
インスタンス&イメージガイド
インスタンスとイメージの管理
概要
前書き
Red Hat OpenStack Platform は、Red Hat Enterprise Linux をベースとして、プライベートまたはパブリックの Infrastructure-as-a-Service (IaaS) クラウドを構築するための基盤を提供します。これにより、スケーラビリティーが極めて高く、耐障害性に優れたプラットフォームをクラウド対応のワークロード開発にご利用いただくことができます。
本ガイドでは、イメージとインスタンスの作成/管理手順について説明します。また、Red Hat OpenStack Platform のインスタンス用ストレージの設定手順も記載しています。
OpenStack Dashboard またはコマンドラインクライアントを使用してクラウドの管理を行うことができます。大半の手順は、これらのいずれかの方法を使用することができますが、一部の高度な手順はコマンドラインのみで実行可能となっています。本ガイドでは、可能な場合には Dashboard を使用する手順を記載しています。
Red Hat OpenStack Platform の全ドキュメントスイートは Red Hat OpenStack Platform の製品ドキュメント で参照してください。
第1章 Image サービス
本章では、Red Hat OpenStack Platform でイメージとストレージを管理するための手順を説明します。
仮想マシンのイメージとは、起動可能なオペレーティングシステムがインストールされた仮想ディスクを含むファイルです。仮想マシンのイメージは、複数の形式をサポートしています。以下は、Red Hat OpenStack Platform で利用可能な形式です。
-
RAW: 非構造化のディスクイメージ形式 -
QCOW2: QEMU エミュレーターでサポートされているディスク形式。この形式には、QEMU 1.1 以降が必要な QCOW2v3 (QCOW3 と呼ばれる場合があります) が含まれます。 -
ISO: ディスク上のデータをセクター単位でコピーし、バイナリーファイルに格納した形式 -
AKI: Amazon Kernel Image -
AMI: Amazon Machine Image -
ARI: Amazon RAMDisk Image -
VDI: VirtualBox の仮想マシンモニターおよび QEMU エミュレーターでサポートされているディスク形式 -
VHD: VMware、VirtualBox などの仮想マシンモニターで使用されている一般的なディスク形式 -
VMDK: 数多くの一般的な仮想マシンモニターでサポートされているディスク形式
通常、仮想マシンイメージの形式に ISO は考慮されませんが、ISO にはオペレーティングシステムがインストール済みのブート可能なファイルシステムが含まれているので、他の形式の仮想マシンイメージファイルと同様に扱うことができます。
公式の Red Hat Enterprise Linux クラウドイメージをダウンロードするには、お使いのアカウントに有効な Red Hat Enterprise Linux サブスクリプションが必要です。
カスタマーポータルにログインしていない場合には、Red Hat アカウントの認証情報を入力するように求められます。
1.1. Image サービスについての理解
OpenStack Image サービス (glance) は、以下のような注目すべき機能を提供しています。
1.1.1. イメージの署名および検証
イメージの署名および検証により、デプロイ担当者がイメージに署名して、その署名と公開鍵の証明書をイメージのプロパティーとして保存できるようにすることで、イメージの整合性と信頼性を保護します。
この機能を活用すると、以下が可能になります。
- 秘密鍵を使用してイメージに署名し、そのイメージ、署名、公開鍵の証明書 (検証メタデータ) への参照をアップロードすることができます。Image サービスは、署名が有効かどうかを検証します。
- Compute サービスでイメージを作成し、Compute サービスがそのイメージに署名し、イメージや検証メタデータをアップロードすることができます。Image サービスは、この場合も、署名が有効であるかどうかを検証します。
- Compute サービスで署名済みのイメージを要求することができます。Image サービスは、イメージと検証メタデータを提供します。これにより、Compute サービスはイメージを起動する前に検証することができます。
イメージの署名および検証に関する詳しい情報は、『 Manage Secrets with OpenStack Key Manager』 の「 Validate Glance images」の章を参照してください。
1.1.2. イメージの変換
イメージの変換は、イメージのインポート中にタスク API を呼び出して、イメージを変換します。
インポートのワークフローの一環として、プラグインがイメージの変換機能を提供します。このプラグインは、デプロイ担当者の設定に基づいて、アクティブ化/非アクティブ化することができます。そのため、デプロイ担当者は、デプロイメントに希望のイメージ形式を指定する必要があります。
内部では、Image サービスが特定の形式でイメージのビットを受信します。これらのビットは、一時的な場所に保管されます。次にプラグインが起動されて、イメージを対象のフォーマットに変換し、最終的な保管場所に移動します。タスクが終了すると、一時的な場所は削除されます。このため、Image サービスでは最初にアップロードした形式は保持されません。
イメージの変換についての詳細は、「イメージ変換の有効化」を参照してください。
イメージの変換は、イメージをインポートする時にだけトリガーされます。イメージのアップロード時には実行されません。以下に例を示します。
$ glance image-create-via-import \
--disk-format qcow2 \
--container-format bare \
--name NAME \
--visibility public \
--import-method web-download \
--uri http://server/image.qcow21.1.3. イメージのイントロスペクション
イメージ形式はすべて、イメージ自体の中にメタデータセットが埋め込まれた状態で提供されます。たとえば、ストリーム最適化 VMDK には、以下のようなパラメーターが含まれます。
$ head -20 so-disk.vmdk # Disk DescriptorFile version=1 CID=d5a0bce5 parentCID=ffffffff createType="streamOptimized" # Extent description RDONLY 209714 SPARSE "generated-stream.vmdk" # The Disk Data Base #DDB ddb.adapterType = "buslogic" ddb.geometry.cylinders = "102" ddb.geometry.heads = "64" ddb.geometry.sectors = "32" ddb.virtualHWVersion = "4"
この vmdk をイントロスペクションすることにより、disk_type が streamOptimized で、adapter_type が buslogic であることを簡単に確認することができます。これらのメタデータパラメーターは、イメージのコンシューマーに役立ちます。Compute では、streamOptimized ディスクをインスタンス化するワークフローは、flat ディスクをインスタンス化するワークフローとは完全に異なります。この新機能により、メタデータの抽出が可能となります。イメージのイントロスペクションは、イメージのインポート中に、タスク API を呼び出すことによって実行できます。管理者は、メタデータの設定をオーバーライドすることができます。
1.1.4. 相互運用可能なイメージのインポート
OpenStack Image サービスでは、相互運用可能なイメージインポートワークフローを使用して、イメージをインポートするための 2 つの方法が提供されています。
-
URI からイメージをインポートする
web-download(デフォルト) -
ローカルファイルシステムからインポートする
glance-direct
1.1.5. Image サービスのキャッシュ機能を使用したスケーラビリティーの向上
glance-api キャッシュメカニズムを使用して、ローカルマシンにイメージのコピーを保存し、イメージを自動的に取得してスケーラビリティーを向上させます。Image サービスのキャッシュ機能を使用することで、複数のホスト上で glance-api を実行することができます。つまり、同じイメージをバックエンドストレージから何度も取得する必要はありません。Image サービスのキャッシュ機能は、Image サービスの動作には一切影響を与えません。
Red Hat OpenStack Platform director (tripleo) heat テンプレートを使用して Image サービスのキャッシュ機能を設定するには、以下の手順を実施します。
手順
環境ファイルの
GlanceCacheEnabledパラメーターの値をtrueに設定します。これにより、glance-api.confHeat テンプレートのflavorの値が自動的にkeystone+cachemanagementに設定されます。parameter_defaults: GlanceCacheEnabled: true-
オーバークラウドを再デプロイする際に、
openstack overcloud deployコマンドにその環境ファイルを追加します。 オプション: オーバークラウドを再デプロイする際に、
glance_cache_prunerを異なる頻度に調節します。5 分間の頻度の例を以下に示します。parameter_defaults: ControllerExtraConfig: glance::cache::pruner::minute: '*/5'ファイルシステムを使い果たす状況を回避するために、ご自分のニーズに合わせて頻度を調節します。異なる頻度を選択する場合は、以下の要素を考慮に入れます。
- 実際の環境でキャッシュするファイルのサイズ
- 利用可能なファイルシステムの容量
- 環境がイメージをキャッシュする頻度
1.1.6. イメージの事前キャッシュ
この機能は、本リリースでは テクノロジープレビュー として提供しているため、Red Hat では全面的にはサポートしていません。これは、テスト用途にのみご利用いただく機能で、実稼働環境にデプロイすべきではありません。テクノロジープレビュー機能についての詳しい情報は、「対象範囲の詳細」を参照してください。
1.1.6.1. 定期的にイメージを事前キャッシュする際のデフォルト間隔の設定
Red Hat OpenStack Platform director は、glance-api サービスの一部としてイメージを事前キャッシュできるようになったので、イメージを事前キャッシュするのに glance-registry は必要なくなりました。デフォルトの間隔は 300 秒です。実際の要件に応じて、デフォルトの間隔を増減することができます。
手順
アンダークラウドの環境ファイルの
ExtraConfigパラメーターを使用して、実際の要件に応じて新しい間隔を追加します。parameter_defaults: ControllerExtraConfig: glance::config::glance_api_config: DEFAULT/cache_prefetcher_interval: value: '<300>'<300> を、イメージを事前キャッシュする間隔の秒数に置き換えてください。
/home/stack/templates/の環境ファイルで間隔を修正したら、stackユーザーとしてログインして設定をデプロイします。$ openstack overcloud deploy --templates \ -e /home/stack/templates/<ENV_FILE>.yaml
<ENV_FILE> は、追加した
ExtraConfig設定が含まれる環境ファイルの名前に置き換えてください。
オーバークラウドの作成時に追加の環境ファイルを渡した場合には、予定外の変更がオーバークラウドに加えられないように、ここで -e オプションを使用して環境ファイルを再度渡します。
openstack overcloud deploy コマンドについての詳しい情報は、『 director のインストールと使用方法』 の「 デプロイメントコマンド 」を参照してください。
1.1.6.2. 定期的なジョブを使用したイメージの事前キャッシュ
前提条件
定期的なジョブを使用してイメージを事前キャッシュするには、glance_api サービスを実行しているノードに直接接続された glance-cache-manage コマンドを使用する必要があります。サービスの要求に応答するノードを非表示にするプロキシーは使用しないでください。アンダークラウドは glance_api サービスを実行しているネットワークにアクセスできない可能性があるため、最初のオーバークラウドノード (デフォルトでは controller-0 という名前です) でコマンドを実行します。
以下のアクションを確認するには、以下の前提条件の手順を実行します。
- 適切なホストからコマンドを実行します。
- 必要な認証情報がある。
glance-apiコンテナー内からglance-cache-manageコマンドを実行している。アンダークラウドに
stackユーザーとしてログインし、controller-0のプロビジョニング IP アドレスを特定します。$ ssh stack@undercloud-0 [stack@undercloud-0 ~]$ source ~/overcloudrc (overcloud) [stack@undercloud-0 ~]$ openstack server list -f value -c Name -c Networks | grep controller overcloud-controller-1 ctlplane=192.168.24.40 overcloud-controller-2 ctlplane=192.168.24.13 overcloud-controller-0 ctlplane=192.168.24.71 (overcloud) [stack@undercloud-0 ~]$
オーバークラウドに対して認証するには、
/home/stack/overcloudrc(デフォルト) に保存されている認証情報をcontroller-0にコピーします。(overcloud) [stack@undercloud-0 ~]$ scp ~/overcloudrc heat-admin@192.168.24.71:/home/heat-admin/
controller-0にheat-adminユーザーとして接続します。(overcloud) [stack@undercloud-0 ~]$ ssh heat-admin@192.168.24.71
controller-0において、heat-adminユーザーとしてglance_api serviceの IP アドレスを特定します。以下の例では、IP アドレスは172.25.1.105です。[heat-admin@controller-0 ~]$ sudo grep -A 10 '^listen glance_api' /var/lib/config-data/puppet-generated/haproxy/etc/haproxy/haproxy.cfg listen glance_api server controller0-0.internalapi.redhat.local 172.25.1.105:9292 check fall 5 inter 2000 rise 2 ...
「glance-cache-manage\」コマンドは
glance_apiコンテナーでしか利用できないので、オーバークラウド認証の環境変数がすでに設定されているコンテナーに対して実行するスクリプトを作成する必要があります。controller-0の/home/heat-adminに、以下の内容でスクリプトglance_pod.shを作成します。sudo podman exec -ti \ -e NOVA_VERSION=$NOVA_VERSION \ -e COMPUTE_API_VERSION=$COMPUTE_API_VERSION \ -e OS_USERNAME=$OS_USERNAME \ -e OS_PROJECT_NAME=$OS_PROJECT_NAME \ -e OS_USER_DOMAIN_NAME=$OS_USER_DOMAIN_NAME \ -e OS_PROJECT_DOMAIN_NAME=$OS_PROJECT_DOMAIN_NAME \ -e OS_NO_CACHE=$OS_NO_CACHE \ -e OS_CLOUDNAME=$OS_CLOUDNAME \ -e no_proxy=$no_proxy \ -e OS_AUTH_TYPE=$OS_AUTH_TYPE \ -e OS_PASSWORD=$OS_PASSWORD \ -e OS_AUTH_URL=$OS_AUTH_URL \ -e OS_IDENTITY_API_VERSION=$OS_IDENTITY_API_VERSION \ -e OS_COMPUTE_API_VERSION=$OS_COMPUTE_API_VERSION \ -e OS_IMAGE_API_VERSION=$OS_IMAGE_API_VERSION \ -e OS_VOLUME_API_VERSION=$OS_VOLUME_API_VERSION \ -e OS_REGION_NAME=$OS_REGION_NAME \ glance_api /bin/bash
source コマンドで
overcloudrcファイルを読み込み、glance_pod.shスクリプトを実行して、オーバークラウドのコントローラーノードに対して認証するのに必要な環境変数が設定されているglance_apiコンテナーに対して実行します。[heat-admin@controller-0 ~]$ source overcloudrc (overcloudrc) [heat-admin@controller-0 ~]$ bash glance_pod.sh ()[glance@controller-0 /]$
glance image-list等のコマンドを使用して、コンテナーでオーバークラウドに対して認証されたコマンドを実行できることを確認します。()[glance@controller-0 /]$ glance image-list +--------------------------------------+----------------------------------+ | ID | Name | +--------------------------------------+----------------------------------+ | ad2f8daf-56f3-4e10-b5dc-d28d3a81f659 | cirros-0.4.0-x86_64-disk.img | +--------------------------------------+----------------------------------+ ()[glance@controller-0 /]$
手順
管理ユーザーとして、キャッシュするイメージをキューに追加します。
()[glance@controller-0 /]$ glance-cache-manage --host=<HOST-IP> queue-image <IMAGE-ID>
<HOST-IP> を
glance-apiコンテナーが実行されているコントローラーノードの IP アドレスに、<IMAGE-ID> をキューに追加するイメージの ID に、それぞれ置き換えてください。事前キャッシュするイメージをキューに追加すると、cache_images定期ジョブはキューに追加されたすべてのイメージを同時に事前取得します。注記イメージキャッシュは各ノードにローカルなので、Red Hat OpenStack Platform が HA 構成でデプロイされている場合 (3、5、または 7 台のコントローラー)、
glance-cache-manageコマンドを実行する際に--hostオプションでホストのアドレスを指定する必要があります。以下のコマンドを実行して、イメージキャッシュ内のイメージを表示します。
()[glance@controller-0 /]$ glance-cache-manage --host=<HOST-IP> list-cached
<HOST-IP> を環境内のホストの IP アドレスに置き換えてください。
この手順を完了したら、コントローラーノードから overcloudrc ファイルを削除します。
関連情報
以下の目的で、さらに glance-cache-manage コマンドを使用することができます。
-
list-cached: 現在キャッシュされているすべてのイメージを一覧表示する。 -
list-queued: キャッシュするために現在キューに追加されているすべてのイメージを一覧表示する。 -
queue-image: キャッシュするためにイメージをキューに追加する。 -
delete-cached-image: キャッシュからイメージを削除する。 -
delete-all-cached-images: キャッシュからすべてのイメージを削除する。 -
delete-cached-image: キャッシュのキューからイメージを削除する。 -
delete-all-queued-images: キャッシュのキューからすべてのイメージを削除する。
1.2. イメージの管理
OpenStack Image サービス (glance) は、ディスクおよびサーバーイメージの検出、登録、および配信のサービスを提供します。サーバーイメージのコピーやスナップショットを作成して直ちに保管する機能を提供します。保管したイメージは、テンプレートとして使用し、新規サーバーを迅速に稼働させるのに使用することができます。これはサーバーのオペレーティングシステムをインストールしてサービスを個別に設定するよりも一貫性の高い方法です。
1.2.1. イメージの作成
本項では、Red Hat Enterprise Linux 7、Red Hat Enterprise Linux 6 または Windows の ISO ファイルを使用して、QCOW2 形式の OpenStack 互換イメージを手動で作成する手順について説明します。
1.2.1.1. Red Hat OpenStack Platform における KVM ゲストイメージの使用
すでに準備済みの RHEL KVM ゲスト QCOW2 イメージを使用することができます。
これらのイメージは、cloud-init を使用して設定されます。適切に機能させるには、ec2 互換のメタデータサービスを利用して SSH キーをプロビジョニングする必要があります。
準備済みの Windows KVM ゲスト QCOW2 イメージはありません。
KVM ゲストイメージでは、以下の点に注意してください。
-
KVM ゲストイメージでは
rootアカウントが無効になっていますが、cloud-userという名前の特別なユーザーにsudoアクセスが許可されています。 -
このイメージには
rootパスワードは設定されていません。
root パスワードは、/etc/shadow で 2 番目のフィールドに !! と記載することによりロックされます。
OpenStack インスタンスでは、OpenStack Dashboard またはコマンドラインから ssh キーペアを生成し、その鍵の組み合わせを使用して、インスタンスに対して root として SSH 公開認証を実行することを推奨します。
インスタンスの起動時には、この公開鍵がインスタンスに挿入されます。続いて、キーペア作成時にダウンロードされた秘密鍵を使用して認証を行うことができます。
キーペアを使用しない場合には、「インスタンスへの admin パスワード挿入」の手順を使用して設定されている admin パスワードを使用することができます。
Red Hat Enterprise Linux または Windows のカスタムイメージを作成する場合は、「Red Hat Enterprise Linux 7 イメージの作成」、「Red Hat Enterprise Linux 6 イメージの作成」、または「Windows イメージの作成」を参照してください。
1.2.1.2. Red Hat Enterprise Linux または Windows のカスタムイメージの作成
前提条件
- イメージを作成する Linux ホストマシン。これは、Linux パッケージをインストール/実行することのできる任意のマシンです。
-
libvirt、virt-manager (
dnf groupinstall -y @virtualizationのコマンドを実行)。ゲストオペレーティングシステムを作成するのに必要な全パッケージがインストールされます。 -
Libguestfs ツール (
dnf install -y libguestfs-tools-cのコマンドを実行)。仮想マシンイメージにアクセスして変更を行うためのツールセットがインストールされます。 - Red Hat Enterprise Linux 7 もしくは 6 ISO ファイル (RHEL 7.2 Binary DVD もしくは RHEL 6.8 Binary DVD を参照)、または Windows ISO ファイル。Windows ISO ファイルがない場合には、Microsoft TechNet Evaluation Center に移動して評価版イメージをダウンロードしてください。
-
キックスタートファイルを編集する必要がある場合にはテキストエディター (RHEL のみ)
アンダークラウドに libguestfs-tools パッケージをインストールする場合は、アンダークラウドの tripleo_iscsid サービスとのポートの競合を避けるために iscsid.socket を無効にします。
$ sudo systemctl disable --now iscsid.socket
以下の手順では、プロンプトに [root@host]# と表示されているコマンドはすべて、お使いのホストマシンで実行する必要があります。
1.2.1.2.1. Red Hat Enterprise Linux 7 イメージの作成
本項では、Red Hat Enterprise Linux 7 の ISO ファイルを使用して、QCOW2 形式の OpenStack 互換イメージを手動で作成する手順について説明します。
以下に示したように
virt-installでインストールを開始します。[root@host]# qemu-img create -f qcow2 rhel7.qcow2 8G [root@host]# virt-install --virt-type kvm --name rhel7 --ram 2048 \ --cdrom /tmp/rhel-server-7.2-x86_64-dvd.iso \ --disk rhel7.qcow2,format=qcow2 \ --network=bridge:virbr0 --graphics vnc,listen=0.0.0.0 \ --noautoconsole --os-type=linux --os-variant=rhel7
このコマンドによりインスタンスが起動し、インストールプロセスが開始されます。
注記インスタンスが自動的に起動しない場合には、
virt-viewerのコマンドを実行して、コンソールを確認します。[root@host]# virt-viewer rhel7
以下の手順に従って、仮想マシンを設定します。
-
インストーラーの初期起動メニューで、
Install Red Hat Enterprise Linux 7.X のオプションを選択します。
- 適切な 言語 および キーボード オプションを選択します。
-
インストールに使用するデバイスタイプを尋ねるプロンプトが表示されたら、自動検出したインストールメディア を選択します。
-
インストール先を尋ねるプロンプトが表示されたら、ローカルの標準ディスク を選択します。
 その他のストレージタイプオプションには、自動構成のパーティション構成 を選択します。
その他のストレージタイプオプションには、自動構成のパーティション構成 を選択します。
- ソフトウェアのオプションには、最小限のインストール を選択します。
-
ネットワークとホスト名の設定では、イーサネットに
eth0を選択し、デバイスのホスト名を指定します。デフォルトのホスト名はlocalhost.localdomainです。 -
rootパスワードを選択します。 インストールプロセスが完了すると、完了しました! の画面が表示されます。
インストールプロセスが完了すると、完了しました! の画面が表示されます。
-
インストーラーの初期起動メニューで、
- インストールが完了した後には、インスタンスを再起動して、root ユーザーとしてログインします。
/etc/sysconfig/network-scripts/ifcfg-eth0ファイルを編集して、以下の値のみが記載されている状態にします。TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no
- マシンを再起動します。
コンテンツ配信ネットワークにマシンを登録します。
# sudo subscription-manager register # sudo subscription-manager attach --pool=Valid-Pool-Number-123456 # sudo subscription-manager repos --enable=rhel-7-server-rpms
システムを更新します。
# dnf -y update
cloud-initパッケージをインストールします。# dnf install -y cloud-utils-growpart cloud-init
/etc/cloud/cloud.cfg設定ファイルを編集して、cloud_init_modulesの下に以下を追加します。- resolv-conf
resolv-confオプションは、インスタンスの初回起動時にresolv.confを自動的に設定します。このファイルには、nameservers、domain、その他のオプションなどのインスタンスに関連した情報が記載されています。/etc/sysconfig/networkに以下の行を追加し、EC2 メタデータサービスへのアクセスで問題が発生するのを回避します。NOZEROCONF=yes
コンソールメッセージが Dashboard の
ログタブおよびnova console-logの出力に表示されるようにするには、以下のブートオプションを/etc/default/grubファイルに追記します。GRUB_CMDLINE_LINUX_DEFAULT="console=tty0 console=ttyS0,115200n8"
grub2-mkconfigコマンドを実行します。# grub2-mkconfig -o /boot/grub2/grub.cfg
以下のような出力が表示されます。
Generating grub configuration file ... Found linux image: /boot/vmlinuz-3.10.0-229.7.2.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-229.7.2.el7.x86_64.img Found linux image: /boot/vmlinuz-3.10.0-121.el7.x86_64 Found initrd image: /boot/initramfs-3.10.0-121.el7.x86_64.img Found linux image: /boot/vmlinuz-0-rescue-b82a3044fb384a3f9aeacf883474428b Found initrd image: /boot/initramfs-0-rescue-b82a3044fb384a3f9aeacf883474428b.img done
仮想マシンの登録を解除して、作成されるイメージをベースにクローン作成される全インスタンスに同じサブスクリプション情報が含まれないようにします。
# subscription-manager repos --disable=* # subscription-manager unregister # dnf clean all
インスタンスの電源をオフにします。
# poweroff
virt-sysprepコマンドでイメージのリセットおよびクリーニングをして、問題なくインスタンスの作成に使用できるようにします。[root@host]# virt-sysprep -d rhel7
virt-sparsifyコマンドを使用してイメージのサイズを縮小します。このコマンドにより、ディスクイメージ内の空き容量は、ホスト内の空き容量に戻ります。[root@host]# virt-sparsify --compress /tmp/rhel7.qcow2 rhel7-cloud.qcow2
このコマンドを実行すると、その場所に
rhel7-cloud.qcow2ファイルが作成されます。
rhel7-cloud.qcow2 イメージファイルを Image サービスにアップロードする準備が整いました。Dashboard を使用して OpenStack デプロイメントにこのイメージをアップロードする方法については、「イメージのアップロード」を参照してください。
1.2.1.2.2. Red Hat Enterprise Linux 6 イメージの作成
本項では、Red Hat Enterprise Linux 6 の ISO ファイルを使用して、QCOW2 形式の OpenStack 互換イメージを手動で作成する手順について説明します。
virt-installでインストールを開始します。[root@host]# qemu-img create -f qcow2 rhel6.qcow2 4G [root@host]# virt-install --connect=qemu:///system --network=bridge:virbr0 \ --name=rhel6 --os-type linux --os-variant rhel6 \ --disk path=rhel6.qcow2,format=qcow2,size=10,cache=none \ --ram 4096 --vcpus=2 --check-cpu --accelerate \ --hvm --cdrom=rhel-server-6.8-x86_64-dvd.iso
このコマンドによりインスタンスが起動し、インストールプロセスが開始されます。
注記インスタンスが自動的に起動しない場合には、
virt-viewerのコマンドを実行して、コンソールを確認します。[root@host]# virt-viewer rhel6
仮想マシンを以下のように設定します。
インストーラーの初期起動メニューで、Install or upgrade an existing system のオプションを選択します。
 インストールのプロンプトに従って順に進みます。デフォルト値を受け入れます。
インストールのプロンプトに従って順に進みます。デフォルト値を受け入れます。
インストーラーは、ディスクの有無を確認して、インストール前にインストールメディアのテストを行うかどうかを決定するように促します。テストを実行するには OK を、テストを行わずに続行するには Skip を選択します。
- 適切な 言語 および キーボード オプションを選択します。
-
インストールに使用するデバイスタイプを尋ねるプロンプトが表示されたら、基本ストレージデバイス を選択します。
-
デバイスの
ホスト名を指定します。デフォルトのホスト名はlocalhost.localdomainです。 -
タイムゾーン と
rootパスワードを指定します。 -
ディスクの空き容量に応じて、インストールのタイプを選択します。
-
SSH サーバーをインストールする 基本サーバー インストールを選択します。
- インストールプロセスが完了し、おめでとうございます。Red Hat Enterprise Linux のインストールが完了しました。の画面が表示されます。
-
インスタンスを再起動して、
rootユーザーとしてログインします。 /etc/sysconfig/network-scripts/ifcfg-eth0ファイルを編集して、以下の値のみが記載されている状態にします。TYPE=Ethernet DEVICE=eth0 ONBOOT=yes BOOTPROTO=dhcp NM_CONTROLLED=no
- マシンを再起動します。
コンテンツ配信ネットワークにマシンを登録します。
# sudo subscription-manager register # sudo subscription-manager attach --pool=Valid-Pool-Number-123456 # sudo subscription-manager repos --enable=rhel-6-server-rpms
システムを更新します。
# dnf -y update
cloud-initパッケージをインストールします。# dnf install -y cloud-utils-growpart cloud-init
/etc/cloud/cloud.cfg設定ファイルを編集して、cloud_init_modulesの下に以下を追加します。- resolv-conf
resolv-confオプションは、インスタンスの初回起動時にresolv.conf設定ファイルを自動的に設定します。このファイルには、nameservers、domain、その他のオプションなどのインスタンスに関連した情報が記載されています。ネットワークの問題が発生するのを防ぐために、以下のように
/etc/udev/rules.d/75-persistent-net-generator.rulesファイルを作成します。# echo "#" > /etc/udev/rules.d/75-persistent-net-generator.rules
これにより、
/etc/udev/rules.d/70-persistent-net.rulesファイルが作成されるのを防ぎます。/etc/udev/rules.d/70-persistent-net.rulesが作成されてしまうと、スナップショットからのブート時にネットワークが適切に機能しなくなる可能性があります (ネットワークインターフェースが「eth0」ではなく「eth1」として作成され、IP アドレスが割り当てられません)。/etc/sysconfig/networkに以下の行を追加し、EC2 メタデータサービスへのアクセスで問題が発生するのを回避します。NOZEROCONF=yes
コンソールメッセージが Dashboard の
ログタブおよびnova console-logの出力に表示されるようにするには、以下のブートオプションを/etc/grub.confファイルに追記します。console=tty0 console=ttyS0,115200n8
仮想マシンの登録を解除して、作成されるイメージをベースにクローン作成されるインスタンスすべてに同じサブスクリプション情報が含まれないようにします。
# subscription-manager repos --disable=* # subscription-manager unregister # dnf clean all
インスタンスの電源をオフにします。
# poweroff
virt-sysprepコマンドでイメージのリセットおよびクリーニングをして、問題なくインスタンスの作成に使用できるようにします。[root@host]# virt-sysprep -d rhel6
virt-sparsifyコマンドを使用してイメージのサイズを縮小します。このコマンドにより、ディスクイメージ内の空き容量は、ホスト内の空き容量に戻ります。[root@host]# virt-sparsify --compress rhel6.qcow2 rhel6-cloud.qcow2
このコマンドを実行すると、その場所に新しい
rhel6-cloud.qcow2ファイルが作成されます。注記インスタンスに適用されているフレーバーのディスクスペースに応じて、イメージをベースとするインスタンスのパーティションを手動でリサイズする必要があります。
rhel6-cloud.qcow2 イメージファイルを Image サービスにアップロードする準備が整いました。Dashboard を使用して OpenStack デプロイメントにこのイメージをアップロードする方法については、「イメージのアップロード」を参照してください。
1.2.1.2.3. Windows イメージの作成
本項では、Windows の ISO ファイルを使用して、QCOW2 形式の OpenStack 互換イメージを手動で作成する手順について説明します。
以下に示したように
virt-installでインストールを開始します。[root@host]# virt-install --name=name \ --disk size=size \ --cdrom=path \ --os-type=windows \ --network=bridge:virbr0 \ --graphics spice \ --ram=RAM
以下のように
virt-installパラメーターの値を置き換えます。- name: Windows ゲストに指定する必要のある名前
- size: ディスクのサイズ (GB)
- path: Windows のインストール ISO ファイルへのパス
RAM: 要求するメモリー容量 (MB)
注記--os-type=windowsパラメーターにより、Windows ゲストのクロックが正しく設定され、Hyper-V エンライトメント機能が有効化されるようになります。デフォルトでは、
virt-installは/var/lib/libvirt/images/name.qcow2としてゲストイメージを保存します。ゲストイメージを別の場所に保存するには、以下のように--diskのオプションを変更してください。--disk path=filename,size=size
filename は、ゲストイメージを保存する必要のあるファイル名 (およびオプションでそのパス) に置き換えてください。たとえば、
path=win8.qcow2,size=8は現在の作業ディレクトリーにwin8.qcow2という名前の 8 GB のファイルを作成します。ヒントゲストが自動的に起動しない場合には、
virt-viewerのコマンドを実行して、コンソールを確認します。[root@host]# virt-viewer name
- Windows システムのインストールは、本書の対象範囲外となります。Windows のインストール方法に関する説明は、適切な Microsoft のドキュメントを参照してください。
-
新規インストールした Windows システムで仮想化ハードウェアを使用できるようにするには、virtio ドライバー をインストールしなければならない場合があります。これには、まずホストシステムで
virtio-winパッケージをインストールします。このパッケージには virtio ISO イメージが含まれており、そのイメージを CD-ROM ドライブとして Windows ゲストにアタッチします。virtio-winパッケージをインストールするには、ゲストに virtio ISO イメージを追加して、virtio ドライバーをインストールする必要があります。『仮想化の設定および管理』の「Windows 仮想マシン用の KVM 準仮想化ドライバーのインストール」を参照してください。 Windows システムで Cloudbase-Init をダウンロード、実行して、設定を完了します。Cloudbase-Init のインストールの最後に、
Run SysprepとShutdownチェックボックスを選択します。Sysprepツールは、特定の Microsoft サービスで使用する OS ID を生成して、ゲストを一意にします。重要Red Hat は Cloudbase-Init に関するテクニカルサポートは提供しません。問題が発生した場合には、contact Cloudbase Solutions からお問い合わせください。
Windows システムがシャットダウンしたら、name.qcow2 イメージファイルを Image サービスにアップロードすることができます。Dashboard またはコマンドラインを使用して OpenStack デプロイメントにこのイメージをアップロードする方法については、「イメージのアップロード」を参照してください。
1.2.1.3. libosinfo の使用
Image サービス (glance) はイメージ用に libosinfo のデータを処理して、インスタンスに最適な仮想ハードウェアをより簡単に設定できるようにすることができます。これは、libosinfo 形式のオペレーティングシステム名前を glance イメージに追加することによって行うことができます。
以下の例では、ID
654dbfd5-5c01-411f-8599-a27bd344d79bのイメージがrhel7.2という libosinfo の値を使用するように指定します。$ openstack image set 654dbfd5-5c01-411f-8599-a27bd344d79b --property os_name=rhel7.2
その結果、Compute は、
654dbfd5-5c01-411f-8599-a27bd344d79bのイメージを使用してインスタンスがビルドされる際に必ず、rhel7.2向けに最適化された仮想ハードウェアを提供するようになります。注記libosinfoの値の完全な一覧は、libosinfo プロジェクトを参照してください (https://gitlab.com/libosinfo/osinfo-db/tree/master/data/os)。
1.2.2. イメージのアップロード
- Dashboard で プロジェクト > コンピュート > イメージ を選択します。
- イメージの作成 をクリックします。
- 各フィールドに値を入力し、完了したら イメージの作成 をクリックします。
表1.1 イメージのオプション
| フィールド | 説明 |
|---|---|
| 名前 | イメージの名前。そのプロジェクト内で一意な名前にする必要があります。 |
| 説明 | イメージを識別するための簡単な説明 |
| イメージソース | イメージソース: イメージの場所 または イメージファイル。ここで選択したオプションに応じて次のフィールドが表示されます。 |
| イメージの場所またはイメージファイル |
|
| 形式 | イメージの形式 (例: qcow2) |
| アーキテクチャー | イメージのアーキテクチャー。たとえば 32 ビットのアーキテクチャーには i686、64 ビットのアーキテクチャーには x86_64 を使用します。 |
| 最小ディスク (GB) | イメージのブートに必要な最小のディスクサイズ。このフィールドに値が指定されていない場合には、デフォルト値は 0 です (最小値なし)。 |
| 最小メモリー (MB) | イメージのブートに必要な最小のメモリーサイズ。このフィールドに値が指定されていない場合には、デフォルト値は 0 です (最小値なし)。 |
| パブリック | このチェックボックスを選択した場合には、プロジェクトにアクセスできる全ユーザーにイメージが公開されます。 |
| 保護 | このチェックボックスを選択した場合には、特定のパーミッションのあるユーザーのみがこのイメージを削除できるようになります。 |
イメージが正常にアップロードされたら、イメージのステータスは、イメージが使用可能であることを示す active に変わります。Image サービスは、アップロードの開始時に使用した Identity サービストークンのライフタイムよりもアップロードの所要時間が長くかかる大容量のイメージも処理することができる点に注意してください。これは、アップロードが完了してイメージのステータスが更新される際に、新しいトークンを取得して使用できるように、Identity サービスは最初に Identity サービスとのトラストを作成するためです。
glance image-create コマンドに property のオプションを指定して実行する方法でイメージをアップロードすることもできます。コマンドラインで操作を行った方が、より多くの値を使用することができます。完全なリストは、「イメージの設定パラメーター」を参照してください。
1.2.3. イメージの更新
- Dashboard で プロジェクト > コンピュート > イメージ を選択します。
ドロップダウンリストから イメージの編集 をクリックします。
注記イメージの編集 オプションは、
adminユーザーとしてログインした場合にのみ使用することができます。demoユーザーとしてログインした場合には、インスタンスの起動 または ボリュームの作成 のオプションを使用することができます。- フィールドを更新して、終了したら イメージの更新 をクリックします。次の値を更新することができます (名前、説明、カーネル ID、RAM ディスク ID、アーキテクチャー、形式、最小ディスク、最小メモリー、パブリック、保護)。
- ドロップダウンメニューをクリックして メタデータの更新 オプションを選択します。
- 左のコラムから右のコラムに項目を追加して、メタデータを指定します。左のコラムには、Image サービスのメタデータカタログからのメタデータの定義が含まれています。その他 を選択して、任意のキーを使用してメタデータを追加し、完了したら 保存 をクリックします。
glance image-update コマンドに property オプションを指定して実行する方法でイメージを更新することもできます。コマンドラインで操作を行った方が、より多くの値を使用することができます。完全なリストは、「イメージの設定パラメーター」を参照してください。
1.2.4. イメージのインポート
URI からイメージをインポートする web-download と ローカルファイルシステムからイメージをインポートする glance-direct を使用して、Image サービス (glance) にイメージをインポートすることができます。デフォルトでは、両方のオプションが有効です。
インポートの方法は、クラウド管理者によって設定されます。glance import-info コマンドを実行して、利用可能なインポートオプションを一覧表示します。
1.2.4.1. リモート URI からのインポート
web-download メソッドを使用して、リモートの URI からイメージをコピーすることができます。
イメージを作成して、インポートするイメージの URI を指定します。
glance image-create --uri <URI>
-
glance image-show <image-ID>コマンドで、イメージの可用性をモニタリングすることができます。ここで ID は、イメージの作成中に提供された ID に置き換えてください。
Image サービスの web-download メソッドでは、2 段階のプロセスでインポートを実施します。まず、イメージのレコードを作成します。次に、指定した URI からイメージを取得します。このメソッドは、Image API v1 で使用されていた非推奨となった copy-from メソッドよりもセキュアにイメージをインポートする方法です。
『Advanced Overcloud Customization』で説明するように、URI にオプションのブラックリストおよびホワイトリストによる絞り込みを適用することができます。
『オーバークラウドの高度なカスタマイズ』で説明するように、Image Property Injection プラグインにより、イメージにメタデータ属性を注入することができます。注入されたこれらの属性により、イメージインスタンスを起動するコンピュートノードが決定されます。
1.2.4.2. ローカルボリュームからのインポート
glance-direct メソッドは、イメージレコードを作成し、それによりイメージ ID が生成されます。ローカルボリュームからイメージがサービスにアップロードされるとステージングエリアに保管され、設定されているチェックに合格した後にアクティブとなります。高可用性 (HA) 構成で使用される場合には、glance-direct メソッドには共通のステージングエリアが必要です。
HA 環境では、glance-direct メソッドを使用したイメージのアップロードは、共通のステージエリアがない場合には失敗します。HA の Active/Active 環境では、API コールは複数の glance コントローラーに分散されます。ダウンロード API コールは、イメージをアップロードする API コールとは別のコントローラーに送信することが可能です。ステージングエリアの設定に関する詳しい情報は、『オーバークラウドの 高度なカスタマイズ』 の「 ストレージの設定 」セクションを参照してください。
glance-direct メソッドは、3 つの異なるコールを使用して、イメージをインポートします。
-
glance image-create -
glance image-stage -
glance image-import
glance image-create-via-import コマンドを使用すると、これらの 3 つのコールを 1 つのコマンドで実行することができます。以下の例では、大文字の語句は適切なオプションに置き換える必要があります。
glance image-create-via-import --container-format FORMAT --disk-format DISKFORMAT --name NAME --file /PATH/TO/IMAGE
イメージがステージングエリアからバックエンドの場所に移動すると、そのイメージはリストされます。ただし、イメージがアクティブになるには、多少時間がかかる場合があります。
glance image-show <image-ID> コマンドで、イメージの可用性をモニタリングすることができます。ここで ID は、イメージの作成中に提供された ID に置き換えてください。
1.2.5. イメージの削除
- Dashboard で プロジェクト > コンピュート > イメージ を選択します。
- 削除するイメージを選択し、イメージの削除 ボタンをクリックします。
1.2.6. イメージの表示または非表示
ユーザーに表示される通常の一覧からパブリックイメージを非表示にすることができます。たとえば、廃止された CentOS 7 イメージを非表示にし、最新バージョンだけを表示してユーザーエクスペリエンスをシンプル化することができます。ユーザーは、非表示のイメージを検出して使用することができます。
イメージを非表示にするには、以下をコマンドを実行します。
glance image-update <image-id> --hidden 'true'
非表示のイメージを作成するには、glance image-create コマンドに --hidden 引数を追加します。
イメージの非表示を解除するには、以下のコマンドを実行します。
glance image-update <image-id> --hidden 'false'
1.2.8. イメージ変換の有効化
GlanceImageImportPlugins パラメーターを有効にすると、QCOW2 イメージをアップロードすることができ、Image サービスはそのイメージを RAW に変換します。
Red Hat Ceph Storage RBD を使用してイメージを保存して Nova インスタンスをブートすると、イメージの変換は自動的に有効になります。
イメージの変換を有効にするには、以下のパラメーター値が含まれる環境ファイルを作成し、-e オプションを使用して新しい環境ファイルを openstack overcloud deploy コマンドに追加します。
parameter_defaults: GlanceImageImportPlugins:'image_conversion'
1.2.9. RAW 形式へのイメージの変換
Red Hat Ceph Storage は QCOW2 イメージを保管することはできますが、そのイメージを使用して仮想マシン (VM) のディスクをホストすることはできません。
アップロードした QCOW2 イメージから仮想マシンを作成する場合には、コンピュートノードはイメージをダウンロードして RAW に変換し、それを Ceph にアップロードし直してからでないと使用することができません。このプロセスは仮想マシンの作成時間に影響を及ぼします (特に、並行して仮想マシンを作成する場合)。
たとえば、複数の仮想マシンを同時に作成する場合には、Ceph クラスターへの変換済みイメージのアップロードが、すでに実行中の負荷に影響を及ぼす可能性があります。IOPS のこれらの負荷に対するリソースがアップロードプロセスにより枯渇し、ストレージの反応が遅くなる場合があります。
Ceph において仮想マシンをより効率的に起動するには (一時バックエンドまたはボリュームからの起動)、glance イメージの形式を RAW にする必要があります。
イメージを RAW に変換すると、イメージサイズが元の QCOW2 イメージファイルより大きくなる場合があります。最終的な RAW イメージのサイズを確認するには、変換前に以下のコマンドを実行します。
qemu-img info <image>.qcow2
イメージを QCOW2 から RAW 形式に変換するには、以下のコマンドを実行します。
qemu-img convert -p -f qcow2 -O raw <original qcow2 image>.qcow2 <new raw image>.raw
1.2.9.1. RAW および ISO だけを受け入れる Image サービスの設定
オプションとして、Image サービスが RAW および ISO イメージ形式だけを受け入れるように設定するには、以下の設定を含む追加の環境ファイルを使用してデプロイを行います。
parameter_defaults:
ExtraConfig:
glance::config::api_config:
image_format/disk_formats:
value: "raw,iso"1.2.10. RAW 形式でのイメージの保存
以前に作成したイメージを RAW 形式で保存するには、GlanceImageImportPlugins パラメーターを有効にして以下のコマンドを実行します。
$ glance image-create-via-import \
--disk-format qcow2 \
--container-format bare \
--name NAME \
--visibility public \
--import-method web-download \
--uri http://server/image.qcow2-
--name:NAMEをイメージ名に置き換えます。この名前がglance image-listに表示されます。 -
--uri:http://server/image.qcow2を QCOW2 イメージの場所およびファイル名に置き換えます。
このコマンド例では、イメージレコードを作成し、web-download メソッドを使用してそのイメージレコードをインポートします。glance-api は、インポートプロセス中に --uri で定義した場所からイメージをダウンロードします。web-download が利用できない場合、glanceclient はイメージデータを自動的にダウンロードすることができません。利用可能なイメージのインポート方法を一覧表示するには、glance import-info コマンドを実行します。
第2章 Compute (nova) サービスの設定
環境ファイルを使用して Compute (nova) サービスをカスタマイズします。Puppet は、この設定を生成して /var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.conf ファイルに保存します。Compute サービスの設定をカスタマイズするには、以下の設定方法を使用します。
Heat パラメーター: 詳細は、『オーバークラウドのパラメーター』の「 Compute(nova) パラメーター」セクションを参照し てください。以下に例を示します。
parameter_defaults: NovaSchedulerDefaultFilters: AggregateInstanceExtraSpecsFilter,RetryFilter,ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter NovaNfsEnabled: true NovaNfsShare: '192.0.2.254:/export/nova' NovaNfsOptions: 'context=system_u:object_r:nfs_t:s0' NovaNfsVersion: '4.2'
Puppet パラメーター:
/etc/puppet/modules/nova/manifests/*で定義されます。parameter_defaults: ComputeExtraConfig: nova::compute::force_raw_images: True注記この方法は、等価な heat パラメーターが存在しない場合にのみ使用してください。
手動での hieradata の上書き: heat パラメーターまたは Puppet パラメーターが存在しない場合の、パラメーターカスタマイズ用。たとえば、以下の設定により Compute ロールの
[DEFAULT]セクションにdisk_allocation_ratioが定義されます。parameter_defaults: ComputeExtraConfig: nova::config::nova_config: DEFAULT/disk_allocation_ratio: value: '2.0'
heat パラメーターが存在する場合は、Puppet パラメーターではなくそのパラメーターを使用する必要があります。Puppet パラメーターは存在するが heat パラメーターが存在しない場合は、手動で上書きする方法ではなく Puppet パラメーターを使用する必要があります。手動で上書きする方法は、等価な heat パラメーターまたは Puppet パラメーターがない場合にのみ使用してください。
特定 の設定をカスタマイズする際に heat パラメーターまたは Puppet パラメーターが利用可能かどうかを判断するには、「変更 するパラメーターの特定」のガイダンスに従ってください。
オーバークラウドサービスの設定に関する詳しい情報は、『オーバークラウドの 高度なカスタマイズ』 の「 パラメーター 」を参照してください。
2.1. オーバーコミットのためのメモリー設定
メモリーのオーバーコミットを使用する場合 (NovaRAMAllocationRatio >= 1.0)、割り当て率をサポートするのに十分なスワップ領域を確保してオーバークラウドをデプロイする必要があります。
NovaRAMAllocationRatio パラメーターが 1 より小さい値 に設定されている場合は、RHEL でのスワップサイズの推奨事項に従ってください。詳しくは、RHEL の『ストレージデバイスの管理』の「システムの推奨スワップ領域」を参照してください。
前提条件
- ノードに必要なスワップサイズが計算されている。詳しくは、「スワップサイズの計算」を参照してください。
手順
/usr/share/openstack-tripleo-heat-templates/environments/enable-swap.yamlファイルを環境ファイルのディレクトリーにコピーします。$ cp /usr/share/openstack-tripleo-heat-templates/environments/enable-swap.yaml /home/stack/templates/enable-swap.yaml
以下のパラメーターを
enable-swap.yamlファイルに追加して、スワップサイズを設定します。parameter_defaults: swap_size_megabytes: <swap size in MB> swap_path: <full path to location of swap, default: /swap>
この設定を適用するには、その他の環境ファイルと共に
enable_swap.yaml環境ファイルをスタックに追加し、オーバークラウドをデプロイします。(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] \ -e /home/stack/templates/enable-swap.yaml \
2.2. コンピュートノード上で確保するホストメモリーの計算
ホストのプロセス用に確保する RAM 容量の合計を判断するには、以下の各項目に十分なメモリーを割り当てる必要があります。
- ノードで実行されるリソース。たとえば、OSD は 3 GB のメモリーを消費します。
- ホスト上のインスタンスを視覚化するのに必要なエミュレーターのオーバーヘッド
- 各インスタンスのハイパーバイザー
メモリーへの追加要求を計算したら、以下の式を使用して各ノードのホストプロセス用に確保するメモリーの容量を決定します。
NovaReservedHostMemory = total_RAM - ( (vm_no * (avg_instance_size + overhead)) + (resource1 * resource_ram) + (resource _n_ * resource_ram))
-
vm_noは、インスタンスの数に置き換えてください。 -
avg_instance_sizeは、各インスタンスが使用できるメモリーの平均容量に置き換えてください。 -
overheadは、各インスタンスに必要なハイパーバイザーのオーバーヘッドに置き換えてください。 -
resource1は、ノード上のリソース種別の数に置き換えてください。 -
resource_ramは、この種別の各リソースに必要な RAM の容量に置き換えてください。
2.3. スワップサイズの計算
割り当てるスワップサイズは、メモリーのオーバーコミットを処理するのに十分な容量でなければなりません。以下の式を使用して、ノードに必要なスワップサイズを計算することができます。
-
overcommit_ratio =
NovaRAMAllocationRatio- 1 -
最小スワップサイズ (MB) =
(total_RAM * overcommit_ratio) + RHEL_min_swap -
推奨 (最大) スワップサイズ (MB) =
total_RAM * (overcommit_ratio + percentage_of_RAM_to_use_for_swap)
percentage_of_RAM_to_use_for_swap 変数は、QEMU のオーバーヘッドおよびオペレーティングシステムまたはホストのサービスが消費するその他のリソースに対応するバッファーです。
たとえば、RAM 容量の合計が 64 GB で NovaRAMAllocationRatio が 1 に設定されている場合、利用可能な RAM の 25% をスワップに使用するには、
- 推奨 (最大) スワップサイズ = 64000 MB * (0 + 0.25) = 16000 MB
NovaReservedHostMemory の値を計算する方法は、「コンピュートノード上で確保するホストメモリーの計算」を参照してください。
RHEL_min_swap の値を決定する方法は、RHEL の『ストレージデバイスの管理』の「システムの推奨スワップ領域」を参照してください。
第3章 OpenStack Compute 用のストレージの設定
本章では、OpenStack Compute (nova) のイメージのバックエンドストレージのアーキテクチャーについて説明し、基本的な設定オプションを記載します。
3.1. アーキテクチャーの概要
Red Hat OpenStack Platform では、OpenStack Compute サービスは KVM ハイパーバイザーを使用してコンピュートのワークロードを実行します。libvirt ドライバーが KVM とのすべての対話を処理し、仮想マシンが作成できるようにします。
コンピュートには、2 種類の libvirt ストレージを考慮する必要があります。
- Image サービスのイメージのコピーをキャッシュ済み/フォーマット済みのベースイメージ
-
libvirtベースを使用して作成され、仮想マシンインスタンスのバックエンドとなるインスタンスディスク。インスタンスディスクデータは、コンピュートの一時ストレージ (libvirtベースを使用) または永続ストレージ (例: Block Storage を使用) のいずれかに保存されます。
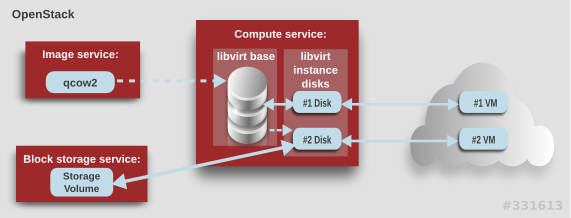
Compute は、以下の手順で仮想マシンインスタンスを作成します。
-
Image サービスのバッキングイメージを
libvirtベースとしてキャッシュします。 - ベースイメージを Raw 形式に変換します (設定されている場合)。
- 仮想マシンのフレーバーの仕様に一致するようにベースイメージのサイズを調節します。
- ベースイメージを使用して libvirt インスタンスディスクを作成します。
上図では、#1 のインスタンスディスクは一時ストレージを使用し、#2 のディスクは Block Storage ボリュームを使用します。
一時ストレージとは、インスタンスで追加で利用可能な、フォーマットされていない空のディスクのことです。このストレージの値は、インスタンスのフレーバーにより定義されます。ユーザーが指定した値は、フレーバーで定義した一時ストレージの値以下でなければなりません。デフォルト値は 0 です。0 を指定すると、一時ストレージが作成されません。
一時ディスクは、外付けのハードドライブや USB ドライブと同じ方法で表示されます。一時ディスクはブロックデバイスとして利用でき、lsblk コマンドを使用して確認することができます。ブロックデバイスとして通常使用するように、フォーマット、マウント、使用が可能です。アタッチ先のインスタンス以外では、このディスクの保存や参照をする方法はありません。
ブロックストレージボリュームは、実行中のインスタンスがどのような状態であっても、インスタンスを利用できる一時ストレージです。
3.2. 設定
Compute (nova) の設定ファイルをカスタマイズして、仮想ディスクのパフォーマンスチューニングおよびセキュリティーを設定することができます。Compute は、『 オーバークラウドのパラメーター』の「 Compute(nova) パラメーター」セクションで説明するパラメーターを使用して、カスタム環境ファイルおよび heat テンプレートで設定します。生成された設定は、/var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.conf ファイルに保存されます。詳細を以下の表に示します。
表3.1 Compute のイメージのパラメーター
| セクション | パラメーター | 説明 | デフォルト |
|---|---|---|---|
| [DEFAULT] |
|
ベースを Raw に変換すると、ハイパーバイザーが直接使用可能なイメージの容量よりも、容量が多く使用されます (例: qcow2 イメージ)。I/O が遅いシステムや空き容量が少ないシステムを使用している場合は、false に指定して、圧縮の際のCPU 要件を軽減することで入力の帯域幅を最小限に抑えます。
Raw ベースイメージは常に |
|
| [DEFAULT] |
|
| true |
| [DEFAULT] |
|
CoW インスタンスディスクを使用しない場合でも、各仮想マシンが取得するコピーはスパースであるため、仮想マシンが ENOSPC でランタイムに予期せず失敗する可能性があります。インスタンスディスクに | none |
| [DEFAULT] |
|
ブロックデバイス (ブール型) を使用してイメージにアクセスすることで、ベースイメージのサイズを直接調節することができるかどうかを設定します。これは、(それ自体ではサイズ調節ができないため) このパラメーターにより、セキュリティーの関係上、無効にされる可能性のあるイメージを直接マウントできるため、デフォルトでは有効化されていません。 |
|
| [DEFAULT] |
|
新規の一時ボリュームに使用されるデフォルトの形式。値は、 |
|
| [DEFAULT] |
|
libvirt コンピュートノードにキャッシュするベースに影響を与える、イメージキャッシュマネージャーを次に実行するまでの待機時間 (秒数)。この時間は、未使用のキャッシュされたイメージを自動削除する際にも使用されます ( |
|
| [DEFAULT] |
|
未使用のベースイメージを自動的に削除できるようにするかどうかを設定します ( |
|
| [DEFAULT] |
|
未使用となったベースイメージが |
|
|
[ |
|
|
|
第4章 仮想マシンインスタンス
OpenStack Compute は、仮想マシンをオンデマンドで提供する中核的なコンポーネントです。Compute は、認証には Identity サービス、イメージ (インスタンスの起動に使用する) には Image サービス、ユーザー/管理者用のインターフェースには Dashboard サービスと対話します。
Red Hat OpenStack Platform により、クラウド内の仮想マシンインスタンスを容易に管理することができます。Compute サービスはインスタンスの作成、スケジューリング、管理を行い、この機能をその他の OpenStackコンポーネントに公開します。本章では、これらの手順に加えて、キーペア、セキュリティーグループ、ホストアグリゲート、フレーバーなどのコンポーネントを追加する手順について説明します。OpenStack では、インスタンス という用語は、仮想マシンインスタンスの意味で使用されます。
4.1. インスタンスの管理
インスタンスを作成する前には、その他の特定の OpenStack コンポーネント (例: ネットワーク、キーペア、イメージ、ブートソースとなるボリュームなど) をそのインスタンスが利用できる状態にしておく必要があります。
本項では、これらのコンポーネントを追加して、インスタンスを作成/管理する手順について説明します。インスタンスの管理には、更新、ログイン、使用状況の確認、リサイズ、削除などの操作が含まれます。
4.1.1. コンポーネントの追加
以下の各項の手順に従って、ネットワーク、キーペアを作成し、イメージまたはボリュームソースをアップロードします。これらのコンポーネントは、インスタンスの作成に使用され、デフォルトでは提供されません。また、新規セキュリティーグループ作成して、ユーザーが SSH アクセスできるようにする必要があります。
- Dashboard で プロジェクト を選択します。
- ネットワーク & gt; ネットワーク を選択し、新規インスタンスを接続することができるプライベートネットワークが存在していることを確認してください(ネットワークの作成方法については、『ネットワーク ガイド』の「ネットワークの 作成 」セクションを参照してください)。
- コンピュート > アクセスとセキュリティー > キーペア を選択して、キーペアが存在していることを確認します (キーペアの作成方法については、「キーペアの作成」を参照)。
ブートソースに使用可能なイメージまたはボリュームのいずれかがあることを確認してください。
- コンピュート > アクセスとセキュリティー > セキュリティーグループ を選択し、セキュリティーグループルールが作成済みであることを確認します(セキュリティーグループの作成については、『 ユーザーおよびアイデンティティー管理ガイド』の「 プロジェクトのセキュリティー管理 」を参照してください)。
4.1.2. インスタンスの起動
Dashboard から 1 つまたは複数のインスタンスを起動します。
デフォルトでは、インスタンスの起動にはインスタンスの起動フォームが使用されます。ただし、必要なステップを簡単に実行することのできるインスタンスの起動ウィザードを有効にすることも可能です。詳細は、「付録B インスタンスの起動ウィザードの有効化」を参照してください。
- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- インスタンスの起動 をクリックします。
- 各フィールド (「*」の付いたフィールドは必須です) に設定値を入力し、起動 をクリックします。
指定したオプションに基づいて、1 つまたは複数のインスタンスが作成され、起動されます。
4.1.2.1. インスタンスの起動オプション
以下の表には、インスタンスの起動フォームを使用して新規インスタンスを起動する際に利用可能なオプションをまとめています。インスタンスの起動ウィザードでも同じオプションが利用できます。
表4.1 インスタンスの起動フォームのオプション
| タブ | フィールド | 説明 |
|---|---|---|
| プロジェクトおよびユーザー | プロジェクト | ドロップダウンリストからプロジェクトを選択します。 |
| ユーザー | ドロップダウンリストからユーザーを選択します。 | |
| 詳細 | アベイラビリティーゾーン | ゾーンとは、インスタンスが配置されるクラウドリソースの論理グループです。不明な場合にはデフォルトのゾーンを使用してください (詳しくは「ホストアグリゲートの管理」を参照)。 |
| インスタンス名 | インスタンスを識別するための名前 | |
| フレーバー | フレーバーは、インスタンスに提供されるリソースを決定します (例: メモリー)。デフォルトのフレーバーの割り当ておよび新規フレーバー作成に関する情報は、「フレーバーの管理」を参照してください。 | |
| インスタンス数 | ここに記載のパラメーターで作成するインスタンスの数。「1」が事前に設定されています。 | |
| インスタンスのブートソース | 選択した項目に応じて異なる新規フィールドが表示され、ソースを選択することができます。
| |
| アクセスとセキュリティー | キーペア | 指定したキーペアがインスタンスに挿入され、SSH を使用したインスタンスへのリモートアクセスに使用されます (直接のログイン情報や静的キーペアが提供されない場合)。通常は 1 プロジェクトあたり 1 つのキーペアが作成されます。 |
| セキュリティーグループ | セキュリティーグループには、インスタンスのネットワークトラフィックの種別と方向をフィルタリングするファイアウォールルールが含まれています(グループの設定についての詳しい説明は、『 ユーザーおよびアイデンティティー 管理ガイド』の「プロジェクトのセキュリティー 管理」を参照してください)。 | |
| ネットワーク | 選択済みネットワーク | ネットワークは、少なくとも 1 つ選択する必要があります。インスタンスは通常プライベートネットワークに割り当てられ、その後に Floating IP アドレスが割り当てられて外部アクセスが可能になります。 |
| 作成後 | カスタマイズスクリプトの入力方法 | インスタンスのブート後に実行されるコマンドセットまたはスクリプトファイルを指定することができます (例: インスタンスのホスト名やユーザーパスワードの設定など)。直接入力 を選択した場合には、スクリプトデータフィールドにコマンドを書き込みます。それ以外の場合には、スクリプトファイルを指定してください。 注記 #cloud-config で開始するスクリプトは、cloud-config 構文を使用するものとして解釈されます (この構文についての情報は、http://cloudinit.readthedocs.org/en/latest/topics/examples.html を参照してください)。 |
| 高度な設定 | ディスクパーティション | デフォルトでは、インスタンスは単一のパーティションとして作成されて、必要に応じて動的にリサイズされます。ただし、パーティションを手動で設定する方法を選択することも可能です。 |
| コンフィグドライブ | このオプションを選択した場合には、OpenStack はメタデータを読み取り専用の設定ドライブに書き込みます。このドライブはインスタンスのブート時に (Compute のメタデータサービスの代わりに) インスタンスに接続されます。インスタンスがブートした後には、このドライブをマウントしてコンテンツを表示することができます (これにより、ユーザーがファイルをインスタンスに提供することが可能となります)。 |
4.1.4. インスタンスのリサイズ
インスタンスのリサイズ (メモリーまたは CPU 数) を行うには、適切な容量のあるインスタンスで新規フレーバーを選択する必要があります。サイズを大きくする場合には、ホストに十分な容量があることをあらかじめ確認することを忘れないようにしてください。
- 各ホストに SSH 鍵認証を設定してホスト間の通信が可能な状態にし、Compute が SSH を使用してディスクを他のホストに移動できるようにします (例: 複数のコンピュートノードが同じ SSH 鍵を共有することが可能です)。
元のホストでリサイズを有効にするには、Compute 環境ファイルの
allow_resize_to_same_hostパラメーターを「True」に設定します。注記allow_resize_to_same_hostパラメーターによって、同じホスト上のインスタンスはリサイズされません。このパラメーターが全コンピュートノードで「True」に指定されている場合でも、スケジューラーは同じホスト上のインスタンスのリサイズを強制しません。これは、想定されている動作です。- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- インスタンスの アクション コラムの矢印をクリックして、インスタンスのリサイズ を選択します。
- 新しいフレーバー フィールドで新規フレーバーを選択します。
起動時にインスタンスのパーティション分割を手動で行うには、以下の手順で設定します (これにより、ビルドタイムが短縮されます)。
- 高度な設定 を選択します。
- ディスクパーティション フィールドで、手動 を選択します。
- リサイズ をクリックします。
4.1.5. インスタンスへの接続
本項では、Dashboard またはコマンドラインインターフェースを使用して、インスタンスのコンソールにアクセスする複数の方法について説明します。また、インスタンスのシリアルポートに直接接続して、ネットワーク接続が失敗しても、デバッグすることが可能です。
4.1.5.1. Dashboard を使用したインスタンスのコンソールへのアクセス
コンソールを使用すると、Dashboard 内でインスタンスに直接アクセスすることができます。
- Dashboard で コンピュート > インスタンス を選択します。
-
インスタンスの ドロップダウンメニュー をクリックして、コンソール を選択します。
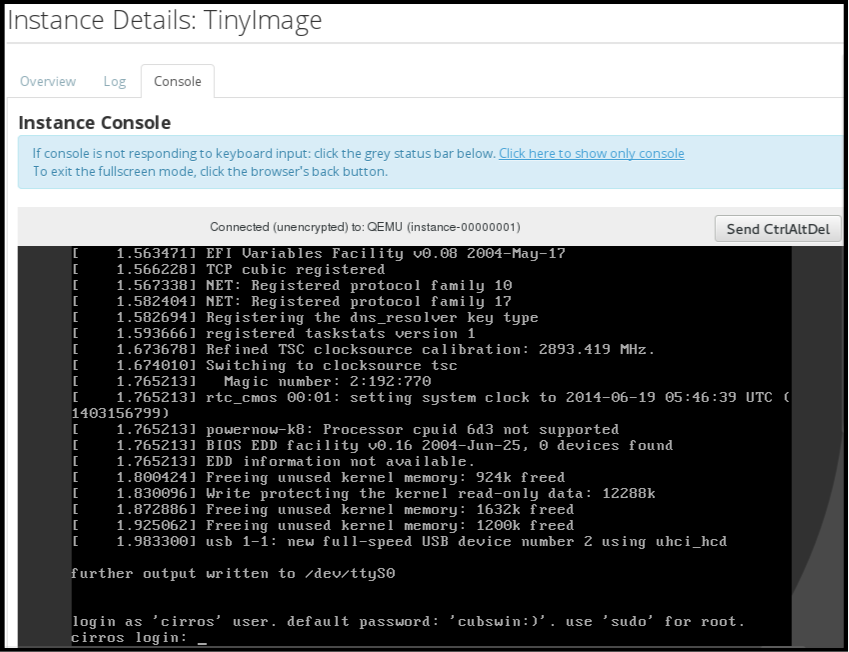
- イメージのユーザー名とパスワードを使用してログインします (例: CirrOS イメージでは「cirros」と「cubswin:)」を使用します)。
4.1.5.2. VNC コンソールへの直接接続
nova get-vnc-console コマンドで返された URL を使用すると、インスタンスの VNC コンソールに直接アクセスすることができます。
- ブラウザー
ブラウザーの URL を取得するには、以下のコマンドを実行します。
$ nova get-vnc-console INSTANCE_ID novnc- Java クライアント
Java クライアントの URL を取得するには、以下のコマンドを実行します。
$ nova get-vnc-console INSTANCE_ID xvpvnc
「nova-xvpvncviewer」は、Java クライアントの最も簡単な例を提供します。クライアントをダウンロードするには、以下のコマンドを実行します。
# git clone https://github.com/cloudbuilders/nova-xvpvncviewer # cd nova-xvpvncviewer/viewer # make
インスタンスの Java クライアント URL を使用してビューアーを実行します。
# java -jar VncViewer.jar URLこのツールは、お客様の便宜のためのみに提供されており、Red Hat では正式にサポートされていません。
4.1.6. インスタンスの使用状況の表示
以下のような使用状況統計が提供されます。
プロジェクト別
プロジェクト別の使用状況を確認するには、プロジェクト > コンピュート > 概要 を選択します。全プロジェクトインスタンスの使用状況の概要が即時に表示されます。
使用状況を照会する期間を指定して 送信 ボタンをクリックすると、特定の期間の統計を表示することもできます。
ハイパーバイザー別
管理者としてログインしている場合には、全プロジェクトの情報を表示することができます。管理 > システム をクリックしてからタブを 1 つ選択します。たとえば、リソース使用状況 タブでは、特定の期間のレポートを確認することができます。また、ハイパーバイザー をクリックすると、現在の仮想 CPU、メモリー、ディスクの統計を確認することができます。
注記仮想 CPU 使用量の値 (y 中 x 使用中) には、全仮想マシンの仮想 CPU の合計数 (x) とハイパーバイザーのコアの合計数 (y) が反映されます。
4.1.7. インスタンスの削除
- Dashboard で プロジェクト > コンピュート > インスタンス を選択して、対象のインスタンスにチェックを付けます。
- インスタンスの削除 をクリックします。
インスタンスを削除しても、接続されていたボリュームは削除されません。この操作は別途実行する必要があります(『 ストレージガイド』の「ボリュームの 削除 」を参照)。
4.1.8. 複数インスタンスの同時管理
同時に複数のインスタンスを起動する必要がある場合には (例: コンピュートまたはコントローラーのメンテナンスでダウンしている場合など)、プロジェクト > コンピュート > インスタンス から簡単に起動できます。
- 起動するインスタンスの最初のコラムにあるチェックボックスをクリックします。全インスタンスを選択するには、表の最初の行のチェックボックスをクリックします。
- 表の上にある その他のアクション をクリックして インスタンスの起動 を選択します。
同様に、適切なアクションを選択して、複数のインスタンスを終了またはソフトリブートすることができます。
4.2. インスタンスのセキュリティーの管理
適切なセキュリティーグループ (ファイアウォールのルールセット) およびキーペア (SSH を介したユーザーのアクセスの有効化) を割り当てることによってインスタンスへのアクセスを管理することができます。また、インスタンスに Floating IP アドレスを割り当てて外部ネットワークへのアクセスを有効にすることができます。以下の各項では、キーペア、セキュリティーグループ、Floating IP アドレスの作成/管理方法と SSH を使用したログインの方法について説明します。また、インスタンスに admin パスワードを挿入する手順についても記載しています。
セキュリティーグループの管理に関する情報は、『 ユーザーおよびアイデンティティー 管理ガイド』の「プロジェクト のセキュリティー管理」を 参照してください。
4.2.1. キーペアの管理
キーペアにより、インスタンスへ SSH でアクセスすることができます。キーペアの生成時には毎回、証明書がローカルマシンにダウンロードされ、ユーザーに配布できます。通常は、プロジェクトごとにキーペアが 1 つ作成されます (そのキーペアは、複数のインスタンスに使用されます)。
既存のキーペアを OpenStack にインポートすることも可能です。
4.2.1.1. キーペアの作成
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブで キーペアの作成 をクリックします。
- キーペア名 フィールドに名前を指定し、キーペアの作成 をクリックします。
キーペアが作成されると、ブラウザーを介してキーペアファイルが自動的にダウンロードされます。後ほど外部のマシンから接続できるように、このファイルを保存します。また、コマンドラインの SSH 接続には、以下のコマンドを実行して、このファイルを SSH にロードすることができます。
# ssh-add ~/.ssh/os-key.pem
4.2.1.2. キーペアのインポート
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブで キーペアのインポート をクリックします。
- キーペア名 のフィールドに名前を指定し、公開鍵の内容をコピーして、公開鍵 のフィールドにペーストします。
- キーペアのインポート をクリックします。
4.2.1.3. キーペアの削除
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- キーペア タブでそのキーの キーペアの削除 ボタンをクリックします。
4.2.2. セキュリティーグループの作成
セキュリティーグループとは、プロジェクトのインスタンスに割り当て可能な IP フィルターのルールセットで、インスタンスへのネットワークのアクセス権限を定義します。セキュリティーグループはプロジェクト別になっており、プロジェクトメンバーは自分のセキュリティーグループのデフォルトルールを編集して新規ルールセットを追加することができます。
- Dashboard で プロジェクト タブを選択して、コンピュート > アクセスとセキュリティー をクリックします。
- セキュリティーグループ タブで、+ セキュリティーグループの作成 をクリックします。
- セキュリティーグループに名前と説明を指定して、セキュリティーグループの作成 をクリックします。
プロジェクトセキュリティーの管理に関する情報は、『 ユーザーおよびアイデンティティー 管理 ガイド』の「プロジェクトのセキュリティー管理」を参照 してください。
4.2.3. Floating IP アドレスの作成、割り当て、および解放
デフォルトでは、インスタンスを最初に作成する際に、そのインスタンスに内部 IP アドレスが割り当てられます。ただし、Floating IP アドレス (外部アドレス) を作成して割り当てることによりパブリックネットワークを介したアクセスを有効にすることができます。インスタンスに割り当てられている IP アドレスは、インスタンスの状態に関わらず変更することができます。
プロジェクトには、使用できる Floating IP アドレスの範囲が限定されているので (デフォルトの上限は 50)、必要がなくなったアドレスは、再利用できるように解放することを推奨します。Floating IP アドレスは、既存の Floating IP プールからのみ確保することができます。『ネットワークガイド』 の「 Floating IP アドレスプールの作成 」を参照してください。
4.2.3.1. プロジェクトへの Floating IP アドレスの確保
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブで Floating IP の確保 をクリックします。
- プール のフィールドで、IP アドレスを確保するネットワークを選択します。
- IP の確保 をクリックします。
4.2.3.2. Floating IP の割り当て
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブでアドレスの 割り当て ボタンをクリックします。
IP アドレスフィールドで割り当てるアドレスを選択します。
注記割り当てることのできるアドレスがない場合には、
+ボタンをクリックして新規アドレスを作成することができます。- IP を割り当てるポート フィールドで割り当て先となるインスタンスを選択します。1 つのインスタンスに割り当てることができる Floating IP アドレスは 1 つのみです。
- 割り当て をクリックします。
4.2.3.3. Floating IP の解放
- Dashboard で プロジェクト > コンピュート > アクセスとセキュリティー を選択します。
- Floating IP タブで、アドレスの 割り当て/割り当て解除 ボタンの横にある矢印メニューをクリックします。
- Floating IP の解放 を選択します。
4.2.4. インスタンスへのログイン
前提条件
- インスタンスのセキュリティーグループには SSH ルールが設定されているようにしてください(『 ユーザーおよびアイデンティティー 管理ガイド』の「プロジェクト のセキュリティー管理」を参照してください)。
- インスタンスに Floating IP アドレス (外部アドレス) が割り当てられていることを確認します (「Floating IP アドレスの作成、割り当て、および解放」を参照)。
- インスタンスのキーペアの証明書を取得します。証明書は、キーペアの作成時にダウンロードされます。キーペアを自分で作成しなかった場合には、管理者に問い合わせてください (「キーペアの管理」を参照)。
最初に、キーペアのファイルを SSH に読み込み、次に名前を指定せずに ssh を使用します。
生成したキーペアの証明書のアクセス権を変更します。
$ chmod 600 os-key.pem
ssh-agentがすでに実行されているかどうかを確認します。# ps -ef | grep ssh-agent
実行されていない場合には、次のコマンドで起動します。
# eval `ssh-agent`
ローカルマシンで、キーペアの証明書を SSH に読み込みます。以下に例を示します。
$ ssh-add ~/.ssh/os-key.pem
- これで、イメージにより提供されるユーザーで、ファイルに SSH アクセスできるようになりました。
以下のコマンドの例は、Red Hat Enterprise Linux のゲストイメージに cloud-user として SSH アクセスする方法を示しています。
$ ssh cloud-user@192.0.2.24
証明書を直接使用することも可能です。以下に例を示します。
$ ssh -i /myDir/os-key.pem cloud-user@192.0.2.24
4.2.5. インスタンスへの admin パスワード挿入
以下の手順に従って、admin (root) パスワードを挿入することができます。
/etc/openstack-dashboard/local_settingsファイルで、change_set_passwordパラメーターの値をTrueに設定します。can_set_password: True
Compute 環境ファイルの
inject_passwordパラメーターを「True」に設定します。inject_password=true
Compute サービスを再起動します。
# service nova-compute restart
nova boot コマンドを使用して、新規インスタンスを起動する際には、コマンドの出力に adminPass パラメーターが表示されます。このパスワードを使用して、インスタンスに root ユーザーとしてログインすることができます。
Compute サービスは、/etc/shadow ファイル内のパスワード値を root ユーザー用に上書きします。以下の手順は、KVM ゲストイメージの root アカウントをアクティブ化するのにも使用することが可能です。KVM ゲストイメージの使用方法についての詳しい情報は、「Red Hat OpenStack Platform における KVM ゲストイメージの使用」を参照してください。
Dashboard からカスタムパスワードを設定することも可能です。これを有効にするには、can_set_password パラメーターを true に設定した後に、以下のコマンドを実行します。
# systemctl restart httpd.service
新規追加された admin パスワードフィールドは以下のように表示されます。
上記のフィールドは、インスタンスの起動/再ビルド時に使用することができます。
4.3. フレーバーの管理
作成する各インスタンスには、インスタンスのサイズや容量を決定するためのフレーバー (リソースのテンプレート) を指定します。また、フレーバーを使用して、セカンダリー一時ストレージやスワップディスク、使用率を制限するためのメタデータ、特別なプロジェクトへのアクセスを指定することも可能です (デフォルトのフレーバーにはこのような追加の属性は一切定義されていません)。
表4.3 デフォルトのフレーバー
| 名前 | 仮想 CPU の数 | メモリー | ルートディスクのサイズ |
|---|---|---|---|
| m1.tiny | 1 | 512 MB | 1 GB |
| m1.small | 1 | 2048 MB | 20 GB |
| m1.medium | 2 | 4096 MB | 40 GB |
| m1.large | 4 | 8192 MB | 80 GB |
| m1.xlarge | 8 | 16384 MB | 160 GB |
エンドユーザーの大半は、デフォルトのフレーバーを使用できます。ただし、特化したフレーバーを作成/管理することができます。たとえば、以下の操作を行うことができます。
- 基になるハードウェアの要件に応じて、デフォルトのメモリーと容量を変更する
- インスタンスに特定の I/O レートを強制するためのメタデータ、またはホストアグリゲートと一致させるためのメターデータを追加する
イメージのプロパティーを使用して設定した動作は、フレーバーを使用して設定した動作よりも優先されます。詳しい説明は、「イメージの管理」を参照してください。
4.3.1. 設定パーミッションの更新
デフォルトでは、フレーバーの作成およびフレーバーの完全リストの表示ができるのは管理者のみです (「管理 > システム > フレーバー」を選択)。全ユーザーがフレーバーを設定できるようにするには、/etc/nova/policy.json ファイル (nova-api サーバー) で以下の値を指定します。
"compute_extension:flavormanage": "",
4.3.2. フレーバーの作成
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
フレーバーの作成 をクリックして、以下のフィールドに入力します。
表4.4 フレーバーのオプション
タブ フィールド 説明 フレーバー情報
名前
一意な名前
ID
一意な ID。デフォルト値は
autoで、UUID4 値を生成しますが、整数または UUID4 値 を手動で指定することもできます。仮想 CPU
仮想 CPU 数
メモリー (MB)
メモリー (メガバイト単位)
ルートディスク (GB)
一時ディスクのサイズ (ギガバイト単位)。ネイティブイメージサイズを使用するには
0を指定します。このディスクは、Instance Boot Source=Boot from Volume と指定されている場合には使用されません。一時ディスク (GB)
インスタンスで利用可能なセカンダリー一時ディスクのサイズ (ギガバイト単位)。このディスクは、インスタンスの削除時に破棄されます。
デフォルト値は
0です。この値を指定すると、一時ディスクは作成されません。スワップディスク (MB)
スワップディスクのサイズ (メガバイト単位)
フレーバーアクセス権
選択済みのプロジェクト
そのフレーバーを使用することができるプロジェクト。プロジェクトが選択されていない場合には、全プロジェクトにアクセスが提供されます (
Public=Yes)。- フレーバーの作成 をクリックします。
4.3.3. 一般属性の更新
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
- 対象のフレーバーの フレーバーの編集 ボタンをクリックします。
- 値を更新して、保存 をクリックします。
4.3.4. フレーバーのメタデータの更新
一般属性の編集に加えて、フレーバーにメタデータ (extra_specs) を追加することが可能です。メタデータは、インスタンスの使用方法を微調整するのに役立ちます。たとえば、最大許容帯域幅やディスクの書き込みを設定する場合などです。
- 事前定義済みのキーにより、ハードウェアサポートやクォータが決定されます。事前定義済みのキーは、使用するハイパーバイザーによって限定されます (libvirt の場合は 表4.5「Libvirt のメタデータ」を参照してください)。
-
事前定義済みおよびユーザー定義のキーはいずれも、インスタンスのスケジューリングを決定します。たとえば、
SpecialComp=Trueと指定すると、このフレーバーを使用するインスタンスはすべてメタデータのキーと値の組み合わせが同じホストアグリゲートでのみ実行可能となります (「ホストアグリゲートの管理」を参照)。
4.3.4.1. メタデータの表示
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
-
フレーバーの メタデータ リンク (
はいまたはいいえ) をクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。
4.3.4.2. メタデータの追加
キーと値 のペアを使用してフレーバーのメタデータを指定します。
- Dashboard に管理ユーザーとしてログインして 管理 > システム > フレーバー を選択します。
-
フレーバーの メタデータ リンク (
はいまたはいいえ) をクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。 - 利用可能なメタデータ で その他 のフィールドをクリックして、追加するキーを指定します (表4.5「Libvirt のメタデータ」を参照)。
- 「+」ボタンをクリックします。選択済みのメタデータ の下に新しいキーが表示されるようになりました。
右側のフィールドにキーの値を入力します。
- キーと値のペアの追加が終了したら 保存 をクリックします。
表4.5 Libvirt のメタデータ
| キー | 説明 |
|---|---|
|
| インスタンスごとにサポート制限を設定するアクション。有効なアクションは以下のとおりです。
例: |
|
| インスタンスの NUMA トポロジーの定義。RAM および仮想 CPU の割り当てがコンピュートホスト内の NUMA ノードのサイズよりも大きいフレーバーの場合には、NUMA トポロジーを定義することでホストが NUMA を効果的に使用してゲスト OS のパフォーマンスを向上することができます。フレーバーで定義された NUMA の定義は、イメージの定義をオーバーライドします。有効な定義は以下のとおりです。
注記
インスタンスに 8 個の仮想 CPU、4 GB の RAM が指定されている場合の例:
スケジューラーは、NUMA ノードが 2 つあり、そのうちの 1 つのノードで 6 つの CPU および 3072 MB または 3 GB のメモリーを実行し、別のノードで 2 つの CPU および 1024 MB または 1 GB のメモリーを実行できるホストを検索します。ホストに 8 つの CPU および 4 GB のメモリーを実行できる NUMA ノードが 1 つある場合は、有効な一致とは見なされません。 |
|
| インスタンスのウォッチドッグデバイスを使用して、インスタンスに何らかの理由でエラー (またはハング) が発生した場合にアクションをトリガーすることができます。有効なアクションは以下のとおりです。
例: |
|
| このパラメーターを使用して、PCI パススルーデバイスおよび SR-IOV インターフェースの NUMA アフィニティーポリシーを指定することができます。以下の有効な値のいずれかに設定します。
例: |
|
|
イメージプロパティーを使用して乱数生成器をインスタンスに追加することができます (Red Hat OpenStack Platform ドキュメントの『Command-Line Interface Reference』で このデバイスを追加した場合の有効なアクションは以下のとおりです。
例: |
|
| ビデオデバイスの最大許容 RAM (MB 単位)
例: |
|
| インスタンスの制限を強制します。有効なオプションは以下のとおりです。
例: さらに、VMware ドライバーは、CPU、メモリー、ディスク、ネットワークの上限、下限を制御する以下のクォータオプションや、プロジェクトで利用可能なリソースの相対割り当てを制御するのに使用可能な 共有 をサポートします。
|
4.4. ホストアグリゲートの管理
パフォーマンスおよび管理目的で、単一の Compute デプロイメントを複数の論理グループにパーティショニングすることができます。OpenStack では以下のような用語を使用しています。
ホストアグリゲート: ホストアグリゲートは、ホストをグループ化してまとめることによって OpenStack デプロイメント内に論理ユニットを作成します。アグリゲートは、割り当てられた Compute ホストと関連付けられたメタデータです。1 台のホストは複数のアグリゲートに属することが可能です。ホストアグリゲートの表示と作成ができるのは管理者のみです。
アグリゲートのメタデータは通常、Compute のスケジューラーで使用する情報を提供します (例: 特定のフレーバーやイメージを複数のホストの 1 つのサブネットに制限するなど)。ホストアグリゲートで指定されるメタデータは、フレーバー内で同じメタデータが指定されているインスタンスにホストの使用を限定します。
管理者は、ホストアグリゲートを使用して、ロードバランスの処理、物理的な分離 (または冗長) の強制、共通の属性を持つサーバーのグループ化、ハードウェアクラスの分類などを行うことができます。アグリゲートの作成時には、ゾーン名を指定する必要があります。この名前がエンドユーザーに表示されます。
アベイラビリティーゾーン: アベイラビリティーゾーンとは、ホストアグリゲートのエンドユーザーのビューです。エンドユーザーはゾーンがどのホストで構成されているかを表示したり、ゾーンのメタデータを確認したりすることはできません。ユーザーが見ることができるのはゾーン名のみです。
一定の機能や一定のエリア内で設定された特定のゾーンを使用するようにエンドユーザーを誘導することができます。
4.4.1. ホストアグリゲートのスケジューリングの有効化
デフォルトでは、ホストアグリゲートのメタデータは、インスタンスの使用先のフィルタリングには使用されません。メタデータの使用を有効にするには、Compute のスケジューラーの設定を更新する必要があります。
- Compute 環境ファイルを開きます。
NovaSchedulerDefaultFiltersパラメーターにまだ以下の値がなければ、値を追加します。ホストアグリゲートのメタデータ用の
AggregateInstanceExtraSpecsFilter注記同じ
NovaSchedulerDefaultFiltersパラメーターの値としてAggregateInstanceExtraSpecsFilterおよびComputeCapabilitiesFilterフィルターの両方を指定する場合には、フレーバーextra_specsの設定にスコープを定義した仕様を使用する必要があります。使用しない場合には、ComputeCapabilitiesFilterは適切なホストの選択に失敗します。これらのフィルター用にフレーバーextra_specsキーのスコープを定義するのに使用する名前空間の詳細は、表4.7「スケジューリングフィルター」 を参照してください。-
インスタンス起動時のアベイラビリティーゾーンのホスト仕様用の
AvailabilityZoneFilter
- 設定ファイルを保存します。
- オーバークラウドをデプロイします。
4.4.2. アベイラビリティーゾーンまたはホストアグリゲートの表示
Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。アベイラビリティーゾーン のセクションには全ゾーンがリストされます。
4.4.3. ホストアグリゲートの追加
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
- ホストアグリゲートの作成 をクリックします。
- 名前 フィールドにアグリゲートの名前を入力します。この名前が アベイラビリティーゾーン フィールドでエンドユーザーに表示されます。
- アグリゲートのホストの管理 をクリックします。
- 「+」アイコンをクリックしてホストを選択します。
- ホストアグリゲートの作成 をクリックします。
4.4.4. ホストアグリゲートの更新
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
インスタンスの 名前 または アベイラビリティーゾーン を更新するには、以下の手順で行います。
- アグリゲートの ホストアグリゲートの編集 ボタンをクリックします。
- 名前 または アベイラビリティーゾーン のフィールドを更新して、保存 をクリックします。
インスタンスの 割り当て済みのホスト を更新するには、以下の手順で行います。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- ホストの管理 をクリックします。
- 「+」または「-」のアイコンをクリックしてホストの割り当てを変更します。
- 終了したら、保存 をクリックします。
インスタンスの メタデータ を更新するには、以下の手順で行います。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- メタデータの更新 ボタンをクリックします。現在の値はすべて右側の 選択済みのメタデータ の下に一覧表示されます。
- 利用可能なメタデータ で その他 のフィールドをクリックして、追加するキーを指定します。事前に定義したキー (表4.6「ホストアグリゲートのメタデータ」を参照) を使用するか、独自のキーを追加します (このキーと全く同じキーがインスタンスのフレーバーに設定されている場合にのみ有効となります)。
「+」ボタンをクリックします。選択済みのメタデータ の下に新しいキーが表示されるようになりました。
注記キーを削除するには、「-」のアイコンをクリックします。
保存 をクリックします。
表4.6 ホストアグリゲートのメタデータ
キー 説明 filter_project_idこれが指定されている場合、アグリゲートはこのプロジェクト(テナント)のみをホストします。これは、Compute のスケジューラーに設定されている
AggregateMultiTenancyIsolationフィルターによって異なります。
4.4.5. ホストアグリゲートの削除
- Dashboard に管理ユーザーとしてログインして 管理 > システム > ホストアグリゲート を選択します。ホストアグリゲート のセクションに現在定義済みのアグリゲートがすべてリストされます。
割り当てられている全ホストをアグリゲートから削除します。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- ホストの管理 をクリックします。
- 「-」アイコンをクリックして、全ホストを削除します。
- 終了したら、保存 をクリックします。
- アクション の下にあるアグリゲートの矢印アイコンをクリックします。
- このダイアログ画面と次の画面で ホストアグリゲートの削除 をクリックします。
4.5. ホストのスケジュール
Compute のスケジューリングサービスは、インスタンスの配置先となるホストまたはホストアグリゲートを決定します。管理者は、設定を使用して、スケジューラーによるインスタンスの配置先の決定方法を定義することができます。たとえば、特定のグループや適切な量の RAM があるホストにスケジューリングを限定することが可能です。
以下のコンポーネントを設定することができます。
- フィルター: インスタンスの配置先候補となるホストの初期セットを決定します (「スケジューリングフィルターの設定」を参照)。
- 重み: フィルタリングの完了時に選出されたホストのセットは重み付けのシステムを使用して優先順位が決定されます。最も高い重みが最優先されます (「スケジューリングの重みの設定」を参照)。
-
スケジューラーサービス: スケジューラーホスト上の
/var/lib/config-data/puppet-generated/<nova_container>/etc/nova/nova.confファイルには数多くの設定オプションがあります。これらのオプションは、スケジューラーがタスクを実行する方法や、重み/フィルターを処理する方法を決定します。 - Placement サービス: ストレージディスクの種別や Intel CPU 拡張命令セットなど、インスタンスがホストに必要な特性を指定します( 「Placement サービスの特性の設定」を参照)。
下図では、フィルタリング後には Host 1 と Host 3 の両方が条件に適合しています。Host 1 の重みが最も高いため、スケジューリングで最優先されます。
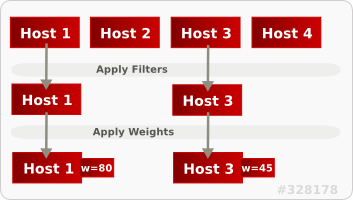
4.5.1. スケジューリングフィルターの設定
スケジューラーが使用するフィルターを定義するには、Compute 環境ファイルの NovaSchedulerDefaultFilters パラメーターを使用します。フィルタを追加したり削除したりすることができます。
デフォルト設定では、スケジューラーで以下のフィルターが実行されます。
- RetryFilter
- AvailabilityZoneFilter
- ComputeFilter
- ComputeCapabilitiesFilter
- ImagePropertiesFilter
- ServerGroupAntiAffinityFilter
- ServerGroupAffinityFilter
一部のフィルターは、以下の方法でインスタンスに渡されるパラメーターの情報を使用します。
-
nova bootコマンド - インスタンスのフレーバー (「フレーバーのメタデータの更新」を参照)
- インスタンスのイメージ (「付録A イメージの設定パラメーター」を参照)
利用可能なすべてのフィルターを一覧にして以下の表に示します。
表4.7 スケジューリングフィルター
| フィルター | 説明 |
|---|---|
|
| インスタンスのイメージのメタデータが一致するホストアグリゲート内のホストのみを渡します。これは、そのインスタンスにホストアグリゲートが指定されている場合にのみ有効です。詳細は、「「イメージの作成」」を参照してください。 |
|
| ホストアグリゲート内のメタデータは、ホストのフレーバーのメタデータと一致する必要があります。詳細は、「「フレーバーのメタデータの更新」」を参照してください。 |
|
このフィルターを
| |
|
|
注記 プロジェクトが他のホストにインスタンスを配置することは可能です。 |
|
| 利用可能な全ホストを渡します (ただし、他のフィルターは無効化しません)。 |
|
| インスタンスに指定されているアベイラビリティーゾーンを使用してフィルタリングします。 |
|
|
Compute のメタデータが正しく読み取られるようにします。「 |
|
| 稼働中の有効なホストのみを渡します。 |
|
|
指定されている単一または複数のホストとは別のホスト上でインスタンスをビルドできるようにします。 |
|
| インスタンスのイメージプロパティーに一致するホストのみを渡します。詳細は、「「イメージの作成」」を参照してください。 |
|
|
|
|
| インスタンスのカスタム JSON フィルターを認識/使用します。
|
|
このフィルターは、クエリーヒントとして
| |
|
| メトリックが利用できないホストを除外します。 |
|
| NUMA トポロジーに基づいてホストを除外します。インスタンスにトポロジーが未定義の場合には、任意のホストを使用することができます。このフィルターは、NUMA トポロジーが完全に同じインスタンスとホストをマッチングするように試みます (そのホスト上ではインスタンスのスケジューリングは試みません)。また、このフィルターは、NUMA ノードの標準的なオーバーサブスクリプションの上限を確認し、それに応じて、コンピュートホストに対して制限を指定します。 |
|
| 重み付け関数はホスト上の PCI デバイスの数とインスタンスに要求された PCI デバイス数に基づいて重みを計算することができます。たとえば、ホストが 3 台利用可能で、PCI デバイスが 1 つのホストが 1 台、複数の PCI デバイスがあるホストが 1 台、PCI デバイスがないホストが 1 台の場合には、Compute はインスタンスの需要に基づいてこれらのホストの優先順位付けを行う必要があります。インスタンスが PCI デバイスを 1 つ要求している場合には 1 番目のホスト、複数の PCI デバイスを要求している場合には 2 番目のホスト、PCI デバイスを要求していない場合には 3 番目のホストが優先されるべきです。 詳しくは、「PCI デバイスがアタッチされている NUMA ノードの確保」を参照してください。 |
|
|
スケジュールを試みて失敗したホストを除外します。 |
|
|
指定されている単一または複数のホストを渡します。 |
|
| 特定のサーバーグループのホストのみを渡します。
|
|
| インスタンスをまだホストしていないサーバーグループ内のホストのみを渡します。
|
|
|
インスタンスの cidr および
|
4.5.2. スケジューリングの重みの設定
ホストは、スケジューリング用に重み付けすることができます。(フィルタリング後に) 重みが最大のホストが選択されます。重み付け関数にはすべて、ノードの重みを正規化した後に適用される乗数が指定されます。ノードの重みは以下のように計算されます。
w1_multiplier * norm(w1) + w2_multiplier * norm(w2) + ...
重みのオプションは、コンピュートノードの設定ファイルで定義することができます。
4.5.2.1. ホストの重みのオプション設定
スケジューラーが使用するホストの重み付け関数は、[DEFAULT] scheduler_weight_classes のオプションで定義することができます。有効な重み付け関数は以下のとおりです。
-
nova.scheduler.weights.ram: ホストの使用可能なメモリーを重み付けします。 -
nova.scheduler.weights.metrics: ホストのメトリックを重み付けします。 -
nova.scheduler.weights.affinity: 特定のサーバーグループ内にある他のホストとのホストの近接性を重み付けします。 -
nova.scheduler.weights.all_weighers: 全ホストの重み付け関数を使用します (デフォルト)。
表4.8 ホストの重みのオプション
| 重み付け関数 | オプション | 説明 |
|---|---|---|
| すべて |
[DEFAULT] |
ホストの選択先のサブセットサイズを定義します (整数)。 |
| affinity |
[default] |
グループソフトアフィニティーのホストを重み付けする際に使用します。正の浮動小数点数を指定してください。これは、負の値を指定すると反対の動作が発生してしまうためです。通常、このような反対の動作は、 |
| affinity |
[default] |
グループソフト非アフィニティーのホストを重み付けする際に使用します。正の浮動小数点数を指定してください。これは、負の値を指定すると反対の動作が発生してしまうためです。通常、このような反対の動作は、 |
| metrics |
[metrics] |
[metrics]
|
| metrics |
[metrics] |
[metrics] |
| metrics |
[metrics] |
メトリックを重み付けする乗数。デフォルトでは |
| metrics |
[metrics] |
重み付けに使用されるメトリックと比率を指定します。
例: |
| ram |
[DEFAULT] |
RAM の乗数 (浮動小数点)。デフォルトでは、 |
4.5.3. Placement サービスの特性の設定
Placement サービスは、コンピュートノード、共有ストレージプール、または IP 割り当てプールなど、リソースプロバイダーのインベントリーおよび使用状況を追跡します。リソースの選択および消費を管理する必要があるサービスは、すべて Placement サービスを使用することができます。
Placement サービスにクエリーを行うには、アンダークラウドに python3-osc-placement パッケージをインストールします。
各リソースプロバイダーには特性のセットがあります。特性は、ストレージディスクの種別や Intel CPU 拡張命令セットなど、リソースプロバイダーの機能的な要素です。インスタンスは、これらの中から要求する特性を指定することができます。
Compute (nova) サービスは、nova-compute および nova-scheduler プロセスを使用して Placement サービスと協調してインスタンスを作成します。
nova-compute- リソースプロバイダーレコードを作成します。
- 利用可能な仮想 CPU の数など、利用可能なリソースを数量的に記述するインベントリーを設定します。
-
リソースプロバイダーの性質的な要素を記述する特性を設定します。
libvirt仮想化ドライバーは、これらの特性を Placement サービスに報告します(詳しくは 「Placement サービスの特性としてのlibvirt仮想化ドライバー機能」 を参照)。
nova-scheduler- Placement サービスに、割り当て候補の一覧を要求します。
- インスタンスが要求する特性に基づいて、サーバーの構築先となるホストを決定します。
4.5.3.1. Placement サービスの特性としての libvirt 仮想化ドライバー機能
libvirt 仮想化ドライバーの機能を Placement サービスの特性として使用することができます。指定することのできる特性は os-traits ライブラリーで定義されます。以下に例を示します。
-
COMPUTE_TRUSTED_CERTS -
COMPUTE_NET_ATTACH_INTERFACE_WITH_TAG -
COMPUTE_IMAGE_TYPE_RAW -
HW_CPU_X86_AVX -
HW_CPU_X86_AVX512VL -
HW_CPU_X86_AVX512CD
インスタンスが特定のハードウェア、仮想化、ストレージ、ネットワーク、またはデバイスの特性に要求することのできる標準化された定数のカタログについては、os-traits ライブラリー を参照してください。
以下の libvirt 仮想化ドライバーは、命令セットの種別 (SSE4、AVX、または AVX-512 等) など、ホスト CPU が提供する機能を自動的に Placement サービスに報告します。
- Libvirt QEMU (x86)
- Libvirt KVM (x86)
- Libvirt KVM (ppc64)
これらのドライバーのいずれかを使用している場合、インスタンス用にフレーバー追加スペックまたはイメージメタデータを設定して、リソースプロバイダーに特定の CPU 機能を要求することができます。
4.5.3.2. Placement サービス特性を使用したリソースプロバイダー要求の指定
以下の方法のいずれかを使用して、インスタンス用に要求するリソースプロバイダー特性を指定することができます。
以下の手順例では、インスタンスは特定の CPU 種別を要求します。
前提条件
-
Placement サービスのパッケージ
python3-osc-placementがアンダークラウドにインストールされている。 デプロイメントで、以下の
libvirt仮想化ドライバーのいずれかが使用されている。- Libvirt QEMU (x86)
- Libvirt KVM (x86)
- Libvirt KVM (ppc64)
手順: イメージメタデータを使用して特性を要求する
新規イメージを作成するか、既存のイメージを変更して、必要な特性を設定します。
$ openstack image create ... $IMAGE $ openstack image set --property trait:HW_CPU_X86_AVX512BW=required $IMAGE
そのイメージを使用してインスタンスをブートします。
$ openstack server create --image=$IMAGE ... $SERVER_NAME
結果: AVX-512 をサポートするホストにインスタンスが作成されます。
手順: フレーバー追加スペックを使用して特性を要求する
新規フレーバーを作成するか、既存のフレーバーを変更して、必要な特性を設定します。
$ openstack flavor create ... $FLAVOR $ openstack flavor set --property trait:HW_CPU_X86_AVX512BW=required $FLAVOR
そのフレーバーを使用してインスタンスをブートします。
$ openstack server create --flavor=$FLAVOR ... $SERVER_NAME
結果: AVX-512 をサポートするホストにインスタンスが作成されます。
4.5.4. 最小帯域幅を確保する QoS の設定
Quality of Service (QoS) ポリシーを使用して、最小帯域幅の確保を要求するインスタンスを作成することができます。
QoS ポリシーと最小帯域幅を確保するルールの組み合わせは、特定の物理ネットワーク上のポートに割り当てられます。設定したポートを使用するインスタンスを作成する場合、Compute のスケジューリングサービスは、この要求を満たすインスタンス用ホストを選択します。Compute のスケジューリングサービスは、インスタンスをデプロイするホストを選択する前に、他のインスタンスが各物理インターフェース上に確保する帯域幅を Placement サービスに問い合わせます。
制限/制約
- 新規インスタンスの作成時にのみ、最小帯域幅を確保する QoS ポリシーを割り当てることができます。Compute サービスがインスタンス用リソースの使用状況を更新するのは作成または移動操作時だけなので、すでに動作中のインスタンスに最小帯域幅を確保する QoS ポリシーを割り当てることはできません。つまり、インスタンスで利用可能な最小帯域幅を保証することはできません。
最小帯域幅を確保する QoS ポリシーなど、リソース要求が設定されたポートを使用するインスタンスのライブマイグレーションを行うことはできません。ポートにリソース要求が設定されているかどうかを確認するには、以下のコマンドを実行します。
$ openstack port show <port_name/port_id>
前提条件
- 最小帯域幅ルールの QoS ポリシーを利用することができる。詳しくは、「 Quality of Service(QoS)ポリシーの設定」を参照してください。
手順
利用可能な QoS ポリシーを一覧表示します。
(overcloud) $ openstack network qos policy list
----------------------------------------------------------------+ | ID | Name | Shared | Default | Project |----------------------------------------------------------------+ | 6d771447-3cf4-4ef1-b613-945e990fa59f | policy2 | True | False | ba4de51bf7694228a350dd22b7a3dc24 | | 78a24462-e3c1-4e66-a042-71131a7daed5 | policy1 | True | False | ba4de51bf7694228a350dd22b7a3dc24 | | b80acc64-4fc2-41f2-a346-520d7cfe0e2b | policy0 | True | False | ba4de51bf7694228a350dd22b7a3dc24 |----------------------------------------------------------------+利用可能な各ポリシーのルールを確認して、必要な最小帯域幅に関するものを特定します。
(overcloud) $ openstack network qos policy show policy0
----------------------------------------------------------------------------------------------------+ | Field | Value |----------------------------------------------------------------------------------------------------+ | description | | | id | b80acc64-4fc2-41f2-a346-520d7cfe0e2b | | is_default | False | | location | cloud=', project.domain_id=, project.domain_name='Default, project.id=ba4de51bf7694228a350dd22b7a3dc24, project.name=admin, region_name=regionOne, zone= | | name | policy0 | | project_id | ba4de51bf7694228a350dd22b7a3dc24 | | rules | [{min_kbps: 100000, direction: egress, id: d46218fe-9218-4e96-952b-9f45a5cb3b3c, qos_policy_id: b80acc64-4fc2-41f2-a346-520d7cfe0e2b, type: minimum_bandwidth}, {min_kbps: 100000, direction: ingress, id: 1202c4e3-a03a-464c-80d5-0bf90bb74c9d, qos_policy_id: b80acc64-4fc2-41f2-a346-520d7cfe0e2b, type: minimum_bandwidth}] | | shared | True | | tags | [] |----------------------------------------------------------------------------------------------------+適切なポリシーからポートを作成します。
(overcloud) $ openstack port create port-normal-qos --network net0 --qos-policy policy0
使用する NIC ポートを指定して、インスタンスを作成します。
$ openstack server create --flavor cirros256 --image cirros-0.3.5-x86_64-disk --nic port-id=port-normal-qos --wait qos_instance
出力の「ACTIVE」ステータスは、要求された最小帯域幅を保証できるホストにインスタンスが正常に作成されていることを示しています。
4.5.4.1. インスタンスからの最小帯域幅を確保する QoS の削除
インスタンスから最小帯域幅を確保する QoS ポリシーの制約を外す場合、インターフェースの割り当てを解除することができます。
インターフェースの割り当てを解除するには、以下のコマンドを入力します。
$ openstack server remove port <vm_name|vm_id> <port_name|port_id>
4.5.5. PCI デバイスがアタッチされている NUMA ノードの確保
Compute はフィルタースケジューラーを使用して、PCI を要求するインスタンスに対して、PCI デバイスがアタッチされたホストの優先順位付けを行います。ホストの重み付けは、PCIWeigher オプションが使用して、ホスト上で利用可能な PCI デバイスの数と、インスタンスによって要求されている PCI デバイスの数に基づいて行われます。インスタンスが PCI デバイスを要求している場合は、より多くの PCI デバイスがアタッチされたホストに、他のホストよりも高い加重値が割り当てられます。インスタンスが PCI デバイスを要求していない場合には、優先順位付けは行われません。
この機能は、以下のような場合に特に役立ちます。
- オペレーターが、PCI デバイスを要求するゲストインスタンス向けに PCI デバイスがアタッチされたノード (通常は高コストでリソースが限定される) を確保する場合
- インスタンスを起動するユーザーが、必要時に PCI デバイスを利用できるようにする場合。
この値が考慮されるようにするには、Compute 環境ファイルの NovaSchedulerDefaultFilters パラメーターに、PciPassthroughFilter または NUMATopologyFilter どちらかの値を追加する必要があります。
pci_weight_multiplier 設定オプションは、正の値でなければなりません。
4.5.6. 専用の物理 CPU で実行されるエミュレータースレッドの設定
Compute のスケジューラーは、CPU リソースの使用状況を確認して、フレーバーの仮想 CPU (vCPU) 数に基づいてインスタンスを配置します。ゲストの代わりにホストで実行されるハイパーバイザー操作は数多くあります。たとえば、QEMU では、QEMU のメインイベントループや、非同期 I/O 操作などに使用されるスレッドがあるので、それらを考慮に入れて、別々にスケジュールする必要があります。
libvirt ドライバーは、KVM 向けの一般的な配置ポリシーを実装しています。このポリシーでは、仮想 CPU を実行しているのと同じ複数の物理 CPU (pCPU) 全体にわたって、QEMU エミュレータースレッドをフローティングさせることができます。これにより、エミュレータースレッドは、仮想 CPU 操作から借りた時間を使用することになります。ゲストに専用の仮想 CPU 割り当てが必要な場合には、エミュレータースレッドに 1 つまたは複数の物理 CPU を割り当てる必要があります。そのため、スケジューラーに対して、ゲストに関連する可能性のある他の CPU の用途を記述して、配置中にそれ計算に入れる必要があります。
NFV デプロイメントでは、パケットロスを回避するために、仮想 CPU が割り込まれないようにする必要があります。
フレーバー上でエミュレータースレッドの配置ポリシーを有効にする前に、以下に示すように heat パラメーターが定義されていることを確認する必要があります。
-
NovaComputeCpuSharedSet: このパラメーターには、エミュレータースレッドを実行するように定義された CPU の一覧を設定します。 -
NovaSchedulerDefaultFilters: 定義するフィルターの一覧にNUMATopologyFilterを含めます。
これらの変更を適用するには、アクティブなクラスターで heat パラメーターの値を定義または変更してから再デプロイします。
エミュレータースレッドを分離するには、以下のように設定したフレーバーを使用する必要があります。
# openstack flavor set FLAVOR-NAME \ --property hw:cpu_policy=dedicated \ --property hw:emulator_threads_policy=share
4.6. インスタンスのスナップショットの管理
インスタンスのスナップショットを使用すると、インスタンスから新規イメージを作成することができます。これは、ベースイメージのアップロードや、公開イメージを取得してローカルで使用するためにカスタマイズする際に非常に便利です。
Image サービスに直接アップロードしたイメージと、スナップショットで作成したイメージの相違点は、スナップショットで作成したイメージには Image サービスデータベースのプロパティーが追加されている点です。これらのプロパティーは image_properties テーブルにあり、以下のパラメーターが含まれます。
表4.9 スナップショットのオプション
| 名前 | 値 |
|---|---|
| image_type | snapshot |
| instance_uuid | <スナップショットを作成したインスタンスの uuid> |
| base_image_ref | <スナップショットを作成したインスタンスのオリジナルイメージの uuid> |
| image_location | snapshot |
スナップショットでは、指定のスナップショットをベースにして新規インスタンスを作成して、その状態にインスタンスを復元することができます。さらに、インスタンスの実行中にスナップショットを作成や復元が可能です。
デフォルトでは、スナップショットをベースとするインスタンスが起動している間は、選択したユーザーとプロジェクトがそのスナップショットにアクセスできます。
4.6.1. インスタンスのスナップショットの作成
インスタンスのスナップショットをテンプレートとして使用して新規インスタンスを作成する場合には、ディスクの状態が一貫していることを確認してください。スナップショットを作成する前に、スナップショットのイメージメタデータのプロパティーを os_require_quiesce=yes に設定します。以下に例を示します。
$ glance image-update IMAGE_ID --property os_require_quiesce=yes
このコマンドが機能するには、ゲストに qemu-guest-agent パッケージがインストール済みで、メタデータプロパティーのパラメーターを hw_qemu_guest_agent=yes に指定してイメージを作成する必要があります。以下に例を示します。
$ glance image-create --name NAME \ --disk-format raw \ --container-format bare \ --file FILE_NAME \ --is-public True \ --property hw_qemu_guest_agent=yes \ --progress
hw_qemu_guest_agent=yes パラメーターを無条件で有効化した場合には、別のデバイスをゲストに追加してください。この設定により、PCI スロットが使用され、ゲストに割り当てることのできる他のデバイスの数が制限されます。また、これにより、Windows ゲストでは、未知のハードウェアデバイスについての警告のメッセージが表示されます。
このような理由により、hw_qemu_guest_agent=yes パラメーターの設定はオプションとなっており、QEMU ゲストエージェントを必要とするそれらのイメージにのみ使用すべきです。
- Dashboard で プロジェクト > コンピュート > インスタンス を選択します。
- スナップショットを作成するインスタンスを選択します。
- アクション コラムで、スナップショットの作成 をクリックします。
スナップショットの作成 ダイアログでは、スナップショットの名前を入力して スナップショットの作成 をクリックします。
イメージ カテゴリーには、インスタンスのスナップショットが表示されます。
スナップショットからインスタンスを起動するには、スナップショットを選択して 起動 をクリックします。
4.6.2. スナップショットの管理
- Dashboard で プロジェクト > イメージ を選択します。
- 作成したスナップショットはすべて プロジェクト オプションの下に表示されます。
作成するスナップショットごとに、ドロップダウンリストを使用して以下の機能を実行できます。
- ボリュームの作成 オプションを使用して、ボリュームを作成してボリューム名の値、説明、イメージソース、ボリューム種別、サイズ、アベイラビリティーゾーンを入力します。詳細は、『 ストレージガイド』 の「 ボリュームの作成」を 参照してください。
- イメージの編集 オプションを使用して、名前、説明、カーネル ID、Ramdisk ID、アーキテクチャー、形式、最小ディスク (GB)、最小メモリー (MB)、パブリックまたはプライベートを更新して、スナップショットのイメージを更新します。詳細は、「イメージの更新」を参照してください。
- イメージの削除 オプションを使用してスナップショットを削除します。
4.6.3. スナップショットの状態へのインスタンスの再ビルド
スナップショットがベースとなっているインスタンスを削除する場合には、スナップショットにはインスタンス ID が保存されます。nova image-list コマンドを使用してこの情報を確認して、スナップショットでインスタンスを復元します。
- Dashboard で プロジェクト > コンピュート > イメージ を選択します。
- インスタンスを復元するスナップショットを選択します。
- アクション コラムで、インスタンスの起動 をクリックします。
- インスタンスの起動 ダイアログで、インスタンスの名前とその他の詳細を入力して 起動 をクリックします。
インスタンスの起動に関する詳細は、「インスタンスの起動」を参照してください。
4.6.4. 一貫性のあるスナップショット
以前のリリースでは、バックアップの一貫性を確保するには、アクティブなインスタンスのスナップショットを作成する前にファイルシステムを手動で停止 (fsfreeze) する必要がありました。
Compute の libvirt ドライバーは、QEMU ゲストーエージェント に、イメージのスナップショット作成中ファイルシステムを (fsfreeze-hook がインストールされている場合には、アプリケーションも対象) フリーズするように自動的に要求するようになりました。ファイルシステムの停止に対するサポートにより、スケジュールされた自動スナップショット作成をブロックデバイスレベルで実行できるようになりました。
この機能は、QEMU ゲストエージェント (qemu-ga) がインストール済みで、かつイメージのメタデータで有効化されている (hw_qemu_guest_agent=yes) 場合にのみ有効です。
スナップショットは、実際のシステムバックアップの代わりとみなすべきではありません。
4.7. インスタンスのレスキューモードの使用
Compute では、仮想マシンをレスキューモードで再起動する方法があります。レスキューモードは、仮想マシンイメージが原因で、インスタンスがアクセス不可能な状態となっている場合に、そのインスタンスにアクセスするためのメカニズムを提供します。レスキューモードの仮想マシンは、ユーザーが仮想マシンに新規 root パスワードを使用してアクセスし、そのマシンを修復することができます。この機能は、インスタンスのファイルシステムが破損した場合に役立ちます。デフォルトでは、レスキューモードのインスタンスは初期イメージから起動して、第 2 のイメージとして現在のブートディスクをアタッチします。
4.7.1. レスキューモードのインスタンス用イメージの準備
ブートディスクとレスキューモード用のディスクには同じ UUID が使用されているため、仮想マシンがレスキューモード用のディスクの代わりにブートディスクから起動されてしまう可能性があります。
この問題を回避するには、「イメージの作成」の手順に従い、レスキューイメージとして新しいイメージを作成してください。
rescue イメージは、デフォルトでは glance に保管され、nova.conf で設定されていますが、レスキューを実行する際に選択することもできます。
4.7.1.1. ext4 ファイルシステムを使用している場合のレスキューイメージ
ベースイメージが ext4 ファイルシステムを使用する場合には、以下の手順を使用してそれをベースにレスキューイメージを作成できます。
tune2fsコマンドを使用して、UUID を無作為な値に変更します。# tune2fs -U random /dev/DEVICE_NODE
DEVICE_NODE はルートデバイスノードに置き換えます (例:
sda、vdaなど)。新しい UUID を含む、ファイルシステムの詳細を確認します。
# tune2fs -l
-
/etc/fstabファイルで UUID を新しい値に置き換えます。fstabにマウントされている追加のパーティションがある場合には、UUID を新しい値に置き換える必要がある場合があります。 -
/boot/grub2/grub.confファイルを更新し、ルートディスクの UUID パラメーターを新しい UUID に置き換えます。 - シャットダウンして、このイメージをレスキューイメージに使用します。これにより、レスキューイメージには新たに無作為な UUID が割り当てられ、レスキューするインスタンスとの競合が発生しなくなります。
XFS ファイルシステムでは、実行中の仮想マシン上のルートデバイスの UUID は変更できません。仮想マシンがレスキューモード用のディスクから起動するまで再起動を続けます。
4.7.2. OpenStack Image サービスへのレスキューイメージの追加
対象のイメージの UUID を変更したら、以下のコマンドを実行して、生成されたレスキューイメージを OpenStack Image サービスに追加します。
Image サービスにレスキューイメージを追加します。
# glance image-create --name IMAGE_NAME --disk-format qcow2 \ --container-format bare --is-public True --file IMAGE_PATH
IMAGE_NAME は、イメージの名前に、IMAGE_PATH はイメージの場所に置き換えます。
image-listコマンドを使用して、インスタンスをレスキューモードで起動するのに必要な IMAGE_ID を取得します。# glance image-list
OpenStack Dashboard を使用してイメージをアップロードすることも可能です。「イメージのアップロード」を参照してください。
4.7.3. レスキューモードでのインスタンスの起動
デフォルトのイメージではなく、特定のイメージを使用してインスタンスをレスキューする必要があるため、
--imageパラメーターを使用します。# nova rescue --image IMAGE_ID VIRTUAL_MACHINE_ID
IMAGE_ID は使用するイメージ ID に、VIRTUAL_MACHINE_ID はレスキューする仮想マシンの ID に置き換えます。
注記nova rescueコマンドを使用すると、インスタンスでソフトシャットダウンを実行することができます。これにより、ゲストオペレーティングシステムは、インスタンスの電源をオフにする前に、制御されたシャットダウンを実行することができます。シャットダウンの動作は、Compute 設定ファイルのshutdown_timeoutを使用して設定されます。この値は、ゲストオペレーティングシステムが完全にシャットダウンするまでの合計時間 (秒単位) を指定します。デフォルトのタイムアウトは 60 秒です。このタイムアウト値は、
os_shutdown_timeoutでイメージ毎に上書きすることが可能です。これは、異なるタイプのオペレーティングシステムでクリーンにシャットダウンするために必要な時間を指定するイメージのメタデータ設定です。- 仮想マシンを再起動します。
-
nova listコマンドまたは Dashboard を使用して、コントローラーノード上で仮想マシンのステータスが RESCUE であることを確認します。 - レスキューモード用のパスワードを使用して、新しい仮想マシンのダッシュボードにログインします。
これで、インスタンスに必要な変更を加えて、問題を修正できる状態となりました。
4.7.4. インスタンスのアンレスキュー
修正したインスタンスは unrescue して、ブートディスクから再起動することができます。
コントローラーノードで以下のコマンドを実行します。
# nova unrescue VIRTUAL_MACHINE_ID
VIRTUAL_MACHINE_ID はアンレスキューする仮想マシンの ID に置き換えます。
アンレスキューの操作が正常に完了すると、インスタンスのステータスは ACTIVE に戻ります。
4.8. インスタンス用のコンフィグドライブの設定
config-drive パラメーターを使用して、読み取り専用のドライブをインスタンスに公開することができます。ファイルを選択してこのドライブに追加すると、インスタンスにアクセスできるようになります。コンフィグドライブは、起動時にインスタンスにアタッチされて、パーティションとしてインスタンスに公開されます。コンフィグドライブは、cloud-init (サーバーのブートストラップ用) と組み合わせる場合や、インスタンスに大容量のファイルを渡す場合に有用です。
4.8.1. コンフィグドライブのオプション
Compute 環境ファイルを使用して、以下のコンフィグドライブパラメーターを設定します。
-
config_drive_format: ドライブの形式を設定して、iso9660とvfatのオプションを確定します。デフォルトではiso9660を使用します。 -
force_config_drive: このオプションでは、全インスタンスにコンフィグドライブを強制的に公開します。「true」に設定します。 -
mkisofs_cmd: ISO ファイルの作成に使用するコマンドを指定します。genisoimage しかサポートされないので、この値は変更しないでください。
4.8.2. コンフィグドライブの使用
インスタンスは、ブート時にコンフィグドライブをアタッチします。これは、--config-drive オプションで有効になります。たとえば、このコマンドは test-instance01 という名前の新しいインスタンスを作成して、/root/user-data.txt という名前のファイルが含まれるドライブをアタッチします。
# nova boot --flavor m1.tiny --config-drive true --file /root/user-data.txt=/root/user-data.txt --image cirros test-instance01
インスタンスが起動すると、そのインスタンスにログインして、/root/user-data.txt という名前のファイルを確認できます。
このコンフィグドライブを cloud-init の情報源として使用できます。インスタンスの初回起動中には、cloud-init は自動的にコンフィグドライブをマウントして、設定スクリプトを実行することができます。
第5章 コンピュートノード間の仮想マシンインスタンスの移行
メンテナンスを実行する場合やワークロードのリバランスを行う場合、あるいは障害が発生した/障害が発生しつつあるノードを置き換える場合に、あるコンピュートノードからオーバークラウド内の別のコンピュートノードにインスタンスを移行しなければならない場合があります。
- コンピュートノードのメンテナンス
- ハードウェアのメンテナンスや修理、カーネルのアップグレードおよびソフトウェアの更新を行うなどの理由により、コンピュートノードを一時的に停止する必要がある場合、コンピュートノード上で実行中のインスタンスを別のコンピュートノードに移行することができます。
- 障害が発生しつつあるコンピュートノード
- コンピュートノードで障害が発生する可能性があり、ノードのサービスまたは置き換えが必要な場合、障害が発生しつつあるコンピュートノードから正常なコンピュートノードにインスタンスを移行することができます。
- 障害が発生したコンピュートノード
- コンピュートノードですでに障害が発生している場合には、インスタンスを退避させることができます。同じ名前、UUID、ネットワークアドレス、およびコンピュートノードに障害が発生する前にインスタンスに割り当てられていたその他すべてのリソースを使用して、元のイメージから別のコンピュートノードにインスタンスを再ビルドすることができます。
- ワークロードのリバランス
- ワークロードをリバランスするために、1 つまたは複数のインスタンスを別のコンピュートノードに移行することができます。たとえば、コンピュートノード上のインスタンスを 1 つにまとめて電力を節約する、他のネットワークリソースに物理的に近いコンピュートノードにインスタンスを移行してレイテンシーを低減する、インスタンスを全コンピュートノードに分散してホットスポットをなくし復元力を向上させる、等が可能です。
director は、すべてのコンピュートノードがセキュアな移行を提供するように設定します。すべてのコンピュートノードには、移行プロセス中それぞれのホストのユーザーが他のコンピュートノードにアクセスできるように、共有 SSH キーも必要です。director は、OS::TripleO::Services::NovaCompute コンポーザブルサービスを使用してこのキーを作成します。このコンポーザブルサービスは、すべての Compute ロールにデフォルトで含まれているメインのサービスの 1 つです。詳しい情報は、『オーバークラウドの 高度なカスタマイズ』 の「 コンポーザブルサービスとカスタムロール 」を参照してください。
機能しているコンピュートノードがあり、バックアップの目的でインスタンスのコピーを作成する場合や、インスタンスを別の環境にコピーする場合には、『director のインストールと使用方法』 の「 オーバークラウドへの仮想マシンのインポート 」に記載の手順に従ってください。
5.1. 移行の種別
Red Hat OpenStack Platform (RHOSP) では、以下の移行種別がサポートされています。
コールドマイグレーション
コールドマイグレーション (あるいは、非ライブマイグレーション) では、動作中のインスタンスをシャットダウンしてから、移行元コンピュートノードから移行先コンピュートノードに移行すします。
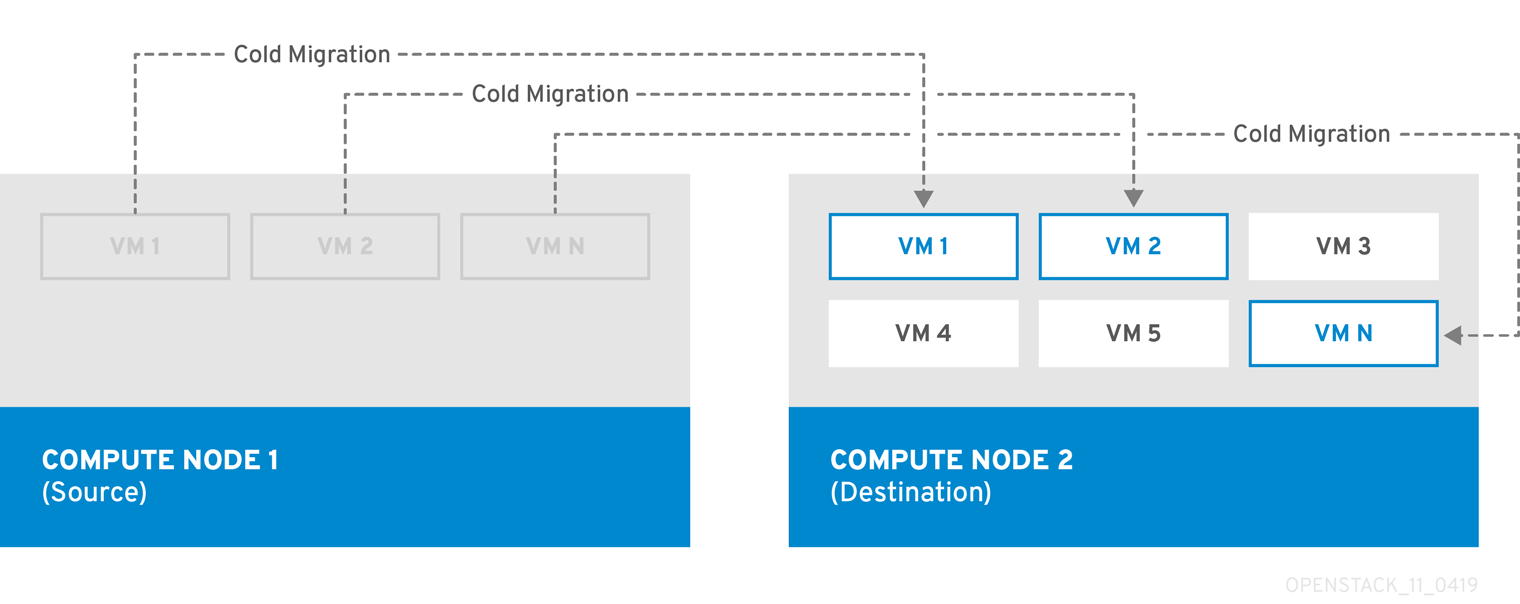
コールドマイグレーションでは、インスタンスに多少のダウンタイムが発生します。移行したインスタンスは、引き続き同じボリュームおよび IP アドレスにアクセスすることができます。
コールドマイグレーションを行うためには、移行元および移行先両方のコンピュートノードが動作状態になければなりません。
ライブマイグレーション
ライブマイグレーションでは、インスタンスをシャットダウンせずに、動作状態を維持しながら移行元コンピュートノードから移行先コンピュートノードに移行します。

インスタンスのライブマイグレーションを行う場合、ダウンタイムはほとんど発生しません。ただし、ライブマイグレーションは、移行操作中のパフォーマンスに影響を及ぼします。したがって、移行中のインスタンスは重要なパスから除外する必要があります。
ライブマイグレーションを行うためには、移行元および移行先両方のコンピュートノードが動作状態になければなりません。
状況によっては、インスタンスのライブマイグレーションを行うことができない場合があります。詳細は、「移行の制約」を参照してください。
退避
コンピュートノードですでに障害が発生しているためインスタンスを移行する必要がある場合、インスタンスを退避させることができます。
5.2. 移行の制約
移行の制約は通常、ブロックマイグレーション、設定ディスク、またはいずれかのインスタンスがコンピュートノード上の物理ハードウェアにアクセスする場合に生じます。
CPU に関する制約
移行元および移行先コンピュートノードの CPU アーキテクチャーは、同一であることが必須です。たとえば、Red Hat では、x86_64 CPU から ppc64le CPU へのインスタンスの移行をサポートしません。CPU ホストパススルーを使用するインスタンス等の場合には、移行元および移行先コンピュートノードの CPU は、完全に同一でなければなりません。すべてのケースで、移行先ノードの CPU 機能は、移行元ノードの CPU 機能の上位セットであることが必須です。
メモリーに関する制約
移行先コンピュートノードでは、十分な RAM が利用可能でなければなりません。メモリーのオーバーサブスクリプションが、移行失敗の原因となる可能性があります。
ブロックマイグレーションに関する制約
インスタンスの使用するディスクがコンピュートノード上にローカルに格納されている場合、その移行には、共有ストレージ (Red Hat Ceph Storage 等) を使用するボリュームベースのインスタンスよりもはるかに長い時間がかかります。このレイテンシーは、OpenStack Compute (nova) がコンピュートノード間でローカルディスクをブロックごとに移行するために発生します。この処理は、デフォルトではコントロールプレーンネットワークを通じて行われます。これとは対照的に、Red Hat Ceph Storage 等の共有ストレージを使用するボリュームベースのインスタンスでは、ボリュームを移行する必要がありません。それぞれのコンピュートノードが、共有ストレージにアクセスできるためです。
大量の RAM を消費するローカルディスクまたはインスタンスの移行により、コントロールプレーンネットワークに輻輳が生じ、コントロールプレーンネットワークを使用する他のシステム (RabbitMQ 等) のパフォーマンスに悪影響を及ぼす場合があります。
読み取り専用ドライブの移行に関する制約
ドライブの移行は、ドライブに読み取りおよび書き込み両方の機能がある場合に限りサポートされます。たとえば、OpenStack Compute (nova) は CD-ROM ドライブまたは読み取り専用のコンフィグドライブを移行することはできません。ただし、OpenStack Compute (nova) は、vfat 等のドライブ形式を持つコンフィグドライブなど、読み取りおよび書き込み両方の機能を持つドライブを移行することができます。
ライブマイグレーションに関する制約
インスタンスのライブマイグレーションでは、さらに制約が生じる場合があります。
- 移行中に新しい操作を行うことができない
- 移行元および移行先ノードのインスタンスのコピー間で状態の整合性を確保するために、RHOSP ではライブマイグレーション中の新規操作を拒否する必要があります。拒否しないと、ライブマイグレーションでメモリーの状態を複製する前にメモリーへの書き込みが行われた場合、ライブマイグレーションに長い時間がかかる状況や、永久に完了しない状況が発生する可能性があります。
- NUMA を使用した CPU ピニング
-
Compute 設定の
NovaSchedulerDefaultFiltersパラメーターには、AggregateInstanceExtraSpecsFilterおよびNUMATopologyFilterの値が含まれている必要があります。 - マルチセルクラウド
- マルチセルクラウドの場合、同じセル内の異なるホストにインスタンスのライブマイグレーションを行うことはできますが、セルをまたがる移行を行うことはできません。
- フローティングインスタンス
-
フローティングインスタンスのライブマイグレーションを行う場合、移行先コンピュートノードの
NovaComputeCpuSharedSetの設定と移行元コンピュートノードのNovaComputeCpuSharedSetの設定が異なると、移行先コンピュートノードでは、インスタンスは共有の (ピニングされていない) インスタンス用に設定された CPU には割り当てられません。したがって、フローティングインスタンスのライブマイグレーションを行う必要がある場合は、専用の (ピニングされた) インスタンスおよび共有の (ピニングされていない) インスタンスに関して、すべてのコンピュートノードに同じ CPU マッピングを設定する必要があります。あるいは、共有のインスタンスにホストアグリゲートを使用します。 - 移行先コンピュートノードの容量
- 移行先コンピュートノードには、移行するインスタンスをホストするのに十分な空き容量が必要です。
- SR-IOV ライブマイグレーション
- SR-IOV ベースのネットワークインターフェースを使用するインスタンスは、ライブマイグレーションが可能です。ダイレクトモードの SR-IOV ネットワークインターフェースが接続されたインスタンスのライブマイグレーションでは、ダイレクトモードのインターフェースが切り離され再接続される間に、ネットワークのダウンタイムが発生します。
ライブマイグレーションの妨げとなる制約
以下の機能を使用するインスタンスのライブマイグレーションを行うことはできません。
- PCI パススルー
- QEMU/KVM ハイパーバイザーでは、コンピュートノード上の PCI デバイスをインスタンスにアタッチすることができます。PCI パススルーを使用すると、インスタンスは PCI デバイスに排他的にアクセスすることができ、これらのデバイスがインスタンスのオペレーティングシステムに物理的に接続されているかのように表示され、動作します。ただし、PCI パススルーには物理アドレスが必要なため、OpenStack Compute は PCI パススルーを使用するインスタンスのライブマイグレーションをサポートしません。
- ポートリソースの要求
最小帯域幅を確保する QoS ポリシーなど、リソース要求が設定されたポートを使用するインスタンスのライブマイグレーションを行うことはできません。ポートにリソース要求があるかどうかを確認するには、以下のコマンドを使用します。
$ openstack port show <port_name/port_id>
5.3. 移行の準備
1 つまたは複数のインスタンスを移行する前に、コンピュートノード名および移行するインスタンスの ID を把握する必要があります。
手順
移行元コンピュートノードのホスト名および移行先コンピュートノードのホスト名を特定します。
(undercloud) $ source ~/overcloudrc (overcloud) $ openstack compute service list
移行元コンピュートノード上のインスタンスを一覧表示し、移行するインスタンスの ID を特定します。
(overcloud) $ openstack server list --host <source> --all-projects
<source>を移行元コンピュートノードの名前または ID に置き換えてください。オプション: ノードのメンテナンスを行うためにインスタンスを移行元コンピュートノードから移行する場合、ノードを無効にして、メンテナンス中にスケジューラーがノードに新規インスタンスを割り当てるのを防ぐ必要があります。
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --disable
<source>を移行元コンピュートノードの名前または ID に置き換えてください。
これで移行を行う準備が整いました。「インスタンスのコールドマイグレーション」または「インスタンスのライブマイグレーション」に詳細を示す必要手順に従います。
5.4. インスタンスのコールドマイグレーション
インスタンスのコールドマイグレーションでは、インスタンスを停止して別のコンピュートノードに移動します。コールドマイグレーションは、PCI パススルーを使用するインスタンスの移行など、ライブマイグレーションでは対応することのできない移行シナリオに対応します。移行先コンピュートノードは、スケジューラーにより自動的に選択されます。詳細は、「移行の制約」を参照してください。
手順
インスタンスのコールドマイグレーションを行うには、以下のコマンドを入力してインスタンスの電源をオフにして移動します。
(overcloud) $ openstack server migrate <vm> --wait
-
<vm>を移行するインスタンスの名前または ID に置き換えてください。 -
ローカルに確保されたボリュームを移行する場合には、
--block-migrationフラグを指定します。
-
- 移行が完了するまで待ちます。インスタンスの移行が完了するのを待つ間、移行のステータスを確認することができます。詳細は、「 移行ステータスの確認 」を参照してください。
インスタンスのステータスを確認します。
(overcloud) $ openstack server list --all-projects
ステータスが「VERIFY_RESIZE」と表示される場合は、移行を確認する、または元に戻す必要があることを示しています。
予想どおりに機能している場合は、移行を確認します。
(overcloud) $ openstack server resize --confirm <vm>`
<vm>を移行するインスタンスの名前または ID に置き換えてください。ステータスが「ACTIVE」と表示される場合は、インスタンスを使用する準備が整っていることを示しています。予想どおりに機能していない場合は、移行を元に戻します。
(overcloud) $ openstack server resize --revert <vm>`
<vm>をインスタンスの名前または ID に置き換えてください。
インスタンスを再起動します。
(overcloud) $ openstack server start <vm>
<vm>をインスタンスの名前または ID に置き換えてください。オプション: メンテナンスのために移行元コンピュートノードを無効にした場合は、新規インスタンスがノードに割り当てられるようにノードを再度有効にする必要があります。
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --enable
<source>を移行元コンピュートノードのホスト名に置き換えてください。
5.5. インスタンスのライブマイグレーション
ライブマイグレーションでは、ダウンタイムを最小限に抑えて、インスタンスを移行元コンピュートノードから移行先コンピュートノードに移動します。ライブマイグレーションがすべてのインスタンスに適しているとは限りません。詳細は、「移行の制約」を参照してください。
手順
インスタンスのライブマイグレーションを行うには、インスタンスおよび移行先コンピュートノードを指定します。
(overcloud) $ openstack server migrate <vm> --live-migration [--host <dest>] --wait
-
<vm>をインスタンスの名前または ID に置き換えてください。 <dest>を移行先コンピュートノードの名前または ID に置き換えてください。注記openstack server migrateコマンドは、共有ストレージを持つインスタンスの移行が対象です。これがデフォルトの設定です。ローカルに確保されたボリュームを移行するには、--block-migrationフラグを指定します。(overcloud) $ openstack server migrate <vm> --live-migration [--host <dest>] --wait --block-migration
-
インスタンスが移行されていることを確認します。
(overloud) $ openstack server show <vm> +----------------------+--------------------------------------+ | Field | Value | +----------------------+--------------------------------------+ | ... | ... | | status | MIGRATING | | ... | ... | +----------------------+--------------------------------------+
- 移行が完了するまで待ちます。インスタンスの移行が完了するのを待つ間、移行のステータスを確認することができます。詳細は、「 移行ステータスの確認 」を参照してください。
インスタンスのステータスをチェックして、移行が成功したかどうかを確認します。
(overcloud) $ openstack server list --host <dest> --all-projects
<dest>を移行先コンピュートノードの名前または ID に置き換えてください。オプション: メンテナンスのために移行元コンピュートノードを無効にした場合は、新規インスタンスがノードに割り当てられるようにノードを再度有効にする必要があります。
(overcloud) $ source ~/stackrc (undercloud) $ openstack compute service set <source> nova-compute --enable
<source>を移行元コンピュートノードのホスト名に置き換えてください。
5.6. 移行ステータスの確認
移行が完了するまでに、さまざまな移行状態を遷移します。正常な移行では、通常、移行状態は以下のように遷移します。
- Queued: Compute サービスはインスタンス移行の要求を受け入れ、移行は保留中です。
- Preparing: Compute サービスはインスタンス移行の準備中です。
- Running: Compute サービスはインスタンスを移行中です。
- Post-migrating: Compute サービスはインスタンスを移行先コンピュートノードにビルドし、移行元コンピュートノードのリソースを解放しています。
- Completed: Compute サービスはインスタンスの移行を完了し、移行元コンピュートノードのリソース解放を終了しています。
手順
インスタンスの移行 ID の一覧を取得します。
$ nova server-migration-list <vm> +----+-------------+----------- (...) | Id | Source Node | Dest Node | (...) +----+-------------+-----------+ (...) | 2 | - | - | (...) +----+-------------+-----------+ (...)
<vm>をインスタンスの名前または ID に置き換えてください。移行のステータスを表示します。
$ <vm> <migration-id>
-
<vm>をインスタンスの名前または ID に置き換えてください。 <migration-id>を移行の ID に置き換えてください。nova server-migration-showコマンドを実行すると、以下の例に示すような出力が返されます。+------------------------+--------------------------------------+ | Property | Value | +------------------------+--------------------------------------+ | created_at | 2017-03-08T02:53:06.000000 | | dest_compute | controller | | dest_host | - | | dest_node | - | | disk_processed_bytes | 0 | | disk_remaining_bytes | 0 | | disk_total_bytes | 0 | | id | 2 | | memory_processed_bytes | 65502513 | | memory_remaining_bytes | 786427904 | | memory_total_bytes | 1091379200 | | server_uuid | d1df1b5a-70c4-4fed-98b7-423362f2c47c | | source_compute | compute2 | | source_node | - | | status | running | | updated_at | 2017-03-08T02:53:47.000000 | +------------------------+--------------------------------------+
ヒントOpenStack Compute サービスは、コピーする残りのメモリーのバイト数によって移行の進捗を測定します。時間が経過してもこの数字が減少しない場合、移行を完了することができず、Compute サービスは移行を中止する可能性があります。
-
インスタンスの移行に長い時間がかったり、エラーが発生したりする場合があります。詳細は、「移行に関するトラブルシューティング」を参照してください。
5.7. インスタンスの退避
インスタンスを障害の発生したコンピュートノードまたはシャットダウンしたコンピュートノードから同じ環境内の新しいホストに移動する場合、インスタンスを退避させることができます。
退避プロセスにより元のインスタンスは破棄され、元のイメージ、インスタンス名、UUID、ネットワークアドレス、およびインスタンスに割り当てられていたその他すべてのリソースを使用して、別のコンピュートノードに元のインスタンスが再ビルドされます。
インスタンスが共有ストレージを使用する場合、インスタンスのルートディスクは退避プロセス中に再ビルドされません。移行先コンピュートノードが引き続きこのディスクにアクセス可能なためです。インスタンスが共有ストレージを使用しない場合は、インスタンスのルートディスクも移行先コンピュートノードに再ビルドされます。
-
コンピュートノードがフェンシングされ、API が報告するコンピュートノードの状態が「down」または「forced-down」である場合に限り、退避を行うことができます。コンピュートノードが「down」または「forced-down」と報告されない場合、
evacuateコマンドは失敗します。 - クラウド管理者でなければ、退避を行うことはできません。
5.7.1. 単一のインスタンスの退避
インスタンスを一度に 1 つずつ退避させることができます。
手順
- 障害の発生したコンピュートノードに管理者としてログインします。
コンピュートノードを無効にします。
(overcloud) [stack@director ~]$ openstack compute service set \ <host> <service> --disable
-
<host>をインスタンスの退避元となるコンピュートノードの名前に置き換えてください。 -
<service>を無効にするサービスの名前 (例:nova-compute) に置き換えてください。
-
インスタンスを退避させるには、以下のコマンドを入力します。
(overcloud) [stack@director ~]$ nova evacuate [--password <pass>] <vm> [<dest>]
-
<pass>を退避するインスタンスに設定する admin パスワードに置き換えてください。パスワードを指定しなかった場合には、無作為に生成され、退避の完了時に出力されます。 -
<vm>を退避させるインスタンスの名前または ID に置き換えてください。 <dest>をインスタンスの退避先となるコンピュートノードの名前に置き換えてください。退避先コンピュートノードを指定しなかった場合には、Compute のスケジューラーがノードを選択します。退避先に指定可能なコンピュートノードを確認するには、以下のコマンドを使用します。(overcloud) [stack@director ~]$ openstack hypervisor list
-
5.7.2. ホスト上の全インスタンスの退避
指定したコンピュートノード上の全インスタンスを退避させることができます。
手順
- 障害の発生したコンピュートノードに管理者としてログインします。
コンピュートノードを無効にします。
(overcloud) [stack@director ~]$ openstack compute service set \ <host> <service> --disable
-
<host>をインスタンスの退避元となるコンピュートノードの名前に置き換えてください。 -
<service>を無効にするサービスの名前 (例:nova-compute) に置き換えてください。
-
指定したコンピュートノード上の全インスタンスを退避させます。
(overcloud) [stack@director ~]$ nova host-evacuate [--target_host <dest>] [--force] <host>
<dest>をインスタンスの退避先となるコンピュートノードの名前に置き換えてください。退避先を指定しなかった場合には、Compute のスケジューラーがノードを選択します。退避先に指定可能なコンピュートノードを確認するには、以下のコマンドを使用します。(overcloud) [stack@director ~]$ openstack hypervisor list
-
<host>をインスタンスの退避元となるコンピュートノードの名前に置き換えてください。
5.8. 移行に関するトラブルシューティング
インスタンスの移行時に、以下の問題が発生する可能性があります。
- 移行プロセスでエラーが生じる。
- 移行プロセスが終了しない。
- 移行後にインスタンスのパフォーマンスが低下する。
5.8.1. 移行中のエラー
以下の問題が発生すると、移行操作が error 状態に遷移します。
- 実行しているクラスターに異なるバージョンの Red Hat OpenStack Platform (RHOSP) が存在する。
- 指定したインスタンス ID が見つからない。
-
移行を試みているインスタンスが
error状態にある。 - Compute サービスが停止している。
- 競合状態が発生する。
-
ライブマイグレーションが
failed状態に移行する。
ライブマイグレーションが failed 状態に移行すると、通常は error 状態になります。failed 状態の原因となる可能性のある典型的な問題を以下に示します。
- 移行先コンピュートホストが利用可能な状態にない。
- スケジューラーの例外が発生する。
- コンピューティングリソースが不十分なため、再ビルドプロセスに失敗する。
- サーバーグループの確認に失敗する。
- 移行先コンピュートノードへの移行が完了する前に、移行元コンピュートノードのインスタンスが削除される。
5.8.2. ライブマイグレーションのスタック
ライブマイグレーションが完了せず、永久に running 状態のままになる可能性があります。ライブマイグレーションが永久に完了しない一般的な理由は、Compute サービスがインスタンスの変更を移行先コンピュートノードに複製するより早く、クライアントのリクエストにより移行元コンピュートノード上で実行中のインスタンスに変更が生じることです。
この状況に対処するには、以下のいずれかの方法を使用します。
- ライブマイグレーションを中止する。
- ライブマイグレーションを強制的に完了させる。
ライブマイグレーションの中止
移行プロセスがインスタンスの状態の変化を移行先ノードにコピーするより早くインスタンスの状態が変化する状況で、インスタンスの動作を一時的に中断したくない場合には、ライブマイグレーションを中止することができます。
手順
インスタンスの移行の一覧を取得します。
$ nova server-migration-list <vm>
<vm>をインスタンスの名前または ID に置き換えてください。ライブマイグレーションを中止します。
$ nova live-migration-abort <vm> <migration-id>
-
<vm>をインスタンスの名前または ID に置き換えてください。 -
<migration-id>を移行の ID に置き換えてください。
-
ライブマイグレーション完了の強制
移行プロセスがインスタンスの状態の変化を移行先ノードにコピーするより早くインスタンスの状態が変化する状況で、インスタンスの動作を一時的に中断して移行を強制的に完了させたい場合には、ライブマイグレーションの手順を強制的に完了させることができます。
ライブマイグレーションを強制的に完了させると、かなりのダウンタイムが発生する可能性があります。
手順
インスタンスの移行の一覧を取得します。
$ nova server-migration-list <vm>
<vm>をインスタンスの名前または ID に置き換えてください。ライブマイグレーションを強制的に完了させます。
$ nova live-migration-force-complete <vm> <migration-id>
-
<vm>をインスタンスの名前または ID に置き換えてください。 -
<migration-id>を移行の ID に置き換えてください。
-
5.8.3. 移行後のインスタンスパフォーマンスの低下
NUMA トポロジーを使用するインスタンスの場合、移行元および移行先コンピュートノードの NUMA トポロジーおよび設定は同一でなければなりません。移行先コンピュートノードの NUMA トポロジーでは、十分なリソースが利用可能でなければなりません。移行元および移行先コンピュートノード間で NUMA 設定が同一でない場合、ライブマイグレーションは成功するがインスタンスのパフォーマンスが低下する可能性があります。たとえば、移行元コンピュートノードは NIC 1 を NUMA ノード 0 にマッピングするが、移行先コンピュートノードは NIC 1 を NUMA ノード 5 にマッピングする場合、移行後にインスタンスはバス内の最初の CPU からのネットワークトラフィックを NUMA ノード 5 の別の CPU にルーティングし、トラフィックを NIC 1 にルーティングする可能性があります。その結果、予想されたとおりに動作はしますが、パフォーマンスが低下します。同様に、移行元コンピュートノードの NUMA ノード 0 では十分な CPU および RAM が利用可能だが、移行先コンピュートノードの NUMA ノード 0 にリソースの一部を使用するインスタンスがすでに存在する場合、インスタンスは正しく動作するがパフォーマンスが低下する可能性があります。詳細は、「移行の制約」を参照してください。
第6章 コンピュートセルを使用したデプロイメントのスケーリング
セルを使用して、大規模なデプロイメントのコンピュートノードをグループに分割することができます。それぞれのグループは、メッセージキューおよびインスタンス情報が含まれる専用のデータベースを持ちます。
デフォルトでは、director はすべてのコンピュートノードを単一のセルとしてオーバークラウドをインストールします。この単一セルのデプロイメントには、すべてのインスタンスおよびインスタンスのメタデータが含まれます。大規模なデプロイメントでは、複数のセルでオーバークラウドをデプロイし、多数のコンピュートノードに対応することができます。
マルチセルのデプロイメントでは、それぞれのセルはセル固有のコンポーネントのスタンドアロンコピーを実行し、そのセル内のインスタンスに関するメタデータだけを保管します。グローバルな情報およびセルのマッピングは、グローバルコントローラーセルに保管されます。これにより、セキュリティーおよびセルのいずれかに障害が発生した時の復元性が向上します。
新しいオーバークラウドをインストールする際に、またはその後の任意の時に、セルを環境に追加することができます。
6.1. セルのコンポーネント
単一セルのデプロイメントでは、すべてのコンポーネントが同じセルに含まれます。マルチセルのデプロイメントでは、グローバルなサービスはメインのコントローラーセルで実行され、それぞれのコンピュートセルではセル固有のコンポーネントのスタンドアロンコピーが実行され、各セルにはそのセル内のコンピュートノードのデータベースおよびメッセージキューが含まれます。
グローバルコンポーネント
以下のコンポーネントは、コンピュートセルの数にかかわらず、オーバークラウドごとに一度コントローラーセルにデプロイされます。
- Compute API
- ユーザーに外部 REST API を提供します。
- Scheduler
- インスタンスを割り当てるコンピュートノードを決定します。
- Placement サービス
- Compute リソースを監視し、インスタンスに割り当てます。
- API データベース
Compute API および Compute のスケジューラーサービスがインスタンスの場所に関する情報を追跡するのに使用されます。また、ビルドされているがスケジュールされていないインスタンスの一時的な場所を提供します。
マルチセルのデプロイメントでは、このデータベースには各セルのデータベース接続を指定する セルのマッピング も含まれます。
cell0データベース- スケジュールに失敗したインスタンスに関する情報を保管する専用のデータベース
- スーパーコンダクター
マルチセルのデプロイメントでは、このサービスはグローバルなサービスと各コンピュートセル間の調整を行います。また、スケジュールに失敗したインスタンスの情報を
cell0データベースに送信します。注記このコンポーネントは、マルチセルのデプロイメントにのみ存在します。
セル固有のコンポーネント
以下のコンポーネントは、それぞれのコンピュートセルにデプロイされます。
- セルデータベース
- インスタンスに関するほとんどの情報が含まれます。グローバル API、コンダクター、および Compute サービスによって使用されます。
- コンダクター
- データベースのクエリーおよび長時間実行されているグローバルなサービスからのタスクの調整を行い、コンピュートノードをデータベースへの直接アクセスから隔離します。
- メッセージキュー
- セル内の各サービス間の通信、およびグローバルなサービスとの通信のために、すべてのサービスによって使用されるメッセージングサービス
設定ファイル
オーバークラウドには、コンピュートセルに関する以下の情報を定義する設定ファイルが含まれます。
-
[DEFAULT]/transport_url: 各セルのメッセージキューエンドポイント -
[DATABASE]/connection: 各セルのデータベース接続 -
[API_DATABASE]/connection: グローバルコンポーネントのルーティングおよび配置情報 - (マルチセルのデプロイメントのみ) グローバル API データベースに保管されるセルマッピングのレコード
この情報は、「マルチセルオーバークラウドのデプロイ」 に記載のマルチセル環境をデプロイする際にオーバークラウドから抽出されます。
6.2. セルデプロイメントのアーキテクチャー
それぞれのデプロイメント種別を使用することで、さまざまなユースケースに合わせてオーバークラウドを最適化することができます。
単一セルのデプロイメントアーキテクチャー (デフォルト)
デフォルトの単一セルオーバークラウドの基本的な構成および対話の例を以下の図に示します。
このデプロイメントでは、すべてのサービスが 1 つのコンダクターを使用して Compute API とコンピュートノード間の通信を行うように設定されます。また、1 つのデータベースに動作中の全インスタンスのデータが保管されます。
小規模なデプロイメントであれば、この構成で十分です。ただし、API レベルの (グローバルな) サービスまたはデータベースに障害が発生すると、高可用性の構成かどうかにかかわらず、Compute デプロイメント全体が情報を送受信できなくなります。
マルチセルのデプロイメントアーキテクチャー (カスタム)
カスタムのマルチセルオーバークラウドの基本的な構成および対話の例を以下の図に示します。
このデプロイメントでは、コンピュートノードは複数のセルに分割され、それぞれのセルは専用のコンダクター、データベース、およびメッセージキューを持ちます。グローバルなサービスは、スーパーコンダクターを使用して各セルと通信を行います。また、グローバルデータベースにはオーバークラウド全体に必要な情報だけが含まれます。
セルレベルのサービスは、グローバルなサービスに直接アクセスすることはできません。この分離により、セキュリティーが向上し、セルに障害が発生した場合のフェイルセーフ機能が得られます。
エッジサイトのデプロイメントでは、最初のセルを中央サイトにデプロイする必要があります。したがって、最初のセルはどのエッジサイトにもデプロイしないでください。最初のセルでは、Compute サービスを実行しないでください。その代わりに、コンピュートノードが含まれる各新規セルをエッジサイトに個別にデプロイします。
6.3. マルチセルのデプロイメントで考慮すべき事項
- マルチセルのデプロイメントにおける最大のコンピュートノード数
- 最大のコンピュートノード数は、全セルの合計で 500 です。
- SSL/TLS
- オーバークラウドで SSL/TLS を有効にすることはできません。
- セル間のインスタンスの移行
あるセル内のホストから別のセル内のホストにインスタンスを移行する操作は、サポートされていません。この制限は、以下の操作に影響を及ぼします。
- コールドマイグレーション
- ライブマイグレーション
- 復元
- サイズ変更
- 退避
- サービスクォータ
Compute サービスのクォータは、データベースで静的に計算されるのではなく、リソースが消費されるそれぞれの時点で動的に計算されます。マルチセルのデプロイメントでは、アクセス不能なセルは使用状況に関する情報をリアルタイムで提供することができないため、セルが再びアクセス可能になるとクォータを超過する可能性があります。
Placement サービスおよび API データベースを使用して、障害の発生したセルまたはアクセス不能なセルに対応するようにクォータの算出を設定することができます。
- API データベース
- Compute API データベースは常にグローバルで (すべてのセルが対象)、セルごとに複製することはできません。
- コンソールプロキシー
-
コンソールトークンの承認はセルのデータベースに保管されるため、セルごとにコンソールプロキシーを設定する必要があります。各コンソールプロキシーサーバーは、対応するセルのデータベースの
database.connectionの情報にアクセスする必要があります。 - セルマッピングのテンプレート URL
グローバルデータベースにクエリーを行うたびに動的に更新される変数を使用して、セルマッピングに
--database_connectionおよび--transport-urlのテンプレートを作成することができます。値は、コンピュートノードの設定ファイルの値が使用されます。テンプレート URL の形式は以下のとおりです。
{scheme}://{username}:{password}@{hostname}/{path}以下の表に、セルマッピング URL で使用できる変数をまとめます。
変数 説明 scheme
://の前のプレフィックスusername
ユーザー名
password
パスワード
hostname
ホスト名または IP アドレス
port
ポート番号 (指定する必要があります)
path
ホスト内のディレクトリーへのパス (先頭のスラッシュなし)
query
文字列引数を含む完全なクエリー (先頭の疑問符なし)
fragment
最初のハッシュ記号
#以降のパス- Compute メタデータ API
Compute メタデータ API をグローバルに、または各セルで実行することができます。以下のいずれかを選択します。
-
ネットワークが複数のセルを対象としている場合は、セル間をブリッジできるようにメタデータ API をグローバルに実行する必要があります。この場合、メタデータ API は
api_database.connectionの情報にアクセスする必要があります。 -
セルごとに個別のセグメントにネットワークがある場合は、メタデータ API を各セルで個別に実行することができます。この設定では、パフォーマンスとデータの分離性が向上します。この場合、
neutron-metadata-agentサービスは対応するnova-api-metadataサービスをポイントします。
api.local_metadata_per_cell設定オプションを使用して、実装する手段を設定します。このオプションの設定に関する詳細は、「マルチセルオーバークラウドのデプロイ」 の「 セルパラメーターを使用した環境ファイルの作成 」セクションを参照してください。-
ネットワークが複数のセルを対象としている場合は、セル間をブリッジできるようにメタデータ API をグローバルに実行する必要があります。この場合、メタデータ API は
6.4. マルチセルオーバークラウドのデプロイ
以下のステージにより、マルチセルオーバークラウドをデプロイします。
- 基本的なオーバークラウドにおいて、デフォルトの最初のセルからパラメーター情報を抽出する。このセルは、オーバークラウドの再デプロイ後にグローバルコントローラーになります。
- セルにカスタムロールおよびフレーバーを設定する。
- セル固有のパラメーターで環境ファイルを作成する。
- 新しいセルスタックでオーバークラウドを再デプロイする。
- このプロセスにより、オーバークラウドにセルが 1 つ追加されます。オーバークラウドにデプロイする追加のセルごとに、これらのステップを繰り返します。
-
以下の手順では、新しいセルの名前を
cell1としています。すべてのコマンドの名前を実際のセル名に置き換えてください。
前提条件
- 必要な数のコントローラーノードおよびコンピュートノードで、基本的なオーバークラウドをデプロイしている。
- 「 「マルチセルのデプロイメントで考慮すべき事項」 」で説明するように、マルチセルオーバークラウドの要件および制限を確認してください。
オーバークラウドからのパラメーター情報の抽出
新しいセル用に新たなディレクトリーを作成し、コンテンツを新しいディレクトリーにエクスポートします。以下に例を示します。
$ source ~/stackrc (undercloud) $ mkdir cell1 (undercloud) $ export DIR=cell1
オーバークラウドからセル用の新たな環境ファイルに、
EndpointMap、HostsEntry、AllNodesConfig、GlobalConfigパラメーター、およびパスワード情報をエクスポートします。以下に例を示します。(undercloud) $ openstack overcloud cell export cell1 -o cell1/cell1-ctrl-input.yaml
注記環境ファイルがすでに存在する場合は、
--force-overwriteまたは-fオプションを指定してコマンドを実行します。
セルのカスタムロールの設定
CellControllerロールをロールデータのファイルに追加し、ファイルを再生成します。以下に例を示します。(undercloud) $ openstack overcloud roles generate --roles-path \ /usr/share/openstack-tripleo-heat-templates/roles \ -o $DIR/cell_roles_data.yaml Compute CellControllerCellControllerカスタムロールには、デフォルトのComputeロールからのサービスおよび以下のサービスの追加設定が含まれます。- Galera データベース
- RabbitMQ
-
nova-conductor -
nova novnc proxy -
nova metadata(NovaLocalMetadataPerCellパラメーターを設定した場合のみ)
ネットワークをグローバルコントローラーとセル間で分離する場合は、作成したロールファイルでネットワークアクセスを設定します。以下に例を示します。
name: Compute description: | Basic Compute Node role CountDefault: 1 # Create external Neutron bridge (unset if using ML2/OVS without DVR) tags: - external_bridge networks: InternalApi: subnet: internal_api_cell1 Tenant: subnet: tenant_subnet Storage: subnet: storage_cell1 ... - name: CellController description: | CellController role for the nova cell_v2 controller services CountDefault: 1 tags: - primary - controller networks: External: subnet: external_cell1 InternalApi: subnet: internal_api_cell1 Storage: subnet: storage_cell1 StorageMgmt: subnet: storage_mgmt_cell1 Tenant: subnet: tenant_subnet
フレーバーの設定およびセルへのノードのタグ付け
cellcontrollerフレーバーを作成し、セルに割り当てるノードをタグ付けします。以下に例を示します。(undercloud) $ openstack flavor create --id auto --ram 4096 --disk 40 --vcpus 1 cellcontroller (undercloud) $ openstack flavor set --property "cpu_arch"="x86_64" \ --property "capabilities:boot_option"="local" \ --property "capabilities:profile"="cellcontroller" \ --property "resources:CUSTOM_BAREMETAL=1" \ --property "resources:DISK_GB=0" \ --property "resources:MEMORY_MB=0" \ --property "resources:VCPU=0" \ cellcontrollerセルに割り当てる各ノードを
cellcontrollerプロファイルにタグ付けします。(undercloud) $ openstack baremetal node set --property \ capabilities='profile:cellcontroller,boot_option:local' <NODE_UUID><NODE_UUID>を、セルに割り当てるコンピュートノードの実際の ID に置き換えてください。
セルパラメーターを設定した環境ファイルの作成
セルのディレクトリーに新しい環境ファイル /cell1/cell1.yaml を作成し、以下のパラメーターを追加します。
resource_registry: # since the same networks are used in this example, the # creation of the different networks is omitted OS::TripleO::Network::External: OS::Heat::None OS::TripleO::Network::InternalApi: OS::Heat::None OS::TripleO::Network::Storage: OS::Heat::None OS::TripleO::Network::StorageMgmt: OS::Heat::None OS::TripleO::Network::Tenant: OS::Heat::None OS::TripleO::Network::Management: OS::Heat::None OS::TripleO::Network::Ports::OVNDBsVipPort: /usr/share/openstack-tripleo-heat-templates/network/ports/noop.yaml OS::TripleO::Network::Ports::RedisVipPort: /usr/share/openstack-tripleo-heat-templates/network/ports/noop.yaml parameter_defaults: # CELL Parameter to reflect that this is an additional CELL NovaAdditionalCell: True # mapping of the CellController flavor to the CellController role CellControllerFlavor: cellcontroller # The DNS names for the VIPs for the cell CloudName: cell1.ooo.test CloudNameInternal: cell1.internalapi.ooo.test CloudNameStorage: cell1.storage.ooo.test CloudNameStorageManagement: cell1.storagemgmt.ooo.test CloudNameCtlplane: cell1.ctlplane.ooo.test # Flavors used for the cell controller and computes OvercloudCellControllerFlavor: cellcontroller OvercloudComputeFlavor: compute # Number of controllers/computes in the cell CellControllerCount: 1 ComputeCount: 1 # Compute node name (must be unique) ComputeHostnameFormat: 'cell1-compute-%index%' # default gateway ControlPlaneStaticRoutes: - ip_netmask: 0.0.0.0/0 next_hop: 192.168.24.1 default: true DnsServers: - x.x.x.x実際のデプロイメントのニーズに合わせて、この例のパラメーター値を変更してください。
ネットワーク設定によっては、セルにネットワークリソースを割り当てなければならない場合があります。ネットワークにセルを登録する必要がある場合は、以下のパラメーターを追加します。
resource_registry: OS::TripleO::CellController::Net::SoftwareConfig: single-nic-vlans/controller.yaml OS::TripleO::Compute::Net::SoftwareConfig: single-nic-vlans/compute.yaml
ネットワークをグローバルコントローラーとセル間で分離し、Compute メタデータ API をグローバルコントローラーではなく各セルで実行する場合は、以下のパラメーターを追加します。
parameter_defaults: NovaLocalMetadataPerCell: True
注記- このファイルのパラメーターにより、オーバークラウドはすべてのセルに単一のネットワークを使用するように制限されます。
- コンピュートホストの名前は、全セルを通じて一意でなければなりません。
network_data.yaml ファイルをコピーし、セル名に応じて名前を付けます。以下に例を示します。
(undercloud) $ cp /usr/share/openstack-tripleo-heat-templates/network_data.yaml cell1/network_data-ctrl.yaml
セルに再利用するネットワークコンポーネントの UUID を、新しいネットワークデータファイルに追加します。
external_resource_network_id: [EXISTING_NETWORK_UUID] external_resource_subnet_id: [EXISTING_SUBNET_UUID] external_resource_segment_id: [EXISTING_SEGMENT_UUID] external_resource_vip_id: [EXISTING_VIP_UUID]
(オプション) セグメント化されたネットワーク用のネットワーク設定
ネットワークをグローバルコントローラーとコンピュートセル間で分離する場合は、routes.yaml 等の環境ファイルを作成し、セルのルーティング情報および仮想 IP アドレス (VIP) 情報を追加します。以下に例を示します。
parameter_defaults:
InternalApiInterfaceRoutes:
- destination: 172.17.2.0/24
nexthop: 172.16.2.254
StorageInterfaceRoutes:
- destination: 172.17.1.0/24
nexthop: 172.16.1.254
StorageMgmtInterfaceRoutes:
- destination: 172.17.3.0/24
nexthop: 172.16.3.254
parameter_defaults:
VipSubnetMap:
InternalApi: internal_api_cell1
Storage: storage_cell1
StorageMgmt: storage_mgmt_cell1
External: external_cell1(オプション) エッジサイト用のネットワーク設定
複数のエッジサイトにコンピュートノードを分散するには、メインのコントローラーセル用に環境ファイルを 1 つ作成し、そのエッジサイトの各コンピュートセル用に個別の環境ファイルを作成します。
-
プライマリー環境ファイルで、コントローラーセルの ComputeCount パラメーターを
0に設定します。このセルは、実際のコンピュートノードが含まれるエッジサイトのコンピュートセルとは別です。 コンピュートセルの環境ファイルに以下のパラメーターを追加して、外部仮想 IP ポートを無効にします。
resource_registry: # Since the compute stack deploys only compute nodes ExternalVIPPorts are not required. OS::TripleO::Network::Ports::ExternalVipPort: /usr/share/openstack-tripleo-heat-templates/network/ports/noop.yaml
オーバークラウドのデプロイ
以下のいずれかを選択します。
- マルチセルのデプロイメントと単一ネットワークの組み合わせ
overcloud deployコマンドを実行して、新しいセルスタックを設定するのに作成した環境ファイルを追加します。以下に例を示します。$ openstack overcloud deploy \ --templates /usr/share/openstack-tripleo-heat-templates \ --stack cell1 \ -r $HOME/$DIR/cell_roles_data.yaml \ -e $HOME/$DIR/cell1-ctrl_input.yaml \ -e $HOME/$DIR/cell1.yaml
- マルチセルのデプロイメントとセグメント化されたネットワークの組み合わせ
前のステップで作成した追加のネットワークデータ環境ファイルを指定して、
overcloud deployコマンドを実行します。overcloud deployコマンドの例を以下に示します。ここでは、セルのネットワークセグメントを指定するのに作成した環境ファイルを追加しています。実際にデプロイするセルの数および名前に合わせて、コマンドを編集します。openstack overcloud deploy \ --templates /usr/share/openstack-tripleo-heat-templates \ --stack cell1-ctrl \ -r $HOME/$DIR/cell_roles_data.yaml \ -n $HOME/$DIR/cell1_routes.yaml \ -n $HOME/$DIR/network_data-ctrl.yaml \ -e $HOME/$DIR/cell1-ctrl-input.yaml \ -e $HOME/$DIR/cell1.yaml
注記エッジサイトにコンピュートセルをデプロイする場合は、それぞれのサイトで
overcloud deployコマンドを実行し、そのサイトの各コンピュートセルに対する環境ファイルおよび設定を指定します。
6.5. セルの作成およびプロビジョニング
「マルチセルオーバークラウドのデプロイ」 の説明に従って新しいセルスタックでオーバークラウドをデプロイしたら、コンピュートセルを作成およびプロビジョニングします。
このプロセスは、作成および起動する各セルに対して繰り返す必要があります。Ansible Playbook で手順を自動化することができます。Ansible Playbook の例については、OpenStack コミュニティーのドキュメントの「Create the cell and discover compute nodes (ansible playbook)」セクションを参照してください。コミュニティーのドキュメントはそのままの状態で提供され、公式にはサポートされません。
コントロールプレーンおよびセルコントローラーの IP アドレスを取得します。
$ CTRL_IP=$(openstack server list -f value -c Networks --name overcloud-controller-0 | sed 's/ctlplane=//') $ CELL_CTRL_IP=$(openstack server list -f value -c Networks --name cellcontroller-0 | sed 's/ctlplane=//')
すべてのコントローラーノードにセル情報を追加します。この情報は、アンダークラウドからセルのエンドポイントに接続するのに使用されます。
(undercloud) [stack@undercloud ~]$ CELL_INTERNALAPI_INFO=$(ssh heat-admin@${CELL_CTRL_IP} egrep \ cellcontrol.*\.internalapi /etc/hosts) (undercloud) [stack@undercloud ~]$ ansible -i /usr/bin/tripleo-ansible-inventory Controller -b \ -m lineinfile -a "dest=/etc/hosts line=\"$CELL_INTERNALAPI_INFO\""コントローラーセルから
transport_urlおよびdatabase.connectionエンドポイント情報を取得します。(undercloud) [stack@undercloud ~]$ CELL_TRANSPORT_URL=$(ssh heat-admin@${CELL_CTRL_IP} sudo \ crudini --get /var/lib/config-data/nova/etc/nova/nova.conf DEFAULT transport_url) (undercloud) [stack@undercloud ~]$ CELL_MYSQL_VIP=$(ssh heat-admin@${CELL_CTRL_IP} sudo \ crudini --get /var/lib/config-data/nova/etc/nova/nova.conf database connection \ | perl -nle'/(\d+\.\d+\.\d+\.\d+)/ && print $1')グローバルコントローラーノードのいずれかにログインし、前のステップで取得した情報に基づいてセルを作成します。以下に例を示します。
$ export CONTAINERCLI='podman' $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 create_cell --name computecell1 \ --database_connection "{scheme}://{username}:{password}@$CELL_MYSQL_VIP/nova?{query}" \ --transport-url "$CELL_TRANSPORT_URL"セルが作成され、セルの一覧に表示されることを確認します。
$ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 list_cells --verboseコントローラーノードで Compute サービスを再起動します。
$ ansible -i /usr/bin/tripleo-ansible-inventory Controller -b -a \ "systemctl restart tripleo_nova_api tripleo_nova_conductor tripleo_nova_scheduler"
セルコントローラーサービスがプロビジョニングされていることを確認します。
(overcloud) [stack@undercloud ~]$ nova service-list
6.6. セルへのコンピュートノードの追加
- コントローラーノードのいずれかにログインします。
セルのコントロールプレーンの IP アドレスを取得し、ホストの検出コマンドを実行してコンピュートホストを公開してセルに割り当てます。
$ CTRL=overcloud-controller-0 $ CTRL_IP=$(openstack server list -f value -c Networks --name $CTRL | sed 's/ctlplane=//') $ export CONTAINERCLI='podman' $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 discover_hosts --by-service --verboseコンピュートホストがセルに割り当てられたことを確認します。
$ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 list_hosts
6.7. アベイラビリティーゾーンの設定
インスタンスの作成および移行時に各セル内のコンピュートノードを維持するには、そのセルをアベイラビリティーゾーン (AZ) に割り当てる必要があります。コントローラーセルは、コンピュートセルの AZ とは別の AZ に属している必要があります。
ホストアグリゲートを使用して、コンピュートセル用の AZ を設定することができます。セル cell1 のホストアグリゲートを作成し、ホストアグリゲートに AZ を定義し、セル内のホストを AZ に追加するコマンド例を以下に示します。
(undercloud)$ source ~/overcloudrc (overcloud)$ openstack aggregate create cell1 --zone cell1 (overcloud)$ openstack aggregate add host cell1 hostA (overcloud)$ openstack aggregate add host cell1 hostB
-
この段階ではセルが作成されていないため、
OS::TripleO::Services::NovaAZConfigパラメーターを使用してデプロイメント時に AZ を自動的に作成することはできません。 - セル間でのインスタンの移行はサポートされていません。インスタンスを別のセルに移動するには、インスタンスを古いセルから削除し、新しいセルに作成し直す必要があります。
ホストアグリゲートおよびアベイラビリティーゾーンについての全般的な情報は、「ホストアグリゲートの管理」を参照してください。
6.8. セルからのコンピュートノードの削除
セルからコンピュートノードを削除するには、セルからインスタンスをすべて削除し、Placement データベースからホスト名を削除する必要があります。
セル内のコンピュートノードからすべてのインスタンスを削除します。
注記セル間でのインスタンの移行はサポートされていません。インスタンスを削除して、別のセルに作成し直す必要があります。
グローバルコントローラーのいずれかで、セルから全コンピュートノードを削除します。
$ CTRL=overcloud-controller-0 $ CTRL_IP=$(openstack server list -f value -c Networks --name $CTRL | sed 's/ctlplane=//') $ export CONTAINERCLI='podman' $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 list_hosts $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 delete_host --cell_uuid <uuid> --host <compute>Placement サービスからセルのリソースプロバイダーを削除し、後で別のセルに同じホスト名のコンピュートノードを追加する場合に、ホスト名が利用できるようにします。以下は例になります。
(undercloud) $ source ~/overcloudrc (overcloud) $ openstack resource provider list +--------------------------------------+---------------------------------------+------------+ | uuid | name | generation | +--------------------------------------+---------------------------------------+------------+ | 9cd04a8b-5e6c-428e-a643-397c9bebcc16 | computecell1-novacompute-0.site1.test | 11 | +--------------------------------------+---------------------------------------+------------+ (overcloud) $ openstack resource provider delete 9cd04a8b-5e6c-428e-a643-397c9bebcc16
6.9. セルの削除
セルを削除するには、「セルからのコンピュートノードの削除」 の説明に従って、まずすべてのインスタンスおよびコンピュートノードをセルから削除する必要があります。続いて、セル自体とセルスタックを削除します。
グローバルコントローラーのいずれかで、セルを削除します。
$ CTRL=overcloud-controller-0 $ CTRL_IP=$(openstack server list -f value -c Networks --name $CTRL | sed 's/ctlplane=//') $ export CONTAINERCLI='podman' $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 list_cells $ ssh heat-admin@${CTRL_IP} sudo ${CONTAINERCLI} exec -i -u root nova_api \ nova-manage cell_v2 delete_cell --cell_uuid <uuid>オーバークラウドからセルスタックを削除します。
$ openstack stack delete <stack name> --wait --yes && openstack overcloud plan delete <STACK_NAME>
注記コントローラーセルとコンピュートセル用に別個のセルスタックをデプロイした場合は、最初にコンピュートセルスタックを削除し、その後にコントローラーセルスタックを削除します。
第7章 パフォーマンス改善のためのコンピュートノードの設定
インスタンスのスケジューリングおよび配置を設定して、最大のパフォーマンスを得ることができます。そのためには、NFV や高性能コンピューティング (HPC) などの特化されたワークロードを対象にするカスタムフレーバーを作成します。
以下の機能を使用して、最大のパフォーマンスを得るためにインスタンスを調整します。
- CPU ピニング: 仮想 CPU を物理 CPU に固定します。
- エミュレータースレッド: インスタンスに関連付けられたエミュレータースレッドを物理 CPU に固定します。
- ヒュージページ: 通常のメモリー (4 KB ページ) とヒュージページ (2 MB または 1 GB ページ) の両方について、インスタンスのメモリー割り当てポリシーを調整します。
これらの機能のいずれかを設定すると、インスタンス上に NUMA トポロジーが存在しない場合、暗黙的な NUMA トポロジーが作成されます。
7.1. コンピュートノードでの CPU ピニングの設定
専用のホスト CPU 上で実行されるようにインスタンスを設定することができます。CPU ピニングを有効にすると、暗示的にゲスト NUMA トポロジーが設定されます。この NUMA トポロジーの各 NUMA ノードは、個別のホストの NUMA ノードにマッピングされます。NUMA の詳細は、『 ネットワーク機能仮想化(NFV)の製品ガイド』 の「 CPU と NUMA ノード 」を参照してください。
ホストシステムの NUMA トポロジーに基づいて、コンピュートノードでの CPU ピニングを設定します。効率を高めるために、全 NUMA ノードにわたって、CPU コアの一部をホストのプロセス用に確保します。残りの CPU コアをインスタンスの管理に割り当てます。
8 つの CPU コアを 2 つの NUMA ノードに分散する例を以下に示します。
表7.1 NUMA トポロジーの例
| NUMA ノード 0 | NUMA ノード 1 | ||
| コア 0 | コア 1 | コア 2 | コア 3 |
| コア 4 | コア 5 | コア 6 | コア 7 |
同じコンピュートノードで、専用の (ピニングされた) インスタンスと共有の (ピニングされていない) インスタンスをスケジューリングすることができます。以下の手順では、コア 0 および 4 をホストのプロセス用に、コア 1、3、5、および 7 を CPU ピニングが必要なインスタンス用に、そしてコア 2 および 6 を CPU ピニングが不要なフローティングインスタンス用に、それぞれ確保します。
ホストが同時マルチスレッド (SMT) をサポートする場合、スレッドシブリングを専用または共有セットのいずれかにグルーピングします。スレッドシブリングは共通のハードウェアを共有するため、あるスレッドシブリング上で動作しているプロセスが、他のスレッドシブリングのパフォーマンスに影響を与える可能性があります。
たとえば、ホストは、4 つのデュアルコア CPU (0、1、2、および 3) を識別し、SMT をサポートします。この 4 つの CPU に対して、スレッドシブリングのペアが 2 つあります。
- スレッドシブリング 1: CPU 0 および 2
- スレッドシブリング 2: CPU 1 および 3
このシナリオでは、CPU 0 および 1 を専用として、2 および 3 を共有として割り当てないでください。そうではなく、0 および 2 を専用として、1 および 3 を共有として割り当てる必要があります。
前提条件
- コンピュートノードの NUMA トポロジーを把握している。詳しくは、『 ネットワーク機能仮想化( NFV)のプランニングおよび設定ガイド』 の「NUMA ノードのトポロジー についての理解」を参照してください。
手順
各コンピュートノードにおいて、Compute 環境ファイルの
NovaComputeCpuDedicatedSet設定を定義して、専用のインスタンス用に物理 CPU コアを確保します。NovaComputeCpuDedicatedSet: 1,3,5,7
各コンピュートノードにおいて、Compute 環境ファイルの
NovaComputeCpuSharedSet設定を定義して、共有のインスタンス用に物理 CPU コアを確保します。NovaComputeCpuSharedSet: 2,6
同じファイルの
NovaReservedHostMemoryオプションを、ホストのプロセス用に確保するメモリー容量に設定します。たとえば、512 MB を確保する場合、設定は以下のようになります。NovaReservedHostMemory: 512
インスタンス用に確保した CPU コアでホストプロセスが実行されないようにするには、各 Compute 環境ファイルの
IsolCpusListパラメーターに、インスタンス用に確保した CPU コアを設定します。スペース区切りの CPU インデックスのリストまたは範囲を使用して、IsolCpusListパラメーターの値を指定します。IsolCpusList: 1 2 3 5 6 7
-
NUMA トポロジーに基づいてホストを除外するには、各 Compute 環境ファイルの
NovaSchedulerDefaultFiltersパラメーターにNUMATopologyFilterを追加します。 この設定を適用するには、デプロイメントコマンドに環境ファイルを追加して、オーバークラウドをデプロイします。
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/<compute_environment_file>.yaml
7.1.1. CPU ピニング設定のアップグレード
Red Hat OpenStack Platform (RHOSP) 16 以降、専用の (ピニングされた) インスタンスと共有の (ピニングされていない) インスタンス種別を別個のホスト上で実行するのに、ホストアグリゲートを使用する必要はありません。また、[DEFAULT] reserved_host_cpus 設定オプションは不要になり、未設定にすることができます。
CPU ピニングの設定を以前のバージョンの RHOSP からアップグレードするには、以下の手順を実施します。
-
これまでピニングされたインスタンス用に使用されていたホストの場合には、
NovaVcpuPinSetの値をNovaComputeCpuDedicatedSetに変更します。 -
これまでピニングされていないインスタンス用に使用されていたホストの場合には、
NovaVcpuPinSetの値をNovaComputeCpuSharedSetに変更します。 -
NovaVcpuPinSetに値が設定されていない場合には、実行中のインスタンスの種別に応じて、すべてのホストコアをNovaComputeCpuDedicatedSetまたはNovaComputeCpuSharedSetのどちらかに割り当てる必要があります。
アップグレードが完了したら、同一のホストで両方のオプションの設定を始めることができます。ただし、そのためには、すべてのインスタンスをホストから移行する必要があります。ピニングされていないインスタンス用のコアが NovaComputeCpuSharedSet に記載されていない場合や、ピニングされたインスタンス用のコアが NovaComputeCpuDedicatedSet に記載されていない場合は、Compute サービスを起動することができないためです。
7.1.2. CPU ピニングが設定されたインスタンスの起動
専用 CPU ポリシーのフレーバーを指定すると、CPU ピニングを使用するインスタンスを起動することができます。
前提条件
- ホストで同時マルチスレッド (SMT) が有効である。
- コンピュートノードが CPU ピニングを許可するように設定されている。詳しくは、「コンピュートノードでの CPU ピニングの設定」を参照してください。
手順
CPU ピニングを要求するインスタンス用のフレーバーを作成します。
(overcloud) $ openstack flavor create --ram <size-mb> --disk <size-gb> --vcpus <no_reserved_vcpus> pinned_cpus
ピニングされた CPU を要求するには、フレーバーの
hw:cpu_policy属性をdedicatedに設定します。(overcloud) $ openstack flavor set --property hw:cpu_policy=dedicated pinned_cpus
それぞれの仮想 CPU をスレッドシブリングに配置するには、フレーバーの
hw:cpu_thread_policy属性をrequireに設定します。(overcloud) $ openstack flavor set --property hw:cpu_thread_policy=require pinned_cpus
注記-
ホストに SMT アーキテクチャーがない場合や、スレッドシブリングが利用可能な CPU コアが十分にない場合には、スケジューリングが失敗します。これを回避するには、
hw:cpu_thread_policyをrequireではなくpreferに設定します。デフォルトのpreferポリシーでは、スレッドシブリングが利用可能な場合には、必ず使用されます。 -
cpu_thread_policy=isolateを使用する場合は、SMT を無効にするか、SMT をサポートしないプラットフォームを使用する必要があります。
-
ホストに SMT アーキテクチャーがない場合や、スレッドシブリングが利用可能な CPU コアが十分にない場合には、スケジューリングが失敗します。これを回避するには、
新しいフレーバーを使用してインスタンスを作成します。
(overcloud) $ openstack server create --flavor pinned_cpus --image <image> pinned_cpu_instance
新規インスタンスが正しく配置されていることを確認するには、以下のコマンドを実行し、その出力で
OS-EXT-SRV-ATTR:hypervisor_hostnameの箇所を確認します。(overcloud) $ openstack server show pinned_cpu_instance
7.1.3. フローティングインスタンスの起動
共有 CPU ポリシーのフレーバーを指定すると、フローティング CPU に配置されているインスタンスを起動することができます。
前提条件
- コンピュートノードがフローティングインスタンス用に物理 CPU コアを確保するように設定されている。詳しくは、「コンピュートノードでの CPU ピニングの設定」を参照してください。
手順
CPU ピニングを要求しないインスタンス用のフレーバーを作成します。
(overcloud) $ openstack flavor create --ram <size-mb> --disk <size-gb> --vcpus <no_reserved_vcpus> floating_cpus
フローティング CPU を要求するには、フレーバーの
hw:cpu_policy属性をsharedに設定します。(overcloud) $ openstack flavor set --property hw:cpu_policy=shared floating_cpus
新しいフレーバーを使用してインスタンスを作成します。
(overcloud) $ openstack server create --flavor floating_cpus --image <image> floating_cpu_instance
新規インスタンスが正しく配置されていることを確認するには、以下のコマンドを実行し、その出力で
OS-EXT-SRV-ATTR:hypervisor_hostnameの箇所を確認します。(overcloud) $ openstack server show floating_cpu_instance
7.2. コンピュートノードでのヒュージページの設定
インスタンスがヒュージページを要求できるようにコンピュートノードを設定します。
手順
インスタンスではないプロセス用に各 NUMA ノードで確保するヒュージページのメモリー量を設定します。
parameter_defaults: NovaReservedHugePages: ["node:0,size:2048,count:64","node:1,size:1GB,count:1"]
各属性についての説明は以下のとおりです。
属性
説明
size
割り当てるヒュージページのサイズ。有効な値は 2048 (2 MB 用) および 1 GB です。
count
NUMA ノードごとに OVS が使用するヒュージページの数。たとえば、Open vSwitch が 4096 のソケットメモリーを使用する場合、この属性を 2 に設定します。
(オプション) インスタンスが 1 GB のヒュージページを割り当てるのを許可するには、CPU 機能フラグ
cpu_model_extra_flagsを設定して「pdpe1gb」を指定します。parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb'注記- インスタンスが 2 MB のヒュージページしか要求しない場合、CPU 機能フラグを設定する必要はありません。
- ホストが 1 GB ヒュージページの割り当てをサポートする場合に限り、インスタンスに 1 GB のヒュージページを割り当てることができます。
-
cpu_modeがhost-modelまたはcustomに設定されている場合に限り、cpu_model_extra_flagsをpdpe1gbに設定する必要があります。 -
ホストが
pdpe1gbをサポートし、cpu_modeにhost-passthroughが使用される場合、cpu_model_extra_flagsにpdpe1gbを設定する必要はありません。pdpe1gbフラグは Opteron_G4 および Opteron_G5 CPU モデルにのみ含まれ、QEMU がサポートする Intel CPU モデルには含まれません。 - Microarchitectural Data Sampling (MDS) 等の CPU ハードウェアの問題を軽減するには、他の CPU フラグを設定しなければならない場合があります。詳しくは、「RHOS Mitigation for MDS ("Microarchitectural Data Sampling") Security Flaws」を参照してください。
Meltdown に対する保護の適用後にパフォーマンスが失われないようにするには、CPU 機能フラグ
cpu_model_extra_flagsを設定して「+pcid」を指定します。parameter_defaults: ComputeExtraConfig: nova::compute::libvirt::libvirt_cpu_mode: 'custom' nova::compute::libvirt::libvirt_cpu_model: 'Haswell-noTSX' nova::compute::libvirt::libvirt_cpu_model_extra_flags: 'vmx, pdpe1gb, +pcid'-
各 Compute 環境ファイルの
NovaSchedulerDefaultFiltersパラメーターにまだNUMATopologyFilterがなければ、このフィルターを追加します。 デプロイコマンドに環境ファイルを追加してオーバークラウドをデプロイし、このヒュージページの設定を適用します。
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/<compute_environment_file>.yaml
7.2.1. インスタンスへのヒュージページの割り当て
インスタンスがヒュージページを使用することを指定するには、hw:mem_page_size 追加仕様キーを使用してフレーバーを作成します。
前提条件
- コンピュートノードがヒュージページに対応する設定である。詳しくは、「コンピュートノードでのヒュージページの設定」を参照してください。
手順
ヒュージページを要求するインスタンス用のフレーバーを作成します。
$ openstack flavor create --ram <size-mb> --disk <size-gb> --vcpus <no_reserved_vcpus> huge_pages
ヒュージページのフレーバーを設定します。
$ openstack flavor set huge_pages --property hw:mem_page_size=1GB
有効な
hw:mem_page_sizeの値は以下のとおりです。-
large: ホストでサポートされる最大のページサイズを選択します。x86_64 システムでは 2 MB または 1 GB です。 -
small: (デフォルト) ホストでサポートされる最小のページサイズを選択します。X86_64 システムでは、4 kB (通常のページ) です。 -
any: libvirt ドライバーで決定される、利用可能な最大のヒュージページサイズを選択します。 - <pagesize>: (文字列) ワークロードに具体的な要件がある場合、ページサイズを明示的に設定します。整数値のページサイズを、kB またはその他の標準単位で指定します。たとえば、4kB、2MB、2048、1GB と設定します。
-
新しいフレーバーを使用してインスタンスを作成します。
$ openstack server create --flavor huge_pages --image <image> huge_pages_instance
検証
スケジューラーは、インスタンスのメモリーをサポートするのに十分なサイズの空きヒュージページを持つホストを特定します。スケジューラーが十分なページを持つホストおよび NUMA ノードを検出できない場合、リクエストは失敗して NoValidHost エラーが報告されます。
第8章 インスタンス用の仮想 GPU の設定
インスタンスで GPU ベースのレンダリングをサポートするには、利用可能な物理 GPU デバイスおよびハイパーバイザーの種別に応じて、仮想 GPU (vGPU) リソースを定義し、管理できます。この設定を使用して、レンダリングの負荷をすべての物理 GPU デバイス間でより効果的に分割し、仮想 GPU 対応のインスタンスをスケジューリングする際の制御性を向上させることができます。
OpenStack Compute で仮想 GPU を有効にするには、クラウドユーザーが仮想 GPU デバイスの設定された Red Hat Enterprise Linux (RHEL) インスタンスを作成するのに使用できるフレーバーを作成します。これにより、各インスタンスは物理 GPU デバイスに対応する仮想 GPU デバイスで GPU 負荷に対応することができます。
OpenStack Compute サービスは、各ホストに定義する GPU プロファイルで利用可能な仮想 GPU デバイスの数を追跡します。Compute サービスはフレーバーに基づいてこれらのホストにインスタンスをスケジュールし、デバイスをアタッチし、使用状況を継続的に監視します。インスタンスが削除されると、Compute サービスは仮想 GPU デバイスを利用可能なプールに戻します。
8.1. サポートされる構成および制限
サポートされる GPU カード
サポートされる NVIDIA GPU カードの一覧については、NVIDIA の Web サイトで「Virtual GPU Software Supported Products」を参照してください。
仮想 GPU デバイスを使用する際の制限
- 各コンピュートノードで有効にできる仮想 GPU の種別は 1 つだけです。
- 各インスタンスが使用できる仮想 GPU のリソースは 1 つだけです。
- ホスト間での仮想 GPU のライブマイグレーションはサポートされていません。
- libvirt の制限により、仮想 GPU 対応インスタンスでの休止操作はサポートされていません。代わりに、インスタンスのスナップショット作成またはシェルブ処理が可能です。
- 仮想 GPU フレーバーが設定されたインスタンスでサイズ変更およびコールドマイグレーション操作を行っても、仮想 GPU のリソースはインスタンスに自動的には再割り当てされません。インスタンスのサイズ変更または移行後に、インスタンスを手動で再ビルドし、仮想 GPU のリソースを再割り当てする必要があります。
- デフォルトでは、コンピュートホストの仮想 GPU の種別は API ユーザーに公開されません。アクセス権限を付与するには、ホストをホストアグリゲートに追加します。詳細は、「ホストアグリゲートの管理」を参照してください。
- NVIDIA アクセラレーターハードウェアを使用する場合は、NVIDIA ライセンス要件に従う必要があります。たとえば、NVIDIA vGPU GRID にはライセンスサーバーが必要です。NVIDIA のライセンス要件の詳細は、NVIDIA の Web サイトで「Virtual GPU License Server Release Notes」を参照してください。
8.2. コンピュートノードでの仮想 GPU の設定
クラウドユーザーが仮想 GPU (vGPU) を使用するインスタンスを作成できるようにするには、物理 GPU を持つコンピュートノードを設定する必要があります。
- GPU 対応のカスタムオーバークラウドイメージをビルドする。
- 仮想 GPU 用のコンピュートノードを指定するために、GPU ロール、プロファイル、およびフレーバーを準備する。
- 仮想 GPU 用のコンピュートノードを設定する。
- オーバークラウドをデプロイする。
NVIDIA GRID vGPU を使用するには、NVIDIA GRID ライセンス要件に従う共に、セルフホストライセンスサーバーの URL が必要です。詳細は、「Virtual GPU License Server Release Notes」の Web ページを参照してください。
8.2.1. GPU 対応カスタムオーバークラウドイメージのビルド
オーバークラウドの Compute イメージに NVIDIA GRID ホストドライバーをインストールし、イメージを OpenStack Image サービス (glance) にアップロードするには、director ノードで以下の手順を実施します。
手順
オーバークラウドイメージをコピーし、コピーしたイメージに
gpuの接尾辞を追加します。$ cp overcloud-full.qcow2 overcloud-full-gpu.qcow2
YUM から ISO イメージ生成器ツールをインストールします。
$ sudo yum install genisoimage -y
NVIDIA の Web サイトから、GPU デバイスに対応する NVIDIA GRID ホストドライバー RPM パッケージをダウンロードします。必要なドライバーを確認するには、NVIDIA ドライバーダウンロードポータル を参照してください。
注記ポータルからドライバーをダウンロードするには、NVIDIA カスタマーとして登録されている必要があります。
ドライバー RPM パッケージから ISO イメージを作成し、イメージを
nvidia-hostディレクトリーに保存します。$ genisoimage -o nvidia-host.iso -R -J -V NVIDIA nvidia-host/ I: -input-charset not specified, using utf-8 (detected in locale settings) 9.06% done, estimate finish Wed Oct 31 11:24:46 2018 18.08% done, estimate finish Wed Oct 31 11:24:46 2018 27.14% done, estimate finish Wed Oct 31 11:24:46 2018 36.17% done, estimate finish Wed Oct 31 11:24:46 2018 45.22% done, estimate finish Wed Oct 31 11:24:46 2018 54.25% done, estimate finish Wed Oct 31 11:24:46 2018 63.31% done, estimate finish Wed Oct 31 11:24:46 2018 72.34% done, estimate finish Wed Oct 31 11:24:46 2018 81.39% done, estimate finish Wed Oct 31 11:24:46 2018 90.42% done, estimate finish Wed Oct 31 11:24:46 2018 99.48% done, estimate finish Wed Oct 31 11:24:46 2018 Total translation table size: 0 Total rockridge attributes bytes: 358 Total directory bytes: 0 Path table size(bytes): 10 Max brk space used 0 55297 extents written (108 MB)
コンピュートノード用のドライバーインストールスクリプトを作成します。このスクリプトにより、スクリプトを実行する各コンピュートノードに NVIDIA GRID ホストドライバーがインストールされます。以下の例では、
install_nvidia.shという名前でスクリプトを作成しています。#/bin/bash # NVIDIA GRID package mkdir /tmp/mount mount LABEL=NVIDIA /tmp/mount rpm -ivh /tmp/mount/NVIDIA-vGPU-rhel-8.1-430.27.x86_64.rpm
ステップ 4 で生成した ISO イメージをアタッチし、ステップ 5 で作成したドライバーインストール用のスクリプトを実行して、オーバークラウドイメージをカスタマイズします。
$ virt-customize --attach nvidia-packages.iso -a overcloud-full-gpu.qcow2 -v --run install_nvidia.sh [ 0.0] Examining the guest ... libguestfs: launch: program=virt-customize libguestfs: launch: version=1.36.10rhel=8,release=6.el8_5.2,libvirt libguestfs: launch: backend registered: unix libguestfs: launch: backend registered: uml libguestfs: launch: backend registered: libvirt
SELinux でカスタマイズしたイメージのラベルを付け直します。
$ virt-customize -a overcloud-full-gpu.qcow2 --selinux-relabel [ 0.0] Examining the guest ... [ 2.2] Setting a random seed [ 2.2] SELinux relabelling [ 27.4] Finishing off
OpenStack Image サービスにアップロードするカスタムイメージファイルを準備します。
$ mkdir /var/image/x86_64/image $ guestmount -a overcloud-full-gpu.qcow2 -i --ro image $ cp image/boot/vmlinuz-3.10.0-862.14.4.el8.x86_64 ./overcloud-full-gpu.vmlinuz $ cp image/boot/initramfs-3.10.0-862.14.4.el8.x86_64.img ./overcloud-full-gpu.initrd
アンダークラウドから、OpenStack Image サービスにカスタムイメージをアップロードします。
(undercloud) $ openstack overcloud image upload --update-existing --os-image-name overcloud-full-gpu.qcow2
8.2.2. 仮想 GPU 向けコンピュートノードの指定
仮想 GPU 負荷用のコンピュートノードを指定するには、仮想 GPU ロールを設定するための新規ロールファイルを作成し、GPU 対応のコンピュートノードをタグ付けするための新規フレーバーを設定する必要があります。
手順
新規
ComputeGPUロールファイルを作成するには、/usr/share/openstack-tripleo-heat-templates/roles/Compute.yamlファイルを/usr/share/openstack-tripleo-heat-templates/roles/ComputeGPU.yamlにコピーし、以下のファイルセクションを編集します。表8.1 ComputeGPU ロールファイルの編集
セクション/パラメーター 現在の値 新しい値 ロールのコメント
Role: ComputeRole: ComputeGpuname (ロール名)
ComputeComputeGpudescriptionBasic Compute Node roleGPU Compute Node roleImageDefaultovercloud-fullovercloud-full-gpuHostnameFormatDefault-compute--computegpu-deprecated_nic_config_namecompute.yamlcompute-gpu.yamlgpu_roles_data.yamlという名前で、Controller、Compute、およびComputeGpuロールが含まれる新しいロールデータファイルを生成します。(undercloud) [stack@director templates]$ openstack overcloud roles generate -o /home/stack/templates/gpu_roles_data.yaml Controller Compute ComputeGpu
ComputeGpuロールの詳細の例を以下に示します。##################################################################### # Role: ComputeGpu # ##################################################################### - name: ComputeGpu description: | GPU Compute Node role CountDefault: 1 ImageDefault: overcloud-full-gpu networks: - InternalApi - Tenant - Storage HostnameFormatDefault: '%stackname%-computegpu-%index%' RoleParametersDefault: TunedProfileName: "virtual-host" # Deprecated & backward-compatible values (FIXME: Make parameters consistent) # Set uses_deprecated_params to True if any deprecated params are used. uses_deprecated_params: True deprecated_param_image: 'NovaImage' deprecated_param_extraconfig: 'NovaComputeExtraConfig' deprecated_param_metadata: 'NovaComputeServerMetadata' deprecated_param_scheduler_hints: 'NovaComputeSchedulerHints' deprecated_param_ips: 'NovaComputeIPs' deprecated_server_resource_name: 'NovaCompute' deprecated_nic_config_name: 'compute-gpu.yaml' ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::BootParams - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::IpaClient - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MetricsQdr - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaLibvirtGuests - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Podman - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timesync - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Tuned - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgent- オーバークラウドノードを登録します。詳しい情報は、『 director のインストールと 使用方法』 の「オーバークラウドノードの登録 」を参照してください。
- ノードのハードウェアを検査します。詳しくは、『 director のインストールと 使用方法』 の「ノードのハードウェアの検査 」を参照してください。
仮想 GPU 負荷用に指定するノードをタグ付けするための、
compute-vgpu-nvidiaフレーバーを作成します。(undercloud) [stack@director templates]$ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute-vgpu-nvidia +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | disk | 40 | | id | 9cb47954-be00-47c6-a57f-44db35be3e69 | | name | compute-vgpu-nvidia | | os-flavor-access:is_public | True | | properties | | | ram | 6144 | | rxtx_factor | 1.0 | | swap | | | vcpus | 4 | +----------------------------+--------------------------------------+
GPU 負荷用に指定するそれぞれのノードを、
compute-vgpu-nvidiaプロファイルでタグ付けします。(undercloud) [stack@director templates]$ openstack baremetal node set --property capabilities='profile:compute-vgpu-nvidia,boot_option:local' <node>
<node>をベアメタルノードの ID に置き換えてください。
8.2.3. 仮想 GPU 向けコンピュートノードの設定およびオーバークラウドのデプロイ
環境内の物理 GPU デバイスに対応する仮想 GPU の種別を取得して割り当て、仮想 GPU 用コンピュートノードを設定するための環境ファイルを準備する必要があります。
手順
- Red Hat Enterprise Linux と NVIDIA GRID ドライバーを一時コンピュートノードにインストールし、そのノードを起動します。NVIDIA GRID ドライバーのインストールについての詳細は、「GPU 対応カスタムオーバークラウドイメージのビルド」を参照してください。
コンピュートノードで、有効にする物理 GPU デバイスに対応する仮想 GPU の種別を確認します。libvirt の場合、仮想 GPU は仲介デバイスまたは
mdev種別のデバイスです。サポートされているmdevデバイスを検出するには、以下のコマンドを入力します。[root@overcloud-computegpu-0 ~]# ls /sys/class/mdev_bus/0000\:06\:00.0/mdev_supported_types/ nvidia-11 nvidia-12 nvidia-13 nvidia-14 nvidia-15 nvidia-16 nvidia-17 nvidia-18 nvidia-19 nvidia-20 nvidia-21 nvidia-210 nvidia-22 [root@overcloud-computegpu-0 ~]# cat /sys/class/mdev_bus/0000\:06\:00.0/mdev_supported_types/nvidia-18/description num_heads=4, frl_config=60, framebuffer=2048M, max_resolution=4096x2160, max_instance=4
compute-gpu.yamlファイルをnetwork-environment.yamlファイルに追加します。resource_registry: OS::TripleO::Compute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute.yaml OS::TripleO::ComputeGpu::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute-gpu.yaml OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller.yaml #OS::TripleO::AllNodes::Validation: OS::Heat::None
以下のパラメーターを
node-info.yamlファイルに追加して、GPU コンピュートノードの数および GPU が指定されたコンピュートノード用に使用するフレーバーを指定します。parameter_defaults: OvercloudControllerFlavor: control OvercloudComputeFlavor: compute OvercloudComputeGpuFlavor: compute-vgpu-nvidia ControllerCount: 1 ComputeCount: 0 ComputeGpuCount: 1
gpu.yamlファイルを作成し、GPU デバイスの仮想 GPU 種別を指定します。parameter_defaults: ComputeGpuExtraConfig: nova::compute::vgpu::enabled_vgpu_types: - nvidia-18注記各物理 GPU がサポートするのは 1 つの仮想 GPU 種別だけです。このプロパティーで複数の仮想 GPU 種別を指定した場合は、最初の種別だけが使用されます。
その他の環境ファイルと共に新たなロールファイルおよび環境ファイルをスタックに追加して、オーバークラウドをデプロイします。
(undercloud) $ openstack overcloud deploy --templates \ -r /home/stack/templates/nvidia/gpu_roles_data.yaml -e /home/stack/templates/node-info.yaml -e /home/stack/templates/network-environment.yaml -e [your environment files] -e /home/stack/templates/gpu.yaml
8.3. 仮想 GPU イメージおよびフレーバーの作成
クラウドユーザーが仮想 GPU (vGPU) を使用するインスタンスを作成できるようにするには、仮想 GPU 対応のカスタムイメージを定義すると共に、仮想 GPU フレーバーを作成することができます。
8.3.1. カスタム GPU インスタンスイメージの作成
GPU 対応のコンピュートノードと共にオーバークラウドをデプロイしたら、NVIDIA GRID ゲストドライバーおよびライセンスファイルを使用して仮想 GPU 対応のカスタムインスタンスイメージを作成することができます。
手順
仮想 GPU インスタンスが必要とするハードウェアおよびソフトウェアプロファイルでインスタンスを作成します。
(overcloud) [stack@director ~]$ openstack server create --flavor <flavor> --image <image> temp_vgpu_instance
-
<flavor>を、仮想 GPU インスタンスが必要とするハードウェアプロファイルを持つフレーバーの名前または ID に置き換えてください。デフォルトのフレーバーに関する情報は、「フレーバーの 管理」を 参照してください。 -
<image>を、仮想 GPU インスタンスが必要とするソフトウェアプロファイルを持つイメージの名前または ID に置き換えてください。RHEL クラウドイメージのダウンロードに関する情報は、「 Image サービス 」を参照してください。
-
- cloud-user としてインスタンスにログインします。詳細は、「インスタンス へのログイン」を参照してください。
-
NVIDIA のガイダンス (「Licensing an NVIDIA vGPU on Linux by Using a Configuration File」) に従って、インスタンス上に
gridd.confNVIDIA GRID ライセンスファイルを作成します。 インスタンスに GPU ドライバーをインストールします。NVIDIA ドライバーのインストールについての詳細は、「Installing the NVIDIA vGPU Software Graphics Driver on Linux」を参照してください。
注記hw_video_modelイメージ属性を使用して GPU ドライバーの種別を定義します。仮想 GPU インスタンスのエミュレートされた GPU を無効にする場合は、noneを選択します。サポートされているドライバーについての詳しい情報は、「付録A イメージの設定パラメーター」を参照してください。インスタンスのイメージスナップショットを作成します。
(overcloud) [stack@director ~]$ openstack server image create --name vgpu_image temp_vgpu_instance
- オプション: インスタンスを削除します。
8.3.2. インスタンス用の仮想 GPU フレーバーの作成
GPU 対応のコンピュートノードと共にオーバークラウドをデプロイしたら、カスタムフレーバーを作成することができます。このフレーバーを使用して、クラウドユーザーは GPU 負荷用のインスタンスを起動することができます。
手順
NVIDIA GPU フレーバーを作成します。以下に例を示します。
(overcloud) [stack@virtlab-director2 ~]$ openstack flavor create --vcpus 6 --ram 8192 --disk 100 m1.small-gpu +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | disk | 100 | | id | a27b14dd-c42d-4084-9b6a-225555876f68 | | name | m1.small-gpu | | os-flavor-access:is_public | True | | properties | | | ram | 8192 | | rxtx_factor | 1.0 | | swap | | | vcpus | 6 | +----------------------------+--------------------------------------+
作成したフレーバーに仮想 GPU のリソースを割り当てます。各インスタンスに割り当てられる仮想 GPU は 1 つだけです。
(overcloud) [stack@virtlab-director2 ~]$ openstack flavor set m1.small-gpu --property "resources:VGPU=1" (overcloud) [stack@virtlab-director2 ~]$ openstack flavor show m1.small-gpu +----------------------------+--------------------------------------+ | Field | Value | +----------------------------+--------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | access_project_ids | None | | disk | 100 | | id | a27b14dd-c42d-4084-9b6a-225555876f68 | | name | m1.small-gpu | | os-flavor-access:is_public | True | | properties | resources:VGPU='1' | | ram | 8192 | | rxtx_factor | 1.0 | | swap | | | vcpus | 6 | +----------------------------+--------------------------------------+
8.3.3. 仮想 GPU インスタンスの起動
GPU 負荷用の GPU 対応インスタンスを作成することができます。
手順
GPU フレーバーおよびイメージを使用して、インスタンスを作成します。以下に例を示します。
(overcloud) [stack@virtlab-director2 ~]$ openstack server create --flavor m1.small-gpu --image vgpu_image --security-group web --nic net-id=internal0 --key-name lambda vgpu-instance
- cloud-user としてインスタンスにログインします。詳細は、「インスタンス へのログイン」を参照してください。
インスタンスが GPU にアクセスできることを確認するには、インスタンスから以下のコマンドを実行します。
$ lspci -nn | grep <gpu_name>
8.4. GPU デバイスの PCI パススルーの有効化
PCI パススルーを使用して、グラフィックカード等の物理 PCI デバイスをインスタンスに接続することができます。デバイスに PCI パススルーを使用する場合、インスタンスはタスクを実行するためにデバイスへの排他的アクセスを確保し、ホストはデバイスを利用することができません。
前提条件
-
pciutilsパッケージが PCI カードを持つ物理サーバーにインストールされている。 - GPU インスタンスにインストールするための GPU ドライバーが利用可能である。詳細は、「GPU 対応カスタムオーバークラウドイメージのビルド」を参照してください。
手順
各パススルーデバイス種別のベンダー ID および製品 ID を確認するには、PCI カードを持つ物理サーバーで以下のコマンドを実行します。
# lspci -nn | grep -i <gpu_name>
たとえば、NVIDIA GPU のベンダーおよび製品 ID を確認するには、以下のコマンドを実行します。
# lspci -nn | grep -i nvidia 3b:00.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1eb8] (rev a1) d8:00.0 3D controller [0302]: NVIDIA Corporation TU104GL [Tesla T4] [10de:1db4] (rev a1)
-
PCI パススルー用にオーバークラウド上のコントローラーノードを設定するには、環境ファイル (例:
pci_passthru_controller.yaml) を作成します。 pci_passthru_controller.yamlのNovaSchedulerDefaultFiltersパラメーターにPciPassthroughFilterを追加します。parameter_defaults: NovaSchedulerDefaultFilters: ['RetryFilter','AvailabilityZoneFilter','ComputeFilter','ComputeCapabilitiesFilter','ImagePropertiesFilter','ServerGroupAntiAffinityFilter','ServerGroupAffinityFilter','PciPassthroughFilter','NUMATopologyFilter']
コントローラーノード上のデバイスの PCI エイリアスを指定するには、以下の設定を
pci_passthru_controller.yamlに追加します。ControllerExtraConfig: nova::pci::aliases: - name: "t4" product_id: "1eb8" vendor_id: "10de" - name: "v100" product_id: "1db4" vendor_id: "10de"注記nova-apiサービスが Controller 以外のロールで実行されている場合は、ControllerExtraConfigを<Role>ExtraConfigの形式でユーザーロールに置き換えます。-
PCI パススルー用にオーバークラウド上のコンピュートノードを設定するには、環境ファイル (例:
pci_passthru_compute.yaml) を作成します。 コンピュートノード上のデバイスに許可される PCI を指定するには、以下の設定を
pci_passthru_compute.yamlに追加します。parameter_defaults: NovaPCIPassthrough: - vendor_id: "10de" product_id: "1eb8"PCI パススルーをサポートするためにコンピュートノードのサーバー BIOS で IOMMU を有効にするには、
pci_passthru_compute.yamlにKernelArgsパラメーターを追加します。parameter_defaults: ... ComputeParameters: KernelArgs: "intel_iommu=on iommu=pt"その他の環境ファイルと共にカスタム環境ファイルをスタックに追加して、オーバークラウドをデプロイします。
(undercloud) $ openstack overcloud deploy --templates \ -e [your environment files] -e /home/stack/templates/pci_passthru_controller.yaml -e /home/stack/templates/pci_passthru_compute.yaml
PCI デバイスを要求するためのフレーバーを設定します。以下の例では、それぞれベンダー ID および製品 ID が
10deおよび13f2の 2 つのデバイスをリクエストします。# openstack flavor set m1.large --property "pci_passthrough:alias"="t4:2"
PCI パススルーデバイスを設定してインスタンスを作成します。
# openstack server create --flavor m1.large --image rhelgpu --wait test-pci
- cloud-user としてインスタンスにログインします。詳細は、「インスタンス へのログイン」を参照してください。
インスタンスに GPU ドライバーをインストールします。たとえば、以下のスクリプトを実行して NVIDIA ドライバーをインストールします。
$ sh NVIDIA-Linux-x86_64-430.24-grid.run
検証
インスタンスが GPU にアクセスできることを確認するには、インスタンスから以下のコマンドを実行します。
$ lspci -nn | grep <gpu_name>
NVIDIA System Management Interface のステータスを確認するには、インスタンスから以下のコマンドを実行します。
$ nvidia-smi
出力例:
-----------------------------------------------------------------------------| NVIDIA-SMI 440.33.01 Driver Version: 440.33.01 CUDA Version: 10.2 | |---------------------------------------------------------------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===========================================================================| | 0 Tesla T4 Off | 00000000:01:00.0 Off | 0 | | N/A 43C P0 20W / 70W | 0MiB / 15109MiB | 0% Default |--------------------------------------------------------------------------------------------------------------------------------------------------------| Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found |-----------------------------------------------------------------------------
第9章 Real-time Compute の設定
一部のユースケースでは、低レイテンシーのポリシーを順守しリアルタイム処理を実行するために、コンピュートノードにインスタンスが必要となります。Real-time コンピュートノードには、リアルタイム対応のカーネル、特定の仮想化モジュール、および最適化されたデプロイメントパラメーターが設定され、リアルタイム処理の要求に対応してレイテンシーを最小限に抑えます。
リアルタイムコンピュートを有効にするプロセスは、以下のステップで構成されます。
- コンピュートノードの BIOS 設定の定義
- real-time カーネルおよび Real-Time KVM (RT-KVM) カーネルモジュールを持つ real-time のイメージのビルド
-
コンピュートノードへの
ComputeRealTimeロールの割り当て
NFV 負荷に対して Real-time Compute をデプロイするユースケースの例については、『 ネットワーク機能仮想化(NFV)のプランニングおよび設定ガイド』の「 例: ODL および VXLAN トンネリングを使用する OVS-DPDK の設定 」セクションを参照してください。
9.1. Real-time 用コンピュートノードの準備
Real-time コンピュートノードは、Red Hat Enterprise Linux バージョン 7.5 以降でのみサポートされます。
オーバークラウドに Real-time Compute をデプロイするには、Red Hat Enterprise Linux Real-Time KVM (RT-KVM) を有効にし、real-time をサポートするように BIOS を設定し、real-time のイメージをビルドする必要があります。
前提条件
- RT-KVM コンピュートノードには、Red Hat 認定済みサーバーを使用する必要があります。詳しくは、Red Hat Enterprise Linux for Real Time 7 用認定サーバー を参照してください。
real-time のイメージをビルドするには、RT-KVM 用の
rhel-8-for-x86_64-nfv-rpmsリポジトリーを有効にする必要があります。注記このリポジトリーにアクセスするためには、Red Hat OpenStack Platform for Real Time に対する別のサブスクリプションが必要です。リポジトリーの管理およびアンダークラウド用のサブスクリプションに関する詳細は、『 director のインストール と使用方法』の「アンダークラウドの登録と 更新 」セクションを参照してください。
リポジトリーからインストールされるパッケージを確認するには、以下のコマンドを実行します。
$ dnf repo-pkgs rhel-8-for-x86_64-nfv-rpms list Loaded plugins: product-id, search-disabled-repos, subscription-manager Available Packages kernel-rt.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-debug.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-debug-devel.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-debug-kvm.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-devel.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-doc.noarch 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms kernel-rt-kvm.x86_64 4.18.0-80.7.1.rt9.153.el8_0 rhel-8-for-x86_64-nfv-rpms [ output omitted…]
real-time のイメージのビルド
Real-time コンピュートノード用のオーバークラウドイメージをビルドするには、以下のステップを実行します。
アンダークラウドに
libguestfs-toolsパッケージをインストールして、virt-customizeツールを取得します。(undercloud) [stack@undercloud-0 ~]$ sudo dnf install libguestfs-tools
重要アンダークラウドに
libguestfs-toolsパッケージをインストールする場合は、アンダークラウドのtripleo_iscsidサービスとのポートの競合を避けるためにiscsid.socketを無効にします。$ sudo systemctl disable --now iscsid.socket
イメージを抽出します。
(undercloud) [stack@undercloud-0 ~]$ tar -xf /usr/share/rhosp-director-images/overcloud-full.tar (undercloud) [stack@undercloud-0 ~]$ tar -xf /usr/share/rhosp-director-images/ironic-python-agent.tar
デフォルトのイメージをコピーします。
(undercloud) [stack@undercloud-0 ~]$ cp overcloud-full.qcow2 overcloud-realtime-compute.qcow2
イメージを登録して、必要なサブスクリプションを設定します。
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --run-command 'subscription-manager register --username=[username] --password=[password]' [ 0.0] Examining the guest ... [ 10.0] Setting a random seed [ 10.0] Running: subscription-manager register --username=[username] --password=[password] [ 24.0] Finishing off
usernameおよびpasswordの値を、ご自分の Red Hat カスタマーアカウント情報に置き換えてください。Real-time オーバークラウドイメージのビルドに関する一般的な情報は、ナレッジベースの記事「Modifying the Red Hat Enterprise Linux OpenStack Platform Overcloud Image with virt-customize」を参照してください。以下の例に示すように、Red Hat OpenStack Platform for Real Time サブスクリプションの SKU を探します。SKU は、同じアカウントおよび認証情報を使用してすでに Red Hat サブスクリプションマネージャーに登録済みのシステムに置かれている場合があります。以下に例を示します。
$ sudo subscription-manager list
Red Hat OpenStack Platform for Real Time サブスクリプションをイメージにアタッチします。
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --run-command 'subscription-manager attach --pool [subscription-pool]'
イメージ上で
rtを設定するためのスクリプトを作成します。(undercloud) [stack@undercloud-0 ~]$ cat rt.sh #!/bin/bash set -eux subscription-manager repos --enable=[REPO_ID] dnf -v -y --setopt=protected_packages= erase kernel.$(uname -m) dnf -v -y install kernel-rt kernel-rt-kvm tuned-profiles-nfv-host # END OF SCRIPT
リアルタイムイメージを設定するスクリプトを実行します。
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 -v --run rt.sh 2>&1 | tee virt-customize.log
SELinux の再ラベル付けをします。
(undercloud) [stack@undercloud-0 ~]$ virt-customize -a overcloud-realtime-compute.qcow2 --selinux-relabel
vmlinuzおよびinitrdを抽出します。以下は例になります。(undercloud) [stack@undercloud-0 ~]$ mkdir image (undercloud) [stack@undercloud-0 ~]$ guestmount -a overcloud-realtime-compute.qcow2 -i --ro image (undercloud) [stack@undercloud-0 ~]$ cp image/boot/vmlinuz-4.18.0-80.7.1.rt9.153.el8_0.x86_64 ./overcloud-realtime-compute.vmlinuz (undercloud) [stack@undercloud-0 ~]$ cp image/boot/initramfs-4.18.0-80.7.1.rt9.153.el8_0.x86_64.img ./overcloud-realtime-compute.initrd (undercloud) [stack@undercloud-0 ~]$ guestunmount image
注記vmlinuzおよびinitramfsのファイル名に含まれるソフトウェアバージョンは、カーネルバージョンによって異なります。イメージをアップロードします。
(undercloud) [stack@undercloud-0 ~]$ openstack overcloud image upload --update-existing --os-image-name overcloud-realtime-compute.qcow2
これで、選択したコンピュートノード上の ComputeRealTime コンポーザブルロールで使用することのできる real-time イメージの準備ができました。
Real-time コンピュートノード上での BIOS 設定の変更
Real-time コンピュートノードのレイテンシーを短縮するには、コンピュートノードの BIOS 設定を変更する必要があります。コンピュートノードの BIOS 設定で、以下のコンポーネントの全オプションを無効にする必要があります。
- 電源管理
- ハイパースレッディング
- CPU のスリープ状態
- 論理プロセッサー
これらの設定に関する説明と、無効化の影響については、『Red Hat Enterprise Linux for Real Time チューニングガイド』の「BIOS パラメーターの設定」を参照してください。BIOS 設定の変更方法に関する詳しい情報は、ハードウェアの製造会社のドキュメントを参照してください。
9.2. Real-time Compute ロールのデプロイメント
Red Hat OpenStack Platform director では、ComputeRealTime ロールのテンプレートが利用可能です。これを使用して、real-time コンピュートノードをデプロイすることができます。コンピュートノードを real-time 用に指定するためには、追加のステップを実施する必要があります。
手順
/usr/share/openstack-tripleo-heat-templates/environments/compute-real-time-example.yaml ファイルをベースに、
ComputeRealTimeロールのパラメーターを設定する compute-real-time.yaml 環境ファイルを作成します。cp /usr/share/openstack-tripleo-heat-templates/environments/compute-real-time-example.yaml /home/stack/templates/compute-real-time.yaml
ファイルには、以下のパラメーター値を含める必要があります。
-
IsolCpusListおよびNovaComputeCpuDedicatedSet: リアルタイム負荷のために確保する分離 CPU コアおよび仮想 CPU のピニングの一覧。この値は、real-time コンピュートノードの CPU ハードウェアにより異なります。 -
NovaComputeCpuSharedSet: エミュレータースレッド用に確保するホスト CPU の一覧 -
KernelArgs: Real-time コンピュートノードのカーネルに渡す引数。たとえば、default_hugepagesz=1G hugepagesz=1G hugepages=<number_of_1G_pages_to_reserve> hugepagesz=2M hugepages=<number_of_2M_pages>を使用して、複数のサイズのヒュージページを持つゲストのメモリー要求を定義することができます。この例では、デフォルトのサイズは 1 GB ですが、2 MB のヒュージページを確保することもできます。
-
ComputeRealTimeロールをロールデータのファイルに追加し、ファイルを再生成します。以下は例になります。$ openstack overcloud roles generate -o /home/stack/templates/rt_roles_data.yaml Controller Compute ComputeRealTime
このコマンドにより、以下の例のような内容で
ComputeRealTimeロールが生成され、ImageDefaultオプションにovercloud-realtime-computeが設定されます。- name: ComputeRealTime description: | Compute role that is optimized for real-time behaviour. When using this role it is mandatory that an overcloud-realtime-compute image is available and the role specific parameters IsolCpusList, NovaComputeCpuDedicatedSet and NovaComputeCpuSharedSet are set accordingly to the hardware of the real-time compute nodes. CountDefault: 1 networks: InternalApi: subnet: internal_api_subnet Tenant: subnet: tenant_subnet Storage: subnet: storage_subnet HostnameFormatDefault: '%stackname%-computerealtime-%index%' ImageDefault: overcloud-realtime-compute RoleParametersDefault: TunedProfileName: "realtime-virtual-host" KernelArgs: "" # these must be set in an environment file IsolCpusList: "" # or similar according to the hardware NovaComputeCpuDedicatedSet: "" # of real-time nodes NovaComputeCpuSharedSet: "" # NovaLibvirtMemStatsPeriodSeconds: 0 ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::BootParams - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::IpaClient - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MetricsQdr - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaLibvirtGuests - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Podman - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::SkydiveAgent - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timesync - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgentカスタムロールおよび roles-data.yaml に関する一般的な情報は、「ロール」セクションを参照 し てください。
リアルタイム負荷用に指定するノードをタグ付けするために、
compute-realtimeフレーバーを作成します。以下は例になります。$ source ~/stackrc $ openstack flavor create --id auto --ram 6144 --disk 40 --vcpus 4 compute-realtime $ openstack flavor set --property "cpu_arch"="x86_64" --property "capabilities:boot_option"="local" --property "capabilities:profile"="compute-realtime" compute-realtime
リアルタイム負荷用に指定するそれぞれのノードを、
compute-realtimeプロファイルでタグ付けします。$ openstack baremetal node set --property capabilities='profile:compute-realtime,boot_option:local' <NODE UUID>
以下の内容の環境ファイルを作成して、
ComputeRealTimeロールをcompute-realtimeフレーバーにマッピングします。parameter_defaults: OvercloudComputeRealTimeFlavor: compute-realtime
-eオプションを使用してopenstack overcloud deployコマンドを実行し、新しいロールファイルと共に作成したすべての環境ファイルを指定します。以下に例を示します。$ openstack overcloud deploy -r /home/stack/templates/rt~/my_roles_data.yaml -e home/stack/templates/compute-real-time.yaml <FLAVOR_ENV_FILE>
9.3. デプロイメントの例およびテストシナリオ
以下の手順の例では、単純な単一ノードのデプロイメントを使用して、環境変数およびその他の補助設定が正しく定義されていることをテストします。実際の実行結果は、クラウドにデプロイするノードおよびゲストの数により異なります。
以下のパラメーターで
compute-real-time.yamlファイルを作成します。parameter_defaults: ComputeRealTimeParameters: IsolCpusList: "1" NovaComputeCpuDedicatedSet: "1" NovaComputeCpuSharedSet: "0" KernelArgs: "default_hugepagesz=1G hugepagesz=1G hugepages=16"ComputeRealTimeロールを設定して新たなrt_roles_data.yamlファイルを作成します。$ openstack overcloud roles generate -o ~/rt_roles_data.yaml Controller ComputeRealTime
その他の環境ファイルと共に、新たなリアルタイムロールデータファイルおよびリアルタイム環境ファイルの両方をスタックに追加して、オーバークラウドをデプロイします。
(undercloud) $ openstack overcloud deploy --templates \ -r /home/stack/rt_roles_data.yaml -e [your environment files] -e /home/stack/templates/compute-real-time.yaml
このコマンドにより、コントローラーノードおよび Real-time コンピュートノードが 1 台ずつデプロイされます。
Real-time コンピュートノードにログインし、以下のパラメーターを確認します。
<...>は、compute-real-time.yamlからの該当するパラメーターの値に置き換えてください。[root@overcloud-computerealtime-0 ~]# uname -a Linux overcloud-computerealtime-0 4.18.0-80.7.1.rt9.153.el8_0.x86_64 #1 SMP PREEMPT RT Wed Dec 13 13:37:53 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux [root@overcloud-computerealtime-0 ~]# cat /proc/cmdline BOOT_IMAGE=/boot/vmlinuz-4.18.0-80.7.1.rt9.153.el8_0.x86_64 root=UUID=45ae42d0-58e7-44fe-b5b1-993fe97b760f ro console=tty0 crashkernel=auto console=ttyS0,115200 default_hugepagesz=1G hugepagesz=1G hugepages=16 [root@overcloud-computerealtime-0 ~]# tuned-adm active Current active profile: realtime-virtual-host [root@overcloud-computerealtime-0 ~]# grep ^isolated_cores /etc/tuned/realtime-virtual-host-variables.conf isolated_cores=<IsolCpusList> [root@overcloud-computerealtime-0 ~]# cat /usr/lib/tuned/realtime-virtual-host/lapic_timer_adv_ns X (X != 0) [root@overcloud-computerealtime-0 ~]# cat /sys/module/kvm/parameters/lapic_timer_advance_ns X (X != 0) [root@overcloud-computerealtime-0 ~]# cat /sys/devices/system/node/node0/hugepages/hugepages-1048576kB/nr_hugepages X (X != 0) [root@overcloud-computerealtime-0 ~]# crudini --get /var/lib/config-data/puppet-generated/nova_libvirt/etc/nova/nova.conf compute cpu_dedicated_set <NovaComputeCpuDedicatedSet> [root@overcloud-computerealtime-0 ~]# crudini --get /var/lib/config-data/puppet-generated/nova_libvirt/etc/nova/nova.conf compute cpu_shared_set <NovaComputeCpuSharedSet>
9.4. Real-time インスタンスの起動およびチューニング
Real-time コンピュートノードをデプロイして設定したら、それらのノードで real-time インスタンスを起動することができます。CPU ピニング、NUMA トポロジーフィルター、およびヒュージページを使用して、これらの real-time インスタンスをさらに設定することができます。
real-time インスタンスの起動
-
「Real-time Compute ロールのデプロイメント」セクションで説明したように、オーバークラウド上に
compute-realtimeフレーバーが存在する状態にしてください。 real-time インスタンスを起動します。
# openstack server create --image <rhel> --flavor r1.small --nic net-id=<dpdk-net> test-rt
オプションとして、割り当てられたエミュレータースレッドをインスタンスが使用していることを確認します。
# virsh dumpxml <instance-id> | grep vcpu -A1 <vcpu placement='static'>4</vcpu> <cputune> <vcpupin vcpu='0' cpuset='1'/> <vcpupin vcpu='1' cpuset='3'/> <vcpupin vcpu='2' cpuset='5'/> <vcpupin vcpu='3' cpuset='7'/> <emulatorpin cpuset='0-1'/> <vcpusched vcpus='2-3' scheduler='fifo' priority='1'/> </cputune>
CPU のピニングおよびエミュレータースレッドポリシーの設定
リアルタイム負荷用に各リアルタイムコンピュートノードの CPU を十分に確保するためには、インスタンス用仮想 CPU (vCPU) の少なくとも 1 つをホストの物理 CPU (pCPU) にピニングする必要があります。その結果、その仮想 CPU のエミュレータースレッドは、ピニングした物理 CPU 専用として維持されます。
専用 CPU のポリシーを使用するようにフレーバーを設定します。そのためには、フレーバーで hw:cpu_policy パラメーターを dedicated に設定します。以下は例になります。
# openstack flavor set --property hw:cpu_policy=dedicated 99
リソースクオータに、Real-time コンピュートノードが消費するのに十分な pCPU があることを確認してください。
ネットワーク設定の最適化
デプロイメントのニーズによっては、特定のリアルタイム負荷に合わせてネットワークをチューニングするために、network-environment.yaml ファイルのパラメーターを設定しなければならない場合があります。
OVS-DPDK 用に最適化した設定の例を確認するには、『 ネットワーク機能仮想化(NFV)のプランニングおよび設定ガイド』の「 OVS-DPDK パラメーター の設定 」セクションを参照してください。
ヒュージページの設定
デフォルトのヒュージページサイズを 1 GB に設定することを推奨します。このように設定しないと、TLB のフラッシュにより仮想 CPU の実行にジッターが生じます。ヒュージページの使用に関する一般的な情報については、『DPDK Getting Started Guide for Linux』の「Running DPDK applications」を参照してください。
Performance Monitoring Unit (PMU) エミュレーションの無効化
イメージまたはフレーバーに仮想 PMU を設定すると、インスタンスは PMU メトリックを提供することができます。PMU メトリクスを提供することにより、レイテンシーが生じます。
cpu_mode=host-passthrough と設定されている場合、仮想 PMU はデフォルトで有効です。
PMU メトリクスが必要ない場合は、インスタンスの作成に使用するイメージまたはフレーバーで PMU 属性を「False」に設定し、仮想 PMU を無効にしてレイテンシーを軽減します。
-
イメージ:
hw_pmu=False -
フレーバー:
hw:pmu=False
付録A イメージの設定パラメーター
以下のキーは、glance image-update および glance image-create の両コマンドの property オプションに使用することができます。
$ glance image-update IMG-UUID --property architecture=x86_64
イメージのプロパティーを使用して設定した動作は、フレーバーを使用して設定した動作よりも優先されます。詳細は、「フレーバーの管理」を参照してください。
表A.1 プロパティーのキー
| 対象コンポーネント | キー | 説明 | サポートされている値 |
|---|---|---|---|
| すべて | architecture |
ハイパーバイザーがサポートする必要のある CPU アーキテクチャー。たとえば、 |
|
| すべて | hypervisor_type | ハイパーバイザーのタイプ |
|
| すべて | instance_uuid | スナップショットイメージの場合、このイメージを作成するのに使用したサーバーの UUID | 有効なサーバーの UUID |
| すべて | kernel_id | AMI 形式のイメージをブートする際にカーネルとして使用する必要のある Image サービスに保管されているイメージの ID | 有効なイメージ ID |
| すべて | os_distro | オペレーティングシステムのディストリビューションの小文字による一般名 (libosinfo project と同じデータボキャブラリーを使用)。このフィールドには認識済みの値のみを指定します。認識済みの値の検索で役立つように、非推奨の値を示します。 |
|
| すべて | os_version | ディストリビューターによって指定されるオペレーティングシステムのバージョン | バージョン番号 (例:「11.10」) |
| すべて | ramdisk_id | AMI 形式のイメージをブートする際に ramdisk として使用する必要のある、Image サービスに保管されているイメージの ID | 有効なイメージ ID |
| すべて | vm_mode | 仮想マシンのモード。仮想マシンに使用されるホスト/ゲストの ABI (アプリケーションバイナリーインターフェース) を示します。 |
|
| libvirt API ドライバー | hw_disk_bus | ディスクデバイスの接続先となるディスクコントローラーのタイプを指定します。 |
|
| libvirt API ドライバー | hw_numa_nodes | インスタンスに公開する NUMA ノードの数 (フレーバーの定義はオーバーライドしません) | 整数。NUMA トポロジー定義の詳しい例は、「メタデータの追加」で「hw:NUMA_def key」を参照してください。 |
| libvirt API ドライバー | hw_numa_cpus.0 | 仮想 CPU N-M から NUMA ノード 0 へのマッピング (フレーバーの定義はオーバーライドしません) | 整数のコンマ区切りリスト |
| libvirt API ドライバー | hw_numa_cpus.1 | 仮想 CPU N-M から NUMA ノード 1 へのマッピング (フレーバーの定義はオーバーライドしません) | 整数のコンマ区切りリスト |
| libvirt API ドライバー | hw_numa_mem.0 | N MB の RAM から NUMA ノード 0 へのマッピング (フレーバーの定義はオーバーライドしません) | 整数 |
| libvirt API ドライバー | hw_numa_mem.1 | N MB の RAM から NUMA ノード 1 へのマッピング (フレーバーの定義はオーバーライドしません) | 整数 |
| libvirt API ドライバー | hw_qemu_guest_agent |
ゲストエージェントのサポート。 |
|
| libvirt API ドライバー | hw_rng_model | 乱数生成器をイメージのインスタンスに追加します。インスタンスのフレーバーを設定することにより、クラウド管理者は、デバイスの動作を有効化して制御することができます。デフォルトでは以下のように設定されます。
|
|
| libvirt API ドライバー | hw_scsi_model | VirtIO SCSI (virtio-scsi) の使用を有効にして、コンピュートインスタンスのブロックデバイスアクセスを提供します。デフォルトでは、インスタンスは VirtIO Block (virtio-blk) を使用します。VirtIO SCSI は準仮想化 SCSI コントローラーデバイスで、より高いスケーラビリティーとパフォーマンスを提供し、高度な SCSI ハードウェアに対応します。 |
|
| libvirt API ドライバー | hw_video_model | 使用されるビデオイメージドライバー |
|
| libvirt API ドライバー | hw_video_ram |
ビデオイメージの最大 RAM。フレーバーの | 整数 (MB 単位。例: 64) |
| libvirt API ドライバー | hw_watchdog_action |
サーバーがハングした場合に指定したアクションを実行する仮想ハードウェアウォッチドッグデバイスを有効にします。このウォッチドッグは、i6300esb デバイスを使用します (PCI Intel 6300ESB をエミュレート)。 |
|
| libvirt API ドライバー | os_command_line | デフォルトではなく、libvirt ドライバーで使用されるカーネルコマンドライン。Linux Containers (LXC) の場合は、この値が初期化の引数として使用されます。このキーは、Amazon カーネル、ramdisk、またはマシンイメージ (aki、ari、または ami) にのみ有効です。 | |
| libvirt API ドライバーおよび VMware API ドライバー | hw_vif_model | 使用する仮想ネットワークインターフェースデバイスのモデルを指定します。 | 設定したハイパーバイザーによって有効なオプションは異なります。
|
| VMware API ドライバー | vmware_adaptertype | ハイパーバイザーが使用する仮想 SCSI または IDE コントローラー |
|
| VMware API ドライバー | vmware_ostype |
イメージにインストールされているオペレーティングシステムを示す VMware GuestID。この値は、仮想マシンの作成時にハイパーバイザーに渡されます。指定しなかった場合には、このキーの値はデフォルトの | 詳細は、「Images with VMware vSphere」を参照してください。 |
| VMware API ドライバー | vmware_image_version | 現在は使用されていません。 |
|
| XenAPI ドライバー | auto_disk_config |
true に指定した場合には、ディスク上の root パーティションは、インスタンスがブートする前に自動的にリサイズされます。この値は、Xen ベースのハイパーバイザーを XenAPI ドライバーと共に使用する場合にのみ Compute サービスによって考慮されます。Compute サービスは、イメージに単一のパーティションがあり、かつそのパーティションが |
|
| libvirt API ドライバーおよび XenAPI ドライバー | os_type |
イメージ上にインストールされるオペレーティングシステム。XenAPI ドライバーには、イメージの |
|
付録B インスタンスの起動ウィザードの有効化
Dashboard からインスタンスを起動するには、2 つの方法があります。
- インスタンスの起動フォーム
- インスタンスの起動ウィザード
インスタンスの起動フォームはデフォルトで有効化されますが、インスタンスの起動ウィザードを随時有効化することができます。インスタンスの起動フォームとウィザードを同時に有効化することも可能です。インスタンスの起動ウィザードにより、インスタンスの作成に必要なステップが簡素化されます。
/etc/openstack-dashboard/local_settingsファイルを編集して以下の値を追加します。LAUNCH_INSTANCE_LEGACY_ENABLED = False LAUNCH_INSTANCE_NG_ENABLED = True
httpd サービスを再起動します。
# systemctl restart httpd
インスタンスの起動フォームとウィザードの設定が更新されます。
これらのオプションのいずれか 1 つのみを有効にした場合には、Dashboard で インスタンスの起動 ボタンをクリックすると、そのオプションがデフォルトで開きます。両方のオプションを有効化した場合には、Dashboard に インスタンスの起動 ボタンが 2 つ表示され、左のボタンはインスタンスの起動ウィザード、右のボタンはインスタンスの起動フォームを表示します。