 정보를 측정 단위로 사용하여 업데이트된 형식을 표시합니다. - -p 패턴
- 지정된 패턴에 대한 노드별 메모리 정보를 표시합니다. 패턴 값이 숫자로 구성된 경우 numastat 은 숫자가 프로세스 식별자라고 가정합니다. 그렇지 않으면 numastat 은 지정된 패턴에 대해 프로세스 명령줄을 검색합니다.
-p옵션 값 뒤에 입력된 명령행 인수는 필터링할 추가 패턴으로 간주됩니다. 추가 패턴은 필터가 좁지 않고 확장됩니다. - -s
- 표시된 데이터를 내림차순으로 정렬하여 가장 큰 메모리 소비자(총 열에 따라)가 먼저 나열됩니다.선택적으로 노드를 지정할 수 있으며 테이블은 노드 열에 따라 정렬됩니다. 이 옵션을 사용하는 경우 다음과 같이 노드 값은
-s옵션을 즉시 따라야 합니다.numastat -s2
옵션과 값 사이에 공백을 포함하지 마십시오. - -v
- 더 자세한 정보를 표시합니다. 즉, 여러 프로세스의 프로세스 정보는 각 프로세스에 대한 자세한 정보를 표시합니다.
- -V
- numastat 버전 정보를 표시합니다.
- -z
- 표시된 정보에서 값이 0인 테이블 행과 열을 생략합니다. 표시 용도로 0으로 반올림되는 일부 값은 표시된 출력에서 생략되지 않습니다.
A.12. numactl
- --hardware
- 노드 간 상대 거리를 포함하여 시스템에서 사용 가능한 노드의 인벤토리를 표시합니다.
- --membind
- 특정 노드에서만 메모리가 할당되도록 합니다. 지정된 위치에 사용 가능한 메모리가 충분하지 않으면 할당이 실패합니다.
- --cpunodebind
- 지정된 명령과 해당 하위 프로세스가 지정된 노드에서만 실행되도록 합니다.
- --phycpubind
- 지정된 명령과 해당 하위 프로세스가 지정된 프로세서에서만 실행되도록 합니다.
- --localalloc
- 메모리가 항상 로컬 노드에서 할당되도록 지정합니다.
- --preferred
- 메모리를 할당할 기본 노드를 지정합니다. 이 지정된 노드에서 메모리를 할당할 수 없는 경우 다른 노드가 폴백으로 사용됩니다.
$ man numactl
A.13. numad
A.13.1. 명령줄에서 numad 사용
# numad
/var/log/numad.log 에 기록됩니다. 다음 명령을 사용하여 중지될 때까지 실행됩니다.
# numad -i 0
# numad -S 0 -p pid
- -p pid
- 이 옵션은 지정된 pid 를 명시적 포함 목록에 추가합니다. 지정된 프로세스는 numad 프로세스 유의 임계값을 충족할 때까지 관리되지 않습니다.
- -S 0
- 이렇게 하면 프로세스 스캔 유형을
0으로 설정하면 numad 관리를 명시적으로 포함된 프로세스로 제한합니다.
$ man numad
A.13.2. numad를 서비스로 사용
/var/log/numad.log 에 기록됩니다.
# systemctl start numad.service
# chkconfig numad on
$ man numad
A.13.3. Pre-Placement Advice
A.13.4. KSM과 numad 사용
/sys/kernel/mm/ksm/merge_nodes 매개변수 값을 0 으로 변경합니다. 그렇지 않으면 KSM이 노드에서 페이지를 병합할 때 원격 메모리 액세스를 늘립니다. 또한 많은 양의 교차 노드 병합 후 커널 메모리 계산 통계가 결국 서로 충돌할 수 있습니다. 따라서 KSM 데몬이 많은 메모리 페이지를 병합한 후 사용 가능한 메모리의 올바른 양 및 위치에 대해 numad 가 혼동될 수 있습니다. KSM은 시스템에서 메모리를 과다 할당하는 경우에만 유용합니다. 시스템에 사용 가능한 메모리가 충분한 경우 KSM 데몬을 끄고 비활성화하여 더 높은 성능을 얻을 수 있습니다.
A.14. OProfile
- ophelp
- 시스템 프로세서에 사용 가능한 이벤트를 각각에 대한 간략한 설명과 함께 표시합니다.
- opimport
- 외부 바이너리 형식에서 시스템의 네이티브 형식으로 샘플 데이터베이스 파일을 변환합니다. 다른 아키텍처의 샘플 데이터베이스를 분석할 때만 이 옵션을 사용합니다.
- opannotate
- 애플리케이션이 디버깅 기호로 컴파일된 경우 실행 파일에 대한 주석이 있는 소스를 생성합니다.
- opcontrol
- 프로파일링 실행에서 수집되는 데이터를 구성합니다.
- operf
- opcontrol 을 대체하기 위한 것입니다. operf 툴은 Linux 성능 이벤트 하위 시스템을 사용하여 프로파일링을 보다 정확하게, 단일 프로세스 또는 시스템 차원으로 대상으로 지정하고 OProfile이 시스템의 성능 모니터링 하드웨어를 사용하여 다른 도구와 더 잘 공존할 수 있도록 합니다. opcontrol 과 달리 초기 설정이 필요하지 않으며
--system-wide옵션을 사용하지 않는 한 루트 권한 없이 사용할 수 있습니다. - opreport
- 프로필 데이터를 검색합니다.
- oprofiled
- 데몬으로 실행하여 샘플 데이터를 디스크에 정기적으로 작성합니다.
$ man oprofile
A.15. 작업 세트
# taskset -pc processors pid
1,3,5-7 )로 바꿉니다. pid 를 재구성할 프로세스의 프로세스 식별자로 바꿉니다.
# taskset -c processors -- application
$ man taskset
A.16. SystemTap
부록 B. 버전 내역
| 고친 과정 | |||
|---|---|---|---|
| 고침 10.13-59 | Mon May 21 2018 | ||
| |||
| 고침 10.14-00 | Fri Apr 6 2018 | ||
| |||
| 고침 10.13-58 | Fri Mar 23 2018 | ||
| |||
| 고침 10.13-57 | Wed Feb 28 2018 | ||
| |||
| 고침 10.13-50 | Thu Jul 27 2017 | ||
| |||
| 고침 10.13-44 | Tue Dec 13 2016 | ||
| |||
| 고침 10.08-38 | Wed Nov 11 2015 | ||
| |||
| 고침 0.3-23 | Tue Feb 17 2015 | ||
| |||
| 고침 0.3-3 | Mon Apr 07 2014 | ||
| |||