
Red Hat Training
A Red Hat training course is available for OpenShift Container Platform
스케일링 및 성능 가이드
OpenShift Container Platform 3.11 확장 및 성능 가이드
초록
1장. 개요
이 가이드에서는 OpenShift Container Platform 클러스터 성능을 향상시키고 OpenShift Container Platform 프로덕션 스택의 다양한 수준에서 스케일링을 수행하는 방법에 대한 절차와 예제를 제공합니다. OpenShift Container Platform 클러스터 빌드, 스케일링 및 튜닝에 대한 권장 사례가 포함되어 있습니다.
튜닝 고려 사항은 클러스터 설정에 따라 달라질 수 있으며 이 가이드의 성능 권장 사항에는 장단점이 있을 수 있습니다.
2장. 권장 설치 사례
2.1. 사전 설치 종속성
노드 호스트는 네트워크에 액세스하여 atomic-openshift-*, iptables, CRI-O 또는 Docker 와 같은 RPMs 종속성을 설치합니다. 이러한 종속성을 미리 설치하여 설치하는 동안 호스트당 여러 번이 아니라 필요할 때만 RPM에 액세스하므로 보다 효율적인 설치를 생성합니다.
이는 보안상의 이유로 레지스트리에 액세스할 수 없는 머신에도 유용합니다.
2.2. Ansible 설치 최적화
OpenShift Container Platform 설치 방법에서는 Ansible을 사용합니다. Ansible은 병렬 작업을 실행하는 데 유용하며, 이는 빠르고 효율적인 설치를 의미합니다. 그러나 추가 튜닝 옵션을 사용하여 이러한 기능을 개선할 수 있습니다. 사용 가능한 Ansible 구성 옵션 목록은 Ansible 구성 구성 섹션을 참조하십시오.
병렬 동작은 이미지 레지스트리 또는 Red Hat Satellite 서버와 같은 콘텐츠 소스를 과도하게 압도할 수 있습니다. 서버의 인프라 Pod 및 운영 체제 패치를 준비하는 것은 이러한 문제를 방지하는 데 도움이 될 수 있습니다.
가장 낮은 대기 시간 제어 노드(LAN 속도)에서 설치 프로그램을 실행합니다. 광범위한 영역 네트워크(octets)를 통해 실행하는 것은 권장되지 않으며, 손실된 네트워크 연결을 통해 설치를 실행하지도 않습니다.
Ansible은 OpenSSH 버전이 ControlPersist 를 지원하는지 확인하는 데 RHEL 6.6 이상을 사용하고 클러스터와 동일한 LAN에서 설치 프로그램을 실행하지만 클러스터의 시스템에서 실행하는 등 성능 및 스케일링에 대한 자체 지침을 제공합니다.
다음은 Ansible에서 설명하는 권장 사항을 통합하는 대규모 클러스터 설치 및 관리에 대한 Ansible 구성의 예입니다.
# cat /etc/ansible/ansible.cfg
출력 예
# config file for ansible -- http://ansible.com/ # ============================================== [defaults] forks = 20 1 host_key_checking = False remote_user = root roles_path = roles/ gathering = smart fact_caching = jsonfile fact_caching_connection = $HOME/ansible/facts fact_caching_timeout = 600 log_path = $HOME/ansible.log nocows = 1 callback_whitelist = profile_tasks [privilege_escalation] become = False [ssh_connection] ssh_args = -o ControlMaster=auto -o ControlPersist=600s -o ServerAliveInterval=60 control_path = %(directory)s/%%h-%%r pipelining = True 2 timeout = 10
2.3. 네트워킹 고려 사항
네트워크 서브넷은 설치 후 변경할 수 있지만 어려움이 있습니다. 크기를 낮추면 클러스터 확장에 문제가 발생할 수 있으므로 설치하기 전에 네트워크 서브넷 크기를 고려하는 것이 훨씬 쉬워집니다.
권장 네트워크 서브넷 지정 방법은 네트워크 최적화 주제를 참조하십시오.
3장. 호스트 관련 권장 사례
3.1. OpenShift Container Platform 마스터 호스트에 대한 권장 사례
Pod 트래픽 외에도 OpenShift Container Platform 인프라에서 가장 많이 사용되는 데이터 경로도 OpenShift Container Platform 마스터 호스트와 etcd 사이입니다. OpenShift Container Platform API 서버(마스터 바이너리의 일부)는 etcd에서 노드 상태, 네트워크 구성, 시크릿 등을 참조합니다.
다음을 통해 이 트래픽 경로를 최적화합니다.
- 마스터 호스트에서 etcd 실행. 기본적으로 etcd는 모든 마스터 호스트의 정적 포드에서 실행됩니다.
- 마스터 호스트 간에 연결되지 않고 대기 시간이 짧은 LAN 통신 링크를 확인합니다.
OpenShift Container Platform 마스터는 CPU 로드를 쉽게하기 위해 적극적으로 리소스의 역직렬화 버전을 캐시합니다. 그러나 Pod가 1,000개 미만인 소규모 클러스터에서 이 캐시는 상당한 CPU 부하 감소를 위해 많은 메모리를 낭비할 수 있습니다. 기본 캐시 크기는 50,000개 항목이며, 리소스 크기에 따라 1~2GB의 메모리를 차지하도록 증가할 수 있습니다. 이 캐시 크기는 /etc/origin/master/master-config.yaml 에서 다음 설정을 사용하여 줄일 수 있습니다.
kubernetesMasterConfig:
apiServerArguments:
deserialization-cache-size:
- "1000"
API 서버로 전송되는 클라이언트 요청 또는 API 호출 수는 QPS(Queries per second) 값에 따라 결정되며 API 서버에서 처리할 수 있는 동시 요청 수는 maxRequestsInFlight 설정에 따라 결정됩니다. 클라이언트가 QPS 수치를 초과할 수 있는 요청 수는 버스트 값에 따라 달라지며, 이는 자연에서 버스트(bursty)되는 애플리케이션에 도움이 되며, 이는 불규칙한 요청 수를 생성할 수 있습니다. 요청에 대한 응답 시간은 특히 대규모 및/또는 밀도가 높은 클러스터의 경우 API 서버에서 많은 동시 요청을 처리하는 경우 대기 시간이 높을 수 있습니다. Prometheus에서 apiserver_request_count 속도 메트릭을 모니터링하고 maxRequestsInFlight 및 QPS 를 적절하게 조정하는 것이 좋습니다.
API 서버의 CPU 및 메모리 사용량을 변경할 때 기본값을 변경할 때는 더 많은 요청을 동시에 처리할 때 etcd IOPS가 증가합니다. 또한 고정 60초 제한 시간이 지나면 API 서버가 취소되고 클라이언트가 재시도를 시작할 때 API 서버에 과부하가 발생할 수도 있습니다.
API 서버 시스템에서 충분한 CPU 및 메모리 리소스를 사용할 수 있는 경우 위에서 언급한 요인을 고려하여 API 서버 요청 과부하 문제를 안전하게 완화할 수 있으며 *_/etc/origin/master/master-config.yaml의 maxRequestsInFlight, API qps 및 burst 값을 사용하여 문제를 해결할 수 있습니다.
masterClients:
openshiftLoopbackClientConnectionOverrides:
burst: 600
qps: 300
servingInfo:
maxRequestsInFlight: 500위의 maxRequestsInFlight, qps 및 burst 값은 OpenShift Container Platform의 기본값입니다. qps는 요청이 1초 미만이면 maxRequestsInFlight 값보다 높을 수 있습니다. 'maxRequestsInFlight'가 0으로 설정된 경우 서버에서 처리할 수 있는 동시 요청 수에 제한이 없습니다.
3.2. OpenShift Container Platform 노드 호스트에 대한 권장 사례
OpenShift Container Platform 노드 구성 파일에는 iptables 동기화 기간, SDN 네트워크의 최대 전송 단위(MTU) 및 프록시 모드와 같은 중요한 옵션이 포함되어 있습니다. 노드를 구성하려면 적절한 노드 구성 맵 을 수정합니다.
node-config.yaml 파일을 직접 편집하지 마십시오.
노드 구성 파일을 사용하면 kubelet(노드) 프로세스에 인수를 전달할 수 있습니다. kubelet --help 를 실행하여 가능한 옵션 목록을 볼 수 있습니다.
OpenShift Container Platform에서 모든 kubelet 옵션이 지원되는 것은 아니며 업스트림 Kubernetes에서 사용됩니다. 즉, 특정 옵션이 제한된 지원 상태에 있음을 의미합니다.
각 OpenShift Container Platform 버전에 대해 지원되는 최대 제한 사항은 클러스터 최대값 페이지를 참조하십시오.
/etc/origin/node/node-config.yaml 파일에서 두 개의 매개변수는 pod- per-core 및 수를 제어합니다. 두 옵션이 모두 사용 중인 경우 두 옵션 중 가장 낮은 값이 노드의 Pod 수를 제한합니다. 이 값을 초과하면 다음과 같은 결과가 발생할 수 있습니다.
max-pods 에 예약할 수 있는 최대 Pod
- OpenShift Container Platform 및 Docker 모두에서 CPU 사용률 증가
- Pod 예약 속도 저하.
- 메모리 부족 시나리오 발생(노드의 메모리 양에 따라 다름).
- IP 주소 모두 소진
- 리소스 초과 커밋으로 인한 사용자 애플리케이션 성능 저하
Kubernetes의 경우 단일 컨테이너를 보유한 하나의 Pod에서 실제로 두 개의 컨테이너가 사용됩니다. 두 번째 컨테이너는 실제 컨테이너 시작 전 네트워킹 설정에 사용됩니다. 따라서 10개의 Pod를 실행하는 시스템에서는 실제로 20개의 컨테이너가 실행됩니다.
pods-per-core 는 노드의 프로세서 코어 수에 따라 노드에서 실행할 수 있는 Pod 수를 설정합니다. 예를 들어 프로세서 코어가 4개인 노드에서 pods-per-core 가 10 으로 설정된 경우 노드에 허용되는 최대 Pod 수는 40입니다.
kubeletArguments:
pods-per-core:
- "10"
pods-per-core 를 0으로 설정하면 이 제한이 비활성화됩니다.
Max-pods 는 노드의 속성에 관계없이 노드가 실행할 수 있는 Pod 수를 고정된 값으로 설정합니다. 클러스터 제한 문서 max-pods 에 대해 지원되는 최대 값.
kubeletArguments:
max-pods:
- "250"
위의 예제를 사용하면 pods-per-core 의 기본값은 10 이고 max-pods 의 기본값은 250 입니다. 즉, 노드에 25개 이상의 코어가 없으면 기본적으로 pods-per-core 가 제한 요인이 됩니다.
OpenShift Container Platform 클러스터에 권장되는 제한 사항은 설치 문서의 고려 사항 지정 섹션을 참조하십시오. 컨테이너 상태 업데이트를 위해 OpenShift Container Platform 및 컨테이너 엔진 조정에 권장되는 크기 조정 계정입니다. 이러한 조정은 마스터 및 컨테이너 엔진 프로세스에 CPU 부담을 줄여 많은 로그 데이터 쓰기를 포함할 수 있습니다.
kubelet이 API 서버와 통신하는 속도는 qps 및 버스트 값에 따라 다릅니다. 각 노드에서 실행 중인 Pod가 제한된 경우 기본값은 충분합니다. 노드에 충분한 CPU 및 메모리 리소스가 있으면 /etc/origin/node/node-config.yaml 파일에서 qps 및 버스트 값을 조정할 수 있습니다.
kubeletArguments: kube-api-qps: - "20" kube-api-burst: - "40"
위의 qps 및 burst 값은 OpenShift Container Platform의 기본값입니다.
3.3. OpenShift Container Platform etcd 호스트에 대한 권장 사례
etcd는 OpenShift Container Platform에서 구성에 사용하는 분산 키-값 저장소입니다.
| OpenShift Container Platform 버전 | etcd 버전 | 스토리지 스키마 버전 |
| 3.3 및 이전 버전 | 2.x | v2 |
| 3.4 및 3.5 | 3.x | v2 |
| 3.6 | 3.x | v2 (upgrades) |
| 3.6 | 3.x | v3 (새 설치) |
| 3.7 이상 | 3.x | v3 |
etcd 3.x는 모든 크기의 클러스터에 대한 CPU, 메모리, 네트워크 및 디스크 요구 사항을 줄이는 중요한 확장성과 성능 향상을 제공합니다. etcd 3.x는 디스크상의 etcd 데이터베이스의 2단계 마이그레이션을 용이하게 하는 이전 버전과 호환되는 스토리지 API도 구현합니다. 마이그레이션을 위해 OpenShift Container Platform 3.5에서 etcd 3.x에서 사용하는 스토리지 모드는 v2 모드로 유지됩니다. OpenShift Container Platform 3.6부터 새로운 설치는 스토리지 모드 v3를 사용합니다. 이전 버전의 OpenShift Container Platform에서 업그레이드해도 v2에서 v3로 데이터가 자동으로 마이그레이션 되지 않습니다. 제공된 플레이북을 사용하고 문서화된 프로세스에 따라 데이터를 마이그레이션해야 합니다.
etcd 버전 3은 디스크의 etcd 데이터베이스를 2단계로 마이그레이션할 수 있도록 이전 버전과 호환되는 스토리지 API를 구현합니다. 마이그레이션을 위해 OpenShift Container Platform 3.5에서 etcd 3.x에서 사용하는 스토리지 모드는 v2 모드로 유지됩니다. OpenShift Container Platform 3.6부터 새로운 설치는 스토리지 모드 v3를 사용합니다. OpenShift Container Platform 3.7로 업그레이드하는 프로세스의 일부로 etcd 스토리지 API를 필요한 경우 v3로 업그레이드합니다. 버전 3.7 이상에서는 v3 API를 사용해야 합니다.
새 설치의 스토리지 모드를 v3으로 변경하는 것 외에도 OpenShift Container Platform 3.6은 모든 OpenShift Container Platform 유형에 대해 쿼럼 읽기 를 적용하기 시작합니다. 이는 etcd에 대한 쿼리가 오래된 데이터를 반환하지 않도록하기 위해 수행됩니다. 단일 노드 etcd 클러스터에서 오래된 데이터는 중요하지 않습니다. 일반적으로 프로덕션 클러스터에 있는 고가용성 etcd 배포에서 쿼럼은 유효한 쿼리 결과를 확인합니다. 쿼럼 읽기는 데이터베이스 용어에 선형 화됩니다. 모든 클라이언트는 클러스터의 최신 업데이트된 상태를 확인하고 모든 클라이언트는 동일한 읽기 및 쓰기 순서를 확인합니다. 성능 향상에 대한 자세한 내용은 etcd 3.1 공지 를 참조하십시오.
OpenShift Container Platform은 etcd를 사용하여 Kubernetes 자체보다 추가 정보를 저장하는 데 필요합니다. 예를 들어 OpenShift Container Platform은 OpenShift Container Platform이 Kubernetes 위에 추가하는 기능에 필요하므로 etcd의 이미지, 빌드 및 기타 구성 요소에 대한 정보를 저장합니다. 궁극적으로 etcd 호스트의 성능 및 크기 조정에 대한 지침은 적절한 방식으로 Kubernetes 및 기타 권장 사항과 다릅니다. Red Hat은 가장 정확한 권장 사항을 생성하기 위해 OpenShift Container Platform 사용 사례 및 매개변수를 사용하여 etcd 확장성과 성능을 테스트합니다.
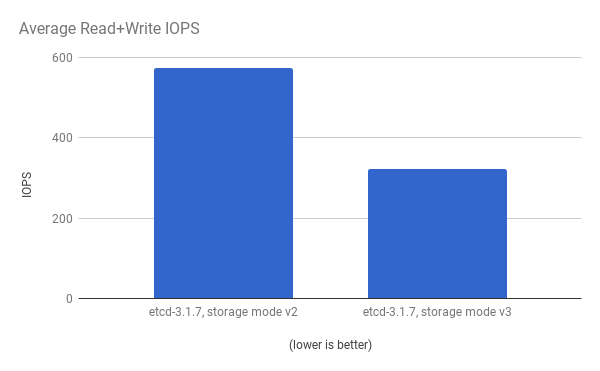
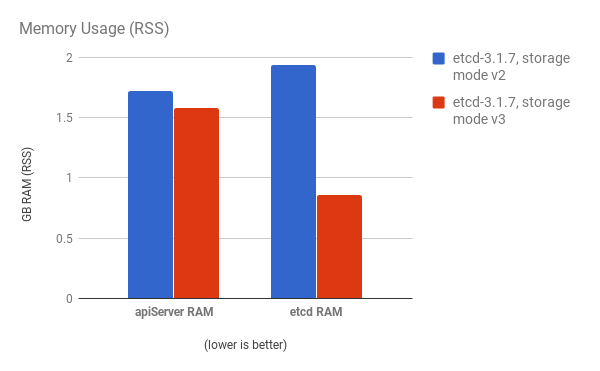
cluster-loader 유틸리티를 사용하여 300-노드 OpenShift Container Platform 3.6 클러스터를 사용하여 성능이 저하되었습니다. etcd 3.x (storage mode v2)와 etcd 3.x (storage 모드 v3) 비교하면 아래 차트에서 명확한 개선 사항이 확인됩니다.
로드 중인 스토리지 IOPS가 크게 줄어듭니다.
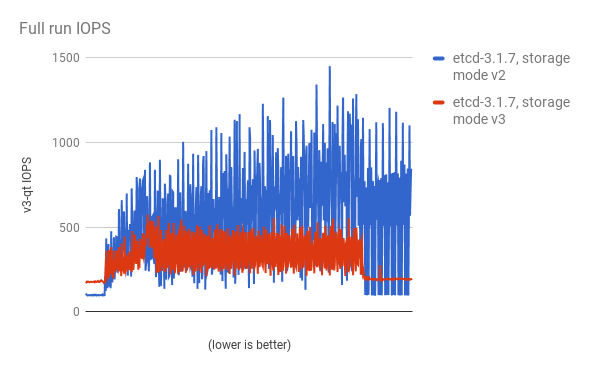
스토리지 IOPS가 정상적인 상태에서도 크게 줄어듭니다.
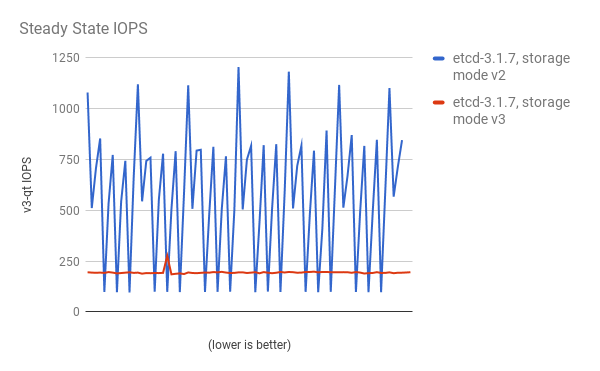
동일한 I/O 데이터를 보고 두 모드에서 평균 IOPS를 플롯합니다.
API 서버(마스터) 및 etcd 프로세스의 CPU 사용량이 감소합니다.
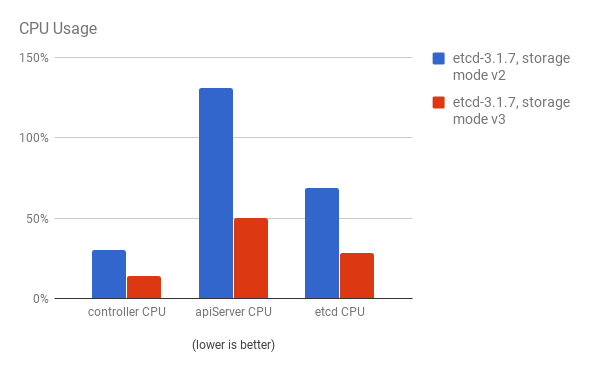
API 서버(마스터)와 etcd 프로세스 둘 다의 메모리 사용률도 감소합니다.
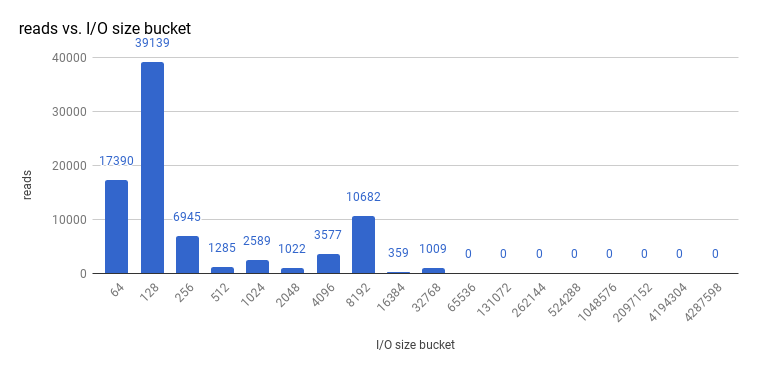
OpenShift Container Platform에서 etcd를 프로파일링한 후 etcd는 종종 소량의 스토리지 입력 및 출력을 수행합니다. SSD와 같은 소규모 읽기/쓰기 작업을 신속하게 처리하는 스토리지로 etcd를 사용하는 것이 좋습니다.
etcd 3.1의 3-노드 클러스터에서 수행한 크기 I/O 작업을 확인(스토리지 v3 모드 사용 및 쿼럼 읽기 사용), 읽기 크기는 다음과 같습니다.
및 쓰기:
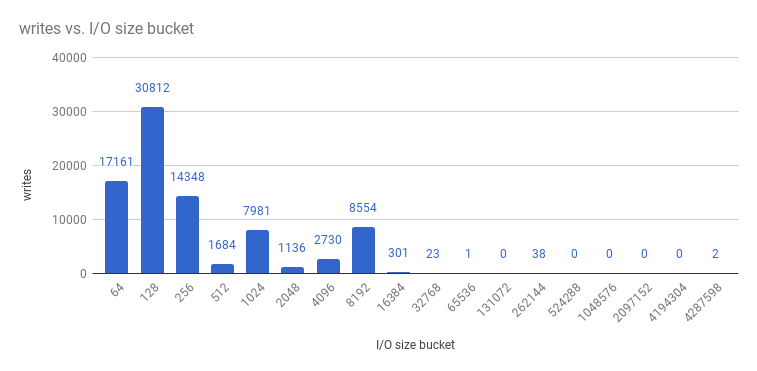
etcd 프로세스는 일반적으로 메모리 집약적입니다. 마스터/ API 서버 프로세스는 CPU 집약적입니다. 이렇게 하면 단일 머신 또는 VM(가상 머신) 내에서 합리적인 공동 배치 쌍입니다. 동일한 호스트에서 공동 배치하거나 전용 네트워크를 제공하여 etcd 호스트와 마스터 호스트 간의 통신을 최적화합니다.
3.3.1. OpenStack에서 PCI 패스스루를 사용하여 etcd 노드에 스토리지 제공
etcd가 대규모로 안정적으로 작동하도록 etcd 노드에 빠른 스토리지를 제공하려면 PCI 통과를 사용하여 NVMe(Non-volatile memory express) 장치를 etcd 노드에 직접 전달합니다. Red Hat OpenStack 11 이상으로 설정하려면 PCI 장치가 존재하는 OpenStack 컴퓨팅 노드에서 다음을 완료합니다.
- BIOS에서 Intel Vt-x가 활성화되어 있는지 확인합니다.
-
IOMMU(Input-output Memory Management Unit)를 활성화합니다. /etc/sysconfig/grub 파일에서 따옴표 안에
intel_iommu=on iommu=pt를GRUB_CMDLINX_LINUX행의 끝에 추가합니다. 다음을 실행하여 /etc/grub2.cfg 를 다시 생성합니다.
$ grub2-mkconfig -o /etc/grub2.cfg
- 시스템을 재부팅합니다.
/etc/nova.conf 의 컨트롤러에서 다음을 수행합니다.
[filter_scheduler] enabled_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,DiskFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter,PciPassthroughFilter available_filters=nova.scheduler.filters.all_filters [pci] alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }-
컨트롤러에서
nova-api및nova-scheduler를 다시 시작합니다. /etc/nova/nova.conf 의 Compute 노드에서 다음을 수행합니다.
[pci] passthrough_whitelist = { "address": "0000:06:00.0" } alias = { "vendor_id":"144d", "product_id":"a820", "device_type":"type-PCI", "name":"nvme" }통과하려는 NVMe 장치의 필요한
주소,vendor_id,product_id값을 검색하려면 다음을 실행합니다.# lspci -nn | grep devicename
-
계산 노드에서
nova-compute를 다시 시작합니다. - NVMe를 사용하고 etcd 노드를 시작하도록 실행 중인 OpenStack 버전을 구성합니다.
3.4. Tuned 프로필을 사용하여 호스트 스케일링
tuned 는 RHEL(Red Hat Enterprise Linux) 및 기타 Red Hat 제품에서 기본적으로 활성화된 튜닝 프로파일 전달 메커니즘입니다. tuned 는 다양한 워크로드 성능 및 확장성 요구 사항에 맞게 운영 체제를 최적화하도록 sysctl, 전원 관리 및 커널 명령줄 옵션과 같은 Linux 설정을 사용자 지정합니다.
OpenShift Container Platform은 tuned 데몬을 활용하고 openshift,openshift-node 및 openshift-control-plane 라는 Tuned 프로필을 포함합니다. 이러한 프로필은 커널에 일반적으로 발생하는 수직 확장 제한 중 일부를 안전하게 늘리며 설치 중에 시스템에 자동으로 적용됩니다.
Tuned 프로필은 프로필 간의 상속을 지원합니다. 또한 가상 환경에서 프로필이 사용되는지 여부에 따라 상위 프로필을 선택하는 자동적인 기능을 지원합니다. openshift 프로필은 이러한 기능을 모두 사용하며 openshift-node 및 openshift-control-plane 프로필의 상위 버전입니다. OpenShift Container Platform 애플리케이션 노드와 컨트롤 플레인 노드 둘 다와 관련된 튜닝이 포함되어 있습니다. openshift-node 및 openshift-control-plane 프로필은 각각 애플리케이션 및 컨트롤 플레인 노드에 설정됩니다.
openshift 프로필이 있는 프로필 계층 구조를 상위로 사용하면 OpenShift Container Platform 시스템에 전달되는 튜닝이 베어 메탈 호스트 및 RHEL Atomic Host 노드의 경우 virtual-guest 의 throughput-performance (기본값)인 통합입니다.
시스템에서 Tuned 프로필이 활성화되어 있는지 확인하려면 다음을 실행합니다.
# tuned-adm active
출력 예
Current active profile: openshift-node
Tuned 에 대한 자세한 내용은 Red Hat Enterprise Linux 성능 튜닝 가이드를 참조하십시오.
4장. 컴퓨팅 리소스 최적화
4.1. 과다 할당
CPU 및 메모리와 같은 리소스에 필요한 클러스터의 일부에서 더 쉽게 액세스할 수 있도록 오버 커밋 절차를 사용할 수 있습니다.
하이퍼바이저와 Kubernetes 간의 스케줄링 충돌로 인해 가중적인 클러스터 동작을 방지하려면 하이퍼바이저 수준에서 오버 커밋하지 마십시오.
오버 커밋할 때 다른 애플리케이션이 필요할 때 필요한 리소스에 액세스할 수 없는 위험이 있으므로 성능이 저하됩니다. 그러나, 이는 밀도 증가 및 비용 절감을 위해 허용되는 절충일 수 있습니다. 예를 들어 개발, 품질 보장(QA) 또는 테스트 환경은 오버 커밋될 수 있는 반면, 프로덕션은 그렇지 않을 수 있습니다.
OpenShift Container Platform은 컴퓨팅 리소스 모델 및 할당량 시스템을 통해 리소스 관리를 구현합니다. OpenShift 리소스 모델에 대한 자세한 내용은 설명서를 참조하십시오.
오버 커밋에 대한 자세한 내용과 전략은 클러스터 관리 가이드의 Overcommiting 설명서를 참조하십시오.
4.2. 이미지 고려 사항
4.2.1. 사전 배포된 이미지를 사용하여 성능 향상
여러 작업이 내장된 기본 OpenShift Container Platform 이미지를 생성하여 효율성을 향상시키고, 모든 노드 호스트에서 구성 일관성을 유지하며, 반복적인 작업을 줄일 수 있습니다. 이를 사전 배포된 이미지라고 합니다.
예를 들어 포드를 실행하기 위해 모든 노드에 ose-pod 이미지가 필요하기 때문에 각 노드는 최신 이미지를 가져오기 위해 주기적으로 컨테이너 이미지 레지스트리에 연결해야 합니다. 동시에 100개의 노드를 시도하는 경우 문제가 발생할 수 있으며 이미지 레지스트리에서 리소스 경합, 네트워크 대역폭 낭비, Pod 시작 시간이 증가할 수 있습니다.
사전 배포된 이미지를 빌드하려면 다음을 수행합니다.
- 필요한 유형 및 크기의 인스턴스를 만듭니다.
- 컨테이너의 영구 볼륨과 별도로 CRI-O 또는 Docker 로컬 이미지 또는 컨테이너 스토리지에 전용 스토리지 장치를 사용할 수 있는지 확인합니다.
- 시스템을 완전히 업데이트하고 CRI-O 또는 Docker가 설치되어 있는지 확인합니다.
- 호스트에서 모든 yum 리포지토리에 액세스할 수 있는지 확인합니다.
- 씬 프로비저닝된 LVM 스토리지를 설정합니다.
- 사전 배포된 이미지에 일반적으로 사용되는 이미지(예: rhel7 기본 이미지) 및 OpenShift Container Platform 인프라 컨테이너 이미지(ose-pod,ose-deployer 등)를 사전 조립했습니다.
OpenStack 또는 AWS 에서 실행할 수 있는 것과 같은 적절한 클러스터 구성 및 기타 클러스터 구성에 대해 사전 배포된 이미지가 구성되었는지 확인합니다.
4.2.2. 이미지 사전 가져오기
이미지를 효율적으로 생성하기 위해 필요한 컨테이너 이미지를 모든 노드 호스트에 사전 가져올 수 있습니다. 즉, 이미지를 처음 가져올 필요가 없으므로 특히 S2I, 메트릭 및 로깅과 같은 이미지의 경우 시간과 성능을 절약할 수 있습니다.
이는 보안상의 이유로 레지스트리에 액세스할 수 없는 머신에도 유용합니다.
또는 지정된 레지스트리의 기본값 대신 로컬 이미지를 사용할 수도 있습니다. 이 작업을 수행하려면 다음을 수행합니다.
-
Pod 구성의
imagePullPolicy매개변수를IfNotPresent또는Never로 설정하여 로컬 이미지에서 가져옵니다. - 클러스터의 모든 노드가 로컬에 저장된 동일한 이미지가 있는지 확인합니다.
노드 구성을 제어할 수 있는 경우 로컬 레지스트리에서 가져오기가 적합합니다. 그러나 GCE와 같이 노드를 자동으로 교체하지 않는 클라우드 공급자에서는 안정적으로 작동하지 않습니다. Google Container Engine (GKE)에서 실행중인 경우 Google Container Registry 인증 정보가 있는 각 노드에 .dockercfg 파일이 이미 있습니다.
4.3. RHEL 툴 컨테이너 이미지를 사용하여 디버깅
Red Hat은 확장 또는 성능 문제를 디버깅하는 데 도움이 되는 rhel-tools 컨테이너 이미지 패키징 툴을 배포합니다. 이 컨테이너 이미지:
- 기본 배포 및 이 지원 컨테이너로 패키지를 이동하여 최소한의 설치 공간 컨테이너 호스트를 배포할 수 있습니다.
- 변경 불가능한 패키지 트리가 있는 Red Hat Enterprise Linux 7 Atomic Host에 대한 디버깅 기능을 제공합니다. RHEL-tools 에는 tcpdump, sosreport, git, gdb, perf 및 더 일반적인 시스템 관리 유틸리티와 같은 유틸리티가 포함되어 있습니다.
다음과 같이 rhel-tools 컨테이너를 사용합니다.
# atomic run rhel7/rhel-tools
자세한 내용은 RHEL Tools 컨테이너 설명서 를 참조하십시오.
4.4. Ansible 기반 상태 검사를 사용하여 디버깅
OpenShift Container Platform 클러스터를 설치하고 관리하는 데 사용되는 Ansible 기반 툴링 을 통해 추가 진단 상태 점검을 사용할 수 있습니다. 현재 OpenShift Container Platform 설치에 대한 일반적인 배포 문제를 보고할 수 있습니다.
이러한 검사는 ansible-playbook 명령( 클러스터 설치중에 사용되는 것과 동일한 방법)을 사용하거나 컨테이너화된 openshift-ansible 버전으로 실행할 수 있습니다. ansible-playbook 방법의 경우 openshift-ansible RPM 패키지에서 검사를 제공합니다. 컨테이너화된 방법의 경우 openshift3/ose-ansible 컨테이너 이미지는 Red Hat Container Registry 를 통해 배포됩니다.
사용 가능한 상태 점검 및 사용 예시에 대한 정보는 클러스터 관리 가이드의 Ansible 기반 상태 점검을 참조하십시오.
5장. 영구 스토리지 최적화
5.1. 개요
스토리지를 최적화하면 모든 리소스에서 스토리지 사용을 최소화할 수 있습니다. 관리자는 스토리지를 최적화하여 기존 스토리지 리소스가 효율적으로 작동하도록 합니다.
이 가이드에서는 주로 영구 스토리지 최적화에 중점을 두고 있습니다. Pod 수 수명 동안 사용되는 데이터용 로컬 임시 스토리지는 더 적은 옵션을 제공합니다. 임시 스토리지 기술 프리뷰를 활성화한 경우에만 임시 스토리지를 사용할 수 있습니다. 이 기능은 기본적으로 비활성화되어 있습니다. 자세한 내용은 임시 스토리지 구성을 참조하십시오.
5.2. 일반 스토리지 지침
다음 표에는 OpenShift Container Platform에서 사용 가능한 영구 스토리지 기술이 나열되어 있습니다.
표 5.1. 사용 가능한 스토리지 옵션
| 스토리지 유형 | 설명 | 예 |
|---|---|---|
| 블록 |
| 통합 모드/독립 모드 GlusterFS [1], iSCSI, Fibre Channel, Ceph RBD, OpenStack Cinder, AWS EBS [1], Dell/EMC Scale.IO, VMware vSphere Volume, GCE Persistent Disk [1], Azure Disk |
| 파일 |
| 통합 모드/독립 모드 GlusterFS [1], RHEL NFS, NetApp NFS [2], Azure File, 벤더 NFS, 벤더 GlusterFS [3], Azure File, AWS EFS |
| 개체 |
| 통합 모드/독립 모드 GlusterFS [1], Ceph Object Storage(RADOS Gateway), OpenStack Swift, Aliyun OSS, AWS S3, Google Cloud Storage, Azure Blob Storage, Vendor S3 [3], Vendor Swift [3] |
- 통합 모드/독립 모드 GlusterFS, Ceph RBD, OpenStack Cinder, AWS EBS, Azure Disk, GCE 영구 디스크 및 VMware vSphere는 OpenShift Container Platform에서 기본적으로 동적 PV(영구 볼륨) 프로비저닝을 지원합니다.
- NetApp NFS는 Trident 플러그인을 사용하는 경우 동적 PV 프로비저닝을 지원합니다.
- 벤더 GlusterFS, Vendor S3 및 Vendor Swift 지원 및 구성 가능성은 다를 수 있습니다.
OpenShift Container Platform 레지스트리, 로깅 및 모니터링을 위해 블록, 파일 및 개체 스토리지에 대해 통합 모드 GlusterFS(동일한 호스팅 스토리지 솔루션) 또는 독립 모드 GlusterFS(외부 호스팅 스토리지 솔루션)를 사용할 수 있습니다.
5.3. 스토리지 권장 사항
다음 표에는 지정된 OpenShift Container Platform 클러스터 애플리케이션에 권장되는 구성 가능한 스토리지 기술이 요약되어 있습니다.
표 5.2. 권장되는 구성 가능한 스토리지 기술
| 스토리지 유형 | RWO [1] | ROX [2] | RWX [3] | Registry | 확장 레지스트리 | 모니터링 | 로깅 | 앱 |
|---|---|---|---|---|---|---|---|---|
| 블록 | 있음 | 예 [4] | 없음 | 구성 가능 | 구성 불가능 | 권장 | 권장 | 권장 |
| 파일 | 있음 | 예 [4] | 있음 | 구성 가능 | 구성 가능 | 구성 가능 [5] | 구성 가능 [7] | 권장 |
| 개체 | 예 | 예 | 예 | 권장 | 권장 | 구성 불가능 | 구성 불가능 | 구성 불가능 [7] |
- ReadWriteOnce
- ReadOnlyMany
- ReadWriteMany
- 물리적 디스크, VM 물리적 디스크, VMDK, NFS를 통한 루프백, AWS EBS, Azure Disk 및 Cinder(블록용 후자)에는 적용되지 않습니다.
- 모니터링 구성 요소의 경우 RWX(ReadWriteMany) 액세스 모드에서 파일 스토리지를 사용할 수 없습니다. 파일 스토리지를 사용하는 경우 모니터링에 사용하도록 구성된 PVC(영구 볼륨 클레임)에서 RWX 액세스 모드를 구성하지 마십시오.
- 로깅의 경우 공유 스토리지 사용은 안티 패턴입니다. 로깅당 하나의 볼륨이 필요합니다.
- OpenShift Container Platform의 PV 또는 PVC를 통해서는 오브젝트 스토리지가 사용되지 않습니다. 앱은 오브젝트 스토리지 REST API와 통합해야 합니다.
확장된 레지스트리는 세 개 이상의 Pod 복제본이 실행되는 OpenShift Container Platform 레지스트리입니다.
5.3.1. 특정 애플리케이션 스토리지 권장 사항
테스트 결과, RHEL NFS 서버를 컨테이너 이미지 레지스트리의 스토리지 백엔드로 사용하는 데 문제가 있는 것으로 표시됩니다. 여기에는 OpenShift Container Registry 및 Quay, 지표 스토리지를 위한 Prometheus, 로깅 스토리지를 위한 ElasticSearch가 포함됩니다. 따라서 RHEL NFS 서버를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
5.3.1.1. Registry
비확장/HA(고가용성) OpenShift Container Platform 레지스트리 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 오브젝트 스토리지, 블록 스토리지 순입니다. 스토리지 기술에서 RWX 액세스 모드를 지원할 필요가 없습니다.
- 스토리지 기술에서 쓰기 후 읽기 일관성을 보장해야 합니다. 모든 NAS 스토리지(오브젝트 스토리지 인터페이스를 사용하므로 통합 모드/독립형 모드 GlusterFS 제외)는 프로덕션 워크로드가 있는 OpenShift Container Platform 레지스트리 클러스터 배포에는 권장되지 않습니다.
-
scaled/HA OpenShift Container Platform Registry에 대해
hostPath볼륨을 구성할 수 있지만 클러스터 배포에는 권장되지 않습니다.
5.3.1.2. 확장 레지스트리
확장/HA OpenShift Container Platform 레지스트리 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 오브젝트 스토리지입니다. 스토리지 기술에서 RWX 액세스 모드를 지원해야 하며 쓰기 후 읽기 일관성을 보장해야 합니다.
- 프로덕션 워크로드가 있는 확장/HA OpenShift Container Platform 레지스트리 클러스터 배포에는 파일 스토리지 및 블록 스토리지를 사용하지 않는 것이 좋습니다.
- 모든 NAS 스토리지(오브젝트 스토리지 인터페이스를 사용하므로 통합 모드/독립형 모드 GlusterFS 제외)는 프로덕션 워크로드가 있는 OpenShift Container Platform 레지스트리 클러스터 배포에는 권장되지 않습니다.
5.3.1.3. 모니터링
OpenShift Container Platform 호스팅 모니터링 클러스터 배포에서는 다음을 수행합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 파일 스토리지를 구성하려는 경우 POSIX 표준을 따르는지 확인하십시오.
테스트 결과 NFS를 사용하여 복구할 수 없는 심각한 손상이 표시되어 있으므로 사용하지 않는 것이 좋습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
5.3.1.4. 로깅
OpenShift Container Platform 호스트 로깅 클러스터 배포에서는 다음 사항에 유의합니다.
- 기본 스토리지 기술은 블록 스토리지입니다.
- 프로덕션 워크로드가 있는 호스트 지표 클러스터 배포에 NAS 스토리지(마지드 모드/독립 모드 GlusterFS 제외)를 사용하는 것은 iSCSI의 블록 스토리지 인터페이스를 사용하므로 사용하지 않는 것이 좋습니다.
테스트 결과 RHEL의 NFS 서버를 컨테이너 이미지 레지스트리의 스토리지 백엔드로 사용하는 데 문제가 있는 것으로 표시됩니다. 여기에는 로깅 스토리지를 위한 ElasticSearch가 포함됩니다. 따라서 NFS를 사용하여 핵심 서비스에서 사용하는 PV를 백업하는 것은 권장되지 않습니다.
마켓플레이스의 다른 NFS 구현에는 이러한 문제가 나타나지 않을 수 있습니다. 이러한 OpenShift 핵심 구성 요소에 대해 완료된 테스트에 대한 자세한 내용은 개별 NFS 구현 공급업체에 문의하십시오.
5.3.1.5. 애플리케이션
애플리케이션 사용 사례는 다음 예에 설명된 대로 애플리케이션마다 다릅니다.
- 동적 PV 프로비저닝을 지원하는 스토리지 기술은 마운트 대기 시간이 짧고 정상 클러스터를 지원하는 노드와 관련이 없습니다.
- 애플리케이션 개발자는 애플리케이션의 스토리지 요구사항을 잘 알고 있으며 제공된 스토리지로 애플리케이션을 작동시켜 애플리케이션이 스토리지 계층을 스케일링하거나 스토리지 계층과 상호 작용할 때 문제가 발생하지 않도록 하는 방법을 이해하고 있어야 합니다.
5.3.2. 다른 특정 애플리케이션 스토리지 권장 사항
- OpenShift Container Platform 내부 etcd: etcd 안정성을 최대화하려면 대기 시간 스토리지 기술이 가장 짧습니다.
- 데이터베이스: 데이터베이스(RDBMS, NoSQL DB 등)는 전용 블록 스토리지를 사용하는 경우 성능이 최대화되는 경향이 있습니다.
5.4. 그래프 드라이버 선택
컨테이너 런타임은 이미지와 컨테이너를 그래프 드라이버(예: DeviceMapper 및 OverlayFS)에 저장합니다. 각각에는 장단점이 있습니다.
지원 가능성 및 사용 경고 등 OverlayFS에 대한 자세한 내용은 해당 버전의 Red Hat Enterprise Linux (RHEL) 7 릴리스 노트 를 참조하십시오.
표 5.3. 그래프 드라이버 비교
| 이름 | 설명 | 혜택 | 제한 사항 |
|---|---|---|---|
| OverlayFS
| 하위 시스템(parent)과 상위(parent) 파일 시스템과 작업 디렉터리(하위 시스템과 동일한 파일 시스템)를 결합합니다. 하위 파일 시스템은 기본 이미지이며 새 컨테이너를 만들 때 델타가 포함된 새로운 상위 파일 시스템이 생성됩니다. |
| POSIX 호환이 아닙니다. |
| 장치 매퍼 씬 프로비저닝 | LVM, 장치 매퍼 및 dm-thinp 커널 모듈을 사용합니다. 루프백 장치를 제거하는 것과는 다릅니다. 원시 파티션(파일 시스템 없음)과 간단히 대화합니다. |
|
|
| 장치 Mapper loop-lvm | 장치 매퍼 씬 프로비저닝 모듈(dm-thin-pool)을 사용하여 CoW(Copy-On-Write) 스냅샷을 구현합니다. 각 장치 매퍼 그래프 위치에 대해 각각 두 개의 블록 장치를 기반으로 하는 씬 풀이 생성됩니다. 하나는 데이터용이고 하나는 메타데이터용입니다. 기본적으로 이러한 블록 장치는 자동으로 생성된 스파스 파일의 루프백 마운트를 사용하여 자동으로 생성됩니다. | 이는 상자 밖으로 작동하므로 프로토타이핑 및 개발 목적에 유용합니다. |
|
성능 향상을 위해 Red Hat은 장치 매퍼를 통해 overlayFS 스토리지 드라이버를 사용하는 것이 좋습니다. 그러나 프로덕션 환경에서 이미 Device Mapper를 사용하는 경우 컨테이너 이미지 및 컨테이너 루트 파일 시스템에 씬 프로비저닝을 사용하는 것이 좋습니다. 그러지 않으면 항상 CRI-O에 Docker 엔진 또는 overlayFS에 overlayfs2를 사용합니다.
루프 장치를 사용하면 성능에 영향을 줄 수 있습니다. 계속 사용할 수 있지만 다음 경고 메시지가 기록됩니다.
devmapper: Usage of loopback devices is strongly discouraged for production use. Please use `--storage-opt dm.thinpooldev` or use `man docker` to refer to dm.thinpooldev section.
간편한 스토리지 설정을 위해 docker-storage-setup 유틸리티를 사용하면 많은 설정 세부 정보를 자동화할 수 있습니다.
Overlay의 경우
/etc/sysconfig/docker-storage-setup 파일을 편집하여 장치 드라이버를 지정합니다.
STORAGE_DRIVER=overlay2
참고CRI-O를 사용하는 경우
STORAGE_DRIVER=overlay를 지정합니다.CRI-O에서는 기본
오버레이스토리지 드라이버에서overlay2최적화를 사용합니다.OverlayFS를 사용하면 다른 논리 볼륨에
imagefs가 필요한 경우CONTAINER_ROOT_LV_NAME및CONTAINER _ROOT_LV_MOUNT_PATH를 설정해야 합니다.CONTAINER_ROOT_LV_MOUNT_PATH를 설정하려면CONTAINER_ROOT_LV_NAME을 설정해야 합니다. 예를 들어CONTAINER_ROOT_LV_NAME="container-root-lv". 자세한 내용은 Overlay Graph 드라이버 사용을 참조하십시오.docker 스토리지(예: /dev/xvdb) 전용 디스크 드라이브가 있는 경우 /etc/sysconfig/docker-storage-setup 파일에 다음을 추가합니다.
DEVS=/dev/xvdb VG=docker_vg
docker-storage-setup서비스를 다시 시작하십시오.# systemctl restart docker-storage-setup
docker가 overlay2를 사용하고 있고 디스크 공간 사용을 모니터링하려면
docker info명령을 실행합니다.# docker info | egrep -i 'storage|pool|space|filesystem'
출력 예
Storage Driver: overlay2 1 Backing Filesystem: extfs- 1
overlay2를 사용할 때docker info출력.
OverlayFS는 Red Hat Enterprise Linux 7.2의 컨테이너 런타임 사용 사례에서도 지원되며, 보다 빠르게 시작 시간 및 페이지 캐시 공유를 제공하므로 전체 메모리 활용도를 줄임으로써 밀도를 향상시킬 수 있습니다.
Thinpool의 경우
/etc/sysconfig/docker-storage-setup 파일을 편집하여 장치 드라이버를 지정합니다.
STORAGE_DRIVER=devicemapper
docker 스토리지(예: /dev/xvdb) 전용 디스크 드라이브가 있는 경우 /etc/sysconfig/docker-storage-setup 파일에 다음을 추가합니다.
DEVS=/dev/xvdb VG=docker_vg
docker-storage-setup서비스를 다시 시작하십시오.# systemctl restart docker-storage-setup
다시 시작한 후
docker-storage-setup은docker_vg라는 볼륨 그룹을 설정하고 thin-pool 논리 볼륨을 생성합니다. RHEL의 씬 프로비저닝 문서는 LVM 관리자 가이드에서 확인할 수 있습니다.lsblk명령을 사용하여 새로 생성된 볼륨을 확인합니다.# lsblk /dev/xvdb
출력 예
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvdb 202:16 0 20G 0 disk └─xvdb1 202:17 0 10G 0 part ├─docker_vg-docker--pool_tmeta 253:0 0 12M 0 lvm │ └─docker_vg-docker--pool 253:2 0 6.9G 0 lvm └─docker_vg-docker--pool_tdata 253:1 0 6.9G 0 lvm └─docker_vg-docker--pool 253:2 0 6.9G 0 lvm
참고씬 프로비저닝된 볼륨은 마운트되지 않으며 파일 시스템(프로덕션 컨테이너에 XFS 파일 시스템이 있음)이 없으므로
df출력에 표시되지 않습니다.docker가 LVM thinpool을 사용하고 있는지 확인하고 디스크 공간 사용을 모니터링하려면
docker info명령을 실행합니다.# docker info | egrep -i 'storage|pool|space|filesystem'
출력 예
Storage Driver: devicemapper 1 Pool Name: docker_vg-docker--pool 2 Pool Blocksize: 524.3 kB Backing Filesystem: xfs Data Space Used: 62.39 MB Data Space Total: 6.434 GB Data Space Available: 6.372 GB Metadata Space Used: 40.96 kB Metadata Space Total: 16.78 MB Metadata Space Available: 16.74 MB
기본적으로 씬 풀은 기본 블록 장치의 40%를 사용하도록 구성됩니다. 스토리지를 사용하면 LVM에서 씬 풀을 100%까지 자동으로 확장합니다. 따라서 Data Space Total 값이 기본 LVM 장치의 전체 크기와 일치하지 않습니다.
개발 시 Red Hat 배포판의 docker는 기본적으로 루프백이 마운트된 스파스 파일로 설정됩니다. 시스템이 루프백 모드를 사용하고 있는지 확인하려면 다음을 수행합니다.
# docker info|grep loop0
출력 예
Data file: /dev/loop0
5.4.1. SELinux에서 OverlayFS 또는 DeviceMapper 사용의 이점
OverlayFS 그래프의 주요 장점은 동일한 노드에서 이미지를 공유하는 컨테이너 간에 Linux 페이지 캐시를 공유하는 것입니다. OverlayFS의 이 특성으로 인해 컨테이너를 시작하는 동안 I/O(I/O)가 감소되고(따라서 여러 100밀리초 동안 컨테이너 시작 시간이 빨라짐) 및 노드에서 유사한 이미지가 실행될 때 메모리 사용량이 감소됩니다. 이 두 가지 결과는 특히 밀도를 최적화하기위한 목표를 가진 많은 환경에서 유용하며 높은 컨테이너 량율 (예: 빌드 파업) 또는 이미지 콘텐츠에 중요한 중복을 가진 사람들이 있습니다.
씬 프로비저닝된 장치가 컨테이너별로 할당되므로 페이지 캐시 공유는 DeviceMapper에서 불가능합니다.
OverlayFS는 RHEL (Red Hat Enterprise Linux) 7.5의 기본 Docker 스토리지 드라이버이며 7.3 이상에서 지원됩니다. 성능을 향상시키기 위해 OverlayFS를 RHEL의 기본 Docker 스토리지 구성으로 설정합니다. Docker 컨테이너 런타임과 함께 사용하려면 OverlayFS 구성 지침을 참조하십시오.
5.4.2. Overlay 및 Overlay2 그래프 드라이버 비교
OverlayFS는 일종의 통합 파일 시스템입니다. 이를 통해 한 파일 시스템을 다른 파일 시스템 위에 오버레이할 수 있습니다. 변경 사항은 상위 파일 시스템에 기록되지만 하위 파일 시스템은 수정되지 않은 상태로 유지됩니다. 이를 통해 여러 사용자가 컨테이너 또는 DVD-ROM과 같은 파일 시스템 이미지를 공유할 수 있습니다. 여기서 기본 이미지는 읽기 전용 미디어에 있습니다.
OverlayFS는 단일 Linux 호스트에 두 개의 디렉터리를 계층화하고 단일 디렉터리로 제공합니다. 이러한 디렉터리를 계층이라고 하며 식별 프로세스를 통합 마운트라고 합니다.
OverlayFS는 두 개의 그래프 드라이버, 오버레이 또는 overlay 2 중 하나를 사용합니다. Red Hat Enterprise Linux 7.2부터 오버레이 는 지원되는 그래프 드라이버가 되었습니다. Red Hat Enterprise Linux 7.4부터 overlay2 가 지원됩니다. docker 데몬의 SELinux가 Red Hat Enterprise Linux 7.4에서 지원되었습니다. 지원 가능성 및 사용 경고 등 RHEL 버전 OverlayFS 사용에 대한 정보는 Red Hat Enterprise Linux 릴리스 노트 를 참조하십시오.
overlay2 드라이버는 기본적으로 최대 128개의 더 낮은 OverlayFS 레이어를 지원하지만 오버레이 드라이버는 단일 더 낮은 OverlayFS 계층에서만 작동합니다. 이 기능으로 인해 overlay2 드라이버는 docker 빌드 와 같은 계층 관련 Docker 명령에 더 나은 성능을 제공하고 백업 파일 시스템에서 더 적은 inode를 사용합니다.
오버레이 드라이버는 단일 더 낮은 OverlayFS 계층에서 작동하기 때문에 다중 계층 이미지를 여러 OverlayFS 계층으로 구현할 수 없습니다. 대신 각 이미지 계층이 /var/lib/docker/overlay 에서 자체 디렉터리로 구현됩니다. 그런 다음 하드 링크가 더 낮은 계층과 공유되는 데이터를 참조할 수 있는 공간 효율적인 방법으로 사용됩니다.
Docker 는 inode 사용 측면에서 더 효율적이므로 오버레이 드라이버가 아닌 OverlayFS와 함께 overlay2 드라이버를 사용하는 것이 좋습니다.
6장. 임시 스토리지 최적화
6.1. 개요
이 주제는 임시 스토리지 기술 프리뷰를 활성화한 경우에만 적용됩니다. 이 기능은 기본적으로 비활성화되어 있습니다. 이 기능을 활성화하려면 임시 스토리지의 구성을 참조하십시오.
기술 프리뷰 릴리스는 Red Hat 프로덕션 서비스 수준 계약(SLA)에서 지원되지 않으며 기능적으로 완전하지 않을 수 있으며 프로덕션에 사용하지 않는 것이 좋습니다. 이러한 기능을 사용하면 향후 제품 기능을 조기에 이용할 수 있어 개발 과정에서 고객이 기능을 테스트하고 피드백을 제공할 수 있습니다. 자세한 내용은 Red Hat 기술 프리뷰 기능 지원 범위를 참조하십시오.
Pod는 임시 파일 저장과 같은 내부 작업에 임시 스토리지를 사용합니다. 이러한 임시 스토리지의 수명은 개별 Pod의 수명 이상으로 연장되지 않으며 이 임시 스토리지는 여러 Pod 사이에서 공유할 수 없습니다.
OpenShift Container Platform 3.10 이전에는 임시 로컬 스토리지가 컨테이너의 쓰기 가능한 계층, 로그 디렉터리, EmptyDir 볼륨을 통해 Pod에 노출되었습니다. 로컬 스토리지 회계 및 격리 부족과 관련한 문제는 다음과 같습니다.
- Pod는 사용할 수 있는 로컬 스토리지의 용량을 알 수 없습니다.
- Pod는 보장되는 로컬 스토리지를 요청할 수 없습니다.
- 로컬 스토리지는 최상의 노력 리소스입니다.
- Pod는 로컬 스토리지를 채우는 다른 Pod로 인해 제거될 수 있으며, 그 후에는 충분한 스토리지를 회수할 때까지 새 Pod가 허용되지 않습니다.
임시 스토리지는 여전히 동일한 방식으로 Pod에 노출되지만 Pod의 임시 스토리지 사용에 대한 요청 및 제한을 구현하는 새로운 방법이 있습니다.
컨테이너 로그 관리는 CRI-O를 컨테이너 런타임으로 사용하고 로깅을 위해 파일 기반 로깅을 사용하는 경우에만 적용됩니다.
임시 스토리지는 시스템의 모든 Pod에서 공유되며 OpenShift Container Platform은 관리자 및 사용자가 설정한 요청 및 제한 이외의 모든 수준의 서비스를 보장하는 메커니즘을 제공하지 않습니다. 예를 들어, 임시 스토리지는 초당 I/O 작업 또는 스토리지 성능의 기타 측정에 대한 처리량, I/O 작업 보장을 보장하지 않습니다.
6.2. 일반 스토리지 지침
노드의 로컬 스토리지는 기본 및 보조 파티션으로 나눌 수 있습니다. 기본 파티션은 임시 로컬 스토리지에 사용할 수 있는 유일한 파티션입니다. 지원되는 두 개의 기본 파티션인 root 및 runtime이 있습니다.
루트
루트 파티션은 kubelet의 루트 디렉터리인
/var/lib/kubelet/및/var/log/디렉터리를 보유합니다. Pod, 운영 체제 및 OpenShift Container Platform 시스템 데몬 간에 이 파티션을 공유할 수 있습니다. Pod는 EmptyDir 볼륨, 컨테이너 로그, 이미지 계층, 컨테이너 쓰기 가능한 컨테이너 계층을 사용하여 이 파티션에 액세스할 수 있습니다. OpenShift Container Platform은 이 파티션의 공유 액세스 및 격리를 관리합니다.런타임
런타임 파티션은 오버레이 파일 시스템에 사용할 수 있는 선택적 파티션입니다. OpenShift Container Platform에서는 이 파티션에 대한 격리와 함께 공유 액세스를 식별하고 제공합니다. 이 파티션에는 컨테이너 이미지 계층과 쓰기 가능한 계층이 포함되어 있습니다. 런타임 파티션이 있는 경우
루트파티션은 이미지 계층 또는 쓰기 가능한 계층을 포함하지 않습니다.
7장. 네트워크 최적화
7.1. 네트워크 성능 최적화
OpenShift SDN 은 OpenvSwitch, VXLAN(가상 확장 가능 LAN) 터널, OpenFlow 규칙 및 iptables를 사용합니다. 이 네트워크는 점보 프레임, NIC(네트워크 인터페이스 카드) 오프로드, 멀티 큐, ethtool 설정을 사용하여 조정할 수 있습니다.
VXLAN은 VLAN에 비해 네트워크 수가 4096개에서 1600만 개 이상으로 증가하고 물리적 네트워크 전반에 걸쳐 계층 2 연결과 같은 이점을 제공합니다. 이를 통해 서비스 뒤에 있는 모든 Pod가 서로 다른 시스템에서 실행되는 경우에도 서로 통신할 수 있습니다.
VXLAN은 사용자 데이터그램 프로토콜(UDP) 패킷의 터널링된 모든 트래픽을 캡슐화합니다. 그러나 이로 인해 CPU 사용량이 증가합니다. 이러한 외부 및 내부 패킷은 전송 중에 데이터가 손상되지 않았음을 보장하기 위해 일반적인 체크섬 규칙을 따릅니다. CPU 성능에 따라 이러한 추가 처리 오버헤드는 처리량이 감소하고 기존 비 오버레이 네트워크에 비해 대기 시간이 증가할 수 있습니다.
클라우드, 가상 머신, 베어 메탈 CPU 성능은 많은 Gbps의 네트워크 처리량을 처리할 수 있습니다. 10 또는 40Gbps와 같은 높은 대역폭 링크를 사용하는 경우 성능이 저하될 수 있습니다. 이 문제는 VXLAN 기반 환경에서 알려진 문제이며 컨테이너 또는 OpenShift Container Platform에만 국한되지 않습니다. VXLAN 터널에 의존하는 네트워크는 VXLAN 구현으로 인해 비슷한 작업을 수행할 수 있습니다.
Gbps을 초과하여 푸시하려는 경우 다음을 수행할 수 있습니다.
- 네이티브 컨테이너 라우팅을 사용합니다. 이 옵션에는 라우터의 라우팅 테이블 업데이트와 같이 OpenShift SDN을 사용할 때 존재하지 않는 중요한 운영 경고가 있습니다.
- BGP (Border Gateway Protocol)와 같은 다른 라우팅 기술을 구현하는 네트워크 플러그인을 평가합니다.
- VXLAN 오프로드 가능 네트워크 어댑터를 사용합니다. VXLAN 오프로드는 패킷 체크섬 계산 및 관련 CPU 오버헤드를 시스템 CPU에서 네트워크 어댑터의 전용 하드웨어로 이동합니다. 이를 통해 Pod 및 애플리케이션에서 사용할 CPU 사이클을 확보하고 사용자는 네트워크 인프라의 전체 대역폭을 사용할 수 있습니다.
VXLAN 오프로드는 대기 시간을 단축시키지 않습니다. 그러나 대기 시간 테스트에서도 CPU 사용량이 감소합니다.
7.1.1. 네트워크에 대한 MTU 최적화
중요한 최대 전송 단위(MTU)는 NIC(네트워크 인터페이스 카드) MTU와 SDN 오버레이의 MTU입니다.
NIC MTU는 네트워크 NIC에서 지원되는 최대 값과 작거나 같아야 합니다. 처리량을 최적화하려면 가능한 가장 큰 값을 선택합니다. 짧은 대기 시간을 최적화하려면 더 낮은 값을 선택하십시오.
SDN 오버레이의 MTU는 NIC MTU보다 최소 50바이트 작아야 합니다. 이 계정은 SDN 오버레이 헤더에 대한 계정입니다. 따라서 일반 이더넷 네트워크에서 이 값을 1450으로 설정합니다. 점보 프레임 이더넷 네트워크에서 이 값을 8950으로 설정합니다.
50바이트 오버레이 헤더는 OpenShift SDN과 관련이 있습니다. 기타 SDN 솔루션에서는 이 값이 더 크거나 작아야 할 수 있습니다.
MTU를 구성하려면 적절한 노드 구성 맵 을 편집하고 다음 섹션을 수정합니다.
networkConfig: mtu: 1450 1 networkPluginName: "redhat/openshift-ovs-subnet" 2
OpenShift Container Platform SDN에 포함되는 모든 마스터 및 노드에서 MTU 크기를 변경해야 합니다. 또한 tun0 인터페이스의 MTU 크기는 클러스터에 속하는 모든 노드에서 같아야 합니다.
7.2. 네트워크 서브넷 구성
OpenShift Container Platform은 Pod 및 서비스 모두에 IP 주소 관리를 제공합니다. 기본값을 사용하면 다음을 수행할 수 있습니다.
- 노드의 최대 클러스터 크기 1024개
- /23이 할당된 각 1024 노드(포드에서 사용 가능한 IP 510 사용 가능)
- 서비스용 약 65,536개의 IP 주소
대부분의 경우 배포 후에는 이러한 네트워크를 변경할 수 없습니다. 따라서 성장을 위해 미리 계획하는 것이 중요합니다.
네트워크 크기 조정에 대한 제한은 SDN 설명서의 문서에 설명되어 있습니다.
더 큰 환경을 계획하려면 Ansible 인벤토리 파일의 [OSE3:vars] 섹션에 추가하는 것이 좋습니다.
[OSE3:vars] osm_cluster_network_cidr=10.128.0.0/10
이렇게 하면 각각 510개의 사용 가능한 IP 주소가 있는 8192 개의 노드가 허용됩니다.
설치 중인 소프트웨어 버전에 대한 노드/포드 제한에 대한 OpenShift Container Platform 설명서의 지원 가능성을 참조하십시오.
7.3. IPSec 최적화
노드 호스트의 암호화 및 암호 해독은 CPU를 사용하기 때문에 사용 중인 IP 보안 시스템에 관계없이 암호화를 사용할 때 노드의 처리량과 CPU 사용량 모두에서 성능에 영향을 미칩니다.
IPsec은 NIC에 도달하기 전에 IP 페이로드 수준에서 트래픽을 암호화하여 NIC 오프로드에 사용되는 필드를 보호합니다. 즉, IPSec가 활성화되면 일부 NIC 가속 기능을 사용할 수 없으며 처리량이 감소하고 CPU 사용량이 증가합니다.
8장. 라우팅 최적화
8.1. OpenShift Container Platform HAProxy 라우터 스케일링
8.1.1. 기본 성능
OpenShift Container Platform 라우터 는 OpenShift Container Platform 서비스를 대상으로 하는 모든 외부 트래픽의 수신 지점입니다.
초당 처리된 HTTP 요청 측면에서 단일 HAProxy 라우터 성능을 평가할 때 성능은 여러 요인에 따라 달라집니다. 특히 중요한 요인은 다음과 같습니다.
- HTTP 연결 유지/닫기 모드
- 경로 유형
- TLS 세션 재개 클라이언트 지원
- 대상 경로당 동시 연결 수
- 대상 경로 수
- 백엔드 서버 페이지 크기
- 기본 인프라(네트워크/SDN 솔루션, CPU 등)
특정 환경의 성능은 다를 수 있지만, 랩 테스트는 크기가 4 vCPU/16GB RAM인 퍼블릭 클라우드 인스턴스에 대한 테스트로, 1kB 정적 페이지를 제공하는 백엔드에 의해 종료된 단일 HAProxy 라우터 처리 100개의 경로를 통해 초당 다음과 같은 수의 트랜잭션을 처리할 수 있습니다.
HTTP 연결 유지 모드 시나리오에서는 다음과 같습니다.
| 암호화 | ROUTER_THREADS 설정되지 않음 | ROUTER_THREADS=4 |
|---|---|---|
| none | 23681 | 24327 |
| edge | 14981 | 22768 |
| passthrough | 34358 | 34331 |
| re-encrypt | 13288 | 24605 |
HTTP 닫기(연결 유지 제외) 시나리오에서는 다음과 같습니다.
| 암호화 | ROUTER_THREADS 설정되지 않음 | ROUTER_THREADS=4 |
|---|---|---|
| none | 3245 | 4527 |
| edge | 1910 | 3043 |
| passthrough | 3408 | 3922 |
| re-encrypt | 1333 | 2239 |
암호화된 경로에는 TLS 세션 재개가 사용되었습니다. HTTP 연결 유지 기능을 사용하면 단일 HAProxy 라우터가 8kB의 작은 페이지 크기에서 1Gbit NIC를 수용할 수 있습니다.
최신 프로세서가 있는 베어 메탈에서 실행하는 경우 성능이 위 퍼블릭 클라우드 인스턴스의 약 2배가 될 것을 예상할 수 있습니다. 이 오버헤드는 퍼블릭 클라우드에서 가상화 계층에 의해 도입되며 프라이빗 클라우드 기반 가상화에도 적용됩니다. 다음 표는 라우터 뒤에서 사용할 애플리케이션 수에 대한 가이드입니다.
| 애플리케이션 수 | 애플리케이션 유형 |
|---|---|
| 5-10 | 정적 파일/웹 서버 또는 캐싱 프록시 |
| 100-1000 | 동적 콘텐츠를 생성하는 애플리케이션 |
일반적으로 HAProxy는 사용 중인 기술에 따라 5~1,000개의 애플리케이션 경로를 지원할 수 있습니다. 라우터 성능은 언어 또는 정적 콘텐츠 대비 동적 콘텐츠 등 뒤에 있는 애플리케이션의 기능과 성능에 따라 제한될 수 있습니다.
라우터 샤딩을 사용하여 애플리케이션에 대한 더 많은 경로를 제공하고 라우팅 계층을 수평으로 확장하는 데 도움이 됩니다.
8.1.2. 성능 최적화
8.1.2.1. 최대 연결 수 설정
HAProxy 확장성에 대한 가장 중요한 조정 가능한 매개변수 중 하나는 maxconn 매개 변수로, 지정된 수로 프로세스별 최대 연결 수를 설정합니다. OpenShift Container Platform HAProxy 라우터의 배포 구성 파일에서 ROUTER_MAX_CONNECTIONS 환경 변수를 편집하여 이 매개변수를 조정합니다.
연결에는 frontend 및 내부 백엔드가 포함됩니다. 이렇게 하면 두 개의 연결로 계산됩니다. ROUTER_MAX_CONNECTIONS 를 만들려는 연결 수보다 두 배로 설정합니다.
8.1.2.2. CPU 및 Interrupt Affinity
OpenShift Container Platform에서 HAProxy 라우터는 단일 프로세스로 실행됩니다. OpenShift Container Platform HAProxy 라우터는 일반적으로 높은 빈도 코어 수가 많은 대칭 멀티 처리(SMP) 시스템이 아닌 더 적은 수의 코어가 있는 시스템에서 더 잘 작동합니다.
HAProxy 프로세스를 하나의 CPU 코어에 고정하고 네트워크 인터럽트를 다른 CPU 코어로 고정하는 것은 네트워크 성능을 향상시키는 경향이 있습니다. 동일한 NUMA(Non-Uniform Memory Access) 노드에 프로세스와 인터럽트가 있으면 공유 L3 캐시를 보장함으로써 메모리 액세스를 방지할 수 있습니다. 그러나 이러한 수준의 제어는 일반적으로 퍼블릭 클라우드 환경에서 불가능합니다. 베어 메탈 호스트에서 irqbalance 는 인터럽트 요청 라인(IRQ)에 대한 주변 구성 요소 상호 연결(PCI) 및 NUMA 선호도를 자동으로 처리합니다. 클라우드 환경에서는 일반적으로 이러한 수준의 정보가 운영 체제에 제공되지 않습니다.
CPU 고정은 taskset 또는 HAProxy의 cpu-map 매개변수를 사용하여 수행합니다. 이 지시문은 프로세스 ID와 CPU 코어 ID의 두 가지 인수를 사용합니다. 예를 들어 HAProxy 프로세스 1 을 CPU 코어 0 에 고정하려면 HAProxy 설정 파일의 전역 섹션에 다음 행을 추가합니다.
cpu-map 1 0
HAProxy 구성 파일을 수정하려면 사용자 지정된 HAProxy 라우터 배포를 참조하십시오.
8.1.2.3. 스레드 수 늘리기
HAProxy 라우터는 OpenShift Container Platform에서 멀티스레딩을 지원합니다. 여러 CPU 코어 시스템에서 스레드 수를 늘리면 특히 라우터에서 SSL을 종료할 때 성능이 저하될 수 있습니다.
HAProxy 라우터의 스레드 수를 지정하려면 HAProxy 스레드 및 라우터 환경 변수 사용을 참조하십시오.
8.1.2.4. Buffer Increases의 영향
OpenShift Container Platform HAProxy 라우터 요청 버퍼 구성은 애플리케이션에서 들어오는 요청 및 응답의 헤더 크기를 제한합니다. HAProxy 매개변수 tune.bufsize 는 더 큰 헤더를 처리할 수 있도록 하고, 많은 퍼블릭 클라우드 공급자가 제공하는 로드 밸런서에서 승인한 것과 같이 매우 큰 쿠키를 가진 애플리케이션이 작동할 수 있도록 할 수 있습니다. 그러나 이는 특히 많은 수의 연결이 열려 있는 경우 총 메모리 사용에 영향을 미칩니다. 열려 있는 연결이 매우 많은 경우 메모리 사용량은 이 튜닝 가능 매개 변수의 증가에 거의 비례합니다.
8.1.2.5. HAProxy 다시 로드 최적화
긴 클라이언트/서버 HAProxy 시간 제한 및 짧은 HAProxy 다시 로드 간격과 같은 WebSocket 연결로 인해 많은 HAProxy 프로세스가 인스턴스화될 수 있습니다. 이러한 프로세스는 HAProxy 구성을 다시 로드하기 전에 시작된 이전 연결을 처리해야 합니다. 시스템에서 불필요한 부하를 유발하고 메모리 부족과 같은 문제로 이어질 수 있으므로 많은 프로세스가 바람직하지 않습니다.
이 동작에 영향을 주는 라우터 환경 변수는 ROUTER_DEFAULT_TUNNEL_TIMEOUT,ROUTER_DEFAULT_CLIENT_TIMEOUT,ROUTER_DEFAULT_SERVER_TIMEOUT, 특히 RELOAD_INTERVAL 입니다.
9장. 클러스터 지표 확장
9.1. 개요
OpenShift Container Platform은 EgressIP .com이 수집하여 백엔드에 저장할 수 있는 지표를 노출합니다. https://github.com/kubernetes/heapster OpenShift Container Platform 관리자는 하나의 사용자 인터페이스에서 컨테이너 및 구성 요소 지표를 볼 수 있습니다. 이러한 지표는 스케일링 시기와 방법을 결정하기 위해 수평 Pod 자동 스케일러 에서도 사용됩니다.
이 주제에서는 지표 구성 요소를 확장하는 방법에 대한 정보를 제공합니다.
Hawkular 및 ProfileBundle과 같은 지표 구성 요소는 OpenShift Container Platform에서 지원되지 않습니다.
9.2. OpenShift Container Platform 권장 사항
- 전용 OpenShift Container Platform 인프라 노드에서 메트릭 Pod를 실행합니다.
-
메트릭을 구성할 때 영구 스토리지를 사용합니다.
USE_PERSISTENT_STORAGE=true를 설정합니다. -
OpenShift Container Platform 메트릭 배포에서
METRICS_RESOLUTION=30매개변수를 유지합니다.METRICS_RESOLUTION의 경우 기본값30보다 낮은 값을 사용하는 것은 권장되지 않습니다. Ansible 지표 설치 프로세스를 사용하는 경우openshift_metrics_resolution매개 변수입니다. - 호스트 시스템에서 초기 용량 부족(CPU 및 메모리)을 탐지하기 위해 호스트 지표 Pod가 있는 OpenShift Container Platform 노드를 밀접하게 모니터링합니다. 이러한 용량 부족으로 인해 메트릭 Pod에 문제가 발생할 수 있습니다.
- OpenShift Container Platform 버전 3.7 테스트에서는 OpenShift Container Platform 클러스터에서 최대 25,000개의 Pod를 모니터링할 수 있습니다.
9.3. 클러스터 메트릭에 대한 용량 계획
210 및 990 OpenShift Container Platform 노드에서 수행되는 테스트에서 10500개의 포드와 11000개의 포드가 각각 모니터링되면 아래 표에 표시된 속도가 가장 빠르게 증가했습니다.
표 9.1. cluster의 노드/포드 수에 따른 vGPU 데이터베이스 스토리지 요구 사항
| 노드 수 | Pod 수 | rhcos Storage의 증가 속도 | day마다 storage growth per day | pool마다 storage growth per week |
|---|---|---|---|---|
| 210 | 10500 | 시간당 500MB | 15GB | 75GB |
| 990 | 11000 | 시간당 1GB | 30GB | 210)GB |
위의 계산에서 스토리지 요구 사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
METRICS_DURATION 및 METRICS_RESOLUTION 값이 기본값인7 일과 15 초 동안 유지되는 경우 위의 값과 같이 주당 FeatureGate 스토리지 크기 요구 사항을 계획하는 것이 안전합니다.
OpenShift Container Platform 지표는 ProfileBundle 데이터베이스를 지표 데이터에 대한 데이터 저장소로 사용하므로, USE_PERSISTENT_STORAGE=true 가 메트릭 설정 프로세스 중에 설정된 경우 PV 는 네트워크 스토리지의 상단에 있으며 NFS를 기본값으로 사용합니다. 그러나 journalctl과 함께 네트워크 스토리지를 사용하는 것은 권장되지 않습니다.
rootpd 데이터베이스를 지표 데이터의 데이터 저장소로 사용하는 경우 해당 권장 사항에 대한 rhcos 설명서를 참조하십시오.
9.4. OpenShift Container Platform 지표 포드 스케일링
지표 Pod 세트(Cassandra/Hawkular/Heapster)는 최소 25,000개의 Pod를 모니터링할 수 있습니다.
OpenShift Container Platform 메트릭 Pod가 실행되는 노드에 시스템 로드를 주의하십시오. 해당 정보를 사용하여 여러 OpenShift Container Platform 메트릭 Pod를 확장하고 여러 OpenShift Container Platform 노드에 부하를 분산해야 하는지 확인합니다. OpenShift Container Platform 지표 힙 관리자 Pod 스케일링은 권장되지 않습니다.
9.4.1. 사전 요구 사항
OpenShift Container Platform 메트릭을 배포하는 데 영구 스토리지를 사용하는 경우 OpenShift Container Platform 지표 ProfileBundle Pod 수를 확장하기 전에 새 EgressIP Pod에 사용할 영구 볼륨(PV)을 생성해야 합니다. 그러나 journalctl이 동적으로 프로비저닝된 PV와 함께 배포된 경우 이 단계는 필요하지 않습니다.
9.4.2. FeatureGate 구성 요소 확장
rhcos 노드는 영구 스토리지를 사용합니다. 따라서 복제 컨트롤러에서 확장 또는 축소할 수 없습니다.
pxe 클러스터를 스케일링하려면 openshift_metrics_cassandra_replicas 변수를 수정하고 배포를 다시 실행해야 합니다. 기본적으로 ProfileBundle 클러스터는 단일 노드 클러스터입니다.
OpenShift Container Platform 지표의 수를 두 개의 복제본으로 축소하려면 다음을 실행합니다.
# oc scale -n openshift-infra --replicas=2 rc hawkular-metrics
또는 인벤토리 파일을 업데이트하고 배포를 다시 실행합니다.
sysfs 클러스터에서 새 노드를 추가하거나 기존 노드를 제거하는 경우 클러스터에 저장된 데이터가 클러스터 전체에서 리밸런스됩니다.
축소하려면 다음을 수행합니다.
컨테이너에 원격으로 액세스하는 경우 삭제하려는 EgressIP 노드에 대해 다음을 실행합니다.
$ oc exec -it <hawkular-cassandra-pod> nodetool decommission
컨테이너에 로컬로 액세스하는 경우 다음을 실행합니다.
$ oc rsh <hawkular-cassandra-pod> nodetool decommission
이 명령은 클러스터 전체에서 데이터를 복사하므로 실행하는 데 시간이 걸릴 수 있습니다.
nodetool netstats -H를 사용하여 해제 진행 상황을 모니터링할 수 있습니다.이전 명령이 성공하면 rhcos 인스턴스의
rc를0으로 축소합니다.# oc scale -n openshift-infra --replicas=0 rc <hawkular-cassandra-rc>
그러면 ProfileBundle 포드가 제거됩니다.
축소 프로세스가 완료되고 기존 KnativeServing 노드가 예상대로 작동하는 경우, 이 rhcos 인스턴스의 rc 와 해당 PVC(영구 볼륨 클레임)도 삭제할 수 있습니다. PVC를 삭제하면 이 vGPU 인스턴스와 연결된 모든 데이터를 영구적으로 삭제할 수 있으므로 축소가 완전히 완료되지 않으면 손실된 데이터를 복구할 수 없습니다.
10장. Cluster Monitoring Operator 스케일링
10.1. 개요
OpenShift Container Platform에서는 cluster-monitoring-operator 에서 백엔드에 수집하고 저장할 수 있는 지표를 노출합니다. OpenShift Container Platform 관리자는 하나의 대시보드 인터페이스인 Grafana에서 시스템 리소스, 컨테이너 및 구성 요소 지표를 볼 수 있습니다.
이 주제에서는 클러스터 모니터링 Operator 확장에 대한 정보를 제공합니다.
영구 스토리지와 함께 Prometheus를 사용하려면 Ansible 인벤토리 파일의 openshift_cluster_monitoring_operator_prometheus_storage_enabled 변수를 true 로 설정해야 합니다.
10.2. OpenShift Container Platform 권장 사항
- 인프라 노드를 3개 이상 사용하십시오.
- NVMe(Non-volatile memory express) 드라이브가 있는 openshift-container-storage 노드를 3개 이상 사용하십시오.
- OpenShift Container Storage(OCS) 블록과 같은 영구 블록 스토리지를 사용합니다.
10.3. Cluster Monitoring Operator의 용량 플래닝
다양한 스케일링 크기에 대해 다양한 테스트가 수행되었습니다. 아래 표에 반영된 Prometheus 데이터베이스 증가.
아래 Prometheus 스토리지 요구 사항은 규정되어 있지 않습니다. 워크로드 활동 및 리소스 사용량에 따라 클러스터에서 리소스 사용량이 높아질 수 있습니다.
표 10.1. 클러스터의 노드/Pod 수에 따른 Prometheus 데이터베이스 스토리지 요구사항
| 노드 수 | Pod 수 | Prometheus 스토리지 증가(1일당) | Prometheus 스토리지 증가(15일당) | RAM 공간(스케일링 크기당) | 네트워크(tsdb 청크당) |
|---|---|---|---|---|---|
| 50 | 1800 | 6.3GB | 94GB | 6GB | 16MB |
| 100 | 3600 | 13GB | 195GB | 10GB | 26MB |
| 150 | 5400 | 19GB | 283GB | 12GB | 36MB |
| 200 | 7200 | 25GB | 375GB | 14GB | 46MB |
위의 계산에서 스토리지 요구 사항이 계산된 값을 초과하지 않도록 예상 크기의 약 20%가 오버헤드로 추가되었습니다.
위의 계산은 기본 OpenShift Container Platform cluster-monitoring-operator 를 위해 개발되었습니다. 더 높은 규모의 경우 Ansible 인벤토리 파일에서 openshift_cluster_monitoring_operator_prometheus_storage_capacity 변수를 편집합니다. 기본값은 50Gi 입니다.
CPU 사용률은 약간의 영향을 미칩니다. 50개 노드 및 1,800개 Pod당 비율이 약 40개 중 1개 코어입니다.
10.3.1. 랩 환경
모든 실험은 OpenStack 환경의 OpenShift Container Platform에서 수행되었습니다.
- 인프라 노드(VM) - 40개 코어, 157GB RAM
- CNS 노드(VM) - 16개 코어, 62GB RAM, NVMe 드라이브
10.3.2. 사전 요구 사항
스케일링 대상에 따라 Prometheus 데이터 저장소에 대한 관련 PV 크기를 계산하고 설정합니다. 기본 Prometheus Pod 복제본은 2개이므로 Pod가 3600개인 노드의 경우 188GB가 필요합니다.
예를 들면 다음과 같습니다.
195 GB (space per 15 days ) * 2 (pods) = 390 GB free
이 식을 기반으로 openshift_cluster_monitoring_operator_prometheus_storage_capacity=195Gi 를 설정합니다.
11장. 클러스터당 테스트된 최대값
OpenShift Container Platform 클러스터를 계획할 때 다음과 같은 테스트된 클러스터 오브젝트 최대값을 고려하십시오.
이러한 지침은 가능한 가장 큰 클러스터를 기반으로 합니다. 크기가 작은 클러스터의 경우 최대값은 비례적으로 낮습니다. etcd 버전 또는 스토리지 데이터 형식을 비롯하여 명시된 임계값에 영향을 주는 요인은 여러 가지가 있습니다.
대부분의 경우 이러한 수치를 초과하면 전체 성능이 저하됩니다. 반드시 클러스터가 실패하는 것은 아닙니다.
OpenShift Container Platform 3.x를 위한 테스트된 클라우드 플랫폼: Red Hat OpenStack, Amazon Web Services 및 Microsoft Azure.
11.1. OpenShift Container Platform 테스트 클러스터 최대 주요 릴리스
| 최대 유형 | 3.x 테스트된 최대값 |
|---|---|
| 노드 수 | 2,000 |
| Pod 수 [1] | 150,000 |
| 250 | |
| 기본값 없음 | |
| 네임스페이스 수 | 10,000 |
| 빌드 수: 파이프라인 전략 | 10,000(기본 Pod RAM 512Mi) |
| 네임스페이스당 Pod 수 [2] | 25,000 |
| 서비스 수 [3] | 10,000 |
| 네임스페이스당 서비스 수 | 5,000 |
| 서비스당 백엔드 수 | 5,000 |
| 네임스페이스당 배포 수 [2] | 2,000 |
- 여기에 표시된 Pod 수는 테스트 Pod 수입니다. 실제 Pod 수는 애플리케이션의 메모리, CPU 및 스토리지 요구 사항에 따라 다릅니다.
- 시스템에는 일부 상태 변경에 대한 대응으로 지정된 네임스페이스의 모든 오브젝트에 대해 반복해야 하는 컨트롤 루프가 많습니다. 단일 네임스페이스에 지정된 유형의 오브젝트가 많이 있으면 루프 비용이 많이 들고 지정된 상태 변경 처리 속도가 느려질 수 있습니다. 최대값은 애플리케이션 요구 사항을 충족하기에 충분한 CPU, 메모리 및 디스크가 시스템에 있다고 가정합니다.
- 각 서비스 포트와 각 서비스 백엔드에는 iptables에 해당 항목이 있습니다. 지정된 서비스의 백엔드 수는 끝점 오브젝트의 크기에 영향을 미치므로 시스템 전체에서 전송되는 데이터의 크기에 영향을 미칩니다.
11.2. OpenShift Container Platform 테스트 클러스터 최대값
| 최대 유형 | 3.7 테스트된 최대값 | 3.9 테스트된 최대값 | 3.10 테스트된 최대값 | 3.11 테스트된 최대값 |
|---|---|---|---|---|
| 노드 수 | 2,000 | 2,000 | 2,000 | 2,000 |
| Pod 수 [1] | 120,000 | 120,000 | 150,000 | 150,000 |
| 250 | 250 | 250 | 250 | |
| 10이 기본값입니다. | 10이 기본값입니다. | 기본값 없음 | 기본값 없음 | |
| 네임스페이스 수 | 10,000 | 10,000 | 10,000 | 10,000 |
| 빌드 수: 파이프라인 전략 | 해당 없음 | 10,000(기본 Pod RAM 512Mi) | 10,000(기본 Pod RAM 512Mi) | 10,000(기본 Pod RAM 512Mi) |
| 네임스페이스당 Pod 수 [2] | 3,000 | 3,000 | 3,000 | 25,000 |
| 서비스 수 [3] | 10,000 | 10,000 | 10,000 | 10,000 |
| 네임스페이스당 서비스 수 | 해당 없음 | 해당 없음 | 5,000 | 5,000 |
| 서비스당 백엔드 수 | 5,000 | 5,000 | 5,000 | 5,000 |
| 네임스페이스당 배포 수 [2] | 2,000 | 2,000 | 2,000 | 2,000 |
- 여기에 표시된 Pod 수는 테스트 Pod 수입니다. 실제 Pod 수는 애플리케이션의 메모리, CPU 및 스토리지 요구 사항에 따라 다릅니다.
- 시스템에는 일부 상태 변경에 대한 대응으로 지정된 네임스페이스의 모든 오브젝트에 대해 반복해야 하는 컨트롤 루프가 많습니다. 단일 네임스페이스에 지정된 유형의 오브젝트가 많이 있으면 루프 비용이 많이 들고 지정된 상태 변경 처리 속도가 느려질 수 있습니다. 최대값은 애플리케이션 요구 사항을 충족하기에 충분한 CPU, 메모리 및 디스크가 시스템에 있다고 가정합니다.
- 각 서비스 포트와 각 서비스 백엔드에는 iptables에 해당 항목이 있습니다. 지정된 서비스의 백엔드 수는 끝점 오브젝트의 크기에 영향을 미치므로 시스템 전체에서 전송되는 데이터의 크기에 영향을 미칩니다.
11.2.1. 경로 최대값
OpenShift Container Platform 3.11.53에서 라우터 테스트는 AWS(Amazon Web Services)의 3-노드 환경에서 완료되었습니다. 100개의 HTTP 경로, 특히 100개의 백엔드 Nginx pod가 있으며 keepalive 가 100 으로 설정되어 있습니다. 결과는 다음과 같습니다.
- 대상 경로당 연결 = 초당 24,327 요청
- 대상 경로당 40개의 연결 = 초당 20,729 요청
- 대상 경로당 200개 연결 = 초당 17,253 요청
11.3. OpenShift Container Platform 클러스터 최대값 테스트 환경 및 구성
Infrastructure as a Service Provider: OpenStack
| 노드 | vCPU | RAM(MiB) | 디스크 크기(GiB) | 패스쓰루(Pass-through) 디스크 | 수량 |
|---|---|---|---|---|---|
| Master/Etcd [1] | 16 | 124672 | 128 | 예, NVMe | 3 |
| 인프라 [2] | 40 | 163584 | 256 | 예, NVMe | 3 |
| 클러스터 DNS | 1 | 1740 | 71 | 없음 | 1 |
| 로드 밸런서 | 4 | 16128 | 96 | 없음 | 1 |
| Container Native Storage [3] | 16 | 65280 | 200 | 예, NVMe | 3 |
| bastion [4] | 16 | 65280 | 200 | 없음 | 1 |
| Worker | 2 | 7936 | 96 | 없음 | 2000 |
- etcd는 I/O 집약적이고 지연 시간에 민감하므로 master/etcd 노드는 NVMe 디스크에 의해 지원됩니다.
- 인프라 노드는 라우터, 레지스트리, 로깅 및 모니터링을 호스팅하고 NVMe 디스크에서 지원합니다.
- Container Native Storage 또는 Ceph 스토리지 노드는 NVMe 디스크에서 지원합니다.
- Bastion 노드는 OpenShift Container Platform 네트워크의 일부이며 성능 및 스케일링 테스트를 오케스트레이션하는 데 사용됩니다.
11.4. 클러스터 최대값에 대한 환경 평가
노드에서 물리적 리소스에 대한 서브스크립션을 초과하면 Pod를 배치하는 동안 Kubernetes 스케줄러가 보장하는 리소스에 영향을 미칩니다. 메모리 교체를 방지하기 위해 수행할 수 있는 조치를 알아보십시오.
테스트된 최대값 중 일부는 단일 차원에서만 확장되므로 클러스터에서 많은 오브젝트가 실행되는 경우 다를 수 있습니다.
이 문서에 명시된 수치는 Red Hat의 테스트 방법론, 설정, 구성, 튜닝을 기반으로 한 것입니다. 고유한 개별 설정 및 환경에 따라 수치가 달라질 수 있습니다.
환경을 계획하는 동안 노드당 적합한 Pod 수를 결정합니다.
Maximum Pods per Cluster / Expected Pods per Node = Total Number of Nodes
노드에 적합한 Pod 수는 애플리케이션 자체에 따라 다릅니다. 애플리케이션의 메모리, CPU 및 스토리지 요구 사항을 고려하십시오.
시나리오 예
클러스터당 2200개의 Pod로 클러스터 범위를 지정하려면 노드당 최대 250개의 Pod가 있다고 가정하여 최소 9개의 노드가 있어야 합니다.
2200 / 250 = 8.8
노드 수를 20으로 늘리면 Pod 배포는 노드당 110개 Pod로 변경됩니다.
2200 / 20 = 110
11.5. 애플리케이션 요구 사항에 맞게 환경 강화 계획
예에 나온 애플리케이션 환경을 고려해 보십시오.
| Pod 유형 | Pod 수량 | 최대 메모리 | CPU 코어 | 영구 스토리지 |
|---|---|---|---|---|
| apache | 100 | 500MB | 0.5 | 1GB |
| node.js | 200 | 1GB | 1 | 1GB |
| postgresql | 100 | 1GB | 2 | 10GB |
| JBoss EAP | 100 | 1GB | 1 | 1GB |
예상 요구사항은 CPU 코어 550개, RAM 450GB 및 스토리지 1.4TB입니다.
노드의 인스턴스 크기는 기본 설정에 따라 높게 또는 낮게 조정될 수 있습니다. 노드에서는 리소스 초과 커밋이 발생하는 경우가 많습니다. 이 배포 시나리오에서는 동일한 양의 리소스를 제공하는 데 더 작은 노드를 추가로 실행하도록 선택할 수도 있고 더 적은 수의 더 큰 노드를 실행하도록 선택할 수도 있습니다. 운영 민첩성 및 인스턴스당 비용과 같은 요인을 고려해야 합니다.
| 노드 유형 | 수량 | CPU | RAM(GB) |
|---|---|---|---|
| 노드(옵션 1) | 100 | 4 | 16 |
| 노드(옵션 2) | 50 | 8 | 32 |
| 노드(옵션 3) | 25 | 16 | 64 |
일부 애플리케이션은 초과 커밋된 환경에 적합하지만 일부 애플리케이션은 그렇지 않습니다. 대부분의 Java 애플리케이션과 대규모 페이지를 사용하는 애플리케이션은 초과 커밋에 적합하지 않은 애플리케이션의 예입니다. 해당 메모리는 다른 애플리케이션에 사용할 수 없습니다. 위의 예에 나온 환경에서는 초과 커밋이 약 30%이며, 이는 일반적으로 나타나는 비율입니다.
12장. Cluster Loader 사용
12.1. Cluster Loader의 기능
Cluster Loader는 많은 수의 다양한 오브젝트를 클러스터에 배포하여 사용자 정의 클러스터 오브젝트를 생성하는 툴입니다. Cluster Loader를 빌드하고, 구성하고, 실행하여 다양한 클러스터 상태에서 OpenShift Container Platform 배포의 성능 지표를 측정하십시오.
12.2. Cluster Loader 설치
Cluster Loader는 atomic-openshift-tests 패키지에 포함되어 있습니다. 설치하려면 다음을 실행합니다.
$ yum install atomic-openshift-tests
설치 후 테스트 실행 파일 extended.test 는 /usr/libexec/atomic-openshift/extended.test 에 있습니다.
12.3. Cluster Loader 실행
KUBECONFIG
변수를관리자kubeconfig의 위치로 설정합니다.$ export KUBECONFIG=${KUBECONFIG-$HOME/.kube/config}다섯 개의 템플릿 빌드를 배포하고 완료될 때까지 대기하는 내장 테스트 구성을 사용하여 Cluster Loader를 실행합니다.
$ cd /usr/libexec/atomic-openshift/
$ ./extended.test --ginkgo.focus="Load cluster"
또는
--viper-config에 대한 플래그를 추가하여 사용자 정의 구성으로 Cluster Loader를 실행합니다.$ ./extended.test --ginkgo.focus="Load cluster" --viper-config=config/test 1- 1
- 이 예에서는 config/ 라는 하위 디렉터리가 있고, test.yml 이라는 구성 파일이 있습니다. 도구에서 파일 유형과 확장자를 자동으로 결정하므로 명령줄에서 구성 파일의 확장을 제외합니다.
12.4. Cluster Loader 구성
여러 템플릿 또는 Pod가 포함된 여러 네임스페이스(프로젝트)를 생성합니다.
config/ 하위 디렉터리에서 Cluster Loader의 구성 파일을 찾습니다. 이러한 구성 예제에서 참조하는 포드 파일 및 템플릿 파일은 content/ 하위 디렉터리에 있습니다.
12.4.1. 구성 필드
표 12.1. 최상위 수준 Cluster Loader 필드
| 필드 | 설명 |
|---|---|
|
|
|
|
|
정의가 하나 이상인 하위 오브젝트입니다. |
|
|
구성당 정의가 하나인 하위 오브젝트입니다. |
|
| 구성당 정의가 하나인 선택적 하위 오브젝트입니다. 오브젝트 생성 중 동기화 가능성을 추가합니다. |
표 12.2. projects 아래 필드
| 필드 | 설명 |
|---|---|
|
| 정수입니다. 생성할 프로젝트 수에 대한 하나의 정의입니다. |
|
|
문자열입니다. 프로젝트의 기본 이름에 대한 하나의 정의입니다. 충돌을 방지하도록 동일한 네임스페이스 수가 |
|
| 문자열입니다. 오브젝트에 적용할 튜닝 세트에 대한 하나의 정의로, 이 네임스페이스 내에서 배포합니다. |
|
|
|
|
| 키-값 쌍 목록입니다. 키는 ConfigMap 이름이고 값은 ConfigMap을 생성하는 파일의 경로입니다. |
|
| 키-값 쌍 목록입니다. 키는 보안 이름이고 값은 보안을 생성하는 파일의 경로입니다. |
|
| 배포할 Pod 정의가 하나 이상인 하위 오브젝트입니다. |
|
| 배포할 템플릿 정의가 하나 이상인 하위 오브젝트입니다. |
표 12.3. pods 및 templates 아래 필드
| 필드 | 설명 |
|---|---|
|
| 이 필드는 사용되지 않습니다. |
|
| 정수입니다. 배포할 Pod 또는 템플릿 수입니다. |
|
| 문자열입니다. 컨테이너 이미지 URL을 가져올 수 있는 리포지토리에 대한 URL입니다. |
|
| 문자열입니다. 생성할 템플릿(또는 Pod)의 기본 이름에 대한 하나의 정의입니다. |
|
| 문자열입니다. 생성할 PodSpec 또는 템플릿이 있는 로컬 파일의 경로입니다. |
|
|
키-값 쌍입니다. |
표 12.4. tuningsets 아래 필드
| 필드 | 설명 |
|---|---|
|
| 문자열입니다. 프로젝트에서 튜닝을 정의할 때 지정된 이름과 일치하는 튜닝 세트의 이름입니다. |
|
|
Pod에 적용할 |
|
|
템플릿에 적용할 |
표 12.5. tuningsets pods 또는 tuningsets templates 아래 필드
| 필드 | 설명 |
|---|---|
|
| 하위 오브젝트입니다. 단계 생성 패턴으로 오브젝트를 생성하려는 경우 사용되는 스테핑 구성입니다. |
|
| 하위 오브젝트입니다. 오브젝트 생성 속도를 제한하는 속도 제한 튜닝 세트 구성입니다. |
표 12.6. tuningsets pods 또는 tuningsets templates, stepping 아래 필드
| 필드 | 설명 |
|---|---|
|
| 정수입니다. 오브젝트 생성을 정지하기 전 생성할 오브젝트 수입니다. |
|
|
정수입니다. |
|
| 정수입니다. 오브젝트 생성에 성공하지 못하는 경우 실패 전 대기하는 시간(초)입니다. |
|
| 정수입니다. 생성 요청 간에 대기하는 시간(밀리초)입니다. |
표 12.7. sync 아래 필드
| 필드 | 설명 |
|---|---|
|
|
|
|
|
부울입니다. |
|
|
부울입니다. |
|
|
|
|
|
문자열입니다. Pod가 |
12.4.2. Cluster Loader 구성 파일의 예
Cluster Loader 구성 파일은 기본 YAML 파일입니다.
provider: local 1 ClusterLoader: cleanup: true projects: - num: 1 basename: clusterloader-cakephp-mysql tuning: default ifexists: reuse templates: - num: 1 file: ./examples/quickstarts/cakephp-mysql.json - num: 1 basename: clusterloader-dancer-mysql tuning: default ifexists: reuse templates: - num: 1 file: ./examples/quickstarts/dancer-mysql.json - num: 1 basename: clusterloader-django-postgresql tuning: default ifexists: reuse templates: - num: 1 file: ./examples/quickstarts/django-postgresql.json - num: 1 basename: clusterloader-nodejs-mongodb tuning: default ifexists: reuse templates: - num: 1 file: ./examples/quickstarts/nodejs-mongodb.json - num: 1 basename: clusterloader-rails-postgresql tuning: default templates: - num: 1 file: ./examples/quickstarts/rails-postgresql.json tuningsets: 2 - name: default pods: stepping: 3 stepsize: 5 pause: 0 s rate_limit: 4 delay: 0 ms
12.5. 확인된 문제
IDENTIFIER 매개변수가 사용자 템플릿에 정의되어 있지 않으면 템플릿 생성에 실패하고 error: unknown parameter name "IDENTIFIER"가 표시됩니다. 템플릿을 배포하는 경우 다음과 같이 이 매개변수를 템플릿에 추가하여 오류를 방지하십시오.
{
"name": "IDENTIFIER",
"description": "Number to append to the name of resources",
"value": "1"
}Pod를 배포하는 경우 매개변수를 추가할 필요가 없습니다.
13장. CPU 관리자 사용
13.1. CPU 관리자가 수행하는 작업
CPU 관리자는 CPU 그룹을 관리하고 워크로드를 특정 CPU로 제한합니다.
CPU 관리자는 다음과 같은 속성 중 일부가 포함된 워크로드에 유용합니다.
- 가능한 한 많은 CPU 시간이 필요합니다.
- 프로세서 캐시 누락에 민감합니다.
- 대기 시간이 짧은 네트워크 애플리케이션입니다.
- 다른 프로세스와 조정하고 단일 프로세서 캐시 공유를 통해 얻는 이점이 있습니다.
13.2. CPU 관리자 설정
CPU 관리자를 설정하려면 다음을 수행합니다.
선택적으로 노드에 레이블을 지정합니다.
# oc label node perf-node.example.com cpumanager=true
대상 노드에서 CPU 관리자 지원을 활성화합니다.
# oc edit configmap <name> -n openshift-node
예를 들면 다음과 같습니다.
# oc edit cm node-config-compute -n openshift-node
출력 예
... kubeletArguments: ... feature-gates: - CPUManager=true cpu-manager-policy: - static cpu-manager-reconcile-period: - 5s system-reserved: 1 - cpu=500m# systemctl restart atomic-openshift-node
- 1
system-reserved는 필수 설정입니다. 환경에 따라 값을 조정해야 할 수 있습니다.
코어를 하나 이상 요청하는 Pod를 생성합니다. 제한 및 요청 둘 다 해당 CPU 값이 정수로 설정되어야 합니다. 해당 숫자는 이 Pod 전용으로 사용할 코어 수입니다.
# cat cpumanager.yaml
출력 예
apiVersion: v1 kind: Pod metadata: generateName: cpumanager- spec: containers: - name: cpumanager image: gcr.io/google_containers/pause-amd64:3.0 resources: requests: cpu: 1 memory: "1G" limits: cpu: 1 memory: "1G" nodeSelector: cpumanager: "true"Pod를 생성합니다.
# oc create -f cpumanager.yaml
레이블 지정한 노드에 Pod가 예약되어 있는지 검증합니다.
# oc describe pod cpumanager
출력 예
Name: cpumanager-4gdtn Namespace: test Node: perf-node.example.com/172.31.62.105 ... Limits: cpu: 1 memory: 1G Requests: cpu: 1 memory: 1G ... QoS Class: Guaranteed Node-Selectors: cpumanager=true region=primarycgroups가 올바르게 설정되었는지 검증합니다. pause 프로세스의 PID를 가져옵니다.# systemd-cgls -l
출력 예
├─1 /usr/lib/systemd/systemd --system --deserialize 20 ├─kubepods.slice │ ├─kubepods-pod0ec1ab8b_e1c4_11e7_bb22_027b30990a24.slice │ │ ├─docker-b24e29bc4021064057f941dc5f3538595c317d294f2c8e448b5e61a29c026d1c.scope │ │ │ └─44216 /pause
QoS 계층
Guaranteed의 Pod는kubepods.slice에 배치됩니다. 다른 QoS 계층의 Pod는kubepods의 하위cgroups에 있습니다.# cd /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-pod0ec1ab8b_e1c4_11e7_bb22_027b30990a24.slice/docker-b24e29bc4021064057f941dc5f3538595c317d294f2c8e448b5e61a29c026d1c.scope # for i in `ls cpuset.cpus tasks` ; do echo -n "$i "; cat $i ; done
출력 예
cpuset.cpus 2 tasks 44216
작업에 허용되는 CPU 목록을 확인합니다.
# grep ^Cpus_allowed_list /proc/44216/status
출력 예
Cpus_allowed_list: 2
시스템의 다른 Pod(이 경우
burstableQoS 계층의 Pod)가GuaranteedPod에 할당된 코어에서 실행할 수 없는지 확인합니다.# cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podbe76ff22_dead_11e7_b99e_027b30990a24.slice/docker-da621bea7569704fc39f84385a179923309ab9d832f6360cccbff102e73f9557.scope/cpuset.cpus 0-1,3
# oc describe node perf-node.example.com
출력 예
... Capacity: cpu: 4 memory: 16266720Ki pods: 40 Allocatable: cpu: 3500m memory: 16164320Ki pods: 40 --- Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits --------- ---- ------------ ---------- --------------- ------------- test cpumanager-4gdtn 1 (28%) 1 (28%) 1G (6%) 1G (6%) test cpumanager-hczts 1 (28%) 1 (28%) 1G (6%) 1G (6%) test cpumanager-r9wrq 1 (28%) 1 (28%) 1G (6%) 1G (6%) ... Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) CPU Requests CPU Limits Memory Requests Memory Limits ------------ ---------- --------------- ------------- 3 (85%) 3 (85%) 5437500k (32%) 9250M (55%)
이 VM에는 4개의 CPU 코어가 있습니다.
system-reserved를 500밀리코어로 설정했습니다. 즉,Node Allocatable수량에 도달할 노드의 총 용량에서 하나의 코어의 절반이 감산됩니다.Allocatable CPU는 3500밀리코어임을 알 수 있습니다. 즉, 각 코어가 하나의 전체 코어를 사용하므로 세 개의 CPU 관리자 Pod를 실행할 수 있습니다. 전체 코어는 1000밀리코어에 해당합니다.네 번째 Pod를 예약하려는 경우 시스템은 Pod를 허용하지만 예약되지는 않습니다.
# oc get pods --all-namespaces |grep test
출력 예
test cpumanager-4gdtn 1/1 Running 0 8m test cpumanager-hczts 1/1 Running 0 8m test cpumanager-nb9d5 0/1 Pending 0 8m test cpumanager-r9wrq 1/1 Running 0 8m
14장. 대규모 페이지 관리
14.1. Huge Page의 기능
메모리는 페이지라는 블록으로 관리됩니다. 대부분의 시스템에서 한 페이지는 4Ki입니다. 1Mi 메모리는 256페이지와 같습니다. 1Gi 메모리는 262,144 페이지 등입니다. CPU에는 하드웨어에서 이러한 페이지 목록을 관리하는 내장 메모리 관리 장치가 있습니다. TLB(Translation Lookaside Buffer)는 가상-물리적 페이지 매핑에 대한 소규모 하드웨어 캐시입니다. TLB에 하드웨어 명령어로 전달된 가상 주소가 있으면 매핑을 신속하게 확인할 수 있습니다. 가상 주소가 없으면 TLB 누락이 발생하고 시스템에서 소프트웨어 기반 주소 변환 속도가 느려져 성능 문제가 발생합니다. TLB 크기는 고정되어 있으므로 TLB 누락 가능성을 줄이는 유일한 방법은 페이지 크기를 늘리는 것입니다.
대규모 페이지는 4Ki보다 큰 메모리 페이지입니다. x86_64 아키텍처에서 일반적인 대규모 페이지 크기는 2Mi와 1Gi입니다. 다른 아키텍처에서는 크기가 달라집니다. 대규모 페이지를 사용하려면 애플리케이션이 인식할 수 있도록 코드를 작성해야 합니다. THP(투명한 대규모 페이지)에서는 애플리케이션 지식 없이 대규모 페이지 관리를 자동화하려고 하지만 한계가 있습니다. 특히 페이지 크기 2Mi로 제한됩니다. THP에서는 THP 조각 모음 작업으로 인해 메모리 사용률이 높아지거나 조각화가 발생하여 노드에서 성능이 저하될 수 있으며 이로 인해 메모리 페이지가 잠길 수 있습니다. 이러한 이유로 일부 애플리케이션은 THP 대신 사전 할당된 대규모 페이지를 사용하도록 설계(또는 권장)할 수 있습니다.
OpenShift Container Platform에서는 Pod의 애플리케이션이 사전 할당된 대규모 페이지를 할당하고 사용할 수 있습니다. 이 주제에서는 방법을 설명합니다.
14.2. 사전 요구 사항
- 노드에서 대규모 페이지 용량을 보고하려면 노드가 대규모 페이지를 사전 할당해야 합니다. 노드는 단일 크기의 대규모 페이지만 사전 할당할 수 있습니다.
14.3. 대규모 페이지 사용
대규모 페이지는 hugepages-<size > 리소스 이름을 사용하여 컨테이너 수준 리소스 요구 사항을 통해 사용할 수 있습니다. 여기서 크기는 특정 노드에서 지원되는 정수 값을 사용하여 가장 컴팩트한 바이너리 표기법입니다. 예를 들어 노드가 2048KiB 페이지 크기를 지원하는 경우 예약 가능한 리소스 hugepages-2Mi 를 노출합니다. CPU 또는 메모리와 달리 대규모 페이지는 과다 할당을 지원하지 않습니다.
kind: Pod
metadata:
generateName: hugepages-volume-
spec:
containers:
- securityContext:
privileged: true
image: rhel7:latest
command:
- sleep
- inf
name: example
volumeMounts:
- mountPath: /hugepages
name: hugepage
resources:
limits:
hugepages-2Mi: 100Mi 1
volumes:
- name: hugepage
emptyDir:
medium: HugePages- 1
hugepages의 메모리 양은 할당할 정확한 양으로 지정하십시오. 이 값을hugepages의 메모리 양과 페이지 크기를 곱한 값으로 지정하지 마십시오. 예를 들어 대규모 페이지 크기가 2MB이고 애플리케이션에 100MB의 대규모 페이지 지원 RAM을 사용하려면 50개의 대규모 페이지를 할당합니다. OpenShift Container Platform에서 해당 계산을 처리합니다. 위의 예에서와 같이100MB를 직접 지정할 수 있습니다.
일부 플랫폼에서는 여러 대규모 페이지 크기를 지원합니다. 특정 크기의 대규모 페이지를 할당하려면 대규모 페이지 부팅 명령 매개변수 앞에 대규모 페이지 크기 선택 매개변수 hugepagesz=<size>를 지정합니다. <size> 값은 바이트 단위로 지정해야 하며 스케일링 접미사 [kKmMgG]를 선택적으로 사용할 수 있습니다. 기본 대규모 페이지 크기는 default_hugepagesz=<size> 부팅 매개변수로 정의할 수 있습니다. 자세한 내용은 Transparent Huge Pages 구성을 참조하십시오.
대규모 페이지 요청은 제한과 같아야 합니다. 제한은 지정되었으나 요청은 지정되지 않은 경우 제한이 기본값입니다.
대규모 페이지는 Pod 범위에서 격리됩니다. 컨테이너 격리는 향후 반복에서 계획됩니다.
대규모 페이지에서 지원하는 EmptyDir 볼륨은 Pod 요청보다 더 많은 대규모 페이지 메모리를 사용하면 안 됩니다.
SHM_HUGETLB로 shmget()를 통해 대규모 페이지를 사용하는 애플리케이션은 proc/sys/vm/hugetlb_shm_group과 일치하는 보조 그룹을 사용하여 실행되어야 합니다.
15장. GlusterFS 스토리지 최적화
15.1. 데이터베이스의 통합 모드 Guidance
애플리케이션에 통합 모드를 사용하는 경우 워크로드 유형에 따라 gluster-block과 GlusterFS 모드 간 정보에 입각하여 이 주제에서 제공되는 지침 및 모범 사례를 따르십시오.
15.2. 테스트된 애플리케이션
OpenShift Container Platform 3.10에서는 다음 (no)SQL 데이터베이스에서 광범위한 테스트를 수행했습니다.
- PostgreSQL SQL v9.6
- MongoDB noSQL v3.2
이러한 데이터베이스의 스토리지는 통합 모드 스토리지 클러스터에서 시작되었습니다.
Postgresql SQL 벤치마킹 pgbench 은 데이터베이스 벤치마킹에 사용되었습니다. MongoDB noSQL 벤치마킹 YCSB Yahoo의 경우 Cloud Serving Benchmark 는 벤치마킹 및 workloada,workloadb,workloadf 를 테스트했습니다.
15.3. 지원 매트릭스
표 15.1. 표 제목 - GlusterFS
| 데이터베이스 | 스토리지 백엔드: GlusterFS | Performance Translators 해제 | 성능 전환기 실행 |
| Postgresql SQL | 있음 |
|
|
| MongoDB noSQL | 있음 |
|
|
표 15.2. 표 제목 - gluster-block
| 데이터베이스 | 스토리지 백엔드: gluster-block |
| postgresql | 있음 |
| MongoDB | 있음 |
위에서 언급한 GlusterFS의 성능 번역기는 이미 최신 통합 모드 이미지와 함께 제공되는 데이터베이스 프로필의 일부입니다.
15.4. 테스트 결과
Postgresql SQL 데이터베이스의 경우 GlusterFS 및 gluster-block은 거의 동일한 성능 결과를 보여주었습니다. MongoDB noSQL 데이터베이스의 경우 gluster-block이 더 잘 수행됩니다. 따라서 MongoDB noSQL 데이터베이스에 gluster-block 기반 스토리지를 사용하십시오.