
Red Hat Hyperconverged Infrastructure for Virtualization のメンテナンス
Red Hat hyperconverged Infrastructure for Virtualization の一般的なメンテナンスタスク
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ をご覧ください。
パート I. 設定タスク
第1章 コンピュートリソースおよびストレージリソースの追加
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) は、6、9、または 12 のノードにスケーリングできます。
コンピュートリソースおよびストレージリソースは、複数の方法で追加できます。
また、コンピュートリソースを拡張しなくても、既存のノードで利用可能な領域を拡張してストレージを拡張することもできます。
Red Hat Hyperconverged Infrastructure for Virtualization(Red Hat OpenShift Container Platform がインストールされた仮想マシンをホストするハイパーコンバージドノード) の上に OpenShift Container Storage を置くことは、サポートされていない設定です。
1.1. ansible を使用した新しいブリックの作成
多くのホストにブリックを一度に作成する場合は、ansible Playbook を作成してプロセスを自動化できます。このプロセスに従い、ハイパーコンバージド環境で使用するブリックを作成、フォーマット、マウントする Playbook を作成および実行します。
前提条件
物理マシンをインストールして、新しいブリックをホストします。
ハイパーコンバージドホストのインストール の手順に従います。
すべてのノードに、パスワードなしでキーベースの SSH 認証を設定します。
これは、Web コンソールを実行しているノードからすべての新規ノード、および最初の新規ノードから他のすべての新規ノードに設定します。
重要RHHI for Virtualization は、IP アドレスと FQDN の両方に対して、これらのノード間でパスワードのないキーベースの SSH 認証を想定します。これらのマシン間で、すべてのストレージおよび管理ネットワークインターフェースの IP アドレスと FQDN の間に、キーベースの SSH 認証を設定するようにしてください。
SSH 認証用のパスワードの代わりにキーペアを使用した方法 に従って、パスワードなしでキーベースの認証を設定します。
- ホストが Virtual Disk Optimization (VDO) レイヤーを使用しないことを確認します。VDO レイヤーがある場合は、代わりに 「Ansible を使用した VDO レイヤーでの新しいブリックの作成」 を使用します。
手順
inventoryファイルの作成以下の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいinventoryファイルを作成します。このファイルは、新しいブリックを作成するホストを一覧表示します。
inventoryファイルの例[hosts] server4.example.com server5.example.com server6.example.com
bricks.yml変数ファイルを作成します。次の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいbricks.ymlファイルを作成します。このファイルは、各ホストで作成または使用される基礎となるストレージインフラストラクチャーおよび設定を定義します。
bricks.yml変数ファイルの例# gluster_infra_disktype # Set a disk type. Options: JBOD, RAID6, RAID10 - Default: JBOD gluster_infra_disktype: RAID10 # gluster_infra_dalign # Dataalignment, for JBOD default is 256K if not provided. # For RAID{6,10} dataalignment is computed by multiplying # gluster_infra_diskcount and gluster_infra_stripe_unit_size. gluster_infra_dalign: 256K # gluster_infra_diskcount # Required only for RAID6 and RAID10. gluster_infra_diskcount: 10 # gluster_infra_stripe_unit_size # Required only in case of RAID6 and RAID10. Stripe unit size always in KiB, do # not provide the trailing `K' in the value. gluster_infra_stripe_unit_size: 128 # gluster_infra_volume_groups # Variables for creating volume group gluster_infra_volume_groups: - { vgname: 'vg_vdb', pvname: '/dev/vdb' } - { vgname: 'vg_vdc', pvname: '/dev/vdc' } # gluster_infra_thick_lvs # Variable for thick lv creation gluster_infra_thick_lvs: - { vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1', size: '10G' } # gluster_infra_thinpools # thinpoolname is optional, if not provided `vgname' followed by _thinpool is # used for name. poolmetadatasize is optional, default 16G is used gluster_infra_thinpools: - {vgname: 'vg_vdb', thinpoolname: 'foo_thinpool', thinpoolsize: '10G', poolmetadatasize: '1G' } - {vgname: 'vg_vdc', thinpoolname: 'bar_thinpool', thinpoolsize: '20G', poolmetadatasize: '1G' } # gluster_infra_lv_logicalvols # Thinvolumes for the brick. `thinpoolname' is optional, if omitted `vgname' # followed by _thinpool is used gluster_infra_lv_logicalvols: - { vgname: 'vg_vdb', thinpool: 'foo_thinpool', lvname: 'vg_vdb_thinlv', lvsize: '500G' } - { vgname: 'vg_vdc', thinpool: 'bar_thinpool', lvname: 'vg_vdc_thinlv', lvsize: '500G' } # Setting up cache using SSD disks gluster_infra_cache_vars: - { vgname: 'vg_vdb', cachedisk: '/dev/vdd', cachethinpoolname: 'foo_thinpool', cachelvname: 'cachelv', cachelvsize: '20G', cachemetalvname: 'cachemeta', cachemetalvsize: '100M', cachemode: 'writethrough' } # gluster_infra_mount_devices gluster_infra_mount_devices: - { path: '/rhgs/thicklv', vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1' } - { path: '/rhgs/thinlv1', vgname: 'vg_vdb', lvname: 'vg_vdb_thinlv' } - { path: '/rhgs/thinlv2', vgname: 'vg_vdc', lvname: 'vg_vdc_thinlv' }重要path:定義が/rhgsで開始しない場合、ブリックは管理ポータルによって自動的に検出されません。create_brick.ymlPlaybook を実行した後にホストストレージを同期し、新しいブリックを管理ポータルに追加します。create_brick.ymlPlaybook ファイルを作成します。以下の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいcreate_brick.ymlファイルを作成します。このファイルは、
gluster.infraロールと、上記で作成した変数ファイルを使用してブリックを作成する作業を定義します。Playbook ファイル
create_brick.ymlの例--- - name: Create a GlusterFS brick on the servers remote_user: root hosts: all gather_facts: false vars_files: - bricks.yml roles: - gluster.infraPlaybook を実行します
/etc/ansible/roles/gluster.infra/playbooksディレクトリーから以下のコマンドを実行し、inventory と上で定義した変数ファイルを使用して作成した Playbook を実行します。# ansible-playbook -i inventory create_brick.yml
ブリックが使用可能であることを確認します。
- Compute → Hosts をクリックし、ホストを選択します。
Storage Devices をクリックし、新しいブリックのストレージデバイスの一覧を確認します。
新しいブリックが表示されない場合は、Sync をクリックし、ストレージデバイスの一覧に表示されるまで待機します。
1.2. Ansible を使用した VDO レイヤーでの新しいブリックの作成
多くのホストにブリックを一度に作成する場合は、ansible Playbook を作成してプロセスを自動化できます。
前提条件
物理マシンをインストールして、新しいブリックをホストします。
ハイパーコンバージドホストのインストール の手順に従います。
すべてのノードに、パスワードなしでキーベースの SSH 認証を設定します。
これは、Web コンソールを実行しているノードからすべての新規ノード、および最初の新規ノードから他のすべての新規ノードに設定します。
重要RHHI for Virtualization は、IP アドレスと FQDN の両方に対して、これらのノード間でパスワードのないキーベースの SSH 認証を想定します。これらのマシン間で、すべてのストレージおよび管理ネットワークインターフェースの IP アドレスと FQDN の間に、キーベースの SSH 認証を設定するようにしてください。
SSH 認証用のパスワードの代わりにキーペアを使用した方法 に従って、パスワードなしでキーベースの認証を設定します。
- ホストが Virtual Disk Optimization (VDO) レイヤーを使用していることを確認します。VDO レイヤーがない場合は、代わりに 「ansible を使用した新しいブリックの作成」 を使用します。
手順
inventoryファイルの作成以下の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいinventoryファイルを作成します。このファイルは、新しいブリックを作成するホストを一覧表示します。
inventoryファイルの例[hosts] server4.example.com server5.example.com server6.example.com
bricks.yml変数ファイルを作成します。次の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいbricks.ymlファイルを作成します。このファイルは、各ホストで作成または使用される基礎となるストレージインフラストラクチャーおよび設定を定義します。
vdo_bricks.yml変数ファイルの例# gluster_infra_disktype # Set a disk type. Options: JBOD, RAID6, RAID10 - Default: JBOD gluster_infra_disktype: RAID10 # gluster_infra_dalign # Dataalignment, for JBOD default is 256K if not provided. # For RAID{6,10} dataalignment is computed by multiplying # gluster_infra_diskcount and gluster_infra_stripe_unit_size. gluster_infra_dalign: 256K # gluster_infra_diskcount # Required only for RAID6 and RAID10. gluster_infra_diskcount: 10 # gluster_infra_stripe_unit_size # Required only in case of RAID6 and RAID10. Stripe unit size always in KiB, do # not provide the trailing `K' in the value. gluster_infra_stripe_unit_size: 128 # VDO creation gluster_infra_vdo: - { name: 'hc_vdo_1', device: '/dev/vdb' } - { name: 'hc_vdo_2', device: '/dev/vdc' } # gluster_infra_volume_groups # Variables for creating volume group gluster_infra_volume_groups: - { vgname: 'vg_vdb', pvname: '/dev/mapper/hc_vdo_1' } - { vgname: 'vg_vdc', pvname: '/dev/mapper/hc_vdo_2' } # gluster_infra_thick_lvs # Variable for thick lv creation gluster_infra_thick_lvs: - { vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1', size: '10G' } # gluster_infra_thinpools # thinpoolname is optional, if not provided `vgname' followed by _thinpool is # used for name. poolmetadatasize is optional, default 16G is used gluster_infra_thinpools: - {vgname: 'vg_vdb', thinpoolname: 'foo_thinpool', thinpoolsize: '10G', poolmetadatasize: '1G' } - {vgname: 'vg_vdc', thinpoolname: 'bar_thinpool', thinpoolsize: '20G', poolmetadatasize: '1G' } # gluster_infra_lv_logicalvols # Thinvolumes for the brick. `thinpoolname' is optional, if omitted `vgname' # followed by _thinpool is used gluster_infra_lv_logicalvols: - { vgname: 'vg_vdb', thinpool: 'foo_thinpool', lvname: 'vg_vdb_thinlv', lvsize: '500G' } - { vgname: 'vg_vdc', thinpool: 'bar_thinpool', lvname: 'vg_vdc_thinlv', lvsize: '500G' } # gluster_infra_mount_devices gluster_infra_mount_devices: - { path: '/rhgs/thicklv', vgname: 'vg_vdb', lvname: 'vg_vdb_thicklv1' } - { path: '/rhgs/thinlv1', vgname: 'vg_vdb', lvname: 'vg_vdb_thinlv' } - { path: '/rhgs/thinlv2', vgname: 'vg_vdc', lvname: 'vg_vdc_thinlv' }重要path:定義が/rhgsで開始しない場合、ブリックは管理ポータルによって自動的に検出されません。create_brick.ymlPlaybook を実行した後にホストストレージを同期し、新しいブリックを管理ポータルに追加します。create_brick.ymlPlaybook ファイルを作成します。以下の例を使用して、
/etc/ansible/roles/gluster.infra/playbooksディレクトリーに新しいcreate_brick.ymlファイルを作成します。このファイルは、
gluster.infraロールと、上記で作成した変数ファイルを使用してブリックを作成する作業を定義します。Playbook ファイル
create_brick.ymlの例--- - name: Create a GlusterFS brick on the servers remote_user: root hosts: all gather_facts: false vars_files: - vdo_bricks.yml roles: - gluster.infraPlaybook を実行します
/etc/ansible/roles/gluster.infra/playbooksディレクトリーから以下のコマンドを実行し、inventory と上で定義した変数ファイルを使用して作成した Playbook を実行します。# ansible-playbook -i inventory create_brick.yml
ブリックが使用可能であることを確認します。
- Compute → Hosts をクリックし、ホストを選択します。
Storage Devices をクリックし、新しいブリックのストレージデバイスの一覧を確認します。
新しいブリックが表示されない場合は、Sync をクリックし、ストレージデバイスの一覧に表示されるまで待機します。
1.3. Red Hat Virtualization Manager からのボリューム拡張
このセクションに従って、新しいハイパーコンバージドノード上の新しいブリック間で既存のボリュームを拡張します。
前提条件
- スケーリングプランがサポートされていることを確認します: スケーリングの要件。
新しいハイパーコンバージドノードとして動作する 3 台の物理マシンをインストールします。
ハイパーコンバージドホストのインストール の手順に従います。
パスワードなしでキーベースの SSH 認証を設定する。
これは、Web コンソールを実行しているノードからすべての新規ノード、および最初の新規ノードから他のすべての新規ノードに設定します。
重要RHHI for Virtualization は、IP アドレスと FQDN の両方に対して、これらのノード間でパスワードのないキーベースの SSH 認証を想定します。これらのマシン間で、すべてのストレージおよび管理ネットワークインターフェースの IP アドレスと FQDN の間に、キーベースの SSH 認証を設定するようにしてください。
SSH 認証用のパスワードの代わりにキーペアを使用 した方法に従って、パスワードなしでキーベースの認証を設定します。
手順
新規ブリックの作成
要件に応じて、ansible を使用してブリックを作成する または ansible を使用した VDO レイヤー上のブリックの作成 の手順に従って、ボリュームを拡張するサーバー上にブリックを作成します。
重要定義した
path:が/rhgsで始まらない場合、ブリックは管理ポータルによって自動的に検出されません。create_brick.ymlPlaybook を実行してからホストストレージを同期し、新しいブリックを管理ポータルに同期します。- Compute → Hosts をクリックし、ホストを選択します。
- Storage Devices をクリックします。
- Sync をクリックします。
新しいブリックを持つホストごとに繰り返します。
ボリュームに新しいブリックを追加する
- RHV 管理コンソールにログインします。
- Storage → Volumes をクリックし、展開するボリュームを選択します。
- Bricks タブをクリックします。
- Add をクリックします。Add Bricks ウィンドウが開きます。
新しいブリックを追加します。
- Host ドロップダウンメニューからブリックホストを選択します。
- Brick Directory ドロップダウンメニューから追加するブリックを選択し、Add をクリックします。
- すべてのブリックがリストされたら、OK をクリックしてボリュームにブリックを追加します。
ボリュームは新しいブリックを自動的に同期します。
1.4. Web コンソールを使用して新規ノードに新しいボリュームを追加してハイパーコンバージドクラスターの拡張
以下の手順に従って、Web コンソールを使用して、新規ノードの新規ボリュームでハイパーコンバージドクラスターを拡張します。
前提条件
- スケーリングプランがサポートされていることを確認します: スケーリングの要件。
新しいハイパーコンバージドノードとして動作する 3 台の物理マシンをインストールします。
ハイパーコンバージドホストのインストール の手順に従います。
パスワードなしでキーベースの SSH 認証を設定する。
これは、Web コンソールを実行しているノードからすべての新規ノード、および最初の新規ノードから他のすべての新規ノードに設定します。
重要RHHI for Virtualization は、IP アドレスと FQDN の両方に対して、これらのノード間でパスワードのないキーベースの SSH 認証を想定します。これらのマシン間で、すべてのストレージおよび管理ネットワークインターフェースの IP アドレスと FQDN の間に、キーベースの SSH 認証を設定するようにしてください。
SSH 認証用のパスワードの代わりにキーペアを使用 した方法に従って、パスワードなしでキーベースの認証を設定します。
手順
- Web コンソールにログインします。
- Virtualization → Hosted Engine をクリックしてから Manage Gluster をクリックします。
Expand Cluster をクリックします。Gluster Deployment ウィンドウが開きます。
Hosts タブで、新しいハイパーコンバージドノードの FQDN または IP アドレスを入力し、Next をクリックします。
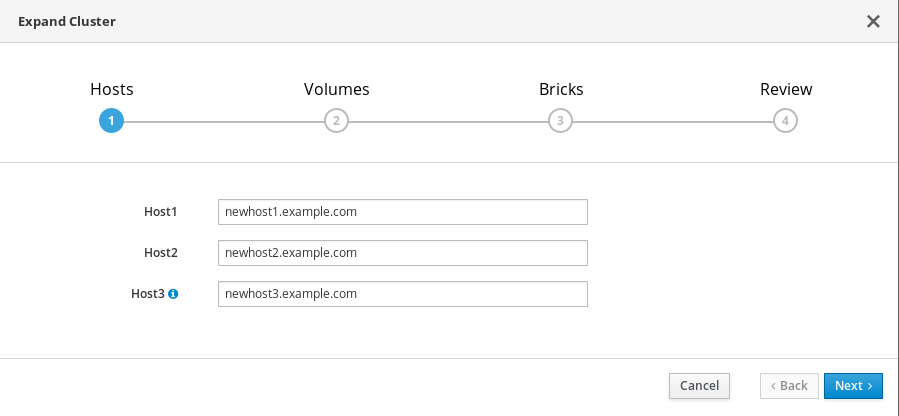
Volumes タブで、作成するボリュームの詳細を指定します。
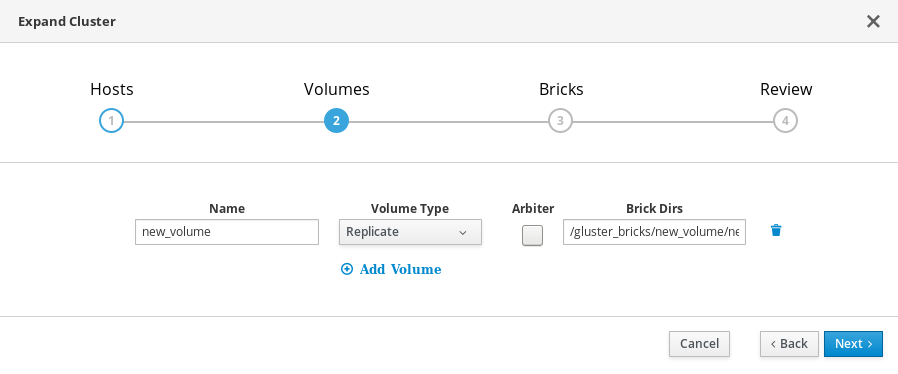
Bricks タブで、Gluster ボリュームの作成に使用するディスクの詳細を指定します。
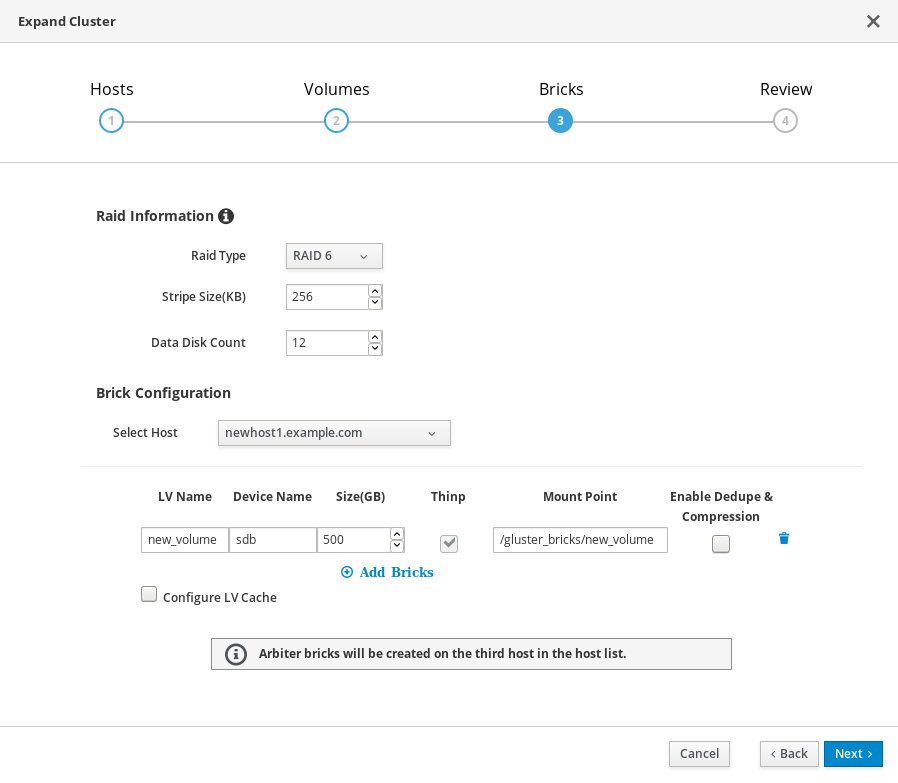
Review タブで、生成されたファイルで問題の有無を確認します。問題がなければ、Deploy をクリックします。
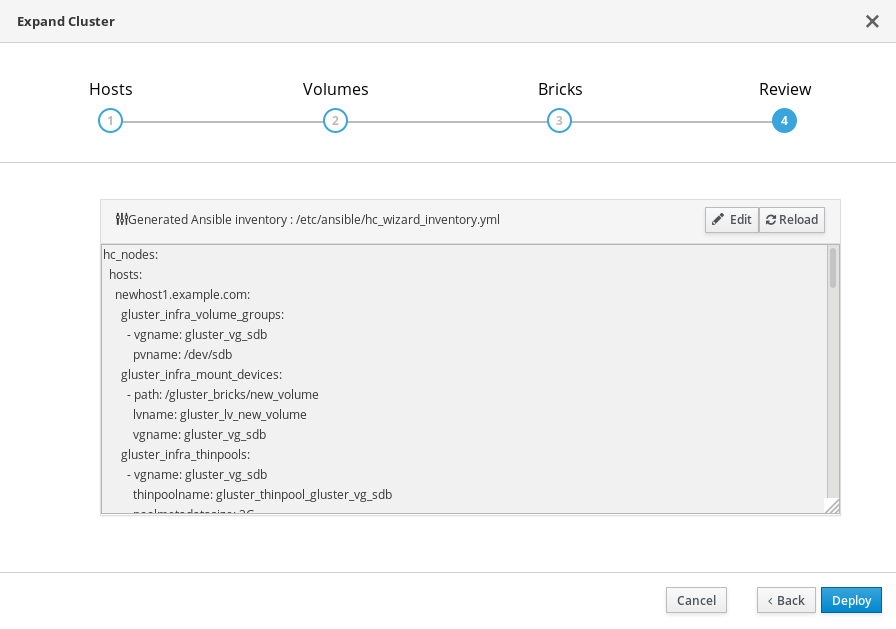
デプロイメントが完了するまでに時間がかかります。クラスターが正常に拡張されると、次の画面が表示されます。
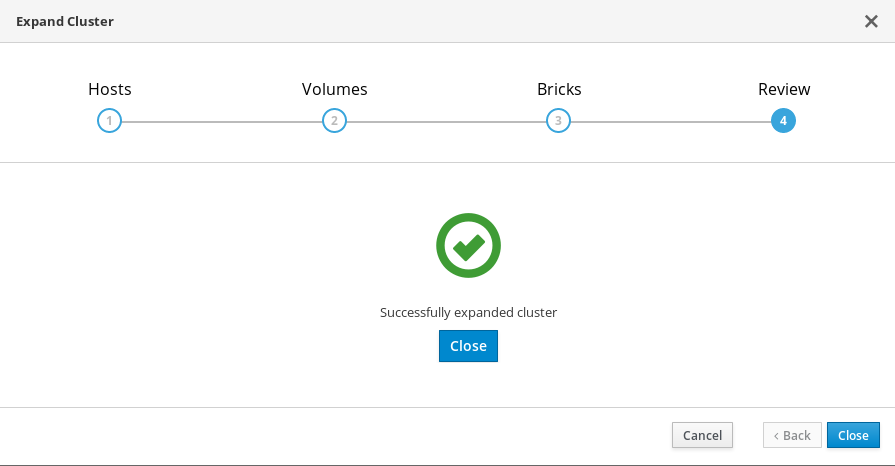
1.4.1. 追加のハイパーコンバージドホストを設定する
IPv6 アドレスを使用している場合、または Web コンソールを使用してホストされたエンジン用に Red Hat Gluster Storage を設定 するの一部として追加のハイパーコンバージドホストを指定しなかった場合は、その他のハイパーコンバージドホストごとに管理ポータルで以下の手順に従います。
- Compute → Hosts をクリックし、New をクリックして New Host ウィンドウを開きます。
- 管理するホストの Name、Hostname、および Password を指定します。
- Advanced Parameters で、Automatically configure host firewall チェックボックスをオフにします。これは、ファイアウォールルールがデプロイメントプロセスによってすでに設定されているためです。
- New Host ダイアログの Hosted Engine タブで、Choose hosted engine deployment action の値を Deploy に設定します。これにより、ホストされたエンジンが新しいホストで実行できるようになります。
- OK をクリックします。
gluster ネットワークを残りのすべてのホストに接続します
- 新しく追加されたホストの名前をクリックして、ホストページに移動します。
- Network Interfaces サブタブをクリックし、Setup Host Networks をクリックします。
- 新しく作成したネットワークを正しいインターフェイスにドラッグアンドドロップします。
- Verify connectivity チェックボックスがオンになっていることを確認します。
- Save network configuration チェックボックスがオンになっていることを確認します。
- OK をクリックして保存します。
このホストの General サブタブで、Hosted Engine HA の値が Active で、スコアが正の整数であることを確認します。
重要スコア が N/A と表示されている場合は、Choose hosted engine deployment action で デプロイ アクションを選択し忘れている可能性があります。Red Hat Hyperconverged Infrastructure for Virtualization のメンテナンス の ハイパーコンバージドホストの再インストール の手順に従って、デプロイ アクションでホストを再インストールします。
ネットワークの状態を確認します
Network Interfaces タブをクリックして、ホストのネットワークの状態を確認します。ネットワークインターフェイスが非同期状態になるか、IP アドレスがない場合は、Management → Refresh Capabilities をクリックします。
詳細については、Red Hat Virtualization 4.4 セルフホストエンジンガイド: https://access.redhat.com/documentation/ja-jp/red_hat_virtualization/4.4/html/self-hosted_engine_guide/chap-installing_additional_hosts_to_a_self-hosted_environment を参照してください。
第2章 フェンシングポリシーを使用して高可用性を設定する
フェンシングにより、クラスターはパフォーマンスと可用性のポリシーを適用し、ハイパーコンバージドホストを自動的に再起動することで予期しないホスト障害に対応できます。
Red Hat Hyperconverged (RHHI for Virtualization) Infrastructure のデプロイメントでフェンシング活動がストレージサービスを中断しないようにするには、Red Hat Gluster Storage に固有のいくつかのポリシーを有効にする必要があります。
これには、クラスターレベルとホストレベルの両方でフェンシングを有効にして設定する必要があります。詳細は、以下のセクションを参照してください。
2.1. クラスターでのフェンシングポリシーの設定
- 管理ポータルで、Compute → Clusters をクリックします。
- クラスターを選択し、Edit をクリックします。Edit Cluster ウィンドウが開きます。
- Fencing policy タブをクリックします。
- Enable fencing チェックボックスをオンにします。
少なくとも次のフェンシングポリシーのチェックボックスをオンにします。
- Skip fencing if gluster bricks are up
- Skip fencing if gluster quorum not met
これらのポリシーの影響の詳細については、付録B Red Hat Gluster Storage のフェンシングポリシー を参照してください。
- OK をクリックして設定を保存します。
2.2. ホストでのフェンシングパラメーターの設定
- 管理ポータルで Compute → Hosts をクリックします。
- 設定するホストを選択し、Edit をクリックして Edit Host ウィンドウを開きます。
Power Management タブをクリックします。
図2.1 電源管理の設定
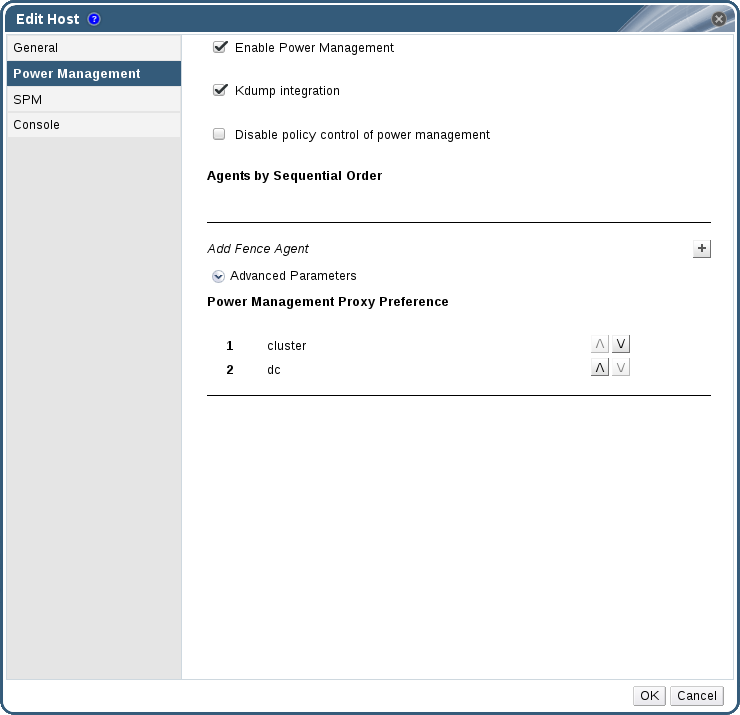
- Enable Power Management チェックボックスをオンにします。これにより、タブの他のフィールドが有効になります。
Kdump integration チェックボックスを選択すると、カーネルクラッシュダンプの実行中にホストがフェンシングするのを防ぐことができます。
重要既存のホストで Kdump 統合を有効にする場合、kdump を設定するにはホストを再インストールする必要があります。ホストの再インストール手順については、11章ハイパーコンバージドホストの再インストール を参照してください。
プラス (+) ボタンをクリックして、新しい電源管理デバイスを追加します。Edit fence agent ウィンドウが開きます。
図2.2 フェンスエージェントの編集
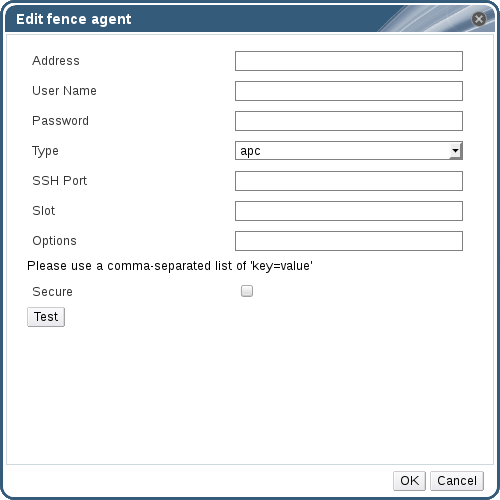
- 電源管理デバイスの Address、User Name、Password を入力します。
- ドロップダウンリストから電源管理デバイスの Type を選択します。
- 電源管理デバイスがホストとの通信に使用する SSH Port の番号を入力します。
- 電源管理デバイスのブレードを識別するための Slot 番号を入力します。
- 電源管理デバイスの オプション を入力します。key=value エントリーのコンマ区切りリストを使用します。
- 電源管理デバイスがホストに安全に接続できるようにするには、Secure チェックボックスを選択します。
Test ボタンをクリックして、設定が正しいことを確認します。Test Succeeded、Host Status is: on 検証が成功すると表示されます。
警告電源管理パラメーター (ユーザー ID、パスワード、オプションなど) は、セットアップ時と Red Hat Virtualization Manager でパラメーター値が手動で変更されたときの 2 つの状況で、Red Hat Virtualization Manager によってテストされます。不正なパラメーターに関する警告を無視したり、Red Hat Virtualization Manager で対応する変更を行わずに電源管理ハードウェアでパラメーターを変更したりするとフェンシングが失敗する可能性があります。
- OK をクリックして、フェンスエージェントの追加を完了します。
- OK をクリックして、ホスト設定を保存します。
ホストの一覧に戻ります。ホスト名の横にあった感嘆符 (!) が消えていることに注意してください。これは電源管理の設定が成功したことを示しています。
第3章 データのバックアップおよびリカバリーオプションの設定
この章では、Red Hat Hyperconverged Infrastructure for Virtualization デプロイメントにディザスターリカバリー機能を追加して、ディスクまたはサーバーの障害後にクラスターを稼働状態に復元できるようにする方法について説明します。
3.1. 前提条件
3.1.1. geo レプリケーションの前提条件
geo レプリケーションを設定する際には、以下の要件と制限に注意してください。
- 2 つの異なるマネージャーが必要です
- geo レプリケーションのソースおよび宛先ボリュームは、Red Hat Virtualization Manager の異なるインスタンスで管理される必要があります。
3.1.2. フェイルオーバーおよびフェイルバック設定の前提条件
- バージョンが環境間で一致している必要があります
- プライマリー環境とセカンダリー環境には、同じバージョンの Red Hat Virtualization Manager が含まれており、同じデータセンターの互換バージョン、クラスターの互換バージョン、および PostgreSQL のバージョンを使用します。
- ホスト型エンジンストレージドメインに仮想マシンディスクがない
- ホスト型エンジン仮想マシンで使用されるストレージドメインはフェイルオーバーしないため、このストレージドメインの仮想マシンディスクはすべて失われます。
- Ansible Playbook を別々のマシンから手動で実行する
Ansible Playbook を Ansible コントローラーノードとして機能する別のマシンから手動で生成し、実行します。このノードには、必要な障害復旧 Ansible ロールをすべて提供する
ovirt-ansible-collectionパッケージが必要です。注記ovirt-ansible-collectionパッケージは、デフォルトで Hosted Engine 仮想マシンとともにインストールされます。ただし、プライマリーサイトに影響を与える障害時に、この仮想マシンは停止している可能性があります。プライマリーサイト外のマシンを使用してこの Playbook を実行することは安全ですが、テスト目的で、Hosted Engine 仮想マシンからこれらの Playbook をトリガーすることができます。
3.2. サポートされているバックアップとリカバリーの設定
Red Hat Hyperconverged Infrastructure for Virtualization デプロイメントにディザスターリカバリー機能を追加するには、2 つの方法がサポートされています。
- セカンダリーボリュームのみへのバックアップの設定
データをリモートセカンダリーボリュームに定期的に同期することで、ディスクやサーバーに障害が発生した場合にデータが失われないようにすることができます。
このオプションは、デプロイメントが次の条件に該当する場合に適しています。
- ディザスターリカバリー用にデータのバックアップのみが必要です。
- 高可用性ストレージは必要ありません。
- セカンダリークラスターを維持する必要はありません。
- 障害が発生した後、手動でデータを復元し、バックアップソリューションを再設定する意思があります。
このオプションを設定するには、セカンダリーボリュームへのバックアップの設定 の指示に従ってください。
- セカンダリークラスターへのフェイルオーバーおよびセカンダリークラスターからのフェイルバックの設定
このオプションは、リモートボリューム上のデータのバックアップに加えて、フェイルオーバーおよびフェイルバック機能を提供します。プライマリークラスターのオペレーションとストレージドメインのセカンダリークラスターへのフェイルオーバーを設定すると、プライマリークラスターでディスクまたはサーバーに障害が発生した場合でも、データを引き続き使用できるようになります。
このオプションは、デプロイメントが次の条件に該当する場合に適しています。
- 可用性の高いストレージが必要です。
- セカンダリークラスターを維持する意思があります。
- 障害が発生した後に、手動でデータを復元したり、バックアップソリューションを再設定したりしたくありません。
このオプションを設定するには、セカンダリークラスターへのフェイルオーバーおよびセカンダリークラスターからのフェイルバックの設定 の手順に従ってください。
Red Hat は、実稼働デプロイメント用に少なくとも 1 つのバックアップボリュームを設定することを推奨します。
3.3. セカンダリーボリュームへのバックアップの設定
このセクションでは、geo レプリケーションを使用して、gluster ボリュームをセカンダリー gluster ボリュームにバックアップする方法について説明します。
これを実行するには、以下を行う必要があります。
- すべての 前提条件 が満たされていることを確認してください。
- geo レプリケーションターゲットとして使用する適切なボリュームを作成します。
- ソースボリュームとターゲットボリューム間の geo レプリケーションセッションを設定 します。
- geo レプリケーションプロセスを スケジュール します。
3.3.1. 前提条件
3.3.1.2. 一致するネットワークプロトコル
すべてのホストが同じインターネットプロトコルバージョンを使用するようにします。
ソースボリュームのホストが IPv4 を使用する場合、ターゲットボリュームのホストは IPv4 も使用する必要があります。
ソースボリュームのホストが IPv6 を使用する場合、ターゲットボリュームのホストは IPv6 を使用する必要があります。さらに、Bug 1855965 を回避するために、IPv6 アドレスの代わりに FQDN を使用して geo レプリケーションを設定します。
3.3.2. geo レプリケーションに適したターゲットボリュームを作成する
ソースボリュームの geo レプリケートされたコピーを保持するセカンダリー gluster ボリュームを準備します。このターゲットボリュームは、別のサイトでホストされている別のクラスターに配置する必要があります。これにより、ソースボリュームとターゲットボリュームが同じ停止の影響を受けるリスクが最小限に抑えられます。
geo レプリケーションのターゲットボリュームでシャーディングが有効になっていることを確認します。ターゲットボリュームをホストする任意のノードで次のコマンドを実行して、そのボリュームでシャーディングを有効にします。
# gluster volume set <volname> features.shard enable
3.3.3. ボリュームをバックアップするための geo レプリケーションの設定
3.3.3.1. geo レプリケーションセッションの作成
アクティブソースボリュームからパッシブターゲットボリュームにデータをレプリケートするには、geo レプリケーションセッションが必要です。
Red Hat Hyperconverged Infrastructure for Virtualization では、rsync ベースの geo レプリケーションのみがサポートされています。
共通の
pem pubファイルを作成します。ターゲットノードにパスワードが設定されていないキーベースの SSH 認証を使用するソースノードで、次のコマンドを実行します。
# gluster system:: execute gsec_create
geo レプリケーションセッションを作成します。
次のコマンドを実行して、作成された
pem pubファイルを認証用に使用して、ソースボリュームとターゲットボリュームの間に geo レプリケーションセッションを作成します。# gluster volume geo-replication <SOURCE_VOL> <TARGET_NODE>::<TARGET_VOL> create push-pem
たとえば、次のコマンドは、ソースボリューム prodvol から、backup.example.com によってホストされている backupvol というターゲットボリュームへの geo レプリケーションセッションを作成します。
# gluster volume geo-replication prodvol backup.example.com::backupvol create push-pem
デフォルトでは、このコマンドは、ターゲットボリュームが使用可能なスペースを持つ有効なターゲットであることを確認します。コマンドに
forceオプションを追加して、失敗した検証を無視することができます。メタボリュームを設定します。
これは、前提条件 で説明されているように、共有ストレージが設定されているソースボリュームに依存します。
# gluster volume geo-replication <SOURCE_VOL> <TARGET_HOST>::<TARGET_VOL> config use_meta_volume true
geo レプリケーションセッションを開始しないでください。geo レプリケーションセッションを開始すると、ソースボリュームからターゲットボリュームへのレプリケーションが開始されます。
3.3.3.2. geo レプリケーションセッションの作成の確認
- 任意のソースノードで管理ポータルにログインします。
- Storage → Volumes をクリックします。
geo レプリケーションアイコンの Info 列を確認します。
このアイコンが表示されている場合、そのボリュームに対して geo レプリケーションが設定されています。
このアイコンが表示されない場合は、synchronizing the volume を試してみてください。
3.3.3.3. 管理ポータルを使用したボリューム状態の同期
- 管理ポータルにログインします。
- Storage → Volumes をクリックします。
- 同期するボリュームを選択します。
- Geo-replication サブタブをクリックします。
- Sync をクリックします。
3.3.4. geo レプリケーションを使用した定期的なバックアップのスケジュール設定
- 任意のソースノードで管理ポータルにログインします。
- Storage から Domains をクリックします。
- バックアップするストレージドメインの名前をクリックします。
- Remote Data Sync Setup サブタブをクリックします。
Setup をクリックします。
Setup Remote Data Synchronization ウィンドウが開きます。
- Geo-replicated to フィールドで、バックアップターゲットを選択します。
Recurrence フィールドで、繰り返し間隔のタイプを選択します。
有効な値は、少なくとも 1 つの平日のチェックボックスが選択された WEEKLY、または DAILY です。
Hours と Minutes フィールドで、同期を開始する時刻を指定します。
注記この時間は、ホストされたエンジンのタイムゾーンに基づいています。
- OK をクリックします。
- 指定した時刻にソースボリュームの Events サブタブをチェックして、Synchronization が正しく機能していることを確認します。
3.4. セカンダリークラスターへのフェイルオーバーおよびセカンダリークラスターからのフェイルバックの設定
このセクションでは、サーバーに障害が発生した場合にクラスターがリモートセカンダリークラスターにフェイルオーバーするように設定する方法について説明します。
これを実行するには、以下を行う必要があります。
- リモートボリュームへのバックアップを設定 します。
- フェイルオーバーターゲットとして使用する適切なクラスターを作成します。
- ソースクラスターとターゲットクラスターの マッピングファイルを準備します。
- フェイルオーバー Playbook を準備します。
- プライマリークラスターの クリーンアップ Playbook を準備します。
- フェイルバック Playbook を準備します。
3.4.1. フェイルオーバー用のセカンダリークラスターの作成
障害が発生した場合にプライマリークラスターの代わりに使用できるセカンダリークラスターをインストールして設定します。
このセカンダリークラスターは、次のいずれかの設定にすることができます。
- Red Hat Hyperconverged Infrastructure
- 詳細については、Red Hat ハイパーコンバージドインフラストラクチャーのデプロイ を参照してください。
- Red Hat Virtualization ストレージドメインとして使用するために設定された Red Hat Gluster Storage
- 詳細については、Red Hat Gluster Storage を使用した Red Hat Virtualization の設定 を参照してください。このユースケースでは、ストレージドメインを作成する必要がないことに注意してください。ストレージドメインはフェイルオーバープロセスの一部としてインポートされます。
セカンダリークラスターのストレージは、フェイルオーバープロセス中にセカンダリーサイトのデータセンターに追加できるように、データセンターに接続しないでください。
3.4.2. ソースクラスターとターゲットクラスター間のマッピングファイルの作成
このセクションに従って、ソースクラスターのストレージをターゲットクラスターのストレージにマップするファイルを作成します。
Red Hat は、最初にストレージをデプロイした直後にこのファイルを作成し、デプロイの変更に合わせて最新の状態に保つことを推奨します。これにより、災害時にクラスター内のすべてが安全にフェイルオーバーされるようになります。
Playbook を作成して、マッピングファイルを生成します。
site、username、password、およびca変数を使用して、クラスターに関する情報をovirt.ovirt.disaster_recoveryロールに渡す Playbook を作成します。Playbook ファイルの例: dr-ovirt-setup.yml
--- - name: Collect mapping variables hosts: localhost connection: local vars: site: https://example.engine.redhat.com/ovirt-engine/api username: admin@internal password: my_password ca: /etc/pki/ovirt-engine/ca.pem var_file: disaster_recovery_vars.yml roles: - ovirt.ovirt.disaster_recoverygenerate_mappingタグを指定して Playbook を実行し、マッピングファイルを生成します。# ansible-playbook dr-ovirt-setup.yml --tags="generate_mapping"
これにより、マッピングファイル
Disaster_recovery_vars.ymlが作成されます。Disaster_recovery_vars.ymlを編集し、セカンダリークラスターに関する情報を追加します。セカンダリーサイトにデータが同期されているストレージドメインのみを指定するようにしてください。他のストレージドメインは削除できます。マッピングファイルで使用される属性の詳細については、Red Hat Virtualization Disaster Recovery Guide の 付録 A: Mapping File Attributes を参照してください。
3.4.3. ソースクラスターとターゲットクラスター間のフェイルオーバー Playbook の作成
フェイルオーバーを処理する Playbook ファイルを作成します。
パスワードファイル (
passwords.ymlなど) を定義して、プライマリーおよびセカンダリーサイトの Manager パスワードを保存します。以下に例を示します。passwords.yml ファイルの例
--- # This file is in plain text, if you want to # encrypt this file, please execute following command: # # $ ansible-vault encrypt passwords.yml # # It will ask you for a password, which you must then pass to # ansible interactively when executing the playbook. # # $ ansible-playbook myplaybook.yml --ask-vault-pass # dr_sites_primary_password: primary_password dr_sites_secondary_password: secondary_password
注記セキュリティーを強化する場合は、パスワードファイルを暗号化できます。ただし、Playbook を実行するときに --ask-vault-pass パラメーターを使用する必要があります。詳細は、Working with files encrypted using Ansible Vault を参照してください。
dr_target_hostおよびdr_source_map変数を使用して、フェイルオーバーのソースおよびターゲットとして使用するハイパーコンバージドホストのリストをovirt.ovirt.disaster_recoveryロールに渡す Playbook ファイルを作成します。Playbook ファイルの例: dr-rhv-failover.yml
--- - name: Failover RHV hosts: localhost connection: local vars: dr_target_host: secondary dr_source_map: primary vars_files: - disaster_recovery_vars.yml - passwords.yml roles: - ovirt.ovirt.disaster_recovery
フェイルオーバーの実行については、セカンダリークラスターへのフェイルオーバー を参照してください。
3.4.4. プライマリークラスターのフェイルオーバークリーンアップ Playbook の作成
フェイルバックターゲットとして使用できるように、プライマリークラスターをクリーンアップする Playbook ファイルを作成します。
Playbook ファイルの例: dr-cleanup.yml
---
- name: Clean RHV
hosts: localhost
connection: local
vars:
dr_source_map: primary
vars_files:
- disaster_recovery_vars.yml
roles:
- ovirt.ovirt.disaster_recovery
フェイルバックの実行については、プライマリークラスターへのフェイルバック を参照してください。
3.4.5. ソースクラスターとターゲットクラスター間のフェイルバック Playbook の作成
dr_target_host および dr_source_map 変数を使用して、ハイパーコンバージドホストのリストをフェイルバックソースおよびターゲットとして使用する ovirt.ovirt.disaster_recovery ロールに渡す Playbook ファイルを作成します。
Playbook ファイルの例: dr-rhv-failback.yml
---
- name: Failback RHV
hosts: localhost
connection: local
vars:
dr_target_host: primary
dr_source_map: secondary
vars_files:
- disaster_recovery_vars.yml
- passwords.yml
roles:
- ovirt.ovirt.disaster_recovery
フェイルバックの実行については、プライマリークラスターへのフェイルバック を参照してください。
第4章 パフォーマンスの改善を設定する
一部のデプロイメントでは、最適なパフォーマンスを実現するために追加の設定が役立ちます。このセクションでは、特定のデプロイメントに推奨される追加の設定について説明します。
4.1. シャードサイズの変更によるボリュームパフォーマンスの改善
shard-block-size パラメーターのデフォルト値は、Red Hat Hyperconverged Infrastructure for Virtualization バージョン 1.0 と 1.1 の間で 4MB から 64MB に変更されました。これは、すべての新しいボリュームが shard-block-size 値 64MB で作成されることを意味します。ただし、既存のボリュームは元の shard-block-size 値である 4MB を保持します。
データを含むボリュームの shard-block-size 値を安全に変更する方法はありません。シャードブロックサイズは、値が設定された後に発生する書き込みにのみ適用されるため、データを含むボリュームで値を変更しようとすると、シャードブロックサイズが混在し、パフォーマンスが低下します。
このセクションでは、Red Hat Hyperconverged Infrastructure for Virtualization 1.1 以降にアップグレードした後、既存のボリュームのシャードブロックサイズを安全に変更して、より大きなシャードサイズのパフォーマンス上の利点を活用する方法を示します。
4.1.1. レプリケートされたボリュームのシャードサイズの変更
インベントリーファイルの作成
次の例に基づいて、
normal_replicated_inventory.ymlというインベントリーファイルを作成します。host1、host2、およびhost3をホストの FQDN に置き換え、環境に合わせてデバイスの詳細を編集します。normal_replicated_inventory.ymlインベントリーファイルの例hc_nodes: hosts: # Host1 host1: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host2 host2: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host3 host3: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } # Common configurations vars: cluster_nodes: - host1 - host2 - host3 gluster_features_hci_cluster: "{{ cluster_nodes }}" gluster_features_hci_volumes: - { volname: 'data', brick: '<brick_mountpoint>' } gluster_features_hci_volume_options: { group: 'virt', storage.owner-uid: '36', storage.owner-gid: '36', network.ping-timeout: '30', performance.strict-o-direct: 'on', network.remote-dio: 'off', cluster.granular-entry-heal: 'enable', features.shard-block-size: '64MB' }normal_replicated.ymlPlaybook の作成次の例を使用して、
normal_replicated.yml Playbookファイルを作成します。normal_replicated.ymlPlaybook の例--- # Safely changing the shard block size parameter value for normal replicated volume - name: Changing the shard block size hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infra - gluster.featuresPlaybook の実行
ansible-playbook -i normal_replicated_inventory.yml normal_replicated.yml
4.1.2. 任意のボリュームでのシャードサイズの変更
インベントリーファイルの作成
以下の例に基づいて
arbitrated_replicated_inventory.ymlという名前のインベントリーファイルを作成します。host1、host2、およびhost3をホストの FQDN に置き換え、環境に合わせてデバイスの詳細を編集します。arbitrated_replicated_inventory.ymlインベントリーファイルの例hc_nodes: hosts: # Host1 host1: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host2 host2: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } #Host3 host3: # Dedupe & Compression config # If logicalsize >= 1000G then slabsize=32G else slabsize=2G #gluster_infra_vdo: # - { name: 'vdo_sdb', device: '/dev/sdb', logicalsize: '3000G', emulate512: 'on', slabsize: '32G', # blockmapcachesize: '128M', readcachesize: '20M', readcache: 'enabled', writepolicy: 'auto' } # With Dedupe & Compression #gluster_infra_volume_groups: # - vgname: <volgroup_name> # pvname: /dev/mapper/vdo_sdb # Without Dedupe & Compression gluster_infra_volume_groups: - vgname: <volgroup_name> pvname: /dev/sdb gluster_infra_mount_devices: - path: <brick_mountpoint> lvname: <lv_name> vgname: <volgroup_name> gluster_infra_thinpools: - {vgname: '<volgroup_name>', thinpoolname: 'thinpool_<volgroup_name>', thinpoolsize: '500G', poolmetadatasize: '4G'} gluster_infra_lv_logicalvols: - vgname: <volgroup_name> thinpool: thinpool_<volgroup_name> lvname: <lv_name> lvsize: <size>G # Mount the devices gluster_infra_mount_devices: - { path: '<brick_mountpoint>', vgname: <volgroup_name>, lvname: <lv_name> } # Common configurations vars: cluster_nodes: - host1 - host2 - host3 gluster_features_hci_cluster: "{{ cluster_nodes }}" gluster_features_hci_volumes: - { volname: 'data_one', brick: '<brick_mountpoint>', arbiter: 1 } gluster_features_hci_volume_options: { group: 'virt', storage.owner-uid: '36', storage.owner-gid: '36', network.ping-timeout: '30', performance.strict-o-direct: 'on', network.remote-dio: 'off', cluster.granular-entry-heal: 'enable', features.shard-block-size: '64MB', }arbitrated_replicated.ymlPlaybook の作成次の例を使用して、
arbitrated_replicated.ymlPlaybook ファイルを作成します。arbitrated_replicated.ymlPlaybook の例--- # Safely changing the shard block size parameter value for arbitrated replicated volume - name: Changing the shard block size hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infra - gluster.featuresPlaybook の実行
ansible-playbook -i arbitrated_replicated_inventory.yml arbitrated_replicated.yml
4.2. 既存のボリュームの論理ボリュームキャッシュ (lvmcache) の設定
メインストレージデバイスがソリッドステートディスク (SSD) でない場合、Red Hat Hyperconverged Infrastructure for Virtualization デプロイメントに必要なパフォーマンスを達成するために、論理ボリュームキャッシュ (lvmcache) を設定することを Red Hat は推奨します。
インベントリーファイルの作成
以下の例に基づいて、
cache_inventory.ymlという名前のインベントリーファイルを作成します。<host1>、<host2>、および<host3>を、キャッシュを設定するホストの FQDN に置き換えます。ファイル全体で次の値を置き換えます。
- <slow_device>,<fast_device>
-
キャッシュを接続するデバイスを指定し、次にキャッシュデバイスをコンマ区切りのリストとして指定します (例
: cachedisk: '/dev/sdb,/dev/sde')。 - <fast_device_name>
-
作成するキャッシュ論理ボリュームの名前を指定します (例:
cachelv_thinpool_gluster_vg_sde)。 - <fast_device_thinpool>
-
作成するキャッシュシンプールの名前を指定します (例:
gluster_thinpool_gluster_vg_sde)。
cache_inventory.yml ファイルの例
hc_nodes: hosts: # Host1 <host1>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethrough #Host2 <host2>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethrough #Host3 <host3>: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: '<slow_device>,<fast_device>' cachelvname: <fast_device_name> cachethinpoolname: <fast_device_thinpool> cachelvsize: '10G' cachemode: writethroughPlaybook ファイルの作成
lvm_cache.ymlという名前の ansible Playbook ファイルを作成します。lvm_cache.yml ファイルの例
--- # Create LVM Cache - name: Setup LVM Cache hosts: hc_nodes remote_user: root gather_facts: no any_errors_fatal: true roles: - gluster.infracachesetupタグを使用して Playbook を実行します次のコマンドを実行して、
lvm_cache.ymlで指定された設定をcache_inventory.ymlで指定されたホストとデバイスに適用します。ansible-playbook -i cache_inventory.yml lvm_cache.yml --tags=cachesetup
第5章 モニタリングの設定
5.1. イベント通知の設定
管理ポータルに表示する通知を設定するには、Red Hat Virtualization 4.4 管理ガイド の 管理ポータルでのイベント通知の設定 を参照してください。
パート II. メンテナンスタスク
第6章 基本操作
多くの管理およびトラブルシューティングタスクには、いくつかの基本的な操作が必要です。このセクションでは、ハイパーコンバージドクラスターのシャットダウンや起動などの基本的なタスクを安全に実行する方法について説明します。
6.1. シャットダウン Playbook の作成
ハイパーコンバージド環境は、特定の順序でシャットダウンする必要があります。これを行う最も簡単な方法は、Hosted Engine 仮想マシンから実行できるシャットダウン Playbook を作成することです。
ovirt.ovirt.shutdown_env ロールは、グローバルメンテナンスモードを有効にし、クラスター内のすべての仮想マシンとホストのシャットダウンを開始します。ホストのシャットダウンは非同期です。ハイパーコンバージドホストが実際にシャットダウンされる前に Playbook が終了します。
前提条件
Hosted Engine 仮想マシンで
ovirt.ovirt.shutdown_envansible ロールが使用可能であることを確認します。# yum install ovirt-ansible-shutdown-env -y
手順
- ホストエンジンの仮想マシンにログインします。
環境のシャットダウン Playbook を作成します。
次のテンプレートを使用して、Playbook ファイルを作成します。
-
ovirt-engine.example.comを Hosted Engine 仮想マシンの FQDN に置き換えます。 -
123456をadmin@internalアカウントのパスワードに置き換えます。
Playbook ファイルの例: shutdown_rhhi-v.yml
--- - name: oVirt shutdown environment hosts: localhost connection: local gather_facts: false vars: engine_url: https://ovirt-engine.example.com/ovirt-engine/api engine_user: admin@internal engine_password: 123456 engine_cafile: /etc/pki/ovirt-engine/ca.pem roles: - ovirt.ovirt.shutdown_env-
6.2. RHHI for Virtualization のシャットダウン
ハイパーコンバージド環境は、特定の順序でシャットダウンする必要があります。Ansible Playbook を使用してこのプロセスを自動化し、環境が安全にシャットダウンされるようにします。
前提条件
- シャットダウン Playbook の 作成 の説明に従って、シャットダウン Playbook を作成します。
Hosted Engine 仮想マシンで
ovirt.ovirt.shutdown_envansible ロールが使用可能であることを確認します。# yum install ovirt-ansible-shutdown-env -y
手順
Hosted Engine 仮想マシンに対してシャットダウン Playbook を実行します。
# ansible-playbook -i localhost <shutdown_rhhi-v.yml>
6.3. ハイパーコンバージドクラスターの起動
ハイパーコンバージドクラスターの起動は、従来のコンピュートクラスターまたはストレージクラスターの起動よりも複雑です。次の手順に従って、ハイパーコンバージドクラスターを安全に起動します。
- クラスター内のすべてのホストの電源を入れます。
必要なサービスが利用可能であることを確認します。
すべてのホストで
glusterdサービスが正しく開始されたことを確認します。# systemctl status glusterd ● glusterd.service - GlusterFS, a clustered file-system server Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled) Drop-In: /etc/systemd/system/glusterd.service.d └─99-cpu.conf Active: active (running) since Wed 2018-07-18 11:15:03 IST; 3min 48s ago [...]glusterd が開始されていない場合は、開始します。
# systemctl start glusterd
ホストネットワークが使用可能であり、ホストに必要なインターフェイスに IP アドレスが割り当てられていることを確認します。
# ip addr show
すべてのホストがストレージクラスターの一部であることを確認します (Peer in Cluster (Connected) として表示されます)。
# gluster peer status Number of Peers: 2 Hostname: 10.70.37.101 Uuid: 773f1140-68f7-4861-a996-b1ba97586257 State: Peer in Cluster (Connected) Hostname: 10.70.37.102 Uuid: fc4e7339-9a09-4a44-aa91-64dde2fe8d15 State: Peer in Cluster (Connected)
すべてのブリックが online として表示されていることを確認します。
# gluster volume status engine Status of volume: engine Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick 10.70.37.28:/gluster_bricks/engine/en gine 49153 0 Y 23160 Brick 10.70.37.29:/gluster_bricks/engine/en gine 49160 0 Y 12392 Brick 10.70.37.30:/gluster_bricks/engine/en gine 49157 0 Y 15200 Self-heal Daemon on localhost N/A N/A Y 23008 Self-heal Daemon on 10.70.37.30 N/A N/A Y 10905 Self-heal Daemon on 10.70.37.29 N/A N/A Y 13568 Task Status of Volume engine ------------------------------------------------------------------------------ There are no active volume tasks
hosted engine 仮想マシンを起動します。
hosted engine ノードにするホストで、次のコマンドを実行します。
# hosted-engine --vm-start
hosted engine 仮想マシンが正常に起動したことを確認します。
# hosted-engine --vm-status
hosted engine 仮想マシンを Global Maintenance モードから取ります。
- 管理ポータルにログインします。
- Compute → Hosts をクリックし、hosted engine ノードを選択します。
- ⋮ → Disable Global HA Maintenance をクリックします。
Web コンソールを使用して他の仮想マシンを起動します。
- Compute → Virtualization をクリックします。
- 起動する仮想マシンを選択し、Run をクリックします。
第7章 重要なファイルのバックアップ
重要な設定ファイル、インベントリーファイル、および変更された Playbook をバックアップすると、クラスターを簡単に復元または再デプロイできます。
Red Hat は、初期デプロイメントの後、およびクラスター内の主要な変更が成功したことを確認した後に、設定をバックアップすることを推奨します。必要に応じて、ノードに障害が発生した後にバックアップを取ることもできます。
前提条件
-
サンプルの Playbook とインベントリーファイルが
/etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deploymentディレクトリーに保存されている。インベントリーおよび Playbook ファイルを手動で作成または変更し、それらをこのディレクトリーに保存しない場合は、それらの場所へのパスを確認する。
手順
- root ユーザーとしてハイパーコンバージドホストにログインします。
hc-ansible-deploymentディレクトリーに移動し、デフォルトのarchive_config_inventory.ymlファイルをバックアップします。# cd /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment # cp archive_config_inventory.yml archive_config_inventory.yml.bk
バックアップするクラスターの詳細を指定して、
archive_config_inventory.ymlファイルを編集します。- hosts
- バックアップするクラスター内の各ホストのバックエンド FQDN。
- backup_dir
- バックアップファイルを保存するディレクトリー。
- nbde_setup
-
Network-Bound Disk Encryption を使用する場合は、これを
trueに設定します。それ以外の場合は、falseに設定します。 - upgrade
-
falseに設定します。
以下に例を示します。
all: hosts: host1-backend.example.com: host2-backend.example.com: host3-backend.example.com: vars: backup_dir: /rhhi-backup nbde_setup: true upgrade: falsebackupfilesタグ付きの更新済みインベントリーファイルを使用して、archive_config.ymlPlaybook を実行します。# ansible-playbook -i archive_config_inventory.yml archive_config.yml --tags=backupfiles
これにより、
/root/rhvh-node-host1-backend.example.com-backup.tar.gzなど、インベントリーのhostsセクションの各ホスト FQDN に固有の/rootディレクトリーにアーカイブが作成されます。バックアップアーカイブを別のマシンに転送します。
# scp /root/rhvh-node-host1-backend.example.com-backup.tar.gz backup-host.example.com:/backups/
第8章 Red Hat hyperconverged Infrastructure for Virtualization のモニタリング
8.1. VDO (Virtual Data Optimizer) のモニタリング
VDO をモニタリングすると、どのような場合に物理ストレージが不足しているのかを把握するのに役立ちます。VDO の物理領域は、シンプロビジョニングされたストレージと同様にモニターする必要があります。より多くの論理領域が使用可能になり、VDO 領域がより効果的な方法で使用されるため、VDO デバイスはシンプロビジョニングを使用する必要があります。デフォルトでは、シンプロビジョニングが有効になり、必要に応じて選択を解除できます。
View Details をクリックして、利用可能なブロック、使用領域、およびデバイス情報を確認できます。
8.1.1. コマンドラインインターフェースを使用した VDO のモニタリング
コマンドラインインターフェースを使用して VDO をモニタリングするオプションは複数あります。
vdostatsコマンド-
このコマンドは、利用可能なブロック、使用されているブロック数、デバイス名、保存した物理ブロックの割合、VDO ボリュームの物理ブロックの割合など、ボリュームの統計情報を表示します。vdostats の詳細については、マニュアルページ
man vdostatsを参照してください。 vdo statusコマンド- このコマンドは、VDO システムとボリュームのステータスを YAML 形式で報告します。
/sys/kvdo/<vdo_volume>/statisticsディレクトリー-
このディレクトリーのファイルには、VDO のボリューム統計情報が含まれます。
vdostatsコマンドを使用する代わりに、これらのファイルを読み取ることができます。
8.1.2. Web コンソールを使用した VDO のモニタリング
VDO の使用に関連するイベントは Notifications タブに表示されます。イベントは、VDO ボリュームに残っている物理領域に関する情報を提供し、追加の物理領域が必要かどうかについて最新情報を得ます。
表8.1 イベント通知の種類
| 型 | テキスト | アクション |
|---|---|---|
| 警告 | 警告、確認済みのディスク容量が不足しています。StorageDomainName ドメインには、DiskSpace GB の空き容量が確認されています。 |
|
第9章 fstrim を使用してシンプロビジョニングされた論理ボリュームのスペースを解放する
fstrim を手動で実行して、未使用の論理ボリュームスペースをシンプールに戻し、他の論理ボリュームで使用できるようにすることができます。
Red Hat は fstrim を毎日実行することを推奨しています。
前提条件
シンプールの論理ボリュームが破棄動作をサポートしていることを確認します。
基になるデバイスに対する次のコマンドの出力がゼロでない場合、破棄がサポートされます。
# cat /sys/block/<device>/queue/discard_max_bytes
注記discard_max_bytesが 0 を返した場合でも、シン論理ボリューム上でfstrimコマンドを実行して、未使用のブロックをシンプールに再利用できます。ただし、discardまたはtrimはブロック層には渡されません。
手順
fstrimを実行して、物理領域をシンプールに復元します。# fstrim -v <mountpoint>
たとえば、次のコマンドは、
/gluster_bricks/data/dataにマウントされた論理ボリュームで見つかった未使用の領域を破棄し、詳細な出力 (-v) を提供します。# fstrim -v /gluster_bricks/data/data
第10章 Red Hat Virtualization Manager へのハイパーコンバージドホストの追加
このプロセスに従って、Red Hat Virtualization Manager が既存のハイパーコンバージドホストを管理できるようにします。
- 管理ポータルにログインします。
- Compute → Hosts をクリックします。
- New をクリックします。New Host 画面が開きます。
General タブで、ハイパーコンバージドホストに関する次の詳細を指定します。
-
Host Cluster -
名前 -
ホスト名 -
Password
-
-
General タブで、Advanced Parameters ドロップダウンをクリックし、
Automatically configure host firewallチェックボックスをオフにします。 - OK をクリックします。
第11章 ハイパーコンバージドホストの再インストール
一部の設定変更では、その変更を有効にする前に、ハイパーコンバージドホストを再インストールする必要があります。次の手順に従って、ハイパーコンバージドホストを再インストールします。
- 管理ポータルにログインします。
- Compute → Hosts をクリックします。
- ホストを選択し、Management > Maintenance > OK をクリックして、このホストをメンテナンスモードにします。
- Installation > Reinstall をクリックして、再インストールウィンドウを開きます。
- General タブで、Automatically Configure Host firewall チェックボックスをオフにします。
-
Hosted Engine タブで、Choose hosted engine deployment action の値を
Deployに設定します。 - OK をクリックして、ホストを再インストールします。
第12章 災害からの復旧
この章では、ディスクまたはサーバーに障害が発生した後にクラスターを稼働状態に復元する方法について説明します。
この章を使用するには、事前にディザスターリカバリーオプションを設定しておく必要があります。詳細は、バックアップとリカバリーのオプション設定 を参照してください。
12.1. バックアップボリュームからのデータの手動復元
このセクションでは、リモートバックアップボリュームから新しくインストールされた Red Hat Hyperconverged Infrastructure for Virtualization の代替デプロイメントにデータを復元する方法について説明します。
これを実行するには、以下を行う必要があります。
- Red Hat Hyperconverged Infrastructure for Virtualization のデプロイ の指示に従って、代替デプロイメントをインストールして設定します。
12.1.1. geo レプリケートされたバックアップからのボリュームの復元
代替のハイパーコンバージドインフラストラクチャーデプロイメントをインストールして設定する
手順については、Red Hat Hyperconverged Infrastructure for Virtualization のデプロイ: https://access.redhat.com/documentation/ja-jp/red_hat_hyperconverged_infrastructure_for_virtualization/1.8/html/deploying_red_hat_hyperconverged_infrastructure_for_virtualization/ を参照してください。
バックアップボリュームで読み取り専用モードを無効にする
geo レプリケートされたボリュームは、各同期後に読み取り専用に設定され、データが変更されないようにします。ボリュームをストレージドメインとしてインポートするには、Red Hat Virtualization に書き込み権限が必要です。
次のコマンドを実行して、バックアップボリュームの読み取り専用モードを無効にします。
# gluster volume set <backup-vol> features.read-only off
ストレージドメインのバックアップをインポートする
新しいハイパーコンバージドインフラストラクチャーのデプロイメントから、管理ポータルで:
- Storage から Domains をクリックします。
- Import Domain をクリックします。Import Pre-Configured Domain ウィンドウが開きます。
- Storage Type フィールドで、GlusterFS を指定します。
- Name フィールドに、バックアップボリュームから作成される新しいボリュームの名前を指定します。
- Path フィールドに、バックアップボリュームへのパスを指定します。
OK をクリックします。次の警告が表示され、アクティブなデータセンターが以下にリストされます。
This operation might be unrecoverable and destructive! Storage Domain(s) are already attached to a Data Center. Approving this operation might cause data corruption if both Data Centers are active.
- Approve operation チェックボックスをオンにして、OK をクリックします。
インポートする仮想マシンのリストを決定する
次のコマンドを実行して、インポートされたドメインの識別子を特定します。
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" https://$ENGINE_FQDN/ovirt-engine/api/storagedomains/
以下に例を示します。
# curl -v -k -X GET -u "admin@example.com:mybadpassword" -H "Accept: application/xml" https://10.0.2.1/ovirt-engine/api/storagedomains/
次のコマンドを実行して、未登録ディスクのリストを確認します。
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" "https://$ENGINE_FQDN/ovirt-engine/api/storagedomains/DOMAIN_ID/vms;unregistered"
以下に例を示します。
# curl -v -k -X GET -u "admin@example.com:mybadpassword" -H "Accept: application/xml" "https://10.0.2.1/ovirt-engine/api/storagedomains/5e1a37cf-933d-424c-8e3d-eb9e40b690a7/vms;unregistered"
各仮想マシンをストレージドメインに部分的にインポートする
クラスター識別子を決定する
次のコマンドは、クラスター識別子を返します。
# curl -v -k -X GET -u "admin@internal:password" -H "Accept: application/xml" https://$ENGINE_FQDN/ovirt-engine/api/clusters/
以下に例を示します。
# curl -v -k -X GET -u "admin@example:mybadpassword" -H "Accept: application/xml" https://10.0.2.1/ovirt-engine/api/clusters/
仮想マシンをインポートする
次のコマンドは、すべてのディスクをストレージドメインで使用可能にする必要なく、仮想マシンをインポートします。
# curl -v -k -u 'admin@internal:password' -H "Content-type: application/xml" -d '<action> <cluster id="CLUSTER_ID"></cluster> <allow_partial_import>true</allow_partial_import> </action>' "https://ENGINE_FQDN/ovirt-engine/api/storagedomains/DOMAIN_ID/vms/VM_ID/register"
以下に例を示します。
# curl -v -k -u 'admin@example.com:mybadpassword' -H "Content-type: application/xml" -d '<action> <cluster id="bf5a9e9e-5b52-4b0d-aeba-4ee4493f1072"></cluster> <allow_partial_import>true</allow_partial_import> </action>' "https://10.0.2.1/ovirt-engine/api/storagedomains/8d21980a-a50b-45e9-9f32-cd8d2424882e/e164f8c6-769a-4cbd-ac2a-ef322c2c5f30/register"
詳細については、Red Hat Virtualization REST API ガイド (https://access.redhat.com/documentation/ja-jp/red_hat_virtualization/4.4/html/rest_api_guide/) を参照してください。
部分的にインポートされたディスクを新しいストレージドメインに移行する
管理ポータルで、Storage → Disks をクリックし、Move Disk オプションをクリックします。インポートしたディスクを同期ボリュームから交換用クラスターのストレージドメインに移動します。詳細は、Red Hat Virtualization 管理ガイド を参照してください。
復元されたディスクを新しい仮想マシンに接続します
Red Hat Virtualization 仮想マシン管理ガイド の指示に従って、交換用ディスクを各仮想マシンに接続します。
12.2. セカンダリークラスターへのフェイルオーバー
このセクションでは、サーバーに障害が発生した場合に、プライマリークラスターからリモートのセカンダリークラスターにフェイルオーバーする方法について説明します。
- リモートクラスターへのフェイルオーバーを設定します。
- ソースクラスターとターゲットクラスターのマッピングファイルが正確であることを確認します。
バックアップボリュームで読み取り専用モードを無効にする
geo レプリケートされたボリュームは、各同期後に読み取り専用に設定され、データが変更されないようにします。ボリュームをストレージドメインとしてインポートするには、Red Hat Virtualization に書き込み権限が必要です。
次のコマンドを実行して、バックアップボリュームの読み取り専用モードを無効にします。
# gluster volume set <backup-vol> features.read-only off
重要フェイルオーバー Playbook を実行する前に、プライマリーサイトでリモート同期スケジュールを停止してください。
プライマリーサイトの Red Hat Virtualization Manager 管理ポータルにアクセスできる場合は、以下の手順を使用して、スケジュールされたリモートデータ同期を削除します。
-
Red Hat Virtualization Manager Administration Portal → Storage の選択 → Domains を選択し、
adminとしてログインします。 - storage domain configured with remote data sync を選択→ Remote Data Sync Setup タブを選択→ Edit → Recurrence を none として選択します。
-
Red Hat Virtualization Manager Administration Portal → Storage の選択 → Domains を選択し、
fail_overタグを使用してフェイルオーバー Playbook を実行します。# ansible-playbook dr-rhv-failover.yml --tags="fail_over"
12.3. プライマリークラスターへのフェイルバック
このセクションでは、サーバー障害の原因を修正した後で、セカンダリークラスターからプライマリークラスターにフェイルバックする方法について説明します。
clean_engineタグを使用してクリーンアップ Playbook を実行して、フェイルバック用にプライマリークラスターを準備します。# ansible-playbook dr-cleanup.yml --tags="clean_engine"
- ソースクラスターとターゲットクラスターのマッピングファイルが正確であることを確認します。
fail_backタグを使用してフェイルバック Playbook を実行することにより、フェイルバックを実行します。# ansible-playbook dr-cleanup.yml --tags="fail_back"
12.4. RHV Manager を使用した geo レプリケーションセッションの停止
geo レプリケーションを介してアクティブソースボリュームからパッシブターゲットボリュームにデータがレプリケートされないようにする場合は、geo レプリケーションセッションを停止します。
データが現在同期されていないことを確認します
Manager の右上にある Tasks アイコンをクリックして、Tasks ページを確認します。
データ同期に関連する継続的なタスクがないことを確認します。
データ同期タスクが存在する場合は、それらが完了するまで待ちます。
geo レプリケーションセッションを停止します
- Storage → Volumes をクリックします。
- geo レプリケーションを停止するボリュームの名前をクリックします。
- Geo-replication サブタブをクリックします。
- 停止するセッションを選択し、Stop をクリックします。
12.5. geo レプリケーションスケジュールを削除して、スケジュールされたバックアップをオフにする
geo レプリケーションスケジュールを削除することで、geo レプリケーションを介してスケジュールされたバックアップを停止できます。
- 任意のソースノードで管理ポータルにログインします。
- Storage から Domains をクリックします。
- バックアップするストレージドメインの名前をクリックします。
- Remote Data Sync Setup サブタブをクリックします。
Setup をクリックします。
Setup Remote Data Synchronization ウィンドウが開きます。
- Recurrence フィールドで、NONE の繰り返し間隔タイプを選択し、OK をクリックします。
(オプション) geo レプリケーションセッションを削除します。
geo レプリケーションマスターノードから次のコマンドを実行します。
# gluster volume geo-replication MASTER_VOL SLAVE_HOST::SLAVE_VOL delete
このコマンドは、
reset-sync-timeパラメーターを指定して実行することもできます。このパラメーターと geo レプリケーションセッションの削除の詳細については、Red Hat Gluster Storage 3.5 管理ガイド の Geo レプリケーションセッションの削除 を参照してください。
パート III. トラブルシューティング
第13章 自己修復が完了しない
自己修復操作が完了しない場合、Gluster ファイル ID (GFID) の不一致が原因である可能性があります。
13.1. Gluster ファイル ID の不一致
診断
自己修復状態を確認します。
次のコマンドを数分間にわたって数回実行します。表示されるエントリーに注意してください。
# gluster volume heal <volname> info
毎回同じエントリーが表示される場合は、これらのエントリーに GFID の不一致がある可能性があります。
各ホストの各エントリーの GFID を確認します。
各ホストで、エントリーごとに次のコマンドを実行します。
# getfattr -d -m. -ehex <backend_path> -h
エントリーの
<backend_path>は、ブリックパスとエントリーで設定されます。たとえば、engineボリュームのブリックに/gluster_bricks/engine/engineのパスがあり、修復情報に表示されるエントリーが58d392a6-e5b1-4aed-9bbc-952210a7137d/ha_agent/hosted-engine.metadataである場合、使用するbackend_pathは/gluster_bricks/engine/engine/58d392a6-e5b1-4aed-9bbc-952210a7137d/ha_agent/hosted-engine.metadataです。各ホストからの出力を比較します。
エントリーの
trusted.gfidがすべてのホストで同じでない場合、GFID の不一致があります。
解決方法
最新の変更時刻を持つ GFID を優先して不一致を解決します。
# gluster volume heal <volume> split-brain latest-mtime <entry>
以下に例を示します。
# gluster volume heal engine split-brain latest-mtime /58d392a6-e5b1-4aed-9bbc-952210a7137d/ha_agent/hosted-engine.metadata
手動でボリュームの回復をトリガーします。
# gluster volume heal <volname>
パート IV. 参考資料
付録A node_prep_inventory.yml ファイルについて
node_prep_inventory.yml ファイルは、Red Hat Hyperconverged Infrastructure for Virtualization クラスターの代替ホストを準備するために使用できる Ansible インベントリーファイルの例です。
このファイルは、いずれかのハイパーコンバージドホストの /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/node_prep_inventory.yml にあります。
A.1. 交換用ノードを準備するための設定パラメーター
A.1.1. 設定するホスト
- hc_nodes
ホストのバックエンド FQDN を使用するハイパーコンバージドホストのリストおよびそのホストの設定詳細。ホスト固有の設定は、ホストのバックエンド FQDN の下に定義されます。すべてのホストに共通する設定は
vars:セクションで定義されます。hc_nodes: hosts: new-host-backend-fqdn.example.com: [configuration specific to this host] vars: [configuration common to all hosts]
A.1.2. マルチパスデバイス
blacklist_mpath_devices(オプション)デフォルトでは、Red Hat Virtualization Host はマルチパス設定を有効にし、ディスクに基礎となるマルチパス設定がなくても、すべてのディスクに一意のマルチパス名とワールドワイド識別子を提供します。マルチパスデバイス名がリスト表示されるデバイスに使用されていないようにマルチパス設定がない場合は、このセクションを追加してください。ここに記載されていないディスクは、マルチパス設定が利用可能であると想定され、インベントリーファイルの後続のセクションで定義する際には、
/dev/sdxの代わりにパスフォーマット/dev/mapper/<WWID>が必要となります。4 つのデバイス (
sda、sdb、sdc、およびsdd) を持つサーバーでは、以下の設定は 2 つのデバイスをブラックリストに指定します。パスの形式/dev/mapper/<WWID>は、このリストに記載されていないデバイスで想定されています。hc_nodes: hosts: new-host-backend-fqdn.example.com: blacklist_mpath_devices: - sdb - sdc重要blacklist_mpath_devicesに暗号化デバイス (luks_*デバイス) をリストしないでください。マルチパス設定が機能する必要があるためです。
A.1.3. 重複排除と圧縮
gluster_infra_vdo(optional)このセクションでは、重複排除と圧縮を使用するデバイスのリストを定義します。これらのデバイスには、
gluster_infra_volume_groupsでボリュームグループとして定義する際に、/dev/mapper/<name>パス形式が必要です。リスト表示される各デバイスには以下の情報が必要です。name-
VDO デバイスの省略名 (
vdo_sdcなど)。 device-
使用するデバイス (例:
/dev/sdc) logicalsize-
VDO ボリュームの論理サイズ。物理ディスクサイズが 10 倍になるようにします。たとえば、500 GB のディスクがある場合は、
logicalsize: '5000G'を設定します。 emulate512-
ブロックサイズが 4 KB のデバイスを使用する場合には、これを
onに設定します。 slabsize-
ボリュームの論理サイズが 1000 GB 以上である場合は、これを
32 Gに設定します。論理サイズが 1000 GB 未満の場合は、これを2 Gに設定します。 blockmapcachesize-
これを
128 Mに設定します。 writepolicy-
これは
autoに設定します。
以下に例を示します。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_vdo: - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' } - { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '500G', emulate512: 'off', slabsize: '2G', blockmapcachesize: '128M', writepolicy: 'auto' }
A.1.4. ストレージインフラストラクチャー
gluster_infra_volume_groups(required)本セクションでは、論理ボリュームを含むボリュームグループを作成します。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_volume_groups: - vgname: gluster_vg_sdb pvname: /dev/sdb - vgname: gluster_vg_sdc pvname: /dev/mapper/vdo_sdcgluster_infra_mount_devices(required)このセクションでは、Gluster ブリックを形成する論理ボリュームを作成します。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdb - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdc - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sddgluster_infra_thinpools(optional)このセクションでは、シンプロビジョニングされたボリュームが使用する論理シンプールを定義します。シンプールは
engineボリュームには適していませんが、vmstoreおよびdataブリックに使用できます。vgname- このシンプールが含まれるボリュームグループの名前。
thinpoolname-
gluster_thinpool_sdcなどのシンプールの名前。 thinpoolsize- このボリュームグループに作成されるすべての論理ボリュームのサイズの合計。
poolmetadatasize-
16 Gに設定します。これは、サポートされるデプロイメント用に推奨されるサイズです。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_thinpools: - {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'} - {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}gluster_infra_cache_vars(optional)このセクションでは、低速なデバイスのパフォーマンスを改善するためにキャッシュ論理ボリュームを定義します。高速キャッシュデバイスはシンプールに割り当てられ、
gluster_infra_thinpoolを定義する必要があります。vgname- 高速な外部キャッシュを必要とするデバイスを持つボリュームグループの名前。
cachedisk-
出力デバイスとファーストデバイスのパスをコンマで区切って指定します。例えば、出力デバイス
sdbでキャッシュデバイスsdeを使用する場合は、/dev/sdb/dev/sdeと指定します。 cachelvname- このキャッシュ論理ボリュームの名前。
cachethinpoolname- 高速キャッシュボリュームが割り当てられているシンプール。
cachelvsize- キャッシュ論理ボリュームのサイズ。このサイズの約 0.01% がキャッシュメタデータに使用されます。
cachemode-
キャッシュモード。有効な値は
writethroughおよびwritebackです。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: /dev/sdb,/dev/sde cachelvname: cachelv_thinpool_sdb cachethinpoolname: gluster_thinpool_sdb cachelvsize: '250G' cachemode: writethroughgluster_infra_thick_lvs(required)ブリックの作成に使用するシックにプロビジョニングされた論理ボリューム。
engineボリュームのブリックはシックにプロビジョニングされている必要があります。vgname- 論理ボリュームを含むボリュームグループの名前。
lvname- 論理ボリュームの名前。
サイズ-
論理ボリュームのサイズ。
engineの論理ボリュームには100 Gが必要です。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_thick_lvs: - vgname: gluster_vg_sdb lvname: gluster_lv_engine size: 100Ggluster_infra_lv_logicalvols(required)ブリックの作成に使用するシンプロビジョニングされた論理ボリューム。
vgname- 論理ボリュームを含むボリュームグループの名前。
thinpool- このボリュームがシンプロビジョニングされている場合、論理ボリュームを含むシンプール。
lvname- 論理ボリュームの名前。
サイズ-
論理ボリュームのサイズ。
engineの論理ボリュームには100 Gが必要です。
hc_nodes: hosts: new-host-backend-fqdn.example.com: gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdc thinpool: gluster_thinpool_sdc lvname: gluster_lv_data lvsize: 200G - vgname: gluster_vg_sdd thinpool: gluster_thinpool_sdd lvname: gluster_lv_vmstore lvsize: 200Ggluster_infra_disktype(required)ディスクの基礎となるハードウェア設定を指定します。お使いのハードウェアに合った値に設定してください。
RAID6、RAID5、JBODのいずれかです。hc_nodes: vars: gluster_infra_disktype: RAID6gluster_infra_diskcount(required)RAID セット内のデータディスクの数を指定します。
JBODディスクタイプの場合は、これを1に設定します。hc_nodes: vars: gluster_infra_diskcount: 10gluster_infra_stripe_unit_size(required)RAID セットのストライプサイズ (メガバイト単位)
hc_nodes: vars: gluster_infra_stripe_unit_size: 256gluster_features_force_varlogsizecheck(required)デプロイメントプロセス中に
/var/logパーティションに十分な空き領域があることを確認する場合は、trueに設定します。ログに十分なスペースを確保することが重要になりますが、スペースの要件を慎重に監視する場合は、デプロイメント時に領域の要件を確認する必要はありません。hc_nodes: vars: gluster_features_force_varlogsizecheck: falsegluster_set_selinux_labels(required)SELinux が有効な場合にボリュームにアクセスできることを確認します。このホストで SELinux が有効になっている場合は、
trueに設定します。hc_nodes: vars: gluster_set_selinux_labels: true
A.1.5. ファイアウォールおよびネットワークインフラストラクチャー
gluster_infra_fw_ports(required)すべてのノード間で開くべきポートのリストで、
<port>/<protocol>の形式で指定します。hc_nodes: vars: gluster_infra_fw_ports: - 2049/tcp - 54321/tcp - 5900-6923/tcp - 16514/tcp - 5666/tcp - 16514/tcpgluster_infra_fw_permanent(必須)ノードの再起動後に、
gluster_infra_fw_portsにリスト表示されるポートが開放されていることを確認します。実稼働環境のユースケースでは、これをtrueに設定します。hc_nodes: vars: gluster_infra_fw_permanent: true
gluster_infra_fw_state(required)ファイアウォールを有効にします。実稼働環境のユースケースで、この値を
enabledに設定します。hc_nodes: vars: gluster_infra_fw_state: enabledgluster_infra_fw_zone(必須)これらの
gluster_infra_fw_\*パラメーターが適用されるファイアウォールゾーンを指定します。hc_nodes: vars: gluster_infra_fw_zone: publicgluster_infra_fw_services(required)ファイアウォールを介して許可するサービスのリスト
glusterfsがここで定義されていることを確認してください。hc_nodes: vars: gluster_infra_fw_services: - glusterfs
A.2. 例 node_prep_inventory.yml
# Section for Host Preparation Phase
hc_nodes:
hosts:
# Host - The node which need to be prepared for replacement
new-host-backend-fqdn.example.com:
# Blacklist multipath devices which are used for gluster bricks
# If you omit blacklist_mpath_devices it means all device will be whitelisted.
# If the disks are not blacklisted, and then its taken that multipath configuration
# exists in the server and one should provide /dev/mapper/<WWID> instead of /dev/sdx
blacklist_mpath_devices:
- sdb
- sdc
# Enable this section gluster_infra_vdo, if dedupe & compression is
# required on that storage volume.
# The variables refers to:
# name - VDO volume name to be used
# device - Disk name on which VDO volume to created
# logicalsize - Logical size of the VDO volume.This value is 10 times
# the size of the physical disk
# emulate512 - VDO device is made as 4KB block sized storage volume(4KN)
# slabsize - VDO slab size. If VDO logical size >= 1000G then
# slabsize is 32G else slabsize is 2G
#
# Following VDO values are as per recommendation and treated as constants:
# blockmapcachesize - 128M
# writepolicy - auto
#
# gluster_infra_vdo:
# - { name: vdo_sdc, device: /dev/sdc, logicalsize: 5000G, emulate512: off, slabsize: 32G,
# blockmapcachesize: 128M, writepolicy: auto }
# - { name: vdo_sdd, device: /dev/sdd, logicalsize: 3000G, emulate512: off, slabsize: 32G,
# blockmapcachesize: 128M, writepolicy: auto }
# When dedupe and compression is enabled on the device,
# use pvname for that device as /dev/mapper/<vdo_device_name> # # The variables refers to: # vgname - VG to be created on the disk # pvname - Physical disk (/dev/sdc) or VDO volume (/dev/mapper/vdo_sdc) gluster_infra_volume_groups: - vgname: gluster_vg_sdb pvname: /dev/sdb - vgname: gluster_vg_sdc pvname: /dev/mapper/vdo_sdc - vgname: gluster_vg_sdd pvname: /dev/mapper/vdo_sdd gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdb - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdc - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sdd # 'thinpoolsize is the sum of sizes of all LVs to be created on that VG
# In the case of VDO enabled, thinpoolsize is 10 times the sum of sizes
# of all LVs to be created on that VG. Recommended values for
# poolmetadatasize is 16GB and that should be considered exclusive of
# thinpoolsize
gluster_infra_thinpools:
- {vgname: gluster_vg_sdc, thinpoolname: gluster_thinpool_sdc, thinpoolsize: 500G, poolmetadatasize: 16G}
- {vgname: gluster_vg_sdd, thinpoolname: gluster_thinpool_sdd, thinpoolsize: 500G, poolmetadatasize: 16G}
# Enable the following section if LVM cache is to enabled
# Following are the variables:
# vgname - VG with the slow HDD device that needs caching
# cachedisk - Comma separated value of slow HDD and fast SSD
# In this example, /dev/sdb is the slow HDD, /dev/sde is fast SSD
# cachelvname - LV cache name
# cachethinpoolname - Thinpool to which the fast SSD to be attached
# cachelvsize - Size of cache data LV. This is the SSD_size - (1/1000) of SSD_size
# 1/1000th of SSD space will be used by cache LV meta
# cachemode - writethrough or writeback
# gluster_infra_cache_vars:
# - vgname: gluster_vg_sdb
# cachedisk: /dev/sdb,/dev/sde
# cachelvname: cachelv_thinpool_sdb
# cachethinpoolname: gluster_thinpool_sdb
# cachelvsize: 250G
# cachemode: writethrough
# Only the engine brick needs to be thickly provisioned
# Engine brick requires 100GB of disk space
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
# Common configurations
vars:
# In case of IPv6 based deployment "gluster_features_enable_ipv6" needs to be enabled,below line needs to be uncommented, like:
# gluster_features_enable_ipv6: true
# Firewall setup
gluster_infra_fw_ports:
- 2049/tcp
- 54321/tcp
- 5900-6923/tcp
- 16514/tcp
- 5666/tcp
- 16514/tcp
gluster_infra_fw_permanent: true
gluster_infra_fw_state: enabled
gluster_infra_fw_zone: public
gluster_infra_fw_services:
- glusterfs
# Allowed values for gluster_infra_disktype - RAID6, RAID5, JBOD
gluster_infra_disktype: RAID6
# gluster_infra_diskcount is the number of data disks in the RAID set.
# Note for JBOD its 1
gluster_infra_diskcount: 10
gluster_infra_stripe_unit_size: 256
gluster_features_force_varlogsizecheck: false
gluster_set_selinux_labels: true第14章 node_replace_inventory.yml ファイルについて
node_replace_inventory.yml ファイルは、Red Hat Hyperconverged Infrastructure for Virtualization クラスターの代替ホストを準備するために使用できる Ansible インベントリーファイルの例です。
このファイルは、いずれかのハイパーコンバージドホストの /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/node_replace_inventory.yml にあります。
14.1. ノード交換の設定パラメーター
hosts(必須)バックエンド FQDN を使用して、クラスター内にアクティブなホストを 1 つ定義します。
cluster_nodes: hosts: host2-backend-fqdn.example.com: vars: [common host configuration]gluster_maintenance_old_node(required)置き換えられるノードのバックエンド FQDN を定義します。
cluster_nodes: hosts: host2-backend-fqdn.example.com: vars: gluster_maintenance_old_node: host1-backend-fqdn.example.comgluster_maintenance_new_node(required)置き換えるノードのバックエンドの FQDN を定義します。
cluster_nodes: hosts: host2-backend-fqdn.example.com: vars: gluster_maintenance_new_node: new-host-backend-fqdn.example.comgluster_maintenance_cluster_node(required)クラスター内のアクティブなノード。
gluster_maintenance_cluster_node_2と同じにすることはできません。cluster_nodes: hosts: host2-backend-fqdn.example.com: vars: gluster_maintenance_cluster_node: host2-backend-fqdn.example.comgluster_maintenance_cluster_node_2(required)クラスター内のアクティブなノード。
gluster_maintenance_cluster_nodeと同じにすることはできません。cluster_nodes: hosts: host2-backend-fqdn.example.com: vars: gluster_maintenance_cluster_node_2: host3-backend-fqdn.example.com
14.2. 例 node_replace_inventory.yml
cluster_node: hosts: host2-backend-fqdn.example.com: vars: gluster_maintenance_old_node: host1-backend-fqdn.example.com gluster_maintenance_new_node: new-host-backend-fqdn.example.com gluster_maintenance_cluster_node: host2-backend-fqdn.example.com gluster_maintenance_cluster_node_2: host3-backend-fqdn.example.com
付録B Red Hat Gluster Storage のフェンシングポリシー
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) のデプロイメントには、次のフェンシングポリシーが必要です。これにより、ブリックプロセスがまだ実行されている場合や、ホストをシャットダウンするとボリュームがクォーラムに到達できなくなる場合に、ホストがシャットダウンされないようにします。
これらのポリシーは、Red Hat Gluster Storage 機能が有効になっている場合、管理ポータルの New Cluster またはクラスターの Edit Cluster ウィンドウで設定できます。
- Skip fencing if gluster bricks are up
- ブリックが実行中で、他のピアからアクセスできる場合、フェンシングはスキップされます。
- Skip fencing if gluster quorum not met
- ブリックが実行されている場合、フェンシングはスキップされ、ホストをシャットダウンするとクォーラムが失われます
これらのポリシーは、ノードがフェンシングされているかどうかを判断するときに、他のすべてのフェンシングポリシーの後にチェックされます。
フェンシングポリシーを追加すると、デプロイメントに役立つ場合があります。フェンシングの詳細については、Red Hat Virtualization Technical Reference (https://access.redhat.com/documentation/ja-jp/red_hat_virtualization/4.4/html/technical_reference/fencing) を参照してください。
付録C Configure Red Hat Gluster Storage as a Red Hat Virtualization storage domain
C.1. gluster トラフィック用の論理ネットワークの作成
管理ポータルにログインする
管理ポータル (例 http://engine.example.com/ovirt-engine) にアクセスし、Web コンソールを使用してホストされたエンジンをデプロイする で設定した管理認証情報を使用してログインします。
gluster トラフィック用の論理ネットワークを作成する
- Network → Networks をクリックしてから New をクリックします。New Logical Network ウィザードが表示されます。
- ウィザードの General タブで、新しい論理ネットワークの Name を指定して、VM Network チェックボックスをオフにします。
- ウィザードの Cluster タブで、Required チェックボックスをオフにします。
- OK をクリックして、新しい論理ネットワークを作成します。
gluster の新しい論理ネットワークを有効にする
- Network → Networks をクリックし、新しい論理ネットワークを選択します。
- Clusters サブタブをクリックし、Manage Network をクリックします。Manage Network ダイアログが表示されます。
- Manage Network ダイアログで、Migration Network および Gluster Network チェックボックスをオンにします。
- OK をクリックして保存します。
gluster ネットワークをホストに接続する
- Compute → Hosts をクリックし、ホストを選択します。
- Network Interfaces サブタブをクリックし、Setup Host Networks をクリックします。Setup Host Networks ウィンドウが開きます。
- 新しく作成したネットワークを正しいインターフェイスにドラッグアンドドロップします。
- Verify connectivity between Host and Engine チェックボックスがオンになっていることを確認します。
- Save network configuration チェックボックスがオンになっていることを確認します。
- OK をクリックして保存します。
ネットワークの状態を確認します
Network Interfaces タブをクリックして、ホストのネットワークの状態を確認します。ネットワークインターフェイスが非同期状態になるか、IP アドレスがない場合は、Management → Refresh Capabilities をクリックします。
C.2. 追加のハイパーコンバージドホストを設定する
IPv6 アドレスを使用している場合、または Web コンソールを使用して Hosted Engine 用に Red Hat Gluster Storage を設定する の一部として追加のハイパーコンバージドホスト (host2、host3) を指定しなかった場合は、他のハイパーコンバージドホストごとに管理ポータルで以下の手順に従います。
- Compute → Hosts をクリックし、New をクリックして New Host ウィンドウを開きます。
- 管理するホストの Name、Hostname、および Password を指定します。
- Advanced Parameters で、Automatically configure host firewall チェックボックスをオフにします。これは、ファイアウォールルールがデプロイメントプロセスによってすでに設定されているためです。
- New Host ダイアログの Hosted Engine タブで、Choose hosted engine deployment action の値を Deploy に設定します。これにより、ホストされたエンジンが新しいホストで実行できるようになります。
OK をクリックします。
- gluster ネットワークを新しいホストに接続する
- 新しく追加されたホストの名前をクリックして、ホストページに移動します。
- Network Interfaces サブタブをクリックし、Setup Host Networks をクリックします。
- 新しく作成したネットワークを正しいインターフェイスにドラッグアンドドロップします。
- Verify connectivity チェックボックスがオンになっていることを確認します。
- Save network configuration チェックボックスがオンになっていることを確認します。
OK をクリックして保存します。
このホストの General サブタブで、Hosted Engine HA の値が Active で、スコアが正の整数であることを確認します。
重要スコア が N/A と表示されている場合は、Choose hosted engine deployment action で デプロイ アクションを選択し忘れている可能性があります。Red Hat Enterprise Linux ベースの RHHI のメンテナンス の ハイパーコンバージドホストの再インストール の手順に従って、デプロイ アクションでホストを再インストールします。
ネットワークの状態を確認します
Network Interfaces タブをクリックして、ホストのネットワークの状態を確認します。ネットワークインターフェイスが非同期状態になるか、IP アドレスがない場合は、Management → Refresh Capabilities をクリックします。
詳細については、Red Hat Virtualization 4.4 セルフホストエンジンガイド: https://access.redhat.com/documentation/ja-jp/red_hat_virtualization/4.4/html/self-hosted_engine_guide/chap-installing_additional_hosts_to_a_self-hosted_environment を参照してください。
付録D Ansible Vault で暗号化されたファイルの使用
Red Hat は、パスワードやその他の機密情報を含むデプロイメントおよび管理ファイルの内容を暗号化することを推奨します。Ansible Vault は、これらのファイルを暗号化する 1 つの方法です。Ansible Vault の詳細は、Ansible documentation を参照してください。
D.1. ファイルの暗号化
ansible-vault create コマンドで暗号化ファイルを作成したり、ansible-vault encrypt コマンドで既存のファイルを暗号化することができます。
暗号化ファイルを作成したり、既存のファイルを暗号化したりすると、パスワードを指定するように求められます。このパスワードは、暗号化後にファイルを復号化するために使用されます。このファイル内の情報を直接使用する場合や、ファイルの内容に依存する Playbook を実行する場合は、このパスワードを指定する必要があります。
暗号化されたファイルの作成
$ ansible-vault create variables.yml
New Vault password:
Confirm New Vault password:
ansible-vault create コマンドは新しいファイルのパスワードを要求し、保存する前にファイルを生成できるようにデフォルトのテキストエディター (シェル環境で $EDITOR として定義) で新規ファイルを開きます。
すでにファイルを作成していて、それを暗号化したい場合は、ansible-vault encrypt コマンドを使用します。
既存のファイルの暗号化
$ ansible-vault encrypt existing-variables.yml
New Vault password:
Confirm New Vault password:
Encryption successful
D.2. 暗号化されたファイルの編集
暗号化されたファイルを編集するには、ansible-vault edit コマンドを使用し、そのファイルの Vault パスワードを指定します。
暗号化ファイルの編集
$ ansible-vault edit variables.yml
New Vault password:
Confirm New Vault password:
ansible-vault edit コマンドは、ファイルのパスワードの入力を求め、デフォルトのテキストエディター (シェル環境で $EDITOR と定義されている) でファイルを開き、ファイルの内容を編集および保存ができるようにします。
D.3. 暗号化されたファイルの新規パスワードへのキーの指定
ansible-vault rekey コマンドを使用して、ファイルの復号化に使用するパスワードを変更できます。
$ ansible-vault rekey variables.yml
Vault password:
New Vault password:
Confirm New Vault password:
Rekey successful
ansible-vault rekey コマンドは、現在の Vault パスワードの入力を要求し、新しい Vault パスワードを設定して確認するプロンプトを表示します。
付録E 用語集
E.1. 仮想化用語
- Administration Portal
- oVirt engine Web ユーザーインターフェイスをベースとする Red Hat Virtualization Manager が提供する Web ユーザーインターフェイス。これにより、管理者はネットワーク、ストレージドメイン、仮想マシンテンプレートなどのクラスターリソースを管理および監視できます。
- ホスト型エンジン
- RHHI for Virtualization を管理する Red Hat Virtualization Manager のインスタンス。
- ホスト型エンジン仮想マシン
- Red Hat Virtualization Manager として機能する仮想マシン。ホスト型 Engine 仮想マシンは、ホスト型 Engine 仮想マシンで実行されている Red Hat Virtualization Manager のインスタンスが管理する仮想化ホストで実行されます。
- Manager ノード
- ホスト型エンジンの仮想マシンで実行するのではなく、Red Hat Virtualization Manager を直接実行する仮想化ホスト。
- Red Hat Enterprise Linux ホスト
- Red Hat Enterprise Linux でインストールした物理マシンと、Red Hat Virtualization ホストと同じ機能を提供する追加パッケージ。このタイプのホストは、RHHI for Virtualization での使用はサポートされません。
- Red Hat Virtualization
- Linux および Microsoft Windows ワークロードのリソース、プロセス、およびアプリケーションを仮想化するためのオペレーティングシステムと管理インターフェイス。
- Red Hat Virtualization ホスト
- Red Hat Virtualization でインストールされた物理マシン。Linux および Microsoft Windows ワークロードのリソース、プロセス、およびアプリケーションの仮想化をサポートする物理リソースを提供します。これは、RHHI for Virtualization でサポートされる唯一のタイプのホストです。
- Red Hat Virtualization Manager
- Red Hat Virtualization の管理および監視機能を実行するサーバー
- セルフホストエンジンのノード
- ホスト型エンジン仮想マシンを含む仮想化ホスト。RHHI for Virtualization デプロイメントのすべてのホストはセルフホストエンジンノードを持つことができますが、一度にセルフホストエンジンノードが 1 つしかありません。
- ストレージドメイン
- イメージ、テンプレート、スナップショット、およびメタデータの名前付きコレクション。ストレージドメインは、ブロックデバイスまたはファイルシステムから設定できます。ストレージドメインは、データセンターにアタッチされ、データセンター内のホストにはイメージ、テンプレートなどのコレクションにアクセスできます。
- virtualization host
- クライアントアクセスのために物理リソース、プロセス、およびアプリケーションを仮想化する機能がある物理マシン。
- VM ポータル
- Red Hat Virtualization Manager が提供する Web ユーザーインターフェイスこれにより、ユーザーは仮想マシンの管理および監視を行うことができます。
E.2. ストレージ用語
- ブリック
- 信頼できるストレージプール内のサーバーにエクスポートされるディレクトリー。
- キャッシュ論理ボリューム
- 大規模で低速な論理ボリュームのパフォーマンスを改善するのに使用される小規模で高速な論理ボリューム。
- geo-replication
- ソースの Gluster ボリュームからターゲットボリュームへのデータの非同期レプリケーション。Geo レプリケーションは、ローカル領域ネットワークおよびインターネット全体で機能します。ターゲットボリュームは、異なる信頼できるストレージプールの Gluster ボリューム、または別のタイプのストレージになります。
- Gluster ボリューム
- ワークロードの要件に応じてデータを分散、複製、または分散するように設定できるブリックの論理グループ。
- 論理ボリューム管理 (LVM)
- 物理ディスクを大きな仮想パーティションに統合する方法。物理ボリュームはボリュームグループに配置され、必要に応じて論理ボリュームに分割できるストレージのプールを形成します。
- Red Hat Gluster Storage
- Red Hat Enterprise Linux をベースとするオペレーティングシステムは、分散型のソフトウェア定義のストレージをサポートする追加パッケージが含まれています。
- ソースボリューム
- データが geo レプリケーション時にコピーされる Gluster ボリューム。
- ストレージホスト
- クライアントアクセス用にストレージを提供する物理マシン。
- ターゲットボリューム
- geo レプリケーション時にデータがコピーされる Gluster ボリュームまたは他のストレージボリューム。
- シンプロビジョニング
- 必要な領域のみが作成時に割り当てられるように、プロビジョニングストレージは、時間の経過に応じてさらに領域を動的に割り当てられるようにします。
- シックプロビジョニング
- すぐに領域が必要かどうかに関係なく、すべての領域が作成時に割り当てられるようにプロビジョニングストレージをプロビジョニングします。
- 信頼できるストレージプール
- 信頼されるピアとして相互に認識する Red Hat Gluster Storage サーバーのグループ。
E.3. ハイパーコンバージドインフラストラクチャーの用語
- Red Hat Hyperconverged Infrastructure(RHHI)for Virtualization
- RHHI for Virtualization は、仮想コンピュートおよび仮想ストレージリソースの両方を提供する単一の製品です。Red Hat Virtualization および Red Hat Gluster Storage は、接続設定にインストールされます。ここでは、両方の製品のサービスがクラスター内の各物理マシンで利用できます。
- ハイパーコンバージドホスト
- 仮想化プロセスとアプリケーションが同じホスト上で実行する物理ストレージを提供する物理マシン。RHHI for Virtualization と共にインストールされるすべてのホストは、ハイパーコンバージドホストです。
- Web コンソール
- RHHI for Virtualization のデプロイ、管理、監視用の Web ユーザーインターフェイス。Web コンソールは、Red Hat Virtualization Manager の Web Console サービスおよびプラグインによって提供されます。