
Red Hat Training
A Red Hat training course is available for RHEL 8
34.9. リッスンキューのロック競合の回避
キューロックの競合により、パケットドロップや CPU 使用率の上昇を引き起こす可能性があり、その結果、レイテンシーが長くなる可能性があります。アプリケーションをチューニングし、送信パケットステアリングを使用することで、受信 (RX) キューと送信 (TX) キューでのキューロックの競合を回避できます。
34.9.1. RX キューのロック競合の回避: SO_REUSEPORT および SO_REUSEPORT_BPF ソケットオプション
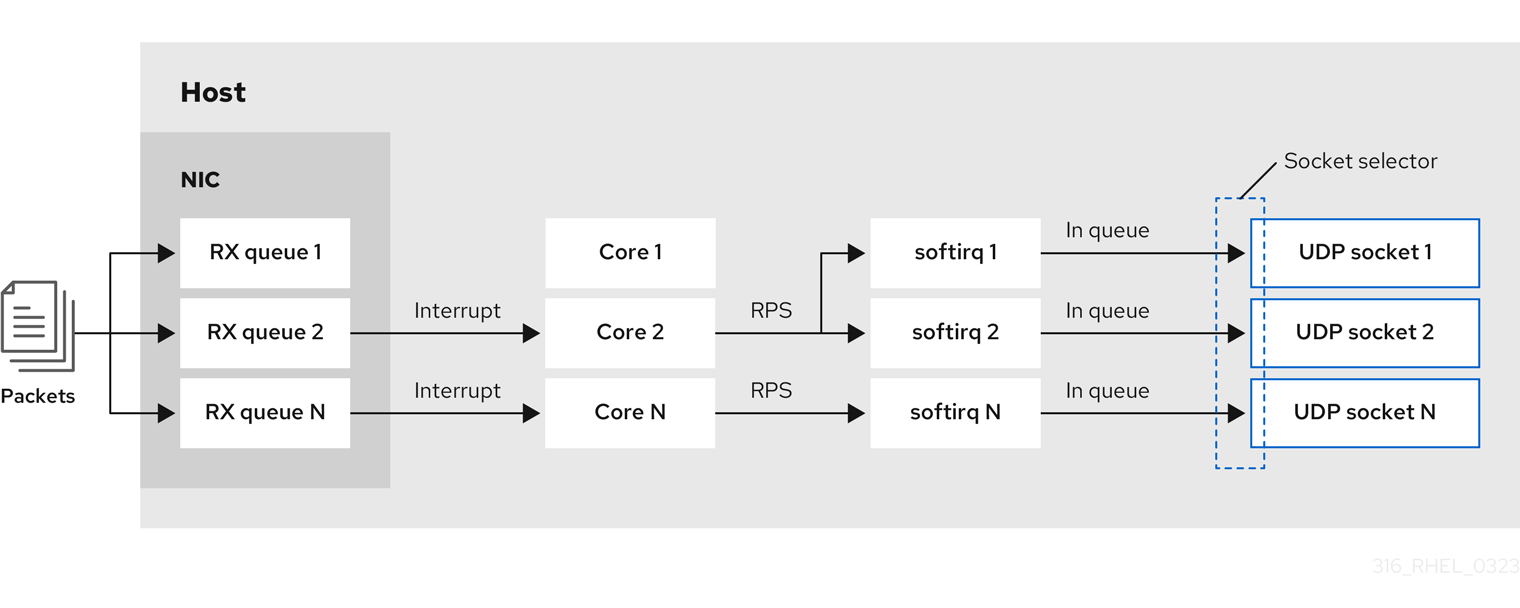
マルチコアシステムでは、アプリケーションが SO_REUSEPORT または SO_REUSEPORT_BPF ソケットオプションを使用してポートを開くと、マルチスレッドネットワークサーバーアプリケーションのパフォーマンスを向上することができます。アプリケーションがこれらのソケットオプションのいずれかを使用しない場合、すべてのスレッドは受信トラフィックを受信するために単一のソケットを共有するように強制されます。単一のソケットを使用すると、次のような問題が発生します。
- パケットドロップや CPU 使用率の上昇を引き起こす可能性のある受信バッファーでの重大な競合。
- CPU 使用率の大幅な増加
- パケットドロップの可能性

SO_REUSEPORT または SO_REUSEPORT_BPF ソケットオプションを使用すると、1 つのホスト上の複数のソケットを同じポートにバインドできます。
Red Hat Enterprise Linux では、カーネルソースで SO_REUSEPORT ソケットオプションを使用する方法のコードサンプルを提供します。コード例にアクセスするには、以下を実行します。
rhel-8-for-x86_64-baseos-debug-rpmsリポジトリーを有効にします。# subscription-manager repos --enable rhel-8-for-x86_64-baseos-debug-rpmskernel-debuginfo-common-x86_64パッケージをインストールします。# yum install kernel-debuginfo-common-x86_64-
コード例は
/usr/src/debug/kernel-<version>/linux-<version>/tools/testing/selftests/net/reuseport_bpf_cpu.cファイルで利用できるようになりました。
関連情報
-
socket(7)man ページ -
/usr/src/debug/kernel-<version>/linux-<version>/tools/testing/selftests/net/reuseport_bpf_cpu.c
34.9.2. TX キューのロック競合の回避: 送信パケットステアリング
複数のキューをサポートするネットワークインターフェイスコントローラー (NIC) を備えたホストでは、送信パケットステアリング (XPS) によって送信ネットワークパケットの処理が複数のキューに分散されます。これにより、複数の CPU が送信ネットワークトラフィックを処理できるようになり、送信キューのロック競合と、その結果として生じるパケットドロップを回避できます。
ixgbe、i40e、mlx5 などの特定のドライバーは、XPS を自動的に設定します。ドライバーがこの機能をサポートしているかどうかを確認するには、NIC ドライバーのドキュメントを参照してください。ドライバーがこの機能をサポートしているかどうかを確認するには、NIC ドライバーのドキュメントを参照してください。ドライバーが XPS 自動チューニングをサポートしていない場合は、CPU コアを送信キューに手動で割り当てることができます。
Red Hat Enterprise Linux には、送信キューを CPU コアに永続的に割り当てるオプションがありません。スクリプトでコマンドを使用し、システムの起動時に実行します。
前提条件
- NIC が複数のキューをサポートする。
-
numactlパッケージがインストールされている。
手順
使用可能なキューの数を表示します。
# ethtool -l enp1s0 Channel parameters for enp1s0: Pre-set maximums: RX: 0 TX: 0 Other: 0 Combined: 4 Current hardware settings: RX: 0 TX: 0 Other: 0 Combined: 1
Pre-set maximumsセクションにはキューの総数が表示され、Current hardware settingsには受信キュー、送信キュー、その他のキュー、または結合されたキューに現在割り当てられているキューの数が表示されます。オプション: 特定のチャネルにキューが必要な場合は、それに応じてキューを割り当てます。たとえば、4 つのキューを
Combinedチャネルに割り当てるには、次のように入力します。# ethtool -L enp1s0 combined 4NIC がどの Non-Uniform Memory Access (NUMA) ノードに割り当てられているかを表示します。
# cat /sys/class/net/enp1s0/device/numa_node 0ファイルが見つからない場合、またはコマンドが
-1を返す場合は、ホストは NUMA システムではありません。ホストが NUMA システムの場合は、どの CPU がどの NUMA ノードに割り当てられているかを表示します。
# lscpu | grep NUMA NUMA node(s): 2 NUMA node0 CPU(s): 0-3 NUMA node1 CPU(s): 4-7上の例では、NIC には 4 つのキューがあり、NIC は NUMA ノード 0 に割り当てられています。このノードは CPU コア 0 - 3 を使用します。したがって、各送信キューを 0 - 3 の CPU コアの 1 つにマッピングします。
# echo 1 > /sys/class/net/enp1s0/queues/tx-0/xps_cpus # echo 2 > /sys/class/net/enp1s0/queues/tx-1/xps_cpus # echo 4 > /sys/class/net/enp1s0/queues/tx-2/xps_cpus # echo 8 > /sys/class/net/enp1s0/queues/tx-3/xps_cpus
CPU コアと送信 (TX) キューの数が同じ場合は、1 対 1 マッピングを使用して、TX キューでのあらゆる種類の競合を回避します。そうしないと、複数の CPU を同じ TX キューにマップすると、異なる CPU での送信操作によって TX キューのロック競合が発生し、送信スループットに悪影響を及ぼします。
CPU のコア番号を含むビットマップをキューに渡す必要があることに注意してください。次のコマンドを使用してビットマップを計算します。
# printf %x $((1 << <core_number> ))
検証
トラフィックを送信するサービスのプロセス ID (PID) を特定します。
# pidof <process_name> 12345 98765
XPS を使用するコアに PID を固定します。
# numactl -C 0-3 12345 98765プロセスがトラフィックを送信している間、
requeuesカウンターを監視します。# tc -s qdisc qdisc fq_codel 0: dev enp10s0u1 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64 Sent 125728849 bytes 1067587 pkt (dropped 0, overlimits 0 requeues 30) backlog 0b 0p requeues 30 ...
requeuesカウンターが大幅な速度で増加しなくなると、TX キューロックの競合は発生しなくなります。
関連情報
-
/usr/share/doc/kernel-doc-_<version>/Documentation/networking/scaling.rst
34.9.3. UDP トラフィックが多いサーバーでの汎用受信オフロード機能の無効化
高速 UDP バルク転送を使用するアプリケーションは、UDP ソケットで UDP Generic Receive Offload (GRO) を有効にして使用する必要があります。ただし、次の条件が当てはまる場合は、GRO を無効にしてスループットを向上させることができます。
- アプリケーションは GRO をサポートしていないため、機能を追加できません。
TCP スループットは関係ありません。
警告GRO を無効にすると、TCP トラフィックの受信スループットが大幅に低下します。したがって、TCP パフォーマンスが関係するホストでは GRO を無効にしないでください。
前提条件
- ホストは主に UDP トラフィックを処理している。
- アプリケーションは GRO を使用していない。
- ホストは、VXLAN などの UDP トンネルプロトコルを使用していない。
- ホストは仮想マシン (VM) やコンテナーを実行していない。
手順
オプション: NetworkManager 接続プロファイルを表示します。
# nmcli connection show NAME UUID TYPE DEVICE example f2f33f29-bb5c-3a07-9069-be72eaec3ecf ethernet enp1s0
接続プロファイルで GRO サポートを無効にします。
# nmcli connection modify example ethtool.feature-gro off接続プロファイルを再度アクティベートします。
# nmcli connection up example
検証
GRO が無効になっていることを確認します。
# ethtool -k enp1s0 | grep generic-receive-offload generic-receive-offload: off- サーバー上のスループットを監視します。この設定がホスト上の他のアプリケーションにマイナスの影響を与える場合は、NetworkManager プロファイルで GRO を再度有効にします。