
Red Hat Training
A Red Hat training course is available for Red Hat OpenStack Platform
エッジサイトへの分散コンピュートノードのデプロイ
エッジサイトにおいて分散コンピュートノード (DCN) を使用するためのガイド
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、弊社の CTO、Chris Wright のメッセージ を参照してください。
第1章 エッジサイトへの分散コンピュートノードのデプロイ
1.1. エッジコンピューティングおよび DCN の概要
Red Hat OpenStack Platform 13 では、エッジコンピューティング とは、一般的なデータセンターではないリモートのロケーションにコンピュートノードをデプロイする構成を指します。たとえば通信分野では、データ処理タスクのためにコンピュートノードをリモートのロケーションにデプロイする場合があります。
Red Hat OpenStack Platform 13 を使用して、分散コンピュートノード (DCN) によるエッジコンピューティングを実装することができます。この構成では、コンピュートノードをリモートのロケーションにデプロイすることができ、またコントローラーサービスにネットワークの問題 (特に接続性およびレイテンシー) に対する耐性を持たせることができます。
1.2. DCN デプロイメントの設計
本章では、エッジサイトへの DCN デプロイメントをプランニングする際に考慮すべき、アーキテクチャーに関する主な要件および制限事項について説明します。
この設計の例では、1 つのオーバークラウド heat スタックが複数のサイトに展開され、それぞれのサイトには固有のアベイラビリティーゾーン (AZ) が割り当てられます。独立した AZ を用いる手法により、特定の負荷をそれぞれの DNC サイトに割り当てることができます。
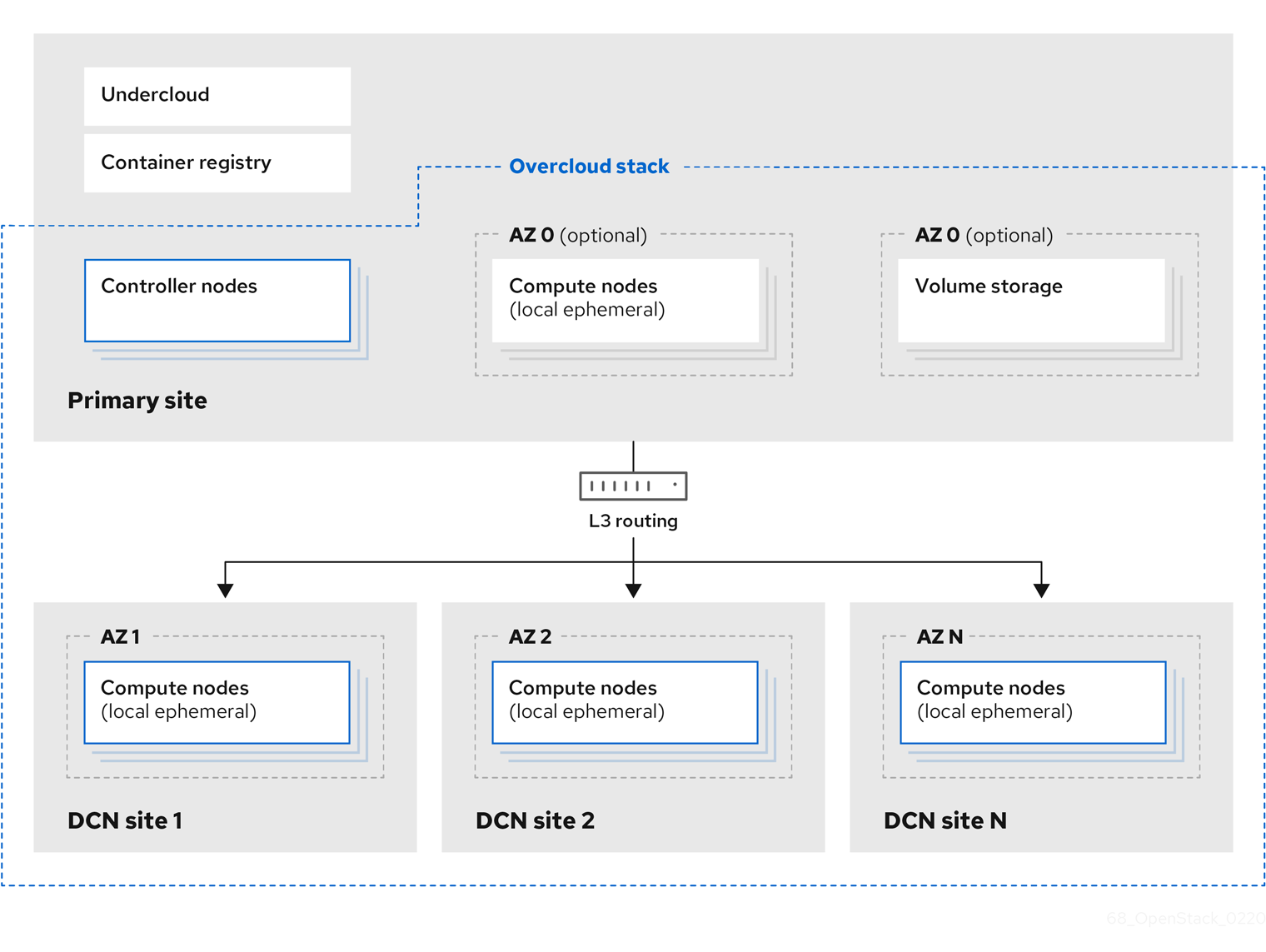
以下のセクションで、これらの設計を決定する理由について説明します。
Block Storage (cinder) ボリュームを中央サイトにアタッチする際に、コンピュートノードと同じ AZ 名を使用することができます。この場合には、cross_az_attach=false を使用してボリュームがリモートインスタンスにアタッチされるのを防ぐことができます。
1.2.1. アベイラビリティーゾーン
それぞれのエッジサイトを独立したアベイラビリティーゾーン (AZ) として設定する必要があります。この AZ にインスタンスをデプロイする場合、リモートのコンピュートノード上で実行されることになります。また、中央サイトも、デフォルトの AZ ではなく特定の AZ (または複数の AZ) 内に含まれている必要があります。アベイラビリティーゾーン間のライブマイグレーションはサポートされていません。
1.2.2. DCN ネットワーク冗長性のプランニング
DCN のデプロイメントを設計する場合には、冗長性を検討する必要があります。DNC では、地理的に異なるさまざまな場所でコンピュートノードをホストすることができます。これらのリモートサイトのどこかで発生する障害に対して耐性を持たせるには、ホストに複数の冗長パスを設定することを検討してください。物理ノードについては、物理接続に冗長性を持たせることを検討してください。
1.2.3. 考慮すべき制限事項
- コンピュートノードのみ: Red Hat OpenStack Platform 13 では、エッジサイトにデプロイすることができるのはコンピュートノードだけです。ストレージ等の他のロールはサポートされていません。
- ネットワークレイテンシー: エッジサイトのコンピュートノードは、より広範なオーバークラウドデプロイメントと統合されます。したがって、ラウンドトリップタイム (RTT) が 100 ms を超えないという、ネットワークレイテンシーに関する要件を満たす必要があります。一部のユースケースでは、エッジサイトおよび中央のコントロールプレーンで L2 接続が利用できず、ある程度信頼性はあるがネットワークレイテンシーの高い WAN が使用されています。
- ネットワークドロップアウト: エッジサイトで一時的にネットワーク接続が失われると、その間は該当するエッジサイトで OpenStack コントロールプレーン API または CLI 操作を実行することができません。たとえば、エッジサイトのコンピュートノードは、インスタンスのスナップショットの作成や認証トークンの発行、イメージの削除ができなくなります。接続喪失の影響に関する詳細な情報は、以下の「起こり得る障害に対するプランニング」を参照してください。この接続喪失の期間中、全般的な OpenStack コントロールプレーン API および CLI 操作は引き続き実施可能で、ネットワーク接続が機能しているその他のエッジサイトへの対応を続けることができます。
イメージのサイズ:
- オーバークラウドノードのイメージ: エッジサイトには固有のプロビジョニングネットワークがありますが、オーバークラウドノードイメージは中央のアンダークラウドノードからダウンロードされます。これらのイメージは、プロビジョニング時に中央サイトからエッジサイトまでの必要なネットワークすべてで転送される大きなファイルである可能性があります。
- インスタンスのイメージ: glance に保管されるあらゆるベースイメージは、そのコンピュートノードでの初回使用時にのみ WAN 接続経由で転送されます。それ以降同じイメージを使用する際には、コンピュートノードでローカルにキャッシュされたイメージが使用されます。イメージはコントローラーノードから配布され、初回使用以降はそれぞれのコンピュートノードでキャッシュされます。イメージのサイズに具体的な制限はありません。転送時間は利用可能な帯域幅およびネットワークレイテンシーにより変動するためです。
- プロバイダーネットワーク: これが DCN デプロイメントの推奨ネットワーク構成です。リモートサイトでプロバイダーネットワークを使用する場合には、利用可能なネットワークのアタッチ先に関して、neutron が何らかの制約を設けたりチェックを行ったりしない点に注意する必要があります。たとえば、エッジサイト A でしかプロバイダーネットワークを使用しない場合には、エッジサイト B のプロバイダーネットワークには決してアタッチしないようにする必要があります。これは、プロバイダーネットワークをコンピュートノードにバインドする際に、プロバイダーネットワークに関するチェックが行われないためです。
- サイト固有のネットワーク: 特定のサイトに固有なネットワークを使用している場合には、DCN のネットワーク設定に制約が生じます。コンピュートノードと共に集中 neutron コントローラーをデプロイする場合には、neutron では特定のコンピュートノードをリモートノードとして識別するトリガーがありません。したがって、コンピュートノードは他のコンピュートノードのリストを取得し、自動的にそれぞれのノード間でトンネルを形成します。トンネルは、エッジサイト/エッジサイト間およびエッジサイト/中央サイト間で形成されます。VXLAN または Geneve を使用している場合には、すべてのサイトの全コンピュートノードが、他のすべてのコンピュートノードおよびコントローラーノードとトンネルを形成することになります (それらが実際にローカルかリモートかにかかわらず)。すべてのノードで同じ neutron ネットワークを使用していれば、これは問題とはなりません。VLAN を使用している場合の neutron 設定では、すべてのコンピュートノードが同じブリッジマッピングを持ち、すべての VLAN が各サイトで利用可能でなければなりません。
-
追加のサイト: 中央サイトから追加のリモートサイトに拡張する必要がある場合には、アンダークラウドで
openstackcli を使用して、新たなネットワークセグメントおよびサブネットを追加することができます。 - 自律性: エッジサイトに対して、特定の自律性要件が適用される場合があります。この要件は、実際の要求により異なります。
1.2.4. ネットワークのプランニング
DCN のデプロイメントには、ルーティング対応 L3 ネットワークが推奨されます。
1.2.4.1. ルーティング対応 L3 ネットワーク
リモートのロケーションには、コンピュートノードとして機能する物理ノードが含まれます。このノードは、プロビジョニングネットワークとして指定されたローカルサブネットにアタッチされます。メインのデータセンターにあるアンダークラウドノードにプロビジョニングトラフィックを渡すには、DHCP リレーが必要です。次に director を使用して、リモートのロケーションをベースとする物理ハードウェアにコンピュートノードをデプロイできます。
L3 ルーティングに関する詳細は、『スパイン/リーフ型ネットワーク』を参照してください。
1.2.4.2. North-South および East-West トラフィックの耐障害性の向上
スパイン/リーフ型ネットワークがお使いのユースケースには適さず、従来の North-South/East-West トポロジーに従う場合には、L3 HA のネットワーク設定により、集中管理の信頼性を向上させることができます。なお、L3 HA 設定では North-South ルーティングだけが提供されます。エッジネットワークの East-West ルーティングの効果は、DVR およびローカルルーティングオプション または高可用性 OVN により向上させることができます。
OVN では自動的に DVR が使用され、Neutron DHCP/L3 エージェントを実行する必要はありません。これにより、DCN のデプロイメントを単純化することができます。
あるいは、外部プロバイダーネットワーク により、North-South および East-West トラフィックで複雑 (かつ効率的) なルーティングトポロジーを使用することができます。
1.2.4.3. ネットワークに関する推奨事項
特定の既知の問題があるため、トンネリングを実施する Neutron バックエンドは、エッジサイトへの DCN デプロイメントに対する最適の選択とは言えない場合があります。
詳細な情報は、以下を参照してください。
従来のネットワークまたはバックボーンルーティングを使用するエッジサイトの外部プロバイダーネットワークは、L3 スパイン/リーフ型トポロジー等のカスタム分散ルーティングソリューションを補うものです。ただし、ネットワーク障害によりエッジサイトと中央サイトのネットワーク接続が失われた場合、復旧時間は SLA の対象ではなく、プロバイダーネットワーク (または選択した特定の SDN ) が保証できるものしか対象になりません。スイッチング対応/ルーティング対応/MPLS プロバイダーネットワークの場合には、サービス停止期間は 数 10 ミリ秒から数秒の間です。サービス停止のしきい値は、一般的には 15 秒と考えられています。この値は、適用されるさまざまな規格に応じて変化します。
動的 IPv4 およびステートフル IPv6 IPAM デプロイメントの場合には、仮想マシンインスタンスに IP アドレスを割り当てるために、これらのプロバイダーネットワーク上に DHCP を設定する必要もあります。外部プロバイダーネットワークでは通常、Neutron DHCP エージェントは必要なく、そのネットワーク上で IPAM (およびルーティング) を処理することができます。従来のネットワークまたは Neutron ルーティング対応プロバイダーネットワーク の場合には、WAN を通じたエッジサイトへの L2 接続がなければ、各プロバイダーネットワーク上に DHCP リレーを設定する必要があります。また、中央サイトのコントローラーに Neutron DHCP エージェントを設定しなければなりません。あるいは、DHCP エージェントをエッジサイトに移動することができます。この場合には、リモートサイトと中央サイトの間に極めて信頼性の高いリンクが必要です。
エッジサイトに DHCP リレーまたは Neutron エージェントを設定する場合には、サポート例外が必要になる場合があります。本件は、エッジサイトの Neutron ルーティング対応プロバイダーネットワークおよび外部プロバイダーネットワークにも適用されます。
リモートサイトの可用性は、ML2 および Open vSwitch プラグインにより改善することができます。これらのプラグインにより、データプレーンによるフェイルオーバーの迅速化が可能なプロトコル (VRRP 等) を使用することができます (『ネットワークガイド』の「allowed-address-pairs の設定」を参照)。また、従来のネットワークボンディングおよび VF/PF DPDK のボンディング により、短/中期間のハードウェア障害に対する全般的な耐性が向上します。
1.2.4.4. IPv6 を使用するオプション
実施可能なもう 1 つのオプションは、プロジェクトおよび中央サイトとエッジサイトを接続するインフラストラクチャートンネルに IPv6 を使用することです。ただし、IPv6 をプロビジョニングネットワークに使用することはできません。
DCN に IPv6 を使用する主なメリットを以下に示します。
- ステートレスアドレス自動設定 (SLAAC): プロバイダーネットワークに DHCP サービスを設定する必要がない。
- 優れたモビリティー: エントポイントおよび NFV 的な API は、ネットワーク接続および IP アドレスを失わずに異なるリンク/エッジサイト間をローミングすることができる。
- エンドツーエンド IPv6: 大規模なネットワークでより優れたパフォーマンスを示す。これは主に、NAT を使用したエンドツーエンド IPv4 接続のパフォーマンスインパクトによるものです。
1.2.5. 設定のメカニズム
エッジロケーションではプロバイダーネットワークだけを使用することを推奨します。したがって、config-drive または IPv6 SLAAC の使用を検討してください。あるいは、cloud-init と共にその他の設定メカニズムを使用します。Config-drive はメタデータ API サーバーとして機能し、BMC コントローラーの仮想メディア機能を使用することができます。このため、エッジサイトの仮想マシンインスタンスが IP アドレスを取得するのに、Neutron Metadata/DHCP エージェントまたは DHCP リレーは必要ありません。ただし、仮想マシンのデプロイメント時に、リモートサイトと中央サイト間の WAN が動作状態でなければなりません。なおデプロイメント後は、仮想マシンは中央サイトとのネットワーク接続がなくても独立して動作することができます。
一部のインスタンスには、対応する Neutron ポートと一致する静的 IP アドレスを設定しなければならない場合があります。NFV に特化した VNF アプライアンス等の config-drive をサポートしないインスタンスの場合に、この設定が必要です。
1.2.6. ストレージに関する推奨事項
DCN は、ローカルの一時ストレージを使用する Compute サービスに限り利用することが可能です。データの可用性、局所性の認識、および複製手段について検討しながらエッジクラウドアプリケーションを設計してください。
1.2.7. 起こり得る障害に対するプランニング
本項では、特定の障害が及ぼし得る影響について説明します。これらのリスクを軽減するために、高可用性が推奨されます。この点についても言及します。
1.2.7.1. 起こり得る障害に対するオーバークラウドのプランニング
DCN の障害シナリオに適切に対応するためには、デプロイメントのプランニングプロセスから検討を始めます。たとえば、あるレベルの SLA が求められる場合には、プロバイダーネットワークを使用する特定の SDN ソリューションの選択を検討してください。
オーバークラウドのプランニングに関する詳細は、『director のインストールと使用方法』の「オーバークラウドのプランニング」を参照してください。
1.2.7.2. コントロールプレーンの喪失
中央のコントロールプレーンで障害が発生した場合の影響は、他の製品アーキテクチャーで見られるものと違いはありません。DCN のデプロイメントで必要な特別な対応はありません。本項では、この障害が DCN サイトに及ぼす影響について説明します。
エッジサイトのネットワーク障害は、中央のコントロールプレーンの障害よりも発生することが多いです。後者は極めて重大で、非常にまれなケースと考えられます。
エッジサイトには独立したコントロールプレーンが存在しないので、このタイプの障害はすべての DCN エッジサイトに影響を及ぼします。したがって、OpenStack コントロールプレーン API または CLI 操作は一切実行することができません。たとえば、インスタンスのスナップショットの作成や認証トークンの発行、イメージの削除を実施することはできません。
API への影響以外については、このイベントによりエッジサイトの負荷にダウンタイムは発生せず、一般的な高可用性 (HA) デプロイメントおよび手順により対処する必要があります。
エッジサイトでホストされるコンピュートインスタンスは、ホストがリブートされない限り動作し続ける必要があります。インスタンスが停止した場合、停止またはクラッシュした負荷を復元するためには、コントロールプレーンをオンライン状態に戻す必要があります。Neutron DHCP エージェントが中央サイトだけにあり、トポロジーが DHCP リクエストを中央サイトに送付する場合には、IP アドレスの更新を試みるいずれの仮想マシンインスタンスも最終的にタイムアウトし、ネットワーク接続を失います。
1 つのコンピュートノードで発生した障害は、通常そのエッジサイトにしか影響を与えず、周りのエッジサイトまたは中央のコントロールプレーンではダウンタイムは発生しません。
コントロールプレーンのアップリンクが回復すると、OpenStack のインフラストラクチャーサービス (Compute 等) は自動的にコントロールサービスに再接続されます。ただし、タイムアウトしたコントロールプレーン操作を再開することはできません。手動でやり直す必要があります。
それぞれの DCN エッジサイトは、独立したアベイラビリティーゾーン (AZ) として設定する必要があります。
1.3. director を使用したエッジサイトへのノードのデプロイ
本章では、DCN エッジコンピューティング用にアンダークラウドおよびオーバークラウドを設定するのに必要な手順について説明します。
1.3.1. アンダークラウドの設定
本項では、DCN 用にアンダークラウドを設定するのに必要な手順について説明します。
1.3.1.1. iSCSI に代わる直接デプロイの使用
デフォルトのアンダークラウド設定では、ironic は iscsi デプロイインターフェースを使用してノードをデプロイします。iscsi デプロイインターフェースを使用する場合には、デプロイ ramdisk がノードのディスクを iSCSI ターゲットとしてパブリッシュし、ironic-conductor サービスがイメージをこのターゲットにコピーします。
DCN のデプロイメントでは、アンダークラウドと分散コンピュートノード間のネットワークレイテンシーが問題になることがあります。レイテンシーの可能性を考慮すると、分散コンピュートノードはアンダークラウドの direct デプロイインターフェースを使用するように設定する必要があります。deploy インターフェースの設定に関する詳細な情報は、「デプロイインターフェースを使用するノードの設定」を参照してください。
direct デプロイインターフェースを使用する場合には、デプロイ ramdisk がアンダークラウドの Swift サービスから HTTP 経由でイメージをダウンロードし、それをノードのディスクにコピーします。ネットワークレイテンシーの影響に関して、HTTP は iSCSI よりも耐性があります。したがって、分散コンピュートノードの場合には、direct デプロイインターフェースを使用することで、より安定したノードのデプロイメントが可能になります。
1.3.1.2. Swift 一時 URL 鍵の設定
イメージは Swift により提供され、ノードは direct デプロイインターフェースを通じて HTTP URL を使用してイメージにアクセスします。一時 URL を作成できるように、Swift に一時 URL 鍵を設定する必要があります。Swift はこの鍵の値を使用して、暗号化署名および一時 URL の検証を行います。
以下のコマンドにより、設定を定義します。この例では、uuidgen を使用してランダムな鍵の値を作成しています。推測が難しい一意な鍵の値を選択してください。以下に例を示します。
$ source ~/stackrc
$ openstack role add --user admin --project service ResellerAdmin
$ openstack --os-project-name service object store account set --property Temp-URL-Key=$(uuidgen | sha1sum | awk '{print $1}')1.3.1.3. デプロイインターフェースを使用するノードの設定
本項では、新規および既存ノード用にデプロイインターフェースを設定する方法について説明します。
1.3.1.3.1. 新規ノード用インターフェース設定の定義
ノードごとに、JSON 構造で直接デプロイインターフェースを指定することができます。例として、“deploy_interface”: “direct” の設定を以下に示します。
{
"nodes":[
{
"mac":[
"bb:bb:bb:bb:bb:bb"
],
"name":"node01",
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"ipmi",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.168.24.205",
“deploy_interface”: “direct”
},
{
"mac":[
"cc:cc:cc:cc:cc:cc"
],
"name":"node02",
"cpu":"4",
"memory":"6144",
"disk":"40",
"arch":"x86_64",
"pm_type":"ipmi",
"pm_user":"admin",
"pm_password":"p@55w0rd!",
"pm_addr":"192.168.24.206"
“deploy_interface”: “direct”
}
]
}1.3.1.3.2. 既存ノード用インターフェース設定の定義
direct デプロイインターフェースを使用するように既存ノードを更新することができます。以下に例を示します。
$ openstack baremetal node set --deploy-interface direct 4b64a750-afe3-4236-88d1-7bb88c962666
1.4. DCN 用オーバークラウドの設定
本項では、DCN 用にオーバークラウドを設定するのに必要な手順について説明します。
1.4.1. デプロイメントロールの作成
エッジサイトでの DCN デプロイメントでサポートされるのは、/usr/share/openstack-tripleo-heat-templates/roles/Compute.yaml で定義されるデフォルトの Compute ロールだけです。ただし、ロールをコピーして名前を変更し、エッジサイトで異なるソフトウェア設定を許可することは可能です。
以下の例で、2 つの異なるロールが 2 つの個別の AZ に同じサービスのセットを使用する設定方法を説明します。
############################################################################## # Role: ComputeAZ1 ############################################################################## - name: ComputeAZ1 description: | Basic Compute Node role for AZ1 CountDefault: 1 networks: - InternalApi1 - Tenant1 - Storage1 HostnameFormatDefault: '%stackname%-compute-az1-%index%' RoleParametersDefault: TunedProfileName: "virtual-host" disable_upgrade_deployment: True ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::Ntp - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::SkydiveAgent - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Tuned - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgent - OS::TripleO::Services::Ptp ############################################################################## # Role: ComputeAZ2 ############################################################################## - name: ComputeAZ2 description: | Basic Compute Node role for AZ2 CountDefault: 1 networks: - InternalApi2 - Tenant2 - Storage2 HostnameFormatDefault: '%stackname%-compute-az2-%index%' RoleParametersDefault: TunedProfileName: "virtual-host" disable_upgrade_deployment: True ServicesDefault: - OS::TripleO::Services::Aide - OS::TripleO::Services::AuditD - OS::TripleO::Services::CACerts - OS::TripleO::Services::CephClient - OS::TripleO::Services::CephExternal - OS::TripleO::Services::CertmongerUser - OS::TripleO::Services::Collectd - OS::TripleO::Services::ComputeCeilometerAgent - OS::TripleO::Services::ComputeNeutronCorePlugin - OS::TripleO::Services::ComputeNeutronL3Agent - OS::TripleO::Services::ComputeNeutronMetadataAgent - OS::TripleO::Services::ComputeNeutronOvsAgent - OS::TripleO::Services::Docker - OS::TripleO::Services::Fluentd - OS::TripleO::Services::Ipsec - OS::TripleO::Services::Iscsid - OS::TripleO::Services::Kernel - OS::TripleO::Services::LoginDefs - OS::TripleO::Services::MySQLClient - OS::TripleO::Services::NeutronBgpVpnBagpipe - OS::TripleO::Services::NeutronLinuxbridgeAgent - OS::TripleO::Services::NeutronVppAgent - OS::TripleO::Services::NovaCompute - OS::TripleO::Services::NovaLibvirt - OS::TripleO::Services::NovaMigrationTarget - OS::TripleO::Services::Ntp - OS::TripleO::Services::ContainersLogrotateCrond - OS::TripleO::Services::OpenDaylightOvs - OS::TripleO::Services::Rhsm - OS::TripleO::Services::RsyslogSidecar - OS::TripleO::Services::Securetty - OS::TripleO::Services::SensuClient - OS::TripleO::Services::SkydiveAgent - OS::TripleO::Services::Snmp - OS::TripleO::Services::Sshd - OS::TripleO::Services::Timezone - OS::TripleO::Services::TripleoFirewall - OS::TripleO::Services::TripleoPackages - OS::TripleO::Services::Tuned - OS::TripleO::Services::Vpp - OS::TripleO::Services::OVNController - OS::TripleO::Services::OVNMetadataAgent - OS::TripleO::Services::Ptp
名前の異なるロールに同じサービスのセットが設定されている点に注意してください。RoleParameters パラメーターを使用して、個別にサービスパラメーターを設定することができます。以下に例を示します。
parameter_defaults:
RoleParameters:
ComputeAZ1:
NovaReservedHostMemory: 4096
ComputeAZ2:
NovaReservedHostMemory: 2048
上記の例では、ComputeAZ1 ロールでデプロイされるノードの NovaReservedHostMemory には 4096 が設定されています。また、ComputeAZ2 ロールでデプロイされるノードの NovaReservedHostMemory には 2048 が設定されています。
ノードを AZ にデプロイするには、物理ノードを新しいロールにタグ付けしてプロビジョニングネットワークにブートアップする一般的なプロビジョニング手順に従います。director のデプロイメントに関する詳しい情報は、『director のインストールと使用方法』を参照してください。
1.4.2. インストール後の設定
1.4.2.1. アベイラビリティーゾーンの作成
director を使用してエッジサイトに DCN をプロビジョニングした後に、エッジサイトにアベイラビリティーゾーンを作成する必要があります。AZ を作成したら、そこでインスタンスを起動することができます。新しいインスタンスが DCN 上で起動します。
このデプロイメントの一環として、中央サイトに新しい AZ が作成されました。新しい中央 AZ に適用可能なコンピュートノードを追加します。AZ の設定に関する詳細は、『インスタンス&イメージガイド』の「ホストアグリゲートの管理」を参照してください。
中央 AZ の設定と一致するように、default_schedule_zone を設定します。この値が新しいインスタンスのデフォルトとして使用されます。
1.5. 運用上の操作手順
1.5.1. ネットワークレイテンシーの監視
エッジサイトでの DCN デプロイメントは、レイテンシーが 100 ms 以上になると大きな影響を受けます。したがって、これらのネットワーク接続に対して監視を行い、レイテンシーのしきい値に達した場合には警告を発行する必要があります。
1.5.2. DCN 更新の管理
BAU 運用のために、ローカルのコンピュートノードを管理するのと同じように DCN ノードを管理することができます。たとえば、更新の適用方法に関しては、DCN と標準のコンピュートノードで違いはありません。更新を適用するノードを管理することができます。つまり、すべてのコンピュートノードを一括して更新するのではなく、サイトごとにノードを更新することができます。
たとえば、openstack overcloud update run の --nodes パラメーターを使用して、コンピュートノードのリストに従い、またはロールごとに更新を実施することができます。それぞれのリモートサイトは固有のロールを持つので、サイトごとにマイナーアップデートを実施したり、更新を特定のノードに限定したりすることができます。詳細は、『Red Hat OpenStack Platform の最新状態の維持』の「全コンピュートノードの更新」を参照してください。
コントローラーノードを更新する場合には、DCN のデプロイメントではスパイン/リーフ構成用に非標準の Controller ロールが使用されていることを思い出してください。たとえば、以下のコマンドを実行する必要があります。
$ openstack overcloud update run --nodes Controller0
1.6. エッジサイトでのデプロイメントのスケーリング
本項では、アンダークラウドおよびオーバークラウドノードをスケールアウトする方法について説明します。
1.6.1. オーバークラウドのスケーリング
オーバークラウドに追加することのできるノードの数は、アンダークラウドが管理することのできるノードの数に制限されます。オーバークラウドデプロイメントのノード数が増えると、管理すべきリソースの数も増えます。
1 つのデプロイメントのノード数は、300 を超えないことを推奨します。この数字は、ハードウェアのサイズ、オーバークラウドの設定、およびその他の要素に強く依存します。物理ハードウェアを使用した過去のテストでは、1 つのアンダークラウドでノード数の合計が 150 のオーバークラウドをデプロイできることが示されています。よりノード数の多いデプロイメントも正常に機能する可能性はありますが、テストされてはいません。現在実施中のテストの結果が評価されるにつれ、この推奨値が上がる可能性がある点に留意してください。
デプロイメントの完了に必要な時間は、さまざまな要素により変動します。これにはアンダークラウドのリソース、ネットワークの帯域幅、およびノードのブートに要する時間が含まれます。ただし、デプロイメント時間に最も大きな影響を及ぼす要素の 1 つは、デプロイメント中のノード数です。
1.6.2. 単一スタックデプロイメントの使用
Red Hat OpenStack Platform 13 において DCN アーキテクチャーをデプロイする際には、アンダークラウドが管理するすべてのノードを同じスタックにデプロイする必要があります。これは、アンダークラウドが 1 つのオーバークラウドスタックしかデプロイすることができないためです。追加のオーバークラウドスタックまたはデプロイメントが必要な場合には、デプロイメントごとに独立したアンダークラウドを使用する必要があります。複数のデプロイメントで複数のアンダークラウドを使用する場合には、デプロイメントは独立したクラウドとみなされ、デプロイメント間での運用上の連携はありません。
1.6.3. 段階的なスケールアップ
すべてのノードが 1 つのスタックにデプロイされるので、いずれかのノードで何らかのデプロイメントの問題が発生すると、デプロイメント全体が停止して失敗し、異常として報告されます。デプロイメントのノード数が増えると、デプロイメント中に新たな問題が発生する可能性が高まります。これらの問題を解消しないと、デプロイメントを続行することはできません。これらの問題に対処するには、問題を修正するか、影響を受けるノードをまとめてデプロイメントから削除します。問題が解決したら、デプロイメントを実行し直します。
デプロイメント中断のリスクを軽減するには、段階的にデプロイメントを実行します。コントロールプレーンサービス (特にコントローラー) のノードおよび少数のコンピュートノードからデプロイメントを始めます。初期デプロイメントが正常に完了したら、コンピュートノードの数を増やして適切なサイズのバッチを追加することができます (10 台、20 台…)。それぞれのスケールアップ試行時に追加するバッチのサイズは、環境的な要素ならびにハードウェアおよびネットワーク内に問題が存在する可能性の大小により異なります。
デプロイメントをスケーリングする場合には、適切なサイズの小規模なバッチでコンピュートノードを追加し、デプロイメントの健全性を確認してから追加を続行する必要があります。
1.7. トラブルシューティング
1.7.1. ネットワークレイテンシーの確認
エッジサイトの DCN が予想に反する挙動を示す場合には、ネットワークレイテンシーを確認してください。高いレイテンシーが、DCN の予期せぬ挙動となって現れる場合があります (レイテンシーの高さによる)。たとえば、当初はネットワーク障害と思われていた事象が、実際には高いレイテンシーの結果だったというケースがあります。
1.7.2. ノードイントロスペクションの失敗
ノードのデプロイメントが Connection timed out および No bootable device エラーにより失敗する場合には、ノードが iscsi ではなく direct デプロイを使用するように設定されていることを確認してください。詳細は、「デプロイインターフェースを使用するノードの設定」を参照してください。