
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
우분투를 위한 설치 가이드
Ubuntu에 Red Hat Ceph Storage 설치
초록
1장. Red Hat Ceph Storage는 무엇입니까?
Red Hat Ceph Storage는 가장 안정적인 버전의 Ceph 스토리지 시스템을 Ceph 관리 플랫폼, 배포 유틸리티 및 지원 서비스와 결합하는 확장 가능한 오픈 소프트웨어 정의 스토리지 플랫폼입니다.
Red Hat Ceph Storage는 클라우드 인프라 및 웹 규모 개체 스토리지를 위해 설계되었습니다. Red Hat Ceph Storage 클러스터는 다음과 같은 유형의 노드로 구성됩니다.
- Red Hat Ceph Storage Ansible 관리 노드
이러한 유형의 노드는 이전 버전의 Red Hat Ceph Storage에서 수행한 기존 Ceph 관리 노드 역할을 합니다. 이 유형의 노드는 다음과 같은 기능을 제공합니다.
- 중앙 집중식 스토리지 클러스터 관리
- Ceph 구성 파일 및 키
- 보안상의 이유로 인터넷에 액세스할 수 없는 노드에 Ceph를 설치하는 경우 선택적으로 로컬 리포지토리
- 노드 모니터링
-
각 모니터 노드는 클러스터 맵의 마스터 사본을 유지 관리하는 모니터 데몬(
ceph-mon)을 실행합니다. 클러스터 맵에는 클러스터 토폴로지가 포함됩니다. Ceph 클러스터에 연결된 클라이언트는 모니터에서 현재 클러스터 맵 사본을 검색하고 이를 통해 클라이언트가 데이터를 읽고 클러스터에 쓸 수 있습니다.
그러나 프로덕션 클러스터에서 고가용성을 보장하기 위해 Ceph를 하나의 모니터로 실행할 수 있지만, Red Hat은 최소 3개의 모니터 노드가 있는 배포만 지원합니다. Red Hat은750 OSD를 초과하는 스토리지 클러스터에 대해 총 5개의 Ceph Monitor를 배포하는 것이 좋습니다.
- OSD 노드
각 OSD(오브젝트 스토리지 장치) 노드는 Ceph OSD 데몬(
ceph-osd)을 실행하여 노드에 연결된 논리 디스크와 상호 작용합니다. Ceph는 이러한 OSD 노드에 데이터를 저장합니다.Ceph는 기본값이 3개지만 프로덕션 클러스터는 매우 적은 OSD 노드로 실행할 수 있지만, 프로덕션 클러스터는 모드 크기(예: 스토리지 클러스터의 50개 OSD)에서 성능이 향상될 수 있습니다. Ceph 클러스터에는 여러 OSD 노드가 있으므로 CRUSH 맵을 생성하여 분리된 오류 도메인을 허용하는 것이 좋습니다.
- MDS 노드
-
각 메타데이터 서버(MDS) 노드는 MDS 데몬(
ceph-mds)을 실행하여 Ceph 파일 시스템(CephFS)에 저장된 파일과 관련된 메타데이터를 관리합니다. MDS 데몬은 공유 클러스터에 대한 액세스도 조정합니다. - Object Gateway 노드
Ceph Object Gateway 노드는 Ceph RADOS Gateway 데몬(
ceph-radosgw)을 실행하고librados상단에 구축된 오브젝트 스토리지 인터페이스로, Ceph Storage 클러스터에 RESTful 게이트웨이를 제공합니다. Ceph Object Gateway는 다음 두 가지 인터페이스를 지원합니다.S3
Amazon S3 RESTful API의 대규모 하위 집합과 호환되는 인터페이스가 포함된 오브젝트 스토리지 기능을 제공합니다.
Swift
OpenStack Swift API의 대규모 하위 집합과 호환되는 인터페이스가 포함된 오브젝트 스토리지 기능을 제공합니다.
Ceph 아키텍처에 대한 자세한 내용은 Red Hat Ceph Storage 3 아키텍처 가이드를 참조하십시오.
최소 권장 하드웨어의 경우 Red Hat Ceph Storage Hardware Selection Guide 3을 참조하십시오.
2장. Red Hat Ceph Storage 설치 요구사항
그림 2.1. 사전 요구 사항 워크플로
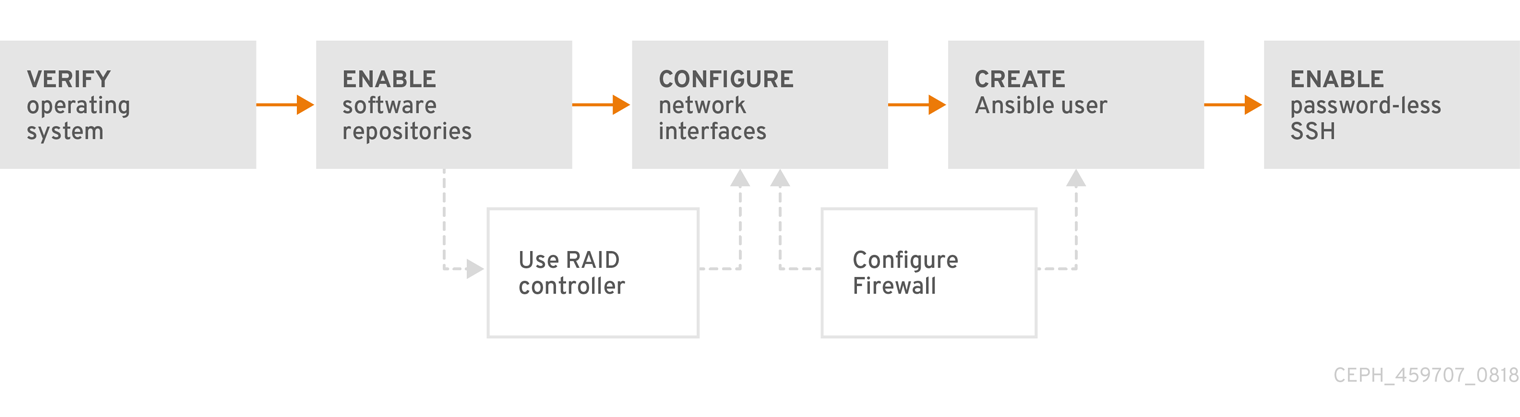
RHCS(Red Hat Ceph Storage)를 설치하기 전에 다음 요구 사항을 검토하고 그에 따라 각 모니터, OSD, 메타데이터 서버 및 클라이언트 노드를 준비합니다.
2.1. 사전 요구 사항
- 하드웨어가 최소 요구 사항을 충족하는지 확인합니다. 자세한 내용은 Red Hat Ceph Storage 3의 하드웨어 가이드 를 참조하십시오.
2.2. Red Hat Ceph Storage 설치를 위한 요구 사항 확인
| Task | 필수 항목 | 섹션 | 권장 사항 |
|---|---|---|---|
| 운영 체제 버전 확인 | 있음 | ||
| Ceph 소프트웨어 리포지토리 활성화 | 있음 | ||
| OSD 노드에서 RAID 컨트롤러 사용 | 없음 | RAID 컨트롤러에서 쓰기-백 캐시를 활성화하면 OSD 노드의 소규모 I/O 쓰기 처리량이 증가할 수 있습니다. | |
| 네트워크 구성 | 있음 | 최소한 공용 네트워크가 필요합니다. 그러나 클러스터 통신용 사설 네트워크가 권장됩니다. | |
| 방화벽 구성 | 없음 | 방화벽은 네트워크에 대한 신뢰 수준을 높일 수 있습니다. | |
| Ansible 사용자 생성 | 있음 | 모든 Ceph 노드에 Ansible 사용자를 생성해야 합니다. | |
| 암호 없는 SSH 활성화 | 있음 | Ansible에 필요합니다. |
기본적으로 ceph-ansible 은 NTP를 요구 사항으로 설치합니다. NTP가 사용자 지정되면 수동으로 Red Hat Ceph Storage 설치에서 네트워크 시간 프로토콜 구성을 참조하십시오.
2.3. Red Hat Ceph Storage의 운영 체제 요구 사항
Red Hat Ceph Storage 3에는 스토리지 클러스터의 모든 Ceph 노드에서 실행되는 AMD64 또는 Intel 64 아키텍처와 같은 동종 버전이 있는 Ubuntu 16.04.04가 필요합니다.
Red Hat은 이기종 운영 체제 또는 버전이 있는 클러스터를 지원하지 않습니다.
추가 리소스
- Red Hat Enterprise Linux 7용 설치 가이드.
- Red Hat Enterprise Linux 7용 시스템 관리자 가이드.
2.4. Red Hat Ceph Storage 리포지토리 활성화
Red Hat Ceph Storage를 설치하려면 먼저 설치 방법을 선택해야 합니다. Red Hat Ceph Storage는 다음 두 가지 설치 방법을 지원합니다.
CDN(Content Delivery Network)
인터넷에 직접 연결할 수 있는 Ceph 노드가 있는 Ceph Storage 클러스터의 경우 Red Hat Subscription Manager를 사용하여 필요한 Ceph 리포지토리를 활성화합니다.
로컬 리포지토리
보안 조치에서 인터넷 액세스가 불가능한 Ceph Storage 클러스터의 경우 로컬 리포지토리를 설치할 수 있는 ISO 이미지로 제공되는 단일 소프트웨어 빌드에서 Red Hat Ceph Storage 3.3을 설치합니다.
RHCS 소프트웨어 리포지토리에 액세스하려면 Red Hat Customer Portal 에서 유효한 Red Hat 로그인 및 암호가 필요합니다.
https://rhcs.download.redhat.com 의 인증 정보를 얻으려면 계정 관리자에게 문의하십시오.
사전 요구 사항
- 유효한 고객 서브스크립션.
- CDN 설치의 경우 RHCS 노드가 인터넷에 연결할 수 있어야 합니다.
절차
CDN 설치의 경우:
Ansible 관리 노드에서 Red Hat Ceph Storage 3 툴 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
ISO 설치의 경우:
- Red Hat 고객 포털에 로그인합니다.
- 소프트웨어 및 다운로드 센터를 방문하려면 다운로드를 클릭합니다.
- Red Hat Ceph Storage 영역에서 Download Software 를 클릭하여 최신 버전의 소프트웨어를 다운로드합니다.
추가 리소스
- Red Hat Enterprise Linux용 시스템 관리자 가이드의 서브스크립션 등록 및 관리 장.
2.5. OSD 노드에서 RAID 컨트롤러 사용 고려 사항(선택 사항)
2GB의 캐시가 설치된 OSD 노드에 RAID 컨트롤러가 있는 경우 나중 쓰기 캐시를 활성화하면 적은 I/O 쓰기 처리량이 증가할 수 있습니다. 그러나 캐시는 비휘발성이어야 합니다.
최신 RAID 컨트롤러는 일반적으로 정전 이벤트 중에 비volatile NAND 메모리에 휘발성 메모리를 드레인할 수 있는 충분한 전력을 제공하는 슈퍼 커패시터가 있습니다. 전원을 복원한 후 특정 컨트롤러와 펌웨어가 작동하는 방식을 이해하는 것이 중요합니다.
일부 RAID 컨트롤러는 수동 개입이 필요합니다. 하드 드라이브는 일반적으로 운영 체제에 디스크 캐시를 사용하도록 설정하거나 비활성화해야 하는지를 알립니다. 그러나 특정 RAID 컨트롤러와 일부 펌웨어는 이러한 정보를 제공하지 않습니다. 파일 시스템 손상을 방지하려면 디스크 수준 캐시가 비활성화되어 있는지 확인합니다.
나중 쓰기 캐시가 활성화된 각 Ceph OSD 데이터 드라이브에 대해 쓰기-back으로 단일 RAID 0 볼륨을 생성합니다.
Serial Attached SCSI (SAS) 또는 SATA 연결 Solid-state Drive (SSD) 디스크도 RAID 컨트롤러에 있는 경우 컨트롤러 및 펌웨어가 패스쓰루 모드를 지원하는지 여부를 조사합니다. 패스스루 모드를 활성화하면 캐싱 논리를 방지할 수 있으며 일반적으로 빠른 미디어의 대기 시간이 훨씬 짧습니다.
2.6. 오브젝트 게이트웨이에서 NVMe 사용 고려 사항(선택 사항)
Red Hat Ceph Storage의 Object Gateway 기능을 사용하고 OSD 노드에 NVMe 기반 SSD 또는 SATA SSD가 있는 경우 Ceph Object Gateway 의 절차에 따라 LVM에서 NVMe를 최적으로 사용하는 것이 좋습니다. 이 절차에서는 SSD에 저널 및 버킷 인덱스를 함께 배치하는 특수 설계된 Ansible 플레이북을 사용하는 방법을 설명합니다. 이렇게 하면 한 장치에 모든 저널이 있는 것보다 성능이 향상됩니다. LVM에서 NVMe를 최적으로 사용하는 방법에 대한 정보는 이 설치 가이드와 함께 참조해야 합니다.
2.7. Red Hat Ceph Storage 네트워크 구성 확인
모든 RHCS(Red Hat Ceph Storage) 노드에는 공용 네트워크가 필요합니다. Ceph 클라이언트가 Ceph 모니터 및 Ceph OSD 노드에 연결할 수 있는 공용 네트워크에 네트워크 인터페이스 카드가 구성되어 있어야 합니다.
Ceph가 공용 네트워크와 별도로 네트워크에서 심부착, 피어링, 복제 및 복구를 수행할 수 있도록 클러스터 네트워크의 네트워크 인터페이스 카드가 있을 수 있습니다.
네트워크 인터페이스 설정을 구성하고 변경 사항을 지속하도록 합니다.
Red Hat은 공용 및 사설 네트워크 모두에 단일 네트워크 인터페이스 카드를 사용하지 않는 것이 좋습니다.
추가 리소스
- 네트워크 구성에 대한 자세한 내용은 Red Hat Ceph Storage 3 구성 가이드 의 네트워크 구성 참조 장을 참조하십시오.
2.8. Red Hat Ceph Storage 방화벽 설정
RHCS(Red Hat Ceph Storage)는 iptables 서비스를 사용합니다.
Monitor 데몬은 Ceph 스토리지 클러스터 내 통신에 포트 6789 를 사용합니다.
각 Ceph OSD 노드에서 OSD 데몬은 6800-7300 범위의 여러 포트를 사용합니다.
- 하나는 클라이언트와 통신하고 공용 네트워크를 통해 모니터링합니다.
- 사용 가능한 경우 클러스터 네트워크를 통해 다른 OSD로 데이터를 전송하는 방법
- 사용 가능한 경우 클러스터 네트워크에서 하트비트 패킷을 교환하는 방법
Ceph Manager(ceph-mgr) 데몬은 6800-7300 범위의 포트를 사용합니다. 동일한 노드에서 Ceph Monitor를 사용하여 ceph-mgr 데몬을 공동 배치하는 것이 좋습니다.
Ceph Metadata Server 노드(ceph-mds)는 6800-7300 범위의 포트를 사용합니다.
Ceph Object Gateway 노드는 기본적으로 포트 8080 을 사용하도록 Ansible에서 구성합니다. 그러나 기본 포트(예: 포트 80 )를 변경할 수 있습니다.
SSL/TLS 서비스를 사용하려면 포트 443 을 엽니다.
사전 요구 사항
- 네트워크 하드웨어가 연결되어 있습니다.
절차
root 사용자로 다음 명령을 실행합니다.
모든 모니터 노드에서 공용 네트워크에서 포트
6789를 엽니다.iptables -I INPUT 1 -i iface -p tcp -s IP_address/netmask_prefix --dport 6789 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
Monitor 노드의 네트워크 주소가 있는 ip
_address입니다. -
CIDR(Classless Inter-domain Routing) 표기법에서 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -p tcp -s 192.168.0.11/24 --dport 6789 -j ACCEPT
모든 OSD 노드에서 공용 네트워크에서 포트
6800-7300을 엽니다.iptables -I INPUT 1 -i iface -m multiport -p tcp -s IP_address/netmask_prefix --dports 6800:7300 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
OSD 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -m multiport -p tcp -s 192.168.0.21/24 --dports 6800:7300 -j ACCEPT
모든 Ceph Manager(
ceph-mgr) 노드(일반적으로 Monitor와 동일한 노드)에서 공용 네트워크에서 포트6800-7300을 엽니다.iptables -I INPUT 1 -i iface -m multiport -p tcp -s IP_address/netmask_prefix --dports 6800:7300 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
OSD 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -m multiport -p tcp -s 192.168.0.21/24 --dports 6800:7300 -j ACCEPT
모든 Ceph 메타데이터 서버(
ceph-mds) 노드에서 공용 네트워크에서 포트6800을 엽니다.iptables -I INPUT 1 -i iface -m multiport -p tcp -s IP_address/netmask_prefix --dports 6800 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
OSD 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -m multiport -p tcp -s 192.168.0.21/24 --dports 6800 -j ACCEPT
모든 Ceph Object Gateway 노드에서 공용 네트워크에서 관련 포트 또는 포트를 엽니다.
기본 Ansible 구성된
8080포트를 엽니다.iptables -I INPUT 1 -i iface -p tcp -s IP_address/netmask_prefix --dport 8080 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
오브젝트 게이트웨이 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -p tcp -s 192.168.0.31/24 --dport 8080 -j ACCEPT
선택 사항: Ansible을 사용하여 Ceph Object Gateway를 설치하고 Ansible에서
8080에서 사용하도록 Ceph Object Gateway를 구성하는 기본 포트를 변경된 경우 포트80으로 이 포트를 엽니다.iptables -I INPUT 1 -i iface -p tcp -s IP_address/netmask_prefix --dport 80 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
오브젝트 게이트웨이 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -p tcp -s 192.168.0.31/24 --dport 80 -j ACCEPT
선택 사항: SSL/TLS를 사용하려면 포트
443을 엽니다.iptables -I INPUT 1 -i iface -p tcp -s IP_address/netmask_prefix --dport 443 -j ACCEPT
- replace
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
iface합니다. -
오브젝트 게이트웨이 노드의 네트워크 주소가 있는 ip
_address. -
CIDR 표기법으로 넷마스크가 있는 넷마스크
_prefix.
-
public 네트워크의 네트워크 인터페이스 카드 이름과 함께
예제
$ sudo iptables -I INPUT 1 -i enp6s0 -p tcp -s 192.168.0.31/24 --dport 443 -j ACCEPT
스토리지 클러스터의 모든 RHCS 노드에서 영구적으로 변경합니다.
iptables-persistent패키지를 설치합니다.$ sudo apt-get install iptables-persistent
표시되는 터미널 UI에서
yes를 선택하여 현재IPv4 iptables규칙을/etc/iptables/rules.v4파일에 저장하고 현재IPv6 iptables규칙을/etc/iptables/rules.v6파일에 저장합니다.참고iptables-persistent를 설치한 후 새iptables규칙을 추가하는 경우 새규칙을 규칙파일에 추가합니다.$ sudo iptables-save >> /etc/iptables/rules.v4
추가 리소스
- 공용 및 클러스터 네트워크에 대한 자세한 내용은 Red Hat Ceph Storage의 네트워크 구성 확인을 참조하십시오.
2.9. sudo 액세스를 사용하여 Ansible 사용자 생성
Ansible은 모든 RHCS(Red Hat Ceph Storage) 노드에 root 권한이 있는 사용자로 로그인하고 암호를 요청하지 않고 구성 파일을 생성할 수 있어야 합니다. Ansible을 사용하여 Red Hat Ceph Storage 클러스터를 배포하고 구성할 때 스토리지 클러스터의 모든 노드에서 암호가 없는 루트 액세스 권한을 가진 Ansible 사용자를 생성해야 합니다.
사전 요구 사항
-
스토리지 클러스터의 모든 노드에
root또는sudo액세스 권한이 있어야 합니다.
절차
Ceph 노드에
root사용자로 로그인합니다.ssh root@$HOST_NAME
- replace
-
$HOST_NAME- Ceph 노드의 호스트 이름이 사용됩니다.
-
예제
# ssh root@mon01
메시지가 표시되면
루트암호를 입력합니다.새 Ansible 사용자를 생성합니다.
adduser $USER_NAME
- replace
-
$USER_NAME- Ansible 사용자의 새 사용자 이름을 지정합니다.
-
예제
$ sudo adduser admin
메시지가 표시되면 이 사용자의 암호를 두 번 입력합니다.
중요ceph를 사용자 이름으로 사용하지 마십시오.ceph사용자 이름은 Ceph 데몬용으로 예약되어 있습니다. 클러스터 전체의 균일한 사용자 이름은 사용 편의성을 향상시킬 수 있지만 침입자가 일반적으로 무차별 공격에 사용하기 때문에 명확한 사용자 이름을 사용하지 마십시오.새로 생성된 사용자에 대해
sudo액세스를 설정합니다.cat << EOF >/etc/sudoers.d/$USER_NAME $USER_NAME ALL = (root) NOPASSWD:ALL EOF
- replace
-
$USER_NAME- Ansible 사용자의 새 사용자 이름을 지정합니다.
-
예제
$ sudo cat << EOF >/etc/sudoers.d/admin admin ALL = (root) NOPASSWD:ALL EOF
올바른 파일 권한을 새 파일에 할당합니다.
chmod 0440 /etc/sudoers.d/$USER_NAME
- replace
-
$USER_NAME- Ansible 사용자의 새 사용자 이름을 지정합니다.
-
예제
$ sudo chmod 0440 /etc/sudoers.d/admin
추가 리소스
- 시스템 관리자 가이드의 새 사용자 추가 섹션.
2.10. Ansible에 대해 암호 없는 SSH 활성화
Ansible 관리 노드에서 SSH 키 쌍을 생성하고, 스토리지 클러스터의 각 노드에 공개 키를 배포하여 Ansible이 암호를 확인하지 않고 노드에 액세스할 수 있도록 합니다.
사전 요구 사항
절차
Ansible 관리 노드 및 Ansible 사용자로 다음 단계를 수행합니다.
SSH 키 쌍을 생성하고 기본 파일 이름을 수락하고 암호를 비워 둡니다.
[user@admin ~]$ ssh-keygen
스토리지 클러스터의 모든 노드에 공개 키를 복사합니다.
ssh-copy-id $USER_NAME@$HOST_NAME
- replace
-
$USER_NAME- Ansible 사용자의 새 사용자 이름을 지정합니다. -
$HOST_NAME- Ceph 노드의 호스트 이름이 사용됩니다.
-
예제
[user@admin ~]$ ssh-copy-id admin@ceph-mon01
~/.ssh/config파일을 만들고 편집합니다.중요~/.ssh/config파일을 생성하고 편집하여ansible-playbook명령을 실행할 때마다-u $USER_NAME옵션을 지정할 필요가 없습니다.SSH
구성파일을 생성합니다.[user@admin ~]$ touch ~/.ssh/config
편집할
구성파일을 엽니다. 스토리지 클러스터의 각 노드에 대한Hostname및User옵션을 설정합니다.Host node1 Hostname $HOST_NAME User $USER_NAME Host node2 Hostname $HOST_NAME User $USER_NAME ...
- replace
-
$HOST_NAME- Ceph 노드의 호스트 이름이 사용됩니다. -
$USER_NAME- Ansible 사용자의 새 사용자 이름을 지정합니다.
-
예제
Host node1 Hostname monitor User admin Host node2 Hostname osd User admin Host node3 Hostname gateway User admin
~/.ssh/config파일에 대해 올바른 파일 권한을 설정합니다.[admin@admin ~]$ chmod 600 ~/.ssh/config
추가 리소스
-
ssh_config(5)매뉴얼 페이지 - Red Hat Enterprise Linux 7용 시스템 관리자 가이드의 OpenSSH 장
3장. Red Hat Ceph Storage 배포
이 장에서는 Ansible 애플리케이션을 사용하여 Red Hat Ceph Storage 클러스터 및 메타데이터 서버 또는 Ceph Object 게이트웨이와 같은 기타 구성 요소를 배포하는 방법을 설명합니다.
- Red Hat Ceph Storage 클러스터를 설치하려면 3.2절. “Red Hat Ceph Storage 클러스터 설치” 를 참조하십시오.
- 메타데이터 서버를 설치하려면 3.4절. “메타데이터 서버 설치” 를 참조하십시오.
-
ceph-client역할을 설치하려면 3.5절. “Ceph 클라이언트 역할 설치” 를 참조하십시오. - Ceph Object Gateway를 설치하려면 3.6절. “Ceph Object Gateway 설치” 를 참조하십시오.
- 다중 사이트 Ceph 개체 게이트웨이를 구성하려면 3.6.1절. “다중 사이트 Ceph Object Gateway 구성” 을 참조하십시오.
-
Ansible
--limit옵션에 대한 자세한 내용은 3.8절. “제한옵션 이해” 을 참조하십시오.
이전에는 Red Hat에서 Ubuntu에 ceph-ansible 패키지를 제공하지 않았습니다. Red Hat Ceph Storage 버전 3 이상에서는 Ansible 자동화 애플리케이션을 사용하여 Ubuntu 노드에서 Ceph 클러스터를 배포할 수 있습니다.
3.1. 사전 요구 사항
- 유효한 고객 서브스크립션을 받으십시오.
클러스터 노드를 준비합니다. 각 노드에서 다음을 수행합니다.
3.2. Red Hat Ceph Storage 클러스터 설치
ceph-ansible 플레이북과 함께 Ansible 애플리케이션을 사용하여 Red Hat Ceph Storage 3을 설치합니다.
프로덕션 Ceph 스토리지 클러스터는 최소 3개의 모니터 호스트 및 여러 OSD 데몬이 포함된 OSD 노드 3개로 시작합니다.
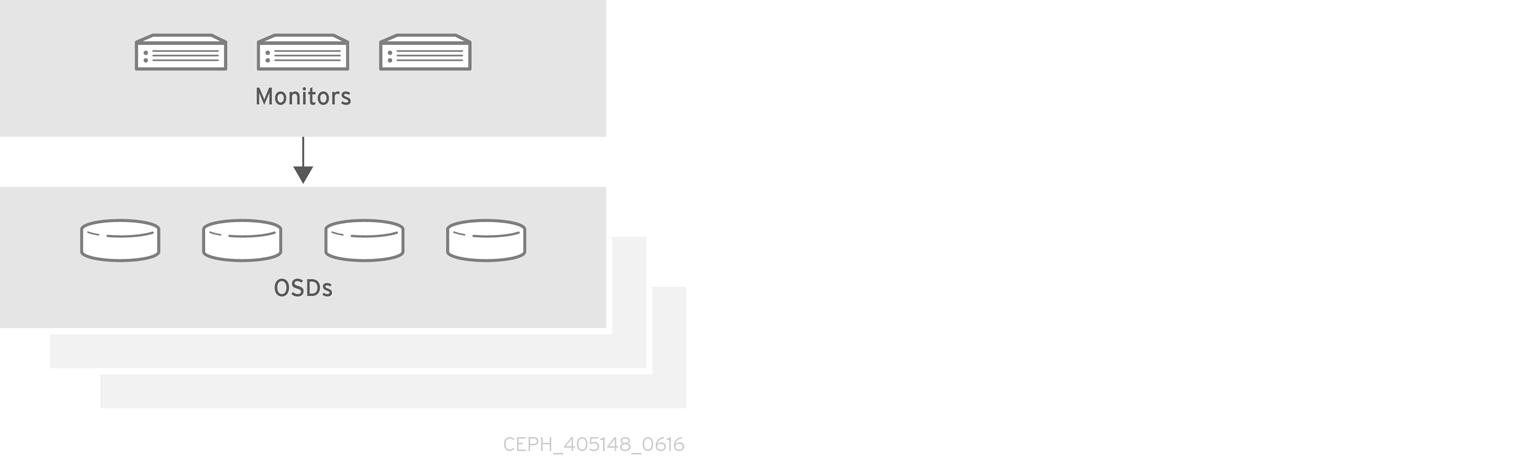
사전 요구 사항
Ansible 관리 노드에서
ceph-ansible패키지를 설치합니다.[user@admin ~]$ sudo apt-get install ceph-ansible
절차
달리 지침이 없는 경우 Ansible 관리 노드에서 다음 명령을 실행합니다.
Ansible 사용자로 Ansible에서
ceph-ansible플레이북에서 생성한 임시 값을 저장하는ceph-ansible-keys디렉터리를 생성합니다.[user@admin ~]$ mkdir ~/ceph-ansible-keys
root로
/etc/ansible/디렉터리의/usr/share/ceph-ansible/group_vars디렉터리에 대한 심볼릭 링크를 생성합니다.[root@admin ~]# ln -s /usr/share/ceph-ansible/group_vars /etc/ansible/group_vars
/usr/share/ceph-ansible/디렉터리로 이동합니다.[root@admin ~]$ cd /usr/share/ceph-ansible
yml.sample파일의 새 복사본을 생성합니다.[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml [root@admin ceph-ansible]# cp site.yml.sample site.yml
복사된 파일을 편집합니다.
group_vars/all.yml파일을 편집합니다. 주석 처리를 위해 가장 일반적인 필수 매개 변수와 선택적 매개변수는 아래 표를 참조하십시오. 테이블에는 모든 매개 변수가 포함되어 있지 않습니다.중요사용자 지정 클러스터 이름 사용은 지원되지 않으므로
cluster: ceph매개변수를ceph이외의 값으로 설정하지 마십시오.표 3.1. 일반 Ansible 설정
옵션 값 필수 항목 참고 ceph_origin리포지토리또는디트로또는로컬있음
리포지토리값은 새 리포지토리를 통해 Ceph가 설치됨을 의미합니다.distro값은 별도의 리포지토리 파일이 추가되지 않으며 Linux 배포에 포함된 모든 Ceph 버전을 가져옵니다.local값은 Ceph 바이너리가 로컬 시스템에서 복사됨을 의미합니다.ceph_repository_typeCDN또는iso있음
ceph_rhcs_iso_pathISO 이미지 경로
예: ISO 이미지를 사용하는 경우
ceph_rhcs_cdn_debian_repo온라인 Ubuntu Ceph 리포지토리에 액세스할 수 있는 자격 증명. 예:
https://username:.있음
ceph_rhcs_cdn_debian_repo_version새로 설치하는 경우
/3-release/를 사용합니다. 업데이트는/3-updates/를 사용합니다.있음
monitor_interface모니터 노드가 수신하는 인터페이스
monitor_interface,monitor_address또는monitor_address_block이 필요합니다.monitor_address모니터 노드가 수신하는 주소입니다.
monitor_address_blockCeph 공용 네트워크의 서브넷
노드의 IP 주소를 알 수 없지만 서브넷을 알 수 없는 경우 사용합니다.
ip_versionipv6예: IPv6 주소를 사용하는 경우
public_networkCeph 공용 네트워크의 IP 주소 및 넷마스크 또는 IPv6를 사용하는 경우 해당 IPv6 주소
있음
cluster_networkCeph 클러스터 네트워크의 IP 주소 및 넷마스크
아니요, 기본값은
public_network입니다.all.yml파일의 예는 다음과 같습니다.ceph_origin: distro ceph_repository: rhcs ceph_repository_type: cdn ceph_rhcs_version: 3 monitor_interface: eth0 public_network: 192.168.0.0/24
참고ceph_origin을all.yml파일에 배포하도록 설정해야 합니다.이렇게 하면 설치 프로세스에서 올바른 다운로드 리포지토리를 사용합니다.참고ceph_rhcs_version옵션을3으로 설정하면 최신 버전의 Red Hat Ceph Storage 3이 가져옵니다.자세한 내용은
all.yml파일을 참조하십시오.group_vars/osds.yml파일을 편집합니다. 주석 처리를 위해 가장 일반적인 필수 매개 변수와 선택적 매개변수는 아래 표를 참조하십시오. 테이블에는 모든 매개 변수가 포함되어 있지 않습니다.중요다른 물리적 장치를 사용하여 운영 체제가 설치된 장치와 OSD를 설치합니다. 운영 체제와 OSD 간에 동일한 장치를 공유하면 성능에 문제가 발생합니다.
표 3.2. OSD Ansible 설정
옵션 값 필수 항목 참고 osd_scenario쓰기 로깅 및 키/값 데이터(BlueStore) 또는 저널(FileStore) 및 OSD 데이터에 동일한 장치를 사용하도록
배치됨SSD 또는 NVMe 미디어와 같은 전용 장치를 사용하여 쓰기 로그 및 키/값 데이터(BlueStore) 또는 저널 데이터(FileStore)를 저장합니다.
LVM에서 논리 볼륨 관리자를 사용하여 OSD 데이터를 저장합니다.있음
osd_scenario를 사용하는 경우,ceph-ansible은장치및dedicated_devices의 변수 수가 일치할 것으로 예상합니다. 예를 들어장치에서10 디스크를 지정하는 경우dedicated_devices에 10 개의 항목을 지정해야 합니다.osd_auto_discoveryOSD를 자동으로 검색하려면
true예:
osd_scenario: collocated장치설정을 사용할 때는 사용할 수 없습니다.devicesceph 데이터가저장된 장치 목록예: 장치 목록을 지정합니다.
osd_auto_discovery설정이 사용되는 경우 사용할 수 없습니다.lvm을osd_scenario로 사용하고devices옵션을 설정하면ceph-volume lvm 배치모드를 사용하면 최적화된 OSD 구성이 생성됩니다.dedicated_devicesceph 저널이저장된 non-collocated OSD의 전용 장치 목록osd_scenario: non-collocated파티션되지 않은 장치여야 합니다.
dmcryptOSD 암호화
없음
기본값은
falselvm_volumesFileStore 또는 BlueStore 사전 목록
예:
osd_scenario를 사용하는 경우: lvm및 스토리지 장치는장치를사용하여 정의되지 않습니다.각 사전에는
데이터,journal및data_vg키가 포함되어야 합니다. 논리 볼륨 또는 볼륨 그룹은 전체 경로가 아닌 이름이어야 합니다.데이터, 및저널키는 논리 볼륨(LV) 또는 파티션이 될 수 있지만 여러데이터LV에는 저널을 사용하지 않습니다.data_vg키는dataLV를 포함하는 볼륨 그룹이어야 합니다. 필요한 경우journal_vg키를 사용하여 저널 LV가 포함된 볼륨 그룹을 지정할 수 있습니다. 지원되는 다양한 구성은 아래 예제를 참조하십시오.osds_per_device장치당 생성할 OSD 수입니다.
없음
기본값은
1입니다.osd_objectstoreOSD의 Ceph 오브젝트 저장소 유형입니다.
없음
기본값은
bluestore입니다. 다른 옵션은filestore입니다. 업그레이드에 필요합니다.다음은 세 개의 OSD 시나리오(, 결합
되지 않은, ,lvm)를 사용할 때osds.yml파일의 예입니다.기본 OSD 개체 저장소 형식은 지정되지 않은 경우 BlueStore입니다.collocated
osd_objectstore: filestore osd_scenario: collocated devices: - /dev/sda - /dev/sdb
지원되지 않는 - BlueStore
osd_objectstore: bluestore osd_scenario: non-collocated devices: - /dev/sda - /dev/sdb - /dev/sdc - /dev/sdd dedicated_devices: - /dev/nvme0n1 - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme1n1
이 지원되지 않는 예에서는 장치당 하나씩 4개의 BlueStore OSD를 생성합니다. 이 예에서 기존의 하드 드라이브(
sda,sdb,sdc,sdd)는 오브젝트 데이터에 사용되며 솔리드 상태 드라이브(SSD) (/dev/nvme0n1,/dev/nvme1n1)는 BlueStore 데이터베이스 및 write-ahead 로그에 사용됩니다. 이 구성은/dev/sda및/dev/sdb장치를/dev/nvme0n1장치를 사용하여 연결하고/dev/sdc및/dev/sdd장치를/dev/nvme1n1장치와 쌍으로 연결합니다.지원되지 않음 - 파일 저장소
osd_objectstore: filestore osd_scenario: non-collocated devices: - /dev/sda - /dev/sdb - /dev/sdc - /dev/sdd dedicated_devices: - /dev/nvme0n1 - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme1n1
LVM simple
osd_objectstore: bluestore osd_scenario: lvm devices: - /dev/sda - /dev/sdb
또는
osd_objectstore: bluestore osd_scenario: lvm devices: - /dev/sda - /dev/sdb - /dev/nvme0n1
이러한 간단한 구성으로
ceph-ansible은 배치 모드(ceph-volume lvm batch)를 사용하여 OSD를 생성합니다.첫 번째 시나리오에서는
장치가기존 하드 드라이브 또는 SSD인 경우 장치당 하나의 OSD가 생성됩니다.두 번째 시나리오에서는 기존 하드 드라이브와 SSD가 혼합되어 있는 경우 데이터는 기존 하드 드라이브(
sda,sdb)에 배치되고 BlueStore 데이터베이스(block.db)는 SSD(nvme0n1)에서 최대한 크게 생성됩니다.LVM advance
osd_objectstore: filestore osd_scenario: lvm lvm_volumes: - data: data-lv1 data_vg: vg1 journal: journal-lv1 journal_vg: vg2 - data: data-lv2 journal: /dev/sda data_vg: vg1또는
osd_objectstore: bluestore osd_scenario: lvm lvm_volumes: - data: data-lv1 data_vg: data-vg1 db: db-lv1 db_vg: db-vg1 wal: wal-lv1 wal_vg: wal-vg1 - data: data-lv2 data_vg: data-vg2 db: db-lv2 db_vg: db-vg2 wal: wal-lv2 wal_vg: wal-vg2이러한 고급 시나리오 예제를 사용하면 볼륨 그룹과 논리 볼륨을 사전에 생성해야 합니다.
ceph-ansible에서 생성되지 않습니다.참고모든 NVMe SSD를 사용하는 경우
osd_scenario: lvm및osds_per_device를 설정합니다. 4옵션. 자세한 내용은 모든 NVMe 스토리지 for Red Hat Enterprise Linux에 대한 OSD Ansible 설정 구성 또는 Red Hat Ceph Storage 설치 가이드 의 모든 NVMe 스토리지 for Ubuntu에 대한 OSD Ansible 설정 구성을 참조하십시오.자세한 내용은
osds.yml파일의 주석을 참조하십시오.
/etc/ansible/hosts에 기본적으로 있는 Ansible 인벤토리 파일을 편집합니다. 예제 호스트를 주석 처리하십시오.[mons]섹션 아래에 모니터 노드를 추가합니다.[mons] MONITOR_NODE_NAME1 MONITOR_NODE_NAME2 MONITOR_NODE_NAME3
[osds]섹션 아래에 OSD 노드를 추가합니다. 노드의 이름이 순차적인 경우 범위를 사용하는 것이 좋습니다.[osds] OSD_NODE_NAME1[1:10]참고새 설치의 OSD의 경우 기본 오브젝트 저장소 형식은 BlueStore입니다.
선택적으로
devices및dedicated_devices옵션을 사용하여 OSD 노드에서 사용할 장치를 지정합니다. 쉼표로 구분된 목록을 사용하여 여러 장치를 나열합니다.구문
[osds] CEPH_NODE_NAME devices="['DEVICE_1', 'DEVICE_2']" dedicated_devices="['DEVICE_3', 'DEVICE_4']"
예제
[osds] ceph-osd-01 devices="['/dev/sdc', '/dev/sdd']" dedicated_devices="['/dev/sda', '/dev/sdb']" ceph-osd-02 devices="['/dev/sdc', '/dev/sdd', '/dev/sde']" dedicated_devices="['/dev/sdf', '/dev/sdg']"
장치를 지정하지 않으면
osds.yml파일에서osd_auto_discovery옵션을true로 설정합니다.참고devices및dedicated_devices매개 변수를 사용하면 OSD에서 이름이 다른 장치를 사용하거나 장치 중 하나가 OSD에서 실패한 경우 유용합니다.
선택적으로 모든 배포, 베어 메탈 또는 컨테이너에 대해 호스트 특정 매개 변수를 사용하려면
host_vars디렉터리에 호스트 파일을 생성하여 호스트와 관련된 모든 매개변수를 포함합니다.스토리지 클러스터에 추가된 새 Ceph OSD 노드의 새 파일을
/etc/ansible/host_vars/디렉터리에 생성합니다.구문
touch /etc/ansible/host_vars/OSD_NODE_NAME예제
[root@admin ~]# touch /etc/ansible/host_vars/osd07
호스트별 매개 변수를 사용하여 파일을 업데이트합니다. 베어 메탈 배포에서는
devices:및dedicated_devices:섹션을 파일에 추가할 수 있습니다.예제
devices: - /dev/sdc - /dev/sdd - /dev/sde - /dev/sdf dedicated_devices: - /dev/sda - /dev/sdb
필요한 경우 모든 배포, 베어 메탈 또는 컨테이너 의 경우
ansible-playbook 을 사용하여 사용자 지정 CRUSH 계층을 생성할 수 있습니다.Ansible 인벤토리 파일을 설정합니다.
osd_crush_location매개변수를 사용하여 OSD 호스트가 CRUSH 맵 계층 구조에 있을 위치를 지정합니다. OSD 위치를 지정하려면 최소 2개의 CRUSH 버킷 유형을 지정해야 하며 하나의 버킷유형이호스트여야 합니다. 기본적으로루트,데이터 센터,방,행,pod, du ,랙,섀시및호스트가포함됩니다.구문
[osds] CEPH_OSD_NAME osd_crush_location="{ 'root': ROOT_BUCKET', 'rack': 'RACK_BUCKET', 'pod': 'POD_BUCKET', 'host': 'CEPH_HOST_NAME' }"
예제
[osds] ceph-osd-01 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'pod': 'monpod', 'host': 'ceph-osd-01' }"crush_rule_config및create_crush_tree매개변수를True로 설정하고 기본 CRUSH 규칙을 사용하지 않으려면 최소 하나의 CRUSH 규칙을 만듭니다. 예를 들어 HDD 장치를 사용하는 경우 다음과 같이 매개 변수를 편집합니다.crush_rule_config: True crush_rule_hdd: name: replicated_hdd_rule root: root-hdd type: host class: hdd default: True crush_rules: - "{{ crush_rule_hdd }}" create_crush_tree: TrueSSD 장치를 사용하는 경우 다음과 같이 매개변수를 편집합니다.
crush_rule_config: True crush_rule_ssd: name: replicated_ssd_rule root: root-ssd type: host class: ssd default: True crush_rules: - "{{ crush_rule_ssd }}" create_crush_tree: True참고기본 규칙에는 정의해야 하는
class매개 변수가 포함되어 있으므로ssd및hddOSD가 모두 배포되지 않으면 기본 CRUSH 규칙이 실패합니다.참고또한 사용자 지정 CRUSH 계층 구조를 위의 단계에 설명된 대로
host_vars디렉터리의 OSD 파일에 추가하여 이 구성 작업을 수행합니다.group_vars/clients.yml파일에서 생성된crush_rules를 사용하여풀생성.예제
>>>>>>> 3993c70c7f25ab628cbfd9c8e27623403ca18c99
copy_admin_key: True user_config: True pool1: name: "pool1" pg_num: 128 pgp_num: 128 rule_name: "HDD" type: "replicated" device_class: "hdd" pools: - "{{ pool1 }}"트리를 봅니다.
[root@mon ~]# ceph osd tree
풀을 검증합니다.
# for i in $(rados lspools);do echo "pool: $i"; ceph osd pool get $i crush_rule;done pool: pool1 crush_rule: HDD
모든 배포, 베어 메탈 또는 컨테이너 의 경우 기본적으로
/etc/ansible/hosts파일을 통해 Ansible 인벤토리 파일을 편집하기 위해 를 엽니다. 예제 호스트를 주석 처리합니다.[mgrs]섹션에 Ceph Manager(ceph-mgr) 노드를 추가합니다. Ceph Manager 데몬을 모니터 노드와 분리합니다.[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>
Ansible 사용자로 Ansible이 Ceph 호스트에 연결할 수 있는지 확인합니다.
[user@admin ~]$ ansible all -m ping
/etc/ansible/ansible.cfg파일에 다음 행을 추가합니다.retry_files_save_path = ~/
root로서/var/log/ansible/디렉터리를 생성하고ansible사용자에게 적절한 권한을 할당합니다.[root@admin ~]# mkdir /var/log/ansible [root@admin ~]# chown ansible:ansible /var/log/ansible [root@admin ~]# chmod 755 /var/log/ansible
/usr/share/ceph-ansible/ansible.cfg파일을 편집하여 다음과 같이log_path값을 업데이트합니다.log_path = /var/log/ansible/ansible.log
Ansible 사용자로
/usr/share/ceph-ansible/디렉터리로 변경합니다.[user@admin ~]$ cd /usr/share/ceph-ansible/
ceph-ansible플레이북을 실행합니다.[user@admin ceph-ansible]$ ansible-playbook site.yml
참고배포 속도를 높이려면
--forks옵션을ansible-playbook에 사용합니다. 기본적으로ceph-ansible은 포크를20으로 설정합니다. 이 설정을 사용하면 최대 20개의 노드가 동시에 설치됩니다. 한 번에 최대 30개의 노드를 설치하려면ansible-playbook --forks 30 PLAYBOOK FILE을실행합니다. 사용하지 않도록 관리 노드의 리소스를 모니터링해야 합니다. 이 값이 있는 경우--forks에 전달된 수를 줄입니다.Monitor 노드에서 root 계정을 사용하여 Ceph 클러스터의 상태를 확인합니다.
[root@monitor ~]# ceph health HEALTH_OK
rados를 사용하여 클러스터가 작동하는지 확인합니다.모니터 노드에서 8개의 배치 그룹이 있는 테스트 풀을 생성합니다.
구문
[root@monitor ~]# ceph osd pool create <pool-name> <pg-number>
예제
[root@monitor ~]# ceph osd pool create test 8
hello-world.txt라는 파일을 생성합니다.구문
[root@monitor ~]# vim <file-name>
예제
[root@monitor ~]# vim hello-world.txt
hello-world.txt오브젝트 이름hello-world를 사용하여 test 풀에 업로드합니다.구문
[root@monitor ~]# rados --pool <pool-name> put <object-name> <object-file>
예제
[root@monitor ~]# rados --pool test put hello-world hello-world.txt
test 풀에서
fetch.txt로hello-world를 다운로드합니다.구문
[root@monitor ~]# rados --pool <pool-name> get <object-name> <object-file>
예제
[root@monitor ~]# rados --pool test get hello-world fetch.txt
fetch.txt의 내용을 확인합니다.[root@monitor ~]# cat fetch.txt
출력은 다음과 같아야 합니다.
"Hello World!"
참고클러스터 상태를 확인하는 것 외에도
ceph-medic유틸리티를 사용하여 Ceph Storage 클러스터를 전반적으로 진단할 수 있습니다. Red Hat Ceph Storage 3 관리 가이드의 Ceph Storage 클러스터 진단 장을 사용하여ceph-medic사용 장을 참조하십시오.
3.3. 모든 NVMe 스토리지에 대한 OSD Ansible 설정 구성
스토리지에 NVMe(Non-volatile Memory express) 장치만 사용할 때 성능을 최적화하려면 각 NVMe 장치에서 4개의 OSD를 구성합니다. 일반적으로 하나의 OSD만 장치별로 구성되며 NVMe 장치의 처리량이 낮습니다.
SSD와 HDD를 혼합하는 경우 OSD가 아닌 저널 또는 block.db 에 SSD가 사용됩니다.
테스트에서는 각 NVMe 장치에서 OSD 4개를 구성하는 것이 최적의 성능을 제공하는 것으로 확인되었습니다. osds_per_device를 설정하는 것이 좋습니다. 4 하지만 필수는 아닙니다. 다른 값은 사용자 환경에서 더 나은 성능을 제공할 수 있습니다.
사전 요구 사항
- Ceph 클러스터에 대한 모든 소프트웨어 및 하드웨어 요구 사항을 충족합니다.
절차
osd_scenario: lvm및osds_per_device를 설정합니다. 4group_vars/osds.yml:osd_scenario: lvm osds_per_device: 4
장치에서 NVMe 장치 나열:
devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1
group_vars/osds.yml의 설정은 다음 예와 유사합니다.osd_scenario: lvm osds_per_device: 4 devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1
lvm_volumes 가 아닌 이 구성으로 장치를 사용해야 합니다. 이는 lvm_volumes 가 일반적으로 미리 생성된 논리 볼륨과 함께 사용되고 osds_per_device 는 Ceph에서 자동 논리 볼륨을 생성하기 때문입니다.
3.4. 메타데이터 서버 설치
Ansible 자동화 애플리케이션을 사용하여 Ceph Metadata Server(MDS)를 설치합니다. Ceph 파일 시스템을 배포하려면 metadata 서버 데몬이 필요합니다.
사전 요구 사항
- 작동 중인 Red Hat Ceph Storage 클러스터.
절차
Ansible 관리 노드에서 다음 단계를 수행합니다.
/etc/ansible/hosts파일에 새 섹션[mdss]를 추가합니다.[mdss] hostname hostname hostname
hostname 을 Ceph 메타데이터 서버를 설치하려는 노드의 호스트 이름으로 바꿉니다.
/usr/share/ceph-ansible디렉토리로 이동합니다.[root@admin ~]# cd /usr/share/ceph-ansible
선택 사항: 기본 변수를 변경합니다.
mdss.yml이라는group_vars/mdss.yml.sample파일의 사본을 생성합니다.[root@admin ceph-ansible]# cp group_vars/mdss.yml.sample group_vars/mdss.yml
-
선택적으로
mdss.yml의 매개변수를 편집합니다. 자세한 내용은mdss.yml을 참조하십시오.
Ansible 사용자로 Ansible 플레이북을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit mdss
- 메타데이터 서버를 설치한 후 구성합니다. 자세한 내용은 Red Hat Ceph Storage 3용 Ceph 파일 시스템 가이드의 메타데이터 서버 데몬 구성 장을 참조하십시오.
추가 리소스
3.5. Ceph 클라이언트 역할 설치
ceph-ansible 유틸리티는 Ceph 구성 파일 및 관리 인증 키를 노드에 복사하는 ceph-client 역할을 제공합니다. 또한 이 역할을 사용하여 사용자 지정 풀 및 클라이언트를 생성할 수 있습니다.
사전 요구 사항
-
실행 중인 Ceph 스토리지 클러스터(특히
활성 + 정리상태)입니다. - 2장. Red Hat Ceph Storage 설치 요구사항 에 나열된 작업을 수행합니다.
절차
Ansible 관리 노드에서 다음 작업을 수행합니다.
/etc/ansible/hosts파일에 새 섹션[clients]를 추가합니다.[clients] <client-hostname>
<client-hostname>을ceph-client역할을 설치하려는 노드의 호스트 이름으로 바꿉니다./usr/share/ceph-ansible디렉토리로 이동합니다.[root@admin ~]# cd /usr/share/ceph-ansible
clients.yml.yml :라는
clients.yml.sample[root@admin ceph-ansible ~]# cp group_vars/clients.yml.sample group_vars/clients.yml
group_vars/clients.yml파일을 열고 다음 행의 주석을 제거합니다.keys: - { name: client.test, caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }client.test를 실제 클라이언트 이름으로 바꾸고 클라이언트 정의 행에 클라이언트 키를 추가합니다. 예를 들면 다음과 같습니다.key: "ADD-KEYRING-HERE=="
이제 전체 예제는 다음과 유사합니다.
- { name: client.test, key: "AQAin8tUMICVFBAALRHNrV0Z4MXupRw4v9JQ6Q==", caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }참고ceph-authtool --gen-print-key명령은 새 클라이언트 키를 생성할 수 있습니다.
선택적으로
ceph-client에 풀 및 클라이언트를 생성하도록 지시합니다.clients.yml을 업데이트합니다.-
user_config설정의 주석을 제거하고true로 설정합니다. -
풀및키섹션의 주석을 제거하고 필요에 따라 업데이트합니다. KnativeServing 기능을 사용하여 사용자 정의 풀 및 클라이언트 이름을 모두정의할 수있습니다.
-
osd_pool_default_pg_num설정을all.yml파일의ceph_conf_overrides섹션에 추가합니다.ceph_conf_overrides: global: osd_pool_default_pg_num: <number><number>를 기본 배치 그룹 수로 바꿉니다.
Ansible Playbook을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit clients
추가 리소스
3.6. Ceph Object Gateway 설치
RADOS 게이트웨이라고도 하는 Ceph Object Gateway는 librados API 상단에 구축된 오브젝트 스토리지 인터페이스로, Ceph 스토리지 클러스터에 RESTful 게이트웨이를 제공합니다.
사전 요구 사항
-
실행 중인 Red Hat Ceph Storage 클러스터, 바람직하게는
활성 + 클린상태입니다. - Ceph Object Gateway 노드에서 2장. Red Hat Ceph Storage 설치 요구사항 에 나열된 작업을 수행합니다.
절차
Ansible 관리 노드에서 다음 작업을 수행합니다.
게이트웨이 호스트를
[rgws]섹션 아래의/etc/ansible/hosts파일에 추가하여 Ansible에 대한 역할을 확인합니다. 호스트에 순차적 이름 지정이 있는 경우 범위를 사용합니다. 예를 들면 다음과 같습니다.[rgws] <rgw_host_name_1> <rgw_host_name_2> <rgw_host_name[3..10]>
Ansible 구성 디렉터리로 이동합니다.
[root@ansible ~]# cd /usr/share/ceph-ansible
샘플 파일에서
rgws.yml파일을 생성합니다.[root@ansible ~]# cp group_vars/rgws.yml.sample group_vars/rgws.yml
group_vars/rgws.yml파일을 열고 편집합니다. 관리자 키를 Ceph Object Gateway 노드에 복사하려면copy_admin_key옵션의 주석을 제거합니다.copy_admin_key: true
rgws.yml파일은 기본 포트7480과 다른 기본 포트를 지정할 수 있습니다. 예를 들면 다음과 같습니다.ceph_rgw_civetweb_port: 80
all.yml파일은radosgw_interface 를 지정해야 합니다. 예를 들면 다음과 같습니다.radosgw_interface: eth0
인터페이스를 지정하면 Civetweb이 동일한 호스트에서 여러 인스턴스를 실행할 때 다른 Civetweb 인스턴스와 동일한 IP 주소에 바인딩되지 않습니다.
일반적으로 기본 설정을 변경하려면
rgw.yml파일의 설정 주석 처리를 해제하고 적절하게 변경합니다.rgw.yml파일에 없는 설정을 추가로 변경하려면all.yml파일에서ceph_conf_overrides:를 사용합니다. 예를 들어 DNS 서버의 호스트를 사용하여rgw_dns_name:을 설정하고 와일드카드가 S3 하위 도메인을 사용하도록 클러스터의 DNS 서버를 구성해야 합니다.ceph_conf_overrides: client.rgw.rgw1: rgw_dns_name: <host_name> rgw_override_bucket_index_max_shards: 16 rgw_bucket_default_quota_max_objects: 1638400고급 구성 정보는 Red Hat Ceph Storage 3 Ceph Object Gateway for Production 가이드를 참조하십시오. 고급 주제는 다음과 같습니다.
- Ansible 그룹 구성
스토리지 전략 개발. 풀을 생성하고 구성하는 방법에 대한 자세한 내용은 루트풀 생성, 시스템 풀 생성, 데이터 배치 전략 생성 섹션을 참조하십시오.
버킷 샤딩에 대한 구성 정보는 Bucket Sharding 을 참조하십시오.
group_vars/all.yml파일의radosgw_interface매개변수의 주석을 제거합니다.radosgw_interface: <interface>
교체:
-
Ceph Object Gateway 노드가 수신하는 인터페이스를 사용하여
<interface>
자세한 내용은
all.yml파일을 참조하십시오.-
Ceph Object Gateway 노드가 수신하는 인터페이스를 사용하여
Ansible Playbook을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rgws
Ansible은 각 Ceph Object Gateway가 실행 중인지 확인합니다.
단일 사이트 구성의 경우 Ansible 구성에 Ceph Object Gateway를 추가합니다.
다중 사이트 배포의 경우 각 영역에 대한 Ansible 구성이 있어야 합니다. 즉, Ansible은 Ceph 스토리지 클러스터 및 해당 영역의 게이트웨이 인스턴스를 만듭니다.
다중 사이트 클러스터에 대한 설치가 완료되면 Ubuntu용 오브젝트 게이트웨이 가이드 의 다중 사이트 장으로 이동하여 다중 사이트용 클러스터를 구성하는 방법에 대한 자세한 내용을 확인하십시오.
추가 리소스
3.6.1. 다중 사이트 Ceph Object Gateway 구성
Ansible은 다중 사이트 환경에서 Ceph Object Gateway의 마스터 및 보조 영역과 함께 영역 zonegroup을 구성합니다.
사전 요구 사항
- Red Hat Ceph Storage 클러스터를 실행하는 두 개.
- Ceph Object Gateway 노드에서 Red Hat Ceph Storage 설치 가이드에 있는 Red Hat Ceph Storage 설치 요구 사항에 나열된 작업을 수행합니다.
- 스토리지 클러스터당 하나의 Ceph Object Gateway를 설치하고 구성합니다.
절차
기본 스토리지 클러스터에 대해 Ansible 노드에서 다음 단계를 수행합니다.
시스템 키를 생성하고
다중 사이트-keys.txt 파일에서 출력을 캡처합니다.[root@ansible ~]# echo system_access_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 20 | head -n 1) > multi-site-keys.txt [root@ansible ~]# echo system_secret_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 40 | head -n 1) >> multi-site-keys.txt
Ansible 구성 디렉터리
/usr/share/ceph-ansible로 이동합니다.[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.yml파일을 열고 편집합니다.$ZONE_NAME,$ZONE_GROUP_NAME,$REALM_NAME,$ACCESS_KEY, 및$SECRET_KEY값을 업데이트하는 것과 함께 다음 옵션을 추가하여 다중 사이트 지원을 활성화합니다.Ceph Object Gateway가 두 개 이상 마스터 영역에 있는 경우
rgw_multisite_endpoints옵션을 설정해야 합니다.rgw_multisite_endpoints옵션의 값은 공백 없이 쉼표로 구분된 목록입니다.예제
rgw_multisite: true rgw_zone: $ZONE_NAME rgw_zonemaster: true rgw_zonesecondary: false rgw_multisite_endpoint_addr: "{{ ansible_fqdn }}" rgw_multisite_endpoints: http://foo.example.com:8080,http://bar.example.com:8080,http://baz.example.com:8080 rgw_zonegroup: $ZONE_GROUP_NAME rgw_zone_user: zone.user rgw_realm: $REALM_NAME system_access_key: $ACCESS_KEY system_secret_key: $SECRET_KEY참고ansible_fqdn도메인 이름은 보조 스토리지 클러스터에서 확인할 수 있어야 합니다.참고새 오브젝트 게이트웨이를 추가할 때 Ansible 플레이북을 실행하기 전에 새 오브젝트 게이트웨이의 엔드포인트 URL을 사용하여
rgw_multisite_endpoints목록 끝에 추가합니다.Ansible Playbook을 실행합니다.
[user@ansible ceph-ansible]$ ansible-playbook site.yml --limit rgws
Ceph Object Gateway 데몬을 다시 시작합니다.
[root@rgw ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`
보조 스토리지 클러스터에 대해 Ansible 노드에서 다음 단계를 수행합니다.
Ansible 구성 디렉터리
/usr/share/ceph-ansible로 이동합니다.[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.yml파일을 열고 편집합니다.$ZONE_NAME,$ZONE_GROUP_NAME,$REALM_NAME,$ACCESS_KEY, 및$SECRET_KEY값을 업데이트하는 것과 함께 다음 옵션을 추가하여 다중 사이트 지원을 활성화합니다.rgw_zone_user,system_access_key,system_secret_key는 마스터 영역 구성에 사용된 것과 동일한 값이어야 합니다.rgw_pullhost옵션은 마스터 영역의 Ceph Object Gateway여야 합니다.Ceph Object Gateway가 보조 영역에 있는 경우
rgw_multisite_endpoints옵션을 설정해야 합니다.rgw_multisite_endpoints옵션의 값은 공백 없이 쉼표로 구분된 목록입니다.예제
rgw_multisite: true rgw_zone: $ZONE_NAME rgw_zonemaster: false rgw_zonesecondary: true rgw_multisite_endpoint_addr: "{{ ansible_fqdn }}" rgw_multisite_endpoints: http://foo.example.com:8080,http://bar.example.com:8080,http://baz.example.com:8080 rgw_zonegroup: $ZONE_GROUP_NAME rgw_zone_user: zone.user rgw_realm: $REALM_NAME system_access_key: $ACCESS_KEY system_secret_key: $SECRET_KEY rgw_pull_proto: http rgw_pull_port: 8080 rgw_pullhost: $MASTER_RGW_NODE_NAME참고ansible_fqdn도메인 이름은 기본 스토리지 클러스터에서 확인할 수 있어야 합니다.참고새 오브젝트 게이트웨이를 추가할 때 Ansible 플레이북을 실행하기 전에 새 오브젝트 게이트웨이의 엔드포인트 URL을 사용하여
rgw_multisite_endpoints목록 끝에 추가합니다.Ansible Playbook을 실행합니다.
[user@ansible ceph-ansible]$ ansible-playbook site.yml --limit rgws
Ceph Object Gateway 데몬을 다시 시작합니다.
[root@rgw ~]# systemctl restart ceph-radosgw@rgw.`hostname -s`
- 마스터 및 보조 스토리지 클러스터에서 Ansible 플레이북을 실행하면 활성-활성 Ceph Object Gateway 구성이 실행됩니다.
다중 사이트 Ceph Object Gateway 구성을 확인합니다.
-
각 사이트의 Ceph Monitor 및 Object Gateway 노드에서 기본 및 보조 사이트를 컬링할
수있어야 합니다. -
두 사이트 모두에서
radosgw-admin 동기화 status명령을 실행합니다.
-
각 사이트의 Ceph Monitor 및 Object Gateway 노드에서 기본 및 보조 사이트를 컬링할
3.7. NFS-Ganesha 게이트웨이 설치
Ceph NFS Ganesha 게이트웨이는 파일 시스템 내의 파일을 Ceph Object Storage로 마이그레이션하기 위한 POSIX 파일 시스템 인터페이스를 Ceph Object Gateway에 제공하기 위해 Ceph Object Gateway 상단에 구축된 NFS 인터페이스입니다.
사전 요구 사항
-
실행 중인 Ceph 스토리지 클러스터(특히
활성 + 정리상태)입니다. - Ceph Object Gateway를 실행하는 하나 이상의 노드.
- 시작하기 전에 절차를 수행하십시오.
절차
Ansible 관리 노드에서 다음 작업을 수행합니다.
샘플 파일에서
nfss파일을 생성합니다.[root@ansible ~]# cd /usr/share/ceph-ansible/group_vars [root@ansible ~]# cp nfss.yml.sample nfss.yml
[nfss]그룹 아래의/etc/ansible/hosts파일에 게이트웨이 호스트를 추가하여 Ansible에 대한 그룹 멤버십을 식별합니다. 호스트에 순차적 이름 지정이 있는 경우 범위를 사용합니다. 예를 들면 다음과 같습니다.[nfss] <nfs_host_name_1> <nfs_host_name_2> <nfs_host_name[3..10]>
Ansible 구성 디렉터리
/etc/ansible/:로 이동합니다.[root@ansible ~]# cd /usr/share/ceph-ansible
관리자 키를 Ceph Object Gateway 노드에 복사하려면
/usr/share/ceph-ansible/group_vars/nfss.yml파일의copy_admin_key설정의 주석 처리를 해제합니다.copy_admin_key: true
/usr/share/ceph-ansible/group_vars/nfss.yml파일의 FSAL (File System Abstraction Layer) 섹션을 구성합니다. ID, S3 사용자 ID, S3 액세스 키 및 시크릿을 제공합니다. NFSv4의 경우 다음과 같이 표시됩니다.################### # FSAL RGW Config # ################### #ceph_nfs_rgw_export_id: <replace-w-numeric-export-id> #ceph_nfs_rgw_pseudo_path: "/" #ceph_nfs_rgw_protocols: "3,4" #ceph_nfs_rgw_access_type: "RW" #ceph_nfs_rgw_user: "cephnfs" # Note: keys are optional and can be generated, but not on containerized, where # they must be configered. #ceph_nfs_rgw_access_key: "<replace-w-access-key>" #ceph_nfs_rgw_secret_key: "<replace-w-secret-key>"
주의액세스 및 시크릿 키는 선택 사항이며 생성할 수 있습니다.
Ansible Playbook을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook site-docker.yml --limit nfss
추가 리소스
3.8. 제한 옵션 이해
이 섹션에는 Ansible --limit 옵션에 대한 정보가 포함되어 있습니다.
Ansible은 인벤토리 파일의 특정 섹션에 대해 사이트 , , site -dockerrolling_upgrade Ansible 플레이북을 사용할 수 있는 --limit 옵션을 지원합니다.
$ ansible-playbook site.yml|rolling_upgrade.yml|site-docker.yml --limit osds|rgws|clients|mdss|nfss|iscsigws
예를 들어 베어 메탈에서 OSD만 재배포하려면 Ansible 사용자로 다음 명령을 실행합니다.
$ ansible-playbook /usr/share/ceph-ansible/site.yml --limit osds
하나의 노드에 Ceph 구성 요소를 배치하는 경우 Ansible은 limit 옵션을 사용하여 하나의 구성 요소 유형만 지정했음에도 불구하고 노드의 모든 구성 요소에 플레이북을 적용합니다. 예를 들어 OSD 및 메타데이터 서버(MDS)가 포함된 노드에서 --limit osds 옵션을 사용하여 rolling_update 플레이북을 실행하면 Ansible에서 구성 요소, OSD 및 MDSs를 모두 업그레이드합니다.
3.9. 추가 리소스
4장. Red Hat Ceph Storage 클러스터 업그레이드
이 섹션에서는 Red Hat Ceph Storage의 새 주요 버전 또는 마이너 버전으로 업그레이드하는 방법을 설명합니다.
이전에는 Red Hat에서 Ubuntu에 ceph-ansible 패키지를 제공하지 않았습니다. Red Hat Ceph Storage 버전 3 이상에서는 Ansible 자동화 애플리케이션을 사용하여 Ubuntu 노드에서 Ceph 클러스터를 업그레이드할 수 있습니다.
- 스토리지 클러스터를 업그레이드하려면 4.1절. “스토리지 클러스터 업그레이드” 을 참조하십시오.
관리 노드의 /usr/share/ceph-ansible/infrastructure-playbooks/ 디렉터리에 있는 Ansible rolling_update.yml 플레이북을 사용하여 Red Hat Ceph Storage의 두 가지 주요 버전 또는 마이너 버전 간에 업그레이드하거나 비동기 업데이트를 적용합니다.
Ansible은 다음과 같은 순서로 Ceph 노드를 업그레이드합니다.
- 노드 모니터링
- MGR 노드
- OSD 노드
- MDS 노드
- Ceph Object Gateway 노드
- 기타 모든 Ceph 클라이언트 노드
Red Hat Ceph Storage 3에서는 /usr/share/ceph-ansible/group_vars/ 디렉터리에 있는 Ansible 구성 파일에 몇 가지 변경 사항이 추가되었습니다. 특정 매개변수의 이름이 변경되거나 제거되었습니다. 따라서 버전 3으로 업그레이드한 후 all.yml.sample 및 osds.yml. sample 파일에서 새 복사본을 생성하기 전에 all.yml 및 osds.yml.yml 파일의 백업 사본을 만듭니다. 변경 사항에 대한 자세한 내용은 부록 H. 버전 2와 3의 Ansible 변수 변경 을 참조하십시오.
Red Hat Ceph Storage 3.1 이상에서는 Object Gateway 및 고속 NVMe 기반 SSD(및 SATA SSD)를 사용할 때 성능을 위해 스토리지를 최적화하는 새로운 Ansible 플레이북을 도입합니다. 플레이북은 SSD에 저널 및 버킷 인덱스를 함께 배치하여 이를 수행하므로 하나의 장치에 모든 저널이 있는 것보다 성능이 향상될 수 있습니다. 이러한 플레이북은 Ceph를 설치할 때 사용하도록 설계되었습니다. 기존 OSD는 계속 작동하고 업그레이드하는 동안 추가 단계가 필요하지 않습니다. 이러한 방식으로 스토리지를 최적화하도록 OSD를 동시에 재구성하는 동안 Ceph 클러스터를 업그레이드할 수 없습니다. 저널 또는 버킷 인덱스에 다른 장치를 사용하려면 OSD를 재프로비저닝해야 합니다. 자세한 내용은 프로덕션을 위해 Ceph Object Gateway 에서 LVM으로 NVMe를 최적으로 사용하여 을 참조하십시오.
rolling_update.yml 플레이북에는 동시에 업데이트할 노드 수를 조정하는 serial 변수가 포함되어 있습니다. Red Hat은 기본값1( 1)을 사용하는 것이 좋습니다. 그러면 Ansible에서 클러스터 노드를 하나씩 업그레이드합니다.
언제든지 업그레이드에 실패하면 ceph status 명령으로 클러스터 상태를 확인하여 업그레이드 실패 이유를 확인합니다. 실패 이유 및 해결 방법이 확실하지 않은 경우 Red Hat 지원팀에 문의하십시오.
rolling_update.yml 플레이북을 사용하여 Red Hat Ceph Storage 3.x 버전으로 업그레이드하는 경우 Ceph File System(CephFS)을 사용하는 사용자는 Metadata Server(MDS) 클러스터를 수동으로 업데이트해야 합니다. 이는 알려진 문제로 인해 발생합니다.
ceph-ansible rolling-upgrade.yml 을 사용하여 전체 클러스터를 업그레이드하기 전에 /etc/ansible/hosts 에서 MDS 호스트를 주석 처리한 다음 MDS를 수동으로 업그레이드합니다. /etc/ansible/hosts 파일에서 다음을 수행합니다.
#[mdss] #host-abc
MDS 클러스터 업데이트 방법을 비롯한 알려진 문제에 대한 자세한 내용은 Red Hat Ceph Storage 3.0 릴리스 노트 를 참조하십시오.
Red Hat Ceph Storage 클러스터를 이전 버전에서 3.2로 업그레이드할 때 Ceph Ansible 구성은 기본적으로 오브젝트 저장소 유형을 BlueStore로 설정합니다. 여전히 FileStore를 OSD 오브젝트 저장소로 사용하려는 경우 Ceph Ansible 구성을 FileStore로 명시적으로 설정합니다. 이렇게 하면 새로 배포되고 교체된 OSD가 FileStore를 사용합니다.
rolling_update.yml 플레이북을 사용하여 Red Hat Ceph Storage 3.x 버전으로 업그레이드할 때 다중 사이트 Ceph Object Gateway 구성을 사용하는 경우 다중 사이트 구성을 지정하기 위해 all.yml 파일을 수동으로 업데이트할 필요가 없습니다.
사전 요구 사항
- Ceph 노드가 Red Hat CDN(Content Delivery Network)에 연결되어 있지 않고 ISO 이미지를 사용하여 Red Hat Ceph Storage를 설치한 경우 로컬 리포지토리를 최신 Red Hat Ceph Storage로 업데이트합니다. 자세한 내용은 2.4절. “Red Hat Ceph Storage 리포지토리 활성화” 을 참조하십시오.
Ansible 관리 노드 및 RBD 미러링 노드에서 Red Hat Ceph Storage 2.x에서 3.x로 업그레이드하는 경우 Red Hat Ceph Storage 3 툴 리포지토리를 활성화합니다.
[root@admin ~]$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' [root@admin ~]$ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' [root@admin ~]$ sudo apt-get update
RHCS 2.x에서 3.x로 업그레이드하거나 RHCS 3.x에서 Ansible 관리 노드의 최신 버전으로 업그레이드하는 경우 최신 버전의
ceph-ansible패키지가 설치되어 있는지 확인합니다.[root@admin ~]$ sudo apt-get install ceph-ansible
rolling_update.yml플레이북에서health_osd_check_retries및health_osd_check_delay값을 각각50및30으로 변경합니다.health_osd_check_retries: 50 health_osd_check_delay: 30
이러한 값을 설정하면 각 OSD 노드에 대해 Ansible이 최대 25분 동안 대기하고 업그레이드 프로세스를 계속하기 전에 30초마다 스토리지 클러스터 상태를 대기합니다.
참고스토리지 클러스터의 사용된 스토리지 용량에 따라
health_osd_check_retries옵션 값을 위 또는 아래로 조정합니다. 예를 들어 436TB 중 218TB를 사용하는 경우 스토리지 용량의 50%를 사용하는 경우health_osd_check_retries옵션을50으로 설정합니다.업그레이드하려는 클러스터에
exclusive-lock기능을 사용하는 Ceph Block Device 이미지가 포함된 경우 모든 Ceph Block Device 사용자에게 클라이언트를 블랙리스트로 지정할 수 있는 권한이 있는지 확인하십시오.ceph auth caps client.<ID> mon 'allow r, allow command "osd blacklist"' osd '<existing-OSD-user-capabilities>'
4.1. 스토리지 클러스터 업그레이드
절차
Ansible 관리 노드의 다음 명령을 사용합니다.
root사용자로/usr/share/ceph-ansible/디렉터리로 이동합니다.[root@admin ~]# cd /usr/share/ceph-ansible/
Red Hat Ceph Storage 버전 3.x에서 최신 버전으로 업그레이드할 때 이 단계를 건너뜁니다.
group_vars/all.yml및group_vars/osds.yml파일을 백업합니다.[root@admin ceph-ansible]# cp group_vars/all.yml group_vars/all_old.yml [root@admin ceph-ansible]# cp group_vars/osds.yml group_vars/osds_old.yml [root@admin ceph-ansible]# cp group_vars/clients.yml group_vars/clients_old.yml
Red Hat Ceph Storage 버전 3.x에서 최신 버전으로 업그레이드할 때 이 단계를 건너뜁니다. Red Hat Ceph Storage 2.x에서 3.x로 업그레이드할 때 각각
group_vars/all.yml.sample,group_vars/osds.yml.sample및group_vars/clients.yml.sample파일의 새 사본을 생성하고group_vars/all.yml, group_vars/osds.yml.yml,group_vars/osds.yml.yml.ymls.yml파일의 새 사본을 각각 생성합니다. 를 열고 그에 따라 편집합니다. 자세한 내용은 부록 H. 버전 2와 3의 Ansible 변수 변경 및 3.2절. “Red Hat Ceph Storage 클러스터 설치” 를 참조하십시오.[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml [root@admin ceph-ansible]# cp group_vars/clients.yml.sample group_vars/clients.yml
Red Hat Ceph Storage 버전 3.x에서 최신 버전으로 업그레이드할 때 이 단계를 건너뜁니다. Red Hat Ceph Storage 2.x에서 3.x로 업그레이드하는 경우
group_vars/clients.yml파일을 열고 다음 줄의 주석을 제거합니다.keys: - { name: client.test, caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }client.test를 실제 클라이언트 이름으로 바꾸고 클라이언트 정의 행에 클라이언트 키를 추가합니다. 예를 들면 다음과 같습니다.key: "ADD-KEYRING-HERE=="
이제 전체 예제는 다음과 유사합니다.
- { name: client.test, key: "AQAin8tUMICVFBAALRHNrV0Z4MXupRw4v9JQ6Q==", caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }참고클라이언트 키를 가져오려면
ceph auth get-or-create명령을 실행하여 named 클라이언트의 키를 확인합니다.
group_vars/all.yml파일에서upgrade_ceph_packages옵션의 주석을 제거하고True로 설정합니다.upgrade_ceph_packages: True
fetch_directory매개변수를group_vars/all.yml파일에 추가합니다.fetch_directory: <full_directory_path>
교체:
-
Ansible 사용자의 홈 디렉터리와 같은 쓰기 가능한 위치가 있는
<full_directory_path>초기 스토리지 클러스터 설치에 사용된 기존 경로를 제공합니다.
기존 경로가 손실되거나 누락된 경우 다음을 먼저 수행합니다.
기존
group_vars/all.yml파일에 다음 옵션을 추가합니다.fsid: <add_the_fsid> generate_fsid: false
take-over-existing-cluster.ymlAnsible 플레이북을 실행합니다.[user@admin ceph-ansible]$ cp infrastructure-playbooks/take-over-existing-cluster.yml . [user@admin ceph-ansible]$ ansible-playbook take-over-existing-cluster.yml
-
Ansible 사용자의 홈 디렉터리와 같은 쓰기 가능한 위치가 있는
업그레이드하려는 클러스터에 Ceph Object Gateway 노드가 포함된 경우
radosgw_interface매개변수를group_vars/all.yml파일에 추가합니다.radosgw_interface: <interface>
교체:
-
Ceph Object Gateway 노드가 수신 대기하는 인터페이스가
<interface>입니다.
-
Ceph Object Gateway 노드가 수신 대기하는 인터페이스가
Red Hat Ceph Storage 3.2부터 기본 OSD 오브젝트 저장소는 BlueStore입니다. 기존의 OSD 오브젝트 저장소를 유지하려면
osd_objectstore옵션을group_vars/all.yml파일의filestore로 명시적으로 설정해야 합니다.osd_objectstore: filestore
참고osd_objectstore옵션이filestore로 설정된 경우 OSD를 교체하면 BlueStore 대신 FileStore를 사용합니다./etc/ansible/hosts에 있는 Ansible 인벤토리 파일에서[mgrs]섹션에 Ceph Manager(ceph-mgr) 노드를 추가합니다. Ceph Manager 데몬을 모니터 노드와 분리합니다. 버전 3.x에서 최신 버전으로 업그레이드할 때 이 단계를 건너뜁니다.[mgrs] <monitor-host-name> <monitor-host-name> <monitor-host-name>
infrastructure-playbooks디렉터리의rolling_update.yml을 현재 디렉터리로 복사합니다.[root@admin ceph-ansible]# cp infrastructure-playbooks/rolling_update.yml .
중요rolling_update.yml플레이북과 함께limitansible 옵션을 사용하지 마십시오./var/log/ansible/디렉터리를 생성하고ansible사용자에게 적절한 권한을 할당합니다.[root@admin ceph-ansible]# mkdir /var/log/ansible [root@admin ceph-ansible]# chown ansible:ansible /var/log/ansible [root@admin ceph-ansible]# chmod 755 /var/log/ansible
/usr/share/ceph-ansible/ansible.cfg파일을 편집하여 다음과 같이log_path값을 업데이트합니다.log_path = /var/log/ansible/ansible.log
Ansible 사용자로 Playbook을 실행합니다.
[user@admin ceph-ansible]$ ansible-playbook rolling_update.yml
RBD 미러링 데몬 노드에
root사용자로 로그인한 동안rbd-mirror를 수동으로 업그레이드합니다.$ sudo apt-get upgrade rbd-mirror
데몬을 다시 시작하십시오.
# systemctl restart ceph-rbd-mirror@<client-id>
-
클러스터 상태가 OK인지 확인합니다. ..log를 통해
root사용자로 모니터 노드에 로그인하고 ceph status 명령을 실행합니다.
[root@monitor ~]# ceph -s
OpenStack 환경에서 작업하는 경우 풀에 RBD 프로필을 사용하도록 모든 KnativeServing 사용자를 업데이트합니다.
다음 명령을root사용자로 실행해야 합니다.Glance 사용자
ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=<glance-pool-name>'
예제
[root@monitor ~]# ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=images'
Cinder 사용자
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'
예제
[root@monitor ~]# ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
OpenStack 일반 사용자
ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=<cinder-volume-pool-name>, profile rbd pool=<nova-pool-name>, profile rbd-read-only pool=<glance-pool-name>'
예제
[root@monitor ~]# ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
중요라이브 클라이언트 마이그레이션을 수행하기 전에 이러한 CAPS 업데이트를 수행합니다. 이를 통해 클라이언트는 메모리에서 실행되는 새 라이브러리를 사용하므로 이전 CAPS 설정이 캐시에서 삭제되고 새 RBD 프로필 설정을 적용할 수 있습니다.
5장. 다음을 어떻게 해야 합니까?
이는 최신 데이터 센터의 어려운 스토리지 요구 사항을 충족하기 위해 Red Hat Ceph Storage가 수행할 수 있는 초기 단계일 뿐입니다. 다음은 다양한 주제에 대한 자세한 정보의 링크입니다.
- 성능 벤치마킹 및 성능 카운터 액세스, Red Hat Ceph Storage 3 관리 가이드의 성능 벤치마크 장을 참조하십시오.
- 스냅샷 생성 및 관리, Red Hat Ceph Storage 3용 블록 장치 가이드의 스냅샷 장을 참조하십시오.
- Red Hat Ceph Storage 클러스터 확장은 Red Hat Ceph Storage 3 관리 가이드의 클러스터 크기 관리 장을 참조하십시오.
- Ceph 블록 장치 미러링은 Red Hat Ceph Storage 3용 블록 장치 가이드의 블록 장치 미러링 장을 참조하십시오.
- 프로세스 관리, Red Hat Ceph Storage 3 관리 가이드의 프로세스 관리 장을 참조하십시오.
- 조정 가능한 매개변수는 Red Hat Ceph Storage 3의 구성 가이드 를 참조하십시오.
- Ceph를 OpenStack의 백엔드 스토리지로 사용하여 Red Hat OpenStack Platform의 스토리지 가이드의 백엔드 섹션을 참조하십시오.
부록 A. 문제 해결
A.1. Ansible은 설치를 중지하기 때문에 Less Devices Than it Expected
Ansible 자동화 애플리케이션은 설치 프로세스를 중지하고 다음 오류를 반환합니다.
- name: fix partitions gpt header or labels of the osd disks (autodiscover disks)
shell: "sgdisk --zap-all --clear --mbrtogpt -- '/dev/{{ item.0.item.key }}' || sgdisk --zap-all --clear --mbrtogpt -- '/dev/{{ item.0.item.key }}'"
with_together:
- "{{ osd_partition_status_results.results }}"
- "{{ ansible_devices }}"
changed_when: false
when:
- ansible_devices is defined
- item.0.item.value.removable == "0"
- item.0.item.value.partitions|count == 0
- item.0.rc != 0이것이 의미하는 것은 다음과 같습니다.
/usr/share/ceph-ansible/group_vars/osds.yml 파일에서 osd_auto_discovery 매개 변수가 true 로 설정된 경우 Ansible은 사용 가능한 모든 장치를 자동으로 탐지하고 구성합니다. 이 프로세스 중에 Ansible은 모든 OSD에서 동일한 장치를 사용할 것으로 예상합니다. 장치는 Ansible이 감지하는 것과 동일한 순서로 이름을 가져옵니다. OSD 중 하나에서 장치 중 하나가 실패하면 Ansible에서 실패한 장치를 감지하지 못하고 전체 설치 프로세스를 중지합니다.
예제 상황:
-
3개의 OSD 노드(
host1,host2,host3)는/dev/sdb,/dev/sdc,dev/sdd디스크를 사용합니다. -
host2에서/dev/sdc디스크가 실패하고 제거됩니다. -
다음 재부팅 시 Ansible은 제거된
/dev/sdchost2,/dev/sdb및 /dev/sdc(이전/dev/sdd)에 사용될 것으로 예상됩니다. - Ansible은 설치 프로세스를 중지하고 위의 오류 메시지를 반환합니다.
문제를 해결하려면 다음을 수행하십시오.
/etc/ansible/hosts 파일에서 오류가 발생한 디스크(위의 예 상황에서host 2)에서 OSD 노드에서 사용하는 장치를 지정합니다.
[osds] host1 host2 devices="[ '/dev/sdb', '/dev/sdc' ]" host3
자세한 내용은 3장. Red Hat Ceph Storage 배포 을 참조하십시오.
부록 B. 수동으로 Red Hat Ceph Storage 설치
Red Hat은 수동으로 배포된 클러스터 업그레이드를 지원하거나 테스트하지 않습니다. 따라서 Red Hat은 Ansible을 사용하여 Red Hat Ceph Storage 3을 사용하여 새 클러스터를 배포하는 것이 좋습니다. 자세한 내용은 3장. Red Hat Ceph Storage 배포 을 참조하십시오.
apt-get 과 같은 명령행 유틸리티를 사용하여 수동으로 배포된 클러스터를 설치할 수 있습니다.
모든 Ceph 클러스터에는 하나 이상의 모니터가 필요하며, 클러스터에 저장된 오브젝트의 사본으로 최소 개수의 OSD가 필요합니다. Red Hat은 프로덕션 환경에 세 개의 모니터와 최소 3개의 오브젝트 스토리지 장치(OSD)를 사용하는 것이 좋습니다.
명령줄 인터페이스를 사용하여 Ceph 스토리지 클러스터를 설치하려면 다음 단계를 수행해야 합니다.
B.1. 사전 요구 사항
Red Hat Ceph Storage의 네트워크 시간 프로토콜 구성
모든 Ceph 모니터 및 OSD 노드는 NTP(Network Time Protocol)를 구성해야 합니다. Ceph 노드가 NTP 피어인지 확인합니다. NTP는 클럭 드리프트에서 발생하는 문제를 선점하는 데 도움이 됩니다.
Ansible을 사용하여 Red Hat Ceph Storage 클러스터를 배포할 때 Ansible은 자동으로 NTP를 설치, 구성 및 활성화합니다.
사전 요구 사항
- 유효한 시간 소스에 대한 네트워크 액세스.
프로시저: RHCS의 네트워크 시간 프로토콜 구성
root 사용자로 스토리지 클러스터의 모든 RHCS 노드에서 다음 단계를 수행합니다.
ntp패키지를 설치합니다.$ sudo apt-get install ntp
$ sudo systemctl start ntp $ sudo systemctl enable ntp
NTP가 클럭을 올바르게 동기화하는지 확인합니다.
$ ntpq -p
추가 리소스
- Red Hat Enterprise Linux 7용 시스템 관리자 가이드의 ntpd를 사용하여 NTP 구성 장.
Bootstrapping 모니터링
모니터를 부트 스트랩하고 Ceph 스토리지 클러스터를 확장하여 다음 데이터가 필요합니다.
- 고유 식별자
-
파일 시스템 식별자(
fsid)는 클러스터의 고유 식별자입니다.fsid는 Ceph 스토리지 클러스터가 기본적으로 Ceph 파일 시스템에 사용될 때 사용되었습니다. Ceph는 이제 기본 인터페이스, 블록 장치 및 오브젝트 스토리지 게이트웨이 인터페이스를 지원하므로fsid는 약간 misnomer입니다. - 클러스터 이름
Ceph 클러스터에는 공백이 없는 간단한 문자열인 클러스터 이름이 있습니다. 기본 클러스터 이름은
ceph이지만 다른 클러스터 이름을 지정할 수 있습니다. 기본 클러스터 이름을 재정의하는 것은 여러 클러스터에서 작업할 때 특히 유용합니다.다중 사이트 아키텍처에서 여러 클러스터를 실행하는 경우 클러스터 이름(예:
us-west)은 현재 명령줄 세션에 대한 클러스터를 식별합니다.참고명령줄 인터페이스에서 클러스터 이름을 확인하려면 클러스터 이름(예:
ceph.conf,us-west.conf,us-east.conf등)을 사용하여 Ceph 구성 파일을 지정합니다.예제:
# ceph --cluster us-west.conf ...
- 모니터링 이름
-
클러스터 내의 각 모니터 인스턴스마다 고유한 이름이 있습니다. 일반적으로 Ceph Monitor 이름은 노드 이름입니다. Red Hat은 노드당 하나의 Ceph Monitor를 권장하고 Ceph OSD 데몬을 함께 배치하지 않는 것이 좋습니다. 짧은 노드 이름을 검색하려면
hostname -s명령을 사용합니다. - 모니터링 맵
초기 모니터를 부트 스트랩하려면 모니터 맵을 생성해야 합니다. 모니터 맵에는 다음이 필요합니다.
-
파일 시스템 식별자(fs
id) -
클러스터 이름 또는
ceph의 기본 클러스터 이름이 사용됩니다. - 하나 이상의 호스트 이름과 IP 주소.
-
파일 시스템 식별자(fs
- 키 링 모니터링
- 모니터는 시크릿 키를 사용하여 서로 통신합니다. Monitor 시크릿 키를 사용하여 인증 키를 생성하고 초기 모니터를 부트스트랩할 때 제공해야 합니다.
- 관리자 키 링
-
ceph명령줄 인터페이스 유틸리티를 사용하려면client.admin사용자를 생성하고 인증 키를 생성합니다. 또한 Monitor 인증 키에client.admin사용자를 추가해야 합니다.
예상 요구 사항은 Ceph 구성 파일 생성을 보장하지 않습니다. 하지만 모범 사례로 Ceph 구성 파일을 만들고 fsid, mon initial members 및 mon host 설정으로 채우는 것이 좋습니다.
런타임 시 모든 Monitor 설정을 가져오고 설정할 수 있습니다. 그러나 Ceph 구성 파일에는 기본값을 재정의하는 설정만 포함될 수 있습니다. Ceph 구성 파일에 설정을 추가하면 이러한 설정이 기본 설정을 재정의합니다. Ceph 구성 파일에서 이러한 설정을 유지 관리하면 클러스터를 보다 쉽게 유지 관리할 수 있습니다.
초기 모니터를 부트 스트랩하려면 다음 단계를 수행합니다.
Red Hat Ceph Storage 3 Monitor 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/MON $(lsb_release -sc) main | tee /etc/apt/sources.list.d/MON.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
초기 모니터 노드에서
root로ceph-mon패키지를 설치합니다.$ sudo apt-get install ceph-mon
root로서/etc/ceph/디렉터리에 Ceph 구성 파일을 만듭니다. 기본적으로 Ceph는ceph.conf를 사용합니다. 여기서ceph는 클러스터 이름을 반영합니다.구문
# touch /etc/ceph/<cluster_name>.conf
예제
# touch /etc/ceph/ceph.conf
root로 클러스터의 고유 식별자를 생성하고 Ceph 구성 파일의[global]섹션에 고유 식별자를 추가합니다.구문
# echo "[global]" > /etc/ceph/<cluster_name>.conf # echo "fsid = `uuidgen`" >> /etc/ceph/<cluster_name>.conf
예제
# echo "[global]" > /etc/ceph/ceph.conf # echo "fsid = `uuidgen`" >> /etc/ceph/ceph.conf
현재 Ceph 구성 파일을 확인합니다.
$ cat /etc/ceph/ceph.conf [global] fsid = a7f64266-0894-4f1e-a635-d0aeaca0e993
root로서 초기 Monitor를 Ceph 구성 파일에 추가합니다.구문
# echo "mon initial members = <monitor_host_name>[,<monitor_host_name>]" >> /etc/ceph/<cluster_name>.conf
예제
# echo "mon initial members = node1" >> /etc/ceph/ceph.conf
root로서 초기 Monitor의 IP 주소를 Ceph 구성 파일에 추가합니다.구문
# echo "mon host = <ip-address>[,<ip-address>]" >> /etc/ceph/<cluster_name>.conf
예제
# echo "mon host = 192.168.0.120" >> /etc/ceph/ceph.conf
참고IPv6 주소를 사용하려면
ms bind ipv6옵션을true로 설정합니다. 자세한 내용은 Red Hat Ceph Storage 3 구성 가이드의 Bind 섹션을 참조하십시오.root로 클러스터에 대한 인증 키를 생성하고 Monitor 시크릿 키를 생성합니다.구문
# ceph-authtool --create-keyring /tmp/<cluster_name>.mon.keyring --gen-key -n mon. --cap mon '<capabilites>'
예제
# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' creating /tmp/ceph.mon.keyring
root로 관리자 인증 키를 생성하고<cluster_name>.client.admin.keyring사용자를 생성하고 사용자를 인증 키에 추가합니다.구문
# ceph-authtool --create-keyring /etc/ceph/<cluster_name>.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon '<capabilites>' --cap osd '<capabilites>' --cap mds '<capabilites>'
예제
# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow' creating /etc/ceph/ceph.client.admin.keyring
루트로서<cluster_name>.client.admin.keyring키를<cluster_name>.mon.keyring:에 추가합니다.구문
# ceph-authtool /tmp/<cluster_name>.mon.keyring --import-keyring /etc/ceph/<cluster_name>.client.admin.keyring
예제
# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring
모니터 맵을 생성합니다. 노드 이름, IP 주소 및
fsid를 초기 모니터로 사용하여 지정하고/tmp/monmap으로 저장합니다.구문
$ monmaptool --create --add <monitor_host_name> <ip-address> --fsid <uuid> /tmp/monmap
예제
$ monmaptool --create --add node1 192.168.0.120 --fsid a7f64266-0894-4f1e-a635-d0aeaca0e993 /tmp/monmap monmaptool: monmap file /tmp/monmap monmaptool: set fsid to a7f64266-0894-4f1e-a635-d0aeaca0e993 monmaptool: writing epoch 0 to /tmp/monmap (1 monitors)
초기 Monitor 노드에서
root로 기본 데이터 디렉터리를 생성합니다.구문
# mkdir /var/lib/ceph/mon/<cluster_name>-<monitor_host_name>
예제
# mkdir /var/lib/ceph/mon/ceph-node1
root로 초기 Monitor 데몬을 Monitor 맵 및 인증 키로 채웁니다.구문
# ceph-mon [--cluster <cluster_name>] --mkfs -i <monitor_host_name> --monmap /tmp/monmap --keyring /tmp/<cluster_name>.mon.keyring
예제
# ceph-mon --mkfs -i node1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring ceph-mon: set fsid to a7f64266-0894-4f1e-a635-d0aeaca0e993 ceph-mon: created monfs at /var/lib/ceph/mon/ceph-node1 for mon.node1
현재 Ceph 구성 파일을 확인합니다.
# cat /etc/ceph/ceph.conf [global] fsid = a7f64266-0894-4f1e-a635-d0aeaca0e993 mon_initial_members = node1 mon_host = 192.168.0.120
다양한 Ceph 구성 설정에 대한 자세한 내용은 Red Hat Ceph Storage 3 구성 가이드를 참조하십시오. Ceph 구성 파일의 다음 예제에는 가장 일반적인 구성 설정이 나열되어 있습니다.
예제
[global] fsid = <cluster-id> mon initial members = <monitor_host_name>[, <monitor_host_name>] mon host = <ip-address>[, <ip-address>] public network = <network>[, <network>] cluster network = <network>[, <network>] auth cluster required = cephx auth service required = cephx auth client required = cephx osd journal size = <n> osd pool default size = <n> # Write an object n times. osd pool default min size = <n> # Allow writing n copy in a degraded state. osd pool default pg num = <n> osd pool default pgp num = <n> osd crush chooseleaf type = <n>
root로서완료된파일을 생성합니다.구문
# touch /var/lib/ceph/mon/<cluster_name>-<monitor_host_name>/done
예제
# touch /var/lib/ceph/mon/ceph-node1/done
root로서 새로 생성된 디렉터리 및 파일에 대한 소유자 및 그룹 권한을 업데이트합니다.구문
# chown -R <owner>:<group> <path_to_directory>
예제
# chown -R ceph:ceph /var/lib/ceph/mon # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown ceph:ceph /etc/ceph/ceph.client.admin.keyring # chown ceph:ceph /etc/ceph/ceph.conf # chown ceph:ceph /etc/ceph/rbdmap
참고Ceph Monitor 노드가 OpenStack 컨트롤러 노드와 함께 배치되는 경우 Glance 및 Cinder 인증 키 파일을 각각
glance및cinder에서 소유해야 합니다. 예를 들면 다음과 같습니다.# ls -l /etc/ceph/ ... -rw-------. 1 glance glance 64 <date> ceph.client.glance.keyring -rw-------. 1 cinder cinder 64 <date> ceph.client.cinder.keyring ...
사용자 지정 이름이 있는 스토리지 클러스터의 경우
root로 다음 행을 추가합니다.구문
$ sudo echo "CLUSTER=<custom_cluster_name>" >> /etc/default/ceph
예제
$ sudo echo "CLUSTER=test123" >> /etc/default/ceph
root로 초기 Monitor 노드에서ceph-mon프로세스를 시작하고 활성화합니다.구문
$ sudo systemctl enable ceph-mon.target $ sudo systemctl enable ceph-mon@<monitor_host_name> $ sudo systemctl start ceph-mon@<monitor_host_name>
예제
$ sudo systemctl enable ceph-mon.target $ sudo systemctl enable ceph-mon@node1 $ sudo systemctl start ceph-mon@node1
root로서 모니터 데몬이 실행 중인지 확인합니다.구문
# sudo systemctl status ceph-mon@<monitor_host_name>
예제
# sudo systemctl status ceph-mon@node1 ● ceph-mon@node1.service - Ceph cluster monitor daemon Loaded: loaded (/usr/lib/systemd/system/ceph-mon@.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2018-06-27 11:31:30 PDT; 5min ago Main PID: 1017 (ceph-mon) CGroup: /system.slice/system-ceph\x2dmon.slice/ceph-mon@node1.service └─1017 /usr/bin/ceph-mon -f --cluster ceph --id node1 --setuser ceph --setgroup ceph Jun 27 11:31:30 node1 systemd[1]: Started Ceph cluster monitor daemon. Jun 27 11:31:30 node1 systemd[1]: Starting Ceph cluster monitor daemon...
스토리지 클러스터에 Red Hat Ceph Storage 모니터를 더 추가하려면 Red Hat Ceph Storage 3 관리 가이드의 모니터 추가 섹션을 참조하십시오.
B.2. 수동으로 Ceph Manager 설치
일반적으로 Ansible 자동화 유틸리티는 Red Hat Ceph Storage 클러스터를 배포할 때 Ceph Manager 데몬(ceph-mgr)을 설치합니다. 그러나 Ansible을 사용하여 Red Hat Ceph Storage를 관리하지 않는 경우 Ceph Manager를 수동으로 설치할 수 있습니다. Red Hat은 동일한 노드에서 Ceph Manager 및 Ceph Monitor 데몬을 배치하는 것이 좋습니다.
사전 요구 사항
- 작동하는 Red Hat Ceph Storage 클러스터
-
root또는sudo액세스 -
rhel-7-server-rhceph-3-mon-els-rpms리포지토리 활성화 -
방화벽이 사용되는 경우 공용 네트워크에서 포트
6800-7300
절차
ceph-mgr 가 배포되는 노드에서 및 root 사용자로 또는 sudo 유틸리티를 사용하여 다음 명령을 사용합니다.
ceph-mgr패키지를 설치합니다.[user@node1 ~]$ sudo apt-get install ceph-mgr
/var/lib/ceph/mgr/ceph-호스트 이름/디렉터리를 생성합니다.mkdir /var/lib/ceph/mgr/ceph-hostnamehostname 을
ceph-mgr데몬이 배포될 노드의 호스트 이름으로 교체합니다. 예를 들면 다음과 같습니다.[user@node1 ~]$ sudo mkdir /var/lib/ceph/mgr/ceph-node1
새로 생성된 디렉터리에서
ceph-mgr데몬에 대한 인증 키를 생성합니다.[user@node1 ~]$ sudo ceph auth get-or-create mgr.`hostname -s` mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mgr/ceph-node1/keyring
/var/lib/ceph/mgr/디렉터리의 소유자 및 그룹을ceph:ceph로 변경합니다.[user@node1 ~]$ sudo chown -R ceph:ceph /var/lib/ceph/mgr
ceph-mgr대상을 활성화합니다.[user@node1 ~]$ sudo systemctl enable ceph-mgr.target
ceph-mgr인스턴스를 활성화하고 시작합니다.systemctl enable ceph-mgr@hostname systemctl start ceph-mgr@hostname
hostname 을
ceph-mgr이 배포할 노드의 호스트 이름으로 교체합니다. 예를 들면 다음과 같습니다.[user@node1 ~]$ sudo systemctl enable ceph-mgr@node1 [user@node1 ~]$ sudo systemctl start ceph-mgr@node1
ceph-mgr데몬이 시작되었는지 확인합니다.ceph -s
출력에는
services:섹션 아래의 다음 행과 유사한 행이 포함됩니다.mgr: node1(active)
-
현재 활성 데몬이 실패하는 경우 더 많은
ceph-mgr데몬을 설치하여 대기 데몬으로 작동합니다.
추가 리소스
OSD 부팅
초기 모니터가 실행되면 OSD(오브젝트 스토리지 장치)를 추가할 수 있습니다. 오브젝트 사본 수를 처리하기에 충분한 OSD가 있을 때까지 클러스터는 활성 + 클린 상태에 도달할 수 없습니다.
오브젝트의 기본 사본 수는 3입니다. 최소 3개의 OSD 노드가 필요합니다. 그러나 오브젝트의 두 사본만 원하는 경우 두 개의 OSD 노드만 추가한 다음, Ceph 구성 파일에서 osd 풀 기본 크기 및 osd 풀의 기본 min size 설정을 업데이트합니다.
자세한 내용은 Red Hat Ceph Storage 3 구성 가이드의 OSD 구성 참조 섹션을 참조하십시오.
초기 모니터를 부트 스트랩하면 클러스터에 기본 CRUSH 맵이 있습니다. 그러나 CRUSH 맵에는 Ceph 노드에 매핑된 Ceph OSD 데몬이 없습니다.
클러스터에 OSD를 추가하고 기본 CRUSH 맵을 업데이트하려면 각 OSD 노드에서 다음을 실행합니다.
Red Hat Ceph Storage 3 OSD 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/OSD $(lsb_release -sc) main | tee /etc/apt/sources.list.d/OSD.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
root로 Ceph OSD 노드에ceph-osd패키지를 설치합니다.$ sudo apt-get install ceph-osd
초기 Monitor 노드에서 OSD 노드로 Ceph 구성 파일 및 관리 인증 키 파일을 복사합니다.
구문
# scp <user_name>@<monitor_host_name>:<path_on_remote_system> <path_to_local_file>
예제
# scp root@node1:/etc/ceph/ceph.conf /etc/ceph # scp root@node1:/etc/ceph/ceph.client.admin.keyring /etc/ceph
OSD에 대한 UUID(Universally Unique Identifier)를 생성합니다.
$ uuidgen b367c360-b364-4b1d-8fc6-09408a9cda7a
root로서 OSD 인스턴스를 생성합니다.구문
# ceph osd create <uuid> [<osd_id>]
예제
# ceph osd create b367c360-b364-4b1d-8fc6-09408a9cda7a 0
참고이 명령은 후속 단계에 필요한 OSD 번호 식별자를 출력합니다.
루트로서 새 OSD에 대한 기본 디렉토리를 만듭니다.구문
# mkdir /var/lib/ceph/osd/<cluster_name>-<osd_id>
예제
# mkdir /var/lib/ceph/osd/ceph-0
루트로서 OSD로 사용할 드라이브를 준비한 후 방금 생성한 디렉터리에 마운트합니다. Ceph 데이터 및 저널용 파티션을 만듭니다. 저널 및 데이터 파티션은 동일한 디스크에 있을 수 있습니다. 이 예에서는 15GB 디스크를 사용합니다.구문
# parted <path_to_disk> mklabel gpt # parted <path_to_disk> mkpart primary 1 10000 # mkfs -t <fstype> <path_to_partition> # mount -o noatime <path_to_partition> /var/lib/ceph/osd/<cluster_name>-<osd_id> # echo "<path_to_partition> /var/lib/ceph/osd/<cluster_name>-<osd_id> xfs defaults,noatime 1 2" >> /etc/fstab
예제
# parted /dev/sdb mklabel gpt # parted /dev/sdb mkpart primary 1 10000 # parted /dev/sdb mkpart primary 10001 15000 # mkfs -t xfs /dev/sdb1 # mount -o noatime /dev/sdb1 /var/lib/ceph/osd/ceph-0 # echo "/dev/sdb1 /var/lib/ceph/osd/ceph-0 xfs defaults,noatime 1 2" >> /etc/fstab
루트로서 OSD 데이터 디렉터리를 초기화합니다.구문
# ceph-osd -i <osd_id> --mkfs --mkkey --osd-uuid <uuid>
예제
# ceph-osd -i 0 --mkfs --mkkey --osd-uuid b367c360-b364-4b1d-8fc6-09408a9cda7a ... auth: error reading file: /var/lib/ceph/osd/ceph-0/keyring: can't open /var/lib/ceph/osd/ceph-0/keyring: (2) No such file or directory ... created new key in keyring /var/lib/ceph/osd/ceph-0/keyring
참고--mkkey옵션을 사용하여ceph-osd를 실행하기 전에 디렉터리가 비어 있어야 합니다. 사용자 지정 클러스터 이름이 있는 경우ceph-osd유틸리티에--cluster옵션이 필요합니다.root로 OSD 인증 키를 등록합니다. 클러스터 이름이ceph와 다른 경우 클러스터 이름을 대신 삽입합니다.구문
# ceph auth add osd.<osd_id> osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/<cluster_name>-<osd_id>/keyring
예제
# ceph auth add osd.0 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-0/keyring added key for osd.0
root로서 OSD 노드를 CRUSH 맵에 추가합니다.구문
# ceph [--cluster <cluster_name>] osd crush add-bucket <host_name> host
예제
# ceph osd crush add-bucket node2 host
root로 OSD 노드를기본CRUSH 트리 아래에 배치합니다.구문
# ceph [--cluster <cluster_name>] osd crush move <host_name> root=default
예제
# ceph osd crush move node2 root=default
root로서 OSD 디스크를 CRUSH 맵에 추가합니다.구문
# ceph [--cluster <cluster_name>] osd crush add osd.<osd_id> <weight> [<bucket_type>=<bucket-name> ...]
예제
# ceph osd crush add osd.0 1.0 host=node2 add item id 0 name 'osd.0' weight 1 at location {host=node2} to crush map참고CRUSH 맵을 컴파일하고 장치 목록에 OSD를 추가할 수도 있습니다. OSD 노드를 버킷으로 추가한 다음 장치를 OSD 노드의 항목으로 추가하고 OSD에 가중치를 할당하고 CRUSH 맵을 다시 컴파일하고 CRUSH 맵을 설정합니다. 자세한 내용은 Red Hat Ceph Storage 3용 스토리지 전략 가이드 의 CRUSH 맵 편집 섹션을 참조하십시오.
root로서 새로 생성된 디렉터리 및 파일에 대한 소유자 및 그룹 권한을 업데이트합니다.구문
# chown -R <owner>:<group> <path_to_directory>
예제
# chown -R ceph:ceph /var/lib/ceph/osd # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown -R ceph:ceph /etc/ceph
사용자 지정 이름이 있는 스토리지 클러스터의 경우
root로서/etc/default/ceph파일에 다음 행을 추가합니다.구문
$ sudo echo "CLUSTER=<custom_cluster_name>" >> /etc/default/ceph
예제
$ sudo echo "CLUSTER=test123" >> /etc/default/ceph
OSD 노드는 Ceph 스토리지 클러스터 구성에 있습니다. 그러나 OSD 데몬은
다운되어에서입니다. 새 OSD는 데이터를받기전에 실행해야 합니다.root로 OSD 프로세스를 활성화하고 시작합니다.구문
$ sudo systemctl enable ceph-osd.target $ sudo systemctl enable ceph-osd@<osd_id> $ sudo systemctl start ceph-osd@<osd_id>
예제
$ sudo systemctl enable ceph-osd.target $ sudo systemctl enable ceph-osd@0 $ sudo systemctl start ceph-osd@0
OSD 데몬을 시작하면
up및 입니다.
이제 모니터와 일부 OSD가 실행 중입니다. 다음 명령을 실행하여 배치 그룹 피어를 확인할 수 있습니다.
$ ceph -w
OSD 트리를 보려면 다음 명령을 실행합니다.
$ ceph osd tree
예제
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -1 2 root default -2 2 host node2 0 1 osd.0 up 1 1 -3 1 host node3 1 1 osd.1 up 1 1
스토리지 클러스터에 새 OSD를 추가하여 스토리지 용량을 확장하려면 Red Hat Ceph Storage 3 관리 가이드 의 OSD 추가 섹션을 참조하십시오.
부록 C. Ceph 명령줄 인터페이스 설치
Ceph CLI(명령줄 인터페이스)를 사용하면 관리자가 Ceph 관리 명령을 실행할 수 있습니다. CLI는 ceph-common 패키지에서 제공하며 다음 유틸리티를 포함합니다.
-
Ceph -
ceph-authtool -
ceph-dencoder -
rados
사전 요구 사항
-
실행 중인 Ceph 스토리지 클러스터(특히
활성 + 정리상태)입니다.
절차
클라이언트 노드에서 Red Hat Ceph Storage 3 툴 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
클라이언트 노드에서
ceph-common패키지를 설치합니다.$ sudo apt-get install ceph-common
초기 모니터 노드에서 Ceph 구성 파일(이 경우
ceph.conf) 및 관리 인증 키를 클라이언트 노드에 복사합니다.구문
# scp /etc/ceph/<cluster_name>.conf <user_name>@<client_host_name>:/etc/ceph/ # scp /etc/ceph/<cluster_name>.client.admin.keyring <user_name>@<client_host_name:/etc/ceph/
예제
# scp /etc/ceph/ceph.conf root@node1:/etc/ceph/ # scp /etc/ceph/ceph.client.admin.keyring root@node1:/etc/ceph/
<client_host_name>을 클라이언트 노드의 호스트 이름으로 바꿉니다.
부록 D. 수동으로 Ceph 블록 장치 설치
다음 절차에서는 씬 프로비저닝된 Ceph 블록 장치를 설치하고 마운트하는 방법을 보여줍니다.
Ceph 블록 장치는 Ceph Monitor 및 OSD 노드에서 별도의 노드에 배포해야 합니다. 동일한 노드에서 커널 클라이언트 및 커널 서버 데몬을 실행하면 커널 교착 상태가 발생할 수 있습니다.
사전 요구 사항
- 부록 C. Ceph 명령줄 인터페이스 설치 섹션에 나열된 작업을 수행해야 합니다.
- Ceph 블록 장치를 QEMU를 사용하는 가상 머신(VM)의 백엔드로 사용하는 경우 기본 파일 설명자를 늘립니다. 자세한 내용은 Ceph - VM을 RBD 디스크 지식베이스에 대량의 데이터를 전송할 때 참조하십시오.
절차
OSD 노드의 파일에 대한 전체 권한을 사용하여
client.rbd라는 Ceph 블록 장치 사용자를 만들고 결과를 인증 키 파일로 출력합니다.ceph auth get-or-create client.rbd mon 'profile rbd' osd 'profile rbd pool=<pool_name>' \ -o /etc/ceph/rbd.keyring
<pool_name>을client.rbd가 액세스할 수 있는 풀 이름으로 바꿉니다(예:rbd:).$ sudo ceph auth get-or-create \ client.rbd mon 'allow r' osd 'allow rwx pool=rbd' \ -o /etc/ceph/rbd.keyring
사용자 생성에 대한 자세한 내용은 Red Hat Ceph Storage 3 관리 가이드 의 사용자 관리 섹션을 참조하십시오.
블록 장치 이미지를 생성합니다.
rbd create <image_name> --size <image_size> --pool <pool_name> \ --name client.rbd --keyring /etc/ceph/rbd.keyring
예를 들어
<image_name>,<image_size>,<pool_name>을 지정합니다.$ rbd create image1 --size 4096 --pool rbd \ --name client.rbd --keyring /etc/ceph/rbd.keyring
주의기본 Ceph 구성에는 다음과 같은 Ceph 블록 장치 기능이 포함됩니다.
-
계층 지정 -
exclusive-lock -
object-map -
deep-flatten -
fast-diff
커널 RBD(octets
d) 클라이언트를 사용하는 경우 Red Hat Enterprise Linux 7.3에 포함된 현재 커널 버전이객체 맵,를 지원하지 않기 때문에 블록 장치 이미지를 매핑할 수 없습니다.딥-플릿 및fast-diff이 문제를 해결하려면 지원되지 않는 기능을 비활성화합니다. 다음을 수행하려면 다음 옵션 중 하나를 사용합니다.
지원되지 않는 기능을 동적으로 비활성화합니다.
rbd feature disable <image_name> <feature_name>
예를 들면 다음과 같습니다.
# rbd feature disable image1 object-map deep-flatten fast-diff
-
rbd create명령에--image-feature옵션을 사용하여 새로 생성된 블록 장치 이미지에서 계층화만 활성화합니다.layering Ceph 구성 파일에서 기능을 기본값으로 비활성화합니다.
rbd_default_features = 1
이는 Red Hat Ceph Storage 3 릴리스 노트 에서 알려진 문제 장을 참조하십시오.
이러한 모든 기능은 사용자 공간 RBD 클라이언트를 사용하여 블록 장치 이미지에 액세스하는 사용자에게 적용됩니다.
-
새로 생성된 이미지를 블록 장치에 매핑합니다.
rbd map <image_name> --pool <pool_name>\ --name client.rbd --keyring /etc/ceph/rbd.keyring
예를 들면 다음과 같습니다.
$ sudo rbd map image1 --pool rbd --name client.rbd \ --keyring /etc/ceph/rbd.keyring
파일 시스템을 생성하여 블록 장치를 사용합니다.
mkfs.ext4 -m5 /dev/rbd/<pool_name>/<image_name>
풀 이름과 이미지 이름을 지정합니다. 예를 들면 다음과 같습니다.
$ sudo mkfs.ext4 -m5 /dev/rbd/rbd/image1
이 작업은 몇 분 정도 걸릴 수 있습니다.
새로 생성된 파일 시스템을 마운트합니다.
mkdir <mount_directory> mount /dev/rbd/<pool_name>/<image_name> <mount_directory>
예를 들면 다음과 같습니다.
$ sudo mkdir /mnt/ceph-block-device $ sudo mount /dev/rbd/rbd/image1 /mnt/ceph-block-device
자세한 내용은 Red Hat Ceph Storage 3의 블록 장치 가이드 를 참조하십시오.
부록 E. 수동으로 Ceph Object Gateway 설치
RADOS 게이트웨이라고도 하는 Ceph 개체 게이트웨이는 librados API 상단에 빌드된 오브젝트 스토리지 인터페이스로, 애플리케이션을 Ceph 스토리지 클러스터에 RESTful 게이트웨이를 제공합니다.
사전 요구 사항
-
실행 중인 Ceph 스토리지 클러스터(특히
활성 + 정리상태)입니다. - 2장. Red Hat Ceph Storage 설치 요구사항 에 나열된 작업을 수행합니다.
절차
Red Hat Ceph Storage 3 툴 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
Object Gateway 노드에서 rados
gw 패키지를설치합니다.$ sudo apt-get install radosgw
초기 모니터 노드에서 다음 단계를 수행합니다.
다음과 같이 Ceph 구성 파일을 업데이트합니다.
[client.rgw.<obj_gw_hostname>] host = <obj_gw_hostname> rgw frontends = "civetweb port=80" rgw dns name = <obj_gw_hostname>.example.com
여기서
<obj_gw_hostname>은 게이트웨이 노드의 짧은 호스트 이름입니다. 짧은 호스트 이름을 보려면hostname -s명령을 사용합니다.업데이트된 구성 파일을 Ceph 스토리지 클러스터의 새 Object Gateway 노드 및 기타 모든 노드에 복사합니다.
구문
$ sudo scp /etc/ceph/<cluster_name>.conf <user_name>@<target_host_name>:/etc/ceph
예제
$ sudo scp /etc/ceph/ceph.conf root@node1:/etc/ceph/
<cluster_name>.client.admin.keyring파일을 새 Object Gateway 노드에 복사합니다.구문
$ sudo scp /etc/ceph/<cluster_name>.client.admin.keyring <user_name>@<target_host_name>:/etc/ceph/
예제
$ sudo scp /etc/ceph/ceph.client.admin.keyring root@node1:/etc/ceph/
Object Gateway 노드에서 데이터 디렉터리를 생성합니다.
구문
$ sudo mkdir -p /var/lib/ceph/radosgw/<cluster_name>-rgw.`hostname -s`
예제
$ sudo mkdir -p /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`
Object Gateway 노드에서 사용자 및 인증 키를 추가하여 오브젝트 게이트웨이를 부트스트랩합니다.
구문
$ sudo ceph auth get-or-create client.rgw.`hostname -s` osd 'allow rwx' mon 'allow rw' -o /var/lib/ceph/radosgw/<cluster_name>-rgw.`hostname -s`/keyring
예제
$ sudo ceph auth get-or-create client.rgw.`hostname -s` osd 'allow rwx' mon 'allow rw' -o /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`/keyring
중요게이트웨이 키에 기능을 제공할 때 읽기 기능을 제공해야 합니다. 그러나 Monitor 쓰기 기능을 제공하는 것은 선택 사항입니다. 사용자가 제공하는 경우 Ceph Object Gateway는 자동으로 풀을 생성할 수 있습니다.
이러한 경우 풀에 적절한 수의 배치 그룹을 지정해야 합니다. 그렇지 않으면 게이트웨이가 기본 번호를 사용하므로 필요에 적합하지 않을 수 있습니다. 자세한 내용은 풀당 Ceph PG(배치 그룹) 를 참조하십시오.
Object Gateway 노드에서
완료된파일을 생성합니다.구문
$ sudo touch /var/lib/ceph/radosgw/<cluster_name>-rgw.`hostname -s`/done
예제
$ sudo touch /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`/done
Object Gateway 노드에서 소유자 및 그룹 권한을 변경합니다.
$ sudo chown -R ceph:ceph /var/lib/ceph/radosgw $ sudo chown -R ceph:ceph /var/log/ceph $ sudo chown -R ceph:ceph /var/run/ceph $ sudo chown -R ceph:ceph /etc/ceph
사용자 지정 이름이 있는 스토리지 클러스터의 경우
root로 다음 행을 추가합니다.구문
$ sudo echo "CLUSTER=<custom_cluster_name>" >> /etc/default/ceph
예제
$ sudo echo "CLUSTER=test123" >> /etc/default/ceph
Object Gateway 노드에서 TCP 포트 80을 엽니다.
$ sudo iptables -I INPUT 1 -i <network_interface> -p tcp -s <ip_address>/<netmask> --dport 80 -j ACCEPT
Object Gateway 노드에서
ceph-radosgw프로세스를 시작하고 활성화합니다.구문
$ sudo systemctl enable ceph-radosgw.target $ sudo systemctl enable ceph-radosgw@rgw.<rgw_hostname> $ sudo systemctl start ceph-radosgw@rgw.<rgw_hostname>
예제
$ sudo systemctl enable ceph-radosgw.target $ sudo systemctl enable ceph-radosgw@rgw.node1 $ sudo systemctl start ceph-radosgw@rgw.node1
설치가 완료되면 Ceph Object Gateway가 모니터에 쓰기 기능이 설정된 경우 자동으로 풀을 생성합니다. 수동으로 풀 생성에 대한 자세한 내용은 스토리지 전략 가이드의 풀 장을 참조하십시오.
추가 세부 정보
- Red Hat Ceph Storage 3 - Ubuntu 용 오브젝트 게이트웨이 가이드
부록 F. Ceph 기본 설정 덮어쓰기
Ansible 구성 파일에 달리 지정하지 않는 한 Ceph는 기본 설정을 사용합니다.
Ansible은 Ceph 구성 파일을 관리하므로 /usr/share/ceph-ansible/group_vars/all.yml 파일을 편집하여 Ceph 구성을 변경합니다. ceph_conf_overrides 설정을 사용하여 기본 Ceph 구성을 재정의합니다.
Ansible은 Ceph 구성 파일과 동일한 섹션, [global], [mon], [osd], [mds], [rgw] 등을 지원합니다. 특정 Ceph Object Gateway 인스턴스와 같은 특정 인스턴스를 덮어쓸 수도 있습니다. 예를 들면 다음과 같습니다.
###################
# CONFIG OVERRIDE #
###################
ceph_conf_overrides:
client.rgw.rgw1:
log_file: /var/log/ceph/ceph-rgw-rgw1.logCeph 구성 파일의 특정 섹션을 참조할 때 Ansible에는 브레이스가 포함되지 않습니다. 섹션 및 설정 이름은 콜론으로 종료됩니다.
CONFIG OVERRIDE 섹션에서 cluster_network 매개 변수를 사용하여 클러스터 네트워크를 설정하지 마십시오. 이로 인해 Ceph 구성 파일에 두 개의 충돌하는 클러스터 네트워크가 설정될 수 있기 때문입니다.
클러스터 네트워크를 설정하려면 CEPH CONFIGURATION 섹션에서 cluster_network 매개 변수를 사용합니다. 자세한 내용은 3.2절. “Red Hat Ceph Storage 클러스터 설치”의 내용을 참조하십시오.
부록 G. Red Hat Ceph Storage 2에서 3으로 수동 업그레이드
클러스터가 실행되는 동안 Ceph Storage 클러스터를 롤링 방식으로 2에서 3으로 업그레이드할 수 있습니다. 클러스터의 각 노드를 순차적으로 업그레이드하고 이전 노드가 완료된 후 다음 노드로만 이동합니다.
다음과 같은 순서로 Ceph 구성 요소를 업그레이드하는 것이 좋습니다.
- 노드 모니터링
- OSD 노드
- Ceph Object Gateway 노드
- 기타 모든 Ceph 클라이언트 노드
Red Hat Ceph Storage 3에는 새로운 데몬 Ceph Manager(ceph-mgr)가 도입되었습니다. Monitor 노드를 업그레이드한 후 ceph-mgr 을 설치합니다.
Red Hat Ceph Storage 2를 3으로 업그레이드하는 방법은 다음 두 가지가 있습니다.
- Red Hat CDN(Content Delivery Network) 사용
- Red Hat 제공 ISO 이미지 파일 사용
스토리지 클러스터를 업그레이드한 후 기존 튜닝 가능 항목을 사용하여 CRUSH 맵에 대한 상태 경고를 받을 수 있습니다. 자세한 내용은 Red Hat Ceph Storage 3용 스토리지 전략 가이드의 CRUSH Tunables 섹션을 참조하십시오.
예제
$ ceph -s
cluster 848135d7-cdb9-4084-8df2-fb5e41ae60bd
health HEALTH_WARN
crush map has legacy tunables (require bobtail, min is firefly)
monmap e1: 1 mons at {ceph1=192.168.0.121:6789/0}
election epoch 2, quorum 0 ceph1
osdmap e83: 2 osds: 2 up, 2 in
pgmap v1864: 64 pgs, 1 pools, 38192 kB data, 17 objects
10376 MB used, 10083 MB / 20460 MB avail
64 active+clean
Red Hat은 모든 Ceph 클라이언트가 Ceph 스토리지 클러스터와 동일한 버전을 실행하도록 권장합니다.
사전 요구 사항
업그레이드하려는 클러스터에
exclusive-lock기능을 사용하는 Ceph Block Device 이미지가 포함된 경우 모든 Ceph Block Device 사용자에게 클라이언트를 블랙리스트로 지정할 수 있는 권한이 있는지 확인하십시오.ceph auth caps client.<ID> mon 'allow r, allow command "osd blacklist"' osd '<existing-OSD-user-capabilities>'
모니터 노드 업그레이드
이 섹션에서는 Ceph Monitor 노드를 최신 버전으로 업그레이드하는 단계를 설명합니다. 홀수의 모니터가 있어야 합니다. 모니터 하나를 업그레이드하는 동안 스토리지 클러스터에는 쿼럼이 있습니다.
절차
스토리지 클러스터의 각 모니터 노드에서 다음 단계를 수행합니다. 한 번에 하나의 Monitor 노드만 업그레이드합니다.
소프트웨어 리포지토리를 사용하여 Red Hat Ceph Storage 2를 설치한 경우 리포지토리를 비활성화합니다.
/etc/apt/sources.list또는/etc/apt/sources.list.d/ceph.list파일에 다음 행이 있는 경우 해시 기호(#)를 라인 시작 부분에 추가하여 Red Hat Ceph Storage 2의 온라인 리포지토리를 주석 처리합니다.deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Installer deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Tools
/etc/apt/sources.list.d/디렉토리에서 다음 파일을 제거하십시오.Installer.list Tools.list
Red Hat Ceph Storage 3 Monitor 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/MON $(lsb_release -sc) main | tee /etc/apt/sources.list.d/MON.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
root로 monitor 프로세스를 중지합니다.구문
$ sudo stop ceph-mon id=<monitor_host_name>
예제
$ sudo stop ceph-mon id=node1
root로ceph-mon패키지를 업데이트합니다.$ sudo apt-get update $ sudo apt-get dist-upgrade $ sudo apt-get install ceph-mon
최신 Red Hat 버전이 설치되었는지 확인합니다.
$ dpkg -s ceph-base | grep Version Version: 10.2.2-19redhat1trusty
root로서 소유자 및 그룹 권한을 업데이트합니다.구문
# chown -R <owner>:<group> <path_to_directory>
예제
# chown -R ceph:ceph /var/lib/ceph/mon # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown ceph:ceph /etc/ceph/ceph.client.admin.keyring # chown ceph:ceph /etc/ceph/ceph.conf # chown ceph:ceph /etc/ceph/rbdmap
참고Ceph Monitor 노드가 OpenStack 컨트롤러 노드와 함께 배치되는 경우 Glance 및 Cinder 인증 키 파일을 각각
glance및cinder에서 소유해야 합니다. 예를 들면 다음과 같습니다.# ls -l /etc/ceph/ ... -rw-------. 1 glance glance 64 <date> ceph.client.glance.keyring -rw-------. 1 cinder cinder 64 <date> ceph.client.cinder.keyring ...
더 이상 필요하지 않은 패키지를 제거하십시오.
$ sudo apt-get purge ceph ceph-osd
root로서 커널에서 장치 이벤트를 재생합니다.# udevadm trigger
root로ceph-mon프로세스를 활성화합니다.$ sudo systemctl enable ceph-mon.target $ sudo systemctl enable ceph-mon@<monitor_host_name>
root로서 Monitor 노드를 재부팅합니다.# shutdown -r now
Monitor 노드가 가동되면 다음 Monitor 노드로 이동하기 전에 Ceph 스토리지 클러스터의 상태를 확인합니다.
# ceph -s
G.1. 수동으로 Ceph Manager 설치
일반적으로 Ansible 자동화 유틸리티는 Red Hat Ceph Storage 클러스터를 배포할 때 Ceph Manager 데몬(ceph-mgr)을 설치합니다. 그러나 Ansible을 사용하여 Red Hat Ceph Storage를 관리하지 않는 경우 Ceph Manager를 수동으로 설치할 수 있습니다. Red Hat은 동일한 노드에서 Ceph Manager 및 Ceph Monitor 데몬을 배치하는 것이 좋습니다.
사전 요구 사항
- 작동하는 Red Hat Ceph Storage 클러스터
-
root또는sudo액세스 -
rhel-7-server-rhceph-3-mon-els-rpms리포지토리 활성화 -
방화벽이 사용되는 경우 공용 네트워크에서 포트
6800-7300
절차
ceph-mgr 가 배포되는 노드에서 및 root 사용자로 또는 sudo 유틸리티를 사용하여 다음 명령을 사용합니다.
ceph-mgr패키지를 설치합니다.[user@node1 ~]$ sudo apt-get install ceph-mgr
/var/lib/ceph/mgr/ceph-호스트 이름/디렉터리를 생성합니다.mkdir /var/lib/ceph/mgr/ceph-hostnamehostname 을
ceph-mgr데몬이 배포될 노드의 호스트 이름으로 교체합니다. 예를 들면 다음과 같습니다.[user@node1 ~]$ sudo mkdir /var/lib/ceph/mgr/ceph-node1
새로 생성된 디렉터리에서
ceph-mgr데몬에 대한 인증 키를 생성합니다.[user@node1 ~]$ sudo ceph auth get-or-create mgr.`hostname -s` mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mgr/ceph-node1/keyring
/var/lib/ceph/mgr/디렉터리의 소유자 및 그룹을ceph:ceph로 변경합니다.[user@node1 ~]$ sudo chown -R ceph:ceph /var/lib/ceph/mgr
ceph-mgr대상을 활성화합니다.[user@node1 ~]$ sudo systemctl enable ceph-mgr.target
ceph-mgr인스턴스를 활성화하고 시작합니다.systemctl enable ceph-mgr@hostname systemctl start ceph-mgr@hostname
hostname 을
ceph-mgr이 배포할 노드의 호스트 이름으로 교체합니다. 예를 들면 다음과 같습니다.[user@node1 ~]$ sudo systemctl enable ceph-mgr@node1 [user@node1 ~]$ sudo systemctl start ceph-mgr@node1
ceph-mgr데몬이 시작되었는지 확인합니다.ceph -s
출력에는
services:섹션 아래의 다음 행과 유사한 행이 포함됩니다.mgr: node1(active)
-
현재 활성 데몬이 실패하는 경우 더 많은
ceph-mgr데몬을 설치하여 대기 데몬으로 작동합니다.
추가 리소스
OSD 노드 업그레이드
이 섹션에서는 Ceph OSD 노드를 최신 버전으로 업그레이드하는 단계를 설명합니다.
사전 요구 사항
OSD 노드를 업그레이드할 때 OSD가 다운되거나 다시 시작될 수 있으므로 일부 배치 그룹이 성능이 저하됩니다. Ceph가 복구 프로세스를 시작하지 못하도록 하려면 Monitor 노드에서 noout 및 norebalance OSD 플래그를 설정합니다.
[root@monitor ~]# ceph osd set noout [root@monitor ~]# ceph osd set norebalance
절차
스토리지 클러스터의 각 OSD 노드에서 다음 단계를 수행합니다. 한 번에 하나의 OSD 노드만 업그레이드합니다. Red Hat Ceph Storage 2.3에 대해 ISO 기반 설치를 수행한 경우 이 첫 번째 단계를 건너뜁니다.
root로서 Red Hat Ceph Storage 2 리포지토리를 비활성화합니다./etc/apt/sources.list또는/etc/apt/sources.list.d/ceph.list파일에 다음 행이 있는 경우 해시 기호(#)를 라인 시작 부분에 추가하여 Red Hat Ceph Storage 2의 온라인 리포지토리를 주석 처리합니다.deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Installer deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Tools
/etc/apt/sources.list.d/ 디렉토리에서 다음 파일을 제거하십시오.
Installer.list Tools.list
참고APT 소스 파일에서 Red Hat Ceph Storage 2에 대한 참조를 제거합니다. Red Hat Ceph Storage 2에 대해 ISO 기반 설치를 수행한 경우 이 첫 번째 단계를 건너뜁니다.
Red Hat Ceph Storage 3 OSD 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/OSD $(lsb_release -sc) main | tee /etc/apt/sources.list.d/OSD.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
root로 실행 중인 OSD 프로세스를 중지합니다.구문
$ sudo stop ceph-osd id=<osd_id>
예제
$ sudo stop ceph-osd id=0
root로ceph-osd패키지를 업데이트합니다.$ sudo apt-get update $ sudo apt-get dist-upgrade $ sudo apt-get install ceph-osd
최신 Red Hat 버전이 설치되었는지 확인합니다.
$ dpkg -s ceph-base | grep Version Version: 10.2.2-19redhat1trusty
root로서 새로 생성된 디렉터리 및 파일에 대한 소유자 및 그룹 권한을 업데이트합니다.구문
# chown -R <owner>:<group> <path_to_directory>
예제
# chown -R ceph:ceph /var/lib/ceph/osd # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown -R ceph:ceph /etc/ceph
참고다음
find명령을 사용하면 다수의 디스크가 많은 Ceph 스토리지 클러스터에서chown명령을 병렬로 사용하여 소유권을 변경하는 프로세스를 빠르게 수행할 수 있습니다.# find /var/lib/ceph/osd -maxdepth 1 -mindepth 1 -print | xargs -P12 -n1 chown -R ceph:ceph
더 이상 필요하지 않은 패키지를 제거하십시오.
$ sudo apt-get purge ceph ceph-mon
참고ceph패키지는 이제 메타 패키지입니다. Monitor 노드에는ceph-mon패키지만 필요하며 OSD 노드에ceph-osd패키지만 필요하며 RADOS Gateway 노드에는ceph-radosgw패키지만 필요합니다.root로서 커널에서 장치 이벤트를 재생합니다.# udevadm trigger
root로ceph-osd프로세스를 활성화합니다.$ sudo systemctl enable ceph-osd.target $ sudo systemctl enable ceph-osd@<osd_id>
root로서 OSD 노드를 재부팅합니다.# shutdown -r now
다음 OSD 노드로 이동합니다.
참고noout및norebalance플래그가 설정된 경우 스토리지 클러스터는HEALTH_WARN상태입니다.$ ceph health HEALTH_WARN noout,norebalance flag(s) set
Ceph Storage 클러스터를 업그레이드한 후 이전에 설정한 OSD 플래그를 설정 해제하고 스토리지 클러스터 상태를 확인합니다.
모니터 노드에서 및 모든 OSD 노드가 업그레이드된 후 noout 및 norebalance 플래그를 설정 해제합니다.
# ceph osd unset noout # ceph osd unset norebalance
또한 ceph osd require-osd-release <release> 명령을 실행합니다. 이 명령을 사용하면 더 이상 Red Hat Ceph Storage 2.3이 있는 OSD를 스토리지 클러스터에 추가할 수 없습니다. 이 명령을 실행하지 않으면 스토리지 상태가 HEALTH_WARN 이 됩니다.
# ceph osd require-osd-release luminous
추가 리소스
- 스토리지 클러스터에 새 OSD를 추가하여 스토리지 용량을 확장하려면 Red Hat Ceph Storage 3 관리 가이드 의 OSD 추가 섹션을 참조하십시오.
Ceph Object Gateway 노드 업그레이드
이 섹션에서는 Ceph Object Gateway 노드를 이후 버전으로 업그레이드하는 단계를 설명합니다.
Red Hat은 이러한 업그레이드 절차를 진행하기 전에 시스템을 백업하도록 권장합니다.
사전 요구 사항
- Red Hat은 HAProxy 와 같은 로드 밸런서 뒤에 Ceph 오브젝트 게이트웨이를 두는 것이 좋습니다. 로드 밸런서를 사용하는 경우 요청이 제공되지 않으면 로드 밸런서에서 Ceph Object Gateway를 제거합니다.
rgw_region_root_pool매개변수에 지정된 리전 풀에 사용자 지정 이름을 사용하는 경우 Ceph 구성 파일의[global]섹션에rgw_zonegroup_root_pool매개변수를 추가합니다.rgw_zonegroup_root_pool의 값을rgw_region_root_pool과 동일하게 설정합니다. 예를 들면 다음과 같습니다.[global] rgw_zonegroup_root_pool = .us.rgw.root
절차
스토리지 클러스터의 각 Ceph Object Gateway 노드에서 다음 단계를 수행합니다. 한 번에 하나의 노드만 업그레이드합니다.
Red Hat Ceph Storage를 설치하기 위해 온라인 리포지토리를 사용한 경우 2 리포지토리를 비활성화합니다.
/etc/apt/sources.list 및
/etc/apt/sources.list.d/ceph.list# deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Installer # deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Tools
/etc/apt/sources.list.d/디렉토리에서 다음 파일을 제거합니다.# rm /etc/apt/sources.list.d/Installer.list # rm /etc/apt/sources.list.d/Tools.list
Red Hat Ceph Storage 3 툴 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
Ceph Object Gateway 프로세스(
ceph-radosgw)를 중지합니다.$ sudo stop radosgw id=rgw.<hostname>
<hostname>을 Ceph Object Gateway 호스트 이름으로 바꿉니다(예:gateway-node).$ sudo stop radosgw id=rgw.node
ceph-radosgw패키지를 업데이트합니다.$ sudo apt-get update $ sudo apt-get dist-upgrade $ sudo apt-get install radosgw
새로 생성된
/var/lib/ceph/radosgw/및/var/log/ceph/디렉터리에 대한 소유자 및 그룹 권한을ceph로 변경합니다.# chown -R ceph:ceph /var/lib/ceph/radosgw # chown -R ceph:ceph /var/log/ceph
더 이상 필요하지 않은 패키지를 제거합니다.
$ sudo apt-get purge ceph
참고ceph패키지는 이제 메타 패키지입니다. 모니터, OSD 및 Ceph Object Gateway 노드에 각각ceph-mon,ceph-osd,ceph-radosgw패키지만 필요합니다.ceph-radosgw프로세스를 활성화합니다.$ sudo systemctl enable ceph-radosgw.target $ sudo systemctl enable ceph-radosgw@rgw.<hostname>
<hostname>을 Ceph Object Gateway 호스트의 이름으로 바꿉니다(예:gateway-node).$ sudo systemctl enable ceph-radosgw.target $ sudo systemctl enable ceph-radosgw@rgw.gateway-node
Ceph Object Gateway 노드를 재부팅합니다.
# shutdown -r now
- 로드 밸런서를 사용하는 경우 Ceph Object Gateway 노드를 다시 로드 밸런서에 추가합니다.
예를 들면 다음과 같습니다.
Ceph 클라이언트 노드 업그레이드
Ceph 클라이언트는 다음과 같습니다.
- Ceph 블록 장치
- OpenStack Nova Compute 노드
- QEMU/KVM 하이퍼바이저
- Ceph 클라이언트 측 라이브러리를 사용하는 사용자 정의 애플리케이션
Red Hat은 모든 Ceph 클라이언트가 Ceph 스토리지 클러스터와 동일한 버전을 실행하도록 권장합니다.
사전 요구 사항
- 예기치 않은 오류가 발생하지 않도록 패키지를 업그레이드하는 동안 Ceph 클라이언트 노드에 대한 모든 I/O 요청을 중지합니다.
절차
소프트웨어 리포지토리를 사용하여 Red Hat Ceph Storage 2 클라이언트를 설치한 경우 리포지토리를 비활성화합니다.
/etc/apt/sources.list또는/etc/apt/sources.list.d/ceph.list파일에 다음 행이 있는 경우 해시 기호(#)를 라인 시작 부분에 추가하여 Red Hat Ceph Storage 2의 온라인 리포지토리를 주석 처리합니다.deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Installer deb https://<customer_name>:<customer_password>@rhcs.download.redhat.com/ubuntu/2-updates/Tools
/etc/apt/sources.list.d/ 디렉토리에서 다음 파일을 제거하십시오.
Installer.list Tools.list
참고APT 소스 파일에서 Red Hat Ceph Storage 2에 대한 참조를 제거합니다.
클라이언트 노드에서 Red Hat Ceph Storage Tools 3 리포지토리를 활성화합니다.
$ sudo bash -c 'umask 0077; echo deb https://customername:customerpasswd@rhcs.download.redhat.com/3-updates/Tools $(lsb_release -sc) main | tee /etc/apt/sources.list.d/Tools.list' $ sudo bash -c 'wget -O - https://www.redhat.com/security/fd431d51.txt | apt-key add -' $ sudo apt-get update
클라이언트 노드에서
ceph-common패키지를 업데이트합니다.$ sudo apt-get install ceph-common
ceph-common 패키지를 업그레이드한 후 Ceph 클라이언트 측 라이브러리에 종속된 애플리케이션을 다시 시작합니다.
QEMU/KVM 인스턴스를 실행하거나 전용 QEMU/KVM 클라이언트를 사용하는 OpenStack Nova 컴퓨팅 노드를 업그레이드하는 경우 이 경우 인스턴스를 다시 시작할 수 없으므로 QEMU/KVM 인스턴스를 중지 및 시작합니다.
부록 H. 버전 2와 3의 Ansible 변수 변경
Red Hat Ceph Storage 3에서는 /usr/share/ceph-ansible/group_vars/ 디렉터리에 있는 구성 파일의 특정 변수가 변경되었거나 삭제되었습니다. 다음 표에는 모든 변경 사항이 나열되어 있습니다. 버전 3으로 업그레이드한 후 all.yml.sample 및 osds.yml.sample 파일을 다시 복사하여 이러한 변경 사항을 반영합니다. 자세한 내용은 Red Hat Ceph Storage 클러스터 업그레이드를 참조하십시오.
| 이전 옵션 | 새로운 옵션 | 파일 |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
부록 I. Ansible로 기존 Ceph 클러스터 가져오기
Ansible 없이 배포된 클러스터를 사용하도록 Ansible을 구성할 수 있습니다. 예를 들어 Red Hat Ceph Storage 1.3 클러스터를 버전 2로 수동으로 업그레이드하는 경우 다음 절차에 따라 Ansible을 사용하도록 구성합니다.
- 버전 1.3에서 버전 2로 수동으로 업그레이드한 후 관리 노드에 Ansible을 설치하고 구성합니다.
-
Ansible 관리 노드에 클러스터의 모든 Ceph 노드에 대한 암호 없는
ssh액세스 권한이 있는지 확인합니다. 자세한 내용은 2.10절. “Ansible에 대해 암호 없는 SSH 활성화”를 참조하십시오. root로서/etc/ansible/디렉터리의 Ansiblegroup_vars디렉터리에 대한 심볼릭 링크를 만듭니다.# ln -s /usr/share/ceph-ansible/group_vars /etc/ansible/group_vars
root로서all.yml.sample 파일에서 all.yml파일을 생성하고 편집을 위해 엽니다.# cd /etc/ansible/group_vars # cp all.yml.sample all.yml # vim all.yml
-
group_vars/all.yml에서generate_fsid설정을false로 설정합니다. -
ceph를 실행하여 현재 클러스터 fsid를 가져옵니다.fsid -
검색된
fsid를group_vars/all.yml에 설정합니다. -
Ceph 호스트를 포함하도록
/etc/ansible/hosts에서 Ansible 인벤토리를 수정합니다.[mons]섹션 아래에 있는 모니터와[osds]섹션 아래에 있는 게이트웨이를 추가하여 Ansible에 대한 역할을 식별합니다. ceph_conf_overrides가all.yml파일의[global],[osd],[mon]및[client]섹션에 사용되는 원래ceph.conf옵션으로 업데이트되었는지 확인합니다.osd journal,public_network및cluster_network와 같은 옵션은 이미all.yml의 일부이므로ceph_conf_overrides에 추가하지 않아야 합니다.all.yml의 일부가 아니며 원래ceph.conf에 있는 옵션만ceph_conf_overrides에 추가해야 합니다./usr/share/ceph-ansible/디렉터리에서 플레이북을 실행합니다.# cd /usr/share/ceph-ansible/ # cp infrastructure-playbooks/take-over-existing-cluster.yml . $ ansible-playbook take-over-existing-cluster.yml -u <username>
부록 J. Ansible을 사용하여 Ceph 클러스터 제거
Ansible을 사용하여 Ceph 클러스터를 배포하고 클러스터를 삭제하려면 infrastructure-playbooks 디렉터리에 있는 purge-cluster.yml Ansible 플레이북을 사용합니다.
Ceph 클러스터를 제거해도 클러스터 OSD에 저장된 데이터가 손실됩니다.
Ceph 클러스터를 제거하기 전에…
osds.yml 파일에서 osd_auto_discovery 옵션을 확인합니다. 이 옵션을 true 로 설정하면 제거가 실패합니다. 실패를 방지하려면 제거를 실행하기 전에 다음 단계를 수행하십시오.
-
osds.yml파일에서 OSD 장치를 선언합니다. 자세한 내용은 3.2절. “Red Hat Ceph Storage 클러스터 설치”를 참조하십시오. -
osds.yml파일의osd_auto_discovery옵션을 주석 처리합니다.
Ceph 클러스터 제거…
루트로서/usr/share/ceph-ansible/디렉터리로 이동합니다.# cd /usr/share/ceph-ansible
root로서purge-cluster.ymlAnsible 플레이북을 현재 디렉터리에 복사합니다.# cp infrastructure-playbooks/purge-cluster.yml .
purge-cluster.ymlAnsible 플레이북을 실행합니다.$ ansible-playbook purge-cluster.yml