
ストレージリソースの管理および割り当て
スナップショットおよびクローンを含む、OpenShift Data Foundation のコアサービスおよびホスト型アプリケーションにストレージを割り当てる方法の手順
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ を参照してください。
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに対するご意見をお聞かせください。ドキュメントの改善点があれば、ぜひお知らせください。フィードバックをお寄せいただくには、以下をご確認ください。
特定の部分についての簡単なコメントをお寄せいただく場合は、以下をご確認ください。
- ドキュメントの表示が Multi-page HTML 形式になっていていることを確認してください。ドキュメントの右上隅に Feedback ボタンがあることを確認してください。
- マウスカーソルを使用して、コメントを追加するテキストの部分を強調表示します。
- 強調表示されたテキストの下に表示される Add Feedback ポップアップをクリックします。
- 表示される指示に従ってください。
より詳細なフィードバックをお寄せいただく場合は、Bugzilla のチケットを作成してください。
- Bugzilla の Web サイトに移動します。
- Component セクションで、documentation を選択します。
- Description フィールドに、ドキュメントの改善に向けたご提案を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- Submit Bug をクリックします。
第1章 概要
本書では、ストレージを作成し、設定し、Red Hat OpenShift Data Foundation のコアサービスまたはホスト型アプリケーションに割り当てる方法について説明します。
- 2章ストレージクラス カスタムのストレージクラスを作成する方法を説明します。
- 3章ブロックプール ブロックプールの作成、更新、および削除方法に関する情報を提供します。
- 4章OpenShift Container Platform サービスのストレージの設定 コアとなる OpenShift Container Platform サービスに OpenShift Data Foundation を使用する方法を説明します。
- 5章OpenShift Data Foundation を使用した OpenShift Container Platform アプリケーションのサポート OpenShift Data Foundation を使用するように OpenShift Container Platform アプリケーションを設定する方法についての情報を提供します。
- 既存の外部の OpenShift Data Foundation クラスターへのファイルおよびオブジェクトストレージの追加
- 7章Red Hat OpenShift Data Foundation に専用のワーカーノードを使用する方法 Red Hat OpenShift Data Foundation に専用のワーカーノードを使用する方法についての情報を提供します。
- 8章Persistent Volume Claim (永続ボリューム要求、PVC) の管理 Persistent Volume Claim (永続ボリューム要求、PVC) の要求の管理とそれらの要求への対応の自動化に関する情報を提供します。
- 9章ターゲットボリュームのスペースを再利用 では、実際に使用可能なストレージスペースを回収する方法を説明しています。
- 10章ボリュームスナップショット ボリュームスナップショットを作成し、復元し、削除する方法を説明します。
- 11章ボリュームのクローン作成 ボリュームのクローンを作成する方法を説明します。
- 12章Container Storage Interface (CSI) コンポーネントの配置の管理 容認を設定してノードでコンテナーストレージのインターフェイスコンポーネントを起動する方法についての情報を提供します。
第2章 ストレージクラス
OpenShift Data Foundation Operator は、使用されるプラットフォームに応じてデフォルトのストレージクラスをインストールします。このデフォルトストレージクラスは Operator によって所有され、制御されるため、削除したり変更したりすることはできません。ただし、カスタムストレージクラスを作成して他のストレージリソースを使用したり、アプリケーションに異なる動作を提供したりできます。
カスタムストレージクラスは、外部モード の OpenShift Data Foundation クラスターではサポートされません。
2.1. ストレージクラスおよびプールの作成
既存のプールを使用してストレージクラスを作成するか、ストレージクラスの作成中にストレージクラスの新規プールを作成できます。
前提条件
-
OpenShift Container Platform の Web コンソールにログインしており、OpenShift Data Foundation クラスターが
Ready状態にあることを確認します。
手順
- Storage → StorageClasses をクリックします。
- Create Storage Class をクリックします。
- ストレージクラスの Name および Description を入力します。
Reclaim Policy は、デフォルトオプションとして
Deleteに設定されています。この設定を使用します。回収ポリシーをストレージクラスで
Retainに変更すると、永続ボリューム要求 (PVC) を削除した後でも、永続ボリューム (PV) はReleased状態のままになります。ボリュームバインディングモードは、デフォルトオプションとして
WaitForConsumerに設定されています。Immediateオプションを選択すると、PVC の作成時に PV がすぐに作成されます。- 永続ボリュームをプロビジョニングするために使用されるプラグインである RBD Provisioner を選択します。
一覧から既存の ストレージプール を選択するか、新規プールを作成します。
注記双方向レプリケーションデータ保護ポリシーの使用は、デフォルトプールではサポートされていません。ただし、追加のプールを作成する場合は、双方向レプリケーションを使用できます。
- 新規プールの作成
- Create New Pool をクリックします。
- Pool name を入力します。
- Data Protection Policy として 2-way-Replication または 3-way-Replication を選択します。
データを圧縮する必要がある場合は、Enable compression を選択します。
圧縮を有効にするとアプリケーションのパフォーマンスに影響がある可能性があり、書き込まれるデータがすでに圧縮または暗号化されている場合は効果的ではない可能性があります。圧縮を有効にする前に書き込まれたデータは圧縮されません。
- Create をクリックして新規ストレージプールを作成します。
- プールの作成後に Finish をクリックします。
- オプション:Enable Encryption チェックボックスを選択します。
- Create をクリックしてストレージクラスを作成します。
2.2. 永続ボリュームの暗号化のためのストレージクラス
永続ボリューム (PV) 暗号化は、テナント (アプリケーション) の分離および機密性を保証します。PV 暗号化を使用する前に、PV 暗号化のストレージクラスを作成する必要があります。永続ボリュームの暗号化は RBD PV の場合にのみ利用できます。
OpenShift Data Foundation は、HashiCorp Vault での暗号化パスフレーズの保存をサポートします。永続的なボリュームの暗号化のために、外部の鍵管理システム (KMS) を使用して、暗号化対応のストレージクラスを作成することができます。ストレージクラスを作成する前に、KMS へのアクセスを設定する必要があります。
PV 暗号化には、有効な Red Hat OpenShift Data Foundation Advanced サブスクリプションが必要です。詳細については、OpenShift Data Foundation サブスクリプションに関するナレッジベースの記事 を参照してください。
2.2.1. Key Management System (KMS) のアクセス設定
ユースケースに基づいて、次のいずれかの方法を使用して KMS へのアクセスを設定する必要があります。
-
vaulttokensの使用: ユーザーはトークンを使用して認証できるようになります。 -
vaulttenantsa(テクノロジープレビュー) の使用: ユーザーはserviceaccountsを使用してVaultで認証できるようになります。
vaulttenantsa を使用した KMS へのアクセスはテクノロジープレビュー機能です。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。これらの機能は、近々発表予定の製品機能をリリースに先駆けてご提供することにより、お客様は機能性をテストし、開発プロセス中にフィードバックをお寄せいただくことができます。
詳細は、テクノロジープレビュー機能のサポート範囲 を参照してください。
2.2.1.1. vaulttokens を使用した KMS へのアクセス設定
前提条件
-
OpenShift Data Foundation クラスターは
Ready状態である。 外部の鍵管理システム (KMS) で、以下を実行します。
-
トークンのあるポリシーが存在し、
Vaultのキー値のバックエンドパスが有効化されていることを確認します。 -
vaulttokensサーバーで署名済みの証明書を使用していることを確認します。
-
トークンのあるポリシーが存在し、
手順
テナントの namespace にシークレットを作成します。
- OpenShift Container Platform Web コンソールで、Workloads → Secrets に移動します。
- Create → Key/value secret をクリックします。
-
Secret Name を
ceph-csi-kms-tokenとして入力します。 -
Key を
tokenとして入力します。 Value を入力します。
これは Vault のトークンです。Browse をクリックしてトークンが含まれるファイルを選択し、アップロードするか、テキストボックスにトークンを直接入力します。
- Create をクリックします。
トークンは、ceph-csi-kms-token を使用するすべての暗号化された PVC が削除された後にのみ削除できます。
2.2.1.2. vaulttenantsa を使用した KMS へのアクセスの設定
前提条件
-
OpenShift Data Foundation クラスターは
Ready状態である。 外部の鍵管理システム (KMS) で、以下を実行します。
- ポリシーが存在し、Vault のキー値のバックエンドパスが有効になっていることを確認します。
- Vault サーバーで署名済みの証明書を使用していることを確認します。
以下のようにテナント namespace に以下の serviceaccount を作成します。
$ cat <<EOF | oc create -f - apiVersion: v1 kind: ServiceAccount metadata: name: ceph-csi-vault-sa EOF
手順
OpenShift Data Foundation が Vault で認証して使用を開始する前に、Kubernetes 認証方法を設定する必要があります。以下の手順では、OpenShift Data Foundation が Vault で認証できるように、serviceAccount、ClusterRole、および ClusterRoleBinding を作成し、設定します。
以下の YAML を Openshift クラスターに適用します。
apiVersion: v1 kind: ServiceAccount metadata: name: rbd-csi-vault-token-review --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-csi-vault-token-review rules: - apiGroups: ["authentication.k8s.io"] resources: ["tokenreviews"] verbs: ["create", "get", "list"] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: rbd-csi-vault-token-review subjects: - kind: ServiceAccount name: rbd-csi-vault-token-review namespace: openshift-storage roleRef: kind: ClusterRole name: rbd-csi-vault-token-review apiGroup: rbac.authorization.k8s.ioOpenShift Container Platform のバージョンに応じて、以下のいずれかを実行します。
OpenShift Container Platform 4.10 の場合:
上記で作成された serviceaccount (SA) に関連付けられたシークレット名を特定します。
$ VAULT_SA_SECRET_NAME=$(oc -n openshift-storage get sa <SA_NAME> -o jsonpath="{.secrets[]['name']}") | grep -o "[^[:space:]]-token-[^[:space:]]*"以下に例を示します。
$ VAULT_SA_SECRET_NAME=$(oc -n openshift-storage get sa rbd-csi-vault-token-review -o jsonpath="{.secrets[]['name']}" | grep -o "[^[:space:]]-token-[^[:space:]]*")
OpenShift Container Platform 4.11 の場合:
serviceaccount トークンおよび CA 証明書のシークレットを作成します。
$ cat <<EOF | oc create -f - apiVersion: v1 kind: Secret metadata: name: rbd-csi-vault-token-review-token namespace: openshift-storage annotations: kubernetes.io/service-account.name: "rbd-csi-vault-token-review" type: kubernetes.io/service-account-token data: {} EOF$ VAULT_SA_SECRET_NAME=rbd-csi-vault-token-review-token
シークレットからトークンと CA 証明書を取得します。
$ SA_JWT_TOKEN=$(oc -n openshift-storage get secret "$VAULT_SA_SECRET_NAME" -o jsonpath="{.data.token}" | base64 --decode; echo) $ SA_CA_CRT=$(oc -n openshift-storage get secret "$VAULT_SA_SECRET_NAME" -o jsonpath="{.data['ca\.crt']}" | base64 --decode; echo)OpenShift クラスターエンドポイントを取得します。
$ OCP_HOST=$(oc config view --minify --flatten -o jsonpath="{.clusters[0].cluster.server}")前の手順で収集した情報を使用して、以下のように Vault で Kubernetes 認証方法を設定します。
$ vault auth enable kubernetes $ vault write auth/kubernetes/config \ token_reviewer_jwt="$SA_JWT_TOKEN" \ kubernetes_host="$OCP_HOST" \ kubernetes_ca_cert="$SA_CA_CRT"テナント namespace の Vault にロールを作成します。
$ vault write "auth/kubernetes/role/csi-kubernetes" bound_service_account_names="ceph-csi-vault-sa" bound_service_account_namespaces=<tenant_namespace> policies=<policy_name_in_vault>
csi-kubernetesは、OpenShift Data Foundation が Vault を検索するデフォルトのロール名です。Openshift Data Foundation クラスターのテナント namespace のデフォルトのサービスアカウント名はceph-csi-vault-saです。これらのデフォルト値は、テナント namespace に ConfigMap を作成して上書きできます。デフォルト名の上書きに関する詳細は、テナント ConfigMap を使用した Vault 接続の詳細の上書き を参照してください。
YAML 例
PV 暗号化の
vaulttenantsaメソッドを使用する storageclass を作成するには、既存の ConfigMap を編集するか、Vault との接続を確立するために必要なすべての情報を保持するcsi-kms-connection-detailsという名前の ConfigMap を作成する必要があります。以下の yaml のサンプルを使用して、
csi-kms-connection-detailConfigMap を更新または作成できます。apiVersion: v1 data: vault-tenant-sa: |- { "encryptionKMSType": "vaulttenantsa", "vaultAddress": "<https://hostname_or_ip_of_vault_server:port>", "vaultTLSServerName": "<vault TLS server name>", "vaultAuthPath": "/v1/auth/kubernetes/login", "vaultAuthNamespace": "<vault auth namespace name>" "vaultNamespace": "<vault namespace name>", "vaultBackendPath": "<vault backend path name>", "vaultCAFromSecret": "<secret containing CA cert>", "vaultClientCertFromSecret": "<secret containing client cert>", "vaultClientCertKeyFromSecret": "<secret containing client private key>", "tenantSAName": "<service account name in the tenant namespace>" } metadata: name: csi-kms-connection-detailsencryptionKMSTypeVault での認証にサービスアカウントを使用するには、
vaulttenantsaに設定します。vaultAddressポート番号を持つ vault サーバーのホスト名または IP アドレス。
vaultTLSServerName(オプション)vault の TLS サーバー名
vaultAuthPath(オプション)Vault で kubernetes 認証メソッドが有効なパス。デフォルトのパスは
kubernetesです。auth メソッドがkubernetes以外のパスで有効になっている場合は、この変数を"/v1/auth/<path>/login"として設定する必要があります。vaultAuthNamespace(オプション)kubernetes 認証メソッドが有効な Vault namespace。
vaultNamespace(オプション) キーの保存に使用されるバックエンドパスが存在する Vault namespace
vaultBackendPath暗号化キーが保存される Vault のバックエンドパス
vaultCAFromSecretVault の CA 証明書が含まれる OpenShift Data Foundation クラスターのシークレット
vaultClientCertFromSecretVault のクライアント証明書を含む OpenShift Data Foundation クラスターのシークレット
vaultClientCertKeyFromSecretVault のクライアントプライベートキーが含まれる OpenShift Data Foundation クラスターのシークレット
tenantSAName(オプション) テナント namespace のサービスアカウント名。デフォルト値は
ceph-csi-vault-saです。別の名前を使用する場合は、この変数を適切に設定する必要があります。
2.2.2. 永続ボリュームの暗号化のためのストレージクラスの作成
前提条件
ユースケースに基づいて、以下のいずれかの KMS へのアクセスを確実に設定する必要があります。
-
vaulttokensの使用:Vaulttokensを使用した KMS へのアクセスの設定 の説明に従って、アクセスを設定してください。 -
vaulttenantsaの使用 (テクノロジープレビュー):vaulttenantsaを使用した KMS へのアクセスの設定 の説明に従って、アクセスを設定してください。
手順
- OpenShift Web コンソールで、Storage → Storage Classes に移動します。
- Create Storage Class をクリックします。
- ストレージクラスの Name および Description を入力します。
- Reclaim Policy について Delete または Retain のいずれかを選択します。デフォルトでは、Delete が選択されます。
- Immediate または WaitForFirstConsumer を Volume binding モード として選択します。WaitForConsumer はデフォルトオプションとして設定されます。
-
永続ボリュームをプロビジョニングするために使用されるプラグインである RBD Provisioner
openshift-storage.rbd.csi.ceph.comを選択します。 - ボリュームデータが保存される Storage Pool をリストから選択するか、新規プールを作成します。
Enable encryption チェックボックスを選択します。KMS 接続の詳細を設定するオプションは 2 つあります。
-
Select existing KMS connection: ドロップダウンリストから既存の KMS 接続を選択します。このリストは、
csi-kms-connection-detailsConfigMap で利用可能な接続の詳細から設定されます。 Create new KMS connection:これは
vaulttokensにのみ適用されます。- Key Management Service Provider はデフォルトで Vault に設定されます。
- Vault サーバーの一意の 接続名、ホスト アドレス、ポート番号および トークン を入力します。
Advanced Settings をデプロイメントして、
Vault設定に基づいて追加の設定および証明書の詳細を入力します。- OpenShift Data Foundation 専用かつ特有のキーと値のシークレットパスを Backend Path に入力します。
- オプション:TLS Server Name および Vault Enterprise Namespace を入力します。
- それぞれの PEM でエンコードされた証明書ファイルをアップロードし、CA 証明書、クライアント証明書、および クライアントの秘密鍵 を提供します。
- Save をクリックします。
- Save をクリックします。
-
Select existing KMS connection: ドロップダウンリストから既存の KMS 接続を選択します。このリストは、
- Create をクリックします。
HashiCorp Vault 設定により、バックエンドパスによって使用されるキー/値 (KV) シークレットエンジン API バージョンの自動検出が許可されない場合は、ConfigMap を編集して
vaultBackendパラメーターを追加します。注記vaultBackendは、バックエンドパスに関連付けられた KV シークレットエンジン API のバージョンを指定するために configmap に追加されるオプションのパラメーターです。値がバックエンドパスに設定されている KV シークレットエンジン API バージョンと一致していることを確認します。一致しない場合には、永続ボリューム要求 (PVC) の作成時に失敗する可能性があります。新規に作成されたストレージクラスによって使用されている encryptionKMSID を特定します。
- OpenShift Web コンソールで、Storage → Storage Classes に移動します。
- Storage class 名 → YAML タブをクリックします。
ストレージクラスによって使用されている encryptionKMSID を取得します。
以下に例を示します。
encryptionKMSID: 1-vault
- OpenShift Web コンソールで Workloads → ConfigMaps に移動します。
- KMS 接続の詳細を表示するには、csi-kms-connection-details をクリックします。
ConfigMap を編集します。
- アクションメニュー (⋮) → Edit ConfigMap をクリックします。
以前に特定した
encryptionKMSIDに設定されるバックエンドに応じて、vaultBackendパラメーターを追加します。KV シークレットエンジン API バージョン 1 の場合は
kvを、KV シークレットエンジン API バージョン 2 の場合はkv-v2を、それぞれ割り当てることができます。以下に例を示します。
kind: ConfigMap apiVersion: v1 metadata: name: csi-kms-connection-details [...] data: 1-vault: |- { "encryptionKMSType": "vaulttokens", "kmsServiceName": "1-vault", [...] "vaultBackend": "kv-v2" } 2-vault: |- { "encryptionKMSType": "vaulttenantsa", [...] "vaultBackend": "kv" }- 保存をクリックします。
次のステップ
ストレージクラスを使用して、暗号化された永続ボリュームを作成できます。詳細は、永続ボリューム要求の管理 を参照してください。
重要Red Hat はテクノロジーパートナーと連携して、本書をお客様へのサービスとして提供します。ただし、Red Hat では、HashiCorp 製品のサポートを提供していません。この製品に関するテクニカルサポートについては、HashiCorp にお問い合わせください。
2.2.2.1. テナント ConfigMap を使用した Vault 接続の詳細の上書き
Vault 接続の詳細は、openshift-storage namespace の csi-kms-connection-details ConfigMap で設定された値とは異なる設定オプションを使用して、OpenShift namespace に ConfigMap を作成することにより、テナントごとに再設定できます。ConfigMap はテナント namespace に配置する必要があります。テナント namespace の ConfigMap の値は、その namespace で作成される暗号化された永続ボリュームの csi-kms-connection-details ConfigMap に設定された値を上書きします。
手順
- テナント namespace にあることを確認します。
- Workloads → ConfigMaps をクリックします。
- Create ConfigMap をクリックします。
yaml ファイルの例を以下に示します。指定のテナント namespace について過剰に使用される値は、以下に示すように
dataセクションで指定できます。--- apiVersion: v1 kind: ConfigMap metadata: name: ceph-csi-kms-config data: vaultAddress: "<vault_address:port>" vaultBackendPath: "<backend_path>" vaultTLSServerName: "<vault_tls_server_name>" vaultNamespace: "<vault_namespace>"
- yaml を編集したら、Create をクリックします。
第3章 ブロックプール
OpenShift Data Foundation Operator は、使用されるプラットフォームに応じてデフォルトのストレージプールのセットをインストールします。これらのデフォルトストレージプールは Operator によって所有され、制御されるため、削除したり変更したりすることはできません。OpenShift Container Platform を使用して、以下の機能を提供するストレージクラスにマップする複数のカスタムストレージプールを作成できます。
- それぞれに高可用性のあるアプリケーションを有効にして、2 つのレプリカを持つ永続ボリュームを使用できるようにします。これにより、アプリケーションのパフォーマンスが向上する可能性があります。
- 圧縮が有効にされているストレージクラスを使用して永続ボリューム要求の領域を節約します。
外部モード の OpenShift Data Foundation クラスターでは、複数のブロックプールはサポートされません。
3.1. ブロックプールの作成
前提条件
- 管理者として OpenShift Container Platform Web コンソールにログインしている必要があります。
手順
- Storage → Data Foundation をクリックします。
- Storage systems タブでストレージシステムを選択し、BlockPools タブをクリックします。
- Create Block Pool をクリックします。
Pool name を入力します。
注記双方向レプリケーションデータ保護ポリシーの使用は、デフォルトプールではサポートされていません。ただし、追加のプールを作成する場合は、双方向レプリケーションを使用できます。
-
Data protection policy を
2-way Replicationまたは3-way Replicationのいずれかとして選択します。 - Volume Type を選択します。
オプション:データを圧縮する必要がある場合は、Enable compression チェックボックスを選択します。
圧縮を有効にするとアプリケーションのパフォーマンスに影響がある可能性があり、書き込まれるデータがすでに圧縮または暗号化されている場合は効果的ではない可能性があります。圧縮を有効にする前に書き込まれたデータは圧縮されません。
- Create をクリックします。
3.2. 既存プールの更新
前提条件
- 管理者として OpenShift Container Platform Web コンソールにログインしている必要があります。
手順
- Storage → Data Foundation をクリックします。
- Storage systems タブでストレージシステムを選択し、BlockPools をクリックします。
- 更新するプールの末尾でアクションメニュー (⋮) をクリックします。
- Edit Block Pool をクリックします。
以下のようにフォームの詳細を変更します。
注記双方向レプリケーションデータ保護ポリシーの使用は、デフォルトプールではサポートされていません。ただし、追加のプールを作成する場合は、双方向レプリケーションを使用できます。
- Data protection policy を 2-way Replication または 3-way Replication のいずれかに変更します。
圧縮オプションを有効または無効にします。
圧縮を有効にするとアプリケーションのパフォーマンスに影響がある可能性があり、書き込まれるデータがすでに圧縮または暗号化されている場合は効果的ではない可能性があります。圧縮を有効にする前に書き込まれたデータは圧縮されません。
- Save をクリックします。
3.3. プールの削除
以下の手順を使用して、OpenShift Data Foundation のプールを削除します。
前提条件
- 管理者として OpenShift Container Platform Web コンソールにログインしている必要があります。
手順
- .Storage → Data Foundation をクリックします。
- Storage systems タブでストレージシステムを選択し、BlockPools タブをクリックします。
- 削除するプールの末尾でアクションメニュー (⋮) をクリックします。
- Delete Block Pool をクリックします。
- Delete をクリックしてプールの削除を確認します。
プールが PVC にバインドされる場合、削除できません。このアクティビティーを実行する前に、すべてのリソースの割り当てを解除する必要があります。
第4章 OpenShift Container Platform サービスのストレージの設定
OpenShift Data Foundation を使用して、イメージレジストリー、モニタリング、およびロギングなどの OpenShift Container Platform サービスのストレージを提供できます。
これらのサービスのストレージを設定するプロセスは、OpenShift Data Foundation デプロイメントで使用されるインフラストラクチャーによって異なります。
これらのサービスに十分なストレージ容量があることを常に確認してください。これらの重要なサービスのストレージ領域が不足すると、クラスターは動作しなくなり、復元が非常に困難になります。
Red Hat は、これらのサービスのキュレーションおよび保持期間を短く設定することを推奨します。詳細は、OpenShift Container Platform ドキュメントのMonitoringの Configuring the Curator schedule と Modifying retention time for Prometheus metrics data を参照してください。
これらのサービスのストレージ領域が不足する場合は、Red Hat カスタマーサポートにお問い合わせください。
4.1. OpenShift Data Foundation を使用するためのイメージレジストリーの設定
OpenShift Container Platform は、クラスターで標準ワークロードとして実行される、組み込まれたコンテナーイメージレジストリーを提供します。通常、レジストリーはクラスター上にビルドされたイメージの公開ターゲットとして、またクラスター上で実行されるワークロードのイメージのソースとして使用されます。
このセクションの手順に従って、OpenShift Data Foundation をコンテナーイメージレジストリーのストレージとして設定します。AWS では、レジストリーのストレージを変更する必要はありません。ただし vSphere およびベアメタルプラットフォームの場合は、OpenShift Data Foundation 永続ボリュームに対してストレージを変更することが推奨されます。
このプロセスでは、データを既存イメージレジストリーから新規イメージレジストリーに移行しません。既存のレジストリーにコンテナーイメージがある場合、このプロセスを完了する前にレジストリーのバックアップを作成し、このプロセスの完了時にイメージを再登録します。
前提条件
- OpenShift Web コンソールへの管理者アクセスがある。
-
OpenShift Data Foundation Operator が
openshift-storagenamespace にインストールされ、実行されている。OpenShift Web Console で、Operators → Installed Operators をクリックしてインストールされた Operator を表示します。 -
イメージレジストリー Operator が
openshift-image-registrynamespace にインストールされ、実行されている。OpenShift Web コンソールで、Administration → Cluster Settings → Cluster Operators をクリックしてクラスター Operator を表示します。 -
プロビジョナー
openshift-storage.cephfs.csi.ceph.comを持つストレージクラスが利用可能である。OpenShift Web コンソールで、Storage → StorageClasses をクリックし、利用可能なストレージクラスを表示します。
手順
使用するイメージレジストリーの Persistent Volume Claim(永続ボリューム要求、PVC) を作成します。
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
-
Project を
openshift-image-registryに設定します。 Create Persistent Volume Claim をクリックします。
-
上記で取得した利用可能なストレージクラスリストから、プロビジョナー
openshift-storage.cephfs.csi.ceph.comで Storage Class を指定します。 -
Persistent Volume Claim(永続ボリューム要求、PVC) の Name を指定します (例:
ocs4registry)。 -
Shared Access (RWX)の Access Mode を指定します。 - 100 GB 以上の Size を指定します。
Create をクリックします。
新規 Persistent Volume Claim(永続ボリューム要求、PVC) のステータスが
Boundとしてリスト表示されるまで待機します。
-
上記で取得した利用可能なストレージクラスリストから、プロビジョナー
クラスターのイメージレジストリーを、新規の Persistent Volume Claim(永続ボリューム要求、PVC) を使用するように設定します。
- Administration → Custom Resource Definitions をクリックします。
-
imageregistry.operator.openshift.ioグループに関連付けられたConfigカスタムリソース定義をクリックします。 - Instances タブをクリックします。
- クラスターインスタンスの横にある Action メニュー (⋮) → Edit Config をクリックします。
イメージレジストリーの新規 Persistent Volume Claim(永続ボリューム要求、PVC) を追加します。
以下を
spec:の下に追加し、必要に応じて既存のstorage:セクションを置き換えます。storage: pvc: claim: <new-pvc-name>以下に例を示します。
storage: pvc: claim: ocs4registry- Save をクリックします。
新しい設定が使用されていることを確認します。
- Workloads → Pods をクリックします。
-
Project を
openshift-image-registryに設定します。 -
新規
image-registry-*Pod がRunningのステータスと共に表示され、以前のimage-registry-*Pod が終了していることを確認します。 -
新規の
image-registry-*Pod をクリックし、Pod の詳細を表示します。 -
Volumes までスクロールダウンし、
registry-storageボリュームに新規 Persistent Volume Claim (永続ボリューム要求、PVC) に一致する Type があることを確認します (例:ocs4registry)。
4.2. OpenShift Data Foundation を使用するためのモニタリングの設定
OpenShift Data Foundation は、Prometheus および Alert Manager で設定されるモニタリングスタックを提供します。
このセクションの手順に従って、OpenShift Data Foundation をモニタリングスタックのストレージとして設定します。
ストレージ領域が不足すると、モニタリングは機能しません。モニタリング用に十分なストレージ容量があることを常に確認します。
Red Hat は、このサービスの保持期間を短く設定することを推奨します。詳細は、OpenShift Container Platform ドキュメントのモニタリングガイドの Prometheus メトリクスデータの保持期間の変更 を参照してください。
前提条件
- OpenShift Web コンソールへの管理者アクセスがある。
-
OpenShift Data Foundation Operator が
openshift-storagenamespace にインストールされ、実行されている。OpenShift Web コンソールで、Operators → Installed Operators をクリックし、インストールされた Operator を表示します。 -
モニタリング Operator が
openshift-monitoringnamespace にインストールされ、実行されている。OpenShift Web コンソールで、Administration → Cluster Settings → Cluster Operators をクリックし、クラスター Operator を表示します。 -
プロビジョナー
openshift-storage.rbd.csi.ceph.comを持つストレージクラスが利用可能である。OpenShift Web コンソールで、Storage → StorageClasses をクリックし、利用可能なストレージクラスを表示します。
手順
- OpenShift Web コンソールで、Workloads → Config Maps に移動します。
-
Project ドロップダウンを
openshift-monitoringに設定します。 - Create Config Map をクリックします。
以下の例を使用して新規の
cluster-monitoring-configConfig Map を定義します。山括弧 (
<、>) 内の内容を独自の値に置き換えます (例:retention: 24hまたはstorage:40Gi)。storageClassName、をプロビジョナー
openshift-storage.rbd.csi.ceph.comを使用するstorageclassに置き換えます。以下の例では、storageclass の名前はocs-storagecluster-ceph-rbdです。cluster-monitoring-configConfig Map の例apiVersion: v1 kind: ConfigMap metadata: name: cluster-monitoring-config namespace: openshift-monitoring data: config.yaml: | prometheusK8s: retention: <time to retain monitoring files, e.g. 24h> volumeClaimTemplate: metadata: name: ocs-prometheus-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi> alertmanagerMain: volumeClaimTemplate: metadata: name: ocs-alertmanager-claim spec: storageClassName: ocs-storagecluster-ceph-rbd resources: requests: storage: <size of claim, e.g. 40Gi>- Create をクリックして、設定マップを保存し、作成します。
検証手順
Persistent Volume Claim (永続ボリューム要求、PVC) が Pod にバインドされていることを確認します。
- Storage → Persistent Volume Claims に移動します。
-
Project ドロップダウンを
openshift-monitoringに設定します。 5 つの Persistent Volume Claim(永続ボリューム要求、PVC) が
Bound(バインド) の状態で表示され、3 つのalertmanager-main-*Pod および 2 つのprometheus-k8s-*Pod に割り当てられていることを確認します。図4.1 作成済みのバインドされているストレージのモニタリング

新規の
alertmanager-main-*Pod がRunning状態で表示されることを確認します。- Workloads → Pods に移動します。
-
新規の
alertmanager-main-*Pod をクリックし、Pod の詳細を表示します。 Volumes にスクロールダウンし、ボリュームに新規 Persistent Volume Claim(永続ボリューム要求、PVC) のいずれかに一致する Type
ocs-alertmanager-claimがあることを確認します (例:ocs-alertmanager-claim-alertmanager-main-0)。図4.2
alertmanager-main-*Pod に割り当てられた Persistent Volume Claim(永続ボリューム要求、PVC)
新規
prometheus-k8s-*Pod がRunning状態で表示されることを確認します。-
新規
prometheus-k8s-*Pod をクリックし、Pod の詳細を表示します。 Volumes までスクロールダウンし、ボリュームに新規の Persistent Volume Claim (永続ボリューム要求、PVC) のいずれかに一致する Type
ocs-prometheus-claimがあることを確認します (例:ocs-prometheus-claim-prometheus-k8s-0)。図4.3
prometheus-k8s-*Pod に割り当てられた Persistent Volume Claim(永続ボリューム要求、PVC)
-
新規
4.3. オーバープロビジョニングレベルのポリシー制御 [テクノロジープレビュー]
オーバープロビジョニング制御は、特定のアプリケーション namespace に基づいて、ストレージクラスターから消費される Persistent Volume Claim(永続ボリューム要求、PVC) の量にクォータを定義できるようにするメカニズムです。
オーバープロビジョニング制御メカニズムを有効にすると、ストレージクラスターから消費される PVC をオーバープロビジョニングするのを防ぐことができます。Open Shift は、ClusterResourceQuota を使用して、クラスタースコープでの集約リソース消費を制限する制約を定義するための柔軟性を提供します。詳細については、OpenShift ClusterResourceQuota を参照してください。
オーバープロビジョニング制御を使用すると、ClusteResourceQuota が開始し、各ストレージクラスのストレージ容量制限を設定できます。容量制限の 80% が消費されると、アラームがトリガーされます。
オーバープロビジョニングレベルのポリシー制御はテクノロジープレビューです。テクノロジープレビュー機能は、Red Hat 製品のサービスレベルアグリーメント (SLA) の対象外であり、機能的に完全ではないことがあります。Red Hat は、実稼働環境でこれらを使用することを推奨していません。これらの機能は、近々発表予定の製品機能をリリースに先駆けてご提供することにより、お客様は機能性をテストし、開発プロセス中にフィードバックをお寄せいただくことができます。詳細は、Technology Preview Features Support Scope. を参照してください。
OpenShift Data Foundation のデプロイメントの詳細については、製品ドキュメント を参照し、プラットフォームに応じたデプロイメント手順を選択してください。
前提条件
- OpenShift Data Foundation クラスターが作成されていることを確認します。
手順
-
コマンドラインインターフェイスまたはユーザーインターフェイスのいずれかから
storageclusterをデプロイします。 アプリケーションの namespace にラベルを付けます。
apiVersion: v1 kind: Namespace metadata: name: <desired_name> labels: storagequota: <desired_label>- <desired_name>
-
アプリケーション namespace の名前を指定します (例:
quota-rbd)。 - <desired_label>
-
ストレージクォータのラベルを指定します (例:
storagequota1)。
storageclusterを編集して、ストレージクラスのクォータ制限を設定します。$ oc edit storagecluster -n openshift-storage <ocs_storagecluster_name>
- <ocs_storagecluster_name>
- ストレージクラスターの名前を指定します。
必要なハード制限を持つオーバープロビジョニング制御のエントリーを
StorageCluster.Specに追加します。apiVersion: ocs.openshift.io/v1 kind: StorageCluster spec: [...] overprovisionControl: - capacity: <desired_quota_limit> storageClassName: <storage_class_name> quotaName: <desired_quota_name> selector: labels: matchLabels: storagequota: <desired_label> [...]- <desired_quota_limit>
-
ストレージクラスに必要なクォータ制限を指定します (例:
27Ti)。 - <storage_class_name>
-
クォータ制限を設定するストレージクラスの名前を指定します (例:
ocs-storagecluster-ceph-rbd)。 - <desired_quota_name>
-
ストレージクォータの名前を指定します (例:
quota1)。 - <desired_label>
-
ストレージクォータのラベルを指定します (例:
storagequota1)。
-
変更された
storageclusterを保存します。 clusterresourcequotaが定義されていることを確認します。注記前の手順で定義した
quotaName(たとえば、quota1) を持つclusterresourcequotaを期待します。$ oc get clusterresourcequota -A $ oc describe clusterresourcequota -A
4.4. OpenShift Data Foundation のクラスターロギング
クラスターロギングをデプロイして、各種の OpenShift Container Platform サービスについてのログを集計できます。クラスターロギングのデプロイ方法は、クラスターロギングのデプロイ を参照してください。
OpenShift Container Platform の初回のデプロイメントでは、OpenShift Data Foundation はデフォルトで設定されず、OpenShift Container Platform クラスターはノードから利用可能なデフォルトストレージのみに依存します。OpenShift ロギング (ElasticSearch) のデフォルト設定を OpenShift Data Foundation で対応されるように編集し、OpenShift Data Foundation でサポートされるロギング (Elasticsearch) を設定できます。
これらのサービスに十分なストレージ容量があることを常に確認してください。これらの重要なサービスのストレージ領域が不足すると、ロギングアプリケーションは動作しなくなり、復元が非常に困難になります。
Red Hat は、これらのサービスのキュレーションおよび保持期間を短く設定することを推奨します。詳細は、OpenShift Container Platform ドキュメントの クラスターロギングキュレーター を参照してください。
これらのサービスのストレージ領域が不足している場合は、Red Hat カスタマーポータルにお問い合わせください。
4.4.1. 永続ストレージの設定
ストレージクラス名およびサイズパラメーターを使用して、 Elasticsearch クラスターの永続ストレージクラスおよびサイズを設定できます。Cluster Logging Operator は、これらのパラメーターに基づいて、Elasticsearch クラスターの各データノードについて Persistent Volume Claim (永続ボリューム要求、PVC) を作成します。以下に例を示します。
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage:
storageClassName: "ocs-storagecluster-ceph-rbd”
size: "200G"
この例では、クラスター内の各データノードが 200GiB の ocs-storagecluster-ceph-rbd ストレージを要求する Persistent Volume Claim(永続ボリューム要求、PVC) にバインドされるように指定します。それぞれのプライマリーシャードは単一のレプリカによってサポートされます。シャードのコピーはすべてのノードにレプリケートされ、常に利用可能となり、冗長性ポリシーにより 2 つ以上のノードが存在する場合にコピーを復元できます。Elasticsearch レプリケーションポリシーの詳細は、クラスターロギングのデプロイおよび設定について の Elasticsearch レプリケーションポリシー について参照してください。
ストレージブロックを省略すると、デプロイメントはデフォルトのストレージでサポートされます。以下に例を示します。
spec:
logStore:
type: "elasticsearch"
elasticsearch:
nodeCount: 3
storage: {}詳細は、クラスターロギングの設定 を参照してください。
4.4.2. OpenShift Data Foundation を使用するためのクラスターロギングの設定
このセクションの手順に従って、OpenShift Data Foundation を OpenShift クラスターロギングのストレージとして設定します。
OpenShift Data Foundation では、ロギングを初めて設定する際に、すべてのログを取得できます。ただし、ロギングをアンインストールして再インストールすると、古いログが削除され、新しいログのみが処理されます。
前提条件
- OpenShift Web コンソールへの管理者アクセスがある。
-
OpenShift Data Foundation Operator が
openshift-storagenamespace にインストールされ、実行されている。 -
Cluster Logging Operator が
openshift-loggingnamespace にインストールされ、実行されている。
手順
- OpenShift Web コンソールの左側のペインから Administration → Custom Resource Definitions をクリックします。
- Custom Resource Definitions ページで、ClusterLogging をクリックします。
- Custom Resource Definition Overview ページで、Actions メニューから View Instances を選択するか、Instances タブをクリックします。
Cluster Logging ページで、Create Cluster Logging をクリックします。
データを読み込むためにページの更新が必要になる場合があります。
YAML において、storageClassName、をプロビジョナー
openshift-storage.rbd.csi.ceph.comを使用するstorageclassに置き換えます。以下の例では、storageclass の名前はocs-storagecluster-ceph-rbdです。apiVersion: "logging.openshift.io/v1" kind: "ClusterLogging" metadata: name: "instance" namespace: "openshift-logging" spec: managementState: "Managed" logStore: type: "elasticsearch" elasticsearch: nodeCount: 3 storage: storageClassName: ocs-storagecluster-ceph-rbd size: 200G # Change as per your requirement redundancyPolicy: "SingleRedundancy" visualization: type: "kibana" kibana: replicas: 1 curation: type: "curator" curator: schedule: "30 3 * * *" collection: logs: type: "fluentd" fluentd: {}OpenShift Data Foundation ノードにテイントのマークが付けられている場合、ロギング用に daemonset Pod のスケジューリングを有効にするために容認を追加する必要があります。
spec: [...] collection: logs: fluentd: tolerations: - effect: NoSchedule key: node.ocs.openshift.io/storage value: 'true' type: fluentd- Save をクリックします。
検証手順
Persistent Volume Claim(永続ボリューム要求、PVC) が
elasticsearchPod にバインドされていることを確認します。- Storage → Persistent Volume Claims に移動します。
-
Project ドロップダウンを
openshift-loggingに設定します。 Persistent Volume Claim(永続ボリューム要求、PVC) が
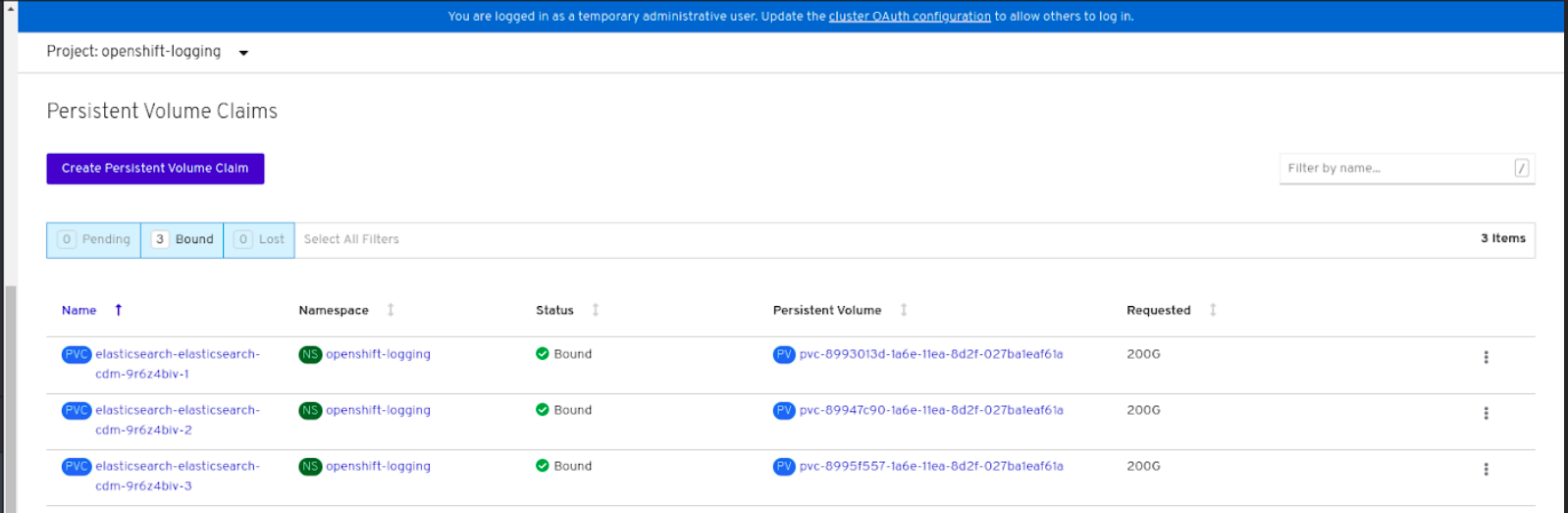
elasticsearch-* Pod に割り当てられ、Bound(バインド) の状態で表示されることを確認します。図4.4 作成済みのバインドされたクラスターロギング
新規クラスターロギングが使用されていることを確認します。
- Workload → Pods をクリックします。
-
プロジェクトを
openshift-loggingに設定します。 -
新規の
elasticsearch-* Pod がRunning状態で表示されることを確認します。 -
新規の
elasticsearch-* Pod をクリックし、Pod の詳細を表示します。 -
Volumes までスクロールダウンし、elasticsearch ボリュームに新規 Persistent Volume Claim (永続ボリューム要求、PVC) に一致する Type があることを確認します (例:
elasticsearch-elasticsearch-cdm-9r624biv-3)。 - Persistent Volume Claim(永続ボリューム要求、PVC) の名前をクリックし、PersistentVolumeClaim Overview ページでストレージクラス名を確認します。
Elasticsearch Pod に割り当てられる PV の詳細シナリオを回避するために、キュレーターの時間を短く設定して使用するようにしてください。
Curator を、保持設定に基づいて Elasticsearch データを削除するように設定できます。以下の 5 日間のインデックスデータの保持期間をデフォルトとして設定することが推奨されます。
config.yaml: |
openshift-storage:
delete:
days: 5詳細は、Elasticsearch データのキュレーション を参照してください。
Persistent Volume Claim(永続ボリューム要求、PVC) がサポートするクラスターロギングをアンインストールするには、それぞれのデプロイメントガイドのアンインストールについての章に記載されている、クラスターロギング Operator の OpenShift Data Foundation からの削除についての手順を使用します。
第5章 OpenShift Data Foundation を使用した OpenShift Container Platform アプリケーションのサポート
OpenShift Container Platform のインストール時に OpenShift Data Foundation を直接インストールすることはできません。ただし、Operator Hub を使用して OpenShift Data Foundation を既存の OpenShift Container Platform にインストールし、OpenShift Container Platform アプリケーションを OpenShift Data Foundation でサポートされるように設定することができます。
前提条件
- OpenShift Container Platform がインストールされ、OpenShift Web コンソールへの管理者アクセスがある。
-
OpenShift Data Foundation が
openshift-storagenamespace にインストールされ、実行されている。
手順
OpenShift Web コンソールで、以下のいずれかを実行します。
Workloads → Deployments をクリックします。
Deployments ページで、以下のいずれかを実行できます。
- 既存のデプロイメントを選択し、Action メニュー (⋮) から Add Storage オプションをクリックします。
新規デプロイメントを作成してからストレージを追加します。
- Create Deployment をクリックして新規デプロイメントを作成します。
-
要件に応じて
YAMLを編集し、デプロイメントを作成します。 - Create をクリックします。
- ページ右上の Actions ドロップダウンメニューから Add Storage を選択します。
Workloads → Deployment Configs をクリックします。
Deployment Configs ページで、以下のいずれかを実行できます。
- 既存のデプロイメントを選択し、Action メニュー (⋮) から Add Storage オプションをクリックします。
新規デプロイメントを作成してからストレージを追加します。
- Create Deployment Config をクリックし、新規デプロイメントを作成します。
-
要件に応じて
YAMLを編集し、デプロイメントを作成します。 - Create をクリックします。
- ページ右上の Actions ドロップダウンメニューから Add Storage を選択します。
Add Storage ページで、以下のオプションのいずれかを選択できます。
- Use existing claim オプションをクリックし、ドロップダウンリストから適切な PVC を選択します。
Create new claim オプションをクリックします。
-
Storage Class ドロップダウンリストから適切な
CephFSまたはRBDストレージクラスを選択します。 - Persistent Volume Claim (永続ボリューム要求、PVC) の名前を指定します。
ReadWriteOnce (RWO) または ReadWriteMany (RWX) アクセスモードを選択します。
注記ReadOnlyMany (ROX) はサポートされないため、非アクティブになります。
必要なストレージ容量のサイズを選択します。
注記ブロック PV を拡張することはできますが、Persistent Volume Claim (永続ボリューム要求、PVC) の作成後にストレージ容量のサイズを縮小することはできません。
-
Storage Class ドロップダウンリストから適切な
- コンテナー内のマウントパスボリュームのマウントパスとサブパス (必要な場合) を指定します。
- Save をクリックします。
検証手順
設定に応じて、以下のいずれかを実行します。
- Workloads → Deployments をクリックします。
- Workloads → Deployment Configs をクリックします。
- 必要に応じてプロジェクトを設定します。
- ストレージを追加したデプロイメントをクリックして、デプロイメントの詳細を表示します。
- Volumes までスクロールダウンし、デプロイメントに、割り当てた Persistent Volume Claim(永続ボリューム要求、PVC) に一致する Type があることを確認します。
- Persistent Volume Claim(永続ボリューム要求、PVC) の名前をクリックし、Persistent Volume Claim Overview ページでストレージクラス名を確認します。
第6章 既存の外部の OpenShift Data Foundation クラスターへのファイルおよびオブジェクトストレージの追加
OpenShift Data Foundation が外部モードで設定されている場合に、Persistent Volume Claim (永続ボリューム要求、PVC) および Object Bucket Claim (オブジェクトバケット要求) 向けにストレージを提供する方法は複数あります。
- ブロックストレージ用の Persistent Volume Claim (永続ボリューム要求、PVC) は、外部の Red Hat Ceph Storage クラスターから直接提供されます。
- ファイルストレージ用の Persistent Volume Claim (永続ボリューム要求、PVC) は、メタデータサーバー (MDS) を外部の Red Hat Ceph Storage クラスターに追加して提供できます。
- オブジェクトストレージのオブジェクトバケット要求は、Multicloud Object Gateway を使用するか、Ceph Object Gateway を外部の Red Hat Ceph Storage クラスターに追加して提供できます。
以下のプロセスを使用して、ブロックストレージだけを提供するために最初にデプロイされていたファイルストレージ (メタデータサバー 使用)、オブジェクトストレージ (Ceph Object Gateway 使用) または両方を外部の OpenShift Data Foundation クラスターに追加します。
前提条件
-
OpenShift Data Foundation 4.10 が OpenShift Container Platform バージョン 4.10 以降にインストールされ、実行されている。また、外部モードの OpenShift Data Foundation Cluster が
Ready状態にある。 外部の Red Hat Ceph Storage クラスターが以下のいずれかまたは両方で設定されている。
- オブジェクトストレージ用に OpenShift Container Platform クラスターがアクセスできる Ceph Object Gateway (RGW) エンドポイント
- ファイルストレージ用のメタデータサーバー (MDS) プール
-
外部の OpenShift Data Foundation クラスターのデプロイメント時に
ceph-external-cluster-details-exporter.pyスクリプトで使用されるパラメーターを把握している。
手順
以下のコマンドを使用して
ceph-external-cluster-details-exporter.pyPython スクリプトの OpenShift Data Foundation バージョンをダウンロードします。oc get csv $(oc get csv -n openshift-storage | grep ocs-operator | awk '{print $1}') -n openshift-storage -o jsonpath='{.metadata.annotations.external\.features\.ocs\.openshift\.io/export-script}' | base64 --decode > ceph-external-cluster-details-exporter.py更新パーミッションは、外部の Red Hat Ceph Storage クラスターのクライアントノードで
ceph-external-cluster-details-exporter.pyを実行して、外部の Red Hat Ceph Storage クラスターを制限します。これを行うには、Red Hat Ceph Storage の管理者に問い合わせる必要がある場合があります。# python3 ceph-external-cluster-details-exporter.py --upgrade \ --run-as-user=ocs-client-name \ --rgw-pool-prefix rgw-pool-prefix
--run-as-user-
OpenShift Data Foundation クラスターのデプロイメント時に使用されるクライアント名。別のクライアント名が設定されていない場合は、デフォルトのクライアント名
client.healthcheckerを使用します。 --rgw-pool-prefix- Ceph Object Gateway プールに使用する接頭辞。デフォルトの接頭辞を使用している場合は、省略できます。
外部の Red Hat Ceph Storage クラスターから設定詳細を生成して保存します。
外部の Red Hat Ceph Storage クラスターのクライアントノードで
ceph-external-cluster-details-exporter.pyを実行して、設定の詳細を生成します。# python3 ceph-external-cluster-details-exporter.py --rbd-data-pool-name rbd-block-pool-name --monitoring-endpoint ceph-mgr-prometheus-exporter-endpoint --monitoring-endpoint-port ceph-mgr-prometheus-exporter-port --run-as-user ocs-client-name --rgw-endpoint rgw-endpoint --rgw-pool-prefix rgw-pool-prefix
--monitoring-endpoint- オプション。OpenShift Container Platform クラスターから到達可能な、アクティブ mgr およびスタンバイ mgr の IP アドレスのコンマ区切りリストを受け入れます。指定しない場合には、値が自動的に入力されます。
--monitoring-endpoint-port-
オプション。
--monitoring-endpointで指定された ceph-mgr Prometheus エクスポーターに関連付けられるポートです。指定しない場合には、値が自動的に入力されます。 --run-as-user- OpenShift Data Foundation クラスターのデプロイメント時に使用されるクライアント名。別のクライアント名が設定されていない場合は、デフォルトのクライアント名 client.healthchecker を使用します。
--rgw-endpoint- このパラメーターを指定して OpenShift Data Foundation の Ceph Object Gateway でオブジェクトストレージをプロビジョニングします (任意のパラメーター)。
--rgw-pool-prefix- Ceph Object Gateway プールに使用する接頭辞。デフォルトの接頭辞を使用している場合は、省略できます。
ユーザーパーミッションは、以下のように更新されます。
caps: [mgr] allow command config caps: [mon] allow r, allow command quorum_status, allow command version caps: [osd] allow rwx pool=default.rgw.meta, allow r pool=.rgw.root, allow rw pool=default.rgw.control, allow rx pool=default.rgw.log, allow x pool=default.rgw.buckets.index
注記Ceph Object Gateway の詳細 (指定されている場合) 以外の全パラメーター (任意の引数を含む) は、OpenShift Data Foundation を外部モードでデプロイした時に使用したものと同じです。
スクリプトの出力を
external-cluster-config.jsonファイルに保存します。以下の出力例では、生成された設定変更を太字で示しています。
[{"name": "rook-ceph-mon-endpoints", "kind": "ConfigMap", "data": {"data": "xxx.xxx.xxx.xxx:xxxx", "maxMonId": "0", "mapping": "{}"}}, {"name": "rook-ceph-mon", "kind": "Secret", "data": {"admin-secret": "admin-secret", "fsid": "<fs-id>", "mon-secret": "mon-secret"}}, {"name": "rook-ceph-operator-creds", "kind": "Secret", "data": {"userID": "<user-id>", "userKey": "<user-key>"}}, {"name": "rook-csi-rbd-node", "kind": "Secret", "data": {"userID": "csi-rbd-node", "userKey": "<user-key>"}}, {"name": "ceph-rbd", "kind": "StorageClass", "data": {"pool": "<pool>"}}, {"name": "monitoring-endpoint", "kind": "CephCluster", "data": {"MonitoringEndpoint": "xxx.xxx.xxx.xxx", "MonitoringPort": "xxxx"}}, {"name": "rook-ceph-dashboard-link", "kind": "Secret", "data": {"userID": "ceph-dashboard-link", "userKey": "<user-key>"}}, {"name": "rook-csi-rbd-provisioner", "kind": "Secret", "data": {"userID": "csi-rbd-provisioner", "userKey": "<user-key>"}}, {"name": "rook-csi-cephfs-provisioner", "kind": "Secret", "data": {"adminID": "csi-cephfs-provisioner", "adminKey": "<admin-key>"}}, {"name": "rook-csi-cephfs-node", "kind": "Secret", "data": {"adminID": "csi-cephfs-node", "adminKey": "<admin-key>"}}, {"name": "cephfs", "kind": "StorageClass", "data": {"fsName": "cephfs", "pool": "cephfs_data"}}, {"name": "ceph-rgw", "kind": "StorageClass", "data": {"endpoint": "xxx.xxx.xxx.xxx:xxxx", "poolPrefix": "default"}}, {"name": "rgw-admin-ops-user", "kind": "Secret", "data": {"accessKey": "<access-key>", "secretKey": "<secret-key>"}}]
生成された JSON ファイルをアップロードします。
- OpenShift Web コンソールにログインします。
- Workloads → Secrets をクリックします。
-
プロジェクト を
openshift-storageに設定します。 - rook-ceph-external-cluster-details をクリックします。
- Actions (⋮) → Edit Secret をクリックします。
-
Browse をクリックして
external-cluster-config.jsonファイルをアップロードします。 - Save をクリックします。
検証手順
OpenShift Data Foundation クラスターが正常であり、データが回復性があることを確認するには、Storage → Data foundation → Storage Systems タブに移動してから、ストレージシステム名をクリックします。
- Overview → Block and File タブで Status カードをチェックして、Storage Cluster に正常であることを示す緑色のチェックマークが表示されていることを確認します。
ファイルストレージ用のメタデータサーバー (MDS) を追加した場合:
-
Workloads → Pods をクリックして、
csi-cephfsplugin-*Pod が新規作成され、状態が Running であることを確認します。 -
Storage → Storage Classes をクリックして
ocs-external-storagecluster-cephfsストレージクラスが作成されていることを確認します。
-
Workloads → Pods をクリックして、
オブジェクトストレージ用に Ceph Object Gateway を追加した場合:
-
Storage → Storage Classes をクリックして
ocs-external-storagecluster-ceph-rgwストレージクラスが作成されていることを確認します。 - OpenShift Data Foundation クラスターが正常であり、データが回復性があることを確認するには、Storage → Data foundation → Storage Systems タブに移動してから、ストレージシステム名をクリックします。
- Object タブをクリックして、Object Service および Data resiliency に正常であることを示す緑色のチェックマークが表示されていることを確認します。
-
Storage → Storage Classes をクリックして
第7章 Red Hat OpenShift Data Foundation に専用のワーカーノードを使用する方法
Red Hat OpenShift Container Platform サブスクリプションには、OpenShift Data Foundation サブスクリプションが必要です。ただし、インフラストラクチャーノードを使用して OpenShift Data Foundation リソースをスケジュールしている場合は、OpenShift Container Platform のサブスクリプションコストを節約できます。
マシン API サポートの有無にかかわらず複数の環境全体で一貫性を維持することが重要です。そのため、いずれの場合でも、worker または infra のいずれかのラベルが付けられたノードの特別なカテゴリーや、両方のロールを使用できるようにすることが強く推奨されます。詳細は、「インフラストラクチャーノードの手動作成」 セクションを参照してください。
7.1. インフラストラクチャーノードの仕組み
OpenShift Data Foundation で使用するインフラストラクチャーノードにはいくつかの属性があります。ノードが RHOCP エンタイトルメントを使用しないようにするには、infra ノードロールのラベルが必要です。infra ノードロールラベルは、OpenShift Data Foundation を実行するノードには OpenShift Data Foundation エンタイトルメントのみが必要となるようにします。
-
node-role.kubernetes.io/infraのラベル
infra ノードが OpenShift Data Foundation リソースのみをスケジュールできるようにするには、NoSchedule effect のある OpenShift Data Foundation テイントを追加する必要もあります。
-
node.ocs.openshift.io/storage="true"のテイント
RHOCP サブスクリプションコストが適用されないように、ラベルは RHOCP ノードを infra ノードとして識別します。テイントは、OpenShift Data Foundation 以外のリソースがテイントのマークが付けられたノードでスケジュールされないようにします。
OpenShift Data Foundation サービスの実行に使用されるインフラストラクチャーノードで必要なテイントおよびラベルの例:
spec:
taints:
- effect: NoSchedule
key: node.ocs.openshift.io/storage
value: "true"
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/worker: ""
node-role.kubernetes.io/infra: ""
cluster.ocs.openshift.io/openshift-storage: ""7.2. インフラストラクチャーノードを作成するためのマシンセット
マシン API が環境でサポートされている場合には、インフラストラクチャーノードのプロビジョニングを行うマシンセットのテンプレートにラベルを追加する必要があります。ラベルをマシン API によって作成されるノードに手動で追加するアンチパターンを回避します。これを実行することは、デプロイメントで作成される Pod にラベルを追加することに似ています。いずれの場合も、Pod/ノードが失敗する場合、置き換え用の Pod/ノードには適切なラベルがありません。
EC2 環境では、3 つのマシンセットが必要です。それぞれは、異なるアベイラビリティーゾーン (us-east-2a、us-east-2b、us-east-2c など) でインフラストラクチャーノードをプロビジョニングするように設定されます。現時点で、OpenShift Data Foundation は 4 つ以上のアベイラビリティーゾーンへのデプロイをサポートしていません。
以下の Machine Set テンプレートのサンプルは、インフラストラクチャーノードに必要な適切なテイントおよびラベルを持つノードを作成します。これは OpenShift Data Foundation サービスを実行するために使用されます。
template:
metadata:
creationTimestamp: null
labels:
machine.openshift.io/cluster-api-cluster: kb-s25vf
machine.openshift.io/cluster-api-machine-role: worker
machine.openshift.io/cluster-api-machine-type: worker
machine.openshift.io/cluster-api-machineset: kb-s25vf-infra-us-west-2a
spec:
taints:
- effect: NoSchedule
key: node.ocs.openshift.io/storage
value: "true"
metadata:
creationTimestamp: null
labels:
node-role.kubernetes.io/infra: ""
cluster.ocs.openshift.io/openshift-storage: ""インフラストラクチャーノードにテイントを追加する場合は、fluentd Pod など、他のワークロードのテイントにも容認を追加する必要があります。詳細は、Red Hat ナレッジベースのソリューション記事 OpenShift 4 のインフラストラクチャーノード を参照してください。
7.3. インフラストラクチャーノードの手動作成
マシン API が環境内でサポートされない場合にのみ、ラベルはノードに直接適用される必要があります。手動作成では、OpenShift Data Foundation サービスをスケジュールするために少なくとも 3 つの RHOCP ワーカーノードが利用可能であり、これらのノードに CPU およびメモリーリソースが十分にある必要があります。RHOCP サブスクリプションコストの発生を防ぐには、以下が必要です。
oc label node <node> node-role.kubernetes.io/infra="" oc label node <node> cluster.ocs.openshift.io/openshift-storage=""
また、NoSchedule OpenShift Data Foundation テイントを追加することも、infra ノードが OpenShift Data Foundation リソースのみをスケジュールし、その他の OpenShift Data Foundation ワークロードを拒否できるようにするために必要です。
oc adm taint node <node> node.ocs.openshift.io/storage="true":NoSchedule
ノードロール node-role.kubernetes.io/worker="" は削除しないでください。
node-role.kubernetes.io/worker="" ノードロールを削除すると、OpenShift スケジューラーおよび MachineConfig リソースの両方に変更が加えられない場合に問題が発生する可能性があります。
すでに削除されている場合は、各 infra ノードに再度追加する必要があります。node-role.kubernetes.io/infra="" ノードロールおよび OpenShift Data Foundation テイントを追加するだけで、エンタイトルメント免除要件を満たすことができます。
7.4. ユーザーインターフェイスからノードのテイント
このセクションでは、OpenShift Data Foundation のデプロイ後にノードをテイントする手順について説明します。
手順
- OpenShift Web Console で、Compute → Nodes をクリックし、テイントする必要のあるノードを選択します。
- Details ページで、Edit taints をクリックします。
- Key <nodes.openshift.ocs.io/storage>、Value <true>、および Effect<Noschedule> フィールドに値を入力します。
- Save をクリックします。
検証手順
次の手順に従って、ノードが正常にテイントされたことを確認します。
- Compute → Nodes に移動します。
- ノードを選択してステータスを確認し、YAML タブをクリックします。
specs セクションで、次のパラメーターの値を確認します。
Taints: Key: nodes.openshift.ocs.io/storage Value: true Effect: Noschedule
関連情報
詳細については、VMware vSphere での OpenShift Data Foundation クラスターの作成 を参照してください。
第8章 Persistent Volume Claim (永続ボリューム要求、PVC) の管理
8.1. OpenShift Data Foundation を使用するためのアプリケーション Pod の設定
このセクションの手順に従って、OpenShift Data Foundation をアプリケーション Pod のストレージとして設定します。
前提条件
- OpenShift Web コンソールへの管理者アクセスがある。
-
OpenShift Data Foundation Operator が
openshift-storagenamespace にインストールされ、実行されている。OpenShift Web Console で、Operators → Installed Operators をクリックしてインストールされた Operator を表示します。 - OpenShift Data Foundation が提供するデフォルトのストレージクラスが利用可能である。OpenShift Web コンソールで Storage → StorageClasses をクリックし、デフォルトのストレージクラスを表示します。
手順
使用するアプリケーションの Persistent Volume Claim(永続ボリューム要求、PVC) を作成します。
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
- アプリケーション Pod の Project を設定します。
Create Persistent Volume Claim をクリックします。
- OpenShift Data Foundation によって提供される Storage Class を指定します。
-
PVC Name (例:
myclaim) を指定します。 必要な Access Mode を選択します。
注記IBM FlashSystem では Access Mode の
Shared access (RWX)はサポートされません。-
Rados Block Device (RBD) の場合、Access mode が ReadWriteOnce (
RWO) であれば、必須の Volume mode を選択します。デフォルトのボリュームモードは、Filesystemです。 - アプリケーション要件に応じて Size を指定します。
-
Create をクリックし、PVC のステータスが
Boundになるまで待機します。
新規または既存のアプリケーション Pod を新規 PVC を使用するように設定します。
新規アプリケーション Pod の場合、以下の手順を実行します。
- Workloads →Pods をクリックします。
- 新規アプリケーション Pod を作成します。
spec:セクションの下にvolumes:セクションを追加し、新規 PVC をアプリケーション Pod のボリュームとして追加します。volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>以下に例を示します。
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
既存のアプリケーション Pod の場合、以下の手順を実行します。
- Workloads →Deployment Configs をクリックします。
- アプリケーション Pod に関連付けられた必要なデプロイメント設定を検索します。
- Action メニュー (⋮) → Edit Deployment Config をクリックします。
spec:セクションの下にvolumes:セクションを追加し、新規 PVC をアプリケーション Pod のボリュームとして追加し、Save をクリックします。volumes: - name: <volume_name> persistentVolumeClaim: claimName: <pvc_name>以下に例を示します。
volumes: - name: mypd persistentVolumeClaim: claimName: myclaim
新しい設定が使用されていることを確認します。
- Workloads → Pods をクリックします。
- アプリケーション Pod の Project を設定します。
-
アプリケーション Pod が
Runningステータスで表示されていることを確認します。 - アプリケーション Pod 名をクリックし、Pod の詳細を表示します。
-
Volumes セクションまでスクロールダウンし、ボリュームに新規 Persistent Vocume Claim (永続ボリューム要求、PVC) に一致する Type があることを確認します (例:
myclaim)。
8.2. Persistent Volume Claim (永続ボリューム要求、PVC) 要求ステータスの表示
以下の手順を使用して、PVC 要求のステータスを表示します。
前提条件
- OpenShift Data Foundation への管理者アクセス。
手順
- OpenShift Web コンソールにログインします。
- Storage → Persistent Volume Claims をクリックします。
- Filter テキストボックスを使用して、必要な PVC 名を検索します。また、リストを絞り込むために Name または Label で PVC のリストをフィルターすることもできます。
- 必要な PVC に対応する Status 列を確認します。
- 必要な Name をクリックして PVC の詳細を表示します。
8.3. Persistent Volume Claim (永続ボリューム要求、PVC) 要求イベントの確認
以下の手順を使用して、Persistent Volume Claim(永続ボリューム要求、PVC) 要求イベントを確認し、これに対応します。
前提条件
- OpenShift Web コンソールへの管理者アクセス。
手順
- OpenShift Web Console で、Storage → Data Foundation をクリックします。
- Storage systems タブでストレージシステムを選択し、Overview → Block and File タブをクリックします。
- Inventory カードを見つけ、エラーのある PVC の数を確認します。
- Storage → Persistent Volume Claims をクリックします。
- Filter テキストボックスを使用して、必要な PVC を検索します。
- PVC 名をクリックし、Events に移動します。
- 必要に応じて、または指示に応じてイベントに対応します。
8.4. Persistent Volume Claim (永続ボリューム要求、PVC) の拡張
OpenShift Data Foundation 4.6 以降では、Persistent Volume Claim (永続ボリューム要求、PVC) を拡張する機能が導入され、永続ストレージリソース管理の柔軟性が向上します。
拡張は、以下の永続ボリュームでサポートされます。
-
ボリュームモードが
Filesystemの Ceph File System (CephFS) をベースとする PVC (ReadWriteOnce (RWO) および ReadWriteMany (RWX) アクセス)。 -
ボリュームモードが
Filesystemの Ceph RADOS Block Device (Ceph RBD) をベースとする PVC (ReadWriteOnce (RWO) アクセス)。 -
ボリュームモードが
Blockの Ceph RADOS Block Device (Ceph RBD) をベースとする PVC (ReadWriteOnce (RWO) アクセス)。
PVC の拡張は OSD、MON、および暗号化された PVC ではサポートされません。
前提条件
- OpenShift Web コンソールへの管理者アクセス。
手順
-
OpenShift Web コンソールで、
Storage→Persistent Volume Claimsに移動します。 - 拡張する Persistent Volume Claim(永続ボリューム要求、PVC) の横にある Action メニュー (⋮) をクリックします。
Expand PVCをクリックします。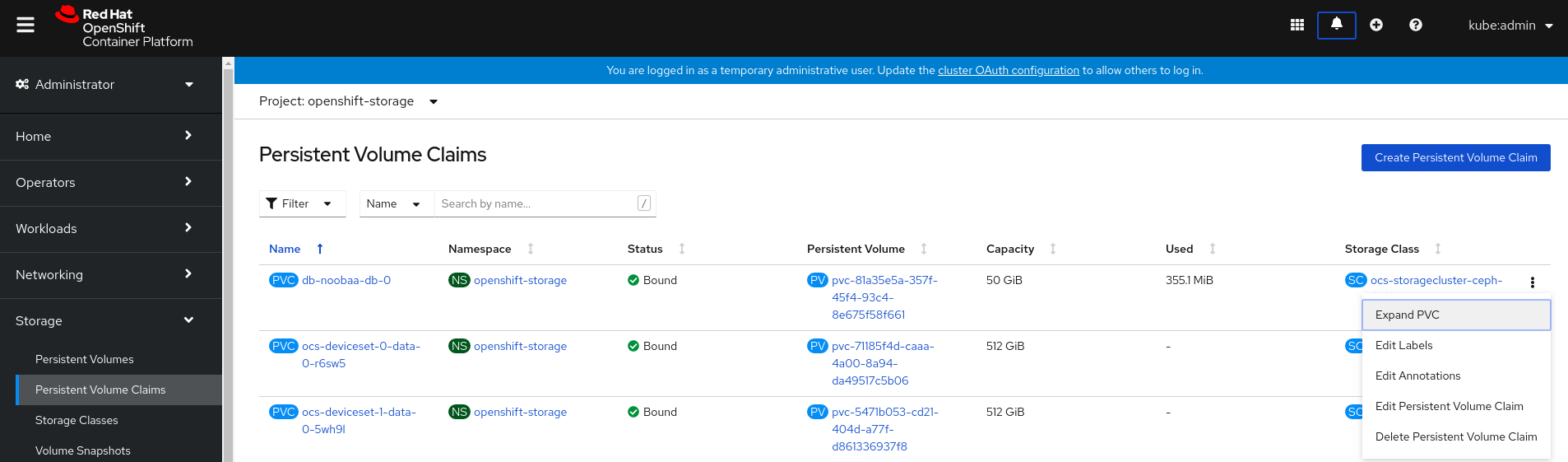
Persistent Volume Claim(永続ボリューム要求、PVC) の新しいサイズを選択してから、
Expandをクリックします。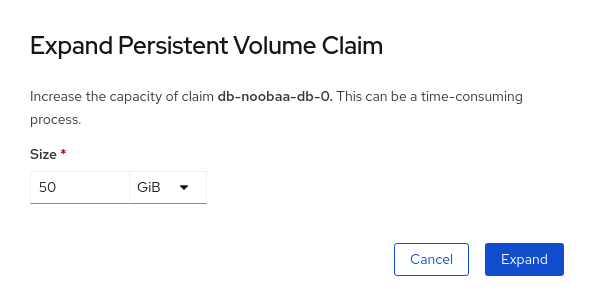
拡張を確認するには、PVC の詳細ページに移動し、
Capacityフィールドでサイズが正しく要求されていることを確認します。注記Ceph RADOS Block Device (RBD) に基づいて PVC を拡張する場合、PVC がまだ Pod に割り当てられていない場合は、PVC の詳細ページで
Condition typeはFileSystemResizePendingになります。ボリュームをマウントすると、ファイルシステムのサイズ変更が正常に実行され、新しいサイズがCapacityフィールドに反映されます。
8.5. 動的プロビジョニング
8.5.1. 動的プロビジョニングについて
StorageClass リソースオブジェクトは、要求可能なストレージを記述し、分類するほか、要求に応じて動的にプロビジョニングされるストレージのパラメーターを渡すための手段を提供します。StorageClass オブジェクトは、さまざまなレベルのストレージおよびストレージへのアクセスを制御するための管理メカニズムとしても機能します。クラスター管理者 (cluster-admin) またはストレージ管理者 (storage-admin) は、ユーザーが基礎となるストレージボリュームソースに関する詳しい知識なしに要求できる StorageClass オブジェクトを定義し、作成します。
OpenShift Container Platform の永続ボリュームフレームワークはこの機能を有効にし、管理者がクラスターに永続ストレージをプロビジョニングできるようにします。フレームワークにより、ユーザーは基礎となるインフラストラクチャーの知識がなくてもこれらのリソースを要求できるようになります。
OpenShift Container Platform では、数多くのストレージタイプを永続ボリュームとして使用することができます。ストレージプラグインは、静的なプロビジョニング、動的プロビジョニング、またはその両方のプロビジョニングタイプをサポートする場合があります。
8.5.2. OpenShift Data Foundation での動的プロビジョニング
Red Hat OpenShift Data Foundation は、コンテナー環境向けに最適化されたソフトウェアで定義されるストレージです。このソフトウェアは、OpenShift Container Platform の Operator として実行されるため、コンテナーの永続ストレージ管理を高度に統合し、簡素化できます。
OpenShift Data Foundation は、以下を含む各種のストレージタイプをサポートします。
- データベースのブロックストレージ
- 継続的な統合、メッセージングおよびデータ集約のための共有ファイルストレージ
- アーカイブ、バックアップおよびメディアストレージのオブジェクトストレージ
バージョン 4 では、Red Hat Ceph Storage を使用して永続ボリュームをサポートするファイル、ブロック、およびオブジェクトストレージを提供し、Rook.io を使用して永続ボリュームおよび要求のプロビジョニングを管理し、オーケストレーションします。NooBaa はオブジェクトストレージを提供し、その Multicloud Gateway は複数のクラウド環境でのオブジェクトのフェデレーションを可能にします (テクノロジープレビューとしてご利用いただけます)。
OpenShift Data Foundation 4 では、RADOS Block Device (RBD) および Ceph File System (CephFS) の Red Hat Ceph Storage Container Storage Interface (CSI) ドライバーが動的プロビジョニング要求を処理します。PVC 要求が動的に送信される場合、CSI ドライバーでは以下のオプションを使用できます。
-
ボリュームモードが
Blockの Ceph RBD をベースとする PVC (ReadWriteOnce (RWO) および ReadWriteMany (RWX) アクセス) を作成します。 -
ボリュームモードが
Filesystemの Ceph RBD をベースとする PVC (ReadWriteOnce (RWO) アクセス) を作成します。 -
ボリュームモードが
Filesystemの CephFS をベースとする PVC (ReadWriteOnce (RWO) および ReadWriteMany (RWX) アクセス) を作成します。
使用するドライバー (RBD または CephFS) の判断は、storageclass.yaml ファイルのエントリーに基づいて行われます。
8.5.3. 利用可能な動的プロビジョニングプラグイン
OpenShift Container Platform は、以下のプロビジョナープラグインを提供します。 これらには、クラスターの設定済みプロバイダーの API を使用して新規ストレージリソースを作成する動的プロビジョニング用の一般的な実装が含まれます。
| ストレージタイプ | プロビジョナープラグインの名前 | 注記 |
|---|---|---|
| OpenStack Cinder |
| |
| AWS Elastic Block Store (EBS) |
|
複数クラスターを複数の異なるゾーンで使用する際の動的プロビジョニングの場合、各ノードに |
| AWS Elastic File System (EFS) | 動的プロビジョニングは、EFS プロビジョナー Pod で実行され、プロビジョナープラグインでは実行されません。 | |
| Azure Disk |
| |
| Azure File |
|
|
| GCE Persistent Disk (gcePD) |
| マルチゾーン設定では、GCE プロジェクトごとに OpenShift Container Platform クラスターを実行し、現行クラスターのノードが存在しないゾーンで PV が作成されないようにすることが推奨されます。 |
|
| ||
| Red Hat Virtualization |
|
選択したプロビジョナープラグインでは、関連するクラウド、ホスト、またはサードパーティープロバイダーを、関連するドキュメントに従って設定する必要もあります。
第9章 ターゲットボリュームのスペースを再利用
ターゲットボリュームでスペースの回収操作を使用して、実際に使用可能なスペースにアクセスできます。回収操作は、永続ボリューム上のファイルまたはデータが削除されたときに使用可能なストレージスペースのあいまいさを取り除きます。この操作は CephRBD で使用できます。オブジェクトは RBD デバイス上に残り、ストレージは Ceph クラスターに解放されないため、これにより、実際に使用可能なストレージスペースの誤った情報が提供されます。
スペースの回収操作は、RBD デバイスで rbd sparsify をトリガーします。これにより、ゼロのイメージエクステントのスペースが回収されます。ファイルシステムモードの場合、fstrim はブロックデバイスにマウントされたファイルシステムでも実行されます。ファイルシステムで fstrim が有効になっている場合、次のモードで Ceph RBD に基づく ReadWriteOnce (RWO) アクセスを使用して PVC を作成できます。
- ボリュームモードブロック
- ボリュームモードファイルシステム
新しくインストールされたクラスターの場合、スペースの回収操作はデフォルトで有効になっています。
アップグレードされたクラスターのスペース回収操作を有効にするには、openshift-storage namespace の rook-ceph-operator-override configmap で CSI_ENABLE_CSIADDONS: "true" を設定します。
$ oc patch cm rook-ceph-operator-config -n openshift-storage -p $'data:\n "CSI_ENABLE_CSIADDONS": "true"'
次の 3 つの方法のいずれかを使用して、スペースを回収できます。
- ReclaimSpaceJob を使用したスペースの回収操作の有効化
- ReclaimSpaceCronJob を使用したスペースの回収操作の有効化
- Annotating PersistentVolumeClaims を使用したスペースの回収操作の有効化 (Red Hat は、スペースの回収操作を有効にするためにこの方法を使用することを推奨します)
9.1. ReclaimSpaceJob を使用したスペースの回収操作の有効化
ReclaimSpaceJob は、ターゲットボリュームでスペースの回収操作を呼び出すように設計された名前付きのカスタムリソースです。これは、スペースの回収操作をすぐに開始する 1 回限りの方法です。ユーザーは、必要に応じて ReclaimSpaceJob CR の作成を繰り返して、スペースの回収操作を繰り返す必要があります。
手順
スペースの回収操作用に次のカスタムリソースを作成して適用します。
apiVersion: csiaddons.openshift.io/v1alpha1 kind: ReclaimSpaceJob metadata: name: sample-1 spec: target: persistentVolumeClaim: pvc-1上記の yaml で使用される変数は次のとおりです。
targetは、操作が実行するボリュームターゲットを示します。-
persistentVolumeClaimには、PersistentVolumeClaimの名前を示す文字列が含まれています。
-
-
backOfflimitは、スペースの回収操作が失敗するまでの最大再試行回数を指定します。指定しない場合、デフォルト値は 6 に設定されます。許可される最大値と最小値は 60 と 0 です。 -
restartDeadlineSecondsは、開始時間に対して操作が終了する可能性のある期間を指定します。その値は正の整数でなければならず、時間の単位は秒単位です。指定しない場合、デフォルトは 600 秒に設定されます。最大許容値は 1800 です。
- 操作の完了後に顧客リソースを削除します。
9.2. ReclaimSpaceCronJob を使用したスペースの回収操作の有効化
ReclaimSpaceCronJob は、指定されたスケジュール (毎日、毎週など) に基づいてスペースの回収操作を呼び出します。永続的なボリュームクレームに対してのみ、ReclaimSpaceCronJob を 1 回作成する必要があります。スケジュール属性を使用すると、CSI-addons コントローラーは、要求された時間と間隔で ReclaimSpaceJob を作成します。
手順
スペースの回収操作用に次のカスタムリソースを作成して適用します
apiVersion: csiaddons.openshift.io/v1alpha1 kind: ReclaimSpaceCronJob metadata: name: reclaimspacecronjob-sample spec: jobTemplate: spec: target: persistentVolumeClaim: data-pvc schedule: '@weekly'上記の yaml で使用される変数は次のとおりです。
-
failedJobsHistoryLimitは、失敗したReclaimSpaceJobsの数を保持します。 -
jobTemplateには、要求されたReclaimSpaceJob操作を含む ReclaimSpaceJob.spec 構造が含まれています。 -
scheduleは、定期的な操作の間隔を設定します。スケジュールの形式については、Kubernetes CronJobs を参照してください。 -
successfulJobsHistoryLimitは、成功したReclaimSpaceJob操作の数を保持します。
-
- 操作の完了後に顧客リソースを削除します。
9.3. Annotating PersistentVolumeClaims を使用してスペースの回収操作を有効にする
この手順を使用して PersistentVolumeClaims にアノテーションを付け、指定されたスケジュールに基づいてスペースの回収操作を自動的に呼び出すことができるようにします。
reclaimspace.csiaddons.openshift.io/schedule: "@midnight"
手順
永続ボリュームクレーム (pvc) の詳細を取得します。
$ oc get pvc data-pvc
以下に例を示します。
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE data-pvc Bound pvc-f37b8582-4b04-4676-88dd-e1b95c6abf74 1Gi RWO ocs-storagecluster-ceph-rbd 20h
アノテーション
reclaimspace.csiaddons.openshift.io/schedule: "@midnight"`を PVC に追加して、reclaimspacecronjobを作成します。$ oc annotate pvc data-pvc "reclaimspace.csiaddons.openshift.io/schedule=@midnight"
以下に例を示します。
persistentvolumeclaim/data-pvc annotated
reclaimspacecronjobが "<pvc-name>-xxxxxxx" の形式で作成されていることを確認します。$ oc get reclaimspacecronjobs.csiaddons.openshift.io
以下に例を示します。
NAME SCHEDULE SUSPEND ACTIVE LASTSCHEDULE AGE data-pvc-1642663516 @midnight 3s
このジョブを自動的に実行するようにスケジュールを変更します。
$ oc annotate pvc data-pvc "reclaimspace.csiaddons.openshift.io/schedule=*/1 * * * *" --overwrite=true
以下に例を示します。
persistentvolumeclaim/data-pvc annotated
reclaimspacecronjobのスケジュールが変更されていることを確認します。$ oc get reclaimspacecronjobs.csiaddons.openshift.io
以下に例を示します。
NAME SCHEDULE SUSPEND ACTIVE LASTSCHEDULE AGE data-pvc-1642664617 */1 * * * * 3s
この例では、次の詳細を提供します。
-
新しく作成された
ReclaimSpaceCronJobの名前を data-pvc-1642664617 として。 -
scheduleは、定期的な操作の間隔を設定します。スケジュールの形式については、Kubernetes CronJobs を参照してください。 - スケジュール値が空または無効な形式の場合、デフォルトのスケジュール値は "@weekly" に設定されます。
ReclaimSpaceCronJob は、schedule が変更されたときに再作成され、アノテーションが削除されたときに削除されます。
第10章 ボリュームスナップショット
ボリュームスナップショットは、特定の時点におけるクラスター内のストレージボリュームの状態を表します。これらのスナップショットは、毎回フルコピーを作成する必要がないので、より効率的にストレージを使用するのに役立ち、アプリケーション開発のビルディングブロックとして使用できます。
ボリュームスナップショットクラスを使用すると、管理者はボリュームスナップショットオブジェクトに属する異なる属性を指定できます。OpenShift Data Foundation Operator は、使用されるプラットフォームに応じてデフォルトのボリュームスナップショットクラスをインストールします。これらのデフォルトボリュームスナップショットクラスは Operator によって所有され、制御されるため、削除したり変更したりすることはできません。
同じ永続ボリューム要求 (PVC) のスナップショットを複数作成できますが、スナップショットの定期的な作成をスケジュールすることはできません。
- CephFS の場合、PVC ごとに最大 100 スナップショットを作成できます。
- RADOS Block Device (RBD) の場合、PVC ごとに最大 512 スナップショットを作成できます。
永続ボリュームの暗号化がボリュームのスナップショットをサポートするようになりました。
10.1. ボリュームスナップショットの作成
Persistent Volume Claim(永続ボリューム要求、PVC) ページまたは Volume Snapshots ページのいずれかからボリュームスナップショットを作成できます。
前提条件
-
一貫性のあるスナップショットを使用するには、PVC は
Bound状態にあり、使用されていない必要があります。スナップショットを作成する前に、必ずすべての IO を停止してください。
Pod が使用している場合、OpenShift Data Foundation は PVC のボリュームスナップショットのクラッシュの一貫性だけを提供します。アプリケーションの一貫性を保つために、まず実行中の Pod を破棄してスナップショットの一貫性を確保するか、アプリケーションが提供する静止メカニズムを使用してこれを確保します。
手順
- Persistent Volume Claims ページで以下を実行します。
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
ボリュームのスナップショットを作成するには、以下のいずれかを実行します。
- 必要な PVC の横にある Action メニュー (⋮) → Create Snapshot をクリックします。
- スナップショットを作成する PVC をクリックし、Actions → Create Snapshot をクリックします。
- ボリュームスナップショットの Name を入力します。
- ドロップダウンリストから Snapshot Class を選択します。
- Create をクリックします。作成されるボリュームスナップショットの Details ページにリダイレクトされます。
- Volume Snapshots ページで以下を実行します。
- OpenShift Web コンソールで Storage → Volume Snapshots をクリックします。
- Volume Snapshots ページで、Create Volume Snapshot をクリックします。
- ドロップダウンリストから必要な Project を選択します。
- ドロップダウンリストから Persistent Volume Claim を選択します。
- スナップショットの Name を入力します。
- ドロップダウンリストから Snapshot Class を選択します。
- Create をクリックします。作成されるボリュームスナップショットの Details ページにリダイレクトされます。
検証手順
- PVC の Details ページに移動し、Volume Snapshots タブをクリックしてボリュームスナップショットのリストを表示します。新規スナップショットがリスト表示されていることを確認します。
- OpenShift Web コンソールで Storage → Volume Snapshots をクリックします。新規スナップショットがリスト表示されていることを確認します。
-
ボリュームスナップショットが
Ready状態になるまで待機します。
10.2. ボリュームスナップショットの復元
ボリュームスナップショットを復元する際に、新規の Persistent Volume Claim(永続ボリューム要求、PVC) が作成されます。復元される PVC はボリュームスナップショットおよび親 PVC とは切り離されています。
Persistent Volume Claim ページまたは Volume Snapshots ページのいずれかからボリュームスナップショットを復元できます。
手順
- Persistent Volume Claims ページで以下を実行します。
親 PVC が存在する場合に限り、Persistent Volume Claims ページからボリュームスナップショットを復元できます。
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
- ボリュームスナップショットと共に PVC 名をクリックし、ボリュームスナップショットを新規 PVC として復元します。
- Volume Snapshots タブで、復元するボリュームスナップショットの横にある Action メニュー (⋮) をクリックします。
- Restore as new PVC をクリックします。
- 新規 PVC の名前を入力します。
Storage Class 名を選択します。
注記Rados Block Device (RBD) の場合、親 PVC と同じプールが指定されるストレージクラスを選択する必要があります。暗号化が有効でないストレージクラスを使用して暗号化された PVC のスナップショットを復元することや、その逆はサポートされていません。
任意の Access Mode を選択します。
重要ReadOnlyMany (ROX) アクセスモードは 開発者プレビュー機能であり、開発者プレビューのサポート制限の対象となります。開発者プレビューリリースは、実稼働環境で実行することは意図されておらず、Red Hat カスタマーポータルのケース管理システムではサポートされません。ReadOnlyMany 機能に関してサポートが必要な場合には、ocs-devpreview@redhat.com メーリングリストに連絡してください。Red Hat Development Team のメンバーが稼働状況とスケジュールに応じて可能な限り迅速に対応します。ROX アクセスモードの使用については、Creating a clone or restoring a snapshot with the new readonly access mode について参照してください。
- オプション:RBD の場合、Volume mode を選択します。
- Restore をクリックします。新規 PVC の詳細ページにリダイレクトされます。
- Volume Snapshots ページで以下を実行します。
- OpenShift Web コンソールで Storage → Volume Snapshots をクリックします。
- Volume Snapshots タブで、復元するボリュームスナップショットの横にある Action メニュー (⋮) をクリックします。
- Restore as new PVC をクリックします。
- 新規 PVC の名前を入力します。
Storage Class 名を選択します。
注記Rados Block Device (RBD) の場合、親 PVC と同じプールが指定されるストレージクラスを選択する必要があります。暗号化が有効でないストレージクラスを使用して暗号化された PVC のスナップショットを復元することや、その逆はサポートされていません。
任意の Access Mode を選択します。
重要ReadOnlyMany (ROX) アクセスモードは 開発者プレビュー機能であり、開発者プレビューのサポート制限の対象となります。開発者プレビューリリースは、実稼働環境で実行することは意図されておらず、Red Hat カスタマーポータルのケース管理システムではサポートされません。ReadOnlyMany 機能に関してサポートが必要な場合には、ocs-devpreview@redhat.com メーリングリストに連絡してください。Red Hat Development Team のメンバーが稼働状況とスケジュールに応じて可能な限り迅速に対応します。ROX アクセスモードの使用については、Creating a clone or restoring a snapshot with the new readonly access mode について参照してください。
- オプション:RBD の場合、Volume mode を選択します。
- Restore をクリックします。新規 PVC の詳細ページにリダイレクトされます。
検証手順
- OpenShift Web コンソールから Storage → Persistent Volume Claims をクリックし、新規 PVC が Persistent Volume Claims ページにリスト表示されていることを確認します。
-
新規 PVC が
Boundの状態になるまで待機します。
10.3. ボリュームスナップショットの削除
前提条件
- ボリュームスナップショットを削除する場合は、その特定のボリュームスナップショットで使用されるボリュームスナップショットクラスが存在している必要があります。
手順
- Persistent Volume Claims ページで以下を実行します。
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
- 削除する必要のあるボリュームスナップショットがある PVC 名をクリックします。
- Volume Snapshots タブで、必要なボリュームスナップショットの横にある Action メニュー (⋮) → Delete Volume Snapshot をクリックします。
- Volume Snapshots ページで以下を実行します。
- OpenShift Web コンソールで Storage → Volume Snapshots をクリックします。
- Volume Snapshots ページで、必要なスナップショットの横にある Action メニュー (⋮) → Delete Volume Snapshot をクリックします。
検証手順
- 削除されたボリュームスナップショットが PVC の詳細ページの Volume Snapshots タブにないことを確認します。
- Storage → Volume Snapshots をクリックし、削除されたボリュームスナップショットがリスト表示されていないことを確認します。
第11章 ボリュームのクローン作成
クローンは、標準のボリュームとして使用される既存のストレージボリュームの複製です。ボリュームのクローンを作成し、データの特定の時点のコピーを作成します。永続ボリューム要求 (PVC) は別のサイズでクローンできません。CephFS および RADOS Block Device (RBD) の両方で、PVC ごとに最大 512 のクローンを作成できます。
11.1. クローンの作成
前提条件
-
ソース PVC は
Bound状態にある必要があり、使用中の状態にすることはできません。
Pod が PVC を使用している場合は、PVC のクローンを作成しません。これを実行すると、PVC が一時停止 (停止) されないため、データが破損する可能性があります。
手順
- OpenShift Web コンソールで、Storage → Persistent Volume Claims をクリックします。
クローンを作成するには、以下のいずれかを実行します。
- 必要な PVC の横にある Action メニュー (⋮) → Clone PVC をクリックします。
- クローンを作成する必要のある PVC をクリックし、Actions → Clone PVC をクリックします。
- クローンの Name を入力します。
任意のアクセスモードを選択します。
重要ReadOnlyMany (ROX) アクセスモードは 開発者プレビュー機能であり、開発者プレビューのサポート制限の対象となります。開発者プレビューリリースは、実稼働環境で実行することは意図されておらず、Red Hat カスタマーポータルのケース管理システムではサポートされません。ReadOnlyMany 機能に関してサポートが必要な場合には、ocs-devpreview@redhat.com メーリングリストに連絡してください。Red Hat Development Team のメンバーが稼働状況とスケジュールに応じて可能な限り迅速に対応します。ROX アクセスモードの使用については、Creating a clone or restoring a snapshot with the new readonly access mode について参照してください。
- Clone をクリックします。新規 PVC の詳細ページにリダイレクトされます。
クローン作成された PVC のステータスが
Boundになるまで待機します。クローン作成された PVC が Pod で使用できるようになります。このクローン作成された PVC は dataSource PVC とは切り離されています。
第12章 Container Storage Interface (CSI) コンポーネントの配置の管理
各クラスターは、infra や storage ノードなどの数多くの専用ノードで設定されます。ただし、カスタムテイントを持つ infra ノードは、ノードで OpenShift Data Foundation Persistent Volume Claims (永続ボリューム要求、PVC) を使用することができません。そのため、このようなノードを使用する必要がある場合は、容認を設定してノードで csi-plugins を起動することができます。詳細は、https://access.redhat.com/solutions/4827161 を参照してください。
手順
configmap を編集して、カスタムテイントの容認を追加します。エディターを終了する前に必ず保存します。
$ oc edit configmap rook-ceph-operator-config -n openshift-storage
configmapを表示して、追加された容認を確認します。$ oc get configmap rook-ceph-operator-config -n openshift-storage -o yaml
テイント
nodetype=infra:NoScheduleの追加された容認の出力例apiVersion: v1 data: [...] CSI_PLUGIN_TOLERATIONS: | - key: nodetype operator: Equal value: infra effect: NoSchedule - key: node.ocs.openshift.io/storage operator: Equal value: "true" effect: NoSchedule [...] kind: ConfigMap metadata: [...]注記容認の value フィールドで、すべての文字列以外の値に二重引用符が含まれていることを確認してください。たとえば、boolean 型の値 true と int 型の値
1は、"true" と "1" という形で入力する必要があります。独自の infra ノードで
csi-cephfsplugin-* およびcsi-rbdplugin-* Pod の起動に失敗した場合、rook-ceph-operatorを再起動します。$ oc delete -n openshift-storage pod <name of the rook_ceph_operator pod>
Example
$ oc delete -n openshift-storage pod rook-ceph-operator-5446f9b95b-jrn2j pod "rook-ceph-operator-5446f9b95b-jrn2j" deleted
検証手順
csi-cephfsplugin-* および csi-rbdplugin-* Pod が infra ノードで実行されていることを確認します。