
블록 장치 가이드
Red Hat Ceph Storage 블록 장치 관리, 생성, 구성 및 사용
초록
1장. Ceph 블록 장치 소개
블록은 시퀀스의 바이트 집합 길이입니다(예: 데이터의 512바이트 블록). 여러 블록을 단일 파일로 결합하면 읽고 쓸 수 있는 스토리지 장치로 사용할 수 있습니다. 블록 기반 스토리지 인터페이스는 다음과 같은 회전 미디어를 사용하여 데이터를 저장하는 가장 일반적인 방법입니다.
- 하드 드라이브
- CD/DVD 디스크
- 플로피 디스크
- 기존 9 추적 테이프
블록 장치 인터페이스의 유비쿼리티는 가상 블록 장치를 Red Hat Ceph Storage와 같은 대량 데이터 스토리지 시스템과 상호 작용하기에 적합한 후보로 만듭니다.
Ceph 블록 장치는 Ceph 스토리지 클러스터에서 여러 OSD(오브젝트 스토리지 장치)를 통해 제거된 씬 프로비저닝, 조정 가능 및 저장 데이터입니다. Ceph 블록 장치는 RADOS(Reliable Autonomic Distributed Object Store) 블록 장치(RBD)라고도 합니다. Ceph 블록 장치는 다음과 같은 RADOS 기능을 활용합니다.
- 스냅샷
- 복제
- 데이터 일관성
Ceph 블록 장치는 librbd 라이브러리를 사용하여 OSD와 상호 작용합니다.
Ceph 블록 장치는 libvirt 및 QEMU 유틸리티를 사용하여 Ceph 블록 장치와 통합되는 OpenStack과 같은 KVM(커널 가상 시스템) 및 클라우드 기반 컴퓨팅 시스템에 무한 확장성을 제공합니다. 동일한 스토리지 클러스터를 사용하여 Ceph Object Gateway 및 Ceph 블록 장치를 동시에 작동할 수 있습니다.
Ceph 블록 장치를 사용하려면 실행 중인 Ceph 스토리지 클러스터에 액세스할 수 있어야 합니다. Red Hat Ceph Storage 클러스터 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드를 참조하십시오.
2장. Ceph 블록 장치 명령
Ceph의 블록 장치 명령을 잘 알고 있는 스토리지 관리자는 Red Hat Ceph Storage 클러스터를 효과적으로 관리하는 데 도움이 됩니다. Ceph 블록 장치의 다양한 기능을 활성화 및 비활성화하고 함께 블록 장치 풀 및 이미지를 생성하고 관리할 수 있습니다.
2.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
2.2. 명령 도움말 표시
명령줄 인터페이스의 명령 및 하위 명령 온라인 도움말을 표시합니다.
h 옵션은 사용 가능한 모든 명령에 대한 도움말을 계속 표시합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
rbd help명령을 사용하여 특정rbd명령과 해당 하위 명령에 대한 도움말을 표시합니다.구문
rbd help COMMAND SUBCOMMAND
snap list명령에 대한 도움말을 표시하려면 다음을 수행합니다.[root@rbd-client ~]# rbd help snap list
2.3. 블록 장치 풀 생성
블록 장치 클라이언트를 사용하기 전에 rbd 의 풀이 활성화 및 초기화되었는지 확인합니다.
풀을 먼저 만들어야 해당 풀을 소스로 지정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
rbd풀을 만들려면 다음을 실행합니다.구문
ceph osd pool create POOL_NAME PG_NUM ceph osd pool application enable POOL_NAME rbd rbd pool init -p POOL_NAME
예제
[root@rbd-client ~]# ceph osd pool create example 128 [root@rbd-client ~]# ceph osd pool application enable example rbd [root@rbd-client ~]# rbd pool init -p example
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Storage Strategies Guide 의 풀 장을 참조하십시오.
2.4. 블록 장치 이미지 생성
블록 장치를 노드에 추가하기 전에 Ceph 스토리지 클러스터에 블록 장치를 만듭니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
블록 장치 이미지를 생성하려면 다음 명령을 실행합니다.
구문
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME
예제
[root@rbd-client ~]# rbd create data --size 1024 --pool stack
이 예제에서는
stack이라는 풀에 정보를 저장하는data라는 1GB 이미지를 생성합니다.참고이미지를 생성하기 전에 풀이 있는지 확인합니다.
추가 리소스
- 자세 한 내용은 Red Hat Ceph Storage Block Device Guide 의 블록 장치 풀 생성 섹션을 참조하십시오.
2.5. 블록 장치 이미지 나열
블록 장치 이미지를 나열합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
rbd풀의 블록 장치를 나열하려면 다음 명령을 실행합니다(rbd는 기본 풀 이름임).[root@rbd-client ~]# rbd ls
특정 풀의 블록 장치를 나열하려면 다음 명령을 실행하되,
POOL_NAME을 풀 이름으로 바꿉니다.구문
rbd ls POOL_NAME예제
[root@rbd-client ~]# rbd ls swimmingpool
2.6. 블록 장치 이미지 정보 검색
블록 장치 이미지에 대한 정보를 검색합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
특정 이미지에서 정보를 검색하려면 다음 명령을 실행하고
IMAGE_NAME을 이미지 이름으로 바꿉니다.구문
rbd --image IMAGE_NAME info예제
[root@rbd-client ~]# rbd --image foo info
풀 내에서 이미지에서 정보를 검색하려면 다음 명령을 실행하고
IMAGE_NAME을 이미지 이름으로 바꾸고POOL_NAME을 풀 이름으로 바꿉니다.구문
rbd --image IMAGE_NAME -p POOL_NAME info
예제
[root@rbd-client ~]# rbd --image bar -p swimmingpool info
2.7. 블록 장치 이미지 크기 조정
Ceph 블록 장치 이미지는 씬 프로비저닝됩니다. 데이터 저장을 시작할 때까지 실제 스토리지를 사용하지 않습니다. 그러나 최대 용량은 --size 옵션으로 설정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
Ceph 블록 장치 이미지의 최대 크기를 늘리거나 줄입니다.
구문
[root@rbd-client ~]# rbd resize --image IMAGE_NAME --size SIZE
2.8. 블록 장치 이미지 제거
블록 장치 이미지를 제거합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
블록 장치를 제거하려면 다음을 실행하되
IMAGE_NAME을 삭제하려는 이미지 이름으로 교체합니다.구문
rbd rm IMAGE_NAME예제
[root@rbd-client ~]# rbd rm foo
풀에서 블록 장치를 제거하려면 다음을 실행하되
IMAGE_NAME을 삭제 및 제거할 이미지 이름으로 교체하여POOL_NAME을 풀 이름으로 교체합니다.구문
rbd rm IMAGE_NAME -p POOL_NAME
예제
[root@rbd-client ~]# rbd rm bar -p swimmingpool
2.9. 휴지통 명령을 사용하여 블록 장치 이미지 관리
RADOS 블록 장치(RBD) 이미지는 rbd 휴지통 명령을 사용하여 휴지통으로 이동할 수 있습니다.
이 명령은 다음과 같은 다양한 옵션을 제공합니다.
- 휴지통에서 이미지를 제거합니다.
- 휴지통의 이미지 나열.
- 휴지통에서 이미지 삭제 지연.
- 휴지통에서 이미지를 삭제합니다.
- 휴지통에서 이미지 복원
- 휴지통에서 이미지를 복원하고 이름을 바꿉니다.
- 휴지통에서 만료된 이미지 삭제.
- 휴지통에서 제거 예약.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
이미지를 휴지통으로 이동합니다.
구문
rbd trash mv POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd trash mv mypool/myimage
이미지가 휴지통에 있으면 고유한 이미지 ID가 할당됩니다.
참고나중에 휴지통 옵션을 사용해야 하는 경우 이미지를 지정하려면 이 이미지 ID가 필요합니다.
휴지통에 이미지를 나열합니다.
구문
rbd trash ls POOL_NAME예제
[root@rbd-client ~]# rbd trash ls mypool 1558a57fa43b rename_image
고유한 IMAGE_ID
1558a57fa43b는 모든 휴지통 옵션에 사용할 수 있습니다.이미지를 휴지통으로 이동하고 휴지통에서 이미지 삭제를 지연합니다.
구문
rbd trash mv POOL_NAME/IMAGE_NAME --expires-at "EXPIRATION_TIME"
EXPIRATION_TIME 은 초, 시간, 날짜, "HH:MM:SS" 또는 "tomorrow"의 시간일 수 있습니다.
예제
[root@rbd-client ~]# rbd trash mv mypool/myimage --expires-at "60 seconds"
이 예제에서
myimage는 휴지통으로 이동됩니다. 그러나 60 초까지 휴지통에서 삭제할 수 없습니다.휴지통에서 이미지를 복원합니다.
구문
rbd trash restore POOL_NAME/IMAGE_ID
예제
[root@rbd-client ~]# rbd trash restore mypool/14502ff9ee4d
휴지통에서 이미지를 삭제합니다.
구문
rbd trash rm POOL_NAME/IMAGE_ID [--force]
예제
[root@rbd-client ~]# rbd trash rm mypool/14502ff9ee4d Removing image: 100% complete...done.
이미지가 삭제 지연되면 만료까지 휴지통에서 삭제할 수 없습니다. 다음과 같은 오류 메시지가 표시됩니다.
예제
Deferment time has not expired, please use --force if you really want to remove the image Removing image: 0% complete...failed. 2021-12-02 06:37:49.573 7fb5d237a500 -1 librbd::api::Trash: remove: error: deferment time has not expired.
중요이미지가 휴지통에서 삭제되면 복원할 수 없습니다.
이미지의 이름을 변경하고 휴지통에서 복원합니다.
구문
rbd trash restore POOL_NAME/IMAGE_ID --image NEW_IMAGE_NAME
예제
[root@rbd-client ~]# rbd trash restore mypool/14502ff9ee4d --image test_image
휴지통에서 만료된 이미지를 제거합니다.
구문
rbd trash purge POOL_NAME예제
[root@rbd-client ~]# rbd trash purge mypool
이 예제에서는
mypool에서 휴지통을 가진 모든 이미지가 제거됩니다.
2.10. 이미지 기능 활성화 및 비활성화
기존 이미지에서 fast-diff,exclusive-lock,object-map 또는 저널링 과 같은 이미지 기능을 활성화하거나 비활성화할 수 있습니다.
딥 flatten 기능은 기존 이미지에서만 비활성화할 수 있지만 사용할 수는 없습니다. 딥 플랫 을 사용하려면 이미지를 생성할 때 활성화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
기능을 활성화하려면 다음을 수행합니다.
구문
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME
데이터풀의image1이미지에서배타적 잠금기능을 활성화하려면 다음을 수행합니다.예제
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock
중요fast-diff및object-map기능을 활성화하면 오브젝트 맵을 다시 빌드합니다.+ .Syntax
rbd object-map rebuild POOL_NAME/IMAGE_NAME
기능을 비활성화하려면 다음을 수행합니다.
구문
rbd feature disable POOL_NAME/IMAGE_NAME FEATURE_NAME
데이터풀의image2이미지에서fast-diff기능을 비활성화하려면 다음을 수행합니다.예제
[root@rbd-client ~]# rbd feature disable data/image2 fast-diff
2.11. 이미지 메타데이터 작업
Ceph는 사용자 지정 이미지 메타데이터를 키-값 쌍으로 추가할 수 있도록 지원합니다. 쌍에는 엄격한 형식이 없습니다.
또한 메타데이터를 사용하면 특정 이미지에 대해 RADOS Block Device(RBD) 구성 매개변수를 설정할 수 있습니다.
rbd image-meta 명령을 사용하여 메타데이터로 작업합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
새 메타데이터 키-값 쌍을 설정하려면 다음을 수행합니다.
구문
rbd image-meta set POOL_NAME/IMAGE_NAME KEY VALUE
예제
[root@rbd-client ~]# rbd image-meta set data/dataset last_update 2016-06-06
이 예에서는 데이터 풀의
데이터 세트 이미지에.last_update키를2016-06-06값으로 설정합니다메타데이터 키-값 쌍을 제거하려면 다음을 수행합니다.
구문
rbd image-meta remove POOL_NAME/IMAGE_NAME KEY
예제
[root@rbd-client ~]# rbd image-meta remove data/dataset last_update
이 예제에서는 데이터 풀의
데이터 세트이미지에서last_update키-값 쌍을 제거합니다.키 값을 보려면 다음을 수행합니다.
구문
rbd image-meta get POOL_NAME/IMAGE_NAME KEY
예제
[root@rbd-client ~]# rbd image-meta get data/dataset last_update
이 예제에서는
last_update키의 값을 봅니다.이미지의 모든 메타데이터를 표시하려면 다음을 수행합니다.
구문
rbd image-meta list POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd data/dataset image-meta list
이 예에서는 데이터 풀의
데이터 세트 이미지에 대한 메타데이터 세트를 나열합니다.Ceph 구성 파일에 특정 이미지의 RBD 이미지 구성 설정을 재정의하려면 다음을 수행합니다.
구문
rbd config image set POOL_NAME/IMAGE_NAME PARAMETER VALUE
예제
[root@rbd-client ~]# rbd config image set data/dataset rbd_cache false
이 예제에서는 데이터 풀에서
데이터 세트이미지에 대한 RBD 캐시를 비활성화합니다.
추가 리소스
- 가능한 구성 옵션 목록은 Red Hat Ceph Storage Block Device Guide 의 블록 장치 일반 옵션 섹션을 참조하십시오.
2.12. 풀 간 이미지 이동
RADOS Block Device(RBD) 이미지를 동일한 클러스터 내의 여러 풀 간에 이동할 수 있습니다. 마이그레이션은 복제된 풀, 삭제 코드된 풀 또는 복제된 풀과 삭제 코드된 풀 간에 마이그레이션할 수 있습니다.
이 프로세스 중에 소스 이미지가 모든 스냅샷 기록으로 대상 이미지에 복사되고 선택적으로 소스 이미지의 상위에 대한 링크가 있어 스파스성을 보존할 수 있습니다. 소스 이미지는 읽기 전용이며 대상 이미지는 쓸 수 있습니다. 마이그레이션이 진행 중인 동안 대상 이미지가 소스 이미지에 연결됩니다.
새 대상 이미지가 사용 중인 동안 이 프로세스를 백그라운드에서 안전하게 실행할 수 있습니다. 그러나 준비 단계를 수행하기 전에 대상 이미지를 사용하는 모든 클라이언트를 중지하여 이미지를 사용하는 클라이언트가 새 대상 이미지를 가리키도록 업데이트되었는지 확인합니다.
krbd 커널 모듈은 현재 실시간 마이그레이션을 지원하지 않습니다.
사전 요구 사항
- 소스 이미지를 사용하는 모든 클라이언트를 중지합니다.
- 클라이언트 노드에 대한 루트 수준 액세스.
절차
소스 및 대상 이미지를 상호 연결하는 새 대상 이미지를 생성하여 마이그레이션을 준비합니다.
구문
rbd migration prepare SOURCE_IMAGE TARGET_IMAGE
교체:
- 이동할 이미지 이름이 SOURCE_IMAGE 입니다. POOL/IMAGE_NAME 형식을 사용합니다.
- 새 이미지 이름으로 TARGET_IMAGE. POOL/IMAGE_NAME 형식을 사용합니다.
예제
[root@rbd-client ~]# rbd migration prepare data/source stack/target
새 대상 이미지의 상태를 확인합니다.
준비됨:구문
rbd status TARGET_IMAGE예제
[root@rbd-client ~]# rbd status stack/target Watchers: none Migration: source: data/source (5e2cba2f62e) destination: stack/target (5e2ed95ed806) state: prepared- 선택적으로 새 대상 이미지 이름을 사용하여 클라이언트를 다시 시작합니다.
대상 이미지에 소스 이미지를 복사합니다.
구문
rbd migration execute TARGET_IMAGE예제
[root@rbd-client ~]# rbd migration execute stack/target
마이그레이션이 완료되었는지 확인합니다.
예제
[root@rbd-client ~]# rbd status stack/target Watchers: watcher=1.2.3.4:0/3695551461 client.123 cookie=123 Migration: source: data/source (5e2cba2f62e) destination: stack/target (5e2ed95ed806) state: executed소스 이미지와 대상 이미지 간의 교차 링크를 제거하여 마이그레이션을 커밋하고 소스 이미지도 제거됩니다.
구문
rbd migration commit TARGET_IMAGE예제
[root@rbd-client ~]# rbd migration commit stack/target
소스 이미지가 하나 이상의 복제본의 상위인 경우 복제 이미지가 사용되지 않도록 한 후
--force옵션을 사용합니다.예제
[root@rbd-client ~]# rbd migration commit stack/target --force
- 준비 단계 후에 클라이언트를 다시 시작하지 않은 경우 새 대상 이미지 이름을 사용하여 클라이언트를 다시 시작합니다.
2.13. rbdmap 서비스
systemd 장치 파일 rbdmap.service 는 ceph-common 패키지에 포함되어 있습니다. rbdmap.service 장치는 rbdmap 쉘 스크립트를 실행합니다.
이 스크립트는 하나 이상의 RBD 이미지에 대해 RADOS 블록 장치(RBD) 매핑 및 매핑 해제를 자동화합니다. 이 스크립트는 언제든지 수동으로 실행할 수 있지만 일반적인 사용 사례는 부팅 시 RBD 이미지를 자동으로 마운트하고 종료 시 마운트 해제하는 것입니다. 이 스크립트는 RBD 이미지를 마운트하기 위해 매핑 또는 매핑 해제 할 수 있는 단일 인수를 사용합니다. 이 스크립트는 구성 파일을 구문 분석합니다. 기본값은 /etc/ceph/rbdmap 이지만 RBDMAPFILE 이라는 환경 변수를 사용하여 재정의할 수 있습니다. 구성 파일의 각 행은 RBD 이미지에 해당합니다.
구성 파일 형식의 형식은 다음과 같습니다.
IMAGE_SPEC RBD_OPTS
여기서 IMAGE_SPEC 는 POOL_NAME / IMAGE_NAME 또는 POOL_NAME 만 지정합니다. 이 경우 POOL_NAME 은 rbd 로 설정됩니다. RBD_OPTS 는 기본 rbd 맵 명령에 전달할 옵션 목록입니다. 이러한 매개변수와 해당 값은 쉼표로 구분된 문자열로 지정해야 합니다.
OPT1=VAL1,OPT2=VAL2,…,OPT_N=VAL_N
이로 인해 스크립트에서 다음과 같은 rbd 맵 명령을 발행합니다.
rbd map POOLNAME/IMAGE_NAME --OPT1 VAL1 --OPT2 VAL2
쉼표 또는 같음 표시가 포함된 옵션과 값의 경우 간단한 apostrophe를 사용하여 교체하지 않도록 할 수 있습니다.
성공하면 rbd 맵 작업은 이미지를 /dev/rbdX 장치에 매핑합니다. 여기서 udev 규칙이 트리거되면 친숙한 장치 이름 symlink(예: /dev/rbd/ POOL_NAME /POOL_NAME/ POOL_NAME )가 생성되어 실제 매핑된 장치를 가리킵니다. 마운트 또는 마운트 해제하려면 친숙한 장치 이름에 /etc/fstab 파일에 해당 항목이 있어야 합니다. RBD 이미지에 대한 /etc/fstab 항목을 작성할 때 noauto 또는 nofail 마운트 옵션을 지정하는 것이 좋습니다. 이렇게 하면 장치가 발생하기 전에 init 시스템이 장치를 너무 일찍 마운트하지 않습니다.
추가 리소스
-
사용 가능한 옵션의 전체 목록은
rbdmanpage를 참조하십시오.
2.14. rbdmap 서비스 구성
부팅 시 RADOS 블록 장치(RBD)를 자동으로 매핑 및 마운트 해제 또는 마운트 해제하거나 각각 종료하십시오.
사전 요구 사항
- 마운트를 수행하는 노드에 대한 루트 수준 액세스.
-
ceph-common패키지 설치.
절차
-
/etc/ceph/rbdmap구성 파일을 편집하려면 을 엽니다. 구성 파일에 RBD 이미지 또는 이미지를 추가합니다.
예제
foo/bar1 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring foo/bar2 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring,options='lock_on_read,queue_depth=1024'
- 구성 파일에 변경 사항을 저장합니다.
RBD 매핑 서비스를 활성화합니다.
예제
[root@client ~]# systemctl enable rbdmap.service
추가 리소스
-
RBD 시스템 서비스에 대한 자세한 내용은 Red Hat Ceph Storage Block Device Guide 의
rbdmap서비스 섹션을 참조하십시오.
2.15. 명령줄 인터페이스를 사용하여 Ceph 블록 장치의 성능 모니터링
Red Hat Ceph Storage 4.1부터 성능 지표 수집 프레임워크는 Ceph OSD 및 Manager 구성 요소에 통합되어 있습니다. 이 프레임워크는 다른 Ceph 블록 장치 성능 모니터링 솔루션이 구축된 기본 제공 방법을 제공합니다.
새 Ceph Manager 모듈rbd_support 는 활성화된 경우 성능 지표를 집계합니다. rbd 명령에는 iotop 및 iostat 의 두 가지 새로운 동작이 있습니다.
이러한 작업의 초기 사용은 데이터 필드를 채우는 데 약 30초가 걸릴 수 있습니다.
사전 요구 사항
- Ceph 모니터 노드에 대한 사용자 수준 액세스.
절차
rbd_supportCeph Manager 모듈을 활성화합니다.예제
[user@mon ~]$ ceph mgr module enable rbd_support
"iotop" 유형의 이미지를 표시하려면 다음을 수행합니다.
예제
[user@mon ~]$ rbd perf image iotop
참고오른쪽 및 왼쪽 화살표 키를 사용하여 ops, read-ops, write-bytes, write-latency 및 read-latency 열을 동적으로 정렬할 수 있습니다.
이미지의 "iostat" 스타일을 표시하려면 다음을 수행합니다.
예제
[user@mon ~]$ rbd perf image iostat
참고이 명령의 출력은 JSON 또는 XML 형식일 수 있으며 다른 명령줄 툴을 사용하여 정렬할 수 있습니다.
2.16. 추가 리소스
-
매핑 및 매핑되지 않은 블록 장치에 대한 자세한 내용은 3장.
rbd커널 모듈 을 참조하십시오.
3장. rbd 커널 모듈
스토리지 관리자는 rbd 커널 모듈을 통해 Ceph 블록 장치에 액세스할 수 있습니다. 블록 장치를 매핑 및 매핑 해제하고 해당 매핑을 표시할 수 있습니다. 또한 rbd kernel 모듈을 통해 이미지 목록을 가져올 수 있습니다.
RHEL(Red Hat Enterprise Linux) 이외의 Linux 배포판의 커널 클라이언트는 허용되지만 지원되지 않습니다. 이러한 커널 클라이언트를 사용할 때 스토리지 클러스터에서 문제가 발견되면 Red Hat은 이러한 문제를 해결하지만 근본 원인이 커널 클라이언트측에 있는 경우 소프트웨어 벤더가 해결해야 합니다.
3.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
3.2. Ceph 블록 장치 생성 및 Linux 커널 모듈 클라이언트에서 사용
스토리지 관리자는 Red Hat Ceph Storage 대시보드에서 Linux 커널 모듈 클라이언트에 대한 Ceph 블록 장치를 생성할 수 있습니다. 시스템 관리자는 명령줄을 사용하여 Linux 클라이언트에서 해당 블록 장치를 매핑하고 파티션, 포맷, 마운트할 수 있습니다. 이렇게 하면 파일을 읽고 쓸 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Enterprise Linux 클라이언트.
3.2.1. 대시보드를 사용하여 Linux 커널 모듈 클라이언트용 Ceph 블록 장치 생성
필요한 기능만 활성화하여 대시보드 웹 인터페이스를 사용하여 Linux 커널 모듈 클라이언트를 위해 Ceph Block Device를 생성할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
절차
- 대시보드에 로그인합니다.
네비게이션 바에서 Pools (풀)를 클릭합니다.
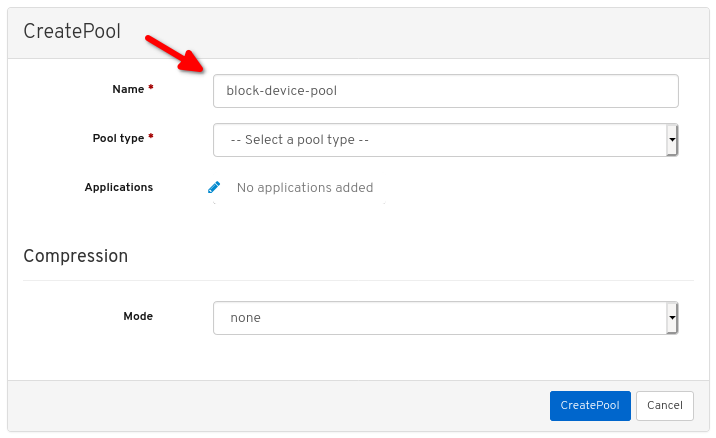
생성 버튼을 클릭합니다.

대화 상자에서 이름을 설정합니다.
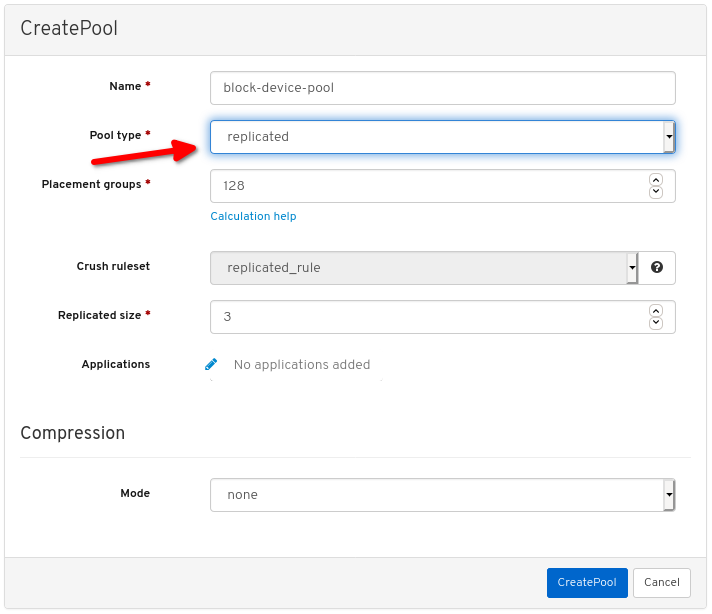
풀 유형을 replicated로 설정합니다.
PG(배치 그룹) 번호를 설정합니다.
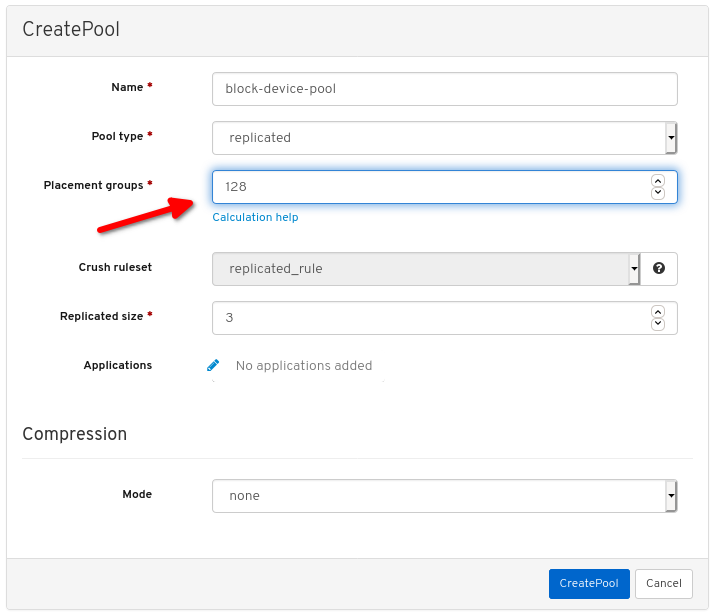
PG 번호 선택에 대한 지원을 받으려면 PG 계산기 를 사용하십시오. 확실하지 않은 경우 Red Hat 기술 지원에 문의하십시오.
복제된 크기를 설정합니다.
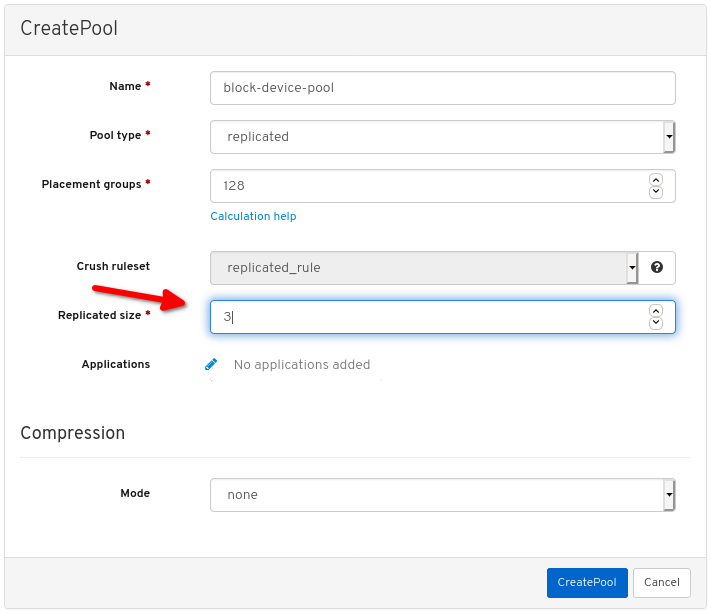
rbd애플리케이션을 활성화합니다.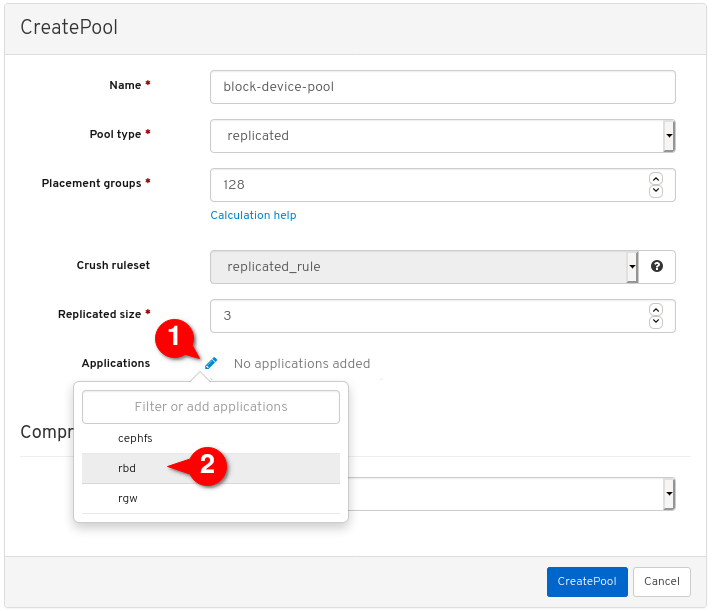
풀 생성을 클릭합니다.

풀이 성공적으로 생성되었음을 나타내는 알림을 확인합니다.
Block 을 클릭합니다.
이미지 를 클릭합니다.
생성 을 클릭합니다.
 원하는 이미지 이름,
원하는 이미지 이름,
 풀을 이전에 생성한 풀 로 설정하고
풀을 이전에 생성한 풀 로 설정하고
 에서 원하는 이미지 크기를 설정하며,
에서 원하는 이미지 크기를 설정하며,
 계층화 및 제외 잠금 이 유일한 활성화된 기능인지 확인합니다.
계층화 및 제외 잠금 이 유일한 활성화된 기능인지 확인합니다.

CreateRBD:를 클릭합니다.

이미지가 성공적으로 생성되었음을 나타내는 알림을 확인합니다.
추가 리소스
- 자세 한 내용은 명령줄을 사용하여 Linux에서 Ceph 블록 장치 맵 및 마운트를 참조하십시오.
- 자세한 내용은 대시보드 가이드 를 참조하십시오.
3.2.2. 명령줄을 사용하여 Linux에서 Ceph 블록 장치 매핑 및 마운트
Linux rbd 커널 모듈을 사용하여 Red Hat Enterprise Linux 클라이언트에서 Ceph 블록 장치를 매핑할 수 있습니다. 매핑 후 파티션, 포맷 및 마운트할 수 있으므로 파일을 쓸 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Linux 커널 모듈 클라이언트용 Ceph 블록 장치가 생성되었습니다.
- Red Hat Enterprise Linux 클라이언트.
절차
Red Hat Enterprise Linux 클라이언트 노드에서 Red Hat Ceph Storage 4 툴 리포지토리를 활성화합니다.
Red Hat Enterprise Linux 7
[root@client1 ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
Red Hat Enterprise Linux 8
[root@client1 ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ceph-commonRPM 패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@client1 ~]# yum install ceph-common
Red Hat Enterprise Linux 8
[root@client1 ~]# dnf install ceph-common
모니터 노드에서 클라이언트 노드로 Ceph 구성 파일을 복사합니다.
scp root@MONITOR_NODE:/etc/ceph/ceph.conf /etc/ceph/ceph.conf예제
[root@client1 ~]# scp root@cluster1-node2:/etc/ceph/ceph.conf /etc/ceph/ceph.conf root@192.168.0.32's password: ceph.conf 100% 497 724.9KB/s 00:00
모니터 노드에서 클라이언트 노드로 키 파일을 복사합니다.
scp root@MONITOR_NODE:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring예제
[root@client1 ~]# scp root@cluster1-node2:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ceph.client.admin.keyring root@192.168.0.32's password: ceph.client.admin.keyring 100% 151 265.0KB/s 00:00
이미지를 매핑합니다.
rbd map --pool POOL_NAME IMAGE_NAME --id admin
예제
[root@client1 ~]# rbd map --pool block-device-pool image1 --id admin /dev/rbd0 [root@client1 ~]#
블록 장치에 파티션 테이블을 만듭니다.
parted /dev/MAPPED_BLOCK_DEVICE mklabel msdos예제
[root@client1 ~]# parted /dev/rbd0 mklabel msdos Information: You may need to update /etc/fstab.
XFS 파일 시스템의 파티션을 생성합니다.
parted /dev/MAPPED_BLOCK_DEVICE mkpart primary xfs 0% 100%예제
[root@client1 ~]# parted /dev/rbd0 mkpart primary xfs 0% 100% Information: You may need to update /etc/fstab.
파티션을 포맷합니다.
mkfs.xfs /dev/MAPPED_BLOCK_DEVICE_WITH_PARTITION_NUMBER예제
[root@client1 ~]# mkfs.xfs /dev/rbd0p1 meta-data=/dev/rbd0p1 isize=512 agcount=16, agsize=163824 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=1, sparse=1, rmapbt=0 = reflink=1 data = bsize=4096 blocks=2621184, imaxpct=25 = sunit=16 swidth=16 blks naming =version 2 bsize=4096 ascii-ci=0, ftype=1 log =internal log bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=16 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0에 새 파일 시스템을 마운트할 디렉토리를 생성합니다.
mkdir PATH_TO_DIRECTORY예제
[root@client1 ~]# mkdir /mnt/ceph
파일 시스템을 마운트합니다.
mount /dev/MAPPED_BLOCK_DEVICE_WITH_PARTITION_NUMBER PATH_TO_DIRECTORY
예제
[root@client1 ~]# mount /dev/rbd0p1 /mnt/ceph/
파일 시스템이 마운트되어 올바른 크기를 표시하는지 확인합니다.
df -h PATH_TO_DIRECTORY예제
[root@client1 ~]# df -h /mnt/ceph/ Filesystem Size Used Avail Use% Mounted on /dev/rbd0p1 10G 105M 9.9G 2% /mnt/ceph
추가 리소스
- 자세 한 내용은 대시보드를 사용하여 Linux 커널 모듈 클라이언트의 Ceph 블록 장치 만들기를 참조하십시오.
- 자세한 내용은 Managing file systems for Red Hat Enterprise Linux 8을 참조하십시오.
- 자세한 내용은 Red Hat Enterprise Linux 7의 스토리지 관리 가이드 를 참조하십시오.
3.3. 이미지 목록 가져오기
Ceph 블록 장치 이미지 목록을 가져옵니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
블록 장치 이미지를 마운트하려면 먼저 이미지 목록을 반환합니다.
[root@rbd-client ~]# rbd list
3.4. 블록 장치 매핑
rbd 를 사용하여 이미지 이름을 커널 모듈에 매핑합니다. 이미지 이름, 풀 이름 및 사용자 이름을 지정해야 합니다. RBD 커널 모듈이 아직 로드되지 않은 경우 RBD 커널 모듈이 로드됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
커널 모듈에 이미지 이름을 매핑합니다.
구문
rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME
예제
[root@rbd-client ~]# rbd device map rbd/myimage --id admin
인증 키 또는 시크릿이 포함된 파일을 통해
cephx인증을 사용할 때 보안을 지정합니다.구문
[root@rbd-client ~]# rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME --keyring PATH_TO_KEYRING
또는
[root@rbd-client ~]# rbd device map POOL_NAME/IMAGE_NAME --id USER_NAME --keyfile PATH_TO_FILE
3.5. 매핑된 블록 장치 표시
rbd 명령을 사용하여 커널 모듈에 매핑되는 블록 장치 이미지를 표시할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
매핑된 블록 장치를 표시합니다.
[root@rbd-client ~]# rbd device list
3.6. 블록 장치 매핑 해제
unmap 옵션을 사용하고 장치 이름을 제공하여 rbd 명령으로 블록 장치 이미지를 매핑할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
블록 장치 이미지를 매핑 해제합니다.
구문
rbd device unmap /dev/rbd/POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd device unmap /dev/rbd/rbd/foo
3.7. 동일한 풀 내에서 격리된 네임스페이스 내에서 이미지 분리
OpenStack 또는 OpenShift Container Storage와 같은 고급 시스템 없이 Ceph 블록 장치를 직접 사용하는 경우 특정 블록 장치 이미지에 대한 사용자 액세스를 제한할 수 없었습니다. CephX 기능과 함께 사용자는 특정 풀 네임스페이스로 제한하여 이미지에 대한 액세스를 제한할 수 있습니다.
새 수준의 ID인 RADOS 네임스페이스를 사용하여 오브젝트를 식별하고 풀 내에서 rados 클라이언트 간의 격리를 제공할 수 있습니다. 예를 들어 클라이언트는 해당하는 네임스페이스에 대한 전체 권한만 가질 수 있습니다. 이렇게 하면 테넌트마다 다른 RADOS 클라이언트를 사용할 수 있습니다. 이는 특히 다양한 테넌트가 자체 블록 장치 이미지에 액세스하는 블록 장치에 유용합니다.
동일한 풀 내에서 격리된 네임스페이스 내에서 블록 장치 이미지를 분리할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 모든 커널을 4x로 업그레이드하고 모든 클라이언트에서 librbd 및 librados로 업그레이드합니다.
- 모니터 및 클라이언트 노드에 대한 루트 수준 액세스.
절차
rbd풀을 만듭니다.구문
ceph osd pool create POOL_NAME PG_NUM
예제
[root@mon ~]# ceph osd pool create mypool 100 pool 'mypool' created
rbd풀을 RBD 애플리케이션과 연결합니다.구문
ceph osd pool application enable POOL_NAME rbd예제
[root@mon ~]# ceph osd pool application enable mypool rbd enabled application 'rbd' on pool 'mypool'
RBD 애플리케이션으로 풀을 초기화합니다.
구문
rbd pool init -p POOL_NAME예제
[root@mon ~]# rbd pool init -p mypool
두 개의 네임스페이스를 생성합니다.
구문
rbd namespace create --namespace NAMESPACE예제
[root@mon ~]# rbd namespace create --namespace namespace1 [root@mon ~]# rbd namespace create --namespace namespace2 [root@mon ~]# rbd namespace ls --format=json [{"name":"namespace2"},{"name":"namespace1"}]두 사용자의 네임스페이스에 대한 액세스 권한을 제공합니다.
구문
ceph auth get-or-create client.USER_NAME mon 'profile rbd' osd 'profile rbd pool=rbd namespace=NAMESPACE' -o /etc/ceph/client.USER_NAME.keyring
예제
[root@mon ~]# ceph auth get-or-create client.testuser mon 'profile rbd' osd 'profile rbd pool=rbd namespace=namespace1' -o /etc/ceph/client.testuser.keyring [root@mon ~]# ceph auth get-or-create client.newuser mon 'profile rbd' osd 'profile rbd pool=rbd namespace=namespace2' -o /etc/ceph/client.newuser.keyring
클라이언트의 키를 가져옵니다.
구문
ceph auth get client.USER_NAME예제
[root@mon ~]# ceph auth get client.testuser [client.testuser] key = AQDMp61hBf5UKRAAgjQ2In0Z3uwAase7mrlKnQ== caps mon = "profile rbd" caps osd = "profile rbd pool=rbd namespace=namespace1" exported keyring for client.testuser [root@mon ~]# ceph auth get client.newuser [client.newuser] key = AQDfp61hVfLFHRAA7D80ogmZl80ROY+AUG4A+Q== caps mon = "profile rbd" caps osd = "profile rbd pool=rbd namespace=namespace2" exported keyring for client.newuser
블록 장치 이미지를 생성하고 풀 내에서 사전 정의된 네임스페이스를 사용합니다.
구문
rbd create --namespace NAMESPACE IMAGE_NAME --size SIZE_IN_GB
예제
[root@mon ~]# rbd create --namespace namespace1 image01 --size 1G [root@mon ~]# rbd create --namespace namespace2 image02 --size 1G
선택 사항: 네임스페이스 및 관련 이미지의 세부 정보를 가져옵니다.
구문
rbd --namespace NAMESPACE ls --long예제
[root@mon ~]# rbd --namespace namespace1 ls --long NAME SIZE PARENT FMT PROT LOCK image01 1 GiB 2 [root@mon ~]# rbd --namespace namespace2 ls --long NAME SIZE PARENT FMT PROT LOCK image02 1 GiB 2
Ceph Monitor 노드의 Ceph 구성 파일을 클라이언트 노드로 복사합니다.
scp /etc/ceph/ceph.conf root@CLIENT_NODE:/etc/ceph/예제
[root@mon ~]# scp /etc/ceph/ceph.conf root@host02:/etc/ceph/ root@host02's password: ceph.conf 100% 497 724.9KB/s 00:00
Ceph Monitor 노드에서 클라이언트 노드로 관리자 인증 키를 복사합니다.
구문
scp /etc/ceph/ceph.client.admin.keyring root@CLIENT_NODE:/etc/ceph예제
[root@mon ~]# scp /etc/ceph/ceph.client.admin.keyring root@host02:/etc/ceph/ root@host02's password: ceph.client.admin.keyring 100% 151 265.0KB/s 00:00
Ceph 모니터 노드에서 클라이언트 노드로 사용자의 인증 키를 복사합니다.
구문
scp /etc/ceph/ceph.client.USER_NAME.keyring root@CLIENT_NODE:/etc/ceph/
예제
[root@mon ~]# scp /etc/ceph/client.newuser.keyring root@host02:/etc/ceph/ [root@mon ~]# scp /etc/ceph/client.testuser.keyring root@host02:/etc/ceph/
블록 장치 이미지를 매핑합니다.
구문
rbd map --name NAMESPACE IMAGE_NAME -n client.USER_NAME --keyring /etc/ceph/client.USER_NAME.keyring
예제
[root@mon ~]# rbd map --namespace namespace1 image01 -n client.testuser --keyring=/etc/ceph/client.testuser.keyring /dev/rbd0 [root@mon ~]# rbd map --namespace namespace2 image02 -n client.newuser --keyring=/etc/ceph/client.newuser.keyring /dev/rbd1
동일한 풀에 있는 다른 네임스페이스의 사용자에게 액세스할 수 없습니다.
예제
[root@mon ~]# rbd map --namespace namespace2 image02 -n client.testuser --keyring=/etc/ceph/client.testuser.keyring rbd: warning: image already mapped as /dev/rbd1 rbd: sysfs write failed rbd: error asserting namespace: (1) Operation not permitted In some cases useful info is found in syslog - try "dmesg | tail". 2021-12-06 02:49:08.106 7f8d4fde2500 -1 librbd::api::Namespace: exists: error asserting namespace: (1) Operation not permitted rbd: map failed: (1) Operation not permitted [root@mon ~]# rbd map --namespace namespace1 image01 -n client.newuser --keyring=/etc/ceph/client.newuser.keyring rbd: warning: image already mapped as /dev/rbd0 rbd: sysfs write failed rbd: error asserting namespace: (1) Operation not permitted In some cases useful info is found in syslog - try "dmesg | tail". 2021-12-03 12:16:24.011 7fcad776a040 -1 librbd::api::Namespace: exists: error asserting namespace: (1) Operation not permitted rbd: map failed: (1) Operation not permitted
장치를 확인합니다.
예제
[root@mon ~]# rbd showmapped id pool namespace image snap device 0 rbd namespace1 image01 - /dev/rbd0 1 rbd namespace2 image02 - /dev/rbd1
4장. 스냅샷 관리
Ceph 스냅샷 기능에 익숙한 스토리지 관리자는 Red Hat Ceph Storage 클러스터에 저장된 이미지의 스냅샷 및 복제본을 관리하는 데 도움이 됩니다.
4.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
4.2. Ceph 블록 장치 스냅샷
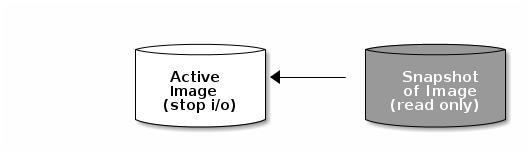
스냅샷은 특정 시점의 이미지 상태에 대한 읽기 전용 사본입니다. Ceph 블록 장치의 고급 기능 중 하나는 이미지의 스냅샷을 작성하여 이미지 상태 기록을 유지할 수 있다는 것입니다. 또한 Ceph에서는 스냅샷 계층 지정을 지원하므로 이미지를 빠르고 쉽게 복제할 수 있습니다(예: 가상 시스템 이미지). Ceph는 QEMU,libvirt, OpenStack 및 CloudStack을 포함하여 rbd 명령과 더 높은 수준의 인터페이스를 사용하여 블록 장치 스냅샷을 지원합니다.
I/O 가 발생하는 동안 스냅샷을 만든 경우 스냅샷에 이미지의 정확한 또는 최신 데이터를 얻지 못할 수 있으며 스냅샷을 마운트하기 위해 스냅샷을 새 이미지에 복제해야 할 수 있습니다. Red Hat은 이미지 스냅샷을 생성하기 전에 I/O 를 중지하도록 권장합니다. 이미지에 파일 시스템이 포함된 경우 스냅샷을 생성하기 전에 파일 시스템이 일관된 상태여야 합니다. I/O 를 중지하려면 fsfreeze 명령을 사용할 수 있습니다. 가상 머신의 경우 qemu-guest-agent 를 사용하여 스냅샷을 생성할 때 파일 시스템을 자동으로 정지할 수 있습니다.
추가 리소스
-
자세한 내용은
fsfreeze(8)매뉴얼 페이지를 참조하십시오.
4.3. Ceph 사용자 및 인증 키
cephx 가 활성화된 경우 사용자 이름 또는 ID와 사용자의 해당 키가 포함된 인증 키의 경로를 지정해야 합니다.
cephx 는 기본적으로 활성화되어 있습니다.
CEPH_ARGS 환경 변수를 추가하여 다음 매개변수의 재입력을 방지할 수 있습니다.
구문
rbd --id USER_ID --keyring=/path/to/secret [commands] rbd --name USERNAME --keyring=/path/to/secret [commands]
예제
[root@rbd-client ~]# rbd --id admin --keyring=/etc/ceph/ceph.keyring [commands] [root@rbd-client ~]# rbd --name client.admin --keyring=/etc/ceph/ceph.keyring [commands]
CEPH_ARGS 환경 변수에 사용자와 시크릿을 추가하여 매번 입력할 필요가 없습니다.
4.4. 블록 장치 스냅샷 생성
Ceph 블록 장치의 스냅샷을 만듭니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
snap create옵션, 풀 이름 및 이미지 이름을 지정합니다.구문
rbd --pool POOL_NAME snap create --snap SNAP_NAME IMAGE_NAME rbd snap create POOL_NAME/IMAGE_NAME@SNAP_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap create --snap snapname foo [root@rbd-client ~]# rbd snap create rbd/foo@snapname
4.5. 블록 장치 스냅샷 나열
블록 장치 스냅샷을 나열합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
풀 이름과 이미지 이름을 지정합니다.
구문
rbd --pool POOL_NAME snap ls IMAGE_NAME rbd snap ls POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap ls foo [root@rbd-client ~]# rbd snap ls rbd/foo
4.6. 블록 장치 스냅샷 롤백
블록 장치 스냅샷을 롤백합니다.
이미지를 스냅샷으로 롤백한다는 것은 스냅샷의 데이터로 현재 버전의 이미지를 덮어쓰는 것을 의미합니다. 롤백을 실행하는 데 걸리는 시간은 이미지 크기에 따라 증가합니다. 이미지 를 스냅샷으로 롤백하는 것보다 스냅샷에서 복제하는 것이 더 빠르 며, 기존 상태로 되돌리는 것이 좋습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
snap rollback옵션, 풀 이름, 이미지 이름 및 스냅 이름을 지정합니다.구문
rbd --pool POOL_NAME snap rollback --snap SNAP_NAME IMAGE_NAME rbd snap rollback POOL_NAME/IMAGE_NAME@SNAP_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap rollback --snap snapname foo [root@rbd-client ~]# rbd snap rollback rbd/foo@snapname
4.7. 블록 장치 스냅샷 삭제
Ceph 블록 장치의 스냅샷을 삭제합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
snap rm옵션, 풀 이름, 이미지 이름 및 스냅샷 이름을 지정합니다.구문
rbd --pool POOL_NAME snap rm --snap SNAP_NAME IMAGE_NAME rbd snap rm POOL_NAME-/IMAGE_NAME@SNAP_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap rm --snap snapname foo [root@rbd-client ~]# rbd snap rm rbd/foo@snapname
이미지에 복제본이 있는 경우 복제된 이미지에는 상위 이미지 스냅샷에 대한 참조가 유지됩니다. 상위 이미지 스냅샷을 삭제하려면 먼저 하위 이미지를 병합해야 합니다.
Ceph OSD 데몬은 데이터를 비동기적으로 삭제하므로 스냅샷을 삭제하면 디스크 공간이 즉시 확보되지 않습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide 의 클라 우팅된 이미지 를 참조하십시오.
4.8. 블록 장치 스냅샷 삭제
블록 장치 스냅샷을 제거합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
snap purge옵션과 이미지 이름을 지정합니다.구문
rbd --pool POOL_NAME snap purge IMAGE_NAME rbd snap purge POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap purge foo [root@rbd-client ~]# rbd snap purge rbd/foo
4.9. 블록 장치 스냅샷 이름 변경
블록 장치 스냅샷의 이름을 변경합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
스냅샷의 이름을 변경하려면 다음을 수행합니다.
구문
rbd snap rename POOL_NAME/IMAGE_NAME@ORIGINAL_SNAPSHOT_NAME POOL_NAME/IMAGE_NAME@NEW_SNAPSHOT_NAME
예제
[root@rbd-client ~]# rbd snap rename data/dataset@snap1 data/dataset@snap2
이렇게 하면 데이터 풀에서
데이터 세트이미지의snap1스냅샷의 이름을snap2로 변경합니다.-
rbd help snap rename명령을 실행하여 스냅샷 이름 바꾸기에 대한 추가 세부 정보를 표시합니다.
4.10. Ceph 블록 장치 계층 지정
Ceph는 블록 장치 스냅샷의 많은 COW(Copy-On-Write) 또는 copy-on-read(COR) 복제본을 생성하는 기능을 지원합니다. 스냅샷 계층을 사용하면 Ceph 블록 장치 클라이언트가 이미지를 매우 빠르게 생성할 수 있습니다. 예를 들어 Linux VM이 작성된 블록 장치 이미지를 생성할 수 있습니다. 그런 다음 이미지를 스냅샷을 만들고 스냅샷을 보호하며 원하는 수만큼 복제본을 만듭니다. 스냅샷은 읽기 전용이므로 스냅샷을 복제하면 의미를 간소화하여 복제본을 신속하게 생성할 수 있습니다.
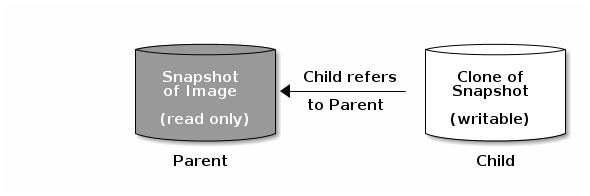
상위 및 라는 용어는 Ceph 블록 장치 스냅샷, 상위 및 스냅샷에서 복제된 해당 이미지를 의미합니다. 이러한 용어는 아래의 명령줄 사용에 중요합니다.
하위
복제된 각 이미지인 하위는 상위 이미지에 대한 참조를 저장하므로 복제된 이미지가 상위 스냅샷을 열고 읽을 수 있습니다. 이 참조는 스냅샷의 정보가 완전히 복제 에 완전히 복사되는 경우 복제본을 병합할 때 제거됩니다.
스냅샷 복제본은 다른 Ceph 블록 장치 이미지와 동일하게 작동합니다. 복제된 이미지의 읽기, 쓰기, 복제, 크기 조정할 수 있습니다. 복제된 이미지에는 특별한 제한이 없습니다. 그러나 스냅샷 복제본은 스냅샷을 참조하므로 복제하기 전에 스냅샷을 보호해야 합니다.
스냅샷 복제본은 COW(Copy-On-Write) 또는 COR(copy-on-read) 복제본일 수 있습니다. COR(Copy-On-Write)을 명시적으로 활성화해야 하는 경우 복제본에 대해 COW(Copy-On-Write)가 항상 활성화됩니다. COW(Copy-On-Write)는 복제 내에서 할당되지 않은 오브젝트에 쓸 때 상위에서 복제본으로 데이터를 복사합니다. COR(Copy-on-read)은 복제본 내의 할당되지 않은 개체에서 읽을 때 상위에서 복제본으로 데이터를 복사합니다. 복제본에서 데이터를 읽는 경우 개체가 복제에 아직 없는 경우에만 상위에서 데이터를 읽습니다. RADOS 블록 장치는 큰 이미지를 여러 오브젝트로 분할합니다. 기본값은 4MB로 설정되고 모든 COW(Copy-On-Write) 및 COR(Copy-on-read) 작업이 전체 개체에서 발생하며 복제본에 1바이트를 작성하면 4MB 개체가 상위에서 읽은 후 이전 COWCOR 작업의 복제본에 아직 존재하지 않는 경우 복제에 기록됩니다.
COR(Copy-on-read)이 활성화되어 있는지 여부에 관계없이 복제본에서 기본 오브젝트를 읽어 충족할 수 없는 모든 읽기는 상위로 다시 라우팅됩니다. 실제로 부모 수에 제한이 없으므로 복제본을 복제할 수 있으므로 이 리라우는 개체가 발견되거나 기본 상위 이미지에 도달할 때까지 계속됩니다. COR(Copy-on-read)이 활성화된 경우 복제본에서 직접 충족하지 못한 모든 읽기는 부모에서 전체 오브젝트를 읽고 복제본에 해당 데이터를 기록하여 나중에 복제본에서 읽을 필요 없이 복제 자체에서 확인할 수 있도록 합니다.
이는 기본적으로 온디맨드 개체 단위 병합 작업입니다. 이는 복제가 다른 지리적 위치에 있는 다른 풀의 부모인 부모로부터 지연 시간이 길어질 때 특히 유용합니다. COR(Copy-on-read)은 읽기의 모호한 대기 시간을 줄입니다. 예를 들어, 복제본에서 1바이트를 읽고 복제본에서 4MB를 읽어야 하므로 처음 몇 개의 읽기 시간이 길어집니다. 그러나 이제 4MB는 부모에서 읽고 복제본에 기록되지만 모든 향후 읽기는 복제 자체에서 제공됩니다.
스냅샷에서 copy-on-read(COR) 복제본을 생성하려면 ceph.conf 파일의 [global] 또는 [client] 섹션에 rbd_clone_copy_on_read = true 를 추가하여 이 기능을 명시적으로 활성화해야 합니다.
추가 리소스
-
플랫링에 대한 자세한 내용은 Red Hat Ceph Storage Block Device Gudie 의 복제된 이미지 추가 섹션을 참조하십시오.
4.11. 블록 장치 스냅샷 보호
복제본은 상위 스냅샷에 액세스합니다. 사용자가 실수로 상위 스냅샷을 삭제하면 모든 복제본이 손상됩니다. 기본적으로 데이터 손실을 방지하려면 스냅샷을 복제하기 전에 보호해야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
다음 명령에
POOL_NAME,IMAGE_NAME및SNAP_SHOT_NAME을 지정합니다.구문
rbd --pool POOL_NAME snap protect --image IMAGE_NAME --snap SNAPSHOT_NAME rbd snap protect POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap protect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap protect rbd/my-image@my-snapshot
참고보호된 스냅샷을 삭제할 수 없습니다.
4.12. 블록 장치 스냅샷 복제
블록 장치 스냅샷을 복제하여 동일한 풀 또는 다른 풀 내에 스냅샷의 읽기 또는 쓰기를 생성합니다. 한 가지 사용 사례는 읽기 전용 이미지와 스냅샷을 한 풀의 템플릿으로 유지하고 다른 풀에서 쓰기 가능한 복제본을 유지하는 것입니다.
기본적으로 스냅샷을 보호하려면 복제할 수 있습니다. 복제 전에 스냅샷을 보호할 필요가 없도록 하려면 ceph osd set-require-min-compat-client mimic 을 설정합니다. 또한 마이크보다 더 높은 버전으로 설정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
스냅샷을 복제하려면 상위 풀, 스냅샷, 하위 풀 및 이미지 이름을 지정해야 합니다.
구문
rbd --pool POOL_NAME --image PARENT_IMAGE --snap SNAP_NAME --dest-pool POOL_NAME --dest CHILD_IMAGE_NAME rbd clone POOL_NAME/PARENT_IMAGE@SNAP_NAME POOL_NAME/CHILD_IMAGE_NAME
예제
[root@rbd-client ~]# rbd --pool rbd --image my-image --snap my-snapshot --dest-pool rbd --dest new-image [root@rbd-client ~]# rbd clone rbd/my-image@my-snapshot rbd/new-image
4.13. 블록 장치 스냅샷 보호 해제
스냅샷을 삭제하려면 먼저 보호를 해제해야 합니다. 또한 복제본의 참조 가 있는 스냅샷을 삭제하지 못 할 수 있습니다. 스냅샷을 삭제하기 전에 스냅샷의 각 복제본을 병합해야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
다음 명령을 실행합니다.
구문
rbd --pool POOL_NAME snap unprotect --image IMAGE_NAME --snap SNAPSHOT_NAME rbd snap unprotect POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME
예제
[root@rbd-client ~]# rbd --pool rbd snap unprotect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap unprotect rbd/my-image@my-snapshot
4.14. 스냅샷의 하위 항목 나열
스냅샷의 하위 항목을 나열합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
스냅샷의 하위 항목을 나열하려면 다음을 실행합니다.
구문
rbd --pool POOL_NAME children --image IMAGE_NAME --snap SNAP_NAME rbd children POOL_NAME/IMAGE_NAME@SNAPSHOT_NAME
예제
rbd --pool rbd children --image my-image --snap my-snapshot rbd children rbd/my-image@my-snapshot
4.15. 복제된 이미지 병합
복제된 이미지에는 상위 스냅샷에 대한 참조가 유지됩니다. 하위 복제본에서 상위 스냅샷에 대한 참조를 제거하면 스냅샷에서 복제본으로 정보를 복사하여 이미지를 효과적으로 "병합"합니다. 복제본 병합에 걸리는 시간은 스냅샷 크기와 함께 증가합니다. 병합된 이미지에는 스냅샷의 모든 정보가 포함되어 있으므로 병합된 이미지는 계층화된 복제본보다 더 많은 스토리지 공간을 사용합니다.
이미지에서 deep flatten 기능을 활성화하면 이미지 복제가 기본적으로 상위에서 해제됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
하위 이미지와 연결된 상위 이미지 스냅샷을 삭제하려면 먼저 하위 이미지를 병합해야 합니다.
구문
rbd --pool POOL_NAME flatten --image IMAGE_NAME rbd flatten POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd --pool rbd flatten --image my-image [root@rbd-client ~]# rbd flatten rbd/my-image
5장. Ceph 블록 장치 미러링
스토리지 관리자는 Red Hat Ceph Storage 클러스터 간에 데이터 이미지를 미러링하여 Ceph 블록 장치에 다른 중복 계층을 추가할 수 있습니다. Ceph 블록 장치 미러링을 이해하고 사용하면 사이트 장애와 같은 데이터 손실을 보호할 수 있습니다. Ceph 블록 장치 미러링에는 단방향 미러링 또는 양방향 미러링의 두 가지 구성이 있으며 풀 및 개별 이미지에서 미러링을 구성할 수 있습니다.
5.1. 사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- 두 스토리지 클러스터 간의 네트워크 연결.
- 각 Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 액세스할 수 있습니다.
5.2. Ceph 블록 장치 미러링
RADOS Block Device(RBD) 미러링은 둘 이상의 Ceph 스토리지 클러스터 간에 Ceph 블록 장치 이미지의 비동기 복제 프로세스입니다. RBD Mirroring은 서로 다른 지리적 위치에서 Ceph 스토리지 클러스터를 찾아 사이트 재해에서 복구하는 데 도움이 될 수 있습니다. 저널 기반 Ceph 블록 장치 미러링은 읽기 및 쓰기, 블록 장치 크기 조정, 스냅샷, 복제본 및 플랫화를 포함하여 이미지에 대한 특정 시점의 일관성 있는 복제본을 보장합니다.
RBD 미러링은 전용 잠금과 저널링 기능을 사용하여 해당 문제가 발생하는 순서대로 이미지에 대한 모든 수정 사항을 기록합니다. 이렇게 하면 이미지의 충돌 불일치 미러를 사용할 수 있습니다.
블록 장치 이미지를 미러링하는 기본 및 보조 풀은 동일한 용량 및 성능 특성을 유지해야 하며 과도한 대기 시간 없이 미러링을 보장하기 위한 적절한 대역폭이 있어야 합니다. 예를 들어 기본 스토리지 클러스터의 이미지에 XMB/s 평균 쓰기 처리량이 있는 경우 네트워크는 보조 사이트에 대한 네트워크 연결에서 N * X 처리량과 N 이미지를 미러링하는 데 Y%의 안전 요소를 지원해야 합니다.
rbd-mirror 데몬은 원격 기본 이미지에서 변경 사항을 가져오고 이러한 변경 사항을 로컬 비기본 이미지에 기록하여 하나의 Ceph 스토리지 클러스터에서 다른 Ceph 스토리지 클러스터에 이미지를 동기화합니다. rbd-mirror 데몬은 단방향 미러링을 위해 단일 Ceph 스토리지 클러스터에서 또는 미러링 관계에 참여하는 양방향 미러링을 위해 두 개의 Ceph 스토리지 클러스터에서 실행할 수 있습니다.
RBD 미러링이 작동하려면 단방향 또는 양방향 복제를 사용하는 경우 몇 가지 가정이 수행됩니다.
- 동일한 이름의 풀이 두 스토리지 클러스터에 있습니다.
- 풀에는 미러링하려는 저널 지원 이미지가 포함되어 있습니다.
단방향 또는 양방향 복제에서 rbd-mirror 의 각 인스턴스는 다른 Ceph 스토리지 클러스터에 동시에 연결할 수 있어야 합니다. 또한 네트워크에는 미러링을 처리하기 위해 두 데이터 센터 사이트 간에 충분한 대역폭이 있어야 합니다.
단방향 복제
한 스토리지 클러스터의 기본 이미지 또는 이미지 풀이 보조 스토리지 클러스터에 복제되는 것을 의미합니다. 단방향 미러링은 여러 보조 스토리지 클러스터에 대한 복제도 지원합니다.
보조 스토리지 클러스터에서 이미지는 기본이 아닌 복제본입니다. 즉 Ceph 클라이언트는 이미지에 쓸 수 없습니다. 데이터가 주 스토리지 클러스터에서 보조 스토리지 클러스터로 미러링되면 rbd-mirror 는 보조 스토리지 클러스터에서만 실행됩니다.
일방향 미러링이 작동하려면 몇 가지 가정이 수행됩니다.
- 두 개의 Ceph 스토리지 클러스터가 있으며 기본 스토리지 클러스터에서 보조 스토리지 클러스터로 이미지를 복제하려고 합니다.
-
보조 스토리지 클러스터에는
rbd-mirror데몬을 실행하는 Ceph 클라이언트 노드가 연결되어 있습니다.rbd-mirror데몬은 이미지를 보조 스토리지 클러스터에 동기화하도록 기본 스토리지 클러스터에 연결합니다.
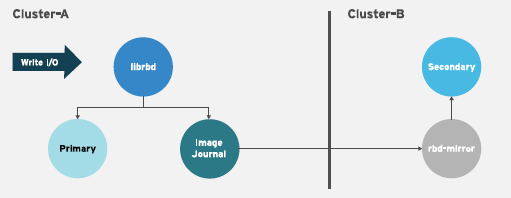
양방향 복제
양방향 복제는 기본 클러스터에 rbd-mirror 데몬을 추가하여 이미지를 시연하고 보조 클러스터에서 승격할 수 있습니다. 그런 다음 보조 클러스터의 이미지를 변경하면 보조 클러스터에서 보조 클러스터로 리디렉션 방향으로 복제됩니다. 두 클러스터에 모두 rbd-mirror 가 실행 중이어야 합니다. 두 클러스터에는 두 클러스터에서 이미지를 승격하고 설명할 수 있도록 rbd-mirror가 실행되고 있어야 합니다. 현재 양방향 복제는 두 사이트 간에만 지원됩니다.
양방향 미러링이 작동하려면 몇 가지 가정이 수행됩니다.
- 두 개의 스토리지 클러스터가 있으며 두 가지 방향으로 이미지를 복제할 수 있습니다.
-
두 스토리지 클러스터에는
rbd-mirror데몬을 실행하는 클라이언트 노드가 연결되어 있습니다. 보조 스토리지 클러스터에서 실행 중인rbd-mirror데몬은 기본 스토리지 클러스터에 연결하여 이미지를 보조에 동기화하고, 기본 스토리지 클러스터에서 실행 중인rbd-mirror데몬이 보조 스토리지 클러스터에 연결하여 이미지를 기본 클러스터에 동기화합니다.
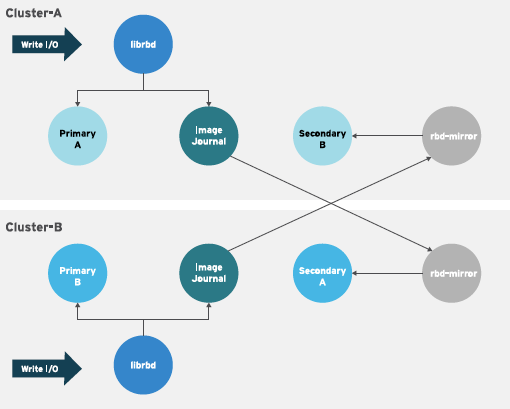
Red Hat Ceph Storage 4에서는 단일 클러스터에서 여러 개의 활성 rbd-mirror 데몬을 실행할 수 있습니다.
미러링 모드
미러링은 미러 피어링 스토리지 클러스터가 있는 풀별로 구성됩니다. Ceph는 풀의 이미지 유형에 따라 두 가지 미러링 모드를 지원합니다.
- 풀 모드
- 저널링 기능이 활성화된 풀의 모든 이미지가 미러링됩니다.
- 이미지 모드
- 풀 내 특정 이미지 하위 집합만 미러링됩니다. 각 이미지에 대해 별도로 미러링을 활성화해야 합니다.
이미지 상태
이미지를 수정할 수 있는지 여부는 상태에 따라 달라집니다.
- 기본 상태의 이미지를 수정할 수 있습니다.
- 기본이 아닌 상태의 이미지는 수정할 수 없습니다.
이미지는 이미지에서 미러링을 처음 활성화하면 자동으로 primary로 승격됩니다. 승격이 발생할 수 있습니다.
- 풀 모드에서 미러링을 활성화하여 암시적으로 수행됩니다.
- 특정 이미지 미러링을 활성화하여 명시적으로 다음을 수행합니다.
기본 이미지를 시연하고 기본 이미지가 아닌 이미지를 승격할 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide 의 이미지 승격 및 데모 섹션을 참조하십시오.
5.3. Ansible을 사용하여 단방향 미러링 구성
이 절차에서는 ceph-ansible 을 사용하여 site-b라는 기본 스토리지 클러스터에서 일방향 이미지 복제 를 라고 하는 보조 스토리지 클러스터에 구성합니다. 다음 예에서 site- b데이터 는 미러링할 이미지를 포함하는 풀의 이름입니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터가 실행 중인 2개입니다.
- Ceph 클라이언트 노드.
- 동일한 이름의 풀이 두 클러스터에 있습니다.
- 풀 내의 이미지에는 저널 기반 미러링에 사용할 수 있는 독점 잠금 및 저널링이 활성화되어 있어야 합니다.
단방향 복제를 사용하는 경우 여러 보조 스토리지 클러스터에 미러링할 수 있습니다.
절차
이미지가 시작된 클러스터에서 이미지에서 배타적 잠금 및 저널링 기능을 활성화합니다.
새 이미지 의 경우
--image-feature옵션을 사용합니다.구문
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE[,FEATURE]
예제
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling
기존 이미지 의 경우
rbd 기능 enable 명령을사용합니다.구문
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME
예제
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling
기본적으로 모든 새 이미지에서 배타적 잠금 및 저널링을 활성화하려면 Ceph 구성 파일에 다음 설정을 추가합니다.
rbd_default_features = 125
site-a클러스터에서 다음 단계를 완료합니다.모니터 노드에서
rbd-mirror데몬이 클러스터에 연결하는 데 사용할 사용자를 만듭니다. 이 예제에서는site-a사용자를 생성하고 이 키를site-a.client.site-a.keyring이라는 파일에 출력합니다.구문
ceph auth get-or-create client.CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/CLUSTER_NAME.client.USER_NAME.keyring
예제
[root@mon ~]# ceph auth get-or-create client.site-a mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-a.client.site-a.keyring
-
모니터링 노드에서 Ceph 구성 파일 및 새로 생성된 키 파일을
site-b모니터 및 클라이언트 노드로 복사합니다. -
Ceph 구성 파일의 이름을
ceph.conf에서 CLUSTER-NAME.conf로 변경합니다. 이 예제에서 파일은/etc/ceph/site-a.conf입니다.
site-b클러스터에서 다음 단계를 완료합니다.-
Ansible 관리 노드에서 Ansible 인벤토리 파일에
[rbdmirrors]그룹을 추가합니다. 일반적인 인벤토리 파일은/etc/ansible/hosts입니다. [rbdmirrors]그룹에서rbd-mirrors 데몬을 실행할site-b클라이언트 노드의 이름을 추가합니다. 데몬은site-a에서site-b로 이미지 변경 사항을 가져옵니다.[rbdmirrors] ceph-client
/usr/share/ceph-ansible/디렉터리로 이동합니다.[root@admin ~]# cd /usr/share/ceph-ansible
group_vars/
rbdmirrors.yml.sample을 group_vars/rbdmirrors.yml에 복사하여 새rbdmirrors.yml 파일을 만듭니다.[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml
-
편집할
group_vars/rbdmirrors.yml파일을 엽니다. ceph_rbd_mirror_configure를true로 설정합니다.ceph_rbd_mirror_pool을 이미지를 미러링할 풀로 설정합니다. 이 예제에서데이터는 풀 이름입니다.ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"
기본적으로
ceph-ansible은 풀의 모든 이미지를 미러링하는 풀 모드를 사용하여 미러링을 구성합니다. 미러링이 명시적으로 활성화된 이미지만 미러링된 이미지만 활성화하는 이미지 모드를 활성화합니다. 이미지 모드를 활성화하려면ceph_rbd_mirror_mode를image로 설정합니다.ceph_rbd_mirror_mode: image
rbd-mirror에서 가져올 클러스터의 이름을 설정합니다. 이 예제에서 다른 클러스터는site-a입니다.ceph_rbd_mirror_remote_cluster: "site-a"
Ansible 관리 노드에서
ceph_rbd_mirror_remote_user를 사용하여 키의 사용자 이름을 설정합니다. 키를 만들 때 사용한 것과 동일한 이름을 사용합니다. 이러한 예에서 사용자는client.site-a라는 이름으로 지정됩니다.ceph_rbd_mirror_remote_user: "client.site-a"
ceph-ansible 사용자로 Ansible 플레이북을 실행합니다.
베어 메탈 배포:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts
컨테이너 배포:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
Ansible 관리 노드에서 Ansible 인벤토리 파일에
site-a및site-b클러스터 모두에서 원하는 이미지에서 미러링을 명시적으로 활성화합니다.구문
저널 기반 미러링:
rbd mirror image enable POOL/IMAGE
스냅샷 기반 미러링:
rbd mirror image enable POOL/IMAGE snapshot
예제
[root@mon ~]# rbd mirror image enable data/image1 [root@mon ~]# rbd mirror image enable data/image1 snapshot
참고새 이미지를 피어 클러스터에 미러링할 때마다 이 단계를 반복합니다.
미러링 상태를 확인합니다.
site-b클러스터의 Ceph Monitor 노드에서 다음 명령을 실행합니다.예제
저널 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying 1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2019-04-22 13:19:27스냅샷 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying 1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57참고사이트 간 연결에 따라 미러링은 이미지를 동기화하는 데 시간이 오래 걸릴 수 있습니다.
5.4. Ansible을 사용하여 양방향 미러링 구성
이 절차에서는 ceph-ansible 을 사용하여 양방향 복제를 구성하여 site-a 및 site-b 라고 하는 두 클러스터 간의 이미지를 미러링할 수 있습니다. 다음 예에서 데이터 는 미러링할 이미지를 포함하는 풀의 이름입니다.
양방향 미러링은 두 클러스터의 동일한 이미지에 동시 쓰기를 허용하지 않습니다. 이미지는 한 클러스터에서 승격되고 다른 클러스터에서 강등됩니다. 상태에 따라 한 방향 또는 다른 방향으로 미러링됩니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터가 실행 중인 2개입니다.
- 각 클러스터에는 클라이언트 노드가 있습니다.
- 동일한 이름의 풀이 두 클러스터에 있습니다.
- 풀 내의 이미지에는 저널 기반 미러링에 사용할 수 있는 독점 잠금 및 저널링이 활성화되어 있어야 합니다.
절차
이미지가 시작된 클러스터에서 이미지에서 배타적 잠금 및 저널링 기능을 활성화합니다.
새 이미지 의 경우
--image-feature옵션을 사용합니다.구문
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE[,FEATURE]
예제
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling
기존 이미지 의 경우
rbd 기능 enable 명령을사용합니다.구문
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE_NAME
예제
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling
기본적으로 모든 새 이미지에서 배타적 잠금 및 저널링을 활성화하려면 Ceph 구성 파일에 다음 설정을 추가합니다.
rbd_default_features = 125
site-a클러스터에서 다음 단계를 완료합니다.모니터 노드에서
rbd-mirror데몬이 클러스터에 연결하는 데 사용할 사용자를 만듭니다. 이 예제에서는site-a사용자를 생성하고 해당 키를site-a.client.site-a.keyring이라는 파일에 출력하고 Ceph 구성 파일은/etc/ceph/site-a.conf입니다.구문
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring -c /etc/ceph/PRIMARY_CLUSTER_NAME.conf
예제
[root@mon ~]# ceph auth get-or-create client.site-a mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-a.client.site-a.keyring -c /etc/ceph/site-a.conf
인증 키를
site-b클러스터에 복사합니다.rbd-daemon이 실행될site-b클러스터의 클라이언트 노드에 파일을 복사합니다. 파일을/etc/ceph/site-a.client.site-a.keyring에 저장합니다.구문
scp /etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring root@SECONDARY_CLIENT_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.client.USER_NAME.keyring
예제
[root@mon ~]# scp /etc/ceph/site-a.client.site-a.keyring root@client.site-b:/etc/ceph/site-a.client.site-a.keyring
모니터 노드에서
site-b모니터 노드 및 클라이언트 노드로 Ceph 구성 파일을 복사합니다. 이 예제의 Ceph 구성 파일은/etc/ceph/site-a.conf입니다.구문
scp /etc/ceph/PRIMARY_CLUSTER_NAME.conf root@SECONDARY_MONITOR_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.conf scp /etc/ceph/PRIMARY_CLUSTER_NAME.conf user@SECONDARY_CLIENT_NODE_NAME:/etc/ceph/PRIMARY_CLUSTER_NAME.conf
예제
[root@mon ~]# scp /etc/ceph/site-a.conf root@mon.site-b:/etc/ceph/site-a.conf [root@mon ~]# scp /etc/ceph/site-a.conf user@client.site-b:/etc/ceph/site-a.conf
site-b클러스터에서 다음 단계를 완료합니다.-
site-a에서site-b로 미러링을 구성합니다. Ansible 관리 노드에서 Ansible 인벤토리 파일(일반적으로/usr/share/ceph-ansible/hosts)에[rbdmirrors]그룹을 추가합니다. [rbdmirrors]그룹에서rbd-mirrors 데몬에서 실행할site-b클라이언트 노드의 이름을 추가합니다. 이 데몬은site-a에서site-b로 이미지 변경 사항을 가져옵니다.예제
[rbdmirrors] client.site-b
/usr/share/ceph-ansible/디렉터리로 이동합니다.[root@admin ~]$ cd /usr/share/ceph-ansible
group_vars/
rbdmirrors.yml.sample을 group_vars/rbdmirrors.yml에 복사하여 새rbdmirrors.yml 파일을 만듭니다.[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml
-
group_vars/rbdmirrors.yml파일을 편집하기 위해 을 엽니다. ceph_rbd_mirror_configure를true로 설정하고ceph_rbd_mirror_pool을 미러할 풀로 설정합니다. 이 예제에서데이터는 풀 이름입니다.ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"
기본적으로
ceph-ansible은 풀의 모든 이미지를 미러링하는 풀 모드를 사용하여 미러링을 구성합니다. 미러링이 명시적으로 활성화된 이미지만 미러링된 이미지만 활성화하는 이미지 모드를 활성화합니다. 이미지 모드를 활성화하려면ceph_rbd_mirror_mode를image로 설정합니다.ceph_rbd_mirror_mode: image
group_vars/rbdmirrors.yml파일에서rbd-mirror에서 클러스터의 이름을 설정합니다. 이 예제에서 다른 클러스터는site-a입니다.ceph_rbd_mirror_remote_cluster: "site-a"
Ansible 관리 노드에서
group_vars/rbdmirrors.yml파일에서ceph_rbd_mirror_remote_user를 사용하여 키의 사용자 이름을 설정합니다. 키를 만들 때 사용한 것과 동일한 이름을 사용합니다. 이러한 예에서 사용자는client.site-a라는 이름으로 지정됩니다.ceph_rbd_mirror_remote_user: "client.site-a"
ansible 사용자로 Ansible 플레이북을 실행합니다.
베어 메탈 배포:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts
컨테이너 배포:
[user@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
미러링 상태를 확인합니다.
site-b클러스터의 Ceph Monitor 노드에서 다음 명령을 실행합니다.예제
저널 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying 1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 13:19:27스냅샷 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying 1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57참고사이트 간 연결에 따라 미러링은 이미지를 동기화하는 데 시간이 오래 걸릴 수 있습니다.
site-b클러스터에서 다음 단계를 완료합니다. 단계는 주로 위와 동일합니다.모니터 노드에서
rbd-mirror데몬이 클러스터에 연결하는 데 사용할 사용자를 만듭니다. 이 예제에서는site-b사용자를 생성하고 해당 키를site-b.client.site-b.keyring이라는 파일에 출력하고 Ceph 구성 파일은/etc/ceph/site-b.conf입니다.구문
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring -c /etc/ceph/SECONDARY_CLUSTER_NAME.conf
예제
[root@mon ~]# ceph auth get-or-create client.site-b mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-b.client.site-b.keyring -c /etc/ceph/site-b.conf
인증 키를
site-a클러스터에 복사합니다.rbd의 클라이언트 노드에 파일을 복사합니다. 파일을-daemon이 실행될 클러스터/etc/ceph/site-b.client.site-b.keyring에 저장합니다.구문
scp /etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring root@PRIMARY_CLIENT_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.client.USER_NAME.keyring
예제
[root@mon ~]# scp /etc/ceph/site-b.client.site-b.keyring root@client.site-a:/etc/ceph/site-b.client.site-b.keyring
모니터 노드에서
site-amonitor 노드 및 클라이언트 노드로 Ceph 구성 파일을 복사합니다. 이 예제의 Ceph 구성 파일은/etc/ceph/site-b.conf입니다.구문
scp /etc/ceph/SECONDARY_CLUSTER_NAME.conf root@PRIMARY_MONITOR_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.conf scp /etc/ceph/SECONDARY_CLUSTER_NAME.conf user@PRIMARY_CLIENT_NODE_NAME:/etc/ceph/SECONDARY_CLUSTER_NAME.conf
예제
[root@mon ~]# scp /etc/ceph/site-b.conf root@mon.site-a:/etc/ceph/site-b.conf [root@mon ~]# scp /etc/ceph/site-b.conf user@client.site-a:/etc/ceph/site-b.conf
site-a클러스터에서 다음 단계를 완료합니다.-
site-b에서site-a로 미러링을 구성합니다. Ansible 관리 노드에서 Ansible 인벤토리 파일(일반적으로/usr/share/ceph-ansible/hosts)에[rbdmirrors]그룹을 추가합니다. [rbdmirrors]그룹에서rbd-mirrors 데몬에서 실행할site-a클라이언트 노드의 이름을 추가합니다. 이 데몬은site-b에서site-a로 이미지 변경 사항을 가져옵니다.예제
[rbdmirrors] client.site-a
/usr/share/ceph-ansible/디렉터리로 이동합니다.[root@admin ~]# cd /usr/share/ceph-ansible
group_vars/
rbdmirrors.yml.sample을 group_vars/rbdmirrors.yml에 복사하여 새rbdmirrors.yml 파일을 만듭니다.[root@admin ceph-ansible]# cp group_vars/rbdmirrors.yml.sample group_vars/rbdmirrors.yml
-
group_vars/rbdmirrors.yml파일을 편집하기 위해 을 엽니다. ceph_rbd_mirror_configure를true로 설정하고ceph_rbd_mirror_pool을 미러할 풀로 설정합니다. 이 예제에서데이터는 풀 이름입니다.ceph_rbd_mirror_configure: true ceph_rbd_mirror_pool: "data"
기본적으로
ceph-ansible은 풀의 모든 이미지를 미러링하는 풀 모드를 사용하여 미러링을 구성합니다. 미러링이 명시적으로 활성화된 이미지만 미러링된 이미지만 활성화하는 이미지 모드를 활성화합니다. 이미지 모드를 활성화하려면ceph_rbd_mirror_mode를image로 설정합니다.ceph_rbd_mirror_mode: image
Ansible 관리 노드에서
group_vars/rbdmirrors.yml파일에서rbd-mirror에서 클러스터의 이름을 설정합니다. 예를 들어 다른 클러스터의 이름은site-b입니다.ceph_rbd_mirror_remote_cluster: "site-b"
Ansible 관리 노드에서
group_vars/rbdmirrors.yml파일에서ceph_rbd_mirror_remote_user를 사용하여 키의 사용자 이름을 설정합니다. 이 예제에서는 user의 이름은client.site-b입니다.ceph_rbd_mirror_remote_user: "client.site-b"
관리 노드에서 Ansible 사용자로 Ansible 플레이북을 실행합니다.
베어 메탈 배포:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rbdmirrors -i hosts
컨테이너 배포:
[user@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rbdmirrors -i hosts
-
site-a및site-b클러스터 모두에서 원하는 이미지에서 미러링을 명시적으로 활성화합니다.구문
저널 기반 미러링:
rbd mirror image enable POOL/IMAGE
스냅샷 기반 미러링:
rbd mirror image enable POOL/IMAGE snapshot
예제
[root@mon ~]# rbd mirror image enable data/image1 [root@mon ~]# rbd mirror image enable data/image1 snapshot
참고새 이미지를 피어 클러스터에 미러링할 때마다 이 단계를 반복합니다.
미러링 상태를 확인합니다.
site-a클러스터의 클라이언트 노드에서 다음 명령을 실행합니다.예제
저널 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped 1 description: local image is primary last_update: 2021-04-16 15:45:31스냅샷 기반 미러링:
[root@mon ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped 1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])
5.5. 명령줄 인터페이스를 사용하여 단방향 미러링 구성
다음 절차에서는 기본 스토리지 클러스터에서 보조 스토리지 클러스터로 풀의 단방향 복제를 구성합니다.
단방향 복제를 사용하는 경우 여러 보조 스토리지 클러스터에 미러링할 수 있습니다.
이 섹션의 예는 기본 이미지를 site-a 로 참조하며 이미지를 site-b 로 복제하는 보조 스토리지 클러스터를 참조하여 두 스토리지 클러스터를 구분합니다. 이 예제에서 사용되는 풀 이름을 data 라고 합니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터 최소 2개 이상 정상 및 실행 중인.
- 각 스토리지 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 풀 내의 이미지에는 저널 기반 미러링에 사용할 수 있는 독점 잠금 및 저널링이 활성화되어 있어야 합니다.
절차
site-b스토리지 클러스터에 연결된 클라이언트 노드에rbd-mirror패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@rbd-client ~]# yum install rbd-mirror
Red Hat Enterprise Linux 8
[root@rbd-client ~]# dnf install rbd-mirror
참고패키지는 Red Hat Ceph Storage Tools 리포지토리에서 제공됩니다.
이미지에서 배타적 잠금 및 저널링 기능을 활성화합니다.
새 이미지 의 경우
--image-feature옵션을 사용합니다.구문
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE [,FEATURE]
예제
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling
기존 이미지 의 경우
rbd 기능 enable 명령을사용합니다.구문
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE [,FEATURE]
예제
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling
기본적으로 모든 새 이미지에서 배타적 잠금 및 저널링을 활성화하려면 Ceph 구성 파일에 다음 설정을 추가합니다.
rbd_default_features = 125
미러링 모드(풀 또는 이미지 모드)를 선택합니다.
중요스냅샷 기반 미러링에 이미지 모드를 사용합니다.
풀 모드 활성화:
구문
rbd mirror pool enable POOL_NAME MODE
예제
[root@rbd-client ~]# rbd mirror pool enable data pool
이 예제에서는
data라는 전체 풀을 미러링할 수 있습니다.이미지 모드 활성화:
구문
rbd mirror pool enable POOL_NAME MODE
예제
[root@rbd-client ~]# rbd mirror pool enable data image
이 예제에서는
data라는 풀에서 이미지 모드 미러링을 활성화합니다.미러링이 성공적으로 활성화되었는지 확인합니다.
구문
rbd mirror pool info POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: 94cbd9ca-7f9a-441a-ad4b-52a33f9b7148 Peer Sites: none
site-a클러스터에서 다음 단계를 완료합니다.Ceph 클라이언트 노드에서 사용자를 생성합니다.
구문
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring
예제
[root@rbd-client-site-a ~]# ceph auth get-or-create client.rbd-mirror.site-a mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-a.keyring
인증 키를
site-b클러스터에 복사합니다.구문
scp /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring root@SECONDARY_CLUSTER:_PATH_
예제
[root@rbd-client-site-a ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-a.keyring root@rbd-client-site-b:/etc/ceph/
Ceph 클라이언트 노드에서 스토리지 클러스터 피어를 부트스트랩합니다.
스토리지 클러스터 피어를 풀에 등록합니다.
구문
rbd mirror pool peer bootstrap create --site-name LOCAL_SITE_NAME POOL_NAME > PATH_TO_BOOTSTRAP_TOKEN
예제
[root@rbd-client-site-a ~]# rbd mirror pool peer bootstrap create --site-name rbd-mirror.site-a data > /root/bootstrap_token_rbd-mirror.site-a
참고이 예제 bootstrap 명령은
client.rbd-mirror-peerCeph 사용자를 생성합니다.부트스트랩 토큰 파일을
site-b스토리지 클러스터에 복사합니다.구문
scp PATH_TO_BOOTSTRAP_TOKEN root@SECONDARY_CLUSTER:/root/
예제
[root@rbd-client-site-a ~]# scp /root/bootstrap_token_site-a root@ceph-rbd2:/root/
site-b클러스터에서 다음 단계를 완료합니다.클라이언트 노드에서 사용자를 생성합니다.
구문
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring
예제
[root@rbd-client-site-b ~]# ceph auth get-or-create client.rbd-mirror.site-b mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-b.keyring
인증 키를 Ceph 클라이언트 노드인
site-a클러스터에 복사합니다.구문
scp /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring root@PRIMARY_CLUSTER:_PATH_
예제
[root@rbd-client-site-b ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-b.keyring root@rbd-client-site-a:/etc/ceph/
부트스트랩 토큰을 가져옵니다.
구문
rbd mirror pool peer bootstrap import --site-name LOCAL_SITE_NAME --direction rx-only POOL_NAME PATH_TO_BOOTSTRAP_TOKEN
예제
[root@rbd-client-site-b ~]# rbd mirror pool peer bootstrap import --site-name rbd-mirror.site-b --direction rx-only data /root/bootstrap_token_rbd-mirror.site-a
참고단방향 RBD 미러링의 경우 피어를 부트 스트랩할 때 양방향 미러링이 기본값이므로
--direction rx-only인수를 사용해야 합니다.클라이언트 노드에서
rbd-mirror데몬을 활성화하고 시작합니다.구문
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@rbd-mirror.CLIENT_ID systemctl start ceph-rbd-mirror@rbd-mirror.CLIENT_ID
CLIENT_ID를 이전에 만든 Ceph 사용자로 교체합니다.예제
[root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a
중요각
rbd-mirror데몬에는 고유한 클라이언트 ID가 있어야 합니다.미러링 상태를 확인하려면
site-a및site-b클러스터의 Ceph Monitor 노드에서 다음 명령을 실행합니다.구문
rbd mirror image status POOL_NAME/IMAGE_NAME
예제
저널 기반 미러링:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped 1 description: local image is primary last_update: 2021-04-22 13:45:31스냅샷 기반 미러링:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped 1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])예제
저널 기반 미러링:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying 1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 14:19:27스냅샷 기반 미러링:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying 1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57참고사이트 간 연결에 따라 미러링은 이미지를 동기화하는 데 시간이 오래 걸릴 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
- Ceph 사용자에 대한 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 사용자 관리 섹션을 참조하십시오.
5.6. 명령줄 인터페이스를 사용하여 양방향 미러링 구성
다음 절차에서는 기본 스토리지 클러스터와 보조 스토리지 클러스터 간에 풀의 양방향 복제를 구성합니다.
양방향 복제를 사용하는 경우 두 스토리지 클러스터 간에만 미러링할 수 있습니다.
이 섹션의 예는 기본 이미지를 site-a 로 참조하며 이미지를 site-b 로 복제하는 보조 스토리지 클러스터를 참조하여 두 스토리지 클러스터를 구분합니다. 이 예제에서 사용되는 풀 이름을 data 라고 합니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터 최소 2개 이상 정상 및 실행 중인.
- 각 스토리지 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 풀 내의 이미지에는 저널 기반 미러링에 사용할 수 있는 독점 잠금 및 저널링이 활성화되어 있어야 합니다.
절차
site-a스토리지 클러스터에 연결된 클라이언트 노드와site-b스토리지 클러스터에 연결된 클라이언트 노드에rbd-mirror패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@rbd-client ~]# yum install rbd-mirror
Red Hat Enterprise Linux 8
[root@rbd-client ~]# dnf install rbd-mirror
참고패키지는 Red Hat Ceph Storage Tools 리포지토리에서 제공됩니다.
이미지에서 배타적 잠금 및 저널링 기능을 활성화합니다.
새 이미지 의 경우
--image-feature옵션을 사용합니다.구문
rbd create IMAGE_NAME --size MEGABYTES --pool POOL_NAME --image-feature FEATURE [,FEATURE]
예제
[root@rbd-client ~]# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling
기존 이미지 의 경우
rbd 기능 enable 명령을사용합니다.구문
rbd feature enable POOL_NAME/IMAGE_NAME FEATURE [,FEATURE]
예제
[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock,journaling
기본적으로 모든 새 이미지에서 배타적 잠금 및 저널링을 활성화하려면 Ceph 구성 파일에 다음 설정을 추가합니다.
rbd_default_features = 125
미러링 모드(풀 또는 이미지 모드)를 선택합니다.
중요스냅샷 기반 미러링에 이미지 모드를 사용합니다.
풀 모드 활성화:
구문
rbd mirror pool enable POOL_NAME MODE
예제
[root@rbd-client ~]# rbd mirror pool enable data pool
이 예제에서는
data라는 전체 풀을 미러링할 수 있습니다.이미지 모드 활성화:
구문
rbd mirror pool enable POOL_NAME MODE
예제
[root@rbd-client ~]# rbd mirror pool enable data image
이 예제에서는
data라는 풀에서 이미지 모드 미러링을 활성화합니다.미러링이 성공적으로 활성화되었는지 확인합니다.
구문
rbd mirror pool info POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: 94cbd9ca-7f9a-441a-ad4b-52a33f9b7148 Peer Sites: none
site-a클러스터에서 다음 단계를 완료합니다.Ceph 클라이언트 노드에서 사용자를 생성합니다.
구문
ceph auth get-or-create client.PRIMARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring
예제
[root@rbd-client-site-a ~]# ceph auth get-or-create client.rbd-mirror.site-a mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-a.keyring
인증 키를
site-b클러스터에 복사합니다.구문
scp /etc/ceph/ceph.PRIMARY_CLUSTER_NAME.keyring root@SECONDARY_CLUSTER:_PATH_
예제
[root@rbd-client-site-a ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-a.keyring root@rbd-client-site-b:/etc/ceph/
Ceph 클라이언트 노드에서 스토리지 클러스터 피어를 부트스트랩합니다.
스토리지 클러스터 피어를 풀에 등록합니다.
구문
rbd mirror pool peer bootstrap create --site-name LOCAL_SITE_NAME POOL_NAME > PATH_TO_BOOTSTRAP_TOKEN
예제
[root@rbd-client-site-a ~]# rbd mirror pool peer bootstrap create --site-name rbd-mirror.site-a data > /root/bootstrap_token_rbd-mirror.site-a
참고이 예제 bootstrap 명령은
client.rbd-mirror-peerCeph 사용자를 생성합니다.부트스트랩 토큰 파일을
site-b스토리지 클러스터에 복사합니다.구문
scp PATH_TO_BOOTSTRAP_TOKEN root@SECONDARY_CLUSTER:/root/
예제
[root@rbd-client-site-a ~]# scp /root/bootstrap_token_site-a root@ceph-rbd2:/root/
site-b클러스터에서 다음 단계를 완료합니다.클라이언트 노드에서 사용자를 생성합니다.
구문
ceph auth get-or-create client.SECONDARY_CLUSTER_NAME mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring
예제
[root@rbd-client-site-b ~]# ceph auth get-or-create client.rbd-mirror.site-b mon 'profile rbd-mirror' osd 'profile rbd' -o /etc/ceph/ceph.client.rbd-mirror.site-b.keyring
인증 키를 Ceph 클라이언트 노드인
site-a클러스터에 복사합니다.구문
scp /etc/ceph/ceph.SECONDARY_CLUSTER_NAME.keyring root@PRIMARY_CLUSTER:_PATH_
예제
[root@rbd-client-site-b ~]# scp /etc/ceph/ceph.client.rbd-mirror.site-b.keyring root@rbd-client-site-a:/etc/ceph/
부트스트랩 토큰을 가져옵니다.
구문
rbd mirror pool peer bootstrap import --site-name LOCAL_SITE_NAME --direction rx-tx POOL_NAME PATH_TO_BOOTSTRAP_TOKEN
예제
[root@rbd-client-site-b ~]# rbd mirror pool peer bootstrap import --site-name rbd-mirror.site-b --direction rx-tx data /root/bootstrap_token_rbd-mirror.site-a
참고양방향 미러링은 피어를 부트 스트랩할 때 기본 설정이므로
--direction인수는 선택 사항입니다.
기본 및 보조 클라이언트 노드에서
rbd-mirror데몬을 활성화하고 시작합니다.구문
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@rbd-mirror.CLIENT_ID systemctl start ceph-rbd-mirror@rbd-mirror.CLIENT_ID
CLIENT_ID를 이전에 만든 Ceph 사용자로 교체합니다.예제
[root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-a ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-a ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-b [root@rbd-client-site-a ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-b
위의 예에서 사용자는 기본 클러스터
사이트-a에서 사용하도록 설정되어 있습니다.예제
[root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-a [root@rbd-client-site-b ~]# systemctl enable ceph-rbd-mirror@rbd-mirror.site-b [root@rbd-client-site-b ~]# systemctl start ceph-rbd-mirror@rbd-mirror.site-b
위의 예에서 사용자는 보조 클러스터
site-b에서 사용하도록 설정되어 있습니다.중요각
rbd-mirror데몬에는 고유한 클라이언트 ID가 있어야 합니다.미러링 상태를 확인하려면
site-a및site-b클러스터의 Ceph Monitor 노드에서 다음 명령을 실행합니다.구문
rbd mirror image status POOL_NAME/IMAGE_NAME
예제
저널 기반 미러링:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped 1 description: local image is primary last_update: 2021-04-22 13:45:31스냅샷 기반 미러링:
[root@mon-site-a ~]# rbd mirror image status data/image1 image1: global_id: 47fd1aae-5f19-4193-a5df-562b5c644ea7 state: up+stopped 1 description: local image is primary service: admin on ceph-rbd1-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:42:54 peer_sites: name: rbd-mirror.site-b state: up+replaying description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642693094,"remote_snapshot_timestamp":1642693094,"replay_state":"idle"} last_update: 2022-01-20 12:42:59 snapshots: 5 .mirror.primary.47fd1aae-5f19-4193-a5df-562b5c644ea7.dda146c6-5f21-4e75-ba93-660f6e57e301 (peer_uuids:[bfd09289-c9c9-40c8-b2d3-ead9b6a99a45])예제
저널 기반 미러링:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying 1 description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2021-04-22 14:19:27스냅샷 기반 미러링:
[root@mon-site-b ~]# rbd mirror image status data/image1 image1: global_id: 06acc9e6-a63d-4aa1-bd0d-4f3a79b0ae33 state: up+replaying 1 description: replaying, {"bytes_per_second":0.0,"bytes_per_snapshot":0.0,"local_snapshot_timestamp":1642689843,"remote_snapshot_timestamp":1642689843,"replay_state":"idle"} service: admin on ceph-rbd2-vasi-43-5hwia4-node2 last_update: 2022-01-20 12:41:57참고사이트 간 연결에 따라 미러링은 이미지를 동기화하는 데 시간이 오래 걸릴 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
- Ceph 사용자에 대한 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 사용자 관리 섹션을 참조하십시오.
5.7. Ceph 블록 장치 미러링을 위한 관리
스토리지 관리자는 Ceph 블록 장치 미러링 환경을 관리하는 데 도움이 되도록 다양한 작업을 수행할 수 있습니다. 다음 작업을 수행할 수 있습니다.
- 스토리지 클러스터 피어에 대한 정보 보기.
- 스토리지 클러스터 피어를 추가하거나 제거합니다.
- 풀 또는 이미지에 대한 미러링 상태 가져오기.
- 풀 또는 이미지에서 미러링 활성화
- 풀 또는 이미지에서 미러링 비활성화.
- 블록 장치 복제 지연.
- 이미지 승격 및 데모.
5.7.1. 사전 요구 사항
- 최소 2개의 정상 실행 Red Hat Ceph Storage 클러스터.
- Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 단방향 또는 양방향 Ceph 블록 장치 미러링 관계입니다.
5.7.2. 피어에 대한 정보 보기
스토리지 클러스터 피어에 대한 정보를 봅니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
피어에 대한 정보를 보려면 다음을 수행합니다.
구문
rbd mirror pool info POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool info data Mode: pool Site Name: site-a Peer Sites: UUID: 950ddadf-f995-47b7-9416-b9bb233f66e3 Name: site-b Mirror UUID: 4696cd9d-1466-4f98-a97a-3748b6b722b3 Direction: rx-tx Client: client.site-b
5.7.3. 풀에서 미러링 활성화
두 피어 클러스터에서 다음 명령을 실행하여 풀에서 미러링을 활성화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
풀에서 미러링을 활성화하려면 다음을 수행합니다.
구문
rbd mirror pool enable POOL_NAME MODE
예제
[root@rbd-client ~]# rbd mirror pool enable data pool
이 예제에서는
data라는 전체 풀을 미러링할 수 있습니다.예제
[root@rbd-client ~]# rbd mirror pool enable data image
이 예제에서는
data라는 풀에서 이미지 모드 미러링을 활성화합니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.4. 풀에서 미러링 비활성화
미러링을 비활성화하기 전에 피어 클러스터를 제거합니다.
풀에서 미러링을 비활성화할 때 이미지 모드에서 미러링이 별도로 활성화된 풀 내의 이미지에서도 이를 비활성화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
풀에서 미러링을 비활성화하려면 다음을 수행합니다.
구문
rbd mirror pool disable POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool disable data
이 예제에서는
data라는 풀의 미러링을 비활성화합니다.
추가 리소스
- 자세 한 내용은 Red Hat Ceph Storage Block Device Guide 의 이미지 단방향 미러링 섹션을 참조하십시오.
- 자세 한 내용은 Red Hat Ceph Storage Block Device Guide 의 스토리지 클러스터 피어 제거 섹션을 참조하십시오.
5.7.5. 이미지 미러링 활성화
두 피어 스토리지 클러스터에서 이미지 모드에서 전체 풀에서 미러링을 활성화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
풀 내의 특정 이미지에 대한 미러링을 활성화합니다.
구문
rbd mirror image enable POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image enable data/image2
이 예제에서는
데이터풀에서image2이미지에 대한 미러링을 활성화합니다.
추가 리소스
- 자세 한 내용은 Red Hat Ceph Storage Block Device Guide 의 pool에서 미러링 활성화 섹션을 참조하십시오.
5.7.6. 이미지 미러링 비활성화
이미지의 미러를 비활성화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
특정 이미지에 대한 미러링을 비활성화하려면 다음을 수행합니다.
구문
rbd mirror image disable POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image disable data/image2
이 예제에서는
데이터풀에서image2이미지 미러링을 비활성화합니다.
5.7.7. 이미지 승격 및 데모
이미지를 승격하거나 시연합니다.
승격 후 이미지가 유효하지 않으므로 계속 동기화되는 비기본 이미지를 강제로 승격하지 마십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
기본이 아닌 이미지를 시연하려면 다음을 수행하십시오.
구문
rbd mirror image demote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image demote data/image2
이 예제에서는
data풀에서image2이미지를 시연합니다.이미지를 primary로 승격하려면 다음을 수행하십시오.
구문
rbd mirror image promote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image promote data/image2
이 예제에서는
데이터풀에서image2를 승격합니다.사용 중인 미러링 유형에 따라 단계별 미러링이 있는 재해 복구 또는 양방향 미러링 이 있는 재해에서 복구를 참조하십시오.
--force옵션을 사용하여 기본이 아닌 이미지를 강제로 승격합니다.구문
rbd mirror image promote --force POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image promote --force data/image2
데모를 피어 Ceph 스토리지 클러스터로 전파할 수 없는 경우 강제 승격을 사용합니다. 예를 들어 클러스터 오류 또는 통신 중단으로 인해.
추가 리소스
5.7.8. 이미지 재동기화
이미지를 다시 동기화합니다. 두 피어 클러스터 간에 일관성 없는 상태의 경우 rbd-mirror 데몬은 불일치를 유발하는 이미지를 미러링하지 않습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
기본 이미지로 재동기화를 요청하려면 다음을 수행합니다.
구문
rbd mirror image resync POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image resync data/image2
이 예제에서는
데이터풀에서image2의 resynchronization을 요청합니다.
추가 리소스
- 재해로 인해 일관성 없는 상태에서 복구하려면 단방향 미러링 을 통해 재해 복구 또는 자세한 내용은 양방향 미러링 을 통해 재해에서 복구를 참조하십시오.
5.7.9. 스토리지 클러스터 피어 추가
rbd-mirror 데몬의 스토리지 클러스터 피어를 추가하여 피어 스토리지 클러스터를 검색합니다. 예를 들어 site-a 스토리지 클러스터를 site-b 스토리지 클러스터에 피어로 추가하려면 site-b 스토리지 클러스터의 클라이언트 노드에서 다음 절차를 따르십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
피어를 풀에 등록합니다.
구문
rbd --cluster CLUSTER_NAME mirror pool peer add POOL_NAME PEER_CLIENT_NAME@PEER_CLUSTER_NAME -n CLIENT_NAME
예제
[root@rbd-client ~]# rbd --cluster site-b mirror pool peer add data client.site-a@site-a -n client.site-b
5.7.10. 스토리지 클러스터 피어 제거
피어 UUID를 지정하여 스토리지 클러스터 피어를 제거합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
풀 이름과 UUID(Universally Unique Identifier)를 지정합니다.
구문
rbd mirror pool peer remove POOL_NAME PEER_UUID
예제
[root@rbd-client ~]# rbd mirror pool peer remove data 7e90b4ce-e36d-4f07-8cbc-42050896825d
작은 정보피어 UUID를 보려면
rbd 미러 pool info명령을 사용합니다.
5.7.11. 풀의 미러링 상태 가져오기
풀의 미러 상태를 가져옵니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
미러링 풀 요약을 가져오려면 다음을 수행합니다.
구문
rbd mirror pool status POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool status data health: OK images: 1 total
작은 정보풀의 모든 미러링 이미지에 대한 상태 세부 정보를 출력하려면
--verbose옵션을 사용합니다.
5.7.12. 단일 이미지에 대한 미러링 상태 가져오기
이미지의 미러 상태를 가져옵니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
미러링된 이미지의 상태를 가져오려면 다음을 수행합니다.
구문
rbd mirror image status POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 703c4082-100d-44be-a54a-52e6052435a5 state: up+replaying description: replaying, master_position=[object_number=0, tag_tid=3, entry_tid=0], mirror_position=[object_number=0, tag_tid=3, entry_tid=0], entries_behind_master=0 last_update: 2019-04-23 13:39:15
이 예제에서는
데이터풀에서image2이미지의 상태를 가져옵니다.
5.7.13. 블록 장치 복제 지연
one- 또는 양방향 복제를 사용하는 경우 RADOS Block Device(RBD) 미러링 이미지 간 복제를 지연할 수 있습니다. 원하지 않는 변경을 주 이미지로 변경하면 보조 이미지로 복제되기 전에 지연된 복제를 구현해야 하는 경우 지연된 복제를 구현할 수 있습니다.
지연된 복제를 구현하려면 대상 스토리지 클러스터 내의 rbd-mirror 데몬에서 rbd_mirroring_replay_delay = MINIMUM_DELAY_IN_SECONDS 구성 옵션을 설정해야 합니다. 이 설정은 rbd-mirror 데몬이나 개별 이미지 기반으로 사용하는 ceph.conf 파일 내에서 전역으로 적용할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
지연된 복제를 특정 이미지에 활용하려면 기본 이미지에서 다음
rbdCLI 명령을 실행합니다.구문
rbd image-meta set POOL_NAME/IMAGE_NAME conf_rbd_mirroring_replay_delay MINIMUM_DELAY_IN_SECONDS
예제
[root@rbd-client ~]# rbd image-meta set vms/vm-1 conf_rbd_mirroring_replay_delay 600
이 예제에서는 vms 풀의 이미지
vm-1에서 10분의 최소 복제 지연을설정합니다.
5.7.14. 비동기 업데이트 및 Ceph 블록 장치 미러링
비동기 업데이트로 Ceph 블록 장치 미러링을 사용하여 스토리지 클러스터를 업데이트할 때 Red Hat Ceph Storage 설치 가이드 의 업데이트 지침을 따르십시오. 업데이트가 완료되면 Ceph 블록 장치 인스턴스를 다시 시작합니다.
인스턴스를 재시작하는 데 필요한 순서가 없습니다. Red Hat은 기본 이미지 다음에 미러링된 풀을 가리키는 인스턴스를 재시작하는 것이 좋습니다.
5.7.15. 이미지 mirror-snapshot 생성
스냅샷 기반 미러링을 사용할 때 RBD 이미지의 변경된 내용을 미러링해야 하는 경우 이미지 mirror-snapshot을 만듭니다.
사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 스냅샷 미러가 생성되는 Red Hat Ceph Storage 클러스터에 액세스합니다.
기본적으로 이미지당 3개의 이미지 mirror-snapshots만 생성할 수 있습니다. 제한에 도달하면 최신 이미지 mirror-snapshot이 자동으로 제거됩니다. 필요한 경우 이 제한은 rbd_mirroring_max_mirroring_snapshots 구성을 통해 재정의할 수 있습니다. 이미지를 제거하거나 미러링이 비활성화된 경우 이미지 mirror-snapshots는 자동으로 삭제됩니다.
절차
image-mirror 스냅샷을 생성하려면 다음을 수행합니다.
구문
rbd --cluster CLUSTER_NAME mirror image snapshot POOL_NAME/IMAGE_NAME
예제
root@rbd-client ~]# rbd --cluster site-a mirror image snapshot data/image1
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.16. mirror-snapshots 예약
mirror-snapshots는 mirror-snapshot schedules가 정의되면 자동으로 생성될 수 있습니다. mirror-snapshot은 전역, 풀당 또는 이미지 수준까지 예약할 수 있습니다. 여러 mirror-snapshot 일정은 모든 수준에서 정의할 수 있지만 미러링된 개별 이미지와 일치하는 가장 구체적인 스냅샷 일정만 실행할 수 있습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.17. mirror-snapshot 일정 생성
mirror-snapshot 일정을 생성합니다.
사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 스냅샷 미러가 생성되는 Red Hat Ceph Storage 클러스터에 액세스합니다.
절차
mirror-snapshot 일정을 생성하려면 다음을 수행합니다.
구문
rbd mirror snapshot schedule add --pool POOL_NAME --image IMAGE_NAME INTERVAL START_TIME
간격은 각각 d, h 또는 m 접미사를 사용하여 일, 시간 또는 분 단위로 지정할 수 있습니다. 선택적 START_TIME은 ISO 8601 시간 형식을 사용하여 지정할 수 있습니다.
예제
이미지 수준에서 예약:
[root@rbd-client ~]# rbd mirror snapshot schedule add --pool data --image image1 6h
풀 수준에서 예약:
[root@rbd-client ~]# rbd mirror snapshot schedule add --pool data 24h 14:00:00-05:00
글로벌 수준의 예약:
[root@rbd-client ~]# rbd mirror snapshot schedule add 48h
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.18. 특정 수준에서 모든 스냅샷 일정 나열
특정 수준의 모든 스냅샷 일정을 나열합니다.
사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 스냅샷 미러가 생성되는 Red Hat Ceph Storage 클러스터에 액세스합니다.
절차
선택적 풀 또는 이미지 이름을 사용하여 특정 글로벌, 풀 또는 이미지 수준에 대한 모든 스냅샷 일정을 나열하려면 다음을 수행합니다.
구문
rbd --cluster site-a mirror snapshot schedule ls --pool POOL_NAME --recursive또한 '-
recursive옵션을 지정하여 다음과 같이 지정된 수준에서 모든 일정을 나열할 수 있습니다.예제
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule ls --pool data --recursive POOL NAMESPACE IMAGE SCHEDULE data - - every 1d starting at 14:00:00-05:00 data - image1 every 6h
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.19. mirror-snapshot 일정 제거
mirror-snapshot 일정을 제거합니다.
사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 스냅샷 미러가 생성되는 Red Hat Ceph Storage 클러스터에 액세스합니다.
절차
mirror-snapshot 일정을 제거하려면 다음을 수행합니다.
구문
rbd --cluster CLUSTER_NAME mirror snapshot schedule remove POOL_NAME/IMAGE_NAME INTERVAL START_TIME
d, h, m 접미사를 각각 사용하여 간격을 일, 시간 또는 분 단위로 지정할 수 있습니다. 선택적 START_TIME은 ISO 8601 시간 형식을 사용하여 지정할 수 있습니다.
예제
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule remove data/image1 6h
예제
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule remove data/image1 24h 14:00:00-05:00
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.7.20. 생성할 다음 스냅샷의 상태 보기
스냅샷 기반 미러링 RBD 이미지에 대해 생성할 다음 스냅샷의 상태를 확인합니다.
사전 요구 사항
- 최소 2개의 정상 실행 중인 Red Hat Ceph Storage 클러스터.
- Red Hat Ceph Storage 클러스터의 Ceph 클라이언트 노드에 대한 루트 수준 액세스.
- 관리자 수준의 기능이 있는 CephX 사용자.
- 스냅샷 미러가 생성되는 Red Hat Ceph Storage 클러스터에 액세스합니다.
절차
생성할 다음 스냅샷의 상태를 보려면 다음을 수행합니다.
구문
rbd --cluster site-a mirror snapshot schedule status POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd --cluster site-a mirror snapshot schedule status SCHEDULE TIME IMAGE 2020-02-26 18:00:00 data/image1
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
5.8. 재해 복구
스토리지 관리자는 미러링이 구성된 다른 스토리지 클러스터에서 데이터를 복구하는 방법을 알면 최종 하드웨어 장애에 대비할 수 있습니다.
예에서는 기본 스토리지 클러스터를 site-a 라고 하며 보조 스토리지 클러스터는 site-b 라고 합니다. 또한 스토리지 클러스터에는 image1 및 image2 라는 두 개의 이미지가 있는 데이터 풀이 있습니다.
5.8.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 단방향 또는 양방향 미러링이 구성되었습니다.
5.8.2. 재해 복구
두 개 이상의 Red Hat Ceph Storage 클러스터 간의 블록 데이터 비동기 복제는 다운타임을 줄이고 중요한 데이터 센터 장애 발생 시 데이터 손실을 방지합니다. 이러한 실패는 큰 폭발 반경이라고도하는 광범위한 영향을 미치며 전력망 및 자연 재해에 미치는 영향으로 발생할 수 있습니다.
이러한 시나리오에서는 고객 데이터를 보호해야 합니다. 볼륨은 일관성 및 효율성으로 복제되어야 하며 복구 지점 목표(RPO) 및 복구 시간 목표(RTO) 대상 내에서도 복제해야 합니다. 이 솔루션을 Wide Area Network- Disaster Recovery(WAN-DR)라고 합니다.
이러한 시나리오에서는 기본 시스템과 데이터 센터를 복원하기가 어렵습니다. 복구하는 가장 빠른 방법은 애플리케이션을 대체 Red Hat Ceph Storage 클러스터(재별 복구 사이트)로 장애 조치하고 최신 데이터 사본과 함께 클러스터를 작동하는 것입니다. 이러한 오류 시나리오에서 복구하는 데 사용되는 솔루션은 애플리케이션에 의해 안내됩니다.
- RPO(Recovery Point Objective): 최악의 경우 애플리케이션이 허용되는 데이터 손실의 양입니다.
- RTO(Recover Time Objective): 애플리케이션을 사용 가능한 최신 데이터 사본과 함께 사용하여 애플리케이션을 다시 얻는 데 걸린 시간입니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Block Device Guide의 Ceph 블록 장치 미러링 섹션을 참조하십시오.
- 암호화된 상태에서 유선을 통한 데이터 전송에 대한 자세한 내용은 Red Hat Ceph Storage Data Security 및 Hardening Guide 의 전송 중인 암호화를 참조하십시오.
5.8.3. 일방향 미러링으로 재해 복구
일방향 미러링을 사용할 때 재해에서 복구하려면 다음 절차를 사용합니다. 기본 클러스터가 종료된 후 보조 클러스터에 장애 조치하는 방법과 다시 실패하는 방법을 보여줍니다. 종료는 순서가 지정되지 않거나 순서가 지정되지 않을 수 있습니다.
단방향 미러링은 여러 보조 사이트를 지원합니다. 추가 보조 클러스터를 사용하는 경우 장애 조치(failover)할 보조 클러스터 중 하나를 선택합니다. 오류가 발생한 동안 동일한 클러스터에서 동기화합니다.
5.8.4. 양방향 미러링을 사용하여 재해에서 복구
양방향 미러링을 사용할 때 재해에서 복구하려면 다음 절차를 사용합니다. 기본 클러스터가 종료된 후 미러 클러스터에서 미러링된 데이터에 장애 조치하는 방법과 장애 조치 방법을 보여줍니다. 종료는 순서가 지정되지 않거나 순서가 지정되지 않을 수 있습니다.
추가 리소스
- 이미지 데모, 승격 및 재동기에 대한 자세 한 내용은 Red Hat Ceph Storage Block Device Guide 의 이미지 미러링 구성 섹션을 참조하십시오.
5.8.5. 순서 종료 후 장애 조치(failover)
순서를 종료한 후 보조 스토리지 클러스터로 장애 조치(failover)합니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터를 실행 중인 최소 2개 이상.
- 노드에 대한 루트 수준 액세스.
- 풀 미러링 또는 이미지 미러링은 단방향 미러링 으로 구성됩니다.
절차
- 기본 이미지를 사용하는 모든 클라이언트를 중지합니다. 이 단계는 이미지를 사용하는 클라이언트에 따라 다릅니다. 예를 들어 이미지를 사용하는 모든 OpenStack 인스턴스에서 볼륨을 분리합니다.
site-a클러스터의 모니터 노드에서 다음 명령을 실행하여 site--a클러스터에 있는 기본 이미지를 시연합니다.구문
rbd mirror image demote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image demote data/image1 [root@rbd-client ~]# rbd mirror image demote data/image2
site-b클러스터의 모니터 노드에서 다음 명령을 실행하여 사이트-b 클러스터에 있는 기본이 아닌 이미지를 승격합니다.구문
rbd mirror image promote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image promote data/image1 [root@rbd-client ~]# rbd mirror image promote data/image2
잠시 후
site-b클러스터의 모니터 노드에서 이미지 상태를 확인합니다.위쪽+stopped의 상태가 표시되고 기본 상태로 나열되어야 합니다.[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37
- 이미지에 대한 액세스를 재개합니다. 이 단계는 이미지를 사용하는 클라이언트에 따라 다릅니다.
추가 리소스
- Red Hat OpenStack Platform 스토리지 가이드의 블록 스토리지 및 볼륨 장을 참조하십시오.
5.8.6. 순서가 아닌 종료 후 장애 조치(failover)
순서가 지정되지 않은 경우 보조 스토리지 클러스터 장애 조치(failover)입니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터를 실행 중인 최소 2개 이상.
- 노드에 대한 루트 수준 액세스.
- 풀 미러링 또는 이미지 미러링은 단방향 미러링 으로 구성됩니다.
절차
- 기본 스토리지 클러스터가 다운되었는지 확인합니다.
- 기본 이미지를 사용하는 모든 클라이언트를 중지합니다. 이 단계는 이미지를 사용하는 클라이언트에 따라 다릅니다. 예를 들어 이미지를 사용하는 모든 OpenStack 인스턴스에서 볼륨을 분리합니다.
site-b스토리지 클러스터의 Ceph Monitor 노드에서 기본이 아닌 이미지를 승격합니다. demotion을site-a스토리지 클러스터로 전파할 수 없기 때문에--force옵션을 사용합니다.구문
rbd mirror image promote --force POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image promote --force data/image1 [root@rbd-client ~]# rbd mirror image promote --force data/image2
site-b스토리지 클러스터의 Ceph Monitor 노드에서 이미지 상태를 확인합니다.up+stopping_replay의 상태를 표시해야 하며 설명은force promoted:예제
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06
추가 리소스
- Red Hat OpenStack Platform 스토리지 가이드의 블록 스토리지 및 볼륨 장을 참조하십시오.
5.8.7. 실패에 대비하십시오.
두 스토리지 클러스터가 원래 일회성 미러링에 대해서만 구성된 경우 다시 실패하도록 기본 스토리지 클러스터를 구성하여 이미지를 반대 방향으로 복제하도록 미러링을 구성합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
site-a스토리지 클러스터의 클라이언트 노드에rbd-mirror패키지를 설치합니다.[root@rbd-client ~]# yum install rbd-mirror
참고패키지는 Red Hat Ceph Storage Tools 리포지토리에서 제공됩니다.
site-a스토리지 클러스터의 클라이언트 노드에서CLUSTER옵션을/etc/sysconfig/ceph파일에 추가하여 스토리지 클러스터 이름을 지정합니다.CLUSTER=site-b
site-bCeph 구성 파일 및 인증 키 파일을site-bCeph Monitor 노드에서site-aCeph Monitor 및 클라이언트 노드로 복사합니다.구문
scp /etc/ceph/ceph.conf USER@SITE_A_MON_NODE_NAME:/etc/ceph/site-b.conf scp /etc/ceph/site-b.client.site-b.keyring root@SITE_A_MON_NODE_NAME:/etc/ceph/ scp /etc/ceph/ceph.conf user@SITE_A_CLIENT_NODE_NAME:/etc/ceph/site-b.conf scp /etc/ceph/site-b.client.site-b.keyring user@SITE_A_CLIENT_NODE_NAME:/etc/ceph/
참고site-b Ceph Monitor 노드에서
site-bCeph Monitor 노드에 Ceph 구성 파일을 전송하는scp명령은 파일 이름을site-a.confsite-a인증 키 파일을site-aCeph Monitor 노드에서site-a클라이언트 노드로 복사합니다.구문
scp /etc/ceph/site-a.client.site-a.keyring <user>@SITE_A_CLIENT_HOST_NAME:/etc/ceph/site-a클라이언트 노드에서rbd-mirror데몬을 활성화하고 시작합니다.구문
systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@CLIENT_ID systemctl start ceph-rbd-mirror@CLIENT_ID
rbd-mirror데몬이 사용할 Ceph Storage 클러스터 사용자로CLIENT_ID를 변경합니다. 사용자에게 스토리지 클러스터에 대한 적절한cephx액세스 권한이 있어야 합니다.예제
[root@rbd-client ~]# systemctl enable ceph-rbd-mirror.target [root@rbd-client ~]# systemctl enable ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl start ceph-rbd-mirror@site-a
site-a클러스터의 클라이언트 노드에서site-b클러스터를 피어로 추가합니다.예제
[root@rbd-client ~]# rbd --cluster site-a mirror pool peer add data client.site-b@site-b -n client.site-a
보조 스토리지 클러스터를 여러 개 사용하는 경우 장애 조치(failover)하도록 선택한 보조 스토리지 클러스터만 추가해야 합니다.
site-a스토리지 클러스터의 모니터 노드에서site-b스토리지 클러스터가 피어로 성공적으로 추가되었는지 확인합니다.구문
rbd mirror pool info POOL_NAME예제
[root@rbd-client ~]# rbd mirror pool info data Mode: image Site Name: site-a Peer Sites: UUID: 950ddadf-f995-47b7-9416-b9bb233f66e3 Name: site-b Mirror UUID: 4696cd9d-1466-4f98-a97a-3748b6b722b3 Direction: rx-tx Client: client.site-b
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 사용자 관리 장을 참조하십시오.
5.8.7.1. 기본 스토리지 클러스터로 장애 복구
이전의 기본 스토리지 클러스터가 복구되면 기본 스토리지 클러스터로 다시 실패합니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터를 실행 중인 최소 2개 이상.
- 노드에 대한 루트 수준 액세스.
- 풀 미러링 또는 이미지 미러링은 단방향 미러링 으로 구성됩니다.
절차
site-b클러스터의 모니터 노드에서 이미지의 상태를 다시 확인합니다.위쪽으로 표시된 상태를 표시해야 하며 설명에서로컬 이미지가 기본이라고 합니다.예제
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:37:48 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:38:18
사이트-스토리지 클러스터의 Ceph Monitor 노드에서는이미지가 여전히 기본 설정되어 있는지 확인합니다.구문
rbd info POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd info data/image1 [root@rbd-client ~]# rbd info data/image2
명령의 출력에서
primary: true 또는를 사용하여 상태를 확인합니다.mirroring primary: false스토리지 클러스터의 Ceph Monitor 노드에서 다음과 같이 명령을 실행하여 1차로 나열된 이미지를 시연합니다.
구문
rbd mirror image demote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image demote data/image1
순서가 지정되지 않은 경우에만 이미지를 다시 동기화합니다. site-b에서 site-b에서
site-a스토리지 클러스터의 모니터 노드에서 다음 명령을 실행하여 이미지를site-b에서site-a로 다시 동기화합니다.구문
rbd mirror image resync POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image resync data/image1 Flagged image for resync from primary [root@rbd-client ~]# rbd mirror image resync data/image2 Flagged image for resync from primary
잠시 후 이미지 재동화가 완료되었는지 확인하여 이미지가
up+replaying상태에 있는지 확인합니다.site-a스토리지 클러스터의 모니터 노드에서 다음 명령을 실행하여 상태를 확인합니다.구문
rbd mirror image status POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image status data/image1 [root@rbd-client ~]# rbd mirror image status data/image2
site-b스토리지 클러스터의 Ceph Monitor 노드에서 다음 명령을 실행하여site-b스토리지 클러스터에서 이미지를 시연합니다.구문
rbd mirror image demote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image demote data/image1 [root@rbd-client ~]# rbd mirror image demote data/image2
참고보조 스토리지 클러스터가 여러 개인 경우 승격된 보조 스토리지 클러스터에서만 수행해야 합니다.
스토리지 클러스터의 Ceph Monitor 노드에서 다음 명령
을 실행하여 사이트-스토리지 클러스터에 있는 이전 기본 이미지를스토리지 클러스터에 승격합니다.구문
rbd mirror image promote POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image promote data/image1 [root@rbd-client ~]# rbd mirror image promote data/image2
스토리지 클러스터의 Ceph Monitor 노드에서 이미지 상태를 확인합니다.
위쪽+stopped의 상태를 표시해야 하며 설명은 로컬 이미지가 기본이라고 합니다.구문
rbd mirror image status POOL_NAME/IMAGE_NAME
예제
[root@rbd-client ~]# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51 [root@rbd-client ~]# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51
5.8.8. 양방향 미러링 제거
실패가 완료되면 양방향 미러링을 제거하고 Ceph 블록 장치 미러링 서비스를 비활성화할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
site-b스토리지 클러스터를site-a스토리지 클러스터에서 피어로 제거합니다.예제
[root@rbd-client ~]# rbd mirror pool peer remove data client.remote@remote --cluster local [root@rbd-client ~]# rbd --cluster site-a mirror pool peer remove data client.site-b@site-b -n client.site-a
site-a클라이언트에서rbd-mirror데몬을 중지하고 비활성화합니다.구문
systemctl stop ceph-rbd-mirror@CLIENT_ID systemctl disable ceph-rbd-mirror@CLIENT_ID systemctl disable ceph-rbd-mirror.target
예제
[root@rbd-client ~]# systemctl stop ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl disable ceph-rbd-mirror@site-a [root@rbd-client ~]# systemctl disable ceph-rbd-mirror.target
6장. Ceph 블록 장치 Python 모듈 사용
rbd python 모듈은 Ceph 블록 장치 이미지에 대한 파일 유사 액세스를 제공합니다. 이 기본 제공 도구를 사용하려면 rbd 및 rados Python 모듈을 가져옵니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스.
절차
RADOS에 연결하고 IO 컨텍스트를 엽니다.
cluster = rados.Rados(conffile='my_ceph.conf') cluster.connect() ioctx = cluster.open_ioctx('mypool')이미지를 생성하는 데 사용하는
:class:rbd.RBD오브젝트를 인스턴스화합니다.rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size)
이미지에서 I/O를 수행하려면
:class:rbd.Image오브젝트를 인스턴스화합니다.image = rbd.Image(ioctx, 'myimage') data = 'foo' * 200 image.write(data, 0)
이것은 'foo'를 이미지의 처음 600바이트에 씁니다. 데이터는
:type:unicode일 수 없음 -librbd는:c:type:char보다 큰 문자를 처리하는 방법을 알 수 없습니다.이미지, IO 컨텍스트 및 RADOS에 대한 연결을 종료합니다.
image.close() ioctx.close() cluster.shutdown()
각 호출은 별도의
:finally블록 내에 있어야 합니다.import rados import rbd cluster = rados.Rados(conffile='my_ceph_conf') try: ioctx = cluster.open_ioctx('my_pool') try: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) image = rbd.Image(ioctx, 'myimage') try: data = 'foo' * 200 image.write(data, 0) finally: image.close() finally: ioctx.close() finally: cluster.shutdown()이는 번거로울 수 있으므로 Rados,Ioctx 및 이미지 클래스를 자동으로 닫거나 종료하는 컨텍스트 관리자로 사용할 수 있습니다. 컨텍스트 관리자로 이를 사용하면 위 예제는 다음과 같습니다.
with rados.Rados(conffile='my_ceph.conf') as cluster: with cluster.open_ioctx('mypool') as ioctx: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) with rbd.Image(ioctx, 'myimage') as image: data = 'foo' * 200 image.write(data, 0)
7장. Ceph iSCSI 게이트웨이(Limited Availability)
스토리지 관리자는 Red Hat Ceph Storage 클러스터에 대한 iSCSI 게이트웨이를 설치하고 구성할 수 있습니다. Ceph의 iSCSI 게이트웨이를 사용하면 기존 SAN(Storage Area Network)의 모든 기능과 이점을 갖춘 완전히 통합된 블록 스토리지 인프라를 효과적으로 실행할 수 있습니다.
이 기술은 제한적입니다. 자세한 내용은 더 이상 사용되지 않는 기능 장을 참조하십시오.
SCSI 영구 예약은 지원되지 않습니다. SCSI 영구 예약을 사용하지 않는 클러스터 인식 파일 시스템 또는 클러스터링 소프트웨어를 사용하는 경우 여러 iSCSI 이니시에이터를 RBD 이미지에 매핑할 수 있습니다. 예를 들어 ATS를 사용하는 VMware vSphere 환경은 지원되지만 MSCS(Microsoft의 클러스터링 서버) 사용은 지원되지 않습니다.
7.1. Ceph iSCSI 게이트웨이 소개
일반적으로 Ceph 스토리지 클러스터에 대한 블록 수준 액세스는 QEMU 및 librbd 로 제한되어 있으며, 이는 OpenStack 환경 내에서 채택을 위한 핵심 활성화자입니다. 이제 Ceph 스토리지 클러스터에 대한 블록 수준 액세스로 iSCSI 표준을 활용하여 데이터 스토리지를 제공할 수 있습니다.
iSCSI 게이트웨이는 Red Hat Ceph Storage와 iSCSI 표준을 통합하여 RADOS Block Device(RBD) 이미지를 SCSI 디스크로 내보내는 고가용성(HA) iSCSI 대상을 제공합니다. iSCSI 프로토콜을 사용하면 이니시에이터라고 하는 클라이언트가 TCP/IP 네트워크를 통해 타겟이라는 SCSI 스토리지 장치에 SCSI 명령을 보낼 수 있습니다. 이를 통해 Microsoft Windows와 같은 이기종 클라이언트가 Red Hat Ceph Storage 클러스터에 액세스할 수 있습니다.
그림 7.1. Ceph iSCSI 게이트웨이 HA 설계

7.2. iSCSI 대상의 요구사항
Red Hat Ceph Storage Highly Available (HA) iSCSI 게이트웨이 솔루션에는 OSD를 탐지하기 위한 게이트웨이 노드 수, 메모리 용량 및 타이머 설정이 필요합니다.
필요한 노드 수
최소 두 개의 iSCSI 게이트웨이 노드를 설치합니다. 복원력 및 I/O 처리를 늘리려면 최대 4개의 iSCSI 게이트웨이 노드를 설치합니다.
메모리 요구 사항
RBD 이미지의 메모리 공간이 큰 크기로 증가할 수 있습니다. iSCSI 게이트웨이 노드에 매핑된 각 RBD 이미지는 약 90MB의 메모리를 사용합니다. iSCSI 게이트웨이 노드에 매핑된 각 RBD 이미지를 지원할 수 있는 충분한 메모리가 있는지 확인합니다.
Down OSD 감지
Ceph Monitor 또는 OSD에 대한 특정 iSCSI 게이트웨이 옵션은 없지만, 이니시에이터 시간 초과 가능성을 줄이기 위해 OSD를 탐지하는 기본 타이머를 낮추는 것이 중요합니다. OSD를 감지하는 데 필요한 타이머 설정을 단축하여 이니시에이터 시간 초과 가능성을 줄입니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage Hardware Selection 가이드 를 참조하십시오.
7.3. iSCSI 게이트웨이 설치
스토리지 관리자는 Ceph iSCSI 게이트웨이의 이점을 활용하기 전에 필요한 소프트웨어 패키지를 설치해야 합니다. Ansible 배포 툴을 사용하거나 명령줄 인터페이스 를 사용하여 Ceph iSCSI 게이트웨이를 설치할 수 있습니다.
각 iSCSI 게이트웨이는 Linux I/O 대상 커널 하위 시스템(LIO)을 실행하여 iSCSI 프로토콜 지원을 제공합니다. LIO는 사용자 공간 통과(TCMU)를 사용하여 Ceph librbd 라이브러리와 상호 작용하여 RBD 이미지를 iSCSI 클라이언트에 노출합니다. Ceph iSCSI 게이트웨이를 사용하면 기존 SAN(Storage Area Network)의 모든 기능과 이점을 갖춘 완전히 통합된 블록 스토리지 인프라를 효과적으로 실행할 수 있습니다.
7.3.1. 사전 요구 사항
- Red Hat Enterprise Linux 8 또는 7.7 이상.
- 실행 중인 Red Hat Ceph Storage 4 이상의 클러스터.
7.3.2. Ansible을 사용하여 Ceph iSCSI 게이트웨이 설치
Ansible 유틸리티를 사용하여 패키지를 설치하고 Ceph iSCSI 게이트웨이의 데몬을 설정합니다.
사전 요구 사항
-
ceph-ansible패키지가 설치된 Ansible 관리 노드.
절차
- iSCSI 게이트웨이 노드에서 Red Hat Ceph Storage 4 Tools 리포지토리를 활성화합니다. 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 Red Hat Ceph Storage 리포지토리 활성화 섹션을 참조하십시오.
Ansible 관리 노드에서 게이트웨이 그룹의
/etc/ansible/hosts파일에 항목을 추가합니다. iSCSI 게이트웨이를 OSD 노드와 함께 변경하면 OSD 노드를[iscsigws]섹션에 추가합니다.[iscsigws] ceph-igw-1 ceph-igw-2
-
Ansible은
/usr/share/ceph-ansible/group_vars/디렉터리에iscsigws.yml.sample파일을 배치합니다.iscsigws.yml.sample파일의 사본을iscsigws.yml으로 만듭니다. -
편집할
iscsigws.yml파일을 엽니다. IPv4 또는 IPv6 주소를 사용하여
trusted_ip_list옵션의 주석을 제거하고 그에 따라 값을 업데이트합니다.예제
IPv4 주소가 10.172.19.21 및 10.172.19.22인 두 개의 게이트웨이를 추가하면 다음과 같이
trusted_ip_list를 구성합니다.trusted_ip_list: 10.172.19.21,10.172.19.22
필요한 경우 iSCSI 게이트웨이 변수 섹션의 Ansible 변수 및 설명을 검토하고 필요에 따라
iscsigws.yml을 업데이트합니다.주의게이트웨이 구성 변경은 한 번에 하나의 게이트웨이에서만 지원됩니다. 여러 게이트웨이를 통해 변경 사항을 동시에 실행하려고 하면 구성 불안정성 및 불일치가 발생할 수 있습니다.
주의Ansible은
ansible-playbook명령을 사용할 때group_vars/iscsigws.yml파일의 설정에 따라ceph-iscsi패키지를 설치하고,/etc/ceph/iscsi-gateway.cfg파일을 생성합니다. 명령줄 인터페이스 를 사용하여 iSCSI 게이트웨이 설치에 설명된 명령줄 인터페이스를 사용하여ceph-iscsi패키지를 이전에 설치한 경우iscsi-gateway.cfg 파일의 기존 설정을group_vars/iscsigws.yml파일에 복사합니다.Ansible 관리 노드에서 Ansible 플레이북을 실행합니다.
베어 메탈 배포:
[admin@ansible ~]$ cd /usr/share/ceph-ansible [admin@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
컨테이너 배포:
[admin@ansible ~]$ cd /usr/share/ceph-ansible [admin@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
주의독립형 iSCSI 게이트웨이 노드에서 올바른 Red Hat Ceph Storage 4 소프트웨어 리포지토리가 활성화되어 있는지 확인합니다. 사용할 수 없는 경우 Ansible에서 잘못된 패키지를 설치할 수 있습니다.
대상, LUN 및 클라이언트를 생성하려면
gwcli유틸리티 또는 Red Hat Ceph Storage 대시보드를 사용합니다.중요targetcli유틸리티를 사용하여 구성을 변경하지 마십시오. 그러면 ALUA 구성 및 경로 장애 조치(failover) 문제 등 다음과 같은 문제가 발생합니다. 데이터가 손상되고, iSCSI 게이트웨이 간에 일치하지 않는 구성 및 WWN 정보가 일치하지 않아 클라이언트의 경로 지정 문제가 발생할 수 있습니다.
추가 리소스
-
전체 샘플 파일을 보려면 Sample
iscsigws.yml파일 을 참조하십시오. - 명령줄 인터페이스를 사용하여 iSCSI 대상 구성
- iSCSI 대상 생성
7.3.3. 명령줄 인터페이스를 사용하여 Ceph iSCSI 게이트웨이 설치
Ceph iSCSI 게이트웨이는 iSCSI 대상 노드이며 Ceph 클라이언트 노드이기도 합니다. Ceph iSCSI 게이트웨이는 독립형 노드이거나 Ceph OSD(Object Store Disk) 노드에 배치할 수 있습니다. Ceph iSCSI 게이트웨이를 설치하려면 다음 단계를 완료합니다.
사전 요구 사항
- Red Hat Enterprise Linux 8 또는 7.7 이상
- Red Hat Ceph Storage 4 클러스터 이상
스토리지 클러스터의 모든 Ceph Monitor 노드에서
root사용자로ceph-mon서비스를 다시 시작합니다.구문
systemctl restart ceph-mon@MONITOR_HOST_NAME예제
[root@mon ~]# systemctl restart ceph-mon@monitor1
-
Ceph iSCSI 게이트웨이가 OSD 노드에 배치되지 않은 경우 스토리지 클러스터에서 실행 중인 Ceph 노드에서 모든 iSCSI 게이트웨이 노드로
/etc/ceph/디렉터리에 있는 Ceph 구성 파일을 복사합니다. Ceph 구성 파일은/etc/ceph/의 iSCSI 게이트웨이 노드에 있어야 합니다. - 모든 Ceph iSCSI 게이트웨이 노드에서 Ceph 툴 리포지토리를 활성화합니다. 자세한 내용은 설치 가이드 의 Red Hat Ceph Storage 리포지토리 활성화 섹션을 참조하십시오.
- 모든 Ceph iSCSI 게이트웨이 노드에서 Ceph 명령줄 인터페이스를 설치하고 구성합니다. 자세한 내용은 Red Hat Ceph Storage 4 설치 가이드의 Ceph 명령줄 인터페이스 설치 장을 참조하십시오.
- 필요한 경우 모든 Ceph iSCSI 노드의 방화벽에서 TCP 포트 3260 및 5000을 엽니다.
- 새로 만들거나 기존 RADOS Block Device(RBD)를 사용합니다.
절차
모든 Ceph iSCSI 게이트웨이 노드에서
ceph-iscsi및tcmu-runner패키지를 설치합니다.[root@iscsigw ~]# yum install ceph-iscsi tcmu-runner
중요이러한 패키지의 이전 버전이 있는 경우 최신 버전을 설치하기 전에 해당 패키지를 제거하십시오. Red Hat Ceph Storage 리포지토리에서 이러한 최신 버전을 설치해야 합니다.
필요한 경우 모든 Ceph iSCSI 게이트웨이 노드에서 OpenSSL 유틸리티를 설치하고 구성합니다.
openssl패키지를 설치합니다.[root@iscsigw ~]# yum install openssl
기본 iSCSI 게이트웨이 노드에서 SSL 키를 저장할 디렉터리를 만듭니다.
[root@iscsigw ~]# mkdir ~/ssl-keys [root@iscsigw ~]# cd ~/ssl-keys
기본 iSCSI 게이트웨이 노드에서 인증서 및 키 파일을 만듭니다. 메시지가 표시되면 환경 정보를 입력합니다.
[root@iscsigw ~]# openssl req -newkey rsa:2048 -nodes -keyout iscsi-gateway.key -x509 -days 365 -out iscsi-gateway.crt
기본 iSCSI 게이트웨이 노드에서 PEM 파일을 생성합니다.
[root@iscsigw ~]# cat iscsi-gateway.crt iscsi-gateway.key > iscsi-gateway.pem
기본 iSCSI 게이트웨이 노드에서 공개 키를 생성합니다.
[root@iscsigw ~]# openssl x509 -inform pem -in iscsi-gateway.pem -pubkey -noout > iscsi-gateway-pub.key
-
기본 iSCSI 게이트웨이 노드에서
iscsi-gateway.crt,iscsi-gateway.pem,iscsi-gateway-pub.key,iscsi-gateway.key파일을 다른 iSCSI 게이트웨이 노드의/etc/ceph/디렉터리에 복사합니다.
Ceph iSCSI 게이트웨이 노드에서 구성 파일을 만든 다음 모든 iSCSI 게이트웨이 노드에 복사합니다.
/etc/ceph/디렉터리에iscsi-gateway.cfg라는 파일을 생성합니다.[root@iscsigw ~]# touch /etc/ceph/iscsi-gateway.cfg
iscsi-gateway.cfg파일을 편집하고 다음 행을 추가합니다.구문
[config] cluster_name = CLUSTER_NAME gateway_keyring = CLIENT_KEYRING api_secure = false trusted_ip_list = IP_ADDR,IP_ADDR
예제
[config] cluster_name = ceph gateway_keyring = ceph.client.admin.keyring api_secure = false trusted_ip_list = 192.168.0.10,192.168.0.11
-
iscsi-gateway.cfg파일을 모든 iSCSI 게이트웨이 노드에 복사합니다. 파일은 모든 iSCSI 게이트웨이 노드에서 동일해야 합니다.
모든 Ceph iSCSI 게이트웨이 노드에서 API 서비스를 활성화하고 시작합니다.
[root@iscsigw ~]# systemctl enable rbd-target-api [root@iscsigw ~]# systemctl start rbd-target-api [root@iscsigw ~]# systemctl enable rbd-target-gw [root@iscsigw ~]# systemctl start rbd-target-gw
- 다음으로 대상, LUN 및 클라이언트를 구성합니다. 자세한 내용은 명령줄 인터페이스 섹션을 사용하여 iSCSI 대상 구성 을 참조하십시오.
추가 리소스
- 옵션에 대한 자세한 내용은 iSCSI 게이트웨이 변수 섹션을 참조하십시오.
- iSCSI 대상 생성
7.3.4. 추가 리소스
- Ceph iSCSI 게이트웨이 Anisble 변수에 대한 자세한 내용은 부록 B. iSCSI 게이트웨이 변수 을 참조하십시오.
7.4. iSCSI 대상 구성
스토리지 관리자는 gwcli 명령줄 유틸리티를 사용하여 대상, LUN, 클라이언트를 구성할 수 있습니다. iSCSI 대상의 성능을 최적화 하려면 gwcli reconfigure 하위 명령을 사용할 수도 있습니다.
Red Hat은 Ceph iSCSI 게이트웨이 툴(예: gwcli 및 ceph-ansible )에서 내보낸 Ceph 블록 장치 이미지 관리를 지원하지 않습니다. 또한 rbd 명령을 사용하여 Ceph iSCSI 게이트웨이에서 내보낸 RBD 이미지의 이름을 변경하거나 제거하면 불안정한 스토리지 클러스터가 발생할 수 있습니다.
iSCSI 게이트웨이 구성에서 RBD 이미지를 제거하기 전에 표준 절차를 따라 운영 체제에서 스토리지 장치를 제거합니다. 자세 한 내용은 Red Hat Enterprise Linux 7용 스토리지 관리 가이드 의 스토리지 장치 제거 장 또는 Red Hat Enterprise Linux 8용 시스템 설계 가이드 를 참조하십시오.
7.4.1. 사전 요구 사항
- Ceph iSCSI 게이트웨이 소프트웨어 설치.
7.4.2. 명령줄 인터페이스를 사용하여 iSCSI 대상 구성
Ceph iSCSI 게이트웨이는 iSCSI 대상 노드이며 Ceph 클라이언트 노드이기도 합니다. 독립 실행형 노드에서 Ceph iSCSI 게이트웨이를 구성하거나 Ceph OSD(오브젝트 스토리지 장치) 노드로 연결합니다.
이 문서에 명시된 경우를 제외하고 gwcli reconfigure 하위 명령을 사용하여 다른 옵션을 조정하지 마십시오.
사전 요구 사항
- Ceph iSCSI 게이트웨이 소프트웨어 설치.
절차
iSCSI 게이트웨이 명령줄 인터페이스를 시작합니다.
[root@iscsigw ~]# gwcli
IPv4 또는 IPv6 주소를 사용하여 iSCSI 게이트웨이를 만듭니다.
구문
>/iscsi-targets create iqn.2003-01.com.redhat.iscsi-gw:_target_name_ > goto gateways > create ISCSI_GW_NAME IP_ADDR_OF_GW > create ISCSI_GW_NAME IP_ADDR_OF_GW
예제
>/iscsi-targets create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-1 10.172.19.21 > create ceph-gw-2 10.172.19.22
참고IPv4 및 IPv6 주소를 혼합하여 사용할 수 없습니다.
Ceph 블록 장치를 추가합니다.
구문
> cd /disks >/disks/ create POOL_NAME image=IMAGE_NAME size=IMAGE_SIZE_m|g|t
예제
> cd /disks >/disks/ create rbd image=disk_1 size=50g
참고풀 또는 이미지 이름에 마침표(
.)를 사용하지 마십시오.클라이언트를 생성합니다.
구문
> goto hosts > create iqn.1994-05.com.redhat:_client_name_ > auth use username=USER_NAME password=PASSWORD
예제
> goto hosts > create iqn.1994-05.com.redhat:rh7-client > auth username=iscsiuser1 password=temp12345678
중요Red Hat은 클라이언트 혼합, 일부 챌린지 핸드셰이크 인증 프로토콜(CHAP) 사용 및 일부 CHAP 비활성화를 지원하지 않습니다. 모든 클라이언트에는 CHAP이 활성화되거나 CHAP이 비활성화된 상태여야 합니다. 기본 동작은 이니시에이터 이름으로만 이니시에이터를 인증하는 것입니다.
이니시에이터가 대상에 로그인하지 못하는 경우 일부 이니시에이터에 대해 CHAP 인증이 올바르게 구성되지 않을 수 있습니다. 예를 들면 다음과 같습니다.
o- hosts ................................ [Hosts: 2: Auth: MISCONFIG]
호스트수준에서 다음 명령을 사용하여 모든 CHAP 인증을 재설정합니다./> goto hosts /iscsi-target...csi-igw/hosts> auth nochap ok ok /iscsi-target...csi-igw/hosts> ls o- hosts ................................ [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ........... [Auth: None, Disks: 4(310G)] o- iqn.1994-05.com.redhat:rh7-client .. [Auth: None, Disks: 0(0.00Y)]
클라이언트에 디스크를 추가합니다.
구문
>/iscsi-target..eph-igw/hosts > cd iqn.1994-05.com.redhat:_CLIENT_NAME_ > disk add POOL_NAME/IMAGE_NAME
예제
>/iscsi-target..eph-igw/hosts > cd iqn.1994-05.com.redhat:rh7-client > disk add rbd/disk_1
API가 올바르게 사용 중인지 확인하려면 /var/log/
rbd-target-api.log 또는/var/log/rbd-target-api.log에 있는rbd-target-api 로그 파일을 검색합니다.예를 들면https의 경우 다음과 같습니다.Aug 01 17:27:42 test-node.example.com python[1879]: * Running on https://0.0.0.0:5000/
Ceph ISCSI 게이트웨이가 작동하는지 확인합니다.
/> goto gateways /iscsi-target...-igw/gateways> ls o- gateways ............................ [Up: 2/2, Portals: 2] o- ceph-gw-1 ........................ [ 10.172.19.21 (UP)] o- ceph-gw-2 ........................ [ 10.172.19.22 (UP)]
상태가
UNKNOWN인 경우 네트워크 문제 및 잘못된 설정을 확인합니다. 방화벽을 사용하는 경우 적절한 TCP 포트가 열려 있는지 확인합니다. iSCSI 게이트웨이가trusted_ip_list옵션에 나열되어 있는지 확인합니다.rbd-target-api서비스가 iSCSI 게이트웨이 노드에서 실행 중인지 확인합니다.필요한 경우
max_data_area_mb옵션을 다시 구성합니다.구문
>/disks/ reconfigure POOL_NAME/IMAGE_NAME max_data_area_mb NEW_BUFFER_SIZE
예제
>/disks/ reconfigure rbd/disk_1 max_data_area_mb 64
참고max_data_area_mb옵션은 각 이미지가 iSCSI 대상과 Ceph 클러스터 간에 SCSI 명령 데이터를 전달하는 데 사용할 수 있는 메모리(MB)를 제어합니다. 이 값이 너무 작으면 과도한 대기열의 전체 재시도 횟수가 발생하여 성능에 영향을 미칠 수 있습니다. 값이 너무 크면 한 디스크가 너무 많은 시스템 메모리를 사용하므로 다른 하위 시스템에 할당 실패가 발생할 수 있습니다.max_data_area_mb옵션의 기본값은8입니다.- iSCSI 이니시에이터를 구성합니다.
추가 리소스
- 자세한 내용은 iSCSI 게이트웨이 설치 를 참조하십시오.
- 자세한 내용은 iSCSI 이니시에이터 구성 섹션을 참조하십시오.
7.4.3. iSCSI 대상의 성능 최적화
iSCSI 대상에서 네트워크를 통해 데이터를 전송하는 방법을 제어하는 설정이 많이 있습니다. 이러한 설정은 iSCSI 게이트웨이의 성능을 최적화하는 데 사용할 수 있습니다.
Red Hat 지원에서 지시하거나 이 문서에 지정된 대로만 해당 설정을 변경합니다.
gwcli reconfigure 하위 명령은 iSCSI 게이트웨이의 성능을 최적화하는 데 사용되는 설정을 제어합니다.
iSCSI 대상의 성능에 영향을 미치는 설정
-
max_data_area_mb -
cmdsn_depth -
immediate_data -
initial_r2t -
max_outstanding_r2t -
first_burst_length -
max_burst_length -
max_recv_data_segment_length -
max_xmit_data_segment_length
추가 리소스
-
gwcli reconfigure를 사용하여 조정하는 방법을 보여주는 예제를 포함하여max_data_area_mb에 대한 정보는 명령줄 인터페이스를 사용하여 iSCSI 대상 구성 섹션에 있습니다.
7.4.4. OSD를 탐지하기 위한 타이머 설정 감소
OSD를 탐지하기 위한 타이머 설정을 줄여야 하는 경우가 있습니다. 예를 들어 Red Hat Ceph Storage를 iSCSI 게이트웨이로 사용하는 경우 OSD를 탐지하는 데 필요한 타이머 설정을 줄여 이니시에이터 시간 초과 가능성을 줄일 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ansible 관리 노드에 액세스
절차
새 타이머 설정을 사용하도록 Ansible을 구성합니다.
Ansible 관리 노드에서 다음과 같이 표시되는
group_vars/all.yml파일에ceph_conf_overrides섹션을 추가하거나 다음과 같이 기존ceph_conf_overrides섹션을 편집합니다.ceph_conf_overrides: osd: osd_client_watch_timeout: 15 osd_heartbeat_grace: 20 osd_heartbeat_interval: 5Ansible 플레이북이 실행될 때 OSD 노드의
ceph.conf구성 파일에 위의 설정이 추가됩니다.ceph-ansible디렉터리로 변경합니다.[admin@ansible ~]$ cd /usr/share/ceph-ansible
Ansible을 사용하여
ceph.conf파일을 업데이트하고 모든 OSD 노드에서 OSD 데몬을 다시 시작합니다. Ansible admin 노드에서 다음 명령을 실행합니다.베어메탈 배포
[admin@ansible ceph-ansible]$ ansible-playbook site.yml --limit osds
컨테이너 배포
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml --limit osds -i hosts
타이머 설정이
ceph_conf_overrides에 설정된 것과 동일한지 확인합니다.구문
ceph daemon osd.OSD_ID config get osd_client_watch_timeout ceph daemon osd.OSD_ID config get osd_heartbeat_grace ceph daemon osd.OSD_ID config get osd_heartbeat_interval
예제
[root@osd ~]# ceph daemon osd.0 config get osd_client_watch_timeout { "osd_client_watch_timeout": "15" } [root@osd ~]# ceph daemon osd.0 config get osd_heartbeat_grace { "osd_heartbeat_grace": "20" } [root@osd ~]# ceph daemon osd.0 config get osd_heartbeat_interval { "osd_heartbeat_interval": "5" }선택 사항: OSD 데몬을 즉시 다시 시작할 수 없는 경우 Ceph Monitor 노드에서 온라인 업데이트를 수행하거나 모든 Ceph OSD 노드를 직접 업데이트할 수 있습니다. OSD 데몬을 다시 시작할 수 있게 되면 위에서 설명한 대로 Ansible을 사용하여 재부팅 시 설정이 유지되도록 새 타이머 설정을
ceph.conf에 추가합니다.Ceph Monitor 노드에서 OSD 타이머 설정을 온라인으로 업데이트하려면 다음을 수행합니다.
구문
ceph tell osd.OSD_ID injectargs '--osd_client_watch_timeout 15' ceph tell osd.OSD_ID injectargs '--osd_heartbeat_grace 20' ceph tell osd.OSD_ID injectargs '--osd_heartbeat_interval 5'
예제
[root@mon ~]# ceph tell osd.0 injectargs '--osd_client_watch_timeout 15' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_grace 20' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_interval 5'
Ceph OSD 노드에서 OSD 타이머 설정을 온라인으로 업데이트하려면 다음을 수행합니다.
구문
ceph daemon osd.OSD_ID config set osd_client_watch_timeout 15 ceph daemon osd.OSD_ID config set osd_heartbeat_grace 20 ceph daemon osd.OSD_ID config set osd_heartbeat_interval 5
예제
[root@osd ~]# ceph daemon osd.0 config set osd_client_watch_timeout 15 [root@osd ~]# ceph daemon osd.0 config set osd_heartbeat_grace 20 [root@osd ~]# ceph daemon osd.0 config set osd_heartbeat_interval 5
추가 리소스
- Red Hat Ceph Storage를 iSCSI 게이트웨이로 사용하는 방법에 대한 자세한 내용은 Red Hat Ceph Storage 블록 장치 가이드의 Ceph iSCSI 게이트웨이 를 참조하십시오.
7.4.5. 명령줄 인터페이스를 사용하여 iSCSI 호스트 그룹 구성
Ceph iSCSI 게이트웨이는 동일한 디스크 구성을 공유하는 여러 서버를 관리하기 위해 호스트 그룹을 구성할 수 있습니다. iSCSI 호스트 그룹은 그룹의 각 호스트에 액세스할 수 있는 논리적 호스트 그룹과 디스크를 생성합니다.
여러 호스트로 디스크 장치를 공유하는 경우 클러스터 인식 파일 시스템을 사용해야 합니다.
사전 요구 사항
- Ceph iSCSI 게이트웨이 소프트웨어 설치.
- Ceph iSCSI 게이트웨이 노드에 대한 루트 수준 액세스.
절차
iSCSI 게이트웨이 명령줄 인터페이스를 시작합니다.
[root@iscsigw ~]# gwcli
새 호스트 그룹을 생성합니다.
구문
cd iscsi-targets/ cd IQN/host-groups create group_name=GROUP_NAME
예제
/> cd iscsi-targets/ /iscsi-targets> cd iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/host-groups/ /iscsi-target.../host-groups> create group_name=igw_grp01
호스트 그룹에 호스트를 추가합니다.
구문
cd GROUP_NAME host add client_iqn=CLIENT_IQN
예제
> cd igw_grp01 /iscsi-target.../host-groups/igw_grp01> host add client_iqn=iqn.1994-05.com.redhat:rh8-client
이 단계를 반복하여 그룹에 호스트를 추가합니다.
호스트 그룹에 디스크를 추가합니다.
구문
cd /disks/ /disks> create pool=POOL image=IMAGE_NAME size=SIZE cd /IQN/host-groups/GROUP_NAME disk add POOL/IMAGE_NAME
예제
> cd /disks/ /disks> create pool=rbd image=rbdimage size=1G /> cd iscsi-targets/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/host-groups/igw_grp01/ /iscsi-target...s/igw_grp01> disk add rbd/rbdimage
이 단계를 반복하여 그룹에 디스크를 추가합니다.
7.4.6. 추가 리소스
- Red Hat Ceph Storage 대시보드를 사용하여 iSCSI 대상을 구성하는 방법에 대한 자세한 내용은 Red Hat Ceph Storage 대시보드 가이드의 iSCSI 대상 생성 섹션을 참조하십시오.
7.5. iSCSI 이니시에이터 구성
다음 플랫폼의 Ceph iSCSI 게이트웨이에 연결하도록 iSCSI 이니시에이터를 구성할 수 있습니다.
7.5.1. Red Hat Enterprise Linux용 iSCSI 이니시에이터 구성
사전 요구 사항
- Red Hat Enterprise Linux 7.7 이상.
-
패키지
iscsi-initiator-utils-6.2.0.873-35이상이 설치되어 있어야 합니다. -
패키지
device-mapper-multipath-0.4.9-99또는 newer를 설치해야 합니다.
절차
iSCSI 이니시에이터 및 다중 경로 툴을 설치합니다.
[root@rhel ~]# yum install iscsi-initiator-utils [root@rhel ~]# yum install device-mapper-multipath
-
/etc/iscsi/initiatorname.iscsi파일을 편집하여 이니시에이터 이름을 설정합니다. 이니시에이터 이름은gwcli명령을 사용하여 초기 설정 중에 사용된 이니시에이터 이름과 일치해야 합니다. 다중 경로 I/O 구성.
기본
/etc/multipath.conf파일을 생성하고multipathd서비스를 활성화합니다.[root@rhel ~]# mpathconf --enable --with_multipathd y
다음과 같이
/etc/multipath.conf파일을 업데이트합니다.devices { device { vendor "LIO-ORG" product "TCMU device" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }multipathd서비스를 다시 시작합니다.[root@rhel ~]# systemctl reload multipathd
CHAP 및 iSCSI 검색 및 로그인을 설정합니다.
/etc/iscsi/iscsid.conf파일을 적절하게 업데이트하여 CHAP 사용자 이름과 암호를 제공합니다. 예를 들면 다음과 같습니다.node.session.auth.authmethod = CHAP node.session.auth.username = user node.session.auth.password = password
대상 포털을 검색합니다.
구문
iscsiadm -m discovery -t st -p IP_ADDRtarget에 로그인합니다.
구문
iscsiadm -m node -T TARGET -l
다중 경로 I/O 구성을 봅니다.
multipathd데몬은multipath.conf파일의 설정에 따라 장치를 자동으로 설정합니다.multipath명령을 사용하여 각 경로의 우선순위 그룹이 있는 장애 조치(failover) 구성에서 장치 설정을 표시합니다. 예를 들면 다음과 같습니다.예제
[root@rhel ~]# multipath -ll mpathbt (360014059ca317516a69465c883a29603) dm-1 LIO-ORG,TCMU device size=1.0G features='0' hwhandler='1 alua' wp=rw |-+- policy='queue-length 0' prio=50 status=active | `- 28:0:0:1 sde 8:64 active ready running `-+- policy='queue-length 0' prio=10 status=enabled `- 29:0:0:1 sdc 8:32 active ready running
multipath -lloutputprio값은 ALUA 상태를 나타냅니다. 여기서prio=50은 ALUA Active-Optimized 상태에서 보유한 iSCSI 게이트웨이의 경로이고prio=10은 Active-non-Optimized 경로임을 나타냅니다.status필드는 사용 중인 경로를 나타냅니다. 여기서active는 현재 사용된 경로를 나타내며활성화된 경우활성상태가 실패하는 경우 장애 조치(failover) 경로를 나타냅니다.장치 이름과 일치하려면, 예를 들어
multipath -ll출력에서 iSCSI 게이트웨이에 대해감소합니다.예제
[root@rhel ~]# iscsiadm -m session -P 3
영구 포털값은gwcli유틸리티에 나열된 iSCSI 게이트웨이에 할당된 IP 주소입니다.
7.5.2. Red Hat Virtualization의 iSCSI 이니시에이터 구성
사전 요구 사항
- Red Hat Virtualization 4.1
- 모든 Red Hat Virtualization 노드에서 MPIO 장치 구성
-
iscsi-initiator-utils-6.2.0.873-35패키지 이상 -
device-mapper-multipath-0.4.9-99패키지 이상
절차
다중 경로 I/O 구성.
/etc/multipath/conf.d/DEVICE_NAME.conf파일을 다음과 같이 업데이트합니다.devices { device { vendor "LIO-ORG" product "TCMU device" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }multipathd서비스를 다시 시작합니다.[root@rhv ~]# systemctl reload multipathd
- Storage 리소스 탭을 클릭하여 기존 스토리지 도메인을 나열합니다.
- New Domain (새 도메인) 버튼을 클릭하여 New Domain (새 도메인) 창을 엽니다.
- 새 스토리지 도메인의 이름 을 입력합니다.
- Data Center (데이터 센터) 드롭다운 메뉴를 사용하여 데이터 센터를 선택합니다.
- 드롭다운 메뉴를 사용하여 Domain Function (도메인 기능) 및 스토리지 유형 을 선택합니다. 선택한 도메인 기능과 호환되지 않는 스토리지 도메인 유형은 사용할 수 없습니다.
- Use Host (호스트 사용) 필드에서 활성 호스트를 선택합니다. 데이터 센터의 첫 번째 데이터 도메인이 아닌 경우 데이터 센터의 SPM 호스트를 선택해야 합니다.
iSCSI를 스토리지 유형으로 선택하면 New Domain (새 도메인) 창에는 사용되지 않는 LUN이 있는 알려진 대상이 자동으로 표시됩니다. 스토리지를 추가하는 대상이 목록에 없으면 대상 검색을 사용하여 해당 대상을 찾을 수 있습니다. 그렇지 않으면 다음 단계로 진행합니다.
- Discover Targets (대상 검색)를 클릭하여 대상 검색 옵션을 활성화합니다. 대상이 검색되고 로그인되면 New Domain (새 도메인) 창에 환경에서 사용하지 않는 LUN이 있는 대상이 자동으로 표시됩니다. 환경 외부의 LUN도 표시됩니다. Discover Targets (대상 검색) 옵션을 사용하여 여러 대상에 LUN을 추가하거나 동일한 LUN에 대한 여러 경로를 추가할 수 있습니다.
- Address(주소) 필드에 iSCSI 호스트의 정규화된 도메인 이름 또는 IP 주소 를 입력합니다.
-
Port(포트) 필드에서 대상을 검색할 때 호스트에 연결할 포트 를 입력합니다. 기본값은 3260
입니다. - 챌린지 핸드셰이크 인증 프로토콜(CHAP)을 사용하여 스토리지를 보호하는 경우 User Authentication (사용자 인증) 확인란을 선택합니다. CHAP 사용자 이름 및 CHAP 암호를 입력합니다.
- Discover (검색) 버튼을 클릭합니다.
검색 결과에서 사용할 대상을 선택하고 Login (로그인) 버튼을 클릭합니다. 또는 Login All (모두 로그인)을 클릭하여 검색된 모든 대상에 로그인합니다.
중요두 개 이상의 경로 액세스가 필요한 경우 모든 필요한 경로를 통해 대상을 검색하고 로그인하십시오. 추가 경로를 추가하기 위해 스토리지 도메인을 수정하는 것은 현재 지원되지 않습니다.
- 원하는 대상 옆에 있는 + 버튼을 클릭합니다. 그러면 항목이 확장되고 대상에 연결된 사용되지 않는 모든 LUN이 표시됩니다.
- 스토리지 도메인을 생성하는 데 사용하는 각 LUN의 확인란을 선택합니다.
선택적으로 고급 매개 변수를 구성할 수 있습니다.
- Advanced Parameters (고급 매개 변수)를 클릭합니다.
- Warning Low Space Indicator 필드에 백분율 값을 입력합니다. 스토리지 도메인에서 사용 가능한 사용 가능한 공간이 이 백분율 미만인 경우 사용자에게 경고 메시지가 표시되고 기록됩니다.
- Critical Space Action Blocker 필드에 GB 값을 입력합니다. 스토리지 도메인에서 사용 가능한 사용 가능한 공간이 이 값보다 작으면 오류 메시지가 사용자에게 표시되고 로그인된 후 일시적으로 공간을 소비하는 새 작업이 차단됩니다.
-
삭제 후
삭제 옵션을 사용하려면 Wipe afterDelete 확인란을 선택합니다. 도메인을 만든 후에는 이 옵션을 편집할 수 있지만, 이렇게 하면 이미 존재하는 디스크의삭제 속성 후 delete가 변경되지 않습니다. - 삭제 후 삭제 옵션을 활성화하려면 Discard after Delete (삭제 후 삭제) 확인란을 선택합니다. 도메인을 생성한 후 이 옵션을 편집할 수 있습니다. 이 옵션은 블록 스토리지 도메인에서만 사용할 수 있습니다.
- OK (확인)를 클릭하여 스토리지 도메인을 생성하고 창을 닫습니다.
7.5.3. Microsoft Windows용 iSCSI 이니시에이터 구성
사전 요구 사항
- Microsoft Windows Server 2016
절차
iSCSI 이니시에이터를 설치하고 검색 및 설정을 구성합니다.
- iSCSI 이니시에이터 드라이버 및 MPIO 툴을 설치합니다.
- MPIO 프로그램을 시작하고, Discover Multi-Paths 탭을 클릭하고, iSCSI 장치 추가 확인란을 선택한 다음 추가 를 클릭합니다.
- MPIO 프로그램을 다시 부팅합니다.
iSCSI 이니시에이터 속성 창의 검색 탭
에서 대상 포털을 추가합니다. Ceph iSCSI 게이트웨이의 IP 주소 또는 DNS 이름
및 포트
를 입력합니다.

대상 탭
에서 대상을 선택하고 연결을 클릭합니다
:
대상에 연결 창에서 다중 경로 활성화 옵션
을 선택하고 고급 버튼
를 클릭합니다.
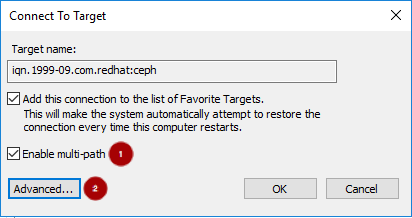
Connect using 섹션에서 대상 포털 IP
를 선택합니다.
에서 CHAP 로그인 활성화를 선택하고 Ceph iSCSI 클라이언트 인증 정보 섹션에서 이름 및 대상 시크릿 값
를 입력하고 확인
을 클릭합니다.
 중요
중요Windows Server 2016은 12바이트 미만의 CHAP 시크릿을 허용하지 않습니다.
- iSCSI 게이트웨이를 설정할 때 정의된 각 대상 포털에 대해 이전 두 단계를 반복합니다.
이니시에이터 이름이 초기 설정 중에 사용된 이니시에이터 이름과 다른 경우 이니시에이터 이름 이름을 바꿉니다. iSCSI 이니시에이터 속성 창의 구성 탭
에서 변경 버튼
을 클릭하여 이니시에이터 이름의 이름을 바꿉니다.
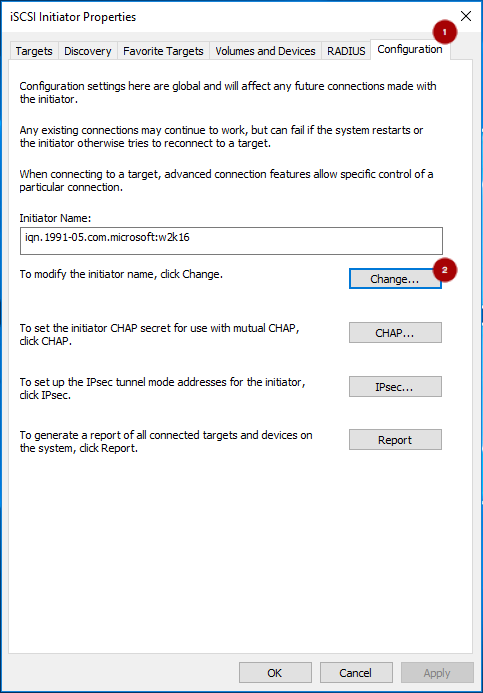
다중 경로I/O 설정. PowerShell에서PDORemovePeriod명령을 사용하여 MPIO 로드 밸런싱 정책과mpclaim명령을 사용하여 로드 밸런싱 정책을 설정합니다. iSCSI Initiator 툴은 나머지 옵션을 구성합니다.참고PDORemovePeriod옵션을 PowerShell에서 120초로 늘리는 것이 좋습니다. 애플리케이션에 따라 이 값을 조정해야 할 수도 있습니다. 모든 경로가 다운되면 120초가 만료되면 운영 체제가 실패한 I/O 요청을 시작합니다.Set-MPIOSetting -NewPDORemovePeriod 120
장애 조치 정책 설정
mpclaim.exe -l -m 1
장애 조치 정책 확인
mpclaim -s -m MSDSM-wide Load Balance Policy: Fail Over Only
iSCSI Initiator 툴을 사용하여 대상 탭
에서 devices… 버튼을 클릭합니다.
:
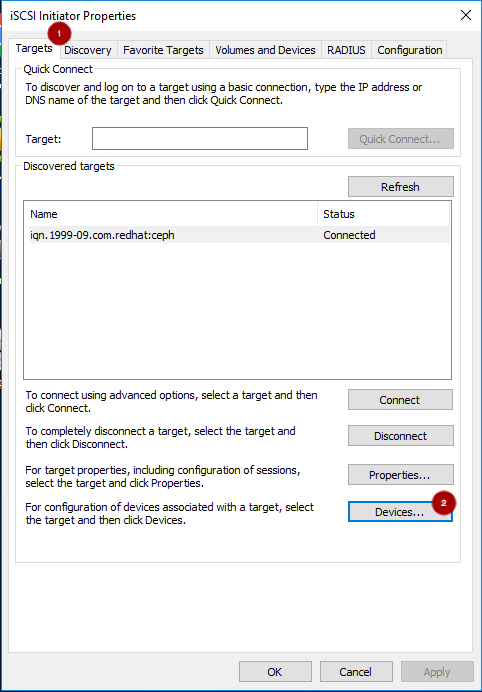
장치 창에서 디스크
를 선택하고 MPIO… 버튼
을 클릭합니다.
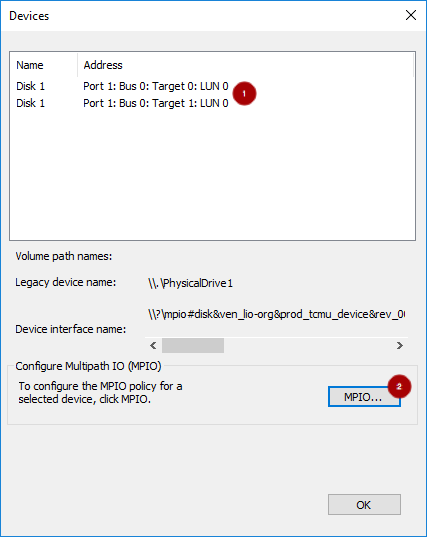
장치 세부 정보 창에 각 대상 포털의 경로가 표시됩니다. 로드 밸런싱 정책(Lail Over)은 반드 시 선택되어 있어야 합니다.
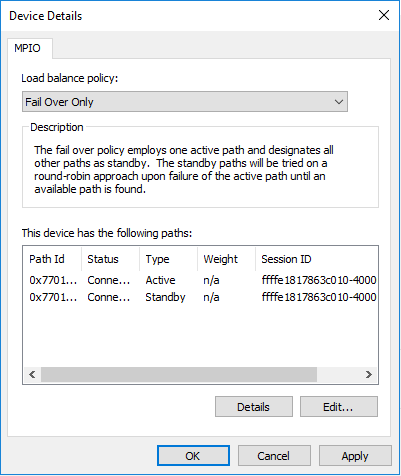
PowerShell에서
다중 경로구성을 확인합니다.mpclaim -s -d MPIO_DISK_IDMPIO_DISK_ID 를 적절한 디스크 식별자로 바꿉니다.
참고LUN을 소유하는 iSCSI 게이트웨이 노드의 경로인 Active/Optimized 경로가 1개 있으며 서로 다른 iSCSI 게이트웨이 노드에 대해 Active/Unoptimized 경로가 있습니다.
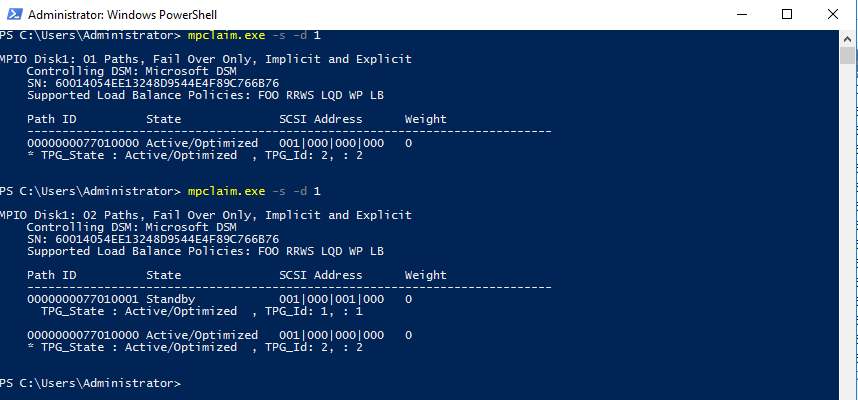
선택적으로 설정을 조정합니다. 다음 레지스트리 설정을 사용하는 것이 좋습니다.
Windows 디스크 시간 제한
키
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Disk
값
TimeOutValue = 65
Microsoft iSCSI Initiator 드라이버
키
HKEY_LOCAL_MACHINE\\SYSTEM\CurrentControlSet\Control\Class\{4D36E97B-E325-11CE-BFC1-08002BE10318}\<Instance_Number>\Parameters값
LinkDownTime = 25 SRBTimeoutDelta = 15
7.5.4. VMware ESXi용 iSCSI 이니시에이터 구성
사전 요구 사항
- 지원되는 VMware ESXi 버전에 대한 고객 포털 지식베이스 문서 의 iSCSI 게이트웨이(IGW) 섹션을 참조하십시오.
- VMware Host Client에 대한 액세스.
-
VMware ESXi 호스트에 대한 루트 액세스로
esxcli명령을 실행합니다.
절차
HardwareAcceleratedMove(XCOPY)를 비활성화합니다.> esxcli system settings advanced set --int-value 0 --option /DataMover/HardwareAcceleratedMove
iSCSI 소프트웨어를 활성화합니다. Navigator 창에서 스토리지
를 클릭합니다. 어댑터 탭
을 선택합니다. iSCSI
구성을 클릭합니다.
이름 및 별칭 섹션에서 이니시에이터 이름을 확인합니다
.
gwcli를 사용하여 초기 설정 중에 클라이언트를 생성할 때 사용하는 이니시에이터 이름과 다른 경우 이니시에이터 이름을 변경합니다. VMware ESX 호스트에서 다음esxcli명령을 사용합니다.iSCSI 소프트웨어의 어댑터 이름을 가져옵니다.
> esxcli iscsi adapter list > Adapter Driver State UID Description > ------- --------- ------ ------------- ---------------------- > vmhba64 iscsi_vmk online iscsi.vmhba64 iSCSI Software Adapter
이니시에이터 이름을 설정합니다.
구문
> esxcli iscsi adapter set -A ADAPTOR_NAME -n INITIATOR_NAME
예제
> esxcli iscsi adapter set -A vmhba64 -n iqn.1994-05.com.redhat:rh7-client
CHAP을 구성합니다. CHAP 인증 섹션
을 확장합니다. "대상에 의해 필요하지 않은 경우 CHAP을 사용하지 않음"을 선택합니다.
. 초기 설정에 사용된 CHAP 이름 및 시크릿
인증 정보를 입력합니다. 상호 CHAP 인증 섹션
에 " CHAP을 사용하지 않음"이 선택되어 있는지 확인합니다.
 주의
주의VMware Host Client의 버그로 인해 CHAP 설정이 처음에 사용되지 않습니다. Ceph iSCSI 게이트웨이 노드에서 커널 로그에 다음 버그가 표시됩니다.
> kernel: CHAP user or password not set for Initiator ACL > kernel: Security negotiation failed. > kernel: iSCSI Login negotiation failed.
이 버그를 해결하려면
esxcli명령을 사용하여 CHAP 설정을 구성합니다.authname인수는 vSphere Web Client의 이름입니다.> esxcli iscsi adapter auth chap set --direction=uni --authname=myiscsiusername --secret=myiscsipassword --level=discouraged -A vmhba64
iSCSI 설정을 구성합니다. 고급 설정
을 확장합니다. recoveryTimeout 값을 25
로 설정합니다.

검색 주소를 설정합니다. 동적 대상 섹션에서 동적 대상
추가 를 클릭합니다.
주소
에서 Ceph iSCSI 게이트웨이 중 하나의 IP 주소를 추가합니다. 하나의 IP 주소만 추가해야 합니다. 마지막으로 구성 저장 버튼
을 클릭합니다. 기본 인터페이스의 장치 탭에 RBD 이미지가 표시됩니다.
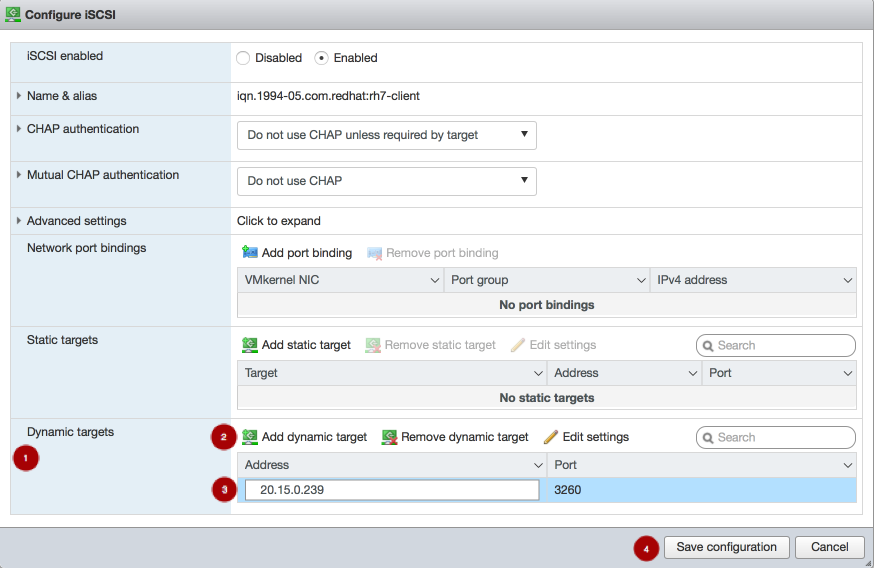 참고
참고LUN은 ALUA SATP 및 MRU PSP를 사용하여 자동으로 설정됩니다. 다른 SATP 및 PSP를 사용하지 마십시오.
esxcli명령으로 이를 확인할 수 있습니다.구문
esxcli storage nmp path list -d eui.DEVICE_IDDEVICE_ID 를 적절한 장치 식별자로 바꿉니다.
다중 경로가 올바르게 설정되었는지 확인합니다.
장치를 나열합니다.
예제
> esxcli storage nmp device list | grep iSCSI Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Device Display Name: LIO-ORG iSCSI Disk (naa.6001405057360ba9b4c434daa3c6770c)
이전 단계에서 Ceph iSCSI 디스크의 다중 경로 정보를 가져옵니다.
예제
> esxcli storage nmp path list -d naa.6001405f8d087846e7b4f0e9e3acd44b iqn.2005-03.com.ceph:esx1-00023d000001,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,1-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C0:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active Array Priority: 0 Storage Array Type Path Config: {TPG_id=1,TPG_state=AO,RTP_id=1,RTP_health=UP} Path Selection Policy Path Config: {current path; rank: 0} iqn.2005-03.com.ceph:esx1-00023d000002,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,2-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C1:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active unoptimized Array Priority: 0 Storage Array Type Path Config: {TPG_id=2,TPG_state=ANO,RTP_id=2,RTP_health=UP} Path Selection Policy Path Config: {non-current path; rank: 0}예제 출력에서 각 경로에는 다음 부분이 포함된 iSCSI 또는 SCSI 이름이 있습니다.
이니시에이터 이름 =
iqn.2005-03.com.ceph:esx1ISID =00023d000002대상 이름 =iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw대상 그룹 =2장치 id =naa.6001405f8d087846e7b4f0e3f0e3Group State값active는 iSCSI 게이트웨이의 Active-Optimized 경로임을 나타냅니다.gwcli명령은 iSCSI 게이트웨이 소유자로활성을 나열합니다. 나머지 경로에는 최적화되지 않은Group State값이 있으며 활성 경로가 dead 상태로 전환되면 장애 조치(failover) 경로입니다.The rest of the paths have the Group State value ofunoptimizedand are the failover path, if theactivepath goes into adeadstate.
해당 iSCSI 게이트웨이의 모든 경로를 일치시키려면 다음을 수행합니다.
예제
> esxcli iscsi session connection list vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000001,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000001 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.21 RemoteAddress: 10.172.19.21 LocalAddress: 10.172.19.11 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:45 State: logged_in vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000002,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000002 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.22 RemoteAddress: 10.172.19.22 LocalAddress: 10.172.19.12 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:41 State: logged_in
ISID값과 경로 이름과 일치하고RemoteAddress값은 자체 iSCSI 게이트웨이의 IP 주소입니다.
7.6. iSCSI 서비스 관리
ceph-iscsi 패키지에서는 구성 관리 논리와 rbd-target-gw 및 rbd-target-api systemd 서비스를 설치합니다.
rbd-target-api 서비스는 시작 시 Linux iSCSI 대상 상태를 복원하고 gwcli 및 Red Hat Ceph Storage 대시보드와 같은 툴에서 ceph-iscsi REST API 호출에 응답합니다. rbd-target-gw 서비스는 Prometheus 플러그인을 사용하여 지표를 제공합니다.
rbd-target-api 서비스는 Linux 커널의 대상 계층의 유일한 사용자라고 가정합니다. rbd-target-api 를 사용하는 경우 targetcli 패키지와 함께 설치된 target 서비스를 사용하지 마십시오. Ansible은 Ceph iSCSI 게이트웨이 설치 중에 targetcli 대상 서비스를 자동으로 비활성화합니다.
절차
서비스를 시작하려면 다음을 수행합니다.
# systemctl start rbd-target-api # systemctl start rbd-target-gw
서비스를 다시 시작하려면 다음을 수행합니다.
# systemctl restart rbd-target-api # systemctl restart rbd-target-gw
서비스를 다시 로드하려면 다음을 수행합니다.
# systemctl reload rbd-target-api # systemctl reload rbd-target-gw
reload요청은rbd-target-api가 구성을 다시 읽고 현재 실행 중인 환경에 적용합니다. 변경 사항은 Ansible에서 모든 iSCSI 게이트웨이 노드로 병렬로 배포되므로 일반적으로 필요하지 않습니다.서비스를 중지하려면 다음을 수행합니다.
# systemctl stop rbd-target-api # systemctl stop rbd-target-gw
stop요청은 게이트웨이의 포털 인터페이스를 종료하여 클라이언트에 대한 연결을 삭제하고 커널에서 현재 Linux iSCSI 대상 구성을 삭제합니다. 그러면 iSCSI 게이트웨이가 clean 상태로 반환됩니다. 클라이언트가 연결이 끊어지면 활성 I/O가 클라이언트 측 다중 경로 계층에 의해 다른 iSCSI 게이트웨이로 다시 예약됩니다.
7.7. 더 많은 iSCSI 게이트웨이 추가
스토리지 관리자는 gwcli 명령줄 도구 또는 Red Hat Ceph Storage 대시보드를 사용하여 초기 2개의 iSCSI 게이트웨이를 4개의 iSCSI 게이트웨이로 확장할 수 있습니다. iSCSI 게이트웨이를 추가하면 로드 밸런싱 및 페일오버 옵션을 사용할 때 더 많은 중복성을 제공할 때 유연성이 향상됩니다.
7.7.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 4 클러스터
- 예비 노드 또는 기존 OSD 노드
-
루트권한
7.7.2. Ansible을 사용하여 iSCSI 게이트웨이 추가
Ansible 자동화 유틸리티를 사용하여 추가 iSCSI 게이트웨이를 추가할 수 있습니다. 이 절차에서는 두 개의 iSCSI 게이트웨이의 기본 설치를 네 개의 iSCSI 게이트웨이로 확장합니다. 독립 실행형 노드에서 iSCSI 게이트웨이를 구성하거나 기존 OSD 노드와 함께 배치할 수 있습니다.
사전 요구 사항
- Red Hat Enterprise Linux 7.7 이상.
- 실행 중인 Red Hat Ceph Storage 클러스터.
- iSCSI 게이트웨이 소프트웨어 설치.
-
Ansible 관리 노드에서
관리자액세스 권한이 있어야 합니다. -
새 노드에서
root사용자 액세스 권한이 있어야 합니다.
절차
새로운 iSCSI 게이트웨이 노드에서 Red Hat Ceph Storage Tools 리포지토리를 활성화합니다.
Red Hat Enterprise Linux 7
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
Red Hat Enterprise Linux 8
[root@iscsigw ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ceph-iscsi-config패키지를 설치합니다.[root@iscsigw ~]# yum install ceph-iscsi-config
게이트웨이 그룹의
/etc/ansible/hosts파일에 있는 목록에 추가합니다.예제
[iscsigws] ... ceph-igw-3 ceph-igw-4
참고OSD 노드와 함께 iSCSI 게이트웨이를 일치시키면 OSD 노드를
[iscsigws]섹션에 추가합니다.ceph-ansible디렉터리로 변경합니다.[admin@ansible ~]$ cd /usr/share/ceph-ansible
Ansible 관리 노드에서 적절한 Ansible 플레이북을 실행합니다.
베어 메탈 배포:
[admin@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
컨테이너 배포:
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
중요gateway_ip_list옵션에 IP 주소를 제공해야 합니다. IPv4 및 IPv6 주소를 혼합하여 사용할 수 없습니다.- iSCSI 이니시에이터에서 새로 추가된 iSCSI 게이트웨이를 사용하도록 다시 로그인합니다.
추가 리소스
- iSCSI Initiator 사용에 대한 자세한 내용은 iSCSI Initiator 구성 을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 Red Hat Ceph Storage 리포지토리 활성화 섹션을 참조하십시오.
7.7.3. gwcli 를 사용하여 iSCSI 게이트웨이 추가
gwcli 명령줄 도구를 사용하여 iSCSI 게이트웨이를 추가할 수 있습니다. 이 절차에서는 두 개의 iSCSI 게이트웨이의 기본값을 네 개의 iSCSI 게이트웨이로 확장합니다.
사전 요구 사항
- Red Hat Enterprise Linux 7.7 이상.
- 실행 중인 Red Hat Ceph Storage 클러스터.
- iSCSI 게이트웨이 소프트웨어 설치.
-
root사용자가 새 노드 또는 OSD 노드에 액세스할 수 있어야 합니다.
절차
-
Ceph iSCSI 게이트웨이가 OSD 노드에 배치되지 않은 경우 스토리지 클러스터에서 실행 중인 Ceph 노드에서 새 iSCSI 게이트웨이 노드로
/etc/ceph/디렉터리에 있는 Ceph 구성 파일을 복사합니다. Ceph 구성 파일은/etc/ceph/디렉터리의 iSCSI 게이트웨이 노드에 있어야 합니다. - Ceph 명령줄 인터페이스를 설치하고 구성합니다.
새로운 iSCSI 게이트웨이 노드에서 Red Hat Ceph Storage Tools 리포지토리를 활성화합니다.
Red Hat Enterprise Linux 7
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
Red Hat Enterprise Linux 8
[root@iscsigw ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ceph-iscsi및tcmu-runner패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@iscsigw ~]# yum install ceph-iscsi tcmu-runner
Red Hat Enterprise Linux 8
[root@iscsigw ~]# dnf install ceph-iscsi tcmu-runner
필요한 경우
openssl패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@iscsigw ~]# yum install openssl
Red Hat Enterprise Linux 8
[root@iscsigw ~]# dnf install openssl
기존 iSCSI 게이트웨이 노드 중 하나에서
/etc/ceph/iscsi-gateway.cfg파일을 편집하고 새 iSCSI 게이트웨이 노드의 새 IP 주소에trusted_ip_list옵션을 추가합니다. 예를 들면 다음과 같습니다.[config] ... trusted_ip_list = 10.172.19.21,10.172.19.22,10.172.19.23,10.172.19.24
업데이트된
/etc/ceph/iscsi-gateway.cfg파일을 모든 iSCSI 게이트웨이 노드에 복사합니다.중요iscsi-gateway.cfg파일은 모든 iSCSI 게이트웨이 노드에서 동일해야 합니다.-
SSL을 사용하는 경우 기존 iSCSI 노드 중 하나에서 기존 iSCSI 노드 중 하나에서
~/ssl-keys/iscsi-keys/iscsi-gateway.pem,~/ssl-keys파일도 복사합니다./iscsi-gateway.key 새 iSCSI 게이트웨이 노드에서 API 서비스를 활성화하고 시작합니다.
[root@iscsigw ~]# systemctl enable rbd-target-api [root@iscsigw ~]# systemctl start rbd-target-api
iSCSI 게이트웨이 명령줄 인터페이스를 시작합니다.
[root@iscsigw ~]# gwcli
IPv4 또는 IPv6 주소를 사용하여 iSCSI 게이트웨이 생성:
구문
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:_TARGET_NAME_ > goto gateways > create ISCSI_GW_NAME IP_ADDR_OF_GW > create ISCSI_GW_NAME IP_ADDR_OF_GW
예제
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-3 10.172.19.23 > create ceph-gw-4 10.172.19.24
중요IPv4 및 IPv6 주소를 혼합하여 사용할 수 없습니다.
- iSCSI 이니시에이터에서 새로 추가된 iSCSI 게이트웨이를 사용하도록 다시 로그인합니다.
추가 리소스
- iSCSI Initiator 사용에 대한 자세한 내용은 iSCSI Initiator 구성 을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 설치 가이드의 Ceph 명령줄 인터페이스 설치 장을 참조하십시오.
7.8. 이니시에이터가 iSCSI 대상에 연결되어 있는지 확인
iSCSI 게이트웨이를 설치하고 iSCSI 대상 및 이니시에이터를 구성한 후 이니시에이터가 iSCSI 대상에 올바르게 연결되어 있는지 확인합니다.
사전 요구 사항
- Ceph iSCSI 게이트웨이 소프트웨어 설치.
- iSCSI 대상을 구성합니다.
- iSCSI 이니시에이터 구성.
절차
iSCSI 게이트웨이 명령줄 인터페이스를 시작합니다.
[root@iscsigw ~]# gwcli
이니시에이터가 iSCSI 타겟에 연결되어 있는지 확인합니다.
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts .............................. [Hosts: 1: Auth: None] o- iqn.1994-05.com.redhat:rh7-client [LOGGED-IN, Auth: None, Disks: 0(0.00Y)]
이니시에이터 상태는 연결된 경우
LOGGED-IN입니다.LUN이 iSCSI 게이트웨이 간에 균형을 이루는지 확인합니다.
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts ................................. [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ............ [Auth: None, Disks: 4(310G)] | o- lun 0 ............................. [rbd.disk_1(100G), Owner: ceph-gw-1] | o- lun 1 ............................. [rbd.disk_2(10G), Owner: ceph-gw-2]
디스크를 만들 때 매핑된 LUN 수가 가장 낮은 게이트웨이에 따라 디스크에 iSCSI 게이트웨이가
소유자로 할당됩니다. 이 번호가 균형을 맞추면 라운드 로빈 할당에 따라 게이트웨이가 할당됩니다. 현재 LUN 분산은 동적이지 않으며 사용자가 선택할 수 없습니다.이니시에이터가 대상에 로그인하고
다중 경로계층이 최적화된 상태이면 이니시에이터의 운영 체제다중 경로유틸리티에서소유자게이트웨이의 경로를 ALUAAOptimized(AOptimized) 상태로 보고합니다.다중 경로유틸리티는 다른 경로를 ALUA Active-non-Optimized (ANO) 상태로 보고합니다.AO 경로가 실패하면 다른 iSCSI 게이트웨이 중 하나가 사용됩니다. 장애 조치 게이트웨이의 순서는 일반적으로 시작자의
다중 경로계층에 따라 달라집니다. 이 순서는 먼저 검색된 경로를 기반으로 합니다.
7.9. Ansible을 사용하여 Ceph iSCSI 게이트웨이 업그레이드
Red Hat Ceph Storage iSCSI 게이트웨이 업그레이드는 롤링 업그레이드용으로 설계된 Ansible 플레이북을 사용하여 수행할 수 있습니다.
사전 요구 사항
- 실행 중인 Ceph iSCSI 게이트웨이.
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 스토리지 클러스터의 모든 노드에 대한 관리자 수준 액세스.
관리 사용자로 또는 root로 업그레이드 절차를 실행할 수 있습니다. root로 실행하려면 ssh 가 Ansible과 함께 사용하도록 설정되어 있는지 확인합니다.
절차
-
올바른 iSCSI 게이트웨이 노드가 Ansible 인벤토리 파일(
/etc/ansible/hosts)에 나열되어 있는지 확인합니다. 롤링 업그레이드 플레이북을 실행합니다.
[admin@ansible ceph-ansible]$ ansible-playbook rolling_update.yml
적절한 플레이북을 실행하여 업그레이드를 완료합니다.
베어메탈 배포
[admin@ansible ceph-ansible]$ ansible-playbook site.yml --limit iscsigws -i hosts
컨테이너 배포
[admin@ansible ceph-ansible]$ ansible-playbook site-container.yml --limit iscsigws -i hosts
추가 리소스
7.10. 명령줄 인터페이스를 사용하여 Ceph iSCSI 게이트웨이 업그레이드
한 번에 하나의 베어 메탈 iSCSI 게이트웨이 노드를 업그레이드하여 Red Hat Ceph Storage iSCSI 게이트웨이를 롤링 방식으로 업그레이드할 수 있습니다.
Ceph OSD를 업그레이드 및 다시 시작하는 동안 iSCSI 게이트웨이를 업그레이드하지 마십시오. OSD 업그레이드가 완료되고 스토리지 클러스터가 active+clean 상태가 될 때까지 기다립니다.
사전 요구 사항
- 실행 중인 Ceph iSCSI 게이트웨이.
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
iSCSI 게이트웨이 노드에 대한
루트액세스 권한 보유.
절차
iSCSI 게이트웨이 패키지를 업데이트합니다.
[root@iscsigw ~]# yum update ceph-iscsi
iSCSI 게이트웨이 데몬을 중지합니다.
[root@iscsigw ~]# systemctl stop rbd-target-api [root@iscsigw ~]# systemctl stop rbd-target-gw
iSCSI 게이트웨이 데몬이 완전히 중지되었는지 확인합니다.
[root@iscsigw ~]# systemctl status rbd-target-gw
-
rbd-target-gw서비스가 성공적으로 중지되면 4 단계로 건너뜁니다. rbd-target-gw서비스가 중지되지 않으면 다음 단계를 수행합니다.targetcli패키지가 설치되지 않은 경우targetcli패키지를 설치합니다.[root@iscsigw ~]# yum install targetcli
기존 대상 오브젝트를 확인합니다.
[root@iscsigw ~]# targetcli ls
예제
o- / ............................................................. [...] o- backstores .................................................... [...] | o- user:rbd ..................................... [Storage Objects: 0] o- iscsi .................................................. [Targets: 0]
backstores및Storage Objects이 비어 있으면 iSCSI 대상이 완전히 종료되고 4 단계로 건너뛸 수 있습니다.대상 오브젝트가 여전히 있는 경우 다음 명령을 사용하여 모든 대상 오브젝트를 강제로 제거합니다.
[root@iscsigw ~]# targetcli clearconfig confirm=True
주의iSCSI 대상을 여러 서비스에서 사용하는 경우
targetcli를 대화형 모드로 사용하여 특정 오브젝트를 삭제합니다.
-
tcmu-runner패키지를 업데이트합니다.[root@iscsigw ~]# yum update tcmu-runner
tcmu-runner서비스를 중지합니다.[root@iscsigw ~]# systemctl stop tcmu-runner
iSCSI 게이트웨이 서비스를 다음 순서로 다시 시작합니다.
[root@iscsigw ~]# systemctl start tcmu-runner [root@iscsigw ~]# systemctl start rbd-target-gw [root@iscsigw ~]# systemctl start rbd-target-api
7.11. iSCSI 게이트웨이 모니터링
Red Hat Ceph Storage 클러스터는 이제 OSD 및 MGR에 일반 메트릭 수집 프레임워크를 통합하여 모니터링을 제공합니다. 메트릭은 Red Hat Ceph Storage 클러스터 내에서 생성되며 메트릭을 스크랩하기 위해 클라이언트 노드에 액세스할 필요가 없습니다. RBD 이미지의 성능을 모니터링하기 위해 Ceph에는 개별 RADOS 개체 지표를 초당 입력/출력(I/O) 작업에 대한 집계된 RBD 이미지 지표로 변환하는 MGR Prometheus Exporter 모듈이 내장되어 있습니다. Ceph iSCSI 게이트웨이는 또한 Linux-IO(LIO) 수준 성능 지표에 대한 Prometheus 내보내기를 제공하여 Grafana와 같은 모니터링 및 시각화 도구를 지원합니다. 이러한 메트릭에는 정의된 대상 포털 그룹(TPG) 및 LUN 상태당 LUN(Logical Unit Number) 및 초당 입력 출력 작업 수(IOPS)에 대한 정보가 포함되며, 클라이언트당 LUN당 읽기 바이트 및 쓰기 바이트 수가 포함됩니다. 기본적으로 Prometheus 내보내기가 활성화됩니다. iscsi-gateway.cfg 에서 다음 옵션을 사용하여 기본 설정을 변경할 수 있습니다.
예제
[config] prometheus_exporter = True prometheus_port = 9287 prometheus_host = xx.xx.xx.xxx
Ceph iSCSI 게이트웨이 환경에서 내보낸 Ceph 블록 장치(RBD) 이미지의 성능을 모니터링하는 데 사용되는 gwtop 툴은 더 이상 사용되지 않습니다.
추가 리소스
- Red Hat Ceph Storage 대시보드를 사용하여 iSCSI 게이트웨이를 모니터링하는 방법에 대한 자세한 내용은 Red Hat Ceph Storage 대시보드 가이드의 iSCSI 기능 섹션을 참조하십시오.
7.12. iSCSI 구성 제거
iSCSI 구성을 제거하려면 gwcli 유틸리티를 사용하여 호스트 및 디스크를 제거하고 Ansible purge-iscsi-gateways.yml 플레이북을 사용하여 iSCSI 대상 구성을 제거합니다.
purge-iscsi-gateways.yml 플레이북을 사용하는 것은 iSCSI 게이트웨이 환경에 대한 파괴적인 작업입니다.
RBD 이미지에 스냅샷 또는 복제본이 있고 Ceph iSCSI 게이트웨이를 통해 내보낸 경우 purge-iscsi-gateways.yml 을 사용하지 않습니다.
사전 요구 사항
모든 iSCSI 이니시에이터의 연결을 끊습니다.
Red Hat Enterprise Linux 이니시에이터:
구문
iscsiadm -m node -T TARGET_NAME --logoutTARGET_NAME을 구성된 iSCSI 대상 이름으로 교체합니다. 예를 들면 다음과 같습니다.예제
# iscsiadm -m node -T iqn.2003-01.com.redhat.iscsi-gw:ceph-igw --logout Logging out of session [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] Logging out of session [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] Logout of [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] successful. Logout of [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] successful.
Windows 이니시에이터:
자세한 내용은 Microsoft 설명서 를 참조하십시오.
VMware ESXi 이니시에이터:
자세한 내용은 VMware 설명서 를 참조하십시오.
절차
iSCSI 게이트웨이 명령줄 유틸리티를 실행합니다.
[root@iscsigw ~]# gwcli
호스트를 제거합니다.
구문
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:$TARGET_NAME/hosts /> /iscsi-target...TARGET_NAME/hosts> delete CLIENT_NAME
TARGET_NAME을 구성된 iSCSI 대상 이름으로 바꾸고CLIENT_NAME을 iSCSI 이니시에이터 이름으로 교체합니다. 예를 들면 다음과 같습니다.예제
/> cd /iscsi-target/iqn.2003-01.com.redhat.iscsi-gw:ceph-igw/hosts /> /iscsi-target...eph-igw/hosts> delete iqn.1994-05.com.redhat:rh7-client
디스크를 제거합니다.
구문
/> cd /disks/ /disks> delete POOL_NAME.IMAGE_NAME
POOL_NAME을 풀 이름으로,IMAGE_NAME을 이미지 이름으로 바꿉니다.예제
/> cd /disks/ /disks> delete rbd.disk_1
루트 사용자로, 컨테이너화된 배포 의 경우 iSCSI 게이트웨이 노드에서 모든 Red Hat Ceph Storage 툴과 리포지토리가 활성화되었는지 확인합니다.
Red Hat Enterprise Linux 7
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-rpms [root@admin ~]# subscription-manager repos --enable=rhel-7-server-extras-rpms [root@admin ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms --enable=rhel-7-server-ansible-2.9-rpms
Red Hat Enterprise Linux 8
[root@admin ~]# subscription-manager repos --enable=rhel-8-for-x86_64-baseos-rpms [root@admin ~]# subscription-manager repos --enable=rhel-8-for-x86_64-appstream-rpms [root@admin ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms --enable=ansible-2.9-for-rhel-8-x86_64-rpms
참고베어 메탈 배포의 경우 클라이언트 설치를 통해 Ceph 도구가 활성화됩니다.
각 iSCSI 게이트웨이 노드에서
ceph-common및ceph-iscsi패키지를 설치합니다.Red Hat Enterprise Linux 7
[root@admin ~]# yum install -y ceph-common [root@admin ~]# yum install -y ceph-iscsi
Red Hat Enterprise Linux 8
[root@admin ~]# dnf install -y ceph-common [root@admin ~]# dnf install -y ceph-iscsi
-
yum history list명령을 실행하고ceph-iscsi설치의 트랜잭션 ID를 가져옵니다. Ansible 사용자로 전환합니다.
예제
[root@admin ~]# su ansible
/usr/share/ceph-ansible/디렉터리로 이동합니다.예제
[ansible@admin ~]# cd /usr/share/ceph-ansible
ansible 사용자로 iSCSI 게이트웨이를 실행하면 Ansible Playbook을 삭제합니다.
[ansible@admin ceph-ansible]$ ansible-playbook purge-iscsi-gateways.yml
메시지가 표시되면 제거 유형을 입력합니다.
lio- 이 모드에서는 정의된 모든 iSCSI 게이트웨이에서 Linux iSCSI 대상 구성이 제거됩니다. 생성된 디스크는 Ceph 스토리지 클러스터에서 그대로 유지됩니다.
all-
모두선택되면 iSCSI 게이트웨이 환경에 정의된 모든 RBD 이미지와 함께 Linux iSCSI 대상 구성이 제거되며 다른 관련 없는 RBD 이미지는 제거되지 않습니다. 이 작업에서는 데이터를 삭제하므로 올바른 모드를 선택해야 합니다.
예제
[ansible@rh7-iscsi-client ceph-ansible]$ ansible-playbook purge-iscsi-gateways.yml Which configuration elements should be purged? (all, lio or abort) [abort]: all PLAY [Confirm removal of the iSCSI gateway configuration] ********************* GATHERING FACTS *************************************************************** ok: [localhost] TASK: [Exit playbook if user aborted the purge] ******************************* skipping: [localhost] TASK: [set_fact ] ************************************************************* ok: [localhost] PLAY [Removing the gateway configuration] ************************************* GATHERING FACTS *************************************************************** ok: [ceph-igw-1] ok: [ceph-igw-2] TASK: [igw_purge | purging the gateway configuration] ************************* changed: [ceph-igw-1] changed: [ceph-igw-2] TASK: [igw_purge | deleting configured rbd devices] *************************** changed: [ceph-igw-1] changed: [ceph-igw-2] PLAY RECAP ******************************************************************** ceph-igw-1 : ok=3 changed=2 unreachable=0 failed=0 ceph-igw-2 : ok=3 changed=2 unreachable=0 failed=0 localhost : ok=2 changed=0 unreachable=0 failed=0
활성 컨테이너가 제거되었는지 확인합니다.
Red Hat Enterprise Linux 7
[root@admin ~]# docker ps
Red Hat Enterprise Linux 8
[root@admin ~]# podman ps
Ceph iSCSI 컨테이너 ID가 제거됩니다.
선택사항:
ceph-iscsi패키지를 제거합니다.구문
yum history undo TRANSACTION_ID예제
[root@admin ~]# yum history undo 4
주의ceph-common패키지를 제거하지 마십시오. 이렇게 하면/etc/ceph의 콘텐츠가 제거되고 시작할 수 없는 노드의 데몬이 렌더링됩니다.
7.13. 추가 리소스
- Red Hat Ceph Storage 대시보드를 사용하여 iSCSI 게이트웨이를 관리하는 방법에 대한 자세한 내용은 Red Hat Ceph Storage 4 대시보드 가이드 의 iSCSI 기능 섹션을 참조하십시오.
부록 A. Ceph 블록 장치 구성 참조
스토리지 관리자는 사용 가능한 다양한 옵션을 통해 Ceph 블록 장치의 동작을 미세 조정할 수 있습니다. 이 참조를 사용하여 기본 Ceph 블록 장치 옵션 및 Ceph 블록 장치 캐싱 옵션과 같은 항목을 볼 수 있습니다.
A.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
A.2. 블록 장치 기본 옵션
이미지를 생성하기 위한 기본 설정을 덮어쓸 수 있습니다. Ceph는 2 형식 및 스트라이핑 없이 이미지를 생성합니다.
- rbd_default_format
- 설명
-
다른 형식이 지정되지 않은 경우 기본 형식(
2)입니다. 형식1은 모든 버전의librbd및 커널 모듈과 호환되지만 복제와 같은 최신 기능은 지원하지 않는 새 이미지의 원본 형식입니다. 형식2는librbd및 버전 3.11 이후 커널 모듈에서 지원됩니다(제거 제외). 형식2는 복제 지원을 추가하고 향후 더 많은 기능을 허용하기 위해 더 쉽게 확장할 수 있습니다. - 유형
- 정수
- 기본값
-
2
- rbd_default_order
- 설명
- 다른 순서가 지정되지 않은 경우 기본 순서입니다.
- 유형
- 정수
- 기본값
-
22
- rbd_default_stripe_count
- 설명
- 다른 스트라이프 수가 지정되지 않은 경우 기본 스트라이프 수입니다. 기본값을 변경하려면 v2 기능을 제거해야 합니다.
- 유형
- 64비트 서명되지 않은 Integer
- 기본값
-
0
- rbd_default_stripe_unit
- 설명
-
다른 스트라이프 장치가 지정되지 않은 경우 기본 스트라이프 단위입니다. 단위를
0에서 변경 하려면 (즉, 오브젝트 크기) 스트라이핑 v2 기능이 필요합니다. - 유형
- 64비트 서명되지 않은 Integer
- 기본값
-
0
- rbd_default_features
- 설명
블록 장치 이미지를 생성할 때 활성화된 기본 기능입니다. 이 설정은 형식 2 이미지에만 적용됩니다. 설정은 다음과 같습니다.
1: 계층 지원. Layering을 사용하면 복제를 사용할 수 있습니다.
2 : v2 지원 제거 스트라이핑은 여러 오브젝트에 데이터를 분산합니다. 스트라핑은 순차적으로 읽기/쓰기 워크로드에 대해 병렬 처리에 도움이 됩니다.
4: 독점 잠금 지원. 이 기능을 활성화하면 쓰기 전에 클라이언트가 개체에 잠금을 받아야 합니다.
8: 오브젝트 맵 지원. 블록 장치는 씬 프로비저닝되며 실제로 존재하는 데이터만 저장합니다. 오브젝트 맵은 실제로 존재하는 오브젝트(드라이브에 저장된 데이터)를 추적하는 데 도움이 됩니다. 오브젝트 맵을 활성화하면 복제를 위한 I/O 작업 또는 스파스로 채워진 이미지를 가져오고 내보낼 수 있습니다.
16: 빠른 지원. fast-diff 지원은 오브젝트 맵 지원 및 독점 잠금 지원에 따라 다릅니다. 개체 맵에 다른 속성을 추가하므로 이미지의 스냅샷과 스냅샷의 실제 데이터 사용량이 훨씬 더 빠르게 발생합니다.
32: 딥 팽창 지원. deep-flatten은 이미지 자체 외에도 이미지의 모든 스냅샷에서
rbd flatten을 작동하도록 합니다. 이미지가 없으면 이미지의 스냅샷이 상위 항목에 의존하므로 스냅샷이 삭제될 때까지 상위 항목이 삭제할 수 없습니다. 딥 flatten은 스냅샷이 있는 경우에도 복제본과 관계없이 부모를 만듭니다.64: 저널링 지원. 저널링은 이미지가 발생하는 순서대로 이미지에 대한 모든 수정 사항을 기록합니다. 이렇게 하면 원격 이미지의 충돌 불일치 미러를 로컬에서 사용할 수 있습니다.
활성화된 기능은 숫자 설정의 합계입니다.
- 유형
- 정수
- 기본값
61- 계층화, 배타적-lock, object-map, fast-diff, deep-flatten이 사용 가능중요현재 기본 설정은 RBD 커널 드라이버 또는 이전 RBD 클라이언트와 호환되지 않습니다.
- rbd_default_map_options
- 설명
-
대부분의 옵션은 디버깅 및 벤치마킹에 주로 유용합니다. 자세한 내용은
Map Options아래의man rbd를 참조하십시오. - 유형
- 문자열
- 기본값
-
""
A.3. 블록 장치 일반 옵션
- rbd_op_threads
- 설명
- 블록 장치 작업 스레드 수입니다.
- 유형
- 정수
- 기본값
-
1
1 보다 큰 수로 설정하면 데이터 손상이 발생할 수 있으므로 rbd_op_threads 의 기본값을 변경하지 마십시오.
- rbd_op_thread_timeout
- 설명
- 블록 장치 작업 스레드의 시간 초과(초)입니다.
- 유형
- 정수
- 기본값
-
60
- rbd_non_blocking_aio
- 설명
-
true인 경우 Ceph는 차단을 방지하기 위해 작업자 스레드에서 블록 장치 비동기 I/O 작업을 처리합니다. - 유형
- 부울
- 기본값
-
true
- rbd_concurrent_management_ops
- 설명
- 비행의 최대 동시 관리 작업 수입니다(예: 이미지 삭제 또는 크기 조정).
- 유형
- 정수
- 기본값
-
10
- rbd_request_timed_out_seconds
- 설명
- 유지 관리 요청 시간이 초과되기 전의 시간(초)입니다.
- 유형
- 정수
- 기본값
-
30
- rbd_clone_copy_on_read
- 설명
-
true로 설정하면 copy-on-read cloning이 활성화됩니다. - 유형
- 부울
- 기본값
-
false
- rbd_enable_alloc_hint
- 설명
-
true인 경우 할당 힌트가 활성화되고 블록 장치는 OSD 백엔드에 힌트를 발행하여 예상되는 크기 오브젝트를 나타냅니다. - 유형
- 부울
- 기본값
-
true
- rbd_skip_partial_discard
- 설명
-
true인 경우 블록 장치는 개체 내부의 범위를 삭제하려고 할 때 범위를 건너 뛰습니다. - 유형
- 부울
- 기본값
-
false
- rbd_tracing
- 설명
-
Linux Trace Toolkit Next Generation User Space Tracer(LTTng-UST) 추적 지점을 활성화하려면 이 옵션을
true로 설정합니다. 자세한 내용은 RBD Replay 기능을 사용하여 RADOS Block Device(RBD) 워크로드 추적 을 참조하십시오. - 유형
- 부울
- 기본값
-
false
- rbd_validate_pool
- 설명
-
RBD 호환성을 위한 빈 풀의 유효성을 검사하려면 이 옵션을
true로 설정합니다. - 유형
- 부울
- 기본값
-
true
- rbd_validate_names
- 설명
-
이미지 사양을 검증하려면 이 옵션을
true로 설정합니다. - 유형
- 부울
- 기본값
-
true
A.4. 블록 장치 캐싱 옵션
Ceph 블록 장치인 librbd 의 사용자 공간 구현은 Linux 페이지 캐시를 활용할 수 없으므로 RBD 캐싱이라는 자체 메모리 내 캐싱이 포함되어 있습니다. Ceph 블록 장치 캐싱은 잘 사용된 하드 디스크 캐싱과 동일하게 작동합니다. 운영 체제가 장벽 또는 플러시 요청을 보내면 모든 더티 데이터가 Ceph OSD에 작성됩니다. 즉, 플러시를 올바르게 보내는 가상 머신, 즉 Linux 커널 버전 2.6.32 이상과 함께 잘 작동하는 물리적 하드 디스크를 사용하는 것과 마찬가지로 나중 쓰기 캐싱을 사용하는 것이 안전합니다. 이 캐시는 Least Recently Used(LRU) 알고리즘을 사용하며 나중 쓰기 모드에서는 처리량 향상을 위해 연속 요청을 병합할 수 있습니다.
Ceph 블록 장치는 나중 쓰기 캐싱을 지원합니다. 나중 쓰기 캐싱을 활성화하려면 Ceph 구성 파일의 [client] 섹션에 rbd_cache = true 를 설정합니다. 기본적으로 librbd 는 캐싱을 수행하지 않습니다. 쓰기 및 읽기는 스토리지 클러스터에 직접 이동하고 쓰기는 데이터가 모든 복제본의 디스크에 있을 때만 반환됩니다. 캐시가 활성화된 상태에서 rbd_cache_max_dirty 이외의 바이트가 없으면 쓰기가 즉시 반환됩니다. 이 경우 쓰기는 쓰기를 트리거하고 충분한 바이트가 플러시될 때까지 차단됩니다.
Ceph 블록 장치는 동시 쓰기 캐싱을 지원합니다. 캐시 크기를 설정할 수 있으며 나중 쓰기 캐싱에서 쓰기 캐싱으로 전환할 대상 및 제한을 설정할 수 있습니다. write-through 모드를 활성화하려면 rbd_cache_max_dirty 를 0으로 설정합니다. 즉, 쓰기는 모든 복제본에서 데이터가 디스크에 있을 때만 반환되지만 읽기는 캐시에서 가져올 수 있습니다. 캐시는 클라이언트의 메모리에 있으며 각 Ceph 블록 장치 이미지에는 자체 가 있습니다. 캐시는 클라이언트에 로컬이므로 다른 사용자가 이미지에 액세스하는 경우 일관성이 유지되지 않습니다. Ceph 블록 장치 상단에 GFS 또는 OCFS와 같은 다른 파일 시스템을 실행하면 활성화된 캐싱에서 작동하지 않습니다.
Ceph 블록 장치의 Ceph 구성 설정은 기본적으로 /etc/ceph/ceph.conf 의 Ceph 구성 파일의 [client] 섹션에 설정해야 합니다.
설정은 다음과 같습니다.
- rbd_cache
- 설명
- RADOS Block Device(RBD)의 캐싱을 활성화합니다.
- 유형
- 부울
- 필수 항목
- 없음
- 기본값
-
true
- rbd_cache_size
- 설명
- RBD 캐시 크기(바이트)입니다.
- 유형
- 64비트 Integer
- 필수 항목
- 없음
- 기본값
-
32 MiB
- rbd_cache_max_dirty
- 설명
-
캐시
가 나중 쓰기를 트리거하는 더티(바이트)입니다.0인 경우 동시 쓰기 캐싱을 사용합니다. - 유형
- 64비트 Integer
- 필수 항목
- 없음
- 제약 조건
-
rbd 캐시 크기보다 작아야 합니다. - 기본값
-
24 MiB
- rbd_cache_target_dirty
- 설명
-
캐시가 데이터 스토리지에 데이터 쓰기를 시작하기 전 더
티 대상입니다. 캐시 쓰기를 차단하지 않습니다. - 유형
- 64비트 Integer
- 필수 항목
- 없음
- 제약 조건
-
rbd 캐시 최대 더티 캐시보다 작아야합니다. - 기본값
-
16 MiB
- rbd_cache_max_dirty_age
- 설명
- writeback을 시작하기 전에 더티 데이터가 캐시에 있는 시간(초)입니다.
- 유형
- float
- 필수 항목
- 없음
- 기본값
-
1.0
- rbd_cache_max_dirty_object
- 설명
-
개체의 더티 제한 -
rbd_cache_size에서 자동 계산에 대해0으로 설정합니다. - 유형
- 정수
- 기본값
-
0
- rbd_cache_block_writes_upfront
- 설명
-
true인 경우aio_write호출이 완료되기 전에 캐시에 쓰기를 차단합니다.false인 경우aio_completion이 호출되기 전에 차단됩니다. - 유형
- 부울
- 기본값
-
false
- rbd_cache_writethrough_until_flush
- 설명
- 동시 쓰기 모드로 시작되고 첫 번째 플러시 요청이 수신된 후 나중 쓰기로 전환합니다. 이 기능을 활성화하면 rbd에서 실행되는 VM이 2.6.32 이전의 Linux의 virtio 드라이버와 같이 플러시를 보낼 수 없는 경우 안전한 설정입니다.
- 유형
- 부울
- 필수 항목
- 없음
- 기본값
-
true
A.5. 블록 장치 상위 및 하위 읽기 옵션
- rbd_balance_snap_reads
- 설명
- 일반적으로 Ceph는 기본 OSD에서 오브젝트를 읽습니다. 읽기는 변경할 수 없으므로 이 기능을 사용하여 기본 OSD와 복제본 간에 snap 읽기의 균형을 조정할 수 있습니다.
- 유형
- 부울
- 기본값
-
false
- rbd_localize_snap_reads
- 설명
-
그러나
rbd_balance_snap_reads는 스냅샷을 읽을 복제본을 무작위로 설정합니다.rbd_localize_snap_reads를 활성화하면 블록 장치는 매일 읽을 수 있도록 가장 가까운 OSD 또는 로컬 OSD를 찾습니다. - 유형
- 부울
- 기본값
-
false
- rbd_balance_parent_reads
- 설명
- 일반적으로 Ceph는 기본 OSD에서 오브젝트를 읽습니다. 읽기는 변경할 수 없으므로 이 기능을 사용하여 기본 OSD와 복제본 간에 상위 읽기의 균형을 조정할 수 있습니다.
- 유형
- 부울
- 기본값
-
false
- rbd_localize_parent_reads
- 설명
-
rbd_balance_parent_reads는 부모를 읽기 위한 복제본을 임의적으로 설정합니다.rbd_localize_parent_reads를 활성화하면 블록 장치는 CRUSH 맵과 함께 가장 근접하거나 로컬 OSD를 찾아 부모를 읽는 데 가장 근접하거나 로컬 OSD를 찾습니다. - 유형
- 부울
- 기본값
-
true
A.6. 블록 장치 미리 보기 옵션
RBD는 작은 순차적 읽기를 최적화할 수 있도록 read-ahead/prefetching을 지원합니다. 일반적으로 VM의 경우 게스트 OS에서 처리해야 하지만 부트 로더는 효율적으로 읽을 수 없습니다. 캐싱이 비활성화된 경우 미리 읽기가 자동으로 비활성화됩니다.
- rbd_readahead_trigger_requests
- 설명
- 읽기를 트리거하는 데 필요한 순차적 읽기 요청 수입니다.
- 유형
- 정수
- 필수 항목
- 없음
- 기본값
-
10
- rbd_readahead_max_bytes
- 설명
- 미리 읽기 요청의 최대 크기입니다. 0이면 read-ahead가 비활성화됩니다.
- 유형
- 64비트 Integer
- 필수 항목
- 없음
- 기본값
-
512 KiB
- rbd_readahead_disable_after_bytes
- 설명
- RBD 이미지에서 이 바이트를 읽은 후에는 해당 이미지가 닫힐 때까지 해당 이미지에 대해 read-ahead가 비활성화됩니다. 이를 통해 게스트 OS가 부팅되면 게스트 OS가 읽기를 초과할 수 있습니다. 0이면 read-ahead가 활성화됩니다.
- 유형
- 64비트 Integer
- 필수 항목
- 없음
- 기본값
-
50 MiB
A.7. 블록 장치 블랙리스트 옵션
- rbd_blacklist_on_break_lock
- 설명
- 잠금이 손상된 클라이언트를 블랙리스트로 지정할지 여부입니다.
- 유형
- 부울
- 기본값
-
true
- rbd_blacklist_expire_seconds
- 설명
- OSD 기본값의 경우 블랙리스트로 설정할 시간(초)입니다.
- 유형
- 정수
- 기본값
-
0
A.8. 블록 장치 저널 옵션
- rbd_journal_order
- 설명
-
저널 오브젝트 최대 크기를 계산하는 데 사용할 비트 수입니다. 값은
12에서64사이입니다. - 유형
- 32비트 서명되지 않은 Integer
- 기본값
-
24
- rbd_journal_splay_width
- 설명
- 활성 저널 오브젝트 수입니다.
- 유형
- 32비트 서명되지 않은 Integer
- 기본값
-
4
- rbd_journal_commit_age
- 설명
- 커밋 시간 간격(초)입니다.
- 유형
- 정확한 부동 소수점 숫자 두 배
- 기본값
-
5
- rbd_journal_object_flush_interval
- 설명
- 저널 오브젝트당 보류 중인 커밋의 최대 수입니다.
- 유형
- 정수
- 기본값
-
0
- rbd_journal_object_flush_bytes
- 설명
- 저널 오브젝트당 보류 중인 바이트 수입니다.
- 유형
- 정수
- 기본값
-
0
- rbd_journal_object_flush_age
- 설명
- 보류 중인 커밋의 최대 시간 간격(초)입니다.
- 유형
- 정확한 부동 소수점 숫자 두 배
- 기본값
-
0
- rbd_journal_pool
- 설명
- 저널 오브젝트의 풀을 지정합니다.
- 유형
- 문자열
- 기본값
-
""
A.9. 블록 장치 구성 덮어쓰기 옵션
글로벌 및 풀 수준에 대한 블록 장치 구성 덮어쓰기 옵션. 블록 장치 구성의 QoS 설정은 krbd 가 아닌 librbd 에서만 작동합니다.
글로벌 수준
사용 가능한 키
rbd_qos_bps_burst- 설명
- 필요한 IO 바이트의 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_bps_limit- 설명
- 초당 IO 바이트 수 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_iops_burst- 설명
- 필요한 IO 작업의 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_iops_limit- 설명
- 초당 IO 작업의 원하는 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_read_bps_burst- 설명
- 읽기 바이트의 원하는 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_read_bps_limit- 설명
- 초당 읽기 바이트 수입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_read_iops_burst- 설명
- 필요한 읽기 작업의 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_read_iops_limit- 설명
- 초당 읽기 작업의 원하는 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_write_bps_burst- 설명
- 쓰기 바이트의 원하는 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_write_bps_limit- 설명
- 초당 쓰기 바이트 수입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_write_iops_burst- 설명
- 쓰기 작업의 원하는 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
rbd_qos_write_iops_limit- 설명
- 초당 쓰기 작업의 원하는 버스트 제한입니다.
- 유형
- 정수
- 기본값
-
0
위의 키는 다음에 사용할 수 있습니다.
RBD 구성 글로벌 설정 CONFIG_ENTITY KEY VALUE- 설명
- 글로벌 수준 구성 재정의를 설정합니다.
RBD 구성 글로벌 get CONFIG_ENTITY KEY- 설명
- 글로벌 수준 구성 재정의를 가져옵니다.
RBD 구성 글로벌 목록 CONFIG_ENTITY- 설명
- 글로벌 수준 구성 덮어쓰기를 나열합니다.
RBD 구성 글로벌 제거 CONFIG_ENTITY KEY- 설명
- 글로벌 수준 구성 재정의를 제거합니다.
풀 수준
RBD 구성 풀 설정 POOL_NAME KEY VALUE- 설명
- 풀 수준 구성 덮어쓰기를 설정합니다.
RBD 구성 풀 get POOL_NAME KEY- 설명
- 풀 수준 구성 덮어쓰기를 가져옵니다.
RBD 구성 풀 목록 POOL_NAME- 설명
- 풀 수준 구성 덮어쓰기를 나열합니다.
RBD 구성 풀 제거 POOL_NAME KEY- 설명
- 풀 수준 구성 덮어쓰기를 제거합니다.
CONFIG_ENTITY 는 글로벌, 클라이언트 또는 클라이언트 ID입니다. KEY (키)는 config 키입니다. VALUE 는 config 값입니다. POOL_NAME 은 풀 이름입니다.
부록 B. iSCSI 게이트웨이 변수
iSCSI 게이트웨이 일반 변수
seed_monitor- 목적
-
각 iSCSI 게이트웨이는 RADOS 및 RBD 호출을 위해 Ceph 스토리지 클러스터에 액세스해야 합니다. 즉, iSCSI 게이트웨이에 적절한
/etc/ceph/디렉터리가 정의되어 있어야 합니다.seed_monitor호스트는 iSCSI 게이트웨이의/etc/ceph/디렉터리를 채우는 데 사용됩니다.
gateway_keyring- 목적
- 사용자 정의 인증 키 이름을 정의합니다.
perform_system_checks- 목적
-
이는 각 iSCSI 게이트웨이에서 다중 경로 및 LVM 구성 설정을 확인하는 부울 값입니다. 최소한 첫 번째 실행에서
multipathd데몬과 LVM이 올바르게 구성되었는지 확인하려면 최소 첫 번째 실행에서true로 설정해야 합니다.
iSCSI Gateway RBD-TARGET-API 변수
api_user- 목적
-
API의 사용자 이름입니다. 기본값은
admin입니다.
api_password- 목적
-
API 사용의 암호입니다. 기본값은
admin입니다.
api_port- 목적
-
API 사용의 TCP 포트 번호입니다. 기본값은
5000입니다.
api_secure- 목적
-
값은
true또는false일 수 있습니다. 기본값은false입니다.
loop_delay- 목적
-
iSCSI 관리 오브젝트를 폴링하기 위해 유휴 간격(초)을 제어합니다. 기본값은
1입니다.
trusted_ip_list- 목적
- API에 액세스할 수 있는 IPv4 또는 IPv6 주소 목록입니다. 기본적으로 iSCSI 게이트웨이 노드만 액세스할 수 있습니다.
부록 C. 샘플 iscsigws.yml 파일
# Variables here are applicable to all host groups NOT roles
# This sample file generated by generate_group_vars_sample.sh
# Dummy variable to avoid error because ansible does not recognize the
# file as a good configuration file when no variable in it.
dummy:
# You can override vars by using host or group vars
###########
# GENERAL #
###########
# Whether or not to generate secure certificate to iSCSI gateway nodes
#generate_crt: False
#iscsi_conf_overrides: {}
#iscsi_pool_name: rbd
#iscsi_pool_size: "{{ osd_pool_default_size }}"
#copy_admin_key: True
##################
# RBD-TARGET-API #
##################
# Optional settings related to the CLI/API service
#api_user: admin
#api_password: admin
#api_port: 5000
#api_secure: false
#loop_delay: 1
#trusted_ip_list: 192.168.122.1
##########
# DOCKER #
##########
# Resource limitation
# For the whole list of limits you can apply see: docs.docker.com/engine/admin/resource_constraints
# Default values are based from: https://access.redhat.com/documentation/en-us/red_hat_ceph_storage/2/html/red_hat_ceph_storage_hardware_guide/minimum_recommendations
# These options can be passed using the 'ceph_mds_docker_extra_env' variable.
# TCMU_RUNNER resource limitation
#ceph_tcmu_runner_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_tcmu_runner_docker_cpu_limit: 1
# RBD_TARGET_GW resource limitation
#ceph_rbd_target_gw_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_rbd_target_gw_docker_cpu_limit: 1
# RBD_TARGET_API resource limitation
#ceph_rbd_target_api_docker_memory_limit: "{{ ansible_memtotal_mb }}m"
#ceph_rbd_target_api_docker_cpu_limit: 1