
オペレーションガイド
Red Hat Openshift Container Storage の設定および管理
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ を参照してください。
パート I. 管理
第1章 クラスターの管理
Heketi を使用すると、管理者は 1 つまたは複数の Red Hat Gluster Storage クラスターを管理してストレージ容量を追加および削除できます。
Heketi は、Red Hat Gluster Storage ボリュームのライフサイクルを管理するために使用できる RESTful 管理インターフェイスを提供します。Heketi を使用すると、OpenStack Manila、Kubernetes および OpenShift などのクラウドサービスは、サポートされる持続性のタイプで Red Hat Gluster Storage ボリュームを動的にプロビジョニングできます。Heketi は、クラスター全体でブリックの場所を自動的に決定し、ブリックとそのレプリカを異なる障害ドメインに配置できるようにします。Heketi は、任意の数の Red Hat Gluster Storage クラスターもサポートしており、クラウドサービスは単一の Red Hat Gluster Storage クラスターに限定されることなくネットワークファイルストレージを提供できます。
Heketi を使用すると、管理者はブリック、ディスク、または信頼済みストレージプールを管理または設定しなくなりました。Heketi サービスは、管理者のすべてのハードウェアを管理し、オンデマンドでストレージを割り当てることができます。Heketi に登録されているディスクは raw 形式で提供する必要があります。これは、提供されたディスク上で LVM を使用して管理されます。
レプリカ 3 および arbiter ボリュームは、Heketi を使用して作成できるサポート対象のボリュームタイプです。
Heketi ボリュームの作成
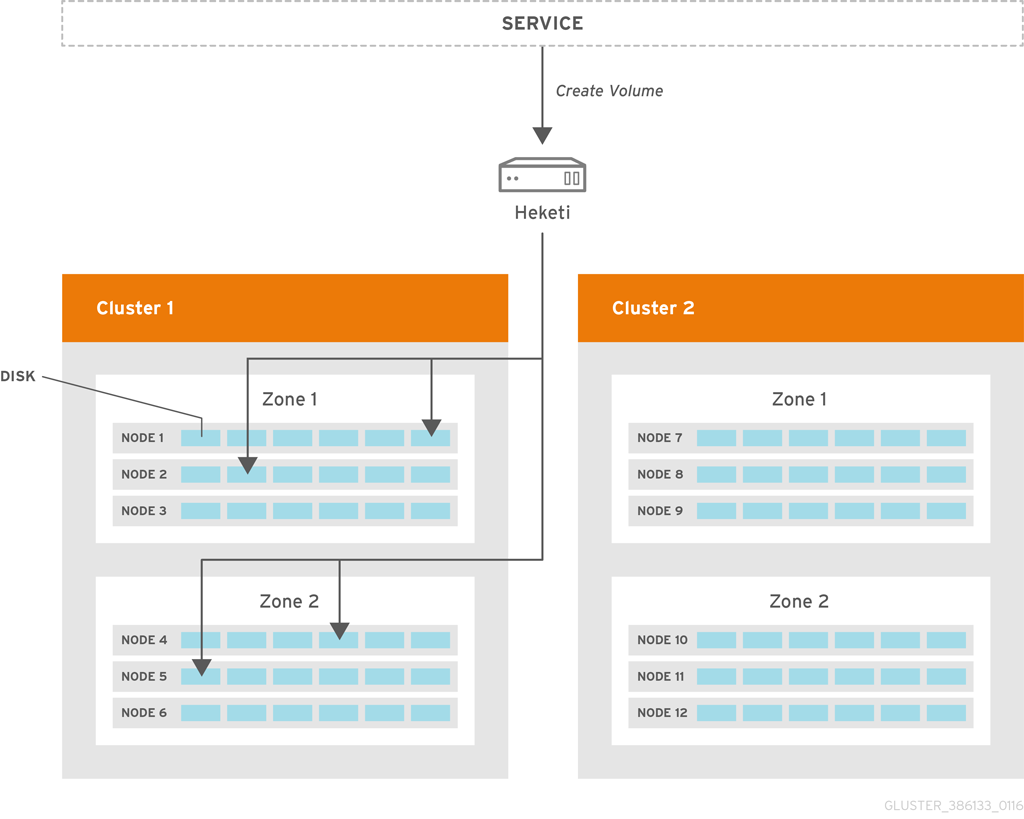
Heketi へのボリューム作成リクエストにより、2 つのゾーンと 4 つのノードに分散したブリックを選択することになります。Red Hat Gluster Storage でボリュームが作成された後に、Heketi は要求を最初に行ったサービスにボリューム情報を提供します。
1.1. ストレージの容量の増加
以下のいずれかの方法でストレージ容量を増やすことができます。
- デバイスの追加
- 新規ノードの追加
- 完全に新しいクラスターの追加
1.1.1. 新しいデバイスの追加
既存のノードにデバイスを追加して、ストレージ容量を増やすことができます。デバイスを追加する場合は、必ずデバイスをセットとして追加する必要があります。たとえば、レプリカ数がレプリカ 2 の分散レプリケートされたボリュームを拡張する場合は、少なくとも 2 つのノードに 1 つのデバイスを追加する必要があります。レプリカ 3 を使用する場合は、少なくとも 1 つのデバイスを少なくとも 3 つのノードに追加する必要があります。
以下のように CLI を使用してデバイスを追加できます。
指定したデバイスを登録します。以下のコマンド例は、デバイス /dev/sde をノード d6f2c22f2757bf67b1486d868dcb7794 に追加する方法を示しています。
# heketi-cli device add --name=/dev/sde --node=d6f2c22f2757bf67b1486d868dcb7794 OUTPUT: Device added successfully
1.1.2. 新規ノードの追加
ストレージを Heketi に追加する別の方法は、新しいノードをクラスターに追加することです。デバイスの追加と同様に、CLI を使用して新しいノードを既存のクラスターに追加できます。新規ノードをクラスターに追加したら、新しいデバイスをそのノードに登録する必要があります。
ノードを正常に追加するには、glusterd 通信のポートが開いていることを確認します。ポートの詳細は https://access.redhat.com/documentation/ja-jp/red_hat_gluster_storage/3.5/html/installation_guide/port_information を参照してください。
OCP クラスターを拡張して、新規ノードを追加します。詳細は https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#adding-cluster-hosts_adding-hosts-to-cluster を参照してください。
注記- 新規ノードがすでに OCP クラスターの一部である場合は、このステップを省略してステップ 2 に進みます。
- OCP クラスターをスケールアップして、コンピュートノードまたはインフラノードのいずれかとして新規ノードを追加できます。たとえば、インフラの場合は node3.example.com openshift_node_group_name='node-config-infra' で、コンピュートノードの場合は node3.example.com openshift_node_group_name='node-config-compute' になります。
ファイアウォールルールを設定します。
注記ノードを正常に追加するには、glusterd 通信のポートが開いていることを確認します。ポートの詳細は https://access.redhat.com/documentation/ja-jp/red_hat_gluster_storage/3.5/html/installation_guide/port_information を参照してください。
以下のルールを、新たに追加した glusterfs ノードの
/etc/sysconfig/iptablesファイルに追加します。-A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 24007 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 24008 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 2222 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m multiport --dports 49152:49664 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 24010 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 3260 -j ACCEPT -A OS_FIREWALL_ALLOW -p tcp -m state --state NEW -m tcp --dport 111 -j ACCEPT
iptables を再読み込み/再起動します。
# systemctl restart iptables
RHGS コンテナーがデプロイされるノードにラベルを追加するには、以下の手順を実行します。
以下のコマンドを実行して、Red Hat Openshift Container Storage が既存プロジェクトでデプロイされ、予想通りに機能していることを確認します。
# oc get ds
以下に例を示します。
# oc get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE glusterfs-storage 3 3 3 3 3 glusterfs=storage-host 1d
新たに追加される各ノードのラベルを追加します。ここでは、Red Hat Gluster Storage Pod が新規クラスターに追加されます。
# oc label node <NODE_NAME> glusterfs=<node_label>
ここで、
- NODE_NAME: 新規に作成されたノードの名前です。
-
node_label: 既存のデーモンセットで使用される名前です。これは、直前の手順で
oc get dsを実行する際に取得した値です。
以下に例を示します。
# oc label node 192.168.90.3 glusterfs=storage-host node "192.168.90.3" labeled
以下のコマンドを実行して、Red Hat Gluster Storage Pod が新規に追加されたノードで実行されているかどうかを確認します。
これらの新規ノードで起動する追加の Gluster Storage Pod を確認します。
# oc get pods
以下に例を示します。
# oc get pods NAME READY STATUS RESTARTS AGE glusterfs-356cf 1/1 Running 0 30d glusterfs-fh4gm 1/1 Running 0 30d glusterfs-hg4tk 1/1 Running 0 30d glusterfs-v759z 0/1 Running 0 1m
追加の Gluster Storage Pod が表示されるはずです。この例では、以前の 3 つではなく 4 つの gluster Pod が表示されるはずです。それらは正常な状態になるまでに 1 - 2 分かかります (例: glusterfs-v759z 0/1 not healthy yet)。
Red Hat Gluster Storage Pod が実行中であることを確認します。
# oc get pods -o wide -l glusterfs=storage-pod
Heketi CLI を使用して新規ノードをクラスターに追加します。以下では、CLI を使用して、
zone 1の新規ノードを 597fceb5d6c876b899e48f599b988f54 クラスターに追加する方法を示しています。# heketi-cli node add --zone=1 --cluster=597fceb5d6c876b899e48f599b988f54 --management-host-name=node4.example.com --storage-host-name=192.168.10.104 OUTPUT: Node information: Id: 095d5f26b56dc6c64564a9bc17338cbf State: online Cluster Id: 597fceb5d6c876b899e48f599b988f54 Zone: 1 Management Hostname node4.example.com Storage Hostname 192.168.10.104
- Heketi CLI を使用してデバイスをクラスターに追加します。デバイスの追加に関する詳細は、「新しいデバイスの追加」を参照してください。
- heketi を使用して、ノードが gluster の信頼済みストレージプールに追加しても自動的に更新されないため、エンドポイントを手動で更新します。エンドポイントの更新方法に関する詳細は、「新規ノードの追加後のエンドポイントの更新」 を参照してください。
1.1.2.1. 新規ノードの追加後のエンドポイントの更新
手順
古い IP アドレスが設定されたすべての namespace にエンドポイントを一覧表示します。
# oc get ep --all-namespaces | grep <OLD_IP><OLD_IP>-
10.0.0.57などの古い IP アドレスを指定します。
例1.1 出力例
NAMESPACE NAME ENDPOINTS AGE glusterfs glusterfs-dynamic-3901a1fb-ee2c-11eb-9447-001a4a0005a7 10.0.0.181:1,10.0.0.57:1,10.0.0.43:1 112d glusterfs glusterfs-dynamic-3bcc23bf-a5c0-11eb-b69a-001a4a0005a7 10.0.0.181:1,10.0.0.57:1,10.0.0.43:1 205d glusterfs glusterfs-dynamic-a4a000f5-ee28-11eb-9447-001a4a0005a7 10.0.0.181:1,10.0.0.57:1,10.0.0.43:1 113d glusterfs heketi-db-storage-endpoints 10.0.0.57:1,10.0.0.181:1,10.74.251.23:1 217dオプション: 新しいノードの IP アドレス (例:
10.0.0.64) が追加されていることを確認します。# oc get ep <heketi-db-endpoint_name>例1.2 例
# oc get ep heketi-db-storage-endpoints
例1.3 出力例
NAME ENDPOINTS AGE heketi-db-storage-endpoints 10.0.0.181:1,10.0.0.57:1,10.0.0.43:1 217d
任意の gluster ボリュームを選択し、関連する heketi Pod に移動して、次のコマンドを実行します。
# heketi-cli volume endpoint patch <volume_id><volume_id>gluster ファイルベースのボリュームの ID を指定します (例:
253778390e76e7ab803231504dc266d4)。例1.4 例
# heketi-cli volume endpoint patch 253778390e76e7ab803231504dc266d4
例1.5 出力例
{"subsets": [{"addresses":[{"ip":"10.0.0.181"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.57"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.43"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.64"}],"ports":[{"port":1}]}]}
この例では、IP アドレス
10.0.0.64を持つ新しいノードが追加されます。デフォルトでは、heketi は各 gluster ボリュームに新規 IP アドレスを表示します。oc bastionから以下のコマンドを実行し、新規ノードの IP アドレスをheketi-db-endpointに追加します。# oc patch ep <heketi-db-endpoint_name> -p <patch_json>
<heketi-db-endpoint_name>-
heketi-db エンドポイントの名前を指定します (例:
heketi-db-storage-endpoints)。 <patch_json>-
heketi-cliコマンドが生成する JSON パッチです。
例1.6 例
# oc patch ep heketi-db-storage-endpoints -p '{"subsets": [{"addresses":[{"ip":"10.0.0.181"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.57"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.43"}],"ports":[{"port":1}]},{"addresses":[{"ip":"10.0.0.64"}],"ports":[{"port":1}]}]}'古い IP アドレスは、gluster エンドポイント上の新規ノードの IP アドレスに置き換えます。
# oc get ep --all-namespaces | grep glusterfs-dynamic | tr -s ' ' | while read LINE; do NS=$(echo $LINE|cut -d' ' -f1); EP=$(echo $LINE|cut -d' ' -f2); echo $NS $EP; oc -n $NS get ep $EP -o yaml | sed 's/<old_ip_address>/<new_ip_address>/g' | oc -n $NS replace -f - ; done
<old_ip_address>- 古い IP アドレスを指定します。
<new_ip_address>-
新しいノードの IP アドレスを指定します (例:
10.0.0.64)。
このコマンドは、すべての heketi エンドポイント (通常は
glusterfs-dynamicという名前で始まる) を編集し、古い IP アドレスを新しい IP アドレスに置き換えます。- 古い IP アドレスは、gluster-block ベースのボリューム上の新規ノードの IP アドレスに置き換えます。詳細は、Red Hat ナレッジベースのソリューション Gluster block PV are not updated with new IPs after gluster node replacement を参照してください。
オプション: ノードがまだ存在する場合は、OpenShift Container Storage からノードを退避して削除する必要があります。
デバイスを削除し、削除します。古いノードからデバイスを削除し、削除する方法は、「デバイスの削除」 を参照してください。
重要-
heketi-cli device delete <device_ID>コマンドとともに、--force-forgetオプションを使用して、障害が発生したデバイスを削除できます。ただし、このオプションは、device delete コマンドが失敗した場合にのみ使用することが推奨されます。 -
システムコマンドを使って、デバイスが削除されているか、 heketi 以外でシステムがクリーンであることを確認した後にのみ、
--force-forgetオプションを使用する必要があります。
-
オプション: ディスクまたはデバイスがまだ存在する場合は、一度に 1 つのデバイスを削除し、自己修復操作が完了するまで待ってから次のデバイスを削除する必要があります。
注記修復操作は、古いノードのすべてのブリックを交換ノードに置き換えるため、完了するまでに時間がかかる場合があります。
- ノードを削除します。heketi 設定からノードを削除する方法は、「ノードの削除」 を参照してください。
-
heketi エンドポイントで古い IP アドレスを新しいノードの IP アドレスに置き換えたときにエンドポイントがすでに更新されている場合は、
heketi-cli volume endpoint patchまたはoc patch epコマンドを実行する必要はありません。前の手順 2 および 3 を参照してください。 - オプション: Persistent Volume (PV)、ブロックボリュームベースの gluster ブロックがある場合は、次の手順 11 ~ 16 に従います。「Block Storage 上のノードの置き換え」 PV 定義と iSCSI ターゲットレイヤーで新しい IP アドレスを更新する必要があるためです。
- 古いノードからストレージラベルを削除します。OpenShift Container Platform から古いノードを削除し、アンインストールする方法の詳細は、ノードのアンインストール を参照してください。
1.1.3. 新規クラスターの既存の Red Hat Openshift Container Storage インストールへの追加
ストレージ容量は、Red Hat Gluster Storage の新規クラスターを追加することで増やすことができます。新規クラスターのノードは、OCP ノード (コンバージドモード) または RHGS ノード (インデペンデントモード) として準備する必要があります。新規クラスターを既存の Red Hat Openshift Container Storage インストールに追加するには、以下のコマンドを実行します。
以下のコマンドを実行して、Red Hat Openshift Container Storage が既存プロジェクトでデプロイされ、予想通りに機能していることを確認します。
# oc get ds
以下に例を示します。
# oc get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE glusterfs-storage 3 3 3 3 3 glusterfs=storage-host 1d
注記「新規ノードの追加」セクションでステップ 1 とステップ 2 を実行して、新しいホストを追加します。追加するすべてのノードで、ステップを繰り返します。
以下のコマンドを実行して、Red Hat Gluster Storage Pod が実行されているかどうかを確認します。
# oc get pods
新たに追加される各ノードのラベルを追加します。ここでは、以下のコマンドを実行して Red Hat Gluster Storage Pod が新規クラスターに追加され、実行されます。
# oc label node <NODE_NAME> glusterfs=<node_label>
ここで、
- NODE_NAME: 新規に作成されたノードの名前です。
- node_label: 既存のデーモンセットで使用される名前です。
以下に例を示します。
# oc label node 192.168.90.3 glusterfs=storage-host node "192.168.90.3" labeled
これらの新規ノードで起動する追加の Gluster Storage Pod を確認します。
# oc get pods
以下に例を示します。
# oc get pods NAME READY STATUS RESTARTS AGE glusterfs-356cf 1/1 Running 0 30d glusterfs-fh4gm 1/1 Running 0 30d glusterfs-hg4tk 1/1 Running 0 30d glusterfs-v759z 0/1 Running 0 1m glusterfs-rgs3k 0/1 Running 0 1m glusterfs-gtq9f 0/1 Running 0 1m
追加の Gluster Storage Pod が表示されるはずです。この例では、以前の 3 つではなく 6 つの gluster Pod が表示されるはずです。それらは正常な状態になるまでに 1 - 2 分かかります (例: glusterfs-v759z, glusterfs-rgs3k, and glusterfs-gtq9f 0/1 not healthy yet)。
以下のコマンドを実行して、Red Hat Gluster Storage Pod が実行されているかどうかを確認します。
# oc get ds
以下に例を示します。
# oc get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE glusterfs-storage 6 6 6 6 6 glusterfs=storage-host 2h
以下のコマンドを使用して、Heketi に新しいクラスターを作成します。
# heketi-cli cluster create
- 新しいデバイスの追加 および 新規ノードの追加 で説明されているように、新たに作成されたクラスターにノードとデバイスを追加します。
1.2. ストレージ容量の削減
Heketi は、ストレージ容量の削減にも対応します。デバイス、ノード、およびクラスターを削除して、ストレージを減らすことができます。これらのリクエストは、Heketi CLI または API を使用してのみ実行できます。コマンドライン API の使用方法は、Heketi API(https://github.com/heketi/heketi/wiki/API) を参照してください。
ID は、heketi-cli topology info コマンドを実行して取得できます。
# heketi-cli topology info
-
heketidbstorageボリュームは、heketi データベースが含まれるため削除できません。
1.2.1. ボリュームの削除
以下の Heketi CLI コマンドを使用してボリュームを削除できます。
# heketi-cli volume delete <volume_id>
以下に例を示します。
# heketi-cli volume delete 12b2590191f571be9e896c7a483953c3 Volume 12b2590191f571be9e896c7a483953c3 deleted
1.2.2. ブリックの削除
以下の Heketi CLI コマンドを使用して、ボリュームからブリックを削除できます。
# heketi-cli brick evict <brick_id>
以下に例を示します。
# heketi-cli brick evict 000e649d15e7d2a7615de3c2878ee270 Brick 000e649d15e7d2a7615de3c2878ee270 evicted
ブリック ID は Heketi トポロジーから判断できます。ブリックは 1 つのボリュームに属するため、ブリック ID のみが必要になります。Heketi は、ブリックが関連付けられているボリュームを自動的に判断し、新しいブリックに置き換えます。
1.2.3. デバイスの削除
デバイスを削除すると、heketi のトポロジーからデバイスが削除されます。ブリックを持つデバイスは削除できません。デバイスを無効にして削除することで、ブリックがないことを確認する必要があります。
1.2.3.1. デバイスの無効化および有効化
デバイスを無効にすると、デバイスへのブリックの割り当てが停止します。以下の Heketi CLI コマンドを使用してデバイスを無効にできます。
# heketi-cli device disable <device_id>
以下に例を示します。
# heketi-cli device disable f53b13b9de1b5125691ee77db8bb47f4 Device f53b13b9de1b5125691ee77db8bb47f4 is now offline
デバイスを再度有効にする場合は、以下のコマンドを実行します。デバイスを有効にすると、デバイスへのブリックの割り当てが可能になります。
# heketi-cli device enable <device_id>
以下に例を示します。
# heketi-cli device enable f53b13b9de1b5125691ee77db8bb47f4 Device f53b13b9de1b5125691ee77db8bb47f4 is now online
1.2.3.2. デバイスの削除
デバイスを削除すると、既存のブリックをデバイスから別のデバイスに移動します。これにより、デバイスにブリックがない状態にするのに役立ちます。デバイスは、無効にされた後にのみ削除できます。
以下のコマンドを使用してデバイスを削除します。
# heketi-cli device remove <device_id>
以下に例を示します。
# heketi-cli device remove e9ef1d9043ed3898227143add599e1f9 Device e9ef1d9043ed3898227143add599e1f9 is now removed
以下のコマンドを使用してデバイスを削除します。
# heketi-cli device delete <device_id>
以下に例を示します。
# heketi-cli device delete 56912a57287d07fad0651ba0003cf9aa Device 56912a57287d07fad0651ba0003cf9aa deleted
削除したデバイスを再利用する唯一の方法は、そのデバイスを heketi のトポロジーに再度追加することです。
1.2.4. ノードの削除
デバイスが追加されたノードは削除できません。ノードを削除するには、ノードに関連付けられたデバイスを削除する必要があります。ノードを無効にして削除することで、基礎となるすべてのデバイスも削除されます。ノードが削除されると、そのノード内のすべてのデバイスを削除し、最終的にノードを削除できます。
1.2.4.1. ノードの無効化および有効化
ノードを無効にすると、ノードに関連付けられたすべてのデバイスへのブリックの割り当てが停止します。以下の Heketi CLI コマンドを使用してノードを無効にできます。
# heketi-cli node disable <node_id>
以下に例を示します。
# heketi-cli node disable 5f0af88b968ed1f01bf959fe4fe804dc Node 5f0af88b968ed1f01bf959fe4fe804dc is now offline
ノードを再度有効にする必要がある場合は、以下のコマンドを実行します。
# heketi-cli node enable <node_id>
以下に例を示します。
# heketi-cli node enable 5f0af88b968ed1f01bf959fe4fe804dc Node 5f0af88b968ed1f01bf959fe4fe804dc is now online
1.2.4.2. ノードの削除
ノードを削除すると、既存のブリックがノードのすべてのデバイスからクラスター内の他のデバイスに移動します。これにより、ノード内のすべてのデバイスにブリックがない状態にするのに役立ちます。デバイスは、無効にされた後にのみ削除できます。
以下のコマンドを実行してノードを削除します。
# heketi-cli node remove <node_id>
以下に例を示します。
# heketi-cli node remove 5f0af88b968ed1f01bf959fe4fe804dc Node 5f0af88b968ed1f01bf959fe4fe804dc is now removed
関連付けられたデバイスがあるノードは削除できないため、以下のコマンドを実行して、ノードに関連付けられているデバイスを削除します。
# heketi-cli device delete <device_id>
以下に例を示します。
# heketi-cli device delete 56912a57287d07fad0651ba0003cf9aa Device 56912a57287d07fad0651ba0003cf9aa deleted
ノード上のすべてのデバイスに対してコマンドを実行します。
以下のコマンドを使用してノードを削除します。
# heketi-cli node delete <node_id>
以下に例を示します。
# heketi-cli node delete 5f0af88b968ed1f01bf959fe4fe804dc Node 5f0af88b968ed1f01bf959fe4fe804dc deleted
ノードを削除すると、heketi トポロジーからノードが削除されます。削除したノードを再利用する唯一の方法は、そのノードを heketi のトポロジーに再度追加することです。
注記-
heketi を使用して、gluster 信頼済みストレージプールからノードを削除しても、既存のエンドポイントは自動的に更新されません。
エンドポイントを更新するには、以下のコマンドを実行します。
# heketi-cli volume endpoint patch <volume-id>
# oc patch ep <heketi-db-endpoint-name> -p <changes>
- オプション:heketi を使用して、gluster 信頼済みストレージプールからノードを削除しても、削除されたノードで実行されている Pod は依然として存在します。Pod を削除するには、以下のコマンドを実行します。
# oc label nodes <node name> glusterfs-
以下に例を示します。
# oc label node 192.168.90.3 glusterfs- node "192.168.90.3" labeled
glusterfs=storage-host ラベルはノードから削除され、削除された glusterfs Pod が停止され、削除されたノードから削除されます。メンテナーンス前の必要な手順の詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/operations_guide/index#necessary_steps_to_be_followed_before_maintenance のリンクを参照してください。
-
heketi を使用して、gluster 信頼済みストレージプールからノードを削除しても、既存のエンドポイントは自動的に更新されません。
1.2.5. クラスターの削除
以下の Heketi CLI コマンドを使用してクラスターを削除できます。
クラスターを削除する前に、クラスター内のすべてのノードが削除されていることを確認してください。
# heketi-cli cluster delete <cluster_id>
以下に例を示します。
# heketi-cli cluster delete 0e949d91c608d13fd3fc4e96f798a5b1 Cluster 0e949d91c608d13fd3fc4e96f798a5b1 deleted
1.3. クラスターリソースの置き換え
Heketi は、デバイスおよびノードの置き換えをサポートします。以下のセクションで、デバイスとノードを置き換える手順を説明します。
1.3.1. デバイスの置き換え
Heketi は、デバイスを別のデバイスに一対一に置き換えることを許可しません。ただし、デバイスに障害が発生した場合には、障害が発生したデバイスの置き換えに必要な操作シーケンスについて以下の例に従ってください。
以下のコマンドを使用して、障害が発生しているデバイスを探します。
# heketi-cli topology info
… … ... Nodes: Node Id: 8faade64a9c8669de204b66bc083b10d ... ... … Id:a811261864ee190941b17c72809a5001 Name:/dev/vdc State:online Size (GiB):499 Used (GiB):281 Free (GiB):218 Bricks: Id:34c14120bef5621f287951bcdfa774fc Size (GiB):280 Path: /var/lib/heketi/mounts/vg_a811261864ee190941b17c72809a5001/brick_34c14120bef5621f287951bcdfa774fc/brick … … ...以下の例は、障害が発生したデバイスの置き換えに必要な操作シーケンスを説明しています。この例では、ID
8faade64a9c8669de204b66bc083b10dasを持つノードに属するデバイス IDa811261864ee190941b17c72809a5001を使用します。置き換えられるデバイスと同じノードに新しいデバイスを追加することが推奨されます。
# heketi-cli device add --name /dev/vdd --node 8faade64a9c8669de204b66bc083b10d Device added successfully
障害が発生したデバイスを無効にします。
# heketi-cli device disable a811261864ee190941b17c72809a5001 Device a811261864ee190941b17c72809a5001 is now offline
障害が発生したデバイスを削除します。
# heketi-cli device remove a811261864ee190941b17c72809a5001 Device a811261864ee190941b17c72809a5001 is now removed
この段階で、ブリックは障害が発生したデバイスから移行されます。Heketi は、ブリック割り当てアルゴリズムに基づいて適切なデバイスを選択します。その結果、すべてのブリックが新たに追加されたデバイスに移行されない可能性があります。
障害が発生したデバイスを削除します。
以下の heketi-cli delete コマンドを使用してデバイスを削除します。
# heketi-cli device delete a811261864ee190941b17c72809a5001 Device a811261864ee190941b17c72809a5001 deleted
注記-
Heketi-cli device delete <device-ID>コマンドとともに、--force-forgetオプションを使用して、障害が発生したデバイスを削除できます。ただし、このオプションは、device delete コマンドが失敗した場合のみ使用することが推奨されます。 -
システムコマンドを使って、デバイスが削除されているか、 heketi 以外でシステムがクリーンであることを確認した後にのみ、
--force-forgetオプションを使用する必要があります。
-
修復を完了できるように、
performance.read-aheadオプションは無効にする必要があります。# gluster volume set <VOLUME> performance.read-ahead off
注記ボリューム修復タスクが完了するまで
performance.read-aheadオプションを OFF に設定します。修復が完了したら、デフォルト状態のON に戻します。- 100,000 を超えるエントリーに修復が必要な場合は、追加の shd を開始する必要があります。追加の自己修復デーモンの起動方法は https://access.redhat.com/solutions/3794011 を参照してください。
別のデバイスで上記の手順を繰り返す前に、自己修復操作が完了するのを待つ必要があります。Number of entries の値が 0 の値を返すと、自己修復操作が完了していることを確認できます。
# oc rsh <any_gluster_pod_name> for each in $(gluster volume list) ; do gluster vol heal $each info | grep "Number of entries:" ; done Number of entries: 0 Number of entries: 0 Number of entries: 0
1.3.2. ノードの置き換え
Heketi は、ノードを別のノードに一対一に置き換えることを許可しません。ただし、ノードに障害が発生した場合には、障害が発生したノードおよびその個々のデバイスの置き換えに必要な操作シーケンスについて以下の例に従ってください。
以下のコマンドを使用して、障害が発生しているノードを探します。
# heketi-cli topology info … … ... Nodes: Node Id: 8faade64a9c8669de204b66bc083b10d ... ... … Id:a811261864ee190941b17c72809a5001 Name:/dev/vdc State:online Size (GiB):499 Used (GiB):281 Free (GiB):218 Bricks: Id:34c14120bef5621f287951bcdfa774fc Size (GiB):280 Path: /var/lib/heketi/mounts/vg_a811261864ee190941b17c72809a5001/brick_34c14120bef5621f287951bcdfa774fc/brick … … ...以下の例は、障害が発生したノードの置き換えに必要な操作シーケンスを説明しています。この例では、ノード ID 8faade64a9c8669de204b66bc083b10d を使用します。
OCP クラスターを拡張して、置き換え用のノードを追加します。ノードの追加方法に関する詳細は、「新規ノードの追加」セクションの手順を参照してください。
注記置き換え用のノードがすでに OCP クラスターの一部である場合は、このステップを省略してステップ 2 に進みます。
交換するノードと同じ数のデバイスとサイズの新しいノードを追加することを推奨します。「新規ノードの追加」 の手順を参照してください。
# heketi-cli node add --zone=1 --cluster=597fceb5d6c876b899e48f599b988f54 --management-host-name=node4.example.com --storage-host-name=192.168.10.104 # heketi-cli device add --name /dev/vdd --node 8faade64a9c8669de204b66bc083b10d Node and device added successfully
障害が発生したノードを無効にします。
# heketi-cli node disable 8faade64a9c8669de204b66bc083b10d Node 8faade64a9c8669de204b66bc083b10d is now offline
障害のあるノードを削除します。
# heketi-cli node remove 8faade64a9c8669de204b66bc083b10d Node 8faade64a9c8669de204b66bc083b10d is now removed
この段階で、ブリックは障害が発生したノードから移行されます。Heketi は、ブリック割り当てアルゴリズムに基づいて適切なデバイスを選択します。
関連付けられたデバイスがあるノードは削除できないため、以下のコマンドを実行して、ノードに関連付けられているデバイスを削除します。
# heketi-cli device delete <device_id>
以下に例を示します。
# heketi-cli device delete 56912a57287d07fad0651ba0003cf9aa Device 56912a57287d07fad0651ba0003cf9aa deleted
ノード上のすべてのデバイスに対してコマンドを実行します。
障害のあるノードを削除します。
# heketi-cli node delete 8faade64a9c8669de204b66bc083b10d Node 8faade64a9c8669de204b66bc083b10d deleted
注記ノードからブロックを置き換える場合は、「Block Storage 上のノードの置き換え」を参照してください。
第2章 OpenShift 環境における Red Hat Gluster Storage Pod での操作
本章では、Red Hat Gluster Storage Pod(gluster Pod) で実行できるさまざまな操作を一覧表示します。
Pod を一覧表示するには、以下のコマンドを実行します。
# oc get pods -n <storage_project_name>
以下に例を示します。
# oc get pods -n storage-project NAME READY STATUS RESTARTS AGE storage-project-router-1-v89qc 1/1 Running 0 1d glusterfs-dc-node1.example.com 1/1 Running 0 1d glusterfs-dc-node2.example.com 1/1 Running 1 1d glusterfs-dc-node3.example.com 1/1 Running 0 1d heketi-1-k1u14 1/1 Running 0 23m
以下は、上記の例の gluster Pod です。
glusterfs-dc-node1.example.com glusterfs-dc-node2.example.com glusterfs-dc-node3.example.com
注記topology.json ファイルは、指定の 信頼済みストレージプール (TSP) のノードの詳細を提供します。上記の例では、3 つの Red Hat Gluster Storage ノードはすべて同じ TSP から取得されます。
gluster Pod シェルに入るには、以下のコマンドを実行します。
# oc rsh <gluster_pod_name> -n <storage_project_name>
以下に例を示します。
# oc rsh glusterfs-dc-node1.example.com -n storage-project sh-4.2#
ピアステータスを取得するには、以下のコマンドを実行します。
# gluster peer status
以下に例を示します。
# gluster peer status Number of Peers: 2 Hostname: node2.example.com Uuid: 9f3f84d2-ef8e-4d6e-aa2c-5e0370a99620 State: Peer in Cluster (Connected) Other names: node1.example.com Hostname: node3.example.com Uuid: 38621acd-eb76-4bd8-8162-9c2374affbbd State: Peer in Cluster (Connected)
信頼済みストレージプールの gluster ボリュームを一覧表示するには、以下のコマンドを実行します。
# gluster volume info
以下に例を示します。
Volume Name: heketidbstorage Type: Distributed-Replicate Volume ID: 2fa53b28-121d-4842-9d2f-dce1b0458fda Status: Started Number of Bricks: 2 x 3 = 6 Transport-type: tcp Bricks: Brick1: 192.168.121.172:/var/lib/heketi/mounts/vg_1be433737b71419dc9b395e221255fb3/brick_c67fb97f74649d990c5743090e0c9176/brick Brick2: 192.168.121.233:/var/lib/heketi/mounts/vg_0013ee200cdefaeb6dfedd28e50fd261/brick_6ebf1ee62a8e9e7a0f88e4551d4b2386/brick Brick3: 192.168.121.168:/var/lib/heketi/mounts/vg_e4b32535c55c88f9190da7b7efd1fcab/brick_df5db97aa002d572a0fec6bcf2101aad/brick Brick4: 192.168.121.233:/var/lib/heketi/mounts/vg_0013ee200cdefaeb6dfedd28e50fd261/brick_acc82e56236df912e9a1948f594415a7/brick Brick5: 192.168.121.168:/var/lib/heketi/mounts/vg_e4b32535c55c88f9190da7b7efd1fcab/brick_65dceb1f749ec417533ddeae9535e8be/brick Brick6: 192.168.121.172:/var/lib/heketi/mounts/vg_7ad961dbd24e16d62cabe10fd8bf8909/brick_f258450fc6f025f99952a6edea203859/brick Options Reconfigured: performance.readdir-ahead: on Volume Name: vol_9e86c0493f6b1be648c9deee1dc226a6 Type: Distributed-Replicate Volume ID: 940177c3-d866-4e5e-9aa0-fc9be94fc0f4 Status: Started Number of Bricks: 2 x 3 = 6 Transport-type: tcp Bricks: Brick1: 192.168.121.168:/var/lib/heketi/mounts/vg_3fa141bf2d09d30b899f2f260c494376/brick_9fb4a5206bdd8ac70170d00f304f99a5/brick Brick2: 192.168.121.172:/var/lib/heketi/mounts/vg_7ad961dbd24e16d62cabe10fd8bf8909/brick_dae2422d518915241f74fd90b426a379/brick Brick3: 192.168.121.233:/var/lib/heketi/mounts/vg_5c6428c439eb6686c5e4cee56532bacf/brick_b3768ba8e80863724c9ec42446ea4812/brick Brick4: 192.168.121.172:/var/lib/heketi/mounts/vg_7ad961dbd24e16d62cabe10fd8bf8909/brick_0a13958525c6343c4a7951acec199da0/brick Brick5: 192.168.121.168:/var/lib/heketi/mounts/vg_17fbc98d84df86756e7826326fb33aa4/brick_af42af87ad87ab4f01e8ca153abbbee9/brick Brick6: 192.168.121.233:/var/lib/heketi/mounts/vg_5c6428c439eb6686c5e4cee56532bacf/brick_ef41e04ca648efaf04178e64d25dbdcb/brick Options Reconfigured: performance.readdir-ahead: on
ボリュームのステータスを取得するには、以下のコマンドを実行します。
# gluster volume status <volname>
以下に例を示します。
# gluster volume status vol_9e86c0493f6b1be648c9deee1dc226a6 Status of volume: vol_9e86c0493f6b1be648c9deee1dc226a6 Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick 192.168.121.168:/var/lib/heketi/mounts/v g_3fa141bf2d09d30b899f2f260c494376/brick_9f b4a5206bdd8ac70170d00f304f99a5/brick 49154 0 Y 3462 Brick 192.168.121.172:/var/lib/heketi/mounts/v g_7ad961dbd24e16d62cabe10fd8bf8909/brick_da e2422d518915241f74fd90b426a379/brick 49154 0 Y 115939 Brick 192.168.121.233:/var/lib/heketi/mounts/v g_5c6428c439eb6686c5e4cee56532bacf/brick_b3 768ba8e80863724c9ec42446ea4812/brick 49154 0 Y 116134 Brick 192.168.121.172:/var/lib/heketi/mounts/v g_7ad961dbd24e16d62cabe10fd8bf8909/brick_0a 13958525c6343c4a7951acec199da0/brick 49155 0 Y 115958 Brick 192.168.121.168:/var/lib/heketi/mounts/v g_17fbc98d84df86756e7826326fb33aa4/brick_af 42af87ad87ab4f01e8ca153abbbee9/brick 49155 0 Y 3481 Brick 192.168.121.233:/var/lib/heketi/mounts/v g_5c6428c439eb6686c5e4cee56532bacf/brick_ef 41e04ca648efaf04178e64d25dbdcb/brick 49155 0 Y 116153 NFS Server on localhost 2049 0 Y 116173 Self-heal Daemon on localhost N/A N/A Y 116181 NFS Server on node1.example.com 2049 0 Y 3501 Self-heal Daemon on node1.example.com N/A N/A Y 3509 NFS Server on 192.168.121.172 2049 0 Y 115978 Self-heal Daemon on 192.168.121.172 N/A N/A Y 115986 Task Status of Volume vol_9e86c0493f6b1be648c9deee1dc226a6 ------------------------------------------------------------------------------ There are no active volume tasks
スナップショット機能を使用するには、いずれかのノードで以下のコマンドを使用してスナップショットモジュールを読み込みます。
# modprobe dm_snapshot
重要スナップショットの使用に関する制限
- スナップショットの作成後に、ユーザーサービス可能なスナップショット機能のみを使用してアクセスする必要があります。これは、以前のバージョンのファイルを必要な場所にコピーするために使用できます。
- ボリュームをスナップショットの状態に戻すことはサポートされていないため、データの一貫性を損傷する可能性があるため、実行しないでください。
- スナップショットのあるボリュームでは、ボリューム拡張などのボリューム変更操作を実行できません。
- gluster ブロックベースの PV の一貫したスナップショットを作成できません。
gluster ボリュームのスナップショットを作成するには、以下のコマンドを実行します。
# gluster snapshot create <snapname> <volname>
以下に例を示します。
# gluster snapshot create snap1 vol_9e86c0493f6b1be648c9deee1dc226a6 snapshot create: success: Snap snap1_GMT-2016.07.29-13.05.46 created successfully
スナップショットを一覧表示するには、以下のコマンドを実行します。
# gluster snapshot list
以下に例を示します。
# gluster snapshot list snap1_GMT-2016.07.29-13.05.46 snap2_GMT-2016.07.29-13.06.13 snap3_GMT-2016.07.29-13.06.18 snap4_GMT-2016.07.29-13.06.22 snap5_GMT-2016.07.29-13.06.26
スナップショットを削除するには、以下のコマンドを実行します。
# gluster snap delete <snapname>
以下に例を示します。
# gluster snap delete snap1_GMT-2016.07.29-13.05.46 Deleting snap will erase all the information about the snap. Do you still want to continue? (y/n) y snapshot delete: snap1_GMT-2016.07.29-13.05.46: snap removed successfully
スナップショットの管理に関する詳細は https://access.redhat.com/documentation/ja-jp/red_hat_gluster_storage/3.5/html-single/administration_guide/index#chap-Managing_Snapshots を参照してください。
Red Hat Openshift Container Storage 以外のリモートサイトへの geo レプリケーション用に、Red Hat Openshift Container Storage ボリュームを設定できます。geo レプリケーションは、マスター/スレーブモデルを使用します。ここでは、Red Hat Openshift Container Storage ボリュームはマスターボリュームとして機能します。geo レプリケーションを設定するには、gluster Pod で geo レプリケーションコマンドを実行する必要があります。gluster Pod シェルに入るには、以下のコマンドを実行します。
# oc rsh <gluster_pod_name> -n <storage_project_name>
geo レプリケーションの設定に関する詳細は https://access.redhat.com/documentation/ja-jp/red_hat_gluster_storage/3.5/html/administration_guide/chap-managing_geo-replication を参照してください。
ブリック多重化は、1 つのプロセスに複数のブリックを含めることができる機能です。これにより、リソース消費が減少し、同じメモリー消費量で前より多くのブリックを実行できるようになります。
ブリック多重化は、Container-Native Storage 3.6 以降デフォルトで有効になっています。これを無効にする場合は、以下のコマンドを実行します。
# gluster volume set all cluster.brick-multiplex off
glusterfs libfuse の
auto_unmountオプションが有効になっていると、アンマウントを実行する別のモニタープロセスを実行することで、FUSE サーバーの終了時にファイルシステムがアンマウントされるようにします。Openshift の GlusterFS プラグインは、gluster マウントの
auto_unmountオプションを有効にします。
2.1. ノードのメンテナーンス
2.1.1. メンテナーンスの前に必要な手順
glusterfs daemonsetのセレクターであるラベル glusterfs または同等のラベルを削除します。Pod が終了するまで待機します。以下のコマンドを実行して
node selectorを取得します。# oc get ds
以下に例を示します。
# oc get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE glusterfs-storage 3 3 3 3 3 NODE SELECTOR AGE glusterfs=storage-host 12d以下のコマンドを使用して glusterfs ラベルを削除します。
# oc label node <storge_node1> glusterfs-
以下に例を示します。
# oc label node <storge_node1> glusterfs- node/<storage_node1> labeled
glusterfs Pod が終了するまで待機します。以下のコマンドを使用して検証します。
# oc get pods -l glusterfs
以下に例を示します。
# oc get pods -l glusterfs NAME READY STATUS RESTARTS AGE glusterblock-storage-provisioner 1/1 Running 0 7m glusterfs-storage-4tc9c 1/1 Terminating 0 5m glusterfs-storage-htrfg 1/1 Running 0 1d glusterfs-storage-z75bc 1/1 Running 0 1d heketi-storage-1-shgrr 1/1 Running 0 1d
以下のコマンドを実行して、ノードをスケジュール対象外にします。
# oc adm manage-node --schedulable=false <storage_node1>
以下に例を示します。
# oc adm manage-node --schedulable=false <storage_node1> NAME STATUS ROLES AGE VERSION storage_node1 Ready,SchedulingDisabled compute 12d v1.11.0+d4cacc0
以下のコマンドを使用してノードをドレイン (解放) します。
# oc adm drain --ignore-daemonsets <storage_node1>
注記メンテナーンスを実行し、必要に応じて再起動します。
2.1.2. メンテナーンス後の必要な手順
以下のコマンドを使用して、ノードをスケジューリング可能な状態にします。
# oc adm manage-node --schedulable=true <storage_node1>
以下に例を示します。
# oc adm manage-node --schedulable=true <storage_node1> NAME STATUS ROLES AGE VERSION node1 Ready compute 12d v1.11.0+d4cacc0
glusterfs daemonsetのセレクターであるラベル glusterfs または同等のラベルを追加します。Pod が使用できる状態になるまで待機します。以下のコマンドを実行して
node selectorを取得します。# oc get ds
以下に例を示します。
# oc get ds NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE glusterfs-storage 3 3 3 3 3 NODE SELECTOR AGE glusterfs=storage-host 12d上記のノードセレクターと以下のコマンドを使用して glusterfs ノードにラベルを付けます。
# oc label node <storage_node1> glusterfs=storage-host
以下に例を示します。
# oc label node <storage_node1> glusterfs=storage-host node/<storage_node1> labeled
Pod が Ready 状態になるまで待機します。
# oc get pods
以下に例を示します。
# oc get pods NAME READY STATUS RESTARTS AGE glusterblock-storage-provisioner 1/1 Running 0 3m glusterfs-storage-4tc9c 0/1 Running 0 50s glusterfs-storage-htrfg 1/1 Running 0 1d glusterfs-storage-z75bc 1/1 Running 0 1d heketi-storage-1-shgrr 1/1 Running 0 1d
Pod が 1/1 Ready 状態になるまで待機します。
以下に例を示します。
# oc get pods NAME READY STATUS RESTARTS AGE glusterblock-storage-provisioner 1/1 Running 0 3m glusterfs-storage-4tc9c 1/1 Running 0 58s glusterfs-storage-htrfg 1/1 Running 0 1d glusterfs-storage-z75bc 1/1 Running 0 1d heketi-storage-1-shgrr 1/1 Running 0 1d
修復が完了するまで待ち、oc rsh を使用して glusterfs Pod のシェルを取得し、以下のコマンドを使用して修復を監視し、Number of entries がゼロ (0) になるまで待機します。
# for each_volume in
gluster volume list; do gluster volume heal $each_volume info ; done以下に例を示します。
# for each_volume in
gluster volume list; do gluster volume heal $each_volume info ; done Brick 10.70.46.210:/var/lib/heketi/mounts/vg_64e90b4b94174f19802a8026f652f6d7/brick_564f7725cef192f0fd2ba1422ecbf590/brick Status: Connected Number of entries: 0 Brick 10.70.46.243:/var/lib/heketi/mounts/vg_4fadbf84bbc67873543472655e9660ec/brick_9c9c8c64c48d24c91948bc810219c945/brick Status: Connected Number of entries: 0 Brick 10.70.46.224:/var/lib/heketi/mounts/vg_9fbaf0c06495e66f5087a51ad64e54c3/brick_75e40df81383a03b1778399dc342e794/brick Status: Connected Number of entries: 0 Brick 10.70.46.224:/var/lib/heketi/mounts/vg_9fbaf0c06495e66f5087a51ad64e54c3/brick_e0058f65155769142cec81798962b9a7/brick Status: Connected Number of entries: 0 Brick 10.70.46.210:/var/lib/heketi/mounts/vg_64e90b4b94174f19802a8026f652f6d7/brick_3cf035275dc93e0437fdfaea509a3a44/brick Status: Connected Number of entries: 0 Brick 10.70.46.243:/var/lib/heketi/mounts/vg_4fadbf84bbc67873543472655e9660ec/brick_2cfd11ce587e622fe800dfaec101e463/brick Status: Connected Number of entries: 0
パート II. 操作
第3章 永続ボリュームの作成
OpenShift Container Platform クラスターは、GlusterFS を使用している 永続ストレージ を使ってプロビジョニングすることが可能です。
永続ボリューム (PV) と Persistent Volume Claim (永続ボリューム要求、PVC) は、単一プロジェクトでボリュームを共有できます。PV 定義に含まれる GlusterFS に固有の情報は、Pod 定義で直接定義することも可能ですが、この方法の場合にはボリュームが一意のクラスターリソースとして作成されされないため、ボリュームが競合の影響を受けやすくなります。
ラベルおよびセレクターによる PV のバインド
ラベルは OpenShift Container Platform の機能であり、ユーザー定義のタグ (キーと値のペア) をオブジェクトの仕様の一部としてサポートします。その主な目的は、オブジェクト間で同一ラベルを定義してオブジェクトを任意にグループ化できるようにすることです。定義したラベルをセレクターでターゲットとして指定すると、指定のラベル値を持つすべてのオブジェクトが一致します。この機能により、PVC を PV にバインドすることができます。
ラベルを使用して、ボリューム間で共有している共通の属性や特性を識別できます。たとえば、gluster ボリュームを定義し、storage-tier という名前のカスタム属性 (キー) を持たせて、gold という値を割り当てることができます。要求で storage-tier=gold を使用して PV を選択すると、その PV に一致します。
ファイルベースのストレージでのボリュームのプロビジョニングに関する詳細は、「ファイルストレージ」を参照してください。同様に、ブロックベースのストレージでボリュームをプロビジョニングする方法は、「Block Storage」で提供されています。
3.1. ファイルストレージ
ファイルストレージ (ファイルレベルまたはファイルベースのストレージとも呼ばれます) は、データを階層構造に保存します。データはファイルとフォルダーに保存され、格納しているシステムと取得するシステムの両方に同じ形式で表示されます。ボリュームは、ファイルベースのストレージ用に静的または動的にプロビジョニングできます。
3.1.1. ボリュームの静的プロビジョニング
OpenShift および Kubernetes で永続ボリュームのサポートを有効にするには、いくつかのエンドポイントとサービスを作成する必要があります。
OpenShift Container Storage が (デフォルトの)Ansible インストーラーを使用してデプロイされた場合、以下の手順は必要ありません。
glusterfs エンドポイントファイルのサンプル (sample-gluster-endpoints.yaml) および glusterfs サービスファイルのサンプル (sample-gluster-service.yaml) は、/usr/share/heketi/templates/ ディレクトリーで利用できます。
Ansible デプロイメントの場合、/usr/share/heketi/templates/ ディレクトリーは作成されないため、サンプルエンドポイントやサービスファイルは利用できません。
サンプル glusterfs エンドポイントファイル / glusterfs サービスファイルを任意の場所にコピーしてから、コピーしたファイルを編集してください。以下に例を示します。
# cp /usr/share/heketi/templates/sample-gluster-endpoints.yaml /<_path_>/gluster-endpoints.yaml
作成するエンドポイントを指定するには、コピーした sample-gluster-endpoints.yaml ファイルを、環境に基づいて作成されるエンドポイントで更新します。Red Hat Gluster Storage の信頼済みストレージプールには、それぞれ、信頼済みストレージプールのノードの IP を持つ独自のエンドポイントが必要です。
# cat sample-gluster-endpoints.yaml apiVersion: v1 kind: Endpoints metadata: name: glusterfs-cluster subsets: - addresses: - ip: 192.168.10.100 ports: - port: 1 - addresses: - ip: 192.168.10.101 ports: - port: 1 - addresses: - ip: 192.168.10.102 ports: - port: 1- name
- エンドポイントの名前。
- ip
- Red Hat Gluster Storage ノードの IP アドレス。
以下のコマンドを実行してエンドポイントを作成します。
# oc create -f <name_of_endpoint_file>
以下に例を示します。
# oc create -f sample-gluster-endpoints.yaml endpoints "glusterfs-cluster" created
エンドポイントが作成されたことを確認するには、以下のコマンドを実行します。
# oc get endpoints
以下に例を示します。
# oc get endpoints NAME ENDPOINTS AGE storage-project-router 192.168.121.233:80,192.168.121.233:443,192.168.121.233:1936 2d glusterfs-cluster 192.168.121.168:1,192.168.121.172:1,192.168.121.233:1 3s heketi 10.1.1.3:8080 2m heketi-storage-endpoints 192.168.121.168:1,192.168.121.172:1,192.168.121.233:1 3m
以下のコマンドを実行して gluster サービスを作成します。
# oc create -f <name_of_service_file>
以下に例を示します。
# cat sample-gluster-service.yaml apiVersion: v1 kind: Service metadata: name: glusterfs-cluster spec: ports: - port: 1
# oc create -f sample-gluster-service.yaml service "glusterfs-cluster" created
サービスが作成されたことを確認するには、以下のコマンドを実行します。
# oc get service
以下に例を示します。
# oc get service NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE storage-project-router 172.30.94.109 <none> 80/TCP,443/TCP,1936/TCP 2d glusterfs-cluster 172.30.212.6 <none> 1/TCP 5s heketi 172.30.175.7 <none> 8080/TCP 2m heketi-storage-endpoints 172.30.18.24 <none> 1/TCP 3m
注記エンドポイントとサービスは、永続ストレージを必要とする各プロジェクトに対して作成する必要があります。
GlusterFS から Replica 3 の 100 G 永続ボリュームを作成し、このボリュームを記述する永続ボリュームの仕様を pv001.json ファイルに出力します。
$ heketi-cli volume create --size=100 --persistent-volume-file=pv001.json
cat pv001.json { "kind": "PersistentVolume", "apiVersion": "v1", "metadata": { "name": "glusterfs-f8c612ee", "creationTimestamp": null }, "spec": { "capacity": { "storage": "100Gi" }, "glusterfs": { "endpoints": "TYPE ENDPOINT HERE", "path": "vol_f8c612eea57556197511f6b8c54b6070" }, "accessModes": [ "ReadWriteMany" ], "persistentVolumeReclaimPolicy": "Retain" }, "status": {}重要Labels 情報は .json ファイルに手動で追加する必要があります。
以下は、参照用の YAML ファイルの例です。
apiVersion: v1 kind: PersistentVolume metadata: name: pv-storage-project-glusterfs1 labels: storage-tier: gold spec: capacity: storage: 12Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain glusterfs: endpoints: TYPE END POINTS NAME HERE, path: vol_e6b77204ff54c779c042f570a71b1407- name
- ボリュームの名前。
- storage
- このボリュームに割り当てられるストレージの量。
- glusterfs
- 使用されているボリュームタイプ。この場合は glusterfs プラグインです。
- endpoints
- 作成された信頼済みストレージプールを定義するエンドポイント名
- path
- 信頼済みストレージプールからアクセスされる Red Hat Gluster Storage ボリューム。
- accessModes
- accessModes は、PV と PVC を一致させるためのラベルとして使用されます。現時点で、これらはいずれの形態のアクセス制御も定義しません。
- labels
- ラベルを使用して、ボリューム間で共有している共通の属性や特性を識別します。この例では、gluster ボリュームを定義し、storage-tier という名前のカスタム属性 (キー) を持たせて、gold という値を割り当てています。要求で storage-tier=gold を使用して PV を選択すると、その PV に一致します。
注記-
heketi-cli は、コマンドラインのエンドポイント名 (--persistent-volume-endpoint="TYPE ENDPOINT HERE") も受け入れます。次に、これをパイプで
oc create -f -に渡して永続ボリュームをすぐに作成できます。 -
環境内に複数の Red Hat Gluster Storage の信頼済みストレージプールがある場合は、
heketi-cli volume listコマンドを使用して、ボリュームが作成される信頼済みストレージプールを確認できます。このコマンドはクラスター名を一覧表示します。次に、pv001.json ファイルのエンドポイント情報を適宜更新できます。 - レプリカ数がデフォルト値の 3(レプリカ 3) に設定された 2 つのノードのみを持つ Heketi ボリュームを作成する場合、3 つの異なるノードに 3 つのディスクのレプリカセットを作成するスペースがないため、Heketi がエラー"No space"を表示します。
- すべての heketi-cli 書き込み操作 (volume create、cluster create など) が失敗し、読み取り操作 (例:topology info、volume info など) に成功すると、gluster ボリュームが読み取り専用モードで動作している可能性があります。
pv001.json ファイルを編集し、エンドポイントのセクションにエンドポイントの名前を入力します。
cat pv001.json { "kind": "PersistentVolume", "apiVersion": "v1", "metadata": { "name": "glusterfs-f8c612ee", "creationTimestamp": null, "labels": { "storage-tier": "gold" } }, "spec": { "capacity": { "storage": "12Gi" }, "glusterfs": { "endpoints": "glusterfs-cluster", "path": "vol_f8c612eea57556197511f6b8c54b6070" }, "accessModes": [ "ReadWriteMany" ], "persistentVolumeReclaimPolicy": "Retain" }, "status": {} }以下のコマンドを実行して永続ボリュームを作成します。
# oc create -f pv001.json
以下に例を示します。
# oc create -f pv001.json persistentvolume "glusterfs-4fc22ff9" created
永続ボリュームが作成されたことを確認するには、以下のコマンドを実行します。
# oc get pv
以下に例を示します。
# oc get pv NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE glusterfs-4fc22ff9 100Gi RWX Available 4s
永続ボリューム要求ファイルを作成します。以下に例を示します。
# cat pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: glusterfs-claim spec: accessModes: - ReadWriteMany resources: requests: storage: 100Gi selector: matchLabels: storage-tier: gold以下のコマンドを実行して、永続ボリュームを永続ボリューム要求 (PVC) にバインドします。
# oc create -f pvc.yaml
以下に例を示します。
# oc create -f pvc.yaml persistentvolumeclaim"glusterfs-claim" created
永続ボリュームと永続ボリューム要求がバインドされていることを確認するには、以下のコマンドを実行します。
# oc get pv # oc get pvc
以下に例を示します。
# oc get pv NAME CAPACITY ACCESSMODES STATUS CLAIM REASON AGE glusterfs-4fc22ff9 100Gi RWX Bound storage-project/glusterfs-claim 1m
# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE glusterfs-claim Bound glusterfs-4fc22ff9 100Gi RWX 11s
この要求はアプリケーションで使用できます。以下に例を示します。
# cat app.yaml apiVersion: v1 kind: Pod metadata: name: busybox spec: containers: - image: busybox command: - sleep - "3600" name: busybox volumeMounts: - mountPath: /usr/share/busybox name: mypvc volumes: - name: mypvc persistentVolumeClaim: claimName: glusterfs-claim# oc create -f app.yaml pod "busybox" created
アプリケーションで glusterfs 要求を使用する方法についての詳細は https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-storage-examples-gluster-example を参照してください。
Pod が作成されたことを確認するには、以下のコマンドを実行します。
# oc get pods -n <storage_project_name>
以下に例を示します。
# oc get pods -n storage-project NAME READY STATUS RESTARTS AGE block-test-router-1-deploy 0/1 Running 0 4h busybox 1/1 Running 0 43s glusterblock-provisioner-1-bjpz4 1/1 Running 0 4h glusterfs-7l5xf 1/1 Running 0 4h glusterfs-hhxtk 1/1 Running 3 4h glusterfs-m4rbc 1/1 Running 0 4h heketi-1-3h9nb 1/1 Running 0 4h
永続ボリュームがコンテナー内でマウントされていることを確認するには、以下のコマンドを実行します。
# oc rsh busybox
/ $ df -h Filesystem Size Used Available Use% Mounted on /dev/mapper/docker-253:0-1310998-81732b5fd87c197f627a24bcd2777f12eec4ee937cc2660656908b2fa6359129 100.0G 34.1M 99.9G 0% / tmpfs 1.5G 0 1.5G 0% /dev tmpfs 1.5G 0 1.5G 0% /sys/fs/cgroup 192.168.121.168:vol_4fc22ff934e531dec3830cfbcad1eeae 99.9G 66.1M 99.9G 0% /usr/share/busybox tmpfs 1.5G 0 1.5G 0% /run/secrets /dev/mapper/vg_vagrant-lv_root 37.7G 3.8G 32.0G 11% /dev/termination-log tmpfs 1.5G 12.0K 1.5G 0% /var/run/secretgit s/kubernetes.io/serviceaccount
マウントポイントでパーミッション拒否エラーが発生した場合は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-storage-examples-gluster-example で Gluster Volume Security の セクションを参照してください。
3.1.2. ボリュームの動的プロビジョニング
動的プロビジョニングにより、ボリュームを事前に作成せずに、Red Hat Gluster Storage ボリュームを実行中のアプリケーションコンテナーにプロビジョニングできます。ボリュームは要求を受け取る際に動的に作成され、まったく同じサイズのボリュームがアプリケーションコンテナーにプロビジョニングされます。
OpenShift Container Storage が (デフォルトの)Ansible インストーラーを使用してデプロイされた場合、以下に概要を示す手順は必要ありません。インストール時に作成されたデフォルトのストレージクラス (glusterfs-storage) が使用されます。
3.1.2.1. ボリュームの動的プロビジョニングの設定
ボリュームの動的プロビジョニングを設定するには、管理者はクラスターで提供されるストレージの指定の"classes"を記述する StorageClass オブジェクトを定義する必要があります。Storage Class の作成後に、heketi 認証のシークレットを作成してから、Persistent Volume Claim(永続ボリューム要求、PVC) の作成を続行する必要があります。
3.1.2.1.1. Heketi 認証のシークレットの作成
Heketi 認証のシークレットを作成するには、以下のコマンドを実行します。
admin-key の値 (ボリュームの詳細を取得するために heketi にアクセスするためのシークレット) が Red Hat Openshift Container Storage のデプロイメント時に設定されていない場合、以下の手順を実行は省略できます。
以下のコマンドを実行して、パスワードのエンコードされた値を作成します。
# echo -n "<key>" | base64
ここで、"key" は、Red Hat Openshift Container Storage のデプロイ時に作成された 「admin-key」 の値です。
以下に例を示します。
# echo -n "mypassword" | base64 bXlwYXNzd29yZA==
シークレットファイルを作成します。以下はシークレットファイルの例です。
# cat glusterfs-secret.yaml apiVersion: v1 kind: Secret metadata: name: heketi-secret namespace: default data: # base64 encoded password. E.g.: echo -n "mypassword" | base64 key: bXlwYXNzd29yZA== type: kubernetes.io/glusterfs
以下のコマンドを実行して OpenShift にシークレットを登録します。
# oc create -f glusterfs-secret.yaml secret "heketi-secret" created
3.1.2.1.2. ストレージクラスの登録
永続ボリュームのプロビジョニング用に StorageClass オブジェクトを設定する場合、管理者は使用するプロビジョナーのタイプと、クラスに属する PersistentVolume をプロビジョニングする際にプロビジョナーによって使用されるパラメーターを記述する必要があります。
ストレージクラスを作成するには、以下のコマンドを実行します。
# cat > glusterfs-storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: gluster-container provisioner: kubernetes.io/glusterfs reclaimPolicy: Retain parameters: resturl: "http://heketi-storage-project.cloudapps.mystorage.com" restuser: "admin" volumetype: "replicate:3" clusterid: "630372ccdc720a92c681fb928f27b53f,796e6db1981f369ea0340913eeea4c9a" secretNamespace: "default" secretName: "heketi-secret" volumeoptions: "client.ssl on, server.ssl on" volumenameprefix: "test-vol" allowVolumeExpansion: true
ここで、
- resturl
- Gluster REST サービス/Heketi サービスの URL。これは、gluster ボリュームをオンデマンドでプロビジョニングします。一般的な形式は IPaddress:Port でなければならず、GlusterFS 動的プロビジョナーの場合必須のパラメーターです。Heketi サービスが openshift/kubernetes 設定でルーティング可能なサービスとして公開される場合、これには http://heketi-storage-project.cloudapps.mystorage.com と同様の形式を設定できます。ここで、fqdn は解決可能な heketi サービスの URL です。
- restuser
- 信頼済みストレージプールでボリュームを作成できる Gluster REST サービス/Heketi ユーザー
- volumetype
使用されているボリュームタイプを指定します。
注記分散 3 方向レプリケーションが、サポートされている唯一のボリューム種別です。これには、標準の 3 方向のレプリケーションボリュームと arbiter 2+1 の両方が含まれます。
- clusterid
これは、ボリュームのプロビジョニング時に Heketi によって使用されるクラスターの ID です。また、クラスター ID のコンマ区切りリストも指定できます。これはオプションのパラメーターです。
注記クラスター ID を取得するには、以下のコマンドを実行します。
# heketi-cli cluster list
- secretNamespace + secretName
Gluster REST サービスとの通信時に使用されるユーザーパスワードを含む Secret インスタンスの識別。これらのパラメーターはオプションです。空のパスワードは、secretNamespace と secretName の両方を省略する場合に使用されます。
注記永続ボリュームが動的にプロビジョニングされると、GlusterFS プラグインによってエンドポイントと gluster-dynamic-<claimname> という名前のヘッドレスサービスが自動的に作成されます。この動的エンドポイントとサービスは、永続ボリューム要求 (PVC) が削除されると自動的に削除されます。
- volumeoptions
これはオプションのパラメーターです。これにより、パラメーターを"client.ssl on, server.ssl on" に設定して、暗号化を有効にして glusterfs ボリュームを作成できます。暗号化の有効化に関する詳細は、8章暗号化の有効化を参照してください。
注記暗号化が有効でない場合は、このパラメーターを storageclass に追加しないでください。
- volumenameprefix
これはオプションのパラメーターです。これは、heketi で作成されたボリュームの名前を示しています。詳細は、「(オプション) 永続ボリュームのカスタムボリューム名の接頭辞の指定」を参照してください。
注記このパラメーターの値には、storageclass に
_を含めることができません。- allowVolumeExpansion
-
PV クレームの値を増やすには、storageclass ファイルの allowVolumeExpansion パラメーターを
trueに設定してください。詳細は、「Persistent Volume Claim(永続ボリューム要求、PVC) の拡張」を参照してください。
ストレージクラスを Openshift に登録するには、以下のコマンドを実行します。
# oc create -f glusterfs-storageclass.yaml storageclass "gluster-container" created
ストレージクラスの詳細を取得するには、以下のコマンドを実行します。
# oc describe storageclass gluster-container Name: gluster-container IsDefaultClass: No Annotations: <none> Provisioner: kubernetes.io/glusterfs Parameters: resturl=http://heketi-storage-project.cloudapps.mystorage.com,restuser=admin,secretName=heketi-secret,secretNamespace=default No events.
3.1.2.1.3. Persistent Volume Claim(永続ボリューム要求、PVC) の作成
永続ボリューム要求 (PVC) を作成するには、以下のコマンドを実行します。
Persistent Volume Claim(永続ボリューム要求、PVC) ファイルを作成します。Persistent Volume Claim(永続ボリューム要求、PVC) のサンプルは以下のとおりです。
# cat glusterfs-pvc-claim1.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: claim1 annotations: volume.beta.kubernetes.io/storage-class: gluster-container spec: persistentVolumeReclaimPolicy: Retain accessModes: - ReadWriteOnce resources: requests: storage: 5Gi- persistentVolumeReclaimPolicy
これはオプションのパラメーターです。このパラメーターを"Retain"に設定すると、対応する永続ボリューム要求 (PVC) が削除されても、基礎となる永続ボリュームが保持されます。
注記PVC の削除時に、"persistentVolumeReclaimPolicy:"が"Retain"に設定されている場合、基礎となる heketi および gluster ボリュームは削除されません。ボリュームを削除するには、heketi cli を使用して PV を削除する必要があります。
以下のコマンドを実行して要求を登録します。
# oc create -f glusterfs-pvc-claim1.yaml persistentvolumeclaim "claim1" created
要求の詳細を取得するには、以下のコマンドを実行します。
# oc describe pvc <_claim_name_>
以下に例を示します。
# oc describe pvc claim1 Name: claim1 Namespace: default StorageClass: gluster-container Status: Bound Volume: pvc-54b88668-9da6-11e6-965e-54ee7551fd0c Labels: <none> Capacity: 4Gi Access Modes: RWO No events.
3.1.2.1.4. 要求作成の確認
要求が作成されているかどうかを確認するには、以下のコマンドを実行します。
永続ボリューム要求 (PVC) および永続ボリュームの詳細を取得するには、以下のコマンドを実行します。
# oc get pv,pvc NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE pv/pvc-962aa6d1-bddb-11e6-be23-5254009fc65b 4Gi RWO Delete Bound storage-project/claim1 3m NAME STATUS VOLUME CAPACITY ACCESSMODES AGE pvc/claim1 Bound pvc-962aa6d1-bddb-11e6-be23-5254009fc65b 4Gi RWO 4m
エンドポイントとサービスが要求の作成時に作成されたかどうかを確認するには、以下のコマンドを実行します。
# oc get endpoints,service NAME ENDPOINTS AGE ep/storage-project-router 192.168.68.3:443,192.168.68.3:1936,192.168.68.3:80 28d ep/gluster-dynamic-claim1 192.168.68.2:1,192.168.68.3:1,192.168.68.4:1 5m ep/heketi 10.130.0.21:8080 21d ep/heketi-storage-endpoints 192.168.68.2:1,192.168.68.3:1,192.168.68.4:1 25d NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/storage-project-router 172.30.166.64 <none> 80/TCP,443/TCP,1936/TCP 28d svc/gluster-dynamic-claim1 172.30.52.17 <none> 1/TCP 5m svc/heketi 172.30.129.113 <none> 8080/TCP 21d svc/heketi-storage-endpoints 172.30.133.212 <none> 1/TCP 25d
3.1.2.1.5. (オプション) 永続ボリュームのカスタムボリューム名の接頭辞の指定
作成する永続ボリュームに、カスタムボリューム名の接頭辞を指定できます。カスタムのボリューム名の接頭辞を指定すると、以下に基づいてボリュームを簡単に検索/フィルターできるようになります。
- storageclass ファイルの"volnameprefix"フィールドの値として提供された文字列。
- Persistent Volume Claim(永続ボリューム要求、PVC) 名。
- プロジェクト/namespace 名。
名前を設定するには、パラメーター volumenameprefix をストレージクラスファイルに追加していることを確認します。詳細は「ストレージクラスの登録」を参照してください。
このパラメーターの値には、storageclass に _ を含めることができません。
カスタムのボリューム名の接頭辞が設定されているかどうかを確認するには、以下のコマンドを実行します。
# oc describe pv <pv_name>
以下に例を示します。
# oc describe pv pvc-f92e3065-25e8-11e8-8f17-005056a55501
Name: pvc-f92e3065-25e8-11e8-8f17-005056a55501
Labels: <none>
Annotations: Description=Gluster-Internal: Dynamically provisioned PV
gluster.kubernetes.io/heketi-volume-id=027c76b24b1a3ce3f94d162f843529c8
gluster.org/type=file
kubernetes.io/createdby=heketi-dynamic-provisioner
pv.beta.kubernetes.io/gid=2000
pv.kubernetes.io/bound-by-controller=yes
pv.kubernetes.io/provisioned-by=kubernetes.io/glusterfs
volume.beta.kubernetes.io/mount-options=auto_unmount
StorageClass: gluster-container-prefix
Status: Bound
Claim: glusterfs/claim1
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 1Gi
Message:
Source:
Type: Glusterfs (a Glusterfs mount on the host that shares a pod's lifetime)
EndpointsName: glusterfs-dynamic-claim1
Path: test-vol_glusterfs_claim1_f9352e4c-25e8-11e8-b460-005056a55501
ReadOnly: false
Events: <none>Path の値には、namespace および要求名に割り当てられたカスタムのボリューム名の接頭辞が付けられます。ここでは"test-vol"です。
3.1.2.1.6. Pod での要求の使用
Pod で要求を使用するには、以下の手順を実行します。
アプリケーションで要求を使用するには、たとえば、以下のようになります。
# cat app.yaml apiVersion: v1 kind: Pod metadata: name: busybox spec: containers: - image: busybox command: - sleep - "3600" name: busybox volumeMounts: - mountPath: /usr/share/busybox name: mypvc volumes: - name: mypvc persistentVolumeClaim: claimName: claim1# oc create -f app.yaml pod "busybox" created
アプリケーションで glusterfs 要求を使用する方法についての詳細は https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-storage-examples-gluster-example を参照してください。
Pod が作成されたことを確認するには、以下のコマンドを実行します。
# oc get pods -n storage-project NAME READY STATUS RESTARTS AGE storage-project-router-1-at7tf 1/1 Running 0 13d busybox 1/1 Running 0 8s glusterfs-dc-192.168.68.2-1-hu28h 1/1 Running 0 7d glusterfs-dc-192.168.68.3-1-ytnlg 1/1 Running 0 7d glusterfs-dc-192.168.68.4-1-juqcq 1/1 Running 0 13d heketi-1-9r47c 1/1 Running 0 13d
永続ボリュームがコンテナー内でマウントされていることを確認するには、以下のコマンドを実行します。
# oc rsh busybox
/ $ df -h Filesystem Size Used Available Use% Mounted on /dev/mapper/docker-253:0-666733-38050a1d2cdb41dc00d60f25a7a295f6e89d4c529302fb2b93d8faa5a3205fb9 10.0G 33.8M 9.9G 0% / tmpfs 23.5G 0 23.5G 0% /dev tmpfs 23.5G 0 23.5G 0% /sys/fs/cgroup /dev/mapper/rhgs-root 17.5G 3.6G 13.8G 21% /run/secrets /dev/mapper/rhgs-root 17.5G 3.6G 13.8G 21% /dev/termination-log /dev/mapper/rhgs-root 17.5G 3.6G 13.8G 21% /etc/resolv.conf /dev/mapper/rhgs-root 17.5G 3.6G 13.8G 21% /etc/hostname /dev/mapper/rhgs-root 17.5G 3.6G 13.8G 21% /etc/hosts shm 64.0M 0 64.0M 0% /dev/shm 192.168.68.2:vol_5b05cf2e5404afe614f8afa698792bae 4.0G 32.6M 4.0G 1% /usr/share/busybox tmpfs 23.5G 16.0K 23.5G 0% /var/run/secrets/kubernetes.io/serviceaccount tmpfs 23.5G 0 23.5G 0% /proc/kcore tmpfs 23.5G 0 23.5G 0% /proc/timer_stats
3.1.2.1.7. Persistent Volume Claim(永続ボリューム要求、PVC) の拡張
PV クレームの値を増やすには、storageclass ファイルの allowVolumeExpansion パラメーターを true に設定してください。詳細は、「ストレージクラスの登録」を参照してください。
OpenShift Container Platform 3.11 Web コンソールで PV のサイズを変更することもできます。
永続ボリューム要求の値を拡張するには、以下のコマンドを実行します。
既存の永続ボリュームサイズを確認するには、アプリケーション Pod で以下のコマンドを実行します。
# oc rsh busybox
# df -h
以下に例を示します。
# oc rsh busybox / # df -h Filesystem Size Used Available Use% Mounted on /dev/mapper/docker-253:0-100702042-0fa327369e7708b67f0c632d83721cd9a5b39fd3a7b3218f3ff3c83ef4320ce7 10.0G 34.2M 9.9G 0% / tmpfs 15.6G 0 15.6G 0% /dev tmpfs 15.6G 0 15.6G 0% /sys/fs/cgroup /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /dev/termination-log /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /run/secrets /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/resolv.conf /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/hostname /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/hosts shm 64.0M 0 64.0M 0% /dev/shm 10.70.46.177:test-vol_glusterfs_claim10_d3e15a8b-26b3-11e8-acdf-005056a55501 2.0G 32.6M 2.0G 2% /usr/share/busybox tmpfs 15.6G 16.0K 15.6G 0% /var/run/secrets/kubernetes.io/serviceaccount tmpfs 15.6G 0 15.6G 0% /proc/kcore tmpfs 15.6G 0 15.6G 0% /proc/timer_list tmpfs 15.6G 0 15.6G 0% /proc/timer_stats tmpfs 15.6G 0 15.6G 0% /proc/sched_debug tmpfs 15.6G 0 15.6G 0% /proc/scsi tmpfs 15.6G 0 15.6G 0% /sys/firmwareこの例では、永続ボリュームのサイズは 2 Gi です。
Persistent Volume Claim(永続ボリューム要求、PVC) の値を編集するには、以下のコマンドを実行して以下のストレージパラメーターを編集します。
resources: requests: storage: <storage_value># oc edit pvc <claim_name>
たとえば、ストレージの値を 20 Gi に拡張するには、以下を実行します。
# oc edit pvc claim3 apiVersion: v1 kind: PersistentVolumeClaim metadata: annotations: pv.kubernetes.io/bind-completed: "yes" pv.kubernetes.io/bound-by-controller: "yes" volume.beta.kubernetes.io/storage-class: gluster-container2 volume.beta.kubernetes.io/storage-provisioner: kubernetes.io/glusterfs creationTimestamp: 2018-02-14T07:42:00Z name: claim3 namespace: storage-project resourceVersion: "283924" selfLink: /api/v1/namespaces/storage-project/persistentvolumeclaims/claim3 uid: 8a9bb0df-115a-11e8-8cb3-005056a5a340 spec: accessModes: - ReadWriteOnce resources: requests: storage: 20Gi volumeName: pvc-8a9bb0df-115a-11e8-8cb3-005056a5a340 status: accessModes: - ReadWriteOnce capacity: storage: 2Gi phase: Bound検証するには、アプリケーション Pod で以下のコマンドを実行します。
# oc rsh busybox
/ # df -h
以下に例を示します。
# oc rsh busybox # df -h Filesystem Size Used Available Use% Mounted on /dev/mapper/docker-253:0-100702042-0fa327369e7708b67f0c632d83721cd9a5b39fd3a7b3218f3ff3c83ef4320ce7 10.0G 34.2M 9.9G 0% / tmpfs 15.6G 0 15.6G 0% /dev tmpfs 15.6G 0 15.6G 0% /sys/fs/cgroup /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /dev/termination-log /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /run/secrets /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/resolv.conf /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/hostname /dev/mapper/rhel_dhcp47--150-root 50.0G 7.4G 42.6G 15% /etc/hosts shm 64.0M 0 64.0M 0% /dev/shm 10.70.46.177:test-vol_glusterfs_claim10_d3e15a8b-26b3-11e8-acdf-005056a55501 20.0G 65.3M 19.9G 1% /usr/share/busybox tmpfs 15.6G 16.0K 15.6G 0% /var/run/secrets/kubernetes.io/serviceaccount tmpfs 15.6G 0 15.6G 0% /proc/kcore tmpfs 15.6G 0 15.6G 0% /proc/timer_list tmpfs 15.6G 0 15.6G 0% /proc/timer_stats tmpfs 15.6G 0 15.6G 0% /proc/sched_debug tmpfs 15.6G 0 15.6G 0% /proc/scsi tmpfs 15.6G 0 15.6G 0% /sys/firmwareサイズが 2 Gi(以前) から 20 Gi に変更されていることが確認できます。
3.1.2.1.8. Persistent Volume Claim(永続ボリューム要求、PVC) の削除
storageclass の登録時に"persistentVolumeReclaimPolicy"パラメーターが "Retain"に設定されている場合、基礎となる PV と対応するボリュームは、PVC が削除されてもそのまま残ります。
要求を削除するには、以下のコマンドを実行します。
# oc delete pvc <claim-name>
以下に例を示します。
# oc delete pvc claim1 persistentvolumeclaim "claim1" deleted
要求が削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get pvc <claim-name>
以下に例を示します。
# oc get pvc claim1 No resources found.
ユーザーが動的プロビジョニングで作成された永続ボリュームにバインドされている永続ボリューム要求 (PVC) を削除すると、永続ボリューム要求の削除とは別に、Kubernetes は永続ボリューム、エンドポイント、サービス、および実際のボリュームも削除します。これを検証する必要がある場合は、以下のコマンドを実行します。
永続ボリュームが削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get pv <pv-name>
以下に例を示します。
# oc get pv pvc-962aa6d1-bddb-11e6-be23-5254009fc65b No resources found.
エンドポイントが削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get endpoints <endpointname>
以下に例を示します。
# oc get endpoints gluster-dynamic-claim1 No resources found.
サービスが削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get service <servicename>
以下に例を示します。
# oc get service gluster-dynamic-claim1 No resources found.
3.1.3. ボリュームのセキュリティー
ボリュームの UID/GID は 0(root) です。アプリケーション Pod がボリュームに書き込むには、UID/GID が 0(root) でなければなりません。ボリュームのセキュリティー機能により、管理者は一意の GID でボリュームを作成し、アプリケーション Pod がこの一意の GID を使用してボリュームに書き込みできるようになりました。
静的にプロビジョニングされたボリュームのボリュームセキュリティー
GID を指定して静的にプロビジョニングされたボリュームを作成するには、以下のコマンドを実行します。
$ heketi-cli volume create --size=100 --persistent-volume-file=pv001.json --gid=590
上記のコマンドでは、GID が 590 の 100 G 永続ボリュームが作成され、このボリュームを記述する永続ボリューム仕様の出力は pv001.json ファイルに追加されます。
この GID を使用してボリュームにアクセスする方法は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html/configuring_clusters/persistent-storage-examples#install-config-storage-examples-gluster-example を参照してください。
動的にプロビジョニングされたボリュームのボリュームセキュリティー
2 つの新規パラメーター gidMin および gidMax が動的プロビジョナーに導入されました。これらの値により、管理者はストレージクラスのボリュームの GID 範囲を設定できます。GID の値を設定し、動的にプロビジョニングされたボリュームのボリュームのセキュリティーを提供するには、以下のコマンドを実行します。
GID の値を指定してストレージクラスファイルを作成します。以下に例を示します。
# cat glusterfs-storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: gluster-container provisioner: kubernetes.io/glusterfs parameters: resturl: "http://heketi-storage-project.cloudapps.mystorage.com" restuser: "admin" secretNamespace: "default" secretName: "heketi-secret" gidMin: "2000" gidMax: "4000"
注記gidMin値およびgidMax値が指定されていない場合、動的にプロビジョニングされたボリュームには 2000 から 2147483647 までの GID が設定されます。- 永続ボリューム要求 (PVC) を作成します。詳細は、「Persistent Volume Claim(永続ボリューム要求、PVC) の作成」を参照してください。
- Pod の要求を使用します。この Pod が特権を持たないことを確認します。詳細は、「Pod での要求の使用」を参照してください。
GID が指定の範囲内にあるかどうかを確認するには、以下のコマンドを実行します。
# oc rsh busybox
$ id
以下に例を示します。
$ id uid=1000060000 gid=0(root) groups=0(root),2001
ここで、上記の出力の 2001 は、永続ボリュームに割り当てられた GID で、ストレージクラスで指定された範囲内にあります。割り当てられた GID を使用して、このボリュームに書き込むことができます。
注記永続ボリューム要求 (PVC) が削除されると、永続ボリュームの GID がプールから解放されます。
3.1.4. heketi でのデバイスの階層化
Heketi は、ボリュームを配置する際に特定のデバイスを使用するための単純なタグマッチングアプローチをサポートします。ユーザーは、特定のデバイスセットにキーと値のペアを指定して、ボリュームオプションキー user.heketi.device-tag-match と単純なマッチングルールで新規ボリュームを作成する必要があります。
手順
必要なタグを heketi デバイスに適用します。
# heketi-cli device settags <device-name> <key>:<value>
例:
# heketi-cli device settags 1fe1b83e5660efb53cc56433cedf7771 disktype:hdd
適用されたタグをデバイスから削除します。
# heketi-cli device rmtags <device-name> <key>
例:
# heketi-cli device rmtags 1fe1b83e5660efb53cc56433cedf7771 disktype
デバイスに追加されたタグを確認します。
# heketi-cli device info <device-name>
例:
# heketi-cli device info 1fe1b83e5660efb53cc56433cedf7771
出力例:
Device Id: 1fe1b83e5660efb53cc56433cedf7771 State: online Size (GiB): 49 Used (GiB): 41 Free (GiB): 8 Create Path: /dev/vdc Physical Volume UUID: GpAnb4-gY8e-p5m9-0UU3-lV3J-zQWY-zFgO92 Known Paths: /dev/disk/by-id/virtio-bf48c436-04a9-48ed-9 /dev/disk/by-path/pci-0000:00:08.0 /dev/disk/by-path/virtio-pci-0000:00:08.0 /dev/vdc Tags: disktype: hdd ---> added tag
タグ付けされたデバイスを使用してボリュームを作成します。
# heketi-cli volume create --size=<size in GiB> --gluster-volume-options'user.heketi.device-tag-match <key>=<value>’
重要-
ボリュームの作成時に、新しいボリュームオプション
user.heketi.device-tag-matchを渡す必要があります。ここで、オプションの値は、タグキーに続いて"=" または "!="のいずれか、これにタグの値が続きます。 - すべての一致は完全一致であり、大文字と小文字が区別され、1 つの device-tag-match のみを指定できます。
例:
# heketi-cli volume create --size=5 --gluster-volume-options 'user.heketi.device-tag-match disktype=hdd’
注記ボリュームが作成されると、ボリュームオプションの一覧が固定されます。tag-match ルールは、ボリューム拡張およびブリックの置き換えの目的で、ボリュームのメタデータと共に永続化されます。
-
ボリュームの作成時に、新しいボリュームオプション
ストレージクラスを作成します。
ハードディスク上にのみボリュームを作成するストレージクラスを作成します。
# cat hdd-storageclass.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: annotations: storageclass.kubernetes.io/is-default-class: "false" name: glusterfs-storage-hdd selfLink: /apis/storage.k8s.io/v1/storageclasses/glusterfs-storage parameters: resturl: http://heketi-storage.glusterfs.svc:8080 restuser: admin secretName: heketi-storage-admin-secret secretNamespace: glusterfs volumeoptions: "user.heketi.device-tag-match disktype=hdd" provisioner: kubernetes.io/glusterfs reclaimPolicy: Delete volumeBindingMode: Immediateより高速なソリッドステートストレージだけを使用してボリュームを作成するストレージクラスを作成します。
重要ハードディスクデバイスを除外する負のタグのマッチングルールを使用する必要があります。
# cat sdd-storageclass.yaml
apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: annotations: storageclass.kubernetes.io/is-default-class: "false" name: glusterfs-storage-dd selfLink: /apis/storage.k8s.io/v1/storageclasses/glusterfs-storage parameters: resturl: http://heketi-storage.glusterfs.svc:8080 restuser: admin secretName: heketi-storage-admin-secret secretNamespace: glusterfs volumeoptions: "user.heketi.device-tag-match disktype!=hdd" provisioner: kubernetes.io/glusterfs reclaimPolicy: Delete volumeBindingMode: Immediate
3.2. Block Storage
ブロックストレージにより、個別のストレージユニットを高く作成できます。glusterfs がサポートする従来のファイルストレージ機能とは異なり、各ストレージボリューム/ブロックデバイスを独立したディスクドライブとして扱うことができるため、各ストレージボリューム/ブロックデバイスが個別のファイルシステムをサポートできます。
gluster-block は、ブロックデバイスの分散管理フレームワークです。Gluster がサポートするブロックストレージの作成とメンテナーンスを可能な限りシンプルにすることが目的です。gluster-block はブロックデバイスをプロビジョニングし、複数のノードで iSCSI LUN としてエクスポートし、データ転送に SCSI ブロック/コマンドとして iSCSI プロトコルを使用します。
- ブロックボリューム拡張が OpenShift Container Storage 3.11 でサポートされるようになりました。「ブロックボリューム拡張」を参照してください。
- ボリュームの静的プロビジョニングは、ブロックストレージではサポートされません。ボリュームの動的プロビジョニングが、サポートされる唯一の方法です。
ブロックストレージに推奨される Red Hat Enterprise Linux(RHEL) バージョンは RHEL 7.5.4 です。カーネルのバージョンが 3.10.0-862.14.4.el7.x86_64 と一致していることを確認してください。確認するには、以下を実行します。
# uname -r
最新のカーネル更新を有効にするためにノードを再起動します。
3.2.1. Block Storage 用ボリュームの動的プロビジョニング
動的プロビジョニングにより、ボリュームを事前に作成せずに、Red Hat Gluster Storage ボリュームを実行中のアプリケーションコンテナーにプロビジョニングできます。ボリュームは要求を受け取る際に動的に作成され、まったく同じサイズのボリュームがアプリケーションコンテナーにプロビジョニングされます。
OpenShift Container Storage が (デフォルトの)Ansible インストーラーを使用してデプロイされた場合、以下に概要を示す手順は必要ありません。インストール時に作成されたデフォルトのストレージクラス (glusterfs-storage-block) が使用されます。
3.2.1.1. ボリュームの動的プロビジョニングの設定
ボリュームの動的プロビジョニングを設定するには、管理者はクラスターで提供されるストレージの指定の"classes"を記述する StorageClass オブジェクトを定義する必要があります。Storage Class の作成後に、heketi 認証のシークレットを作成してから、Persistent Volume Claim(永続ボリューム要求、PVC) の作成を続行する必要があります。
3.2.1.1.1. すべてのイニシエーターでのマルチパスの設定
iSCSI イニシエーターが iSCSI ターゲットと通信し、マルチパスを使用して HA を実現できるようにするには、アプリケーション Pod がホストされるすべての OpenShift ノード (iSCSI イニシエーター) で以下の手順を実行します。
イニシエーターを設定する必要があるすべてのノードにイニシエーター関連のパッケージをインストールするには、以下のコマンドを実行します。
# yum install iscsi-initiator-utils device-mapper-multipath
マルチパスを有効にするには、次のコマンドを実行します。
# mpathconf --enable
multipath.conf ファイルに以下の内容を作成して追加します。
注記アップグレードする場合は、multipath.conf への変更と multipathd のリロードは、すべてのサーバーノードがアップグレードされた後にのみ実行されるようにしてください。
# cat >> /etc/multipath.conf <<EOF # LIO iSCSI devices { device { vendor "LIO-ORG" user_friendly_names "yes" # names like mpatha path_grouping_policy "failover" # one path per group hardware_handler "1 alua" path_selector "round-robin 0" failback immediate path_checker "tur" prio "alua" no_path_retry 120 } } EOF以下のコマンドを実行して、マルチパスデーモンを起動し、マルチパス設定を (再) 読み込みします。
# systemctl start multipathd
# systemctl reload multipathd
3.2.1.1.2. Heketi 認証のシークレットの作成
Heketi 認証のシークレットを作成するには、以下のコマンドを実行します。
admin-key の値 (ボリュームの詳細を取得するために heketi にアクセスするためのシークレット) が Red Hat Openshift Container Storage のデプロイメント時に設定されていない場合、以下の手順を実行は省略できます。
以下のコマンドを実行して、パスワードのエンコードされた値を作成します。
# echo -n "<key>" | base64
ここで、
keyは、CNS のデプロイ時に作成されたadmin-keyの値です。以下に例を示します。
# echo -n "mypassword" | base64 bXlwYXNzd29yZA==
シークレットファイルを作成します。以下はシークレットファイルの例です。
# cat glusterfs-secret.yaml apiVersion: v1 kind: Secret metadata: name: heketi-secret namespace: default data: # base64 encoded password. E.g.: echo -n "mypassword" | base64 key: bXlwYXNzd29yZA== type: gluster.org/glusterblock
以下のコマンドを実行して OpenShift にシークレットを登録します。
# oc create -f glusterfs-secret.yaml secret "heketi-secret" created
3.2.1.1.3. ストレージクラスの登録
永続ボリュームのプロビジョニング用に StorageClass オブジェクトを設定する場合、管理者は使用するプロビジョナーのタイプと、クラスに属する PersistentVolume をプロビジョニングする際にプロビジョナーによって使用されるパラメーターを記述する必要があります。
ストレージクラスを作成します。以下は、ストレージクラスのサンプルファイルです。
# cat > glusterfs-block-storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: gluster-block provisioner: gluster.org/glusterblock-infra-storage reclaimPolicy: Retain parameters: resturl: "http://heketi-storage-project.cloudapps.mystorage.com" restuser: "admin" restsecretnamespace: "default" restsecretname: "heketi-secret" hacount: "3" clusterids: "630372ccdc720a92c681fb928f27b53f,796e6db1981f369ea0340913eeea4c9a" chapauthenabled: "true" volumenameprefix: "test-vol"
ここで、
- provisioner
provisioner 名は、
glusterblock provisionerPod がデプロイされたプロビジョナーの名前と一致している必要があります。provisioner nameを取得するには、次のコマンドを使用します。# oc describe pod <glusterblock_provisioner_pod_name> |grep PROVISIONER_NAME
以下に例を示します。
# oc describe pod glusterblock-registry-provisioner-dc-1-5j8l9 |grep PROVISIONER_NAME PROVISIONER_NAME: gluster.org/glusterblock-infra-storage- resturl
- Gluster REST サービス/Heketi サービスの URL。これは、gluster ボリュームをオンデマンドでプロビジョニングします。一般的な形式は IPaddress:Port でなければならず、GlusterFS 動的プロビジョナーの場合必須のパラメーターです。Heketi サービスが openshift/kubernetes 設定でルーティング可能なサービスとして公開される場合、これには http://heketi-storage-project.cloudapps.mystorage.com と同様の形式を設定できます。ここで、fqdn は解決可能な heketi サービスの URL です。
- restuser
- 信頼済みストレージプールでボリュームを作成できる Gluster REST サービス/Heketi ユーザー
- restsecretnamespace + restsecretname
-
Gluster REST サービスとの通信時に使用するユーザーパスワードを含むシークレットインスタンスの識別。これらのパラメーターはオプションです。空のパスワードは、
restsecretnamespaceとrestsecretnameの両方を省略する場合に使用されます。 - hacount
-
これは、ブロックターゲットサーバーへのパスの数です。
hacountは、iSCSI のマルチパス機能を使用して高可用性を提供します。パスに障害が発生した場合、I/O は中断されず、別の利用可能なパスを介して提供されます。 - clusterids
これは、ボリュームのプロビジョニング時に Heketi によって使用されるクラスターの ID です。また、クラスター ID のコンマ区切りリストも指定できます。これはオプションのパラメーターです。
注記クラスター ID を取得するには、以下のコマンドを実行します。
# heketi-cli cluster list
- chapauthenabled
- CHAP 認証を有効にしてブロックボリュームをプロビジョニングする場合は、この値を true に設定する必要があります。これはオプションのパラメーターです。
- volumenameprefix
これはオプションのパラメーターです。これは、heketi で作成されたボリュームの名前を示しています。詳細は、「(オプション) 永続ボリュームのカスタムボリューム名の接頭辞の指定」を参照してください。
注記このパラメーターの値には、storageclass に
_を含めることができません。
ストレージクラスを Openshift に登録するには、以下のコマンドを実行します。
# oc create -f glusterfs-block-storageclass.yaml storageclass "gluster-block" created
ストレージクラスの詳細を取得するには、以下のコマンドを実行します。
# oc describe storageclass gluster-block Name: gluster-block IsDefaultClass: No Annotations: <none> Provisioner: gluster.org/glusterblock-infra-storage Parameters: chapauthenabled=true,hacount=3,opmode=heketi,restsecretname=heketi-secret,restsecretnamespace=default,resturl=http://heketi-storage-project.cloudapps.mystorage.com,restuser=admin Events: <none>
3.2.1.1.4. Persistent Volume Claim(永続ボリューム要求、PVC) の作成
永続ボリューム要求 (PVC) を作成するには、以下のコマンドを実行します。
Persistent Volume Claim(永続ボリューム要求、PVC) ファイルを作成します。Persistent Volume Claim(永続ボリューム要求、PVC) のサンプルは以下のとおりです。
# cat glusterfs-block-pvc-claim.yaml kind: PersistentVolumeClaim apiVersion: v1 metadata: name: claim1 annotations: volume.beta.kubernetes.io/storage-class: gluster-block spec: persistentVolumeReclaimPolicy: Retain accessModes: - ReadWriteOnce resources: requests: storage: 5Gi- persistentVolumeReclaimPolicy
これはオプションのパラメーターです。このパラメーターを"Retain"に設定すると、対応する永続ボリューム要求 (PVC) が削除されても、基礎となる永続ボリュームが保持されます。
注記PVC の削除時に、"persistentVolumeReclaimPolicy:"が"Retain"に設定されている場合、基礎となる heketi および gluster ボリュームは削除されません。ボリュームを削除するには、heketi cli を使用して PV を削除する必要があります。
以下のコマンドを実行して要求を登録します。
# oc create -f glusterfs-block-pvc-claim.yaml persistentvolumeclaim "claim1" created
要求の詳細を取得するには、以下のコマンドを実行します。
# oc describe pvc <_claim_name_>
以下に例を示します。
# oc describe pvc claim1 Name: claim1 Namespace: block-test StorageClass: gluster-block Status: Bound Volume: pvc-ee30ff43-7ddc-11e7-89da-5254002ec671 Labels: <none> Annotations: control-plane.alpha.kubernetes.io/leader={"holderIdentity":"8d7fecb4-7dba-11e7-a347-0a580a830002","leaseDurationSeconds":15,"acquireTime":"2017-08-10T15:02:30Z","renewTime":"2017-08-10T15:02:58Z","lea... pv.kubernetes.io/bind-completed=yes pv.kubernetes.io/bound-by-controller=yes volume.beta.kubernetes.io/storage-class=gluster-block volume.beta.kubernetes.io/storage-provisioner=gluster.org/glusterblock Capacity: 5Gi Access Modes: RWO Events: FirstSeen LastSeen Count From SubObjectPath Type Reason Message --------- -------- ----- ---- ------------- -------- ------ ------- 1m 1m 1 gluster.org/glusterblock 8d7fecb4-7dba-11e7-a347-0a580a830002 Normal Provisioning External provisioner is provisioning volume for claim "block-test/claim1" 1m 1m 18 persistentvolume-controller Normal ExternalProvisioning cannot find provisioner "gluster.org/glusterblock", expecting that a volume for the claim is provisioned either manually or via external software 1m 1m 1 gluster.org/glusterblock 8d7fecb4-7dba-11e7-a347-0a580a830002 Normal ProvisioningSucceeded Successfully provisioned volume pvc-ee30ff43-7ddc-11e7-89da-5254002ec671
3.2.1.1.5. 要求作成の確認
要求が作成されているかどうかを確認するには、以下のコマンドを実行します。
永続ボリューム要求 (PVC) および永続ボリュームの詳細を取得するには、以下のコマンドを実行します。
# oc get pv,pvc NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE pv/pvc-ee30ff43-7ddc-11e7-89da-5254002ec671 5Gi RWO Delete Bound block-test/claim1 gluster-block 3m NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE pvc/claim1 Bound pvc-ee30ff43-7ddc-11e7-89da-5254002ec671 5Gi RWO gluster-block 4m
ブロックボリュームとブロックホストボリュームを特定するには、https://access.redhat.com/solutions/3897581 を参照してください。
3.2.1.1.6. (オプション) 永続ボリュームのカスタムボリューム名の接頭辞の指定
作成する永続ボリュームに、カスタムボリューム名の接頭辞を指定できます。カスタムのボリューム名の接頭辞を指定すると、以下に基づいてボリュームを簡単に検索/フィルターできるようになります。
- storageclass ファイルの"volnameprefix"フィールドの値として提供された文字列。
- Persistent Volume Claim(永続ボリューム要求、PVC) 名。
- プロジェクト/namespace 名。
名前を設定するには、パラメーター volumenameprefix をストレージクラスファイルに追加していることを確認します。詳細は、「ストレージクラスの登録」を参照してください。
このパラメーターの値には、storageclass に _ を含めることができません。
カスタムのボリューム名の接頭辞が設定されているかどうかを確認するには、以下のコマンドを実行します。
# oc describe pv <pv_name>
以下に例を示します。
# oc describe pv pvc-4e97bd84-25f4-11e8-8f17-005056a55501
Name: pvc-4e97bd84-25f4-11e8-8f17-005056a55501
Labels: <none>
Annotations: AccessKey=glusterblk-67d422eb-7b78-4059-9c21-a58e0eabe049-secret
AccessKeyNs=glusterfs
Blockstring=url:http://172.31.251.137:8080,user:admin,secret:heketi-secret,secretnamespace:glusterfs
Description=Gluster-external: Dynamically provisioned PV
gluster.org/type=block
gluster.org/volume-id=cd37c089372040eba20904fb60b8c33e
glusterBlkProvIdentity=gluster.org/glusterblock
glusterBlockShare=test-vol_glusterfs_bclaim1_4eab5a22-25f4-11e8-954d-0a580a830003
kubernetes.io/createdby=heketi
pv.kubernetes.io/provisioned-by=gluster.org/glusterblock
v2.0.0=v2.0.0
StorageClass: gluster-block-prefix
Status: Bound
Claim: glusterfs/bclaim1
Reclaim Policy: Delete
Access Modes: RWO
Capacity: 5Gi
Message:
Source:
Type: ISCSI (an ISCSI Disk resource that is attached to a kubelet's host machine and then exposed to the pod)
TargetPortal: 10.70.46.177
IQN: iqn.2016-12.org.gluster-block:67d422eb-7b78-4059-9c21-a58e0eabe049
Lun: 0
ISCSIInterface default
FSType: xfs
ReadOnly: false
Portals: [10.70.46.142 10.70.46.4]
DiscoveryCHAPAuth: false
SessionCHAPAuth: true
SecretRef: {glusterblk-67d422eb-7b78-4059-9c21-a58e0eabe049-secret }
InitiatorName: <none>
Events: <none>glusterBlockShare の値には、namespace および要求名に割り当てられたカスタムのボリューム名の接頭辞が付けられます。ここでは"test-vol"です。
3.2.1.1.7. Pod での要求の使用
Pod で要求を使用するには、以下の手順を実行します。
アプリケーションで要求を使用するには、たとえば、以下のようになります。
# cat app.yaml apiVersion: v1 kind: Pod metadata: name: busybox spec: containers: - image: busybox command: - sleep - "3600" name: busybox volumeMounts: - mountPath: /usr/share/busybox name: mypvc volumes: - name: mypvc persistentVolumeClaim: claimName: claim1# oc create -f app.yaml pod "busybox" created
アプリケーションで glusterfs 要求を使用する方法についての詳細は https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-storage-examples-gluster-example を参照してください。
Pod が作成されたことを確認するには、以下のコマンドを実行します。
# oc get pods -n storage-project NAME READY STATUS RESTARTS AGE block-test-router-1-deploy 0/1 Running 0 4h busybox 1/1 Running 0 43s glusterblock-provisioner-1-bjpz4 1/1 Running 0 4h glusterfs-7l5xf 1/1 Running 0 4h glusterfs-hhxtk 1/1 Running 3 4h glusterfs-m4rbc 1/1 Running 0 4h heketi-1-3h9nb 1/1 Running 0 4h
永続ボリュームがコンテナー内でマウントされていることを確認するには、以下のコマンドを実行します。
# oc rsh busybox
/ # df -h Filesystem Size Used Available Use% Mounted on /dev/mapper/docker-253:1-11438-39febd9d64f3a3594fc11da83d6cbaf5caf32e758eb9e2d7bdd798752130de7e 10.0G 33.9M 9.9G 0% / tmpfs 3.8G 0 3.8G 0% /dev tmpfs 3.8G 0 3.8G 0% /sys/fs/cgroup /dev/mapper/VolGroup00-LogVol00 7.7G 2.8G 4.5G 39% /dev/termination-log /dev/mapper/VolGroup00-LogVol00 7.7G 2.8G 4.5G 39% /run/secrets /dev/mapper/VolGroup00-LogVol00 7.7G 2.8G 4.5G 39% /etc/resolv.conf /dev/mapper/VolGroup00-LogVol00 7.7G 2.8G 4.5G 39% /etc/hostname /dev/mapper/VolGroup00-LogVol00 7.7G 2.8G 4.5G 39% /etc/hosts shm 64.0M 0 64.0M 0% /dev/shm /dev/mpatha 5.0G 32.2M 5.0G 1% /usr/share/busybox tmpfs 3.8G 16.0K 3.8G 0% /var/run/secrets/kubernetes.io/serviceaccount tmpfs 3.8G 0 3.8G 0% /proc/kcore tmpfs 3.8G 0 3.8G 0% /proc/timer_list tmpfs 3.8G 0 3.8G 0% /proc/timer_stats tmpfs 3.8G 0 3.8G 0% /proc/sched_debug
3.2.1.1.8. Persistent Volume Claim(永続ボリューム要求、PVC) の削除
storageclass の登録時に"persistentVolumeReclaimPolicy"パラメーターが "Retain"に設定されている場合、基礎となる PV と対応するボリュームは、PVC が削除されてもそのまま残ります。
要求を削除するには、以下のコマンドを実行します。
# oc delete pvc <claim-name>
以下に例を示します。
# oc delete pvc claim1 persistentvolumeclaim "claim1" deleted
要求が削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get pvc <claim-name>
以下に例を示します。
# oc get pvc claim1 No resources found.
ユーザーが動的プロビジョニングで作成された永続ボリュームにバインドされている永続ボリューム要求 (PVC) を削除すると、永続ボリューム要求の削除とは別に、Kubernetes は永続ボリューム、エンドポイント、サービス、および実際のボリュームも削除します。これを検証する必要がある場合は、以下のコマンドを実行します。
永続ボリュームが削除されたかどうかを確認するには、以下のコマンドを実行します。
# oc get pv <pv-name>
以下に例を示します。
# oc get pv pvc-962aa6d1-bddb-11e6-be23-5254009fc65b No resources found.
次のステップ: Red Hat Openshift Container Storage 3.11 をインストールし、ロギングおよびメトリクスのバックエンドストレージとしてブロックストレージを使用する場合は、7章ロギングおよびメトリクス用バックエンドとしての Gluster Block Storage に進みます。
3.2.2. Block Storage 上のノードの置き換え
リソースが不足しているか、または異常が発生したノードからブロックを置き換える場合は、新しいノードに置き換えることができます。
以下のコマンドを実行します。
以下のコマンドを実行して、heketi からゾーンおよびクラスター情報を取得します。
# heketi-cli topology info --user=<user> --secret=<user key>
- --user
- heketi ユーザー
- --secret
- 指定されたユーザーのシークレットキー
- クラスター ID およびゾーン ID を取得したら、Adding New Nodes を参照して新規ノードを追加します。
次のコマンドを実行してデバイスを追加します。
# heketi-cli device add --name=<device name> --node=<node id> --user=<user> --secret=<user key>
- --name
- 追加するデバイスの名前
- --node
- 新たに追加されたノードの ID
以下に例を示します。
# heketi-cli device add --name=/dev/vdc --node=2639c473a2805f6e19d45997bb18cb9c --user=admin --secret=adminkey Device added successfully
新規ノードとその関連デバイスを heketi に追加した後に、障害が発生したまたは不要なノードを heketi から削除できます。
heketi からノードを削除するには、以下のワークフローに従います。
- ノードの無効化 (オフラインにしてノードの使用の禁止する)
- ノードの置き換え (ノードとその関連デバイスすべてを Heketi から削除する)
- デバイスの削除 (Heketi ノードからデバイスを削除する)
- ノードの削除 (Heketi 管理からのノードを削除する)
以下のコマンドを実行して、heketi からノード一覧を取得します。
#heketi-cli node list --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli node list --user=admin --secret=adminkey Id:05746c562d6738cb5d7de149be1dac04 Cluster:607204cb27346a221f39887a97cf3f90 Id:ab37fc5aabbd714eb8b09c9a868163df Cluster:607204cb27346a221f39887a97cf3f90 Id:c513da1f9bda528a9fd6da7cb546a1ee Cluster:607204cb27346a221f39887a97cf3f90 Id:e6ab1fe377a420b8b67321d9e60c1ad1 Cluster:607204cb27346a221f39887a97cf3f90
以下のコマンドを実行して、heketi から削除する必要があるノードのノード情報を取得します。
# heketi-cli node info <nodeid> --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli node info c513da1f9bda528a9fd6da7cb546a1ee --user=admin --secret=adminkey Node Id: c513da1f9bda528a9fd6da7cb546a1ee State: online Cluster Id: 607204cb27346a221f39887a97cf3f90 Zone: 1 Management Hostname: dhcp43-171.lab.eng.blr.redhat.com Storage Hostname: 10.70.43.171 Devices: Id:3a1e0717e6352a8830ab43978347a103 Name:/dev/vdc State:online Size (GiB):499 Used (GiB):100 Free (GiB):399 Bricks:1 Id:89a57ace1c3184826e1317fef785e6b7 Name:/dev/vdd State:online Size (GiB):499 Used (GiB):10 Free (GiB):489 Bricks:5
以下のコマンドを実行して、heketi からノードを無効にします。これにより、ノードがオフラインになります。
# heketi-cli node disable <node-id> --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli node disable ab37fc5aabbd714eb8b09c9a868163df --user=admin --secret=adminkey Node ab37fc5aabbd714eb8b09c9a868163df is now offline
以下のコマンドを実行して、Heketi からノードとその関連デバイスをすべて削除します。
#heketi-cli node remove <node-id> --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli node remove ab37fc5aabbd714eb8b09c9a868163df --user=admin --secret=adminkey Node ab37fc5aabbd714eb8b09c9a868163df is now removed
以下のコマンドを実行して、heketi ノードからデバイスを削除します。
# heketi-cli device delete <device-id> --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli device delete 0fca78c3a94faabfbe5a5a9eef01b99c --user=admin --secret=adminkey Device 0fca78c3a94faabfbe5a5a9eef01b99c deleted
以下のコマンドを実行して、Heketi 管理からノードを削除します。
#heketi-cli node delete <nodeid> --user=<user> --secret=<user key>
以下に例を示します。
# heketi-cli node delete ab37fc5aabbd714eb8b09c9a868163df --user=admin --secret=adminkey Node ab37fc5aabbd714eb8b09c9a868163df deleted
いずれかの gluster Pod で以下のコマンドを実行して、障害のあるノードを新しいノードに置き換えます。
以下のコマンドを実行して、block-hosting-volume 配下でホストされるブロックボリュームの一覧を取得します。
# gluster-block list <block-hosting-volume> --json-pretty
以下のコマンドを実行して、ブロックボリュームをホストするサーバーの一覧を取得し、後で使用できるように GBID および PASSWORD の値を保存します。
# gluster-block info <block-hosting-volume>/<block-volume> --json-pretty
以下のコマンドを実行して、障害のあるノードを新しいノードに置き換えます。
# gluster-block replace <volname/blockname> <old-node> <new-node> [force]
以下に例を示します。
{ "NAME":"block", "CREATE SUCCESS":"192.168.124.73", "DELETE SUCCESS":"192.168.124.63", "REPLACE PORTAL SUCCESS ON":[ "192.168.124.79" ], "RESULT":"SUCCESS" } Note: If the old node is down and does not come up again then you can force replace: gluster-block replace sample/block 192.168.124.63 192.168.124.73 force --json-pretty { "NAME":"block", "CREATE SUCCESS":"192.168.124.73", "DELETE FAILED (ignored)":"192.168.124.63", "REPLACE PORTAL SUCCESS ON":[ "192.168.124.79" ], "RESULT":"SUCCESS" }
注記次の手順は、置き換えるブロックがまだ使用中の場合にのみ実行されます。
ブロックボリュームが現在マウントされていない場合は、この手順を省略します。ブロックボリュームがアプリケーションで使用されている場合は、イニシエーター側でマッパーデバイスをリロードする必要があります。
イニシエーターノードとターゲット名を特定します。
イニシエーターノードを把握するには、以下を実行します。
# oc get pods -o wide | grep <podname>
ここで、podname は、ブロックボリュームがマウントされる Pod の名前です。
以下に例を示します。
# oc get pods -o wide | grep cirros1 cirros1-1-x6b5n 1/1 Running 0 1h 10.130.0.5 dhcp46-31.lab.eng.blr.redhat.com <none>
ターゲット名を把握するには、以下を実行します。
# oc describe pv <pv_name> | grep IQN
以下に例を示します。
# oc describe pv pvc-c50c69db-5f76-11ea-b27b-005056b253d1 | grep IQN IQN: iqn.2016-12.org.gluster-block:87ffbcf3-e21e-4fa5-bd21-7db2598e8d3f
イニシエーターノードで以下のコマンドを実行して、マッパーデバイスを把握します。
# mount | grep <targetname>
マッパーデバイスを再読み込みします。
# multipath -r mpathX
以下に例を示します。
# mount | grep iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a/dev/mapper/mpatha on /var/lib/origin/openshift.local.volumes/plugins/kubernetes.io/iscsi/iface-default/192.168.124.63:3260-iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a-lun-0 type xfs (rw,relatime,seclabel,attr2,inode64,noquota) # multipath -r mpatha
イニシエーターで以下のコマンドを実行し、古いポータルからログアウトします。
# iscsiadm -m node -T <targetname> -p <old node> -u
以下に例を示します。
# iscsiadm -m node -T iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a -p 192.168.124.63 -u Logging out of session [sid: 8, target: iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a, portal: 192.168.124.63,3260] Logout of [sid: 8, target: iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a, portal: 192.168.124.63,3260] successful.
新しいノードを再検出するには、以下のコマンドを実行します。
# iscsiadm -m discovery -t st -p <new node>
以下に例を示します。
# iscsiadm -m discovery -t st -p 192.168.124.73 192.168.124.79:3260,1 iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a 192.168.124.73:3260,2 iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a
以下を実行して新しいポータルにログインします。
認証の認証情報を更新します (ステップ 11ii の GBID および PASSWORD を使用)
# iscsiadm -m node -T <targetname> -o update -n node.session.auth.authmethod -v CHAP -n node.session.auth.username -v <GBID> -n node.session.auth.password -v <PASSWORD> -p <new node ip>
新しいポータルにログインします。
# iscsiadm -m node -T <targetname> -p <new node ip> -l
以下に例を示します。
# iscsiadm -m node -T iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a -o update -n node.session.auth.authmethod -v CHAP -n node.session.auth.username -v d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a -n node.session.auth.password -v a6a9081f-3d0d-4e8b-b9b0-d2be703b455d -p 192.168.124.73 # iscsiadm -m node -T iqn.2016-12.org.gluster-block:d6d18f43-8a74-4b2c-a5b7-df1fa3f5bc9a -p 192.168.124.73 -l
有効にしたホストボリュームが正常に置き換えられ、実行されているかどうかを確認するには、イニシエーターで以下のコマンドを実行します。
# ll /dev/disk/by-path/ip-* | grep <targetname> | grep <“new node ip”>
gluster ブロックの永続ボリューム (PV) を新しい IP アドレスで更新してください。
PV は定義によって不変であるため、PV を編集することはできません。つまり、PV の古い IP アドレスを変更できません。この問題を回避する手順 (新しい PV を作成し、ストレージデバイスで古い PV 定義を削除) を含むドキュメントが作成されました。Red Hat ナレッジベースソリューションの Gluster block PVs are not updated with new IPs after gluster node replacement を参照してください。
3.2.3. ブロックボリューム拡張
ブロック永続ボリューム要求 (PVC) を拡張して、アプリケーション Pod のストレージの量を増やすことができます。これには、オフラインサイズ変更およびオンラインサイズ変更の 2 つの方法があります。
3.2.3.1. オフラインのサイズ変更
ブロック PVC を拡張する前に、ブロックホストボリュームに十分なサイズがあることを確認します。
PVC の Heketi ブロックボリューム ID を取得するには、プライマリー OCP ノードで以下のコマンドを実行します。
# oc get pv $(oc get pvc <PVC-NAME> --no-headers -o=custom-columns=:.spec.volumeName) -o=custom-columns=:.metadata.annotations."gluster\.org/volume-id"
ブロックボリューム ID を取得するには、以下のコマンドを実行します。
# heketi-cli blockvolume info <block-volume-id>
ブロックホスティングボリューム情報を取得するには、以下のコマンドを実行します。
# heketi-cli volume info <block-hosting-volume-id>
注記十分な空きサイズがあることを確認します。
- アプリケーション Pod を停止します。
heketi-cli を使用してブロックボリュームを拡張するには、以下のコマンドを実行します。
# heketi-cli blockvolume expand <block-volume-id> --new-size=<net-new-size>
以下に例を示します。
# heketi-cli blockvolume expand d911d4bcfd4f11bf07b9688a4798b5dc --new-size=7 Name: blk_glusterfs_claim2_fc40d362-aaf9-11ea-bb32-0a580a820004 Size: 7 UsableSize: 7 Volume Id: d911d4bcfd4f11bf07b9688a4798b5dc Cluster Id: 8d1656d29fb8dc6780388cf797351a6d Hosts: [10.70.53.185 10.70.53.203 10.70.53.198] IQN: iqn.2016-12.org.gluster-block:8ce8eb4c-4951-4777-9b42-244b7ea525cd LUN: 0 Hacount: 3 Username: 8ce8eb4c-4951-4777-9b42-244b7ea525cd Password: b83a74be-df90-4fd7-b1a1-928fdcfed8c4 Block Hosting Volume: 2224ac1da64c1737604456a1f511574e
注記expandの出力で Size および UsableSize が一致するようにしてください。ステップ 4 から 8 は、Size と UsableSize が一致する場合に実行できます。
PVC-NAMEを実際の PVC に置き換え、ブロックボリュームサイズを更新するためのジョブを作成します。apiVersion: batch/v1 kind: Job metadata: name: refresh-block-size spec: completions: 1 template: spec: containers: - image: rhel7 env: - name: HOST_ROOTFS value: "/rootfs" - name: EXEC_ON_HOST value: "nsenter --root=$(HOST_ROOTFS) nsenter -t 1 -m" command: ['sh', '-c', 'echo -e "# df -Th /mnt" && df -Th /mnt && DEVICE=$(df --output=source /mnt | sed -e /^Filesystem/d) && MOUNTPOINT=$($EXEC_ON_HOST lsblk $DEVICE -n -o MOUNTPOINT) && $EXEC_ON_HOST xfs_growfs $MOUNTPOINT > /dev/null && echo -e "\n# df -Th /mnt" && df -Th /mnt'] name: rhel7 volumeMounts: - mountPath: /mnt name: block-pvc - mountPath: /dev name: host-dev - mountPath: /rootfs name: host-rootfs securityContext: privileged: true volumes: - name: block-pvc persistentVolumeClaim: claimName: <PVC-NAME> - name: host-dev hostPath: path: /dev - name: host-rootfs hostPath: path: / restartPolicy: NeverPod のログで新規サイズを確認するには、以下のコマンドを実行します。
# oc logs refresh-block-size-xxxxx
注記xfs_growfs後のdf -Thの出力が新しいサイズを反映することを確認します。以下に例を示します。
# oc logs refresh-block-size-jcbzh # df -Th /mnt Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/mpatha xfs 5.0G 33M 5.0G 1% /mnt
# df -Th /mnt Filesystem Type Size Used Avail Use% Mounted on /dev/mapper/mpatha xfs 7.0G 34M 6.0G 1% /mnt
ジョブが成功したことを確認するには、以下のコマンドを実行します。
# oc get jobs NAME DESIRED SUCCESSFUL AGE refresh-block-size 1 1 36m
ジョブを正常に実行したら削除するには、以下のコマンドを実行します。
# oc delete job refresh-block-size job.batch "refresh-block-size" deleted
- アプリケーション Pod を起動した後に新規サイズを使用できます。
3.2.3.2. オンラインのサイズ変更
ブロック PVC を拡張する前に、ブロックホストボリュームに十分なサイズがあることを確認します。
PVC の Heketi ブロックボリューム ID を取得するには、プライマリー OCP ノードで以下のコマンドを実行します。
# oc get pv $(oc get pvc <PVC-NAME> --no-headers -o=custom-columns=:.spec.volumeName) -o=custom-columns=:.metadata.annotations."gluster\.org/volume-id"
ブロックボリューム ID を取得するには、以下のコマンドを実行します。
# heketi-cli blockvolume info <block-volume-id>
ブロックホスティングボリューム情報を取得するには、以下のコマンドを実行します。
# heketi-cli volume info <block-hosting-volume-id>
注記十分な空きサイズがあることを確認します。
heketi-cli を使用してブロックボリュームを拡張するには、以下のコマンドを実行します。
# heketi-cli blockvolume expand <BLOCK-VOLUME-ID> --new-size=<net-new-size>
以下に例を示します。
# heketi-cli blockvolume expand d911d4bcfd4f11bf07b9688a4798b5dc --new-size=7 Name: blk_glusterfs_claim2_fc40d362-aaf9-11ea-bb32-0a580a820004 Size: 7 UsableSize: 7 Volume Id: d911d4bcfd4f11bf07b9688a4798b5dc Cluster Id: 8d1656d29fb8dc6780388cf797351a6d Hosts: [10.70.53.185 10.70.53.203 10.70.53.198] IQN: iqn.2016-12.org.gluster-block:8ce8eb4c-4951-4777-9b42-244b7ea525cd LUN: 0 Hacount: 3 Username: 8ce8eb4c-4951-4777-9b42-244b7ea525cd Password: b83a74be-df90-4fd7-b1a1-928fdcfed8c4 Block Hosting Volume: 2224ac1da64c1737604456a1f511574e
注記expandの出力で Size および UsableSize が一致するようにしてください。ステップ 3 から 9 は、Size と UsableSize が一致する場合に実行できます。
PV にマッピングされた iSCSI ターゲット IQN 名を取得するには、以下のコマンドを実行して、以降の参照用にその情報をメモしてください。
# oc get pv <PV-NAME> -o=custom-columns=:.spec.iscsi.iqn
以下に例を示します。
# oc get pv pvc-fc3e9160-aaf9-11ea-a29f-005056b781de -o=custom-columns=:.spec.iscsi.iqn iqn.2016-12.org.gluster-block:8ce8eb4c-4951-4777-9b42-244b7ea525cd
アプリケーション Pod のホストノードにログインします。
アプリケーション Pod のノード名を取得するには、以下のコマンドを実行します。
# oc get pods <POD-NAME> -o=custom-columns=:.spec.nodeName
以下に例を示します。
# oc get pods cirros2-1-8x6w5 -o=custom-columns=:.spec.nodeName dhcp53-203.lab.eng.blr.redhat.com
アプリケーション Pod のホストノードにログインするには、以下のコマンドを実行します。
# ssh <NODE-NAME>
以下に例を示します。
# ssh dhcp53-203.lab.eng.blr.redhat.com
以降の参照用に、マルチパスマッパーのデバイス名 ( mpathaなど)、個別パス (例:sdd、sde および sdf) の現在のサイズ、ならびにマッパーデバイスをコピーします。
# lsblk | grep -B1 <pv-name>
以下に例を示します。
# lsblk | grep -B1 pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdd 8:48 0 6G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sde 8:64 0 6G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdf 8:80 0 6G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de # df -Th| grep <PV-NAME> For example: # df -Th | grep pvc-fc3e9160-aaf9-11ea-a29f-005056b781de /dev/mapper/mpatha xfs 6.0G 44M 6.0G 1% /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de以下のコマンドを実行して、ステップ 3 の IQN 名を使用し、アプリケーション Pod(iSCSI イニシエーター) のホストノードでデバイスを再スキャンできます。
# iscsiadm -m node -R -T <iqn-name>
以下に例を示します。
# iscsiadm -m node -R -T iqn.2016-12.org.gluster-block:a951f673-1a17-47b8-ac02-197baa32b9b1 Rescanning session [sid: 1, target:iqn.2016-12.org.gluster-block:a951f673-1a17-47b8-ac02-197baa32b9b1, portal: 192.168.124.80,3260] Rescanning session [sid: 2, target:iqn.2016-12.org.gluster-block:a951f673-1a17-47b8-ac02-197baa32b9b1, portal: 192.168.124.73,3260] Rescanning session [sid: 3, target:iqn.2016-12.org.gluster-block:a951f673-1a17-47b8-ac02-197baa32b9b1, portal: 192.168.124.63,3260]
注記これで、個々のパス (sdd、sde および sdf) に反映する新しいサイズが表示されます。
# lsblk | grep -B1 <pv-name>
以下に例を示します。
# lsblk | grep -B1 pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdd 8:48 0 7G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sde 8:64 0 7G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdf 8:80 0 7G 0 disk └─mpatha 253:18 0 6G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de
マルチパスデバイスのサイズを更新するには、次のコマンドを実行します。
-
lsblkの出力から、ステップ 6 からマルチパスマッパーのデバイス名を取得します。 マルチパスマッパーデバイスを更新するには、以下のコマンドを実行します。
# multipathd -k'resize map <multipath-mapper-name>'
以下に例を示します。
# multipathd -k'resize map mpatha' Ok
注記マッパーデバイスの mpatha に反映する新しいサイズが表示されるはずです。以降の参照用に、以下のコマンド出力からマウントポイントパスをコピーします。
# lsblk | grep -B1 <PV-NAME>
以下に例を示します。
# lsblk | grep -B1 pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdd 8:48 0 7G 0 disk └─mpatha 253:18 0 7G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sde 8:64 0 7G 0 disk └─mpatha 253:18 0 7G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de sdf 8:80 0 7G 0 disk └─mpatha 253:18 0 7G 0 mpath /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de
# df -Th | grep <pv-name>
以下に例を示します。
# df -Th | grep pvc-fc3e9160-aaf9-11ea-a29f-005056b781de /dev/mapper/mpatha xfs 6.0G 44M 6.0G 1% /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de
-
ファイルシステムのレイアウトを拡張するには、以下のコマンドを実行します。
# xfs_growfs <mount-point>
以下に例を示します。
# xfs_growfs /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de meta-data=/dev/mapper/mpatha isize=512 agcount=24, agsize=65536 blks = sectsz=512 attr=2, projid32bit=1 = crc=1 finobt=0 spinodes=0 data = bsize=4096 blocks=1572864, imaxpct=25 = sunit=0 swidth=0 blks naming =version 2 bsize=4096 ascii-ci=0 ftype=1 log =internal bsize=4096 blocks=2560, version=2 = sectsz=512 sunit=0 blks, lazy-count=1 realtime =none extsz=4096 blocks=0, rtextents=0 data blocks changed from 1572864 to 1835008# df -Th | grep <pv-name>
以下に例を示します。
# df -Th | grep pvc-fc3e9160-aaf9-11ea-a29f-005056b781de /dev/mapper/mpatha xfs 7.0G 44M 7.0G 1% /var/lib/origin/openshift.local.volumes/pods/44b76db5-afa2-11ea-a29f-005056b781de/volumes/kubernetes.io~iscsi/pvc-fc3e9160-aaf9-11ea-a29f-005056b781de
- アプリケーション Pod を再起動せずに新規サイズを使用できるようになりました。
第4章 gluster-block クライアントノードのシャットダウン
以下の手順に従って、gluster-block クライアントノードをシャットダウンします。
- Pod を退避させます。詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/cluster_administration/#evacuating-pods-on-nodes を参照してください。
- システムに gluster ブロックマウントがないことを確認します。
- ノードを再起動します。詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/cluster_administration/#rebooting-nodes を参照してください。
第5章 Red Hat Openshift Container Storage 環境における S3 互換オブジェクトストア
Container-Native Storage での S3 と互換性のあるオブジェクトストアのサポートは、テクノロジープレビューです。テクノロジープレビュー機能は Red Hat のサービスレベルアグリーメント (SLA) では完全にはサポートされていないため、機能的に完全でない可能性があり、実稼働環境での使用を目的としていません。
テクノロジープレビュー機能は、近々発表予定の製品イノベーションをリリースに先駆けてご提供することにより、お客様は機能性をテストし、開発プロセス中にフィードバックを提供することができます。
Red Hat では、テクノロジープレビュー機能の今後のバージョンを一般的に利用可能にすることを検討しており、お客様がこれらの機能を使用する際に経験され報告された問題を解決するために、商業的に妥当な努力を行います。
オブジェクトストアが提供するデータストレージ用のシステムでは、ユーザーは (オブジェクトとファイルの両方として) 同じデータにアクセスすることができ、これにより、管理とストレージコストの制御が簡素化されます。S3 API は、オブジェクトストレージサービスへの HTTP ベースのアクセスについての事実上の標準です。
S3 と互換性のあるオブジェクトストアは、Red Hat Openshift Container Storage 3.11.4 以前リリースでのみ利用可能です。
5.1. Red Hat Openshift Container Storage 用の S3 と互換性のあるオブジェクトストアのセットアップ
S3 互換の Object Store をセットアップする前に、cns-deploy パッケージがインストールされていることを確認します。cns-deploy パッケージのインストール方法に関する詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/deployment_guide/#part-Appendix を参照してください。
/usr/share/heketi/templates/ ディレクトリーから以下の手順を実行し、Red Hat Openshift Container Storage 用の S3 と互換性のあるオブジェクトストアをセットアップします。
(オプション): heketi のシークレットを作成する場合は、以下のコマンドを実行します。
# oc create secret generic heketi-${NAMESPACE}-admin-secret --from-literal=key=${ADMIN_KEY} --type=kubernetes.io/glusterfs以下に例を示します。
# oc create secret generic heketi-storage-project-admin-secret --from-literal=key=abcd --type=kubernetes.io/glusterfs
以下のコマンドを実行してシークレットにラベルを付けます。
# oc label --overwrite secret heketi-${NAMESPACE}-admin-secret glusterfs=s3-heketi-${NAMESPACE}-admin-secret gluster-s3=heketi-${NAMESPACE}-admin-secret以下に例を示します。
# oc label --overwrite secret heketi-storage-project-admin-secret glusterfs=s3-heketi-storage-project-admin-secret gluster-s3=heketi-storage-project-admin-secret
GlusterFS StorageClass ファイルを作成します。現在のセットアップから
HEKETI_URLおよびNAMESPACEを使用し、STORAGE_CLASS名を設定します。# sed -e 's/${HEKETI_URL}/<HEKETI_URL>/g' -e 's/${STORAGE_CLASS}/<STORAGE_CLASSNAME>/g' -e 's/${NAMESPACE}/<NAMESPACE_NAME>/g' /usr/share/heketi/templates/gluster-s3-storageclass.yaml | oc create -f -以下に例を示します。
# sed -e 's/${HEKETI_URL}/heketi-storage-project.cloudapps.mystorage.com/g' -e 's/${STORAGE_CLASS}/gluster-s3-store/g' -e 's/${NAMESPACE}/storage-project/g' /usr/share/heketi/templates/gluster-s3-storageclass.yaml | oc create -f -storageclass "gluster-s3-store" created注記以下のコマンドを実行して HEKETI_URL を取得できます。
# oc get routes --all-namespaces | grep heketi
コマンドの出力例を以下に示します。
glusterfs heketi-storage heketi-storage-glusterfs.router.default.svc.cluster.local heketi-storage <all> None
出力に複数の行がある場合は、最も関連する行を選択できます。
以下のコマンドを実行して NAMESPACE を取得できます。
oc get project
コマンドの出力例を以下に示します。
# oc project Using project "glusterfs" on server "master.example.com:8443"
ここで、glusterfs は NAMESPACE です。
ストレージクラスを使用して Persistent Volume Claim(永続ボリューム要求、PVC) を作成します。
# sed -e 's/${VOLUME_CAPACITY}/<NEW SIZE in Gi>/g' -e 's/${STORAGE_CLASS}/<STORAGE_CLASSNAME>/g' /usr/share/heketi/templates/gluster-s3-pvcs.yaml | oc create -f -以下に例を示します。
# sed -e 's/${VOLUME_CAPACITY}/2Gi/g' -e 's/${STORAGE_CLASS}/gluster-s3-store/g' /usr/share/heketi/templates/gluster-s3-pvcs.yaml | oc create -f - persistentvolumeclaim "gluster-s3-claim" created persistentvolumeclaim "gluster-s3-meta-claim" created直前の手順で作成された
STORAGE_CLASSを使用します。環境要件に応じてVOLUME_CAPACITYを変更します。PVC がバインドされるまで待機します。以下のコマンドを使用して、同じことを確認します。# oc get pvc NAME STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-s3-claim Bound pvc-0b7f75ef-9920-11e7-9309-00151e000016 2Gi RWX 2m gluster-s3-meta-claim Bound pvc-0b87a698-9920-11e7-9309-00151e000016 1Gi RWX 2m
テンプレートを使用して、glusters3 オブジェクトストレージサービスを起動します。
S3_ACCOUNT名、S3_USER名、およびS3_PASSWORDを設定します。PVCおよびMETA_PVCは直前のステップから取得されます。# oc new-app /usr/share/heketi/templates/gluster-s3-template.yaml \ --param=S3_ACCOUNT=testvolume --param=S3_USER=adminuser \ --param=S3_PASSWORD=itsmine --param=PVC=gluster-s3-claim \ --param=META_PVC=gluster-s3-meta-claim --> Deploying template "storage-project/gluster-s3" for "/usr/share/heketi/templates/gluster-s3-template.yaml" to project storage-project gluster-s3 --------- Gluster s3 service template * With parameters: * S3 Account Name=testvolume * S3 User=adminuser * S3 User Password=itsmine * Primary GlusterFS-backed PVC=gluster-s3-claim * Metadata GlusterFS-backed PVC=gluster-s3-meta-claim --> Creating resources ... service "gluster-s3-service" created route "gluster-s3-route" created deploymentconfig "gluster-s3-dc" created --> Success Run 'oc status' to view your app.以下のコマンドを実行して、S3 Pod が起動しているかどうかを確認します。
# oc get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE gluster-s3-azkys 1/1 Running 0 4m 10.130.0.29 node3 ..
5.2. オブジェクト操作
このセクションでは、実行できるオブジェクト操作の一部を紹介します。
S3 OS を提供するルートの URL を取得します。
# s3_storage_url=$(oc get routes | grep "gluster.*s3" | awk '{print $2}')注記s3curl ツールを https://aws.amazon.com/code/128 からダウンロードするようにしてください。このツールは、オブジェクト操作の確認に使用されます。
s3curl.pl r には Digest::HMAC_SHA1 および Digest::MD5 が必要です。これを取得するには、perl-Digest-HMAC パッケージをインストールします。以下のコマンドを実行して perl-Digest-HMAC パッケージをインストールできます。
# yum install perl-Digest-HMAC
取得された glusters3object url で s3curl.pl perl スクリプトを更新します。
以下に例を示します。
my @endpoints = ( 'glusters3object-storage-project.cloudapps.mystorage.com');
バケットの
PUT操作を実行するには、以下を実行します。s3curl.pl --debug --id "testvolume:adminuser" --key "itsmine" --put /dev/null -- -k -v http://$s3_storage_url/bucket1
バケット内でオブジェクトの
PUT操作を実行するには、以下を実行します。s3curl.pl --debug --id "testvolume:adminuser" --key "itsmine" --put my_object.jpg -- -k -v -s http://$s3_storage_url/bucket1/my_object.jpg
バケットのオブジェクトの一覧を確認するには、以下を実行します。
s3curl.pl --debug --id "testvolume:adminuser" --key "itsmine" -- -k -v -s http://$s3_storage_url/bucket1/
第6章 クラスター管理者のセットアップ
認証
AllowAll Authentication メソッドを使用して認証を設定します。
AllowAll 認証
すべてのパスワードを許可する認証モデルを設定します。OpenShift マスターで /etc/origin/master/master-config.yaml を編集し、DenyAll PasswordIdentityProvider の値を AllowAllPasswordIdentityProvider に変更します。次に、OpenShift マスターを再起動します。
認証モデルが設定されたため、admin/admin など、ユーザーとしてログインします。
# oc login openshift master e.g. https://1.1.1.1:8443 --username=admin --password=adminadmin ユーザーアカウントに cluster-admin ロールを付与します。
# oc login -u system:admin -n default Logged into "https:// <<openshift_master_fqdn>>:8443" as "system:admin" using existing credentials. You have access to the following projects and can switch between them with 'oc project <projectname>': *default glusterfs infra-storage kube-public kube-system management-infra openshift openshift-infra openshift-logging openshift-node openshift-sdn openshift-web-console Using project "default". # oc adm policy add-cluster-role-to-user cluster-admin admin cluster role "cluster-admin" added: "admin"
認証方法の詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#identity-providers-configuring を参照してください。
第7章 ロギングおよびメトリクス用バックエンドとしての Gluster Block Storage
以下のセクションでは、Gluster Block Storage をロギングおよびメトリクス用のバックエンドストレージとして設定する方法を説明します。
ブロックボリューム拡張が OpenShift Container Storage 3.11 でサポートされるようになりました。「ブロックボリューム拡張」を参照してください。
7.1. 前提条件
gluster ブロックストレージをロギングまたはメトリクスのバックエンドとして設定する前に、以下の前提条件を満たしていることを確認してください。
storageclass ファイルで、デフォルトのストレージクラスが gluster ブロックのストレージクラスに設定されているかどうかを確認します。以下に例を示します。
# oc get storageclass NAME TYPE gluster-block gluster.org/glusterblock
デフォルトが
gluster-block(または指定したその他の名前) に設定されていない場合は、以下のコマンドを実行します。以下に例を示します。# oc patch storageclass gluster-block -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'以下のコマンドを実行して確認します。
oc get storageclass NAME TYPE gluster-block (default) gluster.org/glusterblock
7.2. Gluster Block Storage のロギングのバックエンドとしての有効化
以下のタスクに従い、ロギング用バックエンドとして Gluster Block Storage を有効にします。
- OpenShift Container Platform でロギングを有効にするには、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-aggregate-logging を参照してください。
openshift_logging_es_pvc_dynamicAnsible 変数を true に設定する必要があります。[OSEv3:vars] openshift_logging_es_pvc_dynamic=true
たとえば、openshift_logging_ の変数セットの例を以下に示します。
openshift_logging_install_logging=true openshift_logging_es_pvc_dynamic=true openshift_logging_kibana_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_logging_curator_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_logging_es_pvc_size=10Gi openshift_logging_es_pvc_storage_class_name="glusterfs-registry-block"- Ansible Playbook を実行します。詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-aggregate-logging を参照してください。
確認するには、以下のコマンドを実行します。
# oc get pods -n openshift-logging
7.3. Gluster Block Storage のメトリクスのバックエンドとしての有効化
以下のタスクに従い、メトリクス用バックエンドとして Gluster Block Storage を有効にします。
デフォルトでは、Container Native Storage は 3 方向のレプリケーションを実行するため、クラスター内のどこからでも再起動したノードでデータを利用できます。そのため、容量のオーバーヘッドを回避するために Cassandra レベルのレプリケーションをオフにすることが推奨されます。
- Openshift Container Platform でメトリクスを有効にするには、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-cluster-metrics を参照してください。
openshift_metrics_cassandra_storage_typeAnsible 変数はdynamicに設定する必要があります。[OSEv3:vars]openshift_metrics_cassandra_storage_type=dynamic
たとえば、openshift_metrics_ の変数セットの例を以下に示します。
openshift_metrics_install_metrics=true openshift_metrics_storage_kind=dynamic openshift_metrics_hawkular_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_metrics_cassandra_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_metrics_heapster_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_metrics_storage_volume_size=10Gi openshift_metrics_cassandra_pvc_storage_class_name="glusterfs-registry-block"- Ansible Playbook を実行します。詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#install-config-cluster-metrics を参照してください。
確認するには、以下のコマンドを実行します。
# oc get pods --namespace openshift-infra
実行中の以下の Pod が一覧表示されるはずです。
heapster-cassandra heapster-metrics hawkular-&*9
メトリクスストレージに関する考慮事項についての詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html-single/configuring_clusters/#metrics-data-storage を参照してください。
7.4. Gluster Block がバックエンドとしてセットアップされているかどうかの確認
以下のコマンドを実行して、gluster ブロックがロギングおよびメトリクスのバックエンドとして設定されていることを確認します。
インフラストラクチャーの概要を取得するには、以下のコマンドを実行します。
# oc get pods -n logging -o jsonpath='{range .items[].status.containerStatuses[]}{"Name: "}{.name}{"\n "}{"Image: "}{.image}{"\n"}{" State: "}{.state}{"\n"}{end}'すべての永続ボリューム要求 (PVC) を取得するには、以下のコマンドを実行します。
# oc get pvc
pvc の詳細を取得するには、以下のコマンドを実行します。
# oc describe pvc <claim_name>
ボリュームがマウント可能であること、およびパーミッションが読み取り/書き込みを許可していることを確認します。また、PVC 要求名は、動的にプロビジョニングされた gluster ブロックストレージクラスと一致する必要があります。
パート III. セキュリティー
第8章 暗号化の有効化
Red Hat Gluster Storage は、TLS/SSL を使用したネットワーク暗号化をサポートします。Red Hat Gluster Storage は、通常の接続に使用される自己の認証フレームワークの代わりに、認証および承認に TLS/SSL を使用します。Red Hat Gluster Storage は以下の暗号化タイプをサポートします。
- I/O 暗号化:Red Hat Gluster Storage クライアントとサーバー間の I/O 接続の暗号化。
- 管理暗号化 - 信頼済みトレージプール内の管理 (glusterd) 接続の暗号化。
8.1. 前提条件
暗号化を有効にするには、ノードごとに 3 つの証明書 (glusterfs.key、gluserfs.pem および glusterfs.ca) が必要です。前提条件として実行すべき手順の詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_gluster_storage/3.5/html-single/administration_guide/index#chap-Network_Encryption-Preparing_Certificates を参照してください。
volumeoptions パラメーターを使用して storageclass ファイルを登録する際に暗号化を有効にします。ファイルストレージの storageclass ファイルを登録する方法は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/operations_guide/index#chap-Documentation-Red_Hat_Gluster_Storage_Container_Native_with_OpenShift_Platform-OpenShift_Creating_Persistent_Volumes-Dynamic_Prov を参照してください。
- マスター以外のすべての OpenShift ノードで手順を実行します。
- すべての Red Hat Gluster Storage ボリュームは OpenShift ノードにマウントされ、次にアプリケーション Pod にバインドマウントされます。そのため、特にアプリケーション Pod で暗号化関連の操作を行う必要はありません。
8.2. 新規 Red Hat Openshift Container Storage 設定での暗号化の有効化
I/O 暗号化と管理暗号化の両方について、新規 Red Hat Openshift Container Storage セットアップのネットワーク暗号化を設定できます。
8.2.1. 管理暗号化の有効化
Red Hat Gluster Storage では、管理暗号化を使用せずに I/O 暗号化のみを設定できますが、管理暗号化を行うことが推奨されます。I/O パスでのみ SSL を有効にする場合は、このセクションを省略して「ボリュームの I/O 暗号化の有効化」に進みます。
サーバー上
すべてのサーバー (つまり、Red Hat Gluster Storage Pod が実行されている OpenShift ノード) で以下を実行します。
/var/lib/glusterd/secure-access ファイルを作成します。
# touch /var/lib/glusterd/secure-access
クライアント上
クライアント上で (つまり、Red Hat Gluster Storage が実行されていない残りのすべての OpenShift ノード上で) 以下を実行します。
/var/lib/glusterd/secure-access ファイルを作成します。
# touch /var/lib/glusterd/secure-access
すべての Red Hat Gluster Storage ボリュームは OpenShift ノードにマウントされ、次にアプリケーション Pod にバインドマウントされます。そのため、特にアプリケーション Pod で暗号化関連の操作を行う必要はありません。
サーバーおよびクライアントでコマンドを実行してから、Red Hat Openshift Container Storage をデプロイします。詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/deployment_guide/#chap-Documentation-Red_Hat_Gluster_Storage_Container_Native_with_OpenShift_Platform-Setting_the_environment-Deploy_CNS を参照してください。
8.2.2. ボリュームの I/O 暗号化の有効化
サーバーとクライアント間の I/O 暗号化を有効にします。
サーバーとは、Red Hat Gluster Storage Pod が実行されている OpenShift ノードです。
クライアントとは、Red Hat Gluster Storage が実行されていない残りの OpenShift ノードです。
- さらなる手順に進む前に、Red Hat Openshift Container Storage がデプロイされていることを確認します。詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/deployment_guide/#chap-Documentation-Red_Hat_Gluster_Storage_Container_Native_with_OpenShift_Platform-Setting_the_environment-Deploy_CNS を参照してください。
静的にプロビジョニングされたボリュームまたは動的にプロビジョニングされたボリュームを作成できます。ボリュームの静的プロビジョニングの詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/operations_guide/#chap-Documentation-Red_Hat_Gluster_Storage_Container_Native_with_OpenShift_Platform-OpenShift_Creating_Persistent_Volumes-Static_Prov を参照してください。ボリュームの動的プロビジョニングに関する詳細は、https://access.redhat.com/documentation/ja-jp/red_hat_openshift_container_storage/3.11/html-single/operations_guide/#chap-Documentation-Red_Hat_Gluster_Storage_Container_Native_with_OpenShift_Platform-OpenShift_Creating_Persistent_Volumes-Dynamic_Prov を参照してください。
注記静的にプロビジョニングされたボリュームの作成時に暗号化を有効にするには、以下のコマンドを実行します。
# heketi-cli volume create --size=100 --gluster-volume-options="client.ssl on","server.ssl on"
以下のコマンドを実行してボリュームを停止します。
# oc rsh <gluster_pod_name> gluster volume stop VOLNAME
gluster pod nameは、ボリュームが属する信頼済みストレージプールの Red Hat Gluster Storage Pod のいずれかの名前です。
注記VOLNAME を取得するには、以下のコマンドを実行します。
# oc describe pv <pv_name>
以下に例を示します。
# oc describe pv pvc-01569c5c-1ec9-11e7-a794-005056b38171 Name: pvc-01569c5c-1ec9-11e7-a794-005056b38171 Labels: <none> StorageClass: fast Status: Bound Claim: storage-project/storage-claim68 Reclaim Policy: Delete Access Modes: RWO Capacity: 1Gi Message: Source: Type: Glusterfs (a Glusterfs mount on the host that shares a pod's lifetime) EndpointsName: glusterfs-dynamic-storage-claim68 Path: vol_0e81e5d6e46dcbf02c11ffd9721fca28 ReadOnly: false No events.VOLNAME は、上記の出力の"path"の値です。
ボリュームにアクセスする全サーバーの共通名の一覧を設定します。ボリュームにアクセスできるクライアントの共通名を含めるようにしてください。
# oc rsh <gluster_pod_name> gluster volume set VOLNAME auth.ssl-allow 'server1,server2,server3,client1,client2,client3'
注記auth.ssl-allow オプションの値として* を設定すると、TLS 認証されたクライアントはアプリケーション側からボリュームをマウントおよびアクセスできます。したがって、オプションの値を * に設定するか、または信頼済みストレージプールのノードおよびクライアントの共通名を指定します。
ボリュームで client.ssl オプションおよび server.ssl オプションを有効にします。
# oc rsh <gluster_pod_name> gluster volume set VOLNAME client.ssl on # oc rsh <gluster_pod_name> gluster volume set VOLNAME server.ssl on
ボリュームを起動します。
# oc rsh <gluster_pod_name> gluster volume start VOLNAME
8.3. 既存の Red Hat Openshift Container Storage セットアップの暗号化の有効化
I/O 暗号化と管理暗号化の両方について、既存の Red Hat Openshift Container Storage Storage セットアップにネットワーク暗号化を設定できます。
8.3.1. ボリュームの I/O 暗号化の有効化
ボリュームのサーバーとクライアント間の I/O 暗号化を有効にします。
サーバーとは、Red Hat Gluster Storage Pod が実行されている OpenShift ノードです。
クライアントとは、Red Hat Gluster Storage が実行されていない残りの OpenShift ノードです。
- Red Hat Gluster Storage ボリュームを持つすべてのアプリケーション Pod を停止します。
ボリュームを停止します。
# oc rsh <gluster_pod_name> gluster volume stop VOLNAME
gluster pod nameは、ボリュームが属する信頼済みストレージプールの Red Hat Gluster Storage Pod のいずれかの名前です。
ボリュームにアクセスできるクライアントの共通名の一覧を設定します。すべてのサーバーの共通名を含めるようにしてください。
# oc rsh <gluster_pod_name> gluster volume set VOLNAME auth.ssl-allow 'server1,server2,server3,client1,client2,client3'
注記auth.ssl-allow オプションの値として* を設定すると、TLS 認証されたクライアントはアプリケーション側からボリュームをマウントおよびアクセスできます。したがって、オプションの値を * に設定するか、または信頼済みストレージプールのノードおよびクライアントの共通名を指定します。
以下のコマンドを使用して、ボリュームで client.ssl および server.ssl を有効にします。
# oc rsh <gluster_pod_name> gluster volume set VOLNAME client.ssl on # oc rsh <gluster_pod_name> gluster volume set VOLNAME server.ssl on
ボリュームを起動します。
# oc rsh <gluster_pod_name> gluster volume start VOLNAME
- アプリケーション Pod を起動し、I/O が暗号化された Red Hat Gluster Storage ボリュームを使用します。
8.3.2. 管理暗号化の有効化
Red Hat Gluster Storage では、管理暗号化を使用せずに I/O 暗号化のみを設定できますが、管理暗号化を行うことが推奨されます。サーバーおよびクライアントが実行されている既存のインストールで、ボリューム、アプリケーション、クライアント、およびその他のエンドユーザーのダウンタイムをスケジュールして管理暗号化を有効にします。
現在、暗号化されていない接続と暗号化された接続を動的に切り替えることはできません。サーバーおよびクライアントのブリックおよびその他のローカルサービスは、管理暗号化への切り替えが行われたときに実行されている場合、glusterd から通知を受信しません。
- Red Hat Gluster Storage ボリュームを持つすべてのアプリケーション Pod を停止します。
すべてのボリュームを停止します。
# oc rsh <gluster_pod_name> gluster volume stop VOLNAME
Red Hat Gluster Storage Pod を停止します。
# oc delete daemonset glusterfs-storage
デーモンセットを削除すると、Pod がダウンします。Pod がダウンしているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
すべての OpenShift ノードに /var/lib/glusterd/secure-access ファイルを作成します。
# touch /var/lib/glusterd/secure-access
以下のコマンドを実行して、Red Hat Gluster Storage daemonset を作成します。
注記Ansible デプロイメントでは、コマンドを実行する前に、イメージ名とバージョンをテンプレートで指定する必要があります。
# oc process glusterfs | oc create -f -
デーモンセットを作成すると、Pod が起動します。Pod が起動しているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
すべてのボリュームを起動します。
# oc rsh <gluster_pod_name> gluster volume start VOLNAME
- アプリケーション Pod を起動して、管理が暗号化された Red Hat Gluster Storage を使用します。
8.4. 暗号化の無効化
以下の 2 つのシナリオで、Red Hat Openshift Container Storage セットアップの暗号化を無効にできます。
- ボリュームの I/O 暗号化の無効化
- 管理暗号化の無効化
8.4.1. すべてのボリュームの I/O 暗号化の無効化
以下のコマンドを実行して、ボリュームのサーバーとクライアント間の I/O 暗号化を無効にします。
サーバーとは、Red Hat Gluster Storage Pod が実行されている OpenShift ノードです。
クライアントとは、Red Hat Gluster Storage が実行されていない残りの OpenShift ノードです。
- Red Hat Gluster Storage ボリュームを持つすべてのアプリケーション Pod を停止します。
すべてのボリュームを停止します。
# oc rsh <gluster_pod_name> gluster volume stop VOLNAME
ボリュームの暗号化オプションをすべてリセットします。
# oc rsh <gluster_pod_name> gluster volume reset VOLNAME auth.ssl-allow # oc rsh <gluster_pod_name> gluster volume reset VOLNAME client.ssl # oc rsh <gluster_pod_name> gluster volume reset VOLNAME server.ssl
すべての OpenShift ノードで以下のコマンドを使用して、ネットワークの暗号化に使用したファイルを削除します。
# rm /etc/ssl/glusterfs.pem /etc/ssl/glusterfs.key /etc/ssl/glusterfs.ca
注記管理暗号化が有効なセットアップでこれらのファイルを削除すると、glusterd がすべての gluster Pod で失敗するため、回避する必要があります。
Red Hat Gluster Storage Pod を停止します。
# oc delete daemonset glusterfs
デーモンセットを削除すると、Pod がダウンします。Pod がダウンしているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
以下のコマンドを実行して、Red Hat Gluster Storage daemonset を作成します。
注記Ansible デプロイメントでは、コマンドを実行する前に、イメージ名とバージョンをテンプレートで指定する必要があります。
# oc process glusterfs | oc create -f -
デーモンセットを作成すると、Pod が起動します。Pod が起動しているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
ボリュームを起動します。
# oc rsh <gluster_pod_name> gluster volume start VOLNAME
- アプリケーション Pod を起動し、I/O が暗号化された Red Hat Gluster Storage ボリュームを使用します。
8.4.2. 管理暗号化の無効化
現在、暗号化されていない接続と暗号化された接続を動的に切り替えることはできません。サーバーおよびクライアントのブリックおよびその他のローカルサービスは、管理暗号化への切り替えが行われたときに実行されている場合、glusterd から通知を受信しません。
以下のコマンドを実行して管理暗号化を無効にします。
- Red Hat Gluster Storage ボリュームを持つすべてのアプリケーション Pod を停止します。
すべてのボリュームを停止します。
# oc rsh <gluster_pod_name> gluster volume stop VOLNAME
Red Hat Gluster Storage Pod を停止します。
# oc delete daemonset glusterfs
デーモンセットを削除すると、Pod がダウンします。Pod がダウンしているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
すべての OpenShift ノードで /var/lib/glusterd/secure-access ファイルを削除して、管理暗号化を無効にします。
# rm /var/lib/glusterd/secure-access
すべての OpenShift ノードで以下のコマンドを使用して、ネットワークの暗号化に使用したファイルを削除します。
# rm /etc/ssl/glusterfs.pem /etc/ssl/glusterfs.key /etc/ssl/glusterfs.ca
以下のコマンドを実行して、Red Hat Gluster Storage daemonset を作成します。
注記Ansible デプロイメントでは、コマンドを実行する前に、イメージ名とバージョンをテンプレートで指定する必要があります。
# oc process glusterfs | oc create -f -
デーモンセットを作成すると、Pod が起動します。Pod が起動しているかどうかを確認するには、以下のコマンドを実行します。
# oc get pods
すべてのボリュームを起動します。
# oc rsh <gluster_pod_name> gluster volume start VOLNAME
- アプリケーション Pod を起動して、管理が暗号化された Red Hat Gluster Storage を使用します。
パート IV. 移行
第9章 ストレージのバックエンドとしての Red Hat Openshift Container Storage を使用したレジストリーの更新
OpenShift Container Platform は、自動的にセットアップされる NFS がサポートする永続ボリュームを使用するストレージで統合レジストリーを提供します。Red Hat Openshift Container Storage では、これをレジストリーストレージの Gluster 永続ボリュームに置き換えることができます。これにより、信頼性、スケーラビリティー、およびフェイルオーバーが向上します。
OpenShift Container Platform および docker-registry の詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html/configuring_clusters/setting-up-the-registry を参照してください。
9.1. Openshift Container Platform レジストリーデプロイメントの検証
レジストリーが適切にデプロイされていることを確認するには、以下のコマンドを実行します。
マスターまたはクライアントで、以下のコマンドを実行し、クラスター管理者としてログインします。
# oc login
以下に例を示します。
# oc login Authentication required for https://master.example.com:8443 (openshift) Username: <cluster-admin-user> Password: <password> Login successful. You have access to the following projects and can switch between them with 'oc project <projectname>': * default management-infra openshift openshift-infra Using project "default".プロジェクトのデフォルトに自動的にログインしない場合は、以下のコマンドを実行してこれに切り替えます。
# oc project default
Pod が作成されたことを確認するには、以下のコマンドを実行します。
# oc get pods
以下に例を示します。
# oc get pods NAME READY STATUS RESTARTS AGE docker-registry-2-mbu0u 1/1 Running 4 6d docker-registry-2-spw0o 1/1 Running 3 6d registry-console-1-rblwo 1/1 Running 3 6d
エンドポイントが作成されたことを確認するには、以下のコマンドを実行します。
# oc get endpoints
以下に例を示します。
# oc get endpoints NAME ENDPOINTS AGE docker-registry 10.128.0.15:5000,10.129.0.9:5000 7d kubernetes 192.168.234.143:8443,192.168.234.143:8053,192.168.234.143:8053 7d registry-console 10.128.0.17:9090 7d router 192.168.234.144:443,192.168.234.145:443,192.168.234.144:1936 + 3 more... 7d
永続ボリュームが作成されたことを確認するには、以下のコマンドを実行します。
# oc get pv NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE registry-volume 5Gi RWX Retain Bound default/registry-claim 7d
NFS レジストリー用に作成された永続ボリュームの詳細を取得するには、以下のコマンドを実行します。
# oc describe pv registry-volume Name: registry-volume Labels: <none> StorageClass: Status: Bound Claim: default/registry-claim Reclaim Policy: Retain Access Modes: RWX Capacity: 5Gi Message: Source: Type: NFS (an NFS mount that lasts the lifetime of a pod) Server: cns30.rh73 Path: /exports/registry ReadOnly: false No events.
9.2. Red Hat Openshift Container Storage を使用した Openshift Container Platform レジストリーの変換
このセクションでは、Red Hat Gluster Storage ボリュームを作成し、これを使用して統合レジストリーのストレージを提供する手順について説明します。
Red Hat Gluster Storage 永続ボリュームの設定
以下のコマンドを実行して、レジストリーデータを保存する Red Hat Gluster Storage ボリュームを作成し、永続ボリュームを作成します。
コマンドは、defaultプロジェクトで実行する必要があります。
default プロジェクトにログインします。
# oc project default
以下に例を示します。
# oc project default Now using project "default" on server "https://cns30.rh73:8443"
以下のコマンドを実行して gluster-registry-endpoints.yaml ファイルを作成します。
oc get endpoints <heketi-db-storage-endpoint-name> -o yaml --namespace=<project-name> > gluster-registry-endpoints.yaml
注記Red Hat Gluster Storage レジストリーを使用する各プロジェクトのエンドポイントを作成する必要があります。そのため、defaultプロジェクトと前述のステップで作成された新規プロジェクト (storage-project) の両方にサービスとエンドポイントがあります。
gluster-registry-endpoints.yaml ファイルを編集します。名前を gluster-registry-endpoints に変更し、他のすべてのメタデータを削除し、その他はすべて同じままにします。
# cat gluster-registry-endpoints.yaml apiVersion: v1 kind: Endpoints metadata: name: gluster-registry-endpoints subsets: - addresses: - ip: 192.168.124.114 - ip: 192.168.124.52 - ip: 192.168.124.83 ports: - port: 1 protocol: TCP以下のコマンドを実行してエンドポイントを作成します。
# oc create -f gluster-registry-endpoints.yaml endpoints "gluster-registry-endpoints" created
エンドポイントの作成を確認するには、以下のコマンドを実行します。
# oc get endpoints NAME ENDPOINTS AGE docker-registry 10.129.0.8:5000,10.130.0.5:5000 28d gluster-registry-endpoints 192.168.124.114:1,192.168.124.52:1,192.168.124.83:1 10s kubernetes 192.168.124.250:8443,192.168.124.250:8053,192.168.124.250:8053 28d registry-console 10.131.0.6:9090 28d router 192.168.124.114:443,192.168.124.83:443,192.168.124.114:1936 + 3 more... 28d
以下のコマンドを実行して gluster-registry-service.yaml ファイルを作成します。
oc get services <heketi-storage-endpoint-name> -o yaml --namespace=<project-name> > gluster-registry-service.yaml
gluster-registry-service.yaml ファイルを編集します。名前を gluster-registry-service に変更し、他のすべてのメタデータを削除します。また、特定のクラスター IP アドレスを削除します。
# cat gluster-registry-service.yaml apiVersion: v1 kind: Service metadata: name: gluster-registry-service spec: ports: - port: 1 protocol: TCP targetPort: 1 sessionAffinity: None type: ClusterIP status: loadBalancer: {}以下のコマンドを実行してサービスを作成します。
# oc create -f gluster-registry-service.yaml services "gluster-registry-service" created
以下のコマンドを実行して、サービスが実行中かどうかを確認します。
# oc get services NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE docker-registry 172.30.197.118 <none> 5000/TCP 28d gluster-registry-service 172.30.0.183 <none> 1/TCP 6s kubernetes 172.30.0.1 <none> 443/TCP,53/UDP,53/TCP 29d registry-console 172.30.146.178 <none> 9000/TCP 28d router 172.30.232.238 <none> 80/TCP,443/TCP,1936/TCP 28d
以下のコマンドを実行して、既存の docker-registry Pod の fsGroup GID を取得します。
# export GID=$(oc get po --selector="docker-registry=default" -o go-template --template='{{printf "%.0f" ((index .items 0).spec.securityContext.fsGroup)}}')以下のコマンドを実行してボリュームを作成します。
# heketi-cli volume create --size=5 --name=gluster-registry-volume --gid=${GID}Red Hat Gluster Storage ボリュームの永続ボリュームファイルを作成します。
# cat gluster-registry-volume.yaml kind: PersistentVolume apiVersion: v1 metadata: name: gluster-registry-volume labels: glusterfs: registry-volume spec: capacity: storage: 5Gi glusterfs: endpoints: gluster-registry-endpoints path: gluster-registry-volume accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain以下のコマンドを実行して永続ボリュームを作成します。
# oc create -f gluster-registry-volume.yaml
以下のコマンドを実行して、作成された永続ボリュームの詳細を確認し、取得します。
# oc get pv/gluster-registry-volume NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM REASON AGE gluster-registry-volume 5Gi RWX Retain Available 21m
新規の永続ボリューム要求 (PVC) を作成します。以下は、既存の registry-storage ボリューム要求を置き換えるために使用される Persistent Volume Claim(永続ボリューム要求、PVC) のサンプルです。
# cat gluster-registry-claim.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: gluster-registry-claim spec: accessModes: - ReadWriteMany resources: requests: storage: 5Gi selector: matchLabels: glusterfs: registry-volume以下のコマンドを実行して Persistent Volume Claim(永続ボリューム要求、PVC) を作成します。
# oc create -f gluster-registry-claim.yaml
以下に例を示します。
# oc create -f gluster-registry-claim.yaml persistentvolumeclaim "gluster-registry-claim" created
以下のコマンドを実行して、要求がバインドされているかどうかを確認します。
# oc get pvc/gluster-registry-claim
以下に例を示します。
# oc get pvc/gluster-registry-claim NAME STATUS VOLUME CAPACITY ACCESSMODES AGE gluster-registry-claim Bound gluster-registry-volume 5Gi RWX 22s
以下のコマンドを実行してレジストリーを読み取り専用にします。
# oc set env -n default dc/docker-registry 'REGISTRY_STORAGE_MAINTENANCE_READONLY={"enabled":true}'値が読み取り専用に設定されていることを確認するには、以下のコマンドを実行します。
# oc set env -n default dc/docker-registry --list
データを古いレジストリーから Red Hat Gluster Storage レジストリーに移行する場合は、以下のコマンドを実行します。
注記これらの手順はオプションです。
以下のコマンドを実行して、古いレジストリーのデプロイメント設定 (dc) に Red Hat Gluster Storage レジストリーを追加します。
# oc set volume dc/docker-registry --add --name=gluster-registry-storage -m /gluster-registry -t pvc --claim-name=gluster-registry-claim
以下のコマンドを実行してレジストリー Pod 名を保存します。
# export REGISTRY_POD=$(oc get po --selector="docker-registry=default" -o go-template --template='{{printf "%s" ((index .items 0).metadata.name)}}')以下のコマンドを実行して、以前のレジストリーディレクトリーから Red Hat Gluster Storage レジストリーディレクトリーにデータをコピーします。
# oc rsh -T $REGISTRY_POD cp -aTv /registry/ /gluster-registry/
以下のコマンドを実行して、古い dc レジストリーから Red Hat Gluster Storage レジストリーを削除します。
# oc volume dc/docker-registry --remove --name=gluster-registry-storage
既存の registry-storage ボリュームを、新しい gluster-registry-claim PVC に置き換えます。
# oc set volume dc/docker-registry --add --name=registry-storage -t pvc --claim-name=gluster-registry-claim --overwrite
以下のコマンドを実行して、レジストリーを読み取り/書き込みに設定します。
# oc set env dc/docker-registry REGISTRY_STORAGE_MAINTENANCE_READONLY-
設定が読み取り/書き込みに設定されているかどうかを確認するには、以下のコマンドを実行します。
# oc set env -n default dc/docker-registry --list
レジストリーへのアクセスについての詳細は、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html/configuring_clusters/setting-up-the-registry#install-config-registry-accessing を参照してください。
パート V. モニタリング
第10章 OpenShift 3.10 および 3.11 でのボリュームメトリクスの有効化
Prometheus はスタンドアロンのオープンソースのシステムモニターリングおよびアラートツールキットで、OpenShift に同梱されています。Prometheus を使用して、PV や heketi 等のサービスなどの OpenShift Container Platform システムリソースのメトリクスおよびアラートを可視化できます。
heketi は、GlusterFS ボリュームのライフサイクルを管理できる RESTful 管理インターフェイスと、Prometheus でスクレープできるメトリクスエンドポイントを提供します。
Prometheus を OpenShift と統合する方法は、OCP 3.10 と 3.11 で若干異なります。
OCP 3.10 で Prometheus を設定する方法は、Prometheus on OpenShift Container Platform を参照してください。
OCP 3.11 で Prometheus を設定する方法は、Prometheus Cluster Monitoring を参照してください。
10.1. ファイルストレージおよびブロックストレージで利用可能なメトリクス
以下の一覧は、Prometheus で表示できる PV のさまざまなメトリクスを提供します。
- kubelet_volume_stats_available_bytes
- ボリュームで利用可能なバイト数。
- kubelet_volume_stats_capacity_bytes
- ボリュームの容量 (バイト単位)。
- kubelet_volume_stats_inodes
- ボリューム内の inode の最大数。
- kubelet_volume_stats_inodes_free
- ボリューム内の空き inode の数。
- kubelet_volume_stats_inodes_used
- ボリュームで使用されている inode の数。
- kubelet_volume_stats_used_bytes
- ボリュームで使用されているバイト数。
Heketi サービスは以下のメトリクスを提供します。
- heketi_cluster_count
- クラスター数。
- heketi_device_brick_count
- デバイス上のブリックの数。
- heketi_device_count
- ホスト上のデバイス数。
- heketi_device_free_bytes
- デバイスで利用可能な空き領域の容量。
- heketi_device_size_bytes
- デバイスの合計サイズ。
- heketi_device_used_bytes
- デバイスで使用されている領域のサイズ。
- heketi_nodes_count
- クラスター上のノード数。
- heketi_up
- heketi が実行中かどうかを確認します。
- heketi_volumes_count
- クラスターのボリューム数。
- heketi_block_volumes_count
- クラスターのブロックボリュームの数。
10.2. OpenShift 3.10 での Heketi メトリクスの有効化
OCP 3.10 の Prometheus で Heketi メトリクスを表示するには、以下のコマンドを実行します。
heketi-storageサービス (通常は app-storage namespace で実行される) にアノテーションを追加します。# oc project app-storage # oc annotate svc heketi-storage prometheus.io/scheme=http # oc annotate svc heketi-storage prometheus.io/scrape=true
# oc describe svc heketi-storage Name: heketi-storage Namespace: app-storage Labels: glusterfs=heketi-storage-service heketi=storage-service Annotations: description=Exposes Heketi service prometheus.io/scheme=http prometheus.io/scrape=true Selector: glusterfs=heketi-storage-pod Type: ClusterIP IP: 172.30.90.87 Port: heketi 8080/TCP TargetPort: 8080/TCP Endpoints: 172.18.14.2:8080 Session Affinity: None
Prometheus configmap に heketi サービスの
app-storagenamespace を追加します。# oc get cm prometheus -o yaml -n openshift-metrics .... - job_name: 'kubernetes-service-endpoints' tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt # TODO: this should be per target insecure_skip_verify: true kubernetes_sd_configs: - role: endpoints relabel_configs: # only scrape infrastructure components - source_labels: [__meta_kubernetes_namespace] action: keep regex: 'default|logging|metrics|kube-.+|openshift|openshift-.+|app-storage'他のすべてのストレージ namespace(例:infra-storage) に対して上記を行います。
-
prometheus-0Pod を再起動して、Prometheus の Heketi メトリクスにクエリーを行います。
10.3. OpenShift 3.11 での Heketi メトリクスの有効化
OCP 3.11 では、Prometheus はサービスモニターを使用します。これは、Prometheus Operator によって導入される新規リソースです。サービスモニターは、すべてのストレージ namespace に対して作成する必要があり、監視するターゲットのセットを記述します。
OCP 3.11 の Prometheus で Heketi メトリクスを表示するには、以下のコマンドを実行します。
heketi-storageサービスにアノテーションを追加します。# oc project app-storage # oc annotate svc heketi-storage prometheus.io/scheme=http # oc annotate svc heketi-storage prometheus.io/scrape=true
以下のテンプレートを使用して、openshift-monitoring namespace に
heketi-appサービスモニターを作成します。# cat heketi-app-sm.yml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: heketi-app labels: k8s-app: heketi-app namespace: openshift-monitoring spec: endpoints: - bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token interval: 30s port: heketi scheme: http targetPort: 0 namespaceSelector: matchNames: - app-storage selector: matchLabels: heketi: storage-serviceここで、namespaceSelector およびラベルは heketi-storage サービスの値と一致する必要があります。
# oc describe svc heketi-storage -n app-storage Name: heketi-storage Namespace: app-storage Labels: glusterfs=heketi-storage-service heketi=storage-service Annotations: description=Exposes Heketi service prometheus.io/scheme=http prometheus.io/scrape=true Selector: glusterfs=heketi-storage-pod Type: ClusterIP IP: 172.30.3.92 Port: heketi 8080/TCP TargetPort: 8080/TCP Endpoints: 10.128.4.12:8080 Session Affinity: None Events: <none>正しいセレクターセットで、正しいセレクターセットを使用してサービスモニターを openshift-monitoring namespace に作成します。
# oc create -f heketi-app-sm.yml -n openshift-monitoring servicemonitor.monitoring.coreos.com "heketi-app" created
# oc get servicemonitor -n openshift-monitoring NAME AGE alertmanager 20d cluster-monitoring-operator 20d heketi-app 1m kube-apiserver 20d kube-controllers 20d kube-state-metrics 20d kubelet 20d node-exporter 20d prometheus 20d prometheus-operator 20d
- 複数の OCS クラスターがある場合、上記の手順を使用して OCS クラスターごとに 1 つのサービスモニターを作成する必要があります。
以下のコマンドを実行して、cluster-reader 権限を Prometheus に追加します。
# oc adm policy add-cluster-role-to-user cluster-reader \ system:serviceaccount:openshift-monitoring:prometheus-k8s -n \ openshift-monitoring cluster role "cluster-reader" added: "system:serviceaccount:openshift-monitoring:prometheus-k8s"
- 数分後に、Prometheus は新規サービスモニターを読み込みます。
10.4. メトリクスの表示
メトリクスを表示するには、以下を実行します。
- Prometheus にメトリクス名を追加し、Execute をクリックします。
Graph タブでは、ボリュームのメトリクスの値がグラフとして表示されます。
たとえば、以下のイメージでは、利用可能なバイト数を確認するために、
kubelet_volume_stats_available_bytesメトリクスが Prometheus の検索バーに追加されています。Execute をクリックすると、利用可能なバイト数がグラフとして表示されます。ラインにマウスをかざすと、詳細情報を取得できます。(イメージの詳細を表示するには、右クリックし、View Image を選択します。)
パート VI. トラブルシューティング
第11章 トラブルシューティング
本章では、Red Hat Openshift Container Storage に関連する最も一般的なトラブルシューティングシナリオを説明します。
- Red Hat Openshift Container Storage ノードに障害が発生した場合の操作について
Red Hat Openshift Container Storage ノードに障害が発生し、これを削除する必要がある場合には、ノードを削除する前にノードを無効にします。詳細は、「ノードの削除」を参照してください。
Red Hat Openshift Container Storage ノードに障害が発生し、それを置き換える必要がある場合は、「ノードの置き換え」を参照してください。
- Red Hat Openshift Container Storage デバイスに障害が発生した場合の操作について
Red Hat Openshift Container Storage デバイスに障害が発生し、これを削除する必要がある場合には、デバイスを削除する前に無効にしてください。詳細は、「デバイスの削除」を参照してください。
Red Hat Openshift Container Storage デバイスに障害が発生し、それを置き換える必要がある場合は、「デバイスの置き換え」を参照してください。
- Red Hat Openshift Container Storage ボリュームに追加の容量が必要な場合の操作について
- デバイスの追加、クラスターサイズの拡大、または全く新しいクラスターを追加して、ストレージ容量を増やすことができます。詳細は、「ストレージの容量の増加」を参照してください。
- Red Hat Openshift Container Storage のインストール時に Openshift をアップグレードする方法
- Openshift Container Platform をアップグレードするには、https://access.redhat.com/documentation/ja-jp/openshift_container_platform/3.11/html/upgrading_clusters/install-config-upgrading-automated-upgrades#upgrading-to-ocp-3-10 を参照してください。
- ログファイルの表示
Red Hat Gluster Storage コンテナーログの表示
Red Hat Gluster Storage コンテナーに関連するデバッグ情報が、コンテナーを起動するホストに保存されます。具体的には、ログおよび設定ファイルは、Red Hat Gluster Storage サーバーコンテナーが実行される Openshift ノードの以下の場所にあります。
- /etc/glusterfs
- /var/lib/glusterd
- /var/log/glusterfs
Heketi ログの表示
Heketi に関連するデバッグ情報は、コンテナーにローカルに格納されるか、Heketi コンテナーに提供される永続ボリュームにに保存されます。
コンテナーが実行されている Openshift ノードで
docker logs <container-id>コマンドを実行して、Heketi のログを取得できます。
- heketi コマンドがエラーなし、または空のエラーで返される
heketi-cli コマンドを実行すると、エラーなし、または_ Error_のような空のエラーで返されることがあります。これは、heketi サーバーが適切に設定されていないことがほとんどです。まず、Heketi サーバーが利用可能であることを確認するために ping を送信し、後で curl コマンドおよび /hello endpoint で検証する必要があります。
# curl http://deploy-heketi-storage-project.cloudapps.mystorage.com/hello
- トポロジーファイルの読み込み中に heketi がエラーを報告する
- heketi-cli レポートの実行: トポロジーファイルの読み込み中にエラー "Unable to open topology file" エラー。これは、JSON オプションの接頭辞として単一ハイフン (-) の古い構文が使用されたことが理由の可能性があります。ダブルハイフンの新しい構文を使用し、トポロジーファイルをリロードする必要があります。
- heketi サーバーへの cURL コマンドが失敗するか、応答しない
ルーターまたは heketi が適切に設定されていない場合、heketi からのエラーメッセージが明確ではない場合があります。トラブルシューティングを行うには、エンドポイントと IP アドレスを使用して heketi サービスに ping を送信します。IP アドレスによる ping 送信に成功し、エンドポイントによる ping 送信が失敗する場合、これはルーター設定エラーを示します。
ルーターを適切に設定した後に、以下のように単純な curl コマンドを実行します。
# curl http://deploy-heketi-storage-project.cloudapps.mystorage.com/hello
heketi が正しく設定されている場合には、heketi からのウェルカムメッセージが表示されます。そうでない場合は、heketi 設定を確認します。
- heketi.db ファイルの保存に Red Hat Gluster Storage ボリュームを使用すると、heketi が起動に失敗する
heketi.db の保存に Red Hat Gluster Storage ボリュームが使用される場合、Heketi が起動に失敗し、以下のエラーを報告することがあります。
[heketi] INFO 2016/06/23 08:33:47 Loaded kubernetes executor [heketi] ERROR 2016/06/23 08:33:47 /src/github.com/heketi/heketi/apps/glusterfs/app.go:149: write /var/lib/heketi/heketi.db: read-only file system ERROR: Unable to start application
Red Hat Gluster Storage ボリュームをバックエンドとして使用すると、上記のように読み取り専用ファイルシステムエラーが表示される場合があります。これは、Red Hat Gluster Storage ボリュームでクォーラムが失われた場合である可能性があります。レプリカ 3 ボリュームでは、3 つのブリックの 2 つがダウンしている場合に見られます。heketi gluster ボリュームにクォーラムが満たされており、heketi.db ファイルに再び書き込みできることを確認する必要があります。
異なるエラーが表示される場合でも、heketi.db ファイルを提供する Red Hat Gluster Storage ボリュームが利用できるかどうかを確認することが推奨されます。heketi.db ファイルへのアクセス拒否は、起動しない最も一般的な理由です。
第12章 ポート転送を使用したクライアント設定
ルーターが利用できない場合には、heketi-cli が Heketi サービスと通信できるようにポート転送を設定できます。ポート転送用に以下のコマンドを実行します。
以下のコマンドを実行して Heketi サービス Pod 名を取得します。
# oc get pods
ローカルシステムのポートを Pod に転送するには、ローカルシステムの別のターミナルで以下のコマンドを実行します。
# oc port-forward <heketi pod name> 8080:8080元のターミナルで以下のコマンドを実行して、サーバーとの通信をテストします。
# curl http://localhost:8080/hello
これにより、ローカルポート 8080 を Pod ポート 8080 に転送します。
以下のコマンドを実行して Heketi サーバー環境変数を設定します。
# export HEKETI_CLI_SERVER=http://localhost:8080
以下のコマンドを実行して、Heketi から情報を取得します。
# heketi-cli topology info