
백업 및 복원
OpenShift Container Platform 클러스터 백업 및 복원
초록
1장. 백업 및 복원
1.1. 컨트롤 플레인 백업 및 복원 작업
클러스터 관리자는 기간 동안 OpenShift Container Platform 클러스터를 중지하고 나중에 다시 시작해야 할 수 있습니다. 클러스터를 다시 시작하는 몇 가지 이유는 클러스터에서 유지보수를 수행하거나 리소스 비용을 절감해야 한다는 것입니다. OpenShift Container Platform에서는 나중에 클러스터를 쉽게 다시 시작할 수 있도록 클러스터의 정상 종료 를 수행할 수 있습니다.
클러스터를 종료하기 전에 etcd 데이터를 백업 해야 합니다. etcd는 모든 리소스 오브젝트의 상태를 유지하는 OpenShift Container Platform의 키-값 저장소입니다. etcd 백업은 재해 복구에 중요한 역할을 합니다. OpenShift Container Platform에서는 비정상적인 etcd 멤버도 교체할 수 있습니다.
클러스터를 다시 실행하려면 클러스터를 정상적으로 다시 시작합니다.
클러스터 인증서는 설치 날짜 이후 1년 후에 만료됩니다. 인증서가 여전히 유효한 상태에서 클러스터를 종료하고 정상적으로 다시 시작할 수 있습니다. 클러스터는 만료된 컨트롤 플레인 인증서를 자동으로 검색하지만 CSR(인증서 서명 요청)을 계속 승인해야 합니다.
OpenShift Container Platform이 예상대로 작동하지 않는 여러 상황이 발생할 수 있습니다.
- 노드 장애 또는 네트워크 연결 문제와 같은 예기치 않은 조건으로 인해 재시작 후 작동하지 않는 클러스터가 있습니다.
- 실수로 클러스터에서 중요한 것을 삭제했습니다.
- 대부분의 컨트롤 플레인 호스트가 손실되어 etcd 쿼럼이 손실됩니다.
저장된 etcd 스냅샷을 사용하여 클러스터를 이전 상태로 복원하면 항상 재해 상황을 복구할 수 있습니다.
추가 리소스
1.2. 애플리케이션 백업 및 복원 작업
클러스터 관리자는 OADP(OpenShift API for Data Protection)를 사용하여 OpenShift Container Platform에서 실행되는 애플리케이션을 백업하고 복원할 수 있습니다.
OADP는 Velero CLI 툴 다운로드 의 표에 따라 설치하는 OADP 버전에 적합한 Velero 버전을 사용하여 네임스페이스 단위로 Kubernetes 리소스 및 내부 이미지를 백업 및 복원합니다. OADP는 스냅샷 또는 Restic을 사용하여 PV(영구 볼륨)를 백업하고 복원합니다. 자세한 내용은 OADP 기능을 참조하십시오.
1.2.1. OADP 요구사항
OADP에는 다음과 같은 요구 사항이 있습니다.
-
cluster-admin역할의 사용자로 로그인해야 합니다. 다음 스토리지 유형 중 하나와 같이 백업을 저장하기 위한 오브젝트 스토리지가 있어야 합니다.
- OpenShift Data Foundation
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- S3 호환 오브젝트 스토리지
OCP 4.11 이상에서 CSI 백업을 사용하려면 OADP 1.1.x 를 설치하십시오.
OADP 1.0.x 는 OCP 4.11 이상에서 CSI 백업을 지원하지 않습니다. OADP 1.0.x 에는 Velero 1.7이 포함되어 있으며 OCP 4.11 이상에는 존재하지 않는 API 그룹 snapshot.storage.k8s.io/v1beta1 이 예상됩니다.
S3 스토리지의 CloudStorage API는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
스냅샷으로 PV를 백업하려면 기본 스냅샷 API가 있거나 다음 공급자와 같은 CSI(Container Storage Interface) 스냅샷을 지원하는 클라우드 스토리지가 있어야 합니다.
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- Ceph RBD 또는 Ceph FS와 같은 CSI 스냅샷 지원 클라우드 스토리지
스냅샷을 사용하여 PV를 백업하지 않으려면 기본적으로 OADP Operator에 의해 설치된 Restic 을 사용할 수 있습니다.
1.2.2. 애플리케이션 백업 및 복원
Backup CR(사용자 정의 리소스)을 생성하여 애플리케이션을 백업합니다. Backup CR 생성을 참조하십시오. 다음 백업 옵션을 구성할 수 있습니다.
- 백업 작업 전후에 명령을 실행할 백업 후크 생성
- 백업 예약
- Restic 백업
-
복원(CR)을 생성하여 애플리케이션 백업을
복원합니다. Restore CR 생성을 참조하십시오. - 복원 작업 중에 init 컨테이너 또는 애플리케이션 컨테이너에서 명령을 실행하도록 복원 후크 를 구성할 수 있습니다.
2장. 클러스터를 안전하게 종료
이 문서에서는 클러스터를 안전하게 종료하는 프로세스를 설명합니다. 유지 관리를 위해 또는 리소스 비용을 절약하기 위해 일시적으로 클러스터를 종료해야 할 수 있습니다.
2.1. 전제 조건
클러스터를 종료하기 전에 etcd 백업을 수행하십시오.
중요클러스터를 다시 시작할 때 문제가 발생할 경우 클러스터를 복원 할 수 있도록 이 단계를 수행하기 전에 etcd 백업을 해 두는 것이 중요합니다.
예를 들어 다음 조건으로 인해 재시작된 클러스터가 손상될 수 있습니다.
- 종료 중 etcd 데이터 손상
- 하드웨어로 인한 노드 오류
- 네트워크 연결 문제
클러스터를 복구하지 못하는 경우 다음 단계에 따라 이전 클러스터 상태로 복원 하십시오.
2.2. 클러스터 종료
나중에 클러스터를 다시 시작하기 위해 안전한 방법으로 클러스터를 종료할 수 있습니다.
설치 날짜부터 1년까지 클러스터를 종료하고 정상적으로 다시 시작할 수 있습니다. 설치 날짜로부터 1년 후에는 클러스터 인증서가 만료됩니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. - etcd 백업이 수행되었습니다.
절차
장기간 클러스터를 종료하려는 경우 클러스터 인증서가 만료되는 날짜를 확인합니다.
인증서가 만료되기 전에 클러스터를 다시 시작해야 합니다. 클러스터가 재시작되면 프로세스에서 kubelet 인증서를 복구하기 위해 보류 중인 인증서 서명 요청(CSR)을 수동으로 승인해야 할 수 있습니다.
kube-apiserver-to-kubelet-signerCA 인증서의 만료 날짜를 확인합니다.$ oc -n openshift-kube-apiserver-operator get secret kube-apiserver-to-kubelet-signer -o jsonpath='{.metadata.annotations.auth\.openshift\.io/certificate-not-after}{"\n"}'출력 예
2023-08-05T14:37:50Z
kubelet 인증서의 만료 날짜를 확인합니다.
다음 명령을 실행하여 컨트롤 플레인 노드의 디버그 세션을 시작합니다.
$ oc debug node/<node_name>
다음 명령을 실행하여 root 디렉토리를
/host로 변경합니다.sh-4.4# chroot /host
다음 명령을 실행하여 kubelet 클라이언트 인증서 만료 날짜를 확인합니다.
sh-5.1# openssl x509 -in /var/lib/kubelet/pki/kubelet-client-current.pem -noout -enddate
출력 예
notAfter=Jun 6 10:50:07 2023 GMT
다음 명령을 실행하여 kubelet 서버 인증서 만료 날짜를 확인합니다.
sh-5.1# openssl x509 -in /var/lib/kubelet/pki/kubelet-server-current.pem -noout -enddate
출력 예
notAfter=Jun 6 10:50:07 2023 GMT
- 디버그 세션을 종료합니다.
- 이 단계를 반복하여 모든 컨트롤 플레인 노드에서 인증서 만료 날짜를 확인합니다. 클러스터를 정상적으로 다시 시작할 수 있도록 인증서 만료일보다 먼저 다시 시작합니다.
클러스터의 모든 노드를 종료합니다. 클라우드 공급자의 웹 콘솔에서 이 작업을 수행하거나 다음 루프를 실행할 수 있습니다.
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 1; done 1- 1
-H 1은 컨트롤 플레인 노드가 종료되기 전에 이 프로세스가 몇 분 내에 지속되는지를 나타냅니다. 10개 이상의 노드가 있는 대규모 클러스터의 경우 모든 컴퓨팅 노드를 먼저 종료할 시간이 있도록 10분 이상 설정합니다.
출력 예
Starting pod/ip-10-0-130-169us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:17 UTC, use 'shutdown -c' to cancel. Removing debug pod ... Starting pod/ip-10-0-150-116us-east-2computeinternal-debug ... To use host binaries, run `chroot /host` Shutdown scheduled for Mon 2021-09-13 09:36:29 UTC, use 'shutdown -c' to cancel.
이러한 방법 중 하나를 사용하여 노드를 종료하면 pod가 정상적으로 종료되어 데이터 손상 가능성을 줄일 수 있습니다.
참고대규모 클러스터의 경우 종료 시간을 더 길게 조정합니다.
$ for node in $(oc get nodes -o jsonpath='{.items[*].metadata.name}'); do oc debug node/${node} -- chroot /host shutdown -h 10; done참고종료하기 전에 OpenShift Container Platform과 함께 제공되는 표준 Pod의 컨트롤 플레인 노드를 드레인할 필요가 없습니다.
클러스터 관리자는 클러스터를 다시 시작한 후 워크로드를 완전히 다시 시작해야 합니다. 사용자 지정 워크로드로 인해 종료하기 전에 컨트롤 플레인 노드를 드레 이한 경우 다시 시작한 후 클러스터가 다시 작동하기 전에 컨트롤 플레인 노드를 스케줄 대상으로 표시해야합니다.
외부 스토리지 또는 LDAP 서버와 같이 더 이상 필요하지 않은 클러스터 종속성을 중지합니다. 이 작업을 수행하기 전에 공급 업체의 설명서를 확인하십시오.
중요클라우드 공급자 플랫폼에 클러스터를 배포한 경우, 연결된 클라우드 리소스를 종료, 일시 중단 또는 삭제하지 마십시오. 중단된 가상 머신의 클라우드 리소스를 삭제하면 OpenShift Container Platform이 성공적으로 복원되지 않을 수 있습니다.
2.3. 추가 리소스
3장. 클러스터를 정상적으로 다시 시작
이 문서에서는 정상 종료 후 클러스터를 다시 시작하는 프로세스에 대해 설명합니다.
다시 시작한 후 클러스터가 정상적으로 작동할 것으로 예상되지만 예상치 못한 상황으로 인해 클러스터가 복구되지 않을 수 있습니다. 예를 들면 다음과 같습니다.
- 종료 중 etcd 데이터 손상
- 하드웨어로 인한 노드 오류
- 네트워크 연결 문제
클러스터를 복구하지 못하는 경우 다음 단계에 따라 이전 클러스터 상태로 복원 하십시오.
3.1. 전제 조건
3.2. 클러스터를 다시 시작
클러스터가 정상적으로 종료된 후 클러스터를 다시 시작할 수 있습니다.
전제 조건
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. - 이 프로세스에서는 클러스터를 정상적으로 종료하고 있는 것을 전제로 하고 있습니다.
프로세스
- 외부 스토리지 또는 LDAP 서버와 같은 클러스터의 종속 장치를 시작합니다.
모든 클러스터 시스템을 시작합니다.
클라우드 제공 업체의 웹 콘솔에서 시스템을 시작하는 것과 같이 클라우드 환경에 적합한 방법을 사용하여 시스템을 시작합니다.
약 10분 정도 기다린 후 컨트롤 플레인 노드의 상태를 확인합니다.
모든 컨트롤 플레인 노드가 준비되었는지 확인합니다.
$ oc get nodes -l node-role.kubernetes.io/master
다음 출력에 표시된 대로 노드의 상태가
Ready인 경우 컨트롤 플레인 노드는 준비된 것입니다.NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 75m v1.24.0 ip-10-0-170-223.ec2.internal Ready master 75m v1.24.0 ip-10-0-211-16.ec2.internal Ready master 75m v1.24.0
컨트롤 플레인 노드가 준비되지 않은 경우 승인해야하는 보류중인 인증서 서명 요청(CSR)이 있는지 확인합니다.
현재 CSR의 목록을 가져옵니다.
$ oc get csr
CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name> 1- 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한 CSR을 승인합니다.
$ oc adm certificate approve <csr_name>
컨트롤 플레인 노드가 준비되면 모든 작업자 노드가 준비되었는지 확인합니다.
$ oc get nodes -l node-role.kubernetes.io/worker
다음 출력에 표시된 대로 작업자 노드의 상태가
Ready인 경우 작업자 노드는 준비된 것입니다.NAME STATUS ROLES AGE VERSION ip-10-0-179-95.ec2.internal Ready worker 64m v1.24.0 ip-10-0-182-134.ec2.internal Ready worker 64m v1.24.0 ip-10-0-250-100.ec2.internal Ready worker 64m v1.24.0
작업자 노드가 준비되지 않은 경우 승인해야하는 보류중인 인증서 서명 요청(CSR)이 있는지 확인합니다.
현재 CSR의 목록을 가져옵니다.
$ oc get csr
CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name> 1- 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한 CSR을 승인합니다.
$ oc adm certificate approve <csr_name>
클러스터가 제대로 시작되었는지 확인합니다.
성능이 저하된 클러스터 Operator가 없는지 확인합니다.
$ oc get clusteroperators
DEGRADED조건이True로 설정된 클러스터 Operator가 없는지 확인합니다.NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE authentication 4.10.0 True False False 59m cloud-credential 4.10.0 True False False 85m cluster-autoscaler 4.10.0 True False False 73m config-operator 4.10.0 True False False 73m console 4.10.0 True False False 62m csi-snapshot-controller 4.10.0 True False False 66m dns 4.10.0 True False False 76m etcd 4.10.0 True False False 76m ...
모든 노드가
Ready상태에 있는지 확인합니다.$ oc get nodes
모든 노드의 상태가
Ready상태인지 확인합니다.NAME STATUS ROLES AGE VERSION ip-10-0-168-251.ec2.internal Ready master 82m v1.24.0 ip-10-0-170-223.ec2.internal Ready master 82m v1.24.0 ip-10-0-179-95.ec2.internal Ready worker 70m v1.24.0 ip-10-0-182-134.ec2.internal Ready worker 70m v1.24.0 ip-10-0-211-16.ec2.internal Ready master 82m v1.24.0 ip-10-0-250-100.ec2.internal Ready worker 69m v1.24.0
클러스터가 제대로 시작되지 않은 경우 etcd 백업을 사용하여 클러스터를 복원해야 할 수 있습니다.
추가 리소스
4장. OADP 애플리케이션 백업 및 복원
4.1. 데이터 보호를 위한 OpenShift API 소개
OADP(OpenShift API for Data Protection) 제품은 OpenShift Container Platform에서 고객 애플리케이션을 보호합니다. OpenShift Container Platform 애플리케이션, 애플리케이션 관련 클러스터 리소스, 영구 볼륨 및 내부 이미지를 다루는 포괄적인 재해 복구 보호 기능을 제공합니다. OADP는 컨테이너화된 애플리케이션과 VM(가상 머신)을 모두 백업할 수 있습니다.
그러나 OADP는 etcd 또는 OpenShift Operator의 재해 복구 솔루션 역할을 하지 않습니다.
4.1.1. OpenShift API for Data Protection API
OADP(OpenShift API for Data Protection)는 여러 가지 접근 방식을 통해 백업을 사용자 지정하고 불필요하거나 부적절한 리소스가 포함되지 않도록 하는 API를 제공합니다.
OADP는 다음 API를 제공합니다.
추가 리소스
4.2. OADP 릴리스 정보
OADP(OpenShift API for Data Protection) 릴리스 노트에서는 새로운 기능 및 향상된 기능, 더 이상 사용되지 않는 기능, 제품 권장 사항, 알려진 문제 및 해결된 문제를 설명합니다.
4.2.1. OADP 1.2.3 릴리스 노트
4.2.1.1. 새로운 기능
OADP(OpenShift API for Data Protection) 1.2.3 릴리스에는 새로운 기능이 없습니다.
4.2.1.2. 해결된 문제
다음 강조 표시된 문제는 OADP 1.2.3에서 해결됩니다.
여러 HTTP/2가 활성화된 웹 서버는 DDoS 공격(Rapid Reset Attack)에 취약합니다.
이전 버전의 OADP 1.2에서는 요청 취소가 여러 스트림을 빠르게 재설정할 수 있기 때문에 HTTP/2 프로토콜이 서비스 거부 공격에 취약했습니다. 서버는 스트림을 설정하고 해체하는 동시에 연결당 최대 활성 스트림 수에 대한 서버 측 제한에 도달하지 않아야 했습니다. 이로 인해 서버 리소스 사용량으로 인해 서비스가 거부되었습니다. 이 CVE와 관련된 모든 OADP 문제 목록은 다음 Jira 목록을 참조하십시오.
자세한 내용은 CVE-2023-39325 (Rapid Reset Attack) 를 참조하십시오.
OADP 1.2.3 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.2.3 해결된 문제 목록을 참조하십시오.
4.2.1.3. 확인된 문제
OADP 1.2.3 릴리스에는 알려진 문제가 없습니다.
4.2.2. OADP 1.2.2 릴리스 노트
4.2.2.1. 새로운 기능
OADP(OpenShift API for Data Protection) 1.2.2 릴리스에는 새로운 기능이 없습니다.
4.2.2.2. 해결된 문제
다음 강조 표시된 문제는 OADP 1.2.2에서 해결됩니다.
Pod 보안 표준으로 인해 Restic 복원이 부분적으로 실패했습니다.
이전 릴리스의 OADP 1.2에서 OpenShift Container Platform 4.14는 Restic 복원 프로세스 중에 Pod 준비 상태를 방해하는 PSA(Pod 보안 승인) 정책을 적용했습니다.
이 문제는 OADP 1.2.2 및 OADP 1.1.6 릴리스에서 해결되었습니다. 따라서 사용자는 이러한 릴리스로 업그레이드하는 것이 좋습니다.
자세한 내용은 변경된 PSA 정책으로 인해 OCP 4.14에서 부분적으로 실패한 Restic 복원을 참조하십시오. (OADP-2094)
내부 이미지가 있는 앱 백업이 플러그인 패닉 오류와 함께 부분적으로 실패했습니다.
이전 릴리스의 OADP 1.2 릴리스에서는 플러그인 패닉 오류가 반환되어 내부 이미지가 부분적으로 실패한 애플리케이션의 백업이 실패했습니다. Velero 로그에서 이 오류와 함께 백업이 부분적으로 실패합니다.
time="2022-11-23T15:40:46Z" level=info msg="1 errors encountered backup up item" backup=openshift-adp/django-persistent-67a5b83d-6b44-11ed-9cba-902e163f806c logSource="/remote-source/velero/app/pkg/backup/backup.go:413" name=django-psql-persistent time="2022-11-23T15:40:46Z" level=error msg="Error backing up item" backup=openshift-adp/django-persistent-67a5b83d-6b44-11ed-9cba-902e163f8
이 문제는 OADP 1.2.2에서 해결되었습니다. (OADP-1057).
복원 주문으로 인해 ACM 클러스터 복원이 예상대로 작동하지 않았습니다.
이전 릴리스의 OADP 1.2에서는 복원 주문으로 인해 ACM 클러스터 복원이 예상대로 작동하지 않았습니다. ACM 애플리케이션은 복원 활성화 후 관리 클러스터에서 제거 및 다시 생성되었습니다. (OADP-2505)
볼륨 크기 불일치로 인해 백업 및 복원 시 VM의 filesystemOverhead 사용 실패
이전 릴리스에서는 스토리지 공급자 구현 선택 사항으로 인해 애플리케이션 PVC(영구 볼륨 클레임) 스토리지 요청과 동일한 PVC의 스냅샷 크기에 차이가 있을 때마다 백업 및 복원 시 VM의 filesystemOverhead가 실패했습니다. 이 문제는 OADP 1.2.2의 데이터 Mover에서 해결되었습니다. (OADP-2144)
OADP에는 collectdSync 복제 소스 정리 간격을 설정하는 옵션이 포함되어 있지 않았습니다.
이전 릴리스의 OADP 1.2에서는 ballSync 복제 소스 pruneInterval 을 설정할 수 있는 옵션이 없었습니다. (OADP-2052)
Velero가 여러 네임스페이스에 설치된 경우 가능한 Pod 볼륨 백업 실패
이전 릴리스의 OADP 1.2 릴리스에서는 Velero가 여러 네임스페이스에 설치된 경우 Pod 볼륨 백업 오류가 발생할 수 있었습니다. (OADP-2409)
VSL에서 사용자 정의 시크릿을 사용하는 경우 백업 스토리지 위치가 사용할 수 없는 단계로 이동
이전 릴리스의 OADP 1.2 릴리스에서는 Volume Snapshot Location이 사용자 정의 시크릿을 사용한 경우 Backup Storage Locations를 사용할 수 없는 단계로 이동했습니다. (OADP-1737)
OADP 1.2.2 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.2.2 해결된 문제 목록을 참조하십시오.
4.2.2.3. 확인된 문제
다음 문제는 OADP 1.2.2 릴리스에서 알려진 문제로 강조되어 있습니다.
must-gather 명령이 ClusterRoleBinding 리소스를 제거하지 못했습니다
oc adm must-gather 명령은 승인 Webhook로 인해 클러스터에 남아 있는 ClusterRoleBinding 리소스를 제거하지 못합니다. 따라서 ClusterRoleBinding 리소스 제거 요청이 거부됩니다. (OADP-27730)
admission webhook "clusterrolebindings-validation.managed.openshift.io" denied the request: Deleting ClusterRoleBinding must-gather-p7vwj is not allowed
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.2.2 알려진 문제 목록을 참조하십시오.
4.2.3. OADP 1.2.1 릴리스 노트
4.2.3.1. 새로운 기능
OADP(OpenShift API for Data Protection) 1.2.1 릴리스에는 새로운 기능이 없습니다.
4.2.3.2. 해결된 문제
OADP 1.2.1 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.2.1 해결 문제 목록을 참조하십시오.
4.2.3.3. 확인된 문제
다음 문제는 OADP 1.2.1 릴리스에서 알려진 문제로 강조되어 있습니다.
DataMover Restic 유지 및 정리 정책이 예상대로 작동하지 않음
CryostatSync 및 Restic이 제공하는 보존 및 정리 기능은 예상대로 작동하지 않습니다. collectdSync 복제에 정리 간격을 설정하는 작업 옵션이 없으므로 OADP 외부에서 S3 스토리지에 원격으로 저장된 백업을 관리하고 정리해야 합니다. 자세한 내용은 다음을 참조하십시오.
OADP Data Mover는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.2.1 알려진 문제 목록을 참조하십시오.
4.2.4. OADP 1.2.0 릴리스 노트
OADP 1.2.0 릴리스 노트에는 새로운 기능, 버그 수정 및 알려진 문제에 대한 정보가 포함되어 있습니다.
4.2.4.1. 새로운 기능
리소스 제한 시간
새 resourceTimeout 옵션은 다양한 Velero 리소스에서 대기할 때까지 시간 초과 기간을 분 단위로 지정합니다. 이 옵션은 Velero CRD 가용성, volumeSnapshot 삭제 및 백업 리포지토리 가용성과 같은 리소스에 적용됩니다. 기본 기간은 10분입니다.
AWS S3 호환 백업 스토리지 공급자
AWS S3 호환 공급자에서 오브젝트 및 스냅샷을 백업할 수 있습니다. 자세한 내용은 Amazon Web Services 구성을 참조하십시오.
4.2.4.1.1. 기술 프리뷰 기능
Data Mover
OADP Data Mover를 사용하면 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소에 백업할 수 있습니다. Data Mover를 활성화하면 실수로 클러스터 삭제, 클러스터 장애 또는 데이터 손상의 경우 오브젝트 저장소에서 가져온 CSI 볼륨 스냅샷을 사용하여 상태 저장 애플리케이션을 복원할 수 있습니다. 자세한 내용은 CSI 스냅샷에 데이터 Mover 사용을 참조하십시오.
OADP Data Mover는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
4.2.4.2. 해결된 문제
이 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.2.0 해결 문제 목록을 참조하십시오.
4.2.4.3. 확인된 문제
다음 문제는 OADP 1.2.0 릴리스에서 알려진 문제로 강조되어 있습니다.
여러 HTTP/2가 활성화된 웹 서버는 DDoS 공격(Rapid Reset Attack)에 취약합니다.
요청 취소가 여러 스트림을 빠르게 재설정할 수 있으므로 HTTP/2 프로토콜은 서비스 거부 공격에 취약합니다. 서버는 스트림을 설정하고 해체해야 하지만 연결당 최대 활성 스트림 수에 대한 서버 측 제한에 도달하지 않아야 합니다. 이로 인해 서버 리소스 사용량으로 인해 서비스 거부가 발생합니다. 이 CVE와 관련된 모든 OADP 문제 목록은 다음 Jira 목록을 참조하십시오.
이 문제를 해결하려면 OADP 1.2.3으로 업그레이드하는 것이 좋습니다.
자세한 내용은 CVE-2023-39325 (Rapid Reset Attack) 를 참조하십시오.
4.2.5. OADP 1.1.7 릴리스 노트
OADP 1.1.7 릴리스 노트에는 해결된 문제와 알려진 문제가 나열되어 있습니다.
4.2.5.1. 해결된 문제
다음의 강조된 문제는 OADP 1.1.7에서 해결됩니다.
여러 HTTP/2가 활성화된 웹 서버는 DDoS 공격(Rapid Reset Attack)에 취약합니다.
이전 버전의 OADP 1.1에서는 요청 취소가 여러 스트림을 빠르게 재설정할 수 있기 때문에 HTTP/2 프로토콜이 서비스 거부 공격에 취약했습니다. 서버는 스트림을 설정하고 해체하는 동시에 연결당 최대 활성 스트림 수에 대한 서버 측 제한에 도달하지 않아야 했습니다. 이로 인해 서버 리소스 사용량으로 인해 서비스가 거부되었습니다. 이 CVE와 관련된 모든 OADP 문제 목록은 다음 Jira 목록을 참조하십시오.
자세한 내용은 CVE-2023-39325 (Rapid Reset Attack) 를 참조하십시오.
OADP 1.1.7 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.1.7 문제 목록을 참조하십시오.
4.2.5.2. 확인된 문제
OADP 1.1.7 릴리스에는 알려진 문제가 없습니다.
4.2.6. OADP 1.1.6 릴리스 노트
OADP 1.1.6 릴리스 노트에는 새로운 기능, 해결된 문제 및 버그, 알려진 문제가 나열되어 있습니다.
4.2.6.1. 해결된 문제
Pod 보안 표준으로 인해 Restic 복원이 부분적으로 실패함
OCP 4.14에서는 권한 있는 프로필이 적용됨을 나타내는 Pod 보안 표준이 도입 되었습니다. 이전 릴리스의 OADP에서 이 프로필로 인해 Pod에서 권한 거부 오류가 발생했습니다. 이 문제는 복원 순서 때문에 발생했습니다. Pod는 SCC(보안 컨텍스트 제약 조건) 리소스 전에 생성되었습니다. 이 Pod가 Pod 보안 표준을 위반했기 때문에 Pod가 거부되어 실패했습니다. OADP-2420
작업 리소스에 대해 부분적으로 실패함
이전 릴리스의 OADP에서는 OCP 4.14에서 작업 리소스 복원이 부분적으로 실패했습니다. 이 문제는 이전 OCP 버전에서 볼 수 없었습니다. 이 문제는 이전 OCP 버전에 없는 작업 리소스에 대한 추가 레이블로 인해 발생했습니다. OADP-2530
이 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.1.6 해결 문제 목록을 참조하십시오.
4.2.6.2. 확인된 문제
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.1.6 알려진 문제 목록을 참조하십시오.
4.2.7. OADP 1.1.5 릴리스 노트
OADP 1.1.5 릴리스 노트에는 새로운 기능, 해결된 문제 및 버그, 알려진 문제가 나열되어 있습니다.
4.2.7.1. 새로운 기능
이 버전의 OADP는 서비스 릴리스입니다. 이 버전에는 새로운 기능이 추가되지 않습니다.
4.2.7.2. 해결된 문제
이 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.1.5 해결 문제 목록을 참조하십시오.
4.2.7.3. 확인된 문제
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.1.5 알려진 문제 목록을 참조하십시오.
4.2.8. OADP 1.1.4 릴리스 노트
OADP 1.1.4 릴리스 노트에는 새로운 기능, 해결된 문제 및 알려진 문제가 나열되어 있습니다.
4.2.8.1. 새로운 기능
이 버전의 OADP는 서비스 릴리스입니다. 이 버전에는 새로운 기능이 추가되지 않습니다.
4.2.8.2. 해결된 문제
모든 velero 배포 서버 인수에 대한 지원 추가
이전 릴리스에서 OADP는 모든 업스트림 Velero 서버 인수를 지원하지 않았습니다. 이 문제는 OADP 1.1.4에서 해결되었으며 모든 업스트림 Velero 서버 인수가 지원됩니다. OADP-1557
복원 이름과 pvc 이름에 두 개 이상의 VSR이 있는 경우 데이터 Mover가 잘못된 스냅샷에서 복원할 수 있습니다.
이전 릴리스에서는 동일한 Velero 복원 이름 및 영구 볼륨 클레임(pvc) 이름에 대해 클러스터에 VSR( Volume Snapshot Restore) 리소스가 두 개 이상 있는 경우 OADP Data Mover가 잘못된 스냅샷에서 복원할 수 있었습니다. OADP-1822
Cloud Storage API BSL에 OwnerReference 필요
이전 릴리스에서 ACM BackupSchedules는 dpa.spec.backupLocations.bucket 으로 생성된 백업 스토리지 위치(BSL)에서 누락된 OwnerReference 로 인해 검증에 실패했습니다. OADP-1511
이 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.1.4 해결 문제 목록을 참조하십시오.
4.2.8.3. 확인된 문제
이 릴리스에는 다음과 같은 알려진 문제가 있습니다.
클러스터에서 UID/GID 범위가 변경될 수 있으므로 OADP 백업이 실패할 수 있습니다.
OADP 백업은 애플리케이션이 복원된 클러스터에서 UID/GID 범위가 변경될 수 있기 때문에 실패할 수 있으며, OADP가 OpenShift Container Platform UID/GID 범위 메타데이터를 백업하지 않고 복원하지 않습니다. 문제를 방지하려면 백업 애플리케이션에 특정 UUID가 필요한 경우 복원 시 범위를 사용할 수 있는지 확인하십시오. 추가 해결 방법은 OADP가 복원 작업에 네임스페이스를 생성하도록 허용하는 것입니다.
ArgoCD에서 사용하는 레이블로 인해 프로세스 중에 ArgoCD를 사용하는 경우 복원이 실패할 수 있습니다.
ArgoCD, app.kubernetes.io/instance 에서 사용하는 레이블로 인해 프로세스 중에 ArgoCD를 사용하는 경우 복원이 실패할 수 있습니다. 이 레이블은 ArgoCD를 관리해야 하는 리소스를 식별하여 복원 시 리소스를 관리하는 OADP 절차와 충돌을 생성할 수 있습니다. 이 문제를 해결하려면 ArgoCD YAML에서 .spec.resource>-<ingMethod 를 annotation+label 또는 주석 으로 설정합니다. 문제가 계속되면 복원을 시작하기 전에 ArgoCD를 비활성화하고 복원이 완료되면 다시 활성화합니다.
OADP Velero 플러그인 반환 "Received EOF, stop recv loop" 메시지
Velero 플러그인은 별도의 프로세스로 시작됩니다. Velero 작업이 완료되면 해당 작업이 성공적으로 종료됩니다. 따라서 디버그 로그에서 recv 루프 메시지를 중지하는 EOF가 수신되면 오류가 발생하지 않습니다. 이 메시지는 플러그인 작업이 완료되었음을 나타냅니다. OADP-2176
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.1.4 알려진 문제 목록을 참조하십시오.
4.2.9. OADP 1.1.3 릴리스 노트
OADP 1.1.3 릴리스 노트에는 새로운 기능, 해결된 문제 및 버그, 알려진 문제가 나열되어 있습니다.
4.2.9.1. 새로운 기능
이 버전의 OADP는 서비스 릴리스입니다. 이 버전에는 새로운 기능이 추가되지 않습니다.
4.2.9.2. 해결된 문제
이 릴리스에서 해결된 모든 문제의 전체 목록은 Jira의 OADP 1.1.3 해결 문제 목록을 참조하십시오.
4.2.9.3. 확인된 문제
이 릴리스에서 알려진 모든 문제의 전체 목록은 Jira의 OADP 1.1.3 알려진 문제 목록을 참조하십시오.
4.2.10. OADP 1.1.2 릴리스 노트
OADP 1.1.2 릴리스 노트에는 제품 권장 사항, 수정된 버그 목록 및 알려진 문제에 대한 설명이 포함되어 있습니다.
4.2.10.1. 제품 권장 사항
VolSync
IKEvSync 0.5.1에서 dess stable 채널에서 사용 가능한 최신 버전으로 업그레이드를 준비하려면 다음 명령을 실행하여 openshift-adp 네임스페이스에 이 주석을 추가해야 합니다.
$ oc annotate --overwrite namespace/openshift-adp volsync.backube/privileged-movers='true'
Velero
이번 릴리스에서는 Velero가 버전 1.9.2에서 버전 1.9.5 로 업그레이드되었습니다.
Restic
이번 릴리스에서는 Restic이 버전 0.13.1에서 버전 0.14.0 으로 업그레이드되었습니다.
4.2.10.2. 해결된 문제
이번 릴리스에서는 다음 문제가 해결되었습니다.
4.2.10.3. 확인된 문제
이 릴리스에는 다음과 같은 알려진 문제가 있습니다.
4.2.11. OADP 1.1.1 릴리스 노트
OADP 1.1.1 릴리스 노트에는 제품 권장 사항 및 알려진 문제에 대한 설명이 포함되어 있습니다.
4.2.11.1. 제품 권장 사항
OADP 1.1.1를 설치하기 전에ECDHESync 0.5.1을 설치하거나 업그레이드 하는 것이 좋습니다.
4.2.11.2. 확인된 문제
이 릴리스에는 다음과 같은 알려진 문제가 있습니다.
여러 HTTP/2가 활성화된 웹 서버는 DDoS 공격(Rapid Reset Attack)에 취약합니다.
요청 취소가 여러 스트림을 빠르게 재설정할 수 있으므로 HTTP/2 프로토콜은 서비스 거부 공격에 취약합니다. 서버는 스트림을 설정하고 해체해야 하지만 연결당 최대 활성 스트림 수에 대한 서버 측 제한에 도달하지 않아야 합니다. 이로 인해 서버 리소스 사용량으로 인해 서비스 거부가 발생합니다. 이 CVE와 관련된 모든 OADP 문제 목록은 다음 Jira 목록을 참조하십시오.
이 문제를 해결하려면 OADP 1.1.7 또는 1.2.3으로 업그레이드하는 것이 좋습니다.
자세한 내용은 CVE-2023-39325 (Rapid Reset Attack) 를 참조하십시오.
- OADP는 현재 Velero의 restic (OADP-778)을 사용하여 AWS EFS 볼륨의 백업 및 복원을 지원하지 않습니다.
PVC당
VolumeSnapshotContent스냅샷의 Ceph 제한으로 인해 CSI 백업이 실패할 수 있습니다.동일한 PVC(영구 볼륨 클레임)의 스냅샷을 여러 개 생성할 수 있지만 스냅샷의 주기적 생성은 예약할 수 없습니다.
4.3. OADP 기능 및 플러그인
OADP(OpenShift API for Data Protection) 기능은 애플리케이션 백업 및 복원 옵션을 제공합니다.
기본 플러그인을 사용하면 Velero가 특정 클라우드 공급자와 통합하고 OpenShift Container Platform 리소스를 백업 및 복원할 수 있습니다.
4.3.1. OADP 기능
OADP(OpenShift API for Data Protection)는 다음과 같은 기능을 지원합니다.
- Backup
OADP를 사용하여 OpenShift Platform의 모든 애플리케이션을 백업하거나 유형, 네임스페이스 또는 레이블별로 리소스를 필터링할 수 있습니다.
OADP는 Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 저장하여 백업합니다. OADP는 네이티브 클라우드 스냅샷 API 또는 CSI(Container Storage Interface)를 사용하여 스냅샷을 생성하여 PV(영구 볼륨)를 백업합니다. 스냅샷을 지원하지 않는 클라우드 공급자의 경우 OADP는 Restic을 사용하여 리소스 및 PV 데이터를 백업합니다.
참고백업 및 복원에 성공하려면 애플리케이션의 백업에서 Operator를 제외해야 합니다.
- Restore
백업에서 리소스 및 PV를 복원할 수 있습니다. 백업의 모든 오브젝트를 복원하거나 네임스페이스, PV 또는 라벨별로 오브젝트를 필터링할 수 있습니다.
참고백업 및 복원에 성공하려면 애플리케이션의 백업에서 Operator를 제외해야 합니다.
- 스케줄
- 지정된 간격으로 백업을 예약할 수 있습니다.
- 후크
-
후크를 사용하여 Pod의 컨테이너에서 명령을 실행할 수 있습니다(예:
fsfreeze) 파일 시스템을 정지합니다. 백업 또는 복원 전후에 실행되도록 후크를 구성할 수 있습니다. 복구 후크는 init 컨테이너 또는 애플리케이션 컨테이너에서 실행될 수 있습니다.
4.3.2. OADP 플러그인
OADP(OpenShift API for Data Protection)는 백업 및 스냅샷 작업을 지원하기 위해 스토리지 공급자와 통합된 기본 Velero 플러그인을 제공합니다. Velero 플러그인을 기반으로 사용자 지정 플러그인 을 생성할 수 있습니다.
OADP는 OpenShift Container Platform 리소스 백업, OpenShift Virtualization 리소스 백업 및 CSI(Container Storage Interface) 스냅샷에 대한 플러그인도 제공합니다.
표 4.1. OADP 플러그인
| OADP 플러그인 | 함수 | 스토리지 위치 |
|---|---|---|
|
| Kubernetes 오브젝트를 백업하고 복원합니다. | AWS S3 |
| 스냅샷을 사용하여 볼륨을 백업하고 복원합니다. | AWS EBS | |
|
| Kubernetes 오브젝트를 백업하고 복원합니다. | Microsoft Azure Blob 스토리지 |
| 스냅샷을 사용하여 볼륨을 백업하고 복원합니다. | Microsoft Azure 관리 디스크 | |
|
| Kubernetes 오브젝트를 백업하고 복원합니다. | Google Cloud Storage |
| 스냅샷을 사용하여 볼륨을 백업하고 복원합니다. | Google Compute Engine Disks | |
|
| OpenShift Container Platform 리소스를 백업하고 복원합니다. [1] | 오브젝트 저장소 |
|
| OpenShift Virtualization 리소스를 백업하고 복원합니다. [2] | 오브젝트 저장소 |
|
| CSI 스냅샷을 사용하여 볼륨을 백업 및 복원합니다. [3] | CSI 스냅샷을 지원하는 클라우드 스토리지 |
- 필수 항목입니다.
- 가상 머신 디스크는 CSI 스냅샷 또는 Restic으로 백업됩니다.
-
csi플러그인은 Velero CSI 베타 스냅샷 API 를 사용합니다.
4.3.3. OADP Velero 플러그인 정보
Velero를 설치할 때 다음 두 가지 유형의 플러그인을 구성할 수 있습니다.
- 기본 클라우드 공급자 플러그인
- 사용자 정의 플러그인
두 가지 유형의 플러그인은 모두 선택 사항이지만 대부분의 사용자는 하나 이상의 클라우드 공급자 플러그인을 구성합니다.
4.3.3.1. 기본 Velero 클라우드 공급자 플러그인
배포 중에 oadp_v1alpha1_dpa.yaml 파일을 구성할 때 다음과 같은 기본 Velero 클라우드 공급자 플러그인을 설치할 수 있습니다.
-
AWS(Amazon Web Services) -
GCP(Google Cloud Platform) -
azure(Microsoft Azure) -
OpenShift(OpenShift Velero 플러그인) -
CSI(컨테이너 스토리지 인터페이스) -
KubeVirt(KubeVirt)
배포 중에 oadp_v1alpha1_dpa.yaml 파일에 원하는 기본 플러그인을 지정합니다.
예제 파일
다음 .yaml 파일은 openshift,aws,azure, gcp 플러그인을 설치합니다.
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- aws
- azure
- gcp4.3.3.2. 사용자 정의 Velero 플러그인
배포 중에 oadp_v1alpha1_dpa.yaml 파일을 구성할 때 플러그인 이미지 및 이름을 지정하여 사용자 정의 Velero 플러그인을 설치할 수 있습니다.
배포 중에 oadp_v1alpha1_dpa.yaml 파일에 원하는 사용자 지정 플러그인을 지정합니다.
예제 파일
다음 .yaml 파일은 기본 openshift,azure, gcp 플러그인 및 이름이 custom-plugin-example 이고 quay.io/example-repo/custom-velero-plugin 이미지가 있는 사용자 정의 플러그인을 설치합니다.
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
velero:
defaultPlugins:
- openshift
- azure
- gcp
customPlugins:
- name: custom-plugin-example
image: quay.io/example-repo/custom-velero-plugin4.3.3.3. Velero 플러그인에서 "received EOF, stop recv loop" 메시지를 반환
Velero 플러그인은 별도의 프로세스로 시작됩니다. Velero 작업이 성공적으로 완료되거나 실패하면 종료됩니다. 디버그 로그에서 recv 루프 메시지를 중지하여 수신된 EOF 를 수신하면 플러그인 작업이 완료되었음을 나타냅니다. 이는 오류가 발생했음을 의미하지 않습니다.
4.3.4. OADP에서 지원되는 아키텍처
OADP(OpenShift API for Data Protection)는 다음과 같은 아키텍처를 지원합니다.
- AMD64
- ARM64
- PPC64le
- s390x
OADP 1.2.0 이상 버전은 ARM64 아키텍처를 지원합니다.
4.3.5. IBM Power 및 IBM Z에 대한 OADP 지원
OADP(OpenShift API for Data Protection)는 플랫폼 중립적입니다. 다음 정보는 IBM Power 및 IBM Z에 대해서만 관련이 있습니다.
OADP 1.1.0은 IBM Power 및 IBM Z의 OpenShift Container Platform 4.11에 대해 성공적으로 테스트되었습니다. 다음 섹션에서는 이러한 시스템의 백업 위치 측면에서 OADP 1.1.0에 대한 테스트 및 지원 정보를 제공합니다.
4.3.5.1. IBM Power를 사용하여 대상 백업 위치에 대한 OADP 지원
OpenShift Container Platform 4.11 및 4.12에서 실행되는 IBM Power와 OADP(OpenShift API for Data Protection) 1.1.2가 AWS S3 백업 위치 대상에 대해 성공적으로 테스트되었습니다. 이 테스트는 AWS S3 대상만 포함되었지만 Red Hat은 AWS가 아닌 모든 S3 백업 위치 대상에 대해 OpenShift Container Platform 4.11 및 OADP 1.1.2를 사용하여 IBM Power를 실행할 수 있도록 지원합니다.
4.3.5.2. IBM Z를 사용하여 대상 백업 위치에 대한 OADP 테스트 및 지원
OpenShift Container Platform 4.11 및 4.12에서 실행되는 IBM Z와 OADP(OpenShift API for Data Protection) 1.1.2가 AWS S3 백업 위치 대상에 대해 성공적으로 테스트되었습니다. 이 테스트는 AWS S3 대상만 포함되었지만 Red Hat은 AWS가 아닌 모든 S3 백업 위치 대상에 대해 OpenShift Container Platform 4.11 및 OADP 1.1.2를 사용하여 IBM Z를 실행할 수 있도록 지원합니다.
4.4. OADP 설치 및 구성
4.4.1. OADP 설치 정보
클러스터 관리자는 OADP Operator를 설치하여 데이터 보호(OADP)를 OpenShift API를 설치합니다. OADP Operator는 Velero 1.11 을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Kubernetes 리소스 및 내부 이미지를 백업하려면 다음 스토리지 유형 중 하나와 같은 백업 위치로 오브젝트 스토리지가 있어야 합니다.
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- Multicloud Object Gateway
- AWS S3 호환 오브젝트 스토리지(예: Multicloud Object Gateway 또는 MinIO)
달리 지정하지 않는 한 "NooBa"는 경량 오브젝트 스토리지를 제공하는 오픈 소스 프로젝트를 나타내며 "MCG(Multicloud Object Gateway)는 NooBaa의 Red Hat 배포를 나타냅니다.
MCG에 대한 자세한 내용은 애플리케이션을 사용하여 Multicloud Object Gateway 액세스를 참조하십시오.
오브젝트 스토리지를 위한 버킷 생성을 자동화하는 CloudStorage API는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
스냅샷 또는 Restic을 사용하여 PV(영구 볼륨)를 백업할 수 있습니다.
스냅샷으로 PV를 백업하려면 다음 클라우드 공급자 중 하나와 같은 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원하는 클라우드 공급자가 있어야 합니다.
- Amazon Web Services
- Microsoft Azure
- Google Cloud Platform
- OpenShift Data Foundation과 같은 CSI 스냅샷 지원 클라우드 공급자
OCP 4.11 이상에서 CSI 백업을 사용하려면 OADP 1.1.x 를 설치하십시오.
OADP 1.0.x 는 OCP 4.11 이상에서 CSI 백업을 지원하지 않습니다. OADP 1.0.x 에는 Velero 1.7이 포함되어 있으며 OCP 4.11 이상에는 존재하지 않는 API 그룹 snapshot.storage.k8s.io/v1beta1 이 예상됩니다.
클라우드 공급자가 스냅샷을 지원하지 않거나 스토리지가 NFS인 경우 오브젝트 스토리지에서 Restic 백업을 사용하여 애플리케이션을 백업할 수 있습니다.
기본 보안을 생성한 다음 데이터 보호 애플리케이션을 설치합니다.
4.4.1.1. AWS S3 호환 백업 스토리지 공급자
OADP는 다양한 백업 및 스냅샷 작업에 사용하기 위해 많은 오브젝트 스토리지 공급자와 호환됩니다. 여러 오브젝트 스토리지 공급자가 완전히 지원되며, 일부 오브젝트 스토리지 공급자는 지원되지만 작동하지 않으며 일부에는 알려진 제한 사항이 있습니다.
4.4.1.1.1. 지원되는 백업 스토리지 공급자
다음 AWS S3 호환 오브젝트 스토리지 공급자는 AWS 플러그인을 통해 백업 스토리지 위치로 사용하기 위해 OADP에서 완전히 지원합니다.
- MinIO
- MCG(Multicloud Object Gateway)
- AWS(Amazon Web Services) S3
다음과 같은 호환 오브젝트 스토리지 공급자가 지원되며 자체 Velero 오브젝트 저장소 플러그인이 있습니다.
- GCP(Google Cloud Platform)
- Microsoft Azure
4.4.1.1.2. 지원되지 않는 백업 스토리지 공급자
다음 AWS S3 호환 오브젝트 스토리지 공급자는 백업 스토리지 위치로 사용하기 위해 AWS 플러그인을 통해 Velero와 함께 작업하는 것으로 알려져 있지만 이는 지원되지 않으며 Red Hat에서 테스트하지 않았습니다.
- IBM Cloud
- Oracle Cloud
- DigitalOcean
- MCG(Multicloud Object Gateway)를 사용하여 설치하지 않는 한 NooBaa
- Tencent Cloud
- Ceph RADOS v12.2.7
- Quobyte
- Cloudian HyperStore
달리 지정하지 않는 한 "NooBa"는 경량 오브젝트 스토리지를 제공하는 오픈 소스 프로젝트를 나타내며 "MCG(Multicloud Object Gateway)는 NooBaa의 Red Hat 배포를 나타냅니다.
MCG에 대한 자세한 내용은 애플리케이션을 사용하여 Multicloud Object Gateway 액세스를 참조하십시오.
4.4.1.1.3. 알려진 제한이 있는 백업 스토리지 공급자
다음 AWS S3 호환 오브젝트 스토리지 공급자는 제한된 기능 세트로 AWS 플러그인을 통해 Velero와 함께 작동하는 것으로 알려져 있습니다.
- Swift - 백업 스토리지의 백업 스토리지 위치로 사용하기 위해 작동하지만 파일 시스템 기반 볼륨 백업 및 복원에는 Restic과 호환되지 않습니다.
4.4.1.2. OpenShift Data Foundation에서 재해 복구를 위해 MCG(Multicloud Object Gateway) 구성
OpenShift Data Foundation에서 MCG 버킷 backupStorageLocation 에 클러스터 스토리지를 사용하는 경우 MCG를 외부 오브젝트 저장소로 구성합니다.
MCG를 외부 오브젝트 저장소로 구성하지 않으면 백업을 사용할 수 없게 될 수 있습니다.
달리 지정하지 않는 한 "NooBa"는 경량 오브젝트 스토리지를 제공하는 오픈 소스 프로젝트를 나타내며 "MCG(Multicloud Object Gateway)는 NooBaa의 Red Hat 배포를 나타냅니다.
MCG에 대한 자세한 내용은 애플리케이션을 사용하여 Multicloud Object Gateway 액세스를 참조하십시오.
절차
- 하이브리드 또는 Multicloud용 스토리지 리소스 추가 에 설명된 대로 MCG를 외부 오브젝트 저장소로 구성합니다.
추가 리소스
4.4.1.3. OADP 업데이트 채널 정보
OADP Operator를 설치할 때 업데이트 채널을 선택합니다. 이 채널은 OADP Operator 및 수신하는 Velero에 대한 업그레이드를 결정합니다. 언제든지 채널을 변경할 수 있습니다.
다음 업데이트 채널을 사용할 수 있습니다.
-
stable 채널이 더 이상 사용되지 않습니다. stable 채널에는
oadp.v1.1.z및oadp.v1.0.z의 이전 버전에 대한 OADPClusterServiceVersion의 패치 (z-stream 업데이트)가 포함되어 있습니다. -
stable-1.0 채널에는 최신 OADP 1.0
ClusterServiceVersion인oadp.v1.0.z가 포함되어 있습니다. -
stable-1.1 채널에는 최신 OADP 1.1
ClusterServiceVersion인oadp.v1.1.z가 포함되어 있습니다. -
stable-1.2 채널에는 최신 OADP 1.2
ClusterServiceVersion인oadp.v1.2.z가 포함되어 있습니다. -
stable-1.3 채널에는 최신 OADP 1.3
ClusterServiceVersion인oadp.v1.3.z가 포함되어 있습니다.
어떤 업데이트 채널을 사용할 수 있습니까?
-
stable 채널이 더 이상 사용되지 않습니다. 이미 stable 채널을 사용하고 있는 경우
oadp.v1.1.z.에서 업데이트를 계속 받을 수 있습니다. - stable-1.y 업데이트 채널을 선택하여 OADP 1.y 를 설치하고 계속 패치를 수신합니다. 이 채널을 선택하면 버전 1에 대한 모든 z-stream 패치가 제공됩니다.y.z.
언제 업데이트 채널을 전환해야합니까?
- OADP 1.y 가 설치되어 있고 해당 y-stream에 대한 패치만 받으려면 stable 업데이트 채널에서 stable-1 로 전환해야 합니다. 그런 다음 버전 1.y. z에 대한 모든z -stream 패치가 제공됩니다.
- OADP 1.0이 설치되어 있고 OADP 1.1로 업그레이드하려는 경우 패치는 stable-1.0 업데이트 채널에서 stable-1.1 업데이트 채널로 전환해야 합니다. 그런 다음 버전 1.1.z 에 대한 모든 z-stream 패치가 제공됩니다.
- OADP 1. y 가 0보다 크게 설치되어 있고 OADP 1.0으로 전환하려는 경우 OADP Operator를 제거한 다음 stable-1.0 업데이트 채널을 사용하여 다시 설치해야 합니다. 그러면 버전 1.0.z 에 대한 모든 z-stream 패치가 제공됩니다.
업데이트 채널을 전환하여 OADP 1.y 에서 OADP 1.0으로 전환할 수 없습니다. Operator를 제거한 다음 다시 설치해야 합니다.
4.4.1.4. 여러 네임스페이스에 OADP 설치
OADP를 동일한 클러스터의 여러 네임스페이스에 설치할 수 있으므로 여러 프로젝트 소유자가 자체 OADP 인스턴스를 관리할 수 있습니다. 이 사용 사례는 Restic 및 CSI에서 검증되었습니다.
다음 추가 요구 사항을 사용하여 이 문서에 포함된 플랫폼별 절차에 따라 OADP의 각 인스턴스를 설치합니다.
- 동일한 클러스터에 있는 OADP의 모든 배포는 동일한 버전이어야 합니다(예: 1.1.4). 동일한 클러스터에 다른 버전의 OADP를 설치할 수 없습니다.
-
OADP의 각 개별 배포에는 고유한 자격 증명 세트와 고유한
BackupStorageLocation구성이 있어야 합니다. - 기본적으로 각 OADP 배포에는 네임스페이스에서 클러스터 수준 액세스 권한이 있습니다. OpenShift Container Platform 관리자는 보안 및 RBAC 설정을 주의 깊게 검토하고 각 OADP 인스턴스에 올바른 권한이 있는지 확인하기 위해 필요한 사항을 변경해야 합니다.
추가 리소스
4.4.1.5. 수집된 데이터를 기반으로 하는 Velero CPU 및 메모리 요구 사항
다음 권장 사항은 규모 및 성능 랩에서 수행된 성능 관찰을 기반으로 합니다. 백업 및 복원 리소스는 플러그인 유형, 해당 백업 또는 복원에 필요한 리소스 양, 해당 리소스와 관련된 PV(영구 볼륨)에 포함된 해당 데이터의 영향을 받을 수 있습니다.
4.4.1.5.1. 구성에 대한 CPU 및 메모리 요구 사항
| 구성 유형 | [1] 평균 사용량 | [2] 대규모 사용 | resourceTimeouts |
|---|---|---|---|
| CSI | Velero: cpu- 요청 200m, 제한 1000m memory - 256Mi 요청, 제한 1024Mi | Velero: CPU- 요청 200m, 제한 2000m memory- requests 256Mi, Limits 2048Mi | 해당 없음 |
| Restic | [3] Restic: CPU- 요청 1000m, 제한 2000m memory - 16Gi 요청, 32Gi 제한 | [4] Restic: CPU - 2000m 요청, 8000m 제한 Memory - 16Gi 요청, 제한 40Gi | 900m |
| [5] DataMover | 해당 없음 | 해당 없음 | 10m - 평균 사용량 60m - 대규모 사용 |
- 평균 사용량 - 대부분의 사용 상황에 대해 이러한 설정을 사용합니다.
- 대규모 사용 - 대규모 PV(500GB 사용), 다중 네임스페이스(100+) 또는 단일 네임스페이스(2000 pods+) 내의 여러 Pod 및 대규모 데이터 세트와 관련된 백업 및 복원을 위한 최적의 성능을 위해 이러한 설정을 사용합니다.
- Restic 리소스 사용량은 데이터 양 및 데이터 유형에 해당합니다. 예를 들어 많은 작은 파일 또는 대량의 데이터가 있으면 Restic이 대량의 리소스를 활용할 수 있습니다. Velero 문서는 500m을 제공된 기본값으로 참조합니다. 대부분의 테스트에서는 1000m 제한으로 적합한 200m 요청을 발견했습니다. Velero 문서에서 인용한 대로 정확한 CPU 및 메모리 사용은 환경 제한 외에도 파일 및 디렉터리의 크기에 따라 달라집니다.
- CPU를 늘리면 백업 및 복원 시간 개선에 큰 영향을 미칩니다.
- DataMover - DataMover 기본 리소스 제한 시간은 10m입니다. 테스트 결과 대규모 PV(500GB 사용량)를 복원하려면 resourceTimeout을 60m로 늘려야 합니다.
가이드 전체에 나열된 리소스 요구 사항은 평균 사용량 전용입니다. 큰 용도의 경우 위의 표에 설명된 대로 설정을 조정합니다.
4.4.1.5.2. 대규모 사용을 위한 nodeagent CPU
테스트 결과 NodeAgent CPU를 늘리면 OADP(OpenShift API for Data Protection)를 사용할 때 백업 및 복원 시간을 크게 향상시킬 수 있습니다.
Kopia의 적극적인 리소스 사용으로 인해 프로덕션 워크로드를 실행하는 노드의 프로덕션 환경에서 제한 없이 Kopia를 사용하지 않는 것이 좋습니다. 그러나 너무 낮은 제한으로 Kopia를 실행하면 CPU 제한 및 백업 속도가 느려지고 복원 상황이 발생합니다. 테스트 결과 20개 코어 및 32Gi 메모리가 있는 Kopia를 실행하면 100GB 이상의 데이터, 여러 네임스페이스 또는 2000개 이상의 Pod가 단일 네임스페이스에서 백업 및 복원 작업을 지원했습니다.
이러한 리소스 사양을 사용하여 CPU 제한 또는 메모리 포화 상태로 감지된 테스트입니다.
rook-ceph Pod에서 CPU 및 메모리 리소스 변경 절차에 따라 Ceph MDS Pod 에서 이러한 제한을 설정할 수 있습니다.
제한을 설정하려면 스토리지 클러스터 CR(사용자 정의 리소스)에 다음 행을 추가해야 합니다.
resources:
mds:
limits:
cpu: "3"
memory: 128Gi
requests:
cpu: "3"
memory: 8Gi4.4.2. OADP Operator 설치
OLM(Operator Lifecycle Manager)을 사용하여 OpenShift Container Platform 4.11에 OADP(OpenShift API for Data Protection) Operator를 설치할 수 있습니다.
OADP Operator는 Velero 1.11 을 설치합니다.
사전 요구 사항
-
cluster-admin권한이 있는 사용자로 로그인해야 합니다.
절차
- OpenShift Container Platform 웹 콘솔에서 Operator → OperatorHub를 클릭합니다.
- 키워드로 필터링 필드를 사용하여 OADP Operator 를 찾습니다.
- OADP Operator 를 선택하고 설치를 클릭합니다.
-
openshift-adp프로젝트에 Operator를 설치하려면 설치를 클릭합니다. - Operators → 설치된 Operators 를 클릭하여 설치를 확인합니다.
4.4.2.1. OADP-Velero-OpenShift Container Platform 버전 관계
4.4.3. Amazon Web Services를 사용하여 데이터 보호를 위한 OpenShift API 구성
OADP Operator를 설치하여 AWS(Amazon Web Services)와 함께 OADP(OpenShift API for Data Protection)를 설치합니다. Operator는 Velero 1.11 을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Velero에 대한 AWS를 구성하고 기본 시크릿 을 생성한 다음 데이터 보호 애플리케이션을 설치합니다. 자세한 내용은 OADP Operator 설치를 참조하십시오.
제한된 네트워크 환경에 OADP Operator를 설치하려면 먼저 기본 OperatorHub 소스를 비활성화하고 Operator 카탈로그를 미러링해야 합니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
4.4.3.1. Amazon Web Services 구성
OADP(OpenShift API for Data Protection)를 위해 AWS(Amazon Web Services)를 구성합니다.
사전 요구 사항
- AWS CLI 가 설치되어 있어야 합니다.
절차
BUCKET변수를 설정합니다.$ BUCKET=<your_bucket>
REGION변수를 설정합니다.$ REGION=<your_region>
AWS S3 버킷을 생성합니다.
$ aws s3api create-bucket \ --bucket $BUCKET \ --region $REGION \ --create-bucket-configuration LocationConstraint=$REGION 1- 1
us-east-1은LocationConstraint를 지원하지 않습니다. 리전이us-east-1인 경우--create-bucket-configuration LocationConstraint=$REGION을 생략합니다.
IAM 사용자를 생성합니다.
$ aws iam create-user --user-name velero 1- 1
- Velero를 사용하여 여러 S3 버킷이 있는 여러 클러스터를 백업하려면 각 클러스터에 대해 고유한 사용자 이름을 생성합니다.
velero-policy.json파일을 생성합니다.$ cat > velero-policy.json <<EOF { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "ec2:DescribeVolumes", "ec2:DescribeSnapshots", "ec2:CreateTags", "ec2:CreateVolume", "ec2:CreateSnapshot", "ec2:DeleteSnapshot" ], "Resource": "*" }, { "Effect": "Allow", "Action": [ "s3:GetObject", "s3:DeleteObject", "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::${BUCKET}/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation", "s3:ListBucketMultipartUploads" ], "Resource": [ "arn:aws:s3:::${BUCKET}" ] } ] } EOF정책을 연결하여
velero사용자에게 필요한 최소 권한을 부여합니다.$ aws iam put-user-policy \ --user-name velero \ --policy-name velero \ --policy-document file://velero-policy.json
velero사용자에 대한 액세스 키를 생성합니다.$ aws iam create-access-key --user-name velero
출력 예
{ "AccessKey": { "UserName": "velero", "Status": "Active", "CreateDate": "2017-07-31T22:24:41.576Z", "SecretAccessKey": <AWS_SECRET_ACCESS_KEY>, "AccessKeyId": <AWS_ACCESS_KEY_ID> } }credentials-velero파일을 생성합니다.$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOF
Data Protection 애플리케이션을 설치하기 전에
credentials-velero파일을 사용하여 AWS용Secret오브젝트를 생성합니다.
4.4.3.2. 백업 및 스냅샷 위치 및 시크릿 정보
DataProtectionApplication CR(사용자 정의 리소스)에서 백업 및 스냅샷 위치와 해당 시크릿을 지정합니다.
백업 위치
Multicloud Object Gateway 또는 MinIO와 같은 S3 호환 오브젝트 스토리지를 백업 위치로 지정합니다.
Velero는 OpenShift Container Platform 리소스, Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 백업합니다.
스냅샷 위치
클라우드 공급자의 네이티브 스냅샷 API를 사용하여 영구 볼륨을 백업하는 경우 클라우드 공급자를 스냅샷 위치로 지정해야 합니다.
CSI(Container Storage Interface) 스냅샷을 사용하는 경우 CSI 드라이버를 등록할 VolumeSnapshotClass CR을 생성하므로 스냅샷 위치를 지정할 필요가 없습니다.
Restic을 사용하는 경우 Restic이 오브젝트 스토리지의 파일 시스템을 백업하므로 스냅샷 위치를 지정할 필요가 없습니다.
보안
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 시크릿 을 생성합니다.
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의 시크릿 오브젝트를 생성합니다.
-
DataProtectionApplicationCR에서 지정하는 백업 위치에 대한 사용자 지정시크릿입니다. -
DataProtectionApplicationCR에서 참조되지 않는 스냅샷 위치의 기본시크릿입니다.
데이터 보호 애플리케이션에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다.
설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 보안을 생성할 수 있습니다.
4.4.3.2.1. 기본 보안 생성
백업 및 스냅샷 위치에 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 보안을 생성합니다.
시크릿 의 기본 이름은 cloud-credentials 입니다.
DataProtectionApplication CR(사용자 정의 리소스)에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다. 백업 위치 Secret 의 이름이 지정되지 않은 경우 기본 이름이 사용됩니다.
설치 중에 백업 위치 인증 정보를 사용하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 이름으로 보안을 생성할 수 있습니다.
사전 요구 사항
- 오브젝트 스토리지 및 클라우드 스토리지(있는 경우)는 동일한 인증 정보를 사용해야 합니다.
- Velero의 오브젝트 스토리지를 구성해야 합니다.
-
적절한 형식으로 오브젝트 스토리지에 대한
credentials-velero파일을 생성해야 합니다.
절차
기본 이름으로 보안을 생성합니다.
$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
데이터 보호 애플리케이션을 설치할 때 DataProtectionApplication CR의 spec.backupLocations.credential 블록에서 시크릿 을 참조합니다.
4.4.3.2.2. 다양한 인증 정보에 대한 프로필 생성
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 credentials-velero 파일에 별도의 프로필을 생성합니다.
그런 다음 Secret 오브젝트를 생성하고 DataProtectionApplication CR(사용자 정의 리소스)에서 프로필을 지정합니다.
절차
다음 예와 같이 백업 및 스냅샷 위치에 대한 별도의 프로필을 사용하여
credentials-velero파일을 생성합니다.[backupStorage] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> [volumeSnapshot] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY>
credentials-velero파일을 사용하여Secret오브젝트를 생성합니다.$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero 1다음 예와 같이
DataProtectionApplicationCR에 프로필을 추가합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name> prefix: <prefix> config: region: us-east-1 profile: "backupStorage" credential: key: cloud name: cloud-credentials snapshotLocations: - name: default velero: provider: aws config: region: us-west-2 profile: "volumeSnapshot"
4.4.3.3. 데이터 보호 애플리케이션 구성
Velero 리소스 할당을 설정하거나 자체 서명된 CA 인증서를 활성화하여 데이터 보호 애플리케이션을 구성할 수 있습니다.
4.4.3.3.1. Velero CPU 및 메모리 리소스 할당 설정
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 Velero Pod에 대한 CPU 및 메모리 리소스 할당을 설정합니다.
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.podConfig.ResourceAllocations블록의 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.3.3.2. 자체 서명 CA 인증서 활성화
알 수 없는 기관에서 서명한 인증서를 방지하기 위해 활성화해야 합니다.
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 오브젝트 스토리지에 대해 자체 서명 CA 인증서를
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
DataProtectionApplicationCR 매니페스트의spec.backupLocations.velero.objectStorage.caCert매개변수 및spec.backupLocations.velero.config매개변수를 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 ...
4.4.3.4. 데이터 보호 애플리케이션 설치
DataProtectionApplication API 인스턴스를 생성하여 DPA( Data Protection Application )를 설치합니다.
사전 요구 사항
- OADP Operator를 설치해야 합니다.
- 오브젝트 스토리지를 백업 위치로 구성해야 합니다.
- 스냅샷을 사용하여 PV를 백업하는 경우 클라우드 공급자는 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
-
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하는 경우 기본 이름
cloud-credentials로Secret을 생성해야 합니다. 백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 백업 및 스냅샷 위치 자격 증명에 대한 별도의 프로필이 포함된 기본 이름
cloud-credentials을 사용하여 보안을 생성해야 합니다.참고설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈
credentials-velero파일을사용하여기본 보안을 생성할 수 있습니다. 기본Secret이 없으면 설치에 실패합니다.참고Velero는 기본 백업 리포지토리 암호가 포함된 OADP 네임스페이스에
velero-repo-credentials라는 시크릿을 생성합니다. 백업 리포지토리를 대상으로 하는 첫 번째 백업을 실행하기 전에 base64로 인코딩된 고유한 암호로 시크릿을 업데이트할 수 있습니다. 업데이트할 키의 값은Data[repository-password]입니다.DPA를 생성한 후 백업 리포지토리를 대상으로 하는 백업을 처음 실행하면 Velero에서 시크릿이 기본 암호 또는 교체한 암호가 포함된
velero-repo-credentials인 백업 리포지토리를 생성합니다. 첫 번째 백업 후 시크릿 암호를 업데이트하면 새 암호가velero-repo-credentials의 암호와 일치하지 않으므로 Velero는 이전 백업과 연결할 수 없습니다.
절차
- Operators → 설치된 Operator 를 클릭하고 OADP Operator를 선택합니다.
- 제공된 API 아래에서 DataProtectionApplication 상자에서 인스턴스 생성을 클릭합니다.
YAML 보기를 클릭하고
DataProtectionApplication매니페스트의 매개변수를 업데이트합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - openshift 1 - aws resourceTimeout: 10m 2 restic: enable: true 3 podConfig: nodeSelector: <node_selector> 4 backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket_name> 5 prefix: <prefix> 6 config: region: <region> profile: "default" credential: key: cloud name: cloud-credentials 7 snapshotLocations: 8 - name: default velero: provider: aws config: region: <region> 9 profile: "default"- 1
openshift플러그인은 필수입니다.- 2
- Velero CRD 가용성, volumeSnapshot 삭제, 백업 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 분을 지정합니다. 기본값은 10m입니다.
- 3
- Restic 설치를 비활성화하려면 이 값을
false로 설정합니다. Restic은 데몬 세트를 배포합니다. 즉, Restic pod는 각 작업 노드에서 실행됩니다. OADP 버전 1.2 이상에서는BackupCR에spec.defaultVolumesToFsBackup: true를 추가하여 백업에 대해 Restic을 구성할 수 있습니다. OADP 버전 1.1에서BackupCR에spec.defaultVolumesToRestic: true를 추가합니다. - 4
- Restic을 사용할 수 있는 노드를 지정합니다. 기본적으로 Restic은 모든 노드에서 실행됩니다.
- 5
- 버킷을 백업 스토리지 위치로 지정합니다. 버킷이 Velero 백업의 전용 버킷이 아닌 경우 접두사를 지정해야 합니다.
- 6
- 버킷이 여러 목적으로 사용되는 경우 Velero 백업의 접두사(예:
velero)를 지정합니다. - 7
- 생성한
Secret오브젝트의 이름을 지정합니다. 이 값을 지정하지 않으면 기본 이름cloud-credentials가 사용됩니다. 사용자 지정 이름을 지정하면 백업 위치에 사용자 지정 이름이 사용됩니다. - 8
- CSI 스냅샷 또는 Restic을 사용하여 PV를 백업하지 않는 한 스냅샷 위치를 지정합니다.
- 9
- 스냅샷 위치는 PV와 동일한 리전에 있어야 합니다.
- 생성을 클릭합니다.
OADP 리소스를 확인하여 설치를 확인합니다.
$ oc get all -n openshift-adp
출력 예
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.3.4.1. DataProtectionApplication CR에서 CSI 활성화
CSI 스냅샷을 사용하여 영구 볼륨을 백업하기 위해 DataProtectionApplication CR(사용자 정의 리소스)에서 CSI(Container Storage Interface)를 활성화합니다.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csi기본 플러그인을 추가합니다.
4.4.4. Microsoft Azure를 사용하여 데이터 보호를 위한 OpenShift API 구성
OADP Operator를 설치하여 Microsoft Azure와 함께 OADP(OpenShift API for Data Protection)를 설치합니다. Operator는 Velero 1.11 을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Velero에 대한 Azure를 구성하고 기본 시크릿 을 생성한 다음 데이터 보호 애플리케이션을 설치합니다. 자세한 내용은 OADP Operator 설치를 참조하십시오.
제한된 네트워크 환경에 OADP Operator를 설치하려면 먼저 기본 OperatorHub 소스를 비활성화하고 Operator 카탈로그를 미러링해야 합니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
4.4.4.1. Microsoft Azure 구성
OADP(OpenShift API for Data Protection)를 위해 Microsoft Azure를 구성합니다.
사전 요구 사항
- Azure CLI 가 설치되어 있어야 합니다.
절차
Azure에 로그인합니다.
$ az login
AZURE_RESOURCE_GROUP변수를 설정합니다.$ AZURE_RESOURCE_GROUP=Velero_Backups
Azure 리소스 그룹을 생성합니다.
$ az group create -n $AZURE_RESOURCE_GROUP --location CentralUS 1- 1
- 위치를 지정합니다.
AZURE_STORAGE_ACCOUNT_ID변수를 설정합니다.$ AZURE_STORAGE_ACCOUNT_ID="velero$(uuidgen | cut -d '-' -f5 | tr '[A-Z]' '[a-z]')"
Azure 스토리지 계정을 생성합니다.
$ az storage account create \ --name $AZURE_STORAGE_ACCOUNT_ID \ --resource-group $AZURE_RESOURCE_GROUP \ --sku Standard_GRS \ --encryption-services blob \ --https-only true \ --kind BlobStorage \ --access-tier HotBLOB_CONTAINER변수를 설정합니다.$ BLOB_CONTAINER=velero
Azure Blob 스토리지 컨테이너를 생성합니다.
$ az storage container create \ -n $BLOB_CONTAINER \ --public-access off \ --account-name $AZURE_STORAGE_ACCOUNT_ID
스토리지 계정 액세스 키를 가져옵니다.
$ AZURE_STORAGE_ACCOUNT_ACCESS_KEY=`az storage account keys list \ --account-name $AZURE_STORAGE_ACCOUNT_ID \ --query "[?keyName == 'key1'].value" -o tsv`
필요한 최소 권한이 있는 사용자 지정 역할을 생성합니다.
AZURE_ROLE=Velero az role definition create --role-definition '{ "Name": "'$AZURE_ROLE'", "Description": "Velero related permissions to perform backups, restores and deletions", "Actions": [ "Microsoft.Compute/disks/read", "Microsoft.Compute/disks/write", "Microsoft.Compute/disks/endGetAccess/action", "Microsoft.Compute/disks/beginGetAccess/action", "Microsoft.Compute/snapshots/read", "Microsoft.Compute/snapshots/write", "Microsoft.Compute/snapshots/delete", "Microsoft.Storage/storageAccounts/listkeys/action", "Microsoft.Storage/storageAccounts/regeneratekey/action" ], "AssignableScopes": ["/subscriptions/'$AZURE_SUBSCRIPTION_ID'"] }'credentials-velero파일을 생성합니다.$ cat << EOF > ./credentials-velero AZURE_SUBSCRIPTION_ID=${AZURE_SUBSCRIPTION_ID} AZURE_TENANT_ID=${AZURE_TENANT_ID} AZURE_CLIENT_ID=${AZURE_CLIENT_ID} AZURE_CLIENT_SECRET=${AZURE_CLIENT_SECRET} AZURE_RESOURCE_GROUP=${AZURE_RESOURCE_GROUP} AZURE_STORAGE_ACCOUNT_ACCESS_KEY=${AZURE_STORAGE_ACCOUNT_ACCESS_KEY} 1 AZURE_CLOUD_NAME=AzurePublicCloud EOF- 1
- 필수 항목입니다.
credentials-velero파일에 서비스 주체 자격 증명만 포함된 경우 내부 이미지를 백업할 수 없습니다.
credentials-velero파일을 사용하여 데이터 보호 애플리케이션을 설치하기 전에 Azure용Secret오브젝트를 생성합니다.
4.4.4.2. 백업 및 스냅샷 위치 및 시크릿 정보
DataProtectionApplication CR(사용자 정의 리소스)에서 백업 및 스냅샷 위치와 해당 시크릿을 지정합니다.
백업 위치
Multicloud Object Gateway 또는 MinIO와 같은 S3 호환 오브젝트 스토리지를 백업 위치로 지정합니다.
Velero는 OpenShift Container Platform 리소스, Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 백업합니다.
스냅샷 위치
클라우드 공급자의 네이티브 스냅샷 API를 사용하여 영구 볼륨을 백업하는 경우 클라우드 공급자를 스냅샷 위치로 지정해야 합니다.
CSI(Container Storage Interface) 스냅샷을 사용하는 경우 CSI 드라이버를 등록할 VolumeSnapshotClass CR을 생성하므로 스냅샷 위치를 지정할 필요가 없습니다.
Restic을 사용하는 경우 Restic이 오브젝트 스토리지의 파일 시스템을 백업하므로 스냅샷 위치를 지정할 필요가 없습니다.
보안
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 시크릿 을 생성합니다.
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의 시크릿 오브젝트를 생성합니다.
-
DataProtectionApplicationCR에서 지정하는 백업 위치에 대한 사용자 지정시크릿입니다. -
DataProtectionApplicationCR에서 참조되지 않는 스냅샷 위치의 기본시크릿입니다.
데이터 보호 애플리케이션에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다.
설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 보안을 생성할 수 있습니다.
4.4.4.2.1. 기본 보안 생성
백업 및 스냅샷 위치에 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 보안을 생성합니다.
시크릿 의 기본 이름은 cloud-credentials-azure 입니다.
DataProtectionApplication CR(사용자 정의 리소스)에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다. 백업 위치 Secret 의 이름이 지정되지 않은 경우 기본 이름이 사용됩니다.
설치 중에 백업 위치 인증 정보를 사용하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 이름으로 보안을 생성할 수 있습니다.
사전 요구 사항
- 오브젝트 스토리지 및 클라우드 스토리지(있는 경우)는 동일한 인증 정보를 사용해야 합니다.
- Velero의 오브젝트 스토리지를 구성해야 합니다.
-
적절한 형식으로 오브젝트 스토리지에 대한
credentials-velero파일을 생성해야 합니다.
절차
기본 이름으로 보안을 생성합니다.
$ oc create secret generic cloud-credentials-azure -n openshift-adp --from-file cloud=credentials-velero
데이터 보호 애플리케이션을 설치할 때 DataProtectionApplication CR의 spec.backupLocations.credential 블록에서 시크릿 을 참조합니다.
4.4.4.2.2. 다른 인증 정보에 대한 보안 생성
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 두 개의 Secret 오브젝트를 생성해야 합니다.
-
사용자 지정 이름이 있는 백업 위치
시크릿. 사용자 지정 이름은DataProtectionApplicationCR(사용자 정의 리소스)의spec.backupLocations블록에 지정됩니다. -
기본 이름이
cloud-credentials-azure인 스냅샷 위치시크릿. 이보안은DataProtectionApplicationCR에 지정되지 않습니다.
절차
-
클라우드 공급자에 대한 적절한 형식으로 스냅샷 위치에 대한
credentials-velero파일을 만듭니다. 기본 이름을 사용하여 스냅샷 위치에 대한 보안을 생성합니다.
$ oc create secret generic cloud-credentials-azure -n openshift-adp --from-file cloud=credentials-velero
-
오브젝트 스토리지에 적합한 형식으로 백업 위치에 대한
credentials-velero파일을 생성합니다. 사용자 지정 이름을 사용하여 백업 위치에 대한 보안을 생성합니다.
$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero
다음
예와 같이 사용자 지정 이름으로 보안을DataProtectionApplicationCR에 추가합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: resourceGroup: <azure_resource_group> storageAccount: <azure_storage_account_id> subscriptionId: <azure_subscription_id> storageAccountKeyEnvVar: AZURE_STORAGE_ACCOUNT_ACCESS_KEY credential: key: cloud name: <custom_secret> 1 provider: azure default: true objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" name: default provider: azure- 1
- 사용자 지정 이름이 있는 백업 위치
시크릿.
4.4.4.3. 데이터 보호 애플리케이션 구성
Velero 리소스 할당을 설정하거나 자체 서명된 CA 인증서를 활성화하여 데이터 보호 애플리케이션을 구성할 수 있습니다.
4.4.4.3.1. Velero CPU 및 메모리 리소스 할당 설정
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 Velero Pod에 대한 CPU 및 메모리 리소스 할당을 설정합니다.
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.podConfig.ResourceAllocations블록의 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.4.3.2. 자체 서명 CA 인증서 활성화
알 수 없는 기관에서 서명한 인증서를 방지하기 위해 활성화해야 합니다.
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 오브젝트 스토리지에 대해 자체 서명 CA 인증서를
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
DataProtectionApplicationCR 매니페스트의spec.backupLocations.velero.objectStorage.caCert매개변수 및spec.backupLocations.velero.config매개변수를 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 ...
4.4.4.4. 데이터 보호 애플리케이션 설치
DataProtectionApplication API 인스턴스를 생성하여 DPA( Data Protection Application )를 설치합니다.
사전 요구 사항
- OADP Operator를 설치해야 합니다.
- 오브젝트 스토리지를 백업 위치로 구성해야 합니다.
- 스냅샷을 사용하여 PV를 백업하는 경우 클라우드 공급자는 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
-
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하는 경우 기본 이름
cloud-credentials-azure로 보안을 생성해야 합니다. 백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의
시크릿을 생성해야 합니다.-
백업 위치에 대한 사용자 정의 이름이 있는
시크릿입니다. 이 보안을DataProtectionApplicationCR에 추가합니다. 스냅샷 위치의 기본 이름
cloud-credentials-azure를 사용하는시크릿입니다. 이보안은DataProtectionApplicationCR에서 참조되지 않습니다.참고설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈
credentials-velero파일을사용하여기본 보안을 생성할 수 있습니다. 기본Secret이 없으면 설치에 실패합니다.참고Velero는 기본 백업 리포지토리 암호가 포함된 OADP 네임스페이스에
velero-repo-credentials라는 시크릿을 생성합니다. 백업 리포지토리를 대상으로 하는 첫 번째 백업을 실행하기 전에 base64로 인코딩된 고유한 암호로 시크릿을 업데이트할 수 있습니다. 업데이트할 키의 값은Data[repository-password]입니다.DPA를 생성한 후 백업 리포지토리를 대상으로 하는 백업을 처음 실행하면 Velero에서 시크릿이 기본 암호 또는 교체한 암호가 포함된
velero-repo-credentials인 백업 리포지토리를 생성합니다. 첫 번째 백업 후 시크릿 암호를 업데이트하면 새 암호가velero-repo-credentials의 암호와 일치하지 않으므로 Velero는 이전 백업과 연결할 수 없습니다.
-
백업 위치에 대한 사용자 정의 이름이 있는
절차
- Operators → 설치된 Operator 를 클릭하고 OADP Operator를 선택합니다.
- 제공된 API 아래에서 DataProtectionApplication 상자에서 인스턴스 생성을 클릭합니다.
YAML 보기를 클릭하고
DataProtectionApplication매니페스트의 매개변수를 업데이트합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - azure - openshift 1 resourceTimeout: 10m 2 restic: enable: true 3 podConfig: nodeSelector: <node_selector> 4 backupLocations: - velero: config: resourceGroup: <azure_resource_group> 5 storageAccount: <azure_storage_account_id> 6 subscriptionId: <azure_subscription_id> 7 storageAccountKeyEnvVar: AZURE_STORAGE_ACCOUNT_ACCESS_KEY credential: key: cloud name: cloud-credentials-azure 8 provider: azure default: true objectStorage: bucket: <bucket_name> 9 prefix: <prefix> 10 snapshotLocations: 11 - velero: config: resourceGroup: <azure_resource_group> subscriptionId: <azure_subscription_id> incremental: "true" name: default provider: azure- 1
openshift플러그인은 필수입니다.- 2
- Velero CRD 가용성, volumeSnapshot 삭제, 백업 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 분을 지정합니다. 기본값은 10m입니다.
- 3
- Restic 설치를 비활성화하려면 이 값을
false로 설정합니다. Restic은 데몬 세트를 배포합니다. 즉, Restic pod는 각 작업 노드에서 실행됩니다. OADP 버전 1.2 이상에서는BackupCR에spec.defaultVolumesToFsBackup: true를 추가하여 백업에 대해 Restic을 구성할 수 있습니다. OADP 버전 1.1에서BackupCR에spec.defaultVolumesToRestic: true를 추가합니다. - 4
- Restic을 사용할 수 있는 노드를 지정합니다. 기본적으로 Restic은 모든 노드에서 실행됩니다.
- 5
- Azure 리소스 그룹을 지정합니다.
- 6
- Azure 스토리지 계정 ID를 지정합니다.
- 7
- Azure 서브스크립션 ID를 지정합니다.
- 8
- 이 값을 지정하지 않으면 기본 이름
cloud-credentials-azure이 사용됩니다. 사용자 지정 이름을 지정하면 백업 위치에 사용자 지정 이름이 사용됩니다. - 9
- 버킷을 백업 스토리지 위치로 지정합니다. 버킷이 Velero 백업의 전용 버킷이 아닌 경우 접두사를 지정해야 합니다.
- 10
- 버킷이 여러 목적으로 사용되는 경우 Velero 백업의 접두사(예:
velero)를 지정합니다. - 11
- PV를 백업하려면 CSI 스냅샷 또는 Restic을 사용하는 경우 스냅샷 위치를 지정할 필요가 없습니다.
- 생성을 클릭합니다.
OADP 리소스를 확인하여 설치를 확인합니다.
$ oc get all -n openshift-adp
출력 예
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.4.4.1. DataProtectionApplication CR에서 CSI 활성화
CSI 스냅샷을 사용하여 영구 볼륨을 백업하기 위해 DataProtectionApplication CR(사용자 정의 리소스)에서 CSI(Container Storage Interface)를 활성화합니다.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csi기본 플러그인을 추가합니다.
4.4.5. Google Cloud Platform을 사용하여 데이터 보호를 위한 OpenShift API 구성
OADP Operator를 설치하여 GCP(Google Cloud Platform)를 사용하여 OADP(Data Protection)를 OpenShift API를 설치합니다. Operator는 Velero 1.11 을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Velero에 대한 GCP를 구성하고 기본 시크릿 을 생성한 다음 데이터 보호 애플리케이션을 설치합니다. 자세한 내용은 OADP Operator 설치를 참조하십시오.
제한된 네트워크 환경에 OADP Operator를 설치하려면 먼저 기본 OperatorHub 소스를 비활성화하고 Operator 카탈로그를 미러링해야 합니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
4.4.5.1. GCP(Google Cloud Platform) 구성
OADP(Data Protection)를 위해 OpenShift API를 위해 GCP(Google Cloud Platform)를 구성합니다.
사전 요구 사항
-
gcloud및gsutilCLI 툴이 설치되어 있어야 합니다. 자세한 내용은 Google 클라우드 설명서를 참조하십시오.
절차
GCP에 로그인합니다.
$ gcloud auth login
BUCKET변수를 설정합니다.$ BUCKET=<bucket> 1- 1
- 버킷 이름을 지정합니다.
스토리지 버킷을 생성합니다.
$ gsutil mb gs://$BUCKET/
PROJECT_ID변수를 활성 프로젝트로 설정합니다.$ PROJECT_ID=$(gcloud config get-value project)
서비스 계정을 생성합니다.
$ gcloud iam service-accounts create velero \ --display-name "Velero service account"서비스 계정을 나열합니다.
$ gcloud iam service-accounts list
email값과 일치하도록SERVICE_ACCOUNT_EMAIL변수를 설정합니다.$ SERVICE_ACCOUNT_EMAIL=$(gcloud iam service-accounts list \ --filter="displayName:Velero service account" \ --format 'value(email)')정책을 연결하여
velero사용자에게 필요한 최소 권한을 부여합니다.$ ROLE_PERMISSIONS=( compute.disks.get compute.disks.create compute.disks.createSnapshot compute.snapshots.get compute.snapshots.create compute.snapshots.useReadOnly compute.snapshots.delete compute.zones.get storage.objects.create storage.objects.delete storage.objects.get storage.objects.list iam.serviceAccounts.signBlob )velero.server사용자 정의 역할을 생성합니다.$ gcloud iam roles create velero.server \ --project $PROJECT_ID \ --title "Velero Server" \ --permissions "$(IFS=","; echo "${ROLE_PERMISSIONS[*]}")"프로젝트에 IAM 정책 바인딩을 추가합니다.
$ gcloud projects add-iam-policy-binding $PROJECT_ID \ --member serviceAccount:$SERVICE_ACCOUNT_EMAIL \ --role projects/$PROJECT_ID/roles/velero.serverIAM 서비스 계정을 업데이트합니다.
$ gsutil iam ch serviceAccount:$SERVICE_ACCOUNT_EMAIL:objectAdmin gs://${BUCKET}IAM 서비스 계정 키를 현재 디렉터리의
credentials-velero파일에 저장합니다.$ gcloud iam service-accounts keys create credentials-velero \ --iam-account $SERVICE_ACCOUNT_EMAILData Protection 애플리케이션을 설치하기 전에
credentials-velero파일을 사용하여 GCP용Secret오브젝트를 생성합니다.
4.4.5.2. 백업 및 스냅샷 위치 및 시크릿 정보
DataProtectionApplication CR(사용자 정의 리소스)에서 백업 및 스냅샷 위치와 해당 시크릿을 지정합니다.
백업 위치
Multicloud Object Gateway 또는 MinIO와 같은 S3 호환 오브젝트 스토리지를 백업 위치로 지정합니다.
Velero는 OpenShift Container Platform 리소스, Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 백업합니다.
스냅샷 위치
클라우드 공급자의 네이티브 스냅샷 API를 사용하여 영구 볼륨을 백업하는 경우 클라우드 공급자를 스냅샷 위치로 지정해야 합니다.
CSI(Container Storage Interface) 스냅샷을 사용하는 경우 CSI 드라이버를 등록할 VolumeSnapshotClass CR을 생성하므로 스냅샷 위치를 지정할 필요가 없습니다.
Restic을 사용하는 경우 Restic이 오브젝트 스토리지의 파일 시스템을 백업하므로 스냅샷 위치를 지정할 필요가 없습니다.
보안
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 시크릿 을 생성합니다.
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의 시크릿 오브젝트를 생성합니다.
-
DataProtectionApplicationCR에서 지정하는 백업 위치에 대한 사용자 지정시크릿입니다. -
DataProtectionApplicationCR에서 참조되지 않는 스냅샷 위치의 기본시크릿입니다.
데이터 보호 애플리케이션에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다.
설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 보안을 생성할 수 있습니다.
4.4.5.2.1. 기본 보안 생성
백업 및 스냅샷 위치에 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 보안을 생성합니다.
보안의 기본 이름은 입니다.
cloud -credentials-gcp
DataProtectionApplication CR(사용자 정의 리소스)에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다. 백업 위치 Secret 의 이름이 지정되지 않은 경우 기본 이름이 사용됩니다.
설치 중에 백업 위치 인증 정보를 사용하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 이름으로 보안을 생성할 수 있습니다.
사전 요구 사항
- 오브젝트 스토리지 및 클라우드 스토리지(있는 경우)는 동일한 인증 정보를 사용해야 합니다.
- Velero의 오브젝트 스토리지를 구성해야 합니다.
-
적절한 형식으로 오브젝트 스토리지에 대한
credentials-velero파일을 생성해야 합니다.
절차
기본 이름으로 보안을 생성합니다.
$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero
데이터 보호 애플리케이션을 설치할 때 DataProtectionApplication CR의 spec.backupLocations.credential 블록에서 시크릿 을 참조합니다.
4.4.5.2.2. 다른 인증 정보에 대한 보안 생성
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 두 개의 Secret 오브젝트를 생성해야 합니다.
-
사용자 지정 이름이 있는 백업 위치
시크릿. 사용자 지정 이름은DataProtectionApplicationCR(사용자 정의 리소스)의spec.backupLocations블록에 지정됩니다. -
기본 이름이
cloud-credentials-gcp인 스냅샷 위치시크릿. 이보안은DataProtectionApplicationCR에 지정되지 않습니다.
절차
-
클라우드 공급자에 대한 적절한 형식으로 스냅샷 위치에 대한
credentials-velero파일을 만듭니다. 기본 이름을 사용하여 스냅샷 위치에 대한 보안을 생성합니다.
$ oc create secret generic cloud-credentials-gcp -n openshift-adp --from-file cloud=credentials-velero
-
오브젝트 스토리지에 적합한 형식으로 백업 위치에 대한
credentials-velero파일을 생성합니다. 사용자 지정 이름을 사용하여 백업 위치에 대한 보안을 생성합니다.
$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero
다음
예와 같이 사용자 지정 이름으로 보안을DataProtectionApplicationCR에 추가합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: provider: gcp default: true credential: key: cloud name: <custom_secret> 1 objectStorage: bucket: <bucket_name> prefix: <prefix> snapshotLocations: - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west1- 1
- 사용자 지정 이름이 있는 백업 위치
시크릿.
4.4.5.3. 데이터 보호 애플리케이션 구성
Velero 리소스 할당을 설정하거나 자체 서명된 CA 인증서를 활성화하여 데이터 보호 애플리케이션을 구성할 수 있습니다.
4.4.5.3.1. Velero CPU 및 메모리 리소스 할당 설정
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 Velero Pod에 대한 CPU 및 메모리 리소스 할당을 설정합니다.
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.podConfig.ResourceAllocations블록의 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.5.3.2. 자체 서명 CA 인증서 활성화
알 수 없는 기관에서 서명한 인증서를 방지하기 위해 활성화해야 합니다.
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 오브젝트 스토리지에 대해 자체 서명 CA 인증서를
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
DataProtectionApplicationCR 매니페스트의spec.backupLocations.velero.objectStorage.caCert매개변수 및spec.backupLocations.velero.config매개변수를 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 ...
4.4.5.4. 데이터 보호 애플리케이션 설치
DataProtectionApplication API 인스턴스를 생성하여 DPA( Data Protection Application )를 설치합니다.
사전 요구 사항
- OADP Operator를 설치해야 합니다.
- 오브젝트 스토리지를 백업 위치로 구성해야 합니다.
- 스냅샷을 사용하여 PV를 백업하는 경우 클라우드 공급자는 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
-
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하는 경우 기본 이름
cloud-credentials-gcp를 사용하여 보안을 생성해야 합니다. 백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의
시크릿을 생성해야 합니다.-
백업 위치에 대한 사용자 정의 이름이 있는
시크릿입니다. 이 보안을DataProtectionApplicationCR에 추가합니다. 스냅샷 위치의 기본 이름
cloud-credentials-gcp를 사용하는시크릿입니다. 이보안은DataProtectionApplicationCR에서 참조되지 않습니다.참고설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈
credentials-velero파일을사용하여기본 보안을 생성할 수 있습니다. 기본Secret이 없으면 설치에 실패합니다.참고Velero는 기본 백업 리포지토리 암호가 포함된 OADP 네임스페이스에
velero-repo-credentials라는 시크릿을 생성합니다. 백업 리포지토리를 대상으로 하는 첫 번째 백업을 실행하기 전에 base64로 인코딩된 고유한 암호로 시크릿을 업데이트할 수 있습니다. 업데이트할 키의 값은Data[repository-password]입니다.DPA를 생성한 후 백업 리포지토리를 대상으로 하는 백업을 처음 실행하면 Velero에서 시크릿이 기본 암호 또는 교체한 암호가 포함된
velero-repo-credentials인 백업 리포지토리를 생성합니다. 첫 번째 백업 후 시크릿 암호를 업데이트하면 새 암호가velero-repo-credentials의 암호와 일치하지 않으므로 Velero는 이전 백업과 연결할 수 없습니다.
-
백업 위치에 대한 사용자 정의 이름이 있는
절차
- Operators → 설치된 Operator 를 클릭하고 OADP Operator를 선택합니다.
- 제공된 API 아래에서 DataProtectionApplication 상자에서 인스턴스 생성을 클릭합니다.
YAML 보기를 클릭하고
DataProtectionApplication매니페스트의 매개변수를 업데이트합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - gcp - openshift 1 resourceTimeout: 10m 2 restic: enable: true 3 podConfig: nodeSelector: <node_selector> 4 backupLocations: - velero: provider: gcp default: true credential: key: cloud name: cloud-credentials-gcp 5 objectStorage: bucket: <bucket_name> 6 prefix: <prefix> 7 snapshotLocations: 8 - velero: provider: gcp default: true config: project: <project> snapshotLocation: us-west1 9- 1
openshift플러그인은 필수입니다.- 2
- Velero CRD 가용성, volumeSnapshot 삭제, 백업 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 분을 지정합니다. 기본값은 10m입니다.
- 3
- Restic 설치를 비활성화하려면 이 값을
false로 설정합니다. Restic은 데몬 세트를 배포합니다. 즉, Restic pod는 각 작업 노드에서 실행됩니다. OADP 버전 1.2 이상에서는BackupCR에spec.defaultVolumesToFsBackup: true를 추가하여 백업에 대해 Restic을 구성할 수 있습니다. OADP 버전 1.1에서BackupCR에spec.defaultVolumesToRestic: true를 추가합니다. - 4
- Restic을 사용할 수 있는 노드를 지정합니다. 기본적으로 Restic은 모든 노드에서 실행됩니다.
- 5
- 이 값을 지정하지 않으면 기본 이름
cloud-credentials-gcp가 사용됩니다. 사용자 지정 이름을 지정하면 백업 위치에 사용자 지정 이름이 사용됩니다. - 6
- 버킷을 백업 스토리지 위치로 지정합니다. 버킷이 Velero 백업의 전용 버킷이 아닌 경우 접두사를 지정해야 합니다.
- 7
- 버킷이 여러 목적으로 사용되는 경우 Velero 백업의 접두사(예:
velero)를 지정합니다. - 8
- CSI 스냅샷 또는 Restic을 사용하여 PV를 백업하지 않는 한 스냅샷 위치를 지정합니다.
- 9
- 스냅샷 위치는 PV와 동일한 리전에 있어야 합니다.
- 생성을 클릭합니다.
OADP 리소스를 확인하여 설치를 확인합니다.
$ oc get all -n openshift-adp
출력 예
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.5.4.1. DataProtectionApplication CR에서 CSI 활성화
CSI 스냅샷을 사용하여 영구 볼륨을 백업하기 위해 DataProtectionApplication CR(사용자 정의 리소스)에서 CSI(Container Storage Interface)를 활성화합니다.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csi기본 플러그인을 추가합니다.
4.4.6. Multicloud Object Gateway를 사용하여 데이터 보호를 위한 OpenShift API 구성
OADP Operator를 설치하여 MCG(Multicloud Object Gateway)와 함께 OADP(OpenShift API for Data Protection)를 설치합니다. Operator는 Velero 1.11 을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Multicloud Object Gateway 를 백업 위치로 구성합니다. MCG는 OpenShift Data Foundation의 구성 요소입니다. MCG를 DataProtectionApplication CR(사용자 정의 리소스)에서 백업 위치로 구성합니다.
오브젝트 스토리지를 위한 버킷 생성을 자동화하는 CloudStorage API는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
백업 위치에 대한 보안을 생성한 다음 데이터 보호 애플리케이션을 설치합니다. 자세한 내용은 OADP Operator 설치를 참조하십시오.
제한된 네트워크 환경에 OADP Operator를 설치하려면 먼저 기본 OperatorHub 소스를 비활성화하고 Operator 카탈로그를 미러링해야 합니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
4.4.6.1. 멀티 클라우드 오브젝트 게이트웨이 인증 정보 검색
OADP(데이터 보호)용 OpenShift API에 대한 Secret CR(사용자 정의 리소스)을 생성하려면 MCG(Multicloud Object Gateway) 인증 정보를 검색해야 합니다.
MCG는 OpenShift Data Foundation의 구성 요소입니다.
사전 요구 사항
- 적절한 OpenShift Data Foundation 배포 가이드를 사용하여 OpenShift Data Foundation 을 배포해야 합니다.
절차
-
NooBaa사용자 정의 리소스에서describe명령을 실행하여 S3 끝점,AWS_ACCESS_KEY 및AWS_SECRET_ACCESS_KEY를 가져옵니다. credentials-velero파일을 생성합니다.$ cat << EOF > ./credentials-velero [default] aws_access_key_id=<AWS_ACCESS_KEY_ID> aws_secret_access_key=<AWS_SECRET_ACCESS_KEY> EOF
credentials-velero파일을 사용하여 Data Protection 애플리케이션을 설치할 때Secret오브젝트를 생성합니다.
4.4.6.2. 백업 및 스냅샷 위치 및 시크릿 정보
DataProtectionApplication CR(사용자 정의 리소스)에서 백업 및 스냅샷 위치와 해당 시크릿을 지정합니다.
백업 위치
Multicloud Object Gateway 또는 MinIO와 같은 S3 호환 오브젝트 스토리지를 백업 위치로 지정합니다.
Velero는 OpenShift Container Platform 리소스, Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 백업합니다.
스냅샷 위치
클라우드 공급자의 네이티브 스냅샷 API를 사용하여 영구 볼륨을 백업하는 경우 클라우드 공급자를 스냅샷 위치로 지정해야 합니다.
CSI(Container Storage Interface) 스냅샷을 사용하는 경우 CSI 드라이버를 등록할 VolumeSnapshotClass CR을 생성하므로 스냅샷 위치를 지정할 필요가 없습니다.
Restic을 사용하는 경우 Restic이 오브젝트 스토리지의 파일 시스템을 백업하므로 스냅샷 위치를 지정할 필요가 없습니다.
보안
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 시크릿 을 생성합니다.
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의 시크릿 오브젝트를 생성합니다.
-
DataProtectionApplicationCR에서 지정하는 백업 위치에 대한 사용자 지정시크릿입니다. -
DataProtectionApplicationCR에서 참조되지 않는 스냅샷 위치의 기본시크릿입니다.
데이터 보호 애플리케이션에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다.
설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 보안을 생성할 수 있습니다.
4.4.6.2.1. 기본 보안 생성
백업 및 스냅샷 위치에 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 보안을 생성합니다.
시크릿 의 기본 이름은 cloud-credentials 입니다.
DataProtectionApplication CR(사용자 정의 리소스)에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다. 백업 위치 Secret 의 이름이 지정되지 않은 경우 기본 이름이 사용됩니다.
설치 중에 백업 위치 인증 정보를 사용하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 이름으로 보안을 생성할 수 있습니다.
사전 요구 사항
- 오브젝트 스토리지 및 클라우드 스토리지(있는 경우)는 동일한 인증 정보를 사용해야 합니다.
- Velero의 오브젝트 스토리지를 구성해야 합니다.
-
적절한 형식으로 오브젝트 스토리지에 대한
credentials-velero파일을 생성해야 합니다.
절차
기본 이름으로 보안을 생성합니다.
$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
데이터 보호 애플리케이션을 설치할 때 DataProtectionApplication CR의 spec.backupLocations.credential 블록에서 시크릿 을 참조합니다.
4.4.6.2.2. 다른 인증 정보에 대한 보안 생성
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 두 개의 Secret 오브젝트를 생성해야 합니다.
-
사용자 지정 이름이 있는 백업 위치
시크릿. 사용자 지정 이름은DataProtectionApplicationCR(사용자 정의 리소스)의spec.backupLocations블록에 지정됩니다. -
기본 이름이
cloud-credentials인 스냅샷 위치시크릿. 이보안은DataProtectionApplicationCR에 지정되지 않습니다.
절차
-
클라우드 공급자에 대한 적절한 형식으로 스냅샷 위치에 대한
credentials-velero파일을 만듭니다. 기본 이름을 사용하여 스냅샷 위치에 대한 보안을 생성합니다.
$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
-
오브젝트 스토리지에 적합한 형식으로 백업 위치에 대한
credentials-velero파일을 생성합니다. 사용자 지정 이름을 사용하여 백업 위치에 대한 보안을 생성합니다.
$ oc create secret generic <custom_secret> -n openshift-adp --from-file cloud=credentials-velero
다음
예와 같이 사용자 지정 이름으로 보안을DataProtectionApplicationCR에 추가합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: ... backupLocations: - velero: config: profile: "default" region: minio s3Url: <url> insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: <custom_secret> 1 objectStorage: bucket: <bucket_name> prefix: <prefix>- 1
- 사용자 지정 이름이 있는 백업 위치
시크릿.
4.4.6.3. 데이터 보호 애플리케이션 구성
Velero 리소스 할당을 설정하거나 자체 서명된 CA 인증서를 활성화하여 데이터 보호 애플리케이션을 구성할 수 있습니다.
4.4.6.3.1. Velero CPU 및 메모리 리소스 할당 설정
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 Velero Pod에 대한 CPU 및 메모리 리소스 할당을 설정합니다.
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.podConfig.ResourceAllocations블록의 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.6.3.2. 자체 서명 CA 인증서 활성화
알 수 없는 기관에서 서명한 인증서를 방지하기 위해 활성화해야 합니다.
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 오브젝트 스토리지에 대해 자체 서명 CA 인증서를
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
DataProtectionApplicationCR 매니페스트의spec.backupLocations.velero.objectStorage.caCert매개변수 및spec.backupLocations.velero.config매개변수를 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 ...
4.4.6.4. 데이터 보호 애플리케이션 설치
DataProtectionApplication API 인스턴스를 생성하여 DPA( Data Protection Application )를 설치합니다.
사전 요구 사항
- OADP Operator를 설치해야 합니다.
- 오브젝트 스토리지를 백업 위치로 구성해야 합니다.
- 스냅샷을 사용하여 PV를 백업하는 경우 클라우드 공급자는 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
-
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하는 경우 기본 이름
cloud-credentials로Secret을 생성해야 합니다. 백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의
시크릿을 생성해야 합니다.-
백업 위치에 대한 사용자 정의 이름이 있는
시크릿입니다. 이 보안을DataProtectionApplicationCR에 추가합니다. 스냅샷 위치의 기본 이름
cloud-credentials를 사용하는시크릿입니다. 이보안은DataProtectionApplicationCR에서 참조되지 않습니다.참고설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈
credentials-velero파일을사용하여기본 보안을 생성할 수 있습니다. 기본Secret이 없으면 설치에 실패합니다.참고Velero는 기본 백업 리포지토리 암호가 포함된 OADP 네임스페이스에
velero-repo-credentials라는 시크릿을 생성합니다. 백업 리포지토리를 대상으로 하는 첫 번째 백업을 실행하기 전에 base64로 인코딩된 고유한 암호로 시크릿을 업데이트할 수 있습니다. 업데이트할 키의 값은Data[repository-password]입니다.DPA를 생성한 후 백업 리포지토리를 대상으로 하는 백업을 처음 실행하면 Velero에서 시크릿이 기본 암호 또는 교체한 암호가 포함된
velero-repo-credentials인 백업 리포지토리를 생성합니다. 첫 번째 백업 후 시크릿 암호를 업데이트하면 새 암호가velero-repo-credentials의 암호와 일치하지 않으므로 Velero는 이전 백업과 연결할 수 없습니다.
-
백업 위치에 대한 사용자 정의 이름이 있는
절차
- Operators → 설치된 Operator 를 클릭하고 OADP Operator를 선택합니다.
- 제공된 API 아래에서 DataProtectionApplication 상자에서 인스턴스 생성을 클릭합니다.
YAML 보기를 클릭하고
DataProtectionApplication매니페스트의 매개변수를 업데이트합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> namespace: openshift-adp spec: configuration: velero: defaultPlugins: - aws - openshift 1 resourceTimeout: 10m 2 restic: enable: true 3 podConfig: nodeSelector: <node_selector> 4 backupLocations: - velero: config: profile: "default" region: minio s3Url: <url> 5 insecureSkipTLSVerify: "true" s3ForcePathStyle: "true" provider: aws default: true credential: key: cloud name: cloud-credentials 6 objectStorage: bucket: <bucket_name> 7 prefix: <prefix> 8- 1
openshift플러그인은 필수입니다.- 2
- Velero CRD 가용성, volumeSnapshot 삭제, 백업 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 분을 지정합니다. 기본값은 10m입니다.
- 3
- Restic 설치를 비활성화하려면 이 값을
false로 설정합니다. Restic은 데몬 세트를 배포합니다. 즉, Restic pod는 각 작업 노드에서 실행됩니다. OADP 버전 1.2 이상에서는BackupCR에spec.defaultVolumesToFsBackup: true를 추가하여 백업에 대해 Restic을 구성할 수 있습니다. OADP 버전 1.1에서BackupCR에spec.defaultVolumesToRestic: true를 추가합니다. - 4
- Restic을 사용할 수 있는 노드를 지정합니다. 기본적으로 Restic은 모든 노드에서 실행됩니다.
- 5
- S3 끝점의 URL을 지정합니다.
- 6
- 이 값을 지정하지 않으면 기본 이름
cloud-credentials가 사용됩니다. 사용자 지정 이름을 지정하면 백업 위치에 사용자 지정 이름이 사용됩니다. - 7
- 버킷을 백업 스토리지 위치로 지정합니다. 버킷이 Velero 백업의 전용 버킷이 아닌 경우 접두사를 지정해야 합니다.
- 8
- 버킷이 여러 목적으로 사용되는 경우 Velero 백업의 접두사(예:
velero)를 지정합니다.
- 생성을 클릭합니다.
OADP 리소스를 확인하여 설치를 확인합니다.
$ oc get all -n openshift-adp
출력 예
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.6.4.1. DataProtectionApplication CR에서 CSI 활성화
CSI 스냅샷을 사용하여 영구 볼륨을 백업하기 위해 DataProtectionApplication CR(사용자 정의 리소스)에서 CSI(Container Storage Interface)를 활성화합니다.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csi기본 플러그인을 추가합니다.
4.4.7. OpenShift Data Foundation으로 데이터 보호를 위한 OpenShift API 구성
OADP Operator를 설치하고 백업 위치와 스냅샷 위치를 구성하여 OpenShift Data Foundation과 함께 OADP(OpenShift API for Data Protection)를 설치합니다. 그런 다음 데이터 보호 애플리케이션을 설치합니다.
OADP 1.0.4부터 모든 OADP 1.0.z 버전은 MTC Operator의 종속성으로만 사용할 수 있으며 독립 실행형 Operator로 사용할 수 없습니다.
Multicloud Object Gateway 또는 S3 호환 개체 스토리지를 백업 위치로 구성할 수 있습니다.
오브젝트 스토리지를 위한 버킷 생성을 자동화하는 CloudStorage API는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
백업 위치에 대한 보안을 생성한 다음 데이터 보호 애플리케이션을 설치합니다. 자세한 내용은 OADP Operator 설치를 참조하십시오.
제한된 네트워크 환경에 OADP Operator를 설치하려면 먼저 기본 OperatorHub 소스를 비활성화하고 Operator 카탈로그를 미러링해야 합니다. 자세한 내용은 제한된 네트워크에서 Operator Lifecycle Manager 사용을 참조하십시오.
4.4.7.1. 백업 및 스냅샷 위치 및 시크릿 정보
DataProtectionApplication CR(사용자 정의 리소스)에서 백업 및 스냅샷 위치와 해당 시크릿을 지정합니다.
백업 위치
Multicloud Object Gateway 또는 MinIO와 같은 S3 호환 오브젝트 스토리지를 백업 위치로 지정합니다.
Velero는 OpenShift Container Platform 리소스, Kubernetes 오브젝트 및 내부 이미지를 오브젝트 스토리지의 아카이브 파일로 백업합니다.
스냅샷 위치
클라우드 공급자의 네이티브 스냅샷 API를 사용하여 영구 볼륨을 백업하는 경우 클라우드 공급자를 스냅샷 위치로 지정해야 합니다.
CSI(Container Storage Interface) 스냅샷을 사용하는 경우 CSI 드라이버를 등록할 VolumeSnapshotClass CR을 생성하므로 스냅샷 위치를 지정할 필요가 없습니다.
Restic을 사용하는 경우 Restic이 오브젝트 스토리지의 파일 시스템을 백업하므로 스냅샷 위치를 지정할 필요가 없습니다.
보안
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 시크릿 을 생성합니다.
백업 및 스냅샷 위치에서 다른 인증 정보를 사용하는 경우 다음 두 개의 시크릿 오브젝트를 생성합니다.
-
DataProtectionApplicationCR에서 지정하는 백업 위치에 대한 사용자 지정시크릿입니다. -
DataProtectionApplicationCR에서 참조되지 않는 스냅샷 위치의 기본시크릿입니다.
데이터 보호 애플리케이션에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다.
설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 보안을 생성할 수 있습니다.
4.4.7.1.1. 기본 보안 생성
백업 및 스냅샷 위치에 동일한 인증 정보를 사용하거나 스냅샷 위치가 필요하지 않은 경우 기본 보안을 생성합니다.
DataProtectionApplication CR(사용자 정의 리소스)에는 기본 시크릿 이 필요합니다. 그러지 않으면 설치에 실패합니다. 백업 위치 Secret 의 이름이 지정되지 않은 경우 기본 이름이 사용됩니다.
설치 중에 백업 위치 인증 정보를 사용하지 않으려면 빈 credentials-velero 파일을 사용하여 기본 이름으로 보안을 생성할 수 있습니다.
사전 요구 사항
- 오브젝트 스토리지 및 클라우드 스토리지(있는 경우)는 동일한 인증 정보를 사용해야 합니다.
- Velero의 오브젝트 스토리지를 구성해야 합니다.
-
적절한 형식으로 오브젝트 스토리지에 대한
credentials-velero파일을 생성해야 합니다.
절차
기본 이름으로 보안을 생성합니다.
$ oc create secret generic cloud-credentials -n openshift-adp --from-file cloud=credentials-velero
데이터 보호 애플리케이션을 설치할 때 DataProtectionApplication CR의 spec.backupLocations.credential 블록에서 시크릿 을 참조합니다.
4.4.7.2. 데이터 보호 애플리케이션 구성
Velero 리소스 할당을 설정하거나 자체 서명된 CA 인증서를 활성화하여 데이터 보호 애플리케이션을 구성할 수 있습니다.
4.4.7.2.1. Velero CPU 및 메모리 리소스 할당 설정
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 Velero Pod에 대한 CPU 및 메모리 리소스 할당을 설정합니다.
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.podConfig.ResourceAllocations블록의 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... configuration: velero: podConfig: nodeSelector: <node selector> 1 resourceAllocations: 2 limits: cpu: "1" memory: 1024Mi requests: cpu: 200m memory: 256Mi
4.4.7.2.1.1. 수집된 데이터를 기반으로 Ceph CPU 및 메모리 요구 사항 조정
다음 권장 사항은 규모 및 성능 랩에서 수행된 성능 관찰을 기반으로 합니다. 변경 사항은 특히 {odf-first}와 관련이 있습니다. {odf-short}로 작업하는 경우 공식 권장 사항은 적절한 튜닝 가이드를 참조하십시오.
4.4.7.2.1.1.1. 구성에 대한 CPU 및 메모리 요구 사항
백업 및 복원 작업에는 대량의 CephFS PersistentVolume (PV)이 필요합니다. 메모리 부족(OOM) 오류로 Ceph MDS Pod를 재시작하지 않으려면 다음 설정이 권장됩니다.
| 구성 유형 | 요청 | 최대 제한 |
|---|---|---|
| CPU | 3으로 변경됨 | 최대 제한 3 |
| 메모리 | 8Gi로 변경됨 | 최대 제한 128Gi |
4.4.7.2.2. 자체 서명 CA 인증서 활성화
알 수 없는 기관에서 서명한 인증서를 방지하기 위해 활성화해야 합니다.
DataProtectionApplication CR(사용자 정의 리소스) 매니페스트를 편집하여 오브젝트 스토리지에 대해 자체 서명 CA 인증서를
사전 요구 사항
- OADP(OpenShift API for Data Protection) Operator가 설치되어 있어야 합니다.
절차
DataProtectionApplicationCR 매니페스트의spec.backupLocations.velero.objectStorage.caCert매개변수 및spec.backupLocations.velero.config매개변수를 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_sample> spec: ... backupLocations: - name: default velero: provider: aws default: true objectStorage: bucket: <bucket> prefix: <prefix> caCert: <base64_encoded_cert_string> 1 config: insecureSkipTLSVerify: "false" 2 ...
4.4.7.3. 데이터 보호 애플리케이션 설치
DataProtectionApplication API 인스턴스를 생성하여 DPA( Data Protection Application )를 설치합니다.
사전 요구 사항
- OADP Operator를 설치해야 합니다.
- 오브젝트 스토리지를 백업 위치로 구성해야 합니다.
- 스냅샷을 사용하여 PV를 백업하는 경우 클라우드 공급자는 네이티브 스냅샷 API 또는 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
백업 및 스냅샷 위치에서 동일한 인증 정보를 사용하는 경우 기본 이름
cloud-credentials로Secret을 생성해야 합니다.참고설치 중에 백업 또는 스냅샷 위치를 지정하지 않으려면 빈
credentials-velero파일을사용하여기본 보안을 생성할 수 있습니다. 기본Secret이 없으면 설치에 실패합니다.참고Velero는 기본 백업 리포지토리 암호가 포함된 OADP 네임스페이스에
velero-repo-credentials라는 시크릿을 생성합니다. 백업 리포지토리를 대상으로 하는 첫 번째 백업을 실행하기 전에 base64로 인코딩된 고유한 암호로 시크릿을 업데이트할 수 있습니다. 업데이트할 키의 값은Data[repository-password]입니다.DPA를 생성한 후 백업 리포지토리를 대상으로 하는 백업을 처음 실행하면 Velero에서 시크릿이 기본 암호 또는 교체한 암호가 포함된
velero-repo-credentials인 백업 리포지토리를 생성합니다. 첫 번째 백업 후 시크릿 암호를 업데이트하면 새 암호가velero-repo-credentials의 암호와 일치하지 않으므로 Velero는 이전 백업과 연결할 수 없습니다.
절차
- Operators → 설치된 Operator 를 클릭하고 OADP Operator를 선택합니다.
- 제공된 API 아래에서 DataProtectionApplication 상자에서 인스턴스 생성을 클릭합니다.
-
YAML 보기를 클릭하고
DataProtectionApplication매니페스트의 매개변수를 업데이트합니다. - 생성을 클릭합니다.
OADP 리소스를 확인하여 설치를 확인합니다.
$ oc get all -n openshift-adp
출력 예
NAME READY STATUS RESTARTS AGE pod/oadp-operator-controller-manager-67d9494d47-6l8z8 2/2 Running 0 2m8s pod/restic-9cq4q 1/1 Running 0 94s pod/restic-m4lts 1/1 Running 0 94s pod/restic-pv4kr 1/1 Running 0 95s pod/velero-588db7f655-n842v 1/1 Running 0 95s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/oadp-operator-controller-manager-metrics-service ClusterIP 172.30.70.140 <none> 8443/TCP 2m8s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/restic 3 3 3 3 3 <none> 96s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/oadp-operator-controller-manager 1/1 1 1 2m9s deployment.apps/velero 1/1 1 1 96s NAME DESIRED CURRENT READY AGE replicaset.apps/oadp-operator-controller-manager-67d9494d47 1 1 1 2m9s replicaset.apps/velero-588db7f655 1 1 1 96s
4.4.7.3.1. OpenShift Data Foundation에서 재해 복구에 대한 오브젝트 버킷 클레임 생성
OpenShift Data Foundation에서 MCG(Multicloud Object Gateway) 버킷 backupStorageLocation 에 클러스터 스토리지를 사용하는 경우 OpenShift 웹 콘솔을 사용하여 OBC(Object Bucket Claim)를 생성합니다.
OBC(Object Bucket Claim)를 구성하지 않으면 백업을 사용할 수 없습니다.
달리 지정하지 않는 한 "NooBa"는 경량 오브젝트 스토리지를 제공하는 오픈 소스 프로젝트를 나타내며 "MCG(Multicloud Object Gateway)는 NooBaa의 Red Hat 배포를 나타냅니다.
MCG에 대한 자세한 내용은 애플리케이션을 사용하여 Multicloud Object Gateway 액세스를 참조하십시오.
절차
- OpenShift 웹 콘솔을 사용하여 Object Bucket Claim 생성에 설명된 대로 OpenShift 웹 콘솔을 사용하여 Object Bucket 클레임(OBC)을 생성합니다.
4.4.7.3.2. DataProtectionApplication CR에서 CSI 활성화
CSI 스냅샷을 사용하여 영구 볼륨을 백업하기 위해 DataProtectionApplication CR(사용자 정의 리소스)에서 CSI(Container Storage Interface)를 활성화합니다.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
절차
다음 예와 같이
DataProtectionApplicationCR을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... spec: configuration: velero: defaultPlugins: - openshift - csi 1- 1
csi기본 플러그인을 추가합니다.
4.5. OADP 설치 제거
4.5.1. 데이터 보호를 위한 OpenShift API 설치 제거
OADP Operator를 삭제하여 OADP(OpenShift API for Data Protection)를 설치 제거합니다. 자세한 내용은 클러스터에서 Operator 삭제를 참조하십시오.
4.6. OADP 백업
4.6.1. 애플리케이션 백업
Backup CR(사용자 정의 리소스)을 생성하여 애플리케이션을 백업합니다. Backup CR 생성을 참조하십시오.
Backup CR은 Kubernetes 리소스 및 내부 이미지, S3 오브젝트 스토리지, 클라우드 공급자가 기본 스냅샷 API 또는 CSI(Container Storage Interface)를 사용하는 경우 OpenShift Data Foundation 4와 같은 스냅샷을 생성하는 경우 S3 오브젝트 스토리지, 영구 볼륨(PV)에 대한 백업 파일을 생성합니다.
CSI 볼륨 스냅샷에 대한 자세한 내용은 CSI 볼륨 스냅샷을 참조하십시오.
S3 스토리지의 CloudStorage API는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
-
클라우드 공급자에 기본 스냅샷 API가 있거나 CSI 스냅샷을 지원하는 경우
BackupCR은 스냅샷을 생성하여 PV(영구 볼륨)를 백업합니다. CSI 스냅샷 작업에 대한 자세한 내용은 CSI 스냅샷을 사용하여 영구 볼륨 백업을 참조하십시오. - 클라우드 공급자가 스냅샷을 지원하지 않거나 애플리케이션이 NFS 데이터 볼륨에 있는 경우 Restic을 사용하여 백업을 생성할 수 있습니다. Restic을 사용하여 애플리케이션 백업을 참조하십시오.
OADP(OpenShift API for Data Protection)는 다른 소프트웨어에 의해 생성된 볼륨 스냅샷 백업 기능을 지원하지 않습니다.
백업 작업 전이나 후에 명령을 실행하기 위해 백업 후크를 생성할 수 있습니다. 백업 후크 생성 을 참조하십시오.
Backup CR 대신 Schedule CR을 생성하여 백업을 예약할 수 있습니다. 백업 일정을 참조하십시오.
4.6.1.1. 확인된 문제
OpenShift Container Platform 4.14는 Restic 복원 프로세스 중에 Pod 준비 상태를 방해할 수 있는 PSA(Pod 보안 승인) 정책을 적용합니다.
이 문제는 OADP 1.1.6 및 OADP 1.2.2 릴리스에서 해결되어 사용자가 이러한 릴리스로 업그레이드하는 것이 좋습니다.
4.6.2. 백업 CR 생성
Backup CR(사용자 정의 리소스)을 생성하여 Kubernetes 이미지, 내부 이미지 및 영구 볼륨(PV)을 백업합니다.
사전 요구 사항
- OpenShift API for Data Protection(OADP) Operator를 설치해야 합니다.
-
DataProtectionApplicationCR은Ready상태에 있어야 합니다. 백업 위치 사전 요구 사항:
- Velero용으로 구성된 S3 오브젝트 스토리지가 있어야 합니다.
-
DataProtectionApplicationCR에 백업 위치가 구성되어 있어야 합니다.
스냅샷 위치 사전 요구 사항:
- 클라우드 공급자에는 네이티브 스냅샷 API가 있거나 CSI(Container Storage Interface) 스냅샷을 지원해야 합니다.
-
CSI 스냅샷의 경우 CSI 드라이버를 등록하려면
VolumeSnapshotClassCR을 생성해야 합니다. -
DataProtectionApplicationCR에 볼륨 위치가 구성되어 있어야 합니다.
절차
다음 명령을 입력하여
backupStorageLocationsCR을 검색합니다.$ oc get backupStorageLocations -n openshift-adp
출력 예
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m
다음 예와 같이
BackupCR을 생성합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: hooks: {} includedNamespaces: - <namespace> 1 includedResources: [] 2 excludedResources: [] 3 storageLocation: <velero-sample-1> 4 ttl: 720h0m0s labelSelector: 5 matchLabels: app=<label_1> app=<label_2> app=<label_3> orLabelSelectors: 6 - matchLabels: app=<label_1> app=<label_2> app=<label_3>- 1
- 백업할 네임스페이스 배열을 지정합니다.
- 2
- 선택 사항: 백업에 포함할 리소스 배열을 지정합니다. 리소스는 바로 가기(예: 'pods'의 경우 'po')이거나 정규화될 수 있습니다. 지정하지 않으면 모든 리소스가 포함됩니다.
- 3
- 선택 사항: 백업에서 제외할 리소스 배열을 지정합니다. 리소스는 바로 가기(예: 'pods'의 경우 'po')이거나 정규화될 수 있습니다.
- 4
backupStorageLocationsCR의 이름을 지정합니다.- 5
- 지정된 라벨이 모두 있는 백업 리소스의 {key,value} 쌍의 맵입니다.
- 6
- 지정된 라벨이 하나 이상 있는 백업 리소스의 {key,value} 쌍의 맵입니다.
BackupCR의 상태가Completed인지 확인합니다.$ oc get backup -n openshift-adp <backup> -o jsonpath='{.status.phase}'
4.6.3. CSI 스냅샷을 사용하여 영구 볼륨 백업
Backup CR을 생성하기 전에 클라우드 스토리지의 VolumeSnapshotClass CR(사용자 정의 리소스)을 편집하여 CSI(Container Storage Interface) 스냅샷을 사용하여 영구 볼륨을 백업 합니다. CSI 볼륨 스냅샷을 참조하십시오.
자세한 내용은 Backup CR 생성을 참조하십시오.
사전 요구 사항
- 클라우드 공급자는 CSI 스냅샷을 지원해야 합니다.
-
DataProtectionApplicationCR에서 CSI를 활성화해야 합니다.
절차
VolumeSnapshotClassCR에metadata.labels.velero.io/csi-volumesnapshot-class: "true"키-값 쌍을 추가합니다.apiVersion: snapshot.storage.k8s.io/v1 kind: VolumeSnapshotClass metadata: name: <volume_snapshot_class_name> labels: velero.io/csi-volumesnapshot-class: "true" driver: <csi_driver> deletionPolicy: Retain
이제 Backup CR을 생성할 수 있습니다.
4.6.4. Restic으로 애플리케이션 백업
클라우드 공급자가 스냅샷을 지원하지 않거나 애플리케이션이 NFS 데이터 볼륨에 있는 경우 Restic을 사용하여 백업을 생성할 수 있습니다.
Restic 은 기본적으로 OADP Operator에 의해 설치됩니다.
Restic과 OADP 통합은 거의 모든 유형의 Kubernetes 볼륨을 백업하고 복원하는 솔루션을 제공합니다. 이러한 통합은 기존 기능을 대체하지 않고 OADP 기능에 추가됩니다.
Backup 사용자 정의 리소스(CR)를 편집하여 Kubernetes 리소스, 내부 이미지 및 영구 볼륨을 Restic으로 백업합니다.
DataProtectionApplication CR에서 스냅샷 위치를 지정할 필요가 없습니다.
Restic은 hostPath 볼륨 백업을 지원하지 않습니다. 자세한 내용은 추가 Restic 제한 사항을 참조하십시오.
사전 요구 사항
- OpenShift API for Data Protection(OADP) Operator를 설치해야 합니다.
-
DataProtectionApplicationCR에서spec.configuration.restic.enable을false로 설정하여 기본 Restic 설치를 비활성화해서는 안 됩니다. -
DataProtectionApplicationCR은Ready상태에 있어야 합니다.
절차
다음 예와 같이
BackupCR을 생성합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> labels: velero.io/storage-location: default namespace: openshift-adp spec: defaultVolumesToRestic: true 1 ...- 1
spec블록에defaultVolumesToRestic: true를 추가합니다.
4.6.5. 백업 후크 생성
백업을 수행할 때 백업 중인 Pod에 따라 Pod 내의 컨테이너에서 실행할 하나 이상의 명령을 지정할 수 있습니다.
사용자 정의 작업 처리(사전 후크) 전에 또는 모든 사용자 정의 작업이 완료되고 사용자 정의 작업에서 지정한 추가 항목이 백업되기 전에 수행하도록 명령을 구성할 수 있습니다.
후 후크는 백업 후 실행됩니다.
Backup CR(사용자 정의 리소스)을 편집하여 Pod의 컨테이너에서 명령을 실행하는 백업 후크를 생성합니다.
절차
다음 예와 같이
BackupCR의spec.hooks블록에 후크를 추가합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace> 1 excludedNamespaces: 2 - <namespace> includedResources: [] - pods 3 excludedResources: [] 4 labelSelector: 5 matchLabels: app: velero component: server pre: 6 - exec: container: <container> 7 command: - /bin/uname 8 - -a onError: Fail 9 timeout: 30s 10 post: 11 ...- 1
- 선택 사항: 후크가 적용되는 네임스페이스를 지정할 수 있습니다. 이 값을 지정하지 않으면 후크가 모든 네임스페이스에 적용됩니다.
- 2
- 선택 사항: 후크가 적용되지 않는 네임스페이스를 지정할 수 있습니다.
- 3
- 현재 Pod는 후크를 적용할 수 있는 유일한 지원 리소스입니다.
- 4
- 선택 사항: 후크가 적용되지 않는 리소스를 지정할 수 있습니다.
- 5
- 선택 사항: 이 후크는 레이블과 일치하는 오브젝트에만 적용됩니다. 이 값을 지정하지 않으면 후크가 모든 네임스페이스에 적용됩니다.
- 6
- 백업 전에 실행할 후크 배열입니다.
- 7
- 선택 사항: 컨테이너를 지정하지 않으면 Pod의 첫 번째 컨테이너에서 명령이 실행됩니다.
- 8
- 추가되는
init컨테이너의 진입점입니다. - 9
- 오류 처리에 허용되는 값은
Fail및Continue입니다. 기본값은Fail입니다. - 10
- 선택 사항: 명령을 실행할 때까지 대기하는 시간입니다. 기본값은
30s입니다. - 11
- 이 블록은 사전 백업 후크와 동일한 매개변수를 사용하여 백업 후에 실행할 후크 배열을 정의합니다.
4.6.6. 스케줄 CR을 사용하여 백업 예약
schedule 작업을 사용하면 Cron 표현식에 정의된 지정된 시간에 데이터 백업을 생성할 수 있습니다.
Backup CR 대신 Schedule CR(사용자 정의 리소스)을 생성하여 백업을 예약합니다.
다른 백업이 생성되기 전에 백업이 완료될 수 있도록 백업 일정에 충분한 시간을 남겨 둡니다.
예를 들어 네임스페이스의 백업이 일반적으로 10분 정도 걸리는 경우 15분마다 백업을 더 자주 예약하지 마십시오.
사전 요구 사항
- OpenShift API for Data Protection(OADP) Operator를 설치해야 합니다.
-
DataProtectionApplicationCR은Ready상태에 있어야 합니다.
절차
backupStorageLocationsCR을 검색합니다.$ oc get backupStorageLocations -n openshift-adp
출력 예
NAMESPACE NAME PHASE LAST VALIDATED AGE DEFAULT openshift-adp velero-sample-1 Available 11s 31m
다음 예와 같이
ScheduleCR을 생성합니다.$ cat << EOF | oc apply -f - apiVersion: velero.io/v1 kind: Schedule metadata: name: <schedule> namespace: openshift-adp spec: schedule: 0 7 * * * 1 template: hooks: {} includedNamespaces: - <namespace> 2 storageLocation: <velero-sample-1> 3 defaultVolumesToRestic: true 4 ttl: 720h0m0s EOF
예약된 백업이 실행된 후
ScheduleCR의 상태가Completed인지 확인합니다.$ oc get schedule -n openshift-adp <schedule> -o jsonpath='{.status.phase}'
4.6.7. 백업 삭제
Backup CR(사용자 정의 리소스)을 삭제하여 백업 파일을 제거할 수 있습니다.
Backup CR 및 관련 오브젝트 스토리지 데이터를 삭제한 후에는 삭제된 데이터를 복구할 수 없습니다.
사전 요구 사항
-
백업CR을 생성했습니다. -
BackupCR의 이름과 이를 포함하는 네임스페이스를 알고 있습니다. - Velero CLI 툴을 다운로드했습니다.
- 클러스터에서 Velero 바이너리에 액세스할 수 있습니다.
절차
BackupCR을 삭제하려면 다음 작업 중 하나를 선택합니다.BackupCR을 삭제하고 연결된 오브젝트 스토리지 데이터를 유지하려면 다음 명령을 실행합니다.$ oc delete backup <backup_CR_name> -n <velero_namespace>
BackupCR을 삭제하고 연결된 오브젝트 스토리지 데이터를 삭제하려면 다음 명령을 실행합니다.$ velero backup delete <backup_CR_name> -n <velero_namespace>
다음과 같습니다.
- <backup_CR_name>
-
Backup사용자 정의 리소스의 이름을 지정합니다. - <velero_namespace>
-
Backup사용자 정의 리소스가 포함된 네임스페이스를 지정합니다.
4.6.8. Kopia 정보
Kopia는 데이터의 암호화된 스냅샷을 작성하고 선택한 원격 또는 클라우드 스토리지에 스냅샷을 저장할 수 있는 빠르고 안전한 오픈 소스 백업 및 복원 도구입니다.
Kopia는 네트워크 및 로컬 스토리지 위치와 다음을 포함한 많은 클라우드 또는 원격 스토리지 위치를 지원합니다.
- Amazon S3 및 S3와 호환되는 모든 클라우드 스토리지
- Azure Blob Storage
- Google Cloud Storage Platform
Kopia는 스냅샷을 위해 콘텐츠 주소 지정 가능 스토리지를 사용합니다.
- 각 스냅샷은 항상 증분입니다. 즉, 모든 데이터가 파일 콘텐츠를 기반으로 리포지토리에 한 번 업로드됩니다. 파일은 수정된 경우에만 리포지토리에 업로드됩니다.
- 동일한 파일의 여러 복사본이 한 번 저장되므로 중복 제거가 수행됩니다. 대용량 파일을 이동하거나 변경한 후 Kopia는 동일한 콘텐츠가 있고 다시 업로드하지 않는다는 것을 인식할 수 있습니다.
4.6.8.1. Kopia와 OADP 통합
OADP 1.3은 Restic 외에도 Pod 볼륨 백업의 백업 메커니즘으로 Kopia를 지원합니다. 설치 시 DataProtectionApplication CR(사용자 정의 리소스)에서 uploaderType 필드를 설정하여 설치 시 하나 이상을 선택해야 합니다. 가능한 값은 restic 또는 kopia 입니다. uploaderType 을 지정하지 않으면 OADP 1.3의 기본값은 Kopia를 백업 메커니즘으로 사용합니다. 데이터는 통합 리포지토리로 작성 및 읽습니다.
Kopia DataProtectionApplication 구성
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true
uploaderType: kopia
# ...
4.7. OADP 복원
4.7.1. 애플리케이션 복원
Restore CR(사용자 정의 리소스)을 생성하여 애플리케이션 백업을 복원합니다. Restore CR 생성을 참조하십시오.
복원(CR)을 편집하여 애플리케이션을 복원하는 동안 Pod의 컨테이너에서 명령을 실행하기 위해 복원 후크를 생성할 수 있습니다. 복원 후크 생성참조
4.7.1.1. Restore CR 생성
Restore CR을 생성하여 Backup CR(사용자 정의 리소스)을 복원 합니다.
사전 요구 사항
- OpenShift API for Data Protection(OADP) Operator를 설치해야 합니다.
-
DataProtectionApplicationCR은Ready상태에 있어야 합니다. -
Velero
BackupCR이 있어야 합니다. - PV(영구 볼륨) 용량이 백업 시 요청된 크기와 일치하도록 요청된 크기를 조정합니다.
절차
다음 예와 같이
RestoreCR을 생성합니다.apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: backupName: <backup> 1 includedResources: [] 2 excludedResources: - nodes - events - events.events.k8s.io - backups.velero.io - restores.velero.io - resticrepositories.velero.io restorePVs: true 3
다음 명령을 입력하여
RestoreCR의 상태가Completed인지 확인합니다.$ oc get restore -n openshift-adp <restore> -o jsonpath='{.status.phase}'다음 명령을 입력하여 백업 리소스가 복원되었는지 확인합니다.
$ oc get all -n <namespace> 1- 1
- 백업한 네임스페이스입니다.
Restic을 사용하여
DeploymentConfig오브젝트를 복원하거나 post-restore 후크를 사용하는 경우 다음 명령을 입력하여dc-restic-post-restore.shcleanup 스크립트를 실행합니다.$ bash dc-restic-post-restore.sh <restore-name>
참고복원 프로세스 과정에서 OADP Velero 플러그인은
DeploymentConfig오브젝트를 축소하고 Pod를 독립 실행형 Pod로 복원하여 클러스터가 복원 시 복원된DeploymentConfigPod를 즉시 삭제하지 못하도록 하고 Restic 및 post-restore 후크를 허용하여 복원된 Pod에서 작업을 완료할 수 있습니다. cleanup 스크립트는 이러한 연결이 끊긴 Pod를 제거하고DeploymentConfig오브젝트를 적절한 복제본 수로 백업합니다.예 4.1.
dc-restic-post-restore.shcleanup script#!/bin/bash set -e # if sha256sum exists, use it to check the integrity of the file if command -v sha256sum >/dev/null 2>&1; then CHECKSUM_CMD="sha256sum" else CHECKSUM_CMD="shasum -a 256" fi label_name () { if [ "${#1}" -le "63" ]; then echo $1 return fi sha=$(echo -n $1|$CHECKSUM_CMD) echo "${1:0:57}${sha:0:6}" } OADP_NAMESPACE=${OADP_NAMESPACE:=openshift-adp} if [[ $# -ne 1 ]]; then echo "usage: ${BASH_SOURCE} restore-name" exit 1 fi echo using OADP Namespace $OADP_NAMESPACE echo restore: $1 label=$(label_name $1) echo label: $label echo Deleting disconnected restore pods oc delete pods -l oadp.openshift.io/disconnected-from-dc=$label for dc in $(oc get dc --all-namespaces -l oadp.openshift.io/replicas-modified=$label -o jsonpath='{range .items[*]}{.metadata.namespace}{","}{.metadata.name}{","}{.metadata.annotations.oadp\.openshift\.io/original-replicas}{","}{.metadata.annotations.oadp\.openshift\.io/original-paused}{"\n"}') do IFS=',' read -ra dc_arr <<< "$dc" if [ ${#dc_arr[0]} -gt 0 ]; then echo Found deployment ${dc_arr[0]}/${dc_arr[1]}, setting replicas: ${dc_arr[2]}, paused: ${dc_arr[3]} cat <<EOF | oc patch dc -n ${dc_arr[0]} ${dc_arr[1]} --patch-file /dev/stdin spec: replicas: ${dc_arr[2]} paused: ${dc_arr[3]} EOF fi done
4.7.1.2. 복원 후크 생성
Restore CR(사용자 정의 리소스)을 편집하여 애플리케이션을 복원하는 동안 Pod의 컨테이너에서 명령을 실행하도록 복원 후크를 생성합니다.
두 가지 유형의 복원 후크를 생성할 수 있습니다.
init후크는 애플리케이션 컨테이너가 시작되기 전에 설정 작업을 수행하는 Pod에 init 컨테이너를 추가합니다.Restic 백업을 복원하면 복구 후크 init 컨테이너보다 먼저
restic-waitinit 컨테이너가 추가됩니다.-
exec후크는 복원된 Pod의 컨테이너에서 명령 또는 스크립트를 실행합니다.
절차
다음 예와 같이
RestoreCR의spec.hooks블록에 후크를 추가합니다.apiVersion: velero.io/v1 kind: Restore metadata: name: <restore> namespace: openshift-adp spec: hooks: resources: - name: <hook_name> includedNamespaces: - <namespace> 1 excludedNamespaces: - <namespace> includedResources: - pods 2 excludedResources: [] labelSelector: 3 matchLabels: app: velero component: server postHooks: - init: initContainers: - name: restore-hook-init image: alpine:latest volumeMounts: - mountPath: /restores/pvc1-vm name: pvc1-vm command: - /bin/ash - -c timeout: 4 - exec: container: <container> 5 command: - /bin/bash 6 - -c - "psql < /backup/backup.sql" waitTimeout: 5m 7 execTimeout: 1m 8 onError: Continue 9- 1
- 선택사항: 후크가 적용되는 네임스페이스의 배열입니다. 이 값을 지정하지 않으면 후크가 모든 네임스페이스에 적용됩니다.
- 2
- 현재 Pod는 후크를 적용할 수 있는 유일한 지원 리소스입니다.
- 3
- 선택 사항: 이 후크는 라벨 선택기와 일치하는 오브젝트에만 적용됩니다.
- 4
- 선택 사항: Timeout은 Velero가
initContainers가 완료될 때까지의 최대 시간을 지정합니다. - 5
- 선택 사항: 컨테이너를 지정하지 않으면 Pod의 첫 번째 컨테이너에서 명령이 실행됩니다.
- 6
- 이는 추가되는 init 컨테이너의 진입점입니다.
- 7
- 선택 사항: 컨테이너가 준비될 때까지 대기하는 시간입니다. 컨테이너가 시작되고 동일한 컨테이너의 이전 후크가 완료될 때까지 충분히 길어야 합니다. 설정되지 않은 경우 복원 프로세스는 무기한 대기합니다.
- 8
- 선택 사항: 명령을 실행할 때까지 대기하는 시간입니다. 기본값은
30s입니다. - 9
- 오류 처리에 허용되는 값은
Fail및Continue:-
계속: 명령 실패만 기록됩니다. -
fail: 모든 Pod의 컨테이너에서 더 이상 복원 후크가 실행되지 않습니다.RestoreCR의 상태는PartiallyFailed가 됩니다.
-
4.8. OADP 데이터 Mover
4.8.1. OADP Data Mover 소개
OADP Data Mover를 사용하면 오류, 실수로 삭제 또는 클러스터 손상이 발생할 경우 저장소에서 상태 저장 애플리케이션을 복원할 수 있습니다.
OADP 1.1 Data Mover는 기술 프리뷰 기능입니다.
OADP 1.2 Data Mover는 기능 및 성능이 크게 개선되었지만 여전히 기술 프리뷰 기능입니다.
OADP Data Mover는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
- OADP Data Mover를 사용하여 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소에 백업할 수 있습니다. CSI 스냅샷의 Data Mover 사용을 참조하십시오.
- OADP 1.2 Data Mover를 사용하여 CephFS, CephRBD 또는 둘 다 사용하는 클러스터의 애플리케이션 데이터를 백업하고 복원할 수 있습니다. OADP 1.2 Data Mover with Ceph Storage를 참조하십시오.
- OADP 1.1 Data Mover를 사용하는 경우 백업을 수행한 후 데이터 정리를 수행해야 합니다. OADP 1.1 Data Mover를 사용하여 백업 후 정리 를 참조하십시오.
마이그레이션 후 후크는 OADP 1.3 Data Mover에서 제대로 작동하지 않을 수 있습니다.
OADP 1.1 및 OADP 1.2 데이터 이동자는 동기 프로세스를 사용하여 애플리케이션 데이터를 백업 및 복원합니다. 프로세스는 동기적이므로 사용자는 데이터 Mover의 PVC(영구 볼륨 클레임)에 의해 관련 Pod의 영구 볼륨(PV)이 릴리스된 후에만 모든 복원 후 후크가 시작되도록 할 수 있습니다.
그러나 OADP 1.3 Data Mover는 비동기 프로세스를 사용합니다. 이러한 차이로 인해 Data Mover의 PVC에 의해 관련 PV를 릴리스하기 전에 복원 후 후크가 호출될 수 있습니다. 이 경우 Pod는 Pending 상태로 유지되며 후크를 실행할 수 없습니다. 후크 시도는 Pod가 릴리스되기 전에 시간 초과되어 PartiallyFailed 복원 작업을 수행할 수 있습니다.
4.8.1.1. OADP 데이터 Mover 사전 요구 사항
- 별도의 네임스페이스에서 상태 저장 애플리케이션이 실행되고 있습니다.
- OLM(Operator Lifecycle Manager)을 사용하여 OADP Operator를 설치했습니다.
-
적절한
VolumeSnapshotClass및StorageClass를 생성했습니다. - OLM을 사용하여volSync Operator를 설치했습니다.
4.8.2. CSI 스냅샷에 Data Mover 사용
OADP Data Mover를 통해 고객은 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소에 백업할 수 있습니다. Data Mover가 활성화되면 오류, 실수로 삭제 또는 클러스터 손상이 발생하는 경우 오브젝트 저장소에서 가져온 CSI 볼륨 스냅샷을 사용하여 상태 저장 애플리케이션을 복원할 수 있습니다.
Data Mover 솔루션은volSync의 Restic 옵션을 사용합니다.
Data Mover는 CSI 볼륨 스냅샷의 백업 및 복원만 지원합니다.
OADP 1.2에서 VSB(Data Mover VolumeSnapshotBackups ) 및 VolumeSnapshotRestores (VSR)는 VolumeSnapshotMover(VSM)를 사용하여 큐에 추가됩니다. VSM의 성능은 동시에 진행 중 VSB 및 VSR 수를 지정하여 향상됩니다. 모든 비동기 플러그인 작업이 완료되면 백업이 완료된 것으로 표시됩니다.
OADP 1.1 Data Mover는 기술 프리뷰 기능입니다.
OADP 1.2 Data Mover는 기능 및 성능이 크게 개선되었지만 여전히 기술 프리뷰 기능입니다.
OADP Data Mover는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
Red Hat은 ODF CephFS 볼륨을 백업 및 복원하기 위해 OADP 1.2 Data Mover를 사용하는 고객은 성능을 개선하기 위해 OpenShift Container Platform 버전 4.12 이상을 업그레이드하거나 설치하는 것이 좋습니다. OADP Data Mover는 OpenShift Container Platform 버전 4.12 이상에서 CephFS shallow 볼륨을 활용할 수 있으며, 이 볼륨은 백업 시간을 개선할 수 있습니다.
사전 요구 사항
-
StorageClass및VolumeSnapshotClassCR(사용자 정의 리소스)에서 CSI를 지원하는지 확인했습니다. 하나의
VolumeSnapshotClassCR에만 주석snapshot.storage.kubernetes.io/is-default-class: "true"가 있는지 확인했습니다.참고OpenShift Container Platform 버전 4.12 이상에서 이것이 유일한 기본
VolumeSnapshotClass인지 확인합니다.-
VolumeSnapshotClassCR의deletionPolicy가Retain으로 설정되어 있는지 확인했습니다. -
하나의
StorageClassCR에만 주석storageclass.kubernetes.io/is-default-class: "true"가 있는지 확인했습니다. -
VolumeSnapshotClassCR에velero.io/csi-volumesnapshot-class: "true"레이블이 포함되어 있습니다. OADP 네임스페이스에주석이 있는지 확인했습니다.oc annotate --overwrite namespace/openshift-adp volsync.backube/privileged-movers="true"참고OADP 1.1에서 위의 설정은 필수입니다.
OADP 1.2에서는 대부분의 시나리오에서
privileged-movers설정이 필요하지 않습니다. 컨테이너 권한 복원은volsync 사본에 적합해야 합니다. 일부 사용자 시나리오에서는privileged-mover=true설정이 해결되어야 하는 권한 오류가 있을 수 있습니다.OLM(Operator Lifecycle Manager)을 사용하여 VolSync Operator를 설치했습니다.
참고OADP Data Mover를 사용하려면volSync Operator가 필요합니다.
- OLM을 사용하여 OADP Operator를 설치했습니다.
절차
다음과 같이
.yaml파일을 생성하여 Restic 시크릿을 구성합니다.apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: openshift-adp type: Opaque stringData: RESTIC_PASSWORD: <secure_restic_password>
참고기본적으로 Operator는
dm-credential이라는 시크릿을 찾습니다. 다른 이름을 사용하는 경우dpa.spec.features.dataMover.credentialName을 사용하여 DPA(Data Protection Application) CR을 통해 이름을 지정해야 합니다.다음 예와 유사한 DPA CR을 생성합니다. 기본 플러그인에는 CSI가 포함됩니다.
DPA(Data Protection Application) CR 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <bucket_name> prefix: <bucket-prefix> provider: aws configuration: restic: enable: <true_or_false> velero: itemOperationSyncFrequency: "10s" defaultPlugins: - openshift - aws - csi - vsm 1 features: dataMover: credentialName: restic-secret enable: true maxConcurrentBackupVolumes: "3" 2 maxConcurrentRestoreVolumes: "3" 3 pruneInterval: "14" 4 volumeOptions: 5 sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteOnce cacheCapacity: 2Gi destinationVolumeOptions: storageClass: other-storageclass-name cacheAccessMode: ReadWriteMany snapshotLocations: - velero: config: profile: default region: us-west-2 provider: aws- 1
- OADP 1.2만 해당
- 2
- OADP 1.2만 해당 선택 사항: 백업에 대해 대기열에 추가할 수 있는 스냅샷 수의 상한을 지정합니다. 기본값은 10입니다.
- 3
- OADP 1.2만 해당 선택 사항: 복원을 위해 대기열에 지정할 수 있는 스냅샷 수의 상한을 지정합니다. 기본값은 10입니다.
- 4
- OADP 1.2만 해당 선택 사항: 리포지토리에서 Restic 정리를 실행하는 사이의 일 수를 지정합니다. 정리 작업에서는 데이터를 사용 가능한 공간으로 다시 구성하지만 프로세스의 일부로 중요한 I/O 트래픽을 생성할 수도 있습니다. 이 옵션을 설정하면 더 이상 참조되지 않는 데이터에서 스토리지 소비와 액세스 비용 간의 절충이 가능합니다.
- 5
- OADP 1.2만 해당 선택 사항: 백업 및 복원을 위해 VolumeSync 볼륨 옵션을 지정합니다.
OADP Operator는 두 개의 CRD(사용자 정의 리소스 정의),
VolumeSnapshotBackup및VolumeSnapshotRestore를 설치합니다.VolumeSnapshotBackupCRD의 예apiVersion: datamover.oadp.openshift.io/v1alpha1 kind: VolumeSnapshotBackup metadata: name: <vsb_name> namespace: <namespace_name> 1 spec: volumeSnapshotContent: name: <snapcontent_name> protectedNamespace: <adp_namespace> 2 resticSecretRef: name: <restic_secret_name>
VolumeSnapshotRestoreCRD의 예apiVersion: datamover.oadp.openshift.io/v1alpha1 kind: VolumeSnapshotRestore metadata: name: <vsr_name> namespace: <namespace_name> 1 spec: protectedNamespace: <protected_ns> 2 resticSecretRef: name: <restic_secret_name> volumeSnapshotMoverBackupRef: sourcePVCData: name: <source_pvc_name> size: <source_pvc_size> resticrepository: <your_restic_repo> volumeSnapshotClassName: <vsclass_name>
다음 단계를 수행하여 볼륨 스냅샷을 백업할 수 있습니다.
백업 CR을 생성합니다.
apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns> 1 spec: includedNamespaces: - <app_ns> 2 storageLocation: velero-sample-1
최대 10분 정도 기다린 후 다음 명령을 입력하여
VolumeSnapshotBackupCR 상태가 완료되었는지 확인합니다.$ oc get vsb -n <app_ns>
$ oc get vsb <vsb_name> -n <app_ns> -o jsonpath="{.status.phase}"오브젝트는 DPA에서 구성된 오브젝트 저장소에서 생성됩니다.
참고VolumeSnapshotBackupCR의 상태가실패가 되는 경우 문제를 해결하려면 Velero 로그를 참조하십시오.
다음 단계를 수행하여 볼륨 스냅샷을 복원할 수 있습니다.
-
Velero CSI 플러그인에서 생성한 애플리케이션 네임스페이스 및
VolumeSnapshotContent를 삭제합니다. RestoreCR을 생성하고restorePV를true로 설정합니다.RestoreCR의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name> restorePVs: true
최대 10분 정도 기다린 후 다음 명령을 입력하여
VolumeSnapshotRestoreCR 상태가 완료되었는지 확인합니다.$ oc get vsr -n <app_ns>
$ oc get vsr <vsr_name> -n <app_ns> -o jsonpath="{.status.phase}"애플리케이션 데이터 및 리소스가 복원되었는지 확인합니다.
참고VolumeSnapshotRestoreCR의 상태가 'Failed'가 되면 문제 해결을 위해 Velero 로그를 참조하십시오.
-
Velero CSI 플러그인에서 생성한 애플리케이션 네임스페이스 및
4.8.3. Ceph 스토리지에서 OADP 1.2 Data Mover 사용
OADP 1.2 Data Mover를 사용하여 CephFS, CephRBD 또는 둘 다 사용하는 클러스터의 애플리케이션 데이터를 백업하고 복원할 수 있습니다.
OADP 1.2 Data Mover는 대규모 환경을 지원하는 Ceph 기능을 활용합니다. 이러한 방법 중 하나는 OpenShift Container Platform 4.12 이상에서 사용할 수 있는 단순 복사 방법입니다. 이 기능은 소스 PVC(영구 볼륨 클레임)에 있는 것 이외의 StorageClass 및 AccessMode 리소스 백업 및 복원을 지원합니다.
CephFS shallow copy 기능은 백업 기능입니다. 복원 작업의 일부가 아닙니다.
4.8.3.1. Ceph 스토리지와 함께 OADP 1.2 Data Mover를 사용하기 위한 사전 요구 사항
다음 사전 요구 사항은 Ceph 스토리지를 사용하는 클러스터에서 OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하는 모든 데이터 백업 및 복원 작업에 적용됩니다.
- OpenShift Container Platform 4.12 이상을 설치했습니다.
- OADP Operator가 설치되어 있습니다.
-
네임스페이스
openshift-adp에 시크릿cloud-credentials를 생성했습니다. - Red Hat OpenShift Data Foundation을 설치했습니다.
- Operator Lifecycle Manager를 사용하여 최신volSync Operator를 설치했습니다.
4.8.3.2. OADP 1.2 Data Mover와 함께 사용할 사용자 정의 리소스 정의
Red Hat OpenShift Data Foundation을 설치하면 기본 CephFS 및 CephRBD StorageClass 및 VolumeSnapshotClass CR(사용자 정의 리소스)이 자동으로 생성됩니다. OADP(OpenShift API for Data Protection) 1.2 Data Mover와 함께 사용하려면 이러한 CR을 정의해야 합니다.
CR을 정의한 후 백업 및 복원 작업을 수행하기 전에 환경에 몇 가지 다른 변경을 수행해야 합니다.
4.8.3.2.1. OADP 1.2 Data Mover와 함께 사용할 CephFS 사용자 정의 리소스 정의
Red Hat OpenShift Data Foundation을 설치하면 기본 CephFS StorageClass 사용자 정의 리소스(CR) 및 기본 CephFS VolumeSnapshotClass CR이 자동으로 생성됩니다. OADP(OpenShift API for Data Protection) 1.2 Data Mover와 함께 사용할 이러한 CR을 정의할 수 있습니다.
절차
다음 예와 같이
VolumeSnapshotClassCR을 정의합니다.VolumeSnapshotClassCR의 예apiVersion: snapshot.storage.k8s.io/v1 deletionPolicy: Retain 1 driver: openshift-storage.cephfs.csi.ceph.com kind: VolumeSnapshotClass metadata: annotations: snapshot.storage.kubernetes.io/is-default-class: true 2 labels: velero.io/csi-volumesnapshot-class: true 3 name: ocs-storagecluster-cephfsplugin-snapclass parameters: clusterID: openshift-storage csi.storage.k8s.io/snapshotter-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/snapshotter-secret-namespace: openshift-storage
다음 예와 같이
StorageClassCR을 정의합니다.StorageClassCR의 예kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-cephfs annotations: description: Provides RWO and RWX Filesystem volumes storageclass.kubernetes.io/is-default-class: true 1 provisioner: openshift-storage.cephfs.csi.ceph.com parameters: clusterID: openshift-storage csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage fsName: ocs-storagecluster-cephfilesystem reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate- 1
true로 설정해야 합니다.
4.8.3.2.2. OADP 1.2 Data Mover와 함께 사용할 CephRBD 사용자 정의 리소스 정의
Red Hat OpenShift Data Foundation을 설치하면 기본 CephRBD StorageClass CR(사용자 정의 리소스) 및 기본 CephRBD VolumeSnapshotClass CR이 자동으로 생성됩니다. OADP(OpenShift API for Data Protection) 1.2 Data Mover와 함께 사용할 이러한 CR을 정의할 수 있습니다.
절차
다음 예와 같이
VolumeSnapshotClassCR을 정의합니다.VolumeSnapshotClassCR의 예apiVersion: snapshot.storage.k8s.io/v1 deletionPolicy: Retain 1 driver: openshift-storage.rbd.csi.ceph.com kind: VolumeSnapshotClass metadata: labels: velero.io/csi-volumesnapshot-class: true 2 name: ocs-storagecluster-rbdplugin-snapclass parameters: clusterID: openshift-storage csi.storage.k8s.io/snapshotter-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/snapshotter-secret-namespace: openshift-storage
다음 예와 같이
StorageClassCR을 정의합니다.StorageClassCR의 예kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-ceph-rbd annotations: description: 'Provides RWO Filesystem volumes, and RWO and RWX Block volumes' provisioner: openshift-storage.rbd.csi.ceph.com parameters: csi.storage.k8s.io/fstype: ext4 csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-rbd-provisioner csi.storage.k8s.io/node-stage-secret-name: rook-csi-rbd-node csi.storage.k8s.io/controller-expand-secret-name: rook-csi-rbd-provisioner imageFormat: '2' clusterID: openshift-storage imageFeatures: layering csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage pool: ocs-storagecluster-cephblockpool csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate
4.8.3.2.3. OADP 1.2 Data Mover와 함께 사용할 추가 사용자 정의 리소스 정의
기본 StorageClass 및 CephRBD VolumeSnapshotClass CR(사용자 정의 리소스)을 생성한 후 다음 CR을 생성해야 합니다.
-
shallow 복사 기능을 사용하도록 정의된 CephFS
StorageClassCR -
Restic
SecretCR
절차
CephFS
StorageClassCR을 생성하고 다음 예와 같이backingSnapshot매개변수를true로 설정합니다.backingSnapshot이true로 설정된 CephFSStorageClassCR의 예kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: ocs-storagecluster-cephfs-shallow annotations: description: Provides RWO and RWX Filesystem volumes storageclass.kubernetes.io/is-default-class: false provisioner: openshift-storage.cephfs.csi.ceph.com parameters: csi.storage.k8s.io/provisioner-secret-namespace: openshift-storage csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner clusterID: openshift-storage fsName: ocs-storagecluster-cephfilesystem csi.storage.k8s.io/controller-expand-secret-namespace: openshift-storage backingSnapshot: true 1 csi.storage.k8s.io/node-stage-secret-namespace: openshift-storage reclaimPolicy: Delete allowVolumeExpansion: true volumeBindingMode: Immediate- 1
true로 설정해야 합니다.
중요CephFS
VolumeSnapshotClass및StorageClassCR의 값이provisioner에 대해 동일한지 확인합니다.다음 예와 같이 Restic
SecretCR을 구성합니다.Restic
SecretCR의 예apiVersion: v1 kind: Secret metadata: name: <secret_name> namespace: <namespace> type: Opaque stringData: RESTIC_PASSWORD: <restic_password>
4.8.3.3. OADP 1.2 Data Mover 및 CephFS 스토리지를 사용하여 데이터 백업 및 복원
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 CephFS의 단순 복사 기능을 활성화하여 CephFS 스토리지를 사용하여 데이터를 백업하고 복원할 수 있습니다.
사전 요구 사항
- 상태 저장 애플리케이션은 CephFS를 프로비저너로 사용하는 PVC(영구 볼륨 클레임)가 있는 별도의 네임스페이스에서 실행됩니다.
-
StorageClass및VolumeSnapshotClassCR(사용자 정의 리소스)은 CephFS 및 OADP 1.2 데이터 Mover에 대해 정의됩니다. -
openshift-adp네임스페이스에는 시크릿cloud-credentials가 있습니다.
4.8.3.3.1. CephFS 스토리지와 함께 사용할 DPA 생성
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 CephFS 스토리지를 사용하여 데이터를 백업하고 복원하기 전에 DPA(Data Protection Application) CR을 생성해야 합니다.
절차
다음 명령을 실행하여
VolumeSnapshotClassCR의deletionPolicy필드가Retain으로 설정되어 있는지 확인합니다.$ oc get volumesnapshotclass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"Retention Policy: "}{.deletionPolicy}{"\n"}{end}'다음 명령을 실행하여
VolumeSnapshotClassCR의 레이블이true로 설정되어 있는지 확인합니다.$ oc get volumesnapshotclass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"labels: "}{.metadata.labels}{"\n"}{end}'다음 명령을 실행하여
StorageClassCR의storageclass.kubernetes.io/is-default-class주석이true로 설정되어 있는지 확인합니다.$ oc get storageClass -A -o jsonpath='{range .items[*]}{"Name: "}{.metadata.name}{" "}{"annotations: "}{.metadata.annotations}{"\n"}{end}'다음 예와 유사한 DPA(Data Protection Application) CR을 생성합니다.
DPA CR 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <my_bucket> prefix: velero provider: aws configuration: restic: enable: false 1 velero: defaultPlugins: - openshift - aws - csi - vsm features: dataMover: credentialName: <restic_secret_name> 2 enable: true 3 volumeOptionsForStorageClasses: ocs-storagecluster-cephfs: sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteMany cacheStorageClassName: ocs-storagecluster-cephfs storageClassName: ocs-storagecluster-cephfs-shallow
4.8.3.3.2. OADP 1.2 데이터 Mover 및 CephFS 스토리지를 사용하여 데이터 백업
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 CephFS 스토리지의 부분 복사 기능을 활성화하여 CephFS 스토리지를 사용하여 데이터를 백업할 수 있습니다.
절차
다음 예와 같이
BackupCR을 생성합니다.BackupCR의 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns> spec: includedNamespaces: - <app_ns> storageLocation: velero-sample-1
다음 단계를 완료하여
VolumeSnapshotBackupCR의 진행 상황을 모니터링합니다.모든
VolumeSnapshotBackupCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsb -n <app_ns>
특정
VolumeSnapshotBackupCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsb <vsb_name> -n <app_ns> -ojsonpath="{.status.phase}`
-
VolumeSnapshotBackupCR의 상태가Completed가 될 때까지 몇 분 정도 기다립니다. -
Restic 시크릿에 제공된 오브젝트 저장소에 스냅샷이 하나 이상 있는지
확인합니다./<OADP_namespace> 접두사가 있는 대상.BackupStorageLocation스토리지 공급자에서 이 스냅샷을 확인할 수 있습니다
4.8.3.3.3. OADP 1.2 Data Mover 및 CephFS 스토리지를 사용하여 데이터 복원
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 백업 프로세스에 CephFS 스토리지의 부분 복사 기능이 활성화된 경우 CephFS 스토리지를 사용하여 데이터를 복원할 수 있습니다. 단순 복사 기능은 복원 프로시저에서 사용되지 않습니다.
절차
다음 명령을 실행하여 애플리케이션 네임스페이스를 삭제합니다.
$ oc delete vsb -n <app_namespace> --all
다음 명령을 실행하여 백업 중에 생성된
VolumeSnapshotContentCR을 삭제합니다.$ oc delete volumesnapshotcontent --all
다음 예와 같이
RestoreCR을 생성합니다.RestoreCR의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name>
다음을 수행하여
VolumeSnapshotRestoreCR의 진행 상황을 모니터링합니다.모든
VolumeSnapshotRestoreCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsr -n <app_ns>
특정
VolumeSnapshotRestoreCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsr <vsr_name> -n <app_ns> -ojsonpath="{.status.phase}
다음 명령을 실행하여 애플리케이션 데이터가 복원되었는지 확인합니다.
$ oc get route <route_name> -n <app_ns> -ojsonpath="{.spec.host}"
4.8.3.4. OADP 1.2 Data Mover 및 분할 볼륨을 사용하여 데이터 백업 및 복원(CephFS 및 Ceph RBD)
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 CephFS 및 CephRBD를 모두 사용하는 환경인 분할 볼륨이 있는 환경에서 데이터를 백업하고 복원할 수 있습니다.
사전 요구 사항
- 상태 저장 애플리케이션은 CephFS를 프로비저너로 사용하는 PVC(영구 볼륨 클레임)가 있는 별도의 네임스페이스에서 실행됩니다.
-
StorageClass및VolumeSnapshotClassCR(사용자 정의 리소스)은 CephFS 및 OADP 1.2 데이터 Mover에 대해 정의됩니다. -
openshift-adp네임스페이스에는 시크릿cloud-credentials가 있습니다.
4.8.3.4.1. 분할 볼륨과 함께 사용할 DPA 생성
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 분할 볼륨을 사용하여 데이터를 백업하고 복원하기 전에 DPA(Data Protection Application) CR을 생성해야 합니다.
절차
다음 예와 같이 DPA(Data Protection Application) CR을 생성합니다.
분할 볼륨이 있는 환경의 DPA CR의 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: velero-sample namespace: openshift-adp spec: backupLocations: - velero: config: profile: default region: us-east-1 credential: key: cloud name: cloud-credentials default: true objectStorage: bucket: <my-bucket> prefix: velero provider: aws configuration: restic: enable: false velero: defaultPlugins: - openshift - aws - csi - vsm features: dataMover: credentialName: <restic_secret_name> 1 enable: true volumeOptionsForStorageClasses: 2 ocs-storagecluster-cephfs: sourceVolumeOptions: accessMode: ReadOnlyMany cacheAccessMode: ReadWriteMany cacheStorageClassName: ocs-storagecluster-cephfs storageClassName: ocs-storagecluster-cephfs-shallow ocs-storagecluster-ceph-rbd: sourceVolumeOptions: storageClassName: ocs-storagecluster-ceph-rbd cacheStorageClassName: ocs-storagecluster-ceph-rbd destinationVolumeOptions: storageClassName: ocs-storagecluster-ceph-rbd cacheStorageClassName: ocs-storagecluster-ceph-rbd
4.8.3.4.2. OADP 1.2 Data Mover 및 분할 볼륨을 사용하여 데이터 백업
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 볼륨이 분할된 환경에서 데이터를 백업할 수 있습니다.
절차
다음 예와 같이
BackupCR을 생성합니다.BackupCR의 예apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> namespace: <protected_ns> spec: includedNamespaces: - <app_ns> storageLocation: velero-sample-1
다음 단계를 완료하여
VolumeSnapshotBackupCR의 진행 상황을 모니터링합니다.모든
VolumeSnapshotBackupCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsb -n <app_ns>
특정
VolumeSnapshotBackupCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsb <vsb_name> -n <app_ns> -ojsonpath="{.status.phase}`
-
VolumeSnapshotBackupCR의 상태가Completed가 될 때까지 몇 분 정도 기다립니다. -
Restic 시크릿에 제공된 오브젝트 저장소에 스냅샷이 하나 이상 있는지
확인합니다./<OADP_namespace> 접두사가 있는 대상.BackupStorageLocation스토리지 공급자에서 이 스냅샷을 확인할 수 있습니다
4.8.3.4.3. OADP 1.2 Data Mover 및 분할 볼륨을 사용하여 데이터 복원
OADP(OpenShift API for Data Protection) 1.2 Data Mover를 사용하여 백업 프로세스에 CephFS 스토리지의 부분 복사 기능이 활성화된 경우 볼륨이 분할된 환경에서 데이터를 복원할 수 있습니다. 단순 복사 기능은 복원 프로시저에서 사용되지 않습니다.
절차
다음 명령을 실행하여 애플리케이션 네임스페이스를 삭제합니다.
$ oc delete vsb -n <app_namespace> --all
다음 명령을 실행하여 백업 중에 생성된
VolumeSnapshotContentCR을 삭제합니다.$ oc delete volumesnapshotcontent --all
다음 예와 같이
RestoreCR을 생성합니다.RestoreCR의 예apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> namespace: <protected_ns> spec: backupName: <previous_backup_name>
다음을 수행하여
VolumeSnapshotRestoreCR의 진행 상황을 모니터링합니다.모든
VolumeSnapshotRestoreCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsr -n <app_ns>
특정
VolumeSnapshotRestoreCR의 진행 상황을 확인하려면 다음 명령을 실행합니다.$ oc get vsr <vsr_name> -n <app_ns> -ojsonpath="{.status.phase}
다음 명령을 실행하여 애플리케이션 데이터가 복원되었는지 확인합니다.
$ oc get route <route_name> -n <app_ns> -ojsonpath="{.spec.host}"
4.8.4. OADP 1.1 Data Mover를 사용하여 백업 후 정리
OADP 1.1 Data Mover의 경우 백업을 수행한 후 데이터 정리를 수행해야 합니다.
정리는 다음 리소스를 삭제하는 것으로 구성됩니다.
- 버킷의 스냅샷
- 클러스터 리소스
- 스케줄에 의해 실행되거나 반복적으로 실행되는 백업 프로시저 후VSB(volume snapshot backups)
4.8.4.1. 버킷에서 스냅샷 삭제
데이터 Mover는 백업 후 버킷에 하나 이상의 스냅샷을 남겨 둘 수 있습니다. 모든 스냅샷을 삭제하거나 개별 스냅샷을 삭제할 수 있습니다.
절차
-
버킷의 모든 스냅샷을 삭제하려면 DPA(Data Protection Application)
.spec.backupLocation.objectStorage.bucket리소스에 지정된/<protected_namespace> 폴더를 삭제합니다. 개별 스냅샷을 삭제하려면 다음을 수행합니다.
-
DPA
.spec.backupLocation.objectStorage.bucket리소스에 지정된/<protected_namespace> 폴더를 찾습니다. -
/<volumeSnapshotContent name>-pvc접두사가 있는 적절한 폴더를 삭제합니다. 여기서 <VolumeSnapshotContent_name>은 PVC당 Data Mover에 의해 생성된VolumeSnapshotContent입니다.
-
DPA
4.8.4.2. 클러스터 리소스 삭제
OADP 1.1 Data Mover는 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소에 성공적으로 백업할지 여부에 관계없이 클러스터 리소스를 남겨 둘 수 있습니다.
4.8.4.2.1. 성공적인 백업 및 데이터 Mover를 사용한 복원 후 클러스터 리소스 삭제
성공적인 백업 후 애플리케이션 네임스페이스에 남아 있는 VolumeSnapshotBackup 또는 VolumeSnapshotRestore CR을 삭제하고 Data Mover를 사용한 복원을 삭제할 수 있습니다.
절차
Data Mover를 사용하는 백업 후 애플리케이션 PVC가 있는 네임스페이스인 애플리케이션 네임스페이스에 남아 있는 클러스터 리소스를 삭제합니다.
$ oc delete vsb -n <app_namespace> --all
Data Mover를 사용하는 복원 후에도 남아 있는 클러스터 리소스를 삭제합니다.
$ oc delete vsr -n <app_namespace> --all
필요한 경우 백업 후에도 남아 있는
VolumeSnapshotContent리소스를 삭제하고 Data Mover를 사용하는 위치를 복원합니다.$ oc delete volumesnapshotcontent --all
4.8.4.2.2. 부분적으로 성공한 또는 실패한 백업 후 클러스터 리소스 삭제 및 Data Mover를 사용한 복원
Data Mover를 사용하는 백업 및 복원 작업이 실패하거나 부분적으로만 성공하면 애플리케이션 네임스페이스에 존재하는 VolumeSnapshotBackup (VSB) 또는 VolumeSnapshotRestore CRD(사용자 정의 리소스 정의)를 정리하고 이러한 컨트롤러에서 생성한 추가 리소스를 정리해야 합니다.
절차
다음 명령을 입력하여 Data Mover를 사용한 백업 작업 후에도 남아 있는 클러스터 리소스를 정리합니다.
애플리케이션 네임스페이스에서 VSB CRD를 삭제하고 백업하고 복원할 애플리케이션 PVC가 있는 네임스페이스를 삭제합니다.
$ oc delete vsb -n <app_namespace> --all
VolumeSnapshotCR을 삭제합니다.$ oc delete volumesnapshot -A --all
VolumeSnapshotContentCR을 삭제합니다.$ oc delete volumesnapshotcontent --all
보호된 네임스페이스에서 PVC를 삭제하고 Operator가 설치된 네임스페이스를 삭제합니다.
$ oc delete pvc -n <protected_namespace> --all
네임스페이스에서
ReplicationSource리소스를 삭제합니다.$ oc delete replicationsource -n <protected_namespace> --all
다음 명령을 입력하여 Data Mover를 사용하여 복원 작업 후에도 남아 있는 클러스터 리소스를 정리합니다.
VSR CRD를 삭제합니다.
$ oc delete vsr -n <app-ns> --all
VolumeSnapshotCR을 삭제합니다.$ oc delete volumesnapshot -A --all
VolumeSnapshotContentCR을 삭제합니다.$ oc delete volumesnapshotcontent --all
네임스페이스에서
ReplicationDestination리소스를 삭제합니다.$ oc delete replicationdestination -n <protected_namespace> --all
4.9. OADP 1.3 Data Mover
4.9.1. OADP 1.3 Data Mover 정보
OADP 1.3에는 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소로 이동하는 데 사용할 수 있는 기본 제공 데이터 Mover가 포함되어 있습니다. 기본 제공 Data Mover를 사용하면 오류, 실수로 삭제 또는 클러스터 손상이 발생하는 경우 원격 오브젝트 저장소에서 상태 저장 애플리케이션을 복원할 수 있습니다. Kopia 를 업로드기 메커니즘으로 사용하여 스냅샷 데이터를 읽고 통합 리포지토리에 씁니다.
OADP는 다음에서 CSI 스냅샷을 지원합니다.
- Red Hat OpenShift Data Foundation
- Kubernetes Volume Snapshot API를 지원하는 CSI(Container Storage Interface) 드라이버가 있는 기타 클라우드 스토리지 공급자
OADP 내장 Data Mover는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
4.9.1.1. 기본 제공 데이터 Mover 활성화
기본 제공 데이터 Mover를 활성화하려면 CSI 플러그인을 포함하고 DataProtectionApplication CR(사용자 정의 리소스)에서 노드 에이전트를 활성화해야 합니다. 노드 에이전트는 데이터 이동 모듈을 호스팅하는 Kubernetes 데몬 세트입니다. 여기에는 데이터 Mover 컨트롤러, 업로드자 및 리포지토리가 포함됩니다.
DataProtectionApplication 매니페스트의 예
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: dpa-sample
spec:
configuration:
nodeAgent:
enable: true 1
uploaderType: kopia 2
velero:
defaultPlugins:
- openshift
- aws
- csi 3
# ...
4.9.1.2. 기본 제공 데이터 Mover 컨트롤러 및 CRD(사용자 정의 리소스 정의)
기본 제공 Data Mover 기능에는 백업 및 복원을 관리하기 위해 CRD로 정의된 새로운 API 오브젝트 3개가 도입되었습니다.
-
DataDownload: 볼륨 스냅샷의 데이터 다운로드를 나타냅니다. CSI 플러그인은 복원할 볼륨당 하나의DataDownload오브젝트를 생성합니다.DataDownloadCR에는 대상 볼륨, 지정된 데이터 Mover, 현재 데이터 다운로드의 진행 상황, 지정된 백업 리포지토리 및 프로세스가 완료된 후 현재 데이터 다운로드 결과가 포함됩니다. -
DataUpload: 볼륨 스냅샷의 데이터 업로드를 나타냅니다. CSI 플러그인은 CSI 스냅샷당 하나의DataUpload오브젝트를 생성합니다.DataUploadCR에는 지정된 스냅샷, 지정된 데이터 Mover, 지정된 백업 리포지토리, 현재 데이터 업로드 진행률, 프로세스가 완료된 후 현재 데이터 업로드 결과가 포함됩니다. -
BackupRepository: 백업 리포지토리의 라이프사이클을 나타내며 관리합니다. OADP는 네임스페이스에 대한 첫 번째 CSI 스냅샷 백업 또는 복원이 요청되면 네임스페이스당 백업 리포지토리를 생성합니다.
4.9.2. CSI 스냅샷 백업 및 복원
OADP 1.3 Data Mover를 사용하여 영구 볼륨을 백업하고 복원할 수 있습니다.
4.9.2.1. CSI 스냅샷을 사용하여 영구 볼륨 백업
OADP 데이터 Mover를 사용하여 CSI(Container Storage Interface) 볼륨 스냅샷을 원격 오브젝트 저장소에 백업할 수 있습니다.
사전 요구 사항
-
cluster-admin역할을 사용하여 클러스터에 액세스할 수 있습니다. - OADP Operator가 설치되어 있습니다.
-
CSI 플러그인을 포함하고
DataProtectionApplicationCR(사용자 정의 리소스)에 노드 에이전트를 활성화했습니다. - 별도의 네임스페이스에서 영구 볼륨이 실행되는 애플리케이션이 있습니다.
-
metadata.labels.velero.io/csi-volumesnapshot-class: "true"키-값 쌍을VolumeSnapshotClassCR에 추가했습니다.
절차
다음 예와 같이
Backup오브젝트에 대한 YAML 파일을 생성합니다.BackupCR의 예kind: Backup apiVersion: velero.io/v1 metadata: name: backup namespace: openshift-adp spec: csiSnapshotTimeout: 10m0s defaultVolumesToFsBackup: false includedNamespaces: - mysql-persistent itemOperationTimeout: 4h0m0s snapshotMoveData: true 1 storageLocation: default ttl: 720h0m0s volumeSnapshotLocations: - dpa-sample-1 # ...- 1
- CSI 스냅샷을 원격 오브젝트 스토리지로 이동하려면
true로 설정합니다.
매니페스트를 적용합니다.
$ oc create -f backup.yaml
DataUploadCR은 스냅샷 생성이 완료된 후 생성됩니다.
검증
DataUploadCR의status.phase필드를 모니터링하여 스냅샷 데이터가 원격 오브젝트 저장소로 성공적으로 전송되었는지 확인합니다. 가능한 값은진행중 ,완료됨,실패또는취소됨입니다. 오브젝트 저장소는DataProtectionApplicationCR의backupLocations스탠자에 구성됩니다.다음 명령을 실행하여 모든
DataUpload오브젝트 목록을 가져옵니다.$ oc get datauploads -A
출력 예
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp backup-test-1-sw76b Completed 9m47s 108104082 108104082 dpa-sample-1 9m47s ip-10-0-150-57.us-west-2.compute.internal openshift-adp mongo-block-7dtpf Completed 14m 1073741824 1073741824 dpa-sample-1 14m ip-10-0-150-57.us-west-2.compute.internal
다음 명령을 실행하여 특정
DataUpload오브젝트의status.phase필드 값을 확인합니다.$ oc get datauploads <dataupload_name> -o yaml
출력 예
apiVersion: velero.io/v2alpha1 kind: DataUpload metadata: name: backup-test-1-sw76b namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 csiSnapshot: snapshotClass: "" storageClass: gp3-csi volumeSnapshot: velero-mysql-fq8sl operationTimeout: 10m0s snapshotType: CSI sourceNamespace: mysql-persistent sourcePVC: mysql status: completionTimestamp: "2023-11-02T16:57:02Z" node: ip-10-0-150-57.us-west-2.compute.internal path: /host_pods/15116bac-cc01-4d9b-8ee7-609c3bef6bde/volumes/kubernetes.io~csi/pvc-eead8167-556b-461a-b3ec-441749e291c4/mount phase: Completed 1 progress: bytesDone: 108104082 totalBytes: 108104082 snapshotID: 8da1c5febf25225f4577ada2aeb9f899 startTimestamp: "2023-11-02T16:56:22Z"- 1
- 스냅샷 데이터가 원격 오브젝트 저장소로 성공적으로 전송되었음을 나타냅니다.
4.9.2.2. CSI 볼륨 스냅샷 복원
Restore CR을 생성하여 볼륨 스냅샷을 복원할 수 있습니다.
OAPD 1.3 기본 제공 데이터 Mover를 사용하여 OADP 1.2의 reflectsync 백업을 복원할 수 없습니다. OADP 1.3으로 업그레이드하기 전에 Restic을 사용하여 모든 워크로드의 파일 시스템 백업을 수행하는 것이 좋습니다.
사전 요구 사항
-
cluster-admin역할을 사용하여 클러스터에 액세스할 수 있습니다. -
데이터를 복원할 OADP
BackupCR이 있습니다.
절차
다음 예와 같이
RestoreCR에 대한 YAML 파일을 생성합니다.RestoreCR의 예apiVersion: velero.io/v1 kind: Restore metadata: name: restore namespace: openshift-adp spec: backupName: <backup> # ...
매니페스트를 적용합니다.
$ oc create -f restore.yaml
복원이 시작될 때
DataDownloadCR이 생성됩니다.
검증
DataDownloadCR의status.phase필드를 확인하여 복원 프로세스의 상태를 모니터링할 수 있습니다. 가능한 값은진행중 ,완료됨,실패또는취소됨입니다.모든
DataDownload오브젝트 목록을 가져오려면 다음 명령을 실행합니다.$ oc get datadownloads -A
출력 예
NAMESPACE NAME STATUS STARTED BYTES DONE TOTAL BYTES STORAGE LOCATION AGE NODE openshift-adp restore-test-1-sk7lg Completed 7m11s 108104082 108104082 dpa-sample-1 7m11s ip-10-0-150-57.us-west-2.compute.internal
다음 명령을 입력하여 특정
DataDownload오브젝트의status.phase필드 값을 확인합니다.$ oc get datadownloads <datadownload_name> -o yaml
출력 예
apiVersion: velero.io/v2alpha1 kind: DataDownload metadata: name: restore-test-1-sk7lg namespace: openshift-adp spec: backupStorageLocation: dpa-sample-1 operationTimeout: 10m0s snapshotID: 8da1c5febf25225f4577ada2aeb9f899 sourceNamespace: mysql-persistent targetVolume: namespace: mysql-persistent pv: "" pvc: mysql status: completionTimestamp: "2023-11-02T17:01:24Z" node: ip-10-0-150-57.us-west-2.compute.internal phase: Completed 1 progress: bytesDone: 108104082 totalBytes: 108104082 startTimestamp: "2023-11-02T17:00:52Z"- 1
- CSI 스냅샷 데이터가 성공적으로 복원되었음을 나타냅니다.
4.10. 문제 해결
OpenShift CLI 툴 또는 Velero CLI 툴 을 사용하여 Velero CR(사용자 정의 리소스)을 디버깅할 수 있습니다. Velero CLI 툴에서는 자세한 로그 및 정보를 제공합니다.
설치 문제,백업 및 복원 CR 문제, Restic 문제 등을 확인할 수 있습니다.
must-gather 툴 을 사용하여 로그 및 CR 정보를 수집할 수 있습니다.
다음을 통해 Velero CLI 툴을 가져올 수 있습니다.
- Velero CLI 툴 다운로드
- 클러스터의 Velero 배포에서 Velero 바이너리에 액세스
4.10.1. Velero CLI 툴 다운로드
Velero 문서 페이지의 지침에 따라 Velero CLI 툴을 다운로드하여 설치할 수 있습니다.
페이지에는 다음에 대한 지침이 포함되어 있습니다.
- Homebrew를 사용하여 macOS
- GitHub
- Chocolatey를 사용하여 Windows
사전 요구 사항
- DNS 및 컨테이너 네트워킹이 활성화된 Kubernetes 클러스터 v1.16 이상에 액세스할 수 있습니다.
-
kubectl을 로컬로 설치했습니다.
절차
- 브라우저를 열고 Velero 웹 사이트에서 "Install the CLI" 로 이동합니다.
- macOS, GitHub 또는 Windows에 대한 적절한 절차를 따르십시오.
- OADP 및 OpenShift Container Platform 버전에 적합한 Velero 버전을 다운로드합니다.
4.10.1.1. OADP-Velero-OpenShift Container Platform 버전 관계
4.10.2. 클러스터의 Velero 배포에서 Velero 바이너리에 액세스
shell 명령을 사용하여 클러스터의 Velero 배포에서 Velero 바이너리에 액세스할 수 있습니다.
사전 요구 사항
-
DataProtectionApplication사용자 정의 리소스의 상태는Reconcile complete.
절차
다음 명령을 입력하여 필요한 별칭을 설정합니다.
$ alias velero='oc -n openshift-adp exec deployment/velero -c velero -it -- ./velero'
4.10.3. OpenShift CLI 툴을 사용하여 Velero 리소스 디버깅
OpenShift CLI 툴을 사용하여 Velero CR(사용자 정의 리소스) 및 Velero 포드 로그를 확인하여 실패한 백업 또는 복원을 디버깅할 수 있습니다.
Velero CR
oc describe 명령을 사용하여 백업 또는 복원 CR과 관련된 경고 및 오류 요약을 검색합니다.
$ oc describe <velero_cr> <cr_name>
Velero Pod 로그
oc logs 명령을 사용하여 Velero Pod 로그를 검색합니다.
$ oc logs pod/<velero>
Velero Pod 디버그 로그
다음 예와 같이 DataProtectionApplication 리소스에서 Velero 로그 수준을 지정할 수 있습니다.
이 옵션은 OADP 1.0.3부터 사용할 수 있습니다.
apiVersion: oadp.openshift.io/v1alpha1
kind: DataProtectionApplication
metadata:
name: velero-sample
spec:
configuration:
velero:
logLevel: warning
다음 logLevel 값을 사용할 수 있습니다.
-
trace -
debug -
info -
경고 -
error -
fatal -
panic
대부분의 로그에 debug 를 사용하는 것이 좋습니다.
4.10.4. Velero CLI 툴을 사용하여 Velero 리소스 디버깅
Backup 및 Restore CR(사용자 정의 리소스)을 디버그하고 Velero CLI 툴을 사용하여 로그를 검색할 수 있습니다.
Velero CLI 툴은 OpenShift CLI 툴보다 자세한 정보를 제공합니다.
구문
oc exec 명령을 사용하여 Velero CLI 명령을 실행합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> <command> <cr_name>
예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
도움말 옵션
velero --help 옵션을 사용하여 모든 Velero CLI 명령을 나열합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ --help
Describe 명령
velero describe 명령을 사용하여 Backup 또는 Restore CR과 관련된 경고 및 오류 요약을 검색합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> describe <cr_name>
예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ backup describe 0e44ae00-5dc3-11eb-9ca8-df7e5254778b-2d8ql
Logs 명령
velero logs 명령을 사용하여 Backup 또는 Restore CR의 로그를 검색합니다.
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ <backup_restore_cr> logs <cr_name>
예제
$ oc -n openshift-adp exec deployment/velero -c velero -- ./velero \ restore logs ccc7c2d0-6017-11eb-afab-85d0007f5a19-x4lbf
4.10.5. 메모리 또는 CPU 부족으로 인해 Pod 충돌 또는 재시작
메모리 또는 CPU 부족으로 인해 Velero 또는 Restic Pod가 충돌하는 경우 해당 리소스 중 하나에 대한 특정 리소스 요청을 설정할 수 있습니다.
추가 리소스
4.10.5.1. Velero Pod에 대한 리소스 요청 설정
oadp_v1alpha1_dpa.yaml 파일에서 configuration.velero.podConfig.resourceAllocations 사양 필드를 사용하여 Velero Pod에 대한 특정 리소스 요청을 설정할 수 있습니다.
절차
YAML 파일에서
cpu및memory리소스 요청을 설정합니다.Velero 파일의 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: velero: podConfig: resourceAllocations: 1 requests: cpu: 200m memory: 256Mi- 1
- 나열된
resourceAllocations는 평균 사용량입니다.
4.10.5.2. Restic Pod에 대한 리소스 요청 설정
configuration.restic.podConfig.resourceAllocations 사양 필드를 사용하여 Restic Pod에 대한 특정 리소스 요청을 설정할 수 있습니다.
절차
YAML 파일에서
cpu및memory리소스 요청을 설정합니다.Restic 파일 예
apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication ... configuration: restic: podConfig: resourceAllocations: 1 requests: cpu: 1000m memory: 16Gi- 1
- 나열된
resourceAllocations는 평균 사용량입니다.
리소스 요청 필드의 값은 Kubernetes 리소스 요구 사항과 동일한 형식을 따라야 합니다. 또한 configuration.velero.podConfig.resourceAllocations 또는 configuration.restic.podConfig.resourceAllocations 를 지정하지 않으면 Velero Pod 또는 Restic Pod의 기본 리소스 사양은 다음과 같습니다.
requests: cpu: 500m memory: 128Mi
4.10.6. Velero 및 승인 Webhook 관련 문제
Velero는 복원 중 승인 Webhook 문제를 해결할 수 있는 기능이 제한되어 있습니다. 승인 Webhook가 있는 워크로드가 있는 경우 추가 Velero 플러그인을 사용하거나 워크로드를 복원하는 방법을 변경해야 할 수 있습니다.
일반적으로 승인 Webhook가 있는 워크로드에서는 먼저 특정 종류의 리소스를 생성해야 합니다. 승인 Webhook가 일반적으로 하위 리소스를 차단하기 때문에 워크로드에 하위 리소스가 있는 경우 특히 중요합니다.
예를 들어 service.serving.knative.dev 와 같은 최상위 오브젝트를 생성하거나 복원하면 일반적으로 하위 리소스가 자동으로 생성됩니다. 먼저 이 작업을 수행하는 경우 Velero를 사용하여 이러한 리소스를 생성하고 복원할 필요가 없습니다. 그러면 Velero가 사용할 수 있는 승인 Webhook에 의해 차단되는 하위 리소스의 문제를 방지할 수 있습니다.
4.10.6.1. 승인 Webhook를 사용하는 Velero 백업의 해결방법 복원
이 섹션에서는 승인 Webhook를 사용하는 여러 유형의 Velero 백업에 대한 리소스를 복원하는 데 필요한 추가 단계를 설명합니다.
4.10.6.1.1. Knative 리소스 복원
승인 Webhook를 사용하는 Knative 리소스를 백업하려면 Velero를 사용하여 문제가 발생할 수 있습니다.
승인 Webhook를 사용하는 Knative 리소스를 백업 및 복원할 때마다 최상위 서비스 리소스를 복원하여 이러한 문제를 방지할 수 있습니다.
절차
최상위
서비스.serving.knavtive.dev Service리소스를 복원합니다.$ velero restore <restore_name> \ --from-backup=<backup_name> --include-resources \ service.serving.knavtive.dev
4.10.6.1.2. IBM AppConnect 리소스 복원
승인 Webhook가 있는 IBM AppConnect 리소스를 복원하기 위해 Velero를 사용할 때 문제가 발생하는 경우 이 프로세스에서 검사를 실행할 수 있습니다.
절차
클러스터에 변경 승인 플러그인이 있는지 확인합니다
: MutatingWebhookConfiguration.$ oc get mutatingwebhookconfigurations
-
각
kind: MutatingWebhookConfiguration의 YAML 파일을 검사하여 문제가 발생한 오브젝트의 규칙 블록 생성이 없는지 확인합니다. 자세한 내용은 공식 Kubernetes 설명서를 참조하십시오. -
유형에 있는이 설치된 Operator에서 지원되는지 확인합니다.spec.version: Configuration.appconnect.ibm.com/v1beta1
4.10.6.2. Velero 플러그인에서 "received EOF, stop recv loop" 메시지를 반환
Velero 플러그인은 별도의 프로세스로 시작됩니다. Velero 작업이 성공적으로 완료되거나 실패하면 종료됩니다. 디버그 로그에서 recv 루프 메시지를 중지하여 수신된 EOF 를 수신하면 플러그인 작업이 완료되었음을 나타냅니다. 이는 오류가 발생했음을 의미하지 않습니다.
4.10.7. 설치 문제
데이터 보호 애플리케이션을 설치할 때 유효하지 않은 디렉토리 또는 잘못된 자격 증명을 사용하여 발생한 문제가 발생할 수 있습니다.
4.10.7.1. 백업 스토리지에 잘못된 디렉터리가 포함되어 있습니다.
Velero 포드 로그에 오류 메시지가 표시되고 Backup 스토리지에 잘못된 최상위 디렉터리가 포함되어 있습니다.
원인
오브젝트 스토리지에는 Velero 디렉터리가 아닌 최상위 디렉터리가 포함되어 있습니다.
해결책
오브젝트 스토리지가 Velero에 전용되지 않은 경우 DataProtectionApplication 매니페스트에서 spec.backupLocations.velero.objectStorage.prefix 매개변수를 설정하여 버킷의 접두사를 지정해야 합니다.
4.10.7.2. 잘못된 AWS 인증 정보
oadp-aws-registry Pod 로그에 오류 메시지 InvalidAccessKeyId: AWS Access Key Id가 기록에 존재하지 않습니다.
Velero 포드 로그에 오류 메시지 NoCredentialProviders: no valid providers in chain 을 표시합니다.
원인
Secret 오브젝트를 생성하는 데 사용되는 credentials-velero 파일이 잘못 포맷됩니다.
해결책
다음 예와 같이 credentials-velero 파일이 올바르게 포맷되었는지 확인합니다.
credentials-velero 파일의 예
[default] 1 aws_access_key_id=AKIAIOSFODNN7EXAMPLE 2 aws_secret_access_key=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
4.10.8. OADP Operator 문제
OADP(OpenShift API for Data Protection) Operator는 해결할 수 없는 문제로 인해 문제가 발생할 수 있습니다.
4.10.8.1. OADP Operator가 자동으로 실패
OADP Operator의 S3 버킷은 비어 있을 수 있지만 oc get po -n <OADP_Operator_namespace> 명령을 실행하면 Operator의 상태가 임을 확인할 수 있습니다. 이러한 경우 Operator는 실행 중이라고 잘못 보고하기 때문에 자동으로 실패했다고 합니다.
Running
원인
클라우드 인증 정보가 충분하지 않은 권한을 제공하는 경우 문제가 발생합니다.
해결책
백업 스토리지 위치(BSL) 목록을 검색하고 인증 정보 문제는 각 BSL의 매니페스트를 확인합니다.
절차
다음 명령 중 하나를 실행하여 BSL 목록을 검색합니다.
OpenShift CLI 사용:
$ oc get backupstoragelocation -A
Velero CLI 사용:
$ velero backup-location get -n <OADP_Operator_namespace>
BSL 목록을 사용하여 다음 명령을 실행하여 각 BSL의 매니페스트를 표시하고 각 매니페스트에 오류가 있는지 검사합니다.
$ oc get backupstoragelocation -n <namespace> -o yaml
결과 예
apiVersion: v1
items:
- apiVersion: velero.io/v1
kind: BackupStorageLocation
metadata:
creationTimestamp: "2023-11-03T19:49:04Z"
generation: 9703
name: example-dpa-1
namespace: openshift-adp-operator
ownerReferences:
- apiVersion: oadp.openshift.io/v1alpha1
blockOwnerDeletion: true
controller: true
kind: DataProtectionApplication
name: example-dpa
uid: 0beeeaff-0287-4f32-bcb1-2e3c921b6e82
resourceVersion: "24273698"
uid: ba37cd15-cf17-4f7d-bf03-8af8655cea83
spec:
config:
enableSharedConfig: "true"
region: us-west-2
credential:
key: credentials
name: cloud-credentials
default: true
objectStorage:
bucket: example-oadp-operator
prefix: example
provider: aws
status:
lastValidationTime: "2023-11-10T22:06:46Z"
message: "BackupStorageLocation \"example-dpa-1\" is unavailable: rpc
error: code = Unknown desc = WebIdentityErr: failed to retrieve credentials\ncaused
by: AccessDenied: Not authorized to perform sts:AssumeRoleWithWebIdentity\n\tstatus
code: 403, request id: d3f2e099-70a0-467b-997e-ff62345e3b54"
phase: Unavailable
kind: List
metadata:
resourceVersion: ""
4.10.9. OADP 시간 초과
시간 제한을 늘리면 복잡하고 리소스를 많이 사용하는 프로세스가 조기 종료되지 않고 성공적으로 완료할 수 있습니다. 이 구성을 사용하면 오류, 재시도 또는 실패 가능성을 줄일 수 있습니다.
프로세스의 기본 문제를 숨길 수 있는 과도하게 긴 시간 초과를 구성하지 않도록 시간 초과 확장의 균형을 조정해야 합니다. 프로세스 및 전체 시스템 성능을 충족하는 적절한 시간 초과 값을 신중하게 고려하고 모니터링합니다.
다음은 이러한 매개변수를 구현하는 방법과 시기에 대한 지침이 포함된 다양한 OADP 시간 초과입니다.
4.10.9.1. Restic 타임아웃
시간 초과는 Restic 타임아웃을 정의합니다. 기본값은 1h 입니다.
다음 시나리오에 대해 Restic 타임아웃 을 사용합니다.
- 500GB보다 큰 총 PV 데이터 사용량이 있는 Restic 백업의 경우
다음 오류로 인해 백업이 시간 초과되는 경우:
level=error msg="Error backing up item" backup=velero/monitoring error="timed out waiting for all PodVolumeBackups to complete"
절차
다음 예와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.restic.timeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: restic: timeout: 1h # ...
4.10.9.2. Velero 리소스 시간 초과
resourceTimeout 은 Velero CRD(사용자 정의 리소스 정의) 가용성, volumeSnapshot 삭제 및 리포지토리 가용성과 같이 시간 초과가 발생하기 전에 여러 Velero 리소스를 대기하는 시간을 정의합니다. 기본값은 10m 입니다.
다음 시나리오에 대해 resourceTimeout 을 사용합니다.
총 PV 데이터 사용량이 1TB 이상인 백업의 경우 이 매개 변수는 Velero가 백업을 완료로 표시하기 전에 CSI(Container Storage Interface) 스냅샷을 정리하거나 삭제하려고 할 때 시간 초과 값으로 사용됩니다.
- 이 정리의 하위 작업은 VSC 패치를 시도하며 이 시간 초과는 해당 작업에 사용할 수 있습니다.
- Restic 또는 Kopia에 대한 파일 시스템 기반 백업에 대한 백업 리포지토리를 생성하거나 확인하려면 다음을 수행합니다.
- CR(사용자 정의 리소스) 또는 리소스를 백업에서 복원하기 전에 클러스터에서 Velero CRD를 사용할 수 있는지 확인하려면 다음을 수행합니다.
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.resourceTimeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: resourceTimeout: 10m # ...
4.10.9.3. 데이터 Mover 시간 초과
timeout 은 VolumeSnapshotBackup 및 VolumeSnapshotRestore 를 완료하는 사용자 제공 타임아웃입니다. 기본값은 10m 입니다.
다음 시나리오에 대해 Data Mover 시간 초과 를 사용합니다.
-
VolumeSnapshotBackups(VSB) 및VolumeSnapshotRestores(VSR)를 생성하는 경우 10분 후에 시간 초과됩니다. -
총 PV 데이터 사용량이 500GB 이상인 대규모 환경의 경우
1h에 시간 제한을 설정합니다. -
VolumeSnapshotMover(VSM) 플러그인 사용 - OADP 1.1.x에서만 사용
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.features.dataMover.timeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: features: dataMover: timeout: 10m # ...
4.10.9.4. CSI 스냅샷 시간 초과
CSISnapshotTimeout 은 오류를 시간 초과로 반환하기 전에 CSI VolumeSnapshot 상태가 ReadyToUse 상태가 될 때까지 대기하는 시간을 지정합니다. 기본값은 10m 입니다.
다음 시나리오에 CSISnapshotTimeout 을 사용합니다.
- CSI 플러그인 사용
- 스냅샷에 10분 이상 걸릴 수 있는 대용량 스토리지 볼륨의 경우. 로그에 시간 초과가 있는 경우 이 시간 제한을 조정합니다.
일반적으로 기본 설정은 대규모 스토리지 볼륨을 수용할 수 있으므로 CSISnapshotTimeout 의 기본값을 조정할 필요가 없습니다.
절차
다음 예제와 같이
BackupCR 매니페스트의spec.csiSnapshotTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: csiSnapshotTimeout: 10m # ...
4.10.9.5. Velero 기본 항목 작업 시간 초과
DefaultItemOperationTimeout은 시간 초과 전에 비동기 BackupItemActions 및 RestoreItemActions 가 완료될 때까지 대기하는 시간을 정의합니다. 기본값은 1h 입니다.
다음 시나리오에 defaultItemOperationTimeout 을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
- 특정 백업 또는 복원이 완료될 때까지 대기해야 하는 시간을 지정하려면 다음을 수행합니다. OADP 기능의 컨텍스트에서 이 값은 CSI(Container Storage Interface) 데이터 Mover 기능과 관련된 비동기 작업에 사용됩니다.
-
defaultItemOperationTimeout이defaultItemOperationTimeout을 사용하여 DPA(Data Protection Application)에 정의되면 백업 및 복원 작업에 모두 적용됩니다.itemOperationTimeout을 사용하여 다음 "Item operation timeout - restore" 섹션과 "Item operation timeout - backup" 섹션에 설명된 대로 해당 CR의 백업 또는 복원만 정의할 수 있습니다.
절차
다음 예제와 같이
DataProtectionApplicationCR 매니페스트의spec.configuration.velero.defaultItemOperationTimeout블록에서 값을 편집합니다.apiVersion: oadp.openshift.io/v1alpha1 kind: DataProtectionApplication metadata: name: <dpa_name> spec: configuration: velero: defaultItemOperationTimeout: 1h # ...
4.10.9.6. 항목 작업 시간 초과 - 복원
ItemOperationTimeout 은 RestoreItemAction 작업을 기다리는 데 사용되는 시간을 지정합니다. 기본값은 1h 입니다.
다음 시나리오에는 복원 ItemOperationTimeout 을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
-
Data Mover가
BackupStorageLocation에 업로드 및 다운로드되는 경우 . 시간 초과에 도달하면 복원 작업이 완료되지 않으면 실패로 표시됩니다. 스토리지 볼륨 크기 때문에 시간 초과 문제로 인해 데이터 Mover 작업이 실패하는 경우 이 시간 초과 설정을 늘려야 할 수 있습니다.
절차
다음 예제와 같이
RestoreCR 매니페스트의Restore.spec.itemOperationTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Restore metadata: name: <restore_name> spec: itemOperationTimeout: 1h # ...
4.10.9.7. 항목 작업 제한 시간 - 백업
ItemOperationTimeout 은 비동기 BackupItemAction 작업을 대기하는 데 사용되는 시간을 지정합니다. 기본값은 1h 입니다.
다음 시나리오에는 ItemOperationTimeout 백업을 사용합니다.
- Data Mover 1.2.x만 사용할 수 있습니다.
-
Data Mover가
BackupStorageLocation에 업로드 및 다운로드되는 경우 . 시간 초과에 도달하면 백업 작업이 완료되지 않으면 실패로 표시됩니다. 스토리지 볼륨 크기 때문에 시간 초과 문제로 인해 데이터 Mover 작업이 실패하는 경우 이 시간 초과 설정을 늘려야 할 수 있습니다.
절차
다음 예제와 같이
BackupCR 매니페스트의Backup.spec.itemOperationTimeout블록에서 값을 편집합니다.apiVersion: velero.io/v1 kind: Backup metadata: name: <backup_name> spec: itemOperationTimeout: 1h # ...
4.10.10. CR 백업 및 복원
백업 및 복원 사용자 정의 리소스(CR)와 관련된 일반적인 문제가 발생할 수 있습니다.
4.10.10.1. Backup CR은 볼륨을 검색할 수 없습니다.
Backup CR에 오류 메시지 InvalidVolume.NotFound: 볼륨 'vol-xxxx'이 존재하지 않습니다.
원인
PV(영구 볼륨) 및 스냅샷 위치는 다른 지역에 있습니다.
해결책
-
스냅샷 위치가 PV와 동일한 리전에 있도록
DataProtectionApplication매니페스트의spec.snapshotLocations.velero.config.region키 값을 편집합니다. -
새
BackupCR을 생성합니다.
4.10.10.2. Backup CR 상태는 진행 중인 상태로 유지됩니다.
Backup CR의 상태는 InProgress 단계에 남아 있으며 완료되지 않습니다.
원인
백업이 중단된 경우 다시 시작할 수 없습니다.
해결책
BackupCR의 세부 정보를 검색합니다.$ oc -n {namespace} exec deployment/velero -c velero -- ./velero \ backup describe <backup>BackupCR을 삭제합니다.$ oc delete backup <backup> -n openshift-adp
진행 중인
BackupCR이 오브젝트 스토리지에 파일을 업로드하지 않았기 때문에 백업 위치를 정리할 필요가 없습니다.-
새
BackupCR을 생성합니다.
4.10.10.3. Backup CR 상태는 PartiallyFailed에 남아 있습니다.
Restic이 사용되지 않은 Backup CR의 상태는 PartiallyFailed 단계에 남아 있으며 완료되지 않습니다. 관련 PVC의 스냅샷이 생성되지 않습니다.
원인
CSI 스냅샷 클래스를 기반으로 백업을 생성하지만 라벨이 누락된 경우 CSI 스냅샷 플러그인이 스냅샷을 생성하지 못합니다. 결과적으로 Velero pod는 다음과 유사한 오류를 기록합니다.
+
time="2023-02-17T16:33:13Z" level=error msg="Error backing up item" backup=openshift-adp/user1-backup-check5 error="error executing custom action (groupResource=persistentvolumeclaims, namespace=busy1, name=pvc1-user1): rpc error: code = Unknown desc = failed to get volumesnapshotclass for storageclass ocs-storagecluster-ceph-rbd: failed to get volumesnapshotclass for provisioner openshift-storage.rbd.csi.ceph.com, ensure that the desired volumesnapshot class has the velero.io/csi-volumesnapshot-class label" logSource="/remote-source/velero/app/pkg/backup/backup.go:417" name=busybox-79799557b5-vprq
해결책
BackupCR을 삭제합니다.$ oc delete backup <backup> -n openshift-adp
-
필요하면
BackupStorageLocation에서 저장된 데이터를 정리하여 공간을 확보합니다. VolumeSnapshotClass오브젝트에velero.io/csi-volumesnapshot-class=true라벨을 적용합니다.$ oc label volumesnapshotclass/<snapclass_name> velero.io/csi-volumesnapshot-class=true
-
새
BackupCR을 생성합니다.
4.10.11. Restic 문제
Restic으로 애플리케이션을 백업할 때 이러한 문제가 발생할 수 있습니다.
4.10.11.1. root_squash가 활성화된 NFS 데이터 볼륨에 대한 Restic 권한 오류
Restic pod 로그에 오류 메시지 controller=pod-volume-backup error="fork/exec/usr/bin/restic: permission denied" 가 표시됩니다.
원인
NFS 데이터 볼륨에 root_squash 가 활성화된 경우 Restic 은 nfsnobody 에 매핑되고 백업을 생성할 수 있는 권한이 없습니다.
해결책
Restic 에 대한 추가 그룹을 생성하고 DataProtectionApplication 매니페스트에 그룹 ID를 추가하여 이 문제를 해결할 수 있습니다.
-
NFS 데이터 볼륨에서
Restic에 대한 보조 그룹을 생성합니다. -
그룹 소유권이 상속되도록 NFS 디렉터리에
setgid비트를 설정합니다. 다음 예제와 같이
spec.configuration.restic.supplementalGroups매개변수와 그룹 ID를DataProtectionApplication매니페스트에 추가합니다.spec: configuration: restic: enable: true supplementalGroups: - <group_id> 1- 1
- 보조 그룹 ID를 지정합니다.
-
변경 사항을 적용할 수 있도록
ResticPod가 다시 시작될 때까지 기다립니다.
4.10.11.2. bucket is emptied 후 Restic Backup CR을 다시 생성할 수 없습니다.
네임스페이스에 대한 Restic Backup CR을 생성하고 오브젝트 스토리지 버킷을 비우고 동일한 네임스페이스에 Backup CR을 다시 생성하면 다시 만든 Backup CR이 실패합니다.
velero Pod 로그에는 다음과 같은 오류 메시지가 표시됩니다. stderr=Fatal: unable to open config file: criteria: specified key does not exist.\nIs there a repository at the following location?.
원인
Velero는 Restic 디렉터리가 오브젝트 스토리지에서 삭제되면 ResticRepository 매니페스트에서 Restic 리포지토리를 다시 생성하거나 업데이트하지 않습니다. 자세한 내용은 Velero issue 4421 을 참조하십시오.
해결책
다음 명령을 실행하여 네임스페이스에서 관련 Restic 리포지토리를 제거합니다.
$ oc delete resticrepository openshift-adp <name_of_the_restic_repository>
다음 오류 로그에서
mysql-persistent는 문제가 있는 Restic 리포지토리입니다. 저장소 이름은 명확성을 위해 이주에 표시됩니다.time="2021-12-29T18:29:14Z" level=info msg="1 errors encountered backup up item" backup=velero/backup65 logSource="pkg/backup/backup.go:431" name=mysql-7d99fc949-qbkds time="2021-12-29T18:29:14Z" level=error msg="Error backing up item" backup=velero/backup65 error="pod volume backup failed: error running restic backup, stderr=Fatal: unable to open config file: Stat: The specified key does not exist.\nIs there a repository at the following location?\ns3:http://minio-minio.apps.mayap-oadp- veleo-1234.qe.devcluster.openshift.com/mayapvelerooadp2/velero1/ restic/mysql-persistent\n: exit status 1" error.file="/remote-source/ src/github.com/vmware-tanzu/velero/pkg/restic/backupper.go:184" error.function="github.com/vmware-tanzu/velero/ pkg/restic.(*backupper).BackupPodVolumes" logSource="pkg/backup/backup.go:435" name=mysql-7d99fc949-qbkds
4.10.12. must-gather 툴 사용
must-gather 툴을 사용하여 OADP 사용자 정의 리소스에 대한 로그, 메트릭 및 정보를 수집할 수 있습니다.
must-gather 데이터는 모든 고객 사례에 첨부되어야 합니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 OpenShift Container Platform 클러스터에 로그인해야 합니다. -
OpenShift CLI(
oc)가 설치되어 있어야 합니다.
절차
-
must-gather데이터를 저장하려는 디렉터리로 이동합니다. 다음 데이터 수집 옵션 중 하나에 대해
oc adm must-gather명령을 실행합니다.$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1
데이터는
must-gather/must-gather.tar.gz로 저장됩니다. Red Hat 고객 포털에서 해당 지원 사례에 이 파일을 업로드할 수 있습니다.$ oc adm must-gather --image=registry.redhat.io/oadp/oadp-mustgather-rhel8:v1.1 \ -- /usr/bin/gather_metrics_dump
이 작업에는 오랜 시간이 걸릴 수 있습니다. 데이터는
must-gather/metrics/prom_data.tar.gz로 저장됩니다.
4.10.12.1. must-gather 툴을 사용할 때 옵션 결합
현재 must-gather 스크립트를 결합할 수 없습니다(예: 비보안 TLS 연결을 허용하는 동안 시간 초과 임계값 지정). 다음 예와 같이 must-gather 명령줄에서 내부 변수를 설정하여 이러한 제한 사항을 해결할 수 있습니다.
$ oc adm must-gather --image=brew.registry.redhat.io/rh-osbs/oadp-oadp-mustgather-rhel8:1.1.1-8 -- skip_tls=true /usr/bin/gather_with_timeout <timeout_value_in_seconds>
이 예제에서는 gather_with_timeout 스크립트를 실행하기 전에 skip_tls 변수를 설정합니다. 결과는 gather_with_timeout 및 gather_without_tls 의 조합입니다.
이렇게 지정할 수 있는 다른 변수는 다음과 같습니다.
-
logs_since기본 값이72h -
request_timeout, 기본값0s
4.10.13. OADP 모니터링
OpenShift Container Platform에서는 사용자와 관리자가 클러스터를 효과적으로 모니터링 및 관리할 수 있는 모니터링 스택을 제공하고, 이벤트가 발생하는 경우 경고 수신을 포함하여 클러스터에서 실행되는 사용자 애플리케이션 및 서비스의 워크로드 성능을 모니터링 및 분석할 수 있습니다.
추가 리소스
4.10.13.1. OADP 모니터링 설정
OADP Operator는 Velero 서비스 끝점에서 지표를 검색하기 위해 OpenShift 모니터링 스택에서 제공하는 OpenShift 사용자 워크로드 모니터링을 활용합니다. 모니터링 스택을 사용하면 OpenShift Metrics 쿼리 프런트 엔드를 사용하여 사용자 정의 경고 규칙을 생성하거나 지표를 쿼리할 수 있습니다.
활성화된 사용자 워크로드 모니터링을 사용하면 Grafana와 같은 Prometheus 호환 타사 UI를 구성하고 사용하여 Velero 지표를 시각화할 수 있습니다.
메트릭을 모니터링하려면 사용자 정의 프로젝트를 모니터링하고 ServiceMonitor 리소스를 생성하여 openshift-adp 네임스페이스에 있는 이미 활성화된 OADP 서비스 끝점에서 해당 메트릭을 스크랩해야 합니다.
사전 요구 사항
-
cluster-admin권한이 있는 계정을 사용하여 OpenShift Container Platform 클러스터에 액세스할 수 있습니다. - 클러스터 모니터링 구성 맵이 생성되어 있습니다.
절차
openshift-monitoring네임스페이스에서cluster-monitoring-configConfigMap오브젝트를 편집합니다.$ oc edit configmap cluster-monitoring-config -n openshift-monitoring
data섹션의config.yaml필드에enableUserWorkload옵션을 추가하거나 활성화합니다.apiVersion: v1 data: config.yaml: | enableUserWorkload: true 1 kind: ConfigMap metadata: # ...- 1
- 이 옵션을 추가하거나
true로 설정합니다.
다음 구성 요소가
openshift-user-workload-monitoring네임스페이스에서 실행 중인지 확인하여 짧은 시간 동안 User Workload Monitoring Setup을 확인합니다.$ oc get pods -n openshift-user-workload-monitoring
출력 예
NAME READY STATUS RESTARTS AGE prometheus-operator-6844b4b99c-b57j9 2/2 Running 0 43s prometheus-user-workload-0 5/5 Running 0 32s prometheus-user-workload-1 5/5 Running 0 32s thanos-ruler-user-workload-0 3/3 Running 0 32s thanos-ruler-user-workload-1 3/3 Running 0 32s
openshift-user-workload-monitoring에user-workload-monitoring-configConfigMap이 있는지 확인합니다. 존재하는 경우 이 절차의 나머지 단계를 건너뜁니다.$ oc get configmap user-workload-monitoring-config -n openshift-user-workload-monitoring
출력 예
Error from server (NotFound): configmaps "user-workload-monitoring-config" not found
User Workload Monitoring에 대한
user-workload-monitoring-configConfigMap오브젝트를 생성하고2_configure_user_workload_monitoring.yaml파일 이름에 저장합니다.출력 예
apiVersion: v1 kind: ConfigMap metadata: name: user-workload-monitoring-config namespace: openshift-user-workload-monitoring data: config.yaml: |
2_configure_user_workload_monitoring.yaml파일을 적용합니다.$ oc apply -f 2_configure_user_workload_monitoring.yaml configmap/user-workload-monitoring-config created
4.10.13.2. OADP 서비스 모니터 생성
OADP는 DPA가 구성될 때 생성되는 openshift-adp-velero-metrics-svc 서비스를 제공합니다. 사용자 워크로드 모니터링에서 사용하는 서비스 모니터는 정의된 서비스를 가리켜야 합니다.
다음 명령을 실행하여 서비스에 대한 세부 정보를 가져옵니다.
절차
openshift-adp-velero-metrics-svc서비스가 있는지 확인합니다.ServiceMonitor오브젝트의 선택기로 사용할app.kubernetes.io/name=velero레이블이 포함되어야 합니다.$ oc get svc -n openshift-adp -l app.kubernetes.io/name=velero
출력 예
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE openshift-adp-velero-metrics-svc ClusterIP 172.30.38.244 <none> 8085/TCP 1h
기존 서비스 레이블과 일치하는
ServiceMonitorYAML 파일을 생성하고 파일을3_create_oadp_service_monitor.yaml로 저장합니다. 서비스 모니터는openshift-adp-velero-metrics-svc 서비스가 있는 openshift-adp네임스페이스에 생성됩니다.ServiceMonitor오브젝트의 예apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: labels: app: oadp-service-monitor name: oadp-service-monitor namespace: openshift-adp spec: endpoints: - interval: 30s path: /metrics targetPort: 8085 scheme: http selector: matchLabels: app.kubernetes.io/name: "velero"3_create_oadp_service_monitor.yaml파일을 적용합니다.$ oc apply -f 3_create_oadp_service_monitor.yaml
출력 예
servicemonitor.monitoring.coreos.com/oadp-service-monitor created
검증
OpenShift Container Platform 웹 콘솔의 관리자 화면을 사용하여 새 서비스 모니터가 Up 상태인지 확인합니다.
- 모니터링 → 대상 페이지로 이동합니다.
-
필터 가 선택되지 않았거나 사용자 소스가 선택되어 있는지 확인하고
텍스트검색 필드에openshift-adp를 입력합니다. 서비스 모니터의 상태 상태가 Up 인지 확인합니다.
그림 4.1. OADP 메트릭 대상
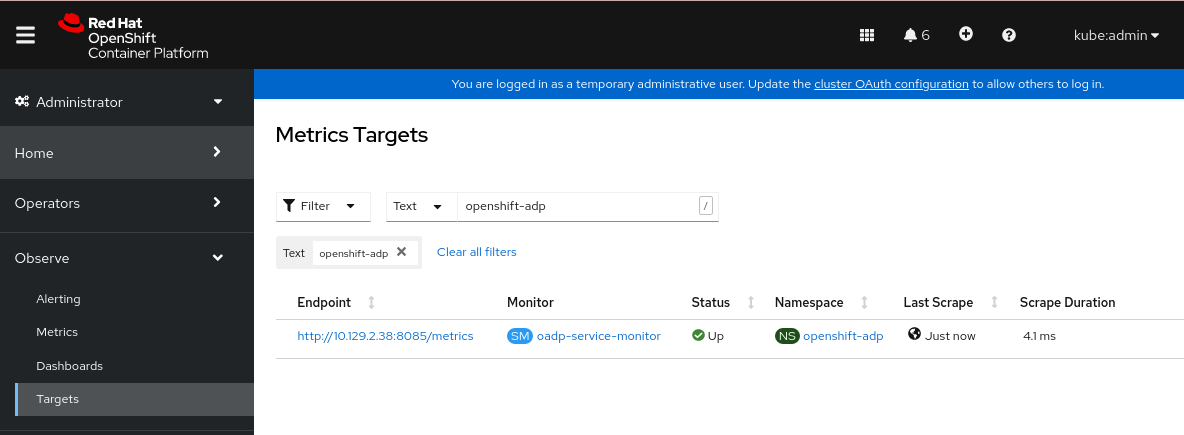
4.10.13.3. 경고 규칙 생성
OpenShift Container Platform 모니터링 스택을 사용하면 경고 규칙을 사용하여 구성된 경고를 수신할 수 있습니다. OADP 프로젝트에 대한 경고 규칙을 생성하려면 사용자 워크로드 모니터링으로 스크랩되는 지표 중 하나를 사용합니다.
절차
샘플
OADPBackupFailing경고를 사용하여PrometheusRuleYAML 파일을 생성하고4_create_oadp_alert_rule.yaml로 저장합니다.샘플
OADPBackupFailing경고apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: name: sample-oadp-alert namespace: openshift-adp spec: groups: - name: sample-oadp-backup-alert rules: - alert: OADPBackupFailing annotations: description: 'OADP had {{$value | humanize}} backup failures over the last 2 hours.' summary: OADP has issues creating backups expr: | increase(velero_backup_failure_total{job="openshift-adp-velero-metrics-svc"}[2h]) > 0 for: 5m labels: severity: warning이 샘플에서는 다음 조건 아래에 경고가 표시됩니다.
- 지난 2시간 동안 0보다 큰 새 오류 백업이 증가하고 상태가 최소 5분 동안 지속됩니다.
-
첫 번째 증가 시간이 5분 미만이면 경고가
Pending상태가 되고 그 후에는 실행 중 상태가 됩니다.
openshift-adp네임스페이스에PrometheusRule오브젝트를 생성하는4_create_oadp_alert_rule.yaml파일을 적용합니다.$ oc apply -f 4_create_oadp_alert_rule.yaml
출력 예
prometheusrule.monitoring.coreos.com/sample-oadp-alert created
검증
경고가 트리거되면 다음과 같은 방법으로 볼 수 있습니다.
- 개발자 화면에서 모니터링 메뉴를 선택합니다.
관리자 관점에서 모니터링 → 경고 메뉴의 필터 상자에서 사용자를 선택합니다. 그렇지 않으면 기본적으로 플랫폼 경고만 표시됩니다.
그림 4.2. OADP 백업 실패 경고
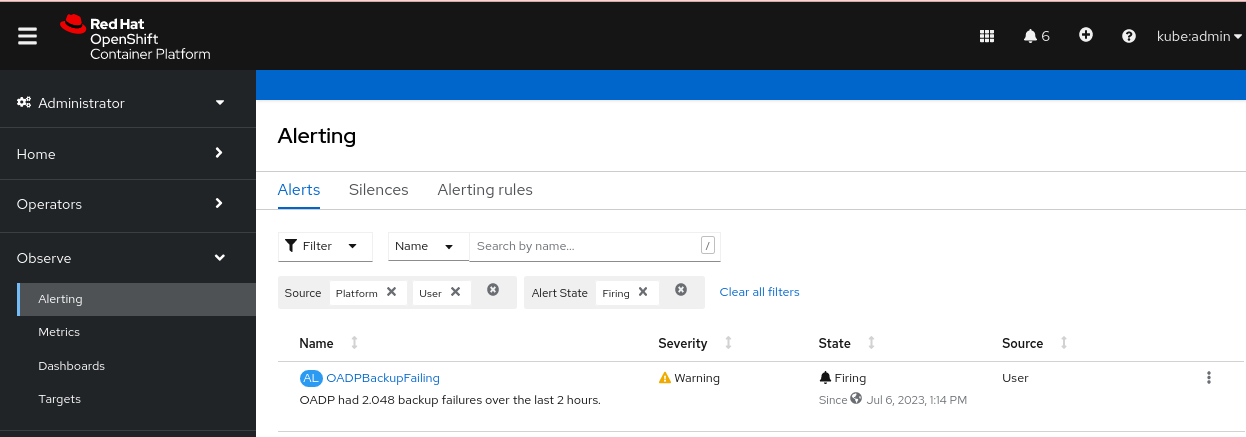
추가 리소스
4.10.13.4. 사용 가능한 메트릭 목록
이러한 지표는 OADP가 해당 유형과 함께 제공하는 메트릭 목록입니다.
| 메트릭 이름 | 설명 | 유형 |
|---|---|---|
|
| 캐시에서 검색된 바이트 수 | 카운터 |
|
| 캐시에서 콘텐츠를 검색한 횟수 | 카운터 |
|
| 캐시에서 잘못된 콘텐츠를 읽은 횟수 | 카운터 |
|
| 캐시에서 콘텐츠를 찾을 수 없고 가져온 횟수 | 카운터 |
|
| 기본 스토리지에서 검색된 바이트 수 | 카운터 |
|
| 기본 스토리지에서 콘텐츠를 찾을 수 없는 횟수 | 카운터 |
|
| 캐시에 콘텐츠를 저장할 수 없는 횟수 | 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
|
| 카운터 |
|
| 시도된 총 백업 수 | 카운터 |
|
| 시도된 총 백업 삭제 수 | 카운터 |
|
| 실패한 백업 삭제 총 수 | 카운터 |
|
| 성공적인 백업 삭제 총 수 | 카운터 |
|
| 백업 완료 시간(초) | 히스토그램 |
|
| 실패한 총 백업 수 | 카운터 |
|
| 백업 중 발생한 총 오류 수 | 게이지 |
|
| 백업된 총 항목 수 | 게이지 |
|
| 백업의 마지막 상태입니다. 1의 값은 success, 0입니다. | 게이지 |
|
| 백업이 성공적으로 실행된 마지막 시간, Unix 타임스탬프(초) | 게이지 |
|
| 부분적으로 실패한 백업의 총 수 | 카운터 |
|
| 총 성공적인 백업 수 | 카운터 |
|
| 백업의 크기(바이트) | 게이지 |
|
| 현재 존재하는 백업 수 | 게이지 |
|
| 총 검증 실패 백업 수 | 카운터 |
|
| 경고된 총 백업 수 | 카운터 |
|
| 총 CSI 시도 볼륨 스냅샷 수 | 카운터 |
|
| 총 CSI 실패 볼륨 스냅샷 수 | 카운터 |
|
| 총 CSI 성공 볼륨 스냅샷 수 | 카운터 |
|
| 시도한 총 복원 수 | 카운터 |
|
| 실패한 총 복원 수 | 카운터 |
|
| 부분적으로 실패한 복원의 총 수 | 카운터 |
|
| 성공적인 총 복원 수 | 카운터 |
|
| 현재 존재하는 복원 수 | 게이지 |
|
| 검증에 실패한 총 복원 수 | 카운터 |
|
| 시도한 총 볼륨 스냅샷 수 | 카운터 |
|
| 실패한 총 볼륨 스냅샷 수 | 카운터 |
|
| 총 볼륨 스냅샷 수 | 카운터 |
4.10.13.5. 모니터링 UI를 사용하여 메트릭 보기
OpenShift Container Platform 웹 콘솔의 관리자 또는 개발자 화면에서 메트릭을 볼 수 있습니다. openshift-adp 프로젝트에 액세스할 수 있어야 합니다.
절차
모니터링 → 메트릭 페이지로 이동합니다.
개발자 화면을 사용하는 경우 다음 단계를 따르십시오.
- 사용자 지정 쿼리 를 선택하거나 PromQL 표시 링크를 클릭합니다.
- 쿼리를 입력하고 Enter 를 클릭합니다.
관리자 화면을 사용하는 경우 텍스트 필드에 표현식을 입력하고 Run Queries 를 선택합니다.
그림 4.3. OADP 메트릭 쿼리
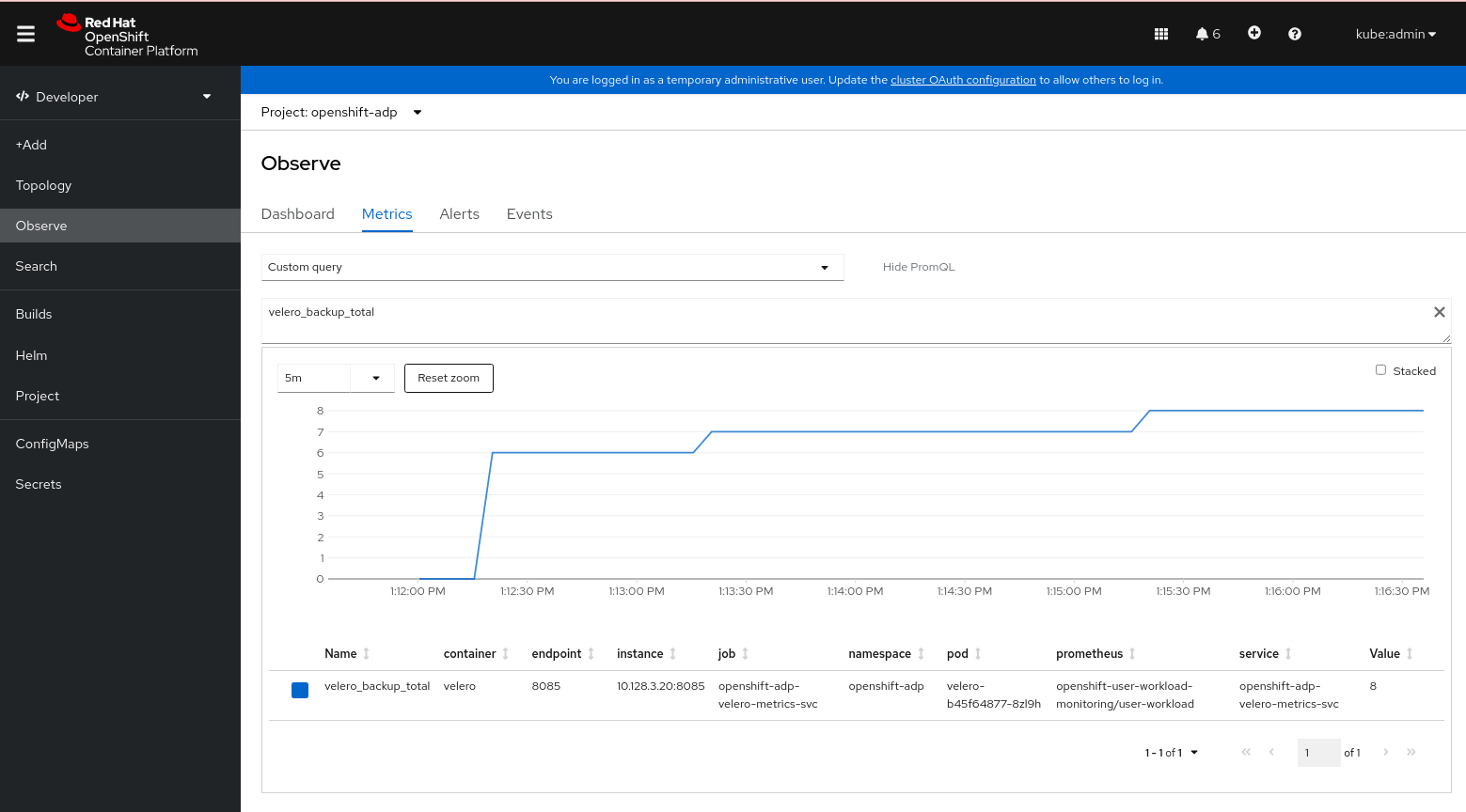
4.11. OADP와 함께 사용되는 API
이 문서에서는 OADP와 함께 사용할 수 있는 다음 API에 대한 정보를 제공합니다.
- Velero API
- OADP API
4.11.1. Velero API
Velero API 문서는 Red Hat이 아닌 Velero API에서 유지 관리합니다. Velero API 유형에서 찾을 수 있습니다.
4.11.2. OADP API
다음 표에서는 OADP API의 구조를 제공합니다.
표 4.2. DataProtectionApplicationSpec
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| |
|
|
| |
|
| map [ UnsupportedImageKey ] string |
개발을 위해 배포된 종속 이미지를 재정의하는 데 사용할 수 있습니다. 옵션은 |
|
| Operator에서 배포한 Pod에 주석을 추가하는 데 사용됩니다. | |
|
| Pod의 DNS 구성을 정의합니다. | |
|
|
| |
|
| *bool | 이미지 백업 및 복원을 위해 레지스트리를 배포할지 여부를 지정하는 데 사용됩니다. |
|
| 데이터 보호 애플리케이션의 서버 구성을 정의하는 데 사용됩니다. | |
|
|
* | 기술 프리뷰 기능을 활성화하기 위한 DPA 구성을 정의합니다. |
표 4.3. BackupLocation
| 속성 | 유형 | 설명 |
|---|---|---|
|
| Backup Storage Location 에 설명된 대로 볼륨 스냅샷을 저장할 위치입니다. | |
|
| [기술 프리뷰] 일부 클라우드 스토리지 공급자에서 백업 스토리지 위치로 사용하기 위해 버킷 생성을 자동화합니다. |
bucket 매개변수는 기술 프리뷰 기능 전용입니다. 기술 프리뷰 기능은 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있습니다. 따라서 프로덕션 환경에서 사용하는 것은 권장하지 않습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다.
Red Hat 기술 프리뷰 기능의 지원 범위에 대한 자세한 내용은 기술 프리뷰 기능 지원 범위를 참조하십시오.
BackupLocation유형의 전체 스키마 정의 입니다.
표 4.4. SnapshotLocation
| 속성 | 유형 | 설명 |
|---|---|---|
|
| 볼륨 스냅샷 위치에 설명된 대로 볼륨 스냅샷을 저장할 위치입니다. |
SnapshotLocation유형의 전체 스키마 정의 입니다.
표 4.5. ApplicationConfig
| 속성 | 유형 | 설명 |
|---|---|---|
|
| Velero 서버의 구성을 정의합니다. | |
|
| Restic 서버의 구성을 정의합니다. |
ApplicationConfig유형의 전체 스키마 정의.
표 4.6. VeleroConfig
| 속성 | 유형 | 설명 |
|---|---|---|
|
| [] string | Velero 인스턴스에 사용할 기능 목록을 정의합니다. |
|
| [] string |
다음과 같은 기본 Velero 플러그인을 설치할 수 있습니다. |
|
| 사용자 지정 Velero 플러그인 설치에 사용됩니다. 기본 플러그인 및 사용자 정의 플러그인은 OADP 플러그인에설명되어 있습니다. | |
|
|
EnableAPIGroupVersions 기능 플래그와 함께 사용할 수 있도록 정의된 경우 생성되는 구성 맵을 나타냅니다.Represents a config map that is created if defined for use in conjunction with the | |
|
|
기본 백업 스토리지 위치 없이 Velero를 설치하려면 설치를 확인하려면 | |
|
|
| |
|
|
Velero 서버의 로그 수준(가장 세분화된 로깅에 |
CustomPlugin유형에 대한 전체 스키마 정의 입니다.
표 4.8. ResticConfig
| 속성 | 유형 | 설명 |
|---|---|---|
|
| *bool |
|
|
| []int64 |
|
|
|
Restic 타임아웃을 정의하는 사용자가 제공하는 기간 문자열입니다. 기본값은 | |
|
|
|
표 4.9. PodConfig
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| |
|
| [] 허용오차 |
Velero 배포 또는 Restic |
|
|
Velero CPU 및 메모리 리소스 할당 설정에 설명된 대로 | |
|
| Pod에 추가할 라벨입니다. |
표 4.10. 기능
| 속성 | 유형 | 설명 |
|---|---|---|
|
| 데이터 장애의 구성을 정의합니다. |
표 4.11. DataMover
| 속성 | 유형 | 설명 |
|---|---|---|
|
|
| |
|
|
Data Mover에 대한 사용자 제공 Restic | |
|
|
|
OADP API는 OADP Operator 에 더 자세히 설명되어 있습니다.
4.12. 고급 OADP 기능 및 기능
이 문서에서는 OADP(OpenShift API for Data Protection)의 고급 기능 및 기능에 대한 정보를 제공합니다.
4.12.1. 동일한 클러스터에서 다양한 Kubernetes API 버전 작업
4.12.1.1. 클러스터의 Kubernetes API 그룹 버전 나열
소스 클러스터는 이러한 버전 중 하나가 기본 API 버전인 여러 버전의 API를 제공할 수 있습니다. 예를 들어 Example 이라는 API가 있는 소스 클러스터는 example.com/v1 및 example.com/v1beta2 API 그룹에서 사용할 수 있습니다.
Velero를 사용하여 이러한 소스 클러스터를 백업하고 복원하는 경우 Velero는 Kubernetes API의 기본 버전을 사용하는 해당 리소스의 버전만 백업합니다.
위 예제로 돌아가려면 example.com/v1 이 기본 API인 경우 Velero는 example.com/v1 을 사용하는 리소스 버전만 백업합니다. 또한 Velero가 대상 클러스터에서 리소스를 복원하기 위해서는 대상 클러스터에 example.com/v1 이 사용 가능한 API 리소스 세트에 등록되어 있어야 합니다.
따라서 기본 API 버전이 사용 가능한 API 리소스 세트에 등록되어 있는지 확인하려면 대상 클러스터에서 Kubernetes API 그룹 버전 목록을 생성해야 합니다.
절차
- 다음 명령을 실행합니다.
$ oc api-resources
4.12.1.2. API 그룹 버전 사용 정보
기본적으로 Velero는 Kubernetes API의 기본 버전을 사용하는 리소스만 백업합니다. 그러나 Velero에는 이러한 제한을 해결하는 기능인 Enable API Group Versions 도 포함되어 있습니다. 소스 클러스터에서 이 기능을 활성화하면 Velero가 기본 기능뿐만 아니라 클러스터에서 지원되는 모든 Kubernetes API 그룹 버전을 백업합니다. 백업 .tar 파일에 버전이 저장된 후 대상 클러스터에서 복원할 수 있습니다.
예를 들어 Example 이라는 API가 있는 소스 클러스터는 example.com/v1 및 example.com/v1beta2 API 그룹에서 사용할 수 있으며 example.com/v1 은 기본 API입니다.
Enable API Group Versions 기능을 활성화하지 않으면 Velero는 예의 기본 API 그룹 버전( 예: example.com/v 1)만 백업합니다. 기능이 활성화된 경우 Velero도 example.com/v1beta2 를 백업합니다.
대상 클러스터에서 Enable API Group Versions 기능이 활성화되면 Velero는 API 그룹 버전의 우선 순위 순서에 따라 복원할 버전을 선택합니다.
API 그룹 버전 활성화는 아직 베타 버전입니다.
Velero는 다음 알고리즘을 사용하여 API 버전에 우선 순위를 지정하고 1 를 최상위 우선 순위로 할당합니다.
- 대상 클러스터의 기본 버전
- source_ 클러스터의 기본 버전
- Kubernetes 버전 우선 순위가 가장 높은 일반적인 지원되지 않는 버전
추가 리소스
4.12.1.3. API 그룹 버전 사용
Velero의 Enable API Group Versions 기능을 사용하여 기본 설정뿐만 아니라 클러스터에서 지원되는 모든 Kubernetes API 그룹 버전을 백업할 수 있습니다.
API 그룹 버전 활성화는 아직 베타 버전입니다.
절차
-
EnableAPIGroupVersions기능을 구성합니다.
apiVersion: oadp.openshift.io/vialpha1
kind: DataProtectionApplication
...
spec:
configuration:
velero:
featureFlags:
- EnableAPIGroupVersions추가 리소스
4.12.2. 한 클러스터에서 데이터를 백업하고 다른 클러스터로 복원
4.12.2.1. 한 클러스터에서 데이터 백업 및 다른 클러스터에서 복원 정보
OADP(OpenShift API for Data Protection)는 동일한 OpenShift Container Platform 클러스터에서 애플리케이션 데이터를 백업하고 복원하도록 설계되었습니다. MTC(Migration Toolkit for Containers)는 하나의 OpenShift Container Platform 클러스터에서 다른 클러스터로 애플리케이션 데이터를 포함한 컨테이너를 마이그레이션하도록 설계되었습니다.
OADP를 사용하여 하나의 OpenShift Container Platform 클러스터에서 애플리케이션 데이터를 백업하고 다른 클러스터에 복원할 수 있습니다. 그러나 이러한 작업은 MTC를 사용하거나 OADP를 사용하여 동일한 클러스터에서 백업 및 복원하는 것보다 더 복잡합니다.
OADP를 사용하여 한 클러스터에서 데이터를 백업하고 다른 클러스터로 복원하려면 OADP를 사용하여 동일한 클러스터에서 데이터를 백업하고 복원하는 데 적용되는 사전 요구 사항 및 절차 외에 다음 요인을 고려해야 합니다.
- Operator
- Velero 사용
- UID 및 GID 범위
4.12.2.1.1. Operator
백업 및 복원에 성공하려면 애플리케이션의 백업에서 Operator를 제외해야 합니다.
4.12.2.1.2. Velero 사용
OADP가 구축된 Velero는 기본적으로 클라우드 공급자 간에 영구 볼륨 스냅샷 마이그레이션을 지원하지 않습니다. 클라우드 플랫폼 간에 볼륨 스냅샷 데이터를 마이그레이션하려면 파일 시스템 수준에서 볼륨 콘텐츠를 백업하는 Velero Restic 파일 시스템 백업 옵션을 활성화 하거나 CSI 스냅샷에 대해 OADP Data Mover를 사용해야 합니다.
OADP 1.1 및 이전 버전에서는 Velero Restic 파일 시스템 백업 옵션을 restic 이라고 합니다. OADP 1.2 이상에서는 Velero Restic 파일 시스템 백업 옵션을 file-system-backup 이라고 합니다.
- 또한 Velero의 파일 시스템 백업을 사용하여 AWS 리전 간에 데이터를 마이그레이션하거나 Microsoft Azure 리전 간에 데이터를 마이그레이션해야 합니다.
- Velero는 소스 클러스터보다 이전 Kubernetes 버전의 클러스터로 데이터 복원을 지원하지 않습니다.
- 이론적으로 소스보다 최신 Kubernetes 버전이 있는 대상으로 워크로드를 마이그레이션할 수 있지만 각 사용자 지정 리소스에 대한 클러스터 간 API 그룹의 호환성을 고려해야 합니다. Kubernetes 버전 업그레이드에서 코어 또는 네이티브 API 그룹의 호환성을 중단하는 경우 먼저 영향을 받는 사용자 정의 리소스를 업데이트해야 합니다.
4.12.2.2. 백업할 Pod 볼륨 확인 정보
파일 시스템 백업(FSB)을 사용하여 백업 작업을 시작하기 전에 백업할 볼륨이 포함된 Pod를 지정해야 합니다. Velero는 이 프로세스를 적절한 Pod 볼륨을 "검색"이라고 합니다.
Velero는 Pod 볼륨을 결정하기 위해 다음 두 가지 접근 방식을 지원합니다.
- 옵트인 접근 방식: 옵트인 접근 방식을 사용하려면 적극적으로 - 옵트인( opt-in ) - 백업에 볼륨(볼륨)을 포함해야 합니다. 볼륨 이름으로 백업할 볼륨이 포함된 각 Pod에 레이블을 지정하여 이 작업을 수행합니다. Velero가 PV(영구 볼륨)를 찾으면 볼륨을 마운트된 Pod를 확인합니다. Pod에 볼륨 이름으로 레이블이 지정되면 Velero가 Pod를 백업합니다.
- 옵트아웃 접근 방식에서는 옵트아웃 접근 방식을 사용하여 백업에서 볼륨을 제외하도록 적극적으로 지정해야 합니다. 볼륨 이름으로 백업하지 않는 볼륨이 포함된 각 Pod에 레이블을 지정하여 이 작업을 수행합니다. Velero가 PV를 찾으면 볼륨을 마운트된 Pod를 확인합니다. Pod에 볼륨 이름으로 레이블이 지정되면 Velero에서 Pod를 백업하지 않습니다.
4.12.2.2.1. 제한
-
FSB는
hostpath볼륨 백업 및 복원을 지원하지 않습니다. 그러나 FSB는 로컬 볼륨 백업 및 복원을 지원합니다. - Velero는 생성하는 모든 백업 리포지토리에 정적, 공통 암호화 키를 사용합니다. 이 정적 키는 백업 스토리지에 액세스할 수 있는 모든 사용자가 백업 데이터를 해독할 수 있음을 의미합니다. 백업 스토리지에 대한 액세스를 제한하는 것이 중요합니다.
PVC의 경우 Pod 일정을 변경할 때마다 모든 증분 백업 체인이 유지됩니다.
emptyDir볼륨과 같이 PVC가 아닌 Pod 볼륨의 경우(예:ReplicaSet또는 배포) Pod가 삭제되거나 다시 생성되는 경우 해당 볼륨의 다음 백업은 증분 백업이 아닌 전체 백업이 됩니다. Pod 볼륨의 라이프사이클이 해당 Pod에 의해 정의되는 것으로 가정합니다.- 백업 데이터를 점진적으로 유지할 수 있지만 데이터베이스와 같은 대용량 파일을 백업하는 데 시간이 오래 걸릴 수 있습니다. FSB는 중복 제거를 사용하여 백업해야 하는 차이점을 찾기 때문입니다.
- FSB는 Pod가 실행 중인 노드의 파일 시스템에 액세스하여 볼륨에서 데이터를 읽고 씁니다. 이러한 이유로 FSB는 PVC에서 직접 마운트하지 않고 Pod에서 마운트된 볼륨만 백업할 수 있습니다. 일부 Velero 사용자는 Velero 백업을 수행하기 전에 이러한 PVC 및 PV 쌍을 마운트하도록 BusyBox 또는 Alpine 컨테이너와 같은 스테이징 Pod를 실행하여 이 제한을 극복했습니다.
-
FSB에서는 <
hostPath>/<pod UID> 아래에 볼륨을 마운트할 것으로 예상하고, <hostPath>를 구성할 수 있습니다. 예를 들어 vCluster와 같은 일부 Kubernetes 시스템은 <pod UID> 하위 디렉터리 아래에 볼륨을 마운트하지 않으며 VFSB는 예상대로 작동하지 않습니다.
4.12.2.2.2. 옵트인 방법을 사용하여 Pod 볼륨 백업
옵트인 방법을 사용하여 파일 시스템 백업(FSB)에서 백업해야 하는 볼륨을 지정할 수 있습니다. backup.velero.io/backup-volumes 명령을 사용하여 이 작업을 수행할 수 있습니다.
절차
백업할 볼륨이 하나 이상 포함된 각 Pod에서 다음 명령을 입력합니다.
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>
다음과 같습니다.
<your_volume_name_x>- Pod 사양에 xth 볼륨의 이름을 지정합니다.
4.12.2.2.3. 옵트아웃 방법을 사용하여 Pod 볼륨 백업
옵트아웃 접근 방식을 사용하는 경우 몇 가지 예외가 있지만 FSB(File System Backup)를 사용하여 모든 Pod 볼륨이 백업됩니다.
- 기본 서비스 계정 토큰, 시크릿 및 구성 맵을 마운트하는 볼륨입니다.
-
hostPath볼륨
옵트아웃 방법을 사용하여 백업 하지 않는 볼륨을 지정할 수 있습니다. backup.velero.io/backup-volumes-excludes 명령을 사용하여 이 작업을 수행할 수 있습니다.
절차
백업하지 않으려는 볼륨이 하나 이상 포함된 각 Pod에서 다음 명령을 실행합니다.
$ oc -n <your_pod_namespace> annotate pod/<your_pod_name> \ backup.velero.io/backup-volumes-excludes=<your_volume_name_1>, \ <your_volume_name_2>>,...,<your_volume_name_n>
다음과 같습니다.
<your_volume_name_x>- Pod 사양에 xth 볼륨의 이름을 지정합니다.
--default-volumes-to-fs-backup 플래그를 사용하여 velero install 명령을 실행하여 모든 Velero 백업에 대해 이 동작을 활성화할 수 있습니다.
4.12.2.3. UID 및 GID 범위
한 클러스터에서 데이터를 백업하고 다른 클러스터로 복원하는 경우 UID(사용자 ID) 및 GID(그룹 ID) 범위에서 문제가 발생할 수 있습니다. 다음 섹션에서는 이러한 잠재적인 문제 및 완화 방법에 대해 설명합니다.
- 문제 요약
- 대상 클러스터에 따라 네임스페이스 UID 및 GID 범위가 변경될 수 있습니다. OADP는 OpenShift UID 범위 메타데이터를 백업하고 복원하지 않습니다. 백업 애플리케이션에 특정 UID가 필요한 경우 범위를 사용할 수 있는지 확인합니다. OpenShift의 UID 및 GID 범위에 대한 자세한 내용은 A Guide to OpenShift and UIDs 를 참조하십시오.
- 문제에 대한 자세한 설명
쉘 명령
oc create namespace를 사용하여 OpenShift Container Platform에서 네임스페이스를 생성할 때 OpenShift Container Platform은 사용 가능한 UID 풀, 추가 그룹(GID) 범위 및 고유한 SELinux MCS 레이블에서 네임스페이스에 고유한 UID(사용자 ID) 범위를 할당합니다. 이 정보는 클러스터의metadata.annotations필드에 저장됩니다. 이 정보는 다음 구성 요소로 구성된 SCC(보안 컨텍스트 제약 조건) 주석의 일부입니다.-
openshift.io/sa.scc.mcs -
openshift.io/sa.scc.supplemental-groups -
openshift.io/sa.scc.uid-range
-
OADP를 사용하여 네임스페이스를 복원하면 대상 클러스터에 대해 재설정하지 않고 metadata.annotations 의 정보를 자동으로 사용합니다. 결과적으로 다음 중 하나라도 해당하는 경우 워크로드가 백업된 데이터에 액세스할 수 없을 수 있습니다.
- 다른 SCC 주석이 있는 기존 네임스페이스가 있습니다(예: 다른 클러스터에). 이 경우 OADP는 복원하려는 네임스페이스 대신 백업 중에 기존 네임스페이스를 사용합니다.
백업 중에 레이블 선택기가 사용되었지만 워크로드가 실행되는 네임스페이스에 레이블이 없습니다. 이 경우 OADP는 네임스페이스를 백업하지 않지만 백업 네임스페이스의 주석이 포함되지 않은 복원 중에 새 네임스페이스를 생성합니다. 그러면 새 UID 범위가 네임스페이스에 할당됩니다.
이는 OpenShift Container Platform에서 영구 볼륨 데이터가 백업된 이후 변경된 네임스페이스 주석을 기반으로 Pod에
securityContextUID를 할당하는 경우 고객 워크로드에 문제가 될 수 있습니다.- 컨테이너의 UID가 더 이상 파일 소유자의 UID와 일치하지 않습니다.
OpenShift Container Platform이 백업 클러스터 데이터와 일치하도록 대상 클러스터의 UID 범위를 변경하지 않았기 때문에 오류가 발생합니다. 결과적으로 백업 클러스터에는 대상 클러스터와 다른 UID가 있으므로 애플리케이션이 대상 클러스터에서 데이터를 읽거나 쓸 수 없습니다.
- 완화 방법
- 다음 완화 방법 중 하나를 사용하여 UID 및 GID 범위 문제를 해결할 수 있습니다.
간단한 완화 방법:
-
BackupCR에서 라벨 선택기를 사용하여 백업에 포함할 오브젝트를 필터링하는 경우 이 라벨 선택기를 작업 공간이 포함된 네임스페이스에 추가해야 합니다. - 동일한 이름의 네임스페이스를 복원하기 전에 대상 클러스터에서 기존 네임스페이스 버전을 제거합니다.
-
고급 완화 방법:
- 마이그레이션 후 OpenShift 네임스페이스에서 UID 범위가 겹치는 UID 범위를 다시 확인하여 UID 범위를 수정합니다. 1단계는 선택 사항입니다.
한 클러스터에서 데이터를 백업하고 다른 클러스터에서 데이터를 복원하는 데 있는 문제를 해결하면서 OpenShift Container Platform의 UID 및 GID 범위에 대한 자세한 내용은 OpenShift 및 UID에 대한 가이드를 참조하십시오.
4.12.2.4. 한 클러스터에서 데이터를 백업하고 다른 클러스터로 복원
일반적으로 하나의 OpenShift Container Platform 클러스터의 데이터를 백업하고 동일한 클러스터에 데이터를 백업하고 복원하는 것과 동일한 방식으로 다른 OpenShift Container Platform 클러스터에 복원합니다. 그러나 한 OpenShift Container Platform 클러스터에서 데이터를 백업하고 다른 OpenShift Container Platform 클러스터에서 복원할 때 프로세스에 몇 가지 추가 사전 요구 사항과 차이점이 있습니다.
사전 요구 사항
- 플랫폼(예: AWS, Microsoft Azure, GCP 등)에서 백업 및 복원을 위한 모든 관련 사전 요구 사항은 이 가이드의 관련 섹션에 설명되어 있습니다.
절차
플랫폼에 지정된 절차를 추가합니다.
- 백업 저장소 위치(BSL) 및 볼륨 스냅샷 위치에 다른 클러스터의 리소스를 복원하는 것과 동일한 이름과 경로가 있는지 확인합니다.
- 클러스터 전체에서 동일한 오브젝트 스토리지 위치 인증 정보를 공유합니다.
- 최상의 결과를 얻으려면 OADP를 사용하여 대상 클러스터에 네임스페이스를 생성합니다.
Velero
file-system-backup옵션을 사용하는 경우 다음 명령을 실행하여 백업 중에 사용할--default-volumes-to-fs-backup플래그를 활성화합니다.$ velero backup create <backup_name> --default-volumes-to-fs-backup <any_other_options>
OADP 1.2 이상에서는 Velero Restic 옵션을 file-system-backup 이라고 합니다.
4.12.3. 추가 리소스
API 그룹 버전에 대한 자세한 내용은 동일한 클러스터에서 다양한 Kubernetes API 버전 작업을 참조하십시오.
OADP Data Mover에 대한 자세한 내용은 CSI 스냅샷에 Data Mover 사용을 참조하십시오.
OADP에서 Restic을 사용하는 방법에 대한 자세한 내용은 Restic을 사용하여 애플리케이션 백업을 참조하십시오.
5장. 컨트롤 플레인 백업 및 복원
5.1. etcd 백업
etcd는 모든 리소스 개체의 상태를 저장하는 OpenShift Container Platform의 키-값 형식의 저장소입니다.
클러스터의 etcd 데이터를 정기적으로 백업하고 OpenShift Container Platform 환경 외부의 안전한 위치에 백업 데이터를 저장하십시오. 설치 후 24 시간 내에 발생하는 첫 번째 인증서 교체가 완료되기 전까지 etcd 백업을 수행하지 마십시오. 인증서 교체가 완료되기 전에 실행하면 백업에 만료된 인증서가 포함됩니다. etcd 스냅샷에는 높은 I/O 비용이 있기 때문에 사용량이 많지 않은 시간 동안 etcd 백업을 수행하는 것이 좋습니다.
클러스터를 업그레이드한 후 etcd 백업을 수행해야 합니다. 이는 클러스터를 복원할 때 동일한 z-stream 릴리스에서 가져온 etcd 백업을 사용해야 하므로 중요합니다. 예를 들어 OpenShift Container Platform 4.y.z 클러스터는 4.y.z에서 가져온 etcd 백업을 사용해야 합니다.
컨트롤 플레인 호스트에서 백업 스크립트를 실행하여 클러스터의 etcd 데이터를 백업합니다. 클러스터의 각 컨트롤 플레인 호스트마다 백업을 수행하지 마십시오.
etcd 백업 후 이전 클러스터 상태로 복원할 수 있습니다.
5.1.1. etcd 데이터 백업
다음 단계에 따라 etcd 스냅샷을 작성하고 정적 pod의 리소스를 백업하여 etcd 데이터를 백업합니다. 이 백업을 저장하여 etcd를 복원해야하는 경우 나중에 사용할 수 있습니다.
단일 컨트롤 플레인 호스트의 백업만 저장합니다. 클러스터의 각 컨트롤 플레인 호스트에서 백업을 수행하지 마십시오.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. 클러스터 전체의 프록시가 활성화되어 있는지 확인해야 합니다.
작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.
절차
컨트롤 플레인 노드의 디버그 세션을 시작합니다.
$ oc debug node/<node_name>
루트 디렉토리를
/host로 변경합니다.sh-4.2# chroot /host
-
클러스터 전체의 프록시가 활성화되어 있는 경우
NO_PROXY,HTTP_PROXY및https_proxy환경 변수를 내보내고 있는지 확인합니다. cluster-backup.sh스크립트를 실행하고 백업을 저장할 위치를 입력합니다.작은 정보cluster-backup.sh스크립트는 etcd Cluster Operator의 구성 요소로 유지 관리되며etcdctl snapshot save명령 관련 래퍼입니다.sh-4.4# /usr/local/bin/cluster-backup.sh /home/core/assets/backup
스크립트 출력 예
found latest kube-apiserver: /etc/kubernetes/static-pod-resources/kube-apiserver-pod-6 found latest kube-controller-manager: /etc/kubernetes/static-pod-resources/kube-controller-manager-pod-7 found latest kube-scheduler: /etc/kubernetes/static-pod-resources/kube-scheduler-pod-6 found latest etcd: /etc/kubernetes/static-pod-resources/etcd-pod-3 ede95fe6b88b87ba86a03c15e669fb4aa5bf0991c180d3c6895ce72eaade54a1 etcdctl version: 3.4.14 API version: 3.4 {"level":"info","ts":1624647639.0188997,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db.part"} {"level":"info","ts":"2021-06-25T19:00:39.030Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"} {"level":"info","ts":1624647639.0301006,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.0.0.5:2379"} {"level":"info","ts":"2021-06-25T19:00:40.215Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"} {"level":"info","ts":1624647640.6032252,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.0.0.5:2379","size":"114 MB","took":1.584090459} {"level":"info","ts":1624647640.6047094,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/core/assets/backup/snapshot_2021-06-25_190035.db"} Snapshot saved at /home/core/assets/backup/snapshot_2021-06-25_190035.db {"hash":3866667823,"revision":31407,"totalKey":12828,"totalSize":114446336} snapshot db and kube resources are successfully saved to /home/core/assets/backup이 예제에서는 컨트롤 플레인 호스트의
/home/core/assets/backup/디렉토리에 두 개의 파일이 생성됩니다.-
snapshot_<datetimestamp>.db:이 파일은 etcd 스냅샷입니다.cluster-backup.sh스크립트는 유효성을 확인합니다. static_kuberesources_<datetimestamp>.tar.gz: 이 파일에는 정적 pod 리소스가 포함되어 있습니다. etcd 암호화가 활성화되어 있는 경우 etcd 스냅 샷의 암호화 키도 포함됩니다.참고etcd 암호화가 활성화되어 있는 경우 보안상의 이유로 이 두 번째 파일을 etcd 스냅 샷과 별도로 저장하는 것이 좋습니다. 그러나 이 파일은 etcd 스냅 샷에서 복원하는데 필요합니다.
etcd 암호화는 키가 아닌 값만 암호화합니다. 이는 리소스 유형, 네임 스페이스 및 개체 이름은 암호화되지 않습니다.
-
5.2. 비정상적인 etcd 멤버 교체
이 문서는 비정상적인 단일 etcd 멤버를 교체하는 프로세스를 설명합니다.
이 프로세스는 시스템이 실행 중이 아니거나 노드가 준비되지 않았거나 etcd pod가 크래시 루프 상태에있는 등 etcd 멤버의 비정상적인 상태에 따라 다릅니다.
대부분의 컨트롤 플레인 호스트가 손실된 경우 재해 복구 절차에 따라 이 프로세스 대신 이전 클러스터 상태로 복원 합니다.
교체된 멤버 에서 컨트롤 플레인 인증서가 유효하지 않은 경우 이 절차 대신 만료된 컨트롤 플레인 인증서 복구 절차를 따라야 합니다.
컨트롤 플레인 노드가 유실되고 새 노드가 생성되는 경우 etcd 클러스터 Operator는 새 TLS 인증서 생성 및 노드를 etcd 멤버로 추가하는 프로세스를 진행합니다.
5.2.1. 사전 요구 사항
- 비정상적인 etcd 멤버를 교체하기 전에 etcd 백업을 수행하십시오.
5.2.2. 비정상 etcd 멤버 식별
클러스터에 비정상적인 etcd 멤버가 있는지 여부를 확인할 수 있습니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다.
프로세스
다음 명령을 사용하여
EtcdMembersAvailable상태의 상태 조건을 확인하십시오.$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="EtcdMembersAvailable")]}{.message}{"\n"}'출력을 확인합니다.
2 of 3 members are available, ip-10-0-131-183.ec2.internal is unhealthy
이 출력 예는
ip-10-0-131-183.ec2.internaletcd 멤버가 비정상임을 보여줍니다.
5.2.3. 비정상적인 etcd 멤버의 상태 확인
비정상적인 etcd 멤버를 교체하는 프로세스는 etcd가 다음의 어떤 상태에 있는지에 따라 달라집니다.
- 컴퓨터가 실행 중이 아니거나 노드가 준비되지 않았습니다.
- etcd pod가 크래시 루프 상태에 있습니다.
다음 프로세스에서는 etcd 멤버가 어떤 상태에 있는지를 확인합니다. 이를 통해 비정상 etcd 멤버를 대체하기 위해 수행해야하는 단계를 확인할 수 있습니다.
시스템이 실행되고 있지 않거나 노드가 준비되지 않았지만 곧 정상 상태로 돌아올 것으로 예상되는 경우 etcd 멤버를 교체하기 위한 절차를 수행할 필요가 없습니다. etcd 클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아 오면 자동으로 동기화됩니다.
사전 요구 사항
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. - 비정상적인 etcd 멤버를 식별하고 있습니다.
프로세스
시스템이 실행되고 있지 않은지를 확인합니다.
$ oc get machines -A -ojsonpath='{range .items[*]}{@.status.nodeRef.name}{"\t"}{@.status.providerStatus.instanceState}{"\n"}' | grep -v running출력 예
ip-10-0-131-183.ec2.internal stopped 1- 1
- 이 출력은 노드와 노드 시스템의 상태를 나열합니다. 상태가
running이 아닌 경우 시스템은 실행되지 않습니다.
시스템이 실행되고 있지 않은 경우, 시스템이 실행되고 있지 않거나 노드가 준비되지 않은 비정상적인 etcd 멤버 교체 프로세스를 수행하십시오.
노드가 준비되지 않았는지 확인합니다.
다음 조건 중 하나에 해당하면 노드가 준비되지 않은 것입니다.
시스템이 실행중인 경우 노드에 액세스할 수 있는지 확인하십시오.
$ oc get nodes -o jsonpath='{range .items[*]}{"\n"}{.metadata.name}{"\t"}{range .spec.taints[*]}{.key}{" "}' | grep unreachable출력 예
ip-10-0-131-183.ec2.internal node-role.kubernetes.io/master node.kubernetes.io/unreachable node.kubernetes.io/unreachable 1- 1
unreachable상태의 노드가 나열되면 노드가 준비되지 않은 것 입니다.
노드에 여전히 액세스할 수 있는 경우 노드가
NotReady로 나열되어 있는지 확인하십시오.$ oc get nodes -l node-role.kubernetes.io/master | grep "NotReady"
출력 예
ip-10-0-131-183.ec2.internal NotReady master 122m v1.24.0 1- 1
- 노드가
NotReady로 표시되면 노드가 준비되지 않은 것입니다.
노드가 준비되지 않은 경우 시스템이 실행되고 있지 않거나 노드가 준비되지 않은 비정상적인 etcd 멤버 교체 프로세스를 수행하십시오.
etcd pod가 크래시 루프 상태인지 확인합니다.
시스템이 실행되고 있고 노드가 준비된 경우 etcd pod가 크래시 루프 상태인지 확인하십시오.
모든 컨트롤 플레인 노드가
Ready로 나열되어 있는지 확인합니다.$ oc get nodes -l node-role.kubernetes.io/master
출력 예
NAME STATUS ROLES AGE VERSION ip-10-0-131-183.ec2.internal Ready master 6h13m v1.24.0 ip-10-0-164-97.ec2.internal Ready master 6h13m v1.24.0 ip-10-0-154-204.ec2.internal Ready master 6h13m v1.24.0
etcd pod의 상태가
Error또는CrashloopBackoff인지 확인하십시오.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m 1 etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m- 1
- 이 pod의 상태는
Error이므로 etcd pod는 크래시 루프 상태입니다.
etcd pod가 크래시 루프 상태인 경우etcd pod가 크래시 루프 상태인 비정상적인 etcd 멤버 교체 프로세스를 수행하십시오.
5.2.4. 비정상적인 etcd 멤버 교체
비정상적인 etcd 멤버의 상태에 따라 다음 절차 중 하나를 사용합니다.
5.2.4.1. 시스템이 실행되고 있지 않거나 노드가 준비되지 않은 비정상적인 etcd 멤버 교체
다음에서는 시스템이 실행되고 있지 않거나 노드가 준비되지 않은 경우의 비정상적인 etcd 멤버를 교체하는 프로세스에 대해 자세히 설명합니다.
사전 요구 사항
- 비정상적인 etcd 멤버를 식별했습니다.
시스템이 실행되고 있지 않거나 노드가 준비되지 않았음을 확인했습니다.
중요다른 컨트롤 플레인 노드의 전원이 꺼진 경우 기다려야 합니다. 비정상 etcd 멤버 교체가 완료될 때까지 컨트롤 플레인 노드의 전원을 꺼야 합니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있어야 합니다. etcd 백업이 수행되었습니다.
중요문제가 발생할 경우 클러스터를 복원할 수 있도록 이 프로세스를 수행하기 전에 etcd 백업을 수행해야합니다.
프로세스
비정상적인 멤버를 제거합니다.
영향을 받는 노드에 없는 pod를 선택합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-ip-10-0-131-183.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m
실행중인 etcd 컨테이너에 연결하고 영향을 받는 노드에 없는 pod 이름을 전달합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal
멤버 목록을 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 6fc1e7c9db35841d | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+
이러한 값은 프로세스의 뒷부분에서 필요하므로 비정상 etcd 멤버의 ID와 이름을 기록해 두십시오.
$ etcdctl endpoint health명령은 교체 절차가 완료되고 새 멤버가 추가될 때까지 제거된 멤버를 나열합니다.etcdctl member remove명령에 ID를 지정하여 비정상적인 etcd 멤버를 제거합니다.sh-4.2# etcdctl member remove 6fc1e7c9db35841d
출력 예
Member 6fc1e7c9db35841d removed from cluster ead669ce1fbfb346
멤버 목록을 다시 표시하고 멤버가 제거되었는지 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+
이제 노드 쉘을 종료할 수 있습니다.
다음 명령을 입력하여 쿼럼 보호기를 끄십시오.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 보안을 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
중요쿼럼 가드를 끄면 나머지 etcd 인스턴스가 재부팅되는 동안 구성 변경 사항을 반영하는 동안 클러스터에 연결할 수 없을 수 있습니다.
참고두 멤버로 실행하는 경우 etcd는 추가 멤버 실패를 허용할 수 없습니다. 나머지 멤버 중 하나를 다시 시작하면 쿼럼이 중단되고 클러스터의 다운 타임이 발생합니다. 쿼럼 가드에서는 다운타임을 일으킬 수 있는 구성 변경으로 인해 etcd가 다시 시작되지 않도록 보호하므로 이 절차를 완료하려면 비활성화해야 합니다.
삭제된 비정상 etcd 멤버의 이전 암호를 제거합니다.
삭제된 비정상 etcd 멤버의 시크릿(secrets)을 나열합니다.
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal 1- 1
- 이 프로세스의 앞부분에서 기록한 비정상 etcd 멤버의 이름을 전달합니다.
다음 출력에 표시된대로 피어, 서빙 및 메트릭 시크릿이 있습니다.
출력 예
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m
제거된 비정상 etcd 멤버의 시크릿을 삭제합니다.
피어 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internal
서빙 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internal
메트릭 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
컨트롤 플레인 시스템을 삭제하고 다시 생성합니다. 이 시스템을 다시 만든 후에는 새 버전이 강제 실행되고 etcd는 자동으로 확장됩니다.
설치 프로그램에서 제공한 인프라를 실행 중이거나 Machine API를 사용하여 컴퓨터를 만든 경우 다음 단계를 수행합니다. 그렇지 않으면 원래 마스터를 만들 때 사용한 방법과 동일한 방법을 사용하여 새 마스터를 작성해야합니다.
비정상 멤버의 컴퓨터를 가져옵니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped 1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 이는 비정상 노드의 컨트롤 플레인 시스템
ip-10-0-131-183.ec2.internal입니다.
시스템 설정을 파일 시스템의 파일에 저장합니다.
$ oc get machine clustername-8qw5l-master-0 \ 1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 비정상 노드의 컨트롤 플레인 시스템의 이름을 지정합니다.
이전 단계에서 만든
new-master-machine.yaml파일을 편집하여 새 이름을 할당하고 불필요한 필드를 제거합니다.전체
status섹션을 삭제합니다.status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatusmetadata.name필드를 새 이름으로 변경합니다.이전 시스템과 동일한 기본 이름을 유지하고 마지막 번호를 사용 가능한 다음 번호로 변경하는 것이 좋습니다. 이 예에서
clustername-8qw5l-master-0은clustername-8qw5l-master-3으로 변경되어 있습니다.예를 들어 다음과 같습니다.
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...
spec.providerID필드를 삭제합니다.providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f
비정상 멤버의 시스템을 삭제합니다.
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-0 1- 1
- 비정상 노드의 컨트롤 플레인 시스템의 이름을 지정합니다.
시스템이 삭제되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running
new-master-machine.yaml파일을 사용하여 새 시스템을 만듭니다.$ oc apply -f new-master-machine.yaml
새 시스템이 생성되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-154-204.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-164-97.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-133-53.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running 1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 새 시스템
clustername-8qw5l-master-3이 생성되고 단계가Provisioning에서Running으로 변경되면 시스템이 준비 상태가 됩니다.
새 시스템을 만드는 데 몇 분이 소요될 수 있습니다. etcd 클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아 오면 자동으로 동기화됩니다.
다음 명령을 입력하여 쿼럼 보호기를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음 명령을 입력하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml
단일 노드 OpenShift를 사용하는 경우 노드를 다시 시작합니다. 그렇지 않으면 etcd 클러스터 Operator에서 다음 오류가 발생할 수 있습니다.
출력 예
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
검증
모든 etcd pod가 올바르게 실행되고 있는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-ip-10-0-133-53.ec2.internal 3/3 Running 0 7m49s etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 123m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 124m
이전 명령의 출력에 두 개의 pod만 나열되는 경우 수동으로 etcd 재배포를 강제 수행할 수 있습니다. 클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge 1- 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
정확히 세 개의 etcd 멤버가 있는지 확인합니다.
실행중인 etcd 컨테이너에 연결하고 영향을 받는 노드에 없는 pod 이름을 전달합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal
멤버 목록을 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 5eb0d6b8ca24730c | started | ip-10-0-133-53.ec2.internal | https://10.0.133.53:2380 | https://10.0.133.53:2379 | | 757b6793e2408b6c | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | ca8c2990a0aa29d1 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+
이전 명령의 출력에 세 개 이상의 etcd 멤버가 나열된 경우 원하지 않는 멤버를 신중하게 제거해야 합니다.
주의올바른 etcd 멤버를 제거하십시오. etcd 멤버를 제거하면 쿼럼이 손실될 수 있습니다.
5.2.4.2. etcd pod가 크래시 루프 상태인 비정상적인 etcd 멤버 교체
이 단계에서는 etcd pod가 크래시 루프 상태에 있는 경우 비정상 etcd 멤버를 교체하는 방법을 설명합니다.
전제 조건
- 비정상적인 etcd 멤버를 식별했습니다.
- etcd pod가 크래시 루프 상태에 있는것으로 확인되었습니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. etcd 백업이 수행되었습니다.
중요문제가 발생할 경우 클러스터를 복원할 수 있도록 이 프로세스를 수행하기 전에 etcd 백업을 수행해야합니다.
프로세스
크래시 루프 상태에 있는 etcd pod를 중지합니다.
크래시 루프 상태의 노드를 디버깅합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc debug node/ip-10-0-131-183.ec2.internal 1- 1
- 이를 비정상 노드의 이름으로 변경합니다.
루트 디렉토리를
/host로 변경합니다.sh-4.2# chroot /host
kubelet 매니페스트 디렉토리에서 기존 etcd pod 파일을 이동합니다.
sh-4.2# mkdir /var/lib/etcd-backup
sh-4.2# mv /etc/kubernetes/manifests/etcd-pod.yaml /var/lib/etcd-backup/
etcd 데이터 디렉토리를 다른 위치로 이동합니다.
sh-4.2# mv /var/lib/etcd/ /tmp
이제 노드 쉘을 종료할 수 있습니다.
비정상적인 멤버를 제거합니다.
영향을 받는 노드에 없는 pod를 선택합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-ip-10-0-131-183.ec2.internal 2/3 Error 7 6h9m etcd-ip-10-0-164-97.ec2.internal 3/3 Running 0 6h6m etcd-ip-10-0-154-204.ec2.internal 3/3 Running 0 6h6m
실행중인 etcd 컨테이너에 연결하고 영향을 받는 노드에 없는 pod 이름을 전달합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal
멤버 목록을 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | 62bcf33650a7170a | started | ip-10-0-131-183.ec2.internal | https://10.0.131.183:2380 | https://10.0.131.183:2379 | | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+
이러한 값은 프로세스의 뒷부분에서 필요하므로 비정상 etcd 멤버의 ID와 이름을 기록해 두십시오.
etcdctl member remove명령에 ID를 지정하여 비정상적인 etcd 멤버를 제거합니다.sh-4.2# etcdctl member remove 62bcf33650a7170a
출력 예
Member 62bcf33650a7170a removed from cluster ead669ce1fbfb346
멤버 목록을 다시 표시하고 멤버가 제거되었는지 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+------------------------------+---------------------------+---------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | +------------------+---------+------------------------------+---------------------------+---------------------------+ | b78e2856655bc2eb | started | ip-10-0-164-97.ec2.internal | https://10.0.164.97:2380 | https://10.0.164.97:2379 | | d022e10b498760d5 | started | ip-10-0-154-204.ec2.internal | https://10.0.154.204:2380 | https://10.0.154.204:2379 | +------------------+---------+------------------------------+---------------------------+---------------------------+
이제 노드 쉘을 종료할 수 있습니다.
다음 명령을 입력하여 쿼럼 보호기를 끄십시오.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 보안을 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
삭제된 비정상 etcd 멤버의 이전 암호를 제거합니다.
삭제된 비정상 etcd 멤버의 시크릿(secrets)을 나열합니다.
$ oc get secrets -n openshift-etcd | grep ip-10-0-131-183.ec2.internal 1- 1
- 이 프로세스의 앞부분에서 기록한 비정상 etcd 멤버의 이름을 전달합니다.
다음 출력에 표시된대로 피어, 서빙 및 메트릭 시크릿이 있습니다.
출력 예
etcd-peer-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m etcd-serving-metrics-ip-10-0-131-183.ec2.internal kubernetes.io/tls 2 47m
제거된 비정상 etcd 멤버의 시크릿을 삭제합니다.
피어 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-peer-ip-10-0-131-183.ec2.internal
서빙 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-serving-ip-10-0-131-183.ec2.internal
메트릭 시크릿을 삭제합니다.
$ oc delete secret -n openshift-etcd etcd-serving-metrics-ip-10-0-131-183.ec2.internal
etcd를 강제로 재배포합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "single-master-recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge 1- 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
etcd 클러스터 Operator가 재배포를 수행하면 모든 컨트롤 플레인 노드가 etcd pod가 작동하는지 확인합니다.
다음 명령을 입력하여 쿼럼 보호기를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음 명령을 입력하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml
단일 노드 OpenShift를 사용하는 경우 노드를 다시 시작합니다. 그렇지 않으면 etcd 클러스터 Operator에서 다음 오류가 발생할 수 있습니다.
출력 예
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
검증
새 멤버가 사용 가능하고 정상적인 상태에 있는지 확인합니다.
실행중인 etcd 컨테이너에 다시 연결합니다.
cluster-admin 사용자로 클러스터에 액세스할 수 있는 터미널에서 다음 명령을 실행합니다.
$ oc rsh -n openshift-etcd etcd-ip-10-0-154-204.ec2.internal
모든 멤버가 정상인지 확인합니다.
sh-4.2# etcdctl endpoint health
출력 예
https://10.0.131.183:2379 is healthy: successfully committed proposal: took = 16.671434ms https://10.0.154.204:2379 is healthy: successfully committed proposal: took = 16.698331ms https://10.0.164.97:2379 is healthy: successfully committed proposal: took = 16.621645ms
5.2.4.3. 시스템이 실행되고 있지 않거나 노드가 준비되지 않은 비정상적인 베어 메탈 etcd 멤버 교체
이 프로세스에서는 시스템이 실행되고 있지 않거나 노드가 준비되지 않았기 때문에 비정상 상태의 베어 메탈 etcd 멤버를 교체하는 단계를 자세히 설명합니다.
설치 관리자 프로비저닝 인프라를 실행 중이거나 Machine API를 사용하여 머신을 생성한 경우 다음 단계를 따르십시오. 그렇지 않으면 원래 생성하는 데 사용된 방법과 동일한 방법으로 새 컨트롤 플레인 노드를 생성해야 합니다.
사전 요구 사항
- 비정상적인 베어 메탈 etcd 멤버를 식별했습니다.
- 시스템이 실행되고 있지 않거나 노드가 준비되지 않았음을 확인했습니다.
-
cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. etcd 백업이 수행되었습니다.
중요문제가 발생할 경우 클러스터를 복원할 수 있도록 이 단계를 수행하기 전에 etcd 백업을 수행해야합니다.
절차
비정상 멤버를 확인하고 제거합니다.
영향을 받는 노드에 없는 pod를 선택합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd -o wide
출력 예
etcd-openshift-control-plane-0 5/5 Running 11 3h56m 192.168.10.9 openshift-control-plane-0 <none> <none> etcd-openshift-control-plane-1 5/5 Running 0 3h54m 192.168.10.10 openshift-control-plane-1 <none> <none> etcd-openshift-control-plane-2 5/5 Running 0 3h58m 192.168.10.11 openshift-control-plane-2 <none> <none>
실행중인 etcd 컨테이너에 연결하고 영향을 받는 노드에 없는 pod 이름을 전달합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0
멤버 목록을 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380/ | https://192.168.10.9:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+---------------------+
이러한 값은 프로세스의 뒷부분에서 필요하므로 비정상 etcd 멤버의 ID와 이름을 기록해 두십시오.
etcdctl endpoint health명령은 교체 절차가 완료되고 새 멤버가 추가될 때까지 제거된 멤버를 나열합니다.etcdctl member remove명령에 ID를 지정하여 비정상적인 etcd 멤버를 제거합니다.주의올바른 etcd 멤버를 제거하십시오. etcd 멤버를 제거하면 쿼럼이 손실될 수 있습니다.
sh-4.2# etcdctl member remove 7a8197040a5126c8
출력 예
Member 7a8197040a5126c8 removed from cluster b23536c33f2cdd1b
멤버 목록을 다시 표시하고 멤버가 제거되었는지 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380/ | https://192.168.10.11:2379/ | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380/ | https://192.168.10.10:2379/ | false | +------------------+---------+--------------------+---------------------------+---------------------------+-------------------------+
이제 노드 쉘을 종료할 수 있습니다.
중요멤버를 제거한 후 나머지 etcd 인스턴스가 재부팅되는 동안 잠시 동안 클러스터에 연결할 수 없습니다.
다음 명령을 입력하여 쿼럼 보호기를 끄십시오.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 보안을 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
다음 명령을 실행하여 제거된 비정상 etcd 멤버의 이전 암호를 제거합니다.
삭제된 비정상 etcd 멤버의 시크릿(secrets)을 나열합니다.
$ oc get secrets -n openshift-etcd | grep openshift-control-plane-2
이 프로세스의 앞부분에서 기록한 비정상 etcd 멤버의 이름을 전달합니다.
다음 출력에 표시된대로 피어, 서빙 및 메트릭 시크릿이 있습니다.
etcd-peer-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-metrics-openshift-control-plane-2 kubernetes.io/tls 2 134m etcd-serving-openshift-control-plane-2 kubernetes.io/tls 2 134m
제거된 비정상 etcd 멤버의 시크릿을 삭제합니다.
피어 시크릿을 삭제합니다.
$ oc delete secret etcd-peer-openshift-control-plane-2 -n openshift-etcd secret "etcd-peer-openshift-control-plane-2" deleted
서빙 시크릿을 삭제합니다.
$ oc delete secret etcd-serving-metrics-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-metrics-openshift-control-plane-2" deleted
메트릭 시크릿을 삭제합니다.
$ oc delete secret etcd-serving-openshift-control-plane-2 -n openshift-etcd secret "etcd-serving-openshift-control-plane-2" deleted
컨트롤 플레인 시스템을 삭제합니다.
설치 프로그램에서 제공한 인프라를 실행 중이거나 Machine API를 사용하여 컴퓨터를 만든 경우 다음 단계를 수행합니다. 그렇지 않으면 원래 생성하는 데 사용된 방법과 동일한 방법으로 새 컨트롤 플레인 노드를 생성해야 합니다.
비정상 멤버의 컴퓨터를 가져옵니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned 1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- 비정상 노드의 컨트롤 플레인 시스템
예cluster-control-plane-2.
시스템 설정을 파일 시스템의 파일에 저장합니다.
$ oc get machine examplecluster-control-plane-2 \ 1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 비정상 노드의 컨트롤 플레인 시스템의 이름을 지정합니다.
이전 단계에서 만든
new-master-machine.yaml파일을 편집하여 새 이름을 할당하고 불필요한 필드를 제거합니다.전체
status섹션을 삭제합니다.status: addresses: - address: "" type: InternalIP - address: fe80::4adf:37ff:feb0:8aa1%ens1f1.373 type: InternalDNS - address: fe80::4adf:37ff:feb0:8aa1%ens1f1.371 type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Machine name: fe80::4adf:37ff:feb0:8aa1%ens1f1.372 uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: machine.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: Machine
metadata.name필드를 새 이름으로 변경합니다.이전 시스템과 동일한 기본 이름을 유지하고 마지막 번호를 사용 가능한 다음 번호로 변경하는 것이 좋습니다. 이 예에서
examplecluster-control-plane-2는examplecluster-control-plane-3으로 변경되었습니다.예를 들어 다음과 같습니다.
apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: examplecluster-control-plane-3 ...
spec.providerID필드를 삭제합니다.providerID: baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135
metadata.annotations및metadata.generation필드를 제거합니다.annotations: machine.openshift.io/instance-state: externally provisioned ... generation: 2spec.conditions,spec.lastUpdated,spec.nodeRef및spec.phase필드를 제거합니다.lastTransitionTime: "2022-08-03T08:40:36Z" message: 'Drain operation currently blocked by: [{Name:EtcdQuorumOperator Owner:clusteroperator/etcd}]' reason: HookPresent severity: Warning status: "False" type: Drainable lastTransitionTime: "2022-08-03T08:39:55Z" status: "True" type: InstanceExists lastTransitionTime: "2022-08-03T08:36:37Z" status: "True" type: Terminable lastUpdated: "2022-08-03T08:40:36Z" nodeRef: kind: Node name: openshift-control-plane-2 uid: 788df282-6507-4ea2-9a43-24f237ccbc3c phase: Running
다음 명령을 실행하여 Bare Metal Operator를 사용할 수 있는지 확인합니다.
$ oc get clusteroperator baremetal
출력 예
NAME VERSION AVAILABLE PROGRESSING DEGRADED SINCE MESSAGE baremetal 4.11.3 True False False 3d15h
다음 명령을 실행하여 이전
BareMetalHost오브젝트를 제거합니다.$ oc delete bmh openshift-control-plane-2 -n openshift-machine-api
출력 예
baremetalhost.metal3.io "openshift-control-plane-2" deleted
다음 명령을 실행하여 비정상 멤버의 시스템을 삭제합니다.
$ oc delete machine -n openshift-machine-api examplecluster-control-plane-2
BareMetalHost및MachineNode오브젝트를 자동으로 삭제합니다.어떤 이유로든 머신 삭제가 지연되거나 명령이 차단되고 지연되면 machine object finalizer 필드를 제거하여 강제로 삭제할 수 있습니다.
중요Ctrl+c를 눌러 머신 삭제를 중단하지 마십시오. 명령이 완료될 수 있도록 허용해야 합니다. 새 터미널 창을 열어 편집하여 종료자 필드를 삭제합니다.다음 명령을 실행하여 머신 구성을 편집합니다.
$ oc edit machine -n openshift-machine-api examplecluster-control-plane-2
Machine사용자 정의 리소스에서 다음 필드를 삭제한 다음 업데이트된 파일을 저장합니다.finalizers: - machine.machine.openshift.io
출력 예
machine.machine.openshift.io/examplecluster-control-plane-2 edited
다음 명령을 실행하여 시스템이 삭제되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned
다음 명령을 실행하여 노드가 삭제되었는지 확인합니다.
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 3h24m v1.24.0+9546431 openshift-control-plane-1 Ready master 3h24m v1.24.0+9546431 openshift-compute-0 Ready worker 176m v1.24.0+9546431 openshift-compute-1 Ready worker 176m v1.24.0+9546431
새
BareMetalHost오브젝트와 시크릿을 생성하여 BMC 자격 증명을 저장합니다.$ cat <<EOF | oc apply -f - apiVersion: v1 kind: Secret metadata: name: openshift-control-plane-2-bmc-secret namespace: openshift-machine-api data: password: <password> username: <username> type: Opaque --- apiVersion: metal3.io/v1alpha1 kind: BareMetalHost metadata: name: openshift-control-plane-2 namespace: openshift-machine-api spec: automatedCleaningMode: disabled bmc: address: redfish://10.46.61.18:443/redfish/v1/Systems/1 credentialsName: openshift-control-plane-2-bmc-secret disableCertificateVerification: true bootMACAddress: 48:df:37:b0:8a:a0 bootMode: UEFI externallyProvisioned: false online: true rootDeviceHints: deviceName: /dev/sda userData: name: master-user-data-managed namespace: openshift-machine-api EOF참고사용자 이름과 암호는 다른 베어 메탈 호스트의 시크릿에서 찾을 수 있습니다.
bmc:address에 사용할 프로토콜은 다른 bmh 개체에서 가져올 수 있습니다.중요기존 컨트롤 플레인 호스트에서
BareMetalHost오브젝트 정의를 재사용하는 경우 externalProvisioned 필드를true로 설정하지 마십시오.기존 컨트롤 플레인
BareMetalHost오브젝트는 OpenShift Container Platform 설치 프로그램에서 프로비저닝한 경우외부Provisioned플래그를true로 설정할 수 있습니다.검사가 완료되면
BareMetalHost오브젝트가 생성되고 프로비저닝할 수 있습니다.사용 가능한
BareMetalHost오브젝트를 사용하여 생성 프로세스를 확인합니다.$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 available examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m
new-master-machine.yaml파일을 사용하여 새 컨트롤 플레인 시스템을 생성합니다.$ oc apply -f new-master-machine.yaml
새 시스템이 생성되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE examplecluster-control-plane-0 Running 3h11m openshift-control-plane-0 baremetalhost:///openshift-machine-api/openshift-control-plane-0/da1ebe11-3ff2-41c5-b099-0aa41222964e externally provisioned 1 examplecluster-control-plane-1 Running 3h11m openshift-control-plane-1 baremetalhost:///openshift-machine-api/openshift-control-plane-1/d9f9acbc-329c-475e-8d81-03b20280a3e1 externally provisioned examplecluster-control-plane-2 Running 3h11m openshift-control-plane-2 baremetalhost:///openshift-machine-api/openshift-control-plane-2/3354bdac-61d8-410f-be5b-6a395b056135 externally provisioned examplecluster-compute-0 Running 165m openshift-compute-0 baremetalhost:///openshift-machine-api/openshift-compute-0/3d685b81-7410-4bb3-80ec-13a31858241f provisioned examplecluster-compute-1 Running 165m openshift-compute-1 baremetalhost:///openshift-machine-api/openshift-compute-1/0fdae6eb-2066-4241-91dc-e7ea72ab13b9 provisioned- 1
- 새 시스템
clustername-8qw5l-master-3이 생성되고 단계가Provisioning에서Running으로 변경되면 시스템이 준비 상태가 됩니다.
새 시스템을 생성하는 데 몇 분이 걸릴 수 있습니다. etcd 클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아 오면 자동으로 동기화됩니다.
베어 메탈 호스트가 프로비저닝되고 다음 명령을 실행하여 오류가 보고되지 않았는지 확인합니다.
$ oc get bmh -n openshift-machine-api
출력 예
$ oc get bmh -n openshift-machine-api NAME STATE CONSUMER ONLINE ERROR AGE openshift-control-plane-0 externally provisioned examplecluster-control-plane-0 true 4h48m openshift-control-plane-1 externally provisioned examplecluster-control-plane-1 true 4h48m openshift-control-plane-2 provisioned examplecluster-control-plane-3 true 47m openshift-compute-0 provisioned examplecluster-compute-0 true 4h48m openshift-compute-1 provisioned examplecluster-compute-1 true 4h48m
다음 명령을 실행하여 새 노드가 추가되고 준비 상태에 있는지 확인합니다.
$ oc get nodes
출력 예
$ oc get nodes NAME STATUS ROLES AGE VERSION openshift-control-plane-0 Ready master 4h26m v1.24.0+9546431 openshift-control-plane-1 Ready master 4h26m v1.24.0+9546431 openshift-control-plane-2 Ready master 12m v1.24.0+9546431 openshift-compute-0 Ready worker 3h58m v1.24.0+9546431 openshift-compute-1 Ready worker 3h58m v1.24.0+9546431
다음 명령을 입력하여 쿼럼 보호기를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음 명령을 입력하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml
단일 노드 OpenShift를 사용하는 경우 노드를 다시 시작합니다. 그렇지 않으면 etcd 클러스터 Operator에서 다음 오류가 발생할 수 있습니다.
출력 예
EtcdCertSignerControllerDegraded: [Operation cannot be fulfilled on secrets "etcd-peer-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-sno-0": the object has been modified; please apply your changes to the latest version and try again, Operation cannot be fulfilled on secrets "etcd-serving-metrics-sno-0": the object has been modified; please apply your changes to the latest version and try again]
검증
모든 etcd pod가 올바르게 실행되고 있는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-openshift-control-plane-0 5/5 Running 0 105m etcd-openshift-control-plane-1 5/5 Running 0 107m etcd-openshift-control-plane-2 5/5 Running 0 103m
이전 명령의 출력에 두 개의 pod만 나열되는 경우 수동으로 etcd 재배포를 강제 수행할 수 있습니다. 클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge 1- 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
정확히 세 개의 etcd 멤버가 있는지 확인하려면 실행중인 etcd 컨테이너에 연결하고 영향을 받는 노드에 없는 pod 이름을 전달합니다. 클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc rsh -n openshift-etcd etcd-openshift-control-plane-0
멤버 목록을 확인합니다.
sh-4.2# etcdctl member list -w table
출력 예
+------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+ | 7a8197040a5126c8 | started | openshift-control-plane-2 | https://192.168.10.11:2380 | https://192.168.10.11:2379 | false | | 8d5abe9669a39192 | started | openshift-control-plane-1 | https://192.168.10.10:2380 | https://192.168.10.10:2379 | false | | cc3830a72fc357f9 | started | openshift-control-plane-0 | https://192.168.10.9:2380 | https://192.168.10.9:2379 | false | +------------------+---------+--------------------+---------------------------+---------------------------+-----------------+
참고이전 명령의 출력에 세 개 이상의 etcd 멤버가 나열된 경우 원하지 않는 멤버를 신중하게 제거해야 합니다.
다음 명령을 실행하여 모든 etcd 멤버가 정상인지 확인합니다.
# etcdctl endpoint health --cluster
출력 예
https://192.168.10.10:2379 is healthy: successfully committed proposal: took = 8.973065ms https://192.168.10.9:2379 is healthy: successfully committed proposal: took = 11.559829ms https://192.168.10.11:2379 is healthy: successfully committed proposal: took = 11.665203ms
다음 명령을 실행하여 모든 노드가 최신 버전인지 확인합니다.
$ oc get etcd -o=jsonpath='{range.items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'AllNodesAtLatestRevision
5.2.5. 추가 리소스
5.3. 재해 복구
5.3.1. 재해 복구 정보
재해 복구 문서에서는 관리자에게 OpenShift Container Platform 클러스터에서 발생할 수있는 여러 재해 상황을 복구하는 방법에 대한 정보를 제공합니다. 관리자는 클러스터를 작동 상태로 복원하려면 다음 절차 중 하나 이상을 수행해야합니다.
재해 복구를 수행하려면 하나 이상의 정상 컨트롤 플레인 호스트가 있어야 합니다.
- 이전 클러스터 상태로 복원
클러스터를 이전 상태로 복원하려는 경우 (예: 관리자가 일부 주요 정보를 삭제한 경우) 이 솔루션을 사용할 수 있습니다. 이에는 대부분의 컨트롤 플레인 호스트가 손실되고 etcd 쿼럼이 손실되고 클러스터가 오프라인인 상태에서도 사용할 수 있습니다. etcd 백업을 수행한 경우 이 절차에 따라 클러스터를 이전 상태로 복원할 수 있습니다.
해당하는 경우 만료된 컨트롤 플레인 인증서를 복구해야 할 수도 있습니다.
주의이전 클러스터 상태로 복원하는 것은 실행 중인 클러스터에서 수행하기에 위험하고 불안정한 작업입니다. 이 절차는 마지막 수단으로만 사용해야 합니다.
복원을 수행하기 전에 클러스터에 미치는 영향에 대한 자세한 내용은 클러스터 상태 복원 을 참조하십시오.
참고대부분의 마스터를 계속 사용할 수 있고 etcd 쿼럼이 있는 경우 절차에 따라 비정상적인 단일 etcd 멤버 교체를 수행합니다.
- 만료된 컨트롤 플레인 인증서 복구
- 컨트롤 플레인 인증서가 만료된 경우 이 솔루션을 사용할 수 있습니다. 예를 들어, 설치 후 24 시간 내에 발생하는 첫 번째 인증서 교체 전에 클러스터를 종료하면 인증서가 교체되지 않고 만료됩니다. 다음 단계에 따라 만료된 컨트롤 플레인 인증서를 복구할 수 있습니다.
5.3.2. 이전 클러스터 상태로 복원
클러스터를 이전 상태로 복원하려면 스냅샷을 작성하여 etcd 데이터를 백업 해야 합니다. 이 스냅샷을 사용하여 클러스터 상태를 복구합니다.
5.3.2.1. 클러스터 상태 복원 정보
etcd 백업을 사용하여 클러스터를 이전 상태로 복원할 수 있습니다. 이를 사용하여 다음과 같은 상황에서 복구할 수 있습니다.
- 클러스터에서 대부분의 컨트롤 플레인 호스트가 손실되었습니다(쿼럼 손실).
- 관리자가 중요한 것을 삭제했으며 클러스터를 복구하려면 복원해야 합니다.
이전 클러스터 상태로 복원하는 것은 실행 중인 클러스터에서 수행하기에 위험하고 불안정한 작업입니다. 이는 마지막 수단으로만 사용해야 합니다.
Kubernetes API 서버를 사용하여 데이터를 검색할 수 있는 경우 etcd를 사용할 수 있으며 etcd 백업을 사용하여 복원할 수 없습니다.
etcd를 복원하려면 클러스터를 효율적으로 복원하는 데 시간이 걸리며 모든 클라이언트가 충돌하는 병렬 기록이 발생합니다. 이는 kubelets, Kubernetes 컨트롤러 관리자, SDN 컨트롤러 및 영구 볼륨 컨트롤러와 같은 구성 요소 모니터링 동작에 영향을 줄 수 있습니다.
이로 인해 etcd의 콘텐츠가 디스크의 실제 콘텐츠와 일치하지 않을 때 Operator가 문제가 발생하여 디스크의 파일이 etcd의 콘텐츠와 충돌할 때 Kubernetes API 서버, Kubernetes 컨트롤러 관리자, Kubernetes 스케줄러 및 etcd의 Operator가 중단될 수 있습니다. 여기에는 문제를 해결하기 위해 수동 작업이 필요할 수 있습니다.
극단적인 경우 클러스터에서 영구 볼륨 추적을 손실하고, 더 이상 존재하지 않는 중요한 워크로드를 삭제하고, 시스템을 다시 이미지화하고, 만료된 인증서로 CA 번들을 다시 작성할 수 있습니다.
5.3.2.2. 이전 클러스터 상태로 복원
저장된 etcd 백업을 사용하여 이전 클러스터 상태를 복원하거나 대부분의 컨트롤 플레인 호스트가 손실된 클러스터를 복원할 수 있습니다.
클러스터에서 컨트롤 플레인 머신 세트를 사용하는 경우 보다 간단한 etcd 복구 절차는 "컨트롤 플레인 머신 세트 문제 해결"을 참조하십시오.
클러스터를 복원할 때 동일한 z-stream 릴리스에서 가져온 etcd 백업을 사용해야 합니다. 예를 들어 OpenShift Container Platform 4.7.2 클러스터는 4.7.2에서 가져온 etcd 백업을 사용해야 합니다.
사전 요구 사항
-
설치 중에 사용된 인증서 기반
kubeconfig파일을 통해cluster-admin역할의 사용자로 클러스터에 액세스할 수 있습니다. - 복구 호스트로 사용할 정상적인 컨트롤 플레인 호스트가 있어야 합니다.
- 컨트롤 플레인 호스트에 대한 SSH 액세스.
-
동일한 백업에서 가져온
etcd스냅샷과 정적 pod 리소스가 모두 포함된 백업 디렉터리입니다. 디렉토리의 파일 이름은snapshot_<datetimestamp>.db및static_kuberesources_<datetimestamp>.tar.gz형식이어야합니다.
복구되지 않은 컨트롤 플레인 노드의 경우 SSH 연결을 설정하거나 정적 pod를 중지할 필요가 없습니다. 복구되지 않은 다른 컨트롤 플레인 시스템을 삭제하고 다시 생성할 수 있습니다.
절차
- 복구 호스트로 사용할 컨트롤 플레인 호스트를 선택합니다. 이는 복구 작업을 실행할 호스트입니다.
복구 호스트를 포함하여 각 컨트롤 플레인 노드에 SSH 연결을 설정합니다.
복원 프로세스가 시작된 후
kube-apiserver에 액세스할 수 없으므로 컨트롤 플레인 노드에 액세스할 수 없습니다. 따라서 다른 터미널에서 각 컨트롤 플레인 호스트에 대한 SSH 연결을 설정하는 것이 좋습니다.중요이 단계를 완료하지 않으면 컨트롤 플레인 호스트에 액세스하여 복구 프로세스를 완료할 수 없으며 이 상태에서 클러스터를 복구할 수 없습니다.
etcd백업 디렉터리를 복구 컨트롤 플레인 호스트에 복사합니다.이 절차에서는
etcd스냅샷과 정적 pod의 리소스가 포함된백업디렉터리를 복구 컨트롤 플레인 호스트의/home/core/디렉터리에 복사하는 것을 전제로 합니다.다른 컨트롤 플레인 노드에서 고정 Pod를 중지합니다.
참고복구 호스트에서 정적 Pod를 중지할 필요가 없습니다.
- 복구 호스트가 아닌 컨트롤 플레인 호스트에 액세스합니다.
다음을 실행하여 kubelet 매니페스트 디렉토리에서 기존 etcd pod 파일을 이동합니다.
$ sudo mv /etc/kubernetes/manifests/etcd-pod.yaml /tmp
다음을 사용하여
etcdpod가 중지되었는지 확인합니다.$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"
이 명령의 출력이 비어 있지 않으면 몇 분 기다렸다가 다시 확인하십시오.
다음을 실행하여 kubelet 매니페스트 디렉토리에서 기존
kube-apiserver파일을 이동합니다.$ sudo mv /etc/kubernetes/manifests/kube-apiserver-pod.yaml /tmp
다음을 실행하여
kube-apiserver컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps | grep kube-apiserver | egrep -v "operator|guard"
이 명령의 출력이 비어 있지 않으면 몇 분 기다렸다가 다시 확인하십시오.
다음을 사용하여 kubelet 매니페스트 디렉토리에서 기존
kube-controller-manager파일을 이동합니다.$ sudo mv /etc/kubernetes/manifests/kube-controller-manager-pod.yaml /tmp
다음을 실행하여
kube-controller-manager컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps | grep kube-controller-manager | egrep -v "operator|guard"
이 명령의 출력이 비어 있지 않으면 몇 분 기다렸다가 다시 확인하십시오.
다음을 사용하여 kubelet 매니페스트 디렉토리에서 기존
kube-scheduler파일을 이동합니다.$ sudo mv /etc/kubernetes/manifests/kube-scheduler-pod.yaml /tmp
다음을 사용하여
kube-scheduler컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps | grep kube-scheduler | egrep -v "operator|guard"
이 명령의 출력이 비어 있지 않으면 몇 분 기다렸다가 다시 확인하십시오.
다음 예와 함께
etcd데이터 디렉터리를 다른 위치로 이동합니다.$ sudo mv /var/lib/etcd/ /tmp
/etc/kubernetes/manifests/keepalived.yaml파일이 있는 경우 다음 단계를 따르십시오.kubelet 매니페스트 디렉토리에서
/etc/kubernetes/manifests/keepalived.yaml파일을 이동합니다.$ sudo mv /etc/kubernetes/manifests/keepalived.yaml /tmp
keepalived데몬에서 관리하는 컨테이너가 중지되었는지 확인합니다.$ sudo crictl ps --name keepalived
이 명령의 출력은 비어 있어야합니다. 비어 있지 않은 경우 몇 분 기다렸다가 다시 확인하십시오.
컨트롤 플레인에 VIP가 할당되어 있는지 확인합니다.
$ ip -o address | egrep '<api_vip>|<ingress_vip>'
보고된 각 VIP에 대해 다음 명령을 실행하여 제거합니다.
$ sudo ip address del <reported_vip> dev <reported_vip_device>
- 복구 호스트가 아닌 다른 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
- 복구 컨트롤 플레인 호스트에 액세스합니다.
keepalived데몬이 사용 중인 경우 복구 컨트롤 플레인 노드가 VIP를 소유하고 있는지 확인합니다.$ ip -o address | grep <api_vip>
VIP 주소가 있는 경우 출력에 강조 표시됩니다. VIP가 잘못 설정되거나 구성되지 않은 경우 이 명령은 빈 문자열을 반환합니다.
클러스터 전체의 프록시가 활성화되어 있는 경우
NO_PROXY,HTTP_PROXY및https_proxy환경 변수를 내보내고 있는지 확인합니다.작은 정보oc get proxy cluster -o yaml의 출력을 확인하여 프록시가 사용 가능한지 여부를 확인할 수 있습니다.httpProxy,httpsProxy및noProxy필드에 값이 설정되어 있으면 프록시가 사용됩니다.복구 컨트롤 플레인 호스트에서 복원 스크립트를 실행하고
etcd백업 디렉터리에 경로를 전달합니다.$ sudo -E /usr/local/bin/cluster-restore.sh /home/core/backup
스크립트 출력 예
...stopping kube-scheduler-pod.yaml ...stopping kube-controller-manager-pod.yaml ...stopping etcd-pod.yaml ...stopping kube-apiserver-pod.yaml Waiting for container etcd to stop .complete Waiting for container etcdctl to stop .............................complete Waiting for container etcd-metrics to stop complete Waiting for container kube-controller-manager to stop complete Waiting for container kube-apiserver to stop ..........................................................................................complete Waiting for container kube-scheduler to stop complete Moving etcd data-dir /var/lib/etcd/member to /var/lib/etcd-backup starting restore-etcd static pod starting kube-apiserver-pod.yaml static-pod-resources/kube-apiserver-pod-7/kube-apiserver-pod.yaml starting kube-controller-manager-pod.yaml static-pod-resources/kube-controller-manager-pod-7/kube-controller-manager-pod.yaml starting kube-scheduler-pod.yaml static-pod-resources/kube-scheduler-pod-8/kube-scheduler-pod.yaml
cluster-restore.sh 스크립트는
etcd,kube-apiserver,kube-controller-manager및kube-schedulerPod가 중지되고 복원 프로세스가 끝날 때 시작되었음을 표시해야합니다.참고마지막
etcd백업 후 노드 인증서가 업데이트된 경우 복원 프로세스에서 노드가NotReady상태가 될 수 있습니다.노드를 확인하여
Ready상태인지 확인합니다.다음 명령을 실행합니다.
$ oc get nodes -w
샘플 출력
NAME STATUS ROLES AGE VERSION host-172-25-75-28 Ready master 3d20h v1.24.0 host-172-25-75-38 Ready infra,worker 3d20h v1.24.0 host-172-25-75-40 Ready master 3d20h v1.24.0 host-172-25-75-65 Ready master 3d20h v1.24.0 host-172-25-75-74 Ready infra,worker 3d20h v1.24.0 host-172-25-75-79 Ready worker 3d20h v1.24.0 host-172-25-75-86 Ready worker 3d20h v1.24.0 host-172-25-75-98 Ready infra,worker 3d20h v1.24.0
모든 노드가 상태를 보고하는 데 몇 분이 걸릴 수 있습니다.
NotReady상태에 있는 노드가 있는 경우 노드에 로그인하고 각 노드의/var/lib/kubelet/pki디렉터리에서 모든 PEM 파일을 제거합니다. 노드에 SSH로 액세스하거나 웹 콘솔의 터미널 창을 사용할 수 있습니다.$ ssh -i <ssh-key-path> core@<master-hostname>
샘플
pki디렉터리sh-4.4# pwd /var/lib/kubelet/pki sh-4.4# ls kubelet-client-2022-04-28-11-24-09.pem kubelet-server-2022-04-28-11-24-15.pem kubelet-client-current.pem kubelet-server-current.pem
모든 컨트롤 플레인 호스트에서 kubelet 서비스를 다시 시작합니다.
복구 호스트에서 다음을 실행합니다.
$ sudo systemctl restart kubelet.service
- 다른 모든 컨트롤 플레인 호스트에서 이 단계를 반복합니다.
보류 중인 인증서 서명 요청(CSR)을 승인합니다.
참고3개의 스케줄링 가능한 컨트롤 플레인 노드로 구성된 단일 노드 클러스터 또는 클러스터와 같은 작업자 노드가 없는 클러스터에는 승인할 보류 중인 CSR이 없습니다. 이 단계에서 나열된 모든 명령을 건너뛸 수 있습니다.
다음을 실행하여 현재 CSR 목록을 가져옵니다.
$ oc get csr
출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending 1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending 2 csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending 3 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending 4 ...
CSR (사용자 프로비저닝 설치용). <2> 보류 중인 node-bootstrapper CSR
CSR의 세부 정보를 검토하여 다음을 실행하여 유효한지 확인합니다.
$ oc describe csr <csr_name> 1- 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
다음을 실행하여 각 유효한
node-bootstrapperCSR을 승인합니다.$ oc adm certificate approve <csr_name>
사용자 프로비저닝 설치의 경우 다음을 실행하여 각 유효한 kubelet 서비스 CSR을 승인합니다.
$ oc adm certificate approve <csr_name>
- 단일 멤버 컨트롤 플레인이 제대로 시작되었는지 확인합니다.
복구 호스트에서 다음을 사용하여
etcd컨테이너가 실행 중인지 확인합니다.$ sudo crictl ps | grep etcd | egrep -v "operator|etcd-guard"
출력 예
3ad41b7908e32 36f86e2eeaaffe662df0d21041eb22b8198e0e58abeeae8c743c3e6e977e8009 About a minute ago Running etcd 0 7c05f8af362f0
복구 호스트에서 다음을 사용하여
etcdpod가 실행 중인지 확인합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
NAME READY STATUS RESTARTS AGE etcd-ip-10-0-143-125.ec2.internal 1/1 Running 1 2m47s
상태가
Pending또는 출력에 두 개 이상의etcdpod가 나열된 경우 몇 분 기다렸다가 다시 확인하십시오.-
OVNKubernetes네트워크 플러그인을 사용하는 경우ovnkube-controlplanePod를 다시 시작해야 합니다.
-
다음을 실행하여 모든
ovnkube-controlplanePod를 삭제합니다.$ oc -n openshift-ovn-kubernetes delete pod -l app=ovnkube-control-plane
다음을 사용하여 모든
ovnkube-controlplanePod가 재배포되었는지 확인합니다.$ oc -n openshift-ovn-kubernetes get pod -l app=ovnkube-control-plane
CNO(Cluster Network Operator)가 OVN-Kubernetes 컨트롤 플레인을 재배포하고 더 이상 복구되지 않은 컨트롤러 IP 주소를 참조하지 않는지 확인합니다. 이 결과를 확인하려면 다음 명령의 출력을 정기적으로 확인하십시오. 다음 단계의 모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 다시 시작하기 전에 빈 결과를 반환할 때까지 기다립니다.
$ oc -n openshift-ovn-kubernetes get ds/ovnkube-master -o yaml | grep -E '<non-recovery_controller_ip_1>|<non-recovery_controller_ip_2>'
참고OVN-Kubernetes 컨트롤 플레인을 재배포하고 이전 명령을 사용하여 빈 출력을 반환하는 데 최소 5-10 분이 걸릴 수 있습니다.
모든 호스트에서 OVN(Open Virtual Network) Kubernetes Pod를 재시작합니다.
참고승인 Webhook 확인 및 변경은 Pod를 거부할 수 있습니다.
failurePolicy를Fail로 설정하여 추가 Webhook를 추가하는 경우 Pod를 거부하고 복원 프로세스가 실패할 수 있습니다. 클러스터 상태를 복원하는 동안 Webhook를 저장하고 삭제하여 이 문제를 방지할 수 있습니다. 클러스터 상태가 성공적으로 복원되면 Webhook를 다시 활성화할 수 있습니다.또는 클러스터 상태를 복원하는 동안
failurePolicy를Ignore로 일시적으로 설정할 수 있습니다. 클러스터 상태가 성공적으로 복원된 후failurePolicy를Fail로 설정할 수 있습니다.
northbound 데이터베이스(nbdb) 및 southbound 데이터베이스(sbdb)를 제거합니다. SSH(Secure Shell)를 사용하여 복구 호스트 및 나머지 컨트롤 플레인 노드에 액세스하고 다음을 실행합니다.
$ sudo rm -f /var/lib/ovn/etc/*.db
다음 명령을 실행하여 모든 OVN-Kubernetes 컨트롤 플레인 Pod를 삭제합니다.
$ oc delete pods -l app=ovnkube-master -n openshift-ovn-kubernetes
다음 명령을 실행하여 OVN-Kubernetes 컨트롤 플레인 Pod가 다시 배포되고
Running상태에 있는지 확인합니다.$ oc get pods -l app=ovnkube-master -n openshift-ovn-kubernetes
출력 예
NAME READY STATUS RESTARTS AGE ovnkube-master-nb24h 4/4 Running 0 48s
다음을 사용하여
ovnkube-nodePod가 다시 실행 중인지 확인합니다.$ oc get pods -n openshift-ovn-kubernetes -o name | grep ovnkube-node | while read p ; do oc delete $p -n openshift-ovn-kubernetes ; done
모든
ovnkube-nodePod가 다시 배포되어 다음 명령을 실행하여Running상태인지 확인합니다.$ oc get pods -n openshift-ovn-kubernetes | grep ovnkube-node
복구되지 않는 다른 컨트롤 플레인 시스템을 삭제하고 하나씩 다시 생성합니다. 머신이 다시 생성되면 새 버전이 강제 생성되고
etcd가 자동으로 확장됩니다.사용자가 프로비저닝한 베어 메탈 설치를 사용하는 경우 원래 사용했던 것과 동일한 방법을 사용하여 컨트롤 플레인 시스템을 다시 생성할 수 있습니다. 자세한 내용은 " 베어 메탈에 사용자 프로비저닝 클러스터 설치"를 참조하십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라를 실행 중이거나 Machine API를 사용하여 머신을 생성한 경우 다음 단계를 따르십시오.
주의복구 호스트의 시스템을 삭제하고 다시 생성하지 마십시오.
설치 관리자 프로비저닝 인프라에 베어 메탈 설치의 경우 컨트롤 플레인 머신이 다시 생성되지 않습니다. 자세한 내용은 " 베어 메탈 컨트롤 플레인 노드 교체"를 참조하십시오.
손실된 컨트롤 플레인 호스트 중 하나에 대한 시스템을 가져옵니다.
cluster-admin 사용자로 클러스터에 액세스할 수 있는 터미널에서 다음 명령을 실행합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-0 Running m4.xlarge us-east-1 us-east-1a 3h37m ip-10-0-131-183.ec2.internal aws:///us-east-1a/i-0ec2782f8287dfb7e stopped 1 clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 이는 손실된 컨트롤 플레인 호스트의 컨트롤 플레인 시스템인
ip-10-0-131-183.ec2.internal입니다.
다음을 실행하여 머신 구성을 파일 시스템의 파일에 저장합니다.
$ oc get machine clustername-8qw5l-master-0 \ 1 -n openshift-machine-api \ -o yaml \ > new-master-machine.yaml- 1
- 손실된 컨트롤 플레인 호스트의 컨트롤 플레인 시스템의 이름을 지정합니다.
이전 단계에서 만든
new-master-machine.yaml파일을 편집하여 새 이름을 할당하고 불필요한 필드를 제거합니다.다음을 실행하여 전체
status섹션을 제거합니다.status: addresses: - address: 10.0.131.183 type: InternalIP - address: ip-10-0-131-183.ec2.internal type: InternalDNS - address: ip-10-0-131-183.ec2.internal type: Hostname lastUpdated: "2020-04-20T17:44:29Z" nodeRef: kind: Node name: ip-10-0-131-183.ec2.internal uid: acca4411-af0d-4387-b73e-52b2484295ad phase: Running providerStatus: apiVersion: awsproviderconfig.openshift.io/v1beta1 conditions: - lastProbeTime: "2020-04-20T16:53:50Z" lastTransitionTime: "2020-04-20T16:53:50Z" message: machine successfully created reason: MachineCreationSucceeded status: "True" type: MachineCreation instanceId: i-0fdb85790d76d0c3f instanceState: stopped kind: AWSMachineProviderStatus다음을 실행하여
metadata.name필드를 새 이름으로 변경합니다.이전 시스템과 동일한 기본 이름을 유지하고 마지막 번호를 사용 가능한 다음 번호로 변경하는 것이 좋습니다. 이 예에서
clustername-8qw5l-master-0이clustername-8qw5l-master-3로 변경됩니다.apiVersion: machine.openshift.io/v1beta1 kind: Machine metadata: ... name: clustername-8qw5l-master-3 ...
다음을 실행하여
spec.providerID필드를 제거합니다.providerID: aws:///us-east-1a/i-0fdb85790d76d0c3f
다음을 실행하여
metadata.annotations및metadata.generation필드를 제거합니다.annotations: machine.openshift.io/instance-state: running ... generation: 2
다음을 실행하여
metadata.resourceVersion및metadata.uid필드를 제거합니다.resourceVersion: "13291" uid: a282eb70-40a2-4e89-8009-d05dd420d31a
다음을 실행하여 손실된 컨트롤 플레인 호스트의 시스템을 삭제합니다.
$ oc delete machine -n openshift-machine-api clustername-8qw5l-master-0 1- 1
- 손실된 컨트롤 플레인 호스트의 컨트롤 플레인 시스템의 이름을 지정합니다.
다음을 실행하여 머신이 삭제되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running
다음을 실행하여
new-master-machine.yaml파일을 사용하여 머신을 생성합니다.$ oc apply -f new-master-machine.yaml
다음을 실행하여 새 시스템이 생성되었는지 확인합니다.
$ oc get machines -n openshift-machine-api -o wide
출력 예:
NAME PHASE TYPE REGION ZONE AGE NODE PROVIDERID STATE clustername-8qw5l-master-1 Running m4.xlarge us-east-1 us-east-1b 3h37m ip-10-0-143-125.ec2.internal aws:///us-east-1b/i-096c349b700a19631 running clustername-8qw5l-master-2 Running m4.xlarge us-east-1 us-east-1c 3h37m ip-10-0-154-194.ec2.internal aws:///us-east-1c/i-02626f1dba9ed5bba running clustername-8qw5l-master-3 Provisioning m4.xlarge us-east-1 us-east-1a 85s ip-10-0-173-171.ec2.internal aws:///us-east-1a/i-015b0888fe17bc2c8 running 1 clustername-8qw5l-worker-us-east-1a-wbtgd Running m4.large us-east-1 us-east-1a 3h28m ip-10-0-129-226.ec2.internal aws:///us-east-1a/i-010ef6279b4662ced running clustername-8qw5l-worker-us-east-1b-lrdxb Running m4.large us-east-1 us-east-1b 3h28m ip-10-0-144-248.ec2.internal aws:///us-east-1b/i-0cb45ac45a166173b running clustername-8qw5l-worker-us-east-1c-pkg26 Running m4.large us-east-1 us-east-1c 3h28m ip-10-0-170-181.ec2.internal aws:///us-east-1c/i-06861c00007751b0a running- 1
- 새 시스템
clustername-8qw5l-master-3이 생성되고 단계가Provisioning에서Running으로 변경되면 시스템이 준비 상태가 됩니다.
새 시스템을 만드는 데 몇 분이 소요될 수 있습니다.
etcd클러스터 Operator는 머신 또는 노드가 정상 상태로 돌아올 때 자동으로 동기화됩니다.복구 호스트가 아닌 손실된 컨트롤 플레인 호스트에 대해 이 단계를 반복합니다.
다음을 입력하여 쿼럼 가드를 끕니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": {"useUnsupportedUnsafeNonHANonProductionUnstableEtcd": true}}}'이 명령을 사용하면 보안을 다시 생성하고 정적 Pod를 롤아웃할 수 있습니다.
복구 호스트 내의 별도의 터미널 창에서 다음을 실행하여 복구
kubeconfig파일을 내보냅니다.$ export KUBECONFIG=/etc/kubernetes/static-pod-resources/kube-apiserver-certs/secrets/node-kubeconfigs/localhost-recovery.kubeconfig
etcd를 강제로 재배포합니다.복구
kubeconfig파일을 내보낸 동일한 터미널 창에서 다음을 실행합니다.$ oc patch etcd cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge 1- 1
forceRedeploymentReason값은 고유해야하므로 타임 스탬프가 추가됩니다.
etcd클러스터 Operator가 재배포를 수행하면 기존 노드가 초기 부트스트랩 확장과 유사한 새 Pod로 시작됩니다.다음을 입력하여 쿼럼 가드를 다시 켭니다.
$ oc patch etcd/cluster --type=merge -p '{"spec": {"unsupportedConfigOverrides": null}}'다음을 실행하여
unsupportedConfigOverrides섹션이 오브젝트에서 제거되었는지 확인할 수 있습니다.$ oc get etcd/cluster -oyaml
모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
cluster-admin사용자로 클러스터에 액세스할 수 있는 터미널에서 다음을 실행합니다.$ oc get etcd -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'etcd의NodeInstallerProgressing상태 조건을 검토하여 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 7 1- 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.etcd를 재배포한 후 컨트롤 플레인에 새 롤아웃을 강제 적용합니다. kubelet이 내부 로드 밸런서를 사용하여 API 서버에 연결되어 있기 때문에kube-apiserver는 다른 노드에 다시 설치됩니다.cluster-admin사용자로 클러스터에 액세스할 수 있는 터미널에서 다음을 실행합니다.
kube-apiserver에 대해 새 롤아웃을 강제 적용합니다.$ oc patch kubeapiserver cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubeapiserver -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 7 1- 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.다음 명령을 실행하여 Kubernetes 컨트롤러 관리자에 대해 새 롤아웃을 강제 적용합니다.
$ oc patch kubecontrollermanager cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge다음을 실행하여 모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubecontrollermanager -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 7 1- 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.다음을 실행하여
kube-scheduler에 새 롤아웃을 강제 적용합니다.$ oc patch kubescheduler cluster -p='{"spec": {"forceRedeploymentReason": "recovery-'"$( date --rfc-3339=ns )"'"}}' --type=merge다음을 사용하여 모든 노드가 최신 버전으로 업데이트되었는지 확인합니다.
$ oc get kubescheduler -o=jsonpath='{range .items[0].status.conditions[?(@.type=="NodeInstallerProgressing")]}{.reason}{"\n"}{.message}{"\n"}'NodeInstallerProgressing상태 조건을 확인하고 모든 노드가 최신 버전인지 확인합니다. 업데이트가 성공적으로 실행되면 출력에AllNodesAtLatestRevision이 표시됩니다.AllNodesAtLatestRevision 3 nodes are at revision 7 1- 1
- 이 예에서 최신 버전 번호는
7입니다.
출력에
2 nodes are at revision 6; 1 nodes are at revision 7와 같은 여러 버전 번호가 표시되면 이는 업데이트가 아직 진행 중임을 의미합니다. 몇 분 기다린 후 다시 시도합니다.모든 컨트롤 플레인 호스트가 클러스터를 시작하여 참여하고 있는지 확인합니다.
클러스터에 액세스할 수 있는 터미널에서
cluster-admin사용자로 다음 명령을 실행합니다.$ oc -n openshift-etcd get pods -l k8s-app=etcd
출력 예
etcd-ip-10-0-143-125.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-154-194.ec2.internal 2/2 Running 0 9h etcd-ip-10-0-173-171.ec2.internal 2/2 Running 0 9h
복구 절차에 따라 모든 워크로드가 정상 작업으로 돌아가도록 하려면 kube-apiserver 정보를 저장하는 각 Pod를 다시 시작합니다. 여기에는 라우터, Operator, 타사 구성 요소와 같은 OpenShift Container Platform 구성 요소가 포함됩니다.
이전 절차 단계를 완료하면 모든 서비스가 복원된 상태로 돌아올 때까지 몇 분 정도 기다려야 할 수 있습니다. 예를 들어, OAuth 서버 pod가 다시 시작될 때까지 oc login을 사용한 인증이 즉시 작동하지 않을 수 있습니다.
즉각적인 인증을 위해 system:admin kubeconfig 파일을 사용하는 것이 좋습니다. 이 방법은 OAuth 토큰에 대해 SSL/TLS 클라이언트 인증서에 대한 인증을 기반으로 합니다. 다음 명령을 실행하여 이 파일로 인증할 수 있습니다.
$ export KUBECONFIG=<installation_directory>/auth/kubeconfig
다음 명령을 실행하여 인증된 사용자 이름을 표시합니다.
$ oc whoami
5.3.2.3. 추가 리소스
5.3.2.4. 영구 스토리지 상태 복원을 위한 문제 및 해결 방법
OpenShift Container Platform 클러스터에서 모든 형식의 영구저장장치를 사용하는 경우 일반적으로 클러스터의 상태가 etcd 외부에 저장됩니다. StatefulSet 오브젝트에서 실행 중인 Pod 또는 데이터베이스에서 실행 중인 Elasticsearch 클러스터일 수 있습니다. etcd 백업에서 복원하면 OpenShift Container Platform의 워크로드 상태도 복원됩니다. 그러나 etcd 스냅샷이 오래된 경우 상태가 유효하지 않거나 오래되었을 수 있습니다.
PV(영구 볼륨)의 내용은 etcd 스냅샷의 일부가 아닙니다. etcd 스냅샷에서 OpenShift Container Platform 클러스터를 복원할 때 중요하지 않은 워크로드가 중요한 데이터에 액세스할 수 있으며 그 반대의 경우로도 할 수 있습니다.
다음은 사용되지 않는 상태를 생성하는 몇 가지 예제 시나리오입니다.
- MySQL 데이터베이스는 PV 오브젝트에서 지원하는 pod에서 실행됩니다. etcd 스냅샷에서 OpenShift Container Platform을 복원해도 스토리지 공급자의 볼륨을 다시 가져오지 않으며 pod를 반복적으로 시작하려고 하지만 실행 중인 MySQL pod는 생성되지 않습니다. 스토리지 공급자에서 볼륨을 복원한 다음 새 볼륨을 가리키도록 PV를 편집하여 이 Pod를 수동으로 복원해야 합니다.
- Pod P1에서는 노드 X에 연결된 볼륨 A를 사용합니다. 다른 pod가 노드 Y에서 동일한 볼륨을 사용하는 동안 etcd 스냅샷을 가져오는 경우 etcd 복원이 수행되면 해당 볼륨이 여전히 Y 노드에 연결되어 있으므로 Pod P1이 제대로 시작되지 않을 수 있습니다. OpenShift Container Platform은 연결을 인식하지 못하고 자동으로 연결을 분리하지 않습니다. 이 경우 볼륨이 노드 X에 연결된 다음 Pod P1이 시작될 수 있도록 노드 Y에서 볼륨을 수동으로 분리해야 합니다.
- etcd 스냅샷을 만든 후 클라우드 공급자 또는 스토리지 공급자 인증 정보가 업데이트되었습니다. 이로 인해 해당 인증 정보를 사용하는 CSI 드라이버 또는 Operator가 작동하지 않습니다. 해당 드라이버 또는 Operator에 필요한 인증 정보를 수동으로 업데이트해야 할 수 있습니다.
etcd 스냅샷을 만든 후 OpenShift Container Platform 노드에서 장치가 제거되거나 이름이 변경됩니다. Local Storage Operator는
/dev/disk/by-id또는/dev디렉터리에서 관리하는 각 PV에 대한 심볼릭 링크를 생성합니다. 이 경우 로컬 PV가 더 이상 존재하지 않는 장치를 참조할 수 있습니다.이 문제를 해결하려면 관리자가 다음을 수행해야 합니다.
- 잘못된 장치가 있는 PV를 수동으로 제거합니다.
- 각 노드에서 심볼릭 링크를 제거합니다.
-
LocalVolume또는LocalVolumeSet오브젝트를 삭제합니다 (스토리지 → 영구 스토리지 구성 → 로컬 볼륨을 사용하는 영구 스토리지 → Local Storage Operator 리소스 삭제참조).
5.3.3. 만료된 컨트롤 플레인 인증서 복구
5.3.3.1. 만료된 컨트롤 플레인 인증서 복구
클러스터는 만료된 컨트롤 플레인 인증서에서 자동으로 복구될 수 있습니다.
그러나 kubelet 인증서를 복구하려면 대기 중인 node-bootstrapper 인증서 서명 요청(CSR)을 수동으로 승인해야 합니다. 사용자 프로비저닝 설치의 경우 보류 중인 kubelet 서비스 CSR을 승인해야 할 수도 있습니다.
보류중인 CSR을 승인하려면 다음 단계를 수행합니다.
절차
현재 CSR의 목록을 가져옵니다.
$ oc get csr
출력 예
NAME AGE SIGNERNAME REQUESTOR CONDITION csr-2s94x 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending 1 csr-4bd6t 8m3s kubernetes.io/kubelet-serving system:node:<node_name> Pending csr-4hl85 13m kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending 2 csr-zhhhp 3m8s kubernetes.io/kube-apiserver-client-kubelet system:serviceaccount:openshift-machine-config-operator:node-bootstrapper Pending ...
CSR의 세부 사항을 검토하여 CSR이 유효한지 확인합니다.
$ oc describe csr <csr_name> 1- 1
<csr_name>은 현재 CSR 목록에 있는 CSR의 이름입니다.
각각의 유효한
node-bootstrapperCSR을 승인합니다.$ oc adm certificate approve <csr_name>
사용자 프로비저닝 설치의 경우 CSR을 제공하는 각 유효한 kubelet을 승인합니다.
$ oc adm certificate approve <csr_name>