
デプロイメントガイド
Red Hat Hyperconverged Infrastructure for Cloud Solution のデプロイ
概要
第1章 Red Hat Hyperconverged Infrastructure for Cloud ソリューションの紹介
Red Hat Hyperconverged Infrastructure (RHHI) for Cloud ソリューションは、幅広いソフトウェア定義の RHHI ソリューションの一部です。RHHI Cloud ソリューションは、Red Hat OpenStack Platform (RHOSP) 13 および Red Hat Ceph Storage (RHCS) 3 テクノロジーを 1 つの製品に統合し、3 つの目的を達成します。
- RHOSP および RHCS のデプロイメントを簡素化します。
- より予測可能なパフォーマンスエクスペリエンスを提供します。
- それぞれのサービスを同じノードにコロケートすることで、RHOSP と RHCS のエントリーのコストを軽減します。
RHHI Cloud のコロケーションシナリオは以下のとおりです。
- 同じノード上の RHOSP コントローラーと RHCS Monitor サービス。
- 同じノード上の RHOSP Nova Compute および RHCS Object Storage Daemon (OSD)サービス。
デプロイメントワークフローの選択
Red Hat Hyperconverged Infrastructure for Cloud のデプロイには、Red Hat OpenStack Platform Director Web インターフェイスまたはコマンドラインインターフェイスのいずれかを選択できます。これは基本的なデプロイメントワークフローです。

関連情報
- 詳細は、Red Hat OpenStack Director を使用した Red Hat Hyperconverged Infrastructure for Cloud のデプロイメント セクションを参照してください。
- 詳細は、コマンドラインインターフェイスを使用した Red Hat Hyperconverged Infrastructure for Cloud のデプロイ セクションを参照してください。
第2章 Red Hat Hyperconverged Infrastructure for Cloud 要件の確認
技術的には、Red Hat Hyperconverged Infrastructure for Cloud ソリューションをデプロイする前に、3 つの中核となる要件を確認する必要があります。
2.1. 前提条件
2.2. Red Hat Hyperconverged Infrastructure for Cloud ハードウェア要件
ハイパーコンバージドインフラストラクチャーの実装は、さまざまなハードウェア設定を反映します。Red Hat は、ハードウェアを検討する際に、以下の最小値を推奨します。
- CPU
- コントローラーノード/モニターノードの場合は、デュアルソケット、8 コア CPU を使用します。コンピュート/OSD ノードの場合は、NVMe ストレージメディアを使用するノードにデュアルソケット、14 コア CPU、SAS/SATA SSD を使用するノードにデュアルソケット 10 コア CPU を使用します。
- RAM
- 常駐 Nova 仮想マシンのワークロードに必要な 2 倍の RAM を設定します。
- OSD ディスク
- 汎用ワークロードには 7200 RPM のエンタープライズ HDD を使用し、IOPS 集約型ワークロードには NVMe SSD を使用します。
- ジャーナルディスク
- 汎用ワークロードには SAS/SATA SSD、IOPS 集約型ワークロードには NVMe SSD を使用します。
- ネットワーク
- Red Hat Ceph Storage (RHCS)ノードに 2 つの 10GbE NIC を使用します。また、Nova 仮想マシンのワークロード要件を満たすには、専用の NIC を使用します。詳細は、ネットワーク要件 を参照してください。
表2.1 ノードの最小数量
| Qty. | Role | 物理/仮想 |
|---|---|---|
| 1 | Red Hat OpenStack Platform director (RHOSP-d) | 次のいずれかになります* |
| 3 | RHOSP コントローラーと RHCS Monitor | 物理的 |
| 3 | RHOSP Compute & RHCS OSD | 物理的 |
RHOSP-d ノードは、小規模なデプロイメント用に仮想化できます。つまり、合計容量は 20TB 未満です。ソリューションのデプロイメントが容量 20TB を超える場合、Red Hat では RHOSP-d ノードが物理ノードであることを推奨しています。ハイパーコンバージドのコンピュートノード/ストレージノードを最初にデプロイしたり、後で追加したりできます。
Red Hat は、複数のデータセンターラック(30 ノード)にまたがるデプロイメントに、スタンドアロンのコンピュートノードおよびストレージノードを使用することを推奨します。
2.3. Red Hat Hyperconverged Infrastructure for Cloud ネットワーク要件
Red Hat は、さまざまなトラフィックロールを提供するために、少なくとも 5 つのネットワークを使用することを推奨します。
- Red Hat Ceph Storage
- Ceph Monitor ノードはパブリックネットワークを使用します。プライベートストレージクラスターネットワークが存在しない場合、Ceph OSD はパブリックネットワークを使用します。必要に応じて、OSD はプライベートストレージクラスターネットワークを使用して、レプリケーション、ハートビート、およびバックフィルに関連付けられたトラフィックを処理し、パブリックネットワークを I/O 専用にしておくことができます。Red Hat は、大規模なデプロイメントにクラスターネットワークを使用することを推奨します。Compute ロールには、このネットワークへのアクセスが必要です。
- 外部
- Red Hat OpenStack Platform director (RHOSP-d)は、外部ネットワークを使用してオーバークラウドのソフトウェア更新をダウンロードし、オーバークラウドの Operator はこれを使用して RHOSP-d を使用してオーバークラウドを管理します。テナントサービスが予約済みの Floating IP アドレス経由で接続を確立する場合、コントローラーは外部ネットワークを使用してトラフィックをインターネットにルーティングします。オーバークラウドユーザーは、外部ネットワークを使用してオーバークラウドにアクセスします。
- OpenStack Internal API
- OpenStack は、パブリック向け API エンドポイントとプライベート API エンドポイントの両方を提供します。これは、プライベートエンドポイント用の分離ネットワークです。
- OpenStack テナントネットワーク
- OpenStack テナントは、このネットワーク上に VLAN または VXLAN により実装されるプライベートネットワークを作成します。
- Red Hat OpenStack Platform Director のプロビジョニング
- Red Hat OpenStack Platform director は、このネットワークから DHCP および PXE サービスを提供し、ベアメタルからオーバークラウドノードにオペレーティングシステムやその他のソフトウェアをインストールします。Red Hat OpenStack Platform director はこのネットワークを使用してオーバークラウドノードを管理し、クラウドオペレーターは必要に応じて ssh でオーバークラウドノードに直接アクセスするためにこのネットワークを使用します。このネットワークプロビジョニングから PXE ブートするようにオーバークラウドノードを設定する必要があります。
図2.1 ネットワークの分離図

NIC は、2 つの物理 NIC の論理ボンディングになります。各ネットワークを同じインターフェイスにトランク接続する必要はありません。
2.4. Red Hat Hyperconverged Infrastructure for Cloud ソフトウェア要件の確認
ノードが必要なソフトウェアリポジトリーにアクセスできることを確認します。Red Hat Hyperconverged Infrastructure (RHHI) for Cloud ソリューションでは、適切に機能させるには、特定のソフトウェアパッケージをインストールする必要があります。
前提条件
- 有効な Red Hat Hyperconverged Infrastructure for Cloud サブスクリプションがある。
- ノードへの root レベルのアクセス。
手順
任意のノードで、利用可能なサブスクリプションを確認します。
# subscription-manager list --available --all --matches="*OpenStack*"
関連情報
- 必要なソフトウェアリポジトリーについては、Red Hat Hyperconverged Infrastructure for Cloud 必須リポジトリー セクションを参照してください。
2.5. 関連情報
- 詳細は、Red Hat Ceph Storage ハードウェアガイド を参照してください。
第3章 アンダークラウドのデプロイ
管理者としてアンダークラウドをデプロイすることができます。これにより、ユーザーは Red Hat OpenStack Platform director インターフェイスを使用してオーバークラウドをデプロイし、管理することができます。
3.1. 前提条件
- 有効な Red Hat Hyperconverged Infrastructure for Cloud サブスクリプションがある。
- Red Hat のコンテンツ配信ネットワーク(CDN)から Red Hat のソフトウェアリポジトリーにアクセスできる。
3.2. デプロイメント間の Ironic のディスククリーニングについて
Ironic のディスククリーニング機能を有効にすると、そのノードがデプロイメントで再び利用可能になる前に、ノード上の全ディスクからすべてのデータが完全に削除されます。
Ironic のディスククリーニング機能を有効にする前に考慮すべき 2 つのファクトがあります。
- director が Ceph をデプロイすると、ceph-disk コマンドを使用して各 OSD を準備します。ceph-disk が OSD を準備する前に、新規 OSD をホストするディスクに古い OSD からのデータがあるかどうかを確認し、存在する場合は、そのデータを上書きしないようにディスクの準備に失敗します。これは安全機能として動作し、データが失われないようにします。
- director でデプロイメントに失敗し、オーバークラウドが削除された後に繰り返されると、デフォルトでは以前のデプロイメントからのデータはサーバーディスク上に置かれます。このデータにより、ceph-disk コマンドがどのように動作するかにより、繰り返されるデプロイメントが失敗する可能性があります。
オーバークラウドノードが誤って削除され、ディスクのクリーニングが有効になっている場合は、データが削除され、Red Hat OpenStack Platform director でノードを再構築して環境に戻すことしかできません。
3.3. アンダークラウドのインストール
アンダークラウドをインストールするには、いくつかのステップを完了する必要があります。以下の手順では、アンダークラウドとして Red Hat OpenStack Platform director (RHOSP-d) をインストールします。インストール手順の概要を以下に示します。
- インストールユーザーを作成します。
- テンプレートとイメージのディレクトリーを作成する
- RHOSP-d ノード名を確認/設定します。
- RHOSP-d ノードを登録します。
- RHOSP-d ソフトウェアをインストールします。
- RHOSP-d ソフトウェアを設定します。
- オーバークラウドのディスクイメージを取得してインポートします。
- アンダークラウドのサブネットに DNS サーバーを設定します。
前提条件
- Red Hat のコンテンツ配信ネットワーク(CDN)から Red Hat のソフトウェアリポジトリーにアクセスできる。
-
Red Hat OpenStack Platform director (RHOSP-d)ノードへの
rootアクセスがある。
手順
RHOSP-d のインストールには、インストールを行うために
sudo権限を持つ root 以外のユーザーが必要です。stackという名前のユーザーを作成します。[root@director ~]# useradd stack
stackのパスワードを設定します。プロンプトが表示されたら、新しいパスワードを入力します。[root@director ~]# passwd stack
stackユーザーのsudoアクセスを設定します。[root@director ~]# echo "stack ALL=(root) NOPASSWD:ALL" | tee -a /etc/sudoers.d/stack [root@director ~]# chmod 0440 /etc/sudoers.d/stack
stackユーザーに切り替えます。[root@director ~]# su - stack
RHOSP-d のインストールは
stackユーザーとして行われます。
stackユーザーのホームディレクトリーに、2 つの新規ディレクトリーを作成します。1 つはtemplatesと、もう 1 つの名前付きimagesです。[stack@director ~]$ mkdir ~/images [stack@director ~]$ mkdir ~/templates
これらのディレクトリーは、後でオーバークラウド環境を作成するのに使用するシステムイメージファイルと Heat テンプレートファイルを整理します。
インストールおよび設定プロセスには、
/etc/hostsファイルのエントリーとともに完全修飾ドメイン名 (FQDN) が必要です。RHOSP-d ノードのホスト名を確認します。
[stack@director ~]$ hostname -f
必要に応じてホスト名を設定します。
sudo hostnamectl set-hostname FQDN_HOST_NAME sudo hostnamectl set-hostname --transient FQDN_HOST_NAME
- 以下を置き換えます。
FQDN_HOST_NAME は、RHOSP-d ノードの完全修飾ドメイン名 (FQDN) に置き換えます。
例
[stack@director ~]$ sudo hostnamectl set-hostname director.example.com [stack@director ~]$ sudo hostnamectl set-hostname --transient director.example.com
RHOSP-d ノード名のエントリーを
/etc/hostsファイルに追加します。/etc/hostsファイルに以下の行を追加します。sudo echo "127.0.0.1 FQDN_HOST_NAME SHORT_HOST_NAME localhost localhost.localdomain localhost4 localhost4.localdomain4" >> /etc/hosts
- 以下を置き換えます。
- FQDN_HOST_NAME は、RHOSP-d ノードの完全修飾ドメイン名に置き換えます。
SHORT_HOST_NAME は、RHOSP-d ノードの短いドメイン名に置き換えます。
例
[stack@director ~]$ sudo echo "127.0.0.1 director.example.com director localhost localhost.localdomain localhost4 localhost4.localdomain4" >> /etc/hosts
Red Hat コンテンツ配信ネットワーク (CDN) に RHOSP-d ノードを登録し、Red Hat Subscription Manager を使用して必要な Red Hat ソフトウェアリポジトリーを有効にします。
RHOSP-d ノードを登録します。
[stack@director ~]$ sudo subscription-manager register
プロンプトが表示されたら、承認されたカスタマーポータルのユーザー名とパスワードを入力します。
RHOSP エンタイトルメントの有効な
Pool IDを検索します。[stack@director ~]$ sudo subscription-manager list --available --all --matches="*Hyperconverged*"
出力例
Subscription Name: Red Hat Hyperconverged Infrastructure for Cloud Provides: Red Hat OpenStack Red Hat Ceph Storage SKU: RS00160 Contract: 1111111 Pool ID: a1b2c3d4e5f6g7h8i9 Provides Management: Yes Available: 1 Suggested: 1 Service Level: Self-Support Service Type: L1-L3 Subscription Type: Standard Ends: 05/27/2018 System Type: Virtual前の手順の
Pool IDを使用して、RHOSP のエンタイトルメントをアタッチします。[stack@director ~]$ sudo subscription-manager attach --pool=POOL_ID- 以下を置き換えます。
POOL_ID は、直前の手順の有効なプール ID に置き換えます。
例
[stack@director ~]$ sudo subscription-manager attach --pool=a1b2c3d4e5f6g7h8i9
デフォルトのソフトウェアリポジトリーを無効にし、必要なソフトウェアリポジトリーを有効にします。
[stack@director ~]$ sudo subscription-manager repos --disable=* [stack@director ~]$ sudo subscription-manager repos --enable=rhel-7-server-rpms --enable=rhel-7-server-extras-rpms --enable=rhel-7-server-rh-common-rpms --enable=rhel-ha-for-rhel-7-server-rpms --enable=rhel-7-server-openstack-13-rpms
必要に応じて、ベースシステムソフトウェアを最新のパッケージバージョンに更新し、RHOSP-d ノードを再起動します。
[stack@director ~]$ sudo yum update [stack@director ~]$ sudo reboot
ノードが完全に起動し、実行されるのを待ってから次のステップに進みます。
すべての RHOSP-d ソフトウェアパッケージをインストールします。
[stack@director ~]$ sudo yum install python-tripleoclient ceph-ansible
RHOSP-d ソフトウェアを設定します。
Red Hat は、使用する基本的なアンダークラウド設定テンプレートを提供しています。
undercloud.conf.sampleファイルをundercloud.confという名前のstackユーザーのホームディレクトリーにコピーします。[stack@director ~]$ cp /usr/share/instack-undercloud/undercloud.conf.sample ~/undercloud.conf
アンダークラウド設定テンプレートには、
[DEFAULT]と[auth]の 2 つのセクションが含まれます。undercloud.confファイルを開いて編集します。undercloud_hostnameを RHOSP-d ノード名で編集します。パラメーターの前に#を削除して、undercloud.confファイルの[DEFAULT]セクションの下にある以下のパラメーターのコメントを解除します。このソリューションのネットワーク設定に必要な適切な値でパラメーター値を編集します。パラメーター
ネットワーク
値の編集
値の例
local_ipプロビジョニング
はい
192.0.2.1/24network_gatewayプロビジョニング
はい
192.0.2.1undercloud_public_vipプロビジョニング
はい
192.0.2.2undercloud_admin_vipプロビジョニング
はい
192.0.2.3local_interfaceプロビジョニング
はい
eth1network_cidrプロビジョニング
はい
192.0.2.0/24masquerade_networkプロビジョニング
はい
192.0.2.0/24dhcp_startプロビジョニング
はい
192.0.2.5dhcp_endプロビジョニング
はい
192.0.2.24inspection_interfaceプロビジョニング
いいえ
br-ctlplaneinspection_iprangeプロビジョニング
はい
192.0.2.100,192.0.2.120inspection_extras該当なし
はい
trueinspection_runbench該当なし
はい
falseinspection_enable_uefi該当なし
はい
trueundercloud.confファイルの編集後に変更を保存します。これらの設定パラメーターの詳細は、アンダークラウド設定パラメーター を参照してください。注記オーバークラウドノードを再び目的にする場合には、Ironic のディスククリーニング機能を有効にすることを検討してください。詳細は、デプロイメント間の Ironic ディスククリーニングを理解する セクションを参照してください。
RHOSP-d 設定スクリプトを実行します。
[stack@director ~]$ openstack undercloud install
注記このスクリプトが完了するまで数分かかります。このスクリプトは、追加のソフトウェアパッケージをインストールし、2 つのファイルを生成します。
undercloud-passwords.conf- director サービスの全パスワード一覧
stackrc- director のコマンドラインツールへアクセスできるようにする初期化変数セット
設定スクリプトがすべての RHOSP サービスを開始および有効化していることを確認します。
[stack@director ~]$ sudo systemctl list-units openstack-*
設定スクリプトにより、
stackユーザーにすべてのコンテナー管理コマンドにアクセスできます。stackユーザーの権限をリフレッシュします。[stack@director ~]$ exec su -l stack
RHOSP-d コマンドラインツールを使用するように
stackユーザーの環境を初期化します。[stack@director ~]$ source ~/stackrc
コマンドプロンプトが変更されます。これは、OpenStack コマンドが認証してアンダークラウドに対して実行されることを示します。
例
(undercloud) [stack@director ~]$
RHOSP-d では、オーバークラウドノードをプロビジョニングするために複数のディスクイメージが必要です。
rhosp-director-imagesおよびrhosp-director-images-ipaソフトウェアパッケージをインストールして、これらのディスクイメージを取得します。(undercloud) [stack@director ~]$ sudo yum install rhosp-director-images rhosp-director-images-ipa
アーカイブファイルを
stackユーザーのホームディレクトリー内のimagesディレクトリーに展開します。(undercloud) [stack@director ~]$ cd ~/images (undercloud) [stack@director ~]$ for x in /usr/share/rhosp-director-images/overcloud-full-latest-13.0.tar /usr/share/rhosp-director-images/ironic-python-agent-latest-13.0.tar ; do tar -xvf $x ; done
ディスクイメージを RHOSP-d にインポートします。
(undercloud) [stack@director ~]$ openstack overcloud image upload --image-path /home/stack/images/
インポートしたディスクイメージの一覧を表示するには、以下のコマンドを実行します。
(undercloud) [stack@director ~]$ openstack image list
Image Name
イメージタイプ
Image Description
bm-deploy-kernelデプロイメント
システムのプロビジョニングとデプロイに使用されるカーネルファイル。
bm-deploy-ramdiskデプロイメント
システムのプロビジョニングとデプロイに使用する ramdisk ファイル。
overcloud-full-vmlinuzオーバークラウド
ノードのディスクに書き込まれるベースシステムに使用されるカーネルファイル。
overcloud-full-initrdオーバークラウド
ノードのディスクに書き込まれるベースシステムに使用する ramdisk ファイル。
overcloud-fullオーバークラウド
ノードのディスクに書き込まれるベースシステムに必要な残りのソフトウェア。
注記openstack image listコマンドは、イントロスペクション PXE ディスクイメージを表示しません。イントロスペクション PXE ディスクイメージが/httpboot/ディレクトリーにコピーされます。(undercloud) [stack@director images]$ ls -l /httpboot total 341460 -rwxr-xr-x. 1 root root 5153184 Mar 31 06:58 agent.kernel -rw-r--r--. 1 root root 344491465 Mar 31 06:59 agent.ramdisk -rw-r--r--. 1 ironic-inspector ironic-inspector 337 Mar 31 06:23 inspector.ipxe
オーバークラウドノードのホスト名が解決されるように DNS サーバーを設定します。
サブネットを一覧表示します。
(undercloud) [stack@director ~]$ openstack subnet list
アンダークラウドの
neutronサブネットを使用してネームサーバーを定義します。openstack subnet set --dns-nameserver DNS_NAMESERVER_IP SUBNET_NAME_or_ID
- 以下を置き換えます。
- DNS_NAMESERVER_IP は、DNS サーバーの IP アドレスに置き換えます。
SUBNET_NAME_or_ID は、
neutronサブネット名または ID に置き換えます。例
(undercloud) [stack@director ~]$ openstack subnet set --dns-nameserver 192.0.2.4 local-subnet
注記各ネームサーバーに
--dns-nameserver DNS_NAMESERVER_IPオプションを再利用します。
サブネットの詳細を表示して、DNS サーバーを確認します。
(undercloud) [stack@director ~]$ openstack subnet show SUBNET_NAME_or_ID- 以下を置き換えます。
SUBNET_NAME_or_ID は、
neutronサブネット名または ID に置き換えます。例
(undercloud) [stack@director ~]$ openstack subnet show local-subnet +-------------------+-----------------------------------------------+ | Field | Value | +-------------------+-----------------------------------------------+ | ... | | | dns_nameservers | 192.0.2.4 | | ... | | +-------------------+-----------------------------------------------+
関連情報
-
undercloud.confファイルにあるすべてのアンダークラウド設定パラメーターについての詳しい情報は、RHOSP director のインストールと使用方法の Director の設定 セクションを参照してください。
3.4. オーバークラウドをデプロイする前にディスクをクリーンアップするためのアンダークラウド設定
オーバークラウドをデプロイする前に、アンダークラウド設定ファイルを更新してディスクをクリーンアップします。
この機能を有効にすると、オーバークラウドのデプロイメントでプロビジョニングされる前に、すべてのディスクのすべてのデータが破棄されます。
前提条件
手順
オーバークラウドをデプロイする前にディスクをクリーニングする方法には、自動または手動の 2 つのオプションがあります。
最初のオプションは、
undercloud.confファイルを編集してディスクを自動的にクリーニングし、以下の行を追加します。clean_nodes = True
注記ベアメタルプロビジョニングサービスは、
wipefs --force --allコマンドを実行してクリーニングを実行します。
警告この機能を有効にすると、オーバークラウドのデプロイメントでプロビジョニングされる前に、すべてのディスクのすべてのデータが破棄されます。また、これにより、初回のイントロスペクション後および各デプロイメントの前に追加の電源サイクルが実行されます。
2 つ目のオプションは、自動クリーニングをオフにして、各 Ceph ノードに対して以下のコマンドを実行します。
[stack@director ~]$ openstack baremetal node manage NODE [stack@director ~]$ openstack baremetal node clean NODE --clean-steps '[{"interface": "deploy", "step": "erase_devices_metadata"}]' [stack@director ~]$ openstack baremetal node provide NODE
- 以下を置き換えます。
- NODE は、Ceph ホスト名に置き換えます。
第4章 Red Hat OpenStack Platform Director を使用した Red Hat Hyperconverged Infrastructure for Cloud のデプロイメント
技術者として、Red Hat OpenStack Platform director インターフェイスを使用して、Red Hat Hyperconverged Infrastructure for Cloud ソリューションをデプロイして管理できます。また、Red Hat OpenStack Platform と Red Hat Ceph Storage との間でリソースの競合が発生しないように、リソースの分離について基本的に理解しておく必要があります。
4.1. 前提条件
- すべての 要件 を満たしていることを確認します。
- アンダークラウドのインストール
4.2. Red Hat OpenStack Platform director を使用したオーバークラウドプランのエクスポート
以下の手順では、OpenStack Platform director を使用してデプロイメントプランをエクスポートします。デフォルトのデプロイメントプランには、一般的かつエクスポート可能なオーバークラウド設定が含まれています。
手順
アンダークラウドの IP アドレスまたはホスト名を Web ブラウザーに入力します。
注記SSL を使用していない場合は、アンダークラウドの URL はポート 3000 を使用する必要があります。例:
http://192.168.0.4:3000正しい認証情報を使用して、Red Hat OpenStack Platform director ユーザーインターフェイスにログインします。
 注記
注記デフォルトのユーザー名は
adminです。以下のコマンドを実行して admin パスワードを取得できます。[stack@director ~]$ sudo hiera admin_password
Plans タブで、オーバークラウド プランからドロップダウンメニュー
 を選択し、Export
を選択し、Export  を選択します。
を選択します。
Downloadボタンをクリックします

これにより、圧縮された tarball ファイルがローカルのハードドライブにダウンロードされます。これには、すべてのプランファイルが含まれます。
重要tarball ファイルに含まれるファイルを追加または変更する必要がある場合は、tarball ファイルをインポートする前に、以下のように tarball ファイルを再作成する必要があります。
例
tar -czf my-deployment-plan.tar.gz -C my-deployment-plan-local-files/ .
注記現在、OpenStack Platform director インターフェイスでは、カスタムネットワーク設定などのプランの事前設定をサポートしていません。ファイルを直接編集して事前に設定を手動で行う必要があります。
4.3. Red Hat OpenStack Platform director を使用したオーバークラウドプランのインポート
以下の手順では、以前にエクスポートされた OpenStack Platform director を使用してデプロイメントプランをインポートします。
手順
アンダークラウドの IP アドレスまたはホスト名を Web ブラウザーに入力します。
注記SSL を使用していない場合は、アンダークラウドの URL はポート 3000 を使用する必要があります。例:
http://192.168.0.4:3000正しい認証情報を使用して、Red Hat OpenStack Platform director ユーザーインターフェイスにログインします。
注記デフォルトのユーザー名は
adminです。以下のコマンドを実行して admin パスワードを取得できます。[stack@director ~]$ sudo hiera admin_password
Plans タブで、Import Plan ボタンを選択します。

Plan Name
と入力し、Choose File ボタン
をクリックします。tarball ファイルの場所を参照し、インポート用に選択します。ファイルを選択したら、Upload Files and Create Plan ボタン
 をクリックします。
をクリックします。
4.4. Red Hat OpenStack Platform director を使用したオーバークラウドのデプロイ
以下の手順では、Red Hat OpenStack Platform director を使用してオーバークラウドをデプロイします。
手順
アンダークラウドの IP アドレスまたはホスト名を Web ブラウザーに入力します。
注記SSL を使用していない場合は、アンダークラウドの URL にポート 3000 を含める必要があります。例:
http://192.168.0.4:3000正しい認証情報を使用して、Red Hat OpenStack Platform director ユーザーインターフェイスにログインします。
注記デフォルトのユーザー名は
adminです。以下のコマンドを実行して admin パスワードを取得できます。[stack@director ~]$ sudo hiera admin_password
デフォルトの overcloud プラン
を選択するか、Import Plan
を選択します。

プランのインポートに関する詳細は、「Red Hat OpenStack Platform director を使用したオーバークラウドプランのインポート」 を参照してください。
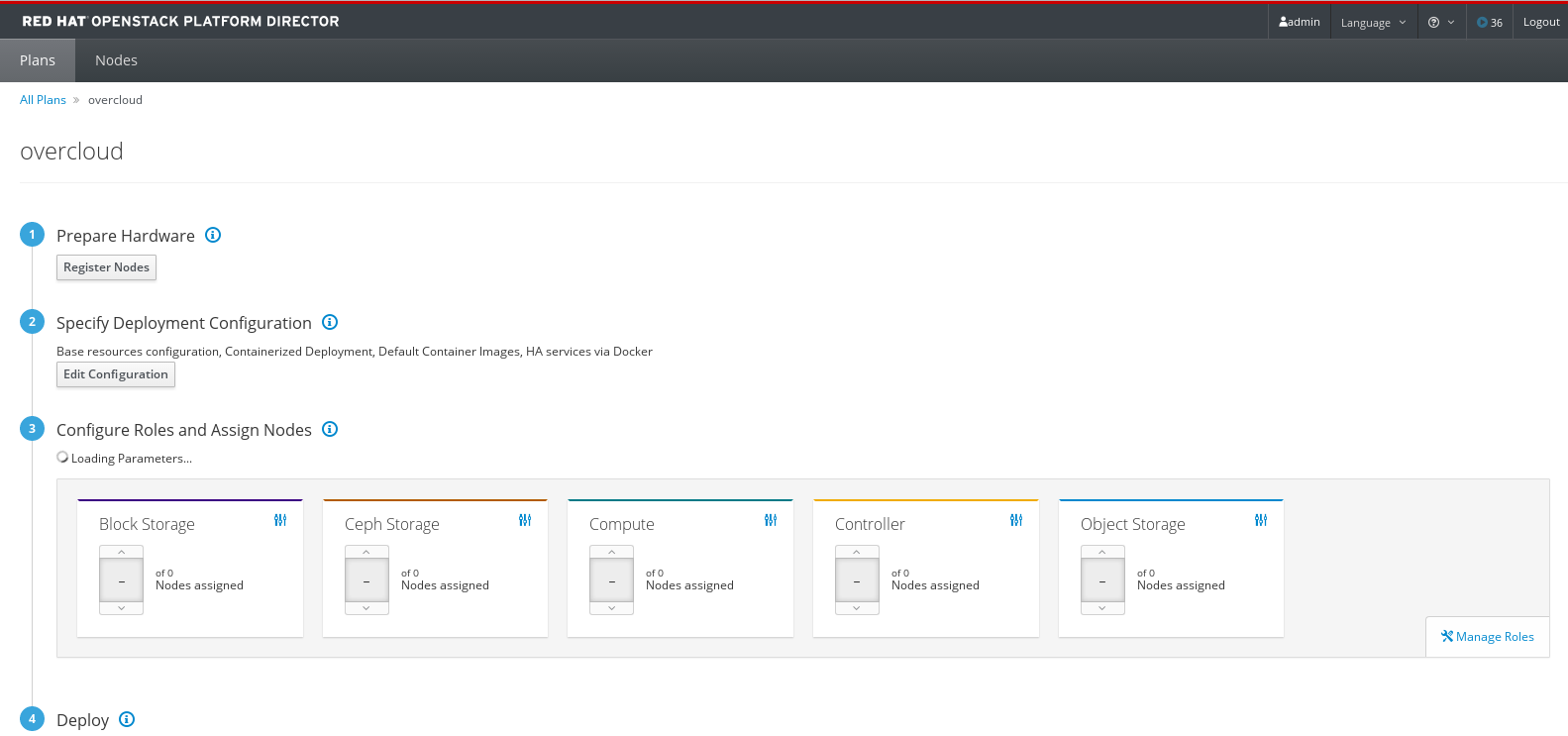
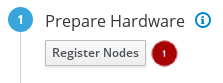
プラン設定ページから、登録したノードを追加してハードウェアを準備します。
図4.1 プラン設定ページの例
ノードの登録には、Register Nodesボタン
をクリックします。
Add New Node ボタン
をクリックします。
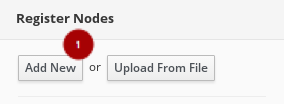
または、
instackenv.jsonホスト定義ファイルをカスタマイズし、アップロードしてノードを準備することができます。カスタムのinstackenv.jsonホスト定義ファイルを作成するには、「ハードウェアの登録およびイントロスペクション」 および 「ルートデバイスの設定」 を参照してノードを準備します。- 登録ノードページで、小規模な赤いアスタリスクで表示されるすべての必須フィールドに入力します。
すべての必須フィールドを入力したら、Register Node ボタン
をクリックします。

ノードが登録されたら、ノード
を選択し、Introspect Nodes
ボタンをクリックします。
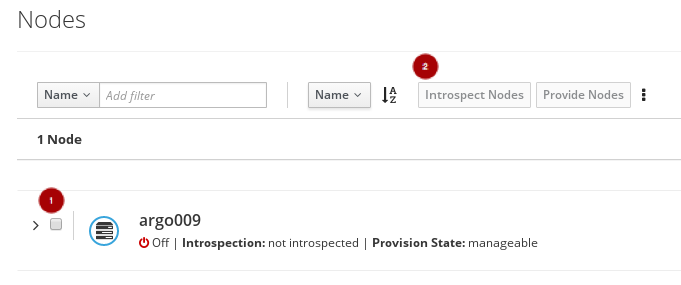
イントロスペクションが完了したら、ノード
を選択し、Provide Nodes
ボタンをクリックします。

プラン設定ページから、デプロイメント設定を編集します。
Edit Configuration ボタン
をクリックします。

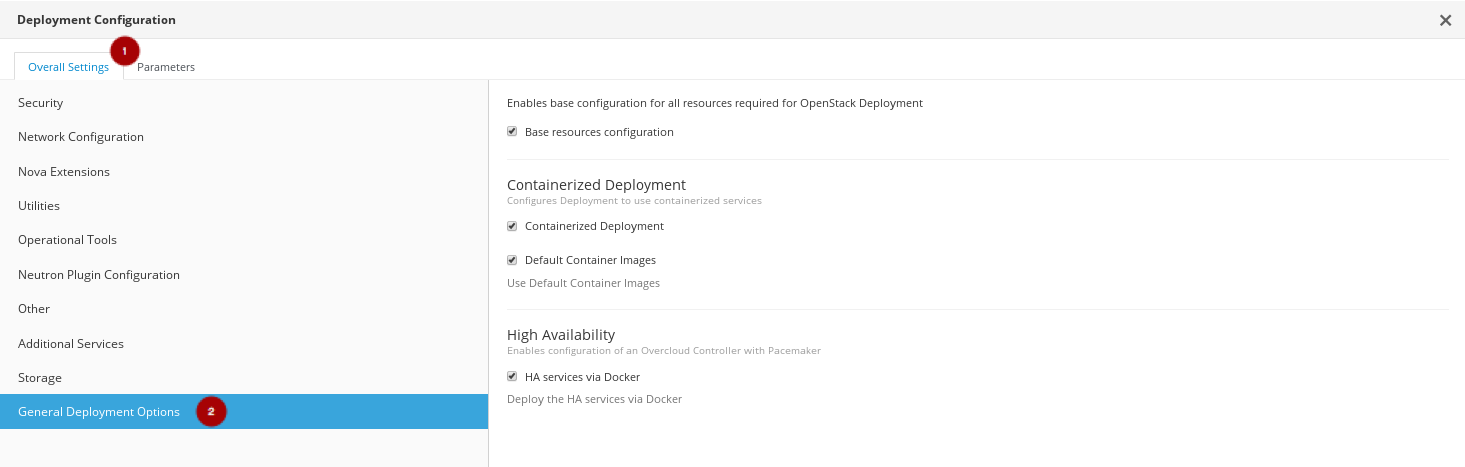
Overall Settings タブ
で、General Deployment Options セクション
をクリックし、Docker を介して HA サービス、Containerized Deployment、および Default Container Images を有効にします。
Overall Settings タブ
で、Storage セクション
をクリックし、Ceph Storage Backend
を有効にします。

Save Changes ボタンをクリックします。

Parameters タブをクリックします。
Ceph Storage Backend セクション
をクリックし、追加の Ceph パラメーターを編集します。
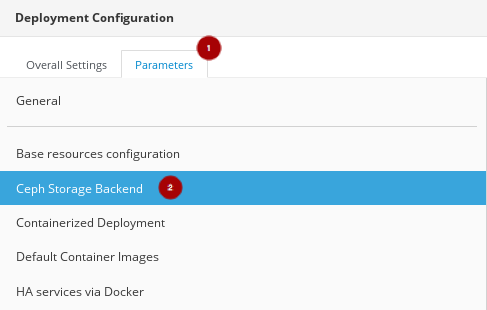
CephAnsibleExtraConfig フィールドを以下の値で更新します。
{"ceph_osd_docker_memory_limit": "5g", "ceph_osd_docker_cpu_limit": 1, "ceph_mds_docker_memory_limit": "4g", "ceph_mds_docker_cpu_limit": 1}CephConfigOverrides フィールドを以下の値で更新します。
{"osd_recovery_op_priority": 3, "osd_recovery_max_active": 3, "osd_max_backfills": 1}CephConfigOverrides フィールドを以下の値で更新します。
{"osd_recovery_op_priority": 3, "osd_recovery_max_active": 3, "osd_max_backfills": 1}CephPoolDefaultSize の値を
3に設定します。CephAnsibleDisksConfig フィールドをディスクリストで更新します。
例
{"devices":["/dev/sda","/dev/sdb","/dev/sdc","/dev/sdd","/dev/sde","/dev/sdf","/dev/sdg","/dev/sdh","/dev/sdi","/dev/sdj","/dev/sdk","/dev/sdl"],"dedicated_devices":["/dev/sdm","/dev/sdm","/dev/sdm","/dev/sdm","/dev/sdn","/dev/sdn","/dev/sdn","/dev/sdn","/dev/sdo","/dev/sdo","/dev/sdo","/dev/sdo"],"journal_size":5120}注記このディスクリストは、OSD として使用されているブロックデバイス (
devices) と、OSD ジャーナルとして専用のブロックデバイス (dedicated_devices) 用です。詳細は、「Red Hat Ceph Storage パラメーターの設定」 を参照してください。Save And Close ボタンをクリックします。
プラン設定ページに戻ると、保存された設定変更は Specify Deployment Configuration のステップの下に表示されます。

Manage Roles リンクをクリックして、ハイパーコンバージドノードのロールを設定します。

-
、CephStorage
、および コンピュート
ロールをクリックして BlockStorage の選択を解除します

ComputeHCI
ロールをクリックして選択します。

プラン設定ページに戻り、逆引きアイコン
をクリックして Compute HCI ロールを設定します。

パラメーター タブで、次のパラメーターを更新します。
計算されたリソース割り当て値を含む ExtraConfig フィールド。
適切な値を計算する方法は、付録E Nova 確保メモリーと CPU 割り当ての手動チューニング を参照してください。
ComputeHCIIPs フィールドには、環境に関連するすべての IP アドレスが含まれます。
例
{"storage_mgmt":["172.16.2.203","172.16.2.204","172.16.2.205"],"storage":["172.16.1.203","172.16.1.204","172.16.1.205"],"tenant":["192.168.3.203","192.168.3.204","192.168.3.205"],"internal_api":["192.168.2.203","192.168.2.204","192.168.2.205"]}OvercloudComputeHCIFlavor フィールドに、以下の値を指定します。
osd-compute
ComputeHCISchedulerHints フィールドには、以下の値を指定します。
{"capabilities:node":"hci-%index%"}
Save And Close ボタンをクリックします。
プラン設定ページに戻り、逆引きアイコン
をクリックして Controller ロールを設定します。

Parameters タブ
で、ControllerIPs フィールドを関連する IP アドレスで更新します。
例
{"storage_mgmt":["172.16.2.200","172.16.2.201","172.16.2.202"],"storage":["172.16.1.200","172.16.1.201","172.16.1.202"],"tenant":["192.168.3.200","192.168.3.201","192.168.3.202"],"internal_api":["192.168.2.200","192.168.2.201","192.168.2.202"]}Services タブ
の Ntp セクション
の NtpServer フィールド
を該当する NTP サーバー名で更新します。
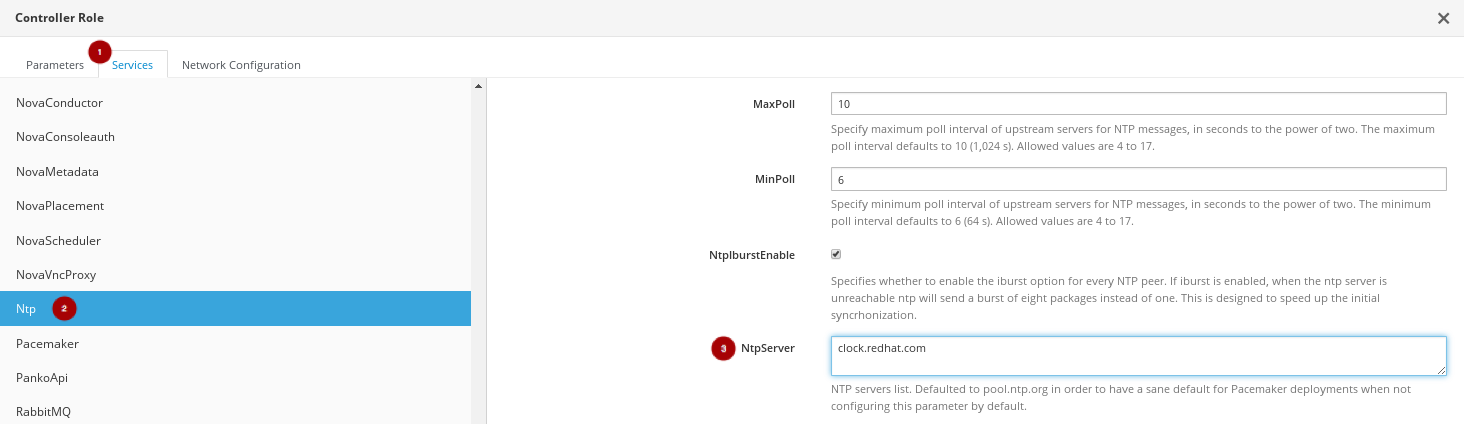
Save And Close ボタンをクリックします。
各ロールに、環境に必要なノード数を割り当てます。
図4.2 例

プラン設定ページから、Edit Configuration ボタン
をクリックします。
ネットワーク設定セクション
をクリックして Network Configuration を編集し、Network Isolation
を選択します。

NIC 設定テンプレートの 1 つを選択するか、カスタムプランを使用します。

環境内で NIC をカスタマイズするには、まずプランをエクスポートする必要があります。
プランのエクスポート方法については、「Red Hat OpenStack Platform director を使用したオーバークラウドプランのエクスポート」 を参照してください。
プランの tarball ファイルをダウンロードし、必要な追加または変更をローカルで行います。
例
プランの tarball ファイルを更新したら、ドロップダウンメニューをクリックし、Edit を選択します。

プランをインポートします。Plan Name
と入力し、Choose File ボタン
をクリックします。tarball ファイルの場所を参照し、インポート用に選択します。ファイルを選択したら、Upload Files and Create Plan ボタン
をクリックします。
Edit Configuration ボタンをクリックします。
-
Overall Settings タブ
で、Other セクション
をクリックします。
- Others セクションを選択し、カスタムテンプレートを追加します。
ファイルリストから新規ファイルまたは変更されたファイルを選択します。
例

- Parameters タブをクリックして、適切な値を更新します。
これでプランをデプロイします。プラン設定ページから Validate and Deploy ボタンをクリックして、オーバークラウドプランをデプロイします。

- オーバークラウドのデプロイメントが完了するまで待ちます。
4.5. 関連情報
- リソース分離の詳細は、付録E Nova 確保メモリーと CPU 割り当ての手動チューニング を参照してください。
第5章 コマンドラインインターフェイスを使用した Red Hat Hyperconverged Infrastructure for Cloud のデプロイ
コマンドラインインターフェイスを使用して、Red Hat Hyperconverged Infrastructure for Cloud ソリューションをデプロイして管理できます。
5.1. 前提条件
- すべての 要件 を満たしていることを確認します。
- アンダークラウドのインストール
5.2. コマンドラインインターフェイスを使用したオーバークラウドのデプロイ前のノードの準備
技術的には、オーバークラウドをデプロイする前に、アンダークラウドが環境で使用されているハードウェアを理解する必要があります。
Red Hat OpenStack Platform director (RHOSP-d)は、アンダークラウドとしても知られています。
5.2.1. 前提条件
- すべての 要件 を満たしていることを確認します。
- アンダークラウドのインストール
5.2.2. ハードウェアの登録およびイントロスペクション
Red Hat OpenStack Platform director (RHOSP-d) は、各ノードでイントロスペクションプロセスを実行し、ノードのハードウェアに関するデータを収集します。このイントロスペクションデータは RHOSP-d ノードに保存され、ベンチマークやルートディスクの割り当てなどのさまざまな目的で使用されます。
前提条件
- RHOSP-d ノードのソフトウェアインストールを完了します。
- ネットワークインターフェイスカード (NIC) の MAC アドレス。
- IPMI ユーザー名およびパスワード
手順
RHOSP-d ノードで、stack ユーザーとして以下の手順を実行します。
osd-computeフレーバーを作成します。[stack@director ~]$ openstack flavor create --id auto --ram 2048 --disk 40 --vcpus 2 osd-compute [stack@director ~]$ openstack flavor set --property "capabilities:boot_option"="local" --property "capabilities:profile"="osd-compute" osd-compute
ノードを管理するために Ironic サービスのホスト定義ファイルを作成し、設定します。
instackenv.jsonホスト定義ファイルを作成します。[stack@director ~]$ touch ~/instackenv.json
以下のテンプレートを使用して、
ノードスタンザの角括弧 ({"nodes": []}) の間に各ノードの定義ブロックを追加します。{ "pm_password": "IPMI_USER_PASSWORD", "name": "NODE_NAME", "pm_user": "IPMI_USER_NAME", "pm_addr": "IPMI_IP_ADDR", "pm_type": "pxe_ipmitool", "mac": [ "NIC_MAC_ADDR" ], "arch": "x86_64", "capabilities": "node:_NODE_ROLE-INSTANCE_NUM_,boot_option:local" },- 以下を置き換えます。
- IPMI_USER_PASSWORD と IPMI パスワード。
- ノードのわかりやすい名前を持つ NODE_NAME。これはオプションのパラメーターです。
- IPMI_USER_NAME は、ノードの電源をオンまたはオフにすることのできる IPMI ユーザー名に置き換えます。
- IPMI_IP_ADDR は、IPMI IP アドレスに置き換えます。
- PXE ブートを処理するネットワークカードの MAC アドレスを持つ NIC_MAC_ADDR。
NODE_ROLE-INSTANCE_NUM とノードのロール、およびノード番号。このソリューションは、
controlとosd-computeの 2 つのロールを使用します。例
{ "nodes": [ { "pm_password": "AbC1234", "name": "m630_slot1", "pm_user": "ipmiadmin", "pm_addr": "10.19.143.61", "pm_type": "pxe_ipmitool", "mac": [ "c8:1f:66:65:33:41" ], "arch": "x86_64", "capabilities": "node:control-0,boot_option:local" }, { "pm_password": "AbC1234", "name": "m630_slot2", "pm_user": "ipmiadmin", "pm_addr": "10.19.143.62", "pm_type": "pxe_ipmitool", "mac": [ "c8:1f:66:65:33:42" ], "arch": "x86_64", "capabilities": "node:osd-compute-0,boot_option:local" }, ... Continue adding node definition blocks for each node in the initial deployment here. ] }注記osd-computeロールは、後のステップで作成されたカスタムロールです。ノードの配置を予測どおりに制御するには、これらのノードを順番に追加します。以下に例を示します。[stack@director ~]$ grep capabilities ~/instackenv.json "capabilities": "node:control-0,boot_option:local" "capabilities": "node:control-1,boot_option:local" "capabilities": "node:control-2,boot_option:local" "capabilities": "node:osd-compute-0,boot_option:local" "capabilities": "node:osd-compute-1,boot_option:local" "capabilities": "node:osd-compute-2,boot_option:local"
ノードを Ironic データベースにインポートします。
[stack@director ~]$ openstack baremetal import ~/instackenv.json
openstack baremetal importコマンドが、全ノードで Ironic データベースに投入されていることを確認します。[stack@director ~]$ openstack baremetal node list
ベアメタルブートカーネルと RAMdisk イメージをすべてのノードに割り当てます。
[stack@director ~]$ openstack baremetal configure boot
ノードを起動してハードウェアデータを収集し、その情報を Ironic データベースに保存するには、次のコマンドを実行します。
[stack@director ~]$ openstack baremetal introspection bulk start
注記インポートされたノードの数によっては、一括イントロスペクションが完了するまでに時間がかかる場合があります。
~/undercloud.confファイルでinspection_runbenchの値をfalseに設定すると、一括イントロスペクションプロセスが高速化されますが、sysbenchおよびfioベンチマークデータを収集しません。これは RHOSP-d に役立つデータになります。すべてのノードでエラーなしにイントロスペクションプロセスが完了したことを確認します。
[stack@director ~]$ openstack baremetal introspection bulk status
関連情報
- ノード識別パラメーターの割り当てについての詳細は、RHOSP Advanced Overcloud カスタマイズガイドの ノードの配置を制御する の章を参照してください。
5.2.3. ルートデバイスの設定
Red Hat OpenStack Platform director (RHOSP-d) は、ノードをプロビジョニングするルートディスクを識別する必要があります。デフォルトでは、Ironic は最初のブロックデバイスをイメージ化します。通常、このブロックデバイスは /dev/sda になります。以下の手順に従って、Compute/OSD ノードのディスク設定に従ってルートディスクデバイスを変更します。
以下の手順では、例として以下の Compute/OSD ノードのディスク設定を使用します。
-
OSD:
/dev/[sda, sdb, …, sdl]ブロックデバイスとして表示される 12 x 1TB SAS ディスク -
OSD ジャーナル:
/dev/[sdm, sdn, sdo]ブロックデバイスとして表示される 3 x 400GB SATA SSD ディスク -
オペレーティングシステム:
/dev/sdpブロックデバイスとして提示される RAID1 で設定された 2 x 250GB SAS ディスク
OSD は /dev/sda を使用するため、Ironic は /dev/sdp、RAID 1 ディスクを代わりにルートディスクとして使用します。ハードウェアイントロスペクションプロセス中に、Ironic は World-wide number (WWN) および各ブロックデバイスのサイズを保存します。
前提条件
- ハードウェアイントロスペクションの手順 を完了します。
手順
RHOSP-d ノードで以下のコマンドのいずれかを実行します。
smallestのルートデバイスを使用するようにルートディスクデバイスを設定します。[stack@director ~]$ openstack baremetal configure boot --root-device=smallest
または
ディスクの
by-path名を使用するようにルートディスクデバイスを設定します。[stack@director ~]$ openstack baremetal configure boot --root-device=disk/by-path/pci-0000:00:1f.1-scsi-0:0:0:0
Ironic は、このルートデバイスディレクティブを Ironic のデータベース内のすべてのノードに適用します。
正しいルートディスクデバイスが設定されていることを確認します。
openstack baremetal introspection data save NODE_NAME_or_UUID | jq .- 以下を置き換えます。
- NODE_NAME_or_UUID をノードのホスト名または UUID に置き換えます。
関連情報
- ノードのルートディスクの定義 に関する詳細については、RHOSP Director インストールおよび使用ガイドのセクションを参照してください。
5.2.4. Ironic のディスククリーニングが機能していることの確認
Ironic のディスククリーニング機能が動作しているかどうかを確認するには、ノードの状態を切り替えてから、ノードの状態がクリーニング状態になるかどうかを観察します。
前提条件
- アンダークラウドのインストール
手順
ノードの状態を manage に設定します。
openstack baremetal node manage $NODE_NAME
例
[stack@director ~]$ openstack baremetal node manage osdcompute-0
ノードの状態を以下を提供するように設定します。
openstack baremetal node provide NODE_NAME例
[stack@director ~]$ openstack baremetal node provide osdcompute-0
ノードのステータスを確認します。
openstack node list
5.2.5. 関連情報
- 詳細は、RHOSP-d インストールおよび使用ガイド を参照してください。
5.3. コンテナーイメージのソースの設定
技術者はオーバークラウドをコンテナー化できますが、これにはまず、必要なコンテナーイメージを含むレジストリーにアクセスする必要があります。ここでは、レジストリーの準備方法および Red Hat OpenStack Platform 用のコンテナーイメージを使用するためのオーバークラウド設定について説明します。
ユースケースに基づいて、オーバークラウドがレジストリーを使用するように設定する方法は複数あります。
5.3.1. レジストリーメソッド
Red Hat Hyperconverged Infrastructure for Cloud は、以下のレジストリータイプをサポートします。以下のいずれかの方法を選択します。
- リモートレジストリー
-
オーバークラウドは、
registry.access.redhat.comから直接コンテナーイメージをプルします。これは、初期設定を生成するための最も簡単な方法です。ただし、それぞれのオーバークラウドノードが Red Hat Container Catalog から各イメージを直接プルするので、ネットワークの輻輳が生じてデプロイメントが遅くなる可能性があります。また、Red Hat Container Catalog にアクセスするためのインターネットアクセスが全オーバークラウドノードに必要です。 - ローカルレジストリー
-
アンダークラウド上にローカルレジストリーを作成し、
registry.access.redhat.comからイメージを同期し、オーバークラウドはアンダークラウドからコンテナーイメージをプルします。この方法では、内部にレジストリーを保管することが可能なので、デプロイメントを迅速化してネットワークの輻輳を軽減することができます。ただし、アンダークラウドは基本的なレジストリーとしてのみ機能し、コンテナーイメージのライフサイクル管理は限定されます。
5.3.2. Red Hat OpenStack Platform サービス用の追加のコンテナーイメージの追加
Red Hat Hyperconverged Infrastructure for Cloud は、コアの Red Hat OpenStack Platform サービス以外の追加のサービスを使用します。これらの追加サービスには追加のコンテナーイメージが必要で、対応する環境ファイルでこれらのサービスを有効にします。これらの環境ファイルは、オーバークラウドのコンポーザブルサービスを有効化します。director はこれらのサービスが有効化されていることを認識して、イメージを準備する必要があります。
前提条件
- 動作中のアンダークラウド
手順
アンダークラウドノードで
stackユーザーとして、openstack overcloud container image prepareコマンドを使用して追加のサービスを追加します。-eオプションを使用して、以下の環境ファイルを追加します。-
Ceph Storage クラスター:
/usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml
-
Ceph Storage クラスター:
Red Hat Ceph Storage の以下の
--setオプションを含めます。--set ceph_namespace- Red Hat Ceph Storage コンテナーイメージの名前空間を定義します。
--set ceph_image-
Red Hat Ceph Storage コンテナーイメージの名前を定義します。イメージ名
rhceph-3-rhel7を使用します。 --set ceph_tag-
Red Hat Ceph Storage コンテナーイメージに使用するタグを定義します。
--tag-from-labelが指定されている場合には、バージョンタグはこのタグから検出が開始されます。
image prepare コマンドを実行します。
例
[stack@director ~]$ openstack overcloud container image prepare \ ... -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ --set ceph_namespace=registry.access.redhat.com/rhceph \ --set ceph_image=rhceph-3-rhel7 \ --tag-from-label {version}-{release} \ ...注記これらのオプションは、
openstack overcloud container image prepareコマンドに渡す必要があるその他のオプション (…) に加えて渡されます。
5.3.3. Red Hat レジストリーをリモートレジストリーソースとして使用する方法
Red Hat では、オーバークラウドのコンテナーイメージを registry.access.redhat.com でホストしています。リモートレジストリーからイメージをプルするのは最も簡単な方法です。レジストリーはすでにセットアップされており、プルするイメージの URL と名前空間が必要であるためです。
前提条件
- 実行中の Red Hat Hyperconverged Infrastructure for Cloud 10 環境。
- インターネットへのアクセス。
手順
イメージを直接
registry.access.redhat.comからオーバークラウドデプロイメントにプルするには、イメージパラメーターを指定するための環境ファイルが必要となります。以下のコマンドにより、この環境ファイルが自動的に作成されます。(undercloud) [stack@director ~]$ openstack overcloud container image prepare \ --namespace=registry.access.redhat.com/rhosp13 \ --prefix=openstack- \ --tag-from-label {version}-{release} \ --output-env-file=/home/stack/templates/overcloud_images.yaml注記任意のサービス用の環境ファイルを指定するには、
-eオプションを使用します。-
これで、イメージの場所が記載された
overcloud_images.yaml環境ファイルがアンダークラウド上に作成されます。今後のアップグレードとデプロイメントの操作ではすべてこのファイルを追加してください。
関連情報
- 詳細は、Red Hat Hyperconverged Infrastructure for Cloud 開発ガイド の Red Hat OpenStack Platform サービス用コンテナイメージの追加 セクション を参照してください。
5.3.4. ローカルレジストリーとしてアンダークラウドを使用する方法
アンダークラウド上でローカルレジストリーを設定して、オーバークラウドのコンテナーイメージを保管することができます。この方法は、以下の操作を伴います。
-
director が
registry.access.redhat.comから各イメージをプルする director がオーバークラウドを作成する
- オーバークラウドの作成中に、ノードが適切なイメージをアンダークラウドからプルする
前提条件
- 実行中の Red Hat Hyperconverged Infrastructure for Cloud 環境。
- インターネットへのアクセス。
手順
イメージをローカルレジストリーにプルするためのテンプレートを作成します。
(undercloud) [stack@director ~]$ openstack overcloud container image prepare \ --namespace=registry.access.redhat.com/rhosp13 \ --prefix=openstack- \ --tag-from-label {version}-{release} \ --output-images-file /home/stack/local_registry_images.yaml任意のサービス用の環境ファイルを指定するには、
-eオプションを使用します。注記上記の
openstack overcloud container image prepareコマンドは、registry.access.redhat.comのレジストリーをターゲットにしてイメージの一覧を生成します。この後のステップでは、openstack overcloud container image prepareコマンドで別の値を使用します。
これにより、コンテナーイメージ情報と共に
local_registry_images.yamlというファイルが作成されます。local_registry_images.yamlファイルを使用してイメージをプルします。(undercloud) [stack@director ~]$ sudo openstack overcloud container image upload \ --config-file /home/stack/local_registry_images.yaml \ --verbose
注記コンテナーイメージは、およそ 10 GB のディスク領域を使用します。
ローカルイメージの名前空間を検索します。名前空間は以下のパターンを使用します。
<REGISTRY_IP_ADDRESS>:8787/rhosp13
アンダークラウドの IP アドレスを使用します。これは
undercloud.confファイルのlocal_ipパラメーターで以前に設定していました。または、以下のコマンドで完全な名前空間を取得することもできます。(undercloud) [stack@director ~]$ docker images | grep -v redhat.com | grep -o '^.*rhosp13' | sort -u
アンダークラウド上のローカルレジストリーで イメージを使用するためのテンプレートを作成します。以下に例を示します。
(undercloud) [stack@director ~]$ openstack overcloud container image prepare \ --namespace=192.168.24.1:8787/rhosp13 \ --prefix=openstack- \ --tag-from-label {version}-{release} \ --output-env-file=/home/stack/templates/overcloud_images.yaml-
任意のサービス用の環境ファイルを指定するには、
-eオプションを使用します。 -
Ceph Storage を使用している場合には、Ceph Storage 用のコンテナーイメージの場所を定義する追加のパラメーターを指定します:
--set ceph_namespace、--set ceph_image、--set ceph_tag
注記このステップの
openstack overcloud container image prepareコマンドは、Red Hat Satellite サーバーをターゲットにします。ここでは、前のステップで使用したopenstack overcloud container image prepareコマンドとは異なる値を指定します。-
任意のサービス用の環境ファイルを指定するには、
-
これで、イメージの場所が記載された
overcloud_images.yaml環境ファイルがアンダークラウド上に作成されます。今後のアップグレードとデプロイメントの操作ではすべてこのファイルを追加してください。
関連情報
- 詳細は、Red Hat Hyperconverged Infrastructure for Cloud 開発ガイド の Red Hat OpenStack Platformサービス用コンテナイメージの追加 セクション を参照してください。
次のステップ
- アップグレードに向けてオーバークラウドを準備する。
5.3.5. 関連情報
- 詳細は、Red Hat OpenStack Platform Fast Forward アップグレードガイド の セクション 4.2 を参照してください。
5.4. コマンドラインインターフェイスを使用したリソースの分離およびオーバークラウドのチューニング
Red Hat OpenStack Platform (RHOSP)と Red Hat Ceph Storage (RHCS)との間のリソースの競合により、いずれかのサービスのパフォーマンスが低下する可能性があります。そのため、Red Hat Hyperconverged Infrastructure Cloud ソリューションでは、システムリソースを分離することが重要です。
同様に、特定のワークロードに対するより予測可能なパフォーマンスの結果については、オーバークラウドを調整することが重要になります。
リソースを分離してオーバークラウドを調整するには、以前に作成したカスタムテンプレートを引き続き改良します。
5.4.1. 前提条件
- オーバークラウドを定義 して、オーバークラウドの基盤を構築します。
5.4.2. ハイパーコンバージドノード向けの CPU およびメモリーリソースの確保
デフォルトでは、Nova Compute サービスのパラメーターは Ceph OSD サービスが同じノード上に配置されていることは考慮に入れません。安定性を維持し、可能なインスタンスの数を最大化するには、ハイパーコンバージドノードを調整する必要があります。プラン環境ファイルを使用すると、ハイパーコンバージドノード上の Nova コンピュートサービスのリソース制約を設定することができます。プラン環境ファイルはワークフローを定義し、Red Hat OpenStack Platform director (RHOSP-d)は OpenStack Workflow (Mistral)サービスでプランファイルを実行します。
RHOSP-d は、ハイパーコンバージドノード上のリソース制約を設定するためのデフォルトのプラン環境ファイルも提供します。
/usr/share/openstack-tripleo-heat-templates/plan-samples/plan-environment-derived-params.yaml
-p パラメーターを使用すると、オーバークラウドのデプロイメント中にプラン環境ファイルが呼び出されます。
このプラン環境ファイルは、OpenStack Workflow に以下の操作を指示します。
- ハードウェアイントロスペクションデータを取得します。
- そのデータに基づいた、ハイパーコンバージドノード上の Compute に最適な CPU とメモリーの制約の算出
- それらの制約を設定するために必要なパラメーターの自動生成
plan-environment-derived-params.yaml プラン環境ファイルでは、hci_profile_config オプションは、複数の CPU およびメモリーの割り当てワークロードプロファイルを定義します。hci_profile パラメーターは、有効にするワークロードプロファイルを設定します。
以下は、デフォルトの hci_profile です。
デフォルトの例
hci_profile: default
hci_profile_config:
default:
average_guest_memory_size_in_mb: 2048
average_guest_cpu_utilization_percentage: 50
many_small_vms:
average_guest_memory_size_in_mb: 1024
average_guest_cpu_utilization_percentage: 20
few_large_vms:
average_guest_memory_size_in_mb: 4096
average_guest_cpu_utilization_percentage: 80
nfv_default:
average_guest_memory_size_in_mb: 8192
average_guest_cpu_utilization_percentage: 90
上記の例では、平均ゲストが CPU の 2 GB のメモリーと 50% を使用することを前提としています。
新しいプロファイルを hci_profile_config セクションに追加することで、環境用のカスタムワークロードプロファイルを作成できます。hci_profile パラメーターをプロファイルの名前に設定して、このカスタムワークロードプロファイルを有効にすることができます。
カスタムの例
hci_profile: my_workload
hci_profile_config:
default:
average_guest_memory_size_in_mb: 2048
average_guest_cpu_utilization_percentage: 50
many_small_vms:
average_guest_memory_size_in_mb: 1024
average_guest_cpu_utilization_percentage: 20
few_large_vms:
average_guest_memory_size_in_mb: 4096
average_guest_cpu_utilization_percentage: 80
nfv_default:
average_guest_memory_size_in_mb: 8192
average_guest_cpu_utilization_percentage: 90
my_workload:
average_guest_memory_size_in_mb: 131072
average_guest_cpu_utilization_percentage: 100
my_workload プロファイルは、平均ゲストが 128 GB の RAM と、ゲストに割り当てられた CPU の 100% を使用することを前提としています。
関連情報
- 詳細は、Red Hat OpenStack Platform ハイパーコンバージドインフラストラクチャーガイド を参照してください。
5.4.3. Ceph 用 CPU リソースの確保
ハイパーコンバージドデプロイメントでは、CPU リソースの Nova コンピュートプロセスと Ceph プロセス間で競合が発生する可能性があります。デフォルトでは、ceph-ansible は docker run コマンドで --cpu-quota オプションを使用して各 OSD を 1 つの仮想 CPU に制限します。ceph_osd_docker_cpu_limit オプションは、このデフォルト制限を上書きし、各 Ceph OSD プロセスにより多くの vCPU を使用できるようにします。以下に例を示します。
CephAnsibleExtraConfig: ceph_osd_docker_cpu_limit: 2
Red Hat は、ceph_osd_docker_cpu_limit の値を開始点として 2 に設定し、使用されているハードウェアとこのハイパーコンバージド環境で実行されるワークロードに基づいてこの値を調節することを推奨します。この設定オプションは、~/templates/ceph.yaml ファイルで設定できます。
実稼働環境で実行する前に、ワークロードを常にテストしてください。
関連情報
-
~/templates/ceph.yamlファイルの詳細は、Red Hat Ceph Storage パラメーターの設定 セクションを参照してください。 - 詳細は、Red Hat Ceph Storage ハードウェア選択ガイド の コンテナ型 Ceph クラスターに推奨される最小限のハードウェア セクションを参照してください。
- 詳細は、Red Hat Ceph ストレージコンテナガイド の コロケートされたデーモンのための専用リソースの設定 を参照してください。
5.4.4. Ceph 用メモリーリソースの確保
ハイパーコンバージドデプロイメントでは、Nova のコンピュートと Ceph プロセスがメモリーリソースで競合する可能性があります。Red Hat Hyperconverged Infrastructure for Cloud ソリューションのデプロイメントでは、ceph-ansible を使用して Ceph のメモリー設定を自動的にチューニングし、コロケートされたプロセス間のメモリー競合を軽減します。BlueStore オブジェクトストアは、メモリー処理機能が高いため、ハイパーコンバージドデプロイメントに推奨されるバックエンドです。
ceph_osd_docker_memory_limit オプションは、FileStore または BlueStore のいずれかで使用される Ceph オブジェクトストアバックエンドに関係なく、Ansible が検出したノードの最大メモリーサイズに自動的に設定されます。
Red Hat は、ceph_osd_docker_memory_limit オプションを上書きしないことを推奨します。
osd_memory_target オプションは、Ceph OSD プロセスによるメモリーの増加を抑えるための推奨される方法です。is_hci オプションが true に設定されている場合、osd_memory_target オプションは自動的に設定されます。以下に例を示します。
CephAnsibleExtraConfig: is_hci: true
これらの設定オプションは ~/templates/ceph.yaml ファイルで設定できます。
osd_memory_target オプションは、Red Hat Ceph Storage 3.2 以降の BlueStore オブジェクトストア機能で導入されました。
関連情報
-
~/templates/ceph.yamlファイルの詳細は、Red Hat Ceph Storage パラメーターの設定 セクションを参照してください。 - 詳細は、Red Hat Ceph Storage ハードウェア選択ガイド の コンテナ型 Ceph クラスターに推奨される最小限のハードウェア セクションを参照してください。
- 詳細は、Red Hat Ceph ストレージコンテナガイド の コロケートされたデーモンのための専用リソースの設定 を参照してください。
5.4.5. Ceph のバックフィルおよびリカバリー操作のチューニング
Ceph はバックフィルおよびリカバリープロセスを使用して、OSD が削除されるたびにストレージクラスターのリバランスを行います。これは、配置グループポリシーに従って、データの複数のコピーを保持するために行われます。これらの 2 つの操作はシステムリソースを使用するため、Ceph ストレージクラスターが負荷がかかっている場合、Ceph はリソースをバックフィルおよびリカバリープロセスに迂回するため、Ceph のパフォーマンスが低下します。OSD の削除時に Ceph ストレージの許容可能なパフォーマンスを維持するには、バックフィルおよびリカバリー操作の優先度を下げます。優先度を減らすためのトレードオフは、長期間のデータレプリカが少なく、データを若干リスクにさらすことです。
変更する 3 つの変数は以下のとおりです。
osd_recovery_max_active- OSD ごとに一度のアクティブな復旧要求の数。リクエストが増えれば復旧も早くなりますが、その分クラスターへの負荷も大きくなります。
osd_max_backfills- 単一の OSD との間で許容されるバックフィルの最大数。
osd_recovery_op_priority- 復元の操作に設定されている優先順位。これは、osd client op priority と相対的になります。
osd_recovery_max_active パラメーターおよび osd_max_backfills パラメーターはすでに正しい値に設定されているため、ceph.yaml ファイルに追加する必要はありません。デフォルト値である 3 と 1 をそれぞれ上書きする場合は、それらを ceph.yaml ファイルに追加します。
関連情報
- OSD の設定可能なパラメーターの詳細は、Red Hat Ceph Storage 設定ガイド を参照してください。
5.4.6. 関連情報
- オーバークラウドパラメーターの詳細については、Red Hat OpenStack Platform 10 Director インストールおよび使用ガイドの 表 5.2 デプロメントパラメーター を参照してください。
- 詳細は、仮想マシンの設定のカスタマイズ を参照してください。
-
openstack overcloud deployコマンドの実行に関する詳細は、「deploy コマンドの実行」 を参照してください。 - Ceph OSD を非同種のノードのディスクレイアウトにマッピングする方法については、コンテナー化された Red Hat Ceph によるオーバークラウドのデプロイ ガイドの ディスクレイアウトを非同種の Ceph ストレージノードにマッピングする を参照してください。
5.5. コマンドラインインターフェイスを使用したオーバークラウドの定義
管理者として、オーバークラウドを定義する TripleO Heat テンプレートのカスタマイズ可能なセットを作成することができます。
5.5.1. 前提条件
Red Hat Hyperconverged Infrastructure for Cloud オーバークラウドを定義するための高度な手順:
- カスタムテンプレート のディレクトリーの作成
- オーバークラウドネットワークの 設定
- コントローラーおよび ComputeHCI ロールの作成
- オーバークラウド用の Red Hat Ceph Storageの設定
- オーバークラウドノードのプロファイルレイアウトの設定
5.5.2. カスタムテンプレートのディレクトリーの作成
Red Hat OpenStack Platform director (RHOSP-d) をインストールすると、TripleO Heat テンプレートのセットが作成されます。これらの TripleO Heat テンプレートは /usr/share/openstack-tripleo-heat-templates/ ディレクトリーにあります。Red Hat は、これらのテンプレートをカスタマイズする前にこれらのテンプレートをコピーすることを推奨します。
前提条件
- アンダークラウド をデプロイします。
手順
RHOSP-d ノードのコマンドラインインターフェイスで以下の手順を実行します。
カスタムテンプレートの新規ディレクトリーを作成します。
[stack@director ~]$ mkdir -p ~/templates/nic-configs
5.5.3. オーバークラウドネットワークの設定
以下の手順では、分離ネットワークのネットワーク設定ファイルをカスタマイズし、それらを Red Hat OpenStack Platform (RHOSP) サービスに割り当てます。
前提条件
- すべてのネットワーク要件を満たしていることを確認します。
手順
RHOSP director ノードで、stack ユーザーとして以下の手順を実施します。
環境に適用されるコンピュート NIC 設定テンプレートを選択します。
-
/usr/share/openstack-tripleo-heat-templates/network/config/single-nic-vlans/compute.yaml -
/usr/share/openstack-tripleo-heat-templates/network/config/single-nic-linux-bridge-vlans/compute.yaml -
/usr/share/openstack-tripleo-heat-templates/network/config/multiple-nics/compute.yaml /usr/share/openstack-tripleo-heat-templates/network/config/bond-with-vlans/compute.yaml注記NIC の設定に関する詳しい情報は、各テンプレートの個々のディレクトリーで
README.mdを参照してください。
-
~/templates/ ディレクトリーに新規ディレクトリーを作成します。
[stack@director ~]$ touch ~/templates/nic-configs
選択したテンプレートを
~/templates/nic-configs/ディレクトリーにコピーし、その名前をcompute-hci.yamlに変更します。例
[stack@director ~]$ cp /usr/share/openstack-tripleo-heat-templates/network/config/bond-with-vlans/compute.yaml ~/templates/nic-configs/compute-hci.yaml
~/templates/nic-configs/compute-hci.yamlファイルのparameters:セクションに、以下の定義がすでに存在する場合は追加します。StorageMgmtNetworkVlanID: default: 40 description: Vlan ID for the storage mgmt network traffic. type: number各ノードで
StorageMgmtNetworkVlanIDを特定の NIC にマッピングします。たとえば、VLAN を単一の NIC にトランク接続する場合(single-nic-vlans/compute.yaml)、以下のエントリーを~/templates/nic-configs/compute-hci.yamlのnetwork_config:セクションに追加します。type: vlan device: em2 mtu: 9000 use_dhcp: false vlan_id: {get_param: StorageMgmtNetworkVlanID} addresses: - ip_netmask: {get_param: StorageMgmtIpSubnet}重要Red Hat は、NIC を
StorageMgmtNetworkVlanIDにマッピングする際に、mtuを9000に設定することを推奨します。この MTU 設定により、Red Hat Ceph Storage のパフォーマンスが大幅に向上します。詳細は、Red Hat OpenStack Platform Advanced Overcloud カスタマイゼーションの Jumbo Frames の設定 を参照してください。カスタムテンプレートディレクトリーに新規ファイルを作成します。
[stack@director ~]$ touch ~/templates/network.yaml
network.yamlファイルを開いて編集します。resource_registryセクションを追加します。resource_registry:
resource_registry:セクションに次の 2 つの行を追加します。OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller-nics.yaml OS::TripleO::Compute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute-nics.yaml
これら 2 行は、RHOSP サービスが Controller/Monitor ノードおよび Compute/OSD ノードのネットワーク設定をそれぞれ指します。
parameter_defaultsセクションを追加します。parameter_defaults:
テナントネットワークの Neutron ブリッジマッピング用に、以下のデフォルトパラメーターを追加します。
NeutronBridgeMappings: 'datacentre:br-ex,tenant:br-tenant' NeutronNetworkType: 'vxlan' NeutronTunnelType: 'vxlan' NeutronExternalNetworkBridge: "''"
これは、論理ネットワークに割り当てられたブリッジマッピングを定義し、テナントが
vxlanを使用できるようにします。ステップ 2b で参照されている 2 つの TripleO Heat テンプレートは、各ネットワークを定義するパラメーターを必要とします。
parameter_defaultsセクションに以下の行を追加します。# Internal API used for private OpenStack Traffic InternalApiNetCidr: IP_ADDR_CIDR InternalApiAllocationPools: [{'start': 'IP_ADDR_START', 'end': 'IP_ADDR_END'}] InternalApiNetworkVlanID: VLAN_ID # Tenant Network Traffic - will be used for VXLAN over VLAN TenantNetCidr: IP_ADDR_CIDR TenantAllocationPools: [{'start': 'IP_ADDR_START', 'end': 'IP_ADDR_END'}] TenantNetworkVlanID: VLAN_ID # Public Storage Access - Nova/Glance <--> Ceph StorageNetCidr: IP_ADDR_CIDR StorageAllocationPools: [{'start': 'IP_ADDR_START', 'end': 'IP_ADDR_END'}] StorageNetworkVlanID: VLAN_ID # Private Storage Access - Ceph cluster/replication StorageMgmtNetCidr: IP_ADDR_CIDR StorageMgmtAllocationPools: [{'start': 'IP_ADDR_START', 'end': 'IP_ADDR_END'}] StorageMgmtNetworkVlanID: VLAN_ID # External Networking Access - Public API Access ExternalNetCidr: IP_ADDR_CIDR # Leave room for floating IPs in the External allocation pool (if required) ExternalAllocationPools: [{'start': 'IP_ADDR_START', 'end': 'IP_ADDR_END'}] # Set to the router gateway on the external network ExternalInterfaceDefaultRoute: IP_ADDRESS # Gateway router for the provisioning network (or undercloud IP) ControlPlaneDefaultRoute: IP_ADDRESS # The IP address of the EC2 metadata server, this is typically the IP of the undercloud EC2MetadataIp: IP_ADDRESS # Define the DNS servers (maximum 2) for the Overcloud nodes DnsServers: ["DNS_SERVER_IP","DNS_SERVER_IP"]
- 以下を置き換えます。
- 適切な IP アドレスとネットマスク (CIDR) を持つ IP_ADDR_CIDR。
- IP_ADDR_START を適切な開始 IP アドレスに置き換えます。
- IP_ADDR_END を適切な終了 IP アドレスに置き換えます。
- IP_ADDRESS を適切な IP アドレスに置き換えます。
- 対応するネットワークの適切な VLAN 識別番号を持つ VLAN_ID。
DNS_SERVER_IP をコンマ (
,) で区切って、2 つの DNS サーバーを定義するための適切な IP アドレスに置き換えます。network.yamlファイルのサンプルについては、付録 を参照してください。
関連情報
- ネットワーク分離 に関する詳しい情報は、Red Hat OpenStack Platform Advance Overcloud カスタマイズガイドを参照してください。
5.5.4. Controller ロールおよび ComputeHCI ロールの作成
オーバークラウドには、Controller、Compute、BlockStorage、ObjectStorage、および CephStorage の 5 つのデフォルトロールがあります。これらのロールには、サービスの一覧が含まれます。これらのサービスを組み合わせて、カスタムの deployable ロールを作成できます。
前提条件
- アンダークラウド とも呼ばれる Red Hat OpenStack Platform director をデプロイします。
- カスタムテンプレート のディレクトリーを作成します。
手順
Red Hat OpenStack Platform director ノードで、stack ユーザーとして以下の手順を実施します。
ControllerおよびComputeHCIが含まれるカスタムのroles_data_custom.yamlファイルを生成します。[stack@director ~]$ openstack overcloud roles generate -o ~/custom-templates/roles_data_custom.yaml Controller ComputeHCI
関連情報
- これらのカスタムロールの使用に関する詳細は、Red Hat Hyperconverged Infrastructure for Cloud デプロイメントガイド の コマンドラインを使用したオーバークラウドのデプロイ を参照してください。
5.5.5. Red Hat Ceph Storage パラメーターの設定
この手順では、使用する Red Hat Ceph Storage (RHCS) OSD パラメーターを定義します。
前提条件
- アンダークラウド とも呼ばれる Red Hat OpenStack Platform director をデプロイします。
- カスタムテンプレート のディレクトリーを作成します。
手順
Red Hat OpenStack Platform director ノードで、stack ユーザーとして以下の手順を実施します。
~/templates/ceph.yamlファイルを編集するために開きます。BlueStore オブジェクトストアバックエンドを使用するには、
CephAnsibleExtraConfigセクションの下にある以下の行を更新します。例
CephAnsibleExtraConfig: osd_scenario: lvm osd_objectstore: bluestore
parameter_defaultsセクションで以下のオプションを更新します。例
parameter_defaults: CephPoolDefaultSize: 3 CephPoolDefaultPgNum: NUM CephAnsibleDisksConfig: osd_scenario: lvm osd_objectstore: bluestore devices: - /dev/sda - /dev/sdb - /dev/sdc - /dev/sdd - /dev/nvme0n1 - /dev/sde - /dev/sdf - /dev/sdg - /dev/nvme1n1 CephAnsibleExtraConfig: osd_scenario: lvm osd_objectstore: bluestore ceph_osd_docker_cpu_limit: 2 is_hci: true CephConfigOverrides: osd_recovery_op_priority: 3 osd_recovery_max_active: 3 osd_max_backfills: 1- 以下を置き換えます。
NUM は、Ceph PG calculator から計算された値に置き換えます。
以下の例では、以下の Compute/OSD ノードのディスク設定が使用されています。
-
OSD :
/dev/[sda, sdb, …, sdg]ブロックデバイスとして表示される 12 x 1TB SAS ディスク -
OSD WAL および DB デバイス:
/dev/[nvme0n1, nvme1n1]ブロックデバイスとして提示される 2 x 400GB NVMe SSD ディスク
-
OSD :
関連情報
- Ceph OSD パラメーターのチューニングに関する詳細は、Red Hat Ceph Storage ストレージストラテジーガイド を参照してください。
- BlueStore オブジェクトストアの使用に関する詳細は、Red Hat Ceph Storage 管理ガイド を参照してください。
- LVM シナリオの例については、Red Hat Ceph Storage インストールガイド の LVM simple and LVM advance セクションを参照してください。
5.5.6. オーバークラウドノードのレイアウトの設定
ノードのオーバークラウドレイアウトは、種別、割り当てる IP アドレスのプール、およびその他のパラメーターに基づいてデプロイするノード数を定義します。
前提条件
- アンダークラウド とも呼ばれる Red Hat OpenStack Platform director をデプロイします。
- カスタムテンプレート のディレクトリーを作成します。
手順
Red Hat OpenStack Platform director ノードで、stack ユーザーとして以下の手順を実施します。
カスタムテンプレートディレクトリーに
layout.yamlファイルを作成します。[stack@director ~]$ touch ~/templates/layout.yaml
layout.yamlファイルを開いて編集します。以下の行を追加してリソースレジストリーセクションを追加します。
resource_registry:
IP アドレスのプールを使用するように
ControllerロールおよびComputeHCIロールを設定するには、resource_registryセクションに以下の行を追加します。OS::TripleO::Controller::Ports::InternalApiPort: /usr/share/openstack-tripleo-heat-templates/network/ports/internal_api_from_pool.yaml OS::TripleO::Controller::Ports::TenantPort: /usr/share/openstack-tripleo-heat-templates/network/ports/tenant_from_pool.yaml OS::TripleO::Controller::Ports::StoragePort: /usr/share/openstack-tripleo-heat-templates/network/ports/storage_from_pool.yaml OS::TripleO::Controller::Ports::StorageMgmtPort: /usr/share/openstack-tripleo-heat-templates/network/ports/storage_mgmt_from_pool.yaml OS::TripleO::ComputeHCI::Ports::InternalApiPort: /usr/share/openstack-tripleo-heat-templates/network/ports/internal_api_from_pool.yaml OS::TripleO::ComputeHCI::Ports::TenantPort: /usr/share/openstack-tripleo-heat-templates/network/ports/tenant_from_pool.yaml OS::TripleO::ComputeHCI::Ports::StoragePort: /usr/share/openstack-tripleo-heat-templates/network/ports/storage_from_pool.yaml OS::TripleO::ComputeHCI::Ports::StorageMgmtPort: /usr/share/openstack-tripleo-heat-templates/network/ports/storage_mgmt_from_pool.yaml
parameter_defaultsという名前のパラメーターのデフォルトに新しいセクションを追加し、このセクションの下に以下のパラメーターを追加します。parameter_defaults: NtpServer: NTP_IP_ADDR ControllerHostnameFormat: 'controller-%index%' ComputeHCIHostnameFormat: 'compute-hci-%index%' ControllerCount: 3 ComputeHCICount: 3 OvercloudComputeFlavor: compute OvercloudComputeHCIFlavor: osd-compute- 以下を置き換えます。
NTP_IP_ADDR は、NTP ソースの IP アドレスに置き換えます。時間同期は非常に重要になります。
例
parameter_defaults: NtpServer: 10.5.26.10 ControllerHostnameFormat: 'controller-%index%' ComputeHCIHostnameFormat: 'compute-hci-%index%' ControllerCount: 3 ComputeHCICount: 3 OvercloudComputeFlavor: compute OvercloudComputeHCIFlavor: osd-compute
ControllerCountおよびComputeHCICountパラメーターの3の値は、3 つのコントローラー/モニターノードと 3 つの Compute/OSD ノードがデプロイされることを意味します。
parameter_defaultsセクションで、ControllerSchedulerHintsと呼ばれるスケジューラーヒントと、ComputeHCISchedulerHintsと呼ばれる 2 つのスケジューラーヒントを追加します。各スケジューラーヒントの下に、予測可能なノード配置用のノード名の形式を以下のように追加します。ControllerSchedulerHints: 'capabilities:node': 'control-%index%' ComputeHCISchedulerHints: 'capabilities:node': 'osd-compute-%index%'parameter_defaultsセクションで、各ノードプロファイルに必要な IP アドレスを追加します。以下に例を示します。例
ControllerIPs: internal_api: - 192.168.2.200 - 192.168.2.201 - 192.168.2.202 tenant: - 192.168.3.200 - 192.168.3.201 - 192.168.3.202 storage: - 172.16.1.200 - 172.16.1.201 - 172.16.1.202 storage_mgmt: - 172.16.2.200 - 172.16.2.201 - 172.16.2.202 ComputeHCIIPs: internal_api: - 192.168.2.203 - 192.168.2.204 - 192.168.2.205 tenant: - 192.168.3.203 - 192.168.3.204 - 192.168.3.205 storage: - 172.16.1.203 - 172.16.1.204 - 172.16.1.205 storage_mgmt: - 172.16.2.203 - 172.16.2.204 - 172.16.2.205この例では、ノード
control-0には次の IP アドレスがあります:192.168.2.200、192.168.3.200、172.16.1.200および172.16.2.200。
5.5.7. 関連情報
- 詳細は、Red Hat OpenStack Platform Advanced Overcloud カスタマイゼーションガイド を参照してください。
5.6. コマンドラインインターフェイスを使用したオーバークラウドのデプロイ
技術者として、Nova Compute と Ceph OSD サービスが同じノードにコロケーションされるようにオーバークラウドノードをデプロイメントすることができます。
5.6.1. 前提条件
- アンダークラウドをデプロイします。
- オーバークラウドを定義 します。
5.6.2. Ironic で利用可能なノードの確認
オーバークラウドノードをデプロイする前に、ノードの電源がオフになり、利用可能であることを確認します。
ノードがメンテナンスモードであることはできません。
前提条件
-
Red Hat OpenStack Platform director ノードで
stackユーザーが利用できる。
手順
以下のコマンドを実行して、全ノードの電源がオフになり、利用可能であることを確認します。
[stack@director ~]$ openstack baremetal node list
5.6.3. Pacemaker フェンシング用のコントローラーの設定
データの破損が発生しないようにクラスター内のノードを分離することは、フェンシングと呼ばれます。フェンシングは、クラスターおよびクラスターリソースの整合性を保護します。
前提条件
- IPMI ユーザーおよびパスワード
-
Red Hat OpenStack Platform director ノードで
stackユーザーが利用できる。
手順
フェンシング Heat 環境ファイルを生成します。
[stack@director ~]$ openstack overcloud generate fencing --ipmi-lanplus instackenv.json --output fencing.yaml
-
openstack overcloud deployコマンドにfencing.yamlファイルを追加します。
5.6.4. deploy コマンドの実行
すべてのカスタマイズとチューニング後に、オーバークラウドをデプロイします。
デプロイメントのサイズに応じて、オーバークラウドのデプロイメントが完了するまでに時間がかかる場合があります。
前提条件
- ノードの準備
- コンテナーイメージのソースの設定
- オーバークラウドの定義
- リソースの分離とチューニング
-
Red Hat OpenStack Platform director ノードで
stackユーザーが利用できる。
手順
以下のコマンドを実行します。
[stack@director ~]$ time openstack overcloud deploy \ --templates /usr/share/openstack-tripleo-heat-templates \ --stack overcloud \ -p /usr/share/openstack-tripleo-heat-templates/plan-samples/plan-environment-derived-params.yaml -r /home/stack/templates/roles_data_custom.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/docker.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/docker-ha.yaml \ -e /home/stack/templates/overcloud_images.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml \ -e /usr/share/openstack-tripleo-heat-templates/environments/ceph-ansible/ceph-ansible.yaml \ -e ~/templates/network.yaml \ -e ~/templates/ceph.yaml \ -e ~/templates/layout.yaml -e /home/stack/fencing.yaml
- コマンドの詳細
-
timeコマンドは、デプロイメントにかかる時間を示すために使用されます。 -
openstack overcloud deployコマンドは実際のデプロイメントを実行します。 -
$NTP_IP_ADDRは、NTP ソースの IP アドレスに置き換えます。時間同期は非常に重要になります。 -
--templates引数は、デプロイする TripleO Heat テンプレートが含まれるデフォルトのディレクトリー(/usr/share/openstack-tripleo-heat-templates/)を使用します。 -
-p引数は、HCI デプロイメントのプラン環境ファイルを参照します。詳細は、ハイパーコンバージドノード向けの CPU およびメモリーリソースの 確保 セクションを参照してください。 -
-r引数はロールファイルを参照し、デフォルトのrole_data.yamlファイルをオーバーライドします。 -
-e引数は、デプロイメント時に使用する明示的なテンプレートファイルを参照します。 -
puppet-pacemaker.yamlファイルは、高可用性の Pacemaker クラスターでコントローラーノードサービスを設定します。 -
storage-environment.yamlファイルは、Ceph をストレージバックエンドとして設定します。parameter_defaultsはカスタムテンプレートceph.yamlによって渡されます。 -
network-isolation.yamlファイルは、異なるサービスのネットワーク分離を設定します。このサービスは、カスタムテンプレートnetwork.yamlによって渡されます。このファイルは、デプロイメントの開始時に自動的に作成されます。 -
network.yamlファイルについては、オーバークラウドネットワークの設定 セクションを参照してください。 -
ceph.yamlファイルについては、Red Hat Ceph Storage パラメーターの 設定セクションで説明されています。 -
compute.yamlファイルについては、Nova 予約メモリーと CPU 割り当ての変更 セクションで詳しく説明しています。 -
layout.yamlファイルについては、オーバークラウドノードのプロファイルレイアウトの設定 セクションを参照してください。 fencing.yamlファイルについては、Pacemaker フェンシング用のコントローラーの設定 セクションを参照してください。重要引数の順序は重要です。カスタムテンプレートファイルは、デフォルトのテンプレートファイルをオーバーライドします。
注記パッケージインストール用のソフトウェアリポジトリーとして Red Hat OpenStack Platform director (RHOSP-d) ノードを使用する場合は、
--rhel-reg、--reg-method、--reg-orgオプションを追加します。
-
- オーバークラウドのデプロイメントが完了するまで待ちます。
関連情報
- オーバークラウドパラメーターに関する詳しい情報は、Red Hat OpenStack Platform 13 Director インストールおよび使用ガイドの 表 5.2 デプロイメントパラメーター を参照してください。
5.6.5. オーバークラウドのデプロイメントが正常に行われたことの確認
オーバークラウドのデプロイメントが成功したかどうかを確認することが重要です。
前提条件
-
Red Hat OpenStack Platform director ノードで
stackユーザーが利用できる。
手順
デプロイメントプロセスを監視し、エラーを探します。
[stack@director ~]$ heat resource-list -n5 overcloud | egrep -i 'fail|progress'
オーバークラウドのデプロイメントに成功した出力例:
2016-12-20 23:25:04Z [overcloud]: CREATE_COMPLETE Stack CREATE completed successfully Stack overcloud CREATE_COMPLETE Started Mistral Workflow. Execution ID: aeca4d71-56b4-4c72-a980-022623487c05 /home/stack/.ssh/known_hosts updated. Original contents retained as /home/stack/.ssh/known_hosts.old Overcloud Endpoint: http://10.19.139.46:5000/v2.0 Overcloud Deployed
デプロイメントが完了したら、オーバークラウドノードの IP アドレスを表示します。
[stack@director ~]$ openstack server list
第6章 Red Hat Hyperconverged Infrastructure for Cloud ソリューションの最新バージョンへの更新
技術者として、Red HatHyperconverged Infrastructure for Cloud ソリューションを最新バージョンの Red Hat OpenStack Platform 13、および Red Hat Ceph Storage 3 に更新することができます。Red Hat Hyperconverged Infrastructure for Cloud ソフトウェアセットを最新バージョンに更新するには、Red Hat OpenStack Platform 13 ドキュメントの手順に従います。
付録A Red Hat Hyperconverged Infrastructure for Cloud に必要なリポジトリー
表A.1 必要なリポジトリー
| 名前 | リポジトリー | 要件の説明 |
| Red Hat Enterprise Linux 7 Server (RPM) |
| ベースオペレーティングシステムのリポジトリー |
| Red Hat Enterprise Linux 7 Server - Extras (RPM) |
| Red Hat OpenStack Platform の依存関係が含まれます。 |
| Red Hat Enterprise Linux 7 Server - RH Common (RPMs) |
| Red Hat OpenStack Platform のデプロイと設定用のツールが含まれます。 |
| Red Hat Enterprise Linux High Availability (for RHEL 7 Server) (RPMs) |
| Red Hat Enterprise Linux の高可用性ツール。コントローラーノードの高可用性に使用します。 |
| Red Hat Enterprise Linux OpenStack Platform 13 for RHEL 7 (RPMs) |
| Red Hat OpenStack Platform のコアリポジトリー。Red Hat OpenStack Platform director のパッケージも含まれます。 |
| Red Hat Ceph Storage 3 OSD for Red Hat Enterprise Linux 7 Server (RPMs) |
| RHCS Object Storage Daemon (OSD) のリポジトリー。コンピュートノードで有効化されている。 |
| Red Hat Ceph Storage 3 MON for Red Hat Enterprise Linux 7 Server (RPMs) |
| RHCS Monitor デーモンのリポジトリー。コントローラーノードで有効化されている。 |
| Red Hat Ceph Storage 3 Tools for Red Hat Enterprise Linux 7 Workstation (RPMs) |
| Ceph Object Gateway などの RHCS ツールおよびクライアントのリポジトリー。 |
付録B Red Hat Hyper-converaged Infrastructure for Cloud undercloud configuration parameters
local_ip- director のプロビジョニングネットワーク用に定義する IP アドレス。これは、director が DHCP および PXE ブートサービスに使用する IP アドレスでもあります。
network_gateway- オーバークラウドインスタンスのゲートウェイ。外部ネットワークにトラフィックを転送するアンダークラウドのノードです。
undercloud_public_vip- director のパブリック API 用に定義する IP アドレス他の IP アドレスまたはアドレス範囲と競合しないプロビジョニングネットワークで IP アドレスを使用します。director の設定により、この IP アドレスは、/32 ネットマスクを使用するルーティングされた IP アドレスとしてソフトウェアブリッジにアタッチされます。
undercloud_admin_vip- director の管理 API 用に定義する IP アドレス。他の IP アドレスまたはアドレス範囲と競合しないプロビジョニングネットワークで IP アドレスを使用します。director の設定により、この IP アドレスは、/32 ネットマスクを使用するルーティングされた IP アドレスとしてソフトウェアブリッジにアタッチされます。
local_interface-
director のプロビジョニング NIC 用に選択するインターフェイス。これは、director が DHCP および PXE ブートサービスに使用するデバイスでもあります。この設定スクリプトにより、このインターフェイスが
inspection_interfaceパラメーターで定義したカスタムのブリッジにアタッチされます。 network_cidr- オーバークラウドインスタンスの管理に director が使用するネットワーク。これは、アンダークラウドの neutron サービスが管理するプロビジョニングネットワークです。
masquerade_network- 外部アクセスのためにマスカレードするネットワークを定義します。このパラメーターにより、director 経由で外部ネットワークにアクセスすることができるように、プロビジョニングネットワークにネットワークアドレス変換 (NAT) の一部メカニズムが提供されます。
dhcp_start- オーバークラウドノードの DHCP 割り当て範囲の開始。この範囲には、すべてのノードに割り当てるのに十分な IP アドレスが含まれていることを確認してください。
dhcp_end- オーバークラウドノードの DHCP 割り当て範囲の最後。この範囲には、すべてのノードに割り当てるのに十分な IP アドレスが含まれていることを確認してください。
inspection_interface-
ノードのイントロスペクションに director が使用するブリッジ。これは、director の設定により作成されるカスタムのブリッジです。
local_interfaceでこのブリッジをアタッチします。これは、デフォルトのbr-ctlplaneのままにします。 inspection_iprange-
director のイントロスペクションサービスが PXE ブートとプロビジョニングプロセスの際に使用する IP アドレス範囲。コンマ区切りの値を使用して、開始アドレスと終了アドレスを定義します。この範囲には、使用するノードに十分な数の IP アドレスが含まれるようにし、
dhcp_startとdhcp_endの範囲とは競合しないように設定してください。 inspection_extras-
イントロスペクション時に追加のハードウェアコレクションを有効化するかどうかを定義します。イントロスペクションイメージでは
python-hardwareまたはpython-hardware-detectパッケージが必要です。 inspection_runbench-
ノードイントロスペクション時に一連のベンチマークを実行します。有効にするには、
trueに設定します。このオプションは、登録ノードのハードウェアを検査する際にベンチマーク分析を実行する場合に必要です。 inspection_enable_uefi- UEFI のみのファームウェアを使用するノードのイントロスペクションをサポートするかどうかを定義します。
付録C Red Hat Hyperconverged Infrastructure for Cloud - Nova メモリーおよび CPU calculator スクリプトソース
これは、nova_mem_cpu_calc.py スクリプトの Python ソースコードです。
#!/usr/bin/env python
# Filename: nova_mem_cpu_calc.py
# Supported Langauge(s): Python 2.7.x
# Time-stamp: <2017-03-10 20:31:18 jfulton>
# -------------------------------------------------------
# This program was originally written by Ben England
# -------------------------------------------------------
# Calculates cpu_allocation_ratio and reserved_host_memory
# for nova.conf based on on the following inputs:
#
# input command line parameters:
# 1 - total host RAM in GB
# 2 - total host cores
# 3 - Ceph OSDs per server
# 4 - average guest size in GB
# 5 - average guest CPU utilization (0.0 to 1.0)
#
# It assumes that we want to allow 3 GB per OSD
# (based on prior Ceph Hammer testing)
# and that we want to allow an extra 1/2 GB per Nova (KVM guest)
# based on test observations that KVM guests' virtual memory footprint
# was actually significantly bigger than the declared guest memory size
# This is more of a factor for small guests than for large guests.
# -------------------------------------------------------
import sys
from sys import argv
NOTOK = 1 # process exit status signifying failure
MB_per_GB = 1000
GB_per_OSD = 3
GB_overhead_per_guest = 0.5 # based on measurement in test environment
cores_per_OSD = 1.0 # may be a little low in I/O intensive workloads
def usage(msg):
print msg
print(
("Usage: %s Total-host-RAM-GB Total-host-cores OSDs-per-server " +
"Avg-guest-size-GB Avg-guest-CPU-util") % sys.argv[0])
sys.exit(NOTOK)
if len(argv) < 5: usage("Too few command line params")
try:
mem = int(argv[1])
cores = int(argv[2])
osds = int(argv[3])
average_guest_size = int(argv[4])
average_guest_util = float(argv[5])
except ValueError:
usage("Non-integer input parameter")
average_guest_util_percent = 100 * average_guest_util
# print inputs
print "Inputs:"
print "- Total host RAM in GB: %d" % mem
print "- Total host cores: %d" % cores
print "- Ceph OSDs per host: %d" % osds
print "- Average guest memory size in GB: %d" % average_guest_size
print "- Average guest CPU utilization: %.0f%%" % average_guest_util_percent
# calculate operating parameters based on memory constraints only
left_over_mem = mem - (GB_per_OSD * osds)
number_of_guests = int(left_over_mem /
(average_guest_size + GB_overhead_per_guest))
nova_reserved_mem_MB = MB_per_GB * (
(GB_per_OSD * osds) +
(number_of_guests * GB_overhead_per_guest))
nonceph_cores = cores - (cores_per_OSD * osds)
guest_vCPUs = nonceph_cores / average_guest_util
cpu_allocation_ratio = guest_vCPUs / cores
# display outputs including how to tune Nova reserved mem
print "\nResults:"
print "- number of guests allowed based on memory = %d" % number_of_guests
print "- number of guest vCPUs allowed = %d" % int(guest_vCPUs)
print "- nova.conf reserved_host_memory = %d MB" % nova_reserved_mem_MB
print "- nova.conf cpu_allocation_ratio = %f" % cpu_allocation_ratio
if nova_reserved_mem_MB > (MB_per_GB * mem * 0.8):
print "ERROR: you do not have enough memory to run hyperconverged!"
sys.exit(NOTOK)
if cpu_allocation_ratio < 0.5:
print "WARNING: you may not have enough CPU to run hyperconverged!"
if cpu_allocation_ratio > 16.0:
print(
"WARNING: do not increase VCPU overcommit ratio " +
"beyond OSP8 default of 16:1")
sys.exit(NOTOK)
print "\nCompare \"guest vCPUs allowed\" to \"guests allowed based on memory\" for actual guest count"付録D Red Hat Hyperconverged Infrastructure for Cloud - example network.yaml file
例
resource_registry:
OS::TripleO::OsdCompute::Net::SoftwareConfig: /home/stack/templates/nic-configs/compute-nics.yaml
OS::TripleO::Controller::Net::SoftwareConfig: /home/stack/templates/nic-configs/controller-nics.yaml
parameter_defaults:
NeutronBridgeMappings: 'datacentre:br-ex,tenant:br-tenant'
NeutronNetworkType: 'vxlan'
NeutronTunnelType: 'vxlan'
NeutronExternalNetworkBridge: "''"
# Internal API used for private OpenStack Traffic
InternalApiNetCidr: 192.168.2.0/24
InternalApiAllocationPools: [{'start': '192.168.2.10', 'end': '192.168.2.200'}]
InternalApiNetworkVlanID: 4049
# Tenant Network Traffic - will be used for VXLAN over VLAN
TenantNetCidr: 192.168.3.0/24
TenantAllocationPools: [{'start': '192.168.3.10', 'end': '192.168.3.200'}]
TenantNetworkVlanID: 4050
# Public Storage Access - Nova/Glance <--> Ceph
StorageNetCidr: 172.16.1.0/24
StorageAllocationPools: [{'start': '172.16.1.10', 'end': '172.16.1.200'}]
StorageNetworkVlanID: 4046
# Private Storage Access - Ceph background cluster/replication
StorageMgmtNetCidr: 172.16.2.0/24
StorageMgmtAllocationPools: [{'start': '172.16.2.10', 'end': '172.16.2.200'}]
StorageMgmtNetworkVlanID: 4047
# External Networking Access - Public API Access
ExternalNetCidr: 10.19.137.0/21
# Leave room for floating IPs in the External allocation pool (if required)
ExternalAllocationPools: [{'start': '10.19.139.37', 'end': '10.19.139.48'}]
# Set to the router gateway on the external network
ExternalInterfaceDefaultRoute: 10.19.143.254
# Gateway router for the provisioning network (or Undercloud IP)
ControlPlaneDefaultRoute: 192.168.1.1
# The IP address of the EC2 metadata server. Generally the IP of the Undercloud
EC2MetadataIp: 192.168.1.1
# Define the DNS servers (maximum 2) for the overcloud nodes
DnsServers: ["10.19.143.247","10.19.143.248"]
付録E Nova 確保メモリーと CPU 割り当ての手動チューニング
計画された作業負荷に対して Nova 環境をチューニングすることは、試行錯誤の連続です。Red Hat は、起動後にデフォルトのベースセットを計算し、そこからチューニングすることを推奨します。
reserved_host_memory_mb パラメーターおよび cpu_allocation_ratio パラメーターを調整することで、ワークロードで可能なゲストの数を最大化できます。また、これらの値を微調整することで、ワークロードの決定性とゲストホスティング能力の間の望ましいトレードオフを見つけることができます。
Nova 確保メモリーのチューニング
Nova の reserved_host_memory_mb パラメーターは、ノード用に確保するメモリー容量 (メガバイト(MB)単位) です。ハイパーコンバージド Compute/OSD ノードでは、必要なリソースのサービスが不足しないように、2 つのサービス間でメモリーを共有する必要があることに注意してください。
以下は、ハイパーコンバージドノードの reserved_host_memory_mb 値を決定する方法の例になります。RAM が 256 GB、10 の OSD を持つノードで、各 OSD が 3 GB の RAM を消費し、Ceph 用に 30GB の RAM を消費し、Nova Compute 用に 226GB の RAM を残していることを前提とします。平均ゲストがそれぞれ 2 GB の RAM を使用する場合は、システム全体のゲストマシンが 113 個のゲストマシンをホストする可能性があります。ただし、考慮する必要のあるハイパーバイザーで実行している各ゲストマシンには、追加のオーバーヘッドがあります。このオーバーヘッドを 500MB と仮定すると、2GB のゲストマシンの最大稼働数は約 90 台となります。
以下は数式です。
ゲストマシンの概算数 = (Nova で使用可能なメモリー (GB) / (ゲストマシンごとのメモリー (GB) + ハイパーバイザーのメモリーオーバーヘッド (GB))
例
90.4 = ( 226 / ( 2 + .5 ) )
ゲストマシンの概算数と OSD 数については、Nova 用に確保するメモリー量を計算することができます。
Nova の予約メモリー (MB) = 1000 * (OSD メモリーサイズ (GB) * OSD の数) + (ゲストマシンの概算数 * ハイパーバイザーのメモリーオーバーヘッド (GB))
例
75000 = 1000 * ( ( 3 * 10 ) + ( 90 * .5 ) )
したがって、reserved_host_memory_mb は 75000 と等しくなります。パラメーターの値はメガバイト (MB) でなければなりません。
CPU 割り当て率のチューニング
Nova の cpu_allocation_ratio パラメーターは、ゲストマシンを実行するコンピュートノードを選択する際に Nova スケジューラーによって使用されます。ゲストマシンとコンピュートノードとの比率が 16:1 で、ノード上のコア(vCPU)の数が 56 の場合、Nova スケジューラーは 896 コアを消費するのに十分なゲストをスケジュールしてから、ノードが追加のゲストマシンを処理できないとみなすことができます。理由は、Nova スケジューラーが Nova スケジューラーと同じノードで実行されている Ceph OSD サービスの CPU ニーズを考慮しないためです。cpu_allocation_ratio パラメーターを変更すると、Ceph は、CPU リソースを Nova Compute に指定せずに効果的に動作する必要がある CPU リソースを持つことができます。
ハイパーコンバージドノードの cpu_allocation_ratio 値を決定する方法の例を以下に示します。ノードに 56 コアおよび 10 OSD があり、1 つのコアが各 OSD で使用されることを前提とし、Nova 用に 46 コアを残します。各ゲストマシンがコアの 100% を使用する場合、ゲストマシンで利用可能なコア数はノード上のコアの合計数で除算されます。このシナリオでは、cpu_allocation_ratio の値は 0.821429 です。
ただし、ゲストマシンはコアの 100% を使用しないため、この比率はゲストマシンごとのコア数を決定する際に予想される使用率率を考慮する必要があります。ゲストマシンごとに平均 10% のコア使用率が予想されるシナリオでは、cpu_allocation_ratio の値は 8.214286 である必要があります。
以下は数式です。
- 非 Ceph コア数 = ノード上の総コア数 - (OSD あたりのコア数 * OSD の数)
- ゲストマシンの vCPU 数 = Ceph 以外のコア数/ゲストマシンの平均 CPU 使用率
- CPU 割当率 = ゲストマシンの vCPU 数/ノード上の総コア数
例
- 46 = 56 - ( 1 * 10 )
- 460 = 46 / .1
- 8.214286 = 460 / 56
Nova メモリーおよび CPU の計算
Red Hat は、これらすべての計算を行うための calculator スクリプトを提供しています。スクリプト名は nova_mem_cpu_calc.py で、5 つの入力パラメーターを取ります。
nova_mem_cpu_calc.py TOTAL_NODE_RAM_GB TOTAL_NODE_CORES NUM_OSDs_PER_NODE AVG_GUEST_MEM_SIZE_GB AVG_GUEST_CPU_UTIL
- 以下を置き換えます。
- TOTAL_NODE_RAM_GB に、ノード上の RAM の合計サイズ (GB) を指定します。
- TOTAL_NODE_CORES ノード上のコアの総数を表します。
- NUM_OSDs_PER_NODE にノードあたりの Ceph OSD の数を指定します。
- AVG_GUEST_MEM_SIZE_GB に、ゲストマシンの平均メモリーサイズ (GB) を指定します。
- AVG_GUEST_CPU_UTIL に、ゲストマシンの平均 CPU 使用率 (10 進数で表示) を指定します。
例
[stack@director ~]$ ./nova_mem_cpu_calc.py 256 56 10 2 0.1
関連情報
-
nova_mem_cpu_calc.pyスクリプトの完全なソースコードは、付録 を参照してください。
付録F Nova 確保メモリーと CPU 割り当ての手動変更
reserved_host_memory_mb および cpu_allocation_ratio のデフォルト値を上書きするカスタムテンプレートを作成します。
前提条件
- アンダークラウド とも呼ばれる Red Hat OpenStack Platform director (RHOSP-d)をデプロイします。
- カスタムテンプレート のディレクトリーを作成します。
手順
RHOSP-d ノードで、stack ユーザーとして以下の手順を実行します。
カスタムテンプレートディレクトリーに
compute.yamlファイルを作成します。[stack@director ~]$ touch ~/templates/compute.yaml
compute.yamlファイルを開いて編集します。パラメーター defaults セクションで、
reserved_host_memoryおよびcpu_allocation_ratio設定パラメーターをExtraConfigセクションに追加します。parameter_defaults: ExtraConfig: nova::compute::reserved_host_memory: MEMORY_SIZE_IN_MB nova::cpu_allocation_ratio: CPU_RATIO- 以下を置き換えます。
- メモリーサイズがメガバイト (MB) の MEMORY_SIZE_IN_MB。
CPU_RATIO の比率 (10 進数)
例
nova::compute::reserved_host_memory: 75000 nova::cpu_allocation_ratio: 8.2注記Red Hat OpenStack Platform director は、Nova が
reserved_host_memoryパラメーターとして使用するreserved_host_memory_mbパラメーターを参照します。