
7.5. Hibernate Search を使用した Lucene クエリーの実行
手順
Hibernate Search は Lucene クエリーを実行し、InfinispanHibernate セッションによって管理されるドメインオブジェクトを取得できます。この検索は、Hibernate パラダイムを離れることなく Lucene の機能を提供し、HQL、基準クエリー、ネイティブ SQL クエリーなど、Hibernate の従来の検索メカニズムに別の特性を与えます。
クエリーの準備と実行は、以下の 4 つの手順で設定されます。
- FullTextSession の作成
- Hibernate QueryHibernate Search クエリー DSL (推奨) または Lucene Query API を使用した Lucene クエリーの作成
- org.hibernate.Query を使用した Lucene クエリーのラップ
- サンプルの list() または scroll() を呼び出して検索を実行すると、検索が実行されます。
クエリー機能にアクセスするには、FullTextSession を使用します。この検索固有のセッションは、クエリーおよびインデックス機能を提供するために通常の org.hibernate.Session をラップします。
例: FullTextSession の作成
Session session = sessionFactory.openSession(); ... FullTextSession fullTextSession = Search.getFullTextSession(session);
FullTextSession を使用して、Hibernate Search クエリー DSL またはネイティブの Lucene クエリーのいずれかでフルテキストクエリーを構築します。
Hibernate Search クエリー DSL を使用する場合は、以下のコードを使用します。
final QueryBuilder b = fullTextSession.getSearchFactory().buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
List result = fullTextQuery.list(); //return a list of managed objectsまたは、Lucene クエリーパーサーまたは Lucene プログラム API を使用して Lucene クエリーを書き込みます。
例: QueryParser を使用した Lucene クエリーの作成
SearchFactory searchFactory = fullTextSession.getSearchFactory();
org.apache.lucene.queryParser.QueryParser parser =
new QueryParser("title", searchFactory.getAnalyzer(Myth.class) );
try {
org.apache.lucene.search.Query luceneQuery = parser.parse( "history:storm^3" );
}
catch (ParseException e) {
//handle parsing failure
}
org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery(luceneQuery);
List result = fullTextQuery.list(); //return a list of managed objects
Lucene クエリーに構築された Hibernate クエリーは org.hibernate.Query です。このクエリーは、HQL (Hibernate Query Language)、Native、および Criteria などの他の Hibernate クエリー機能と同じパラダイムに残ります。クエリーで list()、uniqueResult()、repeat()、および scroll () などのメソッドを使用します。
Hibernate Jakarta Persistence では、同じ拡張機能を利用できます。
例: Jakarta Persistence を使用した検索クエリーの作成
EntityManager em = entityManagerFactory.createEntityManager();
FullTextEntityManager fullTextEntityManager =
org.hibernate.search.jpa.Search.getFullTextEntityManager(em);
...
final QueryBuilder b = fullTextEntityManager.getSearchFactory()
.buildQueryBuilder().forEntity( Myth.class ).get();
org.apache.lucene.search.Query luceneQuery =
b.keyword()
.onField("history").boostedTo(3)
.matching("storm")
.createQuery();
javax.persistence.Query fullTextQuery = fullTextEntityManager.createFullTextQuery( luceneQuery );
List result = fullTextQuery.getResultList(); //return a list of managed objects
これらの例では、Hibernate API が使われています。FullTextQuery の取得方法を調整すると、同じ例を Jakarta Persistence で記述することもできます。
7.5.1. クエリーの構築
Hibernate Search クエリーは Lucene クエリーにビルドされるため、ユーザーはすべての Lucene クエリータイプを使用できます。クエリーを構築すると、Hibernate Search はクエリー操作 API として org.hibernate.Query を使用して追加のクエリー処理を行います。
7.5.1.1. Lucene API を使用した Lucene クエリーの構築
Lucene API では、クエリーパーサー (簡単なクエリー) または Lucene プログラム API (複雑なクエリー) のいずれかを使用します。Lucene クエリーの構築は、Hibernate Search ドキュメントの範囲外です。詳細は、オンラインの Lucene ドキュメント、またはLucene in Action または Hibernate Search in Action を参照してください。
7.5.1.2. Lucene クエリーの構築
Lucene プログラム API は、フルテキストクエリーを有効にします。ただし、Lucene プログラム API を使用する場合は、パラメーターを同等の文字列に変換する必要があります。また、正しいアナライザーを正しいフィールドに適用する必要もあります。たとえば、ngram アナライザーは、特定の単語に対するトークンとして複数の ngrams を使用するため、そのように検索する必要があります。このタスクには QueryBuilder を使用することが推奨されます。
Hibernate Search のクエリー API は変動しており、以下の主要な特徴があります。
- メソッド名は英語です。そのため、API 操作は、一連の英語のフレーズおよび命令として読み取り、理解することができます。
- IDE オートコンプリートを使用します。これは、現在の入力接頭辞の完了を容易にし、ユーザーが適切なオプションを選択できるようにします。
- 多くの場合、チェーンメソッドパターンを使用します。
- API 操作を簡単に使用でき、読み取ることができます。
API を使用するには、まず、指定の indexedentitytype に割り当てられるクエリービルダーを作成します。この QueryBuilder は、使用するアナライザーと、適用するフィールドブリッジを認識します。複数の QueryBuilder (クエリーのルートに関連するエンティティータイプごとに 1 つ) を作成できます。QueryBuilder は SearchFactory から派生します。
QueryBuilder mythQB = searchFactory.buildQueryBuilder().forEntity( Myth.class ).get();
特定のフィールドに使用されるアナライザーも上書きできます。
QueryBuilder mythQB = searchFactory.buildQueryBuilder()
.forEntity( Myth.class )
.overridesForField("history","stem_analyzer_definition")
.get();クエリービルダーを使用して Lucene クエリーをビルドできるようになりました。Lucene プログラム API を使用してアセンブルされた Lucene のクエリーパーサーまたはクエリーオブジェクトを使用して生成されたカスタマイズされたクエリーは、Hibernate Search DSL とともに使用されます。
7.5.1.3. キーワードのクエリー
以下の例は、特定の単語を検索する方法を示しています。
Query luceneQuery = mythQB.keyword().onField("history").matching("storm").createQuery();表7.10 キーワードクエリーパラメーター
| Parameter | 説明 |
|---|---|
| keyword() | 特定の単語を検索するには、このパラメーターを使用します。 |
| onField() | このパラメーターを使用して、単語を検索する lucene フィールドを指定します。 |
| matching() | このパラメーターを使用して、検索文字列の一致を指定します。 |
| createQuery() | Lucene クエリーオブジェクトを作成します。 |
-
storm という値が
historyFieldBridge から渡されます。これは、数値または日付が必要な場合に便利です。 -
フィールドブリッジの値は、
historyフィールドインデックス化に使用されるアナライザーに渡されます。これにより、クエリーはインデックス (小文字、ngram、スチミングなど) よりも、同じ用語変換を使用します。分析プロセスで指定の単語が複数生成されると、ブールクエリーがSHOULD論理 (おおよそOR論理) とともに使用されます。
タイプ文字列ではないプロパティーを検索します。
@Indexed
public class Myth {
@Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
public Date getCreationDate() { return creationDate; }
public Date setCreationDate(Date creationDate) { this.creationDate = creationDate; }
private Date creationDate;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("creationDate").matching(birthdate).createQuery();プレーンの Lucene では、Date オブジェクトは文字列表現 (この場合は年) に変換する必要がありました。
この変換は、FieldBridge に objectToString メソッド (およびすべての組み込み FieldBridge 実装) がある場合、すべてのオブジェクトに対して機能します。
以下の例では、ngram アナライザーを使用するフィールドを検索します。ngram アナライザーは単語の ngrams インデックスを連続させるため、ユーザーの誤字を防ぎます。たとえば、hibernate という単語の 3 グラムは hib、ibe、ber、ern、rna、nat、ate です。
@AnalyzerDef(name = "ngram",
tokenizer = @TokenizerDef(factory = StandardTokenizerFactory.class ),
filters = {
@TokenFilterDef(factory = StandardFilterFactory.class),
@TokenFilterDef(factory = LowerCaseFilterFactory.class),
@TokenFilterDef(factory = StopFilterFactory.class),
@TokenFilterDef(factory = NGramFilterFactory.class,
params = {
@Parameter(name = "minGramSize", value = "3"),
@Parameter(name = "maxGramSize", value = "3") } )
}
)
public class Myth {
@Field(analyzer=@Analyzer(definition="ngram")
public String getName() { return name; }
public String setName(String name) { this.name = name; }
private String name;
...
}
Date birthdate = ...;
Query luceneQuery = mythQb.keyword().onField("name").matching("Sisiphus")
.createQuery();
一致する単語 Sisiphus は小文字になり、3 つのグラム (sis、isi、sip、iph、phu、hus) に分けられます。これらの各 ngram はクエリーの一部になります。ユーザーは、Sysiphus myth ( y) を見つけることができます。ユーザーに透過的に実行されます。
ユーザーが特定のフィールドでフィールドブリッジまたはアナライザーを使用しない場合は、ignoreAnalyzer() 関数または ignoreFieldBridge() 関数を呼び出しできます。
同一フィールドで複数の使用可能な単語を検索するには、それらすべてを一致するシーケンスに追加します。
//search document with storm or lightning in their history
Query luceneQuery =
mythQB.keyword().onField("history").matching("storm lightning").createQuery();複数のフィールドで同じ単語を検索するには、onField メソッドを使用します。
Query luceneQuery = mythQB
.keyword()
.onFields("history","description","name")
.matching("storm")
.createQuery();場合によっては、同じ用語を検索する場合でも、あるフィールドを別のフィールドとは異なる方法で処理する必要があります。その場合は、andField() メソッドを使用します。
Query luceneQuery = mythQB.keyword()
.onField("history")
.andField("name")
.boostedTo(5)
.andField("description")
.matching("storm")
.createQuery();上記の例では、フィールド名のみが 5 に改善されています。
7.5.1.4. Fuzzy クエリー
Levenshtein 距離アルゴリズムに基づく fuzzy クエリーを実行するには、keyword クエリーから始め、fuzzy フラグを追加します。
Query luceneQuery = mythQB
.keyword()
.fuzzy()
.withThreshold( .8f )
.withPrefixLength( 1 )
.onField("history")
.matching("starm")
.createQuery();
threshold は、両方の用語で照合が考慮される制限です。0 から 1 までの小数で、デフォルト値は 0.5 です。prefixLength は、fuzzyness で無視される接頭辞の長さです。デフォルト値は 0 ですが、多数の異なる用語を含むインデックスにはゼロ以外の値が推奨されます。
7.5.1.5. ワイルドカードクエリー
ワイルドカードクエリーは、単語の一部のみが認識される状況で役に立ちます。? は単一文字で、* は複数文字を表します。パフォーマンス維持のために、クエリーは ? または * で開始しないことが推奨されます。
Query luceneQuery = mythQB
.keyword()
.wildcard()
.onField("history")
.matching("sto*")
.createQuery();
ワイルドカードクエリーは、一致する用語にアナライザーを適用しません。経験のある * または ? のリスクが高すぎます。
7.5.1.6. フレーズクエリー
これまで、単語または単語セットを見てきましたが、ユーザーは正確な単語または概算した単語を検索することもできます。これを行うには、phrase() を使用します。
Query luceneQuery = mythQB
.phrase()
.onField("history")
.sentence("Thou shalt not kill")
.createQuery();おおよその文は、slop 係数を追加することで検索できます。slop 係数は、文内で許可される他の単語の数を表します。これは、within または near 演算子のように機能します。
Query luceneQuery = mythQB
.phrase()
.withSlop(3)
.onField("history")
.sentence("Thou kill")
.createQuery();7.5.1.7. 範囲クエリー
範囲クエリーは、指定された範囲内 (含まれるかどうか) または特定の範囲を下回る、もしくは上回る値を検索します。
//look for 0 <= starred < 3
Query luceneQuery = mythQB
.range()
.onField("starred")
.from(0).to(3).excludeLimit()
.createQuery();
//look for myths strictly BC
Date beforeChrist = ...;
Query luceneQuery = mythQB
.range()
.onField("creationDate")
.below(beforeChrist).excludeLimit()
.createQuery();7.5.1.8. クエリーの統合
クエリーを組み合わせてより複雑なクエリーを作成できます。以下の集計演算子を使用できます。
-
SHOULD: クエリーには、サブクエリーの一致する要素が含まれる必要があります。 -
MUST: クエリーには、サブクエリーの一致する要素が含まれる必要があります。 -
MUST NOT: クエリーには、サブクエリーの一致する要素を含めないでください。
サブクエリーは、ブール値クエリー自体を含む任意の Lucene クエリーにすることができます。
例: SHOULD クエリー
//look for popular myths that are preferably urban
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();
例: MUST クエリー
//look for popular urban myths
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.must( mythQB.range().onField("starred").above(4).createQuery() )
.createQuery();
例: MUST NOT クエリー
//look for popular modern myths that are not urban
Date twentiethCentury = ...;
Query luceneQuery = mythQB
.bool()
.must( mythQB.keyword().onField("description").matching("urban").createQuery() )
.not()
.must( mythQB.range().onField("starred").above(4).createQuery() )
.must( mythQB
.range()
.onField("creationDate")
.above(twentiethCentury)
.createQuery() )
.createQuery();
7.5.1.9. クエリーオプション
Hibernate Search クエリー DSL は使いやすく、読みやすいクエリー API です。Lucene クエリーを受け入れて生成すると、DSL で対応していないクエリータイプを組み込むことができます。
以下は、クエリータイプおよびフィールドのクエリーオプションの要約です。
- boostedTo (クエリータイプおよびフィールド上) は、クエリー全体または特定のフィールドを指定された係数に改善します。
- constantScore (クエリー上) では、クエリーに一致するすべての結果の、定数スコアがブーストと等しくなります。
- filteredBy(Filter) (クエリー上) は、Filter インスタンスを使用してクエリー結果をフィルターします。
- ignoreAnalyzer (フィールド上) は、このフィールドを処理するときにアナライザーを無視します。
- ignoreFieldBridge (フィールド上) は、このフィールドを処理するときにフィールドブリッジを無視します。
例: クエリーオプションの組み合わせ
Query luceneQuery = mythQB
.bool()
.should( mythQB.keyword().onField("description").matching("urban").createQuery() )
.should( mythQB
.keyword()
.onField("name")
.boostedTo(3)
.ignoreAnalyzer()
.matching("urban").createQuery() )
.must( mythQB
.range()
.boostedTo(5).withConstantScore()
.onField("starred").above(4).createQuery() )
.createQuery();
7.5.1.10. Hibernate Search クエリーの構築
7.5.1.10.1. 一般性
Lucene クエリーの構築後に、Hibernate クエリー内にラップします。クエリーはインデックス化されたすべてのエンティティーを検索し、明示的に設定しない限り、インデックス化されたクラスのすべてのタイプを返します。
例: Hibernate クエリーでの Lucene クエリーのラップ
FullTextSession fullTextSession = Search.getFullTextSession( session ); org.hibernate.Query fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery );
パフォーマンスを改善するために、返されたタイプを以下のように制限します。
例: エンティティータイプによる検索結果のフィルター
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Customer.class );
// or
fullTextQuery = fullTextSession
.createFullTextQuery( luceneQuery, Item.class, Actor.class );
次の例の最初の部分は、一致する Customers のみを返します。同じ例の次の部分は、一致する Actors と item を返します。タイプ制限はポリモーフィックです。そのため、2 つのサブクラス Sales man と、ベースクラス Person の Customer は、結果タイプに基づいてフィルタリングする Person.class を指定します。
7.5.1.10.2. ページネーション
パフォーマンスの低下を回避するには、クエリーごとに返されたオブジェクトの数を制限することが推奨されます。あるページから別のページに移動するユーザーは、非常に一般的なユースケースです。ページネーションを定義する方法は、プレーンの HQL または基準クエリーでのページネーションの定義と似ています。
例: 検索クエリーのページネーションの定義
org.hibernate.Query fullTextQuery =
fullTextSession.createFullTextQuery( luceneQuery, Customer.class );
fullTextQuery.setFirstResult(15); //start from the 15th element
fullTextQuery.setMaxResults(10); //return 10 elements
fulltextQuery.getResultSize() によるページネーションに関係なく、一致する要素の合計数を取得できます。
7.5.1.10.3. ソート
Apache Lucene には、柔軟で強力な結果ソートメカニズムが含まれています。デフォルトの並び替えは関連により行われ、さまざまなユースケースに適しています。Lucene Sort オブジェクトを使用し、他のプロパティーでソートするようにソートメカニズムを変更できます。
例: Lucene ソートの指定
org.hibernate.search.FullTextQuery query = s.createFullTextQuery( query, Book.class );
org.apache.lucene.search.Sort sort = new Sort(
new SortField("title", SortField.STRING));
List results = query.list();
ソートに使用されるフィールドは、トークン化できません。トークン化についての詳細は、@Field を参照してください 。
7.5.1.10.4. ストラテジーの取得
Hibernate Search は、戻り値の型が単一のクラスに制限されている場合に、単一のクエリーを使用してオブジェクトをロードします。Hibernate Search は、ドメインモデルで定義された静的なフェッチストラテジーによって制限されます。以下のように、特定のユースケースのフェッチストラテジーを微調整すると便利です。
例: クエリーでの FetchMode の指定
Criteria criteria =
s.createCriteria( Book.class ).setFetchMode( "authors", FetchMode.JOIN );
s.createFullTextQuery( luceneQuery ).setCriteriaQuery( criteria );
この例では、クエリーは LuceneQuery に一致するすべての Books を返します。Authors コレクションは、SQL の外部結合を使用して同じクエリーからロードされます。
条件クエリー定義では、タイプは提供された基準クエリーに基づいて推測されます。そのため、返されたエンティティータイプを制限する必要はありません。
フェッチモードは、唯一の調整可能なプロパティーです。getResultSize() は制限のある Criteria とともに使用された場合に SearchException を出力するため、Criteria クエリーで制限 (完全な句) を使用しないでください。
複数のエンティティーが予想される場合は、setGatewayQuery を使用しないでください。
7.5.1.10.5. プロジェクション
場合によっては、プロパティーの小さなサブセットのみが必要となります。Hibernate Search を使用して、以下のようにプロパティーのサブセットを取得します。
Hibernate Search は Lucene インデックスからプロパティーを抽出し、それらをオブジェクト表現に変換し、Object[] のリストを返します。プロジェクションは、データベースのラウンドトリップが長くなるのを防ぎます。ただし、以下の制限があります。
-
予測されるプロパティーはインデックス (
@Field(store=Store.YES)) に保存され、インデックスサイズが増えます。 予測されるプロパティーは、org.hibernate.search.bridge.TwoWayFieldBridge または
org.hibernate.search.bridge.TwoWayStringBridgeを実装するFieldBridgeを使用する必要があり、後者はより単純なバージョンになります。注記Hibernate Search の組み込みタイプはすべて双方向です。
- インデックス化されたエンティティーまたはその埋め込み関連の簡単なプロパティーのみを展開できます。したがって、埋め込みエンティティー全体を展開できません。
- @IndexedEmbedded でインデックス化されるコレクションやマップで機能しません。
Lucene は、クエリー結果に関するメタデータ情報を提供します。インジェクト定数を使用してメタデータを取得します。
例: メタデータの取得へのプロジェクションの使用
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.;
List results = query.list();
Object[] firstResult = (Object[]) results.get(0);
float score = firstResult[0];
Book book = firstResult[1];
String authorName = firstResult[2];
フィールドは、以下のプロジェクションと組み合わせることができます。
- FullTextQuery.THIS: 初期化され管理されたエンティティーを返します (展開されていないクエリーが実行される場合)。
- FullTextQuery.DOCUMENT: 展開されるオブジェクトに関連する Lucene ドキュメントを返します。
- FullTextQuery.OBJECT_CLASS: インデックス化されたエンティティーのクラスを返します。
- FullTextQuery.SCORE: クエリーのドキュメントスコアを返します。スコアは、あるクエリーの結果を別のクエリーに対する比較には便利ですが、異なるクエリーの結果を比較する場合に有用ではありません。
- FullTextQuery.ID: 予測されるオブジェクトの ID プロパティー値。
- FullTextQuery.DOCUMENT_ID: Lucene ドキュメント ID。この値を Lucene ドキュメント ID として使用すると、異なる 2 つの IndexReader を開くたびに変更される可能性があります。
- FullTextQuery.explanation: 指定のクエリーの一致するオブジェクト/ドキュメントの Lucene Explanation オブジェクトを返します。これは、大量のデータを取得するのには適していません。通常、実行の説明は、一致する要素ごとに Lucene クエリー全体を実行することを意味します。そのため、展開が推奨されます。
7.5.1.10.6. オブジェクト初期化ストラテジーのカスタマイズ
デフォルトでは、Hibernate Search は最適なストラテジーを使用して、完全なテキストクエリーに一致するエンティティーを初期化します。必要なエンティティーを取得するためにクエリーを実行します。このアプローチでは、取得したエンティティーが永続コンテキスト (セッション) または 2 次レベルキャッシュにほとんど存在しないデータベースのストライプが最小限に抑えられます。
2 次キャッシュにエンティティーが存在する場合は、データベースオブジェクトを取得する前に、Hibernate Search が強制的にキャッシュを調べます。
例: クエリーを使用する前の 2 次キャッシュのチェック
FullTextQuery query = session.createFullTextQuery(luceneQuery, User.class);
query.initializeObjectWith(
ObjectLookupMethod.SECOND_LEVEL_CACHE,
DatabaseRetrievalMethod.QUERY
);
ObjectLookupMethod は、オブジェクトをデータベースから取得せずに簡単にアクセスできるかどうかを確認するストラテジーを定義します。その他のオプションは以下のとおりです。
-
ObjectLookupMethod.PERSISTENCE_CONTEXTは、一致する多くのエンティティーが永続コンテキストにすでにロードされている場合に使用されます (Session または EntityManager にロードされている場合)。 -
ObjectLookupMethod.SECOND_LEVEL_CACHEは永続コンテキストをチェックし、2 次キャッシュを確認します。
2 次キャッシュで検索するには、以下を設定します。
- 2 次キャッシュを正しく設定およびアクティブ化します。
- 関連するエンティティーの 2 次キャッシュを有効にします。これは、@Cacheable などのアノテーションを使用してを行います。
-
Session、EntityManager、または Query のいずれかの 2 次キャッシュ読み取りアクセスを有効にします。Hibernate ネイティブ API では
CacheMode.NORMALを使用し、Jakarta Persistence ではCacheRetrieveMode.USEを使用します。
2 次キャッシュ実装が Infinispan でない場合、ObjectLookupMethod.SECOND_LEVEL_CACHE は使用しないでください。他の 2 次レベルのキャッシュプロバイダーはこのオペレーションを効率的に実装しません。
DatabaseRetrievalMethod を使用して、以下のようにデータベースからオブジェクトを読み込む方法をカスタマイズします。
- QUERY (デフォルト) はクエリーのセットを使用して、複数のオブジェクトを各バッチに読み込みます。このアプローチが推奨されます。
-
find_BY_ID は
Session.getまたはEntityManager.findセマンティックを使用して一度にオブジェクトをロードします。これは、Hibernate Core がエンティティーをバッチでロードできるようにする、エンティティーにバッチサイズが設定されている場合に推奨されます。
7.5.1.10.7. クエリー時間の制限
Hibernate Guide で、以下のようにクエリーにかかる時間を制限します。
- 制限を指定して受信する際に例外を発生させます。
- 時間制限が発生したときに取得する結果の数に制限します。
7.5.1.10.8. 時間制限の例外発生
クエリー使用する時間が定義した時間を超える場合は、QueryTimeoutException が発生します (プログラム API に応じた、org.hibernate.QueryTimeoutException または javax.persistence.QueryTimeoutException)。
ネイティブの Hibernate API を使用する際に制限を定義するには、以下のいずれかの方法を使用します。
例: クエリー実行でのタイムアウトの定義
Query luceneQuery = ...;
FullTextQuery query = fullTextSession.createFullTextQuery(luceneQuery, User.class);
//define the timeout in seconds
query.setTimeout(5);
//alternatively, define the timeout in any given time unit
query.setTimeout(450, TimeUnit.MILLISECONDS);
try {
query.list();
}
catch (org.hibernate.QueryTimeoutException e) {
//do something, too slow
}
getResultSize()、iterate()、および scroll() は、メソッド呼び出しの終了までタイムアウトを受け入れます。その結果、Iterable または ScrollableResults は、タイムアウトを無視します。また、explain() はこのタイムアウト期間を受け入れません。この方法は、デバッグに使用され、クエリーのパフォーマンス低下の原因をチェックします。
以下は、Jakarta Persistence を使用した実行時間を制限する標準的な方法です。
例: クエリー実行でのタイムアウトの定義
Query luceneQuery = ...;
FullTextQuery query = fullTextEM.createFullTextQuery(luceneQuery, User.class);
//define the timeout in milliseconds
query.setHint( "javax.persistence.query.timeout", 450 );
try {
query.getResultList();
}
catch (javax.persistence.QueryTimeoutException e) {
//do something, too slow
}
サンプルコードは、クエリーが指定の結果量で停止することを保証しません。
7.5.2. 結果の取得
Hibernate クエリーの構築後、HQL または Criteria クエリーと同じように実行されます。同じ準仮想化とオブジェクトセマンティックが Lucene クエリーに適用され、list()、uniqueResult()、iterate()、scroll() などの一般的な操作を使用できます。
7.5.2.1. パフォーマンスに関する考慮事項
妥当な数の結果 (たとえば、ページネーションの使用) が想定され、それらすべてで動作することが予想される場合は、list() または uniqueResult() が推奨されます。list() は、エンティティー batch-size が正しく設定されている場合に最適に機能します。list()、uniqueResult()、iterate() を使用する場合は、Hibernate Search が Lucene Hits 要素 (ページネーション内) をすべて処理する必要があることに注意してください。
Lucene ドキュメントの負荷を最小限に抑える必要がある場合には、scroll() の方が適しています。完了したら、Lucene リソースを保持するため、Scrollable Mission オブジェクトを閉じることを忘れないでください。スクロールを使用することが予測されても、オブジェクトを一括して読み込む必要がある場合は、query.setFetchSize() を使用できます。オブジェクトにアクセスし、読み込まれていない場合、Hibernate Search は次の fetchSize オブジェクトをパスに読み込みます。
ページネーションが、スクロールよりも好まれます。
7.5.2.2. 結果サイズ
一致するドキュメントの合計数を把握しておくと役に立つ場合があります。
- Google 検索で提供された、全体的な検索結果機能を提供たとえば、"約 888,000,000 件のうちの 1-10 のようになります。
- 高速なページネーションナビゲーションを実装する
- クエリーがゼロを返すか、十分な結果がない場合に概算を追加する複数ステップの検索エンジンを実装するには、以下を実行します。
当然ながら、一致するドキュメントをすべて取得することはできません。Hibernate Search を使用すると、ページネーションパラメーターに関係なく、一致するドキュメントの合計数を取得できます。さらに注意深く、単一のオブジェクト負荷をトリガーせずに一致する要素の数を取得できます。
例: クエリーの結果サイズの決定
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
//return the number of matching books without loading a single one
assert 3245 == ;
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setMaxResult(10);
List results = query.list();
//return the total number of matching books regardless of pagination
assert 3245 == ;
Google と同様に、インデックスがデータベースと完全に更新されていない場合は、結果の数は概算されます (例: 非同期クラスター)。
7.5.2.3. ResultTransformer
プロジェクション結果はオブジェクト配列として返されます。オブジェクトに使用されるデータ構造がアプリケーションの要件と一致しない場合は、ResultTransformer を適用します。ResultTransformer は、クエリーの実行後に必要なデータ構造を構築します。
例: プロジェクトでの ResultTransformer の使用
org.hibernate.search.FullTextQuery query =
s.createFullTextQuery( luceneQuery, Book.class );
query.setProjection( "title", "mainAuthor.name" );
query.setResultTransformer( new StaticAliasToBeanResultTransformer( BookView.class, "title", "author" ) );
List<BookView> results = (List<BookView>) query.list();
for(BookView view : results) {
log.info( "Book: " + view.getTitle() + ", " + view.getAuthor() );
}
ResultTransformer 実装の例は、ibernate Core codebase を参照してください。
7.5.2.4. 結果について
クエリーの結果が適切でない場合、Luke ツールは結果を理解する際に役立ちます。ただし、Hibernate Search を使用すると、所定の結果 (特定のクエリー内) の Lucene Explanation オブジェクトにアクセスできます。このクラスは Lucene ユーザーに非常に高度なものとみなされますが、オブジェクトの性質をよく理解することができます。特定の結果について Explanation オブジェクトにアクセスするには、以下のいずれかの方法があります。
-
fullTextQuery.explain(int)メソッドを使用します。 - プロジェクションの使用
最初の方法は、ドキュメント ID をパラメーターとして取り、Explanation オブジェクトを返します。ドキュメント ID は、インジェクトと FullTextQuery.DOCUMENT_ID 定数を使用して取得できます。
ドキュメント ID はエンティティー ID に関連しません。これらの概念を混同しないように注意してください。
次の方法では、FullTextQuery.EXPLANATION 定数を使用して Explanation オブジェクトをプロジェクトします。
例: プロジェクトを使用した Lucene の説明オブジェクトの取得
FullTextQuery ftQuery = s.createFullTextQuery( luceneQuery, Dvd.class )
.setProjection(
FullTextQuery.DOCUMENT_ID,
,
FullTextQuery.THIS );
@SuppressWarnings("unchecked") List<Object[]> results = ftQuery.list();
for (Object[] result : results) {
Explanation e = (Explanation) result[1];
display( e.toString() );
}
Explanation オブジェクトは、Lucene クエリーを再度実行するときのように、必要とされる場合にのみ使用してください。
7.5.2.5. フィルター
Apache Lucene には、カスタムフィルタープロセスに応じてクエリーの結果をフィルタリングできる強力な機能があります。これは、特にフィルターをキャッシュして再利用できるため、追加のデータ制限を適用する非常に強力な方法です。ユースケースには以下が含まれます。
- セキュリティー
- 一時的なデータ (例: 先月のデータのみ表示)
- 予測フィルター (例: 検索は所定カテゴリーに限定される)
Hibernate Search は、透過的にキャッシュされるパラメーター可能な名前付きフィルターの概念を導入することで、この概念をさらにプッシュします。Hibernate Core フィルターの概念を熟知しているユーザーにとって、API は非常に似ています。
例: クエリーのフルテキストフィルターの有効化
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("bestDriver");
fullTextQuery.enableFullTextFilter("security").setParameter( "login", "andre" );
fullTextQuery.list(); //returns only best drivers where andre has credentials
この例では、クエリーの上に複数のフィルターを有効化しています。フィルターはいくつでも有効または無効にできます。
宣言フィルターは @FullTextFilterDef アノテーションを使用して実行されます。このアノテーションは、フィルターが後に適用されるクエリーに関係なく、@Indexed エンティティーに設定できます。これは、フィルター定義がグローバルであり、名前が一意である必要があることを意味します。同じ名前を持つ @FullTextFilterDef アノテーションが定義される場合は、SearchException が発生します。名前付きの各フィルターは、実際のフィルター実装を指定する必要があります。
例: フィルターの定義および実装
@FullTextFilterDefs( {
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilter.class),
@FullTextFilterDef(name = "security", impl = SecurityFilterFactory.class)
})
public class Driver { ... }
public class BestDriversFilter extends org.apache.lucene.search.Filter {
public DocIdSet getDocIdSet(IndexReader reader) throws IOException {
OpenBitSet bitSet = new OpenBitSet( reader.maxDoc() );
TermDocs termDocs = reader.termDocs( new Term( "score", "5" ) );
while ( termDocs.next() ) {
bitSet.set( termDocs.doc() );
}
return bitSet;
}
}
BestDriversFilter は簡単な Lucene フィルターの例です。これにより、スコアが 5 のドライバーに設定された結果が減少します。この例では、指定したフィルターは org.apache.lucene.search.Filter を直接実装し、no-arg コンストラクターが含まれます。
フィルターの作成に追加のステップが必要な場合や、使用するフィルターに no-arg コンストラクターがない場合は、ファクトリーパターンを使用できます。
例: ファクトリーパターンを使用したフィルターの作成
@FullTextFilterDef(name = "bestDriver", impl = BestDriversFilterFactory.class)
public class Driver { ... }
public class BestDriversFilterFactory {
@Factory
public Filter getFilter() {
//some additional steps to cache the filter results per IndexReader
Filter bestDriversFilter = new BestDriversFilter();
return new CachingWrapperFilter(bestDriversFilter);
}
}
Hibernate Search は @Factory アノテーションが付けられたメソッドを検索し、そのメソッドを使用してフィルターインスタンスを作成します。ファクトリーには no-arg コンストラクターが必要です。
Infinispan Query は @Factory アノテーションが付けられたメソッドを使用してフィルターインスタンスを構築します。ファクトリーには引数コンストラクターは使えません。
名前付きフィルターを使用すると、パラメーターをフィルターに渡すことができます。たとえば、セキュリティーフィルターを適用すると、適用するセキュリティーレベルが分かります。
例: 定義されたフィルターにパラメーターを渡す
fullTextQuery = s.createFullTextQuery( query, Driver.class );
fullTextQuery.enableFullTextFilter("security").setParameter( "level", 5 );
各パラメーター名は、フィルターや、ターゲットとなる名前付きフィルター定義のフィルターまたはフィルターファクトリーのいずれかに関連するセッターを持つ必要があります。
例: フィルター実装におけるパラメーターの使用
public class SecurityFilterFactory {
private Integer level;
/**
* injected parameter
*/
public void setLevel(Integer level) {
this.level = level;
}
@Key public FilterKey getKey() {
StandardFilterKey key = new StandardFilterKey();
key.addParameter( level );
return key;
}
@Factory
public Filter getFilter() {
Query query = new TermQuery( new Term("level", level.toString() ) );
return new CachingWrapperFilter( new QueryWrapperFilter(query) );
}
}
@Key アノテーションが付けられたメソッドは FilterKey オブジェクトを返すことに注意してください。返されたオブジェクトには特別なコントラクトを持ちます。キーオブジェクトは equals() / hashCode() を実装し、指定される Filter タイプが同一で、パラメーターのセットが同じである場合にのみ、両方の鍵が同じになるようにする必要があります。つまり、鍵の生成元となるフィルターが交換可能な場合、あるいは交換可能である場合にのみ、両方のフィルター鍵が同等になります。キーオブジェクトは、キャッシュメカニズムのキーとして使用されます。
@Key メソッドは以下の場合にのみ必要です。
- フィルターキャッシングシステムが有効になっている (デフォルトでは有効)。
- フィルターにはパラメーターがあります。
多くの場合、StandardFilterKey 実装を使用すれば十分です。これは、equals() / hashCode() 実装をそれぞれのパラメーター equals および hashcode メソッドに委譲します。
定義されたフィルターがデフォルトのキャッシュされ、キャッシュは、必要に応じてハード参照とソフト参照の組み合わせを使用してメモリーの破損を可能にします。ハード参照キャッシュは、最近使用されたフィルターを追跡し、必要に応じて SoftReferences に最も使用されるフィルターを変換します。ハード参照キャッシュの制限に達すると、追加のフィルターが SoftReferences としてキャッシュされます。ハード参照キャッシュのサイズを調整するには、hibernate.search.filter.cache_strategy.size (デフォルトは 128 に設定) を使用します。フィルターキャッシングの高度な使用のために、独自の FilterCachingStrategy を実装します。classname は hibernate.search.filter.cache_strategy によって定義されます。
このフィルターキャッシュメカニズムは、実際のフィルター結果をキャッシュするのと混同しないようにしてください。Lucene では、CachingWrapperFilter を中心に IndexReader を使用してフィルターをラッピングすることが一般的です。ラッパーは、getDocIdSet(IndexReader reader) メソッドから返される DocIdSet をキャッシュして、高価な再構築を防ぎます。リーダーは、開いた時点のインデックスの状態を効果的に表示するため、計算した DocIdSet が同じ IndexReader インスタンスに対してのみキャッシュ可能であることを示すことが重要です。ドキュメントリストは、開いている IndexReader 内では変更できません。ただし、別の、新しい IndexReader インスタンスの場合は、(別のインデックスから、または単にインデックスが変更されたため) 異なるファイルのセットで動作する可能性があるため、キャッシュされた DocIdSet を再計算する必要があります。
また、Hibernate Search はキャッシングのこの側面にも役立ちます。@FullTextFilterDef の cache フラグは、デフォルトでは FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS に設定されています。これにより、フィルターインスタンスを自動的にキャッシュし、CachingWrapperFilter の Hibernate 固有の実装に指定されたフィルターをラップします。このクラスの Lucene のバージョンとは対照的に、SoftReferences はハード参照数とともに使用されます (フィルターキャッシュについて参照)。ハード参照数は、hibernate.search.filter.cache_docidresults.size (デフォルトは 5 に設定) を使用して調整できます。ラッピング動作は、the@FullTextFilterDef.cache パラメーターを使用して制御できます。このパラメーターには、以下の異なる値があります。
| 値 | 定義 |
|---|---|
| FilterCacheModeType.NONE | フィルターインスタンスがなく、Hibernate Search によって結果がキャッシュされません。フィルター呼び出しごとに、新しいフィルターインスタンスが作成されます。この設定は、データセットまたはメモリーが制限される環境を迅速に変更する際に役に立つことがあります。 |
| FilterCacheModeType.INSTANCE_ONLY | フィルターインスタンスは、同時に Filter.getDocIdSet() 呼び出しでキャッシュされ、再利用されます。DocIdSet の結果はキャッシュされません。この設定は、フィルターが固有のキャッシングメカニズムを使用するか、アプリケーション固有のイベントにより DocIdSet をキャッシュする必要がない場合に動的にフィルターの結果が変更される場合に役立ちます。 |
| FilterCacheModeType.INSTANCE_AND_DOCIDSETRESULTS | フィルターインスタンスと DocIdSet 両方の結果がキャッシュされます。これがデフォルト値になります。 |
フィルターは以下の状況でキャッシュする必要があります。
- システムはターゲットエンティティーインデックスを頻繁に更新しません (つまり、IndexReader は頻繁に再利用されます)。
- Filter の DocIdSet の計算には、クエリーの実行にかかった時間と比較して負荷がかかります。
7.5.2.6. シャード化された環境でのフィルターの使用
シャード化された環境では、利用可能なシャードのサブセットでクエリーを実行することができます。これを行う方法は 2 つあります。
インデックスシャードのサブセットのクエリー
- フィルター設定に応じて IndexManager のサブセットを選択するシャード化ストラテジーを作成します。
- クエリー時にフィルターをアクティブにします。
例: インデックスシャードのサブセットのクエリー
この例では、customer フィルターがアクティブな場合は、クエリーが特定の顧客シャードに対して実行されます。
public class CustomerShardingStrategy implements IndexShardingStrategy {
// stored IndexManagers in an array indexed by customerID
private IndexManager[] indexManagers;
public void initialize(Properties properties, IndexManager[] indexManagers) {
this.indexManagers = indexManagers;
}
public IndexManager[] getIndexManagersForAllShards() {
return indexManagers;
}
public IndexManager getIndexManagerForAddition(
Class<?> entity, Serializable id, String idInString, Document document) {
Integer customerID = Integer.parseInt(document.getFieldable("customerID").stringValue());
return indexManagers[customerID];
}
public IndexManager[] getIndexManagersForDeletion(
Class<?> entity, Serializable id, String idInString) {
return getIndexManagersForAllShards();
}
/**
* Optimization; don't search ALL shards and union the results; in this case, we
* can be certain that all the data for a particular customer Filter is in a single
* shard; simply return that shard by customerID.
*/
public IndexManager[] getIndexManagersForQuery(
FullTextFilterImplementor[] filters) {
FullTextFilter filter = getCustomerFilter(filters, "customer");
if (filter == null) {
return getIndexManagersForAllShards();
}
else {
return new IndexManager[] { indexManagers[Integer.parseInt(
filter.getParameter("customerID").toString())] };
}
}
private FullTextFilter getCustomerFilter(FullTextFilterImplementor[] filters, String name) {
for (FullTextFilterImplementor filter: filters) {
if (filter.getName().equals(name)) return filter;
}
return null;
}
}
この例では、custom という名前のフィルターがある場合、この顧客専用のシャードのみがクエリーされ、それ以外の場合はすべてのシャードが返されます。所定のシャード化ストラテジーは、単一または複数のフィルターに対応し、それらのパラメーターに依存します。
次のステップでは、クエリー時にフィルターをアクティブにします。フィルターは、クエリーの後に Lucene 結果をフィルターする (定義されている) 通常のフィルターですが、シャード化ストラテジーにのみ渡される特殊フィルターを使用することができます (その他は無視されます)。
この機能を使用するには、フィルターの宣言時に ShardSensitiveOnlyFilter クラスを指定します。
@Indexed
@FullTextFilterDef(name="customer", impl=ShardSensitiveOnlyFilter.class)
public class Customer {
...
}
FullTextQuery query = ftEm.createFullTextQuery(luceneQuery, Customer.class);
query.enableFulltextFilter("customer").setParameter("CustomerID", 5);
@SuppressWarnings("unchecked")
List<Customer> results = query.getResultList();ShardSensitiveOnlyFilter を使用して Lucene フィルターを実装する必要はありません。シャード化された環境のクエリーを加速するには、これらのフィルターに対応するフィルターおよびシャード化ストラテジーを使用することが推奨されます。
7.5.3. ファセット
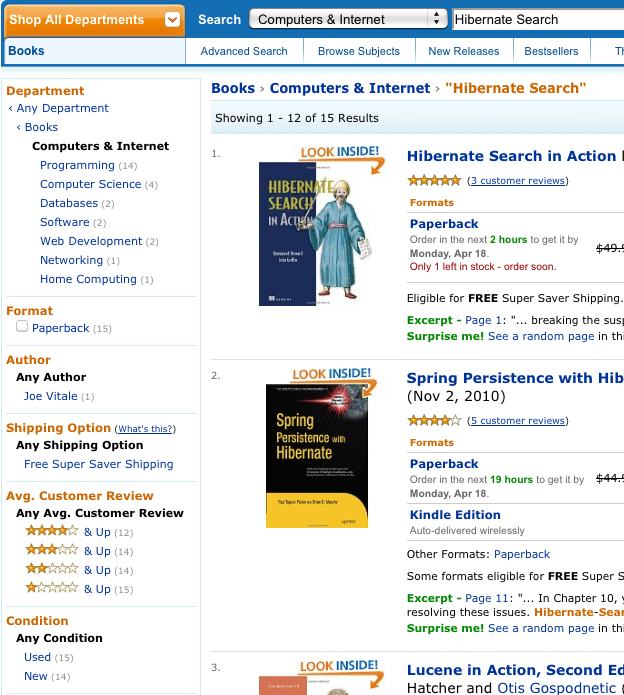
ファセット検索は、クエリーの結果を複数のカテゴリーに分割できる技術です。この分類には、各カテゴリーのヒット数の計算や、これらのファイン (カテゴリー) に基づいて検索結果をさらに制限する機能が含まれます。以下の例は、ファセットの例を示しています。ページのメイン部分に表示される検索結果が表示されます。ただし、左側のナビゲーションバーには、Programming、Computer Science、Databases、Software、Web Development、Networking、Home Computing のサブカテゴリーを持つ Computers & Internet カテゴリーが表示されています。各サブカテゴリーについて、主要な検索条件に合致し、それぞれのサブカテゴリーに属する Book の数が表示されます。Computers & Internet のカテゴリーの区分は、特定の検索ファセットです。その他には、平均的なカスタマーレビューなどが挙げられます。
ファセット検索は、クエリーの結果をカテゴリーに分割します。この分類は、各カテゴリーのヒット数の計算を含み、これらのファセット (カテゴリー) に基づいて検索結果をさらに制限します。以下の例では、ファセット検索結果がメインページに表示されます。
左側のナビゲーションバーには、カテゴリーとサブカテゴリーが表示されます。各サブカテゴリーについて、Book の数は主要な検索条件と一致し、それぞれのサブカテゴリーに属します。この Computers & Internet カテゴリーの区分は、特定の検索ファセットです。もう 1 つの例は、平均的なカスタマーレビューです。
例: Amazon での Hibernate Search の検索
Hibernate Search の QueryBuilder クラスおよび FullTextQuery クラスは、ファセット API へのエントリーポイントです。前者は要求を作成し、後者は FacetManager にアクセスします。FacetManager はクエリーにファセット要求を適用し、検索結果を絞り込むために既存のクエリーに追加されるブックマークを選択します。この例では、以下の例のように Cd エンティティーを使用します。
例: エンティティー Cd
@Indexed
public class Cd {
private int id;
@Fields( {
@Field,
@Field(name = "name_un_analyzed", analyze = Analyze.NO)
})
private String name;
@Field(analyze = Analyze.NO)
@NumericField
private int price;
Field(analyze = Analyze.NO)
@DateBridge(resolution = Resolution.YEAR)
private Date releaseYear;
@Field(analyze = Analyze.NO)
private String label;
// setter/getter
...
Hibernate Search 5.2 よりも前のバージョンでは、@Facet アノテーションを明示的に使用する必要がなくなりました。Hibernate Search 5.2 では、Lucene のネイティブファセッティング API を使用するために必要になりました。
7.5.3.1. ファセット要求の作成
ファセット検索に対する最初のステップは、FacetingRequest を作成することです。現時点では、2 種類のセッティング要求がサポートされています。最初のタイプは discrete faceting と呼ばれ、次のタイプは range faceting 要求と呼ばれます。個別のファセットリクエストの場合は、ファセット (分類) を行うインデックスフィールドと、適用するファセットオプションを指定します。個別のファセッティング要求の例は、以下の例で確認できます。
例: 個別のファセット要求の作成
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest labelFacetingRequest = builder.facet()
.name( "labelFaceting" )
.onField( "label")
.discrete()
.orderedBy( FacetSortOrder.COUNT_DESC )
.includeZeroCounts( false )
.maxFacetCount( 1 )
.createFacetingRequest();
このファセットリクエストを実行すると、インデックス設定された label フィールドの個別値ごとに Facet インスタンスが作成されます。Facet インスタンスは、元のクエリー結果内でこの特定のフィールドの値が発生する頻度を含む実際のフィールド値を記録します。orderdBy、includeZeroCounts および maxFacetCount は任意のオプションのパラメーターで、すべてのファセット要求に適用できます。ordersBy では、作成されたブックマークが返される順序を指定できます。デフォルトは FacetSortOrder.COUNT_DESC ですが、フィールドの値または範囲の指定順序でソートすることもできます。includeZeroCount は、結果内に含まれるブックマーク数 (デフォルトでは 0) を判断し、maxFacetCount により、返されるワイルドカードの最大数を制限できます。
現時点では、ファセッティングを適用するためにインデックス化されたフィールドを満たす必要のあるいくつかの前提条件があります。インデックス付きプロパティーは String、Date、または Number および null の値を持つものは使用しないでください。さらに、プロパティーは Analyze.NO でインデックス化する必要があり、数値プロパティー @NumericField を指定する場合は指定する必要があります。
一定の範囲のファセットリクエストの作成は、ブックマークするフィールド値の範囲を指定する必要がある点以外は非常に似ています。一定の範囲のファセットリクエストは、複数の異なるレート範囲が指定されている場合に以下で確認できます。below および above は 1 度のみ指定できますが、from - to は必要なだけ指定できます。各範囲の境界は、excludeLimit で、範囲に含まれるかどうかを指定することもできます。
例: 範囲ファセット要求の作成
QueryBuilder builder = fullTextSession.getSearchFactory()
.buildQueryBuilder()
.forEntity( Cd.class )
.get();
FacetingRequest priceFacetingRequest = builder.facet()
.name( "priceFaceting" )
.onField( "price" )
.range()
.below( 1000 )
.from( 1001 ).to( 1500 )
.above( 1500 ).excludeLimit()
.createFacetingRequest();
7.5.3.2. ファセット要求の適用
ファセット要求は、FullTextQuery クラスを介して取得できる FacetManager クラスでクエリーに適用されます。
ファセットリクエストはいくつでも有効にでき、ファセット要求名を指定して getFacets() で後から取得できます。また、名前を指定してファセット要求を無効にできる disableFaceting() メソッドもあります。
ファセット要求は、FullTextQuery から取得できる FacetManager を使用してクエリーに適用できます。
例: ファセット要求の適用
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, Cd.class ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cds List<Cd> cds = fullTextQuery.list(); ... // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); ...
getFacets() を使用して、ファセットリクエスト名を指定することで、複数のファセット名を取得できます。
disableFaceting() メソッドは、名前を指定してブックマーク要求を無効にします。
7.5.3.3. クエリー結果の制限
最後でも重要ですが、ドルダウン機能を実装するために、元のクエリーに追加の基準として返されたすべての Facets を適用できます。そのためには、FacetSelection を使用できます。FacetSelections は FacetManager 経由で利用可能で、クエリー基準としてファセットを選択できます。(selectFacets)、ファセットの制限を削除して、すべてのファセット制限 (deselectFacets) を削除し、現在選択しているすべてのファセット (getSelectedFacets) を取得します。以下のスニペットは例になります。
// create a fulltext query Query luceneQuery = builder.all().createQuery(); // match all query FullTextQuery fullTextQuery = fullTextSession.createFullTextQuery( luceneQuery, clazz ); // retrieve facet manager and apply faceting request FacetManager facetManager = fullTextQuery.getFacetManager(); facetManager.enableFaceting( priceFacetingRequest ); // get the list of Cd List<Cd> cds = fullTextQuery.list(); assertTrue(cds.size() == 10); // retrieve the faceting results List<Facet> facets = facetManager.getFacets( "priceFaceting" ); assertTrue(facets.get(0).getCount() == 2) // apply first facet as additional search criteria facetManager.getFacetGroup( "priceFaceting" ).selectFacets( facets.get( 0 ) ); // re-execute the query cds = fullTextQuery.list(); assertTrue(cds.size() == 2);
7.5.4. クエリープロセスの最適化
クエリーのパフォーマンスは、以下の基準に依存します。
- Lucene クエリー。
- 読み込まれたオブジェクト数: ページネーション (常時) またはインデックス処理 (必要な場合) を使用します。
- Hibernate Search が Lucene リーダーと対話する方法: 適切なリーダーストラテジーを定義します。
- インデックスから頻繁に抽出された値をキャッシュします。詳細は、Caching Index Values: FieldCache を参照してください。
7.5.4.1. インデックス値のキャッシュ: FieldCache
Lucene インデックスの主な機能は、クエリーへの一致を識別することです。クエリーが実行された後に、結果が分析され、有用な情報が抽出される必要があります。通常、Hibernate Search はクラスターイプとプライマリーキーを抽出する必要があります。
インデックスから必要な値を抽出するには、パフォーマンス負荷がかかります。パフォーマンス負荷が極めて低く、気付かない場合もありますが、キャッシュを行うのに役立つ場合もあります。
この要件は、使用されている Projections によって異なります。これは、クラスターイプがクエリーコンテキストまたは他の方法で推測される可能性があるため、クラスターイプが不要なためです。
@CacheFromIndex アノテーションを使用すると、Hibernate Search に必要なメインのメタデータフィールドのキャッシュをさまざまな方法で試すことができます。
import static org.hibernate.search.annotations.FieldCacheType.CLASS;
import static org.hibernate.search.annotations.FieldCacheType.ID;
@Indexed
@CacheFromIndex( { CLASS, ID } )
public class Essay {
...このアノテーションを使用してクラスターイプと ID をキャッシュできます。
CLASS: Hibernate Search は Lucene FieldCache を使用して、インデックスからクラスターイプの抽出のパフォーマンスを改善します。この値はデフォルトで有効になっており、@CacheFromIndex アノテーションを指定しない場合に Hibernate Search が適用されます。
-
ID: プライマリー識別子はキャッシュを使用します。これにより、パフォーマンスが最も高いクエリーが提供されますが、消費するメモリーが多くなり、パフォーマンスが低下する可能性があります。
ウォームアップ後のパフォーマンスおよびメモリー消費の影響を測定します (一部のクエリーの実行)。パフォーマンスは、フィールドキャッシュを有効にすることによって改善される可能性がありますが、常に改善されるわけではありません。
FieldCache の使用は、以下の点を考慮してください。
- メモリー使用量: このキャッシュには、かなりメモリーがハングします。通常、CLASS キャッシュの要件は ID キャッシュの要件よりも低くなります。
- インデックスウォームアップ: フィールドキャッシュを使用する場合、新しいインデックスまたはセグメントの最初のクエリーは、キャッシュが有効になっていない場合よりも遅くなります。
一部のクエリーでは、クラスターイプは全く不要です。その場合、CLASS フィールドキャッシュを有効にしても使用されない可能性があります。たとえば、単一クラスをターゲットとしている場合は、返される値はすべてそのタイプのものになります (これは各クエリー実行時に評価されます)。
ID FieldCache を使用するには、ターゲットエンティティーの ID が TwoWayFieldBridge (すべてのブリッジの構築として) を使用し、特定のクエリーに読み込まれるすべてのタイプが id のフィールド名を使用し、同じタイプの ID が割り当てられている必要があります (これは各クエリー実行時に評価されます)。