
확장 및 성능
프로덕션 환경에서 OpenShift Container Platform 클러스터 스케일링 및 성능 튜닝
초록
1장. 호스트 관련 권장 사례
이 주제에서는 OpenShift Container Platform의 호스트 관련 권장 사례를 설명합니다.
이러한 지침은 OVN(Open Virtual Network)이 아닌 SDN(소프트웨어 정의 네트워킹)을 사용하는 OpenShift Container Platform에 적용됩니다.
1.1. 노드 호스트 관련 권장 사례
OpenShift Container Platform 노드 구성 파일에는 중요한 옵션이 포함되어 있습니다. 예를 들어 두 개의 매개변수 podsPerCore 및 maxPods는 하나의 노드에 대해 예약할 수 있는 최대 Pod 수를 제어합니다.
옵션을 둘 다 사용하는 경우 한 노드의 Pod 수는 두 값 중 작은 값으로 제한됩니다. 이 값을 초과하면 다음과 같은 결과가 발생할 수 있습니다.
- CPU 사용률 증가
- Pod 예약 속도 저하
- 노드의 메모리 크기에 따라 메모리 부족 시나리오 발생
- IP 주소 모두 소진
- 리소스 초과 커밋으로 인한 사용자 애플리케이션 성능 저하
Kubernetes의 경우 단일 컨테이너를 보유한 하나의 Pod에서 실제로 두 개의 컨테이너가 사용됩니다. 두 번째 컨테이너는 실제 컨테이너 시작 전 네트워킹 설정에 사용됩니다. 따라서 10개의 Pod를 실행하는 시스템에서는 실제로 20개의 컨테이너가 실행됩니다.
클라우드 공급자의 디스크 IOPS 제한이 CRI-O 및 kubelet에 영향을 미칠 수 있습니다. 노드에서 다수의 I/O 집약적 Pod가 실행되고 있는 경우 오버로드될 수 있습니다. 노드에서 디스크 I/O를 모니터링하고 워크로드에 대해 처리량이 충분한 볼륨을 사용하는 것이 좋습니다.
podsPerCore는 노드의 프로세서 코어 수에 따라 노드가 실행할 수 있는 Pod 수를 설정합니다. 예를 들어 프로세서 코어가 4개인 노드에서 podsPerCore가 10으로 설정된 경우 노드에 허용되는 최대 Pod 수는 40이 됩니다.
kubeletConfig: podsPerCore: 10
podsPerCore를 0으로 설정하면 이 제한이 비활성화됩니다. 기본값은 0입니다. podsPerCore는 maxPods를 초과할 수 없습니다.
maxPods는 노드의 속성에 관계없이 노드가 실행할 수 있는 Pod 수를 고정된 값으로 설정합니다.
kubeletConfig:
maxPods: 2501.2. KubeletConfig CRD를 생성하여 kubelet 매개변수 편집
kubelet 구성은 현재 Ignition 구성으로 직렬화되어 있으므로 직접 편집할 수 있습니다. 하지만 MCC(Machine Config Controller)에 새 kubelet-config-controller도 추가되어 있습니다. 이를 통해 KubeletConfig CR(사용자 정의 리소스)을 사용하여 kubelet 매개변수를 편집할 수 있습니다.
kubeletConfig 오브젝트의 필드가 Kubernetes 업스트림에서 kubelet으로 직접 전달되므로 kubelet은 해당 값을 직접 검증합니다. kubeletConfig 오브젝트의 값이 유효하지 않으면 클러스터 노드를 사용할 수 없게 될 수 있습니다. 유효한 값은 Kubernetes 설명서를 참조하십시오.
다음 지침 사항을 고려하십시오.
-
해당 풀에 필요한 모든 구성 변경 사항을 사용하여 각 머신 구성 풀에 대해 하나의
KubeletConfigCR을 생성합니다. 모든 풀에 동일한 콘텐츠를 적용하는 경우 모든 풀에 대해 하나의KubeletConfigCR만 필요합니다. -
기존
KubeletConfigCR을 편집하여 각 변경 사항에 대한 CR을 생성하는 대신 기존 설정을 수정하거나 새 설정을 추가합니다. 변경 사항을 되돌릴 수 있도록 다른 머신 구성 풀을 수정하거나 임시로 변경하려는 변경 사항만 수정하기 위해 CR을 생성하는 것이 좋습니다. -
필요에 따라 클러스터당 10개로 제한되는 여러
KubeletConfigCR을 생성합니다. 첫 번째KubeletConfigCR의 경우 MCO(Machine Config Operator)는kubelet에 추가된 머신 구성을 생성합니다. 이후 각 CR을 통해 컨트롤러는 숫자 접미사가 있는 다른kubelet머신 구성을 생성합니다. 예를 들어,-2접미사가 있는kubelet머신 구성이 있는 경우 다음kubelet머신 구성에-3이 추가됩니다.
머신 구성을 삭제하려면 제한을 초과하지 않도록 해당 구성을 역순으로 삭제합니다. 예를 들어 kubelet-2 머신 구성을 삭제하기 전에 kubelet-3 머신 구성을 삭제합니다.
kubelet-9 접미사가 있는 머신 구성이 있고 다른 KubeletConfig CR을 생성하는 경우 kubelet 머신 구성이 10개 미만인 경우에도 새 머신 구성이 생성되지 않습니다.
KubeletConfig CR 예
$ oc get kubeletconfig
NAME AGE set-max-pods 15m
KubeletConfig 머신 구성 표시 예
$ oc get mc | grep kubelet
... 99-worker-generated-kubelet-1 b5c5119de007945b6fe6fb215db3b8e2ceb12511 3.2.0 26m ...
다음 프로세스는 작업자 노드의 각 노드에 대한 최대 Pod 수를 구성하는 방법을 보여줍니다.
사전 요구 사항
구성하려는 노드 유형의 정적
MachineConfigPoolCR와 연관된 라벨을 가져옵니다. 다음 중 하나를 실행합니다.Machine config pool을 표시합니다.
$ oc describe machineconfigpool <name>
예를 들면 다음과 같습니다.
$ oc describe machineconfigpool worker
출력 예
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: creationTimestamp: 2019-02-08T14:52:39Z generation: 1 labels: custom-kubelet: set-max-pods 1- 1
- 라벨이 추가되면
labels아래에 표시됩니다.
라벨이 없으면 키/값 쌍을 추가합니다.
$ oc label machineconfigpool worker custom-kubelet=set-max-pods
절차
이 명령은 선택할 수 있는 사용 가능한 머신 구성 오브젝트를 표시합니다.
$ oc get machineconfig
기본적으로 두 개의 kubelet 관련 구성은
01-master-kubelet및01-worker-kubelet입니다.노드당 최대 Pod의 현재 값을 확인하려면 다음을 실행합니다.
$ oc describe node <node_name>
예를 들면 다음과 같습니다.
$ oc describe node ci-ln-5grqprb-f76d1-ncnqq-worker-a-mdv94
Allocatable스탠자에서value: pods: <value>를 찾습니다.출력 예
Allocatable: attachable-volumes-aws-ebs: 25 cpu: 3500m hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 15341844Ki pods: 250
작업자 노드에서 노드당 최대 Pod 수를 설정하려면 kubelet 구성이 포함된 사용자 정의 리소스 파일을 생성합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods 1 kubeletConfig: maxPods: 500 2참고kubelet이 API 서버와 통신하는 속도는 QPS(초당 쿼리) 및 버스트 값에 따라 달라집니다. 노드마다 실행되는 Pod 수가 제한된 경우 기본 값인
50(kubeAPIQPS인 경우) 및100(kubeAPIBurst인 경우)이면 충분합니다. 노드에 CPU 및 메모리 리소스가 충분한 경우 kubelet QPS 및 버스트 속도를 업데이트하는 것이 좋습니다.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: set-max-pods spec: machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods kubeletConfig: maxPods: <pod_count> kubeAPIBurst: <burst_rate> kubeAPIQPS: <QPS>라벨을 사용하여 작업자의 머신 구성 풀을 업데이트합니다.
$ oc label machineconfigpool worker custom-kubelet=large-pods
KubeletConfig오브젝트를 생성합니다.$ oc create -f change-maxPods-cr.yaml
KubeletConfig오브젝트가 생성되었는지 확인합니다.$ oc get kubeletconfig
출력 예
NAME AGE set-max-pods 15m
클러스터의 작업자 노드 수에 따라 작업자 노드가 하나씩 재부팅될 때까지 기다립니다. 작업자 노드가 3개인 클러스터의 경우 약 10~15분이 걸릴 수 있습니다.
변경 사항이 노드에 적용되었는지 확인합니다.
작업자 노드에서
maxPods값이 변경되었는지 확인합니다.$ oc describe node <node_name>
Allocatable스탠자를 찾습니다.... Allocatable: attachable-volumes-gce-pd: 127 cpu: 3500m ephemeral-storage: 123201474766 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 14225400Ki pods: 500 1 ...- 1
- 이 예에서
pods매개변수는KubeletConfig오브젝트에 설정한 값을 보고해야 합니다.
KubeletConfig오브젝트에서 변경 사항을 확인합니다.$ oc get kubeletconfigs set-max-pods -o yaml
상태가 표시되어야 합니다. "true"및type:Success:spec: kubeletConfig: maxPods: 500 machineConfigPoolSelector: matchLabels: custom-kubelet: set-max-pods status: conditions: - lastTransitionTime: "2021-06-30T17:04:07Z" message: Success status: "True" type: Success
1.4. 컨트롤 플레인 노드 크기 조정
컨트롤 플레인 노드 리소스 요구사항은 클러스터의 노드 수에 따라 달라집니다. 다음 컨트롤 플레인 노드 크기 권장 사항은 컨트롤 플레인 밀도 중심 테스트 결과를 기반으로 합니다. 컨트롤 플레인 테스트에서는 노드 수에 따라 각 네임스페이스의 클러스터에서 다음 오브젝트를 생성합니다.
- 12개의 이미지 스트림
- 3개의 빌드 구성
- 6개의 빌드
- 각각 두 개의 시크릿을 마운트하는 2개의 Pod 복제본이 있는 배포 1개
- 2개의 배포에 1개의 Pod 복제본이 2개의 시크릿을 마운트함
- 이전 배포를 가리키는 서비스 3개
- 이전 배포를 가리키는 경로 3개
- 10개의 시크릿, 이 중 2 개는 이전 배포에 의해 마운트됨
- 10개의 구성 맵, 이 중 두 개는 이전 배포에 의해 마운트됨
| 작업자 노드 수 | 클러스터 로드(네임스페이스) | CPU 코어 수 | 메모리(GB) |
|---|---|---|---|
| 25 | 500 | 4 | 16 |
| 100 | 1000 | 8 | 32 |
| 250 | 4000 | 16 | 96 |
3개의 마스터 또는 컨트롤 플레인 노드가 있는 대규모 및 고밀도 클러스터에서는 노드 중 하나가 중지되거나, 재부팅 또는 실패할 때 CPU 및 메모리 사용량이 증가합니다. 비용 절감을 위해 클러스터를 종료한 후 클러스터를 재시작하는 의도적인 경우 외에도 전원, 네트워크 또는 기본 인프라와 관련된 예기치 않은 문제로 인해 오류가 발생할 수 있습니다. 나머지 두 컨트롤 플레인 노드는 고가용성이 되기 위해 부하를 처리하여 리소스 사용량을 늘려야 합니다. 이는 마스터가 직렬로 연결, 드레이닝, 재부팅되어 운영 체제 업데이트를 적용하고 컨트롤 플레인 Operator 업데이트를 적용하기 때문에 업그레이드 중에도 이 문제가 발생할 수 있습니다. 단계적 오류를 방지하려면 컨트롤 플레인 노드의 전체 CPU 및 메모리 리소스 사용량을 리소스 사용량 급증을 처리하기 위해 사용 가능한 모든 용량의 60%로 유지합니다. 리소스 부족으로 인한 다운타임을 방지하기 위해 컨트롤 플레인 노드에서 CPU 및 메모리를 늘립니다.
노드 크기 조정은 클러스터의 노드 수와 개체 수에 따라 달라집니다. 또한 클러스터에서 개체가 현재 생성되는지에 따라 달라집니다. 개체 생성 중에 컨트롤 플레인은 개체가 running 단계에 있을 때보다 리소스 사용량 측면에서 더 활성화됩니다.
OLM(Operator Lifecycle Manager)은 컨트롤 플레인 노드에서 실행되며, 메모리 공간은 OLM이 클러스터에서 관리해야 하는 네임스페이스 및 사용자 설치된 operator 수에 따라 다릅니다. OOM이 종료되지 않도록 컨트를 플레인 노드의 크기를 적절하게 조정해야 합니다. 다음 데이터 지점은 클러스터 최대값 테스트 결과를 기반으로 합니다.
| 네임스페이스 수 | 유휴 상태의 OLM 메모리(GB) | 5명의 사용자 operator가 설치된 OLM 메모리(GB) |
|---|---|---|
| 500 | 0.823 | 1.7 |
| 1000 | 1.2 | 2.5 |
| 1500 | 1.7 | 3.2 |
| 2000 | 2 | 4.4 |
| 3000 | 2.7 | 5.6 |
| 4000 | 3.8 | 7.6 |
| 5000 | 4.2 | 9.02 |
| 6000 | 5.8 | 11.3 |
| 7000 | 6.6 | 12.9 |
| 8000 | 6.9 | 14.8 |
| 9000 | 8 | 17.7 |
| 10,000 | 9.9 | 21.6 |
설치 관리자 프로비저닝 인프라 설치 방법을 사용하는 경우 실행 중인 OpenShift Container Platform 4.8 클러스터에서 컨트롤 플레인 노드 크기를 변경할 수 없습니다. 대신 총 노드 수를 추정하고 설치하는 동안 권장되는 컨트롤 플레인 노드 크기를 사용해야 합니다.
권장 사항은 OpenShift SDN이 있는 OpenShift Container Platform 클러스터에서 네트워크 플러그인으로 캡처된 데이터 포인트를 기반으로 합니다.
OpenShift Container Platform 3.11 및 이전 버전과 비교하면, OpenShift Container Platform 4.8에서는 기본적으로 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 이러한 점을 고려하여 크기가 결정됩니다.
1.4.1. AWS(Amazon Web Services) 마스터 인스턴스의 플레이버 크기 증가
클러스터에 AWS 마스터 노드에 과부하가 발생하고 마스터 노드에 더 많은 리소스가 필요한 경우 마스터 인스턴스의 플레이버 크기를 늘릴 수 있습니다.
AWS 마스터 인스턴스의 플레이버 크기를 늘리기 전에 etcd를 백업하는 것이 좋습니다.
사전 요구 사항
- AWS에 IPI(설치 프로그램 프로비저닝 인프라) 또는 UPI(사용자 프로비저닝 인프라) 클러스터가 있습니다.
절차
- AWS 콘솔을 열고 마스터 인스턴스를 가져옵니다.
- 하나의 마스터 인스턴스를 중지합니다.
- 중지된 인스턴스를 선택하고 작업 → 인스턴스 설정 → 인스턴스 유형 변경을 클릭합니다.
-
인스턴스를 더 큰 유형으로 변경하고 유형이 이전 선택과 동일한 기본인지 확인하고 변경 사항을 적용합니다. 예를 들어
m5.xlarge를 m로 변경할 수 있습니다.5.2xlarge또는m5.4xlarge - 인스턴스를 백업하고 다음 master 인스턴스에 대한 단계를 반복합니다.
추가 리소스
1.5. etcd 관련 권장 사례
etcd는 디스크에 데이터를 쓰고 디스크에 제안을 유지하므로 디스크 성능에 따라 성능이 달라집니다. etcd는 특별히 I/O 집약적이 아니지만 성능과 안정성을 최적화하려면 대기 시간이 짧은 블록 장치가 필요합니다. etcd의 비관성 프로토콜은 메타데이터를 로그에 영구적으로 저장하는 데 따라 달라지므로 etcd는 디스크 쓰기 대기 시간에 민감합니다. 디스크 속도가 느리고 다른 프로세스의 디스크 활동이 길어지면 fsync 대기 시간이 길어질 수 있습니다.
이러한 대기 시간 동안 etcd가 하트비트를 놓치고 새 제안을 제때 디스크에 커밋하지 않고 궁극적으로 요청 시간 초과 및 임시 리더 손실이 발생할 수 있습니다. 또한 쓰기 대기 시간이 길면 OpenShift API 속도가 느려 클러스터 성능에 영향을 미칩니다. 이러한 이유로 컨트롤 플레인 노드에서 다른 워크로드가 배치되지 않도록 합니다.
대기 시간에서는 블록 장치 위에서 etcd를 실행하여 8000바이트 이상의 IOPS를 순차적으로 작성할 수 있습니다. 즉, 대기 시간이 20ms인 경우 fdatasync를 사용하여 WAL의 각 쓰기를 동기화하는 것을 염두에 두십시오. 로드된 클러스터의 경우 8000바이트(2ms)의 순차적 500 IOPS를 사용하는 것이 좋습니다. 이 숫자를 측정하려면 fio와 같은 벤치마킹 도구를 사용할 수 있습니다.
이러한 성능을 얻으려면 대기 시간이 짧고 처리량이 높은 SSD 또는 NVMe 디스크가 지원되는 머신에서 etcd를 실행하십시오. 메모리 셀당 1 비트를 제공하고, 내구성이 있고 신뢰할 수 있으며 쓰기 집약적인 워크로드에 이상적입니다.
다음 하드 디스크 기능은 최적의 etcd 성능을 제공합니다.
- 빠른 읽기 작업을 지원하기 위한 대기 시간이 짧습니다.
- 더 빠른 압축 및 조각 모음을 위한 높은 대역폭 쓰기
- 고 대역폭 읽기를 통해 실패로 인한 복구 속도가 빨라집니다.
- 솔리드 스테이트 드라이브는 최소 선택이지만 NVMe 드라이브가 우선합니다.
- 신뢰성을 높이기 위해 다양한 제조 업체의 서버 등급 하드웨어.
- 성능 향상을 위한 RAID 0 기술
- 전용 etcd 드라이브 etcd 드라이브에 로그 파일 또는 기타 많은 워크로드를 배치하지 마십시오.
NAS 또는 SAN 설정 및 회전 드라이브를 사용하지 마십시오. 항상 fio와 같은 유틸리티를 사용하여 벤치마크를 수행합니다. 증가하는 동안 클러스터 성능을 지속적으로 모니터링합니다.
NFS(Network File System) 프로토콜 또는 기타 네트워크 기반 파일 시스템을 사용하지 마십시오.
배포된 OpenShift Container Platform 클러스터에서 모니터링하기 위한 몇 가지 주요 메트릭은 etcd 디스크 미리 쓰기 시 미리 쓰기 시간 및 etcd 리더 변경 횟수입니다. 이러한 지표를 추적하려면 Prometheus를 사용하십시오.
OpenShift Container Platform 클러스터를 생성하기 전이나 후에 etcd 하드웨어를 확인하려면 fio를 사용할 수 있습니다.
사전 요구 사항
- Podman 또는 Docker와 같은 컨테이너 런타임은 테스트 중인 머신에 설치됩니다.
-
데이터는
/var/lib/etcd경로에 작성됩니다.
프로세스
Fio를 실행하고 결과를 분석합니다.
Podman을 사용하는 경우 다음 명령을 실행합니다.
$ sudo podman run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
Docker를 사용하는 경우 다음 명령을 실행합니다.
$ sudo docker run --volume /var/lib/etcd:/var/lib/etcd:Z quay.io/openshift-scale/etcd-perf
실행에서 캡처된 fsync 지표의 99번째 백분위수를 비교하여 20ms 미만인지 확인하여 디스크 속도가 etcd를 호스팅하기에 충분한지 여부를 출력에서 보고합니다. I/O 성능의 영향을 받을 수 있는 가장 중요한 etcd 지표 중 일부는 다음과 같습니다.
-
etcd_disk_wal_fsync_duration_seconds_bucket지표가 etcd의 WAL fsync 기간 보고 -
etcd_disk_backend_commit_duration_seconds_bucket지표에서 etcd 백엔드 커밋 대기 시간 보고 -
etcd_server_leader_changes_seen_total지표에서 리더 변경을 보고
etcd는 모든 멤버 간에 요청을 복제하므로 성능은 네트워크 입력/출력(I/O) 대기 시간에 따라 크게 달라집니다. 네트워크 대기 시간이 길면 etcd 하트비트가 선택 시간 초과보다 오래 걸리므로 리더 선택이 발생하여 클러스터가 손상될 수 있습니다. 배포된 OpenShift Container Platform 클러스터에서 모니터링되는 주요 메트릭은 각 etcd 클러스터 멤버에서 etcd 네트워크 피어 대기 시간의 99번째 백분위 수입니다. 이러한 메트릭을 추적하려면 Prometheus를 사용하십시오.
histogram_quantile(0.99, rate(etcd_network_peer_round_trip_time_seconds_bucket[2m]) 지표에서 etcd가 멤버 간 클라이언트 요청을 복제하기 위한 왕복 시간을 보고합니다. 50ms보다 작은지 확인하십시오.
1.6. etcd 데이터 조각 모음
대규모 및 밀도가 높은 클러스터의 경우 키 공간이 너무 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. 주기적으로 etcd를 유지 관리하고 조각 모음하여 데이터 저장소에서 공간을 확보합니다. etcd 지표에 대한 Prometheus를 모니터링하고 필요한 경우 조각 모음을 모니터링합니다. 그러지 않으면 etcd에서 키 읽기 및 삭제만 수락하는 유지 관리 모드로 클러스터를 배치하는 클러스터 전체 알람을 생성할 수 있습니다.
다음 주요 메트릭을 모니터링합니다.
-
etcd_server_quota_backend_bytes, 현재 할당량 제한 -
etcd_mvcc_db_total_size_in_use_in_bytes. 이는 기록 압축 후 실제 데이터베이스 사용량을 나타냅니다. -
etcd_debugging_mvcc_db_total_size_in_bytes. 여기에는 조각 모음 대기 중인 여유 공간을 포함하여 데이터베이스 크기가 표시됩니다.
etcd 기록 압축과 같은 디스크 조각화를 초래하는 이벤트 후 디스크 공간을 회수하기 위해 etcd 데이터를 조각 모음합니다.
기록 압축은 5분마다 자동으로 수행되며 백엔드 데이터베이스에서 공백이 남습니다. 이 분할된 공간은 etcd에서 사용할 수 있지만 호스트 파일 시스템에서 사용할 수 없습니다. 호스트 파일 시스템에서 이 공간을 사용할 수 있도록 etcd 조각을 정리해야 합니다.
etcd는 디스크에 데이터를 쓰기 때문에 etcd 성능은 디스크 성능에 따라 크게 달라집니다. 매달 또는 한달에 한 두 번 또는 클러스터에 필요한 경우 etcd를 조각을 정리하는 것이 좋습니다. etcd_db_total_size_in_bytes 메트릭을 모니터링하여 조각 모음이 필요한지 여부를 결정할 수도 있습니다.
PromQL 표현식을 사용하여 조각 모음을 사용하여 해제할 etcd 데이터베이스 크기를 MB 단위로 확인하여 조각 모음이 필요한지 여부를 확인할 수도 있습니다. (etcd_mvcc_db_total_size_in_in_bytes - etcd_mvcc_in_in_use_in_bytes)/1024/1024
etcd를 분리하는 것은 차단 작업입니다. 조각화 처리가 완료될 때까지 etcd 멤버는 응답하지 않습니다. 따라서 각 pod의 조각 모음 작업 간에 클러스터가 정상 작동을 재개할 수 있도록 1분 이상 대기해야 합니다.
각 etcd 멤버의 etcd 데이터 조각 모음을 수행하려면 다음 절차를 따릅니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
절차
리더가 최종 조각화 처리를 수행하므로 어떤 etcd 멤버가 리더인지 확인합니다.
etcd pod 목록을 가져옵니다.
$ oc get pods -n openshift-etcd -o wide | grep -v quorum-guard | grep etcd
출력 예
etcd-ip-10-0-159-225.example.redhat.com 3/3 Running 0 175m 10.0.159.225 ip-10-0-159-225.example.redhat.com <none> <none> etcd-ip-10-0-191-37.example.redhat.com 3/3 Running 0 173m 10.0.191.37 ip-10-0-191-37.example.redhat.com <none> <none> etcd-ip-10-0-199-170.example.redhat.com 3/3 Running 0 176m 10.0.199.170 ip-10-0-199-170.example.redhat.com <none> <none>
Pod를 선택하고 다음 명령을 실행하여 어떤 etcd 멤버가 리더인지 확인합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com etcdctl endpoint status --cluster -w table
출력 예
Defaulting container name to etcdctl. Use 'oc describe pod/etcd-ip-10-0-159-225.example.redhat.com -n openshift-etcd' to see all of the containers in this pod. +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
이 출력의
ISLEADER 열에 따르면https://10.0.199.170:2379엔드 포인트가 리더입니다. 이전 단계의 출력과 이 앤드 포인트가 일치하면 리더의 Pod 이름은etcd-ip-10-0199-170.example.redhat.com입니다.
etcd 멤버를 분리합니다.
실행중인 etcd 컨테이너에 연결하고 리더가 아닌 pod 이름을 전달합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-159-225.example.redhat.com
ETCDCTL_ENDPOINTS환경 변수를 설정 해제합니다.sh-4.4# unset ETCDCTL_ENDPOINTS
etcd 멤버를 분리합니다.
sh-4.4# etcdctl --command-timeout=30s --endpoints=https://localhost:2379 defrag
출력 예
Finished defragmenting etcd member[https://localhost:2379]
시간 초과 오류가 발생하면 명령이 성공할 때까지
--command-timeout의 값을 늘립니다.데이터베이스 크기가 감소되었는지 확인합니다.
sh-4.4# etcdctl endpoint status -w table --cluster
출력 예
+---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | https://10.0.191.37:2379 | 251cd44483d811c3 | 3.4.9 | 104 MB | false | false | 7 | 91624 | 91624 | | | https://10.0.159.225:2379 | 264c7c58ecbdabee | 3.4.9 | 41 MB | false | false | 7 | 91624 | 91624 | | 1 | https://10.0.199.170:2379 | 9ac311f93915cc79 | 3.4.9 | 104 MB | true | false | 7 | 91624 | 91624 | | +---------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+이 예에서는 etcd 멤버의 데이터베이스 크기가 시작 크기인 104MB와 달리 현재 41MB임을 보여줍니다.
다음 단계를 반복하여 다른 etcd 멤버에 연결하고 조각 모음을 수행합니다. 항상 리더의 조각 모음을 마지막으로 수행합니다.
etcd pod가 복구될 수 있도록 조각 모음 작업에서 1분 이상 기다립니다. etcd pod가 복구될 때까지 etcd 멤버는 응답하지 않습니다.
공간 할당량을 초과하여
NOSPACE경고가 발생하는 경우 이를 지우십시오.NOSPACE경고가 있는지 확인합니다.sh-4.4# etcdctl alarm list
출력 예
memberID:12345678912345678912 alarm:NOSPACE
경고를 지웁니다.
sh-4.4# etcdctl alarm disarm
1.7. OpenShift Container Platform 인프라 구성 요소
다음 인프라 워크로드에서는 OpenShift Container Platform 작업자 서브스크립션이 발생하지 않습니다.
- 마스터에서 실행되는 Kubernetes 및 OpenShift Container Platform 컨트롤 플레인 서비스
- 기본 라우터
- 통합된 컨테이너 이미지 레지스트리
- HAProxy 기반 Ingress 컨트롤러
- 사용자 정의 프로젝트를 모니터링하기위한 구성 요소를 포함한 클러스터 메트릭 수집 또는 모니터링 서비스
- 클러스터 집계 로깅
- 서비스 브로커
- Red Hat Quay
- Red Hat OpenShift Container Storage
- Red Hat Advanced Cluster Manager
- Red Hat Advanced Cluster Security for Kubernetes
- Red Hat OpenShift GitOps
- Red Hat OpenShift Pipelines
다른 컨테이너, Pod 또는 구성 요소를 실행하는 모든 노드는 서브스크립션을 적용해야 하는 작업자 노드입니다.
추가 리소스
- 인프라 노드 및 인프라 노드에서 실행할 수 있는 구성 요소에 대한 자세한 내용은 엔터프라이즈 Kubernetes 문서의 OpenShift 크기 조정 및 서브스크립션 가이드의 "Red Hat OpenShift 컨트롤 플레인 및 인프라 노드" 섹션을 참조하십시오.
1.8. 모니터링 솔루션 이동
모니터링 스택에는 Prometheus, Grafana, Alertmanager를 포함한 여러 구성 요소가 포함됩니다. Cluster Monitoring Operator는 이 스택을 관리합니다. 모니터링 스택을 인프라 노드에 재배포하려면 사용자 정의 구성 맵을 생성하고 적용할 수 있습니다.
프로세스
cluster-monitoring-config구성 맵을 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: |+ alertmanagerMain: nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusK8s: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute prometheusOperator: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute grafana: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute k8sPrometheusAdapter: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute kubeStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute telemeterClient: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute openshiftStateMetrics: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute thanosQuerier: nodeSelector: node-role.kubernetes.io/infra: "" tolerations: - key: node-role.kubernetes.io/infra value: reserved effect: NoSchedule - key: node-role.kubernetes.io/infra value: reserved effect: NoExecute모니터링 pod가 새 머신으로 이동하는 것을 확인합니다.
$ watch 'oc get pod -n openshift-monitoring -o wide'
구성 요소가
infra노드로 이동하지 않은 경우 이 구성 요소가 있는 pod를 제거합니다.$ oc delete pod -n openshift-monitoring <pod>
삭제된 pod의 구성 요소가
infra노드에 다시 생성됩니다.
1.9. 기본 레지스트리 이동
Pod를 다른 노드에 배포하도록 레지스트리 Operator를 구성합니다.
전제 조건
- OpenShift Container Platform 클러스터에서 추가 머신 세트를 구성합니다.
프로세스
config/instance개체를 표시합니다.$ oc get configs.imageregistry.operator.openshift.io/cluster -o yaml
출력 예
apiVersion: imageregistry.operator.openshift.io/v1 kind: Config metadata: creationTimestamp: 2019-02-05T13:52:05Z finalizers: - imageregistry.operator.openshift.io/finalizer generation: 1 name: cluster resourceVersion: "56174" selfLink: /apis/imageregistry.operator.openshift.io/v1/configs/cluster uid: 36fd3724-294d-11e9-a524-12ffeee2931b spec: httpSecret: d9a012ccd117b1e6616ceccb2c3bb66a5fed1b5e481623 logging: 2 managementState: Managed proxy: {} replicas: 1 requests: read: {} write: {} storage: s3: bucket: image-registry-us-east-1-c92e88cad85b48ec8b312344dff03c82-392c region: us-east-1 status: ...config/instance개체를 편집합니다.$ oc edit configs.imageregistry.operator.openshift.io/cluster
spec: affinity: podAntiAffinity: preferredDuringSchedulingIgnoredDuringExecution: - podAffinityTerm: namespaces: - openshift-image-registry topologyKey: kubernetes.io/hostname weight: 100 logLevel: Normal managementState: Managed nodeSelector: 1 node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 톨러레이션도 추가합니다.
레지스트리 pod가 인프라 노드로 이동되었는지 검증합니다.
다음 명령을 실행하여 레지스트리 pod가 있는 노드를 식별합니다.
$ oc get pods -o wide -n openshift-image-registry
노드에 지정된 레이블이 있는지 확인합니다.
$ oc describe node <node_name>
명령 출력을 확인하고
node-role.kubernetes.io/infra가LABELS목록에 있는지 확인합니다.
1.10. 라우터 이동
라우터 Pod를 다른 머신 세트에 배포할 수 있습니다. 기본적으로 Pod는 작업자 노드에 배포됩니다.
전제 조건
- OpenShift Container Platform 클러스터에서 추가 머신 세트를 구성합니다.
프로세스
라우터 Operator의
IngressController사용자 정의 리소스를 표시합니다.$ oc get ingresscontroller default -n openshift-ingress-operator -o yaml
명령 출력은 다음 예제와 유사합니다.
apiVersion: operator.openshift.io/v1 kind: IngressController metadata: creationTimestamp: 2019-04-18T12:35:39Z finalizers: - ingresscontroller.operator.openshift.io/finalizer-ingresscontroller generation: 1 name: default namespace: openshift-ingress-operator resourceVersion: "11341" selfLink: /apis/operator.openshift.io/v1/namespaces/openshift-ingress-operator/ingresscontrollers/default uid: 79509e05-61d6-11e9-bc55-02ce4781844a spec: {} status: availableReplicas: 2 conditions: - lastTransitionTime: 2019-04-18T12:36:15Z status: "True" type: Available domain: apps.<cluster>.example.com endpointPublishingStrategy: type: LoadBalancerService selector: ingresscontroller.operator.openshift.io/deployment-ingresscontroller=defaultingresscontroller리소스를 편집하고infra레이블을 사용하도록nodeSelector를 변경합니다.$ oc edit ingresscontroller default -n openshift-ingress-operator
spec: nodePlacement: nodeSelector: 1 matchLabels: node-role.kubernetes.io/infra: "" tolerations: - effect: NoSchedule key: node-role.kubernetes.io/infra value: reserved - effect: NoExecute key: node-role.kubernetes.io/infra value: reserved- 1
- 적절한 값이 설정된
nodeSelector매개변수를 이동하려는 구성 요소에 추가합니다. 표시된 형식으로nodeSelector를 사용하거나 노드에 지정된 값에 따라<key>: <value>쌍을 사용할 수 있습니다. 인프라 노드에 테인트를 추가한 경우 일치하는 허용 오차도 추가합니다.
라우터 pod가
infra노드에서 실행되고 있는지 확인합니다.라우터 pod 목록을 표시하고 실행중인 pod의 노드 이름을 기록해 둡니다.
$ oc get pod -n openshift-ingress -o wide
출력 예
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES router-default-86798b4b5d-bdlvd 1/1 Running 0 28s 10.130.2.4 ip-10-0-217-226.ec2.internal <none> <none> router-default-955d875f4-255g8 0/1 Terminating 0 19h 10.129.2.4 ip-10-0-148-172.ec2.internal <none> <none>
이 예에서 실행중인 pod는
ip-10-0-217-226.ec2.internal노드에 있습니다.실행중인 pod의 노드 상태를 표시합니다.
$ oc get node <node_name> 1- 1
- pod 목록에서 얻은
<node_name>을 지정합니다.
출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-217-226.ec2.internal Ready infra,worker 17h v1.21.0
역할 목록에
infra가 포함되어 있으므로 pod가 올바른 노드에서 실행됩니다.
1.11. 인프라 노드 크기 조정
인프라 노드는 OpenShift Container Platform 환경의 일부를 실행하도록 레이블이 지정된 노드입니다. 인프라 노드 리소스 요구사항은 클러스터 사용 기간, 노드, 클러스터의 오브젝트에 따라 달라집니다. 이러한 요인으로 인해 Prometheus의 지표 또는 시계열 수가 증가할 수 있기 때문입니다. 다음 인프라 노드 크기 권장 사항은 클러스터 최대값 및 컨트롤 플레인 밀도 중심 테스트 결과를 기반으로 합니다.
| 작업자 노드 수 | CPU 코어 수 | 메모리(GB) |
|---|---|---|
| 25 | 4 | 16 |
| 100 | 8 | 32 |
| 250 | 16 | 128 |
| 500 | 32 | 128 |
일반적으로 클러스터당 세 개의 인프라 노드를 사용하는 것이 좋습니다.
이러한 크기 조정 권장 사항은 클러스터에서 많은 수의 오브젝트를 생성하는 스케일링 테스트를 기반으로 합니다. 이 테스트에는 일부 클러스터 최대값에 도달하는 테스트가 포함되어 있습니다. OpenShift Container Platform 4.8 클러스터에서 노드 수가 250~500개인 경우 최대값은 Pod가 61,000개, 배포가 10,000개, 보안이 181,000개, 구성 맵이 400개 등인 네임스페이스 10,000개입니다. Prometheus는 고도의 메모리 집약적 애플리케이션입니다. 리소스 사용량은 노드 수, 오브젝트, Prometheus 지표 스크래핑 간격, 지표 또는 시계열, 클러스터 사용 기간 등 다양한 요인에 따라 달라집니다. 디스크 크기도 보존 기간에 따라 달라집니다. 이와 같은 요인을 고려하여 적절하게 크기를 조정해야 합니다.
이러한 크기 조정 권장 사항은 클러스터 설치 중에 설치되는 인프라 구성 요소인 Prometheus, 라우터 및 레지스트리에만 적용됩니다. 로깅은 Day 2 작업에서 이러한 권장 사항은 포함되어 있지 않습니다.
OpenShift Container Platform 3.11 및 이전 버전과 비교하면, OpenShift Container Platform 4.8에서는 기본적으로 CPU 코어의 절반(500밀리코어)이 시스템에 의해 예약되어 있습니다. 명시된 크기 조정 권장 사항은 이러한 요인의 영향을 받습니다.
1.12. 추가 리소스
2장. IBM Z 및 LinuxONE 환경에 대한 권장 호스트 사례
이 주제에서는 IBM Z 및 LinuxONE의 OpenShift Container Platform에 대한 호스트 권장 사례를 설명합니다.
s390x 아키텍처는 여러 면에서 고유합니다. 따라서 여기에 제시된 일부 권장 사항은 다른 플랫폼에 적용되지 않을 수 있습니다.
별도로 명시하지 않는 한, 이러한 방법은 IBM Z 및 LinuxONE에 z/VM 및 RHEL(Red Hat Enterprise Linux) KVM 설치에 모두 적용됩니다.
2.1. CPU 과다 할당 관리
고도로 가상화된 IBM Z 환경에서는 인프라 설정 및 크기 조정을 신중하게 계획해야 합니다. 가상화의 가장 중요한 기능 중 하나는 리소스 과다 할당을 수행하여 하이퍼바이저 수준에서 실제로 사용 가능한 것보다 가상 시스템에 더 많은 리소스를 할당하는 기능입니다. 이 방법은 워크로드에 따라 다르며 모든 설정에 적용할 수 있는 결정적인 규칙이 없습니다.
설정에 따라 CPU 과다 할당과 관련된 모범 사례를 고려하십시오.
- LPAR 레벨(PR/SM 하이퍼바이저)에서는 사용 가능한 모든 물리적 코어(IFL)를 각 LPAR에 할당하지 않도록 합니다. 예를 들어, 물리적 IFL 4개를 사용할 수 있는 경우 각각 4개의 논리적 IFL이 있는 3개의 LPAR을 정의해서는 안 됩니다.
- LPAR 공유 및 가중치 확인 및 이해.
- 과도한 가상 CPU 수는 성능에 부정적인 영향을 줄 수 있습니다. 논리 프로세서가 LPAR에 정의된 것보다 게스트에 더 많은 가상 프로세서를 정의하지 마십시오.
- 게스트당 가상 프로세서 수를 최대 업무 부하가 아닌 구성.
- 소규모로 시작하고 워크로드를 모니터링합니다. 필요에 따라 vCPU 수를 점진적으로 늘립니다.
- 모든 워크로드가 높은 과다 할당 비율에 적합한 것은 아닙니다. 워크로드가 CPU를 많이 사용하는 경우 성능 문제 없이 높은 비율을 달성할 수 없을 것입니다. I/O 집약성이 높은 워크로드는 높은 과다 할당 비율을 통해서도 일관된 성능을 유지할 수 있습니다.
2.2. Transparent Huge Pages 비활성화
THP(Transparent Huge Pages)는 대규모 페이지를 생성, 관리 및 사용하는 대부분의 측면을 자동화하려고 합니다. THP는 대규모 페이지를 자동으로 관리하므로 모든 유형의 워크로드에 대해 항상 최적으로 처리되지는 않습니다. THP는 많은 애플리케이션에서 자체적으로 대규모 페이지를 처리하므로 성능 저하가 발생할 수 있습니다. 따라서 THP를 비활성화하는 것이 좋습니다.
2.3. 수신 흐름으로 네트워킹 성능 향상
RFS(Receive Packet Buildering)는 네트워크 대기 시간을 추가로 줄임으로써 수신 패킷 제거(RPS)를 확장합니다. ss는 기술적으로 RPS를 기반으로 하며 CPU 캐시 적중 속도를 늘려 패킷 처리 효율성을 향상시킵니다. 이를 통해 이를 달성하고, 캐시 적중이 CPU 내에서 발생할 가능성이 높아지도록 계산에 가장 편리한 CPU를 결정함으로써 대기열 길이를 고려합니다. 따라서 CPU 캐시가 무효화되고 캐시를 다시 빌드하려면 더 적은 사이클이 필요합니다. 이렇게 하면 패킷 처리 실행 시간을 줄일 수 있습니다.
2.3.1. MCO(Machine Config Operator)를 사용하여 HFSS 활성화
절차
다음 MCO 샘플 프로필을 YAML 파일에 복사합니다. 예를 들어
enable-rfs.yaml:apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 50-enable-rfs spec: config: ignition: version: 2.2.0 storage: files: - contents: source: data:text/plain;charset=US-ASCII,%23%20turn%20on%20Receive%20Flow%20Steering%20%28RFS%29%20for%20all%20network%20interfaces%0ASUBSYSTEM%3D%3D%22net%22%2C%20ACTION%3D%3D%22add%22%2C%20RUN%7Bprogram%7D%2B%3D%22/bin/bash%20-c%20%27for%20x%20in%20/sys/%24DEVPATH/queues/rx-%2A%3B%20do%20echo%208192%20%3E%20%24x/rps_flow_cnt%3B%20%20done%27%22%0A filesystem: root mode: 0644 path: /etc/udev/rules.d/70-persistent-net.rules - contents: source: data:text/plain;charset=US-ASCII,%23%20define%20sock%20flow%20enbtried%20for%20%20Receive%20Flow%20Steering%20%28RFS%29%0Anet.core.rps_sock_flow_entries%3D8192%0A filesystem: root mode: 0644 path: /etc/sysctl.d/95-enable-rps.confMCO 프로필을 생성합니다.
$ oc create -f enable-rfs.yaml
50-enable-rfs라는 항목이 나열되는지확인합니다.$ oc get mc
비활성화하려면 다음을 입력합니다.
$ oc delete mc 50-enable-rfs
추가 리소스
- IBM Z의 OpenShift Container Platform: an network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the network performance with the
- 수신 흐름 제거(RFS) 구성
- Linux 네트워킹 스택에서 확장
2.4. 네트워크 설정을 선택하십시오
네트워킹 스택은 OpenShift Container Platform과 같은 Kubernetes 기반 제품에 가장 중요한 구성 요소 중 하나입니다. IBM Z 설정의 경우 네트워킹 설정은 선택한 하이퍼바이저에 따라 다릅니다. 워크로드 및 애플리케이션에 따라 일반적으로 사용 사례 및 트래픽 패턴에 따라 가장 적합한 것이 좋습니다.
설정에 따라 다음 모범 사례를 고려하십시오.
- 트래픽 패턴을 최적화하려면 네트워킹 장치와 관련된 모든 옵션을 고려하십시오. OSA-Express, RoCE Express, HiperSockets, z/VM VSwitch, Linux Bridge(KVM) 등의 장점을 살펴보고 설치 시 가장 큰 이점을 제공하는 옵션을 결정하십시오.
- 항상 사용 가능한 최신 NIC 버전을 사용합니다. 예를 들어 OSA Express 7S 10 GbE는 모두 10GbE 어댑터이지만 트랜잭션 워크로드 유형의 OSA Express 6S 10GbE에 비해 훨씬 향상되었습니다.
- 각 가상 스위치는 추가 대기 시간 계층을 추가합니다.
- 로드 밸런서는 클러스터 외부의 네트워크 통신에 중요한 역할을 합니다. 애플리케이션이 중요한 경우 프로덕션급 하드웨어 로드 밸런서를 사용하는 것이 좋습니다.
- OpenShift Container Platform SDN에는 네트워킹 성능에 영향을 주는 흐름과 규칙이 도입되었습니다. 통신이 중요한 서비스의 지역으로부터 혜택을 받으려면 포드 선호도 및 배치를 고려해야 합니다.
- 성능과 기능 간의 장단점 균형을 맞추십시오.
2.5. z/VM에서 HyperPAV로 높은 디스크 성능 확인
DASD 및 ECKD 장치는 일반적으로 IBM Z 환경에서 디스크 유형으로 사용됩니다. z/VM 환경의 일반적인 OpenShift Container Platform 설정에서 DASD 디스크는 노드의 로컬 스토리지를 지원하는 데 일반적으로 사용됩니다. z/VM 게스트를 지원하는 DASD 디스크에 대해 더 많은 처리량과 전반적으로 개선된 I/O 성능을 제공하도록 HyperPAV 별칭 장치를 설정할 수 있습니다.
로컬 스토리지 장치에 HyperPAV를 사용하면 성능이 크게 향상됩니다. 그러나 처리량과 CPU 비용 간에 장단점이 있다는 점에 유의해야 합니다.
2.5.1. z/VM full-pack minidisks를 사용하여 노드에서 HyperPAV 별칭을 활성화하려면 MCO(Machine Config Operator)를 사용합니다.
전체 팩 미니 디스크를 사용하는 z/VM 기반 OpenShift Container Platform 설정의 경우 모든 노드에서 HyperPAV 별칭을 활성화하여 MCO 프로필의 이점을 활용할 수 있습니다. 컨트롤 플레인 및 컴퓨팅 노드 모두에 YAML 구성을 추가해야 합니다.
절차
다음 MCO 샘플 프로필을 컨트롤 플레인 노드의 YAML 파일에 복사합니다. 예를 들면
05-master-kernelarg-hpav.yaml:$ cat 05-master-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: master name: 05-master-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805다음 MCO 샘플 프로필을 계산 노드의 YAML 파일에 복사합니다. 예를 들면
05-worker-kernelarg-hpav.yaml:$ cat 05-worker-kernelarg-hpav.yaml apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfig metadata: labels: machineconfiguration.openshift.io/role: worker name: 05-worker-kernelarg-hpav spec: config: ignition: version: 3.1.0 kernelArguments: - rd.dasd=800-805참고장치 ID에 맞게
rd.dasd인수를 수정해야 합니다.MCO 프로필을 생성합니다.
$ oc create -f 05-master-kernelarg-hpav.yaml
$ oc create -f 05-worker-kernelarg-hpav.yaml
비활성화하려면 다음을 입력합니다.
$ oc delete -f 05-master-kernelarg-hpav.yaml
$ oc delete -f 05-worker-kernelarg-hpav.yaml
2.6. IBM Z 호스트의 RHEL KVM 권장 사항
KVM 가상 서버 환경 최적화는 가상 서버의 워크로드와 사용 가능한 리소스에 따라 크게 달라집니다. 한 환경에서 성능을 개선하는 것과 동일한 조치는 다른 환경에서 부정적인 영향을 미칠 수 있습니다. 특정 설정의 최적의 균형을 찾는 것은 어려운 일이며, 종종 실험이 필요합니다.
다음 섹션에서는 IBM Z 및 LinuxONE 환경에서 RHEL KVM과 함께 OpenShift Container Platform을 사용할 때 몇 가지 모범 사례를 소개합니다.
2.6.1. VirtIO 네트워크 인터페이스에 여러 큐 사용
여러 가상 CPU를 사용하면 들어오고 나가는 패킷에 여러 큐를 제공하는 경우 동시에 패키지를 전송할 수 있습니다. 드라이버 요소의 queues 특성을 사용하여 여러 큐를 구성합니다. 가상 서버의 가상 CPU 수를 초과하지 않는 정수 2를 지정합니다.
다음 예제 사양은 네트워크 인터페이스에 대해 두 개의 입력 및 출력 대기열을 구성합니다.
<interface type="direct">
<source network="net01"/>
<model type="virtio"/>
<driver ... queues="2"/>
</interface>다중 대기열은 네트워크 인터페이스에 향상된 성능을 제공하도록 설계되었지만 메모리 및 CPU 리소스도 사용합니다. 사용 중인 인터페이스에 사용할 두 개의 큐 정의로 시작합니다. 그런 다음 사용 중인 인터페이스에 대해 트래픽이 적거나 대기열이 2개 이상인 인터페이스에 대해 두 개의 대기열을 시도합니다.
2.6.2. 가상 블록 장치에 I/O 스레드 사용
가상 블록 장치가 I/O 스레드를 사용하도록 하려면 이러한 I/O 스레드 중 하나를 사용하도록 가상 서버 및 각 가상 블록 장치에 대해 하나 이상의 I/O 스레드를 구성해야 합니다.
다음 예제에서는 연속 10진수 스레드 ID 1, 2 및 3을 사용하여 3개의 I /O 스레드를 구성하도록 <iothreads>3</iothreads>를 지정합니다. The iothread" 매개 변수는 ID 2와 함께 I/O 스레드를 사용하도록 디스크 장치의 드라이버 요소를 지정합니다.
I/O 스레드 사양 샘플
... <domain> <iothreads>3</iothreads>1 ... <devices> ... <disk type="block" device="disk">2 <driver ... iothread="2"/> </disk> ... </devices> ... </domain>
스레드는 디스크 장치의 I/O 작업의 성능을 향상시킬 수 있지만 메모리 및 CPU 리소스도 사용합니다. 동일한 스레드를 사용하도록 여러 장치를 구성할 수 있습니다. 스레드를 장치에 가장 잘 매핑하는 방법은 사용 가능한 리소스 및 워크로드에 따라 다릅니다.
소수의 I/O 스레드로 시작합니다. 종종 모든 디스크 장치에 대한 단일 I/O 스레드만으로 충분합니다. 가상 CPU 수보다 많은 스레드를 구성하지 말고 유휴 스레드를 구성하지 마십시오.
virsh iothreadadd 명령을 사용하여 실행 중인 가상 서버에 특정 스레드 ID가 있는 I/O 스레드를 추가할 수 있습니다.
2.6.3. 가상 SCSI 장치 방지
SCSI별 인터페이스를 통해 장치를 해결해야 하는 경우에만 가상 SCSI 장치를 구성합니다. 호스트의 백업과 관계없이 디스크 공간을 가상 SCSI 장치가 아닌 가상 블록 장치로 구성합니다.
그러나 다음을 위해 SCSI 관련 인터페이스가 필요할 수 있습니다.
- 호스트에서 SCSI 연결 테이프 드라이브의 LUN입니다.
- 가상 DVD 드라이브에 마운트된 호스트 파일 시스템의 DVD ISO 파일입니다.
2.6.4. 디스크에 게스트 캐싱 설정
호스트가 아닌 게스트가 캐싱을 수행하도록 디스크 장치를 구성합니다.
디스크 장치의 드라이버 요소에 cache="none" 및 매개변수가 포함되어 있는지 확인합니다.
io="native"
<disk type="block" device="disk">
<driver name="qemu" type="raw" cache="none" io="native" iothread="1"/>
...
</disk>2.6.5. 메모리 증대 장치 제외
동적 메모리 크기가 필요하지 않은 경우 메모리 balloon 장치를 정의하지 말고 libvirt가 사용자를 위해 파일을 생성하지 않도록 합니다. memballoon 매개 변수를 도메인 구성 XML 파일의 devices 요소의 하위 항목으로 포함합니다.
활성 프로파일 목록을 확인합니다.
<memballoon model="none"/>
2.6.6. 호스트 스케줄러의 CPU 마이그레이션 알고리즘 조정
결과를 이해하는 전문가인 경우가 아니면 스케줄러 설정을 변경하지 마십시오. 테스트하지 않고 프로덕션 시스템에 변경 사항을 적용하지 않고 변경 사항을 적용하고 의도한 영향을 미치는지 확인하지 마십시오.
kernel.sched_migration_cost_ns 매개변수는 나노초 단위로 시간 간격을 지정합니다. 작업을 마지막으로 실행한 후에는 이 간격이 만료될 때까지 CPU 캐시에 유용한 콘텐츠가 있는 것으로 간주됩니다. 이 간격을 늘리면 작업 마이그레이션이 줄어듭니다. 기본값은 500000 ns입니다.
실행 가능한 프로세스가 있을 때 CPU 유휴 시간이 예상보다 크면 이 간격을 줄이십시오. CPU 또는 노드 간에 너무 자주 바운싱되는 경우 작업을 늘리십시오.
간격을 60000 ns로 동적으로 설정하려면 다음 명령을 입력합니다.
# sysctl kernel.sched_migration_cost_ns=60000
값을 60000 ns로 영구적으로 변경하려면 /etc/sysctl.conf에 다음 항목을 추가합니다.
kernel.sched_migration_cost_ns=60000
2.6.7. cpuset cgroup 컨트롤러 비활성화
이 설정은 cgroup 버전 1이 있는 KVM 호스트에만 적용됩니다. 호스트에서 CPU 핫플러그를 활성화하려면 cgroup 컨트롤러를 비활성화합니다.
절차
-
선택한 편집기를 사용하여
/etc/libvirt/qemu.conf를 엽니다. -
cgroup_controllers행으로 이동합니다. - 전체 행을 복제하고 복사에서 선행 기호(#)를 제거합니다.
다음과 같이
cpuset항목을 제거합니다.cgroup_controllers = [ "cpu", "devices", "memory", "blkio", "cpuacct" ]
새 설정을 적용하려면 libvirtd 데몬을 다시 시작해야 합니다.
- 모든 가상 시스템을 중지합니다.
다음 명령을 실행합니다.
# systemctl restart libvirtd
- 가상 시스템을 다시 시작합니다.
이 설정은 호스트 재부팅 시 유지됩니다.
2.6.8. 유휴 가상 CPU의 폴링 기간 조정
가상 CPU가 유휴 상태가 되면 KVM은 호스트 리소스를 할당하기 전에 가상 CPU의 시작 조건을 폴링합니다. /sys/module/kvm/parameters/halt_poll_ns 의 sysfs에서 폴링이 발생하는 시간 간격을 지정할 수 있습니다. 지정된 시간 동안 폴링을 수행하면 리소스 사용량을 희생할 때 가상 CPU의 대기 시간이 줄어듭니다. 워크로드에 따라 폴링 시간이 길거나 짧을 수 있습니다. 시간 간격은 나노초 단위로 지정됩니다. 기본값은 50000 ns입니다.
낮은 CPU 소비를 최적화하려면 작은 값을 입력하거나 0을 작성하여 폴링을 비활성화합니다.
# echo 0 > /sys/module/kvm/parameters/halt_poll_ns
트랜잭션 워크로드의 경우 대기 시간이 짧도록 최적화하려면 큰 값을 입력합니다.
# echo 80000 > /sys/module/kvm/parameters/halt_poll_ns
3장. 클러스터 스케일링 관련 권장 사례
이 섹션의 지침은 클라우드 공급자 통합을 통한 설치에만 관련이 있습니다.
이러한 지침은 OVN(Open Virtual Network)이 아닌 SDN(소프트웨어 정의 네트워킹)을 사용하는 OpenShift Container Platform에 적용됩니다.
다음 모범 사례를 적용하여 OpenShift Container Platform 클러스터의 작업자 머신 수를 스케일링하십시오. 작업자 머신 세트에 정의된 복제본 수를 늘리거나 줄여 작업자 머신을 스케일링합니다.
3.1. 클러스터 스케일링에 대한 권장 사례
노드 수가 많아지도록 클러스터를 확장하는 경우 다음을 수행합니다.
- 고가용성을 위해 모든 사용 가능한 영역으로 노드를 분산합니다.
- 한 번에 확장하는 머신 수가 25~50개를 넘지 않도록 합니다.
- 주기적인 공급자 용량 제약 조건을 완화하는 데 도움이 되도록 유사한 크기의 대체 인스턴스 유형을 사용하여 사용 가능한 각 영역에 새 머신 세트를 생성하는 것을 고려해 봅니다. 예를 들어 AWS에서 m5.large 및 m5d.large를 사용합니다.
클라우드 제공자는 API 서비스 할당량을 구현할 수 있습니다. 따라서 점진적으로 클러스터를 스케일링하십시오.
머신 세트의 복제본이 한 번에 모두 더 높은 숫자로 설정되면 컨트롤러가 머신을 생성하지 못할 수 있습니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에서 처리할 수 있는 요청 수는 프로세스에 영향을 미칩니다. 컨트롤러는 상태를 사용하여 머신을 생성하고, 점검하고, 업데이트하는 동안 더 많이 쿼리하기 시작합니다. OpenShift Container Platform이 배포된 클라우드 플랫폼에는 API 요청 제한이 있으며 과도한 쿼리는 클라우드 플랫폼 제한으로 인한 머신 생성 실패로 이어질 수 있습니다.
노드 수가 많아지도록 스케일링하는 경우 머신 상태 점검을 활성화하십시오. 실패가 발생하면 상태 점검에서 상태를 모니터링하고 비정상 머신을 자동으로 복구합니다.
대규모 및 밀도가 높은 클러스터의 노드 수를 줄이는 경우 이 프로세스가 종료할 노드에서 실행되는 개체의 드레이닝 또는 제거가 동시에 실행되기 때문에 많은 시간이 걸릴 수 있습니다. 또한 제거할 개체가 너무 많으면 클라이언트 요청 처리에 병목 현상이 발생할 수 있습니다. 기본 클라이언트 QPS 및 버스트 비율은 현재 5 및 10으로 각각 설정되어 있으며 OpenShift Container Platform에서 수정할 수 없습니다.
3.2. 머신 세트 수정
머신 세트를 변경하려면 MachineSet YAML을 편집합니다. 다음으로 각 머신을 삭제하거나 복제본 수가 0이 되도록 머신 세트를 축소하여 머신 세트와 연관된 모든 머신을 제거합니다. 복제본을 필요한 수로 다시 조정합니다. 머신 세트를 변경해도 기존 머신에는 영향을 미치지 않습니다.
다른 변경을 수행하지 않고 머신 세트를 스케일링해야 하는 경우 머신을 삭제할 필요가 없습니다.
기본적으로 OpenShift Container Platform 라우터 Pod는 작업자에게 배포됩니다. 라우터는 웹 콘솔을 포함한 일부 클러스터 리소스에 액세스해야 하므로 먼저 라우터 Pod를 재배치하지 않는 한 작업자 머신 세트를 0으로 스케일링하지 마십시오.
전제 조건
-
OpenShift Container Platform 클러스터 및
oc명령행을 설치합니다. -
cluster-admin권한이 있는 사용자로oc에 로그인합니다.
프로세스
머신 세트를 편집합니다.
$ oc edit machineset <machineset> -n openshift-machine-api
머신 세트를
0으로 축소합니다.$ oc scale --replicas=0 machineset <machineset> -n openshift-machine-api
또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api
작은 정보다음 YAML을 적용하여 머신 세트를 확장할 수도 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 0
머신이 제거될 때까지 기다립니다.
필요에 따라 머신 세트를 확장합니다.
$ oc scale --replicas=2 machineset <machineset> -n openshift-machine-api
또는 다음을 수행합니다.
$ oc edit machineset <machineset> -n openshift-machine-api
작은 정보다음 YAML을 적용하여 머신 세트를 확장할 수도 있습니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineSet metadata: name: <machineset> namespace: openshift-machine-api spec: replicas: 2
머신이 시작될 때까지 기다립니다. 새 머신에는 머신 세트에 대한 변경사항이 포함되어 있습니다.
3.3. 머신 상태 점검 정보
머신 상태 점검에서는 특정 머신 풀의 비정상적인 머신을 자동으로 복구합니다.
머신 상태를 모니터링하기 위해 컨트롤러 구성을 정의할 리소스를 만듭니다. NotReady 상태를 5 분 동안 유지하거나 노드 문제 탐지기(node-problem-detector)에 영구적인 조건을 표시하는 등 검사할 조건과 모니터링할 머신 세트의 레이블을 설정합니다.
마스터 역할이 있는 머신에는 머신 상태 점검을 적용할 수 없습니다.
MachineHealthCheck 리소스를 관찰하는 컨트롤러에서 정의된 상태를 확인합니다. 머신이 상태 확인에 실패하면 머신이 자동으로 삭제되고 대체할 머신이 만들어집니다. 머신이 삭제되면 machine deleted 이벤트가 표시됩니다.
머신 삭제로 인한 영향을 제한하기 위해 컨트롤러는 한 번에 하나의 노드 만 드레인하고 삭제합니다. 대상 머신 풀에서 허용된 maxUnhealthy 임계값 보다 많은 비정상적인 머신이 있는 경우 수동 개입이 수행될 수 있도록 복구가 중지됩니다.
워크로드 및 요구 사항을 살펴보고 신중하게 시간 초과를 고려하십시오.
- 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
-
시간 초과가 너무 짧으면 수정 루프가 발생할 수 있습니다. 예를 들어
NotReady상태를 확인하는 시간은 머신이 시작 프로세스를 완료할 수 있을 만큼 충분히 길어야 합니다.
검사를 중지하려면 리소스를 제거합니다.
예를 들어 클러스터의 노드를 일시적으로 사용할 수 없게 되므로 업그레이드 프로세스 중에 검사를 중지해야 합니다. MachineHealthCheck는 비정상적인 노드를 식별하고 재부팅할 수 있습니다. 이러한 노드를 재부팅하지 않으려면 클러스터를 업데이트하기 전에 배포한 MachineHealthCheck 리소스를 제거합니다. 그러나 기본적으로 배포되는 MachineHealthCheck 리소스(예: machine-api-termination-handler)는 제거할 수 없으며 다시 생성됩니다.
3.3.1. 머신 상태 검사 배포 시 제한 사항
머신 상태 점검을 배포하기 전에 고려해야 할 제한 사항은 다음과 같습니다.
- 머신 세트가 소유한 머신만 머신 상태 검사를 통해 업데이트를 적용합니다.
- 컨트롤 플레인 시스템은 현재 지원되지 않으며 비정상적인 경우 업데이트 적용되지 않습니다.
- 머신의 노드가 클러스터에서 제거되면 머신 상태 점검에서 이 머신을 비정상적으로 간주하고 즉시 업데이트를 적용합니다.
-
nodeStartupTimeout후 시스템의 해당 노드가 클러스터에 참여하지 않으면 업데이트가 적용됩니다. -
Machine리소스 단계가Failed하면 즉시 머신에 업데이트를 적용합니다.
3.4. MachineHealthCheck 리소스 샘플
베어 메탈 이외의 모든 클라우드 기반 설치 유형에 대한 MachineHealthCheck 리소스는 다음 YAML 파일과 유사합니다.
apiVersion: machine.openshift.io/v1beta1 kind: MachineHealthCheck metadata: name: example 1 namespace: openshift-machine-api spec: selector: matchLabels: machine.openshift.io/cluster-api-machine-role: <role> 2 machine.openshift.io/cluster-api-machine-type: <role> 3 machine.openshift.io/cluster-api-machineset: <cluster_name>-<label>-<zone> 4 unhealthyConditions: - type: "Ready" timeout: "300s" 5 status: "False" - type: "Ready" timeout: "300s" 6 status: "Unknown" maxUnhealthy: "40%" 7 nodeStartupTimeout: "10m" 8
- 1
- 배포할 머신 상태 점검의 이름을 지정합니다.
- 2 3
- 확인할 머신 풀의 레이블을 지정합니다.
- 4
- 추적할 머신 세트를
<cluster_name>-<label>-<zone>형식으로 지정합니다. 예를 들어prod-node-us-east-1a입니다. - 5 6
- 노드 상태에 대한 시간 제한을 지정합니다. 시간 제한 기간 중 상태가 일치되면 머신이 수정됩니다. 시간 제한이 길어지면 비정상 머신의 워크로드에 대한 다운타임이 길어질 수 있습니다.
- 7
- 대상 풀에서 동시에 복구할 수 있는 시스템 수를 지정합니다. 이는 백분율 또는 정수로 설정할 수 있습니다. 비정상 머신의 수가
maxUnhealthy에서의 설정 제한을 초과하면 복구가 수행되지 않습니다. - 8
- 머신 상태가 비정상으로 확인되기 전에 노드가 클러스터에 참여할 때까지 기다려야 하는 시간 초과 기간을 지정합니다.
matchLabels는 예제일 뿐입니다. 특정 요구에 따라 머신 그룹을 매핑해야 합니다.
3.4.1. 쇼트 서킷 (Short Circuit) 머신 상태 점검 및 수정
쇼트 서킷 (Short Circuit)은 클러스터가 정상일 경우에만 머신 상태 점검을 통해 머신을 조정합니다. 쇼트 서킷은 MachineHealthCheck 리소스의 maxUnhealthy 필드를 통해 구성됩니다.
사용자가 시스템을 조정하기 전에 maxUnhealthy 필드 값을 정의하는 경우 MachineHealthCheck는 비정상적으로 결정된 대상 풀 내의 maxUnhealthy 값과 비교합니다. 비정상 머신의 수가 maxUnhealthy 제한을 초과하면 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 설정되지 않은 경우 기본값은 100%로 설정되고 클러스터 상태와 관계없이 머신이 수정됩니다.
적절한 maxUnhealthy 값은 배포하는 클러스터의 규모와 MachineHealthCheck에서 다루는 시스템 수에 따라 달라집니다. 예를 들어 maxUnhealthy 값을 사용하여 여러 가용 영역에서 여러 머신 세트를 처리할 수 있으므로 전체 영역을 손실하면 maxUnhealthy 설정이 클러스터 내에서 추가 수정을 방지 할 수 있습니다.
maxUnhealthy 필드는 정수 또는 백분율로 설정할 수 있습니다. maxUnhealthy 값에 따라 다양한 수정을 적용할 수 있습니다.
3.4.1.1. 절대 값을 사용하여 maxUnhealthy 설정
maxUnhealthy가 2로 설정된 경우
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
이러한 값은 머신 상태 점검에서 확인할 수 있는 머신 수와 관련이 없습니다.
3.4.1.2. 백분율을 사용하여 maxUnhealthy 설정
maxUnhealthy가 40%로 설정되어 있고 25 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 10개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 11개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행되지 않습니다.
maxUnhealthy가 40%로 설정되어 있고 6 대의 시스템이 확인되고 있는 경우 다음을 수행하십시오.
- 2개 이상의 노드가 비정상인 경우 수정을 위한 업데이트가 수행됩니다.
- 3개 이상의 노드가 비정상이면 수정을 위한 업데이트가 수행되지 않습니다
maxUnhealthy 머신의 백분율이 정수가 아닌 경우 허용되는 머신 수가 반올림됩니다.
3.5. MachineHealthCheck 리소스 만들기
클러스터의 모든 MachineSets에 대해 MachineHealthCheck 리소스를 생성할 수 있습니다. 컨트롤 플레인 시스템을 대상으로 하는 MachineHealthCheck 리소스를 생성해서는 안 됩니다.
사전 요구 사항
-
oc명령행 인터페이스를 설치합니다.
프로세스
-
머신 상태 점검 정의가 포함된
healthcheck.yml파일을 생성합니다. healthcheck.yml파일을 클러스터에 적용합니다.$ oc apply -f healthcheck.yml
4장. Node Tuning Operator 사용
Node Tuning Operator에 대해 알아보고, Node Tuning Operator를 사용하여 Tuned 데몬을 오케스트레이션하고 노드 수준 튜닝을 관리하는 방법도 알아봅니다.
4.1. Node Tuning Operator 정보
Node Tuning Operator는 TuneD 데몬을 오케스트레이션하여 노드 수준 튜닝을 관리하는 데 도움이 됩니다. 대부분의 고성능 애플리케이션에는 일정 수준의 커널 튜닝이 필요합니다. Node Tuning Operator는 노드 수준 sysctls 사용자에게 통합 관리 인터페이스를 제공하며 사용자의 필요에 따라 지정되는 사용자 정의 튜닝을 추가할 수 있는 유연성을 제공합니다.
Operator는 OpenShift Container Platform의 컨테이너화된 TuneD 데몬을 Kubernetes 데몬 세트로 관리합니다. 클러스터에서 실행되는 모든 컨테이너화된 TuneD 데몬에 사용자 정의 튜닝 사양이 데몬이 이해할 수 있는 형식으로 전달되도록 합니다. 데몬은 클러스터의 모든 노드에서 노드당 하나씩 실행됩니다.
컨테이너화된 TuneD 데몬을 통해 적용되는 노드 수준 설정은 프로필 변경을 트리거하는 이벤트 시 또는 컨테이너화된 TuneD 데몬이 종료 신호를 수신하고 처리하여 정상적으로 종료될 때 롤백됩니다.
버전 4.1 이상에서는 Node Tuning Operator가 표준 OpenShift Container Platform 설치에 포함되어 있습니다.
4.2. Node Tuning Operator 사양 예에 액세스
이 프로세스를 사용하여 Node Tuning Operator 사양 예에 액세스하십시오.
프로세스
다음을 실행합니다.
$ oc get Tuned/default -o yaml -n openshift-cluster-node-tuning-operator
기본 CR은 OpenShift Container Platform 플랫폼의 표준 노드 수준 튜닝을 제공하기 위한 것이며 Operator 관리 상태를 설정하는 경우에만 수정할 수 있습니다. Operator는 기본 CR에 대한 다른 모든 사용자 정의 변경사항을 덮어씁니다. 사용자 정의 튜닝의 경우 고유한 Tuned CR을 생성합니다. 새로 생성된 CR은 노드 또는 Pod 라벨 및 프로필 우선 순위에 따라 OpenShift Container Platform 노드에 적용된 기본 CR 및 사용자 정의 튜닝과 결합됩니다.
특정 상황에서는 Pod 라벨에 대한 지원이 필요한 튜닝을 자동으로 제공하는 편리한 방법일 수 있지만 이러한 방법은 권장되지 않으며 특히 대규모 클러스터에서는 이러한 방법을 사용하지 않는 것이 좋습니다. 기본 Tuned CR은 Pod 라벨이 일치되지 않은 상태로 제공됩니다. Pod 라벨이 일치된 상태로 사용자 정의 프로필이 생성되면 해당 시점에 이 기능이 활성화됩니다. Pod 레이블 기능은 Node Tuning Operator의 향후 버전에서 더 이상 사용되지 않을 수 있습니다.
4.3. 클러스터에 설정된 기본 프로필
다음은 클러스터에 설정된 기본 프로필입니다.
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: default
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- name: "openshift"
data: |
[main]
summary=Optimize systems running OpenShift (parent profile)
include=${f:virt_check:virtual-guest:throughput-performance}
[selinux]
avc_cache_threshold=8192
[net]
nf_conntrack_hashsize=131072
[sysctl]
net.ipv4.ip_forward=1
kernel.pid_max=>4194304
net.netfilter.nf_conntrack_max=1048576
net.ipv4.conf.all.arp_announce=2
net.ipv4.neigh.default.gc_thresh1=8192
net.ipv4.neigh.default.gc_thresh2=32768
net.ipv4.neigh.default.gc_thresh3=65536
net.ipv6.neigh.default.gc_thresh1=8192
net.ipv6.neigh.default.gc_thresh2=32768
net.ipv6.neigh.default.gc_thresh3=65536
vm.max_map_count=262144
[sysfs]
/sys/module/nvme_core/parameters/io_timeout=4294967295
/sys/module/nvme_core/parameters/max_retries=10
- name: "openshift-control-plane"
data: |
[main]
summary=Optimize systems running OpenShift control plane
include=openshift
[sysctl]
# ktune sysctl settings, maximizing i/o throughput
#
# Minimal preemption granularity for CPU-bound tasks:
# (default: 1 msec# (1 + ilog(ncpus)), units: nanoseconds)
kernel.sched_min_granularity_ns=10000000
# The total time the scheduler will consider a migrated process
# "cache hot" and thus less likely to be re-migrated
# (system default is 500000, i.e. 0.5 ms)
kernel.sched_migration_cost_ns=5000000
# SCHED_OTHER wake-up granularity.
#
# Preemption granularity when tasks wake up. Lower the value to
# improve wake-up latency and throughput for latency critical tasks.
kernel.sched_wakeup_granularity_ns=4000000
- name: "openshift-node"
data: |
[main]
summary=Optimize systems running OpenShift nodes
include=openshift
[sysctl]
net.ipv4.tcp_fastopen=3
fs.inotify.max_user_watches=65536
fs.inotify.max_user_instances=8192
recommend:
- profile: "openshift-control-plane"
priority: 30
match:
- label: "node-role.kubernetes.io/master"
- label: "node-role.kubernetes.io/infra"
- profile: "openshift-node"
priority: 404.4. TuneD 프로필이 적용되었는지 검증
클러스터 노드에 적용되는 TuneD 프로필을 확인합니다.
$ oc get profile -n openshift-cluster-node-tuning-operator
출력 예
NAME TUNED APPLIED DEGRADED AGE master-0 openshift-control-plane True False 6h33m master-1 openshift-control-plane True False 6h33m master-2 openshift-control-plane True False 6h33m worker-a openshift-node True False 6h28m worker-b openshift-node True False 6h28m
-
NAME: Profile 오브젝트의 이름입니다. 노드당 하나의 Profile 오브젝트가 있고 해당 이름이 일치합니다. -
TUNED: 적용할 TuneD 프로필의 이름입니다. -
적용됨: TuneD 데몬이 원하는 프로필을 적용한 경우True입니다. (True/False/Unknown). -
DEGRADED: TuneD 프로파일 적용 중에 오류가 보고된 경우True/False/Unknown입니다. -
AGE: Profile 오브젝트 생성 이후 경과 시간입니다.
4.5. 사용자 정의 튜닝 사양
Operator의 CR(사용자 정의 리소스)에는 두 가지 주요 섹션이 있습니다. 첫 번째 섹션인 profile:은 TuneD 프로필 및 해당 이름의 목록입니다. 두 번째인 recommend:은 프로필 선택 논리를 정의합니다.
여러 사용자 정의 튜닝 사양은 Operator의 네임스페이스에 여러 CR로 존재할 수 있습니다. 새로운 CR의 존재 또는 오래된 CR의 삭제는 Operator에서 탐지됩니다. 기존의 모든 사용자 정의 튜닝 사양이 병합되고 컨테이너화된 TuneD 데몬의 해당 오브젝트가 업데이트됩니다.
관리 상태
Operator 관리 상태는 기본 Tuned CR을 조정하여 설정됩니다. 기본적으로 Operator는 Managed 상태이며 기본 Tuned CR에는 spec.managementState 필드가 없습니다. Operator 관리 상태에 유효한 값은 다음과 같습니다.
- Managed: 구성 리소스가 업데이트되면 Operator가 해당 피연산자를 업데이트합니다.
- Unmanaged: Operator가 구성 리소스에 대한 변경을 무시합니다.
- Removed: Operator가 프로비저닝한 해당 피연산자 및 리소스를 Operator가 제거합니다.
프로필 데이터
profile: 섹션에는 TuneD 프로필 및 해당 이름이 나열됩니다.
profile:
- name: tuned_profile_1
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_1 profile
[sysctl]
net.ipv4.ip_forward=1
# ... other sysctl's or other TuneD daemon plugins supported by the containerized TuneD
# ...
- name: tuned_profile_n
data: |
# TuneD profile specification
[main]
summary=Description of tuned_profile_n profile
# tuned_profile_n profile settings권장 프로필
profile: 선택 논리는 CR의 recommend: 섹션에 의해 정의됩니다. recommend: 섹션은 선택 기준에 따라 프로필을 권장하는 항목의 목록입니다.
recommend: <recommend-item-1> # ... <recommend-item-n>
목록의 개별 항목은 다음과 같습니다.
- machineConfigLabels: 1 <mcLabels> 2 match: 3 <match> 4 priority: <priority> 5 profile: <tuned_profile_name> 6 operand: 7 debug: <bool> 8
- 1
- 선택 사항입니다.
- 2
- 키/값
MachineConfig라벨 사전입니다. 키는 고유해야 합니다. - 3
- 생략하면 우선 순위가 높은 프로필이 먼저 일치되거나
machineConfigLabels가 설정되어 있지 않으면 프로필이 일치하는 것으로 가정합니다. - 4
- 선택사항 목록입니다.
- 5
- 프로필 순서 지정 우선 순위입니다. 숫자가 작을수록 우선 순위가 높습니다(
0이 가장 높은 우선 순위임). - 6
- 일치에 적용할 TuneD 프로필입니다. 예를 들어
tuned_profile_1이 있습니다. - 7
- 선택적 피연산자 구성입니다.
- 8
- TuneD 데몬의 디버깅을 켜거나 끕니다. off의 경우 on 또는
false의 경우 옵션이true입니다. 기본값은false입니다.
<match>는 다음과 같이 재귀적으로 정의되는 선택사항 목록입니다.
- label: <label_name> 1 value: <label_value> 2 type: <label_type> 3 <match> 4
<match>를 생략하지 않으면 모든 중첩 <match> 섹션도 true로 평가되어야 합니다. 생략하면 false로 가정하고 해당 <match> 섹션이 있는 프로필을 적용하지 않거나 권장하지 않습니다. 따라서 중첩(하위 <match> 섹션)은 논리 AND 연산자 역할을 합니다. 반대로 <match> 목록의 항목이 일치하면 전체 <match> 목록이 true로 평가됩니다. 따라서 이 목록이 논리 OR 연산자 역할을 합니다.
machineConfigLabels 가 정의되면 지정된 recommend: 목록 항목에 대해 머신 구성 풀 기반 일치가 설정됩니다. <mcLabels> 는 머신 구성의 라벨을 지정합니다. 머신 구성은 <tuned_profile_name> 프로필에 대해 커널 부팅 매개변수와 같은 호스트 설정을 적용하기 위해 자동으로 생성됩니다. 여기에는 <mcLabels>와 일치하는 머신 구성 선택기가 있는 모든 머신 구성 풀을 찾고 머신 구성 풀이 할당된 모든 노드에서 <tuned_profile_name> 프로필을 설정하는 작업이 포함됩니다. 마스터 및 작업자 역할이 모두 있는 노드를 대상으로 하려면 마스터 역할을 사용해야 합니다.
목록 항목 match 및 machineConfigLabels는 논리 OR 연산자로 연결됩니다. match 항목은 단락 방식으로 먼저 평가됩니다. 따라서 true로 평가되면 machineConfigLabels 항목이 고려되지 않습니다.
머신 구성 풀 기반 일치를 사용하는 경우 동일한 하드웨어 구성을 가진 노드를 동일한 머신 구성 풀로 그룹화하는 것이 좋습니다. 이 방법을 따르지 않으면 TuneD 피연산자가 동일한 머신 구성 풀을 공유하는 두 개 이상의 노드에 대해 충돌하는 커널 매개변수를 계산할 수 있습니다.
예: 노드 또는 Pod 라벨 기반 일치
- match:
- label: tuned.openshift.io/elasticsearch
match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
type: pod
priority: 10
profile: openshift-control-plane-es
- match:
- label: node-role.kubernetes.io/master
- label: node-role.kubernetes.io/infra
priority: 20
profile: openshift-control-plane
- priority: 30
profile: openshift-node
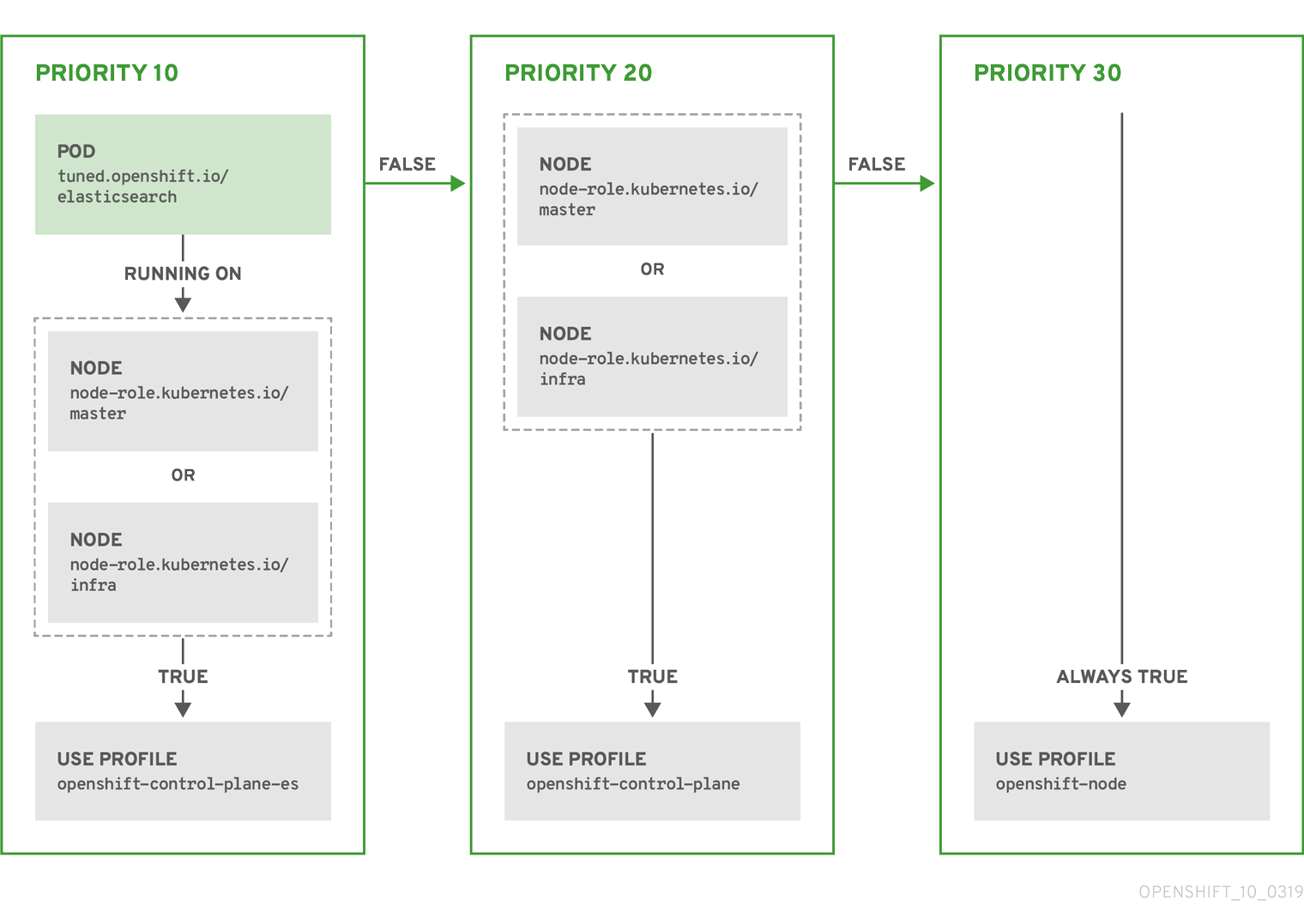
위의 CR은 컨테이너화된 TuneD 데몬의 프로필 우선 순위에 따라 recommended.conf 파일로 변환됩니다. 우선 순위가 가장 높은 프로필(10)이 openshift-control-plane-es이므로 이 프로필을 첫 번째로 고려합니다. 지정된 노드에서 실행되는 컨테이너화된 TuneD 데몬은 tuned.openshift.io/elasticsearch 라벨이 설정된 동일한 노드에서 실행되는 Pod가 있는지 확인합니다. 없는 경우 전체 <match> 섹션이 false로 평가됩니다. 라벨이 있는 Pod가 있는 경우 <match> 섹션을 true로 평가하려면 노드 라벨도 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra여야 합니다.
우선 순위가 10인 프로필의 라벨이 일치하면 openshift-control-plane-es 프로필이 적용되고 다른 프로필은 고려되지 않습니다. 노드/Pod 라벨 조합이 일치하지 않으면 두 번째로 높은 우선 순위 프로필(openshift-control-plane)이 고려됩니다. 컨테이너화된 TuneD Pod가 node-role.kubernetes.io/master 또는 node-role.kubernetes.io/infra. 라벨이 있는 노드에서 실행되는 경우 이 프로필이 적용됩니다.
마지막으로, openshift-node 프로필은 우선 순위가 가장 낮은 30입니다. 이 프로필에는 <match> 섹션이 없으므로 항상 일치합니다. 지정된 노드에서 우선 순위가 더 높은 다른 프로필이 일치하지 않는 경우 openshift-node 프로필을 설정하는 데 catch-all 프로필 역할을 합니다.
예: 머신 구성 풀 기반 일치
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-custom
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile with an additional kernel parameter
include=openshift-node
[bootloader]
cmdline_openshift_node_custom=+skew_tick=1
name: openshift-node-custom
recommend:
- machineConfigLabels:
machineconfiguration.openshift.io/role: "worker-custom"
priority: 20
profile: openshift-node-custom
노드 재부팅을 최소화하려면 머신 구성 풀의 노드 선택기와 일치하는 라벨로 대상 노드에 라벨을 지정한 후 위의 Tuned CR을 생성하고 마지막으로 사용자 정의 머신 구성 풀을 생성합니다.
4.6. 사용자 정의 튜닝 예
기본 CR에서 TuneD 프로파일 사용
다음 CR에서는 tuned.openshift.io/ingress-node-label 레이블이 임의의 값으로 설정된 OpenShift Container Platform 노드에 대해 사용자 정의 노드 수준 튜닝을 적용합니다.
예: openshift-control-plane TuneD 프로필을 사용한 사용자 정의 튜닝
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: ingress
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=A custom OpenShift ingress profile
include=openshift-control-plane
[sysctl]
net.ipv4.ip_local_port_range="1024 65535"
net.ipv4.tcp_tw_reuse=1
name: openshift-ingress
recommend:
- match:
- label: tuned.openshift.io/ingress-node-label
priority: 10
profile: openshift-ingress
사용자 정의 프로필 작성자는 기본 TuneD CR에 제공된 기본 Tuned 데몬 프로필을 포함하는 것이 좋습니다. 위의 예에서는 기본 openshift-control-plane 프로필을 사용하여 작업을 수행합니다.
내장된 TuneD 프로필 사용
NTO 관리 데몬 세트가 성공적으로 롤아웃되면 TuneD 피연산자는 모두 동일한 버전의 TuneD 데몬을 관리합니다. 데몬에서 지원하는 기본 제공 TuneD 프로필을 나열하려면 다음 방식으로 TuneD Pod를 쿼리합니다.
$ oc exec $tuned_pod -n openshift-cluster-node-tuning-operator -- find /usr/lib/tuned/ -name tuned.conf -printf '%h\n' | sed 's|^.*/||'
사용자 정의 튜닝 사양에서 이 명령으로 검색한 프로필 이름을 사용할 수 있습니다.
예: 기본 제공 hpc-compute TuneD 프로필 사용
apiVersion: tuned.openshift.io/v1
kind: Tuned
metadata:
name: openshift-node-hpc-compute
namespace: openshift-cluster-node-tuning-operator
spec:
profile:
- data: |
[main]
summary=Custom OpenShift node profile for HPC compute workloads
include=openshift-node,hpc-compute
name: openshift-node-hpc-compute
recommend:
- match:
- label: tuned.openshift.io/openshift-node-hpc-compute
priority: 20
profile: openshift-node-hpc-compute
기본 제공 hpc-compute 프로필 외에도 위의 예제에는 기본 Tuned CR 내에 제공된 openshift-node TuneD 데몬 프로필이 포함되어 컴퓨팅 노드에 OpenShift별 튜닝을 사용합니다.
4.7. 지원되는 TuneD 데몬 플러그인
Tuned CR의 profile: 섹션에 정의된 사용자 정의 프로필을 사용하는 경우 [main] 섹션을 제외한 다음 TuneD 플러그인이 지원됩니다.
- audio
- cpu
- disk
- eeepc_she
- modules
- mounts
- net
- scheduler
- scsi_host
- selinux
- sysctl
- sysfs
- usb
- video
- vm
일부 플러그인에서 제공하는 동적 튜닝 기능은 지원되지 않습니다. 다음 TuneD 플러그인은 현재 지원되지 않습니다.
- bootloader
- script
- systemd
자세한 내용은 사용 가능한 TuneD 플러그인 및 TuneD 시작하기 를 참조하십시오.
5장. Cluster Loader 사용
Cluster Loader는 많은 수의 다양한 오브젝트를 클러스터에 배포하여 사용자 정의 클러스터 오브젝트를 생성하는 툴입니다. Cluster Loader를 빌드하고, 구성하고, 실행하여 다양한 클러스터 상태에서 OpenShift Container Platform 배포의 성능 지표를 측정하십시오.
클러스터 로더는 더 이상 사용되지 않으며 향후 릴리스에서 제거됩니다.
5.1. Cluster Loader 설치
프로세스
컨테이너 이미지를 가져오려면 다음을 실행합니다.
$ podman pull quay.io/openshift/origin-tests:4.8
5.2. Cluster Loader 실행
전제 조건
- 리포지토리에서 인증하라는 메시지를 표시합니다. 레지스트리 자격 증명을 사용하면 공개적으로 제공되지 않는 이미지에 액세스할 수 있습니다. 설치의 기존 인증 자격 증명을 사용하십시오.
프로세스
다섯 개의 템플릿 빌드를 배포하고 완료될 때까지 대기하는 내장 테스트 구성을 사용하여 Cluster Loader를 실행합니다.
$ podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z -i \ quay.io/openshift/origin-tests:4.8 /bin/bash -c 'export KUBECONFIG=/root/.kube/config && \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'또는
VIPERCONFIG환경 변수를 설정하여 사용자 정의 구성으로 Cluster Loader를 실행합니다.$ podman run -v ${LOCAL_KUBECONFIG}:/root/.kube/config:z \ -v ${LOCAL_CONFIG_FILE_PATH}:/root/configs/:z \ -i quay.io/openshift/origin-tests:4.8 \ /bin/bash -c 'KUBECONFIG=/root/.kube/config VIPERCONFIG=/root/configs/test.yaml \ openshift-tests run-test "[sig-scalability][Feature:Performance] Load cluster \ should populate the cluster [Slow][Serial] [Suite:openshift]"'이 예에서는
${LOCAL_KUBECONFIG}가 로컬 파일 시스템의kubeconfig경로를 참조합니다.test.yaml구성 파일이 있는 컨테이너에 마운트되는${LOCAL_CONFIG_FILE_PATH}디렉터리도 있습니다.test.yaml이 외부 템플릿 파일 또는 podspec 파일을 참조하는 경우 해당 파일도 컨테이너에 마운트되어야 합니다.
5.3. Cluster Loader 구성
이 툴에서는 여러 템플릿 또는 Pod를 포함하는 여러 네임스페이스(프로젝트)를 생성합니다.
5.3.1. Cluster Loader 구성 파일 예
Cluster Loader 구성 파일은 기본 YAML 파일입니다.
provider: local 1 ClusterLoader: cleanup: true projects: - num: 1 basename: clusterloader-cakephp-mysql tuning: default ifexists: reuse templates: - num: 1 file: cakephp-mysql.json - num: 1 basename: clusterloader-dancer-mysql tuning: default ifexists: reuse templates: - num: 1 file: dancer-mysql.json - num: 1 basename: clusterloader-django-postgresql tuning: default ifexists: reuse templates: - num: 1 file: django-postgresql.json - num: 1 basename: clusterloader-nodejs-mongodb tuning: default ifexists: reuse templates: - num: 1 file: quickstarts/nodejs-mongodb.json - num: 1 basename: clusterloader-rails-postgresql tuning: default templates: - num: 1 file: rails-postgresql.json tuningsets: 2 - name: default pods: stepping: 3 stepsize: 5 pause: 0 s rate_limit: 4 delay: 0 ms
이 예에서는 외부 템플릿 파일 또는 Pod 사양 파일에 대한 참조도 컨테이너에 마운트되었다고 가정합니다.
Microsoft Azure에서 Cluster Loader를 실행하는 경우 AZURE_AUTH_LOCATION 변수를 설치 프로그램 디렉터리에 있는 terraform.azure.auto.tfvars.json 출력이 포함된 파일로 설정해야 합니다.
5.3.2. 구성 필드
표 5.1. 최상위 수준 Cluster Loader 필드
| 필드 | 설명 |
|---|---|
|
|
|
|
|
정의가 하나 이상인 하위 오브젝트입니다. |
|
|
구성당 하나의 정의가 있는 하위 오브젝트입니다. |
|
| 구성당 정의가 하나인 선택적 하위 오브젝트입니다. 오브젝트 생성 중 동기화 가능성을 추가합니다. |
표 5.2. projects 아래 필드
| 필드 | 설명 |
|---|---|
|
| 정수입니다. 생성할 프로젝트 수에 대한 하나의 정의입니다. |
|
|
문자열입니다. 프로젝트의 기본 이름에 대한 하나의 정의입니다. 충돌을 방지하도록 동일한 네임스페이스 수가 |
|
| 문자열입니다. 오브젝트에 적용할 튜닝 세트에 대한 하나의 정의로, 이 네임스페이스 내에서 배포합니다. |
|
|
|
|
| 키-값 쌍 목록입니다. 키는 구성 맵 이름이고 값은 구성 맵을 생성하는 파일의 경로입니다. |
|
| 키-값 쌍 목록입니다. 키는 보안 이름이고 값은 보안을 생성하는 파일의 경로입니다. |
|
| 배포할 Pod 정의가 하나 이상인 하위 오브젝트입니다. |
|
| 배포할 템플릿 정의가 하나 이상인 하위 오브젝트입니다. |
표 5.3. pods 및 templates 아래 필드
| 필드 | 설명 |
|---|---|
|
| 정수입니다. 배포할 Pod 또는 템플릿 수입니다. |
|
| 문자열입니다. docker 이미지를 가져올 수 있는 리포지토리에 대한 docker 이미지 URL입니다. |
|
| 문자열입니다. 생성할 템플릿(또는 Pod)의 기본 이름에 대한 하나의 정의입니다. |
|
| 문자열입니다. 생성할 Pod 사양 또는 템플릿이 있는 로컬 파일에 대한 경로입니다. |
|
|
키-값 쌍입니다. |
표 5.4. tuningsets 아래 필드
| 필드 | 설명 |
|---|---|
|
| 문자열입니다. 프로젝트에서 튜닝을 정의할 때 지정된 이름과 일치하는 튜닝 세트의 이름입니다. |
|
|
Pod에 적용할 |
|
|
템플릿에 적용할 |
표 5.5. tuningsets pods 또는 tuningsets templates 아래 필드
| 필드 | 설명 |
|---|---|
|
| 하위 오브젝트입니다. 단계 생성 패턴으로 오브젝트를 생성하려는 경우 사용되는 스테핑 구성입니다. |
|
| 하위 오브젝트입니다. 오브젝트 생성 속도를 제한하는 속도 제한 튜닝 세트 구성입니다. |
표 5.6. tuningsets pods 또는 tuningsets templates, stepping 아래 필드
| 필드 | 설명 |
|---|---|
|
| 정수입니다. 오브젝트 생성을 정지하기 전 생성할 오브젝트 수입니다. |
|
|
정수입니다. |
|
| 정수입니다. 오브젝트 생성에 성공하지 못하는 경우 실패 전 대기하는 시간(초)입니다. |
|
| 정수입니다. 생성 요청 간에 대기하는 시간(밀리초)입니다. |
표 5.7. sync 아래 필드
| 필드 | 설명 |
|---|---|
|
|
|
|
|
부울입니다. |
|
|
부울입니다. |
|
|
|
|
|
문자열입니다. Pod가 |
5.4. 알려진 문제
- 구성없이 Cluster Loader를 호출하는 경우 실패합니다. (BZ#1761925)
IDENTIFIER매개변수가 사용자 템플릿에 정의되어 있지 않으면 템플릿 생성에 실패하고error: unknown parameter name "IDENTIFIER"가 표시됩니다. 템플릿을 배포하는 경우 다음과 같이 이 매개변수를 템플릿에 추가하여 오류를 방지하십시오.{ "name": "IDENTIFIER", "description": "Number to append to the name of resources", "value": "1" }Pod를 배포하는 경우 매개변수를 추가할 필요가 없습니다.
6장. CPU 관리자 사용
CPU 관리자는 CPU 그룹을 관리하고 워크로드를 특정 CPU로 제한합니다.
CPU 관리자는 다음과 같은 속성 중 일부가 포함된 워크로드에 유용합니다.
- 가능한 한 많은 CPU 시간이 필요합니다.
- 프로세서 캐시 누락에 민감합니다.
- 대기 시간이 짧은 네트워크 애플리케이션입니다.
- 다른 프로세스와 조정하고 단일 프로세서 캐시 공유를 통해 얻는 이점이 있습니다.
6.1. CPU 관리자 설정
절차
선택 사항: 노드에 레이블을 지정합니다.
# oc label node perf-node.example.com cpumanager=true
CPU 관리자를 활성화해야 하는 노드의
MachineConfigPool을 편집합니다. 이 예에서는 모든 작업자의 CPU 관리자가 활성화됩니다.# oc edit machineconfigpool worker
작업자 머신 구성 풀에 레이블을 추가합니다.
metadata: creationTimestamp: 2020-xx-xxx generation: 3 labels: custom-kubelet: cpumanager-enabledKubeletConfig,cpumanager-kubeletconfig.yaml, CR(사용자 정의 리소스)을 생성합니다. 이전 단계에서 생성한 레이블을 참조하여 올바른 노드가 새 kubelet 구성으로 업데이트되도록 합니다.machineConfigPoolSelector섹션을 참조하십시오.apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2동적 kubelet 구성을 생성합니다.
# oc create -f cpumanager-kubeletconfig.yaml
그러면 kubelet 구성에 CPU 관리자 기능이 추가되고 필요한 경우 MCO(Machine Config Operator)가 노드를 재부팅합니다. CPU 관리자를 활성화하는 데는 재부팅이 필요하지 않습니다.
병합된 kubelet 구성을 확인합니다.
# oc get machineconfig 99-worker-XXXXXX-XXXXX-XXXX-XXXXX-kubelet -o json | grep ownerReference -A7
출력 예
"ownerReferences": [ { "apiVersion": "machineconfiguration.openshift.io/v1", "kind": "KubeletConfig", "name": "cpumanager-enabled", "uid": "7ed5616d-6b72-11e9-aae1-021e1ce18878" } ]작업자에서 업데이트된
kubelet.conf를 확인합니다.# oc debug node/perf-node.example.com sh-4.2# cat /host/etc/kubernetes/kubelet.conf | grep cpuManager
출력 예
cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s 2
코어를 하나 이상 요청하는 Pod를 생성합니다. 제한 및 요청 둘 다 해당 CPU 값이 정수로 설정되어야 합니다. 해당 숫자는 이 Pod 전용으로 사용할 코어 수입니다.
# cat cpumanager-pod.yaml
출력 예
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Pod를 생성합니다.
# oc create -f cpumanager-pod.yaml
레이블 지정한 노드에 Pod가 예약되어 있는지 검증합니다.
# oc describe pod cpumanager
출력 예
Name: cpumanager-6cqz7 Namespace: default Priority: 0 PriorityClassName: <none> Node: perf-node.example.com/xxx.xx.xx.xxx ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=truecgroups가 올바르게 설정되었는지 검증합니다.pause프로세스의 PID(프로세스 ID)를 가져옵니다.# ├─init.scope │ └─1 /usr/lib/systemd/systemd --switched-root --system --deserialize 17 └─kubepods.slice ├─kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice │ ├─crio-b5437308f1a574c542bdf08563b865c0345c8f8c0b0a655612c.scope │ └─32706 /pause
QoS(Quality of Service) 계층
Guaranteed의 Pod는kubepods.slice에 있습니다. 다른 QoS 계층의 Pod는kubepods의 하위cgroups에 있습니다.# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod69c01f8e_6b74_11e9_ac0f_0a2b62178a22.slice/crio-b5437308f1ad1a7db0574c542bdf08563b865c0345c86e9585f8c0b0a655612c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done
출력 예
cpuset.cpus 1 tasks 32706
작업에 허용되는 CPU 목록을 확인합니다.
# grep ^Cpus_allowed_list /proc/32706/status
출력 예
Cpus_allowed_list: 1
GuaranteedPod용으로 할당된 코어에서는 시스템의 다른 Pod(이 경우burstableQoS 계층의 Pod)를 실행할 수 없는지 검증합니다.# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-podc494a073_6b77_11e9_98c0_06bba5c387ea.slice/crio-c56982f57b75a2420947f0afc6cafe7534c5734efc34157525fa9abbf99e3849.scope/cpuset.cpus 0 # oc describe node perf-node.example.com
출력 예
... Capacity: attachable-volumes-aws-ebs: 39 cpu: 2 ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 8162900Ki pods: 250 Allocatable: attachable-volumes-aws-ebs: 39 cpu: 1500m ephemeral-storage: 124768236Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 7548500Ki pods: 250 ------- ---- ------------ ---------- --------------- ------------- --- default cpumanager-6cqz7 1 (66%) 1 (66%) 1G (12%) 1G (12%) 29m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 1440m (96%) 1 (66%)
이 VM에는 두 개의 CPU 코어가 있습니다.
system-reserved설정은 500밀리코어로 설정되었습니다. 즉,Node Allocatable양이 되는 노드의 전체 용량에서 한 코어의 절반이 감산되었습니다.Allocatable CPU는 1500 밀리코어임을 확인할 수 있습니다. 즉, Pod마다 하나의 전체 코어를 사용하므로 CPU 관리자 Pod 중 하나를 실행할 수 있습니다. 전체 코어는 1000밀리코어에 해당합니다. 두 번째 Pod를 예약하려고 하면 시스템에서 해당 Pod를 수락하지만 Pod가 예약되지 않습니다.NAME READY STATUS RESTARTS AGE cpumanager-6cqz7 1/1 Running 0 33m cpumanager-7qc2t 0/1 Pending 0 11s
7장. 토폴로지 관리자 사용
토폴로지 관리자는 동일한 NUMA(Non-Uniform Memory Access) 노드의 모든 QoS(Quality of Service) 클래스에 대해 CPU 관리자, 장치 관리자, 기타 힌트 공급자로부터 힌트를 수집하여 CPU, SR-IOV VF, 기타 장치 리소스 등의 Pod 리소스를 정렬합니다.
토폴로지 관리자는 토폴로지 관리자 정책 및 요청된 Pod 리소스를 기반으로 수집된 힌트의 토폴로지 정보를 사용하여 노드에서 Pod를 수락하거나 거부할 수 있는지 결정합니다.
토폴로지 관리자는 하드웨어 가속기를 사용하여 대기 시간이 중요한 실행과 처리량이 높은 병렬 계산을 지원하는 워크로드에 유용합니다.
토폴로지 관리자를 사용하려면 정책이 static 상태인 CPU 관리자를 사용해야 합니다. CPU 관리자에 대한 자세한 내용은 CPU 관리자 사용을 참조하십시오.
7.1. 토폴로지 관리자 정책
토폴로지 관리자는 CPU 관리자 및 장치 관리자와 같은 힌트 공급자로부터 토폴로지 힌트를 수집하고 수집된 힌트로 Pod 리소스를 정렬하는 방법으로 모든 QoS(Quality of Service) 클래스의 Pod 리소스를 정렬합니다.
Pod 사양에서 요청된 다른 리소스와 CPU 리소스를 정렬하려면 static CPU 관리자 정책을 사용하여 CPU 관리자를 활성화해야 합니다.
토폴로지 관리자는 cpumanager-enabled CR(사용자 정의 리소스)에서 할당하는 데 다음 4가지 할당 정책을 지원합니다.
none정책- 기본 정책으로, 토폴로지 정렬을 수행하지 않습니다.
best-effort정책-
best-effort토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 해당 정보를 저장하고 노드에 대해 Pod를 허용합니다. restricted정책-
restricted토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 해당 컨테이너의 기본 NUMA 노드 선호도를 저장합니다. 선호도를 기본 설정하지 않으면 토폴로지 관리자가 노드에서 이 Pod를 거부합니다. 그러면 Pod는Terminated상태가 되고 Pod 허용 실패가 발생합니다. single-numa-node정책-
single-numa-node토폴로지 관리 정책을 사용하는 Pod의 각 컨테이너에서는 kubelet이 각 힌트 공급자를 호출하여 해당 리소스 가용성을 검색합니다. 토폴로지 관리자는 이 정보를 사용하여 단일 NUMA 노드 선호도가 가능한지 여부를 결정합니다. 가능한 경우 노드에 대해 Pod가 허용됩니다. 단일 NUMA 노드 선호도가 가능하지 않은 경우 토폴로지 관리자가 노드에서 Pod를 거부합니다. 그러면 Pod는 Terminated 상태가 되고 Pod 허용 실패가 발생합니다.
7.2. 토폴로지 관리자 설정
토폴로지 관리자를 사용하려면 cpumanager-enabled CR(사용자 정의 리소스)에서 할당 정책을 구성해야 합니다. CPU 관리자를 설정한 경우 해당 파일이 존재할 수 있습니다. 파일이 없으면 파일을 생성할 수 있습니다.
전제 조건
-
CPU 관리자 정책을
static으로 구성하십시오. 확장 및 성능 섹션에서 CPU 관리자 사용을 확인하십시오.
절차
토폴로지 관리자를 활성화하려면 다음을 수행합니다.
cpumanager-enabledCR(사용자 정의 리소스)에서 토폴로지 관리자 할당 정책을 구성합니다.$ oc edit KubeletConfig cpumanager-enabled
apiVersion: machineconfiguration.openshift.io/v1 kind: KubeletConfig metadata: name: cpumanager-enabled spec: machineConfigPoolSelector: matchLabels: custom-kubelet: cpumanager-enabled kubeletConfig: cpuManagerPolicy: static 1 cpuManagerReconcilePeriod: 5s topologyManagerPolicy: single-numa-node 2
추가 리소스
- CPU 관리자에 대한 자세한 내용은 CPU 관리자 사용을 참조하십시오.
7.3. Pod와 토폴로지 관리자 정책 간의 상호 작용
아래 Pod 사양의 예는 Pod와 토폴로지 관리자 간 상호 작용을 보여주는 데 도움이 됩니다.
다음 Pod는 리소스 요청 또는 제한이 지정되어 있지 않기 때문에 BestEffort QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
다음 Pod는 요청이 제한보다 작기 때문에 Burstable QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
선택한 정책이 none이 아니면 토폴로지 관리자는 이러한 Pod 사양 중 하나를 고려하지 않습니다.
아래 마지막 예의 Pod는 요청이 제한과 동일하기 때문에 Guaranteed QoS 클래스에서 실행됩니다.
spec:
containers:
- name: nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "2"
example.com/device: "1"
requests:
memory: "200Mi"
cpu: "2"
example.com/device: "1"토폴로지 관리자는 이러한 Pod를 고려합니다. 토폴로지 관리자는 사용 가능한 CPU의 토폴로지를 반환하는 CPU 관리자 static 정책을 참조합니다. 토폴로지 관리자는 example.com/device에 대해 사용 가능한 장치의 토폴로지를 검색하는 장치 관리자도 참조합니다.
토폴로지 관리자는 이러한 정보를 사용하여 이 컨테이너에 가장 적합한 토폴로지를 저장합니다. 이 Pod의 경우 CPU 관리자와 장치 관리자는 리소스 할당 단계에서 이러한 저장된 정보를 사용합니다.
8장. Cluster Monitoring Operator 스케일링
OpenShift Container Platform에서는 Cluster Monitoring Operator가 수집하여 Prometheus 기반 모니터링 스택에 저장하는 지표를 공개합니다. 관리자는 시스템 리소스, 컨테이너 및 구성 요소 지표를 하나의 대시보드 인터페이스인 Grafana에서 볼 수 있습니다.
8.1. Prometheus 데이터베이스 스토리지 요구사항
Red Hat은 여러 스케일링 크기에 대해 다양한 테스트를 수행했습니다.
아래 Prometheus 스토리지 요구 사항은 규정되어 있지 않습니다. 워크로드 활동 및 리소스 사용량에 따라 클러스터에서 리소스 사용량이 높아질 수 있습니다.
표 8.1. 클러스터의 노드/Pod 수에 따른 Prometheus 데이터베이스 스토리지 요구사항
| 노드 수 | Pod 수 | Prometheus 스토리지 증가(1일당) | Prometheus 스토리지 증가(15일당) | RAM 공간(스케일링 크기당) | 네트워크(tsdb 청크당) |
|---|---|---|---|---|---|
| 50 | 1800 | 6.3GB | 94GB | 6GB | 16MB |
| 100 | 3600 | 13GB | 195GB | 10GB | 26MB |
| 150 | 5400 | 19GB | 283GB | 12GB | 36MB |
| 200 | 7200 | 25GB | 375GB | 14GB | 46MB |
스토리지 요구사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
위의 계산은 기본 OpenShift Container Platform Cluster Monitoring Operator용입니다.
CPU 사용률은 약간의 영향을 미칩니다. 50개 노드 및 1,800개 Pod당 비율이 약 40개 중 1개 코어입니다.
OpenShift Container Platform 권장 사항
- 인프라 노드를 3개 이상 사용하십시오.
- NVMe(Non-Volatile Memory Express) 드라이브를 사용하는 경우 openshift-container-storage 노드를 3개 이상 사용하십시오.
8.2. 클러스터 모니터링 구성
클러스터 모니터링 스택에서 Prometheus 구성 요소의 스토리지 용량을 늘릴 수 있습니다.
프로세스
Prometheus의 스토리지 용량을 늘리려면 다음을 수행합니다.
YAML 구성 파일
cluster-monitoring-config.yaml을 생성합니다. 예를 들면 다음과 같습니다.apiVersion: v1 kind: ConfigMap data: config.yaml: | prometheusK8s: retention: {{PROMETHEUS_RETENTION_PERIOD}} 1 nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 2 resources: requests: storage: {{PROMETHEUS_STORAGE_SIZE}} 3 alertmanagerMain: nodeSelector: node-role.kubernetes.io/infra: "" volumeClaimTemplate: spec: storageClassName: {{STORAGE_CLASS}} 4 resources: requests: storage: {{ALERTMANAGER_STORAGE_SIZE}} 5 metadata: name: cluster-monitoring-config namespace: openshift-monitoring- 1
- 일반적인 값은
PROMETHEUS_RETENTION_PERIOD=15d입니다. 단위는 s, m, h, d 접미사 중 하나를 사용하는 시간으로 측정됩니다. - 2 4
- 클러스터의 스토리지 클래스입니다.
- 3
- 일반적인 값은
PROMETHEUS_STORAGE_SIZE=2000Gi입니다. 스토리지 값은 일반 정수이거나 이러한 접미사 중 하나를 사용하는 고정 포인트 정수일 수 있습니다. E, P, T, G, M, K. 2의 거듭제곱을 사용할 수도 있습니다: EI, Pi, Ti, Gi, Mi, Ki. - 5
- 일반적인 값은
ALERTMANAGER_STORAGE_SIZE=20Gi입니다. 스토리지 값은 일반 정수이거나 이러한 접미사 중 하나를 사용하는 고정 포인트 정수일 수 있습니다. E, P, T, G, M, K. 2의 거듭제곱을 사용할 수도 있습니다: EI, Pi, Ti, Gi, Mi, Ki.
- 보존 기간, 스토리지 클래스 및 스토리지 크기에 대한 값을 추가합니다.
- 파일을 저장합니다.
다음을 실행하여 변경사항을 적용합니다.
$ oc create -f cluster-monitoring-config.yaml
9장. Node Feature Discovery Operator
Node Feature Discovery (NFD) Operator 및 이를 사용하여 하드웨어 기능과 시스템 구성을 감지하기 위한 Kubernetes 애드온 기능인 NFD(Node Feature Discovery)을 오케스트레이션하여 노드 수준 정보를 공개하는 방법을 설명합니다.
9.1. Node Feature Discovery Operator 정보
NFD(Node Feature Discovery Operator)는 하드웨어 관련 정보로 노드에 레이블을 지정하여 OpenShift Container Platform 클러스터에서 하드웨어 기능 및 구성 검색을 관리합니다. NFD는 PCI 카드, 커널, 운영 체제 버전과 같은 노드별 속성을 사용하여 호스트에 레이블을 지정합니다.
NFD Operator는 "Node Feature Discovery"을 검색하여 Operator Hub에서 확인할 수 있습니다.
9.2. Node Feature Discovery Operator 설치
NFD(Node Feature Discovery) Operator는 NFD 데몬 세트를 실행하는 데 필요한 모든 리소스를 오케스트레이션합니다. 클러스터 관리자는 OpenShift Container Platform CLI 또는 웹 콘솔을 사용하여 NFD Operator를 설치할 수 있습니다.
9.2.1. CLI를 사용하여 NFD Operator 설치
클러스터 관리자는 CLI를 사용하여 NFD Operator를 설치할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
NFD Operator의 네임스페이스를 생성합니다.
openshift-nfd네임스페이스를 정의하는 다음NamespaceCR(사용자 정의 리소스)을 생성하고nfd-namespace.yaml파일에 YAML을 저장합니다.apiVersion: v1 kind: Namespace metadata: name: openshift-nfd
다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc create -f nfd-namespace.yaml
다음 오브젝트를 생성하여 이전 단계에서 생성한 네임스페이스에 NFD Operator를 설치합니다.
다음
OperatorGroupCR을 생성하고 해당 YAML을nfd-operatorgroup.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd spec: targetNamespaces: - openshift-nfd
다음 명령을 실행하여
OperatorGroupCR을 생성합니다.$ oc create -f nfd-operatorgroup.yaml
다음 명령을 실행하여 후속 단계에 필요한
채널값을 가져옵니다.$ oc get packagemanifest nfd -n openshift-marketplace -o jsonpath='{.status.defaultChannel}'출력 예
4.8
다음
SubscriptionCR을 생성하고 해당 YAML을nfd-sub.yaml파일에 저장합니다.서브스크립션의 예
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "4.8" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace
다음 명령을 실행하여 서브스크립션 오브젝트를 생성합니다.
$ oc create -f nfd-sub.yaml
openshift-nfd프로젝트로 변경합니다.$ oc project openshift-nfd
검증
Operator 배포가 완료되었는지 확인하려면 다음을 실행합니다.
$ oc get pods
출력 예
NAME READY STATUS RESTARTS AGE nfd-controller-manager-7f86ccfb58-vgr4x 2/2 Running 0 10m
성공적인 배포에는
Running상태가 표시됩니다.
9.2.2. 웹 콘솔을 사용하여 NFD Operator 설치
클러스터 관리자는 웹 콘솔을 사용하여 NFD Operator를 설치할 수 있습니다.
이전 섹션에서 언급한 것처럼 Namespace를 만들 것을 권장합니다.
절차
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 사용 가능한 Operator 목록에서 Node Feature Discovery를 선택한 다음 설치를 클릭합니다.
- Operator 설치 페이지에서 클러스터에서 특정 네임스페이스를 선택하고 이전 섹션에서 생성된 네임스페이스를 선택한 다음 설치를 클릭합니다.
검증
다음과 같이 NFD Operator가 설치되었는지 확인합니다.
- Operator → 설치된 Operator 페이지로 이동합니다.
Node Feature Discovery가 openshift-nfd 프로젝트에 InstallSucceeded 상태로 나열되어 있는지 확인합니다.
참고설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 InstallSucceeded 메시지와 함께 설치에 성공하면 이 실패 메시지를 무시할 수 있습니다.
문제 해결
Operator가 설치된 것으로 나타나지 않으면 다음과 같이 추가 문제 해결을 수행합니다.
- Operator → 설치된 Operator 페이지로 이동하고 Operator 서브스크립션 및 설치 계획 탭의 상태에 장애나 오류가 있는지 검사합니다.
-
Workloads → Pod 페이지로 이동하여
openshift-nfd프로젝트에서 Pod 로그를 확인합니다.
9.3. Node Feature Discovery Operator 사용
NFD(Node Feature Discovery) Operator는 NodeFeatureDiscovery CR을 확인하여 Node-Versionature-Discovery 데몬 세트를 실행하는 데 필요한 모든 리소스를 오케스트레이션합니다. NodefeatureatureDiscovery CR을 기반으로 Operator는 원하는 네임스페이스에 피연산자(NFD) 구성 요소를 생성합니다. CR을 편집하여 다른 옵션 중에서 다른 namespace, image, imagePullPolicy, nfd-worker-conf를 선택할 수 있습니다.
클러스터 관리자는 OpenShift Container Platform CLI 또는 웹 콘솔을 사용하여 NodeFeatureDiscovery 인스턴스를 만들 수 있습니다.
9.3.1. CLI를 사용하여 NodeEnatureDiscovery 인스턴스 생성
클러스터 관리자는 CLI를 사용하여 NodefeatureatureDiscovery CR 인스턴스를 생성할 수 있습니다.
사전 요구 사항
- OpenShift Container Platform 클러스터
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다. - NFD Operator를 설치합니다.
절차
다음
NodeEnatureDiscovery사용자 정의 리소스(CR)를 생성한 다음 YAML을NodefeatureatureDiscovery.yaml파일에 저장합니다.apiVersion: nfd.openshift.io/v1 kind: NodeFeatureDiscovery metadata: name: nfd-instance namespace: openshift-nfd spec: instance: "" # instance is empty by default operand: namespace: openshift-nfd image: quay.io/openshift/origin-node-feature-discovery:4.8 imagePullPolicy: Always workerConfig: configData: | #core: # labelWhiteList: # noPublish: false # sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time configurable ## and require a nfd-worker restart to take effect after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false #sources: # cpu: # cpuid: ## NOTE: whitelist has priority over blacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" # pci: # deviceClassWhitelist: # - "0200" # - "03" # - "12" # deviceLabelFields: # - "class" # - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"]다음 명령어를 실행하여
NodeFeatureDiscoveryCR 인스턴스를 만듭니다.$ oc create -f NodeFeatureDiscovery.yaml
검증
인스턴스가 생성되었는지 확인하려면 다음을 실행합니다.
$ oc get pods
출력 예
NAME READY STATUS RESTARTS AGE nfd-controller-manager-7f86ccfb58-vgr4x 2/2 Running 0 11m nfd-master-hcn64 1/1 Running 0 60s nfd-master-lnnxx 1/1 Running 0 60s nfd-master-mp6hr 1/1 Running 0 60s nfd-worker-vgcz9 1/1 Running 0 60s nfd-worker-xqbws 1/1 Running 0 60s
성공적인 배포에는
Running상태가 표시됩니다.
9.3.2. 웹 콘솔을 사용하여 NodeEnatureDiscovery CR 만들기
절차
- Operator → 설치된 Operator 페이지로 이동합니다.
- Node Feature Discovery를 찾고 제공된 APIs아래에 있는 상자를 확인합니다.
- 인스턴스 만들기를 클릭합니다.
-
NodefeatureatureDiscoveryCR의 값을 편집합니다. - 생성을 클릭합니다.
9.4. Node Feature Discovery Operator 설정
9.4.1. 코어
core 섹션에는 특정 기능 소스와 관련이 없는 일반적인 구성 설정이 포함되어 있습니다.
core.sleepInterval
core.sleepInterval은 기능 검색 또는 재검색의 연속 통과 간격과 노드 레이블 재지정 간격을 지정합니다. 양수가 아닌 값은 무한 절전 상태를 의미합니다. 재검색되거나 레이블이 다시 지정되지 않습니다.
이 값은 지정된 경우 더 이상 사용되지 않는 --sleep-interval 명령줄 플래그로 재정의됩니다.
사용 예
core:
sleepInterval: 60s 1
기본값은 60s입니다.
core.sources
core.sources는 활성화된 기능 소스 목록을 지정합니다. 특수한 값 all은 모든 기능 소스를 활성화합니다.
이 값은 지정된 경우 더 이상 사용되지 않는 --sources 명령줄 플래그로 재정의됩니다.
기본값: [all]
사용 예
core:
sources:
- system
- custom
core.labelWhiteList
core.labelWhiteList는 레이블 이름을 기반으로 기능 레이블을 필터링하기 위한 정규식을 지정합니다. 일치하지 않는 레이블은 게시되지 않습니다.
정규 표현식은 레이블의 기반 이름 부분인 '/' 뒤에 있는 이름의 부분과만 일치합니다. 레이블 접두사 또는 네임스페이스가 생략됩니다.
이 값은 지정된 경우 더 이상 사용되지 않는 --label-whitelist 명령줄 플래그로 재정의됩니다.
기본값: null
사용 예
core: labelWhiteList: '^cpu-cpuid'
core.noPublish
core.noPublish를 true로 설정하면 nfd-master와의 모든 통신이 비활성화됩니다. 이것은 실질적으로는 드라이런 플래그입니다. nfd-worker는 정상적으로 기능 감지를 실행하지만 레이블 요청은 nfd-master로 전송되지 않습니다.
이 값은 지정된 경우 --no-publish 명령줄 플래그로 재정의됩니다.
예제:
사용 예
core:
noPublish: true 1
기본값은 false입니다.
core.klog
다음 옵션은 대부분 런타임에 동적으로 조정할 수 있는 로거 구성을 지정합니다.
로거 옵션은 명령줄 플래그를 사용하여 지정할 수도 있으며, 이러한 옵션은 해당 구성 파일 옵션보다 우선합니다.
core.klog.addDirHeader
true로 설정하면core.klog.addDirHeader에서 파일 디렉터리를 로그 메시지의 헤더에 추가합니다.
기본값: false
런타임 설정 가능: yes
core.klog.alsologtostderr
표준 오류 및 파일에 기록합니다.
기본값: false
런타임 설정 가능: yes
core.klog.logBacktraceAt
로깅이 file:N 행에 도달하면 스택 추적을 출력합니다.
기본값: empty
런타임 설정 가능: yes
core.klog.logDir
비어 있지 않은 경우 이 디렉터리에 로그 파일을 작성합니다.
기본값: empty
런타임 설정 가능: no
core.klog.logFile
비어 있지 않은 경우 이 로그 파일을 사용합니다.
기본값: empty
런타임 설정 가능: no
core.klog.logFileMaxSize
core.klog.logFileMaxSize는 로그 파일의 최대 크기를 정의합니다. 단위는 메가바이트입니다. 값이 0인 경우 최대 파일 크기는 무제한입니다.
기본값: 1800
런타임 설정 가능: no
core.klog.logtostderr
파일 대신 표준 오류에 기록합니다.
기본값: true
런타임 설정 가능: yes
core.klog.skipHeaders
core.klog.skipHeaders가 true로 설정된 경우 로그 메시지에서 헤더 접두사를 사용하지 않습니다.
기본값: false
런타임 설정 가능: yes
core.klog.skipLogHeaders
core.klog.skipLogHeaders가 true로 설정된 경우 로그 파일을 열 때 헤더를 사용하지 않습니다.
기본값: false
런타임 설정 가능: no
core.klog.stderrthreshold
임계값 이상의 로그는 stderr에 있습니다.
기본값: 2
런타임 설정 가능: yes
core.klog.v
core.klog.v는 로그 수준 세부 정보 표시의 수치입니다.
기본값: 0
런타임 설정 가능: yes
core.klog.vmodule
core.klog.vmodule은 파일 필터링된 로깅의 쉼표로 구분된 pattern=N 설정 목록입니다.
기본값: empty
런타임 설정 가능: yes
9.4.2. 소스
source 섹션에는 기능 소스 관련 구성 매개변수가 포함되어 있습니다.
sources.cpu.cpuid.attributeBlacklist
이 옵션에 나열된 cpuid 기능만을 공개합니다.
이 값은 sources.cpu.cpuid.attributeWhitelist로에 의해 재정의됩니다.
기본값: [BMI1, BMI2, CLMUL, CMOV, CX16, ERMS, F16C, HTT, LZCNT, MMX, MMXEXT, NX, POPCNT, RDRAND, RDSEED, RDTSCP, SGX, SGXLC, SSE, SSE2, SSE3, SSE4.1, SSE4.2, SSSE3]
사용 예
sources:
cpu:
cpuid:
attributeBlacklist: [MMX, MMXEXT]
sources.cpu.cpuid.attributeWhitelist
이 옵션에 나열된 cpuid 기능만 게시합니다.
sources.cpu.cpuid.attributeWhitelist는 sources.cpu.cpuid.attributeBlacklist보다 우선합니다.
기본값: empty
사용 예
sources:
cpu:
cpuid:
attributeWhitelist: [AVX512BW, AVX512CD, AVX512DQ, AVX512F, AVX512VL]
sources.kernel.kconfigFile
sources.kernel.kconfigFile은 커널 구성 파일의 경로입니다. 비어 있는 경우 NFD는 일반적인 표준 위치에서 검색을 실행합니다.
기본값: empty
사용 예
sources:
kernel:
kconfigFile: "/path/to/kconfig"
sources.kernel.configOpts
Source.kernel.configOpts는 기능 레이블로 게시하는 커널 구성 옵션을 나타냅니다.
기본값: [NO_HZ, NO_HZ_IDLE, NO_HZ_FULL, PREEMPT]
사용 예
sources:
kernel:
configOpts: [NO_HZ, X86, DMI]
sources.pci.deviceClassWhitelist
source.pci.deviceClassWhitelist 는 레이블을 게시할 PCI 장치 클래스 ID 목록입니다. 메인 클래스로만 (예: 03) 또는 전체 클래스-하위 클래스 조합(예: 0300)으로 지정할 수 있습니다. 전자는 모든 하위 클래스가 허용됨을 의미합니다. 레이블 형식은 deviceLabelFields를 사용하여 추가로 구성할 수 있습니다.
기본값: ["03", "0b40", "12"]
사용 예
sources:
pci:
deviceClassWhitelist: ["0200", "03"]
sources.pci.deviceLabelFields
source.pci.deviceLabelFields 는 기능 레이블의 이름을 구성할 때 사용할 PCI ID 필드의 집합입니다. 유효한 필드는 class,vendor,device,subsystem_vendor 및 subsystem_device입니다.
기본값: [class, vendor]
사용 예
sources:
pci:
deviceLabelFields: [class, vendor, device]
위의 설정 예제에서 NFD는 feature.node.kubernetes.io/pci-<class-id>_<vendor-id>_<device-id>.present=true와 같은 레이블을 게시합니다.
sources.usb.deviceClassWhitelist
source.usb.deviceClassWhitelist 는 기능 레이블을 게시할 USB 장치 클래스 ID 목록입니다. 레이블 형식은 deviceLabelFields를 사용하여 추가로 구성할 수 있습니다.
기본값: ["0e", "ef", "fe", "ff"]
사용 예
sources:
usb:
deviceClassWhitelist: ["ef", "ff"]
sources.usb.deviceLabelFields
source.usb.deviceLabelFields 는 기능 레이블의 이름을 구성할 USB ID 필드의 집합입니다. 유효한 필드는 class,vendor, device입니다.
기본값: [class, vendor, device]
사용 예
sources:
pci:
deviceLabelFields: [class, vendor]
위의 config 예제에서 NFD는 feature.node.kubernetes.io/usb-<class-id>_<vendor-id>.present=true와 같은 레이블을 게시합니다.
sources.custom
source.custom 은 사용자별 레이블을 생성하기 위해 사용자 지정 기능 소스에서 처리할 규칙 목록입니다.
기본값: empty
사용 예
source:
custom:
- name: "my.custom.feature"
matchOn:
- loadedKMod: ["e1000e"]
- pciId:
class: ["0200"]
vendor: ["8086"]
10장. 드라이버 툴킷
드라이버 툴킷(Driver Toolkit)과 이 툴킷을 Kubernetes에서 특수 소프트웨어 및 하드웨어 장치를 활성화하기 위한 드라이버 컨테이너의 기본 이미지로 사용하는 방법에 대해 알아 보십시오.
드라이버 툴킷(Driver Toolkit)은 기술 프리뷰 기능으로만 사용할 수 있습니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 https://access.redhat.com/support/offerings/techpreview/를 참조하십시오.
10.1. 드라이버 툴킷 정보
배경
Driver Toolkit은 드라이버 컨테이너를 빌드할 수 있는 기본 이미지로 사용되는 OpenShift Container Platform 페이로드의 컨테이너 이미지입니다. Driver Toolkit 이미지에는 커널 모듈을 빌드하거나 설치하는 데 일반적으로 필요한 커널 패키지와 드라이버 컨테이너에 필요한 몇 가지 툴이 포함되어 있습니다. 이러한 패키지의 버전은 해당 OpenShift Container Platform 릴리스의 RHCOS(Red Hat Enterprise Linux CoreOS) 노드에서 실행되는 커널 버전과 동일합니다.
드라이버 컨테이너는 RHCOS와 같은 컨테이너 운영 체제에서 트리 외부 커널 모듈 및 드라이버를 빌드하고 배포하는 데 사용되는 컨테이너 이미지입니다. 커널 모듈과 드라이버는 운영 체제 커널에서 높은 수준의 권한으로 실행되는 소프트웨어 라이브러리입니다. 커널 기능을 확장하거나 새 장치를 제어하는 데 필요한 하드웨어별 코드를 제공합니다. 예를 들어 Field Programmable Gate Arrays(예: Field Programmable Gate Arrays) 또는 GPU와 같은 하드웨어 장치, Lustre 병렬 파일 시스템과 같은 소프트웨어 정의 스토리지(SDS) 솔루션은 클라이언트 시스템에 커널 모듈이 필요합니다. 드라이버 컨테이너는 Kubernetes에서 이러한 기술을 활성화하는 데 사용되는 소프트웨어 스택의 첫 번째 계층입니다.
Driver Toolkit의 커널 패키지 목록에는 다음과 같은 종속성이 포함되어 있습니다.
-
kernel-core -
kernel-devel -
kernel-headers -
kernel-modules -
kernel-modules-extra
또한 Driver Toolkit에는 해당 실시간 커널 패키지도 포함되어 있습니다.
-
kernel-rt-core -
kernel-rt-devel -
kernel-rt-modules -
kernel-rt-modules-extra
또한 Driver Toolkit에는 다음을 포함하여 커널 모듈을 빌드하고 설치하는 데 일반적으로 필요한 여러 도구가 있습니다.
-
elfutils-libelf-devel -
kmod -
binutilskabi-dw -
kernel-abi-whitelists - 위의 종속 항목
목적
Driver Toolkit이 출시하기 전에는 권한이 부여된 빌드를 사용하거나 호스트 machine-os-content의 커널 RPM에서 설치하여 OpenShift Container Platform의 Pod에 커널 패키지를 설치할 수 있었습니다. Driver Toolkit은 인타이틀먼트 단계를 제거하여 프로세스를 간소화하고 Pod에서 machine-os-content에 액세스하는 권한 있는 작업을 피할 수 있습니다. Driver Toolkit은 사전 릴리스된 OpenShift Container Platform 버전에 액세스할 수 있는 파트너가 향후 OpenShift Container Platform 릴리스를 위한 하드웨어 장치용 드라이버 컨테이너를 사전 구축하는 데 사용할 수도 있습니다.
Driver Toolkit은 현재 OperatorHub에서 커뮤니티 Operator로 사용할 수 있는 SAR(Special Resource Operator)에서도 사용됩니다. SRO는 외부 및 타사 커널 드라이버와 기본 운영 체제에 대한 지원 소프트웨어를 지원합니다. SRO에 대한 레시피 를 생성하여 드라이버 컨테이너를 빌드하고 배포할 수 있으며 장치 플러그인 또는 메트릭과 같은 지원 소프트웨어를 생성할 수 있습니다. 레시피에는 Driver Toolkit을 기반으로 드라이버 컨테이너를 빌드하는 빌드 구성이 포함될 수 있으며, SRO는 사전 빌드된 드라이버 컨테이너를 배포할 수 있습니다.
10.2. Driver Toolkit 컨테이너 이미지 가져오기
driver-toolkit 이미지는 Red Hat Ecosystem Catalog의 컨테이너 이미지 섹션과 OpenShift Container Platform 릴리스 페이로드에서 사용할 수 있습니다. OpenShift Container Platform의 최신 마이너 릴리스에 해당하는 이미지에는 카탈로그의 버전 번호로 태그가 지정됩니다. 특정 릴리스의 이미지 URL은 oc adm CLI 명령을 사용하여 찾을 수 있습니다.
10.2.1. registry.redhat.io에서 Driver Toolkit 컨테이너 이미지 가져오기
registry.redhat.io에서 podman 또는 OpenShift Container Platform을 사용하여 driver-toolkit 이미지를 가져오는 방법은 Red Hat Ecosystem Catalog에서 확인할 수 있습니다. 최신 마이너 릴리스의 driver-toolkit 이미지는 registry.redhat.io/openshift4/driver-toolkit-rhel8:v4.8의 마이너 릴리스 버전에 태그가 지정됩니다.
10.2.2. 페이로드에서 Driver Toolkit 이미지 URL 검색
사전 요구 사항
- Red Hat OpenShift Cluster Manager에서 이미지 풀 시크릿 을 가져왔습니다.
-
OpenShift CLI(
oc)를 설치합니다.
절차
특정 릴리스에 해당하는
driver-toolkit의 이미지 URL은oc adm명령을 사용하여 릴리스 이미지에서 얻을 수 있습니다.$ oc adm release info 4.8.0 --image-for=driver-toolkit
출력 예
quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:0fd84aee79606178b6561ac71f8540f404d518ae5deff45f6d6ac8f02636c7f4
- 이 이미지는 OpenShift Container Platform을 설치하는 데 필요한 pull secret과 같은 유효한 풀 시크릿을 사용하여 가져올 수 있습니다.
$ podman pull --authfile=path/to/pullsecret.json quay.io/openshift-release-dev/ocp-v4.0-art-dev@sha256:<SHA>
10.3. Driver Toolkit 사용
예를 들어 Driver Toolkit은 simple-kmod라는 매우 간단한 커널 모듈을 빌드하기 위한 기본 이미지로 사용할 수 있습니다.
10.3.1. 클러스터에서 simple-kmod 드라이버 컨테이너를 빌드하고 실행합니다.
사전 요구 사항
- OpenShift Container Platform 클러스터
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
네임스페이스를 생성합니다. 예를 들면 다음과 같습니다.
$ oc new-project simple-kmod-demo
YAML은
simple-kmod드라이버 컨테이너 이미지를 저장하기 위한ImageStream과 컨테이너 빌드를 위한BuildConfig를 정의합니다. 이 YAML을0000-buildconfig.yaml.template로 저장합니다.apiVersion: image.openshift.io/v1 kind: ImageStream metadata: labels: app: simple-kmod-driver-container name: simple-kmod-driver-container namespace: simple-kmod-demo spec: {} --- apiVersion: build.openshift.io/v1 kind: BuildConfig metadata: labels: app: simple-kmod-driver-build name: simple-kmod-driver-build namespace: simple-kmod-demo spec: nodeSelector: node-role.kubernetes.io/worker: "" runPolicy: "Serial" triggers: - type: "ConfigChange" - type: "ImageChange" source: git: ref: "master" uri: "https://github.com/openshift-psap/kvc-simple-kmod.git" type: Git dockerfile: | FROM DRIVER_TOOLKIT_IMAGE WORKDIR /build/ RUN yum -y install git make sudo gcc \ && yum clean all \ && rm -rf /var/cache/dnf # Expecting kmod software version as an input to the build ARG KMODVER # Grab the software from upstream RUN git clone https://github.com/openshift-psap/simple-kmod.git WORKDIR simple-kmod # Prep and build the module RUN make buildprep KVER=$(rpm -q --qf "%{VERSION}-%{RELEASE}.%{ARCH}" kernel-core) KMODVER=${KMODVER} \ && make all KVER=$(rpm -q --qf "%{VERSION}-%{RELEASE}.%{ARCH}" kernel-core) KMODVER=${KMODVER} \ && make install KVER=$(rpm -q --qf "%{VERSION}-%{RELEASE}.%{ARCH}" kernel-core) KMODVER=${KMODVER} # Add the helper tools WORKDIR /root/kvc-simple-kmod ADD Makefile . ADD simple-kmod-lib.sh . ADD simple-kmod-wrapper.sh . ADD simple-kmod.conf . RUN mkdir -p /usr/lib/kvc/ \ && mkdir -p /etc/kvc/ \ && make install RUN systemctl enable kmods-via-containers@simple-kmod strategy: dockerStrategy: buildArgs: - name: KMODVER value: DEMO output: to: kind: ImageStreamTag name: simple-kmod-driver-container:demo"DRIVER_TOOLKIT_IMAGE" 대신 실행 중인 OpenShift Container Platform 버전에 대해 올바른 드라이버 툴킷 이미지를 다음 명령으로 대체하십시오.
$ OCP_VERSION=$(oc get clusterversion/version -ojsonpath={.status.desired.version})$ DRIVER_TOOLKIT_IMAGE=$(oc adm release info $OCP_VERSION --image-for=driver-toolkit)
$ sed "s#DRIVER_TOOLKIT_IMAGE#${DRIVER_TOOLKIT_IMAGE}#" 0000-buildconfig.yaml.template > 0000-buildconfig.yaml참고드라이버 툴킷은 버전 4.6.30의 OpenShift Container Platform 4.6, 버전 4.7.11의 4.7 및 4.8에 도입되었습니다.
이미지 스트림 및 빌드 구성을 만듭니다.
$ oc create -f 0000-buildconfig.yaml
빌더 Pod가 성공적으로 완료되면 드라이버 컨테이너 이미지를
DaemonSet으로 배포합니다.호스트에서 커널 모듈을 로드하려면 드라이버 컨테이너를 권한 있는 보안 컨텍스트로 실행해야 합니다. 다음 YAML 파일에는 RBAC 규칙과 드라이버 컨테이너 실행을 위한
DaemonSet이 포함되어 있습니다. 이 YAML을1000-drivercontainer.yaml로 저장합니다.apiVersion: v1 kind: ServiceAccount metadata: name: simple-kmod-driver-container --- apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: simple-kmod-driver-container rules: - apiGroups: - security.openshift.io resources: - securitycontextconstraints verbs: - use resourceNames: - privileged --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: simple-kmod-driver-container roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: simple-kmod-driver-container subjects: - kind: ServiceAccount name: simple-kmod-driver-container userNames: - system:serviceaccount:simple-kmod-demo:simple-kmod-driver-container --- apiVersion: apps/v1 kind: DaemonSet metadata: name: simple-kmod-driver-container spec: selector: matchLabels: app: simple-kmod-driver-container template: metadata: labels: app: simple-kmod-driver-container spec: serviceAccount: simple-kmod-driver-container serviceAccountName: simple-kmod-driver-container containers: - image: image-registry.openshift-image-registry.svc:5000/simple-kmod-demo/simple-kmod-driver-container:demo name: simple-kmod-driver-container imagePullPolicy: Always command: ["/sbin/init"] lifecycle: preStop: exec: command: ["/bin/sh", "-c", "systemctl stop kmods-via-containers@simple-kmod"] securityContext: privileged: true nodeSelector: node-role.kubernetes.io/worker: ""RBAC 규칙 및 데몬 세트를 생성합니다.
$ oc create -f 1000-drivercontainer.yaml
작업자 노드에서 pod가 실행된 후
lsmod가 있는 호스트 시스템에simple_kmod커널 모듈이 제대로 로드되었는지 확인합니다.pod가 실행 중인지 확인합니다.
$ oc get pod -n simple-kmod-demo
출력 예
NAME READY STATUS RESTARTS AGE simple-kmod-driver-build-1-build 0/1 Completed 0 6m simple-kmod-driver-container-b22fd 1/1 Running 0 40s simple-kmod-driver-container-jz9vn 1/1 Running 0 40s simple-kmod-driver-container-p45cc 1/1 Running 0 40s
드라이버 컨테이너 Pod에서
lsmod명령을 실행합니다.$ oc exec -it pod/simple-kmod-driver-container-p45cc -- lsmod | grep simple
출력 예
simple_procfs_kmod 16384 0 simple_kmod 16384 0
11장. 오브젝트 최대값에 따른 환경 계획
OpenShift Container Platform 클러스터를 계획하는 경우 다음과 같은 테스트된 오브젝트 최대값을 고려하십시오.
이러한 지침은 가능한 가장 큰 클러스터를 기반으로 합니다. 크기가 작은 클러스터의 경우 최대값이 더 낮습니다. etcd 버전 또는 스토리지 데이터 형식을 비롯하여 명시된 임계값에 영향을 주는 요인은 여러 가지가 있습니다.
이러한 지침은 OVN(Open Virtual Network)이 아닌 SDN(소프트웨어 정의 네트워킹)을 사용하는 OpenShift Container Platform에 적용됩니다.
대부분의 경우 이러한 수치를 초과하면 전체 성능이 저하됩니다. 반드시 클러스터가 실패하는 것은 아닙니다.
11.1. OpenShift Container Platform에 대해 테스트된 클러스터 최대값(주요 릴리스)
OpenShift Container Platform 3.x에 대해 테스트된 클라우드 플랫폼은 다음과 같습니다. RHOSP(Red Hat OpenStack Platform), Amazon Web Services 및 Microsoft Azure. OpenShift Container Platform 4.x에 대해 테스트된 클라우드 플랫폼은 다음과 같습니다. Amazon Web Services, Microsoft Azure 및 Google Cloud Platform.
| 최대값 유형 | 3.x 테스트된 최대값 | 4.x 테스트된 최대값 |
|---|---|---|
| 노드 수 | 2,000 | 2,000 |
| Pod 수 [1] | 150,000 | 150,000 |
| 노드당 Pod 수 | 250 | 500 [2] |
| 코어당 Pod 수 | 기본값 없음 | 기본값 없음 |
| 네임스페이스 수 [3] | 10,000 | 10,000 |
| 빌드 수 | 10,000(기본 Pod RAM 512Mi) - Pipeline 전략 | 10,000(기본 Pod RAM 512Mi) - S2I(Source-to-Image) 빌드 전략 |
| 네임스페이스당 Pod 수 [4] | 25,000 | 25,000 |
| Ingress 컨트롤러당 경로 및 백엔드 수 | 라우터당 2,000개 | 라우터당 2,000개 |
| 보안 수 | 80,000 | 80,000 |
| 구성 맵 수 | 90,000 | 90,000 |
| 서비스 수 [5] | 10,000 | 10,000 |
| 네임스페이스당 서비스 수 | 5,000 | 5,000 |
| 서비스당 백엔드 수 | 5,000 | 5,000 |
| 네임스페이스당 배포 수 [4] | 2,000 | 2,000 |
| 빌드 구성 수 | 12,000 | 12,000 |
| CRD(사용자 정의 리소스 정의) 수 | 기본값 없음 | 512 [6] |
- 여기에 표시된 Pod 수는 테스트 Pod 수입니다. 실제 Pod 수는 애플리케이션 메모리, CPU 및 스토리지 요구사항에 따라 달라집니다.
-
이 테스트는 작업자 노드가 100개이며 작업자 노드당 Pod가 500개인 클러스터에서 수행되었습니다. 기본
maxPods는 계속 250입니다.maxPods가 500이 되도록 하려면 사용자 정의 kubelet 구성을 사용하여500으로 설정된maxPods가 포함된 클러스터를 생성해야 합니다. 500개의 사용자 Pod가 필요한 경우 노드에서 이미 실행되고 있는 시스템 Pod가 10~15개가 있으므로hostPrefix22가 필요합니다. 연결된 PVC(영구 볼륨 클레임)가 있는 Pod의 최대 수는 PVC가 할당된 스토리지 백엔드에 따라 달라집니다. 이 테스트에서는 OpenShift Container Storage (OCS v4)만 이 문서에서 설명하는 노드당 Pod 수를 충족할 수 있었습니다. - 활성 프로젝트 수가 많은 경우 키 공간이 지나치게 커져서 공간 할당량을 초과하면 etcd 성능이 저하될 수 있습니다. etcd 스토리지를 확보하기 위해 조각 모음을 포함한 etcd의 유지보수를 정기적으로 사용하는 것이 좋습니다.
- 시스템에는 일부 상태 변경에 대한 대응으로 지정된 네임스페이스의 모든 오브젝트에서 반복해야 하는 컨트롤 루프가 많습니다. 단일 네임스페이스에 지정된 유형의 오브젝트가 많이 있으면 루프 비용이 많이 들고 지정된 상태 변경 처리 속도가 느려질 수 있습니다. 이 제한을 적용하면 애플리케이션 요구사항을 충족하기에 충분한 CPU, 메모리 및 디스크가 시스템에 있다고 가정합니다.
- 각 서비스 포트와 각 서비스 백엔드는 iptables에 해당 항목이 있습니다. 지정된 서비스의 백엔드 수는 끝점 오브젝트의 크기에 영향을 미치므로 시스템 전체에서 전송되는 데이터의 크기에 영향을 미칩니다.
-
OpenShift Container Platform에는 OpenShift Container Platform에서 설치한 제품, OpenShift Container Platform 및 사용자 생성 CRD와 통합된 제품을 포함하여 총 512개의 CRD(사용자 정의 리소스 정의) 제한이 있습니다. 512개 이상의 CRD가 생성되는 경우
oc명령 요청이 제한될 수 있습니다.
Red Hat은 OpenShift Container Platform 클러스터 크기 조정에 대한 직접적인 지침을 제공하지 않습니다. 이는 클러스터가 지원되는 OpenShift Container Platform 범위 내에 있는지 여부를 확인하기 때문에 클러스터 규모를 제한하는 모든 다차원 요소를 고려해야 하기 때문입니다.
11.2. 클러스터 최대값 테스트를 위한 OpenShift Container Platform 환경 및 구성
AWS 클라우드 플랫폼:
| 노드 | 플레이버 | vCPU | RAM(GiB) | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 | 리전 |
|---|---|---|---|---|---|---|---|
| Master/etcd [1] | r5.4xlarge | 16 | 128 | gp3 | 220 | 3 | us-west-2 |
| 인프라 [2] | m5.12xlarge | 48 | 192 | gp3 | 100 | 3 | us-west-2 |
| 워크로드 [3] | m5.4xlarge | 16 | 64 | gp3 | 500 [4] | 1 | us-west-2 |
| Worker | m5.2xlarge | 8 | 32 | gp3 | 100 | 3/25/250/500 [5] | us-west-2 |
- etcd는 대기 시간에 민감하기 때문에 3000 IOPS 및 125MiB의 성능이 있는 gp3 디스크는 컨트롤 플레인/etcd 노드에 사용됩니다. gp3 볼륨은 버스트 성능을 사용하지 않습니다.
- 인프라 노드는 모니터링, Ingress 및 레지스트리 구성 요소를 호스팅하는데 사용되어 대규모로 실행할 수 있는 충분한 리소스가 있는지 확인합니다.
- 워크로드 노드는 성능 및 확장 가능한 워크로드 생성기 실행 전용입니다.
- 성능 및 확장성 테스트 실행 중에 수집되는 대량의 데이터를 저장할 수 있는 충분한 공간을 확보 할 수 있도록 큰 디스크 크기가 사용됩니다.
- 클러스터는 반복적으로 확장되며 성능 및 확장성 테스트는 지정된 노드 수에 따라 실행됩니다.
IBM Power Systems 플랫폼:
| 노드 | vCPU | RAM(GiB) | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 |
|---|---|---|---|---|---|
| Master/etcd [1] | 16 | 32 | io1 | GiB당 120 / 10 IOPS | 3 |
| 인프라 [2] | 16 | 64 | gp2 | 120 | 2 |
| 워크로드 [3] | 16 | 256 | gp2 | 120 [4] | 1 |
| Worker | 16 | 64 | gp2 | 120 | 3/25/250/500 [5] |
- etcd는 I/O 집약적이고 지연 시간에 민감하므로 GB당 120/3 IOPS의 io1 디스크가 master/etcd 노드에 사용됩니다.
- 인프라 노드는 모니터링, Ingress 및 레지스트리 구성 요소를 호스팅하는데 사용되어 대규모로 실행할 수 있는 충분한 리소스가 있는지 확인합니다.
- 워크로드 노드는 성능 및 확장 가능한 워크로드 생성기 실행 전용입니다.
- 성능 및 확장성 테스트 실행 중에 수집되는 대량의 데이터를 저장할 수 있는 충분한 공간을 확보 할 수 있도록 큰 디스크 크기가 사용됩니다.
- 클러스터는 반복적으로 확장되며 성능 및 확장성 테스트는 지정된 노드 수에 따라 실행됩니다.
11.2.1. IBM Z 플랫폼
| 노드 | vCPU [4] | RAM(GiB)[5] | 디스크 유형 | 디스크 크기(GiB)/IOS | 수량 |
|---|---|---|---|---|---|
| 컨트롤 플레인/etcd [1,2] | 8 | 32 | ds8k | 300 / LCU 1 | 3 |
| Compute [1,3] | 8 | 32 | ds8k | 150 / LCU 2 | 노드 4개 (노드당 100/250/500 Pod로 확장) |
- etcd는 I/O 집약적이고 지연 시간에 민감하므로 두 개의 논리 제어 단위(LCU)에 분산되어 컨트롤 플레인/etcd 노드의 디스크 I/O 로드를 최적화합니다. etcd I/O 수요가 다른 워크로드를 방해하지 않아야 합니다.
- 컴퓨팅 노드 4개가 동시에 100/250/500개의 Pod로 여러 반복을 실행하는 테스트에 사용됩니다. 먼저 유휴 Pod를 사용하여 Pod를 인스턴스할 수 있는지 평가합니다. 다음으로, 네트워크 및 CPU의 우선 순위 클라이언트/서버 워크로드가 강조되는 시스템의 안정성을 평가하는 데 사용되었습니다. 클라이언트 및 서버 Pod가 쌍으로 배포되었으며 각 쌍이 두 개의 컴퓨팅 노드에 분배되었습니다.
- 별도의 워크로드 노드가 사용되지 않았습니다. 워크로드는 두 개의 컴퓨팅 노드 간에 마이크로 서비스 워크로드를 시뮬레이션합니다.
- 사용되는 물리적 프로세서 수는 6개의 IIFL(Integrated F facility)입니다.
- 사용된 총 물리 메모리는 512GiB입니다.
11.3. 테스트된 클러스터 최대값에 따라 환경을 계획하는 방법
노드에서 물리적 리소스에 대한 서브스크립션을 초과하면 Pod를 배치하는 동안 Kubernetes 스케줄러가 보장하는 리소스에 영향을 미칩니다. 메모리 교체가 발생하지 않도록 하기 위해 수행할 수 있는 조치를 알아보십시오.
테스트된 최대값 중 일부는 단일 차원에서만 확장됩니다. 클러스터에서 실행되는 오브젝트가 많으면 최대값이 달라집니다.
이 문서에 명시된 수치는 Red Hat의 테스트 방법론, 설정, 구성, 튜닝을 기반으로 한 것입니다. 고유한 개별 설정 및 환경에 따라 수치가 달라질 수 있습니다.
환경을 계획하는 동안 노드당 몇 개의 Pod가 적합할 것으로 예상되는지 결정하십시오.
required pods per cluster / pods per node = total number of nodes needed
노드당 최대 Pod 수는 현재 250입니다. 하지만 노드에 적합한 Pod 수는 애플리케이션 자체에 따라 달라집니다. 애플리케이션 요구사항에 따라 환경을 계획하는 방법에 설명된 대로 애플리케이션의 메모리, CPU 및 스토리지 요구사항을 고려하십시오.
시나리오 예
클러스터당 2,200개의 Pod로 클러스터 규모를 지정하려면 노드당 최대 500개의 Pod가 있다고 가정하여 최소 5개의 노드가 있어야 합니다.
2200 / 500 = 4.4
노드 수를 20으로 늘리면 Pod 배포는 노드당 110개 Pod로 변경됩니다.
2200 / 20 = 110
다음과 같습니다.
required pods per cluster / total number of nodes = expected pods per node
11.4. 애플리케이션 요구사항에 따라 환경을 계획하는 방법
예에 나온 애플리케이션 환경을 고려해 보십시오.
| Pod 유형 | Pod 수량 | 최대 메모리 | CPU 코어 수 | 영구 스토리지 |
|---|---|---|---|---|
| apache | 100 | 500MB | 0.5 | 1GB |
| node.js | 200 | 1GB | 1 | 1GB |
| postgresql | 100 | 1GB | 2 | 10GB |
| JBoss EAP | 100 | 1GB | 1 | 1GB |
예상 요구 사항: 550개의 CPU 코어, 450GB RAM 및 1.4TB 스토리지.
노드의 인스턴스 크기는 기본 설정에 따라 높게 또는 낮게 조정될 수 있습니다. 노드에서는 리소스 초과 커밋이 발생하는 경우가 많습니다. 이 배포 시나리오에서는 동일한 양의 리소스를 제공하는 데 더 작은 노드를 추가로 실행하도록 선택할 수도 있고 더 적은 수의 더 큰 노드를 실행하도록 선택할 수도 있습니다. 운영 민첩성 및 인스턴스당 비용과 같은 요인을 고려해야 합니다.
| 노드 유형 | 수량 | CPU | RAM(GB) |
|---|---|---|---|
| 노드(옵션 1) | 100 | 4 | 16 |
| 노드(옵션 2) | 50 | 8 | 32 |
| 노드(옵션 3) | 25 | 16 | 64 |
어떤 애플리케이션은 초과 커밋된 환경에 적합하지만 어떤 애플리케이션은 그렇지 않습니다. 대부분의 Java 애플리케이션과 대규모 페이지를 사용하는 애플리케이션은 초과 커밋에 적합하지 않은 애플리케이션의 예입니다. 해당 메모리는 다른 애플리케이션에 사용할 수 없습니다. 위의 예에 나온 환경에서는 초과 커밋이 약 30%이며, 이는 일반적으로 나타나는 비율입니다.
애플리케이션 Pod는 환경 변수 또는 DNS를 사용하여 서비스에 액세스할 수 있습니다. 환경 변수를 사용하는 경우 노드에서 Pod가 실행될 때 활성 서비스마다 kubelet을 통해 변수를 삽입합니다. 클러스터 인식 DNS 서버는 새로운 서비스의 Kubernetes API를 확인하고 각각에 대해 DNS 레코드 세트를 생성합니다. 클러스터 전체에서 DNS가 활성화된 경우 모든 Pod가 자동으로 해당 DNS 이름을 통해 서비스를 확인할 수 있어야 합니다. 서비스가 5,000개를 넘어야 하는 경우 DNS를 통한 서비스 검색을 사용할 수 있습니다. 서비스 검색에 환경 변수를 사용하는 경우 네임스페이스에서 서비스가 5,000개를 넘은 후 인수 목록이 허용되는 길이를 초과하면 Pod 및 배포가 실패하기 시작합니다. 이 문제를 해결하려면 배포의 서비스 사양 파일에서 서비스 링크를 비활성화하십시오.
---
apiVersion: template.openshift.io/v1
kind: Template
metadata:
name: deployment-config-template
creationTimestamp:
annotations:
description: This template will create a deploymentConfig with 1 replica, 4 env vars and a service.
tags: ''
objects:
- apiVersion: apps.openshift.io/v1
kind: DeploymentConfig
metadata:
name: deploymentconfig${IDENTIFIER}
spec:
template:
metadata:
labels:
name: replicationcontroller${IDENTIFIER}
spec:
enableServiceLinks: false
containers:
- name: pause${IDENTIFIER}
image: "${IMAGE}"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: ENVVAR1_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR2_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR3_${IDENTIFIER}
value: "${ENV_VALUE}"
- name: ENVVAR4_${IDENTIFIER}
value: "${ENV_VALUE}"
resources: {}
imagePullPolicy: IfNotPresent
capabilities: {}
securityContext:
capabilities: {}
privileged: false
restartPolicy: Always
serviceAccount: ''
replicas: 1
selector:
name: replicationcontroller${IDENTIFIER}
triggers:
- type: ConfigChange
strategy:
type: Rolling
- apiVersion: v1
kind: Service
metadata:
name: service${IDENTIFIER}
spec:
selector:
name: replicationcontroller${IDENTIFIER}
ports:
- name: serviceport${IDENTIFIER}
protocol: TCP
port: 80
targetPort: 8080
clusterIP: ''
type: ClusterIP
sessionAffinity: None
status:
loadBalancer: {}
parameters:
- name: IDENTIFIER
description: Number to append to the name of resources
value: '1'
required: true
- name: IMAGE
description: Image to use for deploymentConfig
value: gcr.io/google-containers/pause-amd64:3.0
required: false
- name: ENV_VALUE
description: Value to use for environment variables
generate: expression
from: "[A-Za-z0-9]{255}"
required: false
labels:
template: deployment-config-template
네임스페이스에서 실행할 수 있는 애플리케이션 Pod 수는 서비스 검색에 환경 변수가 사용될 때 서비스 수와 서비스 이름의 길이에 따라 달라집니다. ARG_MAX는 새로운 프로세스의 최대 인수 길이를 정의하고 기본적으로 2097152 KiB로 설정됩니다. Kubelet은 네임스페이스에서 실행되도록 예약된 각 pod에 환경 변수를 삽입합니다. 여기에는 다음이 포함됩니다.
-
<SERVICE_NAME>_SERVICE_HOST=<IP> -
<SERVICE_NAME>_SERVICE_PORT=<PORT> -
<SERVICE_NAME>_PORT=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP=tcp://<IP>:<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_PROTO=tcp -
<SERVICE_NAME>_PORT_<PORT>_TCP_PORT=<PORT> -
<SERVICE_NAME>_PORT_<PORT>_TCP_ADDR=<ADDR>
인수 길이가 허용된 값을 초과하고 서비스 이름의 문자 수에 영향을 미치는 경우 네임스페이스의 Pod가 실패합니다. 예를 들어, 5000개의 서비스가 있는 네임스페이스에서 서비스 이름의 제한은 33자이며, 네임스페이스에서 5000개의 Pod를 실행할 수 있습니다.
12장. 스토리지 최적화
스토리지를 최적화하면 모든 리소스에서 스토리지 사용을 최소화할 수 있습니다. 관리자는 스토리지를 최적화하여 기존 스토리지 리소스가 효율적으로 작동하도록 합니다.
12.1. 사용 가능한 영구 스토리지 옵션
OpenShift Container Platform 환경을 최적화할 수 있도록 영구 스토리지 옵션에 대해 알아보십시오.
표 12.1. 사용 가능한 스토리지 옵션
| 스토리지 유형 | 설명 | 예 |
|---|---|---|
| 블록 |
| AWS EBS 및 VMware vSphere는 OpenShift Container Platform에서 기본적으로 동적 PV(영구 볼륨) 프로비저닝을 지원합니다. |
| 파일 |
| RHEL NFS, NetApp NFS [1] 및 Vendor NFS |
| 개체 |
| AWS S3 |
- NetApp NFS는 Trident 플러그인을 사용할 때 동적 PV 프로비저닝을 지원합니다.
OpenShift Container Platform 4.8에서는 현재 CNS가 지원되지 않습니다.
12.2. 권장되는 구성 가능한 스토리지 기술
다음 표에는 지정된 OpenShift Container Platform 클러스터 애플리케이션에 권장되는 구성 가능한 스토리지 기술이 요약되어 있습니다.
표 12.2. 권장되는 구성 가능한 스토리지 기술
| 스토리지 유형 | ROX1 | RWX2 | Registry | 확장 레지스트리 | Metrics3 | 로깅 | 앱 |
|---|---|---|---|---|---|---|---|
|
1
2 3 Prometheus는 메트릭에 사용되는 기본 기술입니다. 4 물리적 디스크, VM 물리적 디스크, VMDK, NFS를 통한 루프백, AWS EBS 및 Azure Disk에는 적용되지 않습니다.
5 메트릭의 경우 RWX( 6 로깅의 경우 공유 스토리지를 사용하는 것이 패턴 차단입니다. Elasticsearch당 하나의 볼륨이 필요합니다. 7 OpenShift Container Platform의 PV 또는 PVC를 통해서는 오브젝트 스토리지가 사용되지 않습니다. 앱은 오브젝트 스토리지 REST API와 통합해야 합니다. | |||||||
| 블록 | 제공됨4 | 없음 | 구성 가능 | 구성 불가능 | 권장 | 권장 | 권장 |
| 파일 | 제공됨4 | 예 | 구성 가능 | 구성 가능 | 구성 가능5 | 구성 가능6 | 권장 |
| 개체 | 예 | 예 | 권장 | 권장 | 구성 불가능 | 구성 불가능 | 구성 불가능7 |
확장 레지스트리는 두 개 이상의 Pod 복제본이 실행되는 OpenShift Container Platform 레지스트리입니다.
12.2.1. 특정 애플리케이션 스토리지 권장 사항
테스트에서는 RHEL(Red Hat Enterprise Linux)의 NFS 서버를 핵심 서비스용 스토리지 백엔드로 사용하는 데 문제가 있는 것을 보여줍니다. 여기에는 OpenShift Container Registry and Quay, 스토리지 모니터링을 위한 Prometheus, 로깅 스토리지를 위한 Elasticsearch가 포함됩니다. 따라서 RHEL NFS를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift Container Platform 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
12.2.1.1. 레지스트리
비확장/HA(고가용성) OpenShift Container Platform 레지스트리 클러스터 배포에서는 다음 사항에 유의합니다.
- 스토리지 기술에서 RWX 액세스 모드를 지원할 필요가 없습니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지, 블록 스토리지 순입니다.
- 프로덕션 워크로드가 있는 OpenShift Container Platform 레지스트리 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
12.2.1.2. 확장 레지스트리
확장/HA OpenShift Container Platform 레지스트리 클러스터 배포에서는 다음 사항에 유의합니다.
- 스토리지 기술은 RWX 액세스 모드를 지원해야 합니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다.
- 기본 스토리지 기술은 오브젝트 스토리지입니다.
- Amazon S3(Amazon Simple Storage Service), GCS(Google Cloud Storage), Microsoft Azure Blob Storage 및 OpenStack Swift가 지원됩니다.
- 오브젝트 스토리지는 S3 또는 Swift와 호환되어야 합니다.
- vSphere, 베어 메탈 설치 등 클라우드 이외의 플랫폼에서는 구성 가능한 유일한 기술이 파일 스토리지입니다.
- 블록 스토리지는 구성 불가능합니다.
12.2.1.3. 지표
OpenShift Container Platform 호스트 지표 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 구성 불가능합니다.
프로덕션 워크로드가 있는 호스트 지표 클러스터 배포에는 파일 스토리지를 사용하지 않는 것이 좋습니다.
12.2.1.4. 로깅
OpenShift Container Platform 호스트 로깅 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 오브젝트 스토리지는 구성 불가능합니다.
12.2.1.5. 애플리케이션
애플리케이션 사용 사례는 다음 예에 설명된 대로 애플리케이션마다 다릅니다.
- 동적 PV 프로비저닝을 지원하는 스토리지 기술은 마운트 대기 시간이 짧고 정상 클러스터를 지원하는 노드와 관련이 없습니다.
- 애플리케이션 개발자는 애플리케이션의 스토리지 요구사항을 잘 알고 있으며 제공된 스토리지로 애플리케이션을 작동시켜 애플리케이션이 스토리지 계층을 스케일링하거나 스토리지 계층과 상호 작용할 때 문제가 발생하지 않도록 하는 방법을 이해하고 있어야 합니다.
12.2.2. 다른 특정 애플리케이션 스토리지 권장 사항
etcd 와 같은 쓰기 집약적 워크로드에서는 RAID 구성을 사용하지 않는 것이 좋습니다. RAID 구성으로 etcd 를 실행하는 경우 워크로드의 성능 문제가 발생할 위험이 있을 수 있습니다.
- RHOSP(Red Hat OpenStack Platform) Cinder: RHOSP Cinder는 ROX 액세스 모드 사용 사례에 적응하는 경향이 있습니다.
- 데이터베이스: 데이터베이스(RDBMS, NoSQL DB 등)는 전용 블록 스토리지에서 최상의 성능을 발휘하는 경향이 있습니다.
- etcd 데이터베이스에는 대규모 클러스터를 활성화하려면 충분한 스토리지와 충분한 성능 용량이 있어야 합니다. 충분한 스토리지 및 고성능 환경을 구축하기 위한 모니터링 및 벤치마킹 툴에 대한 정보는 권장 etcd 관행에 설명되어 있습니다.
12.3. 데이터 스토리지 관리
다음 표에는 OpenShift Container Platform 구성 요소가 데이터를 쓰는 기본 디렉터리가 요약되어 있습니다.
표 12.3. OpenShift Container Platform 데이터를 저장하는 기본 디렉터리
| 디렉터리 | 참고 | 크기 조정 | 예상 증가 |
|---|---|---|---|
| /var/log | 모든 구성 요소의 로그 파일입니다. | 10~30GB입니다. | 로그 파일이 빠르게 증가할 수 있습니다. 크기는 디스크를 늘리거나 로그 회전을 사용하여 관리할 수 있습니다. |
| /var/lib/etcd | 데이터베이스를 저장할 때 etcd 스토리지에 사용됩니다. | 20GB 미만입니다. 데이터베이스는 최대 8GB까지 증가할 수 있습니다. | 환경과 함께 천천히 증가합니다. 메타데이터만 저장합니다. 추가로 메모리가 8GB 증가할 때마다 추가로 20~25GB가 증가합니다. |
| /var/lib/containers | CRI-O 런타임의 마운트 옵션입니다. Pod를 포함한 활성 컨테이너 런타임에 사용되는 스토리지 및 로컬 이미지 스토리지입니다. 레지스트리 스토리지에는 사용되지 않습니다. | 16GB 메모리가 있는 노드의 경우 50GB가 증가합니다. 이 크기 조정은 최소 클러스터 요구사항을 결정하는 데 사용하면 안 됩니다. 추가로 메모리가 8GB 증가할 때마다 추가로 20~25GB가 증가합니다. | 컨테이너 실행 용량에 의해 증가가 제한됩니다. |
| /var/lib/kubelet | Pod용 임시 볼륨 스토리지입니다. 런타임 시 컨테이너로 마운트된 외부 요소가 모두 포함됩니다. 영구 볼륨에서 지원하지 않는 환경 변수, kube 보안 및 데이터 볼륨이 포함됩니다. | 변동 가능 | 스토리지가 필요한 Pod가 영구 볼륨을 사용하는 경우 최소입니다. 임시 스토리지를 사용하는 경우 빠르게 증가할 수 있습니다. |
13장. 라우팅 최적화
OpenShift Container Platform HAProxy 라우터는 스케일링을 통해 성능을 최적화합니다.
13.1. 기본 Ingress 컨트롤러(라우터) 성능
OpenShift Container Platform Ingress 컨트롤러 또는 라우터는 OpenShift Container Platform 서비스를 대상으로 하는 모든 외부 트래픽의 Ingress 지점입니다.
초당 처리된 HTTP 요청 측면에서 단일 HAProxy 라우터 성능을 평가할 때 성능은 여러 요인에 따라 달라집니다. 특히 중요한 요인은 다음과 같습니다.
- HTTP 연결 유지/닫기 모드
- 경로 유형
- TLS 세션 재개 클라이언트 지원
- 대상 경로당 동시 연결 수
- 대상 경로 수
- 백엔드 서버 페이지 크기
- 기본 인프라(네트워크/SDN 솔루션, CPU 등)
특정 환경의 성능은 달라질 수 있으나 Red Hat 랩은 크기가 4 vCPU/16GB RAM인 퍼블릭 클라우드 인스턴스에서 테스트합니다. 1kB 정적 페이지를 제공하는 백엔드에서 종료한 100개의 경로를 처리하는 단일 HAProxy 라우터가 처리할 수 있는 초당 트랜잭션 수는 다음과 같습니다.
HTTP 연결 유지 모드 시나리오에서는 다음과 같습니다.
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 21515 | 29622 |
| edge | 16743 | 22913 |
| passthrough | 36786 | 53295 |
| re-encrypt | 21583 | 25198 |
HTTP 닫기(연결 유지 제외) 시나리오에서는 다음과 같습니다.
| Encryption | LoadBalancerService | HostNetwork |
|---|---|---|
| none | 5719 | 8273 |
| edge | 2729 | 4069 |
| passthrough | 4121 | 5344 |
| re-encrypt | 2320 | 2941 |
ROUTER_THREADS=4로 설정된 기본 Ingress 컨트롤러 구성이 사용되었고 두 개의 서로 다른 끝점 게시 전략(LoadBalancerService/HostNetwork)이 테스트되었습니다. 암호화된 경로에는 TLS 세션 재개가 사용되었습니다. HTTP 연결 유지 기능을 사용하면 단일 HAProxy 라우터가 8kB의 작은 페이지 크기에서 1Gbit NIC를 수용할 수 있습니다.
최신 프로세서가 있는 베어 메탈에서 실행하는 경우 성능이 위 퍼블릭 클라우드 인스턴스의 약 2배가 될 것을 예상할 수 있습니다. 이 오버헤드는 퍼블릭 클라우드에서 가상화 계층에 의해 도입되며 프라이빗 클라우드 기반 가상화에도 적용됩니다. 다음 표는 라우터 뒤에서 사용할 애플리케이션 수에 대한 가이드입니다.
| 애플리케이션 수 | 애플리케이션 유형 |
|---|---|
| 5-10 | 정적 파일/웹 서버 또는 캐싱 프록시 |
| 100-1000 | 동적 콘텐츠를 생성하는 애플리케이션 |
일반적으로 HAProxy는 사용 중인 기술에 따라 5~1,000개의 애플리케이션 경로를 지원할 수 있습니다. Ingress 컨트롤러 성능은 언어 또는 정적 콘텐츠 대비 동적 콘텐츠 등 지원하는 애플리케이션의 기능과 성능에 따라 제한될 수 있습니다.
Ingress 또는 라우터 샤딩을 사용하여 애플리케이션에 대한 경로를 더 많이 제공하면 라우팅 계층을 수평으로 확장하는 데 도움이 됩니다.
Ingress 샤딩에 대한 자세한 내용은 경로 레이블을 사용하여 Ingress 컨트롤러 샤딩 구성 및 네임스페이스 레이블을 사용하여 Ingress 컨트롤러 샤딩 구성을 참조하십시오.
13.2. Ingress 컨트롤러(라우터) 성능 최적화
OpenShift Container Platform에서는 ROUTER_THREADS, ROUTER_DEFAULT_TUNNEL_TIMEOUT, ROUTER_DEFAULT_CLIENT_TIMEOUT, ROUTER_DEFAULT_SERVER_TIMEOUT 및 RELOAD_INTERVAL과 같은 환경 변수를 설정하여 Ingress 컨트롤러 배포를 수정하는 작업을 더 이상 지원하지 않습니다.
Ingress 컨트롤러 배포를 수정할 수 있지만 Ingress Operator가 활성화된 경우 구성을 덮어씁니다.
14장. 네트워킹 최적화
OpenShift SDN은 OpenvSwitch, VXLAN(Virtual Extensible LAN) 터널, OpenFlow 규칙 및 iptables를 사용합니다. 이 네트워크는 점보 프레임, NIC(네트워크 인터페이스 컨트롤러) 오프로드, 멀티 큐 및 ethtool 설정을 사용하여 조정할 수 있습니다.
OVN-Kubernetes는 VXLAN 대신 Geneve(Generic Network Virtualization Encapsulation)를 터널 프로토콜로 사용합니다.
VXLAN은 VLAN에 비해 네트워크 수가 4096개에서 1600만 개 이상으로 증가하고 물리적 네트워크 전반에 걸쳐 계층 2 연결과 같은 이점을 제공합니다. 이를 통해 서비스 뒤에 있는 모든 Pod가 서로 다른 시스템에서 실행되는 경우에도 서로 통신할 수 있습니다.
VXLAN은 사용자 데이터그램 프로토콜(UDP) 패킷의 터널링된 모든 트래픽을 캡슐화합니다. 그러나 이로 인해 CPU 사용량이 증가합니다. 이러한 외부 및 내부 패킷은 전송 중에 데이터가 손상되지 않도록하기 위해 일반 체크섬 규칙을 따릅니다. CPU 성능에 따라 이러한 추가 처리 오버헤드는 처리량이 감소하고 기존 비 오버레이 네트워크에 비해 대기 시간이 증가할 수 있습니다.
클라우드, 가상 머신, 베어 메탈 CPU 성능은 많은 Gbps의 네트워크 처리량을 처리할 수 있습니다. 10 또는 40Gbps와 같은 높은 대역폭 링크를 사용하는 경우 성능이 저하될 수 있습니다. 이 문제는 VXLAN 기반 환경에서 알려진 문제이며 컨테이너 또는 OpenShift Container Platform에만 국한되지 않습니다. VXLAN 터널에 의존하는 네트워크는 VXLAN 구현으로 인해 비슷한 작업을 수행할 수 있습니다.
Gbps을 초과하여 푸시하려는 경우 다음을 수행할 수 있습니다.
- BGP(Border Gateway Protocol)와 같은 다른 라우팅 기술을 구현하는 네트워크 플러그인을 평가합니다.
- VXLAN 오프로드 가능 네트워크 어댑터를 사용합니다. VXLAN 오프로드는 패킷 체크섬 계산 및 관련 CPU 오버헤드를 시스템 CPU에서 네트워크 어댑터의 전용 하드웨어로 이동합니다. 이를 통해 Pod 및 애플리케이션에서 사용할 CPU 사이클을 확보하고 사용자는 네트워크 인프라의 전체 대역폭을 사용할 수 있습니다.
VXLAN 오프로드는 대기 시간을 단축시키지 않습니다. 그러나 대기 시간 테스트에서도 CPU 사용량이 감소합니다.
14.1. 네트워크에 대한 MTU 최적화
중요한 최대 전송 단위(MTU)는 NIC(네트워크 인터페이스 컨트롤러) MTU와 클러스터 네트워크 MTU입니다.
NIC MTU는 OpenShift Container Platform을 설치할 때만 구성됩니다. MTU는 네트워크 NIC에서 지원되는 최대 값과 작거나 같아야 합니다. 처리량을 최적화하려면 가능한 가장 큰 값을 선택합니다. 최소 지연을 최적화하려면 더 낮은 값을 선택합니다.
SDN 오버레이의 MTU는 NIC MTU보다 최소 50바이트 작아야 합니다. 이 계정은 SDN 오버레이 헤더에 대한 계정입니다. 일반적인 이더넷 네트워크에서는 이 값을 1450으로 설정합니다. 점보 프레임 이더넷 네트워크에서는 이 값을 8950으로 설정합니다.
OVN 및 Geneve의 경우 MTU는 NIC MTU보다 최소 100바이트 작아야 합니다.
50바이트 오버레이 헤더는 OpenShift SDN과 관련이 있습니다. 기타 SDN 솔루션에서는 이 값이 더 크거나 작아야 할 수 있습니다.
14.2. 대규모 클러스터 설치에 대한 권장 사례
대규모 클러스터를 설치하거나 클러스터 스케일링을 통해 노드 수를 늘리는 경우 install-config.yaml 파일에서 클러스터 네트워크 cidr을 적절하게 설정한 후 클러스터를 설치하십시오.
networking:
clusterNetwork:
- cidr: 10.128.0.0/14
hostPrefix: 23
machineCIDR: 10.0.0.0/16
networkType: OpenShiftSDN
serviceNetwork:
- 172.30.0.0/16
클러스터 크기가 500개 노드를 초과하는 경우 기본 클러스터 네트워크 cidr 10.128.0.0/14를 사용할 수 없습니다. 노드 수가 500개를 초과하게 되면 10.128.0.0/12 또는 10.128.0.0/10으로 설정해야 합니다.
14.3. IPsec 영향
노드 호스트의 암호화 및 암호 해독은 CPU를 사용하기 때문에 사용 중인 IP 보안 시스템에 관계없이 암호화를 사용할 때 노드의 처리량과 CPU 사용량 모두에서 성능에 영향을 미칩니다.
IPsec은 NIC에 도달하기 전에 IP 페이로드 수준에서 트래픽을 암호화하여 NIC 오프로드에 사용되는 필드를 보호합니다. 즉, IPSec가 활성화되면 일부 NIC 가속 기능을 사용할 수 없으며 처리량이 감소하고 CPU 사용량이 증가합니다.
15장. 베어 메탈 호스트 관리
베어 메탈 클러스터에 OpenShift Container Platform을 설치할 때 클러스터에 있는 베어 메탈 호스트에 대한 machine 및 machineset CR(사용자 정의 리소스)을 사용하여 베어 메탈 노드를 프로비저닝하고 관리할 수 있습니다.
15.1. 베어 메탈 호스트 및 노드 정보
RHCOS(Red Hat Enterprise Linux CoreOS) 베어 메탈 호스트를 클러스터에서 노드로 프로비저닝하려면 먼저 베어 메탈 호스트 하드웨어에 해당하는 MachineSet CR(사용자 정의 리소스) 오브젝트를 생성합니다. 베어 메탈 호스트 머신 세트는 구성과 관련된 인프라 구성 요소를 설명합니다. 이러한 머신에 특정 Kubernetes 레이블을 적용한 다음 해당 머신 세트에서만 실행되도록 인프라 구성 요소를 업데이트합니다.
machine CR은 metal3.io/autoscale-to-hosts 주석이 포함된 관련 MachineSet을 확장하면 자동으로 생성됩니다. OpenShift Container Platform은 Machine CR을 사용하여 MachineSet CR에 지정된 대로 호스트에 해당하는 베어 메탈 노드를 프로비저닝합니다.
15.2. 베어 메탈 호스트 유지관리
OpenShift Container Platform 웹 콘솔에서 클러스터의 베어 메탈 호스트의 세부 정보를 유지 관리할 수 있습니다. 컴퓨팅 → 베어 메탈 호스트로 이동하여 작업 드롭다운 메뉴에서 작업을 선택합니다. 여기에서 BMC 세부 정보, 호스트의 MAC 주소 부팅, 전원 관리 활성화 등의 항목을 관리할 수 있습니다. 네트워크 인터페이스의 세부 정보와 호스트에 대한 드라이브도 검토할 수 있습니다.
베어 메탈 호스트를 유지 관리 모드로 이동할 수 있습니다. 호스트를 유지 관리 모드로 이동할 때 스케줄러는 모든 관리 워크로드를 해당 베어 메탈 노드에서 이동합니다. 유지 관리 모드에서는 새 워크로드가 예약되지 않습니다.
웹 콘솔에서 베어 메탈 호스트를 프로비저닝 해제할 수 있습니다. 호스트 프로비저닝 해제는 다음 작업을 수행합니다.
-
cluster.k8s.io/delete-machine: true를 사용하여 베어 메탈 호스트 CR에 주석을 답니다. - 관련 머신 세트를 축소합니다.
먼저 데몬 세트와 관리되지 않는 정적 Pod를 다른 노드로 이동하지 않고 호스트의 전원을 끄면 서비스가 중단되고 데이터가 손실될 수 있습니다.
추가 리소스
15.2.1. 웹 콘솔을 사용하여 클러스터에 베어 메탈 호스트 추가
웹 콘솔의 클러스터에 베어 메탈 호스트를 추가할 수 있습니다.
사전 요구 사항
- 베어 메탈에 RHCOS 클러스터 설치
-
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
- 웹 콘솔에서 Compute → Bare Metal Hosts로 이동합니다.
- Add Host → New with Dialog를 선택합니다.
- 새 베어 메탈 호스트의 고유 이름을 지정합니다.
- Boot MAC address를 설정합니다.
- Baseboard Management Console (BMC) Address를 설정합니다.
- 선택 사항: 호스트의 전원 관리를 활성화합니다. 이를 통해 OpenShift Container Platform에서 호스트의 전원 상태를 제어할 수 있습니다.
- 호스트의 BMC(Baseboard Management Controller)에 대한 사용자 인증 정보를 입력합니다.
- 생성 후 호스트 전원을 켜도록선택하고 Create를 선택합니다.
- 사용 가능한 베어 메탈 호스트 수와 일치하도록 복제본 수를 확장합니다. Compute → MachineSets로 이동하고 Actions 드롭다운 메뉴에서 Edit Machine count을 선택하여 클러스터에서 머신 복제본 수를 늘립니다.
oc scale 명령 및 적절한 베어 메탈 머신 세트를 사용하여 베어 메탈 노드 수를 관리할 수도 있습니다.
15.2.2. 웹 콘솔에서 YAML을 사용하여 클러스터에 베어 메탈 호스트 추가
베어 메탈 호스트를 설명하는 YAML 파일을 사용하여 웹 콘솔의 클러스터에 베어 메탈 호스트를 추가할 수 있습니다.
사전 요구 사항
- 클러스터에 사용할 RHCOS 컴퓨팅 머신을 베어메탈 인프라에 설치합니다.
-
cluster-admin권한이 있는 사용자로 로그인합니다. -
베어 메탈 호스트의
SecretCR을 생성합니다.
절차
- 웹 콘솔에서 Compute → Bare Metal Hosts로 이동합니다.
- Add Host → New from YAML을 선택합니다.
아래 YAML을 복사하고 붙여넣고 호스트의 세부 정보로 관련 필드를 수정합니다.
apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: <bare_metal_host_name> spec: online: true bmc: address: <bmc_address> credentialsName: <secret_credentials_name> 1 disableCertificateVerification: True bootMACAddress: <host_boot_mac_address> hardwareProfile: unknown- Create를 선택하여 YAML을 저장하고 새 베어 메탈 호스트를 생성합니다.
사용 가능한 베어 메탈 호스트 수와 일치하도록 복제본 수를 확장합니다. Compute → MachineSets로 이동하고 Actions 드롭다운 메뉴에서 Edit Machine count를 선택하여 클러스터의 머신 수를 늘립니다.
참고oc scale명령 및 적절한 베어 메탈 머신 세트를 사용하여 베어 메탈 노드 수를 관리할 수도 있습니다.
15.2.3. 사용 가능한 베어 메탈 호스트 수로 머신 자동 스케일링
사용 가능한 BareMetalHost 오브젝트 수와 일치하는 Machine 오브젝트 수를 자동으로 생성하려면 MachineSet 오브젝트에 metal3.io/autoscale-to-hosts 주석을 추가합니다.
사전 요구 사항
-
클러스터에서 사용할 RHCOS 베어 메탈 컴퓨팅 머신을 설치하고 해당
BareMetalHost오브젝트를 생성합니다. -
OpenShift Container Platform CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
metal3.io/autoscale-to-hosts주석을 추가하여 자동 스케일링을 구성할 머신 세트에 주석을 답니다.<machineset>를 머신 세트 이름으로 바꿉니다.$ oc annotate machineset <machineset> -n openshift-machine-api 'metal3.io/autoscale-to-hosts=<any_value>'
새로 확장된 머신이 시작될 때까지 기다립니다.
BareMetalHost 오브젝트를 사용하여 클러스터에 머신을 생성하고 레이블 또는 선택기가 BareMetalHost에서 변경되면 Machine 오브젝트가 생성된 MachineSet에 대해 BareMetalHost 오브젝트가 계속 계산됩니다.
15.2.4. provisioner 노드에서 베어 메탈 호스트 제거
특정 상황에서는 프로비저너 노드에서 베어 메탈 호스트를 일시적으로 삭제할 수 있습니다. 예를 들어 OpenShift Container Platform 관리 콘솔을 사용하거나 Machine Config Pool 업데이트로 인해 베어 메탈 호스트 재부팅이 트리거되는 경우 OpenShift Container Platform은 통합된 Dell Remote Access Controller(iDrac)에 로그인하여 작업 대기열 삭제를 발행합니다.
사용 가능한 BareMetalHost 오브젝트 수와 일치하는 Machine 오브젝트 수를 관리하지 않으려면 baremetalhost.metal3.io/detached 주석을 MachineSet 오브젝트에 추가합니다.
이 주석은 Provisioned,ExternallyProvisioned 또는 Ready/Available 상태인 BareMetalHost 오브젝트에만 적용됩니다.
사전 요구 사항
-
클러스터에서 사용할 RHCOS 베어 메탈 컴퓨팅 머신을 설치하고 해당
BareMetalHost오브젝트를 생성합니다. -
OpenShift Container Platform CLI (
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
절차
baremetalhost.metal3.io/detached주석을 추가하여 프로비저너 노드에서 삭제할 컴퓨팅 머신 세트에 주석을 답니다.$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached'
새 머신이 시작될 때까지 기다립니다.
참고BareMetalHost오브젝트를 사용하여 클러스터에 머신을 생성하고 레이블 또는 선택기가BareMetalHost에서 변경되면Machine오브젝트가 생성된MachineSet에 대해BareMetalHost오브젝트가 계속 계산됩니다.프로비저닝 사용 사례에서 다음 명령을 사용하여 재부팅 후 주석을 제거합니다.
$ oc annotate machineset <machineset> -n openshift-machine-api 'baremetalhost.metal3.io/detached-'
16장. 대규모 페이지의 기능과 애플리케이션에서 대규모 페이지를 사용하는 방법
16.1. 대규모 페이지의 기능
메모리는 페이지라는 블록으로 관리됩니다. 대부분의 시스템에서 한 페이지는 4Ki입니다. 1Mi 메모리는 256페이지와 같고 1Gi 메모리는 256,000페이지에 해당합니다. CPU에는 하드웨어에서 이러한 페이지 목록을 관리하는 내장 메모리 관리 장치가 있습니다. TLB(Translation Lookaside Buffer)는 가상-물리적 페이지 매핑에 대한 소규모 하드웨어 캐시입니다. TLB에 하드웨어 명령어로 전달된 가상 주소가 있으면 매핑을 신속하게 확인할 수 있습니다. 가상 주소가 없으면 TLB 누락이 발생하고 시스템에서 소프트웨어 기반 주소 변환 속도가 느려져 성능 문제가 발생합니다. TLB 크기는 고정되어 있으므로 TLB 누락 가능성을 줄이는 유일한 방법은 페이지 크기를 늘리는 것입니다.
대규모 페이지는 4Ki보다 큰 메모리 페이지입니다. x86_64 아키텍처의 일반적인 대규모 페이지 크기는 다음과 같습니다. 2Mi 및 1Gi. 다른 아키텍처에서는 크기가 달라집니다. 대규모 페이지를 사용하려면 애플리케이션이 인식할 수 있도록 코드를 작성해야 합니다. THP(투명한 대규모 페이지)에서는 애플리케이션 지식 없이 대규모 페이지 관리를 자동화하려고 하지만 한계가 있습니다. 특히 페이지 크기 2Mi로 제한됩니다. THP에서는 THP 조각 모음 작업으로 인해 메모리 사용률이 높아지거나 조각화가 발생하여 노드에서 성능이 저하될 수 있으며 이로 인해 메모리 페이지가 잠길 수 있습니다. 이러한 이유로 일부 애플리케이션은 THP 대신 사전 할당된 대규모 페이지를 사용하도록 설계(또는 권장)할 수 있습니다.
OpenShift Container Platform에서는 Pod의 애플리케이션이 사전 할당된 대규모 페이지를 할당하고 사용할 수 있습니다.
16.2. 앱에서 대규모 페이지를 사용하는 방법
노드에서 대규모 페이지 용량을 보고하려면 노드가 대규모 페이지를 사전 할당해야 합니다. 노드는 단일 크기의 대규모 페이지만 사전 할당할 수 있습니다.
대규모 페이지는 hugepages-<size> 리소스 이름으로 컨테이너 수준 리소스 요구사항에 따라 사용할 수 있습니다. 여기서 크기는 특정 노드에서 지원되는 정수 값이 사용된 가장 간단한 바이너리 표현입니다. 예를 들어 노드에서 2,048KiB 페이지 크기를 지원하는 경우 예약 가능한 리소스 hugepages-2Mi를 공개합니다. CPU 또는 메모리와 달리 대규모 페이지는 초과 커밋을 지원하지 않습니다.
apiVersion: v1
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /dev/hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
memory: "1Gi"
cpu: "1"
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepages의 메모리 양은 할당할 정확한 양으로 지정하십시오. 이 값을hugepages의 메모리 양과 페이지 크기를 곱한 값으로 지정하지 마십시오. 예를 들어 대규모 페이지 크기가 2MB이고 애플리케이션에 100MB의 대규모 페이지 지원 RAM을 사용하려면 50개의 대규모 페이지를 할당합니다. OpenShift Container Platform에서 해당 계산을 처리합니다. 위의 예에서와 같이100MB를 직접 지정할 수 있습니다.
특정 크기의 대규모 페이지 할당
일부 플랫폼에서는 여러 대규모 페이지 크기를 지원합니다. 특정 크기의 대규모 페이지를 할당하려면 대규모 페이지 부팅 명령 매개변수 앞에 대규모 페이지 크기 선택 매개변수 hugepagesz=<size>를 지정합니다. <size> 값은 바이트 단위로 지정해야 하며 스케일링 접미사 [kKmMgG]를 선택적으로 사용할 수 있습니다. 기본 대규모 페이지 크기는 default_hugepagesz=<size> 부팅 매개변수로 정의할 수 있습니다.
대규모 페이지 요구사항
- 대규모 페이지 요청은 제한과 같아야 합니다. 제한은 지정되었으나 요청은 지정되지 않은 경우 제한이 기본값입니다.
- 대규모 페이지는 Pod 범위에서 격리됩니다. 컨테이너 격리는 향후 반복에서 계획됩니다.
-
대규모 페이지에서 지원하는
EmptyDir볼륨은 Pod 요청보다 더 많은 대규모 페이지 메모리를 사용하면 안 됩니다. -
SHM_HUGETLB로shmget()를 통해 대규모 페이지를 사용하는 애플리케이션은 proc/sys/vm/hugetlb_shm_group과 일치하는 보조 그룹을 사용하여 실행되어야 합니다.
16.3. Downward API를 사용하여 Huge Page 리소스 사용
Downward API를 사용하여 컨테이너에서 사용하는 Huge Page 리소스에 대한 정보를 삽입할 수 있습니다.
리소스 할당을 환경 변수, 볼륨 플러그인 또는 둘 다로 삽입할 수 있습니다. 컨테이너에서 개발하고 실행하는 애플리케이션은 지정된 볼륨에서의 환경 변수 또는 파일을 읽고 사용할 수 있는 리소스를 확인할 수 있습니다.
절차
다음 예와 유사한
hugepages-volume-pod.yaml파일을 생성합니다.apiVersion: v1 kind: Pod metadata: generateName: hugepages-volume- labels: app: hugepages-example spec: containers: - securityContext: capabilities: add: [ "IPC_LOCK" ] image: rhel7:latest command: - sleep - inf name: example volumeMounts: - mountPath: /dev/hugepages name: hugepage - mountPath: /etc/podinfo name: podinfo resources: limits: hugepages-1Gi: 2Gi memory: "1Gi" cpu: "1" requests: hugepages-1Gi: 2Gi env: - name: REQUESTS_HUGEPAGES_1GI <.> valueFrom: resourceFieldRef: containerName: example resource: requests.hugepages-1Gi volumes: - name: hugepage emptyDir: medium: HugePages - name: podinfo downwardAPI: items: - path: "hugepages_1G_request" <.> resourceFieldRef: containerName: example resource: requests.hugepages-1Gi divisor: 1Gi<.>
requests.hugepages-1Gi에서 리소스 사용을 읽고 값을REQUESTS_HUGEPAGES_1GI환경 변수로 표시하도록 지정합니다. <.>는requests.hugepages-1Gi에서 리소스 사용을 읽고 값을 파일/etc/podinfo/hugepages_1G_request로 표시하도록 지정합니다.volume-pod.yaml파일에서 Pod를 생성합니다.$ oc create -f hugepages-volume-pod.yaml
검증
REQUESTS_HUGEPAGES_1GI환경 변수 값을 확인합니다.$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- env | grep REQUESTS_HUGEPAGES_1GI출력 예
REQUESTS_HUGEPAGES_1GI=2147483648
/etc/podinfo/hugepages_1G_request파일의 값을 확인합니다.$ oc exec -it $(oc get pods -l app=hugepages-example -o jsonpath='{.items[0].metadata.name}') \ -- cat /etc/podinfo/hugepages_1G_request출력 예
2
16.4. 대규모 페이지 구성
노드는 OpenShift Container Platform 클러스터에서 사용되는 대규모 페이지를 사전 할당해야 합니다. 대규모 페이지 예약은 부팅 시 예약하는 방법과 런타임 시 예약하는 방법 두 가지가 있습니다. 부팅 시 예약은 메모리가 아직 많이 조각화되어 있지 않으므로 성공할 가능성이 높습니다. Node Tuning Operator는 현재 특정 노드에서 대규모 페이지에 대한 부팅 시 할당을 지원합니다.
16.4.1. 부팅 시
프로세스
노드 재부팅을 최소화하려면 다음 단계를 순서대로 수행해야 합니다.
동일한 대규모 페이지 설정이 필요한 모든 노드에 하나의 레이블을 지정합니다.
$ oc label node <node_using_hugepages> node-role.kubernetes.io/worker-hp=
다음 콘텐츠로 파일을 생성하고 이름을
hugepages-tuned-boottime.yaml로 지정합니다.apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: hugepages 1 namespace: openshift-cluster-node-tuning-operator spec: profile: 2 - data: | [main] summary=Boot time configuration for hugepages include=openshift-node [bootloader] cmdline_openshift_node_hugepages=hugepagesz=2M hugepages=50 3 name: openshift-node-hugepages recommend: - machineConfigLabels: 4 machineconfiguration.openshift.io/role: "worker-hp" priority: 30 profile: openshift-node-hugepages
Tuned
hugepages오브젝트를 생성합니다.$ oc create -f hugepages-tuned-boottime.yaml
다음 콘텐츠로 파일을 생성하고 이름을
hugepages-mcp.yaml로 지정합니다.apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-hp labels: worker-hp: "" spec: machineConfigSelector: matchExpressions: - {key: machineconfiguration.openshift.io/role, operator: In, values: [worker,worker-hp]} nodeSelector: matchLabels: node-role.kubernetes.io/worker-hp: ""머신 구성 풀을 생성합니다.
$ oc create -f hugepages-mcp.yaml
조각화되지 않은 메모리가 충분한 경우 worker-hp 머신 구성 풀의 모든 노드에 50개의 2Mi 대규모 페이지가 할당되어 있어야 합니다.
$ oc get node <node_using_hugepages> -o jsonpath="{.status.allocatable.hugepages-2Mi}"
100Mi
이 기능은 현재 RHCOS(Red Hat Enterprise Linux CoreOS) 8.x 작업자 노드에서만 지원됩니다. RHEL (Red Hat Enterprise Linux) 7.x 작업자 노드에서는 현재 TuneD [bootloader] 플러그인이 지원되지 않습니다.
16.5. Transparent Huge Pages 비활성화
THP(Transparent Huge Pages)는 대규모 페이지를 생성, 관리 및 사용하는 대부분의 측면을 자동화하려고 합니다. THP는 대규모 페이지를 자동으로 관리하므로 모든 유형의 워크로드에 대해 항상 최적으로 처리되지는 않습니다. THP는 많은 애플리케이션에서 자체적으로 대규모 페이지를 처리하므로 성능 저하가 발생할 수 있습니다. 따라서 THP를 비활성화하는 것이 좋습니다. 다음 단계에서는 Node Tuning Operator(NTO)를 사용하여 THP를 비활성화하는 방법을 설명합니다.
프로세스
다음 콘텐츠를 사용하여 파일을 생성하고 이름을
thp-disable-tuned.yaml로 지정합니다.apiVersion: tuned.openshift.io/v1 kind: Tuned metadata: name: thp-workers-profile namespace: openshift-cluster-node-tuning-operator spec: profile: - data: | [main] summary=Custom tuned profile for OpenShift to turn off THP on worker nodes include=openshift-node [vm] transparent_hugepages=never name: openshift-thp-never-worker recommend: - match: - label: node-role.kubernetes.io/worker priority: 25 profile: openshift-thp-never-workerTuned 오브젝트를 생성합니다.
$ oc create -f thp-disable-tuned.yaml
활성 프로파일 목록을 확인합니다.
$ oc get profile -n openshift-cluster-node-tuning-operator
검증
노드 중 하나에 로그인하고 일반 THP 검사를 수행하여 노드가 프로필을 성공적으로 적용했는지 확인합니다.
$ cat /sys/kernel/mm/transparent_hugepage/enabled
출력 예
always madvise [never]
17장. 대기 시간이 짧은 노드를 위한 Performance Addon Operator
17.1. 짧은 대기 시간 이해
Telco/5G 영역에서 Edge 컴퓨팅이 등장하여 대기 시간 및 정체 문제를 줄이고 애플리케이션 성능을 개선하는 데 핵심적인 역할을 하고 있습니다.
간단히 말해, 대기 시간이 데이터(패킷)가 발신자에서 수신자로 이동하고 수신자의 처리 후 발신자로 반환되는 속도를 결정합니다. 5G의 네트워크 성능 요구사항을 충족하려면 대기 시간 지연이 가능한 한 짧아지도록 네트워크 아키텍처를 유지보수하는 것이 중요합니다. 평균 대기 시간이 50ms인 4G 기술에 비해, 5G에서는 1ms 이하의 대기 시간 수치에 도달하는 것을 목표로 합니다. 이렇게 대기 시간이 감소하면 무선 처리량이 10배 증가합니다.
Telco 공간에 배포된 많은 애플리케이션에서는 제로 패킷 손실이 가능한 짧은 대기 시간을 요구하고 있습니다. 제로 패킷 손실 튜닝은 네트워크 성능을 저하시키는 고유한 문제를 완화하는 데 도움이 됩니다. 자세한 내용은 RHOSP(Red Hat OpenStack Platform)에서 제로 패킷 손실 튜닝을 참조하십시오.
Edge 컴퓨팅 이니셔티브는 대기 시간을 줄이는 데에도 큰 역할을 합니다. 말 그대로 클라우드 엣지(Edge)에 있어 사용자에게 더 가깝다고 생각해 보십시오. 이렇게 되면 멀리 있는 데이터 센터와 사용자 간 거리를 크게 줄여 애플리케이션 응답 시간과 성능 대기 시간이 단축됩니다.
관리자는 많은 엣지 사이트와 로컬 서비스를 중앙 집중식으로 관리하여 가능한 한 가장 낮은 관리 비용으로 모든 배포를 실행할 수 있어야 합니다. 또한, 실시간 짧은 대기 시간과 높은 성능을 실현할 수 있도록 클러스터의 특정 노드를 쉽게 배포하고 구성할 수 있어야 합니다. 대기 시간이 짧은 노드는 CNF(클라우드 네이티브 네트워크 기능) 및 DPDK(데이터 플레인 개발 키트)와 같은 애플리케이션에 유용합니다.
OpenShift Container Platform에서는 현재 실시간 실행과 짧은 대기 시간(약 20마이크로초 미만의 반응 시간)을 지원하기 위해 OpenShift Container Platform 클러스터의 소프트웨어를 튜닝하는 메커니즘을 제공합니다. 이 메커니즘에는 커널 및 OpenShift Container Platform 설정 값 튜닝, 커널 설치, 머신 재구성이 포함되어 있습니다. 하지만 이 방법을 사용하려면 4가지 Operator를 설정해야 하며 수동으로 수행할 경우 복잡하고 실수하기 쉬운 많은 구성을 수행해야 합니다.
OpenShift Container Platform에서는 OpenShift 애플리케이션에 대해 짧은 대기 시간 성능을 실현할 수 있도록 자동 튜닝을 구현하는 Performance Addon Operator를 제공합니다. 클러스터 관리자는 이 성능 프로필 구성을 사용하여 보다 안정적인 방식으로 이러한 변경을 더욱 쉽게 수행할 수 있습니다. 관리자는 커널을 kernel-rt로 업데이트할지 여부를 지정하고, Pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 CPU를 예약하고, 애플리케이션 컨테이너의 CPU를 분리하여 워크로드를 실행할 수 있습니다.
17.1.1. 짧은 대기 시간과 실시간 애플리케이션의 하이퍼 스레딩 정보
하이퍼 스레딩은 물리 CPU 프로세서 코어가 두 개의 논리 코어로 작동하여 두 개의 독립 스레드를 동시에 실행할 수 있는 Intel 프로세서 기술입니다. 하이퍼 스레딩을 사용하면 병렬 처리가 효과적인 특정 워크로드 유형에 대한 시스템 처리량이 향상시킬 수 있습니다. 기본 OpenShift Container Platform 설정에서는 기본적으로 하이퍼 스레딩을 활성화하도록 설정해야합니다.
통신 애플리케이션의 경우 가능한 한 대기 시간을 최소화하도록 애플리케이션 인프라를 설계하는 것이 중요합니다. 하이퍼 스레딩은 성능을 저하시킬 수 있으며 대기 시간이 짧은 컴퓨팅 집약적 워크로드의 처리량에 부정적인 영향을 미칠 수 있습니다. 하이퍼 스레딩을 비활성화하면 예측 가능한 성능이 보장되고 이러한 워크로드의 처리 시간을 줄일 수 있습니다.
OpenShift Container Platform을 실행하는 하드웨어에 따라 하이퍼 스레딩 구현 및 구성이 다릅니다. 해당 하드웨어와 관련된 하이퍼 스레딩 구현에 대한 자세한 내용은 관련 호스트 하드웨어 튜닝 정보를 참조하십시오. 하이퍼 스레딩을 비활성화하면 클러스터 코어당 비용이 증가할 수 있습니다.
추가 리소스
17.2. Performance Addon Operator 설치
Performance Addon Operator는 노드 세트에서 고급 노드 성능 튜닝을 활성화하는 기능을 제공합니다. 클러스터 관리자는 OpenShift Container Platform CLI 또는 웹 콘솔을 사용하여 Performance Addon Operator를 설치할 수 있습니다.
17.2.1. CLI를 사용하여 Operator 설치
클러스터 관리자는 CLI를 사용하여 Operator를 설치할 수 있습니다.
전제 조건
- 클러스터가 베어 메탈 하드웨어에 설치되어 있어야 합니다.
-
OpenShift CLI(
oc)를 설치합니다. -
cluster-admin권한이 있는 사용자로 로그인합니다.
프로세스
다음 조치를 완료하여 Performance Addon Operator의 네임스페이스를 생성합니다.
openshift-performance-addon-operator네임스페이스를 정의하는 다음 네임스페이스 CR(사용자 정의 리소스)을 생성하고 해당 YAML을pao-namespace.yaml파일에 저장합니다.apiVersion: v1 kind: Namespace metadata: name: openshift-performance-addon-operator annotations: workload.openshift.io/allowed: management다음 명령을 실행하여 네임스페이스를 생성합니다.
$ oc create -f pao-namespace.yaml
다음 오브젝트를 생성하여 이전 단계에서 생성한 네임스페이스에 Performance Addon Operator를 설치합니다.
다음
OperatorGroupCR을 생성하고 해당 YAML을pao-operatorgroup.yaml파일에 저장합니다.apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: openshift-performance-addon-operator namespace: openshift-performance-addon-operator
다음 명령을 실행하여
OperatorGroupCR을 생성합니다.$ oc create -f pao-operatorgroup.yaml
다음 명령을 실행하여 후속 단계에 필요한
채널값을 가져옵니다.$ oc get packagemanifest performance-addon-operator -n openshift-marketplace -o jsonpath='{.status.defaultChannel}'출력 예
4.8
다음 서브스크립션 CR을 생성하고 해당 YAML을
pao-sub.yaml파일에 저장합니다.서브스크립션의 예
apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: openshift-performance-addon-operator-subscription namespace: openshift-performance-addon-operator spec: channel: "<channel>" 1 name: performance-addon-operator source: redhat-operators 2 sourceNamespace: openshift-marketplace
다음 명령을 실행하여 서브스크립션 오브젝트를 생성합니다.
$ oc create -f pao-sub.yaml
openshift-performance-addon-operator프로젝트로 변경합니다.$ oc project openshift-performance-addon-operator
17.2.2. 웹 콘솔을 사용하여 Performance Addon Operator 설치
클러스터 관리자는 웹 콘솔을 사용하여 Performance Addon Operator를 설치할 수 있습니다.
이전 섹션에서 언급한 것처럼 Namespace CR 및 OperatorGroup CR을 생성해야 합니다.
프로세스
OpenShift Container Platform 웹 콘솔을 사용하여 Performance Addon Operator를 설치합니다.
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 사용 가능한 Operator 목록에서 Performance Addon Operator를 선택하고 설치를 클릭합니다.
- Install Operator 페이지에서 All namespaces on the cluster를 선택합니다. 그런 다음, 설치를 클릭합니다.
선택 사항: performance-addon-operator가 성공적으로 설치되었는지 확인합니다.
- Operator → 설치된 Operator 페이지로 전환합니다.
Performance Addon Operator 가 openshift-operators 프로젝트에 성공 상태로 나열되어 있는지 확인합니다.
참고설치 중에 Operator는 실패 상태를 표시할 수 있습니다. 나중에 Succeeded 메시지와 함께 설치에 성공하면 실패 메시지를 무시할 수 있습니다.
Operator가 설치된 것으로 나타나지 않으면 추가 문제를 해결할 수 있습니다.
- Operator → 설치된 Operator 페이지로 이동하고 Operator 서브스크립션 및 설치 계획 탭의 상태에 장애나 오류가 있는지 검사합니다.
-
워크로드 → Pod 페이지로 이동하여
openshift-operators프로젝트에서 Pod 로그를 확인합니다.
17.3. Performance Addon Operator 업그레이드
웹 콘솔을 사용하여 수동으로 Performance Addon Operator의 다음 마이너 버전으로 업그레이드하고 업데이트 상태를 모니터링할 수 있습니다.
17.3.1. Performance Addon Operator 업그레이드 정보
- OpenShift Container Platform 웹 콘솔을 사용하여 Operator 서브스크립션 채널을 변경하면 Performance Addon Operator의 다음 마이너 버전으로 업그레이드 할 수 있습니다.
- Performance Addon Operator 설치 중에 자동 z-stream 업데이트를 활성화할 수 있습니다.
- 업데이트는 OpenShift Container Platform 설치 중에 배포되는 Marketplace Operator를 통해 제공됩니다. Marketplace Operator는 클러스터에서 외부 Operator를 사용할 수 있도록 합니다.
- 업데이트를 완료하는 데 걸리는 시간은 네트워크 연결에 따라 달라집니다. 대부분의 자동 업데이트는 15분 이내에 완료됩니다.
17.3.1.1. Performance Addon Operator 업그레이드가 클러스터에 미치는 영향
- 대기 시간이 짧은 튜닝이나 많은 페이지 수는 클러스터에 영향을 미치지 않습니다.
- Operator 업데이트로 인해 예기치 않은 재부팅이 발생하지 않습니다.
17.3.1.2. Performance Addon Operator를 다음 마이너 버전으로 업그레이드
OpenShift Container Platform 웹 콘솔을 사용하여 Operator 서브스크립션 채널을 변경하면 수동으로 Performance Addon Operator를 다음 마이너 버전으로 업그레이드할 수 있습니다.
전제 조건
- cluster-admin 역할을 가진 사용자로 클러스터에 액세스합니다.
절차
- 웹 콘솔에 액세스하여 Operators → Installed Operators로 이동합니다.
- Performance Addon Operator를 클릭하여 Operator details 페이지를 엽니다.
- Subscription 탭을 클릭하여 Subscription details 페이지를 엽니다.
- Update channel 창에서 버전 번호 오른쪽의 연필 아이콘을 클릭하여 Change Subscription update channel 창을 엽니다.
- 다음 마이너 버전을 선택합니다. 예를 들어 Performance Addon Operator 4.8로 업그레이드하려면 4.8을 선택합니다.
- 저장을 클릭합니다.
Operator → 설치된 Operator로 이동하여 업그레이드 상태를 확인합니다. 다음
oc명령을 실행하여 상태를 확인할 수도 있습니다.$ oc get csv -n openshift-performance-addon-operator
17.3.1.3. 이전에 특정 네임스페이스에 설치된 경우 Performance Addon Operator 업그레이드
이전에 Performance Addon Operator를 클러스터의 특정 네임스페이스 (예: openshift-performance-addon-operator)에 설치한 경우를 업그레이드하기 전에 OperatorGroup 개체를 수정하여 targetNamespaces 항목을 제거하십시오.
사전 요구 사항
- OpenShift Container Platform CLI, oc를 설치합니다.
- cluster-admin 권한이 있는 사용자로 OpenShift 클러스터에 로그인합니다.
절차
Performance Addon Operator
OperatorGroupCR을 편집하고 다음 명령을 실행하여targetNamespaces항목이 포함된spec요소를 제거합니다.$ oc patch operatorgroup -n openshift-performance-addon-operator openshift-performance-addon-operator --type json -p '[{ "op": "remove", "path": "/spec" }]'- OLM(Operator Lifecycle Manager)이 변경 사항을 처리할 때까지 기다립니다.
OperatorGroup CR 변경이 성공적으로 적용되었는지 확인합니다.
OperatorGroupCRspec요소가 제거되었는지 확인합니다.$ oc describe -n openshift-performance-addon-operator og openshift-performance-addon-operator
- Performance Addon Operator 업그레이드를 진행합니다.
17.3.2. 업그레이드 상태 모니터링
Performance Addon Operator 업그레이드 상태를 모니터링하는 가장 좋은 방법은 CSV(ClusterServiceVersion) PHASE를 확인하는 것입니다. 웹 콘솔에서 또는 oc get csv 명령을 실행하여 CSV 상태를 모니터링할 수도 있습니다.
PHASE 및 조건 값은 사용 가능한 정보를 기반으로 한 근사치입니다.
전제 조건
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. -
OpenShift CLI(
oc)를 설치합니다.
절차
다음 명령을 실행합니다.
$ oc get csv
PHASE필드를 확인하여 출력을 검토합니다. 예를 들면 다음과 같습니다.VERSION REPLACES PHASE 4.8.0 performance-addon-operator.v4.8.0 Installing 4.7.0 Replacing
get csv를 다시 실행하여 출력을 검증합니다.# oc get csv
출력 예
NAME DISPLAY VERSION REPLACES PHASE performance-addon-operator.v4.8.0 Performance Addon Operator 4.8.0 performance-addon-operator.v4.7.0 Succeeded
17.4. 실시간 및 짧은 대기 시간 워크로드 프로비저닝
많은 업계와 조직에서 매우 높은 성능의 컴퓨팅을 필요로 하고 있으며 특히 금융 및 통신 업계에서는 짧고 예측 가능한 대기 시간이 요구될 수 있습니다. 고유한 요구사항을 가지고 있는 이러한 업계에서 사용할 수 있도록 OpenShift Container Platform에서는 OpenShift Container Platform 애플리케이션에 대해 짧은 대기 시간 성능과 일관된 응답 시간을 실현할 수 있도록 자동 튜닝을 구현하는 Performance Addon Operator를 제공합니다.
클러스터 관리자는 이 성능 프로필 구성을 사용하여 보다 안정적인 방식으로 이러한 변경을 수행할 수 있습니다. 관리자는 커널을 kernel-rt(실시간)로 업데이트할지 여부를 지정하고, Pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 CPU를 예약하고, 애플리케이션 컨테이너의 CPU를 분리하여 워크로드를 실행할 수 있습니다.
보장된 CPU가 필요한 애플리케이션과 함께 실행 프로브를 사용하면 대기 시간이 급증할 수 있습니다. 올바르게 구성된 네트워크 프로브 세트와 같은 기타 프로브를 대안으로 사용하는 것이 좋습니다.
17.4.1. 실시간에 대한 알려진 제한 사항
RT 커널은 작업자 노드에서만 지원됩니다.
실시간 모드를 완전히 활용하려면 상승된 권한으로 컨테이너를 실행해야 합니다. 권한 부여에 대한 자세한 내용은 컨테이너에 대한 기능 설정을 참조하십시오.
OpenShift Container Platform에서는 허용되는 기능을 제한하므로 SecurityContext를 생성해야 할 수도 있습니다.
RHCOS(Red Hat Enterprise Linux CoreOS) 시스템을 사용하는 베어 메탈 설치에서는 이러한 절차가 완전하게 지원됩니다.
적합한 성능 기대치를 설정한다는 것은 실시간 커널이 만능 해결책이 아니라는 것을 나타냅니다. 설정의 목표는 예측 가능한 응답 시간을 제공하는 일관되고 대기 시간이 짧은 결정성을 갖추는 것입니다. 실시간 커널에는 연관된 추가 커널 오버헤드가 있습니다. 이러한 오버헤드는 주로 별도로 예약된 스레드에서 하드웨어 중단을 처리하는 데서 발생합니다. 일부 워크로드에서 오버헤드가 증가하면 전반적으로 처리량 성능이 저하됩니다. 정확한 저하 수치는 워크로드에 따라 달라지며, 범위는 0%에서 30% 사이입니다. 하지만 이러한 저하는 결정성에 대한 대가입니다.
17.4.2. 실시간 기능이 있는 작업자 프로비저닝
- 클러스터에 Performance Addon Operator를 설치합니다.
- 선택 사항: OpenShift Container Platform 클러스터에 노드를 추가합니다. BIOS 매개변수 설정을 참조하십시오.
-
oc명령을 사용하여 실시간 기능이 필요한 작업자 노드에worker-rt레이블을 추가합니다. 실시간 노드에 대한 새 머신 구성 풀을 생성합니다.
apiVersion: machineconfiguration.openshift.io/v1 kind: MachineConfigPool metadata: name: worker-rt labels: machineconfiguration.openshift.io/role: worker-rt spec: machineConfigSelector: matchExpressions: - { key: machineconfiguration.openshift.io/role, operator: In, values: [worker, worker-rt], } paused: false nodeSelector: matchLabels: node-role.kubernetes.io/worker-rt: ""worker-rt 레이블이 있는 노드 그룹에 대해 머신 구성 풀
worker-rt가 생성됩니다.노드 역할 레이블을 사용하여 적절한 머신 구성 풀에 노드를 추가합니다.
참고실시간 워크로드로 구성된 노드를 결정해야 합니다. 클러스터의 모든 노드 또는 노드의 하위 집합을 구성할 수 있습니다. 모든 노드를 예상하는 Performance Addon Operator는 전용 머신 구성 풀의 일부입니다. 모든 노드를 사용하는 경우 작업자 노드 역할 레이블을 Performance Addon Operator를 가리켜야 합니다. 서브 세트를 사용하는 경우 해당 노드를 새 머신 구성 풀로 그룹화해야 합니다.
-
적절한 하우스키핑 코어 세트와
realTimeKernel: enabled: true를 사용하여PerformanceProfile을 생성합니다. PerformanceProfile에서machineConfigPoolSelector를 설정해야 합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: ... realTimeKernel: enabled: true nodeSelector: node-role.kubernetes.io/worker-rt: "" machineConfigPoolSelector: machineconfiguration.openshift.io/role: worker-rt레이블과 일치하는 머신 구성 풀이 있는지 검증합니다.
$ oc describe mcp/worker-rt
출력 예
Name: worker-rt Namespace: Labels: machineconfiguration.openshift.io/role=worker-rt
- OpenShift Container Platform에서 노드 구성을 시작합니다. 이 작업에서는 여러 번 재부팅이 수행될 수 있습니다. 노드가 설정될 때까지 기다리십시오. 사용하는 하드웨어에 따라 시간이 오래 걸릴 수 있으며 노드당 20분으로 예상됩니다.
- 모든 요소가 예상대로 작동하는지 검증하십시오.
17.4.3. 실시간 커널 설치 검증
다음 명령을 사용하여 실시간 커널이 설치되었는지 검증합니다.
$ oc get node -o wide
4.18.0-211.rt5.23.el8.x86_64 문자열이 포함된 worker-rt 역할의 작업자를 확인합니다.
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME rt-worker-0.example.com Ready worker,worker-rt 5d17h v1.22.1 128.66.135.107 <none> Red Hat Enterprise Linux CoreOS 46.82.202008252340-0 (Ootpa) 4.18.0-211.rt5.23.el8.x86_64 cri-o://1.21.0-90.rhaos4.8.git4a0ac05.el8-rc.1 [...]
17.4.4. 실시간으로 작동하는 워크로드 생성
실시간 기능을 사용할 워크로드를 준비하려면 다음 절차를 사용하십시오.
프로세스
-
QoS 클래스가
Guaranteed인 Pod를 생성합니다. - 선택 사항: DPDK의 CPU 로드 밸런싱을 비활성화합니다.
- 적절한 노드 선택기를 할당합니다.
애플리케이션을 작성하는 경우 애플리케이션 튜닝 및 배포에 설명된 일반 권장 사항을 따르십시오.
17.4.5. QoS 클래스가 Guaranteed인 Pod 생성
QoS 클래스가 Guaranteed로 지정된 Pod를 생성하는 경우 다음 사항에 유의하십시오.
- Pod의 모든 컨테이너에는 메모리 제한과 메모리 요청이 있어야 하며 동일해야 합니다.
- Pod의 모든 컨테이너에는 CPU 제한과 CPU 요청이 있어야 하며 동일해야 합니다.
다음 예에서는 컨테이너가 하나인 Pod의 구성 파일을 보여줍니다. 이 컨테이너에는 메모리 제한과 메모리 요청이 있으며 둘 다 200MiB입니다. 이 컨테이너에는 CPU 제한과 CPU 요청이 있으며 둘 다 CPU 1개입니다.
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: <image-pull-spec>
resources:
limits:
memory: "200Mi"
cpu: "1"
requests:
memory: "200Mi"
cpu: "1"Pod를 생성합니다.
$ oc apply -f qos-pod.yaml --namespace=qos-example
Pod에 대한 자세한 정보를 봅니다.
$ oc get pod qos-demo --namespace=qos-example --output=yaml
출력 예
spec: containers: ... status: qosClass: Guaranteed참고컨테이너가 자체 메모리 제한은 지정하지만 메모리 요청은 지정하지 않으면 OpenShift Container Platform에서 제한과 일치하는 메모리 요청을 자동으로 할당합니다. 마찬가지로, 컨테이너가 자체 CPU 제한은 지정하지만 CPU 요청은 지정하지 않으면 OpenShift Container Platform에서 제한과 일치하는 CPU 요청을 자동으로 할당합니다.
17.4.6. 선택 사항: DPDK의 CPU 로드 밸런싱 비활성화
CPU 부하 분산을 비활성화하거나 활성화하는 기능은 CRI-O 수준에서 구현됩니다. CRI-O 아래의 코드는 다음 요구사항이 충족되는 경우에만 CPU 부하 분산을 비활성화하거나 활성화합니다.
Pod는
performance-<profile-name>런타임 클래스를 사용해야 합니다. 다음과 같이 성능 프로필의 상태를 보고 적절한 이름을 가져올 수 있습니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile ... status: ... runtimeClass: performance-manual
-
Pod에는
cpu-load-balancing.crio.io: true주석이 있어야 합니다.
Performance Addon Operator는 관련 노드 아래에 고성능 런타임 처리기 구성 스니펫을 생성해야 하고 클러스터 아래에 고성능 런타임 클래스를 생성해야 합니다. CPU 부하 분산 구성 기능을 활성화하는 것을 제외하고는 기본 런타임 처리기와 콘텐츠가 동일합니다.
Pod에 대해 CPU 부하 분산을 비활성화하려면 Pod 사양에 다음 필드가 포함되어야 합니다.
apiVersion: v1
kind: Pod
metadata:
...
annotations:
...
cpu-load-balancing.crio.io: "disable"
...
...
spec:
...
runtimeClassName: performance-<profile_name>
...CPU 관리자 static 정책이 활성화되어 있는 경우 전체 CPU를 사용하는 guaranteed QoS가 있는 Pod에 대해서만 CPU 부하 분산을 비활성화하십시오. 그렇지 않은 경우 CPU 부하 분산을 비활성화하면 클러스터에 있는 다른 컨테이너의 성능에 영향을 미칠 수 있습니다.
17.4.7. 적절한 노드 선택기 할당
노드에 Pod를 할당하는 기본 방법은 다음과 같이 성능 프로필에서 사용한 것과 동일한 노드 선택기를 사용하는 것입니다.
apiVersion: v1
kind: Pod
metadata:
name: example
spec:
# ...
nodeSelector:
node-role.kubernetes.io/worker-rt: ""자세한 내용은 노드 선택기를 사용하여 특정 노드에 Pod 배치를 참조하십시오.
17.4.8. 실시간 기능이 있는 작업자에 대해 워크로드 예약
Performance Addon Operator에서 짧은 대기 시간을 위해 구성한 머신 구성 풀에 연결된 노드와 일치하는 레이블 선택기를 사용합니다. 자세한 내용은 노드에 Pod 할당을 참조하십시오.
17.4.9. 보장된 pod 분리 CPU의 장치 중단 처리 관리
Performance Addon Operator는 호스트 CPU를 pod 인프라 컨테이너를 포함하여 클러스터 및 운영 체제 하우스키핑 작업을 위해 예약된 CPU와 워크로드를 실행하는 애플리케이션 컨테이너를 위한 분리된 CPU로 나누어 호스트 CPU를 관리할 수 있습니다. 이를 통해 대기 시간이 짧은 워크로드의 CPU를 분리된 상태로 설정할 수 있습니다.
장치 중단은 보장된 pod가 실행 중인 CPU를 제외하고 CPU의 과부하를 방지하기 위해 모든 분리된 CPU와 예약된 CPU 간에 균형을 유지합니다. pod에 관련 주석이 설정되어 있으면 보장된 Pod CPU가 장치 인터럽트를 처리하지 못합니다.
새로운 성능 프로파일 필드 globallyDisableIrqLoadBalancing은 장치 중단을 처리할지 여부를 관리하는 데 사용할 수 있습니다. 특정 워크로드의 경우 예약된 CPU는 장치 인터럽트를 처리하기에 충분하지 않으며, 이러한 이유로 장치 인터럽트는 분리된 CPU에서 전역적으로 비활성화되지 않습니다. 기본적으로 Performance Addon Operator는 분리된 CPU에서 장치 인터럽트를 비활성화하지 않습니다.
워크로드에 대한 대기 시간을 단축하기 위해 일부(전체) pod에는 장치 인터럽트를 처리하지 않기 위한 실행 중인 CPU가 필요합니다. pod 주석 irq-load-balancing.crio.io는 장치 인터럽트의 처리 여부를 정의하는 데 사용됩니다. 설정되어 있는 경우 CRI-O는 pod가 실행되는 경우에만 장치 인터럽트를 비활성화합니다.
17.4.9.1. CPU CFS 할당량 비활성화
보장된 개별 Pod의 CPU 제한을 줄이려면 cpu-quota.crio.io: "disable" 주석이 있는 Pod 사양을 생성합니다. 이 주석은 Pod 실행 시 CPU를 완전히 공정한 스케줄러(CFS) 할당량을 비활성화합니다. 다음 Pod 사양에는 이 주석이 포함되어 있습니다.
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
cpu-quota.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...CPU 관리자 static 정책이 활성화되고 전체 CPU를 사용하는 보장된 QoS가 있는 Pod의 경우 CPU CFS 할당량만 비활성화합니다. 그러지 않으면 CPU CFS 할당량을 비활성화하면 클러스터의 다른 컨테이너 성능에 영향을 줄 수 있습니다.
17.4.9.2. Performance Addon Operator에서 글로벌 장치 인터럽트 처리 비활성화
분리된 CPU 세트에 대한 글로벌 장치 인터럽트를 비활성화하도록 Performance Addon Operator를 구성하려면 성능 프로필에서 globallyDisableIrqLoadBalancing 필드를 true로 설정합니다. true인 경우 충돌하는 Pod 주석이 무시됩니다. false인 경우 IRQ 로드는 모든 CPU에서 균형을 유지합니다.
성능 프로파일 스니펫에서는 이 설정을 보여줍니다.
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: globallyDisableIrqLoadBalancing: true ...
17.4.9.3. 개별 pod에 대한 인터럽트 처리 비활성화
개별 pod의 인터럽트 처리를 비활성화하려면 성능 프로필에서 globallyDisableIrqLoadBalancing이 false 로 설정되어 있는지 확인합니다. 그런 다음 Pod 사양에서 irq-load-balancing.crio.io Pod 주석을 비활성화하도록 설정합니다. 다음 Pod 사양에는 이 주석이 포함되어 있습니다.
apiVersion: performance.openshift.io/v2
kind: Pod
metadata:
annotations:
irq-load-balancing.crio.io: "disable"
spec:
runtimeClassName: performance-<profile_name>
...17.4.10. 장치 인터럽트 처리를 사용하기 위해 성능 프로파일을 업그레이드
Performance Addon Operator 성능 프로필 CRD(사용자 정의 리소스 정의)를 v1 또는 v1alpha1에서 v2 로 업그레이드하는 경우 기존 프로필에서 globallyDisableIrqLoadBalancing이 true로 설정됩니다.
격리된 CPU 세트에 대해 IRQ 로드 밸런싱이 비활성화되는지의 globallyDisableIrqLoadBalancing 토글입니다. 옵션을 true 로 설정하면 격리된 CPU 세트에 대한 IRQ 로드 밸런싱이 비활성화됩니다. 옵션을 false 로 설정하면 IRQ를 모든 CPU 간에 분산할 수 있습니다.
17.4.10.1. 지원되는 API 버전
Performance Addon Operator는 성능 프로파일 apiVersion 필드의 v2, v1, v1alpha1을 지원합니다. v1 및 v1alpha1 API는 동일합니다. v2 API에는 기본값인 false 값을 사용하여 선택적 부울 필드 loballyDisableIrqLoadBalancing이 포함됩니다.
17.4.10.1.1. Performance Addon Operator의 v1alpha1에서 v1으로 업그레이드
Performance Addon Operator API 버전을 v1alpha1에서 v1로 업그레이드하는 경우 "None" 변환 전략을 사용하여 v1alpha1 성능 프로파일이 즉시 변환되며 API 버전 v1을 사용하여 Performance Addon Operator에 제공됩니다.
17.4.10.1.2. Performance Addon Operator API를 v1alpha1 또는 v1에서 v2로 업그레이드
이전 Performance Addon Operator API 버전에서 업그레이드할 때 기존 v1 및 v1alpha1 성능 프로파일은 true 값으로 globallyDisableIrqLoadBalancing 필드에 삽입하는 변환 Webhook를 사용하여 변환됩니다.
17.4.11. IRQ 동적 로드 밸런싱을 위한 노드 구성
IRQ 동적 로드 밸런싱을 처리하도록 클러스터 노드를 구성하려면 다음을 수행합니다.
- cluster-admin 역할의 사용자로 OpenShift Container Platform 클러스터에 로그인합니다.
-
performance.openshift.io/v2를 사용하도록 성능 프로파일의apiVersion을 설정합니다. -
globallyDisableIrqLoadBalancing필드를 삭제제거하거나false로 설정합니다. 적절한 분리 및 예약된 CPU를 설정합니다. 다음 스니펫에서는 두 개의 CPU를 예약하는 프로파일을 보여줍니다.
isolatedCPU 세트에서 실행되는 Pod에 대해 IRQ 로드 밸런싱이 활성화됩니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: dynamic-irq-profile spec: cpu: isolated: 2-5 reserved: 0-1 ...참고예약 및 분리된 CPU를 구성하면 Pod의 인프라 컨테이너는 예약된 CPU를 사용하고 애플리케이션 컨테이너는 분리된 CPU를 사용합니다.
전용 CPU를 사용하는 pod를 생성하고
irq-load-balancing.crio.io및cpu-quota.crio.io주석을disable로 설정합니다. 예를 들면 다음과 같습니다.apiVersion: v1 kind: Pod metadata: name: dynamic-irq-pod annotations: irq-load-balancing.crio.io: "disable" cpu-quota.crio.io: "disable" spec: containers: - name: dynamic-irq-pod image: "quay.io/openshift-kni/cnf-tests:4.8" command: ["sleep", "10h"] resources: requests: cpu: 2 memory: "200M" limits: cpu: 2 memory: "200M" nodeSelector: node-role.kubernetes.io/worker-cnf: "" runtimeClassName: performance-dynamic-irq-profile ...-
performance-<profile_name> 형식으로 pod
runtimeClassName을 입력합니다. 여기서<profile_name>은PerformanceProfileYAML의name입니다 (예:performance- dynamic-irq-profile). - 노드 선택기를 cnf-worker 을 대상으로 설정합니다.
Pod가 올바르게 실행되고 있는지 확인합니다. 상태가
running이어야 하며 올바른 cnf-worker 노드를 설정해야 합니다.$ oc get pod -o wide
예상 출력
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES dynamic-irq-pod 1/1 Running 0 5h33m <ip-address> <node-name> <none> <none>
IRQ 동적 로드 밸런싱을 위해 구성된 Pod가 실행되는 CPU를 가져옵니다.
$ oc exec -it dynamic-irq-pod -- /bin/bash -c "grep Cpus_allowed_list /proc/self/status | awk '{print $2}'"예상 출력
Cpus_allowed_list: 2-3
노드 구성이 올바르게 적용되었는지 확인합니다. 구성을 확인하려면 노드에 SSH를 실행합니다.
$ oc debug node/<node-name>
예상 출력
Starting pod/<node-name>-debug ... To use host binaries, run `chroot /host` Pod IP: <ip-address> If you don't see a command prompt, try pressing enter. sh-4.4#
노드 파일 시스템을 사용할 수 있는지 확인합니다.
sh-4.4# chroot /host
예상 출력
sh-4.4#
기본 시스템 CPU 선호도 마스크에
dynamic-irq-podCPU (예: CPU 2 및 3)가 포함되지 않도록 합니다.$ cat /proc/irq/default_smp_affinity
출력 예
33
IRQ가
dynamic-irq-podCPU에서 실행되도록 구성되어 있지 않은지 확인합니다.find /proc/irq/ -name smp_affinity_list -exec sh -c 'i="$1"; mask=$(cat $i); file=$(echo $i); echo $file: $mask' _ {} \;출력 예
/proc/irq/0/smp_affinity_list: 0-5 /proc/irq/1/smp_affinity_list: 5 /proc/irq/2/smp_affinity_list: 0-5 /proc/irq/3/smp_affinity_list: 0-5 /proc/irq/4/smp_affinity_list: 0 /proc/irq/5/smp_affinity_list: 0-5 /proc/irq/6/smp_affinity_list: 0-5 /proc/irq/7/smp_affinity_list: 0-5 /proc/irq/8/smp_affinity_list: 4 /proc/irq/9/smp_affinity_list: 4 /proc/irq/10/smp_affinity_list: 0-5 /proc/irq/11/smp_affinity_list: 0 /proc/irq/12/smp_affinity_list: 1 /proc/irq/13/smp_affinity_list: 0-5 /proc/irq/14/smp_affinity_list: 1 /proc/irq/15/smp_affinity_list: 0 /proc/irq/24/smp_affinity_list: 1 /proc/irq/25/smp_affinity_list: 1 /proc/irq/26/smp_affinity_list: 1 /proc/irq/27/smp_affinity_list: 5 /proc/irq/28/smp_affinity_list: 1 /proc/irq/29/smp_affinity_list: 0 /proc/irq/30/smp_affinity_list: 0-5
일부 IRQ 컨트롤러는 IRQ 재조정을 지원하지 않으며 항상 모든 온라인 CPU를 IRQ 마스크로 공개합니다. 이러한 IRQ 컨트롤러는 CPU 0에서 효과적으로 실행됩니다. 호스트 구성에 대한 보다 자세한 내용은 호스트로 SSH를 실행하고 <irq-num>을 쿼리할 CPU 번호를 입력하여 다음을 실행합니다.
$ cat /proc/irq/<irq-num>/effective_affinity
17.4.12. 클러스터의 하이퍼 스레딩 구성
OpenShift Container Platform 클러스터의 하이퍼 스레딩을 구성하려면 성능 프로파일의 CPU 스레드를 예약 또는 분리된 CPU 풀에 구성된 동일한 코어로 설정합니다.
성능 프로파일을 구성하고 호스트의 하이퍼 스레딩 구성을 변경하는 경우 PerformanceProfile YAML의 CPU isolated 및 reserved 필드를 새 구성과 일치하도록 업데이트해야 합니다.
이전에 활성화된 호스트 하이퍼 스레딩 구성을 비활성화하면 PerformanceProfile YAML에 나열된 CPU 코어 ID가 올바르지 않을 수 있습니다. 이렇게 잘못된 구성으로 인해 나열된 CPU를 더 이상 찾을 수 없으므로 노드를 사용할 수 없게 될 가능성이 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - OpenShift CLI(oc)를 설치합니다.
절차
구성할 호스트의 모든 CPU에서 실행중인 스레드를 확인합니다.
클러스터에 로그인하고 다음 명령을 실행하여 호스트 CPU에서 실행중인 스레드를 볼 수 있습니다.
$ lscpu --all --extended
출력 예
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ 0 0 0 0 0:0:0:0 yes 4800.0000 400.0000 1 0 0 1 1:1:1:0 yes 4800.0000 400.0000 2 0 0 2 2:2:2:0 yes 4800.0000 400.0000 3 0 0 3 3:3:3:0 yes 4800.0000 400.0000 4 0 0 0 0:0:0:0 yes 4800.0000 400.0000 5 0 0 1 1:1:1:0 yes 4800.0000 400.0000 6 0 0 2 2:2:2:0 yes 4800.0000 400.0000 7 0 0 3 3:3:3:0 yes 4800.0000 400.0000
이 예에서는 4개의 물리적 CPU 코어에서 실행 중인 논리 CPU 코어가 8개 있습니다. CPU0 및 CPU4는 물리적 Core0에서 실행되고 CPU1 및 CPU5는 물리적 Core 1에서 실행되고 있습니다.
또는 특정 물리적 CPU 코어(다음 예에서는
cpu0)에 설정된 스레드를 보려면 명령 프롬프트를 열고 다음을 실행합니다.$ cat /sys/devices/system/cpu/cpu0/topology/thread_siblings_list
출력 예
0-4
PerformanceProfileYAML에서 분리 및 예약된 CPU를 적용합니다. 예를 들어 논리 코어 CPU0 및 CPU4를 분리하여 논리 코어 CPU1을 CPU3으로, CPU5를예약된 대로 CPU7로 설정할 수 있습니다. 예약 및 분리된 CPU를 구성하면 Pod의 인프라 컨테이너는 예약된 CPU를 사용하고 애플리케이션 컨테이너는 분리된 CPU를 사용합니다.... cpu: isolated: 0,4 reserved: 1-3,5-7 ...참고예약된 CPU 풀과 분리된 CPU 풀은 중복되지 않아야 하며 함께 작업자 노드의 사용 가능한 모든 코어에 걸쳐 있어야 합니다.
하이퍼 스레딩은 대부분의 Intel 프로세서에서 기본적으로 활성화되어 있습니다. 하이퍼 스레딩을 활성화하면 특정 코어에서 처리되는 모든 스레드를 동일한 코어에서 분리하거나 처리해야 합니다.
17.4.12.1. 지연 시간이 짧은 애플리케이션의 하이퍼 스레딩 비활성화
지연 시간이 짧은 프로세스를 위해 클러스터를 구성할 때 클러스터를 배포하기 전에 하이퍼 스레딩을 비활성화할지 여부를 고려하십시오. 하이퍼 스레딩을 비활성화하려면 다음을 수행합니다.
- 하드웨어 및 토폴로지에 적합한 성능 프로필을 생성합니다.
nosmt를 추가 커널 인수로 설정합니다. 다음 성능 프로파일 예에서는 이 설정에 대해 설명합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: example-performanceprofile spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - idle=poll - intel_idle.max_cstate=0 - nosmt cpu: isolated: 2-3 reserved: 0-1 hugepages: defaultHugepagesSize: 1G pages: - count: 2 node: 0 size: 1G nodeSelector: node-role.kubernetes.io/performance: '' realTimeKernel: enabled: true참고예약 및 분리된 CPU를 구성하면 Pod의 인프라 컨테이너는 예약된 CPU를 사용하고 애플리케이션 컨테이너는 분리된 CPU를 사용합니다.
17.5. 성능 프로필을 사용하여 짧은 대기 시간을 실현하도록 노드 튜닝
성능 프로필을 사용하면 특정 머신 구성 풀에 속한 노드의 대기 시간 튜닝 측면을 제어할 수 있습니다. 설정을 지정하면 PerformanceProfile 오브젝트가 실제 노드 수준 튜닝을 수행하는 여러 오브젝트로 컴파일됩니다.
-
MachineConfig파일은 노드를 조작합니다. -
KubeletConfig파일은 토폴로지 관리자, CPU 관리자 및 OpenShift Container Platform 노드를 구성합니다. - Tuned 프로필은 Node Tuning Operator를 구성합니다.
성능 프로필을 사용하여 커널을 kernel-rt로 업데이트할지 여부를 지정하고, 대규모 페이지를 할당하고, CPU를 분할하여 하우스키핑 작업 수행 또는 워크로드 실행에 사용할 CPU를 분할할 수 있습니다.
PerformanceProfile 오브젝트를 수동으로 생성하거나 PPC(성능 프로필 생성)를 사용하여 성능 프로필을 생성할 수 있습니다. PPC에 대한 자세한 내용은 아래 추가 리소스를 참조하십시오.
성능 프로파일의 예
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: "5-15" 1 reserved: "0-4" 2 hugepages: defaultHugepagesSize: "1G" pages: - size: "1G" count: 16 node: 0 realTimeKernel: enabled: true 3 numa: 4 topologyPolicy: "best-effort" nodeSelector: node-role.kubernetes.io/worker-cnf: "" 5
- 1
- 이 필드를 사용하여 워크로드의 애플리케이션 컨테이너와 함께 사용할 특정 CPU를 분리합니다.
- 2
- 이 필드를 사용하여 하우스키핑을 위해 인프라 컨테이너와 함께 사용할 특정 CPU를 예약합니다.
- 3
- 이 필드를 사용하여 노드에 실시간 커널을 설치합니다. 유효한 값은
true또는false입니다.true값을 설정하면 실시간 커널이 설치됩니다. - 4
- 이 필드를 사용하여 토폴로지 관리자 정책을 구성합니다. 유효한 값은
none(기본값),best-effort,restricted및single-numa-node입니다. 자세한 내용은 토폴로지 관리자 정책을 참조하십시오. - 5
- 이 필드를 사용하여 특정 노드에 성능 프로파일을 적용할 노드 선택기를 지정합니다.
추가 리소스
- 성능 프로필 생성기(PPC)를 사용하여 성능 프로필을 생성하는 방법에 대한 자세한 내용은 성능 프로필 생성을 참조하십시오.
17.5.1. 대규모 페이지 구성
노드는 OpenShift Container Platform 클러스터에서 사용되는 대규모 페이지를 사전 할당해야 합니다. Performance Addon Operator를 사용하여 특정 노드에 대규모 페이지를 할당하십시오.
OpenShift Container Platform에서는 대규모 페이지를 생성하고 할당하는 방법을 제공합니다. Performance Addon Operator는 성능 프로필을 사용하여 더 쉽게 이 작업을 수행하는 방법을 제공합니다.
예를 들어 성능 프로필의 hugepages pages 섹션에서 size, count 및 node(선택사항)로 된 여러 블록을 지정할 수 있습니다.
hugepages:
defaultHugepagesSize: "1G"
pages:
- size: "1G"
count: 4
node: 0 1- 1
node는 대규모 페이지가 할당된 NUMA 노드입니다.node를 생략하면 페이지가 모든 NUMA 노드에 균등하게 분산됩니다.
관련 머신 구성 풀 상태에 업데이트가 완료된 것으로 나타날 때까지 기다립니다.
대규모 페이지를 할당하기 위해 수행해야 하는 구성 단계는 이것이 전부입니다.
검증
구성을 검증하려면 노드의
/proc/meminfo파일을 참조하십시오.$ oc debug node/ip-10-0-141-105.ec2.internal
# grep -i huge /proc/meminfo
출력 예
AnonHugePages: ###### ## ShmemHugePages: 0 kB HugePages_Total: 2 HugePages_Free: 2 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: #### ## Hugetlb: #### ##
oc describe를 사용하여 새 크기를 보고합니다.$ oc describe node worker-0.ocp4poc.example.com | grep -i huge
출력 예
hugepages-1g=true hugepages-###: ### hugepages-###: ###
17.5.2. 여러 대규모 페이지 크기 할당
동일한 컨테이너에서 다양한 크기의 대규모 페이지를 요청할 수 있습니다. 이 경우 다양한 대규모 페이지 크기 요구사항이 있는 컨테이너로 구성된 더 복잡한 Pod를 정의할 수 있습니다.
예를 들어 1G 및 2M 크기를 정의할 수 있습니다. 그러면 Performance Addon Operator가 다음과 같이 노드에서 크기를 둘 다 구성합니다.
spec:
hugepages:
defaultHugepagesSize: 1G
pages:
- count: 1024
node: 0
size: 2M
- count: 4
node: 1
size: 1G17.5.3. 인프라 및 애플리케이션 컨테이너의 CPU 제한
일반 하우스키핑 및 워크로드 작업은 대기 시간에 민감한 프로세스에 영향을 줄 수 있는 방식으로 CPU를 사용합니다. 기본적으로 컨테이너 런타임은 모든 온라인 CPU를 사용하여 모든 컨테이너를 함께 실행하여 컨텍스트 전환과 대기 시간이 급증할 수 있습니다. CPU를 파티셔닝하면 유휴 프로세스가 서로 분리되어 대기 시간에 민감한 프로세스를 방해하지 못합니다. 다음 표는 Performance Add-On Operator를 사용하여 노드를 조정한 후 CPU에서 실행되는 방법을 설명합니다.
표 17.1. 프로세스의 CPU 할당
| 프로세스 유형 | 세부 정보 |
|---|---|
|
| 대기 시간이 짧은 워크로드가 실행 중인 경우를 제외하고 모든 CPU에서 실행됩니다. |
| 인프라 Pod | 대기 시간이 짧은 워크로드가 실행 중인 경우를 제외하고 모든 CPU에서 실행됩니다. |
| 인터럽트 | 예약된 CPU로 리디렉션(OpenShift Container Platform 4.7 이상에서 선택 사항) |
| 커널 프로세스 | 예약된 CPU에 대한 고정 |
| 대기 시간에 민감한 워크로드 Pod | 격리된 풀에서 특정 전용 CPU 집합에 고정 |
| OS 프로세스/시스템 서비스 | 예약된 CPU에 대한 고정 |
모든 QoS 프로세스 유형, Burstable,BestEffort 또는 Guaranteed 의 Pod에 대해 노드에 있는 코어의 할당 가능 용량은 격리된 풀의 용량과 동일합니다. 예약된 풀의 용량은 클러스터 및 운영 체제 하우스키핑 작업에서 사용할 노드의 총 코어 용량에서 제거됩니다.
예시 1
노드에는 100개의 코어 용량이 있습니다. 클러스터 관리자는 성능 프로필을 사용하여 분리된 풀에 50개의 코어를 할당하고 예약된 풀에 50개의 코어를 할당합니다. 클러스터 관리자는 BestEffort 또는 Burstable Pod에 대해 QoS가 보장된 Pod 및 25개의 코어를 25개에 할당합니다. 이는 격리된 풀의 용량과 일치합니다.
예시 2
노드에는 100개의 코어 용량이 있습니다. 클러스터 관리자는 성능 프로필을 사용하여 분리된 풀에 50개의 코어를 할당하고 예약된 풀에 50개의 코어를 할당합니다. 클러스터 관리자는 QoS가 보장된 Pod에 50개의 코어를 할당하고 BestEffort 또는 Burstable Pod의 코어 1개를 할당합니다. 이는 하나의 코어로 격리된 풀의 용량을 초과합니다. CPU 용량이 부족하여 Pod 예약에 실패합니다.
사용할 정확한 파티셔닝 패턴은 하드웨어, 워크로드 특성 및 예상 시스템 부하와 같은 여러 요인에 따라 다릅니다. 일부 샘플 사용 사례는 다음과 같습니다.
- 대기 시간에 민감한 워크로드가 NIC(네트워크 인터페이스 컨트롤러)와 같은 특정 하드웨어를 사용하는 경우 격리된 풀의 CPU가 이 하드웨어에 최대한 가까운지 확인합니다. 최소한 동일한 NUMA(Non-Uniform Memory Access) 노드에 워크로드를 배치해야 합니다.
- 예약된 풀은 모든 인터럽트를 처리하는 데 사용됩니다. 시스템 네트워킹에 따라 들어오는 모든 패킷 인터럽트를 처리할 충분한 크기의 예약 풀을 할당합니다. 4.8 이상 버전에서는 워크로드에 선택적으로 중요로 레이블이 지정될 수 있습니다.
예약 및 격리된 파티션에 특정 CPU를 사용해야 하는 결정에는 상세한 분석과 측정이 필요합니다. 장치와 메모리의 NUMA 선호도와 같은 요인은 역할을 수행합니다. 선택 사항은 워크로드 아키텍처 및 특정 사용 사례에 따라 달라집니다.
예약된 CPU 풀과 분리된 CPU 풀은 중복되지 않아야 하며 함께 작업자 노드의 사용 가능한 모든 코어에 걸쳐 있어야 합니다.
하우스키핑 작업과 워크로드가 서로 방해하지 않도록 하려면 성능 프로필의 spec 섹션에 두 개의 CPU 그룹을 지정합니다.
-
isolated- 애플리케이션 컨테이너 워크로드의 CPU를 지정합니다. 이러한 CPU는 대기 시간이 가장 짧습니다. 이 그룹의 프로세스에는 중단이 발생하지 않으므로 예를 들어 프로세스가 훨씬 더 높은 DPDK 제로 패킷 손실 대역폭에 도달할 수 있습니다. -
reserved- 클러스터 및 운영 체제 하우스키핑 작업의 CPU를 지정합니다.예약된 그룹의 스레드가 사용 중인 경우가 많습니다.예약된 그룹에서 대기 시간에 민감한 애플리케이션을 실행하지 마십시오. 대기 시간에 민감한 애플리케이션은격리된그룹에서 실행됩니다.
절차
- 환경의 하드웨어 및 토폴로지에 적합한 성능 프로필을 만듭니다.
인프라 및 애플리케이션 컨테이너에 대해
reserved및isolated하려는 CPU와 함께 예약 및 격리된 매개변수를 추가합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: infra-cpus spec: cpu: reserved: "0-4,9" 1 isolated: "5-8" 2 nodeSelector: 3 node-role.kubernetes.io/worker: ""
17.6. Performance Addon Operator를 사용하여 NIC 큐 단축
Performance Addon Operator를 사용하면 성능 프로필을 구성하여 각 네트워크 장치에 대해 NIC(네트워크 인터페이스 컨트롤러) 대기열 수를 조정할 수 있습니다. 장치 네트워크 대기열을 사용하면 서로 다른 물리적 대기열 간에 패킷을 배포할 수 있으며 각 대기열은 패킷 처리를 위해 별도의 스레드를 가져옵니다.
실시간 또는 짧은 대기 시간 시스템에서 분리된 CPU에 고정된 불필요한 인터럽트 요청 라인(IRQ)을 예약 또는 하우스키핑 CPU로 이동해야 합니다.
시스템이 필요한 애플리케이션 배포에서 OpenShift Container Platform 네트워킹 또는 DPDK(Data Plane Development Kit) 워크로드와의 혼합 배포에서 우수한 처리량을 달성하려면 여러 대기열이 필요하며 NIC 큐 수는 조정되거나 변경되지 않아야 합니다. 예를 들어 대기 시간을 단축하려면 DPDK 기반 워크로드의 NIC 대기열 수를 예약 또는 하우스키핑 CPU 수만큼 줄여야 합니다.
각 CPU에 대해 기본적으로 너무 많은 대기열이 생성되며 낮은 대기 시간을 위해 튜닝할 때 하우스키핑 CPU에 대한 인터럽트 테이블에 맞지 않습니다. 큐 수를 줄이면 적절한 튜닝이 가능합니다. 큐 수가 적을수록 IRQ 테이블에 맞는 인터럽트 수가 적다는 것을 의미합니다.
17.6.1. 성능 프로파일을 사용하여 NIC 큐 조정
성능 프로파일을 사용하면 각 네트워크 장치의 대기열 수를 조정할 수 있습니다.
지원되는 네트워크 장치는 다음과 같습니다.
- 비가상 네트워크 장치
- 멀티 큐(채널)를 지원하는 네트워크 장치
지원되지 않는 네트워크 장치는 다음과 같습니다.
- Pure Software 네트워크 인터페이스
- 블록 장치
- Intel DPDK 가상 기능
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. -
OpenShift CLI(
oc)를 설치합니다.
절차
-
cluster-admin권한이 있는 사용자로 Performance Addon Operator를 실행하는 OpenShift Container 클러스터에 로그인합니다. - 하드웨어 및 토폴로지에 적합한 성능 프로파일을 만들고 적용합니다. 프로파일 생성에 대한 지침은 "성능 프로파일 생성" 섹션을 참조하십시오.
생성된 성능 프로파일을 편집합니다.
$ oc edit -f <your_profile_name>.yaml
spec필드를net오브젝트로 채웁니다. 오브젝트 목록에는 다음 두 개의 필드가 포함될 수 있습니다.-
userLevelNetworking은 부울 플래그로 지정된 필수 필드입니다.userLevelNetworking이true인 경우 지원되는 모든 장치에 대해 대기열 수가 예약된 CPU 수로 설정됩니다. 기본값은false입니다. devices는 예약된 CPU 수로 큐를 설정할 장치 목록을 지정하는 선택적 필드입니다. 장치 목록이 비어 있으면 구성이 모든 네트워크 장치에 적용됩니다. 구성은 다음과 같습니다.interfaceName: 이 필드는 인터페이스 이름을 지정하며 양수 또는 음수일 수 있는 쉘 스타일 와일드카드를 지원합니다.-
와일드카드 구문의 예는 다음과 같습니다.
<string> .* -
음수 규칙 앞에는 느낌표가 붙습니다. 제외된 목록이 아닌 모든 장치에 넷 큐 변경 사항을 적용하려면
!<device>를 사용합니다(예:!eno1).
-
와일드카드 구문의 예는 다음과 같습니다.
-
vendorID: 네트워크 장치 벤더 ID는0x접두사가 있는 16비트 16진수로 표시됩니다. deviceID:0x접두사가 있는 16진수로 표시되는 네트워크 장치 ID(model)입니다.참고deviceID가 지정되어 있는 경우vendorID도 정의해야 합니다. 장치 항목interfaceName,vendorID,vendorID및deviceID의 쌍에 지정된 모든 장치 식별자와 일치하는 장치는 네트워크 장치로 간주됩니다. 그러면 이 네트워크 장치의 네트워크 대기열 수가 예약된 CPU 수로 설정됩니다.두 개 이상의 장치가 지정되면 네트워크 대기열 수가 해당 장치 중 하나와 일치하는 모든 네트워크 장치로 설정됩니다.
-
다음 예제 성능 프로필을 사용하여 대기열 수를 모든 장치에 예약된 CPU 수로 설정합니다.
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true nodeSelector: node-role.kubernetes.io/worker-cnf: ""다음 예제 성능 프로필을 사용하여 정의된 장치 식별자와 일치하는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - interfaceName: “eth1” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""다음 예제 성능 프로필을 사용하여 인터페이스 이름
eth로 시작하는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth*” nodeSelector: node-role.kubernetes.io/worker-cnf: ""이 예제 성능 프로필을 사용하여 이름이
eno1이외의 인터페이스가 있는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “!eno1” nodeSelector: node-role.kubernetes.io/worker-cnf: ""인터페이스 이름
eth0,0x1af4의vendorID및0x1000의deviceID는 모든 장치에 대해 대기열 수를 예약된 CPU 수로 설정합니다. 성능 프로파일 예는 다음과 같습니다.apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: manual spec: cpu: isolated: 3-51,54-103 reserved: 0-2,52-54 net: userLevelNetworking: true devices: - interfaceName: “eth0” - vendorID: “0x1af4” - deviceID: “0x1000” nodeSelector: node-role.kubernetes.io/worker-cnf: ""업데이트된 성능 프로필을 적용합니다.
$ oc apply -f <your_profile_name>.yaml
추가 리소스
17.6.2. 대기열 상태 확인
이 섹션에서는 다양한 성능 프로필과 변경 사항이 적용되었는지 확인하는 방법에 대한 여러 예시가 있습니다.
예시 1
이 예에서 네트워크 대기열 수는 지원되는 모든 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
성능 프로필의 관련 섹션은 다음과 같습니다.
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
# ...다음 명령을 사용하여 장치와 연결된 대기열의 상태를 표시합니다.
참고성능 프로필이 적용된 노드에서 이 명령을 실행합니다.
$ ethtool -l <device>
프로필을 적용하기 전에 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 4
프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
- 결합된 채널은 지원되는 모든 장치에 대해 예약된 CPU의 총 수가 2임을 보여줍니다. 이는 성능 프로필에 구성된 항목과 일치합니다.
예시 2
이 예에서 네트워크 대기열 수는 특정 vendorID가 있는 지원되는 모든 네트워크 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
성능 프로필의 관련 섹션은 다음과 같습니다.
apiVersion: performance.openshift.io/v2
metadata:
name: performance
spec:
kind: PerformanceProfile
spec:
cpu:
reserved: 0-1 #total = 2
isolated: 2-8
net:
userLevelNetworking: true
devices:
- vendorID = 0x1af4
# ...다음 명령을 사용하여 장치와 연결된 대기열의 상태를 표시합니다.
참고성능 프로필이 적용된 노드에서 이 명령을 실행합니다.
$ ethtool -l <device>
프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1
- 1
vendorID=0x1af4를 사용하는 지원되는 모든 장치에 대해 예약된 CPU의 총 수는 2입니다. 예를 들어vendorID=0x1af4가 있는 다른 네트워크 장치ens2가 별도로 존재하는 경우 총 네트워크 대기열 수는 2입니다. 이는 성능 프로필에 구성된 항목과 일치합니다.
예시 3
이 예에서 네트워크 대기열 수는 정의된 장치 식별자와 일치하는 지원되는 모든 네트워크 장치에 대해 예약된 CPU 수(2)로 설정됩니다.
udevadm info는 장치에 대한 자세한 보고서를 제공합니다. 이 예에서 장치는 다음과 같습니다.
# udevadm info -p /sys/class/net/ens4 ... E: ID_MODEL_ID=0x1000 E: ID_VENDOR_ID=0x1af4 E: INTERFACE=ens4 ...
# udevadm info -p /sys/class/net/eth0 ... E: ID_MODEL_ID=0x1002 E: ID_VENDOR_ID=0x1001 E: INTERFACE=eth0 ...
interfaceName이eth0인 장치 및 다음 성능 프로필이 있는vendorID=0x1af4가 있는 모든 장치에 대해 네트워크 대기열을 2로 설정합니다.apiVersion: performance.openshift.io/v2 metadata: name: performance spec: kind: PerformanceProfile spec: cpu: reserved: 0-1 #total = 2 isolated: 2-8 net: userLevelNetworking: true devices: - interfaceName = eth0 - vendorID = 0x1af4 ...프로필이 적용된 후 대기열 상태를 확인합니다.
$ ethtool -l ens4
출력 예
Channel parameters for ens4: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 2 1- 1
vendorID=0x1af4를 사용하는 지원되는 모든 장치에 대해 예약된 CPU의 총 개수가 2로 설정됩니다. 예를 들어vendorID=0x1af4가 있는 다른 네트워크 장치ens2가 있는 경우 총 네트워크 대기열도 2로 설정됩니다. 마찬가지로interfaceName이eth0인 장치에는 총 네트워크 대기열이 2로 설정됩니다.
17.6.3. NIC 대기열 조정과 관련된 로깅
할당된 장치를 자세히 설명하는 로그 메시지는 각 Tuned 데몬 로그에 기록됩니다. /var/log/tuned/tuned.log 파일에 다음 메시지가 기록될 수 있습니다.
성공적으로 할당된 장치를 자세히 설명하는
INFO메시지가 기록됩니다.INFO tuned.plugins.base: instance net_test (net): assigning devices ens1, ens2, ens3
장치를 할당할 수 없는 경우
WARNING메시지가 기록됩니다.WARNING tuned.plugins.base: instance net_test: no matching devices available
17.7. 짧은 대기 시간 CNF 튜닝 상태 디버깅
PerformanceProfile CR(사용자 정의 리소스)에는 튜닝 상태를 보고하고 대기 시간 성능 저하 문제를 디버깅하기 위한 상태 필드가 있습니다. 이러한 필드는 상태를 보고하여 Operator 조정 기능의 상태에 대해 설명합니다.
일반적으로 성능 프로필에 연결된 머신 구성 풀의 상태가 성능 저하 상태이면 PerformanceProfile이 성능 저하 상태가 되는 문제가 발생할 수 있습니다. 이 경우 머신 구성 풀에서 실패 메시지를 발행합니다.
Performance Addon Operator에는 performanceProfile.spec.status.Conditions 상태 필드가 있습니다.
Status:
Conditions:
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Available
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: True
Type: Upgradeable
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Progressing
Last Heartbeat Time: 2020-06-02T10:01:24Z
Last Transition Time: 2020-06-02T10:01:24Z
Status: False
Type: Degraded
Status 필드에는 성능 프로필의 상태를 나타내는 Type 값을 지정하는 Conditions가 포함되어 있습니다.
Available- 모든 머신 구성 및 Tuned 프로필이 성공적으로 생성되었으며 구성 요소에서 처리해야 하는 클러스터에 사용할 수 있습니다(NTO, MCO, Kubelet).
Upgradeable- Operator에서 유지보수하는 리소스가 업그레이드하기에 안전한 상태인지를 나타냅니다.
Progressing- 성능 프로필의 배포 프로세스가 시작되었음을 나타냅니다.
Degraded다음과 같은 경우 오류를 표시합니다.
- 성능 프로필 검증에 실패했습니다.
- 모든 관련 구성 요소 생성이 성공적으로 완료되지 않았습니다.
이러한 각 유형에는 다음 필드가 포함되어 있습니다.
상태-
특정 유형의 상태(
true또는false)입니다. Timestamp- 트랜잭션 타임스탬프입니다.
Reason string- 머신에서 읽을 수 있는 이유입니다.
Message string- 상태 및 오류 세부 정보(있는 경우)를 설명하는 사람이 읽을 수 있는 이유입니다.
17.7.1. 머신 구성 풀
성능 프로필 및 생성된 제품은 연관 MCP(머신 구성 풀)에 따라 노드에 적용됩니다. MCP에는 성능 애드온을 통해 생성되었고 커널 인수, kube 구성, 대규모 페이지 할당, rt-커널 배포를 포괄하는 머신 구성의 적용 진행 상황에 대한 중요한 정보가 들어 있습니다. 성능 애드온 컨트롤러는 MCP의 변경사항을 모니터링하여 성능 프로필 상태를 적절하게 업데이트합니다.
MCP가 성능 프로필 상태로 값을 반환하는 유일한 상태는 MCP가 Degraded인 경우이며, 이 경우에는 performaceProfile.status.condition.Degraded = true가 됩니다.
예
다음은 생성된 연관 머신 구성 풀(worker-cnf)이 있는 성능 프로필의 예입니다.
연관 머신 구성 풀이 성능 저하 상태입니다.
# oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-2ee57a93fa6c9181b546ca46e1571d2d True False False 3 3 3 0 2d21h worker rendered-worker-d6b2bdc07d9f5a59a6b68950acf25e5f True False False 2 2 2 0 2d21h worker-cnf rendered-worker-cnf-6c838641b8a08fff08dbd8b02fb63f7c False True True 2 1 1 1 2d20h
MCP의
describe섹션은 이유를 보여줍니다.# oc describe mcp worker-cnf
출력 예
Message: Node node-worker-cnf is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found" Reason: 1 nodes are reporting degraded status on syncdegraded = true로 표시된 성능 프로필status필드 아래에도 성능 저하 상태가 표시되어야 합니다.# oc describe performanceprofiles performance
출력 예
Message: Machine config pool worker-cnf Degraded Reason: 1 nodes are reporting degraded status on sync. Machine config pool worker-cnf Degraded Message: Node yquinn-q8s5v-w-b-z5lqn.c.openshift-gce-devel.internal is reporting: "prepping update: machineconfig.machineconfiguration.openshift.io \"rendered-worker-cnf-40b9996919c08e335f3ff230ce1d170\" not found". Reason: MCPDegraded Status: True Type: Degraded
17.8. Red Hat 지원을 받기 위한 짧은 대기 시간 튜닝 디버깅 데이터 수집
지원 사례를 여는 경우 클러스터에 대한 디버깅 정보를 Red Hat 지원에 제공하면 도움이 됩니다.
must-gather 툴을 사용하면 노드 튜닝과 NUMA 토폴로지, 짧은 대기 시간 설정으로 인한 문제를 디버깅하는 데 필요한 다른 정보를 비롯하여 OpenShift Container Platform 클러스터에 대한 진단 정보를 수집할 수 있습니다.
즉각 지원을 받을 수 있도록 OpenShift Container Platform 및 짧은 대기 시간 튜닝 둘 다에 대한 진단 정보를 제공하십시오.
17.8.1. must-gather 툴 정보
oc adm must-gather CLI 명령은 다음과 같이 문제를 디버깅하는 데 필요할 가능성이 높은 클러스터 정보를 수집합니다.
- 리소스 정의
- 감사 로그
- 서비스 로그
--image 인수를 포함하여 명령을 실행하는 경우 이미지를 하나 이상 지정할 수 있습니다. 이미지를 지정하면 툴에서 해당 기능 또는 제품과 관련된 데이터를 수집합니다. oc adm must-gather를 실행하면 클러스터에 새 Pod가 생성됩니다. 해당 Pod에 대한 데이터가 수집되어 must-gather.local로 시작하는 새 디렉터리에 저장됩니다. 이 디렉터리는 현재 작업 디렉터리에 생성됩니다.
17.8.2. 짧은 대기 시간 튜닝 데이터 수집 정보
oc adm must-gather CLI 명령을 사용하여 다음과 같은 짧은 대기 시간 튜닝과 연관된 기능 및 오브젝트를 포함한 클러스터 정보를 수집합니다.
- Performance Addon Operator 네임스페이스 및 하위 오브젝트.
-
MachineConfigPool및 연관MachineConfig오브젝트. - Node Tuning Operator 및 연관 Tuned 오브젝트.
- Linux Kernel 명령줄 옵션.
- CPU 및 NUMA 토폴로지.
- 기본 PCI 장치 정보 및 NUMA 위치.
must-gather 를 사용하여 Performance Addon Operator 디버깅 정보를 수집하려면 Performance Addon Operator must-gather 이미지를 지정해야 합니다.
--image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.8.
17.8.3. 특정 기능에 대한 데이터 수집
oc adm must-gather CLI 명령을 --image 또는 --image-stream 인수와 함께 사용하여 특정 기능에 대한 디버깅 정보를 수집할 수 있습니다. must-gather 툴은 여러 이미지를 지원하므로 단일 명령을 실행하여 둘 이상의 기능에 대한 데이터를 수집할 수 있습니다.
특정 기능 데이터 외에도 기본 must-gather 데이터를 수집하려면 --image-stream=openshift/must-gather 인수를 추가하십시오.
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. - OpenShift Container Platform CLI(oc)가 설치되어 있어야 합니다.
프로세스
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. --image또는--image-stream인수를 하나 이상 사용하여oc adm must-gather명령을 실행합니다. 예를 들어 다음 명령은 기본 클러스터 데이터와 Performance Addon Operator 관련 정보를 모두 수집합니다.$ oc adm must-gather \ --image-stream=openshift/must-gather \ 1 --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.8 2
작업 디렉터리에 생성된
must-gather디렉터리의 압축 파일을 생성합니다. 예를 들어 Linux 운영 체제를 사용하는 컴퓨터에서 다음 명령을 실행합니다.$ tar cvaf must-gather.tar.gz must-gather.local.5421342344627712289/ 1- 1
must-gather-local.5421342344627712289/를 실제 디렉터리 이름으로 바꿉니다.
- Red Hat Customer Portal에서 해당 지원 사례에 압축 파일을 첨부합니다.
추가 리소스
- MachineConfig 및 KubeletConfig에 대한 자세한 내용은 노드 관리를 참조하십시오.
- Node Tuning Operator에 대한 자세한 내용은 Node Tuning Operator 사용을 참조하십시오.
- PerformanceProfile에 대한 자세한 내용은 대규모 페이지 구성을 참조하십시오.
- 컨테이너에서 대규모 페이지를 사용하는 방법에 대한 자세한 내용은 앱에서 대규모 페이지를 사용하는 방법을 참조하십시오.
18장. 플랫폼 검증을 위해 대기 시간 테스트 수행
CNF(클라우드 네이티브 네트워크 기능) 테스트 이미지를 사용하여 CNF 워크로드 실행에 필요한 모든 구성 요소가 설치된 CNF 지원 OpenShift Container Platform 클러스터에서 대기 시간 테스트를 실행할 수 있습니다. 대기 시간 테스트를 실행하여 워크로드에 대한 노드 튜닝을 검증합니다.
cnf-tests 컨테이너 이미지는 registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 에서 사용할 수 있습니다.
cnf-tests 이미지에는 현재 Red Hat에서 지원하지 않는 여러 테스트도 포함되어 있습니다. Red Hat에서 대기 시간 테스트만 지원합니다.
18.1. 대기 시간 테스트 실행을 위한 사전 요구 사항
대기 시간 테스트를 실행하려면 클러스터가 다음 요구 사항을 충족해야 합니다.
- Performance Addon Operator를 사용하여 성능 프로필을 구성했습니다.
- 클러스터에 필요한 모든 CNF 구성을 적용했습니다.
-
클러스터에 기존
MachineConfigPoolCR이 적용되어 있습니다. 기본 작업자 풀은worker-cnf입니다.
추가 리소스
- 클러스터 성능 프로필을 생성하는 방법에 대한 자세한 내용은 실시간 프로비저닝 및 짧은 대기 시간 워크로드를 참조하십시오.
18.2. 대기 시간 테스트의 검색 모드 정보
검색 모드를 사용하여 구성을 변경하지 않고 클러스터의 기능을 검증합니다. 기존 환경 구성이 테스트에 사용됩니다. 테스트에서는 필요한 구성 항목을 찾고 해당 항목을 사용하여 테스트를 실행할 수 있습니다. 특정 테스트를 실행하는 데 필요한 리소스를 찾을 수 없는 경우에는 테스트를 건너뛰고 사용자에게 적절한 메시지를 제공합니다. 테스트 완료 후 사전 구성한 구성 항목을 정리하지 않으며, 테스트 환경을 다른 테스트 실행에 즉시 사용할 수 있습니다.
대기 시간 테스트를 실행하는 경우 항상 -e DISCOVERY_MODE=true 로 테스트를 실행하고 -ginkgo.focus 를 적절한 대기 시간 테스트로 설정합니다. 검색 모드에서 대기 시간 테스트를 실행하지 않으면 테스트 실행에 의해 기존 라이브 클러스터 성능 프로필 구성이 수정됩니다.
테스트 중 사용되는 노드 제한
NODES_SELECTOR 환경 변수(예: -e NODES_SELECTOR=node-role.kubernetes.io/worker-cnf )를 지정하여 테스트가 실행되는 노드를 제한할 수 있습니다. 테스트에서 생성된 리소스는 라벨이 일치하는 노드로 제한됩니다.
기본 작업자 풀을 재정의하려면 -e ROLE_WORKER_CNF=<custom_worker_pool > 변수를 적절한 레이블을 지정하는 명령에 전달합니다.
18.3. 대기 시간 측정
cnf-tests 이미지는 oslat 툴을 사용하여 시스템의 대기 시간을 측정합니다.
- oslat
- CPU 집약적 DPDK 애플리케이션과 유사하게 작동하며 CPU 사용량이 많은 데이터 처리를 시뮬레이션하는 사용 중인 루프에 대한 모든 중단 및 중단을 측정합니다.
테스트에서는 다음과 같은 환경 변수를 도입합니다.
표 18.1. 대기 시간 테스트 환경 변수
| 환경 변수 | 설명 |
|---|---|
|
| 테스트 실행을 시작한 후 시간(초)을 지정합니다. 변수를 사용하여 CPU 관리자가 조정되는 루프를 허용하여 기본 CPU 풀을 업데이트할 수 있습니다. 기본값은 0입니다. |
|
| 대기 시간 테스트를 실행하는 Pod에서 사용하는 CPU 수를 지정합니다. 변수를 설정하지 않으면 기본 구성에 분리된 모든 CPU가 포함됩니다. |
|
| 대기 시간 테스트를 실행해야 하는 시간(초)을 지정합니다. 기본값은 300초입니다. |
|
|
|
|
|
테스트 실행 여부를 나타내는 부울 매개변수입니다. |
18.4. 대기 시간 테스트 실행
클러스터 대기 시간 테스트를 실행하여 CNF(클라우드 네이티브 네트워크 기능) 워크로드에 대한 노드 튜닝을 검증합니다.
항상 DISCOVERY_MODE=true 세트를 사용하여 대기 시간 테스트를 실행합니다. 그렇지 않은 경우 테스트 모음에서 실행 중인 클러스터 구성을 변경합니다.
podman 명령을 루트가 아닌 사용자 또는 권한이 없는 사용자로 실행하는 경우 권한 거부 오류로 인해 마운트 경로가 실패할 수 있습니다. podman 명령이 작동하도록 하려면 :Z 를 볼륨 생성에 추가합니다(예: -v $(pwd)/:/kubeconfig:Z ). 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
프로세스
kubeconfig파일이 포함된 디렉터리에서 쉘 프롬프트를 엽니다.테스트 이미지에 현재 디렉터리에
kubeconfig파일 및 볼륨을 통해 마운트된 관련$KUBECONFIG환경 변수를 제공합니다. 이를 통해 실행 중인 컨테이너에서 컨테이너 내부에서kubeconfig파일을 사용할 수 있습니다.다음 명령을 입력하여 대기 시간 테스트를 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
-
선택 사항: 시험 실행 모드에서 대기 시간 테스트를 실행하려면
-ginkgo.dryRun을 추가합니다. 이 명령은 테스트 실행을 확인하는 데 유용합니다. -
선택 사항: 향상된 상세 정보 표시로 테스트를 실행하려면
-ginkgo.v를 추가합니다. 선택 사항: 특정 성능 프로필에 대해 대기 시간 테스트를 실행하려면 다음 명령을 실행하여 적절한 값을 대체합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e LATENCY_TEST_RUNTIME=600 -e OSLAT_MAXIMUM_LATENCY=20 \ -e PERF_TEST_PROFILE=<performance_profile> registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/test-run.sh -ginkgo.focus="[performance]\ Latency\ Test"
다음과 같습니다.
- <performance_profile>
- 는 대기 시간 테스트를 실행할 성능 프로필의 이름입니다.
중요유효한 대기 시간 테스트 결과의 경우 최소 12시간 동안 테스트를 실행합니다.
18.4.1. oslat 실행
oslat 테스트는 CPU 집약적 DPDK 애플리케이션을 시뮬레이션하고 모든 중단 및 중단을 측정하여 클러스터가 CPU의 과도한 데이터 처리를 처리하는 방법을 테스트합니다.
항상 DISCOVERY_MODE=true 세트를 사용하여 대기 시간 테스트를 실행합니다. 그렇지 않은 경우 테스트 모음에서 실행 중인 클러스터 구성을 변경합니다.
podman 명령을 루트가 아닌 사용자 또는 권한이 없는 사용자로 실행하는 경우 권한 거부 오류로 인해 마운트 경로가 실패할 수 있습니다. podman 명령이 작동하도록 하려면 :Z 를 볼륨 생성에 추가합니다(예: -v $(pwd)/:/kubeconfig:Z ). 이렇게 하면 podman 에서 적절한 SELinux 레이블을 다시 지정할 수 있습니다.
사전 요구 사항
-
고객 포털 인증 정보를 사용하여
registry.redhat.io에 로그인했습니다. - Performance Addon Operator를 사용하여 클러스터 성능 프로필을 적용했습니다.
프로세스
oslat테스트를 수행하려면 다음 명령을 실행하여 변수 값을 적절하게 대체합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e LATENCY_TEST_RUN=true -e DISCOVERY_MODE=true -e ROLE_WORKER_CNF=worker-cnf \ -e LATENCY_TEST_CPUS=7 -e LATENCY_TEST_RUNTIME=600 -e OSLAT_MAXIMUM_LATENCY=20 \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/test-run.sh -ginkgo.v -ginkgo.focus="oslat"
LATENCY_TEST_CPUS는oslat명령으로 테스트할 CPU 목록을 표시합니다.이 명령은 OS
lat툴을 10분(600초) 동안 실행합니다. 최대 관찰 대기 시간이OSLAT_MAXIMUM_LATENCY(20 ECDHEs)보다 작으면 테스트가 성공적으로 실행됩니다.결과가 대기 시간 임계값을 초과하면 테스트가 실패합니다.
중요유효한 결과의 경우 테스트는 최소 12시간 동안 실행되어야 합니다.
실패 출력 예
running /usr/bin//validationsuite -ginkgo.v -ginkgo.focus=oslat I0829 12:36:55.386776 8 request.go:668] Waited for 1.000303471s due to client-side throttling, not priority and fairness, request: GET:https://api.cnfdc8.t5g.lab.eng.bos.redhat.com:6443/apis/authentication.k8s.io/v1?timeout=32s Running Suite: CNF Features e2e validation ========================================== Discovery mode enabled, skipping setup running /usr/bin//cnftests -ginkgo.v -ginkgo.focus=oslat I0829 12:37:01.219077 20 request.go:668] Waited for 1.050010755s due to client-side throttling, not priority and fairness, request: GET:https://api.cnfdc8.t5g.lab.eng.bos.redhat.com:6443/apis/snapshot.storage.k8s.io/v1beta1?timeout=32s Running Suite: CNF Features e2e integration tests ================================================= Random Seed: 1630240617 Will run 1 of 142 specs SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS ------------------------------ [performance] Latency Test with the oslat image should succeed /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:134 STEP: Waiting two minutes to download the latencyTest image STEP: Waiting another two minutes to give enough time for the cluster to move the pod to Succeeded phase Aug 29 12:37:59.324: [INFO]: found mcd machine-config-daemon-wf4w8 for node cnfdc8.clus2.t5g.lab.eng.bos.redhat.com • Failure [49.246 seconds] [performance] Latency Test /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:59 with the oslat image /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:112 should succeed [It] /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:134 The current latency 27 is bigger than the expected one 20 1 Expected <bool>: false to be true /go/src/github.com/openshift-kni/cnf-features-deploy/vendor/github.com/openshift-kni/performance-addon-operators/functests/4_latency/latency.go:168 Log file created at: 2021/08/29 13:25:21 Running on machine: oslat-57c2g Binary: Built with gc go1.16.6 for linux/amd64 Log line format: [IWEF]mmdd hh:mm:ss.uuuuuu threadid file:line] msg I0829 13:25:21.569182 1 node.go:37] Environment information: /proc/cmdline: BOOT_IMAGE=(hd0,gpt3)/ostree/rhcos-612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/vmlinuz-4.18.0-305.10.2.rt7.83.el8_4.x86_64 ip=dhcp random.trust_cpu=on console=tty0 console=ttyS0,115200n8 ostree=/ostree/boot.0/rhcos/612d89f4519a53ad0b1a132f4add78372661bfb3994f5fe115654971aa58a543/0 ignition.platform.id=openstack root=UUID=5a4ddf16-9372-44d9-ac4e-3ee329e16ab3 rw rootflags=prjquota skew_tick=1 nohz=on rcu_nocbs=1-3 tuned.non_isolcpus=000000ff,ffffffff,ffffffff,fffffff1 intel_pstate=disable nosoftlockup tsc=nowatchdog intel_iommu=on iommu=pt isolcpus=managed_irq,1-3 systemd.cpu_affinity=0,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103 default_hugepagesz=1G hugepagesz=2M hugepages=128 nmi_watchdog=0 audit=0 mce=off processor.max_cstate=1 idle=poll intel_idle.max_cstate=0 I0829 13:25:21.569345 1 node.go:44] Environment information: kernel version 4.18.0-305.10.2.rt7.83.el8_4.x86_64 I0829 13:25:21.569367 1 main.go:53] Running the oslat command with arguments \ [--duration 600 --rtprio 1 --cpu-list 4,6,52,54,56,58 --cpu-main-thread 2] I0829 13:35:22.632263 1 main.go:59] Succeeded to run the oslat command: oslat V 2.00 Total runtime: 600 seconds Thread priority: SCHED_FIFO:1 CPU list: 4,6,52,54,56,58 CPU for main thread: 2 Workload: no Workload mem: 0 (KiB) Preheat cores: 6 Pre-heat for 1 seconds... Test starts... Test completed. Core: 4 6 52 54 56 58 CPU Freq: 2096 2096 2096 2096 2096 2096 (Mhz) 001 (us): 19390720316 19141129810 20265099129 20280959461 19391991159 19119877333 002 (us): 5304 5249 5777 5947 6829 4971 003 (us): 28 14 434 47 208 21 004 (us): 1388 853 123568 152817 5576 0 005 (us): 207850 223544 103827 91812 227236 231563 006 (us): 60770 122038 277581 323120 122633 122357 007 (us): 280023 223992 63016 25896 214194 218395 008 (us): 40604 25152 24368 4264 24440 25115 009 (us): 6858 3065 5815 810 3286 2116 010 (us): 1947 936 1452 151 474 361 ... Minimum: 1 1 1 1 1 1 (us) Average: 1.000 1.000 1.000 1.000 1.000 1.000 (us) Maximum: 37 38 49 28 28 19 (us) Max-Min: 36 37 48 27 27 18 (us) Duration: 599.667 599.667 599.667 599.667 599.667 599.667 (sec)- 1
- 이 예에서 측정된 대기 시간은 최대 허용된 값 외부에 있습니다.
18.5. 대기 시간 테스트 실패 보고서 생성
다음 절차에 따라 JUnit 대기 시간 테스트 출력 및 테스트 실패 보고서를 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
--report매개변수를 보고서가 덤프되는 경로와 함께 전달하여 문제 해결을 위한 클러스터 상태 및 리소스에 대한 정보가 포함된 테스트 실패 보고서를 생성합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/reportdest:<report_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/test-run.sh --report <report_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
다음과 같습니다.
- <report_folder_path>
- 보고서가 생성된 폴더의 경로입니다.
18.6. JUnit 대기 시간 테스트 보고서 생성
다음 절차에 따라 JUnit 대기 시간 테스트 출력 및 테스트 실패 보고서를 생성합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
보고서가 덤프되는 경로와 함께
--junit매개변수를 전달하여 JUnit 호환 XML 보고서를 생성합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -v $(pwd)/junitdest:<junit_folder_path> \ -e KUBECONFIG=/kubeconfig/kubeconfig -e DISCOVERY_MODE=true \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/test-run.sh --junit <junit_folder_path> \ -ginkgo.focus="\[performance\]\ Latency\ Test"
다음과 같습니다.
- <junit_folder_path>
- junit 보고서가 생성되는 폴더의 경로입니다.
18.7. 연결이 끊긴 클러스터에서 대기 시간 테스트 실행
CNF 테스트 이미지는 연결이 끊긴 클러스터에서 외부 레지스트리에 연결할 수 없는 테스트를 실행할 수 있습니다. 여기에는 두 단계가 필요합니다.
-
cnf-tests이미지를 사용자 연결 해제된 레지스트리에 미러링합니다. - 사용자 연결 해제된 레지스트리의 이미지를 사용하도록 테스트에 지시합니다.
클러스터에서 액세스할 수 있는 사용자 정의 레지스트리로 이미지 미러링
이미지에 미러 실행 파일이 제공되어 oc 에서 테스트 이미지를 로컬 레지스트리에 미러링하는 데 필요한 입력을 제공합니다.
클러스터에 액세스할 수 있는 임시 머신에서 다음 명령을 실행합니다. registry.redhat.io:
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ /usr/bin/mirror -registry <disconnected_registry> | oc image mirror -f -
다음과 같습니다.
- <disconnected_registry>
-
구성한 연결이 끊긴 미러 레지스트리(예:
my.local.registry:5000/)입니다.
cnf-tests이미지를 연결이 끊긴 레지스트리에 미러링한 경우 테스트를 실행할 때 이미지를 가져오는 데 사용되는 원래 레지스트리를 재정의해야 합니다. 예를 들면 다음과 같습니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e IMAGE_REGISTRY="<disconnected_registry>" \ -e CNF_TESTS_IMAGE="cnf-tests-rhel8:v4.8" \ /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
사용자 정의 레지스트리의 이미지를 사용하도록 테스트 구성
CNF_TESTS_IMAGE 및 IMAGE_REGISTRY 변수를 사용하여 사용자 정의 테스트 이미지 및 이미지 레지스트리를 사용하여 대기 시간 테스트를 실행할 수 있습니다.
사용자 정의 테스트 이미지 및 이미지 레지스트리를 사용하도록 대기 시간 테스트를 구성하려면 다음 명령을 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e IMAGE_REGISTRY="<custom_image_registry>" \ -e CNF_TESTS_IMAGE="<custom_cnf-tests_image>" \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 /usr/bin/test-run.sh
다음과 같습니다.
- <custom_image_registry>
-
사용자 정의 이미지 레지스트리(예:
custom.registry:5000/)입니다. - <custom_cnf-tests_image>
-
사용자 지정 cnf-tests 이미지입니다(예:
custom-cnf-tests-image:latest).
클러스터 내부 레지스트리로 이미지 미러링
OpenShift Container Platform은 클러스터에서 표준 워크로드로 실행되는 내장 컨테이너 이미지 레지스트리를 제공합니다.
프로세스
경로를 통해 레지스트리를 공개하여 레지스트리에 대한 외부 액세스 권한을 얻습니다.
$ oc patch configs.imageregistry.operator.openshift.io/cluster --patch '{"spec":{"defaultRoute":true}}' --type=merge다음 명령을 실행하여 레지스트리 끝점을 가져옵니다.
$ REGISTRY=$(oc get route default-route -n openshift-image-registry --template='{{ .spec.host }}')이미지를 공개하는 데 사용할 네임스페이스를 생성합니다.
$ oc create ns cnftests
테스트에 사용되는 모든 네임스페이스에서 이미지 스트림을 사용할 수 있도록 설정합니다. 테스트 네임스페이스가
cnf-tests이미지 스트림에서 이미지를 가져올 수 있도록 하는 데 필요합니다. 다음 명령을 실행합니다.$ oc policy add-role-to-user system:image-puller system:serviceaccount:cnf-features-testing:default --namespace=cnftests
$ oc policy add-role-to-user system:image-puller system:serviceaccount:performance-addon-operators-testing:default --namespace=cnftests
다음 명령을 실행하여 Docker 보안 이름 및 인증 토큰을 검색합니다.
$ SECRET=$(oc -n cnftests get secret | grep builder-docker | awk {'print $1'}$ TOKEN=$(oc -n cnftests get secret $SECRET -o jsonpath="{.data['\.dockercfg']}" | base64 --decode | jq '.["image-registry.openshift-image-registry.svc:5000"].auth')dockerauth.json파일을 생성합니다. 예를 들면 다음과 같습니다.$ echo "{\"auths\": { \"$REGISTRY\": { \"auth\": $TOKEN } }}" > dockerauth.json이미지 미러링을 수행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:4.8 \ /usr/bin/mirror -registry $REGISTRY/cnftests | oc image mirror --insecure=true \ -a=$(pwd)/dockerauth.json -f -
테스트를 실행합니다.
$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ -e DISCOVERY_MODE=true -e IMAGE_REGISTRY=image-registry.openshift-image-registry.svc:5000/cnftests \ cnf-tests-local:latest /usr/bin/test-run.sh -ginkgo.focus="\[performance\]\ Latency\ Test"
다른 테스트 이미지 세트 미러링
선택적으로 대기 시간 테스트를 위해 미러링된 기본 업스트림 이미지를 변경할 수 있습니다.
프로세스
mirror명령은 기본적으로 업스트림 이미지를 미러링합니다. 다음 형식의 파일을 이미지에 전달하여 재정의할 수 있습니다.[ { "registry": "public.registry.io:5000", "image": "imageforcnftests:4.8" } ]파일을
mirror명령에 전달합니다. 예를 들어images.json으로 로컬로 저장합니다. 다음 명령을 사용하면 로컬 경로가 컨테이너 내/kubeconfig에 마운트되어 mirror 명령에 전달될 수 있습니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 /usr/bin/mirror \ --registry "my.local.registry:5000/" --images "/kubeconfig/images.json" \ | oc image mirror -f -
18.8. cnf-tests 컨테이너로 오류 문제 해결
대기 시간 테스트를 실행하려면 cnf-tests 컨테이너 내에서 클러스터에 액세스할 수 있어야 합니다.
사전 요구 사항
-
OpenShift CLI(
oc)가 설치되어 있습니다. -
cluster-admin권한이 있는 사용자로 로그인했습니다.
프로세스
다음 명령을 실행하여
cnf-tests컨테이너 내부에서 클러스터에 액세스할 수 있는지 확인합니다.$ podman run -v $(pwd)/:/kubeconfig:Z -e KUBECONFIG=/kubeconfig/kubeconfig \ registry.redhat.io/openshift4/cnf-tests-rhel8:v4.8 \ oc get nodes
이 명령이 작동하지 않으면 DNS, MTU 크기 또는 방화벽 액세스와 관련된 오류가 발생할 수 있습니다.
19장. 성능 프로파일 작성
Performance Profile Creator(PPC)와 이를 사용하여 성능 프로필을 만드는 방법을 설명합니다.
19.1. 성능 프로파일 작성툴 정보
PPC(Performance Profile creator)는 성능 프로필을 생성하는 데 사용되는 Performance Addon Operator와 함께 제공되는 명령행 툴입니다. 이 툴은 클러스터의 must-gather 데이터와 여러 사용자가 제공하는 프로필 인수를 사용합니다. PPC는 하드웨어 및 토폴로지에 적합한 성능 프로필을 생성합니다.
툴은 다음 방법 중 하나로 실행됩니다.
-
podman호출 - 래퍼 스크립트 호출
19.1.1. must-gather 명령을 사용하여 클러스터에 대한 데이터 수집
PPC(Performance Profile creator) 툴에는 must-gather 데이터가 필요합니다. 클러스터 관리자는 must-gather 명령을 실행하여 클러스터에 대한 정보를 캡처합니다.
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. - Performance Addon Operator 이미지에 액세스합니다.
-
OpenShift CLI(
oc)가 설치되어 있습니다.
프로세스
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. 클러스터에서
must-gather를 실행합니다.$ oc adm must-gather --image=<PAO_image> --dest-dir=<dir>
참고must-gather명령은performance-addon-operator-must-gather이미지를 사용하여 실행해야 합니다. 출력을 선택적으로 압축할 수 있습니다. Performance Profile Creator 래퍼 스크립트를 실행하는 경우 압축 출력이 필요합니다.예
$ oc adm must-gather --image=registry.redhat.io/openshift4/performance-addon-operator-must-gather-rhel8:v4.8 --dest-dir=must-gather
must-gather디렉터리에서 압축 파일을 만듭니다.$ tar cvaf must-gather.tar.gz must-gather/
19.1.2. podman을 사용하여 Performance Profile Creator 실행
클러스터 관리자는 podman 및 Performance Profile Creator를 실행하여 성능 프로필을 만들 수 있습니다.
사전 요구 사항
-
cluster-admin역할을 가진 사용자로 클러스터에 액세스합니다. - 클러스터가 베어 메탈 하드웨어에 설치되어 있어야 합니다.
-
podman및 OpenShift CLI(oc)가 설치된 노드가 있습니다.
프로세스
머신 구성 풀을 확인합니다.
$ oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
Podman을 사용하여
registry.redhat.io를 인증합니다.$ podman login registry.redhat.io
Username: myrhusername Password: ************
선택 사항: PPC 도구에 대한 도움말을 표시합니다.
$ podman run --entrypoint performance-profile-creator registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.8 -h
출력 예
A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled검색 모드에서 Performance Profile Creator 툴을 실행합니다.
참고검색 모드는
must-gather의 출력을 사용하여 클러스터를 검사합니다. 생성된 출력에는 다음에 대한 정보가 포함됩니다.- 할당된 CPU ID로 NUMA 셀 파티셔닝
- 하이퍼스레딩 활성화 여부
이 정보를 사용하여 Performance Profile Creator 툴에 제공된 일부 인수에 대해 적절한 값을 설정할 수 있습니다.
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.8 --info log --must-gather-dir-path /must-gather
참고이 명령은 Performance Profile Creator 툴을
podman의 새 진입점으로 사용합니다. 호스트의must-gather데이터를 컨테이너 이미지에 매핑하고 필요한 사용자 제공 프로필 인수를 호출하여my-performance-profile.yaml파일을 생성합니다.-v옵션은 다음 중 하나로 설정할 수 있습니다.-
must-gather출력 디렉터리 -
must-gather압축 해제된 tarball이 포함된 기존 디렉터리
info옵션에는 출력 형식을 지정하는 값이 필요합니다. 가능한 값은 log 및 JSON입니다. JSON 형식은 디버깅을 위해 예약되어 있습니다.podman을 실행합니다.$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.8 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=false --topology-manager-policy=single-numa-node --must-gather-dir-path /must-gather --power-consumption-mode=ultra-low-latency > my-performance-profile.yaml
참고Performance Profile Creator 인수는 Performance Profile Creator 인수 테이블에 표시됩니다. 다음 인수가 필요합니다.
-
reserved-cpu-count -
mcp-name -
rt-kernel
이 예제의
mcp-name인수는oc get mcp명령의 출력에 따라worker-cnf로 설정됩니다. SNO(Single Node OpenShift)는--mcp-name=master를 사용합니다.-
생성된 YAML 파일을 검토합니다.
$ cat my-performance-profile.yaml
출력 예
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: additionalKernelArgs: - nmi_watchdog=0 - audit=0 - mce=off - processor.max_cstate=1 - intel_idle.max_cstate=0 - idle=poll cpu: isolated: 1,3,5,7,9,11,13,15,17,19-39,41,43,45,47,49,51,53,55,57,59-79 reserved: 0,2,4,6,8,10,12,14,16,18,40,42,44,46,48,50,52,54,56,58 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: single-numa-node realTimeKernel: enabled: true생성된 프로필을 적용합니다.
참고프로필을 적용하기 전에 Performance Addon Operator를 설치합니다.
$ oc apply -f my-performance-profile.yaml
19.1.2.1. podman을 실행하여 성능 프로파일을 만드는 방법
다음 예제에서는 podman을 실행하여 NUMA 노드 간에 분할될 예약된 20개의 CPU가 있는 성능 프로필을 생성하는 방법을 보여줍니다.
노드 하드웨어 구성:
- 80 CPU
- 하이퍼 스레딩 활성화
- 두 개의 NUMA 노드
- 짝수 번호의 CPU는 NUMA 노드 0에서 실행되고 홀수 번호의 CPU는 NUMA 노드 1에서 실행
podman을 실행하여 성능 프로필을 생성합니다.
$ podman run --entrypoint performance-profile-creator -v /must-gather:/must-gather:z registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.8 --mcp-name=worker-cnf --reserved-cpu-count=20 --rt-kernel=true --split-reserved-cpus-across-numa=true --must-gather-dir-path /must-gather > my-performance-profile.yaml
생성된 프로필은 다음 YAML에 설명되어 있습니다.
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: performance
spec:
cpu:
isolated: 10-39,50-79
reserved: 0-9,40-49
nodeSelector:
node-role.kubernetes.io/worker-cnf: ""
numa:
topologyPolicy: restricted
realTimeKernel:
enabled: true이 경우 NUMA 노드 0에 CPU 10개가 예약되고 NUMA 노드 1에 CPU 10개가 예약됩니다.
19.1.3. Performance Profile Creator 래퍼 스크립트 실행
성능 프로필 래퍼 스크립트는 PPC(Performance Profile Creator) 툴의 실행을 간소화합니다. podman 실행과 관련된 복잡성을 숨기고 매핑 디렉터리를 지정하면 성능 프로필을 만들 수 있습니다.
사전 요구 사항
- Performance Addon Operator 이미지에 액세스합니다.
-
must-gathertarball에 액세스합니다.
프로세스
예를 들어 다음과 같이
run-perf-profile-creator.sh라는 이름의 파일을 로컬 시스템에 생성합니다$ vi run-perf-profile-creator.sh
다음 코드를 파일에 붙여넣습니다.
#!/bin/bash readonly CONTAINER_RUNTIME=${CONTAINER_RUNTIME:-podman} readonly CURRENT_SCRIPT=$(basename "$0") readonly CMD="${CONTAINER_RUNTIME} run --entrypoint performance-profile-creator" readonly IMG_EXISTS_CMD="${CONTAINER_RUNTIME} image exists" readonly IMG_PULL_CMD="${CONTAINER_RUNTIME} image pull" readonly MUST_GATHER_VOL="/must-gather" PAO_IMG="registry.redhat.io/openshift4/performance-addon-rhel8-operator:v4.8" MG_TARBALL="" DATA_DIR="" usage() { print "Wrapper usage:" print " ${CURRENT_SCRIPT} [-h] [-p image][-t path] -- [performance-profile-creator flags]" print "" print "Options:" print " -h help for ${CURRENT_SCRIPT}" print " -p Performance Addon Operator image" print " -t path to a must-gather tarball" ${IMG_EXISTS_CMD} "${PAO_IMG}" && ${CMD} "${PAO_IMG}" -h } function cleanup { [ -d "${DATA_DIR}" ] && rm -rf "${DATA_DIR}" } trap cleanup EXIT exit_error() { print "error: $*" usage exit 1 } print() { echo "$*" >&2 } check_requirements() { ${IMG_EXISTS_CMD} "${PAO_IMG}" || ${IMG_PULL_CMD} "${PAO_IMG}" || \ exit_error "Performance Addon Operator image not found" [ -n "${MG_TARBALL}" ] || exit_error "Must-gather tarball file path is mandatory" [ -f "${MG_TARBALL}" ] || exit_error "Must-gather tarball file not found" DATA_DIR=$(mktemp -d -t "${CURRENT_SCRIPT}XXXX") || exit_error "Cannot create the data directory" tar -zxf "${MG_TARBALL}" --directory "${DATA_DIR}" || exit_error "Cannot decompress the must-gather tarball" chmod a+rx "${DATA_DIR}" return 0 } main() { while getopts ':hp:t:' OPT; do case "${OPT}" in h) usage exit 0 ;; p) PAO_IMG="${OPTARG}" ;; t) MG_TARBALL="${OPTARG}" ;; ?) exit_error "invalid argument: ${OPTARG}" ;; esac done shift $((OPTIND - 1)) check_requirements || exit 1 ${CMD} -v "${DATA_DIR}:${MUST_GATHER_VOL}:z" "${PAO_IMG}" "$@" --must-gather-dir-path "${MUST_GATHER_VOL}" echo "" 1>&2 } main "$@"이 스크립트에 모든 사용자에 대한 실행 권한을 추가합니다.
$ chmod a+x run-perf-profile-creator.sh
선택 사항:
run-perf-profile-creator.sh명령 사용을 표시합니다.$ ./run-perf-profile-creator.sh -h
예상 출력
Wrapper usage: run-perf-profile-creator.sh [-h] [-p image][-t path] -- [performance-profile-creator flags] Options: -h help for run-perf-profile-creator.sh -p Performance Addon Operator image 1 -t path to a must-gather tarball 2 A tool that automates creation of Performance Profiles Usage: performance-profile-creator [flags] Flags: --disable-ht Disable Hyperthreading -h, --help help for performance-profile-creator --info string Show cluster information; requires --must-gather-dir-path, ignore the other arguments. [Valid values: log, json] (default "log") --mcp-name string MCP name corresponding to the target machines (required) --must-gather-dir-path string Must gather directory path (default "must-gather") --power-consumption-mode string The power consumption mode. [Valid values: default, low-latency, ultra-low-latency] (default "default") --profile-name string Name of the performance profile to be created (default "performance") --reserved-cpu-count int Number of reserved CPUs (required) --rt-kernel Enable Real Time Kernel (required) --split-reserved-cpus-across-numa Split the Reserved CPUs across NUMA nodes --topology-manager-policy string Kubelet Topology Manager Policy of the performance profile to be created. [Valid values: single-numa-node, best-effort, restricted] (default "restricted") --user-level-networking Run with User level Networking(DPDK) enabled
참고두 가지 유형의 인수가 있습니다.
-
래퍼 인수 즉
-h,-p및-t - PPC 인수
-
래퍼 인수 즉
검색 모드에서 performance profile creator 툴을 실행합니다.
참고검색 모드는
must-gather의 출력을 사용하여 클러스터를 검사합니다. 생성된 출력에는 다음에 대한 정보가 포함됩니다.- 할당된 CPU ID로 NUMA 셀 파티션을 분할
- 하이퍼스레딩 활성화 여부
이 정보를 사용하여 Performance Profile Creator 툴에 제공된 일부 인수에 대해 적절한 값을 설정할 수 있습니다.
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --info=log
참고info옵션에는 출력 형식을 지정하는 값이 필요합니다. 가능한 값은 log 및 JSON입니다. JSON 형식은 디버깅을 위해 예약되어 있습니다.머신 구성 풀을 확인합니다.
$ oc get mcp
출력 예
NAME CONFIG UPDATED UPDATING DEGRADED MACHINECOUNT READYMACHINECOUNT UPDATEDMACHINECOUNT DEGRADEDMACHINECOUNT AGE master rendered-master-acd1358917e9f98cbdb599aea622d78b True False False 3 3 3 0 22h worker-cnf rendered-worker-cnf-1d871ac76e1951d32b2fe92369879826 False True False 2 1 1 0 22h
성능 프로파일을 생성합니다.
$ ./run-perf-profile-creator.sh -t /must-gather/must-gather.tar.gz -- --mcp-name=worker-cnf --reserved-cpu-count=2 --rt-kernel=true > my-performance-profile.yaml
참고Performance Profile Creator 인수는 Performance Profile Creator 인수 테이블에 표시됩니다. 다음 인수가 필요합니다.
-
reserved-cpu-count -
mcp-name -
rt-kernel
이 예제의
mcp-name인수는oc get mcp명령의 출력에 따라worker-cnf로 설정됩니다. SNO(Single Node OpenShift)는--mcp-name=master를 사용합니다.-
생성된 YAML 파일을 검토합니다.
$ cat my-performance-profile.yaml
출력 예
apiVersion: performance.openshift.io/v2 kind: PerformanceProfile metadata: name: performance spec: cpu: isolated: 1-39,41-79 reserved: 0,40 nodeSelector: node-role.kubernetes.io/worker-cnf: "" numa: topologyPolicy: restricted realTimeKernel: enabled: false생성된 프로필을 적용합니다.
참고프로필을 적용하기 전에 Performance Addon Operator를 설치합니다.
$ oc apply -f my-performance-profile.yaml
19.1.4. Performance Profile Creator 인수
표 19.1. Performance Profile Creator 인수
| 인수 | 설명 |
|---|---|
|
| 하이퍼스레딩을 비활성화합니다.
가능한 값:
기본값: 주의
이 인수가 |
|
|
이는 클러스터 정보를 캡처하며 검색 모드에서만 사용됩니다. 검색 모드에서는 가능한 값은 다음과 같습니다.
기본값: |
|
|
대상 머신에 해당하는 MCP 이름 (예: |
|
| 디렉터리 경로를 수집해야 합니다. 이 매개 변수는 필수입니다.
사용자가 래퍼 스크립트 |
|
| 전력 소비 모드입니다. 가능한 값은 다음과 같습니다.
기본값: |
|
|
생성할 성능 프로파일의 이름입니다. 기본값: |
|
| 예약된 CPU 수입니다. 이 매개 변수는 필수입니다. 참고 이것은 자연수여야 합니다. 0 값은 허용되지 않습니다. |
|
| 실시간 커널을 활성화합니다. 이 매개 변수는 필수입니다.
가능한 값: |
|
| NUMA 노드에서 예약된 CPU를 분할합니다.
가능한 값:
기본값: |
|
| 생성할 성능 프로필의 Kubelet Topology Manager 정책입니다. 가능한 값은 다음과 같습니다.
기본값: |
|
| DPDK(사용자 수준 네트워킹)가 활성화된 상태에서 실행합니다.
가능한 값:
기본값: |
19.2. 추가 리소스
-
must-gather툴에 대한 자세한 내용은 클러스터에 대한 데이터 수집을 참조하십시오.