Red Hat Training
A Red Hat training course is available for Red Hat JBoss Enterprise Application Platform
23.2.5. ワーカー設定
workder 設定では、Hibernate Search が Lucene と対話する方法を詳細化することができます。複数のアーキテクチャーコンポーネントと可能な拡張ポイントが存在します。詳しく見てみましょう。
最初に
ワーカーがあります。ワーカー インターフェースの実装は、すべてのエンティティーの変更を受け取り、コンテキストでキューイングし、コンテキストが終了するとそれらを適用します。特に ORM との接続で最も直感的なコンテキストはトランザクションです。このため、Hibernate Search はデフォルトで TransactionalWorker を使用してトランザクションごとのすべての変更のスコープを設定します。ただし、コンテキストがエンティティーの変更数や他のアプリケーション(lifecycle)イベントの数に依存するシナリオを考えてみます。このため、表23.1「スコープ設定」 に示されるように、Worker 実装は設定可能です。
表23.1 スコープ設定
| プロパティー | 説明 |
| hibernate.search.worker.scope | 使用する ワーカー 実装の完全修飾クラス名。このプロパティーが設定されていない場合、空または トランザクション の場合はデフォルトの TransactionalWorker が使用されます。 |
| hibernate.search.worker.* | 接頭辞 hibernate.search.worker が付いたすべての設定プロパティーは初期化中にワーカーに渡されます。これにより、カスタムのワーカー固有のパラメーターを追加できます。 |
| hibernate.search.worker.batch_size | コンテキストごとにバッチ処理されるインデックス操作の最大数を定義します。制限に達すると、コンテキストが終了していなくてもインデックスがトリガーされます。このプロパティーは、Worker 実装によってキューに追加された作業を BatchedQueueingProcessor に委譲する場合にのみ機能します( TransactionalWorker が実行する動作です)。 |
コンテキストが終了すると、インデックスの変更を準備して適用します。これは、新規スレッド内で同期または非同期に実行できます。同期更新には、常にインデックスがデータベースと同期しているという利点があります。一方、非同期のアップデートは、ユーザーの応答時間を最小限に抑えるのに役立ちます。欠点は、データベースとインデックスの状態間で不一致が生じる可能性があることです。表23.2「実行設定」 に記載されている設定オプションを確認しましょう。
注記
以下のオプションはインデックスごとに異なる場合があります。実際には、indexName 接頭辞が必要になるか、
default を使用してすべてのインデックスのデフォルト値を設定する必要があります。
表23.2 実行設定
| プロパティー | 説明 |
| hibernate.search.<indexName>.worker.execution | sync: 同期実行 (デフォルト)
async: 非同期実行
|
| hibernate.search.<indexName>.worker.thread_pool.size | バックエンドは、スレッドプールを使用して、同じトランザクションコンテキスト(またはバッチ)からの更新を並行して適用することができます。デフォルト値は 1 です。トランザクションごとに多数の操作がある場合は、大きな値を試すことができます。 |
| hibernate.search.<indexName>.worker.buffer_queue.max | スレッドポーリングが不足している場合、ワークキューの最大数を定義します。非同期実行のみに便利です。デフォルトは infinite です。制限に達すると、ワークはメインスレッドによって行われます。 |
これまでは、実行モードに関係なく、すべての作業が同じ仮想マシン(VM)内で実行されます。単一仮想マシンの作業合計量は変更されていません。常に、より適切なアプローチ (つまり委任) があります。hibernate.search.default.worker.backend を設定して、インデックスを別のサーバーに送信することができます。表23.3「バックエンドの設定」 を参照してください。このオプションも、インデックスごとに異なる方法で設定できます。
表23.3 バックエンドの設定
| プロパティー | 説明 |
| hibernate.search.<indexName>.worker.backend | lucene: 同じ仮想マシンでインデックスの更新を実行するデフォルトのバックエンド。プロパティーが定義されていないか、または空の場合に使用されます。
JMS: JMS バックエンド。インデックスの更新は JMS キューに送信され、インデックスマスターによって処理されます。追加の設定オプションは 表23.4「JMS バックエンドの設定」 で、この設定の詳細な説明は 「JMS マスター/ スレーブバックエンド」 を参照してください。
BlackHole: 主にテスト/開発者の設定で、すべてのインデックス作業を無視します。
BackendQueueProcessor を実装するクラスの完全修飾名を指定することもできます。これにより、独自の通信層を実装することができます。この実装は実行時に Runnable インスタンスを返し、インデックスが機能するようにします。
|
表23.4 JMS バックエンドの設定
| プロパティー | 説明 |
|---|---|
| hibernate.search.<indexName>.worker.jndi.* | JNDI プロパティーを定義して InitialContext を開始します(必要な場合)。JNDI は JMS バックエンドによってのみ使用されます。 |
| hibernate.search.<indexName>.worker.jms.connection_factory | JMS バックエンドには必須です。JMS 接続ファクトリーを検索する JNDI 名を定義します (Red Hat JBoss Enterprise Application Platform では、/ConnectionFactory がデフォルト)。 |
| hibernate.search.<indexName>.worker.jms.queue | JMS バックエンドには必須です。JMS キューを検索する JNDI 名を定義します。キューはワークメッセージをポストするために使用されます。 |
警告
おそらく、表示されるプロパティーの一部は関連付けられるため、プロパティー値のすべての組み合わせが適切であるとは限りません。実際には、機能以外の設定を行うことができます。これは、特に、ここに示されるインターフェースの独自の実装を提供する場合が該当します。独自の
Worker または BackendQueueProcessor 実装を作成する前に、既存のコードを調査してください。
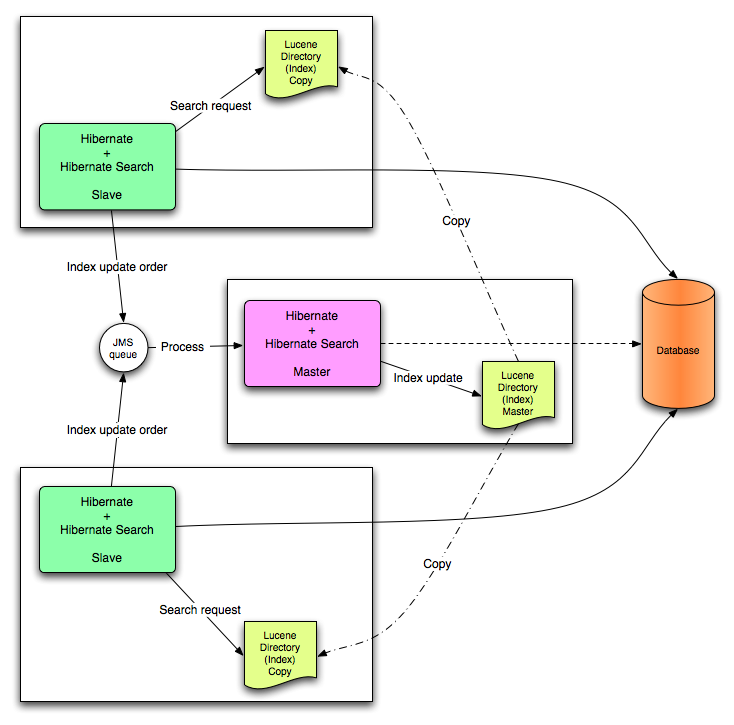
23.2.5.1. JMS マスター/ スレーブバックエンド
本セクションでは、Master/Slave Hibernate Search アーキテクチャーを設定する方法を説明します。
図23.3 JMS バックエンドの設定