
Red Hat Training
A Red Hat training course is available for Red Hat OpenStack Platform
第5章 NFV のパフォーマンスの考慮事項
NFV ソリューションが有用であるためには、VF が物理実装のパフォーマンス以上である必要があります。Red Hat の仮想化技術は、OpenStack およびクラウドのデプロイメントで一般的に使用されている高フォーマンスの Kernel-based Virtual Machine (KVM) ハイパーバイザーをベースにしています。
5.1. CPU と NUMA ノード
以前は、x86 システムの全メモリーは、システム内のどの CPU からでも同等にアクセスできていたために、システム内で操作を行う CPU、Uniform Memory Access (UMA) を参照する CPU がどれでも、メモリーのアクセス時間は同じでした。
Non-Uniform Memory Access (NUMA) では、システムメモリーは、特定の CPU またはソケットに割り当てられるノードと呼ばれるゾーンに分割されます。CPU のローカルにあるメモリーには、そのシステムのリモートの CPU に接続されているメモリーにアクセスするよりも高速です。通常、NUMA システム上のソケットにはそれぞれローカルのメモリーノードがあり、別の CPU のローカルにあるノードのメモリーや、全 CPU で共有されるバス上のメモリーよりもコンテンツに早くアクセスできます。
同様に、物理 NIC はコンピュートノードのハードウェア上の PCI スロットに配置されます。これらのスロットは、特定の NUMA ノードに関連付けられた特定の CPU ソケットに接続されます。 パフォーマンスを最適化するには、CPU の設定で指定されているのと同じ NUMA ノードにデータパス NIC を接続します。
NUMA を使用しない場合のパフォーマンスへの影響は大きく、一般的に、パフォーマンス 10 % 以上が影響を受けます。各 CPU ソケットには、仮想化を目的とする個別の CPU として扱われる複数の CPU コアを配置することができます。
OpenStack Compute は、インスタンスの起動時にスマートなスケジューリングや配置の意思決定を行います。管理者はこのような機能を活用すると、NFV や高性能コンピューティング (HPC) などの特化されたワークロードを対象にするカスタマイズされたパフォーマンスフレーバーを構築することができます。
NUMA についての予備知識は、「What is NUMA and how does it work on Linux?」の記事に記載されています。
5.2. NUMA ノードの例
以下の図では、2 つのノードからなる NUMA システムの例と、CPU コアとメモリーページを利用可能にする方法の例が提供されています。
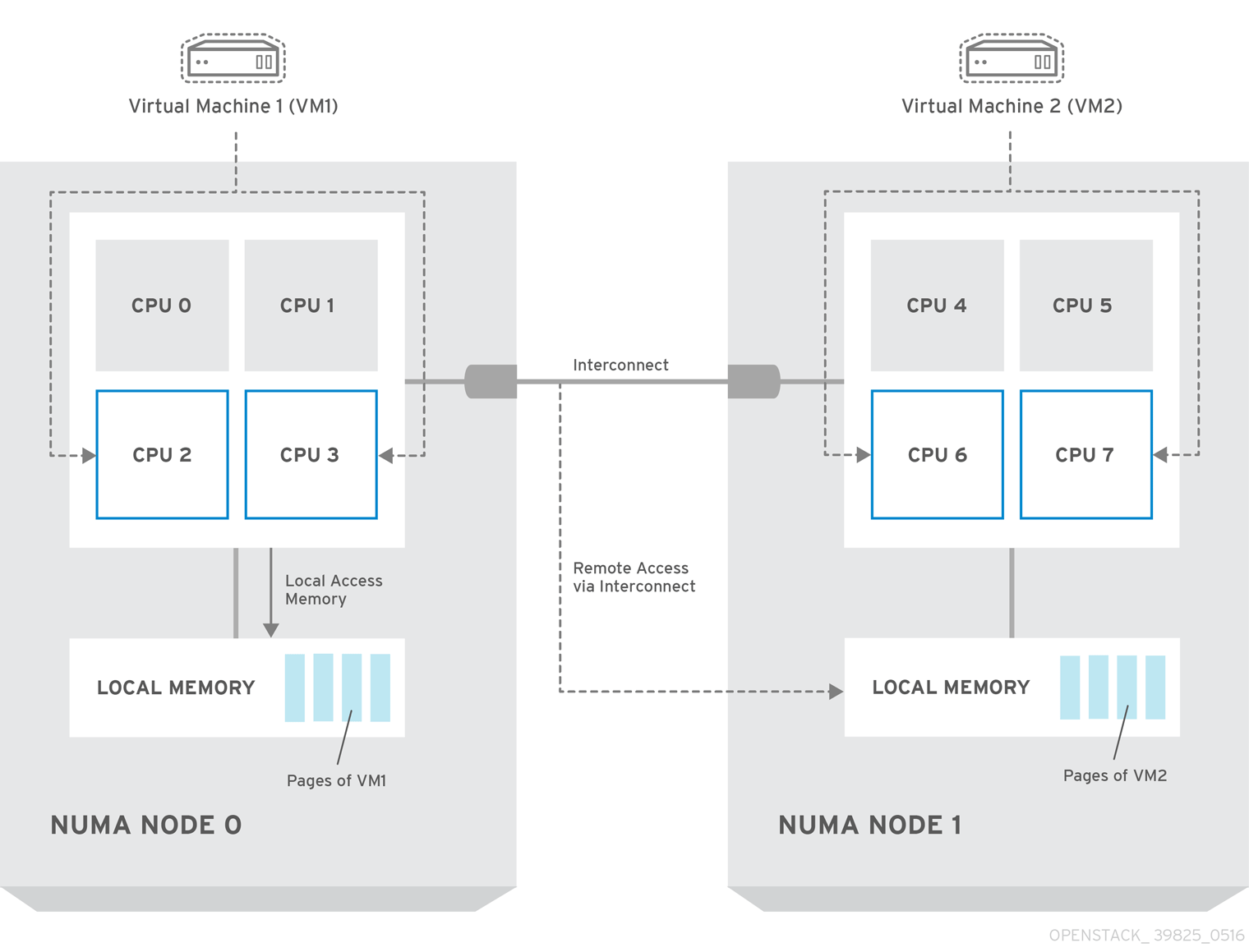
Interconnect 経由で利用可能なリモートのメモリーには、NUMA ノード 0 からの VM 1 に NUMA ノード 1 の CPU コアがある場合 のみ アクセスされます。このような場合には、NUMA ノード 1 のメモリーは、VM 1 の 3 番目の CPU コアのローカルとして機能しますが (例: 上記の図では、VM1 は CPU4 が割り当てられています)、同じ VM の別の CPU コアに対してはリモートメモリーとして機能します。
5.3. CPU ピニング
CPU ピニングは、指定のホスト内にある特定の物理 CPU 上で特定の仮想マシンの仮想 CPU を実行する機能のことです。vCPU ピニングでは、ベアメタルシステムへのピニングタスクと同様の利点が得られます。仮想マシンは、ホストのオペレーティングシステムのユーザー空間タスクとして実行されるので、ピニングすることでキャッシュの効率性が向上されます。
詳しい情報は、「Configure CPU Pinning with NUMA」を参照してください。
5.4. hugepage
物理メモリーは、ページと呼ばれる連続した一連のリージョンに分割されます。効率化を図るため、システムは、各メモリーバイトにアクセスするのではなく、ページ全体にアクセスしてメモリーを取得します。このような変換を実行するには、システムは、最新のページまたは頻繁に使用されるページの物理から仮想アドレスのマッピングが含まれるトランスレーションルックアサイドバッファー (TLB: Translation Lookaside Buffers) をチェックします。検索したマッピングが TLB にない場合には、プロセッサーは全ページテーブルで同じ処理を反復して、アドレスマッピングを判断する必要があるため、パフォーマンスペナルティーの原因となります。そのため、対象のプロセスがなるべく TLB ミスを回避できるように TLB を最適化することが推奨されます。
x86 システムの一般的なページサイズは 4KB で、他にこれよりもページサイズが大きいものもあります。ページサイズが大きいと、全体的なページ数が少なくなるので、TLB に仮想から物理アドレスの変換を保存可能なシステムメモリー量が増えることになります。その結果、TLB ミスの可能性が低くなり、パフォーマンスが向上します。ページサイズが大きいと、プロセスはページに割り当てる必要があため、メモリーを無駄にする可能性が高くなりますが、すべてのメモリーが必要となることはあまりありません。そのため、ページサイズを選択する際には、より大きいページを使用してアクセス時間を早くするか、より小さいページを使用して最大限にメモリーが使用されるようにするかで、トレードオフが生じます。