
Red Hat Training
A Red Hat training course is available for Red Hat OpenStack Platform
director のインストールと使用方法
Red Hat OpenStack Platform director を使用した OpenStack クラウド作成のエンドツーエンドシナリオ
概要
第1章 はじめに
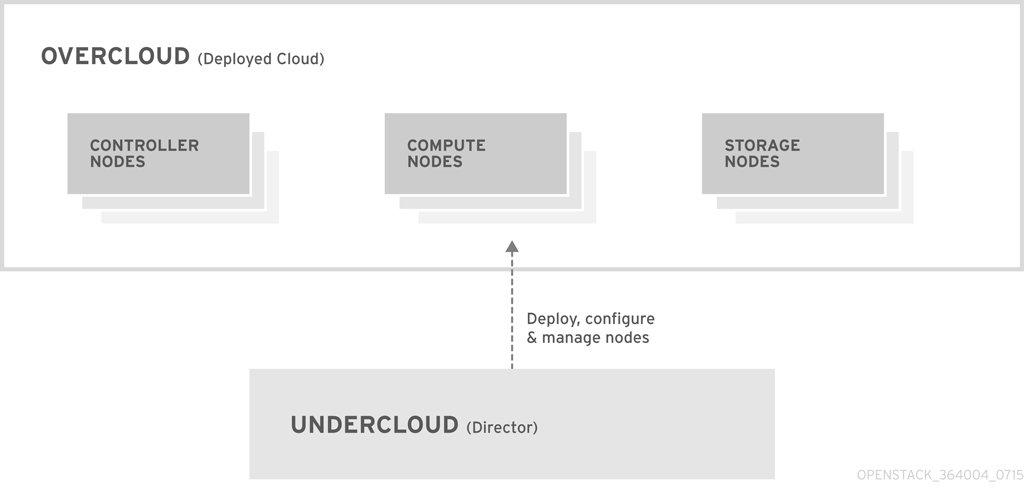
Red Hat OpenStack Platform director は、完全な OpenStack 環境のインストールおよび管理を行うためのツールセットです。director は、主に OpenStack プロジェクト TripleO (「OpenStack-On-OpenStack」の略語) をベースとしてます。このプロジェクトは、OpenStack のコンポーネントを活用して、完全に機能する OpenStack 環境をインストールします。これには、OpenStack ノードとして使用するベアメタルシステムをプロビジョニングし、制御する新しい OpenStack のコンポーネントが含まれます。
Red Hat OpenStack Platform director は、アンダークラウドとオーバークラウドという 2 つの主要な概念を採用しています。以下の数項では、それぞれの概念について説明します。
1.1. アンダークラウド
アンダークラウドは、OpenStack Platform director ツールセットが含まれる主要管理ノードです。OpenStack をインストールした単一システムで、OpenStack 環境 (オーバークラウド) を構成する OpenStack ノードをプロビジョニング/管理するためのコンポーネントが含まれます。アンダークラウドを形成するコンポーネントは、さまざまな機能を提供します。
- 環境のプランニング
- アンダークラウドは、ユーザーが特定のノードロールを作成するためのプランニング機能を提供します。アンダークラウドには、コンピュート、コントローラー、さまざまなストレージロールなどのデフォルトのノードセットが含まれるだけでなく、カスタムロールを使用する機能も提供されています。さらに、各ノードロールにどの OpenStack Platform サービスを含めるかを選択でき、新しいノード種別をモデル化するか、独自のホストで特定のコンポーネントを分離する方法を提供します。
- ベアメタルシステムの制御
- アンダークラウドは、各ノードの Intelligent Platform Management Interface (IPMI) などのアウトバウンド管理インターフェースを使用して電源管理機能を制御し、PXE ベースのサービスを使用してハードウェア属性を検出し、各ノードに OpenStack をインストールします。この機能により、ベアメタルシステムを OpenStack ノードとしてプロビジョニングする方法が提供されます。電源管理ドライバーの完全一覧については、「付録B 電源管理ドライバー」を参照します。
- Orchestration
- アンダークラウドでは、環境のプランとして機能する YAML テンプレートセットが提供されています。アンダークラウドは、これらのプランをインポートして、その指示に従い、目的の OpenStack 環境を作成します。このプランには、環境作成プロセスの途中にある特定のポイントで、カスタマイズを組み込めるようにするフックも含まれます。
- コマンドラインツールおよび Web UI
- Red Hat OpenStack Platform director は、ターミナルベースのコマンドラインインターフェースまたは Web ベースのユーザーインターフェースで、これらのアンダークラウド機能を実行します。
- アンダークラウドのコンポーネント
アンダークラウドは、OpenStack のコンポーネントをベースのツールセットとして使用します。各コンポーネントは、アンダークラウドの個別のコンテナー内で動作します。OpenStack のコンポーネントを以下に示します。
- OpenStack Identity (keystone): director のコンポーネントの認証および承認
- OpenStack Bare Metal (Ironic) および OpenStack Compute (Nova): ベアメタルノードの管理
- OpenStack Networking (Neutron) および Open vSwitch: ベアメタルノードのネットワークの制御
- OpenStack Image サービス (Glance): ベアメタルマシンへ書き込むイメージの格納
- OpenStack Orchestation (Heat) および Puppet: director がオーバークラウドイメージをディスクに書き込んだ後のノードのオーケストレーションおよび設定
OpenStack Telemetry (Ceilometer): 監視とデータの収集。これには、以下が含まれます。
- OpenStack Telemetry Metrics (gnocchi): メトリック向けの時系列データベース
- OpenStack Telemetry Alarming (aodh): モニタリング向けのアラームコンポーネント
- OpenStack Telemetry Event Storage (panko): モニタリング向けのイベントストレージ
- OpenStack Workflow サービス (mistral): プランのインポートやデプロイなど、特定の director 固有のアクションに対してワークフローセットを提供します。
- OpenStack Messaging Service (zaqar): OpenStack Workflow サービスのメッセージサービスを提供します。
OpenStack Object Storage (swift): 以下のさまざまな OpenStack Platform のコンポーネントに対してオブジェクトストレージを提供します。
- OpenStack Image サービスのイメージストレージ
- OpenStack Bare Metal のイントロスペクションデータ
- OpenStack Workflow サービスのデプロイメントプラン
1.2. オーバークラウド
オーバークラウドは、アンダークラウドを使用して構築した Red Hat OpenStack Platform 環境で、以下のノード種別の 1 つまたは複数で構成されます。これには、作成予定の OpenStack Platform 環境をベースに定義するさまざまなロールが含まれます。アンダークラウドには、以下などのオーバークラウドノードのロールがデフォルトで含まれます。
- コントローラー
OpenStack 環境に管理、ネットワーク、高可用性の機能を提供するノード。理想的な OpenStack 環境には、このノード 3 台で高可用性クラスターを構成することを推奨します。
デフォルトのコントローラーノードには、以下のコンポーネントが含まれます。
- OpenStack Dashboard (horizon)
- OpenStack Identity (keystone)
- OpenStack Compute (nova) API
- OpenStack Networking (neutron)
- OpenStack Image サービス (glance)
- OpenStack Block Storage (cinder)
- OpenStack Object Storage (swift)
- OpenStack Orchestration (heat)
- OpenStack Telemetry (ceilometer)
- OpenStack Telemetry Metrics (gnocchi)
- OpenStack Telemetry Alarming (aodh)
- OpenStack Telemetry Event Storage (panko)
- OpenStack Clustering (sahara)
- OpenStack Shared File Systems (manila)
- OpenStack Bare Metal (ironic)
- MariaDB
- Open vSwitch
- 高可用性サービス向けの Pacemaker および Galera
- Compute
これらのノードは OpenStack 環境にコンピュートリソースを提供します。コンピュートノードをさらに追加して、環境を徐々にスケールアウトすることができます。デフォルトのコンピュートノードには、以下のコンポーネントが含まれます。
- OpenStack Compute (nova)
- KVM/QEMU
- OpenStack Telemetry (ceilometer) エージェント
- Open vSwitch
- ストレージ
OpenStack 環境にストレージを提供するノード。これには、以下のストレージ用のノードが含まれます。
- Ceph Storage ノード: ストレージクラスターを構成するために使用します。各ノードには、Ceph Object Storage Daemon (OSD) が含まれており、Ceph Storage ノードをデプロイする場合には、director により Ceph Monitor がコンピュートノードにインストールされます。
Block storage (Cinder): HA コントローラーノードの外部ブロックストレージとして使用します。このノードには、以下のコンポーネントが含まれます。
- OpenStack Block Storage (cinder) ボリューム
- OpenStack Telemetry (ceilometer) エージェント
- Open vSwitch
Object Storage (swift): これらのノードは、OpenStack Swift の外部ストレージ層を提供します。コントローラーノードは、Swift プロキシーを介してこれらのノードにアクセスします。このノードには、以下のコンポーネントが含まれます。
- OpenStack Object Storage (swift) のストレージ
- OpenStack Telemetry (ceilometer) エージェント
- Open vSwitch
1.3. 高可用性
Red Hat OpenStack Platform director は、OpenStack Platform 環境に高可用性サービスを提供するためにコントローラーノードクラスターを使用します。director は、各コントローラーノードにコンポーネントの複製セットをインストールし、それらをまとめて単一のサービスとして管理します。このタイプのクラスター構成では、1 つのコントローラーノードが機能しなくなった場合にフォールバックするので、OpenStack のユーザーには一定の運用継続性が提供されます。
OpenStack Platform director は、複数の主要なソフトウェアを使用して、コントローラーノード上のコンポーネントを管理します。
- Pacemaker: Pacemaker はクラスターリソースマネージャーで、クラスター内の全ノードにおける OpenStack コンポーネントの可用性を管理/監視します。
- HA Proxy: クラスターに負荷分散およびプロキシーサービスを提供します。
- Galera: クラスター全体の OpenStack Platform データベースを複製します。
- Memcached: データベースのキャッシュを提供します。
- Red Hat OpenStack Platform director は複数のコントローラーノードの高可用性を一括に自動設定します。ただし、電源管理制御を有効化するには、ノードを手動で設定する必要があります。本ガイドでは、これらの手順を記載しています。
- バージョン 13 から、director を使用してコンピュートインスタンスの高可用性 (インスタンス HA) をデプロイできるようになりました。インスタンス HA により、コンピュートノードで障害が発生した際にそのノードからインスタンスを自動的に退避することができます。
1.4. コンテナー化
アンダークラウドおよびオーバークラウド上の各 OpenStack Platform サービスは、対応するノード上の個別の Linux コンテナー内で実行されます。これにより、それぞれのサービスを分離し、OpenStack Platform を簡単に維持およびアップグレードすることができます。以下に示すように、Red Hat では、オーバークラウド用コンテナーイメージを取得するためのさまざまな方法をサポートしています。
- Red Hat Container Catalog から直接イメージをプルする
- アンダークラウド上でイメージをホストする
- Satellite 6 サーバー上でイメージをホストする
本ガイドでは、レジストリー情報の設定および基本的なコンテナー操作の実施方法について説明します。
1.5. Ceph Storage
一般的に、OpenStack を使用する大規模な組織では、数千単位またはそれ以上のクライアントにサービスを提供します。OpenStack クライアントは、ブロックストレージリソースを消費する際には、それぞれに固有のニーズがある可能性が高く、Glance (イメージ)、Cinder (ボリューム)、Nova (コンピュート) を単一ノードにデプロイすると、数千単位のクライアントがある大規模なデプロイメントでの管理ができなくなる可能性があります。このような課題は、OpenStack をスケールアウトすることによって解決できます。
ただし、実際には、Red Hat Ceph Storage などのソリューションを活用して、ストレージ層を仮想化する必要もでてきます。ストレージ層の仮想化により、Red Hat OpenStack Platform のストレージ層を数十テラバイト規模からペタバイトさらにはエクサバイトのストレージにスケーリングすることが可能です。Red Hat Ceph Storage は、市販のハードウェアを使用しながらも、高可用性/高パフォーマンスのストレージ仮想化層を提供します。仮想化によってパフォーマンスが低下するというイメージがありますが、Ceph はブロックデバイスイメージをクラスター全体でオブジェクトとしてストライプ化するため、大きい Ceph のブロックデバイスイメージはスタンドアロンのディスクよりもパフォーマンスが優れているということになります。Ceph ブロックデバイスでは、パフォーマンスを強化するために、キャッシュ、Copy On Write クローン、Copy On Read クローンもサポートされています。
Red Hat Ceph Storage に関する情報は、Red Hat Ceph Storage を参照してください。
マルチアーキテクチャークラウドでは、事前にインストール済みの Ceph または外部の Ceph しかサポートされません。詳細は、『Integrating an Overcloud with an Existing Red Hat Ceph Cluster』および「付録G Red Hat OpenStack Platform for POWER」を参照してください。
パート I. director のインストールと設定
第2章 アンダークラウドのプランニング
2.1. コンテナー化されたアンダークラウド
アンダークラウド は、最終的な OpenStack Platform 環境 (オーバークラウド と呼ばれる) の設定、インストール、および管理をコントロールするノードです。アンダークラウド自体は、コンテナー化された OpenStack Platform コンポーネントを使用して、OpenStack Platform director と呼ばれるツールセットを作成します。この場合、アンダークラウドはレジストリーソースからコンテナーイメージのセットをプルし、コンテナーの設定を生成し、各 OpenStack Platform サービスをコンテナーとして実行します。その結果、アンダークラウドにより、オーバークラウドを作成/管理するためのツールセットとして機能する、コンテナー化されたサービスのセットが提供されます。
アンダークラウドおよびオーバークラウドの両方でコンテナーが使用されているので、どちらも同じアーキテクチャーを使用してコンテナーをプル、設定、および実行します。このアーキテクチャーは、ノードプロビジョニング用の OpenStack Orchestration サービス (Heat とも呼ばれる) ならびにサービスおよびコンテナー設定用の Ansible をベースにしています。異常発生時のトラブルシューティングに役立つので、Heat および Ansible に関する知識を習得することを推奨します。
2.2. アンダークラウドネットワークの準備
アンダークラウドでは、2 つの主要ネットワークへのアクセスが必要です。
- プロビジョニングまたはコントロールプレーンネットワーク: director は、このネットワークを使用してノードをプロビジョニングし、Ansible 設定の実行時に SSH 経由でこれらのノードにアクセスします。アンダークラウドからオーバークラウドノードへの SSH アクセスにも、このネットワークが使用されます。アンダークラウドは、このネットワークに他のノードのイントロスペクションおよびプロビジョニング用 DHCP サービスを提供します。つまり、このネットワーク上にその他の DHCP サービスが存在している必要はありません。director がこのネットワークのインターフェースを設定します。
- 外部ネットワーク: アンダークラウドは、このネットワークを使用して OpenStack Platform リポジトリー、コンテナーイメージソース、および DNS サーバーや NTP サーバー等の他のサーバーにアクセスすることができます。通常は、このネットワークを使用してご自分のワークステーションからアンダークラウドにアクセスします。つまり、外部ネットワークにアクセスするためには、アンダークラウド上で手動でインターフェースを設定する必要があります。
結果的に、アンダークラウドには少なくとも 2 枚の 1 Gbps ネットワークインターフェースカードが必要です。ただし、特にオーバークラウド環境で多数のノードをプロビジョニングする場合には、プロビジョニングネットワークのトラフィック用に 10 Gbps インターフェースの使用を推奨します。
以下の点に注意してください。
- プロビジョニング/コントロールプレーン用には、ワークステーションから director マシンへのアクセスに使用する NIC とは別の NIC を使用してください。director のインストールでは、プロビジョニング NIC を使用してブリッジが作成され、リモート接続はドロップされます。director システムへリモート接続する場合には、外部 NIC を使用します。
プロビジョニングネットワークには、環境のサイズに適した IP 範囲が必要です。以下のガイドラインを使用して、この範囲に含めるべき IP アドレスの総数を決定してください。
- イントロスペクション中は、プロビジョニングネットワークに接続されているノードごとに少なくとも 1 つの一時 IP アドレスを含めます。
- デプロイメント中は、プロビジョニングネットワークに接続されているノードごとに少なくとも 1 つの永続的な IP アドレスを含めます。
- プロビジョニングネットワーク上のオーバークラウド高可用性クラスターの仮想 IP 用に、追加の IP アドレスを含めます。
- 環境のスケーリング用に、この範囲にさらに IP アドレスを追加します。
2.3. 環境規模の判断
アンダークラウドをインストールする前に、環境の規模を判断することが重要です。検討すべき項目を以下に示します。
- オーバークラウド内のノードの数: アンダークラウドは、オーバークラウド内の各ノードを管理します。オーバークラウドノードのプロビジョニングには、アンダークラウドのリソースが使用されます。したがって、オーバークラウドノードを適切にプロビジョニングし管理するには、アンダークラウドに十分なリソースを提供する必要があります。
- アンダークラウドで実行する同時操作の数: アンダークラウド上の OpenStack サービスの多くは、ワーカー のセットを使用します。それぞれのワーカーは、そのサービスに固有の操作を実行します。複数のワーカーを用いると、同時に操作を実行することができます。アンダークラウドのワーカー数のデフォルト値は、アンダークラウド CPU の合計スレッド数の半分です[1]。たとえば、アンダークラウドが 16 スレッドの CPU を持つ場合、デフォルトでは director は 8 つのワーカーを提供します。デフォルトでは、director のサービスに最小および最大のワーカー数が適用される点にも注意してください。
| サービス | 最小値 | 最大値 |
|---|---|---|
|
OpenStack Orchestration (heat) |
4 |
24 |
|
その他すべてのサービス |
2 |
12 |
アンダークラウドの CPU およびメモリーの最低要件を以下に示します。
- Intel 64 または AMD64 CPU 拡張機能をサポートする、8 スレッド 64 ビット x86 プロセッサー。これにより、各アンダークラウドサービスに 4 つのワーカーが提供されます。
- 最小 24 GB の RAM。
より多くのワーカーを使用する場合には、アンダークラウドにより多くの仮想 CPU およびメモリーが必要になります。以下の要件に従ってください。
- 最小値: 1 スレッドあたり 1.5 GB のメモリーを使用します。たとえば、48 スレッドのマシンには 72 GB の RAM が必要です。これは、Heat 用 24 ワーカーとその他のサービス用 12 ワーカーを提供するのに最低限必要なリソースです。
- 推奨値: 1 スレッドあたり 3 GB のメモリーを使用します。たとえば、48 スレッドのマシンには 144 GB の RAM が必要です。これは、Heat 用 24 ワーカーとその他のサービス用 12 ワーカーを提供するのに推奨されるリソースです。
2.4. アンダークラウドのディスクサイズ
アンダークラウド用として、ルートディスク上に少なくとも 100 GB の空きディスク領域があることが推奨されます。この領域の内訳は以下のとおりです。
- コンテナーイメージ用に 20 GB
- QCOW2 イメージの変換とノードのプロビジョニングプロセスのキャッシュ用に 10 GB
- 一般用途、ログの記録、メトリック、および将来の拡張用に 70 GB 以上
2.5. アンダークラウドのリポジトリー
アンダークラウドのインストールおよび設定には、以下のリポジトリーが必要です。
表2.1 コアリポジトリー
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Enterprise Linux 7 Server (RPMS) |
|
x86_64 システム用ベースオペレーティングシステムのリポジトリー |
|
Red Hat Enterprise Linux 7 Server - Extras (RPMs) |
|
Red Hat OpenStack Platform の依存関係が含まれます。 |
|
Red Hat Enterprise Linux 7 Server - RH Common (RPMs) |
|
Red Hat OpenStack Platform のデプロイと設定ツールが含まれます。 |
|
Red Hat Satellite Tools for RHEL 7 Server RPMs x86_64 |
|
Red Hat Satellite 6 でのホスト管理ツール |
|
Red Hat Enterprise Linux High Availability (for RHEL 7 Server) (RPMs) |
|
Red Hat Enterprise Linux の高可用性ツール。コントローラーノードの高可用性に使用します。 |
|
Red Hat OpenStack Platform 14 for RHEL 7 (RPMs) |
|
Red Hat OpenStack Platform のコアリポジトリー。Red Hat OpenStack Platform director のパッケージが含まれます。 |
表2.2 Ceph 用リポジトリー
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Ceph Storage Tools 3 for Red Hat Enterprise Linux 7 Server (RPMs) |
|
ノードが Ceph Storage クラスターと通信するためのツールが提供されます。オーバークラウドで Ceph Storage を使用する場合には、アンダークラウドにこのリポジトリーからの |
IBM POWER 用リポジトリー
これらのリポジトリーは、POWER PC アーキテクチャー上で Openstack Platform を構築するのに使われます。コアリポジトリーの該当リポジトリーの代わりに、これらのリポジトリーを使用してください。
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Enterprise Linux for IBM Power, little endian |
|
ppc64le システム用ベースオペレーティングシステムのリポジトリー |
|
Red Hat OpenStack Platform 14 for RHEL 7 (RPMs) |
|
ppc64le システム用 Red Hat OpenStack Platform のコアリポジトリー |
第3章 director インストールの準備
3.1. アンダークラウドの準備
director のインストールには、以下の項目が必要です。
- コマンドを実行するための非 root ユーザー
- イメージとテンプレートを管理するためのディレクトリー
- 解決可能なホスト名
- Red Hat サブスクリプション
- イメージの準備および director のインストールを行うためのコマンドラインツール
手順
-
アンダークラウドに
rootユーザーとしてログインします。 stackユーザーを作成します。[root@director ~]# useradd stack
そのユーザーのパスワードを設定します。
[root@director ~]# passwd stack
sudoを使用する場合にパスワードを要求されないようにします。[root@director ~]# echo "stack ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/stack [root@director ~]# chmod 0440 /etc/sudoers.d/stack
新規作成した
stackユーザーに切り替えます。[root@director ~]# su - stack [stack@director ~]$
director はシステムのイメージと Heat テンプレートを使用して、オーバークラウド環境を構築します。これらのファイルを整理するには、イメージとテンプレート用にディレクトリーを作成するように推奨します。
[stack@director ~]$ mkdir ~/images [stack@director ~]$ mkdir ~/templates
アンダークラウドのベースおよび完全なホスト名を確認します。
[stack@director ~]$ hostname [stack@director ~]$ hostname -f
上記のコマンドのいずれかで正しいホスト名が出力されなかったり、エラーが表示される場合には、
hostnamectlでホスト名を設定します。[stack@director ~]$ sudo hostnamectl set-hostname manager.example.com [stack@director ~]$ sudo hostnamectl set-hostname --transient manager.example.com
director では、
/etc/hostsにシステムのホスト名とベース名も入力する必要があります。/etc/hostsの IP アドレスは、アンダークラウドのパブリック API に使用する予定のアドレスと一致する必要があります。たとえば、システムの名前がmanager.example.comで、IP アドレスに10.0.0.1を使用する場合には、/etc/hostsに以下のように入力する必要があります。10.0.0.1 manager.example.com manager
Red Hat コンテンツ配信ネットワークまたは Red Hat Satellite のどちらかにシステムを登録します。たとえば、プロンプトが表示されたら、カスタマーポータルのユーザー名とパスワードを使用してコンテンツ配信ネットワークに登録します。
[stack@director ~]$ sudo subscription-manager register
Red Hat OpenStack Platform director のエンタイトルメントプール ID を検索します。以下に例を示します。
[stack@director ~]$ sudo subscription-manager list --available --all --matches="Red Hat OpenStack" Subscription Name: Name of SKU Provides: Red Hat Single Sign-On Red Hat Enterprise Linux Workstation Red Hat CloudForms Red Hat OpenStack Red Hat Software Collections (for RHEL Workstation) Red Hat Virtualization SKU: SKU-Number Contract: Contract-Number Pool ID: Valid-Pool-Number-123456 Provides Management: Yes Available: 1 Suggested: 1 Service Level: Support-level Service Type: Service-Type Subscription Type: Sub-type Ends: End-date System Type: PhysicalPool IDの値を特定して、Red Hat OpenStack Platform 14 のエンタイトルメントをアタッチします。[stack@director ~]$ sudo subscription-manager attach --pool=Valid-Pool-Number-123456
デフォルトのリポジトリーをすべて無効にしてから、必要な Red Hat Enterprise Linux リポジトリーを有効にします。
[stack@director ~]$ sudo subscription-manager repos --disable=* [stack@director ~]$ sudo subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpms --enable=rhel-7-server-openstack-14-rpms
これらのリポジトリーには、director のインストールに必要なパッケージが含まれます。
システムで更新を実行して、ベースシステムパッケージを最新の状態にします。
[stack@director ~]$ sudo yum update -y [stack@director ~]$ sudo reboot
director のインストールと設定を行うためのコマンドラインツールをインストールします。
[stack@director ~]$ sudo yum install -y python-tripleoclient
Ceph Storage ノードを使ってオーバークラウドを作成する場合は、さらに
ceph-ansibleパッケージをインストールします。[stack@director ~]$ sudo yum install -y ceph-ansible
3.2. コンテナーイメージの準備
アンダークラウドの設定には、イメージの取得先およびその保存方法を定義するための初期レジストリーの設定が必要です。以下のプロセスで、コンテナーイメージを準備するための環境ファイルを生成およびカスタマイズする方法を説明します。
手順
- アンダークラウドホストに stack ユーザーとしてログインします。
デフォルトのコンテナーイメージ準備ファイルを生成します。
$ openstack tripleo container image prepare default \ --local-push-destination \ --output-env-file containers-prepare-parameter.yaml
上記のコマンドでは、以下の追加オプションを使用しています。
-
--local-push-destination: コンテナーイメージの保管場所として、アンダークラウド上のレジストリーを設定します。つまり、director は必要なイメージを Red Hat Container Catalog からプルし、それをアンダークラウド上のレジストリーにプッシュします。アンダークラウドのインストール時に、director はこのレジストリーをコンテナーイメージのソースとして使用します。Red Hat Container Catalog から直接プルする場合には、このオプションを省略します。 --output-env-file: 環境ファイルの名前です。このファイルには、アンダークラウド用コンテナーイメージを準備するためのパラメーターが含まれます。ここでは、ファイル名をcontainers-prepare-parameter.yamlとしています。注記オーバークラウドをデプロイする場合にも、コンテナーイメージのソースを定義するのに
containers-prepare-parameter.yamlファイルを使用することができます。
-
-
containers-prepare-parameter.yamlを編集し、必要に応じて変更を加えます。
3.3. コンテナーイメージ準備のパラメーター
コンテナー準備用のこのデフォルトファイル (containers-prepare-parameter.yaml) には、ContainerImagePrepare Heat パラメーターが含まれます。このパラメーターで、イメージのセットを準備するためのさまざまな設定を定義します。
parameter_defaults: ContainerImagePrepare: - (strategy one) - (strategy two) - (strategy three) ...
それぞれの設定では、サブパラメーターのセットにより使用するイメージやイメージの使用方法を定義することができます。ContainerImagePrepare の各設定で使用するサブパラメーターの一覧を、以下の表に示します。
| パラメーター | 説明 |
|---|---|
|
|
目的のイメージのタグに追加する文字列 |
|
|
除外フィルターに使用するイメージ名に含まれる文字列のリスト |
|
|
イメージ名に含まれる文字列のリスト。少なくとも 1 つのイメージ名が一致している必要があります。includes パラメーターを指定すると、excludes の設定はすべて無視されます。 |
|
|
イメージのアップロード中 (ただし目的のレジストリーにプッシュする前) に実行する Ansible ロール名の文字列 |
|
|
|
|
|
変更するイメージを絞り込むのに使用するイメージラベルのディクショナリー。イメージが定義したラベルと一致する場合には、director はそのイメージを変更プロセスに含めます。 |
|
|
アップロードプロセス中にイメージをプッシュするレジストリーの名前空間。このパラメーターで名前空間を指定すると、すべてのイメージパラメーターでもこの名前空間が使用されます。 |
|
|
元のコンテナーイメージをプルするソースレジストリー |
|
|
初期イメージの取得場所を定義する、 |
|
|
得られたイメージをタグ付けするラベルパターンを定義します。通常は、 |
set パラメーターには、複数の キー:値 定義を設定することができます。それらのキーの一覧を、以下の表に示します。
| キー | 説明 |
|---|---|
|
|
Ceph Storage コンテナーイメージの名前 |
|
|
Ceph Storage コンテナーイメージの名前空間 |
|
|
Ceph Storage コンテナーイメージのタグ |
|
|
各 OpenStack サービスイメージの接頭辞 |
|
|
各 OpenStack サービスイメージの接尾辞 |
|
|
各 OpenStack サービスイメージの名前空間 |
|
|
使用する OpenStack Networking (neutron) コンテナーを定義するのに使用するドライバー。標準の |
|
|
プルするイメージを識別するタグ |
set セクションには、openshift_ で始まるさまざまなパラメーターを含めることができます。これらのパラメーターは、「OpenShift on OpenStack」を用いるさまざまなシナリオに使用されます。
3.4. イメージ準備エントリーの階層化
ContainerImagePrepare の値は YAML リストです。したがって、複数のエントリーを指定することができます。以下の例で、2 つのエントリーを指定するケースを説明します。この場合、director はすべてのイメージの最新バージョンを使用しますが、nova-api イメージについてのみ、14.0-44 とタグ付けされたバージョンを使用します。
ContainerImagePrepare:
- tag_from_label: "{version}-{release}"
push_destination: true
excludes:
- nova-api
set:
namespace: registry.access.redhat.com/rhosp14
name_prefix: openstack-
name_suffix: ''
tag: latest
- push_destination: true
includes:
- nova-api
set:
namespace: registry.access.redhat.com/rhosp14
tag: 14.0-44
includes および excludes のエントリーで、それぞれのエントリーでのイメージ絞り込み方法をコントロールします。includes 設定と一致するイメージが、excludes と一致するイメージに優先します。一致するとみなされるためには、イメージ名に設定値が含まれていなければなりません。
3.5. 準備プロセスにおけるイメージの変更
準備プロセス中にイメージを変更して必要な修正を加え、直ちにこれらの変更を反映してデプロイすることが可能です。イメージを変更するユースケースを以下に示します。
- デプロイメント前にテスト中の修正でイメージが変更される、継続的インテグレーションのパイプラインの一部として。
- ローカルの変更をテストおよび開発のためにデプロイしなければならない、開発ワークフローの一部として。
- 変更をデプロイしなければならないが、イメージビルドパイプラインでは利用することができない場合 (プロプライエタリーのアドオン、緊急の修正)。
変更が必要な各イメージで Ansible ロールを呼び出して、変更を行います。ロールはソースイメージを取得して必要な変更を行った後に、その結果をタグ付けします。続いて prepare コマンドでイメージをプッシュし、変更したイメージを参照するように heat パラメーターを設定することができます。
Ansible ロール tripleo-modify-image は要求されたロールインターフェースに従い、変更のユースケースに必要な処理を行います。変更は、ContainerImagePrepare パラメーターの modify 固有のキーでコントロールします。
-
modify_roleでは、変更する各イメージについて呼び出す Ansible ロールを指定します。 -
modify_append_tagは、ソースイメージタグの最後に文字列を追加するのに使用します。これにより、そのイメージが変更されていることが明確になります。すでに push_destination レジストリーに変更されたイメージが含まれている場合には、このパラメーターを使用して変更を省略することもできます。したがって、イメージを変更する場合には、必ず modify_append_tag を変更することを推奨します。 -
modify_varsは、ロールに渡す Ansible 変数のディクショナリーです。
ロール tripleo-modify-image が処理する別のユースケースを選択するには、tasks_from 変数をそのロールで必要なファイルに設定します。
イメージを変更する ContainerImagePrepare エントリーを開発およびテストする場合には、イメージが想定どおりに変更されていることを確認するために、prepare コマンド単体で実行することを推奨します。
sudo openstack tripleo container image prepare \ -e ~/containers-prepare-parameter.yaml
3.6. コンテナーイメージの既存パッケージの更新
以下のエントリーにより、イメージのパッケージが全て更新されます。ただし、アンダークラウドホストの yum リポジトリー設定が使用されます。
ContainerImagePrepare:
- push_destination: true
...
modify_role: tripleo-modify-image
modify_append_tag: "-updated"
modify_vars:
tasks_from: yum_update.yml
compare_host_packages: true
yum_repos_dir_path: /etc/yum.repos.d
...3.7. コンテナーイメージへの追加 RPM ファイルのインストール
RPM ファイルのディレクトリーをインストールすることができます。この機能は、ホットフィックス、ローカルパッケージビルド、またはパッケージリポジトリーからは入手できないパッケージのインストールに役立ちます。たとえば、以下のエントリーにより、centos-binary-nova-compute イメージだけにホットフィックスパッケージがインストールされます。
ContainerImagePrepare:
- push_destination: true
...
includes:
- nova-compute
modify_role: tripleo-modify-image
modify_append_tag: "-hotfix"
modify_vars:
tasks_from: rpm_install.yml
rpms_path: /home/stack/nova-hotfix-pkgs
...3.8. カスタム Dockerfile を使用したコンテナーイメージの変更
柔軟性を高めるために、Dockerfile を含むディレクトリーを指定して必要な変更を加えることが可能です。ロールが呼び出されると、Dockerfile.modified ファイルが生成され、これにより FROM ディレクティブが変更され新たな LABEL ディレクティブが追加されます。以下の例では、centos-binary-nova-compute イメージでカスタム Dockerfile が実行されます。
ContainerImagePrepare:
- push_destination: true
...
includes:
- nova-compute
modify_role: tripleo-modify-image
modify_append_tag: "-hotfix"
modify_vars:
tasks_from: modify_image.yml
modify_dir_path: /home/stack/nova-custom
.../home/stack/nova-custom/Dockerfile の例を以下に示します。USER root ディレクティブを実行した後は、元のイメージのデフォルトユーザーに戻す必要があります。
FROM docker.io/tripleomaster/centos-binary-nova-compute:latest USER root COPY customize.sh /tmp/ RUN /tmp/customize.sh USER "nova"
3.9. コンテナーイメージ管理用 Satellite サーバーの準備
Red Hat Satellite 6 には、レジストリーの同期機能が備わっています。これにより、複数のイメージを Satellite サーバーにプルし、アプリケーションライフサイクルの一環として管理することができます。また、他のコンテナー対応システムも Satellite をレジストリーとして使うことができます。コンテナーイメージ管理の詳細は、『Red Hat Satellite 6 コンテンツ管理ガイド』の「コンテナーイメージの管理」を参照してください。
以下の手順は、Red Hat Satellite 6 の hammer コマンドラインツールを使用した例を示しています。組織には、例として ACME という名称を使用しています。この組織は、実際に使用する Satellite 6 の組織に置き換えてください。
手順
デフォルトのオーバークラウドおよびアンダークラウド用に利用可能な全コンテナーイメージの一覧を作成します。
$ openstack overcloud container image prepare \ -r /usr/share/openstack-tripleo-heat-templates/roles_data.yaml \ --output-images-file /home/stack/satellite_images_overcloud $ openstack overcloud container image prepare \ -r /usr/share/openstack-tripleo-heat-templates/roles_data_undercloud.yaml \ --output-images-file /home/stack/satellite_images_undercloud
- これで、コンテナーイメージ情報が含まれる 2 つのファイルが作成されます。このファイルを使用して、コンテナーイメージを Satellite 6 サーバーに同期します。
ファイルから YAML 固有の情報を削除して、個別のイメージ一覧のみが記載されたフラットファイルにマージします。この操作は、以下のコマンドで実行します。
$ awk -F ':' '{if (NR!=1) {gsub("[[:space:]]", ""); print $2}}' ~/satellite_images_overcloud | sed "s/registry.access.redhat.com\///g" > ~/satellite_images_overcloud_names $ awk -F ':' '{if (NR!=1) {gsub("[[:space:]]", ""); print $2}}' ~/satellite_images_undercloud | sed "s/registry.access.redhat.com\///g" > ~/satellite_images_undercloud_names $ cat ~/satellite_images_overcloud_names ~/satellite_images_undercloud_names | sort | uniq > ~/satellite_images_namesこれにより、Satellite サーバーにプルするイメージのリストが提供されます。
-
satellite_images_namesファイルを、Satellite 6 のhammerツールが含まれるシステムにコピーします。あるいは、『Hammer CLI ガイド』に記載の手順に従って、hammerツールをアンダークラウドにインストールします。 以下の
hammerコマンドを実行して、実際の Satellite 組織に新規製品 (OSP14 Containers) を作成します。$ hammer product create \ --organization "ACME" \ --name "OSP14 Containers"
このカスタム製品に、イメージを保管します。
製品にベースコンテナーイメージを追加します。
$ hammer repository create \ --organization "ACME" \ --product "OSP14 Containers" \ --content-type docker \ --url https://registry.access.redhat.com \ --docker-upstream-name rhosp14/openstack-base \ --name base
satellite_imagesファイルからオーバークラウドのコンテナーイメージを追加します。$ while read IMAGE; do \ IMAGENAME=$(echo $IMAGE | cut -d"/" -f2 | sed "s/openstack-//g" | sed "s/:.*//g") ; \ hammer repository create \ --organization "ACME" \ --product "OSP14 Containers" \ --content-type docker \ --url https://registry.access.redhat.com \ --docker-upstream-name $IMAGE \ --name $IMAGENAME ; done < satellite_images_names
コンテナーイメージを同期します。
$ hammer product synchronize \ --organization "ACME" \ --name "OSP14 Containers"
Satellite サーバーが同期を完了するまで待ちます。
注記設定によっては、
hammerから Satellite サーバーのユーザー名およびパスワードが要求される場合があります。設定ファイルを使って自動的にログインするようにhammerを設定することができます。詳細は、『Hammer CLI ガイド』の「認証」セクションを参照してください。-
お使いの Satellite 6 サーバーでコンテンツビューが使われている場合には、新たなバージョンのコンテンツビューを作成してイメージを反映し、アプリケーションライフサイクルの環境に従ってプロモートします。この作業は、アプリケーションライフサイクルの構成状況に大きく依存します。たとえば、ライフサイクルで
productionという名称の環境を使用していて、その環境でコンテナーイメージを利用可能にする場合には、コンテナーイメージを含むコンテンツビューを作成し、そのコンテンツビューをproduction環境にプロモートします。詳細は、『Red Hat Satellite コンテンツ管理ガイド』の「コンテンツビューによるコンテナーイメージの管理」を参照してください。 baseイメージに利用可能なタグを確認します。$ hammer docker tag list --repository "base" \ --organization "ACME" \ --environment "production" \ --content-view "myosp14" \ --product "OSP14 Containers"
このコマンドにより、特定環境のコンテンツビューでの OpenStack Platform コンテナーイメージのタグが表示されます。
アンダークラウドに戻り、Satellite サーバーをソースとして使用して、イメージ準備用のデフォルト環境ファイルを生成します。環境ファイルを生成するコマンドの例を以下に示します。
(undercloud) $ openstack tripleo container image prepare default \ --output-env-file containers-prepare-parameter.yaml
-
--output-env-file: 環境ファイルの名前です。このファイルには、アンダークラウド用コンテナーイメージを準備するためのパラメーターが含まれます。ここでは、ファイル名をcontainers-prepare-parameter.yamlとしています。
-
containers-prepare-parameter.yamlファイルを編集して以下のパラメーターを変更します。-
namespace: Satellite サーバー上のレジストリーの URL およびポート。Red Hat Satellite のデフォルトのレジストリーポートは 5000 です。 name_prefix: プレフィックスは Satellite 6 の命名規則に基づきます。これは、コンテンツビューを使用するかどうかによって異なります。-
コンテンツビューを使用する場合、構成は
[org]-[environment]-[content view]-[product]-となります (例:acme-production-myosp14-osp14_containers-)。 -
コンテンツビューを使用しない場合、構成は
[org]-[product]-となります (例:acme-osp14_containers-)。
-
コンテンツビューを使用する場合、構成は
-
ceph_namespace、ceph_image、ceph_tag: Ceph Storage を使用する場合には、Ceph Storage のコンテナーイメージの場所を定義する追加のパラメーターを指定します。ceph_imageに Satellite 固有のプレフィックスが追加された点に注意してください。このプレフィックスは、name_prefixオプションと同じ値です。
-
Satellite 固有のパラメーターが含まれる環境ファイルの例を以下に示します。
parameter_defaults:
ContainerImagePrepare:
- push_destination: true
set:
ceph_image: acme-production-myosp14-osp14_containers-rhceph-3-rhel7
ceph_namespace: satellite.example.com:5000
ceph_tag: latest
name_prefix: acme-production-myosp14-osp14_containers-
name_suffix: ''
namespace: satellite.example.com:5000
neutron_driver: null
tag: latest
...
tag_from_label: '{version}-{release}'アンダークラウドおよびオーバークラウドの両方を作成する際に、この環境ファイルを使用します。
第4章 director のインストール
4.1. director の設定
director のインストールプロセスには、ネットワーク設定を判断する特定の設定が必要です。この設定は、stack ユーザーのホームディレクトリーに undercloud.conf として配置されているテンプレートに保存されています。以下の手順では、デフォルトのテンプレートをベースに使用して設定を行う方法についてを説明します。
手順
Red Hat は、インストールに必要な設定を判断しやすいように、基本テンプレートを提供しています。このテンプレートは、
stackユーザーのホームディレクトリーにコピーします。[stack@director ~]$ cp \ /usr/share/python-tripleoclient/undercloud.conf.sample \ ~/undercloud.conf
-
undercloud.confファイルを編集します。このファイルには、アンダークラウドを設定するための設定値が含まれています。パラメーターを省略したり、コメントアウトした場合には、アンダークラウドのインストールでデフォルト値が使用されます。
4.2. director の設定パラメーター
undercloud.conf ファイルで設定するパラメーターの一覧を以下に示します。
デフォルト
undercloud.conf ファイルの [DEFAULT] セクションで定義されているパラメーターを以下に示します。
- additional_architectures
オーバークラウドがサポートする追加の (カーネル) アーキテクチャーの一覧。現在、このパラメーターの値は
ppc64leだけに制限されています。注記ppc64le のサポートを有効にする場合には、
ipxe_enabledをFalseに設定する必要もあります。- certificate_generation_ca
-
要求した証明書を署名する CA の
certmongerのニックネーム。generate_service_certificateパラメーターを設定した場合のみこのオプションを使用します。localCA を選択する場合は、certmonger はローカルの CA 証明書を/etc/pki/ca-trust/source/anchors/cm-local-ca.pemに抽出して、トラストチェーンに追加します。 - clean_nodes
- デプロイメントを再実行する前とイントロスペクションの後にハードドライブを消去するかどうかを定義します。
- cleanup
-
一時ファイルをクリーンナップします。このパラメーターを
Falseに設定すると、デプロイメント時に使用した一時ファイルをコマンド実行後もそのまま残します。ファイルを残すと、生成されたファイルのデバッグを行う場合やエラーが発生した場合に役に立ちます。 - container_images_file
コンテナーイメージ情報が含まれる Heat 環境ファイル。このパラメーターは、以下のいずれかに設定します。
- 必要なすべてのコンテナーイメージのパラメーター。
-
必要なイメージの準備を実施する
ContainerImagePrepareパラメーター。このパラメーターが含まれるファイルの名前は、通常containers-prepare-parameter.yamlです。
- custom_env_files
- アンダークラウドのインストールに追加する新たな環境ファイル。
- deployment_user
-
アンダークラウドをインストールするユーザー。現在のデフォルトユーザー (
stack) を使用する場合には、このパラメーターを未設定のままにします。 - discovery_default_driver
-
自動的に登録されたノードのデフォルトドライバーを設定します。
enable_node_discoveryを有効にし、enabled_hardware_typesファイルにドライバーを含める必要があります。 - docker_insecure_registries
-
使用する
dockerのセキュアではないレジストリーの一覧。プライベートコンテナーレジストリー等の別のソースからイメージをプルする場合には、通常このパラメーターが必要になります。多くの場合、docker は Red Hat Container Catalog または Satellite サーバー (アンダークラウドが登録されている場合) のどちらかからコンテナーイメージをプルするための証明書を持ちます。 - docker_registry_mirror
-
/etc/docker/daemon.jsonで設定されるオプションのregistry-mirror。 - enable_ironic、enable_ironic_inspector、enable_mistral、enable_tempest、enable_validations、enable_zaqar
-
director で有効にするコアサービスを定義します。
trueに設定されたままにします。 - enable_ui
-
director の Web UI をインストールするかどうかを定義します。これにより、グラフィカル Web インターフェースを使用して、オーバークラウドのプランニングやデプロイメントが可能になります。UI は、
undercloud_service_certificateまたはgenerate_service_certificateのいずれかを使用して SSL/TLS を有効にしている場合にのみ使用できる点にご注意ください。 - enable_node_discovery
-
イントロスペクションの ramdisk を PXE ブートする不明なノードを自動的に登録します。新規ノードは、
fake_pxeドライバーをデフォルトとして使用しますが、discovery_default_driverを設定して上書きすることもできます。また、イントロスペクションルールを使用して、新しく登録したノードにドライバーの情報を指定することもできます。 - enable_novajoin
-
アンダークラウドの
novajoinメタデータサービスをインストールするかどうかを定義します。 - enable_routed_networks
- ルーティングされたコントロールプレーンネットワークのサポートを有効にします。
- enable_swift_encryption
- 保存データの Swift 暗号化を有効にするかどうかを定義します。
- enable_telemetry
-
アンダークラウドに OpenStack Telemetry サービス (ceilometer、aodh、panko、gnocchi) をインストールするかどうかを定義します。Red Hat OpenStack Platform では、Telemetry のメトリックバックエンドは gnocchi によって提供されます。
enable_telemetryパラメーターをtrueに設定すると、Telemetry サービスが自動的にインストール/設定されます。デフォルト値はfalseで、アンダークラウド上の telemetry が無効になります。このパラメーターは、Red Hat CloudForms などのメトリックデータを消費する他の製品を使用している場合に必要です。 - enabled_hardware_types
- アンダークラウドで有効にするハードウェアタイプの一覧。
- generate_service_certificate
-
アンダークラウドのインストール時に SSL/TLS 証明書を生成するかを定義します。これは
undercloud_service_certificateパラメーターに使用します。アンダークラウドのインストールで、作成された証明書/etc/pki/tls/certs/undercloud-[undercloud_public_vip].pemを保存します。certificate_generation_caパラメーターで定義される CA はこの証明書を署名します。 - heat_container_image
- 使用する heat コンテナーイメージの URL。未設定のままにします。
- heat_native
-
ネイティブの heat テンプレートを使用します。
trueのままにします。 - hieradata_override
-
hieradataオーバーライドファイルへのパス。設定されている場合は、アンダークラウドのインストールでこのファイルが/etc/puppet/hieradataにコピーされ、この階層の最初のファイルとして設定されます。サービスに対して、undercloud.confパラメーター以外に、サービスに対するカスタム設定を行うには、これを使用します。 - inspection_extras
-
イントロスペクション時に追加のハードウェアコレクションを有効化するかどうかを定義します。イントロスペクションイメージでは
python-hardwareまたはpython-hardware-detectパッケージが必要です。 - inspection_interface
-
ノードのイントロスペクションに director が使用するブリッジ。これは、director の設定により作成されるカスタムのブリッジです。
LOCAL_INTERFACEでこのブリッジをアタッチします。これは、デフォルトのbr-ctlplaneのままにします。 - inspection_runbench
-
ノードのイントロスペクション時に一連のベンチマークを実行します。有効にするには、
trueに設定します。このオプションは、登録ノードのハードウェアを検査する際にベンチマーク分析を実行する場合に必要です。 - ipa_otp
-
IPA サーバーにアンダークラウドノードを登録するためのワンタイムパスワードを定義します。これは、
enable_novajoinが有効な場合に必要です。 - ipxe_enabled
-
iPXE と標準の PXE のどちらを使用するかを定義します。デフォルトは
trueで、iPXE を有効にします。標準の PXE を選択するには、falseに設定します。 - local_interface
director のプロビジョニング NIC 用に選択するインターフェース。これは、director が DHCP および PXE ブートサービスに使用するデバイスでもあります。どのデバイスが接続されているかを確認するには、
ip addrコマンドを使用します。以下にip addrコマンドの出力結果の例を示します。2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:75:24:09 brd ff:ff:ff:ff:ff:ff inet 192.168.122.178/24 brd 192.168.122.255 scope global dynamic eth0 valid_lft 3462sec preferred_lft 3462sec inet6 fe80::5054:ff:fe75:2409/64 scope link valid_lft forever preferred_lft forever 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noop state DOWN link/ether 42:0b:c2:a5:c1:26 brd ff:ff:ff:ff:ff:ffこの例では、外部 NIC は
eth0を、プロビジョニング NIC は未設定のeth1を使用します。今回は、local_interfaceをeth1に設定します。この設定スクリプトにより、このインターフェースがinspection_interfaceパラメーターで定義したカスタムのブリッジにアタッチされます。- local_ip
-
director のプロビジョニング NIC 用に定義する IP アドレス。これは、director が DHCP および PXE ブートサービスに使用する IP アドレスでもあります。環境内の既存の IP アドレスまたはサブネットと競合するなど、プロビジョニングネットワークに別のサブネットを使用する場合以外は、この値はデフォルトの
192.168.24.1/24のままにします。 - local_mtu
-
local_interfaceに使用する MTU。 - local_subnet
-
PXE ブートと DHCP インターフェースに使用するローカルサブネット。
local_ipアドレスがこのサブネットに含まれている必要があります。デフォルトはctlplane-subnetです。 - net_config_override
-
ネットワーク設定のオーバーライドテンプレートへのパス。これが設定されている場合にはアンダークラウドは JSON 形式のテンプレートを使用して
os-net-configでネットワークを設定します。これは、undercloud.confに設定されているネットワークパラメーターを無視します。/usr/share/python-tripleoclient/undercloud.conf.sampleの例を参照してください。 - output_dir
- 状態、処理された heat テンプレート、および Ansible デプロイメントファイルを出力するディレクトリー。
- overcloud_domain_name
オーバークラウドのデプロイ時に使用する DNS ドメイン名。
注記オーバークラウドのパラメーター
CloudDomainは対応する一致する値に設定する必要があります。- roles_file
- オーバークラウドのインストールで上書きするロールファイル。director のインストールにデフォルトのロールファイルが使用されるように、未設定のままにすることを強く推奨します。
- scheduler_max_attempts
- スケジューラーがインスタンスのデプロイを試行する最大回数。これは、スケジューリング時に競合状態にならないように、1 度にデプロイする予定のベアメタルノードの数以上に指定するようにしてください。
- service_principal
- この証明書を使用するサービスの Kerberos プリンシパル。CA で FreeIPA などの Kerberos プリンシパルが必要な場合にのみ使用します。
- subnets
-
プロビジョニングおよびイントロスペクション用のルーティングネットワークのサブネットの一覧。詳しくは、「サブネット」を参照してください。デフォルト値に含まれるのは、
ctlplane-subnetサブネットのみです。 - templates
- 上書きするヒートテンプレートファイル。
- undercloud_admin_host
-
SSL/TLS を使用する際に、director の管理 API 用に定義する IP アドレス。これは、SSL/TLS で管理エンドポイントにアクセスするための IP アドレスです。director の設定により、この IP アドレスは
/32ネットマスクを使用するルーティングされた IP アドレスとしてソフトウェアブリッジに接続されます。 - undercloud_debug
-
アンダークラウドサービスのログレベルを
DEBUGに設定します。この値はtrueに設定して有効化します。 - undercloud_enable_selinux
-
デプロイメント時に、SELinux を有効または無効にします。問題をデバッグする場合以外は、
trueに設定されたままにすることを強く推奨します。 - undercloud_hostname
- アンダークラウドの完全修飾ホスト名を定義します。設定されている場合には、アンダークラウドのインストールで全システムのホスト名が設定されます。設定されていない場合には、アンダークラウドは現在のホスト名を使用しますが、ユーザーは適切に全システムのホスト名の設定を行う必要があります。
- undercloud_log_file
-
アンダークラウドのインストール/アップグレードログを保管するログファイルへのパス。デフォルトでは、ログファイルはホームディレクトリー内の
install-undercloud.logです (例:/home/stack/install-undercloud.log)。 - undercloud_nameservers
- アンダークラウドのホスト名解決に使用する DNS ネームサーバーの一覧
- undercloud_ntp_servers
- アンダークラウドの日付と時間を同期できるようにする Network Time Protocol サーバーの一覧
- undercloud_public_host
-
SSL/TLS を使用する際に、director のパブリック API 用に定義する IP アドレス。これは、SSL/TLS で外部の director エンドポイントにアクセスするための IP アドレスです。director の設定により、この IP アドレスは
/32ネットマスクを使用するルーティングされた IP アドレスとしてソフトウェアブリッジに接続されます。 - undercloud_service_certificate
- OpenStack SSL/TLS 通信の証明書の場所とファイル名。理想的には、信頼できる認証局からこの証明書を取得します。それ以外の場合は、独自の自己署名の証明書を作成します。
- undercloud_update_packages
- アンダークラウドのインストール時にパッケージを更新するかどうかを定義します。
サブネット
undercloud.conf ファイルには、各プロビジョニングサブネットの名前が付いたセクションがあります。たとえば、ctlplane-subnet という名前のサブネットを作成するとセクションは以下のようになります。
[ctlplane-subnet] cidr = 192.168.24.0/24 dhcp_start = 192.168.24.5 dhcp_end = 192.168.24.24 inspection_iprange = 192.168.24.100,192.168.24.120 gateway = 192.168.24.1 masquerade = true
プロビジョニングネットワークは、環境に応じて、必要なだけ指定することができます。
- gateway
-
オーバークラウドインスタンスのゲートウェイ。外部ネットワークにトラフィックを転送するアンダークラウドのホストです。director に別の IP アドレスを使用する場合または外部ゲートウェイを直接使用する場合以外は、この値はデフォルト (
192.168.24.1) のままにします。
director の設定は、適切な sysctl カーネルパラメーターを使用して IP フォワーディングも自動的に有効にします。
- cidr
-
オーバークラウドインスタンスの管理に director が使用するネットワーク。これは、アンダークラウドの
neutronが管理するプロビジョニングネットワークです。プロビジョニングネットワークに別のサブネットを使用しない限り、この値はデフォルト (192.168.24.0/24) のままにします。 - masquerade
-
外部アクセス向けに、
cidrで定義したネットワークをマスカレードするかどうかを定義します。このパラメーターにより、director 経由で外部ネットワークにアクセスすることができるように、プロビジョニングネットワークにネットワークアドレス変換 (NAT) の一部メカニズムが提供されます。 - dhcp_start; dhcp_end
- オーバークラウドノードの DHCP 割り当て範囲 (開始アドレスと終了アドレス)。ノードを割り当てるのに十分な IP アドレスがこの範囲に含まれるようにします。
これらのパラメーターの値は、構成に応じて変更してください。完了したら、ファイルを保存します。
4.3. director のインストール
以下の手順では、director をインストールしてインストール後の基本的なタスクを実行します。
手順
以下のコマンドを実行して、アンダークラウドに director をインストールします。
[stack@director ~]$ openstack undercloud install
このコマンドで、director の設定スクリプトを起動します。director により、追加のパッケージがインストールされ、
undercloud.confの設定に合わせてサービスを設定します。このスクリプトは、完了までに数分かかります。スクリプトにより、完了時には 2 つのファイルが生成されます。
-
undercloud-passwords.conf: director サービスの全パスワード一覧 -
stackrc: director のコマンドラインツールへアクセスできるようにする初期化変数セット
-
このスクリプトは、全 OpenStack Platform サービスのコンテナーも自動的に起動します。以下のコマンドを使用して、有効化されたコンテナーを確認してください。
[stack@director ~]$ sudo docker ps
スクリプトにより、
dockerグループにstackユーザーも追加され、そのstackユーザーはコンテナー管理コマンドを使用できるようになります。stackユーザーのアクセス権限を最新の状態に更新するには、以下のコマンドを実行します。[stack@director ~]$ exec su -l stack
このコマンドでは再度ログインを要求されます。stack ユーザーのパスワードを入力します。
stackユーザーを初期化してコマンドラインツールを使用するには、以下のコマンドを実行します。[stack@director ~]$ source ~/stackrc
プロンプトには、OpenStack コマンドがアンダークラウドに対して認証および実行されることが表示されるようになります。
(undercloud) [stack@director ~]$
director のインストールが完了しました。これで、director のコマンドラインツールが使用できるようになりました。
4.4. オーバークラウドノードのイメージの取得
director では、オーバークラウドのノードをプロビジョニングする際に、複数のディスクが必要です。必要なディスクは以下のとおりです。
- イントロスペクションのカーネルおよび ramdisk: PXE ブートでベアメタルシステムのイントロスペクションに使用
- デプロイメントカーネルおよび ramdisk: システムのプロビジョニングおよびデプロイメントに使用
- オーバークラウドカーネル、ramdisk、完全なイメージ: ノードのハードディスクに書き込まれるベースのオーバークラウドシステム
以下の手順は、これらのイメージの取得およびインストールの方法について説明します。
4.4.1. 単一アーキテクチャーのオーバークラウド
デプロイメントおよびオーバークラウドには、以下のイメージおよび手順が必要です。
手順
stackrcファイルを読み込んで、director のコマンドラインツールを有効にします。[stack@director ~]$ source ~/stackrc
rhosp-director-imagesおよびrhosp-director-images-ipaパッケージをインストールします。(undercloud) [stack@director ~]$ sudo yum install rhosp-director-images rhosp-director-images-ipa
stackユーザーのホームのimagesディレクトリー (/home/stack/images) にイメージアーカイブを展開します。(undercloud) [stack@director ~]$ cd ~/images (undercloud) [stack@director images]$ for i in /usr/share/rhosp-director-images/overcloud-full-latest-14.0.tar /usr/share/rhosp-director-images/ironic-python-agent-latest-14.0.tar; do tar -xvf $i; done
これらのイメージを director にインポートします。
(undercloud) [stack@director images]$ openstack overcloud image upload --image-path /home/stack/images/
このコマンドにより、以下のイメージが director にアップロードされます。
-
bm-deploy-kernel -
bm-deploy-ramdisk -
overcloud-full -
overcloud-full-initrd -
overcloud-full-vmlinuz
スクリプトにより、director の PXE サーバー上にイントロスペクションイメージもインストールされます。
-
これらのイメージが正常にアップロードされたことを確認するには、以下のコマンドを実行します。
(undercloud) [stack@director images]$ openstack image list +--------------------------------------+------------------------+ | ID | Name | +--------------------------------------+------------------------+ | 765a46af-4417-4592-91e5-a300ead3faf6 | bm-deploy-ramdisk | | 09b40e3d-0382-4925-a356-3a4b4f36b514 | bm-deploy-kernel | | ef793cd0-e65c-456a-a675-63cd57610bd5 | overcloud-full | | 9a51a6cb-4670-40de-b64b-b70f4dd44152 | overcloud-full-initrd | | 4f7e33f4-d617-47c1-b36f-cbe90f132e5d | overcloud-full-vmlinuz | +--------------------------------------+------------------------+
この一覧には、イントロスペクションの PXE イメージは表示されません。director は、これらのファイルを
/httpbootにコピーします。(undercloud) [stack@director images]$ ls -l /httpboot total 341460 -rwxr-xr-x. 1 root root 5153184 Mar 31 06:58 agent.kernel -rw-r--r--. 1 root root 344491465 Mar 31 06:59 agent.ramdisk -rw-r--r--. 1 ironic-inspector ironic-inspector 337 Mar 31 06:23 inspector.ipxe
4.4.2. 複数のアーキテクチャーのオーバークラウド
デプロイメントおよびオーバークラウドには、以下のイメージおよび手順が必要です。
手順
stackrcファイルを読み込んで、director のコマンドラインツールを有効にします。[stack@director ~]$ source ~/stackrc
rhosp-director-images-allパッケージをインストールします。(undercloud) [stack@director ~]$ sudo yum install rhosp-director-images-all
アーキテクチャー個別のディレクトリーにアーカイブを展開します。このディレクトリーは、
stackユーザーのホームのimagesディレクトリー (/home/stack/images) 下に作成します。(undercloud) [stack@director ~]$ cd ~/images (undercloud) [stack@director images]$ for arch in x86_64 ppc64le ; do mkdir $arch ; done (undercloud) [stack@director images]$ for arch in x86_64 ppc64le ; do for i in /usr/share/rhosp-director-images/overcloud-full-latest-14.0-${arch}.tar /usr/share/rhosp-director-images/ironic-python-agent-latest-14.0-${arch}.tar ; do tar -C $arch -xf $i ; done ; doneこれらのイメージを director にインポートします。
(undercloud) [stack@director ~]$ cd ~/images (undercloud) [stack@director images]$ openstack overcloud image upload --image-path ~/images/ppc64le --architecture ppc64le --whole-disk --http-boot /tftpboot/ppc64le (undercloud) [stack@director images]$ openstack overcloud image upload --image-path ~/images/x86_64/ --http-boot /tftpboot
このコマンドにより、以下のイメージが director にアップロードされます。
-
bm-deploy-kernel -
bm-deploy-ramdisk -
overcloud-full -
overcloud-full-initrd -
overcloud-full-vmlinuz -
ppc64le-bm-deploy-kernel -
ppc64le-bm-deploy-ramdisk ppc64le-overcloud-fullスクリプトにより、director の PXE サーバー上にイントロスペクションイメージもインストールされます。
-
これらのイメージが正常にアップロードされたことを確認するには、以下のコマンドを実行します。
(undercloud) [stack@director images]$ openstack image list +--------------------------------------+---------------------------+--------+ | ID | Name | Status | +--------------------------------------+---------------------------+--------+ | 6d1005ba-ec82-473b-8e33-88aadb5b6792 | bm-deploy-kernel | active | | fb723b33-9f11-45f5-b25b-c008bf509290 | bm-deploy-ramdisk | active | | 6a6096ba-8f79-4343-b77c-4349f7b94960 | overcloud-full | active | | de2a1bde-9351-40d2-bbd7-7ce9d6eb50d8 | overcloud-full-initrd | active | | 67073533-dd2a-4a95-8e8b-0f108f031092 | overcloud-full-vmlinuz | active | | 69a9ffe5-06dc-4d81-a122-e5d56ed46c98 | ppc64le-bm-deploy-kernel | active | | 464dd809-f130-4055-9a39-cf6b63c1944e | ppc64le-bm-deploy-ramdisk | active | | f0fedcd0-3f28-4b44-9c88-619419007a03 | ppc64le-overcloud-full | active | +--------------------------------------+---------------------------+--------+
この一覧には、イントロスペクションの PXE イメージは表示されません。director は、これらのファイルを
/tftpbootにコピーします。(undercloud) [stack@director images]$ ls -l /tftpboot /tftpboot/ppc64le/ /tftpboot: total 422624 -rwxr-xr-x. 1 root root 6385968 Aug 8 19:35 agent.kernel -rw-r--r--. 1 root root 425530268 Aug 8 19:35 agent.ramdisk -rwxr--r--. 1 ironic ironic 20832 Aug 8 02:08 chain.c32 -rwxr--r--. 1 ironic ironic 715584 Aug 8 02:06 ipxe.efi -rw-r--r--. 1 root root 22 Aug 8 02:06 map-file drwxr-xr-x. 2 ironic ironic 62 Aug 8 19:34 ppc64le -rwxr--r--. 1 ironic ironic 26826 Aug 8 02:08 pxelinux.0 drwxr-xr-x. 2 ironic ironic 21 Aug 8 02:06 pxelinux.cfg -rwxr--r--. 1 ironic ironic 69631 Aug 8 02:06 undionly.kpxe /tftpboot/ppc64le/: total 457204 -rwxr-xr-x. 1 root root 19858896 Aug 8 19:34 agent.kernel -rw-r--r--. 1 root root 448311235 Aug 8 19:34 agent.ramdisk -rw-r--r--. 1 ironic-inspector ironic-inspector 336 Aug 8 02:06 default
デフォルトの overcloud-full.qcow2 イメージは、フラットなパーティションイメージですが、ディスクイメージ全体をインポート、使用することも可能です。詳しい情報は、「付録C 完全なディスクイメージ」を参照してください。
4.5. コントロールプレーン用のネームサーバーの設定
オーバークラウドで cdn.redhat.com などの外部のホスト名を解決する予定の場合は、オーバークラウドノード上にネームサーバーを設定することを推奨します。ネットワークを分離していない標準のオーバークラウドの場合には、ネームサーバーはアンダークラウドのコントロールプレーンのサブネットを使用して定義されます。環境でネームサーバーを定義するには、以下の手順に従ってください。
手順
stackrcファイルを読み込んで、director のコマンドラインツールを有効にします。[stack@director ~]$ source ~/stackrc
ctlplane-subnetサブネット用のネームサーバーを設定します。(undercloud) [stack@director images]$ openstack subnet set --dns-nameserver [nameserver1-ip] --dns-nameserver [nameserver2-ip] ctlplane-subnet
各ネームサーバーに
--dns-nameserverオプションを使用します。サブネットを表示してネームサーバーを確認します。
(undercloud) [stack@director images]$ openstack subnet show ctlplane-subnet +-------------------+-----------------------------------------------+ | Field | Value | +-------------------+-----------------------------------------------+ | ... | | | dns_nameservers | 8.8.8.8 | | ... | | +-------------------+-----------------------------------------------+
サービストラフィックを別のネットワークに分離する場合は、オーバークラウドのノードはネットワーク環境ファイルの DnsServers パラメーターを使用します。
4.6. 次のステップ
これで director の設定およびインストールが完了しました。次の章では、ノードの登録、検査、さまざまなノードロールのタグ付けなど、オーバークラウドの基本的な設定について説明します。
パート II. 基本的なオーバークラウドのデプロイメント
第5章 オーバークラウドのプランニング
以下の項には、ノードロールの定義、ネットワークトポロジーのプランニング、ストレージなど、Red Hat OpenStack Platform 環境のさまざまな面のプランニングに関するガイドラインを記載します。
5.1. ノードロール
director はオーバークラウドの構築に、デフォルトで複数のノード種別を提供します。これらのノード種別は以下のとおりです。
- コントローラー
環境を制御するための主要なサービスを提供します。これには、Dashboard (Horizon)、認証 (Keystone)、イメージストレージ (Glance)、ネットワーク (Neutron)、オーケストレーション (Heat)、高可用性サービスが含まれます。高可用性の場合は、Red Hat OpenStack Platform 環境にコントローラーノードが 3 台必要です。
注記1 台のノードで構成される環境はテスト目的で使用することができます。2 台のノードまたは 4 台以上のノードで構成される環境はサポートされません。
- Compute
- ハイパーバイザーとして機能し、環境内で仮想マシンを実行するのに必要な処理能力を提供する物理サーバー。基本的な Red Hat OpenStack Platform 環境には少なくとも 1 つのコンピュートノードが必要です。
- Ceph Storage
- Red Hat Ceph Storage を提供するホスト。Ceph Storage ホストはクラスターに追加され、クラスターをスケーリングします。このデプロイメントロールはオプションです。
- Swift ストレージ
- OpenStack の Swift サービスに外部オブジェクトストレージを提供するホスト。このデプロイメントロールはオプションです。
以下の表には、オーバークラウドの構成例と各シナリオで使用するノードタイプの定義をまとめています。
表5.1 各種シナリオに使用するノードデプロイメントロール
|
コントローラー |
Compute |
Ceph Storage |
Swift ストレージ |
合計 | |
|
小規模のオーバークラウド |
3 |
1 |
- |
- |
4 |
|
中規模のオーバークラウド |
3 |
3 |
- |
- |
6 |
|
追加のオブジェクトストレージがある中規模のオーバークラウド |
3 |
3 |
- |
3 |
9 |
|
Ceph Storage クラスターがある中規模のオーバークラウド |
3 |
3 |
3 |
- |
9 |
さらに、個別のサービスをカスタムのロールに分割するかどうかを検討します。コンポーザブルロールのアーキテクチャーに関する詳しい情報は『オーバークラウドの高度なカスタマイズ』の「コンポーザブルサービスとカスタムロール」を参照してください。
5.2. オーバークラウドネットワーク
ロールとサービスを適切にマッピングして相互に正しく通信できるように、環境のネットワークトポロジーおよびサブネットのプランニングを行うことが重要です。Red Hat OpenStack Platform では、自律的に動作してソフトウェアベースのネットワーク、静的/Floating IP アドレス、DHCP を管理する Openstack Networking (neutron) サービスを使用します。
デフォルトでは、director は接続に プロビジョニング / コントロールプレーン を使用するようにノードを設定します。ただし、ネットワークトラフィックを一連の コンポーザブルネットワーク に分離し、カスタマイズしてサービスを割り当てることができます。
一般的な Red Hat OpenStack Platform のシステム環境では通常、ネットワーク種別の数は物理ネットワークのリンク数を超えます。全ネットワークを正しいホストに接続するには、オーバークラウドは VLAN タグ付けを使用して、1 つのインターフェースに複数のネットワークを提供します。ネットワークの多くは、サブネットが分離されていますが、インターネットアクセスまたはインフラストラクチャーにネットワーク接続ができるようにルーティングを提供するレイヤー 3 のゲートウェイが必要です。ネットワークトラフィックの種別を分離するのに VLAN を使用している場合には、802.1Q 標準をサポートするスイッチを使用してタグ付けされた VLAN を提供します。
デプロイ時に neutron VLAN モード (トンネリングは無効) を使用する場合でも、プロジェクトネットワーク (GRE または VXLAN でトンネリング) をデプロイすることを推奨します。これには、デプロイ時にマイナーなカスタマイズを行う必要があり、将来ユーティリティーネットワークまたは仮想化ネットワークとしてトンネルネットワークを使用するためのオプションが利用可能な状態になります。VLAN を使用してテナントネットワークを作成することは変わりませんが、テナントの VLAN を消費せずに特別な用途のネットワーク用に VXLAN トンネルを作成することも可能です。また、テナント VLAN を使用するデプロイメントに VXLAN 機能を追加することは可能ですが、サービスを中断せずにテナント VLAN を既存のオーバークラウドに追加することはできません。
director には、NIC を分離コンポーザブルネットワークと連携させるための、さまざまなテンプレートも用意されています。
- シングル NIC 構成: ネイティブ VLAN 上のプロビジョニングネットワークと、オーバークラウドネットワークの種別ごとのサブネットを使用するタグ付けされた VLAN 用に NIC を 1つ。
- ボンディングされた NIC 構成: ネイティブ VLAN 上のプロビジョニングネットワーク用に NIC を 1 つと、オーバークラウドネットワークの種別ごとのタグ付けされた VLAN 用にボンディング構成の 2 つの NIC。
- 複数 NIC 構成: 各 NIC は、オーバークラウドネットワークの種別ごとのサブセットを使用します。
専用のテンプレートを作成して、特定の NIC 構成をマッピングすることもできます。
ネットワーク構成を検討する上で、以下の点を考慮することも重要です。
- オーバークラウドの作成時には、全オーバークラウドマシンで 1 つの名前を使用して NIC を参照します。理想としては、混乱を避けるため、対象のネットワークごとに、各オーバークラウドノードで同じ NIC を使用してください。たとえば、プロビジョニングネットワークにはプライマリー NIC を使用して、OpenStack サービスにはセカンダリー NIC を使用します。
- すべてのオーバークラウドシステムをプロビジョニング NIC から PXE ブートするように設定して、同システム上の外部 NIC およびその他の NIC の PXE ブートを無効にします。また、プロビジョニング NIC の PXE ブートは、ハードディスクや CD/DVD ドライブよりも優先されるように、起動順序の最上位に指定します。
- オーバークラウドのベアメタルシステムにはすべて、Intelligent Platform Management Interface (IPMI) などのサポート対象の電源管理インターフェースが必要です。このインターフェースにより、director は各ノードの電源管理を制御することが可能となります。
- 各オーバークラウドシステムの詳細 (プロビジョニング NIC の MAC アドレス、IPMI NIC の IP アドレス、IPMI ユーザー名、IPMI パスワード) をメモしてください。この情報は、後でオーバークラウドノードを設定する際に役立ちます。
- インスタンスが外部のインターネットからアクセス可能である必要がある場合には、パブリックネットワークから Floating IP アドレスを割り当てて、そのアドレスをインスタンスに関連付けます。インスタンスは、引き続きプライベートの IP アドレスを確保しますが、ネットワークトラフィックは NAT を使用して、Floating IP アドレスに到達します。Floating IP アドレスは、複数のプライベート IP アドレスではなく、単一のインスタンスにのみ割り当て可能である点に注意してください、ただし、Floating IP アドレスは、単一のテナントで使用するように確保され、そのテナントは必要に応じて特定のインスタンスに関連付け/関連付け解除することができます。この構成を使用すると、インフラストラクチャーが外部のインターネットに公開されるので、適切なセキュリティープラクティスを順守しているかどうかを確認する必要があるでしょう。
- 1 つのブリッジには単一のインターフェースまたは単一のボンディングのみをメンバーにすると、Open vSwitch でネットワークループが発生するリスクを緩和することができます。複数のボンディングまたはインターフェースが必要な場合には、複数のブリッジを設定することが可能です。
- オーバークラウドノードが Red Hat Content Delivery Network やネットワークタイムサーバーなどの外部のサービスに接続できるようにするには、DNS によるホスト名解決を使用することを推奨します。
5.3. オーバークラウドのストレージ
任意のドライバーまたはバックエンド種別のバックエンド cinder ボリュームを使用するゲストインスタンスで LVM を使用すると、パフォーマンスとボリュームの可視性/可用性で問題が生じます。このような問題は、LVM フィルターを使用すると緩和することができます。詳しくは、『Storage Guide』の「Back Ends」および KCS の記事「Using LVM on a cinder volume exposes the data to the compute host」を参照してください。
director は、オーバークラウド環境にさまざまなストレージオプションを提供します。オプションは以下のとおりです。
- Ceph Storage ノード
director は、Red Hat Ceph Storage を使用して拡張可能なストレージノードセットを作成します。オーバークラウドは、各種ノードを以下の目的で使用します。
- イメージ: Glance は仮想マシンのイメージを管理します。イメージは変更できないため、OpenStack はイメージバイナリーブロブとして処理し、それに応じてイメージをダウンロードします。Ceph ブロックデバイスでイメージを格納するには、Glance を使用することができます。
- ボリューム: Cinder ボリュームはブロックデバイスです。OpenStack は、仮想マシンの起動や、実行中の仮想マシンへのボリュームのアタッチにボリュームを使用し、Cinder サービスを使用してボリュームを管理します。さらに、イメージの CoW (Copy-on-Write) のクローンを使用して仮想マシンを起動する際には Cinder を使用します。
- ファイルシステム: manila 共有はファイルシステムによりバッキングされます。OpenStack ユーザーは、manila サービスを使用して共有を管理します。manila を使用して、Ceph Storage ノードにデータを保管する CephFS ファイルシステムにバッキングされる共有を管理することができます。
ゲストディスク: ゲストディスクは、ゲストオペレーティングシステムのディスクです。デフォルトでは、Nova で仮想マシンを起動すると、ディスクは、ハイパーバイザーのファイルシステム上のファイルとして表示されます (通常
/var/lib/nova/instances/<uuid>/の配下)。Ceph 内にあるすべての仮想マシンは、Cinder を使用せずに起動することができます。これにより、ライブマイグレーションのプロセスを使用して、簡単にメンテナンス操作を実行することができます。また、ハイパーバイザーが停止した場合には、nova evacuateをトリガーして仮想マシンを別の場所で実行することもできるので便利です。重要サポートされるイメージフォーマットの情報については、『Instances and Images Guide』の「Image Service」の章を参照してください
その他の情報については、『Red Hat Ceph Storage Architecture Guide』を参照してください。
- Swift Storage ノード
- director は、外部オブジェクトストレージノードを作成します。これは、オーバークラウド環境でコントローラーノードをスケーリングまたは置き換える必要があるが、高可用性クラスター外にオブジェクトストレージを保持する必要がある場合に便利です。
5.4. オーバークラウドのセキュリティー
OpenStack Platform の実装のセキュリティーレベルは、その環境のセキュリティーレベルと同等です。ネットワーク環境内の適切なセキュリティー原則に従って、ネットワークアクセスが正しく制御されるようにします。以下に例を示します。
- ネットワークのセグメント化を使用して、ネットワークトラフィックを軽減し、機密データを分離します。フラットなネットワークはセキュリティーレベルがはるかに低くなります。
- サービスアクセスとポートを最小限に制限します。
- 適切なファイアウォールルールとパスワードが使用されるようにします。
- SELinux が有効化されていることを確認します。
システムのセキュリティー保護については、以下のドキュメントを参照してください。
5.5. オーバークラウドの高可用性
高可用性なオーバークラウドをデプロイするために、director は複数のコントローラー、コンピュート、およびストレージノードを単一のクラスターとして連携するように設定します。ノードで障害が発生すると、障害が発生したノードのタイプに応じて、自動フェンシングおよび再起動プロセスがトリガーされます。オーバークラウド高可用性アーキテクチャーおよびサービスに関する情報は、『Understanding Red Hat OpenStack Platform High Availability』を参照してください。
director を使用して、コンピュートインスタンスの高可用性 (インスタンス HA) を設定することもできます。このメカニズムにより、ノードで障害が発生するとコンピュートノード上のインスタンスが自動的に退避および再起動されます。インスタンス HA に対する要件は通常のオーバークラウドの要件と同じですが、追加のステップを実施してデプロイメントのために環境を準備する必要があります。インスタンス HA の仕組みおよびインストール手順に関する情報は、『High Availability for Compute Instances』を参照してください。
5.6. コントローラーノードの要件
コントローラーノードは、Red Hat OpenStack Platform 環境の中核となるサービス (例: Horizon Dashboard、バックエンドのデータベースサーバー、Keystone 認証、高可用性サービスなど) をホストする役割を果たします。
- プロセッサー
- Intel 64 または AMD64 CPU 拡張機能のサポートがある 64 ビットの x86 プロセッサー
- メモリー
最小のメモリー容量は 32 GB です。ただし、推奨のメモリー容量は、仮想 CPU の数によって異なります (CPU コアをハイパースレッディングの値で乗算した数値に基づいています)。以下の計算を参考にしてください。
コントローラーの最小メモリー容量の算出:
- 1 仮想 CPU あたり 1.5 GB のメモリーを使用します。たとえば、仮想 CPU が 48 個あるマシンにはメモリーは 72 GB 必要です。
コントローラーの推奨メモリー容量の算出:
- 1 仮想 CPU あたり 3 GB のメモリーを使用します。たとえば、仮想 CPU が 48 個あるマシンにはメモリーは 144 GB 必要です。
メモリーの要件に関する詳しい情報は、Red Hat カスタマーポータルで「Red Hat OpenStack Platform Hardware Requirements for Highly Available Controllers」の記事を参照してください。
- ディスクストレージとレイアウト
最小で 40 GB のストレージが必要です。ただし、Telemetry (
gnocchi) と Object Storage (swift) のサービスはいずれもコントローラーにインストールされ、ルートディスクを使用するように設定されます。これらのデフォルトは、コモディティーハードウェア上に構築される小型のオーバークラウドのデプロイに適しています。これは、概念検証およびテストの標準的な環境です。これらのデフォルトにより、最小限のプランニングでオーバークラウドをデプロイすることができますが、ワークロードキャパシティーとパフォーマンスの面ではあまり優れていません。ただし、Telemetry がストレージに絶えずアクセスするため、エンタープライズ環境では、これによって大きなボトルネックが生じる可能性があります。これにより、ディスク I/O が過度に使用されて、その他すべてのコントローラーサービスに深刻な影響をもたらします。このタイプの環境では、オーバークラウドのプランニングを行って、適切に設定する必要があります。
Red Hat は、Telemetry と Object Storage の両方の推奨設定をいくつか提供しています。詳しくは、『Deployment Recommendations for Specific Red Hat OpenStack Platform Services』を参照してください。
- ネットワークインターフェースカード
- 最小 2 枚の 1 Gbps ネットワークインターフェースカード。タグ付けされた VLAN トラフィックを委譲する場合や、ボンディングインターフェース向けの場合には追加のネットワークインターフェースを使用します。
- 電源管理
- 各コントローラーノードには、Intelligent Platform Management Interface (IPMI) 機能などのサポート対象の電源管理インターフェースがサーバーのマザーボードに搭載されている必要があります。
5.7. コンピュートノードの要件
コンピュートノードは、仮想マシンインスタンスが起動した後にそれらを稼働させる役割を果たします。コンピュートノードは、ハードウェアの仮想化をサポートしている必要があります。また、ホストする仮想マシンインスタンスの要件をサポートするのに十分なメモリーとディスク容量も必要です。
- プロセッサー
- Intel 64 または AMD64 CPU 拡張機能をサポートする 64 ビット x86 プロセッサーで Intel VT または AMD-V のハードウェア仮想化拡張機能が有効化されていること。このプロセッサーには最小でも 4 つのコアが搭載されていることを推奨しています。
- IBM POWER 8 プロセッサー
- メモリー
- 最小で 6 GB のメモリー。これに、仮想マシンインスタンスに割り当てるメモリー容量に基づいて、追加の RAM を加算します。
- ディスク領域
- 最小 40 GB の空きディスク領域
- ネットワークインターフェースカード
- 最小 1 枚の 1 Gbps ネットワークインターフェースカード (実稼働環境では最低でも NIC を 2 枚使用することを推奨)。タグ付けされた VLAN トラフィックを委譲する場合や、ボンディングインターフェース向けの場合には追加のネットワークインターフェースを使用します。
- 電源管理
- 各コンピュートノードには、Intelligent Platform Management Interface (IPMI) 機能などのサポート対象の電源管理インターフェースがサーバーのマザーボードに搭載されている必要があります。
5.8. Ceph Storage ノードの要件
Ceph Storage ノードは、Red Hat OpenStack Platform 環境でオブジェクトストレージを提供する役割を果たします。
- プロセッサー
- Intel 64 または AMD64 CPU 拡張機能のサポートがある 64 ビットの x86 プロセッサー
- メモリー
- 一般的には、OSD ホスト毎に 16 GB の RAM をベースとし、さらに OSD デーモン毎に 2 GB の RAM を追加することを推奨します。
- ディスクのレイアウト
サイズはストレージの要件によって異なります。Red Hat Ceph Storage ノードの推奨設定では、少なくとも 3 つ、またはそれ以上のディスクを以下と同様のレイアウトで構成する必要があります。
-
/dev/sda: ルートディスク。director は、主なオーバークラウドイメージをディスクにコピーします。このディスクには、少なくとも 40 GB の空き容量が必要です。 -
/dev/sdb: ジャーナルディスク。このディスクは、/dev/sdb1、/dev/sdb2、/dev/sdb3などのように、Ceph OSD ジャーナル向けにパーティションを分割します。ジャーナルディスクは通常、システムパフォーマンスの向上に役立つ Solid State Drive (SSD) です。 /dev/sdc以降: OSD ディスク。ストレージ要件で必要な数のディスクを使用します。注記Red Hat OpenStack Platform director では
ceph-ansibleが使われますが、OSD を Ceph Storage ノードのルートディスクにインストールすることには対応していません。つまり、サポートされる Ceph Storage ノード用に少なくとも 2 つのディスクが必要になります。
-
- ネットワークインターフェースカード
- 最小で 1 x 1 Gbps ネットワークインターフェースカード (実稼働環境では、最低でも NIC を 2 つ以上使用することを推奨します)。ボンディングインターフェース向けの場合や、タグ付けされた VLAN トラフィックを委譲する場合には、追加のネットワークインターフェースを使用します。特に大量のトラフィックにサービスを提供する OpenStack Platform 環境を構築する場合には、ストレージノードには 10 Gbps インターフェースを使用することを推奨します。
- 電源管理
- 各コントローラーノードには、Intelligent Platform Management Interface (IPMI) 機能などのサポート対象の電源管理インターフェースがサーバーのマザーボードに搭載されている必要があります。
Ceph Storage クラスターを使用するオーバークラウドのインストールについては、『Deploying an Overcloud with Containerized Red Hat Ceph』を参照してください。
5.9. オブジェクトストレージノードの要件
オブジェクトストレージノードは、オーバークラウドのオブジェクトストレージ層を提供します。Object Storage プロキシーは、コントローラーノードにインストールされます。ストレージ層には、ノードごとに複数のディスクを持つベアメタルノードが必要です。
- プロセッサー
- Intel 64 または AMD64 CPU 拡張機能のサポートがある 64 ビットの x86 プロセッサー
- メモリー
- メモリー要件はストレージ容量によって異なります。ハードディスク容量 1 TB あたり最小で 1 GB のメモリーを使用するのが理想的です。最適なパフォーマンスを得るには、特にワークロードが小さいファイル (100 GB 未満) の場合にはハードディスク容量 1 TB あたり 2 GB のメモリーを使用することを推奨します。
- ディスク領域
ストレージ要件は、ワークロードに必要とされる容量により異なります。アカウントとコンテナーのデータを保存するには SSD ドライブを使用することを推奨します。アカウントおよびコンテナーデータとオブジェクトの容量比率は、約 1 % です。たとえば、ハードドライブの容量 100 TB ごとに、アカウントおよびコンテナーデータの SSD 容量は 1 TB 用意するようにします。
ただし、これは保存したデータの種類により異なります。保存するオブジェクトサイズの大半が小さい場合には、SSD の容量がさらに必要です。オブジェクトが大きい場合には (ビデオ、バックアップなど)、SSD の容量を減らします。
- ディスクのレイアウト
推奨のノード設定には、以下のようなディスクレイアウトが必要です。
-
/dev/sda: ルートディスク。director は、主なオーバークラウドイメージをディスクにコピーします。 -
/dev/sdb: アカウントデータに使用します。 -
/dev/sdc: コンテナーデータに使用します。 -
/dev/sdc以降: オブジェクトサーバーディスク。ストレージ要件で必要な数のディスクを使用します。
-
- ネットワークインターフェースカード
- 最小 2 枚の 1 Gbps ネットワークインターフェースカード。タグ付けされた VLAN トラフィックを委譲する場合や、ボンディングインターフェース向けの場合には追加のネットワークインターフェースを使用します。
- 電源管理
- 各コントローラーノードには、Intelligent Platform Management Interface (IPMI) 機能などのサポート対象の電源管理インターフェースがサーバーのマザーボードに搭載されている必要があります。
5.10. オーバークラウドのリポジトリー
アンダークラウドのインストールおよび設定には、以下のリポジトリーが必要です。
表5.2 コアリポジトリー
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Enterprise Linux 7 Server (RPMS) |
|
x86_64 システム用ベースオペレーティングシステムのリポジトリー |
|
Red Hat Enterprise Linux 7 Server - Extras (RPMs) |
|
Red Hat OpenStack Platform の依存関係が含まれます。 |
|
Red Hat Enterprise Linux 7 Server - RH Common (RPMs) |
|
Red Hat OpenStack Platform のデプロイと設定ツールが含まれます。 |
|
Red Hat Satellite Tools for RHEL 7 Server RPMs x86_64 |
|
Red Hat Satellite 6 でのホスト管理ツール |
|
Red Hat Enterprise Linux High Availability (for RHEL 7 Server) (RPMs) |
|
Red Hat Enterprise Linux の高可用性ツール。コントローラーノードの高可用性に使用します。 |
|
Red Hat OpenStack Platform 14 for RHEL 7 (RPMs) |
|
Red Hat OpenStack Platform のコアリポジトリー |
表5.3 Ceph 用リポジトリー
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Ceph Storage OSD 3 for Red Hat Enterprise Linux 7 Server (RPMs) |
|
(Ceph Storage ノード向け) Ceph Storage Object Storage デーモンのリポジトリー。Ceph Storage ノードにインストールします。 |
|
Red Hat Ceph Storage MON 3 for Red Hat Enterprise Linux 7 Server (RPMs) |
|
(Ceph Storage ノード向け) Ceph Storage Monitor デーモンのリポジトリー。Ceph Storage ノードを使用して OpenStack 環境にあるコントローラーノードにインストールします。 |
|
Red Hat Ceph Storage Tools 3 for Red Hat Enterprise Linux 7 Server (RPMs) |
|
Ceph Storage クラスターと通信するためのノード用のツールを提供します。このリポジトリーは、Ceph Storage クラスターを使用するオーバークラウドをデプロイする際に、全ノードに有効化する必要があります。 |
表5.4 NFV 用リポジトリー
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Enterprise Linux for Real Time for NFV (RHEL 7 Server) (RPMs) |
|
NFV 向けの Real Time KVM (RT-KVM) のリポジトリー。リアルタイムカーネルを有効化するためのパッケージが含まれています。このリポジトリーは、RT-KVM 対象の全コンピュートノードで有効化する必要があります。このリポジトリーにアクセスするためには、 |
IBM POWER 用リポジトリー
これらのリポジトリーは、POWER PC アーキテクチャー上で Openstack Platform を構築するのに使われます。コアリポジトリーの該当リポジトリーの代わりに、これらのリポジトリーを使用してください。
| 名前 | リポジトリー | 要件の説明 |
|---|---|---|
|
Red Hat Enterprise Linux for IBM Power, little endian |
|
ppc64le システム用ベースオペレーティングシステムのリポジトリー |
|
Red Hat OpenStack Platform 14 for RHEL 7 (RPMs) |
|
ppc64le システム用 Red Hat OpenStack Platform のコアリポジトリー |
第6章 CLI ツールを使用した基本的なオーバークラウドの設定
本章では、CLI ツールを使用した OpenStack Platform 環境の基本的な設定手順を説明します。基本設定のオーバークラウドには、カスタムの機能は含まれていませんが、『オーバークラウドの高度なカスタマイズ』に記載の手順に従って、この基本的なオーバークラウドに高度な設定オプションを追加して、仕様に合わせてカスタマイズすることができます。
6.1. オーバークラウドへのノードの登録
director では、手動で作成したノード定義のテンプレートが必要です。このファイルは JSON または YAML 形式を使用し、ノードのハードウェアおよび電源管理の情報が含まれます。
手順
ノードの一覧が含まれるテンプレートを作成します。JSON 形式のテンプレートの例を以下に示します。
{ "nodes":[ { "mac":[ "bb:bb:bb:bb:bb:bb" ], "name":"node01", "cpu":"4", "memory":"6144", "disk":"40", "arch":"x86_64", "pm_type":"ipmi", "pm_user":"admin", "pm_password":"p@55w0rd!", "pm_addr":"192.168.24.205" }, { "mac":[ "cc:cc:cc:cc:cc:cc" ], "name":"node02", "cpu":"4", "memory":"6144", "disk":"40", "arch":"x86_64", "pm_type":"ipmi", "pm_user":"admin", "pm_password":"p@55w0rd!", "pm_addr":"192.168.24.206" } ] }また、YAML 形式の類似ノードテンプレートの例を以下に示します。
nodes: - mac: - "bb:bb:bb:bb:bb:bb" name: "node01" cpu: 4 memory: 6144 disk: 40 arch: "x86_64" pm_type: "ipmi" pm_user: "admin" pm_password: "p@55w0rd!" pm_addr: "192.168.24.205" - mac: - cc:cc:cc:cc:cc:cc name: "node02" cpu: 4 memory: 6144 disk: 40 arch: "x86_64" pm_type: "ipmi" pm_user: "admin" pm_password: "p@55w0rd!" pm_addr: "192.168.24.206"このテンプレートでは、以下の属性を使用します。
- name
- ノードの論理名
- pm_type
使用する電源管理ドライバー。この例で使用しているのは IPMI ドライバー (
ipmi) で、電源管理の推奨ドライバーです。注記IPMI が推奨されるサポート対象電源管理ドライバーです。これ以外のサポート対象電源管理ドライバーおよびそのオプションに関する詳細は、「付録B 電源管理ドライバー」を参照してください。それらの電源管理ドライバーが想定どおりに機能しない場合には、電源管理に IPMI を使用してください。
- pm_user; pm_password
- IPMI のユーザー名およびパスワード
- pm_addr
- IPMI デバイスの IP アドレス
- mac
- (オプション) ノード上のネットワークインターフェースの MAC アドレス一覧。各システムのプロビジョニング NIC の MAC アドレスのみを使用します。
- cpu
- (オプション) ノード上の CPU 数
- memory
- (オプション) メモリーサイズ (MB)
- disk
- (オプション) ハードディスクのサイズ (GB)
- arch
(オプション) システムアーキテクチャー
重要マルチアーキテクチャークラウドをビルドする場合には、
x86_64アーキテクチャーを使用するノードとppc64leアーキテクチャーを使用するノードを区別するためにarchキーが必須です。
テンプレートの作成後に、
stackユーザーのホームディレクトリーにファイルを保存して (/home/stack/nodes.json)、以下のコマンドを使用して director にインポートします。$ source ~/stackrc (undercloud) $ openstack overcloud node import ~/nodes.json
このコマンドでテンプレートをインポートして、テンプレートから director に各ノードを登録します。
ノードを登録して設定が完了した後に、CLI でこれらのノードの一覧を表示します。
(undercloud) $ openstack baremetal node list
6.2. ノードのハードウェアの検査
director は各ノードでイントロスペクションプロセスを実行することができます。このプロセスを実行すると、各ノードが PXE を介してイントロスペクションエージェントを起動します。このエージェントは、ノードからハードウェアのデータを収集して、director に送り返します。次に director は、director 上で実行中の OpenStack Object Storage (swift) サービスにこのイントロスペクションデータを保管します。director は、プロファイルのタグ付け、ベンチマーキング、ルートディスクの手動割り当てなど、さまざまな目的でハードウェア情報を使用します。
手順
以下のコマンドを実行して、各ノードのハードウェア属性を検証します。
(undercloud) $ openstack overcloud node introspect --all-manageable --provide
-
--all-manageableオプションは、管理状態のノードのみをイントロスペクションします。上記の例では、すべてのノードが対象です。 -
--provideオプションは、イントロスペクション後に全ノードをavailableの状態にします。
-
別のターミナルウィンドウで以下のコマンドを使用してイントロスペクションの進捗状況をモニタリングします。
(undercloud) $ sudo journalctl -l -u openstack-ironic-inspector -u openstack-ironic-inspector-dnsmasq -u openstack-ironic-conductor -f
重要このプロセスが最後まで実行されて正常に終了したことを確認してください。ベアメタルの場合には、通常 15 分ほどかかります。
-
イントロスペクション完了後には、すべてのノードが
availableの状態に変わります。
6.3. プロファイルへのノードのタグ付け
各ノードのハードウェアを登録、検査した後には、特定のプロファイルにノードをタグ付けします。このプロファイルタグにより、ノードがフレーバーに照合され、次にそのフレーバーがデプロイメントロールに割り当てられます。以下の例では、コントローラーノードのロール、フレーバー、プロファイル、ノード間の関係を示しています。
| タイプ | 説明 |
|---|---|
|
ロール |
|
|
フレーバー |
|
|
プロファイル |
|
|
ノード |
また、各ノードに |
アンダークラウドのインストール時に、デフォルトプロファイルのフレーバー compute、control、swift-storage、ceph-storage、block-storage が作成され、大半の環境で変更なしに使用することができます。
手順
特定のプロファイルにノードをタグ付けする場合には、各ノードの
properties/capabilitiesパラメーターにprofileオプションを追加します。たとえば、2 つのノードをタグ付けしてコントローラープロファイルとコンピュートプロファイルをそれぞれ使用するには、以下のコマンドを実行します。(undercloud) $ openstack baremetal node set --property capabilities='profile:compute,boot_option:local' 58c3d07e-24f2-48a7-bbb6-6843f0e8ee13 (undercloud) $ openstack baremetal node set --property capabilities='profile:control,boot_option:local' 1a4e30da-b6dc-499d-ba87-0bd8a3819bc0
profile:computeとprofile:controlオプションを追加することで、この 2 つのノードがそれぞれのプロファイルにタグ付けされます。これらのコマンドにより、各ノードの起動方法を定義する
boot_option:localパラメーターも設定されます。ノードのタグ付けが完了した後には、割り当てたプロファイルまたはプロファイルの候補を確認します。
(undercloud) $ openstack overcloud profiles list
6.4. UEFI ブートモードの設定
デフォルトのブートモードは、レガシー BIOS モードです。新しいシステムでは、レガシー BIOS モードの代わりに UEFI ブートモードが必要な可能性があります。以下の手順を使用して、UEFI モードに変更します。
手順
undercloud.confファイルで以下のパラメーターを設定します。ipxe_enabled = True inspection_enable_uefi = True
このファイルを保存して、アンダークラウドのインストールを実行します。
$ openstack undercloud install
インストールスクリプトが完了するまで待ちます。
登録済みの各ノードのブートモードを
uefiに設定します。たとえば、capabilitiesプロパティーにboot_modeパラメーターを追加する場合や既存のパラメーターを置き換える場合には、以下のコマンドを実行します。$ NODE=<NODE NAME OR ID> ; openstack baremetal node set --property capabilities="boot_mode:uefi,$(openstack baremetal node show $NODE -f json -c properties | jq -r .properties.capabilities | sed "s/boot_mode:[^,]*,//g")" $NODE
注記profileおよびboot_optionのケイパビリティーが保持されていることを確認してください。+
$ openstack baremetal node show r530-12 -f json -c properties | jq -r .properties.capabilities
各フレーバーのブートモードを
uefiに設定します。$ openstack flavor set --property capabilities:boot_mode='uefi' control
6.5. ノードのルートディスクの定義
一部のノードでは、複数のディスクが使用される場合があります。このため、director はプロビジョニング中ルートディスクとして使用するディスクを特定する必要があります。プロビジョニングプロセス中、director は QCOW2 overcloud-full イメージをルートディスクに書き込みます。
director がルートディスクを容易に特定できるようにするには、以下のようなプロパティーを使用することができます。
-
model(文字列): デバイスの ID -
vendor(文字列): デバイスのベンダー -
serial(文字列): ディスクのシリアル番号 -
hctl(文字列): SCSI のホスト:チャネル:ターゲット:Lun -
size(整数):デバイスのサイズ (GB) -
wwn(文字列): ストレージの一意識別子 -
wwn_with_extension(文字列): ベンダー拡張が末尾に付いたストレージの一意識別子 -
wwn_vendor_extension(文字列): ベンダーのストレージの一意識別子 -
rotational(ブール値): 回転式デバイス (HDD) には true、そうでない場合 (SSD) には false。 -
name(文字列): デバイス名 (例: /dev/sdb1)
name は、永続デバイス名が付いたデバイスのみに使用します。name で他のデバイスのルートディスクを設定しないでください。この値は、ノードのブート時に変更される可能性があります。
シリアル番号を使用してルートデバイスを指定する方法を、以下の例で説明します。
手順
各ノードのハードウェアイントロスペクションからのディスク情報を確認します。以下のコマンドは、ノードからのディスク情報を表示します。
(undercloud) $ openstack baremetal introspection data save 1a4e30da-b6dc-499d-ba87-0bd8a3819bc0 | jq ".inventory.disks"
たとえば、1 つのノードのデータで 3 つのディスクが表示される場合があります。
[ { "size": 299439751168, "rotational": true, "vendor": "DELL", "name": "/dev/sda", "wwn_vendor_extension": "0x1ea4dcc412a9632b", "wwn_with_extension": "0x61866da04f3807001ea4dcc412a9632b", "model": "PERC H330 Mini", "wwn": "0x61866da04f380700", "serial": "61866da04f3807001ea4dcc412a9632b" } { "size": 299439751168, "rotational": true, "vendor": "DELL", "name": "/dev/sdb", "wwn_vendor_extension": "0x1ea4e13c12e36ad6", "wwn_with_extension": "0x61866da04f380d001ea4e13c12e36ad6", "model": "PERC H330 Mini", "wwn": "0x61866da04f380d00", "serial": "61866da04f380d001ea4e13c12e36ad6" } { "size": 299439751168, "rotational": true, "vendor": "DELL", "name": "/dev/sdc", "wwn_vendor_extension": "0x1ea4e31e121cfb45", "wwn_with_extension": "0x61866da04f37fc001ea4e31e121cfb45", "model": "PERC H330 Mini", "wwn": "0x61866da04f37fc00", "serial": "61866da04f37fc001ea4e31e121cfb45" } ]以下の例では、ルートデバイスをシリアル番号が
61866da04f380d001ea4e13c12e36ad6の disk 2 に設定する方法を説明します。そのためには、ノード定義のroot_deviceパラメーターを変更する必要があります。(undercloud) $ openstack baremetal node set --property root_device='{"serial": "61866da04f380d001ea4e13c12e36ad6"}' 1a4e30da-b6dc-499d-ba87-0bd8a3819bc0注記各ノードの BIOS を設定して、選択したルートディスクからの起動が含まれるようにします。推奨のブート順は最初がネットワークブートで、次にルートディスクブートです。
6.6. アーキテクチャーに固有なロールの作成
マルチアーキテクチャークラウドをビルドする場合には、roles_data.yaml にアーキテクチャー固有のロールを追加する必要があります。以下に示す例では、デフォルトのロールに加えて ComputePPC64LE ロールを追加しています。『オーバークラウドの高度なカスタマイズ』の「roles_data ファイルの作成」セクションには、ロールについての情報が記載されています。
openstack overcloud roles generate \
--roles-path /usr/share/openstack-tripleo-heat-templates/roles -o ~/templates/roles_data.yaml \
Controller Compute ComputePPC64LE BlockStorage ObjectStorage CephStorage6.7. 環境ファイル
アンダークラウドには、オーバークラウドの作成プランとして機能するさまざまな Heat テンプレートが含まれます。YAML フォーマットの環境ファイルを使って、オーバークラウドの特性をカスタマイズすることができます。このファイルで、コア Heat テンプレートコレクションのパラメーターおよびリソースを上書きします。必要に応じていくつでも環境ファイルを追加することができますが、後で実行される環境ファイルで定義されているパラメーターとリソースが優先されることになるため、環境ファイルの順番は重要です。以下の一覧は、環境ファイルの順序の例です。
- 各ロールおよびそのフレーバーごとのノード数。オーバークラウドを作成するには、この情報の追加は不可欠です。
- コンテナー化された OpenStack サービスのコンテナーイメージの場所。
-
任意のネットワーク分離ファイル。Heat テンプレートコレクションの初期化ファイル (
environments/network-isolation.yaml) から開始して、次にカスタムの NIC 設定ファイル、最後に追加のネットワーク設定の順番です。 - 外部のロードバランシングの環境ファイル。
- Ceph Storage、NFS、iSCSI などのストレージ環境ファイル。
- Red Hat CDN または Satellite 登録用の環境ファイル。
- その他のカスタム環境ファイル。
カスタム環境ファイルは、別のディレクトリーで管理することを推奨します (たとえば、templates ディレクトリー)。
『オーバークラウドの高度なカスタマイズ』を使用して、オーバークラウドの詳細機能をカスタマイズできます。
基本的なオーバークラウドでは、ブロックストレージにローカルの LVM ストレージを使用しますが、この設定はサポートされません。ブロックストレージには、外部ストレージソリューション (Red Hat Ceph Storage 等) を使用することを推奨します。
これ以降の数セクションで、オーバークラウドに必要な環境ファイルを作成する方法について説明します。
6.8. ノード数とフレーバーを定義する環境ファイルの作成
デフォルトでは、director は baremetal フレーバーを使用して 1 つのコントローラーノードとコンピュートノードを持つオーバークラウドをデプロイします。ただし、この設定は概念検証のためのデプロイメントにしか適しません。異なるノード数およびフレーバーを指定して、デフォルトの設定をオーバーライドすることができます。小規模な実稼働環境では、コントローラーノードとコンピュートノードを少なくとも 3 つにし、適切なリソース仕様でノードが作成されるように特定のフレーバーを割り当てる必要があります。以下の手順では、ノード数およびフレーバー割り当てを定義する環境ファイル node-info.yaml の作成方法を説明します。
手順
/home/stack/templates/ディレクトリーにnode-info.yamlファイルを作成します。(undercloud) $ touch /home/stack/templates/node-info.yaml
ファイルを編集し、必要なノード数およびフレーバーを設定します。以下の例では、3 つのコントローラーノード、コンピュートノード、および Ceph Storage ノードをデプロイします。
parameter_defaults: OvercloudControllerFlavor: control OvercloudComputeFlavor: compute ControllerCount: 3 ComputeCount: 3
6.9. アンダークラウド CA を信頼するための環境ファイルの作成
アンダークラウドで TLS が使用され CA が一般に信頼できない場合には、以下の手順に従う必要があります。アンダークラウドでは、SSL エンドポイント暗号化のために自己の認証局 (CA) が運用されます。デプロイメントの他の要素からアンダークラウドのエンドポイントにアクセスできるようにするには、アンダークラウドの CA を信頼するようにオーバークラウドノードを設定します。
この手法が機能するためには、オーバークラウドノードにアンダークラウドの公開エンドポイントへのネットワークルートが必要です。スパイン/リーフ型ネットワークに依存するデプロイメントでは、この設定を適用する必要があります。
アンダークラウドで使用することのできるカスタム証明書には、2 つのタイプがあります。
-
ユーザーの提供する証明書: 自己の証明書を提供している場合がこれに該当します。自己の CA からの証明書、または自己署名の証明書がその例です。この証明書は
undercloud_service_certificateオプションを使用して渡されます。この場合、自己署名の証明書または CA のどちらかを信頼する必要があります (デプロイメントによります)。 -
自動生成される証明書:
certmongerにより自己のローカル CA を使用して証明書を生成する場合がこれに該当します。このプロセスは、generate_service_certificateオプションを使用して有効にします。この場合、CA 証明書 (/etc/pki/ca-trust/source/anchors/cm-local-ca.pem) およびアンダークラウドの HAProxy インスタンスが使用するサーバー証明書が用いられます。この証明書を OpenStack に提示するには、CA 証明書をinject-trust-anchor-hiera.yamlファイルに追加する必要があります。
手順
以下の例では、/home/stack/ca.crt.pem に保存された自己署名の証明書が使われています。自動生成される証明書を使用する場合には、代わりに /etc/pki/ca-trust/source/anchors/cm-local-ca.pem を使用してください。
証明書ファイルを開き、証明書部分だけをコピーします。鍵を含めないでください。
$ vi /home/stack/ca.crt.pem
必要となる証明書部分の例を、以下に示します。
-----BEGIN CERTIFICATE----- MIIDlTCCAn2gAwIBAgIJAOnPtx2hHEhrMA0GCSqGSIb3DQEBCwUAMGExCzAJBgNV BAYTAlVTMQswCQYDVQQIDAJOQzEQMA4GA1UEBwwHUmFsZWlnaDEQMA4GA1UECgwH UmVkIEhhdDELMAkGA1UECwwCUUUxFDASBgNVBAMMCzE5Mi4xNjguMC4yMB4XDTE3 -----END CERTIFICATE-----
以下に示す内容で
/home/stack/inject-trust-anchor-hiera.yamlという名称の新たな YAML ファイルを作成し、PEM ファイルからコピーした証明書を追加します。parameter_defaults: CAMap: ... undercloud-ca: content: | -----BEGIN CERTIFICATE----- MIIDlTCCAn2gAwIBAgIJAOnPtx2hHEhrMA0GCSqGSIb3DQEBCwUAMGExCzAJBgNV BAYTAlVTMQswCQYDVQQIDAJOQzEQMA4GA1UEBwwHUmFsZWlnaDEQMA4GA1UECgwH UmVkIEhhdDELMAkGA1UECwwCUUUxFDASBgNVBAMMCzE5Mi4xNjguMC4yMB4XDTE3 -----END CERTIFICATE-----注記証明書の文字列は、PEM の形式に従う必要があります。
オーバークラウドのデプロイメント時に CA 証明書がそれぞれのオーバークラウドノードにコピーされ、アンダークラウドの SSL エンドポイントが提示する暗号化を信頼するようになります。環境ファイル追加の詳細は、「オーバークラウドデプロイメントへの環境ファイルの追加」を参照してください。
6.10. デプロイメントコマンド
OpenStack 環境作成における最後の段階では、openstack overcloud deploy コマンドを実行して OpenStack 環境を作成します。このコマンドを実行する前に、キーオプションやカスタムの環境ファイルの追加方法を十分に理解しておく必要があります。
バックグラウンドプロセスとして openstack overcloud deploy を実行しないでください。バックグラウンドのプロセスとして開始された場合にはオーバークラウドの作成は途中で停止してしまう可能性があります。
6.11. デプロイメントコマンドのオプション
以下の表では、openstack overcloud deploy コマンドを使用する際の追加パラメーターを一覧表示します。
表6.1 デプロイメントコマンドのオプション
| パラメーター | 説明 |
|---|---|
|
|
デプロイする Heat テンプレートが格納されているディレクトリー。空欄にした場合には、コマンドはデフォルトのテンプレートの場所である |
|
|
作成または更新するスタックの名前 |
|
|
デプロイメントのタイムアウト (分単位) |
|
|
ハイパーバイザーに使用する仮想化タイプ |
|
|
時刻の同期に使用する Network Time Protocol (NTP) サーバー。コンマ区切りリストで複数の NTP サーバーを指定することも可能です (例: |
|
|
環境変数 no_proxy のカスタム値を定義します。これにより、プロキシー通信から特定のホスト名は除外されます。 |
|
|
オーバークラウドノードにアクセスする SSH ユーザーを定義します。通常、SSH アクセスは |
|
|
オーバークラウドデプロイメントに渡す追加の環境ファイル。複数回指定することが可能です。 |
|
|
デプロイメントに追加する環境ファイルが格納されているディレクトリー。このコマンドは、これらの環境ファイルを最初に番号順、その後にアルファベット順で処理します。 |
|
|
オーバークラウドの作成プロセスでは、デプロイメントの前に一連のチェックが行われます。このオプションは、デプロイメント前のチェックで何らかの致命的でないエラーが発生した場合に終了します。どのようなエラーが発生してもデプロイメントが失敗するので、このオプションを使用することを推奨します。 |
|
|
オーバークラウドの作成プロセスでは、デプロイメントの前に一連のチェックが行われます。このオプションは、デプロイメント前のチェックで何らかのクリティカルではない警告が発生した場合に終了します。 |
|
|
オーバークラウドに対する検証チェックを実行しますが、オーバークラウドを実際には作成しません。 |
|
|
オーバークラウドのデプロイ後の設定を省略します。 |
|
|
オーバークラウドのデプロイ後の設定を強制的に行います。 |
|
|
|
|
|
引数とパラメーターが記載された YAML ファイルへのパス |
|
|
カスタマーポータルまたは Satellite 6 にオーバークラウドノードを登録します。 |
|
|
オーバークラウドノードに使用する登録方法。Red Hat Satellite 6 または Red Hat Satellite 5 は |
|
|
登録に使用する組織 |
|
|
すでに登録済みでもシステムを登録します。 |
|
|
オーバークラウドノードを登録する Satellite サーバーのベース URL。このパラメーターには、HTTPS URL ではなく、Satellite の HTTP URL を使用します。たとえば、https://satellite.example.com ではなく http://satellite.example.com を使用します。オーバークラウドの作成プロセスではこの URL を使用して、どのサーバーが Red Hat Satellite 5 または Red Hat Satellite 6 サーバーであるかを判断します。Red Hat Satellite 6 サーバーの場合は、オーバークラウドは |
|
|
登録に使用するアクティベーションキー |
オプションの完全一覧については、以下のコマンドを実行します。
(undercloud) $ openstack help overcloud deploy
環境ファイルの parameter_defaults セクションに追加する Heat テンプレートのパラメーターの使用が優先されるため、一部のコマンドラインパラメーターは古いか非推奨となっています。以下の表では、非推奨となったパラメーターと、それに相当する Heat テンプレートのパラメーターを対照しています。
表6.2 非推奨の CLI パラメーターと Heat テンプレートのパラメーターの対照表
| パラメーター | 説明 | Heat テンプレートのパラメーター |
|---|---|---|
|
|
スケールアウトするコントローラーノード数 |
|
|
|
スケールアウトするコンピュートノード数 |
|
|
|
スケールアウトする Ceph Storage ノードの数 |
|
|
|
スケールアウトする Cinder ノード数 |
|
|
|
スケールアウトする Swift ノード数 |
|
|
|
コントローラーノードに使用するフレーバー |
|
|
|
コンピュートノードに使用するフレーバー |
|
|
|
Ceph Storage ノードに使用するフレーバー |
|
|
|
Cinder ノードに使用するフレーバー |
|
|
|
Swift Storage ノードに使用するフレーバー |
|
|
|
フラットなネットワークが neutron プラグインで設定されるように定義します。外部ネットワークを作成ができるようにデフォルトは「datacentre」に設定されています。 |
|
|
|
各ハイパーバイザーで作成する Open vSwitch ブリッジ。デフォルト値は「br-ex」で、通常この値は変更する必要はないはずです。 |
|
|
|
使用する論理ブリッジから物理ブリッジへのマッピング。ホスト (br-ex) の外部ブリッジを物理名 (datacentre) にマッピングするようにデフォルト設定されています。これは、デフォルトの Floating ネットワークに使用されます。 |
|
|
|
ネットワークノード向けにインターフェースを br-ex にブリッジするインターフェースを定義します。 |
|
|
|
Neutron のテナントネットワーク種別 |
|
|
|
neutron テナントネットワークのトンネリング種別。複数の値を指定するには、コンマ区切りの文字列を使用します。 |
|
|
|
テナントネットワークを割り当てに使用できる GRE トンネリングの ID 範囲 |
|
|
|
テナントネットワークを割り当てに使用できる VXLAN VNI の ID 範囲 |
|
|
|
サポートされる Neutron ML2 および Open vSwitch VLAN マッピングの範囲。デフォルトでは、物理ネットワーク「datacentre」上の VLAN を許可するように設定されています。 |
|
|
|
neutron テナントネットワークのメカニズムドライバー。デフォルトでは、「openvswitch」に設定されており、複数の値を指定するにはコンマ区切りの文字列を使用します。 |
|
|
|
VLAN で区切られたネットワークまたは neutron でのフラットネットワークを使用するためにトンネリングを無効化します。 |
パラメーターのマッピングなし |
|
|
オーバークラウドの作成プロセスでは、デプロイメントの前に一連のチェックが行われます。このオプションは、デプロイメント前のチェックで何らかの致命的なエラーが発生した場合に終了します。どのようなエラーが発生してもデプロイメントが失敗するので、このオプションを使用することを推奨します。 |
パラメーターのマッピングなし |
これらのパラメーターは、Red Hat OpenStack Platform の今後のリリースで削除される予定です。
6.12. オーバークラウドデプロイメントへの環境ファイルの追加
オーバークラウドをカスタマイズするには、-e を指定して、環境ファイルを追加します。必要に応じていくつでも環境ファイルを追加することができますが、後で実行される環境ファイルで定義されているパラメーターとリソースが優先されることになるため、環境ファイルの順番は重要です。以下の一覧は、環境ファイルの順序の例です。
- 各ロールおよびそのフレーバーごとのノード数。オーバークラウドを作成するには、この情報の追加は不可欠です。
- コンテナー化された OpenStack サービスのコンテナーイメージの場所。
-
任意のネットワーク分離ファイル。Heat テンプレートコレクションの初期化ファイル (
environments/network-isolation.yaml) から開始して、次にカスタムの NIC 設定ファイル、最後に追加のネットワーク設定の順番です。 - 外部のロードバランシングの環境ファイル。
- Ceph Storage、NFS、iSCSI などのストレージ環境ファイル。
- Red Hat CDN または Satellite 登録用の環境ファイル。
- その他のカスタム環境ファイル。
-e オプションを使用してオーバークラウドに追加した環境ファイルは、すべてオーバークラウドのスタック定義の一部となります。
以下のコマンドは、本シナリオの初期に定義した環境ファイルを使用してオーバークラウドの作成を開始する方法の一例です。
(undercloud) $ openstack overcloud deploy --templates \ -e /home/stack/templates/node-info.yaml\ -e /home/stack/templates/overcloud_images.yaml \ -e /home/stack/inject-trust-anchor-hiera.yaml -r /home/stack/templates/roles_data.yaml \
上記のコマンドでは、以下の追加オプションも使用できます。
- --templates
-
/usr/share/openstack-tripleo-heat-templatesの Heat テンプレートコレクションをベースとして使用し、オーバークラウドを作成します。 - -e /home/stack/templates/node-info.yaml
- 各ロールに使用するノード数とフレーバーを定義する環境ファイルを追加します。
- -e /home/stack/templates/overcloud_images.yaml
- コンテナーイメージソースを含む環境ファイルを追加します。
- -e /home/stack/inject-trust-anchor-hiera.yaml
- アンダークラウドにカスタム証明書をインストールする環境ファイルを追加します。
- -r /home/stack/templates/roles_data.yaml
- (オプション) カスタムロールを使用する、またはマルチアーキテクチャークラウドを有効にする場合に生成されるロールデータ。詳しくは、「アーキテクチャーに固有なロールの作成」を参照してください。
director は、「9章オーバークラウド作成後のタスクの実行」に記載の再デプロイおよびデプロイ後の機能にこれらの環境ファイルを必要とします。これらのファイルが含まれていない場合には、オーバークラウドが破損する可能性があります。
オーバークラウド設定を後で変更する予定の場合には、以下の作業を行う必要があります。
- カスタムの環境ファイルおよび Heat テンプレートのパラメーターを変更します。
-
同じ環境ファイルを指定して
openstack overcloud deployコマンドを再度実行します。
オーバークラウドを手動で編集しても、director を使用してオーバークラウドスタックの更新を行う際に director の設定で上書きされてしまうので、設定は直接編集しないでください。
6.13. デプロイメント操作を行う前のオーバークラウド設定の検証
オーバークラウドのデプロイメント操作を実行する前に、Heat テンプレートと環境ファイルにエラーがないかどうかを検証します。
手順
オーバークラウドのコア Heat テンプレートは、Jinja2 形式となっています。テンプレートを検証するには、以下のコマンドを使用して Jinja 2 のフォーマットなしでバージョンをレンダリングします。
$ cd /usr/share/openstack-tripleo-heat-templates $ ./tools/process-templates.py -o ~/overcloud-validation
以下のコマンドを使用して、テンプレート構文を検証します。
(undercloud) $ openstack orchestration template validate --show-nested \ --template ~/overcloud-validation/overcloud.yaml -e ~/overcloud-validation/overcloud-resource-registry-puppet.yaml \ -e [ENVIRONMENT FILE] \ -e [ENVIRONMENT FILE]
検証には、
overcloud-resource-registry-puppet.yamlの環境ファイルにオーバークラウド固有のリソースを含める必要があります。環境ファイルをさらに追加するには、このコマンドに-eオプションを使用してください。また、--show-nestedオプションを追加して、ネストされたテンプレートからパラメーターを解決します。- 検証コマンドにより、テンプレート内の構文エラーが特定されます。テンプレートの構文の検証が正常に行われた場合には、出力には、作成されるオーバークラウドのテンプレートのプレビューが表示されます。
6.14. オーバークラウドデプロイメントの出力
オーバークラウドの作成が完了すると、オーバークラウドを設定するために実施された Ansible のプレイの概要が director により提示されます。
PLAY RECAP ************************************************************* overcloud-compute-0 : ok=160 changed=67 unreachable=0 failed=0 overcloud-controller-0 : ok=210 changed=93 unreachable=0 failed=0 undercloud : ok=10 changed=7 unreachable=0 failed=0 Tuesday 15 October 2018 18:30:57 +1000 (0:00:00.107) 1:06:37.514 ****** ========================================================================
director により、オーバークラウドへのアクセス情報も提供されます。
Ansible passed. Overcloud configuration completed. Overcloud Endpoint: http://192.168.24.113:5000 Overcloud Horizon Dashboard URL: http://192.168.24.113:80/dashboard Overcloud rc file: /home/stack/overcloudrc Overcloud Deployed
6.15. オーバークラウドへのアクセス
director は、director ホストからオーバークラウドに対話するための設定を行い、認証をサポートするスクリプトを作成して、stack ユーザーのホームディレクトリーにこのファイル (overcloudrc) を保存します。このファイルを使用するには、以下のコマンドを実行します。
(undercloud) $ source ~/overcloudrc
これで、director のホストの CLI からオーバークラウドと対話するために必要な環境変数が読み込まれます。コマンドプロンプトが変わり、オーバークラウドと対話していることが示されます。
(overcloud) $
director のホストとの対話に戻るには、以下のコマンドを実行します。
(overcloud) $ source ~/stackrc (undercloud) $
オーバークラウドの各ノードには、heat-admin と呼ばれるユーザーが含まれます。stack ユーザーには、各ノードに存在するこのユーザーに SSH 経由でアクセスすることができます。SSH でノードにアクセスするには、希望のノードの IP アドレスを特定します。
(undercloud) $ openstack server list
次に、heat-admin ユーザーとノードの IP アドレスを使用して、ノードに接続します。
(undercloud) $ ssh heat-admin@192.168.24.23
6.16. 次のステップ
これで、コマンドラインツールを使用したオーバークラウドの作成が完了しました。作成後の機能については、「9章オーバークラウド作成後のタスクの実行」を参照してください。
第7章 Web UI を使用した基本的なオーバークラウドの設定
本章では、Web UI を使用した OpenStack Platform 環境の基本的な設定手順を説明します。基本設定のオーバークラウドには、カスタムの機能は含まれていませんが、『オーバークラウドの高度なカスタマイズ』に記載の手順に従って、この基本的なオーバークラウドに高度な設定オプションを追加して、仕様に合わせてカスタマイズすることができます。
本章の例では、すべてのノードが電源管理に IPMI を使用したベアメタルシステムとなっています。電源管理の種別およびそのオプションに関する詳細は、「付録B 電源管理ドライバー」を参照してください。
ワークフロー
- ノードの定義テンプレートを使用して、空のノードを登録します。
- 全ノードのハードウェアを検査します。
- director にオーバークラウドプランをアップロードします。
- ノードをロールに割り当てます。
要件
- 「4章director のインストール」でインストールして UI を有効化した director ノード
- ノードに使用するベアメタルマシンのセット。必要なノード数は、作成予定のオーバークラウドのタイプにより異なります。これらのマシンは、各ノード種別に設定された要件にも従う必要があります。これらのノードにはオペレーティングシステムは必要ありません。director が Red Hat Enterprise Linux 7 のイメージを各ノードにコピーします。
- ネイティブ VLAN として設定したプロビジョニングネットワーク用のネットワーク接続 1 つ。全ノードは、このネットワークに接続する必要があります。
- その他のネットワーク種別はすべて、OpenStack サービスにプロビジョニングネットワークを使用しますが、ネットワークトラフィックの他のタイプに追加でネットワークを作成することができます。
マルチアーキテクチャークラウドでは、UI ワークフローはサポートされません。「6章CLI ツールを使用した基本的なオーバークラウドの設定」に記載の手順に従ってください。
7.1. Web UI へのアクセス
director の Web UI には、SSL 経由で undercloud.conf ファイルの undercloud_public_host パラメーターに設定した IP アドレスからアクセスします。たとえば、アンダークラウドのパブリック IP アドレスが 192.168.24.2 の場合には、https://192.168.24.2 から UI にアクセスすることができます。
Web UI はまず、以下のフィールドが含まれるログイン画面を表示します。
-
Username: director の管理ユーザー。デフォルトは
adminです。 -
Password: 管理ユーザーのパスワード。アンダークラウドホストのターミナルで
stackユーザーとしてsudo hiera admin_passwordを実行してパスワードを確認してください。
UI へのログイン時に、UI は OpenStack Identity のパブリック API にアクセスして、他のパブリック API サービスのエンドポイントを取得します。これらのサービスには、以下のコンポーネントが含まれます。
| コンポーネント | UI の目的 |
|---|---|
|
OpenStack Identity ( |
UI への認証と他のサービスのエンドポイント検出 |
|
OpenStack Orchestration ( |
デプロイメントのステータス |
|
OpenStack Bare Metal ( |
ノードの制御 |
|
OpenStack Object Storage ( |
Heat テンプレートコレクションまたはオーバークラウドの作成に使用したプランのストレージ |
|
OpenStack Workflow ( |
director タスクのアクセスおよび実行 |
|
OpenStack Messaging ( |
特定のタスクのステータスを検索する Websocket ベースのサービス |
7.2. Web UI のナビゲーション
UI は主に 3 つのセクションで構成されています。
- プラン
UI 上部のメニューアイテム。このページは UI のメインセクションとして機能し、オーバークラウドの作成に使用するプラン、各ロールに割り当てるノード、現在のオーバークラウドのステータスを定義できます。このセクションでは、デプロイメントワークフローが提供され、デプロイメントのパラメーターの設定やロールへのノードの割り当てなどオーバークラウドの作成プロセスをステップごとにガイドします。
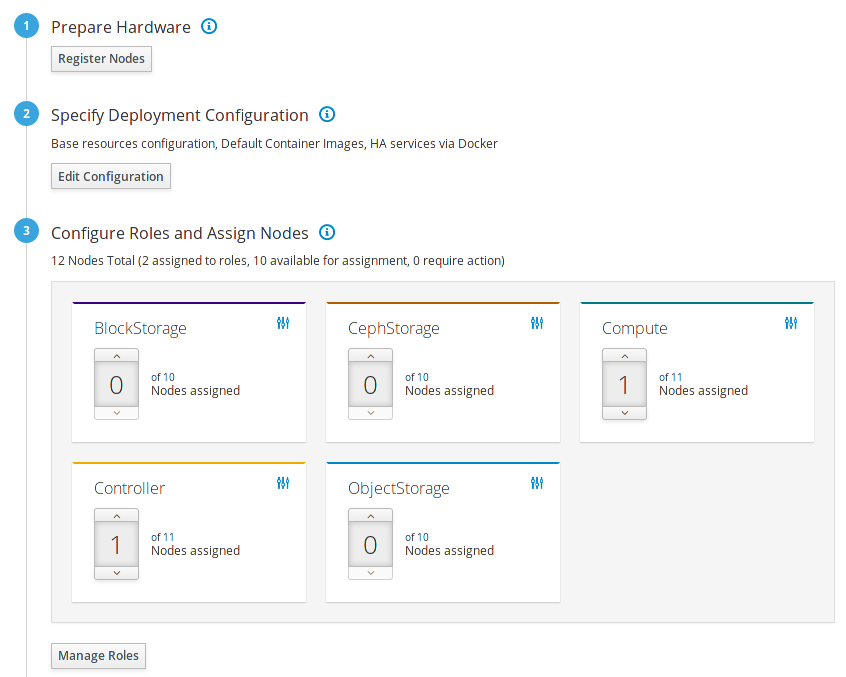
- ノード
UI 上部のメニューアイテム。このページはノードの設定セクションとして機能し、新規ノードの登録や登録したノードのイントロスペクションの手段を提供します。このセクションには、電源の状態、イントロスペクションのステータス、プロビジョニングの状態、およびハードウェア情報なども表示されます。
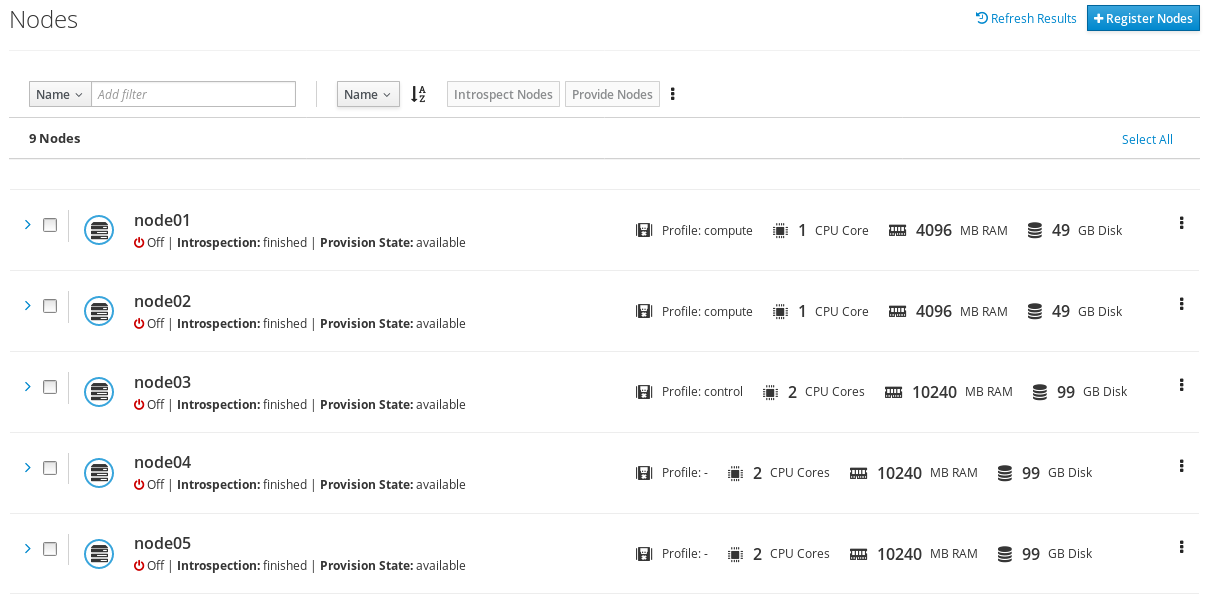
各ノードの右端にあるオーバーフローメニュー項目 (3 つの点) をクリックすると、選択したノードのディスク情報が表示されます。
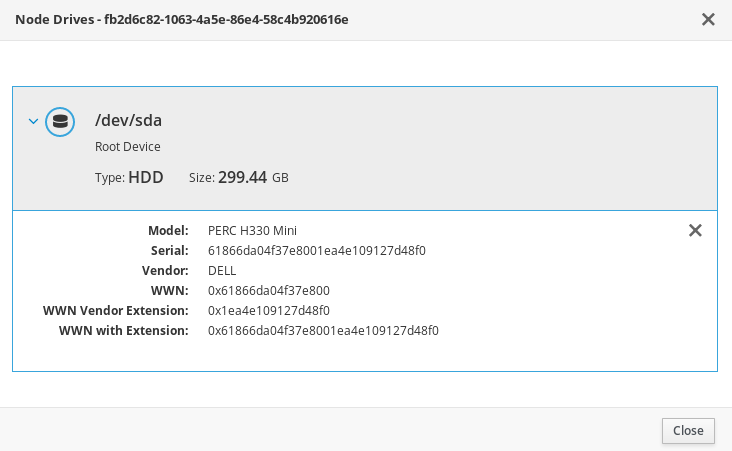
- 検証
検証 メニューオプションをクリックすると、ページの右側にパネルが表示されます。
このセクションには、以下の時点で実施される、さまざまなシステムチェックが表示されます。
- デプロイメント前
- デプロイメント後
- イントロスペクション前
- アップグレード前
- アップグレード後
これらの検証タスクは、デプロイメントの特定の時点で自動的に実行されますが、手動で実行することもできます。実行する検証タスクの 再生 ボタンをクリックします。各検証タスクのタイトルをクリックして実行するか、検証タイトルをクリックして詳細情報を表示します。
7.3. Web UI を使用したオーバークラウドプランのインポート
director UI でのオーバークラウド設定の前に、プランが必要です。このプランは通常、/usr/share/openstack-tripleo-heat-templates にあるアンダークラウド上のテンプレートなど、Heat テンプレートコレクションです。さらに、ハードウェアや環境の要件に合わせてプランをカスタマイズすることができます。オーバークラウドのカスタマイズに関する詳しい情報は『オーバークラウドの高度なカスタマイズ』を参照してください。
プランには、オーバークラウドの設定に関する 6 つの主要な手順が表示されます。
- ハードウェアの準備: ノードの登録およびイントロスペクション
- デプロイメントの設定の指定: オーバークラウドのパラメーターの設定と追加する環境ファイルの定義
- ロールの設定とノードの割り当て: ロールへのノード割り当てと、ロール固有のパラメーターの変更
- ネットワークの設定: オーバークラウドのネットワークトポロジーの確認
- Prepare Container Images: オーバークラウド用コンテナーイメージを準備/取得するためのパラメーターの編集
- デプロイ: オーバークラウド作成の開始
アンダークラウドのインストールと設定を実行すると、プランが自動的にアップロードされます。Web UI に複数のプランをインポートすることも可能です。プラン 画面のパンくずリストで すべてのプラン をクリックすると、現在の プラン のリストが表示されます。プランを切り替えるには、カードをクリックします。
プランのインポート をクリックすると、以下の情報を尋ねるウィンドウが表示されます。
-
プラン名:
overcloudなど、プランのプレーンテキスト名 アップロードの種別: テンプレートのアップロードに使用する方法を選択します。
- デフォルトのテンプレートを使用してください: デフォルトの Heat テンプレートコレクションを使用します。
- Tar アーカイブ (.tar.gz or .tgz): テンプレートが含まれるアーカイブを使用します。
- ローカルディレクトリー (Google Chrome のみ): クライアントシステムのローカルディレクトリーからアップロードします。
- Git リポジトリーの URL: パブリック Git リポジトリーの URL を使用します。
- プランファイル: ブラウザーをクリックして、ローカルのファイルシステム上のプランを選択します。
director の Heat テンプレートコレクションをクライアントのマシンにコピーする必要がある場合には、ファイルをアーカイブしてコピーします。
$ cd /usr/share/openstack-tripleo-heat-templates/ $ tar -cf ~/overcloud.tar * $ scp ~/overcloud.tar user@10.0.0.55:~/.
director UI がプランをアップロードしたら、プランが プラン のリストに表示され、設定を行うことができます。選択するプランのカードをクリックします。

7.4. Web UI を使用したノードの登録
オーバークラウド設定の最初の手順は、ノードの登録です。以下のいずれかで、ノードの登録プロセスを開始します。
- プラン 画面の 1 ハードウェアの準備 にある ノードの登録 をクリックします。
- ノード 画面の ノードの登録 をクリックします。
ノードの登録 ウィンドウが表示されます。
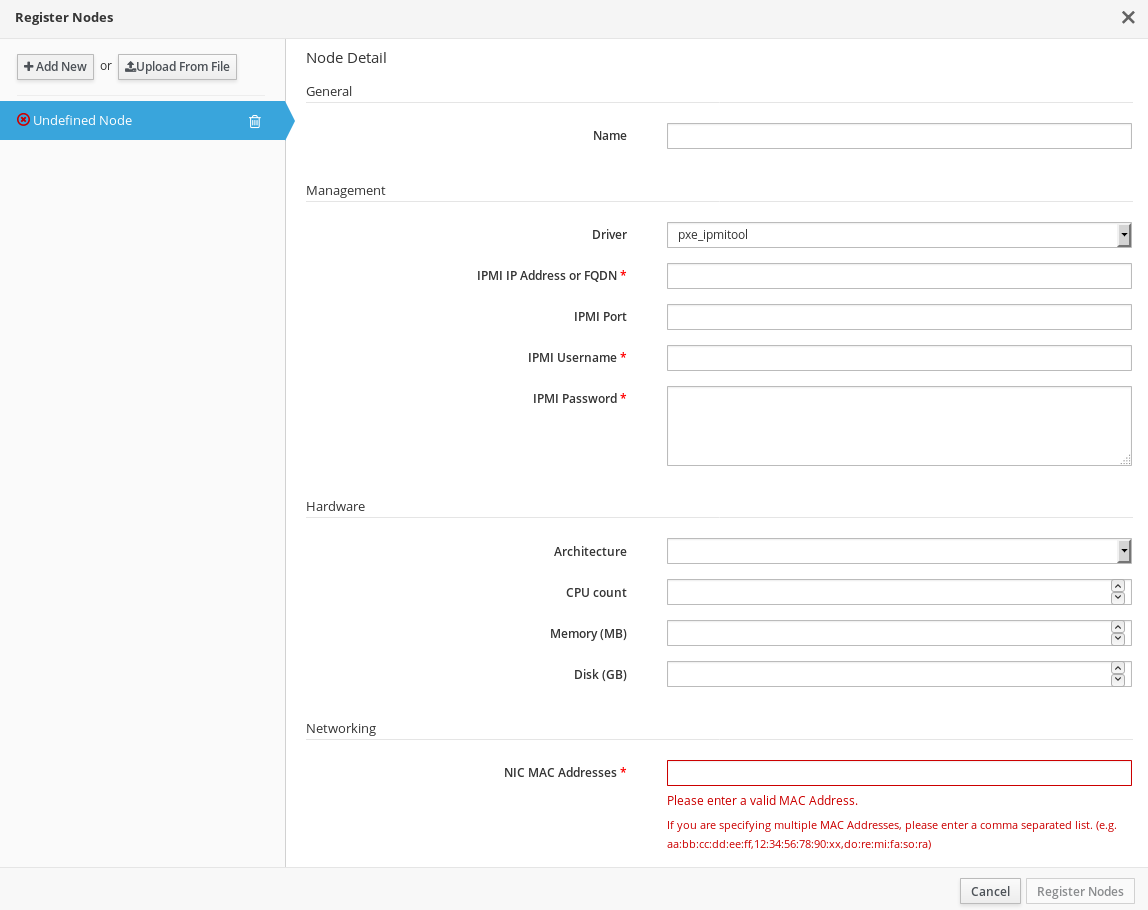
director には、登録するノードの一覧が必要です。以下のいずれかの方法でリストを取得できます。
- ノード定義テンプレートのアップロード: これには、ファイルからアップロード ボタンをクリックして、ファイルを選択してください。ノードの定義テンプレートの構文については、「オーバークラウドへのノードの登録」を参照してください。
- 各ノードの手動登録: これには、新規追加 をクリックして、ノードの詳細を提供します。
手動登録に必要な情報は以下のとおりです。
- 名前
- ノードのプレーンテキスト名。RFC3986 の非予約文字のみを使用するようにしてください。
- ドライバー
-
使用する電源管理ドライバー。この例では IPMI ドライバーを使用しますが (
ipmi)、他のドライバーも利用できます。利用可能なドライバーについては、「付録B 電源管理ドライバー」を参照してください。 - IPMI IP アドレス
- IPMI デバイスの IP アドレス
- IPMI ポート
- IPMI デバイスにアクセスするためのポート
- IPMI のユーザー名およびパスワード
- IPMI のユーザー名およびパスワード
- アーキテクチャー
- (オプション) システムアーキテクチャー
- CPU 数
- (オプション) ノード上の CPU 数
- メモリー (MB)
- (オプション) メモリーサイズ (MB)
- ディスク (GB)
- (オプション) ハードディスクのサイズ (GB)
- NIC の MAC アドレス
- ノード上のネットワークインターフェースの MAC アドレス一覧。各システムのプロビジョニング NIC の MAC アドレスのみを使用します。
UI では、Dell Remote Access Controller (DRAC) 電源管理を使用するノードの登録を行うこともできます。これらのノードでは、pxe_drac ドライバーが使われます。詳細は、「Dell Remote Access Controller (DRAC)」を参照してください。
ノードの情報を入力した後に、ウィンドウの下の ノードの登録 をクリックします。
director によりノードが登録されます。登録が完了すると、UI を使用してノードのイントロスペクションを実行できるようになります。
7.5. Web UI を使用したノードのハードウェアのイントロスペクション
director UI は各ノードでイントロスペクションプロセスを実行することができます。このプロセスを実行すると、各ノードが PXE を介してイントロスペクションエージェントを起動します。このエージェントは、ノードからハードウェアのデータを収集して、director に送り返します。次に director は、director 上で実行中の OpenStack Object Storage (swift) サービスにこのイントロスペクションデータを保管します。director は、プロファイルのタグ付け、ベンチマーキング、ルートディスクの手動割り当てなど、さまざまな目的でハードウェア情報を使用します。
ポリシーファイルを作成して、イントロスペクションの直後にノードをプロファイルに自動でタグ付けすることも可能です。ポリシーファイルを作成してイントロスペクションプロセスに組み入れる方法に関する詳しい情報は、「付録E プロファイルの自動タグ付け」を参照してください。または、UI を使用してプロファイルにノードをタグ付けすることもできます。手動でのノードのタグ付けに関する情報は、「Web UI を使用したロールへのノードの割り当て」を参照してください。
イントロスペクションのプロセスを開始するには以下のステップを実行します。
- ノード 画面に移動します。
- イントロスペクションを行うノードをすべて選択します。
- イントロスペクション をクリックします。
このプロセスが最後まで実行されて正常に終了したことを確認してください。ベアメタルの場合には、通常 15 分ほどかかります。
イントロスペクションのプロセスを完了したら、プロビジョニングの状態 が manageable に設定されているノードをすべて選択して、プロビジョン ボタンをクリックします。プロビジョニングの状態 が available になるまで待ちます。
ノードのタグ付けおよびプロビジョニングの準備ができました。
7.6. Web UI を使用したプロファイルへのノードのタグ付け
各ノードにプロファイルのセットを割り当てることができます。それぞれのプロファイルが、個々のフレーバーおよびロールに対応します (詳細は、「プロファイルへのノードのタグ付け」を参照してください)。
ノード 画面には、さらにトグルメニューがあり、ノードのタグ付け などのその他のノード管理操作を選択することができます。
ノードのセットをタグ付けするには、以下の手順を実行します。
- タグ付けするノードをチェックボックスで選択します。
- メニュートグルをクリックします。
- ノードのタグ付け をクリックします。
既存のプロファイルを選択します。新規プロファイルを作成するには、カスタムプロファイルを指定する を選択して カスタムプロファイル に名前を入力します。
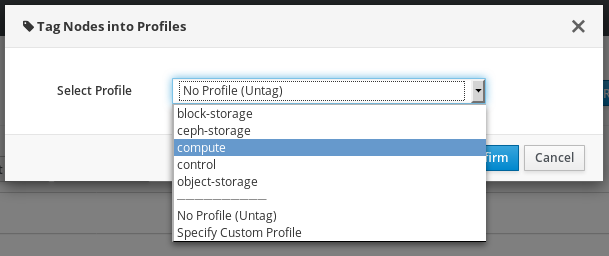 注記
注記カスタムプロファイルを作成する場合は、プロファイルタグを新規フレーバーに割り当てる必要もあります。新規フレーバー作成についての詳しい情報は、「プロファイルへのノードのタグ付け」を参照してください。
- 確認 をクリックしてノードをタグ付けします。
7.7. Web UI を使用したオーバークラウドプランのパラメーターの編集
プラン 画面では、アップロードしたプランをカスタマイズすることができます。2 デプロイメントの設定の指定 で、設定の編集 リンクをクリックして、ベースのオーバークラウドの設定を変更します。
ウィンドウには、2 つの主要なタブが表示されます。
- 全体の設定
このタブでは、オーバークラウドからの異なる機能を追加する方法を提供します。これらの機能は、プランの
capabilities-map.yamlファイルに定義されており、機能毎に異なるファイルを使用します。たとえば、Storage で Storage Environment を選択すると、プランはenvironments/storage-environment.yamlファイルにマッピングされ、オーバークラウドの NFS、iSCSI、Ceph の設定を行うことができます。Other タブには、プランで検出されているが、プランに含まれるカスタムの環境ファイルを追加するのに役立つcapabilities-map.yamlには記載されていない環境ファイルが一覧表示されます。追加する機能を選択したら、変更の保存 をクリックしてください。
- パラメーター
このタブには、オーバークラウドのさまざまなベースレベルパラメーターおよび環境ファイルパラメーターが含まれます。パラメーターを変更した場合には 変更の保存 をクリックしてください。
7.8. Web UI でのロールの追加
3 ロールの設定とノードの割り当て セクションの左下には、ロールの管理 アイコンがあります。
このアイコンをクリックすると、環境に追加できるロールを示すカードの選択肢が表示されます。ロールを追加するには、そのロールの右上にあるチェックボックスにチェックを付けます。

ロールを選択したら、変更の保存 をクリックします。
7.9. Web UI を使用したロールへのノードの割り当て
各ノードのハードウェアを登録、検査した後には、プランの画面からロールに割り当てます。
ロールにノードを割り当てるには、プラン の画面で 3 ロールの設定とノードの割り当て セクションまでスクロールします。各ロールで、スピナーウィジェットを使ってノード数をロールに割り当てます。それぞれのロールで利用可能なノードの数は、「Web UI を使用したプロファイルへのノードのタグ付け」でタグ付けしたノードに基づきます。

この操作により、各ロールの *Count パラメーターが変更されます。たとえば、コントローラーロールのノード数を 3 に変更すると、ControllerCount パラメーターが 3 に設定されます。デプロイメント設定の パラメーター タブで、これらのカウント値を表示および編集することもできます。詳細は、「Web UI を使用したオーバークラウドプランのパラメーターの編集」を参照してください。
7.10. Web UI を使用したロールパラメーターの編集
各ノードのロールにより、ロール固有のパラメーターを設定する手段が提供されます。プラン の画面で 3 ロールの設定とノードの割り当て セクションまでスクロールします。ロール名の横にある Edit Role Parameters アイコンをクリックします。
ウィンドウには、2 つの主要なタブが表示されます。
- パラメーター
これには、さまざまなロール固有のパラメーターが含まれます。たとえば、コントローラーロールを編集する場合には、
OvercloudControlFlavorパラメーターを使用して、そのロールのデフォルトのフレーバーを変更することができます。ロール固有のパラメーターを変更したら、変更の保存 をクリックします。
- サービス
これにより、選択したロールのサービス固有のパラメーターが定義されます。左のパネルでは、選択して変更したサービス一覧が表示されます。たとえば、タイムゾーンを変更するには、
OS::TripleO:Services:TimezoneサービスをクリックしてTimeZoneパラメーターを希望のタイムゾーンに変更します。サービス固有のパラメーターを変更したら、変更の保存 をクリックしてください。
- ネットワーク設定
ネットワーク設定では、オーバークラウドのさまざまなネットワークに対して IP アドレスまたはサブネットの範囲を定義できます。
ロールのサービスパラメーターは UI に表示されますが、デフォルトではサービスは無効になっている場合があります。「Web UI を使用したオーバークラウドプランのパラメーターの編集」の説明に沿って、これらのサービスを有効化することができます。これらのサービスの有効化に関する情報は、『オーバークラウドの高度なカスタマイズ』の「コンポーザブルサービスとカスタムロール」セクションも参照してください。
7.11. Web UI でのネットワークトポロジーの表示
前提条件
デプロイメント設定の第 2 ステップでネットワーク分離を有効にしていることを確認してください。
手順
デプロイメントの前にネットワーク設定を確認するには、以下の手順を実行します。
- プラン のページで 4 ネットワークの設定 までスクロールします。
- 設定の編集 をクリックします。ネットワークトポロジーがウィンドウに表示されるので、設定を確認することができます。
7.12. Web UI でのコンテナーイメージの準備
オーバークラウド用コンテナーイメージを準備するには、以下の手順を使用して詳細を定義します。
手順
- プラン のページで 5 Prepare Container Image までスクロールします。
- 設定の編集 をクリックします。コンテナーイメージの詳細に関するウィンドウが表示されます。
コンテナーイメージの詳細情報を編集します。
- Registry Namespace: 各 OpenStack サービスイメージの名前空間
- Name Prefix: 各 OpenStack サービスイメージの接頭辞
- Name Suffix: 各 OpenStack サービスイメージの接尾辞
-
Tag: ソースレジストリーからプルするイメージを識別するために director が使用するタグ。通常、このキーは
latestに設定したままにします。 - Push Destination: アップロードプロセス中にイメージをプッシュするレジストリーの名前空間。このパラメーターで名前空間を指定すると、すべてのイメージパラメーターでもこの名前空間が使用されます。このパラメーターは、アンダークラウドのレジストリーまたは外部のカスタムレジストリーのいずれかに設定することができます。アップロードプロセスをスキップして Red Hat Container Catalog から直接イメージをプルするには、Don’t push images を選択して直接プルします。この場合、各オーバークラウドノードが Red Hat Container Catalog から同じコンテナーイメージをプルするので、外部ルートが輻輳する点に注意してください。
-
Tag from Label: 得られたイメージをタグ付けするラベルパターンを定義します。通常は、
\{version}-\{release}に設定します。
- これらの詳細情報を編集したら、Next をクリックします。
- オーバークラウド用コンテナーイメージの設定を確認し、Save Changes をクリックします。
7.13. Web UI を使用したオーバークラウドの作成開始
オーバークラウドプランが設定されたら、オーバークラウドのデプロイメントを開始することができます。そのためには、6 デプロイ セクションまでスクロールして、検証とデプロイ をクリックしてください。

アンダークラウドの検証をすべて実行しなかった場合や、すべての検証に合格しなかった場合には、警告メッセージが表示されます。アンダークラウドのホストが要件を満たしていることを確認してから、デプロイメントを実行してください。
デプロイメントの準備ができたら デプロイ をクリックしてください。
UI では、定期的に オーバークラウド作成の進捗がモニタリングされ、現在の進捗の割合を示すプログレスバーが表示されます。詳細情報の表示 リンクでは、オーバークラウドにおける現在の OpenStack Orchestration スタックのログが表示されます。
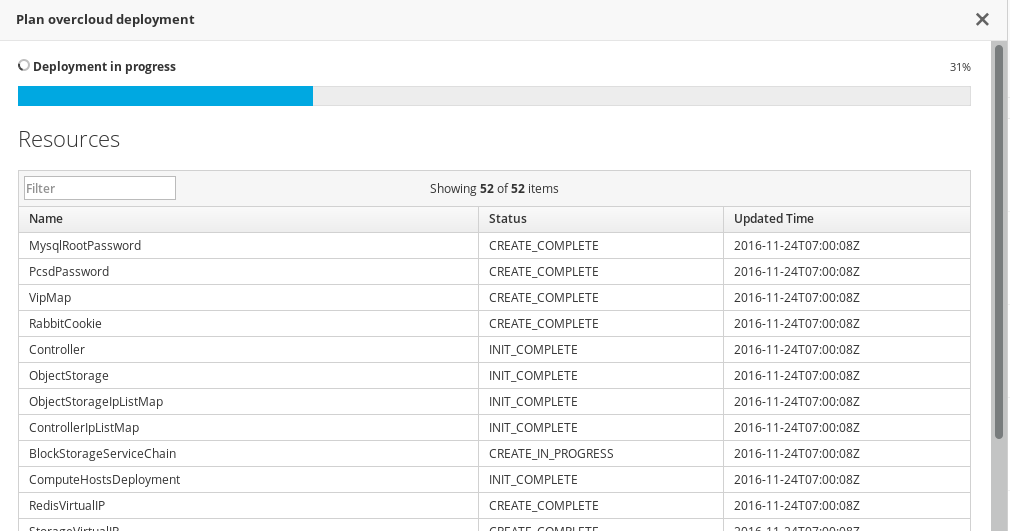
オーバークラウドのデプロイメントが完了するまで待ちます。
オーバークラウドの作成プロセスが完了したら、6 デプロイ セクションに、現在のオーバークラウドの状況と以下の詳細が表示されます。
- オーバークラウドの IP アドレス: オーバークラウドにアクセスするための IP アドレス
-
パスワード: オーバークラウドの
adminユーザーのパスワード
この情報を使用してオーバークラウドにアクセスします。
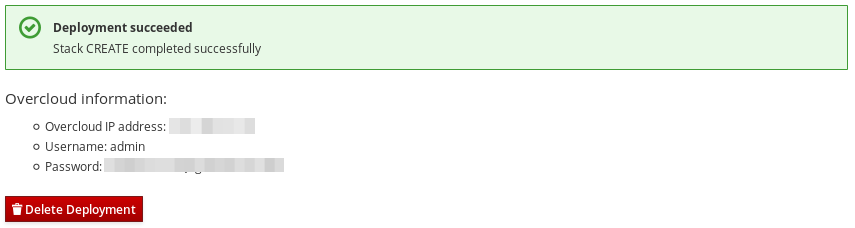
7.14. オーバークラウド作成の完了
これで director の UI を使用したオーバークラウドの作成が完了しました。作成後の機能については、「9章オーバークラウド作成後のタスクの実行」を参照してください。
第8章 事前にプロビジョニングされたノードを使用した基本的なオーバークラウドの設定
本章では、OpenStack Platform 環境を設定します。事前にプロビジョニングされたノードを使用して OpenStack Platform 環境を設定する基本的な手順を説明します。以下のシナリオは、標準のオーバークラウド作成のシナリオとはさまざまな点で異なります。
- 外部ツールを使用してノードをプロビジョニングしてから、director でオーバークラウドの設定のみを制御することができます。
- director のプロビジョニングの方法に依存せずにノードを使用することができます。これは、電源管理制御なしでオーバークラウドを作成する場合や、DHCP/PXE ブートの制限があるネットワークを使用する場合に便利です。
- director は、ノードの管理に OpenStack Compute (nova)、OpenStack Bare Betal (ironic) または OpenStack Image (glance) を使用しません。
-
事前にプロビジョニングされたノードでは、QCOW2
overcloud-fullイメージに依存しないカスタムパーティショニングレイアウトを使用することができます。
このシナリオでは、カスタム機能のない基本的な設定を行いますが、『オーバークラウドの高度なカスタマイズ』に記載の手順に従って、この基本的なオーバークラウドに高度な設定オプションを追加して、仕様に合わせてカスタマイズすることができます。
事前にプロビジョニングされたノードと director がプロビジョニングしたノードが混在するオーバークラウド環境はサポートされていません。
要件
- 「4章director のインストール」で作成した director ノード
- ノードに使用するベアメタルマシンのセット。必要なノード数は、作成予定のオーバークラウドのタイプにより異なります。これらのマシンは、各ノード種別に設定された要件にも従う必要があります。これらのノードには、ホストオペレーティングシステムとして Red Hat Enterprise Linux 7.5 以降をインストールする必要があります。Red Hat では、利用可能な最新バージョンの使用を推奨します。
- 事前にプロビジョニングされたノードを管理するためのネットワーク接続 1 つ。このシナリオでは、オーケストレーションエージェントの設定のために、ノードへの SSH アクセスが中断されないようにする必要があります。
コントロールプレーンネットワーク用のネットワーク接続 1 つ。このネットワークには、主に 2 つのシナリオがあります。
プロビジョニングネットワークをコントロールプレーンとして使用するデフォルトのシナリオ。このネットワークは通常、事前にプロビジョニングされたノードから director への Layer 3 (L3) を使用したルーティング可能なネットワーク接続です。このシナリオの例では、以下の IP アドレスの割り当てを使用します。
表8.1 プロビジョニングネットワークの IP 割り当て
ノード名 IP アドレス director
192.168.24.1
コントローラー
192.168.24.2
Compute
192.168.24.3
- 別のネットワークを使用するシナリオ。director のプロビジョニングネットワークがプライベートのルーティング不可能なネットワークの場合には、サブネットからノードの IP アドレスを定義して、パブリック API エンドポイント経由で director と通信することができます。このシナリオには特定の注意事項があります。これについては、本章の後半の「オーバークラウドノードに別のネットワークを使用する方法」で考察します。
- この例で使用するその他すべてのネットワーク種別には、OpenStack サービス用のコントロールプレーンネットワークも使用しますが、他のネットワークトラフィック種別用に追加のネットワークを作成することができます。
8.1. ノード設定のためのユーザーの作成
このプロセスの後半では、director が オーバークラウドノードに stack ユーザーとして SSH アクセスする必要があります。
各オーバークラウドノードで、
stackという名前のユーザーを作成して、それぞれにパスワードを設定します。たとえば、コントローラーノードでは以下のコマンドを使用します。[root@controller ~]# useradd stack [root@controller ~]# passwd stack # specify a password
sudoを使用する際に、このユーザーがパスワードを要求されないようにします。[root@controller ~]# echo "stack ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/stack [root@controller ~]# chmod 0440 /etc/sudoers.d/stack
事前にプロビジョニングされた全ノードで
stackユーザーの作成と設定が完了したら、director ノードから各オーバークラウドノードにstackユーザーの公開 SSH 鍵をコピーします。たとえば、director の公開 SSH 鍵をコントローラーノードにコピーするには、以下のコマンドを実行します。[stack@director ~]$ ssh-copy-id stack@192.168.24.2
8.2. ノードのオペレーティングシステムの登録
ノードごとに Red Hat サブスクリプションへのアクセスが必要です。以下の手順は、各ノードを Red Hat コンテンツ配信ネットワークに登録する方法を説明しています。各ノードで以下の手順を実行してください。
登録コマンドを実行して、プロンプトが表示されたらカスタマーポータルのユーザー名とパスワードを入力します。
[root@controller ~]# sudo subscription-manager register
Red Hat OpenStack Platform 14 のエンタイトルメントプールを検索します。
[root@controller ~]# sudo subscription-manager list --available --all --matches="Red Hat OpenStack"
上記のステップで特定したプール ID を使用して、Red Hat OpenStack Platform 14 のエンタイトルメントをアタッチします。
[root@controller ~]# sudo subscription-manager attach --pool=pool_id
デフォルトのリポジトリーをすべて無効にします。
[root@controller ~]# sudo subscription-manager repos --disable=*
必要な Red Hat Enterprise Linux リポジトリーを有効にします。
x86_64 システムの場合には、以下のコマンドを実行します。
[root@controller ~]# sudo subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpms --enable=rhel-7-server-openstack-14-rpms --enable=rhel-7-server-rhceph-2-osd-rpms --enable=rhel-7-server-rhceph-2-mon-rpms --enable=rhel-7-server-rhceph-2-tools-rpms
POWER システムの場合には、以下のコマンドを実行します。
[root@controller ~]# sudo subscription-manager repos --enable=rhel-7-for-power-le-rpms --enable=rhel-7-server-openstack-14-for-power-le-rpms
重要記載されたリポジトリーのみを有効にします。追加のリポジトリーを使用すると、パッケージとソフトウェアの競合が発生する場合があります。他のリポジトリーは有効にしないでください。
システムを更新して、ベースシステムのパッケージを最新の状態にします。
[root@controller ~]# sudo yum update -y [root@controller ~]# sudo reboot
このノードをオーバークラウドに使用する準備ができました。
8.3. director への SSL/TLS アクセスの設定
director が SSL/TLS を使用する場合は、事前にプロビジョニングされたノードには、director の SSL/TLS 証明書の署名に使用する認証局ファイルが必要です。独自の認証局を使用する場合には、各オーバークラウドノード上で以下のステップを実行します。
-
事前にプロビジョニングされた各ノードの
/etc/pki/ca-trust/source/anchors/ディレクトリーに認証局ファイルをコピーします。 各オーバークラウドノード上で以下のコマンドを実行します。
[root@controller ~]# sudo update-ca-trust extract
これにより、オーバークラウドノードが director のパブリック API に SSL/TLS 経由でアクセスできるようにします。
8.4. コントロールプレーンのネットワークの設定
事前にプロビジョニングされたオーバークラウドノードは、標準の HTTP 要求を使用して director からメタデータを取得します。これは、オーバークラウドノードでは以下のいずれかに対して L3 アクセスが必要であることを意味します。
-
director のコントロールプレーンネットワーク。これは、
undercloud.confファイルのnetwork_cidrパラメーターで定義されたサブネットです。ノードには、このサブネットへの直接アクセスまたはルーティング可能なアクセスのいずれかが必要です。 -
undercloud.confファイルのundercloud_public_hostパラメーターとして指定された director のパブリック API のエンドポイント。コントロールプレーンへの L3 ルートがない場合や、SSL/TLS 通信を使用する場合に、このオプションを利用できます。オーバークラウドがパブリック API エンドポイントを使用するための追加の設定手順については、「オーバークラウドノードに別のネットワークを使用する方法」を参照してください。
director は、コントロールプレーンネットワークを使用して標準のオーバークラウドを管理、設定します。事前にプロビジョニングされたノードを使用したオーバークラウドの場合には、director が事前にプロビジョニングされたノードと通信する方法に対応するために、ネットワーク設定を変更する必要がある場合があります。
ネットワーク分離の使用
ネットワークを分離すると、コントロールプレーンなど、固有のネットワークを使用するようにサービスをグループ化できます。『オーバークラウドの高度なカスタマイズ』には、ネットワーク分離の方法が複数記載されています。また、コントロールプレーン上のノードに固有の IP アドレスを定義することも可能です。ネットワーク分離や予測可能なノード配置方法の策定に関する詳しい情報は、『オーバークラウドの高度なカスタマイズ』の以下のセクションを参照してください。
ネットワーク分離を使用する場合には、NIC テンプレートに、アンダークラウドのアクセスに使用する NIC を含めないようにしてください。これらのテンプレートにより NIC が再構成され、デプロイメント時に接続性や設定の問題が発生する可能性があります。
IP アドレスの割り当て
ネットワーク分離を使用しない場合には、単一のコントロールプレーンを使用して全サービスを管理することができます。これには、各ノード上のコントロールプレーンの NIC を手動で設定して、コントロールプレーンネットワークの範囲内の IP アドレスを使用するようにする必要があります。director のプロビジョニングネットワークをコントロールプレーンとして使用する場合には、選択したオーバークラウドの IP アドレスが、プロビジョニング (dhcp_start および dhcp_end) とイントロスペクション (inspection_iprange) の両方の DHCP 範囲外になるようにしてください。
標準のオーバークラウド作成中には、director はプロビジョニング/コントロールプレーンネットワークのオーバークラウドノードに IP アドレスを自動的に割り当てるための OpenStack Networking (neutron) ポートを作成します。ただし、これにより、各ノードに手動で設定した IP アドレスとは異なるアドレスを director が割り当ててしまう可能性があります。このような場合には、予測可能な IP アドレス割り当て方法を使用して、director がコントロールプレーン上で事前にプロビジョニングされた IP の割り当てを強制的に使用するようにしてください。
予測可能可能な IP アドレス割り当て方法の例では、以下のように IP アドレスを割り当てた環境ファイル (ctlplane-assignments.yaml) を使用します。
resource_registry:
OS::TripleO::DeployedServer::ControlPlanePort: /usr/share/openstack-tripleo-heat-templates/deployed-server/deployed-neutron-port.yaml
parameter_defaults:
DeployedServerPortMap:
controller-ctlplane:
fixed_ips:
- ip_address: 192.168.24.2
subnets:
- cidr: 24
compute-ctlplane:
fixed_ips:
- ip_address: 192.168.24.3
subnets:
- cidr: 24
この例では、OS::TripleO::DeployedServer::ControlPlanePort リソースはパラメーターセットを director に渡して、事前にプロビジョニングされたノードの IP 割り当てを定義します。DeployedServerPortMap パラメーターは、各オーバークラウドノードに対応する IP アドレスおよびサブネット CIDR を定義します。このマッピングは以下を定義します。
-
割り当ての名前は、
<node_hostname>-<network>の形式です (例:controller-ctlplane、compute-ctlplane)。 以下のパラメーターパターンを使用する IP 割り当て
-
fixed_ips/ip_address: コントロールプレーンの固定 IP アドレスを定義します。複数の IP アドレスを定義する場合には、複数のip_addressパラメーターを一覧で指定してください。 -
subnets/cidr: サブネットの CIDR 値を定義します。
-
本章の後半のステップでは、作成された環境ファイル (ctlplane-assignments.yaml) を openstack overcloud deploy コマンドの一部として使用します。
8.5. オーバークラウドノードに別のネットワークを使用する方法
デフォルトでは、director はオーバークラウドのコントロールプレーンとしてプロビジョニングネットワークを使用しますが、このネットワークが分離されて、ルーティング不可能な場合には、ノードは設定中に director の内部 API との通信ができません。このような状況では、ノードに別のネットワークを定義して、パブリック API 経由で director と通信できるように設定する必要がある場合があります。
このシナリオには、以下のような複数の要件があります。
- オーバークラウドノードは、「コントロールプレーンのネットワークの設定」からの基本的なネットワーク設定に対応する必要があります。
- パブリック API エンドポイントを使用できるように director 上で SSL/TLS を有効化する必要があります。詳しい情報は、「director の設定パラメーター」と「付録A SSL/TLS 証明書の設定」を参照してください。
-
director 向けにアクセス可能な完全修飾ドメイン名 (FQDN) を定義する必要があります。この FQDN は、director にルーティング可能な IP アドレスを解決する必要があります。
undercloud.confファイルのundercloud_public_hostパラメーターを使用して、この FQDN を設定します。
本項に記載する例では、主要なシナリオとは異なる IP アドレスの割り当てを使用します。
表8.2 プロビジョニングネットワークの IP 割り当て
| ノード名 | IP アドレスまたは FQDN |
|---|---|
|
director (内部 API) |
192.168.24.1 (プロビジョニングネットワークおよびコントロールプレーン) |
|
director (パブリック API) |
10.1.1.1 / director.example.com |
|
オーバークラウドの仮想 IP |
192.168.100.1 |
|
コントローラー |
192.168.100.2 |
|
Compute |
192.168.100.3 |
以下の項では、オーバークラウドノードに別のネットワークが必要な場合の追加の設定について説明します。
IP アドレスの割り当て
IP の割り当て方法は、「コントロールプレーンのネットワークの設定」と似ていますが、コントロールプレーンはデプロイしたサーバーからルーティング可能ではないので、DeployedServerPortMap パラメーターを使用して、コントロールプレーンにアクセスする仮想 IP アドレスなど、選択したオーバークラウドノードのサブネットから IP アドレスを割り当てます。以下は、このネットワークアーキテクチャーに対応するように、「コントロールプレーンのネットワークの設定」の ctlplane-assignments.yaml 環境ファイルを変更したバージョンです。
resource_registry: OS::TripleO::DeployedServer::ControlPlanePort: /usr/share/openstack-tripleo-heat-templates/deployed-server/deployed-neutron-port.yaml OS::TripleO::Network::Ports::ControlPlaneVipPort: /usr/share/openstack-tripleo-heat-templates/deployed-server/deployed-neutron-port.yaml OS::TripleO::Network::Ports::RedisVipPort: /usr/share/openstack-tripleo-heat-templates/network/ports/noop.yaml 1 parameter_defaults: NeutronPublicInterface: eth1 EC2MetadataIp: 192.168.100.1 2 ControlPlaneDefaultRoute: 192.168.100.1 DeployedServerPortMap: control_virtual_ip: fixed_ips: - ip_address: 192.168.100.1 subnets: - cidr: 24 controller0-ctlplane: fixed_ips: - ip_address: 192.168.100.2 subnets: - cidr: 24 compute0-ctlplane: fixed_ips: - ip_address: 192.168.100.3 subnets: - cidr: 24
- 1
RedisVipPortリソースは、network/ports/noop.yamlにマッピングされます。このマッピングは、デフォルトの Redis VIP アドレスがコントロールプレーンから割り当てられていることが理由です。このような場合には、noopを使用して、このコントロールプレーンマッピングを無効化します。- 2
EC2MetadataIpとControlPlaneDefaultRouteパラメーターは、コントロールプレーンの仮想 IP アドレスの値に設定されます。デフォルトの NIC 設定テンプレートでは、これらのパラメーターが必須で、デプロイメント中に実行される検証に合格するには、ping 可能な IP アドレスを使用するように設定する必要があります。または、これらのパラメーターが必要ないように NIC 設定をカスタマイズします。
8.6. 事前にプロビジョニングされたノードのホスト名のマッピング
事前にプロビジョニングされたノードを設定する場合には、Heat ベースのホスト名をそれらの実際のホスト名にマッピングして、ansible-playbook が解決されたホストに到達できるようにする必要があります。それらの値は、HostnameMap を使用してマッピングします。
手順
環境ファイル (例:
hostname-map.yaml) を作成して、HostnameMapパラメーターとホスト名のマッピングを指定します。以下の構文を使用してください。parameter_defaults: HostnameMap: [HEAT HOSTNAME]: [ACTUAL HOSTNAME] [HEAT HOSTNAME]: [ACTUAL HOSTNAME][HEAT HOSTNAME]は通常[STACK NAME]-[ROLE]-[INDEX]の表記法に従います。以下に例を示します。parameter_defaults: HostnameMap: overcloud-controller-0: controller-00-rack01 overcloud-controller-1: controller-01-rack02 overcloud-controller-2: controller-02-rack03 overcloud-compute-0: compute-00-rack01 overcloud-compute-1: compute-01-rack01 overcloud-compute-2: compute-02-rack01-
hostname-map.yamlの内容を保存します。
8.7. 事前にプロビジョニングされたノードでのオーバークラウドの作成
オーバークラウドのデプロイメントには、「デプロイメントコマンド」に記載の標準の CLI の方法を使用します。事前にプロビジョニングされたノードの場合は、デプロイメントコマンドに追加のオプションと、コア Heat テンプレートコレクションからの環境ファイルが必要です。
-
--disable-validations: 事前にプロビジョニングされたインフラストラクチャーで使用しないサービスに対する基本的な CLI 検証を無効化します。無効化しないと、デプロイメントに失敗します。 -
environments/deployed-server-environment.yaml: 事前にプロビジョニングされたインフラストラクチャーを作成、設定するための主要な環境ファイル。この環境ファイルは、OS::Nova::ServerリソースをOS::Heat::DeployedServerリソースに置き換えます。 -
environments/deployed-server-bootstrap-environment-rhel.yaml: 事前にプロビジョニングされたサーバー上でブートストラップのスクリプトを実行する環境ファイル。このスクリプトは、追加パッケージをインストールして、オーバークラウドノードの基本設定を提供します。 -
environments/deployed-server-pacemaker-environment.yaml: 事前にプロビジョニングされたコントローラーノードで Pacemaker の設定を行う環境ファイル。このファイルに登録されるリソースの名前空間は、deployed-server/deployed-server-roles-data.yamlからのコントローラーのロール名を使用します。デフォルトでは、ControllerDeployedServerとなっています。 deployed-server/deployed-server-roles-data.yaml: カスタムロールのサンプルファイル。これは、デフォルトのroles_data.yamlが複製されたファイルですが、各ロールのdisable_constraints: Trueパラメーターも含まれています。このパラメーターは、生成されたロールテンプレートのオーケストレーションの制約を無効にします。これらの制約は、事前にプロビジョニングされたインフラストラクチャーで使用しないサービスが対象です。独自のカスタムロールファイルを使用する場合には、各ロールに
disable_constraints: Trueパラメーターを追加するようにしてください。以下に例を示します。- name: ControllerDeployedServer disable_constraints: True CountDefault: 1 ServicesDefault: - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephMon - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CephRgw ...
以下は、事前にプロビジョニングされたアーキテクチャー固有の環境ファイルを使用したオーバークラウドデプロイメントのコマンド例です。
$ source ~/stackrc (undercloud) $ openstack overcloud deploy \ [other arguments] \ --disable-validations \ -e /usr/share/openstack-tripleo-heat-templates/environments/deployed-server-environment.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/deployed-server-bootstrap-environment-rhel.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/deployed-server-pacemaker-environment.yaml \ -e /home/stack/templates/hostname-map.yaml / -r /usr/share/openstack-tripleo-heat-templates/deployed-server/deployed-server-roles-data.yaml --overcloud-ssh-user stack \ --overcloud-ssh-key ~/.ssh/id_rsa \ [OTHER OPTIONS]
--overcloud-ssh-user および --overcloud-ssh-key オプションは、設定ステージ中に各オーバークラウドノードに SSH 接続して、初期 tripleo-admin ユーザーを作成し、SSH キーを /home/tripleo-admin/.ssh/authorized_keys に挿入するのに使用します。SSH キーを挿入するには、初回の SSH 接続で --overcloud-ssh-user と --overcloud-ssh-key (~/.ssh/id_rsa がデフォルト) を使用して認証情報を指定します。--overcloud-ssh-key で指定した秘密鍵の公開を制限するために、director は Heat や Mistral などのどの API サービスにもこの鍵を渡さず、openstack overcloud deploy コマンドのみがこの鍵を使用して tripleo-admin ユーザーのアクセスを有効化します。
8.8. オーバークラウドデプロイメントの出力
オーバークラウドの作成が完了すると、オーバークラウドを設定するために実施された Ansible のプレイの概要が director により提示されます。
PLAY RECAP ************************************************************* overcloud-compute-0 : ok=160 changed=67 unreachable=0 failed=0 overcloud-controller-0 : ok=210 changed=93 unreachable=0 failed=0 undercloud : ok=10 changed=7 unreachable=0 failed=0 Tuesday 15 October 2018 18:30:57 +1000 (0:00:00.107) 1:06:37.514 ****** ========================================================================
director により、オーバークラウドへのアクセス情報も提供されます。
Ansible passed. Overcloud configuration completed. Overcloud Endpoint: http://192.168.24.113:5000 Overcloud Horizon Dashboard URL: http://192.168.24.113:80/dashboard Overcloud rc file: /home/stack/overcloudrc Overcloud Deployed
8.9. オーバークラウドへのアクセス
director は、director ホストからオーバークラウドに対話するための設定を行い、認証をサポートするスクリプトを作成して、stack ユーザーのホームディレクトリーにこのファイル (overcloudrc) を保存します。このファイルを使用するには、以下のコマンドを実行します。
(undercloud) $ source ~/overcloudrc
これで、director のホストの CLI からオーバークラウドと対話するために必要な環境変数が読み込まれます。コマンドプロンプトが変わり、オーバークラウドと対話していることが示されます。
(overcloud) $
director のホストとの対話に戻るには、以下のコマンドを実行します。
(overcloud) $ source ~/stackrc (undercloud) $
8.10. 事前にプロビジョニングされたノードのスケーリング
事前にプロビジョニングされたノードをスケーリングするプロセスは、「11章オーバークラウドノードのスケーリング」に記載の標準のスケーリングの手順と似ていますが、事前にプロビジョニングされたノードを新たに追加するプロセスは異なります。これは、事前にプロビジョニングされたノードが OpenStack Bare Metal (ironic) および OpenStack Compute (nova) からの標準の登録および管理プロセスを使用しないためです。
事前にプロビジョニングされたノードのスケールアップ
事前にプロビジョニングされたノードでオーバークラウドをスケールアップする際には、各ノードで director のノード数に対応するようにオーケストレーションエージェントを設定する必要があります。
事前にプロビジョニングされたノードをスケールアップするプロセスの概要は、以下のとおりです。
- 「要件」の説明に従って、事前にプロビジョニングされたノードを新たに準備します。
- ノードをスケールアップします。手順については「11章オーバークラウドノードのスケーリング」を参照してください。
- デプロイメントコマンドを実行した後に、director が新しいノードリソースを作成して設定を開始するまで待ちます。
事前にプロビジョニングされたノードのスケールダウン
事前にプロビジョニングされたノードを持つオーバークラウドをスケールダウンするには、「11章オーバークラウドノードのスケーリング」に記載の通常のスケールダウンの手順に従います。
ほとんどのスケーリング操作では、ノードの UUID 値を取得して openstack overcloud node delete に渡す必要があります。この UUID を取得するには、ロールを指定してリソースの一覧を表示します。
$ openstack stack resource list overcloud -c physical_resource_id -c stack_name -n5 --filter type=OS::TripleO::<RoleName>Server
上記コマンドの <RoleName> を、スケールダウンする実際のロール名に置き換えます。ComputeDeployedServer ロールの例を以下に示します。
$ openstack stack resource list overcloud -c physical_resource_id -c stack_name -n5 --filter type=OS::TripleO::ComputeDeployedServerServer
コマンド出力の stack_name 列から、各ノードに関連付けられた UUID を確認します。以下の出力例に示すように、stack_name には Heat リソースグループ内のノードインデックスである整数値が含まれます。
+------------------------------------+----------------------------------+ | physical_resource_id | stack_name | +------------------------------------+----------------------------------+ | 294d4e4d-66a6-4e4e-9a8b- | overcloud-ComputeDeployedServer- | | 03ec80beda41 | no7yfgnh3z7e-1-ytfqdeclwvcg | | d8de016d- | overcloud-ComputeDeployedServer- | | 8ff9-4f29-bc63-21884619abe5 | no7yfgnh3z7e-0-p4vb3meacxwn | | 8c59f7b1-2675-42a9-ae2c- | overcloud-ComputeDeployedServer- | | 2de4a066f2a9 | no7yfgnh3z7e-2-mmmaayxqnf3o | +------------------------------------+----------------------------------+
stack_name 列のインデックス 0、1、または 2 は、Heat リソースグループ内のノード順に対応します。physical_resource_id 列の該当する UUID 値を、openstack overcloud node delete コマンドに渡します。
スタックからオーバークラウドノードを削除したら、それらのノードの電源をオフにします。標準のデプロイメントでは、director のベアメタルサービスがこの機能を制御しますが、事前にプロビジョニングされたノードでは、これらのノードを手動でシャットダウンするか、物理システムごとに電源管理制御を使用します。スタックからノードを削除した後にノードの電源をオフにしないと、稼動状態が続き、オーバークラウド環境の一部として再接続されてしまう可能性があります。
削除したノードの電源をオフにした後には、再プロビジョニングしてベースのオペレーティングシステムの設定に戻し、それらのノードが意図せずにオーバークラウドに加わってしまうことがないようにします。
オーバークラウドから以前に削除したノードは、再プロビジョニングしてベースオペレーティングシステムを新規インストールしてからでなければ、再利用しないようにしてください。スケールダウンのプロセスでは、オーバークラウドスタックからノードを削除するだけで、パッケージはアンインストールされません。
8.11. 事前にプロビジョニングされたオーバークラウドの削除
標準のオーバークラウドと同じ手順で、事前にプロビジョニングされたノードを使用するオーバークラウド全体を削除します。詳しい情報は、「オーバークラウドの削除」を参照してください。
オーバークラウドの削除後には、全ノードの電源をオフにしてから再プロビジョニングして、ベースオペレーティングシステムの設定に戻します。
オーバークラウドから削除したノードは、再プロビジョニングしてベースオペレーティングシステムを新規インストールしてからでなければ再利用しないでください。削除のプロセスでは、オーバークラウドスタックを削除するだけで、パッケージはアンインストールされません。
8.12. オーバークラウド作成の完了
これで、事前にプロビジョニングされたノードを使用したオーバークラウドの作成が完了しました。作成後の機能については、「9章オーバークラウド作成後のタスクの実行」を参照してください。
パート III. デプロイメント後操作
第9章 オーバークラウド作成後のタスクの実行
本章では、任意のオーバークラウドを作成後に実行するタスクについて考察します。
9.1. オーバークラウドデプロイメントステータスの確認
オーバークラウドのデプロイメントステータスを確認するには、openstack overcloud status コマンドを使用します。このコマンドの出力に、全デプロイメントステップの結果が表示されます。
手順
source コマンドで
stackrcファイルを読み込みます。$ source ~/stackrc
デプロイメントステータスの確認コマンドを実行します。
$ openstack overcloud status
このコマンドの出力に、ステータスが表示されます。
+-----------+---------------------+---------------------+-------------------+ | Plan Name | Created | Updated | Deployment Status | +-----------+---------------------+---------------------+-------------------+ | overcloud | 2018-05-03 21:24:50 | 2018-05-03 21:27:59 | DEPLOY_SUCCESS | +-----------+---------------------+---------------------+-------------------+
ご自分のオーバークラウドに別の名前が使用されている場合には、
--plan引数を使用してその名前のオーバークラウドを選択します。$ openstack overcloud status --plan my-deployment
9.2. コンテナー化されたサービスの管理
OpenStack Platform では、アンダークラウドおよびオーバークラウドノード上のコンテナー内でサービスが実行されます。特定の状況では、1 つのホスト上で個別のサービスを制御しなければならない場合があります。本項では、コンテナー化されたサービスを管理するためにノード上で実行できる、一般的な docker コマンドについて説明します。docker を使用したコンテナー管理に関する包括的な情報は、『Getting Started with Containers』の「Working with Docker formatted containers」を参照してください。
コンテナーとイメージの一覧表示
実行中のコンテナーを一覧表示するには、以下のコマンドを実行します。
$ sudo docker ps
停止中またはエラーの発生したコンテナーも一覧表示するには、コマンドに --all オプションを追加します。
$ sudo docker ps --all
コンテナーイメージを一覧表示するには、以下のコマンドを実行します。
$ sudo docker images
コンテナーのプロパティーの確認
コンテナーまたはコンテナーイメージのプロパティーを確認するには、docker inspect コマンドを使用します。たとえば、keystone コンテナーを確認するには、以下のコマンドを実行します。
$ sudo docker inspect keystone
基本的なコンテナー操作の管理
コンテナー化されたサービスを再起動するには、docker restart コマンドを使用します。たとえば、keystone コンテナーを再起動するには、以下のコマンドを実行します。
$ sudo docker restart keystone
コンテナー化されたサービスを停止するには、docker stop コマンドを使用します。たとえば、keystone のコンテナーを停止するには、以下のコマンドを実行します。
$ sudo docker stop keystone
停止されているコンテナー化されたサービスを起動するには、docker start コマンドを使用します。たとえば、keystone のコンテナーを起動するには、以下のコマンドを実行します。
$ sudo docker start keystone
コンテナー内のサービス設定ファイルに加えた変更は、コンテナーの再起動後には元に戻ります。これは、コンテナーがノードのローカルファイルシステム上の /var/lib/config-data/puppet-generated/ にあるファイルに基づいてサービス設定を再生成するためです。たとえば、keystone コンテナー内の /etc/keystone/keystone.conf を編集してコンテナーを再起動すると、そのコンテナーはノードのローカルシステム上にある /var/lib/config-data/puppet-generated/keystone/etc/keystone/keystone.conf を使用して設定を再生成します。再起動前にコンテナー内で加えられた変更は、この設定によって上書きされます。
コンテナーのモニター
コンテナー化されたサービスのログを確認するには、docker logs コマンドを使用します。たとえば、keystone のログを確認するには、以下のコマンドを実行します。
$ sudo docker logs keystone
コンテナーへのアクセス
コンテナー化されたサービスのシェルに入るには、docker exec コマンドを使用して /bin/bash を起動します。たとえば、keystone コンテナーのシェルに入るには、以下のコマンドを実行します。
$ sudo docker exec -it keystone /bin/bash
keystone コンテナーのシェルに root ユーザーとして入るには、以下のコマンドを実行します。
$ sudo docker exec --user 0 -it <NAME OR ID> /bin/bash
コンテナーから出るには、以下のコマンドを実行します。
# exit
アンダークラウドおよびオーバークラウド上での swift-ring-builder の有効化
Object Storage (swift) ビルドの持続性を考慮し、swift-ring-builder および swift_object_server コマンドはアンダークラウドおよびオーバークラウドノードに含まれなくなりました。ただし、コマンドは引き続きコンテナーで使用することができます。それぞれのコンテナー内でこれらのコマンドを実行するには、以下のコマンドを実行します。
docker exec -ti -u swift swift_object_server swift-ring-builder /etc/swift/object.builder
これらのコマンドが必要な場合には、アンダークラウドでは stack ユーザーとして、オーバークラウドでは heat-admin ユーザーとして、以下のパッケージをインストールします。
sudo yum install -y python-swift sudo yum install -y python2-swiftclient
OpenStack Platform のコンテナー化されたサービスのトラブルシューティングに関する情報は、「コンテナー化されたサービスのエラー」を参照してください。
9.3. オーバークラウドのテナントネットワークの作成
オーバークラウドには、インスタンス用のテナントネットワークが必要です。source コマンドで overcloud を読み込んで、Neutron で初期テナントネットワークを作成します。以下に例を示します。
$ source ~/overcloudrc (overcloud) $ openstack network create default (overcloud) $ openstack subnet create default --network default --gateway 172.20.1.1 --subnet-range 172.20.0.0/16
上記のステップにより、default という名前の基本的な Neutron ネットワークが作成されます。オーバークラウドは、内部 DHCP メカニズムを使用したこのネットワークから、IP アドレスを自動的に割り当てます。
作成したネットワークを確認します。
(overcloud) $ openstack network list +-----------------------+-------------+--------------------------------------+ | id | name | subnets | +-----------------------+-------------+--------------------------------------+ | 95fadaa1-5dda-4777... | default | 7e060813-35c5-462c-a56a-1c6f8f4f332f | +-----------------------+-------------+--------------------------------------+
9.4. オーバークラウドの外部ネットワークの作成
インスタンスに Floating IP を割り当てることができるように、オーバークラウドで外部ネットワークを作成する必要があります。
ネイティブ VLAN の使用
以下の手順では、外部ネットワーク向けの専用インターフェースまたはネイティブの VLAN が設定されていることが前提です。
source コマンドで overcloud を読み込み、Neutron で外部ネットワークを作成します。以下に例を示します。
$ source ~/overcloudrc (overcloud) $ openstack network create public --external --provider-network-type flat --provider-physical-network datacentre (overcloud) $ openstack subnet create public --network public --dhcp --allocation-pool start=10.1.1.51,end=10.1.1.250 --gateway 10.1.1.1 --subnet-range 10.1.1.0/24
以下の例では、public という名前のネットワークを作成します。オーバークラウドには、デフォルトの Floating IP プールにこの特定の名前が必要です。このネットワークは、「オーバークラウドの検証」の検証テストでも重要となります。
このコマンドにより、ネットワークと datacentre の物理ネットワークのマッピングも行われます。デフォルトでは、datacentre は br-ex ブリッジにマッピングされます。オーバークラウドの作成時にカスタムの Neutron の設定を使用していない限りは、このオプションはデフォルトのままにしてください。
非ネイティブ VLAN の使用
ネイティブ VLAN を使用しない場合には、以下のコマンドでネットワークを VLAN に割り当てます。
$ source ~/overcloudrc (overcloud) $ openstack network create public --external --provider-network-type vlan --provider-physical-network datacentre --provider-segment 104 (overcloud) $ openstack subnet create public --network public --dhcp --allocation-pool start=10.1.1.51,end=10.1.1.250 --gateway 10.1.1.1 --subnet-range 10.1.1.0/24
provider:segmentation_id の値は、使用する VLAN を定義します。この場合は、104 を使用します。
作成したネットワークを確認します。
(overcloud) $ openstack network list +-----------------------+-------------+--------------------------------------+ | id | name | subnets | +-----------------------+-------------+--------------------------------------+ | d474fe1f-222d-4e32... | public | 01c5f621-1e0f-4b9d-9c30-7dc59592a52f | +-----------------------+-------------+--------------------------------------+
9.5. 追加の Floating IP ネットワークの作成
Floating IP ネットワークは、以下の条件を満たす限りは、br-ex だけでなく、どのブリッジにも使用することができます。
-
ネットワーク環境ファイルで、
NeutronExternalNetworkBridgeが"''"に設定されている。 デプロイ中に追加のブリッジをマッピングしている。たとえば、
br-floatingという新規ブリッジをfloatingという物理ネットワークにマッピングするには、環境ファイルで以下の設定を使用します。parameter_defaults: NeutronBridgeMappings: "datacentre:br-ex,floating:br-floating"
オーバークラウドの作成後に Floating IP ネットワークを作成します。
$ source ~/overcloudrc (overcloud) $ openstack network create ext-net --external --provider-physical-network floating --provider-network-type vlan --provider-segment 105 (overcloud) $ openstack subnet create ext-subnet --network ext-net --dhcp --allocation-pool start=10.1.2.51,end=10.1.2.250 --gateway 10.1.2.1 --subnet-range 10.1.2.0/24
9.6. オーバークラウドのプロバイダーネットワークの作成
プロバイダーネットワークは、デプロイしたオーバークラウドの外部に存在するネットワークに物理的に接続されたネットワークです。これは、既存のインフラストラクチャーネットワークや、Floating IP の代わりにルーティングによって直接インスタンスに外部アクセスを提供するネットワークを使用することができます。
プロバイダーネットワークを作成する際には、ブリッジマッピングを使用する物理ネットワークに関連付けます。これは、Floating IP ネットワークの作成と同様です。コンピュートノードは、仮想マシンの仮想ネットワークインターフェースをアタッチされているネットワークインターフェースに直接接続するため、プロバイダーネットワークはコントローラーとコンピュートの両ノードに追加します。
たとえば、使用するプロバイダーネットワークが br-ex ブリッジ上の VLAN の場合には、以下のコマンドを使用してプロバイダーネットワークを VLAN 201 上に追加します。
$ source ~/overcloudrc (overcloud) $ openstack network create provider_network --provider-physical-network datacentre --provider-network-type vlan --provider-segment 201 --share
このコマンドにより、共有ネットワークが作成されます。また、--share と指定する代わりにテナントを指定することも可能です。そのネットワークは、指定されたテナントに対してのみ提供されます。プロバイダーネットワークを外部としてマークした場合には、そのネットワークでポートを作成できるのはオペレーターのみとなります。
Neutron が DHCP サービスをテナントのインスタンスに提供するように設定するには、プロバイダーネットワークにサブネットを追加します。
(overcloud) $ openstack subnet create provider-subnet --network provider_network --dhcp --allocation-pool start=10.9.101.50,end=10.9.101.100 --gateway 10.9.101.254 --subnet-range 10.9.101.0/24
他のネットワークがプロバイダーネットワークを介して外部にアクセスする必要がある場合があります。このような場合には、新規ルーターを作成して、他のネットワークがプロバイダーネットワークを介してトラフィックをルーティングできるようにします。
(overcloud) $ openstack router create external (overcloud) $ openstack router set --external-gateway provider_network external
このルーターに他のネットワークを接続します。たとえば、subnet1 という名前のサブネットがある場合には、以下のコマンドを実行してルーターに接続することができます。
(overcloud) $ openstack router add subnet external subnet1
これにより、subnet1 がルーティングテーブルに追加され、subnet1 を使用するトラフィックをプロバイダーネットワークにルーティングできるようになります。
9.7. 基本的なオーバークラウドフレーバーの作成
本ガイドの検証ステップは、インストール環境にフレーバーが含まれていることを前提としてます。まだ 1 つのフレーバーも作成していない場合には、以下のコマンドを使用してさまざまなストレージおよび処理能力に対応する基本的なデフォルトフレーバーセットを作成してください。
$ openstack flavor create m1.tiny --ram 512 --disk 0 --vcpus 1 $ openstack flavor create m1.smaller --ram 1024 --disk 0 --vcpus 1 $ openstack flavor create m1.small --ram 2048 --disk 10 --vcpus 1 $ openstack flavor create m1.medium --ram 3072 --disk 10 --vcpus 2 $ openstack flavor create m1.large --ram 8192 --disk 10 --vcpus 4 $ openstack flavor create m1.xlarge --ram 8192 --disk 10 --vcpus 8
コマンドオプション
- ram
-
フレーバーの最大 RAM を定義するには、
ramオプションを使用します。 - disk
-
フレーバーのハードディスク容量を定義するには、
diskオプションを使用します。 - vcpus
-
フレーバーの仮想 CPU 数を定義するには、
vcpusオプションを使用します。
openstack flavor create コマンドについての詳しい情報は、$ openstack flavor create --help で確認してください。
9.8. オーバークラウドの検証
オーバークラウドは、OpenStack Integration Test Suite (tempest) ツールセットを使用して、一連の統合テストを行います。本項には、統合テストの実行準備に関する情報を記載します。OpenStack Integration Test Suite の使用方法に関する詳しい説明は、『OpenStack Integration Test Suite Guide』を参照してください。
Integration Test Suite の実行前
アンダークラウドからこのテストを実行する場合は、アンダークラウドのホストがオーバークラウドの内部 API ネットワークにアクセスできるようにします。たとえば、172.16.0.201/24 のアドレスを使用して内部 API ネットワーク (ID: 201) にアクセスするにはアンダークラウドホストに一時的な VLAN を追加します。
$ source ~/stackrc (undercloud) $ sudo ovs-vsctl add-port br-ctlplane vlan201 tag=201 -- set interface vlan201 type=internal (undercloud) $ sudo ip l set dev vlan201 up; sudo ip addr add 172.16.0.201/24 dev vlan201
OpenStack Integration Test Suite を実行する前に、heat_stack_owner ロールがオーバークラウドに存在することを確認してください。
$ source ~/overcloudrc (overcloud) $ openstack role list +----------------------------------+------------------+ | ID | Name | +----------------------------------+------------------+ | 6226a517204846d1a26d15aae1af208f | swiftoperator | | 7c7eb03955e545dd86bbfeb73692738b | heat_stack_owner | +----------------------------------+------------------+
このロールが存在しない場合は、作成します。
(overcloud) $ openstack role create heat_stack_owner
Integration Test Suite の実行後
検証が完了したら、オーバークラウドの内部 API への一時接続を削除します。この例では、以下のコマンドを使用して、以前にアンダークラウドで作成した VLAN を削除します。
$ source ~/stackrc (undercloud) $ sudo ovs-vsctl del-port vlan201
9.9. オーバークラウド環境の変更
オーバークラウドを変更して、別機能を追加したり、操作の方法を変更したりする場合があります。オーバークラウドを変更するには、カスタムの環境ファイルと Heat テンプレートに変更を加えて、最初に作成したオーバークラウドから openstack overcloud deploy コマンドをもう 1 度実行します。たとえば、「デプロイメントコマンド」の方法を使用してオーバークラウドを作成した場合には、以下のコマンドを再度実行します。
$ source ~/stackrc (undercloud) $ openstack overcloud deploy --templates \ -e ~/templates/node-info.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \ -e ~/templates/network-environment.yaml \ -e ~/templates/storage-environment.yaml \ --ntp-server pool.ntp.org
director は Heat 内の overcloud スタックを確認してから、環境ファイルと Heat テンプレートのあるスタックで各アイテムを更新します。オーバークラウドは再度作成されずに、既存のオーバークラウドに変更が加えられます。
新規環境ファイルを追加する場合には、openstack overcloud deploy コマンドで -e オプションを使用して そのファイルを追加します。以下に例を示します。
$ source ~/stackrc (undercloud) $ openstack overcloud deploy --templates \ -e ~/templates/new-environment.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \ -e ~/templates/network-environment.yaml \ -e ~/templates/storage-environment.yaml \ -e ~/templates/node-info.yaml \ --ntp-server pool.ntp.org
これにより、環境ファイルからの新規パラメーターやリソースがスタックに追加されます。
director により後で上書きされてしまう可能性があるので、オーバークラウドの設定には手動で変更を加えないことを推奨します。
9.10. 動的インベントリースクリプトの実行
director を使用すると、Ansible ベースの自動化を OpenStack Platform 環境で実行することができます。director は、tripleo-ansible-inventory コマンドを使用して、環境内にノードの動的インベントリーを生成します。
手順
ノードの動的インベントリーを表示するには、
stackrcを読み込んだ後にtripleo-ansible-inventoryコマンドを実行します。$ source ~/stackrc (undercloud) $ tripleo-ansible-inventory --list
--listオプションを指定すると、全ホストの詳細が表示されます。これにより、動的インベントリーが JSON 形式で出力されます。{"overcloud": {"children": ["controller", "compute"], "vars": {"ansible_ssh_user": "heat-admin"}}, "controller": ["192.168.24.2"], "undercloud": {"hosts": ["localhost"], "vars": {"overcloud_horizon_url": "http://192.168.24.4:80/dashboard", "overcloud_admin_password": "abcdefghijklm12345678", "ansible_connection": "local"}}, "compute": ["192.168.24.3"]}お使いの環境で Ansible のプレイブックを実行するには、
ansibleコマンドを実行し、-iオプションを使用して動的インベントリーツールの完全パスを追加します。以下に例を示します。(undercloud) $ ansible [HOSTS] -i /bin/tripleo-ansible-inventory [OTHER OPTIONS]
[HOSTS]は使用するホストの種別に置き換えます。以下に例を示します。-
全コントローラーノードの場合には
controller -
全コンピュートノードの場合には
compute -
controllerおよびcomputeなど、全オーバークラウドの子ノードの場合にはovercloud -
アンダークラウドの場合には
undercloud -
全ノードの場合には
"*"
-
全コントローラーノードの場合には
[OTHER OPTIONS]は追加の Ansible オプションに置き換えてください。役立つオプションには以下が含まれます。-
--ssh-extra-args='-o StrictHostKeyChecking=no'は、ホストキーのチェックを省略します。 -
-u [USER]は、Ansible の自動化を実行する SSH ユーザーを変更します。オーバークラウドのデフォルトの SSH ユーザーは、動的インベントリーのansible_ssh_userパラメーターで自動的に定義されます。-uオプションは、このパラメーターより優先されます。 -
-m [MODULE]は、特定の Ansible モジュールを使用します。デフォルトはcommandで Linux コマンドを実行します。 -
-a [MODULE_ARGS]は選択したモジュールの引数を定義します。
-
オーバークラウドの Ansible 自動化は、標準のオーバークラウドスタックとは異なります。つまり、この後に openstack overcloud deploy コマンドを実行すると、オーバークラウドノード上の OpenStack Platform サービスに対する Ansible ベースの設定を上書きする可能性があります。
9.11. オーバークラウドへの仮想マシンのインポート
既存の OpenStack 環境があり、仮想マシンを Red Hat OpenStack Platform 環境に移行する予定がある場合には、以下の手順を使用します。
実行中のサーバーのスナップショットを作成して新規イメージを作成し、そのイメージをダウンロードします。
$ source ~/overcloudrc (overcloud) $ openstack server image create instance_name --name image_name (overcloud) $ openstack image save image_name --file exported_vm.qcow2
エクスポートしたイメージをオーバークラウドにアップロードして、新しいインスタンスを起動します。
(overcloud) $ openstack image create imported_image --file exported_vm.qcow2 --disk-format qcow2 --container-format bare (overcloud) $ openstack server create imported_instance --key-name default --flavor m1.demo --image imported_image --nic net-id=net_id
各仮想マシンのディスクは、既存の OpenStack 環境から新規の Red Hat OpenStack Platform にコピーする必要があります。QCOW を使用したスナップショットでは、元の階層化システムが失われます。
9.12. コンピュートノードからのインスタンスの移行
オーバークラウドのコンピュートノードでメンテナンスを行う場合があります。ダウンタイムを防ぐには、そのコンピュートノード上の仮想マシンを同じオーバークラウド内の別のコンピュートノードに移行します。
director は、すべてのコンピュートノードがセキュアな移行を提供するように設定します。全コンピュートノードには、各ホストの nova ユーザーが移行プロセス中に他のコンピュートノードにアクセスすることができるようにするための共有 SSH キーも必要です。director は、OS::TripleO::Services::NovaCompute コンポーザブルサービスを使用してこのキーを作成します。このコンポーザブルサービスは、全コンピュートロールにデフォルトで含まれているメインのサービスの 1 つです (『オーバークラウドの高度なカスタマイズ』の「コンポーザブルサービスとカスタムロール」を参照)。
手順
アンダークラウドから、コンピュートノードを選択し、そのノードを無効にします。
$ source ~/overcloudrc (overcloud) $ openstack compute service list (overcloud) $ openstack compute service set [hostname] nova-compute --disable
コンピュートノード上の全インスタンスを一覧表示します。
(overcloud) $ openstack server list --host [hostname] --all-projects
以下のコマンドの 1 つを使用して、インスタンスを移行します。
選択した特定のホストにインスタンスを移行します。
(overcloud) $ openstack server migrate [instance-id] --live [target-host]--wait
nova-schedulerにより対象のホストが自動的に選択されるようにします。(overcloud) $ nova live-migration [instance-id]
一度にすべてのインスタンスのライブマイグレーションを行います。
$ nova host-evacuate-live [hostname]
注記novaコマンドで非推奨の警告が表示される可能性がありますが、安全に無視することができます。
- 移行が完了するまで待ちます。
正常に移行したことを確認します。
(overcloud) $ openstack server list --host [hostname] --all-projects
- 選択したコンピュートノードのインスタンスがなくなるまで、移行を続けます。
これにより、コンピュートノードからすべてのインスタンスが移行されます。インスタンスのダウンタイムなしにノードでメンテナンスを実行できるようになります。コンピュートノードを有効な状態に戻すには、以下のコマンドを実行します。
$ source ~/overcloudrc (overcloud) $ openstack compute service set [hostname] nova-compute --enable
9.13. オーバークラウドの削除防止
heat stack-delete overcloud コマンドで誤って削除されないように、Heat には特定のアクションを制限するポリシーセットが含まれます。/etc/heat/policy.json を開いて、以下のパラメーターを検索します。
"stacks:delete": "rule:deny_stack_user"
このパラメーターの設定を以下のように変更します。
"stacks:delete": "rule:deny_everybody"
ファイルを保存します。
これにより heat クライアントでオーバークラウドが削除されないように阻止されます。オーバークラウドを削除できるように設定するには、ポリシーを元の値に戻します。
9.14. オーバークラウドの削除
オーバークラウドはすべて、必要に応じて削除することができます。
既存のオーバークラウドを削除します。
$ source ~/stackrc (undercloud) $ openstack overcloud delete overcloud
オーバークラウドが削除されていることを確認します。
(undercloud) $ openstack stack list
削除には、数分かかります。
削除が完了したら、デプロイメントシナリオの標準ステップに従って、オーバークラウドを再度作成します。
9.15. トークンのフラッシュ間隔の確認
Identity サービス (keystone) は、他の OpenStack サービスに対するアクセス制御にトークンベースのシステムを使用します。ある程度の期間が過ぎた後には、データベースに未使用のトークンが多数蓄積されます。デフォルトの cronjob は毎日トークンをフラッシュします。環境をモニタリングして、必要に応じてトークンのフラッシュ間隔を調節することを推奨します。
オーバークラウドでは、KeystoneCronToken の値を使用して間隔を調整することができます。詳しい情報は、『オーバークラウドのパラメーター』を参照してください。
第10章 Ansible を使用したオーバークラウドの設定
Ansible は、オーバークラウドの設定を適用する主要な方法です。本章では、オーバークラウドの Ansible 設定を操作する手順を説明します。
director は Ansible Playbook を自動生成しますが、Ansible の構文を十分に理解しておくと役立ちます。Ansible の使用方法については、https://docs.ansible.com/ を参照してください。
Ansible では、roles の概念も使用します。これは、OpenStack Platform director のロールとは異なります。
10.1. Ansible ベースのオーバークラウド設定 (config-download)
config-download の機能により、director はオーバークラウドを設定します。director は OpenStack Orchestration サービス (heat) および OpenStack Workflow サービス (mistral) と共に config-download を使用し、ソフトウェア設定を生成して各オーバークラウドノードに適用します。Heat は SoftwareDeployment リソースから全デプロイメントデータを作成して、オーバークラウドのインストールと設定を行いますが、設定の適用は一切行いません。Heat は API から設定データの提供のみを行います。director によりスタックが作成されたら、Mistral ワークフローが Heat API に対して設定データ取得のクエリーを実行し、Ansible Playbook のセットを生成してオーバークラウドに適用します。
結果として、openstack overcloud deploy コマンドを実行すると、以下のプロセスが実行されます。
-
director は
openstack-tripleo-heat-templatesを元に新たなデプロイメントプランを作成し、プランをカスタマイズするための環境ファイルおよびパラメーターをすべて追加します。 - director は Heat を使用してデプロイメントプランを翻訳し、オーバークラウドスタックとすべての子リソースを作成します。これには、OpenStack Bare Metal (ironic) を使用したノードのプロビジョニングも含まれます。
- Heat はデプロイメントプランからソフトウェア設定も作成します。director はこのソフトウェア設定から Ansible Playbook をコンパイルします。
- director は、特に Ansible SSH アクセス用としてオーバークラウドノードに一時ユーザー (tripleo-admin1) を生成します。
- director は Heat ソフトウェア設定をダウンロードし、Heat の出力を使用して Ansible Playbook のセットを生成します。
-
director は、
ansible-playbookを使用してオーバークラウドノードに Ansible Playbook を適用します。
10.2. config-download の作業ディレクトリー
director により、config-download プロセス用に Ansible Playbook のセットが生成されます。これらの Playbook は /var/lib/mistral/ 内の作業ディレクトリーに保管されます。このディレクトリーには、オーバークラウドの名前が付けられます。したがって、デフォルトでは overcloud です。
作業ディレクトリーには、各オーバークラウドロールの名前が付けられた複数のサブディレクトリーが存在します。これらのサブディレクトリーには、オーバークラウドロールのノードの設定に関連するすべてのタスクが含まれます。さらに、これらのサブディレクトリーには、特定のノードの名前が付けられたサブディレクトリーが存在します。これらのサブディレクトリーには、オーバークラウドロールのタスクに適用するノード固有の変数が含まれます。したがって、作業ディレクトリー内のオーバークラウドロールは、以下のような構成になります。
─ /var/lib/mistral/overcloud
│
├─── Controller
│ ├── overcloud-controller-0
│ ├── overcloud-controller-1
│ └── overcloud-controller-2
├─── Compute
│ ├── overcloud-compute-0
│ ├── overcloud-compute-1
│ └── overcloud-compute-2
...それぞれの作業ディレクトリーは、各デプロイメント操作後の変更を記録するローカルの Git リポジトリーとしても機能します。このことは、各デプロイメント間の設定変更を追跡するのに役立ちます。
10.3. config-download の作業ディレクトリーへのアクセスの有効化
/var/lib/mistral/ にある作業ディレクトリー内の全ファイルの所有者は、OpenStack Workflow サービス (mistral) コンテナーの mistral ユーザーです。アンダークラウドの stack ユーザーに、このディレクトリー内の全ファイルへのアクセス権限を付与することができます。この設定は、ディレクトリー内の特定操作を実施するのに役立ちます。
手順
アンダークラウドの
stackユーザーにこれらのファイルへのアクセス権限を付与するには、setfaclコマンドを使用します。$ sudo setfacl -R -m u:stack:rwx /var/lib/mistral
このコマンドを実行しても、
mistralユーザーのディレクトリーへのアクセス権限は維持されます。
10.4. config-download ログの確認
config-download プロセス中、Ansible によりアンダークラウド内の config-download の作業ディレクトリーにログファイルが作成されます。
手順
lessコマンドを使用して、config-downloadの作業ディレクトリー内のログを表示します。以下の例では、overcloud作業ディレクトリーが使われています。$ less /var/lib/mistral/overcloud/ansible.log
10.5. 手動での config-download の実行
/var/lib/mistral/overcloud 作業ディレクトリーには、ansible-playbook と直接対話するために必要な Playbook とスクリプトが含まれています。以下の手順では、これらのファイルとの対話方法について説明します。
手順
Ansible Playbook のディレクトリーに移動します。
$ cd /var/lib/mistral/overcloud/
作業ディレクトリーに移動したら、
ansible-playbook-command.shを実行して、デプロイメントを再現します。$ ./ansible-playbook-command.sh
このスクリプトには、追加の Ansible 引数を渡すことができます。それらの引数は、
ansible-playbookコマンドに未変更で渡されます。これにより、チェックモード (--check)、ホストの限定 (--limit)、変数のオーバーライド (-e) などの Ansible の機能を更に活用することが可能となります。以下に例を示します。$ ./ansible-playbook-command.sh --limit Controller
作業ディレクトリーには、オーバークラウドの設定を実行する
deploy_steps_playbook.yamlという名前の Playbook が含まれています。この Playbook を表示するには、以下のコマンドを実行します。$ less deploy_steps_playbook.yaml
Playbook は、作業ディレクトリーに含まれているさまざまなタスクファイルを使用します。タスクファイルには、OpenStack Platform の全ロールに共通するものと、特定の OpenStack Platform ロールおよびサーバー固有のものがあります。
作業ディレクトリーには、オーバークラウドの
roles_dataファイルで定義されている各ロールに対応するサブディレクトリーも含まれます。以下に例を示します。$ ls Controller/
各 OpenStack Platform ロールにディレクトリーには、そのロール種別の個々のサーバー用のサブディレクトリーも含まれます。これらのディレクトリーには、コンポーザブルロールのホスト名の形式を使用します。以下に例を示します。
$ ls Controller/overcloud-controller-0
Ansible のタスクはタグ付けられます。タグの全一覧を確認するには、
ansible-playbookで CLI の引数--list-tagsを使用します。$ ansible-playbook -i tripleo-ansible-inventory.yaml --list-tags deploy_steps_playbook.yaml
次に、
ansible-playbook-command.shスクリプトで--tags、--skip-tags、--start-at-taskのいずれかを使用して、タグ付けた設定を適用します。以下に例を示します。$ ./ansible-playbook-command.sh --tags overcloud
--tags、--skip-tags、--start-at-task などの ansible-playbook CLI 引数を使用する場合には、デプロイメントの設定は、間違った順序で実行したり適用したりしないでください。これらの CLI 引数は、以前に失敗したタスクを再度実行する場合や、初回のデプロイメントを繰り返す場合に便利な方法です。ただし、デプロイメントの一貫性を保証するには、deploy_steps_playbook.yaml の全タスクを順番通りに実行する必要があります。
10.6. 作業ディレクトリーでの Git 操作の実施
config-download の作業ディレクトリーは、ローカルの Git リポジトリーとして機能します。デプロイメント操作を実行するたびに、director は該当する変更に関する Git コミットを作業ディレクトリーに追加します。これにより、Git 操作を実施して、さまざまなステージでのデプロイメント設定を表示したり、異なるデプロイメント間で設定を比較したりすることができます。
作業ディレクトリーには制約がある点に注意してください。たとえば、Git を使用して config-download の作業ディレクトリーを前のバージョンに戻しても、作業ディレクトリー内の設定が影響を受けるだけで、以下の設定は影響を受けません。
- オーバークラウドデータスキーマ: 作業ディレクトリーのソフトウェア設定の前のバージョンを適用しても、データ移行およびスキーマ変更は取り消されません。
- オーバークラウドのハードウェアレイアウト: 以前のソフトウェア設定に戻しても、スケールアップ/ダウン等のオーバークラウドハードウェアに関する変更は取り消されません。
-
Heat スタック: 作業ディレクトリーを前のバージョンに戻しても、Heat スタックに保管された設定は影響を受けません。Heat スタックは新たなバージョンのソフトウェア設定を作成し、それがオーバークラウドに適用されます。つまり、オーバークラウドに永続的な変更を加えるには、
openstack overcloud deployを再度実行する前に、オーバークラウドスタックに適用する環境ファイルを変更する必要があります。
以下の手順で、Git を使用して config-download の作業ディレクトリー内の異なるコミットを比較する方法を説明します。
手順
オーバークラウドに関する
config-downloadの作業ディレクトリーに移動します。この例の作業ディレクトリーは、overcloudという名前のオーバークラウド用です。$ cd /var/lib/mistral/overcloud
git logコマンドを実行して、作業ディレクトリー内のコミットの一覧を表示します。ログの出力に日付が表示されるようにフォーマットを設定することもできます。$ git log --format=format:"%h%x09%cd%x09" a7e9063 Mon Oct 8 21:17:52 2018 +1000 dfb9d12 Fri Oct 5 20:23:44 2018 +1000 d0a910b Wed Oct 3 19:30:16 2018 +1000 ...
デフォルトでは、最新のコミットから順に表示されます。
2 つのコミットのハッシュに対して
git diffコマンドを実行し、デプロイメント間の違いをすべて表示します。$ git diff a7e9063 dfb9d12
10.7. 手動での config-download ファイルの作成
特定の状況では、標準のワークフローとは別に専用の config-download ファイルを生成する場合があります。たとえば、個別に設定を適用できるように、openstack overcloud deploy コマンドに --stack-only オプションを設定して、オーバークラウド Heat スタックを生成することがあります。以下の手順では、専用の config-download ファイルを手動で作成する方法について説明します。
手順
config-downloadファイルを生成します。$ openstack overcloud config download \ --name overcloud \ --config-dir ~/config-download
-
--nameは、Ansible ファイルのエクスポートに使用するオーバークラウドです。 -
--config-dirは、config-downloadファイルを保存する場所です。
-
config-downloadファイルが含まれるディレクトリーに移動します。$ cd ~/config-download
静的なインベントリーファイルを生成します。
$ tripleo-ansible-inventory \ --ansible_ssh_user heat-admin \ --static-yaml-inventory inventory.yaml
これにより、手動で生成した config-download ファイルを使用して設定を実施するのに必要なファイルが得られます。デプロイメント用の Playbook を実行するには、ansible-playbook コマンドを実行します。
$ ansible-playbook \ -i inventory.yaml \ --private-key ~/.ssh/id_rsa \ --become \ ~/config-download/deploy_steps_playbook.yaml
この設定から手動で overcloudrc ファイルを生成するには、以下のコマンドを実行します。
$ openstack action execution run \
--save-result \
--run-sync \
tripleo.deployment.overcloudrc \
'{"container":"overcloud"}' \
| jq -r '.["result"]["overcloudrc.v3"]' > overcloudrc.v310.8. config-download の主要ファイル
config-download の作業ディレクトリー内の主要なファイルを以下に示します。
Ansible の設定および実行
config-download の作業ディレクトリー内の以下のファイルは、Ansible を設定/実行するための専用ファイルです。
- ansible.cfg
-
ansible-playbook実行時に使用する設定ファイル。 - ansible.log
-
最後に実行した
ansible-playbookに関するログファイル。 - ansible-errors.json
- デプロイメントエラーが含まれる JSON 構造のファイル。
- ansible-playbook-command.sh
-
この実行可能スクリプトを使用して、最後のデプロイメント操作の
ansible-playbookコマンドを再実行することができます。 - ssh_private_key
- Ansible がオーバークラウドノードにアクセスする際に使用する SSH 秘密鍵。
- tripleo-ansible-inventory.yaml
- すべてのオーバークラウドノードのホストおよび変数が含まれる Ansible インベントリーファイル。
- overcloud-config.tar.gz
- 作業ディレクトリーのアーカイブ。
Playbook
以下のファイルは、config-download の作業ディレクトリー内の Playbook です。
- deploy_steps_playbook.yaml
- デプロイメントのメインステップ。この Playbook により、オーバークラウド設定の主要な操作が実施されます。
- pre_upgrade_rolling_steps_playbook.yaml
- メジャーアップグレードのための事前アップグレードステップ。
- upgrade_steps_playbook.yaml
- メジャーアップグレードのステップ。
- post_upgrade_steps_playbook.yaml
- メジャーアップグレードに関するアップグレード後ステップ。
- update_steps_playbook.yaml
- マイナーアップデートのステップ。
- fast_forward_upgrade_playbook.yaml
- Fast Forward Upgrade のタスク。OpenStack Platform のロングライフバージョンから次のロングライフバージョンにアップグレードする場合にのみ使用します。この Playbook を OpenStack Platform の本リリースに使用しないでください。
10.9. config-download のタグ
Playbook では、オーバークラウドに適用されるタスクを管理するのにタグ付けされたタスクを使用します。ansible-playbook CLI の引数 --tags または --skip-tags でタグを使用して、実行するタスクを管理します。有効なタグを以下に示します。
- facts
- ファクト収集操作。
- common_roles
- すべてのノードに共通な Ansible ロール。
- overcloud
- オーバークラウドデプロイメント用のすべてのプレイ。
- pre_deploy_steps
-
deploy_stepsの操作の前に実施されるデプロイメント。 - host_prep_steps
- ホスト準備のステップ。
- deploy_steps
- デプロイメントのステップ。
- post_deploy_steps
-
deploy_stepsの操作の後に実施されるデプロイメント。 - external
- すべての外部デプロイメントタスク。
- external_deploy_steps
- アンダークラウドでのみ実行される外部デプロイメントタスク。
10.10. config-download のデプロイメントステップ
オーバークラウドの設定には、deploy_steps_playbook.yaml Playbook が使用されます。この Playbook により、オーバークラウドデプロイメントプランに基づき完全なオーバークラウドをデプロイするのに必要なすべてのソフトウェア設定が適用されます。
本項では、この Playbook で使用されるさまざまな Ansible プレイの概要について説明します。本項のプレイと同じ名前が、Playbook 内で使用され ansible-playbook の出力にも表示されます。各プレイに設定される Ansible タグも、以下に示します。
- Gather facts from undercloud
アンダークラウドノードからのファクト収集。
タグ:
facts- Gather facts from overcloud
オーバークラウドノードからのファクト収集。
タグ:
facts- Load global variables
global_vars.yamlからの変数をすべて読み込みます。タグ:
always- Common roles for TripleO servers
共通の Ansible ロールをすべてのオーバークラウドノードに適用します。これには、ブートストラップパッケージをインストールする tripleo-bootstrap および ssh の既知のホストを設定する tripleo-ssh-known-hosts が含まれます。
タグ:
common_roles- Overcloud deploy step tasks for step 0
deploy_steps_tasks テンプレートインターフェースからのタスクを適用します。
タグ:
overcloud、deploy_steps- Server deployments
ネットワーク設定や hieradata 等の設定に、サーバー固有の Heat デプロイメントを適用します。これには、NetworkDeployment、<Role>Deployment、<Role>AllNodesDeployment 等が含まれます。
タグ:
overcloud、pre_deploy_steps- Host prep steps
host_prep_steps テンプレートインターフェースからのタスクを適用します。
タグ:
overcloud、host_prep_steps- External deployment step [1,2,3,4,5]
external_deploy_steps_tasks テンプレートインターフェースからのタスクを適用します。これらのタスクは、アンダークラウドノードに対してのみ実行されます。
タグ:
external、external_deploy_steps- Overcloud deploy step tasks for [1,2,3,4,5]
deploy_steps_tasks テンプレートインターフェースからのタスクを適用します。
タグ:
overcloud、deploy_steps- Overcloud common deploy step tasks [1,2,3,4,5]
各ステップで実施される共通タスクを適用します。これには、puppet ホストの設定、docker-puppet.py、および paunch (コンテナー設定) が含まれます。
タグ:
overcloud、deploy_steps- Server Post Deployments
5 ステップのデプロイメントプロセス後に実施される設定に、サーバー固有の Heat デプロイメントを適用します。
タグ:
overcloud、post_deploy_steps- External deployment Post Deploy tasks
external_post_deploy_steps_tasks テンプレートインターフェースからのタスクを適用します。これらのタスクは、アンダークラウドノードに対してのみ実行されます。
タグ:
external、external_deploy_steps
10.11. 次のステップ
これで、通常のオーバークラウドの操作を続行できるようになりました。
第11章 オーバークラウドノードのスケーリング
オーバークラウドからノードを削除する場合は、openstack server delete を使用しないでください。本セクションで説明する手順をよく読み、適切にノードの削除/置き換えを行ってください。
オーバークラウドの作成後に、ノードを追加または削除する必要がある場合があります。たとえば、オーバークラウドのコンピュートノードを追加する場合などです。このような状況では、オーバークラウドの更新が必要です。
以下の表を使用して、各ノード種別のスケーリングに対するサポートを判断してください。
表11.1 各ノード種別のスケーリングサポート
|
ノード種別 |
スケールアップ |
スケールダウン |
備考 |
|
コントローラー |
非対応 |
非対応 |
「12章コントローラーノードの置き換え」に記載の手順を使用して、コントローラーノードを置き換えることができます。 |
|
Compute |
対応 |
対応 | |
|
Ceph Storage ノード |
対応 |
非対応 |
オーバークラウドを最初に作成する際に Ceph Storage ノードを 1 つ以上設定する必要があります。 |
|
オブジェクトストレージノード |
対応 |
対応 |
オーバークラウドをスケーリングする前には、空き領域が少なくとも 10 GB あることを確認してください。この空き領域は、イメージの変換やノードのプロビジョニングプロセスのキャッシュに使用されます。
11.1. オーバークラウドへのノード追加
director のノードプールにさらにノードを追加するには、以下の手順を実施します。
手順
登録する新規ノードの詳細を記載した新しい JSON ファイル (
newnodes.json) を作成します。{ "nodes":[ { "mac":[ "dd:dd:dd:dd:dd:dd" ], "cpu":"4", "memory":"6144", "disk":"40", "arch":"x86_64", "pm_type":"ipmi", "pm_user":"admin", "pm_password":"p@55w0rd!", "pm_addr":"192.168.24.207" }, { "mac":[ "ee:ee:ee:ee:ee:ee" ], "cpu":"4", "memory":"6144", "disk":"40", "arch":"x86_64", "pm_type":"ipmi", "pm_user":"admin", "pm_password":"p@55w0rd!", "pm_addr":"192.168.24.208" } ] }以下のコマンドを実行して、新規ノードを登録します。
$ source ~/stackrc (undercloud) $ openstack overcloud node import newnodes.json
新規ノードを追加したら、各新規ノードごとに以下のコマンドを実行してイントロスペクションプロセスを起動します。
(undercloud) $ openstack baremetal node manage [NODE UUID] (undercloud) $ openstack overcloud node introspect [NODE UUID] --provide
このプロセスにより、ノードのハードウェアプロパティーの検出とベンチマークが実行されます。
ノードのイメージプロパティーを設定します。
(undercloud) $ openstack overcloud node configure [NODE UUID]
11.2. ロールのノード数の追加
特定ロールのオーバークラウドノード (たとえばコンピュートノード) をスケーリングするには、以下の手順を実施します。
手順
それぞれの新規ノードを希望するロールにタグ付けします。たとえば、ノードをコンピュートロールにタグ付けするには、以下のコマンドを実行します。
(undercloud) $ openstack baremetal node set --property capabilities='profile:compute,boot_option:local' [NODE UUID]
オーバークラウドをスケーリングするには、ノード数が含まれる環境ファイルを編集してオーバークラウドを再デプロイする必要があります。たとえば、オーバークラウドをコンピュートノード 5 台にスケーリングするには、
ComputeCountパラメーターを編集します。parameter_defaults: ... ComputeCount: 5 ...
更新したファイルを使用して、デプロイメントのコマンドを再度実行します。このファイルは、以下の例では、
node-info.yamlという名前です。(undercloud) $ openstack overcloud deploy --templates -e /home/stack/templates/node-info.yaml [OTHER_OPTIONS]
コンピュート以外のノードに対する同様のスケジューリングパラメーターなど、最初に作成したオーバークラウドからの環境ファイルおよびオプションをすべて追加するようにしてください。
- デプロイメント操作が完了するまで待ちます。
11.3. コンピュートノードの削除
オーバークラウドからコンピュートノードを削除する必要がある状況が出てくる可能性があります。たとえば、問題のあるコンピュートノードを置き換える必要がある場合などです。
オーバークラウドからコンピュートノードを削除する前に、インスタンスをそのノードから別のコンピュートノードに移行してください。詳しくは、「コンピュートノードからのインスタンスの移行」を参照してください。
手順
source コマンドでオーバークラウド設定を読み込みます。
$ source ~/stack/overcloudrc
オーバークラウド上で削除するノードの Compute サービスを無効にし、ノードで新規インスタンスがスケジューリングされないようにします。
(overcloud) $ openstack compute service list (overcloud) $ openstack compute service set [hostname] nova-compute --disable
source コマンドでアンダークラウド設定を読み込みます。
(overcloud) $ source ~/stack/stackrc
オーバークラウドノードを削除するには、ローカルのテンプレートファイルを使用して director のオーバークラウドスタックを更新する必要があります。まず、オーバークラウドスタックの UUID を特定します。
(undercloud) $ openstack stack list
削除するノードの UUID を特定します。
(undercloud) $ openstack server list
以下のコマンドを実行してスタックからノードを削除し、それに応じてプランを更新します。
(undercloud) $ openstack overcloud node delete --stack [STACK_UUID] --templates -e [ENVIRONMENT_FILE] [NODE1_UUID] [NODE2_UUID] [NODE3_UUID]
重要オーバークラウドの作成時に追加の環境ファイルを渡した場合には、オーバークラウドに、不要な変更が手動で加えられないように、ここで
-eまたは--environment-fileオプションを使用して環境ファイルを再度指定します。-
操作を続行する前に、
openstack overcloud node deleteコマンドが完全に終了したことを確認します。openstack stack listコマンドを使用して、overcloudスタックがUPDATE_COMPLETEのステータスに切り替わっているかどうかをチェックしてください。 ノードから Compute サービスを削除します。
(undercloud) $ source ~/stack/overcloudrc (overcloud) $ openstack compute service list (overcloud) $ openstack compute service delete [service-id]
ノードから Open vSwitch エージェントを削除します。
(overcloud) $ openstack network agent list (overcloud) $ openstack network agent delete [openvswitch-agent-id]
オーバークラウドから自由にノードを削除して、別の目的でそのノードを再プロビジョニングすることができます。
11.4. Ceph Storage ノードの置き換え
director を使用して、director で作成したクラスター内の Ceph Storage ノードを置き換えることができます。手順については、『Deploying an Overcloud with Containerized Red Hat Ceph』を参照してください。
11.5. オブジェクトストレージノードの置き換え
本項の手順で、クラスターの整合性を保ちながらオブジェクトストレージノードを置き換える方法を説明します。以下の例では、3 台のノードで構成されるオブジェクトストレージクラスターで、ノード overcloud-objectstorage-1 を置き換えます。この手順の目的は、ノードを 1 台追加し、その後 overcloud-objectstorage-1 を削除することです (結果的に、置き換えることになります)。
手順
ObjectStorageCountパラメーターを使用してオブジェクトストレージ数を増やします。このパラメーターは、通常ノード数を指定する環境ファイルのnode-info.yamlに含まれています。parameter_defaults: ObjectStorageCount: 4
ObjectStorageCountパラメーターで、環境内のオブジェクトストレージノードの数を定義します。今回の例では、ノードを 3 つから 4 つにスケーリングします。更新した
ObjectStorageCountパラメーターを使用して、デプロイメントコマンドを実行します。$ source ~/stackrc (undercloud) $ openstack overcloud deploy --templates -e node-info.yaml ENVIRONMENT_FILES- デプロイメントコマンドの実行が完了すると、オーバークラウドには追加のオブジェクトストレージノードが含まれるようになります。
新しいノードにデータを複製します。ノードを削除する前に (この場合は
overcloud-objectstorage-1)、複製のパス が新規ノードで完了するのを待ちます。/var/log/swift/swift.logファイルで複製パスの進捗を確認することができます。パスが完了すると、Object Storage サービスは以下の例のようなエントリーをログに残します。Mar 29 08:49:05 localhost object-server: Object replication complete. Mar 29 08:49:11 localhost container-server: Replication run OVER Mar 29 08:49:13 localhost account-server: Replication run OVER
リングから不要になったノードを削除するには、
ObjectStorageCountパラメーターの数を減らして不要になったノードを削除します。今回は 3 に減らします。parameter_defaults: ObjectStorageCount: 3
新規環境ファイル (
remove-object-node.yaml) を作成します。このファイルでオブジェクトストレージノードを特定し、そのノードを削除します。以下の内容ではovercloud-objectstorage-1の削除を指定します。parameter_defaults: ObjectStorageRemovalPolicies: [{'resource_list': ['1']}]デプロイメントコマンドに
node-info.yamlファイルとremove-object-node.yamlファイルの両方を含めます。(undercloud) $ openstack overcloud deploy --templates -e node-info.yaml ENVIRONMENT_FILES -e remove-object-node.yaml
director は、オーバークラウドからオブジェクトストレージノードを削除して、オーバークラウド上の残りのノードを更新し、ノードの削除に対応します。
11.6. ノードのブラックリスト登録
オーバークラウドノードがデプロイメントの更新を受け取らないように除外することができます。これは、既存のノードがコア Heat テンプレートコレクションから更新されたパラメーターセットやリソースを受け取らないように除外した状態で、新規ノードをスケーリングする場合に役立ちます。つまり、ブラックリストに登録されているノードは、スタック操作の影響を受けなくなります。
ブラックリストを作成するには、環境ファイルの DeploymentServerBlacklist パラメーターを使います。
ブラックリストの設定
DeploymentServerBlacklist パラメーターは、サーバー名のリストです。新たな環境ファイルを作成するか、既存のカスタム環境ファイルにパラメーター値を追加して、ファイルをデプロイメントコマンドに渡します。
parameter_defaults:
DeploymentServerBlacklist:
- overcloud-compute-0
- overcloud-compute-1
- overcloud-compute-2パラメーター値のサーバー名には、実際のサーバーホスト名ではなく、OpenStack Orchestation (Heat) で定義されている名前を使用します。
openstack overcloud deploy コマンドで、この環境ファイルを指定します。
$ source ~/stackrc (undercloud) $ openstack overcloud deploy --templates \ -e server-blacklist.yaml \ [OTHER OPTIONS]
Heat はリスト内のサーバーをすべてブラックリストし、Heat デプロイメントの更新を受け取らないようにします。スタック操作が完了した後には、ブラックリストに登録されたサーバーは以前の状態のままとなります。操作中に os-collect-config エージェントの電源をオフにしたり、停止したりすることもできます。
- ノードをブラックリストに登録する場合には、注意が必要です。ブラックリストを有効にした状態で要求された変更を適用する方法を十分に理解していない限り、ブラックリストは使用しないでください。ブラックリスト機能を使うと、スタックがハングしたり、オーバークラウドが誤って設定されたりする場合があります。たとえば、クラスター設定の変更が Pacemaker クラスターの全メンバーに適用される場合には、この変更の間に Pacemaker クラスターのメンバーをブラックリストに登録すると、クラスターが機能しなくなる場合があります。
- 更新またはアップグレードの操作中にブラックリストを使わないでください。これらの操作には、特定のサーバーに対する変更を分離するための独自の方法があります。詳細は、『Upgrading Red Hat OpenStack Platform』のドキュメントを参照してください。
- サーバーをブラックリストに追加すると、そのサーバーをブラックリストから削除するまでは、それらのノードにはさらなる変更は適用されません。これには、更新、アップグレード、スケールアップ、スケールダウン、およびノードの置き換えが含まれます。
ブラックリストのクリア
その後のスタック操作のためにブラックリストをクリアするには、DeploymentServerBlacklist を編集して空の配列を使用します。
parameter_defaults: DeploymentServerBlacklist: []
DeploymentServerBlacklist パラメーターを単に削除しないでください。パラメーターを削除しただけの場合には、オーバークラウドデプロイメントには、前回保存された値が使用されます。
第12章 コントローラーノードの置き換え
特定の状況では、高可用性クラスター内のコントローラーノードに障害が発生することがあり、その場合は、そのコントローラーノードをクラスターから削除して新しいコントローラーノードに置き換える必要があります。
以下のシナリオの手順を実施して、コントローラーノードを置き換えます。コントローラーノードを置き換えるプロセスでは、openstack overcloud deploy コマンドを実行し、コントローラーノードを置き換えるリクエストでオーバークラウドを更新します。
以下の手順は、高可用性環境にのみ適用されます。コントローラーノード 1 台の場合には、この手順は使用しないでください。
12.1. コントローラー置き換えの準備
オーバークラウドコントローラーノードの置き換えを試みる前に、Red Hat OpenStack Platform 環境の現在の状態をチェックしておくことが重要です。このチェックしておくと、コントローラーの置き換えプロセス中に複雑な事態が発生するのを防ぐことができます。以下の事前チェックリストを使用して、コントローラーノードの置き換えを実行しても安全かどうかを確認してください。チェックのためのコマンドはすべてアンダークラウドで実行します。
手順
アンダークラウドで、
overcloudスタックの現在の状態をチェックします。$ source stackrc (undercloud) $ openstack stack list --nested
overcloudスタックと後続の子スタックは、CREATE_COMPLETEまたはUPDATE_COMPLETEのステータスである必要があります。データベースクライアントツールをインストールします。
(undercloud) $ sudo yum -y install mariadb
root ユーザーのデータベースへのアクセス権限を設定します。
(undercloud) $ sudo cp /var/lib/config-data/puppet-generated/mysql/root/.my.cnf /root/.
アンダークラウドデータベースのバックアップを実行します。
(undercloud) $ mkdir /home/stack/backup (undercloud) $ sudo mysqldump --all-databases --quick --single-transaction | gzip > /home/stack/backup/dump_db_undercloud.sql.gz
- アンダークラウドに、新規ノードプロビジョニング時のイメージのキャッシュと変換に対応できる 10 GB の空きストレージ領域があることを確認します。
コントローラーノードで実行中の Pacemaker の状態をチェックします。たとえば、実行中のコントローラーノードの IP アドレスが 192.168.0.47 の場合には、以下のコマンドで Pacemaker のステータス情報を取得します。
(undercloud) $ ssh heat-admin@192.168.0.47 'sudo pcs status'
出力には、既存のノードで実行中のサービスと、障害が発生しているノードで停止中のサービスがすべて表示されるはずです。
オーバークラウド MariaDB クラスターの各ノードで以下のパラメーターをチェックします。
-
wsrep_local_state_comment: Synced wsrep_cluster_size: 2実行中のコントローラーノードで以下のコマンドを使用して、パラメーターをチェックします。以下の例では、コントローラーノードの IP アドレスは、それぞれ 192.168.0.47 と 192.168.0.46 です。
(undercloud) $ for i in 192.168.0.47 192.168.0.46 ; do echo "*** $i ***" ; ssh heat-admin@$i "sudo mysql -p\$(sudo hiera -c /etc/puppet/hiera.yaml mysql::server::root_password) --execute=\"SHOW STATUS LIKE 'wsrep_local_state_comment'; SHOW STATUS LIKE 'wsrep_cluster_size';\""; done
-
RabbitMQ のステータスをチェックします。たとえば、実行中のコントローラーノードの IP アドレスが 192.168.0.47 の場合には、以下のコマンドを実行してステータスを取得します。
(undercloud) $ ssh heat-admin@192.168.0.47 "sudo docker exec \$(sudo docker ps -f name=rabbitmq-bundle -q) rabbitmqctl cluster_status"
running_nodesキーには、障害が発生しているノードは表示されず、稼働中のノード 2 台のみが表示されるはずです。フェンシングが有効化されている場合には無効にします。たとえば、実行中のコントローラーノードの IP アドレスが 192.168.0.47 の場合には、以下のコマンドを実行してフェンシングを無効にします。
(undercloud) $ ssh heat-admin@192.168.0.47 "sudo pcs property set stonith-enabled=false"
以下のコマンドを実行してフェンシングのステータスを確認します。
(undercloud) $ ssh heat-admin@192.168.0.47 "sudo pcs property show stonith-enabled"
director ノードで Compute サービスがアクティブであることを確認します。
(undercloud) $ openstack hypervisor list
出力では、メンテナンスモードに入っていないすべてのノードが
upのステータスで表示されるはずです。アンダークラウドコンテナーがすべて実行中であることを確認します。
(undercloud) $ sudo docker ps
12.2. Ceph monitor デーモンの削除
ストレージクラスターから ceph-mon デーモンを削除するには、以下の手順に従います。コントローラーノードが Ceph monitor サービスを実行している場合には、以下の手順を実施して、ceph-mon デーモンを削除してください。この手順は、コントローラーが到達可能であることを前提としています。
クラスターに新しいコントローラーを追加すると、新しい Ceph monitor デーモンも自動的に追加されます。
手順
置き換えるコントローラーに接続して、root になります。
# ssh heat-admin@192.168.0.47 # sudo su -
注記コントローラーが到達不可能な場合には、ステップ 1 と 2 をスキップして、稼働している任意のコントローラーノードでステップ 3 から手順を続行してください。
root として monitor を停止します。
# systemctl stop ceph-mon@<monitor_hostname>
例:
# systemctl stop ceph-mon@overcloud-controller-1
- 置き換えるコントローラーとの接続を終了します。
既存のコントローラーのいずれかに接続します。
# ssh heat-admin@192.168.0.46 # sudo su -
クラスターから monitor を削除します。
# ceph mon remove <mon_id>
すべてのコントローラーノード上で、
/etc/ceph/ceph.confから monitor のエントリーを削除します。たとえば、controller-1 を削除する場合には、controller-1 の IP アドレスとホスト名を削除します。編集前:
mon host = 172.18.0.21,172.18.0.22,172.18.0.24 mon initial members = overcloud-controller-2,overcloud-controller-1,overcloud-controller-0
編集後:
mon host = 172.18.0.22,172.18.0.24 mon initial members = overcloud-controller-2,overcloud-controller-0
注記置き換え用のコントローラーノードが追加されると、director によって該当するオーバークラウドノード上の
ceph.confファイルが更新されます。通常は、director がこの設定ファイルを管理するだけで、手動でファイルを編集する必要はありません。ただし、新規ノードが追加される前に他のノードが再起動してしまった場合には、一貫性を保つために手動でファイルを編集することができます。オプションとして、monitor データをアーカイブし、アーカイブを別のサーバーに保存します。
# mv /var/lib/ceph/mon/<cluster>-<daemon_id> /var/lib/ceph/mon/removed-<cluster>-<daemon_id>
12.3. コントローラーを置き換えるためのクラスター準備
古いノードを置き換える場合には、Pacemaker がノード上で実行されていないことを確認してからそのノードを Pacemaker クラスターから削除する必要があります。
手順
コントローラーノードの IP アドレスの一覧を取得します。
(undercloud) $ openstack server list -c Name -c Networks +------------------------+-----------------------+ | Name | Networks | +------------------------+-----------------------+ | overcloud-compute-0 | ctlplane=192.168.0.44 | | overcloud-controller-0 | ctlplane=192.168.0.47 | | overcloud-controller-1 | ctlplane=192.168.0.45 | | overcloud-controller-2 | ctlplane=192.168.0.46 | +------------------------+-----------------------+
まだ古いノードにアクセスできる場合は、残りのノードのいずれかにログインし、古いノード上の Pacemaker を停止します。以下の例では、overcloud-controller-1 上の Pacemaker を停止しています。
(undercloud) $ ssh heat-admin@192.168.0.47 "sudo pcs status | grep -w Online | grep -w overcloud-controller-1" (undercloud) $ ssh heat-admin@192.168.0.47 "sudo pcs cluster stop overcloud-controller-1"
注記古いノードが物理的に利用できない、または停止している場合には、そのノードでは Pacemaker はすでに停止しているので、この操作を実施する必要はありません。
古いノード上の Pacemaker を停止したら、各ノードの Corosync 設定から古いノードを削除して、Corosync を再起動します。古いノード上の Pacemaker のステータスを確認するには、
pcs statusコマンドを実行し、ステータスがStoppedであることを確認します。以下のコマンドの例では、
overcloud-controller-0およびovercloud-controller-2にログインし、overcloud-controller-1を削除しています。(undercloud) $ for NAME in overcloud-controller-0 overcloud-controller-2; do IP=$(openstack server list -c Networks -f value --name $NAME | cut -d "=" -f 2) ; ssh heat-admin@$IP "sudo pcs cluster localnode remove overcloud-controller-1; sudo pcs cluster reload corosync"; done
残りのノードの中の 1 台にログインして、
crm_nodeコマンドで対象のノードをクラスターから削除します。(undercloud) $ ssh heat-admin@192.168.0.47 [heat-admin@overcloud-controller-0 ~]$ sudo crm_node -R overcloud-controller-1 --force
オーバークラウドデータベースは、置き換え手順の実行中に稼働し続ける必要があります。この手順の実行中に Pacemaker が Galera を停止しないようにするには、実行中のコントローラーノードを選択して、そのコントローラーノードの IP アドレスを使用して、アンダークラウドで以下のコマンドを実行します。
(undercloud) $ ssh heat-admin@192.168.0.47 "sudo pcs resource unmanage galera-bundle"
12.4. コントローラーノードの置き換え
コントローラーノードを置き換えるには、置き換えるノードのインデックスを特定します。
- ノードが仮想ノードの場合には、障害の発生したディスクが含まれるノードを特定し、バックアップからそのディスクをリストアします。障害の発生したサーバー上での PXE ブートに使用する NIC の MAC アドレスは、ディスク置き換え後も同じアドレスにしてください。
- ノードがベアメタルノードの場合には、ディスクを置き換え、オーバークラウド設定で新しいディスクを準備し、新しいハードウェア上でノードのイントロスペクションを実施します。
overcloud-controller-1 ノードを overcloud-controller-3 ノードに置き換えるには、以下の手順例を実施します。overcloud-controller-3 ノードの ID は 75b25e9a-948d-424a-9b3b-f0ef70a6eacf です。
ノードを既存の ironic ノードに置き換えるには、director がノードを自動的に再プロビジョニングしないように、削除するノードをメンテナンスモードに切り替える必要があります。
手順
source コマンドで
stackrcファイルを読み込みます。$ source ~/stackrc
overcloud-controller-1ノードのインデックスを特定します。$ INSTANCE=$(openstack server list --name overcloud-controller-1 -f value -c ID)
インスタンスに関連付けられたベアメタルノードを特定します。
$ NODE=$(openstack baremetal node list -f csv --quote minimal | grep $INSTANCE | cut -f1 -d,)
ノードをメンテナンスモードに切り替えます。
$ openstack baremetal node maintenance set $NODE
コントローラーノードが仮想ノードの場合には、コントローラーホストで以下のコマンドを実行し、障害の発生した仮想ディスクをバックアップからの仮想ディスクに置き換えます。
$ cp <VIRTUAL_DISK_BACKUP> /var/lib/libvirt/images/<VIRTUAL_DISK>
<VIRTUAL_DISK_BACKUP>を障害の発生した仮想ディスクのバックアップへのパスに、<VIRTUAL_DISK>を置き換える仮想ディスクの名前にそれぞれ置き換えます。削除するノードのバックアップがない場合には、新しい仮想ノードを使用する必要があります。
コントローラーノードがベアメタルノードの場合には、以下の手順を実施してディスクを新しいベアメタルディスクに置き換えます。
- 物理ハードドライブまたはソリッドステートドライブを置き換えます。
- 障害が発生したノードと同じ設定のノードを準備します。
関連付けられていないノードの一覧を表示し、新規ノードの ID を特定します。
$ openstack baremetal node list --unassociated
新規ノードを
controlプロファイルにタグ付けします。(undercloud) $ openstack baremetal node set --property capabilities='profile:control,boot_option:local' 75b25e9a-948d-424a-9b3b-f0ef70a6eacf
12.5. コントローラーノード置き換えのトリガー
古いコントローラーノードを削除して新規コントローラーノードに置き換えるには、以下の手順を実施します。
手順
削除するノードのインデックスを定義する環境ファイルを作成します (
~/templates/remove-controller.yaml)。parameters: ControllerRemovalPolicies: [{'resource_list': ['1']}]ご自分の環境に該当するその他の環境ファイルと共に
remove-controller.yaml環境ファイルを指定して、オーバークラウドデプロイメントコマンドを実行します。(undercloud) $ openstack overcloud deploy --templates \ -e /home/stack/templates/remove-controller.yaml \ -e /home/stack/templates/node-info.yaml \ [OTHER OPTIONS]注記-e ~/templates/remove-controller.yamlは、デプロイメントコマンドのこのインスタンスに対してのみ指定します。これ以降のデプロイメント操作からは、この環境ファイルを削除してください。director は古いノードを削除して、新しいノードを作成してから、オーバークラウドスタックを更新します。以下のコマンドを使用すると、オーバークラウドスタックのステータスをチェックすることができます。
(undercloud) $ openstack stack list --nested
デプロイメントコマンドの実行が完了すると、director の出力には古いノードが新規ノードに置き換えられたことが表示されます。
(undercloud) $ openstack server list -c Name -c Networks +------------------------+-----------------------+ | Name | Networks | +------------------------+-----------------------+ | overcloud-compute-0 | ctlplane=192.168.0.44 | | overcloud-controller-0 | ctlplane=192.168.0.47 | | overcloud-controller-2 | ctlplane=192.168.0.46 | | overcloud-controller-3 | ctlplane=192.168.0.48 | +------------------------+-----------------------+
これで、新規ノードが稼動状態のコントロールプレーンサービスをホストするようになります。
12.6. コントローラーノード置き換え後のクリーンアップ
ノードの置き換えが完了したら、以下の手順を実施してコントローラークラスターの最終処理を行います。
手順
- コントローラーノードにログインします。
Galera クラスターの Pacemaker 管理を有効にし、新規ノード上で Galera を起動します。
[heat-admin@overcloud-controller-0 ~]$ sudo pcs resource refresh galera-bundle [heat-admin@overcloud-controller-0 ~]$ sudo pcs resource manage galera-bundle
最終のステータスチェックを実行して、サービスが正しく実行されていることを確認します。
[heat-admin@overcloud-controller-0 ~]$ sudo pcs status
注記エラーが発生したサービスがある場合には、
pcs resource refreshコマンドを使用して問題を解決し、そのサービスを再起動します。director を終了します。
[heat-admin@overcloud-controller-0 ~]$ exit
オーバークラウドと対話できるようにするために、source コマンドで
overcloudrcファイルを読み込みます。$ source ~/overcloudrc
オーバークラウド環境のネットワークエージェントを確認します。
(overcloud) $ openstack network agent list
古いノードにエージェントが表示される場合には、そのエージェントを削除します。
(overcloud) $ for AGENT in $(openstack network agent list --host overcloud-controller-1.localdomain -c ID -f value) ; do openstack network agent delete $AGENT ; done
必要に応じて、新規ノード上の L3 エージェントホストにルーターを追加します。以下のコマンドは、UUID に 2d1c1dc1-d9d4-4fa9-b2c8-f29cd1a649d4 を使用して L3 エージェントに r1 という名称のルーターを追加する例です。
(overcloud) $ openstack network agent add router --l3 2d1c1dc1-d9d4-4fa9-b2c8-f29cd1a649d4 r1
削除したノードの Compute サービスがオーバークラウドにまだ存在しているので、削除する必要があります。削除したノードの Compute サービスを確認します。
[stack@director ~]$ source ~/overcloudrc (overcloud) $ openstack compute service list --host overcloud-controller-1.localdomain
削除したノードのコンピュートサービスを削除します。
(overcloud) $ for SERVICE in $(openstack compute service list --host overcloud-controller-1.localdomain -c ID -f value ) ; do openstack compute service delete $SERVICE ; done
第13章 ノードのリブート
アンダークラウドおよびオーバークラウドで、ノードをリブートしなければならない場合があります。以下の手順では、異なるノード種別をリブートする方法を説明します。以下の点に注意してください。
- 1 つのロールで全ノードをリブートする場合には、各ノードを個別にリブートすることを推奨しています。この方法は、リブート中にそのロールのサービスを保持するのに役立ちます。
- OpenStack Platform 環境の全ノードをリブートする場合、リブートの順序は以下のリストを参考にしてください。
推奨されるノードリブート順
- director のリブート
- コントローラーノードおよびその他のコンポーザブルノードのリブート
- Ceph Storage ノードのリブート
- コンピュートノードのリブート
13.1. アンダークラウドノードのリブート
以下の手順では、アンダークラウドノードをリブートします。
手順
-
アンダークラウドに
stackユーザーとしてログインします。 アンダークラウドをリブートします。
$ sudo reboot
- ノードが起動するまで待ちます。
13.2. コントローラーノードおよびコンポーザブルノードのリブート
以下の手順では、コントローラーノードと、コンポーザブルロールをベースとするスタンドアロンのノードをリブートします。これには、コンピュートノードと Ceph Storage ノードは含まれません。
手順
リブートするノードを選択します。そのノードにログインして、リブートする前にクラスターを停止します。
[heat-admin@overcloud-controller-0 ~]$ sudo pcs cluster stop
ノードをリブートします。
[heat-admin@overcloud-controller-0 ~]$ sudo reboot
- ノードが起動するまで待ちます。
ノードのクラスターを再び有効にします。
[heat-admin@overcloud-controller-0 ~]$ sudo pcs cluster start
ノードにログインしてサービスをチェックします。以下に例を示します。
ノードが Pacemaker サービスを使用している場合には、ノードがクラスターに再度参加したかどうかを確認します。
[heat-admin@overcloud-controller-0 ~]$ sudo pcs status
ノードが Systemd サービスを使用している場合には、全サービスが有効化されているかどうかを確認します。
[heat-admin@overcloud-controller-0 ~]$ sudo systemctl status
13.3. Ceph Storage (OSD) クラスターのリブート
以下の手順では、Ceph Storage (OSD) ノードのクラスターをリブートします。
手順
Ceph MON またはコントローラーノードにログインして、Ceph Storage クラスターのリバランスを一時的に無効にします。
$ sudo ceph osd set noout $ sudo ceph osd set norebalance
- リブートする最初の Ceph Storage ノードを選択して、ログインします。
ノードをリブートします。
$ sudo reboot
- ノードが起動するまで待ちます。
ノードにログインして、クラスターのステータスを確認します。
$ sudo ceph -s
pgsがpgmapにより通常通りに報告されていることを確認します (active+clean)。- ノードからログアウトして、次のノードをリブートし、ステータスを確認します。全 Ceph Storage ノードがリブートされるまで、このプロセスを繰り返します。
完了したら、Ceph MON またはコントローラーノードにログインして、クラスターのリバランスを再度有効にします。
$ sudo ceph osd unset noout $ sudo ceph osd unset norebalance
最終のステータスチェックを実行して、クラスターが
HEALTH_OKを報告していることを確認します。$ sudo ceph status
13.4. コンピュートノードのリブート
以下の手順では、コンピュートノードをリブートします。OpenStack Platform 環境内のインスタンスのダウンタイムを最小限に抑えるために、この手順には、選択したコンピュートノードからインスタンスを移行するステップも含まれています。これは、以下のワークフローを伴います。
- リブートするコンピュートノードを選択して無効にし、新規インスタンスをプロビジョニングしないようにします。
- インスタンスを別のコンピュートノードに移行します。
- 空のコンピュートノードをリブートして有効化します。
手順
-
アンダークラウドに
stackユーザーとしてログインします。 全コンピュートノードとその UUID を一覧表示します。
$ source ~/stackrc (undercloud) $ openstack server list --name compute
リブートするコンピュートノードの UUID を特定します。
アンダークラウドから、コンピュートノードを選択し、そのノードを無効にします。
$ source ~/overcloudrc (overcloud) $ openstack compute service list (overcloud) $ openstack compute service set [hostname] nova-compute --disable
コンピュートノード上の全インスタンスを一覧表示します。
(overcloud) $ openstack server list --host [hostname] --all-projects
以下のコマンドの 1 つを使用して、インスタンスを移行します。
選択した特定のホストにインスタンスを移行します。
(overcloud) $ openstack server migrate [instance-id] --live [target-host]--wait
nova-schedulerにより対象のホストが自動的に選択されるようにします。(overcloud) $ nova live-migration [instance-id]
一度にすべてのインスタンスのライブマイグレーションを行います。
$ nova host-evacuate-live [hostname]
注記novaコマンドで非推奨の警告が表示される可能性がありますが、安全に無視することができます。
- 移行が完了するまで待ちます。
正常に移行したことを確認します。
(overcloud) $ openstack server list --host [hostname] --all-projects
- 選択したコンピュートノードのインスタンスがなくなるまで、移行を続けます。
コンピュートノードにログインして、リブートします。
[heat-admin@overcloud-compute-0 ~]$ sudo reboot
- ノードが起動するまで待ちます。
コンピュートノードを再度有効化します。
$ source ~/overcloudrc (overcloud) $ openstack compute service set [hostname] nova-compute --enable
コンピュートノードが有効化されているかどうかを確認します。
(overcloud) $ openstack compute service list
パート IV. director に関するその他の操作および設定
第14章 その他のイントロスペクション操作
14.1. ノードイントロスペクションの個別実行
available の状態のノードで個別にイントロスペクションを実行するには、ノードを管理モードに設定して、イントロスペクションを実行します。
(undercloud) $ openstack baremetal node manage [NODE UUID] (undercloud) $ openstack overcloud node introspect [NODE UUID] --provide
イントロスペクションが完了すると、ノードは available の状態に変わります。
14.2. 初回のイントロスペクション後のノードイントロスペクションの実行
--provide オプションを指定したので、初回のイントロスペクションの後には、全ノードが available の状態に入るはずです。初回のイントロスペクション後に全ノードにイントロスペクションを実行するには、すべてのノードを manageable の状態にして、一括のイントロスペクションコマンドを実行します。
(undercloud) $ for node in $(openstack baremetal node list --fields uuid -f value) ; do openstack baremetal node manage $node ; done (undercloud) $ openstack overcloud node introspect --all-manageable --provide
イントロスペクション完了後には、すべてのノードが available の状態に変わります。
14.3. ネットワークイントロスペクションの実行によるインターフェース情報の取得
ネットワークイントロスペクションにより、Link Layer Discovery Protocol (LLDP) データがネットワークスイッチから取得されます。以下のコマンドにより、ノード上の全インターフェースに関する LLDP 情報のサブセット、または特定のノードおよびインターフェースに関するすべての情報が表示されます。この情報は、トラブルシューティングに役立ちます。director では、デフォルトで LLDP データ収集が有効になっています。
ノード上のインターフェースのリストを取得するには、以下のコマンドを実行します。
(undercloud) $ openstack baremetal introspection interface list [NODE UUID]
例:
(undercloud) $ openstack baremetal introspection interface list c89397b7-a326-41a0-907d-79f8b86c7cd9 +-----------+-------------------+------------------------+-------------------+----------------+ | Interface | MAC Address | Switch Port VLAN IDs | Switch Chassis ID | Switch Port ID | +-----------+-------------------+------------------------+-------------------+----------------+ | p2p2 | 00:0a:f7:79:93:19 | [103, 102, 18, 20, 42] | 64:64:9b:31:12:00 | 510 | | p2p1 | 00:0a:f7:79:93:18 | [101] | 64:64:9b:31:12:00 | 507 | | em1 | c8:1f:66:c7:e8:2f | [162] | 08:81:f4:a6:b3:80 | 515 | | em2 | c8:1f:66:c7:e8:30 | [182, 183] | 08:81:f4:a6:b3:80 | 559 | +-----------+-------------------+------------------------+-------------------+----------------+
インターフェースのデータおよびスイッチポートの情報を表示するには、以下のコマンドを実行します。
(undercloud) $ openstack baremetal introspection interface show [NODE UUID] [INTERFACE]
例:
(undercloud) $ openstack baremetal introspection interface show c89397b7-a326-41a0-907d-79f8b86c7cd9 p2p1
+--------------------------------------+------------------------------------------------------------------------------------------------------------------------+
| Field | Value |
+--------------------------------------+------------------------------------------------------------------------------------------------------------------------+
| interface | p2p1 |
| mac | 00:0a:f7:79:93:18 |
| node_ident | c89397b7-a326-41a0-907d-79f8b86c7cd9 |
| switch_capabilities_enabled | [u'Bridge', u'Router'] |
| switch_capabilities_support | [u'Bridge', u'Router'] |
| switch_chassis_id | 64:64:9b:31:12:00 |
| switch_port_autonegotiation_enabled | True |
| switch_port_autonegotiation_support | True |
| switch_port_description | ge-0/0/2.0 |
| switch_port_id | 507 |
| switch_port_link_aggregation_enabled | False |
| switch_port_link_aggregation_id | 0 |
| switch_port_link_aggregation_support | True |
| switch_port_management_vlan_id | None |
| switch_port_mau_type | Unknown |
| switch_port_mtu | 1514 |
| switch_port_physical_capabilities | [u'1000BASE-T fdx', u'100BASE-TX fdx', u'100BASE-TX hdx', u'10BASE-T fdx', u'10BASE-T hdx', u'Asym and Sym PAUSE fdx'] |
| switch_port_protocol_vlan_enabled | None |
| switch_port_protocol_vlan_ids | None |
| switch_port_protocol_vlan_support | None |
| switch_port_untagged_vlan_id | 101 |
| switch_port_vlan_ids | [101] |
| switch_port_vlans | [{u'name': u'RHOS13-PXE', u'id': 101}] |
| switch_protocol_identities | None |
| switch_system_name | rhos-compute-node-sw1 |
+--------------------------------------+------------------------------------------------------------------------------------------------------------------------+ハードウェアイントロスペクション情報の取得
Bare Metal サービスでは、ハードウェア検査時に追加のハードウェア情報を取得するためのパラメーター (inspection_extras) がデフォルトで有効になっています。これらのハードウェア情報を使って、オーバークラウドを設定することができます。undercloud.conf ファイルの inspection_extras パラメーターに関する詳細は、「director の設定」を参照してください。
たとえば、numa_topology コレクターは、このハードウェア inspection_extras の一部で、各 NUMA ノードに関する以下の情報が含まれます。
- RAM (キロバイト単位)
- 物理 CPU コアおよびそのシブリングスレッド
- NUMA ノードに関連付けられた NIC
この情報を取得するには、ベアメタルノードの UUID を指定して、openstack baremetal introspection data save _UUID_ | jq .numa_topology コマンドを実行します。
取得されるベアメタルノードの NUMA 情報の例を、以下に示します。
{
"cpus": [
{
"cpu": 1,
"thread_siblings": [
1,
17
],
"numa_node": 0
},
{
"cpu": 2,
"thread_siblings": [
10,
26
],
"numa_node": 1
},
{
"cpu": 0,
"thread_siblings": [
0,
16
],
"numa_node": 0
},
{
"cpu": 5,
"thread_siblings": [
13,
29
],
"numa_node": 1
},
{
"cpu": 7,
"thread_siblings": [
15,
31
],
"numa_node": 1
},
{
"cpu": 7,
"thread_siblings": [
7,
23
],
"numa_node": 0
},
{
"cpu": 1,
"thread_siblings": [
9,
25
],
"numa_node": 1
},
{
"cpu": 6,
"thread_siblings": [
6,
22
],
"numa_node": 0
},
{
"cpu": 3,
"thread_siblings": [
11,
27
],
"numa_node": 1
},
{
"cpu": 5,
"thread_siblings": [
5,
21
],
"numa_node": 0
},
{
"cpu": 4,
"thread_siblings": [
12,
28
],
"numa_node": 1
},
{
"cpu": 4,
"thread_siblings": [
4,
20
],
"numa_node": 0
},
{
"cpu": 0,
"thread_siblings": [
8,
24
],
"numa_node": 1
},
{
"cpu": 6,
"thread_siblings": [
14,
30
],
"numa_node": 1
},
{
"cpu": 3,
"thread_siblings": [
3,
19
],
"numa_node": 0
},
{
"cpu": 2,
"thread_siblings": [
2,
18
],
"numa_node": 0
}
],
"ram": [
{
"size_kb": 66980172,
"numa_node": 0
},
{
"size_kb": 67108864,
"numa_node": 1
}
],
"nics": [
{
"name": "ens3f1",
"numa_node": 1
},
{
"name": "ens3f0",
"numa_node": 1
},
{
"name": "ens2f0",
"numa_node": 0
},
{
"name": "ens2f1",
"numa_node": 0
},
{
"name": "ens1f1",
"numa_node": 0
},
{
"name": "ens1f0",
"numa_node": 0
},
{
"name": "eno4",
"numa_node": 0
},
{
"name": "eno1",
"numa_node": 0
},
{
"name": "eno3",
"numa_node": 0
},
{
"name": "eno2",
"numa_node": 0
}
]
}第15章 ベアメタルノードの自動検出
auto-discovery を使用すると、最初に instackenv.json ファイルを作成せずに、アンダークラウドノードを登録してそのメタデータを生成することができます。この改善により、最初のノード情報取得に費す時間を短縮できます。たとえば、IPMI IP アドレスを照合し、その後に instackenv.json ファイルを作成する必要がなくなります。
15.1. 要件
- すべてのオーバークラウドノードの BMC が、IPMI を通じて director にアクセスできるように設定されていること
- すべてのオーバークラウドノードが、アンダークラウドのコントロールプレーンネットワークに接続された NIC から PXE ブートするように設定されていること
15.2. 自動検出の有効化
undercloud.confでベアメタルの自動検出を有効にします。enable_node_discovery = True discovery_default_driver = ipmi
-
enable_node_discovery: 有効にすると、PXE を使ってイントロスペクション ramdisk をブートするすべてのノードが Ironic に登録されます。 -
discovery_default_driver: 検出されたノードに使用するドライバーを設定します。例:ipmi
-
IPMI の認証情報を Ironic に追加します。
IPMI の認証情報を
ipmi-credentials.jsonという名前のファイルに追加します。以下の例で使用しているユーザー名とパスワードの値は、お使いの環境に応じて置き換える必要があります。[ { "description": "Set default IPMI credentials", "conditions": [ {"op": "eq", "field": "data://auto_discovered", "value": true} ], "actions": [ {"action": "set-attribute", "path": "driver_info/ipmi_username", "value": "SampleUsername"}, {"action": "set-attribute", "path": "driver_info/ipmi_password", "value": "RedactedSecurePassword"}, {"action": "set-attribute", "path": "driver_info/ipmi_address", "value": "{data[inventory][bmc_address]}"} ] } ]
IPMI の認証情報ファイルを Ironic にインポートします。
$ openstack baremetal introspection rule import ipmi-credentials.json
15.3. 自動検出のテスト
- 必要なノードの電源をオンにします。
openstack baremetal node listを実行します。新しいノードがenrollの状態でリストに表示されるはずです。$ openstack baremetal node list +--------------------------------------+------+---------------+-------------+--------------------+-------------+ | UUID | Name | Instance UUID | Power State | Provisioning State | Maintenance | +--------------------------------------+------+---------------+-------------+--------------------+-------------+ | c6e63aec-e5ba-4d63-8d37-bd57628258e8 | None | None | power off | enroll | False | | 0362b7b2-5b9c-4113-92e1-0b34a2535d9b | None | None | power off | enroll | False | +--------------------------------------+------+---------------+-------------+--------------------+-------------+
各ノードにリソースクラスを設定します。
$ for NODE in `openstack baremetal node list -c UUID -f value` ; do openstack baremetal node set $NODE --resource-class baremetal ; done
各ノードにカーネルと ramdisk を設定します。
$ for NODE in `openstack baremetal node list -c UUID -f value` ; do openstack baremetal node manage $NODE ; done $ openstack overcloud node configure --all-manageable
全ノードを利用可能な状態に設定します。
$ for NODE in `openstack baremetal node list -c UUID -f value` ; do openstack baremetal node provide $NODE ; done
15.4. ルールを使用して異なるベンダーのハードウェアを検出する方法
異種のハードウェアが混在する環境では、イントロスペクションルールを使って、認証情報の割り当てやリモート管理を行うことができます。たとえば、DRAC を使用する Dell ノードを処理するには、別の検出ルールが必要になる場合があります。
以下の内容で、
dell-drac-rules.jsonという名前のファイルを作成します。この例で使用しているユーザー名およびパスワードの値は、お使いの環境に応じて置き換える必要があります。[ { "description": "Set default IPMI credentials", "conditions": [ {"op": "eq", "field": "data://auto_discovered", "value": true}, {"op": "ne", "field": "data://inventory.system_vendor.manufacturer", "value": "Dell Inc."} ], "actions": [ {"action": "set-attribute", "path": "driver_info/ipmi_username", "value": "SampleUsername"}, {"action": "set-attribute", "path": "driver_info/ipmi_password", "value": "RedactedSecurePassword"}, {"action": "set-attribute", "path": "driver_info/ipmi_address", "value": "{data[inventory][bmc_address]}"} ] }, { "description": "Set the vendor driver for Dell hardware", "conditions": [ {"op": "eq", "field": "data://auto_discovered", "value": true}, {"op": "eq", "field": "data://inventory.system_vendor.manufacturer", "value": "Dell Inc."} ], "actions": [ {"action": "set-attribute", "path": "driver", "value": "idrac"}, {"action": "set-attribute", "path": "driver_info/drac_username", "value": "SampleUsername"}, {"action": "set-attribute", "path": "driver_info/drac_password", "value": "RedactedSecurePassword"}, {"action": "set-attribute", "path": "driver_info/drac_address", "value": "{data[inventory][bmc_address]}"} ] } ]ルールを Ironic にインポートします。
$ openstack baremetal introspection rule import dell-drac-rules.json
パート V. トラブルシューティング
第16章 director の問題のトラブルシューティング
director プロセスの特定の段階で、エラーが発生する可能性があります。本項では、一般的な問題の診断に関する情報を提供します。
director のコンポーネントの共通ログを確認してください。
-
/var/logディレクトリーには、多数の OpenStack Platform の共通コンポーネントのログや、標準の Red Hat Enterprise Linux アプリケーションのログが含まれています。 journaldサービスは、さまざまなコンポーネントのログを提供します。Ironic はopenstack-ironic-apiとopenstack-ironic-conductorの 2 つのユニットを使用する点に注意してください。同様に、ironic-inspectorはopenstack-ironic-inspectorとopenstack-ironic-inspector-dnsmasqの 2 つのユニットを使用します。該当するコンポーネントごとに両ユニットを使用します。以下に例を示します。$ source ~/stackrc (undercloud) $ sudo journalctl -u openstack-ironic-inspector -u openstack-ironic-inspector-dnsmasq
-
ironic-inspectorは、/var/log/ironic-inspector/ramdisk/に ramdisk ログを gz 圧縮の tar ファイルとして保存します。ファイル名には、日付、時間、ノードの IPMI アドレスが含まれます。イントロスペクションの問題を診断するには、これらのログを使用します。
16.1. ノード登録のトラブルシューティング
ノード登録における問題は通常、ノードの情報が間違っていることが原因で発生します。このような場合には、ironic を使用して、登録したノードデータの問題を修正します。以下にいくつか例を示します。
割り当てられたポートの UUID を確認します。
$ source ~/stackrc (undercloud) $ openstack baremetal port list --node [NODE UUID]
MAC アドレスを更新します。
(undercloud) $ openstack baremetal port set --address=[NEW MAC] [PORT UUID]
次のコマンドを実行します。
(undercloud) $ openstack baremetal node set --driver-info ipmi_address=[NEW IPMI ADDRESS] [NODE UUID]
16.2. ハードウェアイントロスペクションのトラブルシューティング
イントロスペクションのプロセスは最後まで実行する必要があります。ただし、Ironic の Discovery Daemon (ironic-inspector) は、検出する ramdisk が応答しない場合にはデフォルトの 1 時間が経過するとタイムアウトします。検出する ramdisk のバグが原因とされる場合もありますが、通常は特に BIOS の起動設定などの環境の誤設定が原因で発生します。
以下には、環境設定が間違っている場合の一般的なシナリオと、診断/解決方法に関するアドバイスを示します。
ノードのイントロスペクション開始におけるエラー
通常、イントロスペクションプロセスは、openstack overcloud node introspect コマンドを使用します。ただし、ironic-inspector で直接イントロスペクションを実行している場合には、「AVAILABLE」の状態のノードの検出に失敗する可能性があります。このコマンドは、デプロイメント用であり、検出用ではないためです。検出前に、ノードのステータスを「MANAGEABLE」に変更します。
$ source ~/stackrc (undercloud) $ openstack baremetal node manage [NODE UUID]
検出が完了したら、状態を「AVAILABLE」に戻してからプロビジョニングを行います。
(undercloud) $ openstack baremetal node provide [NODE UUID]
検出プロセスの停止
イントロスペクションのプロセスを停止します。
$ source ~/stackrc (undercloud) $ openstack baremetal introspection abort [NODE UUID]
プロセスがタイムアウトするまで待つことも可能です。必要であれば、/etc/ironic-inspector/inspector.conf の timeout 設定を別の時間 (分単位) に変更します。
イントロスペクション ramdisk へのアクセス
イントロスペクションの ramdisk は、動的なログイン要素を使用します。これは、イントロスペクションのデバッグ中にノードにアクセスするための一時パスワードまたは SSH キーのいずれかを提供できることを意味します。以下のプロセスを使用して、ramdisk アクセスを設定します。
以下のように
openssl passwd -1コマンドに一時パスワードを指定して MD5 ハッシュを生成します。$ openssl passwd -1 mytestpassword $1$enjRSyIw$/fYUpJwr6abFy/d.koRgQ/
/httpboot/inspector.ipxeファイルを編集して、kernelで開始する行を特定し、rootpwdパラメーターと MD5 ハッシュを追記します。以下に例を示します。kernel http://192.2.0.1:8088/agent.kernel ipa-inspection-callback-url=http://192.168.0.1:5050/v1/continue ipa-inspection-collectors=default,extra-hardware,logs systemd.journald.forward_to_console=yes BOOTIF=${mac} ipa-debug=1 ipa-inspection-benchmarks=cpu,mem,disk rootpwd="$1$enjRSyIw$/fYUpJwr6abFy/d.koRgQ/" selinux=0または、
sshkeyパラメーターに SSH 公開キーを追記します。注記rootpwdおよびsshkeyのパラメーターにはいずれも引用符が必要です。イントロスペクションを開始し、
arpコマンドまたは DHCP のログから IP アドレスを特定します。$ arp $ sudo journalctl -u openstack-ironic-inspector-dnsmasq
一時パスワードまたは SSH キーを使用して、root ユーザーとして SSH 接続します。
$ ssh root@192.168.24.105
イントロスペクションストレージのチェック
director は OpenStack Object Storage (swift) を使用して、イントロスペクションプロセス中に取得したハードウェアデータを保存します。このサービスが稼働していない場合には、イントロスペクションは失敗する場合があります。以下のコマンドを実行して、OpenStack Object Storage に関連したサービスをすべてチェックし、このサービスが稼働中であることを確認します。
$ sudo systemctl list-units openstack-swift*
16.3. workflow および execution のトラブルシューティング
OpenStack Workflow (mistral) サービスは、複数の OpenStack タスクをワークフローにグループ化します。Red Hat OpenStack Platform は、これらのワークフローセットを使用して、CLI と Web UI で共通の機能を実行します。これには、ベアメタルノードの制御、検証、プラン管理、オーバークラウドのデプロイメントが含まれます。
たとえば openstack overcloud deploy コマンドを実行すると、OpenStack Workflow サービスは 2 つのワークフローを実行します。最初はデプロイメントプランのアップロードです。
Removing the current plan files Uploading new plan files Started Mistral Workflow. Execution ID: aef1e8c6-a862-42de-8bce-073744ed5e6b Plan updated
2 つ目は、オーバークラウドのデプロイメントを開始します。
Deploying templates in the directory /tmp/tripleoclient-LhRlHX/tripleo-heat-templates Started Mistral Workflow. Execution ID: 97b64abe-d8fc-414a-837a-1380631c764d 2016-11-28 06:29:26Z [overcloud]: CREATE_IN_PROGRESS Stack CREATE started 2016-11-28 06:29:26Z [overcloud.Networks]: CREATE_IN_PROGRESS state changed 2016-11-28 06:29:26Z [overcloud.HeatAuthEncryptionKey]: CREATE_IN_PROGRESS state changed 2016-11-28 06:29:26Z [overcloud.ServiceNetMap]: CREATE_IN_PROGRESS state changed ...
Workflow オブジェクト
OpenStack Workflow では、以下のオブジェクトを使用して、ワークフローを記録します。
- Actions
- Shell スクリプトの実行や HTTP 要求の実行など、関連タスクが実行された場合に OpenStack が実行する特定の指示。OpenStack のコンポーネントには、OpenStack Workflow が使用する Actions が含まれます。
- Tasks
- 実行するアクションと、アクションの実行後の結果を定義します。これらのタスクには通常、アクションまたはアクションに関連付けられたワークフローが含まれます。タスクが完了したら、ワークフローは、タスクが成功したか否かによって、別のタスクに指示を出します。
- Workflows
- グループ化されて、特定の順番で実行されるタスクセット
- Executions
- 実行する特定のアクション、タスク、またはワークフローを定義します。
Workflow のエラー診断
OpenStack Workflow では、実行に関して着実にログを取ることもできるので、特定のコマンドが失敗した場合に問題を特定しやすくなります。たとえば、ワークフローの実行に失敗した場合には、どの部分で失敗したかを特定することができます。ワークフローの実行に失敗した状態 (ERROR) のものを表示します。
$ source ~/stackrc (undercloud) $ openstack workflow execution list | grep "ERROR"
失敗したワークフローの実行の UUID を取得して (例: dffa96b0-f679-4cd2-a490-4769a3825262)、実行とその出力を表示します。
(undercloud) $ openstack workflow execution show dffa96b0-f679-4cd2-a490-4769a3825262 (undercloud) $ openstack workflow execution output show dffa96b0-f679-4cd2-a490-4769a3825262
これにより、実行で失敗したタスクに関する情報を取得できます。openstack workflow execution show は、実行に使用したワークフローも表示します (例: tripleo.plan_management.v1.publish_ui_logs_to_swift)。以下のコマンドを使用して完全なワークフロー定義を表示することができます。
(undercloud) $ openstack workflow definition show tripleo.plan_management.v1.publish_ui_logs_to_swift
これは、特定のタスクがワークフローのどの部分で発生するかを特定する際に便利です。
同様のコマンド構文を使用して、アクションの実行と、その結果を表示することもできます。
(undercloud) $ openstack action execution list (undercloud) $ openstack action execution show 8a68eba3-0fec-4b2a-adc9-5561b007e886 (undercloud) $ openstack action execution output show 8a68eba3-0fec-4b2a-adc9-5561b007e886
これは、問題を引き起こす固有のアクションを特定する際に便利です。
16.4. オーバークラウドの作成のトラブルシューティング
デプロイメントが失敗する可能性のあるレイヤーは 3 つあります。
- Orchestration (Heat および Nova サービス)
- Bare Metal Provisioning (Ironic サービス)
- デプロイメント後の設定 (Ansible および Puppet)
オーバークラウドのデプロイメントがこれらのレベルで失敗した場合には、OpenStack クライアントおよびサービスログファイルを使用して、失敗したデプロイメントの診断を行います。
16.4.1. デプロイメントコマンド履歴へのアクセス
director のデプロイメントコマンドおよび引数の履歴を把握することは、トラブルシューティングおよびサポートに役立ちます。/home/stack/.tripleo/history で、これらの情報を確認することができます。
16.4.2. Orchestration
多くの場合は、オーバークラウドの作成に失敗した後に、Heat により失敗したオーバークラウドスタックが表示されます。
$ source ~/stackrc (undercloud) $ openstack stack list --nested --property status=FAILED +-----------------------+------------+--------------------+----------------------+ | id | stack_name | stack_status | creation_time | +-----------------------+------------+--------------------+----------------------+ | 7e88af95-535c-4a55... | overcloud | CREATE_FAILED | 2015-04-06T17:57:16Z | +-----------------------+------------+--------------------+----------------------+
スタック一覧が空の場合には、初期の Heat 設定に問題があることが分かります。Heat テンプレートと設定オプションをチェックし、さらに openstack overcloud deploy を実行後のエラーメッセージを確認してください。
16.4.3. ベアメタルプロビジョニング
ironic をチェックして、全登録ノードと現在の状態を表示します。
$ source ~/stackrc (undercloud) $ openstack baremetal node list +----------+------+---------------+-------------+-----------------+-------------+ | UUID | Name | Instance UUID | Power State | Provision State | Maintenance | +----------+------+---------------+-------------+-----------------+-------------+ | f1e261...| None | None | power off | available | False | | f0b8c1...| None | None | power off | available | False | +----------+------+---------------+-------------+-----------------+-------------+
プロビジョニングプロセスでよく発生する問題を以下に示します。
結果の表の「Provision State」および「Maintenance」の列を確認します。以下をチェックしてください。
- 空の表または、必要なノード数よりも少ない
- 「Maintenance」が True に設定されている
-
プロビジョニングの状態が
manageableに設定されている。これにより、登録または検出プロセスに問題があることが分かります。たとえば、「Maintenance」が True に自動的に設定された場合は通常、ノードの電源管理の認証情報が間違っています。
-
「Provision State」が
availableの場合には、ベアメタルのデプロイメントが開始される前に問題が発生します。 -
「Provision State」が
activeで、「Power State」がpower onの場合には、ベアメタルのデプロイメントは正常に完了しますが、問題は、デプロイメント後の設定ステップで発生することになります。 -
ノードの「Provision State」が
wait call-backの場合には、このノードではまだ Bare Metal Provisioning プロセスが完了していません。このステータスが変わるまで待ってください。ステータスが変わらない場合には、問題のあるノードの仮想コンソールに接続して、出力を確認します。 「Provision State」が
errorまたはdeploy failedの場合には、このノードの Bare Metal Provisioning は失敗しています。ベアメタルノードの詳細を確認してください。(undercloud) $ openstack baremetal node show [NODE UUID]
エラーの説明が含まれる
last_errorフィールドがないか確認します。エラーメッセージは曖昧なため、ログを使用して解明します。(undercloud) $ sudo journalctl -u openstack-ironic-conductor -u openstack-ironic-api
-
wait timeout errorが表示されており、「Power State」がpower onの場合には、問題のあるノードの仮想コンソールに接続して、出力を確認します。
16.4.4. オーバークラウド設定エラーの確認
オーバークラウドのデプロイメント操作が Ansible の設定ステージで失敗する場合には、openstack overcloud failures コマンドを使用してエラーの発生した設定ステップを表示します。
手順
source コマンドで
stackrcファイルを読み込みます。$ source ~/stackrc
デプロイメントのエラー発生ステップ確認コマンドを実行します。
$ openstack overcloud failures
16.5. プロビジョニングネットワークでの IP アドレスの競合に対するトラブルシューティング
宛先のホストに、すでに使用中の IP アドレスが割り当てられている場合には、検出およびデプロイメントのタスクは失敗します。この問題を回避するには、プロビジョニングネットワークのポートスキャンを実行して、検出の IP アドレス範囲とホストの IP アドレス範囲が解放されているかどうかを確認することができます。
アンダークラウドホストで以下のステップを実行します。
nmap をインストールします。
$ sudo yum install nmap
nmap を使用して、アクティブなアドレスの IP アドレス範囲をスキャンします。この例では、192.168.24.0/24 の範囲をスキャンします。この値は、プロビジョニングネットワークの IP サブネットに置き換えてください (CIDR 表記のビットマスク)。
$ sudo nmap -sn 192.168.24.0/24
nmap スキャンの出力を確認します。
たとえば、アンダークラウドおよびサブネット上に存在するその他のホストの IP アドレスを確認する必要があります。アクティブな IP アドレスが undercloud.conf の IP アドレス範囲と競合している場合には、オーバークラウドノードのイントロスペクションまたはデプロイを実行する前に、IP アドレスの範囲を変更するか、IP アドレスを解放するかのいずれかを行う必要があります。
$ sudo nmap -sn 192.168.24.0/24 Starting Nmap 6.40 ( http://nmap.org ) at 2015-10-02 15:14 EDT Nmap scan report for 192.168.24.1 Host is up (0.00057s latency). Nmap scan report for 192.168.24.2 Host is up (0.00048s latency). Nmap scan report for 192.168.24.3 Host is up (0.00045s latency). Nmap scan report for 192.168.24.5 Host is up (0.00040s latency). Nmap scan report for 192.168.24.9 Host is up (0.00019s latency). Nmap done: 256 IP addresses (5 hosts up) scanned in 2.45 seconds
16.6. "No Valid Host Found" エラーのトラブルシューティング
/var/log/nova/nova-conductor.log に、以下のエラーが含まれる場合があります。
NoValidHost: No valid host was found. There are not enough hosts available.
これは、Nova Scheduler が新規インスタンスを起動するのに適したベアメタルノードを検出できなかったことを意味し、そうなると通常は、Nova が検出を想定しているリソースと、Ironic が Nova に通知するリソースが一致しなくなります。その場合には、以下の点をチェックしてください。
イントロスペクションが正常に完了することを確認してください。または、各ノードに必要な Ironic ノードのプロパティーが含まれていることをチェックしてください。各ノードに以下のコマンドを実行します。
$ source ~/stackrc (undercloud) $ openstack baremetal node show [NODE UUID]
propertiesJSON フィールドのcpus、cpu_arch、memory_mb、local_gbキーに有効な値が指定されていることを確認してください。使用する Nova フレーバーが、必要なノード数において、上記の Ironic ノードプロパティーを超えていないかどうかを確認します。
(undercloud) $ openstack flavor show [FLAVOR NAME]
-
openstack baremetal node listの出力で、availableの状態のノードの数が十分かどうかを確認します。ノードの状態がmanageableの場合は通常、イントロスペクションに失敗しています。 また、ノードがメンテナンスモードではないことを確認します。
openstack baremetal node listを使用してチェックしてください。通常、自動でメンテナンスモードに切り替わるノードは、電源の認証情報が間違っています。認証情報を確認して、メンテナンスモードをオフにします。(undercloud) $ openstack baremetal node maintenance unset [NODE UUID]
-
Automated Health Check (AHC) ツールを使用して、自動でノードのタグ付けを行う場合には、各フレーバー/フレーバーに対応するノードが十分に存在することを確認します。
propertiesフィールドのcapabilitiesキーにopenstack baremetal node showがないか確認します。たとえば、コンピュートロールのタグを付けられたノードには、profile:computeが含まれているはずです。 イントロスペクションの後に Ironic から Nova にノードの情報が反映されるには若干時間がかかります。これは通常、director のツールが原因です。ただし、一部のステップを手動で実行した場合には、短時間ですが、Nova でノードが利用できなくなる場合があります。以下のコマンドを使用して、システム内の合計リソースをチェックします。
(undercloud) $ openstack hypervisor stats show
16.7. オーバークラウド作成後のトラブルシューティング
オーバークラウドを作成した後には、将来そのオーバークラウドで特定の操作を行うようにすることができます。たとえば、利用可能なノードをスケーリングしたり、障害の発生したノードを置き換えたりすることができます。このような操作を行うと、特定の問題が発生する場合があります。本項には、オーバークラウド作成後の操作が失敗した場合の診断とトラブルシューティングに関するアドバイスを記載します。
16.7.1. オーバークラウドスタックの変更
director を使用して overcloud スタックを変更する際に問題が発生する場合があります。スタックの変更例には、以下のような操作が含まれます。
- ノードのスケーリング
- ノードの削除
- ノードの置き換え
スタックの変更は、スタックの作成と似ており、director は要求されたノード数が利用可能かどうかをチェックして追加のノードをプロビジョニングしたり、既存のノードを削除したりしてから、Puppet の設定を適用します。overcloud スタックを変更する場合に従うべきガイドラインを以下に記載します。
以下のセクションには、特定の種別のノード上の問題診断に関するアドバイスを記載します。
16.7.2. コントローラーサービスのエラー
オーバークラウドコントローラーノードには、Red Hat OpenStack Platform のサービスの大部分が含まれます。同様に、高可用性のクラスターで複数のコントローラーノードを使用することができます。ノード上の特定のサービスに障害が発生すると、高可用性のクラスターは一定レベルのフェイルオーバーを提供します。ただし、オーバークラウドをフル稼働させるには、障害のあるサービスの診断が必要となります。
コントローラーノードは、Pacemaker を使用して高可用性クラスター内のリソースとサービスを管理します。Pacemaker Configuration System (pcs) コマンドは、Pacemaker クラスターを管理するツールです。クラスター内のコントローラーノードでこのコマンドを実行して、設定およびモニタリングの機能を実行します。高可用性クラスター上のオーバークラウドサービスのトラブルシューティングに役立つコマンドを以下にいくつか記載します。
pcs status- 有効なリソース、エラーが発生したリソース、オンラインのノードなど、クラスター全体のステータス概要を提供します。
pcs resource show- リソースの一覧をそれぞれのノードで表示します。
pcs resource disable [resource]- 特定のリソースを停止します。
pcs resource enable [resource]- 特定のリソースを起動します。
pcs cluster standby [node]- ノードをスタンバイモードに切り替えます。そのノードはクラスターで利用できなくなります。このコマンドは、クラスターに影響を及ぼさずに特定のノードメンテナンスを実行するのに役立ちます。
pcs cluster unstandby [node]- ノードをスタンバイモードから解除します。ノードはクラスター内で再度利用可能となります。
これらの Pacemaker コマンドを使用して障害のあるコンポーネントおよびノードを特定します。コンポーネントを特定した後には、/var/log/ でそれぞれのコンポーネントのログファイルを確認します。
16.7.3. コンテナー化されたサービスのエラー
オーバークラウドのデプロイメント中またはデプロイメント後にコンテナー化されたサービスでエラーが発生した場合には、以下の推奨事項に従って、エラーの根本的な原因を特定してください。
これらのコマンドを実行する前には、オーバークラウドノードにログイン済みであることを確認し、これらのコマンドをアンダークラウドで実行しないようにしてください。
コンテナーログの確認
各コンテナーは、主要プロセスからの標準出力を保持します。この出力はログとして機能し、コンテナー実行時に実際に何が発生したのかを特定するのに役立ちます。たとえば、keystone コンテナーのログを確認するには、以下のコマンドを使用します。
$ sudo docker logs keystone
大半の場合は、このログにコンテナーのエラーの原因が記載されています。
コンテナーの検査
状況によっては、コンテナーに関する情報を検証する必要がある場合があります。たとえば、以下のコマンドを使用して keystone コンテナーのデータを確認します。
$ sudo docker inspect keystone
これにより、ローレベルの設定データが含まれた JSON オブジェクトが提供されます。その出力を jq コマンドにパイプして、特定のデータを解析することが可能です。たとえば、keystone コンテナーのマウントを確認するには、以下のコマンドを実行します。
$ sudo docker inspect keystone | jq .[0].Mounts
--format オプションを使用して、データを単一行に解析することができます。これは、コンテナーデータのセットに対してコマンドを実行する場合に役立ちます。たとえば、keystone コンテナーを実行するのに使用するオプションを再生成するには、以下のように inspect コマンドに --format オプションを指定して実行します。
$ sudo docker inspect --format='{{range .Config.Env}} -e "{{.}}" {{end}} {{range .Mounts}} -v {{.Source}}:{{.Destination}}{{if .Mode}}:{{.Mode}}{{end}}{{end}} -ti {{.Config.Image}}' keystone
--format オプションは、Go 構文を使用してクエリーを作成します。
これらのオプションを docker run コマンドとともに使用して、トラブルシューティング目的のコンテナーを再度作成します。
$ OPTIONS=$( sudo docker inspect --format='{{range .Config.Env}} -e "{{.}}" {{end}} {{range .Mounts}} -v {{.Source}}:{{.Destination}}{{if .Mode}}:{{.Mode}}{{end}}{{end}} -ti {{.Config.Image}}' keystone )
$ sudo docker run --rm $OPTIONS /bin/bashコンテナー内でのコマンドの実行
状況によっては、特定の Bash コマンドでコンテナー内の情報を取得する必要がある場合があります。このような場合には、以下の docker コマンドを使用して、稼働中のコンテナー内でコマンドを実行します。たとえば、keystone コンテナーで次のコマンドを実行します。
$ sudo docker exec -ti keystone <COMMAND>
-ti オプションを指定すると、コマンドは対話式の擬似ターミナルで実行されます。
<COMMAND> は必要なコマンドに置き換えます。たとえば、各コンテナーには、サービスの接続を確認するためのヘルスチェックスクリプトがあります。keystone にヘルスチェックスクリプトを実行するには、以下のコマンドを実行します。
$ sudo docker exec -ti keystone /openstack/healthcheck
コンテナーのシェルにアクセスするには、/bin/bash をコマンドとして使用する docker exec を実行します。
$ sudo docker exec -ti keystone /bin/bash
コンテナーのエクスポート
コンテナーが失敗した場合には、ファイルの詳細を調べる必要があります。この場合は、コンテナーの全ファイルシステムを tar アーカイブとしてエクスポートすることができます。たとえば、keystone コンテナーのファイルシステムをエクスポートするには、以下のコマンドを実行します。
$ sudo docker export keystone -o keystone.tar
このコマンドにより keystone.tar アーカイブが作成されます。これを抽出して、調べることができます。
16.7.4. Compute サービスのエラー
コンピュートノードは、Compute サービスを使用して、ハイパーバイザーベースの操作を実行します。これは、このサービスを中心にコンピュートノードのメインの診断が行われていることを意味します。以下に例を示します。
コンテナーのステータスを表示します。
$ sudo docker ps -f name=nova_compute
-
コンピュートノードの主なログファイルは
/var/log/containers/nova/nova-compute.logです。コンピュートノードの通信で問題が発生した場合に、通常はこのログが診断を開始するのに適した場所です。 - コンピュートノードでメンテナンスを実行する場合には、既存のインスタンスをホストから稼働中のコンピュートノードに移行し、ノードを無効にします。ノードの移行についての詳しい情報は、「コンピュートノードからのインスタンスの移行」を参照してください。
16.7.5. Ceph Storage サービスのエラー
Red Hat Ceph Storage クラスターで発生した問題については、『Red Hat Ceph Storage Configuration Guide』の「Logging Configuration Reference」を参照してください。この項には、全 Ceph Storage サービスのログ診断についての情報が記載されています。
16.8. アンダークラウドの調整
このセクションでのアドバイスは、アンダークラウドのパフォーマンスを向上に役立たせることが目的です。必要に応じて、推奨事項を実行してください。
-
Identity Service (keystone) は、他の OpenStack サービスに対するアクセス制御にトークンベースのシステムを使用します。ある程度の期間が過ぎた後には、データベースに未使用のトークンが多数蓄積されます。デフォルトの cronjob は毎日トークンをフラッシュします。環境をモニタリングして、トークンのフラッシュ間隔を調節することを推奨します。アンダークラウドの場合は、
crontab -u keystone -eのコマンドで間隔を調整することができます。この変更は一時的で、openstack undercloud updateを実行すると、この cronjob の設定はデフォルトに戻ってしまう点に注意してください。 Heat は、
openstack overcloud deployを実行するたびにデータベースのraw_templateテーブルにある全一時ファイルのコピーを保存します。raw_templateテーブルは、過去のテンプレートをすべて保持し、サイズが増加します。raw_templatesテーブルにある未使用のテンプレートを削除するには、以下のように、日次の cron ジョブを作成して、未使用のまま 1 日以上データベースに存在するテンプレートを消去してください。0 04 * * * /bin/heat-manage purge_deleted -g days 1
openstack-heat-engineおよびopenstack-heat-apiサービスは、一度に過剰なリソースを消費する可能性があります。そのような場合は/etc/heat/heat.confでmax_resources_per_stack=-1を設定して、Heat サービスを再起動します。$ sudo systemctl restart openstack-heat-engine openstack-heat-api
directorには、同時にノードをプロビジョニングするリソースが十分にない場合があります。同時に提供できるノード数はデフォルトで 10 個となっています。同時にプロビジョニングするノード数を減らすには、
/etc/nova/nova.confのmax_concurrent_buildsパラメーターを 10 未満に設定して Nova サービスを再起動します。$ sudo systemctl restart openstack-nova-api openstack-nova-scheduler
/etc/my.cnf.d/server.cnfファイルを編集します。調整が推奨される値は、以下のとおりです。- max_connections
- データベースに同時接続できる数。推奨の値は 4096 です。
- innodb_additional_mem_pool_size
- データベースがデータのディクショナリーの情報や他の内部データ構造を保存するのに使用するメモリープールサイズ (バイト単位)。デフォルトは通常 8 M ですが、アンダークラウドの理想の値は 20 M です。
- innodb_buffer_pool_size
- データベースがテーブルやインデックスデータをキャッシュするメモリー領域つまり、バッファープールのサイズ (バイト単位)。通常デフォルトは 128 M で、アンダークラウドの理想の値は 1000 M です。
- innodb_flush_log_at_trx_commit
- コミット操作の厳密な ACID 準拠と、コミット関連の I/O 操作を再編成してバッチで実行することによって実現可能なパフォーマンス向上の間のバランスを制御します。1 に設定します。
- innodb_lock_wait_timeout
- データベースのトランザクションが、行のロック待ちを中断するまでの時間 (秒単位)。
- innodb_max_purge_lag
- この変数は、解析操作が遅れている場合に INSERT、UPDATE、DELETE 操作を遅延させる方法を制御します。10000 に設定します。
- innodb_thread_concurrency
- 同時に実行するオペレーティングシステムのスレッド数の上限。理想的には、各 CPU およびディスクリソースに対して少なくとも 2 つのスレッドを提供します。たとえば、クワッドコア CPU と単一のディスクを使用する場合は、スレッドを 10 個使用します。
オーバークラウドを作成する際には、Heat に十分なワーカーが配置されているようにします。通常、アンダークラウドに CPU がいくつあるかにより左右されます。ワーカーの数を手動で設定するには、
/etc/heat/heat.confファイルを編集してnum_engine_workersパラメーターを必要なワーカー数 (理想は 4) に設定し、Heat エンジンを再起動します。$ sudo systemctl restart openstack-heat-engine
16.9. SOS レポートの作成
Red Hat に連絡して OpenStack Platform に関するサポートを受ける必要がある場合は、SOS レポート を生成する必要がある場合があります。SOS レポート の作成方法についての詳しい説明は、以下のナレッジベースの記事を参照してください。
16.10. アンダークラウドとオーバークラウドの重要なログ
以下のログを使用して、トラブルシューティングの際にアンダークラウドとオーバークラウドの情報を割り出します。
表16.1 アンダークラウドの重要なログ
| 情報 | ログの場所 |
|---|---|
|
OpenStack Compute のログ |
|
|
OpenStack Compute API の対話 |
|
|
OpenStack Compute コンダクターのログ |
|
|
OpenStack Orchestration ログ |
|
|
OpenStack Orchestration API の対話 |
|
|
OpenStack Orchestration CloudFormations ログ |
|
|
OpenStack Bare Metal コンダクターのログ |
|
|
OpenStack Bare Metal API の対話 |
|
|
イントロスペクション |
|
|
OpenStack Workflow Engine ログ |
|
|
OpenStack Workflow Executor のログ |
|
|
OpenStack Workflow API の対話 |
|
表16.2 オーバークラウドの重要なログ
| 情報 | ログの場所 |
|---|---|
|
cloud-init ログ |
|
|
オーバークラウドの設定 (最後に実行した Puppet のサマリー) |
|
|
オーバークラウドの設定 (最後に実行した Puppet からのレポート) |
|
|
オーバークラウドの設定 (全 Puppet レポート) |
|
|
オーバークラウドの設定 (実行した Puppet 毎の標準出力) |
|
|
オーバークラウドの設定 (実行した Puppet 毎の標準エラー出力) |
|
|
高可用性ログ |
|
パート VI. 付録
付録A SSL/TLS 証明書の設定
アンダークラウドがパブリックエンドポイントの通信に SSL/TLS を使用するように設定できます。ただし、独自の認証局で発行した SSL 証明書を使用する場合には、その証明書には以下の項に記載する設定のステップが必要です。
オーバークラウドの SSL/TLS 証明書作成については、『オーバークラウドの高度なカスタマイズ』の「オーバークラウドのパブリックエンドポイントでの SSL/TLS の有効化」を参照してください。
A.1. 署名ホストの初期化
署名ホストとは、新規証明書を生成し、認証局を使用して署名するホストです。選択した署名ホスト上で SSL 証明書を作成したことがない場合には、ホストを初期化して新規証明書に署名できるようにする必要がある可能性があります。
/etc/pki/CA/index.txt ファイルは、すべての署名済み証明書の記録を保管します。このファイルが存在しているかどうかを確認してください。存在していない場合には、空のファイルを作成します。
$ sudo touch /etc/pki/CA/index.txt
/etc/pki/CA/serial ファイルは、次に署名する証明書に使用する次のシリアル番号を特定します。このファイルが存在するかどうかを確認し、存在しない場合には、新規ファイルを作成して新しい開始値を指定します。
$ sudo echo '1000' | sudo tee /etc/pki/CA/serial
A.2. 認証局の作成
通常、SSL/TLS 証明書の署名には、外部の認証局を使用します。場合によっては、独自の認証局を使用する場合もあります。たとえば、内部のみの認証局を使用するように設定する場合などです。
たとえば、キーと証明書のペアを生成して、認証局として機能するようにします。
$ openssl genrsa -out ca.key.pem 4096 $ openssl req -key ca.key.pem -new -x509 -days 7300 -extensions v3_ca -out ca.crt.pem
openssl req コマンドは、認証局に関する特定の情報を要求します。それらの情報を指定してください。
これで、ca.crt.pem という名前の認証局ファイルが作成されます。
A.3. クライアントへの認証局の追加
SSL/TLS を使用して通信することを目的としている外部のクライアントの場合は、Red Hat OpenStack Platform 環境にアクセスする必要のある各クライアントに認証局ファイルをコピーします。クライアントへのコピーが完了したら、そのクライアントで以下のコマンドを実行して、認証局のトラストバンドルに追加します。
$ sudo cp ca.crt.pem /etc/pki/ca-trust/source/anchors/ $ sudo update-ca-trust extract
A.4. SSL/TLS 鍵の作成
以下のコマンドを実行して、SSL/TLS キー (server.key.pem) を生成します。このキーは、さまざまな段階で、アンダークラウドとオーバークラウドの証明書を生成するのに使用します。
$ openssl genrsa -out server.key.pem 2048
A.5. SSL/TLS 証明書署名要求の作成
次の手順では、アンダークラウドおよびオーバークラウドのいずれかの証明書署名要求を作成します。
カスタマイズするデフォルトの OpenSSL 設定ファイルをコピーします。
$ cp /etc/pki/tls/openssl.cnf .
カスタムの openssl.cnf ファイルを編集して、director に使用する SSL パラメーターを設定します。変更するパラメーターの種別には以下のような例が含まれます。
[req] distinguished_name = req_distinguished_name req_extensions = v3_req [req_distinguished_name] countryName = Country Name (2 letter code) countryName_default = AU stateOrProvinceName = State or Province Name (full name) stateOrProvinceName_default = Queensland localityName = Locality Name (eg, city) localityName_default = Brisbane organizationalUnitName = Organizational Unit Name (eg, section) organizationalUnitName_default = Red Hat commonName = Common Name commonName_default = 192.168.0.1 commonName_max = 64 [ v3_req ] # Extensions to add to a certificate request basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = @alt_names [alt_names] IP.1 = 192.168.0.1 DNS.1 = instack.localdomain DNS.2 = vip.localdomain DNS.3 = 192.168.0.1
commonName_default は以下のいずれか 1 つに設定します。
-
IP アドレスを使用して SSL/TLS 経由でアクセスする場合には、
undercloud.confでundercloud_public_hostパラメーターを使用します。 - 完全修飾ドメイン名を使用して SSL/TLS でアクセスする場合には、代わりにドメイン名を使用します。
alt_names セクションを編集して、以下のエントリーを追加します。
-
IP: SSL 経由で director にアクセスするためのクライアントの IP アドレス一覧 -
DNS: SSL 経由で director にアクセスするためのクライアントのドメイン名一覧。alt_namesセクションの最後に DNS エントリーとしてパブリック API の IP アドレスも追加します。
openssl.cnf に関する詳しい情報については、man openssl.cnf を実行します。
次のコマンドを実行し、手順 1 で作成したキーストアより公開鍵を使用して証明書署名要求を生成します (server.csr.pem)。
$ openssl req -config openssl.cnf -key server.key.pem -new -out server.csr.pem
「SSL/TLS 鍵の作成」で作成した SSL/TLS 鍵を -key オプションで必ず指定してください。
次の項では、この server.csr.pem ファイルを使用して SSL/TLS 証明書を作成します。
A.6. SSL/TLS 証明書の作成
以下のコマンドで、アンダークラウドまたはオーバークラウドの証明書を作成します。
$ sudo openssl ca -config openssl.cnf -extensions v3_req -days 3650 -in server.csr.pem -out server.crt.pem -cert ca.crt.pem -keyfile ca.key.pem
上記のコマンドでは、以下のオプションを使用しています。
-
v3 拡張機能を指定する設定ファイル。この値は、「
-config」オプションとして追加します。 -
認証局を介して証明書を生成し、署名するために、「SSL/TLS 証明書署名要求の作成」で設定した証明書署名要求。この値は、「
-in」オプションで設定します。 -
証明書への署名を行う、「認証局の作成」で作成した認証局。この値は
-certオプションとして追加します。 -
「認証局の作成」で作成した認証局の秘密鍵。この値は
-keyfileオプションとして追加します。
このコマンドを実行すると、server.crt.pem という名前の証明書が作成されます。この証明書は、「SSL/TLS 鍵の作成」で作成した SSL/TLS キーとともに使用して SSL/TLS を有効にします。
A.7. アンダークラウドで証明書を使用する場合
以下のコマンドを実行して、証明書とキーを統合します。
$ cat server.crt.pem server.key.pem > undercloud.pem
このコマンドにより、undercloud.pem が作成されます。undercloud.conf ファイルの undercloud_service_certificate オプションにこのファイルの場所を指定します。このファイルには、HAProxy ツールが読み取ることができるように、特別な SELinux コンテキストも必要です。以下の例を目安にしてください。
$ sudo mkdir /etc/pki/instack-certs $ sudo cp ~/undercloud.pem /etc/pki/instack-certs/. $ sudo semanage fcontext -a -t etc_t "/etc/pki/instack-certs(/.*)?" $ sudo restorecon -R /etc/pki/instack-certs
undercloud.conf ファイルの undercloud_service_certificate オプションに undercloud.pem の場所を追記します。以下に例を示します。
undercloud_service_certificate = /etc/pki/instack-certs/undercloud.pem
また、「認証局の作成」で作成した認証局をアンダークラウドの信頼済み認証局の一覧に認証局を追加して、アンダークラウド内の異なるサービスが認証局にアクセスできるようにします。
$ sudo cp ca.crt.pem /etc/pki/ca-trust/source/anchors/ $ sudo update-ca-trust extract
「director の設定」の手順に従ってアンダークラウドのインストールを続行します。
付録B 電源管理ドライバー
IPMI は、director が電源管理制御に使用する主要な手法ですが、director は他の電源管理タイプもサポートします。この付録では、サポートされる電源管理機能の一覧を提供します。「オーバークラウドへのノードの登録」には、以下の電源管理設定を使用します。
B.1. Redfish
Distributed Management Task Force (DMTF) の開発した、IT インフラストラクチャー向け標準 RESTful API。
- pm_type
-
このオプションを
redfishに設定します。 - pm_user; pm_password
- Redfish のユーザー名およびパスワード
- pm_addr
- Redfish コントローラーの IP アドレス
- pm_system_id
-
システムリソースの正規のパス。このパスには、そのシステムの root サービス、バージョン、パス/一意 ID が含まれる必要があります (例:
/redfish/v1/Systems/CX34R87)。
B.2. Dell Remote Access Controller (DRAC)
DRAC は、電源管理やサーバー監視などの帯域外 (OOB) リモート管理機能を提供するインターフェースです。
- pm_type
-
このオプションを
idracに設定します。 - pm_user; pm_password
- DRAC のユーザー名およびパスワード
- pm_addr
- DRAC ホストの IP アドレス
B.3. Integrated Lights-Out (iLO)
Hewlett-Packard の iLO は、電源管理やサーバー監視などの帯域外 (OOB) リモート管理機能を提供するインターフェースです。
- pm_type
-
このオプションを
iloに設定します。 - pm_user; pm_password
- iLO のユーザー名およびパスワード
- pm_addr
iLO インターフェースの IP アドレス
-
このドライバーを有効化するには、
undercloud.confのenabled_hardware_typesオプションにiloを追加してから、openstack undercloud installを再実行します。 また director では、iLO 向けに追加のユーティリティーセットが必要です。
python-proliantutilsパッケージをインストールしてopenstack-ironic-conductorサービスを再起動します。$ sudo yum install python-proliantutils $ sudo systemctl restart openstack-ironic-conductor.service
- HP ノードは、正常にイントロスペクションするには 2015 年のファームウェアバージョンが必要です。ファームウェアバージョン 1.85 (2015 年 5 月 13 日) を使用したノードで、director は正常にテストされています。
- 共有 iLO ポートの使用はサポートされません。
-
このドライバーを有効化するには、
B.4. Cisco Unified Computing System (UCS)
Cisco の UCS は、コンピュート、ネットワーク、ストレージのアクセス、仮想化リソースを統合するデータセンタープラットフォームです。このドライバーは、UCS に接続されたベアメタルシステムの電源管理を重視しています。
- pm_type
-
このオプションを
cisco-ucs-managedに設定します。 - pm_user; pm_password
- UCS のユーザー名およびパスワード
- pm_addr
- UCS インターフェースの IP アドレス
- pm_service_profile
使用する UCS サービスプロファイル。通常
org-root/ls-[service_profile_name]の形式を取ります。以下に例を示します。"pm_service_profile": "org-root/ls-Nova-1"
-
このドライバーを有効化するには、
undercloud.confのenabled_hardware_typesオプションにcisco-ucs-managedを追加してから、openstack undercloud installを再実行します。 また director では、iLO 向けに追加のユーティリティーセットが必要です。
python-UcsSdkパッケージをインストールしてopenstack-ironic-conductorサービスを再起動します。$ sudo yum install python-UcsSdk $ sudo systemctl restart openstack-ironic-conductor.service
-
このドライバーを有効化するには、
B.5. Fujitsu Integrated Remote Management Controller (iRMC)
Fujitsu の iRMC は、LAN 接続と拡張された機能を統合した Baseboard Management Controller (BMC) です。このドライバーは、iRMC に接続されたベアメタルシステムの電源管理にフォーカスしています。
iRMC S4 以降のバージョンが必要です。
- pm_type
-
このオプションを
irmcに設定します。 - pm_user; pm_password
- iRMC インターフェースのユーザー名とパスワード
- pm_addr
- iRMC インターフェースの IP アドレス
- pm_port (オプション)
- iRMC の操作に使用するポート。デフォルトは 443 です。
- pm_auth_method (オプション)
-
iRMC 操作の認証方法。
basicまたはdigestを使用します。デフォルトはbasicです。 - pm_client_timeout (オプション)
- iRMC 操作のタイムアウト (秒単位)。デフォルトは 60 秒です。
- pm_sensor_method (オプション)
センサーデータの取得方法。
ipmitoolまたはscciです。デフォルトはipmitoolです。-
このドライバーを有効化するには、
undercloud.confのenabled_hardware_typesオプションにirmcを追加してから、openstack undercloud installを再実行します。 センサーの方法として SCCI を有効にした場合には、director には、追加のユーティリティーセットも必要です。
python-scciclientパッケージをインストールして、openstack-ironic-conductorサービスを再起動します。$ yum install python-scciclient $ sudo systemctl restart openstack-ironic-conductor.service
-
このドライバーを有効化するには、
B.6. Virtual Baseboard Management Controller (VBMC)
director は仮想マシンを KVM ホスト上のノードとして使用することができます。エミュレーションされた IPMI デバイスを使用して電源管理を制御します。これにより、「オーバークラウドへのノードの登録」からの標準の IPMI パラメーターを使用することができますが、仮想ノードに対して使用することになります。
このオプションでは、ベアメタルノードの代わりに仮想マシンを使用するので、テストおよび評価の目的でのみ利用することができます。Red Hat OpenStack Platform のエンタープライズ環境には推奨しません。
KVM ホストの設定
KVM ホスト上で、OpenStack Platform リポジトリーを有効化して python-virtualbmc パッケージをインストールします。
$ sudo subscription-manager repos --enable=rhel-7-server-openstack-14-rpms $ sudo yum install -y python-virtualbmc
vbmc コマンドを使用して、各仮想マシン用に仮想 Baseboard Management Controller (BMC) を作成します。たとえば、Node01 および Node02 という名前の仮想マシンに BMC を作成する場合は、以下のコマンドを実行します。
$ vbmc add Node01 --port 6230 --username admin --password p455w0rd! $ vbmc add Node02 --port 6231 --username admin --password p455w0rd!
これにより、各 BMC にアクセスするポートが定義され、各 BMC の認証情報が設定されます。
仮想マシンごとに異なるポートを使用してください。1025 未満のポート番号には、システムの root 権限が必要です。
以下のコマンドで各 BMC を起動します。
$ vbmc start Node01 $ vbmc start Node02
KVM ホストのリブート後には、このステップを繰り返す必要があります。
ノードの登録
ノードの登録ファイル (/home/stack/instackenv.json) で以下のパラメーターを使用します。
- pm_type
-
このオプションを
ipmiに設定します。 - pm_user; pm_password
- ノードの仮想 BMC デバイスの IPMI ユーザー名とパスワード
- pm_addr
- ノードが含まれている KVM ホストの IP アドレス
- pm_port
- KVM ホスト上の特定のノードにアクセスするポート
- mac
- ノード上のネットワークインターフェースの MAC アドレス一覧。各システムのプロビジョニング NIC の MAC アドレスのみを使用します。
例:
{
"nodes": [
{
"pm_type": "ipmi",
"mac": [
"aa:aa:aa:aa:aa:aa"
],
"pm_user": "admin",
"pm_password": "p455w0rd!",
"pm_addr": "192.168.0.1",
"pm_port": "6230",
"name": "Node01"
},
{
"pm_type": "ipmi",
"mac": [
"bb:bb:bb:bb:bb:bb"
],
"pm_user": "admin",
"pm_password": "p455w0rd!",
"pm_addr": "192.168.0.1",
"pm_port": "6231",
"name": "Node02"
}
]
}既存のノードの移行
既存のノードは、非推奨の pxe_ssh を使用する設定から新しい仮想 BMC の方法を使用するように移行することができます。以下のコマンドは、ノードが ipmi ドライバーを使用するようにし、そのパラメーターを以下のように設定します。
openstack baremetal node set Node01 \
--driver ipmi \
--driver-info ipmi_address=192.168.0.1 \
--driver-info ipmi_port=6230 \
--driver-info ipmi_username="admin" \
--driver-info ipmi_password="p455w0rd!"B.7. Red Hat Virtualization
このドライバーにより、RESTful API を介して、Red Hat Virtualization 内の仮想マシンを制御することができるようになります。
- pm_type
-
このオプションを
staging-ovirtに設定します。 - pm_user; pm_password
-
Red Hat Virtualization 環境のユーザー名とパスワード。ユーザー名には認証プロバイダーも含まれます (例:
admin@internal)。 - pm_addr
- Red Hat Virtualization REST API の IP アドレス
- pm_vm_name
- 制御する仮想マシンの名前
- mac
ノード上のネットワークインターフェースの MAC アドレス一覧。各システムのプロビジョニング NIC の MAC アドレスのみを使用します。
-
このドライバーを有効化するには、
undercloud.confのenabled_hardware_typesオプションにstaging-ovirtを追加してから、openstack undercloud installを再実行します。
-
このドライバーを有効化するには、
B.8. フェイクドライバー
このドライバーは、電源管理なしにベアメタルデバイスを使用する方法を提供します。これは、director が登録されたベアメタルデバイスを制御しないので、イントロスペクションとデプロイの特定の時点に手動で電源をコントロールする必要があることを意味します。
このオプションは、テストおよび評価の目的でのみ利用いただけます。Red Hat OpenStack Platform のエンタープライズ環境には推奨していません。
- pm_type
このオプションを
fake-hardwareに設定します。- このドライバーは、電源管理を制御しないので、認証情報は使用しません。
-
このドライバーを有効にするには、
undercloud.confのenabled_hardware_typesオプションにfakeを追加してから、openstack undercloud installを再実行します。 -
ノードのイントロスペクションを実行する際には、
openstack overcloud node introspectコマンドを実行した後にノードの電源を手動でオフにします。 -
オーバークラウドのデプロイ実行時には、
ironic node-listコマンドでノードのステータスを確認します。ノードのステータスがdeployingからdeploy wait-callbackに変わるまで待ってから、手動でノードの電源をオンにします。 -
オーバークラウドのプロビジョニングプロセスが完了したら、ノードをリブートします。プロビジョニングが完了したかどうかをチェックするには、
ironic node-listコマンドでノードのステータスをチェックし、activeに変わるのを待ってから、すべてのオーバークラウドノードを手動でリブートします。
付録C 完全なディスクイメージ
メインのオーバークラウドイメージは、フラットパーティションイメージです。これは、パーティション情報またはブートローダーがイメージ自体に含まれていないことを意味します。director は、起動時に別のカーネルと ramdisk を使用し、オーバークラウドイメージをディスクに書き込む際には基本的なパーティションレイアウトを作成しますが、パーティションレイアウト、ブートローダー、および強化されたセキュリティー機能が含まれる完全なディスクイメージを作成することが可能です。
以下のプロセスでは、director のイメージ構築機能を使用します。Red Hat では、本項に記載の指針に従ったイメージ構築のみをサポートしています。これらとは異なる仕様でのカスタムのイメージ構築はサポートされていません。
セキュリティーが強化されたイメージには、セキュリティーが重要な機能となるRed Hat OpenStack Platform のデプロイメントに必要な追加のセキュリティー対策が含まれます。イメージをセキュアにするためには、以下のような推奨事項があります。
-
/tmpディレクトリーは、別のボリュームまたはパーティションにマウントされ、rw、nosuid、nodev、noexec、relatimeのフラグが付きます。 -
/var、/var/log、/var/log/auditのディレクトリーは、別のボリュームまたはパーティションにマウントされ、rwおよびrelatimeのフラグが付きます。 -
/homeディレクトリーは、別のパーティションまたはボリュームにマウントされ、rw、nodev、relatimeのフラグが付きます。 GRUB_CMDLINE_LINUXの設定に以下の変更を加えます。-
監査を有効にするには、
audit=1を追加して、追加のカーネルブートフラグを付けます。 -
nousbを追加して、ブートローダー設定を使用した USB のカーネルサポートを無効にします。 -
crashkernel=autoを設定して、セキュアでないブートフラグを削除します。
-
監査を有効にするには、
-
セキュアでないモジュール (
usb-storage、cramfs、freevxfs、jffs2、hfs、hfsplus、squashfs、udf、vfat) をブラックリストに登録して、読み込まれないようにします。 -
イメージから、セキュアでないパッケージ (
kexec-toolsによりインストールされたkdumpとtelnet) を削除します。 -
セキュリティーに必要な新しい
screenパッケージを追加します。
セキュリティー強化されたイメージを構築するには、以下の手順を実行する必要があります。
- ベースの Red Hat Enterprise Linux 7 イメージをダウンロードします。
- 登録固有の環境変数を設定します。
- パーティションスキーマとサイズを変更してイメージをカスタマイズします。
- イメージを作成します。
- そのイメージをデプロイメントにアップロードします。
以下の項では、これらのタスクを実行する手順について詳しく説明します。
C.1. ベースのクラウドイメージのダウンロード
完全なディスクイメージを構築する前に、ベースとして使用する Red Hat Enterprise Linux の既存のクラウドイメージをダウンロードする必要があります。Red Hat カスタマーポータルにナビゲートして、ダウンロードする KVM ゲストイメージを選択します。たとえば、最新の Red Hat Enterprise Linux の KVM ゲストイメージは以下のページにあります。
C.2. ディスクイメージの環境変数
ディスクイメージの構築プロセスとして、director にはベースイメージと、新規クラウドイメージのパッケージを取得するための登録情報が必要です。これらは、Linux の環境変数を使用して定義します。
イメージの構築プロセスにより、イメージは一時的に Red Hat サブスクリプションに登録され、システムがイメージの構築プロセスを完了すると登録を解除します。
ディスクイメージを構築するには、Linux の環境変数をお使いの環境と要件に応じて設定します。
- DIB_LOCAL_IMAGE
- ベースに使用するローカルイメージを設定します。
- REG_ACTIVATION_KEY
- 登録プロセスの一部で代わりにアクティベーションキーを使用します。
- REG_AUTO_ATTACH
- 最も互換性のあるサブスクリプションを自動的にアタッチするかどうかを定義します。
- REG_BASE_URL
-
パッケージをプルするためのコンテンツ配信サーバーのベース URL。カスタマーポータルサブスクリプション管理のデフォルトのプロセスでは
https://cdn.redhat.comを使用します。Red Hat Satellite 6 サーバーを使用している場合は、このパラメーターにお使いの Satellite サーバーのベース URL を使用する必要があります。 - REG_ENVIRONMENT
- 1 つの組織内の 1 つの環境に登録します。
- REG_METHOD
-
登録の方法を設定します。Red Hat カスタマーポータルに登録するには
portalを使用します。Red Hat Satellite 6 で登録するには、satelliteを使用します。 - REG_ORG
- イメージを登録する組織。
- REG_POOL_ID
- 製品のサブスクリプション情報のプール ID
- REG_PASSWORD
- イメージを登録するユーザーアカウントのパスワードを指定します。
- REG_REPOS
コンマ区切りのリポジトリー名の文字列 (空白なし)。この文字列の各リポジトリーは
subscription-managerで有効化されます。以下に示すセキュリティー強化された完全なディスクイメージのリポジトリーを使用します。
-
rhel-7-server-rpms -
rhel-7-server-extras-rpms -
rhel-ha-for-rhel-7-server-rpms -
rhel-7-server-optional-rpms -
rhel-7-server-openstack-14-rpms
-
- REG_SERVER_URL
-
使用するサブスクリプションサービスのホスト名を指定します。Red Hat カスタマーポータルの場合のデフォルトは
subscription.rhn.redhat.comです。Red Hat Satellite 6 サーバーを使用する場合は、このパラメーターにお使いの Satellite サーバーのホスト名を使用する必要があります。 - REG_USER
- イメージを登録するアカウントのユーザー名を指定します。
Red Hat カスタマーポータルにローカルの QCOW2 をイメージ一時的に登録するための環境変数のセットをエクスポートする一連のコマンドの例を以下に示します。
$ export DIB_LOCAL_IMAGE=./rhel-server-7.5-x86_64-kvm.qcow2
$ export REG_METHOD=portal
$ export REG_USER="[your username]"
$ export REG_PASSWORD="[your password]"
$ export REG_REPOS="rhel-7-server-rpms \
rhel-7-server-extras-rpms \
rhel-ha-for-rhel-7-server-rpms \
rhel-7-server-optional-rpms \
rhel-7-server-openstack-14-rpms"C.3. ディスクレイアウトのカスタマイズ
デフォルトでは、セキュリティーが強化されたイメージのサイズは 20 GB で、事前定義されたパーティショニングサイズを使用します。ただし、オーバークラウドのコンテナーイメージを収容するには、パーティショニングレイアウトを若干変更する必要があります。以下のセクションでは、イメージのサイズを 40 GB に増やしています。ご自分のニーズに合わせて、さらにパーティショニングレイアウトやディスクのサイズを変更することができます。
パーティショニングレイアウトとディスクサイズを変更するには、以下の手順に従ってください。
-
DIB_BLOCK_DEVICE_CONFIG環境変数を使用してパーティショニングスキーマを変更します。 -
DIB_IMAGE_SIZE環境変数を更新して、イメージのグローバルサイズを変更します。
C.3.1. パーティショニングスキーマの変更
パーティショニングスキーマを編集して、パーティショニングサイズを変更したり、新規パーティションの作成や既存のパーティションの削除を行うことができます。新規パーティショニングスキーマは以下の環境変数で定義することができます。
$ export DIB_BLOCK_DEVICE_CONFIG='<yaml_schema_with_partitions>'
以下の YAML 構成は、オーバークラウドのコンテナーイメージをプルするのに十分なスペースを提供する、論理ボリュームの変更後のパーティショニングレイアウトを示しています。
export DIB_BLOCK_DEVICE_CONFIG='''
- local_loop:
name: image0
- partitioning:
base: image0
label: mbr
partitions:
- name: root
flags: [ boot,primary ]
size: 40G
- lvm:
name: lvm
base: [ root ]
pvs:
- name: pv
base: root
options: [ "--force" ]
vgs:
- name: vg
base: [ "pv" ]
options: [ "--force" ]
lvs:
- name: lv_root
base: vg
extents: 23%VG
- name: lv_tmp
base: vg
extents: 4%VG
- name: lv_var
base: vg
extents: 45%VG
- name: lv_log
base: vg
extents: 23%VG
- name: lv_audit
base: vg
extents: 4%VG
- name: lv_home
base: vg
extents: 1%VG
- mkfs:
name: fs_root
base: lv_root
type: xfs
label: "img-rootfs"
mount:
mount_point: /
fstab:
options: "rw,relatime"
fsck-passno: 1
- mkfs:
name: fs_tmp
base: lv_tmp
type: xfs
mount:
mount_point: /tmp
fstab:
options: "rw,nosuid,nodev,noexec,relatime"
fsck-passno: 2
- mkfs:
name: fs_var
base: lv_var
type: xfs
mount:
mount_point: /var
fstab:
options: "rw,relatime"
fsck-passno: 2
- mkfs:
name: fs_log
base: lv_log
type: xfs
mount:
mount_point: /var/log
fstab:
options: "rw,relatime"
fsck-passno: 3
- mkfs:
name: fs_audit
base: lv_audit
type: xfs
mount:
mount_point: /var/log/audit
fstab:
options: "rw,relatime"
fsck-passno: 4
- mkfs:
name: fs_home
base: lv_home
type: xfs
mount:
mount_point: /home
fstab:
options: "rw,nodev,relatime"
fsck-passno: 2
'''サンプルの YAML コンテンツをイメージのパーティションスキーマのベースとして使用します。パーティションサイズとレイアウトを必要に応じて変更します。
パーティションサイズはデプロイメント後には変更できないので、正しいパーティションサイズを定義してください。
C.3.2. イメージサイズの変更
変更後のパーティショニングスキーマの合計は、デフォルトのディスクサイズ (20G) を超える可能性があります。そのような場合には、イメージサイズを変更する必要がある場合があります。イメージサイズを変更するには、イメージの作成に使用した設定ファイルを編集します。
/usr/share/openstack-tripleo-common/image-yaml/overcloud-hardened-images.yaml のコピーを作成します。
# cp /usr/share/openstack-tripleo-common/image-yaml/overcloud-hardened-images.yaml \ /home/stack/overcloud-hardened-images-custom.yaml
設定ファイルで DIB_IMAGE_SIZE を編集して、必要に応じて値を調整します。
...
environment:
DIB_PYTHON_VERSION: '2'
DIB_MODPROBE_BLACKLIST: 'usb-storage cramfs freevxfs jffs2 hfs hfsplus squashfs udf vfat bluetooth'
DIB_BOOTLOADER_DEFAULT_CMDLINE: 'nofb nomodeset vga=normal console=tty0 console=ttyS0,115200 audit=1 nousb'
DIB_IMAGE_SIZE: '40' 1
COMPRESS_IMAGE: '1'- 1
- この値は、新しいディスクサイズの合計に応じて調整してください。
このファイルを保存します。
director がオーバークラウドをデプロイする際には、オーバークラウドイメージの RAW バージョンを作成します。これは、アンダークラウドに、その RAW イメージを収容するのに必要な空き容量がなければならないことを意味します。たとえば、セキュリティー強化されたイメージのサイズを 40G に増やした場合には、アンダークラウドのハードディスクに 40G の空き容量が必要となります。
最終的に director が物理ディスクにイメージを書き込む際に、ディスクの最後に 64 MB のコンフィグドライブ一次パーティションが作成されます。完全なディスクイメージを作成する場合には、この追加パーティションを収容できるように、物理ディスクのサイズがディスクイメージより大きいことを確認してください。
C.4. セキュリティー強化された完全なディスクイメージの作成
環境変数を設定してイメージをカスタマイズした後には、openstack overcloud image build コマンドを使用してイメージを作成します。
# openstack overcloud image build \
--image-name overcloud-hardened-full \
--config-file /home/stack/overcloud-hardened-images-custom.yaml \ 1
--config-file /usr/share/openstack-tripleo-common/image-yaml/overcloud-hardened-images-rhel7.yaml- 1
- これは、「イメージサイズの変更」の新規ディスクサイズが含まれたカスタムの設定ファイルです。異なるカスタムディスクサイズを 使用していない 場合には、代わりに元の
/usr/share/openstack-tripleo-common/image-yaml/overcloud-hardened-images.yamlファイルを使用してください。
これにより、overcloud-hardened-full.qcow2 という名前のイメージが作成され、必要なセキュリティー機能がすべて含まれます。
C.5. セキュリティー強化された完全なディスクイメージのアップロード
OpenStack Image (glance) サービスにイメージをアップロードして、Red Hat OpenStack Platform director から使用を開始します。セキュリティー強化されたイメージをアップロードするには、以下の手順を実行してください。
新規作成されたイメージの名前を変更し、イメージディレクトリーに移動します。
# mv overcloud-hardened-full.qcow2 ~/images/overcloud-full.qcow2
オーバークラウドの古いイメージをすべて削除します。
# openstack image delete overcloud-full # openstack image delete overcloud-full-initrd # openstack image delete overcloud-full-vmlinuz
新規オーバークラウドイメージをアップロードします。
# openstack overcloud image upload --image-path /home/stack/images --whole-disk
既存のイメージをセキュリティー強化されたイメージに置き換える場合は、--update-existing フラグを使用します。これにより、元の overcloud-full イメージは、自分で作成した、セキュリティー強化された新しいイメージに置き換えられます。
付録D 代替ブートモード
ノードのデフォルトブートモードは、iPXE を使用した BIOS です。以下の項では、ノードのプロビジョニングおよび検査の際に director が使用する代替ブートモードについて説明します。
D.1. 標準の PXE
iPXE ブートプロセスは、HTTP を使用してイントロスペクションおよびデプロイメントのイメージをブートします。旧システムは、TFTP を介してブートする標準の PXE ブートのみをサポートしている場合があります。
iPXE から PXE に変更するには、director ホスト上の undercloud.conf ファイルを編集して、ipxe_enabled を False に設定します。
ipxe_enabled = False
このファイルを保存して、アンダークラウドのインストールを実行します。
$ openstack undercloud install
このプロセスに関する詳しい情報は、「Changing from iPXE to PXE in Red Hat OpenStack Platform director」の記事を参照してください。
付録E プロファイルの自動タグ付け
イントロスペクションプロセスでは、一連のベンチマークテストを実行します。director は、これらのテストからデータを保存します。このデータをさまざまな方法で使用するポリシーセットを作成することができます。以下に例を示します。
- ポリシーにより、パフォーマンスの低いノードまたは不安定なノードを特定して、オーバークラウドで使用されないように隔離することができます。
- ポリシーにより、ノードを自動的に特定のプロファイルにタグ付けするかどうかを定義することができます。
E.1. ポリシーファイルの構文
ポリシーファイルは、JSON 形式で、ルールセットが記載されます。各ルールは、description、condition、action を定義します。
説明
これは、プレーンテキストで記述されたルールの説明です。
例:
"description": "A new rule for my node tagging policy"
conditions
condition は、以下のキー/値のパターンを使用して評価を定義します。
- field
- 評価するフィールドを定義します。フィールドの種別については、「プロファイルの自動タグ付けのプロパティー」を参照してください。
- op
評価に使用する演算を定義します。これには、以下が含まれます。
-
eq: 等しい -
ne: 等しくない -
lt: より小さい -
gt: より大きい -
le: より小さいか等しい -
ge: より大きいか等しい -
in-net: IP アドレスが指定のネットワーク内にあることをチェックします。 -
matches: 指定の正規表現と完全に一致する必要があります。 -
contains: 値には、指定の正規表現が含まれる必要があります。 -
is-empty: フィールドが空欄であることをチェックします。
-
- invert
- 評価の結果をインバージョン (反転) するかどうかを定義するブール値
- multiple
複数の結果が存在する場合に、使用する評価を定義します。これには、以下が含まれます。
-
any: いずれかの結果が一致する必要があります。 -
all: すべての結果が一致する必要があります。 -
first: 最初の結果が一致する必要があります。
-
- value
- 評価内の値を定義します。フィールドと演算の結果でその値となった場合には、条件は true の結果を返します。そうでない場合には、条件は false の結果を返します。
例:
"conditions": [
{
"field": "local_gb",
"op": "ge",
"value": 1024
}
],Actions
action は、condition が true として返された場合に実行されます。これには、action キーと、action の値に応じて追加のキーが使用されます。
-
fail: イントロスペクションが失敗します。失敗のメッセージには、messageパラメーターが必要です。 -
set-attribute: Ironic ノードで属性を設定します。Ironic の属性へのパス (例:/driver_info/ipmi_address) であるpathフィールドと、設定するvalueが必要です。 -
set-capability: Ironic ノードでケイパビリティーを設定します。新しいケイパビリティーに応じた名前と値を指定するnameおよびvalueのフィールドが必要です。同じケイパビリティーの既存の値は置き換えられます。たとえば、これを使用してノードのプロファイルを定義します。 -
extend-attribute:set-attributeと同じですが、既存の値を一覧として扱い、その一覧に値を追記します。オプションのuniqueパラメーターが True に設定すると、対象の値がすでに一覧に含まれている場合には何も追加されません。
例:
"actions": [
{
"action": "set-capability",
"name": "profile",
"value": "swift-storage"
}
]E.2. ポリシーファイルの例
以下は、適用するイントロスペクションルールを記載した JSON ファイル (rules.json) の一例です。
[
{
"description": "Fail introspection for unexpected nodes",
"conditions": [
{
"op": "lt",
"field": "memory_mb",
"value": 4096
}
],
"actions": [
{
"action": "fail",
"message": "Memory too low, expected at least 4 GiB"
}
]
},
{
"description": "Assign profile for object storage",
"conditions": [
{
"op": "ge",
"field": "local_gb",
"value": 1024
}
],
"actions": [
{
"action": "set-capability",
"name": "profile",
"value": "swift-storage"
}
]
},
{
"description": "Assign possible profiles for compute and controller",
"conditions": [
{
"op": "lt",
"field": "local_gb",
"value": 1024
},
{
"op": "ge",
"field": "local_gb",
"value": 40
}
],
"actions": [
{
"action": "set-capability",
"name": "compute_profile",
"value": "1"
},
{
"action": "set-capability",
"name": "control_profile",
"value": "1"
},
{
"action": "set-capability",
"name": "profile",
"value": null
}
]
}
]上記の例は、3 つのルールで構成されています。
- メモリーが 4096 MiB 未満の場合には、イントロスペクションが失敗します。このようなルールを適用して、クラウドに含まれるべきではないノードを除外することができます。
- ハードドライブのサイズが 1 TiB 以上のノードの場合は swift-storage プロファイルが無条件で割り当てられます。
-
ハードドライブが 1 TiB 未満だが 40 GiB を超えているノードは、コンピュートノードまたはコントロールノードのいずれかに割り当てることができます。
openstack overcloud profiles matchコマンドを使用して、後で最終選択できるように 2 つのケイパビリティー (compute_profileとcontrol_profile) を割り当てています。この設定が機能するように、既存のプロファイルのケイパビリティーは削除しています。削除しなかった場合には、そのケイパビリティーが優先されてしまいます。
他のノードは変更されません。
イントロスペクションルールを使用して profile 機能を割り当てる場合は常に、既存の値よりこの割り当てた値が優先されます。ただし、既存のプロファイル機能があるノードについては、[PROFILE]_profile 機能は無視されます。
E.3. ポリシーファイルのインポート
以下のコマンドで、ポリシーファイルを director にインポートします。
$ openstack baremetal introspection rule import rules.json
次にイントロスペクションプロセスを実行します。
$ openstack overcloud node introspect --all-manageable
イントロスペクションが完了したら、ノードとノードに割り当てられたプロファイルを確認します。
$ openstack overcloud profiles list
イントロスペクションルールで間違いがあった場合には、すべてを削除できます。
$ openstack baremetal introspection rule purge
E.4. プロファイルの自動タグ付けのプロパティー
プロファイルの自動タグ付けは、各条件の field の属性に対する以下のノードプロパティーを評価します。
| プロパティー | 説明 |
|---|---|
|
memory_mb |
ノードのメモリーサイズ (MB) |
|
cpus |
ノードの CPU の合計コア数 |
|
cpu_arch |
ノードの CPU のアーキテクチャー |
|
local_gb |
ノードのルートディスクのストレージの合計容量。ノードのルートディスクの設定についての詳しい説明は、「ノードのルートディスクの定義」を参照してください。 |
付録F セキュリティーの強化
以下の項では、アンダークラウドのセキュリティーを強化するための推奨事項について説明します。
F.1. HAProxy の SSL/TLS の暗号およびルールの変更
アンダークラウドで SSL/TLS を有効化した場合には (「director の設定パラメーター」を参照)、HAProxy 設定を使用する SSL/TLS の暗号とルールを強化することをお勧めします。これにより、POODLE TLS 脆弱性 などの SSL/TLS の脆弱性を回避することができます。
hieradata_override のアンダークラウド設定オプションを使用して、以下の hieradata を設定します。
- tripleo::haproxy::ssl_cipher_suite
- HAProxy で使用する暗号スイート
- tripleo::haproxy::ssl_options
- HAProxy で使用する SSL/TLS ルール
たとえば、以下のような暗号およびルールを使用することができます。
-
暗号:
ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS -
ルール:
no-sslv3 no-tls-tickets
hieradata オーバーライドファイル (haproxy-hiera-overrides.yaml) を作成して、以下の内容を記載します。
tripleo::haproxy::ssl_cipher_suite: ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256:ECDHE-ECDSA-AES128-SHA:ECDHE-RSA-AES256-SHA384:ECDHE-RSA-AES128-SHA:ECDHE-ECDSA-AES256-SHA384:ECDHE-ECDSA-AES256-SHA:ECDHE-RSA-AES256-SHA:DHE-RSA-AES128-SHA256:DHE-RSA-AES128-SHA:DHE-RSA-AES256-SHA256:DHE-RSA-AES256-SHA:ECDHE-ECDSA-DES-CBC3-SHA:ECDHE-RSA-DES-CBC3-SHA:EDH-RSA-DES-CBC3-SHA:AES128-GCM-SHA256:AES256-GCM-SHA384:AES128-SHA256:AES256-SHA256:AES128-SHA:AES256-SHA:DES-CBC3-SHA:!DSS tripleo::haproxy::ssl_options: no-sslv3 no-tls-tickets
暗号のコレクションは、改行なしで 1 行に記述します。
undercloud.conf ファイルで先程作成した hierradata オーバーライドファイルを使用するように hieradata_override パラメーターを設定してから openstack undercloud install を実行します。
[DEFAULT] ... hieradata_override = haproxy-hiera-overrides.yaml ...
付録G Red Hat OpenStack Platform for POWER
Red Hat OpenStack Platform を新規インストールする際に、オーバークラウドのコンピュートノードを POWER (ppc64le) ハードウェアにデプロイできるようになりました。コンピュートノードのクラスターには、同じアーキテクチャーのシステムを使用するか、x86_64 と ppc64le のシステムを混在させることができます。アンダークラウド、コントローラーノード、Ceph Storage ノード、およびその他のシステムはすべて x86_64 ハードウェアでのみサポートされています。各システムのインストール詳細は、本ガイドのこれまでのセクションで説明しています。
G.1. Ceph Storage
マルチアーキテクチャークラウドにおいて外部 Ceph へのアクセスを設定する場合には、クライアントキーおよびその他の Ceph 固有パラメーターと共に CephAnsiblePlaybook パラメーターを /usr/share/ceph-ansible/site.yml.sample に設定します。
例:
parameter_defaults: CephAnsiblePlaybook: /usr/share/ceph-ansible/site.yml.sample CephClientKey: AQDLOh1VgEp6FRAAFzT7Zw+Y9V6JJExQAsRnRQ== CephClusterFSID: 4b5c8c0a-ff60-454b-a1b4-9747aa737d19 CephExternalMonHost: 172.16.1.7, 172.16.1.8
G.2. コンポーザブルサービス
一般にコントローラーノードの一部となる以下のサービスは、テクノロジープレビューとしてカスタムロールでの使用が可能です。したがって、Red Hat による完全なサポートは提供されません。
-
Cinder -
Glance -
Keystone -
Neutron -
Swift
詳しい情報は、『オーバークラウドの高度なカスタマイズ』の「コンポーザブルサービスとカスタムロール」を参照してください。上記のサービスをコントローラーノードから専用の ppc64le ノードに移動する手順の一例を、以下に示します。
(undercloud) [stack@director ~]$ rsync -a /usr/share/openstack-tripleo-heat-templates/. ~/templates
(undercloud) [stack@director ~]$ cd ~/templates/roles
(undercloud) [stack@director roles]$ cat <<EO_TEMPLATE >ControllerPPC64LE.yaml
###############################################################################
# Role: ControllerPPC64LE #
###############################################################################
- name: ControllerPPC64LE
description: |
Controller role that has all the controller services loaded and handles
Database, Messaging and Network functions.
CountDefault: 1
tags:
- primary
- controller
networks:
- External
- InternalApi
- Storage
- StorageMgmt
- Tenant
# For systems with both IPv4 and IPv6, you may specify a gateway network for
# each, such as ['ControlPlane', 'External']
default_route_networks: ['External']
HostnameFormatDefault: '%stackname%-controllerppc64le-%index%'
ImageDefault: ppc64le-overcloud-full
ServicesDefault:
- OS::TripleO::Services::Aide
- OS::TripleO::Services::AuditD
- OS::TripleO::Services::CACerts
- OS::TripleO::Services::CephClient
- OS::TripleO::Services::CephExternal
- OS::TripleO::Services::CertmongerUser
- OS::TripleO::Services::CinderApi
- OS::TripleO::Services::CinderBackendDellPs
- OS::TripleO::Services::CinderBackendDellSc
- OS::TripleO::Services::CinderBackendDellEMCUnity
- OS::TripleO::Services::CinderBackendDellEMCVMAXISCSI
- OS::TripleO::Services::CinderBackendDellEMCVNX
- OS::TripleO::Services::CinderBackendDellEMCXTREMIOISCSI
- OS::TripleO::Services::CinderBackendNetApp
- OS::TripleO::Services::CinderBackendScaleIO
- OS::TripleO::Services::CinderBackendVRTSHyperScale
- OS::TripleO::Services::CinderBackup
- OS::TripleO::Services::CinderHPELeftHandISCSI
- OS::TripleO::Services::CinderScheduler
- OS::TripleO::Services::CinderVolume
- OS::TripleO::Services::Collectd
- OS::TripleO::Services::Docker
- OS::TripleO::Services::Fluentd
- OS::TripleO::Services::GlanceApi
- OS::TripleO::Services::GlanceRegistry
- OS::TripleO::Services::Ipsec
- OS::TripleO::Services::Iscsid
- OS::TripleO::Services::Kernel
- OS::TripleO::Services::Keystone
- OS::TripleO::Services::LoginDefs
- OS::TripleO::Services::MySQLClient
- OS::TripleO::Services::NeutronApi
- OS::TripleO::Services::NeutronBgpVpnApi
- OS::TripleO::Services::NeutronSfcApi
- OS::TripleO::Services::NeutronCorePlugin
- OS::TripleO::Services::NeutronDhcpAgent
- OS::TripleO::Services::NeutronL2gwAgent
- OS::TripleO::Services::NeutronL2gwApi
- OS::TripleO::Services::NeutronL3Agent
- OS::TripleO::Services::NeutronLbaasv2Agent
- OS::TripleO::Services::NeutronLbaasv2Api
- OS::TripleO::Services::NeutronLinuxbridgeAgent
- OS::TripleO::Services::NeutronMetadataAgent
- OS::TripleO::Services::NeutronML2FujitsuCfab
- OS::TripleO::Services::NeutronML2FujitsuFossw
- OS::TripleO::Services::NeutronOvsAgent
- OS::TripleO::Services::NeutronVppAgent
- OS::TripleO::Services::Ntp
- OS::TripleO::Services::ContainersLogrotateCrond
- OS::TripleO::Services::OpenDaylightOvs
- OS::TripleO::Services::Rhsm
- OS::TripleO::Services::RsyslogSidecar
- OS::TripleO::Services::Securetty
- OS::TripleO::Services::SensuClient
- OS::TripleO::Services::SkydiveAgent
- OS::TripleO::Services::Snmp
- OS::TripleO::Services::Sshd
- OS::TripleO::Services::SwiftProxy
- OS::TripleO::Services::SwiftDispersion
- OS::TripleO::Services::SwiftRingBuilder
- OS::TripleO::Services::SwiftStorage
- OS::TripleO::Services::Timezone
- OS::TripleO::Services::TripleoFirewall
- OS::TripleO::Services::TripleoPackages
- OS::TripleO::Services::Tuned
- OS::TripleO::Services::Vpp
- OS::TripleO::Services::OVNController
- OS::TripleO::Services::OVNMetadataAgent
- OS::TripleO::Services::Ptp
EO_TEMPLATE
(undercloud) [stack@director roles]$ sed -i~ -e '/OS::TripleO::Services::\(Cinder\|Glance\|Swift\|Keystone\|Neutron\)/d' Controller.yaml
(undercloud) [stack@director roles]$ cd ../
(undercloud) [stack@director templates]$ openstack overcloud roles generate \
--roles-path roles -o roles_data.yaml \
Controller Compute ComputePPC64LE ControllerPPC64LE BlockStorage ObjectStorage CephStorage