第84章 デシジョンエンジンにおける Phreak ルールアルゴリズム
Red Hat Process Automation Manager のデシジョンエンジンは、ルール評価に Phreak アルゴリズムを使用します。Phreak は、Rete アルゴリズムから発展したもので、これには強化された Rete アルゴリズムの ReteOO も含まれます。ReteOO は、オブジェクト指向システム向けに Red Hat Process Automation Manager の以前のバージョンに導入されました。全体として Phreak は、Rete および ReteOO よりスケーラブルで、大規模なシステムでより迅速に対応します。
Rete は Eager (即時ルール評価) でデータ指向と考えられていますが、Phreak は Lazy (遅延ルール評価) で目標指向と考えられています。Rete アルゴリズムは、すべてのルールに対して部分的な一致を見つけ出すために insert、update、および delete の各アクションを実行中に、多数のアクションを実行します。ルールの一致において Rete アルゴリズムは活発なため、最終的にルールを実行するまでに非常に時間がかかります。これは大規模なシステムにおいて特に顕著です。Phreak の場合は、ルールの部分的な一致を意図的に遅延させ、大量のデータをより効率的に処理します。
Phreak アルゴリズムでは、これまでの Rete アルゴリズムに、以下に示す一連の拡張機能を追加しています。
- コンテキストメモリーの 3 つのレイヤー: ノード、セグメント、およびルールのメモリータイプ
- ルールベース、セグメントベース、およびノードベースのリンク
- Lazy (遅延) ルール評価
- 一時停止と再開を使用したスタックベースの評価
- 孤立したルール評価
- セット指向の伝播
84.1. Phreak でのルール評価
デシジョンエンジンが開始すると、すべてのルールは、ルールのトリガーが可能なパターン一致データに リンクされていない と見なされます。この段階で、デシジョンエンジンの Phreak アルゴリズムはルールを評価しません。insert、update、および delete の各アクションはキューに入れられ、Phreak は、実行する可能性が最も高いルールに基づいてヒューリスティックを使用し、次に評価するルールを計算して選択します。すべての必要な入力値がルールに生成されると、ルールは関連するパターン一致データに リンクされている と見なされます。続いて Phreak は、このルールを表す目標を作成し、ルールの顕著性によって順序付けられた優先度キューにこの目標を置きます。目標が作成されたルールのみが評価され、その他の潜在的なルール評価は遅延されます。個別のルールは評価されますが、ノードの共有は引き続きセグメンテーション処理を通じて行われます。
タプル指向の Rete とは異なり、Phreak 伝播はコレクション指向です。評価されているルールの場合、デシジョンエンジンは最初のノードにアクセスし、キューに入れられたすべての insert、update、および delete の各アクションを処理します。結果は 1 つのセットに追加され、そのセットは子ノードに伝播されます。子ノードでは、キューに入れられたすべての insert、update、および delete の各アクションが処理され、その結果を同じセットに追加します。続いてそのセットは次の子ノードに伝播され、同じ処理が終了ノードに達するまで繰り返されます。このサイクルは、特定のルール設定にパフォーマンス上の利点を提供できるバッチ処理効果をもたらします。
ルールのリンクやリンク解除は、ネットワークセグメンテーションに基づいて、レイヤー化されたビットマスクシステムを使用して行われます。ルールネットワークが構築されると、同じ一連のルールで共有されるルールネットワークノードに対して、複数のセグメントが作成されます。ルールはセグメントのパスで設定されます。ルールが他のどのルールともノードを一切共有しない場合、このルールは単一のセグメントになります。
セグメントの各ノードにビットマスクの補正値が割り当てられます。別のビットマスクは、以下の要件に従って、ルールのパスの各セグメントに割り当てられます。
-
ノードの入力が少なくとも 1 つ存在する場合、ノードビットは
on状態に設定されます。 -
セグメントの各ノードのビットが
on状態に設定されている場合は、セグメントビットもon状態に設定されます。 -
いずれかのノードビットが
off状態に設定されている場合は、セグメントもoff状態に設定されます。 -
ルールのパスの各セグメントが
on状態に設定されている場合、ルールはリンクされていると見なされ、目標が作成され、ルールを評価するためのスケジュールが組まれます。
変更されたノード、セグメント、およびルールを追跡する際に、同じビットマスクの手法が使用されます。この追跡機能により、すでにリンクされたルールの評価目標が作成後に変更された場合は、このルールの評価をスケジュールから外すことができます。その結果、部分的な一致を評価できるルールはありません。
Rete におけるメモリーの単一ユニットとは対照的に、Phreak には、ノード、セグメント、およびルールのメモリータイプから成る 3 つのレイヤーのコンテキストメモリーがあります。そのため、このルール評価の処理は Phreak で可能となります。このようなレイヤーがあることで、ルールを評価する際は、より深くコンテキストを解釈することが可能になります。
図84.1 Phreak の 3 つのレイヤーから成るメモリーシステム

以下の例では、Phreak の 3 つのレイヤーから成るメモリーシステムで、ルールがどのように組織化および評価されているかを説明します。
例 1: 3 つのパターンがある単一のルール (R1): A、B、および C。ルールは、ノード用にビット 1、2、および 4 を持つ単一のセグメントを形成します。単一のセグメントのビットの補正値は 1 です。
図84.2 例 1: 単一ルール

例 2: ルール R2 が追加され、パターン A を共有します。
図84.3 例 2: パターン共有の 2 つのルール
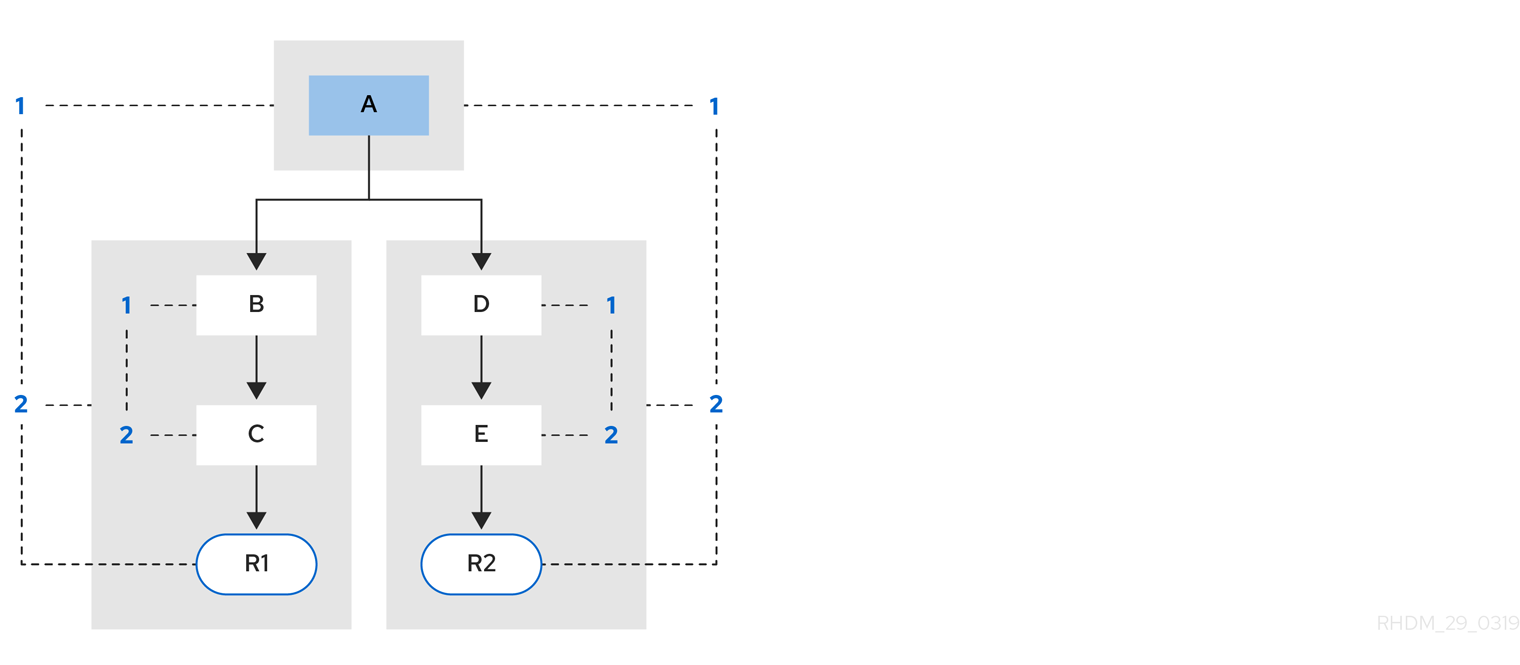
パターン A は独自のセグメントに置かれ、その結果、各ルールには 2 つのセグメントが作成されます。これら 2 つのセグメントは、各ルールのパスを作成します。1 つ目のセグメントは、両方のパスで共有されます。パターン A がリンクされると、セグメントはリンクされます。続いてこのセグメントは、セグメントが共有される各パスでこれを繰り返します。この時ビット 1 は on に設定されます。パターン B および C がその後オンになると、パス R1 の 2 つ目のセグメントがリンクされ、これによりビット 2 が R1 に対してオンになります。ビット 1 およびビット 2 が R1 に対してオンになったことで、ルールがリンクされるようになり、目標が作成され、ルールを今後評価して実行するためのスケジュールが立てられます。
ルールが評価されると、セグメントによって一致の結果が共有できるようになります。各セグメントには、そのセグメントのすべての insert、update、および delete をキューに入れるステージングメモリーがあります。R1 が評価されるとルールはパターン A を処理し、これにより一連のタプルが作成されます。アルゴリズムがセグメンテーションの分割を検出し、セット内の各 insert、update、および delete にピアタプルを作成します。そして、これらを R2 のステージングメモリーに追加します。次にこれらのタプルは、既存のステージタプルとマージされ、最終的に R2 が評価されると実行されます。
例 3: ルール R3 とルール R4 が追加され、パターン A とパターン B を共有します。
図84.4 例 3: パターン共有の 3 つのルール
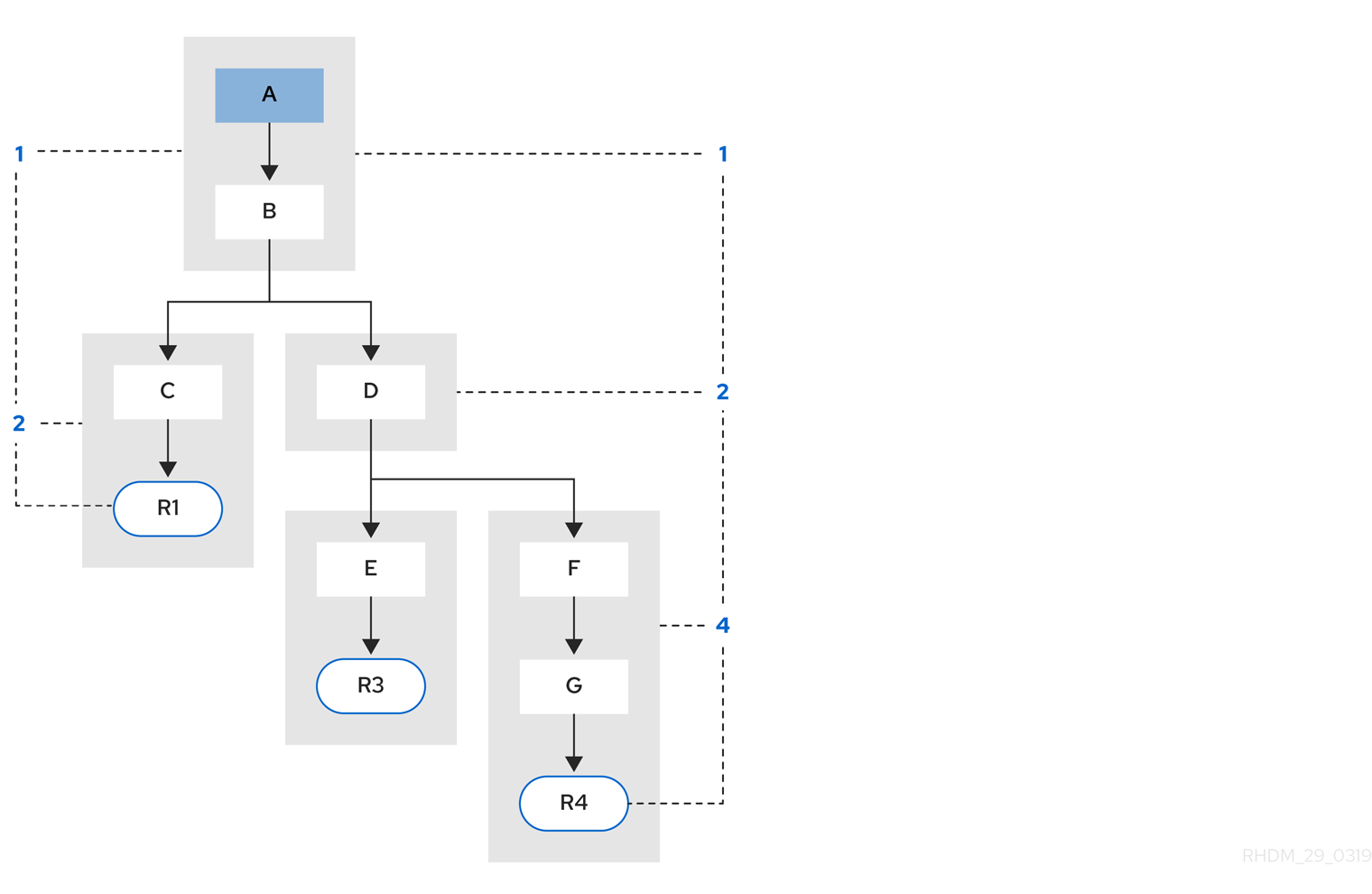
ルール R3 と ルール R4 にはセグメントが 3 つあり、R1 にはセグメントが 2 つあります。R1、R3、および R4 がパターン A とパターン B を共有し、R3 と R4 がパターン D を共有しています。
例 4: パターンの共有なしでサブネットワークがある単一ルール (R1)
図84.5 例 4: パターンの共有なしで、サブネットワークがある単一のルール

Not、Exists、または Accumulate ノードに 1 つ以上の要素がある場合は、サブネットワークが形成されます。この例では、要素 B not( C ) がサブネットワークを形成します。要素 not( C ) は、サブネットワークを必要としない単一要素のため、Not ノード内にマージされます。サブネットワークは専用のセグメントを使用します。ルール R1 には、依然として 2 つのセグメントのパスがあり、サブネットワークは別の内部のパスを形成します。サブネットワークがリンクされると、これは外部のセグメントにもリンクされます。
例 5: ルール R2 と共有するサブネットワークのあるルール R1
図84.6 例 5: 2 つのルールのうち、1 つはサブネットワークとパターンを共有
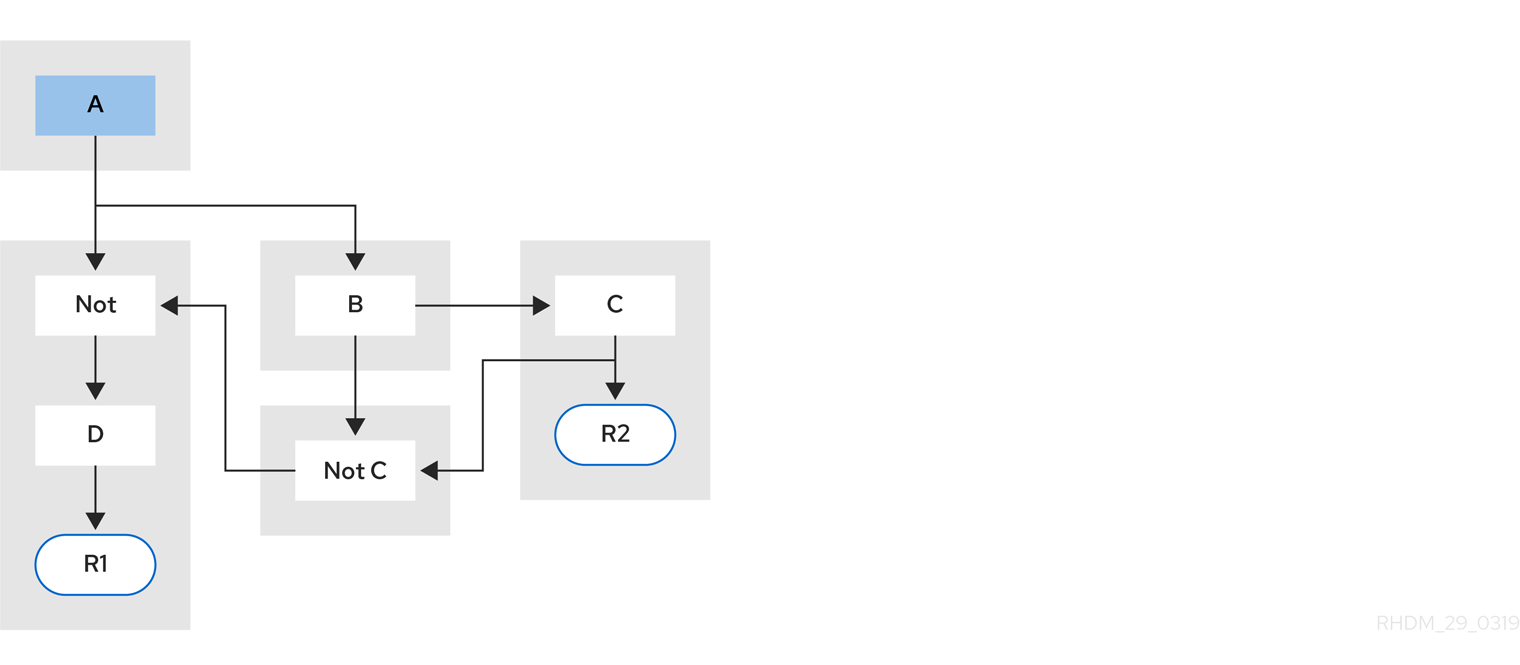
ルールのサブネットワークノードは、サブネットワークのない別のルールと共有することができます。このように共有することで、サブネットワークのセグメントが 2 つのセグメントに分割されることになります。
制約のある Not ノードおよび Accumulate ノードは、セグメントのリンクを外すことは一切できず、ビットがオンになっていると常に考えられています。
Phreak 評価のアルゴリズムは、メソッド再帰ベースではなく、スタックベースです。StackEntry を使用して現在評価中のノードを表す場合は、いつでもルール評価を一時的に停止したり、再開したりすることができます。
ルール評価がサブネットワークに到達すると、StackEntry オブジェクトが、外部パスのセグメントおよびサブネットワークセグメント用に作成されます。最初にサブネットワークのセグメントが評価され、セットがサブネットワークパスの終わりに到達すると、そのセグメントがフィードする外部ノードのステージングリストにマージされます。次に、以前の StackEntry オブジェクトが再開し、サブネットワークの結果を処理できるようになります。この処理には、子ノードに伝播される前にすべての作業がバッチで完了するという付加的な利点があります。これは、Accumulate ノードにとって特に有利です。
同じスタックシステムは、効率的な後向き連鎖に使用されます。ルール評価がクエリーノードに到達すると、評価は一時的に停止し、クエリーがスタックに追加されます。続いてクエリーは、結果セットを生成するために評価されます。結果セットは、再開した StackEntry オブジェクトのメモリーロケーションに保存され、回収されて子ノードに伝播されます。クエリー自体が他のクエリーを呼び出した場合はこの処理は繰り返され、その一方で、現在のクエリーは一時的に停止し、現在のクエリーノード用に新しい評価が設定されます。
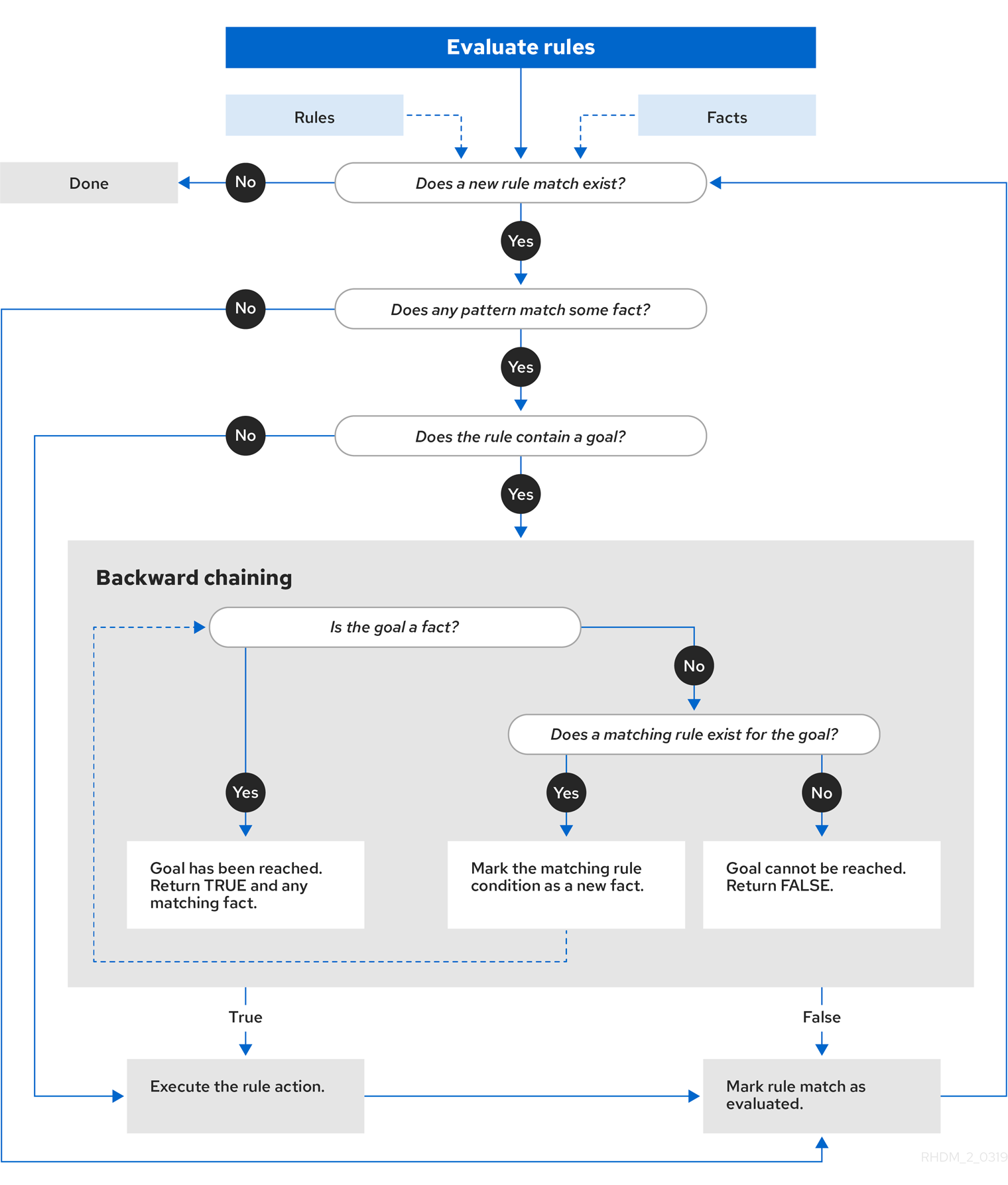
84.1.1. 前向き連鎖と後向き連鎖を使用したルール評価
Red Hat Process Automation Manager のデシジョンエンジンは、前向き連鎖と後向き連鎖の両方を使用してルールを評価する、ハイブリッドの理由付けシステムです。前向き連鎖のルールシステムは、ディジョンエンジンのワーキングメモリーにあるファクトで開始して、そのファクトへの変更に反応するデータ駆動型のシステムです。オブジェクトがワーキングメモリーに挿入されると、その変更の結果として True となるルールの条件はすべて、アジェンダによって実行されるようにスケジュールされます。
反対に、後向き連鎖のルールシステムは、しばしば再帰を使用して、デシジョンエンジンが満たそうとする結論から開始する目的駆動型のシステムです。システムが結論または目的に到達できない場合は、サブとなる目的、つまり、現在の目的の一部を完了する結論を検索します。システムは、最初の結論が満たされるか、すべてのサブとなる目的が満たされるまでこのプロセスを続行します。
以下の図は、デシジョンエンジンが、ロジックフローで後向き連鎖のセグメントと、前向き連鎖全体を使用してルールを評価する方法を例示します。
図84.7 前向き連鎖と後向き連鎖を使用したルール評価のロジック