
관리 가이드
Red Hat Ceph Storage 관리
초록
1장. Ceph 관리
Red Hat Ceph Storage 클러스터는 모든 Ceph 배포의 기반이 됩니다. Red Hat Ceph Storage 클러스터를 배포한 후 Red Hat Ceph Storage 클러스터를 정상 상태로 유지하고 최적의 성능을 유지할 수 있는 관리 작업이 있습니다.
Red Hat Ceph Storage 관리 가이드에서는 다음과 같은 작업을 스토리지 관리자가 수행할 수 있도록 지원합니다.
- Red Hat Ceph Storage 클러스터의 상태를 확인하는 방법은 무엇입니까?
- Red Hat Ceph Storage 클러스터 서비스를 어떻게 시작하고 중지합니다.
- 실행 중인 Red Hat Ceph Storage 클러스터에서 OSD를 추가하거나 제거하려면 어떻게 해야 합니까?
- Red Hat Ceph Storage 클러스터에 저장된 오브젝트에 대한 사용자 인증 및 액세스 제어를 어떻게 관리합니까?
- Red Hat Ceph Storage 클러스터에서 재정의를 사용하는 방법을 이해하고자 합니다.
- Red Hat Ceph Storage 클러스터의 성능을 모니터링하려고 합니다.
기본 Ceph 스토리지 클러스터는 두 가지 유형의 데몬으로 구성됩니다.
- Ceph OSD(오브젝트 스토리지 장치)는 OSD에 할당된 배치 그룹 내의 데이터를 오브젝트로 저장합니다.
- Ceph Monitor는 클러스터 맵의 마스터 사본을 유지 관리합니다.
프로덕션 시스템에는 고가용성을 위해 3개 이상의 Ceph 모니터가 있으며 일반적으로 허용 가능한 로드 밸런싱, 데이터 재조정 및 데이터 복구를 위한 최소 50개의 OSD가 있습니다.
추가 리소스
2장. Ceph의 프로세스 관리 이해
스토리지 관리자는 베어 메탈 또는 컨테이너에서 유형 또는 인스턴스를 통해 다양한 Ceph 데몬을 조작할 수 있습니다. 이러한 데몬을 조작하면 필요에 따라 모든 Ceph 서비스를 시작, 중지 및 다시 시작할 수 있습니다.
2.1. 사전 요구 사항
- Red Hat Ceph Storage 소프트웨어 설치.
2.2. Ceph 프로세스 관리
Red Hat Ceph Storage에서는 Systemd 서비스를 통해 모든 프로세스 관리를 수행합니다. Ceph 데몬을 시작,재시작, 중지할 때마다 데몬 유형 또는 데몬 인스턴스를 지정해야 합니다.
추가 리소스
- Systemd 사용에 대한 자세한 내용은 Red Hat Enterprise Linux 시스템 관리자 가이드의 systemd를 사용하여 서비스 관리 장을 참조하십시오.
2.3. 모든 Ceph 데몬 시작, 중지 및 재시작
노드의 관리자로 모든 Ceph 데몬을 시작, 중지 및 재시작합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
노드에
root액세스 권한이 있어야 합니다.
절차
모든 Ceph 데몬을 시작합니다.
[root@admin ~]# systemctl start ceph.target
모든 Ceph 데몬을 중지합니다.
[root@admin ~]# systemctl stop ceph.target
모든 Ceph 데몬을 다시 시작합니다.
[root@admin ~]# systemctl restart ceph.target
2.4. 유형별로 Ceph 데몬 시작, 중지 및 재시작
특정 유형의 모든 Ceph 데몬을 시작, 중지 또는 다시 시작하려면 Ceph 데몬을 실행하는 노드에서 다음 절차를 따르십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
노드에
root액세스 권한이 있어야 합니다.
절차
Ceph 모니터 노드에서:
시작:
[root@mon ~]# systemctl start ceph-mon.target
중지:
[root@mon ~]# systemctl stop ceph-mon.target
다시 시작:
[root@mon ~]# systemctl restart ceph-mon.target
Ceph Manager 노드에서:
시작:
[root@mgr ~]# systemctl start ceph-mgr.target
중지:
[root@mgr ~]# systemctl stop ceph-mgr.target
다시 시작:
[root@mgr ~]# systemctl restart ceph-mgr.target
Ceph OSD 노드에서:
시작:
[root@osd ~]# systemctl start ceph-osd.target
중지:
[root@osd ~]# systemctl stop ceph-osd.target
다시 시작:
[root@osd ~]# systemctl restart ceph-osd.target
Ceph Object Gateway 노드에서:
시작:
[root@rgw ~]# systemctl start ceph-radosgw.target
중지:
[root@rgw ~]# systemctl stop ceph-radosgw.target
다시 시작:
[root@rgw ~]# systemctl restart ceph-radosgw.target
2.5. 인스턴스에서 Ceph 데몬 시작, 중지 및 재시작
인스턴스에서 Ceph 데몬을 시작, 중지 또는 다시 시작하려면 Ceph 데몬을 실행하는 노드에서 다음 절차를 따르십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
노드에
root액세스 권한이 있어야 합니다.
절차
Ceph 모니터 노드에서 다음을 수행합니다.
시작:
[root@mon ~]# systemctl start ceph-mon@MONITOR_HOST_NAME중지:
[root@mon ~]# systemctl stop ceph-mon@MONITOR_HOST_NAME다시 시작:
[root@mon ~]# systemctl restart ceph-mon@MONITOR_HOST_NAMEreplace
-
MONITOR_HOST_NAME에 Ceph Monitor 노드 이름이 있습니다.
-
Ceph Manager 노드에서 다음을 수행합니다.
시작:
[root@mgr ~]# systemctl start ceph-mgr@MANAGER_HOST_NAME중지:
[root@mgr ~]# systemctl stop ceph-mgr@MANAGER_HOST_NAME다시 시작:
[root@mgr ~]# systemctl restart ceph-mgr@MANAGER_HOST_NAMEreplace
-
MANAGER_HOST_NAME에 Ceph Manager 노드 이름이 있습니다.
-
Ceph OSD 노드에서 다음을 수행합니다.
시작:
[root@osd ~]# systemctl start ceph-osd@OSD_NUMBER중지:
[root@osd ~]# systemctl stop ceph-osd@OSD_NUMBER다시 시작:
[root@osd ~]# systemctl restart ceph-osd@OSD_NUMBERreplace
Ceph OSD의
ID번호가 있는OSD_NUMBER입니다.예를 들어
ceph osd 트리명령 출력을 보면osd.0의ID는0입니다.
Ceph Object Gateway 노드에서:
시작:
[root@rgw ~]# systemctl start ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAME중지:
[root@rgw ~]# systemctl stop ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAME다시 시작:
[root@rgw ~]# systemctl restart ceph-radosgw@rgw.OBJ_GATEWAY_HOST_NAMEreplace
-
OBJ_GATEWAY_HOST_NAME에 Ceph Object Gateway 노드 이름이 있습니다.
-
2.6. 컨테이너에서 실행되는 Ceph 데몬 시작, 중지 및 재시작
컨테이너에서 실행되는 systemctl 명령 start, stop 또는 restart Ceph 데몬을 사용합니다.
사전 요구 사항
- Red Hat Ceph Storage 소프트웨어 설치.
- 노드에 대한 루트 수준 액세스입니다.
절차
컨테이너에서 실행되는 Ceph 데몬을 시작, 중지 또는 다시 시작하려면 다음 형식으로 구성된
root로systemctl명령을 실행합니다.systemctl ACTION ceph-DAEMON@ID
- replace
-
action 은 수행할 작업이며,
시작,중지또는다시 시작합니다. -
DAEMON 은 데몬,
osd,mon,mds또는rgw입니다. ID 는 다음 중 하나입니다.
-
ceph-mon,ceph-mds또는ceph-rgw데몬이 실행되는 짧은 호스트 이름입니다. -
배포된 경우
ceph-osd데몬의 ID입니다.
-
예를 들어 ID가
osd01인ceph-osd데몬을 재시작하려면 다음을 수행합니다.[root@osd ~]# systemctl restart ceph-osd@osd01
ceph-monitor01호스트에서 실행되는ceph-mondemon을 시작하려면 다음을 수행합니다.[root@mon ~]# systemctl start ceph-mon@ceph-monitor01
ceph-rgw01[root@rgw ~]# systemctl stop ceph-radosgw@ceph-rgw01
-
action 은 수행할 작업이며,
작업이 성공적으로 완료되었는지 확인합니다.
systemctl status ceph-DAEMON@ID
예를 들어 다음과 같습니다.
[root@mon ~]# systemctl status ceph-mon@ceph-monitor01
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 Ceph 프로세스 관리이해 장을 참조하십시오.
2.7. 컨테이너에서 실행되는 Ceph 데몬 로그 보기
컨테이너 호스트의 journald 데몬을 사용하여 컨테이너의 Ceph 데몬 로그를 확인합니다.
사전 요구 사항
- Red Hat Ceph Storage 소프트웨어 설치.
- 노드에 대한 루트 수준 액세스입니다.
절차
전체 Ceph 로그를 보려면 다음 형식으로 구성된
root로journalctl명령을 실행합니다.journalctl -u ceph-DAEMON@ID
- replace
-
DAEMON 은 Ceph 데몬,
osd,mon또는rgw입니다. ID 는 다음 중 하나입니다.
-
ceph-mon,ceph-mds또는ceph-rgw데몬이 실행되는 짧은 호스트 이름입니다. -
배포된 경우
ceph-osd데몬의 ID입니다.
-
예를 들어 ID가
osd01인ceph-osd데몬의 전체 로그를 보려면 다음을 수행합니다.[root@osd ~]# journalctl -u ceph-osd@osd01
-
DAEMON 은 Ceph 데몬,
최근 저널 항목만 표시하려면
-f옵션을 사용합니다.journalctl -fu ceph-DAEMON@ID
예를 들어
ceph-monitor01호스트에서 실행되는ceph-mon데몬의 최근 저널 항목만 보려면 다음을 수행합니다.[root@mon ~]# journalctl -fu ceph-mon@ceph-monitor01
sosreport 유틸리티를 사용하여 journald 로그를 볼 수도 있습니다. SOS 보고서에 대한 자세한 내용은 What is an sosreport and how to create one in Red Hat Enterprise Linux에서 참조하십시오. Red Hat 고객 포털의 솔루션.
추가 리소스
-
journalctl(1)매뉴얼 페이지.
2.8. 컨테이너화된 Ceph 데몬의 파일에 로깅 활성화
기본적으로 컨테이너화된 Ceph 데몬은 파일에 기록하지 않습니다. 중앙 집중식 구성 관리를 사용하여 컨테이너화된 Ceph 데몬이 파일에 로그를 기록할 수 있습니다.
사전 요구 사항
- Red Hat Ceph Storage 소프트웨어 설치.
- 컨테이너화된 데몬이 실행되는 노드에 대한 루트 수준 액세스.
절차
var/log/ceph디렉터리로 이동합니다.예제
[root@host01 ~]# cd /var/log/ceph
기존 로그 파일을 기록해 둡니다.
구문
ls -l /var/log/ceph/
예제
[root@host01 ceph]# ls -l /var/log/ceph/ total 396 -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.0.log -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.3.log -rw-r--r--. 1 root root 181641 Feb 5 14:42 ceph-volume.log
이 예제에서는 OSD.0 및 OSD.3용 파일에 로그인할 수 있습니다.
로깅을 활성화하려는 데몬의 컨테이너 이름을 가져옵니다.
Red Hat Enterprise Linux 7
[root@host01 ceph]# docker ps -a
Red Hat Enterprise Linux 8
[root@host01 ceph]# podman ps -a
중앙 집중식 구성 관리를 사용하여 Ceph 데몬의 파일에 로깅할 수 있습니다.
Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file true
Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config set DAEMON_NAME log_to_file true
DAEMON_NAME 은 CONTAINER_NAME 에서 파생됩니다.
ceph-를 제거하고 데몬 ID와 데몬 ID 간의 하이픈을 마침표로 바꿉니다.Red Hat Enterprise Linux 7
[root@host01 ceph]# docker exec ceph-mon-host01 ceph config set mon.host01 log_to_file true
Red Hat Enterprise Linux 8
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config set mon.host01 log_to_file true
선택사항: 클러스터 로그의 파일에 로깅할 수 있도록 하려면
mon_cluster_log_to_file옵션을 사용합니다.Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file true
Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config set DAEMON_NAME mon_cluster_log_to_file true
Red Hat Enterprise Linux 7
[root@host01 ceph]# docker exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file true
Red Hat Enterprise Linux 8
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config set mon.host01 mon_cluster_log_to_file true
업데이트된 구성을 확인합니다.
Red Hat Enterprise Linux 7
docker exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_file
Red Hat Enterprise Linux 8
podman exec CONTAINER_NAME ceph config show-with-defaults DAEMON_NAME | grep log_to_file
예제
[root@host01 ceph]# podman exec ceph-mon-host01 ceph config show-with-defaults mon.host01 | grep log_to_file log_to_file true mon default[false] mon_cluster_log_to_file true mon default[false]
선택 사항: Ceph 데몬을 다시 시작합니다.
구문
systemctl restart ceph-DAEMON@DAEMON_ID
예제
[root@host01 ceph]# systemctl restart ceph-mon@host01
새 로그 파일이 있는지 확인합니다.
구문
ls -l /var/log/ceph/
예제
[root@host01 ceph]# ls -l /var/log/ceph/ total 408 -rw-------. 1 ceph ceph 202 Feb 5 16:06 ceph.audit.log -rw-------. 1 ceph ceph 3182 Feb 5 16:06 ceph.log -rw-r--r--. 1 ceph ceph 2049 Feb 5 16:06 ceph-mon.host01.log -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.0.log -rw-r--r--. 1 ceph ceph 107230 Feb 5 14:42 ceph-osd.3.log -rw-r--r--. 1 root root 181641 Feb 5 14:42 ceph-volume.log
모니터 데몬용
ceph-mon.host01.log와 클러스터 로그에 대한ceph.log의 새 파일이 생성되었습니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 문제 해결 가이드의 로깅 구성 섹션을 참조하십시오.
2.9. Ceph 데몬의 로그 파일 수집
Ceph 데몬의 로그 파일을 수집하려면 gather-ceph-logs.yml Ansible 플레이북을 실행합니다. 현재 Red Hat Ceph Storage는 컨테이너화되지 않은 배포의 로그 수집만 지원합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터가 배포되었습니다.
- Ansible 노드에 대한 관리자 수준 액세스.
절차
/usr/share/ceph-ansible디렉토리로 이동합니다.[ansible@admin ~]# cd /usr/share/ceph-ansible
플레이북을 실행합니다.
[ansible@admin ~]# ansible-playbook infrastructure-playbooks/gather-ceph-logs.yml -i hosts
- Ansible 관리 노드에서 로그가 수집될 때까지 기다립니다.
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 컨테이너에서 실행되는 Ceph데몬의 로그 파일 보기를 참조하십시오.
2.10. Red Hat Ceph Storage 클러스터 전원 끄기 및 재부팅
Ceph 클러스터의 전원을 끄고 재부팅하려면 다음 절차를 따르십시오.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
루트액세스 권한을 갖습니다.
절차
Red Hat Ceph Storage 클러스터 전원 끄기
- 클라이언트가 이 클러스터의 RBD 이미지 및 RADOS 게이트웨이 및 기타 클라이언트를 사용하지 못하도록 중지합니다.
-
계속하기 전에 클러스터는 정상 상태(
Health_OK및 모든 PGsactive+clean)여야 합니다. Ceph Monitor 또는 OpenStack 컨트롤러 노드와 같이 클라이언트 인증 키가 있는 노드에서ceph 상태를실행하여 클러스터가 정상인지 확인합니다. Ceph 파일 시스템(
CephFS)을 사용하는 경우CephFS클러스터를 다운해야 합니다.CephFS클러스터 다운은1로 순위의 수를 줄이고cluster_down플래그를 설정한 다음 마지막 순위를 실패하여 수행합니다.예제:
[root@osd ~]# ceph fs set FS_NAME max_mds 1 [root@osd ~]# ceph mds deactivate FS_NAME:1 # rank 2 of 2 [root@osd ~]# ceph status # wait for rank 1 to finish stopping [root@osd ~]# ceph fs set FS_NAME cluster_down true [root@osd ~]# ceph mds fail FS_NAME:0
cluster_down플래그를 설정하면 대기 상태가 실패한 순위를 초과하지 않습니다.noout,norecover,norebalance,nobackfill,nodown,pause플래그를 설정합니다. 클라이언트 인증 키를 사용하여 노드에서 다음을 실행합니다. 예를 들어 Ceph Monitor 또는 OpenStack 컨트롤러 노드는 다음과 같습니다.[root@mon ~]# ceph osd set noout [root@mon ~]# ceph osd set norecover [root@mon ~]# ceph osd set norebalance [root@mon ~]# ceph osd set nobackfill [root@mon ~]# ceph osd set nodown [root@mon ~]# ceph osd set pause
OSD 노드를 하나씩 종료합니다.
[root@osd ~]# systemctl stop ceph-osd.target
모니터 노드를 하나씩 종료합니다.
[root@mon ~]# systemctl stop ceph-mon.target
Red Hat Ceph Storage 클러스터 재부팅
- 관리 노드의 전원을 켭니다.
모니터 노드의 전원을 켭니다.
[root@mon ~]# systemctl start ceph-mon.target
OSD 노드의 전원을 켭니다.
[root@osd ~]# systemctl start ceph-osd.target
- 모든 노드가 표시될 때까지 기다립니다. 모든 서비스가 가동되고 노드 간에 연결이 완료되었는지 확인합니다.
noout,norecover,norebalance,nobackfill,nodown및pause플래그를 설정 해제합니다. 클라이언트 인증 키를 사용하여 노드에서 다음을 실행합니다. 예를 들어 Ceph Monitor 또는 OpenStack 컨트롤러 노드는 다음과 같습니다.[root@mon ~]# ceph osd unset noout [root@mon ~]# ceph osd unset norecover [root@mon ~]# ceph osd unset norebalance [root@mon ~]# ceph osd unset nobackfill [root@mon ~]# ceph osd unset nodown [root@mon ~]# ceph osd unset pause
Ceph 파일 시스템(
CephFS)을 사용하는 경우cluster_down플래그를false로 설정하여CephFS클러스터를 다시 가져와야 합니다.[root@admin~]# ceph fs set FS_NAME cluster_down false-
클러스터가 정상 상태(
Health_OK및 모든 PGsactive+clean)인지 확인합니다. 클라이언트 인증 키를 사용하여 노드에서ceph 상태를실행합니다. 예를 들어 클러스터가 정상인지 확인하기 위해 Ceph Monitor 또는 OpenStack 컨트롤러 노드입니다.
2.11. 추가 리소스
- Ceph 설치에 대한 자세한 내용은 Red Hat Ceph Storage 설치 가이드를 참조하십시오.
3장. Ceph 스토리지 클러스터 모니터링
스토리지 관리자는 Ceph의 개별 구성 요소의 상태를 모니터링하고 Red Hat Ceph Storage 클러스터의 전반적인 상태를 모니터링할 수 있습니다.
Red Hat Ceph Storage 클러스터를 실행 중이면 스토리지 클러스터 모니터링을 시작하여 Ceph Monitor 및 Ceph OSD 데몬이 높은 수준에서 실행 중인지 확인할 수 있습니다. Ceph 스토리지 클러스터 클라이언트는 Ceph Monitor에 연결하고 스토리지 클러스터 내의 Ceph 풀에 데이터를 읽고 쓸 수 있도록 최신 버전의 스토리지 클러스터 맵을 수신합니다. 따라서 Ceph 클라이언트가 데이터를 읽고 쓰기 전에 모니터 클러스터에서 클러스터 상태에 동의해야 합니다.
Ceph OSD는 보조 OSD의 배치 그룹 사본과 함께 기본 OSD에서 배치 그룹을 피어링해야 합니다. 오류가 발생하면 피어링은 활성 + 정리 상태 이외의 다른 것을 반영합니다.
3.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
3.2. Ceph 스토리지 클러스터의 고급 모니터링
스토리지 관리자는 Ceph 데몬의 상태를 모니터링하여 실행 중인지 확인할 수 있습니다. 높은 수준의 모니터링에는 스토리지 클러스터 용량을 확인하여 스토리지 클러스터의 전체 비율을 초과하지 않습니다. Red Hat Ceph Storage 대시보드 는 고급 모니터링을 수행하는 가장 일반적인 방법입니다. 그러나 명령줄 인터페이스, Ceph 관리 소켓 또는 Ceph API를 사용하여 스토리지 클러스터를 모니터링할 수도 있습니다.
3.2.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
3.2.2. Ceph 명령 인터페이스를 대화식으로 사용
ceph 명령줄 유틸리티를 사용하여 Ceph 스토리지 클러스터와 대화형으로 연결할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
대화형 모드에서
ceph유틸리티를 실행하려면 다음을 수행합니다.베어 메탈 배포:
예제
[root@mon ~]# ceph ceph> health ceph> status ceph> quorum_status ceph> mon_status
컨테이너 배포:
Red Hat Enterprise Linux 7
docker exec -it ceph-mon-MONITOR_NAME /bin/bashRed Hat Enterprise Linux 8
podman exec -it ceph-mon-MONITOR_NAME /bin/bash- replace
docker ps또는podman ps명령을 각각 실행하여 찾은 Ceph Monitor 컨테이너의 이름이 있는 MONITOR_NAME.예제
[root@container-host ~]# podman exec -it ceph-mon-mon01 /bin/bash
이 예에서는
mon01에서 대화형 터미널 세션을 엽니다. 여기서 Ceph 대화형 쉘을 시작할 수 있습니다.
3.2.3. 스토리지 클러스터 상태 확인
Ceph 스토리지 클러스터를 시작한 후 데이터를 읽거나 쓰기 전에 스토리지 클러스터의 상태를 먼저 확인합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
다음을 사용하여 Ceph 스토리지 클러스터의 상태를 확인할 수 있습니다.
[root@mon ~]# ceph health
구성 또는 인증 키에 기본 위치가 아닌 위치를 지정한 경우 해당 위치를 지정할 수 있습니다.
[root@mon ~]# ceph -c /path/to/conf -k /path/to/keyring health
Ceph 클러스터를 시작하면 HEALTH_WARN XXX num 배치 그룹과 같은 상태 경고가 표시됩니다. 잠시 기다렸다가 다시 확인하십시오. 스토리지 클러스터가 준비되면 ceph 상태가 HEALTH_OK 와 같은 메시지를 반환해야 합니다. 이 시점에서 클러스터 사용을 시작하는 것이 좋습니다.
3.2.4. 스토리지 클러스터 이벤트 감시
명령줄 인터페이스를 사용하여 Ceph 스토리지 클러스터에서 발생하는 이벤트를 확인할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
명령줄에서 클러스터의 진행 중인 이벤트를 모니터링하려면 새 터미널을 열고 다음을 입력합니다.
[root@mon ~]# ceph -w
Ceph는 각 이벤트를 출력합니다. 예를 들어 모니터 1개와 2개의 OSD로 구성된 작은 Ceph 클러스터는 다음을 출력할 수 있습니다.
cluster b370a29d-9287-4ca3-ab57-3d824f65e339 health HEALTH_OK monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1 osdmap e63: 2 osds: 2 up, 2 in pgmap v41338: 952 pgs, 20 pools, 17130 MB data, 2199 objects 115 GB used, 167 GB / 297 GB avail 952 active+clean 2014-06-02 15:45:21.655871 osd.0 [INF] 17.71 deep-scrub ok 2014-06-02 15:45:47.880608 osd.1 [INF] 1.0 scrub ok 2014-06-02 15:45:48.865375 osd.1 [INF] 1.3 scrub ok 2014-06-02 15:45:50.866479 osd.1 [INF] 1.4 scrub ok 2014-06-02 15:45:01.345821 mon.0 [INF] pgmap v41339: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail 2014-06-02 15:45:05.718640 mon.0 [INF] pgmap v41340: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail 2014-06-02 15:45:53.997726 osd.1 [INF] 1.5 scrub ok 2014-06-02 15:45:06.734270 mon.0 [INF] pgmap v41341: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail 2014-06-02 15:45:15.722456 mon.0 [INF] pgmap v41342: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail 2014-06-02 15:46:06.836430 osd.0 [INF] 17.75 deep-scrub ok 2014-06-02 15:45:55.720929 mon.0 [INF] pgmap v41343: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail출력에서 다음을 제공합니다.
- 클러스터 ID
- 클러스터 상태
- 모니터 맵 epoch 및 monitor 쿼럼의 상태
- OSD 맵 epoch 및 OSD 상태
- 배치 그룹 맵 버전
- 배치 그룹 및 풀 수
- 저장된 데이터 양 및 저장된 오브젝트 수입니다.
- 저장된 총 데이터 양
3.2.5. Ceph가 데이터 사용량을 계산하는 방법
사용된 값은 사용된 실제 원시 스토리지의 양을 반영합니다. xxx GB / xxx GB 값은 클러스터의 전체 스토리지 용량의 두 숫자 중 사용 가능한 양, 즉 클러스터의 전체 스토리지 용량의 양을 의미합니다. notional number는 저장된 데이터의 크기를 반영한 후 복제, 복제 또는 스냅샷을 생성합니다. 따라서 Ceph는 데이터의 복제본을 만들고 복제 및 스냅샷에 스토리지 용량을 사용할 수 있으므로 실제로 저장된 데이터의 양은 일반적으로 저장되는 양을 초과합니다.
3.2.6. 스토리지 클러스터 사용량 통계 이해
클러스터의 데이터 사용량과 풀 간의 데이터 배포를 확인하려면 df 옵션을 사용합니다. 이는 Linux df 명령과 유사합니다. ceph df 명령 또는 ceph df 세부 정보를 실행할 수 있습니다.
예제
[root@mon ~]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 90 GiB 84 GiB 100 MiB 6.1 GiB 6.78
TOTAL 90 GiB 84 GiB 100 MiB 6.1 GiB 6.78
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
.rgw.root 1 1.3 KiB 4 768 KiB 0 26 GiB
default.rgw.control 2 0 B 8 0 B 0 26 GiB
default.rgw.meta 3 2.5 KiB 12 2.1 MiB 0 26 GiB
default.rgw.log 4 3.5 KiB 208 6.2 MiB 0 26 GiB
default.rgw.buckets.index 5 2.4 KiB 33 2.4 KiB 0 26 GiB
default.rgw.buckets.data 6 9.6 KiB 15 1.7 MiB 0 26 GiB
testpool 10 231 B 5 384 KiB 0 40 GiB
ceph df detail 명령은 할당량 오브젝트, 할당량 바이트, 사용된 압축 및 압축과 같은 기타 풀 통계에 대한 세부 정보를 제공합니다.
예제
[root@mon ~]# ceph df detail
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 90 GiB 84 GiB 100 MiB 6.1 GiB 6.78
TOTAL 90 GiB 84 GiB 100 MiB 6.1 GiB 6.78
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL QUOTA OBJECTS QUOTA BYTES DIRTY USED COMPR UNDER COMPR
.rgw.root 1 1.3 KiB 4 768 KiB 0 26 GiB N/A N/A 4 0 B 0 B
default.rgw.control 2 0 B 8 0 B 0 26 GiB N/A N/A 8 0 B 0 B
default.rgw.meta 3 2.5 KiB 12 2.1 MiB 0 26 GiB N/A N/A 12 0 B 0 B
default.rgw.log 4 3.5 KiB 208 6.2 MiB 0 26 GiB N/A N/A 208 0 B 0 B
default.rgw.buckets.index 5 2.4 KiB 33 2.4 KiB 0 26 GiB N/A N/A 33 0 B 0 B
default.rgw.buckets.data 6 9.6 KiB 15 1.7 MiB 0 26 GiB N/A N/A 15 0 B 0 B
testpool 10 231 B 5 384 KiB 0 40 GiB N/A N/A 5 0 B 0 B
출력의 RAW STORAGE 섹션에서는 스토리지 클러스터가 데이터에 사용하는 스토리지의 개요를 제공합니다.
- CLASS: 사용된 장치의 유형입니다.
크기: 스토리지 클러스터에서 관리하는 전체 스토리지 용량입니다.
위의 예에서
SIZE가 90GiB이면 복제 인수가 없는 총 크기이며 기본적으로 3입니다. 복제 인수에서 사용 가능한 총 용량은 90GiB/3 = 30GiB입니다. 기본적으로 0.85%인 전체 비율에 따라 사용 가능한 최대 공간은 30GiB * 0.85 = 25.5GiB입니다.AVAIL: 스토리지 클러스터에서 사용 가능한 여유 공간의 양입니다.
위의 예에서
SIZE가 90GiB이고USED공간이 6GiB이면AVAIL공간은 84GiB입니다. 복제 요소가 있는 총 사용 가능한 공간(기본적으로 3개)은 84GiB/3 = 28GiB입니다.USED: 사용자 데이터, 내부 오버헤드 또는 예약된 용량에서 사용하는 스토리지 클러스터에서 사용된 공간입니다.
위 예에서 100MiB는 복제 요소를 고려한 후 사용 가능한 총 공간입니다. 실제 사용 가능한 크기는 33MiB입니다.
-
RAW USED: USED 공간의 합계와
db및walBlueStore 파티션이 할당된 공간입니다. -
% RAW USED: RAW USED 의 백분율입니다. 스토리지 클러스터 용량에 도달하지 않도록 하려면 이 숫자를
전체 비율과 거의 전체 비율
출력의 POOLS 섹션에서는 풀 목록과 각 풀의 알림 사용량을 제공합니다. 이 섹션의 출력에 는 복제본, 복제본 또는 스냅샷이 반영되지 않습니다. 예를 들어 1MB의 데이터가 있는 오브젝트를 저장하는 경우 알림 사용량이 1MB가 되지만 실제 사용량은 복제본 수에 따라 3MB 이상일 수 있습니다(예: size = 3, 복제본 및 스냅샷).
- POOL: 풀의 이름입니다.
- ID: 풀 ID입니다.
- STORED: 풀에 사용자가 저장하는 실제 데이터 양입니다.
- OBJECTS: 풀당 저장된 오브젝트 수입니다.
-
USED: 숫자가 메가바이트 또는 G for gigabytes를 위한 M 을 추가하지 않는 한 킬로바이트로 저장되는 일반적인 데이터 양입니다. 크기가
STORED* 복제 비율입니다. - %USED: 풀당 사용되는 스토리지의 주요 백분율입니다.
MAX AVAIL: 이 풀에 쓸 수 있는 데이터의 개념적 양의 추정치입니다. 첫 번째 OSD가 가득 차기 전에 사용할 수 있는 데이터 양입니다. FlexVolume 맵의 디스크에 예상된 데이터를 배포하고 첫 번째 OSD를 사용하여 대상으로 작성합니다.
위의 예에서
MAX AVAIL은 복제 요소를 고려하지 않고 153.85이며 이는 기본적으로 3입니다.MAX AVAIL의 값을 계산하기 위한 간단한 복제 풀에는 기술 자료 문서 ceph df
MAX AVAIL이 올바르지 않습니다.- QUOTA OBJECTS: 할당량 오브젝트 수입니다.
- QUOTA BYTES: 할당량 오브젝트의 바이트 수입니다.
- USEDPR: 압축된 데이터, 할당, 복제 및 삭제 코딩 오버헤드를 포함하여 압축된 데이터에 할당된 공간입니다.
- UNDER 8601PR: 압축을 통해 전달되는 데이터 양이며 압축된 형식으로 저장할 수 있을 만큼의 이점입니다.
POOLS 섹션의 숫자는 필수 항목입니다. 복제본, 스냅샷 또는 복제 수를 포함하지 않습니다. 결과적으로 USED 및 %USED 용량의 합계는 출력의 GLOBAL 섹션에 RAW USED 및 %RAW USED 수량에 추가되지 않습니다.
MAX AVAIL 값은 사용된 복제 또는 내역 코드의 복잡한 기능, 스토리지를 장치에 매핑하는 규칙, 해당 장치의 사용률, 구성된 mon_osd_full_ratio 입니다.
추가 리소스
- 자세한 내용은 Ceph에서 데이터 사용량을 계산하는 방법을 참조하십시오.
- 자세한 내용은 OSD 사용 통계 이해를 참조하십시오.
3.2.7. OSD 사용량 통계 이해
ceph osd df 명령을 사용하여 OSD 사용률 통계를 확인합니다.
[root@mon]# ceph osd df ID CLASS WEIGHT REWEIGHT SIZE USE DATA OMAP META AVAIL %USE VAR PGS 3 hdd 0.90959 1.00000 931GiB 70.1GiB 69.1GiB 0B 1GiB 861GiB 7.53 2.93 66 4 hdd 0.90959 1.00000 931GiB 1.30GiB 308MiB 0B 1GiB 930GiB 0.14 0.05 59 0 hdd 0.90959 1.00000 931GiB 18.1GiB 17.1GiB 0B 1GiB 913GiB 1.94 0.76 57 MIN/MAX VAR: 0.02/2.98 STDDEV: 2.91
- id: OSD의 이름입니다.
- CLASS: OSD에서 사용하는 장치의 유형입니다.
- WEIGHT: CRUSH 맵에 있는 OSD의 가중치입니다.
- REWEIGHT: 기본 reweight 값.
- SIZE: OSD의 전체 스토리지 용량입니다.
- USE: OSD 용량입니다.
- DATA: 사용자 데이터에 사용되는 OSD 용량의 양입니다.
-
OMAP: 개체 맵(
omap) 데이터(인쇄에 저장된 키 값 쌍)를 저장하는 데 사용되는Bluefs스토리지의추정치 값입니다. -
META: Bluestore_
bluefs_min 매개변수에 할당된 bluefs 공간 또는bluestore_bluefs_min매개 변수에 설정된 값은 더 큰 내부 메타데이터로,Bluefs에 할당된 총 공간으로 계산되며 예상omap데이터 크기를 뺀 값입니다. - AVAIL: OSD에서 사용 가능한 공간의 양입니다.
- %USE: OSD에서 사용하는 스토리지의 개념 백분율
- VAR: 평균 사용률보다 크거나 낮은 변동입니다.
- PGS: OSD의 배치 그룹 수입니다.
- MIN/MAX VAR: 모든 OSD에서 최소 및 최대 변형입니다.
추가 리소스
- 자세한 내용은 Ceph에서 데이터 사용량을 계산하는 방법을 참조하십시오.
- 자세한 내용은 OSD 사용 통계 이해를 참조하십시오.
- 자세한 내용은 CRUSH Weights in Red Hat Ceph Storage Strategies Guide 를 참조하십시오.
3.2.8. Red Hat Ceph Storage 클러스터 상태 확인
명령줄 인터페이스에서 Red Hat Ceph Storage 클러스터의 상태를 확인할 수 있습니다. status sub 명령 또는 -s 인수는 스토리지 클러스터의 현재 상태를 표시합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
스토리지 클러스터 상태를 확인하려면 다음을 실행합니다.
[root@mon ~]# ceph status
또는 다음을 수행합니다.
[root@mon ~]# ceph -s
대화형 모드에서 상태를 입력하고 Enter 키를 누릅니다.In interactive mode, type
statusand press Enter:[root@mon ~]# ceph> status
예를 들어 모니터 한 개와 2개의 OSD로 구성된 작은 Ceph 클러스터는 다음을 출력할 수 있습니다.
cluster b370a29d-9287-4ca3-ab57-3d824f65e339 health HEALTH_OK monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1 osdmap e63: 2 osds: 2 up, 2 in pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects 115 GB used, 167 GB / 297 GB avail 1 active+clean+scrubbing+deep 951 active+clean
3.2.9. Ceph Monitor 상태 확인
스토리지 클러스터에 여러 개의 Ceph Monitor가 있는 경우 이는 프로덕션 Red Hat Ceph Storage 클러스터의 요구 사항인 경우 스토리지 클러스터를 시작한 후 그리고 데이터를 읽거나 쓰기 전에 Ceph Monitor 쿼럼 상태를 확인합니다.
여러 개의 모니터가 실행 중인 경우 쿼럼이 있어야 합니다.
Ceph Monitor 상태를 주기적으로 확인하여 실행 중인지 확인합니다. Ceph Monitor에 문제가 있는 경우 스토리지 클러스터 상태에 대한 계약을 방지하는 경우 Ceph 클라이언트가 데이터를 읽고 쓰는 것을 방지할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
모니터 맵을 표시하려면 다음을 실행합니다.
[root@mon ~]# ceph mon stat
또는
[root@mon ~]# ceph mon dump
스토리지 클러스터의 쿼럼 상태를 확인하려면 다음을 실행합니다.
[root@mon ~]# ceph quorum_status -f json-pretty
Ceph가 쿼럼 상태를 반환합니다. 3개의 모니터로 구성된 Red Hat Ceph Storage 클러스터는 다음을 반환할 수 있습니다.
예제
{ "election_epoch": 10, "quorum": [ 0, 1, 2], "monmap": { "epoch": 1, "fsid": "444b489c-4f16-4b75-83f0-cb8097468898", "modified": "2011-12-12 13:28:27.505520", "created": "2011-12-12 13:28:27.505520", "mons": [ { "rank": 0, "name": "a", "addr": "127.0.0.1:6789\/0"}, { "rank": 1, "name": "b", "addr": "127.0.0.1:6790\/0"}, { "rank": 2, "name": "c", "addr": "127.0.0.1:6791\/0"} ] } }
3.2.10. Ceph 관리 소켓 사용
관리 소켓을 사용하여 UNIX 소켓 파일을 사용하여 지정된 데몬과 직접 상호 작용합니다. 예를 들어, 소켓을 사용하면 다음을 수행할 수 있습니다.
- 런타임 시 Ceph 구성 나열
-
Monitors를 사용하지 않고 런타임에 직접 구성 값을 설정합니다. 이 기능은 모니터가
다운된 경우 유용합니다. - 기록 작업 덤프
- 작업 우선 순위 대기열 상태 덤프
- 재부팅하지 않고 덤프 작업
- 성능 카운터 덤프
또한 소켓을 사용하면 모니터 또는 OSD와 관련된 문제를 해결할 때 유용합니다.
관리 소켓은 데몬이 실행되는 동안만 사용할 수 있습니다. 데몬을 올바르게 종료하면 관리 소켓이 제거됩니다. 그러나 데몬이 예기치 않게 종료되면 관리 소켓이 계속될 수 있습니다.
데몬을 실행 중이 아닌 경우 관리 소켓을 사용하려고 할 때 다음 오류가 반환됩니다.
Error 111: Connection Refused
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
소켓을 사용하려면 다음을 수행합니다.
구문
[root@mon ~]# ceph daemon TYPE.ID COMMAND
교체:
-
TYPE: Ceph 데몬 유형(mon,osd,mds)입니다. -
데몬
ID가 있는 ID 실행할 명령이 있는
COMMAND입니다. 지정된 데몬에 사용 가능한 명령을 나열하려면help를 사용합니다.예제
mon.0이라는 Ceph 모니터의 모니터 상태를 보려면 다음을 수행합니다.[root@mon ~]# ceph daemon mon.0 mon_status
-
또는 소켓 파일을 사용하여 Ceph 데몬을 지정합니다.
ceph daemon /var/run/ceph/SOCKET_FILE COMMAND
osd.2라는 Ceph OSD의 상태를 보려면 다음을 수행합니다.[root@mon ~]# ceph daemon /var/run/ceph/ceph-osd.2.asok status
Ceph 프로세스의 모든 소켓 파일을 나열하려면 다음을 수행합니다.
[root@mon ~]# ls /var/run/ceph
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 문제 해결 가이드 를 참조하십시오.
3.2.11. Ceph OSD 상태 이해
OSD의 상태는 클러스터 내 또는 클러스터 외부에 있습니다. 실행 중, up 또는 실행 중이 고 실행 중이 고 실행 되지 않습니다 . OSD가 가동 중인 경우 스토리지 클러스터에서 데이터를 읽고 쓸 수 있거나 스토리지 클러스터에서 데이터를 읽을 수 있습니다. 클러스터에 있고 최근에 클러스터에서 나가면 Ceph 에서 배치 그룹을 다른 OSD로 마이그레이션합니다. OSD가 클러스터 가 아닌 경우 CRUSH는 OSD에 배치 그룹을 할당하지 않습니다. OSD가 다운 된 경우 이기도 합니다.
OSD가 다운 되어 있는 경우 문제가 있으며 클러스터가 정상 상태가 되지 않습니다.

ceph 상태 , 또는 ceph -sceph -w 와 같은 명령을 실행하는 경우 클러스터가 항상 HEALTH OK 를 에코하지 않을 수 있습니다. 패닉을 일으키지 마십시오. OSD와 관련하여 예상되는 몇 가지 상황에서는 클러스터가 HEALTH OK 를 에코 하지 않을 것으로 예상해야 합니다.
- 아직 클러스터를 시작하지 않았으며 응답하지 않습니다.
- 배치 그룹이 생성되고 OSD가 피어링 프로세스에 있기 때문에 클러스터를 시작하거나 다시 시작했으며 아직 준비되지 않았습니다.
- OSD를 방금 추가하거나 제거했습니다.
- 클러스터 맵을 수정했습니다.
OSD를 모니터링하는 중요한 측면은 클러스터가 가동되어 실행 중일 때 클러스터의 모든 OSD가 실행 중인지 확인하는 것입니다.
모든 OSD가 실행 중인지 확인하려면 다음을 실행합니다.
[root@mon ~]# ceph osd stat
또는
[root@mon ~]# ceph osd dump
그 결과 eNNNN의 map epoch, eNNNN, 총 OSD 수, x, y, up, 그리고 얼마나 많은, z 임을 알려주어야 합니다.
eNNNN: x osds: y up, z in
클러스터에 있는 OSD 수가 가동 중인 OSD 수보다 많은 경우. 다음 명령을 실행하여 실행 중이 아닌 ceph-osd 데몬을 확인합니다.
[root@mon ~]# ceph osd tree
예제
# id weight type name up/down reweight -1 3 pool default -3 3 rack mainrack -2 3 host osd-host 0 1 osd.0 up 1 1 1 osd.1 up 1 2 1 osd.2 up 1
잘 설계된 CRUSH 계층 구조를 통해 검색하는 기능은 물리적 위치를 더 빠르게 식별하여 스토리지 클러스터 문제를 해결하는 데 도움이 될 수 있습니다.
OSD가 다운되면 노드에 연결하여 시작합니다. Red Hat Storage Console을 사용하여 OSD 노드를 다시 시작하거나 명령줄을 사용할 수 있습니다.
예제
[root@mon ~]# systemctl start ceph-osd@OSD_ID
3.2.12. 추가 리소스
3.3. Ceph 스토리지 클러스터에 대한 낮은 수준의 모니터링
스토리지 관리자는 하위 수준의 관점에서 Red Hat Ceph Storage 클러스터의 상태를 모니터링할 수 있습니다. 낮은 수준의 모니터링에는 일반적으로 Ceph OSD가 올바르게 피어링되는지 확인해야 합니다. 피어링 오류가 발생하면 배치 그룹이 degraded 상태에서 작동합니다. 이러한 성능 저하 상태는 하드웨어 오류, 중단된 Ceph 데몬, 네트워크 대기 시간 또는 전체 사이트 중단과 같은 다양한 문제로 인해 발생할 수 있습니다.
3.3.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
3.3.2. 배치 그룹 세트 모니터링
CRUSH가 배치 그룹을 OSD에 할당할 때 풀의 복제본 수를 확인하고 배치 그룹을 OSD에 할당하여 배치 그룹의 각 복제본이 다른 OSD에 할당됩니다. 예를 들어 풀에 배치 그룹의 복제본 세 개가 필요한 경우 CRUSH는 각각 osd.1,osd.2 및 osd.3 에 할당할 수 있습니다. CRUSH는 실제로 CRUSH 맵에 설정한 실패 도메인을 고려하기 위한 의사랜덤 배치를 검색하므로 대규모 클러스터에서 가장 가까운 OSD에 할당된 배치 그룹은 거의 볼 수 없습니다. 특정 배치 그룹의 복제본을 동작 세트로 포함해야 하는 OSD 세트를 나타냅니다. 경우에 따라 Acting Set의 OSD가 다운 되거나 배치 그룹의 오브젝트에 대한 요청을 서비스할 수 없습니다. 이러한 상황이 발생하면 패닉이 발생하지 않습니다. 일반적인 예는 다음과 같습니다.
- OSD를 추가하거나 제거했습니다. 그런 다음 CRUSH가 배치 그룹을 다른 OSD에 다시 할당했습니다. 이 경우 Acting Set의 구성을 변경하고 "백필" 프로세스를 사용하여 데이터 마이그레이션을 생성할 수 있습니다.
-
OSD가
다운되어 이제복구 중입니다. -
Checking Set의 OSD가
다운되거나 서비스할 수 없으며 다른 OSD는 일시적으로 업무를 수행한다고 가정합니다.
Ceph에서는 요청을 실제로 처리할 OSD 세트인 Up Set 을 사용하여 클라이언트 요청을 처리합니다. 대부분의 경우 Up Set 및 Acting Set은 사실상 동일합니다. Ceph가 데이터를 마이그레이션하거나, OSD가 복구되고 있거나 문제가 있음을 나타내는 경우 Ceph는 일반적으로 이러한 시나리오에서 "더하기 오래된" 메시지와 함께 HEALTH WARN 상태를 에코합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
배치 그룹 목록을 검색하려면 다음을 수행합니다.
[root@mon ~]# ceph pg dump
특정 배치 그룹에 대해 동작 집합 또는 Up Set에 있는 OSD를 보려면 다음을 수행합니다.
[root@mon ~]# ceph pg map PG_NUM그 결과 osdmap
eNNN, 배치 그룹 번호,PG_NUM, Up Setup[]의 OSD, 작동 설정 세트의 OSD, action[]에 있는 OSD를알려주어야합니다.[root@mon ~]# ceph osdmap eNNN pg PG_NUM-> up [0,1,2] acting [0,1,2]참고Up Set 및 Acting Set이 일치하지 않는 경우 클러스터의 재조정 자체 또는 클러스터에 잠재적인 문제가 있음을 나타내는 표시일 수 있습니다.
3.3.3. Ceph OSD 피어링
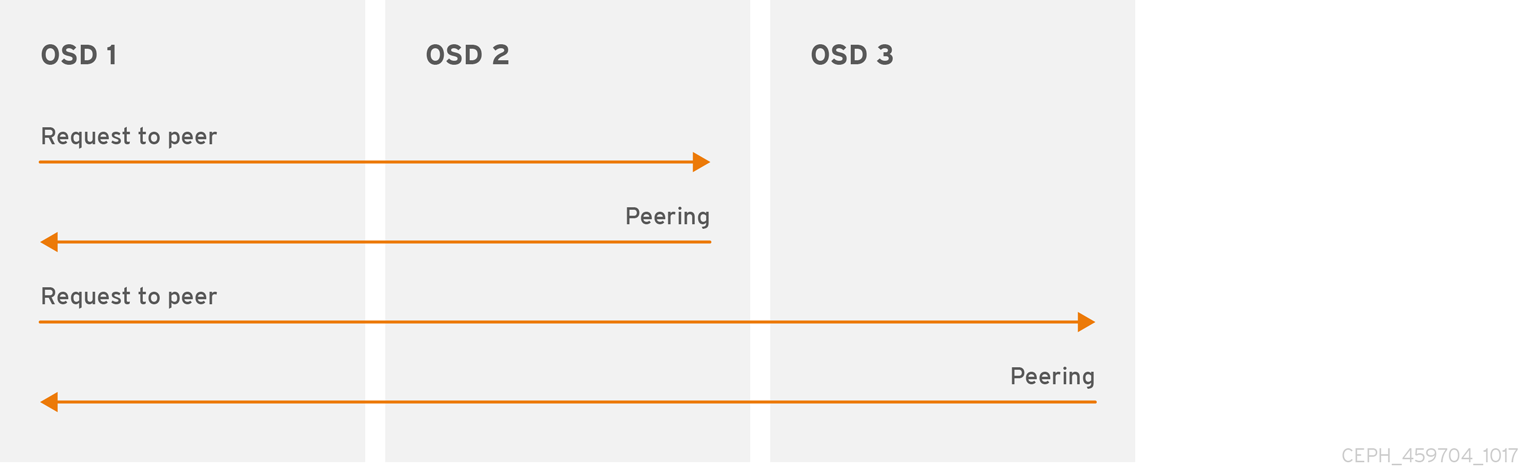
배치 그룹에 데이터를 쓰기 전에 활성 상태여야 하며 정리 중 이어야 합니다. Ceph에서 배치 그룹의 현재 상태를 확인하기 위해 배치 그룹의 기본 OSD인 배치 그룹의 기본 OSD, 작동 세트의 첫 번째 OSD인 배치 그룹의 현재 상태에 대한 연결을 설정하는 보조 및 3차 OSD가 있는 피어입니다. PG의 복제본이 3개인 풀을 가정합니다.
3.3.4. 배치 그룹 상태
ceph 상태 , 또는 ceph -sceph -w 와 같은 명령을 실행하는 경우 클러스터가 항상 HEALTH OK 를 에코하지 않을 수 있습니다. OSD가 실행 중인지 확인한 후 배치 그룹 상태도 확인해야 합니다. 여러 배치 그룹 피어링 관련 상황에서 클러스터가 HEALTH OK 를 에코 하지 않을 것으로 예상해야 합니다.
- 풀 및 배치 그룹을 아직 피어링하지 않았습니다.
- 배치 그룹은 복구 중입니다.
- 방금 OSD를 클러스터에 추가하거나 클러스터에서 OSD를 제거했습니다.
- CRUSH 맵을 수정했는데 배치 그룹이 마이그레이션 중입니다.
- 배치 그룹의 여러 복제본에 일관되지 않은 데이터가 있습니다.
- Ceph가 배치 그룹의 복제본을 스크럽하고 있습니다.
- Ceph에는 백필 작업을 완료할 수 있는 충분한 스토리지 용량이 없습니다.
반복적인 상황 중 하나로 인해 Ceph에서 HEALTH WARN 을 에코하게 되는 경우 패닉이 발생하지 않습니다. 대부분의 경우 클러스터가 자체적으로 복구됩니다. 경우에 따라 조치를 취해야 할 수도 있습니다. 배치 그룹을 모니터링하는 중요한 측면은 클러스터가 가동 및 실행 중일 때 모든 배치 그룹이 활성 상태이고 바람직하게 정리 된 상태에서 있는지 확인하는 것입니다.
모든 배치 그룹의 상태를 보려면 다음을 실행합니다.
[root@mon ~]# ceph pg stat
그 결과 배치 그룹 맵 버전 vNNNN, 총 배치 그룹 수, x, 배치 그룹 y 의 수가 active+clean 과 같은 특정 상태에 있음을 알려주어야 합니다.
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail
Ceph는 배치 그룹에 대한 여러 상태를 보고하는 것이 일반적입니다.
스냅 샷 트리밍 PG 상태
스냅샷이 존재하는 경우 두 개의 추가 PG 상태가 보고됩니다.
-
snaptrim: PG가 현재 트리밍되고 있습니다. -
snaptrim_wait: PG가 트리밍되기를 기다리고 있습니다.
출력 예:
244 active+clean+snaptrim_wait 32 active+clean+snaptrim
배치 그룹 상태 외에도 Ceph는 사용된 데이터 양, aa, 남아 있는 스토리지 용량, bb, 배치 그룹의 총 스토리지 용량을 에코합니다. 이 숫자는 몇 가지 경우에 중요할 수 있습니다.
-
당신은
거의 전체 비율 또는도달하고 있습니다.전체 비율에 - CRUSH 구성의 오류로 인해 데이터가 클러스터 전체에 배포되지 않습니다.
배치 그룹 ID
배치 그룹 ID는 풀 번호가 아니라 풀 이름이 아니라 마침표(.) 및 배치 그룹 ID-a 16진수로 구성됩니다. ceph osd lspools 출력에서 풀 번호와 해당 이름을 볼 수 있습니다. 기본 풀은 데이터,metadata, rbd 는 각각 0,1 및 2 풀 번호에 해당합니다. 정규화된 배치 그룹 ID는 다음과 같습니다.
POOL_NUM.PG_ID
출력 예:
0.1f
배치 그룹 목록을 검색하려면 다음을 수행합니다.
[root@mon ~]# ceph pg dump
출력을 JSON 형식으로 포맷하고 파일에 저장합니다.
[root@mon ~]# ceph pg dump -o FILE_NAME --format=json특정 배치 그룹을 쿼리하려면 다음을 수행합니다.
[root@mon ~]# ceph pg POOL_NUM.PG_ID query
JSON 형식의 출력 예:
{ "state": "active+clean", "up": [ 1, 0 ], "acting": [ 1, 0 ], "info": { "pgid": "1.e", "last_update": "4'1", "last_complete": "4'1", "log_tail": "0'0", "last_backfill": "MAX", "purged_snaps": "[]", "history": { "epoch_created": 1, "last_epoch_started": 537, "last_epoch_clean": 537, "last_epoch_split": 534, "same_up_since": 536, "same_interval_since": 536, "same_primary_since": 536, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174" }, "stats": { "version": "4'1", "reported": "536'782", "state": "active+clean", "last_fresh": "2013-01-25 10:12:23.828271", "last_change": "2013-01-25 10:12:23.828271", "last_active": "2013-01-25 10:12:23.828271", "last_clean": "2013-01-25 10:12:23.828271", "last_unstale": "2013-01-25 10:12:23.828271", "mapping_epoch": 535, "log_start": "0'0", "ondisk_log_start": "0'0", "created": 1, "last_epoch_clean": 1, "parent": "0.0", "parent_split_bits": 0, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174", "log_size": 128, "ondisk_log_size": 128, "stat_sum": { "num_bytes": 205, "num_objects": 1, "num_object_clones": 0, "num_object_copies": 0, "num_objects_missing_on_primary": 0, "num_objects_degraded": 0, "num_objects_unfound": 0, "num_read": 1, "num_read_kb": 0, "num_write": 3, "num_write_kb": 1 }, "stat_cat_sum": { }, "up": [ 1, 0 ], "acting": [ 1, 0 ] }, "empty": 0, "dne": 0, "incomplete": 0 }, "recovery_state": [ { "name": "Started\/Primary\/Active", "enter_time": "2013-01-23 09:35:37.594691", "might_have_unfound": [ ], "scrub": { "scrub_epoch_start": "536", "scrub_active": 0, "scrub_block_writes": 0, "finalizing_scrub": 0, "scrub_waiting_on": 0, "scrub_waiting_on_whom": [ ] } }, { "name": "Started", "enter_time": "2013-01-23 09:35:31.581160" } ] }
추가 리소스
- 스냅샷 트리밍 설정에 대한 자세한 내용은 Red Hat Ceph Storage 4 구성 가이드 의 OSD(Object Storage Daemon) 구성 옵션을 참조하십시오.
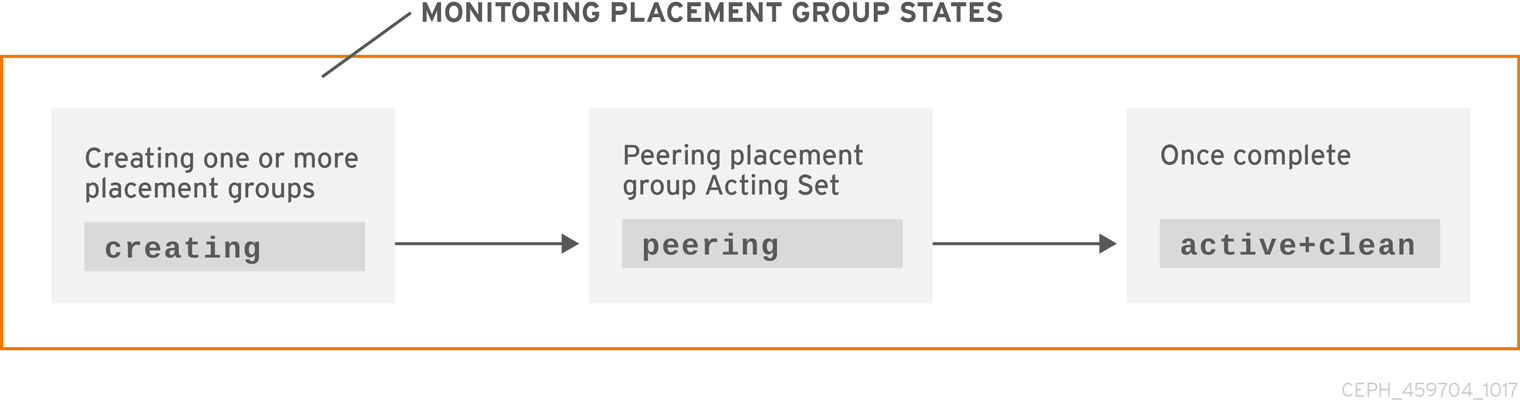
3.3.5. 배치 그룹 상태 생성
풀을 생성할 때 지정한 배치 그룹 수가 생성됩니다. 하나 이상의 배치 그룹을 생성할 때 Ceph에서 생성하는 작업을 수행합니다. 생성된 OSD는 배치 그룹의 acting Set의 일부인 OSD를 피어링합니다. 피어링이 완료되면 배치 그룹 상태가 active+clean 여야 합니다. 즉, Ceph 클라이언트가 배치 그룹에 쓰기를 시작할 수 있습니다.
3.3.6. 배치 그룹 피어링 상태
Ceph가 배치 그룹을 피어링하는 경우 Ceph에서 배치 그룹의 복제본을 배치 그룹의 상태 및 배치 그룹의 상태에 대한 동의 로 저장하는 OSD를 가져옵니다. Ceph가 피어링을 완료하면 배치 그룹을 저장하는 OSD가 배치 그룹의 현재 상태에 동의합니다. 그러나 피어링 프로세스 완료는 각 복제본에 최신 콘텐츠가 있음을 의미하지 않습니다.
신뢰할 수 있는 내역
Ceph 는 작동하는 세트의 모든 OSD가 쓰기 작업을 유지할 때까지 클라이언트에 대한 쓰기 작업을 인식하지 않습니다. 이 관행은 작업 세트의 적어도 하나의 멤버가 마지막으로 성공한 피어링 작업 이후 모든 승인 된 쓰기 작업의 레코드를 가질 수 있도록합니다.
Ceph는 승인한 각 쓰기 작업에 대한 정확한 레코드를 사용하여 배치 그룹의 새로운 권한을 부여하여 구성할 수 있습니다. 이 작업을 수행하면 전체적으로 정렬된 전체 작업 세트가 배치 그룹의 복사본을 최신 상태로 만들 수 있습니다.
3.3.7. 배치 그룹 활성 상태
Ceph가 피어링 프로세스를 완료하면 배치 그룹이 활성 상태가 될 수 있습니다. 활성 상태는 배치 그룹의 데이터를 일반적으로 기본 배치 그룹과 읽기 및 쓰기 작업을 위한 복제본에서 사용할 수 있음을 의미합니다.
3.3.8. 배치 그룹 정리 상태
배치 그룹이 깨끗한 상태인 경우 기본 OSD 및 복제본 OSD가 성공적으로 피어링되어 배치 그룹의 복제본이 없습니다. Ceph가 배치 그룹의 모든 오브젝트를 올바른 횟수만큼 복제합니다.
3.3.9. 배치 그룹 성능 저하 상태
클라이언트에서 기본 OSD에 오브젝트를 쓸 때 기본 OSD는 복제본 OSD에 복제본을 작성합니다. 기본 OSD에서 오브젝트를 스토리지에 기록한 후 Ceph가 복제본 오브젝트를 성공적으로 생성한 복제본 OSD에서 승인을 받을 때까지 배치 그룹은 성능이 저하된 상태로 유지됩니다.
배치 그룹이 active+degraded 될 수 있는 이유는 OSD가 아직 모든 오브젝트를 보유하고 있지 않더라도 활성화 될 수 있기 때문입니다. OSD가 다운되면 Ceph는 OSD에 할당된 각 배치 그룹을 성능 저하된 것으로 표시합니다. OSD가 다시 온라인 상태가 되면 OSD가 다시 피어링되어야 합니다. 그러나 클라이언트는 활성 상태인 경우 성능이 저하된 배치 그룹에 새 오브젝트를 계속 작성할 수 있습니다.
OSD가 다운 되어 성능이 저하된 조건이 지속되면 Ceph에서 down OSD를 클러스터 외부에서 표시하고 down OSD의 데이터를 다른 OSD로 다시 매핑할 수 있습니다. 표시된 것과 표시된 시간은 기본적으로 600 초로 설정된 mon_osd_ 에 의해 제어됩니다.
down _ out _interval
Ceph가 배치 그룹에 있어야 하는 오브젝트를 하나 이상 찾을 수 없기 때문에 배치 그룹도 성능이 저하 될 수 있습니다. unfound 개체를 읽거나 쓸 수는 없지만 성능이 저하된 배치 그룹의 다른 모든 오브젝트에 계속 액세스할 수 있습니다.
복제본 풀의 세 가지 방식으로 OSD가 9개 있다고 가정하겠습니다. OSD 번호 9가 다운되면 OSD 9에 할당된 PG가 성능 저하 상태가 됩니다. OSD 9가 복구되지 않으면 클러스터에서 벗어나 클러스터가 재조정됩니다. 이 시나리오에서 PG는 성능이 저하된 다음 활성 상태로 복구됩니다.
3.3.10. 배치 그룹 복구 상태
Ceph는 하드웨어 및 소프트웨어 문제가 진행 중인 대규모의 내결함성을 위해 설계되었습니다. OSD가 다운되면 해당 콘텐츠는 배치 그룹의 다른 복제본의 현재 상태에 있을 수 있습니다. OSD가 백업 되는 경우 현재 상태를 반영하려면 배치 그룹의 콘텐츠를 업데이트해야 합니다. 해당 기간 동안 OSD는 복구 상태를 반영할 수 있습니다.
하드웨어 장애로 인해 여러 OSD가 잘못될 수 있기 때문에 복구가 쉽지는 않습니다. 예를 들어 랙 또는 cache의 네트워크 스위치가 실패할 수 있으며 이로 인해 여러 호스트 시스템의 OSD가 클러스터의 현재 상태 뒤에 떨어질 수 있습니다. 오류가 해결되면 각 OSD를 하나씩 복구해야 합니다.
Ceph는 새 서비스 요청 간에 리소스 경합을 밸런싱하고 데이터 오브젝트를 복구하고 배치 그룹을 현재 상태로 복원하는 데 필요한 다양한 설정을 제공합니다. osd 복구 지연 시작 설정을 사용하면 OSD에서 복구 프로세스를 시작하기 전에 일부 재생 요청을 다시 시작, 재피어 및 처리할 수 있습니다. osd 복구 스레드 는 기본적으로 하나의 스레드로 복구 프로세스에 대한 스레드 수를 제한합니다. osd 복구 스레드 시간 초과 는 여러 OSD가 실패할 수 있기 때문에 스레드 시간 초과를 설정하고 정지 비율로 다시 피어를 다시 시작합니다. osd 복구 max active 설정은 OSD가 동시에 가져오는 복구 요청 수를 제한하여 OSD가 서비스를 제공하지 못하도록 합니다. osd recovery max chunk 설정은 네트워크 정체를 방지하기 위해 복구된 데이터 청크의 크기를 제한합니다.
3.3.11. 백 채우기 상태
새 OSD가 클러스터에 참여하면 CRUSH는 클러스터의 OSD에서 새로 추가된 OSD로 배치 그룹을 다시 할당합니다. 새 OSD가 다시 할당된 배치 그룹을 즉시 수락하도록 강제하면 새 OSD에 과도한 부하를 줄 수 있습니다. 배치 그룹으로 OSD를 다시 입력하면 이 프로세스가 백그라운드에서 시작할 수 있습니다. 백필(backfilling)이 완료되면 새 OSD가 요청 처리를 시작합니다.
백필 작업 중 하나를 볼 수 있습니다. * 는 백필 작업이 보류 중임을 나타내지만 아직 * 백필 작업이 진행 중임을 나타냅니다 * backfill _waitbackfill_too_full 은 백필 작업이 진행 중임을 나타냅니다. 백필 작업이 요청되었지만 스토리지 용량 부족으로 인해 완료할 수 없었습니다.
배치 그룹을 다시 채울 수 없는 경우 불완전한 것으로 간주될 수 있습니다.
Ceph는 OSD, 특히 새 OSD에 배치 그룹을 다시 할당하는 것과 관련된 부하 급증을 관리하는 다양한 설정을 제공합니다. 기본적으로 osd_max_backfills 는 최대 동시 백필 수를 OSD에서 10으로 설정합니다. OSD가 전체 비율에 도달하면 osd 백필 전체 비율을 사용하면 기본적으로 85%로 전체 비율에 도달하면 OSD에서 백필 요청을 거부할 수 있습니다. OSD가 백필 요청을 거부하면 osd 백필 재시도 간격 을 통해 OSD에서 기본적으로 10초 후에 요청을 다시 시도할 수 있습니다. OSD는 또한 osd 백필 검사 min 및 osd 백필 검사 max 를 설정하여 기본적으로 64 및 512로 검사 간격을 관리할 수 있습니다.
일부 워크로드의 경우 정기적인 복구를 완전히 방지하고 대신 백필을 사용하는 것이 좋습니다. 백필링은 백그라운드에서 이루어지므로 I/O가 OSD의 오브젝트를 계속 진행할 수 있습니다. 복구 대신 백필을 강제 적용하려면 osd_min_pg_log_entries 를 1 로 설정하고 osd_max_pg_log_entries 를 2 로 설정합니다. 이 상황이 워크로드에 적합한 시기에 대한 자세한 내용은 Red Hat 지원 계정 팀에 문의하십시오.
3.3.12. 복구 또는 백필 작업의 우선 순위 변경
일부 배치 그룹(PG)에 복구 및/또는 백필이 필요한 상황이 발생할 수 있으며 일부 배치 그룹에는 다른 배치 그룹보다 더 중요한 데이터가 포함되어 있을 수 있습니다. pg force-recovery 또는 pg force-backfill 명령을 사용하여 우선순위가 높은 데이터가 있는 PG가 먼저 복구 또는 백필되는지 확인합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
pg force-recovery또는pg force-backfill명령을 실행하고 우선순위가 높은 데이터로 PG에 대한 우선 순위 순서를 지정합니다.구문
ceph pg force-recovery PG1 [PG2] [PG3 ...] ceph pg force-backfill PG1 [PG2] [PG3 ...]
예제
[root@node]# ceph pg force-recovery group1 group2 [root@node]# ceph pg force-backfill group1 group2
이 명령을 사용하면 Red Hat Ceph Storage가 다른 배치 그룹을 처리하기 전에 먼저 지정된 PG(배치 그룹)에서 복구하거나 백필(backfill)할 수 있습니다. 명령을 실행해도 현재 실행 중인 백필 또는 복구 작업이 중단되지 않습니다. 현재 실행 중인 작업이 완료되면 지정된 PG에 대해 복구 또는 백필(backfill)이 수행됩니다.
3.3.13. 지정된 배치 그룹에서 복구 또는 백필 작업 변경 또는 취소
스토리지 클러스터에서 특정 배치 그룹(PG)에서 우선순위가 높은 강제 복구 작업을 취소하면 해당 PG에 대한 작업이 기본 복구 또는 백필 설정으로 되돌아갑니다.
복구 또는 강제
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
지정된 배치 그룹에서 복구 또는 백필 작업을 변경하거나 취소하려면 다음을 수행합니다.
구문
ceph pg cancel-force-recovery PG1 [PG2] [PG3 ...] ceph pg cancel-force-backfill PG1 [PG2] [PG3 ...]
예제
[root@node]# ceph pg cancel-force-recovery group1 group2 [root@node]# ceph pg cancel-force-backfill group1 group2
이렇게 하면
force플래그를 취소하고 PG를 기본 순서로 처리합니다.지정된 PG에 대한 복구 또는 백필 작업이 완료되면 처리 순서는 기본값으로 되돌립니다.
추가 리소스
- RADOS의 복구 우선 순위 및 백필 작업 순서에 대한 자세한 내용은 배치 그룹 복구 우선 순위 및 RADOS에서 백필 작업을 참조하십시오.
3.3.14. 풀에 우선순위가 높은 복구 또는 백필 작업 강제 적용
풀의 모든 배치 그룹에 우선순위가 높은 복구 또는 백필이 필요한 경우 force-recovery 또는 force-backfill 옵션을 사용하여 작업을 시작합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
우선순위가 높은 복구를 강제 적용하거나 지정된 풀의 모든 배치 그룹을 다시 채우려면 다음을 수행합니다.
구문
ceph osd pool force-recovery POOL_NAME ceph osd pool force-backfill POOL_NAME
예제
[root@node]# ceph osd pool force-recovery pool1 [root@node]# ceph osd pool force-backfill pool1
참고force-recovery및force-backfill명령을 신중하게 사용합니다. 이러한 작업의 우선 순위를 변경하면 Ceph의 내부 우선 순위 계산 순서가 손상될 수 있습니다.
3.3.15. 우선 순위가 높은 복구 또는 풀의 백필 작업 취소
풀의 모든 배치 그룹에서 우선순위가 높은 강제 복구 작업을 취소하면 해당 풀의 PG에 대한 작업이 기본 복구 또는 백필 설정으로 되돌아갑니다.
복구 또는 강제
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
지정된 풀의 모든 배치 그룹에서 우선순위가 높은 복구 또는 백필 작업을 취소하려면 다음을 수행합니다.
구문
ceph osd pool cancel-force-recovery POOL_NAME ceph osd pool cancel-force-backfill POOL_NAME
예제
[root@node]# ceph osd pool cancel-force-recovery pool1 [root@node]# ceph osd pool cancel-force-backfill pool1
3.3.16. 풀의 복구 또는 백필 작업 우선 순위 조정
현재 동일한 기본 OSD를 사용하는 풀이 여러 개 있고 일부 풀에 우선순위가 높은 데이터가 있는 경우 작업이 실행되는 순서를 다시 정렬할 수 있습니다. recovery_priority 옵션을 사용하여 우선순위가 높은 데이터를 더 높은 풀에 할당합니다. 이러한 풀은 우선 순위가 낮은 풀 또는 기본 우선 순위로 설정된 풀보다 먼저 실행됩니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
풀의 복구/백필 우선 순위를 다시 정렬하려면 다음을 수행합니다.
구문
ceph osd pool set POOL_NAME recovery_priority VALUE
예제
ceph osd pool set pool1 recovery_priority 10
VALUE 는 우선순위 순서를 설정합니다. 예를 들어, 100개의 풀이 있는 경우 우선순위 값이 10인 풀이 먼저 처리되고 그 다음에 우선순위 9가 있는 풀이 처리됩니다. 일부 풀만 우선 순위가 높은 경우 해당 풀에만 우선순위 값을 설정할 수 있습니다. 우선순위 값이 설정되지 않은 풀은 기본 순서로 처리됩니다.
3.3.17. RADOS에서 배치 그룹 복구의 우선 순위
이 섹션에서는 RADOS의 복구 우선 순위 값과 PG(배치 그룹) 백필링에 대해 설명합니다. 더 높은 값이 먼저 처리됩니다. 비활성 PG는 활성 또는 성능이 저하된 PG보다 우선 순위가 높습니다.
| 작업 | 값 | 설명 |
|---|---|---|
| OSD_RECOVERY_PRIORITY_MIN | 0 | 최소 복구 값 |
| OSD_BACKFILL_PRIORITY_BASE | 100 | MBackfillReserve의 기본 백필 우선 순위 |
| OSD_BACKFILL_DEGRADED_PRIORITY_BASE | 140 | MBackfillReserve의 기본 백필 우선 순위 (degraded PG) |
| OSD_RECOVERY_PRIORITY_BASE | 180 | MBackfillReserve의 기본 복구 우선 순위 |
| OSD_BACKFILL_INACTIVE_PRIORITY_BASE | 220 | MBackfillReserve (활성 PG)에 대한 기본 백필 우선 순위 |
| OSD_RECOVERY_INACTIVE_PRIORITY_BASE | 220 | MRecoveryReserve의 기본 복구 우선 순위 (활성 PG) |
| OSD_RECOVERY_PRIORITY_MAX | 253 | max 수동/자동으로 MBackfillReserve의 복구 우선 순위 설정 |
| OSD_BACKFILL_PRIORITY_FORCED | 254 | MBackfillReserve에 대한 백필 우선 순위, 강제 수동 |
| OSD_RECOVERY_PRIORITY_FORCED | 255 | MRecoveryReserve에 대한 복구 우선 순위, 강제 수동 |
| OSD_DELETE_PRIORITY_NORMAL | 179 | OSD가 완전히 지원되지 않는 경우 PG 삭제의 우선 순위 |
| OSD_DELETE_PRIORITY_FULLISH | 219 | OSD가 완전히 접근되면 PG 삭제의 우선 순위 |
| OSD_DELETE_PRIORITY_FULL | 255 | OSD가 가득 차면 삭제의 우선 순위 |
3.3.18. 배치 그룹 재대 매핑 상태
서비스가 배치 그룹이 변경되도록 설정하면 데이터는 이전 작업 집합에서 새로운 작동 집합으로 마이그레이션합니다. 새 기본 OSD가 서비스 요청에 다소 시간이 걸릴 수 있습니다. 따라서 배치 그룹 마이그레이션이 완료될 때까지 이전의 기본 요청을 계속 서비스하도록 요청할 수 있습니다. 데이터 마이그레이션이 완료되면 매핑에서 새로운 작동 세트의 기본 OSD를 사용합니다.
3.3.19. 배치 그룹 부 상태
Ceph는 하트비트를 사용하여 호스트 및 데몬이 실행 중인지 확인하는 반면 ceph-osd 데몬은 적절한 방식으로 통계를 보고하지 않는 상태로 유지될 수도 있습니다. 예를 들어, 일시적인 네트워크 오류입니다. 기본적으로 OSD 데몬은 배치 그룹(하위트, 부팅 및 실패 통계)을 절반씩 보고합니다. 즉, 0.5 는 하트비트 임계값보다 더 많습니다. 배치 그룹의 작동 그룹의 기본 OSD 가 모니터에 보고되지 않거나 다른 OSD가 기본 OSD를 보고한 경우 모니터는 배치 그룹을 오래된 것으로 표시합니다.
스토리지 클러스터를 시작할 때 피어링 프로세스가 완료될 때까지 오래된 상태를 확인하는 것이 일반적입니다. 스토리지 클러스터가 잠시 동안 실행된 후 stale 상태에서 배치 그룹이 표시되면 해당 배치 그룹의 기본 OSD가 다운 되거나 모니터에 배치 그룹 통계를 보고하지 않음을 나타냅니다.
3.3.20. 배치 그룹의 상태가 잘못 배치됨
PG가 OSD에 일시적으로 매핑되는 임시 백필링 시나리오가 있습니다. 이러한 임시 상황이 더 이상 발생하지 않아야 할 때 PG는 여전히 임시 위치에 있고 적절한 위치에 있지 않을 수 있습니다. 이 경우 잘못 배치되어 있다고 합니다. 이는 실제로 올바른 수의 추가 사본이 존재하기 때문에 하나 이상의 복사본이 잘못된 위치에 있습니다.
예를 들어 OSD 3개가 0,1,2 및 모든 PG가 3개씩씩 매핑됩니다. 다른 OSD(OSD 3)를 추가하면 일부 PG가 이제 다른 OSD 대신 OSD 3에 매핑됩니다. 그러나 OSD 3이 다시 입력될 때까지 PG에는 임시 매핑이 있어 이전 매핑에서 I/O를 계속 제공할 수 있습니다. 그 기간 동안 임시 매핑이 있지만 3개의 복사본이 있으므로 성능이 저하 되지 않기 때문에 PG가 잘못 배치 되었습니다.
예제
pg 1.5: up=acting: [0,1,2]
ADD_OSD_3
pg 1.5: up: [0,3,1] acting: [0,1,2]
[0,1,2]는 임시 매핑이므로 up 세트는 작동 세트와 같지 않으며 PG는 잘못 배치 되지만 [0,1,2]는 여전히 3 개의 사본으로 인해 성능이 저하 되지 않습니다.
예제
pg 1.5: up=acting: [0,3,1]
이제 OSD 3이 다시 채워지고 임시 매핑이 저하되지 않고 잘못 배치되지 않습니다.
3.3.21. placement Group 불완전한 상태
불완전한 콘텐츠가 있고 피어링에 실패하면 PG가 불완전한 상태가 됩니다. 즉, 복구 수행에 충분한 완전한 OSD가 없는 경우입니다.
OSD 1, 2 및 3이 작동하는 OSD 세트이고 OSD 1, 4 및 3으로 전환한 다음 osd.1 은 OSD 1, 2 및 3의 임시 작업을 수행하는 동안 백필링 4를 요청합니다. 이 시간 동안 OSD 1, 2 및 3이 모두 다운된 경우 osd.4 는 모든 데이터를 완전히 다시 채우지 않은 유일한 왼쪽이 됩니다. 현재 PG는 복구 수행에 충분한 완전한 OSD가 없음을 나타내는 불완전하게 됩니다.
또는, osd.4 가 관련되지 않고 동작 세트가 OSD 1, 2, 3인 경우 OSD 1, 2, 3이 다운될 때 PG는 작동 세트가 변경되었기 때문에 PG가 확인되지 않았음을 나타낼 수 있습니다. OSD가 없는 이유는 새 OSD에 알립니다.
3.3.22. 중단된 배치 그룹 확인
이전에 언급했듯이 배치 그룹은 상태가 active+clean 이 아니기 때문에 반드시 문제가 되지는 않습니다. 일반적으로 배치 그룹이 중단될 때 Ceph를 자체 복구할 수 있는 기능이 작동하지 않을 수 있습니다. 고정 상태에는 다음이 포함됩니다.
- unclean: 배치 그룹에는 원하는 횟수를 복제하지 않는 오브젝트가 포함되어 있습니다. 회복을 해야 합니다.
-
비활성: 배치 그룹은 최신 데이터가 있는 OSD를 기다리고 있기 때문에 읽기 또는 쓰기를 처리할 수 없습니다.
-
stale: 배치 그룹은 잠시 동안 모니터 클러스터에 보고되지 않았으며
mon osd report timeout설정으로 구성할 수 있으므로 호스트하는 OSD가 알 수 없는 상태입니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
중단된 배치 그룹을 식별하려면 다음을 실행합니다.
ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}
3.3.23. 오브젝트의 위치 찾기
Ceph 클라이언트는 최신 클러스터 맵을 검색하고 CRUSH 알고리즘은 개체를 배치 그룹에 매핑하는 방법을 계산한 다음 배치 그룹을 OSD에 동적으로 할당하는 방법을 계산합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
오브젝트 위치를 찾으려면 오브젝트 이름과 풀 이름이 필요합니다.
ceph osd map POOL_NAME OBJECT_NAME
4장. Ceph 동작 덮어쓰기
스토리지 관리자는 Red Hat Ceph Storage 클러스터에 대한 재정의를 사용하여 런타임 중에 Ceph 옵션을 변경하는 방법을 이해해야 합니다.
4.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
4.2. Ceph 덮어쓰기 옵션 설정 및 설정 해제
Ceph 옵션을 설정하고 설정을 해제하여 Ceph의 기본 동작을 재정의할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
Ceph의 기본 동작을 재정의하려면
ceph osd set명령과 재정의하려는 동작을 사용합니다.ceph osd set FLAG동작을 설정하면 클러스터에 설정한 덮어쓰기가
ceph 상태가반영됩니다.Ceph의 기본 동작 덮어쓰기를 중단하려면
ceph osd unset명령과 중단하려는 재정의를 사용합니다.ceph osd unset FLAG
| 플래그 | 설명 |
|---|---|
|
|
OSD가 클러스터에서 |
|
|
OSD가 클러스터에서 처리되지 |
|
|
OSD가 실행 중으로 취급되지 않도록 합니다. |
|
|
OSD가 |
|
|
클러스터가 |
|
|
Ceph는 읽기 및 쓰기 작업을 중지하지만 , |
|
| Ceph는 새로운 백필 작업을 방지합니다. |
|
| Ceph는 새로운 리밸런싱 작업을 방지합니다. |
|
| Ceph는 새로운 복구 작업을 방지합니다. |
|
| Ceph를 사용하면 새로운 스크럽 작업이 수행되지 않습니다. |
|
| Ceph를 사용하면 새로운 딥 스크럽 작업이 발생하지 않습니다. |
|
| Ceph는 플러시 및 제거에 사용할 cold/dirty 오브젝트를 찾고 있는 프로세스를 비활성화합니다. |
4.3. Ceph 기본 사용 사례
-
noin: 일반적으로noout과 함께 사용하여 잘못된 OSD 문제를 해결합니다. -
no:outmon osd 보고서 시간 제한이초과되고 OSD가 모니터에 보고되지 않은 경우 OSD가 표시됩니다. 이 문제가 잘못 발생하면 문제를 해결하는 동안 OSD가 표시되지 않도록no을 설정할 수 있습니다.out -
noup: 일반적으로nodown과 함께 사용되어 푸핑 OSD를 처리합니다. -
nodown: 네트워킹 문제는 Ceph 'heartbeat' 프로세스를 중단할 수 있으며 OSD는up이지만 계속 표시될 수 있습니다. 문제 해결 중에 OSD가 다운된 상태로 표시되지 않도록nodown을 설정할 수 있습니다. fullfull_ratio에 도달하면 클러스터를 미리 완전히 설정하고 용량을 확장할 수 있습니다.참고클러스터를
full로 설정하면 쓰기 작업이 수행되지 않습니다.-
pause -
nobackfill: 예를 들어 데몬 업그레이드와 같이 OSD 또는 노드를 일시적으로 중단해야 하는 경우 OSD가다운되는 동안 Ceph가 다시 입력되지 않도록nobackfill을 설정할 수 있습니다. -
norecover: OSD 디스크를 교체해야 하며 PG가 핫스테핑 디스크인 동안 다른 OSD로 복구하지 않도록 하려면norecover를 설정하여 다른 OSD가 새 PG 세트를 다른 OSD로 복사하지 못하도록 할 수 있습니다. -
noscrub및nodeep-scrubb: 예를 들어 스크럽, 복구, 백필링 중에 오버헤드를 줄이려면 클러스터가 OSD를 스크럽지 않도록noscrub및/또는nodeep-scrub를 설정할 수 있습니다. -
notieragent: 계층 에이전트 프로세스를 중지하고 백업 스토리지 계층에 플러시하는 콜드 오브젝트를 찾으려면notieragent를 설정할 수 있습니다.
5장. Ceph 사용자 관리
스토리지 관리자는 Red Hat Ceph Storage 클러스터의 오브젝트에 대한 인증, 키링 관리 및 액세스 제어를 제공하여 Ceph 사용자 기반을 관리할 수 있습니다.
5.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터 또는 Ceph 클라이언트 노드에 액세스할 수 있습니다.
5.2. Ceph 사용자 관리 배경
Ceph가 인증 및 권한 부여가 활성화된 상태에서 실행되는 경우 지정된 사용자의 비밀 키가 포함된 사용자 이름과 인증 키를 지정해야 합니다. 사용자 이름을 지정하지 않으면 Ceph에서 client.admin 관리 사용자를 기본 사용자 이름으로 사용합니다. 인증 키를 지정하지 않으면 Ceph 구성에서 인증 키 설정을 사용하여 인증 키 를 찾습니다. 예를 들어 사용자 또는 인증 키를 지정하지 않고 ceph 상태 명령을 실행하는 경우 다음을 수행합니다.
# ceph health
Ceph는 다음과 같이 명령을 해석합니다.
# ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
또는CEPH _ARGS 환경 변수를 사용하여 사용자 이름과 시크릿의 재입력을 방지할 수 있습니다.
Ceph 클라이언트 유형(예: 블록 장치, 오브젝트 저장소, 파일 시스템, 네이티브 API 또는 Ceph 명령줄)과 관계없이 Ceph는 모든 데이터를 풀 내의 오브젝트로 저장합니다. Ceph 사용자는 데이터를 읽고 쓸 수 있도록 풀에 액세스할 수 있어야 합니다. 또한 관리 Ceph 사용자는 Ceph 관리 명령을 실행할 수 있는 권한이 있어야 합니다.
다음 개념은 Ceph 사용자 관리를 이해하는 데 도움이 될 수 있습니다.
스토리지 클러스터 사용자
Red Hat Ceph Storage 클러스터의 사용자는 개인 또는 애플리케이션 중 하나입니다. 사용자를 생성하면 스토리지 클러스터, 해당 풀 및 해당 풀 내의 데이터에 액세스할 수 있는 사람을 제어할 수 있습니다.
Ceph에는 사용자 유형의 개념이 있습니다. 사용자 관리 목적의 경우 유형은 항상 client 가 됩니다. Ceph는 사용자 유형 및 사용자 ID로 구성된 기간(.)으로 사용자를 식별합니다. 예를 들어 TYPE.ID,client.admin 또는 client.user1 입니다. 사용자가 입력하는 이유는 Ceph Monitor와 OSD에서도 Cephx 프로토콜을 사용하지만 클라이언트는 사용하지 않기 때문입니다. 사용자 유형을 구분하면 클라이언트 사용자와 기타 사용자를 구별하는 데 도움이 됩니다. 액세스 제어, 사용자 모니터링 및 추적 기능을 제공합니다.
Ceph 명령줄을 사용하면 명령줄 사용에 따라 유형 사용 여부에 따라 유형의 사용자를 지정할 수 있으므로 Ceph의 사용자 유형이 혼란스러울 수 있습니다. --user 또는 --id 를 지정하면 유형을 생략할 수 있습니다. 따라서 client.user1 은 단순히 user1 로 입력할 수 있습니다. --name 또는 -n 을 지정하는 경우 type 및 name(예: client.user1 )을 지정해야 합니다. 가능한 경우 유형 및 이름을 모범 사례로 사용하는 것이 좋습니다.
Red Hat Ceph Storage 클러스터 사용자는 Ceph Object Gateway 사용자와 동일하지 않습니다. 오브젝트 게이트웨이는 Red Hat Ceph Storage 클러스터 사용자를 사용하여 게이트웨이 데몬과 스토리지 클러스터 간에 통신하지만 게이트웨이에는 최종 사용자를 위한 고유한 사용자 관리 기능이 있습니다.
구문
DAEMON_TYPE 'allow CAPABILITY' [DAEMON_TYPE 'allow CAPABILITY']
monitor Caps: 모니터 기능은
r,w,x,allow profile CAP,profile rbd가 포함되어 있습니다.예제
mon 'allow rwx` mon 'allow profile osd'
OSD 기능: OSD 기능에는
r,w,x,class-read,class-write,profile osd,profile rbdosd 'allow CAPABILITY' [pool=POOL_NAME] [namespace=NAMESPACE_NAME]
Ceph Object Gateway 데몬(radosgw)은 Ceph 스토리지 클러스터의 클라이언트이므로 Ceph 스토리지 클러스터 데몬 유형으로 표시되지 않습니다.
다음 항목은 각 기능에 대해 설명합니다.
|
| 데몬의 액세스 설정 전 precedes |
|
| 사용자에게 읽기 액세스 권한을 부여합니다. CRUSH 맵을 검색하는 데 모니터가 필요합니다. |
|
| 사용자에게 오브젝트에 대한 쓰기 액세스 권한을 부여합니다. |
|
|
사용자에게 클래스 메서드 호출(즉, 읽기 및 쓰기)을 호출하고 모니터에서 |
|
|
사용자에게 클래스 읽기 메서드를 호출하는 기능을 제공합니다. |
|
|
사용자에게 클래스 쓰기 메서드를 호출하는 기능을 제공합니다. |
|
| 사용자에게 특정 데몬 또는 풀에 대한 읽기, 쓰기 및 실행 권한과 관리자 명령을 실행할 수 있는 기능을 제공합니다. |
|
| OSD를 다른 OSD 또는 모니터에 연결할 수 있는 권한을 사용자에게 제공합니다. OSD에서 유추하여 복제 하트비트 트래픽 및 상태 보고를 처리할 수 있습니다. |
|
| OSD를 부트스트랩할 때 키를 추가할 수 있는 권한이 있도록 사용자에게 OSD를 부트스트랩할 수 있는 권한을 제공합니다. |
|
| 사용자에게 Ceph 블록 장치에 대한 읽기-쓰기 액세스 권한을 제공합니다. |
|
| 사용자에게 Ceph 블록 장치에 대한 읽기 전용 액세스 권한을 제공합니다. |
pool
풀은 Ceph 클라이언트의 스토리지 전략을 정의하고 해당 전략의 논리 파티션 역할을 합니다.
Ceph 배포에서 다른 유형의 사용 사례를 지원하는 풀을 만드는 것이 일반적입니다. 예를 들어 클라우드 볼륨 또는 이미지, 오브젝트 스토리지, 핫 스토리지, 콜드 스토리지 등이 있습니다. OpenStack의 백엔드로 Ceph를 배포하는 경우 일반적인 배포에는 볼륨, 이미지, 백업 및 가상 시스템용 풀 및 client.glance .cinder 등 사용자가 있습니다.
네임스페이스
풀 내의 오브젝트는 네임스페이스-a logical group of objects within the pool에 연결할 수 있습니다. 사용자가 풀에 대한 액세스 권한은 네임스페이스 내에서만 수행되며, 사용자가 읽고 쓰는 네임스페이스와 연결할 수 있습니다. 풀 내의 네임스페이스에 작성된 오브젝트는 네임스페이스에 대한 액세스 권한이 있는 사용자만 액세스할 수 있습니다.
현재 네임스페이스는 librados 상단에 작성된 애플리케이션에만 유용합니다. 블록 장치 및 오브젝트 스토리지와 같은 Ceph 클라이언트는 현재 이 기능을 지원하지 않습니다.
네임스페이스의 논리는 각 풀이 OSD에 매핑되는 배치 그룹 세트를 생성하기 때문에 풀은 사용 사례에 따라 데이터를 분리하는 데 비용이 많이 드는 계산 방법이 될 수 있다는 것입니다. 여러 풀에서 동일한 CRUSH 계층 구조와 규칙 세트를 사용하는 경우 부하 증가에 따라 OSD 성능이 저하될 수 있습니다.
예를 들어, 풀은 OSD당 약 100개의 배치 그룹이 있어야 합니다. 따라서 1000개의 OSD가 있는 예시적인 클러스터에는 하나의 풀에 대해 10만 개의 배치 그룹이 있습니다. 동일한 CRUSH 계층 구조에 매핑된 각 풀은 예시 클러스터에 10만 개의 배치 그룹을 생성합니다. 반대로 네임스페이스에 개체를 쓰면 네임스페이스를 개체 이름에 연결하면 별도의 풀의 컴퓨팅 오버헤드가 제거됩니다. 사용자 또는 사용자 집합에 대해 별도의 풀을 생성하는 대신 네임스페이스를 사용할 수 있습니다.
현재 librados 를 사용하는 경우에만 사용할 수 있습니다.
추가 리소스
- 인증 사용에 대한 자세한 내용은 Red Hat Ceph Storage 구성 가이드 를 참조하십시오.
5.3. Ceph 사용자 관리
스토리지 관리자는 사용자를 생성, 수정, 삭제, 가져오는 방식으로 Ceph 사용자를 관리할 수 있습니다. Ceph 클라이언트 사용자는 Ceph 클라이언트를 사용하여 Red Hat Ceph Storage 클러스터 데몬과 상호 작용하는 개인 또는 애플리케이션일 수 있습니다.
5.3.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터 또는 Ceph 클라이언트 노드에 액세스할 수 있습니다.
5.3.2. Ceph 사용자 나열
명령줄 인터페이스를 사용하여 스토리지 클러스터의 사용자를 나열할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
스토리지 클러스터의 사용자를 나열하려면 다음을 실행합니다.
[root@mon ~]# ceph auth list
Ceph는 스토리지 클러스터의 모든 사용자를 나열합니다. 예를 들어 2-노드 예시 스토리지 클러스터에서
ceph 인증 목록은다음과 같은 결과를 출력합니다.예제
installed auth entries: osd.0 key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w== caps: [mon] allow profile osd caps: [osd] allow * osd.1 key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA== caps: [mon] allow profile osd caps: [osd] allow * client.admin key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw== caps: [mds] allow caps: [mon] allow * caps: [osd] allow * client.bootstrap-mds key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww== caps: [mon] allow profile bootstrap-mds client.bootstrap-osd key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw== caps: [mon] allow profile bootstrap-osd
사용자의 TYPE.ID 표기법은 osd.0 유형이 osd 이고 ID가 0 이고client.admin 은 클라이언트의 사용자이며, client. admin 은 기본 client.admin 사용자인 admin 입니다. 각 항목에는 VALUE 항목 및 하나 이상의 caps: 항목이 있습니다.
-o FILE_NAME 옵션을 ceph 인증 목록과 함께 사용하여 출력을 파일에 저장할 수 있습니다.
5.3.3. Ceph 사용자 정보 표시
명령줄 인터페이스를 사용하여 Ceph의 사용자 정보를 표시할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
특정 사용자, 키 및 기능을 검색하려면 다음을 실행합니다.
ceph auth export TYPE.ID
예제
[root@mon ~]# ceph auth get client.admin
-o FILE_NAME옵션을ceph auth get과 함께 사용하여 출력을 파일에 저장할 수도 있습니다. 개발자는 다음을 실행할 수도 있습니다.ceph auth export TYPE.ID
예제
[root@mon ~]# ceph auth export client.admin
auth export 명령은 auth get 와 동일하지만, 내부 auid 도 출력됩니다. 이 명령은 최종 사용자와 관련이 없습니다.
5.3.4. 새 Ceph 사용자 추가
사용자를 추가하면 사용자 이름, 즉 TYPE.ID, secret 키 및 사용자를 생성하는 데 사용하는 명령에 포함된 모든 기능이 생성됩니다.
사용자의 키를 사용하면 Ceph 스토리지 클러스터를 인증할 수 있습니다. 사용자의 기능은 사용자가 Ceph 모니터(mon), Ceph OSD(osd) 또는 Ceph 메타데이터 서버(mds)에서 읽기, 쓰기 또는 실행할 수 있도록 권한을 부여합니다.
사용자를 추가하는 몇 가지 방법이 있습니다.
-
Ceph auth add:이 명령은 사용자를 추가하는 표준 방법입니다. 사용자를 생성하고 키를 생성하고 지정된 기능을 추가합니다. -
Ceph auth get-or-create: 이 명령은 사용자 이름(대괄호로) 및 키가 있는 키 파일 형식을 반환하기 때문에 사용자를 생성하는 가장 편리한 방법입니다. 사용자가 이미 존재하는 경우 이 명령은 키 파일 형식으로 사용자 이름과 키를 반환하기만 하면 됩니다. 출력을 파일에 저장하려면-o FILE_NAME옵션을 사용할 수 있습니다. -
Ceph auth get-or-create-key: 이 명령은 사용자를 생성하고 사용자 키만 반환하는 편리한 방법입니다. 이 명령은 키가 필요한 클라이언트(예:libvirt)에 유용합니다. 사용자가 이미 존재하는 경우 이 명령은 단순히 키를 반환합니다. 출력을 파일에 저장하려면-o FILE_NAME옵션을 사용할 수 있습니다.
클라이언트 사용자를 생성할 때 기능 없이 사용자를 생성할 수 있습니다. 클라이언트가 모니터에서 클러스터 맵을 검색할 수 없기 때문에 기능이 없는 사용자는 단순한 인증보다 쓸모가 없습니다. 그러나 ceph auth caps 명령을 사용하여 나중에 기능 추가를 연기하려는 경우 기능이 없는 사용자를 생성할 수 있습니다.
일반 사용자는 Ceph OSD에서 Ceph 모니터 및 읽기 및 쓰기 기능을 적어도 읽을 수 있습니다. 또한 사용자의 OSD 권한이 특정 풀에 액세스하도록 제한되는 경우가 많습니다. :
[root@mon ~]# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' [root@mon ~]# ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' [root@mon ~]# ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring [root@mon ~]# ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
사용자에게 OSD에 대한 기능을 제공하지만 특정 풀에 대한 액세스 권한을 제한하지 않으면 사용자는 클러스터의 모든 풀에 액세스할 수 있습니다.
5.3.5. Ceph 사용자 수정
ceph auth caps 명령을 사용하면 사용자를 지정하고 사용자의 기능을 변경할 수 있습니다. 새 기능을 설정하면 현재 기능을 덮어씁니다. 따라서 현재 기능을 먼저 보고 새 기능을 추가할 때 포함합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
현재 기능을 확인합니다.
ceph auth get USERTYPE.USERID
예제
[root@mon ~]# ceph auth get client.john exported keyring for client.john [client.john] key = AQAHjy1gkxhIMBAAxsaoFNuxlUhr/zKsmnAZOA== caps mon = "allow r" caps osd = "allow rw pool=liverpool"
기능을 추가하려면 양식을 사용합니다.
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'
예제
[root@mon ~]# ceph auth caps client.john mon 'allow r' osd 'allow rwx pool=liverpool'
이 예에서는 OSD에서 실행 기능이 추가되었습니다.
추가된 기능을 확인합니다.
ceph auth get _USERTYPE_._USERID_
예제
[root@mon ~]# ceph auth get client.john exported keyring for client.john [client.john] key = AQAHjy1gkxhIMBAAxsaoFNuxlUhr/zKsmnAZOA== caps mon = "allow r" caps osd = "allow rwx pool=liverpool"
이 예제에서는 OSD에서 실행 기능을 확인할 수 있습니다.
기능을 제거하려면 제거하려는 기능을 제외한 모든 현재 기능을 설정합니다.
ceph auth caps USERTYPE.USERID DAEMON 'allow [r|w|x|*|...] [pool=POOL_NAME] [namespace=NAMESPACE_NAME]'
예제
[root@mon ~]# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool'
이 예제에서는 OSD에서 실행 기능이 포함되지 않았으므로 제거됩니다.
제거된 기능을 확인합니다.
ceph auth get _USERTYPE_._USERID_
예제
[root@mon ~]# ceph auth get client.john exported keyring for client.john [client.john] key = AQAHjy1gkxhIMBAAxsaoFNuxlUhr/zKsmnAZOA== caps mon = "allow r" caps osd = "allow rw pool=liverpool"
이 예에서는 OSD에서 실행 기능이 더 이상 나열되지 않습니다.
추가 리소스
- 기능에 대한 자세한 내용은 권한 부여 기능을 참조하십시오.
5.3.6. Ceph 사용자 삭제
명령줄 인터페이스를 사용하여 Ceph 스토리지 클러스터에서 사용자를 삭제할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
사용자를 삭제하려면
ceph auth del:를 사용하십시오.[root@mon ~]# ceph auth del TYPE.ID
여기서
TYPE은클라이언트,osd,mon또는mds중 하나이며ID는 데몬의 사용자 이름 또는 ID입니다.
5.3.7. Ceph 사용자 키 출력
명령줄 인터페이스를 사용하여 Ceph 사용자의 주요 정보를 표시할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
사용자의 인증 키를 표준 출력에 출력하려면 다음을 실행합니다.
ceph auth print-key TYPE.ID
여기서
TYPE은클라이언트,osd,mon또는mds중 하나이며ID는 데몬의 사용자 이름 또는 ID입니다.사용자 키를 인쇄하는 것은 클라이언트 소프트웨어를 사용자 키(예:
libvirt)로 채워야 하는 경우에 유용합니다.mount -t ceph HOSTNAME:/MOUNT_POINT -o name=client.user,secret=
ceph auth print-key client.user
5.3.8. Ceph 사용자 가져오기
명령줄 인터페이스를 사용하여 Ceph 사용자를 가져올 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
하나 이상의 사용자를 가져오려면
ceph auth 가져오기를 사용하고 인증 키를 지정합니다.ceph auth import -i /PATH/TO/KEYRING
예제
[root@mon ~]# ceph auth import -i /etc/ceph/ceph.keyring
Ceph 스토리지 클러스터는 새로운 사용자, 키 및 기능을 추가하고 기존 사용자, 키 및 기능을 업데이트합니다.
5.4. Ceph 인증 키 관리
스토리지 관리자는 Red Hat Ceph Storage 클러스터에 액세스하기 위해 Ceph 사용자 키를 관리하는 것이 중요합니다. 인증 키를 만들고, 사용자를 인증 키에 추가하고, 인증 키를 사용하여 사용자를 수정할 수 있습니다.
5.4.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph 모니터 또는 Ceph 클라이언트 노드에 액세스할 수 있습니다.
5.4.2. 인증 키 생성
Ceph 클라이언트가 지정된 사용자의 키를 검색하고 Ceph Storage 클러스터를 인증할 수 있도록 사용자 키를 Ceph 클라이언트에 제공해야 합니다. Ceph Clients 액세스 키 키는 사용자 이름을 조회하고 사용자 키를 검색합니다.
ceph-authtool 유틸리티를 사용하면 인증 키를 만들 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
빈 인증 키를 만들려면
--create-keyring또는-C를 사용합니다.예제
[root@mon ~]# ceph-authtool --create-keyring /path/to/keyring
여러 사용자가 있는 인증 키를 만드는 경우 클러스터 이름을 사용하는 것이 좋습니다. 예를 들어 인증 키 파일 이름의
CLUSTER_NAME.keyring'을/etc/ceph/디렉터리에 저장하여인증 키구성 기본 설정이 Ceph 구성 파일의 로컬 사본에 지정하지 않고 파일 이름을 가져오도록 합니다.다음을 실행하여
ceph.keyring을 생성합니다.[root@mon ~]# ceph-authtool -C /etc/ceph/ceph.keyring
단일 사용자로 인증 키를 생성하는 경우 클러스터 이름, 사용자 유형, 사용자 이름을 사용하여 /etc/ceph/ 디렉터리에 저장하는 것이 좋습니다. 예를 들어, client.admin 사용자의 ceph.client.admin.keyring 입니다.
/etc/ceph/ 에 인증 키를 만들려면 루트로 수행해야 합니다. 즉, 파일에 root 사용자에게만 rw 권한이 있으며 이는 인증 키에 관리자 키가 포함된 경우에만 적합합니다. 그러나 특정 사용자 또는 사용자 그룹에 인증 키를 사용하려면 chown 또는 chmod 를 실행하여 적절한 인증 키 소유권 및 액세스를 설정했는지 확인하십시오.
5.4.3. 인증 키에 사용자 추가
Ceph 스토리지 클러스터에 사용자를 추가할 때 get 절차를 사용하여 사용자, 키 및 기능을 검색한 다음 사용자를 인증 키 파일에 저장할 수 있습니다. 인증 키당 하나의 사용자만 사용하려는 경우 -o 옵션을 사용하여 Display Ceph 사용자 정보 프로시저에서 출력을 키링 파일 형식으로 저장합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
client.admin사용자의 인증 키를 만들려면 다음을 실행합니다.[root@mon ~]# ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
권장 파일 형식을 개별 사용자에게 사용합니다.
사용자를 인증 키로 가져오려면
ceph-authtool을 사용하여 대상 인증 키와 소스 인증 키를 지정할 수 있습니다.[root@mon ~]# ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
5.4.4. 인증 키를 사용하여 Ceph 사용자 생성
Ceph는 Red Hat Ceph Storage 클러스터에서 직접 사용자를 생성하는 기능을 제공합니다. 그러나 Ceph 클라이언트 키링에서 직접 사용자 키 및 기능을 만들 수도 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
사용자를 인증 키로 가져옵니다.
예제
[root@mon ~]# ceph-authtool -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.keyring
인증 키를 만들고 새 사용자를 동시에 인증 키에 추가합니다.
예제:
[root@mon ~]# ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
진행 중인 시나리오에서 새 사용자
client.ringo는 인증 키에만 있습니다.새 사용자를 Ceph 스토리지 클러스터에 추가하려면 다음을 수행합니다.
[root@mon ~]# ceph auth add client.ringo -i /etc/ceph/ceph.keyring
추가 리소스
- 기능에 대한 자세한 내용은 Ceph 사용자 관리 배경 을 참조하십시오.
5.4.5. 인증 키를 사용하여 Ceph 사용자 수정
명령줄 인터페이스를 사용하여 Ceph 사용자 및 해당 인증 키를 수정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
- 인증 키에서 사용자 레코드의 기능을 수정하려면 인증 키를 지정하고 사용자 뒤에 기능을 지정합니다. 예를 들면 다음과 같습니다.
[root@mon ~]# ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'
- 사용자를 Red Hat Ceph Storage 클러스터로 업데이트하려면 인증 키의 사용자를 Red Hat Ceph Storage 클러스터의 사용자 항목으로 업데이트해야 합니다.
[root@mon ~]# ceph auth import -i /etc/ceph/ceph.keyring
스토리지 클러스터에서 직접 사용자 기능을 수정하고, 결과를 인증 키링 파일에 저장한 다음, 인증 키를 기본 ceph.keyring 파일로 가져올 수도 있습니다.
추가 리소스
- 인증 키에서 Red Hat Ceph Storage 클러스터 사용자를 업데이트하는 방법에 대한 자세한 내용은 사용자 가져오기 를 참조하십시오.
5.4.6. Ceph 사용자의 명령줄 사용량
Ceph는 사용자 이름과 시크릿에 대해 다음 사용량을 지원합니다.
--id | --user
- 설명
-
Ceph는 유형과 ID가 있는 사용자를 식별합니다. 예를 들면
TYPE.ID또는client.admin,client.user1입니다.id,name및-n옵션을 사용하면 사용자 이름의 ID 부분을 지정할 수 있습니다. 예를 들어admin,user1또는foo입니다.--id를 사용하여 사용자를 지정하고 유형을 생략할 수 있습니다. 예를 들어 사용자client.foo를 지정하려면 다음을 입력합니다.
[root@mon ~]# ceph --id foo --keyring /path/to/keyring health [root@mon ~]# ceph --user foo --keyring /path/to/keyring health
--name | -n
- 설명
-
Ceph는 유형과 ID가 있는 사용자를 식별합니다. 예를 들면
TYPE.ID또는client.admin,client.user1입니다.name및-n옵션을 사용하면 정규화된 사용자 이름을 지정할 수 있습니다. 사용자 ID를 사용하여 사용자 유형(일반적으로클라이언트)을 지정해야 합니다. 예를 들어 다음과 같습니다.
[root@mon ~]# ceph --name client.foo --keyring /path/to/keyring health [root@mon ~]# ceph -n client.foo --keyring /path/to/keyring health
--keyring
- 설명
-
하나 이상의 사용자 이름과 시크릿을 포함하는 인증 키의 경로입니다.
--secret옵션은 동일한 기능을 제공하지만 다른 용도로--secret을 사용하는 Ceph RADOS 게이트웨이에서는 작동하지 않습니다.ceph auth get-or-create를 사용하여 인증 키를 검색하고 로컬에 저장할 수 있습니다. 인증 키 경로를 전환하지 않고 사용자 이름을 전환할 수 있기 때문에 기본 방법입니다. 예를 들어 다음과 같습니다.
[root@mon ~]# rbd map foo --pool rbd myimage --id client.foo --keyring /path/to/keyring
5.4.7. Ceph 사용자 관리 제한 사항
wget 프로토콜은 Ceph 클라이언트 및 서버를 서로 인증합니다. 이는 사용자를 대신하여 실행되는 사람 또는 애플리케이션의 인증을 처리하기 위한 것이 아닙니다. 액세스 제어 요구 사항을 처리하는 데 이 효과가 필요한 경우 Ceph 오브젝트 저장소에 액세스하는 데 사용되는 프론트 엔드에 특정되는 다른 메커니즘이 있어야 합니다. 이 다른 메커니즘은 허용 가능한 사용자 및 프로그램만 Ceph가 오브젝트 저장소에 액세스할 수 있는 시스템에서 실행할 수 있도록 하는 역할을 합니다.
Ceph 클라이언트 및 서버를 인증하는 데 사용되는 키는 일반적으로 신뢰할 수 있는 호스트에서 적절한 권한이 있는 일반 텍스트 파일에 저장됩니다.
키를 일반 텍스트 파일에 저장하면 보안에 영향을 미치지만 Ceph가 백그라운드에서 사용하는 기본 인증 방법에 따라 사용하지 않는 것이 좋습니다. Ceph 시스템을 설정하는 작업은 이러한 단점을 알고 있어야 합니다.
특히 임의의 사용자 시스템(특히 이식 가능한 시스템)은 Ceph와 직접 상호 작용하도록 구성해서는 안 됩니다. 이 사용 모드에서는 안전하지 않은 시스템에서 일반 텍스트 인증 키를 저장해야 합니다. 해당 시스템을 중단하거나 이에 대한 액세스 권한을 얻은 모든 사람이 자신의 시스템을 Ceph에 인증할 수 있는 키를 얻을 수 있습니다.
잠재적으로 안전하지 않은 시스템이 Ceph 오브젝트 저장소에 직접 액세스할 수 있도록 허용하는 대신 사용자는 목적에 충분한 보안을 제공하는 방법을 사용하여 환경에서 신뢰할 수 있는 시스템에 로그인해야 합니다. 이 신뢰할 수 있는 머신은 사용자에게 일반 텍스트 Ceph 키를 저장합니다. 향후 Ceph 버전에서는 이러한 특정 인증 문제를 보다 완벽하게 해결할 수 있습니다.
현재 Ceph 인증 프로토콜 중 어느 것도 전송 중인 메시지에 대한 비밀성을 제공하지 않습니다. 따라서 전선의 도청(eavesdropper)은 이를 생성하거나 변경할 수 없는 경우에도 Ceph의 클라이언트와 서버 간에 전송되는 모든 데이터를 수신하고 이해할 수 있습니다. Ceph에 중요한 데이터를 저장하는 사용자는 데이터를 Ceph 시스템에 제공하기 전에 암호화해야 합니다.
예를 들어 Ceph Object Gateway는 Ceph Storage 클러스터에 저장하기 전에 Ceph Object Gateway 클라이언트에서 수신한 암호화되지 않은 데이터를 암호화하고 클라이언트에 다시 보내기 전에 Ceph Storage 클러스터에서 검색한 데이터를 유사하게 해독하는 S3 API 서버 측 암호화를 제공합니다. 클라이언트와 Ceph Object Gateway 간 전송 중 암호화를 확인하려면 SSL을 사용하도록 Ceph Object Gateway를 구성해야 합니다.
6장. ceph-volume 유틸리티
스토리지 관리자는 ceph-volume 유틸리티를 사용하여 Ceph OSD를 준비, 생성 및 활성화할 수 있습니다. ceph-volume 유틸리티는 논리 볼륨을 OSD로 배포하는 단일 명령줄 툴입니다. 플러그인 유형 프레임워크를 사용하여 다양한 장치 기술을 사용하여 OSD를 배포합니다. ceph-volume 유틸리티는 OSD 배포를 위한 유사한 워크플로우를 따르며, OSD를 준비, 활성화 및 시작할 수 있는 견고한 방법으로 OSD를 배포할 수 있습니다. 현재는 ceph-volume 유틸리티는 향후 다른 기술을 지원할 계획과 함께 lvm 플러그인만 지원합니다.
ceph-disk 명령은 더 이상 사용되지 않습니다.
6.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
6.2. Ceph 볼륨 lvm 플러그인
LVM 태그를 사용하면 lvm 하위 명령은 OSD와 연결된 장치를 쿼리하여 저장하고 검색할 수 있으므로 활성화할 수 있습니다. 여기에는 dm-cache 와 같은 lvm 기반 기술 지원도 포함됩니다.
ceph-volume 을 사용하는 경우 dm-cache 를 투명하게 사용하고 논리 볼륨과 같이 dm-cache 를 처리합니다. dm-cache 를 사용할 때 성능이 향상되고 손실은 특정 워크로드에 따라 달라집니다. 일반적으로 난수 및 순차적 읽기는 작은 블록 크기에서 성능이 향상되는 것을 볼 수 있습니다. 난수 및 순차적 쓰기는 더 큰 블록 크기에서 성능이 저하되는 것을 확인할 수 있습니다.
LVM 플러그인을 사용하려면 lvm 을 하위 명령으로 ceph-volume 명령에 추가합니다.
[root@osd ~]# ceph-volume lvm
다음과 같이 lvm 하위 명령에는 3개의 하위 명령이 있습니다.
create 하위 명령을 사용하면 prepare 및 activate 하위 명령을 하나의 하위 명령에 결합합니다.
추가 리소스
-
자세한 내용은
create하위 명령 섹션을 참조하십시오.
6.3. ceph-volume 이 ceph-disk 를 교체하는 이유는 무엇입니까?
이전 버전의 Red Hat Ceph Storage는 ceph-disk 유틸리티를 사용하여 OSD를 준비, 활성화 및 만듭니다. Red Hat Ceph Storage 4부터 ceph-disk 는 ceph-volume 유틸리티로 대체되며, OSD를 준비, 활성화 및 생성할 때 빈 볼륨을 OSD로 배포하는 단일 명령줄 툴로 교체되고 OSD를 생성할 때 ceph-disk 에 유사한 API를 유지합니다.
ceph-volume 은 어떻게 작동합니까?
ceph-volume 은 현재 하드웨어 장치 프로비저닝, 레거시 ceph-disk 장치 및 LVM(Logical Volume Manager) 장치의 두 가지 프로비저닝 방법을 지원하는 모듈식 툴입니다. ceph-volume lvm 명령은 LVM 태그를 사용하여 Ceph 관련 장치와 OSD와의 관계에 대한 정보를 저장합니다. 이러한 태그를 사용하여 나중에 OSDS와 연결된 장치를 재검색하고 쿼리하여 활성화할 수 있습니다. 또한 LVM 및 dm-cache 를 기반으로 하는 기술을 지원합니다.
ceph-volume 유틸리티는 dm-cache 를 투명하게 사용하여 이를 논리 볼륨으로 처리합니다. 처리 중인 특정 워크로드에 따라 dm-cache 를 사용할 때 성능 향상과 손실을 고려할 수 있습니다. 일반적으로 임의 및 순차적 읽기 작업의 성능은 더 작은 블록 크기에서 증가하며, 임의 및 순차적 쓰기 작업의 성능은 더 큰 블록 크기에서 감소합니다. ceph-volume 을 사용하면 상당한 성능 저하가 발생하지 않습니다.
ceph-disk 유틸리티는 더 이상 사용되지 않습니다.
ceph-volume simple 명령은 이러한 장치가 여전히 사용 중인 경우 레거시 ceph-disk 장치를 처리할 수 있습니다.
ceph-disk 는 어떻게 작동합니까?
ceph-disk 유틸리티는 장치를 검색할 수 있는 동안 upstart 또는 sysvinit 와 같은 다양한 유형의 init 시스템을 지원해야 했습니다. 이러한 이유로 ceph-disk 는 GUID 파티션 테이블(GPT) 파티션에만 중점을 둡니다. 특히 다음과 같은 질문에 답변할 수 있는 고유한 방식으로 장치에 레이블을 지정하는 GPT GUID를 대상으로 합니다.
-
이 장치가
저널입니까? - 이 장치는 암호화된 데이터 파티션입니까?
- 장치가 부분적으로 준비되지 않았습니다.
이러한 문제를 해결하기 위해 ceph-disk 는 UDEV 규칙을 사용하여 GUID와 일치합니다.
ceph-disk 사용의 단점은 무엇입니까?
UDEV 규칙을 사용하여 ceph-disk 를 호출하면 ceph-disk systemd 장치와 ceph-disk 실행 파일 사이에 백 엔드(back-and-forth)가 발생할 수 있습니다. 프로세스는 매우 신뢰할 수 없으며 시간이 오래 걸리므로 노드의 부팅 프로세스 중에 OSD가 전혀 시작되지 않을 수 있습니다. 또한 UDEV의 비동기 동작을 제공하거나 디버깅하거나 복제하기가 어렵습니다.
ceph-disk 는 GPT 파티션 전용으로 작동하므로 LVM(Logical Volume Manager) 볼륨 또는 유사한 장치 매퍼 장치와 같은 다른 기술을 지원할 수 없습니다.
GPT 파티션이 장치 검색 워크플로에서 제대로 작동하도록 하려면 ceph-disk 에서 많은 수의 특수 플래그를 사용해야 합니다. 또한 이러한 파티션에는 장치가 Ceph에 의해 독점적으로 소유되어야 합니다.
6.4. ceph-volume을 사용하여 Ceph OSD 준비
prepare 하위 명령은 OSD 백엔드 오브젝트 저장소를 준비하고 OSD 데이터와 저널 모두에 논리 볼륨(LV)을 사용합니다. LVM을 사용하여 추가 메타데이터 태그를 추가하는 경우를 제외하고 논리 볼륨은 수정하지 않습니다. 이러한 태그를 사용하면 볼륨을 더 쉽게 검색할 수 있으며, Ceph Storage Cluster의 일부인 볼륨 및 스토리지 클러스터에서 해당 볼륨의 역할도 확인할 수 있습니다.
BlueStore OSD 백엔드는 다음 구성을 지원합니다.
-
블록 장치,
block.wal장치 및block.db장치 -
블록 장치 및
block.wal장치 -
블록 장치 및
block.db장치 - 단일 블록 장치
prepare 하위 명령은 전체 장치 또는 파티션 또는 블록에 대한 논리 볼륨을 허용합니다.
사전 요구 사항
- OSD 노드에 대한 루트 수준 액세스입니다.
- 선택적으로 논리 볼륨을 생성합니다. 물리적 장치에 대한 경로를 제공하는 경우 하위 명령은 장치를 논리 볼륨으로 전환합니다. 이 방법은 더 간단하지만 논리 볼륨 생성 방식을 구성하거나 변경할 수 없습니다.
절차
LVM 볼륨을 준비합니다.
구문
ceph-volume lvm prepare --bluestore --data VOLUME_GROUP/LOGICAL_VOLUME
예제
[root@osd ~]# ceph-volume lvm prepare --bluestore --data example_vg/data_lv
필요한 경우 RocksDB에 별도의 장치를 사용하려면
--block.db및--block.wal옵션을 지정합니다.구문
ceph-volume lvm prepare --bluestore --block.db --block.wal --data VOLUME_GROUP/LOGICAL_VOLUME
예제
[root@osd ~]# ceph-volume lvm prepare --bluestore --block.db --block.wal --data example_vg/data_lv
선택적으로 데이터를 암호화하려면
--dmcrypt플래그를 사용합니다.구문
ceph-volume lvm prepare --bluestore --dmcrypt --data VOLUME_GROUP/LOGICAL_VOLUME
예제
[root@osd ~]# ceph-volume lvm prepare --bluestore --dmcrypt --data example_vg/data_lv
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 활성화 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 생성 섹션을 참조하십시오.
6.5. ceph-volume을 사용하여 Ceph OSD 활성화
활성화 프로세스를 사용하면 부팅 시 systemd 장치를 활성화하여 올바른 OSD ID와 해당 UUID를 활성화 및 마운트할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph OSD 노드에 대한 루트 수준 액세스입니다.
-
ceph-volume유틸리티로 준비된 Ceph OSD.
절차
OSD 노드에서 OSD ID 및 UUID를 가져옵니다.
[root@osd ~]# ceph-volume lvm list
OSD를 활성화합니다.
구문
ceph-volume lvm activate --bluestore OSD_ID OSD_UUID
예제
[root@osd ~]# ceph-volume lvm activate --bluestore 0 0263644D-0BF1-4D6D-BC34-28BD98AE3BC8
활성화할 준비가 된 모든 OSD를 활성화하려면
--all옵션을 사용합니다.예제
[root@osd ~]# ceph-volume lvm activate --all
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 준비 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 생성 섹션을 참조하십시오.
6.6. ceph-volume을 사용하여 Ceph OSD 생성
create 하위 명령은 prepare 하위 명령을 호출한 다음, activate 하위 명령을 호출합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph OSD 노드에 대한 루트 수준 액세스입니다.
생성 프로세스를 더 자세히 제어하려는 경우 create를 사용하는 대신 prepare 및 activate 하위 명령을 별도로 사용하여 OSD를 만들 수 있습니다. 두 하위 명령을 사용하여 새 OSD를 스토리지 클러스터에 점진적으로 도입하고 대량의 데이터를 재조정할 필요가 없습니다. create 하위 명령을 사용하면 완료 후 즉시 OSD가 가동 되고 있는 경우를 제외하고 두 접근 방식 모두 동일한 방식으로 작동합니다.
절차
새 OSD를 만들려면 다음을 수행합니다.
구문
ceph-volume lvm create --bluestore --data VOLUME_GROUP/LOGICAL_VOLUME
예제
[root@osd ~]# ceph-volume lvm create --bluestore --data example_vg/data_lv
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 준비 섹션을 참조하십시오.
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 활성화 섹션을 참조하십시오.
6.7. ceph-volume에서 배치 모드 사용
batch 하위 명령은 단일 장치가 제공될 때 여러 OSD 생성을 자동화합니다.
ceph-volume 명령은 드라이브 유형에 따라 OSD를 만드는 데 사용할 최상의 방법을 결정합니다. Ceph OSD 최적화는 사용 가능한 장치에 따라 다릅니다.
-
모든 장치가 기존의 하드 드라이브인 경우
배치는장치당 하나의 OSD를 생성합니다. -
모든 장치가 견고한 상태 드라이브인 경우
배치는장치당 두 개의 OSD를 만듭니다. -
기존 하드 드라이브와 솔리드 스테이트 드라이브가 혼합된 경우
일괄처리는 기존 하드 드라이브를 데이터에 사용하고 솔리드 스테이트 드라이브에서 가능한 가장 큰 저널(block.db)을 생성합니다.
batch 하위 명령은 write-ahead-log(block.wal) 장치에 대해 별도의 논리 볼륨 생성을 지원하지 않습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- Ceph OSD 노드에 대한 루트 수준 액세스입니다.
절차
여러 드라이브에서 OSD를 생성하려면 다음을 수행합니다.
구문
ceph-volume lvm batch --bluestore PATH_TO_DEVICE [PATH_TO_DEVICE]
예제
[root@osd ~]# ceph-volume lvm batch --bluestore /dev/sda /dev/sdb /dev/nvme0n1
추가 리소스
- 자세한 내용은 Red Hat Ceph Storage 관리 가이드의 'ceph-volume'을 사용하여 CephOSD 생성 섹션을 참조하십시오.
7장. Ceph 성능 벤치마크
스토리지 관리자는 Red Hat Ceph Storage 클러스터의 성능을 벤치마크할 수 있습니다. 이 섹션의 목적은 Ceph 관리자에게 Ceph의 기본 벤치마킹 툴에 대한 기본적인 이해를 제공하는 것입니다. 이러한 툴은 Ceph 스토리지 클러스터의 수행 방법에 대한 몇 가지 통찰력을 제공합니다. 이는 Ceph 성능 벤치마킹에 대한 명확한 가이드가 아니며 그에 따라 Ceph를 조정하는 방법에 대한 가이드도 아닙니다.
7.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
7.2. 성능 기준
저널, 디스크 및 네트워크 처리량을 포함한 OSD에는 각각 비교할 성능 기준이어야 합니다. 기본 성능 데이터를 Ceph 기본 툴의 데이터와 비교하여 잠재적 튜닝 기회를 확인할 수 있습니다. Red Hat Enterprise Linux는 다양한 툴을 제공하며, 다양한 오픈 소스 커뮤니티 툴을 통해 이러한 작업을 수행할 수 있습니다.
추가 리소스
- 사용 가능한 일부 툴에 대한 자세한 내용은 이 지식베이스 문서 를 참조하십시오.
7.3. Ceph 성능 벤치마킹
Ceph에는 RADOS 스토리지 클러스터에서 성능 벤치마킹을 수행하는 rados bench 명령이 포함되어 있습니다. 이 명령은 쓰기 테스트와 두 가지 유형의 읽기 테스트를 실행합니다. --no-cleanup 옵션은 읽기 및 쓰기 성능을 모두 테스트할 때 사용하는 것이 중요합니다. 기본적으로 rados bench 명령은 스토리지 풀에 기록된 오브젝트를 삭제합니다. 이러한 오브젝트 뒤에 있으면 두 읽기 테스트가 순차적이고 임의의 읽기 성능을 측정할 수 있습니다.
이러한 성능 테스트를 실행하기 전에 다음을 실행하여 모든 파일 시스템 캐시를 삭제합니다.
[root@mon~ ]# echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
새 스토리지 풀을 생성합니다.
[root@osd~ ]# ceph osd pool create testbench 100 100
새로 생성된 스토리지 풀에 대해 10초 동안 쓰기 테스트를 실행합니다.
[root@osd~ ]# rados bench -p testbench 10 write --no-cleanup
출력 예
Maintaining 16 concurrent writes of 4194304 bytes for up to 10 seconds or 0 objects Object prefix: benchmark_data_cephn1.home.network_10510 sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 16 16 0 0 0 - 0 2 16 16 0 0 0 - 0 3 16 16 0 0 0 - 0 4 16 17 1 0.998879 1 3.19824 3.19824 5 16 18 2 1.59849 4 4.56163 3.87993 6 16 18 2 1.33222 0 - 3.87993 7 16 19 3 1.71239 2 6.90712 4.889 8 16 25 9 4.49551 24 7.75362 6.71216 9 16 25 9 3.99636 0 - 6.71216 10 16 27 11 4.39632 4 9.65085 7.18999 11 16 27 11 3.99685 0 - 7.18999 12 16 27 11 3.66397 0 - 7.18999 13 16 28 12 3.68975 1.33333 12.8124 7.65853 14 16 28 12 3.42617 0 - 7.65853 15 16 28 12 3.19785 0 - 7.65853 16 11 28 17 4.24726 6.66667 12.5302 9.27548 17 11 28 17 3.99751 0 - 9.27548 18 11 28 17 3.77546 0 - 9.27548 19 11 28 17 3.57683 0 - 9.27548 Total time run: 19.505620 Total writes made: 28 Write size: 4194304 Bandwidth (MB/sec): 5.742 Stddev Bandwidth: 5.4617 Max bandwidth (MB/sec): 24 Min bandwidth (MB/sec): 0 Average Latency: 10.4064 Stddev Latency: 3.80038 Max latency: 19.503 Min latency: 3.19824스토리지 풀에 대해 10초 동안 순차적 읽기 테스트를 실행합니다.
[root@osd~ ]## rados bench -p testbench 10 seq
출력 예
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 Total time run: 0.804869 Total reads made: 28 Read size: 4194304 Bandwidth (MB/sec): 139.153 Average Latency: 0.420841 Max latency: 0.706133 Min latency: 0.0816332
스토리지 풀에 대해 10초 동안 임의 읽기 테스트를 실행합니다.
[root@osd ~]# rados bench -p testbench 10 rand
출력 예
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 16 46 30 119.801 120 0.440184 0.388125 2 16 81 65 129.408 140 0.577359 0.417461 3 16 120 104 138.175 156 0.597435 0.409318 4 15 157 142 141.485 152 0.683111 0.419964 5 16 206 190 151.553 192 0.310578 0.408343 6 16 253 237 157.608 188 0.0745175 0.387207 7 16 287 271 154.412 136 0.792774 0.39043 8 16 325 309 154.044 152 0.314254 0.39876 9 16 362 346 153.245 148 0.355576 0.406032 10 16 405 389 155.092 172 0.64734 0.398372 Total time run: 10.302229 Total reads made: 405 Read size: 4194304 Bandwidth (MB/sec): 157.248 Average Latency: 0.405976 Max latency: 1.00869 Min latency: 0.0378431
동시 읽기 및 쓰기 수를 늘리려면 기본값인 16개 스레드인
-t옵션을 사용합니다. 또한-b매개변수는 작성 중인 오브젝트의 크기를 조정할 수 있습니다. 기본 오브젝트 크기는 4MB입니다. 안전한 최대 오브젝트 크기는 16MB입니다. Red Hat은 이러한 벤치마크 테스트의 여러 사본을 다른 풀에 실행하는 것이 좋습니다. 이렇게 하면 여러 클라이언트의 성능 변경 사항이 표시됩니다.--run-name <label> 옵션을 추가하여 벤치마크 테스트 중에 작성된 오브젝트의 이름을 제어합니다. 실행 중인 각 명령 인스턴스에 대해--run-name레이블을 변경하여 여러rados bench명령을 동시에 실행할 수 있습니다. 이렇게 하면 여러 클라이언트가 동일한 개체에 액세스하려고 하고 다른 클라이언트가 다른 개체에 액세스할 수 있는 경우 발생할 수 있는 잠재적인 I/O 오류가 발생하지 않습니다.--run-name옵션은 실제 워크로드를 시뮬레이션할 때 유용합니다. 예를 들어 다음과 같습니다.[root@osd ~]# rados bench -p testbench 10 write -t 4 --run-name client1
출력 예
Maintaining 4 concurrent writes of 4194304 bytes for up to 10 seconds or 0 objects Object prefix: benchmark_data_node1_12631 sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 4 4 0 0 0 - 0 2 4 6 2 3.99099 4 1.94755 1.93361 3 4 8 4 5.32498 8 2.978 2.44034 4 4 8 4 3.99504 0 - 2.44034 5 4 10 6 4.79504 4 2.92419 2.4629 6 3 10 7 4.64471 4 3.02498 2.5432 7 4 12 8 4.55287 4 3.12204 2.61555 8 4 14 10 4.9821 8 2.55901 2.68396 9 4 16 12 5.31621 8 2.68769 2.68081 10 4 17 13 5.18488 4 2.11937 2.63763 11 4 17 13 4.71431 0 - 2.63763 12 4 18 14 4.65486 2 2.4836 2.62662 13 4 18 14 4.29757 0 - 2.62662 Total time run: 13.123548 Total writes made: 18 Write size: 4194304 Bandwidth (MB/sec): 5.486 Stddev Bandwidth: 3.0991 Max bandwidth (MB/sec): 8 Min bandwidth (MB/sec): 0 Average Latency: 2.91578 Stddev Latency: 0.956993 Max latency: 5.72685 Min latency: 1.91967rados bench명령으로 생성된 데이터를 제거합니다.[root@osd ~]# rados -p testbench cleanup
7.4. Ceph 블록 성능 벤치마킹
Ceph에는 rbd bench-write 명령이 포함되어 있어 블록 장치 측정 처리량 및 대기 시간에 순차적 쓰기를 테스트합니다. 기본 바이트 크기는 4096이며 기본 I/O 스레드 수는 16이며, 작성할 기본 총 바이트 수는 1GB입니다. 이러한 기본값은 --io-size,--io-threads 및 --io-total 옵션으로 각각 수정할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
아직 로드되지 않은 경우
rbd커널 모듈을 로드합니다.[root@mon ~]# modprobe rbd
testbench풀에 1GBrbd이미지 파일을 만듭니다.[root@mon ~]# rbd create image01 --size 1024 --pool testbench
이미지 파일을 장치 파일에 매핑합니다.
[root@mon ~]# rbd map image01 --pool testbench --name client.admin
블록 장치에
ext4파일 시스템을 생성합니다.[root@mon ~]# mkfs.ext4 /dev/rbd/testbench/image01
새 디렉토리를 만듭니다.
[root@mon ~]# mkdir /mnt/ceph-block-device
/mnt/ceph-block-device/에 블록 장치를 마운트합니다.[root@mon ~]# mount /dev/rbd/testbench/image01 /mnt/ceph-block-device
블록 장치에 대해 쓰기 성능 테스트를 실행합니다.
[root@mon ~]# rbd bench --io-type write image01 --pool=testbench
예제
bench-write io_size 4096 io_threads 16 bytes 1073741824 pattern seq SEC OPS OPS/SEC BYTES/SEC 2 11127 5479.59 22444382.79 3 11692 3901.91 15982220.33 4 12372 2953.34 12096895.42 5 12580 2300.05 9421008.60 6 13141 2101.80 8608975.15 7 13195 356.07 1458459.94 8 13820 390.35 1598876.60 9 14124 325.46 1333066.62 ..
추가 리소스
-
rbd명령에 대한 자세한 내용은 Red Hat Ceph Storage Block Device Guide 의 블록 장치 명령 섹션을 참조하십시오.
8장. Ceph 성능 카운터
스토리지 관리자는 Red Hat Ceph Storage 클러스터의 성능 지표를 수집할 수 있습니다. Ceph 성능 카운터는 내부 인프라 지표의 컬렉션입니다. 이 지표 데이터의 수집, 집계 및 그래프는 다양한 툴로 수행할 수 있으며 성능 분석에 유용할 수 있습니다.
8.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
8.2. Ceph 성능 카운터에 액세스
성능 카운터는 Ceph 모니터 및 OSD의 소켓 인터페이스를 통해 사용할 수 있습니다. 각 데몬의 소켓 파일은 기본적으로 /var/run/ceph 에 있습니다. 성능 카운터는 컬렉션 이름으로 함께 그룹화됩니다. 이러한 컬렉션 이름은 하위 시스템 또는 하위 시스템의 인스턴스를 나타냅니다.
다음은 각 항목에 대한 간략한 설명이 포함된 모니터 및 OSD 컬렉션 이름 카테고리의 전체 목록입니다.
컬렉션 이름 범주 모니터링
- 클러스터 지표 - 스토리지 클러스터에 대한 정보를 표시합니다. 모니터, OSD, 풀, PGs
-
수준 데이터베이스 지표 - 백엔드
KeyValueStore데이터베이스에 대한 정보를 표시합니다. - 지표 모니터링 - 일반 모니터 정보 표시
- Paxos Metrics - 클러스터 쿼럼 관리에 대한 정보를 표시
- 제한 지표 - 모니터가 제한되는 방법에 대한 통계를 표시합니다.
OSD 컬렉션 이름 범주
- write Throttle Metrics - write back throttle is tracking unflushed IO를 추적하는 방법에 대한 통계를 표시합니다.
-
수준 데이터베이스 지표 - 백엔드
KeyValueStore데이터베이스에 대한 정보를 표시합니다. - Objecter Metrics - 다양한 오브젝트 기반 작업에 대한 정보를 표시합니다.
- 읽기 및 쓰기 메트릭 - 다양한 읽기 및 쓰기 작업에 대한 정보를 표시합니다.
- 복구 상태 메트릭 - 표시 - 다양한 복구 상태에 대기 시간 표시
- OSD Throttle Metrics - OSD가 제한되는 방법에 대한 통계를 표시
RADOS 게이트웨이 컬렉션 이름 범주
- 오브젝트 게이트웨이 클라이언트 지표 - GET 및 PUT 요청에 대한 통계를 표시
- Objecter Metrics - 다양한 오브젝트 기반 작업에 대한 정보를 표시합니다.
- Object Gateway Throttle Metrics - OSD가 제한되는 방법에 대한 통계를 표시합니다.
8.3. Ceph 성능 카운터 표시
ceph 데몬 .. perf 스키마 명령은 사용 가능한 지표를 출력합니다. 각 메트릭에는 관련 비트 필드 값 유형이 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
메트릭의 스키마를 보려면 다음을 수행합니다.
ceph daemon DAEMON_NAME perf schema참고데몬을 실행하는 노드에서
ceph daemon명령을 실행해야 합니다.Monitor 노드에서
ceph 데몬 .. perf 스키마명령 실행:[root@mon ~]# ceph daemon mon.`hostname -s` perf schema
예제
{ "cluster": { "num_mon": { "type": 2 }, "num_mon_quorum": { "type": 2 }, "num_osd": { "type": 2 }, "num_osd_up": { "type": 2 }, "num_osd_in": { "type": 2 }, ...OSD 노드에서
ceph 데몬 .. perf 스키마명령을 실행합니다.[root@mon ~]# ceph daemon osd.0 perf schema
예제
... "filestore": { "journal_queue_max_ops": { "type": 2 }, "journal_queue_ops": { "type": 2 }, "journal_ops": { "type": 10 }, "journal_queue_max_bytes": { "type": 2 }, "journal_queue_bytes": { "type": 2 }, "journal_bytes": { "type": 10 }, "journal_latency": { "type": 5 }, ...
표 8.1. 비트 필드 값 정의
| Bit | 의미 |
|---|---|
| 1 | 부동 소수점 값 |
| 2 | 서명되지 않은 64비트 정수 값 |
| 4 | 평균 (Sum + Count) |
| 8 | 카운터 |
각 값에는 부동 소수점 또는 정수 값을 나타내는 비트 1 또는 2 세트가 있습니다. 비트 4가 설정되면 읽을 두 개의 값, 합계와 개수가 있습니다. 비트 8이 설정되면 이전 간격의 평균은 이전 간격의 평균은 이전의 읽기가 count delta로 나뉘므로 합계 delta가 됩니다. 또는 값을 오른쪽으로 나누면 수명 평균 값이 제공됩니다. 일반적으로 이 값은 대기 시간, 요청 수 및 요청 대기 시간을 측정하는 데 사용됩니다. 일부 비트 값은 결합됩니다(예: 5, 6 및 10). 5의 비트 값은 비트 1과 비트 4의 조합입니다. 즉, 평균은 부동 소수점 값이 됩니다. 6의 비트 값은 비트 2와 비트 4의 조합입니다. 즉, 평균 값은 정수입니다. 10의 비트 값은 비트 2와 비트 8의 조합입니다. 이 값은 정수 값이 됩니다.This means the counter value will be an integer value.
추가 리소스
- 자세한 내용은 평균 수 및 합계 를 참조하십시오.
8.4. Ceph 성능 카운터 덤프
ceph 데몬 .. perf dump 명령은 현재 값을 출력하고 각 하위 시스템의 컬렉션 이름으로 지표를 그룹화합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
현재 메트릭 데이터를 보려면 다음을 수행합니다.
# ceph daemon DAEMON_NAME perf dump참고데몬을 실행하는 노드에서
ceph daemon명령을 실행해야 합니다.Monitor 노드에서
ceph 데몬 .. perf dump명령을 실행합니다.# ceph daemon mon.`hostname -s` perf dump
예제
{ "cluster": { "num_mon": 1, "num_mon_quorum": 1, "num_osd": 2, "num_osd_up": 2, "num_osd_in": 2, ...OSD 노드에서
ceph 데몬 .. perf dump명령 실행:# ceph daemon osd.0 perf dump
예제
... "filestore": { "journal_queue_max_ops": 300, "journal_queue_ops": 0, "journal_ops": 992, "journal_queue_max_bytes": 33554432, "journal_queue_bytes": 0, "journal_bytes": 934537, "journal_latency": { "avgcount": 992, "sum": 254.975925772 }, ...
추가 리소스
- 사용 가능한 각 모니터 메트릭에 대한 간단한 설명을 보려면 Ceph 모니터 지표 테이블을 참조하십시오.
8.5. 평균 수 및 합계
모든 대기 시간 숫자에는 비트 필드 값이 5입니다. 이 필드에는 평균 개수 및 합계에 대한 부동 소수점 값이 포함되어 있습니다. avgcount 는 이 범위 내의 작업 수이며 합계 는 초 단위의 총 대기 시간입니다. 합계 를 avgcount 로 나눌 때 작업당 대기 시간에 대한 아이디어를 제공합니다.
추가 리소스
- 사용 가능한 각 OSD 메트릭에 대한 간단한 설명을 보려면 Ceph OSD 테이블을 참조하십시오.
8.6. Ceph Monitor 지표
표 8.2. 클러스터 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 모니터 수 |
|
| 2 | 쿼럼의 모니터 수 | |
|
| 2 | 총 OSD 수 | |
|
| 2 | 가동 중인 OSD 수 | |
|
| 2 | 클러스터에 있는 OSD 수 | |
|
| 2 | OSD 맵의 현재 epoch | |
|
| 2 | 클러스터의 총 용량(바이트) | |
|
| 2 | 클러스터에서 사용되는 바이트 수 | |
|
| 2 | 클러스터에서 사용 가능한 바이트 수 | |
|
| 2 | 풀 수 | |
|
| 2 | 총 배치 그룹 수 | |
|
| 2 | active+clean 상태의 배치 그룹 수 | |
|
| 2 | 활성 상태의 배치 그룹 수 | |
|
| 2 | 피어링 상태의 배치 그룹 수 | |
|
| 2 | 클러스터의 총 오브젝트 수 | |
|
| 2 | 성능 저하(복제본 허용) 오브젝트 수 | |
|
| 2 | 잘못된 오브젝트 수(클러스터의 위치) 오브젝트 수 | |
|
| 2 | unfound 오브젝트 수 | |
|
| 2 | 모든 오브젝트의 총 바이트 수 | |
|
| 2 | 작동 중인 MDS 수 | |
|
| 2 | 클러스터에 있는 MDS 수 | |
|
| 2 | 실패한 MDS 수 | |
|
| 2 | MDS 맵의 현재 epoch |
표 8.3. 수준 데이터베이스 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | gets |
|
| 10 | Transactions | |
|
| 10 | 컴팩트 | |
|
| 10 | 범위별 컴팩트 | |
|
| 10 | 압축 큐의 범위 병합 | |
|
| 2 | 컴팩트 큐의 길이 |
표 8.4. 일반 모니터 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 현재 열려 있는 모니터 세션 수 |
|
| 10 | 생성된 모니터 세션 수 | |
|
| 10 | 모니터의 remove_session 호출 수 | |
|
| 10 | 트리밍된 모니터 세션 수 | |
|
| 10 | 선거 모니터 수에 참여했습니다. | |
|
| 10 | 모니터에 의해 시작된 선거 수 | |
|
| 10 | 모니터로 인한 선거 수 | |
|
| 10 | 모니터에 의해 손실된 선택 수 |
표 8.5. Paxos 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | 리더 역할에서 시작 |
|
| 10 | peon 역할에서 시작 | |
|
| 10 | 다시 시작 | |
|
| 10 | 새로 고침 | |
|
| 5 | 대기 시간 새로 고침 | |
|
| 10 | 시작 및 처리 시작 | |
|
| 6 | 트랜잭션을 시작할 키 | |
|
| 6 | 트랜잭션을 시작할 때 데이터 | |
|
| 5 | 시작 작업 대기 시간 | |
|
| 10 | 커밋 | |
|
| 6 | 커밋 시 트랜잭션의 키 | |
|
| 6 | 커밋 시 트랜잭션의 데이터 | |
|
| 5 | 커밋 대기 시간 | |
|
| 10 | peon 수집 | |
|
| 6 | peon collect 트랜잭션의 키 | |
|
| 6 | peon 수집의 데이터 | |
|
| 5 | peon 수집 대기 시간 | |
|
| 10 | 시작 및 처리된 수집에 커밋되지 않은 값 | |
|
| 10 | 시간 초과 수집 | |
|
| 10 | 제한 시간 수락 | |
|
| 10 | 임대 확인 시간 초과 | |
|
| 10 | 리스 제한 시간 | |
|
| 10 | 디스크에 공유 상태 저장 | |
|
| 6 | 저장된 상태의 트랜잭션 키 | |
|
| 6 | 저장된 상태의 데이터 | |
|
| 5 | 상태 대기 시간 저장 | |
|
| 10 | 상태 공유 | |
|
| 6 | 공유 상태의 키 | |
|
| 6 | 공유 상태의 데이터 | |
|
| 10 | 새로운 제안 번호 쿼리 | |
|
| 5 | 대기 시간을 가져오는 새로운 제안 번호 |
표 8.6. 대규모 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | 현재 사용 가능한 throttle |
|
| 10 | throttle의 최대 값 | |
|
| 10 | gets | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | get_or_fail 중에 차단됨 | |
|
| 10 | get_or_fail 중에 성공 | |
|
| 10 | takes | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | bae | |
|
| 10 | 데이터 삽입 | |
|
| 5 | 대기 시간 |
8.7. Ceph OSD 지표
표 8.7. Back Throttle 지표 테이블 작성
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 더티 데이터 |
|
| 2 | 기록된 데이터 | |
|
| 2 | 더티 삭제 작업 | |
|
| 2 | 작성된 작업 | |
|
| 2 | 쓰기 대기 중인 항목 | |
|
| 2 | 작성된 항목 |
표 8.8. 수준 데이터베이스 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | gets |
|
| 10 | Transactions | |
|
| 10 | 컴팩트 | |
|
| 10 | 범위별 컴팩트 | |
|
| 10 | 압축 큐의 범위 병합 | |
|
| 2 | 컴팩트 큐의 길이 |
표 8.9. 오브젝트 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 활성 작업 |
|
| 2 | laggy 작업 | |
|
| 10 | 보낸 작업 | |
|
| 10 | 전송된 데이터 | |
|
| 10 | Resent 작업 | |
|
| 10 | 콜백 커밋 | |
|
| 10 | 작업 커밋 | |
|
| 10 | 작업 | |
|
| 10 | 읽기 작업 | |
|
| 10 | 쓰기 작업 | |
|
| 10 | Read-modify-write 작업 | |
|
| 10 | PG 작업 | |
|
| 10 | 작업 시작 | |
|
| 10 | 오브젝트 작업 생성 | |
|
| 10 | 읽기 작업 | |
|
| 10 | 쓰기 작업 | |
|
| 10 | 전체 오브젝트 작업 쓰기 | |
|
| 10 | 추가 작업 | |
|
| 10 | 오브젝트를 0개의 작업으로 설정 | |
|
| 10 | truncate 오브젝트 작업 | |
|
| 10 | 오브젝트 작업 삭제 | |
|
| 10 | 확장 작업 매핑 | |
|
| 10 | 스파스 읽기 작업 | |
|
| 10 | 복제 범위 작업 | |
|
| 10 | xattr 작업 가져오기 | |
|
| 10 | xattr 작업 설정 | |
|
| 10 | xattr 비교 작업 | |
|
| 10 | xattr 작업 제거 | |
|
| 10 | xattr 작업 재설정 | |
|
| 10 | TMAP 업데이트 작업 | |
|
| 10 | TMAP put 작업 | |
|
| 10 | TMAP 액세스 작업 | |
|
| 10 | 호출(실행) 작업 | |
|
| 10 | 오브젝트 작업 조사 | |
|
| 10 | 오브젝트 작업에 대한 알림 | |
|
| 10 | 다중 작업에서 확장 특성 비교 | |
|
| 10 | 기타 작업 | |
|
| 2 | Active lingering 작업 | |
|
| 10 | LOWI(Larngering) 작업 | |
|
| 10 | Resent lingering 작업 | |
|
| 10 | 지속 가능한 작업에 ping 전송 | |
|
| 2 | 활성 풀 작업 | |
|
| 10 | 전송된 풀 작업 | |
|
| 10 | 리sent 풀 작업 | |
|
| 2 | Active get pool stat operations | |
|
| 10 | pool stat operations sent | |
|
| 10 | 리sent 풀 통계 | |
|
| 2 | statfs 작업 | |
|
| 10 | FS 통계 전송 | |
|
| 10 | resent FS 통계 | |
|
| 2 | 활성 명령 | |
|
| 10 | 보낸 명령 | |
|
| 10 | resent 명령 | |
|
| 2 | OSD 맵 epoch | |
|
| 10 | 수신된 전체 OSD 맵 | |
|
| 10 | 수신한 증분 OSD 맵 | |
|
| 2 | 열려 있는 세션 | |
|
| 10 | 세션이 열립니다. | |
|
| 10 | 세션이 종료됨 | |
|
| 2 | laggy OSD 세션 |
표 8.10. 읽기 및 작업 지표 테이블 읽기 및 쓰기
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 복제 작업 현재 처리 중(주) |
|
| 10 | 클라이언트 작업 총 쓰기 크기 | |
|
| 10 | 클라이언트 작업 총 읽기 크기 | |
|
| 5 | 클라이언트 작업 대기 시간 (Queue 시간 포함) | |
|
| 5 | 클라이언트 작업 대기 시간(Queue 시간 제외) | |
|
| 10 | 클라이언트 읽기 작업 | |
|
| 10 | 클라이언트 데이터 읽기 | |
|
| 5 | 읽기 작업의 대기 시간 (Queue 시간 포함) | |
|
| 5 | 읽기 작업의 대기 시간( 큐 시간 제외) | |
|
| 10 | 클라이언트 쓰기 작업 | |
|
| 10 | 클라이언트 데이터 작성 | |
|
| 5 | 클라이언트 쓰기 작업 읽기/추가 대기 시간 | |
|
| 5 | 쓰기 작업의 대기 시간(Queue 시간 포함) | |
|
| 5 | 쓰기 작업의 대기 시간( 큐 시간 제외) | |
|
| 10 | 클라이언트 읽기-modify-write 작업 | |
|
| 10 | 클라이언트 읽기-modify-write 작업 쓰기 | |
|
| 10 | 클라이언트 읽기-modify-write 작업 읽기 | |
|
| 5 | 클라이언트 읽기-modify-write 작업 읽기/추가 대기 시간 | |
|
| 5 | Read-modify-write 작업의 대기 시간(Queue 시간 포함) | |
|
| 5 | Read-modify-write 작업의 대기 시간(Queue 시간 제외) | |
|
| 10 | Suboperations | |
|
| 10 | Suboperations 총 크기 | |
|
| 5 | 하위 작업 대기 시간 | |
|
| 10 | 복제된 쓰기 | |
|
| 10 | 기록된 데이터 크기 복제 | |
|
| 5 | 복제된 쓰기 대기 시간 | |
|
| 10 | Suboperations pull requests | |
|
| 5 | Suboperations pull latency | |
|
| 10 | 하위 내보내기 메시지 | |
|
| 10 | 내보낸 하위 크기 | |
|
| 5 | 하위 작업 푸시 대기 시간 | |
|
| 10 | 보낸 가져오기 요청 | |
|
| 10 | 보낸 푸시 메시지 | |
|
| 10 | 푸시된 크기 | |
|
| 10 | 인바운드 푸시 메시지 | |
|
| 10 | 인바운드 푸시 크기 | |
|
| 10 | 복구 작업 시작 | |
|
| 2 | CPU 로드 | |
|
| 2 | 할당된 총 버퍼 크기 | |
|
| 2 | 배치 그룹 | |
|
| 2 | 이 필드가 기본 설정된 배치 그룹 | |
|
| 2 | 이 osd가 복제본인 배치 그룹 | |
|
| 2 | 이 osd에서 삭제할 준비가 된 배치 그룹 | |
|
| 2 | 하트비트(ping) 피어링 | |
|
| 2 | 하트비트(ping) 피어를 다시 시작 | |
|
| 10 | OSD 맵 메시지 | |
|
| 10 | OSD 맵 epochs | |
|
| 10 | OSD 맵 중복 | |
|
| 2 | OSD 크기 | |
|
| 2 | 사용된 공간 | |
|
| 2 | 사용 가능한 공간 | |
|
| 10 | RADOS 'copy-from' 작업 | |
|
| 10 | 계층 프로모션 | |
|
| 10 | 계층 플러시 | |
|
| 10 | 실패한 계층 플러시 | |
|
| 10 | 계층 플러시 시도 | |
|
| 10 | 실패한 계층 플러시 시도 | |
|
| 10 | 계층 제거 | |
|
| 10 | 계층 분할 | |
|
| 10 | 더티클리티 계층 플래그 세트 | |
|
| 10 | 더티클리티 계층 플래그 정리 | |
|
| 10 | 계층 지연(에이전트 대기) | |
|
| 10 | 계층 프록시 읽기 | |
|
| 10 | 계층화 에이전트 발생 | |
|
| 10 | 에이전트에서 건너뛰는 오브젝트 | |
|
| 10 | 계층 지정 에이전트 플러시 | |
|
| 10 | 계층 지정 에이전트 제거 | |
|
| 10 | 오브젝트 컨텍스트 캐시 적중 | |
|
| 10 | 오브젝트 컨텍스트 캐시 조회 |
표 8.11. 복구 상태 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 5 | 초기 복구 상태 대기 시간 |
|
| 5 | 복구 상태 대기 시간 시작 | |
|
| 5 | 복구 상태 대기 시간 재설정 | |
|
| 5 | 복구 상태 대기 시간 시작 | |
|
| 5 | 기본 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 | |
|
| 5 | 백필된 복구 상태 대기 시간 | |
|
| 5 | 원격 백필 예약된 복구 상태 대기 시간 대기 | |
|
| 5 | 로컬 백필 예약된 복구 상태 대기 시간 대기 | |
|
| 5 | Notbackfilling 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 복구 | |
|
| 5 | 복구가 예약된 복구 상태 대기 시간 대기 시간 | |
|
| 5 | 다시 채우기로 예약된 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 복구 | |
|
| 5 | 복구 상태 대기 시간 활성화 | |
|
| 5 | 대기 로컬 복구 예약된 복구 상태 대기 시간 | |
|
| 5 | 대기 원격 복구 예약된 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 복구 | |
|
| 5 | 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 정리 | |
|
| 5 | 활성 복구 상태 대기 시간 | |
|
| 5 | 복제본 비활성 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 | |
|
| 5 | Getinfo 복구 상태 대기 시간 | |
|
| 5 | Getlog 복구 상태 대기 시간 | |
|
| 5 | 복구 상태 변경 대기 시간 | |
|
| 5 | 복구 상태 대기 시간 불완전 | |
|
| 5 | 복구 상태 대기 시간 가져오기 | |
|
| 5 | Waitupthru 복구 상태 대기 시간 |
표 8.12. OSD Throttle 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | 현재 사용 가능한 throttle |
|
| 10 | throttle의 최대 값 | |
|
| 10 | gets | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | get_or_fail 중에 차단됨 | |
|
| 10 | get_or_fail 중에 성공 | |
|
| 10 | takes | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | bae | |
|
| 10 | 데이터 삽입 | |
|
| 5 | 대기 시간 |
8.8. Ceph Object Gateway 지표
표 8.13. RADOS 클라이언트 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | 요구 사항 |
|
| 10 | 중단된 요청 | |
|
| 10 | gets | |
|
| 10 | 가져 오기의 크기 | |
|
| 5 | 대기 시간 가져오기 | |
|
| 10 | bae | |
|
| 10 | 개체 크기 | |
|
| 5 | put latency | |
|
| 2 | 대기열 길이 | |
|
| 2 | 활성 요청 대기열 | |
|
| 10 | 캐시 적중 | |
|
| 10 | 캐시 누락 | |
|
| 10 | Keystone 토큰 캐시 적중 | |
|
| 10 | Keystone 토큰 캐시 누락 | |
|
| 10 | Ceph Object Gateway를 마지막으로 다시 시작한 이후 종료된 오브젝트 수 |
표 8.14. 오브젝트 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 2 | 활성 작업 |
|
| 2 | laggy 작업 | |
|
| 10 | 보낸 작업 | |
|
| 10 | 전송된 데이터 | |
|
| 10 | Resent 작업 | |
|
| 10 | 콜백 커밋 | |
|
| 10 | 작업 커밋 | |
|
| 10 | 작업 | |
|
| 10 | 읽기 작업 | |
|
| 10 | 쓰기 작업 | |
|
| 10 | Read-modify-write 작업 | |
|
| 10 | PG 작업 | |
|
| 10 | 작업 시작 | |
|
| 10 | 오브젝트 작업 생성 | |
|
| 10 | 읽기 작업 | |
|
| 10 | 쓰기 작업 | |
|
| 10 | 전체 오브젝트 작업 쓰기 | |
|
| 10 | 추가 작업 | |
|
| 10 | 오브젝트를 0개의 작업으로 설정 | |
|
| 10 | truncate 오브젝트 작업 | |
|
| 10 | 오브젝트 작업 삭제 | |
|
| 10 | 확장 작업 매핑 | |
|
| 10 | 스파스 읽기 작업 | |
|
| 10 | 복제 범위 작업 | |
|
| 10 | xattr 작업 가져오기 | |
|
| 10 | xattr 작업 설정 | |
|
| 10 | xattr 비교 작업 | |
|
| 10 | xattr 작업 제거 | |
|
| 10 | xattr 작업 재설정 | |
|
| 10 | TMAP 업데이트 작업 | |
|
| 10 | TMAP put 작업 | |
|
| 10 | TMAP 액세스 작업 | |
|
| 10 | 호출(실행) 작업 | |
|
| 10 | 오브젝트 작업 조사 | |
|
| 10 | 오브젝트 작업에 대한 알림 | |
|
| 10 | 다중 작업에서 확장 특성 비교 | |
|
| 10 | 기타 작업 | |
|
| 2 | Active lingering 작업 | |
|
| 10 | LOWI(Larngering) 작업 | |
|
| 10 | Resent lingering 작업 | |
|
| 10 | 지속 가능한 작업에 ping 전송 | |
|
| 2 | 활성 풀 작업 | |
|
| 10 | 전송된 풀 작업 | |
|
| 10 | 리sent 풀 작업 | |
|
| 2 | Active get pool stat operations | |
|
| 10 | pool stat operations sent | |
|
| 10 | 리sent 풀 통계 | |
|
| 2 | statfs 작업 | |
|
| 10 | FS 통계 전송 | |
|
| 10 | resent FS 통계 | |
|
| 2 | 활성 명령 | |
|
| 10 | 보낸 명령 | |
|
| 10 | resent 명령 | |
|
| 2 | OSD 맵 epoch | |
|
| 10 | 수신된 전체 OSD 맵 | |
|
| 10 | 수신한 증분 OSD 맵 | |
|
| 2 | 열려 있는 세션 | |
|
| 10 | 세션이 열립니다. | |
|
| 10 | 세션이 종료됨 | |
|
| 2 | laggy OSD 세션 |
표 8.15. RADOS 게이트웨이 Throttle 지표 테이블
| 컬렉션 이름 | 메트릭 이름 | 비트 필드 값 | 짧은 설명 |
|---|---|---|---|
|
|
| 10 | 현재 사용 가능한 throttle |
|
| 10 | throttle의 최대 값 | |
|
| 10 | gets | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | get_or_fail 중에 차단됨 | |
|
| 10 | get_or_fail 중에 성공 | |
|
| 10 | takes | |
|
| 10 | 데이터 가져오기 | |
|
| 10 | bae | |
|
| 10 | 데이터 삽입 | |
|
| 5 | 대기 시간 |
9장. BlueStore
Red Hat Ceph Storage 4부터 BlueStore는 OSD 데몬의 기본 오브젝트 저장소입니다. 이전의 오브젝트 저장소인 FileStore에는 원시 블록 장치 상단에 파일 시스템이 필요합니다. 그런 다음 오브젝트가 파일 시스템에 기록됩니다. BlueStore는 블록 장치에 직접 오브젝트를 배치하기 때문에 bluestore는 초기 파일 시스템이 필요하지 않습니다.
bluestore는 프로덕션 환경에서 OSD 데몬에 대한 고성능 백엔드를 제공합니다. 기본적으로 BlueStore는 자체 조정으로 구성됩니다. BlueStore가 수동으로 튜닝된 상태에서 환경이 더 잘 수행된다고 판단할 경우 Red Hat 지원팀 에 연락하여 구성 세부 정보를 공유하여 자동 튜닝 기능을 개선할 수 있습니다. Red Hat은 고객의 의견을 기다리고 귀하의 권장 사항을 평가해 드립니다.
9.1. Ceph BlueStore
다음은 BlueStore 사용의 몇 가지 주요 기능입니다.
- 스토리지 장치 직접 관리
- bluestore는 원시 블록 장치 또는 파티션을 사용합니다. 이렇게 하면 XFS와 같은 로컬 파일 시스템과 같은 추상화 계층을 사용하지 않으므로 성능을 제한하거나 복잡성을 추가할 수 있습니다.
- RocksDB를 사용한 메타데이터 관리
- bluestore는 RocksDB의 키-값 데이터베이스를 사용하여 개체 이름에서 디스크의 위치 차단과 같은 내부 메타데이터를 관리합니다.
- 전체 데이터 및 메타데이터 체크섬
- 기본적으로 BlueStore에 작성된 모든 데이터 및 메타데이터는 하나 이상의 체크섬으로 보호됩니다. 데이터 또는 메타데이터는 디스크에서 읽거나 확인 없이 사용자에게 반환되지 않습니다.
- 효율적인 copy-on-write
- Ceph 블록 장치 및 Ceph 파일 시스템 스냅샷은 BlueStore에서 효율적으로 구현되는 COW(Copy-On-Write) 복제 메커니즘을 사용합니다. 따라서 일반적인 스냅샷과 삭제 코딩된 풀에 대해 효율적인 I/O를 통해 효율적인 2단계 커밋을 구현할 수 있습니다.
- 큰 이중 쓰기 없음
- bluestore는 먼저 블록 장치의 할당되지 않은 공간에 새 데이터를 쓴 다음 개체 메타데이터를 업데이트하여 디스크의 새 영역을 참조하도록 RocksDB 트랜잭션을 커밋합니다. 쓰기 작업이 구성 가능한 크기 임계값 미만일 때만 FileStore가 작동하는 방식과 유사하게 미리 쓰기 저널링 계획으로 대체됩니다.
- 다중 장치 지원
bluestore는 다른 데이터를 저장하기 위해 여러 블록 장치를 사용할 수 있습니다. 예를 들어, 데이터에 대한 하드 디스크 드라이브(HDD), 메타데이터의 경우 Solid-state Drive(SSD), NVMe(Non-volatile Memory) 또는 NVRAM(Non-volatile random-access memory) 또는 WAL(WAL)용 영구 메모리입니다. 자세한 내용은 Ceph BlueStore 장치를 참조하십시오.
참고ceph-disk유틸리티는 아직 여러 장치를 프로비저닝하지 않았습니다. 여러 장치를 사용하려면 OSD를 수동으로 설정해야 합니다.- 효율적인 블록 장치 사용
- BlueStore는 파일 시스템을 사용하지 않으므로 스토리지 장치 캐시를 지우는 필요성을 최소화합니다.
9.2. Ceph BlueStore 장치
이 섹션에서는 BlueStore 백엔드에서 사용하는 블록 장치에 대해 설명합니다.
bluestore는 하나, 두 개 또는 세 개의 스토리지 장치를 관리합니다.
- primary
- WAL
- DB
가장 간단한 경우 BlueStore는 단일 ( primary) 저장 장치를 사용합니다. 스토리지 장치는 다음을 포함하는 두 부분으로 분할됩니다.
- OSD 메타데이터: OSD에 대한 기본 메타데이터가 포함된 XFS로 포맷된 작은 파티션입니다. 이 데이터 디렉터리에는 OSD에 속하는 클러스터, 개인 인증 키 등의 OSD에 대한 정보가 포함되어 있습니다.
- data: BlueStore에서 직접 관리하고 모든 OSD 데이터를 포함하는 장치의 나머지 부분을 차지하는 큰 파티션입니다. 이 기본 장치는 데이터 디렉터리에서 블록 심볼릭 링크로 식별됩니다.
두 개의 추가 장치를 사용할 수도 있습니다.
-
WAL(쓰기-로그) 장치: BlueStore 내부 저널 또는 write-ahead 로그를 저장하는 장치입니다. 이는 데이터 디렉터리에서
block.wal심볼릭 링크로 식별됩니다. 장치가 기본 장치보다 빠른 경우에만 WAL 장치를 사용하는 것이 좋습니다. 예를 들어, WAL 장치가 SSD 디스크를 사용하고 기본 장치는 HDD 디스크를 사용하는 경우입니다. - DB 장치: BlueStore 내부 메타데이터를 저장하는 장치입니다. 임베디드 RocksDB 데이터베이스는 성능을 개선하기 위해 기본 장치 대신 DB 장치에 가능한 한 많은 메타데이터를 둡니다. DB 장치가 가득 차면 기본 장치에 메타데이터 추가를 시작합니다. 장치가 기본 장치보다 빠른 경우에만 DB 장치를 사용하는 것이 좋습니다.
빠른 장치에서 사용할 수 있는 기가바이트보다 적은 스토리지만 있는 경우 Red Hat은 이를 WAL 장치로 사용하는 것이 좋습니다. 더 빠른 장치를 사용할 수 있는 경우 DB 장치로 사용을 고려하십시오. BlueStore 저널은 항상 가장 빠른 장치에 배치되므로 DB 장치를 사용하면 WAL 장치가 추가 메타데이터를 저장할 수 있는 것과 동일한 이점이 있습니다.
9.3. Ceph BlueStore 캐싱
BlueStore 캐시는 구성에 따라 OSD 데몬이 디스크에서 읽거나 쓸 때 데이터로 채워질 수 있는 버퍼 컬렉션입니다. 기본적으로 Red Hat Ceph Storage에서 BlueStore는 읽기를 캐시하지만 쓰기는 캐시하지 않습니다. 이는 캐시 제거와 관련된 잠재적인 오버헤드를 방지하기 위해 bluestore_default_buffered_write 옵션이 false 로 설정되어 있기 때문입니다.
bluestore_default_buffered_write 옵션이 true 로 설정된 경우 데이터가 먼저 버퍼에 기록된 다음 디스크에 커밋됩니다. 그런 다음 쓰기 승인이 클라이언트로 전송되어 해당 데이터가 제거될 때까지 이미 캐시에 있는 데이터에 대한 읽기 속도가 빨라집니다.
읽기 전용 워크로드는 BlueStore 캐싱의 즉각적인 이점을 얻지 못합니다. 더 많은 읽기가 완료되면 캐시가 시간이 지남에 따라 증가되고 후속 읽기가 성능이 향상되는 것을 알 수 있습니다. 캐시 채우기 속도는 BlueStore 블록 및 데이터베이스 디스크 유형 및 클라이언트의 워크로드 요구 사항에 따라 다릅니다.
bluestore_default_buffered_write 옵션을 활성화하기 전에 Red Hat 지원에 문의하십시오.
9.4. Ceph BlueStore 크기 조정 고려 사항
BlueStore OSD를 사용하여 기존 및 솔리드 상태 드라이브를 혼합할 때는 RocksDB 논리 볼륨(block.db)의 크기를 적절하게 조정해야 합니다. Red Hat은 RocksDB 논리 볼륨이 블록 크기의 4% 미만이며 오브젝트, 파일 및 혼합 워크로드와 함께 사용할 것을 권장합니다. Red Hat은 RocksDB 및 OpenStack 블록 워크로드로 BlueStore 블록 크기의 1%를 지원합니다. 예를 들어, 개체 워크로드에 대해 블록 크기가 1TB인 경우 최소 40GB RocksDB 논리 볼륨을 만듭니다.
드라이브 유형을 혼합하지 않을 때는 별도의 RocksDB 논리 볼륨이 필요하지 않습니다. bluestore는 RocksDB의 크기를 자동으로 관리합니다.
bluestore의 캐시 메모리는 RocksDB, BlueStore 메타데이터 및 오브젝트 데이터에 대한 키-값 쌍 메타데이터에 사용됩니다.
OSD에서 이미 사용하고 있는 메모리 공간 외에도 BlueStore 캐시 메모리 값이 추가되었습니다.
9.5. Ceph BlueStore OSD 추가
이 섹션에서는 BlueStore 백엔드 오브젝트 저장소로 새 Ceph OSD 노드를 설치하는 방법을 설명합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- 노드에 대한 루트 수준 액세스입니다.
절차
Ansible 인벤토리 파일의
[osds]섹션에 새 OSD 노드를 추가합니다. 기본적으로/etc/ansible/hosts에 있습니다.[osds] node1 node2 node3 HOST_NAME교체:
-
OSD 노드의 이름이 있는
HOST_NAME
예제
[osds] node1 node2 node3 node4
-
OSD 노드의 이름이 있는
/usr/share/ceph-ansible/디렉터리로 이동합니다.[user@admin ~]$ cd /usr/share/ceph-ansible
host_vars디렉터리를 생성합니다.[root@admin ceph-ansible] mkdir host_vars
host_vars에 새로 추가된 OSD의 구성 파일을 만듭니다.[root@admin ceph-ansible] touch host_vars/HOST_NAME.yml교체:
-
새로 추가된 OSD의 호스트 이름이 있는
HOST_NAME
예제
[root@admin ceph-ansible] touch host_vars/node4.yml
-
새로 추가된 OSD의 호스트 이름이 있는
새로 생성된 파일에 다음 설정을 추가합니다.
osd_objectstore: bluestore
참고모든 OSD에 BlueStore를 사용하려면
osd_objectstore:bluestore를group_vars/all.yml파일에 추가합니다.host_vars/HOST_NAME.yml에서 BlueStore OSD를 구성합니다.구문
lvm_volumes: - data: DATALV data_vg: DATAVG
교체:
-
데이터 논리 볼륨 이름이 있는
DATALV -
데이터 논리 볼륨 그룹 이름이 있는
DATAVG
예제
lvm_volumes: - data: data-lv1 data_vg: vg1-
데이터 논리 볼륨 이름이 있는
선택 사항: 전용 논리 볼륨에
block.wal및block.db를 저장하려면host_vars/HOST_NAME.yml파일을 다음과 같이 편집합니다.lvm_volumes: - data: DATALV wal: WALLV wal_vg: VG db: DBLV db_vg: VG
교체:
- 데이터를 포함해야 하는 논리 볼륨이 있는 DATALV
- write-ahead-log를 포함해야 하는 논리 볼륨이 있는 WALLV
- 볼륨 그룹이 있는 VG 는 WAL 및/또는 DB 장치 LVs에 있습니다.
- BlueStore 내부 메타데이터가 포함된 논리 볼륨이 있는 DBLV
예제
lvm_volumes: - data: data-lv3 wal: wal-lv1 wal_vg: vg3 db: db-lv3 db_vg: vg3참고lvm_volumes를 사용할 때 :osd_objectstore와 함께lvm_volumesYAML 사전에는 최소한데이터가포함되어야 합니다.wal또는db를 정의할 때 LV 이름과 VG 이름이 모두 있어야 합니다(db와wal은 필수는 아님). 이를 통해 데이터, 데이터, wal, wal 및 wal 및 db 또는 data 및 db라는 네 가지 조합만 가능합니다. 데이터는 원시 장치, lv 또는 파티션이 될 수 있습니다.wal및db는 lv 또는 partition일 수 있습니다. 원시 장치 또는 파티션ceph-volume을 지정하면 논리 볼륨이 그 위에 배치됩니다.참고현재
ceph-ansible에서는 볼륨 그룹 또는 논리 볼륨을 생성하지 않습니다. Anisble 플레이북을 실행하기 전에 이 작업을 수행해야 합니다.선택 사항:
group_vars/all.yml파일에서block.db기본 크기를 덮어쓸 수 있습니다.구문
ceph_conf_overrides: osd: bluestore_block_db_size: VALUE예제
ceph_conf_overrides: osd: bluestore_block_db_size: 24336000000참고bluestore_block_db_size의 값은 2GB보다 커야 합니다.group_vars/all.yml파일을 열고 편집하고osd_memory_target옵션의 주석을 제거합니다. OSD에서 사용할 메모리 양에 대한 값을 조정합니다.참고osd_memory_target옵션의 기본값은4000000000입니다. 이는 4GB입니다. 이 옵션은 BlueStore 캐시를 메모리에 고정합니다.중요osd_memory_target옵션은 BlueStore-backed OSD에만 적용됩니다.다음 Ansible 플레이북을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook site.yml
Ceph 모니터 노드에서 새 OSD가 성공적으로 추가되었는지 확인합니다.
[root@mon ~]# ceph osd tree
9.6. 소규모 쓰기를 위해 Ceph BlueStore 튜닝
BlueStore에서 원시 파티션은 bluestore_min_alloc_size 의 청크로 할당 및 관리됩니다. 기본적으로 bluestore_min_alloc_size 는 HDD의 경우 64KB, SSD의 경우 4KB입니다. 각 청크의 작성되지 않은 영역은 원시 파티션에 쓸 때 0으로 채워집니다. 이로 인해 작은 오브젝트를 작성하는 경우와 같이 워크로드에 맞게 크기가 제대로 조정되지 않은 경우 사용되지 않은 공간이 낭비될 수 있습니다.
Bluestore_min_alloc_size 를 가장 작은 쓰기와 일치하도록 설정하는 것이 가장 좋습니다. 이렇게 하면 정리 오류를 방지할 수 있습니다.
예를 들어 클라이언트가 4KB 오브젝트를 자주 쓰는 경우 ceph-anible 을 사용하여 OSD 노드에서 다음 설정을 구성합니다.
bluestore_min_alloc_size = 4096
bluestore_min_alloc_size_sd 및 bluestore_min_alloc_ sized 설정은 각각 SSD 및 HDD에 고유하지만 bluestore_min_alloc_size _size를 설정하면 해당 설정이 필요하지 않습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
- OSD 노드로 새로 프로비저닝할 수 있는 새 서버 또는:
- 재배포할 수 있는 OSD 노드.
- 기존 Ceph OSD 노드를 재배포하는 경우 Ceph Monitor 노드의 관리자 인증 키입니다.
절차
선택 사항: 기존 OSD 노드를 재배포하는 경우
shrink-osd.ymlAnsible 플레이북을 사용하여 클러스터에서 OSD를 제거합니다.ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=OSD_ID예제
[admin@admin ceph-ansible]$ ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=1
- 기존 OSD 노드를 재배포하는 경우 OSD 드라이브를 지우고 OS를 다시 설치합니다.
- Ansible을 사용하여 OSD 프로비저닝 노드를 준비합니다. 준비 작업의 예로는 Red Hat Ceph Storage 리포지토리 활성화, Ansible 사용자 추가, 암호 없는 SSH 로그인 활성화 등이 있습니다.
group_vars/all.ymlAnsible 플레이북의ceph_conf_overrides섹션에bluestore_min_alloc_size를 추가합니다.ceph_conf_overrides: osd: bluestore_min_alloc_size: 4096새 노드를 배포하는 경우 Ansible 인벤토리 파일, 일반적으로
/etc/ansible/hosts에 추가합니다.[osds] OSD_NODE_NAME예제
[osds] osd1 devices="[ '/dev/sdb' ]"
- 기존 OSD를 재배포하는 경우 Ceph Monitor 노드의 관리 인증 키 파일을 OSD를 배포할 노드에 복사합니다.
Ansible을 사용하여 OSD 노드를 프로비저닝합니다.
ansible-playbook -v site.yml -l OSD_NODE_NAME예제
[admin@admin ceph-ansible]$ ansible-playbook -v site.yml -l osd1
플레이북이 완료되면
ceph daemon명령을 사용하여 설정을 확인합니다.ceph daemon OSD.ID config get bluestore_min_alloc_size예제
[root@osd1 ~]# ceph daemon osd.1 config get bluestore_min_alloc_size { "bluestore_min_alloc_size": "4096" }bluestore_min_alloc_size가 4096바이트로 설정되어 4KiB와 같은 것을 볼 수 있습니다.
추가 리소스
- 자세한 내용은 'Red Hat Ceph Storage 설치 가이드 를 참조하십시오.
9.7. BlueStore 조각화 툴
스토리지 관리자는 BlueStore OSD의 조각화 수준을 정기적으로 확인하려고 합니다. 오프라인 또는 온라인 OSD에 대한 간단한 명령으로 조각화 수준을 확인할 수 있습니다.
9.7.1. 사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 3.3 이상 스토리지 클러스터.
- bluestore OSD.
9.7.2. BlueStore 조각화 툴은 무엇입니까?
BlueStore OSD의 경우 사용 가능한 공간은 기본 스토리지 장치에서 시간이 지남에 따라 조각화됩니다. 일부 조각화는 정상이지만 과도한 조각화가 발생하면 성능이 저하됩니다.
BlueStore 조각화 툴은 BlueStore OSD의 조각화 수준에서 점수를 생성합니다. 이러한 조각화 점수는 범위, 0~1로 지정됩니다. 점수가 0이면 조각화가 없으며 1의 점수는 심각한 조각화를 의미합니다.A score of 0 means no fragmentation, and a score of 1 means severe fragmentation.
표 9.1. 조각화 점수의 의미
| 점수 | 조각화 마운트 |
|---|---|
| 0.0 - 0.4 | 작은 조각화는 없습니다. |
| 0.4 - 0.7 | 작고 허용 가능한 조각화. |
| 0.7 - 0.9 | 상당한, 하지만 안전한 조각화. |
| 0.9 - 1.0 | 조각화와 이로 인해 성능 문제가 발생합니다. |
조각화가 심각하고 문제를 해결하는 데 도움이 필요한 경우 Red Hat 지원에 문의하십시오.
9.7.3. 조각화 확인
BlueStore OSD의 조각화 수준을 확인하는 작업은 온라인 또는 오프라인에서 수행할 수 있습니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 3.3 이상 스토리지 클러스터.
- bluestore OSD.
온라인 BlueStore 조각화 점수
실행중인 BlueStore OSD 프로세스를 검사합니다.
간단한 보고서:
구문
ceph daemon OSD_ID bluestore allocator score block예제
[root@osd ~]# ceph daemon osd.123 bluestore allocator score block
더 자세한 보고서:
구문
ceph daemon OSD_ID bluestore allocator dump block예제
[root@osd ~]# ceph daemon osd.123 bluestore allocator dump block
오프라인 BlueStore 조각화 점수
실행되고 있지 않은 BlueStore OSD 프로세스를 검사합니다.
간단한 보고서:
구문
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-score예제
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-score
더 자세한 보고서:
구문
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-dump예제
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-dump
추가 리소스
- 조각화 점수에 대한 자세한 내용은 Red Hat Ceph Storage 4.1 BlueStore Fragmentation Tool 을 참조하십시오.
9.8. FileStore에서 BlueStore로 오브젝트 저장소를 마이그레이션하는 방법
스토리지 관리자는 기존 오브젝트 저장소 FileStore에서 새 오브젝트 저장소인 BlueStore로 마이그레이션할 수 있습니다.
9.8.1. 사전 요구 사항
- 정상적이고 실행 중인 Red Hat Ceph Storage 클러스터.
9.8.2. FileStore에서 BlueStore로 마이그레이션
bluestore는 기존 FileStore와 비교하여 성능과 견고성을 향상시킵니다. 단일 Red Hat Ceph Storage 클러스터에는 FileStore 및 BlueStore 장치가 모두 혼합되어 있을 수 있습니다.
개별 OSD를 변환해도 제 위치에서 또는 격리할 수 없습니다. 변환 프로세스는 이전(FileStore) 장치에서 새 (BlueStore) 장치로 OSD 콘텐츠를 복사하는 스토리지 클러스터의 일반 복제 및 복구 프로세스 또는 전략에 의존합니다. FileStore에서 BlueStore로 마이그레이션하는 방법은 두 가지가 있습니다.
첫 번째 접근 방식
첫 번째 접근 방식은 각 장치를 차례로 표시하고, 데이터가 스토리지 클러스터에서 복제되고, OSD를 다시 프로비저닝할 때까지 기다린 후 다시 "인"으로 표시하는 것입니다. 이 방법의 장단점은 다음과 같습니다.
- 이점
- 단순.
- 장치별로 수행할 수 있습니다.
- 예비 장치 또는 노드가 필요하지 않습니다.
- 단점
네트워크를 통해 데이터를 복사하는 작업은 두 번 수행됩니다.
참고스토리지 클러스터의 다른 OSD로 복사하면 원하는 수의 복제본을 유지한 다음 다시 프로비저닝된 BlueStore OSD로 다시 복사본을 유지할 수 있습니다.
두 번째 접근 방식
두 번째 방법은 전체 노드 교체를 수행하는 것입니다. 데이터가 없는 빈 노드가 있어야 합니다.
이 작업을 수행하는 방법에는 두 가지가 있습니다. * 스토리지 클러스터의 일부가 아닌 새로운 빈 노드로 시작. * 스토리지 클러스터의 기존 노드에서 데이터를 오프로드합니다.
- 이점
- 데이터는 한 번만 네트워크를 통해 복사됩니다.
- 전체 노드의 OSD를 한 번에 변환합니다.
- 한 번에 여러 노드를 변환하도록 병렬화할 수 있습니다.
- 각 노드에 예비 장치가 필요하지 않습니다.
- 단점
- 예비 노드가 필요합니다.
- 전체 노드의 가치가 있는 OSD는 한 번에 데이터를 마이그레이션합니다. 이는 전체 클러스터 성능에 영향을 줄 가능성이 큽니다.
- 마이그레이션된 모든 데이터는 여전히 네트워크를 통해 하나의 전체 홉을 만듭니다.
9.8.3. Ansible을 사용하여 FileStore에서 BlueStore로 마이그레이션
Ansible을 사용하여 FileStore에서 BlueStore로 마이그레이션하면 감소되고 노드의 모든 OSD가 재배포됩니다. Ansible 플레이북은 마이그레이션을 시작하기 전에 용량 검사를 수행합니다. 그런 다음 ceph-volume 유틸리티에서 OSD를 재배포합니다.
사전 요구 사항
- 정상적이고 실행 중인 Red Hat Ceph Storage 4 클러스터.
-
Ansible 애플리케이션에서 사용할
ansible사용자 계정입니다.
절차
-
Ansible 관리 노드에서
ansible사용자로 로그인합니다. group_vars/osd.yml파일을 편집하고 다음 옵션을 추가하고 설정합니다.nb_retry_wait_osd_up: 50 delay_wait_osd_up: 30
다음 Ansible 플레이북을 실행합니다.
구문
ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit OSD_NODE_TO_MIGRATE예제
[ansible@admin ~]$ ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit osd1
주의Ceph 구성 파일에서
osd_crush_update_on_start = False를 명시적으로 설정하면 변환이 실패합니다. 다른 ID를 사용하여 새 OSD를 생성하고ECDHE 규칙에 잘못 배치합니다. 또한 이전 OSD 데이터 디렉터리를 지우지 않습니다.- 스토리지 클러스터의 다음 OSD 노드에서 마이그레이션을 시작하기 전에 마이그레이션이 완료될 때까지 기다립니다.
9.8.4. 마크 아웃 및 교체 방법을 사용하여 FileStore에서 BlueStore로 마이그레이션
FileStore에서 BlueStore로 마이그레이션하는 가장 간단한 방법은 각 장치를 차례로 표시하고, 스토리지 클러스터에서 복제할 때까지 기다린 후 OSD를 다시 프로비저닝하여 다시 표시하는 것입니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
노드에 대한
루트액세스입니다.
절차
아래의 변수 OSD_ID 를 ODS 식별 번호로 바꿉니다.
교체할 FileStore OSD를 찾습니다.
OSD ID 번호를 가져옵니다.
[root@ceph-client ~]# ceph osd tree
OSD에서 FileStore 또는 BlueStore를 사용 중인지 확인합니다.
구문
ceph osd metadata OSD_ID | grep osd_objectstore예제
[root@ceph-client ~]# ceph osd metadata 0 | grep osd_objectstore "osd_objectstore": "filestore",현재 FileStore 장치 대 BlueStore 장치 수를 보려면 다음을 수행합니다.
[root@ceph-client ~]# ceph osd count-metadata osd_objectstore
FileStore OSD를 표시합니다.
ceph osd out OSD_ID데이터가 OSD에서 마이그레이션될 때까지 기다립니다.
while ! ceph osd safe-to-destroy OSD_ID ; do sleep 60 ; doneOSD를 중지합니다.
systemctl stop ceph-osd@OSD_ID이 OSD가 사용 중인 장치를 캡처합니다.
mount | grep /var/lib/ceph/osd/ceph-OSD_IDOSD를 마운트 해제합니다.
umount /var/lib/ceph/osd/ceph-OSD_ID5단계의 값을
DEVICE로 사용하여 OSD 데이터를 삭제합니다.ceph-volume lvm zap DEVICE중요이 경우 장치의 콘텐츠가 손상되므로 기존 CAREFUL 이 있어야 합니다. 계속하기 전에 장치의 데이터가 필요하지 않은지 확인합니다. 스토리지 클러스터가 정상인지 확인하십시오.
참고OSD가 암호화되면
osd-lockbox를 마운트 해제하고dmsetup remove를 사용하여 OSD를 zapping하기 전에 암호화를 제거합니다.참고OSD에 논리 볼륨이 포함된 경우
ceph-volume lvm zap명령에서--destroy옵션을 사용합니다.OSD가 삭제되었음을 스토리지 클러스터에서 인식할 수 있도록 합니다.
[root@ceph-client ~]# ceph osd destroy OSD_ID --yes-i-really-mean-it5단계에서
DEVICE를 사용하여 OSD를 BlueStoreOSD로 다시 프로비저닝합니다.[root@ceph-client ~]# ceph-volume lvm create --bluestore --data DEVICE --osd-id OSD_ID
이 절차를 반복하십시오.
참고새 BlueStore OSD를 다시 채울 때 스토리지 클러스터가 OSD를 제거하기 전에
HEALTH_OK를 확인하는 한 다음 FileStore OSD를 드레이닝하는 것과 동시에 발생할 수 있습니다. 이렇게 하지 않으면 데이터의 중복을 줄이고 데이터 손실 위험을 증가시킵니다.
9.8.5. 전체 노드 교체 방법을 사용하여 FileStore에서 BlueStore로 마이그레이션
FileStore에서 BlueStore로 마이그레이션하는 것은 한 번만 저장된 데이터의 각 복사본을 전송함으로써 노드별로 할 수 있습니다. 이 마이그레이션은 스토리지 클러스터의 예비 노드를 사용하거나 여유 공간으로 스토리지 클러스터에서 전체 노드를 비울 수 있도록 여유 공간을 확보할 수 있습니다. 이상적으로 노드에는 마이그레이션할 다른 노드와 거의 동일한 용량이 있어야 합니다.
사전 요구 사항
- 실행 중인 Red Hat Ceph Storage 클러스터.
-
노드에 대한
루트액세스입니다. - 데이터가 없는 빈 노드입니다.
절차
-
아래 변수
NEWNODE를 새 노드 이름으로 바꿉니다. -
아래의
EXISTING_NODE_TO_CONVERT변수를 스토리지 클러스터에 이미 존재하는 노드 이름으로 교체합니다. 아래 변수
OSD_ID를 OSD 식별 번호로 바꿉니다.스토리지 클러스터에 없는 새 노드 사용 스토리지 클러스터에 이미 있는 기존 노드를 사용하려면 3단계로 건너뜁니다.
CRUSH 계층 구조에 노드를 추가합니다.
[root@mon ~]# ceph osd crush add-bucket NEWNODE node중요루트에 연결하지 마십시오.
Ceph 소프트웨어 패키지를 설치합니다.
[root@mon ~]# yum install ceph-osd
참고Ceph 구성 파일(기본적으로
/etc/ceph/ceph.conf)을 새 노드에 복사합니다.
- 단계 5로 건너뜁니다.
스토리지 클러스터에 이미 기존 노드를 사용하는 경우 다음 명령을 사용합니다.
[root@mon ~]# ceph osd crush unlink EXISTING_NODE_TO_CONVERT default참고여기서
기본값은CRUSH 맵의 즉시 상위 항목입니다.- 단계 8로 건너뜁니다.
모든 장치에 대해 새 BlueStore OSD를 프로비저닝합니다.
[root@mon ~]# ceph-volume lvm create --bluestore --data /dev/DEVICEOSD가 클러스터에 연결되었는지 확인합니다.
[root@mon ~]# ceph osd tree
노드 이름 아래에 모든 OSD가 있는 새 노드 이름이 표시되지만, 노드를 계층 구조의 다른 노드 아래에 중첩 해서는 안 됩니다.
예제
[root@mon ~]# ceph osd tree ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF -5 0 node newnode 10 ssd 1.00000 osd.10 up 1.00000 1.00000 11 ssd 1.00000 osd.11 up 1.00000 1.00000 12 ssd 1.00000 osd.12 up 1.00000 1.00000 -1 3.00000 root default -2 3.00000 node oldnode1 0 ssd 1.00000 osd.0 up 1.00000 1.00000 1 ssd 1.00000 osd.1 up 1.00000 1.00000 2 ssd 1.00000 osd.2 up 1.00000 1.00000
새 노드를 클러스터의 기존 노드 위치로 교체하십시오.
[root@mon ~]# ceph osd crush swap-bucket NEWNODE EXISTING_NODE_TO_CONVERT
이 시점에서
EXISTING_NODE_TO_CONVERT의 모든 데이터가NEWNODE에서 OSD로 마이그레이션하기 시작합니다.참고이전 노드와 새 노드의 총 용량에 차이가 있는 경우 스토리지 클러스터의 다른 노드로 일부 데이터를 마이그레이션하거나 볼 수 있지만 노드 크기가 유사한 경우 비교적 적은 양의 데이터가 됩니다.
데이터 마이그레이션이 완료될 때까지 기다립니다.
while ! ceph osd safe-to-destroy $(ceph osd ls-tree EXISTING_NODE_TO_CONVERT); do sleep 60 ; doneEXISTING_NODE_TO_CONVERT에 로그인하고 현재 비어 있는EXISTING_NODE_TO_CONVERT에서 이전 OSD를 모두 중지하고 마운트 해제합니다.[root@mon ~]# systemctl stop ceph-osd@OSD_ID [root@mon ~]# umount /var/lib/ceph/osd/ceph-OSD_ID
이전 OSD를 삭제하고 삭제합니다.
for osd in
ceph osd ls-tree EXISTING_NODE_TO_CONVERT; do ceph osd purge $osd --yes-i-really-mean-it ; done이전 OSD 장치를 제거합니다. 이를 위해서는 수동으로 초기화할 장치를 식별해야 합니다. 각 장치에 대해 다음 명령을 수행합니다.
[root@mon ~]# ceph-volume lvm zap DEVICE중요이 경우 장치의 콘텐츠가 손상되므로 기존 CAREFUL 이 있어야 합니다. 계속하기 전에 장치의 데이터가 필요하지 않은지 확인합니다. 즉, 스토리지 클러스터가 정상인지 확인하십시오.
참고OSD가 암호화되면
osd-lockbox를 마운트 해제하고dmsetup remove를 사용하여 OSD를 zapping하기 전에 암호화를 제거합니다.참고OSD에 논리 볼륨이 포함된 경우
ceph-volume lvm zap명령에서--destroy옵션을 사용합니다.- 현재 비어 있는 기존 노드를 새 노드로 사용하고 프로세스를 반복합니다.