
Automating RHHI for Virtualization deployment
Ansible を使用して、手動の介入なしにハイパーコンバージドソリューションをデプロイします。
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、弊社 の CTO、Chris Wright のメッセージ を参照してください。
第1章 Ansible ベースのデプロイメントワークフロー
Ansibleを使用して、Red Hat Hyperconverged Infrastructure for Virtualizationを単一のノード、または3から12のノードに展開することができます。
ユーザー要件に基づくインベントリーファイルの準備は 1 回限りのプロセスで、利用可能なインベントリーファイルのサンプルを使用して作成されます。
Ansible を使用して RHHI for Virtualization をデプロイするワークフローは以下のとおりです。
要件を確認します。
予定されているデプロイメントがサポート要件を満たしていることを確認します。Requirements を満たし、デプロイメントプロセス中に参照できるように installation checklist を入力します。
オペレーティングシステムをインストールします。
- ハイパーコンバージドホストとして機能する各物理マシンにオペレーティングシステムをインストールします。Installing hyperconverged hosts を参照してください。
- (必要に応じて)NBDE(Network-Bound Disk Encryption)キーサーバーとして機能する各物理または仮想マシンにオペレーティングシステムをインストールします。Installing NBDE key servers を参照してください。
追加ソフトウェア向けにファイアウォールルールを変更します。
- (オプション)ディスク暗号化のファイアウォールルールを変更します。「ディスク暗号化のファイアウォールルールの変更」
ハイパーコンバージドホスト間の認証を設定します。
ホストの自動設定を有効にするためにパスワードなしでキーベースの SSH 認証を設定します。Configure key-based SSH authentication を参照してください。
(オプション)ディスクの暗号化を設定します。
- NBDE 鍵サーバーを設定します。
- ハイパーコンバージドホストをNBDEクライアントとして設定します。Configure hyperconverged hosts as NBDE clients を参照してください。
- インベントリーおよび Playbook ファイルで環境の詳細を定義します。Defining deployment details を参照してください。
- Ansible Playbook を実行して RHHI for Virtualization をデプロイします。Executing the deployment playbook を参照してください。
- デプロイメントを確認します。
第2章 サポート要件
このセクションでは、予定されるデプロイメントが Red Hat のサポート要件を満たしていることを確認します。
2.1. オペレーティングシステム
Red Hat Hyperconverged Infrastructure for Virtualization(RHHI for Virtualization)は、その他すべての設定のベースとして Red Hat Virtualization Host 4.4 を使用します。Red Hat Enterprise Linux ホストはサポートされません。
Red Hat Virtualization の要件の詳細については、Red Hat VirtualizationPlanning and Prerequisites Guide のRequirements を参照してください。
2.1.1. ブラウザーの要件
Web コンソールおよび Red Hat Virtualization 管理者ポータルのサポートは、アクセスに使用する Web ブラウザーによって異なります。
通常、Mozilla Firefox、Google Chrome、または Microsoft Edge の最新バージョンを使用します。
Web コンソールのブラウザーサポートの詳細は、Logging in to the web consoleを参照してください。
管理者ポータルのブラウザーサポートの詳細は、Red Hat Virtualization の Browser requirements を参照してください。
2.2. 物理マシン
Red Hat Hyperconverged Infrastructure for Virtualization(RHHI for Virtualization)には、少なくとも 3 台の物理マシン が必要です。6、9、または 12 の物理マシンへのスケーリングもサポートされます。より詳細な要件については、Scaling を参照してください。
各物理マシンには、以下の機能が必要です。
- データおよび管理トラフィックを分離するために、物理マシンごとに少なくとも 2 つの NIC(ネットワークインターフェースコントローラー)が設定されます(詳細は 「ネットワーキング」 を参照してください)。
小規模なデプロイメントの場合:
- 12 コア以上
- 64GB 以上の RAM
- 最大 48TB ストレージ
中規模デプロイメントの場合
- 12 コア以上
- 最小 128GB RAM
- 最大 64TB ストレージ
大規模なデプロイメントの場合
- 16 コア以上
- 256GB 以上の RAM
- 最大 80TB ストレージ
2.3. 仮想マシン
ハイパーコンバージドのデプロイメントで実行できる仮想マシンの数は、それらの仮想マシンの動作と、その中の負荷に大きく依存します。ワークロードの CPU、メモリー、およびスループットの要件をテストし、それに応じてハイパーコンバージド環境をプロビジョニングします。
仮想マシンおよび仮想 CPU の最大数 に関する情報は、Virtualization limits for Red Hat Virtualization を参照してください。また、デプロイメントのプランニングは RHHI for Virtualization Sizing Tool を使用します。
Red Hat Hyperconverged Infrastructure for Virtualization(Red Hat OpenShift Container Platformがインストールされた仮想マシンをホストするハイパーコンバージドノード)の上にOpenShift Container Storageを置くことは、サポートされていない構成です。
2.4. ホスト型エンジン仮想マシン
ホスト型エンジン仮想マシンには、少なくとも以下が必要です。
- 1 つのデュアルコア CPU(1 クアッドコアまたは複数のデュアルコア CPU が推奨)
- 他のプロセスと共有されない 4GB RAM(16GB 推奨)
- 25 GB のローカル、書き込み可能なディスク領域(50GB 推奨)
- 1 NIC(最低 1 Gbps 帯域幅)
詳細は、Red Hat Virtualization 4.4 Planning and Prerequisites Guide の Requirements を参照してください。
2.5. ネットワーキング
DNS で正引きおよび逆引き解決が可能な完全修飾ドメイン名 は、すべてのハイパーコンバージドホストおよびホスト型エンジン仮想マシンに必要です。
外部 DNS が利用できない場合(例: 分離された環境など)、各ノードの /etc/hosts ファイルにすべてのホストおよびホスト型エンジンノードのフロントエンドアドレスが含まれることを確認します。
IPv6 は IPv6 専用環境(DNS およびゲートウェイアドレスを含む)でサポートされています。IPv4 アドレスと IPv6 アドレスの両方を備えた環境はサポートされません。
Red Hat は、仮想マシンのトラフィックに フロントエンド管理ネットワーク と、gluster トラフィックおよび仮想マシンの移行向けの バックエンドストレージネットワーク という別のネットワークを使用することを推奨します。
図2.1 ネットワークダイアグラム
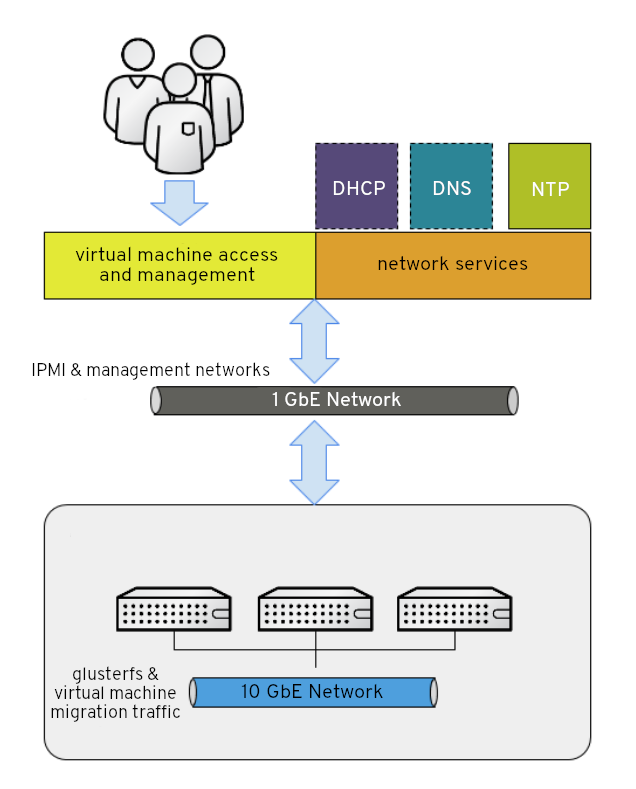
Red Hat では、それぞれのノードに各ネットワーク用にイーサネットポートを 1 つずつ設定することを推奨します。これにより、最適なパフォーマンスが確保されます。高可用性を確保するには、各ネットワークを別個のネットワークスイッチに配置します。フォールトトレランスを強化するために、スイッチごとに個別の電源供給を指定します。
- フロントエンド管理ネットワーク
- Red Hat Virtualization および仮想マシンによって使用されます。
- イーサネット接続に 1Gbps 以上が必要です。
- このネットワークに割り当てられる IP アドレスは、相互に同じサブネット上、およびバックエンドストレージネットワークとは別のサブネット上になければなりません。
- このネットワークの IP アドレスは、管理者が選択できます。
- バックエンドストレージネットワーク
- ハイパーコンバージドノード間のストレージおよび移行トラフィックで使用されます。
- 最低でも1つの10 Gbpsイーサネット接続が必要です。
- ピア間で最大 5 ミリ秒のレイテンシーが必要です。
Intelligent Platform Management Interface(IPMI)を使用するネットワークフェンシングデバイスには、別のネットワークが必要です。
Hosted Engine 仮想マシンに DHCP ネットワーク設定を使用する場合は、Red Hat Hyperconverged Infrastructure for Virtualization を設定する前に DHCP サーバーを設定する必要があります。
データのコピーを保存するために geo レプリケーションを使用して 障害復旧を設定する場合は、信頼できるタイムソースを設定してください。
デプロイメントプロセスを開始する前に、以下の詳細を確認してください。
- ハイパーコンバージドホストへのゲートウェイの IP アドレス。このアドレスは ping 要求に応答する必要があります。
- フロントエンド管理ネットワークの IP アドレス。
- ホスト型エンジン仮想マシンの完全修飾ドメイン名(FQDN)。
- ホスト型エンジンの静的 FQDN および IP アドレスに解決する MAC アドレス。
2.6. ストレージ
ハイパーコンバージドホストは、設定、ログ、およびカーネルダンプを保存し、そのストレージをスワップ領域として使用します。このセクションでは、ハイパーコンバージドホストのディレクトリーの最小サイズを一覧表示します。Red Hat は、この最小値よりも多くのストレージ容量を使用するデフォルトの割り当てを使用することを推奨します。
-
/(root): 6GB -
/home: 1GB -
/tmp: 1GB -
/boot: 1GB -
/var: 15GB -
/var/crash: 10GB /var/log: 8GB重要Red Hat では、
/var/logのサイズを 15 GB 以上に増やして、Red Hat Gluster Storage の追加ロギング要件に十分な領域を提供することを推奨します。Growing a logical volume using the Web Consoleの手順に従って、オペレーティングシステムのインストール後にこのパーティションのサイズを拡大します。
-
/var/log/audit: 2GB -
swap: 1 GB(詳細は 推奨のスワップサイズ を参照) - Anaconda では、将来のメタデータ拡張用に、ボリュームグループ内のシンプールサイズの 20% が確保されます。これは、通常の使用条件においてデフォルト設定でストレージを使い果たすのを防ぐためです。インストール中のシンプールのオーバープロビジョニングもサポートされていません。
- 最小合計: 64GB
2.6.1. ディスク
Red Hat では、最適なパフォーマンスを得るために、SSD(Solid State Disks)を推奨します。ハードドライブのディスク(HDD)を使用する場合は、SSD を LVM キャッシュボリュームとしてさらに小さく設定する必要があります。キャッシュデバイスは、他のボリュームと同じブロックサイズを使用する必要があります。
異なるブロックサイズを持つディスク間で Gluster ボリュームのブリックをホストしないでください。VDOデバイスのデフォルトのブロックサイズがバージョン1.6の512バイトからバージョン1.7では4KBに変更されたため、ボリュームを作成する前にレンガのホストとして使用されているVDOデバイスのブロックサイズを確認してください。以下のコマンドを実行して、ディスクのブロックサイズ(バイト単位)を確認します。
# blockdev --getss <disk_path>
2.6.2. RAID
RAID5 および RAID6 の設定がサポートされます。ただし、RAID 設定制限は、使用中のテクノロジーによって異なります。
- SAS/SATA 7k ディスクは、RAID6 でサポートされています(ほとんどの場合 10+2)
SAS 10k および 15k のディスクは以下でサポートされます。
- RAID5(ほとんどの 7+1)
- RAID6(最大 10+2)
RAID カードは、フラッシュでサポートされる書き込みキャッシュを使用する必要があります。
Red Hat は、各サーバーに少なくとも 1 つのホットペアドライブを提供することを推奨します。
VDO の下の層で RAID ハードウェアを使用する予定の場合には、SSD/NVMe ディスクを使用してパフォーマンスの問題を回避することを推奨します。VDO の下に RAID ハードウェア層を使用していない場合は、スピンアップディスクを使用できます。
2.6.3. JBOD
Red Hat Hyperconverged Infrastructure for Virtualization 1.6 の時点で、JBOD 設定は完全にサポートされ、アーキテクチャーレビューが不要になりました。
2.6.4. 論理ボリューム
エンジン gluster ボリュームを構成する論理ボリュームは、プロビジョニングする必要があります。これにより、Hosted Engine が領域不足、破壊的なボリューム設定の変更、I/O オーバーヘッド、および移行アクティビティーから保護されます。
vmstoreとオプションのdataGlusterボリュームを構成する論理ボリュームはシンプロビジョニングされている必要があります。これにより、基礎となるボリューム設定で柔軟性が向上します。
シンプロビジョニングされたボリュームがハードディスク(HDD)にある場合は、パフォーマンスを向上させるために、小規模かつ高速な Solid State Disk(SSD)を lvmcache として設定します。キャッシュデバイスは、他のボリュームと同じブロックサイズを使用する必要があります。
2.6.5. Red Hat Gluster Storage ボリューム
Red Hat Hyperconverged Infrastructure for Virtualizationには、Red Hat Gluster Storageのボリュームが3から4個搭載される予定です。
- ホステッドエンジン用のエンジンボリューム 1 個
- 仮想マシンのオペレーティングシステムディスクイメージ用のvmstoreボリューム 1 個
- 他の仮想マシンのディスクイメージ用の data ボリューム 1 個
- ジオレプリケーションメタデータ用のshared_storageボリューム 1 個
バックアップに必要なストレージ容量を最小限に抑えるために、vmstoreとdataボリュームを分けることをお勧めします。オペレーティングシステムイメージから分離されている仮想マシンデータを保存すると、vmstore ボリュームのオペレーティングシステムイメージをより簡単に再構築できるため、ストレージ領域がプレミアムにあるときに data ボリュームのみのバックアップを作成する必要があります。
2.6.6. ボリュームタイプ
Red Hat Hyperconverged Infrastructure for Virtualization(RHHI for Virtualization)は、デプロイ時に以下のボリューム種別のみをサポートします。
- Replicated volumes(3つのブリック上の同じデータの3つのコピー、3つのノードにまたがる)。
- Arbitrated replicated volumes(3 つのノードにまたがって、2 つのブリックに同じデータのフルコピーを 2 つ、メタデータを含む 1 つのアービターブリックにコピーしたもの)。
Distributed volume with a single brick(データのコピーは1つ、他のブリックへのレプリケーションはなし)。
注記シングルブリックを使用した分散ボリュームは、Red Hat Hyperconverged Infrastructure for Virtualization のシングルノード展開でのみサポートされます。
ガイドAutomating RHHI for Virtualization deployment に記載されているように、Ansible playbook を使用して Red Hat Hyperconverged Infrastructure for Virtualization の展開中にdistributed replicate または distributed arbitrated replicate を作成することができます。
判定ブリックは、ファイル名、構造、およびメタデータのみを保存することに注意してください。つまり、3 方向の判別複製ボリュームは、同じレベルの一貫性を実現するために、3 方向の複製ボリュームが 75 % である必要があることを意味します。ただし、arbiter ブリックはメタデータのみを格納するため、3 方向の判別複製ボリュームは双方向複製ボリュームのみを提供します。
裁定済みレプリケートボリュームのレイアウトの詳細については、Red Hat Gluster Storage Administration Guide の Creating multiple arbitrated replicated volumes across fewer total nodes を参照してください。
2.7. ディスクの暗号化
ディスクの暗号化は、Red Hat Hyperconverged Infrastructure for Virtualization 1.8. 以降でサポートされています。
サポートされる方法は Network-Bound Disk Encryption(NBDE)です。これは、鍵サーバーを使用して起動時に暗号化されたクライアントに復号化鍵を提供します。これにより、復号化パスワードを手動で入力する必要がなくなります。
NBDE のサポートには、NBDE 鍵サーバーとして機能するため、少なくとも 1 台以上のサーバー(物理または仮想)が必要です。フォールトトレランスのために、Red Hatは 2 台の NBDE キーサーバーを推奨します。
NBDE 鍵サーバーは、Red Hat Hyperconverged Infrastructure for Virtualization クラスターに含めることはできません。
NBDE キーサーバーは、以下のいずれかのオペレーティングシステムを使用できます。
- Red Hat Enterprise Linux 7.8 以降
- Red Hat Enterprise Linux 8.2 以降
ディスクの暗号化では、通常、パフォーマンスが小さくなります。特に、ディスク暗号化を、重複排除や Virtual Disk Optimization による圧縮など、速度が若干低下する他の技術と組み合わせて使用している場合は、本番環境に投入する前にこの構成を十分にテストし、ユースケースのパフォーマンス要件を満たしていることを確認してください。
2.8. VDO (Virtual Data Optimizer)
VDO(Virtual Data Optimizer)層は、Red Hat Hyperconverged Infrastructure for Virtualization 1.6 でサポートされます。
VDO のサポートは、新しいデプロイメントのみに限定されます。既存のデプロイメントに VDO レイヤーを追加しないでください。
VDO デバイスのデフォルトのブロックサイズが、バージョン 1.6 の 512 バイトからバージョン 1.7 で 4 KB に変更されることに注意してください。異なるブロックサイズを持つディスク間で Gluster ボリュームのブリックをホストしないでください。
データの削減には追加の処理コストがあるため、圧縮および重複排除を有効にすると書き込みパフォーマンスが向上します。そのため、パフォーマンス重視ワークロードには VDO は推奨されません。Red Hat は、特にディスク暗号化などのパフォーマンスを低下させる他の技術と併用する前に、特に VDO をデプロイする前に、ワークロードが VDO を有効にしてパフォーマンスを達成することをテストし、検証することを強く推奨します。
2.9. スケーリング
初回のデプロイメントに確保できるノード数は、デプロイメント方法によって異なります。
Web コンソールを使用する場合は、1 つまたは 3 台のハイパーコンバージドノードをデプロイすることができます。
この場合、作成時に 3 つ以上のノードにまたがるボリュームを作成することはできません。まず 3 ノードボリュームを作成してから、デプロイメント後に複数のノードに拡張する必要があります。
- Ansible 自動化を使用する場合は、最大 12 ハイパーコンバージドノードまでデプロイして、デプロイ時に必要なノード数全体でボリュームにまたがることができます。
1 ノードのデプロイメントをスケーリングできません。
他のデプロイメントは、少なくとも 3 つのノードから、6、9、または 12 のノードにスケーリングできます。
ディスクを追加し、Gluster ボリュームを拡張してデプロイメントをスケーリングできます。新規または既存のノードにディスクを追加し、それらを使用して新規 Gluster ボリュームを作成するか、または既存の Gluster ボリュームを拡張します。
2.10. 既存の Red Hat Gluster Storage 設定
Red Hat Hyperconverged Infrastructure for Virtualization は、本書で指定されているとおりにデプロイした場合にのみサポートされます。既存の Red Hat Gluster Storage 設定は、ハイパーコンバージド設定では使用できません。既存の Red Hat Gluster Storage 設定を使用する場合は、Configuring Red Hat Virtualization with Red Hat Gluster Storage に記載されている従来の設定を参照してください。
2.11. 障害回復
Red Hat は、障害復旧ソリューションを設定することを強く推奨します。ディザスタリカバリソリューションとしてのジオレプリケーションの構成については、Maintaining Red Hat Hyperconverged Infrastructure for Virtualization: https://access.redhat.com/documentation/ja-jp/red_hat_hyperconverged_infrastructure_for_virtualization/1.8/html/maintaining_red_hat_hyperconverged_infrastructure_for_virtualization/config-backup-recovery を参照してください。
2.11.1. geo レプリケーションの前提条件
geo レプリケーションを設定する際には、以下の要件と制限に注意してください。
- 2 つの異なるマネージャーが必要です
- geo レプリケーションのソースおよび宛先ボリュームは、Red Hat Virtualization Manager の異なるインスタンスで管理される必要があります。
2.11.2. フェイルオーバーおよびフェイルバック設定の前提条件
- バージョンが環境間で一致している必要があります
- プライマリー環境とセカンダリー環境には、同じバージョンの Red Hat Virtualization Manager が含まれており、同じデータセンターの互換バージョン、クラスターの互換バージョン、および PostgreSQL のバージョンを使用します。
- ホスト型エンジンストレージドメインに仮想マシンディスクがない
- ホスト型エンジン仮想マシンで使用されるストレージドメインはフェイルオーバーしないため、このストレージドメインの仮想マシンディスクはすべて失われます。
- Ansible Playbook を別々のマシンから手動で実行する
Ansible Playbook を Ansible コントローラノードとして機能する別のマシンから手動で生成し、実行します。このノードには、必要な障害復旧 Ansible ロールをすべて提供する
ovirt-ansible-collectionパッケージが必要です。注記ovirt-ansible-collectionパッケージは、デフォルトで Hosted Engine 仮想マシンとともにインストールされます。ただし、プライマリーサイトに影響を与える障害時に、この仮想マシンは停止している可能性があります。プライマリーサイト外のマシンを使用してこの Playbook を実行することは安全ですが、テスト目的で、Hosted Engine 仮想マシンからこれらの Playbook をトリガーすることができます。
2.12. 単一ノードデプロイメントの追加要件
Red Hat Hyperconverged Infrastructure for Virtualization は、以下の追加および例外を除き、すべてのSupport Requirements が満たされていれば、単一ノードでの展開がサポートされます。
単一ノードのデプロイメントには、以下が含まれる物理マシンが必要です。
- 1 ネットワークインターフェースコントローラー
- 12 コア以上
- 64GB 以上の RAM
シングルノードのデプロイメントは、拡張性がなく、高可用性もありません。このデプロイメントタイプはコストが低くなっていますが、可用性のオプションを削除します。
第3章 オペレーティングシステムのインストール
3.1. ハイパーコンバージドホストのインストール
ハイパーコンバージドホストでサポートされるオペレーティングシステムは、最新バージョンの Red Hat Virtualization 4 です。
3.1.1. Red Hat Virtualization 4 を使用したハイパーコンバージドホストのインストール
3.1.1.1. Red Hat Virtualization 4 オペレーティングシステムのダウンロード
- Red Hat カスタマーポータル に移動します。
- Downloads をクリックし、製品ダウンロード一覧を取得します。
- Red Hat Virtualization をクリックします。
- Download latest をクリックします。
-
Product Software(製品ソフトウェア)タブで、最新のハイパーバイザーイメージ
Hypervisor Image for RHV 4.4の横にある Download ボタンをクリックします。 ファイルがダウンロードされたら、その SHA-256 チェックサムがページにあるものと一致することを確認します。
$ sha256sum image.isoダウンロードしたイメージを使用してインストールメディアデバイスを作成します。
Red Hat Enterprise Linux 8 ドキュメントの Creating installation media を参照してください。
3.1.1.2. ハイパーコンバージドホストへの Red Hat Virtualization 4 オペレーティングシステムのインストール
前提条件
- このオペレーティングシステムは、ハイパーコンバージドホストでのみサポートされます。このオペレーティングシステムでは、NBDE(Network-Bound Disk Encryption)キーサーバーをインストールしないでください。
- ハイパーコンバージドホストでディスク暗号化を有効にする場合は、追加のサーバー要件に注意してください。詳細は、Disk encryption requirements を参照してください。
手順
- 準備済みインストールメディアからマシンを起動し、起動します。
- 起動メニューで Install Red Hat Virtualization 4 を選択し、Enter を押します。
- 言語を選択し、Continue をクリックします。
- デフォルトの Localization オプションを受け入れます。
Installation destination をクリックします。
ストレージドメインに使用されるディスクなど、インストールの場所として使用しないディスクの選択を解除します。
警告チェックマークが付いているディスクはフォーマットされ、それらのデータはすべて失われます。このホストを再インストールする場合には、保持するデータと共にディスクがチェックマークが表示されないようにします。
-
Automatic partitioningオプションを選択します。 (オプション)ディスクの暗号化を使用する場合は、Encrypt my data パスワードを指定します。
警告マシンが起動しなくなるので、このパスワードを忘れないようにしてください。
このパスワードは、Network-Bound Disk Encryption の設定時にこのホストの
rootpassphraseとして使用されます。- 完了をクリックします。
Network and Host Name をクリックします。
-
Ethernet スイッチを
ONに切り替えます。 ネットワークインターフェースを選択し、Configure をクリックします。
- General タブで、優先的に自動的に接続するチェックボックスをチェックします。
(オプション)IPv4 の代わりに IPv6 ネットワークを使用するには、IPv 6 設定 タブでネットワークの詳細を指定します。
静的ネットワーク設定では、IPv6 アドレス、プレフィックス、ゲートウェイ、ならびに IPv6 DNS サーバーおよび追加の検索ドメインを指定するようにしてください。
重要IPv4 または IPv6 のいずれかを使用する必要があります。混合ネットワークはサポートされません。
- 保存 をクリックします。
- 完了をクリックします。
-
Ethernet スイッチを
- (オプション)セキュリティーポリシーを設定します。
インストールの開始をクリックします。
root パスワードを設定します。
警告Red Hat は、ローカルのセキュリティー脆弱性が悪用される可能性があるため、ハイパーコンバージドホストに追加のユーザーを作成しないことを推奨します。
- 再起動 をクリックしてインストールを完了します。
/var/logパーティションのサイズを増やします。Red Hat Gluster Storage のロギング要件には、15 GB 以上の空き領域が必要です。Growing a logical volume using the Web Console の手順に従って、このパーティションのサイズを増やします。
3.2. NBDE(Network-Bound Disk Encryption key)サーバーのインストール
Network-Bound Disk Encryption を使用して Red Hat Hyperconverged Infrastructure for Virtualization のディスクのコンテンツを暗号化する場合には、少なくとも 1 つのキーサーバーをインストールする必要があります。
NBDE(Network-Bound Disk Encryption)キーサーバーでサポートされるオペレーティングシステムは、Red Hat Enterprise Linux 7 および 8 の最新バージョンです。
3.2.1. Red Hat Enterprise Linux 8 を使用した NBDE 鍵サーバーのインストール
3.2.1.1. Red Hat Enterprise Linux 8 オペレーティングシステムのダウンロード
- Red Hat カスタマーポータル に移動します。
- Downloads をクリックし、製品ダウンロード一覧を取得します。
- Red Hat Enterprise Linux 8 をクリックします。
-
Product Software(製品ソフトウェア)タブで、最新のバイナリー DVD イメージ(
Red Hat Enterprise Linux 8.2 Binary DVDなど)の横にある Download をクリックします。 ファイルがダウンロードされたら、その SHA-256 チェックサムがページにあるものと一致することを確認します。
$ sha256sum image.isoイメージを使用してインストールメディアデバイスを作成します。
詳細は、Red Hat Enterprise Linux 8 ドキュメントの Creating installation media を参照してください。
3.2.1.2. Red Hat Enterprise Linux 8 オペレーティングシステムの Network-Bound Disk Encryption Key サーバーへのインストール
手順
- 準備済みインストールメディアからマシンを起動し、起動します。
- 起動メニューで Install Red Hat Enterprise Linux 8 を選択し、Enter を押します。
- 言語を選択し、Continue をクリックします。
- デフォルトの Localization および Software オプションを受け入れます。
Installation destination をクリックします。
オペレーティングシステムをインストールするディスクを選択します。
警告チェックマークが付いているディスクはフォーマットされ、それらのデータはすべて失われます。このホストを再インストールする場合には、保持するデータと共にディスクがチェックマークが表示されないようにします。
(オプション)ディスクの暗号化を使用する場合は、Encrypt my data パスワードを指定します。
警告マシンが起動しなくなるので、このパスワードを忘れないようにしてください。
- 完了をクリックします。
Network and Host Name をクリックします。
-
Ethernet スイッチを
ONに切り替えます。 ネットワークインターフェースを選択し、Configure をクリックします。
- General タブで、Connect automatically with priority チェックボックスをチェックします。
(オプション)IPv4 の代わりに IPv6 ネットワークを使用するには、IPv 6 settings タブでネットワークの詳細を指定します。
静的ネットワーク設定では、IPv6 アドレス、プレフィックス、ゲートウェイ、ならびに IPv6 DNS サーバーおよび追加の検索ドメインを指定するようにしてください。
重要IPv4 または IPv6 のいずれかを使用する必要があります。混合ネットワークはサポートされません。
- 保存 をクリックします。
- 完了をクリックします。
-
Ethernet スイッチを
- (オプション)セキュリティーポリシーを設定します。
インストールの開始をクリックします。
- root パスワードを設定します。
- Reboot をクリックしてインストールを完了します。
- 初期セットアップ 画面で、ライセンスアグリーメントに同意して、システムを登録します。
3.2.2. Red Hat Enterprise Linux 7 を使用した NBDE 鍵サーバーのインストール
3.2.2.1. Red Hat Enterprise Linux 7 オペレーティングシステムのダウンロード
- Red Hat カスタマーポータル に移動します。
- Downloads をクリックし、製品ダウンロード一覧を取得します。
- Versions 7 and below をクリックします。
-
Product Software(製品ソフトウェア)タブで、最新のバイナリー DVD イメージの横にある Download をクリックします(例:
Red Hat Enterprise Linux 7.8 Binary DVD)。 ファイルがダウンロードされたら、その SHA-256 チェックサムがページにあるものと一致することを確認します。
$ sha256sum image.isoイメージを使用してインストールメディアデバイスを作成します。
詳細は、Red Hat Enterprise Linux 8 ドキュメントの Creating installation media を参照してください。
3.2.2.2. Red Hat Enterprise Linux 7 オペレーティングシステムの Network-Bound Disk Encryption Key サーバーへのインストール
前提条件
- このオペレーティングシステムは、NBDE(Network-Bound Disk Encryption)キーサーバーでのみサポートされることに注意してください。このオペレーティングシステムを使用するハイパーコンバージドホストをインストールしないでください。
手順
- 準備済みインストールメディアからマシンを起動し、起動します。
- 起動メニューで Install Red Hat Enterprise Linux 7 を選択して Enter を押します。
- 言語を選択し、Continue をクリックします。
Date & Time をクリックします。
- タイムゾーンを選択します。
- 完了をクリックします。
Keyboard をクリックします。
- キーボードレイアウトを選択します。
- 完了をクリックします。
Installation destination をクリックします。
- インストール場所として使用しないディスクの選択を解除します。
ディスクの暗号化を使用する場合は、Encrypt my data パスワードを指定します。
警告マシンが起動しなくなるので、このパスワードを忘れないようにしてください。
- 完了をクリックします。
Network and Host Name をクリックします。
- Configure から General をクリックします。
- Automatically connect to this network when it is available のチェックボックスにチェックを入れます。
- 完了をクリックします。
- 必要に応じて、言語サポート、セキュリティーポリシー、および kdump を設定します。
インストールの開始をクリックします。
- root パスワードを設定します。
- Reboot をクリックしてインストールを完了します。
- 初期セットアップ 画面で、ライセンスアグリーメントに同意して、システムを登録します。
第4章 追加ソフトウェアのインストール
ソフトウェアおよび更新にアクセスするために追加の設定を実行する必要があります。
- ソフトウェア更新にアクセスできることを確認: Configure software repository access using the web console を参照してください。
- ハイパーコンバージドホストがディスクの暗号化を使用する場合は、Install disk encryption software を参照してください。
4.1. ソフトウェアアクセスの設定
4.1.1. Web コンソールを使用したソフトウェアリポジトリーへのアクセスの設定
前提条件
- このプロセスは、Red Hat Virtualization 4 をベースとするハイパーコンバージドホストを対象にしています。
手順
各ハイパーコンバージドホストで以下を行います。
Web コンソールにログインします。
管理 FQDN およびポート 9090 を使用します(例:
https://server1.example.com:9090/)- Subscriptions をクリックします。
Register System をクリックします。
- カスタマーポータルのユーザー名とパスワードを入力します。
完了をクリックします。
Red Hat Virtualization Host のサブスクリプションが自動的にシステムにアタッチされます。
Red Hat Virtualization 4 のリポジトリーを有効にして、Red Hat Virtualization Host に対する後続の更新を可能にします。
# subscription-manager repos \ --enable=rhvh-4-for-rhel-8-x86_64-rpms
(オプション)ディスクの暗号化を使用する場合は、NBDE(Network-Bound Disk Encryption)キーサーバーごとに以下を実行します。
- NBDE 鍵サーバーにログインします。
NBDE 鍵サーバーを Red Hat に登録します。
# subscription-manager register --username=username --password=password
サブスクリプションプールを割り当てます。
# subscription-manager attach --pool=pool_idディスク暗号化ソフトウェアに必要なリポジトリーを有効にします。
Red Hat Enterprise Linux 8 をベースとした NBDE 鍵サーバーの場合:
# subscription-manager repos \ --enable="rhel-8-for-x86_64-baseos-rpms" \ --enable="rhel-8-for-x86_64-appstream-rpms"
Red Hat Enterprise Linux 7 をベースとした NBDE 鍵サーバーの場合
# subscription-manager repos --enable="rhel-7-server-rpms"
4.2. ソフトウェアのインストール
4.2.1. ディスク暗号化ソフトウェアのインストール
Network-Bound Disk Encryption key サーバーには、ディスクの暗号化をサポートする追加のパッケージが必要です。
前提条件
手順
NBDE(Network-Bound Disk Encryption)キーサーバーで、サーバー側のパッケージをインストールします。
# yum install tang -y
第5章 ファイアウォールルールの変更
5.1. ディスク暗号化のファイアウォールルールの変更
NBDE(Network-Bound Disk Encryption)鍵サーバーで、暗号鍵を提供できるようにポートを開く必要があります。
手順
各 NBDE 鍵サーバーで以下を行います。
暗号化キーを提供するために必要なポートを開きます。
注記デフォルトのポートは
80/tcpです。カスタムポートを使用するには、Red Hat Enterprise Linux 8 ドキュメントの Deploying a tang server with SELinux in enforcing mode を参照してください。# firewall-cmd --add-port=80/tcp # firewall-cmd --add-port=80/tcp --permanent
以下のコマンドの出力にポートが表示されることを確認します。
# firewall-cmd --list-ports | grep '80/tcp'
第6章 パスワードなしの公開鍵ベースの SSH 認証の設定
最初のハイパーコンバージドホスト上のルートユーザーに、そのホスト自体を含むすべてのホストに対するパスワードを使用しない公開鍵ベースのSSH認証を設定します。この作業は、すべてのストレージと管理インターフェースについて、IPアドレスとFQDNの両方に対して行います。
6.1. パスワードなしの SSH 鍵ペアの生成
公開鍵と秘密鍵のペアを生成すると、キーベースの SSH 認証を使用できます。パスワードを使用しないキーペアを生成すると、Ansible を使用してデプロイメントおよび設定プロセスを自動化できます。
手順
- 最初のハイパーコンバージドホストに root ユーザーとしてログインします。
パスワードを使用しない SSH キーを生成します。
キー生成プロセスを開始します。
# ssh-keygen -t rsa Generating public/private rsa key pair.
キーの場所を入力します。
括弧で示されているデフォルトの場所は、他の入力が指定されていない場合に使用されます。
Enter file in which to save the key (/home/username/.ssh/id_rsa): <location>/<keyname>
Enterを 2 回 押して、空白パスフレーズを指定および確認します。Enter passphrase (empty for no passphrase): Enter same passphrase again:
秘密鍵は
<location>/<keyname>に保存されます。公開鍵は<location>/<keyname>.pubに保存されます。Your identification has been saved in <location>/<keyname>. Your public key has been saved in <location>/<keyname>.pub. The key fingerprint is SHA256:8BhZageKrLXM99z5f/AM9aPo/KAUd8ZZFPcPFWqK6+M root@server1.example.com The key's randomart image is: +---[ECDSA 256]---+ | . . +=| | . . . = o.o| | + . * . o...| | = . . * . + +..| |. + . . So o * ..| | . o . .+ = ..| | o oo ..=. .| | ooo...+ | | .E++oo | +----[SHA256]-----+
警告この出力での
Your identificationは、あなたの秘密鍵です。秘密鍵を共有しないでください。自分の秘密鍵を持っていると、自分の公開鍵を持っているシステムで、他人が自分になりすますことができます。
6.2. SSH キーのコピー
秘密鍵を使用してホストにアクセスするには、そのホストには公開鍵のコピーが必要です。
前提条件
- パスワードのない公開鍵と秘密鍵のペアを生成します。
手順
- 最初のホストに root ユーザーとしてログインします。
フロントエンドとバックエンドの両方のFQDNを使って、コマンドを実行するホストを含む、アクセスする各ホストに、公開鍵をコピーしてください。
# ssh-copy-id -i <location>/<keyname>.pub <user>@<hostname>
プロンプトが表示されたら、
<user>@<hostname>のパスワードを入力します。警告必ず
.pubで終わるファイルを使用していることを確認してください。秘密鍵を共有しないでください。自分の秘密鍵を持っていると、自分の公開鍵を持っているシステムで、他人が自分になりすますことができます。たとえば、3 ノードのデプロイメントにおいて、root ユーザーとして
server1.example.comにログインしている場合は、以下のコマンドを実行します。# ssh-copy-id -i <location>/<keyname>.pub root@server1front.example.com # ssh-copy-id -i <location>/<keyname>.pub root@server2front.example.com # ssh-copy-id -i <location>/<keyname>.pub root@server3front.example.com # ssh-copy-id -i <location>/<keyname>.pub root@server1back.example.com # ssh-copy-id -i <location>/<keyname>.pub root@server2back.example.com # ssh-copy-id -i <location>/<keyname>.pub root@server3back.example.com
第7章 ディスク暗号化の設定
7.1. NBDE(Network-Bound Disk Encryption key)サーバーの設定
前提条件
- Network-Bound Disk Encryption key serverをインストールしている必要があります(Network-Bound Disk Encryption key serverのインストール)。
手順
tangd サービスを開始して有効にします。
NBDE(Network-Bound Disk Encryption)キーサーバーごとに以下のコマンドを実行します。
# systemctl enable tangd.socket --now
ハイパーコンバージドホストが鍵サーバーにアクセスできることを確認します。
- ハイパーコンバージドホストにログインします。
キーサーバーから復号化鍵を要求します。
# curl key-server.example.com/adv以下のような出力が表示された場合、鍵サーバーはアクセス可能で、キーを正しくアドバタイズします。
{"payload":"eyJrZXlzIjpbeyJhbGciOiJFQ01SIiwiY3J2IjoiUC01MjEiLCJrZXlfb3BzIjpbImRlcml2ZUtleSJdLCJrdHkiOiJFQyIsIngiOiJBQ2ZjNVFwVmlhal9wNWcwUlE4VW52dmdNN1AyRTRqa21XUEpSM3VRUkFsVWp0eWlfZ0Y5WEV3WmU5TmhIdHhDaG53OXhMSkphajRieVk1ZVFGNGxhcXQ2IiwieSI6IkFOMmhpcmNpU2tnWG5HV2VHeGN1Nzk3N3B3empCTzZjZWt5TFJZdlh4SkNvb3BfNmdZdnR2bEpJUk4wS211Y1g3WHUwMlNVWlpqTVVxU3EtdGwyeEQ1SGcifSx7ImFsZyI6IkVTNTEyIiwiY3J2IjoiUC01MjEiLCJrZXlfb3BzIjpbInZlcmlmeSJdLCJrdHkiOiJFQyIsIngiOiJBQXlXeU8zTTFEWEdIaS1PZ04tRFhHU29yNl9BcUlJdzQ5OHhRTzdMam1kMnJ5bDN2WUFXTUVyR1l2MVhKdzdvbEhxdEdDQnhqV0I4RzZZV09vLWRpTUxwIiwieSI6IkFVWkNXUTAxd3lVMXlYR2R0SUMtOHJhVUVadWM5V3JyekFVbUIyQVF5VTRsWDcxd1RUWTJEeDlMMzliQU9tVk5oRGstS2lQNFZfYUlsZDFqVl9zdHRuVGoifV19","protected":"eyJhbGciOiJFUzUxMiIsImN0eSI6Imp3ay1zZXQranNvbiJ9","signature":"ARiMIYnCj7-1C-ZAQ_CKee676s_vYpi9J94WBibroou5MRsO6ZhRohqh_SCbW1jWWJr8btymTfQgBF_RwzVNCnllAXt_D5KSu8UDc4LnKU-egiV-02b61aiWB0udiEfYkF66krIajzA9y5j7qTdZpWsBObYVvuoJvlRo_jpzXJv0qEMi"}
7.2. ハイパーコンバージドホストをNetwork-Bound Disk Encryptionクライアントとして設定する。
7.2.1. ディスク暗号化設定の詳細の定義
- 最初のハイパーコンバージドホストにログインします。
hc-ansible-deploymentディレクトリーに移動します。# cd /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment
今後の参照用に
luks_tang_inventory.ymlファイルのコピーを作成します。cp luks_tang_inventory.yml luks_tang_inventory.yml.backup
luks_tang_inventory.yml ファイルで設定を定義します。
サンプルの
luks_tang_inventory.ymlファイルを使用して、各ホストでディスク暗号化の詳細を定義します。このファイルの概要については、Understanding the luks_tang_inventory.yml ファイルに記載されています。luks_tang_inventory.ymlファイルを編集し、ansible-vaultを使用してパスワードを指定します。luks_tang_inventory.ymlに必要な変数にはパスワードの値が含まれます。そのため、パスワード値を保護するためにファイルを暗号化することが重要です。# ansible-vault encrypt luks_tang_inventory.yml
プロンプトが表示されたら、新しい vault パスワードを入力し、確認します。
7.2.2. ディスク暗号化設定 Playbook の実行
前提条件
-
luks_tang_inventory.ymlPlaybook で設定を定義する: 「ディスク暗号化設定の詳細の定義」. - ハイパーコンバージドホストには、暗号化されたブートディスクが必要です。
手順
- 最初のハイパーコンバージドホストにログインします。
hc-ansible-deployment ディレクトリーに移動します。
# cd /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment
rootユーザーで以下のコマンドを実行すると、設定プロセスが開始されます。
# ansible-playbook -i luks_tang_inventory.yml tasks/luks_tang_setup.yml --tags=blacklistdevices,luksencrypt,bindtang --ask-vault-pass
ディスクの暗号化設定を開始するプロンプトが表示されたら、このファイルの Vault パスワードを入力します。
検証
- 各ホストを再起動して、復号したパスフレーズを手動で入力しなくても、ログインプロンプトに起動できることを確認します。
-
ディスク暗号化を使用するデバイスには、Red Hat Hyperconverged Infrastructure for Virtualization の設定を継続すると、
/dev/mapper/luks_sdXのパスがあることに注意してください。
トラブルシューティング
指定したブートデバイス
/dev/sda2は暗号化されません。TASK [Check if root device is encrypted] fatal: [server1.example.com]: FAILED! => {"changed": false, "msg": "The given boot device /dev/sda2 is not encrypted."}
解決策: 「ハイパーコンバージドホストのインストール」 に記載されている手順でハイパーコンバージドホストを再インストールします。インストールプロセス中にEncrypt my data を選択し、ディスク暗号化に関するすべての指示に従うことを確認してください。
この結果では、no_log: true が指定されているという事実により、出力は表示されません。
TASK [gluster.infra/roles/backend_setup : Encrypt devices using key file] failed: [host1.example.com] (item=None) => {"censored": "the output has been hidden due to the fact that no_log: true was specified for this result", "changed": true}
パスフレーズを公開しないように、この出力が切り替わりました。
Encrypt devices using key fileタスクでこの出力が表示された場合、デバイスの暗号化に失敗しています。インベントリーファイルに誤ったディスクを指定している可能性があります。解決策: デプロイに失敗した後、Cleaning up Network-Bound Disk Encryption after a failed deployment を参照してデプロイメントのクリーンアップします。次に、インベントリーファイルでディスク名を修正します。
Non-zero return code from Tang server
TASK [gluster.infra/roles/backend_setup : Download the advertisement from tang server for IPv4] * failed: [host1.example.com] (item={url: http://tang-server.example.com}) => {"ansible_index_var": "index", "ansible_loop_var": "item", "changed": true, "cmd": "curl -sfg \"http://tang-server.example.com/adv\" -o /etc/adv0.jws", "delta": "0:02:08.703711", "end": "2020-06-10 18:18:09.853701", "index": 0, "item": {"url": "http://tang-server.example.com"}, "msg": "non-zero return code*", "rc": 7, "start": "2020-06-10 18:16:01.149990", "stderr": "", "stderr_lines": [], "stdout": "", "stdout_lines": []}
このエラーは、提供されたFQDNが正しくないか、ホストから見つからないために、サーバーが提供された
urlにアクセスできないことを示しています。解決策: NBDE キーサーバーに提供される
urlの値を修正するか、またはurl値がホストからアクセス可能であることを確認します。次に、bindtangタグを使用して Playbook を再度実行します。# ansible-playbook -i luks_tang_inventory.yml tasks/luks_tang_setup.yml --ask-vault-pass --tags=bindtang- その他の Playbook の失敗については、Cleaning up Network-Bound Disk Encryption after a failed deploymentの手順で、デプロイメントをクリーンアップしてください。設定 Playbook を再度実行する前に、Playbook とインベントリーファイルで誤った値を確認し、すべてのサーバーへのアクセスをテストします。
第8章 デプロイメントの詳細を表示する
Ansible を使用して Red Hat Hyperconverged Infrastructure for Virtualization のデプロイメントを自動化するには、以下の設定ファイルでデプロイメントを定義する必要があります。
これらのファイルはハイパーコンバージドノード上に作成され、自分自身やクラスタ内の他のノードとの間でSSH公開鍵認証を確立します。
gluster_inventory.yml- Glusterボリュームとしてのストレージボリュームとそのレイアウトを定義したインベントリーファイルです。
single_node_gluster_inventory.yml- Gluster ボリュームとしてのストレージボリュームとそのレイアウトを定義したインベントリーファイルです。
he_gluster_vars.json- デプロイメントに必要ないくつかの値を定義した変数ファイルです。
手順
サンプル設定ファイルのバックアップコピーを作成します。
3 から 12 個のノードのデプロイメントでは、以下のコマンドを使用してバックアップコピーを作成します。
# cd /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment # cp gluster_inventory.yml gluster_inventory.yml.backup # cp he_gluster_vars.json he_gluster_vars.json.backup
単一ノードのデプロイメントの場合、以下のコマンドを使用してバックアップコピーを作成します。
#cd/etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment #cp single_node_gluster_inventory.yml single_node_gluster_inventory.yml.backup # cp he_gluster_vars.json he_gluster_vars.json.backup
3 から 12ノードのデプロイの場合は
gluster_inventory.yml、単一ノードのデプロイの場合はsingle_node_gluster_inventory.ymlファイルでデプロイを定義します。gluster_inventory.ymlファイルのサンプルを使用してデプロイメントを定義します。このファイルの完全な概要は Understanding thegluster_inventory.ymlfile を参照してください。he_gluster_vars.jsonファイルでデプロイメント変数を定義します。he_gluster_vars.jsonファイルの例を使用して必要な変数を定義します。このファイルの詳細は Understanding thehe_gluster_vars.jsonfile を参照してください。he_gluster_vars.jsonファイルを作成し、パスワードを指定します。he_gluster_vars.jsonに必要な変数にはパスワード値が含まれるため、パスワード値を保護するためにファイルを暗号化することが重要です。# ansible-vault encrypt he_gluster_vars.json
プロンプトが表示されたら、新しい vault パスワードを入力し、確認します。
このパスワードは、Executing the deployment playbook のプロセスを使用して Red Hat Hyperconverged Infrastructure for Virtualization をデプロイする際に必要です。
詳細は、Working with files encrypted using Ansible Vault を参照してください。
第9章 デプロイメント Playbook の実行
最初のノードの
hc-ansible-deploymentディレクトリーに移動します。# cd /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment
root ユーザーとして以下のコマンドを実行し、デプロイメントプロセスを開始します。
# ansible-playbook -i gluster_inventory.yml hc_deployment.yml --extra-vars='@he_gluster_vars.json' --ask-vault-pass
デプロイメントを開始するプロンプトが表示されたら、vault パスワードを入力します。
重要Red Hat Enterprise Linux 8.6(RHEL 8.6)をベースとした Red Hat Virtualization Host(RHVH)4.4 SP1 を使用している場合は、
-e 'ansible_python_interpreter=/usr/bin/python3.6'パラメーターを追加します。# ansible-playbook -e 'ansible_python_interpreter=/usr/bin/python3.6' -i gluster_inventory.yml hc_deployment.yml --extra-vars='@he_gluster_vars.json' --ask-vault-pass
第10章 デプロイメントの確認
デプロイメントが完了したら、デプロイメントが正常に完了したことを確認します。
管理ポータルを参照します(例: http://engine.example.com/ovirt-engine)
管理コンソールのログイン
ホスト型エンジンのデプロイメント時に追加された管理認証情報を使用してログインします。
ログインに成功すると、Dashboard が表示されます。
管理コンソールダッシュボード
クラスターが利用可能であることを確認します。
アドミニストレーションコンソールのダッシュボード : クラスタ
1 つ以上のホストが利用可能であることを確認します。
ホスト型エンジンのデプロイメント中に追加のホストの詳細を指定した場合は、以下に示すように 3 つのホストが表示されます。
管理コンソールダッシュボード - Hosts
- Compute → Hosts をクリックします。
すべてのホストの Status が
Upと表示されていることを確認します。管理コンソール - Hosts

すべてのストレージドメインが利用可能であることを確認します。
- Storage から Domains をクリックします。
Activeアイコンが最初の列に表示されることを確認します。管理コンソール: ストレージドメイン

パート I. Troubleshoot
第11章 ログファイルの場所
デプロイメントプロセス中に、進捗情報が Web ブラウザーに表示されます。この情報はローカルファイルシステムにも保存され、ログに記録された情報をアーカイブまたは後で確認したりできます。たとえば、Web ブラウザーが応答を停止するか、情報の確認前に閉じられた場合などがこれに該当します。
Web コンソールベースのデプロイメントプロセスのログファイルは、デフォルトで /var/log/cockpit/ovirt-dashboard/gluster-deployment.log ファイルに保存されます。
デプロイメントプロセスの Hosted Engine 設定部分のログファイルは、/var/log/ovirt-hosted-engine-setup ディレクトリーに保存され、ファイル名は ovirt-hosted-engine-setup-<date>.log の形式を取ります。
第12章 デプロイメントエラー
12.1. クリーンアップ操作の順序
デプロイメントが失敗する場所によっては、多くのクリーンアップ操作を実施する必要がある場合があります。
タスク自体の順序に対して、タスクのクリーンアップを逆に実行します。たとえば、デプロイメント時に以下のタスクを実行します。
- Ansible を使用した Network-Bound Disk Encryption(Network-Bound Disk Encryption)を設定します。
- Web コンソールを使用して Red Hat Gluster Storage を設定します。
- Web コンソールを使用して Hosted Engine を設定します。
ステップ 2 でデプロイメントが失敗する場合は、ステップ 2 のクリーンアップを実行します。必要に応じて、手順 1 のクリーンアップを実行します。
12.2. ストレージのデプロイに失敗しました
ストレージのデプロイメント中にエラーが発生した場合には、デプロイメントプロセスは停止し、Deployment failed が表示されます。
Deploying storage failed
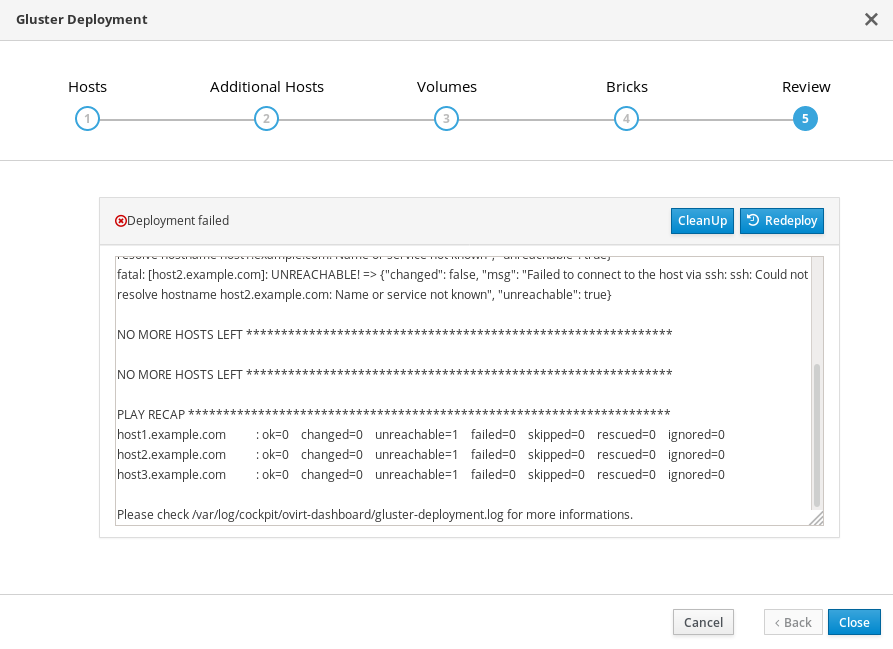
- エラー情報については、Web コンソールの出力を確認します。
- Clean up をクリックして、システムに不正な変更をすべて削除します。配置に Network-Bound Disk Encryption を使用している場合は、Cleaning up Network-Bound Disk Encryption after a failed deployment の手順に従う必要があります。
- Redeploy をクリックし、エラーが出される可能性のある入力値を修正します。エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
- storage deployment に戻って、もう一度試してみてください。
12.2.1. デプロイメントの失敗後のネットワーク境界ディスク暗号化のクリーンアップ
Network-Bound Disk Encryption を使用し、デプロイメントが失敗する場合は、Cleanup ボタンをクリックして再度試行することはできません。また、再起動する前に、luks_device_cleanup.yml Playbook を実行してクリーニングプロセスを完了させる必要もあります。
以下に示すようにこの Playbook を実行し、セットアップ中に指定した luks_tang_inventory.yml ファイルを提供します。
# ansible-playbook -i luks_tang_inventory.yml /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/tasks/luks_device_cleanup.yml --ask-vault-pass
12.2.2. Error: VDO signature detected on device
ストレージのデプロイメント中、Create VDO with specified size の作成は、VDO signature detected on device で失敗する可能性があります。
TASK [gluster.infra/roles/backend_setup : Create VDO with specified size] task path: /etc/ansible/roles/gluster.infra/roles/backend_setup/tasks/vdo_create.yml:9 failed: [host1.example.com] (item={u'writepolicy': u'auto', u'name': u'vdo_sdb', u'readcachesize': u'20M', u'readcache': u'enabled', u'emulate512': u'off', u'logicalsize': u'11000G', u'device': u'/dev/sdb', u'slabsize': u'32G', u'blockmapcachesize': u'128M'}) => {"ansible_loop_var": "item", "changed": false, "err": "vdo: ERROR - vdo signature detected on /dev/sdb at offset 0; use --force to override\n", "item": {"blockmapcachesize": "128M", "device": "/dev/sdb", "emulate512": "off", "logicalsize": "11000G", "name": "vdo_sdb", "readcache": "enabled", "readcachesize": "20M", "slabsize": "32G", "writepolicy": "auto"}, "msg": "Creating VDO vdo_sdb failed.", "rc": 5}
このエラーは、指定したデバイスがすでに VDO デバイスである場合や、デバイスが VDO デバイスとして設定されていて、正しくクリーンアップされなかった場合に発生します。
- VDO デバイスを誤って指定した場合は、ストレージ設定に戻り、VDO 以外のデバイスとは異なるものを指定します。
以前 VDO デバイスとして使用されていたデバイスを指定した場合は、以下を行います。
デバイスの種類を確認します。
# blkid -p /dev/sdb /dev/sdb: UUID="fee52367-c2ca-4fab-a6e9-58267895fe3f" TYPE="vdo" USAGE="other"
出力に
TYPE="vdo"が表示されている場合、このデバイスは正しくクリーニングされていません。- このデバイスを使用するには、Manually cleaning up a VDO device の手順に従ってください。その後、storage deployment に戻り、再度検証します。
クリーンなデバイスを指定し、ストレージデプロイメントウィンドウの Clean up ボタンを使用して、失敗したデプロイメントをクリーンアップしてこのエラーを回避します。
12.2.3. VDO デバイスの手動クリーンアップ
以下の手順に従って、デプロイメントの失敗の原因となった VDO デバイスを手動でクリーンアップします。
これは破壊的プロセスです。クリーンアップするデバイスのデータはすべて失われます。
手順
wipefs を使用してデバイスをクリーンアップします。
# wipefs -a /dev/sdX
検証
デバイスに
TYPE="vdo"が設定されていない ことを確認します。# blkid -p /dev/sdb /dev/sdb: UUID="fee52367-c2ca-4fab-a6e9-58267895fe3f" TYPE="vdo" USAGE="other"
次のステップ
- storage deployment に戻って、もう一度試してみてください。
12.3. 仮想マシンの準備に失敗しました
仮想マシンの デプロイメント中にエラーが発生した場合には、デプロイメントは一時停止し、以下のような画面が表示されます。
Preparing virtual machine failed
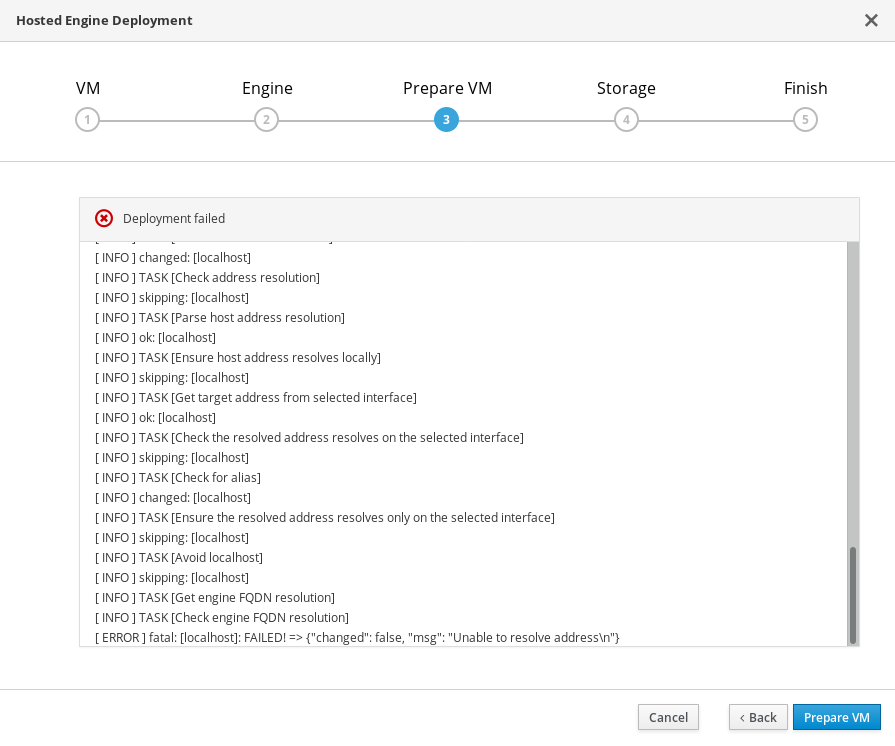
- エラー情報については、Web コンソールの出力を確認します。
- Back をクリックして、エラーの原因となった可能性がある入力値を修正します。ネットワーク設定に適切な値が VM タブに提供されるようにしてください。エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
rhvm-applianceパッケージが最初のハイパーコンバージドホストで利用可能であることを確認します。# yum install rhvm-appliance
Hosted Engine deployment に戻って再試行してください。
エラーを解決している間にデプロイメントウィザードを終了する場合は、デプロイメントプロセスを再試行するときに、Use existing configuration を選択します。
12.4. ホスト型エンジンのデプロイに失敗しました
ホストされているエンジンのデプロイメント中にエラーが発生した場合には、デプロイメントの一時停止と Deployment failed が表示されます。
ホスト型エンジンのデプロイメントに失敗しました
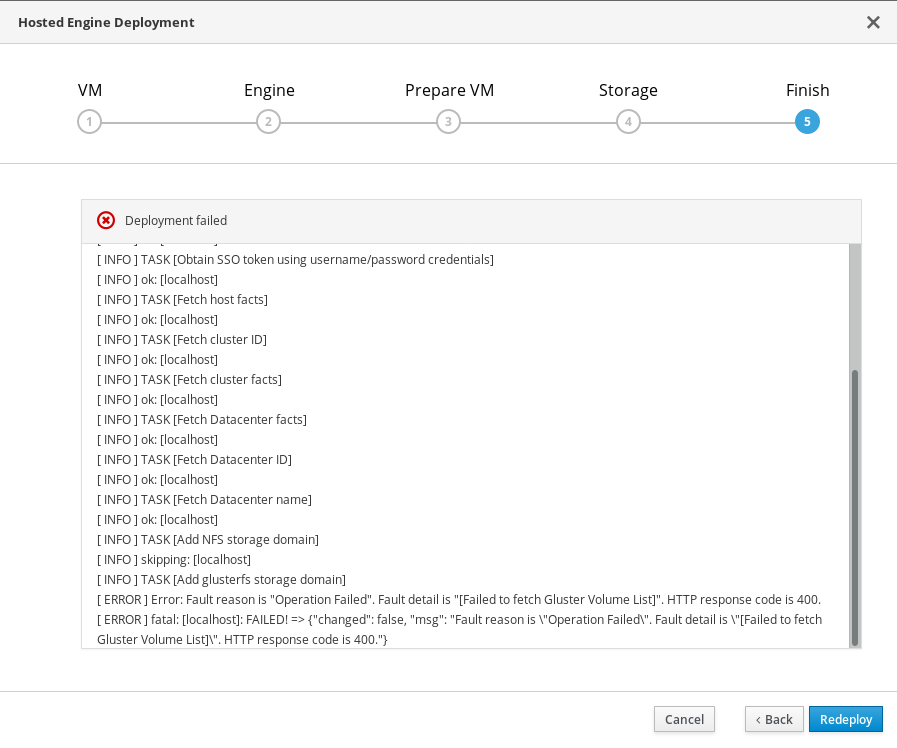
- エラー情報については、Web コンソールの出力を確認します。
engineボリュームの内容を削除します。engineボリュームをマウントします。# mount -t glusterfs <server1>:/engine /mnt/test
ボリュームの内容を削除します。
# rm -rf /mnt/test/*
engineボリュームをアンマウントします。# umount /mnt/test
- Redeploy をクリックし、エラーが出される可能性のある入力値を修正します。
上記のステップ a、b、および c の実行後にデプロイメントが失敗する場合以下の手順を再度実行し、続いてホスト型エンジンをクリーンアップします。
# ovirt-hosted-engine-cleanup
再度試行 するには、deployment に戻ります。
エラーを解決している間にデプロイメントウィザードを終了する場合は、デプロイメントプロセスを再試行するときに、Use existing configuration を選択します。
エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
パート II. 参考資料
付録A Ansible Vault で暗号化されたファイルの使用
Red Hat は、パスワードやその他の機密情報を含むデプロイメントおよび管理ファイルの内容を暗号化することを推奨します。Ansible Vault は、これらのファイルを暗号化する 1 つの方法です。Ansible Vault の詳細は、Ansible documentation を参照してください。
A.1. ファイルの暗号化
ansible-vault createコマンドで暗号化ファイルを作成したり、ansible-vault encryptコマンドで既存のファイルを暗号化することができます。
暗号化ファイルを作成したり、既存のファイルを暗号化したりすると、パスワードを指定するように求められます。このパスワードは、暗号化後にファイルを復号化するために使用されます。このファイル内の情報を直接使用する場合や、ファイルの内容に依存する Playbook を実行する場合は、このパスワードを指定する必要があります。
暗号化されたファイルの作成
$ ansible-vault create variables.yml
New Vault password:
Confirm New Vault password:
ansible-vault create コマンドは新しいファイルのパスワードを要求し、保存する前にファイルを生成できるようにデフォルトのテキストエディター(シェル環境で $EDITOR として定義)で新規ファイルを開きます。
すでにファイルを作成していて、それを暗号化したい場合は、ansible-vault encryptコマンドを使用します。
既存のファイルの暗号化
$ ansible-vault encrypt existing-variables.yml
New Vault password:
Confirm New Vault password:
Encryption successful
A.2. 暗号化されたファイルの編集
暗号化されたファイルを編集するには、ansible-vault editコマンドを使用し、そのファイルのVaultパスワードを指定します。
暗号化ファイルの編集
$ ansible-vault edit variables.yml
New Vault password:
Confirm New Vault password:
ansible-vault editコマンドは、ファイルのパスワードの入力を求め、デフォルトのテキストエディタ(シェル環境で$EDITORと定義されている)でファイルを開き、ファイルの内容を編集および保存ができるようにします。
A.3. 暗号化されたファイルの新規パスワードへのキーの指定
ansible-vault rekey コマンドを使用して、ファイルの復号化に使用するパスワードを変更できます。
$ ansible-vault rekey variables.yml
Vault password:
New Vault password:
Confirm New Vault password:
Rekey successful
ansible-vault rekey コマンドは、現在の Vault パスワードの入力を要求し、新しい Vault パスワードを設定して確認するプロンプトを表示します。
付録B 設定ファイルのサンプルについて
B.1. luks_tang_inventory.yml ファイルについて
B.1.1. ディスク暗号化の設定パラメーター
- hc_nodes(必須)
ホストのバックエンド FQDN を使用するハイパーコンバージドホストの一覧およびそのホストの設定詳細。ホスト固有の設定は、ホストのバックエンド FQDN の下に定義されます。すべてのホストに共通する設定は vars: セクションで定義されます。
hc_nodes: hosts: host1backend.example.com: [configuration specific to this host] host2backend.example.com: host3backend.example.com: host4backend.example.com: host5backend.example.com: host6backend.example.com: vars: [configuration common to all hosts]- blacklist_mpath_devices(オプション)
デフォルトでは、Red Hat Virtualization Host はマルチパス設定を有効にし、ディスクに基礎となるマルチパス設定がなくても、すべてのディスクに一意のマルチパス名とワールドワイド識別子を提供します。マルチパスデバイス名が一覧表示されるデバイスに使用されていないようにマルチパス設定がない場合は、このセクションを追加してください。ここに記載されていないディスクは、マルチパス構成が利用可能であると想定され、インベントリーファイルの後続のセクションで定義する際には、
/dev/sdxの代わりにパスフォーマット/dev/mapper/<WWID>が必要となります。4 つのデバイス(sda、sdb、sdc、および sdd)を持つサーバーでは、以下の設定は 2 つのデバイスのみをブラックリストに指定します。パスの形式 /dev/mapper/<WWID> は、この一覧に記載されていないデバイスで想定されています。
hc_nodes: hosts: host1backend.example.com: blacklist_mpath_devices: - sdb - sdc- gluster_infra_luks_devices (required)
暗号化するデバイスの一覧と、各デバイスに使用する暗号化パスフレーズの一覧。
hc_nodes: hosts: host1backend.example.com: gluster_infra_luks_devices: - devicename: /dev/sdb passphrase: Str0ngPa55#- devicename
-
デバイスの名前(
/dev/sdx形式)。 - passphrase
- 暗号化を設定する際にこのデバイスに使用するパスワード。NBDE(Network-Bound Disk Encryption)を使用したディスク暗号化が設定されると、新しいランダムキーが生成され、セキュリティーが強化されます。
- rootpassphrase(必須)
このホストへのオペレーティングシステムのインストール時に Encrypt my data を選択したときに使用したパスワード。
hc_nodes: hosts: host1backend.example.com: rootpassphrase: h1-Str0ngPa55#- rootdevice(必須)
このホストへのオペレーティングシステムのインストール時に Encrypt my data を選択したときに暗号化されたルートデバイス。
hc_nodes: hosts: host1backend.example.com: rootdevice: /dev/sda2- Networkinterface(必須)
このホストが NBDE 鍵サーバーに到達するために使用するネットワークインターフェース。
hc_nodes: hosts: host1backend.example.com: networkinterface: ens3s0f0- ip_version(必須)
IPv4 ネットワークまたは IPv6 ネットワークを使用するかどうか。有効な値は
IPv4およびIPv6です。デフォルト値はありません。混合ネットワークはサポートされません。hc_nodes: vars: ip_version: IPv4- ip_config_method (required)
DHCP または静的ネットワークを使用するかどうか。有効な値は
dhcpおよびstaticです。デフォルト値はありません。hc_nodes: vars: ip_config_method: dhcpこのオプションの他の有効な値は
staticです。これには、以下の追加パラメーターが必要で、ホストごとに個別に定義されます。hc_nodes: hosts: host1backend.example.com: ip_config_method: static host_ip_addr: 192.168.1.101 host_ip_prefix: 24 host_net_gateway: 192.168.1.100 host2backend.example.com: ip_config_method: static host_ip_addr: 192.168.1.102 host_ip_prefix: 24 host_net_gateway: 192.168.1.100 host3backend.example.com: ip_config_method: static host_ip_addr: 192.168.1.102 host_ip_prefix: 24 host_net_gateway: 192.168.1.100- gluster_infra_tangservers
http://を含む NBDE キーサーバーまたはサーバーのアドレス。サーバーがデフォルト(80)以外のポートを使用する場合は、URL の最後に:_port_を追加してポートを指定します。hc_nodes: vars: gluster_infra_tangservers: - url: http://key-server1.example.com - url: http://key-server2.example.com:80
B.1.2. 例: luks_tang_inventory.yml
動的に割り当てられる IP アドレス
hc_nodes:
hosts:
host1-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host1-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
host2-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host2-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
host3-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host3-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
vars:
ip_version: IPv4
ip_config_method: dhcp
gluster_infra_tangservers:
- url: http://key-server1.example.com:80
- url: http://key-server2.example.com:80
静的 IP アドレス
hc_nodes:
hosts:
host1-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host1-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
host_ip_addr: host1-static-ip
host_ip_prefix: network-prefix
host_net_gateway: default-network-gateway
host2-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host2-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
host_ip_addr: host1-static-ip
host_ip_prefix: network-prefix
host_net_gateway: default-network-gateway
host3-backend.example.com:
blacklist_mpath_devices:
- sda
- sdb
- sdc
gluster_infra_luks_devices:
- devicename: /dev/sdb
passphrase: dev-sdb-encrypt-passphrase
- devicename: /dev/sdc
passphrase: dev-sdc-encrypt-passphrase
rootpassphrase: host3-root-passphrase
rootdevice: /dev/sda2
networkinterface: eth0
host_ip_addr: host1-static-ip
host_ip_prefix: network-prefix
host_net_gateway: default-network-gateway
vars:
ip_version: IPv4
ip_config_method: static
gluster_infra_tangservers:
- url: http://key-server1.example.com:80
- url: http://key-server2.example.com:80
B.2. gluster_inventory.yml ファイルについて
gluster_inventory.yml ファイルは、Ansible インベントリーファイルのサンプルで、Ansible を使用して Red Hat Hyperconverged Infrastructure for Virtualization のデプロイメントを自動化できます。
single_node_gluster_inventory.yml は gluster_inventory.yml ファイルと同じです。単一ノードのデプロイメントにはホストが 1 つしかないため、hosts セクションにのみ変更が行われます。
このファイルは、いずれかのハイパーコンバージドホストの /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/gluster_inventory.yml にあります。
B.2.1. デフォルトのホストグループ
gluster_inventory.yml のサンプルファイルは、2 つのホストグループとその設定を YAML 形式で定義します。すべてのノードがすべてのストレージドメインをホストするようにする必要がある場合に、これらのホストグループを直接使用できます。
- hc_nodes
ホストのバックエンド FQDN を使用するハイパーコンバージドホストの一覧およびそのホストの設定詳細。ホスト固有の設定は、ホストのバックエンド FQDN の下に定義されます。すべてのホストに共通する設定は
vars:セクションで定義されます。hc_nodes: hosts: host1backend.example.com: [configuration specific to this host] host2backend.example.com: host3backend.example.com: host4backend.example.com: host5backend.example.com: host6backend.example.com: vars: [configuration common to all hosts]- gluster
ホストのフロントエンド FQDN を使用するホストの一覧。これらのホストは追加のストレージドメインのアクセスポイントとして機能するため、このノードの一覧には最初のホストは含まれません。
すべてのノードがすべてのストレージドメインをホストするようにするには、
vars:セクションの下にstorage_domains:とすべてのストレージドメインの定義を配置します。gluster: hosts: host2frontend.example.com: host3frontend.example.com: host4frontend.example.com: host5frontend.example.com: host6frontend.example.com: vars: storage_domains: [storage domain definitions common to all hosts]
B.2.2. ハイパーコンバージドノードの設定パラメーター
B.2.2.1. マルチパスデバイス
blacklist_mpath_devices(オプション)デフォルトでは、Red Hat Virtualization Host はマルチパス設定を有効にし、ディスクに基礎となるマルチパス設定がなくても、すべてのディスクに一意のマルチパス名とワールドワイド識別子を提供します。マルチパスデバイス名が一覧表示されるデバイスに使用されていないようにマルチパス設定がない場合は、このセクションを追加してください。ここに記載されていないディスクは、マルチパス構成が利用可能であると想定され、インベントリーファイルの後続のセクションで定義する際には、
/dev/sdxの代わりにパスフォーマット/dev/mapper/<WWID>が必要となります。4 つのデバイス(
sda、sdb、sdc、およびsdd)を持つサーバーでは、以下の設定は 2 つのデバイスをブラックリストに指定します。パスの形式/dev/mapper/<WWID>は、この一覧に記載されていないデバイスで想定されています。hc_nodes: hosts: host1backend.example.com: blacklist_mpath_devices: - sdb - sdc重要blacklist_mpath_devicesに暗号化デバイス(luks_*デバイス)をリストしないでください。マルチパス設定が機能する必要があるためです。
B.2.2.2. 重複排除と圧縮
gluster_infra_vdo(optional)このセクションでは、重複排除と圧縮を使用するデバイスの一覧を定義します。これらのデバイスには、
gluster_infra_volume_groupsでボリュームグループとして定義する際に、/dev/mapper/<name>パス形式が必要です。一覧表示される各デバイスには以下の情報が必要です。name-
VDO デバイスの省略名(
vdo_sdcなど)。 device-
使用するデバイス(例:
/dev/sdc) logicalsize-
VDO ボリュームの論理サイズ。物理ディスクサイズが 10 倍になるようにします。たとえば、500 GB のディスクがある場合は、
logicalsize: '5000G'を設定します。 emulate512-
ブロックサイズが 4 KB のデバイスを使用する場合には、これを
onに設定します。 slabsize-
ボリュームの論理サイズが 1000 GB 以上である場合は、これを
32 Gに設定します。論理サイズが 1000 GB 未満の場合は、これを2 Gに設定します。 blockmapcachesize-
これを
128 Mに設定します。 writepolicy-
これは
autoに設定します。
例:
hc_nodes: hosts: host1backend.example.com: gluster_infra_vdo: - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' } - { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '500G', emulate512: 'off', slabsize: '2G', blockmapcachesize: '128M', writepolicy: 'auto' }
B.2.2.3. クラスター定義
cluster_nodes(required)各ノードのバックエンド FQDN を使用して、クラスターの一部であるノードの一覧を定義し、クラスターを作成します。
hc_nodes: vars: cluster_nodes: - host1backend.example.com - host2backend.example.com - host3backend.example.comgluster_features_hci_cluster(必須)ハイパーコンバージドクラスターの一部として
cluster_nodesを特定します。hc_nodes: vars: gluster_features_hci_cluster: "{{ cluster_nodes }}"gluster_features_hci_volumes(必須)ハイパーコンバージドノード全体で Gluster ボリュームのレイアウトを定義します。
volname- 作成する Gluster ボリュームの名前。
brick- ブリックを作成する場所。
arbiter-
判別ボリュームには
1を、完全に複製されたボリュームの場合は0に設定します。 サーバーこのボリュームのブリックを作成するホストのバックエンド FQDN アドレスの一覧。
このパラメーターには 2 つの形式オプションがあります。デプロイメントごとに、これらの形式のいずれかのみがサポートされます。
形式 1: すべてのホストで、指定したボリュームのブリックを作成します。
hc_nodes: vars: gluster_features_hci_volumes: - volname: engine brick: /gluster_bricks/engine/engine arbiter: 0 - volname: data brick: /gluster_bricks/data1/data1,/gluster_bricks/data2/data2 arbiter: 0 - volname: vmstore brick: /gluster_bricks/vmstore/vmstore arbiter: 0フォーマット 2: 指定されたホストで指定されたボリュームにブリックを作成します。
hc_nodes: vars: gluster_features_hci_volumes: - volname: data brick: /gluster_bricks/data/data arbiter: 0 servers: - host4backend.example.com - host5backend.example.com - host6backend.example.com - host7backend.example.com - host8backend.example.com - host9backend.example.com - volname: vmstore brick: /gluster_bricks/vmstore/vmstore arbiter: 0 servers: - host1backend.example.com - host2backend.example.com - host3backend.example.com
B.2.2.4. ストレージインフラストラクチャー
gluster_infra_volume_groups(required)本セクションでは、論理ボリュームを含むボリュームグループを作成します。
hc_nodes: hosts: host1backend.example.com: gluster_infra_volume_groups: - vgname: gluster_vg_sdb pvname: /dev/sdb - vgname: gluster_vg_sdc pvname: /dev/mapper/vdo_sdcgluster_infra_mount_devices(required)このセクションでは、Gluster ブリックを形成する論理ボリュームを作成します。
hc_nodes: hosts: host1backend.example.com: gluster_infra_mount_devices: - path: /gluster_bricks/engine lvname: gluster_lv_engine vgname: gluster_vg_sdb - path: /gluster_bricks/data lvname: gluster_lv_data vgname: gluster_vg_sdc - path: /gluster_bricks/vmstore lvname: gluster_lv_vmstore vgname: gluster_vg_sddgluster_infra_thinpools(optional)このセクションでは、シンプロビジョニングされたボリュームが使用する論理シンプールを定義します。シンプールは
engineボリュームには適していませんが、vmstoreおよびdataブリックに使用できます。vgname- このシンプールが含まれるボリュームグループの名前。
thinpoolname-
gluster_thinpool_sdcなどのシンプールの名前。 thinpoolsize- このボリュームグループに作成されるすべての論理ボリュームのサイズの合計。
poolmetadatasize-
16 Gに設定します。これは、サポートされるデプロイメント用に推奨されるサイズです。
hc_nodes: hosts: host1backend.example.com: gluster_infra_thinpools: - {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'} - {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}gluster_infra_cache_vars(optional)このセクションでは、低速なデバイスのパフォーマンスを改善するためにキャッシュ論理ボリュームを定義します。高速キャッシュデバイスはシンプールに割り当てられ、
gluster_infra_thinpoolを定義する必要があります。vgname- 高速な外部キャッシュを必要とするデバイスを持つボリュームグループの名前。
cachedisk-
スローデバイスとファーストデバイスのパスをカンマで区切って指定します。例えば、スローデバイス
sdbでキャッシュデバイスsdeを使用する場合は、/dev/sdb/dev/sdeと指定します。 cachelvname- このキャッシュ論理ボリュームの名前。
cachethinpoolname- 高速キャッシュボリュームが割り当てられているシンプール。
cachelvsize- キャッシュ論理ボリュームのサイズ。このサイズの約 0.01% がキャッシュメタデータに使用されます。
cachemode-
キャッシュモード。有効な値は
writethroughおよびwritebackです。
hc_nodes: hosts: host1backend.example.com: gluster_infra_cache_vars: - vgname: gluster_vg_sdb cachedisk: /dev/sdb,/dev/sde cachelvname: cachelv_thinpool_sdb cachethinpoolname: gluster_thinpool_sdb cachelvsize: '250G' cachemode: writethroughgluster_infra_thick_lvs(required)ブリックの作成に使用するシックにプロビジョニングされた論理ボリューム。
engineボリュームのブリックはシックにプロビジョニングされている必要があります。vgname- 論理ボリュームを含むボリュームグループの名前。
lvname- 論理ボリュームの名前。
サイズ-
論理ボリュームのサイズ。
engineの論理ボリュームには100 Gが必要です。
hc_nodes: hosts: host1backend.example.com: gluster_infra_thick_lvs: - vgname: gluster_vg_sdb lvname: gluster_lv_engine size: 100Ggluster_infra_lv_logicalvols(required)ブリックの作成に使用するシンプロビジョニングされた論理ボリューム。
vgname- 論理ボリュームを含むボリュームグループの名前。
thinpool- このボリュームがシンプロビジョニングされている場合、論理ボリュームを含むシンプール。
lvname- 論理ボリュームの名前。
サイズ-
論理ボリュームのサイズ。
engineの論理ボリュームには100 Gが必要です。
hc_nodes: hosts: host1backend.example.com: gluster_infra_lv_logicalvols: - vgname: gluster_vg_sdc thinpool: gluster_thinpool_sdc lvname: gluster_lv_data lvsize: 200G - vgname: gluster_vg_sdd thinpool: gluster_thinpool_sdd lvname: gluster_lv_vmstore lvsize: 200Ggluster_infra_disktype(required)ディスクの基礎となるハードウェア設定を指定します。お使いのハードウェアに合った値に設定してください。
RAID6、RAID5、JBODのいずれかです。hc_nodes: vars: gluster_infra_disktype: RAID6gluster_infra_diskcount(required)RAID セット内のデータディスクの数を指定します。
JBODディスクタイプの場合は、これを1に設定します。hc_nodes: vars: gluster_infra_diskcount: 10gluster_infra_stripe_unit_size(required)RAID セットのストライプサイズ(メガバイト単位)
hc_nodes: vars: gluster_infra_stripe_unit_size: 256gluster_features_force_varlogsizecheck(required)デプロイメントプロセス中に
/var/logパーティションに十分な空き領域があることを確認する場合は、trueに設定します。ログに十分なスペースを確保することが重要になりますが、スペースの要件を慎重に監視する場合は、デプロイメント時に領域の要件を確認する必要はありません。hc_nodes: vars: gluster_features_force_varlogsizecheck: falsegluster_set_selinux_labels(required)SELinux が有効な場合にボリュームにアクセスできることを確認します。このホストで SELinux が有効になっている場合は、
trueに設定します。hc_nodes: vars: gluster_set_selinux_labels: trueRecommendation for LV sizeエンジンブリック用の論理ボリュームは、サイズ 100GB のシック LV、シンプールメタデータ用に 16GB として作成されたその他のブリック、予備メタデータ用に 16GB 予約する必要があります。
以下に例を示します。
If the host has a disk of size 1TB, then engine brick size= 100GB ( thick LV ) Pool metadata size= 16GB Spare metadata size= 16GB Available space for thinpool= 1TB - ( 100GB + 16GB + 16GB ) = 868 GB
ボリューム用の他のブリックは、利用可能な 868 GBのシンプールのストレージスペースで作成することができます。例えば、vmstore ブリックは 200 GB、dataブリックは 668 GBです。
B.2.2.5. ファイアウォールおよびネットワークインフラストラクチャー
gluster_infra_fw_ports(required)すべてのノード間で開くべきポートのリストで、
<port>/<protocol>の形式で指定します。hc_nodes: vars: gluster_infra_fw_ports: - 2049/tcp - 54321/tcp - 5900-6923/tcp - 16514/tcp - 5666/tcp - 16514/tcpgluster_infra_fw_permanent(必須)ノードの再起動後に、
gluster_infra_fw_portsに一覧表示されるポートが開放されていることを確認します。実稼働環境のユースケースでは、これをtrueに設定します。hc_nodes: vars: gluster_infra_fw_permanent: true
gluster_infra_fw_state(required)ファイアウォールを有効にします。実稼働環境のユースケースで、この値を
enabledに設定します。hc_nodes: vars: gluster_infra_fw_state: enabledgluster_infra_fw_zone(必須)これらの
gluster_infra_fw_\*パラメーターが適用されるファイアウォールゾーンを指定します。hc_nodes: vars: gluster_infra_fw_zone: publicgluster_infra_fw_services(required)ファイアウォールを介して許可するサービスの一覧
glusterfsがここで定義されていることを確認してください。hc_nodes: vars: gluster_infra_fw_services: - glusterfs
B.2.2.6. ストレージドメイン
storage_domains(必須)指定したストレージドメインを作成します。
name- 作成するストレージドメインの名前。
host- 最初のホストのフロントエンド FQDN。IP アドレスは使用しないでください。
address- 最初のホストのバックエンド FQDN アドレス。IP アドレスは使用しないでください。
path- ストレージドメインを提供する Gluster ボリュームのパス。
function-
これを
dataに設定します。これは唯一のサポートされているストレージドメインのタイプです。 mount_options-
追加のマウントオプションを指定します。ボリュームを提供する他のホストを指定するには、
backup-volfile-serversオプションが必要です。IPv6の構成には、xlator-option='transport.address-family=inet6'オプションが必要です。
IPv4 設定
gluster: vars: storage_domains: - {"name":"data","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/data","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN"} - {"name":"vmstore","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN"}IPv6 設定
gluster: vars: storage_domains: - {"name":"data","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/data","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN,xlator-option='transport.address-family=inet6'"} - {"name":"vmstore","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN,xlator-option='transport.address-family=inet6'"}
B.2.3. gluster_inventory.yml ファイルの例
hc_nodes:
hosts:
# Host1
<host1-backend-network-FQDN>:
# Blacklist multipath devices which are used for gluster bricks
# If you omit blacklist_mpath_devices it means all device will be whitelisted.
# If the disks are not blacklisted, and then its taken that multipath configuration
# exists in the server and one should provide /dev/mapper/<WWID> instead of /dev/sdx
blacklist_mpath_devices:
- sdb
- sdc
# Enable this section 'gluster_infra_vdo', if dedupe & compression is
# required on that storage volume.
# The variables refers to:
# name - VDO volume name to be used
# device - Disk name on which VDO volume to created
# logicalsize - Logical size of the VDO volume.This value is 10 times
# the size of the physical disk
# emulate512 - VDO device is made as 4KB block sized storage volume(4KN)
# slabsize - VDO slab size. If VDO logical size >= 1000G then
# slabsize is 32G else slabsize is 2G
#
# Following VDO values are as per recommendation and treated as constants:
# blockmapcachesize - 128M
# writepolicy - auto
#
# gluster_infra_vdo:
# - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '5000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# - { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '3000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# When dedupe and compression is enabled on the device,
# use pvname for that device as '/dev/mapper/<vdo_device_name>
#
# The variables refers to:
# vgname - VG to be created on the disk
# pvname - Physical disk (/dev/sdc) or VDO volume (/dev/mapper/vdo_sdc)
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
- vgname: gluster_vg_sdc
pvname: /dev/mapper/vdo_sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
# 'thinpoolsize' is the sum of sizes of all LVs to be created on that VG
# In the case of VDO enabled, 'thinpoolsize' is 10 times the sum of sizes
# of all LVs to be created on that VG. Recommended values for
# 'poolmetadatasize' is 16GB and that should be considered exclusive of
# 'thinpoolsize'
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
# Enable the following section if LVM cache is to enabled
# Following are the variables:
# vgname - VG with the slow HDD device that needs caching
# cachedisk - Comma separated value of slow HDD and fast SSD
# In this example, /dev/sdb is the slow HDD, /dev/sde is fast SSD
# cachelvname - LV cache name
# cachethinpoolname - Thinpool to which the fast SSD to be attached
# cachelvsize - Size of cache data LV. This is the SSD_size - (1/1000) of SSD_size
# 1/1000th of SSD space will be used by cache LV meta
# cachemode - writethrough or writeback
# gluster_infra_cache_vars:
# - vgname: gluster_vg_sdb
# cachedisk: /dev/sdb,/dev/sde
# cachelvname: cachelv_thinpool_sdb
# cachethinpoolname: gluster_thinpool_sdb
# cachelvsize: '250G'
# cachemode: writethrough
# Only the engine brick needs to be thickly provisioned
# Engine brick requires 100GB of disk space
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
#Host2
<host2-backend-network-FQDN>:
# Blacklist multipath devices which are used for gluster bricks
# If you omit blacklist_mpath_devices it means all device will be whitelisted.
# If the disks are not blacklisted, and then its taken that multipath configuration
# exists in the server and one should provide /dev/mapper/<WWID> instead of /dev/sdx
blacklist_mpath_devices:
- sdb
- sdc
# Enable this section 'gluster_infra_vdo', if dedupe & compression is
# required on that storage volume.
# The variables refers to:
# name - VDO volume name to be used
# device - Disk name on which VDO volume to created
# logicalsize - Logical size of the VDO volume.This value is 10 times
# the size of the physical disk
# emulate512 - VDO device is made as 4KB block sized storage volume(4KN)
# slabsize - VDO slab size. If VDO logical size >= 1000G then
# slabsize is 32G else slabsize is 2G
#
# Following VDO values are as per recommendation and treated as constants:
# blockmapcachesize - 128M
# writepolicy - auto
#
# gluster_infra_vdo:
# - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '5000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# - { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '3000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# When dedupe and compression is enabled on the device,
# use pvname for that device as '/dev/mapper/<vdo_device_name>
#
# The variables refers to:
# vgname - VG to be created on the disk
# pvname - Physical disk (/dev/sdc) or VDO volume (/dev/mapper/vdo_sdc)
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
- vgname: gluster_vg_sdc
pvname: /dev/mapper/vdo_sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
# 'thinpoolsize' is the sum of sizes of all LVs to be created on that VG
# In the case of VDO enabled, 'thinpoolsize' is 10 times the sum of sizes
# of all LVs to be created on that VG. Recommended values for
# 'poolmetadatasize' is 16GB and that should be considered exclusive of
# 'thinpoolsize'
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
# Enable the following section if LVM cache is to enabled
# Following are the variables:
# vgname - VG with the slow HDD device that needs caching
# cachedisk - Comma separated value of slow HDD and fast SSD
# In this example, /dev/sdb is the slow HDD, /dev/sde is fast SSD
# cachelvname - LV cache name
# cachethinpoolname - Thinpool to which the fast SSD to be attached
# cachelvsize - Size of cache data LV. This is the SSD_size - (1/1000) of SSD_size
# 1/1000th of SSD space will be used by cache LV meta
# cachemode - writethrough or writeback
# gluster_infra_cache_vars:
# - vgname: gluster_vg_sdb
# cachedisk: /dev/sdb,/dev/sde
# cachelvname: cachelv_thinpool_sdb
# cachethinpoolname: gluster_thinpool_sdb
# cachelvsize: '250G'
# cachemode: writethrough
# Only the engine brick needs to be thickly provisioned
# Engine brick requires 100GB of disk space
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
#Host3
<host3-backend-network-FQDN>:
# Blacklist multipath devices which are used for gluster bricks
# If you omit blacklist_mpath_devices it means all device will be whitelisted.
# If the disks are not blacklisted, and then its taken that multipath configuration
# exists in the server and one should provide /dev/mapper/<WWID> instead of /dev/sdx
blacklist_mpath_devices:
- sdb
- sdd
# Enable this section 'gluster_infra_vdo', if dedupe & compression is
# required on that storage volume.
# The variables refers to:
# name - VDO volume name to be used
# device - Disk name on which VDO volume to created
# logicalsize - Logical size of the VDO volume.This value is 10 times
# the size of the physical disk
# emulate512 - VDO device is made as 4KB block sized storage volume(4KN)
# slabsize - VDO slab size. If VDO logical size >= 1000G then
# slabsize is 32G else slabsize is 2G
#
# Following VDO values are as per recommendation and treated as constants:
# blockmapcachesize - 128M
# writepolicy - auto
#
# gluster_infra_vdo:
# - { name: 'vdo_sdc', device: '/dev/sdc', logicalsize: '5000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# - { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '3000G', emulate512: 'off', slabsize: '32G',
# blockmapcachesize: '128M', writepolicy: 'auto' }
# When dedupe and compression is enabled on the device,
# use pvname for that device as '/dev/mapper/<vdo_device_name>
#
# The variables refers to:
# vgname - VG to be created on the disk
# pvname - Physical disk (/dev/sdc) or VDO volume (/dev/mapper/vdo_sdc)
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
- vgname: gluster_vg_sdc
pvname: /dev/mapper/vdo_sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
# 'thinpoolsize' is the sum of sizes of all LVs to be created on that VG
# In the case of VDO enabled, 'thinpoolsize' is 10 times the sum of sizes
# of all LVs to be created on that VG. Recommended values for
# 'poolmetadatasize' is 16GB and that should be considered exclusive of
# 'thinpoolsize'
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
# Enable the following section if LVM cache is to enabled
# Following are the variables:
# vgname - VG with the slow HDD device that needs caching
# cachedisk - Comma separated value of slow HDD and fast SSD
# In this example, /dev/sdb is the slow HDD, /dev/sde is fast SSD
# cachelvname - LV cache name
# cachethinpoolname - Thinpool to which the fast SSD to be attached
# cachelvsize - Size of cache data LV. This is the SSD_size - (1/1000) of SSD_size
# 1/1000th of SSD space will be used by cache LV meta
# cachemode - writethrough or writeback
# gluster_infra_cache_vars:
# - vgname: gluster_vg_sdb
# cachedisk: /dev/sdb,/dev/sde
# cachelvname: cachelv_thinpool_sdb
# cachethinpoolname: gluster_thinpool_sdb
# cachelvsize: '250G'
# cachemode: writethrough
# Only the engine brick needs to be thickly provisioned
# Engine brick requires 100GB of disk space
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
# Common configurations
vars:
# In case of IPv6 based deployment "gluster_features_enable_ipv6" needs to be enabled,below line needs to be uncommented, like:
# gluster_features_enable_ipv6: true
# Add the required hosts in the cluster. It can be 3,6,9 or 12 hosts
cluster_nodes:
- <host1-backend-network-FQDN>
- <host2-backend-network-FQDN>
- <host3-backend-network-FQDN>
gluster_features_hci_cluster: "{{ cluster_nodes }}"
# Create Gluster volumes for hyperconverged setup in 2 formats
# format-1: Create bricks for gluster 1x3 replica volumes by default
# on the first 3 hosts
# format-2: Create bricks on the specified hosts, and it can create
# nx3 distributed-replicated or distributed arbitrated
# replicate volumes
# Note: format-1 and format-2 are mutually exclusive (ie) either
# format-1 or format-2 to be used. Don't mix the formats for
# different volumes
# Format-1 - Creates gluster 1x3 replicate or arbitrated replicate volume
# - engine, vmstore, data with bricks on first 3 hosts
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
- volname: data
brick: /gluster_bricks/data/data
arbiter: 0
- volname: vmstore
brick: /gluster_bricks/vmstore/vmstore
arbiter: 0
# Format-2 - Allows to create nx3 volumes, with bricks on specified host
#gluster_features_hci_volumes:
# - volname: engine
# brick: /gluster_bricks/engine/engine
# arbiter: 0
# servers:
# - host1
# - host2
# - host3
#
# # Following creates 2x3 'Data' gluster volume with bricks on host4,
# # host5, host6, host7, host8, host9
# - volname: data
# brick: /gluster_bricks/data/data
# arbiter: 0
# servers:
# - host4
# - host5
# - host6
# - host7
# - host8
# - host9
#
# # Following creates 2x3 'vmstore' gluster volume with 2 bricks for
# # each host
# - volname: vmstore
# brick: /gluster_bricks/vmstore1/vmstore1,/gluster_bricks/vmstore2/vmstore2
# arbiter: 0
# servers:
# - host1
# - host2
# - host3
# Firewall setup
gluster_infra_fw_ports:
- 2049/tcp
- 54321/tcp
- 5900-6923/tcp
- 16514/tcp
- 5666/tcp
- 16514/tcp
gluster_infra_fw_permanent: true
gluster_infra_fw_state: enabled
gluster_infra_fw_zone: public
gluster_infra_fw_services:
- glusterfs
# Allowed values for 'gluster_infra_disktype' - RAID6, RAID5, JBOD
gluster_infra_disktype: RAID6
# 'gluster_infra_diskcount' is the number of data disks in the RAID set.
# Note for JBOD its 1
gluster_infra_diskcount: 10
gluster_infra_stripe_unit_size: 256
gluster_features_force_varlogsizecheck: false
gluster_set_selinux_labels: true
## Auto add hosts vars
gluster:
hosts:
<host2-frontend-network-FQDN>:
<host3-frontend-network-FQDN>:
vars:
storage_domains:
- {"name":"data","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/data","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN"}
- {"name":"vmstore","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN"}
# In case of IPv6 based deployment there is additional mount option required i.e. xlator-option="transport.address-family=inet6", below needs to be replaced with above one.
# Ex:
#storage_domains:
#- {"name":"data","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/data","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN,xlator-option="transport.address-family=inet6""}
#- {"name":"vmstore","host":"host1-frontend-network-FQDN","address":"host1-backend-network-FQDN","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN,xlator-option="transport.address-family=inet6""}B.3. he_gluster_vars.json ファイルについて
he_gluster_vars.json ファイルは、Ansible 変数ファイルの例です。Red Hat Hyperconverged Infrastructure for Virtualization をデプロイするには、このファイルの変数を定義する必要があります。
例となるファイルは、任意のハイパーコンバージドホストの /etc/ansible/roles/gluster.ansible/playbooks/hc-ansible-deployment/he_gluster_vars.json にあります。
he_gluster_vars.json ファイルの例
{
"he_appliance_password": "encrypt-password-using-ansible-vault",
"he_admin_password": "UI-password-for-login",
"he_domain_type": "glusterfs",
"he_fqdn": "FQDN-for-Hosted-Engine",
"he_vm_mac_addr": "Valid MAC address",
"he_default_gateway": "Valid Gateway",
"he_mgmt_network": "ovirtmgmt",
"he_storage_domain_name": "HostedEngine",
"he_storage_domain_path": "/engine",
"he_storage_domain_addr": "host1-backend-network-FQDN",
"he_mount_options": "backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN",
"he_bridge_if": "interface name for bridge creation",
"he_enable_hc_gluster_service": true,
"he_mem_size_MB": "16384",
"he_cluster": "Default",
"he_vcpus": "4"
}
Red Hat は、このファイルの暗号化を推奨します。詳細は、Working with files encrypted using Ansible Vault を参照してください。
B.3.1. 必須の変数
he_appliance_password- ホストされるエンジンのパスワード。実稼働クラスターの場合、Ansible Vault で作成された暗号化された値を使用します。
he_admin_password-
ホストされたエンジンの
adminアカウントのパスワードです。実稼働クラスターの場合、Ansible Vault で作成された暗号化された値を使用します。 he_domain_type-
ストレージドメインのタイプ。
glusterfsに設定します。 he_fqdn- ホスト型エンジン仮想マシンの FQDN。
he_vm_mac_addr- ホストされるエンジン仮想マシンの適切なネットワークデバイスの MAC アドレス。このオプションは、静的 IP 設定で、Hosted Engine の MAC アドレスが自動的に生成されます。
he_default_gateway- 使用するゲートウェイの FQDN。
he_mgmt_network-
管理ネットワークの名前。
ovirtmgmtに設定します。 he_storage_domain_name-
ホストエンジン用に作成するストレージドメインの名前。
HostedEngineに設定します。 he_storage_domain_path-
ストレージドメインを提供する Gluster ボリュームのパス。
/engineに設定します。 he_storage_domain_addr-
engineドメインを提供する最初のホストのバックエンド FQDN。 he_mount_options追加のマウントオプションを指定します。
For a three node deployment with IPv4 configurations, set:
"he_mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN"
he_mount_optionは、Red Hat Hyperconverged Infrastructure for Virtualization の IPv4 ベースのシングルノード展開には必要ありません。3つのノードでIPv6の設定を行う場合は、次のように設定します。
"he_mount_options":"backup-volfile-servers=host2-backend-network-FQDN:host3-backend-network-FQDN",xlator-option='transport.address-family=inet6'"
IPv6 設定を使用する単一ノードのデプロイメントでは、以下を設定します。
"he_mount_options":"xlator-option='transport.address-family=inet6'"
he_bridge_if- ブリッジの作成に使用するインターフェースの名前。
he_enable_hc_gluster_service-
Gluster サービスを有効にします。
trueに設定します。 he_mem_size_MB- ホストエンジン仮想マシンに割り当てられるメモリー量(メガバイト単位)。
he_cluster- ハイパーコンバージドホストが配置されるクラスターの名前。
he_vcpus- エンジン仮想マシンで使用される CPU の量。デフォルトでは、ホストエンジンの仮想マシンには 4 つの VCPU が割り当てられます。
B.3.2. 静的ネットワーク設定に必要な変数
DHCP 設定は、デフォルトでホスト型エンジン仮想マシンで使用されます。ただし、静的 IP または FQDN を使用する場合は、以下の変数を定義します。
he_vm_ip_addr- ホスト型エンジン仮想マシン(IPv4 または IPv6)の静的 IP アドレス。
he_vm_ip_prefix- ホスト型エンジン仮想マシン(IPv4 または IPv6)の IP プレフィックス
he_dns_addr- ホスト型エンジン仮想マシン(IPv4 または IPv6)用の DNS サーバー。
he_default_gateway- ホスト型エンジン仮想マシン(IPv4 または IPv6)のデフォルトゲートウェイ。
he_vm_etc_hosts-
ホストエンジンの仮想マシンの IP アドレスと FQDN をホストの
/etc/hostsに指定します(ブール値)。
静的ホスト型エンジン設定を含む he_gluster_vars.json ファイルの例
{
"he_appliance_password": "mybadappliancepassword",
"he_admin_password": "mybadadminpassword",
"he_domain_type": "glusterfs",
"he_fqdn": "engine.example.com",
"he_vm_mac_addr": "00:01:02:03:04:05",
"he_default_gateway": "gateway.example.com",
"he_mgmt_network": "ovirtmgmt",
"he_storage_domain_name": "HostedEngine",
"he_storage_domain_path": "/engine",
"he_storage_domain_addr": "host1-backend.example.com",
"he_mount_options": "backup-volfile-servers=host2-backend.example.com:host3-backend.example.com",
"he_bridge_if": "interface name for bridge creation",
"he_enable_hc_gluster_service": true,
"he_mem_size_MB": "16384",
"he_cluster": "Default",
"he_vm_ip_addr": "10.70.34.43",
"he_vm_ip_prefix": "24",
"he_dns_addr": "10.70.34.6",
"he_default_gateway": "10.70.34.255",
"he_vm_etc_hosts": "false",
"he_network_test": "ping"
}
DNS が利用できない場合は、dns の代わりに he_network_test の ping を使用してください。
Example: "he_network_test": "ping"
付録C 3 ハイパーコンバージドノードを使用するデプロイメントの例
本セクションでは、Red Hat Hyperconverged Infrastructure for Virtualization の 3 つのノードデプロイメントのファイルの例を説明します。
これらのサンプルファイルは、以下の前提条件を満たす必要があります。
すべてのノードが同じディスクを持ち、同じように設定されます。
-
各ノードには、ブートデバイス(
sda)、3 つのストレージデバイス(sdb、sdc、およびsdd)および高速キャッシュデバイス(sde)の 5 つのデバイスがあります。 -
engineボリュームは、すべてのノードでsdbデバイスを使用します。このデバイスはシックにプロビジョニングされています。 -
dataボリュームは、すべてのノードでsdcデバイスを使用します。このデバイスはシンプロビジョニングされており、パフォーマンスを改善するために高速キャッシュ デバイスsdeが アタッチされています。 -
vmstoreボリュームは、すべてのノードでsddデバイスを使用します。このデバイスはマルチパス設定を使用し、シンプロビジョニングされており、重複排除と圧縮が有効になっています。
-
各ノードには、ブートデバイス(
- このクラスターは IPv6 ネットワークを使用します。
he_gluster_vars.json ファイルの例
{
"he_appliance_password": "mybadappliancepassword",
"he_admin_password": "mybadadminpassword",
"he_domain_type": "glusterfs",
"he_fqdn": "engine.example.com",
"he_vm_mac_addr": "00:01:02:03:04:05",
"he_default_gateway": "gateway.example.com",
"he_mgmt_network": "ovirtmgmt",
"he_storage_domain_name": "HostedEngine",
"he_storage_domain_path": "/engine",
"he_storage_domain_addr": "host1-backend.example.com",
"he_mount_options": "backup-volfile-servers=host2-backend.example.com:host3-backend.example.com",
"he_bridge_if": "interface name for bridge creation",
"he_enable_hc_gluster_service": true,
"he_mem_size_MB": "16384",
"he_cluster": "Default"
}
gluster_inventory.yml ファイルの例
hc_nodes:
hosts:
host1-backend.example.com:
host2-backend.example.com:
host3-backend.example.com:
vars:
blacklist_mpath_devices:
- sdb
- sdc
gluster_infra_vdo:
- { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' }
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
- vgname: gluster_vg_sdc
pvname: /dev/sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
gluster_infra_cache_vars:
- vgname: gluster_vg_sdb
cachedisk: /dev/sdb,/dev/sde
cachelvname: cachelv_thinpool_sdb
cachethinpoolname: gluster_thinpool_sdb
cachelvsize: '250G'
cachemode: writethrough
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
gluster_features_enable_ipv6: true
cluster_nodes:
- host1-backend.example.com
- host2-backend.example.com
- host3-backend.example.com
gluster_features_hci_cluster: "{{ cluster_nodes }}"
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
- volname: data
brick: /gluster_bricks/data/data
arbiter: 0
- volname: vmstore
brick: /gluster_bricks/vmstore/vmstore
arbiter: 0
gluster_infra_fw_ports:
- 2049/tcp
- 54321/tcp
- 5900-6923/tcp
- 16514/tcp
- 5666/tcp
- 16514/tcp
gluster_infra_fw_permanent: true
gluster_infra_fw_state: enabled
gluster_infra_fw_zone: public
gluster_infra_fw_services:
- glusterfs
gluster_infra_disktype: RAID6
gluster_infra_diskcount: 10
gluster_infra_stripe_unit_size: 256
gluster_features_force_varlogsizecheck: false
gluster_set_selinux_labels: true
gluster:
hosts:
host2-frontend.example.com:
host3-frontend.example.com:
vars:
storage_domains:
- {"name":"data","host":"host1-frontend.example.com","address":"host1-backend.example.com","path":"/data","function":"data","mount_options":"backup-volfile-servers=host2-backend.example.com:host3-backend.example.com,xlator-option=transport.address-family=inet6"}
- {"name":"vmstore","host":"host1-frontend.example.com","address":"host1-backend.example.com","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host2-backend.example.com:host3-backend.example.com,xlator-option=transport.address-family=inet6"}
付録D ハイパーコンバージドノードを 6 台使用したデプロイメントの例
このセクションには、Red Hat Hyperconverged Infrastructure for Virtualization の 6 つのノードデプロイメントのファイルの例が記載されています。
これらのサンプルファイルは、以下の前提条件を満たす必要があります。
すべてのノードが同じディスクを持ち、同じように設定されます。
-
各ノードには、ブートデバイス(
sda)、3 つのストレージデバイス(sdb、sdc、およびsdd)および高速キャッシュデバイス(sde)の 5 つのデバイスがあります。 -
engineボリュームは、すべてのノードでsdbデバイスを使用します。このデバイスはシックにプロビジョニングされています。 -
dataボリュームは、すべてのノードでsdcデバイスを使用します。このデバイスはシンプロビジョニングされており、パフォーマンスを改善するために高速キャッシュ デバイスsdeが アタッチされています。 -
vmstoreボリュームは、すべてのノードでsddデバイスを使用します。このデバイスはマルチパス設定を使用し、シンプロビジョニングされており、重複排除と圧縮が有効になっています。
-
各ノードには、ブートデバイス(
- このクラスターは IPv6 ネットワークを使用します。
he_gluster_vars.json ファイルの例
{
"he_appliance_password": "mybadappliancepassword",
"he_admin_password": "mybadadminpassword",
"he_domain_type": "glusterfs",
"he_fqdn": "engine.example.com",
"he_vm_mac_addr": "00:01:02:03:04:05",
"he_default_gateway": "gateway.example.com",
"he_mgmt_network": "ovirtmgmt",
"he_storage_domain_name": "HostedEngine",
"he_storage_domain_path": "/engine",
"he_storage_domain_addr": "host1-backend.example.com",
"he_mount_options": "backup-volfile-servers=host2-backend.example.com:host3-backend.example.com",
"he_bridge_if": "interface name for bridge creation",
"he_enable_hc_gluster_service": true,
"he_mem_size_MB": "16384",
"he_cluster": "Default"
}
gluster_inventory.yml ファイルの例
hc_nodes:
hosts:
host1-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
host2-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
host3-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_volume_groups:
- vgname: gluster_vg_sdb
pvname: /dev/sdb
gluster_infra_mount_devices:
- path: /gluster_bricks/engine
lvname: gluster_lv_engine
vgname: gluster_vg_sdb
gluster_infra_thick_lvs:
- vgname: gluster_vg_sdb
lvname: gluster_lv_engine
size: 100G
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
host4-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_vdo:
- { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' }
gluster_infra_volume_groups:
- vgname: gluster_vg_sdc
pvname: /dev/sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
gluster_infra_cache_vars:
- vgname: gluster_vg_sdc
cachedisk: /dev/sdc,/dev/sde
cachelvname: cachelv_thinpool_sdc
cachethinpoolname: gluster_thinpool_sdc
cachelvsize: '250G'
cachemode: writethrough
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
host5-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_vdo:
- { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' }
gluster_infra_volume_groups:
- vgname: gluster_vg_sdc
pvname: /dev/sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
gluster_infra_cache_vars:
- vgname: gluster_vg_sdc
cachedisk: /dev/sdc,/dev/sde
cachelvname: cachelv_thinpool_sdc
cachethinpoolname: gluster_thinpool_sdc
cachelvsize: '250G'
cachemode: writethrough
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
host6-backend.example.com:
blacklist_mpath_devices:
- sdc
gluster_infra_vdo:
- { name: 'vdo_sdd', device: '/dev/sdd', logicalsize: '5000G', emulate512: 'off', slabsize: '32G', blockmapcachesize: '128M', writepolicy: 'auto' }
gluster_infra_volume_groups:
- vgname: gluster_vg_sdc
pvname: /dev/sdc
- vgname: gluster_vg_sdd
pvname: /dev/mapper/vdo_sdd
gluster_infra_mount_devices:
- path: /gluster_bricks/data
lvname: gluster_lv_data
vgname: gluster_vg_sdc
- path: /gluster_bricks/vmstore
lvname: gluster_lv_vmstore
vgname: gluster_vg_sdd
gluster_infra_thinpools:
- {vgname: 'gluster_vg_sdc', thinpoolname: 'gluster_thinpool_sdc', thinpoolsize: '500G', poolmetadatasize: '16G'}
- {vgname: 'gluster_vg_sdd', thinpoolname: 'gluster_thinpool_sdd', thinpoolsize: '500G', poolmetadatasize: '16G'}
gluster_infra_cache_vars:
- vgname: gluster_vg_sdc
cachedisk: /dev/sdc,/dev/sde
cachelvname: cachelv_thinpool_sdc
cachethinpoolname: gluster_thinpool_sdc
cachelvsize: '250G'
cachemode: writethrough
gluster_infra_lv_logicalvols:
- vgname: gluster_vg_sdc
thinpool: gluster_thinpool_sdc
lvname: gluster_lv_data
lvsize: 200G
- vgname: gluster_vg_sdd
thinpool: gluster_thinpool_sdd
lvname: gluster_lv_vmstore
lvsize: 200G
vars:
gluster_features_enable_ipv6: true
cluster_nodes:
- host1-backend.example.com
- host2-backend.example.com
- host3-backend.example.com
- host4-backend.example.com
- host5-backend.example.com
- host6-backend.example.com
gluster_features_hci_cluster: "{{ cluster_nodes }}"
gluster_features_hci_volumes:
- volname: engine
brick: /gluster_bricks/engine/engine
arbiter: 0
servers:
- host1
- host2
- host3
- volname: data
brick: /gluster_bricks/data/data
arbiter: 0
servers:
- host4
- host5
- host6
- volname: vmstore
brick: /gluster_bricks/vmstore/vmstore
arbiter: 0
servers:
- host4
- host5
- host6
gluster_infra_fw_ports:
- 2049/tcp
- 54321/tcp
- 5900-6923/tcp
- 16514/tcp
- 5666/tcp
- 16514/tcp
gluster_infra_fw_permanent: true
gluster_infra_fw_state: enabled
gluster_infra_fw_zone: public
gluster_infra_fw_services:
- glusterfs
gluster_infra_disktype: RAID6
gluster_infra_diskcount: 10
gluster_infra_stripe_unit_size: 256
gluster_features_force_varlogsizecheck: false
gluster_set_selinux_labels: true
gluster:
hosts:
host4-frontend.example.com:
host5-frontend.example.com:
host6-frontend.example.com:
vars:
storage_domains:
- {"name":"data","host":"host4-frontend.example.com","address":"host4-backend.example.com","path":"/data","function":"data","mount_options":"backup-volfile-servers=host5-backend.example.com:host6-backend.example.com,xlator-option=transport.address-family=inet6"}
- {"name":"vmstore","host":"host4-frontend.example.com","address":"host4-backend.example.com","path":"/vmstore","function":"data","mount_options":"backup-volfile-servers=host5-backend.example.com:host6-backend.example.com,xlator-option=transport.address-family=inet6"}