
Red Hat Training
A Red Hat training course is available for Red Hat JBoss Operations Network
第18章 可用性
監視で最も基本的な要素の 1 つは、サーバーまたはアプリケーションが実行されているかどうかを把握することです。可用性 監視は、特定のプロセスが実行中で最小限の応答状態にあることを管理者に指示します。
18.1. コア "Up and down" の監視
監視に関する最初の質問は、リソースが稼働していることですか?リソースの可用性は、全体的なパフォーマンスの確認、サービスレベルの特定、およびインフラストラクチャーの維持にあたり、リソースの可用性です。
可用性(「 up または down monitoring」と呼ばれることもあります)は、リソースが 稼働 しているか、または他の状態にあるかを決定します。
up は、リソースが実行中であり、規定された時間内にエージェントに応答することを意味します。
可用性はリソースによって異なります。プロセス ID または JVM をチェックする可能性があります。リソースタイプの可用性は、プラグイン記述子で定義されます。そのため、プラグインコンテナーはリソースとエージェント間の仲介になります。エージェントは、プラグインコンテナーでリソースの可用性をチェックします。コンテナーはリソースコンポーネントから取得します。
通常、可用性チェックには数秒かかります。特定のリソースや特定の環境では、時間がかかる場合があります。可用性スキャンのタイムアウト期間が、デフォルトで 5 秒に設定されています。リソースが実行中で、その 5 秒間以内に可用性スキャンに応答すると、リソースが稼働していることになります。
可用性(「スケールダウン」または「スケールダウン」)- IT 管理者にとって監視が非常に重要であるため、JBoss ON における可用性の状態は非常に大きく表示されます。可用性は、リソースの詳細ページ、すべてのリソース一覧、グループ、およびモニタリングレポートに表示されます。これは、リソースが稼働しているかどうかを判断するには glance のみを取る必要があります。
図18.1 リソースの可用性

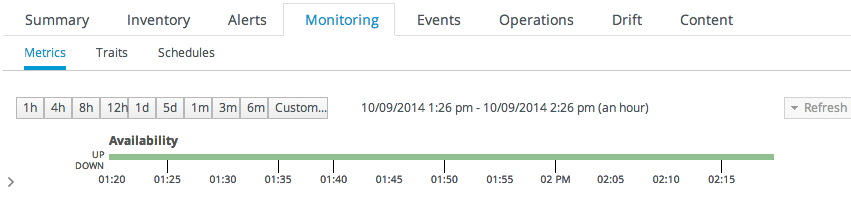
可用性は実際の監視メトリックではありませんが、Monitoring > Metrics ページには、リソースが稼働状態にある表示期間内の時間の割合が示されます。これは、エージェントが収集したその他すべてのメトリクスに影響を与えるため、可用性(および同時稼働時間)が影響を受けるためです。
図18.2 可用性のアップタイムパーセント
注記
多くの場合、リソースが実行中でも可用性がダウンしている場合は、接続設定に問題があることになります。エージェントには、ユーザー名や新しいポート番号など、リソースへの接続に必要な情報がない場合があります。エージェントはリソースに接続できないため、停止していることを前提としています。
18.1.1. 長いスキャン時間と非同期アベイラビリティーコレクション
可用性スキャンは、定義されたリソースタイプに対してリソースプラグイン自体によって実行され、プラグインコンテナーに報告されます。
通常、可用性チェックは 1 秒で非常に高速ですが、可用性チェックにかかる時間が長くなる可能性があります。プラグインコンテナーは、不正なプラグインがエージェントによって管理されるその他すべてのリソースの可用性レポートを遅延しないようにするために、可用性チェックを 5 秒に制限します。
特定のプラグインまたはリソースタイプが 5 秒のタイムアウト期間よりも長いスキャンを行うインスタンスが存在する可能性があります。
カスタムプラグインの場合、プラグイン作成者は 非同期の可用性チェックを設定できます。基本的に、非同期の可用性チェックでは、リソースコンポーネントは独自の独立したスレッドを作成し、可用性チェックを実行します。そのスレッド内では、可用性チェックは、完了する必要がある限り時間がかかります。可用性チェックは、デフォルトで 1 分ごとに非常に頻繁に実行され、完全なチェックの完了までにかかる場合でも可用性の状態が現在の状態であることを確認することもできます。
コンポーネントによってキャッシュされ、最新の可用性の結果がプラグインコンテナーに報告されます。保存される最後の可用性は、プラグインコンテナーが想定する秒数で非常に迅速に提供されます。
Async 可用性チェックは、以下により実装されます。
AvailabilityCollectorRunnable JBoss ON プラグイン API のクラス。このクラスの詳細は、『 Plug-in API』および『Writing Custom Plug-ins Guide』を参照してください。
注記
また、エージェント設定自体のスキャンタイムアウト期間を拡張することで、長時間の可用性チェックに対処することもできます。たとえば、新しいタイムアウト期間を
rhq-agent-env.sh ファイルの ADDITIONAL_JAVA_OPTIONS パラメーターに追加します。
RHQ_AGENT_ADDITIONAL_JAVA_OPTS="$RHQ_AGENT_ADDITIONAL_JAVA_OPTS -Drhq.agent.plugins.availability-scan.timeout=15000"
ただし、このタイムアウト期間は、特定の特定の、低速なプラグインの 1 つのプラグインだけでなく、プラグイン 全体 に適用されます。低速な可用性チェックを実行している複数のプラグインがある場合、可用性レポートが完了するのに時間がかかりすぎる可能性があるため、エージェントが遅延したり、JBoss ON サーバーへ利用可能なレポートを送信できない状態になったりすることがありました。
通常、すべてのプラグインのスキャン間隔をリセットするのではなく、カスタムプラグインで非同期の可用性を設定することが推奨されます。
18.1.2. 同期の可用性
可用性スキャンは、デフォルトで、定義されたスケジュールで、1 分から 20 分間隔で実行されます。つまり、ほとんどの可用性データは非同期です。これは可用性のタイムライン、レポート、およびほとんどの UI で(最新の(現時点では限りない)値に基づいて)表示されます。
リソースの Monitoring タブを表示することで、同期、ほぼリアルタイムの可用性の情報を取得できます。Monitoring タブが開いている限り、可用性の読み取りは設定されたコレクションスケジュールではなく、15 秒ごとにチェックされます。これは、リアルタイムの可用性の情報にできるだけ近いものです。
注記
可用性を収集するためにこのスケジュールが変更されると、リソースのアラートに対するルールが低下する可能性があります。
たとえば、特定の状態が 3 つ(3)発生後にアラートを発生させるために、可用性を 10 分ごとにチェックする場合、アラートの意図は条件が持続する期間が 30 時間 後にのみ実行される場合でも、特定の状態が読み込まれる場合でも、アラートは 1 分未満のアラートを発生させる可能性があります。
18.1.3. 可用性の状態
up と not up の間にはグレーエリアがあります。リソースが起動しない場合がありますが、異なる理由で起動していない可能性があります。たとえば、エージェントを再起動すると、リソースの状態が認識されない可能性があります。または、メンテナンスのためにリソースがオフラインになっている可能性があるため、可用性レポートが送信されません。
異なるリソースの状態がに記載されてい 表18.1「可用性の状態」 ます。
表18.1 可用性の状態
| 状態 | description | icon |
|---|---|---|
| 利用可能な(UP) | リソースが実行され、可用性ステータスチェックに応答します。 | 
|
| down | リソースは可用性チェックに応答しません。 | 
|
| Unknown | エージェントには、リソースの状態を記録しません。これは、リソースがインベントリーに新たに追加され、最初の可用性チェックがないか、またはエージェントがダウンしているためです。 | 
|
| disabled | リソースは、管理者が利用できないとマークされています。リソース(実際には)が実行中または停止している可能性があります。リソースを無効にすると、サーバーがエージェントからの可用性レポートを無視して、(既知の)停止状態または循環状態に基づいて不必要なアラートが発生しないようにします。 | 
|
|
混在(グループのみ) [a]
| グループのリソースには、可用性の状態が異なります。 | 
|
[a]
リソースの詳細ページの上部で、リソースの可用性の横に同様の警告マークが表示されます。この警告は、リソースに対してエラーメッセージや疑わしいメトリクスが返されたことを示しています。リソースの可用性が警告状態にあるわけではありません。
| ||
18.1.4. 親およびバックフィル
可用性は、リソースのツリーの上部から下向きに評価されます。たとえば、アプリケーションサーバーがダウンしている場合は、すべての依存 webapp 子もダウンしていると仮定できます。
これはバックフィルと呼ば れ ます。親の状態は、各子に対して追加の可用性スキャンを実行せずに、子に伝播されます。Backfilling は、子の状態を down、unknown、または disabled の状態に設定することができます。
場合によっては、バックフィルには up 状態も含まれます。一部の依存子リソース(親が実行中の場合のみ実行される優先順位の低いサービス)には、デフォルトで個別に評価される独自の可用性もない場合があります。子の可用性チェックが無効になっている場合、子は前もって親の状態を使用します。親が稼働している場合は、これらの子を起動することが想定されます。
バックフィルにはわずかな違いがあります。プラットフォームがダウンとマークされている場合は、プラットフォームがダウンしている場合は、エージェントがダウンしているのと同じです。つまり、エージェントがサーバーに報告されていないことを意味します。そのため、実際にオフライン状態のサーバーやサービス以外に、複数の理由が考えられます。この場合、プラットフォーム(機能的にエージェント)がダウンするように設定されますが、子には unknown に設定されます。
18.1.5. コレクション間隔とエージェントのスキャン間隔
が示すように、可用性の読み取りはメトリクスコレクションと同じではありません。不適切な類似点がいくつかあり、主にスケジュールに収集され、それら両方がリソースパフォーマンスに関連していることが挙げられます。
内部的には、可用性とメトリクスの処理が異なります。可用性は、異なる機能により呼び出され、個別に報告されます。また、より重要な可用性レポートは、監視レポートを含む、エージェントが送信した他のレポートよりも優先順位が高くなります。
可用性レポートは最初の優先度メッセージとして送信されますが、リソース自体には可用性スキャンの異なる優先度があります。優先度が高い(より重要)リソースはデフォルトで、可用性がより頻繁にチェックされます。
- エージェントのハートビート ping(プラットフォームの可用性に分析)は、1 分ごとにサーバーに送信されます。
- サーバーの可用性は毎分チェックされます。
- サービスの可用性は 10 分ごとにチェックされます。
エージェント自体は、可用性スキャンを 30 秒間隔で実行します。すべてのリソースがスキャンごとにチェックされるわけではありません。エージェントスキャンが実行されると、確認するようにスケジュールされたリソースのみがチェックされます。そのため、機能的に 2 つの可用性スケジュールが連携し、エージェントスキャンの間隔とリソース収集スケジュールが連携します。たとえば、サーバーの可用性チェック用に 60 秒間隔で設定され、エージェントスキャンの期間が 30 秒である場合、サーバーは 2 つのスキャンごとに確認することができます。つまり、サーバーは 約 60 秒間チェックされますが、これはベストエフォートの予測です。エージェントが負荷が大きい場合、またはリソースが多数ある場合、エージェントは 30 秒よりも長いスキャンを実行する可能性があるため、特定のリソースがチェックされるまでの 間隔 が長くなります。
管理リソースの 1 つに可用性状態が変更された場合に限り、エージェントは可用性レポートをサーバーに送信します。
エージェントが停止すると、(デフォルト)エージェントの quiet の期間が 5 分以内にダウン状態が表示されます。エージェントが正常にシャットダウンすると、JBoss ON サーバーは約 1 分以内に状態変化を認識します。サーバーがエージェントがダウンすると、そのエージェントのインベントリー(「親およびバックフィル」)内のすべてのリソースの状態をバックフィルします。
ダウンサーバーは、通常、ダウンから 1 分から 2 分後にダウン状態を記録します。これは必ずしもリアルタイムではありませんが、ほとんどのインフラストラクチャーでは、信頼できるパフォーマンスのベースラインを確立でき、サービスレベルとアップタイムも計算できます。90 秒という期間が短いと、ほとんどのリソースのサイクをキャッチできます。
デフォルトのエージェントスキャン間隔は 30 秒ですが、リソースのスケジュールによっては、一部のサービスがダウンすると 10 分以上かかる可能性があります。管理者が状態が変更されたと疑われる場合は、インタラクティブエージェントプロンプトを介してエージェントのすべてのリソースに対して即時可用性スキャンを強制することが可能です。
> avail -- force
avail コマンドを使用して、すべてのリソースではなく、次回のスケジュールされたリソースのチェックを実行します。
さらに、リソースプラグインを作成して、状態の変更を引き起こす可能性のある操作(start、stop、restart 操作など)が操作の終了時にリソースの可用性チェックを自動的に要求するように設定できます。