
Red Hat Training
A Red Hat training course is available for Red Hat OpenStack Platform
第4章 NUMA ノードを使用する CPU ピニングの設定
本章では、NUMA トポロジーのサポートと、同技術に対応したシステム上における OpenStack 環境の設定について説明します。この構成では、仮想マシンを専用の CPU コアに固定化 (ピニング) することにより、よりスマートなスケジューリングが可能となり、ゲストのパフォーマンスが向上します。
NUMA についての予備知識は、「What is NUMA and how does it work on Linux ?」の記事に記載されています。
以下の図では、2 つのノードからなる NUMA システムの例と、CPU コアとメモリーページを利用可能にする方法の例が提供されています。
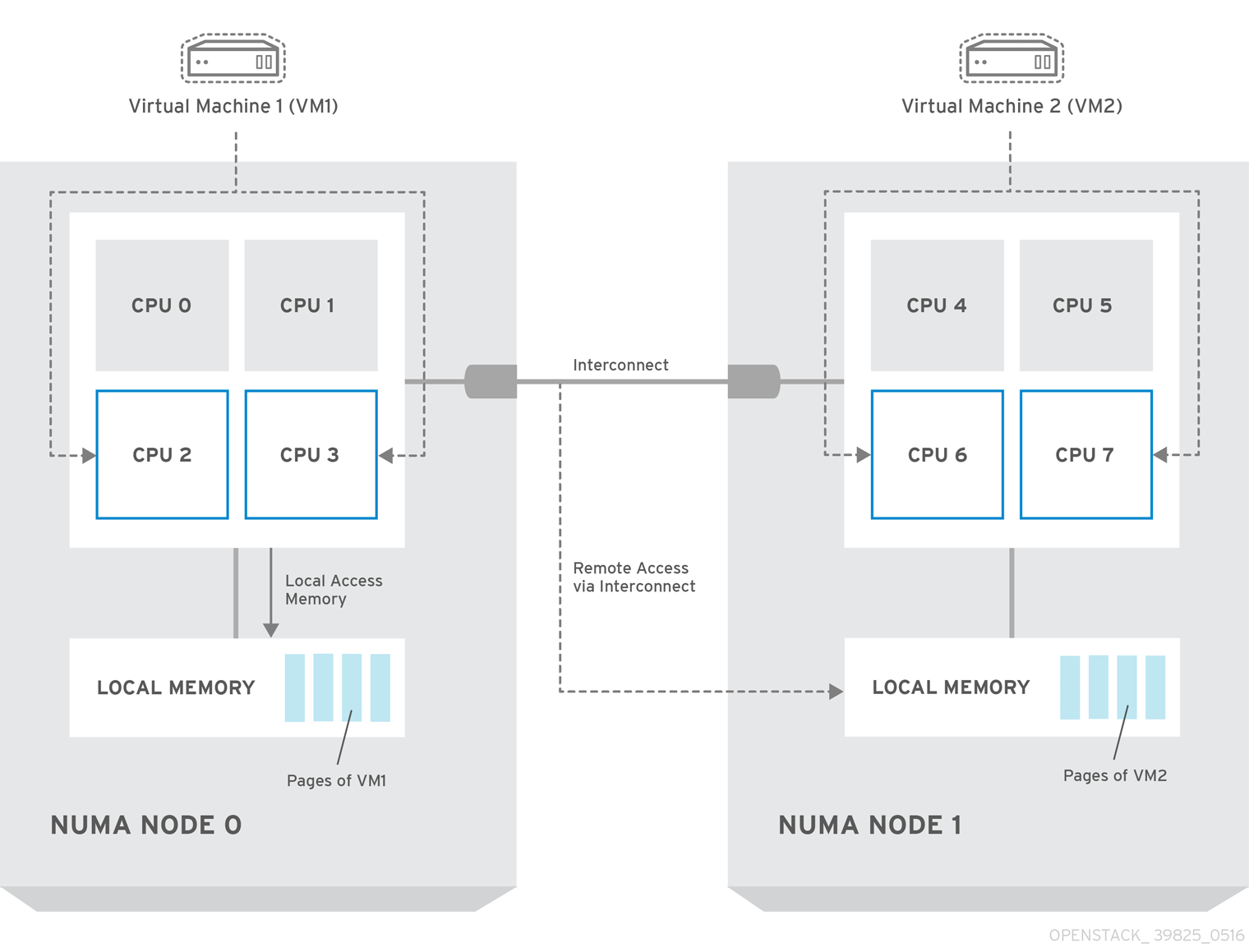
Interconnect 経由で利用可能なリモートのメモリーには、NUMA ノード 0 からの VM 1 に NUMA ノード 1 の CPU コアがある場合 のみ アクセスされます。このような場合には、NUMA ノード 1 のメモリーは、VM 1 の 3 番目の CPU コアのローカルとして機能しますが (例: 上記の図では、VM1 は CPU4 が割り当てられています)、同じ VM の別の CPU コアに対してはリモートメモリーとして機能します。
libvirt での NUMA のチューニングについての詳しい情報は、『仮想化のチューニングと最適化ガイド』を参照してください。
現在、CPU ピニングを使用するように設定されているインスタンスは移行できません。この問題に関する詳しい情報は、「Instance migration fails when using cpu-pinning from a numa-cell and flavor-property "hw:cpu_policy=dedicated"」のソリューションを参照してください。
4.1. コンピュートノードの設定
具体的な設定は、お使いのホストシステムの NUMA トポロジーによって異なりますが、全 NUMA ノードにわたって、CPU コアの一部をホストのプロセス用に確保し、それ以外の CPU コアにゲスト仮想マシンインスタンスを処理させるるようにする必要があります。たとえば、2 つの NUMA ノード全体に 8 つの CPU コアを均等に分散させる場合には、そのレイアウトは以下の表に示したようになります。
表4.1 NUMA トポロジーの例
|
ノード 0 |
ノード 1 | |||
|
ホストのプロセス |
コア 0 |
コア 1 |
コア 4 |
コア 5 |
|
ゲストのプロセス |
コア 2 |
コア 3 |
コア 6 |
コア 7 |
ホストのプロセス用に確保するコア数は、標準的な作業負荷がかかった状態におけるホストのパフォーマンスを観察した上で決定する必要があります。
コンピュートノードの設定は、以下の手順に従って行います。
/etc/nova/nova.confファイルのvcpu_pin_setオプションに、ゲストのプロセス用に確保する CPU コアの一覧を設定します。上記の例を使用する場合、設定は以下のようになります。vcpu_pin_set=2,3,6,7
vcpu_pin_setオプションを設定すると、以下のようなcpuset属性が libvirt の XML 設定ファイルにも追加されます。<vcpu placement='static' cpuset='2-3,6-7'>1</vcpu>
これにより、ゲストの仮想 CPU は一覧に設定されている物理 CPU コアに固定され、スケジューラーにはそれらのコアだけが見えるようになります。
同じファイルの
reserved_host_memory_mbオプションに、ホストのプロセス用に確保するメモリー容量を指定します。512 MB を確保する場合には、設定は以下のようになります。reserved_host_memory_mb=512
以下のコマンドを実行して、コンピュートノードで Compute サービスを再起動します。
systemctl restart openstack-nova-compute.service
システムのブート設定に
isolcpusの引数を追加して、ホストのプロセスがゲストプロセス用に確保されている CPU コアで実行されないようにします。この引数のパラメーターとして、ゲストプロセスに確保されている CPU コアの一覧を使用します。上記の例のトポロジーを使用する場合には、以下のようなコマンドを実行します。grubby --update-kernel=ALL --args="isolcpus=2,3,6,7"
注記cpusetオプションをisolcpusカーネル引数と共に使用することにより、下層のコンピュートノードは、対応する物理 CPU を自らは使用しないようになります。物理 CPU はインスタンス専用となります。ブートレコードを更新して、変更を有効にします。
grub2-install /dev/devicedevice は、ブートレーコードが含まれているデバイスの名前に置き換えます。通常は、sda です。
- システムを再起動します。
4.2. スケジューラーの設定
OpenStack Compute Scheduler を実行している各システムの
/etc/nova/nova.confファイルを編集します。scheduler_default_filtersオプションを確認し、コメントアウトされている場合には、コメント解除して、フィルターのリストにAggregateInstanceExtraSpecFilterとNUMATopologyFilterを追加します。行全体は以下のようになります。scheduler_default_filters=RetryFilter,AvailabilityZoneFilter,RamFilter, ComputeFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,CoreFilter, NUMATopologyFilter,AggregateInstanceExtraSpecsFilter
openstack-nova-scheduler サービスを再起動します。
systemctl restart openstack-nova-scheduler.service
4.3. アグリゲートとフレーバーの設定
システム上で Compute のコマンドラインインターフェースを使用して以下の手順を実行して、OpenStack 環境で、特定のリソースにピニングされた仮想マシンインスタンスを実行するための準備を行います。
adminの認証情報を読み込みます。source ~/keystonerc_admin
ピニング要求を受信するホスト用にアグリゲートを作成します。
nova aggregate-create namename は performance や cpu_pinning などの適切な名前に置き換えます。
アグリゲートのメタデータを編集して、ピニングを有効化します。
nova aggregate-set-metadata 1 pinned=trueこのコマンドで、数字の 1 は、前のステップで作成したアグリゲートの ID に置き換えます。
その他のホスト用のアグリゲートを作成します。
nova aggregate-create namename は、適切な名前 (例: normal) に置き換えます。
このアグリゲートのメタデータを編集します。
nova aggregate-set-metadata 2 pinned=falseこのコマンドでは、数字の 2 を使用しています。これは、最初のアグリゲートの ID 1 の後で作成されたアグリゲートの ID を指定するためです。
既存のフレーバーのスペックを以下のように変更します。
for i in $(nova flavor-list | cut -f 2 -d ' ' | grep -o '[0-9]*'); do nova flavor-key $i set "aggregate_instance_extra_specs:pinned"="false"; done
ピニング要求を受信するホスト用にフレーバーを作成します。
nova flavor-create name ID RAM disk vCPUs
name は適切な名前 (例: m1.small.performance、pinned.small など)、ID は新規フレーバーの識別子 (標準のフレーバーが 5 つある場合には
6、novaが UUID を生成するようにするにはautoを指定)、RAM は指定するメモリー容量 (MB 単位) 、disk は指定するディスク容量 (GB 単位) 、vCPUs は確保する仮想 CPU 数に置き換えます。このフレーバーの
hw:cpu_policyのスペックは、dedicatedに指定して、CPU ピニングを有効化するための専用のリソースを必要とするように設定し、hw:cpu_thread_policyの仕様をrequireに指定して、スレッドシブリングに各 vCPU を配置します。nova flavor-key ID set hw:cpu_policy=dedicated nova flavor-key ID set hw:cpu_thread_policy=require
ID は、前のステップで作成したフレーバーの ID に置き換えます。
注記ホストに SMT アーキテクチャーがない場合や、スレッドシブリングに空きのある CPU コアが十分にない場合には、スケジューリングが失敗します。このような動作が望ましくない場合や、単にホストが SMT アーキテクチャーを備えていない場合には、
hw:cpu_thread_policyの仕様を使わないようにするか、requireの代わりにpreferに設定してください。デフォルトのpreferポリシーにより、スレッドシブリングが利用可能な場合には、必ず使用されます。aggregate_instance_extra_specs:pinnedのスペックは true に指定して、このフレーバーをベースとするインスタンスが、アグリゲートのメタデータ内のこのスペックを使用するように設定します。nova flavor-key ID set aggregate_instance_extra_specs:pinned=trueこの場合にも、ID をフレーバーの ID に置き換えます。
新規アグリゲートにホストを追加します。
nova aggregate-add-host ID_1 host_1
ID_1 は最初の (「パフォーマンス」/「ピニング」用) アグリゲートの ID に、host_1 はアグリゲートに追加するホストのホスト名に置き換えます。
nova aggregate-add-host ID_2 host_2
ID_2 は 2 番目の ID (「通常」の) アグリゲートの ID に、host_2 はアグリゲートに追加するホストのホスト名に置き換えます。
これで新規フレーバーを使用してインスタンスをブートできるようになりました。
nova boot --image image --flavor flavor server_name
image は保存した仮想マシンイメージの名前に (nova image-list を参照)、flavor はフレーバー名に (m1.small.performance、pinned.small、または使用したその他の名前)、 server_name は新規サーバーの名前に置き換えます。
新規サーバーが正しく配置されたことを確認するには、以下のコマンドを実行して、その出力で OS-EXT-SRV-ATTR:hypervisor_hostname の箇所をチェックします。
nova show server_name