
Red Hat Training
A Red Hat training course is available for Red Hat OpenStack Platform
第3章 仮想マシンのインスタンス
OpenStack Compute は、仮想マシンをオンデマンドで提供する中核的なコンポーネントです。Compute は、認証には Identity サービス、イメージ (インスタンスの起動に使用する) には Image サービス、ユーザー/管理者用のインターフェースには Dashboard サービスと対話します。
Red Hat OpenStack Platform により、クラウド内の仮想マシンインスタンスを容易に管理することができます。Compute サービスはインスタンスの作成、スケジューリング、管理を行い、この機能をその他の OpenStackコンポーネントに公開します。本章では、これらの手順に加えて、キーペア、セキュリティーグループ、ホストアグリゲート、フレーバーなどのコンポーネントを追加する手順について説明します。OpenStack では、インスタンス という用語は、仮想マシンインスタンスの意味で使用されます。
3.1. インスタンスの管理
インスタンスを作成する前には、その他の特定の OpenStack コンポーネント (例: ネットワーク、キーペア、イメージ、ブートソースとなるボリュームなど) をそのインスタンスが利用できる状態にしておく必要があります。
本項では、これらのコンポーネントを追加して、インスタンスを作成/管理する手順について説明します。インスタンスの管理には、更新、ログイン、使用状況の確認、リサイズ、削除などの操作が含まれます。
3.1.1. コンポーネントの追加
以下の各項の手順に従って、ネットワーク、キーペアを作成し、イメージまたはボリュームソースをアップロードします。これらのコンポーネントは、インスタンスの作成に使用され、デフォルトでは提供されません。また、新規セキュリティーグループ作成して、ユーザーが SSH アクセスできるようにする必要があります。
- Dashboard で プロジェクト を選択します。
- ネットワーク > ネットワーク を選択し、新規インスタンスに接続することのできるプライベートネットワークが存在していることを確認してください (ネットワークを作成するには、Red Hat OpenStack Platform で『ネットワークガイド』の「ネットワークの追加」の項を参照してください)。
- コンピュート > アクセスとセキュリティー > キーペア を選択して、キーペアが存在していることを確認します (キーペアの作成方法については、「キーペアの作成」を参照)。
ブートソースに使用可能なイメージまたはボリュームのいずれかがあることを確認してください。
- ブートソースのイメージを表示するには、イメージ タブを選択します (イメージを作成する場合は「イメージの作成」を参照してください)。
- ブートソースのボリュームを確認するには、ボリューム タブを選択します (ボリュームの作成方法については、Red Hat OpenStack Platform で『ストレージ管理ガイド』「ボリュームの作成」の項を参照してください)。
- コンピュート > アクセスとセキュリティー > セキュリティーグループ を選択し、セキュリティーグループルールが作成済みであることを確認します (セキュリティーグループの作成については、Red Hat OpenStack Platform で『ユーザーおよびアイデンティティー管理ガイド』の「プロジェクトのセキュリティー管理」の項を参照してください)。
3.1.2. インスタンスの作成
- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- インスタンスの起動 をクリックします。
- 各フィールド (「*」でマークされているフィールドは必須) にインスタンスの設定値を入力し、完了したら 起動 をクリックします。
表3.1 インスタンスのオプション
| タブ | フィールド | 説明 |
|---|---|---|
|
プロジェクトおよびユーザー |
プロジェクト |
ドロップダウンリストからプロジェクトを選択します。 |
|
ユーザー |
ドロップダウンリストからユーザーを選択します。 | |
|
詳細 |
アベイラビリティーゾーン |
ゾーンとは、インスタンスが配置されるクラウドリソースの論理グループです。不明な場合にはデフォルトのゾーンを使用してください (詳しくは「ホストアグリゲートの管理」を参照)。 |
|
インスタンス名 |
インスタンスを識別するための名前 | |
|
フレーバー |
フレーバーは、インスタンスに提供されるリソースを決定します (例: メモリー)。デフォルトのフレーバーの割り当ておよび新規フレーバー作成に関する情報は、「フレーバーの管理」を参照してください。 | |
|
インスタンス数 |
ここに記載のパラメーターで作成するインスタンスの数。「1」が事前に設定されています。 | |
|
インスタンスのブートソース |
選択した項目に応じて異なる新規フィールドが表示され、ソースを選択することができます。
| |
|
アクセスとセキュリティー |
キーペア |
指定したキーペアがインスタンスに挿入され、SSH を使用したインスタンスへのリモートアクセスに使用されます (直接のログイン情報や静的キーペアが提供されない場合)。通常は 1 プロジェクトあたり 1 つのキーペアが作成されます。 |
|
セキュリティーグループ |
セキュリティーグループには、インスタンスのネットワークトラフィックの種別と方向をフィルタリングするためのファイアウォールルールが含まれています (グループの設定についての詳しい情報は、Red Hat OpenStack Platform で『ユーザーおよびアイデンティティー管理ガイド』の「プロジェクトのセキュリティー管理」の項を参照してください)。 | |
|
ネットワーク |
選択済みネットワーク |
ネットワークは、少なくとも 1 つ選択する必要があります。インスタンスは通常プライベートネットワークに割り当てられ、その後に Floating IP アドレスが割り当てられて外部アクセスが可能になります。 |
|
作成後 |
カスタマイズスクリプトの入力方法 |
インスタンスのブート後に実行されるコマンドセットまたはスクリプトファイルを指定することができます (例: インスタンスのホスト名やユーザーパスワードの設定など)。「直接入力」を選択した場合には、スクリプトデータフィールドにコマンドを書き込みます。それ以外の場合には、スクリプトファイルを指定してください。 注記 「#cloud-config」で開始するスクリプトは、cloud-config 構文を使用するものとして解釈されます (この構文についての情報は、http://cloudinit.readthedocs.org/en/latest/topics/examples.html を参照してください)。 |
|
高度な設定 |
ディスクパーティション |
デフォルトでは、インスタンスは単一のパーティションとして作成されて、必要に応じて動的にリサイズされますが、パーティションを手動で設定する方法を選択することも可能です。 |
|
コンフィグドライブ |
このオプションを選択した場合には、OpenStack はメタデータを読み取り専用の設定ドライブに書き込みます。このドライブはインスタンスのブート時に (Compute のメタデータサービスの代わりに) インスタンスに接続されます。インスタンスがブートした後には、このドライブをマウントしてコンテンツを表示することができます (これにより、ユーザーがファイルをインスタンスに提供することが可能となります)。 |
3.1.4. インスタンスのリサイズ
インスタンスのリサイズ (メモリーまたは CPU 数) を行うには、適切な容量のあるインスタンスで新規フレーバーを選択する必要があります。サイズを大きくする場合には、ホストに十分な容量があることをあらかじめ確認することを忘れないようにしてください。
各ホストに SSH 鍵認証を設定してホスト間の通信が可能な状態にし、Compute が SSH を使用してディスクを他のホストに移動できるようにします (例: 複数のコンピュートノードが同じ SSH 鍵を共有することが可能です)。
SSH 鍵認証についての詳しい情報は、Red Hat OpenStack Platform に掲載されている『インスタンスの移行ガイド』の「ノード間の SSH トンネリングの設定」の項を参照してください。
元のホストでリサイズを有効にするには、
/etc/nova/nova.confファイルで以下のパラメーターを設定します。[DEFAULT] allow_resize_to_same_host = True
- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- インスタンスの アクション コラムの矢印をクリックして、インスタンスのリサイズ を選択します。
- 新しいフレーバー フィールドで新規フレーバーを選択します。
起動時にインスタンスのパーティション分割を手動で行うには、以下の手順で設定します (これにより、ビルドタイムが短縮されます)。
- 高度な設定 を選択します。
- ディスクパーティション フィールドで、手動 を設定します。
- リサイズ をクリックします。
3.1.5. インスタンスへの接続
本項では、Dashboard またはコマンドラインインターフェースを使用して、インスタンスのコンソールにアクセスする複数の方法について説明します。また、インスタンスのシリアルポートに直接接続して、ネットワーク接続が失敗しても、デバッグすることが可能です。
3.1.5.1. Dashboard を使用したインスタンスのコンソールへのアクセス
コンソールを使用すると、Dashboard 内でインスタンスに直接アクセスすることができます。
- Dashboard で コンピュート > インスタンス を選択します。
-
インスタンスの ドロップダウンメニュー をクリックして、コンソール を選択します。
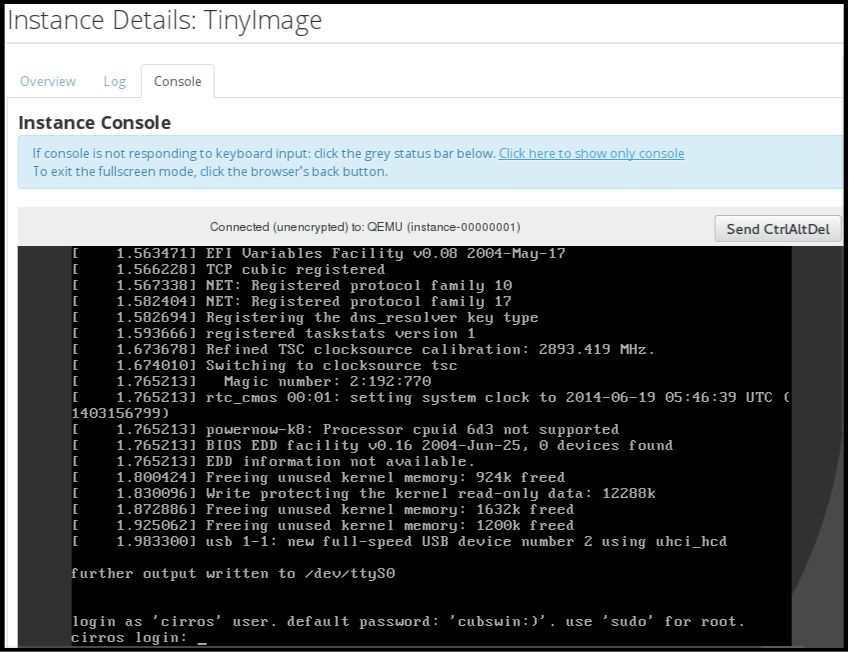
- イメージのユーザー名とパスワードを使用してログインします (例: CirrOS イメージでは「cirros」と「cubswin:)」を使用します)。
3.1.5.2. VNC コンソールへの直接接続
nova get-vnc-console コマンドで返された URL を使用すると、インスタンスの VNC コンソールに直接アクセスすることができます。
- ブラウザー
ブラウザーの URL を取得するには、以下のコマンドを実行します。
$ nova get-vnc-console INSTANCE_ID novnc- Java クライアント
Java クライアントの URL を取得するには、以下のコマンドを実行します。
$ nova get-vnc-console INSTANCE_ID xvpvnc
「nova-xvpvncviewer」は、Java クライアントの最も簡単な例を提供します。クライアントをダウンロードするには、以下のコマンドを実行します。
# git clone https://github.com/cloudbuilders/nova-xvpvncviewer # cd nova-xvpvncviewer/viewer # make
インスタンスの Java クライアント URL を使用してビューアーを実行します。
# java -jar VncViewer.jar URLこのツールは、お客様の便宜のためのみに提供されており、Red Hat では正式にサポートされていません。
3.1.5.3. シリアルコンソールへの直接接続
Websocket クライアントを使用すると、コンソールのシリアルポートに直接アクセスすることが可能です。シリアル接続は、通常デバッグツールで使用されます (たとえば、ネットワーク設定に問題がある場合でもインスタンスにアクセス可能)。実行中のインスタンスのシリアル URL を取得するには、以下のコマンドを実行します。
$ nova get-serial-console INSTANCE_ID「novaconsole」は、Websocket クライアントの最も簡単な例を提供します。クライアントをダウンロードするには、以下のコマンドを実行します。
# git clone https://github.com/larsks/novaconsole/ # cd novaconsole
インスタンスのシリアル URL を使用してクライアントを実行します。
# python console-client-poll.py
このツールは、お客様の便宜のためのみに提供されており、Red Hat では正式にサポートされていません。
ただし、インストールによっては、管理者があらかじめ「nova-serialproxy」サービスを設定する必要がある場合があります。プロキシーサービスは、OpenStack Compute のシリアルポートへの接続が可能な Websocket プロキシーです。
3.1.5.3.1. nova-serialproxy のインストールと設定
nova-serialproxyサービスをインストールします。# yum install openstack-nova-serialproxy
/etc/nova/nova.confのserial_consoleセクションを更新します。nova-serialproxyサービスを有効化します。$ openstack-config --set /etc/nova/nova.conf serial_console enabled true
nova get-serial-consoleコマンドで提供される URL の生成に使用する文字列を指定します。$ openstack-config --set /etc/nova/nova.conf serial_console base_url ws://PUBLIC_IP:6083/PUBLIC_IPは、nova-serialproxyサービスを実行するホストのパブリック IP アドレスに置き換えます。インスタンスのシリアルコンソールをリッスンする IP アドレスを指定します (文字列)。
$ openstack-config --set /etc/nova/nova.conf serial_console listen 0.0.0.0
プロキシークライアントが接続する必要のあるアドレスを指定します (文字列)。
$ openstack-config --set /etc/nova/nova.conf serial_console proxyclient_address ws://HOST_IP:6083/HOST_IPは、Compute ホストの IP アドレスに置き換えます。たとえば、nova-serialproxyサービスを有効化する設定は、以下のようになります。[serial_console] enabled=true base_url=ws://192.0.2.0:6083/ listen=0.0.0.0 proxyclient_address=192.0.2.3
Compute サービスを再起動します。
# openstack-service restart nova
nova-serialproxyサービスを起動します。# systemctl enable openstack-nova-serialproxy # systemctl start openstack-nova-serialproxy
- 実行中のインスタンスを再起動して、正しいソケットをリッスンするようになったことを確認します。
シリアル/コンソール間のポート接続のためにファイアウォールを開きます。シリアルポートは、
/etc/nova/nova.confで[serial_console]port_range を使用して設定します。デフォルトの範囲は、10000:20000 です。以下のコマンドを実行して、iptables を更新します。# iptables -I INPUT 1 -p tcp --dport 10000:20000 -j ACCEPT
3.1.6. インスタンスの使用状況の表示
以下のような使用状況統計が提供されます。
プロジェクト別
プロジェクト別の使用状況を確認するには、プロジェクト > コンピュート > 概要 を選択します。全プロジェクトインスタンスの使用状況の概要が即時に表示されます。
使用状況を照会する期間を指定して 送信 ボタンをクリックすると、特定の期間の統計を表示することもできます。
ハイパーバイザー別
管理者としてログインしている場合には、全プロジェクトの情報を表示することができます。管理 > システム をクリックしてからタブを 1 つ選択します。たとえば、リソース使用状況 タブでは、特定の期間のレポートを確認することができます。また、ハイパーバイザー をクリックすると、現在の仮想 CPU、メモリー、ディスクの統計を確認することができます。
注記仮想 CPU 使用量の値 (y 中 x 使用中) には、全仮想マシンの仮想 CPU の合計数 (x) とハイパーバイザーのコアの合計数 (y) が反映されます。
3.1.7. インスタンスの削除
- Dashboard で プロジェクト > コンピュート > インスタンス を選択して、対象のインスタンスにチェックを付けます。
- インスタンスの削除 をクリックします。
インスタンスを削除しても、そのインスタンスにアタッチされているボリュームは削除されないので、この操作は別々に行う必要があります (Red Hat OpenStack Platform) で 『ストレージ管理ガイド』の「ボリュームの削除」の項を参照してください)。
3.1.8. 複数のインスタンスの一括管理
同時に複数のインスタンスを起動する必要がある場合には (例: コンピュートまたはコントローラーのメンテナンスでダウンしている場合など)、プロジェクト > コンピュート > インスタンス から簡単に起動できます。
- 起動するインスタンスの最初のコラムにあるチェックボックスをクリックします。全インスタンスを選択するには、表の最初の行のチェックボックスをクリックします。
- 表の上にある その他のアクション をクリックして インスタンスの起動 を選択します。
同様に、適切なアクションを選択して、複数のインスタンスを終了またはソフトリブートすることができます。
3.2. インスタンスのセキュリティーの管理
適切なセキュリティーグループ (ファイアウォールのルールセット) およびキーペア (SSH を介したユーザーのアクセスの有効化) を割り当てることによってインスタンスへのアクセスを管理することができます。また、インスタンスに Floating IP アドレスを割り当てて外部ネットワークへのアクセスを有効にすることができます。以下の各項では、キーペア、セキュリティーグループ、Floating IP アドレスの作成/管理方法と SSH を使用したログインの方法について説明します。また、インスタンスに admin パスワードを挿入する手順についても記載しています。
セキュリティーグループの管理に関する情報は、Red Hat OpenStack Platform で『ユーザーおよびアイデンティティー管理ガイド』の「プロジェクトのセキュリティー管理」の項を参照してください。
3.2.1. キーペアの管理
キーペアにより、インスタンスへ SSH でアクセスすることができます。キーペアの生成時には毎回、証明書がローカルマシンにダウンロードされ、ユーザーに配布できます。通常は、プロジェクトごとにキーペアが 1 つ作成されます (そのキーペアは、複数のインスタンスに使用されます)。
既存のキーペアを OpenStack にインポートすることも可能です。
3.2.1.1. キーペアの作成
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブで キーペアの作成 をクリックします。
- キーペア名 フィールドに名前を指定し、キーペアの作成 をクリックします。
キーペアが作成されると、ブラウザーを介してキーペアファイルが自動的にダウンロードされます。後ほど外部のマシンから接続できるように、このファイルを保存します。また、コマンドラインの SSH 接続には、以下のコマンドを実行して、このファイルを SSH にロードすることができます。
# ssh-add ~/.ssh/os-key.pem
3.2.1.2. キーペアのインポート
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブで キーペアのインポート をクリックします。
- キーペア名 のフィールドに名前を指定し、公開鍵の内容をコピーして、公開鍵 のフィールドにペーストします。
- キーペアのインポート をクリックします。
3.2.1.3. キーペアの削除
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブでそのキーの キーペアの削除 ボタンをクリックします。
3.2.2. セキュリティーグループの作成
セキュリティーグループとは、プロジェクトのインスタンスに割り当て可能な IP フィルターのルールセットで、インスタンスへのネットワークのアクセス権限を定義します。セキュリティーグループはプロジェクト別になっており、プロジェクトメンバーは自分のセキュリティーグループのデフォルトルールを編集して新規ルールセットを追加することができます。
- Dashboard で プロジェクト タブを選択して、コンピュート > アクセスとセキュリティー をクリックします。
- セキュリティーグループ タブで、+ セキュリティーグループの作成 をクリックします。
- セキュリティーグループに名前と説明を指定して、セキュリティーグループの作成 をクリックします。
プロジェクトのセキュリティー管理に関する詳しい情報は、Red Hat OpenStack Platform で『ユーザーおよびアイデンティティー管理ガイド』の「プロジェクトのセキュリティー管理」の項を参照してください。
3.2.3. Floating IP アドレスの作成、割り当て、解放
デフォルトでは、インスタンスを最初に作成する際に、そのインスタンスに内部 IP アドレスが割り当てられますが、Floating IP アドレス (外部アドレス) を作成して割り当てることによりパブリックネットワークを介したアクセスを有効にすることができます。インスタンスに割り当てられている IP アドレスは、インスタンスの状態に関わらず変更することができます。
プロジェクトには、使用できる Floating IP アドレスの範囲が限定されているので (デフォルトの上限は 50)、必要がなくなったアドレスは、再利用できるように解放することを推奨します。Floating IP アドレスは、既存の Floating IP プールからのみ確保することができます。Red Hat OpenStack Platform で『ネットワークガイド』の「Floating IP プールの作成」の項を参照してください。
3.2.3.1. プロジェクトへの Floating IP アドレスの確保
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブで Floating IP の確保 をクリックします。
- プール のフィールドから、IP アドレスを確保するネットワークを選択します。
- IP の確保 をクリックします。
3.2.3.2. Floating IP の割り当て
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブでアドレスの 割り当て ボタンをクリックします。
IP アドレスフィールドで割り当てるアドレスを選択します。
注記割り当てることのできるアドレスがない場合には、
+ボタンをクリックして新規アドレスを作成することができます。- IP を割り当てる ポート フィールドで割り当て先となるインスタンスを選択します。1 つのインスタンスに割り当てることができる Floating IP アドレスは 1 つのみです。
- 割り当て をクリックします。
3.2.3.3. Floating IP の解放
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブで、アドレスの 割り当て/割り当て解除 ボタンの横にある矢印メニューをクリックします。
- Floating IP の解放 を選択します。
3.2.4. インスタンスへのログイン
前提条件
- インスタンスのセキュリティーグループには、SSH ルールが設定されていることを確認します (Red Hat OpenStack Platform で『ユーザーおよびアイデンティティー管理ガイド』の「プロジェクトのセキュリティー管理」の項を参照してください)。
- インスタンスに Floating IP アドレス (外部アドレス) が割り当てられていることを確認します (「Floating IP アドレスの作成、割り当て、解放」を参照)。
- インスタンスのキーペアの証明書を取得します。証明書は、キーペアの作成時にダウンロードされます。キーペアを自分で作成しなかった場合には、管理者に問い合わせてください (「キーペアの管理」を参照)。
最初に、キーペアのファイルを SSH に読み込み、次に名前を指定せずに ssh を使用します。
生成したキーペアの証明書のアクセス権を変更します。
$ chmod 600 os-key.pem
ssh-agentがすでに実行されているかどうかを確認します。# ps -ef | grep ssh-agent
実行されていない場合には、次のコマンドで起動します。
# eval `ssh-agent`
ローカルマシンで、キーペアの証明書を SSH に読み込みます。以下に例を示します。
$ ssh-add ~/.ssh/os-key.pem
- これで、イメージにより提供されるユーザーで、ファイルに SSH アクセスできるようになりました。
以下のコマンドの例は、Red Hat Enterprise Linux のゲストイメージに cloud-user として SSH アクセスする方法を示しています。
$ ssh cloud-user@192.0.2.24
証明書を直接使用することも可能です。以下に例を示します。
$ ssh -i /myDir/os-key.pem cloud-user@192.0.2.24
3.2.5. インスタンスへの admin パスワード挿入
以下の手順に従って、admin (root) パスワードを挿入することができます。
/etc/openstack-dashboard/local_settingsファイルで、change_set_passwordパラメーターの値をTrueに設定します。can_set_password: True
/etc/nova/nova.confファイルで、inject_passwordパラメーターをTrueに設定します。inject_password=true
Compute サービスを再起動します。
# service nova-compute restart
nova boot コマンドを使用して、新規インスタンスを起動する際には、コマンドの出力に adminPass パラメーターが表示されます。このパスワードを使用して、インスタンスに root ユーザーとしてログインすることができます。
Compute サービスは、/etc/shadow ファイル内のパスワード値を root ユーザー用に上書きします。以下の手順は、KVM ゲストイメージの root アカウントをアクティブ化するのにも使用することが可能です。KVM ゲストイメージの使用方法についての詳しい情報は、「Red Hat OpenStack Platform における KVM ゲストイメージの使用」を参照してください。
Dashboard からカスタムパスワードを設定することも可能です。これを有効にするには、can_set_password パラメーターを true に設定した後に、以下のコマンドを実行します。
# systemctl restart httpd.service
新規追加された admin パスワードフィールドは以下のように表示されます。
上記のフィールドは、インスタンスの起動/再ビルド時に使用することができます。
3.3. フレーバーの管理
作成する各インスタンスには、インスタンスのサイズや容量を決定するためのフレーバー (リソースのテンプレート) を指定します。また、フレーバーを使用して、セカンダリー一時ストレージやスワップディスク、使用率を制限するためのメタデータ、特別なプロジェクトへのアクセスを指定することも可能です (デフォルトのフレーバーにはこのような追加の属性は一切定義されていません)。
表3.3 デフォルトのフレーバー
| 名前 | 仮想 CPU | メモリー | ルートディスクのサイズ |
|---|---|---|---|
|
m1.tiny |
1 |
512 MB |
1 GB |
|
m1.small |
1 |
2048 MB |
20 GB |
|
m1.medium |
2 |
4096 MB |
40 GB |
|
m1.large |
4 |
8192 MB |
80 GB |
|
m1.xlarge |
8 |
16384 MB |
160 GB |
エンドユーザーの大半は、デフォルトのフレーバーを使用できますが、特化したフレーバーを作成/管理する必要がある場合もあります。たとえば、以下の設定を行うことができます。
- 基になるハードウェアの要件に応じて、デフォルトのメモリーと容量を変更する
- インスタンスに特定の I/O レートを強制するためのメタデータ、またはホストアグリゲートと一致させるためのメターデータを追加する
イメージのプロパティーを使用して設定した動作は、フレーバーを使用して設定した動作よりも優先されます。詳しい説明は、「イメージの管理」を参照してください。
3.3.1. 設定パーミッションの更新
デフォルトでは、フレーバーの作成およびフレーバーの完全リストの表示ができるのは管理者のみです (「管理 > システム > フレーバー」を選択)。全ユーザーがフレーバーを設定できるようにするには、/etc/nova/policy.json ファイル (nova-api サーバー) で以下の値を指定します。
"compute_extension:flavormanage": "",
3.3.2. フレーバーの作成
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
フレーバーの作成 をクリックして、以下のフィールドに入力します。
表3.4 フレーバーのオプション
タブ フィールド 説明 フレーバー情報
名前
一意な名前
ID
一意な ID。デフォルト値は
autoで、 UUID4 値を生成しますが、整数または UUID4 値 を手動で指定することもできます。仮想 CPU
仮想 CPU 数
メモリー (MB)
メモリー (メガバイト単位)
ルートディスク (GB)
一時ディスクのサイズ (ギガバイト単位)。ネイティブイメージサイズを使用するには
0を指定します。このディスクは、Instance Boot Source=Boot from Volume と指定されている場合には使用されません。一時ディスク (GB)
インスタンスで利用可能なセカンダリー一時ディスクのサイズ (ギガバイト単位)。このディスクは、インスタンスの削除時に破棄されます。
デフォルト値は
0です。この値を指定すると、一時ディスクは作成されません。スワップディスク (MB)
スワップディスクのサイズ (メガバイト単位)
フレーバーアクセス権
選択済みのプロジェクト
そのフレーバーを使用することができるプロジェクト。プロジェクトが選択されていない場合には、全プロジェクトにアクセスが提供されます (
Public=Yes)。- フレーバーの作成をクリックします。
3.3.3. 一般属性の更新
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
- 対象のフレーバーの フレーバーの編集 ボタンをクリックします。
- 値を更新して、保存 をクリックします。
3.3.4. フレーバーのメタデータの更新
一般属性の編集に加えて、フレーバーにメタデータ (extra_specs) を追加することが可能です。メタデータは、インスタンスの使用方法を微調整するのに役立ちます。たとえば、最大許容帯域幅やディスクの書き込みを設定する場合などです。
- 事前定義済みのキーにより、ハードウェアサポートやクォータが決定されます。事前定義済みのキーは、使用するハイパーバイザーによって限定されます (libvirt の場合は 表3.5「Libvirt のメタデータ」を参照してください)。
-
事前定義済みおよびユーザー定義のキーはいずれも、インスタンスのスケジューリングを決定します。たとえば、
SpecialComp=Trueと指定すると、このフレーバーを使用するインスタンスはすべてメタデータのキーと値の組み合わせが同じホストアグリゲートでのみ実行可能となります (「ホストアグリゲートの管理」を参照)。
3.3.4.1. メタデータの表示
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
-
フレーバーの メタデータ リンク (
はいまたはいいえ) をクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。
3.3.4.2. メタデータの追加
キーと値 のペアを使用してフレーバーのメタデータを指定します。
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
-
フレーバーの メタデータ リンク (
はいまたはいいえ) をクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。 - 利用可能なメタデータ で その他 のフィールドをクリックして、追加するキーを指定します (表3.5「Libvirt のメタデータ」を参照)。
- 「+」ボタンをクリックします。 選択済みのメタデータ の下に新しいキーが表示されるようになりました。
右側のフィールドにキーの値を入力します。
- キーと値のペアの追加が終了したら 保存 をクリックします。
表3.5 Libvirt のメタデータ
| キー | 説明 |
|---|---|
|
|
インスタンスごとにサポート制限を設定するアクション。有効なアクションは以下の通りです。
例: |
|
|
インスタンスの NUMA トポロジーの定義。RAM および vCPU の割り当てがコンピュートホスト内の NUMA ノードのサイズよりも大きいフレーバーの場合には、NUMA トポロジーを定義することでホストが NUMA を効果的に使用してゲスト OS のパフォーマンスを向上することができます。フレーバーで定義された NUMA の定義は、イメージの定義をオーバーライドします。有効な定義は以下の通りです。
注記
インスタンスに 8 個の vCPU、4 GB の RAM が指定されている場合の例:
スケジューラーは、NUMA ノードが 2 つあり、そのうちの 1 つのノードで 6 つの CPU および 3 GB のメモリーを実行し、別のノードで 2 つの CPU および 1 GB のメモリーを実行できるホストを検索します。ホストに 8 つの CPU および 4 GB のメモリーを実行できる NUMA ノードが 1 つある場合は、有効な一致とは見なされません。 |
|
|
インスタンスのウォッチドッグデバイスを使用して、インスタンスに何らかの理由でエラー (またはハング) が発生した場合にアクションをトリガーすることができます。有効なアクションは以下の通りです。
例: |
|
|
イメージプロパティーを使用して乱数生成器をインスタンスに追加することができます (Red Hat OpenStack Platform ドキュメントの『Command-Line Interface Reference』で このデバイスを追加した場合の有効なアクションは以下の通りです。
例: |
|
|
ビデオデバイスの最大許容 RAM (MB 単位)
例: |
|
|
インスタンスの制限を強制します。有効なオプションは以下の通りです。
例: さらに、VMware ドライバーは、CPU、メモリー、ディスク、ネットワークの上限、下限を制御する以下のクォータオプションや、テナントで利用可能なリソースの相対割り当てを制御するのに使用可能な 共有 をサポートします。
|
3.4. ホストアグリゲートの管理
パフォーマンスおよび管理目的で、単一の Compute デプロイメントを複数の論理グループにパーティショニングすることができます。OpenStack では以下のような用語を使用しています。
ホストアグリゲート: ホストアグリゲートは、ホストをグループ化してまとめることによって OpenStack デプロイメント内に論理ユニットを作成します。アグリゲートは、割り当てられた Compute ホストと関連付けられたメタデータです。1 台のホストは複数のアグリゲートに属することが可能です。ホストアグリゲートの表示と作成ができるのは管理者のみです。
アグリゲートのメタデータは通常、Compute のスケジューラーで使用する情報を提供します (例: 特定のフレーバーやイメージを複数のホストの 1 つのサブネットに制限するなど)。ホストアグリゲートで指定されるメタデータは、フレーバー内で同じメタデータが指定されているインスタンスにホストの使用を限定します。
管理者は、ホストアグリゲートを使用して、ロードバランスの処理、物理的な分離 (または冗長) の強制、共通の属性を持つサーバーのグループ化、ハードウェアクラスの分類などを行うことができます。アグリゲートの作成時には、ゾーン名を指定する必要があります。この名前がエンドユーザーに表示されます。
アベイラビリティーゾーン: アベイラビリティーゾーンとは、ホストアグリゲートのエンドユーザーのビューです。エンドユーザーはゾーンがどのホストで構成されているかを表示したり、ゾーンのメタデータを確認したりすることはできません。ユーザーが見ることができるのはゾーン名のみです。
一定の機能や一定のエリア内で設定された特定のゾーンを使用するようにエンドユーザーを誘導することができます。
3.4.1. ホストアグリゲートのスケジューリングの有効化
デフォルトでは、ホストアグリゲートのメタデータは、インスタンスの使用先のフィルタリングには使用されません。メタデータの使用を有効にするには、Compute のスケジューラーの設定を更新する必要があります。
-
/etc/nova/nova.confファイルを編集します (root または nova ユーザーのパーミッションが必要です)。 scheduler_default_filtersパラメーターに以下の値が含まれていることを確認します。ホストアグリゲートのメタデータ用の
AggregateInstanceExtraSpecsFilter。たとえば、以下のように記載します。scheduler_default_filters=AggregateInstanceExtraSpecsFilter,RetryFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter
インスタンス起動時のアベイラビリティーゾーンのホストの仕様用の
AvailabilityZoneFilter。たとえば、以下のように記載します。scheduler_default_filters=AvailabilityZoneFilter,RetryFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter
- 設定ファイルを保存します。
3.4.2. アベイラビリティーゾーンまたはホストアグリゲートの表示
Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。アベイラビリティーゾーン のセクションには全ゾーンがリストされます。
3.4.3. ホストアグリゲートの追加
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
- ホストアグリゲートの作成 をクリックします。
- 名前 フィールドにアグリゲートの名前を入力します。この名前が アベイラビリティーゾーン フィールドでエンドユーザーに表示されます。
- アグリゲートのホストの管理 をクリックします。
- 「+」アイコンをクリックしてホストを選択します。
- ホストアグリゲートの作成 をクリックします。
3.4.4. ホストアグリゲートの更新
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
インスタンスの 名前 または アベイラビリティーゾーン を更新するには、以下の手順で行います。
- アグリゲートの ホストアグリゲートの編集 ボタンをクリックします。
- 名前 または アベイラビリティーゾーン のフィールドを更新して、保存 をクリックします。
インスタンスの 割り当て済みのホスト を更新するには、以下の手順で行います。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- ホストの管理 をクリックします。
- 「+」または「-」のアイコンをクリックしてホストの割り当てを変更します。
- 終了したら、保存 をクリックします。
インスタンスの メタデータ を更新するには、以下の手順で行います。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- メタデータの更新 ボタンをクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。
- 利用可能なメタデータ で その他 のフィールドをクリックして、追加するキーを指定します。事前に定義したキー (表3.6「ホストアグリゲートのメタデータ」を参照) を使用するか、独自のキーを追加します (このキーと全く同じキーがインスタンスのフレーバーに設定されている場合にのみ有効となります)。
「+」ボタンをクリックします。 選択済みのメタデータ の下に新しいキーが表示されるようになりました。
注記キーを削除するには、「-」のアイコンをクリックします。
保存 をクリックします。
表3.6 ホストアグリゲートのメタデータ
キー 説明 cpu_allocation_ratio物理 CPU に対する仮想 CPU の割り当ての比率を設定します。これは、Compute のスケジューラーに設定されている
AggregateCoreFilterフィルターによって異なります。disk_allocation_ratio物理ディスクに対する仮想ディスクの割り当ての比率を設定します。これは、Compute のスケジューラーに設定されている
AggregateDiskFilterフィルターによって異なります。filter_tenant_id指定した場合には、アグリゲートはこのテナント (プロジェクト) のみをホストします。これは、Compute のスケジューラーに設定されている
AggregateMultiTenancyIsolationフィルターによって異なります。ram_allocation_ratio物理メモリーに対する仮想メモリーの割り当ての比率を設定します。これは、Compute のスケジューラーに設定されている
AggregateRamFilterフィルターによって異なります。
3.4.5. ホストアグリゲートの削除
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
割り当てられている全ホストをアグリゲートから削除します。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- ホストの管理 をクリックします。
- 「-」アイコンをクリックして、全ホストを削除します。
- 終了したら、保存 をクリックします。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- このダイアログ画面と次の画面で ホストアグリゲートの削除 をクリックします。
3.5. ホストとセルのスケジュール
Compute のスケジューリングサービスは、インスタンスの配置先となるセルまたはホスト (もしくはホストアグリゲート) を決定します。管理者は、設定を使用して、スケジューラーによるインスタンスの配置先の決定方法を定義することができます。たとえば、特定のグループや適切な量の RAM があるホストにスケジューリングを限定することが可能です。
以下のコンポーネントを設定することができます。
- フィルター: インスタンスの配置先候補となるホストの初期セットを決定します (「スケジューリングフィルターの設定」を参照)。
- 重み: フィルタリングの完了時に選出されたホストのセットは重み付けのシステムを使用して優先順位が決定されます。最も高い重みが最優先されます (「スケジューリングの重みの設定」を参照)。
-
スケジューラーサービス: スケジューラーホスト上の
/etc/nova/nova.confファイルには数多くの設定オプションがあります。これらのオプションは、スケジューラーがタスクを実行する方法や、重み/フィルターを処理する方法を決定します。ホストとセルの両方にスケジューラーがあります。これらのオプションの一覧は『Configuration Reference』(RHEL OpenStack Platform の製品ドキュメント) を参照してください。
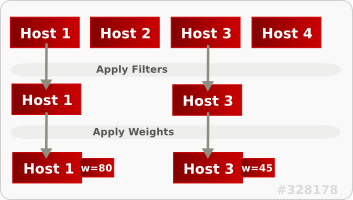
下図では、フィルタリング後には Host 1 と Host 3 の両方が条件に適合しています。Host 1 の重みが最も高いため、スケジューリングで最優先されます。
3.5.1. スケジューリングフィルターの設定
scheduler_default_filters オプションでスケジューラーが使用するフィルターを定義します (/etc/nova/nova.conf ファイル。root または nova ユーザーのパーミッションが必要)。
デフォルトでは、以下のフィルターがスケジューラーで実行されるように設定されています。
scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,ServerGroupAntiAffinityFilter,ServerGroupAffinityFilter
一部のフィルターは、以下の方法でインスタンスに渡されるパラメーターの情報を使用します。
-
nova bootコマンド (RHEL OpenStack Platform ドキュメント の『Command-Line Interface Reference』を参照) - インスタンスのフレーバー (「フレーバーのメタデータの更新」を参照)
- インスタンスのイメージ (「付録A イメージの設定パラメーター」を参照)
以下の表には、利用可能な全フィルターをまとめています。
表3.7 スケジューリングフィルター
| フィルター | 説明 |
|---|---|
|
AggregateCoreFilter |
ホストアグリゲートのメタデータキー cpu_allocation_ratio を使用して、オーバーコミット比 (物理 CPU に対する仮想 CPU の割り当ての比率) を超過したホストを除外します。これは、インスタンスにホストアグリゲートが指定されている場合のみに有効です。 |
|
この比率が設定されている場合には、フィルターは /etc/nova/nova.conf ファイルの cpu_allocation_ratio の値を使用します。デフォルト値は | |
|
AggregateDiskFilter |
ホストアグリゲートのメタデータキー disk_allocation_ratio を使用して、オーバーコミット比 (物理ディスクに対する仮想ディスクの割り当ての比率) を超過したホストを除外します。これは、インスタンスにホストアグリゲートが指定されている場合のみに有効です。 |
|
この比率が設定されている場合には、フィルターは /etc/nova/nova.conf ファイルの disk_allocation_ratio の値を使用します。デフォルト値は | |
|
AggregateImagePropertiesIsolation |
インスタンスのイメージのメタデータが一致するホストアグリゲート内のホストのみを渡します。これは、そのインスタンスにホストアグリゲートが指定されている場合にのみ有効です。詳しい情報は、「イメージの作成」を参照してください。 |
|
AggregateInstanceExtraSpecsFilter |
ホストアグリゲート内のメタデータは、ホストのフレーバーのメタデータと一致する必要があります。詳しい情報は、「フレーバーのメタデータの更新」を参照してください。 |
|
AggregateMultiTenancyIsolation |
filter_tenant_id を指定したホストには、そのテナント (プロジェクト) からのインスタンスのみを配置することができます。 注記 テナントが他のホストにインスタンスを配置することは可能です。 |
|
AggregateRamFilter |
ホストアグリゲートのメタデータキー ram_allocation_ratio を使用して、オーバーコミット比 (物理メモリーに対する仮想メモリーの割り当ての比率) を超過したホストを除外します。これは、インスタンスにホストアグリゲートが指定されている場合のみに有効です。 |
|
この比率が設定されている場合には、フィルターは /etc/nova/nova.conf ファイルの ram_allocation_ratio の値を使用します。デフォルト値は | |
|
AllHostsFilter |
利用可能な全ホストを渡します (ただし、他のフィルターは無効化しません)。 |
|
AvailabilityZoneFilter |
インスタンスに指定されているアベイラビリティーゾーンを使用してフィルタリングします。 |
|
ComputeCapabilitiesFilter |
Compute のメタデータが正しく読み取られるようにします。「 |
|
ComputeFilter |
稼働中の有効なホストのみを渡します。 |
|
CoreFilter |
|
|
DifferentHostFilter |
指定されている単一または複数のホストとは別のホスト上でインスタンスをビルドできるようにします。 |
|
DiskFilter |
|
|
ImagePropertiesFilter |
インスタンスのイメージプロパティーに一致するホストのみを渡します。詳しい情報は、「イメージの作成」を参照してください。 |
|
IsolatedHostsFilter |
|
|
JsonFilter |
インスタンスのカスタム JSON フィルターを認識/使用します。
|
|
このフィルターは、クエリーヒントとして
| |
|
MetricFilter |
メトリックが利用できないホストを除外します。 |
|
NUMATopologyFilter |
NUMA トポロジーに基づいてホストを除外します。インスタンスにトポロジーが未定義の場合には、任意のホストを使用することができます。このフィルターは、NUMA トポロジーが完全に同じインスタンスとホストをマッチングするように試みます (そのホスト上ではインスタンスのスケジューリングは試みません)。また、このフィルターは、NUMA ノードの標準的なオーバーサブスクリプションの上限を確認し、それに応じて、コンピュートホストに対して制限を指定します。 |
|
RamFilter |
|
|
RetryFilter |
スケジュールを試みて失敗したホストを除外します。scheduler_max_attempts の値がゼロを超える場合に有効です (デフォルトでは、 |
|
SameHostFilter |
指定されている単一または複数のホストを渡します。 |
|
ServerGroupAffinityFilter |
特定のサーバーグループのホストのみを渡します。
|
|
ServerGroupAntiAffinityFilter |
インスタンスをまだホストしていないサーバーグループ内のホストのみを渡します。
|
|
SimpleCIDRAffinityFilter |
インスタンスの cidr および
|
3.5.2. スケジューリングの重みの設定
セルとホストはいずれも、スケジューリング用に重み付けすることができます。(フィルタリング後に) 重みが最大のホストまたはセルが選択されます。重み付け関数にはすべて、ノードの重みを正規化した後に適用される乗数が指定されます。ノードの重みは以下のように計算されます。
w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
重みのオプションは、ホストの /etc/nova/nova.conf ファイルで設定することができます (root または nova ユーザーのパーミッションが必要です)。
3.5.2.1. ホストの重みのオプション設定
スケジューラーが使用するホストの重み付け関数は、[DEFAULT] scheduler_weight_classes のオプションで定義することができます。有効な重み付け関数は以下の通りです。
-
nova.scheduler.weights.ram: ホストの使用可能なメモリーを重み付けします。 -
nova.scheduler.weights.metrics: ホストのメトリックを重み付けします。 -
nova.scheduler.weights.affinity: 特定のサーバーグループ内にある他のホストとのホストの近接性を重み付けします。 -
nova.scheduler.weights.all_weighers: 全ホストの重み付け関数を使用します (デフォルト)。
表3.8 ホストの重みのオプション
| 重み付け関数 | オプション | 説明 |
|---|---|---|
|
all |
[DEFAULT] scheduler_host_subset_size |
ホストの選択先のサブセットサイズを定義します (整数)。 |
|
アフィニティー |
[default] |
グループソフトアフィニティーのホストを重み付けする際に使用します。正の浮動小数点数を指定してください。これは、負の値を指定すると反対の動作が発生してしまうためです。通常、このような反対の動作は、 |
|
アフィニティー |
[default] |
グループソフト非アフィニティーのホストを重み付けする際に使用します。正の浮動小数点数を指定してください。これは、負の値を指定すると反対の動作が発生してしまうためです。通常、このような反対の動作は、 |
|
metrics |
[metrics] required |
[metrics]
|
|
metrics |
[metrics] |
[metrics] |
|
metrics |
[metrics] |
メトリックを重み付けする乗数。デフォルトでは |
|
metrics |
[metrics] |
重み付けに使用されるメトリックと比率を指定します。
例: |
|
ram |
[DEFAULT] |
RAM の乗数 (浮動小数点)。デフォルトでは、 |
3.5.2.2. セルの重みオプションの設定
[cells] scheduler_weight_classes オプション (/etc/nova/nova.conf ファイル。root または nova ユーザーのパーミッションが必要) でスケジューラーが使用するセルの重み付け関数を定義します。
本リリースでは、セルの使用機能は テクノロジープレビュー として提供されているため、Red Hat では全面的にはサポートしていません。これは、テスト目的のみでご利用いただく機能で、実稼働環境にデプロイすべきではありません。 テクノロジープレビューについての詳しい情報は Scope of Coverage Details を参照してください。
有効な重み付け関数:
-
nova.cells.weights.all_weighers: すべてのセルの重み付け関数を使用します (デフォルト)。 -
nova.cells.weights.mute_child: セルが容量や機能の更新をしばらく送信していなかったかどうかによって重み付けします。 -
nova.cells.weights.ram_by_instance_type: セルの使用可能な RAM を重み付けします。 nova.cells.weights.weight_offset: セルの重みのオフセットを評価します。注記セルの重みのオフセットは、
--woffset `in the `nova-manage cell createコマンドを使用して指定します。
表3.9 セルの重みのオプション
| 重み付け関数 | オプション | 説明 |
|---|---|---|
|
|
[cells] |
しばらく更新がなかったホストの乗数 (負の浮動小数点)。デフォルトではこの値は |
|
|
[cells] |
更新がなかったホストに適用される重みの値 (正の浮動小数点)。デフォルトでは、この値は |
|
|
[cells] |
RAM の重み付け乗数 (浮動小数点)。デフォルトではこの値は |
|
|
[cells] |
セルを重み付けする乗数 (浮動小数点)。重みのオフセットを |
3.6. インスタンスの退避
停止中またはシャットダウンされたコンピュートノードから同じ環境内の新規ホストサーバーにインスタンスを移動するには (例: サーバーをスワップアウトする必要がある場合など)、nova evacuate を使用してそのサーバーを退避することができます。
- 退避は、インスタンスのディスクが共有ストレージ上にある場合またはインスタンスのディスクが Block Storage ボリュームである場合にのみ有用です。それ以外の場合には、ディスクへのアクセスは不可能なので、新規コンピュートノードからアクセスはできません。
-
インスタンスは、サーバーがシャットダウンされている場合にのみ退避させることができます。サーバーがシャットダウンされなていない場合には、
evacuateコマンドは失敗します。
正常に機能するコンピュートノードがある場合には、以下のような操作が可能です。
-
バックアップ目的またはインスタンスを別の環境にコピーするために静的な (実行中でない) インスタンスのコピーを作成:
nova image-createを使用してスナップショットを作成します (「静的なインスタンスの移行」の記事を参照)。 -
静的 (実行中でない) 状態のインスタンスを同じ環境内の別のホストに移動 (共有ストレージが必要):
nova migrateを使用して移行します (「静的なインスタンスの移行」の記事を参照)。 -
稼働状態 (実行中) のインスタンスを同じ環境内の別のホストに移動:
nova live-migrationコマンドを使用して移行します (「ライブ (実行中の) インスタンスの移行」の記事を参照)。
3.6.1. 単一のインスタンスの退避
以下のコマンドを実行して、インスタンスを 1 つ退避します。
# nova evacuate [--password pass] instance_name [target_host]
各オプションについての説明は以下の通りです。
-
--password: 退避するインスタンスに設定する管理パスワード (--on-shared-storageが指定されている場合には使用できません)。パスワードを指定しなかった場合には、無作為に生成され、退避の完了時に出力されます。 -
instance_name: 退避するインスタンスの名前 target_host: インスタンスの退避先となるホスト。このホストを指定しなかった場合には、Compute のスケジューラーがホストを 1 台選択します。退避先に指定可能なホストを確認するには、以下のコマンドを実行します。# nova host-list | grep compute
以下に例を示します。
# nova evacuate myDemoInstance Compute2_OnEL7.myDomain
-
3.6.2. 全インスタンスの退避
以下のコマンドを実行して、指定したホストに全インスタンスを退避します。
# nova host-evacuate instance_name [--target target_host] source_host
各オプションについての説明は以下の通りです。
--target: インスタンスの退避先となるホスト。このホストを指定しなかった場合には、Compute のスケジューラーがホストを 1 台選択します。退避先に指定可能なホストを確認するには、以下のコマンドを実行します。# nova host-list | grep compute
source_host: 退避されるホストの名前以下に例を示します。
# nova host-evacuate --target Compute2_OnEL7.localdomain myDemoHost.localdomain
3.7. インスタンスのスナップショットの管理
インスタンスのスナップショットを使用すると、インスタンスから新規イメージを作成することができます。これは、ベースイメージのアップロードや、公開イメージを取得してローカルで使用するためにカスタマイズする際に非常に便利です。
Image サービスに直接アップロードしたイメージと、スナップショットで作成したイメージの相違点は、スナップショットで作成したイメージには Image サービスデータベースのプロパティーが追加されている点です。これらのプロパティーは image_properties テーブルにあり、以下のパラメーターが含まれます。
表3.10 スナップショットのオプション
| 名前 | 値 |
|---|---|
|
image_type |
snapshot |
|
instance_uuid |
<スナップショットを作成したインスタンスの uuid> |
|
base_image_ref |
<スナップショットを作成したインスタンスのオリジナルイメージの uuid> |
|
image_location |
snapshot |
スナップショットでは、指定のスナップショットをベースにして新規インスタンスを作成して、その状態にインスタンスを復元することができます。さらに、インスタンスの実行中にスナップショットを作成や復元が可能です。
デフォルトでは、スナップショットをベースとするインスタンスが起動している間は、選択したユーザーとプロジェクトがそのスナップショットにアクセスできます。
3.7.1. インスタンスのスナップショットの作成
インスタンスのスナップショットをテンプレートとして使用して新規インスタンスを作成する場合には、ディスクの状態が一貫していることを確認してください。スナップショットを作成する前に、スナップショットのイメージメタデータのプロパティーを os_require_quiesce=yes に設定します。以下の例を示します。
$ glance image-update IMAGE_ID --property os_require_quiesce=yes
このコマンドが機能するには、ゲストに qemu-guest-agent パッケージがインストール済みで、メタデータプロパティーのパラメーターを hw_qemu_guest_agent=yes に指定してイメージを作成する必要があります。以下に例を示します。
$ glance image-create --name NAME \ --disk-format raw \ --container-format bare \ --file FILE_NAME \ --is-public True \ --property hw_qemu_guest_agent=yes \ --progress
hw_qemu_guest_agent=yes パラメーターを無条件で有効化した場合には、別のデバイスをゲストに追加してください。この設定により、PCI スロットが使用され、ゲストに割り当てることのできる他のデバイスの数が制限されます。また、これにより、Windows ゲストでは、未知のハードウェアデバイスについての警告のメッセージが表示されます。
このような理由により、hw_qemu_guest_agent=yes パラメーターの設定はオプションとなっており、QEMU ゲストエージェントを必要とするそれらのイメージにのみ使用すべきです。
- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- スナップショットを作成するインスタンスを選択します。
- アクション コラムで、スナップショットの作成 をクリックします。
スナップショットの作成 ダイアログでは、スナップショットの名前を入力して スナップショットの作成 をクリックします。
イメージ カテゴリーには、インスタンスのスナップショットが表示されます。
スナップショットからインスタンスを起動するには、スナップショットを選択して 起動 をクリックします。
3.7.2. スナップショットの管理
- Dashboard で プロジェクト > イメージ を選択します。
- 作成したスナップショットはすべて プロジェクト オプションの下に表示されます。
作成するスナップショットごとに、ドロップダウンリストを使用して以下の機能を実行できます。
- ボリュームの作成 オプションを使用して、ボリュームの名前、説明、ソース、種別、サイズ、アベイラビリティーゾーンを入力してボリュームを作成します。詳しくは、Red Hat OpenStack Platform で『ストレージ管理ガイド』の「ボリュームの作成」の項を参照してください。
- イメージの編集 オプションを使用して、名前、説明、カーネル ID、Ramdisk ID、アーキテクチャー、形式、最小ディスク (GB)、最小メモリー (MB)、パブリックまたはプライベートを更新して、スナップショットのイメージを更新します。詳しい情報は 「イメージの更新」 を参照してください。
- イメージの削除 オプションを使用してスナップショットを削除します。
3.7.3. スナップショットの状態へのインスタンスの再構築
スナップショットがベースとなっているインスタンスを削除する場合には、スナップショットにはインスタンス ID が保存されます。nova image-list コマンドを使用してこの情報を確認して、スナップショットでインスタンスを復元します。
- Dashboard で プロジェクト > コンピュート > イメージ を選択します。
- インスタンスを復元するスナップショットを選択します。
- アクション コラムで、インスタンスの起動 をクリックします。
- インスタンスの起動 ダイアログで、インスタンスの名前とその他の詳細を入力して 起動 をクリックします。
インスタンスの起動に関する詳しい情報は 「インスタンスの作成」を参照してください。
3.7.4. 一貫性のあるスナップショット
以前のリリースでは、バックアップの一貫性を確保するには、アクティブなインスタンスのスナップショットを作成する前にファイルシステムを手動で停止 (fsfreeze) する必要がありました。
Compute の libvirt ドライバーは、QEMU ゲストーエージェント にファイルシステムを (fsfreeze-hook がインストールされている場合には、アプリケーションも対象) フリーズするように自動的に要求するようになりました。ファイルシステムの停止に対するサポートにより、スケジュールされた自動スナップショット作成をブロックデバイスレベルで実行できるようになりました。
この機能は、QEMU ゲストエージェント (qemu-ga) がインストール済みで、かつイメージのメタデータで有効化されている (hw_qemu_guest_agent=yes) 場合にのみ有効です。
スナップショットは、実際のシステムバックアップの代わりとみなすべきではありません。
3.8. インスタンスのレスキューモードの使用
Compute では、仮想マシンをレスキューモードで再起動する方法があります。レスキューモードは、仮想マシンイメージが原因で、インスタンスがアクセス不可能な状態となっている場合に、そのインスタンスにアクセスするためのメカニズムを提供します。レスキューモードの仮想マシンは、ユーザーが仮想マシンに新規 root パスワードを使用してアクセスし、そのマシンを修復することができます。この機能は、インスタンスのファイルシステムが破損した場合に役立ちます。デフォルトでは、レスキューモードのインスタンスは初期イメージから起動して、第 2 のイメージとして現在のブートディスクをアタッチします。
3.8.1. レスキューモードのインスタンス用のイメージの準備
ブートディスクとレスキューモード用のディスクには同じ UUID が使用されているため、仮想マシンがレスキューモード用のディスクの代わりにブートディスクから起動されてしまう可能性があります。
この問題を回避するには、「イメージの作成」の手順に従い、レスキューイメージとして新しいイメージを作成してください。
rescue イメージは、デフォルトでは glance に保管され、nova.conf で設定されていますが、レスキューを実行する際に選択することもできます。
3.8.1.1. ext4 ファイルシステムを使用している場合のレスキューイメージ
ベースイメージが ext4 ファイルシステムを使用する場合には、以下の手順を使用してそれをベースにレスキューイメージを作成できます。
tune2fsコマンドを使用して、UUID を無作為な値に変更します。# tune2fs -U random /dev/DEVICE_NODE
DEVICE_NODE はルートデバイスノードに置き換えます (例:
sda、vdaなど)。新しい UUID を含む、ファイルシステムの詳細を確認します。
# tune2fs -l
-
/etc/fstabファイルで UUID を新しい値に置き換えます。fstabにマウントされている追加のパーティションがある場合には、 UUID を新しい値に置き換える必要がある場合があります。 -
/boot/grub2/grub.confファイルを更新し、ルートディスクの UUID パラメーターを新しい UUID に置き換えます。 - シャットダウンして、このイメージをレスキューイメージに使用します。これにより、レスキューイメージには新たに無作為な UUID が割り当てられ、レスキューするインスタンスとの競合が発生しなくなります。
XFS ファイルシステムでは、実行中の仮想マシン上のルートデバイスの UUID は変更できません。仮想マシンがレスキューモード用のディスクから起動するまで再起動を続けます。
3.8.2. OpenStack Image サービスへのレスキューイメージの追加
対象のイメージの UUID を変更したら、以下のコマンドを実行して、生成されたレスキューイメージを OpenStack Image サービスに追加します。
Image サービスにレスキューイメージを追加します。
# glance image-create --name IMAGE_NAME --disk-format qcow2 \ --container-format bare --is-public True --file IMAGE_PATH
IMAGE_NAME は、イメージの名前に、 IMAGE_PATH はイメージの場所に置き換えます。
image-listコマンドを使用して、インスタンスをレスキューモードで起動するのに必要な IMAGE_ID を取得します。# glance image-list
OpenStack Dashboard を使用してイメージをアップロードすることも可能です。「イメージのアップロード」の項を参照してください。
3.8.3. レスキューモードでのインスタンスの起動
デフォルトのイメージではなく、特定のイメージを使用してインスタンスをレスキューする必要があるため、
--rescue_image_refパラメーターを使用します。# nova rescue --rescue_image_ref IMAGE_ID VIRTUAL_MACHINE_ID
IMAGE_ID は使用するイメージ ID に、VIRTUAL_MACHINE_ID はレスキューする仮想マシンの ID に置き換えます。
注記nova rescueコマンドを使用すると、インスタンスでソフトシャットダウンを実行することができます。これにより、ゲストオペレーティングシステムは、インスタンスの電源をオフにする前に、 制御されたシャットダウンを実行することができます。シャットダウンの動作は、nova.confファイルのshutdown_timeoutパラメーターで設定することができます。この値は、ゲストオペレーティングシステムが完全にシャットダウンするまでの合計時間 (秒単位) を指定します。デフォルトのタイムアウトは 60 秒です。このタイムアウト値は、
os_shutdown_timeoutでイメージ毎に上書きすることが可能です。これは、異なるタイプのオペレーティングシステムでクリーンにシャットダウンするために必要な時間を指定するイメージのメタデータ設定です。- 仮想マシンを再起動します。
-
nova listコマンドまたは Dashboard を使用して、コントローラーノード上で仮想マシンのステータスが RESCUE であることを確認します。 - レスキューモード用のパスワードを使用して、新しい仮想マシンのダッシュボードにログインします。
これで、インスタンスに必要な変更を加えて、問題を修正できる状態となりました。
3.8.4. インスタンスのアンレスキュー
修正したインスタンスは unrescue して、ブートディスクから再起動することができます。
コントローラーノードで以下のコマンドを実行します。
# nova unrescue VIRTUAL_MACHINE_ID
VIRTUAL_MACHINE_ID はアンレスキューする仮想マシンの ID に置き換えます。
アンレスキューの操作が正常に完了すると、インスタンスのステータスは ACTIVE に戻ります。