
Kamelets でのアプリケーションの統合
アプリケーションの統合を簡素化するコネクターの設定
概要
前書き
Kamelets は、外部システムに接続するデータパイプライン作成の複雑さを隠す、再利用可能なルートコンポーネントです。
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。これは大規模な取り組みであるため、これらの変更は今後の複数のリリースで段階的に実施されます。詳細は、Red Hat CTO である Chris Wright のメッセージをご覧ください。
第1章 Kamelets の概要
Kamelets は、イベント駆動型のアーキテクチャーソリューションでビルディングブロックとして使用できる高レベルのコネクターです。これらは OpenShift クラスターにインストールし、Camel K インテグレーションで使用できるカスタムリソースです。Kamelets は開発作業を加速します。これらは、データソース (イベントを出力する) およびデータシンク (イベントを消費する) の接続を単純化します。コードを作成するのではなく、kamelet パラメーターを設定します。kamelets を使用するために Camel DSL について理解する必要はありません。
kamelets を使用して、アプリケーションとサービスを直接相互に接続したり、以下に接続できます。
- Kafka トピック (「Connecting to Kafka with Kamelets」に記載)
- Knative 接続先 (チャネルまたはブローカー) (「Connecting to Knative with Kamelets」に記載)
- 特定の Camel URI (「Connecting to an explicit Camel URI」に記載)
1.1. kamelets について
Kamelets は、Camel インテグレーションでコネクターとして動作するルートコンポーネント (カプセル化されたコード) です。kamelets は、データの消費元 (ソース) や、データの送信先 (シンク) を定義するテンプレートと考えることができます。これにより、データのパイプラインをアセンブルできます。Kamelets は、データのフィルタリング、マスク、および単純な計算ロジックを実行することもできます。
kamelets には、以下の 3 つのタイプがあります。
- ソース: データを作成するルート。ソース kamelet を使用してコンポーネントからデータを取得します。
- シンク: データを消費するルート。シンク kamelet を使用してデータをコンポーネントに送信します。
- アクション: データに対してアクションを実行するルート。ソース kamelet からシンク kamelet に渡す際に、アクション kamelet を使用してデータを操作できます。
1.1.1. kamelets を使用する理由
マイクロサービス および イベント駆動型のアーキテクチャー ソリューションでは、kamelets はイベントを出力するソースおよびイベントを消費するシンクのビルディングブロックとして機能できます。
Kamelets は、抽象化 (外部システムへの接続の複雑さを隠します) および再利用性 (コードを再利用し、異なるユースケースに適用する簡単な方法です) を提供します。
使用例を以下に示します。
- アプリケーションが Telegram からのイベントを消費するようにするには、kamelets を使用して Telegram ソースをイベントのチャネルにバインドできます。後に、それらのイベントに反応するように、アプリケーションをそのチャネルに接続できます。
- アプリケーションが Salesforce を直接 Slack に接続することを希望します。
Kamelets を使用すると、統合開発チームの効率が高くなります。kamelets を再利用し、特定のニーズに合わせてインスタンスを設定できるチームメンバーとそれらを共有することができます。基礎となる Camel K Operator はハードな作業を行います。これは、kamelet で定義されるインテグレーションをコンパイルし、ビルドし、パッケージ化し、デプロイします。
1.1.2. kamelets を使用するユーザー
kamelets を使用すると、Camel インテグレーションで行う必要があるコーディングの量を減らすことができるため、Camel DSL に精通していない開発者に適しています。Kamelets は、Camel 以外の開発者の学習曲線を円滑化することができます。Camel を稼働させるのに、別のフレームワークまたは言語を学ぶ必要はありません。
Kamelets は、複雑な Camel インテグレーションロジックを再利用可能な kamelet にカプセル化し、それを他のユーザーと共有したい、経験のある Camel 開発者にも役立ちます。
1.1.3. kamelets を使用する前提条件
Kamelets を使用するには、以下の環境を設定する必要があります。
- 適切なアクセスレベルで OpenShift 4.6 (またはそれ以降の) クラスターにアクセスできること。この場合、プロジェクトの作成および Operator のインストールができること。また、OpenShift および Camel K CLI ツールをローカルシステムにインストールできること。
- 「Installing Camel」で説明されているように、namespace またはクラスター全体に Camel K Operator がインストールされている。
-
OpenShift コマンドライン (
oc) インターフェースツールがインストールされている。 必要に応じて、VS コードまたは別の開発ツールを Camel K プラグインと共にインストールしている。Camel ベースのツールエクステンションには、組み込まれた kamelet カタログを基にした Camel URI の自動補完などの機能が含まれます。詳細は、『Getting Started with Camel Kafka Connector』の「Camel K development tooling」セクションを参照してください。
注記: Visual Studio (VS) Code Tooling エクステンションはコミュニティーのみです。
1.1.4. kamelets の使用方法
通常、kamelet を使用するには、再利用可能なルートスニペットを定義する kamelet 自体と、1 つ以上の kamelets を一緒に参照およびバインドする kamelet バインディングの 2 つのコンポーネントが必要です。kamelet バインディングは OpenShift リソース (KameletBinding) です。
kamelet バインディングリソースでは、以下が可能になります。
- シンクまたはソース kamelet をイベントのチャネルに接続します: Kafka トピックまたは Knative 接続先 (チャネルまたはブローカー)
- シンク kamelet を直接 Camel Uniform Resource Identifier (URI) に接続します。URI とシンク kamelet を接続することが最も一般的なユースケースですが、ソース kamelet を Camel URI に接続することもできます。
- イベントのチャネルを中間層として使用せずに、シンクとソース kamelet を相互に直接接続します。
- 同じ kamelet バインディングで同じ kamelet を複数回参照します。
- ソース kamelet からシンク kamelet に渡す際に、アクション kamelets を追加してデータを操作します。
- イベントデータの送受信時に失敗した場合に Camel K が何を行うべきかを指定する、エラー処理ストラテジーを定義します。
ランタイム時に、Camel K Operator は kamelet バインディングを使用して Camel K インテグレーションを生成および実行します。
注記: Camel DSL の開発者は Camel K インテグレーションで直接 kamelets を使用できますが、kamelets を実装する簡単な方法は、kamelet バインディングリソースを指定して高レベルなイベントフローを構築することです。
1.2. ソースおよびシンクの接続
2 つ以上のコンポーネント (外部アプリケーションまたはサービス) を接続するには、kamelets を使用します。各 kamelet は、基本的に設定プロパティーを持つルートテンプレートです。データの取得元となるコンポーネント (ソース) およびデータの送信先となるコンポーネント (シンク) を知っている必要があります。
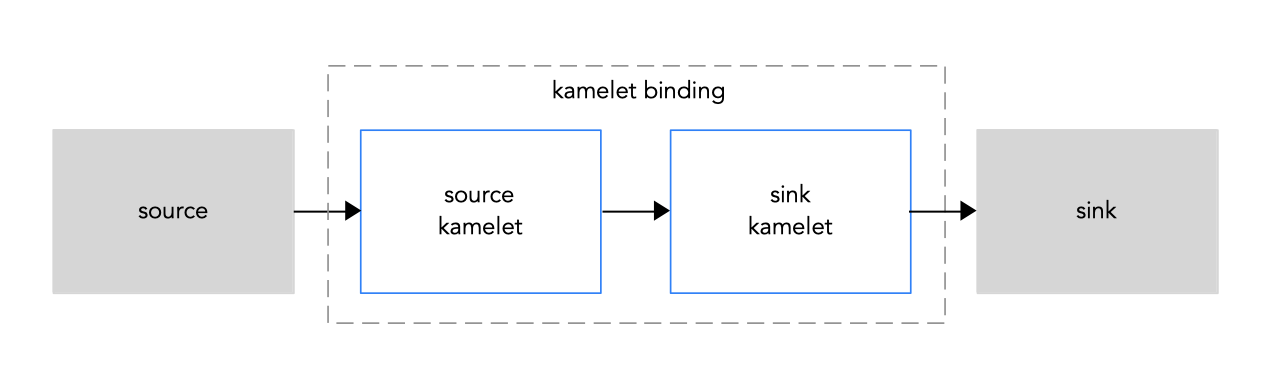
図 1.1: ソースからシンクへの Kamelet バインディング
図 1.1 に記載する kamelet バインディングで kamelets を使用する手順の概要を以下に示します。
- Camel K Operator をインストールします。これには、OpenShift プロジェクトのリソースとして kamelets のカタログが含まれます。
- kamelet バインディングを作成します。kamelet binding 内で接続するサービスまたはアプリケーションを決定します。
- Kamelet Catalog を表示し、使用するソースおよびシンクコンポーネントについての kamelets を見つけます。
- kamelet バインディングに追加する各 kamelet において、設定が必要な設定プロパティーを決定します。
- kamelet バインディングコードで、各 kamelet への参照を追加し、必要なプロパティーを設定します。
- OpenShift プロジェクトのリソースとして kamelet バインディングを適用します。
Camel K Operator は kamelet バインディングを使用してインテグレーションを生成し、実行します。
1.2.1. Camel K のインストール
OperatorHub から OpenShift クラスターで Red Hat Integration - Camel K Operator をインストールできます。OperatorHub は OpenShift Container Platform Web コンソールから利用でき、クラスター管理者が Operator を検出およびインストールするためのインターフェースを提供します。OperatorHub の詳細は、OpenShift ドキュメント を参照してください。
Camel K Operator のインストール後に、コマンドラインですべての Camel K 機能にアクセスする Camel K CLI ツールをインストールできます。
前提条件
適切なアクセスレベルで OpenShift 4.6 (またはそれ以降の) クラスターにアクセスできること。この場合、プロジェクトの作成および Operator のインストールができること。また、CLI ツールをローカルシステムにインストールできること。
注記OpenShift OperatorHub から Camel K をインストールする場合は、プルシークレットを作成する必要はありません。Camel K Operator は OpenShift クラスターレベルの認証を自動的に再利用して、
registry.redhat.ioから Camel K イメージをプルします。-
コマンドラインで OpenShift クラスターと対話できるように OpenShift CLI ツール (
oc) をインストールしていること。OpenShift CLI のインストール方法の詳細は、「Installing the OpenShift CLI」を参照してください。
手順
- OpenShift Container Platform Web コンソールで、クラスター管理者権限を持つアカウントを使用してログインします。
新しい OpenShift プロジェクトを作成します。
- 左側のナビゲーションメニューで、Home > Project > Create Project とクリックします。
-
プロジェクト名 (例:
my-camel-k-project) を入力し、Create をクリックします。
- 左側のナビゲーションメニューで、Operators > OperatorHub とクリックします。
-
Filter by keyword テキストボックスに
Camel Kを入力し、Red Hat Integration - Camel K Operator カードをクリックします。 - Operator に関する情報を確認し、続いて Install をクリックします。Operator のサブスクリプションページが開きます。
以下のサブスクリプション設定を選択します。
- Update Channel > 1.4.x
- Installation Mode > A specific namespace on the cluster > my-camel-k-project
Approval Strategy > Automatic
注記ご使用の環境で必要な場合は Installation mode > All namespaces on the cluster および Approval Strategy > Manual 設定も使用できます。
- Install をクリックし、その後 Camel K Operator が使用できるようになるまでしばらく待ちます。
Camel K CLI ツールをダウンロードし、インストールします。
- OpenShift Web コンソールの上部にある Help メニュー (?) から、Command line tools を選択します。
- kamel - Red Hat Integration - Camel K - Command Line Interface セクションまでスクロールダウンします。
- ローカルのオペレーティングシステム (Linux、Mac、Windows) のバイナリーをダウンロードするためのリンクをクリックします。
- CLI を展開してシステムパスにインストールします。
Kamel K CLI にアクセスできることを確認するには、コマンドウィンドウを開き、以下のコマンドを入力します。
kamel --helpこのコマンドは、Camel K CLI コマンドに関する情報を表示します。
1.2.2. Kamelet カタログの表示
Camel K Operator をインストールする際に、Camel K インテグレーションで使用できる kamelets のカタログが含まれます。
前提条件
「Installing Camel」で説明されているように、作業用 namespace またはクラスター全体に Camel K Operator がインストールされている。
手順
Camel K Operator でインストールされた kamelets の一覧を表示するには、以下を実行します。
- ターミナルウィンドウで、OpenShift クラスターにログインします。
利用可能な kamelets のリスト表示は、Camel K Operator のインストール方法によって異なります (特定の namespace または cluster-mode)。
Camel K Operator が cluster-mode でインストールされている場合は、以下のコマンドを使用して利用可能な kamelets を表示します。
oc get kamelet -n openshift-operatorsCamel K Operator が特定の namespace にインストールされている場合は、以下を行います。
Camel K Operator がインストールされているプロジェクトを開きます。
oc project <camelk-project>たとえば、Camel K Operator が
mycamelkプロジェクトにインストールされている場合は、以下のようになります。oc project mycamelk以下のコマンドを実行します。
oc get kamelets
その他の参考資料
1.2.2.1. Kamelet カタログへのカスタム kamelet の追加
要件に適する kamelet がカタログに表示されない場合、Camel DSL 開発者は「Apache Camel Kamelets Developers Guide」(コミュニティーのドキュメント) で説明されているように、カスタム kamelet を作成することができます。kamelet は YAML 形式でコーディングされ、慣習上 .kamelet.yaml のファイル拡張子を持ちます。
前提条件
- Camel DSL 開発者がカスタム kamelet ファイルを提供している。
- kamelet 名は、Camel K Operator がインストールされている OpenShift namespace に固有のものである必要があります。
手順
カスタム kamelet を OpenShift namespace のリソースとして利用可能にするには、以下を実行します。
-
kamelet
YAMLファイル (例:custom-sink.kamelet.yaml) をローカルフォルダーにダウンロードします。 - OpenShift クラスターにログインします。
ターミナルウィンドウで、Camel K Operator がインストールされているプロジェクトを開きます (例:
mycamelk)。oc project mycamelk以下のコマンドを実行して、カスタム kamelet をリソースとして namespace に追加します (このコマンドは、
custom-sink.kamelet.yamlファイルが現在のディレクトリーにあることを前提としています)。oc apply -f custom-sink.kamelet.yamlkamelet がリソースとして利用できることを確認するには、以下のコマンドを使用して現在の namespace 内のすべての kamelets をアルファベット順を表示し、カスタム kamelet を検索します。
oc get kamelets
1.2.2.2. kamelet の設定パラメーターの決定
kamelet バインディングでは、参照を kamelet に追加する際に、kamelet の名前を指定し、kamelet のパラメーターを設定します。
前提条件
- 作業用 namespace またはクラスター全体に Camel K Operator がインストールされている。
手順
kamelet の名前およびパラメーターを確認するには、以下を実行します。
- ターミナルウィンドウで、OpenShift クラスターにログインします。
kamelet の YAML ファイルを開きます。
oc describe kamelets/<kamelet-name>たとえば、
ftp-sourcekamelet のコードを表示するには、Camel K Operator が現在の namespace にインストールされている場合は、以下のコマンドを使用します。oc describe kamelets/ftp-sourceCamel K Operator が cluster-mode でインストールされている場合は、以下のコマンドを使用します。
oc describe -n openshift-operators kamelets/ftp-sourceYAML ファイルで、
spec.definitionセクション (JSON-schema 形式で記述される) まで下方向にスクロールし、kamelet のプロパティーの一覧を表示します。セクションの最後で、必須フィールドには、kamelet を参照するときに設定が必要なプロパティーが一覧表示されます。たとえば、以下のコードは、
ftp-sourcekamelet のspec.definitionセクションからの抜粋です。本セクションでは、kamelet のすべての設定プロパティーの詳細を説明します。この kamelet に必要なプロパティーはconnectionHost、connectionPort、username、password、およびdirectoryNameです。spec: definition: title: "FTP Source" description: |- Receive data from an FTP Server. required: - connectionHost - connectionPort - username - password - directoryName type: object properties: connectionHost: title: Connection Host description: Hostname of the FTP server type: string connectionPort: title: Connection Port description: Port of the FTP server type: string default: 21 username: title: Username description: The username to access the FTP server type: string password: title: Password description: The password to access the FTP server type: string format: password x-descriptors: - urn:alm:descriptor:com.tectonic.ui:password directoryName: title: Directory Name description: The starting directory type: string passiveMode: title: Passive Mode description: Sets passive mode connection type: boolean default: false x-descriptors: - 'urn:alm:descriptor:com.tectonic.ui:checkbox' recursive: title: Recursive description: If a directory, will look for files in all the sub-directories as well. type: boolean default: false x-descriptors: - 'urn:alm:descriptor:com.tectonic.ui:checkbox' idempotent: title: Idempotency description: Skip already processed files. type: boolean default: true x-descriptors: - 'urn:alm:descriptor:com.tectonic.ui:checkbox'
その他の参考資料
1.2.3. kamelet バインディングでのソースとシンクコンポーネントの接続
kamelet バインディング内で、ソースとシンクコンポーネントを接続します。
この手順の例では、図 1.2 に示されるように以下の kamelets を使用しています。
-
ソース kamelet の例 の名前は
coffee-sourceです。この単純な kamelet は、Web サイトカタログからコーヒーのタイプについて無作為に生成されるデータを取得します。コーヒーのデータを取得する頻度 (秒単位) を決定する 1 つのパラメーター(period:integer値) があります。デフォルト値 (1000 秒) があるため、このパラメーターは必須ではありません。 -
シンク kamelet の例 の名前は
log-sinkです。これはデータを取得し、それをログファイルに出力します。
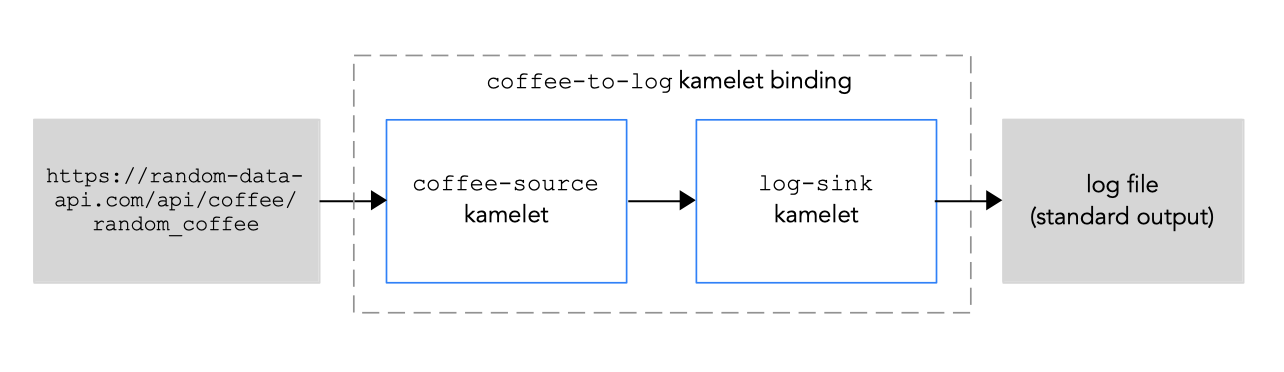
図 1.2: kamelet バインディングの例
前提条件
- Camel K インテグレーションの作成および編集方法を把握している。
- 「Installing Camel K」で説明されているように、Red Hat Integration - Camel K Operator が OpenShift namespace またはクラスターにインストールされ、Red Hat Integration Camel K CLI ツールをダウンロードしている。
- Camel K インテグレーションに追加する kamelets と必要なインスタンスパラメーターを把握している。
- 使用する kamelets が Kamelet カタログで利用可能である。
手順
- OpenShift クラスターにログインします。
Camel K Operator がインストールされている作業プロジェクトを開きます。Camel K Operator を cluster-mode でインストールした場合、クラスター上の任意のプロジェクトで利用できます。
たとえば、
mycamelkという名前の既存のプロジェクトを開くには、以下のコマンドを実行します。oc project mycamelk新しい
KameletBindingリソースを作成します。任意のエディターで、以下の構造で YAML ファイルを作成します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: spec: source: sink:
kamelet binding の名前を追加します。
この例では、バインディングが
coffee-sourcekamelet をlog-sinkkamelet に接続するため、名前はcoffee-to-logになります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: source: sink:
ソース kamelet (例:
coffee-source) を指定し、kamelet のパラメーターを設定します。注記: この例では、このパラメーターは kamelet バインディングの YAML ファイルで定義されます。または、「kamelet インスタンスパラメーターの設定」の説明に従って、プロパティーファイル、configMap、またはシークレットに kamelet のパラメーターを設定することもできます。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: source: ref kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink:シング kamelet (例:
log-sink) を指定し、kamelet のパラメーターを設定します。サンプルのlog-sinkkamelet に必須のパラメーターはありません。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sink-
YAML ファイルを保存します (例:
coffee-to-log.yaml)。 KameletBindingをリソースとして OpenShift namespace に追加します。oc apply -f <kamelet>.yaml以下に例を示します。
oc apply -f coffee-to-log.yamlCamel K Operator は、KameletBinding リソースを使用して Camel K インテグレーションを生成し、実行します。
KameletBinding のステータスを表示するには、次のコマンドを実行します。
oc get kameletbindings-
対応するインテグレーションのステータスを表示するには、
oc get integrationsのコマンドを実行します。 出力を表示するには、以下を実行します。
コマンドラインからのログを表示するには、ターミナルのウィンドウを開き、以下のコマンドを入力します。
kamel log <integration-name>たとえば、インテグレーション名が
coffee-to-logの場合は、以下のコマンドを使用します。kamel log coffee-to-logOpenShift Web コンソールからのログを表示するには、以下を実行します。
- Workloads > Pods を選択します。
Camel K インテグレーションの Pod の名前をクリックし、Logs をクリックします。
以下の例のようなコーヒーイベントの一覧が表示されるはずです。
2021-06-11 17:15:56,725 INFO [log-sink-E80C5C904418150-0000000000000001] (Camel (camel-1) thread #0 - timer://tick) {"id":7259,"uid":"a4ecb7c2-05b8-4a49-b0d2-d1e8db5bc5e2","blend_name":"Postmodern Symphony","origin":"Huila, Colombia","variety":"Kona","notes":"delicate, chewy, black currant, red apple, star fruit","intensifier":"balanced"}
インテグレーションを停止するには、kamelet バインディングを削除します。
oc delete kameletbindings/<kameletbinding-name>以下に例を示します。
oc delete kameletbindings/coffee-to-log
次のステップ
任意で以下を行います。
- 「kamelet バインディングへの操作の追加」で説明されているように、アクション kamelets を中間ステップとして追加します。
- 「kamelet バインディングへのエラーハンドラーポリシーの追加」で説明されているように、kamelet バインディングにエラー処理を追加します。
1.2.4. kamelet インスタンスパラメーターの設定
kamelet を参照する場合は、kamelet のインスタンスパラメーターを定義するのに以下のオプションを使用できます。
kamelet URI を指定する kamelet バインディングに直接指定します。以下の例では、Telegram BotFather が提供するボット承認トークンは
123456です。from("kamelet:telegram-source?authorizationToken=123456")以下の形式で kamelet プロパティーをグローバルに設定します (URI で値を指定する必要がありません)。
"camel.kamelet.<kamelet-name>.<property-name>=<value>”『Deploying Camel K Integrations on OpenShift』の「Configuring Camel K」の章の説明に従って、以下を使用して kamelet パラメーターをグローバルに設定できます。
- プロパティーとしての定義
- プロパティーファイルでの定義
- OpenShift ConfigMap またはシークレットでの定義
その他の参考資料
1.2.5. イベントのチャネルへの接続
kamelets の最も一般的なユースケースとして、kamelet バインディングを使用してイベントのチャネル(Kafka トピックまたは Knative 接続先 (チャネルまたはブローカー)) に接続することです。これを実行する利点は、データソースとシンクが独立しており、お互いに「認識しない」ということです。このように切り離することで、ビジネスシナリオのコンポーネントを個別に開発し、管理できます。ビジネスシナリオの一部として複数のデータシンクおよびソースがある場合、さまざまなコンポーネントを分離することがより重要です。たとえば、イベントシンクをシャットダウンする必要がある場合、イベントソースは影響を受けません。さらに、他のシンクが同じソースを使用する場合、それらは影響を受けません。図 1.3 は、ソースおよびシンク kamelets をイベントチャネルに接続するフローをに示しています。
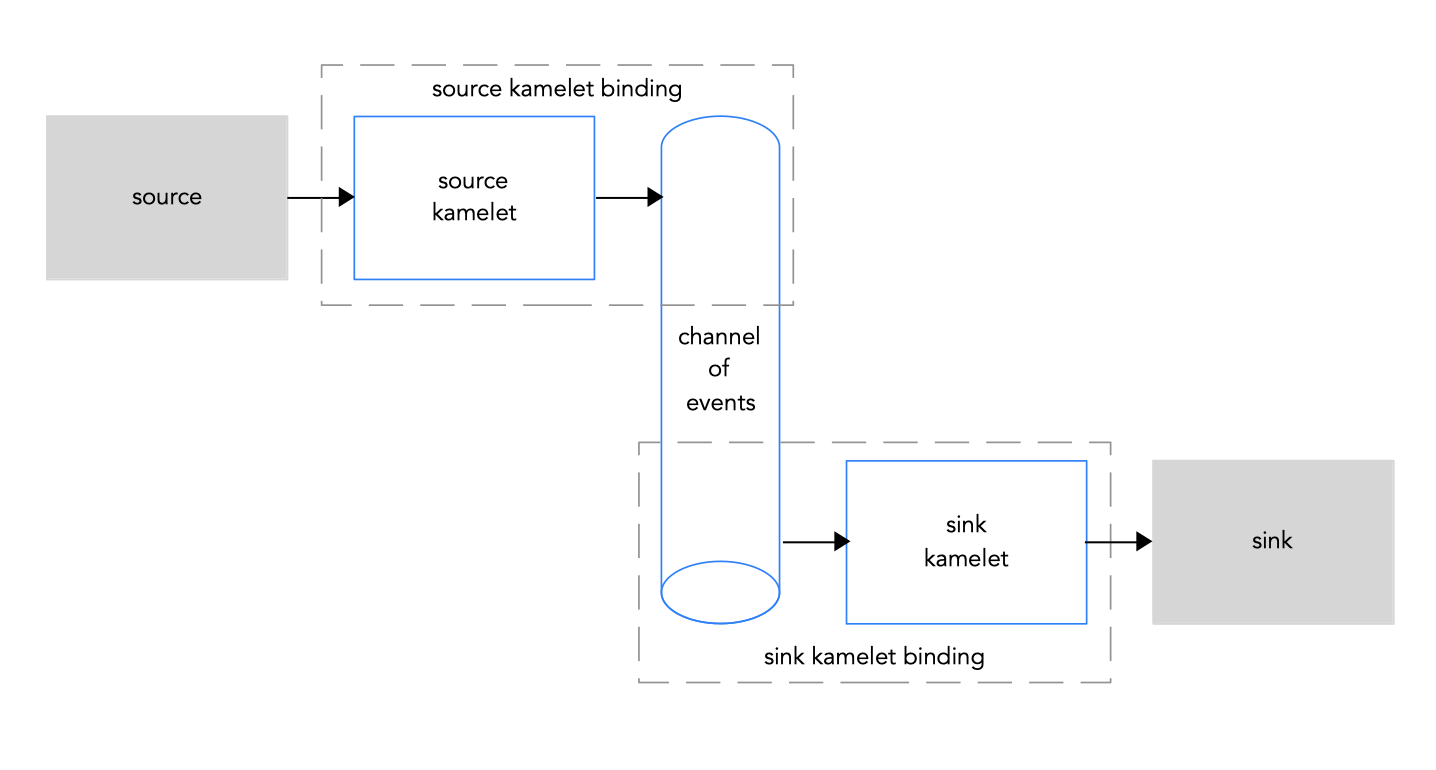
図 1.3: イベントチャネルへのソースおよびシンク kamelets の接続
Apache Kafka ストリームプロセスフレームワークを使用する場合、Kafka トピックへの接続方法の詳細は、「Kamelets を使用した Kafka への接続」を参照してください。
Knative サーバーレスフレームワークを使用する場合、Knative 接続先 (チャネルまたはブローカー) への接続方法の詳細は、「Kamelets を使用した Knative への接続」を参照してください。
1.2.6. 明示的な Camel URI への接続
kamelet がイベントを明示的な Camel URI に送受信する kamelet バインディングを作成できます。通常、ソース kamelet を、イベントを受信できる URI にバインドします (つまり、URI を kamelet バインディングのシンクとして指定します)。イベントを受信する Camel URI の例は HTTP または HTTPS エンドポイントです。
kamelet バインディングで URI をソースとして指定することも可能ですが、一般的な方法ではありません。イベントを送信する Camel URI の例は、タイマー、メール、または FTP エンドポイントです。
kamelet を Camel URI に接続するには、「kamelet バインディングでのソースとシンクコンポーネントの接続」の手順に従い、kameletlet ではなく sink.uri フィールドについて明示的な Camel URI を指定します。
以下の例では、シンクの URI は架空の URI (https://mycompany.com/event-service) です。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: coffee-to-event-service
spec:
source:
ref:
kind: Kamelet
apiVersion: camel.apache.org/v1alpha1
name: coffee-source
properties:
period: 5000
sink:
uri: https://mycompany.com/event-service1.3. コネクション内のデータへの操作の適用
kamelet とイベントチャネル間で渡されるデータで操作を実行する場合は、kamelet バインディング内の中間ステップとして、アクション kamelets を使用します。たとえば、action kamelet を使用してデータをシリアライズまたはデシリアライズしたり、データをフィルターしたり、フィールドやメッセージヘッダーを挿入したりできます。
アクション kamelets には以下が含まれます。
1.3.1. kamelet バインディングへの操作の追加
アクション kamelet を実装するには、kamelet バインディングファイルの spec セクションで、ソースセクションとシンクセクションの間に steps セクションを追加します。
前提条件
- 「Connecting to an event channel」の説明どおりに kamelet バインディングを作成している。
kamelet バインディングに追加するアクション kamelet とアクション kamelet の必須パラメーターを把握している必要があります。
この手順の例では、
predicate-filter-actionkamelet のパラメーターはstringタイプの式で、コーヒーデータをフィルターして "deep" taste intensity を持つコーヒーだけをログに記録するための JSON パス式を提供します。フィールドのフィルタリングや追加などの操作は、JSON データ (つまり、Content-Typeヘッダーがapplication/jsonに設定されている場合) でのみ機能することに注意してください。predicate-filter-actionkamelet では、kamelet バインディングに Builder トレイト設定プロパティーを設定する必要があります。この例には、イベントデータフォーマットが JSON であるため、この場合はオプションのデシリアライズおよびシリアライズアクションも含まれます。イベントデータが JSON 以外の形式 (Avro または Protocol Buffers など) を使用する場合は、操作アクションおよびその後のシリアライズステップ (例:
protobuf-serialize-actionまたはavro-serialize-actionkamelet を参照する) の前にデシリアライズステップ (例:protobuf-deserialize-actionまたはavro-deserialize-actionkamelet を参照する) を追加して、データの形式を変換する必要があります。コネクションのデータ形式を変換する方法は、「データ変換 kamelets」を参照してください。
手順
エディターで
KameletBindingファイルを開きます。たとえば、
coffee-to-log.yamlファイルの内容を以下に示します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sinksourceセクションの上にintegrationセクションを追加し、(predicate-filter-actionkamelet で必要とされるように) 以下の Builder トレイト設定プロパティーを指定します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: integration: traits: builder: configuration: properties: - "quarkus.arc.unremovable-types=com.fasterxml. jackson.databind.ObjectMapper" source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sinksourceセクションとsinkセクションの間にstepsセクションを追加し、アクション kamelet を定義します。以下に例を示します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: integration: traits: builder: configuration: properties: - "quarkus.arc.unremovable-types=com.fasterxml. jackson.databind.ObjectMapper" source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 steps: - ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: json-deserialize-action - ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: predicate-filter-action properties: expression: "@.intensifier =~ /.*deep/" - ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: json-serialize-action sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sink- 変更を保存します。
KameletBindingリソースを更新します。oc apply -f coffee-to-log.yamlCamel K Operator は、更新された
KameletBindingリソースを基に生成する Camel K インテグレーションを再生成し、実行します。kamelet binding のステータスを表示するには、次のコマンドを実行します。
oc get kameletbindings対応するインテグレーションのステータスを表示するには、次のコマンドを実行します。
oc get integrationsログファイルの出力を表示するには、以下を実行します。
インテグレーションの Pod 名を取得します。
oc get podsインテグレーションの Pod のログを表示します。
oc logs <podname of the integration>たとえば、Pod 名が
example-7885bdb9-84ht8の場合、以下のコマンドを実行します。oc logs example-7885bdb9-84ht8
インテグレーションを停止するには、kamelet バインディングを削除します。
oc delete kameletbindings/<kameletbinding-name>以下に例を示します。
oc delete kameletbindings/coffee-to-log
1.3.2. アクション kamelets
1.3.2.1. Data フィルタリング kamelets
たとえば、機密データの漏えいや不要なネットワーク課金の生成を防ぐためやに、ソースとシンクコンポーネント間で渡されるデータをフィルタリングすることができます。
以下の基準に基づいてデータをフィルターできます。
-
Kafka トピック名: Topic Name Matches Filter Action Kamelet (
topic-name-matches-filter-action) を設定して、指定の Java 正規表現に一致する名前を持つ Kafka トピックのイベントをフィルターします。 -
ヘッダーキー: Header Filter Action Kamelet (
has-header-filter-action) を設定して、特定のメッセージヘッダーを持つイベントをフィルターします。 -
null 値: Tombstone Filter Action Kamelet (
is-tombstone-filter-action) を設定して、null ペイロードを持つイベントであるトゥームストーンイベントをフィルターします。 述語: Predicate Filter Action Kamelet (
predicate-filter-action) を設定して、指定の JSON パス式に基づいてイベントをフィルターします。predicate-filter-actionkamelet では、kamelet バインディングに以下の Builder トレイト設定プロパティーを設定する必要があります (https://camel.apache.org/camel-k/latest/traits/builder.html)。spec: integration: traits: builder: configuration: properties: - "quarkus.arc.unremovable-types=com.fasterxml. jackson.databind.ObjectMapper"
Data フィルタリング kamelets は、JSON データで追加設定なしで機能します (Content-Type ヘッダーが application/json に設定されている場合)。イベントデータが JSON 以外の形式を使用する場合は、操作アクションおよびその後のシリアライズステップ (例: protobuf-serialize-action または avro-serialize-action) の前にデシリアライズステップ (例: protobuf-deserialize-action または avro-deserialize-action) を追加して、データの形式を変換する必要があります。コネクションのデータ形式を変換する方法は、「データ変換 kamelets」を参照してください。
1.3.2.2. データ変換 kamelets
以下のデータ変換 kamelets を使うと、ソースとシンクコンポーネント間で渡されるデータの形式をシリアライズおよびデシリアライズすることができます。データ変換は、イベントデータのペイロード (キーまたはヘッダーではない) に適用されます。
Avro: Apache Hadoop 用のデータのシリアライズおよびデータ交換サービスを提供するオープンソースプロジェクト。
-
Avro Deserialize Action Kamelet (
avro-deserialize-action) -
Avro Serialize Action Kamelet (
avro-serialize-action)
-
Avro Deserialize Action Kamelet (
プロトコルバッファー: 内部で使用する Google が開発した高パフォーマンスのコンパクトなバイナリーワイヤ形式で、内部ネットワークサービスと通信できます。
-
Protobuf Deserialize Action Kamelet (
protobuf-deserialize-action) -
Protobuf Serialize Action Kamelet (
protobuf-serialize-action)
-
Protobuf Deserialize Action Kamelet (
JSON (JavaScript Object Notation): JavaScript プログラミング言語のサブセットをベースとしたデータ変換形式。JSON は、言語にまったく依存しないテキスト形式です。
-
JSON Deserialize Action Kamelet (
json-deserialize-action) -
JSON Serialize Action Kamelet (
json-serialize-action)
-
JSON Deserialize Action Kamelet (
Avro および Protobuf シリアライズ/デシリアライズ kamelets でスキーマを指定する必要があります (JSON 形式を使用して単一行として)。JSON シリアライズ/デシリアライズ kamelets で指定する必要はありません。
1.3.2.3. データ変換 kamelets
以下のデータ変換 kamelets を使用すると、ソースとシンクコンポーネント間で渡されるデータに関する簡単な操作を実行できます。
-
ValueToKey: (Kafka の場合)
value-to-key-actionkamelet を使用してレコードキーをペイロードのフィールドのサブセットから作成した新しいキーに置き換えます。イベントキーを、データが Kafka に書き込まれる前に、イベント情報に基づく値に設定できます。たとえば、データベーステーブルからレコードを読み取る場合、顧客 ID に基づいて Kafka のレコードをパーティションできます。 -
MaskField:
mask-field-actionkamelet を使用して、フィールドの値を、0 や空の文字列などのフィールドタイプの有効な null 値、または特定の代替に置き換えます (代替は空ではない文字列または数値である必要があります)。たとえば、リレーショナルデータベースからデータを取得して Kafka に送信することができます。このデータには保護されている (PCI / PII) 情報が含まれ、Kafka クラスターがまだ認定されていないため、保護されている情報をマスクする必要があります。 -
InsertHeader:
insert-header-actionkamelet を使用して、静的データまたはレコードメタデータのいずれかを使用して、フィールド (ヘッダー) を追加します。 -
InsertField:
insert-field-actionkamelet を使用して、静的データまたはレコードメタデータのいずれかを使用して、フィールド (値) を追加します。
1.4. コネクション内でのエラーの処理
イベントデータの送受信時に、稼働中のインテグレーションで障害が発生した場合に Camel K Operator が実行するアクションを指定するには、任意で以下のエラー処理ポリシーのいずれかを kamelet バインディングに追加できます。
- 「エラーハンドラーなし」: インテグレーションで発生した障害を無視します。
- 「ログエラーハンドラー」: ログメッセージを標準出力に送信します。
- 「デッドレターチャネルエラーハンドラー」: 問題のあるイベントを、サードパーティーの URI、キュー、または別の kamelet などの失敗したイベントで特定のロジックを実行可能な別のコンポーネントにリダイレクトします。また、デッドレターエンドポイントに送信する前に、複数の回数メッセージエクスチェンジの再配信の試行にも対応しています。
- 「Bean エラーハンドラー」: エラーを処理するのにカスタム Bean を使用することを指定します。
- 「Ref エラーハンドラー」: エラーを処理するのに Bean を使用することを指定します。Bean は実行時に Camel レジストリーで利用可能である必要があります。
1.4.1. kamelet バインディングへのエラーハンドラーポリシーの追加
ソースとシンクコネクション間でイベントデータを送受信する際のエラーを処理するには、kamelet バインディングにエラーハンドラーポリシーを追加します。
前提条件
- 使用するエラーハンドラーポリシーのタイプを知っている必要があります。
-
既存の
KameletBindingYAML ファイルがある。
手順
kamelet バインディングにエラー処理を実装するには、以下を実行します。
-
エディターで
KameletBindingYAML ファイルを開きます。 sink定義の後に、エラーハンドラーセクションをspecセクションに追加します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: example-kamelet-binding spec: source: ... sink: ... errorHandler: ...たとえば、
coffee-to-logkamelet バインディングでは、ログエラーハンドラーを追加してエラーがログファイルに送信される最大回数を指定します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffee-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sink errorHandler: log: parameters: maximumRedeliveries: 3- ファイルを保存します。
1.4.2. エラーハンドラー
1.4.2.1. エラーハンドラーなし
インテグレーションで発生した失敗を無視する場合は、KameletBinding に errorHandler セクションが含めないか、以下の例に示すように none に設定します。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: my-kamelet-binding
spec:
source:
...
sink:
...
errorHandler:
none:1.4.2.2. ログエラーハンドラー
障害を処理するデフォルトの動作では、ログメッセージを標準出力に送信することです。オプションで、ログエラーハンドラーを使用して再配信や遅延ポリシーなどの他の動作を指定できます。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: my-kamelet-binding
spec:
source:
...
sink:
...
errorHandler:
log: parameters: maximumRedeliveries: 3 redeliveryDelay: 20001.4.2.3. デッドレターチャネルエラーハンドラー
Dead Letter Channel を使用すると、問題のあるイベントを、失敗したイベントの処理方法を定義可能な別のコンポーネント (サードパーティーの URI、キュー、または別の kamelet) にリダイレクトできます。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: my-kamelet-binding
spec:
source:
...
sink:
...
errorHandler:
dead-letter-channel: endpoint: ref: 1 kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: error-handler properties: 2 message: "ERROR!" ... parameters: 3 maximumRedeliveries: 1-
endpoint には、
refまたはuriを使用できます。Camel K Operator は、kind、apiVersion、およびnameの値に従ってrefを解釈します。任意の kamelet、Kafka Topic チャネル、または Knative 送付先を使用できます。 -
エンドポイントに属する Properties (この例では
error-handlerという名前の kamelet)。 - dead-letter-channel エラーハンドラータイプに属する Parameters。
1.4.2.4. Bean エラーハンドラー
Bean エラーハンドラーでは、エラーハンドラーとして使用するカスタム Bean を指定して、Error Handler の機能を拡張できます。type には、ErrorHandlerBuilder の完全修飾名を指定します。プロパティーでは、型に仕様した ErrorHandlerBuilder が必要とするプロパティーを設定します。
Within a kamelet binding, Camel components in URIs require dependency declarations. The Camel K operator generates an integration from a kamelet binding at runtime. For integrations not generated by a kamelet binding, Camel K automatically handles the dependency management and imports all the required libraries from the Camel catalog. However, for this release, you must specify any Camel components that you reference in a URI within a kamelet binding as a dependency. In the following example, because the kamelet binding references the `camel-log` component in the `deadLetterUri`, it includes the `camel-log` as a dependency in the `spec.integration.dependencies` section.
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: my-kamelet-binding spec: integration: dependencies: - camel:log source: source: ... sink: ... errorHandler: bean: type: "org.apache.camel.builder.DeadLetterChannelBuilder" properties: deadLetterUri: log:error
1.4.2.5. Ref エラーハンドラー
Ref エラーハンドラーを使用すると、ランタイム時に Camel レジストリーで見つかることが予想される Bean を使用できます。この例では、my-custom-builder がランタイム時に検索する Bean の名前です。
apiVersion: camel.apache.org/v1alpha1
kind: KameletBinding
metadata:
name: my-kamelet-binding
spec:
source:
...
sink:
...
errorHandler:
ref: my-custom-builder第2章 Kamelets を使用した Kafka への接続
Apache Kafka は、耐障害性のあるリアルタイムデータフィードを作成する、オープンソースの分散型 publish/subscribe メッセージングシステムです。Kafka はデータを素早く保存し、多数のコンシューマー (外部コネクション) 用にデータを複製します。
Kafka は、ストリーミングイベントを処理するソリューションの構築に役立ちます。分散されたイベント駆動型のアーキテクチャーでは、イベントをキャプチャーし、通信し、処理するのに役立つ「バックボーン」が必要です。Kafka は、データソースとイベントをアプリケーションに接続する通信バックボーンとして機能します。
kamelets を使用して Kafka と外部リソースとの間の通信を設定できます。Kamelets を使用すると、コードを作成せずに、Kafka stream-processing フレームワークでデータをあるエンドポイントから別のエンドポイントに移動する方法を設定できます。Kamelets は、パラメーター値を指定して設定するルートテンプレートです。
たとえば、Kafka はデータをバイナリー形式で保存します。kamelets を使用すると、外部接続との間で送受信するためにデータをシリアライズおよびデシリアライズすることができます。kamelets を使用すると、スキーマを検証し、追加、フィルタリング、マスクなどのデータ変更を行うことができます。Kamelets はエラーを処理できます。問題が発生した場合は、エラーが処理される必要があります。
2.1. kamelets を使用した Kafka への接続の概要
Apache Kafka stream-processing フレームワークを使用する場合は、kamelets を使用してサービスおよびアプリケーションを Kafka トピックに接続できます。Kamelet Catalog は、Kafka トピックへの接続専用に、以下の kamelets を提供します。
-
kafka-sink: イベントをデータプロデューサーから Kafka トピックに移動します。kamelet バインディングでは、kafka-sink kamelet をシンクとして指定します。 -
kafka-source: イベントを Kafka トピックからデータコンシューマーに移動します。kamelet バインディングでは、kafka-source kamelet をソースとして指定します。
図 2.1 では、ソースとシンク kamelets を Kafka トピックに接続するフローを示します。
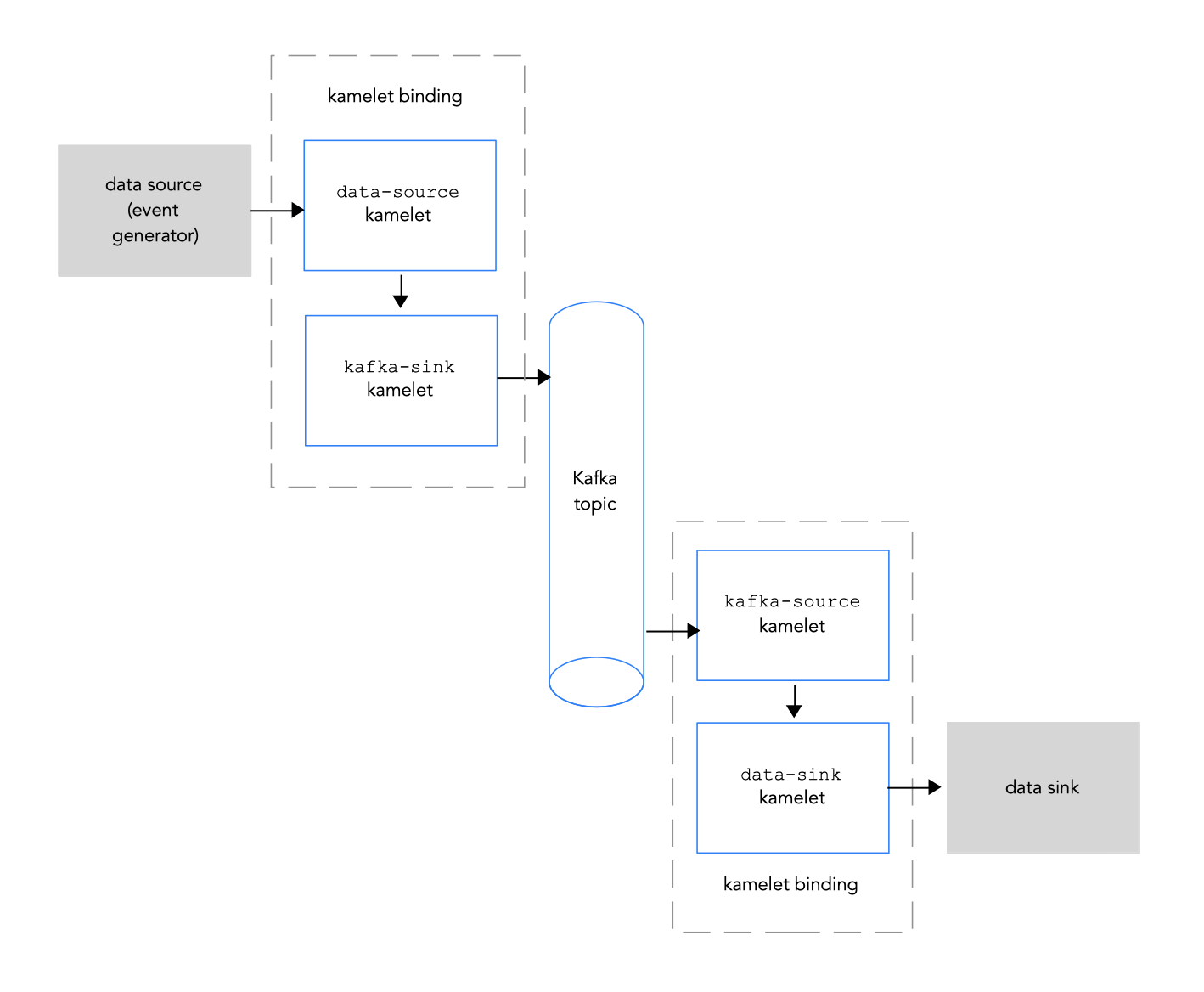
図 2.1: kamelets と Kafka トピックによるデータフロー
以下は、kamelets および kamelet バインディングを使用してアプリケーションやサービスを Kafka トピックに接続するための基本的な手順の概要です。
Kafka を設定します。
必要な OpenShift Operator をインストールします。
- OpenShift Streams for Apache Kafka では、RHOAS および Camel K Operator をインストールします。
- AMQ Streams では、Camel K および AMQ Streams の operator をインストールします。
- Kafka インスタンスを作成します。Kafka インスタンスはメッセージブローカーとして動作します。ブローカーにはトピックが含まれ、ストレージとメッセージの渡しをオーケストレーションします。
- Kafka トピックを作成します。トピックは、データの保存先を提供します。
- Kafka 認証クレデンシャルを取得します。
- Kafka トピックに接続するサービスまたはアプリケーションを決定します。
- kamelet カタログを表示し、インテグレーションに追加するソースおよびシンクコンポーネントの kamelets を見つけます。使用する各 kamelet に必要な設定パラメーターも決定します。
kamelet バインディングを作成します。
-
データソース (データを生成するコンポーネント) を Kafka トピックに接続する kamelet バインディングを作成します (
kafka-sinkkamelet を使用します)。 -
kafka トピックをデータシンク (データを消費するコンポーネント) に接続する kamelet バインディングを作成します (
kafka-sourcekamelet を使用します)。
-
データソース (データを生成するコンポーネント) を Kafka トピックに接続する kamelet バインディングを作成します (
- オプションとして、kamelet バインディング内の中間ステップとして 1 つまたは複数のアクション kamelets を追加して、kafka トピックおよびデータソース/シンク間で渡されるデータを操作します。
- 必要に応じて、kamelet バインディング内でエラーを処理する方法を定義します。
kamelet バインディングをリソースとしてプロジェクトに適用します。
Camel K Operator は、kamelet バインディングごとに個別の Camel K インテグレーションを生成します。
2.2. Kafka の設定
Kafka を設定するには、必要な OpenShift Operator のインストール、Kafka インスタンスの作成、Kafka トピックの作成が必要になります。
以下の Red Hat 製品のいずれかを使用して Kafka を設定します。
- Red Hat Advanced Message Queuing (AMQ) ストリーム: 自己管理の Apache Kafka オファリング。AMQ Streams はオープンソースの Strimzi をベースとしており、Red Hat Integration の一部として組み込まれています。AMQ Streams は、パブリッシュ/サブスクライブメッセージングブローカーが含まれる Apache Kafka をベースとした分散型でスケーラブルなストリーミングプラットフォームです。Kafka Connect は、Kafka ベースのシステムを外部システムと統合するフレームワークを提供します。Kafka Connect を使用すると、外部システムと Kafka ブローカーとの間で双方向にデータをストリーミングするように ソースおよびシンクコネクターを設定できます。
Red Hat OpenShift Streams for Apache Kafka (開発プレビュー): Apache Kafka の実行プロセスを簡素化する管理クラウドサービス。これにより、新しいクラウドネイティブアプリケーションを構築、デプロイ、およびスケーリングする際、または既存システムを現代化する際に、効率的な開発者エクスペリエンスが提供されます。
注記現在、Red Hat OpenShift Streams for Apache Kafka は、開発プレビューで利用できます。開発プレビューリリースは、完全にテストされていない可能性があり、最終的な GA バージョンで変更される可能性がある、限定された機能セットへの早期アクセスを提供します。ユーザーは、開発プレビューソフトウェアを実稼働またはビジネスクリティカルなワークロードで使用しないでください。開発プレビューリリース向けに提供されるドキュメントは限定されており、通常は基本的なユーザーの目的に重点を置いた内容になっています。
2.2.1. AMQ Streams を使用した Kafka の設定
AMQ Streams は、OpenShift クラスターで Apache Kafka を実行するプロセスを簡素化します。
2.2.1.1. OpenShift クラスターの準備
kamelets および Red Hat AMQ Streams を使用するには、以下の Operator およびツールをインストールする必要があります。
- Red Hat Integration - AMQ Streams Operator: OpenShift Cluster と AMQ Streams for Apache Kafka インスタンスの間の通信を管理します。
- Red Hat Integration - Camel K Operator: Camel K (OpenShift のクラウドでネイティブに実行される軽量なインテグレーションフレームワーク) をインストールし、管理します。
- Camel K CLI ツール: すべての Camel K 機能にアクセスできます。
前提条件
- Apache Kafka の概念を理解している。
- 適切なアクセスレベルで OpenShift 4.6 (またはそれ以降の) クラスターにアクセスできること。この場合、プロジェクトの作成および Operator のインストールができること。また、OpenShift および Camel K CLI をローカルシステムにインストールできること。
-
コマンドラインで OpenShift クラスターと対話できるように OpenShift CLI ツール (
oc) をインストールしていること。
手順
kamelets を使用して接続できるように、AMQ Streams を使用して Kafka を設定するには、以下の手順を実施します。
- OpenShift クラスターの Web コンソールにログインします。
- kamelet インテグレーションを作成する予定のプロジェクト (例: my-camel-k-kafka) を作成または開きます。
- 「Installing Camel K」の説明に従って、Camel K Operatorおよび Camel K CLI をインストールします。
AMQ Streams Operator をインストールします。
- 任意のプロジェクトから Operators > OperatorHub を選択します。
- Filter by Keyword フィールドに AMQ Streams を入力します。
Red Hat Integration - AMQ Streams カードをクリックしてから Install をクリックします。
Install Operator ページが開きます。
- デフォルトを受け入れ、Install をクリックします。
- Operators > Installed Operators を選択し、Camel K および AMQ Streams Operator がインストールされていることを確認します。
- 「Managing secure access to Kafka」の説明どおりに Kafka 認証を設定します。
2.2.1.2. AMQ Streams を使用した Kafka トピックの設定
Kafka トピックは、Kafka インスタンスのデータの保存先を提供します。データを送信する前に、Kafka トピックを設定する必要があります。
前提条件
- OpenShift クラスターにアクセスできる。
- 「Preparing your OpenShift cluster」の手順に従って、Red Hat Integration - Camel K および Red Hat Integration - AMQ Streams Operators をインストールしている。
-
OpenShift CLI (
oc) および Camel K CLI (kamel) をインストールしている。
手順
AMQ Streams を使用して Kafka トピックを設定するには、以下を行います。
- OpenShift クラスターの Web コンソールにログインします。
- Projects を選択してから、Red Hat Integration - AMQ Streams Operator をインストールしたプロジェクトをクリックします。たとえば、my-camel-k-kafka プロジェクトをクリックします。
- Operators > Installed Operators の順に選択し、Red Hat Integration - AMQ Streams をクリックします。
Kafka クラスターを作成します。
- Kafka で、Create instance をクリックします。
- kafka-test などクラスターの名前を入力します。
その他のデフォルトを受け入れ、Create をクリックします。
Kafka インスタンスを作成するプロセスの完了に数分かかる場合があります。
ステータスが ready になったら、次のステップに進みます。
Kafka トピックを作成します。
- Operators > Installed Operators の順に選択し、Red Hat Integration - AMQ Streams をクリックします。
- Kafka Topic で Create Kafka Topic をクリックします。
- トピックの名前を入力します (例: test-topic)。
- その他のデフォルトを受け入れ、Create をクリックします。
2.2.2. OpenShift Streams を使用した Kafka の設定
Red Hat OpenShift Streams for Apache Kafka は、Apache Kafka の実行プロセスを簡素化する管理クラウドサービスです。
OpenShift Streams for Apache Kafka を使用するには、Red Hat アカウントにログインする必要があります。
現在、Red Hat OpenShift Streams for Apache Kafka は、開発プレビューで利用できます。開発プレビューリリースは、完全にテストされていない可能性があり、最終的な GA バージョンで変更される可能性がある、限定された機能セットへの早期アクセスを提供します。ユーザーは、開発プレビューソフトウェアを実稼働またはビジネスクリティカルなワークロードで使用しないでください。開発プレビューリリース向けに提供されるドキュメントは限定されており、通常は基本的なユーザーの目的に重点を置いた内容になっています。
2.2.2.1. OpenShift クラスターの準備
Red Hat OpenShift Streams for Apache Kafka 管理クラウドサービスを使用するには、以下の Operator およびツールをインストールする必要があります。
OpenShift Application Services (RHOAS) Operator: OpenShift Cluster と Red Hat OpenShift Streams for Apache Kafka インスタンスの間の通信を管理します。
注記: これはコミュニティー Operator です。
RHOAS CLI: ターミナルからアプリケーションサービスを管理できます。
注記: これは開発者プレビュー機能です。
- Red Hat Integration - Camel K Operator は、Camel K (OpenShift のクラウドでネイティブに実行される軽量なインテグレーションフレームワーク) をインストールし、管理します。
- Camel K CLI ツール: すべての Camel K 機能にアクセスできます。
前提条件
- 適切なアクセスレベルで OpenShift 4.6 (またはそれ以降の) クラスターにアクセスできること。この場合、プロジェクトの作成および Operator のインストールができること。また、OpenShift および Apache Camel K CLI をローカルシステムにインストールできること。
-
コマンドラインで OpenShift クラスターと対話できるように OpenShift CLI ツール (
oc) をインストールしていること。
手順
- クラスター管理者アカウントで OpenShift Web コンソールにログインします。
Kafka と kamelets アプリケーションの接続に使用する OpenShift プロジェクトを作成します。
- Home > Projects を選択します。
- Create Project をクリックします。
-
プロジェクトの名前 (例:
my-camel-k-kafka) を入力し、続いて Create をクリックします。
RHOAS Operator をインストールします。
- 任意のプロジェクトから Operators > OperatorHub を選択します。
- Filter by Keyword フィールドに RHOAS を入力します。
OpenShift Application Services (RHOAS) カード (コミュニティー Operator) をクリックし、Install をクリックします。
Install Operator ページが表示されます。
- デフォルトモード (クラスターのすべての namespace) を使用するか、またはプロジェクトの namespace を選択してから Install をクリックします。
- Getting started with the rhoas CLI の手順に従って、RHOAS CLI をダウンロードし、インストールします。
- 「Installing Camel K」の説明に従って、Camel K Operatorおよび Camel K CLI をインストールします。
- Red Hat Integration - Camel K および OpenShift Application Services (RHOAS) Operators がインストールされていることを確認するには、Operators > Installed Operators をクリックします。
2.2.2.2. RHOAS を使用した Kafka トピックの設定
Kafka は トピック に関するメッセージを整理します。各トピックには名前があります。アプリケーションは、トピックにメッセージを送信し、トピックからメッセージを取得します。Kafka トピックは、Kafka インスタンスのデータの保存先を提供します。データを送信する前に、Kafka トピックを設定する必要があります。
前提条件
- Apache Kafka の概念を理解している。
- 適切なアクセスレベルで OpenShift クラスターにアクセスできること。この場合、プロジェクトの作成および Operator のインストールができること。また、OpenShift および Camel K CLI をローカルシステムにインストールできること。
-
「Preparing your OpenShift cluster」の手順に従って、OpenShift CLI (
oc)、Camel K CLI (kamel)、および RHOAS CLI (rhoas) ツールをインストールしている。 - 「Preparing your OpenShift cluster」の手順に従って、Red Hat Integration - Camel K および OpenShift Application Services (RHOAS) Operators をインストールしている。
- Red Hat Cloud (Beta) サイト にログインしている。
手順
Red Hat OpenShift Streams for Apache Kafka を使用して Kafka トピックを設定するには、以下を行います。
- コマンドラインから OpenShift クラスターにログインします。
以下のように、kamelets で Kafka に接続するプロジェクトを開きます。
oc project my-camel-k-kafka必要な Operator がプロジェクトにインストールされていることを確認します。
oc get csv結果には、Red Hat Camel K および RHOAS Operator が表示され、それらが
Succeededフェーズにあることを示します。Kafka インスタンスを準備し、RHOAS に接続します。
以下のコマンドを使用して RHOAS CLI にログインします。
rhoas loginkafka-test などの kafka インスタンスを作成します。
rhoas kafka create kafka-test
Kafka インスタンスを作成するプロセスの完了に数分かかる場合があります。
Kafka インスタンスのステータスを確認するには、以下を実行します。
rhoas statusWeb コンソールでステータスを表示することもできます。
https://cloud.redhat.com/beta/application-services/streams/kafkas/
ステータスが ready になったら、次のステップに進みます。
新しい Kafka トピックを作成します。
rhoas kafka topic create test-topicKafka インスタンス (クラスター) を Openshift Application Services インスタンスに接続します。
rhoas cluster connectクレデンシャルトークンを取得するスクリプトの手順に従います。
以下のような出力が表示されるはずです。
Token Secret "rh-cloud-services-accesstoken-cli" created successfully Service Account Secret "rh-cloud-services-service-account" created successfully KafkaConnection resource "kafka-test" has been created KafkaConnection successfully installed on your cluster.
RHOAS Operator は、
kafka-testという名前の KafkaConnection カスタムリソースを設定します。
2.2.2.3. Kafka クレデンシャルの取得
アプリケーションまたはサービスを Kafka インスタンスに接続するには、まず以下の Kafka クレデンシャルを取得する必要があります。
- ブートストラップ URL を取得します。
- クレデンシャル (ユーザー名とパスワード) を使用してサービスアカウントを作成します。
OpenShift Streams では、kamelets および kamelet バインディングの認証方法は SASL_SSL です。
前提条件
- Kafka インスタンスを作成し、ステータスが ready である。
- Kafka トピックを作成している。
手順
Kafka ブローカーの URL (ブートストラップ URL) を取得します。
rhoas status kafkaコマンドは、以下のような出力を返します。
Kafka --------------------------------------------------------------- ID: 1ptdfZRHmLKwqW6A3YKM2MawgDh Name: my-kafka Status: ready Bootstrap URL: my-kafka--ptdfzrhmlkwqw-a-ykm-mawgdh.kafka.devshift.org:443
ユーザー名とパスワードを取得するには、以下の構文を使用してサービスアカウントを作成します。
rhoas service-account create --name "<account-name>" --file-format json注記サービスアカウントの作成時に、ファイル形式および場所を選択してクレデンシャルを保存できます。詳細は、
rhoas service-account create --helpを入力します。以下に例を示します。
rhoas service-account create --name "my-service-acct" --file-format jsonサービスアカウントが作成され、JSON ファイルに保存されます。
サービスアカウントのクレデンシャルを確認するには、
credentials.jsonファイルを表示します。cat credentials.jsonコマンドは、以下のような出力を返します。
{"user":"srvc-acct-eb575691-b94a-41f1-ab97-50ade0cd1094", "password":"facf3df1-3c8d-4253-aa87-8c95ca5e1225"}
2.3. Connecting a data source to a Kafka topic in a kamelet binding
データソースを Kafka トピックに接続するには、図 2.2 にあるように kamelet バインディングを作成します。
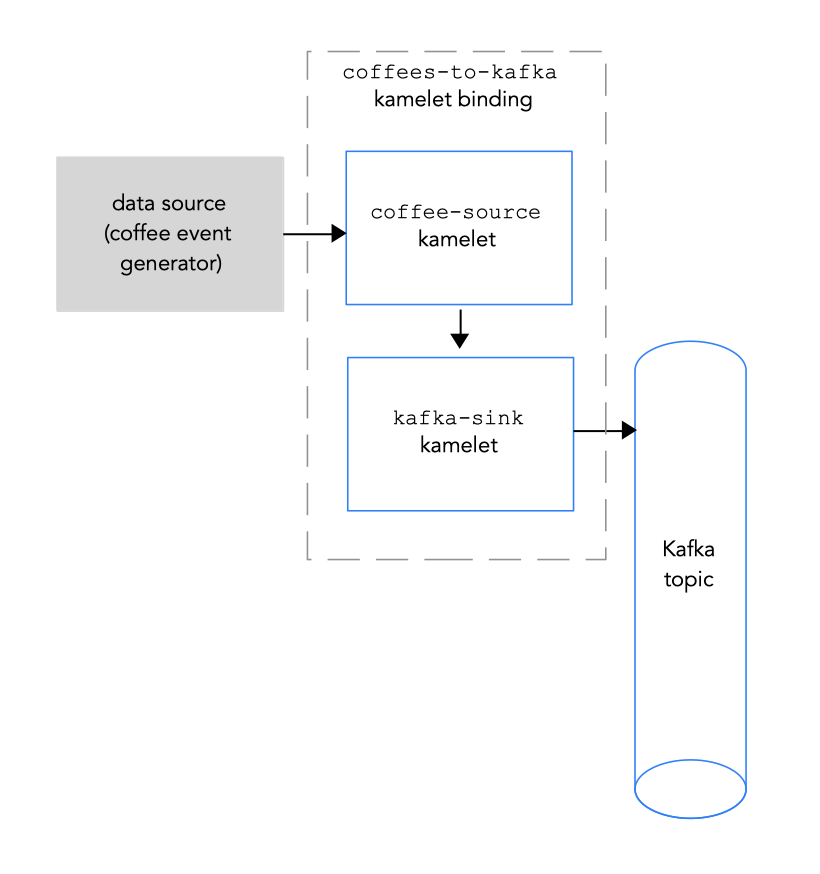 「Kafka トピックへのデータソースの接続」
「Kafka トピックへのデータソースの接続」
前提条件
イベントの送信先となる Kafka トピックの名前を知っておく必要があります。
この手順の例では、イベントを受信するために
test-topicを使用しています。Kafka インスタンスの以下のパラメーターの値を知っている必要があります。
- bootstrapServers: Kafka Broker URL のコンマ区切りリスト
- password: Kafka に対して認証を行うためのパスワード
user: Kafka に対して認証するユーザー名
OpenShift Streams の使用時にこれらの値を取得する方法は、「Kafka クレデンシャルの取得」を参照してください。
AMQストリームでの Kafka 認証に関する詳細は、「Managing secure access to Kafka」を参照してください。
-
Kafka ブローカーとの通信のセキュリティープロトコルを把握している。OpenShift Streams の Kafka クラスターでは、
SASL_SSL(デフォルト) です。AMQ ストリームの Kafka クラスターの場合は、SASL/Plainになります。 Camel K インテグレーションに追加する kamelets と必要なインスタンスパラメーターを把握している。この手順の kamelets の例は、以下のとおりです。
coffee-sourcekamelet: 各イベントを送信する頻度を指定する任意のパラメーターperiodがあります。Example source kamelet のコードを、coffee-source.kamelet.yamlファイルという名前のファイルにコピーしてから、以下のコマンドを実行してこれをリソースとして namespace に追加できます。oc apply -f coffee-source.kamelet.yamlkafka-sinkkamelet: Kamelet Catalog で提供されます。このバインディングでは Kafka トピックがデータを受信するため (データコンシューマー)、kafka-sinkkamelet を使用します。必須パラメーターの値の例は次のとおりです。-
bootstrapServers:
"broker.url:9092" -
password -
"testpassword" -
user:
"testuser" -
topic:
"test-topic" -
securityProtocol: OpenShift Streams の Kafka クラスターでは、
SASL_SSLがデフォルト値であるため、このパラメーターを設定する必要はありません。AMQ ストリームの Kafka クラスターの場合は、このパラメーターの値は“PLAINTEXT”です。
-
bootstrapServers:
手順
データソースを Kafka トピックに接続するには、kamelet バインディングを作成します。
任意のエディターで、以下の基本構造で YAML ファイルを作成します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: spec: source: sink:
kamelet binding の名前を追加します。この例では、バインディングが
coffee-sourcekamelet をkafka-sinkkamelet に接続するため、名前はcoffees-to-kafkaになります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-kafka spec: source: sink:kamelet バインディングのソースの場合は、データソース kamelet を指定し (たとえば、
coffee-sourcekamelet はコーヒーに関するデータが含まれるイベントを生成します)、kamelet のパラメーターを設定します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-kafka spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink:kamelet binding のシンクの場合は、
kafka-sinkkamelets およびその必要なパラメーターを指定します。たとえば、Kafka クラスターが OpenShift Streams にある場合 (
securityProtocolパラメーターを設定する必要はありません)。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-kafka spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: kafka-sink properties: bootstrapServers: "broker.url:9092"" password: "testpassword" topic: "test-topic" user: "testuser"たとえば、Kafka クラスターが AMQ Streams にある場合は、
securityProtocolパラメーターを“PLAINTEXT”に設定する必要があります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-kafka spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: kafka-sink properties: bootstrapServers: "broker.url:9092"" password: "testpassword" topic: "test-topic" user: "testuser" securityProtocol: "PLAINTEXT"-
YAML ファイルを保存します (例:
coffees-to-kafka.yaml)。 - OpenShift プロジェクトにログインします。
KameletBinding をリソースとして OpenShift namespace に追加します。
oc apply -f <kamelet binding filename>以下に例を示します。
oc apply -f coffees-to-kafka.yamlCamel K Operator は、KameletBinding リソースを使用して Camel K インテグレーションを生成し、実行します。ビルドに数分かかる場合があります。
kamelet バインディングリソースのステータスを表示するには、次のコマンドを実行します。
oc get kameletbindingsインテグレーションの状態を表示するには、以下を実行します。
oc get integrationsインテグレーションのログを表示するには、以下を実行します。
kamel logs <integration> -n <project>以下に例を示します。
kamel logs coffees-to-kafka -n my-camel-k-kafka結果は以下の出力に似ています。
... [1] 2021-06-21 07:48:12,696 INFO [io.quarkus] (main) camel-k-integration 1.4.0 on JVM (powered by Quarkus 1.13.0.Final) started in 2.790s.
2.4. Connecting a Kafka topic to a data sink in a kamelet binding
Kafka トピックをデータシンクに接続するには、図 2.3 にあるように kamelet バインディングを作成します。
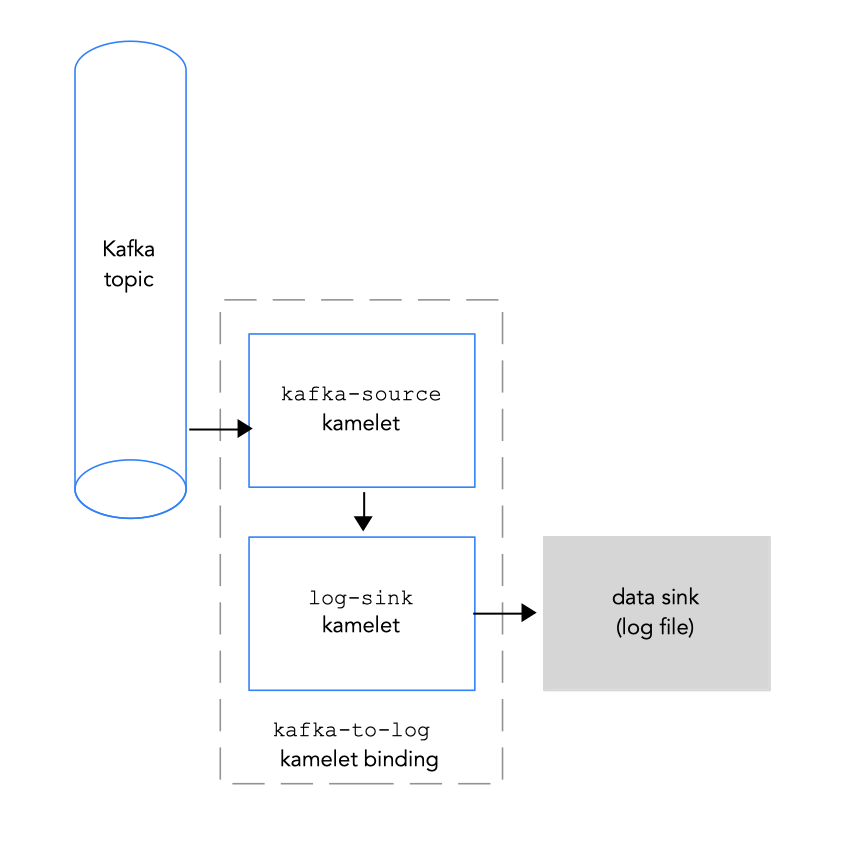 Kafka トピックのデータシンクへの接続
Kafka トピックのデータシンクへの接続
前提条件
-
イベントの送信元となる Kafka トピックの名前を知っておく必要があります。この手順の例では、イベントを送信するために
test-topicを使用しています。これは、「Connecting a data source to a Kafka topic in a kamelet binding」でコーヒーソースからイベントを受信するのに使用したトピックと同じです。 Kafka インスタンスの以下のパラメーターの値を知っている必要があります。
- bootstrapServers: Kafka Broker URL のコンマ区切りリスト
- password: Kafka に対して認証を行うためのパスワード
user: Kafka に対して認証するユーザー名
OpenShift Streams の使用時にこれらの値を取得する方法は、「Kafka クレデンシャルの取得」を参照してください。
AMQストリームでの Kafka 認証に関する詳細は、「Managing secure access to Kafka」を参照してください。
-
Kafka ブローカーとの通信のセキュリティープロトコルを把握している。OpenShift Streams の Kafka クラスターでは、
SASL_SSL(デフォルト) です。AMQ ストリームの Kafka クラスターの場合は、SASL/Plainになります。 Camel K インテグレーションに追加する kamelets と必要なインスタンスパラメーターを把握している。この手順の kamelets の例は、以下のとおりです。
kafka-sourcekamelet: Kamelet Catalog で提供されます。このバインディングでは Kafka トピックがデータを送信するため (データプロデューサー)、kafka-sourcekamelet を使用します。必須パラメーターの値の例は次のとおりです。-
bootstrapServers:
"broker.url:9092" -
password -
"testpassword" -
user:
"testuser" -
topic:
"test-topic" -
securityProtocol: OpenShift Streams の Kafka クラスターでは、
SASL_SSLがデフォルト値であるため、このパラメーターを設定する必要はありません。AMQ ストリームの Kafka クラスターの場合は、このパラメーターの値は“PLAINTEXT”です。
-
bootstrapServers:
log-sinkkamelet: コードを、シンク kamelet の例 からlog-sink.kamelet.yamlファイルという名前のファイルにコピーしてから、以下のコマンドを実行してこれをリソースとして namespace に追加できます。oc apply -f log-sink.kamelet.yaml
手順
Kafka トピックをデータシンクに接続するには、kamelet バインディングを作成します。
任意のエディターで、以下の基本構造で YAML ファイルを作成します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: spec: source: sink:
kamelet binding の名前を追加します。この例では、バインディングが
kafka-sourcekamelet をlog-sinkkamelet に接続するため、名前はkafka-to-logになります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: kafka-to-log spec: source: sink:kamelet バインディングのソースの場合は、
kafka-sourcekamelet を指定し、そのパラメーターを設定します。たとえば、Kafka クラスターが OpenShift Streams にある場合 (
securityProtocolパラメーターを設定する必要はありません)。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: kafka-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: kafka-source properties: bootstrapServers: "broker.url:9092" password: "testpassword" topic: "test-topic" user: "testuser" sink:たとえば、Kafka クラスターが AMQ Streams にある場合は、
securityProtocolパラメーターを“PLAINTEXT”に設定する必要があります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: kafka-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: kafka-source properties: bootstrapServers: "broker.url:9092" password: "testpassword" topic: "test-topic" user: "testuser" securityProtocol: "PLAINTEXT" sink:kamelet バインディングのシンクでは、データコンシューマー kamelet (例:
log-sinkkamelet) を指定し、kamelet のパラメーターを設定します。以下に例を示します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: kafka-to-log spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: kafka-source properties: bootstrapServers: "broker.url:9092" password: "testpassword" topic: "test-topic" user: "testuser" securityProtocol: "PLAINTEXT" // only for AMQ streams sink: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: log-sink-
YAML ファイルを保存します (例:
kafka-to-log.yaml)。 - OpenShift プロジェクトにログインします。
kamelet バインディングをリソースとして OpenShift namespace に追加します。
oc apply -f <kamelet binding filename>以下に例を示します。
oc apply -f kafka-to-log.yamlCamel K Operator は、KameletBinding リソースを使用して Camel K インテグレーションを生成し、実行します。ビルドに数分かかる場合があります。
kamelet バインディングリソースのステータスを表示するには、次のコマンドを実行します。
oc get kameletbindingsインテグレーションの状態を表示するには、以下を実行します。
oc get integrationsインテグレーションのログを表示するには、以下を実行します。
kamel logs <integration> -n <project>以下に例を示します。
kamel logs kafka-to-log -n my-camel-k-kafkaこの出力では、以下の例のようにコーヒーイベントが表示されるはずです。
2021-07-20 17:15:56,725 INFO [log-sink-E80C5C904418150-0000000000000001] (Camel (camel-1) thread #0 - timer://tick) {"id":7259,"uid":"a4ecb7c2-05b8-4a49-b0d2-d1e8db5bc5e2","blend_name":"Postmodern Symphony","origin":"Huila, Colombia","variety":"Kona","notes":"delicate, chewy, black currant, red apple, star fruit","intensifier":"balanced"}実行中のインテグレーションを停止するには、関連付けられた kamelet バインディングリソースを削除します。
oc delete kameletbindings/<kameletbinding-name>以下に例を示します。
oc delete kameletbindings/kafka-to-log
2.5. Applying operations to data within a Kafka connection
kamelet と Kafka トピック間で渡されるデータで操作を実行する場合は、kamelet バインディング内の中間ステップとして、アクション kamelets を使用します。たとえば、以下についてアクション kamelets を使用できます。
その他の参考資料
2.5.1. 異なる宛先トピックへのイベントデータのルーティング
Kafka インスタンスへのコネクションを設定する場合、イベントが異なる Kafka トピックにルーティングされるように、オプションでイベントデータからのトピック情報を変換できます。以下の変換アクション kamelets のいずれかを使用します。
-
Regex Router: 正規表現と代替文字列を使用してメッセージのトピックを変更します。たとえば、トピック接頭辞を削除する場合は、接頭辞を追加するか、トピック名の一部を削除します。Regex Router Action Kamelet (
regex-router-action) を設定します。 -
TimeStamp: 元のトピックとメッセージのタイムスタンプに基づいてメッセージのトピックを変更します。たとえば、タイムスタンプに基づいて異なるテーブルまたはインデックスに書き込む必要があるシンクを使用する場合などです。たとえば、Kafka から Elasticsearch にイベントを書きみ、各イベントはイベント自体の情報に基づいて異なるインデックスに移動する必要がある場合。Timestamp Router Action Kamelet (
timestamp-router-action) を設定します。 -
Message TimeStamp: 元のトピック値とメッセージ値フィールドからのタイムスタンプフィールドに基づいてメッセージのトピックを変更します。Message Timestamp Router Action Kamelet (
message-timestamp-router-action) を設定します。 -
述語: Predicate Filter Action Kamelet (
predicate-filter-action) を設定して、指定の JSON パス式に基づいてイベントをフィルターします。
前提条件
-
「Connecting a data source to a Kafka topic in a kamelet binding」で説明されているように、シンクが
kafka-sinkkamelet である kamelet バインディングを作成している。 - kamelet バインディングに追加する変換のタイプを知っている必要があります。
手順
宛先トピックを変換するには、kamelet バインディング内の中間ステップとして変換アクションの 1 つを使用します。
アクション kamelet を kamelet バインディングに追加する方法の詳細は、「Adding an operation to a kamelet binding」を参照してください。
2.5.2. オフセットの手動によるコミット
Kafka では、各トピックは パーティション に分割されます。各パーティションは、順序付けされたイミュータブルなメッセージのシーケンスです。アプリケーションまたはサービスがメッセージをトピックに送信すると、Kafka はメッセージを選択したパーティションに追加します。Kafka は、オフセット と呼ばれる連続した ID 番号を各メッセージに割り当てて、パーティション内の各メッセージを一意に識別します。
デフォルトでは、Kafka コンシューマー (データシンクなど) が Kafka からメッセージを読み取ると、Kafka は現在のオフセット (読み取り元のパーティションの) を定期的にコミットします。オフセットコミット は、Kafka クラスターが同じパーティションにコミットされたメッセージを再送信しないように、メッセージの処理が成功したことを Kafka に通知します。
Kafka がオフセットをコミットするタイミングをより正確に制御するには (例: アプリケーションがメッセージを非同期的に処理し、問題が発生した場合にオフセットをコミットしないようにする場合)、Kafka の 自動コミット動作を無効にできます。この場合、アプリケーションがオフセットをコミットする必要があります。
kamelets を使用して Kafka に接続する場合、オフセットを手動でコミットするよう指定できます。
前提条件
-
Kafka コンシューマーの
enable.auto.commitプロパティーをfalseに設定して、Kafka の自動コミット動作を無効にしている。 -
「Connecting a data source to a Kafka topic in a kamelet binding」で説明されているように、シンクが
kafka-sinkkamelet である kamelet バインディングを作成している。
手順
「Adding an operation to a kamelet binding」の説明どおりに、kafka-sink kamelet が含まれる kamelet バインディングの中間ステップとして kafka-manual-commit-action kamelet を追加します。
第3章 Kamelets を使用した Knative への接続
kamelets を Knative 宛先 (チャネルまたはブローカー) に接続することができます。Red Hat OpenShift Serverless はオープンソースの Knative プロジェクト をベースとし、エンタープライズレベルのサーバーレスプラットフォームを有効にすることで、ハイブリッドおよびマルチクラウド環境における移植性と一貫性をもたらします。OpenShift Serverless には、Knative Eventing および Knative Serving コンポーネントのサポートが含まれます。
Red Hat OpenShift Serverless、Knative Eventing、および Knative Serving では、サーバーレスアプリケーションと共に イベント駆動型のアーキテクチャー を使用し、パブリッシュサブスクライブまたはイベントストリーミングモデルを使用してイベントプロデューサーとコンシューマー間の関係を切り離すことができます。Knative Eventing は、標準の HTTP POST リクエストを使用してイベントプロデューサーとコンシューマー間でイベントを送受信します。これらのイベントは CloudEvents 仕様 に準拠しており、すべてのプログラミング言語でのイベントの作成、解析、および送受信を可能にします。
kamelets を使用して CloudEvents を Knative に送信し、Knative からイベントコンシューマーに送信できます。Kamelets はメッセージを CloudEvents に変換し、それらを使用して CloudEvents 内のデータの事前処理および後処理を適用できます。
3.1. kamelets を使用した Knative への接続の概要
Knative stream-processing フレームワークを使用する場合は、kamelets を使用してサービスおよびアプリケーションを Knative 宛先 (チャネルまたはブローカー) に接続することができます。
図 3.1 は、ソースとシンク kamelets を Knative 宛先に接続するフローを示します。
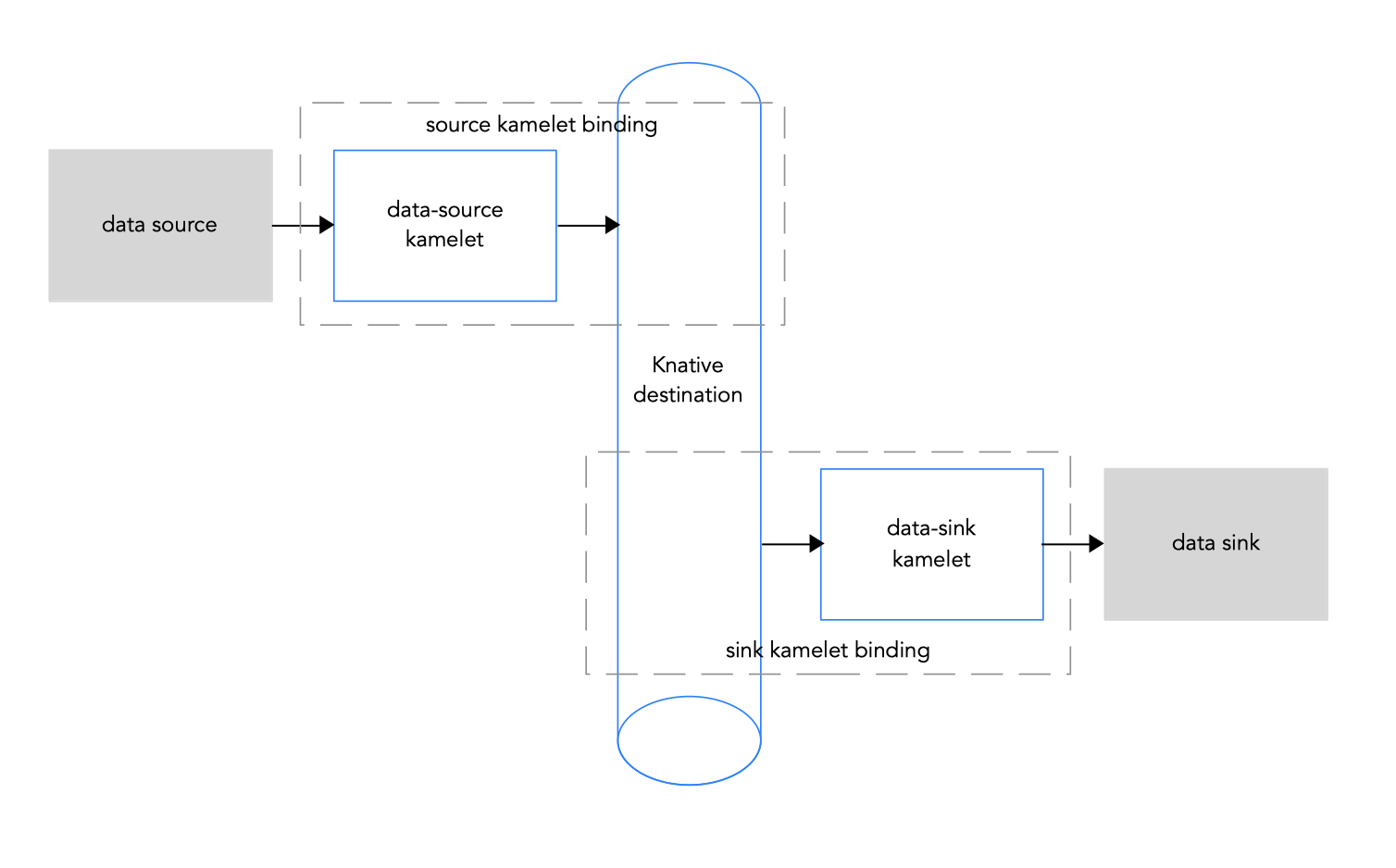
図 3.1: kamelets と Knative チャネルによるデータフロー
以下は、kamelets および kamelet バインディングを使用してアプリケーションやサービスを Knative チャネルに接続するための基本的な手順の概要です。
Knative を設定します。
- Camel K および OpenShift Serverless Operator をインストールして、OpenShift クラスターを準備します。
- 必要な Knative Serving および Eventing コンポーネントをインストールします。
- Knative チャネルまたはブローカーを作成します。
- Knative チャネルまたはブローカーに接続するサービスまたはアプリケーションを決定します。
- Kamelet Catalog を表示し、インテグレーションに追加するソースおよびシンクコンポーネントの kamelets を見つけます。使用する各 kamelet に必要な設定パラメーターも決定します。
kamelet バインディングを作成します。
- ソース kamelet を Knative チャネル (またはブローカー) に接続する kamelet バインディングを作成します。
- Knative チャネル (またはブローカー) をシンク kamelet に接続する kamelet バインディングを作成します。
- オプションとして、kamelet バインディング内の中間ステップとして 1 つまたは複数のアクション kamelets を追加して、Knative チャネル (またはブローカー) およびデータソース/シンク間で渡されるデータを操作します。
- 必要に応じて、kamelet バインディング内でエラーを処理する方法を定義します。
- kamelet バインディングをリソースとしてプロジェクトに適用します。
Camel K Operator は、kamelet バインディングごとに個別の Camel インテグレーションを生成します。
kamelet バインディングを Knative チャネルまたはブローカーをイベントのソースとして使用するように設定する場合、Camel K Operator は対応するインテグレーションを Knative Serving サービスとして実現し、Knative が提供する自動スケーリング機能を活用します。
3.2. Knative の設定
Knative を設定するには、必要な OpenShift Operator をインストールし、Knative チャネルを作成します。
3.2.1. OpenShift クラスターの準備
kamelets および OpenShift Serverless を使用するには、以下の Operator、コンポーネント、および CLI ツールをインストールします。
Red Hat Integration - Camel K Operator および CLI ツール: Operator は Camel K (OpenShift のクラウドでネイティブに実行される軽量なインテグレーションフレームワーク) をインストールし、管理します。
kamelCLI ツールを使用すると、すべての Camel K 機能にアクセスできます。「Installing Camel K」のインストール手順を参照してください。
-
OpenShift Serverless Operator:「サーバーレス」を実行するためのコンテナー、マイクロサービス、および機能を有効にする API のコレクションです。Serverless アプリケーションはオンデマンドでスケールアップおよびスケールダウン (ゼロまで) でき、数多くのイベントソースによりトリガーされます。OpenShift Serverless Operator のインストール時に、これは
knative-servingnamespace (Knative Serving コンポーネントのインストール用) およびknative-eventingnamespace (Knative Eventing コンポーネントのインストールに必要) を自動的に作成します。 - Knative Eventing コンポーネント
- Knative Serving コンポーネント
-
Knative CLI ツール (
kn): コマンドラインまたは Shell スクリプトから Knative リソースを作成できます。
3.2.1.1. OpenShift Serverless のインストール
OperatorHub から OpenShift クラスターに OpenShift Serverless Operator をインストールできます。OperatorHub は OpenShift Container Platform Web コンソールから利用でき、クラスター管理者が Operator を検出およびインストールするためのインターフェースを提供します。OperatorHub の詳細は、OpenShift ドキュメント を参照してください。
OpenShift Serverless Operator は、Knative Serving および Knative Eventing 機能の両方をサポートします。詳細は、「OpenShift Serverless の使用開始」を参照してください。
前提条件
- Camel K Operator がインストールされている OpenShift プロジェクトにクラスター管理者としてアクセスできる。
-
コマンドラインで OpenShift クラスターと対話できるように OpenShift CLI ツール (
oc) をインストールしていること。OpenShift CLI のインストール方法の詳細は、「Installing the OpenShift CLI」を参照してください。
手順
- OpenShift Container Platform Web コンソールで、クラスター管理者権限を持つアカウントを使用してログインします。
- 左側のナビゲーションメニューで、Operators > OperatorHub とクリックします。
-
Filter by keyword テキストボックスで
Serverlessを入力し、OpenShift Serverless Operator を見つけます。 - Operator に関する情報を読み、Install をクリックして Operator サブスクリプションページを表示します。
デフォルトのサブスクリプション設定を選択します。
- Update Channel > (4.7 など、OpenShift バージョンと一致するチャンネルを選択)
- Installation Mode > All namespaces on the cluster
Approval Strategy > Automatic
注記ご使用の環境で必要な場合は Approval Strategy > Manual 設定も使用できます。
- Install をクリックし、Operator が使用できるようになるまでしばらく待ちます。
OpenShift ドキュメントの手順に従って、必要な Knative コンポーネントをインストールします。
任意
OpenShift Serverless CLI ツールをダウンロードし、インストールします。
- OpenShift Web コンソールの上部にある Help メニュー (?) から、Command line tools を選択します。
- kn - OpenShift Serverless - Command Line Interface セクションまでスクロールダウンします。
- ローカルのオペレーティングシステム (Linux、Mac、Windows) のバイナリーをダウンロードするためのリンクをクリックします。
- CLI を展開してシステムパスにインストールします。
kn CLI にアクセスできることを確認するには、コマンドウィンドウを開き、以下のコマンドを入力します。
kn --helpこのコマンドは、OpenShift Serverless CLI コマンドに関する情報を表示します。
詳細は、OpenShift Serverless CLI のドキュメント を参照してください。
その他のリソース
- OpenShift ドキュメントの「OpenShift Serverless のインストール」
3.2.2. Knative チャネルの作成
Knative チャネルは、イベントを転送するカスタムリソースです。イベントがイベントソースまたは生成側からチャネルに送信された後に、これらのイベントはサブスクリプションを使用して複数の Knative サービスまたは他のシンクに送信できます。
この例では、開発の目的で OpenShift Serverless で使用する InMemoryChannel チャネルを使用します。InMemoryChannel タイプのチャネルには、以下の制限事項があることに注意してください。
- イベントの永続性は利用できません。Pod がダウンすると、その Pod のイベントが失われます。
-
InMemoryChannelチャネルはイベントの順序を実装しないため、チャネルで同時に受信される 2 つのイベントはいずれの順序でもサブスクライバーに配信できます。 - サブスクライバーがイベントを拒否する場合、再配信はデフォルトで試行されません。Subscription オブジェクトの delivery 仕様を変更することで、再配信の試行を設定できます。
前提条件
- OpenShift Serverless Operator、Knative Eventing、および Knative Serving コンポーネントが OpenShift Container Platform クラスターにインストールされている。
-
OpenShift Serverless CLI (
kn) がインストールされている。 - OpenShift Container Platform でアプリケーションおよび他のワークロードを作成するために、プロジェクトを作成しているか、適切なロールおよびパーミッションを持つプロジェクトにアクセスできる。
手順
- OpenShift クラスターにログインします。
インテグレーションアプリケーションを作成するプロジェクトを開きます。以下に例を示します。
oc project camel-k-knativeKnative (
kn) CLI コマンドを使用してチャネルを作成します。kn channel create <channel_name> --type <channel_type>たとえば、
mychannelという名前のチャネルを作成するには、以下を実行します。kn channel create mychannel --type messaging.knative.dev:v1:InMemoryChannelチャネルが存在することを確認するには、以下のコマンドを入力してすべての既存チャネルを一覧表示します。
kn channel listチャネルが一覧に表示されます。
次のステップ
3.2.3. Knative ブローカーの作成
Knative ブローカーは、CloudEvents のプールを収集するためのイベントメッシュを定義するカスタムリソースです。OpenShift Serverless は、kn CLI を使用して作成できるデフォルト Knative ブローカーを提供します。
たとえば、アプリケーションが複数のイベントタイプを処理し、各イベントタイプのチャネルを作成したくない場合は、kamelet バインディングのブローカーを使用できます。
前提条件
- OpenShift Serverless Operator、Knative Eventing、および Knative Serving コンポーネントが OpenShift Container Platform クラスターにインストールされている。
-
OpenShift Serverless CLI (
kn) がインストールされている。 - OpenShift Container Platform でアプリケーションおよび他のワークロードを作成するために、プロジェクトを作成しているか、適切なロールおよびパーミッションを持つプロジェクトにアクセスできる。
手順
- OpenShift クラスターにログインします。
インテグレーションアプリケーションを作成するプロジェクトを開きます。以下に例を示します。
oc project camel-k-knativeこの Knative (
kn) CLI コマンドを使用してブローカーを作成します。kn broker create defaultブローカーが存在することを確認するには、以下のコマンドを入力してすべての既存ブローカーを一覧表示します。
kn broker list
デフォルトブローカーが一覧に表示されるはずです。
3.3. データソースの kamelet バインディングの Knative 宛先への接続
データソースを Knative 宛先 (チャネルまたはブローカー) に接続するには、図 3.2 に示されるように kamelet バインディングを作成します。
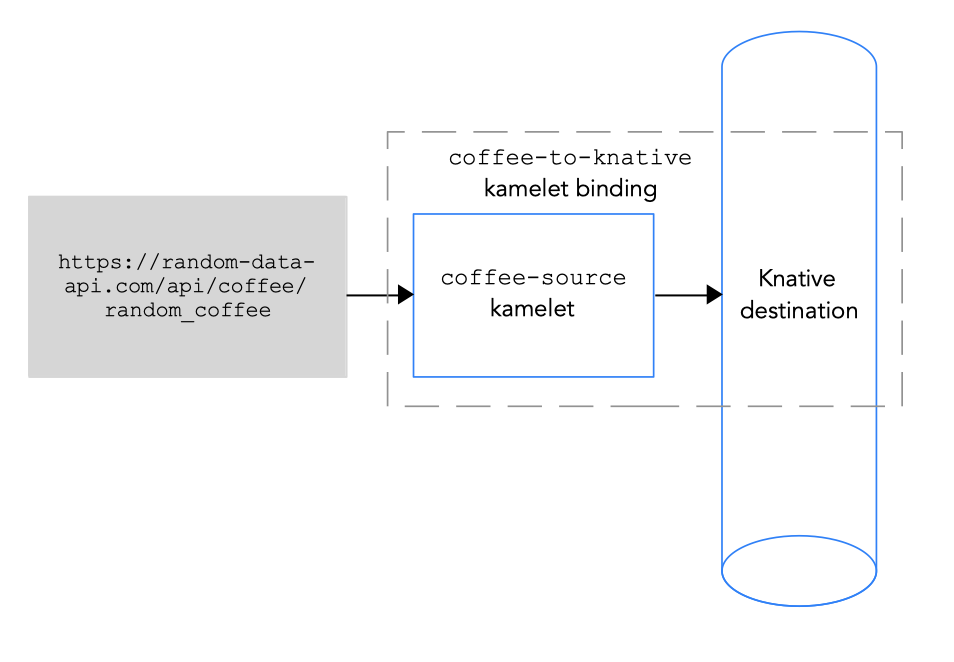
図 3.2 データソースの Knative 宛先への接続
Knative 宛先は Knative チャネルまたは Knative ブローカーになります。
データをチャネルに送信する場合、チャネルには 1 つのイベントタイプのみがあります。kamelet バインディングでチャネルのプロパティー値を指定する必要はありません。
データをブローカーに送信する場合、ブローカーが複数のイベントタイプを処理できるため、kamelet binding でブローカーを参照する場合は、タイププロパティーの値を指定する必要があります。
前提条件
イベントの送信先となる Knative チャネルまたはブローカーの名前およびタイプを知っている必要があります。
この手順の例では、
mychannelという名前のInMemoryChannelチャネルまたはdefaultという名前のブローカーを使用します。ブローカーのサンプルでは、typeプロパティーの値はコーヒーイベントに対してcoffeeになります。Camel インテグレーションに追加する kamelet と必要なインスタンスパラメーターを把握している。
この手順の kamelet の例では、
coffee-sourcekamelet です。各イベントを送信する頻度を指定する任意のパラメーターperiodがあります。Example source kamelet のコードを、coffee-source.kamelet.yamlファイルという名前のファイルにコピーしてから、以下のコマンドを実行してこれをリソースとして namespace に追加できます。oc apply -f coffee-source.kamelet.yaml
手順
データソースを Knative 宛先に接続するには、kamelet バインディングを作成します。
任意のエディターで、以下の基本構造で YAML ファイルを作成します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: spec: source: sink:
kamelet binding の名前を追加します。この例では、バインディングが
coffee-sourcekamelet を Knative 宛先に接続するため、名前はcoffees-to-knativeになります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-knative spec: source: sink:kamelet バインディングのソースの場合は、データソース kamelet を指定し (たとえば、
coffee-sourcekamelet はコーヒーに関するデータが含まれるイベントを生成します)、kamelet のパラメーターを設定します。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-knative spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink:kamelet バインディングのシンクでは、Knative チャネルまたはブローカーおよび必要なパラメーターを指定します。
以下の例では、Knative チャネルをシンクとして指定します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-knative spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: apiVersion: messaging.knative.dev/v1 kind: InMemoryChannel name: mychannelこの例では、Knative ブローカーをシンクとして指定します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: coffees-to-knative spec: source: ref: kind: Kamelet apiVersion: camel.apache.org/v1alpha1 name: coffee-source properties: period: 5000 sink: ref: kind: Broker apiVersion: eventing.knative.dev/v1 name: default properties: type: coffee-
YAML ファイルを保存します (例:
coffees-to-knative.yaml)。 - OpenShift プロジェクトにログインします。
KameletBinding をリソースとして OpenShift namespace に追加します。
oc apply -f <kamelet binding filename>以下に例を示します。
oc apply -f coffees-to-knative.yamlCamel K Operator は、KameletBinding リソースを使用して Camel K インテグレーションを生成し、実行します。ビルドに数分かかる場合があります。
KameletBinding のステータスを表示するには、次のコマンドを実行します。
oc get kameletbindingsインテグレーションの状態を表示するには、以下を実行します。
oc get integrationsインテグレーションのログを表示するには、以下を実行します。
kamel logs <integration> -n <project>以下に例を示します。
kamel logs coffees-to-knative -n my-camel-knative結果は以下の出力に似ています。
... [1] 2021-06-21 07:48:12,696 INFO [io.quarkus] (main) camel-k-integration 1.4.0 on JVM (powered by Quarkus 1.13.0.Final) started in 2.790s.
3.4. Connecting a Knative destination to a data sink in a kamelet binding
Knative 宛先をデータシンクに接続するには、図 3.3 にあるように kamelet バインディングを作成します。

図 3.3 Knative 宛先のデータシンクへの接続
Knative 宛先は Knative チャネルまたは Knative ブローカーになります。
データをチャネルから送信する場合、チャネルには 1 つのイベントタイプのみがあります。kamelet バインディングでチャネルのプロパティー値を指定する必要はありません。
データをブローカーから送信する場合、ブローカーが複数のイベントタイプを処理できるため、kamelet binding でブローカーを参照する場合は、タイププロパティーの値を指定する必要があります。
前提条件
イベントの受信元となる Knative チャネルのタイプまたはブローカーの名前を知っている必要があります。ブローカーでは、受信するイベントのタイプも知っている必要があります。
この手順の例では、mychannel という名前の InMemoryChannel チャネルまたは mybroker という名前のブローカーおよびコーヒーイベント (type プロパティー) を使用します。これらは、「Connecting a data source to a Knative channel in a kamelet binding」でコーヒーソースからイベントを受信するのに使用した宛先の例と同じです。
Camel インテグレーションに追加する kamelet と必要なインスタンスパラメーターを把握している。
この手順の kamelet の例では、
log-sinkkamelet です。コードを、シンク kamelet の例 からlog-sink.kamelet.yamlファイルという名前のファイルにコピーしてから、以下のコマンドを実行してこれをリソースとして namespace に追加できます。oc apply -f log-sink.kamelet.yaml
手順
Knative チャネルをデータシンクに接続するには、kamelet バインディングを作成します。
任意のエディターで、以下の基本構造で YAML ファイルを作成します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: spec: source: sink:
kamelet binding の名前を追加します。この例では、バインディングが Knative 宛先を
log-sinkkamelet に接続するため、名前はknative-to-logになります。apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: knative-to-log spec: source: sink:kamelet バインディングのソースでは、Knative チャネルまたはブローカーおよび必要なパラメーターを指定します。
以下の例では、Knative チャネルをソースとして指定します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: knative-to-log spec: source: ref: apiVersion: messaging.knative.dev/v1 kind: InMemoryChannel name: mychannel sink:この例では、Knative ブローカーをソースとして指定します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: knative-to-log spec: source: ref: kind: Broker apiVersion: eventing.knative.dev/v1 name: default properties: type: coffee sink:kamelet バインディングのシンクでは、データコンシューマー kamelet (例: log-sink kamelet) を指定し、kamelet のパラメーターを設定します。以下に例を示します。
apiVersion: camel.apache.org/v1alpha1 kind: KameletBinding metadata: name: knative-to-log spec: source: ref: apiVersion: messaging.knative.dev/v1 kind: InMemoryChannel name: mychannel sink: ref: apiVersion: camel.apache.org/v1alpha1 kind: Kamelet name: log-sink-
YAML ファイルを保存します (例:
knative-to-log.yaml)。 - OpenShift プロジェクトにログインします。
KameletBinding をリソースとして OpenShift namespace に追加します (
oc apply -f <kamelet binding filename>)。以下に例を示します。
oc apply -f knative-to-log.yamlCamel K Operator は、KameletBinding リソースを使用して Camel K インテグレーションを生成し、実行します。ビルドに数分かかる場合があります。
KameletBinding のステータスを表示するには、次のコマンドを実行します。
oc get kameletbindingsインテグレーションの状態を表示するには、以下を実行します。
oc get integrationsインテグレーションのログを表示するには、以下を実行します。
kamel logs <integration> -n <project>以下に例を示します。
kamel logs knative-to-log -n my-camel-knativeこの出力では、以下の例のようにコーヒーイベントが表示されるはずです。
[1] 2021-07-23 13:06:38,111 INFO [sink] (vert.x-worker-thread-1) {"id":254,"uid":"8e180ef7-8924-4fc7-ab81-d6058618cc42","blend_name":"Good-morning Star","origin":"Santander, Colombia","variety":"Kaffa","notes":"delicate, creamy, lemongrass, granola, soil","intensifier":"sharp"} [1] 2021-07-23 13:06:43,273 INFO [sink] (vert.x-worker-thread-2) {"id":8169,"uid":"3733c3a5-4ad9-43a3-9acc-d4cd43de6f3d","blend_name":"Caf? Java","origin":"Nayarit, Mexico","variety":"Red Bourbon","notes":"unbalanced, full, granola, bittersweet chocolate, nougat","intensifier":"delicate"}実行中のインテグレーションを停止するには、関連付けられた kamelet バインディングリソースを削除します。
oc delete kameletbindings/<kameletbinding-name>以下に例を示します。
oc delete kameletbindings/knative-to-log
第4章 Kamelets 参照
4.1. Kamelet 構造
通常、kamelet は YAML ドメイン固有の言語でコーディングされます。ファイル名の接頭辞は、kamelet の名前です。たとえば、FTP sink という名前の kamelet のファイル名は ftp-sink.kamelet.yaml です。
OpenShift では、kamelet は、(ファイル名ではなく) kamelet の名前を表すリソースであることに注意してください。
概略では、kamelet リソースは以下を説明します。
-
kamelet の ID、および kamelet のタイプ (
source、sink、またはaction) 等のその他の情報が含まれるメタデータセクション。 - kamelet の設定に使用できるパラメーターセットが含まれる定義 (JSON-schema 仕様)。
-
kamelet によって想定される入出力に関する情報が含まれるオプションの
typesセクション。 - kamelet の実装を定義する YAML DSL の Camel フロー。
以下の図は、kamelet とその部分の例を示しています。
kamelet 構造の例
telegram-text-source.kamelet.yaml apiVersion: camel.apache.org/v1alpha1 kind: Kamelet metadata: name: telegram-source 1 annotations: 2 camel.apache.org/catalog.version: "master-SNAPSHOT" camel.apache.org/kamelet.icon: "data:image/..." camel.apache.org/provider: "Red Hat" camel.apache.org/kamelet.group: "Telegram" labels: 3 camel.apache.org/kamelet.type: "source" spec: definition: 4 title: "Telegram Source" description: |- Receive all messages that people send to your telegram bot. required: - authorizationToken type: object properties: authorizationToken: title: Token description: The token to access your bot on Telegram, that you can obtain from the Telegram "Bot Father". type: string format: password x-descriptors: - urn:alm:descriptor:com.tectonic.ui:password types: 5 out: mediaType: application/json dependencies: - "camel:jackson" - "camel:kamelet" - "camel:telegram" flow: 6 from: uri: telegram:bots parameters: authorizationToken: "{{authorizationToken}}" steps: - marshal: json: {} - to: "kamelet:sink"
- kamelet ID: kamelet を参照する場合は Camel K インテグレーションでこの ID を使用します。
- アイコンなどのアノテーションは、kamelet の表示機能を提供します。
- ラベルを使用すると、ユーザーは kamelets にクエリーできます (例:「ソース」、「シンク」、または「アクション」により)。
- JSON-schema 仕様形式の kamelet およびパラメーターの説明。
- 出力のメディアタイプ (スキーマを含む)。
- kamelet の動作を定義するルートテンプレート。
4.2. ソース kamelet の例
以下は、coffee-source kamelet の例の内容です。
apiVersion: camel.apache.org/v1alpha1
kind: Kamelet
metadata:
name: coffee-source
labels:
camel.apache.org/kamelet.type: "source"
spec:
definition:
title: "Coffee Source"
description: "Retrieve a random coffee from a catalog of coffees"
properties:
period:
title: Period
description: The interval between two events in seconds
type: integer
default: 5000
types:
out:
mediaType: application/json
flow:
from:
uri: timer:tick
parameters:
period: "{{period}}"
steps:
- to: "https://random-data-api.com/api/coffee/random_coffee"
- to: "kamelet:sink"4.3. シンク kamelet の例
以下は、log-sink kamelet の例の内容です。
apiVersion: camel.apache.org/v1alpha1
kind: Kamelet
metadata:
name: log-sink
labels:
camel.apache.org/kamelet.type: "sink"
spec:
definition:
title: "Log Sink"
description: "Consume events"
flow:
from:
uri: "kamelet:source"
steps:
- convert-body-to: 'java.lang.String'
- log: "${body}"