
Red Hat Hyperconverged Infrastructure for Virtualization のデプロイ
Red Hat Hyperconverged Infrastructure for Virtualization のデプロイ手順
概要
パート I. プラン
第1章 アーキテクチャー
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) は、1 つのデプロイメントにコンピュート、ストレージ、ネットワーク、および管理機能を組み合わせたものです。
RHHI for Virtualization は 3 台の物理マシンにデプロイされ、Red Hat Gluster Storage 3.4 および Red Hat Virtualization 4.3 を使用して個別のクラスターまたは Pod を作成します。
このデプロイメントの主要なユースケースは、リモートオフィス/ブランチオフィス (ROBO) 環境です。ここでは、リモートオフィスは定期的に中央データセンターにデータを同期しますが、機能するのに中央のデータセンターへの接続を必要としません。
次の図は、1 つのクラスターの基本的なアーキテクチャーを示しています。

1.1. VDO の概要
Red Hat Hyperconverged Infrastructure for Virtualization 1.6 の時点で、VDO (Virtual Data Optimizer) レイヤーを設定して、ストレージのデータ削減と重複排除を提供できます。
VDO は、新規インストールのデプロイ時に有効化された場合にのみサポートされ、RHHI for Virtualization の以前のバージョンからアップグレードされたデプロイメントで有効にすることはできません。
VDO は、以下のタイプのデータ削減を行い、データが必要とする領域を縮小します。
- 重複排除
- ゼロおよび重複するデータブロックを排除します。VDO は、UDS(Universal Deduplication Service) カーネルモジュールを使用して重複データを検出します。重複データを書き込む代わりに、VDO は元のブロックへの参照として記録します。論理ブロックアドレスは、VDO により物理ブロックアドレスにマッピングされます。
- 圧縮
- ディスクに書き込む前に、重複しないブロックを固定の長さ (4 KB) のブロックに一緒にパッキングすることで、データのサイズを縮小します。これにより、ストレージからデータを読み取るパフォーマンスが向上します。
最大で、データは元のサイズの 15% に縮小できます。
データの削減には追加の処理コストが発生するため、圧縮および重複排除を有効にすると書き込みパフォーマンスが低下します。そのため、パフォーマンス重視ワークロードには VDO は推奨されません。Red Hat では、実稼働環境に VDO をデプロイする前に、VDO を有効にしてワークロードが必要なパフォーマンスレベルを達成していることをテストして検証することを強く推奨します。
第2章 サポート要件
このセクションでは、予定されるデプロイメントが Red Hat のサポート要件を満たしていることを確認します。
2.1. オペレーティングシステム
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) は、他のすべての設定のベースとして Red Hat Virtualization Host 4.3 を使用します。Red Hat Enterprise Linux ホストはサポートされません。
次の表は、サポートされている RHHI for Virtualization デプロイメントで使用する各製品のサポートされているバージョンを示しています。
表2.1 バージョンの互換性
| RHHI バージョン | RHGS バージョン | RHV バージョン |
|---|---|---|
| 1.0 | 3.2 | 4.1.0 ~ 4.1.7 |
| 1.1 | 3.3.1 | 4.1.8 ~ 4.2.0 |
| 1.5 | 3.4 Batch 1 更新 | 4.2.7 |
| 1.5.1 | 3.4 Batch 2 更新 | 4.2.8 |
| 1.6 | 3.4 Batch 4 更新 | 4.3 から現在まで |
Red Hat Virtualization の要件の詳細については、Red Hat Virtualization 計画および前提条件ガイド の 要件 を参照してください。
2.2. 物理マシン
Red Hat Hyperconverged Infrastructure for Virtualization(RHHI for Virtualization) には、少なくとも 3 台の物理マシン が必要です。6、9、または 12 の物理マシンへのスケーリングもサポートされます。より詳細な要件については、Scaling を参照してください。
各物理マシンには、以下の機能が必要です。
- データおよび管理トラフィックを分離するために、物理マシンごとに少なくとも 2 つの NIC(ネットワークインターフェイスコントローラー) が設定されます (詳細は 「ネットワーキング」 を参照してください)。
小規模なデプロイメントの場合:
- 12 コア以上
- 64GB 以上の RAM
- 最大 48TB ストレージ
中規模デプロイメントの場合
- 12 コア以上
- 最小 128GB RAM
- 最大 64TB ストレージ
大規模なデプロイメントの場合
- 16 コア以上
- 256GB 以上の RAM
- 最大 80TB ストレージ
2.3. 仮想マシン
ハイパーコンバージドのデプロイメントで実行できる仮想マシンの数は、それらの仮想マシンの動作と、その中の負荷に大きく依存します。ワークロードの CPU、メモリー、およびスループットの要件をテストし、それに応じてハイパーコンバージド環境をプロビジョニングします。
2.4. ホスト型エンジン仮想マシン
ホスト型エンジン仮想マシンには、少なくとも以下が必要です。
- 1 つのデュアルコア CPU(1 クアッドコアまたは複数のデュアルコア CPU が推奨)
- 他のプロセスと共有されない 4GB RAM(16GB 推奨)
- 25 GB のローカル、書き込み可能なディスク領域 (50GB 推奨)
- 1 NIC(最低 1 Gbps 帯域幅)
詳細については、Red Hat Virtualization 4.3 Planning and Prerequisites Guide の 要件 を参照してください。
2.5. ネットワーキング
DNS によって順方向および逆方向に解決可能な完全修飾ドメイン名は、すべてのハイパーコンバージドホストと Red Hat Virtualization Manager を提供する Hosted Engine 仮想マシンに必要です。
IPv6 は、IPv6 専用環境 (DNS およびゲートウェイアドレスを含む) でテクノロジープレビューとしてサポートされます。IPv4 アドレスと IPv6 アドレスの両方を備えた環境はサポートされません。
テクノロジープレビュー機能は、カスタマーポータルの テクノロジープレビュー機能のサポート範囲 で詳しく説明されているように、限定されたサポート範囲で提供されます。
クラスター内のクライアントストレージトラフィックと管理トラフィックは 、フロントエンド管理ネットワーク と バックエンドストレージネットワーク という別のネットワークを使用する必要があります。
各ノードには、ネットワークごとに 1 つずつ、合計 2 つのイーサネットポートが必要です。これにより、最適なパフォーマンスが確保されます。高可用性を確保するには、各ネットワークを別個のネットワークスイッチに配置します。フォールトトレランスを強化するために、スイッチごとに個別の電源供給を指定します。
- フロントエンド管理ネットワーク
- Red Hat Virtualization および仮想マシンによって使用されます。
- イーサネット接続に 1Gbps 以上が必要です。
- このネットワークに割り当てられる IP アドレスは、相互に同じサブネット上、およびバックエンドストレージネットワークとは別のサブネット上になければなりません。
- このネットワークの IP アドレスは、管理者が選択できます。
- バックエンドストレージネットワーク
- ハイパーコンバージドノード間のストレージおよび移行トラフィックで使用されます。
- 最低でも 1 つの 10 Gbps イーサネット接続が必要です。
- ピア間で最大 5 ミリ秒のレイテンシーが必要です。
Intelligent Platform Management Interface(IPMI) を使用するネットワークフェンシングデバイスには、別のネットワークが必要です。
Hosted Engine 仮想マシンに DHCP ネットワーク設定を使用する場合は、Red Hat Hyperconverged Infrastructure for Virtualization を設定する前に DHCP サーバーを設定する必要があります。
geo レプリケーションを使用してデータのコピーを保存することで ディザスターリカバリーを設定する場合は、次のようにします。
- 信頼できるタイムソースを設定します。
IPv6 アドレスは使用しないでください。
警告現在 、バグ 1688239 により、 IPv6 ベースの geo レプリケーションが正しく動作できません。geo レプリケーションを使用した災害復旧機能が必要な場合は、IPv6 アドレスを使用しないでください。
デプロイメントプロセスを開始する前に、以下の詳細を確認してください。
- ハイパーコンバージドホストへのゲートウェイの IP アドレス。このアドレスは ping 要求に応答する必要があります。
- フロントエンド管理ネットワークの IP アドレス。
- ホスト型エンジン仮想マシンの完全修飾ドメイン名 (FQDN)。
- ホスト型エンジンの静的 FQDN および IP アドレスに解決する MAC アドレス。
2.6. ストレージ
ハイパーコンバージドホストは、設定、ログ、およびカーネルダンプを保存し、そのストレージをスワップ領域として使用します。このセクションでは、ハイパーコンバージドホストのディレクトリーの最小サイズを一覧表示します。Red Hat は、この最小値よりも多くのストレージ容量を使用するデフォルトの割り当てを使用することを推奨します。
-
/(root): 6GB -
/home: 1GB -
/tmp: 1GB -
/boot: 1GB -
/var: 15GB -
/var/crash: 10GB /var/log: 8GB重要Red Hat では、
/var/logのサイズを 15 GB 以上に増やして、Red Hat Gluster Storage の追加ロギング要件に十分な領域を提供することを推奨します。オペレーティングシステムのインストール後にこのパーティションのサイズを増やすには 、Web コンソールを使用した論理ボリュームの拡張 の手順に従ってください。
-
/var/log/audit: 2GB -
swap: 1 GB(詳細は 推奨のスワップサイズ を参照) - Anaconda では、将来のメタデータ拡張用に、ボリュームグループ内のシンプールサイズの 20% が確保されます。これは、通常の使用条件においてデフォルト設定でストレージを使い果たすのを防ぐためです。インストール中のシンプールのオーバープロビジョニングもサポートされていません。
- 最小合計 - 55GB
2.6.1. ディスク
Red Hat では、最適なパフォーマンスを得るために、SSD(Solid State Disks) を推奨します。ハードドライブのディスク (HDD) を使用する場合は、SSD を LVM キャッシュボリュームとしてさらに小さく設定する必要があります。
Red Hat Virtualization では 512 バイトエミュレーション (512e) のサポートが必要なため、4K ネイティブデバイスは Red Hat Hyperconverged Infrastructure for Virtualization ではサポートされていません。
2.6.2. RAID
RAID5 および RAID6 の設定がサポートされます。ただし、RAID 設定制限は、使用中のテクノロジーによって異なります。
- SAS/SATA 7k ディスクは、RAID6 でサポートされています (ほとんどの場合 10+2)
SAS 10k および 15k のディスクは以下でサポートされます。
- RAID5(ほとんどの 7+1)
- RAID6(最大 10+2)
RAID カードは、フラッシュでサポートされる書き込みキャッシュを使用する必要があります。
Red Hat は、各サーバーに少なくとも 1 つのホットペアドライブを提供することを推奨します。
2.6.3. JBOD
Red Hat Hyperconverged Infrastructure for Virtualization 1.6 の時点で、JBOD 設定は完全にサポートされ、アーキテクチャーレビューが不要になりました。
2.6.4. 論理ボリューム
エンジン gluster ボリュームを設定する論理ボリュームは、プロビジョニングする必要があります。これにより、Hosted Engine が領域不足、破壊的なボリューム設定の変更、I/O オーバーヘッド、および移行アクティビティーから保護されます。
vmstoreとオプションのdataGluster ボリュームを設定する論理ボリュームはシンプロビジョニングされている必要があります。これにより、基礎となるボリューム設定で柔軟性が向上します。シンプロビジョニングされたボリュームがハードディスク (HDD) にある場合は、パフォーマンスを向上させるために、小規模かつ高速な Solid State Disk(SSD) を lvmcache として設定します。
2.6.5. Red Hat Gluster Storage ボリューム
Red Hat Hyperconverged Infrastructure for Virtualization には、Red Hat Gluster Storage のボリュームが 3 から 4 個搭載される予定です。
- ホステッドエンジン用のエンジンボリューム 1 個
- 仮想マシンのオペレーティングシステムディスクイメージ用のvmstoreボリューム 1 個
- 他の仮想マシンのディスクイメージ用のオプションの データ ボリューム 1 つ
- ジオレプリケーションメタデータ用のshared_storageボリューム 1 個
バックアップに必要なストレージ容量を最小限に抑えるために、vmstoreとdataボリュームを分けることをお勧めします。オペレーティングシステムイメージから分離されている仮想マシンデータを保存すると、vmstore ボリュームのオペレーティングシステムイメージをより簡単に再構築できるため、ストレージ領域がプレミアムにあるときに data ボリュームのみのバックアップを作成する必要があります。
Red Hat Hyperconverged Infrastructure for Virtualization デプロイメントには、geo レプリケーションされたボリュームを最大 1 つ含めることができます。
2.6.6. ボリュームタイプ
Red Hat Hyperconverged Infrastructure for Virtualization(RHHI for Virtualization) は、デプロイ時に以下のボリューム種別のみをサポートします。
レプリケートされたボリューム (3 つのノードにわたる 3 つのブリック上の同じデータの 3 つのコピー)。
これらのボリュームは、デプロイメント後に分散レプリケーションボリュームに拡張できます。
調停されたレプリケートボリューム (3 つのノードにわたる 2 つのブリック上の同じデータの 2 つの完全なコピーと、メタデータを含む 1 つの調停ブリック)。
これらのボリュームは、デプロイメント後に調停された分散複製ボリュームに拡張できます。
- 分散ボリューム (データの 1 コピー、他のブリックへのレプリケーションなし)。
判定ブリックは、ファイル名、構造、およびメタデータのみを保存することに注意してください。つまり、3 方向の判別複製ボリュームは、同じレベルの一貫性を実現するために、3 方向の複製ボリュームが 75 % である必要があることを意味します。ただし、arbiter ブリックはメタデータのみを格納するため、3 方向の判別複製ボリュームは双方向複製ボリュームのみを提供します。
調停レプリケートボリュームのレイアウトの詳細については、Red Hat Gluster Storage 管理ガイド の より少ない合計ノードにわたる複数の調停レプリケートボリュームの作成を 参照してください。
2.7. VDO (Virtual Data Optimizer)
VDO(Virtual Data Optimizer) 層は、Red Hat Hyperconverged Infrastructure for Virtualization 1.6 でサポートされます。
VDO のサポートは、新しいデプロイメントのみに限定されます。既存のデプロイメントに VDO レイヤーを追加しないでください。
2.8. スケーリング
Red Hat Hyperconverged Infrastructure for Virtualization の初期デプロイメントは 1 ノードまたは 3 ノードです。
1 ノードのデプロイメントをスケーリングできません。
次のいずれかの方法を使用して、3 ノードのデプロイメントを 6、9、または 12 ノードに拡張できます。
- 新しいハイパーコンバージドノードを 3 つのセットで最大 12 個のハイパーコンバージドノードまでクラスターに追加します。
- 新規または既存のノード上の新しいディスクを使用して、新しい Gluster ボリュームを作成します。
- 新規または既存のノード上の新しいディスクを使用して、既存の Gluster ボリュームを 6、9、または 12 ノードに拡張します。
作成時に 3 ノードを超えるボリュームを作成することはできません。最初に 3 ノードのボリュームを作成してから、必要に応じてさらに多くのノードに拡張する必要があります。
2.9. 既存の Red Hat Gluster Storage 設定
Red Hat Hyperconverged Infrastructure for Virtualization は、本書で指定されているとおりにデプロイした場合にのみサポートされます。既存の Red Hat Gluster Storage 設定は、ハイパーコンバージド設定では使用できません。既存の Red Hat Gluster Storage 設定を使用する場合は、Red Hat Gluster Storage を使用した Red Hat Virtualization の 設定に記載されている従来の設定を参照してください。
2.10. 障害回復
Red Hat は、障害復旧ソリューションを設定することを強く推奨します。災害復旧ソリューションとして geo レプリケーションを設定する方法の詳細については、Red Hat Hyperconverged Infrastructure for Virtualization のメンテナンスを 参照してください: https://access.redhat.com/documentation/ja-jp/red_hat_hyperconverged_infra Structure_for_virtualization/1.6/html/maintaining_red_hat_hyperconverged_infra Structure_for_virtualization/config-backup- 回復。
現在 、バグ 1688239 により、 IPv6 ベースの geo レプリケーションが正しく動作できません。geo レプリケーションを使用した災害復旧機能が必要な場合は、IPv6 アドレスを使用しないでください。
2.10.1. geo レプリケーションの前提条件
geo レプリケーションを設定する際には、以下の要件と制限に注意してください。
- geo レプリケーションされたボリュームは 1 つだけ
- Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) は、geo レプリケーションされたボリュームを 1 つだけサポートします。Red Hat では、通常、最も貴重なデータが含まれる仮想マシンのデータを保存するボリュームをバックアップすることを推奨します。
- 2 つの異なるマネージャーが必要です
- geo レプリケーションのソースおよび宛先ボリュームは、Red Hat Virtualization Manager の異なるインスタンスで管理される必要があります。
2.10.2. フェイルオーバーおよびフェイルバック設定の前提条件
- バージョンが環境間で一致している必要があります
- プライマリー環境とセカンダリー環境には、同じバージョンの Red Hat Virtualization Manager が含まれており、同じデータセンターの互換バージョン、クラスターの互換バージョン、および PostgreSQL のバージョンを使用します。
- ホスト型エンジンストレージドメインに仮想マシンディスクがない
- ホスト型エンジン仮想マシンで使用されるストレージドメインはフェイルオーバーしないため、このストレージドメインの仮想マシンディスクはすべて失われます。
- 別のマスターノードから Ansible Playbook を手動で実行する
- Ansible マスターノードとして機能する別のマシンから Ansible Playbook を手動で生成して実行します。
2.11. 単一ノードデプロイメントの追加要件
Red Hat Hyperconverged Infrastructure for Virtualization は、すべての サポート要件が 満たされている場合に限り、単一ノードでのデプロイメントがサポートされますが、次の追加および例外があります。
単一ノードのデプロイメントには、以下が含まれる物理マシンが必要です。
- 1 ネットワークインターフェイスコントローラー
- 12 コア以上
- 64GB 以上の RAM
- 最大 48TB ストレージ
単一ノードのデプロイメントは拡張できず、可用性も高くありません。
第3章 推奨事項
このセクションで説明している設定は必須ではありませんが、デプロイメントの安定性またはパフォーマンスを向上させる可能性があります。
3.1. 推奨情報
- デプロイメントが完了したらすぐに完全バックアップを作成し、バックアップを別の場所に保存します。その後は、定期的にバックアップを作成します。詳細については 、バックアップおよびリカバリーのオプションの設定を 参照してください。
- デプロイメントが依存するサービスを同じ RHHI for Virtualization 環境内の仮想マシンとして実行することは避けてください。必要なサービスを同じデプロイメントで実行する必要がある場合は、デプロイメントを慎重に計画して、必要なサービスを実行している仮想マシンのダウンタイムを最小限に抑えるために慎重にデプロイメントを計画してください。
-
ハイパーコンバージドノードに十分なエントロピーを確保してください。
/proc/sys/kernel/random/entropy_availの値が200未満の場合に障害が発生する可能性があります。エントロピーを増やすには、rng-toolsパッケージをインストールして、https://access.redhat.com/solutions/1395493 の手順に従います。 - 環境の操作を行うユーザーが誰でも現在の状態と必要な手順を理解するように、環境を文書化します。
3.2. セキュリティーに関する推奨事項
- ホストまたは仮想マシンで、セキュリティー機能 (HTTPS、SELinux、ファイアウォールなど) を無効にしないでください。
- 最新のセキュリティー更新とエラータを受け取るために、すべてのホストと Red Hat Enterprise Linux 仮想マシンを Red Hat コンテンツ配信ネットワークまたは Red Hat Satellite のいずれかに登録します。
- アクティビティーを適切に追跡するために、多くのユーザーにデフォルトの admin アカウントの使用を許可する代わりに、個別の管理者アカウントを作成します。
- ホストへのアクセスを制限し、別のログインを作成します。すべてのユーザーが使用する 1 つの root ログインを作成しないでください。Red Hat Enterprise Linux 7 システム管理者ガイドの ユーザーとグループの管理 を参照してください。
- ホストに信頼できないユーザーを作成しないでください。
- 解析ツール、コンパイラー等の追加のパッケージ、または不要なセキュリティーリスクを追加するその他のコンポーネントをインストールしないでください。
3.3. ホストの推奨事項
- 同じクラスター内のホストを標準化します。これには、一貫性のあるハードウェアモデルとファームウェアのバージョンが含まれます。同じクラスター内で異なるサーバーハードウェアを混在させると、ホスト間でパフォーマンスが一定しない可能性があります。
- デプロイ時にフェンシングデバイスを設定します。高可用性には、フェンシングデバイスが必要です。
- フェンシングトラフィックには、別のハードウェアスイッチを使用します。同じスイッチで監視とフェンシングが行われると、そのスイッチは、高可用性の対して単一障害点になります。
3.4. ネットワークの推奨事項
- 特に実稼働ホストでは、ネットワークインターフェイスをボンディングします。ボンディングにより、サービスの全体的な可用性と、ネットワークの帯域幅が向上します。管理ガイドの ネットワークボンディング を参照してください。
- 最適なパフォーマンスと簡素化されたトラブルシューティングを行うには、VLAN を使用して異なるトラフィック種別を分離し、10 GbE ネットワークまたは 40 GbE ネットワークを最大限活用します。
-
基礎となるスイッチがジャンボフレームをサポートする場合は、基礎となるスイッチが対応する最大サイズ (例:
9000) に MTU を設定します。この設定により、ほとんどのアプリケーションに対して、帯域幅が高くなり、CPU 使用率が削減され、最適なスループットが得られます。デフォルトの MTU は、基礎となるスイッチでサポートされる最小サイズで決定されます。LLDP が有効化されている場合には、Setup Host Networks ウィンドウの NIC のツールチップで各ホストのピアが対応する MTU が表示されます。 - 1 GbE ネットワークは、管理トラフィックにのみ使用してください。仮想マシンおよびイーサネットベースのストレージには、10 GbE または 40 GbE を使用します。
- ストレージ用に追加の物理インターフェイスをホストに追加する場合は、仮想マシンネットワーク のチェックをクリアし、VLAN が物理インターフェイスに直接割り当てられるようにします。
3.4.1. ホストネットワーク設定の推奨プラクティス
お使いのネットワーク環境が複雑な場合には、ホストを Red Hat Virtualization Manager に追加する前に、ホストネットワークを手動で設定しなければならない場合があります。
Red Hat では、以下に示すホストネットワーク設定のプラクティスを推奨しています。
- Web コンソールを使用してネットワークを設定する。nmtui または nmcli を使用することもできます。
- セルフホストエンジンのデプロイメントまたは Manager へのホスト追加にネットワークが必要ない場合には、ホストを Manager に追加した後に、管理ポータルでネットワークを設定します。Creating a New Logical Network in a Data Center or Cluster を参照してください。
以下の命名規則を使用する。
-
VLAN デバイス:
VLAN_NAME_TYPE_RAW_PLUS_VID_NO_PAD -
VLAN インターフェイス:
physical_device.VLAN_ID(例:eth0.23、eth1.128、enp3s0.50) -
ボンディングインターフェイス:
bondnumber(例:bond0、bond1) -
ボンディングインターフェイスの VLAN:
bondnumber.VLAN_ID(例:bond0.50、bond1.128)
-
VLAN デバイス:
- network bonding を使用します。ネットワークチーミングはサポートされません。
推奨されるボンディングモードを使用。
-
仮想マシンが
ovirtmgmtネットワークを使用しない場合には、ネットワークではサポートされるいずれかのボンディングモードが使用される。 -
ovirtmgmtネットワークが仮想マシンによって使用されている場合は、仮想マシンのゲストまたはコンテナーが接続するブリッジで使用すると、どのボンディングモードが機能しますか? を 参照してください。。 -
Red Hat Virtualization のデフォルトのボンディングモードは
(Mode 4) Dynamic Link Aggregationです。お使いのスイッチがリンクアグリゲーション制御プロトコル (LACP) に対応していない場合には、(Mode 1) Active-Backupを使用してください。詳細は、Bonding Modes を参照してください。
-
仮想マシンが
以下の例に示すように、物理 NIC 上に VLAN を設定します (以下の例では
nmcliを使用していますが、任意のツールを使用できます)。# nmcli connection add type vlan con-name vlan50 ifname eth0.50 dev eth0 id 50 # nmcli con mod vlan50 +ipv4.dns 8.8.8.8 +ipv4.addresses 123.123.0.1/24 +ivp4.gateway 123.123.0.254
以下の例に示すように、ボンディング上に VLAN を設定すします (以下の例では
nmcliを使用していますが、任意のツールを使用することができます)。# nmcli connection add type bond con-name bond0 ifname bond0 bond.options "mode=active-backup,miimon=100" ipv4.method disabled ipv6.method ignore # nmcli connection add type ethernet con-name eth0 ifname eth0 master bond0 slave-type bond # nmcli connection add type ethernet con-name eth1 ifname eth1 master bond0 slave-type bond # nmcli connection add type vlan con-name vlan50 ifname bond0.50 dev bond0 id 50 # nmcli con mod vlan50 +ipv4.dns 8.8.8.8 +ipv4.addresses 123.123.0.1/24 +ivp4.gateway 123.123.0.254
-
firewalldは無効にしないでください。 - ホストを Manager に追加した後に、管理ポータルでファイアウォールルールをカスタマイズします。Configuring Host Firewall Rules を参照してください。
静的 IPv6 アドレスを使用する管理ブリッジを作成する場合は、ホストを追加する前に、インターフェイス設定 (ifcfg) ファイルでネットワークマネージャーコントロールを無効にしてください。詳細は、https://access.redhat.com/solutions/3981311 を参照してください。
3.5. セルフホストエンジンの推奨事項
- Red Hat Virtualization Manager およびその他のインフラストラクチャーレベルのサービス用に、別のデータセンターおよびクラスターを作成します (環境が十分大きく、それが可能な場合)。Manager 用仮想マシンは通常のクラスター内のホストで実行できますが、実稼働仮想マシンから分離することで、バックアップスケジュールが容易になり、パフォーマンス、可用性、およびセキュリティーが向上します。
- Manager 用仮想マシン専用のストレージドメインは、セルフホストエンジンのデプロイメント時に作成されます。他の仮想マシンにはこのストレージドメインを使用しないでください。
- Manager 用仮想マシンがホスト間で安全に移行できるように、セルフホストエンジンノードはすべて同じ CPU ファミリーを持つようにします。さまざまなファミリーがある場合は、最も性能の低いものでインストールを開始します。
- Manager 用仮想マシンのシャットダウンまたは移行が必要な場合、Manager 用仮想マシンを再起動または移行できるだけの十分なメモリーがセルフホスト型エンジンノードに必要です。
パート II. デプロイ
第4章 デプロイメントワークフロー
Red Hat Hyperconverged Infrastructure for Virtualization (RHHI for Virtualization) をデプロイするワークフローは次のとおりです。
- 計画されたデプロイメントがサポート要件を満たしていることを確認します。2章サポート要件。
- ハイパーコンバージドホストとして機能する物理マシンをインストールします。「ホスト物理マシンをインストールする」。
- パスワードを使用せずにキーベースの SSH 認証を設定して、ホストの自動設定を有効にします。5章パスワードなしの公開鍵ベースの SSH 認証の設定。
- Web コンソールを使用して物理ホスト上に Red Hat Gluster Storage を設定します。6章Web コンソールを使用した Hosted Engine 用 Red Hat Gluster Storage の設定。
- Web コンソールを使用してホスト型エンジンをデプロイします。7章Web コンソールを使用した Hosted Engine のデプロイ。
- 管理ポータルを使用して Red Hat Gluster Storage ノードを設定します。管理ポータルにログインして設定を完了します。
4.1. ホスト物理マシンをインストールする
物理マシンをハイパーコンバージドホストとして使用するには、オペレーティングシステムと適切なソフトウェアリポジトリーへのアクセスが必要です。
- Red Hat Virtualization Host を各物理マシンにインストールします。
- 各物理マシンで Red Hat Virtualization Host ソフトウェアリポジトリーを有効にします。
4.1.1. Red Hat Virtualization Host のインストール
Red Hat Virtualization Host は、Red Hat Virtualization のハイパーバイザー、または Red Hat Hyperconverged Infrastructure のハイパーコンバージドホストとして機能する物理マシンをセットアップするために設計された最小限のオペレーティングシステムです。
前提条件
- 物理マシンが 物理マシン で説明されている要件を満たしていることを確認してください。
手順
カスタマーポータルから Red Hat Virtualization Host ISO イメージをダウンロードします。
- カスタマーポータル (https://access.redhat.com) にログインします。
- メニューバーの Downloads をクリックします。
- Red Hat Virtualization をクリックします。上にスクロールして Download Latest をクリックし、製品のダウンロードページにアクセスします。
- Hypervisor Image for RHV 4.3 に移動し、Download Now をクリックします。
- 起動可能なメディアデバイスを作成します。詳細については、Red Hat Enterprise Linux Installation Guide の Making Media を参照してください。
- Red Hat Virtualization Host をインストールするマシンを起動し、準備されたインストールメディアから起動します。
ブートメニューから Install RHVH 4.3 を選択し、Enter を押します。
注記Tab キーを押してカーネルパラメーターを編集することもできます。カーネルパラメーターはスペースで区切る必要があります。Enter キーを押すと、指定したカーネルパラメーターを使用してシステムを起動できます。Esc キーを押すと、カーネルパラメーターへの変更がすべてクリアされ、ブートメニューに戻ります。
- 言語を選択し、Continue をクリックします。
日付と時刻 画面からタイムゾーンを選択し、完了 をクリックします。
重要Red Hat は、すべてのホストで協定世界時 (UTC) を使用することを推奨します。これにより、データ収集と接続が夏時間などの現地時間の変動による影響を受けないようにすることができます。
- キーボード 画面からキーボードレイアウトを選択し、完了 をクリックします。
[インストール先] 画面からインストール先を指定します。
重要- Red Hat は、Automatically configure partitioning オプションを使用することを強くお勧めします。
- デフォルトではすべてのディスクが選択されているため、インストール場所として使用したくないディスクの選択を解除します。
- 保存時の暗号化はサポートされていません。暗号化を有効にしないでください。
Red Hat では、
/var/logのサイズを 15 GB 以上に増やして、Red Hat Gluster Storage の追加ロギング要件に十分な領域を提供することを推奨します。オペレーティングシステムのインストール後にこのパーティションのサイズを増やすには 、Web コンソールを使用した論理ボリュームの拡張 の手順に従ってください。
Done をクリックします。
ネットワークとホスト名 画面からイーサネットネットワークを選択します。
- 設定… → 全般 をクリックし、利用可能な場合、このネットワークに自動的に接続する チェックボックスをオンにします。
- オプションで 言語サポート、セキュリティーポリシー、および Kdump を設定します。インストール概要 画面の各セクションの詳細については 、Red Hat Enterprise Linux 7 インストールガイド の Anaconda を使用したインストール を参照してください。
- Begin Installation をクリックします。
root パスワードを設定し、必要に応じて Red Hat Virtualization Host のインストール中に追加のユーザーを作成します。
警告Red Hat では、ローカルセキュリティーの脆弱性が悪用される可能性があるため、Red Hat Virtualization Host 上に信頼できないユーザーを作成しないことを強く推奨します。
Reboot をクリックしてインストールを完了します。
注記Red Hat Virtualization Host が再起動すると、
nodectl check はホスト上でヘルスチェックを実行し、コマンドラインでログインすると結果が表示されます。node status: OKまたはnode status: DEGRADEDのメッセージはヘルスステータスを示します。nodectl checkを実行して詳細情報を取得します。このサービスはデフォルトで有効になっています。
4.1.2. ソフトウェアリポジトリーの有効化
Web コンソールにログインします。
管理 FQDN とポート
9090を使用します (例:https://server1.example.com:9090/)。Subscriptions に移動し、Register System をクリックしてカスタマーポータルのユーザー名とパスワードを入力します。
Red Hat Virtualization Host のサブスクリプションが自動的にシステムにアタッチされます。
- Terminal をクリックします。
Red Hat Virtualization Host 7のリポジトリーを有効にして、Red Hat Virtualization Host に対する後続の更新を可能にします。# subscription-manager repos --enable=rhel-7-server-rhvh-4-rpms
第5章 パスワードなしの公開鍵ベースの SSH 認証の設定
最初のハイパーコンバージドホスト上のルートユーザーに、そのホスト自体を含むすべてのホストに対するパスワードを使用しない公開鍵ベースの SSH 認証を設定します。この作業は、すべてのストレージと管理インターフェイスについて、IP アドレスと FQDN の両方に対して行います。
5.1. 既知のホストを最初のホストに追加する
SSH を使用して、ホストにまだ認識されていないシステムからホストにログインすると、そのシステムを既知のホストとして追加するように求められます。
- 最初のハイパーコンバージドホストに root ユーザーとしてログインします。
最初のホストを含む、クラスター内の各ホストに対して次の手順を実行します。
SSH を使用して、root ユーザーとしてホストにログインします。
[root@server1]# ssh root@server1.example.com
接続を続行するには、
yesと入力します。[root@server1]# ssh root@server2.example.com The authenticity of host 'server2.example.com (192.51.100.28)' can't be established. ECDSA key fingerprint is SHA256:Td8KqgVIPXdTIasdfa2xRwn3/asdBasdpnaGM. Are you sure you want to continue connecting (yes/no)?
これにより、最初のホストのホストキーがターゲットホストの
known_hostsファイルに自動的に追加されます。Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added '192.51.100.28' (ECDSA) to the list of known hosts.
ターゲットホストの root ユーザーのパスワードを入力して、ログインプロセスを完了します。
root@server2.example.com's password: *************** Last login: Mon May 27 10:04:49 2019 [root@server2]#
ホストからログアウトします。
[root@server2]# exit [root@server1]#
注記最初のホストからそのホストへの SSH セッションからログアウトすると、コマンドラインプロンプトのユーザーとサーバーは同じままになります。変化するのはセッションだけです。
[root@server1]# exit [root@server1]#
5.2. パスワードなしの SSH 鍵ペアの生成
公開鍵と秘密鍵のペアを生成すると、キーベースの SSH 認証を使用できます。パスワードを使用しないキーペアを生成すると、Ansible を使用してデプロイメントおよび設定プロセスを自動化できます。
手順
- 最初のハイパーコンバージドホストに root ユーザーとしてログインします。
パスワードを使用しない SSH キーを生成します。
キー生成プロセスを開始します。
# ssh-keygen -t rsa Generating public/private rsa key pair.
キーの場所を入力します。
括弧で示されているデフォルトの場所は、他の入力が指定されていない場合に使用されます。
Enter file in which to save the key (/home/username/.ssh/id_rsa): <location>/<keyname>
Enterを 2 回押して、空白パスフレーズを指定および確認します。Enter passphrase (empty for no passphrase): Enter same passphrase again:
秘密鍵は
<location>/<keyname>に保存されます。公開鍵は<location>/<keyname>.pubに保存されます。Your identification has been saved in <location>/<keyname>. Your public key has been saved in <location>/<keyname>.pub. The key fingerprint is SHA256:8BhZageKrLXM99z5f/AM9aPo/KAUd8ZZFPcPFWqK6+M root@server1.example.com The key's randomart image is: +---[ECDSA 256]---+ | . . +=| | . . . = o.o| | + . * . o...| | = . . * . + +..| |. + . . So o * ..| | . o . .+ = ..| | o oo ..=. .| | ooo...+ | | .E++oo | +----[SHA256]-----+
警告この出力での
Your identificationは、あなたの秘密鍵です。秘密鍵を共有しないでください。自分の秘密鍵を持っていると、自分の公開鍵を持っているシステムで、他人が自分になりすますことができます。
5.3. SSH キーのコピー
秘密鍵を使用してホストにアクセスするには、そのホストには公開鍵のコピーが必要です。
前提条件
- 公開鍵/秘密鍵のペアを生成します。
- IP アドレスと FQDN の両方を使用して、ホスト上の root ユーザーから同じホスト上のすべてのストレージおよび管理インターフェイスに SSH アクセスします。
手順
- 最初のホストに root ユーザーとしてログインします。
アクセスするホストに公開キーをコピーします。
# ssh-copy-id -i <location>/<keyname>.pub <user>@<hostname>
プロンプトが表示されたら、
<user>@<hostname>のパスワードを入力します。警告必ず
.pubで終わるファイルを使用していることを確認してください。秘密鍵を共有しないでください。自分の秘密鍵を持っていると、自分の公開鍵を持っているシステムで、他人が自分になりすますことができます。
第6章 Web コンソールを使用した Hosted Engine 用 Red Hat Gluster Storage の設定
このデプロイメントプロセスの一部として指定するディスクに、パーティションやラベルがないことを確認してください。
Web コンソールにログインします。
最初のハイパーコンバージドホストの Web コンソール管理インターフェイス (例: https://node1.example.com:9090/) にアクセスし、で作成した認証情報を使用してログインします。「ホスト物理マシンをインストールする」。
デプロイメントウィザードの開始
Virtualization → Hosted Engine をクリックし、Hyperconverged の下の Start をクリックします。

Gluster Configuration ウィンドウが開きます。
Run Gluster Wizard ボタンをクリックします。

Gluster Deployment ウインドウが 3 ノードモードで開きます。
ハイパーコンバージドホストの指定
3 つのハイパーコンバージドホストのストレージネットワーク (管理ネットワークではない) 上のバックエンドの追加ホストを指定します。キーペアを使用して SSH 接続できるハイパーコンバージドホストは、デプロイメントタスクとホストされたエンジンを実行するホストであるため、最初にリストする必要があります。
注記調停されたレプリケートボリュームを作成する予定がある場合は、この画面で調停ブリックを持つホストを Host3 として指定していることを確認してください。
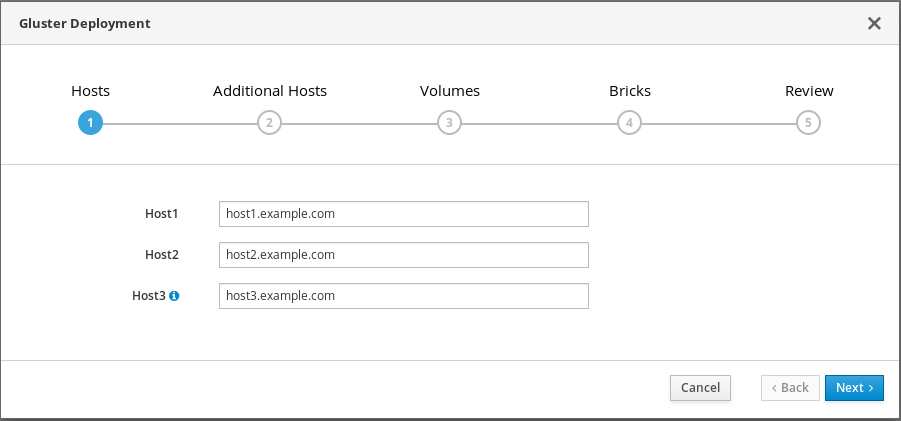
Next をクリックします。
追加のホストを指定する
マルチノードデプロイメントの場合は、フロントエンドの追加ホストまたは他の 2 つのハイパーコンバージドホストの IP アドレスを追加して、デプロイメントの完了時に Red Hat Virtualization Manager に自動的に追加されるようにします。
 重要
重要バグ 1688269 は、 デプロイメントの完了時に、IPv6 アドレスを持つホストが Red Hat Virtualization Manager に自動的に追加されないことを意味します。ホスト型エンジンにハイパーコンバージドホストを追加する に従って、デプロイメント後にそれらを追加できます。
ボリュームの指定
作成するボリュームを指定します。

- 名前。
- 作成するボリュームの名前を指定します。
- Volume Type
- レプリケート ボリュームのタイプを指定します。このリリースではレプリケートされたボリュームのみがサポートされています。
- Arbiter
- 判定ブリックを使用してボリュームを作成するかどうかを指定します。このボックスをチェックすると、3 番目のディスクにはメタデータのみが保存されます。
- ブリック Dir
- このボリュームのブリックが含まれるディレクトリー。
ほとんどのインストールでは、デフォルト値が正しくありません。
ブリックの指定
作成するブリックの詳細を入力します。ホストの選択 ドロップダウンメニューを使用して、設定されているホストを変更します。

- RAID
- 使用する RAID 設定を指定します。これはホストの RAID 設定と一致する必要があります。サポートされる値は、raid5、raid6、jbod です。このオプションを設定すると、RAID 設定用にストレージが正しく調整されるようになります。
- ストライプサイズ
- RAID のストライプサイズを KB 単位で指定します。単位は入力しないでください。この数字のみ入力してください。これは、jbod 設定で無視できます。
- ディスク数
- RAID ボリューム内のデータディスクの数を指定します。これは、jbod 設定で無視できます。
- LV Name
- 作成する論理ボリュームの名前。これは、ウィザードの前のページで指定した名前で事前に入力されます。
- デバイス
- 使用する RAW デバイスを指定します。Red Hat では、パーティションのないデバイスを推奨します。
- サイズ
- 作成する論理ボリュームのサイズを GB 単位で指定します。単位は入力しないでください。この数字のみ入力してください。この数は、複製されたセット内のすべてのブリックで同じである必要があります。Arbiter ブリックは、レプリケーションセット内の他のブリックよりも小さくすることができます。
- マウントポイント
- 論理ボリュームのマウントポイント。これには、ウィザードの前のページで指定したブリックディレクトリーがあらかじめ入力されています。
- 薄い
-
このオプションは有効になっており、シックプロビジョニングする必要がある
エンジンボリュームを除き、ボリュームはデフォルトでシンプロビジョニングされます。 - デプレートおよび圧縮の有効化
- デプロイメント時に圧縮および重複排除に VDO を使用してボリュームをプロビジョニングするかどうかを指定します。
- 論理サイズ (GB)
- VDO ボリュームの論理サイズを指定します。これは物理ボリュームの最大 10 倍のサイズになる可能性があり、絶対最大論理サイズは 4 PB です。
- LV キャッシュの設定
- 必要に応じて、このチェックボックスにチェックを付けて、高速 SSD デバイスを、大規模で低速な論理ボリュームの論理ボリュームキャッシュとして設定します。デバイスパスを SSD フィールドに追加し、サイズを LV サイズ (GB) フィールドに追加し、デバイスで使用される キャッシュモード を設定します。
警告ライトバックモードを使用する際にデータの損失を回避するために、Red Hat は 2 つの異なる SSD/NVMe デバイスを使用することを推奨します。(ソフトウェアまたはハードウェア経由)RAID-1 設定で 2 つのデバイスを設定すると、書き込みが失われる可能性が大幅に削減されます。
lvmcache 設定の詳細については、Red Hat Enterprise Linux 7 LVM 管理 を参照してください。
(オプション) システムにマルチパスデバイスがある場合は、追加の設定が必要です。
マルチパスデバイスを使用するには
RHHI for Virtualization デプロイメントでマルチパスデバイスを使用する場合は、マルチパス WWID を使用してデバイスを指定します。たとえば、
/dev/sdbの代わりに/dev/mapper/3600508b1001caab032303683327a6a2eを使用します。マルチパスデバイスの使用を無効にするには
環境内にマルチパスデバイスが存在するが、RHHI for Virtualization のデプロイメントにそれらを使用したくない場合は、デバイスをブラックリストに登録します。
カスタムマルチパス設定ファイルを作成します。
# touch /etc/multipath/conf.d/99-custom-multipath.conf
次の内容をファイルに追加し、
<device> をブラックリストに登録するデバイスの名前に置き換えます。blacklist { devnodes "<device>" }たとえば、
/dev/sdbデバイスをブラックリストに登録するには、次の行を追加します。blacklist { devnodes "sdb" }マルチパスを再起動します。
# systemctl restart multipathd
lsblkコマンドを使用して、ディスクにマルチパス名が含まれていないことを確認します。マルチパス名がまだ存在する場合は、ホストを再起動します。
設定の確認および編集

Edit をクリックして、生成されたデプロイメント設定ファイルの編集を開始します。
必要な変更を加え、Save をクリックします。
設定ファイルを確認する
すべての設定の詳細が正しい場合は、Deploy をクリックします。
デプロイメントが完了するまで待ちます。
テキストフィールドでデプロイメントの進捗を確認できます。
ウィンドウには、Successfully deployed gluster が表示されます。
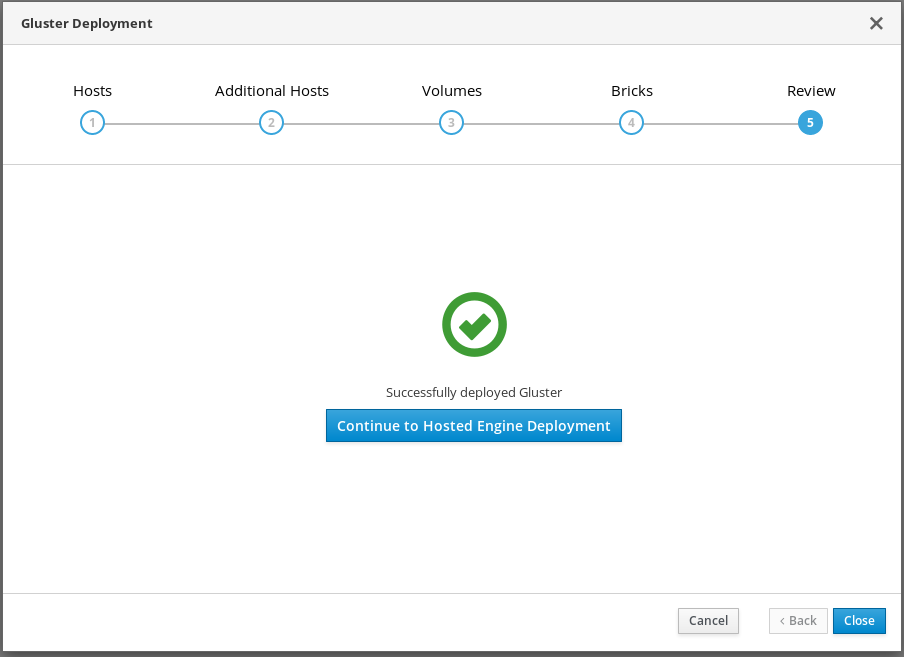
ホステッドエンジンのデプロイメントを続行 をクリックし、次の手順に従ってデプロイメントプロセスを続行します。7章Web コンソールを使用した Hosted Engine のデプロイ。
デプロイメントに失敗した場合は、Clean up をクリックして、システムへの正しくない変更をすべて削除します。
クリーンアップが完了したら、Redeploy をクリックします。これにより Review and edit configuration タブに戻り、デプロイメントを再試行する前に生成された設定ファイルの問題を修正できます。
第7章 Web コンソールを使用した Hosted Engine のデプロイ
本セクションでは、Web コンソールを使用して、Hosted Engine をデプロイする方法を説明します。このプロセスを実行すると、Red Hat Virtualization Manager がデプロイメントの最初の物理マシン上で仮想マシンとして実行されます。また、3 台の物理マシンで設定される Default クラスターを設定し、クラスター内の各マシンに対して Red Hat Gluster Storage 機能とvirtual-host tunedパフォーマンスプロファイルを有効にします。
前提条件
- Web コンソールを使用した Hosted Engine 用 Red Hat Gluster Storage の設定
ホスト型エンジンデプロイメントに必要な情報を収集
デプロイメントプロセスを開始する前に、以下の情報を準備してください。
- hyperconverged ホストへの ping 送信可能なゲートウェイの IP アドレス
- フロントエンド管理ネットワークの IP アドレス
- ホスト型エンジン仮想マシンの完全修飾ドメイン名 (FQDN)
- ホスト型エンジンの静的 FQDN および IP アドレスに解決する MAC アドレス
手順
ホスト型エンジン Deployment ウィザードを開く
Web コンソールを使用した Red Hat Gluster Storage のホスト型エンジンの設定 の最後から直接続行した場合、ウィザードはすでに開いています。
それ以外の場合:
- Virtualization → Hosted Engine をクリックします。
- Hyperconverged の下にある Start をクリックします。
Use existing configuration をクリックします。
重要以前のデプロイメントに失敗した場合は、Use existing configuration ではなく Clean up をクリックして、以前の試行を最初から破棄して開始します。
仮想マシンの詳細の指定
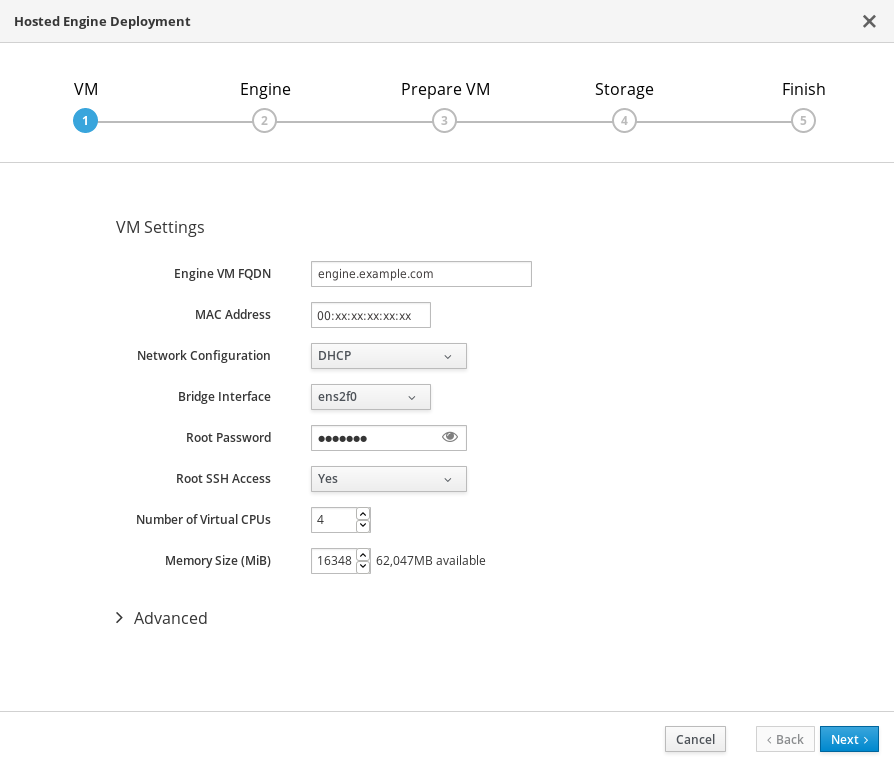
次の詳細を入力し、FQDN フィールドの 検証を クリックします。
- エンジン仮想マシン FQDN
-
ホスト型エンジン仮想マシンに使用される完全修飾ドメイン名 (例:
engine.example.com)。 - MAC Address
Engine VM FQDN に関連付けられた MAC アドレス。
重要事前に設定された MAC アドレスを置き換える必要があります。
- root パスワード
- Hosted Engine 仮想マシンに使用される root パスワード。
- Next をクリックします。FQDN は、次の画面が表示される前に検証されます。
仮想管理の詳細を指定する
管理ポータルで
adminアカウントが使用するパスワードを入力します。ここで通知動作を指定することもできます。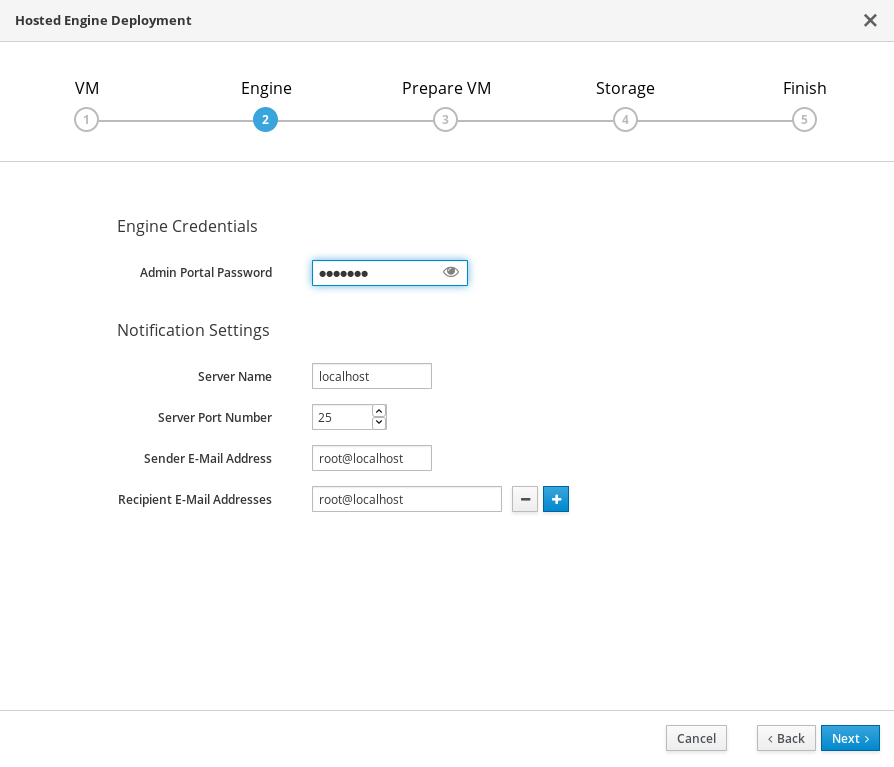
- Next をクリックします。
仮想マシン設定の確認
このタブにリストされている詳細が正しいことを確認します。Back をクリックして、誤った情報を修正します。
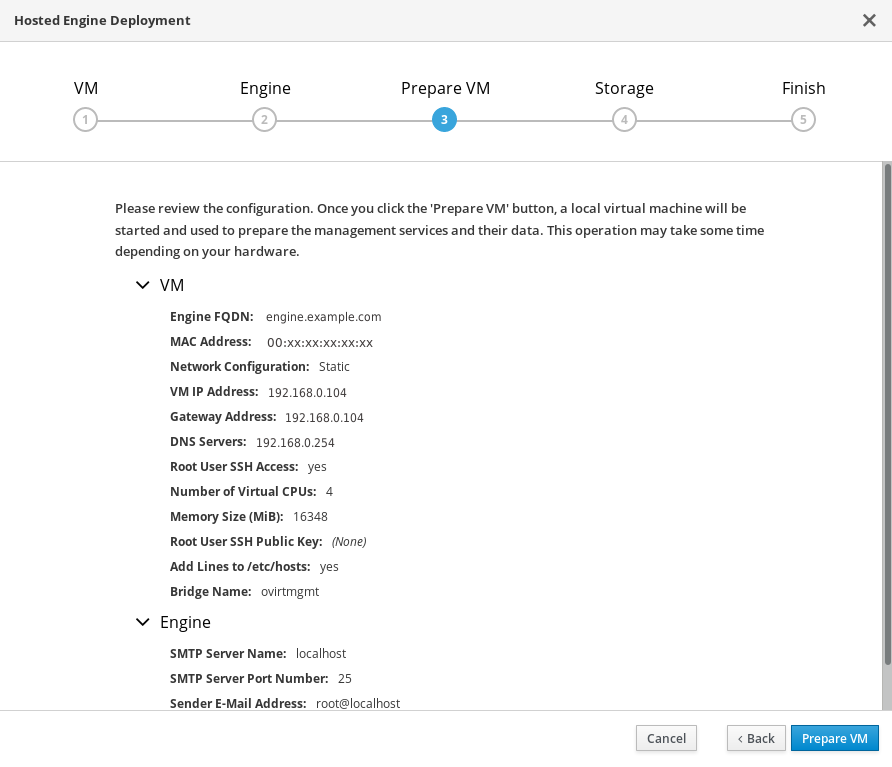
- Prepare VM をクリックします。
仮想マシンの準備が完了するまで待ちます。
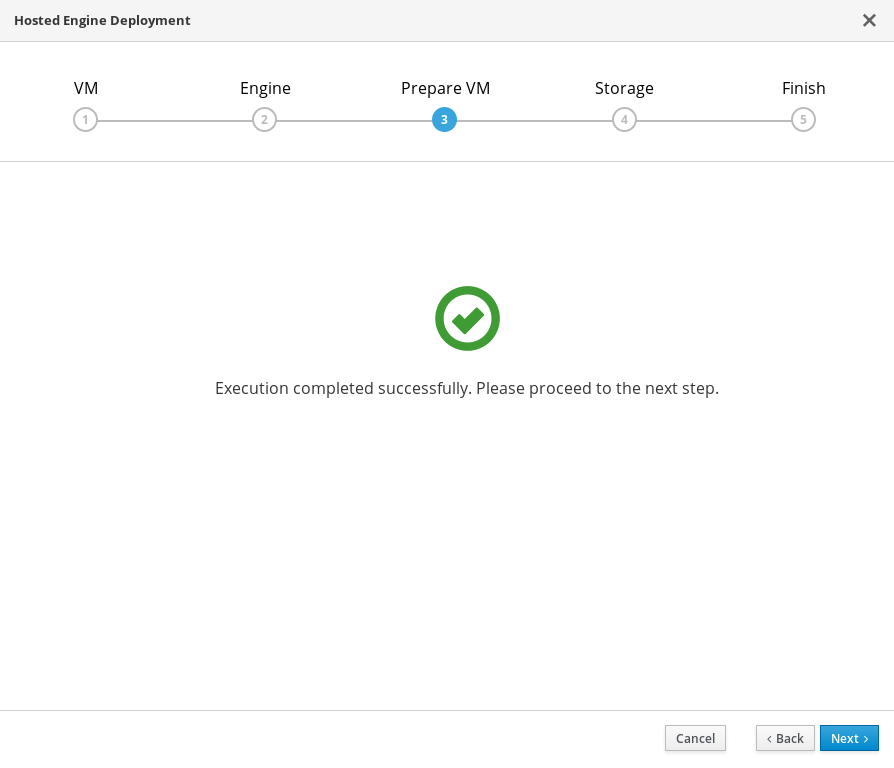
準備が正常に行われない場合は、 Hosted Engine 導入エラーの表示 を参照してください。
- Next をクリックします。
ホスト型エンジン仮想マシンのストレージの指定
-
プライマリーホストと
エンジンボリュームの場所を指定します。 マウントオプション フィールドに正しく入力されていることを確認します。
-
<host2-ip-address> と
<host3-ip-address> の代わりに適切な IP アドレスを挿入して、backup-volfile-servers=<host2-ip-address>:<host3-ip-address>であることを確認します。 環境で IPv6 アドレスを使用している場合は、次のように、
backup-volfile-servers値の後にxlator-option=transport.address-family=inet6オプションを必ず追加してください。backup-volfile-servers=<host2-ip-address>:<host3-ip-address>,xlator-option=transport.address-family=inet6

-
<host2-ip-address> と
- Next をクリックします。
-
プライマリーホストと
ホスト型エンジンのデプロイメントの最終処理
デプロイメントの詳細を確認し、それらが正しいことを確認します。
注記設定中に指定した応答は応答ファイルに保存され、必要に応じてホストされたエンジンを再インストールする上で役立ちます。応答ファイルは、デフォルトで
/etc/ovirt-hosted-engine/answers.confに作成されます。このファイルは、Red Hat サポートの支援なしに手動で変更することができません。
- Finish Deployment をクリックします。
デプロイメントが完了するまで待ちます。
これには最大 30 分かかります。
ウィンドウには、完了すると以下が表示されます。
 重要
重要デプロイメントが正常に完了しない場合は、Hosted Engine デプロイメントエラーの表示を 参照してください。
Close をクリックします。
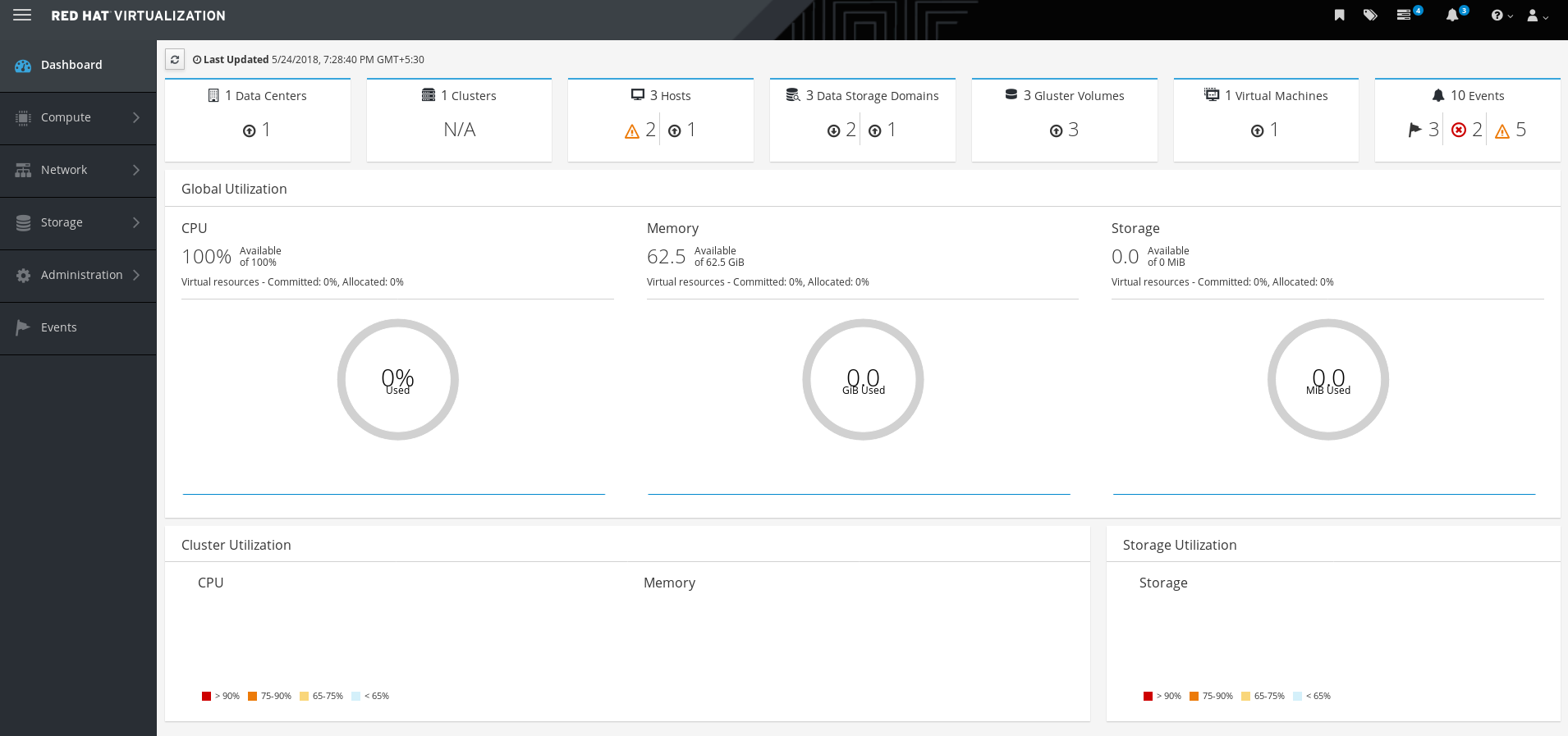
ホストエンジンのデプロイメントの確認
管理ポータル (例: http://engine.example.com/ovirt-engine) を参照し、前のステップで設定した管理認証情報を使用してログインできることを確認します。Dashboard をクリックし、ホスト、ストレージドメイン、および仮想マシンを検索します。
次のステップ
第8章 Configure Red Hat Gluster Storage as a Red Hat Virtualization storage domain
8.1. gluster トラフィック用の論理ネットワークの作成
管理ポータルにログインする
管理ポータル (例: http://engine.example.com/ovirt-engine) にアクセスし、で設定した管理認証情報を使用してログインします。7章Web コンソールを使用した Hosted Engine のデプロイ。
gluster トラフィック用の論理ネットワークを作成する
- Network → Networks をクリックしてから New をクリックします。New Logical Network ウィザードが表示されます。
- ウィザードの General タブで、新しい論理ネットワークの Name を指定して、VM Network チェックボックスをオフにします。
- ウィザードの Cluster タブで、Required チェックボックスをオフにします。
- OK をクリックして、新しい論理ネットワークを作成します。
gluster の新しい論理ネットワークを有効にする
- Network → Networks をクリックし、新しい論理ネットワークを選択します。
- Clusters サブタブをクリックし、Manage Network をクリックします。Manage Network ダイアログが表示されます。
- Manage Network ダイアログで、Migration Network および Gluster Network チェックボックスをオンにします。
- OK をクリックして保存します。
gluster ネットワークをホストに接続する
- Compute → Hosts をクリックし、ホストを選択します。
- Network Interfaces サブタブをクリックし、Setup Host Networks をクリックします。Setup Host Networks ウィンドウが開きます。
- 新しく作成したネットワークを正しいインターフェイスにドラッグアンドドロップします。
- Verify connectivity between Host and Engine チェックボックスがオンになっていることを確認します。
- Save network configuration チェックボックスがオンになっていることを確認します。
- OK をクリックして保存します。
ネットワークの状態を確認します
Network Interfaces タブをクリックして、ホストのネットワークの状態を確認します。ネットワークインターフェイスが非同期状態になるか、IP アドレスがない場合は、Management → Refresh Capabilities をクリックします。
8.2. 追加のハイパーコンバージドホストを設定する
IPv6 アドレスを使用している場合、または Web コンソールを使用してホストされたエンジン用に Red Hat Gluster Storage を設定 するの一部として追加のハイパーコンバージドホストを指定しなかった場合は、その他のハイパーコンバージドホストごとに管理ポータルで以下の手順に従います。
- Compute → Hosts をクリックし、New をクリックして New Host ウィンドウを開きます。
- 管理するホストの Name、Hostname、および Password を指定します。
- Advanced Parameters で、Automatically configure host firewall チェックボックスをオフにします。これは、ファイアウォールルールがデプロイメントプロセスによってすでに設定されているためです。
- New Host ダイアログの Hosted Engine タブで、Choose hosted engine deployment action の値を Deploy に設定します。これにより、ホストされたエンジンが新しいホストで実行できるようになります。
OK をクリックします。
- gluster ネットワークを残りのすべてのホストに接続します
- 新しく追加されたホストの名前をクリックして、ホストページに移動します。
- Network Interfaces サブタブをクリックし、Setup Host Networks をクリックします。
- 新しく作成したネットワークを正しいインターフェイスにドラッグアンドドロップします。
- Verify connectivity チェックボックスがオンになっていることを確認します。
- Save network configuration チェックボックスがオンになっていることを確認します。
OK をクリックして保存します。
このホストの General サブタブで、Hosted Engine HA の値が Active で、スコアが正の整数であることを確認します。
重要スコア が N/A と表示されている場合は、Choose hosted engine deployment action で デプロイ アクションを選択し忘れている可能性があります。Red Hat Hyperconverged Infrastructure for Virtualization のメンテナンス の ハイパーコンバージドホストの再インストール の手順に従って、デプロイ アクションでホストを再インストールします。
ネットワークの状態を確認します
Network Interfaces タブをクリックして、ホストのネットワークの状態を確認します。ネットワークインターフェイスが非同期状態になるか、IP アドレスがない場合は、Management → Refresh Capabilities をクリックします。
詳細については、Red Hat Virtualization 4.3 Self-Hosted Engine Guide を 参照してください: https://access.redhat.com/documentation/ja-jp/red_hat_virtualization/4.3/html/self-hosted_engine_guide/chap-installing_Additional_hosts_to_a_self-hosted_environment
パート III. 検証
第9章 デプロイメントの確認
デプロイメントが完了したら、デプロイメントが正常に完了したことを確認します。
管理ポータルを参照します (例: http://engine.example.com/ovirt-engine)
管理コンソールのログイン
ホスト型エンジンのデプロイメント時に追加された管理認証情報を使用してログインします。
ログインに成功すると、Dashboard が表示されます。
管理コンソールダッシュボード
クラスターが利用可能であることを確認します。
アドミニストレーションコンソールのダッシュボード : クラスター

1 つ以上のホストが利用可能であることを確認します。
ホスト型エンジンのデプロイメント中に追加のホストの詳細を指定した場合は、以下に示すように 3 つのホストが表示されます。
管理コンソールダッシュボード - Hosts
- Compute → Hosts をクリックします。
すべてのホストの Status が
Upと表示されていることを確認します。管理コンソール - Hosts

すべてのストレージドメインが利用可能であることを確認します。
- Storage から Domains をクリックします。
Activeアイコンが最初の列に表示されることを確認します。管理コンソール: ストレージドメイン

パート IV. 次のステップ
第10章 デプロイメント後設定の提案
要件によっては、新たにデプロイした Red Hat Hyperconverged Infrastructure for Virtualization で追加の設定を実行することができます。本セクションでは、追加の設定に推奨される手順を説明します。
これらのプロセスの詳細については 、Maintaining Red Hat Hyperconverged Infrastructure for Virtualization を参照してください。
10.1. 高可用性のためのフェンシングの設定
フェンシングにより、クラスターはパフォーマンスと可用性のポリシーを適用し、ハイパーコンバージドホストを自動的に再起動することで予期しないホスト障害に対応できます。
詳細については 、フェンシングポリシーを使用した高可用性の設定を 参照してください。
10.2. バックアップおよびリカバリーオプションの設定
Red Hat は、すべての実稼働デプロイメントで少なくとも基本的な障害復旧機能を設定することを推奨します。
詳細については、Red Hat Hyperconverged Infrastructure for Virtualization のメンテナンス の バックアップおよびリカバリーオプションの設定を 参照してください。
パート V. トラブルシューティング
第11章 ログファイルの場所
デプロイメントプロセス中に、進捗情報が Web ブラウザーに表示されます。この情報はローカルファイルシステムにも保存され、ログに記録された情報をアーカイブまたは後で確認したりできます。たとえば、Web ブラウザーが応答を停止するか、情報の確認前に閉じられた場合などがこれに該当します。
Web コンソールベースのデプロイメントプロセスのログファイル (次のドキュメントに記載されています)6章Web コンソールを使用した Hosted Engine 用 Red Hat Gluster Storage の設定) は、デフォルトで /var/log/ansible.log ファイルに保存されます。
導入プロセスのホスト型エンジンのセットアップ部分のログファイル (次のドキュメントに記載されています)7章Web コンソールを使用した Hosted Engine のデプロイ) は、ovirt-hosted-engine-setup- <date>.log の形式のファイル名で/var/log/ovirt-hosted-engine-setup ディレクトリーに保存されます。
第12章 導入エラーの表示
12.1. ストレージのデプロイに失敗しました
ストレージのデプロイメント 中にエラーが発生した場合、デプロイメントプロセスは停止し、ⓧデプロイに失敗しました と表示されます。
Deploying storage failed
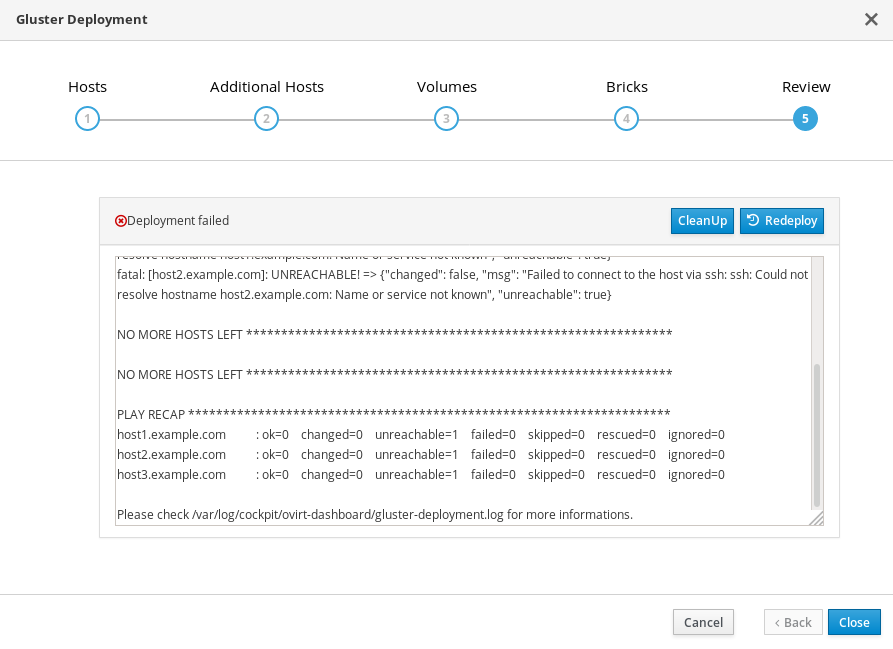
- エラー情報については、Web コンソールの出力を確認します。
- Clean up をクリックして、システムに不正な変更をすべて削除します。
- Redeploy をクリックし、エラーが出される可能性のある入力値を修正します。エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
- ストレージのデプロイメント に戻って、もう一度試してみてください。
12.2. 仮想マシンの準備に失敗しました
Hosted Engine デプロイ で仮想マシンを準備中にエラーが発生した場合、デプロイは一時停止され、次のような画面が表示されます。
仮想マシンの準備に失敗しました
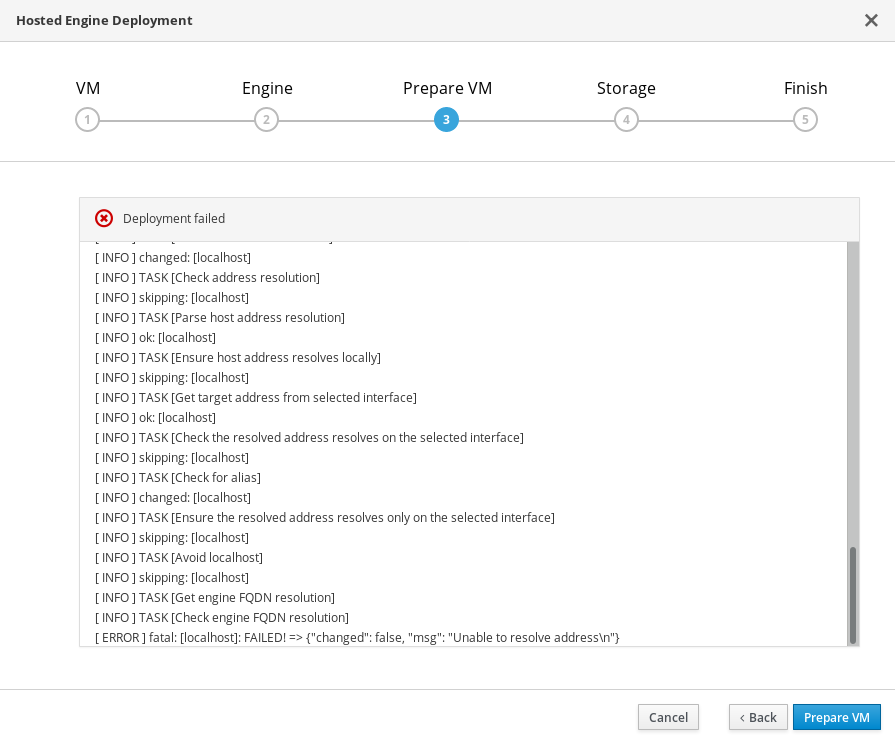
- エラー情報については、Web コンソールの出力を確認します。
- Clean up をクリックして、システムに不正な変更をすべて削除します。
- Redeploy をクリックし、エラーが出される可能性のある入力値を修正します。エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
rhvm-applianceパッケージがすべてのホストで利用可能であることを確認してください。# yum install rhvm-appliance
Hosted Engine のデプロイメント に戻って再試行してください。
エラーを解決している間にデプロイメントウィザードを終了する場合は、デプロイメントプロセスを再試行するときに、Use existing configuration を選択します。
12.3. ホスト型エンジンのデプロイに失敗しました
ホスト型エンジンのデプロイ中にエラーが発生した場合、デプロイは一時停止され、ⓧデプロイに失敗しました と表示されます。
ホスト型エンジンのデプロイメントに失敗しました

- エラー情報については、Web コンソールの出力を確認します。
engineボリュームの内容を削除します。engineボリュームをマウントします。# mount -t glusterfs <server1>:/engine /mnt/test
ボリュームの内容を削除します。
# rm -rf /mnt/test/*
engineボリュームをアンマウントします。# umount /mnt/test
- Clean up をクリックして、システムに不正な変更をすべて削除します。
- Redeploy をクリックし、エラーが出される可能性のある入力値を修正します。エラーの解決に関するヘルプが必要な場合は、詳細について Red Hat サポートにお問い合わせください。
Hosted Engine のデプロイメント に戻って再試行してください。
エラーを解決している間にデプロイメントウィザードを終了する場合は、デプロイメントプロセスを再試行するときに、Use existing configuration を選択します。
パート VI. 参考資料
付録A 用語集
A.1. 仮想化用語
- Administration Portal
- oVirt engine Web ユーザーインターフェイスをベースとする Red Hat Virtualization Manager が提供する Web ユーザーインターフェイス。これにより、管理者はネットワーク、ストレージドメイン、仮想マシンテンプレートなどのクラスターリソースを管理および監視できます。
- ホスト型エンジン
- RHHI for Virtualization を管理する Red Hat Virtualization Manager のインスタンス。
- ホスト型エンジン仮想マシン
- Red Hat Virtualization Manager として機能する仮想マシン。ホスト型 Engine 仮想マシンは、ホスト型 Engine 仮想マシンで実行されている Red Hat Virtualization Manager のインスタンスが管理する仮想化ホストで実行されます。
- Manager ノード
- ホスト型エンジンの仮想マシンで実行するのではなく、Red Hat Virtualization Manager を直接実行する仮想化ホスト。
- Red Hat Enterprise Linux ホスト
- Red Hat Enterprise Linux でインストールした物理マシンと、Red Hat Virtualization ホストと同じ機能を提供する追加パッケージ。このタイプのホストは、RHHI for Virtualization での使用はサポートされません。
- Red Hat Virtualization
- Linux および Microsoft Windows ワークロードのリソース、プロセス、およびアプリケーションを仮想化するためのオペレーティングシステムと管理インターフェイス。
- Red Hat Virtualization ホスト
- Red Hat Virtualization でインストールされた物理マシン。Linux および Microsoft Windows ワークロードのリソース、プロセス、およびアプリケーションの仮想化をサポートする物理リソースを提供します。これは、RHHI for Virtualization でサポートされる唯一のタイプのホストです。
- Red Hat Virtualization Manager
- Red Hat Virtualization の管理および監視機能を実行するサーバー
- セルフホストエンジンのノード
- ホスト型エンジン仮想マシンを含む仮想化ホスト。RHHI for Virtualization デプロイメントのすべてのホストはセルフホストエンジンノードを持つことができますが、一度にセルフホストエンジンノードが 1 つしかありません。
- ストレージドメイン
- イメージ、テンプレート、スナップショット、およびメタデータの名前付きコレクション。ストレージドメインは、ブロックデバイスまたはファイルシステムから設定できます。ストレージドメインは、データセンターにアタッチされ、データセンター内のホストにはイメージ、テンプレートなどのコレクションにアクセスできます。
- virtualization host
- クライアントアクセスのために物理リソース、プロセス、およびアプリケーションを仮想化する機能がある物理マシン。
- VM ポータル
- Red Hat Virtualization Manager が提供する Web ユーザーインターフェイスこれにより、ユーザーは仮想マシンの管理および監視を行うことができます。
A.2. ストレージ用語
- ブリック
- 信頼できるストレージプール内のサーバーにエクスポートされるディレクトリー。
- キャッシュ論理ボリューム
- 大規模で低速な論理ボリュームのパフォーマンスを改善するのに使用される小規模で高速な論理ボリューム。
- geo-replication
- ソースの Gluster ボリュームからターゲットボリュームへのデータの非同期レプリケーション。Geo レプリケーションは、ローカル領域ネットワークおよびインターネット全体で機能します。ターゲットボリュームは、異なる信頼できるストレージプールの Gluster ボリューム、または別のタイプのストレージになります。
- Gluster ボリューム
- ワークロードの要件に応じてデータを分散、複製、または分散するように設定できるブリックの論理グループ。
- 論理ボリューム管理 (LVM)
- 物理ディスクを大きな仮想パーティションに統合する方法。物理ボリュームはボリュームグループに配置され、必要に応じて論理ボリュームに分割できるストレージのプールを形成します。
- Red Hat Gluster Storage
- Red Hat Enterprise Linux をベースとするオペレーティングシステムは、分散型のソフトウェア定義のストレージをサポートする追加パッケージが含まれています。
- ソースボリューム
- データが geo レプリケーション時にコピーされる Gluster ボリューム。
- ストレージホスト
- クライアントアクセス用にストレージを提供する物理マシン。
- ターゲットボリューム
- geo レプリケーション時にデータがコピーされる Gluster ボリュームまたは他のストレージボリューム。
- シンプロビジョニング
- 必要な領域のみが作成時に割り当てられるように、プロビジョニングストレージは、時間の経過に応じてさらに領域を動的に割り当てられるようにします。
- シックプロビジョニング
- すぐに領域が必要かどうかに関係なく、すべての領域が作成時に割り当てられるようにプロビジョニングストレージをプロビジョニングします。
- 信頼できるストレージプール
- 信頼されるピアとして相互に認識する Red Hat Gluster Storage サーバーのグループ。
A.3. ハイパーコンバージドインフラストラクチャーの用語
- Red Hat Hyperconverged Infrastructure(RHHI)for Virtualization
- RHHI for Virtualization は、仮想コンピュートおよび仮想ストレージリソースの両方を提供する単一の製品です。Red Hat Virtualization および Red Hat Gluster Storage は、接続設定にインストールされます。ここでは、両方の製品のサービスがクラスター内の各物理マシンで利用できます。
- ハイパーコンバージドホスト
- 仮想化プロセスとアプリケーションが同じホスト上で実行する物理ストレージを提供する物理マシン。RHHI for Virtualization と共にインストールされるすべてのホストは、ハイパーコンバージドホストです。
- Web コンソール
- RHHI for Virtualization のデプロイ、管理、監視用の Web ユーザーインターフェイス。Web コンソールは、Web コンソールサービスおよび Red Hat Virtualization Manager のプラグインによって提供されます。