
AMQ Broker 구성
AMQ Broker 7.8에서 사용
초록
1장. 개요
AMQ Broker 구성 파일은 브로커 인스턴스에 대한 중요한 설정을 정의합니다. 브로커의 구성 파일을 편집하여 브로커가 환경에서 작동하는 방식을 제어할 수 있습니다.
1.1. AMQ Broker 구성 파일 및 위치
브로커의 모든 구성 파일은 < broker-instance-dir> /etc 에 저장됩니다. 이러한 구성 파일에서 설정을 편집하여 브로커를 구성할 수 있습니다.
각 브로커 인스턴스는 다음 구성 파일을 사용합니다.
broker.xml- 기본 구성 파일입니다. 이 파일을 사용하여 네트워크 연결, 보안 설정, 메시지 주소 등과 같은 브로커의 대부분을 구성합니다.
bootstrap.xml-
AMQ Broker가 브로커 인스턴스를 시작하는 데 사용하는 파일입니다. 이를 사용하여
broker.xml의 위치를 변경하고, 웹 서버를 구성하고, 일부 보안 설정을 설정합니다. logging.properties- 이 파일을 사용하여 브로커 인스턴스의 로깅 속성을 설정합니다.
artemis.profile- 이 파일을 사용하여 브로커 인스턴스가 실행되는 동안 사용되는 환경 변수를 설정합니다.
login.config,artemis-users.properties,artemis-roles.properties- 보안 관련 파일. 이러한 파일을 사용하여 브로커 인스턴스에 대한 사용자 액세스를 위한 인증을 설정합니다.
1.2. 기본 브로커 구성 이해
broker.xml 구성 파일을 편집하여 브로커의 기능을 대부분 구성합니다. 이 파일에는 브로커를 시작하고 작동하는 데 충분한 기본 설정이 포함되어 있습니다. 그러나 기본 설정 중 일부를 변경하고 환경에 브로커를 구성하는 새 설정을 추가해야 할 수도 있습니다.
기본적으로 broker.xml 에는 다음 기능에 대한 기본 설정이 포함되어 있습니다.
- 메시지 지속성
- 수락자
- 보안
- 메시지 주소
기본 메시지 지속성 설정
기본적으로 AMQ Broker 지속성은 디스크의 파일 세트로 구성된 추가 전용 파일 저널을 사용합니다. 저널은 메시지, 트랜잭션 및 기타 정보를 저장합니다.
<configuration ...>
<core ...>
...
<persistence-enabled>true</persistence-enabled>
<!-- this could be ASYNCIO, MAPPED, NIO
ASYNCIO: Linux Libaio
MAPPED: mmap files
NIO: Plain Java Files
-->
<journal-type>ASYNCIO</journal-type>
<paging-directory>data/paging</paging-directory>
<bindings-directory>data/bindings</bindings-directory>
<journal-directory>data/journal</journal-directory>
<large-messages-directory>data/large-messages</large-messages-directory>
<journal-datasync>true</journal-datasync>
<journal-min-files>2</journal-min-files>
<journal-pool-files>10</journal-pool-files>
<journal-file-size>10M</journal-file-size>
<!--
This value was determined through a calculation.
Your system could perform 8.62 writes per millisecond
on the current journal configuration.
That translates as a sync write every 115999 nanoseconds.
Note: If you specify 0 the system will perform writes directly to the disk.
We recommend this to be 0 if you are using journalType=MAPPED and journal-datasync=false.
-->
<journal-buffer-timeout>115999</journal-buffer-timeout>
<!--
When using ASYNCIO, this will determine the writing queue depth for libaio.
-->
<journal-max-io>4096</journal-max-io>
<!-- how often we are looking for how many bytes are being used on the disk in ms -->
<disk-scan-period>5000</disk-scan-period>
<!-- once the disk hits this limit the system will block, or close the connection in certain protocols
that won't support flow control. -->
<max-disk-usage>90</max-disk-usage>
<!-- should the broker detect dead locks and other issues -->
<critical-analyzer>true</critical-analyzer>
<critical-analyzer-timeout>120000</critical-analyzer-timeout>
<critical-analyzer-check-period>60000</critical-analyzer-check-period>
<critical-analyzer-policy>HALT</critical-analyzer-policy>
...
</core>
</configuration>기본 수락자 설정
브로커는 클라이언트가 연결을 만드는 데 사용할 수 있는 포트 및 프로토콜을 정의하는 수락 자 구성 요소를 사용하여 들어오는 클라이언트 연결을 수신 대기합니다. 기본적으로 AMQ Broker에는 지원되는 각 메시징 프로토콜에 대한 수락자 구성이 포함되어 있습니다.
<configuration ...>
<core ...>
...
<acceptors>
<!-- Acceptor for every supported protocol -->
<acceptor name="artemis">tcp://0.0.0.0:61616?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=CORE,AMQP,STOMP,HORNETQ,MQTT,OPENWIRE;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- AMQP Acceptor. Listens on default AMQP port for AMQP traffic -->
<acceptor name="amqp">tcp://0.0.0.0:5672?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=AMQP;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- STOMP Acceptor -->
<acceptor name="stomp">tcp://0.0.0.0:61613?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=STOMP;useEpoll=true</acceptor>
<!-- HornetQ Compatibility Acceptor. Enables HornetQ Core and STOMP for legacy HornetQ clients. -->
<acceptor name="hornetq">tcp://0.0.0.0:5445?anycastPrefix=jms.queue.;multicastPrefix=jms.topic.;protocols=HORNETQ,STOMP;useEpoll=true</acceptor>
<!-- MQTT Acceptor -->
<acceptor name="mqtt">tcp://0.0.0.0:1883?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=MQTT;useEpoll=true</acceptor>
</acceptors>
...
</core>
</configuration>기본 보안 설정
AMQ Broker에는 주소를 기반으로 큐에 보안을 적용하기 위한 유연한 역할 기반 보안 모델이 포함되어 있습니다. 기본 구성에서는 와일드카드를 사용하여 amq 역할 을 모든 주소(숫자 기호 #)에 적용합니다.
<configuration ...>
<core ...>
...
<security-settings>
<security-setting match="#">
<permission type="createNonDurableQueue" roles="amq"/>
<permission type="deleteNonDurableQueue" roles="amq"/>
<permission type="createDurableQueue" roles="amq"/>
<permission type="deleteDurableQueue" roles="amq"/>
<permission type="createAddress" roles="amq"/>
<permission type="deleteAddress" roles="amq"/>
<permission type="consume" roles="amq"/>
<permission type="browse" roles="amq"/>
<permission type="send" roles="amq"/>
<!-- we need this otherwise ./artemis data imp wouldn't work -->
<permission type="manage" roles="amq"/>
</security-setting>
</security-settings>
...
</core>
</configuration>기본 메시지 주소 설정
AMQ Broker에는 생성된 대기열 또는 항목에 적용할 기본 구성 설정 세트를 설정하는 기본 주소가 포함되어 있습니다.
또한 기본 구성은 두 개의 큐를 정의합니다. DLQ (Dead Letter Queue)는 알려진 대상이 없는 메시지를 처리하고 Expiry Queue 에는 만료일을 지난 후 만료된 메시지를 보유하고 있으므로 원래 대상으로 라우팅해서는 안 됩니다.
<configuration ...>
<core ...>
...
<address-settings>
...
<!--default for catch all-->
<address-setting match="#">
<dead-letter-address>DLQ</dead-letter-address>
<expiry-address>ExpiryQueue</expiry-address>
<redelivery-delay>0</redelivery-delay>
<!-- with -1 only the global-max-size is in use for limiting -->
<max-size-bytes>-1</max-size-bytes>
<message-counter-history-day-limit>10</message-counter-history-day-limit>
<address-full-policy>PAGE</address-full-policy>
<auto-create-queues>true</auto-create-queues>
<auto-create-addresses>true</auto-create-addresses>
<auto-create-jms-queues>true</auto-create-jms-queues>
<auto-create-jms-topics>true</auto-create-jms-topics>
</address-setting>
</address-settings>
<addresses>
<address name="DLQ">
<anycast>
<queue name="DLQ" />
</anycast>
</address>
<address name="ExpiryQueue">
<anycast>
<queue name="ExpiryQueue" />
</anycast>
</address>
</addresses>
</core>
</configuration>1.3. 구성 업데이트 다시 로드
기본적으로 브로커는 5000밀리초마다 구성 파일의 변경 사항을 확인합니다. 브로커가 구성 파일의 "최근 수정" 타임 스탬프의 변경을 감지하면 브로커는 구성 변경이 발생했음을 결정합니다. 이 경우 브로커가 구성 파일을 다시 로드하여 변경 사항을 활성화합니다.
브로커가 broker.xml 구성 파일을 다시 로드하면 다음 모듈을 다시 로드합니다.
주소 설정 및 대기열
구성 파일을 다시 로드할 때 주소 설정은 구성 파일에서 삭제된 주소 및 큐를 처리하는 방법을 결정합니다.
config-delete-addresses및config-delete-queues속성을 사용하여 이를 설정할 수 있습니다. 자세한 내용은 부록 B. 주소 설정 구성 요소의 내용을 참조하십시오.보안 설정
기존 허용자에 대한 SSL/TLS 키 저장소 및 truststores를 다시 로드하여 기존 클라이언트에 영향을 주지 않고 새 인증서를 설정할 수 있습니다. 인증서가 오래되었거나 다른 경우에도 연결된 클라이언트는 계속해서 메시지를 보내고 받을 수 있습니다.
diverts
구성을 다시 로드하면 새로 추가된 항목이 배포됩니다. 그러나 구성이나 <
divert> 요소 내의 하위 요소에 대한 변경 사항은 브로커를 다시 시작할 때까지 적용되지 않습니다.
다음 절차에서는 브로커가 broker.xml 구성 파일의 변경 사항을 확인하는 간격을 변경하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core> 요소 내에서 <configuration-file-refresh-period> 요소를 추가하고 새로 고침 기간(밀리초)을 설정합니다.이 예에서는 구성 새로 고침 기간을 60000밀리초로 설정합니다.
<configuration> <core> ... <configuration-file-refresh-period>60000</configuration-file-refresh-period> ... </core> </configuration>
1.4. 브로커 구성 파일 모듈화
공통 구성 설정을 공유하는 여러 브로커가 있는 경우 공통 구성을 별도의 파일에 정의한 다음 이러한 파일을 각 브로커의 broker.xml 구성 파일에 포함할 수 있습니다.
브로커 간에 공유할 수 있는 가장 일반적인 구성 설정은 다음과 같습니다.
- addresses
- 주소 설정
- 보안 설정
절차
공유하려는 각
broker.xml섹션에 대해 별도의 XML 파일을 생성합니다.각 XML 파일은
broker.xml의 단일 섹션만 포함할 수 있습니다(예: 주소 또는 주소 설정 중 하나, 둘 다는 제외). 최상위 요소도 요소 네임스페이스(xmlns="urn:SecurityGroup:core")를정의해야 합니다.이 예에서는
my-security-settings.xml에 정의된 보안 설정 구성을 보여줍니다.my-security-settings.xml
<security-settings xmlns="urn:activemq:core"> <security-setting match="a1"> <permission type="createNonDurableQueue" roles="a1.1"/> </security-setting> <security-setting match="a2"> <permission type="deleteNonDurableQueue" roles="a2.1"/> </security-setting> </security-settings>-
공통 구성 설정을 사용해야 하는 각 브로커에 대해 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 연 각
broker.xml파일에 대해 다음을 수행하십시오.broker.xml의 시작 부분에 있는 <configuration> 요소에서 다음 행이 표시되는지 확인합니다.xmlns:xi="http://www.w3.org/2001/XInclude"
공유 구성 설정을 포함하는 각 XML 파일에 대해 XML 포함을 추가합니다.
이 예제에는
my-security-settings.xml파일이 포함되어 있습니다.broker.xml
<configuration ...> <core ...> ... <xi:include href="/opt/my-broker-config/my-security-settings.xml"/> ... </core> </configuration>필요한 경우
broker.xml의 유효성을 검사하여 XML이 스키마에 대해 유효한지 확인합니다.XML 유효성 검사 프로그램을 사용할 수 있습니다. 이 예제에서는
xmllint를 사용하여artemis-server.xsl스키마에 대해broker.xml의 유효성을 검사합니다.$ xmllint --noout --xinclude --schema /opt/redhat/amq-broker/amq-broker-7.2.0/schema/artemis-server.xsd /var/opt/amq-broker/mybroker/etc/broker.xml /var/opt/amq-broker/mybroker/etc/broker.xml validates
추가 리소스
- XML 포함(X includession)에 대한 자세한 내용은 https://www.w3.org/TR/xinclude/ 에서 참조하십시오.
1.4.1. 모듈식 구성 파일 다시 로드
브로커가 주기적으로 구성 변경 사항(config -file-refresh-period에 의해 지정된 빈도에 따라)을 확인하는 경우 xi:include 를 통해 broker.xml 구성 파일에 포함된 구성 파일의 변경 사항을 자동으로 탐지 하지 않습니다. 예를 들어 broker.xml 에 my-address-settings.xml 이 포함되어 있고 my-address-settings.xml 을 구성 변경하는 경우 브로커는 my-address-settings.xml 의 변경 사항을 자동으로 탐지하고 설정을 다시 로드하지 않습니다.
broker.xml 구성 파일과 여기에 포함된 수정된 구성 파일을 강제 로 다시 로드하려면 broker.xml 구성 파일의 "최근 수정" 시간 스탬프가 변경되었는지 확인해야 합니다. 표준 Linux touch 명령을 사용하여 broker.xml 의 last-modified 타임 스탬프를 다른 변경없이 업데이트할 수 있습니다. 예를 들면 다음과 같습니다.
$ touch -m <broker-instance-dir>/etc/broker.xml1.5. 문서 규칙
이 문서에서는 sudo 명령 및 파일 경로에 대해 다음 규칙을 사용합니다.
sudo 명령
이 문서에서는 root 권한이 필요한 모든 명령에 sudo 가 사용됩니다. 모든 변경 사항이 전체 시스템에 영향을 미칠 수 있으므로 sudo 를 사용할 때는 항상 주의해야 합니다.
sudo 사용에 대한 자세한 내용은 The sudo Command 을 참조하십시오.
이 문서의 파일 경로 사용 정보
이 문서에서는 모든 파일 경로가 Linux, UNIX 및 유사한 운영 체제(예: /home/...)에 유효합니다. Microsoft Windows를 사용하는 경우 동등한 Microsoft Windows 경로(예: C:\Users\...)를 사용해야 합니다.
2장. 네트워크 연결: 수락자 및 커넥터
AMQ Broker에 사용되는 연결에는 네트워크와 In-VM이라는 두 가지 유형의 연결이 있습니다. 네트워크 연결은 동일한 서버 또는 물리적으로 원격에 관계없이 두 당사자가 서로 다른 가상 머신에 있는 경우 사용됩니다. In-VM 연결은 애플리케이션 또는 서버가 브로커와 동일한 가상 머신에 있을 때 클라이언트가 사용됩니다.
네트워크 연결은 Netty를 사용합니다. Netty 는 Java IO 또는 NIO, TCP 소켓, SSL/TLS, HTTP 또는 HTTPS를 통한 터널링과 같은 여러 가지 방법으로 네트워크 연결을 구성할 수 있는 고성능 저급 네트워크 라이브러리입니다. Netty는 또한 모든 메시징 프로토콜에 대해 단일 포트를 사용할 수 있습니다. 브로커는 사용되는 프로토콜을 자동으로 감지하고 추가 처리를 위해 들어오는 메시지를 적절한 처리기로 보냅니다.
네트워크 연결 구성 내의 URI는 해당 유형을 결정합니다. 예를 들어 URI에서 vm 를 사용하면 In-VM 연결이 생성됩니다. 아래 예에서 acceptor 의 URI는 vm 로 시작합니다.
<acceptor name="in-vm-example">vm://0</acceptor>
URI에서 tcp 를 사용하면 네트워크 연결이 생성됩니다.
<acceptor name="network-example">tcp://localhost:61617</acceptor>
이 장에서는 먼저 네트워크 연결인 Acceptors 및 Connectors와 관련된 두 가지 구성 요소에 대해 설명합니다. 다음으로 TCP, HTTP 및 SSL/TLS 네트워크 연결과 In-VM 연결에 대한 구성 단계가 설명되어 있습니다.
2.1. 승인자 정보
AMQ Broker에서 네트워크 연결을 논의할 때 가장 중요한 개념 중 하나는 수락자입니다. 수락자는 브로커에 대한 연결 방식을 정의합니다. 다음은 구성 파일 BROKER_INSTANCE_DIR/etc/broker.xml 내에 있을 수 있는 수용 자 의 일반적인 구성입니다.
<acceptors> <acceptor name="example-acceptor">tcp://localhost:61617</acceptor> </acceptors>
각 수락자는 허용 자 요소 내에서 그룹화됩니다. 서버당 나열할 수 있는 수락자 수에 대한 상한 제한은 없습니다.
수락자 구성
허용 자로 정의된 URI의 쿼리 문자열에 키-값 쌍을 추가하여 허용 자를 구성합니다. 세미콜론(';')을 사용하여 다음 예제와 같이 여러 키-값 쌍을 구분합니다. sslEnabled=true 로 시작하여 URI 끝에 여러 키-값 쌍을 추가하여 SSL/TLS에 대한 허용자를 구성합니다.
<acceptor name="example-acceptor">tcp://localhost:61617?sslEnabled=true;key-store-path=/path</acceptor>
커넥터 구성 매개변수에 대한 자세한 내용은 Acceptor and Connector Configuration Parameters 를 참조하십시오.
2.2. 커넥터 정보
수락자는 서버가 연결을 수락하는 방법을 정의하는 반면, 클라이언트는 커넥터 를 사용하여 서버에 연결하는 방법을 정의합니다.
다음은 BROKER_INSTANCE_DIR/etc/broker.xml 구성 파일에 정의된 일반적인 커넥터 입니다.
<connectors> <connector name="example-connector">tcp://localhost:61617</connector> </connectors>
커넥터는 커넥터 요소 내에서 정의됩니다. 서버당 커넥터 수에 대한 상한 제한은 없습니다.
클라이언트에서 커넥터를 사용하지만 수락자와 마찬가지로 서버에서 구성됩니다. 다음과 같은 몇 가지 중요한 이유가 있습니다.
- 서버 자체는 클라이언트 역할을 할 수 있으므로 다른 서버에 연결하는 방법을 알아야 합니다. 예를 들어 한 서버가 다른 서버로 연결되거나 서버가 클러스터에 참여하면 됩니다.
- 서버는 JMS 클라이언트가 연결 팩토리 인스턴스를 검색하는 데 자주 사용됩니다. 이러한 경우 JNDI는 클라이언트 연결을 생성하는 데 사용되는 연결 팩토리의 세부 정보를 알아야 합니다. JNDI 조회가 수행될 때 클라이언트에 정보가 제공됩니다. 자세한 내용은 Configuring a Connection on the Client Side 를 참조하십시오.
커넥터 구성
어셉터와 마찬가지로 커넥터는 해당 URI의 쿼리 문자열에 해당 구성이 연결되어 있습니다. 다음은 tcpNoDelay 매개변수가 false 로 설정된 커넥터 의 예입니다. 이 커넥터는 이 연결에 대한 Nagle 알고리즘을 비활성화합니다.
<connector name="example-connector">tcp://localhost:61616?tcpNoDelay=false</connector>
커넥터 구성 매개변수에 대한 자세한 내용은 Acceptor and Connector Configuration Parameters 를 참조하십시오.
2.3. TCP 연결 구성
AMQ Broker는 Netty를 사용하여 차단 Java IO 또는 최신 비 차단 Java NIO를 사용하도록 구성할 수 있는 기본, 암호화되지 않은 TCP 기반 연결을 제공합니다. Java NIO는 여러 동시 연결로 더 나은 확장성을 위해 선호됩니다. 그러나 이전 IO를 사용하면 수천 개의 동시 연결을 지원하는 것에 대한 걱정이 줄어들 때 NIO보다 더 나은 대기 시간을 제공할 수 있습니다.
신뢰할 수 없는 네트워크에서 연결을 실행하는 경우 TCP 네트워크 연결이 암호화되지 않은 것을 기억하십시오. 암호화가 우선 순위인 경우 SSL 또는 HTTPS 구성을 사용하여 이 연결을 통해 전송된 메시지를 암호화하는 것이 좋습니다. 자세한 내용은 5.1절. “연결 보안” 을 참조하십시오. TCP 연결을 사용하면 클라이언트 측에서 모든 연결이 시작됩니다. 즉, 서버는 클라이언트에 대한 연결을 시작하지 않으며, 이는 한 방향에서 강제로 연결을 시작하도록 하는 방화벽 정책과 잘 작동합니다.
TCP 연결의 경우 커넥터 URI의 호스트 및 포트는 연결에 사용되는 주소를 정의합니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
연결을 추가하거나 수정하고
tcp를 프로토콜로 사용하는 URI를 포함합니다. IP 또는 호스트 이름 및 포트를 모두 포함해야 합니다.
아래 예제에서 acceptor 는 TCP 연결로 구성됩니다. 이 허용 자로 구성된 브로커는 IP 10.10.10.1 및 포트 61617 에 대한 TCP 연결을 수행하는 클라이언트를 허용합니다.
<acceptors> <acceptor name="tcp-acceptor">tcp://10.10.10.1:61617</acceptor> ... </acceptors>
거의 동일한 방식으로 TCP를 사용하도록 커넥터를 구성합니다.
<connectors> <connector name="tcp-connector">tcp://10.10.10.2:61617</connector> ... </connectors>
위의 커넥터 는 지정된 IP 및 포트 10.10.10.2:61617 에 TCP 연결을 할 때 클라이언트 또는 브로커 자체에서 참조합니다.
TCP 연결에 사용 가능한 구성 매개변수에 대한 자세한 내용은 Acceptor and Connector Configuration Parameters 를 참조하십시오. 대부분의 매개변수는 어셉터 또는 커넥터와 함께 사용할 수 있지만 일부 매개변수는 수락자에서만 사용할 수 있습니다.
2.4. HTTP 연결 구성
HTTP 연결 터널은 HTTP 프로토콜을 통해 패킷을 터널링하며 방화벽이 HTTP 트래픽만 허용하는 시나리오에서 유용합니다. AMQ Broker는 단일 포트 지원을 통해 HTTP가 사용되는지 자동으로 감지하므로 HTTP에 대한 네트워크 연결 구성은 TCP에 대한 연결을 구성하는 것과 동일합니다. HTTP 사용 방법을 보여주는 전체 작업 예제는INSTA LL_DIR /examples/features/standard/.에 있는 http-transport 예제를 참조하십시오.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
연결을 추가하거나 수정하고
tcp를 프로토콜로 사용하는 URI를 포함합니다. IP 또는 호스트 이름 및 포트를 모두 포함해야 합니다.
아래 예제에서 브로커는 IP 주소 10.10.10.1 에서 포트 80 에 연결된 클라이언트로부터 HTTP 통신을 허용합니다. 또한 브로커는 HTTP 프로토콜이 사용 중인지 자동으로 감지하며 그에 따라 클라이언트와 통신합니다.
<acceptors> <acceptor name="http-acceptor">tcp://10.10.10.1:80</acceptor> ... </acceptors>
HTTP용 커넥터 구성은 다시 TCP와 동일합니다.
<connectors> <connector name="http-connector">tcp://10.10.10.2:80</connector> ... </connectors>
위의 예에 있는 구성을 사용하여 브로커는 IP 주소 10.10.10.2에서 포트 80 에 대한 아웃바운드 HTTP 연결을 생성합니다.
HTTP 연결에서는 TCP와 동일한 구성 매개 변수를 사용하지만 자체 매개 변수도 있습니다. HTTP 관련 및 기타 구성 매개변수에 대한 자세한 내용은 Acceptor and Connector Configuration Parameters 를 참조하십시오.
2.5. SSL/TLS 연결 구성
SSL/TLS를 사용하도록 연결을 구성할 수도 있습니다. 자세한 내용은 5.1절. “연결 보안” 을 참조하십시오.
2.6. VM 내 연결 구성
예를 들어 고가용성 솔루션의 일부로 여러 브로커가 동일한 가상 머신에 있는 경우 In-VM 연결을 사용할 수 있습니다. VM 내 연결은 서버와 동일한 JVM에서 실행되는 로컬 클라이언트에서도 사용할 수 있습니다. VM 내 연결의 경우 URI의 권한 부분은 고유한 서버 ID를 정의합니다. 실제로 URI의 다른 부분은 필요하지 않습니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
연결을 추가하거나 수정하고
vm를 프로토콜로 사용하는 URI를 포함합니다.
<acceptors> <acceptor name="in-vm-acceptor">vm://0</acceptor> ... </acceptors>
위의 허용 자는 브로커에게 ID가 0 인 서버의 연결을 수락하도록 지시합니다. 다른 서버는 브로커와 동일한 가상 머신에서 실행 중이어야 합니다.
in-vm 연결로 커넥터를 구성하는 작업은 동일한 구문을 따릅니다.
<connectors> <connector name="in-vm-connector">vm://0</connector> ... </connectors>
위의 예에서 커넥터 는 클라이언트가 동일한 가상 머신에 있는 ID가 0 인 서버에 대한 VM 연결을 설정하는 방법을 정의합니다. 클라이언트는 애플리케이션 또는 브로커일 수 있습니다.
2.7. 클라이언트 Side에서 연결 구성
커넥터는 클라이언트 응용 프로그램에서 간접적으로 사용됩니다. 서버 측에서 커넥터 를 정의하지 않고도 클라이언트 쪽에서 JMS 연결 팩토리를 직접 구성할 수 있습니다.
Map<String, Object> connectionParams = new HashMap<String, Object>();
connectionParams.put(org.apache.activemq.artemis.core.remoting.impl.netty.TransportConstants.PORT_PROP_NAME, 61617);
TransportConfiguration transportConfiguration =
new TransportConfiguration(
"org.apache.activemq.artemis.core.remoting.impl.netty.NettyConnectorFactory", connectionParams);
ConnectionFactory connectionFactory = ActiveMQJMSClient.createConnectionFactoryWithoutHA(JMSFactoryType.CF, transportConfiguration);
Connection jmsConnection = connectionFactory.createConnection();3장. 네트워크 연결: 프로토콜
AMQ Broker에는 플러그형 프로토콜 아키텍처가 있으므로 네트워크 연결을 위해 하나 이상의 프로토콜을 쉽게 활성화할 수 있습니다.
브로커는 다음 프로토콜을 지원합니다.
위의 프로토콜 외에도 브로커는 "Core Protocol"으로 알려진 자체 네이티브 프로토콜을 지원합니다. 이전 버전의 이 프로토콜을 "HornetQ"라고 하며 Red Hat JBoss Enterprise Application Platform에서 사용되었습니다.
3.1. 프로토콜을 사용하도록 네트워크 연결 구성
프로토콜을 사용하기 전에 네트워크 연결과 연결해야 합니다. 네트워크 연결: 네트워크 연결을 만들고 구성하는 방법에 대한 자세한 내용은 Acceptors 및 Connectors 를 참조하십시오. BROKER_INSTANCE_DIR/etc/broker.xml 파일에 이미 정의된 몇 가지 연결이 포함되어 있습니다. 편의를 위해 AMQ Broker에는 지원되는 각 프로토콜에 대한 허용자와 모든 프로토콜을 지원하는 기본 허용자가 포함됩니다.
기본 허용자 개요
다음은 broker.xml 구성 파일에 기본적으로 포함된 수락자입니다.
<configuration>
<core>
...
<acceptors>
<!-- All-protocols acceptor -->
<acceptor name="artemis">tcp://0.0.0.0:61616?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=CORE,AMQP,STOMP,HORNETQ,MQTT,OPENWIRE;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- AMQP Acceptor. Listens on default AMQP port for AMQP traffic -->
<acceptor name="amqp">tcp://0.0.0.0:5672?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=AMQP;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor>
<!-- STOMP Acceptor -->
<acceptor name="stomp">tcp://0.0.0.0:61613?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=STOMP;useEpoll=true</acceptor>
<!-- HornetQ Compatibility Acceptor. Enables HornetQ Core and STOMP for legacy HornetQ clients. -->
<acceptor name="hornetq">tcp://0.0.0.0:5445?anycastPrefix=jms.queue.;multicastPrefix=jms.topic.;protocols=HORNETQ,STOMP;useEpoll=true</acceptor>
<!-- MQTT Acceptor -->
<acceptor name="mqtt">tcp://0.0.0.0:1883?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=MQTT;useEpoll=true</acceptor>
</acceptors>
...
</core>
</configuration>
지정된 네트워크 연결에서 프로토콜을 활성화하는 유일한 요구 사항은 수락자의 URI에 protocols 매개변수를 추가하는 것입니다. 매개 변수의 값은 쉼표로 구분된 프로토콜 이름 목록이어야 합니다. protocol 매개 변수가 URI에서 생략되면 모든 프로토콜이 활성화됩니다.
예를 들어 AMQP 프로토콜을 사용하여 포트 3232에서 메시지를 수신하는 수락자를 생성하려면 다음 단계를 따르십시오.
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
<
acceptors> 스탠자에 다음 행을추가합니다.
<acceptor name="ampq">tcp://0.0.0.0:3232?protocols=AMQP</acceptor>
기본 허용자의 추가 매개변수
최소 허용자 구성에서 프로토콜을 연결 URI의 일부로 지정합니다. 그러나 broker.xml 구성 파일의 기본 허용 항목에는 몇 가지 추가 매개 변수가 구성되어 있습니다. 다음 표에서는 기본 허용자에 대해 구성된 추가 매개 변수를 자세히 설명합니다.
| 수락자(s) | 매개변수 | 설명 |
|---|---|---|
| all-protocols acceptor AMQP STOMP | tcpSendBufferSize |
TCP 전송 버퍼의 크기(바이트)입니다. 기본값은 32768 |
| tcpReceiveBufferSize |
TCP 수신 버퍼의 크기(바이트)입니다. 기본값은 32768 TCP 버퍼 크기는 네트워크의 대역폭 및 대기 시간에 따라 조정되어야 합니다. 요약하면 TCP 전송/받기 버퍼 크기는 다음과 같이 계산되어야 합니다. buffer_size = bandwidth * RTT.
대역폭이 초당 바이트 단위이고 네트워크 왕복 시간(RTT)은 초 단위입니다. RTT는 빠른 네트워크의 경우 버퍼 크기를 기본값에서 늘릴 수 있습니다. | |
| all-protocols acceptor AMQP STOMP HornetQ MQTT | useEpoll |
지원하는 시스템(Linux)을 사용하는 경우 Netty epoll을 사용하십시오. Netty 네이티브 전송은 NIO 전송보다 더 나은 성능을 제공합니다. 이 옵션의 기본값은 |
| all-protocols acceptor AMQP | amqpCredits |
총 메시지 크기에 관계없이 AMQP 생산자가 보낼 수 있는 최대 메시지 수입니다. 기본값은 AMQP 메시지 흐름을 제어하는 데 크레딧을 사용하는 방법에 대한 자세한 내용은 10.2.3절. “AMQP 메시지 차단” 을 참조하십시오. |
| all-protocols acceptor AMQP | amqpLowCredits |
브로커가 생산자 크레딧을 보충하는 임계값을 줄입니다. 기본값은 AMQP 메시지 흐름을 제어하는 데 크레딧을 사용하는 방법에 대한 자세한 내용은 10.2.3절. “AMQP 메시지 차단” 을 참조하십시오. |
| HornetQ 호환성 수락기 | anycastPrefix |
클라이언트가 주소에 연결할 때 클라이언트가 라우팅 유형을 지정할 수 있도록 접두사를 구성하는 방법에 대한 자세한 내용은 4.6절. “수락자 구성에 라우팅 유형 추가” 을 참조하십시오. |
| multicastPrefix |
클라이언트가 주소에 연결할 때 클라이언트가 라우팅 유형을 지정할 수 있도록 접두사를 구성하는 방법에 대한 자세한 내용은 4.6절. “수락자 구성에 라우팅 유형 추가” 을 참조하십시오. |
추가 리소스
- Netty 네트워크 연결에 구성할 수 있는 다른 매개변수에 대한 자세한 내용은 부록 A. 수락 및 커넥터 구성 매개 변수 을 참조하십시오.
3.2. 네트워크 연결에서 AMQP 사용
브로커는 AMQP 1.0 사양을 지원합니다. AMQP 링크는 소스와 대상(즉, 클라이언트 및 브로커) 간의 메시지의 단방향 프로토콜입니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
다음 예와 같이 AMQP 값이 AMQP를 포함하는
protocols매개 변수를 포함하여AMQP클라이언트를 수신하도록수락자를 추가하거나구성합니다.
<acceptors> <acceptor name="amqp-acceptor">tcp://localhost:5672?protocols=AMQP</acceptor> ... </acceptors>
이전 예에서 브로커는 기본 AMQP 포트인 포트 5672에서 AMQP 1.0 클라이언트를 허용합니다.
AMQP 링크에는 두 개의 엔드포인트, 즉 발신자와 수신자가 있습니다. 발신자가 메시지를 전송할 때 브로커가 내부 형식으로 변환하여 브로커의 대상으로 전달할 수 있습니다. 수신자는 브로커의 대상에 연결하고 메시지를 전달하기 전에 AMQP로 다시 변환합니다.
AMQP 링크가 동적인 경우 임시 대기열이 생성되고 원격 소스 또는 원격 대상 주소가 임시 대기열의 이름으로 설정됩니다. 링크가 동적이지 않으면 큐에 원격 대상 또는 소스의 주소가 사용됩니다. 원격 대상 또는 소스가 없는 경우 예외가 전송됩니다.If the remote target or source does not exist, an exception is sent.
링크 대상은 기본 세션을 트랜잭션으로 처리하는 데 사용되는 Coordinator일 수도 있으며 이를 롤백하거나 커밋할 수도 있습니다.A link target can also be a Coordinator, which is used to handle the underlying session as a transaction, either rolling it back or commit it.
AMQP를 사용하면 세션당 여러 트랜잭션을 사용할 수 있습니다. amq p:multi-txns-per-sn. 하지만 현재 AMQ Broker 버전은 세션당 단일 트랜잭션만 지원합니다.
AMQP 내의 XA(Distributed transactions)에 대한 세부 정보는 사양 1.0 버전에서 제공되지 않습니다. 환경에 분산 트랜잭션 지원이 필요한 경우 AMQ Core Protocol JMS를 사용하는 것이 좋습니다.
프로토콜 및 해당 기능에 대한 자세한 내용은 AMQP 1.0 사양을 참조하십시오.
3.2.1. AMQP 링크를 주제로 사용
JMS와 달리 AMQP 프로토콜에는 주제가 포함되어 있지 않습니다. 그러나 큐에서 소비자만 사용하는 것이 아니라 AMQP 소비자 또는 수신자를 서브스크립션으로 처리할 수 있습니다. 기본적으로 Default .topic. 접두사를 사용하여 주소에 연결되는 모든 수신 링크는 서브스크립션으로 처리되며 서브스크립션 큐가 생성됩니다. 서브스크립션 큐는 다음 표에 캡처된 대로 Terminus Durability가 어떻게 구성되는지에 따라 내구성 또는 휘발성 또는 휘발성으로 이루어집니다.
| 멀티 캐스트 전용 queue...에 대한 이러한 종류의 서브스크립션을 만들려면 다음을 수행합니다. | Terminus 내구성을 이…로 설정합니다. |
|---|---|
| 내구성 |
|
| 구성할 수 없음 |
|
내구성이 있는 큐의 이름은 컨테이너 ID와 링크 이름(예: my-container-id:my-link-name )으로 구성됩니다.
AMQ Broker는 qpid-jms 클라이언트도 지원하며 주소에 사용되는 접두사와 관계없이 주제의 사용을 존중합니다.
3.2.2. AMQP 보안 구성
브로커는 AMQP SASL 인증을 지원합니다. 브로커에서 SASL 기반 인증을 구성하는 방법에 대한 자세한 내용은 보안 을 참조하십시오.
3.3. 네트워크 연결에서 MQTT 사용
브로커는 MQTT v3.1.1 (및 이전 v3.1 코드 메시지 형식)을 지원합니다. MQTT는 서버 간 경량 클라이언트, 게시/구독 메시징 프로토콜입니다. MQTT는 메시징 오버헤드 및 네트워크 트래픽과 클라이언트의 코드 풋프린트를 줄입니다. 이러한 이유로 MQTT는 센서 및 액추에이터와 같은 제한된 장치에 적합하며 IoT(사물 인터넷)의 팩트 표준 통신 프로토콜이 빠르게 증가하고 있습니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. - MQTT 프로토콜을 활성화된 상태로 허용자를 추가합니다. 예를 들면 다음과 같습니다.
<acceptors> <acceptor name="mqtt">tcp://localhost:1883?protocols=MQTT</acceptor> ... </acceptors>
MQTT는 다음과 같은 몇 가지 유용한 기능과 함께 제공됩니다.
- 서비스 품질
- 각 메시지는 연결된 서비스 품질을 정의할 수 있습니다. 브로커는 가장 높은 수준의 서비스 수준에서 구독자에게 메시지를 전달하려고 시도합니다.
- 보존 메시지
- 메시지는 특정 주소에 대해 유지될 수 있습니다. 해당 주소에 대한 새 구독자는 고객이 연결되기 전에 보관된 메시지가 전송되어도 다른 메시지보다 먼저 남은 보존 메시지를 수신합니다.
- 와일드카드 서브스크립션
- MQTT 주소는 파일 시스템의 계층 구조와 유사한 계층 구조입니다. 클라이언트는 특정 주제 또는 계층 구조의 전체 분기를 구독할 수 있습니다.
- 자주 묻는 질문
- 클라이언트는 연결 패킷의 일부로 "위처 메시지"를 설정할 수 있습니다. 클라이언트가 비정상적으로 연결이 끊어지면 브로커는 해당 메시지를 지정된 주소에 게시합니다. 다른 구독자는 will 메시지를 수신하고 그에 따라 대응할 수 있습니다.
MQTT 프로토콜에 대한 정보의 가장 좋은 출처는 사양에 있습니다. MQTT v3.1.1 사양은 OASIS 웹 사이트에서 다운로드할 수 있습니다.
3.4. 네트워크 연결로 OpenWire 사용
브로커는 JMS 클라이언트가 브로커와 직접 통신할 수 있는 OpenWire 프로토콜 을 지원합니다. 이 프로토콜을 사용하여 이전 버전의 AMQ Broker와 통신할 수 있습니다.
현재 AMQ Broker는 표준 JMS API만 사용하는 OpenWire 클라이언트를 지원합니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. 다음 예제와
같이 allowor를 추가하여OPENWIRE를protocol매개변수의 일부로 포함하도록 합니다.<acceptors> <acceptor name="openwire-acceptor">tcp://localhost:61616?protocols=OPENWIRE</acceptor> ... </acceptors>
이전 예에서 브로커는 수신 OpenWire 명령을 포트 61616에서 수신합니다.
자세한 내용은INSTA LL_DIR /examples/protocols/openwire에 있는 예제를 참조하십시오.
3.5. 네트워크 연결에서 STOMP 사용
STOMP 는 STOMP 클라이언트가 STOMP 브로커와 통신할 수 있도록 하는 텍스트 지향적인 전선 프로토콜입니다. 브로커는 STOMP 1.0, 1.1 및 1.2를 지원합니다. STOMP 클라이언트는 여러 언어와 플랫폼에서 사용할 수 있으므로 상호 운용성을 위해 좋은 선택이 될 수 있습니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
기존
수락자를 구성하거나새 허용자를 생성하고 아래와 같이STOMP값을 사용하여protocols매개변수를 포함합니다.
<acceptors> <acceptor name="stomp-acceptor">tcp://localhost:61613?protocols=STOMP</acceptor> ... </acceptors>
이전 예에서 브로커는 기본값인 61613 포트에서 STOMP 연결을 허용합니다.
STOMP를 사용하여 브로커를 구성하는 방법의 예는INSTA LL_DIR /examples/protocols에 있는 stomp 예제를 참조하십시오.
3.5.1. STOMP를 사용할 때 제한 사항 이해
STOMP를 사용할 때 다음과 같은 제한 사항이 적용됩니다.
-
브로커는 현재 가상 호스팅을 지원하지 않으므로
CONNECT프레임의호스트헤더가 무시됩니다. -
메시지 확인은 트랜잭션이 아닙니다.
ACK프레임은 트랜잭션의 일부가 될 수 없으며 트랜잭션 헤더가 설정되면 무시됩니다.The ACK frame cannot be part of a transaction, and it is ignored if itstransactionheader is set.
3.5.2. STOMP 메시지 ID 제공
JMS 소비자 또는 QueueBrowser를 통해 STOMP 메시지를 수신할 때 메시지에는 기본적으로 JMS 속성(예: JMSMessageID )이 포함되어 있지 않습니다. 그러나 브로커 paramater를 사용하여 들어오는 각 STOMP 메시지에 메시지 ID를 설정할 수 있습니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
다음 예와 같이 STOMP 연결에 사용되는
수락자에대해stompEnableMessageId매개변수를true로 설정합니다.
<acceptors> <acceptor name="stomp-acceptor">tcp://localhost:61613?protocols=STOMP;stompEnableMessageId=true</acceptor> ... </acceptors>
stompEnableMessageId 매개변수를 사용하면 이 수락자를 사용하여 전송된 각 STOMP 메시지에 추가 속성이 추가됩니다. property 키는mq -message-id 이고 값은 다음 예와 같이 “STOMP” 접두사가 있는 내부 메시지 ID의 문자열 표현입니다.
amq-message-id : STOMP12345
stompEnableMessageId 가 구성에 지정되지 않은 경우 기본값은 false 입니다.
3.5.3. 연결의 TTL(Time to Live) 설정
STOMP 클라이언트는 연결을 종료하기 전에 DISCONNECT 프레임을 보내야 합니다. 이를 통해 브로커는 세션 및 소비자와 같은 서버 측 리소스를 닫을 수 있습니다. 그러나 STOMP 클라이언트가 DISCONNECT 프레임을 전송하지 않고 종료하거나 실패하는 경우 브로커는 클라이언트가 여전히 활성화되어 있는지 여부를 즉시 알 수 없습니다. 따라서 STOMP 연결은 1분의 "Time to Live"(TTL)이 되도록 구성됩니다. 브로커는 STOMP 클라이언트에 대한 연결을 1분 이상 유휴 상태인 경우 해당 클라이언트에 대한 연결을 중지합니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
다음 예와 같이 STOMP 연결에 사용되는
수락자의 URI에connectionTTL매개변수를 추가합니다.
<acceptors> <acceptor name="stomp-acceptor">tcp://localhost:61613?protocols=STOMP;connectionTTL=20000</acceptor> ... </acceptors>
이전 예에서 stomp-acceptor 를 사용하는 모든 STOMP 연결은 TTL을 20초로 설정합니다.
STOMP 프로토콜의 버전 1.0에는 하트비트 프레임이 포함되어 있지 않습니다. 따라서 데이터가 connection-ttl 내에서 전송되는지 확인해야 합니다. 그렇지 않으면 브로커가 클라이언트가 종료된 것으로 가정하고 서버 측 리소스를 정리합니다. 버전 1.1을 사용하면 STOMP 연결의 라이프 사이클을 유지하기 위해 심장 박동을 사용할 수 있습니다.
브로커의 기본 시간 (TTL)을 덮어 씁니다.
앞에서 언급했듯이 STOMP 연결의 기본 TTL은 1분입니다. 브로커 구성에 connection-ttl-override 특성을 추가하여 이 값을 재정의할 수 있습니다.
절차
-
구성 파일
BROKER_INSTANCE_DIR/etc/broker.xml을 엽니다. -
connection-ttl-override특성을 추가하고 새 기본값에 대한 값(밀리초)을 제공합니다. 아래처럼 <core> 스탠자에 속합니다.
<configuration ...>
...
<core ...>
...
<connection-ttl-override>30000</connection-ttl-override>
...
</core>
<configuration>위 예제에서 STOMP 연결의 기본 TTL(Time to Live)은 30000밀리초로 설정됩니다.
3.5.4. JMS에서 STOMP 메시지 전송 및 사용
STOMP는 주로 텍스트 변환 프로토콜입니다. JMS와의 상호 작용을 더 쉽게 수행하기 위해 STOMP 구현에서는 콘텐츠 길이 헤더가 있는지 확인하여 STOMP 메시지를 JMS에 매핑하는 방법을 결정합니다.
| STOMP 메시지가 …에 매핑하려면 | 메시지는…이어야 합니다. |
|---|---|
| JMS TextMessage |
Content |
| JMS BytesMessage |
|
JMS 메시지를 STOMP에 매핑할 때 동일한 논리가 적용됩니다. STOMP 클라이언트는 콘텐츠 길이 헤더의 존재를 확인하여 메시지 본문(문자열 또는 바이트)의 유형을 결정할 수 있습니다.
메시지 헤더에 대한 자세한 내용은 STOMP 사양을 참조하십시오.
3.5.5. STOMP Destinations와 AMQ Broker Addresses and Queues 매핑
메시지를 보내고 구독할 때 STOMP 클라이언트에는 일반적으로 대상 헤더가 포함됩니다. 대상 이름은 문자열 값으로, 브로커의 대상에 매핑됩니다. AMQ Broker에서 이러한 대상은 주소 및 큐에 매핑됩니다. 대상 프레임에 대한 자세한 내용은 STOMP 사양을 참조하십시오.
예를 들어 다음 메시지(headers 및 본문 포함)를 전송하는 STOMP 클라이언트를 사용합니다.
SEND destination:/my/stomp/queue hello queue a ^@
이 경우 브로커는 해당 메시지를 /my/stomp/queue 주소와 연결된 모든 큐에 전달합니다.
예를 들어 STOMP 클라이언트가 SEND 프레임을 사용하여 메시지를 보내면 지정된 대상이 주소에 매핑됩니다.
클라이언트가 SUBSCRIBE 또는 UNSUBSCRIBE 프레임을 전송하는 것과 동일한 방식으로 작동하지만 이 경우 AMQ Broker는 대상 을 큐에 매핑합니다.
SUBSCRIBE destination: /other/stomp/queue ack: client ^@
이전 예에서 브로커는 대상 을 /other/stomp/queue 에 매핑합니다.
STOMP Destinations to JMS Destinations
JMS 대상은 브로커 주소 및 큐에도 매핑됩니다. STOMP를 사용하여 메시지를 JMS 대상으로 보내려면 STOMP 대상은 동일한 규칙을 따라야 합니다.
대기열 이름 앞에
jms.queue.를 추가하여 JMS Queue 에 전송하거나 구독하십시오. 예를 들어주문JMS Queue에 메시지를 보내려면 STOMP 클라이언트에서 프레임을 보내야 합니다.SEND destination:jms.queue.orders hello queue orders ^@
jms.topic.에서 주제 이름을 앞에 추가하여 JMS Topic 을 보내거나 구독합니다. 예를 들어, 주식 JMS 토픽에 가입하려면 STOMP 클라이언트에서 다음과 유사한 프레임을 보내야 합니다.SUBSCRIBE destination:jms.topic.stocks ^@
4장. 주소 및 대기열 구성
4.1. 주소, 큐 및 라우팅 유형
AMQ Broker의 주소 지정 모델에는 세 가지 주요 개념, 주소,큐, 라우팅 유형이 포함되어 있습니다.
주소 는 메시징 끝점을 나타냅니다. 구성 내에서 일반적인 주소에는 고유한 이름, 하나 이상의 큐, 라우팅 유형이 부여됩니다.
큐 는 주소와 연결되어 있습니다. 주소당 큐가 여러 개 있을 수 있습니다. 들어오는 메시지가 주소와 일치하면 구성된 라우팅 유형에 따라 메시지가 하나 이상의 큐로 전송됩니다. 큐는 자동으로 생성 및 삭제되도록 구성할 수 있습니다. 주소(및 관련 대기열)를 내구성이 있는 로서 구성할 수도 있습니다. 큐의 메시지가 영구적인 경우 큐의 메시지도 영구적으로 브로커의 충돌 또는 재시작을 유지할 수 있습니다. 대조적으로, 비내구성 대기열의 메시지는 메시지 자체가 지속되더라도 브로커의 충돌 또는 재시작 후에도 유지되지 않습니다.
라우팅 유형 은 주소와 연결된 큐로 메시지를 전송하는 방법을 결정합니다. AMQ Broker에서는 표에 표시된 대로 두 가지 라우팅 유형을 사용하여 주소를 구성할 수 있습니다.
| 메시지가…로 라우팅되도록 하려면 | 이 라우팅 type… 사용 |
|---|---|
| Point-to-point 방식으로 일치하는 주소 내의 단일 큐 |
|
| 게시-서브스크립션 방식으로 일치하는 주소 내의 모든 큐 |
|
주소에는 하나 이상의 정의된 라우팅 유형이 있어야 합니다.
주소당 두 개 이상의 라우팅 유형을 정의할 수 있지만 이는 권장되지 않습니다.
주소에 두 라우팅 유형이 모두 정의되어 있고 클라이언트에 둘 중 하나의 기본 설정이 표시되지 않는 경우 브로커는 기본적으로 멀티캐스트 라우팅 유형으로 설정됩니다.
추가 리소스
구성에 대한 자세한 내용은 다음을 참조하십시오.
-
anycast라우팅 유형을 사용하는 지점 간 메시징을 참조하십시오. 4.3절. “지점 간 메시징에 대한 주소 구성” -
멀티 캐스트라우팅 유형을 사용하는 게시-서브스크립션 메시징을 참조하십시오. 4.4절. “게시-구독 메시징에 대한 주소 구성”
-
4.1.1. 주소 및 대기열 이름 지정 요구사항
주소 및 큐를 구성할 때 다음 요구 사항에 유의하십시오.
클라이언트가 사용하는 유선 프로토콜에 관계없이 클라이언트가 큐에 연결할 수 있도록 하려면 주소와 큐 이름에 다음 문자를 포함하지 않아야 합니다.
&::,?>-
숫자 기호(
#) 및 별표(*) 문자는 와일드카드 표현용으로 예약되며 주소 및 큐 이름에 사용해서는 안 됩니다. 자세한 내용은 4.2.1절. “AMQ Broker 와일드카드 구문”의 내용을 참조하십시오. - 주소 및 큐 이름은 공백을 포함하지 않아야 합니다.
-
주소 또는 큐 이름에서 단어를 분리하려면 구성된 구분 기호 문자를 사용합니다. 기본 구분 기호 문자는 마침표(
.)입니다. 자세한 내용은 4.2.1절. “AMQ Broker 와일드카드 구문”의 내용을 참조하십시오.
4.2. 주소 세트에 주소 설정 적용
AMQ Broker에서는 일치하는 주소 이름을 나타내는 와일드카드 표현식을 사용하여 address-setting 요소에 지정된 구성을 주소 집합에 적용할 수 있습니다.
다음 섹션에서는 와일드카드 식을 사용하는 방법을 설명합니다.
4.2.1. AMQ Broker 와일드카드 구문
AMQ Broker는 주소 설정에서 와일드카드를 표시하는 데 특정 구문을 사용합니다. 보안 설정 및 소비자 생성 시 와일드카드를 사용할 수도 있습니다.
-
와일드카드 식에는 마침표(
.)로 구분된 단어가 포함되어 있습니다. 숫자 기호(
#) 및 별표(*) 문자는 다음과 같이 특별한 의미를 가지며 단어를 대신할 수 있습니다.- 숫자 기호는 "모든 0개 이상의 단어 시퀀스와 일치"을 의미합니다. 표현식의 끝에 사용합니다.
- 별표 문자는 "단일 단어와 일치"를 의미합니다. 표현식 내 어디에서나 사용할 수 있습니다.
일치는 문자에 따라 지정되지 않지만 각 구분 기호 경계에서 수행됩니다. 예를 들어 이름에 my 큐와 일치하도록 구성된 address-setting 요소는 라는 큐와 일치하지 않습니다.
my queue
address-setting 요소가 두 개 이상의 address-setting 요소가 주소와 일치하는 경우 브로커 오버레이 구성은 가장 적은 특정 일치를 기준으로 사용합니다. 리터럴 표현식은 와일드카드보다 더 구체적이며 별표(*)는 숫자 기호(#)보다 더 구체적입니다. 예를 들어 my.destination 과 my.* 모두 my.destination.destination 주소와 일치합니다. 이 경우 와일드카드 표현식은 리터럴보다 작기 때문에 브로커는 먼저 my.* 에 있는 구성을 적용합니다. 다음으로 브로커는 my.destination address 설정 요소의 구성을 오버레이하여 my.*.*로 공유하는 모든 구성을 덮어씁니다. 예를 들어 다음 구성에서 my.destination 과 연결된 큐에 max-delivery-attempts 가 3 으로 설정되고 last-value-queue 가 false 로 설정됩니다.
<address-setting match="my.*">
<max-delivery-attempts>3</max-delivery-attempts>
<last-value-queue>true</last-value-queue>
</address-setting>
<address-setting match="my.destination">
<last-value-queue>false</last-value-queue>
</address-setting>다음 표의 예제에서는 와일드카드를 사용하여 주소 집합과 일치하는 방법을 보여줍니다.
| 예제 | 설명 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
4.2.2. 브로커 와일드카드 구문 구성
다음 절차에서는 와일드카드 주소에 사용되는 구문을 사용자 지정하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 아래 예제
와 같이 <wildcard-addresses> 섹션을 구성에 추가합니다.<configuration> <core> ... <wildcard-addresses> // <enabled>true</enabled> // <delimiter>,</delimiter> // <any-words>@</any-words> // <single-word>$</single-word> </wildcard-addresses> ... </core> </configuration>enabled-
true로 설정하면 브로커에 사용자 지정 설정을 사용하도록 지시합니다. 구분 기호-
기본값 대신 구분자로 사용할 사용자 지정 문자를 제공합니다
.. any-words-
모든 단어의 값으로 제공되는 문자는 '가장
이상의 단어시퀀스와 일치'을 의미하는 데 사용되며 기본값#을 대체합니다. 표현식 끝에 이 문자를 사용합니다. single-word-
단일 단어의 값으로 제공되는 문자는 '단어일치'를 의미하는 데 사용되며 기본값*를 대체합니다. 표현 내의 어디에서나 이 문자를 사용하십시오.
4.3. 지점 간 메시징에 대한 주소 구성
점대점 메시징은 생산자가 보낸 메시지에 하나의 소비자만 있는 일반적인 시나리오입니다. AMQP 및 JMS 메시지 생산자 및 소비자는 예를 들어 지점 간 메시징 대기열을 사용할 수 있습니다. 주소와 연결된 큐가 지점 간 방식으로 메시지를 수신할 수 있도록 하려면 브로커 구성에서 지정된 주소 요소에 대한 모든cast 라우팅 유형을 정의합니다.
임의의 캐스트 를 사용하여 주소에서 메시지를 수신하면 브로커는 주소와 연결된 큐를 찾아서 메시지를 라우팅합니다. 그러면 소비자가 해당 대기열의 메시지 사용을 요청할 수 있습니다. 여러 사용자가 동일한 대기열에 연결하는 경우 소비자가 동일하게 처리할 수 있는 경우 메시지를 소비자 간에 균등하게 분배됩니다.
다음 그림은 점대점 메시징의 예를 보여줍니다.
4.3.1. 기본 지점 간 메시징 구성
다음 절차에서는 지점 간 메시징을 위해 단일 큐로 주소를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 주소의 선택한.큐요소 주위에임의의cast구성 요소를 래핑합니다address및queue요소의name속성 값이 모두 같은지 확인합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address name="my.anycast.destination"> <anycast> <queue name="my.anycast.destination"/> </anycast> </address> </core> </configuration>
4.3.2. 여러 큐에 대한 지점 간 메시징 구성
anycast 라우팅 유형을 사용하는 주소에 둘 이상의 큐를 정의할 수 있습니다. 브로커는 연결된 모든 큐에 걸쳐 모든 cast 주소로 전송된 메시지를 균등하게 배포합니다. 정규화된 대기열 이름(FQ N)을 지정하여 클라이언트를 특정 대기열에 연결할 수 있습니다. 둘 이상의 소비자가 동일한 대기열에 연결하는 경우 브로커는 소비자 간에 메시지를 균등하게 분배합니다.
다음 그림은 두 개의 대기열을 사용하는 지점 간 메시징의 예를 보여줍니다.
다음 절차에서는 여러 큐가 있는 주소에 대해 지점 간 메시징을 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address요소의큐요소 주위에모든cast구성 요소를 래핑합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address name="my.anycast.destination"> <anycast> <queue name="q1"/> <queue name="q2"/> </anycast> </address> </core> </configuration>
위에서 클러스터의 여러 브로커에 미러링된 것과 같은 구성이 있는 경우 클러스터는 생산자와 소비자에게 불투명한 방식으로 클러스터에서 지점 간 메시징을 로드할 수 있습니다. 정확한 동작은 메시지 로드 밸런싱 정책이 클러스터에 구성된 방법에 따라 달라집니다.
추가 리소스
다음에 대한 자세한 내용은 다음을 수행합니다.
- 정규화된 대기열 이름 지정은 4.9절. “정규화된 대기열 이름 지정” 을 참조하십시오.
- 브로커 클러스터에 대한 메시지 로드 밸런싱을 구성하는 방법은 16.1.1절. “브로커 클러스터에서 메시지 로드의 균형을 조정하는 방법” 을 참조하십시오.
4.4. 게시-구독 메시징에 대한 주소 구성
게시-구독 시나리오에서는 주소를 구독하는 모든 사용자에게 메시지가 전송됩니다. JMS 주제와 MQTT 서브스크립션은 게시-구독 메시징의 두 가지 예입니다. 주소와 연결된 큐가 게시-서브스크립션 방식으로 메시지를 수신하도록 하기 위해 브로커 구성에서 지정된 주소 요소에 대한 멀티캐스트 라우팅 유형을 정의합니다.
멀티캐스트 라우팅 유형이 있는 주소에서 메시지를 수신하면 브로커는 메시지 사본을 주소와 연결된 각 큐로 라우팅합니다. 복사 오버헤드를 줄이기 위해 각 대기열은 전체 사본이 아닌 메시지에 대한 참조 만 보냅니다.
다음 그림은 게시-구독 메시징의 예를 보여줍니다.
다음 절차에서는 게시-서브스크립션 메시징에 대한 주소를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 주소에 빈
멀티 캐스트구성 요소를 추가합니다.<configuration ...> <core ...> ... <address name="my.multicast.destination"> <multicast/> </address> </core> </configuration>(선택 사항) 주소에 하나 이상의
큐요소를 추가하고 해당 요소에멀티 캐스트요소를 래핑합니다. 브로커가 클라이언트가 요청한 각 구독에 대해 큐를 자동으로 생성하므로 이 단계는 일반적으로 필요하지 않습니다.<configuration ...> <core ...> ... <address name="my.multicast.destination"> <multicast> <queue name="client123.my.multicast.destination"/> <queue name="client456.my.multicast.destination"/> </multicast> </address> </core> </configuration>
4.5. 포인트-투-포인트 및 게시-구독 메시징에 대한 주소 구성
point-to-point 및 publish-subscribe 의미 체계를 모두 사용하여 주소를 구성할 수도 있습니다.
point-to-point 및 publish-subscribe 의미를 모두 사용하는 주소를 구성하는 것은 일반적으로 권장되지 않습니다. 그러나 orders 라는 JMS 대기열과 orders 라고도 하는 JMS 주제와 같은 경우 유용 할 수 있습니다. 서로 다른 라우팅 유형은 클라이언트 연결에 대해 주소가 구별되도록 합니다. 이 경우 JMS 대기열 생산자가 보낸 메시지는 anycast 라우팅 유형을 사용합니다. JMS 주제 생산자가 보낸 메시지에는 멀티캐스트 라우팅 유형이 사용됩니다. JMS 주제 소비자가 브로커에 연결하면 자체 서브스크립션 대기열에 연결됩니다. 그러나 JMS 대기열 소비자는 anycast 대기열에 연결됩니다.
다음 그림은 함께 사용되는 포인트 투 포인트 및 게시-구독 메시징의 예를 보여줍니다.
다음 절차에서는 지점 간 및 게시-서브스크립션 메시징에 대한 주소를 구성하는 방법을 보여줍니다.
이 시나리오의 동작은 사용 중인 프로토콜에 따라 다릅니다. JMS의 경우 주제와 큐 생산자와 소비자 간에 명확한 차이점이 있으므로 논리를 간단하게 만듭니다. AMQP와 같은 다른 프로토콜은 이러한 차이를 만들지 않습니다. AMQP를 통해 전송되는 메시지는 기본적으로 anycast 및 멀티 캐스트 가 모두 라우팅되며 소비자는 기본적으로 anycast 로 라우팅됩니다. 자세한 내용은 3장. 네트워크 연결: 프로토콜의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address요소의큐요소 주위에모든cast구성 요소를 래핑합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address name="orders"> <anycast> <queue name="orders"/> </anycast> </address> </core> </configuration>주소에 빈
멀티 캐스트구성 요소를 추가합니다.<configuration ...> <core ...> ... <address name="orders"> <anycast> <queue name="orders"/> </anycast> <multicast/> </address> </core> </configuration>참고일반적으로 브로커는 필요에 따라 서브스크립션 큐를 생성하므로
멀티캐스트요소 내에 특정 큐 요소를 나열할 필요가 없습니다.
4.6. 수락자 구성에 라우팅 유형 추가
일반적으로 anycast 및 멀티 캐스트를 모두 사용하는 주소에서 메시지를 수신하면 anycast 대기열 중 하나와 모든 멀티 캐스트 대기열 중 하나가 메시지 를 수신합니다. 그러나 클라이언트는 주소에 연결할 때 특수 접두사를 지정하여 anycast 또는 멀티 캐스트 를 사용하여 연결할지 여부를 지정할 수 있습니다. 접두사는 브로커 구성의 URL에 있는 anycastPrefix 및 multicastPrefix 매개 변수를 사용하여 지정하는 사용자 지정 값입니다.
다음 절차에서는 지정된 수락자의 접두사를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 수락자의 경우 임의의cast 접두사를 구성하려면 구성된 URL에
anycastPrefix<configuration ...> <core ...> ... <acceptors> <!-- Acceptor for every supported protocol --> <acceptor name="artemis">tcp://0.0.0.0:61616?protocols=AMQP;anycastPrefix=anycast://</acceptor> </acceptors> ... </core> </configuration>앞의 구성에 따라 acceptor는
anycast접두사에anycast://를 사용하도록 구성되어 있습니다. 클라이언트 코드는 클라이언트가 임의의cast 큐 중 하나에만 메시지를 보내야 하는 경우>/를 지정할 수 있습니다.anycast://<my.destination지정된 허용자의 경우
멀티캐스트접두사를 구성하려면 구성된 URL에multicastPrefix를 추가합니다. 사용자 정의 값을 설정합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <acceptors> <!-- Acceptor for every supported protocol --> <acceptor name="artemis">tcp://0.0.0.0:61616?protocols=AMQP;multicastPrefix=multicast://</acceptor> </acceptors> ... </core> </configuration>앞의 구성에 따라 acceptor는 멀티 캐스트 접두사에
multicast://를 사용하도록 구성됩니다.클라이언트 코드는 클라이언트에멀티캐스트 대기열로만 메시지를 보내야 하는 경우 multicast://<my.destination>/를지정할 수 있습니다.
4.7. 서브스크립션 큐 구성
대부분 의 경우 클라이언트가 주소를 처음 구독하도록 요청할 때 프로토콜 관리자가 자동으로 서브스크립션 대기열을 생성하기 때문에 서브스크립션 대기열을 수동으로 생성할 필요가 없습니다. 자세한 내용은 4.8.3절. “프로토콜 관리자 및 주소”를 참조하십시오. 내구성이 있는 서브스크립션의 경우 생성된 대기열 이름은 일반적으로 클라이언트 ID와 주소의 연결입니다.
다음 섹션에서는 필요한 경우 서브스크립션 대기열을 수동으로 생성하는 방법을 보여줍니다.
4.7.1. 내구성 있는 서브스크립션 대기열 구성
큐가 내구성 있는 서브스크립션으로 구성되면 브로커는 비활성 구독자에게 메시지를 저장하고 다시 연결할 때 구독자에게 제공합니다. 따라서 클라이언트는 대기열을 구독한 후 큐에 배달된 각 메시지를 수신할 수 있습니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 선택한 큐에 내구성
있는구성 요소를 추가합니다.true값을 설정합니다.<configuration ...> <core ...> ... <address name="my.durable.address"> <multicast> <queue name="q1"> <durable>true</durable> </queue> </multicast> </address> </core> </configuration>참고큐는 내구성 요소를 포함하여 기본적으로 내구성이 있기 때문에 값을
true로 설정하는 것은 내구성된 큐를 만드는 데 엄격하게 필요하지 않습니다.그러나 요소를 명시적으로 포함하면 필요한 경우 나중에 큐의 동작을 불가능한 것으로 변경할 수 있습니다.However, explicitly including the element enables you to later change the behavior of the queue to non-durable, if necessary.
4.7.3. 구성할 수 없는 서브스크립션 대기열 구성
구성할 수 없는 서브스크립션은 일반적으로 관련 프로토콜 관리자에 의해 관리되므로 임시 대기열을 생성하고 삭제합니다.
그러나 구성할 수 없는 서브스크립션 큐처럼 작동하는 큐를 수동으로 만들려면 큐에서 purge-on-no-consumers 특성을 사용할 수 있습니다. purge-on-no-consumers 가 true 로 설정되면 소비자가 연결될 때까지 큐에서 메시지를 수신하지 않습니다. 또한 마지막 소비자가 큐에서 연결이 끊어지면 큐가 삭제됩니다 (즉, 해당 메시지가 제거됨). 대기열은 새 소비자가 큐에 연결될 때까지 추가 메시지를 받지 않습니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 선택한 각 큐에
purge-on-no-consumers속성을 추가합니다.true값을 설정합니다.<configuration ...> <core ...> ... <address name="my.non.durable.address"> <multicast> <queue name="orders1" purge-on-no-consumers="true"/> </multicast> </address> </core> </configuration>
4.8. 자동으로 주소 및 큐 생성 및 삭제
브로커를 구성하여 주소 및 큐를 자동으로 생성하고, 더 이상 사용하지 않으면 삭제할 수 있습니다. 이렇게 하면 클라이언트가 연결할 수 있기 전에 각 주소를 사전 설정해야 할 필요가 없습니다.
4.8.1. 자동 큐 생성 및 삭제를 위한 구성 옵션
다음 표에는 address-setting 요소를 구성할 때 대기열 및 주소를 자동으로 생성하고 삭제할 수 있는 구성 요소가 나열되어 있습니다.
address-setting 을…로 설정하려는 경우 | 이 configuration… 추가 |
|---|---|
| 클라이언트가 존재하지 않는 주소로 매핑된 큐에서 메시지를 사용하거나 메시지를 사용하려고 할 때 주소를 생성합니다. |
|
| 클라이언트가 메시지를 대기열로 보내거나 대기열에서 메시지를 사용하려고 할 때 큐를 만듭니다. |
|
| 큐가 더 이상 없는 경우 자동으로 생성된 주소를 삭제합니다. |
|
| 큐에 0개의 소비자 및 0개의 메시지가 있는 경우 자동으로 생성된 큐를 삭제합니다. |
|
| 클라이언트가 지정하지 않는 경우 특정 라우팅 유형을 사용합니다. |
|
4.8.2. 주소 및 큐의 자동 생성 및 삭제 구성
다음 절차에서는 주소 및 큐의 자동 생성 및 삭제를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 자동 생성 및 삭제를 위해
address-setting을 구성합니다. 다음 예제에서는 이전 표에 언급된 모든 구성 요소를 사용합니다.<configuration ...> <core ...> ... <address-settings> <address-setting match="activemq.#"> <auto-create-addresses>true</auto-create-addresses> <auto-delete-addresses>true</auto-delete-addresses> <auto-create-queues>true</auto-create-queues> <auto-delete-queues>true</auto-delete-queues> <default-address-routing-type>ANYCAST</default-address-routing-type> </address-setting> </address-settings> ... </core> </configuration>address-setting-
address-setting요소의 구성은 와일드카드 주소 typical.#과 일치하는 모든 주소 또는 큐에적용됩니다. auto-create-addresses- 클라이언트가 아직 존재하지 않는 주소에 연결을 요청하면 브로커가 주소를 생성합니다.
auto-delete-addresses- 큐가 더 이상 연결되어 있지 않으면 자동으로 생성된 주소가 삭제됩니다.
auto-create-queues- 클라이언트가 아직 존재하지 않는 큐에 연결을 요청하면 브로커가 큐를 생성합니다.
auto-delete-queues- 자동 생성된 큐는 더 이상 소비자 또는 메시지가 없는 경우 삭제됩니다.
default-address-routing-type-
연결할 때 클라이언트가 라우팅 유형을 지정하지 않으면 브로커가 메시지를 주소로 전달할 때
ANYCAST를 사용합니다. 기본값은MULTICAST입니다.
추가 리소스
다음에 대한 자세한 내용은 다음을 수행합니다.
- 주소를 구성할 때 사용할 수 있는 와일드카드 구문에는 4.2절. “주소 세트에 주소 설정 적용” 을 참조하십시오.
- 라우팅 유형은 4.1절. “주소, 큐 및 라우팅 유형” 에서 참조하십시오.
4.8.3. 프로토콜 관리자 및 주소
프로토콜 관리자 라는 구성 요소는 AMQ Broker 주소 모델에 사용되는 개념에 프로토콜별 개념, 큐 및 라우팅 유형을 매핑합니다. 특정 상황에서는 프로토콜 관리자가 브로커에 큐를 자동으로 생성할 수 있습니다.
예를 들어, 클라이언트가 주소 /house/room1/lights 및 /house/room2/lights 를 사용하여 MQTT 구독 패킷을 보내면 MQTT 프로토콜 관리자는 두 주소에 멀티캐스트 의미 지정이 필요하다는 것을 이해합니다. 따라서 프로토콜 관리자는 먼저 두 주소에 모두 멀티캐스트 가 활성화되어 있는지 확인합니다. 그렇지 않은 경우 동적으로 생성하려고 시도합니다. 성공적인 경우 프로토콜 관리자는 클라이언트에서 요청한 각 서브스크립션에 대해 특수 서브스크립션 대기열을 생성합니다.
각 프로토콜은 약간 다르게 작동합니다. 아래 표는 다양한 유형의 큐에 대한 프레임을 구독할 때 일반적으로 수행되는 작업을 설명합니다.
| 큐가 이 유형…인 경우 | 프로토콜 관리자에 대한 일반적인 동작은 to…입니다. |
|---|---|
| 내구성 있는 서브스크립션 대기열 |
적절한 주소를 찾고 특수 이름을 사용하면 프로토콜 관리자가 클라이언트의 연결을 끊고 나중에 다시 연결해야 하는 필수 클라이언트 서브스크립션 대기열을 신속하게 식별할 수 있습니다. 클라이언트가 대기열을 구독 취소하면 삭제됩니다. |
| 임시 서브스크립션 대기열 |
적절한 주소를 찾고 클라이언트의 연결을 끊으면 큐가 삭제됩니다. |
| point-to-point 대기열 |
적절한 주소를 찾고 큐가 자동으로 생성되면 소비자가 없고 메시지가 없으면 자동으로 삭제됩니다. |
4.9. 정규화된 대기열 이름 지정
내부적으로 브로커는 주소에 대한 클라이언트 요청을 특정 큐에 매핑합니다. 브로커는 메시지를 보낼 대기열 또는 메시지를 수신할 대기열로 클라이언트를 대신하여 결정합니다. 그러나 고급 사용 사례에서 클라이언트가 대기열 이름을 직접 지정해야 할 수 있습니다. 이러한 경우 클라이언트는 정규화된 대기열 이름 (FQN)을 사용할 수 있습니다. FQN에는 주소 이름과 대기열 이름이 모두 포함되며, a :.
다음 절차에서는 여러 큐가 있는 주소에 연결할 때 FQN을 지정하는 방법을 보여줍니다.
사전 요구 사항
아래 예와 같이 두 개 이상의 큐로 구성된 주소가 있습니다.
<configuration ...> <core ...> ... <addresses> <address name="my.address"> <anycast> <queue name="q1" /> <queue name="q2" /> </anycast> </address> </addresses> </core> </configuration>
절차
클라이언트 코드에서 브로커의 연결을 요청할 때 주소 이름과 대기열 이름을 둘 다 사용합니다. 두 개의 콜론을 사용합니다
:::, to separate the names. 예를 들면 다음과 같습니다.String FQQN = "my.address::q1"; Queue q1 session.createQueue(FQQN); MessageConsumer consumer = session.createConsumer(q1);
4.10. sharded 큐 구성
부분적으로만 순서가 필요한 대기열에서 메시지를 처리하는 일반적인 패턴은 큐 분할 을 사용하는 것입니다. 즉, 단일 논리 대기열 역할을 하지만 많은 기본 물리적 대기열에서 지원하는 anycast 주소를 정의합니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address요소를 추가하고name속성을 설정합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <addresses> <address name="my.sharded.address"></address> </addresses> </core> </configuration>anycast라우팅 유형을 추가하고 원하는 수의 샤드 큐를 포함합니다. 아래 예에서q1,q2및q3대기열이모든cast대상으로 추가됩니다.<configuration ...> <core ...> ... <addresses> <address name="my.sharded.address"> <anycast> <queue name="q1" /> <queue name="q2" /> <queue name="q3" /> </anycast> </address> </addresses> </core> </configuration>
이전 구성에 따라 my.sharded.address 로 전송된 메시지는 q1,q2 및 q3 에 동일하게 배포됩니다. 클라이언트는 FQN(Fully Qualified Queue Name)을 사용할 때 특정 물리적 대기열에 직접 연결하고 해당 특정 대기열로만 전송된 메시지를 수신할 수 있습니다.
특정 대기열에 특정 메시지를 연결하기 위해 클라이언트는 각 메시지에 대한 메시지 그룹을 지정할 수 있습니다. 브로커는 동일한 큐로 메시지를 그룹화하고 하나의 소비자는 모두 처리합니다.
추가 리소스
다음에 대한 자세한 내용은 다음을 수행합니다.
- fully qualified Queue Names, see 4.9절. “정규화된 대기열 이름 지정”
- 메시지 그룹화를 참조하십시오. 11장. 메시지 그룹화
4.11. 마지막 값 대기열 구성
마지막 값 큐는 동일한 마지막 값 키 값이 있는 최신 메시지가 큐에 배치될 때 큐에서 메시지를 삭제하는 큐 유형입니다.A last value queue is a type of queue that discards messages in the queue when a newer message with the same last value key value is placed in the queue. 이 동작을 통해 마지막 값 대기열은 동일한 키의 메시지의 마지막 값만 유지합니다.
마지막 값 대기열의 간단한 사용 사례는 특정 주식에 대한 최신 값만 관심 있는 재고 가격을 모니터링하기 위한 것입니다.
구성된 마지막 값 키가 없는 메시지가 마지막 값 큐에 전송되면 브로커는 이 메시지를 "일반" 메시지로 처리합니다. 이러한 메시지는 구성된 마지막 값 키가 있는 새 메시지가 도착하면 큐에서 제거되지 않습니다.
마지막 값 큐를 개별적으로 또는 주소 집합과 연결된 모든 큐에 대해 구성할 수 있습니다.You can configure last value queues individually, or for all of the queues associated with a set of addresses.
다음 절차에서는 이러한 방식으로 마지막 값 대기열을 구성하는 방법을 보여줍니다.
4.11.1. 마지막 값 큐를 개별적으로 구성
다음 절차에서는 마지막 값 대기열을 개별적으로 구성하는 방법을 보여줍니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 큐의 경우
last-value-key키를 추가하고 사용자 지정 값을 지정합니다. 예를 들면 다음과 같습니다.<address name="my.address"> <multicast> <queue name="prices1" last-value-key="stock_ticker"/> </multicast> </address>또는
_AMQ_LVQ_NAME의 기본 마지막 값 키 이름을 사용하는 마지막 값 큐를 구성할 수 있습니다. 이렇게 하려면 지정된 큐에last-value키를 추가합니다. 값을true로 설정합니다. 예를 들면 다음과 같습니다.<address name="my.address"> <multicast> <queue name="prices1" last-value="true"/> </multicast> </address>
4.11.2. 주소에 대한 마지막 값 대기열 구성
다음 절차에서는 주소 또는 주소 집합에 대한 마지막 값 대기열을 구성하는 방법을 보여줍니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address-setting요소에서 일치하는 주소에 대해default-last-value-key를 추가합니다. 사용자 정의 값을 지정합니다. 예를 들면 다음과 같습니다.<address-setting match="lastValue"> <default-last-value-key>stock_ticker</default-last-value-key> </address-setting>
이전 구성에 따라
lastValue주소와 연결된 모든 큐는 마지막 값 키stock_ticker를 사용합니다. 기본적으로default-last-value-key값은 설정되지 않습니다.주소 집합에 대한 마지막 값 대기열을 구성하려면 주소 와일드카드를 지정할 수 있습니다. 예를 들면 다음과 같습니다.
<address-setting match="lastValue.*"> <default-last-value-key>stock_ticker</default-last-value-key> </address-setting>
또는 주소 또는 주소 세트 와 연결된 모든 큐를 구성하여 기본 마지막 값 키 이름
_AMQ_LVQ_NAME을 사용할 수 있습니다. 이렇게 하려면default-last-value-key대신default-last-value-queue를 추가합니다. 값을true로 설정합니다. 예를 들면 다음과 같습니다.<address-setting match="lastValue"> <default-last-value-queue>true</default-last-value-queue> </address-setting>
추가 리소스
- 주소를 구성할 때 사용할 수 있는 와일드카드 구문에 대한 자세한 내용은 4.2절. “주소 세트에 주소 설정 적용” 을 참조하십시오.
4.11.3. 마지막 값 큐 동작의 예
이 예에서는 마지막 값 대기열의 동작을 보여줍니다.
broker.xml 구성 파일에서 다음과 같은 구성을 추가했다고 가정합니다.
<address name="my.address">
<multicast>
<queue name="prices1" last-value-key="stock_ticker"/>
</multicast>
</address>
앞의 구성은 price1 이라는 큐를 생성하고 마지막 값의 stock_ticker 를 사용합니다.
이제 클라이언트가 두 개의 메시지를 전송한다고 가정합니다. 각 메시지는 속성 stock_ticker 에 대해 ATN 의 값과 같습니다. 각 메시지에는 stock_ price라는 속성에 대해 다른 값이 있습니다. 각 메시지는 동일한 대기열인 price1 로 전송됩니다.
TextMessage message = session.createTextMessage("First message with last value property set");
message.setStringProperty("stock_ticker", "ATN");
message.setStringProperty("stock_price", "36.83");
producer.send(message);TextMessage message = session.createTextMessage("Second message with last value property set");
message.setStringProperty("stock_ticker", "ATN");
message.setStringProperty("stock_price", "37.02");
producer.send(message);
stock_ticker 마지막 값 키에 대해 동일한 두 개의 메시지가 있는 경우(이 경우 ATN)는 prices1 큐에 도착하면 첫 번째 메시지가 제거되고 첫 번째 메시지만 큐에 남아 있습니다. 명령줄에서 다음 행을 입력하여 이 동작을 검증할 수 있습니다.
TextMessage messageReceived = (TextMessage)messageConsumer.receive(5000);
System.out.format("Received message: %s\n", messageReceived.getText());이 예제에서는 두 메시지가 모두 마지막 값 키에 대해 동일한 값을 사용하고 두 번째 메시지가 첫 번째 후 큐에 수신된 두 번째 메시지가 두 번째 메시지입니다.
4.11.4. 마지막 값 큐에 대해 파괴적이지 않은 사용 시행
소비자가 큐에 연결할 때 정상적인 동작은 해당 소비자에게만 전송된 메시지가 소비자에 의해 독점적으로 획득된다는 것입니다. 소비자가 메시지 수신을 승인하면 브로커가 대기열에서 메시지를 제거합니다.
일반적인 사용 동작에 대한 대안으로, 거부 적이지 않은 사용을 강제하도록 큐를 구성할 수 있습니다. 이 경우 큐에서 메시지를 소비자에게 전송하면 다른 사용자가 메시지를 수신할 수 있습니다. 또한 이 메시지는 소비자가 사용하는 경우에도 큐에 남아 있습니다. 이러한 비차적 사용 동작을 적용하면 소비자가 대기열 브라우저 라고 합니다.
파괴적이지 않은 사용을 적용하는 것은 마지막 값 큐에 대한 유용한 구성입니다. 대기열이 항상 특정 마지막 값 키에 대한 최신 값을 보유하도록 하기 때문입니다.
다음 절차에서는 마지막 값 큐에 파괴적이지 않은 사용을 적용하는 방법을 보여줍니다.
사전 요구 사항
마지막 값 큐를 개별적으로 구성했거나 주소 또는 주소 집합 과 연결된 모든 큐에 대해 이미 구성되어 있습니다. 자세한 내용은 다음을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 이전에 큐를 마지막 값 큐로 구성한 경우
파괴적이지 않은키를 추가합니다. 값을true로 설정합니다. 예를 들면 다음과 같습니다.<address name="my.address"> <multicast> <queue name="orders1" last-value-key="stock_ticker" non-destructive="true" /> </multicast> </address>이전에 마지막 값 큐에 대한 주소 또는 주소 세트 를 구성한 경우
default-non-destructive키를 추가합니다. 값을true로 설정합니다. 예를 들면 다음과 같습니다.<address-setting match="lastValue"> <default-last-value-key>stock_ticker </default-last-value-key> <default-non-destructive>true</default-non-destructive> </address-setting>
참고기본적으로
default-non-destructive값은false입니다.
4.12. 만료된 메시지를 만료 주소로 이동
마지막 값 대기열이 아닌 큐의 경우 브로커는 파괴적이지 않은 소비자만 있는 경우 브로커는 큐에서 메시지를 삭제하지 않으며 시간이 지남에 따라 큐 크기가 증가하게 됩니다. 대기열 크기가 제한되지 않은 이러한 증가를 방지하기 위해 메시지가 만료될 때 를 구성하고 브로커가 만료된 메시지를 이동하는 주소를 지정할 수 있습니다.
4.12.1. 메시지 만료 구성
다음 절차에서는 메시지 만료를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. core요소에서message-expiry-scan-period를 설정하여 만료된 메시지에 대한 브로커 검색 빈도를 지정합니다.<configuration ...> <core ...> ... <message-expiry-scan-period>1000</message-expiry-scan-period> ...이전 구성에 따라 브로커는 1000밀리초마다 만료된 메시지의 대기열을 검사합니다.
일치하는 주소 또는 주소 세트 의
address-setting요소에서 만료 주소를 지정합니다. 또한 메시지 만료 시간을 설정합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="stocks"> ... <expiry-address>ExpiryAddress</expiry-address> <expiry-delay>10</expiry-delay> ... </address-setting> ... <address-settings> <configuration ...>expiry-address-
일치하는 주소 또는 주소의 만료 주소입니다. 이전 예에서 브로커는 주식 주소에 대한 만료된 메시지를
ExpiryAddress라는 만료 주소로 보냅니다. expiry-delay브로커가 기본 만료 시간을 사용하는 메시지에 적용되는 만료 시간(밀리초)입니다. 기본적으로 메시지의 만료 시간은 0이며 만료되지 않음을 의미합니다.By default, messages have an expiration time of
0, meaning that they don't expire. 만료 시간이 기본값보다 크면 expiration-delay가 적용되지 않습니다.예를 들어 위 예에 표시된 대로 주소에서
expiry-delay를10으로 설정했다고 가정합니다. 기본 만료 시간이0인 메시지가 이 주소에서 큐에 도달하면 브로커는 메시지의 만료 시간을0에서10으로 변경합니다. 그러나20의 만료 시간을 사용하는 다른 메시지가 도착하면 만료 시간은 변경되지 않습니다. expiry-delay를-1로 설정하면 이 기능이 비활성화됩니다. 기본적으로expiry-delay는-1로 설정됩니다.
또는
expiry-delay에 값을 지정하는 대신 최소 및 최대 만료 지연 값을 지정할 수 있습니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="stocks"> ... <expiry-address>ExpiryAddress</expiry-address> <min-expiry-delay>10</min-expiry-delay> <max-expiry-delay>100</max-expiry-delay> ... </address-setting> ... <address-settings> <configuration ...>min-expiry-delay- 브로커가 메시지에 적용되는 최소 만료 시간(밀리초)입니다.
max-expiry-delay브로커가 메시지에 적용되는 최대 만료 시간(밀리초)입니다.
브로커는 다음과 같이
min-expiry-delay및max-expiry-delay값을 적용합니다.-
기본 만료 시간이
0인 메시지의 경우 브로커는 만료 시간을max-expiry-delay의 지정된 값으로 설정합니다.max-expiry-delay의 값을 지정하지 않은 경우 브로커는 만료 시간을min-expiry-delay로 설정합니다.min-expiry-delay에 대한 값을 지정하지 않은 경우 브로커는 메시지의 만료 시간을 변경하지 않습니다. -
max-expiry-delay보다 높은 만료 시간이 있는 메시지의 경우 브로커는 만료 시간을max-expiry-delay의 지정된 값으로 설정합니다. -
min-expiry-delay값 아래에 만료 시간이 있는 메시지의 경우 브로커는 만료 시간을min-expiry-delay로 설정합니다. -
min-expiry-delay및max-expiry-delay값 간에 만료되는 메시지의 경우 브로커는 메시지의 만료 시간을 변경하지 않습니다. -
expiry-delay(즉, 기본값-1이 아닌)의 값을 지정하면min-expiry-delay및max-expiry-delay에 지정된 모든 값이 재정의됩니다. -
min-expiry-delay및max-expiry-delay의 기본값은-1입니다(즉, 비활성화됨).
-
기본 만료 시간이
구성 파일의
addresses요소에서expiry-address에 대해 이전에 지정된 주소를 구성합니다. 이 주소에서 큐를 정의합니다. 예를 들면 다음과 같습니다.<addresses> ... <address name="ExpiryAddress"> <anycast> <queue name="ExpiryQueue"/> </anycast> </address> ... </addresses>앞의 예제 구성은 만료 큐인
ExpiryQueue를 만료 주소ExpiryAddress와 연결합니다.
4.12.2. 만료 리소스 자동 생성
일반적인 사용 사례는 원래 주소에 따라 만료된 메시지를 분리하는 것입니다. 예를 들어, 소고라는 주소에서 EXP. 라는 만료 큐로 만료된 메시지를 라우팅하도록 선택할 수 있습니다. 마찬가지로 s tocks주문 이라는 주소에서 EXP.orders 라는 만료 큐로 만료된 메시지를 라우팅할 수 있습니다.
이러한 유형의 라우팅 패턴을 사용하면 만료된 메시지를 쉽게 추적, 검사 및 관리할 수 있습니다. 그러나 이러한 패턴은 주로 생성된 주소 및 대기열을 사용하는 환경에서 구현하기 어렵습니다. 이 유형의 환경에서는 관리자가 만료된 메시지를 보유하는 데 필요한 주소 및 대기열을 수동으로 생성하는 데 필요한 추가 작업을 원하지 않습니다.
해결 방법으로 지정된 주소 또는 주소 집합에 대해 만료된 메시지를 처리하기 위해 리소스(즉, 주소 및 대기열)를 자동으로 생성하도록 브로커를 구성할 수 있습니다. 다음 절차에서는 예제를 보여줍니다.
사전 요구 사항
- 지정된 주소 또는 주소 집합에 대한 만료 주소를 이미 구성했습니다. 자세한 내용은 4.12.1절. “메시지 만료 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 이전에 구성 파일에 추가한 <
address-setting> 요소를 찾아 일치하는 주소 또는 주소 세트 의 만료 주소를 정의합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="stocks"> ... <expiry-address>ExpiryAddress</expiry-address> ... </address-setting> ... <address-settings> <configuration ...><
address-setting> 요소에서 브로커에 만료 리소스(즉, 주소 및 큐)를 자동으로 생성하고 이러한 리소스의 이름을 지정하는 방법을 브로커에 지시하는 구성 항목을 추가합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="stocks"> ... <expiry-address>ExpiryAddress</expiry-address> <auto-create-expiry-resources>true</auto-create-expiry-resources> <expiry-queue-prefix>EXP.</expiry-queue-prefix> <expiry-queue-suffix></expiry-queue-suffix> ... </address-setting> ... <address-settings> <configuration ...>auto-create-expiry-resources브로커가 만료된 메시지를 수신할 만료 주소 및 큐를 자동으로 생성하는지 여부를 지정합니다. 기본값은
false입니다.매개변수 값이
true로 설정되면 브로커는 만료주소및 관련 만료 큐를 정의하는 <address> 요소를 자동으로 생성합니다. 자동으로 생성된 <address> 요소의 name 값은 에<expiry-address>지정된 name 값과 일치합니다.자동 생성된 만료 큐에는
멀티 캐스트라우팅 유형이 있습니다. 기본적으로 브로커는 만료된 메시지가 원래 전송된 주소(예: 주식)와 일치하도록 만료 큐의 이름을지정합니다.브로커는 또한
_AMQ_ORIG_ADDRESS속성을 사용하는 만료 대기열에 대한 필터를 정의합니다. 이 필터를 사용하면 만료 큐가 해당 원래 주소로 전송된 메시지만 수신됩니다.expiry-queue-prefix브로커가 자동으로 생성된 만료 큐의 이름에 적용되는 접두사입니다. 기본값은
EXP입니다.접두사 값을 정의하거나 기본값을 유지할 때 만료 큐의 이름은 접두사와 원래 주소(예:
EXP.stocks)의 연결입니다.expiry-queue-suffix- 브로커가 자동으로 생성된 만료 큐의 이름에 적용되는 접미사입니다. 기본값은 정의되지 않습니다(즉, 브로커는 접미사가 적용되지 않음).
큐 이름(예: AMQ Broker Core Protocol JMS 클라이언트를 사용하는 경우)을 사용하거나 정규화된 대기열 이름(예: 다른 JMS 클라이언트를 사용하는 경우)을 사용하여 만료 대기열에 직접 액세스할 수 있습니다.
만료 주소 및 큐가 자동으로 생성되므로 자동으로 생성된 주소 및 큐 삭제와 관련된 모든 주소 설정은 만료 리소스에도 적용됩니다.
추가 리소스
- 자동으로 생성된 주소 및 큐의 자동 삭제를 구성하는 데 사용되는 주소 설정에 대한 자세한 내용은 4.8.2절. “주소 및 큐의 자동 생성 및 삭제 구성” 을 참조하십시오.
4.13. 배달되지 않은 메시지를 dead letter 주소로 이동
클라이언트에 메시지 전달이 실패한 경우 브로커가 메시지 전달을 지속적으로 시도하는 것을 원하지 않을 수 있습니다. 무한 전달 시도를 방지하기 위해 dead letter address 및 하나 이상의 dead letter 큐 를 정의할 수 있습니다. 지정된 수의 전달 시도 후 브로커는 배달되지 않은 메시지를 원래 대기열에서 제거하고 구성된 dead letter 주소로 메시지를 보냅니다. 시스템 관리자는 나중에 배달되지 않은 메시지를 배달되지 않은 대기열에서 사용하여 메시지를 검사할 수 있습니다.
지정된 큐에 대한 dead letter 주소를 구성하지 않으면 브로커는 지정된 전송 시도 횟수 후 큐에서 배달되지 않은 메시지를 영구적으로 제거합니다.
dead letter 큐에서 사용하는 배달되지 않은 메시지에는 다음과 같은 속성이 있습니다.
_AMQ_ORIG_ADDRESS- 메시지의 원래 주소를 지정하는 string 속성입니다.String property that specifies the original address of the message.
_AMQ_ORIG_QUEUE- 메시지의 원래 큐를 지정하는 string 속성입니다.String property that specifies the original queue of the message
4.13.1. dead letter 주소 구성
다음 절차에서는 dead letter 주소와 연결된 배달 못 한 큐를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 대기열 이름과 일치하는 <
address-setting> 요소에서 dead letter 주소 이름 및 최대 전달 시도 수에 대한 값을 설정합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="exampleQueue"> <dead-letter-address>DLA</dead-letter-address> <max-delivery-attempts>3</max-delivery-attempts> </address-setting> ... <address-settings> <configuration ...>match-
브로커가 이
address-setting섹션의 구성을 적용하는 주소입니다. <address-setting> 요소의match특성에 와일드카드 식을 지정할 수 있습니다. 와일드카드 표현식을 사용하는 것은 <address-setting> 요소에 구성된 dead letter 설정을 일치하는 주소 집합 과 연결하려는 경우 유용합니다. dead-letter-address- 배달 못 한 주소의 이름입니다. 이 예에서 브로커는 배달되지 않은 메시지를 대기열 exampleQueue 에서 dead letter address인 DLA 로 이동합니다.
max-delivery-attempts-
배달되지 않은 메시지를 구성된 배달 주소로 이동하기 전에 브로커가 수행한 최대 전송 시도 횟수입니다. 이 예에서 브로커는 전달되지 않은 메시지를 세 가지 실패한 전달 시도 후 배달되지 않은 주소로 이동합니다. 기본값은
10입니다. 브로커가 무한한 수의 재전송 시도 횟수를 제한하도록 하려면-1값을 지정합니다.
addresses섹션에서 dead letteraddress인 DLA 에 대한 address 요소를 추가합니다. dead letter 큐를 dead letter 주소와 연결하려면큐의 이름 값을 지정합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <addresses> <address name="DLA"> <anycast> <queue name="DLQ" /> </anycast> </address> ... </addresses> </core> </configuration>
이전 구성에서 DLQ 라는 dead letter 큐와 dead letter 주소인 DLA 를 연결합니다.
추가 리소스
- 주소 설정에서 와일드카드를 사용하는 방법에 대한 자세한 내용은 4.2절. “주소 세트에 주소 설정 적용” 을 참조하십시오.
4.13.2. dead letter 큐 자동 생성
일반적인 사용 사례는 원래 주소에 따라 배달되지 않은 메시지를 분리하는 것입니다. 예를 들어, 재고라는 주소에서 DLA. 라는 관련 dead letter 큐가 있는 배달 못 한 큐로 전송되지 않은 메시지를 라우팅 s tocks하도록 선택할 수 있습니다. 마찬가지로, 주문 이라는 주소에서 DLA.orders 라는 dead letter 주소로 배달되지 않은 메시지를 라우팅할 수 있습니다.
이러한 유형의 라우팅 패턴을 사용하면 배달되지 않은 메시지를 쉽게 추적, 검사 및 관리할 수 있습니다. 그러나 이러한 패턴은 주로 생성된 주소 및 대기열을 사용하는 환경에서 구현하기 어렵습니다. 이러한 유형의 환경에 대한 시스템 관리자는 배달되지 않은 메시지를 저장하기 위해 수동으로 주소 및 큐를 수동으로 생성하는 데 필요한 추가 노력을 원하지 않을 수 있습니다.
해결 방법으로 다음 절차에 표시된 대로 주소 및 큐를 자동으로 생성하여 배달되지 않은 메시지를 처리하도록 브로커를 구성할 수 있습니다.
사전 요구 사항
- 큐 또는 큐 세트의 dead letter 주소를 이미 구성했습니다. 자세한 내용은 4.13.1절. “dead letter 주소 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 일치하는 큐 또는 큐 세트에 대한 dead letter
주소를 정의하기 위해 이전에 추가한 <address-setting> 요소를 찾습니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="exampleQueue"> <dead-letter-address>DLA</dead-letter-address> <max-delivery-attempts>3</max-delivery-attempts> </address-setting> ... <address-settings> <configuration ...><
address-setting> 요소에서 브로커에 배달 못 한 문자 리소스(즉, 주소 및 큐)를 자동으로 생성하고 이러한 리소스의 이름을 지정하는 방법을 브로커에 지시하는 구성 항목을 추가합니다. 예를 들면 다음과 같습니다.<configuration ...> <core ...> ... <address-settings> ... <address-setting match="exampleQueue"> <dead-letter-address>DLA</dead-letter-address> <max-delivery-attempts>3</max-delivery-attempts> <auto-create-dead-letter-resources>true</auto-create-dead-letter-resources> <dead-letter-queue-prefix>DLQ.</dead-letter-queue-prefix> <dead-letter-queue-suffix></dead-letter-queue-suffix> </address-setting> ... <address-settings> <configuration ...>auto-create-dead-letter-resources브로커가 배달되지 않은 메시지를 수신할 배달 못 한 주소 및 큐를 자동으로 생성할지 여부를 지정합니다. 기본값은
false입니다.auto-create-dead-letter-resources가true로 설정된 경우 브로커는 dead letter주소와 관련 dead letter 큐를 정의하는 <address> 요소를 자동으로 생성합니다. 자동으로 생성된 <address> 요소의 이름은 <dead-letter-address>에 지정하는 name 값과 일치합니다.브로커가 자동 생성된 <
address> 요소에서 정의하는 dead letter 큐에는멀티캐스트라우팅 유형이 있습니다. 기본적으로 브로커는 배달되지 않은 메시지의 원래 주소와 일치하도록 dead letter 큐의 이름을 지정합니다(예:stocks).브로커는 또한
_AMQ_ORIG_ADDRESS속성을 사용하는 dead letter 큐에 대한 필터를 정의합니다. 이 필터를 사용하면 dead letter queue가 해당 원래 주소로 전송된 메시지만 수신됩니다.dead-letter-queue-prefix브로커가 자동으로 생성된 배달 못 한 큐의 이름에 적용되는 접두사입니다. 기본값은
DLQ입니다.접두사 값을 정의하거나 기본값을 유지할 때 dead letter queue의 이름은 접두사와 원래 주소(예:
DLQ.stocks)의 연결입니다.dead-letter-queue-suffix- 브로커가 자동으로 생성된 dead letter 큐에 적용되는 접미사입니다. 기본값은 정의되지 않습니다(즉, 브로커는 접미사가 적용되지 않음).
4.14. 만료된 또는 배달되지 않은 AMQP 메시지의 주석 및 속성
브로커가 만료된 또는 배달되지 않은 AMQP 메시지를 구성한 만료 또는 dead letter 큐로 이동하기 전에 브로커는 주석 및 속성을 메시지에 적용합니다. 클라이언트는 만료 또는 배달 못 한 큐에서 사용할 특정 메시지를 선택하기 위해 이러한 속성 또는 주석을 기반으로 필터를 생성할 수 있습니다.
브로커가 적용되는 속성은 내부 속성입니다 These properties are not exposed to clients for regular use, but can be specified by a client in a filter.
다음 표에서는 브로커가 만료된 또는 배달되지 않은 AMQP 메시지에 적용되는 주석 및 내부 속성을 보여줍니다.
| 주석 이름 | 내부 속성 이름 | 설명 |
|---|---|---|
| x-opt-ORIG-MESSAGE-ID | _AMQ_ORIG_MESSAGE_ID | 메시지가 만료 또는 배달 못 한 큐로 이동하기 전에 원본 메시지 ID. |
| x-opt-ACTUAL-EXPIRY | _AMQ_ACTUAL_EXPIRY | 마지막 epoch가 시작된 후 밀리초로 지정된 메시지 만료 시간입니다. |
| x-opt-ORIG-QUEUE | _AMQ_ORIG_QUEUE | 만료된 또는 배달되지 않은 메시지의 원본 대기열 이름입니다. |
| x-opt-ORIG-ADDRESS | _AMQ_ORIG_ADDRESS | 만료된 또는 배달되지 않은 메시지의 원래 주소 이름입니다. |
추가 리소스
- 주석을 기반으로 AMQP 메시지를 필터링하도록 AMQP 클라이언트를 구성하는 예는 15.3절. “주석에서 속성을 기반으로 AMQP 메시지 필터링” 을 참조하십시오.
4.15. 대기열 비활성화
브로커 구성에 큐를 수동으로 정의하는 경우 기본적으로 큐가 활성화됩니다.
그러나 클라이언트가 구독할 수 있도록 큐를 정의하려고 하지만 메시지 라우팅에 큐를 사용할 수 없는 경우가 있을 수 있습니다.However, there might be a case where you want to define a queue so that clients can subscribe to it, but are not ready to use the queue for message routing. 또는 큐로 메시지 흐름을 중지하지만 계속 클라이언트가 큐에 바인딩된 상태로 유지해야 하는 상황이 있을 수 있습니다. 이 경우 큐를 비활성화할 수 있습니다.
다음 예제에서는 브로커 구성에 정의된 큐를 비활성화하는 방법을 보여줍니다.
사전 요구 사항
- 브로커 구성에 주소 및 관련 큐를 정의하는 방법을 잘 알고 있어야 합니다. 자세한 내용은 4장. 주소 및 대기열 구성의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 이전에 정의한 큐의 경우
enabled속성을 추가합니다. 큐를 비활성화하려면 이 속성의 값을false로 설정합니다. 예를 들면 다음과 같습니다.<addresses> <address name="orders"> <multicast> <queue name="orders" enabled="false"/> </multicast> </address> </addresses>enabled속성의 기본값은true입니다. 값을false로 설정하면 큐에 대한 메시지 라우팅이 비활성화됩니다.
주소에서 모든 대기열을 비활성화하면 해당 주소로 전송된 모든 메시지가 자동으로 삭제됩니다.
4.16. 큐에 연결된 소비자 수 제한
max-consumers 특성을 사용하여 특정 대기열에 연결된 소비자 수를 제한합니다. max-consumers 플래그를 1 로 설정하여 배타적 소비자를 생성합니다. 기본값은 -1 이며, 이 값은 무제한 소비자 수를 설정합니다.
다음 절차에서는 큐에 연결할 수 있는 소비자 수에 대한 제한을 설정하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 큐의 경우
max-consumers키를 추가하고 값을 설정합니다.<configuration ...> <core ...> ... <addresses> <address name="foo"> <anycast> <queue name="q3" max-consumers="20"/> </anycast> </address> </addresses> </core> </configuration>앞의 구성에 따라 20개의 소비자만 동시에 큐
q3에 연결할 수 있습니다.전용 소비자를 만들려면
max-consumers를1로 설정합니다.<configuration ...> <core ...> ... <address name="foo"> <anycast> <queue name="q3" max-consumers="1"/> </anycast> </address> </core> </configuration>무제한의 소비자 수를 허용하려면
max-consumers를-1로 설정합니다.<configuration ...> <core ...> ... <address name="foo"> <anycast> <queue name="q3" max-consumers="-1"/> </anycast> </address> </core> </configuration>
4.17. 전용 대기열 구성
전용 대기열은 모든 메시지를 한 번에 하나의 소비자로만 라우팅하는 특수 대기열입니다. 이 구성은 동일한 소비자가 모든 메시지를 직렬로 처리하도록 할 때 유용합니다. 큐에 대한 소비자가 여러 개 있는 경우 하나의 소비자만 메시지를 받습니다. 해당 소비자가 큐에서 연결을 끊으면 다른 소비자가 선택됩니다.
4.17.1. 전용 대기열 구성
다음 절차에서는 지정된 큐를 배타적으로 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 큐의 경우
전용키를 추가합니다. 값을true로 설정합니다.<configuration ...> <core ...> ... <address name="my.address"> <multicast> <queue name="orders1" exclusive="true"/> </multicast> </address> </core> </configuration>
4.17.2. 주소에 대한 전용 대기열 구성
다음 절차에서는 연결된 모든 큐가 배타적이 되도록 주소 또는 주소 세트 를 구성하는 방법을 보여줍니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address-setting요소에서 일치하는 주소에 대해default-exclusive-queue키를 추가합니다. 값을true로 설정합니다.<address-setting match="myAddress"> <default-exclusive-queue>true</default-exclusive-queue> </address-setting>이전 구성에 따라
myAddress주소와 연결된 모든 대기열은 배타적입니다. 기본적으로default-exclusive-queue값은false입니다.주소 세트에 대한 전용 대기열을 구성하려면 주소 와일드카드를 지정할 수 있습니다. 예를 들면 다음과 같습니다.
<address-setting match="myAddress.*"> <default-exclusive-queue>true</default-exclusive-queue> </address-setting>
추가 리소스
- 주소를 구성할 때 사용할 수 있는 와일드카드 구문에 대한 자세한 내용은 4.2절. “주소 세트에 주소 설정 적용” 을 참조하십시오.
4.18. 링 큐 구성
일반적으로 AMQ 브로커의 대기열은 first-in, first-out(first-out) 의미를 사용합니다. 즉, 브로커가 대기열의 tail에 메시지를 추가하고 헤드에서 메시지를 제거합니다. 링 큐는 지정된 고정된 수의 메시지를 보유하는 특수 유형의 큐입니다. 브로커는 새 메시지가 도착하면 큐의 헤드에서 메시지를 제거하여 고정된 큐 크기를 유지하지만, 큐에 이미 지정된 메시지 수가 있습니다.
예를 들어 크기가 3 이고 메시지 A,B,C 및 D 를 순차적으로 전송하는 생산자로 구성된 링 큐를 고려하십시오. 메시지 C 가 큐에 도착하면 대기열의 메시지 수가 구성된 링 크기에 도달했습니다. 이 시점에서 메시지 A 는 대기열의 헤드에 있지만 메시지 C 는 tail에 있습니다. D 메시지가 큐에 도착하면 브로커는 메시지를 대기열의 tail에 추가합니다. 고정 대기열 크기를 유지하기 위해 브로커는 큐의 헤드(즉, 메시지 A)에서 메시지를 제거합니다. 메시지 B 는 이제 큐의 헤드에 있습니다.
4.18.1. 링 큐 구성
다음 절차에서는 링 대기열을 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 명시적 링 크기가 설정되지 않은 일치하는 주소에 있는 모든 큐의 기본 링 크기를 정의하려면
address-setting요소에default-ring-size값을 지정합니다. 예를 들면 다음과 같습니다.<address-settings> <address-setting match="ring.#"> <default-ring-size>3</default-ring-size> </address-setting> </address-settings>default-ring-size매개변수는 자동 생성된 큐의 기본 크기를 정의하는 데 특히 유용합니다.default-ring-size의 기본값은-1입니다(즉, 크기 제한은 없음).특정 큐에서 링 크기를 정의하려면
ring-size키를queue요소에 추가합니다. 값을 지정합니다. 예를 들면 다음과 같습니다.<addresses> <address name="myRing"> <anycast> <queue name="myRing" ring-size="5" /> </anycast> </address> </addresses>
브로커가 실행되는 동안 ring-size 값을 업데이트할 수 있습니다. 브로커는 동적으로 업데이트를 적용합니다. 새 ring-size 값이 이전 값보다 작으면 브로커는 새 크기를 강제 적용하기 위해 큐의 헤드에서 즉시 메시지를 삭제하지 않습니다. 큐에 전송된 새 메시지는 여전히 이전 메시지의 삭제를 강제하지만 대기열은 클라이언트의 정상적인 메시지 사용을 통해 자연스럽게 메시지를 사용할 때까지 크기가 줄어들 때까지 새로운 메시지에 도달하지 않습니다.
4.18.2. 링 대기열 문제 해결
이 섹션에서는 링 큐의 동작이 구성과 다른 상황에 대해 설명합니다.
In-delivery 메시지 및 롤백
메시지가 소비자에게 전달되면 메시지는 기술적으로 큐에 없는 "in-between" 상태에 있지만 아직 확인되지 않았습니다. 메시지는 소비자가 승인할 때까지 전달 내 상태로 유지됩니다. in-delivery 상태에 남아 있는 메시지는 링 큐에서 제거할 수 없습니다.
브로커가 배달 내 메시지를 제거할 수 없기 때문에 클라이언트는 링 크기 구성에서 허용하는 것보다 더 많은 메시지를 링 큐에 보낼 수 있습니다. 예를 들어 다음 시나리오를 고려해 보십시오.For example, consider this scenario:
-
생산자는
ring-size="3"으로 구성된 링 큐로 세 개의 메시지를 보냅니다. 모든 메시지는 사용자에게 즉시 전달됩니다.
이 시점에서
messageCount=3및deliveringCount=3.생산자는 대기열에 다른 메시지를 보냅니다. 그런 다음 메시지가 소비자에게 디스패치됩니다.
이제
messageCount=4및deliveringCount=4. 메시지 수4는 구성된 링 크기3보다 큽니다. 그러나 브로커는 대기열에서 수신되지 않은 메시지를 제거할 수 없기 때문에 이 상황을 허용해야 합니다.이제 소비자가 메시지를 인정하지 않고 종료한다고 가정합니다.
이 경우 네 개의 배달되지 않은 메시지가 브로커로 다시 취소되고 소비된 순서로 큐의 헤드에 추가됩니다. 이 작업을 수행하면 구성된 링 크기에 큐가 배치됩니다. 링 큐는 헤드의 메시지 위에 대기열의 메시지에서 메시지를 선호하기 때문에 큐는 생산자가 보낸 첫 번째 메시지를 큐의 헤드에 다시 추가했기 때문에 큐에서 보낸 첫 번째 메시지를 삭제합니다. 트랜잭션 또는 핵심 세션 롤백은 동일한 방식으로 처리됩니다.
코어 클라이언트를 직접 사용하거나 AMQ Core Protocol JMS 클라이언트를 사용하는 경우 기본적으로 consumerWindowSize 매개변수(1024 * 1024바이트)의 값을 줄임으로써 배달 메시지 수를 최소화할 수 있습니다.
예약된 메시지
예약된 메시지가 큐에 전송되면 메시지가 일반 메시지와 같은 큐의 tail에 즉시 추가되지 않습니다. 대신 브로커는 중간 버퍼에 예약된 메시지를 보유하고 메시지 세부 사항에 따라 큐의 헤드에 메시지를 예약합니다. 그러나 예약된 메시지는 대기열의 메시지 수에 계속 반영됩니다. in-delivery 메시지와 마찬가지로 이 동작은 브로커가 링 대기열 크기를 강제 적용하지 않는 것처럼 보일 수 있습니다. 예를 들어 다음 시나리오를 고려해 보십시오.For example, consider this scenario:
12:00에서 생산자는
ring-size="3"으로 구성된 링 큐로 메시지A를 보냅니다. 이 메시지는 12:05로 예정되어 있습니다.이 시점에서
messageCount=1및scheduledCount=1.12:01에서 생산자는
B메시지를 동일한 링 대기열로 보냅니다.이제
messageCount=2및scheduledCount=1.12:02에서 생산자는 메시지
C를 동일한 링 대기열로 보냅니다.이제
messageCount=3및scheduledCount=1.12:03에서 생산자는
D메시지를 동일한 링 대기열로 보냅니다.이제
messageCount=4및scheduledCount=1.대기열의 메시지 수가 이제
4이고, 구성된 링 크기3보다 1배 더 큽니다. 그러나 예약된 메시지는 기술적으로 대기열에 있지 않습니다(즉, 브로커에 있으며 큐에 배치하도록 예약됨). 12:05의 예정된 전달 시간에 브로커는 메시지를 대기열의 헤드에 배치합니다. 그러나 링 큐의 구성된 크기에 이미 도달했으므로 예약된 메시지A가 즉시 제거됩니다.
paged 메시지
배달 중인 예약된 메시지 및 메시지와 유사하게, 페이지화된 메시지는 메시지들이 실제로 대기열 수준이 아닌 주소 수준에서 페이지링되기 때문에 브로커에 의해 적용되는 링 큐 크기로 계산되지 않습니다. paged 메시지는 대기열의 messageCount 값에 반영되어 있지만 기술적으로 대기열에 있지 않습니다.
링 큐가 있는 주소에 페이징을 사용하지 않는 것이 좋습니다. 대신 전체 주소가 메모리에 들어갈 수 있는지 확인합니다. 또는 address-full-policy 매개변수를 DROP,BLOCK 또는 FAIL 의 값으로 구성합니다.
추가 리소스
- 브로커는 소급성 주소를 구성할 때 링 큐의 내부 인스턴스를 생성합니다. 자세한 내용은 4.19절. “소급 주소 구성” 에서 참조하십시오.
4.19. 소급 주소 구성
주소를 소 급성으로 구성하면 주소에 아직 바인딩된 대기열이 없는 경우를 포함하여 해당 주소로 전송된 메시지를 보존할 수 있습니다. 나중에 대기열이 생성되고 주소에 바인딩되면 브로커는 메시지를 해당 큐에 소급적으로 배포합니다. 주소가 소급성으로 구성되지 않고 아직 큐가 바인딩되지 않은 경우 브로커는 해당 주소로 전송된 메시지를 삭제합니다.
소급 주소를 구성하면 브로커는 링 큐로 알려진 큐 유형의 내부 인스턴스를 생성합니다. 링 큐는 지정된 고정된 수의 메시지를 보유하는 특수 유형의 큐입니다. 큐가 지정된 크기에 도달하면 큐에 도달하는 다음 메시지는 대기열에서 가장 오래된 메시지를 강제 적용합니다. 소급 주소를 구성하면 내부 링 큐의 크기를 간접적으로 지정합니다. 기본적으로 내부 대기열은 멀티 캐스트 라우팅 유형을 사용합니다.
소급 주소에 사용되는 내부 링 큐는 관리 API를 통해 노출됩니다. 메트릭을 검사하고 큐 비우기와 같은 기타 일반적인 관리 작업을 수행할 수 있습니다. 링 큐는 또한 주소의 전체 메모리 사용량에 영향을 주므로 메시지 페이징과 같은 동작에 영향을 미칩니다.
다음 절차에서는 주소를 소급성으로 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. address-setting요소에서retroactive-message-count매개변수 값을 지정합니다. 지정하는 값은 브로커가 보존할 메시지 수를 정의합니다. 예를 들면 다음과 같습니다.<configuration> <core> ... <address-settings> <address-setting match="orders"> <retroactive-message-count>100</retroactive-message-count> </address-setting> </address-settings> ... </core> </configuration>참고broker.xml구성 파일 또는 관리 API에서 브로커가 실행되는 동안retroactive-message-count값을 업데이트할 수 있습니다. 그러나 이 매개변수의 값 을 줄이 는 경우 링 큐를 통해 소급성 주소가 구현되기 때문에 추가 단계가 필요합니다.ring-size매개변수가 감소하는 링 큐는 새ring-size값을 달성하기 위해 큐에서 메시지를 자동으로 삭제하지 않습니다. 이 동작은 의도하지 않은 메시지 손실에 대한 보호입니다. 이 경우 관리 API를 사용하여 링 대기열의 메시지 수를 수동으로 줄여야 합니다.
추가 리소스
- 링 큐에 대한 자세한 내용은 4.18절. “링 큐 구성” 을 참조하십시오.
4.20. 내부 관리 주소 및 큐에 대한 권고 메시지 비활성화
기본적으로 AMQ 브로커는 OpenWire 클라이언트가 브로커에 연결된 경우 주소 및 큐에 대한 권고 메시지를 생성합니다. 권고 메시지는 브로커가 생성한 내부 관리 주소로 전송됩니다. 이러한 주소는 사용자 배포 주소 및 큐와 동일한 디스플레이 내에 AMQ 관리 콘솔에 표시됩니다. 권고 메시지는 유용한 정보를 제공하지만 브로커가 많은 수의 대상을 관리하는 경우 원하지 않는 결과를 초래할 수 있습니다. 예를 들어 메시지에서 메모리 사용량 또는 스트레인 연결 리소스를 늘릴 수 있습니다. 또한 권고 메시지 보내기 위해 생성된 모든 주소를 표시하려고 할 때 AMQ Management Console이 어려워질 수 있습니다. 이러한 상황을 방지하기 위해 다음 매개변수를 사용하여 브로커에 대한 권고 메시지의 동작을 구성할 수 있습니다.
supportAdvisory-
권고 메시지 또는
false를 생성하려면 이 옵션을true로 설정합니다. 기본값은true입니다. suppressInternalManagementObjects-
JMX 레지스트리 및 AMQ Management Console과 같은 관리 서비스에 권고 메시지를 노출하려면 이 옵션을
true로 설정하거나 공개하지 않으려면false를 설정합니다. 기본값은true입니다.
다음 절차에서는 브로커의 권고 메시지를 비활성화하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. OpenWire 커넥터의 경우
supportAdvisory및suppressInternalManagementObjects매개변수를 구성된 URL에 추가합니다. 이 섹션의 앞부분에서 설명한 대로 값을 설정합니다. 예를 들면 다음과 같습니다.<acceptor name="artemis">tcp://127.0.0.1:61616?protocols=CORE,AMQP,OPENWIRE;supportAdvisory=false;suppressInternalManagementObjects=false</acceptor>
4.21. 주소 및 대기열 추가
페더레이션을 사용하면 브로커가 공통 클러스터에 있을 필요 없이 브로커 간에 메시지를 전송할 수 있습니다. 브로커는 독립 실행형 또는 별도의 클러스터에 있을 수 있습니다. 또한 소스 및 대상 브로커는 서로 다른 관리 도메인에 있을 수 있으므로 브로커에 다른 구성, 사용자 및 보안 설정이 있을 수 있습니다. 브로커는 다른 버전의 AMQ 브로커를 사용할 수도 있습니다.
예를 들어, 페더레이션은 한 클러스터에서 다른 클러스터로 안정적으로 메시지를 보내는 데 적합합니다. 이 전송은 WAN(Wide Area Network), 클라우드 인프라 의 지역 또는 인터넷을 통해 전송될 수 있습니다. 소스 브로커와 대상 브로커로의 연결이 손실되는 경우(예: 네트워크 장애로 인해), 소스 브로커는 대상 브로커가 다시 온라인 상태가 될 때까지 연결을 다시 설정하려고 합니다. 대상 브로커가 다시 온라인 상태가 되면 메시지 전송이 재개됩니다.
관리자는 주소 및 큐 정책을 사용하여 페더레이션을 관리할 수 있습니다. 정책 구성은 특정 주소 또는 큐와 일치하거나 정책에서 주소 또는 큐 세트 와 일치하는 와일드카드 표현식을 포함할 수 있습니다. 따라서, 페더레이션은 일치하는 세트에 큐 또는 주소가 추가되거나 제거될 때 동적으로 적용될 수 있습니다. 정책에는 특정 주소 및 큐가 포함된 여러 표현식이 포함될 수 있습니다. 또한 브로커 또는 브로커 클러스터에 여러 정책을 적용할 수 있습니다.
AMQ Broker에서 두 가지 주요 페더레이션 옵션은 통합 및 대기열 페더레이션입니다. 이러한 옵션은 다음 섹션에 설명되어 있습니다.
브로커는 페더레이션 및 로컬 전용 구성 요소를 위한 구성을 포함할 수 있습니다. 즉, 브로커에서 페더레이션을 구성하는 경우 해당 브로커의 모든 것을 통합 할 필요가 없습니다.
4.21.1. 주소 페더레이션 정보
주소 페더레이션은 연결된 브로커 간의 전체 멀티 캐스트 배포 패턴과 유사합니다. 예를 들어 BrokerA 의 주소로 전송되는 모든 메시지는 해당 브로커의 모든 큐에 전달됩니다. 또한 각 메시지는 BrokerB 및 연결된 모든 큐에 전달됩니다.
주소 페더레이션은 브로커를 원격 브로커의 주소로 동적으로 연결합니다. 예를 들어 로컬 브로커가 원격 브로커의 주소에서 메시지를 가져오려는 경우 원격 주소에 큐가 자동으로 생성됩니다. 그런 다음 원격 브로커의 메시지가 이 큐에 사용됩니다. 마지막으로 메시지는 원래 로컬 주소에 직접 게시되는 것처럼 로컬 브로커의 해당 주소로 복사됩니다.
페더레이션이 주소를 만들 수 있도록 원격 브로커를 재구성할 필요가 없습니다. 그러나 로컬 브로커는 원격 주소에 대한 권한을 부여해야 합니다.
4.21.2. 주소 연합을 위한 공통 토폴로지
주소 페더레이션 사용을 위한 몇 가지 일반적인 토폴로지는 아래에 설명되어 있습니다.
- 대칭 토폴로지
대칭 토폴로지에서 생산자와 소비자는 각 브로커에 연결됩니다. 큐와 해당 소비자는 두 생산자가 게시한 메시지를 수신할 수 있습니다. 대칭 토폴로지의 예는 다음과 같습니다.
그림 4.1. 대칭 토폴로지의 주소 페더레이션
대칭 토폴로지에 대한 주소 연합을 구성할 때 주소 정책의
max-hops속성 값을1로 설정하는 것이 중요합니다. 이렇게 하면 메시지가 한 번만 복사되므로 순환 복제를 방지할 수 있습니다. 이 속성이 더 큰 값으로 설정된 경우 소비자는 동일한 메시지의 여러 복사본을 수신합니다.- 전체 메시 토폴로지
전체 메시 토폴로지는 대칭 설정과 유사합니다. 3개 이상의 브로커는 대칭적으로 서로 연결되고 전체 메시를 생성합니다. 이 설정에서 생산자와 소비자는 각 브로커에 연결됩니다. 큐와 해당 소비자는 모든 생산자가 게시한 메시지를 수신할 수 있습니다. 이 토폴로지의 예는 다음과 같습니다.
그림 4.2. 전체 메시 토폴로지의 주소 페더레이션
대칭 설정과 같이 전체 메시 토폴로지에 대해 주소 페더레이션을 구성할 때 주소 정책의
max-hops속성 값을1로 설정하는 것이 중요합니다. 이렇게 하면 메시지가 한 번만 복사되므로 순환 복제를 방지할 수 있습니다.- 링 토폴로지
브로커 링에서 각 페더레이션 주소는 링에서 서로의 업스트림입니다. 이 토폴로지의 예는 다음과 같습니다.
그림 4.3. 링 토폴로지의 주소 페더레이션
링 토폴로지에 대한 페더레이션을 구성할 때 사이클 복제를 방지하기 위해 주소 정책의
max-hops속성을n-1값으로 설정하는 것이 중요합니다. 여기서 n 은 링의 노드 수입니다. 예를 들어 위에 표시된 링 토폴로지에서max-hops값은5로 설정됩니다. 이렇게 하면 링의 모든 주소가 정확히 한 번 메시지를 볼 수 있습니다.링 토폴로지의 장점은 필요한 물리적 연결 수 측면에서 설정하는 것이 저렴합니다. 그러나 이러한 유형의 토폴로지의 단점은 단일 브로커가 실패하면 전체 링이 실패한다는 것입니다.
- 팬 아웃 토폴로지
팬 아웃 토폴로지에서 단일 마스터 주소는 연합 주소 트리에 의해 연결됩니다. 마스터 주소에 게시된 모든 메시지는 트리의 브로커에 연결된 모든 소비자가 수신할 수 있습니다. 트리를 모든 깊이로 구성할 수 있습니다. 트리의 기존 브로커를 재구성할 필요 없이 트리를 확장할 수도 있습니다. 이 토폴로지의 예는 다음과 같습니다.
그림 4.4. 팬 아웃 토폴로지의 주소 페더레이션
팬 아웃 토폴로지에 대한 페더레이션을 구성할 때 주소 정책의
max-hops속성을n-1씩 설정했는지 확인합니다. 여기서 n 은 트리의 수준 수입니다. 예를 들어 위에 표시된 팬 아웃 토폴로지에서max-hops값은2로 설정됩니다. 이렇게 하면 트리의 모든 주소가 정확히 한 번 표시됩니다.
4.21.3. 주소 연합 구성에서 다양한 바인딩 지원
주소 페더레이션을 구성할 때 주소 정책 구성에서 다양한 바인딩에 대한 지원을 추가할 수 있습니다. 이 지원을 추가하면 연합이 다양한 바인딩에 응답하여 원격 브로커에 지정된 주소에 대한 연합 소비자를 만들 수 있습니다.
예를 들어 test.federation.source 라는 주소가 주소 정책에 포함되어 있고 test.federation.target 이라는 다른 주소가 포함되어 있지 않다고 가정합니다. 일반적으로 test.federation.target 에 큐가 생성 되면 주소가 주소 정책의 일부가 아니 므로 페더레이션 소비자가 생성되지 않습니다. 그러나 test.federation.source 가 소스 주소이고 test.federation.target 이 전달 주소인 등 다양한 바인딩을 생성하면 전달 주소에 내구성 소비자가 생성됩니다. 소스 주소는 여전히 멀티캐스트 라우팅 유형을 사용해야 하지만 대상 주소는 멀티캐스트 또는 사용할 수 있습니다.
임의의cast 를
예제 사용 사례는 JMS 주제(캐스트 주소)를 JMS 대기열(캐스트 주소)으로 리디렉션하는분산 입니다. 이를 통해 JMS 2.0 및 공유 서브스크립션을 지원하지 않는 레거시 소비자의 주제에 대한 메시지 부하 분산이 가능합니다.
4.21.4. 브로커 클러스터에 대한 페더레이션 구성
다음 섹션의 예제에서는 독립 실행형 로컬 및 원격 브로커 간에 주소 및 대기열 페더레이션을 구성하는 방법을 보여줍니다. 독립 실행형 브로커 간의 페더레이션의 경우 연합 구성의 이름과 주소 및 대기열 정책의 이름은 로컬 및 원격 브로커 간에 고유해야 합니다.
그러나 클러스터 의 브로커에 대한 페더레이션을 구성하는 경우 추가 요구 사항이 있습니다. 클러스터형 브로커의 경우 페더레이션 구성의 이름과 해당 구성 내의 모든 주소 및 대기열 정책 이름이 해당 클러스터 의 모든 브로커에 대해 동일해야 합니다.
동일한 클러스터의 브로커가 동일한 페더레이션 구성 및 주소 및 대기열 정책 이름을 사용하도록 하면 메시지 중복이 발생하지 않습니다. 예를 들어, 동일한 클러스터 내의 브로커에 서로 다른 페더레이션 구성 이름이 있는 경우 동일한 주소에 대해 여러 다른 이름 지정 전달 대기열이 생성되어 다운스트림 소비자에 대한 메시지 중복이 발생할 수 있습니다. 대조적으로 동일한 클러스터의 브로커가 동일한 페더레이션 구성 이름을 사용하는 경우, 이는 기본적으로 다운스트림 소비자에게 부하 분산된 클러스터된 전달 대기열을 생성합니다. 이렇게 하면 메시지 중복을 방지할 수 있습니다.
4.21.5. 업스트림 주소 연합 구성
다음 예제에서는 독립 실행형 브로커 간에 업스트림 주소 페더레이션을 구성하는 방법을 보여줍니다. 이 예제에서는 로컬 (즉, 다운스트림 ) 브로커에서 일부 원격 (즉, 업스트림) 브로커에 대한 페더레이션을 구성합니다.
사전 요구 사항
- 다음 예제에서는 독립 실행형 브로커 간에 주소 페더레이션을 구성하는 방법을 보여줍니다. 그러나 브로커 클러스터에 대한 페더레이션 구성 요구 사항도 잘 알고 있어야 합니다. 자세한 내용은 4.21.4절. “브로커 클러스터에 대한 페더레이션 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
feder추가합니다. 예를 들면 다음과 같습니다.ation> 요소를 포함하는 새 <federations> 요소를<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> </federation> </federations>
name- 페더레이션 구성의 이름입니다. 이 예에서 name은 로컬 브로커의 이름에 해당합니다.
user- 업스트림 브로커에 연결하기 위한 공유 사용자 이름입니다.
암호- 업스트림 브로커와의 연결에 대한 공유 암호입니다.
참고원격 브로커에 대해 사용자 및 암호 자격 증명이 다른 경우 구성에 추가할 때 해당 브로커의 인증 정보를 별도로 지정할 수 있습니다. 이 내용은 이 절차의 뒷부분에서 설명합니다.
페더레이션 요소 내에서
<address-policy> 요소를 추가합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <address-policy name="news-address-federation" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" enable-divert-bindings="false" max-hops="1" transformer-ref="news-transformer"> </address-policy> </federation> </federations>name- 주소 정책의 이름입니다. 브로커에 구성된 모든 주소 정책에는 고유한 이름이 있어야 합니다.
자동 삭제-
주소 페더레이션 중에 로컬 브로커는 동적으로 원격 주소에 영구 큐를 생성합니다.
auto-delete속성의 값은 로컬 브로커의 연결이 끊어지면 원격 큐와 auto-delete-delay 및속성에도 도달했는지 여부를 지정합니다. 동적으로 생성된 큐의 정리를 자동화하려는 경우 이 옵션이 유용합니다. 또한 로컬 브로커의 연결이 끊어진 경우 원격 브로커에서 메시지를 빌드하지 않으려는 경우에도 유용합니다. 그러나 연결이 끊긴 동안 메시지가 항상 로컬 브로커에 대해 큐에 남아 있도록 하려면 이 옵션을auto-delete-message-countfalse로 설정하여 로컬 브로커에서 메시지 손실을 방지할 수 있습니다. auto-delete-delay- 로컬 브로커의 연결이 끊어진 후 이 속성의 값은 동적으로 생성된 원격 큐를 자동으로 삭제하기 전에 시간(밀리초)을 지정합니다.
auto-delete-message-count- 로컬 브로커의 연결이 끊어진 후 이 속성의 값은 큐를 자동으로 삭제할 수 있기 전에 동적으로 생성된 원격 큐에 있을 수 있는 최대 메시지 수를 지정합니다.
enable-divert-bindings-
이 속성을
true로 설정하면 개별 바인딩이 요청에 대해 수신 대기됩니다. 주소 정책의 포함된 주소와 일치하는 주소가 포함된 다양한 바인딩이 있는 경우, 요약의 전달 주소와 일치하는 큐 바인딩은 수요가 생성됩니다. 기본값은false입니다. max-hops- 페더레이션 중에 메시지를 만들 수 있는 최대 홉 수입니다. 특정 토폴로지에는 이 속성에 대한 특정 값이 필요합니다. 이러한 요구 사항에 대한 자세한 내용은 4.21.2절. “주소 연합을 위한 공통 토폴로지” 을 참조하십시오.
transformer-ref- 변환기 구성의 이름입니다. 연합 메시지 전송 중에 메시지를 변환하려면 변환기 구성을 추가할 수 있습니다. Transformer 구성은 이 절차의 뒷부분에서 설명합니다.
<
address-policy> 요소 내에서 주소 정책에서 주소를 포함 및 제외하는 address-matching 패턴을 추가합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <address-policy name="news-address-federation" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" enable-divert-bindings="false" max-hops="1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> </federation> </federations>include-
이 요소의
address-match속성 값은 주소 정책에 포함할 주소를 지정합니다. 정확한 주소(예:queue.bbc.new또는queue.usatoday)를 지정할 수 있습니다. 또는 와일드카드 식을 사용하여 일치하는 주소 집합 을 지정할 수 있습니다. 이전 예에서 address 정책에는 문자열queue.news로 시작하는 모든 주소 이름도 포함되어 있습니다. exclude-
이 요소의
address-match속성 값은 주소 정책에서 제외할 주소를 지정합니다. 정확한 주소 이름을 지정하거나 와일드카드 식을 사용하여 일치하는 주소 집합 을 지정할 수 있습니다. 이전 예에서 address 정책은 stringqueue.news.sport로 시작하는 모든 주소 이름을 제외합니다.
(선택 사항) 페더레이션 요소에서 사용자 지정
변환기구현을 참조하는 변환기 요소를 추가합니다.예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <address-policy name="news-address-federation" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" enable-divert-bindings="false" max-hops="1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> </federations>name-
변환기 구성의 이름입니다. 이 이름은 로컬 브로커에서 고유해야 합니다. 이는 주소 정책의
transformer-ref속성에 대한 값으로 지정하는 이름입니다. class-nameorg.apache.activemq.artemis.core.server.transformer.Transformer인터페이스를 구현하는 사용자 정의 클래스의 이름입니다.transformer의
transform()메서드는 메시지를 전송하기 전에 메시지와 함께 호출됩니다. 이를 통해 메시지 헤더 또는 본문이 통합되기 전에 변환할 수 있습니다.속성- 특정 변환기 구성에 대해 키-값 쌍을 유지하는 데 사용됩니다.
페더레이션 요소
내에서 하나이상의업스트림요소를 추가합니다. 각업스트림요소는 원격 브로커와 해당 연결에 적용할 정책을 정의합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <upstream name="eu-east-1"> <static-connectors> <connector-ref>eu-east-connector1</connector-ref> </static-connectors> <policy ref="news-address-federation"/> </upstream> <upstream name="eu-west-1" > <static-connectors> <connector-ref>eu-west-connector1</connector-ref> </static-connectors> <policy ref="news-address-federation"/> </upstream> <address-policy name="news-address-federation" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" enable-divert-bindings="false" max-hops="1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> </federations>static-connectors-
로컬 브로커의
broker.xml구성 파일에서 정의된 커넥터 요소를 참조하는connector-refstatic-connectors요소에서 참조되는 커넥터를 추가하는 방법을 보여줍니다. policy-ref- 업스트림 브로커에 적용되는 다운스트림 브로커에 구성된 주소 정책의 이름입니다.
업스트림요소에 대해 지정할 수 있는 추가 옵션은 아래에 설명되어 있습니다.name-
업스트림 브로커 구성의 이름입니다. 이 예에서 이름은
eu-east-1및eu-west-1이라는 업스트림 브로커에 해당합니다. user-
업스트림 브로커에 대한 연결을 생성할 때 사용할 사용자 이름입니다. 지정하지 않으면 페더레이션 요소의 구성에 지정된 공유 사용자 이름이 사용됩니다.
암호-
업스트림 브로커에 대한 연결을 생성할 때 사용할 암호입니다. 지정하지 않으면 페더레이션 요소의 구성에 지정된 공유 암호가 사용됩니다.
call-failover-timeout-
call-timeout과 유사하지만 장애 조치(failover) 시도 중에 호출이 수행됩니다. 기본값은-1이며, 이는 시간 초과가 비활성화됨을 의미합니다. call-timeout-
페더레이션 연결은 차단 호출인 패킷을 전송할 때 원격 브로커의 응답을 대기하는 시간(밀리초)입니다. 이 시간이 경과하면 연결에서 예외가 발생합니다. 기본값은
30000입니다. check-period-
로컬 브로커가 원격 브로커로 보내는 연속 "보통" 메시지 사이의 기간(밀리초)은 페더레이션 연결의 상태를 확인합니다. 페더레이션 연결이 정상이면 원격 브로커는 각 keep-alive 메시지에 응답합니다. 연결이 비정상인 경우 다운스트림 브로커가 업스트림 브로커에서 응답을 수신하지 못하면 회로 차단기 라는 메커니즘을 사용하여 페더레이션 소비자를 차단합니다. 자세한 내용은
circuit-breaker-timeout매개변수에 대한 설명을 참조하십시오.check-period매개변수의 기본값은30000입니다. circuit-breaker-timeout- 다운스트림과 업스트림 브로커 간의 단일 연결은 많은 연합 큐와 주소 소비자에 의해 공유될 수 있습니다. 브로커 간의 연결이 손실되는 경우 각 연합 소비자는 동시에 다시 연결을 시도할 수 있습니다. 이를 방지하기 위해 회로 차단기 라는 메커니즘은 소비자를 차단합니다. 지정된 시간 초과 값이 경과하면 회로 차단기가 연결을 다시 만듭니다. 성공하면 소비자는 차단 해제됩니다. 그렇지 않으면 회로 차단기가 다시 적용됩니다.
connection-ttl-
원격 브로커에서 메시지 수신을 중지하면 페더레이션 연결이 활성 상태로 유지됩니다. 기본값은
60000입니다. discovery-group-ref-
업스트림 브로커에 대한 연결에 대한 정적 커넥터를 정의하는 대신 이 요소를 사용하여
broker.xml구성 파일의 다른 곳에서 이미 구성된 검색 그룹을 지정할 수 있습니다. 특히 이 요소의discovery-group-name속성에 대한 값으로 기존 검색 그룹을 지정합니다. 검색 그룹에 대한 자세한 내용은 16.1.5절. “브로커 검색 방법” 을 참조하십시오. ha-
업스트림 브로커 연결에 대해 고가용성을 활성화할지 여부를 지정합니다. 이 매개변수의 값이
true로 설정된 경우 로컬 브로커는 업스트림 클러스터에서 사용 가능한 모든 브로커에 연결할 수 있으며 라이브 업스트림 브로커가 종료되면 백업 브로커로 자동으로 실패합니다. 기본값은false입니다. initial-connect-attempts-
다운스트림 브로커가 업스트림 브로커에 연결하려고 하는 초기 시도 수입니다. 연결이 설정되지 않은 경우 업스트림 브로커는 영구적으로 오프라인 상태로 간주됩니다. 다운스트림 브로커는 더 이상 메시지를 업스트림 브로커로 라우팅하지 않습니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다. max-retry-interval-
원격 브로커에 연결할 때 후속 재시도 시도 사이의 최대 시간(밀리초)입니다. 기본값은
2000입니다. reconnect-attempts-
다운스트림 브로커가 연결에 실패한 경우 업스트림 브로커에 다시 연결을 시도하는 횟수입니다. 연결을 재설정하지 않고 이 값에 도달하면 업스트림 브로커는 영구적으로 오프라인 상태로 간주됩니다. 다운스트림 브로커는 더 이상 메시지를 업스트림 브로커로 라우팅하지 않습니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다. retry-interval-
원격 브로커에 대한 연결이 실패한 경우 후속 재시도 시도 사이의 기간(밀리초)입니다. 기본값은
500입니다. retry-interval-multiplier-
retry-interval매개 변수의 값에 적용되는 요인을 곱합니다. 기본값은1입니다. share-connection-
동일한 브로커에 대해 다운스트림 및 업스트림 연결이 모두 구성된 경우 다운스트림 및 업스트림 구성 모두 이 매개 변수의 값을
true로 설정하는 경우 동일한 연결이 공유됩니다. 기본값은false입니다.
로컬 브로커에서 원격 브로커에 커넥터를 추가합니다. 이는 연합 주소 구성의
정적 연결 요소에서 참조되는 커넥터입니다. 예를 들면 다음과 같습니다.<connectors> <connector name="eu-west-1-connector">tcp://localhost:61616</connector> <connector name="eu-east-1-connector">tcp://localhost:61617</connector> </connectors>
4.21.6. 다운스트림 주소 연합 구성
다음 예제에서는 독립 실행형 브로커에 대한 다운스트림 주소 페더레이션을 구성하는 방법을 보여줍니다.
다운스트림 주소 페더레이션을 사용하면 하나 이상의 원격 브로커가 로컬 브로커에 다시 연결하는 데 사용하는 로컬 브로커에 구성을 추가할 수 있습니다. 이 접근 방식의 장점은 모든 페더레이션 구성을 단일 브로커에 유지할 수 있다는 것입니다. 예를 들어 허브 및 스포크 토폴로지에 유용한 접근법이 될 수 있습니다.
다운스트림 주소 페더레이션은 페더레이션 연결과 업스트림 주소 구성의 방향을 역전합니다. 따라서 구성에 원격 브로커를 추가하면 다운스트림 브로커로 간주됩니다. 다운스트림 브로커는 구성의 연결 정보를 사용하여 로컬 브로커로 다시 연결합니다. 이 정보는 업스트림으로 간주됩니다. 이 예제는 원격 브로커에 대한 구성을 추가할 때 이 예제의 뒷부분에서 설명합니다.
사전 요구 사항
- 업스트림 주소 페더레이션의 구성에 대해 잘 알고 있어야 합니다. 4.21.5절. “업스트림 주소 연합 구성” 을 참조하십시오.
- 다음 예제에서는 독립 실행형 브로커 간에 주소 페더레이션을 구성하는 방법을 보여줍니다. 그러나 브로커 클러스터에 대한 페더레이션 구성 요구 사항도 잘 알고 있어야 합니다. 자세한 내용은 4.21.4절. “브로커 클러스터에 대한 페더레이션 구성”의 내용을 참조하십시오.
절차
-
로컬 브로커에서 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
feder추가합니다. 예를 들면 다음과 같습니다.ation> 요소를 포함하는 <federations> 요소를<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> </federation> </federations>주소 정책 구성을 추가합니다. 예를 들면 다음과 같습니다.
<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <address-policy name="news-address-federation" max-hops="1" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> </federation> ... </federations>전송 전에 메시지를 변환하려면 변환기 구성을 추가합니다. 예를 들면 다음과 같습니다.
<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <address-policy name="news-address-federation" max-hops="1" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> ... </federations>각 원격 브로커에 대해
downstream요소를 추가합니다. 예를 들면 다음과 같습니다.<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <downstream name="eu-east-1"> <static-connectors> <connector-ref>eu-east-connector1</connector-ref> </static-connectors> <transport-connector-ref>netty-connector</transport-connector-ref> <policy ref="news-address-federation"/> </downstream> <downstream name="eu-west-1" > <static-connectors> <connector-ref>eu-west-connector1</connector-ref> </static-connectors> <transport-connector-ref>netty-connector</transport-connector-ref> <policy ref="news-address-federation"/> </downstream> <address-policy name="news-address-federation" max-hops="1" auto-delete="true" auto-delete-delay="300000" auto-delete-message-count="-1" transformer-ref="news-transformer"> <include address-match="queue.bbc.new" /> <include address-match="queue.usatoday" /> <include address-match="queue.news.#" /> <exclude address-match="queue.news.sport.#" /> </address-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> ... </federations>이전 구성에 표시된 대로 원격 브로커는 이제 로컬 브로커의 다운스트림으로 간주됩니다. 다운스트림 브로커는 구성의 연결 정보를 사용하여 로컬(즉, 업스트림) 브로커에 다시 연결합니다.
로컬 브로커에서 로컬 및 원격 브로커가 사용하는 커넥터 및 수락자를 추가하여 페더레이션 연결을 설정합니다. 예를 들면 다음과 같습니다.
<connectors> <connector name="netty-connector">tcp://localhost:61616</connector> <connector name="eu-west-1-connector">tcp://localhost:61616</connector> <connector name="eu-east-1-connector">tcp://localhost:61617</connector> </connectors> <acceptors> <acceptor name="netty-acceptor">tcp://localhost:61616</acceptor> </acceptors>
connector name="netty-connector"- 로컬 브로커가 원격 브로커로 전송하는 커넥터 구성입니다. 원격 브로커는 이 구성을 사용하여 다시 로컬 브로커에 연결합니다.
connector name="eu-west-1-connector",connector name="eu-east-1-connector"- 원격 브로커에 연결합니다. 로컬 브로커는 이러한 커넥터를 사용하여 원격 브로커에 연결하고 원격 브로커가 로컬 브로커에 다시 연결하는 데 필요한 구성을 공유합니다.
acceptor name="netty-acceptor"- 원격 브로커가 로컬 브로커에 다시 연결하는 데 사용하는 커넥터에 해당하는 로컬 브로커의 수락입니다.
4.21.7. 대기열 통합 정보
대기열 페더레이션을 통해 다른 원격 브로커 간에 단일 대기열의 부하를 분산시킬 수 있습니다.
부하 분산을 달성하기 위해 로컬 브로커는 로컬 소비자의 메시지에 대한 요구를 충족하기 위해 원격 대기열에서 메시지를 검색합니다. 예는 다음과 같습니다.
그림 4.5. 대칭 대기열 통합
원격 대기열을 재구성할 필요가 없으며 동일한 브로커 또는 동일한 클러스터에 있을 필요가 없습니다. 원격 링크를 설정하는 데 필요한 모든 구성이 로컬 브로커에 있습니다.
4.21.7.1. 대기열 통합의 이점
아래 설명에는 대기열 페더레이션을 구성하도록 선택할 수 있는 몇 가지 이유가 설명되어 있습니다.
- 용량 증가
- 대기열 페더레이션은 여러 브로커에 걸쳐 분산된 "논리적" 큐를 만들 수 있습니다. 이 논리 분산 대기열은 단일 브로커에 있는 단일 대기열보다 용량이 훨씬 많습니다. 이 설정에서 가능한 많은 메시지가 원래 게시 된 브로커에서 소비됩니다. 시스템은 부하 분산이 필요한 경우에만 페더레이션의 메시지를 이동합니다.
- 다중 지역 설정 배포
다중 지역 설정에서는 한 지역 또는 장소에 메시지 생산자가 있고 다른 지역에 소비자가 있을 수 있습니다. 그러나 생산자 및 소비자 연결을 지정된 지역에 로컬로 유지해야 합니다. 이 경우 생산자와 소비자가 있는 각 지역에 브로커를 배포하고 대기열 페더레이션을 사용하여 지역 간에 WAN(Wide Area Network)을 통해 메시지를 이동할 수 있습니다. 예는 다음과 같습니다.
그림 4.6. 멀티 리전 대기열 통합
- 보안 엔터프라이즈 LAN과 DMZ 간 통신
네트워킹 보안에서 DMZ는 엔터프라이즈의 외부 연결 서비스를 포함하는 물리적 또는 논리적 서브네트워크로, 일반적으로 인터넷과 같은 더 큰 규모의 네트워크에 있습니다. 회사의 LAN(Local Area Network)의 나머지 부분은 방화벽 뒤의 외부 네트워크와 격리된 상태로 유지됩니다.
여러 메시지 생산자가 DMZ와 보안 엔터프라이즈 LAN의 다수의 소비자에 있는 경우 생산자가 보안 엔터프라이즈 LAN의 브로커에 연결하는 것이 적절하지 않을 수 있습니다. 이 경우 생산자가 메시지를 게시할 수 있는 DMZ에 브로커를 배포할 수 있습니다. 그런 다음 엔터프라이즈 LAN의 브로커는 DMZ의 브로커에 연결하고 연합 대기열을 사용하여 DMZ 브로커에서 메시지를 수신할 수 있습니다.
4.21.8. 업스트림 대기열 통합 구성
다음 예는 독립 실행형 브로커에 대해 업스트림 대기열 페더레이션을 구성하는 방법을 보여줍니다. 이 예제에서는 로컬 (즉, 다운스트림 ) 브로커에서 일부 원격 (즉, 업스트림) 브로커에 대한 페더레이션을 구성합니다.
사전 요구 사항
- 다음 예제에서는 독립 실행형 브로커 간에 큐 페더레이션을 구성하는 방법을 보여줍니다. 그러나 브로커 클러스터에 대한 페더레이션 구성 요구 사항도 잘 알고 있어야 합니다. 자세한 내용은 4.21.4절. “브로커 클러스터에 대한 페더레이션 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 새로운 <
federations> 요소 내에서 <federation> 요소를추가합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> </federation> </federations>
name- 페더레이션 구성의 이름입니다. 이 예에서 name은 downstream 브로커의 이름에 해당합니다.
user- 업스트림 브로커에 연결하기 위한 공유 사용자 이름입니다.
암호- 업스트림 브로커와의 연결에 대한 공유 암호입니다.
참고- 업스트림 브로커에 대해 사용자 및 암호 인증 정보가 다른 경우 구성에 추가할 때 해당 브로커의 인증 정보를 별도로 지정할 수 있습니다. 이 내용은 이 절차의 뒷부분에서 설명합니다.
페더레이션 요소 내에서
<queue-policy> 요소를 추가합니다. <queue-policy>요소의 속성에 대한 값을 지정합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <queue-policy name="news-queue-federation" include-federated="true" priority-adjustment="-5" transformer-ref="news-transformer"> </queue-policy> </federation> </federations>name- 큐 정책의 이름입니다. 브로커에 구성된 모든 큐 정책에는 고유한 이름이 있어야 합니다.
include-federated이 속성의 값이
false로 설정되면 구성이 이미 제공된 소비자(즉, 페더레이션 대기열의 소비자)를 다시 변형시키지 않습니다. 이를 통해 대칭 또는 폐쇄 루프 토폴로지의 경우 작동하지 않는 소비자가 없으며 메시지는 시스템 전체에서 무한대로 흐르는 상황을 방지할 수 있습니다.닫기 루프 토폴로지가 없는 경우 이 속성의 값을
true로 설정할 수 있습니다.You might set the value of this property to true if you do not have a closed-loop topology. 예를 들어BrokerA및BrokerC의 생산자가 있는 3개의 브로커,BrokerA,BrokerB및BrokerC체인이 있다고 가정합니다. 이 경우BrokerB에서 소비자를BrokerA에 다시 제공하려고 합니다.priority-adjustment-
소비자가 큐에 연결할 때 해당 우선 순위는 업스트림 소비자(즉, 페더레이션) 소비자가 생성될 때 사용됩니다. 연합 소비자의 우선 순위는
우선 순위 속성의 값에 의해 조정됩니다. 이 속성의 기본값은-1이며, 이는 부하 분산 중에 로컬 소비자가 페더레이션 소비자보다 우선 순위를 지정할 수 있습니다. 그러나 필요에 따라 우선순위 조정의 값을 변경할 수 있습니다. transformer-ref- 변환기 구성의 이름입니다. 연합 메시지 전송 중에 메시지를 변환하려면 변환기 구성을 추가할 수 있습니다. Transformer 구성은 이 절차의 뒷부분에서 설명합니다.
<
queue-policy> 요소 내에서 큐 정책에서 주소를 포함 및 제외하는 address-matching 패턴을 추가합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <queue-policy name="news-queue-federation" include-federated="true" priority-adjustment="-5" transformer-ref="news-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> </federation> </federations>include이 요소의
address-match속성 값은 큐 정책에 포함할 주소를 지정합니다. 정확한 주소(예:queue.bbc.new또는queue.usatoday)를 지정할 수 있습니다. 또는 와일드카드 식을 사용하여 일치하는 주소 집합 을 지정할 수 있습니다. 이전 예에서 큐 정책에는 문자열queue.news로 시작하는 모든 주소 이름도 포함되어 있습니다.address-match속성과 함께queue-match속성을 사용하여 큐 정책의 해당 주소에 특정 큐를 포함할 수 있습니다.address-match속성과 마찬가지로 정확한 대기열 이름을 지정하거나 와일드카드 표현식을 사용하여 큐 세트 를 지정할 수 있습니다. 앞의 예제에서 숫자 기호(#) 와일드카드 문자는 각 주소 또는 주소 세트의 모든 큐가 큐 정책에 포함됨을 의미합니다.exclude-
이 요소의
address-match속성 값은 큐 정책에서 제외할 주소를 지정합니다. 정확한 주소를 지정하거나 와일드카드 식을 사용하여 일치하는 주소 집합 을 지정할 수 있습니다. 앞의 예제에서 숫자 기호(#) 와일드카드 문자는 모든 주소에서queue-match속성과 일치하는 모든 큐가 제외됨을 의미합니다. 이 경우.local문자열로 끝나는 모든 큐는 제외됩니다. 이는 특정 대기열이 로컬 대기열로 유지되며 통합되지 않음을 나타냅니다.
페더레이션 요소 내에서
사용자지정변환기구현을 참조하기 위해 변환기 요소를 추가합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <queue-policy name="news-queue-federation" include-federated="true" priority-adjustment="-5" transformer-ref="news-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> </federations>name-
변환기 구성의 이름입니다. 이 이름은 해당 브로커에서 고유해야 합니다. 이 이름을 주소 정책의
transformer-ref속성에 대한 값으로 지정합니다. class-nameorg.apache.activemq.artemis.core.server.transformer.Transformer인터페이스를 구현하는 사용자 정의 클래스의 이름입니다.transformer의
transform()메서드는 메시지를 전송하기 전에 메시지와 함께 호출됩니다. 이를 통해 메시지 헤더 또는 본문이 통합되기 전에 변환할 수 있습니다.속성- 특정 변환기 구성에 대해 키-값 쌍을 유지하는 데 사용됩니다.
페더레이션 요소
내에서 하나이상의업스트림요소를 추가합니다. 각업스트림요소는 해당 연결에 적용할 업스트림 브로커 연결 및 정책을 정의합니다. 예를 들면 다음과 같습니다.<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <upstream name="eu-east-1"> <static-connectors> <connector-ref>eu-east-connector1</connector-ref> </static-connectors> <policy ref="news-queue-federation"/> </upstream> <upstream name="eu-west-1" > <static-connectors> <connector-ref>eu-west-connector1</connector-ref> </static-connectors> <policy ref="news-queue-federation"/> </upstream> <queue-policy name="news-queue-federation" include-federated="true" priority-adjustment="-5" transformer-ref="news-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> </federations>static-connectors-
로컬 브로커의
broker.xml구성 파일에서 정의된 커넥터 요소를 참조하는connector-ref정적 연결 요소에서 참조한 커넥터를 추가하는 방법을 보여줍니다. policy-ref- 업스트림 브로커에 적용되는 다운스트림 브로커에 구성된 큐 정책의 이름입니다.
업스트림요소에 대해 지정할 수 있는 추가 옵션은 아래에 설명되어 있습니다.name-
업스트림 브로커 구성의 이름입니다. 이 예에서 이름은
eu-east-1및eu-west-1이라는 업스트림 브로커에 해당합니다. user-
업스트림 브로커에 대한 연결을 생성할 때 사용할 사용자 이름입니다. 지정하지 않으면 페더레이션 요소의 구성에 지정된 공유 사용자 이름이 사용됩니다.
암호-
업스트림 브로커에 대한 연결을 생성할 때 사용할 암호입니다. 지정하지 않으면 페더레이션 요소의 구성에 지정된 공유 암호가 사용됩니다.
call-failover-timeout-
call-timeout과 유사하지만 장애 조치(failover) 시도 중에 호출이 수행됩니다. 기본값은-1이며, 이는 시간 초과가 비활성화됨을 의미합니다. call-timeout-
페더레이션 연결은 차단 호출인 패킷을 전송할 때 원격 브로커의 응답을 대기하는 시간(밀리초)입니다. 이 시간이 경과하면 연결에서 예외가 발생합니다. 기본값은
30000입니다. check-period-
로컬 브로커가 원격 브로커로 보내는 연속 "보통" 메시지 사이의 기간(밀리초)은 페더레이션 연결의 상태를 확인합니다. 페더레이션 연결이 정상이면 원격 브로커는 각 keep-alive 메시지에 응답합니다. 연결이 비정상인 경우 다운스트림 브로커가 업스트림 브로커에서 응답을 수신하지 못하면 회로 차단기 라는 메커니즘을 사용하여 페더레이션 소비자를 차단합니다. 자세한 내용은
circuit-breaker-timeout매개변수에 대한 설명을 참조하십시오.check-period매개변수의 기본값은30000입니다. circuit-breaker-timeout- 다운스트림과 업스트림 브로커 간의 단일 연결은 많은 연합 큐와 주소 소비자에 의해 공유될 수 있습니다. 브로커 간의 연결이 손실되는 경우 각 연합 소비자는 동시에 다시 연결을 시도할 수 있습니다. 이를 방지하기 위해 회로 차단기 라는 메커니즘은 소비자를 차단합니다. 지정된 시간 초과 값이 경과하면 회로 차단기가 연결을 다시 만듭니다. 성공하면 소비자는 차단 해제됩니다. 그렇지 않으면 회로 차단기가 다시 적용됩니다.
connection-ttl-
원격 브로커에서 메시지 수신을 중지하면 페더레이션 연결이 활성 상태로 유지됩니다. 기본값은
60000입니다. discovery-group-ref-
업스트림 브로커에 대한 연결에 대한 정적 커넥터를 정의하는 대신 이 요소를 사용하여
broker.xml구성 파일의 다른 곳에서 이미 구성된 검색 그룹을 지정할 수 있습니다. 특히 이 요소의discovery-group-name속성에 대한 값으로 기존 검색 그룹을 지정합니다. 검색 그룹에 대한 자세한 내용은 16.1.5절. “브로커 검색 방법” 을 참조하십시오. ha-
업스트림 브로커 연결에 대해 고가용성을 활성화할지 여부를 지정합니다. 이 매개변수의 값이
true로 설정된 경우 로컬 브로커는 업스트림 클러스터에서 사용 가능한 모든 브로커에 연결할 수 있으며 라이브 업스트림 브로커가 종료되면 백업 브로커로 자동으로 실패합니다. 기본값은false입니다. initial-connect-attempts-
다운스트림 브로커가 업스트림 브로커에 연결하려고 하는 초기 시도 수입니다. 연결이 설정되지 않은 경우 업스트림 브로커는 영구적으로 오프라인 상태로 간주됩니다. 다운스트림 브로커는 더 이상 메시지를 업스트림 브로커로 라우팅하지 않습니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다. max-retry-interval-
원격 브로커에 연결할 때 후속 재시도 시도 사이의 최대 시간(밀리초)입니다. 기본값은
2000입니다. reconnect-attempts-
다운스트림 브로커가 연결에 실패한 경우 업스트림 브로커에 다시 연결을 시도하는 횟수입니다. 연결을 재설정하지 않고 이 값에 도달하면 업스트림 브로커는 영구적으로 오프라인 상태로 간주됩니다. 다운스트림 브로커는 더 이상 메시지를 업스트림 브로커로 라우팅하지 않습니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다. retry-interval-
원격 브로커에 대한 연결이 실패한 경우 후속 재시도 시도 사이의 기간(밀리초)입니다. 기본값은
500입니다. retry-interval-multiplier-
retry-interval매개 변수의 값에 적용되는 요인을 곱합니다. 기본값은1입니다. share-connection-
동일한 브로커에 대해 다운스트림 및 업스트림 연결이 모두 구성된 경우 다운스트림 및 업스트림 구성 모두 이 매개 변수의 값을
true로 설정하는 경우 동일한 연결이 공유됩니다. 기본값은false입니다.
로컬 브로커에서 원격 브로커에 커넥터를 추가합니다. 이는 연합 주소 구성의
정적 연결 요소에서 참조되는 커넥터입니다. 예를 들면 다음과 같습니다.<connectors> <connector name="eu-west-1-connector">tcp://localhost:61616</connector> <connector name="eu-east-1-connector">tcp://localhost:61617</connector> </connectors>
4.21.9. 다운스트림 대기열 통합 구성
다음 예제에서는 다운스트림 대기열 페더레이션을 구성하는 방법을 보여줍니다.
다운스트림 대기열 페더레이션을 통해 하나 이상의 원격 브로커가 로컬 브로커에 다시 연결하는 데 사용하는 로컬 브로커에 구성을 추가할 수 있습니다. 이 접근 방식의 장점은 모든 페더레이션 구성을 단일 브로커에 유지할 수 있다는 것입니다. 예를 들어 허브 및 스포크 토폴로지에 유용한 접근법이 될 수 있습니다.
다운스트림 대기열 페더레이션은 페더레이션 연결과 업스트림 대기열 구성의 방향을 역전합니다. 따라서 구성에 원격 브로커를 추가하면 다운스트림 브로커로 간주됩니다. 다운스트림 브로커는 구성의 연결 정보를 사용하여 로컬 브로커로 다시 연결합니다. 이 정보는 업스트림으로 간주됩니다. 이 예제는 원격 브로커에 대한 구성을 추가할 때 이 예제의 뒷부분에서 설명합니다.
사전 요구 사항
- 업스트림 대기열 통합 구성에 대해 잘 알고 있어야 합니다. 4.21.8절. “업스트림 대기열 통합 구성” 을 참조하십시오.
- 다음 예제에서는 독립 실행형 브로커 간에 큐 페더레이션을 구성하는 방법을 보여줍니다. 그러나 브로커 클러스터에 대한 페더레이션 구성 요구 사항도 잘 알고 있어야 합니다. 자세한 내용은 4.21.4절. “브로커 클러스터에 대한 페더레이션 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
feder추가합니다. 예를 들면 다음과 같습니다.ation> 요소를 포함하는 <federations> 요소를<federations> <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> </federation> </federations>
큐 정책 구성을 추가합니다. 예를 들면 다음과 같습니다.
<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <queue-policy name="news-queue-federation" priority-adjustment="-5" include-federated="true" transformer-ref="new-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> </federation> ... </federations>전송 전에 메시지를 변환하려면 변환기 구성을 추가합니다. 예를 들면 다음과 같습니다.
<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <queue-policy name="news-queue-federation" priority-adjustment="-5" include-federated="true" transformer-ref="news-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> ... </federations>각 원격 브로커에 대해
downstream요소를 추가합니다. 예를 들면 다음과 같습니다.<federations> ... <federation name="eu-north-1" user="federation_username" password="32a10275cf4ab4e9"> <downstream name="eu-east-1"> <static-connectors> <connector-ref>eu-east-connector1</connector-ref> </static-connectors> <transport-connector-ref>netty-connector</transport-connector-ref> <policy ref="news-address-federation"/> </downstream> <downstream name="eu-west-1" > <static-connectors> <connector-ref>eu-west-connector1</connector-ref> </static-connectors> <transport-connector-ref>netty-connector</transport-connector-ref> <policy ref="news-address-federation"/> </downstream> <queue-policy name="news-queue-federation" priority-adjustment="-5" include-federated="true" transformer-ref="new-transformer"> <include queue-match="#" address-match="queue.bbc.new" /> <include queue-match="#" address-match="queue.usatoday" /> <include queue-match="#" address-match="queue.news.#" /> <exclude queue-match="#.local" address-match="#" /> </queue-policy> <transformer name="news-transformer"> <class-name>org.foo.NewsTransformer</class-name> <property key="key1" value="value1"/> <property key="key2" value="value2"/> </transformer> </federation> ... </federations>이전 구성에 표시된 대로 원격 브로커는 이제 로컬 브로커의 다운스트림으로 간주됩니다. 다운스트림 브로커는 구성의 연결 정보를 사용하여 로컬(즉, 업스트림) 브로커에 다시 연결합니다.
로컬 브로커에서 로컬 및 원격 브로커가 사용하는 커넥터 및 수락자를 추가하여 페더레이션 연결을 설정합니다. 예를 들면 다음과 같습니다.
<connectors> <connector name="netty-connector">tcp://localhost:61616</connector> <connector name="eu-west-1-connector">tcp://localhost:61616</connector> <connector name="eu-east-1-connector">tcp://localhost:61617</connector> </connectors> <acceptors> <acceptor name="netty-acceptor">tcp://localhost:61616</acceptor> </acceptors>
connector name="netty-connector"- 로컬 브로커가 원격 브로커로 전송하는 커넥터 구성입니다. 원격 브로커는 이 구성을 사용하여 다시 로컬 브로커에 연결합니다.
connector name="eu-west-1-connector",connector name="eu-east-1-connector"- 원격 브로커에 연결합니다. 로컬 브로커는 이러한 커넥터를 사용하여 원격 브로커에 연결하고 원격 브로커가 로컬 브로커에 다시 연결하는 데 필요한 구성을 공유합니다.
acceptor name="netty-acceptor"- 원격 브로커가 로컬 브로커에 다시 연결하는 데 사용하는 커넥터에 해당하는 로컬 브로커의 수락입니다.
5장. 브로커 보안
5.1. 연결 보안
브로커가 메시징 클라이언트 또는 브로커가 다른 브로커에 연결되어 있는 경우, TLS(Transport Layer Security)를 사용하여 이러한 연결을 보호할 수 있습니다.
사용할 수 있는 두 가지 TLS 구성이 있습니다.
- 브로커만 인증서를 제공하는 단방향 TLS입니다. 가장 일반적인 구성입니다.
- 브로커와 클라이언트(또는 기타 브로커) 모두 인증서를 제공하는 양방향(또는 상호) TLS입니다.
이 섹션의 프로시저에서는 단방향 및 양방향 TLS를 모두 구성하는 방법을 보여줍니다.
5.1.1. 단방향 TLS 구성
다음 절차에서는 단방향 TLS에 대해 지정된 수락자를 구성하는 방법을 보여줍니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 수락자의 경우
sslEnabled키를 추가하고 값을true로 설정합니다. 또한keyStorePath및keyStorePassword키를 추가합니다. 브로커 키 저장소에 해당하는 값을 설정합니다. 예를 들면 다음과 같습니다.<acceptor name="artemis">tcp://0.0.0.0:61616?sslEnabled=true;keyStorePath=../etc/broker.keystore;keyStorePassword=1234!</acceptor>
5.1.2. 양방향 TLS 구성
다음 절차에서는 양방향 TLS를 구성하는 방법을 보여줍니다.
사전 요구 사항
- 단방향 TLS에 대해 지정된 허용자가 이미 구성되어 있어야 합니다. 자세한 내용은 5.1.1절. “단방향 TLS 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 단방향 TLS를 위해 이전에 구성한 수락자의 경우
needClientAuth키를 추가합니다. 값을true로 설정합니다. 예를 들면 다음과 같습니다.<acceptor name="artemis">tcp://0.0.0.0:61616?sslEnabled=true;keyStorePath=../etc/broker.keystore;keyStorePassword=1234!;needClientAuth=true</acceptor>
이전 단계의 구성은 클라이언트의 인증서가 신뢰할 수 있는 공급자가 서명한다고 가정합니다. 클라이언트의 인증서가 신뢰할 수 있는 공급자(예: 자체 서명)에서 서명 되지 않은 경우 브로커는 클라이언트의 인증서를 신뢰 저장소로 가져와야 합니다. 이 경우
trustStorePath및trustStorePassword키를 추가합니다. 브로커 신뢰 저장소에 해당하는 값을 설정합니다. 예를 들면 다음과 같습니다.<acceptor name="artemis">tcp://0.0.0.0:61616?sslEnabled=true;keyStorePath=../etc/broker.keystore;keyStorePassword=1234!;needClientAuth=true;trustStorePath=../etc/client.truststore;trustStorePassword=5678!</acceptor>
AMQ Broker는 여러 프로토콜을 지원하며 각 프로토콜 및 플랫폼은 TLS 매개변수를 지정하는 방법이 다릅니다. 그러나 브리지(코어 프로토콜)를 사용하는 클라이언트의 경우 브로커의 수락자와 마찬가지로 TLS 매개 변수가 커넥터 URL에 구성됩니다.
5.1.3. TLS 구성 옵션
다음 표는 사용 가능한 모든 TLS 구성 옵션을 보여줍니다.
| 옵션 | 참고 |
|---|---|
|
|
연결에 대해 SSL을 사용할 수 있는지 여부를 지정합니다. TLS를 활성화하려면 |
|
| 수락자: 경로: 브로커 인증서를 보유한 브로커의 TLS 키 저장소(권한의 자체 서명 또는 서명)에 사용하는 경우.
커넥터: 패스에 사용되는 경우 클라이언트 인증서가 있는 클라이언트의 TLS 키 저장소 경로를 사용합니다. 이는 양방향 TLS를 사용하는 경우에만 커넥터와 관련이 있습니다. 브로커에서 이 값을 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 브로커에서 설정한 경로와 다른 경로를 사용해야 하는 경우 표준 |
|
| 승인자: 브로커의 키 저장소에 대한 암호입니다.
커넥터: 클라이언트의 키 저장소에 대한 암호입니다. 이는 양방향 TLS를 사용하는 경우에만 커넥터와 관련이 있습니다. 브로커에서 이 값을 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 브로커에서 설정한 암호와 다른 암호를 사용해야 하는 경우 표준 |
|
| acceptor: Path to the TLS truststore에 사용할 때 브로커가 신뢰하는 모든 클라이언트의 키를 보유하고 있습니다. 이는 양방향 TLS를 사용하는 경우에만 어셉터와 관련이 있습니다.
커넥터: 클라이언트에서 신뢰하는 모든 브로커의 공개 키를 보유하는 클라이언트에서 TLS 신뢰 저장소에 사용되는 경우. 브로커에서 이 값을 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 서버에서 설정된 것과 다른 경로를 사용해야 하는 경우 표준 |
|
| 수락자: 브로커의 truststore에 대한 암호입니다. 이는 양방향 TLS를 사용하는 경우에만 어셉터와 관련이 있습니다.
커넥터: 클라이언트의 truststore에 대한 암호입니다. 브로커에서 이 값을 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 브로커에서 설정한 암호와 다른 암호를 사용해야 하는 경우 표준 |
|
|
어셉터 또는 커넥터에서 사용하든, 이는 TLS 통신에 사용되는 암호화 제품군의 쉼표로 구분된 목록입니다. 기본값은 |
|
|
수락자 또는 커넥터에서 사용하든, 이는 TLS 통신에 사용되는 쉼표로 구분된 프로토콜 목록입니다. 기본값은 |
|
|
이 속성은 허용자를 위한 것입니다. 두 방향 TLS가 필요하다는 것을 수락자에게 연결하는 클라이언트에 지시합니다. 유효한 값은 |
5.2. 클라이언트 인증
5.2.1. 클라이언트 인증 방법
브로커에서 클라이언트 인증을 구성하려면 다음 방법을 사용할 수 있습니다.
- 사용자 이름 및 암호 기반 인증
다음 옵션 중 하나를 사용하여 사용자 자격 증명을 직접 검증합니다.
- 브로커에 로컬로 저장된 속성 파일 세트에 대해 자격 증명을 확인합니다. 브로커에 대한 제한된 액세스를 허용하는 게스트 계정을 구성하고 보다 복잡한 사용 사례를 지원하기 위해 로그인 모듈을 결합할 수도 있습니다.
- 중앙 X.500 디렉터리 서버에 저장된 사용자 데이터에 대해 클라이언트 자격 증명을 확인하도록 LDAP( Lightweight Directory Access Protocol ) 로그인 모듈을 구성합니다.
- 인증서 기반 인증
- 브로커와 클라이언트가 상호 인증에 대한 인증서를 제공하도록 양방향 TLS( Transport Layer Security )를 구성합니다. 관리자는 승인된 클라이언트 사용자 및 역할을 정의하는 속성 파일도 구성해야 합니다. 이러한 속성 파일은 브로커에 저장됩니다.
- Kerberos 기반 인증
- SASL( Simple Authentication and Security Layer ) 프레임워크에서 GSSAPI 메커니즘을 사용하여 클라이언트에 대한 Kerberos 보안 자격 증명을 인증하도록 브로커를 구성합니다.
다음 섹션에서는 사용자 및 암호 기반 인증과 인증서 기반 인증을 구성하는 방법을 설명합니다.
추가 리소스
LDAP 및 Kerberos의 완전한 인증 및 권한 부여 워크플로에 대한 자세한 내용은 다음을 참조하십시오.
5.2.2. 속성 파일을 기반으로 사용자 및 암호 인증 구성
AMQ Broker는 주소를 기반으로 큐에 보안을 적용하기 위한 유연한 역할 기반 보안 모델을 지원합니다. 대기열은 일대일( point-to-point messaging) 또는 다대일(publish-subscribe) 메시징을 위해 주소에 바인딩됩니다. 메시지가 주소로 전송되면 브로커는 해당 주소에 바인딩된 대기열 세트를 조회하고 메시지를 해당 큐 세트로 라우팅합니다.
기본 사용자 및 암호 인증이 필요한 경우 PropertiesLoginModule 을 사용하여 정의합니다. 이 로그인 모듈은 브로커에 로컬로 저장된 다음 구성 파일에 대해 사용자 자격 증명을 확인합니다.
artemis-users.properties- 사용자 및 해당 암호를 정의하는 데 사용됩니다.
artemis-roles.properties- 역할을 정의하고 사용자를 해당 역할에 할당하는 데 사용됩니다.
login.config- 사용자 및 암호 인증 및 게스트 액세스에 대한 로그인 모듈을 구성하는 데 사용됩니다.
artemis-users.properties 파일은 보안을 위해 해시된 암호를 포함할 수 있습니다.
다음 섹션에서는 구성 방법을 보여줍니다.
5.2.2.1. 기본 사용자 및 암호 인증 구성
다음 절차에서는 기본 사용자 및 암호 인증을 구성하는 방법을 보여줍니다.
절차
<
broker-instance-dir> /etc/login.config구성 파일을 엽니다. 기본적으로 새 AMQ Broker 7.8 인스턴스의 이 파일에는 다음 행이 포함됩니다.activemq { org.apache.activemq.artemis.spi.core.security.jaas.PropertiesLoginModule sufficient debug=false reload=true org.apache.activemq.jaas.properties.user="artemis-users.properties" org.apache.activemq.jaas.properties.role="artemis-roles.properties"; };activemq- 구성의 별칭입니다.
org.apache.activemq.artemis.spi.core.security.jaas.PropertiesLoginModule- 구현 클래스입니다.
sufficientPropertiesLoginModule에 필요한 성공 수준을 지정하는 플래그입니다. 설정할 수 있는 값은 다음과 같습니다.-
필수: 성공하려면 로그인 모듈이 필요합니다. 인증은 성공 또는 실패에 관계없이 지정된 별칭 아래에 구성된 로그인 모듈 목록을 계속 진행합니다. -
requisite: 성공을 위해서는 로그인 모듈이 필요합니다. 실패는 즉시 애플리케이션으로 제어를 반환합니다. 인증은 지정된 별칭 아래에 구성된 로그인 모듈 목록을 진행하지 않습니다. -
sufficient: 성공을 위해 로그인 모듈이 필요하지 않습니다. 성공하면 제어가 애플리케이션으로 돌아가고 인증이 더 이상 진행되지 않습니다. 실패한 경우 인증 시도는 지정된 별칭 아래에 구성된 로그인 모듈 목록을 아래로 진행합니다. -
선택 사항: 성공하려면 로그인 모듈이 필요하지 않습니다. 인증은 성공 또는 실패에 관계없이 지정된 별칭 아래에 구성된 로그인 모듈 목록을 계속 종료합니다.
-
org.apache.activemq.jaas.properties.user- 로그인 모듈 구현에 대한 사용자 및 암호 세트를 정의하는 속성 파일을 지정합니다.
org.apache.activemq.jaas.properties.role- 로그인 모듈 구현에 대해 사용자를 정의된 역할에 매핑하는 속성 파일을 지정합니다.
-
<
broker-instance-dir> /etc/artemis-users.properties구성 파일을 엽니다. 사용자를 추가하고 사용자에게 암호를 할당합니다. 예를 들면 다음과 같습니다.
user1=secret user2=access user3=myPassword
-
<
broker-instance-dir> /etc/artemis-roles.properties구성 파일을 엽니다. 이전에
artemis-users.properties파일에 추가한 사용자에게 역할 이름을 할당합니다. 예를 들면 다음과 같습니다.admin=user1,user2 developer=user3
-
<
broker-instance-dir> /etc/bootstrap.xml구성 파일을 엽니다. 필요한 경우 다음과 같이 파일에 보안 도메인 별칭(이 인스턴스에서 activemq)을 추가합니다.
<jaas-security domain="activemq"/>
5.2.2.2. 게스트 액세스 구성
로그인 자격 증명이 없거나 인증 정보가 실패하는 사용자의 경우 게스트 계정을 사용하여 브로커에 대한 제한된 액세스 권한을 부여할 수 있습니다.
명령줄 스위치 --allow -anymous(- require-login)를 사용하여 게스트 액세스 권한이 활성화된 브로커 인스턴스를 생성할 수 있습니다.
다음 절차에서는 게스트 액세스를 구성하는 방법을 보여줍니다.
사전 요구 사항
- 이 절차에서는 기본 사용자 및 암호 인증이 이미 구성되어 있다고 가정합니다. 자세한 내용은 5.2.2.1절. “기본 사용자 및 암호 인증 구성” 에서 참조하십시오.
절차
-
이전에 기본 사용자 및 암호 인증을 위해 구성한 <
broker-instance-dir> /etc/login.config구성 파일을 엽니다. 이전에 추가한 properties 로그인 모듈 구성 뒤에 게스트 로그인 모듈 구성을 추가합니다. 예를 들면 다음과 같습니다.
activemq { org.apache.activemq.artemis.spi.core.security.jaas.PropertiesLoginModule sufficient debug=true org.apache.activemq.jaas.properties.user="artemis-users.properties" org.apache.activemq.jaas.properties.role="artemis-roles.properties"; org.apache.activemq.artemis.spi.core.security.jaas.GuestLoginModule sufficient debug=true org.apache.activemq.jaas.guest.user="guest" org.apache.activemq.jaas.guest.role="restricted"; };org.apache.activemq.artemis.spi.core.security.jaas.GuestLoginModule- 구현 클래스입니다.
org.apache.activemq.jaas.guest.user- 익명 사용자에게 할당된 사용자 이름입니다.
org.apache.activemq.jaas.guest.role- 익명 사용자에게 할당된 역할입니다.
사용자가 자격 증명을 제공하면 이전 구성을 기반으로 사용자 및 암호 인증 모듈이 활성화됩니다. 사용자가 인증 정보를 제공하지 않거나 제공된 인증 정보가 잘못된 경우 게스트 인증이 활성화됩니다.
5.2.2.2.1. 게스트 액세스 예
다음 예제에서는 인증 정보가 없는 사용자만 게스트로 로그인한 사용 사례에 대한 게스트 액세스 구성을 보여줍니다. 이 예에서는 로그인 모듈의 순서가 이전 구성 절차와 비교되는지 관찰합니다. 또한 properties 로그인 모듈에 연결된 플래그가 필수 조건으로 변경됩니다.
activemq {
org.apache.activemq.artemis.spi.core.security.jaas.GuestLoginModule sufficient
debug=true
credentialsInvalidate=true
org.apache.activemq.jaas.guest.user="guest"
org.apache.activemq.jaas.guest.role="guests";
org.apache.activemq.artemis.spi.core.security.jaas.PropertiesLoginModule requisite
debug=true
org.apache.activemq.jaas.properties.user="artemis-users.properties"
org.apache.activemq.jaas.properties.role="artemis-roles.properties";
};이전 구성에 따라 로그인 자격 증명을 제공하지 않으면 guest 인증 모듈이 활성화됩니다.
이 사용 사례의 경우 게스트 로그인 모듈 구성에서 credentialsInvalidate 옵션을 true 로 설정해야 합니다.
인증 정보가 제공되는 경우 properties 로그인 모듈이 활성화됩니다. 인증 정보가 유효해야 합니다.
추가 리소스
-
JAAS( Java Authentication and Authorization Service )에 대한 자세한 내용은 Java 공급 업체의 설명서를 참조하십시오. 예를 들어
login.config구성에 대한 Oracle 튜토리얼은 Oracle Java 문서의 JAAS 로그인 구성 파일 을 참조하십시오. - 클라이언트 자격 증명을 검증하도록 LDAP 로그인 모듈을 구성하는 방법은 5.4.1절. “클라이언트 인증을 위해 LDAP 구성” 에서 참조하십시오.
- 구성 파일에서 암호를 암호화하는 방법에 대한 자세한 내용은 5.9.2절. “구성 파일에서 암호 암호화” 을 참조하십시오.
5.2.3. 인증서 기반 인증 구성
JAAS( Java Authentication and Authorization Service ) 인증서 로그인 모듈은 TLS(Transport Layer Security)를 사용하는 클라이언트의 인증 및 권한 부여를 처리합니다. 이 모듈에는 TLS( two-way Transport Layer Security )가 사용되고 자체 인증서로 구성할 클라이언트가 있어야 합니다. 인증은 JAAS 인증서 로그인 모듈에서 직접 수행하지 않고 TLS 핸드셰이크 중에 수행됩니다.
인증서 로그인 모듈의 역할은 다음과 같습니다.
- 허용 가능한 사용자 집합을 제한합니다. 관련 속성 파일에 명시적으로 나열 된 사용자의 DNs(DN)만 인증할 수 있습니다.
- 그룹 목록을 수신된 사용자 ID와 연결합니다. 이렇게 하면 권한 부여가 용이해집니다.
- 들어오는 클라이언트 인증서가 있어야 합니다(기본적으로 TLS 계층은 선택적으로 클라이언트 인증서의 존재를 처리하도록 구성됩니다).
인증서 로그인 모듈은 인증서 DN 컬렉션을 플랫 텍스트 파일 쌍에 저장합니다. 파일은 사용자 이름과 그룹 ID 목록을 각 DN과 연결합니다.
인증서 로그인 모듈은 org.apache.activemq.artemis.spi.core.security.jaas.TextFileCertificateLoginModule 클래스에서 구현됩니다.
5.2.3.1. 인증서 기반 인증을 사용하도록 브로커 구성
다음 절차에서는 인증서 기반 인증을 사용하도록 브로커를 구성하는 방법을 보여줍니다.
사전 요구 사항
- 양방향 TLS(Transport Layer Security)를 사용하도록 브로커를 구성해야 합니다. 자세한 내용은 5.1.2절. “양방향 TLS 구성”의 내용을 참조하십시오.
절차
이전에 브로커 키 저장소로 가져온 사용자 인증서에서 제목 Distinguished Names (DN)를 가져옵니다.
키 저장소 파일에서 임시 파일로 인증서를 내보냅니다. 예를 들면 다음과 같습니다.
keytool -export -file <file-name> -alias broker-localhost -keystore broker.ks -storepass <password>
내보낸 인증서의 콘텐츠를 출력합니다.
keytool -printcert -file <file-name>출력은 다음과 유사합니다.
Owner: CN=localhost, OU=broker, O=Unknown, L=Unknown, ST=Unknown, C=Unknown Issuer: CN=localhost, OU=broker, O=Unknown, L=Unknown, ST=Unknown, C=Unknown Serial number: 4537c82e Valid from: Thu Oct 19 19:47:10 BST 2006 until: Wed Jan 17 18:47:10 GMT 2007 Certificate fingerprints: MD5: 3F:6C:0C:89:A8:80:29:CC:F5:2D:DA:5C:D7:3F:AB:37 SHA1: F0:79:0D:04:38:5A:46:CE:86:E1:8A:20:1F:7B:AB:3A:46:E4:34:5COwner항목은 주체 DN입니다. 주체 DN에 입력하는 데 사용되는 형식은 플랫폼에 따라 다릅니다. 위의 문자열도 다음과 같이 나타낼 수 있습니다.Owner: `CN=localhost,\ OU=broker,\ O=Unknown,\ L=Unknown,\ ST=Unknown,\ C=Unknown`
인증서 기반 인증 구성.
<
broker-instance-dir> /etc/login.config구성 파일을 엽니다. 인증서 로그인 모듈을 추가하고 사용자 및 역할 속성 파일을 참조합니다. 예를 들면 다음과 같습니다.activemq { org.apache.activemq.artemis.spi.core.security.jaas.TextFileCertificateLoginModule debug=true org.apache.activemq.jaas.textfiledn.user="artemis-users.properties" org.apache.activemq.jaas.textfiledn.role="artemis-roles.properties"; };org.apache.activemq.artemis.spi.core.security.jaas.TextFileCertificateLoginModule- 구현 클래스입니다.
org.apache.activemq.jaas.textfiledn.user- 로그인 모듈 구현에 대한 사용자 및 암호 세트를 정의하는 속성 파일을 지정합니다.
org.apache.activemq.jaas.textfiledn.role- 로그인 모듈 구현에 대해 사용자를 정의된 역할에 매핑하는 속성 파일을 지정합니다.
<
broker-instance-dir> /etc/artemis-users.properties구성 파일을 엽니다. 사용자 및 해당 DN은 이 파일에 정의되어 있습니다. 예를 들면 다음과 같습니다.system=CN=system,O=Progress,C=US user=CN=humble user,O=Progress,C=US guest=CN=anon,O=Progress,C=DE
위 구성을 기반으로, 예를 들어
systemnamed user는CN=system,O=Progress,C=USSubject DN에 매핑됩니다.<
broker-instance-dir> /etc/artemis-roles.properties구성 파일을 엽니다. 사용 가능한 역할 및 해당 역할을 보유한 사용자는 이 파일에 정의됩니다. 예를 들면 다음과 같습니다.admins=system users=system,user guests=guest
이전 구성에서
users역할에 대해 쉼표로 구분된 목록으로 여러 사용자를 나열합니다.다음과 같이
bootstrap.xml에서 보안 도메인 별칭(이 인스턴스에서 activemq)을 참조했는지 확인합니다.<jaas-security domain="activemq"/>
5.2.3.2. AMQP 클라이언트의 인증서 기반 인증 구성
브로커에 연결할 때 인증서 기반 인증을 위해 AQMP 클라이언트를 구성하려면 SASL( Simple Authentication and Security Layer ) EXTERNAL 메커니즘 구성 매개 변수를 사용합니다.
브로커는 모든 인증서를 인증하는 것과 동일한 방식으로 AMQP 클라이언트의 TLS( Transport Layer Security )/ SSL(Secure Sockets Layer ) 인증서를 인증합니다.
- 브로커는 클라이언트의 TLS/SSL 인증서를 읽고 인증서의 주체에서 ID를 가져옵니다.
- 인증서 주체는 인증서 로그인 모듈을 통해 브로커 ID에 매핑됩니다. 그러면 브로커가 역할에 따라 사용자에게 권한을 부여합니다.
다음 절차에서는 AMQP 클라이언트에 대한 인증서 기반 인증을 구성하는 방법을 보여줍니다. AMQP 클라이언트가 인증서 기반 인증을 사용하도록 설정하려면 클라이언트가 브로커에 연결하는 데 사용하는 구성 매개 변수를 URI에 추가해야 합니다.
사전 요구 사항
다음을 구성해야 합니다.
- 양방향 TLS. 자세한 내용은 5.1.2절. “양방향 TLS 구성”의 내용을 참조하십시오.
- 인증서 기반 인증을 사용하는 브로커입니다. 자세한 내용은 5.2.3.1절. “인증서 기반 인증을 사용하도록 브로커 구성”의 내용을 참조하십시오.
절차
편집할 URI가 포함된 리소스를 엽니다.
amqps://localhost:5500
sslEnabled=true매개변수를 추가하여 연결에 TSL/SSL을 활성화합니다.amqps://localhost:5500?sslEnabled=true
클라이언트 신뢰 저장소 및 키 저장소와 관련된 매개변수를 추가하여 브로커와 TSL/SSL 인증서를 교환할 수 있습니다.
amqps://localhost:5500?sslEnabled=true&trustStorePath=<trust store path>&trustStorePassword=<trust store password>&keyStorePath=<key store path>&keyStorePassword=<key store password>
매개 변수
saslMechanisms=EXTERNAL을 추가하여 브로커가 TSL/SSL 인증서에 있는 ID를 사용하여 클라이언트를 인증하도록 요청합니다.amqps://localhost:5500?sslEnabled=true&trustStorePath=<trust store path>&trustStorePassword=<trust store password>&keyStorePath=<key store path>&keyStorePassword=<key store password>&saslMechanisms=EXTERNAL
추가 리소스
- AMQ Broker의 인증서 기반 인증에 대한 자세한 내용은 5.2.3.1절. “인증서 기반 인증을 사용하도록 브로커 구성” 을 참조하십시오.
- AMQP 클라이언트 구성에 대한 자세한 내용은 Red Hat 고객 포털 로 이동하여 클라이언트와 관련된 제품 설명서를 참조하십시오.
5.3. 클라이언트 인증
5.3.1. 클라이언트 권한 부여 방법
주소 및 큐 생성 및 삭제, 메시지 전송 및 사용과 같은 브로커에서 작업을 수행하도록 클라이언트에 권한을 부여하려면 다음 방법을 사용할 수 있습니다.
- 사용자 및 역할 기반 권한 부여
- 인증된 사용자 및 역할에 대해 브로커 보안 설정을 구성합니다.
- 클라이언트 권한을 부여하도록 LDAP 설정
- 인증 및 권한 부여를 모두 처리하도록 LDAP( Lightweight Directory Access Protocol ) 로그인 모듈을 구성합니다. LDAP 로그인 모듈은 중앙 X.500 디렉터리 서버에 저장된 사용자 데이터에 대해 들어오는 자격 증명을 확인하고 사용자 역할을 기반으로 권한을 설정합니다.
- 클라이언트에 권한을 부여하도록 Kerberos 구성
-
Java Authentication and Authorization Service (JAAS)
Krb5LoginModule로그인 모듈을 구성하여 Kerberos 인증 사용자를 AMQ Broker 역할에 매핑하는PropertiesLoginModule또는LDAPLoginModule로그인 모듈에 자격 증명을 전달합니다.
5.3.2. 사용자 및 역할 기반 권한 부여 구성
5.3.2.1. 권한 설정
권한은 broker.xml 구성 파일의 < security-setting > 요소를 통해 큐(주소 기반)에 대해 정의됩니다. 구성 파일의 < security- >의 여러 인스턴스를 정의할 수 있습니다. 정확한 주소 일치를 지정하거나 숫자 기호(settings> 요소에서 <security- setting#) 및 별표(*) 와일드카드 문자를 사용하여 와일드카드 일치를 정의할 수 있습니다.
주소와 일치하는 큐 세트에 다양한 권한을 부여할 수 있습니다. 이러한 권한은 다음 표에 표시되어 있습니다.
| 사용자가…을 허용하도록 허용 | 이 매개변수 사용… |
|---|---|
| 주소 생성 |
|
| 주소 삭제 |
|
| 일치하는 주소에 있는 영구 큐 생성 |
|
| 일치하는 주소에 있는 내구성 큐 삭제 |
|
| 순서가 지정되지 않은 큐를 일치하는 주소 아래에 생성 |
|
| 순서가 지정되지 않은 큐를 일치하는 주소 아래에 삭제 |
|
| 일치하는 주소로 메시지를 보냅니다. |
|
| 일치하는 주소에 바인딩된 큐의 메시지 사용 |
|
| 관리 주소로 관리 메시지를 전송하여 관리 작업 호출 |
|
| 일치하는 주소로 바인딩된 큐 검색 |
|
각 권한에 대해 권한이 부여된 역할 목록을 지정합니다. 지정된 사용자에게 역할이 모두 있는 경우 해당 주소 집합에 대한 권한이 부여됩니다.
다음 섹션에서는 권한에 대한 몇 가지 구성 예제를 보여줍니다.
5.3.2.1.1. 단일 주소에 대한 메시지 프로덕션 구성
다음 절차에서는 단일 주소에 대한 메시지 프로덕션 권한을 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
security-추가합니다.settings> 요소에 단일 <security-setting> 요소를일치키의 경우 주소를 지정합니다. 예를 들면 다음과 같습니다.<security-settings> <security-setting match="my.destination"> <permission type="send" roles="producer"/> </security-setting> </security-settings>이전 구성에 따라
producer역할의 멤버는 주소my.destination에 대한 권한을보냅니다.
5.3.2.1.2. 단일 주소에 대한 메시지 사용 구성
다음 절차에서는 단일 주소에 대한 메시지 사용 권한을 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
security-추가합니다.settings> 요소에 단일 <security-setting> 요소를일치키의 경우 주소를 지정합니다. 예를 들면 다음과 같습니다.<security-settings> <security-setting match="my.destination"> <permission type="consume" roles="consumer"/> </security-setting> </security-settings>이전 구성에 따라
consumer역할의 멤버는my.destination.destination에 대한 권한을사용합니다.
5.3.2.1.3. 모든 주소에 대한 전체 액세스 구성
다음 절차에서는 모든 주소 및 관련 큐에 대한 전체 액세스를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
security-추가합니다.settings> 요소에 단일 <security-setting> 요소를일치키의 경우 모든 주소에 대한 액세스를 구성하려면 숫자 기호(#) 와일드카드 문자를 지정합니다. 예를 들면 다음과 같습니다.<security-settings> <security-setting match="#"> <permission type="createDurableQueue" roles="guest"/> <permission type="deleteDurableQueue" roles="guest"/> <permission type="createNonDurableQueue" roles="guest"/> <permission type="deleteNonDurableQueue" roles="guest"/> <permission type="createAddress" roles="guest"/> <permission type="deleteAddress" roles="guest"/> <permission type="send" roles="guest"/> <permission type="browse" roles="guest"/> <permission type="consume" roles="guest"/> <permission type="manage" roles="guest"/> </security-setting> </security-settings>이전 구성에 따라 모든 권한이 모든 큐에 대한 guest 역할의 구성원에게 부여됩니다. 이는 모든 사용자에게
게스트역할을 할당하도록 익명 인증이 구성된 개발 시나리오에서 유용할 수 있습니다.
추가 리소스
- 보다 복잡한 사용 사례 구성에 대한 자세한 내용은 5.3.2.1.4절. “여러 보안 설정 구성” 을 참조하십시오.
5.3.2.1.4. 여러 보안 설정 구성
다음 예제 절차에서는 일치하는 주소 집합에 대해 여러 보안 설정을 개별적으로 구성하는 방법을 보여줍니다. 이 섹션에서는 모든 주소에 대한 전체 액세스 권한을 부여하는 방법을 보여주는 이 섹션의 이전 예제와는 대조됩니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
security-추가합니다.settings> 요소에 단일 <security-setting> 요소를일치하는 주소 집합에 설정을 적용하려면 일치키의 경우 숫자 기호(#) 와일드카드 문자를 포함합니다. 예를 들면 다음과 같습니다.<security-setting match="globalqueues.europe.#"> <permission type="createDurableQueue" roles="admin"/> <permission type="deleteDurableQueue" roles="admin"/> <permission type="createNonDurableQueue" roles="admin, guest, europe-users"/> <permission type="deleteNonDurableQueue" roles="admin, guest, europe-users"/> <permission type="send" roles="admin, europe-users"/> <permission type="consume" roles="admin, europe-users"/> </security-setting>
match=globalqueues.europe.#-
숫자 기호(
#) 와일드카드 문자는 브로커가 "모든 단어 시퀀스로 해석됩니다. 마침표(.. )로 구분됩니다. 이 예에서 보안 설정은 globalqueues.europe 문자열으로 시작하는 모든 주소에 적용됩니다. permission type="createDurableQueue"-
admin역할이 있는 사용자만 globalqueues.europe 문자열로 시작하는 주소에 바인딩된 내구성 대기열을 생성하거나 삭제할 수 있습니다. permission type="createNonDurableQueue"-
admin역할,게스트또는europe-users가 있는 모든 사용자는 globalqueues.europe 문자열로 시작하는 주소에 바인딩된 임시 대기열을 생성하거나 삭제할 수 있습니다. 권한 유형="send"-
admin또는europe-users역할이 있는 모든 사용자는 globalqueues.europe 문자열로 시작하는 주소에 바인딩된 큐에 메시지를 보낼 수 있습니다. permission type="consume"-
역할
admin또는europe-users가 있는 모든 사용자는 globalqueues.europe 문자열으로 시작하는 주소로 바인딩된 큐의 메시지를 사용할 수 있습니다.
(선택 사항) 다른 보안 설정을 보다 좁은 주소 세트에 적용하려면 다른 <
security-setting> 요소를 추가합니다.일치키의 경우 보다 구체적인 텍스트 문자열을 지정합니다. 예를 들면 다음과 같습니다.<security-setting match="globalqueues.europe.orders.#"> <permission type="send" roles="europe-users"/> <permission type="consume" roles="europe-users"/> </security-setting>
두 번째
security-setting요소에서globalqueues.europe.orders.#일치는 첫 번째security-setting요소에 지정된globalqueues.europe.#일치 항목보다 더 구체적입니다.globalqueues.europe.orders.#과 일치하는 모든 주소의 경우createDurableQueue,deleteDurableQueue,createNonDurableQueue,deleteNonDurableQueue는 파일의 첫 번째security-setting요소에서 상속 되지 않습니다. 예를 들어globalqueues.europe.orders.plastics주소의 경우 존재하는 유일한 권한은europe-users에게 전송및소비됩니다.따라서 한
security-setting블록에 지정된 권한이 다른 보안 설정 블록에서 상속되지 않으므로 해당 권한을 지정하지 않고 특정security-setting블록에서 권한을 효과적으로 거부할 수 있습니다.
5.3.2.1.5. 사용자를 사용하여 큐 구성
큐가 자동으로 생성되면 연결된 클라이언트의 사용자 이름이 큐에 할당됩니다. 이 사용자 이름은 큐의 메타데이터로 포함됩니다. 이름은 JMX 및 AMQ Broker 관리 콘솔에 의해 노출됩니다.
다음 절차에서는 브로커 구성에 수동으로 정의된 큐에 사용자 이름을 추가하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 지정된 큐의 경우
사용자키를 추가합니다. 값을 할당합니다. 예를 들면 다음과 같습니다.<address name="ExampleQueue"> <anycast> <queue name="ExampleQueue" user="admin"/> </anycast> </address>이전 구성에 따라
admin사용자는 대기열ExampleQueue에 할당됩니다.
- 큐에서 사용자를 구성해도 해당 큐의 보안 의미 체계는 변경되지 않으며 해당 큐의 메타데이터에만 사용됩니다.Configuring a user on a queue does not change any of the security semantics for that queue - it is only used for metadata on that queue.
사용자 간 매핑과 보안 관리자 라는 구성 요소에서 처리하는 역할 간의 매핑입니다. 보안 관리자는 브로커에 저장된 속성 파일에서 사용자 자격 증명을 읽습니다. 기본적으로 AMQ Broker는
org.apache.activemq.artemis.spi.core.security.ActiveMQJAASSecurityManager보안 관리자를 사용합니다. 이 기본 보안 관리자는 JAAS 및 Red Hat JBoss EAP(JBoss Enterprise Application Platform) 보안과의 통합을 제공합니다.사용자 지정 보안 관리자를 사용하는 방법은 5.6절. “사용자 정의 보안 관리자 사용” 을 참조하십시오.
5.3.2.2. 역할 기반 액세스 제어 구성
RBAC( 역할 기반 액세스 제어 )는 MBean의 속성 및 메서드에 대한 액세스를 제한하는 데 사용됩니다. RBAC를 사용하면 관리자는 역할에 따라 웹 콘솔, 관리 인터페이스, 코어 메시지 등과 같은 모든 사용자에게 올바른 수준의 액세스 권한을 부여할 수 있습니다.RBAC enables administrators to grant the correct level of access to all users like web console, management interface, core messages, and so on, based on role.
5.3.2.2.1. 역할 기반 액세스 구성
다음 예제 절차에서는 역할을 특정 MBean과 해당 특성 및 메서드에 매핑하는 방법을 보여줍니다.
사전 요구 사항
- 먼저 사용자와 역할을 정의해야 합니다. 자세한 내용은 5.2.2.1절. “기본 사용자 및 암호 인증 구성”의 내용을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. role-access요소를 검색하고 구성을 편집합니다. 예를 들면 다음과 같습니다.<role-access> <match domain="org.apache.activemq.artemis"> <access method="list*" roles="view,update,amq"/> <access method="get*" roles="view,update,amq"/> <access method="is*" roles="view,update,amq"/> <access method="set*" roles="update,amq"/> <access method="*" roles="amq"/> </match> </role-access>-
이 경우 도메인 이름
org.apache.activemq.apache가 있는 모든 MBean 속성에 일치 항목이 적용됩니다. -
일치하는 MBean 속성에 대한
보기,업데이트또는amq역할에 대한 액세스 권한은list*,get*,set*,is*,*역할을 추가하는 방법에 의해 제어됩니다.method="*"(wildcard) 구문은 구성에 나열되지 않은 다른 모든 메서드를 지정하는 범용 방법으로 사용됩니다. 구성의 각 액세스 방법은 MBean 메서드 호출로 변환됩니다. -
호출된 MBean 방법은 구성에 나열된 메서드와 일치합니다. 예를 들어
org.apache.activemq.artemis도메인이 있는 MBean에서listMessages라는 메서드를 호출하면 브로커가목록메서드의 구성에 정의된 역할에 대한 액세스 권한과 다시 일치합니다. 전체 MBean 메서드 이름을 사용하여 액세스를 구성할 수도 있습니다. 예를 들면 다음과 같습니다.
<access method="listMessages" roles="view,update,amq"/>
-
이 경우 도메인 이름
브로커를 시작하거나 다시 시작합니다.
-
Linux에서 <
;broker-instance-dir> /bin/artemis run -
Windows: <
;broker-instance-dir> \bin\artemis-service.exe 시작
-
Linux에서 <
MBean 속성과 일치하는 키 특성을 추가하여 도메인 내의 특정 MBean과 일치시킬 수도 있습니다.
5.3.2.2.2. 역할 기반 액세스 예
이 섹션에서는 역할 기반 액세스 제어 적용의 다음 예를 보여줍니다.
다음 예제에서는 key 특성을 사용하여 지정된 도메인의 모든 큐에 역할을 매핑하는 방법을 보여줍니다.
<match domain="org.apache.activemq.artemis" key="subcomponent=queues"> <access method="list*" roles="view,update,amq"/> <access method="get*" roles="view,update,amq"/> <access method="is*" roles="view,update,amq"/> <access method="set*" roles="update,amq"/> <access method="*" roles="amq"/> </match>
다음 예제에서는 key 특성을 사용하여 특정 이름이 지정된 특정 큐에 역할을 매핑하는 방법을 보여줍니다. 이 예에서 명명된 큐는 예제Queue 입니다.
<match domain="org.apache.activemq.artemis" key="queue=exampleQueue"> <access method="list*" roles="view,update,amq"/> <access method="get*" roles="view,update,amq"/> <access method="is*" roles="view,update,amq"/> <access method="set*" roles="update,amq"/> <access method="*" roles="amq"/> </match>
다음 예제에서는 지정된 접두사가 포함된 모든 큐에 역할을 매핑하는 방법을 보여줍니다. 이 예제에서 별표(*) 와일드카드 연산자는 접두사 예제 로 시작하는 모든 큐 이름과 일치하도록 사용됩니다.
<match domain="org.apache.activemq.artemis" key="queue=example*"> <access method="list*" roles="view,update,amq"/> <access method="get*" roles="view,update,amq"/> <access method="is*" roles="view,update,amq"/> <access method="set*" roles="update,amq"/> <access method="*" roles="amq"/> </match>
동일한 특성 집합(예: 다른 대기열 세트)에 대해 역할을 다르게 매핑해야 할 수 있습니다. 이 경우 구성 파일에 여러 개의 일치 요소를 포함할 수 있습니다. 그러나 동일한 도메인에 여러 개의 일치 항목이 있을 수 있습니다.
예를 들어 다음과 같이 구성된 두 가지 <match > 요소를 고려하십시오.
<match domain="org.apache.activemq.artemis" key="queue=example*">
및
<match domain="org.apache.activemq.artemis" key="queue=example.sub*">
이 구성을 기반으로 org.apache.activemq.artemis 도메인의 example.sub.queue 라는 큐가 두 와일드카드 키 식과 일치합니다. 따라서 브로커는 큐에 매핑할 역할 집합, 첫 번째 match 요소에 지정된 역할 또는 두 번째 일치 요소에 지정된 역할을 결정하는 우선순위 지정 체계가 필요합니다.
동일한 도메인에 일치하는 항목이 여러 개 있는 경우 브로커는 역할을 매핑할 때 다음과 같은 우선순위 지정 스키마를 사용합니다.
- 정확한 일치는 와일드카드 일치보다 우선 순위가 지정됩니다.
- 더 긴 와일드카드 일치 항목이 짧은 와일드카드 일치보다 우선 순위가 길어집니다.
이 예제에서 더 긴 와일드카드 표현식은 example.sub.queue 의 큐 이름과 가장 근접하게 일치하므로 브로커는 두 번째 < match > 요소에 구성된 역할 매핑을 적용합니다.
default-access 요소는 역할 액세스 또는 all 요소입니다. 허용 목록 구성을 사용하여 처리하지 않는 모든 메서드 호출에 대한 catch-default-access 및 role-access 요소는 동일한 일치 요소 의미 체계를 갖습니다.
5.3.2.2.3. 허용 목록 요소 구성
화이트리스트 는 사용자 인증이 필요하지 않은 사전 승인 도메인 또는 MBeans 세트입니다. 도메인 목록 또는 MBean 목록 또는 인증을 우회해야 하는 두 가지 모두를 제공할 수 있습니다. 예를 들어 허용 목록을 사용하여 실행할 AMQ Broker 관리 콘솔에 필요한 MBean을 지정할 수 있습니다.
다음 예제 절차에서는 허용 목록 요소를 구성하는 방법을 보여줍니다.
절차
-
<
broker_instance_dir> /etc/management.xml구성 파일을 엽니다. 허용 목록요소를 검색하고 구성을 편집합니다.<whitelist> <entry domain="hawtio"/> </whitelist>
이 예에서 도메인
hawtio를 사용하는 모든 MBean은 인증 없이 액세스할 수 있습니다. MBean 속성이 일치하도록 <entry domain="hawtio" key="type=*"/> 형식의 와일드카드 항목을 사용할 수도 있습니다.브로커를 시작하거나 다시 시작합니다.
-
Linux에서 <
;broker_instance_dir> /bin/artemis run -
Windows: <
;broker_instance_dir> \bin\artemis-service.exe 시작
-
Linux에서 <
5.3.2.3. 리소스 제한 설정
경우에 따라 특정 사용자가 권한 부여 및 인증과 관련된 일반적인 보안 설정을 초과할 수 있는 작업에 대해 특정 제한을 설정하는 것이 유용합니다.
5.3.2.3.1. 연결 및 대기열 제한 구성
다음 예제 절차에서는 사용자가 생성할 수 있는 연결 및 대기열 수를 제한하는 방법을 보여줍니다.
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. resource-limit-settings요소를 추가합니다.max-connections및max-queues에 대한 값을 지정합니다. 예를 들면 다음과 같습니다.<resource-limit-settings> <resource-limit-setting match="myUser"> <max-connections>5</max-connections> <max-queues>3</max-queues> </resource-limit-setting> </resource-limit-settings>max-connections-
일치하는 사용자가 브로커에 수행할 수 있는 연결 수를 정의합니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다. max-queues-
일치된 사용자가 생성할 수 있는 대기열 수를 정의합니다. 기본값은
-1이며 이는 제한이 없음을 의미합니다.
브로커 구성의 address-setting 요소에 지정할 수 있는 일치 문자열과 달리 resource-limit-settings 에서 지정하는 일치 문자열은 와일드카드 구문을 사용할 수 없습니다. 대신 일치 문자열은 리소스 제한 설정이 적용되는 특정 사용자를 정의합니다.
5.4. 인증 및 권한 부여에 LDAP 사용
LDAP 로그인 모듈은 X.500 디렉터리 서버에 저장된 사용자 데이터에 대해 들어오는 자격 증명을 확인하여 인증 및 권한을 활성화합니다. 이는 org.apache.activemq.artemis.spi.core.security.jaas.LDAPLoginModule 에 의해 구현됩니다.
5.4.1. 클라이언트 인증을 위해 LDAP 구성
다음 예제 절차에서는 LDAP를 사용하여 클라이언트를 인증하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. security-settings요소 내에서security-setting요소를 추가하여 권한을 구성합니다. 예를 들면 다음과 같습니다.<security-settings> <security-setting match="#"> <permission type="createDurableQueue" roles="user"/> <permission type="deleteDurableQueue" roles="user"/> <permission type="createNonDurableQueue" roles="user"/> <permission type="deleteNonDurableQueue" roles="user"/> <permission type="send" roles="user"/> <permission type="consume" roles="user"/> </security-setting> </security-settings>이전 구성은 모든 큐에 대한 특정 권한을
사용자역할의 구성원에게 할당합니다.-
<
broker-instance-dir> /etc/login.config파일을 엽니다. 사용 중인 디렉터리 서비스를 기반으로 LDAP 로그인 모듈을 설정합니다.
Microsoft Active Directory 디렉터리 서비스를 사용하는 경우 다음 예와 유사한 구성을 추가합니다.
activemq { org.apache.activemq.artemis.spi.core.security.jaas.LDAPLoginModule required debug=true initialContextFactory=com.sun.jndi.ldap.LdapCtxFactory connectionURL="LDAP://localhost:389" connectionUsername="CN=Administrator,CN=Users,OU=System,DC=example,DC=com" connectionPassword=redhat.123 connectionProtocol=s connectionTimeout=5000 authentication=simple userBase="dc=example,dc=com" userSearchMatching="(CN={0})" userSearchSubtree=true readTimeout=5000 roleBase="dc=example,dc=com" roleName=cn roleSearchMatching="(member={0})" roleSearchSubtree=true ; };참고Microsoft Active Directory를 사용하고 있고
connectionUsername의 속성에 대해 지정해야 하는 값에는 공백(예: OU=System Accounts )에 공백(예:OU=System Accounts)이 포함된 경우 해당 값을 큰따옴표("") 쌍으로 묶고 백슬래시(\)를 사용하여 쌍으로 이스케이프해야 합니다. 예를 들어connectionUsername="CN=Administrator,CN=Users,OU=\"System Accounts\",DC=example,DC=com".ApacheDS 디렉터리 서비스를 사용하는 경우 다음 예와 유사한 구성을 추가합니다.
activemq { org.apache.activemq.artemis.spi.core.security.jaas.LDAPLoginModule required debug=true initialContextFactory=com.sun.jndi.ldap.LdapCtxFactory connectionURL="ldap://localhost:10389" connectionUsername="uid=admin,ou=system" connectionPassword=secret connectionProtocol=s connectionTimeout=5000 authentication=simple userBase="dc=example,dc=com" userSearchMatching="(uid={0})" userSearchSubtree=true userRoleName= readTimeout=5000 roleBase="dc=example,dc=com" roleName=cn roleSearchMatching="(member={0})" roleSearchSubtree=true ; };debug-
디버깅을 켜십시오(
true) 또는 off(false). 기본값은false입니다. initialContextFactory-
항상
com.sun.jndi.ldap.LdapCtxFactory로 설정해야 합니다. connectionURL-
LDAP URL을 사용하는 디렉터리 서버의 위치, __<ldap://Host:Port>. 슬래시
/다음에 디렉터리 트리에 특정 노드의 DN을 추가하여 선택적으로 이 URL의 자격을 부여할 수 있습니다. Apache DS의 기본 포트는10389이며 Microsoft AD의 경우 기본값은389입니다. connectionUsername-
디렉터리 서버에 대한 연결을 여는 사용자의 고유 이름(DN)입니다. 예를 들면
uid=admin,ou=system입니다. 디렉터리 서버는 일반적으로 클라이언트가 연결을 열기 위해 사용자 이름/암호 자격 증명을 제공해야 합니다. connectionPassword-
connectionUsername에서 DN과 일치하는 암호입니다. 디렉터리 서버의 DIT( Directory Information Tree )에서 암호는 일반적으로 해당 디렉터리 항목에userPassword속성으로 저장됩니다. connectionProtocol- 모든 값이 지원되지만 효과적으로 사용되지 않습니다. 이 옵션은 기본값이 없으므로 명시적으로 설정해야 합니다.
connectionTimeout브로커가 디렉터리 서버에 연결하는 데 사용할 수 있는 최대 시간(밀리초)을 지정합니다. 브로커가 이 시간 내에 디렉터리에 연결할 수 없는 경우 연결 시도가 중단됩니다. 이 속성에 대해 값을 0 이하로 지정하면 기본 TCP 프로토콜의 시간 초과 값이 대신 사용됩니다.If you specify a value of zero or less for this property, the timeout value of the underlying TCP protocol is used instead. 값을 지정하지 않으면 브로커가 무기한 대기하여 연결을 설정하거나 기본 네트워크 시간이 초과됩니다.
연결 풀링이 연결에 대해 요청되면 이 속성은 최대 풀 크기에 이미 도달하고 풀의 모든 연결이 사용 중인 경우 브로커가 연결을 대기하는 최대 시간을 지정합니다. 값을 0 이하로 지정하면 브로커가 연결을 사용할 수 있을 때까지 무기한 대기합니다. 그렇지 않으면 브로커는 최대 대기 시간에 도달할 때 연결 시도를 중단합니다.
인증-
LDAP 서버에 바인딩할 때 사용되는 인증 방법을 지정합니다. 이 매개변수는
단순(사용자 이름과 암호가 필요한) 또는none( anonymous 액세스를 허용하는)으로 설정할 수 있습니다. userBase-
DIT의 특정 하위 트리를 선택하여 사용자 항목을 검색합니다. 하위 트리는 DN에 의해 지정되며 하위 트리의 기본 노드를 지정합니다. 예를 들어 이 옵션을
ou=User,ou=ActiveMQ,ou=system로 설정하면 사용자 항목 검색이ou=User,ou=ActiveMQ,ou=system노드 아래의 하위 트리로 제한됩니다. userSearchMatching-
userBase에서 선택한 하위 트리에 적용되는 LDAP 검색 필터를 지정합니다. 자세한 내용은 5.4.1.1절. “검색 일치 매개변수” 섹션을 참조하십시오. userSearchSubtree-
userBase에서 지정한 노드와 관련하여 사용자 항목에 대한 검색 깊이를 지정합니다. 이 옵션은 부울입니다.false값을 지정하면 검색이userBase노드의 하위 항목 중 하나와 일치하게 됩니다(maps tojavax.naming.directory.SearchControls.ONELEVEL_SCOPE). 값이true이면 검색에서userBase노드의 하위 트리에 속하는 모든 항목(javax.naming.directory.SearchControls.SUBTREE_SCOPE)과 일치함을 의미합니다. userRoleName- 사용자의 역할 이름 목록이 포함된 사용자 항목의 속성 이름입니다. 역할 이름은 브로커의 권한 부여 플러그인에 의해 그룹 이름으로 해석됩니다. 이 옵션을 생략하면 사용자 항목에서 역할 이름을 추출하지 않습니다.
readTimeout- 브로커가 디렉터리 서버에서 LDAP 요청에 대한 응답을 수신 대기할 수 있는 최대 시간(밀리초)을 지정합니다. 브로커가 현재 디렉터리 서버에서 응답을 받지 못하면 브로커가 요청을 중단합니다. 값을 0 이하로 지정하거나 값을 지정하지 않으면 브로커는 디렉터리 서버에서 LDAP 요청으로의 응답을 무기한 대기합니다.
roleBase-
역할 데이터가 디렉터리 서버에 직접 저장되는 경우
userRoleName옵션을 지정하는 대신 역할 옵션(roleBase,roleSearchMatching,roleSearchSubtree,roleName)의 조합을 사용할 수 있습니다. 이 옵션은 역할/그룹 항목을 검색하기 위해 DIT의 특정 하위 트리를 선택합니다. 하위 트리는 DN에 의해 지정되며 하위 트리의 기본 노드를 지정합니다. 예를 들어 이 옵션을ou=Group,ou=ActiveMQ,ou=system roleName- 역할/그룹의 이름(예: C, O, OU 등)이 포함된 역할 항목의 특성 유형입니다. 이 옵션을 생략하면 역할 검색 기능이 효과적으로 비활성화됩니다.
roleSearchMatching-
역할Base에서 선택한 하위 트리에 적용되는 LDAP 검색 필터를 지정합니다. 자세한 내용은 5.4.1.1절. “검색 일치 매개변수” 섹션을 참조하십시오. roleSearchSubtreeroleBase에서 지정한 노드와 관련하여 역할 항목에 대한 검색 깊이를 지정합니다.false로 설정하면 검색이roleBase노드의 하위 항목 중 하나와 일치하려고 합니다(Javax.naming.directory.SearchControls.ONELEVEL_SCOPE에 매핑).true인 경우 roleBase 노드의 하위 트리에 속하는 모든 항목(javax.naming.directory.SearchControls.SUBTREE_SCOPE)에 매핑합니다.참고Apache DS는 DN 경로의
OID부분을 사용합니다. Microsoft Active Directory는CN부분을 사용합니다. 예를 들어 Apache DS에서oid=testuser,dc=example,dc=com과 같은 DN 경로를 사용할 수 있지만 Microsoft Active Directory의cn=testuser,dc=example,dc=com과 같은 DN 경로를 사용할 수 있습니다.
- 브로커(서비스 또는 프로세스)를 시작하거나 다시 시작합니다.
5.4.1.1. 검색 일치 매개변수
userSearchMatchingLDAP 검색 작업에 전달하기 전에 이 구성 매개변수에 제공된 문자열 값에
java.text.MessageFormat클래스에서 구현하는 대로 문자열 대체가 적용됩니다.
즉,
{0}라는 특수 문자열은 들어오는 클라이언트 자격 증명에서 추출된 대로 사용자 이름으로 대체됩니다. 대체 후 문자열이 LDAP 검색 필터로 해석됩니다. 구문은 IETF 표준 RFC 2254로 정의됩니다.
예를 들어 이 옵션이
(uid={0})로 설정되고 수신된 username이jdoe인 경우 문자열 대체 후 검색 필터는(uid=jdoe)가 됩니다.
결과 검색 필터가 사용자 base
ou=User,ou=ActiveMQ,ou=system에서 선택한 하위 트리에 적용되는 경우uid=jdoe,ou=User,ouMQ,ou=system와 일치합니다.
roleSearchMatching이는 두 개의 대체 문자열을 지원한다는 점을 제외하고는
userSearchMatching옵션과 유사한 방식으로 작동합니다.
대체 문자열
{0}은 일치하는 사용자 항목의 전체 DN(즉, 사용자 검색 결과)을 대체합니다. 예를 들어 사용자인jdoe의 경우 대체 문자열이uid=jdoe,ou=User,ou=system일 수 있습니다.
대체 문자열
{1}은 수신된 사용자 이름을 대체합니다. 예를 들면jdoe.
이 옵션이
(member=uid={1})로 설정되고 수신된 사용자 이름이jdoe인 경우 문자열 대체 (ApacheDS 검색 필터 구문 사용) 뒤에 검색 필터가(member=uid=jdoe)가 됩니다.
결과 검색 필터가 역할 base인
ou=Group,ou=ActiveMQ,ou=system에서 선택한 하위 트리에 적용되는 경우uid=jdoe와 같은member속성이 있는 모든 역할 항목과 일치합니다(member특성의 값은 DN임).
기본값이 없으므로 역할 검색이 비활성화된 경우에도 이 옵션을 항상 설정해야 합니다. OpenLDAP를 사용하는 경우 검색 필터의 구문은
(member:=uid=jdoe)입니다.
추가 리소스
- 검색 필터 구문에 대한 간략한 소개는 Oracle JNDI 튜토리얼 을 참조하십시오.
5.4.2. LDAP 권한 부여 구성
LegacyLDAPSecuritySettingPlugin 보안 설정 플러그인은 이전에 AMQ 6에서 LDAPAuthorizationMap 및 cachedLDAPAuthorizationMap 으로 처리한 보안 정보를 읽고, 가능한 경우 이 정보를 해당 AMQ 7 보안 설정으로 변환합니다.
AMQ 6 및 AMQ 7의 브로커에 대한 보안 구현이 정확히 일치하지 않습니다. 따라서 플러그인은 두 버전 간에 몇 가지 변환을 수행하여 거의 동등한 기능을 달성합니다.
다음 예제에서는 플러그인을 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. security-settings요소 내에서security-setting-plugin요소를 추가합니다. 예를 들면 다음과 같습니다.<security-settings> <security-setting-plugin class-name="org.apache.activemq.artemis.core.server.impl.LegacyLDAPSecuritySettingPlugin"> <setting name="initialContextFactory" value="com.sun.jndi.ldap.LdapCtxFactory"/> <setting name="connectionURL" value="ldap://localhost:1024"/>`ou=destinations,o=ActiveMQ,ou=system` <setting name="connectionUsername" value="uid=admin,ou=system"/> <setting name="connectionPassword" value="secret"/> <setting name="connectionProtocol" value="s"/> <setting name="authentication" value="simple"/> </security-setting-plugin> </security-settings>class-name-
구현은
org.apache.activemq.artemis.core.server.impl.LegacyLDAPSecuritySettingPlugin입니다. initialContextFactory-
LDAP에 연결하는 데 사용되는 초기 컨텍스트 팩토리입니다. 항상
com.sun.jndi.ldap.LdapCtxFactory(기본값)로 설정해야 합니다. connectionURL-
LDAP URL을 사용하여 디렉터리 서버의 위치를 지정합니다. <ldap://Host:Port& gt;. 디렉터리 트리에 특정 노드의 고유 이름(DN)을 추가한 다음 슬래시
/를 추가하여 이 URL의 자격을 선택적으로 지정할 수 있습니다. 예:ldap://ldapserver:10389/ou=system. 기본값은ldap://localhost:1024입니다. connectionUsername-
디렉터리 서버에 대한 연결을 여는 사용자의 DN입니다. 예를 들면
uid=admin,ou=system입니다. 디렉터리 서버는 일반적으로 클라이언트가 연결을 열기 위해 사용자 이름/암호 자격 증명을 제공해야 합니다. connectionPassword-
connectionUsername에서 DN과 일치하는 암호입니다. 디렉터리 서버의 DIT( Directory Information Tree )에서 암호는 일반적으로 해당 디렉터리 항목에userPassword속성으로 저장됩니다. connectionProtocol- 현재는 사용되지 않습니다. 나중에 이 옵션을 사용하면 디렉터리 서버에 연결할 Secure Socket Layer(SSL)을 선택할 수 있습니다. 이 옵션은 기본값이 없으므로 명시적으로 설정해야 합니다.
인증LDAP 서버에 바인딩할 때 사용되는 인증 방법을 지정합니다. 이 매개 변수의 유효한 값은
simple(사용자 이름 및 암호) 또는none(익명)입니다. 기본값은simple입니다.참고ASL(Simple Authentication and Security Layer) 인증은 지원되지 않습니다.
이전 구성 예에 표시되지 않는 다른 설정은 다음과 같습니다.
destinationBase-
모든 대상에 대한 권한을 제공하는 자식이 노드의 DN을 지정합니다. 이 경우 DN은 리터럴 값(즉, 속성 값에서 문자열 대체가 수행되지 않음)입니다. 예를 들어 이 속성의 일반적인 값은
ou=destinations,o=ActiveMQ,ou=system입니다. 기본값은ou=destinations,o=ActiveMQ,ou=system입니다. filter-
LDAP 검색 필터를 지정합니다. 이 필터는 모든 종류의 대상에 대한 권한을 검색할 때 사용됩니다. 검색 필터는 큐 또는 주제 노드의 하위 항목 중 하나와 일치하려고 합니다. 기본값은
(cn=*)입니다. roleAttribute-
역할의 DN에 해당하는
필터값과 일치하는 노드의 속성을 지정합니다. 기본값은uniqueMember입니다. adminPermissionValue-
관리자권한과 일치하는 값을 지정합니다. 기본값은admin입니다. readPermissionValue-
읽기 권한과 일치하는 값을 지정합니다.Specifies a value that matches the
readpermission. 기본값은read입니다. writePermissionValue-
쓰기권한과 일치하는 값을 지정합니다. 기본값은write입니다. enableListener-
LDAP 서버에서 자동으로 업데이트를 수신하고 브로커의 권한 부여 구성을 실시간으로 업데이트하는 리스너를 활성화할지 여부를 지정합니다. 기본값은
true입니다. mapAdminToManage레거시(즉, AMQ 6)
admin권한을 AMQ 7관리권한에 매핑할지 여부를 지정합니다. 아래 표의 매핑 의미 체계에 대한 세부 정보를 참조하십시오. 기본값은false입니다.LDAP에 정의된 큐 또는 항목의 이름은 보안 설정에 대해 "match" 역할을 하며, 권한 값은 AMQ 6 유형에서 AMQ 7 유형으로 매핑되며 역할은 그대로 매핑됩니다. LDAP에 정의된 큐 또는 항목의 이름이 보안 설정에 대한 일치 역할을 하므로 보안 설정이 JMS 대상에 예상대로 적용되지 않을 수 있습니다. 필요에 따라 AMQ 7은 항상 "jms.queue" 또는 "jms.topic"으로 JMS 대상 앞에 추가하기 때문입니다.
AMQ 6에는 세 가지 권한 유형(
읽기,쓰기,관리자등)이 있습니다. 이러한 권한 유형은 ActiveMQ 웹 사이트( 보안 )에 설명되어 있습니다.AMQ 7에는 다음과 같은 권한 유형이 있습니다.
-
createAddress -
deleteAddress -
createDurableQueue -
deleteDurableQueue -
createNonDurableQueue -
deleteNonDurableQueue -
send -
consume -
manage browse이 표는 보안 설정 플러그인이 AMQ 6 권한 유형을 AMQ 7 권한 유형에 매핑하는 방법을 보여줍니다.
AMQ 6 권한 유형 AMQ 7 권한 유형 read
사용, 찾아보기
write
send
admin
createAddress, deleteAddress, createDurableQueue, deleteDurableQueue, createNonDurableQueue, deleteNonDurableQueue, manage (
mapAdminToManage가true로 설정된 경우)아래에 설명 된 바와 같이 플러그인이 equivalence를 달성하기 위해 AMQ 6 및 AMQ 7 권한 유형 사이에서 일부 변환을 수행하는 몇 가지 경우가 있습니다.
-
AMQ 6에는 유사한 권한 유형이 없기 때문에 매핑에는 AMQ 7
관리권한 유형이 포함되어 있지 않습니다. 그러나mapAdminToManage가true로 설정된 경우 플러그인은 AMQ 6admin권한을 AMQ 7관리권한에 매핑합니다. -
AMQ 6의
admin권한 유형은 대상이 없는 경우 브로커가 자동으로 대상을 생성하고 사용자가 메시지를 보냅니다. AMQ 7은 사용자에게 메시지를 대상에 보낼 수 있는 권한이 있는 경우 자동으로 대상을 자동으로 생성할 수 있습니다. 따라서 플러그인은 기본적으로 위에 표시된 AMQ 7 권한에 대한 레거시관리자권한을 매핑합니다. 또한mapAdminToManage가true로 설정된 경우 플러그인은 AMQ 6관리자권한을 AMQ 7관리권한에 매핑합니다.
-
AMQ 6에는 유사한 권한 유형이 없기 때문에 매핑에는 AMQ 7
-
5.4.3. login.config 파일에서 암호 암호화
조직에서는 LDAP를 사용하여 데이터를 자주 저장하므로 login.config 파일에는 브로커가 조직의 LDAP 서버와 통신하는 데 필요한 구성을 포함할 수 있습니다. 이 설정 파일에는 일반적으로 LDAP 서버에 로그인하는 암호가 포함되어 있으므로 이 암호를 암호화해야 합니다.
사전 요구 사항
-
5.4.2절. “LDAP 권한 부여 구성” 에 설명된 대로
login.config파일을 수정하여 필요한 속성을 추가했는지 확인합니다.
절차
다음 절차에서는 < broker_instance_dir> /etc/login.config 파일에 있는 connectionPassword 매개 변수의 값을 마스킹하는 방법을 보여줍니다.
명령 프롬프트에서
mask유틸리티를 사용하여 암호를 암호화합니다.$ <broker_instance_dir>/bin/artemis mask <password>
result: 3a34fd21b82bf2a822fa49a8d8fa115d
<
broker_instance_dir> /etc/login.config파일을 엽니다.connectionPassword매개변수를 찾습니다.connectionPassword = <password>일반 텍스트 암호를 암호화된 값으로 바꿉니다.
connectionPassword = 3a34fd21b82bf2a822fa49a8d8fa115d
암호화된 값을
"ENC()"식별자로 래핑합니다.connectionPassword = "ENC(3a34fd21b82bf2a822fa49a8d8fa115d)"
이제 login.config 파일에 masked 암호가 포함되어 있습니다. 암호는 "ENC()" 식별자로 래핑되므로 AMQ Broker는 사용하기 전에 암호를 해독합니다.
추가 리소스
- AMQ Broker에 포함된 구성 파일에 대한 자세한 내용은 AMQ Broker 구성 파일 및 위치 를 참조하십시오.
5.5. 인증 및 권한 부여에 Kerberos 사용
AMQP 프로토콜을 사용하여 메시지를 보내고 받을 때 클라이언트는 SMTP( Simple Authentication and Security Layer ) 프레임워크의 GSSAPI 메커니즘을 사용하여 AMQ Broker가 인증하는 Kerberos 보안 자격 증명을 보낼 수 있습니다. Kerberos 자격 증명은 인증된 사용자를 LDAP 디렉터리 또는 텍스트 기반 속성 파일에 구성된 할당된 역할에 매핑하여 권한 부여에 사용할 수도 있습니다.
TLS( Transport Layer Security )와 함께 SASL을 사용하여 메시징 애플리케이션을 보호할 수 있습니다. SASL은 사용자 인증을 제공하며 TLS는 데이터 무결성을 제공합니다.
AMQ Broker가 Kerberos 인증 정보를 인증하고 인증하기 전에 Kerberos 인프라를 배포하고 구성해야 합니다. Kerberos 배포에 대한 자세한 내용은 운영 체제 설명서를 참조하십시오.
- RHEL 7의 경우 시스템 수준 인증 가이드의 " Kerberos 사용"을 참조하십시오.
- Windows의 경우 Kerberos 인증 개요 를 참조하십시오.
- Oracle 또는 IBM JDK 사용자는 JCE(Java Cryptography Extension)를 설치해야 합니다. 자세한 내용은 JCE 의 Oracle 버전 또는 JCE IBM 버전의 설명서를 참조하십시오.
다음 절차에서는 인증 및 권한 부여를 위해 Kerberos를 구성하는 방법을 보여줍니다.
5.5.1. Kerberos를 사용하도록 네트워크 연결 구성
AMQ Broker는 SASL( Simple Authentication and Security Layer ) 프레임워크의 GSSAPI 메커니즘을 사용하여 Kerberos 보안 인증 정보와 통합됩니다. AMQ Broker에서 Kerberos를 사용하려면 Kerberos 인증 또는 인증 클라이언트를 수락하거나 승인할 때마다 GSSAPI 메커니즘을 사용하도록 구성해야 합니다.
다음 절차에서는 Kerberos를 사용하도록 수락자를 구성하는 방법을 보여줍니다.
사전 요구 사항
- AMQ Broker가 Kerberos 인증 정보를 인증하고 인증하기 전에 Kerberos 인프라를 배포하고 구성해야 합니다.
절차
브로커를 중지합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis stopWindows에서:
<broker_instance_dir>\bin\artemis-service.exe stop
-
<
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다. 허용자 URL의 쿼리 문자열에 이름-값 쌍saslMechanisms=GSSAPI를 추가합니다.<acceptor name="amqp"> tcp://0.0.0.0:5672?protocols=AMQP;saslMechanisms=GSSAPI </acceptor>
앞의 구성은 수락자가 Kerberos 자격 증명을 인증할 때 GSSAPI 메커니즘을 사용한다는 것을 의미합니다.
(선택 사항)
PLAIN및ANONYMOUSSASL 메커니즘도 지원됩니다. 여러 메커니즘을 지정하려면 쉼표로 구분된 목록을 사용합니다. 예를 들면 다음과 같습니다.<acceptor name="amqp"> tcp://0.0.0.0:5672?protocols=AMQP;saslMechanisms=GSSAPI,PLAIN </acceptor>
그 결과 GSSAPI 및
PLAINSASL 메커니즘을모두사용하는 수락자가 있습니다.브로커를 시작합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis runWindows에서:
<broker_instance_dir>\bin\artemis-service.exe start
추가 리소스
- 수락자에 대한 자세한 내용은 2.1절. “승인자 정보” 을 참조하십시오.
5.5.2. Kerberos 자격 증명을 사용하여 클라이언트 인증
AMQ Broker는 SASL( Simple Authentication and Security Layer ) 프레임워크의 GSSAPI 메커니즘을 사용하는 AMQP 연결의 Kerberos 인증을 지원합니다.
브로커는 JAAS( Java Authentication and Authorization Service )를 사용하여 Kerberos 수락자 자격 증명을 획득합니다. Java 설치에 포함된 JAAS 라이브러리는 Kerberos 자격 증명을 인증하는 로그인 모듈 Krb5LoginModule 과 함께 패키지화됩니다. Krb5LoginModule 에 대한 자세한 내용은 Java 공급 업체의 문서를 참조하십시오. 예를 들어 Oracle은 Java 8 문서 의 일부로 Krb5LoginModule 로그인 모듈에 대한 정보를 제공합니다.
사전 요구 사항
- Kerberos 보안 자격 증명을 사용하여 AMQP 연결을 인증하려면 수락자의 GSSAPI 메커니즘을 활성화해야 합니다. 자세한 내용은 5.5.1절. “Kerberos를 사용하도록 네트워크 연결 구성”의 내용을 참조하십시오.
절차
브로커를 중지합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis stopWindows에서:
<broker_instance_dir>\bin\artemis-service.exe stop
-
<
broker_instance_dir> /etc/login.config구성 파일을 엽니다. amqp-sasl-gssapi라는 구성 범위를 추가합니다. 다음 예제에서는 Oracle 및 OpenJDK 버전의 JDK에 있는Krb5LoginModule의 구성을 보여줍니다.amqp-sasl-gssapi { com.sun.security.auth.module.Krb5LoginModule required isInitiator=false storeKey=true useKeyTab=true principal="amqp/my_broker_host@example.com" debug=true; };amqp-sasl-gssapi-
기본적으로 브로커의 GSSAPI 메커니즘 구현은
amqp-sasl-gssapi라는 JAAS 구성 범위를 사용하여 Kerberos 수락자 자격 증명을 가져옵니다. Krb5LoginModule-
이 버전의
Krb5LoginModule은 Oracle 및 OpenJDK 버전의 JDK에서 제공합니다. Java 공급 업체의 문서를 참조하여Krb5LoginModule의 정규화된 클래스 이름과 사용 가능한 옵션을 확인합니다. useKeyTab-
Krb5LoginModule은 보안 주체를 인증할 때 Kerberos 키탭을 사용하도록 구성되어 있습니다. 키탭은 Kerberos 환경의 툴링을 사용하여 생성됩니다. Kerberos 키탭 생성에 대한 자세한 내용은 공급 업체의 설명서를 참조하십시오. 보안 주체-
보안 주체는
amqp/my_broker_host@example.com로 설정됩니다. 이 값은 Kerberos 환경에서 생성된 서비스 주체에 해당해야 합니다. 서비스 주체 생성에 대한 자세한 내용은 공급 업체의 설명서를 참조하십시오.
브로커를 시작합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis runWindows에서:
<broker_instance_dir>\bin\artemis-service.exe start
5.5.2.1. 대체 구성 범위 사용
AMQP 수락자의 URL에 saslLoginConfigScope 매개변수를 추가하여 대체 구성 범위를 지정할 수 있습니다. 다음 구성 예제에서 매개 변수 saslLoginConfigScope 에는 alternative-sasl-gssapi 값이 제공됩니다. 결과적으로 < broker_instance_dir> /etc/login.config 구성 파일에 선언된 alternative-sasl-gssapi 라는 대체 범위를 사용하는 허용자가 생성됩니다.
<acceptor name="amqp"> tcp://0.0.0.0:5672?protocols=AMQP;saslMechanisms=GSSAPI,PLAIN;saslLoginConfigScope=alternative-sasl-gssapi` </acceptor>
5.5.3. Kerberos 자격 증명을 사용하여 클라이언트 인증
AMQ Broker에는 역할을 매핑할 때 다른 보안 모듈에서 사용할AS Krb5LoginModule 로그인 모듈 구현이 포함되어 있습니다. 이 모듈은 Kerberos 인증 피어 보안 주체를 AMQ Broker UserPrincipal으로 주체의 보안 주체 집합에 추가합니다. 그러면 Kerberos 인증 피어 보안 주체를 AMQ Broker 역할에 매핑하는 PropertiesLoginModule 또는 LDAPLoginModule 모듈에 인증 정보를 전달할 수 있습니다.
Kerberos Peer Principal은 역할 멤버로만 브로커 사용자로 존재하지 않습니다.
사전 요구 사항
- Kerberos 보안 자격 증명을 사용하여 AMQP 연결을 승인하려면 수락자의 GSSAPI 메커니즘을 활성화해야 합니다.
절차
브로커를 중지합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis stopWindows에서:
<broker_instance_dir>\bin\artemis-service.exe stop
-
<
broker_instance_dir> /etc/login.config구성 파일을 엽니다. AMQ Broker
Krb5LoginModule및LDAPLoginModule에 대한 구성을 추가합니다. LDAP 공급자의 문서를 참조하여 구성 옵션을 확인합니다.예제 구성은 다음과 같습니다.
org.apache.activemq.artemis.spi.core.security.jaas.Krb5LoginModule required ; org.apache.activemq.artemis.spi.core.security.jaas.LDAPLoginModule optional initialContextFactory=com.sun.jndi.ldap.LdapCtxFactory connectionURL="ldap://localhost:1024" authentication=GSSAPI saslLoginConfigScope=broker-sasl-gssapi connectionProtocol=s userBase="ou=users,dc=example,dc=com" userSearchMatching="(krb5PrincipalName={0})" userSearchSubtree=true authenticateUser=false roleBase="ou=system" roleName=cn roleSearchMatching="(member={0})" roleSearchSubtree=false ;참고위 예에 표시된
Krb5LoginModule버전은 AMQ Broker와 함께 배포되며, 역할 매핑을 위해 다른 AMQ 모듈에서 사용할 수 있는 브로커 ID로 Kerberos ID를 변환합니다.브로커를 시작합니다.
Linux의 경우:
<broker_instance_dir>/bin/artemis runWindows에서:
<broker_instance_dir>\bin\artemis-service.exe start
추가 리소스
- AMQ Broker에서 GSSAPI 메커니즘 활성화에 대한 자세한 내용은 5.5.1절. “Kerberos를 사용하도록 네트워크 연결 구성” 을 참조하십시오.
-
PropertiesLoginModule에 대한 자세한 내용은 5.2.2.1절. “기본 사용자 및 암호 인증 구성” 를 참조하십시오. -
LDAPLoginModule에 대한 자세한 내용은 5.4.1절. “클라이언트 인증을 위해 LDAP 구성” 을 참조하십시오.
5.6. 사용자 정의 보안 관리자 사용
브로커는 보안 관리자 라는 구성 요소를 사용하여 인증 및 권한 부여를 처리합니다. 기본적으로 AMQ Broker는 org.apache.activemq.artemis.spi.core.security.ActiveMQJAASSecurityManager 보안 관리자를 사용합니다. 이 기본 보안 관리자는 JAAS 및 Red Hat JBoss EAP(JBoss Enterprise Application Platform) 보안과의 통합을 제공합니다.
그러나 시스템 관리자는 브로커 보안 구현을 더 많이 제어해야 할 수 있습니다. 이 경우 브로커 구성에 사용자 지정 보안 관리자를 지정할 수 있습니다. 사용자 지정 보안 관리자는 org.apache.activemq.artemis.spi.core.security.ActiveMQSecurityManager5 인터페이스를 구현하는 사용자 정의 클래스입니다.
5.6.1. 사용자 정의 보안 관리자 지정
다음 절차에서는 브로커 구성에서 사용자 지정 보안 관리자를 지정하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/boostrap.xml구성 파일을 엽니다. security-manager요소에서class-name속성에 대해org.apache.activemq.artemis.spi.core.security.security.ActiveMQSecurityManager5인터페이스에 대한 사용자 정의 구현인 클래스를 지정합니다. 예를 들면 다음과 같습니다.<broker xmlns="http://activemq.org/schema"> ... <security-manager class-name="com.foo.MySecurityManager"> <property key="myKey1" value="myValue1"/> <property key="myKey2" value="myValue2"/> </security-manager> ... </broker>
추가 리소스
-
org.apache.activemq.artemis.spi.core.security.ActiveMQSecurityManager5인터페이스에 대한 자세한 내용은 ActiveMQ Peer Core API 설명서의 Interface ActiveMQSecurityManager5 를 참조하십시오.
5.6.2. 사용자 정의 보안 관리자 예제 실행
AMQ Broker에는 사용자 정의 보안 관리자를 구현하는 방법을 보여주는 예제 프로그램이 포함되어 있습니다. 이 예제에서 사용자 지정 보안 관리자는 인증 및 권한에 대한 세부 정보를 기록한 다음, 세부 정보를 org.apache.activemq.artemis.spi.core.security.ActiveMQJAASSecurityManager (즉, 기본 보안 관리자) 인스턴스에 전달합니다.
다음 절차에서는 사용자 지정 보안 관리자 예제 프로그램을 실행하는 방법을 보여줍니다.
사전 요구 사항
- AMQ Broker 예제 프로그램을 실행하려면 머신을 설정해야 합니다. 자세한 내용은 Running the AMQ Broker 예제 를 참조하십시오.
절차
사용자 지정 보안 관리자 예제가 포함된 디렉터리로 이동합니다.
$ cd <install-dir>/examples/features/standard/security-manager예제를 실행합니다.
$ mvn verify
예제 프로그램을 실행할 때 브로커 인스턴스를 수동으로 생성 및 시작하려는 경우 이전 단계의 명령을 mvn -PnoServer 확인 으로 바꿉니다.
5.7. 보안 비활성화
보안은 기본적으로 활성화되어 있습니다. 다음 절차에서는 브로커 보안을 비활성화하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 핵심요소에서security-enabled값을false로 설정합니다.<security-enabled>false</security-enabled>
-
필요한 경우
security-invalidation-interval에 대해 새 값(밀리초)을 지정합니다. 이 속성의 값은 브로커가 주기적으로 보안 로그인을 무효화하는 시기를 지정합니다. 기본값은10000입니다.
5.8. 검증된 사용자의 메시지 추적
메시지 추적 및 로깅(예: 보안 감사 목적으로)을 활성화하려면 _AMQ_VALIDATED_USER 메시지 키를 사용할 수 있습니다.
broker.xml 구성 파일에서 populate-validated-user 옵션이 true 로 설정된 경우 브로커는 _AMQ_VALIDATED_USER 키를 사용하여 검증된 사용자의 이름을 메시지에 추가합니다. JMS 및 STOMP 클라이언트의 경우 이 메시지 키는 JMSXUserID 키에 매핑됩니다.
브로커는 AMQP JMS 클라이언트가 생성한 메시지에 검증된 사용자 이름을 추가할 수 없습니다. 클라이언트에서 보낸 후 AMQP 메시지의 속성을 수정하는 것은 AMQP 프로토콜을 위반하는 것입니다.
자신의 SSL 인증서를 기반으로 인증된 사용자의 경우 브로커에 의해 채워진 검증된 사용자 이름은 인증서의 DN (DN)이 매핑되는 이름입니다.
broker.xml 구성 파일에서 security-enabled 가 false 이고 populate-validated-user 가 true 인 경우 브로커는 클라이언트가 제공하는 모든 사용자 이름을 채웁니다. populate-validated-user 옵션은 기본적으로 false 입니다.
메시지를 전송할 때 클라이언트가 이미 채워진 사용자 이름(즉, JMSXUserID 키)이 없는 메시지를 거부하도록 브로커를 구성할 수 있습니다. 브로커가 이러한 클라이언트가 보낸 메시지에 대해 검증된 사용자 이름 자체를 채울 수 없기 때문에 AMQP 클라이언트에 유용한 이 옵션을 찾을 수 있습니다.
클라이언트가 설정한 JMSXUserID 없이 메시지를 거부하도록 브로커를 구성하려면 broker.xml 구성 파일에 다음 구성을 추가합니다.
<reject-empty-validated-user>true</reject-empty-validated-user>
기본적으로 reject-empty-validated-user 는 false 로 설정됩니다.
5.9. 구성 파일의 암호 암호화
기본적으로 AMQ 브로커는 구성 파일의 모든 암호를 일반 텍스트로 저장합니다. 무단 액세스를 방지하기 위해 올바른 권한으로 모든 구성 파일을 보호해야 합니다. 또한 일반 텍스트 암호를 암호화하거나 마스킹 하여 원치 않는 시청자가 문서를 읽지 못하도록 암호화하거나 마스킹할 수 있습니다.
5.9.1. 암호화된 암호 정보
암호화된 또는 마스킹된 암호는 일반 텍스트 암호의 암호화된 버전입니다. 암호화된 버전은 AMQ Broker에서 제공하는 마스크 명령줄 유틸리티에 의해 생성됩니다. mask 유틸리티에 대한 자세한 내용은 명령줄 도움말 설명서를 참조하십시오.
$ <broker_instance_dir>/bin/artemis help mask
암호를 마스크하려면 일반 텍스트 값을 암호화된 값으로 바꿉니다. 마스킹된 암호는 실제 값이 필요할 때 해독되도록 식별자 ENC() 로 래핑해야 합니다.
다음 예에서 구성 파일 < broker_instance_dir> /etc/bootstrap.xml 에는 keyStorePassword 및 trustStorePassword 매개변수에 대한 마스킹된 암호가 포함되어 있습니다.
<web bind="https://localhost:8443" path="web"
keyStorePassword="ENC(-342e71445830a32f95220e791dd51e82)"
trustStorePassword="ENC(32f94e9a68c45d89d962ee7dc68cb9d1)">
<app url="activemq-branding" war="activemq-branding.war"/>
</web>다음 구성 파일과 함께 마스킹된 암호를 사용할 수 있습니다.
- broker.xml
- bootstrap.xml
- management.xml
- artemis-users.properties
-
login.config (
LDAPLoginModule과 함께 사용)
구성 파일은 < broker_instance_dir> /etc 에 있습니다.
ctdb-users.properties 는 해시된 마스킹된 암호만 지원합니다. 사용자가 브로커 생성 시 생성되면 artemis-users.properties 에는 기본적으로 해시된 암호가 포함됩니다. 기본 PropertiesLoginModule 은 artemis-users.properties 파일에서 암호를 디코딩하지 않지만 대신 입력을 해시하고 암호 확인을 위해 두 개의 해시된 값을 비교합니다. 해시된 암호를 마스크된 암호로 변경하면 AMQ Broker 관리 콘솔에 액세스할 수 없습니다.
broker.xml,bootstrap.xml,management.xml, login.config 는 마스킹되었지만 해시되지 않은 암호를 지원합니다.
5.9.2. 구성 파일에서 암호 암호화
다음 예제는 broker.xml 구성 파일에서 cluster-password 값을 마스킹하는 방법을 보여줍니다.
절차
명령 프롬프트에서
mask유틸리티를 사용하여 암호를 암호화합니다.$ <broker_instance_dir>/bin/artemis mask <password>
result: 3a34fd21b82bf2a822fa49a8d8fa115d
마스크하려는 일반 텍스트 암호가 포함된 <
broker_instance_dir> /etc/broker.xml구성 파일을 엽니다.<cluster-password> <password> </cluster-password>일반 텍스트 암호를 암호화된 값으로 바꿉니다.
<cluster-password> 3a34fd21b82bf2a822fa49a8d8fa115d </cluster-password>
암호화된 값을
ENC()식별자로 래핑합니다.<cluster-password> ENC(3a34fd21b82bf2a822fa49a8d8fa115d) </cluster-password>
이제 구성 파일에 암호화된 암호가 포함되어 있습니다. 암호는 ENC() 식별자로 래핑되므로 AMQ Broker는 사용하기 전에 암호를 해독합니다.
추가 리소스
- AMQ Broker에 포함된 구성 파일에 대한 자세한 내용은 1.1절. “AMQ Broker 구성 파일 및 위치” 을 참조하십시오.
6장. 메시지 저장
이 장에서는 지속성이 AMQ Broker와 함께 작동하는 방식과 이를 구성하는 방법을 설명합니다.
브로커에는 두 가지 지속성 옵션이 있습니다.
또는 제로 지속성 을 위해 브로커를 구성할 수도 있습니다.
브로커는 메시지 저널 외부에서 큰 메시지를 유지하기 위해 다른 솔루션을 사용합니다. 자세 한 내용은 대용량 메시지 작업 을 참조하십시오. 메모리 부족 상태에서 디스크에 메시지를 페이징하도록 브로커를 구성할 수도 있습니다. 자세 한 내용은 메시지 삭제 를 참조하십시오.
6.1. 저널 기반 지속성 정보
브로커의 저널은 디스크에 파일 만 첨부 하는 세트입니다. 각 파일은 고정된 크기로 미리 만들어지며 처음에는 패딩으로 채워집니다. 메시징 작업이 브로커에서 수행되면 레코드가 저널 끝에 추가됩니다. 레코드를 추가하면 브로커가 디스크 헤드 이동 및 임의의 액세스 작업을 최소화하여 일반적으로 디스크에서 가장 느린 작업을 수행할 수 있습니다. 하나의 저널 파일이 가득 차면 브로커는 새 파일을 사용합니다.
저널 파일 크기는 구성할 수 있으며 각 파일에서 사용하는 디스크 실린더 수를 최소화합니다. 그러나 최신 디스크 토폴로지는 복잡하며 브로커는 파일이 매핑되는 실린더를 제어할 수 없습니다. 따라서 저널 파일 크기 조정은 정확한 과학이 아닙니다.
기타 지속성 관련 기능은 다음과 같습니다.
- 특정 저널 파일이 여전히 사용 중인지 확인하는 정교한 파일 가비지 수집 알고리즘입니다. 그렇지 않은 경우 파일을 회수하고 다시 사용할 수 있습니다.
- 저널에서 제거된 공간을 제거하고 데이터를 압축하는 압축 알고리즘입니다. 그러면 디스크에서 파일을 더 적게 사용하는 저널이 생성됩니다.
- 로컬 트랜잭션 지원.
- AMQ JMS 클라이언트를 사용할 때 XA 트랜잭션 지원
대부분의 저널은 Java로 작성됩니다. 그러나 실제 파일 시스템과의 상호 작용은 추상화되므로 서로 다른 플러그형 구현을 사용할 수 있습니다. AMQ Broker는 다음 두 가지 구현과 함께 제공됩니다.
표준 Java NIO를 사용하여 파일 시스템과 인터페이스합니다. 이는 매우 우수한 성능을 제공하며 Java 6 이상 런타임이 있는 모든 플랫폼에서 실행됩니다.
Linux 비동기 IO
씬 네이티브 래퍼를 사용하여 Linux 비동기 IO 라이브러리(AIO)와 통신합니다. AIO에서 브로커는 데이터가 디스크에 만들어진 후 다시 호출되므로 명시적으로 동기화되지 않습니다. 기본적으로 브로커는 AIO 저널을 사용하려고 하며 AIO를 사용할 수 없는 경우 NIO를 사용하도록 대체합니다.
AIO를 사용하면 일반적으로 Java NIO를 사용하는 것보다 성능이 향상됩니다. libaio를 설치하는 방법에 대한 지침은 AIO 저널 사용을 참조하십시오.
6.1.1. AIO 사용
Java NIO 저널은 성능이 매우 뛰어나지 만 Linux 커널 2.6 이상을 사용하여 브로커를 실행하는 경우 AIO 저널을 사용하여 지속성 성능을 향상시키는 것이 좋습니다. AIO 저널은 다른 운영 체제 또는 이전 버전의 Linux 커널과 함께 사용할 수 없습니다.
AIO 저널을 사용하려면 libaio 가 아직 설치되지 않은 경우 설치해야 합니다.
절차
-
아래의 예와 같이
yum명령을 사용하여libaio를 설치합니다.
yum install libaio
6.2. 저널 기반 지속성 구성
지속성 구성은 BROKER_INSTANCE_DIR/etc/broker.xml 파일에서 유지됩니다. 브로커의 기본 구성은 저널 기반 지속성을 사용하며 아래 표시된 요소를 포함합니다.
<configuration>
<core>
...
<persistence-enabled>true</persistence-enabled>
<journal-type>ASYNCIO</journal-type>
<bindings-directory>./data/bindings</bindings-directory>
<journal-directory>./data/journal</journal-directory>
<journal-datasync>true</journal-datasync>
<journal-min-files>2</journal-min-files>
<journal-pool-files>-1</journal-pool-files>
...
</core>
</configuration>- persistence-enabled
- 메시지 지속성을 위해 파일 기반 저널을 사용할지 여부를 지정합니다.
- journal-type
-
사용할 저널 유형입니다.
ASYNCIO로 설정하면 브로커는 먼저 AIO를 사용하려고 합니다. ASYNCIO를 찾을 수 없는 경우 브로커는 NIO로 돌아갑니다. - bindings-directory
-
바인딩 저널의 파일 시스템 위치. 기본 설정은
BROKER_INSTANCE_DIR상대적입니다. - journal-directory
-
메시징 저널의 파일 시스템 위치. 기본 설정은
BROKER_INSTANCE_DIR상대적입니다. - journal-datasync
-
fdatasync를 사용하여 디스크에 대한 쓰기를 확인할지 여부를 지정합니다. - journal-min-files
- 브로커가 시작될 때 생성할 저널 파일 수입니다.
- journal-pool-files
- 사용되지 않은 파일을 회수한 후 보관할 파일 수입니다. 기본값 -1은 정리하는 동안 파일이 삭제되지 않음을 의미합니다.
6.2.1. 메시지 저널
메시지 저널은 메시지 자체 및 중복 ID 캐시를 포함하여 모든 메시지 관련 데이터를 저장합니다. 이 저널의 파일 앞에는 typical -data가 붙습니다. 각 파일에는 amq 확장자 와 기본 크기가 10485760 바이트가 있습니다. 메시지 저널의 위치는 journal-directory 구성 요소를 사용하여 설정됩니다. 기본값은 BROKER_INSTANCE_DIR/data/journal 입니다. 기본 구성에는 메시징 저널과 관련된 다른 요소가 포함됩니다.
journal-min-files브로커가 시작될 때 사전에 생성할 저널 파일 수입니다. 기본값은
2입니다.journal-pool-files사용되지 않은 파일을 회수한 후 보관할 파일 수입니다. 기본값
-1은 브로커가 생성한 후 삭제되는 파일이 없음을 의미합니다. 그러나 시스템이 무한정 증가할 수 없으므로 이러한 방식으로 바인딩되지 않은 대상에 페이징을 사용해야 합니다. 자세한 내용은 메시지 삭제 장 을 참조하십시오.
메시징 저널에 사용할 수 있는 다른 구성 요소에는 여러 가지가 있습니다. 전체 목록은 부록을 참조하십시오.
6.2.2. 바인딩 저널
바인딩 저널은 서버 및 해당 특성에 배포된 큐 세트와 같은 바인딩 관련 데이터를 저장하는 데 사용됩니다. ID 시퀀스 카운터와 같은 데이터도 저장합니다.
바인딩 저널은 메시지 저널과 비교할 때 일반적으로 처리량이 낮기 때문에 항상 NIO를 사용합니다. 이 저널의 파일 앞에는 typical -bindings가 붙습니다. 각 파일에는 바인딩 확장과 기본 크기가 1048576 바이트가 있습니다.
BROKER_INSTANCE_DIR/etc/broker.xml 에서 다음 구성 요소를 사용하여 바인딩 저널을 구성합니다.
bindings-directory바인딩 저널이 있는 디렉터리입니다. 기본값은
BROKER_INSTANCE_DIR/data/bindings입니다.create-bindings-dirtrue로 설정하면 바인딩 디렉터리가 바인딩 디렉터리에 없는 경우바인딩 디렉터리에 자동으로 생성됩니다. 기본값은true입니다.
6.2.3. JMS journal
JMS 저널은 JMS Queues, Topics, Connection Factories와 이러한 리소스의 JNDI 바인딩을 포함한 모든 JMS 관련 데이터를 저장합니다. 또한 관리 API를 통해 생성된 JMS 리소스는 이 저널에 유지되지만 구성 파일을 통해 구성된 리소스는 유지되지 않습니다. JMS 저널은 JMS가 사용되는 경우에만 생성됩니다.
이 저널의 파일 앞에는 typical -jms 가 붙습니다. 각 파일에는 jms 확장자와 기본 크기가 1048576 바이트가 있습니다.
JMS 저널은 해당 구성을 바인딩 저널과 공유합니다.
6.2.4. 저널 파일 압축
AMQ Broker에는 저널에서 중단된 공간을 제거하고 디스크의 공간을 줄일 수 있도록 데이터를 압축하는 압축 알고리즘이 포함되어 있습니다. 압축을 시작할 시기를 결정하는 데 사용되는 두 가지 기준이 있습니다. 두 기준이 모두 충족되면 압축 프로세스는 저널을 구문 분석하고 모든 실패한 레코드를 제거합니다. 그 결과 저널은 더 적은 파일로 구성됩니다. 기준은 다음과 같습니다.
- 저널에 대해 생성된 파일 수입니다.
- 저널의 파일에 있는 실시간 데이터의 백분율입니다.
BROKER_INSTANCE_DIR/etc/broker.xml 에서 두 기준을 모두 구성합니다.
절차
압축 프로세스에 대한 기준을 구성하려면 아래 예제와 같이 다음 두 요소를 추가합니다.
<configuration> <core> ... <journal-compact-min-files>15</journal-compact-min-files> 1 <journal-compact-percentage>25</journal-compact-percentage> 2 ... </core> </configuration>
CLI를 사용하여 저널 압축
CLI(명령줄 인터페이스)를 사용하여 압축한 저널도 사용할 수 있습니다.
절차
BROKER_INSTANCE_DIR소유자로서 브로커를 중지합니다. 아래 예제에서는 AMQ Broker를 설치하는 동안 사용자amq-broker가 생성되었습니다.su - amq-broker cd __BROKER_INSTANCE_DIR__/bin $ ./artemis stop
(선택 사항) 다음 CLI 명령을 실행하여 데이터 툴의 전체 매개변수 목록을 가져옵니다. 기본적으로 이 툴에서는
BROKER_INSTANCE_DIR/etc/broker.xml에 있는 설정을 사용합니다.$ ./artemis help data compact.
다음 CLI 명령을 실행하여 데이터를 압축합니다.
$ ./artemis data compact.
도구를 성공적으로 압축한 후 브로커를 다시 시작하십시오.
$ ./artemis run
관련 정보
AMQ Broker에는 저널 파일을 관리하기 위한 여러 CLI 명령이 포함되어 있습니다. 자세한 내용은 부록의 명령줄 도구 를 참조하십시오.
6.2.5. 디스크 쓰기 캐시 비활성화
대부분의 디스크에는 하드웨어 쓰기 캐시가 포함되어 있습니다. 쓰기 캐시는 나중에 디스크에 쓰기가 지연되므로 디스크의 명백한 성능을 향상시킬 수 있습니다. 기본적으로 많은 시스템은 디스크 쓰기 캐시가 활성화된 상태로 제공됩니다. 즉, 운영 체제에서 동기화한 후에도 데이터가 실제로 디스크에 만들 것이라는 보장은 없으므로 오류가 발생하면 중요한 데이터를 잃을 수 있습니다.
더 비싼 디스크에는 오류가 발생할 경우 데이터를 손실하지 않아도 되는 비휘발성 또는 배터리 지원 쓰기 캐시가 있지만 테스트해야 합니다. 디스크에 이러한 기능이 없는 경우 쓰기 캐시가 비활성화되었는지 확인해야 합니다. 디스크 쓰기 캐시를 비활성화하면 성능에 부정적인 영향을 미칠 수 있습니다.
절차
-
Linux에서
hdparm( IDE 디스크용) 또는sdparm또는sginfo(Sginfo의 경우) 툴을 사용하여 디스크의 쓰기 캐시 설정을 관리합니다. - Windows에서 디스크를 마우스 오른쪽 버튼으로 클릭하고 속성 을 클릭하여 캐시 설정을 관리합니다.
6.3. JDBC 지속성 구성
JDBC 지속성 저장소는 JDBC 연결을 사용하여 데이터베이스 테이블에 메시지 및 바인딩 데이터를 저장합니다. 테이블의 데이터는 AMQ Broker 저널 인코딩을 사용하여 인코딩됩니다. 지원되는 데이터베이스에 대한 자세한 내용은 Red Hat 고객 포털의 Red Hat AMQ 7 지원 구성 을 참조하십시오.
관리자는 조직의 광범위한 IT 인프라의 요구 사항에 따라 메시징 데이터를 데이터베이스에 저장하도록 선택할 수 있습니다. 그러나 데이터베이스를 사용하면 메시징 시스템의 성능에 부정적인 영향을 미칠 수 있습니다. 특히 JDBC를 통해 데이터베이스 테이블에 메시징 데이터를 작성하면 브로커에 대한 심각한 성능 오버헤드가 발생합니다.
절차
-
적절한 JDBC 클라이언트 라이브러리를 브로커 런타임에 추가합니다. 관련 jar를
BROKER_INSTANCE_DIR/lib디렉토리에 추가하여 이 작업을 수행할 수 있습니다. 아래 예제와 같이
BROKER_INSTANCE_DIR/etc/broker.xml구성 파일에store요소를 생성합니다.<configuration> <core> <store> <database-store> <jdbc-connection-url>jdbc:oracle:data/oracle/database-store;create=true</jdbc-connection-url> <jdbc-user>ENC(5493dd76567ee5ec269d11823973462f)</jdbc-user> <jdbc-password>ENC(56a0db3b71043054269d11823973462f)</jdbc-password> <bindings-table-name>BINDINGS_TABLE</bindings-table-name> <message-table-name>MESSAGE_TABLE</message-table-name> <large-message-table-name>LARGE_MESSAGES_TABLE</large-message-table-name> <page-store-table-name>PAGE_STORE_TABLE</page-store-table-name> <node-manager-store-table-name>NODE_MANAGER_TABLE</node-manager-store-table-name> <jdbc-driver-class-name>oracle.jdbc.driver.OracleDriver</jdbc-driver-class-name> <jdbc-network-timeout>10000</jdbc-network-timeout> <jdbc-lock-renew-period>2000</jdbc-lock-renew-period> <jdbc-lock-expiration>20000</jdbc-lock-expiration> <jdbc-journal-sync-period>5</jdbc-journal-sync-period> </database-store> </store> </core> </configuration>- jdbc-connection-url
- 데이터베이스 서버의 전체 JDBC 연결 URL입니다. 연결 URL에는 모든 구성 매개 변수와 데이터베이스 이름이 포함되어야 합니다.
- jdbc-user
- 데이터베이스 서버의 암호화된 사용자 이름입니다. 구성 파일에 사용할 사용자 이름 및 암호를 암호화하는 방법에 대한 자세한 내용은 5.9절. “구성 파일의 암호 암호화” 을 참조하십시오.
- jdbc-password
- 데이터베이스 서버의 암호화된 암호입니다. 구성 파일에 사용할 사용자 이름 및 암호를 암호화하는 방법에 대한 자세한 내용은 5.9절. “구성 파일의 암호 암호화” 을 참조하십시오.
- bindings-table-name
- 바인딩 데이터가 저장되는 테이블의 이름입니다. 이 테이블 이름을 지정하면 간섭없이 여러 서버 간에 단일 데이터베이스를 공유할 수 있습니다.
- message-table-name
- 메시지 데이터가 저장되는 테이블의 이름입니다. 이 테이블 이름을 지정하면 간섭없이 여러 서버 간에 단일 데이터베이스를 공유할 수 있습니다.
- large-message-table-name
- 대용량 메시지 및 관련 데이터가 유지되는 테이블의 이름입니다. 또한 클라이언트가 청크로 큰 메시지를 스트리밍하는 경우 청크는 이 테이블에 저장됩니다. 이 테이블 이름을 지정하면 간섭없이 여러 서버 간에 단일 데이터베이스를 공유할 수 있습니다.
- page-store-table-name
- paged store 디렉토리 정보가 저장된 테이블의 이름입니다. 이 테이블 이름을 지정하면 간섭없이 여러 서버 간에 단일 데이터베이스를 공유할 수 있습니다.
- node-manager-store-table-name
- 실시간 및 백업 브로커에 대한 공유 저장소 HA(고가용성) 잠금 및 기타 HA 관련 데이터가 브로커 서버에 저장되는 테이블의 이름입니다. 이 테이블 이름을 지정하면 간섭없이 여러 서버 간에 단일 데이터베이스를 공유할 수 있습니다. 공유 저장소 HA를 사용하는 각 라이브 백업 쌍은 동일한 테이블 이름을 사용해야 합니다. 여러 (및 관련이 없는) 실시간 백업 쌍 간에 동일한 테이블을 공유할 수 없습니다.
- jdbc-driver-class-name
- JDBC 데이터베이스 드라이버의 정규화된 클래스 이름입니다. 지원되는 데이터베이스에 대한 자세한 내용은 Red Hat 고객 포털의 Red Hat AMQ 7 지원 구성 을 참조하십시오.
- jdbc-network-timeout
-
JDBC 네트워크 연결 시간 초과(밀리초). 기본값은 20000밀리초입니다. 공유 저장소 HA에 JDBC를 사용하는 경우 시간 제한을
jdbc-lock-expiration보다 작거나 같은 값으로 설정하는 것이 좋습니다. - jdbc-lock-renew-period
- 현재 JDBC 잠금에 대한 갱신 기간의 길이(밀리초)입니다. 이 시간이 지나면 브로커가 잠금을 갱신할 수 있습니다. 기본값은 2000밀리초입니다.
- jdbc-lock-expiration
-
jdbc-lock-renew-period시간이 경과해도 현재 JDBC 잠금이 활성 상태로 간주되는 시간(밀리초)입니다. 이 속성을jdbc-lock-renew-period보다 큰 값으로 설정하면 잠금을 보유한 브로커가 갱신할 때 예기치 않은 지연이 발생하면 즉시 손실되지 않습니다. 만료 시간이 경과된 후 JDBC 잠금이 현재 보유 중인 브로커에 의해 갱신되지 않은 경우 다른 브로커는 JDBC 잠금을 설정할 수 있습니다. 기본값은 20000밀리초입니다. - jdbc-journal-sync-period
- 브로커 저널이 JDBC와 동기화하는 기간(밀리초)입니다. 기본값은 5밀리초입니다.
6.4. 제로 지속성 구성
경우에 따라 메시징 시스템에 제로 지속성이 필요한 경우가 있습니다. 제로 지속성을 수행하도록 브로커를 구성하는 것은 간단합니다. BROKER_INSTANCE_DIR/etc/broker.xml 에서 매개 변수 persistence-enabled 를 false 로 설정합니다.
이 매개변수를 false로 설정하면 지속성 0이 발생합니다. 즉, 바인딩 데이터, 메시지 데이터, 대용량 메시지 데이터, 중복 ID 캐시 또는 페이징 데이터가 유지되지 않습니다.
7장. 페이징 메시지
AMQ Broker는 서버가 제한된 메모리로 실행되는 동안 수백만 개의 메시지가 포함된 대규모 큐를 투명하게 지원합니다.
이러한 상황에서 모든 대기열을 메모리에 한 번에 저장할 수 없으므로 AMQ Broker는 필요한 대로 메시지를 투명하게 페이징 아웃하여 메모리 공간이 낮은 대용량 큐를 허용합니다.
페이징은 주소당 개별적으로 수행됩니다. AMQ Broker는 주소의 메모리의 모든 메시지의 크기가 구성된 최대 크기를 초과할 때 디스크에 페이징 메시지를 시작합니다. 주소에 대한 자세한 내용은 주소 및 대기열 구성을 참조하십시오.
기본적으로 AMQ 브로커는 메시지를 페이징하지 않습니다. 활성화하려면 페이징을 명시적으로 구성해야 합니다.
AMQ Broker에서 페이징 을 사용하는 방법을 보여주는 작업 예제는INSTA LL_DIR /examples/standard/에 있는 페이징 예제를 참조하십시오.
7.1. 페이지 파일 정보
메시지는 파일 시스템의 주소별로 저장됩니다. 각 주소에는 메시지가 여러 파일(페이지 파일)에 저장되는 개별 폴더가 있습니다. 각 파일에는 최대 구성된 크기(page-size-bytes)까지 메시지가 포함됩니다. 시스템은 필요에 따라 파일을 탐색하며 모든 메시지가 해당 지점까지 승인되는 즉시 페이지 파일을 제거합니다.
브라우저는 페이지 반복 시스템을 통해 읽습니다.
선택기가 있는 소비자도 page-files를 탐색하고 기준에 일치하지 않는 메시지는 무시합니다.
큐가 있고 소비자는 큐에서 메시지를 사용할 때까지 페이징에서 더 많은 데이터를 읽을 수 없는 경우 매우 제한적인 선택기로 큐를 필터링 할 수 있습니다.When you have a queue, and consumers filtering the queue with a very restrictive selector you may get into a situation where you won't be able to read more data from paging until you consume messages from the queue.
예: 한 소비자에서 'color="red"'로 선택기를 만들지만 파란색 후 하나의 빨간색 메시지만 있으면 파란색을 사용할 때까지 빨간색을 사용할 수 없습니다. 이는 큐를 공급하는 동안 메시지를 검색하는 동안 및 메시지를 검색하는 동안 전체 대기열을 "browse"하므로 검색하는 것과 다릅니다.
7.2. 복사 디렉토리 위치 구성
페이징 디렉터리의 위치를 설정하려면 다음 예제와 같이 페이징 디렉터리 구성 요소를 브로커의 기본 구성 파일 BROKER_INSTANCE_DIR/etc/broker.xml 에 추가합니다.
<configuration ...>
...
<core ...>
<paging-directory>/somewhere/paging-directory</paging-directory>
...
</core>
</configuration>AMQ Broker는 구성된 위치에 페이징되는 각 주소에 대해 하나의 디렉터리를 생성합니다.
7.3. 일시 중지를 위한 주소 구성
페이지 구성은 아래 예제와 같이 특정 address-settings 에 요소를 추가하여 주소 수준에서 수행됩니다.
<address-settings>
<address-setting match="jms.paged.queue">
<max-size-bytes>104857600</max-size-bytes>
<page-size-bytes>10485760</page-size-bytes>
<address-full-policy>PAGE</address-full-policy>
</address-setting>
</address-settings>
위의 예에서 주소 jms.paged.queue 로 전송된 메시지가 메모리에서 104857600 바이트를 초과하면 브로커가 페이징을 시작합니다.
페이징은 주소당 개별적으로 수행됩니다. 주소에 max-size-bytes 를 지정하면 일치하는 각 주소가 지정한 최대 크기를 초과하지 않습니다. 일치하는 모든 주소의 전체 크기가 max-size-bytes 로 제한된다는 의미는 아닙니다.
이는 주소 설정에서 사용 가능한 매개변수 목록입니다.
표 7.1. 페이징 구성 요소
| 요소 이름 | 설명 | 기본값 |
|---|---|---|
| max-size-bytes | 브로커가 페이지 모드로 전환되기 전에 주소에 허용되는 메모리의 최대 크기입니다. | -1(비활성화됨).
이 매개 변수가 비활성화되면 브로커는 대신 |
| page-size-bytes | 페이징 시스템에 사용되는 각 페이지 파일의 크기입니다. | 10MiB (10 \* 1024 \* 1024 bytes) |
| address-full-policy |
유효한 값은 | PAGE |
| page-max-cache-size | 시스템은 페이징 탐색 중에 IO를 최적화하기 위해 메모리에 있는 이러한 페이지 파일 수를 유지합니다. | 5 |
| page-sync-timeout | 시간(초)은 주기적 페이지 동기화 간입니다. |
비동기 IO 저널(즉, |
7.4. 글로벌 패징 크기 구성
브로커가 다른 사용 패턴이 있는 여러 주소를 관리하는 경우와 같이 주소당 메모리 제한을 구성하는 것이 실용적이지 않는 경우가 있습니다. 이러한 상황에서 global-max-size 매개변수를 사용하여 수신 메시지와 연결된 주소에 대해 구성된 페이지 모드로 입력하기 전에 전역 제한을 사용할 수 있는 메모리 양으로 설정합니다.
global-max-size 의 기본값은 JVM(Java 가상 시스템)에서 사용할 수 있는 최대 메모리의 절반입니다. broker.xml 구성 파일에서 구성하여 이 매개변수에 대해 자체 값을 지정할 수 있습니다. global-max-size 의 값은 바이트 단위이지만 편의를 위해 바이트 표기법("K", "Mb", "GB" 등을 사용할 수 있습니다.
다음 절차에서는 broker.xml 구성 파일에서 global-max-size 매개변수를 구성하는 방법을 보여줍니다.
global-max-size 매개변수 구성
절차
브로커를 중지합니다.
브로커가 Linux에서 실행 중인 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR/bin/artemis stop브로커가 Windows에서 서비스로 실행되는 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR\bin\artemis-service.exe stop
-
BROKER_INSTANCE_DIR/etc아래에 있는broker.xml구성 파일을 엽니다. global-max-size매개변수를broker.xml에 추가하여 브로커에서 사용할 수 있는 메모리 양을 바이트 단위로 제한합니다. 다음 예제와 같이 바이트 표기법(K,Mb,GB)을global-max-size의 값에 사용할 수도 있습니다.<configuration> <core> ... <global-max-size>1GB</global-max-size> ... </core> </configuration>이전 예에서 브로커는 메시지를 처리할 때 사용 가능한 최대 메모리 1GB인
1GB를 사용하도록 구성되어 있습니다. 구성된 제한이 초과되면 브로커는 들어오는 메시지와 연결된 주소에 대해 구성된 페이지 모드를 입력합니다.브로커를 시작합니다.
브로커가 Linux에서 실행 중인 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR/bin/artemis run브로커가 Windows에서 서비스로 실행되는 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR\bin\artemis-service.exe start
관련 정보
주소의 페이징 모드 설정에 대한 자세한 내용은 7.3절. “일시 중지를 위한 주소 구성” 을 참조하십시오.
7.5. 일시 중지 시 디스크 사용량 제한
브로커가 사용하는 물리적 디스크 양을 제한하기 전에 수신 메시지를 차단하는 대신 페이지를 지정할 수 있습니다. max-disk-usage 을 broker.xml 구성 파일에 추가하고 브로커가 메시지를 페이징할 때 사용할 수 있는 디스크 공간의 백분율에 값을 제공합니다. max-disk-usage 의 기본값은 이며 이는 디스크 공간의 90%로 제한이 설정되어 있음을 의미합니다.
90
max-disk-usage구성
절차
브로커를 중지합니다.
브로커가 Linux에서 실행 중인 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR/bin/artemis stop브로커가 Windows에서 서비스로 실행되는 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR\bin\artemis-service.exe stop
-
BROKER_INSTANCE_DIR/etc아래에 있는broker.xml구성 파일을 엽니다. max-disk-usage구성 요소를 추가하고 메시지를 페이징할 때 사용할 디스크 공간의 제한을 설정합니다.<configuration> <core> ... <max-disk-usage>50</max-disk-usage> ... </core> </configuration>이전 예에서 브로커는 메시지를 페이징할 때 디스크 공간의
50%를 사용하도록 제한됩니다. 메시지가 차단되어 디스크의50%가 사용된 후 더 이상 페이징되지 않습니다.브로커를 시작합니다.
브로커가 Linux에서 실행 중인 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR/bin/artemis run브로커가 Windows에서 서비스로 실행되는 경우 다음 명령을 실행합니다.
BROKER_INSTANCE_DIR\bin\artemis-service.exe start
7.6. 메시지 삭제 방법
최대 크기에 도달하면 메시지 페이징 대신 주소가 가득 차면 메시지만 삭제하도록 주소를 구성할 수도 있습니다.
이렇게 하려면 주소 설정에서 address-full-policy 를 DROP 으로 설정합니다.
7.6.1. 메시지 삭제 및 Producers 예외 처리
최대 크기에 도달할 때 메시지 페이징 대신 메시지를 삭제하도록 주소를 구성할 수도 있으며 주소가 꽉 찰 때 클라이언트 측에서 예외를 throw할 수도 있습니다.
이렇게 하려면 주소 설정에서 address-full-policy 를 FAIL 로 설정
7.7. Producers를 차단하는 방법
최대 크기에 도달할 때 메시지 페이징 대신 주소가 주소가 꽉 찰 때 추가 메시지를 전송하지 못하도록 주소를 구성하여 메모리가 서버에서 소진되지 않도록 할 수도 있습니다.
차단은 사용 중인 프로토콜이 지원하는 경우에만 작동합니다. 예를 들어 AMQP 생산자는 브로커가 전송될 때 블록 패킷을 이해하지만 STOMP 생산자는 이해할 수 없습니다.
서버에서 메모리가 해제되면 생산자는 자동으로 차단 해제되어 계속 전송할 수 있습니다.
이렇게 하려면 주소 설정에서 address-full-policy 를 BLOCK 으로 설정합니다.
기본 구성에서 모든 주소는 10MiB의 데이터 주소가 주소에 있는 후 차단하도록 구성됩니다.
7.8. Multicast Queues를 통한 주소 주의
메시지가 멀티캐스트 대기열이 바인딩된 주소로 라우팅되면(예: 주제의 JMS 서브스크립션) 메모리에 메시지 사본이 하나만 있습니다. 각 큐는 참조만 처리합니다.Each queue handles only a reference to it. 이 때문에 메시지를 참조하는 모든 큐가 전달된 후에만 메모리가 확보됩니다.
단일 지연 서브스크립션이 있는 경우 모든 큐에 페이징 시스템의 추가 스토리지를 통해 메시지를 전송하므로 전체 주소가 IO 성능이 저하됩니다.
예를 들면 다음과 같습니다.
- 주소에는 10개의 큐가 있습니다.
- 대기열 중 하나는 메시지를 전달하지 않습니다(속도 소비자 때문에 발생할 수 있음).
- 메시지는 지속적으로 주소에 도착하고 페이징이 시작됩니다.
- 다른 9개의 대기열은 메시지가 전송되어도 비어 있습니다.
이 예제에서는 다른 모든 9 대기열에서 페이지 시스템의 메시지를 사용합니다. 이로 인해 바람직하지 않은 상태이면 성능 문제가 발생할 수 있습니다.
8장. 대용량 메시지 처리
클라이언트는 브로커의 내부 버퍼 크기를 초과할 수 있는 대용량 메시지를 보내 예기치 않은 오류가 발생할 수 있습니다. 이러한 상황을 방지하기 위해 메시지가 지정된 최소 값보다 클 때 메시지를 파일로 저장하도록 브로커를 구성할 수 있습니다. 이러한 방식으로 대용량 메시지를 처리한다는 것은 브로커가 메모리에 메시지를 저장하지 않는다는 것을 의미합니다. 대신 브로커가 큰 메시지 파일을 저장하는 디스크 또는 데이터베이스 테이블에 디렉터리를 지정합니다.
브로커가 메시지를 큰 메시지로 저장할 때 큐는 큰 메시지 디렉터리 또는 데이터베이스 테이블의 파일에 대한 참조를 유지합니다.
대규모 메시지 처리는 코어 프로토콜, AMQP, OpenWire 및 STOMP 프로토콜에 사용할 수 있습니다.
코어 프로토콜 및 OpenWire 프로토콜의 경우 클라이언트는 연결 구성에서 최소 큰 메시지 크기를 지정합니다. AMQP 및 STOMP 프로토콜의 경우 브로커 구성의 각 프로토콜에 대해 정의된 허용자에서 최소 대규모 메시지 크기를 지정합니다.
큰 메시지를 생성하고 사용하는 데 다른 프로토콜을 사용하지 않는 것이 좋습니다. 이를 위해 브로커는 메시지의 여러 변환을 수행해야 할 수 있습니다. 예를 들어 AMQP 프로토콜을 사용하여 메시지를 보내고 OpenWire를 사용하여 수신하려고 합니다. 이 상황에서 브로커는 먼저 큰 메시지의 전체 본문을 읽고 핵심 프로토콜을 사용하도록 변환해야합니다. 그런 다음 브로커는 이번에는 OpenWire 프로토콜로 다른 변환을 수행해야합니다. 이러한 메시지 변환은 브로커에 상당한 처리 오버헤드를 초래합니다.
위의 프로토콜 중 하나에 지정하는 최소 큰 메시지 크기는 사용 가능한 디스크 공간 크기와 메시지 크기와 같은 시스템 리소스의 영향을 받습니다. 여러 값을 사용하여 성능 테스트를 실행하여 적절한 크기를 결정하는 것이 좋습니다.
이 섹션의 절차에는 다음이 표시됩니다.
- 대규모 메시지를 저장하도록 브로커 구성
- 대규모 메시지 처리를 위한 AMQP 및 STOMP 프로토콜에 대한 수용자를 구성
이 섹션은 AMQ Core Protocol 및 AMQ OpenWire JMS 클라이언트 구성에 대한 추가 리소스에 대한 링크로 연결됩니다.
8.1. 대규모 메시지 처리를 위한 브로커 구성
다음 절차에서는 브로커가 큰 메시지 파일을 저장하는 디스크 또는 데이터베이스 테이블에서 디렉터리를 지정하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 브로커가 큰 메시지 파일을 저장할 위치를 지정합니다.
대용량 메시지를 디스크에 저장하는 경우
core요소 내에large-messages-directory매개 변수를 추가하고 파일 시스템 위치를 지정합니다. 예를 들면 다음과 같습니다.<configuration> <core> ... <large-messages-directory>/path/to/my-large-messages-directory</large-messages-directory> ... </core> </configuration>참고large-messages-directory의 값을 명시적으로 지정하지 않으면 브로커는 기본값 <broker-instance-dir> /data/largemessages를 사용합니다.데이터베이스 테이블에 대용량 메시지를 저장하는 경우
database-store요소에large-message-table매개 변수를 추가하고 값을 지정합니다. 예를 들면 다음과 같습니다.<store> <database-store> ... <large-message-table>MY_TABLE</large-message-table> ... </database-store> </store>참고large-message-table의 값을 명시적으로 지정하지 않으면 브로커는 기본값LARGE_MESSAGE_TABLE을 사용합니다.
추가 리소스
- 데이터베이스 저장소 구성에 대한 자세한 내용은 6.3절. “JDBC 지속성 구성” 을 참조하십시오.
8.2. 대규모 메시지 처리를 위한 AMQP 수용자 구성
다음 절차에서는 AMQP 수락자를 구성하여 지정된 크기보다 큰 AMQP 메시지를 큰 메시지로 처리하는 방법을 보여줍니다.
절차
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다.브로커 구성 파일의 기본 AMQP 수락자는 다음과 같습니다.
<acceptors> ... <acceptor name="amqp">tcp://0.0.0.0:5672?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=AMQP;useEpoll=true;amqpCredits=1000;amqpLowCredits=300</acceptor> ... </acceptors>기본 AMQP 수락자(또는 구성한 다른 AMQP 수락자)에서
amqpMinLargeMessageSize속성을 추가하고 값을 지정합니다. 예를 들면 다음과 같습니다.<acceptors> ... <acceptor name="amqp">tcp://0.0.0.0:5672?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=AMQP;useEpoll=true;amqpCredits=1000;amqpLowCredits=300;amqpMinLargeMessageSize=204800</acceptor> ... </acceptors>이전 예에서 브로커는 포트 5672에서 AMQP 메시지를 허용하도록 구성되어 있습니다.
amqpMinLargeMessageSize값에 따라 수락자가 204800바이트(즉, 200킬로바이트)보다 크거나 같은 본문이 있는 AMQP 메시지를 수신하는 경우 브로커는 메시지를 큰 메시지로 저장합니다. 이 속성의 값을 명시적으로 지정하지 않으면 브로커는 기본값 102400(즉, 100킬로바이트)을 사용합니다.
-
mq
pMinLargeMessageSize를 -1로 설정하면 AMQP 메시지에 대한 대규모 메시지 처리가 비활성화됩니다. -
브로커가
amqpMinLargeMessageSize값을 초과하지 않지만 메시징 저널 버퍼의 크기를 초과하는 영구 AMQP 메시지를 수신하는 경우 브로커는저널에저장하기 전에 메시지를 큰 코어 프로토콜 메시지로 변환합니다.
8.3. 대규모 메시지 처리를 위한 STOMP 수락 구성
다음 절차에서는 지정된 크기보다 큰 메시지보다 큰 STOMP 메시지를 처리하도록 STOMP 수락자를 구성하는 방법을 보여줍니다.
절차
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다.브로커 구성 파일의 기본 AMQP 수락자는 다음과 같습니다.
<acceptors> ... <acceptor name="stomp">tcp://0.0.0.0:61613?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=STOMP;useEpoll=true</acceptor> ... </acceptors>기본 STOMP 수락자(또는 사용자가 구성한 다른 STOMP 수락자)에서
stompMinLargeMessageSize속성을 추가하고 값을 지정합니다. 예를 들면 다음과 같습니다.<acceptors> ... <acceptor name="stomp">tcp://0.0.0.0:61613?tcpSendBufferSize=1048576;tcpReceiveBufferSize=1048576;protocols=STOMP;useEpoll=true;stompMinLargeMessageSize=204800</acceptor> ... </acceptors>
이전 예에서 브로커는 포트 61613에서 STOMP 메시지를 수락하도록 구성되어 있습니다. stompMinLargeMessageSize 값에 따라 수락자가 204800 바이트보다 크거나 같은 본문이 있는 STOMP 메시지를 수신하면 브로커가 메시지를 큰 메시지로 저장합니다. 이 속성의 값을 명시적으로 지정하지 않으면 브로커는 기본값 102400(즉, 100킬로바이트)을 사용합니다.
STOMP 소비자에게 큰 메시지를 전달하기 위해 브로커는 자동으로 메시지를 클라이언트로 전송하기 전에 대용량 메시지에서 일반 메시지로 변환합니다. 큰 메시지가 압축되면 브로커는 STOMP 클라이언트로 보내기 전에 압축을 풉니다.
8.4. 대규모 메시지 및 Java 클라이언트
대규모 메시지를 사용하는 클라이언트를 작성하는 Java 개발자에게는 두 가지 옵션이 있습니다.
한 가지 옵션은 InputStream 및 OutputStream 의 인스턴스를 사용하는 것입니다. 예를 들어 FileInputStream 을 사용하여 물리적 디스크의 큰 파일에서 가져온 메시지를 보낼 수 있습니다. 그런 다음 수신자는 FileOutputStream 을 사용하여 로컬 파일 시스템의 위치로 메시지를 스트리밍할 수 있습니다.
또 다른 옵션은 JMS BytesMessage 또는 StreamMessage 를 직접 스트리밍하는 것입니다. 예를 들면 다음과 같습니다.
BytesMessage rm = (BytesMessage)cons.receive(10000);
byte data[] = new byte[1024];
for (int i = 0; i < rm.getBodyLength(); i += 1024)
{
int numberOfBytes = rm.readBytes(data);
// Do whatever you want with the data
}추가 리소스
AMQ Core Protocol JMS 클라이언트에서 큰 메시지 작업에 대해 알아보려면 다음을 참조하십시오.
AMQ OpenWire JMS 클라이언트에서 대용량 메시지 작업에 대해 알아보려면 다음을 참조하십시오.
-
큰 메시지 작업 예를 보려면 AMQ Broker 설치의 <
install-dir> /examples/features/standard/디렉토리의large-message예제를 참조하십시오. 예제 프로그램 실행에 대한 자세한 내용은 Running an AMQ Broker 예제 프로그램 을 참조하십시오.
9장. Dead Connections 탐지
경우에 따라 클라이언트는 예기치 않게 중지되고 리소스를 정리할 수 없습니다. 이 경우 리소스를 결함이 있는 상태로 유지하면 브로커가 메모리 또는 기타 시스템 리소스가 부족해질 수 있습니다. 브로커는 클라이언트의 연결이 가비지 수집 시 제대로 종료되지 않았음을 감지합니다. 그런 다음 연결이 닫히고 아래 것과 유사한 메시지가 로그에 기록됩니다. 로그는 클라이언트 세션이 인스턴스화된 정확한 코드 행을 캡처합니다.The log captures the exact line of code where the client session was instantiated. 이를 통해 오류를 식별하고 수정할 수 있습니다.
[Finalizer] 20:14:43,244 WARNING [org.apache.activemq.artemis.core.client.impl.DelegatingSession] I'm closing a JMS Conection you left open. Please make sure you close all connections explicitly before let
ting them go out of scope!
[Finalizer] 20:14:43,244 WARNING [org.apache.activemq.artemis.core.client.impl.DelegatingSession] The session you didn't close was created here:
java.lang.Exception
at org.apache.activemq.artemis.core.client.impl.DelegatingSession.<init>(DelegatingSession.java:83)
at org.acme.yourproject.YourClass (YourClass.java:666) 1- 1
- 연결이 인스턴스화된 클라이언트 코드의 줄입니다.
클라이언트 Side에서 Dead Connections 탐지
브로커에서 데이터를 수신하는 동안 클라이언트는 연결을 활성으로 간주합니다. client-failure-check-period 속성에 값을 제공하여 클라이언트가 실패 여부를 확인하도록 클라이언트를 구성합니다. 네트워크 연결의 기본 점검 기간은 30000밀리초이며 In-VM 연결의 기본값은 -1 이지만 데이터가 수신되지 않으면 클라이언트가 해당 쪽에서 연결이 실패하지 않음을 의미합니다.
일반적으로 검사 기간을 브로커의 연결 시간 간 라이브에 사용된 값보다 훨씬 낮게 설정하여 클라이언트가 일시적인 오류 발생 시 클라이언트가 다시 연결할 수 있도록 합니다.
아래 예제에서는 코어 JMS 클라이언트를 사용하여 검사 기간을 10000밀리초로 설정하는 방법을 보여줍니다.
절차
dead connections를 탐지하기 위한 검사 기간을 설정합니다.
코어 JMS 클라이언트와 함께 JNDI를 사용하는 경우 JNDI 컨텍스트 환경(예:
jndi.properties) 내에서 확인 기간을 설정합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?clientFailureCheckPeriod=10000
JNDI를 사용하지 않는 경우
ActiveMQConnectionFactory.setClientFailureCheckPeriod()에 값을 전달하여 검사 기간을 직접 설정합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setClientFailureCheckPeriod(10000);
9.1. 연결 시간-투-Live
클라이언트와 서버 간의 네트워크 연결이 실패하고 다시 온라인 상태가 되므로 클라이언트가 다시 연결할 수 있으므로 AMQ Broker는 비활성 서버 쪽 리소스를 정리하도록 기다립니다. 이 대기 기간을 TTL(Time-to-Live)이라고 합니다. 네트워크 기반 연결의 기본 TTL은 60000 밀리초(1분)입니다. In-VM 연결의 기본 TTL은 -1 이며, 이는 브로커가 브로커 측의 연결을 시간 초과하지 않음을 의미합니다.
브로커에서 Time-To-Live 구성
클라이언트가 자체 연결 TTL을 지정하지 않으려면 브로커 측에서 글로벌 값을 설정할 수 있습니다. 브로커 구성에서 connection-ttl-override 요소를 지정하여 이 작업을 수행할 수 있습니다.
TTL 위반에 대한 연결을 확인하는 논리는 connection-ttl-check-interval 요소에 의해 결정된 대로 브로커에서 정기적으로 실행됩니다.
절차
connection-ttl-override구성 요소를 추가하고 아래 예제와 같이 TTL-to-live 값을 제공하여 BROKER_INSTANCE_DIR/etc/broker.xml을 편집합니다.<configuration> <core> ... <connection-ttl-override>30000</connection-ttl-override> 1 <connection-ttl-check-interval>1000</connection-ttl-check-interval> 2 ... </core> </configuration>
클라이언트에서 Time-To-Live 구성
기본적으로 클라이언트는 자체 연결에 대한 TTL을 설정할 수 있습니다. 아래 예제에서는 코어 JMS 클라이언트를 사용하여 Time-To-Live를 설정하는 방법을 보여줍니다.
절차
클라이언트 연결에 대한 Time-To-Live를 설정합니다.
JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우,
connectionTTL매개변수를 사용하여 xml config에 지정할 수 있습니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?connectionTTL=30000
JNDI를 사용하지 않는 경우 연결 TTL은
ActiveMQConnectionFactory인스턴스의ConnectionTTL속성으로 정의됩니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setConnectionTTL(30000);
9.2. 비동기 연결 실행 비활성화
브로커 측에서 수신된 대부분의 패킷은 remoting 스레드에서 실행됩니다. 이러한 패킷은 단기 작업을 나타내며 성능상의 이유로 리모팅 스레드 에서 항상 실행됩니다. 그러나 일부 패킷 유형은 리모팅 스레드 대신 스레드 풀을 사용하여 실행되어 네트워크 대기 시간을 약간 추가합니다.
스레드 풀을 사용하는 패킷 유형은 아래 나열된 Java 클래스 내에서 구현됩니다. 클래스는 모두 org.apache.actiinvemq.artemis.core.protocol.core.impl.wireformat 패키지에 있습니다.
- RollbackMessage
- SessionCloseMessage
- SessionCommitMessage
- SessionXACommitMessage
- SessionXAPrepareMessage
- SessionXARollbackMessage
절차
비동기 연결 실행을 비활성화하려면
async-connection-execution-enabled구성 요소를 BROKER_INSTANCE_DIR/etc/broker.xml에 추가하고 아래 예제와 같이false로 설정합니다. 기본값은true입니다.<configuration> <core> ... <async-connection-execution-enabled>false</async-connection-execution-enabled> ... </core> </configuration>
9.3. 클라이언트 창에서 연결 닫기
클라이언트 애플리케이션은 중단된 연결이 발생하지 않도록 종료하기 전에 제어되는 방식으로 리소스를 종료해야 합니다. Java에서는 finally 블록 내의 연결을 닫는 것이 좋습니다.
Connection jmsConnection = null;
try {
ConnectionFactory jmsConnectionFactory = ActiveMQJMSClient.createConnectionFactoryWithoutHA(...);
jmsConnection = jmsConnectionFactory.createConnection();
...use the connection...
}
finally {
if (jmsConnection != null) {
jmsConnection.close();
}
}10장. 흐름 제어
흐름 제어는 생산자와 소비자가 이들 간의 데이터 흐름을 제한하여 과잉되는 것을 방지합니다. AMQ Broker를 사용하면 소비자와 생산자 모두에 대한 흐름 제어를 구성할 수 있습니다.
10.1. 소비자 흐름 제어
소비자 흐름 제어는 클라이언트가 브로커의 메시지를 사용할 때 브로커와 클라이언트 간의 데이터 흐름을 규제합니다. AMQ Broker Client는 기본적으로 사용자에게 메시지를 전달하기 전에 메시지를 버퍼링합니다. 버퍼가 없으면 클라이언트는 먼저 브로커의 각 메시지를 사용하기 전에 요청해야 합니다. 이러한 유형의 "round-trip" 통신은 비용이 많이 듭니다. 클라이언트 측의 데이터 흐름을 집계하는 것은 소비자가 메시지를 빠르게 처리할 수 없을 때 메모리 문제가 발생하여 들어오는 메시지로 오버플로하기 시작할 때 메모리 문제가 발생할 수 있기 때문에 중요합니다.
10.1.1. 소비자 창 크기 설정
클라이언트 쪽 버퍼에 보관된 메시지의 최대 크기는 창 크기에 따라 결정됩니다. AMQ Broker 클라이언트의 기본 창 크기는 1MiB 또는 1024바이트입니다. 대부분의 사용 사례에는 기본값이 적합합니다. 다른 경우에는 창 크기에 가장 적합한 값을 검색하려면 시스템 벤치마킹이 필요할 수 있습니다. AMQ Broker를 사용하면 기본값을 변경해야 하는 경우 버퍼 창 크기를 설정할 수 있습니다.
창 크기 설정
다음 예제에서는 코어 JMS 클라이언트를 사용할 때 소비자 창 크기 매개 변수를 설정하는 방법을 보여줍니다. 각 예제에서는 소비자 창 크기를 300000 바이트로 설정합니다.
절차
소비자 창 크기를 설정합니다.
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
consumerWindowSize매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?consumerWindowSize=300000
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않으면
ActiveMQConnectionFactory.setConsumerWindowSize()로 값을 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setConsumerWindowSize(300000);
10.1.2. 빠른 소비자 처리
빠른 소비자는 메시지를 사용하는 만큼 빠르게 처리할 수 있습니다. 메시징 시스템의 소비자가 빠른 것으로 확신하는 경우 창 크기를 -1 로 설정합니다. 이 설정을 사용하면 클라이언트 측에서 바인딩되지 않은 메시지 버퍼링이 가능합니다. 그러나 이 설정을 주의해서 사용하십시오. 소비자가 메시지를 수신하는 속도만큼 빠르게 처리할 수 없는 경우 클라이언트 측 메모리를 오버플로울 수 있습니다.
빠른 소비자를 위한 창 크기 설정
절차
아래 예제에서는 빠른 메시지 소비자인 코어 JMS 클라이언트를 사용할 때 창 크기를 -1 로 설정하는 방법을 보여줍니다.
소비자 창 크기를
-1로 설정합니다.코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
consumerWindowSize매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?consumerWindowSize=-1
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않으면
ActiveMQConnectionFactory.setConsumerWindowSize()로 값을 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setConsumerWindowSize(-1);
10.1.3. 하위 소비자 처리
느린 사용자는 각 메시지를 처리하는 데 상당한 시간이 걸립니다. 이 경우 클라이언트 측에서 메시지를 버퍼링하지 않는 것이 좋습니다. 메시지는 다른 소비자가 사용할 준비가 된 브로커 측에서 남아 있습니다. 버퍼를 끄는 한 가지 이점은 큐에서 여러 소비자 간에 결정적 배포를 제공 한다는 것입니다.One benefit of turning off the buffer is that it provides deterministic distribution between multiple consumers on a queue. 클라이언트 측 버퍼를 비활성화하여 느린 소비자를 처리하려면 창 크기를 0 으로 설정합니다.
Slow Consumers의 창 크기 설정
절차
아래 예제에서는 느린 메시지 소비자인 코어 JMS 클라이언트를 사용할 때 창 크기를 0 으로 설정하는 방법을 보여줍니다.
소비자 창 크기를
0으로 설정합니다.코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
consumerWindowSize매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?consumerWindowSize=0
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않으면
ActiveMQConnectionFactory.setConsumerWindowSize()로 값을 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setConsumerWindowSize(0);
관련 정보
느린 소비자를 처리할 때 소비자 버퍼링을 방지하기 위해 브로커를 구성하는 방법을 보여주는 예는INSTA LL_DIR /examples/standard의 no-consumer-buffering 예제를 참조하십시오.
10.1.4. 메시지 사용 비율 설정
사용자가 메시지를 사용할 수 있는 속도를 조정할 수 있습니다. "기호"라고도 하며 소비률을 조정하여 소비자가 구성 허용보다 빠른 속도로 메시지를 사용하지 않도록 합니다.
속도 제한 흐름 제어는 창 기반 흐름 제어와 함께 사용할 수 있습니다. 속도 제한 흐름 제어는 클라이언트가 버퍼에 있는 메시지의 수가 아니라 초당 사용할 수 있는 메시지 수에만 영향을 미칩니다. 느린 속도 제한 및 높은 창 기반 제한으로 클라이언트의 내부 버퍼는 메시지로 빠르게 채워집니다.
이 기능을 사용하려면 속도가 양의 정수여야 하며 초당 메시지 단위로 지정된 최대 메시지 사용률입니다. 이 속도를 -1 로 설정하면 속도 제한 흐름 제어가 비활성화됩니다. 기본값은 -1 입니다.
메시지 사용 비율 설정
절차
아래 예제에서는 메시지를 초당 10 개 메시지로 제한하는 코어 JMS 클라이언트를 사용합니다.
소비자 비율을 설정합니다.
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
consumerMaxRate매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory java.naming.provider.url=tcp://localhost:61616?consumerMaxRate=10
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않는 경우 해당 값을
ActiveMQConnectionFactory.setConsumerMaxRate()로 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setConsumerMaxRate(10);
관련 정보
소비자 속도를 제한하는 방법에 대한 작업 예제는INSTA LL_DIR /examples/standard의 consumer-rate-limit 예제를 참조하십시오.
10.2. 생산자 Flow Control
소비자 창 기반 흐름 제어와 유사한 방식으로 AMQ 브로커는 브로커가 너무 많은 데이터로 인해 브로커가 과잉되지 않도록 생산자에서 브로커로 전송되는 데이터의 양을 제한할 수 있습니다. 생산자의 경우 창 크기는 언제든지 인플라이트할 수 있는 바이트의 양을 결정합니다.
10.2.1. Producer 창 크기 설정
창 크기는 창에 있는 각 바이트에 대한 하나의 크레딧인 크레딧에 따라 브로커와 생산자 간에 협상됩니다. 메시지가 전송되고 크레딧이 사용되므로 생산자는 더 많은 메시지를 보내기 전에 브로커로부터 크레딧을 요청해야 합니다. 생산자와 브로커 간의 크레딧을 교환하면 이들 간의 데이터 흐름이 규제됩니다.
창 크기 설정
다음 예제에서는 코어 JMS 클라이언트를 사용할 때 생산자 창 크기를 1024 바이트로 설정하는 방법을 보여줍니다.
절차
생산자 창 크기를 설정합니다.
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
producerWindowSize매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory java.naming.provider.url=tcp://localhost:61616?producerWindowSize=1024
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않으면
ActiveMQConnectionFactory.setProducerWindowSize()로 값을 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setProducerWindowSize(1024);
10.2.2. 메시지 차단
두 개 이상의 생산자가 동일한 주소와 연관될 수 있으므로 브로커가 실제로 사용 가능한 것보다 더 많은 크레딧을 할당할 수 있습니다. 그러나 브로커가 사용 가능한 것보다 더 많은 크레딧을 전송하지 못하도록하는 모든 주소에 최대 크기를 설정할 수 있습니다.
기본 구성에서는 각 주소에 대해 전역 최대 크기가 100Mb입니다. 주소가 가득 차면 브로커는 큐로 라우팅하지 않고 페이징 저널에 추가 메시지를 작성합니다. 페이징 대신 이전 메시지가 사용될 때까지 클라이언트측에서 더 많은 메시지 전송을 차단할 수 있습니다. 이러한 방식으로 생산자 흐름 제어를 차단하면 브로커가 한 번에 처리할 수 있는 것보다 더 많은 메시지를 전송하므로 브로커가 메모리 부족이 발생하지 않습니다.
구성에서 생산자 흐름 제어 차단은 address-setting 별로 관리됩니다. 구성은 주소에 등록된 모든 큐에 적용됩니다. 즉, 해당 주소에 바인딩된 모든 큐의 총 메모리는 max-size-bytes 용으로 지정된 값으로 제한됩니다.
차단은 프로토콜에 따라 다릅니다. AMQ Broker에서 AMQP, OpenWire 및 Core Protocol은 생산자 흐름 제어를 지원합니다. AMQP는 흐름 제어를 다르게 처리합니다. 자세한 내용은 AMQP를 사용하여 흐름 제어 차단 을 참조하십시오.
주소의 최대 크기 구성
설정된 최대 바이트 수보다 큰 경우 메시지를 차단하도록 브로커를 구성하려면 새 addres-setting 구성 요소를 BROKER_INSTANCE_DIR/etc/broker.xml 에 추가합니다.
절차
-
아래 구성 예에서
address-setting은BLOCK생산자로 설정되고 최대300000바이트에 도달한 후 메시지 전송을 통해 메시지가 전송됩니다.
<configuration>
<core>
...
<address-settings>
<address-setting match="my.blocking.queue"> 1
<max-size-bytes>300000</max-size-bytes> 2
<address-full-policy>BLOCK</address-full-policy> 3
</address-setting>
</address-settings>
</core>
</configuration>10.2.3. AMQP 메시지 차단
이 장의 앞부분에서 설명한 대로 코어 프로토콜은 생산자 창 크기 흐름 제어 시스템을 사용합니다. 이 시스템에서는 크레딧이 바이트를 나타내고 생산자에 할당됩니다. 생산자가 메시지를 전송하려는 경우 메시지를 보내기 전에 메시지의 크기를 수용할 수 있는 충분한 크레딧이 있을 때까지 기다려야 합니다.
AMQP 흐름 제어 크레딧은 바이트를 나타내지 않지만 메시지 크기에 관계없이 생산자가 보낼 수 있는 메시지 수를 나타냅니다. 따라서 AMQP 클라이언트에 대한 일부 시나리오에서는 주소의 max-size-bytes 를 상당히 초과할 수 있습니다.
이 상황을 관리하려면 address-setting 에 max-size-bytes-reject-threshold 요소를 추가하여 주소 크기에 상한을 바이트 단위로 지정합니다. 이 상한에 도달하면 브로커는 AMQP 메시지를 거부합니다. 기본적으로 max-size-bytes-reject-threshold 는 -1 또는 제한 없음으로 설정됩니다.
블록 AMQP 메시지에 브로커 구성
설정된 최대 바이트 수보다 큰 경우 AMQP 메시지를 차단하도록 브로커를 구성하려면 BROKER_INSTANCE_DIR/etc/broker.xml 에 새 addres-setting 구성 요소를 추가합니다.
절차
아래 구성 예제에서는
my.amqp.blocking.queue주소로 라우팅되는 AMQP 메시지에 최대300000바이트의 최대 크기를 적용합니다.<configuration> <core> ... <address-settings> ... <address-setting match="my.amqp.blocking.queue"> 1 <max-size-bytes-reject-threshold>300000</max-size-bytes-reject-threshold> 2 </address-setting> </address-settings> </core> </configuration>
추가 리소스
- AMQP 생산자의 크레딧을 구성하는 방법에 대한 자세한 내용은 3장. 네트워크 연결: 프로토콜 을 참조하십시오.
10.2.4. 메시지 전송 비율 설정
AMQ Broker는 생산자가 메시지를 발송할 수 있는 속도를 제한할 수도 있습니다. 생산자 속도는 초당 메시지 단위로 지정됩니다. 이를 -1 로 설정하면 속도 제한 흐름 제어가 비활성화됩니다.
메시지 전송 비율 설정
아래 예제에서는 생산자가 코어 JMS 클라이언트를 사용하는 경우 메시지를 보내는 속도를 설정하는 방법을 보여줍니다. 각 예제는 초당 10 개의 메시지 전송 속도를 설정합니다.
절차
생산자가 메시지를 보낼 수 있는 속도를 설정합니다.
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하는 경우 연결 문자열 URL의 일부로
producerMaxRate매개변수를 포함합니다. JNDI 컨텍스트 환경에 URL을 저장합니다. 아래 예제에서는jndi.properties파일을 사용하여 URL을 저장합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory java.naming.provider.url=tcp://localhost:61616?producerMaxRate=10
코어 JMS 클라이언트가 JNDI를 사용하여 연결 팩토리를 인스턴스화하지 않는 경우 해당 값을
ActiveMQConnectionFactory.setProducerMaxRate()로 전달합니다.ConnectionFactory cf = ActiveMQJMSClient.createConnectionFactory(...) cf.setProducerMaxRate(10);
관련 정보
메시지 전송 속도를 제한하는 방법의 작동 예는INSTA LL_DIR /examples/standard의 producer-rate-limit 예를 참조하십시오.
11장. 메시지 그룹화
메시지 그룹은 다음과 같은 특성을 가진 메시지 집합입니다.
-
메시지 그룹의 메시지는 동일한 그룹 ID, 즉 동일한 그룹 식별자 속성을 공유합니다. JMS 메시지의 경우 속성은
JMSXGroupID입니다. - 메시지 그룹의 메시지는 대기열에 많은 소비자가 있는 경우에도 항상 동일한 소비자가 사용합니다. 다른 소비자는 원래 소비자가 닫는 경우 메시지 그룹을 수신하도록 선택됩니다.Another consumer is chosen to receive a message group if the original consumer closes.
메시지 그룹은 특정 속성 값에 대한 모든 메시지를 동일한 소비자가 직렬로 처리하도록 할 때 유용합니다. 예를 들어, 특정 주식 구매에 대한 주문은 동일한 소비자에 의해 직렬로 처리되도록 할 수 있습니다. 이렇게 하려면 소비자 풀을 생성한 다음 stock 이름을 message 속성의 값으로 설정할 수 있습니다. 이렇게 하면 특정 주식에 대한 모든 메시지가 항상 동일한 소비자가 처리합니다.
그룹화된 메시지는 대기열의 기본 FIFO 의미로 인해 그룹화되지 않은 메시지의 동시 처리에 영향을 미칠 수 있습니다. 예를 들어 큐의 헤드에 그룹화된 메시지 100개가 있고 그룹에 속하지 않은 메시지가 1,000개이면 그룹화되지 않은 메시지가 모두 적절한 클라이언트에 전송됩니다. 이 시나리오에서 기능적 영향은 모든 그룹화된 메시지가 처리되는 동안 동시 메시지 처리를 일시 중지한 것입니다. 메시지 그룹의 크기를 결정할 때 이러한 잠재적인 성능 병목 현상을 염두에 두십시오. 그룹화되지 않은 메시지에서 그룹화된 메시지를 분리할지 여부를 고려하십시오.
11.1. client-Side Message Grouping
아래 예제에서는 코어 JMS 클라이언트를 사용하여 메시지 그룹화를 사용하는 방법을 보여줍니다.
절차
그룹 ID를 설정합니다.
JNDI를 사용하여 JMS 클라이언트의 JMS 연결 팩토리를 설정하는 경우
groupID매개변수를 추가하고 값을 제공합니다. 이 연결 팩토리를 사용하여 전송된 모든 메시지에는 속성JMSXGroupID가 지정된 값으로 설정됩니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?groupID=MyGroup
JNDI를 사용하지 않는 경우
setStringProperty()메서드를 사용하여JMSXGroupID속성을 설정합니다.Message message = new TextMessage(); message.setStringProperty("JMSXGroupID", "MyGroup"); producer.send(message);
관련 정보
메시지 그룹 구성 및 사용 방법에 대한 작업 예제는INSTA LL_DIR /examples/features/standard의 mesagge-group 및 message-group2 를 참조하십시오.
11.2. 자동 메시지 그룹링
그룹 ID를 직접 제공하는 대신 ID가 자동으로 생성될 수 있습니다. 이 방식으로 그룹화된 메시지는 단일 소비자가 계속 직렬로 처리합니다.
절차
아래 예제에서는 코어 JMS 클라이언트를 사용하여 메시지 그룹화를 활성화하는 방법을 보여줍니다.
그룹 ID 자동 생성을 활성화합니다.
JNDI 컨텍스트 환경을 사용하여 JMS 연결 팩토리를 인스턴스화하는 경우 연결 URL의 쿼리 문자열에
autogroup=truename-value 쌍을 추가합니다.java.naming.factory.initial=org.apache.activemq.artemis.jndi.ActiveMQInitialContextFactory connectionFactory.myConnectionFactory=tcp://localhost:61616?autoGroup=true
JNDI를 사용하지 않는 경우
ActiveMQConnectonFactory에서autogroup을true로 설정합니다.ActiveMQConnectionFactory cf = ActiveMQJMSClient.createConnectionFactoryWithoutHA(...); cf.setAutoGroup(true);
12장. 중복 메시지 탐지
AMQ Broker에는 수신하는 중복된 메시지를 필터링하는 자동 중복 메시지 탐지가 포함되어 있으므로 중복 감지 논리를 코딩할 필요가 없습니다.
중복 탐지가 없으면 클라이언트는 대상 브로커 또는 해당 연결에 실패할 때마다 보낸 메시지가 성공했는지 여부를 확인할 수 없습니다. 예를 들어 브로커가 메시지를 수신하고 처리하기 전에 브로커 또는 연결이 실패하면 메시지가 주소에 도착하지 않으며 실패로 인해 브로커에서 응답을 받지 않습니다. 반면 브로커가 메시지를 수신한 후 브로커 또는 연결이 실패한 경우 메시지가 올바르게 라우팅되지만 클라이언트는 여전히 응답을 받지 못합니다.
또한 트랜잭션을 사용하여 성공을 결정하면 이러한 경우 도움이 되지 않습니다. 예를 들어 트랜잭션 커밋이 처리되는 동안 브로커 또는 연결이 실패하면 클라이언트는 메시지를 성공적으로 전송했는지 여부를 확인할 수 없습니다.
클라이언트가 가정된 오류를 수정하기 위해 마지막 메시지를 다시 보내는 경우 결과는 주소로 전송되는 중복 메시지가 될 수 있으므로 시스템에 부정적인 영향을 미칠 수 있습니다. 중복 메시지를 보내면 구매 발주서가 두 번 충족될 수 있습니다. 다행히도 {AMQ Broker}은 이러한 종류의 문제가 발생하지 않도록 자동 중복 메시지 탐지를 제공합니다.
12.1. Duplicate ID 메시지 속성 사용
중복 메시지 검색을 활성화하려면 메시지 속성 _AMQ_DUPL_ID 에 대한 고유한 값을 제공합니다. 브로커가 메시지를 수신하면 _AMQ_DUPL_ID 에 값이 있는지 확인합니다. 이 경우 브로커는 메모리 캐시에서 해당 값을 사용하여 이미 메시지를 수신했는지 확인합니다. 동일한 값이 있는 메시지를 찾으면 들어오는 메시지가 무시됩니다.
절차
아래 예제에서는 코어 JMS 클라이언트를 사용하여 중복 탐지 속성을 설정하는 방법을 보여줍니다. 편의를 위해 클라이언트 는 중복 ID 속성 _ID의 값을 사용합니다.
_AMQ_DUPL_ID 의 이름에 일정한 org.apache.activemq.api.core.Message.HDR_DUPLICATE_DETECTION
_AMQ_DUPL_ID의 값을 고유한문자열으로 설정합니다.Message jmsMessage = session.createMessage(); String myUniqueID = "This is my unique id"; message.setStringProperty(HDR_DUPLICATE_DETECTION_ID.toString(), myUniqueID);
12.2. 중복 ID 캐시 구성
브로커는 _AMQ_DUPL_ID 속성의 수신된 값의 캐시를 유지 관리합니다. 각 주소에는 고유한 캐시가 있습니다. 캐시는 순환 및 고정되어 있습니다. 새 항목은 캐시 공간 수요로 가장 오래된 항목을 대체합니다.
캐시의 크기를 적절히 조정해야 합니다. 이전 메시지가 동일한 _AMQ_DUPL_ID 로 새 메시지를 도착하기 전에 id-cache-size 메시지보다 많이 도착하면 브로커가 중복을 감지할 수 없습니다. 그러면 브로커가 두 메시지를 모두 처리하게 됩니다.
절차
아래 구성 예제에서는 BROKER_INSTANCE_DIR/etc/broker.xml 에 요소를 추가하여 ID 캐시를 구성하는 방법을 보여줍니다.
<configuration>
<core>
...
<id-cache-size>5000</id-cache-size> 1
<persist-id-cache>false</persist-id-cache> 2
</core>
</configuration>12.3. 중복 탐지 및 트랜잭션
브로커 간에 메시지를 이동하는 데 중복 탐지를 사용하면 메시지를 소비하기 위해 XA 트랜잭션을 사용하는 것과 동일한 한 번만 제공 할 수 있지만, XA를 사용하는 것보다 훨씬 적은 오버헤드와 훨씬 쉽게 구성할 수 있습니다.
트랜잭션에서 메시지를 보내는 경우 트랜잭션의 모든 메시지에 대해 _AMQ_DUPL_ID 를 설정할 필요가 없습니다. 브로커가 트랜잭션의 모든 메시지에 대한 중복 메시지를 감지하면 전체 트랜잭션을 무시합니다.
12.4. 중복 감지 및 클러스터 연결
클러스터 전체에서 이동하는 각 메시지에 대한 중복 ID를 삽입하도록 클러스터 연결을 구성할 수 있습니다.
절차
요소
use-duplicate-detection을BROKER_INSTANCE_DIR/etc/broker.xml에 있는 원하는 클러스터 연결 구성에 추가합니다. 이 매개변수의 기본값은true입니다. 아래 예제에서는 클러스터 연결my-cluster의 구성에 요소가 추가됩니다.<configuration> <core> ... <cluster-connection> <cluster-connection name="my-cluster"> <use-duplicate-detection>true</use-duplicate-detection> ... </cluster-connection> ... </cluster-connections> </core> </configuration>
추가 리소스
- 브로커 클러스터에 대한 자세한 내용은 16.2절. “브로커 클러스터 생성” 을 참조하십시오.
13장. 메시지 가로채기
AMQ Broker를 사용하면 브로커 입력 또는 종료 패킷을 가로채서 패킷을 감사하거나 메시지를 필터링할 수 있습니다. 인터셉터는 가로채는 패킷을 변경할 수 있으므로 이를 통해 강력하면서도 잠재적으로 위험할 수 있습니다.
비즈니스 요구 사항을 충족하기 위해 인터셉터를 개발할 수 있습니다. 인터셉터는 프로토콜별로 고유하며 적절한 인터페이스를 구현해야 합니다.
인터셉터는 부울 값을 반환하는 intercept() 메서드를 구현해야 합니다. 값이 true 이면 메시지 패킷이 계속 수행됩니다. false 인 경우 프로세스가 중단되고 다른 인터셉터는 호출되지 않으며 메시지 패킷은 더 이상 처리되지 않습니다.
13.1. 인터셉터 생성
들어오고 나가는 자체 인터셉터를 생성할 수 있습니다. 모든 인터셉터는 프로토콜별로 고유하며 서버를 각각 입력하거나 종료하는 모든 패킷에 대해 호출됩니다. 이를 통해 인터셉터를 생성하여 감사 패킷과 같은 비즈니스 요구 사항을 충족할 수 있습니다. 인터셉터는 가로채는 패킷을 변경할 수 있습니다. 이렇게하면 강력하며 잠재적으로 위험 할 수 있으므로 신중하게 사용하십시오.
인터셉터 및 해당 종속 항목은 브로커의 Java 클래스 경로에 배치되어야 합니다. 기본적으로 classpath의 일부이므로 BROKER_INSTANCE_DIR/lib 디렉토리를 사용할 수 있습니다.
절차
다음 예제에서는 전달된 각 패킷의 크기를 확인하는 인터셉터를 생성하는 방법을 보여줍니다. 이 예제에서는 각 프로토콜에 대해 특정 인터페이스를 구현합니다.
적절한 인터페이스를 구현하고 해당
intercept()메서드를 재정의합니다.AMQP 프로토콜을 사용하는 경우
org.apache.activemq.artemis.protocol.amqp.broker.AmqpInterceptor인터페이스를 구현합니다.package com.example; import org.apache.activemq.artemis.protocol.amqp.broker.AMQPMessage; import org.apache.activemq.artemis.protocol.amqp.broker.AmqpInterceptor; import org.apache.activemq.artemis.spi.core.protocol.RemotingConnection; public class MyInterceptor implements AmqpInterceptor { private final int ACCEPTABLE_SIZE = 1024; @Override public boolean intercept(final AMQPMessage message, RemotingConnection connection) { int size = message.getEncodeSize(); if (size <= ACCEPTABLE_SIZE) { System.out.println("This AMQPMessage has an acceptable size."); return true; } return false; } }Core Protocol을 사용하는 경우 인터셉터는
org.apache.artemis.activemq.api.core.Interceptor인터페이스를 구현해야 합니다.package com.example; import org.apache.artemis.activemq.api.core.Interceptor; import org.apache.activemq.artemis.core.protocol.core.Packet; import org.apache.activemq.artemis.spi.core.protocol.RemotingConnection; public class MyInterceptor implements Interceptor { private final int ACCEPTABLE_SIZE = 1024; @Override boolean intercept(Packet packet, RemotingConnection connection) throws ActiveMQException { int size = packet.getPacketSize(); if (size <= ACCEPTABLE_SIZE) { System.out.println("This Packet has an acceptable size."); return true; } return false; } }MQTT 프로토콜을 사용하는 경우
org.apache.activemq.artemis.core.protocol.mqtt.MQTTInterceptor인터페이스를 구현합니다.package com.example; import org.apache.activemq.artemis.core.protocol.mqtt.MQTTInterceptor; import io.netty.handler.codec.mqtt.MqttMessage; import org.apache.activemq.artemis.spi.core.protocol.RemotingConnection; public class MyInterceptor implements Interceptor { private final int ACCEPTABLE_SIZE = 1024; @Override boolean intercept(MqttMessage mqttMessage, RemotingConnection connection) throws ActiveMQException { byte[] msg = (mqttMessage.toString()).getBytes(); int size = msg.length; if (size <= ACCEPTABLE_SIZE) { System.out.println("This MqttMessage has an acceptable size."); return true; } return false; } }STOMP 프로토콜을 사용하는 경우
org.apache.activemq.artemis.core.protocol.stomp.StompFrameInterceptor인터페이스를 구현합니다.package com.example; import org.apache.activemq.artemis.core.protocol.stomp.StompFrameInterceptor; import org.apache.activemq.artemis.core.protocol.stomp.StompFrame; import org.apache.activemq.artemis.spi.core.protocol.RemotingConnection; public class MyInterceptor implements Interceptor { private final int ACCEPTABLE_SIZE = 1024; @Override boolean intercept(StompFrame stompFrame, RemotingConnection connection) throws ActiveMQException { int size = stompFrame.getEncodedSize(); if (size <= ACCEPTABLE_SIZE) { System.out.println("This StompFrame has an acceptable size."); return true; } return false; } }
13.2. 인터셉터를 사용하도록 브로커 구성
인터셉터를 생성한 후 사용할 브로커를 구성해야 합니다.
사전 요구 사항
브로커에서 사용할 수 있도록 구성하기 전에 인터셉터 클래스를 생성하고 브로커의 Java 클래스 경로에 이 클래스를 추가해야 합니다. 기본적으로 classpath의 일부이므로 BROKER_INSTANCE_DIR/lib 디렉토리를 사용할 수 있습니다.
절차
BROKER_INSTANCE_DIR/etc/broker.xml에 구성을 추가하여 인터셉터를 사용하도록 브로커를 구성합니다.인터셉터가 수신 메시지의 경우 해당
class-name을remoting-incoming-interceptors목록에 추가합니다.<configuration> <core> ... <remoting-incoming-interceptors> <class-name>org.example.MyIncomingInterceptor</class-name> </remoting-incoming-interceptors> ... </core> </configuration>인터셉터에서 발신 메시지의 경우
class-name을remoting-outgoing-interceptors목록에 추가합니다.<configuration> <core> ... <remoting-outgoing-interceptors> <class-name>org.example.MyOutgoingInterceptor</class-name> </remoting-outgoing-interceptors> </core> </configuration>
13.3. Client Side의 인터셉터
클라이언트는 인터셉터를 사용하여 클라이언트가 서버로 전송하거나 서버에서 클라이언트로 전송할 수 있습니다. 브로커 측 인터셉터의 경우와 같이, false 를 반환하는 경우 다른 인터셉터는 호출되지 않으며 클라이언트는 패킷을 더 이상 처리하지 않습니다. 이 프로세스는 발신 패킷이 차단 방식으로 전송되는 경우를 제외하고 클라이언트에게 투명하게 발생합니다. 이러한 경우 차단이 전송에 안정성을 제공하기 때문에 ActiveMQException 이 호출자에게 발생합니다. ActiveMQException 에 false를 반환한 인터셉터의 이름이 포함되어 있습니다.
서버에서와 마찬가지로 클라이언트 인터셉터 클래스와 해당 종속성을 올바르게 인스턴스화하고 호출하려면 클라이언트의 Java 클래스 경로에 추가해야 합니다.
14장. 메시지 분리 및 메시지 흐름 분할
AMQ Broker에서는 클라이언트 애플리케이션 논리를 변경하지 않고 한 주소에서 다른 주소로 메시지를 투명하게 구분할 수 있도록 divert라는 오브젝트를 구성할 수 있습니다. 또한 메시지 사본 을 지정된 전달 주소로 전달하도록 분산을 구성하여 메시지 흐름을 효과적으로 분할할 수 있습니다.
14.1. Message diverts 작업 방법
요약을 사용하면 클라이언트 애플리케이션 논리를 변경하지 않고 한 주소로 라우팅된 메시지를 다른 주소로 투명하게 구분할 수 있습니다. 브로커 서버의 전환 세트를 메시지의 라우팅 테이블 유형으로 생각하십시오.
해체는 배타적 일 수 있습니다. 즉, 메시지가 원래 주소로 이동하지 않고 지정된 전달 주소로 전달됩니다.
해체는 또한, 메시지가 원래 주소로 계속 이동한다는 것을 의미할 수 있고, 브로커는 특정 전달 주소로 메시지의 사본을 보낸다. 따라서 메시지 흐름을 분할하기 위해 포괄적이지 않은 분산을 사용할 수 있습니다. 예를 들어 주문 대기열에 전송되는 모든 순서를 별도로 모니터링하려는 경우 메시지 흐름을 분할할 수 있습니다.
주소에 배타적이고 비독점이 구성된 경우 브로커는 먼저 배타적인 요약을 처리합니다. 특정 메시지가 이미 독점적인 차이에 의해 요약된 경우, 브로커는 해당 메시지에 대한 임의의 비독점(non-exclusive divert)을 처리하지 않습니다. 이 경우 메시지는 원래 주소로 이동하지 않습니다.
브로커가 메시지를 분산하면 브로커는 새 메시지 ID를 할당하고 메시지 주소를 새 전달 주소로 설정합니다. _AMQ_ORIG_ADDRESS (문자열 유형) 및 _AMQ_ORIG_MESSAGE_ID (긴 유형) 메시지 속성을 통해 원래 메시지 ID 및 주소 값을 검색할 수 있습니다. Core API를 사용하는 경우 Message.HDR_ORIGINAL_ADDRESS 및 Message.HDR_ORIG_MESSAGE_ID 속성을 사용하십시오.
메시지를 동일한 브로커 서버의 주소로만 전환할 수 있습니다. 다른 서버의 주소로 전환하려는 경우 일반적인 해결 방법은 먼저 메시지를 로컬 저장소 및 전달 큐로 이동하는 것입니다. 그런 다음 해당 대기열에서 사용하는 브리지를 설정하고 다른 브로커의 주소로 메시지를 전달합니다. 이 둘을 브리지와 결합하면 지리적으로 분산된 브로커 서버 간 라우팅 연결 네트워크를 생성할 수 있습니다. 이러한 방식으로 글로벌 메시징 메시를 생성할 수 있습니다.
14.2. 메시지 차이 구성
브로커 인스턴스에서 다이버트를 구성하려면 broker.xml 구성 파일의 핵심 요소에 divert 요소를 추가합니다.
<core>
...
<divert name= >
<address> </address>
<forwarding-address> </forwarding-address>
<filter string= >
<routing-type> </routing-type>
<exclusive> </exclusive>
</divert>
...
</core>- divert
-
배열의 이름이 지정된 인스턴스입니다. 각 해마다 고유한 이름이 있는 경우
broker.xml구성 파일에 여러 개의다양한 요소를 추가할 수 있습니다. - 주소
- 메시지를 구분할 수 있는 주소
- forwarding-address
- 메시지 를 전달할 주소
- filter
- 선택적 메시지 필터. 필터를 구성하는 경우 필터 문자열과 일치하는 메시지만 달라집니다. 필터를 지정하지 않으면 모든 메시지가 해산에 따라 일치하는 것으로 간주됩니다.
- routing-type
분산된 메시지의 라우팅 유형입니다. 다음과 같이 리소스를 구성할 수 있습니다.
-
메시지에
anycast또는멀티 캐스트라우팅 유형 적용 - 기존 라우팅 유형 제거(즉, 제거)
- 기존 라우팅 유형(즉, 보존)을 통과
-
메시지에
라우팅 유형 제어는 메시지에 이미 라우팅 유형이 설정되어 있지만 메시지를 다른 라우팅 유형을 사용하는 주소로 전환하려는 경우 유용합니다. 예를 들어, 브로커는 다르트의 routing-type 매개 변수를 MULTICAST 로 설정하지 않는 한 멀티캐스트 를 사용하는 큐로 anycast 라우팅 유형을 사용하여 메시지를 라우팅할 수 없습니다. 다이빙트의 routing-type 매개변수에 유효한 값은 ANYCAST,MULTICAST,PASS, STRIP 입니다. 기본값은 STRIP 입니다.
- 배타적입니다.
-
요약이 배타적인지(속성을
true로 설정) 또는 비정성( property을false로 설정)할지 여부를 지정합니다.
다음 하위 섹션에서는 배타적이고 완전하지 않은 항목에 대한 구성 예제를 보여줍니다.
14.2.1. 독점적인 분산 예
아래에는 배타적 요약 구성의 예가 나와 있습니다. 독점적으로 요약하면 원래 구성된 주소에서 새 주소로 일치하는 모든 메시지가 요약됩니다. 일치하는 메시지는 원래 주소로 라우팅되지 않습니다.
<divert name="prices-divert"> <address>priceUpdates</address> <forwarding-address>priceForwarding</forwarding-address> <filter string="office='New York'"/> <exclusive>true</exclusive> </divert>
앞의 예에서 price -divert 라는 다양한 요소를 정의하여 주소 priceUpdates 로 전송된 모든 메시지를 다른 로컬 주소인 priceForwarding 으로 분류합니다. 메시지 필터 문자열도 지정합니다. 메시지 속성 사무실과 New York 값이 있는 메시지만 달라집니다. 다른 모든 메시지는 원래 주소로 라우팅됩니다. 마지막으로 해설이 배타적인 것으로 지정합니다.
14.2.2. 포괄적이지 않는 다이프트 예제
아래 예제는 제외된 다르트에 대한 구성의 예입니다. 미결정적인 결정에서, 메시지는 계속 원래 주소로 이동하고, 브로커는 또한 특정 전달 주소로 메시지의 사본을 보낸다. 따라서, 비독점(non-exclusive divert)은 메시지 흐름을 분할하는 방법입니다.
<divert name="order-divert"> <address>orders</address> <forwarding-address>spyTopic</forwarding-address> <exclusive>false</exclusive> </divert>
앞의 예에서 주소 주문에 전송된 모든 메시지의 사본을 가져와 spyTopic 라는 로컬 주소로 보내는 순서-디버트( order-divert )를 정의합니다. 또한 요약되지 않음을 지정합니다.
추가 리소스
전용 및 비독점 모두를 사용하고 다른 브로커로 메시지를 전달하기 위해 브리지를 사용하는 자세한 예는 Divert Example (external)을 참조하십시오.
15장. 메시지 필터링
AMQ Broker는 SQL 92 표현식 구문의 하위 집합을 기반으로 강력한 필터 언어를 제공합니다. 필터 언어는 JMS 선택기에 사용된 것과 동일한 구문을 사용하지만 사전 정의된 식별자는 다릅니다. 아래 표에는 AMQ Broker 메시지에 적용되는 식별자가 나열되어 있습니다.
| 식별자 | 속성 |
|---|---|
| AMQPriority |
메시지의 우선 순위입니다. 메시지 우선순위는 |
| AMQExpiration | 메시지의 만료 시간입니다. 값은 긴 정수입니다.The value is a long integer. |
| AMQDurable |
메시지가 내구성인지 아니면 내구성이 있는지 여부입니다. 값은 문자열입니다. 유효한 값은 |
| AMQTimestamp | 메시지를 생성할 때의 타임 스탬프입니다. 값은 긴 정수입니다.The value is a long integer. |
| AMQSize |
메시지의 |
코어 필터 식에 사용되는 다른 식별자는 메시지의 속성으로 간주됩니다. JMS 메시지의 선택기 구문에 대한 문서는 Java EE API 를 참조하십시오.
15.1. 필터를 사용하도록 대기열 구성
BROKER_INSTANCE_DIR/etc/broker.xml 에서 구성한 큐에 필터를 추가할 수 있습니다. 필터 식과 일치하는 메시지만 큐에 들어갑니다.
절차
필터요소를 원하는큐에추가하고 요소 값으로 적용하려는 필터를 포함합니다. 아래 예제에서는NEWS='tech 필터가대기열technologyQueue에 추가됩니다.<configuration> <core> ... <addresses> <address name="myQueue"> <anycast> <queue name="myQueue"> <filter string="NEWS='technology'"/> </queue> </anycast> </address> </addresses> </core> </configuration>
15.2. JMS 메시지 속성 필터링
JMS 사양에서는 선택기에 사용할 때 String 속성을 숫자 유형으로 변환할 수 없다고 명시되어 있습니다. 예를 들어 메시지에 String 값 21로 설정된 age 속성이 있는 경우 선택기 age > 18이 일치하지 않아야 합니다.For example, if a message has the age property set to the String value must not match it. 이 제한 사항은 STOMP 클라이언트가 String 속성을 사용하여 메시지만 보낼 수 있기 때문에 제한됩니다.
21, the selector age > 18
문자열을 숫자로 변환하도록 필터 구성
문자열 속성을 숫자 형식으로 변환하려면 접두사 convert_string_expressions: 를 필터 값에 추가합니다.
절차
접두사
convert_string을 편집합니다. 아래 예에서는_expressions:를 원하는필터에적용하여BROKER_INSTANCE_DIR/etc/broker.xmlage > 18에서filter값을 편집하여convert_string_expressions:age > 18을 선택합니다.<configuration> <core> ... <addresses> <address name="myQueue"> <anycast> <queue name="myQueue"> <filter string="convert_string_expressions='age > 18'"/> </queue> </anycast> </address> </addresses> </core> </configuration>
15.3. 주석에서 속성을 기반으로 AMQP 메시지 필터링
브로커가 만료된 또는 배달되지 않은 AMQP 메시지를 구성한 만료 또는 dead letter 큐로 이동하기 전에 브로커는 주석 및 속성을 메시지에 적용합니다. 클라이언트는 만료 또는 배달 못 한 큐에서 사용할 특정 메시지를 선택하기 위해 속성 또는 주석을 기반으로 필터를 생성할 수 있습니다.
브로커가 적용되는 속성은 내부 속성입니다 These properties are not exposed to clients for regular use, but can be specified by a client in a filter.
다음은 메시지 속성 및 주석을 기반으로 하는 필터의 예입니다. 속성을 기반으로 하는 필터링은 가능한 경우 브로커의 처리가 더 적기 때문에 권장되는 접근 방식입니다.
메시지 속성에 따라 필터링합니다.
ConnectionFactory factory = new JmsConnectionFactory("amqp://localhost:5672");
Connection connection = factory.createConnection();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
connection.start();
javax.jms.Queue queue = session.createQueue("my_DLQ");
MessageConsumer consumer = session.createConsumer(queue, "_AMQ_ORIG_ADDRESS='original_address_name'");
Message message = consumer.receive();
메시지 주석에 따라 필터링
ConnectionFactory factory = new JmsConnectionFactory("amqp://localhost:5672");
Connection connection = factory.createConnection();
Session session = connection.createSession(false, Session.AUTO_ACKNOWLEDGE);
connection.start();
javax.jms.Queue queue = session.createQueue("my_DLQ");
MessageConsumer consumer = session.createConsumer(queue, "\"m.x-opt-ORIG-ADDRESS\"='original_address_name'");
Message message = consumer.receive();
주석에 따라 AMQP 메시지를 사용하는 경우 클라이언트는 위 예제와 같이 메시지 주석에 m. 접두사를 추가해야 합니다.
추가 리소스
- 브로커가 만료된 또는 배달되지 않은 AMQP 메시지에 적용되는 주석 및 속성에 대한 자세한 내용은 4.14절. “만료된 또는 배달되지 않은 AMQP 메시지의 주석 및 속성” 을 참조하십시오.
16장. 브로커 클러스터 설정
클러스터는 함께 그룹화된 여러 브로커 인스턴스로 구성됩니다. 브로커 클러스터는 여러 브로커에 메시지 처리 부하를 분산하여 성능을 향상시킵니다. 또한 브로커 클러스터는 고가용성을 통해 가동 중지 시간을 최소화할 수 있습니다.
여러 다른 클러스터 토폴로지에서 브로커를 연결할 수 있습니다. 클러스터 내에서 각 활성 브로커는 자체 메시지를 관리하고 자체 연결을 처리합니다.
또한 클러스터 전체에서 클라이언트 연결의 균형을 유지하고 메시지를 재배포하여 브로커 고정을 방지할 수 있습니다.
16.1. 브로커 클러스터 이해
브로커 클러스터를 생성하기 전에 몇 가지 중요한 클러스터링 개념을 이해해야 합니다.
16.1.1. 브로커 클러스터에서 메시지 로드의 균형을 조정하는 방법
브로커를 연결하여 클러스터를 형성하면 AMQ Broker는 브로커 간 메시지 로드의 균형을 자동으로 조정합니다. 이렇게 하면 클러스터가 메시지 처리량을 유지할 수 있습니다.
4개의 브로커로 구성된 대칭 클러스터를 고려하십시오. 각 브로커는 OrderQueue 라는 큐로 구성됩니다. OrderProducer 클라이언트는 Broker1 에 연결하고 메시지를 OrderQueue 에 보냅니다. Broker1 은 라운드 로빈 방식으로 다른 브로커에 메시지를 전달합니다. 각 브로커에 연결된 OrderConsumer 클라이언트는 메시지를 사용합니다. 정확한 순서는 브로커가 시작된 순서에 따라 달라집니다.
그림 16.1. 메시지 로드 밸런싱

메시지 로드 밸런싱이 없으면 Broker1 로 전송된 메시지는 Broker1 에 남아 있으며 OrderConsumer1 만 사용할 수 있습니다.
AMQ Broker는 기본적으로 메시지의 부하를 자동으로 부하 분산하는 반면, 관련 소비자가 있는 브로커에 대해 메시지만 로드 밸런싱하도록 클러스터를 구성할 수 있습니다. 소비자가 소비자가 있는 큐에 메시지를 자동으로 재배포하도록 메시지 재배포를 구성할 수도 있습니다.
추가 리소스
-
메시지 로드 밸런싱 정책은 각 브로커의 클러스터 연결에서
message-load-balancing속성으로 구성됩니다. 자세한 내용은 부록 C. 클러스터 연결 구성 요소의 내용을 참조하십시오. - 메시지 재배포에 대한 자세한 내용은 16.4.2절. “메시지 재배포 구성” 을 참조하십시오.
16.1.2. 브로커 클러스터가 안정성을 향상시키는 방법
브로커 클러스터는 고가용성 및 페일오버를 가능하게 하여 독립 실행형 브로커보다 더 신뢰할 수 있습니다. 고가용성을 구성하면 브로커가 실패 이벤트가 발생하더라도 클라이언트 애플리케이션이 계속 메시지를 보내고 받을 수 있습니다.
고가용성을 통해 클러스터의 브로커는 라이브 백업 그룹으로 그룹화됩니다. 라이브 백업 그룹은 클라이언트 요청을 제공하는 라이브 브로커와 오류가 발생할 경우 수동으로 대기하여 라이브 브로커를 대체하는 하나 이상의 백업 브로커로 구성됩니다. 오류가 발생하면 백업 브로커는 live-backup 그룹에서 라이브 브로커를 교체하고 클라이언트가 작업을 다시 연결하고 계속합니다.
16.1.3. 노드 ID 이해
브로커 노드 ID 는 브로커 인스턴스의 저널을 처음 생성하고 초기화할 때 프로그래밍 방식으로 생성된 GUID(Globally Unique Identifier)입니다. 노드 ID는 server.lock 파일에 저장됩니다. 노드 ID는 브로커가 독립 실행형 인스턴스인지 클러스터의 일부인지에 관계없이 브로커 인스턴스를 고유하게 식별하는 데 사용됩니다. 라이브 백업 브로커 쌍은 동일한 저널을 공유하므로 동일한 노드 ID를 공유합니다.
브로커 클러스터에서 브로커 인스턴스(nodes)는 서로 연결하고 브리지와 내부 "store-and-forward" 큐를 생성합니다. 이러한 내부 대기열의 이름은 다른 브로커 인스턴스의 노드 ID를 기반으로 합니다. 브로커 인스턴스는 자체와 일치하는 노드 ID의 클러스터 브로드캐스트도 모니터링합니다. 브로커가 중복 ID를 식별하는 경우 로그에 경고 메시지를 생성합니다.
HA(복제 고가용성) 정책을 사용하는 경우 마스터 브로커가 시작 및 check-for-live-server 설정이 true 로 설정되어 있는 경우 노드 ID를 사용하는 브로커를 검색합니다. 마스터 브로커가 동일한 노드 ID를 사용하여 다른 브로커를 찾는 경우 HA 구성에 따라 시작되지 않거나 failback을 시작합니다.
노드 ID는 내 구성 이 있습니다. 즉, 브로커의 재시작 후에도 유지됩니다. 그러나 브로커 인스턴스를 삭제하는 경우( 저널 포함) 노드 ID도 영구적으로 삭제됩니다.
추가 리소스
- 복제 HA 정책 구성에 대한 자세한 내용은 복제 고가용성 구성을 참조하십시오.
16.1.4. 공통 브로커 클러스터 토폴로지
브로커를 연결하여 대 칭 또는 체인 클러스터 토폴로지를 구성할 수 있습니다. 구현하는 토폴로지는 환경 및 메시징 요구 사항에 따라 다릅니다.
대칭 클러스터
대칭 클러스터에서는 모든 브로커가 다른 모든 브로커에 연결됩니다. 즉, 모든 브로커는 다른 브로커에서 한 홉을 넘지 않습니다.
그림 16.2. 대칭 클러스터
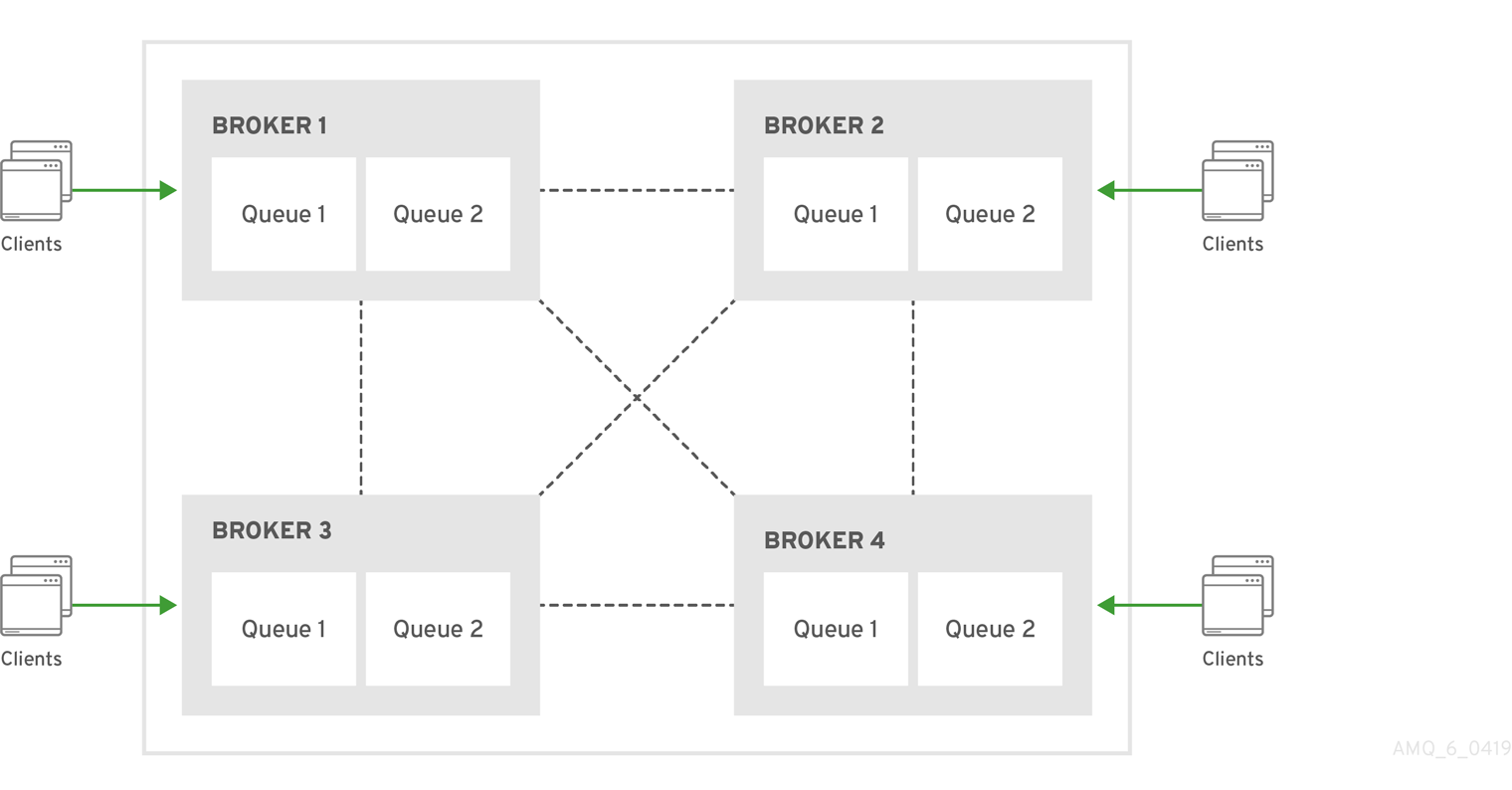
대칭 클러스터의 각 브로커는 클러스터의 다른 모든 브로커와 해당 큐에서 수신 대기하는 모든 대기열을 알고 있습니다. 따라서 대칭 클러스터는 체인 클러스터보다 최적의 메시지를 로드 밸런싱하고 재배포할 수 있습니다.
대칭 클러스터는 체인 클러스터보다 설정하기가 쉽지만 네트워크 제한으로 인해 브로커가 직접 연결되지 않는 환경에서 사용하기 어려울 수 있습니다.
체인 클러스터
체인 클러스터에서는 클러스터의 각 브로커가 클러스터의 모든 브로커에 직접 연결되지 않습니다. 대신 브로커는 체인의 각 끝에서 브로커와 함께 체인을 형성하고 다른 모든 브로커는 체인의 이전 및 다음 브로커에 연결합니다.
그림 16.3. 체인 클러스터
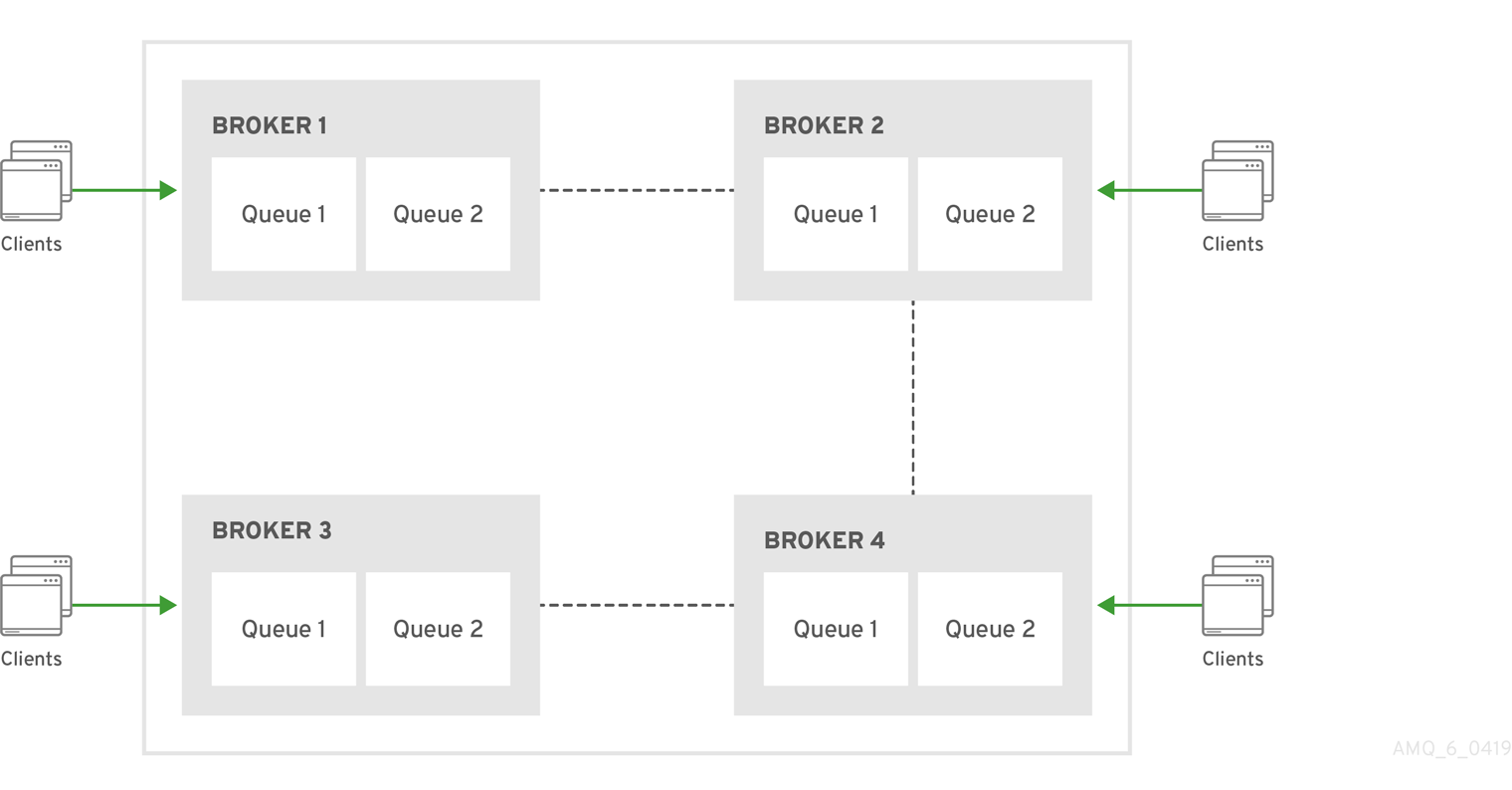
체인 클러스터는 대칭 클러스터보다 설정하기가 더 어렵지만 브로커가 별도의 네트워크에 있고 직접 연결할 수 없는 경우 유용할 수 있습니다. 체인 클러스터를 사용하여 중간 브로커는 두 브로커를 간접적으로 연결하여 두 브로커가 직접 연결되지 않더라도 메시지 간에 메시지를 전달할 수 있습니다.
16.1.5. 브로커 검색 방법
Discovery는 클러스터의 브로커가 연결 세부 정보를 서로 전파하는 메커니즘입니다. AMQ Broker는 동적 검색 및 정적 검색 을 모두 지원합니다.
동적 검색
클러스터의 각 브로커는 UDP 멀티캐스트 또는 JGroups를 통해 다른 구성원에게 연결 설정을 브로드캐스트합니다. 이 방법에서는 각 브로커가 다음을 사용합니다.
- 클러스터 연결에 대한 정보를 클러스터의 다른 잠재적인 멤버로 푸시하는 브로드캐스트 그룹입니다.
- 클러스터의 다른 브로커에 대한 클러스터 연결 정보를 수신하고 저장하는 검색 그룹입니다.
정적 검색
네트워크에서 UDP 또는 JGroups를 사용할 수 없거나 클러스터의 각 멤버를 수동으로 지정하려면 정적 검색을 사용할 수 있습니다. 이 방법에서는 브로커가 두 번째 브로커에 연결하고 연결 세부 정보를 전송하여 클러스터를 "연결"합니다. 그런 다음 두 번째 브로커는 해당 세부 사항을 클러스터의 다른 브로커로 전달합니다.
16.1.6. 클러스터 크기 조정 고려 사항
브로커 클러스터를 생성하기 전에 메시징 처리량, 토폴로지 및 고가용성 요구 사항을 고려하십시오. 이러한 요소는 클러스터에 포함할 브로커 수에 영향을 미칩니다.
클러스터를 생성한 후 브로커를 추가하고 제거하여 크기를 조정할 수 있습니다. 메시지를 손실하지 않고 브로커를 추가하고 제거할 수 있습니다.
메시징 처리량
클러스터에 필요한 메시징 처리량을 제공하기에 충분한 브로커가 포함되어야 합니다. 클러스터에서 브로커 수가 많을수록 처리량이 증가합니다. 그러나 대규모 클러스터는 관리하기가 복잡할 수 있습니다.
토폴로지
대칭 클러스터 또는 체인 클러스터를 생성할 수 있습니다. 선택하는 토폴로지 유형은 필요할 수 있는 브로커 수에 영향을 미칩니다.
자세한 내용은 16.1.4절. “공통 브로커 클러스터 토폴로지”의 내용을 참조하십시오.
고가용성
HA(고가용성)가 필요한 경우 클러스터를 생성하기 전에 HA 정책을 선택하는 것이 좋습니다. 각 마스터 브로커에는 슬레이브 브로커가 하나 이상 있어야 하므로 HA 정책은 클러스터 크기에 영향을 미칩니다.
자세한 내용은 16.3절. “고가용성 구현”의 내용을 참조하십시오.
16.2. 브로커 클러스터 생성
클러스터에 참여해야 하는 각 브로커에 대한 클러스터 연결을 구성하여 브로커 클러스터를 생성합니다. 클러스터 연결은 브로커가 다른 브로커에 연결하는 방법을 정의합니다.
정적 검색 또는 동적 검색(UDP 멀티캐스트 또는 JGroups)을 사용하는 브로커 클러스터를 생성할 수 있습니다.
사전 요구 사항
브로커 클러스터의 크기를 결정해야 합니다.
자세한 내용은 16.1.6절. “클러스터 크기 조정 고려 사항”의 내용을 참조하십시오.
16.2.1. 정적 검색을 사용하여 브로커 클러스터 생성
브로커 목록을 지정하여 브로커 클러스터를 생성할 수 있습니다. 네트워크에서 UDP 멀티 캐스트 또는 JGroups를 사용할 수 없는 경우 이 정적 검색 방법을 사용하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core> 요소 내에서 다음 커넥터를 추가합니다.- 다른 브로커가이 브로커에 연결하는 방법을 정의하는 커넥터
- 이 브로커가 클러스터의 다른 브로커에 연결하는 방법을 정의하는 하나 이상의 커넥터
<configuration> <core> ... <connectors> <connector name="netty-connector">tcp://localhost:61617</connector> 1 <connector name="broker2">tcp://localhost:61618</connector> 2 <connector name="broker3">tcp://localhost:61619</connector> </connectors> ... </core> </configuration>커넥터에 대한 자세한 내용은 2.2절. “커넥터 정보” 을 참조하십시오.
클러스터 연결을 추가하고 정적 검색을 사용하도록 구성합니다.
기본적으로 클러스터 연결은 대칭 토폴로지의 모든 주소에 대한 메시지의 부하를 분산합니다.
<configuration> <core> ... <cluster-connections> <cluster-connection name="my-cluster"> <connector-ref>netty-connector</connector-ref> <static-connectors> <connector-ref>broker2-connector</connector-ref> <connector-ref>broker3-connector</connector-ref> </static-connectors> </cluster-connection> </cluster-connections> ... </core> </configuration>cluster-connection-
name특성을 사용하여 클러스터 연결의 이름을 지정합니다. connector-ref- 다른 브로커들이 어떻게 연결할 수 있는지 정의하는 커넥터입니다.
static-connectors- 이 브로커가 클러스터의 다른 브로커에 초기 연결을 수행하는 데 사용할 수 있는 하나 이상의 커넥터입니다. 이 초기 연결을 수행한 후 브로커는 클러스터의 다른 브로커를 검색합니다. 클러스터가 정적 검색을 사용하는 경우에만 이 속성을 구성해야 합니다.
클러스터 연결에 대한 추가 속성을 구성합니다.
이러한 추가 클러스터 연결 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다.Therefore, you only need to configure these properties if you do not want the default behavior. 자세한 내용은 부록 C. 클러스터 연결 구성 요소의 내용을 참조하십시오.
클러스터 사용자 및 암호를 만듭니다.
AMQ Broker는 기본 클러스터 인증 정보와 함께 제공되지만 권한이 없는 원격 클라이언트가 브로커에 연결하는 데 이러한 기본 인증 정보를 사용하지 않도록 변경해야 합니다.
중요클러스터 암호는 클러스터의 모든 브로커에서 동일해야 합니다.
<configuration> <core> ... <cluster-user>cluster_user</cluster-user> <cluster-password>cluster_user_password</cluster-password> ... </core> </configuration>추가 브로커에 대해 이 절차를 반복합니다.
클러스터 구성을 각 추가 브로커에 복사할 수 있습니다. 그러나 다른 AMQ Broker 데이터 파일(예: 바인딩, 저널 및 대용량 메시지 디렉터리)은 복사하지 마십시오. 이러한 파일은 클러스터의 노드 간에 고유해야 하며 클러스터가 제대로 형성되지 않습니다.
추가 리소스
-
정적 검색을 사용하는 브로커 클러스터의 예는
clustered-static-discoveryAMQ Broker 예제 프로그램 을 참조하십시오.
16.2.2. UDP 기반 동적 검색으로 브로커 클러스터 생성
브로커가 UDP 멀티 캐스트를 통해 동적으로 서로를 검색하는 브로커 클러스터를 생성할 수 있습니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core>요소 내에서 커넥터를 추가합니다.이 커넥터는 다른 브로커가 이 커넥터에 연결하는 데 사용할 수 있는 연결 정보를 정의합니다. 이 정보는 검색 중에 클러스터의 다른 브로커로 전송됩니다.
<configuration> <core> ... <connectors> <connector name="netty-connector">tcp://localhost:61617</connector> </connectors> ... </core> </configuration>UDP 브로드캐스트 그룹을 추가합니다.
브로드캐스트 그룹을 사용하면 브로커가 클러스터 연결에 대한 정보를 클러스터의 다른 브로커로 내보낼 수 있습니다. 이 브로드캐스트 그룹은 연결 설정을 브로드캐스트하기 위해 UDP를 사용합니다.
<configuration> <core> ... <broadcast-groups> <broadcast-group name="my-broadcast-group"> <local-bind-address>172.16.9.3</local-bind-address> <local-bind-port>-1</local-bind-port> <group-address>231.7.7.7</group-address> <group-port>9876</group-port> <broadcast-period>2000</broadcast-period> <connector-ref>netty-connector</connector-ref> </broadcast-group> </broadcast-groups> ... </core> </configuration>별도로 명시하지 않는 한 다음 매개변수가 필요합니다.
broadcast-group-
name특성을 사용하여 브로드캐스트 그룹의 고유한 이름을 지정합니다. local-bind-address- UDP 소켓이 바인딩되는 주소입니다. 브로커에 여러 네트워크 인터페이스가 있는 경우 브로드캐스트에 사용할 인터페이스를 지정해야 합니다. 이 속성을 지정하지 않으면 소켓이 운영 체제에서 선택한 IP 주소에 바인딩됩니다. UDP 관련 특성입니다.
local-bind-port-
데이터그램 소켓이 바인딩되는 포트입니다. 대부분의 경우 익명 포트를 지정하는
-1의 기본값을 사용합니다. 이 매개변수는local-bind-address와 관련하여 사용됩니다. UDP 관련 특성입니다. group-address-
데이터가 브로드캐스트될 멀티캐스트 주소입니다.
224.0.0.0-239.255.255.255.255 범위의 D IP 주소입니다.255 범위에 포함됩니다.224.0.0.0주소는 예약되어 있으며 사용할 수 없습니다. UDP 관련 특성입니다. group-port- 브로드캐스트에 사용되는 UDP 포트 번호입니다. UDP 관련 특성입니다.
broadcast-period(선택 사항)- 연속 브로드캐스트 사이의 간격(밀리초)입니다. 기본값은 2000밀리초입니다.
connector-ref- 이전에 구성된 클러스터 커넥터를 브로드캐스트해야 합니다.
UDP 검색 그룹을 추가합니다.
검색 그룹은 이 브로커가 다른 브로커로부터 커넥터 정보를 수신하는 방법을 정의합니다. 브로커는 커넥터 목록을 유지합니다(각 브로커당 하나의 항목). 브로커에서 브로드캐스트를 수신하므로 해당 항목을 업데이트합니다. 브로커에서 일정 기간 동안 브로드캐스트를 수신하지 못하면 항목이 제거됩니다.
이 검색 그룹은 UDP를 사용하여 클러스터의 브로커를 검색합니다.
<configuration> <core> ... <discovery-groups> <discovery-group name="my-discovery-group"> <local-bind-address>172.16.9.7</local-bind-address> <group-address>231.7.7.7</group-address> <group-port>9876</group-port> <refresh-timeout>10000</refresh-timeout> </discovery-group> <discovery-groups> ... </core> </configuration>별도로 명시하지 않는 한 다음 매개변수가 필요합니다.
discovery-group-
name특성을 사용하여 검색 그룹의 고유한 이름을 지정합니다. local-bind-address(선택 사항)- 브로커가 실행 중인 시스템에서 여러 네트워크 인터페이스를 사용하는 경우 검색 그룹이 수신 대기해야 하는 네트워크 인터페이스를 지정할 수 있습니다. UDP 관련 특성입니다.
group-address-
수신 대기할 그룹의 멀티캐스트 주소입니다. 수신 대기하려는 브로드캐스트 그룹의
group-address와 일치해야 합니다. UDP 관련 특성입니다. group-port-
멀티캐스트 그룹의 UDP 포트 번호입니다. 수신 대기하려는 브로드캐스트 그룹의
group-port와 일치해야 합니다. UDP 관련 특성입니다. refresh-timeout(선택 사항)검색 그룹에서 해당 브로커의 커넥터 쌍 항목을 제거하기 전에 특정 브로커에서 마지막 브로드캐스트를 수신한 후 대기하는 시간(밀리초)입니다. 기본값은 10000밀리초(10초)입니다.
이 값을 브로드캐스트 그룹의
broadcast-period보다 훨씬 높은 값으로 설정합니다. 그렇지 않으면 브로커는 여전히 브로드캐스트되어 있더라도 목록에서 주기적으로 사라질 수 있습니다 (시간에 약간의 차이로 인해).
클러스터 연결을 생성하고 동적 검색을 사용하도록 구성합니다.
기본적으로 클러스터 연결은 대칭 토폴로지의 모든 주소에 대한 메시지의 부하를 분산합니다.
<configuration> <core> ... <cluster-connections> <cluster-connection name="my-cluster"> <connector-ref>netty-connector</connector-ref> <discovery-group-ref discovery-group-name="my-discovery-group"/> </cluster-connection> </cluster-connections> ... </core> </configuration>cluster-connection-
name특성을 사용하여 클러스터 연결의 이름을 지정합니다. connector-ref- 다른 브로커들이 어떻게 연결할 수 있는지 정의하는 커넥터입니다.
discovery-group-ref- 이 브로커가 클러스터의 다른 구성원을 찾는 데 사용해야 하는 검색 그룹입니다. 클러스터가 동적 검색을 사용하는 경우에만 이 속성을 구성해야 합니다.
클러스터 연결에 대한 추가 속성을 구성합니다.
이러한 추가 클러스터 연결 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다.Therefore, you only need to configure these properties if you do not want the default behavior. 자세한 내용은 부록 C. 클러스터 연결 구성 요소의 내용을 참조하십시오.
클러스터 사용자 및 암호를 만듭니다.
AMQ Broker는 기본 클러스터 인증 정보와 함께 제공되지만 권한이 없는 원격 클라이언트가 브로커에 연결하는 데 이러한 기본 인증 정보를 사용하지 않도록 변경해야 합니다.
중요클러스터 암호는 클러스터의 모든 브로커에서 동일해야 합니다.
<configuration> <core> ... <cluster-user>cluster_user</cluster-user> <cluster-password>cluster_user_password</cluster-password> ... </core> </configuration>추가 브로커에 대해 이 절차를 반복합니다.
클러스터 구성을 각 추가 브로커에 복사할 수 있습니다. 그러나 다른 AMQ Broker 데이터 파일(예: 바인딩, 저널 및 대용량 메시지 디렉터리)은 복사하지 마십시오. 이러한 파일은 클러스터의 노드 간에 고유해야 하며 클러스터가 제대로 형성되지 않습니다.
추가 리소스
-
UDP에서 동적 검색을 사용하는 브로커 클러스터 구성의 예는
clustered-queueAMQ Broker 예제 프로그램 을 참조하십시오.
16.2.3. JGroups 기반 동적 검색으로 브로커 클러스터 생성
이미 환경에서 JGroups를 사용하는 경우 브로커를 동적으로 검색하는 브로커 클러스터를 만드는 데 사용할 수 있습니다.
사전 요구 사항
JGroups를 설치하고 구성해야 합니다.
JGroups 구성 파일의 예는
clustered-jgroupsAMQ Broker 예제 프로그램 을 참조하십시오.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core>요소 내에서 커넥터를 추가합니다.이 커넥터는 다른 브로커가 이 커넥터에 연결하는 데 사용할 수 있는 연결 정보를 정의합니다. 이 정보는 검색 중에 클러스터의 다른 브로커로 전송됩니다.
<configuration> <core> ... <connectors> <connector name="netty-connector">tcp://localhost:61617</connector> </connectors> ... </core> </configuration><
core> 요소 내에서 JGroups 브로드캐스트 그룹을 추가합니다.브로드캐스트 그룹을 사용하면 브로커가 클러스터 연결에 대한 정보를 클러스터의 다른 브로커로 내보낼 수 있습니다. 이 브로드캐스트 그룹은 JGroups를 사용하여 연결 설정을 브로드캐스트합니다.
<configuration> <core> ... <broadcast-groups> <broadcast-group name="my-broadcast-group"> <jgroups-file>test-jgroups-file_ping.xml</jgroups-file> <jgroups-channel>activemq_broadcast_channel</jgroups-channel> <broadcast-period>2000</broadcast-period> <connector-ref>netty-connector</connector-ref> </broadcast-group> </broadcast-groups> ... </core> </configuration>별도로 명시하지 않는 한 다음 매개변수가 필요합니다.
broadcast-group-
name특성을 사용하여 브로드캐스트 그룹의 고유한 이름을 지정합니다. jgroups-file- JGroups 채널을 초기화하기 위한 JGroups 구성 파일의 이름입니다. 파일이 Java 리소스 경로에 있어야 브로커가 로드될 수 있습니다.
jgroups-channel- 브로드캐스트에 연결할 JGroups 채널의 이름입니다.
broadcast-period(선택 사항)- 연속 브로드캐스트 사이의 간격(밀리초)입니다. 기본값은 2000밀리초입니다.
connector-ref- 이전에 구성된 클러스터 커넥터를 브로드캐스트해야 합니다.
JGroups 검색 그룹을 추가합니다.
검색 그룹은 커넥터 정보를 수신하는 방법을 정의합니다. 브로커는 커넥터 목록을 유지합니다(각 브로커당 하나의 항목). 브로커에서 브로드캐스트를 수신하므로 해당 항목을 업데이트합니다. 브로커에서 일정 기간 동안 브로드캐스트를 수신하지 못하면 항목이 제거됩니다.
이 검색 그룹은 JGroups를 사용하여 클러스터에서 브로커를 검색합니다.
<configuration> <core> ... <discovery-groups> <discovery-group name="my-discovery-group"> <jgroups-file>test-jgroups-file_ping.xml</jgroups-file> <jgroups-channel>activemq_broadcast_channel</jgroups-channel> <refresh-timeout>10000</refresh-timeout> </discovery-group> <discovery-groups> ... </core> </configuration>별도로 명시하지 않는 한 다음 매개변수가 필요합니다.
discovery-group-
name특성을 사용하여 검색 그룹의 고유한 이름을 지정합니다. jgroups-file- JGroups 채널을 초기화하기 위한 JGroups 구성 파일의 이름입니다. 파일이 Java 리소스 경로에 있어야 브로커가 로드될 수 있습니다.
jgroups-channel- 브로드캐스트 수신을 위해 연결할 JGroups 채널의 이름입니다.
refresh-timeout(선택 사항)검색 그룹에서 해당 브로커의 커넥터 쌍 항목을 제거하기 전에 특정 브로커에서 마지막 브로드캐스트를 수신한 후 대기하는 시간(밀리초)입니다. 기본값은 10000밀리초(10초)입니다.
이 값을 브로드캐스트 그룹의
broadcast-period보다 훨씬 높은 값으로 설정합니다. 그렇지 않으면 브로커는 여전히 브로드캐스트되어 있더라도 목록에서 주기적으로 사라질 수 있습니다 (시간에 약간의 차이로 인해).
클러스터 연결을 생성하고 동적 검색을 사용하도록 구성합니다.
기본적으로 클러스터 연결은 대칭 토폴로지의 모든 주소에 대한 메시지의 부하를 분산합니다.
<configuration> <core> ... <cluster-connections> <cluster-connection name="my-cluster"> <connector-ref>netty-connector</connector-ref> <discovery-group-ref discovery-group-name="my-discovery-group"/> </cluster-connection> </cluster-connections> ... </core> </configuration>cluster-connection-
name특성을 사용하여 클러스터 연결의 이름을 지정합니다. connector-ref- 다른 브로커들이 어떻게 연결할 수 있는지 정의하는 커넥터입니다.
discovery-group-ref- 이 브로커가 클러스터의 다른 구성원을 찾는 데 사용해야 하는 검색 그룹입니다. 클러스터가 동적 검색을 사용하는 경우에만 이 속성을 구성해야 합니다.
클러스터 연결에 대한 추가 속성을 구성합니다.
이러한 추가 클러스터 연결 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다.Therefore, you only need to configure these properties if you do not want the default behavior. 자세한 내용은 부록 C. 클러스터 연결 구성 요소의 내용을 참조하십시오.
클러스터 사용자 및 암호를 만듭니다.
AMQ Broker는 기본 클러스터 인증 정보와 함께 제공되지만 권한이 없는 원격 클라이언트가 브로커에 연결하는 데 이러한 기본 인증 정보를 사용하지 않도록 변경해야 합니다.
중요클러스터 암호는 클러스터의 모든 브로커에서 동일해야 합니다.
<configuration> <core> ... <cluster-user>cluster_user</cluster-user> <cluster-password>cluster_user_password</cluster-password> ... </core> </configuration>추가 브로커에 대해 이 절차를 반복합니다.
클러스터 구성을 각 추가 브로커에 복사할 수 있습니다. 그러나 다른 AMQ Broker 데이터 파일(예: 바인딩, 저널 및 대용량 메시지 디렉터리)은 복사하지 마십시오. 이러한 파일은 클러스터의 노드 간에 고유해야 하며 클러스터가 제대로 형성되지 않습니다.
추가 리소스
-
JGroups를 사용하여 동적 검색을 사용하는 브로커 클러스터의 예는
클러스터형-jgroupsAMQ Broker 예제 프로그램 을 참조하십시오.
16.3. 고가용성 구현
브로커 클러스터를 생성한 후 HA(고가용성)를 구현하여 안정성을 개선할 수 있습니다. HA를 사용하면 하나 이상의 브로커가 오프라인 상태인 경우에도 브로커 클러스터는 계속 작동할 수 있습니다.
HA 구현에는 다음과 같은 몇 가지 단계가 포함됩니다.
- 실시간 백업 그룹이 무엇인지 이해하고 요구 사항에 가장 적합한 HA 정책을 선택해야 합니다. AMQ Broker에서 HA가 작동하는 방법 이해 를 참조하십시오.
적절한 HA 정책을 선택한 경우 클러스터의 각 브로커에 HA 정책을 구성합니다. 다음 내용을 참조하십시오.
- 장애 조치( failover)를 사용하도록 클라이언트 애플리케이션을 구성합니다.
이후 고가용성을 위해 구성된 브로커 클러스터의 문제를 해결해야 하는 경우 클러스터에서 브로커를 실행하는 각 JVM(Java Virtual Machine) 인스턴스에 대해 Garbage Collection(GC) 로깅을 활성화하는 것이 좋습니다. JVM에서 GC 로그를 활성화하는 방법에 대한 자세한 내용은 JVM에서 사용하는 JDK(Java Development Kit) 버전에 대한 공식 설명서를 참조하십시오. AMQ Broker가 지원하는 JVM 버전에 대한 자세한 내용은 Red Hat AMQ 7 지원 구성 을 참조하십시오.
16.3.1. 고가용성 이해
AMQ Broker에서는 클러스터의 브로커를 라이브 백업 그룹으로 그룹화하여 HA(고가용성)를 구현합니다. 실시간 백업 그룹에서 라이브 브로커는 백업 브로커와 연결되어 있으며 실패할 경우 라이브 브로커에 대해 넘겨받을 수 있습니다. AMQ Broker는 실시간 백업 그룹 내에서 페일오버( HA 정책라고도 함)에 대한 몇 가지 다른 전략도 제공합니다.
16.3.1.1. 라이브 백업 그룹이 고가용성을 제공하는 방법
AMQ Broker에서는 클러스터의 브로커를 함께 연결하여 실시간 백업 그룹 을 구성하여 HA(고가용성)를 구현합니다. 라이브 백업 그룹은 장애 조치( failover )를 제공합니다. 즉, 하나의 브로커가 실패하면 다른 브로커가 메시지 처리를 대신할 수 있습니다.
실시간 백업 그룹은 하나 이상의 백업 브로커( 하위 브로커라고 함)에 연결된 하나의 라이브 브로커( 마스터 브로커라고도 함)로 구성됩니다. 라이브 브로커는 클라이언트 요청을 제공하는 반면 백업 브로커는 패시브 모드로 대기합니다. 라이브 브로커가 실패하면 백업 브로커가 라이브 브로커를 대체하여 클라이언트가 작업을 다시 연결하고 계속할 수 있습니다.
16.3.1.2. 고가용성 정책
HA(고가용성) 정책은 실시간 백업 그룹에서 페일오버가 발생하는 방식을 정의합니다. AMQ Broker는 다음과 같은 다양한 HA 정책을 제공합니다.
- 공유 저장소(권장)
실시간 및 백업 브로커는 공유 파일 시스템의 공통 디렉터리에 메시징 데이터를 저장합니다. 일반적으로 SAN(Storage Area Network) 또는 NFS(네트워크 파일 시스템) 서버. JDBC 기반 지속성을 구성한 경우 지정된 데이터베이스에 브로커 데이터를 저장할 수도 있습니다. 공유 저장소를 사용하면 라이브 브로커가 실패하는 경우 백업 브로커는 공유 저장소에서 메시지 데이터를 로드하여 실패한 라이브 브로커에 대해 인수합니다.
대부분의 경우 복제 대신 공유 저장소를 사용해야 합니다. 공유 저장소는 네트워크를 통해 데이터를 복제하지 않으므로 일반적으로 복제보다 성능이 향상됩니다. 공유 저장소는 또한 라이브 브로커와 해당 백업이 동시에 작동하는 네트워크 분리 (split brain") 문제를 방지할 수 있습니다.

- 복제
라이브 및 백업 브로커는 네트워크를 통해 메시징 데이터를 지속적으로 동기화합니다. 라이브 브로커가 실패하면 백업 브로커가 동기화된 데이터를 로드하고 실패한 라이브 브로커에 대해 인수합니다.
라이브 브로커와 백업 브로커 간의 데이터 동기화를 통해 실시간 브로커가 실패하면 메시징 데이터가 손실되지 않습니다. 라이브 및 백업 브로커가 처음에 함께 참여하면 라이브 브로커는 네트워크를 통해 모든 기존 데이터를 백업 브로커에 복제합니다. 이 초기 단계가 완료되면 라이브 브로커가 수신될 때 실시간 브로커에 영구 데이터를 백업 브로커에 복제합니다. 즉, 라이브 브로커가 네트워크를 벗어나면 백업 브로커는 라이브 브로커가 해당 시점까지 받은 모든 영구 데이터가 있습니다.
복제는 네트워크를 통해 데이터를 동기화하므로 네트워크 실패로 인해 라이브 브로커와 해당 백업이 동시에 활성화된 네트워크가 격리될 수 있습니다.
- 실시간 전용(제한 HA)
라이브 브로커가 정상적으로 중지되면 메시지 및 트랜잭션 상태를 다른 라이브 브로커에 복사한 다음 종료합니다. 그런 다음 클라이언트는 다른 브로커에 다시 연결하여 메시지를 계속 보내고 받을 수 있습니다.
추가 리소스
- live-backup 그룹의 브로커 간에 공유되는 영구 메시지 데이터에 대한 자세한 내용은 6.1절. “저널 기반 지속성 정보” 을 참조하십시오.
16.3.1.3. 복제 정책 제한 사항
네트워크 격리(때로 "split brain")라고 하는 것은 HA(복제 고가용성) 정책의 제한입니다. 어떻게 작동하는지, 그리고 그것을 피하는 방법을 이해해야합니다.
네트워크 격리는 라이브 브로커와 백업이 연결이 끊어지면 발생할 수 있습니다. 이러한 상황에서 라이브 브로커와 백업 모두 동시에 활성화될 수 있습니다. 특히 백업 브로커가 클러스터의 라이브 브로커의 절반 이상에 연결할 수 있는 경우에도 활성 상태가 됩니다. 이 상황에서 브로커 간에 메시지 복제가 없기 때문에 각각 클라이언트를 제공하고 다른 하나는 이를 인식하지 않고 메시지를 처리합니다. 이 경우 각 브로커는 완전히 다른 저널을 가지고 있습니다. 이 상황에서 복구하는 것은 매우 어려울 수 있으며 경우에 따라서는 불가능합니다.
네트워크 분리를 방지하려면 다음을 고려하십시오.
- 네트워크 분리 가능성 을 제거 하려면 공유 저장소 HA 정책을 사용하십시오.
복제 HA 정책을 사용하는 경우 최소 3개의 라이브 백업 쌍 을 사용하여 네트워크 격리 발생 가능성을 줄일 수 있습니다.
최소 3개의 라이브 백업 쌍을 사용하면 실시간 백업 브로커 쌍에서 복제 중단을 경험할 때 발생하는 쿼럼 투표에서 대부분의 결과를 얻을 수 있습니다.
복제 HA 정책을 사용할 때 몇 가지 추가 고려 사항은 다음과 같습니다.
- 라이브 브로커가 실패하고 백업 전환이 라이브로 전환되면 새 백업 브로커가 라이브에 연결되거나 원래 라이브 브로커에 failback이 발생할 때까지 추가 복제가 발생하지 않습니다.
- 라이브 백업 그룹의 백업 브로커가 실패하면 라이브 브로커는 계속 메시지를 제공합니다. 그러나 다른 브로커가 백업으로 추가되거나 원래 백업 브로커가 다시 시작될 때까지 메시지가 복제되지 않습니다. 이 기간 동안 메시지는 실시간 브로커로만 유지됩니다.
- 실시간 백업 쌍의 두 브로커가 이전에 종료되었지만 이제 다시 시작할 수 있다고 가정합니다. 이 경우 메시지 손실을 방지하려면 가장 최근의 활성 브로커를 먼저 다시 시작해야 합니다. 가장 최근의 활성 브로커가 백업 브로커인 경우 먼저 다시 시작하기 위해 이 브로커를 마스터 브로커로 수동으로 재구성해야 합니다.
16.3.3. 복제 고가용성 구성
HA(복제 고가용성) 정책을 사용하여 브로커 클러스터에서 HA를 구현할 수 있습니다. 복제를 사용하면 라이브 및 백업 브로커 간에 영구 데이터가 동기화됩니다. 라이브 브로커가 실패하는 경우 메시지 데이터는 백업 브로커와 동기화되며 실패한 라이브 브로커에 대해 인수됩니다.
공유 파일 시스템이 없는 경우 공유 저장소에 대한 대안으로 복제를 사용해야 합니다. 그러나 복제를 사용하면 라이브 브로커와 해당 백업이 동시에 작동하는 네트워크 분리가 발생할 수 있습니다.
복제에는 네트워크 격리 위험을 줄일 수 있도록 최소 세 개의 라이브 백업 쌍이 필요합니다.Replication requires at least three live-backup pairs to lessen (but not eliminate) the risk of network isolation. 라이브 백업 브로커 쌍을 3개 이상 사용하면 클러스터에서 쿼럼 투표를 사용하여 두 개의 라이브 브로커가 발생하지 않습니다.
다음 섹션에서는 쿼럼 투표가 작동하는 방법과 3개 이상의 실시간 백업 쌍을 사용하여 브로커 클러스터의 복제 HA를 구성하는 방법을 설명합니다.
실시간 및 백업 브로커가 네트워크를 통해 메시징 데이터를 동기화해야 하므로 복제는 성능 오버헤드를 추가합니다. 이 동기화 프로세스는 저널 작업을 차단하지만 클라이언트를 차단하지는 않습니다. 데이터 동기화를 위해 저널 작업을 차단할 수 있는 최대 시간을 구성할 수 있습니다.
16.3.3.1. 쿼럼 투표 정보
라이브 브로커와 백업이 중단된 복제 연결이 발생하는 경우 쿼럼 투표 프로세스를 구성하여 네트워크 격리(또는 "split brain") 문제를 완화할 수 있습니다. 네트워크 분리 중에 라이브 브로커와 해당 백업이 동시에 활성화될 수 있습니다.
다음 표에서는 AMQ Broker에서 사용하는 두 가지 유형의 쿼럼 투표를 설명합니다.
| 투표 유형 | 설명 | 이니시에이터 | 필수 구성 | 참가자 | 투표 결과에 따른 작업 |
|---|---|---|---|---|---|
| 백업 투표 | 백업 브로커가 라이브 브로커에 대한 복제 연결을 분실하는 경우 백업 브로커는 이 투표의 결과에 따라 시작할지 여부를 결정합니다. | 백업 브로커 | 없음. 백업 브로커가 복제 파트너에 대한 연결이 끊어지면 백업 투표가 자동으로 수행됩니다. 그러나 이러한 매개변수에 사용자 정의 값을 지정하여 백업 투표의 속성을 제어할 수 있습니다.
| 클러스터의 다른 실시간 브로커 | 백업 브로커는 클러스터의 다른 라이브 브로커로부터 대다수(즉, 쿼럼) 투표를 수신하면 시작되며 복제 파트너를 더 이상 사용할 수 없음을 나타냅니다. |
| 라이브 투표 | 라이브 브로커가 복제 파트너에 대한 연결이 끊어지면, 라이브 브로커는 이 투표에 따라 계속 실행할지 여부를 결정합니다. | 실시간 브로커 |
실시간 투표는 라이브 브로커가 복제 파트너에 대한 연결을 잃고 | 클러스터의 다른 실시간 브로커 | 클러스터 연결이 여전히 활성 상태임을 나타내는 클러스터 의 다른 라이브 브로커로부터 대다수의 투표를 받지 못 하면 실시간 브로커가 종료됩니다. |
아래에는 브로커 클러스터 구성이 쿼럼 투표 동작에 미치는 영향에 대한 몇 가지 중요한 사항이 나와 있습니다.
- 쿼럼 투표가 성공하려면 클러스터의 크기를 통해 대부분의 결과를 얻을 수 있어야 합니다. 따라서 복제 HA 정책을 사용하는 경우 클러스터에 3개 이상의 라이브 백업 브로커 쌍이 있어야 합니다.
- 클러스터에 추가하는 라이브 백업 브로커 쌍을 더 많이 사용하면 클러스터의 전반적인 내결함성을 높일 수 있습니다. 예를 들어, 세 개의 라이브 백업 쌍이 있다고 가정합니다. 전체 실시간 백업 쌍이 손실되면 나머지 두 개의 라이브 백업 쌍은 후속 쿼럼 투표에서 대부분의 결과를 얻을 수 없습니다. 이 경우 클러스터에서 추가 복제 중단으로 인해 라이브 브로커가 종료되고 백업 브로커가 시작되지 않을 수 있습니다. 5개 브로커 쌍을 사용하여 클러스터를 구성하면 클러스터에서 두 개 이상의 오류가 발생할 수 있으며 쿼럼 투표로 인한 대부분의 결과를 얻을 수 있습니다.
- 클러스터의 라이브 백업 브로커 쌍 수를 의도적으로 줄이 면 대다수 투표에 대한 이전에 설정된 임계값이 자동으로 감소되지 않습니다. 이 기간 동안 손실된 복제 연결에 의해 트리거된 쿼럼 투표는 성공할 수 없으므로 클러스터가 네트워크 격리에 더 취약합니다. 클러스터에서 쿼럼 투표에 대한 대다수 임계값을 다시 계산하도록 하려면 먼저 클러스터에서 제거 중인 실시간 백업 쌍을 종료합니다. 그런 다음 클러스터에서 나머지 실시간 백업 쌍을 다시 시작합니다. 나머지 브로커를 모두 다시 시작하면 클러스터에서 쿼럼 투표 임계값을 다시 계산합니다.
16.3.3.2. 복제 고가용성을 위한 브로커 클러스터 구성
다음 절차에서는 6-broker 클러스터에 대해 HA(고가용성)를 구성하는 방법을 설명합니다. 이 토폴로지에서는 6개의 브로커가 3개의 라이브 백업 쌍으로 그룹화됩니다. 세 개의 라이브 브로커는 각각 전용 백업 브로커와 연결됩니다.
복제에는 네트워크 격리 위험을 줄일 수 있도록 최소 세 개의 라이브 백업 쌍이 필요합니다.Replication requires at least three live-backup pairs to lessen (but not eliminate) the risk of network isolation.
사전 요구 사항
6개 이상의 브로커가 있는 브로커 클러스터가 있어야 합니다.
6 명의 브로커는 3 개의 라이브 백업 쌍으로 구성됩니다. 클러스터에 브로커를 추가하는 방법에 대한 자세한 내용은 16장. 브로커 클러스터 설정 을 참조하십시오.
절차
클러스터의 브로커를 라이브 백업 그룹으로 그룹화합니다.
대부분의 경우 라이브 백업 그룹은 라이브 브로커와 백업 브로커라는 두 개의 브로커로 구성되어야 합니다. 클러스터에 6개의 브로커가 있는 경우 라이브 백업 그룹 3개가 필요합니다.
하나의 라이브 브로커와 하나의 백업 브로커로 구성된 첫 번째 라이브 백업 그룹을 생성합니다.
-
라이브 브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 실시간 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <master> <check-for-live-server>true</check-for-live-server> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </master> </replication> </ha-policy> ... </core> </configuration>check-for-live-server실시간 브로커가 실패하면 이 속성은 클라이언트가 재시작할 때 클라이언트가 해당 브로커로 장애 조치할지 여부를 제어합니다.
이 속성을
true로 설정하면 이전 장애 조치 후 라이브 브로커가 다시 시작되면 동일한 노드 ID를 사용하여 클러스터에서 다른 브로커를 검색합니다. 라이브 브로커가 동일한 노드 ID로 다른 브로커를 찾는 경우, 이는 라이브 브로커가 실패했을 때 백업 브로커가 성공적으로 시작되었음을 나타냅니다. 이 경우 라이브 브로커는 데이터를 백업 브로커와 동기화합니다. 그런 다음 라이브 브로커는 백업 브로커를 종료하도록 요청합니다. 다음과 같이 백업 브로커가 failback에 대해 구성된 경우 해당 브로커가 종료됩니다. 그런 다음 라이브 브로커는 활성 역할을 다시 시작하고 클라이언트가 다시 연결합니다.주의실시간 브로커에서
check-for-live-server를true로 설정하지 않으면 이전 페일오버 후 실시간 브로커를 다시 시작할 때 중복 메시징 처리가 발생할 수 있습니다. 특히 이 속성이false로 설정된 실시간 브로커를 다시 시작하면 라이브 브로커는 데이터를 백업 브로커와 동기화하지 않습니다. 이 경우 라이브 브로커는 백업 브로커가 이미 처리한 것과 동일한 메시지를 처리하여 중복을 일으킬 수 있습니다.group-name- 이 Live-backup 그룹의 이름입니다. 실시간 백업 그룹을 만들려면 라이브 및 백업 브로커를 동일한 그룹 이름으로 구성해야 합니다.
vote-on-replication-failure이 속성은 라이브 브로커가 중단된 복제 연결 시 실시간 투표라고 하는 쿼럼 투표를 시작하는지 여부를 제어합니다.
실시간 투표는 라이브 브로커가 중단 된 복제 연결의 원인인지 아니면 파트너가 있는지 여부를 결정하는 방법입니다. 투표 결과에 따라 실시간 브로커는 계속 실행 중이거나 종료됩니다.
중요쿼럼 투표가 성공하려면 클러스터의 크기를 통해 대부분의 결과를 얻을 수 있어야 합니다. 따라서 복제 HA 정책을 사용하는 경우 클러스터에 3개 이상의 라이브 백업 브로커 쌍이 있어야 합니다.
클러스터에서 구성하는 브로커 쌍이 많을수록 클러스터의 전체 내결함성을 늘릴 수 있습니다. 예를 들어, 세 개의 라이브 백업 브로커 쌍이 있다고 가정합니다. 전체 실시간 백업 쌍에 대한 연결이 끊어지면 나머지 두 라이브 백업 쌍은 더 이상 쿼럼 투표로 인한 대부분의 결과를 얻을 수 없습니다. 이러한 상황은 후속 복제 중단으로 인해 라이브 브로커가 종료되고 백업 브로커가 시작되지 않을 수 있습니다. 5개 브로커 쌍을 사용하여 클러스터를 구성하면 클러스터에서 두 개 이상의 오류가 발생할 수 있으며 쿼럼 투표로 인한 대부분의 결과를 얻을 수 있습니다.
라이브 브로커에 대한 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다.Therefore, you only need to configure these properties if you do not want the default behavior. 자세한 내용은 부록 F. 복제 고가용성 구성 요소의 내용을 참조하십시오.
-
백업 브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. HA 정책에 복제를 사용하도록 백업(즉, 슬레이브) 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <slave> <allow-failback>true</allow-failback> <restart-backup>true</restart-backup> <group-name>my-group-1</group-name> <vote-on-replication-failure>true</vote-on-replication-failure> ... </slave> </replication> </ha-policy> ... </core> </configuration>allow-failback장애 조치가 발생하고 백업 브로커가 실시간 브로커에 대해 인수한 경우 이 속성은 백업 브로커가 다시 시작되고 클러스터에 다시 연결할 때 백업 브로커가 원래 라이브 브로커로 실패할지 여부를 제어합니다.
참고failback은 실시간 백업 쌍(단일 백업 브로커와 연결된 라이브 브로커)을 위한 것입니다. 라이브 브로커가 여러 백업으로 구성된 경우 failback이 발생하지 않습니다. 대신 장애 조치(failover) 이벤트가 발생하면 백업 브로커가 활성 상태가 되고 다음 백업이 백업됩니다.Instead, if a failover event occurs, the backup broker will become live, and the next backup will become its backup. 원래의 라이브 브로커가 다시 온라인 상태가 되면 현재 활성 상태인 브로커에 백업이 있기 때문에 failback을 시작할 수 없습니다.
restart-backup-
이 속성은 백업 브로커가 라이브 브로커로 다시 실패한 후 자동으로 다시 시작되는지 여부를 제어합니다. 이 속성의 기본값은
true입니다. group-name- 이 백업이 연결해야 하는 라이브 브로커의 그룹 이름입니다. 백업 브로커는 동일한 그룹 이름을 공유하는 라이브 브로커에만 연결됩니다.
vote-on-replication-failure이 속성은 라이브 브로커가 중단된 복제 연결 시 실시간 투표라고 하는 쿼럼 투표를 시작하는지 여부를 제어합니다. 활성 상태가 된 백업 브로커는 실시간 브로커로 간주되며 실시간 투표를 시작할 수 있습니다.
실시간 투표는 라이브 브로커가 중단 된 복제 연결의 원인인지 아니면 파트너가 있는지 여부를 결정하는 방법입니다. 투표 결과에 따라 실시간 브로커는 계속 실행 중이거나 종료됩니다.
(선택 사항) 백업 브로커가 시작하는 쿼럼 투표의 속성을 구성합니다.
<configuration> <core> ... <ha-policy> <replication> <slave> ... <vote-retries>12</vote-retries> <vote-retry-wait>5000</vote-retry-wait> ... </slave> </replication> </ha-policy> ... </core> </configuration>vote-retries- 이 속성은 백업 브로커가 백업 브로커를 시작할 수 있는 대부분의 결과를 수신하기 위해 백업 브로커가 투표를 재시도하는 횟수를 제어합니다.
vote-retry-wait- 이 속성은 쿼럼 투표를 재시도할 때마다 백업 브로커가 대기하는 시간(밀리초)을 제어합니다.
백업 브로커에 대한 추가 HA 속성을 구성합니다.
이러한 추가 HA 속성에는 대부분의 일반적인 사용 사례에 적합한 기본값이 있습니다. 따라서 기본 동작을 원하지 않는 경우에만 이러한 속성을 구성해야 합니다.Therefore, you only need to configure these properties if you do not want the default behavior. 자세한 내용은 부록 F. 복제 고가용성 구성 요소의 내용을 참조하십시오.
-
라이브 브로커의 <
클러스터의 추가 라이브 백업 그룹에 대해 2단계를 반복합니다.
클러스터에 6개의 브로커가 있는 경우 이 절차를 두 번 반복하여 나머지 라이브 백업 그룹에 대해 한 번 더 반복합니다.
추가 리소스
- HA에 복제를 사용하는 브로커 클러스터의 예는 HA 예제 프로그램 을 참조하십시오.
- 노드 ID에 대한 자세한 내용은 노드 ID 이해를 참조하십시오.
16.3.4. 라이브 전용으로 제한된 고가용성 구성
실시간 전용 HA 정책을 사용하면 메시지를 손실하지 않고 클러스터에서 브로커를 종료할 수 있습니다. 실시간 브로커를 정상적으로 중지하면 메시지 및 트랜잭션 상태를 다른 라이브 브로커에 복사한 다음 종료합니다. 그런 다음 클라이언트는 다른 브로커에 다시 연결하여 메시지를 계속 보내고 받을 수 있습니다.
실시간 전용 HA 정책은 브로커가 정상적으로 중지되는 경우에만 처리합니다. 예기치 않은 브로커 오류를 처리하지 않습니다.
실시간 HA는 메시지 손실을 방지하지만 메시지 순서를 유지하지 않을 수 있습니다. 실시간 전용 HA로 구성된 브로커가 중지되면 해당 메시지는 다른 브로커의 대기열 끝에 추가됩니다.
브로커를 축소할 준비가 되면 새 브로커를 처리할 준비가 되어 있는지에 대한 연결이 끊어지기 전에 메시지를 클라이언트에 보냅니다. 그러나 초기 브로커의 확장을 완료한 후에만 클라이언트가 새 브로커에 다시 연결해야 합니다. 이렇게 하면 클라이언트가 다시 연결할 때 큐 또는 트랜잭션과 같은 상태를 다른 브로커에서 사용할 수 있습니다. 일반 다시 연결 설정은 클라이언트가 다시 연결할 때 적용되므로 축소하는 데 필요한 시간을 처리하기에 충분한 높은 값을 설정해야 합니다.
다음 절차에서는 축소하도록 클러스터에서 각 브로커를 구성하는 방법을 설명합니다. 이 절차를 완료하면 브로커가 정상적으로 중지될 때마다 메시지 및 트랜잭션 상태를 클러스터의 다른 브로커에 복사합니다.
절차
-
첫 번째 브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. 실시간 전용 HA 정책을 사용하도록 브로커를 구성합니다.
<configuration> <core> ... <ha-policy> <live-only> </live-only> </ha-policy> ... </core> </configuration>브로커 클러스터를 축소하는 방법을 구성합니다.
이 브로커를 축소해야 하는 브로커 또는 브로커 그룹을 지정합니다.
축소하려면… do this… 클러스터의 특정 브로커
축소할 브로커의 커넥터를 지정합니다.
<live-only> <scale-down> <connectors> <connector-ref>broker1-connector</connector-ref> </connectors> </scale-down> </live-only>클러스터의 모든 브로커
브로커 클러스터의 검색 그룹을 지정합니다.
<live-only> <scale-down> <discovery-group-ref discovery-group-name="my-discovery-group"/> </scale-down> </live-only>특정 브로커 그룹의 브로커
브로커 그룹을 지정합니다.
<live-only> <scale-down> <group-name>my-group-name</group-name> </scale-down> </live-only>- 클러스터의 나머지 각 브로커에 대해 이 절차를 반복합니다.
추가 리소스
- 클러스터를 축소하기 위해 라이브 전용으로 사용하는 브로커 클러스터의 예는 축소된 예제 프로그램 을 참조하십시오.
16.3.5. 복사된 백업을 사용하여 고가용성 구성
실시간 백업 그룹을 구성하는 대신 다른 라이브 브로커와 동일한 JVM에서 백업 브로커를 조정할 수 있습니다. 이 구성에서 각 라이브 브로커는 다른 라이브 브로커를 요청하여 JVM에서 백업 브로커를 생성하고 시작하도록 구성됩니다.
그림 16.4. 라이브 및 백업 브로커

공유 저장소 또는 HA(고가용성) 정책으로 공유 저장소 또는 복제를 사용할 수 있습니다. 새 백업 브로커는 라이브 브로커의 구성을 상속하여 이를 생성합니다. 백업 이름은 co placed _backup_n 으로 설정됩니다. 여기서 n 은 라이브 브로커가 생성한 백업 수입니다.
또한 백업 브로커는 커넥터에 대한 구성을 상속하고 이를 생성하는 라이브 브로커의 수락자를 상속합니다. 기본적으로 100의 포트 오프셋은 각각에 적용됩니다. 예를 들어 라이브 브로커가 포트 61616에 대한 수락자가 있는 경우 생성된 첫 번째 백업 브로커는 포트 61716을 사용하므로 두 번째 백업은 61816을 사용합니다.
저널, 큰 메시지 및 페이징의 디렉터리는 선택한 HA 정책에 따라 설정됩니다. 공유 저장소를 선택하는 경우 요청 브로커는 사용할 디렉터리를 대상 브로커에게 알립니다. 복제를 선택하면 생성되는 브로커에서 디렉터리가 상속되고 새 백업의 이름이 추가됩니다.
이 절차에서는 공유 저장소 HA를 사용하도록 클러스터의 각 브로커를 구성하고 클러스터의 다른 브로커와 함께 백업을 생성하고 공동 배치하도록 요청합니다.
절차
-
첫 번째 브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. HA 정책 및 공동 할당을 사용하도록 브로커를 구성합니다.
이 예에서 브로커는 공유 저장소 HA 및 공동 배치로 구성됩니다.
<configuration> <core> ... <ha-policy> <shared-store> <colocated> <request-backup>true</request-backup> <max-backups>1</max-backups> <backup-request-retries>-1</backup-request-retries> <backup-request-retry-interval>5000</backup-request-retry-interval/> <backup-port-offset>150</backup-port-offset> <excludes> <connector-ref>remote-connector</connector-ref> </excludes> <master> <failover-on-shutdown>true</failover-on-shutdown> </master> <slave> <failover-on-shutdown>true</failover-on-shutdown> <allow-failback>true</allow-failback> <restart-backup>true</restart-backup> </slave> </colocated> </shared-store> </ha-policy> ... </core> </configuration>request-backup-
이 속성을
true로 설정하면 이 브로커는 클러스터의 다른 라이브 브로커에 의해 백업 브로커를 생성하도록 요청합니다. max-backups-
이 브로커가 생성할 수 있는 백업 브로커 수입니다. 이 속성을
0으로 설정하면 이 브로커는 클러스터의 다른 브로커의 백업 요청을 허용하지 않습니다. backup-request-retries-
이 브로커가 생성되도록 백업 브로커를 요청해야 하는 횟수입니다. 기본값은
-1이며 무제한 시도를 의미합니다. backup-request-retry-interval-
백업 브로커를 생성하기 위해 요청을 재시도하기 전에 브로커가 기다려야 하는 시간(밀리초)입니다. 기본값은
5000또는 5초입니다. backup-port-offset-
새 백업 브로커의 수락자 및 커넥터에 사용할 포트 오프셋입니다. 이 브로커가 클러스터에 있는 다른 브로커에 대한 백업을 생성하는 요청을 수신하면 이 양의 포트 오프셋으로 백업 브로커를 생성합니다. 기본값은
100입니다. excludes(선택 사항)-
백업 포트 오프셋에서 커넥터를 제외합니다. 백업 포트 오프셋에서 제외해야 하는 외부 브로커에 대한 커넥터를 구성한 경우 각 커넥터에 <
connector-ref>를 추가합니다. master- 이 브로커에 대한 공유 저장소 또는 복제 장애 조치 구성입니다.
slave- 이 브로커의 백업에 대한 공유 저장소 또는 복제 장애 조치 구성입니다.
- 클러스터의 나머지 각 브로커에 대해 이 절차를 반복합니다.
추가 리소스
- 공동 배치된 백업을 사용하는 브로커 클러스터의 예는 HA 예제 프로그램 을 참조하십시오.
16.3.6. 장애 조치(failover)하도록 클라이언트 구성
브로커 클러스터에서 고가용성을 구성한 후 장애 조치(failover)하도록 클라이언트를 구성합니다. 클라이언트 장애 조치(failover)를 통해 브로커에 연결된 클라이언트가 다운타임을 최소화하여 클러스터의 다른 브로커에 다시 연결할 수 있습니다.
일시적인 네트워크 문제가 발생하는 경우 AMQ Broker는 자동으로 동일한 브로커에 연결을 다시 연결합니다. 이는 클라이언트가 동일한 브로커에 다시 연결하는 경우를 제외하고 장애 조치(failover)와 유사합니다.
다음 두 가지 유형의 클라이언트 장애 조치(failover)를 구성할 수 있습니다.You can configure two different types of client failover:
- 자동 클라이언트 장애 조치
- 클라이언트는 처음 연결할 때 브로커 클러스터에 대한 정보를 수신합니다. 연결된 브로커가 실패하면 클라이언트는 자동으로 브로커의 백업에 다시 연결되고 백업 브로커는 장애 조치 전에 각 연결에 존재했던 세션과 소비자를 다시 만듭니다.
- 애플리케이션 수준 클라이언트 장애 조치
- 자동 클라이언트 장애 조치 대신 실패 처리기에서 자체 사용자 지정 리 연결 논리를 사용하여 클라이언트 애플리케이션을 코딩할 수 있습니다.As an alternative to automatic client failover, you can instead code your client applications with your own custom reconnection logic in a failure handler.
절차
AMQ Core Protocol JMS를 사용하여 자동 또는 애플리케이션 수준 페일오버로 클라이언트 애플리케이션을 구성합니다.
자세한 내용은 AMQ Core Protocol JMS Client 사용을 참조하십시오.
16.4. 메시지 재배포 활성화
브로커 클러스터에서 온디맨드 메시지 부하 분산을 사용하는 경우 메시지를 재배포 하여 메시지를 사용하는 소비자가 없는 큐의 "stuck"이되지 않도록 메시지 재배포를 구성할 수 있습니다.
이 섹션에서는 다음에 대한 정보를 제공합니다.
16.4.1. 메시지 재배포 이해
브로커 클러스터는 로드 밸런싱을 사용하여 클러스터 전체에 메시지 로드를 배포합니다. 클러스터 연결에서 부하 분산을 구성할 때 message-load-balancing 를 ON_DEMAND 로 설정하면 브로커는 소비자와 일치하는 다른 브로커에게만 메시지를 전달합니다. 이 동작을 사용하면 메시지에서 메시지를 사용하는 소비자가 없는 대기열로 이동하지 않습니다. 그러나 메시지가 브로커로 전송된 후 큐에 연결된 소비자가 브로커로 전달되면 해당 메시지는 큐에서 "stuck"되고 사용되지 않습니다. 이 문제는 종종 별명( starvation )이라고 합니다.
메시지 재배포는 소비자가 일치하는 클러스터의 브로커가 없는 큐에서 메시지를 자동으로 다시 배포함으로써 시작할 수 없습니다.
16.4.1.1. 메시지 필터를 사용하여 메시지 재배포의 제한
메시지 재배포 는 소비자가 필터(selector 라고도 함) 사용을 지원하지 않습니다. 필터가 있는 소비자의 일반적인 사용 사례는 상관 관계 ID를 사용하는 요청 시 패턴입니다. 예를 들어 다음 시나리오를 고려하십시오.
-
brokerA및brokerB의 두 브로커 클러스터가 있습니다. 각 브로커는0으로 설정된redistribution-delay로 구성되며ON_DEMAND로 설정된message-load-balancing를 설정합니다. -
brokerA및brokerB에는 각각myQueue라는 큐가 있습니다. -
요청을 기반으로 생산자는
brokerA에서myQueue를 대기열에 전송하도록 라우팅되는 메시지를 보냅니다. 메시지에는myCorrelID라는 상관 관계 ID 속성이 있으며, 값은10입니다. -
소비자가
myCorrelID=5필터를 사용하여brokerA의 큐myQueue에 연결합니다. 이 필터는 메시지의 상관 관계 ID 값과 일치하지 않습니다. 다른 소비자는
myCorrelID=10필터를 사용하여brokerB에서myQueue를 대기열에 연결합니다. 이 필터는 메시지의 상관 관계 ID 값과 일치합니다.이 경우
brokerB에 있는 소비자 필터가 메시지와 일치하더라도myQueue의 소비자가brokerAbrokerB로 재배포 되지 않습니다.
이전 시나리오에서는 요청이 생산자로 전송되기 전에 소비자를 생성하여 의도한 클라이언트가 메시지를 수신하도록 할 수 있습니다. 메시지는 메시지의 상관 관계 ID와 일치하는 필터를 사용하여 사용자에게 즉시 라우팅됩니다. 재배포가 필요하지 않습니다.
추가 리소스
- 클러스터 부하 분산에 대한 자세한 내용은 16.1.1절. “브로커 클러스터에서 메시지 로드의 균형을 조정하는 방법” 을 참조하십시오.
16.4.2. 메시지 재배포 구성
다음 절차에서는 메시지 재배포를 구성하는 방법을 보여줍니다.
절차
-
<
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
cluster-connection> 요소에서 <message-load-balancing>가 <ON_DEMAND>로 설정되어 있는지 확인합니다.<configuration> <core> ... <cluster-connections> <cluster-connection name="my-cluster"> ... <message-load-balancing>ON_DEMAND</message-load-balancing> ... </cluster-connection> </cluster-connections> </core> </configuration><
address-settings> 요소 내에서 큐 또는 큐 세트에 대한 재배포 지연을 설정합니다.이 예에서는
my.queue에 분산된 메시지가 마지막 소비자 종료 후 5000밀리초 후에 재배포됩니다.<configuration> <core> ... <address-settings> <address-setting match="my.queue"> <redistribution-delay>5000</redistribution-delay> </address-setting> </address-settings> ... </core> </configuration>address-setting-
match속성을 메시지를 재배포할 대기열의 이름으로 설정합니다. 브로커 와일드카드 구문을 사용하여 다양한 큐를 지정할 수 있습니다. 자세한 내용은 4.2절. “주소 세트에 주소 설정 적용”의 내용을 참조하십시오. redistribution-delay-
브로커가 클러스터의 다른 브로커에 메시지를 반환하기 전에 이 대기열의 최종 소비자가 닫은 후 기다려야 하는 시간(밀리초)입니다. 이 값을
0으로 설정하면 메시지가 즉시 재배포됩니다. 그러나 일반적으로 반환하기 전에 지연을 설정해야 합니다. 소비자는 일반적으로 동일한 큐에서 빠르게 생성될 수 있습니다.
- 클러스터의 각 추가 브로커에 대해 이 절차를 반복합니다.
추가 리소스
-
메시지를 재배포하는 브로커 클러스터 구성의 예는
queue-message-redistributionAMQ Broker 예제 프로그램 을 참조하십시오.
16.5. 클러스터형 메시지 그룹화 구성
메시지 그룹화를 사용하면 클라이언트가 동일한 소비자에 의해 직렬적으로 특정 유형의 메시지 그룹을 보낼 수 있습니다. 클러스터의 각 브로커에 그룹화 처리기를 추가하면 클라이언트가 클러스터의 모든 브로커에 그룹화된 메시지를 보내고 동일한 소비자가 해당 메시지를 올바른 순서로 사용할 수 있는지 확인합니다.
그룹화 핸들러에는 로컬 핸들러와 원격 핸들러 의 두 가지 유형이 있습니다. 브로커 클러스터는 의도한 소비자가 올바른 순서로 사용할 수 있도록 특정 그룹의 모든 메시지를 적절한 대기열로 라우팅할 수 있습니다.
사전 요구 사항
클러스터의 각 브로커에 하나 이상의 소비자가 있어야 합니다.
메시지가 대기열의 소비자에게 고정되면 동일한 그룹 ID를 가진 모든 메시지가 해당 큐로 라우팅됩니다. 소비자가 제거되면 소비자가 없는 경우에도 큐는 메시지를 계속 수신합니다.
절차
클러스터의 하나의 브로커에서 로컬 처리기를 구성합니다.
고가용성을 사용하는 경우 마스터 브로커여야 합니다.
-
브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core>요소 내에 로컬 처리기를 추가합니다.로컬 처리기는 원격 처리기에 대한 중재자 역할을 합니다. 경로 정보를 저장하고 이를 다른 브로커에게 전달합니다.
<configuration> <core> ... <grouping-handler name="my-grouping-handler"> <type>LOCAL</type> <timeout>10000</timeout> </grouping-handler> ... </core> </configuration>grouping-handler-
name특성을 사용하여 그룹화 처리기의 고유한 이름을 지정합니다. type-
이 값을
LOCAL으로 설정합니다. timeout메시지를 라우팅할 위치에 대한 결정을 내릴 때까지 대기하는 시간(밀리초)입니다. 기본값은 5000밀리초입니다. 라우팅 결정을 내리기 전에 시간 초과에 도달하면 엄격한 메시지 순서를 확인하는 예외가 throw됩니다.
브로커가 그룹 ID를 사용하여 메시지를 수신하면 소비자가 연결된 큐에 대한 경로를 제안합니다. 클러스터의 다른 브로커의 그룹화 핸들러에서 경로를 허용하는 경우 경로가 설정됩니다. 클러스터의 모든 브로커는 이 그룹 ID를 사용하여 해당 큐로 메시지를 전달합니다. 브로커의 경로 제안이 거부되면 경로가 수락될 때까지 프로세스를 반복하여 대체 경로를 제안합니다.
-
브로커의 <
고가용성을 사용하는 경우 로컬 처리기 구성을 마스터 브로커의 슬레이브 브로커에 복사합니다.
로컬 처리기 구성을 슬레이브 브로커에 복사하면 로컬 처리기에 대한 단일 실패 지점이 방지됩니다.
클러스터의 나머지 각 브로커에서 원격 핸들러를 구성합니다.
-
브로커의 <
broker-instance-dir> /etc/broker.xml구성 파일을 엽니다. <
core>요소 내에 원격 처리기를 추가합니다.<configuration> <core> ... <grouping-handler name="my-grouping-handler"> <type>REMOTE</type> <timeout>5000</timeout> </grouping-handler> ... </core> </configuration>grouping-handler-
name특성을 사용하여 그룹화 처리기의 고유한 이름을 지정합니다. type-
이 값을
REMOTE(REMOTE)로 설정합니다. timeout- 메시지를 라우팅할 위치에 대한 결정을 내릴 때까지 대기하는 시간(밀리초)입니다. 기본값은 5000밀리초입니다. 이 값을 로컬 처리기 값의 절반 이상으로 설정합니다.
-
브로커의 <
추가 리소스
-
메시지 그룹화를 위해 구성
된 브로커 클러스터의 예는 클러스터형 그룹화 AMQ Broker 예제 프로그램을참조하십시오.
16.6. 브로커 클러스터에 클라이언트 연결
AMQ JMS 클라이언트를 사용하여 클러스터에 연결할 수 있습니다. JMS를 사용하면 브로커 목록을 동적으로 또는 정적으로 검색하도록 메시징 클라이언트를 구성할 수 있습니다. 또한 클러스터 간 연결에서 생성된 클라이언트 세션을 배포하도록 클라이언트 측 부하 분산을 구성할 수도 있습니다.
절차
AMQ Core Protocol JMS를 사용하여 브로커 클러스터에 연결하도록 클라이언트 애플리케이션을 구성합니다.
자세한 내용은 AMQ Core Protocol JMS Client 사용을 참조하십시오.
17장. 다중 사이트 내결함성 메시징 시스템 구성
대규모 엔터프라이즈 메시징 시스템에는 일반적으로 지리적으로 분산된 데이터 센터에 있는 개별 브로커 클러스터가 있습니다. 데이터 센터 중단 시 시스템 관리자는 기존 메시징 데이터를 유지하고 클라이언트 애플리케이션이 계속 메시지를 생성 및 사용할 수 있도록 해야 할 수도 있습니다. 특정 브로커 토폴로지 및 Red Hat Ceph Storage 소프트웨어 정의 스토리지 플랫폼을 사용하여 데이터 센터가 중단되는 동안 메시징 시스템의 연속성을 보장할 수 있습니다. 이러한 유형의 솔루션을 다중 사이트 내결함성 아키텍처라고 합니다.
다음 섹션에서는 데이터 센터 정전으로부터 메시징 시스템을 보호하는 방법에 대해 설명합니다. 다음 섹션에서는 다음에 대한 정보를 제공합니다.
다중 사이트 내결함성은 데이터 센터 내에서 HA(고가용성) 브로커 중복을 대체하지 않습니다. 실시간 백업 그룹을 기반으로 하는 브로커 중복은 단일 클러스터 내에서 단일 브로커 실패에 대한 자동 보호를 제공합니다. 반면 다중 사이트 내결함성은 대규모 데이터 센터 중단으로부터 보호합니다.
Red Hat Ceph Storage를 사용하여 메시징 시스템의 지속성을 보장하려면 공유 저장소 HA(고가용성) 정책을 사용하도록 브로커를 구성해야 합니다. 복제 HA 정책을 사용하도록 브로커를 구성할 수 없습니다. 이러한 정책에 대한 자세한 내용은 고가용성 구현을 참조하십시오.
17.1. Red Hat Ceph Storage 클러스터의 작동 방식
Red Hat Ceph Storage는 클러스터형 오브젝트 스토리지 시스템입니다. Red Hat Ceph Storage는 개체 및 정책 기반 복제의 데이터 분할을 사용하여 데이터 무결성 및 시스템 가용성을 보장합니다.
Red Hat Ceph Storage는 CRUSH(Controlled Replication Under scalable Hashing)라는 알고리즘을 사용하여 데이터 스토리지 위치를 자동으로 계산하여 데이터를 저장하고 검색하는 방법을 결정합니다. CRUSH 맵 이라는 Ceph 항목을 구성합니다. 이 항목은 클러스터의 정보를 자세히 설명하고 스토리지 클러스터에서 데이터가 복제되는 방식을 지정합니다.
CRUSH 맵에는 장치를 장애 도메인 계층 구조로 집계하기 위한 'buckets' 목록, CRUSH가 Ceph 클러스터의 풀에서 데이터를 복제할 수 있는 규칙 목록이 포함되어 있습니다.
설치의 기본 물리적 조직을 반영함으로써 CRUSH 맵은 모델링할 수 있으며 이를 통해 물리적 근접성, 공유 전원 소스 및 공유 네트워크와 같은 상관 관계가 있는 장치 오류의 잠재적인 소스를 처리할 수 있습니다. CRUSH는 이 정보를 클러스터 맵으로 인코딩하여 서로 다른 장애 도메인(예: 데이터 센터)에서 개체 복제본을 분리할 수 있으며 스토리지 클러스터에서 데이터의 의사 임의 배포를 유지 관리할 수 있습니다. 이를 통해 데이터 손실을 방지하고 클러스터가 성능이 저하된 상태에서 작동할 수 있습니다.
Red Hat Ceph Storage 클러스터에는 여러 노드(실제 또는 가상)가 필요합니다. 클러스터에는 다음 유형의 노드가 포함되어야 합니다.
노드 모니터링
각 모니터(MON) 노드는 모니터 데몬(ceph-mon)을 실행하여 클러스터 맵의 마스터 사본을 유지 관리합니다. 클러스터 맵에는 클러스터 토폴로지가 포함됩니다. Ceph 클러스터에 연결하는 클라이언트는 모니터에서 클러스터 맵의 현재 사본을 검색하므로 클라이언트가 클러스터에서 데이터를 읽고 쓸 수 있습니다.
Red Hat Ceph Storage 클러스터는 모니터 노드 1개로 실행될 수 있지만 프로덕션 클러스터에서 고가용성을 보장하기 위해 Red Hat은 모니터 노드가 3개 이상 있는 배포만 지원합니다. 최소 3개의 모니터 노드는 하나의 모니터가 실패하거나 하나만 사용할 수 없는 경우 클러스터의 나머지 모니터 노드에 쿼럼이 존재하여 새 리더를 선택합니다.
Manager 노드
각 Manager(MGR) 노드는 Ceph Manager 데몬(ceph-mgr)을 실행하여 스토리지 사용률, 현재 성능 지표 및 시스템 로드를 포함하여 런타임 지표 및 Ceph 클러스터의 현재 상태를 추적합니다. 일반적으로 Manager 노드는 모니터 노드와 함께 동일한 호스트 시스템에 배치(즉, 동일한 호스트 시스템에) 배치됩니다.
Object Storage 장치 노드
각 OSD(오브젝트 스토리지 장치) 노드는 노드에 연결된 논리 디스크와 상호 작용하는 Ceph OSD 데몬(ceph-osd)을 실행합니다. Ceph는 OSD 노드에 데이터를 저장합니다. Ceph는 매우 적은 수의 OSD 노드(기본값은 3개임)로 실행할 수 있지만, 스토리지 클러스터에서는 스토리지 클러스터에서 OSD가 50개인 모드 확장 시 성능이 향상됩니다. 스토리지 클러스터에 여러 개의 OSD가 있으면 시스템 관리자가 CRUSH 맵 내에서 격리된 장애 도메인을 정의할 수 있습니다.
메타데이터 서버 노드
각 메타데이터 서버(MDS) 노드는 MDS 데몬(ceph-mds)을 실행하여 Ceph 파일 시스템(CephFS)에 저장된 파일과 관련된 메타데이터를 관리합니다. MDS 데몬은 공유 클러스터에 대한 액세스도 조정합니다.
추가 리소스
Red Hat Ceph Storage에 대한 자세한 내용은 Red Hat Ceph Storage란 무엇입니까?
17.2. Red Hat Ceph Storage 설치
AMQ Broker 다중 사이트, 내결함성 아키텍처는 Red Hat Ceph Storage 3을 사용합니다. Red Hat Ceph Storage 클러스터는 데이터 센터에서 데이터를 복제하여 별도의 데이터 센터에서 브로커에 사용할 수 있는 공유 저장소를 효과적으로 생성합니다. 공유 저장소 HA(고가용성) 정책을 사용하고 Red Hat Ceph Storage 클러스터에 메시징 데이터를 저장하도록 브로커를 구성합니다.
프로덕션 환경에서 사용하기 위한 Red Hat Ceph Storage 클러스터의 최소 수는 다음과 같습니다.
- 3개의 모니터(MON) 노드
- 3개의 Manager (MGR) 노드
- 여러 OSD 데몬을 포함하는 OSD(오브젝트 스토리지 장치) 노드 3개
- 3개의 메타데이터 서버(MDS) 노드
동일한 또는 별도의 물리적 또는 가상 시스템에서 OSD, MON, MGR 및 MDS 노드를 실행할 수 있습니다. 그러나 Red Hat Ceph Storage 클러스터 내에서 내결함성을 보장하기 위해 이러한 각 유형의 노드를 별도의 데이터 센터에 배포하는 것이 좋습니다. 특히 단일 데이터 센터 중단 시 스토리지 클러스터에 최소 두 개의 MON 노드가 있는지 확인해야 합니다. 따라서 클러스터에 3개의 MON 노드가 있는 경우 이러한 각 노드는 별도의 데이터 센터의 개별 호스트 시스템에서 실행되어야 합니다. 이 데이터 센터에 오류가 발생하면 스토리지 클러스터가 남아 있는 MON 노드가 하나뿐이므로 단일 데이터 센터에서 MON 노드 두 개를 실행하지 마십시오. 이 경우 스토리지 클러스터가 더 이상 작동할 수 없습니다.
이 섹션의 프로시저는 MON, MGR, OSD 및 MDS 노드를 포함하는 Red Hat Ceph Storage 3 클러스터를 설치하는 방법을 보여줍니다.
사전 요구 사항
Red Hat Ceph Storage 설치 준비에 대한 자세한 내용은 다음을 참조하십시오.
절차
MON, MGR, OSD 및 MDS 노드가 포함된 Red Hat Ceph 3 스토리지 클러스터를 설치하는 방법을 보여주는 절차는 다음을 참조하십시오.
17.3. Red Hat Ceph Storage 클러스터 구성
다음 예제 절차에서는 내결함성을 위해 Red Hat Ceph 스토리지 클러스터를 구성하는 방법을 보여줍니다. CRUSH 버킷을 생성하여 OSD(오브젝트 스토리지 장치) 노드를 실제 설치를 반영하는 데이터 센터로 집계합니다. 또한 CRUSH에게 스토리지 풀의 데이터를 복제하는 방법을 알려주는 규칙을 만듭니다. 이 단계에서는 Ceph 설치에 의해 생성된 기본 CRUSH 맵을 업데이트합니다.
사전 요구 사항
- 이미 Red Hat Ceph Storage 클러스터가 설치되어 있습니다. 자세한 내용은 Red Hat Ceph Storage 설치 를 참조하십시오.
- Red Hat Ceph Storage에서 PG(배치 그룹)를 사용하여 풀에 대량의 데이터 오브젝트를 구성하는 방법과 풀에 사용할 PG 수를 계산하는 방법을 이해해야 합니다. 자세한 내용은 PG (배치 그룹)를 참조하십시오.
- 풀에서 오브젝트 복제본 수를 설정하는 방법을 이해해야 합니다. 자세한 내용은 오브젝트 복제본 수를 설정합니다.
절차
CRUSH 버킷을 생성하여 OSD 노드를 구성합니다. 버킷은 데이터 센터와 같은 물리적 위치를 기반으로 하는 OSD 목록입니다. Ceph에서 이러한 물리적 위치를 장애 도메인 이라고 합니다.
ceph osd crush add-bucket dc1 datacenter ceph osd crush add-bucket dc2 datacenter
OSD 노드의 호스트 시스템을 생성한 데이터 센터 CRUSH 버킷으로 이동합니다. 호스트 이름
host1-host4를 호스트 시스템의 이름으로 바꿉니다.ceph osd crush move host1 datacenter=dc1 ceph osd crush move host2 datacenter=dc1 ceph osd crush move host3 datacenter=dc2 ceph osd crush move host4 datacenter=dc2
생성한 CRUSH 버킷이
기본CRUSH 트리의 일부인지 확인합니다.ceph osd crush move dc1 root=default ceph osd crush move dc2 root=default
데이터 센터에서 스토리지 오브젝트 복제본을 매핑하는 규칙을 생성합니다. 이를 통해 데이터 손실을 방지하고 단일 데이터 센터 중단 시 클러스터의 실행을 유지할 수 있습니다.
규칙을 생성하는 명령은 다음 구문을 사용합니다.
ceph osd crush 규칙 create-replicated <rule-name> <root> <failure-domain> <class>. 예는 다음과 같습니다.ceph osd crush rule create-replicated multi-dc default datacenter hdd
참고이전 명령에서 스토리지 클러스터가 SSD(솔리드 스테이트 드라이브)를 사용하는 경우
hdd(하드 디스크 드라이브) 대신ssd를 지정합니다.생성한 규칙을 사용하도록 Ceph 데이터 및 메타데이터 풀을 구성합니다. 처음에 이 경우 CRUSH 알고리즘에 의해 결정된 스토리지 대상에 데이터가 다시 입력될 수 있습니다.
ceph osd pool set cephfs_data crush_rule multi-dc ceph osd pool set cephfs_metadata crush_rule multi-dc
메타데이터 및 데이터 풀의 PG(배치 그룹) 수 및 PG(배치 그룹) 수를 지정합니다. PGP 값은 PG 값과 같아야 합니다.
ceph osd pool set cephfs_metadata pg_num 128 ceph osd pool set cephfs_metadata pgp_num 128 ceph osd pool set cephfs_data pg_num 128 ceph osd pool set cephfs_data pgp_num 128
데이터 및 메타데이터 풀에서 사용할 복제본 수를 지정합니다.
ceph osd pool set cephfs_data min_size 1 ceph osd pool set cephfs_metadata min_size 1 ceph osd pool set cephfs_data size 2 ceph osd pool set cephfs_metadata size 2
다음 그림은 이전 예제 프로시저에서 생성한 Red Hat Ceph Storage 클러스터를 보여줍니다. 스토리지 클러스터에는 데이터 센터에 해당하는 CRUSH 버킷으로 구성된 OSD가 있습니다.
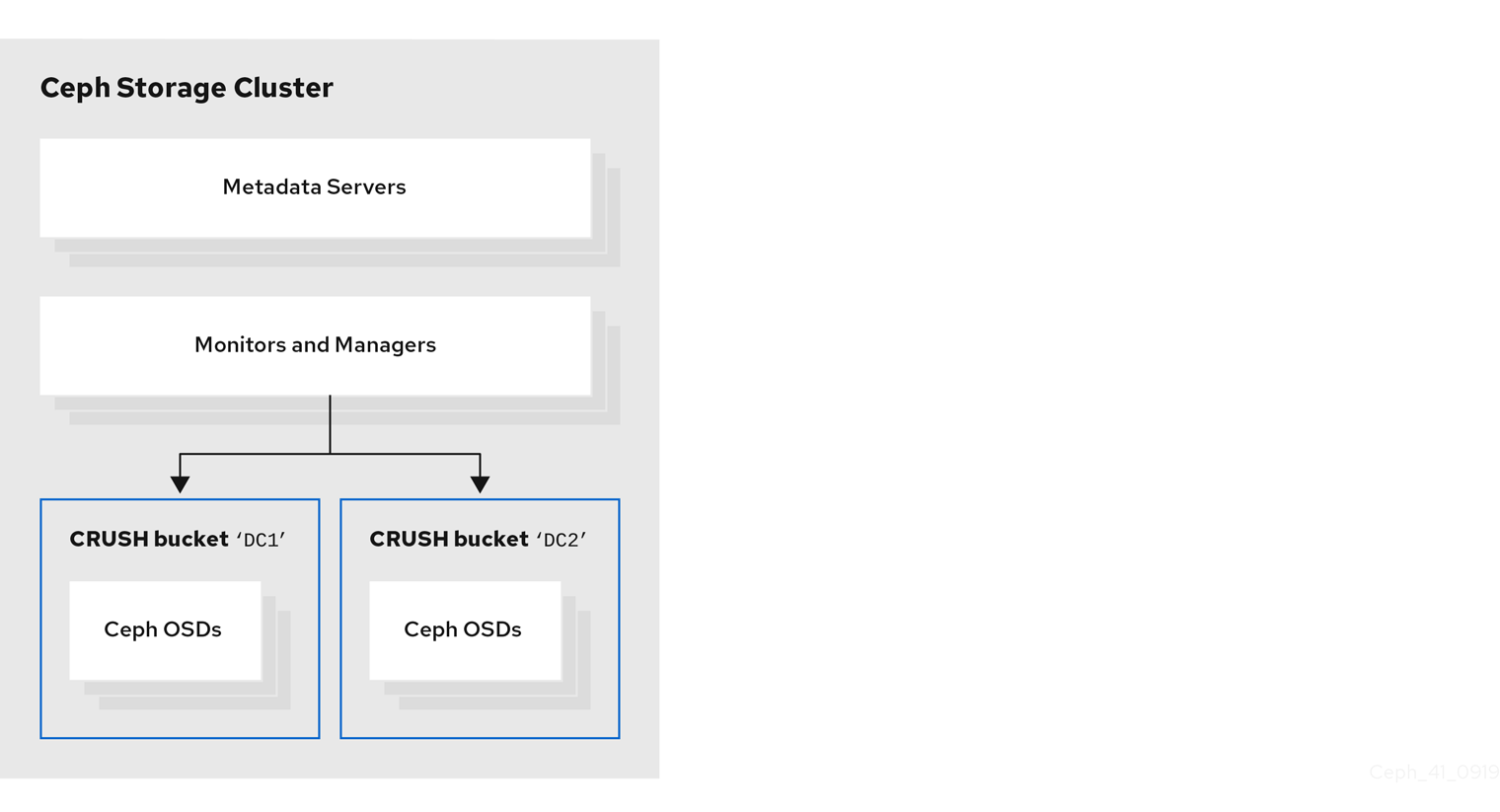
다음 그림은 브로커 서버를 포함하여 첫 번째 데이터 센터의 가능한 레이아웃을 보여줍니다. 특히 데이터 센터 호스트:
- 두 개의 라이브 백업 브로커 쌍의 서버
- 이전 프로세스의 첫 번째 데이터 센터에 할당한 OSD 노드
- 단일 메타데이터 서버, 모니터 및 관리자 노드. 모니터 및 관리자 노드는 일반적으로 동일한 컴퓨터에 배치됩니다.
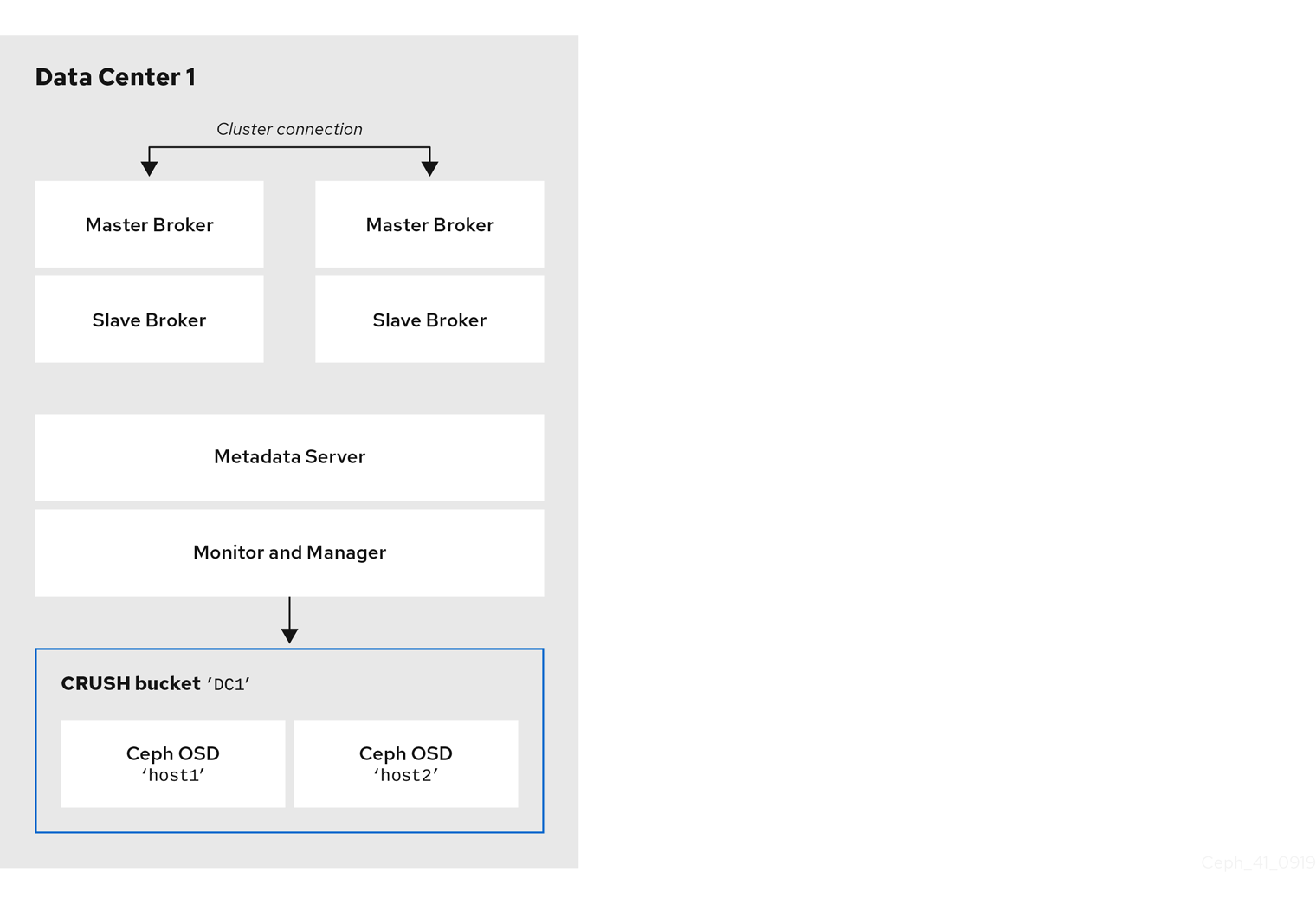
동일한 또는 별도의 물리적 또는 가상 시스템에서 OSD, MON, MGR 및 MDS 노드를 실행할 수 있습니다. 그러나 Red Hat Ceph Storage 클러스터 내에서 내결함성을 보장하기 위해 이러한 각 유형의 노드를 별도의 데이터 센터에 배포하는 것이 좋습니다. 특히 단일 데이터 센터 중단 시 스토리지 클러스터에 최소 두 개의 MON 노드가 있는지 확인해야 합니다. 따라서 클러스터에 3개의 MON 노드가 있는 경우 이러한 각 노드는 별도의 데이터 센터의 개별 호스트 시스템에서 실행되어야 합니다.
다음 그림은 전체 예제 토폴로지를 보여줍니다. 스토리지 클러스터에서 내결함성을 보장하기 위해 MON, MGR 및 MDS 노드가 세 개의 개별 데이터 센터에 배포됩니다.
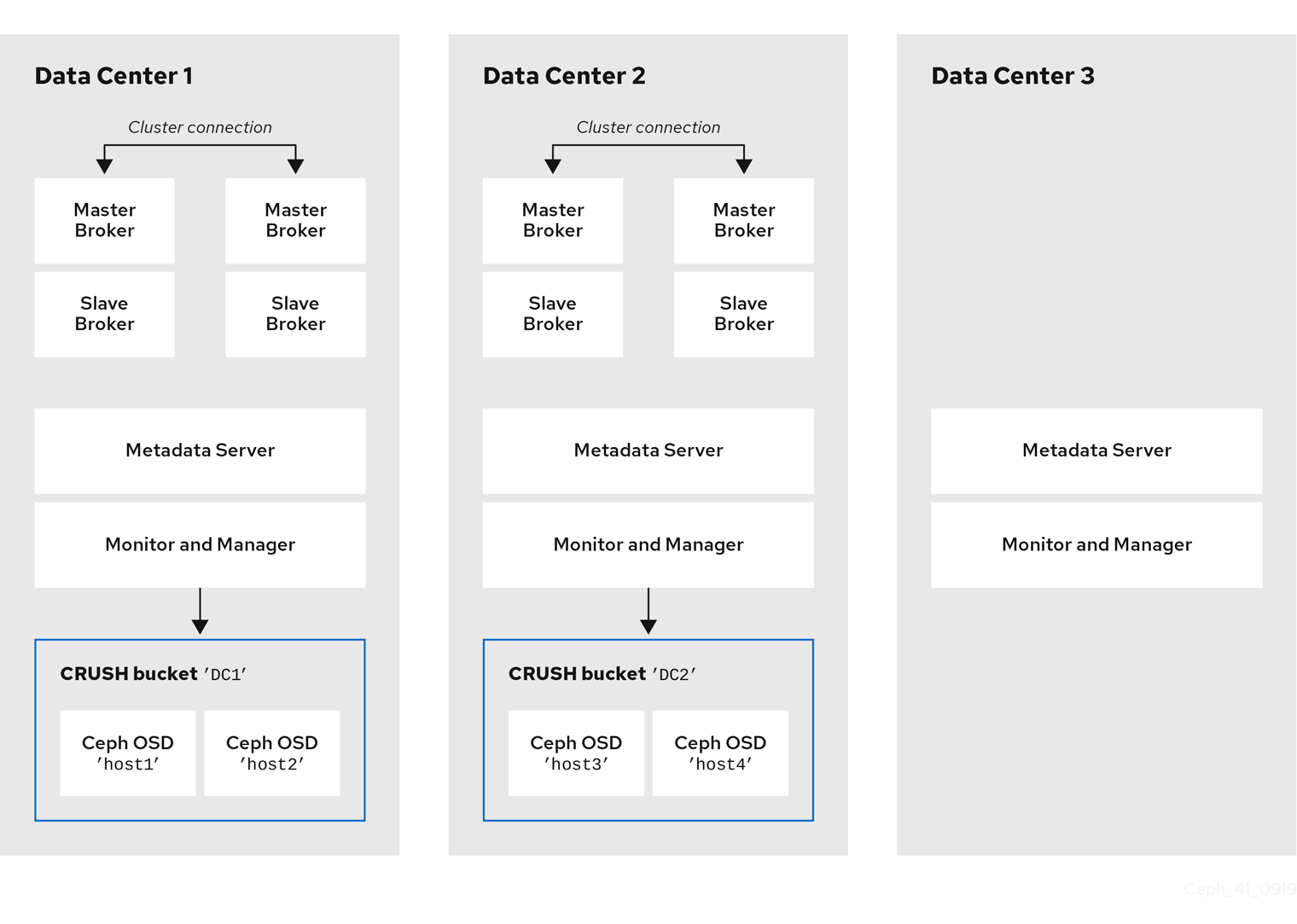
브로커 서버와 동일한 데이터 센터에서 특정 OSD 노드의 호스트 시스템을 검색하면 해당 특정 OSD 노드에 메시징 데이터를 저장하는 것은 아닙니다. Ceph 파일 시스템의 지정된 디렉터리에 메시징 데이터를 저장하도록 브로커를 구성합니다. 그런 다음 클러스터의 Metadata Server 노드는 데이터 센터에서 사용 가능한 모든 OSD에 저장된 데이터를 배포하고 데이터 센터 간에 이 데이터의 복제를 처리하는 방법을 결정합니다. 다음 섹션에서는 Ceph 파일 시스템에 메시징 데이터를 저장하도록 브로커를 구성하는 방법을 보여줍니다.
아래 그림은 브로커 서버가 있는 두 데이터 센터 간 데이터 복제를 보여줍니다.

추가 리소스
다음에 대한 자세한 내용은 다음을 수행합니다.
- Red Hat Ceph Storage 클러스터에 대한 CRUSH 관리 내용은 CRUSH 관리를 참조하십시오.
- 스토리지 풀에 설정할 수 있는 전체 특성 세트는 풀 값을 참조하십시오.
17.4. 브로커 서버에 Ceph 파일 시스템 마운트
메시징 시스템에서 브로커를 구성하여 Red Hat Ceph Storage 클러스터에 메시징 데이터를 저장하기 전에 먼저 Ceph 파일 시스템(CephFS)을 마운트해야 합니다.
이 섹션의 링크 절차에서는 브로커 서버에 CephFS를 마운트하는 방법을 보여줍니다.
사전 요구 사항
현재 위치:
- Red Hat Ceph Storage 클러스터 설치 및 구성. 자세한 내용은 Red Hat Ceph Storage 설치 및 Red Hat Ceph Storage 클러스터 구성을 참조하십시오.
-
3개 이상의 Ceph Metadata Server 데몬(
ceph-mds)을 설치하고 구성합니다. 자세한 내용은 메타데이터 서버 설치 및 메타데이터 서버 데몬 구성을 참조하십시오. - 모니터 노드에서 Ceph 파일 시스템을 생성합니다. 자세한 내용은 Ceph 파일 시스템 생성을 참조하십시오.
- 브로커 서버가 권한 있는 액세스에 사용할 수 있는 키를 사용하여 Ceph File System 클라이언트 사용자를 생성했습니다. 자세한 내용은 Ceph File System Client 사용자 생성 을 참조하십시오.
절차
브로커 서버에 Ceph 파일 시스템을 마운트하는 방법은 Ceph 파일 시스템 마운트를 커널 클라이언트로 참조하십시오.
17.5. 다중 사이트 내결함성 메시징 시스템에서 브로커 구성
브로커를 다중 사이트 내결함성 메시징 시스템의 일부로 구성하려면 다음을 수행해야 합니다.
17.5.1. 백업 브로커 추가
각 데이터 센터 내에서 데이터 센터 중단 시 종료되는 라이브 마스터-슬레이브 브로커 그룹에서 수행할 수 있는 유휴 백업 브로커를 추가해야 합니다. 유휴 백업 브로커에서 라이브 마스터 브로커의 구성을 복제해야 합니다. 기존 브로커와 동일한 방식으로 클라이언트 연결을 허용하도록 백업 브로커를 구성해야 합니다.
이후 절차에서는 기존 master-slave 브로커 그룹에 참여하도록 유휴 백업 브로커를 구성하는 방법을 확인합니다. 별도의 데이터 센터에서 라이브 마스터-슬레이브 브로커 그룹의 유휴 백업 브로커를 찾아야 합니다. 또한 유휴 백업 브로커를 데이터 센터 실패 시에만 수동으로 시작하는 것이 좋습니다.
다음 그림은 토폴로지 예를 보여줍니다.
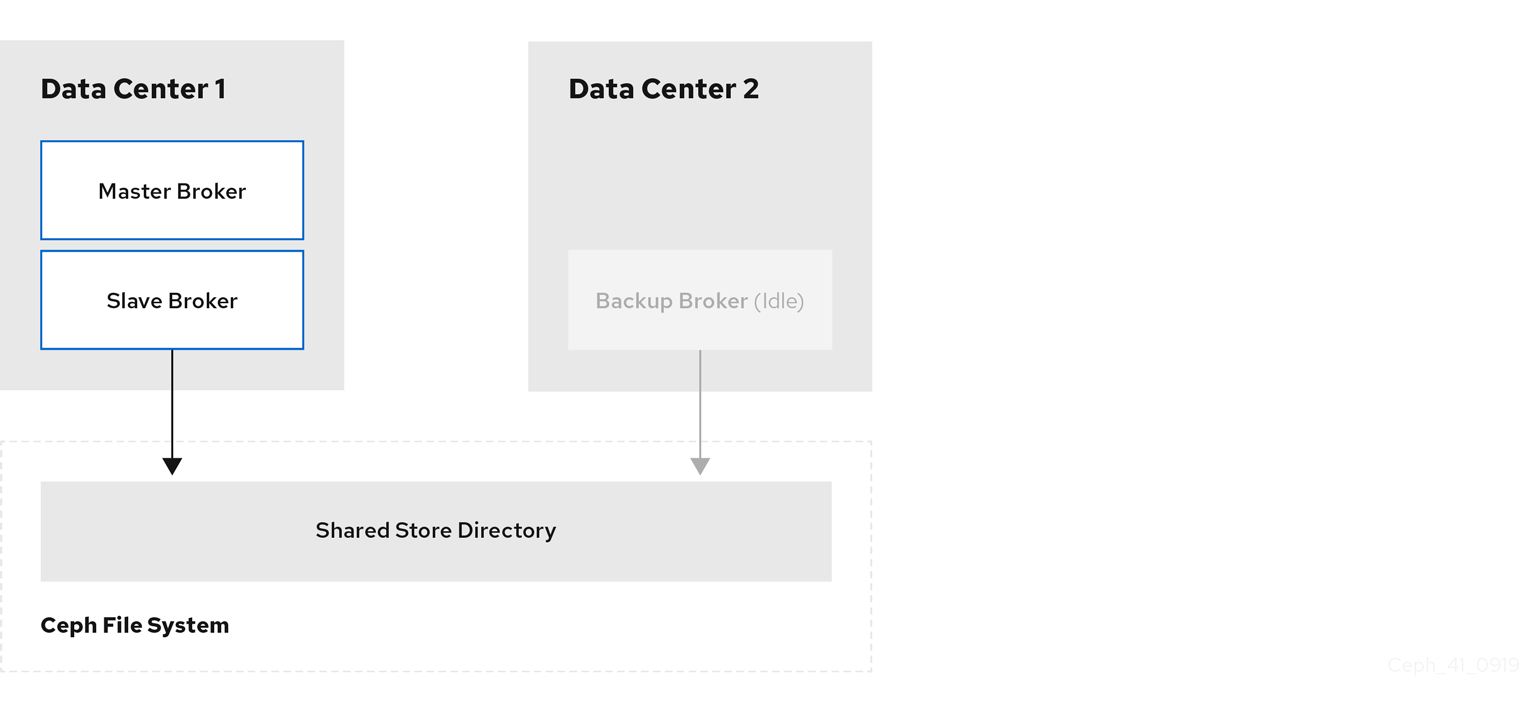
추가 리소스
- 추가 브로커 인스턴스를 생성하는 방법을 알아보려면 독립 실행형 브로커 생성을 참조하십시오.
- 브로커 네트워크 연결 구성에 대한 자세한 내용은 네트워크 연결: 수락자 및 커넥터를 참조하십시오.
17.5.2. 브로커를 Ceph 클라이언트로 구성
내결함성 시스템에 필요한 백업 브로커를 추가한 경우 Ceph 클라이언트 역할을 사용하여 모든 브로커 서버를 구성해야 합니다. 클라이언트 역할을 사용하면 브로커가 Red Hat Ceph Storage 클러스터에 데이터를 저장할 수 있습니다.
Ceph 클라이언트를 구성하는 방법에 대한 자세한 내용은 Ceph 클라이언트 역할 설치를 참조하십시오.
17.6. 다중 사이트 내결함성 메시징 시스템에서 클라이언트 구성
내부 클라이언트 애플리케이션은 브로커 서버와 동일한 데이터 센터에 있는 시스템에서 실행 중인 애플리케이션입니다. 다음 그림은 이 토폴로지를 보여줍니다.
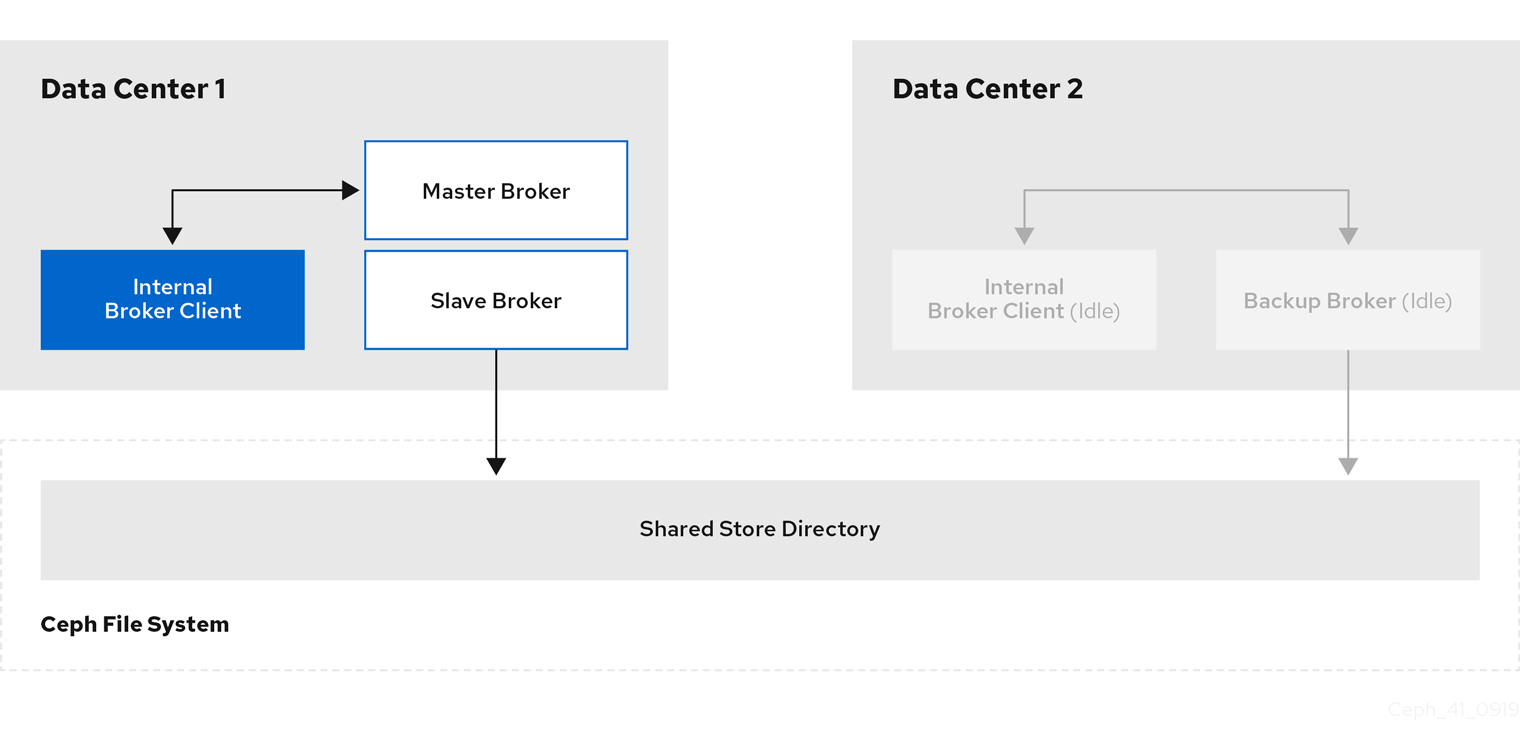
외부 클라이언트 애플리케이션은 브로커 데이터 센터 외부에 있는 시스템에서 실행 중인 것입니다. 다음 그림은 이 토폴로지를 보여줍니다.
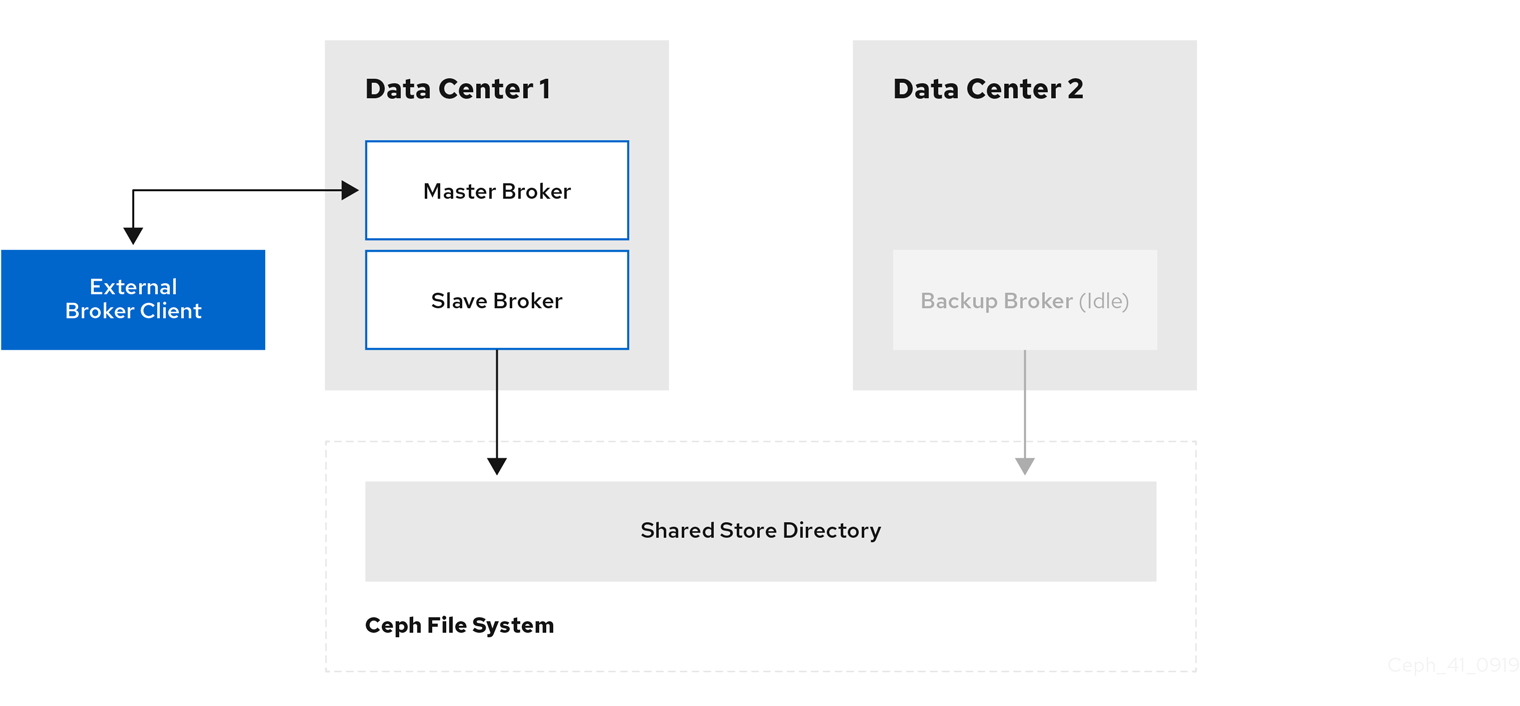
다음 하위 섹션에서는 데이터 센터 중단 시 다른 데이터 센터의 백업 브로커에 연결하도록 내부 및 외부 클라이언트 애플리케이션을 구성하는 방법을 보여줍니다.
17.6.1. 내부 클라이언트 구성
데이터 센터 중단이 발생하면 내부 클라이언트 애플리케이션이 브로커와 함께 종료됩니다. 이러한 상황을 완화하려면 별도의 데이터 센터에서 클라이언트 애플리케이션의 다른 인스턴스를 사용할 수 있어야 합니다. 데이터 센터 중단이 발생하는 경우 백업 클라이언트를 수동으로 시작하여 수동으로 시작한 백업 브로커에 연결합니다.
백업 클라이언트가 백업 브로커에 연결할 수 있도록 하려면 기본 데이터 센터의 클라이언트와 유사하게 클라이언트 연결을 구성해야 합니다.
예제
마스터-슬레이브 브로커 그룹에 대한 AMQ Core Protocol JMS 클라이언트에 대한 기본 연결 구성은 다음과 같습니다. 이 예제에서 host1 및 host2 는 마스터 및 슬레이브 브로커의 호스트 서버입니다.
<ConnectionFactory connectionFactory = new ActiveMQConnectionFactory(“(tcp://host1:port,tcp://host2:port)?ha=true&retryInterval=100&retryIntervalMultiplier=1.0&reconnectAttempts=-1”);
데이터 센터 중단 시 백업 브로커에 연결하도록 백업 클라이언트를 구성하려면 유사한 연결 구성을 사용하지만 백업 브로커 서버의 호스트 이름만 지정합니다. 이 예에서 백업 브로커 서버는 host3입니다.
<ConnectionFactory connectionFactory = new ActiveMQConnectionFactory(“(tcp://host3:port)?ha=true&retryInterval=100&retryIntervalMultiplier=1.0&reconnectAttempts=-1”);
추가 리소스
브로커 및 클라이언트 네트워크 연결 구성에 대한 자세한 내용은 다음을 참조하십시오.
17.6.2. 외부 클라이언트 구성
외부 브로커 클라이언트가 데이터 센터 중단 시 메시징 데이터를 계속 생성하거나 사용할 수 있도록 하려면 다른 데이터 센터의 브로커로 장애 조치하도록 클라이언트를 구성해야 합니다. 다중 사이트 내결함성 시스템의 경우 중단 시 수동으로 시작하는 백업 브로커로 장애 조치하도록 클라이언트를 구성합니다.
예제
다음은 기본 마스터-슬레이브 그룹을 사용할 수 없는 경우 백업 브로커로 장애 조치하도록 AMQ Core Protocol JMS 및 AMQP JMS 클라이언트를 구성하는 예입니다. 이 예제에서 host1 및 host2 는 기본 마스터 및 슬레이브 브로커를 위한 호스트 서버이고 host3 는 데이터 센터 중단 시 수동으로 시작하는 백업 브로커의 호스트 서버입니다.
AMQ Core Protocol JMS 클라이언트를 구성하려면 클라이언트가 연결을 시도하는 브로커 목록에 백업 브로커를 포함합니다.
<ConnectionFactory connectionFactory = new ActiveMQConnectionFactory(“(tcp://host1:port,tcp://host2:port,tcp://host3:port)?ha=true&retryInterval=100&retryIntervalMultiplier=1.0&reconnectAttempts=-1”);
AMQP JMS 클라이언트를 구성하려면 클라이언트에서 구성하는 페일오버 URI에 백업 브로커를 포함합니다.
failover:(amqp://host1:port,amqp://host2:port,amqp://host3:port)?jms.clientID=foo&failover.maxReconnectAttempts=20
추가 리소스
장애 조치 구성에 대한 자세한 내용은 다음을 수행합니다.
- AMQ Core Protocol JMS 클라이언트는 연결 및 장애 조치(failover) 를 참조하십시오.
- AMQP JMS 클라이언트는 장애 조치(failover) 옵션 을 참조하십시오.
- 기타 지원되는 클라이언트는 Red Hat AMQ 7.8 제품 문서의 AMQ Clients 섹션에 있는 클라이언트 관련 설명서를 참조하십시오.
17.7. 데이터 센터 중단 중 스토리지 클러스터 상태 확인
내결함성을 위해 Red Hat Ceph Storage 클러스터를 구성한 경우 데이터 센터 중 하나가 실패하는 경우에도 클러스터가 데이터 손실 없이 성능이 저하된 상태로 계속 실행됩니다.
다음 절차에서는 성능이 저하된 상태에서 클러스터 상태를 확인하는 방법을 보여줍니다.
절차
Ceph 스토리지 클러스터의 상태를 확인하려면
health또는status명령을 사용합니다.# ceph health # ceph status
명령줄에서 클러스터의 진행 중인 이벤트를 보려면 새 터미널을 엽니다. 다음으로 다음을 입력합니다.
# ceph -w
이전 명령을 실행하는 경우 스토리지 클러스터가 여전히 실행 중이지만 성능이 저하되었음을 나타내는 출력이 표시됩니다. 특히 다음과 유사한 경고가 표시됩니다.
health: HEALTH_WARN
2 osds down
Degraded data redundancy: 42/84 objects degraded (50.0%), 16 pgs unclean, 16 pgs degraded추가 리소스
- Red Hat Ceph Storage 클러스터의 상태를 모니터링하는 방법에 대한 자세한 내용은 모니터링 을 참조하십시오.
17.8. 데이터 센터 중단 중 메시징 연속성 유지
다음 절차에서는 데이터 센터 중단 중에 클라이언트가 브로커 및 관련 메시징 데이터를 사용할 수 있도록 유지하는 방법을 보여줍니다. 특히 데이터 센터에 실패하는 경우 다음을 수행해야 합니다.
- 실패한 데이터 센터의 브로커에서 복구하도록 생성한 유휴 백업 브로커를 수동으로 시작합니다.
- 내부 또는 외부 클라이언트를 새 활성 브로커에 연결합니다.
사전 요구 사항
다음이 있어야 합니다.
- Red Hat Ceph Storage 클러스터 설치 및 구성. 자세한 내용은 Red Hat Ceph Storage 설치 및 Red Hat Ceph Storage 클러스터 구성을 참조하십시오.
- Ceph 파일 시스템을 마운트합니다. 자세한 내용은 브로커 서버에 Ceph 파일 시스템 마운트를 참조하십시오.
- 데이터 센터 장애 발생 시 실시간 브로커에서 복구하도록 유휴 백업 브로커를 추가했습니다. 자세한 내용은 백업 브로커 추가를 참조하십시오.
- Ceph 클라이언트 역할을 사용하여 브로커 서버를 구성합니다. 자세한 내용은 브로커 구성을 Ceph 클라이언트로 설정합니다.
- 각 브로커는 공유 저장소 HA(고가용성) 정책을 사용하도록 구성하여 각 브로커가 메시징 데이터를 저장하는 위치를 지정합니다. 자세한 내용은 공유 저장소 고가용성 구성을 참조하십시오.
- 데이터 센터 중단 시 백업 브로커에 연결하도록 클라이언트를 구성합니다. 자세 한 내용은 다중 사이트 내결함성 메시징 시스템에서 클라이언트 구성을 참조하십시오.
절차
실패한 데이터 센터의 각 master-slave 브로커 쌍에 대해 추가한 유휴 백업 브로커를 수동으로 시작합니다.
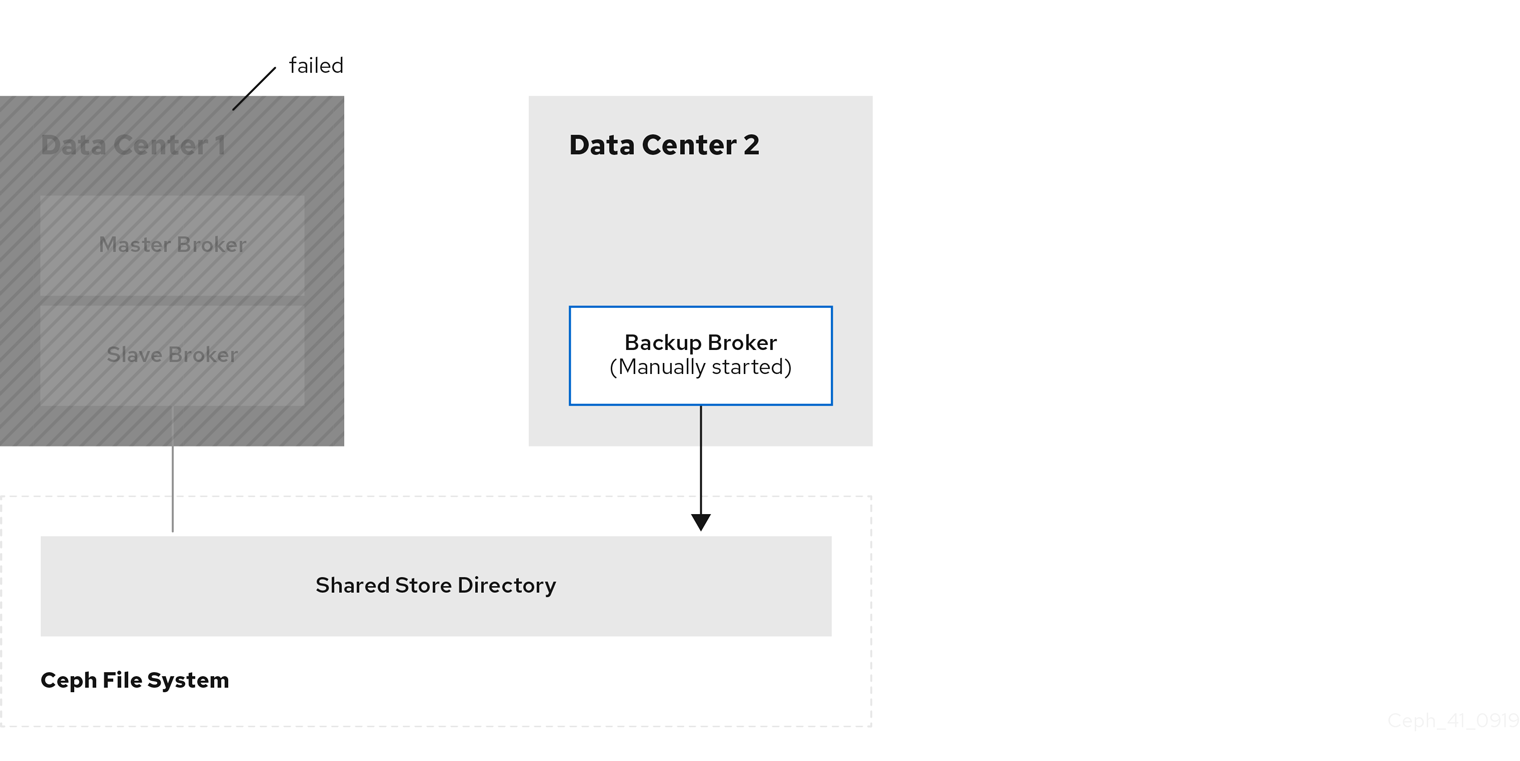
클라이언트 연결을 다시 설정합니다.
실패한 데이터 센터에서 내부 클라이언트를 사용하는 경우 생성한 백업 클라이언트를 수동으로 시작합니다. 다중 사이트 내결함성 메시징 시스템에서 클라이언트 구성에 설명된 대로 수동으로 시작한 백업 브로커에 연결하도록 클라이언트를 구성해야 합니다.
다음 그림은 새 토폴로지를 보여줍니다.
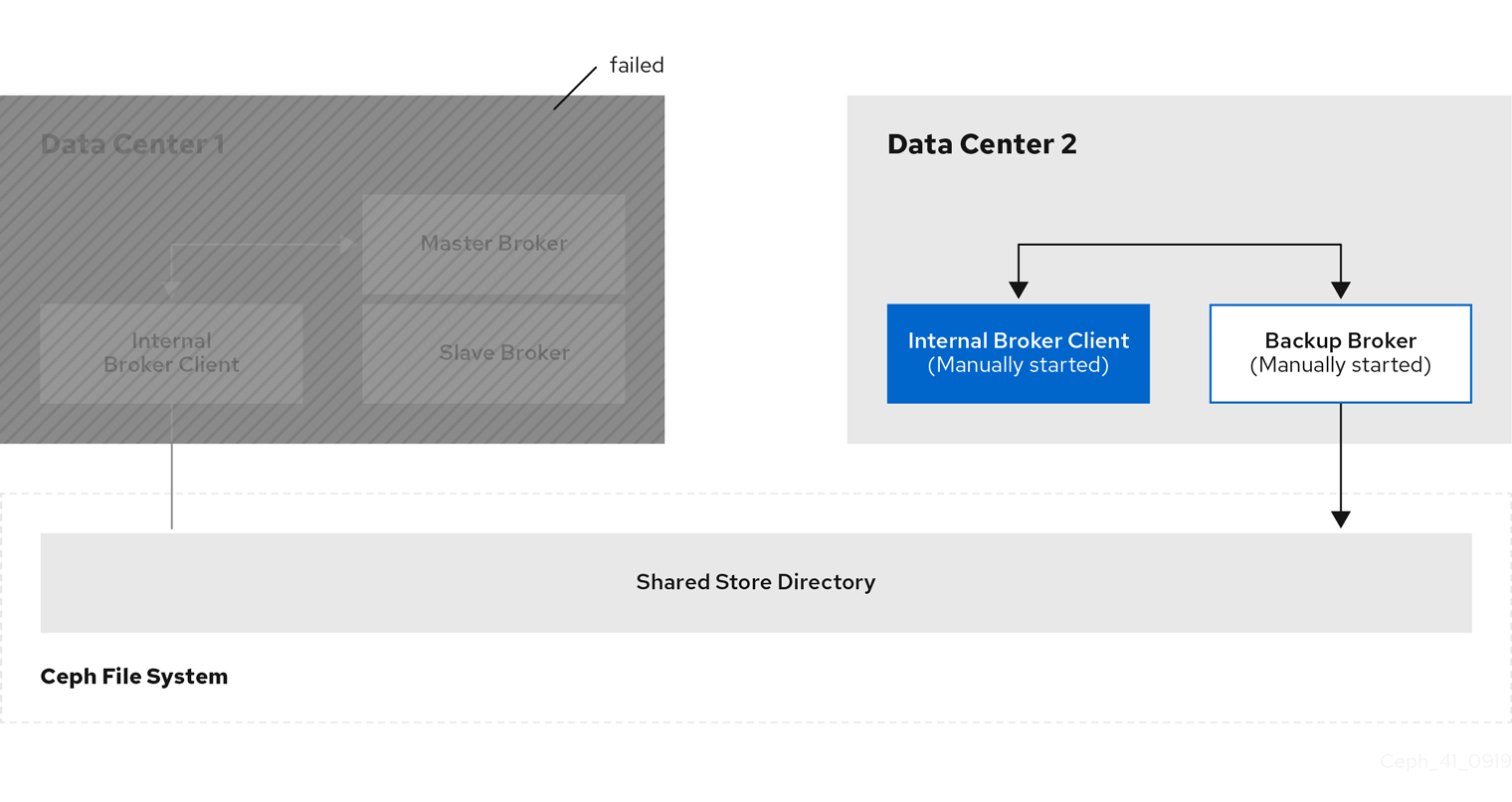
외부 클라이언트가 있는 경우 외부 클라이언트를 새 활성 브로커에 수동으로 연결하거나 구성에 따라 클라이언트가 자동으로 새 활성 브로커로 장애 조치를 수행하는 것을 관찰합니다. 자세한 내용은 외부 클라이언트 구성을 참조하십시오.
다음 그림은 새 토폴로지를 보여줍니다.
17.9. 이전에 실패한 데이터 센터 재시작
이전에 실패한 데이터 센터가 다시 온라인 상태가 되면 다음 단계에 따라 메시징 시스템의 원래 상태를 복원합니다.
- Red Hat Ceph Storage 클러스터의 노드를 호스팅하는 서버를 재시작
- 메시징 시스템에서 브로커 다시 시작
- 클라이언트 애플리케이션에서 복원된 브로커로 연결 재설정
다음 하위 섹션에서는 이러한 단계를 수행하는 방법을 보여줍니다.
17.9.1. 스토리지 클러스터 서버 재시작
모니터, 메타데이터 서버, 관리자 및 OSD(오브젝트 서버, 관리자, Object Storage Device) 노드를 재시작하면 이전에 실패한 데이터 센터의 OSD 노드, Red Hat Ceph Storage 클러스터 자체 복구로 전체 데이터 중복성을 복구할 수 있습니다. 이 프로세스 중에 Red Hat Ceph Storage는 필요에 따라 복원된 OSD 노드에 데이터를 자동으로 백필합니다.
스토리지 클러스터가 자동으로 자동 복구 및 전체 데이터 중복 복원인지 확인하려면 데이터 센터 중단 중에 스토리지 클러스터 상태를 확인하는 데 이전에 표시된 명령을 사용합니다. 이러한 명령을 다시 실행하면 이전 HEALTH_WARN 메시지에서 표시된 백분율 성능 저하가 100%로 반환될 때까지 개선이 시작되는 것을 확인할 수 있습니다.
17.9.2. 브로커 서버 다시 시작
다음 절차에서는 스토리지 클러스터가 성능이 저하된 상태에서 더 이상 작동하지 않을 때 브로커 서버를 다시 시작하는 방법을 보여줍니다.
절차
- 데이터 센터 중단이 발생할 때 수동으로 시작한 백업 브로커에 연결된 클라이언트 애플리케이션을 중지합니다.
수동으로 시작한 백업 브로커를 중지합니다.
Linux의 경우:
BROKER_INSTANCE_DIR/bin/artemis stop
Windows에서:
BROKER_INSTANCE_DIR\bin\artemis-service.exe stop
이전에 실패한 데이터 센터에서 원래 마스터 및 슬레이브 브로커를 다시 시작합니다.
Linux의 경우:
BROKER_INSTANCE_DIR/bin/artemis run
Windows에서:
BROKER_INSTANCE_DIR\bin\artemis-service.exe start
원래 마스터 브로커는 다시 시작할 때 자동으로 해당 역할을 마스터로 다시 시작합니다.
17.9.3. 클라이언트 연결 복원
브로커 서버를 다시 시작하면 클라이언트 애플리케이션을 해당 브로커에 다시 연결합니다. 다음 하위 섹션에서는 내부 및 외부 클라이언트 애플리케이션을 다시 연결하는 방법을 설명합니다.
17.9.3.1. 내부 클라이언트 다시 연결
내부 클라이언트는 이전에 실패한 데이터 센터와 복원된 브로커와 동일한 데이터 센터에서 실행 중인 시스템입니다. 내부 클라이언트를 다시 연결하려면 다시 시작합니다. 각 클라이언트 애플리케이션은 연결 구성에 지정된 복원된 마스터 브로커에 다시 연결합니다.
브로커 및 클라이언트 네트워크 연결 구성에 대한 자세한 내용은 다음을 참조하십시오.
17.9.3.2. 외부 클라이언트 다시 연결
외부 클라이언트는 이전에 실패한 데이터 센터 외부에서 실행 중인 이름입니다. 클라이언트 유형 및 외부 브로커 클라이언트 구성 의 정보를 기반으로 백업 브로커로 자동 장애 조치하도록 클라이언트를 구성했거나 이 연결을 수동으로 설정했습니다. 이전에 실패한 데이터 센터를 복원할 때 아래에 설명된 대로 클라이언트가 복원된 마스터 브로커로의 연결을 다시 설정합니다.
- 백업 브로커로 자동으로 장애 조치하도록 외부 클라이언트를 구성한 경우 백업 브로커를 종료하고 원래 마스터 브로커를 다시 시작할 때 클라이언트가 자동으로 원래 마스터 브로커로 실패합니다.
- 데이터 센터 중단이 발생할 때 외부 클라이언트를 백업 브로커에 수동으로 연결한 경우 다시 시작한 원래 마스터 브로커에 클라이언트를 수동으로 다시 연결해야 합니다.
18장. 로깅
AMQ Broker는 JBoss Logging 프레임워크를 사용하여 로깅을 수행하고 BROKER_INSTANCE_DIR/etc/logging.properties 구성 파일을 통해 구성할 수 있습니다. 이 구성 파일은 키-값 쌍 목록입니다.
아래에 표시된 것처럼 logging.properties 구성 파일의 loggers 키에 포함하여 브로커 구성에 로거를 지정합니다.
loggers=org.eclipse.jetty,org.jboss.logging,org.apache.activemq.artemis.core.server,org.apache.activemq.artemis.utils,org.apache.activemq.artemis.journal,org.apache.activemq.artemis.jms.server,org.apache.activemq.artemis.integration.bootstrap,org.apache.activemq.audit.base,org.apache.activemq.audit.message,org.apache.activemq.audit.resource
AMQ Broker에서 사용할 수 있는 로거는 다음 표에 표시되어 있습니다.
| logger | 설명 |
|---|---|
| org.jboss.logging | 루트 로거입니다. 다른 브로커 로거에서 처리되지 않은 호출을 기록합니다. |
| org.apache.activemq.artemis.core.server | 브로커 코어를 기록합니다. |
| org.apache.activemq.artemis.utils | 유틸리티 호출을 기록합니다. |
| org.apache.activemq.artemis.journal | 로그 저널 호출 |
| org.apache.activemq.artemis.jms | JMS 호출을 기록합니다. |
| org.apache.activemq.artemis.integration.bootstrap | 부트스트랩 호출을 로그 |
| org.apache.activemq.audit.base | 모든 JMX 오브젝트 메서드에 대한 액세스 로그 |
| org.apache.activemq.audit.message | 메시지 검색, 프로덕션, 사용 및 검색과 같은 메시지 작업 로그 |
| org.apache.activemq.audit.resource | JMX 또는 AMQ Broker 관리 콘솔에서 인증 이벤트, 브로커 리소스 생성 또는 삭제, 관리 콘솔에서 메시지 검색 |
아래 표시된 대로 logger.handlers 키에는 두 개의 기본 로깅 핸들러도 구성됩니다.
logger.handlers=FILE,CONSOLE
logger.handlers=FILE- 로거는 로그 항목을 파일에 출력합니다.
logger.handlers=CONSOLE- 로거는 로그 항목을 AMQ Broker 관리 콘솔에 출력합니다.
18.1. 로깅 수준 변경
모든 로거의 기본 로깅 수준은 INFO 이며 루트 로거에서 다음과 같이 구성됩니다.
logger.level=INFO
다음과 같이 다른 모든 로거에 대한 로깅 수준을 개별적으로 구성할 수 있습니다.
logger.org.apache.activemq.artemis.core.server.level=INFO logger.org.apache.activemq.artemis.journal.level=INFO logger.org.apache.activemq.artemis.utils.level=INFO logger.org.apache.activemq.artemis.jms.level=INFO logger.org.apache.activemq.artemis.integration.bootstrap.level=INFO logger.org.apache.activemq.audit.base.level=INFO logger.org.apache.activemq.audit.message.level=INFO logger.org.apache.activemq.audit.resource.level=INFO
사용 가능한 로깅 수준은 다음 표에 설명되어 있습니다. 로깅 수준은 최소한의 세부 사항부터 최대한의 오름차순으로 나열됩니다.
| level | 설명 |
|---|---|
| FATAL | 중요한 서비스 실패를 나타내는 이벤트에 대해 FATAL 로깅 수준을 사용합니다. 서비스에 FATAL 오류가 발생하면 모든 종류의 요청을 완전히 실행할 수 없습니다. |
| ERROR | 요청 중단 또는 요청을 서비스하는 기능을 나타내는 이벤트의 ERROR 로깅 수준을 사용합니다. 서비스에는 이 오류 수준이 있을 때 요청을 계속 서비스할 수 있는 일부 용량이 있어야 합니다. |
| WARN | 중요하지 않은 서비스 오류를 나타내는 이벤트의 WARN 로깅 수준을 사용합니다. 다시 사용 가능한 오류 또는 요청 예상에서 약간의 위반은 이 설명을 충족합니다. WARN과 ERROR의 차이점은 애플리케이션 개발자가 만드는 것입니다. 이러한 구별에 대한 간단한 기준은 오류가 사용자가 기술 지원을 요청해야 하는지 여부입니다. 오류에 기술 지원이 필요한 경우 로깅 수준을 ERROR로 설정합니다. 그렇지 않으면 레벨을 WARN으로 설정합니다. |
| INFO | 서비스 라이프사이클 이벤트 및 기타 중요한 관련 정보에 대해 INFO 로깅 수준을 사용합니다. 지정된 서비스 범주에 대한 INFO-level 메시지는 서비스가 어떤 상태에 있는지 명확하게 표시해야 합니다. |
| DEBUG | 라이프사이클 이벤트에 대한 추가 정보를 전달하는 로그 메시지에 DEBUG 로깅 수준을 사용합니다. 개발자 지향 정보 또는 기술 지원에 필요한 세부 정보에 이 로깅 수준을 사용합니다. DEBUG 로깅 수준을 활성화하면 서버 요청 수에 비례하여 JBoss 서버 로그가 증가해 서는 안 됩니다. 지정된 서비스 범주에 대한 DEBUG- 및 INFO-level 메시지는 서비스가 어떤 상태에 있는지, 사용 중인 브로커 리소스(포트, 인터페이스, 로그 파일 등)를 명확하게 표시해야 합니다. |
| TRACE |
요청 활동과 직접 연결된 로그 메시지에 TRACE 로깅 수준을 사용합니다. 이러한 메시지는 로거 범주 우선 순위 임계값이 메시지가 렌더링됨을 나타내지 않는 한 로거에 제출해서는 안 됩니다. |
-
INFO는logger.org.apache.activemq.audit.base,logger.org.apache.activemq.audit.message,logger.org.apache.activemq.audit.resource감사 로거에서 사용할 수 있는 유일한 로깅 수준입니다. -
루트 로거에 지정된 로깅 수준은 다른 로거에 대한 자세한 로깅 수준이 구성에 지정된 경우에도 모든 로거에 대해 가장 상세한 로깅 수준을 결정합니다. 예를 들어,
org.apache.activemq.artemis.utils의 지정된 로깅이DEBUG이고 루트 로거(org.jboss.logging)에WARN의 지정된 로깅 수준이 있다고 가정합니다. 이 경우 두 로거 모두WARN의 로깅 수준을 사용합니다.
18.2. 감사 로깅 활성화
세 가지 감사 로거, 기본 감사 로거, 메시지 감사 로거 및 리소스 감사 로거를 활성화할 수 있습니다.
- 기본 감사 로거(org.apache.activemq.audit.base)
- 주소 및 큐의 생성 및 삭제와 같은 모든 JMX 오브젝트 방법에 대한 액세스 를 기록합니다. 로그 는 이러한 작업이 성공했는지 여부를 나타내지 않습니다.
- 메시지 감사 로거(org.apache.activemq.audit.message)
- 메시지 프로덕션, 사용 또는 메시지 검색과 같은 메시지 관련 브로커 작업을 기록합니다.
- 리소스 감사 로거(org.apache.activemq.audit.resource)
- 클라이언트, 경로 및 AMQ 브로커 관리 콘솔에서 인증 성공 또는 실패를 기록합니다. 또한 JMX 또는 관리 콘솔에서 대기열 생성, 업데이트 또는 삭제와 관리 콘솔에서 메시지 검색도 기록합니다.
각 감사 로거를 다른 감사 로거와 독립적으로 활성화할 수 있습니다. 기본적으로 각 감사 로거는 비활성화됩니다(즉, 로깅 수준은 ERROR 로 설정되며 감사 로거에 유효한 로깅 수준이 아님). 감사 로거 중 하나를 활성화하려면 로깅 수준을 INFO (정보)로 설정합니다. 예를 들면 다음과 같습니다.
logger.org.apache.activemq.audit.base.level=INFO
메시지 감사 로거는 브로커의 성능 집약적인 경로에서 실행됩니다. 로거를 활성화하면 특히 브로커가 높은 메시징 로드로 실행되는 경우 브로커의 성능에 부정적인 영향을 미칠 수 있습니다. 높은 처리량이 필요한 메시징 시스템에서 메시지 감사 로거를 사용하는 것은 권장되지 않습니다.
18.3. 콘솔 로깅 구성
다음 키를 사용하여 콘솔 로깅을 구성할 수 있습니다.
handler.CONSOLE=org.jboss.logmanager.handlers.ConsoleHandler handler.CONSOLE.properties=autoFlush handler.CONSOLE.level=DEBUG handler.CONSOLE.autoFlush=true handler.CONSOLE.formatter=PATTERN
handler.CONSOLE 는 logger.handlers 키에 지정된 이름을 나타냅니다.
콘솔 로깅 구성 옵션은 다음 표에 설명되어 있습니다.
| 속성 | 설명 |
|---|---|
|
| 처리기 이름 |
|
| 처리기에서 사용하는 문자 인코딩 |
|
| 로깅 수준: 로그된 메시지 수준을 지정합니다. 이 값보다 낮은 메시지 수준은 삭제됩니다. |
|
| formatter를 정의합니다. 18.5절. “로깅 형식 구성” 을 참조하십시오. |
|
| 각 쓰기 후 자동으로 로그를 플러시할지 여부 |
|
| 콘솔 처리기의 대상입니다. 값은 SYSTEM_OUT 또는 SYSTEM_ERR일 수 있습니다. |
18.4. 파일 로깅 구성
다음 키를 사용하여 파일 로깅을 구성할 수 있습니다.
handler.FILE=org.jboss.logmanager.handlers.PeriodicRotatingFileHandler
handler.FILE.level=DEBUG
handler.FILE.properties=suffix,append,autoFlush,fileName
handler.FILE.suffix=.yyyy-MM-dd
handler.FILE.append=true
handler.FILE.autoFlush=true
handler.FILE.fileName=${artemis.instance}/log/artemis.log
handler.FILE.formatter=PATTERN
handler.FILE 은 logger.handlers 키에 지정된 이름을 나타냅니다.
파일 로깅 구성 옵션은 다음 표에 설명되어 있습니다.
| 속성 | 설명 |
|---|---|
|
| 처리기 이름 |
|
| 처리기에서 사용하는 문자 인코딩 |
|
| 로깅 수준: 로그된 메시지 수준을 지정합니다. 이 값보다 낮은 메시지 수준은 삭제됩니다. |
|
| formatter를 정의합니다. 18.5절. “로깅 형식 구성” 을 참조하십시오. |
|
| 각 쓰기 후 자동으로 로그를 플러시할지 여부 |
|
| 대상 파일에 추가할지 여부를 지정합니다. |
|
| 경로 및 경로와 관련된 선택 사항으로 구성된 파일 설명입니다. |
18.5. 로깅 형식 구성
formatter는 로그 메시지를 표시하는 방법을 설명합니다. 다음은 기본 구성입니다.
formatter.PATTERN=org.jboss.logmanager.formatters.PatternFormatter
formatter.PATTERN.properties=pattern
formatter.PATTERN.pattern=%d{HH:mm:ss,SSS} %-5p [%c] %s%E%n
이전 구성에서 %s 는 메시지이고 %E 는 예외이며 존재하는 경우 %E입니다.
형식은 Log4J 형식과 동일합니다. 자세한 설명은 여기에서 찾을 수 있습니다.
18.6. 클라이언트 또는 포함된 서버 로깅
클라이언트에서 로깅을 활성화하려면 클라이언트의 클래스 경로에 JBoss 로깅 JAR을 포함해야 합니다. Maven을 사용하는 경우 다음 종속 항목을 추가합니다.
<dependency> <groupId>org.jboss.logmanager</groupId> <artifactId>jboss-logmanager</artifactId> <version>1.5.3.Final</version> </dependency> <dependency> <groupId>org.apache.activemq</groupId> <artifactId>artemis-core-client</artifactId> <version>1.0.0.Final</version> </dependency>
Java 프로그램을 시작할 때 설정해야 하는 두 가지 속성이 있습니다. 첫 번째는 JBoss Log Manager를 사용하도록 Log Manager를 설정하는 것입니다. 이 작업은 '-Djava.util.logging.manager'property를 설정하여 수행됩니다. 예를 들면 다음과 같습니다.
-Djava.util.logging.manager=org.jboss.logmanager.LogManager
두 번째는 사용할 logging.properties 파일의 위치를 설정하는 것입니다. 이 작업은 -Dlogging.configuration 속성을 유효한 URL로 설정하여 수행됩니다. 예를 들면 다음과 같습니다.
-Dlogging.configuration=file:///home/user/projects/myProject/logging.properties
다음은 클라이언트에 대한 일반적인 logging.properties 파일입니다.
# Root logger option
loggers=org.jboss.logging,org.apache.activemq.artemis.core.server,org.apache.activemq.artemis.utils,org.apache.activemq.artemis.journal,org.apache.activemq.artemis.jms,org.apache.activemq.artemis.ra
# Root logger level
logger.level=INFO
# ActiveMQ Artemis logger levels
logger.org.apache.activemq.artemis.core.server.level=INFO
logger.org.apache.activemq.artemis.utils.level=INFO
logger.org.apache.activemq.artemis.jms.level=DEBUG
# Root logger handlers
logger.handlers=FILE,CONSOLE
# Console handler configuration
handler.CONSOLE=org.jboss.logmanager.handlers.ConsoleHandler
handler.CONSOLE.properties=autoFlush
handler.CONSOLE.level=FINE
handler.CONSOLE.autoFlush=true
handler.CONSOLE.formatter=PATTERN
# File handler configuration
handler.FILE=org.jboss.logmanager.handlers.FileHandler
handler.FILE.level=FINE
handler.FILE.properties=autoFlush,fileName
handler.FILE.autoFlush=true
handler.FILE.fileName=activemq.log
handler.FILE.formatter=PATTERN
# Formatter pattern configuration
formatter.PATTERN=org.jboss.logmanager.formatters.PatternFormatter
formatter.PATTERN.properties=pattern
formatter.PATTERN.pattern=%d{HH:mm:ss,SSS} %-5p [%c] %s%E%n18.7. AMQ Broker 플러그인 지원
AMQ는 사용자 정의 플러그인을 지원합니다. 플러그인을 사용하면 디버그 로그를 통해서만 사용할 수 있는 다양한 유형의 이벤트에 대한 정보를 로깅할 수 있습니다. 여러 플러그인을 함께 등록, 연결 및 실행할 수 있습니다. 플러그인은 등록 순서에 따라 실행됩니다. 즉, 등록된 첫 번째 플러그인이 항상 먼저 실행됩니다.
사용자 정의 플러그인을 생성하고 ActiveMQServerPlugin 인터페이스를 사용하여 구현할 수 있습니다. 이 인터페이스는 플러그인이 classpath에 있고 브로커에 등록되어 있는지 확인합니다. 모든 인터페이스 메서드가 기본적으로 구현되므로 구현해야 하는 필수 동작만 추가해야 합니다.
18.7.1. 클래스 경로에 플러그인 추가
관련 .jar 파일을 BROKER_INSTANCE_DIR/lib 디렉터리에 추가하여 사용자 정의 생성된 브로커 플러그인을 브로커 런타임에 추가합니다.
임베디드 시스템을 사용하는 경우 포함된 애플리케이션의 일반 클래스 경로에 .jar 파일을 배치합니다.
18.7.2. 플러그인 등록
broker.xml 구성 파일에 broker-plugins 요소를 추가하여 플러그인을 등록해야 합니다. 속성 자식 요소를 사용하여 플러그인 구성 값을 지정할 수 있습니다. 이러한 속성은 플러그인이 인스턴스화된 후 플러그인의 init (Map<String, String>) 작업을 읽고 전달합니다.
<broker-plugins> <broker-plugin class-name="some.plugin.UserPlugin"> <property key="property1" value="val_1" /> <property key="property2" value="val_2" /> </broker-plugin> </broker-plugins>
18.7.3. 프로그래밍 방식으로 플러그인 등록
플러그인을 프로그래밍 방식으로 등록하려면 registerBrokerPlugin() 메서드를 사용하여 플러그인의 새 인스턴스를 전달합니다. 아래 예제에서는 UserPlugin 플러그인의 등록을 보여줍니다.
Configuration config = new ConfigurationImpl();
config.registerBrokerPlugin(new UserPlugin());18.7.4. 특정 이벤트 로깅
기본적으로 AMQ 브로커는 특정 브로커 이벤트를 로깅할 수 있도록 LoggingActiveMQServerPlugin 플러그인을 제공합니다. LoggingActiveMQServerplugin 플러그인은 기본적으로 주석 처리되며 정보를 기록하지 않습니다.
다음 표에서는 각 플러그인 속성에 대해 설명합니다. 이벤트를 로깅하려면 구성 속성 값을 true 로 설정합니다.
| 속성 | 설명 |
|
| 연결을 만들거나 삭제할 때 정보를 기록합니다. |
|
| 세션을 만들거나 닫을 때 정보를 기록합니다. |
|
| 소비자가 만들거나 닫힐 때 정보를 기록합니다. |
|
| 메시지가 소비자에게 전달될 때 및 사용자가 메시지를 승인할 때 정보를 기록합니다. |
|
| 메시지가 주소로 전송되고 브로커 내에서 메시지가 라우팅되면 정보를 기록합니다. |
|
| 큐가 생성되거나 삭제될 때, 메시지가 만료될 때, 브리지가 배포될 때 및 심각한 실패가 발생할 때 정보를 기록합니다. |
|
| 위의 모든 이벤트에 대한 정보를 기록합니다. |
연결 이벤트를 로깅하도록 LoggingActiveMQServerPlugin 플러그인을 구성하려면 broker.xml 구성 파일의 < broker-plugins > 섹션의 주석을 제거합니다. 주석 처리된 기본 예제에서 모든 이벤트의 값이 true 로 설정됩니다.
<configuration ...>
...
<!-- Uncomment the following if you want to use the Standard LoggingActiveMQServerPlugin plugin to log in events -->
<broker-plugins>
<broker-plugin class-name="org.apache.activemq.artemis.core.server.plugin.impl.LoggingActiveMQServerPlugin">
<property key="LOG_ALL_EVENTS" value="true"/>
<property key="LOG_CONNECTION_EVENTS" value="true"/>
<property key="LOG_SESSION_EVENTS" value="true"/>
<property key="LOG_CONSUMER_EVENTS" value="true"/>
<property key="LOG_DELIVERING_EVENTS" value="true"/>
<property key="LOG_SENDING_EVENTS" value="true"/>
<property key="LOG_INTERNAL_EVENTS" value="true"/>
</broker-plugin>
</broker-plugins>
...
</configuration>
< broker-plugins > 섹션 내에서 구성 매개변수를 변경한 경우 브로커를 다시 시작하여 구성 업데이트를 다시 로드해야 합니다. 이러한 구성 변경은 configuration-file-refresh-period 설정에 따라 다시 로드 되지 않습니다.
로그 수준이 INFO (정보)로 설정되면 이벤트가 발생한 후 항목이 기록됩니다. 로그 수준이 DEBUG 로 설정된 경우 이벤트 전후에 대해 로그 항목이 생성됩니다(예: CreateConsumer() 및 afterCreateConsumer() ). 로그 수준이 DEBUG 로 설정된 경우 로거는 사용 가능한 경우 알림에 대한 자세한 정보를 기록합니다.
부록 A. 수락 및 커넥터 구성 매개 변수
아래 표에는 Netty 네트워크 연결을 구성하는 데 사용되는 몇 가지 사용 가능한 매개 변수가 자세히 설명되어 있습니다. 매개 변수 및 해당 값은 연결 문자열의 URI에 추가됩니다.Parameters and their values are appended to the URI of the connection string. 자세한 내용은 네트워크 연결: 수락자 및 커넥터 를 참조하십시오. 각 표에는 허용자 또는 커넥터와 함께 사용할 수 있는지 여부에 따라 이름과 메모에 따라 매개 변수가 나열되어 있습니다. 예를 들어 일부 매개변수는 수락자에서만 사용할 수 있습니다.
모든 Netty 매개변수는 org.apache.activemq.artemis.core.remoting.impl.netty.TransportConstants 에 정의되어 있습니다. 소스 코드는 고객 포털에서 다운로드할 수 있습니다.
표 A.1. Netty TCP 매개 변수
| 매개변수 | with… 사용 | 설명 |
|---|---|---|
| batchDelay | 둘 다 |
수락자 또는 커넥터에 패킷을 작성하기 전에 최대 |
| connectionsAllowed | 수락자 | 수락자가 허용할 연결 수를 제한합니다. 이 제한에 도달하면 DEBUG 수준 메시지가 로그에 발행되고 연결이 거부됩니다. 사용 중인 클라이언트 유형에 따라 연결이 거부될 때 발생하는 상황이 결정됩니다. |
| directDeliver | 둘 다 |
메시지가 서버에 도착하고 대기 소비자에게 전달되면 기본적으로 배달은 메시지가 도착한 것과 동일한 스레드에서 수행됩니다. 이렇게 하면 상대적으로 적은 메시지와 소비자 수가 적은 환경에서 적절한 대기 시간을 제공할 수 있지만, 특히 멀티코어 시스템에서 전체 처리량과 확장성에 따라 비용이 많이 듭니다. 대기 시간을 줄이고 처리량이 감소할 수 있는 경우 |
| handshake-timeout | 수락자 | 인증되지 않은 클라이언트가 많은 수의 연결을 열고 이를 열어 두지 않도록 합니다. 각 연결에는 파일 처리가 필요하므로 다른 클라이언트에서 사용할 수 없는 리소스를 사용합니다. 이 제한 시간은 연결에서 인증하지 않고 리소스를 사용할 수 있는 시간을 제한합니다. 연결이 인증되면 리소스 제한 설정을 사용하여 리소스 사용을 제한할 수 있습니다.
기본값은 timeout 값을 편집한 후 브로커를 다시 시작해야 합니다. |
| localAddress | 커넥터 | 원격 주소에 연결할 때 클라이언트가 사용할 로컬 주소를 지정합니다. 일반적으로 Application Server에서 사용되거나 embedded를 실행하여 아웃바운드 연결에 사용되는 주소를 제어할 때 사용됩니다. local-address가 설정되지 않은 경우 커넥터는 사용 가능한 로컬 주소를 사용합니다. |
| localPort | 커넥터 | 원격 주소에 연결할 때 클라이언트가 사용할 로컬 포트를 지정합니다. 일반적으로 Application Server에서 사용되거나 embedded를 실행하여 아웃바운드 연결에 사용되는 포트를 제어할 때 사용됩니다. 기본값을 사용하는 경우 0이면 커넥터가 시스템에서 임시 포트를 선택하도록 합니다. 유효한 포트는 0에서 65535까지입니다. |
| nioRemotingThreads | 둘 다 |
NIO를 사용하도록 설정한 경우 브로커는 기본적으로 들어오는 패킷을 처리하기 위해 |
| tcpNoDelay | 둘 다 |
만약 이것이 |
| tcpReceiveBufferSize | 둘 다 |
TCP 수신 버퍼의 크기(▂ 바이트)를 결정합니다.Determines the size of the TCP receive buffer in bytes. 기본값은 32768 |
| tcpSendBufferSize | 둘 다 |
TCP 전송 버퍼의 크기를 바이트 단위로 결정합니다. 기본값은 32768 TCP 버퍼 크기는 네트워크의 대역폭 및 대기 시간에 따라 조정되어야 합니다. 요약하면 TCP 전송/받기 버퍼 크기는 다음과 같이 계산되어야 합니다. buffer_size = bandwidth * RTT.
대역폭이 초당 바이트 단위이고 네트워크 왕복 시간(RTT)은 초 단위입니다. RTT는 빠른 네트워크의 경우 버퍼 크기를 기본값에서 늘릴 수 있습니다. |
표 A.2. Netty HTTP 매개변수
| 매개변수 | with… 사용 | 설명 |
|---|---|---|
| httpClientIdleTime | 수락자 | 연결을 활성 상태로 유지하기 위해 빈 HTTP 요청을 보내기 전에 클라이언트가 유휴 상태일 수 있는 시간입니다. |
| httpClientIdleScanPeriod | 수락자 | 유휴 클라이언트에 대해 검사하는 빈도(밀리초)입니다. |
| httpEnabled | 수락자 | 더 이상 필요하지 않습니다. 단일 포트를 지원하는 경우 브로커는 이제 HTTP가 사용되고 있는지 자동으로 탐지하고 자체적으로 구성합니다. |
| httpRequiresSessionId | 둘 다 |
|
| httpResponseTime | 수락자 | 연결이 활성 상태로 유지하기 위해 서버가 빈 HTTP 응답을 보내기 전에 대기할 수 있는 시간입니다. |
| httpServerScanPeriod | 수락자 | 응답이 필요한 클라이언트를 스캔하는 빈도(밀리초)입니다. |
표 A.3. Netty TLS/SSL 매개변수
| 매개변수 | with… 사용 | 설명 |
|---|---|---|
| enabledCipherSuites | 둘 다 | SSL 통신에 사용되는 암호화 제품군의 쉼표로 구분된 목록입니다. 기본값은 비어 있습니다. 즉 JVM의 기본값이 사용됩니다. |
| enabledProtocols | 둘 다 | SSL 통신에 사용되는 프로토콜의 쉼표로 구분된 목록입니다. 기본값은 비어 있습니다. 즉 JVM의 기본값이 사용됩니다. |
| forceSSLParameters | 커넥터 |
커넥터에서 매개변수로 설정된 SSL 설정이 JVM 시스템 속성(
유효한 값은 |
| keyStorePassword | 둘 다 | 허용자에서 사용하는 경우 이는 서버 측 키 저장소의 암호입니다.
커넥터에 사용되는 경우 클라이언트 측 키 저장소의 암호입니다. 이는 양방향 SSL(즉, 상호 인증)을 사용하는 경우에만 커넥터와 관련이 있습니다. 이 값은 서버에서 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 서버에서 설정한 암호와 다른 암호를 사용해야 하는 경우 customary |
| keyStorePath | 둘 다 | 수락자에서 사용하는 경우 이는 서버의 SSL 키 저장소의 경로입니다(유사 기관의 자체 서명 또는 서명 여부).
커넥터에서 사용하는 경우 클라이언트 인증서를 보유하는 클라이언트 측 SSL 키 저장소의 경로입니다. 이는 양방향 SSL(즉, 상호 인증)을 사용하는 경우에만 커넥터와 관련이 있습니다. 이 값은 서버에 구성되어 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 서버에서 설정된 것과 다른 경로를 사용해야 하는 경우 customary |
| needClientAuth | 수락자 |
이 수락에 연결하는 클라이언트에 두방향 SSL이 필요하다는 것을 알려줍니다. 유효한 값은 |
| sslEnabled | 둘 다 |
SSL을 활성화하려면 |
| trustManagerFactoryPlugin | 둘 다 |
이는
지정된 플러그인을 브로커의 Java classpath에 배치해야 합니다. 기본적으로 classpath의 일부이므로 |
| trustStorePassword | 둘 다 | 수락자에서 사용하는 경우 이는 서버 측 신뢰 저장소의 암호입니다. 이는 양방향 SSL(즉, 상호 인증)을 사용하는 경우에만 동의어와 관련이 있습니다.
커넥터에 사용하는 경우 클라이언트 측 truststore의 암호입니다. 이 값은 서버에서 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트에서 서버에서 설정한 암호와 다른 암호를 사용해야 하는 경우 customary |
| sniHost | 둘 다 |
수락자에서 사용되는 경우
들어오는 연결에
커넥터에서 사용하는 경우 |
| sslProvider | 둘 다 |
이 옵션은 OpenSSL을 통해 지원되지만 JDK 공급자를 통해 지원되지 않는 특수 암호suite-elliptic 곡선 조합을 사용하려는 경우 유용할 수 있습니다. |
| trustStorePath | 둘 다 | 수락자에서 사용하는 경우 이는 서버가 신뢰하는 모든 클라이언트의 키를 보유하는 서버 측 SSL 키 저장소의 경로입니다. 이는 양방향 SSL(즉, 상호 인증)을 사용하는 경우에만 동의어와 관련이 있습니다.
커넥터에서 사용하는 경우 이 경로는 클라이언트가 신뢰하는 모든 서버의 공개 키를 보유하는 클라이언트 측 SSL 키 저장소의 경로입니다. 이 값은 서버에서 구성할 수 있지만 클라이언트에서 다운로드하여 사용합니다. 클라이언트가 서버에서 설정된 것과 다른 경로를 사용해야 하는 경우 customary |
| useDefaultSslContext | 커넥터 |
커넥터가 클라이언트에서 프로그래밍 방식으로 설정할 수 있는 "기본" SSL 컨텍스트(
이 매개변수가 |
| verifyHost | 둘 다 | 수락자에 사용되는 경우 연결 클라이언트의 SSL 인증서의 CN을 호스트 이름과 비교하여 일치하는지 확인합니다. 이 기능은 양방향 SSL에만 유용합니다. 커넥터에 사용되는 경우 서버의 SSL 인증서의 CN을 호스트 이름과 비교하여 일치하는지 확인합니다. 이 기능은 단방향 SSL과 양방향 SSL 모두에 유용합니다.
유효한 값은 |
| wantClientAuth | 수락자 |
이 수락에 연결하는 클라이언트에 두방향 SSL이 요청되었지만 필수는 아님을 알려줍니다. 유효한 값은
속성 |
부록 B. 주소 설정 구성 요소
아래 표에는 address-setting 의 모든 구성 요소가 나열되어 있습니다. 일부 요소에는 DEPRECATED가 표시되어 있습니다. 제안된 교체를 사용하여 잠재적인 문제를 방지합니다.
표 B.1. 주소 설정 요소
| 이름 | 설명 |
|---|---|
| address-full-policy |
참고 BLOCK 정책은 흐름 제어를 기능하기 때문에 AMQP, OpenWire 및 Core Protocol 프로토콜에서만 작동합니다. |
| auto-create-addresses |
클라이언트가 메시지를 에 전송할 때 자동으로 주소를 만들거나 큐가 없는 주소에 매핑된 큐의 메시지를 사용하려고 합니다. 기본값은 |
| auto-create-dead-letter-resources |
브로커가 배달되지 않은 메시지를 수신할 배달 못 한 주소 및 큐를 자동으로 생성할지 여부를 지정합니다. 기본값은
매개변수가 |
| auto-create-jms-queues |
DEPRECATED: |
| auto-create-jms-topics |
DEPRECATED: |
| auto-create-queues |
클라이언트가 메시지를 로 보내거나 대기열에서 메시지를 사용할 때 큐를 자동으로 생성할지 여부입니다. 기본값은 |
| auto-delete-addresses |
브로커에 더 이상 큐가 없는 경우 자동 생성 주소를 삭제할지 여부입니다. 기본값은 |
| auto-delete-jms-queues |
DEPRECATED: |
| auto-delete-jms-topics |
DEPRECATED: |
| auto-delete-queues |
대기열에 소비자가 없고 메시지가 없을 때 자동 생성된 큐를 삭제할지 여부입니다. 기본값은 |
| config-delete-addresses | 구성 파일이 다시 로드되면 이 설정은 구성 파일에서 삭제된 주소(및 해당 대기열)를 처리하는 방법을 지정합니다. 다음 값을 지정할 수 있습니다.
|
| config-delete-queues | 구성 파일이 다시 로드되면 이 설정은 구성 파일에서 삭제된 대기열을 처리하는 방법을 지정합니다. 다음 값을 지정할 수 있습니다.
|
| dead-letter-address | 브로커가 dead 메시지를 보내는 주소입니다. |
| dead-letter-queue-prefix |
브로커가 자동으로 생성된 배달 못 한 큐의 이름에 적용되는 접두사입니다. 기본값은 |
| dead-letter-queue-suffix | 브로커가 자동으로 생성된 dead letter 큐에 적용되는 접미사입니다. 기본값은 정의되지 않습니다(즉, 브로커는 접미사가 적용되지 않음). |
| default-address-routing-type |
자동 생성된 주소에 사용되는 routing-type. 기본값은 |
| default-max-consumers |
한 번에 이 큐에 허용되는 최대 소비자 수입니다. 기본값은 |
| default-purge-on-no-consumers |
소비자가 없는 경우 큐의 콘텐츠를 제거할지 여부입니다. 기본값은 |
| default-queue-routing-type |
자동 생성된 큐에 사용되는 routing-type. 기본값은 |
| enable-metrics |
Prometheus 플러그인과 같이 구성된 지표 플러그인이 일치하는 주소 또는 주소 집합에 대한 지표를 수집하는지 여부를 지정합니다. 기본값은 |
| expiry-address | 만료된 메시지를 수신할 주소입니다. |
| expiry-delay |
기본 만료 시간을 사용하는 메시지에 사용할 만료 시간(밀리초)을 정의합니다. 기본값은 |
| last-value-queue |
대기열에서 마지막 값만 사용하는지 여부입니다. 기본값은 |
| management-browse-page-size |
관리 리소스에서 검색할 수 있는 메시지 수는 몇 개입니까. 기본값은 |
| max-delivery-attempts |
dead letter 주소로 보내기 전에 메시지를 전송하려고 시도하는 횟수입니다. 기본값은 |
| max-redelivery-delay | redelivery-delay의 최대 값(밀리초)입니다. |
| max-size-bytes |
이 주소의 최대 메모리 크기이며 바이트 단위로 지정됩니다. |
| max-size-bytes-reject-threshold |
|
| message-counter-history-day-limit |
이 주소에 대한 메시지 카운터 기록을 유지하는 일 수입니다. 기본값은 |
| page-max-cache-size |
페이징 탐색 중에 I/O를 최적화하기 위해 메모리에 보관할 페이지 파일 수입니다. 기본값은 |
| page-size-bytes |
페이징 크기(바이트)입니다. 또한 |
| redelivery-delay |
취소된 메시지를 다시 전달할 때까지 대기하는 시간(밀리초)입니다. 기본값은 |
| redelivery-delay-multiplier |
redelivery-delay 매개변수에 적용할 수 있는 multiplier입니다. 기본값은 |
| redistribution-delay |
메시지를 반환하기 전에 마지막 소비자가 대기열에서 종료된 후 밀리초 단위로 대기하는 시간을 정의합니다. 기본값은 |
| send-to-dla-on-no-route |
|
| slow-consumer-check-period |
느린 소비자를 위한 시간(초)을 확인하는 빈도입니다. 기본값은 |
| slow-consumer-policy |
느린 사용자가 식별될 때 어떤 일이 발생하는지 결정합니다. 유효한 옵션은 |
| slow-consumer-threshold |
소비자가 느리게 간주되기 전에 허용되는 메시지 소비의 최소 비율입니다. 메시지(초당)로 측정됩니다. 기본값은 |
부록 C. 클러스터 연결 구성 요소
아래 표에는 클러스터 연결 의 모든 구성 요소가 나열되어 있습니다.
표 C.1. 클러스터 연결 구성 요소
| 이름 | 설명 |
|---|---|
| 주소 |
각 클러스터 연결은
참고 동일한 메시지가 두 개 이상의 클러스터 연결 간에 분산될 수 있기 때문에 중복된 주소(예: "europe" 및 "europe.news")가 있는 여러 클러스터 연결이 없어야 합니다. |
| call-failover-timeout |
장애 조치(failover) 시도 중에 호출이 수행됩니다.Use when a call is made during a failover attempt. 기본값은 |
| call-timeout |
패킷이 클러스터 연결을 통해 전송되고 차단 호출인 경우 |
| check-period |
검사 간격(밀리초)에서 클러스터 연결이 다른 브로커의 ping을 수신하지 않았는지 확인합니다. 기본값은 |
| confirmation-window-size |
에 연결된 브로커에서 확인을 보내는 데 사용되는 창의 크기(바이트)입니다. 브로커가 |
| connector-ref |
올바른 클러스터 토폴로지를 갖도록 클러스터의 다른 브로커로 전송할 |
| connection-ttl |
클러스터 연결에서 클러스터의 특정 브로커에서 메시지를 수신하지 않는 경우 클러스터 연결이 활성 상태를 유지해야 하는 시간을 결정합니다. 기본값은 |
| discovery-group-ref |
클러스터의 다른 브로커와 통신하는 데 사용할 |
| initial-connect-attempts |
시스템에서 처음에 브로커를 연결하려고 하는 횟수를 설정합니다. max-retry가 달성되면 이 브로커는 영구적으로 다운되며 시스템은 이 브로커로 메시지를 라우팅하지 않습니다. 기본값은 |
| max-hops |
체인의 중간으로 다른 브로커와 간접적으로 연결될 수 있는 브로커에 메시지를 로드 밸런싱하도록 브로커를 구성합니다. 이렇게 하면 보다 복잡한 토폴로지를 통해 메시지 로드 밸런싱을 계속 제공할 수 있습니다. 기본값은 |
| max-retry-interval |
재시도 횟수(밀리초)의 최대 지연입니다. 기본값은 |
| message-load-balancing |
클러스터의 다른 브로커 간에 메시지를 분산할지 여부와 방법을 결정합니다. 로드 밸런싱을 활성화하려면
|
| min-large-message-size |
메시지 크기(바이트)가 |
| notification-attempts |
클러스터에 연결할 때 클러스터 연결이 자체적으로 브로드캐스트되는 횟수를 설정합니다. 기본값은 |
| notification-interval |
클러스터에 연결할 때 클러스터 연결이 자체적으로 브로드캐스트되는 빈도(밀리초)를 설정합니다. 기본값은 |
| producer-window-size |
클러스터 연결을 통한 생산자 흐름의 크기(바이트)입니다. 기본적으로 비활성화되어 있지만 클러스터에서 실제로 큰 메시지를 사용하는 경우 값을 설정하려고 할 수 있습니다. 값 |
| reconnect-attempts |
시스템이 클러스터의 브로커에 다시 연결하려고 하는 횟수를 설정합니다. max-retry가 달성되면 이 브로커는 영구적으로 다운된 것으로 간주되며 시스템은 이 브로커에 대한 메시지 라우팅을 중지합니다. 기본값은 |
| retry-interval | 다시 시도 사이에 간격(밀리초)을 결정합니다. 클러스터 연결이 생성되고 대상 브로커가 시작되지 않았거나 부팅 중인 경우 다른 브로커의 클러스터 연결이 백업될 때까지 대상에 연결을 다시 시도합니다. 이 매개변수는 선택 사항입니다. 기본값은 500밀리초입니다. |
| retry-interval-multiplier |
다시 연결할 때마다 다시 시도한 후 |
| use-duplicate-detection |
클러스터 연결에서는 브리지를 사용하여 브로커를 연결하고 전달된 각 메시지에 중복 ID 속성을 추가하도록 브리지를 구성할 수 있습니다. 브리지의 대상 브로커가 충돌하여 복구되면 소스 브로커에서 메시지가 다시 전달될 수 있습니다. |
부록 D. 명령줄 도구
AMQ Broker에는 메시징 저널을 관리할 수 있도록 CLI(명령줄 인터페이스) 도구 세트가 포함되어 있습니다. 아래 표에는 각 도구의 이름과 설명이 나열되어 있습니다.
| 툴 | 설명 |
|---|---|
| EXP | 특별하고 독립적인 XML 형식을 사용하여 메시지 데이터를 내보냅니다. |
| imp |
|
| data | 저널 레코드에 대한 보고서를 인쇄하고 해당 데이터를 압축합니다. |
| 인코딩 | String으로 인코딩된 저널의 내부 형식을 표시합니다. |
| decode | 인코딩에서 내부 저널 형식을 가져옵니다. |
각 툴에 사용할 수 있는 전체 명령 목록은 help 매개 변수 다음에 도구의 이름을 사용합니다. 아래 예제에서 CLI 출력에는 사용자가 ./ artemis 도움말 툴에서 사용할 수 있는 모든 명령이 나열됩니다.
데이터 를 입력한 후 데이터
$ ./artemis help data
NAME
artemis data - data tools group
(print|imp|exp|encode|decode|compact) (example ./artemis data print)
SYNOPSIS
artemis data
artemis data compact [--broker <brokerConfig>] [--verbose]
[--paging <paging>] [--journal <journal>]
[--large-messages <largeMessges>] [--bindings <binding>]
artemis data decode [--broker <brokerConfig>] [--suffix <suffix>]
[--verbose] [--paging <paging>] [--prefix <prefix>] [--file-size <size>]
[--directory <directory>] --input <input> [--journal <journal>]
[--large-messages <largeMessges>] [--bindings <binding>]
artemis data encode [--directory <directory>] [--broker <brokerConfig>]
[--suffix <suffix>] [--verbose] [--paging <paging>] [--prefix <prefix>]
[--file-size <size>] [--journal <journal>]
[--large-messages <largeMessges>] [--bindings <binding>]
artemis data exp [--broker <brokerConfig>] [--verbose]
[--paging <paging>] [--journal <journal>]
[--large-messages <largeMessges>] [--bindings <binding>]
artemis data imp [--host <host>] [--verbose] [--port <port>]
[--password <password>] [--transaction] --input <input> [--user <user>]
artemis data print [--broker <brokerConfig>] [--verbose]
[--paging <paging>] [--journal <journal>]
[--large-messages <largeMessges>] [--bindings <binding>]
COMMANDS
With no arguments, Display help information
print
Print data records information (WARNING: don't use while a
production server is running)
...
도구에서 도움말을 사용하여 각 도구의 명령을 실행하는 방법에 대한 자세한 정보를 얻을 수 있습니다. 예를 들어 CLI는 사용자가 ./ artemis 도움말 데이터 인쇄를 입력한 후 data print 명령에 대한 자세한 정보를 나열합니다.
$ ./artemis help data print
NAME
artemis data print - Print data records information (WARNING: don't use
while a production server is running)
SYNOPSIS
artemis data print [--bindings <binding>] [--journal <journal>]
[--paging <paging>]
OPTIONS
--bindings <binding>
The folder used for bindings (default ../data/bindings)
--journal <journal>
The folder used for messages journal (default ../data/journal)
--paging <paging>
The folder used for paging (default ../data/paging)부록 E. 메시징 저널 구성 요소
아래 표에는 AMQ Broker 메시징 저널과 관련된 모든 구성 요소가 나열되어 있습니다.
표 E.1. 주소 설정 요소
| 이름 | 설명 |
|---|---|
| journal-directory |
메시지 저널이 있는 디렉터리입니다. 기본값은 최상의 성능을 위해서는 디스크 헤드 이동을 최소화하기 위해 자체 물리 볼륨에 저널이 있어야 합니다. 저널이 다른 파일(예: 바인딩 저널, 데이터베이스 또는 트랜잭션 코디네이터)을 쓰는 다른 프로세스와 공유되는 볼륨에 있는 경우 디스크 헤드가 이러한 파일을 쓰는 것처럼 빠르게 이동할 수 있으므로 성능이 크게 저하될 수 있습니다. SAN을 사용하는 경우 각 저널 인스턴스에 자체 LUN(논리 단위)이 지정되어야 합니다. |
| create-journal-dir |
|
| journal-type |
유효한 값은
|
| journal-sync-transactional |
|
| journal-sync-non-transactional |
|
| journal-file-size |
각 저널 파일의 크기(바이트)입니다. 기본값은 |
| journal-min-files | 브로커가 시작될 때 미리 생성된 최소 파일 수입니다. 파일은 기존 메시지 데이터가 없는 경우에만 미리 생성됩니다. 대기열에서 일정 상태에 포함될 것으로 예상되는 데이터의 양에 따라 예상되는 총 데이터 양과 일치하도록 이 파일 수를 조정해야 합니다. |
| journal-pool-files |
시스템은 필요한 만큼 많은 파일을 생성하지만 파일을 회수할 때
기본값은 |
| journal-max-io | 한 번에 IO 대기열에 있을 수 있는 최대 쓰기 요청 수를 제어합니다. 큐가 가득 차면 쓰기는 공간이 해제될 때까지 차단됩니다.
NIO를 사용할 때 이 값은 항상 |
| journal-buffer-timeout | 버퍼가 플러시될 때의 시간 제한을 제어합니다. AIO는 일반적으로 NIO보다 높은 플러시 속도를 유지할 수 있으므로 시스템은 NIO 및 AIO 둘 다에 대해 다른 기본값을 유지합니다.
NIO의 기본값은 참고 시간 제한을 늘리면 처리량과 대기 시간 사이에 적절한 균형을 제공하기 위해 기본값이 선택되므로 대기 시간이 저하되는 경우 시스템 처리량을 늘릴 수 있습니다. |
| journal-buffer-size |
AIO의 시간 버퍼 크기입니다. 기본값은 |
| journal-compact-min-files |
브로커가 저널을 압축하기 전에 필요한 최소 파일 수입니다. 압축 알고리즘은 최소 참고
값을 |
| journal-compact-percentage |
압축을 시작하는 임계값입니다. |
부록 F. 복제 고가용성 구성 요소
다음 표에는 복제 HA 정책을 사용할 때 유효한 ha-policy 구성 요소가 나열되어 있습니다.
표 F.1. 복제 고가용성을 사용할 때 구성 요소 사용 가능
| 이름 | 설명 |
|---|---|
| check-for-live-server |
마스터 브로커로 구성된 브로커에만 적용됩니다. 원래 마스터 브로커가 시작할 때 자체 서버 ID를 사용하여 다른 라이브 브로커에 대해 클러스터를 확인하는지 여부를 지정합니다. 원래 마스터 브로커로 돌아가 "스플릿 뇌" 상황을 피하려면 |
| cluster-name | 복제에 사용할 클러스터 구성의 이름입니다. 이 설정은 여러 클러스터 연결을 구성하는 경우에만 필요합니다. 구성된 경우 이 이름의 클러스터 구성이 클러스터에 연결할 때 사용됩니다. 설정되지 않으면 구성에 정의된 첫 번째 클러스터 연결이 사용됩니다. |
| group-name |
설정된 경우 백업 브로커는 |
| initial-replication-sync-timeout | 복제 브로커가 복제본에 필요한 모든 데이터를 수신했는지 확인할 초기 복제 프로세스가 완료될 때까지 대기하는 시간입니다. 이 속성의 기본값은000밀리초입니다. 참고 이 간격 동안 다른 저널 관련 작업이 차단됩니다. |
| max-saved-replicated-journals-size |
백업 브로커에만 적용됩니다. 백업 브로커가 보유하는 백업 저널 파일 수를 지정합니다. 이 값에 도달하면 브로커는 가장 오래된 저널 파일을 삭제하여 새 백업 저널 파일의 공간을 만듭니다. 이 속성의 기본값은 |
| allow-failback |
백업 브로커에만 적용됩니다. 라이브 브로커와 같은 다른 브로커가 이를 수행하도록 요청할 때 백업 브로커가 원래 역할을 재개하는지 여부를 결정합니다. 이 속성의 기본값은 |
| restart-backup |
백업 브로커에만 적용됩니다. 백업 브로커가 다른 브로커로 다시 실패한 후 자동으로 다시 시작하는지 여부를 결정합니다. 이 속성의 기본값은 |
2022-09-24 22:41:21 +1000 수정