
Red Hat Training
A Red Hat training course is available for RHEL 8
さまざまな種類のサーバーのデプロイメント
Web サーバーとリバースプロキシー、ネットワークファイルサービス、データベースサーバー、メールトランスポートエージェント、およびプリンターのセットアップと設定
概要
多様性を受け入れるオープンソースの強化
Red Hat では、コード、ドキュメント、Web プロパティーにおける配慮に欠ける用語の置き換えに取り組んでいます。まずは、マスター (master)、スレーブ (slave)、ブラックリスト (blacklist)、ホワイトリスト (whitelist) の 4 つの用語の置き換えから始めます。この取り組みは膨大な作業を要するため、今後の複数のリリースで段階的に用語の置き換えを実施して参ります。詳細は、Red Hat CTO である Chris Wright のメッセージ をご覧ください。
Red Hat ドキュメントへのフィードバック (英語のみ)
Red Hat ドキュメントに関するご意見やご感想をお寄せください。また、改善点があればお知らせください。
Jira からのフィードバック送信 (アカウントが必要)
- Jira の Web サイトにログインします。
- 上部のナビゲーションバーで Create をクリックします。
- Summary フィールドにわかりやすいタイトルを入力します。
- Description フィールドに、ドキュメントの改善に関するご意見を記入してください。ドキュメントの該当部分へのリンクも追加してください。
- ダイアログの下部にある Create をクリックします。
第1章 Apache HTTP Web サーバーの設定
1.1. Apache HTTP Web サーバーの概要
Web サーバー は、Web 経由でクライアントにコンテンツを提供するネットワークサービスです。これは通常 Web ページを指しますが、他のドキュメントも当てはまります。Web サーバーは、ハイパーテキスト転送プロトコル (HTTP) を使用するため、HTTP サーバーとも呼ばれます。
Apache HTTP Server (httpd) は、Apache Software Foundation が開発したオープンソースの Web サーバーです。
Red Hat Enterprise Linux の以前のリリースからアップグレードする場合は、適切に httpd サービス設定を更新する必要があります。本セクションでは、新たに追加された機能の一部と、以前の設定ファイルの更新を説明します。
1.2. Apache HTTP Server への主な変更点
Apache HTTP Server が、RHEL 7 のバージョン 2.4.6 から、RHEL 8 のバージョン 2.4.37 に更新されました。この更新バージョンには新機能がいくつか含まれていますが、外部モジュールの設定および Application Binary Interface (ABI) のレベルでは、RHEL 7 バージョンとの後方互換性を維持します。
新機能は次のとおりです。
-
httpdモジュール含まれるmod_http2パッケージにより、HTTP/2に対応するようになりました。 -
systemd ソケットのアクティベーションが対応します。詳細は、man ページの
httpd.socket(8)を参照してください。
新しいモジュールが複数追加されています。
-
mod_proxy_hcheck- プロキシーのヘルスチェックモジュール -
mod_proxy_uwsgi- Web Server Gateway Interface (WSGI) プロキシー -
mod_proxy_fdpass- クライアントのソケットを別のプロセスに渡す -
mod_cache_socache- HTTP キャッシュ (例: memcache バックエンドを使用) -
mod_md- ACME プロトコルの SSL/TLS 証明書サービス
-
以下のモジュールはデフォルトで読み込まれるようになりました。
-
mod_request -
mod_macro -
mod_watchdog
-
-
新しいサブパッケージ
httpd-filesystemが追加されています。これには、Apache HTTP Server の基本的なディレクトリーレイアウト (ディレクトリーの適切な権限を含む) が含まれます。 -
インスタンス化されたサービスのサポート
httpd@.serviceが導入されました。詳細は、man ページのhttpd.serviceを参照してください。
-
新しい
httpd-init.serviceが%post scriptに置き換わり、自己署名の鍵ペアmod_sslを作成します。
-
(
Let's Encryptなどの証明書プロバイダーで使用するため) 自動証明書管理環境 (ACME) プロトコルを使用した、TLS 証明書の自動プロビジョニングおよび更新に、mod_mdパッケージで対応するようになりました。 -
Apache HTTP Server が、
PKCS#11モジュールを利用して、ハードウェアのセキュリティートークンから、TLS 証明書および秘密鍵を直接読み込むようになりました。これにより、mod_ssl設定で、PKCS#11URL を使用して、SSLCertificateKeyFileディレクティブおよびSSLCertificateFileディレクティブに、TLS 秘密鍵と、必要に応じて TLS 証明書をそれぞれ指定できるようになりました。 /etc/httpd/conf/httpd.confファイルの新しいListenFreeディレクティブに対応するようになりました。Listenディレクティブと同様、ListenFreeは、サーバーがリッスンする IP アドレス、ポート、または IP アドレスとポートの組み合わせに関する情報を提供します。ただし、ListenFreeを使用すると、IP_FREEBINDソケットオプションがデフォルトで有効になります。したがって、httpdは、ローカルではない IP アドレス、または今はまだ存在していない IP アドレスにバインドすることもできます。これにより、httpdがソケットをリッスンできるようになり、httpdがバインドしようとするときに、基になるネットワークインターフェイスまたは指定した動的 IP アドレスを起動する必要がなくなります。ListenFreeディレクティブは、現在 RHEL 8 でのみ利用できます。ListenFreeの詳細は、以下の表を参照してください。表1.1 ListenFree ディレクティブの構文、状態、およびモジュール
構文 状態 モジュール ListenFree [IP-address:]portnumber [protocol]
MPM
event、worker、prefork、mpm_winnt、mpm_netware、mpmt_os2
その他の主な変更点は次の通りです。
以下のモジュールが削除されました。
-
mod_file_cache mod_nss代わりに
mod_sslを使用します。mod_nssからの移行に関する詳細は、「Apache Web Server 設定で秘密鍵と証明書を使用できるように NSS データベースからの証明書のエクスポート」 を参照してください。-
mod_perl
-
-
RHEL 8 の Apache HTTP Server が使用するデフォルトの DBM 認証データベースのデフォルトタイプが、
SDBMからdb5に変更になりました。 -
Apache HTTP Server の
mod_wsgiモジュールが Python 3 に更新されました。WSGI アプリケーションは Python 3 でしか対応していないため、Python 2 から移行する必要があります。 Apache HTTP Server を使用してデフォルトで設定されたマルチプロセッシングモジュール (MPM) は、マルチプロセスのフォークモデル (
preforkとして知られています) から、高パフォーマンスのマルチスレッドモデルeventに変更しました。スレッドセーフではないサードパーティーのモジュールは、交換または削除する必要があります。設定した MPM を変更するには、
/etc/httpd/conf.modules.d/00-mpm.confファイルを編集します。詳細は、man ページのhttpd.service(8)を参照してください。- suEXEC によりユーザーに許可される最小 UID および GID はそれぞれ 1000 および 500 です (以前は 100 および 100 でした)。
-
/etc/sysconfig/httpdファイルは、httpdサービスへの環境変数の設定に対応するインターフェイスではなくなりました。systemd サービスに、httpd.service(8)の man ページが追加されています。 -
httpdサービスを停止すると、デフォルトで自動停止が使用されます。 -
mod_auth_kerbモジュールが、mod_auth_gssapiモジュールに置き換わりました。
1.3. 設定の更新
Red Hat Enterprise Linux 7 で使用されている Apache HTTP Server バージョンから設定ファイルを更新するには、以下のいずれかのオプションを選択します。
-
/etc/sysconfig/httpdを使用して環境変数を設定する場合は、代わりに systemd ドロップインファイルを作成します。 - サードパーティーのモジュールを使用する場合は、そのモジュールがスレッド化 MPM と互換性があることを確認してください。
- suexec を使用する場合は、ユーザーおよびグループの ID が新しい最小値に合致していることを確認します。
以下のコマンドを使用すると、設定に誤りがないかどうかを確認できます。
# apachectl configtest
Syntax OK1.4. Apache 設定ファイル
デフォルトでは、httpd は起動後に設定ファイルを読み取ります。次の表に、設定ファイルの場所のリストを示します。
表1.2 httpd サービスの設定ファイル
| パス | 詳細 |
|---|---|
|
| 主要設定ファイル。 |
|
| 主要設定ファイル内に含まれている設定ファイル用の補助ディレクトリー。 |
|
| Red Hat Enterprise Linux にパッケージ化されたインストール済みの動的モジュールを読み込む設定ファイルの補助ディレクトリー。デフォルト設定では、この設定ファイルが最初に処理されます。 |
デフォルト設定はほとんどの状況に適していますが、その他の設定オプションを使用することもできます。変更を有効にするには、まず Web サーバーを再起動します。
設定に誤りがないことを確認するには、シェルプロンプトで以下のコマンドを実行します。
# apachectl configtest
Syntax OK間違いからの復元を容易にするため、編集する前にオリジナルファイルのコピーを作成します。
1.5. httpd サービスの管理
本セクションでは、httpd サービスを起動、停止、および再起動する方法を説明します。
前提条件
- Apache HTTP Server がインストールされている。
手順
httpdサービスを起動するには、以下を入力します。# systemctl start httpdhttpdサービスを停止するには、以下を入力します。# systemctl stop httpdhttpdサービスを再起動するには、以下を入力します。# systemctl restart httpd
1.6. シングルインスタンスの Apache HTTP Server 設定
シングルインスタンスの Apache HTTP Server を設定して、静的 HTML コンテンツを提供できます。
Web サーバーに関連付けられた全ドメインにサーバーから同じコンテンツを提供する必要がある場合は、この手順に従います。異なるドメインに異なるコンテンツを提供する場合は、名前ベースの仮想ホストを設定します。詳細は Apache 名ベースの仮想ホストの設定 を参照してください。
手順
httpdパッケージをインストールします。# yum install httpdfirewalldを使用する場合は、ローカルのファイアウォールで TCP ポート80を開きます。# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
httpdサービスを有効にして起動します。# systemctl enable --now httpd必要に応じて、HTML ファイルを
/var/www/html/ディレクトリーに追加します。注記/var/www/html/にコンテンツを追加する場合には、httpdを実行するユーザーが、デフォルトでファイルとディレクトリーを読み取れるようにする必要があります。コンテンツの所有者は、rootユーザーおよびrootユーザーグループ、または管理者別のユーザーまたはグループのいずれかになります。コンテンツの所有者がrootユーザーおよびrootユーザーグループの場合には、他のユーザーがファイルを読み取れるようにする必要があります。すべてのファイルとディレクトリーの SELinux コンテキストはhttpd_sys_content_tである必要があります。これはデフォルトで/var/wwwディレクトリー内の全コンテンツに適用されます。
検証手順
Web ブラウザーで
http://server_IP_or_host_name/に接続します。/var/www/html/ディレクトリーが空であるか、index.htmlまたはindex.htmファイルが含まれていない場合は、Apache がRed Hat Enterprise Linux Test Pageを表示します。/var/www/html/に異なる名前の HTML ファイルが含まれる場合は、http://server_IP_or_host_name/example.htmlなど、そのファイル名に URL を指定して読み込むことができます。
関連情報
- Apache マニュアル: Apache HTTP サーバーマニュアルのインストール
-
httpd.service(8)man ページを参照してください。
1.7. Apache 名前ベースの仮想ホストの設定
名前ベースの仮想ホストを使用すると、Apache は、サーバーの IP アドレスに解決されるドメイン別に異なるコンテンツを提供できます。
別々のドキュメントルートディレクトリーを使用して、example.com ドメインと example.net ドメインの両方に仮想ホストを設定できます。どちらの仮想ホストも静的 HTML コンテンツを提供します。
前提条件
クライアントおよび Web サーバーは、
example.comおよびexample.netドメインを Web サーバーの IP アドレスに解決します。これらのエントリーは DNS サーバーに手動で追加する必要がある点に注意してください。
手順
httpdパッケージをインストールします。# yum install httpd/etc/httpd/conf/httpd.confファイルを編集します。example.comドメイン向けに以下の仮想ホスト設定を追加します。<VirtualHost *:80> DocumentRoot "/var/www/example.com/" ServerName example.com CustomLog /var/log/httpd/example.com_access.log combined ErrorLog /var/log/httpd/example.com_error.log </VirtualHost>これらの設定は以下を設定します。
-
<VirtualHost *:80>ディレクティブの全設定は、この仮想ホストに固有のものです。 -
DocumentRootは、仮想ホストの Web コンテンツへのパスを設定します。 ServerNameは、この仮想ホストがコンテンツを提供するドメインを設定します。複数のドメインを設定するには、
ServerAliasパラメーターを設定に追加し、追加のドメインをスペース区切りで、このパラメーターに指定します。-
CustomLogは、仮想ホストのアクセスログへのパスを設定します。 ErrorLogは、仮想ホストのエラーログへのパスを設定します。注記Apache は、
ServerNameおよびServerAliasパラメーターに設定したドメインどれにも一致しない要求の場合でも、設定で最初に検出された仮想マシンを使用します。これには、サーバーの IP アドレス対してに送信される要求も含まれます。
-
example.netドメイン向けに同様の仮想ホスト設定を追加します。<VirtualHost *:80> DocumentRoot "/var/www/example.net/" ServerName example.net CustomLog /var/log/httpd/example.net_access.log combined ErrorLog /var/log/httpd/example.net_error.log </VirtualHost>両方の仮想ホストのドキュメントルートを作成します。
# mkdir /var/www/example.com/ # mkdir /var/www/example.net/
DocumentRootパラメーターのパスが/var/www/内にない設定を行う場合は、両方のドキュメントルートにhttpd_sys_content_tコンテキストを設定します。# semanage fcontext -a -t httpd_sys_content_t "/srv/example.com(/.*)?" # restorecon -Rv /srv/example.com/ # semanage fcontext -a -t httpd_sys_content_t "/srv/example.net(/.\*)?" # restorecon -Rv /srv/example.net/
以下のコマンドは、
/srv/example.com/および/srv/example.net/ディレクトリーにhttpd_sys_content_tコンテキストを設定します。policycoreutils-python-utilsパッケージをインストールしてrestoreconコマンドを実行する必要があります。firewalldを使用する場合は、ローカルのファイアウォールでポート80を開きます。# firewall-cmd --permanent --add-port=80/tcp # firewall-cmd --reload
httpdサービスを有効にして起動します。# systemctl enable --now httpd
検証手順
仮想ホストのドキュメントルートごとに異なるサンプルファイルを作成します。
# echo "vHost example.com" > /var/www/example.com/index.html # echo "vHost example.net" > /var/www/example.net/index.html
-
ブラウザーを使用して
http://example.comに接続します。Web サーバーは、example.com仮想ホストからのサンプルファイルを表示します。 -
ブラウザーを使用して
http://example.netに接続します。Web サーバーは、example.net仮想ホストからのサンプルファイルを表示します。
1.8. Apache HTTP Web サーバーの Kerberos 認証の設定
Apache HTTP Web サーバーで Kerberos 認証を実行するために、RHEL 8 は mod_auth_gssapi Apache モジュールを使用します。Generic Security Services API (GSSAPI) は、Kerberos などのセキュリティーライブラリーを使用する要求を行うアプリケーションのインターフェイスです。gssproxy サービスでは、httpd サーバーに特権の分離を実装できます。これにより、セキュリティーの観点からこのプロセスが最適化されます。
削除した mod_auth_kerb モジュールは、mod_auth_gssapi モジュールに置き換わります。
前提条件
-
httpdパッケージおよびgssproxyパッケージがインストールされている。 -
Apache Web サーバーが設定され、
httpdサービスが実行している。
1.8.1. IdM 環境で GSS-Proxy の設定
この手順では、Apache HTTP Web サーバーで Kerberos 認証を実行するように GSS-Proxy を設定する方法を説明します。
手順
サービスプリンシパルを作成し、HTTP/<SERVER_NAME>@realm プリンシパルの
keytabファイルへのアクセスを有効にします。# ipa service-add HTTP/<SERVER_NAME>/etc/gssproxy/http.keytabファイルに保存されているプリンシパルのkeytabを取得します。# ipa-getkeytab -s $(awk '/^server =/ {print $3}' /etc/ipa/default.conf) -k /etc/gssproxy/http.keytab -p HTTP/$(hostname -f)このステップでは、パーミッションを 400 に設定すると、
rootユーザーのみがkeytabファイルにアクセスできます。apacheユーザーは異なります。以下の内容で
/etc/gssproxy/80-httpd.confファイルを作成します。[service/HTTP] mechs = krb5 cred_store = keytab:/etc/gssproxy/http.keytab cred_store = ccache:/var/lib/gssproxy/clients/krb5cc_%U euid = apache
gssproxyサービスを再起動して、有効にします。# systemctl restart gssproxy.service # systemctl enable gssproxy.service
関連情報
-
gssproxy(8)の man ページ -
gssproxy-mech(8)の man ページ -
gssproxy.conf(5)の man ページ
1.9. Apache HTTP サーバーで TLS 暗号化の設定
デフォルトでは、Apache は暗号化されていない HTTP 接続を使用してクライアントにコンテンツを提供します。本セクションでは、TLS 暗号化を有効にし、Apache HTTP Server で頻繁に使用される暗号化関連の設定を行う方法を説明します。
前提条件
- Apache HTTP Server がインストールされ、実行している。
1.9.1. Apache HTTP Server への TLS 暗号化の追加
example.com ドメインの Apache HTTP サーバーで TLS 暗号化を有効にすることができます。
前提条件
- Apache HTTP Server がインストールされ、実行している。
秘密鍵が
/etc/pki/tls/private/example.com.keyファイルに保存されている。秘密鍵および証明書署名要求 (CSR) を作成する方法と、認証局 (CA) からの証明書を要求する方法は、CA のドキュメントを参照してください。または、お使いの CA が ACME プロトコルに対応している場合は、
mod_mdモジュールを使用して、TLS 証明書の取得およびプロビジョニングを自動化できます。-
TLS 証明書は
/etc/pki/tls/certs/example.com.crtファイルに保存されます。別のパスを使用する場合は、この手順で対応する手順を調整します。 -
認証局証明書は
/etc/pki/tls/certs/ca.crtに保存されています。別のパスを使用する場合は、この手順で対応する手順を調整します。 - クライアントおよび Web サーバーは、サーバーのホスト名を Web サーバーの IP アドレスに対して解決します。
手順
mod_sslパッケージをインストールします。# yum install mod_ssl/etc/httpd/conf.d/ssl.confファイルを編集し、以下の設定を<VirtualHost _default_:443>ディレクティブに追加します。サーバー名を設定します。
ServerName example.com
重要サーバー名は、証明書の
Common Nameフィールドに設定されているエントリーと一致している必要があります。必要に応じて、証明書の
Subject Alt Names(SAN) フィールドに追加のホスト名が含まれる場合に、これらのホスト名にも TLS 暗号化を提供するようにmod_sslを設定できます。これを設定するには、ServerAliasesパラメーターと対応する名前を追加します。ServerAlias www.example.com server.example.com秘密鍵、サーバー証明書、および CA 証明書へのパスを設定します。
SSLCertificateKeyFile "/etc/pki/tls/private/example.com.key" SSLCertificateFile "/etc/pki/tls/certs/example.com.crt" SSLCACertificateFile "/etc/pki/tls/certs/ca.crt"
セキュリティー上の理由から、
rootユーザーのみが秘密鍵ファイルにアクセスできるように設定します。# chown root:root /etc/pki/tls/private/example.com.key # chmod 600 /etc/pki/tls/private/example.com.key
警告秘密鍵に権限のないユーザーがアクセスした場合は、証明書を取り消し、新しい秘密鍵を作成し、新しい証明書を要求します。そうでない場合は、TLS 接続が安全ではなくなります。
firewalldを使用する場合は、ローカルのファイアウォールでポート443を開きます。# firewall-cmd --permanent --add-port=443/tcp # firewall-cmd --reload
httpdサービスを再起動します。# systemctl restart httpd注記パスワードで秘密鍵ファイルを保護した場合は、
httpdサービスの起動時に毎回このパスワードを入力する必要があります。
検証手順
-
ブラウザーを使用して、
https://example.comに接続します。
1.9.2. Apache HTTP サーバーでサポートされる TLS プロトコルバージョンの設定
デフォルトでは、RHEL の Apache HTTP Server は、最新のブラウザーにも互換性のある安全なデフォルト値を定義するシステム全体の暗号化ポリシーを使用します。たとえば、DEFAULT ポリシーでは、TLSv1.2 および TLSv1.3 プロトコルバージョンのみが Apache で有効になるように定義します。
Apache HTTP Server がサポートする TLS プロトコルのバージョンを手動で設定できます。たとえば、環境が特定の TLS プロトコルバージョンのみを有効にする必要がある場合には、以下の手順に従います。
-
お使いの環境のクライアントで、セキュリティーの低い
TLS1(TLSv1.0) プロトコルまたはTLS1.1プロトコルも使用できるようにする必要がある場合。 -
Apache が
TLSv1.2プロトコルまたはTLSv1.3プロトコルのみに対応するように設定する場合。
前提条件
- Apache HTTP Server への TLS 暗号化の追加 で説明されているとおり、TLS 暗号化がサーバーで有効になります。
手順
/etc/httpd/conf/httpd.confファイルを編集し、TLS プロトコルバージョンを設定する<VirtualHost>ディレクティブに以下の設定を追加します。たとえば、TLSv1.3プロトコルのみを有効にするには、以下を実行します。SSLProtocol -All TLSv1.3httpdサービスを再起動します。# systemctl restart httpd
検証手順
以下のコマンドを使用して、サーバーが
TLSv1.3に対応していることを確認します。# openssl s_client -connect example.com:443 -tls1_3以下のコマンドを使用して、サーバーが
TLSv1.2に対応していないことを確認します。# openssl s_client -connect example.com:443 -tls1_2サーバーがプロトコルに対応していない場合には、このコマンドは以下のエラーを返します。
140111600609088:error:1409442E:SSL routines:ssl3_read_bytes:tlsv1 alert protocol version:ssl/record/rec_layer_s3.c:1543:SSL alert number 70
- 必要に応じて、他の TLS プロトコルバージョンのコマンドを繰り返し実行します。
関連情報
-
update-crypto-policies(8)の man ページ - Using system-wide cryptographic policies.
-
SSLProtocolパラメーターの詳細については、Apache マニュアルのmod_sslのドキュメント Apache HTTP サーバーマニュアルのインストール を参照してください。
1.9.3. Apache HTTP サーバーで対応している暗号の設定
デフォルトでは、Apache HTTP サーバーは、安全なデフォルト値を定義するシステム全体の暗号化ポリシーを使用します。これは、最近のブラウザーとも互換性があります。システム全体の暗号化で使用可能な暗号化のリストは、/etc/crypto-policies/back-ends/openssl.config ファイルを参照してください。
Apache HTTP Server がサポートする暗号を手動で設定できます。お使いの環境で特定の暗号が必要な場合は、以下の手順に従います。
前提条件
- Apache HTTP Server への TLS 暗号化の追加 で説明されているとおり、TLS 暗号化がサーバーで有効になります。
手順
/etc/httpd/conf/httpd.confファイルを編集し、TLS 暗号を設定する<VirtualHost>ディレクティブにSSLCipherSuiteパラメーターを追加します。SSLCipherSuite "EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH:!SHA1:!SHA256"この例では、
EECDH+AESGCM、EDH+AESGCM、AES256+EECDH、およびAES256+EDH暗号のみを有効にし、SHA1およびSHA256メッセージ認証コード (MAC) を使用するすべての暗号を無効にします。httpdサービスを再起動します。# systemctl restart httpd
検証手順
Apache HTTP Server が対応する暗号化のリストを表示するには、以下を行います。
nmapパッケージをインストールします。# yum install nmapnmapユーティリティーを使用して、対応している暗号を表示します。# nmap --script ssl-enum-ciphers -p 443 example.com ... PORT STATE SERVICE 443/tcp open https | ssl-enum-ciphers: | TLSv1.2: | ciphers: | TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384 (ecdh_x25519) - A | TLS_DHE_RSA_WITH_AES_256_GCM_SHA384 (dh 2048) - A | TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256 (ecdh_x25519) - A ...
関連情報
-
update-crypto-policies(8)の man ページ - Using system-wide cryptographic policies.
- SSLCipherSuite
1.10. TLS クライアント証明書認証の設定
クライアント証明書認証を使用すると、管理者は、証明書で認証したユーザーのみが Web サーバーのリソースにアクセスできるようにすることが可能です。/var/www/html/Example/ ディレクトリーにクライアント証明書認証を設定できます。
Apache HTTP Server が TLS 1.3 プロトコルを使用する場合、特定のクライアントには追加の設定が必要です。たとえば、Firefox で、about:config メニューの security.tls.enable_post_handshake_auth パラメーターを true に設定します。詳細は、Transport Layer Security version 1.3 in Red Hat Enterprise Linux 8 を参照してください。
前提条件
- Apache HTTP Server への TLS 暗号化の追加 で説明されているとおり、TLS 暗号化がサーバーで有効になります。
手順
/etc/httpd/conf/httpd.confファイルを編集し、以下の設定をクライアント認証を設定する<VirtualHost>ディレクティブに追加します。<Directory "/var/www/html/Example/"> SSLVerifyClient require </Directory>
SSLVerifyClient requireの設定では、/var/www/html/Example/ディレクトリーのコンテンツにクライアントがアクセスする前に、サーバーがクライアント証明書を正常に検証する必要があることを定義します。httpdサービスを再起動します。# systemctl restart httpd
検証手順
curlユーティリティーを使用して、クライアント認証なしでhttps://example.com/Example/URL にアクセスします。$ curl https://example.com/Example/ curl: (56) OpenSSL SSL_read: error:1409445C:SSL routines:ssl3_read_bytes:tlsv13 alert certificate required, errno 0このエラーは、Web サーバーにクライアント証明書認証が必要であることを示しています。
クライアントの秘密鍵と証明書、および CA 証明書を
curlに指定して、クライアント認証で同じ URL にアクセスします。$ curl --cacert ca.crt --key client.key --cert client.crt https://example.com/Example/要求に成功すると、
curlは/var/www/html/Example/ディレクトリーに保存されているindex.htmlファイルを表示します。
関連情報
1.11. ModSecurity を使用した Web サーバー上の Web アプリケーションの保護
ModSecurity は、Apache、Nginx、IIS などのさまざまな Web サーバーでサポートされているオープンソースの Web アプリケーションファイアウォール (WAF) であり、Web アプリケーションのセキュリティーリスクを軽減します。ModSecurity は、サーバーを設定するためのカスタマイズ可能なルールセットを提供します。
mod_security-crs パッケージには、クロス Web サイトスクリプティング、不正なユーザーエージェント、SQL インジェクション、トロイの木馬、セッションハイジャック、およびその他の不正使用に対するルールを含むコアルールセット (CRS) が含まれています。
1.11.1. Apache 用 ModSecurity Web ベースアプリケーションファイアウォールのデプロイ
ModSecurity をデプロイして、Web サーバー上で Web ベースアプリケーションの実行に関連するリスクを軽減するには、Apache HTTP サーバー用の mod_security および mod_security_crs パッケージをインストールします。mod_security_crs パッケージは、ModSecurity Web ベースのアプリケーションファイアウォール (WAF) モジュールのコアルールセット (CRS) を提供します。
手順
mod_security、mod_security_crs、およびhttpdパッケージをインストールします。# yum install -y mod_security mod_security_crs httpdhttpdサーバーを起動します。# systemctl restart httpd
検証
ModSecurity Web ベースアプリケーションファイアウォールが Apache HTTPサーバーで有効になっていることを確認します。
# httpd -M | grep security security2_module (shared)/etc/httpd/modsecurity.d/activated_rules/ディレクトリーにmod_security_crsによって提供されるルールが含まれていることを確認します。# ls /etc/httpd/modsecurity.d/activated_rules/ ... REQUEST-921-PROTOCOL-ATTACK.conf REQUEST-930-APPLICATION-ATTACK-LFI.conf ...
1.11.2. ModSecurity へのカスタムルールの追加
ModSecurity コアルールセット (CRS) に含まれるルールがシナリオに適合せず、追加の攻撃の可能性を防ぎたい場合は、カスタムルールを ModSecurity Web ベースアプリケーションファイアウォールで使用されるルールセットに追加できます。次の例は、単純なルールの追加を示しています。より複雑なルールを作成するには、ModSecurity Wiki Web サイトのリファレンスマニュアルを参照してください。
前提条件
- ModSecurity for Apache がインストールされ、有効になっている。
手順
任意のテキストエディターで
/etc/httpd/conf.d/mod_security.confファイルを開きます。以下はその例です。# vi /etc/httpd/conf.d/mod_security.confSecRuleEngine Onで始まる行の後に、次のサンプルルールを追加します。SecRule ARGS:data "@contains evil" "deny,status:403,msg:'param data contains evil data',id:1"
前のルールでは、
dataパラメーターにevilの文字列が含まれている場合、ユーザーによるリソースの使用を禁止しています。- 変更を保存し、エディターを終了します。
httpdサーバーを再起動します。# systemctl restart httpd
検証
test.htmlページを作成します。# echo "mod_security test" > /var/www/html/test.htmlhttpdサーバーを再起動します。# systemctl restart httpdHTTP リクエストの
GET変数に悪意のあるデータが含まれないtest.htmlをリクエストします。$ curl http://localhost/test.html?data=good mod_security testHTTP リクエストの
GET変数に悪意のあるデータが含まれるtest.htmlをリクエストします。$ curl localhost/test.html?data=xxxevilxxx <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <html><head> <title>403 Forbidden</title> </head><body> <h1>Forbidden</h1> <p>You do not have permission to access this resource.</p> </body></html>/var/log/httpd/error_logファイルを確認し、param data containing an evil dataメッセージでアクセスを拒否するログエントリーを見つけます。[Wed May 25 08:01:31.036297 2022] [:error] [pid 5839:tid 139874434791168] [client ::1:45658] [client ::1] ModSecurity: Access denied with code 403 (phase 2). String match "evil" at ARGS:data. [file "/etc/httpd/conf.d/mod_security.conf"] [line "4"] [id "1"] [msg "param data contains evil data"] [hostname "localhost"] [uri "/test.html"] [unique_id "Yo4amwIdsBG3yZqSzh2GuwAAAIY"]
関連情報
1.12. Apache HTTP Server のマニュアルのインストール
Apache HTTP Server のマニュアルをインストールできます。このマニュアルには、以下のような詳細なドキュメントが含まれます。
- 設定パラメーターおよびディレクティブ
- パフォーマンスチューニング
- 認証設定
- モジュール
- コンテンツのキャッシュ
- セキュリティーに関するヒント
- TLS 暗号化の設定
マニュアルをインストールした後は、Web ブラウザーを使用して表示できます。
前提条件
- Apache HTTP Server がインストールされ、実行している。
手順
httpd-manualパッケージをインストールします。# yum install httpd-manual必要に応じて、デフォルトでは、Apache HTTP Server に接続するすべてのクライアントはマニュアルを表示できます。
192.0.2.0/24サブネットなど、特定の IP 範囲へのアクセスを制限するには、/etc/httpd/conf.d/manual.confファイルを編集し、Require ip 192.0.2.0/24設定を<Directory "/usr/share/httpd/manual">ディレクティブに追加します。<Directory "/usr/share/httpd/manual"> ... Require ip 192.0.2.0/24 ... </Directory>httpdサービスを再起動します。# systemctl restart httpd
検証手順
-
Apache HTTP Server のマニュアルを表示するには、Web ブラウザーで
http://host_name_or_IP_address/manual/に接続します。
1.13. Apache モジュールの操作
httpd サービスはモジュラーアプリケーションであり、多数の 動的共有オブジェクト (DSO) で拡張できます。動的共有オブジェクト は、必要に応じて実行時に動的にロードまたはアンロードできるモジュールです。これらのモジュールは /usr/lib64/httpd/modules/ ディレクトリーにあります。
1.13.1. DSO モジュールのロード
管理者は、サーバーがロードするモジュールを設定することにより、サーバーに含める機能を選択できます。特定の DSO モジュールを読み込むには、LoadModule ディレクティブを使用します。別のパッケージが提供するモジュールは、多くの場合、/etc/httpd/conf.modules.d/ ディレクトリーに独自の設定ファイルがあることに注意してください。
前提条件
-
httpdパッケージをインストールしている。
手順
/etc/httpd/conf.modules.d/ディレクトリーの設定ファイルでモジュール名を検索します。# grep mod_ssl.so /etc/httpd/conf.modules.d/*モジュール名が見つかった設定ファイルを編集し、モジュールの
LoadModuleディレクティブをコメント解除します。LoadModule ssl_module modules/mod_ssl.soRHEL パッケージがモジュールを提供していないなどの理由でモジュールが見つからなかった場合は、次のディレクティブを使用して
/etc/httpd/conf.modules.d/30-example.confなどの設定ファイルを作成します。LoadModule ssl_module modules/<custom_module>.sohttpdサービスを再起動します。# systemctl restart httpd
1.13.2. カスタム Apache モジュールのコンパイル
独自のモジュールを作成し、モジュールのコンパイルに必要なインクルードファイル、ヘッダーファイル、および APache eXtenSion (apxs) ユーティリティーを含む httpd-devel パッケージを使用してビルドできます。
前提条件
-
httpd-develパッケージがインストールされている。
手順
次のコマンドでカスタムモジュールをビルドします。
# apxs -i -a -c module_name.c
検証手順
- DSO モジュールのロード で説明されている方法でモジュールをロードします。
1.14. Apache Web Server 設定で秘密鍵と証明書を使用できるように NSS データベースからの証明書のエクスポート
RHEL 8 では Apache Web Server に mod_nss モジュールが提供されなくなります。Red Hat は mod_ssl モジュールの使用を推奨します。たとえば、RHEL 7 から RHEL 8 へ Web サーバーを移行したなどして、秘密鍵と証明書を Network Security Services (NSS) データベースに保存する場合は、以下の手順に従って、Privacy Enhanced Mail (PEM) 形式の鍵および証明書を抽出します。次に Apache HTTP サーバーでの TLS 暗号化の設定 で説明されているとおり、mod_ssl 設定でファイルを使用できます。
この手順では、NSS データベースが /etc/httpd/alias/ に保存され、エクスポートした秘密鍵と証明書を /etc/pki/tls/ ディレクトリーに保存することを前提としています。
前提条件
- 秘密鍵、証明書、および認証局 (CA) の証明書は NSS データベースに保存されます。
手順
NSS データベースの証明書をリスト表示します。
# certutil -d /etc/httpd/alias/ -L Certificate Nickname Trust Attributes SSL,S/MIME,JAR/XPI Example CA C,, Example Server Certificate u,u,u
次の手順では、証明書のニックネームが必要です。
秘密鍵を抽出するには、鍵を PKCS #12 ファイルに一時的にエクスポートする必要があります。
秘密鍵に関連付けられた証明書のニックネームを使用して、鍵を PKCS #12 ファイルにエクスポートします。
# pk12util -o /etc/pki/tls/private/export.p12 -d /etc/httpd/alias/ -n "Example Server Certificate" Enter password for PKCS12 file: password Re-enter password: password pk12util: PKCS12 EXPORT SUCCESSFUL
PKCS #12 ファイルにパスワードを設定する必要があります。次の手順では、このパスワードが必要です。
PKCS #12 ファイルから秘密鍵をエクスポートします。
# openssl pkcs12 -in /etc/pki/tls/private/export.p12 -out /etc/pki/tls/private/server.key -nocerts -nodes Enter Import Password: password MAC verified OK
PKCS #12 の一時ファイルを削除します。
# rm /etc/pki/tls/private/export.p12
/etc/pki/tls/private/server.keyにパーミッションを設定し、rootユーザーのみがこのファイルにアクセスできるようにします。# chown root:root /etc/pki/tls/private/server.key # chmod 0600 /etc/pki/tls/private/server.key
NSS データベースのサーバー証明書のニックネームを使用して CA 証明書をエクスポートします。
# certutil -d /etc/httpd/alias/ -L -n "Example Server Certificate" -a -o /etc/pki/tls/certs/server.crt/etc/pki/tls/certs/server.crtにパーミッションを設定し、rootユーザーのみがこのファイルにアクセスできるようにします。# chown root:root /etc/pki/tls/certs/server.crt # chmod 0600 /etc/pki/tls/certs/server.crt
NSS データベースの CA 証明書のニックネームを使用して、CA 証明書をエクスポートします。
#certutil -d /etc/httpd/alias/ -L -n "Example CA" -a -o /etc/pki/tls/certs/ca.crtApache HTTP サーバーでの TLS 暗号化の設定 に従い、Apache Web サーバーを設定します。
-
SSLCertificateKeyFileパラメーターを/etc/pki/tls/private/server.keyに設定します。 -
SSLCertificateFileパラメーターを/etc/pki/tls/certs/server.crtに設定します。 -
SSLCACertificateFileパラメーターを/etc/pki/tls/certs/ca.crtに設定します。
-
関連情報
-
certutil(1)man ページ -
pk12util(1)の man ページ -
pkcs12(1ssl)の man ページ
1.15. 関連情報
-
httpd(8) -
httpd.service(8) -
httpd.conf(5) -
apachectl(8) - GSS-Proxy を使用した Apache httpd の操作。
- PKCS #11 で暗号化ハードウェアを使用するようにアプリケーションを設定
第2章 NGINX の設定および設定
NGINX は、次のように使用できる高パフォーマンスなモジュラーサーバーです。
- Web サーバー
- リバースプロキシー
- ロードバランサー
本セクションでは、このシナリオで NGINX を行う方法を説明します。
2.1. NGINX のインストールおよび準備
Red Hat は、アプリケーションストリームを使用して NGINX の異なるバージョンを提供します。以下を実行できます。
- ストリームを選択し、NGINX をインストールします。
- ファイアウォールで必要なポートを開きます。
-
nginxサービスの有効化および開始
デフォルト設定を使用すると、NGINX はポート 80 の Web サーバーとして実行され、/usr/share/nginx/html/ ディレクトリーからコンテンツを提供します。
前提条件
- RHEL 8 がインストールされている。
- ホストが Red Hat カスタマーポータルにサブスクライブしている。
-
firewalldサービスが有効化され、開始されている。
手順
利用可能な NGINX モジュールストリームを表示します。
# yum module list nginx Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary nginx 1.14 [d] common [d] nginx webserver nginx 1.16 common [d] nginx webserver ... Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalledデフォルト以外のストリームをインストールする場合は、そのストリームを選択します。
# yum module enable nginx:stream_versionnginxパッケージをインストールします。# yum install nginxNGINX がファイアウォールでサービスを提供するポートを開きます。たとえば、
firewalldで HTTP (ポート 80) および HTTPS (ポート 443) のデフォルトポートを開くには、次のコマンドを実行します。# firewall-cmd --permanent --add-port={80/tcp,443/tcp} # firewall-cmd --reload
nginxサービスがシステムの起動時に自動的に起動するようにします。# systemctl enable nginx必要に応じて、
nginxサービスを起動します。# systemctl start nginxデフォルト設定を使用しない場合は、この手順を省略し、サービスを起動する前に NGINX を適切に設定します。
検証手順
yumユーティリティーを使用して、nginxパッケージがインストールされていることを確認します。# yum list installed nginx Installed Packages nginx.x86_64 1:1.14.1-9.module+el8.0.0+4108+af250afe @rhel-8-for-x86_64-appstream-rpmsNGINX がサービスを提供するポートが firewalld で開いていることを確認します。
# firewall-cmd --list-ports 80/tcp 443/tcpnginxサービスが有効になっていることを確認します。# systemctl is-enabled nginx enabled
関連情報
- Subscription Manager の詳細は、Subscription Manager の使用および設定 ガイドを参照してください。
- アプリケーションストリーム、モジュール、およびインストールパッケージの詳細は、ユーザー空間コンポーネントのインストール、管理、および削除 を参照してください。
- ファイアウォールの設定に関する詳細は、ネットワークのセキュリティー保護 を参照してください。
2.2. ドメインごとに異なるコンテンツを提供する Web サーバーとしての NGINX の設定
デフォルトでは、NGINX は Web サーバーとして機能し、サーバーの IP アドレスに関連付けられた全ドメイン名のクライアントに、同じコンテンツを提供します。この手順では、NGINX を設定する方法を説明します。
-
/var/www/example.com/ディレクトリーのコンテンツで、example.comドメインに対するリクエストに対応する。 -
/var/www/example.net/ディレクトリーのコンテンツで、example.netドメインに対するリクエストに対応する。 -
その他の全リクエスト (たとえば、サーバーの IP アドレスまたはサーバーの IP アドレスに関連付けられたその他のドメイン) に
/usr/share/nginx/html/ディレクトリーのコンテンツを指定します。
前提条件
- NGINX がインストールされている
クライアントおよび Web サーバーは、
example.comおよびexample.netドメインを Web サーバーの IP アドレスに解決します。これらのエントリーは DNS サーバーに手動で追加する必要がある点に注意してください。
手順
/etc/nginx/nginx.confファイルを編集します。デフォルトでは、
/etc/nginx/nginx.confファイルには catch-all 設定がすでに含まれています。設定からこの部分を削除した場合は、以下のserverブロックを/etc/nginx/nginx.confファイルのhttpブロックに追加し直します。server { listen 80 default_server; listen [::]:80 default_server; server_name _; root /usr/share/nginx/html; }これらの設定は以下を設定します。
-
listenディレクティブは、サービスがリッスンする IP アドレスとポートを定義します。この場合、NGINX は IPv4 と IPv6 の両方のアドレスのポート80でリッスンします。default_serverパラメーターは、NGINX がこのserverブロックを IP アドレスとポートに一致するリクエストのデフォルトとして使用していることを示します。 -
server_nameパラメーターは、このserverブロックに対応するホスト名を定義します。server_nameを_に設定すると、このserverブロックのホスト名を受け入れるように NGINX を設定します。 -
rootディレクティブは、このserverブロックの Web コンテンツへのパスを設定します。
-
example.comドメインの同様のserverブロックをhttpブロックに追加します。server { server_name example.com; root /var/www/example.com/; access_log /var/log/nginx/example.com/access.log; error_log /var/log/nginx/example.com/error.log; }-
access_logディレクティブは、このドメインに別のアクセスログファイルを定義します。 -
error_logディレクティブは、このドメインに別のエラーログファイルを定義します。
-
example.netドメインの同様のserverブロックをhttpブロックに追加します。server { server_name example.net; root /var/www/example.net/; access_log /var/log/nginx/example.net/access.log; error_log /var/log/nginx/example.net/error.log; }
両方のドメインのルートディレクトリーを作成します。
# mkdir -p /var/www/example.com/ # mkdir -p /var/www/example.net/
両方のルートディレクトリーに
httpd_sys_content_tコンテキストを設定します。# semanage fcontext -a -t httpd_sys_content_t "/var/www/example.com(/.*)?" # restorecon -Rv /var/www/example.com/ # semanage fcontext -a -t httpd_sys_content_t "/var/www/example.net(/.\*)?" # restorecon -Rv /var/www/example.net/
これらのコマンドは、
/var/www/example.com/ディレクトリーおよび/var/www/example.net/ディレクトリーにhttpd_sys_content_tコンテキストを設定します。policycoreutils-python-utilsパッケージをインストールしてrestoreconコマンドを実行する必要があります。両方のドメインのログディレクトリーを作成します。
# mkdir /var/log/nginx/example.com/ # mkdir /var/log/nginx/example.net/
nginxサービスを再起動します。# systemctl restart nginx
検証手順
仮想ホストのドキュメントルートごとに異なるサンプルファイルを作成します。
# echo "Content for example.com" > /var/www/example.com/index.html # echo "Content for example.net" > /var/www/example.net/index.html # echo "Catch All content" > /usr/share/nginx/html/index.html
-
ブラウザーを使用して
http://example.comに接続します。Web サーバーは、/var/www/example.com/index.htmlファイルからのサンプルコンテンツを表示します。 -
ブラウザーを使用して
http://example.netに接続します。Web サーバーは、/var/www/example.net/index.htmlファイルからのサンプルコンテンツを表示します。 -
ブラウザーを使用して
http://IP_address_of_the_serverに接続します。Web サーバーは、/usr/share/nginx/html/index.htmlファイルからのサンプルコンテンツを表示します。
2.3. NGINX Web サーバーへの TLS 暗号化の追加
example.com ドメインの NGINX Web サーバーで TLS 暗号化を有効にすることができます。
前提条件
- NGINX がインストールされている。
秘密鍵が
/etc/pki/tls/private/example.com.keyファイルに保存されている。秘密鍵および証明書署名要求 (CSR) を作成する方法と、認証局 (CA) からの証明書を要求する方法は、CA のドキュメントを参照してください。
-
TLS 証明書は
/etc/pki/tls/certs/example.com.crtファイルに保存されます。別のパスを使用する場合は、この手順で対応する手順を調整します。 - CA 証明書がサーバーの TLS 証明書ファイルに追加されている。
- クライアントおよび Web サーバーは、サーバーのホスト名を Web サーバーの IP アドレスに対して解決します。
-
ポート
443が、ローカルのファイアウォールで開放されている。
手順
/etc/nginx/nginx.confファイルを編集し、設定のhttpブロックに以下のserverブロックを追加します。server { listen 443 ssl; server_name example.com; root /usr/share/nginx/html; ssl_certificate /etc/pki/tls/certs/example.com.crt; ssl_certificate_key /etc/pki/tls/private/example.com.key; }セキュリティー上の理由から、
rootユーザーのみが秘密鍵ファイルにアクセスできるように設定します。# chown root:root /etc/pki/tls/private/example.com.key # chmod 600 /etc/pki/tls/private/example.com.key
警告秘密鍵に権限のないユーザーがアクセスした場合は、証明書を取り消し、新しい秘密鍵を作成し、新しい証明書を要求します。そうでない場合は、TLS 接続が安全ではなくなります。
nginxサービスを再起動します。# systemctl restart nginx
検証手順
-
ブラウザーを使用して、
https://example.comに接続します。
2.4. HTTP トラフィックのリバースプロキシーとしての NGINX の設定
NGINX Web サーバーは、HTTP トラフィックのリバースプロキシーとして機能するように設定できます。たとえば、この機能を使用すると、リモートサーバーの特定のサブディレクトリーに要求を転送できます。クライアント側からは、クライアントはアクセス先のホストからコンテンツを読み込みます。ただし、NGINX は実際のコンテンツをリモートサーバーから読み込み、クライアントに転送します。
この手順では、Web サーバーの /example ディレクトリーへのトラフィックを、URL https://example.com に転送する方法を説明します。
前提条件
- NGINX は、NGINX のインストールと準備 の説明に従ってインストールされます。
- 必要に応じて、TLS 暗号化がリバースプロキシーで有効になっている。
手順
/etc/nginx/nginx.confファイルを編集し、リバースプロキシーを提供するserverブロックに以下の設定を追加します。location /example { proxy_pass https://example.com; }locationブロックでは、NGINX が/exampleディレクトリー内の全要求をhttps://example.comに渡すことを定義します。SELinux ブール値パラメーター
httpd_can_network_connectを1に設定して、SELinux が NGINX がトラフィックを転送できるように設定します。# setsebool -P httpd_can_network_connect 1nginxサービスを再起動します。# systemctl restart nginx
検証手順
-
ブラウザーを使用して
http://host_name/exampleに接続すると、https://example.comの内容が表示されます。
2.5. NGINX の HTTP ロードバランサーとしての設定
NGINX リバースプロキシー機能を使用してトラフィックを負荷分散できます。この手順では、HTTP ロードバランサーとして NGINX を設定して、アクティブな接続数が最も少ないサーバーがどれかを基にして、要求を異なるサーバーに送信する方法を説明します。どちらのサーバーも利用できない場合には、この手順でフォールバックを目的とした 3 番目のホストも定義します。
前提条件
- NGINX は、NGINX のインストールと準備 の説明に従ってインストールされます。
手順
/etc/nginx/nginx.confファイルを編集し、以下の設定を追加します。http { upstream backend { least_conn; server server1.example.com; server server2.example.com; server server3.example.com backup; } server { location / { proxy_pass http://backend; } } }backendという名前のホストグループのleast_connディレクティブは、アクティブな接続数が最も少ないサーバーがどれかを基にして、NGINX が要求をserver1.example.comまたはserver2.example.comに送信することを定義します。NGINX は、他の 2 つのホストが利用できない場合は、server3.example.comのみをバックアップとして使用します。proxy_passディレクティブをhttp://backendに設定すると、NGINX はリバースプロキシーとして機能し、backendホストグループを使用して、このグループの設定に基づいて要求を配信します。least_conn負荷分散メソッドの代わりに、以下を指定することができます。- ラウンドロビンを使用し、サーバー全体で要求を均等に分散する方法はありません。
-
ip_hash: クライアントの IPv4 アドレスのオクテットの内、最初の 3 つ、または IPv6 アドレス全体から計算されたハッシュに基づいて、あるクライアントアドレスから同じサーバーに要求を送信します。 -
hash: ユーザー定義のキーに基づいてサーバーを判断します。これは、文字列、変数、または両方の組み合わせになります。consistentパラメーターは、ユーザー定義のハッシュ化された鍵の値に基づいて、NGINX がすべてのサーバーに要求を分散するように設定します。 -
random: 無作為に選択されたサーバーに要求を送信します。
nginxサービスを再起動します。# systemctl restart nginx
2.6. 関連情報
- 公式の NGINX のドキュメントについては、https://nginx.org/en/docs/ を参照してください。Red Hat はこのドキュメントを管理しておらず、インストールした NGINX バージョンで機能しない可能性があることに注意してください。
- PKCS #11 で暗号化ハードウェアを使用するようにアプリケーションを設定
第3章 Samba をサーバーとして使用
Samba は、Red Hat Enterprise Linux にサーバーメッセージブロック (SMB) プロトコルを実装します。SMB プロトコルは、ファイル共有、共有プリンターなど、サーバーのリソースにアクセスするのに使用されます。また、Samba は、Microsoft Windows が使用する分散コンピューティング環境のリモートプロシージャコール (DCE RPC) のプロトコルを実装します。
Samba は以下のように実行できます。
- Active Directory (AD) または NT4 ドメインメンバー
- スタンドアロンサーバー
NT4 プライマリードメインコントローラー (PDC) またはバックアップドメインコントローラー (BDC)
注記Red Hat は、NT4 ドメインに対応する Windows バージョンの既存のインストールでのみ、PDC モードおよび BDC モードをサポートします。Red Hat では、新しい Samba NT4 ドメインを設定しないことを推奨します。これは、Windows 7 および Windows Server 2008 R2 以降の Microsoft オペレーティングシステムが NT4 ドメインに対応していないためです。
Red Hat は、Samba を AD ドメインコントローラー (DC) として実行することはサポートしていません。
インストールモードとは関係なく、必要に応じてディレクトリーやプリンターを共有できます。これにより、Samba がファイルサーバーおよびプリントサーバーとして機能できるようになります。
3.1. さまざまな Samba サービスおよびモードについて
samba パッケージは複数のサービスを提供します。環境と設定するシナリオに応じて、これらのサービスが 1 つ以上必要となり、Samba をさまざまなモードで設定します。
3.1.1. Samba サービス
Samba は以下のサービスを提供します。
smbdこのサービスは、SMB プロトコルを使用してファイル共有およびプリントサービスを提供します。また、サービスは、リソースのロックと、接続ユーザーの認証を担当します。ドメインメンバーを認証するには、
smbdにwinbinddが必要です。smbsystemdサービスが起動し、smbdデーモンが停止します。smbdサービスを使用するには、sambaパッケージをインストールします。nmbdこのサービスは、NetBIOS over IPv4 プロトコルを使用してホスト名および IP 解決を提供します。名前解決に加え、
nmbdサービスで SMB ネットワークを参照して、ドメイン、作業グループ、ホスト、ファイル共有、およびプリンターを探すことができます。このため、サービスはこの情報をブロードキャストクライアントに直接報告するか、ローカルまたはマスターのブラウザーに転送します。nmbsystemdサービスは、nmbdデーモンを起動し、停止します。最近の SMB ネットワークは、クライアントおよび IP アドレスの解決に DNS を使用することに注意してください。Kerberos の場合は、稼働中の DNS 設定が必要です。
nmbdサービスを使用するには、sambaパッケージをインストールします。winbinddこのサービスは、ローカルシステムの AD または NT4 のドメインユーザーおよびグループを使用する Name Service Switch (NSS) のインターフェイスを提供します。これにより、たとえばドメインユーザーを、Samba サーバーにホストされるサービスや他のローカルサービスに認証できます。
winbindsystemdサービスは、winbinddデーモンを開始および停止します。Samba をドメインメンバーとして設定する場合は、
smbdサービスの前にwinbinddを起動する必要があります。そうしないと、ドメインユーザーおよびグループはローカルシステムで使用できなくなります。winbinddサービスを使用するには、samba-winbindパッケージをインストールします。重要Red Hat は、ドメインユーザーおよびグループをローカルシステムに提供するために、Samba を、
winbinddサービスを使用するサーバーとして実行することのみをサポートします。Windows アクセス制御リスト (ACL) のサポート、NT LAN Manager (NTLM) のフォールバックがないなど、特定の制限により、SSSD に対応しません。
3.1.2. Samba セキュリティーサービス
/etc/samba/smb.conf ファイルの [global] セクションの security パラメーターは、Samba がサービスに接続しているユーザーを認証する方法を管理します。Samba をインストールするモードに応じて、パラメーターは異なる値に設定する必要があります。
- AD ドメインメンバーに、
security = adsを設定する。 このモードでは、Samba は Kerberos を使用して AD ユーザーを認証します。
Samba をドメインメンバーとして設定する方法の詳細については、Samba を AD ドメインメンバーサーバーとして設定 を参照してください。
- スタンドアロンサーバーで、
security = userを設定する。 このモードでは、Samba がローカルデータベースを使用して接続ユーザーを認証します。
Samba をスタンドアロンサーバーとしてセットアップする方法の詳細については、スタンドアロンサーバーとしての Samba の設定 を参照してください。
- NT4 PDC または BDC に
security = userを設定する。 - Samba は、このモードでは、ユーザーをローカルまたは LDAP データベースに認証します。
- NT4 ドメインメンバーで、
security = domainを設定する。 Samba は、このモードでは、NT4 PDC または BDC にユーザーを接続する認証を行います。このモードは、AD ドメインメンバーには使用できません。
Samba をドメインメンバーとして設定する方法の詳細については、Samba を AD ドメインメンバーサーバーとして設定 を参照してください。
関連情報
-
smb.conf(5)man ページのsecurityパラメーター
3.1.3. Samba サービスおよび Samba クライアントユーティリティーが設定を読み込み、再読み込みするシナリオ
以下は、Samba サービスおよびユーティリティーによる設定の読み込み、再読み込み時について説明します。
Samba サービスは、設定を再読み込みする時:
- 3 分ごとに自動更新
-
手動要求の場合に
smbcontrol all reload-configコマンドを実行するとします。
- Samba クライアントユーティリティーは、起動時にのみ設定を読み取ります。
security などの特定のパラメーターの適用には、smb サービスの再起動が必要です。再読み込みだけでは十分ではないことに注意してください。
関連情報
-
smb.conf(5)man ページのHow configuration changes are applyセクション -
smbd(8)、nmbd(8)、およびwinbindd(8)man ページ
3.1.4. 安全な方法での Samba 設定の編集
Samba サービスは、3 分ごとに設定を自動的に再読み込みします。testparm ユーティリティーでの設定の検証前にサービスが変更を再読み込みしないように、安全な方法で Samba 設定を編集できます。
前提条件
- Samba がインストールされている。
手順
/etc/samba/smb.confファイルのコピーを作成します。# cp /etc/samba/smb.conf /etc/samba/samba.conf.copy- コピーして作成したファイルを編集し、必要な変更を加えます。
/etc/samba/samba.conf.copyファイルの設定を確認します。# testparm -s /etc/samba/samba.conf.copytestparmがエラーを報告した場合は、修正してもう一度コマンドを実行します。/etc/samba/smb.confファイルを新しい設定に上書きします。# mv /etc/samba/samba.conf.copy /etc/samba/smb.confSamba サービスが設定を自動的に再読み込みするか、手動で設定を再読み込みするまで待ちます。
# smbcontrol all reload-config
3.2. testparm ユーティリティーを使用した smb.conf ファイルの検証
testparm ユーティリティーは、/etc/samba/smb.conf ファイルの Samba 設定が正しいことを確認します。このユーティリティーは、無効なパラメーターおよび値を検出しますが、ID マッピングなどの間違った設定も検出します。testparm が問題を報告しないと、Samba サービスは /etc/samba/smb.conf ファイルを正常に読み込みます。testparm は、設定されたサービスが利用可能であること、または期待通りに機能するかを確認できないことに注意してください。
Red Hat では、このファイルの変更後に毎回 testparm を使用して、/etc/samba/smb.conf ファイルを検証することが推奨されます。
前提条件
- Samba をインストールしている。
-
/etc/samba/smb.confファイルが存在する。
手順
rootユーザーでtestparmユーティリティーを実行します。# testparm Load smb config files from /etc/samba/smb.conf rlimit_max: increasing rlimit_max (1024) to minimum Windows limit (16384) Unknown parameter encountered: "log levell" Processing section "[example_share]" Loaded services file OK. ERROR: The idmap range for the domain * (tdb) overlaps with the range of DOMAIN (ad)! Server role: ROLE_DOMAIN_MEMBER Press enter to see a dump of your service definitions # Global parameters [global] ... [example_share] ...
上記の出力例では、存在しないパラメーターと間違った ID マッピングの設定が報告されます。
-
testparmが設定内の間違ったパラメーター、値、またはその他のエラーを報告する場合は、問題を修正してから再度ユーティリティーを実行してください。
3.3. Samba をスタンドアロンサーバーとして設定
Samba は、ドメインのメンバーではないサーバーとして設定できます。このインストールモードでは、Samba はユーザーを中央 DC ではなくローカルデータベースに認証します。また、ゲストアクセスを有効にして、ユーザーが、認証なしで 1 つまたは複数のサービスに接続できるようにすることもできます。
3.3.1. スタンドアロンサーバーのサーバー設定の設定
Samba スタンドアロンサーバーのサーバー設定を設定できます。
手順
sambaパッケージをインストールします。# yum install samba/etc/samba/smb.confファイルを編集して、以下のパラメーターを設定します。[global] workgroup = Example-WG netbios name = Server security = user log file = /var/log/samba/%m.log log level = 1
この設定では、
Example-WGワークグループに、スタンドアロンサーバー (Server) を定義します。また、この設定により最小レベル (1) でのログ記録が可能になり、ログファイルは/var/log/samba/ディレクトリーに保存されます。Samba は、log fileパラメーターの%mマクロを、接続しているクライアントの NetBIOS 名までデプロイメントします。これにより、クライアントごとに個別のログファイルが有効になります。オプションで、ファイルまたはプリンターの共有を設定します。参照:
/etc/samba/smb.confファイルを検証します。# testparm認証が必要な共有を設定する場合は、ユーザーアカウントを作成します。
詳細は ローカルユーザーアカウントの作成および有効化 を参照してください。
firewall-cmdユーティリティーを使用して必要なポートを開き、ファイアウォール設定を再読み込みします。# firewall-cmd --permanent --add-service=samba # firewall-cmd --reload
smbサービスを有効にして起動します。# systemctl enable --now smb
関連情報
-
smb.conf(5)man ページ
3.3.2. ローカルユーザーアカウントの作成および有効化
共有への接続時にユーザーが認証を行えるようにするには、オペレーティングシステムと Samba データベースの両方で Samba ホストにアカウントを作成する必要があります。Samba では、ファイルシステムオブジェクトでアクセス制御リスト (ACL) を検証するオペレーティングシステムアカウントと、接続ユーザーの認証を行う Samba アカウントが必要です。
passdb backend = tdbsam のデフォルト設定を使用すると、Samba はユーザーアカウントを /var/lib/samba/private/passdb.tdb データベースに保存します。
example という名前のローカル Samba ユーザーを作成できます。
前提条件
- Samba が、スタンドアロンサーバーとしてインストールされている。
手順
オペレーティングシステムアカウントを作成します。
# useradd -M -s /sbin/nologin exampleこのコマンドは、ホームディレクトリーを作成せずに、
exampleアカウントを追加します。アカウントが Samba への認証のみに使用される場合は、/sbin/nologinコマンドをシェルとして割り当て、アカウントがローカルでログインしないようにします。オペレーティングシステムのアカウントにパスワードを設定して、これを有効にします。
# passwd example Enter new UNIX password:
passwordRetype new UNIX password:passwordpasswd: password updated successfullySamba は、オペレーティングシステムのアカウントに設定されたパスワードを使用して認証を行いません。ただし、アカウントを有効にするには、パスワードを設定する必要があります。アカウントが無効になると、そのユーザーが接続した時に Samba がアクセスを拒否します。
Samba データベースにユーザーを追加し、そのアカウントにパスワードを設定します。
# smbpasswd -a example New SMB password:
passwordRetype new SMB password:passwordAdded user example.このアカウントを使用して Samba 共有に接続する場合に、このパスワードを使用して認証を行います。
Samba アカウントを有効にします。
# smbpasswd -e example Enabled user example.
3.4. Samba ID マッピングの理解および設定
Windows ドメインは、ユーザーおよびグループを一意のセキュリティー識別子 (SID) で区別します。ただし、Linux では、ユーザーおよびグループごとに一意の UID と GID が必要です。Samba をドメインメンバーとして実行する場合は、winbindd サービスが、ドメインユーザーおよびグループに関する情報をオペレーティングシステムに提供します。
winbindd サービスが、ユーザーおよびグループの一意の ID を Linux に提供するようにするには、/etc/samba/smb.conf ファイルで ID マッピングを設定する必要があります。
- ローカルデータベース (デフォルトドメイン)
- Samba サーバーがメンバーになっている AD または NT4 のドメイン
- ユーザーがこの Samba サーバーのリソースにアクセスする必要のある信頼ドメイン
Samba は、特定の設定に対して異なる ID マッピングバックエンドを提供します。最も頻繁に使用されるバックエンドは、以下の通りです。
| バックエンド | ユースケース |
|---|---|
|
|
|
|
| AD ドメインのみ |
|
| AD ドメインおよび NT4 ドメイン |
|
|
AD、NT4、および |
3.4.1. Samba ID 範囲の計画
Linux の UID および GID を AD に保存するか、Samba がそれを生成するように設定するかに関係なく、各ドメイン設定には、他のドメインと重複しない一意の ID 範囲が必要です。
重複する ID 範囲を設定すると、Samba が正常に機能しなくなります。
例3.1 一意の ID 範囲
以下は、デフォルト (*)、AD-DOM、および TRUST-DOM のドメインの非オーバーランディングの ID マッピング範囲を示しています。
[global] ... idmap config * : backend = tdb idmap config * : range = 10000-999999 idmap config AD-DOM:backend = rid idmap config AD-DOM:range = 2000000-2999999 idmap config TRUST-DOM:backend = rid idmap config TRUST-DOM:range = 4000000-4999999
1 つのドメインに割り当てられるのは 1 つの範囲だけです。したがって、ドメイン範囲間で十分な容量を残しておきます。これにより、ドメインが拡大した場合に、後で範囲を拡張できます。
後で別の範囲をドメインに割り当てると、このユーザーおよびグループが作成したファイルおよびディレクトリーの所有権が失われます。
3.4.2. * デフォルトドメイン
ドメイン環境では、以下の各 ID マッピング設定を追加します。
- Samba サーバーがメンバーとなっているドメイン
- Samba サーバーにアクセスできる信頼された各ドメイン
ただし、Samba が、その他のすべてのオブジェクトに、デフォルトドメインから ID を割り当てます。これには以下が含まれます。
- ローカルの Samba ユーザーおよびグループ
-
Samba の組み込みアカウントおよびグループ (
BUILTIN\Administratorsなど)
Samba が正常に機能できるようにするには、説明に従ってデフォルトのドメインを設定する必要があります。
割り当てられた ID を永続的に格納するには、デフォルトのドメインバックエンドを書き込み可能にする必要があります。
デフォルトドメインには、以下のいずれかのバックエンドを使用できます。
tdbデフォルトのドメインを、
tdbバックエンドを使用するように設定する場合は、ID 範囲を設定します。この ID 範囲には、将来作成されるオブジェクトや、定義されたドメイン ID マッピング設定には含まれないオブジェクトを追加できます。たとえば、
/etc/samba/smb.confファイルの[global]セクションで以下を設定します。idmap config * : backend = tdb idmap config * : range = 10000-999999
詳細は、TDB ID マッピングバックエンドの使用 を参照してください。
autoridautoridバックエンドを使用するように、デフォルトのドメインを設定する場合、ドメイン用の ID マッピング設定を追加するかどうかは任意になります。たとえば、
/etc/samba/smb.confファイルの[global]セクションで以下を設定します。idmap config * : backend = autorid idmap config * : range = 10000-999999
詳細は、autorid ID マッピングバックエンドの使用 を参照してください。
3.4.3. tdb ID マッピングバックエンドの使用
winbindd サービスは、デフォルトで書き込み可能な tdb ID マッピングバックエンドを使用して、セキュリティー識別子 (SID)、UID、および GID のマッピングテーブルを格納します。これには、ローカルユーザー、グループ、組み込みプリンシパルが含まれます。
このバックエンドは、* デフォルトドメインにのみ使用してください。以下に例を示します。
idmap config * : backend = tdb idmap config * : range = 10000-999999
関連情報
3.4.4. ad ID マッピングバックエンドの使用
ad ID マッピングバックエンドを使用するように Samba AD メンバーを設定できます。
ad ID マッピングバックエンドは、読み取り専用 API を実装し、AD からアカウントおよびグループの情報を読み取ります。これには、以下の利点があります。
- ユーザーとグループの全設定は、AD に集中的に保存されます。
- ユーザーおよびグループの ID は、このバックエンドを使用するすべての Samba サーバーで一貫しています。
- ID は、破損する可能性のあるローカルデータベースには保存されないため、ファイルの所有権は失われません。
ad ID マッピングバックエンドは、一方向の信頼を使用する Active Directory ドメインに対応していません。一方向の信頼で Active Directory のドメインメンバーを設定する場合は、tdb、 rid、または autorid のいずれかの ID マッピングバックエンドを使用します。
ad バックエンドは、AD から以下の属性を読み込みます。
| AD 属性名 | オブジェクトの種類 | マッピング先 |
|---|---|---|
|
| ユーザーおよびグループ | オブジェクトのユーザー名またはグループ名 |
|
| ユーザー | ユーザー ID (UID) |
|
| グループ | グループ ID (GID) |
|
| ユーザー | ユーザーのシェルのパス |
|
| ユーザー | ユーザーのホームディレクトリーのパス |
|
| ユーザー | プライマリーグループ ID |
[a]
idmap config DOMAIN:unix_nss_info = yes を設定している場合に限り、Samba がこの属性を読み込みます。
[b]
idmap config DOMAIN:unix_primary_group = yes を設定している場合に限り、Samba がこの属性を読み込みます。
| ||
前提条件
-
ユーザーおよびグループはいずれも、AD で一意の ID が設定され、ID が、
/etc/samba/smb.confファイルで設定されている範囲内にある。ID が範囲外にあるオブジェクトは、Samba サーバーでは利用できません。 - ユーザーおよびグループには、AD ですべての必須属性が設定されている。必要な属性がないと、ユーザーまたはグループは Samba サーバーで使用できなくなります。必要な属性は、設定によって異なります。前提条件:
- Samba をインストールしている。
-
ID マッピングを除く Samba 設定が
/etc/samba/smb.confファイルにある。
手順
/etc/samba/smb.confファイルの[global]セクションを編集します。デフォルトドメイン (
*) に ID マッピング設定が存在しない場合は追加します。以下に例を示します。idmap config * : backend = tdb idmap config * : range = 10000-999999AD ドメインの
adID マッピングバックエンドを有効にします。idmap config DOMAIN : backend = adAD ドメインのユーザーおよびグループに割り当てられている ID の範囲を設定します。以下に例を示します。
idmap config DOMAIN : range = 2000000-2999999
重要この範囲は、このサーバーの他のドメイン設定と重複させることはできません。また、この範囲には、今後割り当てられる ID がすべて収まる大きさを設定する必要があります。詳細は、Samba ID 範囲の計画 を参照してください。
Samba が AD から属性を読み取る際に RFC 2307 スキーマを使用するように設定します。
idmap config DOMAIN : schema_mode = rfc2307Samba が、対応する AD 属性からログインシェルおよびユーザーホームディレクトリーのパスを読み取るようにする場合は、以下を設定します。
idmap config DOMAIN : unix_nss_info = yesまたは、すべてのユーザーに適用される、ドメイン全体のホームディレクトリーのパスおよびログインシェルを統一して設定できます。以下に例を示します。
template shell = /bin/bash template homedir = /home/%U
デフォルトでは、Samba は、ユーザーオブジェクトの
primaryGroupID属性を、Linux のユーザーのプライマリーグループとして使用します。または、代わりにgidNumber属性に設定されている値を使用するように Samba を設定できます。idmap config DOMAIN : unix_primary_group = yes
/etc/samba/smb.confファイルを検証します。# testparmSamba 設定を再読み込みします。
# smbcontrol all reload-config
関連情報
- * デフォルトドメイン
-
smb.conf(5)およびidmap_ad(8)man ページ -
smb.conf(5)man ページのVARIABLE SUBSTITUTIONSセクション
3.4.5. rid ID マッピングバックエンドの使用
rid ID マッピングバックエンドを使用するように Samba ドメインメンバーを設定できます。
Samba は、Windows SID の相対識別子 (RID) を使用して、Red Hat Enterprise Linux で ID を生成できます。
RID は、SID の最後の部分です。たとえば、ユーザーの SID が S-1-5-21-5421822485-1151247151-421485315-30014 の場合、対応する RID は 30014 になります。
rid ID マッピングバックエンドは、AD ドメインおよび NT4 ドメインのアルゴリズムマッピングスキームに基づいてアカウントおよびグループの情報を計算する読み取り専用 API を実装します。バックエンドを設定する場合は、idmap config DOMAIN : range パラメーターで、RID の最小値および最大値を設定する必要があります。Samba は、このパラメーターで設定される RID の最小値および最大値を超えるユーザーまたはグループをマッピングしません。
読み取り専用のバックエンドとして、rid は、BUILTIN グループなど、新しい ID を割り当てることができません。したがって、* デフォルトドメインにはこのバックエンドを使用しないでください。
rid バックエンドを使用した利点
- 設定された範囲内の RID があるドメインユーザーとグループはすべて、自動的にドメインメンバーで利用可能になります。
- ID、ホームディレクトリー、およびログインシェルを手動で割り当てる必要はありません。
rid バックエンドを使用した場合の短所
- すべてのドメインユーザーは、割り当てられた同じログインシェルとホームディレクトリーを取得します。ただし、変数を使用できます。
-
同じ ID 範囲設定で
ridバックエンドを使用している Samba ドメインメンバーでは、ユーザー ID とグループ ID が同じになります。 - ドメインメンバーで個々のユーザーまたはグループを除外して、利用できないようにすることはできません。設定されている範囲外にあるユーザーとグループのみが除外されます。
-
異なるドメインのオブジェクトの RID が同じ場合は、
winbinddサービスが ID の計算に使用する式に基づき、複数ドメインの環境で重複する ID が発生する場合があります。
前提条件
- Samba をインストールしている。
-
ID マッピングを除く Samba 設定が
/etc/samba/smb.confファイルにある。
手順
/etc/samba/smb.confファイルの[global]セクションを編集します。デフォルトドメイン (
*) に ID マッピング設定が存在しない場合は追加します。以下に例を示します。idmap config * : backend = tdb idmap config * : range = 10000-999999ドメインの
ridID マッピングバックエンドを有効にします。idmap config DOMAIN : backend = rid今後割り当てられるすべての RID が収まる大きさの範囲を設定します。以下に例を示します。
idmap config DOMAIN : range = 2000000-2999999
Samba は、そのドメインの RID がその範囲内にないユーザーおよびグループを無視します。
重要この範囲は、このサーバーの他のドメイン設定と重複させることはできません。また、この範囲には、今後割り当てられる ID がすべて収まる大きさを設定する必要があります。詳細は、Samba ID 範囲の計画 を参照してください。
すべてのマッピングユーザーに割り当てられるシェルおよびホームディレクトリーのパスを設定します。以下に例を示します。
template shell = /bin/bash template homedir = /home/%U
/etc/samba/smb.confファイルを検証します。# testparmSamba 設定を再読み込みします。
# smbcontrol all reload-config
関連情報
- * デフォルトドメイン
-
smb.conf(5)man ページのVARIABLE SUBSTITUTIONSセクション -
RID からのローカル ID の計算については、
idmap_rid(8)man ページを参照してください。
3.4.6. autorid ID マッピングバックエンドの使用
autorid ID マッピングバックエンドを使用するように Samba ドメインメンバーを設定できます。
autorid バックエンドは、rid ID マッピングバックエンドと同様の動作をしますが、異なるドメインに対して自動的に ID を割り当てることができます。これにより、以下の状況で autorid バックエンドを使用できます。
-
*デフォルトドメインのみ -
*デフォルトドメインと追加のドメインでは、追加のドメインごとに ID マッピング設定を作成する必要はありません。 - 特定のドメインのみ
デフォルトドメインに autorid を使用する場合は、ドメイン用の ID マッピング設定を追加するかどうかは任意です。
このセクションの一部は、Samba Wiki に公開されているドキュメント idmap config autorid に掲載されています。ライセンスは、CC BY 4.0 にあります。著者および貢献者は、Wiki ページの history タブを参照してください。
autorid バックエンドを使用した利点
- 設定された範囲内に計算した UID と GID があるすべてのドメインユーザーおよびグループは、ドメインメンバーで自動的に利用可能になります。
- ID、ホームディレクトリー、およびログインシェルを手動で割り当てる必要はありません。
- 複数ドメイン環境内の複数のオブジェクトが同じ RID を持つ場合でも、重複する ID はありません。
短所
- Samba ドメインメンバー間では、ユーザー ID とグループ ID は同じではありません。
- すべてのドメインユーザーは、割り当てられた同じログインシェルとホームディレクトリーを取得します。ただし、変数を使用できます。
- ドメインメンバーで個々のユーザーまたはグループを除外して、利用できないようにすることはできません。計算された UID または GID が、設定された範囲外にあるユーザーとグループのみが除外されます。
前提条件
- Samba をインストールしている。
-
ID マッピングを除く Samba 設定が
/etc/samba/smb.confファイルにある。
手順
/etc/samba/smb.confファイルの[global]セクションを編集します。*デフォルトドメインのautoridID マッピングバックエンドを有効にします。idmap config * : backend = autorid
既存および将来の全オブジェクトに ID を割り当てられる大きさの範囲を設定します。以下に例を示します。
idmap config * : range = 10000-999999Samba は、このドメインで計算した ID が範囲内にないユーザーおよびグループを無視します。
警告範囲を設定し、Samba がそれを使用して開始してからは、範囲の上限を小さくすることはできません。範囲にその他の変更を加えると、新しい ID 割り当てが発生し、ファイルの所有権が失われる可能性があります。
必要に応じて、範囲サイズを設定します。以下に例を示します。
idmap config * : rangesize = 200000Samba は、
idmap config * : rangeパラメーターに設定されている範囲からすべての ID を取得するまで、各ドメインのオブジェクトにこの数の連続 ID を割り当てます。注記rangesize を設定する場合は、適宜範囲を調整する必要があります。この範囲は rangesize の倍数である必要があります。
すべてのマッピングユーザーに割り当てられるシェルおよびホームディレクトリーのパスを設定します。以下に例を示します。
template shell = /bin/bash template homedir = /home/%U
必要に応じて、ドメイン用の ID マッピング設定を追加します。個別のドメインの設定が利用できない場合、Samba は以前に設定した
*デフォルトドメインのautoridバックエンド設定を使用して ID を計算します。重要この範囲は、このサーバーの他のドメイン設定と重複させることはできません。また、この範囲には、今後割り当てられる ID がすべて収まる大きさを設定する必要があります。詳細は、Samba ID 範囲の計画 を参照してください。
/etc/samba/smb.confファイルを検証します。# testparmSamba 設定を再読み込みします。
# smbcontrol all reload-config
関連情報
-
idmap_autorid(8)man ページのTHE MAPPING FORMULASセクション -
idmap_autorid(8)man ページのrangesizeパラメーターの説明 -
smb.conf(5)man ページのVARIABLE SUBSTITUTIONSセクション
3.5. Samba を AD ドメインメンバーサーバーとして設定
AD または NT4 のドメインを実行している場合は、Samba を使用して Red Hat Enterprise Linux サーバーをメンバーとしてドメインに追加し、以下を取得します。
- その他のドメインメンバーのドメインリソースにアクセスする
-
sshdなどのローカルサービスに対してドメインユーザーを認証する - サーバーにホストされているディレクトリーおよびプリンターを共有して、ファイルサーバーおよびプリントサーバーとして動作する
3.5.1. RHEL システムの AD ドメインへの参加
Samba Winbind は、Red Hat Enterprise Linux (RHEL) システムを Active Directory (AD) に接続するための System Security Services Daemon (SSSD) の代替手段です。realmd を使用して Samba Winbind を設定することで、RHEL システムを AD ドメインに参加させることができます。
手順
AD で Kerberos 認証に非推奨の RC4 暗号化タイプが必要な場合は、RHEL でこの暗号のサポートを有効にします。
# update-crypto-policies --set DEFAULT:AD-SUPPORT以下のパッケージをインストールします。
# yum install realmd oddjob-mkhomedir oddjob samba-winbind-clients \ samba-winbind samba-common-tools samba-winbind-krb5-locator
ドメインメンバーでディレクトリーまたはプリンターを共有するには、
sambaパッケージをインストールします。# yum install samba既存の Samba 設定ファイル
/etc/samba/smb.confをバックアップします。# mv /etc/samba/smb.conf /etc/samba/smb.conf.bakドメインに参加します。たとえば、ドメイン
ad.example.comに参加するには、以下のコマンドを実行します。# realm join --membership-software=samba --client-software=winbind ad.example.com上記のコマンドを使用すると、
realmユーティリティーが自動的に以下を実行します。-
ad.example.comドメインのメンバーシップに/etc/samba/smb.confファイルを作成します。 -
ユーザーおよびグループの検索用の
winbindモジュールを、/etc/nsswitch.confファイルに追加します。 -
/etc/pam.d/ディレクトリーの PAM (プラグ可能な認証モジュール) 設定ファイルを更新します。 -
winbindサービスを起動し、システムの起動時にサービスを起動できるようにします。
-
-
必要に応じて、
/etc/samba/smb.confファイルの別の ID マッピングバックエンド、またはカスタマイズした ID マッピングを設定します。詳細は、SambaID マッピングの理解と設定 を参照してください。 winbindサービスが稼働していることを確認します。# systemctl status winbind ... Active: active (running) since Tue 2018-11-06 19:10:40 CET; 15s ago重要Samba がドメインのユーザーおよびグループの情報をクエリーできるようにするには、
smbを起動する前にwinbindサービスを実行する必要があります。sambaパッケージをインストールしてディレクトリーおよびプリンターを共有している場合は、smbサービスを有効化して開始します。# systemctl enable --now smb-
必要に応じて、Active Directory へのローカルログインを認証する場合は、
winbind_krb5_localauthプラグインを有効にします。MIT Kerberos 用のローカル承認プラグインの使用
検証手順
AD ドメインの AD 管理者アカウントなど、AD ユーザーの詳細を表示します。
# getent passwd "AD\administrator" AD\administrator:*:10000:10000::/home/administrator@AD:/bin/bashAD ドメイン内のドメインユーザーグループのメンバーをクエリーします。
# getent group "AD\Domain Users" AD\domain users:x:10000:user1,user2オプションで、ファイルやディレクトリーに権限を設定する際に、ドメインのユーザーおよびグループを使用できることを確認します。たとえば、
/srv/samba/example.txtファイルの所有者をAD\administratorに設定し、グループをAD\Domain Usersに設定するには、以下のコマンドを実行します。# chown "AD\administrator":"AD\Domain Users" /srv/samba/example.txtKerberos 認証が期待どおりに機能することを確認します。
AD ドメインメンバーで、
administrator@AD.EXAMPLE.COMプリンシパルのチケットを取得します。# kinit administrator@AD.EXAMPLE.COMキャッシュされた Kerberos チケットを表示します。
# klist Ticket cache: KCM:0 Default principal: administrator@AD.EXAMPLE.COM Valid starting Expires Service principal 01.11.2018 10:00:00 01.11.2018 20:00:00 krbtgt/AD.EXAMPLE.COM@AD.EXAMPLE.COM renew until 08.11.2018 05:00:00
利用可能なドメインの表示:
# wbinfo --all-domains BUILTIN SAMBA-SERVER AD
関連情報
- 非推奨の RC4 暗号化を使用しない場合は、AD で AES 暗号化タイプを有効にすることができます。詳細は、
- GPO を使用した Active Directory で AES 暗号化タイプの有効化
-
realm(8)man ページ
3.5.2. MIT Kerberos 用のローカル承認プラグインの使用
winbind サービスは、Active Directory ユーザーをドメインメンバーに提供します。特定の状況では、管理者が、ドメインメンバーで実行している SSH サーバーなどのローカルサービスに対して、ドメインユーザーが認証を行えるようにします。Kerberos を使用してドメインユーザーを認証している場合は、winbind サービスを介して、winbind_krb5_localauth プラグインが Kerberos プリンシパルを Active Directory アカウントに正しくマッピングできるようにします。
たとえば、Active Directory ユーザーの sAMAccountName 属性を EXAMPLE に設定し、小文字のユーザー名でユーザーがログインしようとすると、Kerberos はユーザー名を大文字で返します。その結果、エントリーは認証の失敗に一致しません。
winbind_krb5_localauth プラグインを使用すると、アカウント名が正しくマッピングされます。これは GSSAPI 認証にのみ適用され、初期のチケット付与チケット (TGT) の取得には該当しません。
前提条件
- Samba が Active Directory のメンバーとして設定されている。
- Red Hat Enterprise Linux が、Active Directory に対してログイン試行を認証している。
-
winbindサービスが実行している。
手順
/etc/krb5.conf ファイルを編集し、以下のセクションを追加します。
[plugins]
localauth = {
module = winbind:/usr/lib64/samba/krb5/winbind_krb5_localauth.so
enable_only = winbind
}関連情報
-
winbind_krb5_localauth(8)man ページ.
3.6. IdM ドメインメンバーでの Samba の設定
Red Hat Identity Management (IdM) ドメインに参加しているホスト上で Samba をセットアップできます。IdM のユーザー、および可能であれば、信頼された Active Directory (AD) ドメインのユーザーは、Samba が提供する共有およびプリンターサービスにアクセスできます。
IdM ドメインメンバーで Samba を使用する機能は、テクノロジープレビュー機能で、特定の制限が含まれています。たとえば、IdM 信頼コントローラーは Active Directory グローバルカタログサービスをサポートしておらず、分散コンピューティング環境/リモートプロシージャコール (DCE/RPC) プロトコルを使用した IdM グループの解決をサポートしていません。結果として、AD ユーザーは、他の IdM クライアントにログインしている場合、IdM クライアントでホストされている Samba 共有とプリンターにのみアクセスできます。Windows マシンにログインしている AD ユーザーは、IdM ドメインメンバーでホストされている Samba 共有にアクセスできません。
IdM ドメインメンバーに Samba をデプロイしているお客様は、ぜひ Red Hat にフィードバックをお寄せください。
AD ドメインのユーザーが Samba によって提供される共有およびプリンターサービスにアクセスする必要がある場合は、AES 暗号化タイプが AD になっていることを確認してください。詳細は、GPO を使用した Active Directory での AES 暗号化タイプの有効化 を参照してください。
前提条件
- ホストは、クライアントとして IdM ドメインに参加している。
- IdM サーバーとクライアントの両方が RHEL 8.1 以降で実行されている必要がある。
3.6.1. Samba をドメインメンバーにインストールするための IdM ドメインの準備
IdM クライアントに Samba を設定する前に、IdM サーバーで ipa-adtrust-install ユーティリティーを使用して IdM ドメインを準備する必要があります。
ipa-adtrust-install コマンドを自動的に実行するシステムは、AD 信頼コントローラーになります。ただし、ipa-adtrust-install は、IdM サーバーで 1 回のみ実行する必要があります。
前提条件
- IdM サーバーがインストールされている。
- パッケージをインストールし、IdM サービスを再起動するには、root 権限が必要です。
手順
必要なパッケージをインストールします。
[root@ipaserver ~]# yum install ipa-server-trust-ad samba-clientIdM 管理ユーザーとして認証します。
[root@ipaserver ~]# kinit adminipa-adtrust-installユーティリティーを実行します。[root@ipaserver ~]# ipa-adtrust-install統合 DNS サーバーとともに IdM がインストールされていると、DNS サービスレコードが自動的に作成されます。
IdM が統合 DNS サーバーなしで IdM をインストールすると、
ipa-adtrust-installは、続行する前に DNS に手動で追加する必要があるサービスレコードのリストを出力します。スクリプトにより、
/etc/samba/smb.confがすでに存在し、書き換えられることが求められます。WARNING: The smb.conf already exists. Running ipa-adtrust-install will break your existing Samba configuration. Do you wish to continue? [no]:
yesこのスクリプトは、従来の Linux クライアントが信頼できるユーザーと連携できるようにする互換性プラグインである
slapi-nisプラグインを設定するように求めるプロンプトを表示します。Do you want to enable support for trusted domains in Schema Compatibility plugin? This will allow clients older than SSSD 1.9 and non-Linux clients to work with trusted users. Enable trusted domains support in slapi-nis? [no]:
yesプロンプトが表示されたら、IdM ドメインの NetBIOS 名を入力するか、Enter を押して提案された名前を使用します。
Trust is configured but no NetBIOS domain name found, setting it now. Enter the NetBIOS name for the IPA domain. Only up to 15 uppercase ASCII letters, digits and dashes are allowed. Example: EXAMPLE. NetBIOS domain name [IDM]:
SID 生成タスクを実行して、既存ユーザーに SID を作成するように求められます。
Do you want to run the ipa-sidgen task? [no]:
yesこれはリソースを集中的に使用するタスクであるため、ユーザー数が多い場合は別のタイミングで実行できます。
(必要に応じて) デフォルトでは、Windows Server 2008 以降での動的 RPC ポートの範囲は
49152-65535として定義されます。ご使用の環境に異なる動的 RPC ポート範囲を定義する必要がある場合は、Samba が異なるポートを使用するように設定し、ファイアウォール設定でそのポートを開くように設定します。以下の例では、ポート範囲を55000-65000に設定します。[root@ipaserver ~]# net conf setparm global 'rpc server dynamic port range' 55000-65000 [root@ipaserver ~]# firewall-cmd --add-port=55000-65000/tcp [root@ipaserver ~]# firewall-cmd --runtime-to-permanent
ipaサービスを再起動します。[root@ipaserver ~]# ipactl restartsmbclientユーティリティーを使用して、Samba が IdM からの Kerberos 認証に応答することを確認します。[root@ipaserver ~]#
smbclient -L server.idm.example.com -U user_name --use-kerberos=requiredlp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- IPC$ IPC IPC Service (Samba 4.15.2) ...
3.6.2. IdM クライアントでの Samba サーバーのインストールおよび設定
IdM ドメインに登録されたクライアントに Samba をインストールして設定できます。
前提条件
- IdM サーバーとクライアントの両方が RHEL 8.1 以降で実行されている必要がある。
- IdM ドメインは、ドメインメンバーに Samba をインストールするための IdM ドメインの準備 の説明に従って準備されます。
- IdM に AD で設定された信頼がある場合は、Kerberos の AES 暗号化タイプを有効にします。たとえば、グループポリシーオブジェクト (GPO) を使用して、AES 暗号化の種類を有効にします。詳細は、GPO を使用した Active Directory での AES 暗号化の有効化 を参照してください。
手順
ipa-client-sambaパッケージをインストールします。[root@idm_client]# yum install ipa-client-sambaipa-client-sambaユーティリティーを使用して、クライアントを準備し、初期 Samba 設定を作成します。[root@idm_client]# ipa-client-samba Searching for IPA server... IPA server: DNS discovery Chosen IPA master: idm_server.idm.example.com SMB principal to be created: cifs/idm_client.idm.example.com@IDM.EXAMPLE.COM NetBIOS name to be used: IDM_CLIENT Discovered domains to use: Domain name: idm.example.com NetBIOS name: IDM SID: S-1-5-21-525930803-952335037-206501584 ID range: 212000000 - 212199999 Domain name: ad.example.com NetBIOS name: AD SID: None ID range: 1918400000 - 1918599999 Continue to configure the system with these values? [no]: yes Samba domain member is configured. Please check configuration at /etc/samba/smb.conf and start smb and winbind services
デフォルトでは、
ipa-client-sambaは、ユーザーが接続したときにそのユーザーのホームディレクトリーを動的に共有するために、/etc/samba/smb.confファイルに[homes]セクションが自動的に追加されます。ユーザーがこのサーバーにホームディレクトリーがない場合、または共有したくない場合は、/etc/samba/smb.confから次の行を削除します。[homes] read only = noディレクトリーとプリンターを共有します。詳細は、以下を参照してください。
ローカルファイアウォールで Samba クライアントに必要なポートを開きます。
[root@idm_client]# firewall-cmd --permanent --add-service=samba-client [root@idm_client]# firewall-cmd --reload
smbサービスおよびwinbindサービスを有効にして開始します。[root@idm_client]# systemctl enable --now smb winbind
検証手順
samba-client パッケージがインストールされている別の IdM ドメインメンバーで次の検証手順を実行します。
Kerberos 認証を使用して、Samba サーバー上の共有をリスト表示します。
$
smbclient -L idm_client.idm.example.com -U user_name --use-kerberos=requiredlp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.15.2) ...
関連情報
-
ipa-client-samba(1)の man ページ
3.6.3. IdM が新しいドメインを信頼する場合は、ID マッピング設定を手動で追加
Samba では、ユーザーがリソースにアクセスする各ドメインの ID マッピング設定が必要です。IdM クライアントで実行している既存の Samba サーバーでは、管理者が Active Directory (AD) ドメインに新しい信頼を追加した後、ID マッピング設定を手動で追加する必要があります。
前提条件
- IdM クライアントで Samba を設定している。その後、IdM に新しい信頼が追加されている。
- Kerberos の暗号化タイプ DES および RC4 は、信頼できる AD ドメインで無効にしている。セキュリティー上の理由から、RHEL 8 はこのような弱い暗号化タイプに対応していません。
手順
ホストのキータブを使用して認証します。
[root@idm_client]# kinit -kipa idrange-findコマンドを使用して、新しいドメインのベース ID と ID 範囲のサイズの両方を表示します。たとえば、次のコマンドはad.example.comドメインの値を表示します。[root@idm_client]# ipa idrange-find --name="AD.EXAMPLE.COM_id_range" --raw --------------- 1 range matched --------------- cn: AD.EXAMPLE.COM_id_range ipabaseid: 1918400000 ipaidrangesize: 200000 ipabaserid: 0 ipanttrusteddomainsid: S-1-5-21-968346183-862388825-1738313271 iparangetype: ipa-ad-trust ---------------------------- Number of entries returned 1 ----------------------------
次の手順で、
ipabaseid属性およびipaidrangesize属性の値が必要です。使用可能な最高の ID を計算するには、次の式を使用します。
maximum_range = ipabaseid + ipaidrangesize - 1
前の手順の値を使用すると、
ad.example.comドメインで使用可能な最大 ID は1918599999(1918400000 + 200000 - 1) です。/etc/samba/smb.confファイルを編集し、ドメインの ID マッピング設定を[global]セクションに追加します。idmap config AD : range = 1918400000 - 1918599999 idmap config AD : backend = sss
ipabaseid属性の値を最小値として指定し、前の手順で計算された値を範囲の最大値として指定します。smbサービスおよびwinbindサービスを再起動します。[root@idm_client]# systemctl restart smb winbind
検証手順
Kerberos 認証を使用して、Samba サーバー上の共有をリスト表示します。
$
smbclient -L idm_client.idm.example.com -U user_name --use-kerberos=requiredlp_load_ex: changing to config backend registry Sharename Type Comment --------- ---- ------- example Disk IPC$ IPC IPC Service (Samba 4.15.2) ...
3.6.4. 関連情報
3.13. MacOS クライアント向けの Samba の設定
fruit 仮想ファイルシステム (VFS) の Samba モジュールは、Apple サーバーメッセージブロック (SMB) クライアントとの互換性を強化します。
3.15. プリントサーバーとしての Samba の設定
Samba をプリントサーバーとして設定すると、ネットワーク上のクライアントが Samba を使用して印刷できます。さらに、Windows クライアントは、(Samba サーバーが設定されている場合は) Samba サーバーからドライバーをダウンロードすることもできます。
このセクションの一部は、Samba Wiki に公開されているドキュメント Setting up Samba as a Print Server に掲載されています。ライセンスは、CC BY 4.0 にあります。著者および貢献者は、Wiki ページの history タブを参照してください。
前提条件
Samba が、以下のいずれかのモードで設定されている。
3.15.1. Samba でのプリントサーバーのサポートの有効化
デフォルトでは、プリントサーバーサポートは Samba で有効になっていません。Samba をプリントサーバーとして使用するには、Samba を適切に設定する必要があります。
印刷ジョブとプリンター操作には、リモートプロシージャコール (RPC) が必要です。デフォルトでは、Samba は RPC を管理するためにオンデマンドで rpcd_spoolss サービスを開始します。最初の RPC 呼び出し中、または CUPS でプリンターリストを更新するときに、Samba は CUPS からプリンター情報を取得します。これには、プリンターごとに約 1 秒かかる場合があります。そのため、プリンターが 50 台を超える場合は、rpcd_spoolss 設定を調整してください。
前提条件
プリンターが CUPS サーバーで設定されている。
CUPS でプリンターを設定する方法は、プリントサーバーの CUPS Web コンソール (https://print_server_host_name:631/help) で提供されているドキュメントを参照してください。
手順
/etc/samba/smb.confファイルを編集します。[printers]セクションを追加して、Samba で印刷バックエンドを有効にします。[printers] comment = All Printers path = /var/tmp/ printable = yes create mask = 0600
重要[printers]共有名はハードコーディングされており、変更はできません。CUPS サーバーが別のホストまたはポートで実行されている場合は、
printersセクションで設定を指定します。cups server = printserver.example.com:631多数のプリンターがある場合は、待機秒数を CUPS に接続されているプリンターの数よりも大きい値に設定します。たとえば、100 台のプリンターがある場合は、
[global]セクションに次のように設定します。rpcd_spoolss:idle_seconds = 200この設定が環境内でスケーリングされない場合は、
[global]セクションでrpcd_spoolssワーカーの数も増やします。rpcd_spoolss:num_workers = 10デフォルトでは、
rpcd_spoolssは 5 つのワーカーを開始します。
/etc/samba/smb.confファイルを検証します。# testparmfirewall-cmdユーティリティーを使用して必要なポートを開き、ファイアウォール設定を再読み込みします。# firewall-cmd --permanent --add-service=samba # firewall-cmd --reload
smbサービスを再起動します。# systemctl restart smbサービスを再起動すると、Samba は CUPS バックエンドに設定したすべてのプリンターを自動的に共有します。特定のプリンターのみを手動で共有する場合は、特定のプリンターの手動共有 を参照してください。
検証
印刷ジョブを送信します。たとえば、PDF ファイルを印刷するには、次のように入力します。
# smbclient -Uuser //sambaserver.example.com/printer_name -c "print example.pdf"
3.15.2. 特定のプリンターの手動共有
Samba をプリントサーバーとして設定している場合、Samba は、デフォルトで CUPS バックエンドで設定されたプリンターをすべて共有します。以下の手順では、特定のプリンターのみを共有する方法を説明します。
前提条件
- Samba がプリントサーバーとして設定されている。
手順
/etc/samba/smb.confファイルを編集します。[global]セクションで、以下の設定で自動プリンター共有を無効にします。load printers = no
共有するプリンターごとにセクションを追加します。たとえば、Samba で CUPS バックエンドで
exampleという名前のプリンターをExample-Printerとして共有するには、以下のセクションを追加します。[Example-Printer] path = /var/tmp/ printable = yes printer name = example各プリンターに個別のスプールディレクトリーは必要ありません。
[printers]セクションに設定したのと同じ spool ディレクトリーを、プリンターのpathパラメーターに設定できます。
/etc/samba/smb.confファイルを検証します。# testparmSamba 設定を再読み込みします。
# smbcontrol all reload-config
3.16. Samba プリントサーバーでの Windows クライアント用の自動プリンタードライバーダウンロードの設定
Windows クライアント用に Samba プリントサーバーを実行している場合は、ドライバーをアップロードし、プリンターを事前設定できます。ユーザーがプリンターに接続すると、Windows により、ドライバーが自動的にクライアントにダウンロードされ、インストールされます。ユーザーがインストールするのに、ローカル管理者の権限を必要としません。また、Windows は、トレイの数などの事前設定済みのドライバー設定を適用します。
このセクションの一部は、Samba Wiki で公開されているドキュメント Setting up Automatic Printer Driver Downloads for Windows Clients に掲載されています。ライセンスは、CC BY 4.0 にあります。著者および貢献者は、Wiki ページの history タブを参照してください。
前提条件
- Samba がプリントサーバーとして設定されている。
3.16.1. プリンタードライバーに関する基本情報
本セクションでは、プリンタードライバーに関する一般的な情報を説明します。
対応しているドライバーモデルのバージョン
Samba は、Windows 2000 以降および Windows Server 2000 以降でサポートされているプリンタードライバーのモデルバージョン 3 のみに対応します。Samba は、Windows 8 および Windows Server 2012 で導入されたドライバーモデルのバージョン 4 には対応していません。ただし、これ以降の Windows バージョンは、バージョン 3 のドライバーにも対応しています。
パッケージ対応ドライバー
Samba は、パッケージ対応ドライバーに対応していません。
アップロードするプリンタードライバーの準備
Samba プリントサーバーにドライバーをアップロードする場合は、以下を行います。
- ドライバーが圧縮形式で提供されている場合は、ドライバーをデプロイメントします。
一部のドライバーでは、Windows ホストにドライバーをローカルにインストールするセットアップアプリケーションを起動する必要があります。特定の状況では、インストーラーはセットアップの実行中にオペレーティングシステムの一時フォルダーに個別のファイルを抽出します。アップロードにドライバーファイルを使用するには、以下のコマンドを実行します。
- インストーラーを起動します。
- 一時フォルダーから新しい場所にファイルをコピーします。
- インストールをキャンセルします。
プリントサーバーへのアップロードをサポートするドライバーは、プリンターの製造元にお問い合わせください。
クライアントに 32 ビットおよび 64 ビットのプリンター用ドライバーを提供
32 ビットと 64 ビットの両方の Windows クライアントのプリンターにドライバーを提供するには、両方のアーキテクチャーに対して、同じ名前のドライバーをアップロードする必要があります。たとえば、32 ビットのドライバー Example PostScript および 64 ビットのドライバー Example PostScript (v1.0) をアップロードする場合は、その名前が一致しません。その結果、ドライバーのいずれかをプリンターに割り当てることしかできなくなり、両方のアーキテクチャーでそのドライバーが使用できなくなります。
3.16.2. ユーザーがドライバーをアップロードおよび事前設定できるようにする
プリンタードライバーをアップロードおよび事前設定できるようにするには、ユーザーまたはグループに SePrintOperatorPrivilege 特権が付与されている必要があります。printadmin グループにユーザーを追加する必要があります。Red Hat Enterprise Linux に samba パッケージをインストールすると、このグループが自動的に作成されます。printadmin グループには、1000 未満で利用可能な一番小さい動的システムの GID が割り当てられます。
手順
たとえば、
SePrintOperatorPrivilege権限をprintadminグループに付与するには、以下のコマンドを 実行します。# net rpc rights grant "printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator" Enter DOMAIN\administrator's password: Successfully granted rights.
注記ドメイン環境では、
SePrintOperatorPrivilegeをドメイングループに付与します。これにより、ユーザーのグループメンバーシップを更新し、権限を集中的に管理できます。SePrintOperatorPrivilegeが付与されているユーザーとグループのリストを表示するには、以下を実行します。# net rpc rights list privileges SePrintOperatorPrivilege -U "DOMAIN\administrator" Enter administrator's password: SePrintOperatorPrivilege: BUILTIN\Administrators DOMAIN\printadmin
3.16.4. クライアントが Samba プリントサーバーを信頼できるようにする GPO の作成
セキュリティー上の理由から、最新の Windows オペレーティングシステムでは、クライアントが、信頼できないサーバーから、パッケージ対応ではないプリンタードライバーをダウンロードできないようにします。プリントサーバーが AD のメンバーである場合は、Samba サーバーを信頼するために、ドメインに Group Policy Object (GPO) を作成できます。
前提条件
- Samba プリントサーバーが、AD ドメインのメンバーである。
- GPO の作成に使用する Windows コンピューターに、RSAT (Windows Remote Server Administration Tools) がインストールされている。詳細は、Windows のドキュメントを参照してください。
手順
-
AD ドメインの
管理者ユーザーなど、グループポリシーの編集が可能なアカウントを使用して、Windows コンピューターにログインします。 -
Group Policy Management Consoleを開きます。 AD ドメインを右クリックし、
Create a GPO in this domain, and Link it hereを選択します。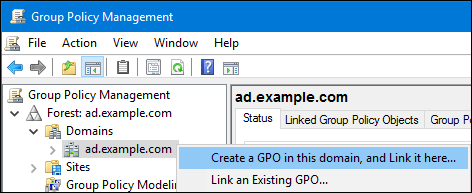
-
Legacy Printer Driver Policyなどの GPO の名前を入力して、OKをクリックします。新しい GPO がドメインエントリーの下に表示されます。 -
新たに作成した GPO を右クリックして
Editを選択し、Group Policy Management Editorを開きます。 → → → の順にクリックします。

ウィンドウの右側で、
Point and Print Restrictionをダブルクリックして、ポリシーを編集します。ポリシーを有効にし、以下のオプションを設定します。
-
Users can only point and print to these serversを選択し、このオプションの横にあるフィールドに、Samba プリントサーバーの完全修飾ドメイン名 (FQDN) を入力します。 Security Promptsの両チェックボックスで、Do not show warning or elevation promptを選択します。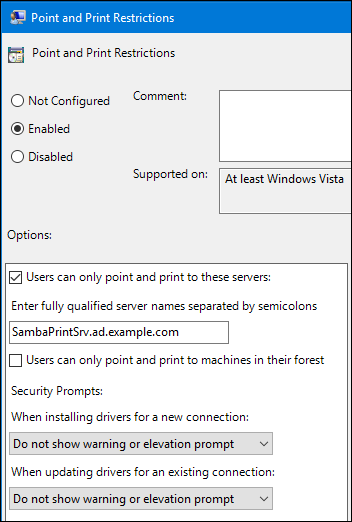
-
- OK をクリックします。
Package Point and Print - Approved serversをダブルクリックして、ポリシーを編集します。-
ポリシーを有効にして、
Showボタンをクリックします。 Samba プリントサーバーの FQDN を入力します。
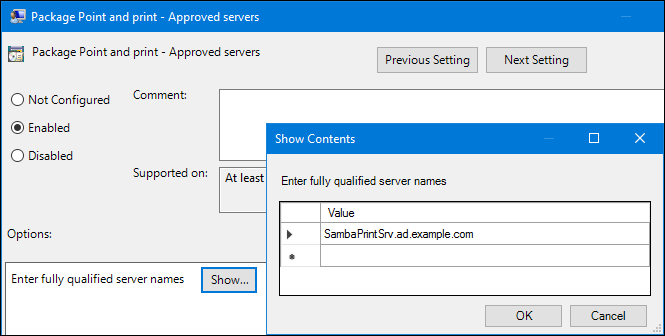
-
OKをクリックして、Show Contentsウィンドウとポリシーのプロパティーウィンドウの両方を閉じます。
-
ポリシーを有効にして、
-
Group Policy Management Editorを閉じます。 -
Group Policy Management Consoleを閉じます。
Windows ドメインメンバーがこのグループポリシーを適用すると、ユーザーがプリンターに接続する際に、プリンタードライバーが Samba サーバーから自動的にダウンロードされます。
関連情報
- グループポリシーの使用については、Windows のドキュメントを参照してください。
3.16.5. ドライバーのアップロードおよびプリンターの事前設定
Windows クライアントで Print Management アプリケーションを使用してドライバーをアップロードし、Samba プリントサーバーでホストされるプリンターを事前設定します。詳細は、Windows のドキュメントを参照してください。
3.17. FIPS モードが有効なサーバーでの Samba の実行
本セクションでは、FIPS モードが有効な状態で Samba を実行する制限の概要を説明します。また、Samba を実行している Red Hat Enterprise Linux ホストで FIPS モードを有効にする手順も提供します。
3.17.1. FIPS モードでの Samba の使用制限
以下の Samba モードと機能は、指定された条件下で FIPS モードで動作します。
- Samba は、AES 暗号化を使用する Kerberos 認証を使用する Active Directory (AD) または Red Hat Identity Management (IdM) 環境でのみ、ドメインメンバーとして使用できます。
- Active Directory ドメインメンバーのファイルサーバーとして Samba を使用する。ただし、クライアントは Kerberos を使用してサーバーに対して認証する必要があります。
FIPS のセキュリティーが強化されているため、FIPS モードが有効な場合は、以下の Samba 機能およびモードは機能しません。
- RC4 暗号がブロックされていることによる NT LAN Manager (NTLM) 認証
- サーバーメッセージブロックバージョン 1 (SMB1) プロトコル
- NTLM 認証を使用することによるスタンドアロンファイルサーバーモード
- NT4- スタイルのドメインコントローラー
- NT4- スタイルのドメインメンバーRed Hat は、IdM がバックグラウンドで使用するプライマリードメインコントローラー (PDC) 機能のサポートを継続することに留意してください。
- Samba サーバーに対するパスワード変更Active Directory ドメインコントローラーに対して Kerberos を使用してパスワードの変更のみを実行できます。
以下の機能は FIPS モードでテストされていないため、Red Hat ではサポートされていません。
- プリントサーバーとしての Samba の実行
3.17.2. FIPS モードでの Samba の使用
Samba を実行する RHEL ホストで FIPS モードを有効にすることができます。
前提条件
- Samba が Red Hat Enterprise Linux ホストに設定されている。
- Samba は、FIPS モードでサポートされるモードで実行する。
手順
RHEL で FIPS モードを有効にします。
# fips-mode-setup --enableサーバーを再起動します。
# reboottestparmユーティリティーを使用して、設定を確認します。# testparm -sコマンドがエラーや非互換性を表示する場合は、Samba が正常に機能するように修正してください。
3.18. Samba サーバーのパフォーマンスチューニング
特定の状況で Samba のパフォーマンスを向上させることができる設定と、パフォーマンスに悪影響を与える可能性がある設定について説明します。
このセクションの一部は、Samba Wiki に公開されているドキュメント Performance Tuning に掲載されています。ライセンスは、CC BY 4.0 にあります。著者および貢献者は、Wiki ページの history タブを参照してください。
前提条件
- Samba が、ファイルサーバーまたはプリントサーバーとして設定されている。
3.18.1. SMB プロトコルバージョンの設定
新しい SMB バージョンごとに機能が追加され、プロトコルのパフォーマンスが向上します。最新の Windows および Windows Server オペレーティングシステムは、常に最新のプロトコルバージョンに対応しています。Samba がプロトコルの最新バージョンも使用している場合は、Samba に接続する Windows クライアントで、このパフォーマンス改善を活用できます。Samba では、server max protocol のデフォルト値が、対応している安定した SMB プロトコルの最新バージョンに設定されます。
常に最新の安定した SMB プロトコルバージョンを有効にするには、server max protocol パラメーターを設定しないでください。このパラメーターを手動で設定する場合は、最新のプロトコルバージョンを有効にするために、それぞれ新しいバージョンの SMB プロトコルで設定を変更する必要があります。
次の手順では、server max protocol パラメーターでデフォルト値を使用する方法を説明します。
手順
-
/etc/samba/smb.confファイルの[global]セクションから、server max protocolパラメーターを削除します。 Samba 設定を再読み込みします。
# smbcontrol all reload-config
3.18.3. パフォーマンスが低下する可能性のある設定
デフォルトでは、Red Hat Enterprise Linux のカーネルは、ネットワークパフォーマンスが高くなるように調整されています。たとえば、カーネルはバッファーサイズに自動チューニングメカニズムを使用しています。/etc/samba/smb.conf ファイルに socket options パラメーターを設定すると、このカーネル設定が上書きされます。その結果、このパラメーターの設定により、ほとんどの場合は、Samba ネットワークのパフォーマンスが低下します。
カーネルの最適化された設定を使用するには、/etc/samba/smb.conf の [global] セクションから socket options パラメーターを削除します。
3.19. Samba がデフォルトの SMB バージョンよりも前のバージョンのクライアントと互換対応するような設定
Samba は、サポート対象の最小サーバーメッセージブロック (SMB) バージョンに妥当で安全なデフォルト値を使用します。ただし、以前の SMB バージョンを必要とするクライアントがある場合は、Samba を設定してサポートできます。
3.19.1. Samba サーバーで対応している最小 SMB プロトコルバージョンの設定
Samba では、/etc/samba/smb.conf ファイルの server min protocol パラメーターは、Samba サーバーが対応する SMB (server message block) プロトコルの最小バージョンを定義します。SMB プロトコルの最小バージョンを変更できます。
デフォルトでは、RHEL 8.2 以降の Samba では、SMB2 以降のプロトコルバージョンのみに対応します。Red Hat は、非推奨の SMB1 プロトコルを使用することは推奨されません。ただし、お使いの環境で SMB1 が必要な場合は、server min protocol パラメーターを手動で NT1 に設定して、SMB1 を再度有効にできます。
前提条件
- Samba がインストールされ、設定されている。
手順
/etc/samba/smb.confファイルを編集し、server min protocolパラメーターを追加して、そのサーバーが対応する最小 SMB プロトコルバージョンに設定できます。たとえば、最小の SMB プロトコルバージョンをSMB3に設定するには、以下を追加します。server min protocol = SMB3
smbサービスを再起動します。# systemctl restart smb
関連情報
-
smb.conf(5)man ページ
3.20. 頻繁に使用される Samba コマンドラインユーティリティー
本章では、Samba サーバーで作業する場合によく使用されるコマンドを説明します。
3.20.1. net ads join コマンドおよび net rpc join コマンドの使用
net ユーティリティーの join サブコマンドを使用すると、Samba を AD ドメインまたは NT4 ドメインに参加させることができます。ドメインに参加するには、/etc/samba/smb.conf ファイルを手動で作成し、必要に応じて PAM などの追加設定を更新する必要があります。
Red Hat は、realm ユーティリティーを使用してドメインに参加させることを推奨します。realm ユーティリティーは、関連するすべての設定ファイルを自動的に更新します。
手順
以下の設定で
/etc/samba/smb.confファイルを手動で作成します。AD ドメインメンバーの場合:
[global] workgroup = domain_name security = ads passdb backend = tdbsam realm = AD_REALM
NT4 ドメインメンバーの場合:
[global] workgroup = domain_name security = user passdb backend = tdbsam
-
/etc/samba/smb.confファイルの[global]セクションに、*デフォルトドメインおよび参加するドメイン用の ID マッピング設定を追加します。 /etc/samba/smb.confファイルを検証します。# testparmドメイン管理者としてドメインに参加します。
AD ドメインに参加するには、以下のコマンドを実行します。
# net ads join -U "DOMAIN\administrator"NT4 ドメインに参加するには、以下のコマンドを実行します。
# net rpc join -U "DOMAIN\administrator"
/etc/nsswitch.confファイルのデータベースエントリーpasswdおよびgroupにwinbindソースを追加します。passwd: files
winbindgroup: fileswinbindwinbindサービスを有効にして起動します。# systemctl enable --now winbind必要に応じて、
authselectユーティリティーを使用して PAM を設定します。詳細は、man ページの
authselect(8)を参照してください。AD 環境では、必要に応じて Kerberos クライアントを設定します。
詳細は、Kerberos クライアントのドキュメントを参照してください。
3.20.2. net rpc rights コマンドの使用
Windows では、アカウントおよびグループに特権を割り当て、共有での ACL の設定やプリンタードライバーのアップロードなどの特別な操作を実行できます。Samba サーバーでは、net rpc rights コマンドを使用して権限を管理できます。
設定可能な権限のリスト表示
利用可能な特権とその所有者をすべて表示するには、net rpc rights list コマンドを使用します。以下に例を示します。
# net rpc rights list -U "DOMAIN\administrator" Enter DOMAIN\administrator's password: SeMachineAccountPrivilege Add machines to domain SeTakeOwnershipPrivilege Take ownership of files or other objects SeBackupPrivilege Back up files and directories SeRestorePrivilege Restore files and directories SeRemoteShutdownPrivilege Force shutdown from a remote system SePrintOperatorPrivilege Manage printers SeAddUsersPrivilege Add users and groups to the domain SeDiskOperatorPrivilege Manage disk shares SeSecurityPrivilege System security
特権の付与
アカウントまたはグループへの特権を付与するには、net rpc rights grant コマンドを使用します。
たとえば、SePrintOperatorPrivilege 権限を、DOMAIN\printadmin グループに付与します。
# net rpc rights grant "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator" Enter DOMAIN\administrator's password: Successfully granted rights.
特権の取り消し
アカウントまたはグループから特権を取り消すには、net rpc rights revoke コマンドを使用します。
たとえば、DOMAIN\printadmin グループから SePrintOperatorPrivilege 権限を取り消すには、以下のコマンドを実行します。
# net rpc rights remoke "DOMAIN\printadmin" SePrintOperatorPrivilege -U "DOMAIN\administrator" Enter DOMAIN\administrator's password: Successfully revoked rights.
3.20.4. net user コマンドの使用
net user コマンドを使用すると、AD DC または NT4 PDC で以下の操作を実行できます。
- すべてのユーザーアカウントのリストを表示
- ユーザーの追加
- ユーザーの削除
AD ドメイン用の ads、NT4 ドメイン用の rpc などの接続方法の指定は、ドメインユーザーアカウントをリスト表示する場合にのみ必要です。その他のユーザー関連のサブコマンドは、接続メソッドを自動検出できます。
-U user_name パラメーターをコマンドに渡して、要求されたアクションを実行できるユーザーを指定します。
ドメインユーザーアカウントのリスト表示
AD ドメイン内のユーザーをリスト表示するには、以下を実行します。
# net ads user -U "DOMAIN\administrator"NT4 ドメインのユーザーをリスト表示するには、以下を実行します。
# net rpc user -U "DOMAIN\administrator"ユーザーアカウントのドメインへの追加
Samba ドメインメンバーの場合は、net user add コマンドを使用して、ユーザーアカウントをドメインに追加できます。
たとえば、user アカウントをドメインに追加します。
以下のアカウントを追加します。
# net user add user password -U "DOMAIN\administrator" User user added
必要に応じて、リモートプロシージャコール (RPC) シェルを使用して、AD DC または NT4 PDC でアカウントを有効にします。以下に例を示します。
# net rpc shell -U DOMAIN\administrator -S DC_or_PDC_name Talking to domain DOMAIN (S-1-5-21-1424831554-512457234-5642315751) net rpc>
user edit disabled user: noSet user's disabled flag from [yes] to [no] net rpc>exit
ドメインからのユーザーアカウントの削除
Samba ドメインメンバーの場合は、net user delete コマンドを使用して、ドメインからユーザーアカウントを削除できます。
たとえば、ドメインから user アカウントを削除するには、以下のコマンドを実行します。
# net user delete user -U "DOMAIN\administrator" User user deleted
3.20.5. rpcclient ユーティリティーの使用
rpcclient ユーティリティーを使用すると、ローカルまたはリモートの SMB サーバーでクライアント側の Microsoft Remote Procedure Call (MS-RPC) 機能を手動で実行できます。ただし、ほとんどの機能は、Samba が提供する個別のユーティリティーに統合されています。rpcclient は、MS-PRC 関数のテストにのみ使用します。
前提条件
-
samba-clientパッケージがインストールされている。
例
たとえば、rpcclient ユーティリティーを使用して以下を行うことができます。
プリンターのスプールサブシステム (SPOOLSS) を管理します。
例3.7 プリンターへのドライバーの割り当て
# rpcclient server_name -U "DOMAIN\administrator" -c 'setdriver "printer_name" "driver_name"' Enter DOMAIN\administrators password: Successfully set printer_name to driver driver_name.
SMB サーバーに関する情報を取得します。
例3.8 すべてのファイル共有および共有プリンターのリスト表示
# rpcclient server_name -U "DOMAIN\administrator" -c 'netshareenum' Enter DOMAIN\administrators password: netname: Example_Share remark: path: C:\srv\samba\example_share\ password: netname: Example_Printer remark: path: C:\var\spool\samba\ password:
Security Account Manager Remote (SAMR) プロトコルを使用して操作を実行します。
例3.9 SMB サーバー上のユーザーのリスト表示
# rpcclient server_name -U "DOMAIN\administrator" -c 'enumdomusers' Enter DOMAIN\administrators password: user:[user1] rid:[0x3e8] user:[user2] rid:[0x3e9]
スタンドアロンサーバーまたはドメインメンバーに対してコマンドを実行すると、ローカルデータベースのユーザーのリストが表示されます。ADDC または NT4 PDC に対してコマンドを実行すると、ドメインユーザーのリストが表示されます。
関連情報
-
rpcclient(1)man ページ
3.20.6. samba-regedit アプリケーションの使用
プリンター設定などの特定の設定は、Samba サーバーのレジストリーに保存されます。ncurses ベースの samba-regedit アプリケーションを使用して、Samba サーバーのレジストリーを編集できます。
前提条件
-
samba-clientパッケージがインストールされている。
手順
アプリケーションを起動するには、次のコマンドを入力します。
# samba-regedit次のキーを使用します。
- カーソルを上下に動かして、レジストリーツリーと値の間を移動します。
- Enter - キーを開くか、値を編集します。
-
Tab -
KeyペインとValueペインを切り替えます。 - Ctrl+C - アプリケーションを閉じます。
3.20.7. smbcontrol ユーティリティーの使用
smbcontrol ユーティリティーを使用すると、smbd、nmbd、winbindd、またはこのすべてのサービスにコマンドメッセージを送信できます。この制御メッセージは、設定の再読み込みなどのサービスを指示します。
前提条件
-
samba-common-toolsパッケージがインストールされている。
手順
-
reload-configメッセージタイプをall宛に送信して、smbd、nmbd、winbinddサービスの設定をリロードします。
# smbcontrol all reload-config関連情報
-
smbcontrol(1)man ページ
3.20.8. smbpasswd ユーティリティーの使用
smbpasswd ユーティリティーは、ローカルの Samba データベースでユーザーアカウントおよびパスワードを管理します。
前提条件
-
samba-common-toolsパッケージがインストールされている。
手順
ユーザーとしてコマンドを実行すると、
smbpasswdはコマンドを実行するユーザーの Samba パスワードを変更します。以下に例を示します。[user@server ~]$ smbpasswd New SMB password: password Retype new SMB password: password
rootでsmbpasswdを実行すると、たとえば以下のようにユーティリティーを使用できます。新しいユーザーを作成します。
[root@server ~]# smbpasswd -a user_name New SMB password:
passwordRetype new SMB password:passwordAdded user user_name.注記Samba データベースにユーザーを追加する前に、ローカルのオペレーティングシステムにアカウントを作成する必要があります。基本的なシステム設定の設定の コマンドラインでの新規ユーザーの追加 セクションを参照してください。
Samba ユーザーを有効にします。
[root@server ~]# smbpasswd -e user_name Enabled user user_name.
Samba ユーザーを無効にします。
[root@server ~]# smbpasswd -x user_name Disabled user user_name
ユーザーを削除します。
[root@server ~]# smbpasswd -x user_name Deleted user user_name.
関連情報
-
smbpasswd(8)man ページ
3.20.9. smbstatus ユーティリティーの使用
smbstatus ユーティリティーは以下について報告します。
-
各
smbdデーモンの PID ごとの接続を Samba サーバーに接続します。このレポートには、ユーザー名、プライマリーグループ、SMB プロトコルのバージョン、暗号、および署名の情報が含まれます。 -
Samba 共有ごとの接続このレポートには、
smbdデーモンの PID、接続しているマシンの IP、接続が確立された時点のタイムスタンプ、暗号、および署名情報が含まれます。 - ロックされたファイルのリスト。レポートエントリーには、日和見ロック (oplock) タイプなどの詳細が含まれます。
前提条件
-
sambaパッケージがインストールされている。 -
smbdサービスが実行している。
手順
# smbstatus Samba version 4.15.2 PID Username Group Machine Protocol Version Encryption Signing ....------------------------------------------------------------------------------------------------------------------------- 963 DOMAIN\administrator DOMAIN\domain users client-pc (ipv4:192.0.2.1:57786) SMB3_02 - AES-128-CMAC Service pid Machine Connected at Encryption Signing: ....--------------------------------------------------------------------------- example 969 192.0.2.1 Thu Nov 1 10:00:00 2018 CEST - AES-128-CMAC Locked files: Pid Uid DenyMode Access R/W Oplock SharePath Name Time ....-------------------------------------------------------------------------------------------------------- 969 10000 DENY_WRITE 0x120089 RDONLY LEASE(RWH) /srv/samba/example file.txt Thu Nov 1 10:00:00 2018
関連情報
-
smbstatus(1)man ページ
3.20.10. smbtar ユーティリティーの使用
smbtar ユーティリティーは、SMB 共有またはそのサブディレクトリーのコンテンツのバックアップを作成し、そのコンテンツを tar アーカイブに保存します。または、コンテンツをテープデバイスに書き込むこともできます。
前提条件
-
samba-clientパッケージがインストールされている。
手順
以下のコマンドを使用して、
//server/example/共有上のdemoディレクトリーのコンテンツをバックアップして、/root/example.tarアーカイブにコンテンツを保存するには、以下を実行します。# smbtar -s server -x example -u user_name -p password -t /root/example.tar
関連情報
-
smbtar(1)の man ページ
3.20.11. wbinfo ユーティリティーの使用
wbinfo ユーティリティーは、winbindd サービスが作成および使用する情報をクエリーし、返します。
前提条件
-
samba-winbind-clientsパッケージがインストールされている。
手順
たとえば、以下のように、wbinfo を使用できます。
ドメインユーザーのリストを表示します。
# wbinfo -u AD\administrator AD\guest ...ドメイングループのリストを表示します。
# wbinfo -g AD\domain computers AD\domain admins AD\domain users ...ユーザーの SID を表示します。
# wbinfo --name-to-sid="AD\administrator" S-1-5-21-1762709870-351891212-3141221786-500 SID_USER (1)
ドメインおよび信頼に関する情報を表示します。
# wbinfo --trusted-domains --verbose Domain Name DNS Domain Trust Type Transitive In Out BUILTIN None Yes Yes Yes server None Yes Yes Yes DOMAIN1 domain1.example.com None Yes Yes Yes DOMAIN2 domain2.example.com External No Yes Yes
関連情報
-
wbinfo(1)man ページ
3.21. 関連情報
-
smb.conf(5)man ページ -
/usr/share/docs/samba-version/ディレクトリーには、Samba プロジェクトが提供する一般的なドキュメント、サンプルスクリプト、および LDAP スキーマファイルが含まれています。 - Setting up Samba and the Clustered Trivial Database (CDTB) to share directories stored on an GlusterFS volume
- Red Hat Enterprise Linux での SMB 共有のマウント
第4章 BIND DNS サーバーのセットアップおよび設定
BIND は、Internet Engineering Task Force (IETF) の DNS 標準およびドラフト標準に完全に準拠した機能豊富な DNS サーバーです。たとえば、管理者は BIND を次のように頻繁に使用します。
- ローカルネットワークでの DNS サーバーのキャッシング
- ゾーンの権威 DNS サーバー
- ゾーンに高可用性を提供するセカンダリーサーバー
4.1. SELinux を使用した BIND の保護または change-root 環境での BIND の実行に関する考慮事項
BIND インストールを保護するには、次のことができます。
change-root 環境なしで
namedサービスを実行します。この場合、enforcingモードの SELinux は、既知の BIND セキュリティー脆弱性の悪用を防ぎます。デフォルトでは、Red Hat Enterprise Linux は SELinux をenforcingモードで使用します。重要RHEL で SELinux を
enforcingモードで使用して BIND を実行すると、change-root 環境で BIND を実行するよりも安全です。name-chrootサービスを change-root 環境で実行します。管理者は、change-root 機能を使用して、プロセスとそのサブプロセスのルートディレクトリーが
/ディレクトリーとは異なるものであることを定義できます。named-chrootサービスを開始すると、BIND はそのルートディレクトリーを/var/named/chroot/に切り替えます。その結果、サービスはmount --bindコマンドを使用して、/etc/named-chroot.filesにリストされているファイルおよびディレクトリーを/var/named/chroot/で使用できるようにし、プロセスは/var/named/chroot/以外のファイルにアクセスできません。
BIND を使用する場合:
-
通常モードでは、
namedサービスを使用します。 -
change-root 環境では、
named-chrootサービスを使用します。これには、named-chrootパッケージを追加でインストールする必要があります。
関連情報
-
named(8)man ページのRed Hat SELinux BIND security profileセクション
4.2. BIND 管理者リファレンスマニュアル
bind パッケージに含まれる総合的な BIND Administrator Reference Manual には、次の内容が記載されています。
- 設定例
- 高度な機能に関するドキュメント
- 設定リファレンス
- セキュリティーに関する考慮事項
bind パッケージがインストールされているホストで BIND Administrator Reference Manual を表示するには、ブラウザーで /usr/share/doc/bind/Bv9ARM.html ファイルを開きます。
4.3. BIND をキャッシュ DNS サーバーとして設定する
デフォルトでは、BIND DNS サーバーは、成功したルックアップと失敗したルックアップを解決してキャッシュします。その後、サービスはキャッシュから同じレコードへの要求に応答します。これにより、DNS ルックアップの速度が大幅に向上します。
前提条件
- サーバーの IP アドレスは静的です。
手順
bindパッケージおよびbind-utilsパッケージをインストールします。# yum install bind bind-utilsこれらのパッケージは BIND 9.11 を提供します。BIND 9.16 が必要な場合は、
bind9.16およびbind9.16-utilsパッケージをインストールしてください。BIND を change-root 環境で実行する場合は、
bind-chrootパッケージをインストールします。# yum install bind-chrootデフォルトである
enforcingモードで SELinux を使用するホストで BIND を実行すると、より安全になることに注意してください。/etc/named.confファイルを編集し、optionsステートメントに次の変更を加えます。listen-onおよびlisten-on-v6ステートメントを更新して、BIND がリッスンする IPv4 インターフェイスおよび IPv6 インターフェイスを指定します。listen-on port 53 { 127.0.0.1; 192.0.2.1; }; listen-on-v6 port 53 { ::1; 2001:db8:1::1; };
allow-queryステートメントを更新して、クライアントがこの DNS サーバーにクエリーを実行できる IP アドレスおよび範囲を設定します。allow-query { localhost; 192.0.2.0/24; 2001:db8:1::/64; };allow-recursionステートメントを追加して、BIND が再帰クエリーを受け入れる IP アドレスおよび範囲を定義します。allow-recursion { localhost; 192.0.2.0/24; 2001:db8:1::/64; };警告サーバーのパブリック IP アドレスで再帰を許可しないでください。そうしないと、サーバーが大規模な DNS 増幅攻撃の一部になる可能性があります。
デフォルトでは、BIND は、ルートサーバーから権限のある DNS サーバーに再帰的にクエリーを実行することにより、クエリーを解決します。または、プロバイダーのサーバーなど、他の DNS サーバーにクエリーを転送するように BIND を設定することもできます。この場合、BIND がクエリーを転送する DNS サーバーの IP アドレスのリストを含む
forwardersステートメントを追加します。forwarders { 198.51.100.1; 203.0.113.5; };フォールバック動作として、フォワーダーサーバーが応答しないと、BIND はクエリーを再帰的に解決します。この動作を無効にするには、
forward only;ステートメントを追加します。
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
着信 DNS トラフィックを許可するように
firewalldルールを更新します。# firewall-cmd --permanent --add-service=dns # firewall-cmd --reload
BIND を開始して有効にします。
# systemctl enable --now namedchange-root 環境で BIND を実行する場合は、
systemctl enable --now named-chrootコマンドを使用して、サービスを有効にして開始します。
検証
新しく設定した DNS サーバーを使用してドメインを解決します。
# dig @localhost www.example.org ... www.example.org. 86400 IN A 198.51.100.34 ;; Query time: 917 msec ...
この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。初めてレコードをクエリーした後、BIND はエントリーをそのキャッシュに追加します。
前のクエリーを繰り返します。
# dig @localhost www.example.org ... www.example.org. 85332 IN A 198.51.100.34 ;; Query time: 1 msec ...
エントリーがキャッシュされるため、エントリーの有効期限が切れるまで、同じレコードに対するそれ以降のリクエストは大幅に高速化されます。
次のステップ
- この DNS サーバーを使用するようにネットワーク内のクライアントを設定します。DHCP サーバーが DNS サーバー設定をクライアントに提供する場合は、それに応じて DHCP サーバーの設定を更新します。
関連情報
- SELinux を使用した BIND の保護または change-root 環境での BIND の実行に関する考慮事項
-
named.conf(5)man ページ -
/usr/share/doc/bind/sample/etc/named.conf - BIND 管理者リファレンスマニュアル
4.4. BIND DNS サーバーでのログの設定
bind パッケージによって提供されるデフォルトの /etc/named.conf ファイル内の設定は、default_debug チャネルを使用し、メッセージのログを /var/named/data/named.run ファイルに記録します。default_debug チャネルは、サーバーのデバッグレベルがゼロ以外の場合にのみエントリーをログに記録します。
さまざまなチャネルおよびカテゴリーを使用して、BIND を設定して、定義された重大度でさまざまなイベントを個別のファイルに書き込むことができます。
前提条件
- BIND は、たとえばキャッシングネームサーバーとしてすでに設定されています。
-
namedまたはnamed-chrootサービスが実行しています。
手順
/etc/named.confファイルを編集し、categoryおよびchannelフレーズをloggingステートメントに追加します。次に例を示します。logging { ... category notify { zone_transfer_log; }; category xfer-in { zone_transfer_log; }; category xfer-out { zone_transfer_log; }; channel zone_transfer_log { file "/var/named/log/transfer.log" versions 10 size 50m; print-time yes; print-category yes; print-severity yes; severity info; }; ... };この設定例では、BIND はゾーン転送に関連するメッセージのログを
/var/named/log/transfer.logに記録します。BIND は最大10バージョンのログファイルを作成し、最大サイズが50MB に達するとローテーションします。category句は、BIND がカテゴリーのメッセージを送信するチャネルを定義します。channel句は、バージョン数、最大ファイルサイズ、および BIND がチャネルにログ記録する必要がある重大度レベルを含むログメッセージの宛先を定義します。イベントのタイムスタンプ、カテゴリー、および重大度のログ記録を有効にするなどの追加設定はオプションですが、デバッグ目的で役立ちます。ログディレクトリーが存在しない場合は作成し、このディレクトリーの
namedユーザーに書き込み権限を付与します。# mkdir /var/named/log/ # chown named:named /var/named/log/ # chmod 700 /var/named/log/
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
BIND を再起動します。
# systemctl restart namedchange-root 環境で BIND を実行する場合は、
systemctl restart named-chrootコマンドを使用してサービスを再起動します。
検証
ログファイルの内容を表示します。
# cat /var/named/log/transfer.log ... 06-Jul-2022 15:08:51.261 xfer-out: info: client @0x7fecbc0b0700 192.0.2.2#36121/key example-transfer-key (example.com): transfer of 'example.com/IN': AXFR started: TSIG example-transfer-key (serial 2022070603) 06-Jul-2022 15:08:51.261 xfer-out: info: client @0x7fecbc0b0700 192.0.2.2#36121/key example-transfer-key (example.com): transfer of 'example.com/IN': AXFR ended
関連情報
-
named.conf(5)man ページ - BIND 管理者リファレンスマニュアル
4.5. BIND ACL の作成
BIND の特定の機能へのアクセスを制御することで、サービス拒否 (DoS) などの不正アクセスや攻撃を防ぐことができます。BIND アクセス制御リスト (acl) ステートメントは、IP アドレスと範囲のリストです。各 ACL には、指定された IP アドレスと範囲を参照するために allow-query などのいくつかのステートメントで使用できるニックネームがあります。
BIND は、ACL で最初に一致したエントリーのみを使用します。たとえば、ACL { 192.0.2/24; !192.0.2.1; } を定義し、IP アドレス 192.0.2.1 でホストが接続すると、2 番目のエントリーでこのアドレスが除外されていてもアクセスが許可されます。
BIND には次の組み込み ACL があります。
-
none: どのホストとも一致しません。 -
any: すべてのホストに一致します。 -
localhost: ループバックアドレス127.0.0.1と::1、および BIND を実行するサーバー上のすべてのインターフェイスの IP アドレスに一致します。 -
localnets: ループバックアドレス127.0.0.1と::1、および BIND を実行するサーバーが直接接続しているすべてのサブネットに一致します。
前提条件
- BIND は、たとえばキャッシングネームサーバーとしてすでに設定されています。
-
namedまたはnamed-chrootサービスが実行しています。
手順
/etc/named.confファイルを編集して、次の変更を行います。aclステートメントをファイルに追加します。たとえば、127.0.0.1、192.0.2.0/24、および2001:db8:1::/64に対してinternal-networksという名前の ACL を作成するには、次のように入力します。acl internal-networks { 127.0.0.1; 192.0.2.0/24; 2001:db8:1::/64; }; acl dmz-networks { 198.51.100.0/24; 2001:db8:2::/64; };
ACL のニックネームをサポートするステートメントで使用します。たとえば、次のようになります。
allow-query { internal-networks; dmz-networks; }; allow-recursion { internal-networks; };
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
検証
設定された ACL を使用する機能をトリガーするアクションを実行します。たとえば、この手順の ACL は、定義された IP アドレスからの再帰クエリーのみを許可します。この場合は、ACL の定義に含まれていないホストで次のコマンドを入力して、外部ドメインの解決を試みます。
# dig +short @192.0.2.1 www.example.comコマンドが出力を返さないと、BIND はアクセスを拒否し、ACL は機能しています。クライアントで詳細な出力を得るには、
+shortオプションを指定せずにコマンドを使用します。# dig @192.0.2.1 www.example.com ... ;; WARNING: recursion requested but not available ...
関連情報
-
The BIND Administrator Reference Manual の
Access control listsセクション。
4.6. BIND DNS サーバーでのゾーンの設定
DNS ゾーンは、ドメインスペース内の特定のサブツリーのリソースレコードを含むデータベースです。たとえば、example.com ドメインを担当している場合は、BIND でそのゾーンを設定できます。その結果、クライアントは www.example.com をこのゾーンで設定された IP アドレスに解決できます。
4.6.1. ゾーンファイルの SOA レコード
SOA (Start of Authority) レコードは、DNS ゾーンで必要なレコードです。このレコードは、たとえば、複数の DNS サーバーがゾーンだけでなく DNS リゾルバーに対しても権限を持っている場合に重要です。
BIND の SOA レコードの構文は次のとおりです。
name class type mname rname serial refresh retry expire minimum
読みやすくするために、管理者は通常、ゾーンファイル内のレコードを、セミコロン (;) で始まるコメントを使用して複数の行に分割します。SOA レコードを分割する場合は、括弧でレコードをまとめることに注意してください。
@ IN SOA ns1.example.com. hostmaster.example.com. ( 2022070601 ; serial number 1d ; refresh period 3h ; retry period 3d ; expire time 3h ) ; minimum TTL
完全修飾ドメイン名 (FQDN) の末尾にあるドットに注意してください。FQDN は、ドットで区切られた複数のドメインラベルで設定されます。DNS ルートには空のラベルがあるため、FQDN はドットで終わります。したがって、BIND はゾーン名を末尾のドットなしで名前に追加します。末尾にドットがないホスト名 (例: ns1.example.com) は、ns1.example.com.example.com. に展開されます。これは、プライマリーネームサーバーの正しいアドレスではありません。
SOA レコードのフィールドは次のとおりです。
-
name: ゾーンの名前 (つまりorigin)。このフィールドを@に設定すると、BIND はそれを/etc/named.confで定義されたゾーン名に展開します。 -
class: SOA レコードでは、このフィールドを常に Internet (IN) に設定する必要があります。 -
type: SOA レコードでは、このフィールドを常にSOAに設定する必要があります。 -
mname(マスター名): このゾーンのプライマリーネームサーバーのホスト名。 -
rname(責任者名): このゾーンの責任者の電子メールアドレス。形式が異なりますのでご注意ください。アットマーク (@) をドット (.) に置き換える必要があります。 serial: このゾーンファイルのバージョン番号。セカンダリーネームサーバーは、プライマリーサーバーのシリアル番号の方が大きい場合にのみ、ゾーンのコピーを更新します。形式は任意の数値にすることができます。一般的に使用される形式は
<year><month><day><two-digit-number>です。この形式を使用すると、理論的には、ゾーンファイルを 1 日に 100 回まで変更できます。-
refresh: ゾーンが更新された場合は、プライマリーサーバーをチェックする前にセカンダリーサーバーが待機する時間。 -
retry: 試行が失敗した後、セカンダリーサーバーがプライマリーサーバーへのクエリーを再試行するまでの時間。 -
expire: 以前の試行がすべて失敗した場合に、セカンダリーサーバーがプライマリーサーバーへのクエリーを停止した後の時間。 -
minimum: RFC 2308 は、このフィールドの意味を負のキャッシュ時間に変更しました。準拠リゾルバーは、NXDOMAIN名エラーをキャッシュする期間を決定するために使用します。
refresh、retry、expire、および maximum フィールドの数値は、時間を秒単位で定義します。ただし、読みやすくするために、時間の接尾辞 (m は分、h は時間、d は日など) を使用してください。たとえば、3h は 3 時間を表します。
4.6.2. BIND プライマリーサーバーでの正引きゾーンの設定
正引きゾーンは、名前を IP アドレスやその他の情報にマップします。たとえば、ドメイン example.com を担当している場合は、BIND で転送ゾーンを設定して、www.example.com などの名前を解決できます。
前提条件
- BIND は、たとえばキャッシングネームサーバーとしてすでに設定されています。
-
namedまたはnamed-chrootサービスが実行しています。
手順
/etc/named.confファイルにゾーン定義を追加します。zone "example.com" { type master; file "example.com.zone"; allow-query { any; }; allow-transfer { none; }; };
これらの設定により、次が定義されます。
-
このサーバーは、
example.comゾーンのプライマリーサーバー (type master) です。 -
/var/named/example.com.zoneファイルはゾーンファイルです。この例のように相対パスを設定すると、このパスは、optionsステートメントのdirectoryに設定したディレクトリーからの相対パスになります。 - どのホストもこのゾーンにクエリーを実行できます。または、IP 範囲または BIND アクセス制御リスト (ACL) のニックネームを指定して、アクセスを制限します。
- どのホストもゾーンを転送できません。ゾーン転送を許可するのは、セカンダリーサーバーをセットアップする際に限られ、セカンダリーサーバーの IP アドレスに対してのみ許可します。
-
このサーバーは、
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
たとえば、次の内容で
/var/named/example.com.zoneファイルを作成します。$TTL 8h @ IN SOA ns1.example.com. hostmaster.example.com. ( 2022070601 ; serial number 1d ; refresh period 3h ; retry period 3d ; expire time 3h ) ; minimum TTL IN NS ns1.example.com. IN MX 10 mail.example.com. www IN A 192.0.2.30 www IN AAAA 2001:db8:1::30 ns1 IN A 192.0.2.1 ns1 IN AAAA 2001:db8:1::1 mail IN A 192.0.2.20 mail IN AAAA 2001:db8:1::20
このゾーンファイル:
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 8 時間に設定します。時間の
hなどの時間接尾辞がない場合、BIND は値を秒として解釈します。 - ゾーンに関する詳細を含む、必要な SOA リソースレコードが含まれています。
-
このゾーンの権威 DNS サーバーとして
ns1.example.comを設定します。ゾーンを機能させるには、少なくとも 1 つのネームサーバー (NS) レコードが必要です。ただし、RFC 1912 に準拠するには、少なくとも 2 つのネームサーバーが必要です。 -
example.comドメインのメールエクスチェンジャー (MX) としてmail.example.comを設定します。ホスト名の前の数値は、レコードの優先度です。値が小さいエントリーほど優先度が高くなります。 -
www.example.com、mail.example.com、およびns1.example.comの IPv4 アドレスおよび IPv6 アドレスを設定します。
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 8 時間に設定します。時間の
namedグループだけがそれを読み取ることができるように、ゾーンファイルに安全なアクセス許可を設定します。# chown root:named /var/named/example.com.zone # chmod 640 /var/named/example.com.zone
/var/named/example.com.zoneファイルの構文を確認します。# named-checkzone example.com /var/named/example.com.zone zone example.com/IN: loaded serial 2022070601 OK
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
検証
example.comゾーンからさまざまなレコードをクエリーし、出力がゾーンファイルで設定したレコードと一致することを確認します。# dig +short @localhost AAAA www.example.com 2001:db8:1::30 # dig +short @localhost NS example.com ns1.example.com. # dig +short @localhost A ns1.example.com 192.0.2.1
この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。
4.6.3. BIND プライマリーサーバーでの逆引きゾーンの設定
逆ゾーンは、IP アドレスを名前にマップします。たとえば、IP 範囲 192.0.2.0/24 を担当している場合は、BIND で逆引きゾーンを設定して、この範囲の IP アドレスをホスト名に解決できます。
クラスフルネットワーク全体の逆引きゾーンを作成する場合は、それに応じてゾーンに名前を付けます。たとえば、クラス C ネットワーク 192.0.2.0/24 の場合は、ゾーンの名前が 2.0.192.in-addr.arpa です。192.0.2.0/28 など、異なるネットワークサイズの逆引きゾーンを作成する場合は、ゾーンの名前が 28-2.0.192.in-addr.arpa です。
前提条件
- BIND は、たとえばキャッシングネームサーバーとしてすでに設定されています。
-
namedまたはnamed-chrootサービスが実行しています。
手順
/etc/named.confファイルにゾーン定義を追加します。zone "2.0.192.in-addr.arpa" { type master; file "2.0.192.in-addr.arpa.zone"; allow-query { any; }; allow-transfer { none; }; };
これらの設定により、次が定義されます。
-
2.0.192.in-addr.arpa逆引きゾーンのプライマリーサーバー (type master) としてのこのサーバー。 -
/var/named/2.0.192.in-addr.arpa.zoneファイルはゾーンファイルです。この例のように相対パスを設定すると、このパスは、optionsステートメントのdirectoryに設定したディレクトリーからの相対パスになります。 - どのホストもこのゾーンにクエリーを実行できます。または、IP 範囲または BIND アクセス制御リスト (ACL) のニックネームを指定して、アクセスを制限します。
- どのホストもゾーンを転送できません。ゾーン転送を許可するのは、セカンダリーサーバーをセットアップする際に限られ、セカンダリーサーバーの IP アドレスに対してのみ許可します。
-
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
たとえば、次の内容で
/var/named/2.0.192.in-addr.arpa.zoneファイルを作成します。$TTL 8h @ IN SOA ns1.example.com. hostmaster.example.com. ( 2022070601 ; serial number 1d ; refresh period 3h ; retry period 3d ; expire time 3h ) ; minimum TTL IN NS ns1.example.com. 1 IN PTR ns1.example.com. 30 IN PTR www.example.com.
このゾーンファイル:
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 8 時間に設定します。時間の
hなどの時間接尾辞がない場合、BIND は値を秒として解釈します。 - ゾーンに関する詳細を含む、必要な SOA リソースレコードが含まれています。
-
ns1.example.comをこの逆引きゾーンの権威 DNS サーバーとして設定します。ゾーンを機能させるには、少なくとも 1 つのネームサーバー (NS) レコードが必要です。ただし、RFC 1912 に準拠するには、少なくとも 2 つのネームサーバーが必要です。 -
192.0.2.1および192.0.2.30アドレスのポインター (PTR) レコードを設定します。
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 8 時間に設定します。時間の
namedグループのみがそれを読み取ることができるように、ゾーンファイルに安全なアクセス許可を設定します。# chown root:named /var/named/2.0.192.in-addr.arpa.zone # chmod 640 /var/named/2.0.192.in-addr.arpa.zone
/var/named/2.0.192.in-addr.arpa.zoneファイルの構文を確認します。# named-checkzone 2.0.192.in-addr.arpa /var/named/2.0.192.in-addr.arpa.zone zone 2.0.192.in-addr.arpa/IN: loaded serial 2022070601 OK
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
検証
逆引きゾーンからさまざまなレコードをクエリーし、出力がゾーンファイルで設定したレコードと一致することを確認します。
# dig +short @localhost -x 192.0.2.1 ns1.example.com. # dig +short @localhost -x 192.0.2.30 www.example.com.
この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。
4.6.4. BIND ゾーンファイルの更新
サーバーの IP アドレスが変更された場合など、特定の状況では、ゾーンファイルを更新する必要があります。複数の DNS サーバーが 1 つのゾーンを担ってる場合は、この手順をプライマリーサーバーでのみ実行してください。ゾーンのコピーを保存する他の DNS サーバーは、ゾーン転送を通じて更新を受け取ります。
前提条件
- ゾーンが設定されました。
-
namedまたはnamed-chrootサービスが実行しています。
手順
オプション:
/etc/named.confファイル内のゾーンファイルへのパスを特定します。options { ... directory "/var/named"; } zone "example.com" { ... file "example.com.zone"; };ゾーンの定義の
fileステートメントで、ゾーンファイルへのパスを見つけます。相対パスは、optionsステートメントのdirectoryに設定されたディレクトリーからの相対パスです。ゾーンファイルを編集します。
- 必要な変更を行います。
SOA (Start of Authority) レコードのシリアル番号を増やします。
重要シリアル番号が以前の値以下の場合、セカンダリーサーバーはゾーンのコピーを更新しません。
ゾーンファイルの構文を確認します。
# named-checkzone example.com /var/named/example.com.zone zone example.com/IN: loaded serial 2022062802 OK
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
検証
追加、変更、または削除したレコードを照会します。たとえば、次のようになります。
# dig +short @localhost A ns2.example.com 192.0.2.2この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。
4.6.5. 自動鍵生成およびゾーン保守機能を使用した DNSSEC ゾーン署名
DNSSEC (Domain Name System Security Extensions) でゾーンに署名して、認証およびデータの整合性を確保できます。このようなゾーンには、追加のリソースレコードが含まれます。クライアントはそれらを使用して、ゾーン情報の信頼性を検証できます。
ゾーンの DNSSEC ポリシー機能を有効にすると、BIND は次のアクションを自動的に実行します。
- キーを作成します。
- ゾーンに署名します
- 鍵の再署名や定期的な交換など、ゾーンを維持します。
外部 DNS サーバーがゾーンの信頼性を検証できるようにするには、ゾーンの公開キーを親ゾーンに追加する必要があります。これを行う方法の詳細については、ドメインプロバイダーまたはレジストリーにお問い合わせください。
この手順では、BIND に組み込まれている default の DNSSEC ポリシーを使用します。このポリシーは、単一の ECDSAP256SHA 鍵署名を使用します。または、独自のポリシーを作成して、カスタムキー、アルゴリズム、およびタイミングを使用します。
前提条件
-
BIND 9.16 以降がインストールされている。この要件を満たすには、
bindの代わりにbind9.16パッケージをインストールします。 - DNSSEC を有効にするゾーンが設定されている。
-
namedまたはnamed-chrootサービスが実行しています。 - サーバーは時刻をタイムサーバーと同期します。DNSSEC 検証では、正確なシステム時刻が重要です。
手順
/etc/named.confファイルを編集し、DNSSEC を有効にするゾーンにdnssec-policy default;を追加します。zone "example.com" { ... dnssec-policy default; };
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。BIND は公開鍵を
/var/named/K<zone_name>.+<algorithm>+<key_ID>.keyファイルに保存します。このファイルを使用して、親ゾーンが必要とする形式でゾーンの公開鍵を表示します。DS レコード形式:
# dnssec-dsfromkey /var/named/Kexample.com.+013+61141.key example.com. IN DS 61141 13 2 3E184188CF6D2521EDFDC3F07CFEE8D0195AACBD85E68BAE0620F638B4B1B027
DNSKEY 形式:
# grep DNSKEY /var/named/Kexample.com.+013+61141.key example.com. 3600 IN DNSKEY 257 3 13 sjzT3jNEp120aSO4mPEHHSkReHUf7AABNnT8hNRTzD5cKMQSjDJin2I3 5CaKVcWO1pm+HltxUEt+X9dfp8OZkg==
- ゾーンの公開鍵を親ゾーンに追加するように要求します。これを行う方法の詳細については、ドメインプロバイダーまたはレジストリーにお問い合わせください。
検証
DNSSEC 署名を有効にしたゾーンのレコードについて、独自の DNS サーバーにクエリーを実行します。
# dig +dnssec +short @localhost A www.example.com 192.0.2.30 A 13 3 28800 20220718081258 20220705120353 61141 example.com. e7Cfh6GuOBMAWsgsHSVTPh+JJSOI/Y6zctzIuqIU1JqEgOOAfL/Qz474 M0sgi54m1Kmnr2ANBKJN9uvOs5eXYw==
この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。公開鍵が親ゾーンに追加され、他のサーバーに伝播されたら、サーバーが署名付きゾーンへのクエリーで認証済みデータ (
ad) フラグを設定することを確認します。# dig @localhost example.com +dnssec ... ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ...
4.7. BIND DNS サーバー間のゾーン転送の設定
ゾーン転送により、ゾーンのコピーを持つすべての DNS サーバーが最新のデータを使用することが保証されます。
前提条件
- 将来のプライマリーサーバーでは、ゾーン転送を設定するゾーンが設定されている。
- 将来のセカンダリーサーバーでは、BIND はキャッシュネームサーバーなどとして設定されている。
-
両方のサーバーで、
namedサービスまたはnamed-chrootサービスが実行している。
手順
既存のプライマリーサーバーで、以下を行います。
共有キーを作成し、
/etc/named.confファイルに追加します。# tsig-keygen example-transfer-key | tee -a /etc/named.conf key "example-transfer-key" { algorithm hmac-sha256; secret "q7ANbnyliDMuvWgnKOxMLi313JGcTZB5ydMW5CyUGXQ="; };
このコマンドは、
tsig-keygenコマンドの出力を表示し、自動的に/etc/named.confに追加します。後でセカンダリーサーバーでもコマンドの出力が必要になります。
/etc/named.confファイルのゾーン定義を編集します。allow-transferステートメントで、サーバーがゾーンを転送するためにexample-transfer-keyステートメントで指定されたキーを提供する必要があることを定義します。zone "example.com" { ... allow-transfer { key example-transfer-key; }; };
または、
allow-transferステートメントで BIND アクセス制御リスト (ACL) ニックネームを使用します。デフォルトでは、ゾーンが更新された後、BIND は、このゾーンにネームサーバー (
NS) レコードを持つすべてのネームサーバーに通知します。セカンダリーサーバーのNSレコードをゾーンに追加する予定がない場合は、BIND がこのサーバーに通知するように設定できます。そのために、このセカンダリーサーバーの IP アドレスを含むalso-notifyステートメントをゾーンに追加します。zone "example.com" { ... also-notify { 192.0.2.2; 2001:db8:1::2; }; };
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
将来のセカンダリーサーバーで、以下を行います。
/etc/named.confファイルを次のように編集します。プライマリーサーバーと同じキー定義を追加します。
key "example-transfer-key" { algorithm hmac-sha256; secret "q7ANbnyliDMuvWgnKOxMLi313JGcTZB5ydMW5CyUGXQ="; };
/etc/named.confファイルにゾーン定義を追加します。zone "example.com" { type slave; file "slaves/example.com.zone"; allow-query { any; }; allow-transfer { none; }; masters { 192.0.2.1 key example-transfer-key; 2001:db8:1::1 key example-transfer-key; }; };
これらの設定状態:
-
このサーバーは、
example.comゾーンのセカンダリーサーバー (type slave) です。 -
/var/named/slaves/example.com.zoneファイルはゾーンファイルです。この例のように相対パスを設定すると、このパスは、optionsステートメントのdirectoryに設定したディレクトリーからの相対パスになります。このサーバーがセカンダリーであるゾーンファイルをプライマリーサーバーから分離するには、それを/var/named/slaves/ディレクトリーなどに保存します。 - どのホストもこのゾーンにクエリーを実行できます。または、IP 範囲または ACL ニックネームを指定して、アクセスを制限します。
- このサーバーからゾーンを転送できるホストはありません。
-
このゾーンのプライマリーサーバーの IP アドレスは
192.0.2.1および2001:db8:1::2です。または、ACL ニックネームを指定できます。このセカンダリーサーバーは、example-transfer-keyという名前のキーを使用して、プライマリーサーバーに対する認証を行います。
-
このサーバーは、
/etc/named.confファイルの構文を確認します。# named-checkconfBIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
-
オプション: プライマリーサーバーのゾーンファイルを変更し、新しいセカンダリーサーバーの
NSレコードを追加します。
検証
セカンダリーサーバーで次の手順を実行します。
namedサービスのsystemdジャーナルエントリーを表示します。# journalctl -u named ... Jul 06 15:08:51 ns2.example.com named[2024]: zone example.com/IN: Transfer started. Jul 06 15:08:51 ns2.example.com named[2024]: transfer of 'example.com/IN' from 192.0.2.1#53: connected using 192.0.2.2#45803 Jul 06 15:08:51 ns2.example.com named[2024]: zone example.com/IN: transferred serial 2022070101 Jul 06 15:08:51 ns2.example.com named[2024]: transfer of 'example.com/IN' from 192.0.2.1#53: Transfer status: success Jul 06 15:08:51 ns2.example.com named[2024]: transfer of 'example.com/IN' from 192.0.2.1#53: Transfer completed: 1 messages, 29 records, 2002 bytes, 0.003 secs (667333 bytes/sec)change-root 環境で BIND を実行する場合は、
journalctl -u named-chrootコマンドを使用してジャーナルエントリーを表示します。BIND がゾーンファイルを作成したことを確認します。
# ls -l /var/named/slaves/ total 4 -rw-r--r--. 1 named named 2736 Jul 6 15:08 example.com.zoneデフォルトでは、セカンダリーサーバーはゾーンファイルを未修正のバイナリー形式で保存することに注意してください。
セカンダリーサーバーから転送されたゾーンのレコードをクエリーします。
# dig +short @192.0.2.2 AAAA www.example.com 2001:db8:1::30この例では、この手順で設定したセカンダリーサーバーが IP アドレス
192.0.2.2でリッスンしていると想定しています。
4.8. DNS レコードを上書きするように BIND で応答ポリシーゾーンを設定する
管理者は、DNS のブロックとフィルタリングを使用して、DNS 応答を書き換えて、特定のドメインまたはホストへのアクセスをブロックできます。BIND では、応答ポリシーゾーン (RPZ) がこの機能を提供します。NXDOMAIN エラーを返す、クエリーに応答しないなど、ブロックされたエントリーに対してさまざまなアクションを設定できます。
環境内に複数の DNS サーバーがある場合は、この手順を使用してプライマリーサーバーで RPZ を設定し、後でゾーン転送を設定して、セカンダリーサーバーで RPZ を使用できるようにします。
前提条件
- BIND は、たとえばキャッシングネームサーバーとしてすでに設定されています。
-
namedまたはnamed-chrootサービスが実行しています。
手順
/etc/named.confファイルを編集し、次の変更を行います。optionsステートメントにresponse-policy定義を追加します。options { ... response-policy { zone "rpz.local"; }; ... }response-policyのzoneステートメントで RPZ のカスタム名を設定できます。ただし、次のステップのゾーン定義で同じ名前を使用する必要があります。前の手順で設定した RPZ の
zone定義を追加します。zone "rpz.local" { type master; file "rpz.local"; allow-query { localhost; 192.0.2.0/24; 2001:db8:1::/64; }; allow-transfer { none; }; };
これらの設定状態:
-
このサーバーは、
rpz.localという名前の RPZ のプライマリーサーバー (type master) です。 -
/var/named/rpz.localファイルはゾーンファイルです。この例のように相対パスを設定すると、このパスは、optionsステートメントのdirectoryに設定したディレクトリーからの相対パスになります。 -
allow-queryで定義されたホストは、この RPZ をクエリーできます。または、IP 範囲または BIND アクセス制御リスト (ACL) のニックネームを指定して、アクセスを制限します。 - どのホストもゾーンを転送できません。ゾーン転送を許可するのは、セカンダリーサーバーをセットアップする際に限られ、セカンダリーサーバーの IP アドレスに対してのみ許可します。
-
このサーバーは、
/etc/named.confファイルの構文を確認します。# named-checkconfコマンドが出力を表示しない場合は、構文に間違いがありません。
たとえば、次の内容で
/var/named/rpz.localファイルを作成します。$TTL 10m @ IN SOA ns1.example.com. hostmaster.example.com. ( 2022070601 ; serial number 1h ; refresh period 1m ; retry period 3d ; expire time 1m ) ; minimum TTL IN NS ns1.example.com. example.org IN CNAME . *.example.org IN CNAME . example.net IN CNAME rpz-drop. *.example.net IN CNAME rpz-drop.
このゾーンファイル:
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 10 分に設定します。時間の
hなどの時間接尾辞がない場合、BIND は値を秒として解釈します。 - ゾーンに関する詳細を含む、必要な SOA (Start of Authority) リソースレコードが含まれます。
-
このゾーンの権威 DNS サーバーとして
ns1.example.comを設定します。ゾーンを機能させるには、少なくとも 1 つのネームサーバー (NS) レコードが必要です。ただし、RFC 1912 に準拠するには、少なくとも 2 つのネームサーバーが必要です。 -
このドメイン内の
example.orgおよびホストへのクエリーに対してNXDOMAINエラーを返します。 -
このドメイン内の
example.netおよびホストにクエリーを破棄します。
アクションおよび例の完全なリストは、IETF draft: DNS Response Policy Zones (RPZ) を参照してください。
-
リソースレコードのデフォルトの有効期限 (TTL) 値を 10 分に設定します。時間の
/var/named/rpz.localファイルの構文を確認します。# named-checkzone rpz.local /var/named/rpz.local zone rpz.local/IN: loaded serial 2022070601 OK
BIND をリロードします。
# systemctl reload namedchange-root 環境で BIND を実行する場合は、
systemctl reload named-chrootコマンドを使用してサービスをリロードします。
検証
NXDOMAINエラーを返すように RPZ で設定されているexample.orgのホストを解決しようとします。# dig @localhost www.example.org ... ;; ->>HEADER<<- opcode: QUERY, status: NXDOMAIN, id: 30286 ...
この例では、BIND が同じホストで実行し、
localhostインターフェイスでクエリーに応答することを前提としています。RPZ でクエリーを破棄するように設定されている
example.netドメイン内のホストの解決を試みます。# dig @localhost www.example.net ... ;; connection timed out; no servers could be reached ...
4.9. dnstap を使用して DNS クエリーを記録する
ネットワーク管理者は、ドメインネームシステム (DNS) の詳細を記録して、DNS トラフィックパターンの分析、DNS サーバーのパフォーマンスの監視、DNS 問題のトラブルシューティングを行うことができます。受信する名前クエリーの詳細を監視してログに記録する高度な方法が必要な場合は、named サービスから送信されたメッセージを記録する dnstap インターフェイスを使用します。DNS クエリーをキャプチャーおよび記録して、Web サイトまたは IP アドレスに関する情報を収集できます。
前提条件
-
bind-9.11.26-2パッケージ以降のバージョンがインストールされている。
BIND バージョンがすでにインストールされ、実行されている場合、新しいバージョンの BIND を追加すると、既存のバージョンが上書きされます。
手順
/etc/named.confファイルのoptionsブロックを編集して、dnstapとターゲットファイルを有効にします。options { # ... dnstap { all; }; # Configure filter dnstap-output file "/var/named/data/dnstap.bin"; # ... }; # end of optionsログに記録する DNS トラフィックのタイプを指定するには、
/etc/named.confファイルのdnstapブロックにdnstapフィルターを追加します。次のフィルターを使用できます。-
auth: 権威ゾーンの応答または回答。 -
client: 内部クライアントクエリーまたは回答。 -
forwarder: 転送クエリーまたは応答。 -
resolver: 反復的解決クエリーまたは応答。 -
update: 動的ゾーン更新要求。 -
all: 上記のオプションのいずれか。 queryまたはresponse:queryまたはresponseキーワードを指定しない場合、dnstapは両方を記録します。注記dnstapフィルターでは、dnstap {}ブロック内に;で区切った複数の定義を含めます。次の構文を使用してください。dnstap { ( all | auth | client | forwarder | resolver | update ) [ ( query | response ) ]; … };
-
変更を適用するために、
namedサービスを再起動します。# systemctl restart named.serviceアクティブなログの定期的なロールアウトを設定します。
次の例では、
cronスケジューラーは、ユーザーが編集したスクリプトの内容を 1 日に 1 回実行します。rollオプションに値3指定し、dnstapが最大 3 つのバックアップログファイルを作成できるようにしています。この値3は、dnstap-output変数のversionパラメーターをオーバーライドし、バックアップログファイルの数を 3 に制限します。また、バイナリーログファイルは別のディレクトリーに移動されて名前が変更されます。3 つのバックアップログファイルがすでに存在する場合でも、ファイルの接尾辞が.2に達することはありません。サイズ制限に基づくバイナリーログの自動ローリングで十分な場合は、このステップを省略できます。Example: sudoedit /etc/cron.daily/dnstap #!/bin/sh rndc dnstap -roll 3 mv /var/named/data/dnstap.bin.1 /var/log/named/dnstap/dnstap-$(date -I).bin # use dnstap-read to analyze saved logs sudo chmod a+x /etc/cron.daily/dnstap
dnstap-readユーティリティーを使用して、人間が判読できる形式でログを処理および分析します。次の例では、
dnstap-readユーティリティーは出力をYAMLファイル形式で出力します。Example: dnstap-read -y [file-name]
第5章 NFS サーバーのデプロイ
ネットワークファイルシステム (NFS) プロトコルを使用すると、リモートユーザーはネットワーク経由で共有ディレクトリーをマウントし、ローカルにマウントされたときと同じように使用できます。また、リソースを、ネットワークの集中化サーバーに統合できるようになります。
5.1. NFSv4 のマイナーバージョンの主な機能
NFSv4 の各マイナーバージョンでは、パフォーマンスとセキュリティーの向上を目的とした機能強化が行われています。これらの改善点を使用して NFSv4 の可能性を最大限に活用し、ネットワーク全体で効率的かつ信頼性の高いファイル共有を確保します。
NFSv4.2 の主な機能
- サーバー側コピー
- サーバー側コピーは、ネットワーク上でデータをやり取りせずにサーバー上のファイルをコピーする NFS サーバーの機能です。
- スパースファイル
- ファイルに 1 つ以上の空のスペースまたはギャップを含めることができます。ギャップとは、ゼロのみで設定される未割り当てまたは初期化されていないデータブロックです。これにより、アプリケーションはスパースファイル内のホールの位置をマッピングできるようになります。
- 領域の予約
- クライアントは、データを書き込む前にストレージサーバー上のスペースを予約または割り当てることができます。これにより、サーバーのスペースが不足するのを防ぎます。
- ラベル付き NFS
- データアクセス権を強制し、NFS ファイルシステム上の個々のファイルに対して、クライアントとサーバーとの間の SELinux ラベルを有効にします。
- レイアウトの機能強化
- Parallel NFS (pNFS) サーバーがより優れたパフォーマンス統計を収集できるようにする機能を提供します。
NFSv4.1 の主な機能
- pNFS のクライアント側のサポート
- クラスター化されたサーバーへの高速 I/O のサポートにより、複数のマシンにデータを保存し、データへの直接アクセスとメタデータの更新の同期が可能になります。
- Sessions
- セッションは、クライアントに属する接続に関連したサーバーの状態を維持します。これらのセッションは、各リモートプロシージャコール (RPC) 操作の接続の確立と終了に関連するオーバーヘッドを削減することにより、パフォーマンスと効率を向上させます。
NFSv4.0 の主な機能
- RPC とセキュリティー
-
RPCSEC_GSSフレームワークは、RPC セキュリティーを強化します。NFSv4 プロトコルでは、帯域内セキュリティーネゴシエーションのための新しい操作が導入されています。これにより、クライアントはファイルシステムリソースに安全にアクセスするためのサーバーポリシーをクエリーできるようになります。 - 手順と運用構造
-
NFS 4.0 では
COMPOUNDプロシージャが導入されており、クライアントは複数の操作を 1 つのリクエストにマージして RPC を削減できます。 - ファイルシステムモデル
NFS 4.0 は階層ファイルシステムモデルを保持し、ファイルをバイトストリームとして扱い、国際化のために名前を UTF-8 でエンコードします。
ファイルハンドルの種類
揮発性ファイルハンドルを使用すると、サーバーはファイルシステムの変更に適応でき、クライアントは永続的なファイルハンドルを必要とせずに必要に応じて適応できるようになります。
属性タイプ
ファイル属性構造には、必須属性、推奨属性、および名前付き属性が含まれており、それぞれが異なる目的を果たします。NFSv3 から派生した必須属性はファイルタイプを区別するために不可欠ですが、ACL などの推奨属性は強化されたアクセス制御を提供します。
マルチサーバー名前空間
ネームスペースは複数のサーバーにまたがり、属性に基づいてファイルシステム転送を簡素化し、参照、冗長性、シームレスなサーバー移行をサポートします。
- OPEN および CLOSE 操作
- これらの操作により、ファイルの検索、作成、セマンティック共有を 1 カ所で組み合わせることができ、ファイルアクセス管理をより効率的に行うことができます。
- ファイルのロック
- ファイルのロックはプロトコルの一部であるため、RPC コールバックの必要がなくなります。ファイルのロック状態は、リースベースのモデルに基づいてサーバーによって管理され、リースの更新に失敗すると、サーバーによって状態が解放される場合があります。
- クライアントのキャッシュと委任
- キャッシュは以前のバージョンと似ており、属性およびディレクトリーのキャッシュのタイムアウトはクライアントによって決定されます。NFS 4.0 の委任により、サーバーはクライアントに特定の責任を割り当てることができ、特定のファイル共有セマンティクスが保証され、サーバーとの即時対話なしでローカルファイル操作が可能になります。
5.2. AUTH_SYS 認証方法
AUTH_SYS メソッドは AUTH_UNIX とも呼ばれ、クライアント認証メカニズムです。AUTH_SYS を使用すると、クライアントはユーザーのユーザー ID (UID) とグループ ID (GID) をサーバーに送信し、ファイルにアクセスするときにそのアイデンティティーと権限を確認します。クライアントが提供する情報に依存するため、設定を誤ると不正アクセスを受けやすくなるため、安全性が低いと考えられています。
マッピングメカニズムにより、UID と GID の割り当てがシステム間で異なる場合でも、NFS クライアントはサーバー上の適切な権限でファイルにアクセスできるようになります。UID と GID は、次のメカニズムによって NFS クライアントとサーバーの間でマッピングされます。
- ダイレクトマッピング
UID と GID は、ローカルシステムとリモートシステムの間で NFS サーバーとクライアントによって直接マッピングされます。これには、NFS ファイル共有に参加しているすべてのシステムにわたって、一貫した UID と GID の割り当てが必要です。たとえば、クライアント上の UID 1000 を持つユーザーは、サーバー上の UID 1000 を持つユーザーがアクセスできる共有上のファイルにのみアクセスできます。
NFS 環境での ID 管理を簡素化するために、管理者は多くの場合、LDAP やネットワーク情報サービス (NIS) などの集中サービスを利用して、複数のシステムにわたる UID および GID マッピングを管理します。
- ユーザーとグループ ID のマッピング
-
NFS サーバーとクライアントは、
idmapdサービスを使用して、異なるシステム間で UID と GID を変換し、一貫した識別と権限の割り当てを実現できます。
5.3. AUTH_GSS 認証方式
Kerberos は、安全でないネットワーク上でクライアントとサーバーの安全な認証を可能にするネットワーク認証プロトコルです。対称キー暗号化を使用しており、ユーザーとサービスを認証するには信頼できるキー配布センター (KDC) が必要です。
AUTH_SYS とは異なり、RPCSEC_GSS Kerberos メカニズムを使用すると、サーバーは、どのユーザーがファイルにアクセスしているかを正確に表すためにクライアントに依存しません。代わりに、暗号を使用してサーバーにユーザーを認証し、悪意のあるクライアントがそのユーザーの Kerberos 認証情報を持たずにユーザーになりすますことがないようにします。
/etc/exports ファイルでは、sec オプションにより、共有が提供する Kerberos セキュリティーの 1 つまたは複数のメソッドが定義され、クライアントはこれらのメソッドの 1 つを使用して共有をマウントできます。sec オプションは次の値をサポートします。
-
sys: 暗号化保護なし (デフォルト) -
krb5- 認証のみ -
krb5i: 認証と完全性保護 -
krb5p: 認証、整合性チェック、トラフィック暗号化
メソッドが提供する暗号化機能が増えるほど、パフォーマンスが低下することに注意してください。
5.4. エクスポートされたファイルシステムのファイル権限
エクスポートされたファイルシステムのファイルアクセス許可により、NFS 経由でファイルとディレクトリーにアクセスするクライアントのファイルとディレクトリーへのアクセス権が決まります。
NFS ファイルシステムがリモートホストによってマウントされると、各共有ファイルが保護されるのはそのファイルシステムのアクセス許可だけになります。同じユーザー ID (UID) 値を共有する 2 人のユーザーが同じ NFS ファイルシステムを異なるクライアントシステムにマウントする場合、互いのファイルを変更できます。
NFS は、クライアント上の root ユーザーをサーバー上の root ユーザーと同等に扱います。ただし、デフォルトでは、NFS サーバーは、NFS 共有にアクセスするときに root をnobody アカウントにマップします。root_squash オプションはこの動作を制御します。
関連情報
-
exports(5)man ページ
5.5. NFS サーバーに必要なサービス
Red Hat Enterprise Linux (RHEL) は、カーネルモジュールとユーザー空間プロセスを組み合わせて使用して、NFS ファイル共有を提供します。
表5.1 NFS サーバーに必要なサービス
| サービス名 | NFS バージョン | 詳細 |
|---|---|---|
|
| 3, 4 | 共有 NFS ファイルシステムに対する要求を処理する NFS カーネルモジュール。 |
|
| 3 |
このプロセスは、ローカルのリモートプロシージャコール (RPC) サービスからポート予約を受け入れ、それらを利用可能またはアドバタイズして、対応するリモート RPC サービスがそれらにアクセスできるようにします。 |
|
| 3, 4 |
このサービスは、NFSv3 クライアントからの 要求された NFS 共有が現在 NFS サーバーによってエクスポートされており、クライアントがその共有にアクセスできることを確認します。 |
|
| 3, 4 | このプロセスは、サーバーが定義する明示的な NFS バージョンとプロトコルをアドバタイズします。カーネルと連携して、NFS クライアントが接続するたびにサーバースレッドを提供するなど、NFS クライアントの動的な要求に応えます。
|
|
| 3 | このカーネルモジュールは、クライアントがサーバー上のファイルをロックできるようにする Network Lock Manager (NLM) プロトコルを実装します。RHEL は、NFS サーバーの実行時にモジュールを自動的にロードします。 |
|
| 3, 4 | このサービスは、リモートユーザーにユーザークォータ情報を提供します。 |
|
| 4 | このプロセスは、NFSv4 名 (`user@domain` の形式の文字列) とローカルユーザー ID およびグループ ID の間でマッピングする NFSv4 クライアントおよびサーバーのアップコールを提供します。 |
|
| 3, 4 |
このサービスは、 |
|
| 4 | このサービスは、サーバーの再起動と組み合わせたネットワーク分割中に他のクライアントが競合するロックを取得した場合に、サーバーがロックの再利用を許可しないようにする NFSv4 クライアント追跡デーモンを提供します。 |
|
| 3 | このサービスは、ローカルホストの再起動時に他の NFSv3 クライアントに通知を提供し、リモート NFSv3 ホストの再起動時にカーネルに通知を提供します。 |
関連情報
-
rpcbind (8)、rpc.mountd (8)、rpc.nfsd (8)、rpc.statd (8)、rpc.rquotad (8)、rpc.idmapd (8)、nfsdcld (8) のman ページ
5.6. /etc/exports 設定ファイル
/etc/exports ファイルは、サーバーがエクスポートするディレクトリーを制御します。各行には、エクスポートポイント、ディレクトリーのマウントを許可されている空白で区切られたクライアントのリスト、および各クライアントのオプションが含まれます。
<directory> <host_or_network_1>(<options_1>) <host_or_network_n>(<options_n>)...
/etc/exports エントリーの個々の部分は次のとおりです。
- <export>
- エクスポートされるディレクトリー。
- <host_or_network>
- エクスポートが共有されるホストまたはネットワーク。たとえば、ホスト名、IP アドレス、または IP ネットワークを指定できます。
- <options>
- ホストまたはネットワークのオプション。
クライアントとオプションの間にスペースを追加すると、動作が変わります。たとえば、次の行は同じ意味を持ちません。
/projects client.example.com(rw) /projects client.example.com (rw)
最初の行では、サーバーは client.example.com のみに読み取り/書き込みモードで /projects ディレクトリーをマウントすることを許可し、他のホストは共有をマウントできません。ただし、2 行目の client.example.com と (rw) の間にスペースがあるため、サーバーはディレクトリーを読み取り専用モード (デフォルト設定) で client.example.com にエクスポートしますが、他のすべてのホストは共有をマウントできます。読み書きモードで。
NFS サーバーは、エクスポートされたディレクトリーごとに次のデフォルト設定を使用します。
表5.2 /etc/exports 内のエントリーのデフォルトオプション
| デフォルト設定 | 詳細 |
|---|---|
|
| ディレクトリーを読み取り専用モードでエクスポートします。 |
|
| NFS サーバーは、以前の要求による変更がディスクに書き込まれるまでは要求に応答しません。 |
|
| サーバーは、別の書き込み要求が保留されていると疑われる場合、ディスクへの書き込みを遅延します。 |
|
|
クライアントの |
5.7. NFSv4 専用サーバーの設定
ネットワーク内に NFSv3 クライアントが存在しない場合は、NFSv4 またはその特定のマイナープロトコルバージョンのみをサポートするように NFS サーバーを設定できます。サーバー上で NFSv4 のみを使用すると、ネットワークに対して開かれるポートの数が減ります。
手順
nfs-utilsパッケージをインストールします。# dnf install nfs-utils/etc/nfs.confファイルを編集し、次の変更を加えます。[nfsd]セクションのvers3パラメーターを無効にして、NFSv3 を無効にします。[nfsd] vers3=n
オプション: 特定の NFSv4 マイナーバージョンのみが必要な場合は、すべての
vers4.<minor_version>パラメーターのコメントを解除し、それに応じて設定します。次に例を示します。[nfsd] vers3=n # vers4=y vers4.0=n vers4.1=n vers4.2=y
この設定では、サーバーは NFS バージョン 4.2 のみを提供します。
重要特定の NFSv4 マイナーバージョンのみが必要な場合は、マイナーバージョンのパラメーターのみを設定します。マイナーバージョンの予期しないアクティブ化または非アクティブ化を避けるために、
vers4パラメーターのコメントを解除しないでください。デフォルトでは、vers4パラメーターはすべての NFSv4 マイナーバージョンを有効または無効にします。ただし、vers4 を他のversパラメーターと組み合わせて設定すると、この動作が変わります。
すべての NFSv3 関連サービスを無効にします。
# systemctl mask --now rpc-statd.service rpcbind.service rpcbind.socketオプション: 共有するディレクトリーを作成します。例:
# mkdir -p /nfs/projects/既存のディレクトリーを共有する場合は、この手順をスキップしてください。
/nfs/projects/ディレクトリーに必要な権限を設定します。# chmod 2770 /nfs/projects/ # chgrp users /nfs/projects/
これらのコマンドは、
/nfs/projects/ディレクトリーのユーザーグループに書き込み権限を設定し、このディレクトリーに作成された新しいエントリーに同じグループが自動的に設定されるようにします。共有する各ディレクトリーの
/etc/exportsファイルにエクスポートポイントを追加します。/nfs/projects/ 192.0.2.0/24(rw) 2001:db8::/32(rw)
このエントリーは、
/nfs/projects/ディレクトリーを共有し、192.0.2.0/24および2001:db8::/32サブネット内のクライアントに読み取りおよび書き込みアクセスでアクセスできるようにします。firewalldで関連するポートを開きます。# firewall-cmd --permanent --add-service nfs # firewall-cmd --reload
NFS サーバーを有効にして起動します。
# systemctl enable --now nfs-server
検証
サーバー上で、サーバーが設定した NFS バージョンのみを提供していることを確認します。
# cat /proc/fs/nfsd/versions -3 +4 -4.0 -4.1 +4.2クライアントで次の手順を実行します。
nfs-utilsパッケージをインストールします。# dnf install nfs-utilsエクスポートされた NFS 共有をマウントします。
# mount server.example.com:/nfs/projects/ /mnt/usersグループのメンバーであるユーザーとして、/mnt/にファイルを作成します。# touch /mnt/fileディレクトリーをリスト表示して、ファイルが作成されたことを確認します。
# ls -l /mnt/ total 0 -rw-r--r--. 1 demo users 0 Jan 16 14:18 file
5.8. オプションの NFSv4 サポートを使用した NFSv3 サーバーの設定
まだ NFSv3 クライアントを使用しているネットワークでは、NFSv3 プロトコルを使用して共有を提供するようにサーバーを設定します。ネットワーク内に新しいクライアントもある場合は、さらに NFSv4 を有効にすることができます。デフォルトでは、Red Hat Enterprise Linux NFS クライアントはサーバーが提供する最新の NFS バージョンを使用します。
手順
nfs-utilsパッケージをインストールします。# dnf install nfs-utilsオプション: デフォルトでは、NFSv3 と NFSv4 が有効になっています。NFSv4 が必要ない場合、または特定のマイナーバージョンのみが必要な場合は、すべての
vers4.<minor_version>パラメーターのコメントを解除し、それに応じて設定します。[nfsd] # vers3=y # vers4=y vers4.0=n vers4.1=n vers4.2=y
この設定では、サーバーは NFS バージョン 3 と 4.2 のみを提供します。
重要特定の NFSv4 マイナーバージョンのみが必要な場合は、マイナーバージョンのパラメーターのみを設定します。マイナーバージョンの予期しないアクティブ化または非アクティブ化を避けるために、
vers4パラメーターのコメントを解除しないでください。デフォルトでは、vers4パラメーターはすべての NFSv4 マイナーバージョンを有効または無効にします。ただし、vers4 を他のversパラメーターと組み合わせて設定すると、この動作が変わります。デフォルトでは、NFSv3 RPC サービスはランダムポートを使用します。ファイアウォール設定を有効にするには、
/etc/nfs.confファイルで固定ポート番号を設定します。[lockd]セクションで、nlockmgrRPC サービスの固定ポート番号を設定します。次に例を示します。[lockd] port=5555この設定を使用すると、サービスはこのポート番号を UDP プロトコルと TCP プロトコルの両方に自動的に使用します。
[statd]セクションで、rpc.statdサービスの固定ポート番号を設定します。次に例を示します。[statd] port=6666この設定を使用すると、サービスはこのポート番号を UDP プロトコルと TCP プロトコルの両方に自動的に使用します。
オプション: 共有するディレクトリーを作成します。例:
# mkdir -p /nfs/projects/既存のディレクトリーを共有する場合は、この手順をスキップしてください。
/nfs/projects/ディレクトリーに必要な権限を設定します。# chmod 2770 /nfs/projects/ # chgrp users /nfs/projects/
これらのコマンドは、
/nfs/projects/ディレクトリーのユーザーグループに書き込み権限を設定し、このディレクトリーに作成された新しいエントリーに同じグループが自動的に設定されるようにします。共有する各ディレクトリーの
/etc/exportsファイルにエクスポートポイントを追加します。/nfs/projects/ 192.0.2.0/24(rw) 2001:db8::/32(rw)
このエントリーは、
/nfs/projects/ディレクトリーを共有し、192.0.2.0/24および2001:db8::/32サブネット内のクライアントに読み取りおよび書き込みアクセスでアクセスできるようにします。firewalldで関連するポートを開きます。# firewall-cmd --permanent --add-service={nfs,rpc-bind,mountd} # firewall-cmd --permanent --add-port={5555/tcp,5555/udp,6666/tcp,6666/udp} # firewall-cmd --reload
NFS サーバーを有効にして起動します。
# systemctl enable --now rpc-statd nfs-server
検証
サーバー上で、サーバーが設定した NFS バージョンのみを提供していることを確認します。
# cat /proc/fs/nfsd/versions +3 +4 -4.0 -4.1 +4.2クライアントで次の手順を実行します。
nfs-utilsパッケージをインストールします。# dnf install nfs-utilsエクスポートされた NFS 共有をマウントします。
# mount -o vers=<version> server.example.com:/nfs/projects/ /mnt/共有が指定された NFS バージョンでマウントされていることを確認します。
# mount | grep "/mnt" server.example.com:/nfs/projects/ on /mnt type nfs (rw,relatime,vers=3,...
usersグループのメンバーであるユーザーとして、/mnt/にファイルを作成します。# touch /mnt/fileディレクトリーをリスト表示して、ファイルが作成されたことを確認します。
# ls -l /mnt/ total 0 -rw-r--r--. 1 demo users 0 Jan 16 14:18 file
5.9. NFS サーバーでのクォータサポートの有効化
ユーザーまたはグループが保存できるデータの量を制限したい場合は、ファイルシステムにクォータを設定できます。NFS サーバーでは、rpc-rquotad サービスにより、クォータが NFS クライアント上のユーザーにも適用されるようになります。
手順
エクスポートするディレクトリーでクォータが有効になっていることを確認します。
外部ファイルシステムの場合は、次のように入力します。
# quotaon -p /nfs/projects/ group quota on /nfs/projects (/dev/sdb1) is on user quota on /nfs/projects (/dev/sdb1) is on project quota on /nfs/projects (/dev/sdb1) is offXFS ファイルシステムの場合は、次のように入力します。
# findmnt /nfs/projects TARGET SOURCE FSTYPE OPTIONS /nfs/projects /dev/sdb1 xfs rw,relatime,seclabel,attr2,inode64,logbufs=8,logbsize=32k,usrquota,grpquota
クォータ -rpcパッケージをインストールします。# dnf install rpc-quotadオプション: デフォルトでは、クォータ RPC サービスはポート 875 で実行されます。サービスを別のポートで実行する場合は、
/etc/sysconfig/rpc-rquotadファイルのRPCRQUOTADOPTS変数に-p <port_number>を追加します。RPCRQUOTADOPTS="-p __<port_number>__"
オプション: デフォルトでは、リモートホストはクォータの読み取りのみが可能です。クライアントがクォータを設定できるようにするには、
/etc/sysconfig/rpc-rquotadファイルのRPCRQUOTADOPTS変数に-Sオプションを追加します。RPCRQUOTADOPTS="-S"
firewalldでポートを開きます。# firewall-cmd --permanent --add-port=875/udp # firewall-cmd --reload
rpc-quotadサービスを有効にして開始します。# systemctl enable --now rpc-rquotad
検証
クライアント上:
エクスポートされた共有をマウントします。
# mount server.example.com:/nfs/projects/ /mnt/クォータを表示します。コマンドは、エクスポートされたディレクトリーのファイルシステムによって異なります。以下に例を示します。
マウントされているすべての ext ファイルシステム上の特定のユーザーのクォータを表示するには、次のように入力します。
# quota -u <user_name> Disk quotas for user demo (uid 1000): Filesystem space quota limit grace files quota limit grace server.example.com:/nfs/projects 0K 100M 200M 0 0 0XFS ファイルシステム上のユーザーとグループのクォータを表示するには、次のように入力します。
# xfs_quota -x -c "report -h" /mnt/ User quota on /nfs/projects (/dev/vdb1) Blocks User ID Used Soft Hard Warn/Grace ---------- --------------------------------- root 0 0 0 00 [------] demo 0 100M 200M 00 [------]
関連情報
-
クォータ (1)マンページ -
xfs_quota(8)man page
5.10. NFS サーバーでの NFS over RDMA の有効化
リモートダイレクトメモリーアクセス (RDMA) は、クライアントシステムがストレージサーバーのメモリーから独自のメモリーにデータを直接転送できるようにするプロトコルです。これにより、ストレージのスループットが向上し、サーバーとクライアント間のデータ転送の遅延が減少し、両端の CPU 負荷が軽減されます。NFS サーバーとクライアントの両方が RDMA 経由で接続されている場合、クライアントは NFSoRDMA を使用して、エクスポートされたディレクトリーをマウントできます。
前提条件
- NFS サービスが実行され、設定されています
- InfiniBand または RDMA over Converged Ethernet (RoCE) デバイスがサーバーにインストールされています。
- IP over InfiniBand (IPoIB) がサーバー上で設定されており、InfiniBand デバイスには IP アドレスが割り当てられています。
手順
rdma-coreパッケージをインストールします。# dnf install rdma-coreパッケージがすでにインストールされている場合は、
/etc/rdma/modules/rdma.conf ファイル内のxprtrdmaモジュールとsvcrdmaモジュールのコメントが解除されていることを確認します。# NFS over RDMA client support xprtrdma # NFS over RDMA server support svcrdma
オプション: デフォルトでは、NFS over RDMA はポート 20049 を使用します。別のポートを使用する場合は、
/etc/nfs.confファイルの[nfsd]セクションでrdma-port設定を設定します。rdma-port=_<port>_
firewalldで NFSoRDMA ポートを開きます。# firewall-cmd --permanent --add-port={20049/tcp,20049/udp} # firewall-cmd --reload
20049 以外のポートを設定する場合は、ポート番号を調整します。
nfs-serverサービスを再起動します。# systemctl restart nfs-server
検証
InfiniBand ハードウェアを備えたクライアントで、次の手順を実行します。
以下のパッケージをインストールします。
# dnf install nfs-utils rdma-coreエクスポートされた NFS 共有を RDMA 経由でマウントします。
# mount -o rdma server.example.com:/nfs/projects/ /mnt/デフォルト (20049) 以外のポート番号を設定する場合は、コマンドに
port= <port_number>を渡します。# mount -o rdma,port=<port_number> server.example.com:/nfs/projects/ /mnt/共有が
rdmaオプションを使用してマウントされていることを確認します。# mount | grep "/mnt" server.example.com:/nfs/projects/ on /mnt type nfs (...,proto=rdma,...)
5.11. Red Hat Identity management ドメインでの Kerberos を使用した NFS サーバーのセットアップ
Red Hat Identity management (IdM) を使用している場合は、NFS サーバーを IdM ドメインに参加させることができます。これにより、ユーザーとグループを一元管理し、認証、整合性保護、トラフィック暗号化に Kerberos を使用できるようになります。
前提条件
- NFS サーバーは Red Hat Identity management (IdM) ドメインに 登録されます。
- NFS サーバーが実行され、設定されています。
手順
IdM 管理者として Kerberos チケットを取得します。
# kinit adminnfs/<FQDN>サービスプリンシパルを作成します。# ipa service-add nfs/nfs_server.idm.example.comIdM から
nfsサービスプリンシパルを取得し、/etc/krb5.keytabファイルに保存します。# ipa-getkeytab -s idm_server.idm.example.com -p nfs/nfs_server.idm.example.com -k /etc/krb5.keytabオプション:
/etc/krb5.keytabファイル内のプリンシパルを表示します。# klist -k /etc/krb5.keytab Keytab name: FILE:/etc/krb5.keytab KVNO Principal ---- -------------------------------------------------------------------------- 1 nfs/nfs_server.idm.example.com@IDM.EXAMPLE.COM 1 nfs/nfs_server.idm.example.com@IDM.EXAMPLE.COM 1 nfs/nfs_server.idm.example.com@IDM.EXAMPLE.COM 1 nfs/nfs_server.idm.example.com@IDM.EXAMPLE.COM 7 host/nfs_server.idm.example.com@IDM.EXAMPLE.COM 7 host/nfs_server.idm.example.com@IDM.EXAMPLE.COM 7 host/nfs_server.idm.example.com@IDM.EXAMPLE.COM 7 host/nfs_server.idm.example.com@IDM.EXAMPLE.COMデフォルトでは、ホストを IdM ドメインに参加させるときに、IdM クライアントはホストプリンシパルを
/etc/krb5.keytabファイルに追加します。ホストプリンシパルが見つからない場合は、ipa-getkeytab -s idm_server.idm.example.com -p host/nfs_server.idm.example.com -k/etc/krb5.keytabコマンドを使用して追加します。ipa-client-automountユーティリティーを使用して、IdM ID のマッピングを設定します。# ipa-client-automount Searching for IPA server... IPA server: DNS discovery Location: default Continue to configure the system with these values? [no]: yes Configured /etc/idmapd.conf Restarting sssd, waiting for it to become available. Started autofs
/etc/exportsファイルを更新し、クライアントオプションに Kerberos セキュリティーメソッドを追加します。以下に例を示します。/nfs/projects/ 192.0.2.0/24(rw,sec=krb5i)クライアントが複数のセキュリティー方式から選択できるようにしたい場合は、コロンで区切って指定します。
/nfs/projects/ 192.0.2.0/24(rw,sec=krb5:krb5i:krb5p)エクスポートされたファイルシステムをリロードします。
# exportfs -r
第6章 Squid キャッシングプロキシーサーバーの設定
Squid は、コンテンツをキャッシュして帯域幅を削減し、Web ページをより迅速に読み込むプロキシーサーバーです。本章では、HTTP、HTTPS、FTP のプロトコルのプロキシーとして Squid を設定する方法と、アクセスの認証および制限を説明します。
6.1. 認証なしで Squid をキャッシングプロキシーとして設定
認証なしで Squid をキャッシュプロキシーとして設定できます。以下の手順では、IP 範囲に基づいてプロキシーへのアクセスを制限します。
前提条件
-
/etc/squid/squid.confファイルが、squidパッケージにより提供されている。このファイルを編集した場合は、ファイルを削除して、パッケージを再インストールしている。
手順
squidパッケージをインストールします。# yum install squid/etc/squid/squid.confファイルを編集します。localnetアクセス制御リスト (ACL) を、プロキシーを使用できる IP 範囲と一致するように変更します。acl localnet src 192.0.2.0/24 acl localnet 2001:db8:1::/64
デフォルトでは、
/etc/squid/squid.confファイルにはlocalnetACL で指定されたすべての IP 範囲のプロキシーを使用できるようにするhttp_access allow localnetルールが含まれます。http_access allow localnetルールの前に、localnetの ACL をすべて指定する必要があります。重要環境に一致しない既存の
acl localnetエントリーをすべて削除します。以下の ACL はデフォルト設定にあり、HTTPS プロトコルを使用するポートとして
443を定義します。acl SSL_ports port 443
ユーザーが他のポートでも HTTPS プロトコルを使用できるようにするには、ポートごとに ACL を追加します。
acl SSL_ports port port_numberSquid が接続を確立できるポートに設定する
acl Safe_portsルールの一覧を更新します。たとえば、プロキシーを使用するクライアントがポート 21 (FTP)、80 (HTTP)、443 (HTTPS) のリソースにのみアクセスできるようにするには、その設定の以下のacl Safe_portsステートメントのみを保持します。acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
デフォルトでは、設定には
http_access deny !Safe_portsルールが含まれ、Safe_portsACL で定義されていないポートへのアクセス拒否を定義します。cache_dirパラメーターにキャッシュの種類、キャッシュディレクトリーへのパス、キャッシュサイズ、さらにキャッシュの種類ごとの設定を設定します。cache_dir ufs /var/spool/squid 10000 16 256この設定により、以下が可能になります。
-
Squid は、
ufsキャッシュタイプを使用します。 -
Squid は、キャッシュを
/var/spool/squid/ディレクトリーに保存します。 -
キャッシュのサイズが
10000MB まで大きくなります。 -
Squid は、
16個の レベル 1 サブディレクトリーを/var/spool/squid/ディレクトリーに作成します。 Squid は、レベル 1 の各ディレクトリーに
256個のサブディレクトリーを作成します。cache_dirディレクティブを設定しないと、Squid はキャッシュをメモリーに保存します。
-
Squid は、
cache_dirパラメーターに/var/spool/squid/以外のキャッシュディレクトリーを設定する場合は、以下を行います。キャッシュディレクトリーを作成します。
# mkdir -p path_to_cache_directoryキャッシュディレクトリーの権限を設定します。
# chown squid:squid path_to_cache_directorySELinux を
enforcingモードで実行する場合は、squid_cache_tコンテキストをキャッシュディレクトリーに設定します。# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
semanageユーティリティーがシステムで利用できない場合は、policycoreutils-python-utilsパッケージをインストールします。
ファイアウォールで
3128ポートを開きます。# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
squidサービスを有効にして開始します。# systemctl enable --now squid
検証手順
プロキシーが正しく機能することを確認するには、curl ユーティリティーを使用して Web ページをダウンロードします。
# curl -O -L "https://www.redhat.com/index.html" -x "proxy.example.com:3128"
curl でエラーが表示されず、index.html ファイルが現在のディレクトリーにダウンロードされている場合は、プロキシーが動作します。
6.2. LDAP 認証を使用したキャッシングプロキシーとしての Squid の設定
Squid を、LDAP を使用してユーザーを認証するキャッシングプロキシーとして設定できます。この手順では、認証されたユーザーのみがプロキシーを使用できるように設定します。
前提条件
-
/etc/squid/squid.confファイルが、squidパッケージにより提供されている。このファイルを編集した場合は、ファイルを削除して、パッケージを再インストールしている。 -
uid=proxy_user,cn=users,cn=accounts,dc=example,dc=comなどのサービスユーザーが LDAP ディレクトリーに存在します。Squid はこのアカウントを使用して認証ユーザーを検索します。認証ユーザーが存在する場合、Squid はこのユーザーをディレクトリーにバインドして、認証を確認します。
手順
squidパッケージをインストールします。# yum install squid/etc/squid/squid.confファイルを編集します。basic_ldap_authヘルパーユーティリティーを設定するには、/etc/squid/squid.confに以下の設定エントリーを追加します。auth_param basic program /usr/lib64/squid/basic_ldap_auth -b "cn=users,cn=accounts,dc=example,dc=com" -D "uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f "(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389以下では、上記の
basic_ldap_authヘルパーユーティリティーに渡されるパラメーターを説明します。-
-b base_DNは LDAP 検索ベースを設定します。 -
-D proxy_service_user_DNは、Squid が、ディレクトリー内の認証ユーザーを検索する際に使用するアカウントの識別名 (DN) を設定します。 -
-W path_to_password_fileは、プロキシーサービスユーザーのパスワードが含まれるファイルへのパスを設定します。パスワードファイルを使用すると、オペレーティングシステムのプロセスリストにパスワードが表示されなくなります。 -f LDAP_filterは 、DAP 検索フィルターを指定します。Squid は、%s変数を、認証ユーザーにより提供されるユーザー名に置き換えます。上記の例の
(&(objectClass=person)(uid=%s))フィルターは、ユーザー名がuid属性に設定された値と一致する必要があり、ディレクトリーエントリーにpersonオブジェクトクラスが含まれることを定義します。-ZZは、STARTTLSコマンドを使用して、LDAP プロトコルで TLS 暗号化接続を強制します。以下の状況で-ZZを省略します。- LDAP サーバーは、暗号化された接続にを対応しません。
- URL に指定されたポートは、LDAPS プロトコルを使用します。
- -H LDAP_URL パラメーターは、プロトコル、ホスト名、IP アドレス、および LDAP サーバーのポートを URL 形式で指定します。
-
以下の ACL およびルールを追加して、Squid で、認証されたユーザーのみがプロキシーを使用できるように設定します。
acl ldap-auth proxy_auth REQUIRED http_access allow ldap-auth
重要http_access deny allルールの前にこの設定を指定します。次のルールを削除して、
localnetACL で指定された IP 範囲のプロキシー認証の回避を無効にします。http_access allow localnet以下の ACL はデフォルト設定にあり、HTTPS プロトコルを使用するポートとして
443を定義します。acl SSL_ports port 443
ユーザーが他のポートでも HTTPS プロトコルを使用できるようにするには、ポートごとに ACL を追加します。
acl SSL_ports port port_numberSquid が接続を確立できるポートに設定する
acl Safe_portsルールの一覧を更新します。たとえば、プロキシーを使用するクライアントがポート 21 (FTP)、80 (HTTP)、443 (HTTPS) のリソースにのみアクセスできるようにするには、その設定の以下のacl Safe_portsステートメントのみを保持します。acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
デフォルトでは、設定には
http_access deny !Safe_portsルールが含まれ、Safe_portsACL で定義されていないポートへのアクセス拒否を定義します。cache_dirパラメーターにキャッシュの種類、キャッシュディレクトリーへのパス、キャッシュサイズ、さらにキャッシュの種類ごとの設定を設定します。cache_dir ufs /var/spool/squid 10000 16 256この設定により、以下が可能になります。
-
Squid は、
ufsキャッシュタイプを使用します。 -
Squid は、キャッシュを
/var/spool/squid/ディレクトリーに保存します。 -
キャッシュのサイズが
10000MB まで大きくなります。 -
Squid は、
16個の レベル 1 サブディレクトリーを/var/spool/squid/ディレクトリーに作成します。 Squid は、レベル 1 の各ディレクトリーに
256個のサブディレクトリーを作成します。cache_dirディレクティブを設定しないと、Squid はキャッシュをメモリーに保存します。
-
Squid は、
cache_dirパラメーターに/var/spool/squid/以外のキャッシュディレクトリーを設定する場合は、以下を行います。キャッシュディレクトリーを作成します。
# mkdir -p path_to_cache_directoryキャッシュディレクトリーの権限を設定します。
# chown squid:squid path_to_cache_directorySELinux を
enforcingモードで実行する場合は、squid_cache_tコンテキストをキャッシュディレクトリーに設定します。# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
semanageユーティリティーがシステムで利用できない場合は、policycoreutils-python-utilsパッケージをインストールします。
LDAP サービスユーザーのパスワードを
/etc/squid/ldap_passwordファイルに保存し、ファイルに適切なパーミッションを設定します。# echo "password" > /etc/squid/ldap_password # chown root:squid /etc/squid/ldap_password # chmod 640 /etc/squid/ldap_password
ファイアウォールで
3128ポートを開きます。# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
squidサービスを有効にして開始します。# systemctl enable --now squid
検証手順
プロキシーが正しく機能することを確認するには、curl ユーティリティーを使用して Web ページをダウンロードします。
# curl -O -L "https://www.redhat.com/index.html" -x "user_name:password@proxy.example.com:3128"
curl がエラーを表示せず、index.html ファイルが現在のディレクトリーにダウンロードされている場合は、プロキシーが動作します。
トラブルシューティングの手順
ヘルパーユーティリティーが正しく機能していることを確認するには、以下の手順を行います。
auth_paramパラメーターで使用したのと同じ設定で、ヘルパーユーティリティーを手動で起動します。# /usr/lib64/squid/basic_ldap_auth -b "cn=users,cn=accounts,dc=example,dc=com" -D "uid=proxy_user,cn=users,cn=accounts,dc=example,dc=com" -W /etc/squid/ldap_password -f "(&(objectClass=person)(uid=%s))" -ZZ -H ldap://ldap_server.example.com:389有効なユーザー名とパスワードを入力し、Enter を押します。
user_name passwordヘルパーユーティリティーが
OKを返すと、認証に成功しました。
6.3. kerberos 認証を使用したキャッシングプロキシーとしての Squid の設定
Squid を、Kerberos を使用して Active Directory (AD) に対してユーザーを認証するキャッシングプロキシーとして設定できます。この手順では、認証されたユーザーのみがプロキシーを使用できるように設定します。
前提条件
-
/etc/squid/squid.confファイルが、squidパッケージにより提供されている。このファイルを編集した場合は、ファイルを削除して、パッケージを再インストールしている。
手順
以下のパッケージをインストールします。
# yum install squid krb5-workstationAD ドメイン管理者として認証します。
# kinit administrator@AD.EXAMPLE.COMSquid 用のキータブを作成し、これを
/etc/squid/HTTP.keytabファイルに保存します。# export KRB5_KTNAME=FILE:/etc/squid/HTTP.keytab # net ads keytab CREATE -U administrator
HTTPサービスプリンシパルをキータブに追加します。# net ads keytab ADD HTTP -U administratorキータブファイルの所有者を
squidユーザーに設定します。# chown squid /etc/squid/HTTP.keytab必要に応じて、キータブファイルに、プロキシーサーバーの完全修飾ドメイン名 (FQDN) の
HTTPサービスプリンシパルが含まれていることを確認します。# klist -k /etc/squid/HTTP.keytab Keytab name: FILE:/etc/squid/HTTP.keytab KVNO Principal ---- --------------------------------------------------- ... 2 HTTP/proxy.ad.example.com@AD.EXAMPLE.COM .../etc/squid/squid.confファイルを編集します。negotiate_kerberos_authヘルパーユーティリティーを設定するには、/etc/squid/squid.conf部に以下の設定エントリーを追加します。auth_param negotiate program /usr/lib64/squid/negotiate_kerberos_auth -k /etc/squid/HTTP.keytab -s HTTP/proxy.ad.example.com@AD.EXAMPLE.COM以下は、上記の例で
negotiate_kerberos_authヘルパーユーティリティーに渡されるパラメーターを説明します。-
-k fileは、キータブファイルへのパスを設定します。squid ユーザーには、このファイルに対する読み取り権限があることに注意してください。 -s HTTP/host_name@kerberos_realmは、Squid が使用する Kerberos プリンシパルを設定します。必要に応じて、以下のパラメーターのいずれかまたは両方をヘルパーユーティリティーに渡すことによりロギングを有効にできます。
-
-iは、認証ユーザーなどの情報メッセージをログに記録します。 -dは、デバッグロギングを有効にします。Squid は、ヘルパーユーティリティーから、
/var/log/squid/cache.logファイルにデバッグ情報のログに記録します。
-
以下の ACL およびルールを追加して、Squid で、認証されたユーザーのみがプロキシーを使用できるように設定します。
acl kerb-auth proxy_auth REQUIRED http_access allow kerb-auth
重要http_access deny allルールの前にこの設定を指定します。次のルールを削除して、
localnetACL で指定された IP 範囲のプロキシー認証の回避を無効にします。http_access allow localnet以下の ACL はデフォルト設定にあり、HTTPS プロトコルを使用するポートとして
443を定義します。acl SSL_ports port 443ユーザーが他のポートでも HTTPS プロトコルを使用できるようにするには、ポートごとに ACL を追加します。
acl SSL_ports port port_numberSquid が接続を確立できるポートに設定する
acl Safe_portsルールの一覧を更新します。たとえば、プロキシーを使用するクライアントがポート 21 (FTP)、80 (HTTP)、443 (HTTPS) のリソースにのみアクセスできるようにするには、その設定の以下のacl Safe_portsステートメントのみを保持します。acl Safe_ports port 21 acl Safe_ports port 80 acl Safe_ports port 443
デフォルトでは、設定には
http_access deny !Safe_portsルールが含まれ、Safe_portsACL で定義されていないポートへのアクセス拒否を定義します。cache_dirパラメーターにキャッシュの種類、キャッシュディレクトリーへのパス、キャッシュサイズ、さらにキャッシュの種類ごとの設定を設定します。cache_dir ufs /var/spool/squid 10000 16 256この設定により、以下が可能になります。
-
Squid は、
ufsキャッシュタイプを使用します。 -
Squid は、キャッシュを
/var/spool/squid/ディレクトリーに保存します。 -
キャッシュのサイズが
10000MB まで大きくなります。 -
Squid は、
16個の レベル 1 サブディレクトリーを/var/spool/squid/ディレクトリーに作成します。 Squid は、レベル 1 の各ディレクトリーに
256個のサブディレクトリーを作成します。cache_dirディレクティブを設定しないと、Squid はキャッシュをメモリーに保存します。
-
Squid は、
cache_dirパラメーターに/var/spool/squid/以外のキャッシュディレクトリーを設定する場合は、以下を行います。キャッシュディレクトリーを作成します。
# mkdir -p path_to_cache_directoryキャッシュディレクトリーの権限を設定します。
# chown squid:squid path_to_cache_directorySELinux を
enforcingモードで実行する場合は、squid_cache_tコンテキストをキャッシュディレクトリーに設定します。# semanage fcontext -a -t squid_cache_t "path_to_cache_directory(/.*)?" # restorecon -Rv path_to_cache_directory
semanageユーティリティーがシステムで利用できない場合は、policycoreutils-python-utilsパッケージをインストールします。
ファイアウォールで
3128ポートを開きます。# firewall-cmd --permanent --add-port=3128/tcp # firewall-cmd --reload
squidサービスを有効にして開始します。# systemctl enable --now squid
検証手順
プロキシーが正しく機能することを確認するには、curl ユーティリティーを使用して Web ページをダウンロードします。
# curl -O -L "https://www.redhat.com/index.html" --proxy-negotiate -u : -x "proxy.ad.example.com:3128"
curl がエラーを表示せず、index.html ファイルが現在のディレクトリーに存在すると、プロキシーが機能します。
トラブルシューティングの手順
Kerberos 認証を手動でテストするには、以下を行います。
AD アカウントの Kerberos チケットを取得します。
# kinit user@AD.EXAMPLE.COM必要に応じて、キーを表示します。
# klistnegotiate_kerberos_auth_testユーティリティーを使用して認証をテストします。# /usr/lib64/squid/negotiate_kerberos_auth_test proxy.ad.example.comヘルパーユーティリティーがトークンを返す場合は、認証に成功しました。
Token: YIIFtAYGKwYBBQUCoIIFqDC...
6.4. Squid でのドメイン拒否リストの設定
多くの場合、管理者は特定のドメインへのアクセスをブロックする必要があります。本セクションでは、Squid でドメインの拒否リストを設定する方法を説明します。
前提条件
- Squid が設定され、ユーザーはプロキシーを使用できます。
手順
/etc/squid/squid.confファイルを編集し、以下の設定を追加します。acl domain_deny_list dstdomain "/etc/squid/domain_deny_list.txt" http_access deny all domain_deny_list
重要ユーザーまたはクライアントへのアクセスを許可する最初の
http_access allowステートメントの前にこれらのエントリーを追加します。/etc/squid/domain_deny_list.txtファイルを作成し、ブロックするドメインを追加します。たとえば、サブドメインを含むexample.comへのアクセスをブロックして、example.netをブロックするには、以下を追加します。.example.com example.net
重要squid 設定の
/etc/squid/domain_deny_list.txtファイルを参照している場合は、このファイルは空にすることはできません。このファイルが空の場合、Squid は起動できません。squidサービスを再開します。# systemctl restart squid
6.5. Squid サービスが特定のポートまたは IP アドレスをリッスンするように設定
デフォルトでは、Squid プロキシーサービスは、すべてのネットワークインターフェイスの 3128 ポートでリッスンします。ポートを変更し、Squid が特定の IP アドレスをリッスンするように設定できます。
前提条件
-
squidパッケージがインストールされている。
手順
/etc/squid/squid.confファイルを編集します。Squid サービスがリッスンするポートを設定するには、
http_portパラメーターにポート番号を設定します。たとえば、ポートを8080に設定するには、以下を設定します。http_port 8080Squid サービスがリッスンする IP アドレスを設定するには、
http_portパラメーターに IP アドレスとポート番号を設定します。たとえば、Squid が、3128ポートの IP アドレス192.0.2.1でのみリッスンするように設定するには、以下を設定します。http_port 192.0.2.1:3128複数の
http_portパラメーターを設定ファイルに追加して、Squid が複数のポートおよび IP アドレスでリッスンするように設定します。http_port 192.0.2.1:3128 http_port 192.0.2.1:8080
Squid が別のポートをデフォルト (
3128) として使用するように設定する場合は、以下のようになります。ファイアウォールのポートを開きます。
# firewall-cmd --permanent --add-port=port_number/tcp # firewall-cmd --reload
enforcing モードで SELinux を実行した場合は、ポートを
squid_port_tポートタイプ定義に割り当てます。# semanage port -a -t squid_port_t -p tcp port_numbersemanageユーティリティーがシステムで利用できない場合は、policycoreutils-python-utilsパッケージをインストールします。
squidサービスを再開します。# systemctl restart squid
6.6. 関連情報
-
設定パラメーター
usr/share/doc/squid-<version>/squid.conf.documented
第7章 データベースサーバー
7.1. データベースサーバーの概要
データベースサーバーは、データベース管理システム (DBMS) の機能を提供するサービスです。DBMS は、データベース管理のためのユーティリティーを提供し、エンドユーザー、アプリケーション、およびデータベースと対話します。
Red Hat Enterprise Linux 8 は、以下のデータベース管理システムを提供します。
- MariaDB 10.3
- MariaDB 10.5 - RHEL 8.4 以降で利用できます。
- MySQL 8.0
- PostgreSQL 10
- PostgreSQL 9.6
- PostgreSQL 12 - RHEL 8.1.1 以降で利用できます。
- PostgreSQL 13 - RHEL 8.4 以降で利用できます。
- PostgreSQL 15 - RHEL 8.8 以降で利用できます。
7.2. MariaDB の使用
MariaDB サーバーは、MySQL テクノロジーに基づくオープンソースの高速で堅牢なデータベースサーバーです。MariaDB は、データを構造化情報に変換して、データにアクセスする SQL インターフェイスを提供するリレーショナルデータベースです。これには、複数のストレージエンジンとプラグイン、および地理的な情報システム (GIS) および JSON (JavaScript Object Notation) 機能が含まれます。
RHEL システムに MariaDB をインストールして設定する方法、MariaDB データをバックアップする方法、MariaDB の以前のバージョンから移行する方法、および MariaDB Galera クラスター を使用してデータベースを複製する方法について説明します。
7.2.1. MariaDB のインストール
RHEL 8 では、MariaDB サーバーは、それぞれ個別のストリームにより提供される以下のバージョンで利用できます。
- MariaDB 10.3
- MariaDB 10.5 - RHEL 8.4 以降で利用できます。
MariaDB をインストールするには、以下の手順を行います。
手順
mariadbモジュールからストリーム (バージョン) を選択し、serverプロファイルを指定して MariaDB サーバーパッケージをインストールします。以下に例を示します。# yum module install mariadb:10.3/servermariadbサービスを起動します。# systemctl start mariadb.servicemariadbサービスが、システムの起動時に起動するようにします。# systemctl enable mariadb.serviceMariaDB 10.3 に推奨: MariaDB をインストールする際のセキュリティーを向上させるには、次のコマンドを実行します。
$ mysql_secure_installationこのコマンドは、完全にインタラクティブなスクリプトを起動して、プロセスの各ステップのプロンプトを表示します。このスクリプトを使用すると、次の方法でセキュリティーを改善できます。
- root アカウントのパスワードの設定
- 匿名ユーザーの削除
リモート root ログインの拒否 (ローカルホスト外)
注記mysql_secure_installation スクリプトは、MariaDB 10.5 以降では価値がなくなりました。セキュリティーの強化は、MariaDB 10.5 以降のデフォルトの動作の一部です。
RPM パッケージが競合しているため、RHEL 8 では MariaDB および MySQL データベースサーバーを同時にインストールすることはできません。RHEL 7 用の Red Hat Software Collections では、コンポーネントの同時インストールが可能です。RHEL 8 では、コンテナー内で異なるバージョンのデータベースサーバーを使用できます。
7.2.2. MariaDB の設定
MariaDB サーバーをネットワーク用に設定するには、以下の手順に従います。
手順
/etc/my.cnf.d/mariadb-server.cnfファイルの[mysqld]セクションを編集します。以下の設定ディレクティブを設定できます。bind-address: サーバーがリッスンするアドレスです。設定可能なオプションは以下のとおりです。- ホスト名
- IPv4 アドレス
- IPv6 アドレス
skip-networking: サーバーが TCP/IP 接続をリッスンするかどうかを制御します。以下の値が使用できます。- 0 - すべてのクライアントをリッスンする
- 1 - ローカルクライアントのみをリッスンする
-
port: MariaDB が TCP/IP 接続をリッスンするポート。
mariadbサービスを再起動します。# systemctl restart mariadb.service
7.2.3. MariaDB サーバーでの TLS 暗号化の設定
デフォルトでは、MariaDB は暗号化されていない接続を使用します。安全な接続のために、MariaDB サーバーで TLS サポートを有効にし、暗号化された接続を確立するようにクライアントを設定します。
7.2.3.1. MariaDB サーバーに CA 証明書、サーバー証明書、および秘密鍵を配置する
MariaDB サーバーで TLS 暗号化を有効にする前に、認証局 (CA) 証明書、サーバー証明書、および秘密鍵を MariaDB サーバーに保存します。
前提条件
Privacy Enhanced Mail(PEM) 形式の以下のファイルがサーバーにコピーされています。
-
サーバーの秘密鍵:
server.example.com.key.pem -
サーバー証明書:
server.example.com.crt.pem -
認証局 (CA) 証明書:
ca.crt.pem
秘密鍵および証明書署名要求 (CSR) の作成や、CA からの証明書要求に関する詳細は、CA のドキュメントを参照してください。
-
サーバーの秘密鍵:
手順
CA およびサーバー証明書を
/etc/pki/tls/certs/ディレクトリーに保存します。# mv <path>/server.example.com.crt.pem /etc/pki/tls/certs/ # mv <path>/ca.crt.pem /etc/pki/tls/certs/
MariaDB サーバーがファイルを読み込めるように、CA およびサーバー証明書にパーミッションを設定します。
# chmod 644 /etc/pki/tls/certs/server.example.com.crt.pem /etc/pki/tls/certs/ca.crt.pem証明書は、セキュアな接続が確立される前は通信の一部であるため、任意のクライアントは認証なしで証明書を取得できます。そのため、CA およびサーバーの証明書ファイルに厳密なパーミッションを設定する必要はありません。
サーバーの秘密鍵を
/etc/pki/tls/private/ディレクトリーに保存します。# mv <path>/server.example.com.key.pem /etc/pki/tls/private/サーバーの秘密鍵にセキュアなパーミッションを設定します。
# chmod 640 /etc/pki/tls/private/server.example.com.key.pem # chgrp mysql /etc/pki/tls/private/server.example.com.key.pem
承認されていないユーザーが秘密鍵にアクセスできる場合は、MariaDB サーバーへの接続は安全ではなくなります。
SELinux コンテキストを復元します。
# restorecon -Rv /etc/pki/tls/
7.2.3.2. MariaDB サーバーでの TLS の設定
セキュリティーを向上させるには、MariaDB サーバーで TLS サポートを有効にします。その結果、クライアントは TLS 暗号化を使用してサーバーでデータを送信できます。
前提条件
- MariaDB サーバーをインストールしている。
-
mariadbサービスが実行している。 Privacy Enhanced Mail(PEM) 形式の以下のファイルがサーバー上にあり、
mysqlユーザーが読み取りできます。-
サーバーの秘密鍵:
/etc/pki/tls/private/server.example.com.key.pem -
サーバー証明書:
/etc/pki/tls/certs/server.example.com.crt.pem -
認証局 (CA) 証明書
/etc/pki/tls/certs/ca.crt.pem
-
サーバーの秘密鍵:
- サーバー証明書のサブジェクト識別名 (DN) またはサブジェクトの別名 (SAN) フィールドは、サーバーのホスト名と一致します。
手順
/etc/my.cnf.d/mariadb-server-tls.cnfファイルを作成します。以下の内容を追加して、秘密鍵、サーバー、および CA 証明書へのパスを設定します。
[mariadb] ssl_key = /etc/pki/tls/private/server.example.com.key.pem ssl_cert = /etc/pki/tls/certs/server.example.com.crt.pem ssl_ca = /etc/pki/tls/certs/ca.crt.pem
証明書失効リスト (CRL) がある場合は、それを使用するように MariaDB サーバーを設定します。
ssl_crl = /etc/pki/tls/certs/example.crl.pem必要に応じて、MariaDB 10.5.2 以降を実行する場合は、暗号化せずに接続を拒否できます。この機能を有効にするには、以下を追加します。
require_secure_transport = on必要に応じて、MariaDB 10.4.6 以降を実行する場合は、サーバーが対応する TLS バージョンを設定できます。たとえば、TLS 1.2 および TLS 1.3 をサポートするには、以下を追加します。
tls_version = TLSv1.2,TLSv1.3デフォルトでは、サーバーは TLS 1.1、TLS 1.2、および TLS 1.3 をサポートします。
mariadbサービスを再起動します。# systemctl restart mariadb
検証
トラブルシューティングを簡素化するには、ローカルクライアントが TLS 暗号化を使用するように設定する前に、MariaDB サーバーで以下の手順を実行します。
MariaDB で TLS 暗号化が有効になっていることを確認します。
# mysql -u root -p -e "SHOW GLOBAL VARIABLES LIKE 'have_ssl';" +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | have_ssl | YES | +---------------+-----------------+have_ssl変数がyesに設定されている場合、TLS 暗号化が有効になります。MariaDB サービスが特定の TLS バージョンのみをサポートするように設定している場合は、
tls_version変数を表示します。# mysql -u root -p -e "SHOW GLOBAL VARIABLES LIKE 'tls_version';" +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | tls_version | TLSv1.2,TLSv1.3 | +---------------+-----------------+
7.2.3.3. 特定のユーザーアカウントに TLS で暗号化された接続を要求する
機密データにアクセスできるユーザーは、ネットワーク上で暗号化されていないデータ送信を回避するために、常に TLS で暗号化された接続を使用する必要があります。
すべての接続にセキュアなトランスポートが必要なサーバーで設定できない場合は (require_secure_transport = on)、TLS 暗号化を必要とするように個別のユーザーアカウントを設定します。
前提条件
- MariaDB サーバーで TLS サポートが有効になっている。
- セキュアなトランスポートを必要とするように設定するユーザーが存在する。
- クライアントは、サーバーの証明書を発行した CA 証明書を信頼している。
手順
管理ユーザーとしてMariaDB サーバーに接続します。
# mysql -u root -p -h server.example.com管理ユーザーがリモートでサーバーにアクセスする権限を持たない場合は、MariaDB サーバーでコマンドを実行し、
localhostに接続します。REQUIRE SSL句を使用して、ユーザーが TLS 暗号化接続を使用して接続する必要があるよう強制します。MariaDB [(none)]> ALTER USER 'example'@'%' REQUIRE SSL;
検証
TLS 暗号化を使用して、
exampleユーザーとしてサーバーに接続します。# mysql -u example -p -h server.example.com --ssl ... MariaDB [(none)]>エラーが表示されず、インタラクティブな MariaDB コンソールにアクセスできる場合は、TLS との接続は成功します。
TLS を無効にして、
exampleユーザーとして接続を試みます。# mysql -u example -p -h server.example.com --skip-ssl ERROR 1045 (28000): Access denied for user 'example'@'server.example.com' (using password: YES)このユーザーに TLS が必要だが無効になっているため、サーバーはログインの試行を拒否しました (
--skip-ssl)。
7.2.4. MariaDB クライアントでの TLS 暗号化のグローバルな有効化
MariaDB サーバーが TLS 暗号化に対応している場合は、安全な接続のみを確立し、サーバー証明書を検証するようにクライアントを設定します。この手順では、サーバー上のすべてのユーザーで TLS サポートを有効にする方法を説明します。
7.2.4.1. デフォルトで TLS 暗号化を使用するように MariaDB クライアントを設定する
RHEL では、MariaDB クライアントが TLS 暗号化を使用するようにグローバルに設定でき、サーバー証明書の Common Name (CN) が、ユーザーが接続するホスト名と一致することを検証します。これにより、man-in-the-middle 攻撃 (中間者攻撃) を防ぎます。
前提条件
- MariaDB サーバーで TLS サポートが有効になっている。
- サーバー証明書を発行した認証局 (CA) が RHEL で信頼されていない場合は、CA 証明書がクライアントにコピーされています。
手順
RHEL が、サーバー証明書を発行した CA を信頼しない場合は、以下を行います。
CA 証明書を
/etc/pki/ca-trust/source/anchors/ディレクトリーにコピーします。# cp <path>/ca.crt.pem /etc/pki/ca-trust/source/anchors/すべてのユーザーが CA 証明書ファイルを読み取りできるようにするパーミッションを設定します。
# chmod 644 /etc/pki/ca-trust/source/anchors/ca.crt.pemCA 信頼データベースを再構築します。
# update-ca-trust
以下の内容で
/etc/my.cnf.d/mariadb-client-tls.cnfファイルを作成します。[client-mariadb] ssl ssl-verify-server-cert
これらの設定は、MariaDB クライアントが TLS 暗号化 (
ssl) を使用し、クライアントがホスト名をサーバー証明書 (ssl-verify-server-cert) の CN と比較することを定義します。
検証
ホスト名を使用してサーバーに接続し、サーバーの状態を表示します。
# mysql -u root -p -h server.example.com -e status ... SSL: Cipher in use is TLS_AES_256_GCM_SHA384SSLエントリーにCipher in use is…が含まれている場合、接続は暗号化されています。このコマンドで使用するユーザーには、リモートで認証するパーミッションがあることに注意してください。
接続するホスト名がサーバーの TLS 証明書のホスト名と一致しない場合、
ssl-verify-server-certパラメーターにより接続が失敗します。たとえば、localhostに接続する場合は、以下のようになります。# mysql -u root -p -h localhost -e status ERROR 2026 (HY000): SSL connection error: Validation of SSL server certificate failed
関連情報
-
mysql(1)man ページの--ssl*パラメーターの説明。
7.2.5. MariaDB データのバックアップ
Red Hat EnterpriseLinux 8 で MariaDB データベースからデータをバックアップする主な方法は 2 つあります。
- 論理バックアップ
- 物理バックアップ
論理バックアップ は、データの復元に必要な SQL ステートメントで設定されます。この種類のバックアップは、情報およびレコードをプレーンテキストファイルにエクスポートします。
物理バックアップに対する論理バックアップの主な利点は、移植性と柔軟性です。データは、物理バックアップではできない他のハードウェア設定である MariaDB バージョンまたはデータベース管理システム (DBMS) で復元できます。
mariadb.service が稼働している場合は、論理バックアップを実行できることに注意してください。論理バックアップには、ログと設定ファイルが含まれません。
物理バックアップ は、コンテンツを格納するファイルおよびディレクトリーのコピーで設定されます。
物理バックアップは、論理バックアップと比較して、以下の利点があります。
- 出力が少なくなる。
- バックアップのサイズが小さくなる。
- バックアップおよび復元が速くなる。
- バックアップには、ログファイルと設定ファイルが含まれる。
mariadb.service が実行していない場合や、データベースのすべてのテーブルがロックされていて、バックアップ中に変更しないようにする場合は、物理バックアップを実行する必要があります。
以下のいずれかの MariaDB バックアップ方法で、MariaDB データベースのデータのバックアップを使用できます。
-
mysqldumpを使用した論理バックアップ -
Mariabackupユーティリティーを使用した物理的なオンラインバックアップ - ファイルシステムのバックアップ
- バックアップソリューションとしてレプリケーションを使用
7.2.5.1. mysqldump を使用した論理バックアップの実行
mysqldump クライアントはバックアップユーティリティーで、バックアップ目的でデータベースまたはデータベースの集合をダンプしたり、別のデータベースサーバーに転送したりできます。通常、mysqldump の出力は、サーバーテーブル構造を再作成する、それにデータを取り込む、またはその両方の SQL ステートメントで設定されます。mysqldump は、XML および (CSV などの) コンマ区切りテキスト形式など、他の形式でファイルを生成することもできます。
mysqldump バックアップを実行するには、以下のいずれかのオプションを使用できます。
- 選択したデータベースを 1 つまたは複数バックアップ
- すべてのデータベースをバックアップする。
- あるデータベースのテーブルのサブセットのバックアップを作成する。
手順
単一のデータベースをダンプするには、以下を実行します。
# mysqldump [options] --databases db_name > backup-file.sql複数のデータベースを一度にダンプするには、次のコマンドを実行します。
# mysqldump [options] --databases db_name1 [db_name2 …] > backup-file.sqlすべてのデータベースをダンプするには、以下を実行します。
# mysqldump [options] --all-databases > backup-file.sql1 つ以上のダンプされたフルデータベースをサーバーにロードし直すには、以下を実行します。
# mysql < backup-file.sqlデータベースをリモート MariaDB サーバーにロードするには、以下を実行します。
# mysql --host=remote_host < backup-file.sqlあるデータベースでテーブルのサブセットをダンプするには、
mysqldumpコマンドの末尾に、選択したテーブルのリストを追加します。# mysqldump [options] db_name [tbl_name …] > backup-file.sql1 つのデータベースからダンプされたテーブルのサブセットをロードするには、以下を実行します。
# mysql db_name < backup-file.sql注記この時点で、db_name データベースが存在している必要があります。
mysqldump がサポートするオプションのリストを表示するには、以下を実行します。
$ mysqldump --help
関連情報
- mysqldump を使用した論理バックアップの詳細は、MariaDB Documentation を参照してください。
7.2.5.2. Mariabackup ユーティリティーを使用した物理的なオンラインバックアップの実行
Mariabackup は、Percona XtraBackup テクノロジーをベースとしたユーティリティーです。これにより、InnoDB、Aria、および MyISAM テーブルの物理的なオンラインバックアップを実行できます。このユーティリティーは、AppStream リポジトリーから mariadb-backup パッケージで提供されます。
Mariabackup は、MariaDB サーバーの完全バックアップ機能に対応します。これには、暗号化されたデータおよび圧縮データが含まれます。
前提条件
mariadb-backupパッケージがシステムにインストールされている。# yum install mariadb-backup
- Mariabackup には、バックアップを実行するユーザーの認証情報を指定する必要があります。認証情報はコマンドラインまたは設定ファイルで指定できます。
-
Mariabackup のユーザーは、
RELOAD、LOCK TABLES、およびREPLICATION CLIENTの権限が必要です。
Mariabackup を使用してデータベースのバックアップを作成するには、以下の手順を行います。
手順
コマンドラインで認証情報を提供する間にバックアップを作成するには、以下を実行します。
$ mariabackup --backup --target-dir <backup_directory> --user <backup_user> --password <backup_passwd>target-dirオプションは、バックアップファイルを格納するディレクトリーを定義します。完全バックアップを実行する場合は、ターゲットディレクトリーが空であるか、存在しない必要があります。ユーザーオプションおよびパスワードオプションにより、ユーザー名とパスワードを設定できます。設定ファイルに認証情報を設定してバックアップを作成するには、次のコマンドを実行します。
-
/etc/my.cnf.d/ディレクトリーに設定ファイルを作成します (例:/etc/my.cnf.d/mariabackup.cnf)。 以下の行を新規ファイルの
[xtrabackup]セクションまたは[mysqld]セクションに追加します。[xtrabackup] user=myuser password=mypassword
バックアップを実行します。
$ mariabackup --backup --target-dir <backup_directory>
-
Mariabackup は、設定ファイルの [mariadb] セクションのオプションは読み込みません。MariaDB サーバーにデフォルト以外のデータディレクトリーが指定されている場合は、Mariabackup がデータディレクトリーを見つけることができるように、設定ファイルの [xtrabackup] セクションまたは [mysqld] セクションでこのディレクトリーを指定する必要があります。
デフォルト以外のデータディレクトリーを指定するには、MariaDB 設定ファイルの [xtrabackup] セクションまたは [mysqld] セクションに以下の行を追加します。
datadir=/var/mycustomdatadir
7.2.5.3. Mariabackup ユーティリティーを使用したデータの復元
バックアップが完了したら、mariabackup コマンドに以下のいずれかのオプションを使用して、バックアップからデータを復元できます。
-
--copy-backを使用すると、元のバックアップファイルを保持できます。 -
--move-backは、バックアップファイルをデータディレクトリーに移動し、元のバックアップファイルを削除します。
Mariabackup ユーティリティーを使用してデータを復元するには、以下の手順に従います。
前提条件
mariadbサービスが実行されていないことを確認します。# systemctl stop mariadb.service- データディレクトリーが空であることを確認します。
-
Mariabackup のユーザーは、
RELOAD、LOCK TABLES、およびREPLICATION CLIENTの権限が必要です。
手順
mariabackupコマンドを実行します。データを復元し、元のバックアップファイルを保持するには、
--copy-backオプションを使用します。$ mariabackup --copy-back --target-dir=/var/mariadb/backup/データを復元し、元のバックアップファイルを削除するには、
--move-backオプションを使用します。$ mariabackup --move-back --target-dir=/var/mariadb/backup/
ファイルの権限を修正します。
データベースを復元するとき、Mariabackup は、バックアップのファイルおよびディレクトリーの権限を保持します。ただし、Mariabackup は、ユーザーおよびグループがデータベースを復元する際にファイルをディスクに書き込みます。バックアップの復元後、MariaDB サーバーのユーザーおよびグループ (通常は共に
mysql) が一致するように、データディレクトリーの所有者の調整が必要になる場合があります。たとえば、ファイルの所有権を
mysqlユーザーおよびグループに再帰的に変更するには、次のコマンドを実行します。# chown -R mysql:mysql /var/lib/mysql/mariadbサービスを起動します。# systemctl start mariadb.service
7.2.5.4. ファイルシステムのバックアップの実行
MariaDB データファイルのファイルシステムバックアップを作成するには、MariaDB データディレクトリーの内容をバックアップ場所にコピーします。
現在の設定またはログファイルのバックアップも作成するには、以下の手順の中から任意の手順を選択します。
手順
mariadbサービスを停止します。# systemctl stop mariadb.serviceデータファイルを必要な場所にコピーします。
# cp -r /var/lib/mysql /backup-location必要に応じて、設定ファイルを必要な場所にコピーします。
# cp -r /etc/my.cnf /etc/my.cnf.d /backup-location/configuration必要に応じて、ログファイルを必要な場所にコピーします。
# cp /var/log/mariadb/* /backup-location/logsmariadbサービスを起動します。# systemctl start mariadb.serviceバックアップされたデータをバックアップ場所から
/var/lib/mysqlディレクトリーに読み込む際は、mysql:mysqlが/var/lib/mysql内のすべてのデータの所有者であることを確認してください。# chown -R mysql:mysql /var/lib/mysql
7.2.5.5. バックアップソリューションとしてレプリケーションを使用
レプリケーションは、ソースサーバー用の代替バックアップソリューションです。ソースサーバーの複製となるレプリカサーバーを作成すると、ソースに影響を与えずにレプリカでバックアップを実行できます。ソースは、レプリカをシャットダウンする間に依然として実行でき、レプリカからデータのバックアップを作成できます。
レプリケーション自体は、バックアップソリューションとしては十分ではありません。レプリケーションは、ハードウェア障害からソースサーバーを保護しますが、データ損失に対する保護は保証していません。この方法とともに、レプリカでその他のバックアップソリューションを使用することが推奨されます。
7.2.6. MariaDB 10.3 への移行
RHEL 7 には、MySQL データベースファミリーからのサーバーのデフォルトの実装として、MariaDB 5.5 が同梱されています。新しいバージョンの MariaDB データベースサーバーは、RHEL 7 の Software Collections として利用できます。RHEL 8 は、MariaDB 10.3、MariaDB 10.5、および MySQL 8.0 を提供します。
ここでは、MariaDB の RHEL 7 または Red Hat Software Collections バージョンから MariaDB 10.3 への移行を説明します。RHEL 8 内で MariaDB 10.3 から MariaDB 10.5 へ移行する場合は、MariaDB 10.3 から MariaDB 10.5 へのアップグレード を参照してください。
7.2.6.1. RHEL 7 と RHEL 8 のバージョンにおける MariaDB の主な相違点
MariaDB 5.5 および MariaDB 10.3 における最も重要な変更点を以下に示します。
- 10.1 以降、同期マルチソースクラスターのMariaDB Galera クラスター は、MariaDB の標準部分です。
- ARCHIVE ストレージエンジンはデフォルトで有効ではなくなるため、プラグインを明示的に有効にする必要があります。
- BLACKHOLE ストレージエンジンはデフォルトで有効ではなくなるため、プラグインを明示的に有効にする必要があります。
InnoDB は、MariaDB 10.1 以前のバージョンで使用されていた XtraDB ではなく、デフォルトのストレージエンジンとして使用されます。
詳細は、Why does MariaDB 10.2 use InnoDB instead of XtraDB? を参照してください。
-
新しい
mariadb-connector-cパッケージは、MySQL と MariaDB に共通のクライアントライブラリーを提供します。このライブラリーは、データベースサーバー MySQL および MariaDB のすべてのバージョンで使用できます。その結果、Red Hat Enterprise Linux 8 に同梱される MySQL サーバーまたは MariaDB サーバーのいずれかに構築されるアプリケーションの 1 つに接続できます。
MariaDB 5.5 から MariaDB 10.3 に移行するには、MariaDB への移行 の説明に従って複数の設定変更を実行する必要があります。
7.2.6.2. 設定変更
MariaDB 5.5 から MariaDB 10.3 への推奨される移行パスは、最初に MariaDB 10.0 にアップグレードしてから、1 バージョンずつ順次アップグレードすることです。
一度に 1 つのマイナーバージョンをアップグレードする主な利点は、変更に対するデータと設定の両方を含む、データベースの適合に優れている点です。アップグレードは、RHEL 8 (MariaDB 10.3) で利用可能なものと同じメジャーバージョンで終了します。これにより、設定変更やその他の問題が大幅に低下します。
MariaDB 5.5 から MariaDB 10.0 への移行時の設定の変更の詳細は、Red Hat Software Collections の MariaDB 10.0 への移行 を参照してください。
以下の後続バージョンの MariaDB への以降と、必要な設定変更は、以下のドキュメントで説明します。
- Red Hat Software Collections ドキュメントの Migrating to MariaDB 10.1
- Red Hat Software Collections ドキュメントの Migrating to MariaDB 10.2
- Red Hat Software Collections ドキュメントの Migrating to MariaDB 10.3
MariaDB 5.5 から MariaDB 10.3 へ直接移行することもできますが、上記の移行ドキュメントに記載されている違いにより必要とされる設定変更をすべて実行する必要があります。
7.2.6.3. mysql_upgrade ユーティリティーを使用したインプレースアップグレード
データベースファイルを RHEL 8 に移行するには、RHEL 7 の MariaDB ユーザーは、mysql_upgrade ユーティリティーを使用してインプレースアップグレードを実行する必要があります。mysql_upgrade ユーティリティーは、mariadb-server-utils サブパッケージにより提供され、mariadb-server パッケージの依存関係としてインストールされます。
インプレースアップグレードを実行するには、RHEL 8 システムの /var/lib/mysql/ データディレクトリーにバイナリーデータファイルをコピーして、mysql_upgrade ユーティリティーを使用する必要があります。
この方法を使用すると、以下からデータを移行できます。
- Red Hat Enterprise Linux 7 バージョンの MariaDB 5.5
Red Hat Software Collections のバージョンは、以下の通りです。
- MariaDB 5.5 (サポート対象外になりました)
- MariaDB 10.0 (サポート対象外になりました)
- MariaDB 10.1 (サポート対象外になりました)
- MariaDB 10.2 (サポート対象外になりました)
MariaDB 10.3
MariaDB 10.3 へのアップグレードは、バージョンごとに連続して行うことが推奨されます。移行は、Release Notes for Red Hat Software Collections で該当する章を参照してください。
RHEL 7 バージョンの MariaDB からアップグレードする場合は、ソースデータは /var/lib/mysql/ ディレクトリーに保存されます。Red Hat Software Collections バージョンの MariaDB の場合、ソースデータディレクトリーは /var/opt/rh/<collection_name>/lib/mysql/ です (/opt/rh/mariadb55/root/var/lib/mysql/ データディレクトリーを使用する mariadb55 を除く)。
mysql_upgrade ユーティリティーを使用してアップグレード を実行するには、以下の手順を行います。
前提条件
- アップグレードを実行する前に、MariaDB データベースに保存されている全データのバックアップを作成します。
手順
RHEL 8 システムに
mariadb-serverパッケージがインストールされていることを確認します。# yum install mariadb-serverデータのコピー時に、
mariadbサービスがソースおよびターゲットのシステムで稼働していないことを確認します。# systemctl stop mariadb.service-
ソースの場所から RHEL 8 ターゲットシステムの
/var/lib/mysql/ディレクトリーにデータをコピーします。 ターゲットシステムでコピーされたファイルに適切なパーミッションと SELinux コンテキストを設定します。
# restorecon -vr /var/lib/mysqlターゲットシステムで、MariaDB サーバーを起動します。
# systemctl start mariadb.servicemysql_upgradeコマンドを実行して、内部テーブルをチェックし、修復します。$ mysql_upgrade-
アップグレードが完了したら、
/etc/my.cnf.d/ディレクトリー内のすべての設定ファイルに MariaDB 10.3 に対して有効なオプションのみが含まれていることを確認します。
インプレースアップグレードに関連する特定のリスクと既知の問題があります。たとえば、一部のクエリーが動作しなかったり、アップグレード前とは異なる順序で実行される場合があります。これらのリスクと問題、およびインプレースアップグレードに関する全般的な情報は、MariaDB 10.3 Release Notes を参照してください。
7.2.7. MariaDB 10.3 から MariaDB 10.5 へのアップグレード
ここでは、RHEL 8 における MariaDB 10.3 から MariaDB 10.5 への移行について説明します。
7.2.7.1. MariaDB 10.3 と MariaDB 10.5 の主な相違点
MariaDB 10.3 と MariaDB 10.5 の間の重要な変更点には以下が含まれます。
-
MariaDB はデフォルトで
unix_socket認証プラグインを使用するようになりました。このプラグインを使用すると、ローカルの UNIX ソケットファイルを介して MariaDB に接続する際に、オペレーティングシステムの資格情報を使用できます。 -
MariaDBは、mariadb-*という名前のバイナリーと、mariadb-*バイナリーを指すmysql*シンボリックリンクを追加します。たとえば、mysqladmin、mysqlaccess、およびmysqlshowのシンボリックリンクは、mariadb-admin、mariadb-access、およびmariadb-showのバイナリーをそれぞれポイントします。 -
各ユーザーロールに合わせて、
SUPER特権が複数の特権に分割されました。その結果、一部のステートメントで必要な特権が変更されました。 -
並列のレプリケーションでは、
slave_parallel_modeはデフォルトでoptimisticに設定されるようになりました。 -
InnoDB ストレージエンジンで、変数のデフォルトが変更されました (
innodb_adaptive_hash_indexはOFFへ、innodb_checksum_algorithmはfull_crc32へ変更)。 MariaDB は、以前使用された
readlineライブラリーではなく、MariaDB コマンド履歴 (.mysql_historyファイル) を管理する基盤となるソフトウェアのlibedit実装を使用するようになりました。この変更は、.mysql_historyファイルを直接使用しているユーザーに影響します。.mysql_historyは MariaDB または MySQL アプリケーションによって管理されるファイルであるため、ユーザーは直接ファイルでは機能しないことに注意してください。人間が判読可能な外観は偶然です。注記セキュリティーを強化するために、履歴ファイルの維持を考慮することができます。コマンド履歴の記録を無効にするには、以下を実行します。
-
存在する場合は、
.mysql_historyファイルを削除します。 以下のいずれかの方法を使用します。
-
MYSQL_HISTFILE変数を/dev/nullに設定し、これをシェルの起動ファイルに追加します。 .mysql_historyファイルを/dev/nullへのシンボリックリンクに変更します。$ ln -s /dev/null $HOME/.mysql_history
-
-
存在する場合は、
MariaDB Galera クラスター がバージョン 4 にアップグレードされ、以下の主な変更点が加えられました。
- Galera は、サイズ制限なしのトランザクションの複製をサポートする、新しいストリーミングレプリケーション機能を追加します。ストリーミングレプリケーションの実行時に、クラスターは小さなフラグメントでトランザクションを複製します。
- Galera が Global Transaction ID (GTID) に完全に対応するようになりました。
-
/etc/my.cnf.d/galera.cnfファイルのwsrep_onオプションのデフォルト値が1から0に変更され、エンドユーザーが必要な追加オプションを設定せずにwsrepレプリケーションを開始できないようにします。
MariaDB 10.5 の PAM プラグインへの変更には、以下が含まれます。
-
MariaDB 10.5 は、PAM (Pluggable Authentication Modules) プラグインの新バージョンを追加します。PAM プラグインバージョン 2.0 は、個別の
setuid rootヘルパーバイナリーを使用して PAM 認証を実行します。これにより、MariaDB が追加の PAM モジュールを使用できるようになります。 -
ヘルパーバイナリーは、
mysqlグループのユーザーによってのみ実行できます。デフォルトでは、グループにはmysqlユーザーのみが含まれます。Red Hat では、このヘルパーユーティリティーを介してスロットルまたはログの記録をせずにパスワード推測攻撃を防ぐために、管理者がmysqlグループにユーザーをさらに追加しないことを推奨しています。 -
MariaDB 10.5 では、プラグ可能な認証モジュール (PAM) プラグインとその関連ファイルが新しいパッケージ
mariadb-pamに移動しました。したがって、MariaDBに PAM 認証を使用しないシステムに、新しいsetuid rootバイナリーが導入されることはありません。 -
mariadb-pamパッケージには、両方の PAM プラグインバージョンが含まれています。バージョン 2.0 はデフォルトで、バージョン 1.0 はauth_pam_v1共有オブジェクトライブラリーとして利用できます。 -
MariaDB サーバーでは、
mariadb-pamパッケージはデフォルトでインストールされません。MariaDB 10.5 で PAM 認証プラグインを利用できるようにするには、mariadb-pamパッケージを手動でインストールします。
7.2.7.2. RHEL 8 バージョンの MariaDB 10.3 から MariaDB 10.5 へのアップグレード
この手順では、yum および mariadb-upgrade ユーティリティーを使用して、mariadb:10.3 モジュールストリームから mariadb:10.5 モジュールストリームにアップグレードする方法を説明します。
mariadb-upgrade ユーティリティーは、mariadb-server-utils サブパッケージにより提供され、mariadb-server パッケージの依存関係としてインストールされます。
前提条件
- アップグレードを実行する前に、MariaDB データベースに保存されている全データのバックアップを作成します。
手順
MariaDB サーバーを停止します。
# systemctl stop mariadb.service以下のコマンドを実行して、後続のストリームに切り替えるためのシステムの準備が整っているかどうかを判断します。
# yum distro-syncこのコマンドは、Nothing to do.Complete! のメッセージで終了する必要があります。詳細は、後続のストリームへの切り替え を参照してください。
システムで
mariadbモジュールをリセットします。# yum module reset mariadb新しい
mariadb:10.5モジュールストリームを有効にします。# yum module enable mariadb:10.5インストール済みパッケージを同期し、ストリーム間の変更を実行します。
# yum distro-syncこれにより、インストールされている MariaDB パッケージがすべて更新されます。
-
/etc/my.cnf.d/にあるオプションファイルに MariaDB 10.5 に対して有効なオプションのみが含まれるように、設定を調整します。詳細は、MariaDB 10.4 および MariaDB 10.5 のアップストリームドキュメントを参照してください。 MariaDB サーバーを起動します。
スタンドアロンを実行しているデータベースをアップグレードする場合:
# systemctl start mariadb.serviceGalera クラスターノードをアップグレードする場合:
# galera_new_clustermariadbサービスが自動的に起動します。
mariadb-upgrade ユーティリティーを実行して、内部テーブルをチェックし、修復します。
スタンドアロンを実行しているデータベースをアップグレードする場合:
# mariadb-upgradeGalera クラスターノードをアップグレードする場合:
# mariadb-upgrade --skip-write-binlog
インプレースアップグレードに関連する特定のリスクと既知の問題があります。たとえば、一部のクエリーが動作しなかったり、アップグレード前とは異なる順序で実行される場合があります。これらのリスクと問題、およびインプレースアップグレードに関する全般的な情報は、MariaDB 10.5 Release Notes を参照してください。
7.2.8. Galera で MariaDB を複製する
本セクションでは、Red Hat Enterprise Linux 8 の Galera ソリューションを使用して、MariaDB データベースを複製する方法を説明します。
7.2.8.1. MariaDB Galera クラスターの概要
Galera レプリケーションは、複数の MariaDB サーバーで設定される同期マルチソース MariaDB Galera クラスター の作成に基づいています。レプリカが通常読み取り専用である従来のプライマリー/レプリカ設定とは異なり、MariaDB Galera クラスターのノードはすべて書き込み可能にすることができます。
Galera レプリケーションと MariaDB データベースとの間のインターフェイスは、書き込みセットレプリケーション API (wsrep API) で定義されます。
MariaDB Galera クラスター の主な機能は以下のとおりです。
- 同期のレプリケーション
- アクティブ/アクティブのマルチソーストポロジー
- クラスターノードへの読み取りおよび書き込み
- 自動メンバーシップ制御、失敗したノードのクラスターからの削除
- 自動ノードの参加
- 行レベルの並列レプリケーション
- ダイレクトクライアント接続: ユーザーはクラスターノードにログインし、レプリケーションの実行中にノードを直接操作できます。
同期レプリケーションとは、サーバーがトランザクションに関連付けられた書き込みセットをクラスター内のすべてのノードにブロードキャストすることで、コミット時にトランザクションをレプリケートすることを意味します。クライアント (ユーザーアプリケーション) はデータベース管理システム (DBMS) に直接接続し、ネイティブの MariaDB と同様の動作が発生します。
同期レプリケーションは、クラスター内の 1 つのノードで発生した変更が、クラスター内の他のノードで同時に発生することを保証します。
そのため、同期レプリケーションには、非同期のレプリケーションと比べて次のような利点があります。
- 特定のクラスターノード間の変更の伝播に遅延がない
- すべてのクラスターノードには常に一貫性がある
- いずれかのクラスターノードがクラッシュしても、最新の変更は失われない
- すべてのクラスターノードのトランザクションが並列に実行する
- クラスター全体にわたる因果関係
7.2.8.2. MariaDB Galera クラスターを構築するためのコンポーネント
MariaDB Galera クラスター を構築するには、システムに以下のパッケージをインストールする必要があります。
-
mariadb-server-galera: MariaDB Galera クラスター のサポートファイルとスクリプトが含まれます。 -
mariadb-server: MariaDB アップストリームがパッチを適用し、書き込みセットレプリケーション API (wsrep API) を組み込みます。この API は、Galera レプリケーションと MariaDB との間のインターフェイスを提供します。 galera: MariaDB アップストリームがパッチを適用し、MariaDB の完全サポートを追加します。galeraパッケージには、以下の内容が含まれます。- Galera Replication Library は、レプリケーション機能全体を提供します。
- Galera Arbitrator ユーティリティーは、スプリットブレインのシナリオで投票に参加するクラスターメンバーとして使用できます。ただし、Galera Arbitrator は実際のレプリケーションには参加できません。
-
Galera Arbitrator ユーティリティーのデプロイに使用される Galera Systemd service および Galera wrapper script。RHEL 8 の MariaDB 10.3 および MariaDB 10.5 には、Red Hat バージョンの
garbdsystemd サービスと、/usr/lib/systemd/system/garbd.serviceファイルおよび/usr/sbin/garbd-wrapperファイルにそれぞれあるgaleraパッケージのラッパースクリプトが含まれています。RHEL 8.6 以降、MariaDB 10.3 および MariaDB 10.5 は、/usr/share/doc/galera/garb-systemdおよび/usr/share/doc/galera/garbd.serviceにあるこれらのファイルのアップストリームバージョンも提供するようになりました。
7.2.8.3. MariaDB Galera クラスターのデプロイメント
前提条件
mariadbモジュールからストリーム (バージョン) を選択し、galeraプロファイルを指定して、MariaDB Galera クラスター パッケージをインストールします。以下に例を示します。# yum module install mariadb:10.3/galeraこれにより、以下のパッケージがインストールされます。
-
mariadb-server-galera -
mariadb-server galeramariadb-server-galeraパッケージがmariadb-serverパッケージおよびgaleraパッケージを依存関係としてプルします。MariaDB Galera Cluster をビルドするためにインストールする必要があるパッケージについては、MariaDB クラスターをビルドするためのコンポーネント を参照してください。
-
MariaDB サーバーのレプリケーション設定は、システムを初めてクラスターに追加する前に更新する必要があります。
デフォルト設定は、
/etc/my.cnf.d/galera.cnfファイルで配布されます。MariaDB Galera クラスター をデプロイする前に、以下の文字列で開始するように、すべてのノードの
/etc/my.cnf.d/galera.cnfファイルにwsrep_cluster_addressオプションを設定します。gcomm://
初期ノードでは、
wsrep_cluster_addressを空のリストとして設定できます。wsrep_cluster_address="gcomm://"
その他のすべてのノードに
wsrep_cluster_addressを設定して、実行中のクラスターに属するノードへのアドレスを追加します。以下に例を示します。wsrep_cluster_address="gcomm://10.0.0.10"
Galera Cluster アドレスの設定方法は、Galera Cluster Address を参照してください。
手順
ノードで以下のラッパーを実行して、新規クラスターの最初のノードをブートストラップします。
# galera_new_clusterこのラッパーにより、MariaDB サーバーデーモン (
mysqld) に--wsrep-new-clusterオプションが指定されて実行されるようになります。このオプションは、接続する既存クラスターがないという情報を提供します。したがって、ノードは新規 UUID を作成し、新しいクラスターを特定します。注記mariadbサービスは、複数の MariaDB サーバープロセスと対話する systemd メソッドをサポートします。したがって、複数の MariaDB サーバーを実行している場合は、インスタンス名を接尾辞として指定して、特定のインスタンスをブートストラップできます。# galera_new_cluster mariadb@node1各ノードで次のコマンドを実行して、その他のノードをクラスターに接続します。
# systemctl start mariadbその結果、ノードはクラスターに接続し、それ自体をクラスターの状態と同期します。
7.2.8.4. 新規ノードの MariaDB Galera クラスターへの追加
新規ノードを MariaDB Galera クラスター に追加するには、以下の手順に従います。
この手順に従って、既存のノードを再接続することもできます。
手順
特定のノードで、
/etc/my.cnf.d/galera.cnf設定ファイルの[mariadb]セクション内にあるwsrep_cluster_addressオプションで、1 つ以上の既存クラスターメンバーにアドレスを指定します。[mariadb] wsrep_cluster_address="gcomm://192.168.0.1"新規ノードを既存クラスターノードのいずれかに接続すると、クラスター内のすべてのノードを表示できるようになります。
ただし、
wsrep_cluster_addressのクラスターの全ノードを表示することが推奨されます。したがって、1 つ以上のクラスターノードがダウンしても、その他のクラスターノードに接続することでノードがクラスターに参加できます。すべてのメンバーがメンバーシップに同意すると、クラスターの状態が変更します。新規ノードの状態がクラスターの状態と異なる場合、新しいノードは Incremental State Transfer (IST) または State Snapshot Transfer (SST) のいずれかを要求し、他のノードとの一貫性を確保します。
7.2.8.5. MariaDB Galera クラスターの再起動
すべてのノードを同時にシャットダウンすると、クラスターが終了し、実行中のクラスターは存在しなくなります。ただし、クラスターのデータは引き続き存在します。
クラスターを再起動するには、MariaDB Galera クラスターの設定の説明に従って、最初のノードをブートストラップします。
クラスターがブートストラップされず、最初のノードの mysqld が systemctl start mariadb コマンドでのみ起動した場合、ノードは /etc/my.cnf.d/galera.cnf ファイルの wsrep_cluster_address オプションに記載されている少なくとも 1 つのノードに接続しようとします。ノードが現在実行していない場合は、再起動に失敗します。
7.2.9. MariaDB クライアントアプリケーションの開発
Red Hat では、MariaDB クライアントライブラリーに対して MariaDB クライアントアプリケーションを開発することを推奨します。
MariaDB クライアントライブラリーに対してアプリケーションを構築するために必要な開発ファイルとプログラムは、mariadb-connector-c-devel パッケージによって提供されます。
直接ライブラリー名を使用する代わりに、mariadb-connector-c-devel パッケージで配布されている mariadb_config プログラムを使用します。このプログラムは、正しいビルドフラグが返されることを保証します。
7.3. MySQL の使用
MySQL サーバーは、オープンソースの高速で堅牢なデータベースサーバーです。MySQL は、データを構造化情報に変換して、データにアクセスする SQL インターフェイスを提供するリレーショナルデータベースです。これには、複数のストレージエンジンとプラグイン、および地理的な情報システム (GIS) および JSON (JavaScript Object Notation) 機能が含まれます。
RHEL システムに MySQL をインストールして設定する方法、MySQL データをバックアップする方法、MySQL の以前のバージョンから移行する方法、および MySQL を複製する方法について説明します。
7.3.1. MySQL のインストール
RHEL 8 では、MySQL 8.0 サーバーは mysql:8.0 モジュールストリームとして利用できます。
MySQL をインストールするには、以下の手順に従います。
手順
mysqlモジュールから8.0ストリーム (バージョン) を選択し、serverプロファイルを指定して、MySQL サーバーパッケージをインストールします。# yum module install mysql:8.0/servermysqldサービスを開始します。# systemctl start mysqld.servicemysqldサービスを有効にして、起動時に起動するようにします。# systemctl enable mysqld.service推奨手順: MySQL のインストール時にセキュリティーを強化するには、次のコマンドを実行します。
$ mysql_secure_installationこのコマンドは、完全にインタラクティブなスクリプトを起動して、プロセスの各ステップのプロンプトを表示します。このスクリプトを使用すると、次の方法でセキュリティーを改善できます。
- root アカウントのパスワードの設定
- 匿名ユーザーの削除
- リモート root ログインの拒否 (ローカルホスト外)
RPM パッケージが競合しているため、RHEL 8 では MySQL および MariaDB データベースサーバーを同時にインストールすることはできません。RHEL 7 用の Red Hat Software Collections では、コンポーネントの同時インストールが可能です。RHEL 8 では、コンテナー内で異なるバージョンのデータベースサーバーを使用できます。
7.3.2. MySQL の設定
MySQL サーバーをネットワーク用に設定するには、以下の手順に従います。
手順
/etc/my.cnf.d/mysql-server.cnfファイルの[mysqld]セクションを編集します。以下の設定ディレクティブを設定できます。bind-address: サーバーがリッスンするアドレスです。設定可能なオプションは以下のとおりです。- ホスト名
- IPv4 アドレス
- IPv6 アドレス
skip-networking: サーバーが TCP/IP 接続をリッスンするかどうかを制御します。以下の値が使用できます。- 0 - すべてのクライアントをリッスンする
- 1 - ローカルクライアントのみをリッスンする
-
port: MySQL が TCP/IP 接続をリッスンするポート。
mysqldサービスを再起動します。# systemctl restart mysqld.service
7.3.3. MySQL サーバーでの TLS 暗号化の設定
デフォルトでは、MySQL は暗号化されていない接続を使用します。安全な接続のために、MySQL サーバーで TLS サポートを有効にし、暗号化された接続を確立するようにクライアントを設定します。
7.3.3.1. MySQL サーバーに CA 証明書、サーバー証明書、および秘密鍵を配置する
MySQL サーバーで TLS 暗号化を有効にする前に、認証局 (CA) 証明書、サーバー証明書、および秘密鍵を MySQL サーバーに保存します。
前提条件
Privacy Enhanced Mail(PEM) 形式の以下のファイルがサーバーにコピーされています。
-
サーバーの秘密鍵:
server.example.com.key.pem -
サーバー証明書:
server.example.com.crt.pem -
認証局 (CA) 証明書:
ca.crt.pem
秘密鍵および証明書署名要求 (CSR) の作成や、CA からの証明書要求に関する詳細は、CA のドキュメントを参照してください。
-
サーバーの秘密鍵:
手順
CA およびサーバー証明書を
/etc/pki/tls/certs/ディレクトリーに保存します。# mv <path>/server.example.com.crt.pem /etc/pki/tls/certs/ # mv <path>/ca.crt.pem /etc/pki/tls/certs/
MySQL サーバーがファイルを読み込めるように、CA およびサーバー証明書にパーミッションを設定します。
# chmod 644 /etc/pki/tls/certs/server.example.com.crt.pem /etc/pki/tls/certs/ca.crt.pem証明書は、セキュアな接続が確立される前は通信の一部であるため、任意のクライアントは認証なしで証明書を取得できます。そのため、CA およびサーバーの証明書ファイルに厳密なパーミッションを設定する必要はありません。
サーバーの秘密鍵を
/etc/pki/tls/private/ディレクトリーに保存します。# mv <path>/server.example.com.key.pem /etc/pki/tls/private/サーバーの秘密鍵にセキュアなパーミッションを設定します。
# chmod 640 /etc/pki/tls/private/server.example.com.key.pem # chgrp mysql /etc/pki/tls/private/server.example.com.key.pem
承認されていないユーザーが秘密鍵にアクセスできる場合は、MySQL サーバーへの接続は安全ではなくなります。
SELinux コンテキストを復元します。
# restorecon -Rv /etc/pki/tls/
7.3.3.2. MySQL サーバーでの TLS の設定
セキュリティーを強化するには、MySQL サーバーで TLS サポートを有効にします。その結果、クライアントは TLS 暗号化を使用してサーバーでデータを送信できます。
前提条件
- MySQL サーバーをインストールしている。
-
mysqldサービスが実行されている。 Privacy Enhanced Mail(PEM) 形式の以下のファイルがサーバー上にあり、
mysqlユーザーが読み取りできます。-
サーバーの秘密鍵:
/etc/pki/tls/private/server.example.com.key.pem -
サーバー証明書:
/etc/pki/tls/certs/server.example.com.crt.pem -
認証局 (CA) 証明書
/etc/pki/tls/certs/ca.crt.pem
-
サーバーの秘密鍵:
- サーバー証明書のサブジェクト識別名 (DN) またはサブジェクトの別名 (SAN) フィールドは、サーバーのホスト名と一致します。
手順
/etc/my.cnf.d/mysql-server-tls.cnfファイルを作成します。以下の内容を追加して、秘密鍵、サーバー、および CA 証明書へのパスを設定します。
[mysqld] ssl_key = /etc/pki/tls/private/server.example.com.key.pem ssl_cert = /etc/pki/tls/certs/server.example.com.crt.pem ssl_ca = /etc/pki/tls/certs/ca.crt.pem
証明書失効リスト (CRL) がある場合は、それを使用するように MySQL サーバーを設定します。
ssl_crl = /etc/pki/tls/certs/example.crl.pemオプション: 暗号化なしの接続試行を拒否します。この機能を有効にするには、以下を追加します。
require_secure_transport = onオプション: サーバーがサポートする必要がある TLS バージョンを設定します。たとえば、TLS 1.2 および TLS 1.3 をサポートするには、以下を追加します。
tls_version = TLSv1.2,TLSv1.3デフォルトでは、サーバーは TLS 1.1、TLS 1.2、および TLS 1.3 をサポートします。
mysqldサービスを再起動します。# systemctl restart mysqld
検証
トラブルシューティングを簡素化するには、ローカルクライアントが TLS 暗号化を使用するように設定する前に、MySQL サーバーで以下の手順を実行します。
MySQL で TLS 暗号化が有効になっていることを確認します。
# mysql -u root -p -h <MySQL_server_hostname> -e "SHOW session status LIKE 'Ssl_cipher';" +---------------+------------------------+ | Variable_name | Value | +---------------+------------------------+ | Ssl_cipher | TLS_AES_256_GCM_SHA384 | +---------------+------------------------+MySQL サーバーが特定の TLS バージョンのみをサポートするように設定している場合は、
tls_version変数を表示します。# mysql -u root -p -e "SHOW GLOBAL VARIABLES LIKE 'tls_version';" +---------------+-----------------+ | Variable_name | Value | +---------------+-----------------+ | tls_version | TLSv1.2,TLSv1.3 | +---------------+-----------------+サーバーが正しい CA 証明書、サーバー証明書、および秘密鍵ファイルを使用していることを確認します。
# mysql -u root -e "SHOW GLOBAL VARIABLES WHERE Variable_name REGEXP '^ssl_ca|^ssl_cert|^ssl_key';" +-----------------+-------------------------------------------------+ | Variable_name | Value | +-----------------+-------------------------------------------------+ | ssl_ca | /etc/pki/tls/certs/ca.crt.pem | | ssl_capath | | | ssl_cert | /etc/pki/tls/certs/server.example.com.crt.pem | | ssl_key | /etc/pki/tls/private/server.example.com.key.pem | +-----------------+-------------------------------------------------+
7.3.3.3. 特定のユーザーアカウントに TLS で暗号化された接続を要求する
機密データにアクセスできるユーザーは、ネットワーク上で暗号化されていないデータ送信を回避するために、常に TLS で暗号化された接続を使用する必要があります。
すべての接続にセキュアなトランスポートが必要なサーバーで設定できない場合は (require_secure_transport = on)、TLS 暗号化を必要とするように個別のユーザーアカウントを設定します。
前提条件
- MySQL サーバーで TLS サポートが有効になっている。
- セキュアなトランスポートを必要とするように設定するユーザーが存在する。
- CA 証明書がクライアントに保存されている。
手順
管理ユーザーとして MySQL サーバーに接続します。
# mysql -u root -p -h server.example.com管理ユーザーがリモートでサーバーにアクセスする権限を持たない場合は、MySQL サーバーでコマンドを実行し、
localhostに接続します。REQUIRE SSL句を使用して、ユーザーが TLS 暗号化接続を使用して接続する必要があるよう強制します。MySQL [(none)]> ALTER USER 'example'@'%' REQUIRE SSL;
検証
TLS 暗号化を使用して、
exampleユーザーとしてサーバーに接続します。# mysql -u example -p -h server.example.com ... MySQL [(none)]>エラーが表示されず、インタラクティブな MySQL コンソールにアクセスできる場合は、TLS との接続は成功します。
デフォルトでは、サーバーが TLS 暗号化を提供している場合、クライアントは自動的にその TLS 暗号化を使用します。したがって、
--ssl-ca=ca.crt.pemおよび--ssl-mode=VERIFY_IDENTITYオプションは必須ではありません。ただし、これらのオプションを使用するとクライアントはサーバーの ID を検証するため、セキュリティーが向上します。TLS を無効にして、
exampleユーザーとして接続を試みます。# mysql -u example -p -h server.example.com --ssl-mode=DISABLED ERROR 1045 (28000): Access denied for user 'example'@'server.example.com' (using password: YES)このユーザーには TLS が必要なのにもかかわらず無効になっているため、サーバーはログインの試行を拒否しました (
--ssl-mode=DISABLED)。
関連情報
7.3.4. MySQL クライアントで CA 証明書の検証を使用して TLS 暗号化をグローバルで有効にする
MySQL サーバーが TLS 暗号化に対応している場合は、安全な接続のみを確立し、サーバー証明書を検証するようにクライアントを設定します。この手順では、サーバー上のすべてのユーザーで TLS サポートを有効にする方法を説明します。
7.3.4.1. デフォルトで TLS 暗号化を使用するように MySQL クライアントを設定する
RHEL では、MySQL クライアントが TLS 暗号化を使用するようにグローバルに設定でき、サーバー証明書の Common Name (CN) が、ユーザーが接続するホスト名と一致することを検証します。これにより、man-in-the-middle 攻撃 (中間者攻撃) を防ぎます。
前提条件
- MySQL サーバーで TLS サポートが有効になっている。
-
CA 証明書は、クライアントの
/etc/pki/tls/certs/ca.crt.pemファイルに保存されます。
手順
以下の内容で
/etc/my.cnf.d/mysql-client-tls.cnfファイルを作成します。[client] ssl-mode=VERIFY_IDENTITY ssl-ca=/etc/pki/tls/certs/ca.crt.pem
これらの設定は、MySQL クライアントが TLS 暗号化を使用すること、およびクライアントがホスト名をサーバー証明書の CN と比較すること (
ssl-mode=VERIFY_IDENTITY) を定義します。さらに、CA 証明書 (ssl-ca) へのパスも指定します。
検証
ホスト名を使用してサーバーに接続し、サーバーの状態を表示します。
# mysql -u root -p -h server.example.com -e status ... SSL: Cipher in use is TLS_AES_256_GCM_SHA384SSLエントリーにCipher in use is…が含まれている場合、接続は暗号化されています。このコマンドで使用するユーザーには、リモートで認証するパーミッションがあることに注意してください。
接続するホスト名がサーバーの TLS 証明書のホスト名と一致しない場合、
ssl-mode=VERIFY_IDENTITYパラメーターにより接続が失敗します。たとえば、localhostに接続する場合は、以下のようになります。# mysql -u root -p -h localhost -e status ERROR 2026 (HY000): SSL connection error: error:0A000086:SSL routines::certificate verify failed
関連情報
-
mysql(1)man ページの--ssl*パラメーターの説明。
7.3.5. MySQL データのバックアップ
Red Hat Enterprise Linux 8 でMySQL データベースからデータをバックアップする主な方法は 2 つあります。
- 論理バックアップ
- 物理バックアップ
論理バックアップ は、データの復元に必要な SQL ステートメントで設定されます。この種類のバックアップは、情報およびレコードをプレーンテキストファイルにエクスポートします。
物理バックアップに対する論理バックアップの主な利点は、移植性と柔軟性です。データは、物理バックアップではできない他のハードウェア設定である MySQL バージョンまたはデータベース管理システム (DBMS) で復元できます。
mysqld.service が実行されている場合は、論理バックアップを実行できることに注意してください。論理バックアップには、ログと設定ファイルが含まれません。
物理バックアップ は、コンテンツを格納するファイルおよびディレクトリーのコピーで設定されます。
物理バックアップは、論理バックアップと比較して、以下の利点があります。
- 出力が少なくなる。
- バックアップのサイズが小さくなる。
- バックアップおよび復元が速くなる。
- バックアップには、ログファイルと設定ファイルが含まれる。
mysqld.service が実行されていない場合、またはバックアップ中の変更を防ぐためにデータベース内のすべてのテーブルがロックされている場合は、物理バックアップを実行する必要があることに注意してください。
以下の MySQL バックアップアプローチのいずれかを使用して、MySQL データベースからデータをバックアップできます。
-
mysqldumpを使用した論理バックアップ - ファイルシステムのバックアップ
- バックアップソリューションとしてレプリケーションを使用
7.3.5.1. mysqldump を使用した論理バックアップの実行
mysqldump クライアントはバックアップユーティリティーで、バックアップ目的でデータベースまたはデータベースの集合をダンプしたり、別のデータベースサーバーに転送したりできます。通常、mysqldump の出力は、サーバーテーブル構造を再作成する、それにデータを取り込む、またはその両方の SQL ステートメントで設定されます。mysqldump は、XML および (CSV などの) コンマ区切りテキスト形式など、他の形式でファイルを生成することもできます。
mysqldump バックアップを実行するには、以下のいずれかのオプションを使用できます。
- 選択したデータベースを 1 つまたは複数バックアップ
- すべてのデータベースをバックアップする。
- あるデータベースのテーブルのサブセットのバックアップを作成する。
手順
単一のデータベースをダンプするには、以下を実行します。
# mysqldump [options] --databases db_name > backup-file.sql複数のデータベースを一度にダンプするには、次のコマンドを実行します。
# mysqldump [options] --databases db_name1 [db_name2 ...] > backup-file.sqlすべてのデータベースをダンプするには、以下を実行します。
# mysqldump [options] --all-databases > backup-file.sql1 つ以上のダンプされたフルデータベースをサーバーにロードし直すには、以下を実行します。
# mysql < backup-file.sqlデータベースをリモート MySQL サーバーにロードするには、以下を実行します。
# mysql --host=remote_host < backup-file.sqlあるデータベースでリテラルなテーブルのサブセットをダンプするには、
mysqldumpコマンドの末尾に、選択したテーブルのリストを追加します。# mysqldump [options] db_name [tbl_name ...] > backup-file.sql1 つのデータベースからダンプされたリテラルなテーブルのサブセットをロードするには、次のコマンドを実行します。
# mysql db_name < backup-file.sql注記この時点で、db_name データベースが存在している必要があります。
mysqldump がサポートするオプションのリストを表示するには、以下を実行します。
$ mysqldump --help
7.3.5.2. ファイルシステムのバックアップの実行
MySQL データファイルのファイルシステムバックアップを作成するには、MySQL データディレクトリーの内容をバックアップ場所にコピーします。
現在の設定またはログファイルのバックアップも作成するには、以下の手順の中から任意の手順を選択します。
手順
mysqldサービスを停止します。# systemctl stop mysqld.serviceデータファイルを必要な場所にコピーします。
# cp -r /var/lib/mysql /backup-location必要に応じて、設定ファイルを必要な場所にコピーします。
# cp -r /etc/my.cnf /etc/my.cnf.d /backup-location/configuration必要に応じて、ログファイルを必要な場所にコピーします。
# cp /var/log/mysql/* /backup-location/logsmysqldサービスを開始します。# systemctl start mysqld.serviceバックアップされたデータをバックアップ場所から
/var/lib/mysqlディレクトリーに読み込む際は、mysql:mysqlが/var/lib/mysql内のすべてのデータの所有者であることを確認してください。# chown -R mysql:mysql /var/lib/mysql
7.3.5.3. バックアップソリューションとしてレプリケーションを使用
レプリケーションは、ソースサーバー用の代替バックアップソリューションです。ソースサーバーの複製となるレプリカサーバーを作成すると、ソースに影響を与えずにレプリカでバックアップを実行できます。ソースは、レプリカをシャットダウンする間に依然として実行でき、レプリカからデータのバックアップを作成できます。
MySQLデータベースを複製する方法の手順については、MySQL の複製 を参照してください。
レプリケーション自体は、バックアップソリューションとしては十分ではありません。レプリケーションは、ハードウェア障害からソースサーバーを保護しますが、データ損失に対する保護は保証していません。この方法とともに、レプリカでその他のバックアップソリューションを使用することが推奨されます。
7.3.6. MySQL 8.0 の RHEL 8 バージョンへの移行
RHEL 7 には、MySQL データベースファミリーからのサーバーのデフォルトの実装として、MariaDB 5.5 が同梱されています。RHEL 7 用の Red Hat Software Collections オファリングは、MySQL 8.0 と MariaDB のいくつかのバージョンを提供します。RHEL 8 は、MySQL 8.0、MariaDB 10.3、および MariaDB 10.5 を提供します。
この手順では、mysql_upgrade ユーティリティーを使用した MySQL 8.0 の Red Hat Software Collections バージョンから MySQL 8.0 の RHEL8 バージョンへの移行について説明します。mysql_upgrade ユーティリティーは、mysql-server パッケージによって提供されます。
MySQLの Red Hat Software Collections バージョンでは、ソースデータディレクトリーは /var/opt/rh/rh-mysql80/lib/mysql/ です。RHEL 8 では、MySQL データは /var/lib/mysql/ ディレクトリーに保存されます。
前提条件
- アップグレードを実行する前に、MySQL データベースに保存されているすべてのデータをバックアップすること。
手順
mysql-serverパッケージが RHEL 8 システムにインストールされていることを確認します。# yum install mysql-serverデータのコピー時に、
mysqldサービスがソースシステムとターゲットシステムのどちらでも実行されていないことを確認してください。# systemctl stop mysqld.service-
RHEL 7 ソースシステムの
/var/opt/rh/rh-mysql80/lib/mysql/ディレクトリーから RHEL 8 ターゲットシステムの/var/lib/mysql/ディレクトリーにデータをコピーします。 ターゲットシステムでコピーされたファイルに適切なパーミッションと SELinux コンテキストを設定します。
# restorecon -vr /var/lib/mysqlmysql:mysqlが、/var/lib/mysqlディレクトリー内のすべてのデータの所有者であることを確認してください。# chown -R mysql:mysql /var/lib/mysqlターゲットシステムで MySQL サーバーを起動します。
# systemctl start mysqld.service注意: MySQL の以前のバージョンでは、内部テーブルをチェックおよび修復するために
mysql_upgradeコマンドが必要でした。これは、サーバーの起動時に自動的に実行されるようになりました。
7.3.7. MySQL の複製
MySQL には、基本的なものから高度なものまで、レプリケーション用のさまざまな設定オプションが用意されています。このセクションでは、グローバルトランザクション識別子 (GTID) を使用して、新しくインストールした MySQL サーバーに MySQL でレプリケートするトランザクションベースの方法について説明します。GTID を使用すると、トランザクションの識別と整合性の検証が簡素化されます。
MySQL でレプリケーションを設定するには、以下を行う必要があります。
レプリケーションに既存の MySQL サーバーを使用する場合は、最初にデータを同期する必要があります。詳細は、アップストリームのドキュメント を参照してください。
7.3.7.1. MySQL ソースサーバーの設定
MySQL ソースサーバーがデータベースサーバーで行われたすべての変更を適切に実行および複製するために必要な設定オプションを設定できます。
前提条件
- ソースサーバーがインストールされている。
手順
[mysqld]セクションの/etc/my.cnf.d/mysql-server.cnfファイルに以下のオプションを含めます。bind-address=source_ip_adressこのオプションは、レプリカからソースへの接続に必要です。
server-id=idid は一意である必要があります。
log_bin=path_to_source_server_logこのオプションは、MySQL ソースサーバーのバイナリーログファイルへのパスを定義します。例:
log_bin=/var/log/mysql/mysql-bin.loggtid_mode=ONこのオプションは、サーバー上でグローバルトランザクション識別子 (GTID) を有効にします。
enforce-gtid-consistency=ONサーバーは、GTID を使用して安全にログに記録できるステートメントのみの実行を許可することにより、GTID の整合性を強化します。
オプション:
binlog_do_db=db_name選択したデータベースのみを複製する場合は、このオプションを使用します。選択した複数のデータベースを複製するには、各データベースを個別に指定します。
binlog_do_db=db_name1 binlog_do_db=db_name2 binlog_do_db=db_name3
オプション:
binlog_ignore_db=db_nameこのオプションを使用して、特定のデータベースをレプリケーションから除外します。
mysqldサービスを再起動します。# systemctl restart mysqld.service
7.3.7.2. MySQL レプリカサーバーの設定
レプリケーションを成功させるために MySQL レプリカサーバーに必要な設定オプションを設定できます。
前提条件
- レプリカサーバーがインストールされている。
手順
[mysqld]セクションの/etc/my.cnf.d/mysql-server.cnfファイルに以下のオプションを含めます。server-id=idid は一意である必要があります。
relay-log=path_to_replica_server_logリレーログは、レプリケーション中に MySQL レプリカサーバーによって作成されたログファイルのセットです。
log_bin=path_to_replica_sever_logこのオプションは、MySQL レプリカサーバーのバイナリーログファイルへのパスを定義します。例:
log_bin=/var/log/mysql/mysql-bin.logこのオプションはレプリカでは必須ではありませんが、強く推奨します。
gtid_mode=ONこのオプションは、サーバー上でグローバルトランザクション識別子 (GTID) を有効にします。
enforce-gtid-consistency=ONサーバーは、GTID を使用して安全にログに記録できるステートメントのみの実行を許可することにより、GTID の整合性を強化します。
log-replica-updates=ONこのオプションにより、ソースサーバーから受信した更新がレプリカのバイナリーログに記録されます。
skip-replica-start=ONこのオプションは、レプリカサーバーの起動時に、レプリカサーバーがレプリケーションスレッドを開始しないようにします。
オプション:
binlog_do_db=db_name特定のデータベースのみを複製する場合は、このオプションを使用します。複数のデータベースを複製するには、各データベースを個別に指定します。
binlog_do_db=db_name1 binlog_do_db=db_name2 binlog_do_db=db_name3
オプション:
binlog_ignore_db=db_nameこのオプションを使用して、特定のデータベースをレプリケーションから除外します。
mysqldサービスを再起動します。# systemctl restart mysqld.service
7.3.7.3. MySQL ソースサーバーでのレプリケーションユーザーの作成
レプリケーションユーザーを作成し、このユーザーにレプリケーショントラフィックに必要なパーミッションを付与する必要があります。この手順は、適切なパーミッションを持つレプリケーションユーザーを作成する方法を示しています。これらの手順は、ソースサーバーでのみ実行してください。
前提条件
- ソースサーバーは、MySQL ソースサーバーの設定 で説明されているように、インストールおよび設定されている。
手順
レプリケーションユーザーを作成します。
mysql> CREATE USER 'replication_user'@'replica_server_ip' IDENTIFIED WITH mysql_native_password BY 'password';ユーザーにレプリケーション権限を付与します。
mysql> GRANT REPLICATION SLAVE ON *.* TO 'replication_user'@'replica_server_ip';MySQL データベースの付与テーブルを再読み込みします。
mysql> FLUSH PRIVILEGES;ソースサーバーを読み取り専用状態に設定します。
mysql> SET @@GLOBAL.read_only = ON;
7.3.7.4. レプリカサーバーをソースサーバーに接続する
MySQL レプリカサーバーでは、認証情報とソースサーバーのアドレスを設定する必要があります。次の手順を使用して、レプリカサーバーを実装します。
前提条件
- ソースサーバーは、MySQL ソースサーバーの設定 で説明されているように、インストールおよび設定されている。
- レプリカサーバーは、MySQL レプリカサーバーの設定 で説明されているように、インストールおよび設定されている。
- レプリケーションユーザーを作成している。MySQL ソースサーバーでのレプリケーションユーザーの作成 を参照してください。
手順
レプリカサーバーを読み取り専用状態に設定します。
mysql> SET @@GLOBAL.read_only = ON;レプリケーションソースを設定します。
mysql> CHANGE REPLICATION SOURCE TO -> SOURCE_HOST='source_ip_address', -> SOURCE_USER='replication_user', -> SOURCE_PASSWORD='password', -> SOURCE_AUTO_POSITION=1;
MySQL レプリカサーバーでレプリカスレッドを開始します。
mysql> START REPLICA;ソースサーバーとレプリカサーバーの両方で、読み取り専用状態の設定を解除します。
mysql> SET @@GLOBAL.read_only = OFF;オプション: デバッグの目的で、レプリカサーバーのステータスを検査します。
mysql> SHOW REPLICA STATUS\G;注記レプリカサーバーの起動または接続に失敗した場合は、
SHOW MASTER STATUSコマンドの出力に表示されるバイナリーログファイルの位置に続く特定の数のイベントをスキップできます。たとえば、定義された位置から最初のイベントをスキップします。mysql> SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;レプリカサーバーを再起動してみてください。
オプション: レプリカサーバーでレプリカスレッドを停止します。
mysql> STOP REPLICA;
7.3.7.5. 検証手順
ソースサーバーにサンプルデータベースを作成します。
mysql> CREATE DATABASE test_db_name;-
test_db_nameデータベースが、レプリカサーバーで複製されていることを確認します。 ソースサーバーまたはレプリカサーバーのいずれかで以下のコマンドを実行して、MySQL サーバーのバイナリーログファイルに関するステータス情報を表示します。
mysql> SHOW MASTER STATUS;ソースで実行されたトランザクションの GTID のセットを示す
Executed_Gtid_Set列は、空であってはなりません。注記レプリカサーバーで
SHOW SLAVE STATUSを使用すると、同じ GTID のセットがExecuted_Gtid_Set行に表示されます。
7.3.7.6. 関連情報
7.3.8. MySQL クライアントアプリケーションの開発
Red Hat では、MySQL クライアントアプリケーションを MariaDB クライアントライブラリーに対して開発することを推奨します。クライアントとサーバー間の通信プロトコルは、MariaDB と MySQL の間で互換性があります。MariaDB クライアントライブラリーは、MySQL 実装に固有の限られた数の機能を除き、ほとんどの一般的な MySQL シナリオで動作します。
MariaDB クライアントライブラリーに対してアプリケーションを構築するために必要な開発ファイルとプログラムは、mariadb-connector-c-devel パッケージによって提供されます。
直接ライブラリー名を使用する代わりに、mariadb-connector-c-devel パッケージで配布されている mariadb_config プログラムを使用します。このプログラムは、正しいビルドフラグが返されることを保証します。
7.4. PostgreSQL の使用
PostgreSQL サーバーは、SQL 言語をベースにした、オープンソースの堅牢かつ拡張性に優れたデータベースサーバーです。PostgreSQL サーバーは、オブジェクトリレーショナルデータベースシステムを提供します。これにより、広範なデータセットと多数の同時ユーザーを管理できます。このような理由から、PostgreSQL サーバーは、大量のデータを管理するためにクラスターで使用できます。
PostgreSQL サーバーには、データの整合性の確保、耐障害性のある環境やアプリケーションの構築を行うための機能が含まれます。PostgreSQL サーバーを使用すると、データベースを再コンパイルすることなく、独自のデータ型、カスタム関数、またはさまざまなプログラミング言語のコードでデータベースを拡張できます。
RHEL システムに PostgreSQL をインストールして設定する方法、PostgreSQL データをバックアップする方法、および PostgreSQL の以前のバージョンから移行する方法について説明します。
7.4.1. PostgreSQL のインストール
RHEL 8 では、PostgreSQL サーバーは複数のバージョンで利用でき、各バージョンは個別のストリームで提供されます。
- PostgreSQL 10 - デフォルトのストリーム
- PostgreSQL 9.6
- PostgreSQL 12 - RHEL 8.1.1 以降で利用できます。
- PostgreSQL 13 - RHEL 8.4 以降で利用できます。
- PostgreSQL 15 - RHEL 8.8 以降で利用できます。
設計上、同じモジュールの複数のバージョン (ストリーム) を並行してインストールすることはできません。したがって、postgresql モジュールから利用可能なストリームのいずれかを選択する必要があります。RHEL 7 用の Red Hat Software Collections では、コンポーネントの同時インストールが可能です。RHEL 8 では、コンテナー内で異なるバージョンのデータベースサーバーを使用できます。
PostgreSQL をインストールするには、以下の手順に従います。
手順
postgresqlモジュールからストリーム (バージョン) を選択し、サーバープロファイルを指定して PostgreSQL サーバーパッケージをインストールします。以下に例を示します。# yum module install postgresql:15/serverpostgresのスーパーユーザーが自動的に作成されます。データベースクラスターを初期化します。
# postgresql-setup --initdbRed Hat は、デフォルトの
/var/lib/pgsql/dataディレクトリーにデータを保存することを推奨します。postgresqlサービスを開始します。# systemctl start postgresql.servicepostgresqlサービスが、システムの起動時に起動するようにします。# systemctl enable postgresql.service
モジュールストリームの使用方法は、ユーザー空間コンポーネントのインストール、管理、および削除 を参照してください。
RHEL 8 内の以前の postgresql ストリームからアップグレードする場合は、後続のストリームへの切り替え および 「RHEL 8 バージョンの PostgreSQL への移行」 に記載されている両手順を実行します。
7.4.2. PostgreSQL ユーザーの作成
PostgreSQL ユーザーは以下のタイプのものです。
-
postgresUNIX システムユーザー: PostgreSQL サーバーおよびクライアントアプリケーション (pg_dumpなど) を実行する場合にのみ使用してください。データベース作成およびユーザー管理などの、PostgreSQL 管理上の対話的な作業には、postgresシステムユーザーを使用しないでください。 -
データベースのスーパーユーザー: デフォルトの
postgresPostgreSQL スーパーユーザーは、postgresシステムユーザーとは関係ありません。pg_hba.confファイルのpostgresのスーパーユーザーのアクセスを制限することができます。制限しない場合には、その他のパーミッションの制限はありません。他のデータベースのスーパーユーザーを作成することもできます。 特定のデータベースアクセスパーミッションを持つロール:
- データベースユーザー: デフォルトでログインするパーミッションがある。
- ユーザーのグループ: グループ全体のパーミッションを管理できるようにします。
ロールはデータベースオブジェクト (テーブルや関数など) を所有することができ、SQL コマンドを使用してオブジェクト権限を他のロールに割り当てることができます。
標準のデータベース管理権限には SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、および USAGE が含まれます。
ロール属性は、LOGIN、SUPERUSER、CREATEDB、および CREATEROLE などの特別な権限です。
Red Hat は、スーパーユーザーではないロールとしてほとんどのタスクを実行することを推奨します。一般的な方法として、CREATEDB および CREATEROLE の権限を持つロールを作成し、このロールをデータベースおよびロールのすべてのルーチン管理に使用します。
前提条件
- PostgreSQL サーバーがインストールされている
- データベースクラスターが初期化されている
手順
ユーザーを作成するには、ユーザーのパスワードを設定し、ユーザーに
CREATEROLEおよびCREATEDBの権限を割り当てます。postgres=# CREATE USER mydbuser WITH PASSWORD 'mypasswd' CREATEROLE CREATEDB;mydbuser をユーザー名に、mypasswd をユーザーのパスワードに置き換えます。
例7.1 PostgreSQL データベースの初期化、作成、接続
この例では、PostgreSQL データベースを初期化方法、日常的なデータベース管理権限を持つデータベースユーザーの作成方法、および管理権限を持つデータベースユーザーを介して任意のシステムアカウントからアクセスできるデータベースの作成方法を示します。
PosgreSQL サーバーをインストールします。
# yum module install postgresql:13/serverデータベースクラスターを初期化します。
# postgresql-setup --initdb * Initializing database in '/var/lib/pgsql/data' * Initialized, logs are in /var/lib/pgsql/initdb_postgresql.logパスワードハッシュアルゴリズムを
scram-sha-256に設定します。/var/lib/pgsql/data/postgresql.confファイルで、次の行を変更します。#password_encryption = md5 # md5 or scram-sha-256
更新後は次のようになります。
password_encryption = scram-sha-256
/var/lib/pgsql/data/pg_hba.confファイルで、IPv4 ローカル接続用に次の行を変更します。host all all 127.0.0.1/32 ident
更新後は次のようになります。
host all all 127.0.0.1/32 scram-sha-256
postgresql サービスを起動します。
# systemctl start postgresql.servicepostgresという名前のシステムユーザーとしてログインします。# su - postgresPostgreSQL インタラクティブターミナルを起動します。
$ psql psql (13.7) Type "help" for help. postgres=#オプション: 現在のデータベース接続に関する情報を取得します。
postgres=# \conninfo You are connected to database "postgres" as user "postgres" via socket in "/var/run/postgresql" at port "5432".mydbuserという名前のユーザーを作成し、mydbuserのパスワードを設定して、CREATEROLEおよびCREATEDBの権限をmydbuserに割り当てます。postgres=# CREATE USER mydbuser WITH PASSWORD 'mypasswd' CREATEROLE CREATEDB; CREATE ROLEこれで、
mydbuserユーザーは、日常的なデータベース管理操作 (データベースの作成とユーザーインデックスの管理) を実行できるようになりました。\qメタコマンドを使用して、インタラクティブターミナルからログアウトします。postgres=# \qpostgresユーザーセッションからログアウトします。$ logoutmydbuserとして PostgreSQL ターミナルにログインし、ホスト名を指定して、初期化中に作成されたデフォルトのpostgresデータベースに接続します。# psql -U mydbuser -h 127.0.0.1 -d postgres Password for user mydbuser: Type the password. psql (13.7) Type "help" for help. postgres=>mydatabaseという名前のデータベースを作成します。postgres=> CREATE DATABASE mydatabase; CREATE DATABASE postgres=>セッションからログアウトします。
postgres=# \qmydbuserとして mydatabase に接続します。# psql -U mydbuser -h 127.0.0.1 -d mydatabase Password for user mydbuser: psql (13.7) Type "help" for help. mydatabase=>オプション: 現在のデータベース接続に関する情報を取得します。
mydatabase=> \conninfo You are connected to database "mydatabase" as user "mydbuser" on host "127.0.0.1" at port "5432".
7.4.3. PostgreSQL の設定
PostgreSQL データベースでは、データおよび設定ファイルはすべて、データベースクラスターと呼ばれる 1 つのディレクトリーに保存されます。Red Hat は、設定ファイルを含むすべてのデータをデフォルトの /var/lib/pgsql/data/ ディレクトリーに保存することを推奨しています。
PostgreSQL 設定は、以下のファイルで設定されます。
-
postgresql.conf: データベースのクラスターパラメーターの設定に使用されます。 -
postgresql.auto.conf:postgresql.confと同様の基本的な PostgreSQL 設定を保持します。ただし、このファイルはサーバーの制御下にあります。これは、ALTER SYSTEMクエリーにより編集され、手動で編集することはできません。 -
pg_ident.conf: 外部認証メカニズムから PostgreSQL ユーザー ID へのユーザー ID のマッピングに使用されます。 -
pg_hba.conf: PostgreSQL データベースのクライアント認証の設定に使用されます。
PostgreSQL 設定を変更するには、以下の手順に従います。
手順
-
各設定ファイル (例:
/var/lib/pgsql/data/postgresql.conf) を編集します。 postgresqlサービスを再起動して、変更を有効にします。# systemctl restart postgresql.service
例7.2 PostgreSQL データベースクラスターパラメーターの設定
以下の例では、/var/lib/pgsql/data/postgresql.conf ファイルのデータベースクラスターパラメーターの基本設定を示しています。
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB password_encryption = scram-sha-256
例7.3 PostgreSQL でのクライアント認証の設定
以下の例では、/var/lib/pgsql/data/pg_hba.conf ファイルでクライアント認証を設定する方法を説明します。
# TYPE DATABASE USER ADDRESS METHOD local all all trust host postgres all 192.168.93.0/24 ident host all all .example.com scram-sha-256
7.4.4. PostgreSQL サーバーにおける TLS 暗号化の設定
デフォルトでは、PostgreSQL は暗号化されていない接続を使用します。よりセキュアな接続のために、PostgreSQL サーバーで Transport Layer Security (TLS) サポートを有効にし、暗号化された接続を確立するようにクライアントを設定できます。
前提条件
- PostgreSQL サーバーがインストールされている
- データベースクラスターが初期化されている
手順
OpenSSL ライブラリーをインストールします。
# yum install opensslTLS 証明書とキーを生成します。
# openssl req -new -x509 -days 365 -nodes -text -out server.crt \ -keyout server.key -subj "/CN=dbhost.yourdomain.com"
dbhost.yourdomain.com を データベースのホストとドメイン名に置き換えます。
署名済み証明書と秘密鍵をデータベースサーバー上の必要なロケーションにコピーします。
# cp server.{key,crt} /var/lib/pgsql/data/.署名付き証明書と秘密鍵の所有者とグループの所有権を
postgresユーザーに変更します。# chown postgres:postgres /var/lib/pgsql/data/server.{key,crt}所有者だけが読み取れるように、秘密鍵の権限を制限します。
# chmod 0400 /var/lib/pgsql/data/server.key/var/lib/pgsql/data/postgresql.confファイルの次の行を変更して、パスワードハッシュアルゴリズムをscram-sha-256に設定します。#password_encryption = md5 # md5 or scram-sha-256
更新後は次のようになります。
password_encryption = scram-sha-256
/var/lib/pgsql/data/postgresql.confファイルの次の行を変更して、SSL/TLS を使用するように PostgreSQL を設定します。#ssl = off
更新後は次のようになります。
ssl=on
/var/lib/pgsql/data/pg_hba.confファイルの IPv4 ローカル接続で次の行を変更して、TLS を使用するクライアントからの接続のみを受け入れるように、すべてのデータベースへのアクセスを制限します。host all all 127.0.0.1/32 ident
更新後は次のようになります。
hostssl all all 127.0.0.1/32 scram-sha-256
または、次の行を新たに追加して、単一のデータベースとユーザーのアクセスを制限できます。
hostssl mydatabase mydbuser 127.0.0.1/32 scram-sha-256
mydatabase をデータベース名に、mydbuser をユーザー名に置き換えます。
postgresqlサービスを再起動して、変更を有効にします。# systemctl restart postgresql.service
検証
接続が暗号化されていることを手動で確認するには、以下を行います。
mydbuser ユーザーとして PostgreSQL データベースに接続し、ホスト名とデータベース名を指定します。
$ psql -U mydbuser -h 127.0.0.1 -d mydatabase Password for user mydbuser:
mydatabase をデータベース名に、mydbuser をユーザー名に置き換えます。
現在のデータベース接続に関する情報を取得します。
mydbuser=> \conninfo You are connected to database "mydatabase" as user "mydbuser" on host "127.0.0.1" at port "5432". SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off)
PostgreSQL への接続が暗号化されているかどうかを検証する簡単なアプリケーションを作成できます。この例は、
libpq-develパッケージで提供されるlibpqクライアントライブラリーを使用する C で記述されたアプリケーションを示しています。#include <stdio.h> #include <stdlib.h> #include <libpq-fe.h> int main(int argc, char* argv[]) { //Create connection PGconn* connection = PQconnectdb("hostaddr=127.0.0.1 password=mypassword port=5432 dbname=mydatabase user=mydbuser"); if (PQstatus(connection) ==CONNECTION_BAD) { printf("Connection error\n"); PQfinish(connection); return -1; //Execution of the program will stop here } printf("Connection ok\n"); //Verify TLS if (PQsslInUse(connection)){ printf("TLS in use\n"); printf("%s\n", PQsslAttribute(connection,"protocol")); } //End connection PQfinish(connection); printf("Disconnected\n"); return 0; }mypassword をパスワードに、mydatabase をデータベース名に、myduser をユーザー名に置き換えます。
注記-lpqオプションを使用して、コンパイルのためにpqライブラリーをロードする必要があります。たとえば、GCC コンパイラーを使用してアプリケーションをコンパイルするには、次のようにします。$ gcc source_file.c -lpq -o myapplicationこの source_file.c には上記のサンプルコードが含まれており、myapplication はセキュアな PostgreSQL 接続を検証するためのアプリケーションの名前です。
例7.4 TLS 暗号化を使用した PostgreSQL データベースの初期化、作成、接続
この例では、PostgreSQL データベースの初期化方法、データベースユーザーとデータベースの作成方法、セキュアな接続を使用したデータベースへの接続方法を示します。
PosgreSQL サーバーをインストールします。
# yum module install postgresql:13/serverデータベースクラスターを初期化します。
# postgresql-setup --initdb * Initializing database in '/var/lib/pgsql/data' * Initialized, logs are in /var/lib/pgsql/initdb_postgresql.logOpenSSL ライブラリーをインストールします。
# yum install opensslTLS 証明書とキーを生成します。
# openssl req -new -x509 -days 365 -nodes -text -out server.crt \ -keyout server.key -subj "/CN=dbhost.yourdomain.com"
dbhost.yourdomain.com を データベースのホストとドメイン名に置き換えます。
署名済み証明書と秘密鍵をデータベースサーバー上の必要なロケーションにコピーします。
# cp server.{key,crt} /var/lib/pgsql/data/.署名付き証明書と秘密鍵の所有者とグループの所有権を
postgresユーザーに変更します。# chown postgres:postgres /var/lib/pgsql/data/server.{key,crt}所有者だけが読み取れるように、秘密鍵の権限を制限します。
# chmod 0400 /var/lib/pgsql/data/server.keyパスワードハッシュアルゴリズムを
scram-sha-256に設定します。/var/lib/pgsql/data/postgresql.confファイルで、次の行を変更します。#password_encryption = md5 # md5 or scram-sha-256
更新後は次のようになります。
password_encryption = scram-sha-256
SSL/TLS を使用するように PostgreSQL を設定します。
/var/lib/pgsql/data/postgresql.confファイルで、次の行を変更します。#ssl = off
更新後は次のようになります。
ssl=on
postgresqlサービスを開始します。# systemctl start postgresql.servicepostgresという名前のシステムユーザーとしてログインします。# su - postgrespostgresユーザーとして PostgreSQL インタラクティブターミナルを起動します。$ psql -U postgres psql (13.7) Type "help" for help. postgres=#mydbuserという名前のユーザーを作成し、mydbuserのパスワードを設定します。postgres=# CREATE USER mydbuser WITH PASSWORD 'mypasswd'; CREATE ROLE postgres=#mydatabaseという名前のデータベースを作成します。postgres=# CREATE DATABASE mydatabase; CREATE DATABASE postgres=#すべての権限を
mydbuserユーザーに付与します。postgres=# GRANT ALL PRIVILEGES ON DATABASE mydatabase TO mydbuser; GRANT postgres=#インタラクティブターミナルからログアウトします。
postgres=# \qpostgresユーザーセッションからログアウトします。$ logout/var/lib/pgsql/data/pg_hba.confファイルの IPv4 ローカル接続で次の行を変更して、TLS を使用するクライアントからの接続のみを受け入れるように、すべてのデータベースへのアクセスを制限します。host all all 127.0.0.1/32 ident
更新後は次のようになります。
hostssl all all 127.0.0.1/32 scram-sha-256
postgresqlサービスを再起動して、変更を有効にします。# systemctl restart postgresql.servicemydbuserユーザーとして PostgreSQL データベースに接続し、ホスト名とデータベース名を指定します。$ psql -U mydbuser -h 127.0.0.1 -d mydatabase Password for user mydbuser: psql (13.7) SSL connection (protocol: TLSv1.3, cipher: TLS_AES_256_GCM_SHA384, bits: 256, compression: off) Type "help" for help. mydatabase=>
7.4.5. PostgreSQL データのバックアップ
PostgreSQL データをバックアップするには、以下のいずれかの方法を使用します。
- SQL ダンプ
- Backing up with SQL dump を参照してください。
- ファイルシステムレベルのバックアップ
- File system level backup を参照してください。
- 継続的アーカイブ
- 継続的アーカイブ を参照してください。
7.4.5.1. SQL ダンプを使用した PostgreSQL データのバックアップ
SQL ダンプのメソッドは、SQL コマンドを使用したダンプファイルの生成に基づいています。ダンプがデータベースサーバーにアップロードされると、ダンプ時と同じ状態でデータベースが再作成されます。
SQL ダンプは、以下の PostgreSQL クライアントアプリケーションによって保証されます。
- pg_dump は、ロールまたはテーブル空間に関するクラスター全体の情報なしに単一のデータベースをダンプします。
- pg_dumpall は、指定のクラスターに各データベースをダンプし、ロールやテーブル空間定義などのクラスター全体のデータを保持します。
デフォルトでは、pg_dump コマンドおよび pg_dumpall コマンドは、結果を標準出力に書き込みます。ダンプをファイルに保存するには、出力を SQL ファイルにリダイレクトします。作成される SQL ファイルは、テキスト形式またはその他の形式のいずれかになります。これにより並列処理が可能になり、オブジェクトの復元をより詳細に制御できます。
データベースにアクセスできる任意のリモートホストから、SQL ダンプを実行できます。
7.4.5.1.1. SQL ダンプの長所と短所
SQL ダンプには、他の PostgreSQL バックアップ方法と比較して、以下の長所があります。
- SQL ダンプは、サーバーのバージョン固有ではない唯一の PostgreSQL バックアップメソッドです。pg_dump ユーティリティーの出力は、PostgreSQL の後続のバージョンに再読み込みできます。これは、ファイルシステムレベルのバックアップ、または継続的なアーカイブにはできません。
- SQL ダンプは、32 ビットサーバーから 64 ビットサーバーへなど、異なるアーキテクチャーにデータベースを転送する際に有効な唯一の方法です。
- SQL ダンプは、内部的に一貫性のあるダンプを提供します。ダンプは、pg_dump の実行開始時のデータベースのスナップショットを表します。
- pg_dump ユーティリティーは、実行中のデータベースの他の操作をブロックしません。
SQL ダンプの短所は、ファイルシステムレベルのバックアップと比較して時間がかかることです。
7.4.5.1.2. pg_dump を使用した SQL ダンプの実行
クラスター全体の情報なしに単一のデータベースをダンプするには、pg_dump ユーティリティーを使用します。
前提条件
-
ダンプするすべてのテーブルへの読み取りアクセスが必要です。データベース全体をダンプするには、
postgresのスーパーユーザーまたはデータベースの管理者権限を持つユーザーとして、コマンドを実行する必要があります。
手順
クラスター全体の情報なしでデータベースをダンプします。
$ pg_dump dbname > dumpfile
pg_dump が接続するデータベースサーバーを指定するには、以下のコマンドラインオプションを使用します。
ホストを定義する
-hオプションデフォルトのホストは、ローカルホストか、
PGHOST環境変数で指定されているものです。ポートを定義する
-pオプションデフォルトのポートは、
PGPORT環境変数またはコンパイル済みデフォルトで示されます。
7.4.5.1.3. pg_dumpall を使用した SQL ダンプの実行
特定のデータベースクラスターで各データベースをダンプし、クラスター全体のデータを保持するには、pg_dumpall ユーティリティーを使用します。
前提条件
-
postgresスーパーユーザーまたはデータベースの管理者権限を持つユーザーとして、コマンドを実行する必要があります。
手順
データベースクラスターのすべてのデータベースをダンプし、クラスター全体のデータを保存します。
$ pg_dumpall > dumpfile
pg_dumpall が接続するデータベースサーバーを指定するには、以下のコマンドラインオプションを使用します。
ホストを定義する
-hオプションデフォルトのホストは、ローカルホストか、
PGHOST環境変数で指定されているものです。ポートを定義する
-pオプションデフォルトのポートは、
PGPORT環境変数またはコンパイル済みデフォルトで示されます。デフォルトのデータベースを定義する
-lオプションこのオプションにより、初期化時に自動的に作成された
postgresデータベースとは異なるデフォルトのデータベースを選択できます。
7.4.5.1.4. pg_dump を使用したダンプされたデータベースの復元
pg_dump ユーティリティーを使用してダンプした SQL ダンプからデータベースを復元するには、以下の手順に従います。
前提条件
-
postgresスーパーユーザーまたはデータベースの管理者権限を持つユーザーとして、コマンドを実行する必要があります。
手順
新しいデータベースを作成します。
$ createdb dbname- ダンプされたデータベースのオブジェクトを所有するか、オブジェクトに対する権限が許可されたユーザーがすべて存在していることを検証してください。このようなユーザーが存在しない場合、復元は元の所有権と権限でオブジェクトの再作成に失敗します。
psql ユーティリティーを実行して、pg_dump ユーティリティーが作成したテキストファイルのダンプを復元します。
$ psql dbname < dumpfileここでの
dumpfileは、pg_dumpコマンドの出力になります。非テキストファイルのダンプを復元するには、代わりにpg_restoreユーティリティーを使用します。$ pg_restore non-plain-text-file
7.4.5.1.5. pg_dumpall を使用したダンプされたデータベースの復元
pg_dumpall ユーティリティーを使用してダンプしたデータベースクラスターからデータを復元するには、以下の手順に従います。
前提条件
-
postgresスーパーユーザーまたはデータベースの管理者権限を持つユーザーとして、コマンドを実行する必要があります。
手順
- ダンプされたデータベースのオブジェクトを所有するか、オブジェクトに対する権限が許可されたユーザーがすべて、すでに存在していることを検証してください。このようなユーザーが存在しない場合、復元は元の所有権と権限でオブジェクトの再作成に失敗します。
psql ユーティリティーを実行して、pg_dumpall ユーティリティーにより作成されたテキストファイルのダンプを復元します。
$ psql < dumpfileここでの
dumpfileは、pg_dumpallコマンドの出力になります。
7.4.5.1.6. 別のサーバーでのデータベースの SQL ダンプの実行
pg_dump および psql はパイプに対する読み書きが可能であるため、あるサーバーから別のサーバーにデータベースを直接ダンプできます。
手順
データベースを、サーバーから別のサーバーにダンプするには、以下のコマンドを実行します。
$ pg_dump -h host1 dbname | psql -h host2 dbname
7.4.5.1.7. 復元中の SQL エラーの処理
デフォルトでは、SQL エラーが発生した場合、psql は実行を継続します。これにより、データベースの復元は一部のみとなります。
デフォルトの動作を変更するには、ダンプを復元する際に以下のいずれかの方法を使用します。
前提条件
-
postgresスーパーユーザーまたはデータベースの管理者権限を持つユーザーとして、コマンドを実行する必要があります。
手順
ON_ERROR_STOP変数を設定して SQL エラーが発生した場合は、終了ステータスが 3 で psql を終了します。$ psql --set ON_ERROR_STOP=on dbname < dumpfileダンプ全体が単一のトランザクションとして復元されるように指定して、復元が完全に完了するかキャンセルされるようにします。
psqlユーティリティーを使用してテキストファイルのダンプを復元する場合:$ psql -1pg_restoreユーティリティーを使用してテキストファイル以外のダンプを復元する場合:$ pg_restore -eこの方法を使用する場合は、多少のエラーでも、すでに何時間も実行している復元操作をキャンセルできます。
7.4.5.1.8. 関連情報
7.4.5.2. ファイルシステムレベルのバックアップを使用した PostgreSQL データのバックアップ
ファイルシステムレベルのバックアップを実行するには、PostgreSQL データベースファイルを別の場所に作成します。たとえば、以下のいずれかの方法を使用できます。
- tar ユーティリティーを使用してアーカイブファイルを作成します。
- rsync ユーティリティーを使用して、ファイルを別の場所にコピーします。
- データディレクトリーの一貫したスナップショットを作成します。
7.4.5.2.1. ファイルシステムのバックアップを作成する利点と制限
ファイルシステムレベルのバックアップは、他の PostgreSQL バックアップ方法と比較して、以下の長所があります。
- 通常、ファイルシステムレベルのバックアップは、SQL ダンプよりも高速です。
ファイルシステムレベルのバックアップは、他の PostgreSQL バックアップ方法と比較して、以下の制限があります。
- このバックアップメソッドは、RHEL 7 から RHEL 8 にアップグレードし、アップグレードしたシステムにデータを移行する場合には適していません。ファイルシステムレベルのバックアップは、アーキテクチャーと RHEL メジャーバージョンに固有のものです。アップグレードに成功しなかった場合は、RHEL 7 システムでデータを復元できますが、RHEL 8 システムではデータを復元できません。
- データをバックアップおよび復元する前に、データベースサーバーをシャットダウンする必要があります。
- 特定のファイルまたはテーブルを個々にバックアップまたは復元することはできません。ファイルシステムのバックアップは、データベースクラスター全体を完全にバックアップおよび復元する場合にのみ機能します。
7.4.5.2.2. ファイルシステムレベルのバックアップの実行
ファイルシステムレベルのバックアップを実行するには、次の手順を使用します。
手順
データベースクラスターの場所を選択し、このクラスターを初期化します。
# postgresql-setup --initdbpostgresql サービスを停止します。
# systemctl stop postgresql.service任意のメソッドを使用してファイルシステムのバックアップを作成します (例:
tarアーカイブ)。$ tar -cf backup.tar /var/lib/pgsql/datapostgresql サービスを起動します。
# systemctl start postgresql.service
7.4.5.3. 継続的にアーカイブして PostgreSQL データのバックアップを作成
7.4.5.3.1. 継続的なアーカイブの概要
PostgreSQL は、データベースのデータファイルに対するすべての変更を、クラスターのデータディレクトリーの pg_wal/ サブディレクトリーで利用可能なログ先行書き込み (WAL) ファイルに記録します。このログは、主にクラッシュからの復元を目的としています。クラッシュ後、最後のチェックポイント以降に作成されたログエントリーを使用して、データベースの整合性まで復元できます。
オンラインバックアップとも呼ばれる継続的なアーカイブメソッドは、WAL ファイルを、稼働中のサーバーまたはファイルシステムレベルのバックアップで実行されるベースバックアップの形式でデータベースクラスターのコピーと組み合わせます。
データベース復元が必要な場合は、データベースクラスターのコピーからデータベースを復元してから、バックアップを作成した WAL ファイルからログを再生して、システムを現在の状態にすることができます。
継続的なアーカイブメソッドでは、少なくとも最後のベースバックアップの開始時間までさかのぼって、アーカイブされたすべての WAL ファイルの連続したシーケンスを保持する必要があります。そのため、基本バックアップの理想的な頻度は、次の条件により異なります。
- アーカイブされた WAL ファイルで利用可能なストレージボリューム。
- 復元が必要な場合の、データ復元の最大許容期間。最後のバックアップからの期間が長い場合、システムはより多くの WAL セグメントを再生するため、回復に時間がかかります。
pg_dump および pg_dumpall SQL ダンプは、継続的にアーカイブするバックアップソリューションの一部として使用することができません。SQL ダンプは論理バックアップを生成しますが、WAL 再生で使用する上で十分な情報は含まれていません。
継続的なアーカイブメソッドを使用してデータベースのバックアップと復元を実行するには、以下の手順に従います。
データを復元するには、連続アーカイブを使用したデータベースの復元 の手順に従います。
7.4.5.3.2. 継続的なアーカイブの長所と短所
継続的なアーカイブは、PostgreSQL のその他のバックアップ方法と比較して、以下の利点があります。
- 継続的なバックアップメソッドでは、バックアップ内の内部不整合がログ再生により修正されるため、整合性が完全に取れないベースバックアップを使用することができます。したがって、実行中の PostgreSQL サーバーでベースバックアップを実行できます。
-
ファイルシステムのスナップショットは必要ありません。
tarまたは同様のアーカイブユーティリティーで十分です。 - 継続的にバックアップを行うには、継続的に WAL ファイルをアーカイブします。これは、ログ再生用の WAL ファイルの順序が無限に長くなる可能性があるためです。これは、特に大規模なデータベースで有用です。
- 継続的バックアップは、特定の時点への復旧 (ポイントインタイムリカバリー) をサポートします。WAL エントリーを最後まで再生する必要はありません。再生はいつでも停止でき、ベースバックアップを作成してから、データベースをいつでもその状態に復元できます。
- 一連の WAL ファイルが同じベースのバックアップファイルで読み込まれた別のマシンが継続的に利用可能である場合は、任意の時点で、データベースで現在に一番近いコピーで、他のマシンを復元できます。
継続的なアーカイブには、その他の PostgreSQL バックアップ方法と比較して、以下の短所があります。
- 継続バックアップ方法は、サブセットではなく、データベースクラスター全体の復元のみをサポートします。
- 継続的にバックアップするには、大きなアーカイブストレージが必要です。
7.4.5.3.3. WAL アーカイブの設定
稼働中の PostgreSQL サーバーでは、ログ先行書き込み (WAL) レコードのシーケンスを生成します。サーバーは、このシーケンスを WAL セグメントファイルに物理的に分割します。このファイルには、WAL シーケンスの位置を反映する数値名が与えられます。WAL のアーカイブを使用しない場合は、セグメントファイルは再利用され、より大きなセグメント番号に名前が変更されます。
WAL データをアーカイブする場合、各セグメントファイルの内容がキャプチャーされ、新しい場所に保存されてから、セグメントファイルが再利用されます。別のマシン上の NFS マウントディレクトリー、テープドライブ、または CD など、コンテンツの保存場所には複数のオプションがあります。
WAL レコードには、設定ファイルへの変更が含まれていないことに注意してください。
WAL のアーカイブを有効にするには、以下の手順に従います。
手順
/var/lib/pgsql/data/postgresql.confファイルで以下を行います。-
wal_level設定パラメーターをreplica以降に設定します。 -
archive_modeパラメーターをonに設定します。 -
archive_command設定パラメーターでシェルコマンドを指定します。cpコマンド、別のコマンド、またはシェルスクリプトを使用できます。
-
postgresqlサービスを再起動して、変更を適用します。# systemctl restart postgresql.service- アーカイブコマンドをテストして、既存のファイルを上書きせず、失敗するとゼロ以外の終了ステータスを返すことを確認します。
- データを保護するには、セグメントファイルがグループまたはワールド読み取りアクセスを持たないディレクトリーにアーカイブされていることを確認してください。
archive コマンドは、完了した WAL セグメントでのみ実行されます。WAL トラフィックをほとんど生成しないサーバーでは、トランザクションの完了とアーカイブストレージへの安全な記録の間にかなりの遅延が生じる可能性があります。アーカイブされていないデータの古さを制限するには、以下を行います。
-
archive_timeoutパラメーターを設定して、サーバーが特定の頻度で新しい WAL セグメントファイルに切り替えるように強制します。 -
pg_switch_walパラメーターを使用して、セグメント切り替えを強制し、トランザクションが終了後すぐにアーカイブされるようにします。
例7.5 WAL セグメントをアーカイブするためのシェルコマンド
この例は、archive_command 設定パラメーターに設定できる簡単なシェルコマンドを示しています。
以下のコマンドは、完了したセグメントファイルを必要な場所にコピーします。
archive_command = 'test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f'
%p パラメーターは、アーカイブするファイルの相対パスに置き換えられ、%f パラメーターはファイル名に置き換えられます。
このコマンドは、アーカイブ可能な WAL セグメントを /mnt/server/archivedir/ ディレクトリーにコピーします。%p パラメーターおよび %f パラメーターを置き換えると、実行されたコマンドは以下のようになります。
test ! -f /mnt/server/archivedir/00000001000000A900000065 && cp pg_wal/00000001000000A900000065 /mnt/server/archivedir/00000001000000A900000065アーカイブされる新規ファイルごとに同様のコマンドが生成されます。
関連情報
7.4.5.3.4. ベースバックアップの作成
ベースバックアップは、複数の方法で作成できます。ベースバックアップを実行する最も簡単な方法は、実行中の PostgreSQL サーバーで pg_basebackup ユーティリティーを使用することです。
ベースバックアッププロセスは、WAL アーカイブ領域に保存され、ベースバックアップに必要な最初の WAL セグメントファイルにちなんで名付けられたバックアップ履歴ファイルを作成します。
バックアップ履歴ファイルは、開始時間および終了時間、およびバックアップの WAL セグメントが含まれる小さなテキストファイルです。ラベル文字列を使用して関連するダンプファイルを特定した場合は、バックアップ履歴ファイルを使用して復元するダンプファイルを判断できます。
データを確実に復元できるようにするために、複数のバックアップセットを維持することを検討してください。
ベースバックアップを実行するには、以下の手順を行います。
前提条件
-
postgresスーパーユーザー、データベースの管理者権限のあるユーザー、または少なくともREPLICATIONパーミッションを持つ別のユーザーとして、コマンドを実行する必要があります。 - ベースバックアップ中およびベースバックアップ後に生成されたすべての WAL セグメントファイルを保持する必要があります。
手順
pg_basebackupユーティリティーを使用してベースバックアップを実行します。個々のファイル (プレーン形式) としてベースバックアップを作成するには、以下を実行します。
$ pg_basebackup -D backup_directory -Fpbackup_directory を希望のバックアップの場所に置き換えます。
テーブル空間を使用し、サーバーと同じホストでベースバックアップを実行する場合は、
--tablespace-mappingオプションも使用する必要があります。そうしないと、バックアップを同じ場所に書き込もうとすると、バックアップが失敗します。tarアーカイブ (tarおよび圧縮形式) としてベースバックアップを作成するには、以下を実行します。$ pg_basebackup -D backup_directory -Ft -zbackup_directory を希望のバックアップの場所に置き換えます。
このようなデータを復元するには、ファイルを正しい場所に手動で抽出する必要があります。
- ベースバックアッププロセスが完了すると、バックアップ履歴ファイルで指定されている、データベースクラスターのコピーとバックアップ中に使用された WAL セグメントファイルを安全にアーカイブします。
- ベースバックアップで使用されている WAL セグメントファイルよりも数値が小さい WAL セグメントを削除します。これらはベースバックアップよりも古く、復元には必要ないためです。
pg_basebackup が接続するデータベースサーバーを指定するには、以下のコマンドラインオプションを使用します。
ホストを定義する
-hオプションデフォルトのホストは、ローカルホストまたは
PGHOST環境変数により指定されたホストです。ポートを定義する
-pオプションデフォルトのポートは、
PGPORT環境変数またはコンパイル済みデフォルトで示されます。
7.4.5.3.5. 継続的なアーカイブバックアップを使用したデータベースの復元
継続バックアップを使用してデータベースを復元するには、以下の手順を行います。
手順
サーバーを停止します。
# systemctl stop postgresql.service必要なデータを一時的な場所にコピーします。
必要に応じて、クラスターデータのディレクトリー全体と、すべてのテーブル空間をコピーします。既存データベースのコピーを 2 つ保持するには、システムに十分な空き領域が必要になることに注意してください。
十分な容量がない場合は、クラスターの
pg_walディレクトリーの内容を保存します。これには、システムがダウンする前にアーカイブされなかったログが含まれます。- クラスターデータディレクトリー、および使用しているテーブル空間のルートディレクトリー下の既存ファイルおよびサブディレクトリーをすべて削除します。
ベースバックアップからデータベースファイルを復元します。
以下の点を確認してください。
-
ファイルは、正しい所有権 (
rootではなくデータベースシステムのユーザー) で復元されます。 - ファイルは、正しい権限で復元されます。
-
pg_tblspc/サブディレクトリーのシンボリックリンクが正しく復元されます。
-
ファイルは、正しい所有権 (
pg_wal/サブディレクトリーにあるファイルをすべて削除します。このファイルは、ベースバックアップから作成されるため、非推奨になりました。
pg_wal/をアーカイブしていない場合は、適切な権限で再作成します。-
手順 2 で保存したアーカイブされていない WAL セグメントファイルを
pg_wal/にコピーします。 クラスターデータディレクトリーの
recovery.confリカバリーコマンドファイルを作成し、restore_command設定パラメーターにシェルコマンドを指定します。cpコマンド、別のコマンド、またはシェルスクリプトを使用できます。以下に例を示します。restore_command = 'cp /mnt/server/archivedir/%f "%p"'サーバーを起動します。
# systemctl start postgresql.serviceサーバーは復元モードに入り、引き続き必要なアーカイブファイル (WAL) を読み込みます。
外部エラーにより復元が終了した場合は、サーバーを再起動して復元を続行します。復元プロセスが完了すると、サーバーは
recovery.confの名前をrecovery. doneに変更します。これにより、サーバーが通常のデータベース操作を開始した後に、誤ってリカバリーモードに戻るのを防ぐことができます。データベースのコンテンツを確認して、データベースが必要な状態に復元されたことを検証します。
データベースが必要な状態に復元されていない場合は、手順 1 に戻ります。データベースが必要な状態に復元された場合は、
pg_hba.confファイルでクライアント認証設定を復元して接続できるようにします。
継続バックアップを使用した復元の詳細は、PostgreSQL ドキュメント を参照してください。
7.4.5.3.6. 関連情報
7.4.6. RHEL 8 バージョンの PostgreSQL への移行
Red Hat Enterprise Linux 7 には、PostgreSQL 9.2 が、PostgreSQL サーバーのデフォルトバージョンとして含まれます。また、RHEL 7 の Software Collections として、複数の PostgreSQL のバージョンが提供されます。
Red Hat Enterprise Linux 8 は、PostgreSQL 10 (デフォルトの postgresql ストリーム)、PostgreSQL 9.6、PostgreSQL 12、PostgreSQL 13、および PostgreSQL 15 を提供します。
Red Hat Enterprise Linux 上の PostgreSQL のユーザーは、データベースファイルの移行パスを使用できます。
高速アップグレードメソッドは、ダンプおよび復元のプロセスよりも速くなります。ただし、場合によっては高速アップグレードが機能せず、ダンプおよび復元プロセスしか使用できない場合があります。そのようなケースには、以下が含まれます。
- アーキテクチャー間のアップグレード
-
plpythonまたはplpython2拡張を使用するシステム。RHEL 8 AppStream リポジトリーにはpostgresql-plpython3パッケージのみが含まれ、postgresql-plpython2パッケージは含まれません。 - 高速アップグレードは、PostgreSQLの Red Hat Software Collections バージョンからの移行ではサポートされません。
新しいバージョンの PostgreSQL に移行するための前提条件として、すべての PostgreSQL データベースをバックアップします。
データベースをダンプし、SQL ファイルのバックアップを実行することは、ダンプおよび復元プロセスで必要であり、高速アップグレードメソッドとして推奨されます。
新しいバージョンの PostgreSQL に移行する前に、移行する PostgreSQL バージョンと、移行元と移行先のバージョンの間にあるすべて PostgreSQL バージョンの アップストリームの互換性ノート を参照してください。
7.4.6.1. PostgreSQL 13 と PostgreSQL 15 間の主な違い
PostgreSQL 15 では、以下の後方互換性のない変更が導入されました。
パブリックスキーマのデフォルトパーミッション
パブリックスキーマのデフォルトパーミッションは、PostgreSQL 15 で変更されています。新規に作成されたユーザーは、GRANT ALL ON SCHEMA public TO myuser; コマンドを使用して、権限を明示的に付与する必要があります。
以下の例は、PostgreSQL 13 以前で動作します。
postgres=# CREATE USER mydbuser; postgres=# \c postgres mydbuser postgres=$ CREATE TABLE mytable (id int);
以下の例は PostgreSQL 15 で動作します。
postgres=# CREATE USER mydbuser; postgres=# GRANT ALL ON SCHEMA public TO mydbuser; postgres=# \c postgres mydbuser postgres=$ CREATE TABLE mytable (id int);
pg_hba.conf ファイルで mydbuser アクセスが適切に設定されていることを確認してください。詳細は、PostgreSQL ユーザーの作成 を参照してください。
PQsendQuery() がパイプラインモードでサポートされなくなる
PostgreSQL 15 以降、libpq PQsendQuery() 関数はパイプラインモードでサポートされなくなりました。影響を受けるアプリケーションを変更して、代わりに PQsendQueryParams() 関数を使用します。
7.4.6.2. pg_upgrade ユーティリティーを使用した高速アップグレード
高速アップグレードでは、バイナリーデータファイルを /var/lib/pgsql/data/ ディレクトリーにコピーし、pg_upgrade ユーティリティーを使用する必要があります。
この方法を使用すると、データを移行できます。
- RHEL 7 システムバージョンの PostgreSQL 9.2 から、RHEL 8 バージョンの PostgreSQL 10 へ
- RHEL 8 バージョンの PostgreSQL 10 から、RHEL 8 バージョンの PostgreSQL 12 へ
- RHEL 8 バージョンの PostgreSQL 12 から、RHEL 8 バージョンの PostgreSQL 13 へ
- RHEL 8 バージョンの PostgreSQL 13 から、RHEL 8 バージョンの PostgreSQL 15 へ
RHEL 8 内の以前の postgresql ストリームからアップグレードする場合は 後続のストリームへの切り替え の説明に従い、PostgreSQL データを移行します。
RHEL 内の PostgreSQL バージョンの組み合わせと、Red Hat Software Collections バージョンの PostgreSQL から RHEL への移行には、アップグレードのダンプおよび復元 を使用します。
以下の手順では、高速アップグレードメソッドを使用して、RHEL 7 システムバージョンの PostgreSQL 9.2 から、RHEL 8 バージョンの PostgreSQL へ移行する方法を説明します。
前提条件
-
アップグレードを実行する前に、PostgreSQL データベースに保存されているすべてのデータのバックアップを作成します。デフォルトでは、すべてのデータは、RHEL 7 および RHEL 8 システムの両方の
/var/lib/pgsql/data/ディレクトリーに保存されます。
手順
RHEL 8 システムで、移行するストリーム (バージョン) を有効にします。
# yum module enable postgresql:streamstream は、選択した PostgreSQL サーバーのバージョンに置き換えます。
PostgreSQL 10 を提供するデフォルトストリームを使用する場合は、この手順を省略できます。
RHEL 8 システムで、
postgresql-serverパッケージおよびpostgresql-upgradeパッケージをインストールします。# yum install postgresql-server postgresql-upgrade必要に応じて、RHEL 7 で PostgreSQL サーバーモジュールを使用している場合は、その 2 つのバージョンを RHEL 8 システムにインストールし、PostgreSQL 9.2 (
postgresql-upgradeパッケージでインストール) および対象バージョンの PostgreSQL (postgresql-serverパッケージでインストール) の両方に対してコンパイルします。サードパーティーの PostgreSQL サーバーモジュールをコンパイルする必要がある場合は、postgresql-develパッケージとpostgresql-upgrade-develパッケージの両方に対してビルドしてください。以下の項目を確認します。
-
基本設定 - RHEL 8 システムで、サーバーがデフォルトの
/var/lib/pgsql/dataディレクトリーを使用し、データベースが正しく初期化され、有効になっているかどうかを確認します。さらに、データファイルは、/usr/lib/systemd/system/postgresql.serviceファイルに記載されているパスと同じパスに保存する必要があります。 - PostgreSQL サーバー - システムは複数の PostgreSQL サーバーを実行できます。これらのすべてのサーバーのデータディレクトリーが独立して処理されていることを確認してください。
-
PostgreSQL サーバーモジュール - RHEL 7 で使用されていた PostgreSQL サーバーモジュールも、RHEL 8 システムにインストールされていることを確認してください。プラグインは、
/usr/lib64/pgsql/ディレクトリー (32 ビットシステムの/usr/lib/pgsql/ディレクトリー) にインストールされます。
-
基本設定 - RHEL 8 システムで、サーバーがデフォルトの
データのコピー時に、
postgresqlサービスがソースおよびターゲットのシステムで稼働していないことを確認します。# systemctl stop postgresql.service-
データベースファイルをソースの場所から RHEL 8 システムの
/var/lib/pgsql/data/ディレクトリーにコピーします。 PostgreSQL ユーザーで以下のコマンドを実行して、アップグレードプロセスを実行します。
# postgresql-setup --upgradeこれでバックグラウンドで
pg_upgradeプロセスが開始します。障害が発生すると、
postgresql-setupは通知のエラーメッセージを提供します。/var/lib/pgsql/data-oldから新規クラスターに、以前の設定をコピーします。高速アップグレードは、新しいデータスタックで以前の設定を再利用せず、設定がゼロから生成されることに注意してください。古い設定と新しい設定を手動で組み合わせたい場合は、データディレクトリーの *.conf ファイルを使用します。
新しい PostgreSQL サーバーを起動します。
# systemctl start postgresql.service新しいデータベースクラスターを分析します。
PostgreSQL 13 以前の場合:
su postgres -c '~/analyze_new_cluster.sh'PostgreSQL 15 の場合:
su postgres -c 'vacuumdb --all --analyze-in-stages'
システムの起動時に、新しい PostgreSQL サーバーを自動的に起動させる場合は、次のコマンドを実行します。
# systemctl enable postgresql.service
7.4.6.3. ダンプおよび復元のアップグレード
ダンプおよび復元のアップグレードを使用する場合は、すべてのデータベースのコンテンツを SQL ファイルのダンプファイルにダンプする必要があります。
ダンプおよび復元のアップグレードは高速アップグレード方法よりも低速であり、生成された SQL ファイルで手動修正が必要になる場合があります。
この方法を使用すると、以下からデータを移行できます。
- Red Hat Enterprise Linux 7 システムバージョンの PostgreSQL 9.2
- 以前の Red Hat Enterprise Linux 8 バージョンの PostgreSQL
Red Hat Software Collections の PostgreSQL の以前のバージョンまたは同等バージョン:
- PostgreSQL 9.2 (サポート対象外になりました)
- PostgreSQL 9.4 (サポート対象外になりました)
- PostgreSQL 9.6 (サポート対象外になりました)
- PostgreSQL 10
- PostgreSQL 12
- PostgreSQL 13
RHEL 7 および RHEL 8 システムでは、PostgreSQL データは、デフォルトで /var/lib/pgsql/data/ ディレクトリーに保存されます。Red Hat Software Collections バージョンの PostgreSQLの場合、デフォルトのデータディレクトリーは /var/opt/rh/collection_name/lib/pgsql/data/ です (/opt/rh/postgresql92/root/var/lib/pgsql/data/ ディレクトリーを使用する postgresql92 を除く)。
RHEL 8 内の以前の postgresql ストリームからアップグレードする場合は 後続のストリームへの切り替え の説明に従い、PostgreSQL データを移行します。
ダンプおよび復元のアップグレードを実行するには、ユーザーを root に変更します。
以下の手順では、RHEL 7 システムバージョンの PostgreSQL 9.2 から、RHEL 8 バージョンの PostgreSQL への移行方法を説明します。
手順
RHEL 7 システムで PostgreSQL 9.2 サーバーを起動します。
# systemctl start postgresql.serviceRHEL 7 システムで、すべてのデータベースのコンテンツを
pgdump_file.sqlファイルにダンプします。su - postgres -c "pg_dumpall > ~/pgdump_file.sql"データベースが正しくダンプされたことを確認します。
su - postgres -c 'less "$HOME/pgdump_file.sql"'これにより、ダンプされた sql ファイルのパスが
/var/lib/pgsql/pgdump_file.sqlに表示されます。RHEL 8 システムで、移行するストリーム (バージョン) を有効にします。
# yum module enable postgresql:streamstream は、選択した PostgreSQL サーバーのバージョンに置き換えます。
PostgreSQL 10 を提供するデフォルトストリームを使用する場合は、この手順を省略できます。
RHEL 8 システムで、
postgresql-serverパッケージをインストールします。# yum install postgresql-server必要に応じて、RHEL 7 で PostgreSQL サーバーモジュールを使用している場合は、RHEL 8 システムにもインストールしてください。サードパーティーの PostgreSQL サーバーモジュールをコンパイルする必要がある場合は、
postgresql-develパッケージに対してビルドします。RHEL 8 システムで、新しい PostgreSQL サーバーのデータディレクトリーを初期化します。
# postgresql-setup --initdbRHEL 8 システムで、
pgdump_file.sqlを PostgreSQL ホームディレクトリーにコピーし、ファイルが正しくコピーされたことを確認します。su - postgres -c 'test -e "$HOME/pgdump_file.sql" && echo exists'RHEL 7 システムから設定ファイルをコピーします。
su - postgres -c 'ls -1 $PGDATA/*.conf'コピーされる設定ファイルは、以下のとおりです。
-
/var/lib/pgsql/data/pg_hba.conf -
/var/lib/pgsql/data/pg_ident.conf -
/var/lib/pgsql/data/postgresql.conf
-
RHEL 8 システムで、新しい PostgreSQL サーバーを起動します。
# systemctl start postgresql.serviceRHEL 8 システムで、ダンプされた sql ファイルからデータをインポートします。
su - postgres -c 'psql -f ~/pgdump_file.sql postgres'
Red Hat Software Collections バージョンの PostgreSQL からアップグレードする場合は、scl enable collection_name が含まれるようにコマンドを調整します。たとえば、rh-postgresql96 Software Collection からデータをダンプする場合は、以下のコマンドを使用します。
su - postgres -c 'scl enable rh-postgresql96 "pg_dumpall > ~/pgdump_file.sql"'第8章 Postfix SMTP サーバーのデプロイと設定
システム管理者は、Postfix などのメールトランスポートエージェント (MTA) を使用して、電子メールインフラストラクチャーを設定し、SMTP プロトコルを使用してホスト間で電子メールメッセージを転送できます。Postfix は、メールのルーティングと配信を行うサーバー側アプリケーションです。Postfix を使用して、ローカルメールサーバーの設定、null クライアントメールリレーの作成、複数のドメインの宛先としての Postfix サーバーの使用、検索用ファイルに代わる LDAP ディレクトリーの選択を行うことができます。
Postfix の主な機能:
- 一般的なメール関連の脅威から保護するためのセキュリティー機能
- 仮想ドメインおよびエイリアスのサポートを含むカスタマイズオプション
8.1. 主な Postfix 設定ファイルの概要
postfix パッケージは、/etc/postfix/ ディレクトリーに複数の設定ファイルを提供します。
電子メールインフラストラクチャーを設定するには、次の設定ファイルを使用します。
-
main.cf— Postfix のグローバル設定が含まれています。 -
master.cf— メール配信を実現するために、さまざまなプロセスとの Postfix の対話を指定します。 -
access— Postfix に接続できるホストなどのアクセスルールを指定します。 -
transport— 電子メールアドレスをリレーホストにマッピングします。 -
aliases— ユーザー ID エイリアスを説明するメールプロトコルで必要な設定可能な一覧が含まれます。このファイルは、/etc/ディレクトリーにあることに留意してください。
8.2. Postfix SMTP サーバーのインストールおよび設定
電子メールメッセージを受信、保存、配信するように Postfix SMTP サーバーを設定できます。システムのインストール時にメールサーバーパッケージが選択されていない場合、Postfix はデフォルトで利用できません。Postfix をインストールするには、以下の手順を実行します。
前提条件
- root アクセスがある。
- システムを登録する。
Sendmail を無効にして削除するには、以下を実行します。
# yum remove sendmail
手順
Postfix をインストールします。
# yum install postfixPostfix を設定するには、
/etc/postfix/main.cfファイルを編集し、以下の変更を加えます。デフォルトでは、Postfix は
loopbackインターフェイスでのみメールを受信します。特定のインターフェイスをリッスンするように Postfix を設定するには、inet_interfacesパラメーターをこれらのインターフェイスの IP アドレスに更新します。inet_interfaces = 127.0.0.1/32, [::1]/128, 192.0.2.1, [2001:db8:1::1]
すべてのインターフェイスをリッスンするように Postfix を設定するには、以下を設定します。
inet_interfaces = all
gethostname()関数によって返される完全修飾ドメイン名 (FQDN) とは異なるホスト名を Postfix が使用するようにしたい場合は、myhostnameパラメーターを追加します。myhostname = <smtp.example.com>たとえば、Postfix はこのホスト名を、処理するメールのヘッダーに追加します。
ドメイン名が
myhostnameパラメーターのものと異なる場合は、mydomainパラメーターを追加します。mydomain = <example.com>myoriginパラメーターを追加し、mydomainの値に設定します。myorigin = $mydomain
この設定では、Postfix はホスト名ではなく、ローカルで投稿されたメールの発信元としてドメイン名を使用します。
mynetworksパラメーターを追加し、メールの送信が許可される信頼できるネットワークの IP 範囲を定義します。mynetworks = 127.0.0.1/32, [::1]/128, 192.0.2.1/24, [2001:db8:1::1]/64
インターネットなどの信頼できないネットワークからのクライアントがこのサーバー経由でメールを送信できるようにする必要がある場合は、後の手順でリレー制限を設定する必要があります。
main.cfファイルの Postfix 設定が正しいか確認します。$ postfix checkpostfixサービスが起動時に開始できるように有効化し、開始します。# systemctl enable --now postfixsmtp トラフィックがファイアウォールを通過することを許可し、ファイアウォールルールをリロードします。
# firewall-cmd --permanent --add-service smtp # firewall-cmd --reload
検証
postfixサービスが実行していることを確認します。# systemctl status postfixオプション: 出力が停止し、待機中、またはサービスが実行されていない場合は、
postfixサービスを再起動します。# systemctl restart postfixオプション:
/etc/postfix/ディレクトリーの設定ファイル内のオプションを変更した後、postfixサービスをリロードして、これらの変更を適用します。# systemctl reload postfix
システム上のローカルユーザー間の電子メール通信を確認します。
# echo "This is a test message" | mail -s <SUBJECT> <user@mydomain.com>クライアント (server1) からメールサーバー (server2) へ、ドメイン外のメールアドレスにメールを送信して、メールサーバーがオープンリレーではないことを確認します。
次のように、server1 の
/etc/postfix/main.cfファイルを編集します。relayhost = <ip_address_of_server2>次のように、server2 の
/etc/postfix/main.cfファイルを編集します。mynetworks = <ip_address_of_server2>server1 で、以下のメールを送信します。
# echo "This is an open relay test message" | mail -s <SUBJECT> <user@example.com>/var/log/maillogファイルを確認します。554 Relay access denied - the server is not going to relay. 250 OK or similar - the server is going to relay.
トラブルシューティング
-
エラーが発生した場合は、
/var/log/maillogを確認してください。
関連情報
-
/etc/postfix/main.cf設定ファイル -
/usr/share/doc/postfix/README_FILESディレクトリー - firewalld の使用および設定
8.3. Postfix サーバーの TLS 設定のカスタマイズ
電子メールトラフィックを暗号化してよりセキュアにするために、自己署名証明書の代わりに、信頼できる認証局 (CA) からの証明書を使用し、Transport Layer Security (TLS) セキュリティー設定をカスタマイズするように Postfix を設定できます。RHEL 8 では、TLS 暗号化プロトコルが Postfix サーバーでデフォルトで有効になっています。基本的な Postfix TLS 設定には、受信 SMTP 用の自己署名証明書と、発信 SMTP の日和見 TLS が含まれています。
前提条件
- root アクセスがある。
-
サーバーに
postfixパッケージがインストールされている。 - 信頼できる認証局 (CA) によって署名された証明書と秘密鍵を持っている。
以下のファイルを Postfix サーバーにコピーしている。
-
サーバー証明書:
/etc/pki/tls/certs/postfix.pem -
秘密鍵y:
/etc/pki/tls/private/postfix.key
-
サーバー証明書:
手順
以下の行を
/etc/postfix/main.cfファイルに追加して、Postfix が実行されているサーバー上の証明書と秘密鍵ファイルへのパスを設定します。smtpd_tls_cert_file = /etc/pki/tls/certs/postfix.pem smtpd_tls_key_file = /etc/pki/tls/private/postfix.key
/etc/postfix/main.cfファイルを編集して、受信した SMTP 接続を認証されたユーザーのみに制限します。smtpd_tls_auth_only = yes
postfixサービスをリロードして変更を適用します。# systemctl reload postfix
検証
TLS 暗号化を使用してメールを送信するようにクライアントを設定します。
注記Postfix クライアント TLS アクティビティーに関する追加情報を取得するには、
/etc/postfix/main.cfの次の行を変更して、ログレベルを0から1に増やします。smtp_tls_loglevel = 1
8.4. すべての電子メールをメールリレーに転送するように Postfix を設定する
すべての電子メールをメールリレーに転送する場合は、Postfix サーバーを Null クライアントとして設定できます。この設定では、Postfix はメールを別のメールサーバーに転送するだけで、メールの受信はできません。
前提条件
- root アクセスがある。
-
サーバーに
postfixパッケージがインストールされている。 - メールを転送するリレーホストの IP アドレスまたはホスト名がある。
手順
Postfix がローカルの電子メール配信を受け入れ、それが Null クライアントになるのを防ぐには、
/etc/postfix/main.cfファイルを編集し、以下の変更を加えます。mydestinationパラメーターを空の値に等しくなるように設定して、すべてのメールを転送するように Postfix を設定します。mydestination =
この設定では、Postfix サーバーはメールの宛先ではなく、null クライアントとして機能します。
Null クライアントからメールを受信するメールリレーサーバーを指定します。
relayhost = <[ip_address_or_hostname]>リレーホストはメール配信を行います。
<ip_address_or_hostname>を角括弧で囲みます。メールを配信するために、ループバックインターフェイスでのみリッスンするように Postfix メールサーバーを設定します。
inet_interfaces = loopback-only
Postfix がすべての送信メールの送信者ドメインをリレーメールサーバーの企業ドメインに書き換えるには、以下を設定します。
myorigin = <relay.example.com>ローカルメール配信を無効にするには、設定ファイルの最後に次のディレクティブを追加します。
local_transport = error: local delivery disabled
mynetworksパラメーターを追加して、Postfix が 127.0.0.0/8 IPv4 ネットワークと [::1]/128 IPv6 ネットワークから送信されたローカルシステムからの電子メールをメールリレーサーバーに転送するようにします。mynetworks = 127.0.0.0/8, [::1]/128
main.cfファイルの Postfix 設定が正しいか確認します。$ postfix checkpostfixサービスを再起動して変更を適用します。# systemctl restart postfix
検証
電子メール通信がメールリレーに転送されていることを確認します。
# echo "This is a test message" | mail -s <SUBJECT> <user@example.com>
トラブルシューティング
-
エラーが発生した場合は、
/var/log/maillogを確認してください。
関連情報
-
/etc/postfix/main.cf設定ファイル
8.5. Postfix を複数のドメインの宛先として設定する
Postfix を、複数のドメインのメールを受信できるメールサーバーとして設定できます。この設定では、Postfix は、指定されたドメイン内のアドレスに送信された電子メールの最終宛先として機能します。以下を設定できます。
- 同じ電子メール宛先を指す複数の電子メールアドレスを設定する。
- 複数のドメインの受信メールを同じ Postfix サーバーにルーティングする。
前提条件
- root アクセスがある。
- Postfix サーバーを設定している。
手順
/etc/postfix/virtual仮想エイリアスファイルで、各ドメインのメールアドレスを指定します。各電子メールアドレスを新しい行に追加します。<info@example.com> <user22@example.net> <sales@example.com> <user11@example.org>
この例では、Postfix は info@example.com に送信されたすべての電子メールを user22@example.net にリダイレクトし、sales@example.com に送信された電子メールを user11@example.org にリダイレクトします。
仮想エイリアスマップのハッシュファイルを作成します。
# postmap /etc/postfix/virtualこのコマンドは、
/etc/postfix/virtual.dbファイルを作成します。/etc/postfix/virtualファイルを更新した後に、このコマンドを常に再実行する必要があります。Postfix
/etc/postfix/main.cf設定ファイルで、virtual_alias_mapsパラメーターを追加して、ハッシュファイルを指すようにします。virtual_alias_maps = hash:/etc/postfix/virtual
postfixサービスをリロードして変更を適用します。# systemctl reload postfix
検証
- 仮想メールアドレスの 1 つに電子メールを送信して、設定をテストします。
トラブルシューティング
-
エラーが発生した場合は、
/var/log/maillogを確認してください。
8.6. LDAP ディレクトリーの検索テーブルとしての使用
Lightweight Directory Access Protocol (LDAP) サーバーを使用してアカウント、ドメイン、またはエイリアスを保存する場合は、LDAP サーバーを検索テーブルとして使用するように Postfix を設定できます。検索用ファイルの代わりに LDAP を使用すると、中央データベースを使用できます。
前提条件
- root アクセスがある。
-
サーバーに
postfixパッケージがインストールされている。 - 必要なスキーマおよびユーザークレデンシャルを持つ LDAP サーバーがある。
-
Postfix を実行しているサーバーに
postfix-ldapプラグインがインストールされている。
手順
以下の内容で
/etc/postfix/ldap-aliases.cfファイルを作成して、LDAP 検索パラメーターを設定します。LDAP サーバーのホスト名を指定します。
server_host = <ldap.example.com>LDAP 検索のベースドメイン名を指定します。
search_base = dc=<example>,dc=<com>
-
オプション: 要件に応じて LDAP 検索フィルターと属性をカスタマイズします。ディレクトリーを検索するフィルターのデフォルトは
query_filter = mailacceptinggeneralid=%sです。
以下の内容を追加して、LDAP ソースを
/etc/postfix/main.cf設定ファイルの検索テーブルとして有効にします。virtual_alias_maps = ldap:/etc/postfix/ldap-aliases.cf
postmapコマンドを実行して LDAP 設定を確認します。これは、構文エラーまたは接続の問題をチェックします。# postmap -q @<example.com> ldap:/etc/postfix/ldap-aliases.cfpostfixサービスをリロードして変更を適用します。# systemctl reload postfix
検証
-
テストメールを送信して、LDAP 検索が正しく機能していることを確認します。
/var/log/maillogのメールログでエラーがないか確認します。
関連情報
-
/usr/share/doc/postfix/README_FILES/LDAP_READMEファイル -
/usr/share/doc/postfix/README_FILES/DATABASE_READMEファイル
8.7. 認証されたユーザーのリレーを行う送信メールサーバーとしての Postfix の設定
認証されたユーザーのメールをリレーするように Postfix を設定できます。このシナリオでは、SMTP 認証、TLS 暗号化、および送信者アドレス制限を備えた送信メールサーバーとして Postfix を設定することで、ユーザーが自分自身を認証し、自分の電子メールアドレスを使用して SMTP サーバー経由でメールを送信できるようにします。
前提条件
- root アクセスがある。
- Postfix サーバーを設定している。
手順
Postfix を送信メールサーバーとして設定するには、
/etc/postfix/main.cfファイルを編集し、以下を追加します。SMTP 認証を有効にします。
smtpd_sasl_auth_enable = yes broken_sasl_auth_clients = yes
TLS を使用しないアクセスを無効にします。
smtpd_tls_auth_only = yes
認証されたユーザーに対してのみメールリレーを許可します。
smtpd_relay_restrictions = permit_mynetworks permit_sasl_authenticated defer_unauth_destination
オプション: ユーザーが自分の電子メールアドレスを送信者としてのみ使用するように制限します。
smtpd_sender_restrictions = reject_sender_login_mismatch
postfixサービスをリロードして変更を適用します。# systemctl reload postfix
検証
- TLS および SASL をサポートする SMTP クライアントで認証します。テストメールを送信して、SMTP 認証が正しく機能していることを確認します。
8.8. 同じホストで実行している Postfix から Dovecot への電子メールの配信
UNIX ソケット経由で LMTP を使用して、受信メールを同じホスト上の Dovecot に配信するように Postfix を設定できます。このソケットは、ローカルマシンの Postfix と Dovecot との間の直接通信を有効にします。
前提条件
- root アクセスがある。
- Postfix サーバーを設定している。
- Dovecot サーバーを設定している。Dovecot IMAP および POP3 サーバーの設定と管理 を参照してください。
- Dovecot サーバーに LMTP ソケットを設定している。LMTP ソケットと LMTPS リスナーの設定 を参照してください。
手順
/etc/postfix/main.cfファイルの Dovecot にメールを配信するために LMTP プロトコルと UNIX ドメインソケットを使用するように Postfix を設定します。仮想メールボックスを使用する場合は、次のコンテンツを追加します。
virtual_transport = lmtp:unix:/var/run/dovecot/lmtp
仮想以外のメールボックスを使用する場合は、次のコンテンツを追加します。
mailbox_transport = lmtp:unix:/var/run/dovecot/lmtp
postfixをリロードして変更を適用します。# systemctl reload postfix
検証
-
テストメールを送信して、LMTP ソケットが正常に動作することを確認します。
/var/log/maillogのメールログでエラーがないか確認します。
8.9. Postfix から別のホストで実行されている Dovecot への電子メールの配信
ネットワーク経由で Postfix メールサーバーと Dovecot 配信エージェントの間にセキュアな接続を確立できます。これを行うには、メールサーバー間でのメール配信にネットワークソケットを使用するように LMTP サービスを設定します。デフォルトでは、LMTP プロトコルは暗号化されていません。ただし、TLS 暗号化を設定した場合、Dovecot は LMTP サービスに同じ設定を自動的に使用します。続いて、SMTP サーバーは、LMTP 経由で STARTTLS コマンドを使用してそれに接続できます。
前提条件
- root アクセスがある。
- Postfix サーバーを設定している。
- Dovecot サーバーを設定している。Dovecot IMAP および POP3 サーバーの設定と管理 を参照してください。
- Dovecot サーバーに LMTP サービスを設定している。LMTP ソケットと LMTPS リスナーの設定 を参照してください。
手順
以下の内容を追加して、
/etc/postfix/main.cfファイルで Dovecot にメールを配信するために LMTP プロトコルと INET ドメインソケットを使用するように Postfix を設定します。mailbox_transport = lmtp:inet:<dovecot_host>:<port>
<dovecot_host>を Dovecot サーバーの IP アドレスまたはホスト名に置き換え、<port>を LMTP サービスのポート番号に置き換えます。postfixサービスをリロードして変更を適用します。# systemctl reload postfix
検証
- リモート Dovecot サーバーがホストするアドレスにテストメールを送信し、Dovecot ログをチェックして、メールが正常に配信されたことを確認します。
8.10. Postfix サービスを保護する
Postfix は、SMTP (Simple Mail Transfer Protocol) を使用して他の MTA 間で電子メッセージを配信したり、クライアントや配信エージェントに電子メールを送信したりするメール転送エージェント (MTA) です。MTA は相互間のトラフィックを暗号化できますが、デフォルトではそうしない場合があります。設定をより安全な値に変更することで、さまざまな攻撃に対するリスクを軽減することもできます。
8.10.2. DoS 攻撃を制限するための Postfix 設定オプション
攻撃者は、トラフィックでサーバーをあふれさせたり、クラッシュを引き起こす情報を送信したりして、サービス拒否 (DoS) 攻撃を引き起こす可能性があります。/etc/postfix/main.cf ファイルで制限を設定することにより、このような攻撃のリスクを軽減するようにシステムを設定できます。既存のディレクティブの値を変更するか、<directive> = <value> 形式のカスタム値で新しいディレクティブを追加できます。
DoS 攻撃を制限するには、次のディレクティブリストを使用します。
- smtpd_client_connection_rate_limit
-
このディレクティブは、時間単位ごとにクライアントがこのサービスに対して行うことができる接続試行の最大数を制限します。デフォルト値は
0です。これは、クライアントが時間単位で Postfix が受け入れることができる数と同じ数の接続を行うことができることを意味します。デフォルトでは、ディレクティブは信頼できるネットワークのクライアントを除外します。 - anvil_rate_time_unit
-
このディレクティブは、レート制限を計算する時間単位です。デフォルト値は
60秒です。 - smtpd_client_event_limit_exceptions
- このディレクティブは、接続およびレート制限コマンドからクライアントを除外します。デフォルトでは、ディレクティブは信頼できるネットワークのクライアントを除外します。
- smtpd_client_message_rate_limit
- このディレクティブは、単位時間当たりのクライアントからリクエストへのメッセージ配信の最大数を定義します (Postfix が実際にそれらのメッセージを受け入れるかどうかに関係なく)。
- default_process_limit
-
このディレクティブは、特定のサービスを提供する Postfix 子プロセスのデフォルトの最大数を定義します。
master.cfファイル内の特定のサービスについては、このルールを無視できます。デフォルトでは、値は100です。 - queue_minfree
-
このディレクティブは、キューファイルシステムでメールを受信するために必要な空き容量の最小量を定義します。このディレクティブは現在、Postfix SMTP サーバーがメールを受け入れるかどうかを決定するために使用されています。デフォルトでは、Postfix SMTP サーバーは、空き容量が
message_size_limitの 1.5 倍未満の場合に、MAIL FROMコマンドを拒否します。空き容量の最小値をこれよりも高く指定するには、message_size_limitの 1.5 倍以上のqueue_minfree値を指定します。デフォルトのqueue_minfree値は0です。 - header_size_limit
-
このディレクティブは、メッセージヘッダーを格納するためのメモリーの最大量をバイト単位で定義します。ヘッダーが大きい場合、余分なヘッダーは破棄されます。デフォルトでは、値は
102400バイトです。 - message_size_limit
-
このディレクティブは、エンベロープ情報を含むメッセージの最大サイズをバイト単位で定義します。デフォルトでは、値は
10240000バイトです。
8.10.3. Postfix が SASL を使用する設定
Postfix は Simple Authentication and Security Layer (SASL) ベースの SMTP 認証 (AUTH) をサポートしています。SMTP AUTH は Simple Mail Transfer Protocol の拡張です。現在、Postfix SMTP サーバーは次の方法で SASL 実装をサポートしています:
- Dovecot SASL
- Postfix SMTP サーバーは、UNIX ドメインソケットまたは TCP ソケットのいずれかを使用して、Dovecot SASL 実装と通信できます。Postfix と Dovecot アプリケーションが別のマシンで実行している場合は、この方法を使用します。
- Cyrus SASL
- 有効にすると、SMTP クライアントは、サーバーとクライアントの両方でサポートおよび受け入れられる認証方法を使用して、SMTP サーバーで認証する必要があります。
前提条件
-
dovecotパッケージがシステムにインストールされている
手順
Dovecot をセットアップします。
/etc/dovecot/conf.d/10-master.confファイルに次の行を含めます。service auth { unix_listener /var/spool/postfix/private/auth { mode = 0660 user = postfix group = postfix } }前の例では、Postfix と Dovecot の間の通信に UNIX ドメインソケットを使用しています。また、
/var/spool/postfix/ディレクトリーにあるメールキュー、およびpostfixユーザーとグループの下で実行しているアプリケーションを含む Postfix SMTP サーバーのデフォルト設定を想定しています。オプション: TCP 経由で Postfix 認証リクエストをリッスンするように Dovecot をセットアップします。
service auth { inet_listener { port = port-number } }/etc/dovecot/conf.d/10-auth.confファイルのauth_mechanismsパラメーターを編集して、電子メールクライアントが Dovecot での認証に使用する方法を指定します。auth_mechanisms = plain login
auth_mechanismsパラメーターは、さまざまなプレーンテキストおよび非プレーンテキストの認証方法をサポートしています。
/etc/postfix/main.cfファイルを変更して Postfix をセットアップします。Postfix SMTP サーバーで SMTP 認証を有効にします。
smtpd_sasl_auth_enable = yes
SMTP 認証用の Dovecot SASL 実装の使用を有効にします。
smtpd_sasl_type = dovecot
Postfix キューディレクトリーに相対的な認証パスを指定します。相対パスを使用すると、Postfix サーバーが
chrootで実行しているかどうかに関係なく、設定が確実に機能することに注意してください。smtpd_sasl_path = private/auth
この手順では、Postfix と Dovecot の間の通信に UNIX ドメインソケットを使用します。
通信に TCP ソケットを使用する場合に、別のマシンで Dovecot を探すように Postfix を設定するには、次のような設定値を使用します。
smtpd_sasl_path = inet: ip-address : port-number
前の例で、ip-address を Dovecot マシンの IP アドレスに置き換え、port-number を Dovecot の
/etc/dovecot/conf.d/10-master.confファイルで指定されたポート番号に置き換えます。Postfix SMTP サーバーがクライアントに提供する SASL メカニズムを指定します。暗号化されたセッションと暗号化されていないセッションに異なるメカニズムを指定できることに注意してください。
smtpd_sasl_security_options = noanonymous, noplaintext smtpd_sasl_tls_security_options = noanonymous
前のディレクティブは、暗号化されていないセッションでは匿名認証が許可されず、暗号化されていないユーザー名またはパスワードを送信するメカニズムが許可されていないことを指定しています。暗号化セッション (TLS を使用) の場合、非匿名認証メカニズムのみが許可されます。
第9章 Dovecot IMAP および POP3 サーバーの設定と管理
Dovecot は、セキュリティーを重視する高パフォーマンスのメール配信エージェント (MDA) です。IMAP または POP3 互換の電子メールクライアントを使用して Dovecot サーバーに接続し、電子メールを読んだりダウンロードしたりできます。
Dovecot の主な機能:
- セキュリティーを重視する設計と実装
- 大規模環境でのパフォーマンスを向上させるために、高可用性を実現する双方向レプリケーションをサポート
-
高パフォーマンスの
dboxメールボックス形式だけでなく、互換性の理由からmboxとMaildirもサポート - 破損したインデックスファイルの修正などの自己修復機能
- IMAP 標準への準拠
- IMAP および POP3 クライアントのバグを回避するための回避策をサポート
9.1. PAM 認証を使用した Dovecot サーバーのセットアップ
Dovecot は、ユーザーデータベースとして Name Service Switch (NSS) インターフェイスをサポートし、認証バックエンドとして Pluggable Authentication Module (PAM) フレームワークをサポートします。この設定により、Dovecot は、NSS を介してサーバー上でローカルに利用可能なユーザーにサービスを提供できます。
アカウントが次の場合に PAM 認証を使用します。
-
/etc/passwdファイルでローカルに定義されている。 - リモートデータベースに保存されているが、System Security Services Daemon (SSSD) またはその他の NSS プラグインを介してローカルで利用できる。
9.1.1. Dovecot のインストール
dovecot パッケージは以下を提供します。
-
dovecotサービスとそれを管理するユーティリティー - Dovecot がオンデマンドで開始するサービス (認証など)
- サーバーサイドメールフィルタリングなどのプラグイン
-
/etc/dovecot/ディレクトリーの設定ファイル -
/usr/share/doc/dovecot/ディレクトリーのドキュメント
手順
dovecotパッケージをインストールします。# yum install dovecot注記Dovecot がすでにインストールされていて、クリーンな設定ファイルが必要な場合は、
/etc/dovecot/ディレクトリーを名前変更するか削除してください。その後、パッケージを再インストールします。設定ファイルを削除しないと、yum uninstall dovecotコマンドは/etc/dovecot/内の設定ファイルをリセットしません。
次のステップ
9.1.2. Dovecot サーバーでの TLS 暗号化の設定
Dovecot はセキュアなデフォルト設定を提供します。たとえば、TLS はデフォルトで有効になっており、認証情報と暗号化されたデータをネットワーク経由で送信します。Dovecot サーバーで TLS を設定するには、証明書と秘密鍵ファイルへのパスを設定するだけです。さらに、Diffie-Hellman パラメーターを生成して使用し、Perfect Forward Secrecy (PFS) を提供することで、TLS 接続のセキュリティーを強化できます。
前提条件
- Dovecot がインストールされています。
次のファイルが、サーバー上のリストされた場所にコピーされました。
-
サーバー証明書:
/etc/pki/dovecot/certs/server.example.com.crt -
秘密鍵:
/etc/pki/dovecot/private/server.example.com.key -
認証局 (CA) 証明書:
/etc/pki/dovecot/certs/ca.crt
-
サーバー証明書:
-
サーバー証明書の
Subject DNフィールドのホスト名は、サーバーの完全修飾ドメイン名 (FQDN) と一致します。
手順
秘密鍵ファイルにセキュアな権限を設定します。
# chown root:root /etc/pki/dovecot/private/server.example.com.key # chmod 600 /etc/pki/dovecot/private/server.example.com.key
Diffie-Hellman パラメーターを使用してファイルを生成します。
# openssl dhparam -out /etc/dovecot/dh.pem 4096サーバーのハードウェアとエントロピーによっては、4096 ビットの Diffie-Hellman パラメーターを生成するのに数分かかる場合があります。
/etc/dovecot/conf.d/10-ssl.confファイルで証明書と秘密鍵ファイルへのパスを設定します。ssl_certおよびssl_keyパラメーターを更新し、サーバーの証明書と秘密鍵へのパスを使用するように設定します。ssl_cert = </etc/pki/dovecot/certs/server.example.com.crt ssl_key = </etc/pki/dovecot/private/server.example.com.key
ssl_caパラメーターをコメント解除し、CA 証明書へのパスを使用するように設定します。ssl_ca = </etc/pki/dovecot/certs/ca.crtssl_dhパラメーターをコメント解除し、Diffie-Hellman パラメーターファイルへのパスを使用するように設定します。ssl_dh = </etc/dovecot/dh.pem
重要Dovecot がファイルからパラメーターの値を確実に読み取るようにするには、パスの先頭に
<文字を付ける必要があります。
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/SSL.DovecotConfiguration.txt
9.1.3. 仮想ユーザーを使用するための Dovecot の準備
デフォルトでは、Dovecot はサービスを使用するユーザーとして、ファイルシステム上で多くのアクションを実行します。ただし、1 人のローカルユーザーを使用してこれらのアクションを実行するように Dovecot バックエンドを設定すると、複数の利点があります。
- Dovecot は、ユーザーの ID (UID) を使用する代わりに、特定のローカルユーザーとしてファイルシステムアクションを実行します。
- ユーザーは、サーバー上でローカルに利用できる必要はありません。
- すべてのメールボックスとユーザー固有のファイルを 1 つのルートディレクトリーに保存できます。
- ユーザーは UID とグループ ID (GID) を必要としないため、管理作業が軽減されます。
- サーバー上のファイルシステムにアクセスできるユーザーは、これらのファイルにアクセスできないため、メールボックスやインデックスを危険にさらす可能性はありません。
- レプリケーションのセットアップはより簡単です。
前提条件
- Dovecot がインストールされています。
手順
vmailユーザーを作成します。# useradd --home-dir /var/mail/ --shell /usr/sbin/nologin vmailDovecot は後でこのユーザーを使用してメールボックスを管理します。セキュリティー上の理由から、この目的で
dovecotまたはdovenullシステムユーザーを使用しないでください。/var/mail/以外のパスを使用する場合は、それに SELinux コンテキストmail_spool_tを設定します。例:# semanage fcontext -a -t mail_spool_t "<path>(/.*)?" # restorecon -Rv <path>
/var/mail/への書き込み権限をvmailユーザーにのみ付与します。# chown vmail:vmail /var/mail/ # chmod 700 /var/mail/
/etc/dovecot/conf.d/10-mail.confファイルのmail_locationパラメーターをコメント解除し、メールボックスの形式と場所を設定します。mail_location = sdbox:/var/mail/%n/この設定の場合:
-
Dovecot は、
singleモードで高パフォーマンスのdboxメールボックス形式を使用します。このモードでは、サービスは、maildir形式と同様に、各メールを個別のファイルに保存します。 -
Dovecot はパス内の
%n変数をユーザー名に解決します。これは、各ユーザーがメールボックス用に個別のディレクトリーを持つようにするために必要です。
-
Dovecot は、
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/VirtualUsers.txt -
/usr/share/doc/dovecot/wiki/MailLocation.txt -
/usr/share/doc/dovecot/wiki/MailboxFormat.dbox.txt -
/usr/share/doc/dovecot/wiki/Variables.txt
9.1.4. PAM を Dovecot 認証バックエンドとして使用する
デフォルトでは、Dovecot は Name Service Switch (NSS) インターフェイスをユーザーデータベースとして使用し、Pluggable Authentication Module (PAM) フレームワークを認証バックエンドとして使用します。
設定をカスタマイズして Dovecot を環境に適応させ、仮想ユーザー機能を使用して管理を簡素化します。
前提条件
- Dovecot がインストールされています。
- 仮想ユーザー機能が設定されています。
手順
/etc/dovecot/conf.d/10-mail.confファイルのfirst_valid_uidパラメーターを更新して、Dovecot に対して認証できる最小のユーザー ID (UID) を定義します。first_valid_uid = 1000デフォルトでは、
1000以上の UID を持つユーザーが認証を受けることができます。必要に応じて、last_valid_uidパラメーターを設定して、Dovecot がログインを許可する最大の UID を定義することもできます。/etc/dovecot/conf.d/auth-system.conf.extファイルで、次のようにoverride_fieldsパラメーターをuserdbセクションに追加します。userdb { driver = passwd override_fields = uid=vmail gid=vmail home=/var/mail/%n/ }固定値のため、Dovecot は
/etc/passwdファイルからこれらの設定をクエリーしません。そのため、/etc/passwdに定義されたホームディレクトリーが存在する必要はありません。
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/PasswordDatabase.PAM.txt -
/usr/share/doc/dovecot/wiki/VirtualUsers.Home.txt
9.1.5. Dovecot 設定の完了
Dovecot をインストールして設定したら、firewalld サービスで必要なポートを開き、サービスを有効にして開始します。その後、サーバーをテストできます。
前提条件
以下は Dovecot で設定されています。
- TLS 暗号化
- 認証バックエンド
- クライアントは認証局 (CA) 証明書を信頼します。
手順
IMAP または POP3 サービスのみをユーザーに提供する場合は、
/etc/dovecot/dovecot.confファイルのprotocolパラメーターをコメント解除し、必要なプロトコルに設定します。たとえば、POP3 を必要としない場合は、次のように設定します。protocols = imap lmtpデフォルトでは、
imap、pop3、およびlmtpプロトコルが有効になっています。ローカルファイアウォールでポートを開きます。たとえば、IMAPS、IMAP、POP3S、および POP3 プロトコルのポートを開くには、次のように入力します。
# firewall-cmd --permanent --add-service=imaps --add-service=imap --add-service=pop3s --add-service=pop3 # firewall-cmd --reload
dovecotサービスを有効にして開始します。# systemctl enable --now dovecot
検証
Dovecot に接続して電子メールを読むには、Mozilla Thunderbird などのメールクライアントを使用します。メールクライアントの設定は、使用するプロトコルによって異なります。
表9.1 Dovecot サーバーへの接続設定
デフォルトでは、Dovecot は TLS を使用しない接続ではプレーンテキスト認証を受け入れないため、この表には暗号化されていない接続の設定がリストされていないことに注意してください。
デフォルト以外の値を含む設定を表示します。
# doveconf -n
関連情報
-
firewall-cmd(1)man ページ
9.2. LDAP 認証を使用した Dovecot サーバーのセットアップ
インフラストラクチャーが LDAP サーバーを使用してアカウントを保存している場合、それに対して Dovecot ユーザーを認証できます。この場合、アカウントをディレクトリーで集中管理するため、ユーザーは Dovecot サーバー上のファイルシステムにローカルでアクセスする必要はありません。
複数の Dovecot サーバーをレプリケーションでセットアップして、メールボックスを高可用性にする予定がある場合にも、集中管理されたアカウントは利点があります。
9.2.1. Dovecot のインストール
dovecot パッケージは以下を提供します。
-
dovecotサービスとそれを管理するユーティリティー - Dovecot がオンデマンドで開始するサービス (認証など)
- サーバーサイドメールフィルタリングなどのプラグイン
-
/etc/dovecot/ディレクトリーの設定ファイル -
/usr/share/doc/dovecot/ディレクトリーのドキュメント
手順
dovecotパッケージをインストールします。# yum install dovecot注記Dovecot がすでにインストールされていて、クリーンな設定ファイルが必要な場合は、
/etc/dovecot/ディレクトリーを名前変更するか削除してください。その後、パッケージを再インストールします。設定ファイルを削除しないと、yum uninstall dovecotコマンドは/etc/dovecot/内の設定ファイルをリセットしません。
次のステップ
9.2.2. Dovecot サーバーでの TLS 暗号化の設定
Dovecot はセキュアなデフォルト設定を提供します。たとえば、TLS はデフォルトで有効になっており、認証情報と暗号化されたデータをネットワーク経由で送信します。Dovecot サーバーで TLS を設定するには、証明書と秘密鍵ファイルへのパスを設定するだけです。さらに、Diffie-Hellman パラメーターを生成して使用し、Perfect Forward Secrecy (PFS) を提供することで、TLS 接続のセキュリティーを強化できます。
前提条件
- Dovecot がインストールされています。
次のファイルが、サーバー上のリストされた場所にコピーされました。
-
サーバー証明書:
/etc/pki/dovecot/certs/server.example.com.crt -
秘密鍵:
/etc/pki/dovecot/private/server.example.com.key -
認証局 (CA) 証明書:
/etc/pki/dovecot/certs/ca.crt
-
サーバー証明書:
-
サーバー証明書の
Subject DNフィールドのホスト名は、サーバーの完全修飾ドメイン名 (FQDN) と一致します。
手順
秘密鍵ファイルにセキュアな権限を設定します。
# chown root:root /etc/pki/dovecot/private/server.example.com.key # chmod 600 /etc/pki/dovecot/private/server.example.com.key
Diffie-Hellman パラメーターを使用してファイルを生成します。
# openssl dhparam -out /etc/dovecot/dh.pem 4096サーバーのハードウェアとエントロピーによっては、4096 ビットの Diffie-Hellman パラメーターを生成するのに数分かかる場合があります。
/etc/dovecot/conf.d/10-ssl.confファイルで証明書と秘密鍵ファイルへのパスを設定します。ssl_certおよびssl_keyパラメーターを更新し、サーバーの証明書と秘密鍵へのパスを使用するように設定します。ssl_cert = </etc/pki/dovecot/certs/server.example.com.crt ssl_key = </etc/pki/dovecot/private/server.example.com.key
ssl_caパラメーターをコメント解除し、CA 証明書へのパスを使用するように設定します。ssl_ca = </etc/pki/dovecot/certs/ca.crtssl_dhパラメーターをコメント解除し、Diffie-Hellman パラメーターファイルへのパスを使用するように設定します。ssl_dh = </etc/dovecot/dh.pem
重要Dovecot がファイルからパラメーターの値を確実に読み取るようにするには、パスの先頭に
<文字を付ける必要があります。
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/SSL.DovecotConfiguration.txt
9.2.3. 仮想ユーザーを使用するための Dovecot の準備
デフォルトでは、Dovecot はサービスを使用するユーザーとして、ファイルシステム上で多くのアクションを実行します。ただし、1 人のローカルユーザーを使用してこれらのアクションを実行するように Dovecot バックエンドを設定すると、複数の利点があります。
- Dovecot は、ユーザーの ID (UID) を使用する代わりに、特定のローカルユーザーとしてファイルシステムアクションを実行します。
- ユーザーは、サーバー上でローカルに利用できる必要はありません。
- すべてのメールボックスとユーザー固有のファイルを 1 つのルートディレクトリーに保存できます。
- ユーザーは UID とグループ ID (GID) を必要としないため、管理作業が軽減されます。
- サーバー上のファイルシステムにアクセスできるユーザーは、これらのファイルにアクセスできないため、メールボックスやインデックスを危険にさらす可能性はありません。
- レプリケーションのセットアップはより簡単です。
前提条件
- Dovecot がインストールされています。
手順
vmailユーザーを作成します。# useradd --home-dir /var/mail/ --shell /usr/sbin/nologin vmailDovecot は後でこのユーザーを使用してメールボックスを管理します。セキュリティー上の理由から、この目的で
dovecotまたはdovenullシステムユーザーを使用しないでください。/var/mail/以外のパスを使用する場合は、それに SELinux コンテキストmail_spool_tを設定します。例:# semanage fcontext -a -t mail_spool_t "<path>(/.*)?" # restorecon -Rv <path>
/var/mail/への書き込み権限をvmailユーザーにのみ付与します。# chown vmail:vmail /var/mail/ # chmod 700 /var/mail/
/etc/dovecot/conf.d/10-mail.confファイルのmail_locationパラメーターをコメント解除し、メールボックスの形式と場所を設定します。mail_location = sdbox:/var/mail/%n/この設定の場合:
-
Dovecot は、
singleモードで高パフォーマンスのdboxメールボックス形式を使用します。このモードでは、サービスは、maildir形式と同様に、各メールを個別のファイルに保存します。 -
Dovecot はパス内の
%n変数をユーザー名に解決します。これは、各ユーザーがメールボックス用に個別のディレクトリーを持つようにするために必要です。
-
Dovecot は、
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/VirtualUsers.txt -
/usr/share/doc/dovecot/wiki/MailLocation.txt -
/usr/share/doc/dovecot/wiki/MailboxFormat.dbox.txt -
/usr/share/doc/dovecot/wiki/Variables.txt
9.2.4. LDAP を Dovecot 認証バックエンドとして使用する
通常、LDAP ディレクトリー内のユーザーは、ディレクトリーサービスに対して自分自身を認証できます。Dovecot は、これを使用して、ユーザーが IMAP または POP3 サービスにログインする場合、ユーザーを認証できます。この認証方法には、次のとおり、多くの利点があります。
- 管理者は、ディレクトリーでユーザーを集中管理できます。
- LDAP アカウントには、特別な属性は必要ありません。LDAP サーバーから認証を受けることができれば十分です。したがって、この方法は、LDAP サーバーで使用されるパスワード保存方式とは無関係です。
- ユーザーは、Name Service Switch (NSS) インターフェイスと Pluggable Authentication Module (PAM) フレームワークを介して、サーバー上でローカルに利用できる必要はありません。
前提条件
- Dovecot がインストールされています。
- 仮想ユーザー機能が設定されています。
- LDAP サーバーへの接続は、TLS 暗号化をサポートします。
- Dovecot サーバー上の RHEL は、LDAP サーバーの認証局 (CA) 証明書を信頼します。
- ユーザーが LDAP ディレクトリーの異なるツリーに保存されている場合、ディレクトリーを検索するための Dovecot 専用の LDAP アカウントが存在します。このアカウントには、他のユーザーの識別名 (DN) を検索する権限が必要です。
手順
/etc/dovecot/conf.d/10-auth.confファイルで認証バックエンドを設定します。不要な
auth-*.conf.ext認証バックエンド設定ファイルのincludeステートメントをコメントアウトします。次に例を示します。#!include auth-system.conf.ext次の行をコメント解除して、LDAP 認証を有効にします。
!include auth-ldap.conf.ext
/etc/dovecot/conf.d/auth-ldap.conf.extファイルを編集し、次のようにoverride_fieldsパラメーターをuserdbセクションに追加します。userdb { driver = ldap args = /etc/dovecot/dovecot-ldap.conf.ext override_fields = uid=vmail gid=vmail home=/var/mail/%n/ }固定値のため、Dovecot は LDAP サーバーからこれらの設定をクエリーしません。したがって、これらの属性も存在する必要はありません。
次の設定で
/etc/dovecot/dovecot-ldap.conf.extファイルを作成します。LDAP 構造に応じて、次のいずれかを設定します。
ユーザーが LDAP ディレクトリーの異なるツリーに保存されている場合は、動的 DN 検索を設定します。
dn = cn=dovecot_LDAP,dc=example,dc=com dnpass = password pass_filter = (&(objectClass=posixAccount)(uid=%n))
Dovecot は、指定された DN、パスワード、およびフィルターを使用して、ディレクトリー内の認証ユーザーの DN を検索します。この検索では、Dovecot はフィルター内の
%nをユーザー名に置き換えます。LDAP 検索で返される結果は 1 つだけであることに注意してください。すべてのユーザーが特定のエントリーに保存されている場合は、DN テンプレートを設定します。
auth_bind_userdn = cn=%n,ou=People,dc=example,dc=com
LDAP サーバーへの認証バインドを有効にして、Dovecot ユーザーを確認します。
auth_bind = yesURL を LDAP サーバーに設定します。
uris = ldaps://LDAP-srv.example.comセキュリティー上の理由から、LDAP プロトコル上で LDAPS または
STARTTLSコマンドを使用した暗号化された接続のみを使用してください。後者の場合は、さらにtls = yesを設定に追加します。証明書の検証を機能させるには、LDAP サーバーのホスト名が TLS 証明書で使用されているホスト名と一致する必要があります。
LDAP サーバーの TLS 証明書の検証を有効にします。
tls_require_cert = hardベース DN には、ユーザーの検索を開始する DN を設定します。
base = ou=People,dc=example,dc=com検索範囲を設定します。
scope = onelevelDovecot は、指定されたベース DN のみを
onelevelスコープで検索し、サブツリーもsubtreeスコープで検索します。
/etc/dovecot/dovecot-ldap.conf.extファイルにセキュアな権限を設定します。# chown root:root /etc/dovecot/dovecot-ldap.conf.ext # chmod 600 /etc/dovecot/dovecot-ldap.conf.ext
次のステップ
関連情報
-
/usr/share/doc/dovecot/example-config/dovecot-ldap.conf.ext -
/usr/share/doc/dovecot/wiki/UserDatabase.Static.txt -
/usr/share/doc/dovecot/wiki/AuthDatabase.LDAP.txt -
/usr/share/doc/dovecot/wiki/AuthDatabase.LDAP.AuthBinds.txt -
/usr/share/doc/dovecot/wiki/AuthDatabase.LDAP.PasswordLookups.txt
9.2.5. Dovecot 設定の完了
Dovecot をインストールして設定したら、firewalld サービスで必要なポートを開き、サービスを有効にして開始します。その後、サーバーをテストできます。
前提条件
以下は Dovecot で設定されています。
- TLS 暗号化
- 認証バックエンド
- クライアントは認証局 (CA) 証明書を信頼します。
手順
IMAP または POP3 サービスのみをユーザーに提供する場合は、
/etc/dovecot/dovecot.confファイルのprotocolパラメーターをコメント解除し、必要なプロトコルに設定します。たとえば、POP3 を必要としない場合は、次のように設定します。protocols = imap lmtpデフォルトでは、
imap、pop3、およびlmtpプロトコルが有効になっています。ローカルファイアウォールでポートを開きます。たとえば、IMAPS、IMAP、POP3S、および POP3 プロトコルのポートを開くには、次のように入力します。
# firewall-cmd --permanent --add-service=imaps --add-service=imap --add-service=pop3s --add-service=pop3 # firewall-cmd --reload
dovecotサービスを有効にして開始します。# systemctl enable --now dovecot
検証
Dovecot に接続して電子メールを読むには、Mozilla Thunderbird などのメールクライアントを使用します。メールクライアントの設定は、使用するプロトコルによって異なります。
表9.2 Dovecot サーバーへの接続設定
デフォルトでは、Dovecot は TLS を使用しない接続ではプレーンテキスト認証を受け入れないため、この表には暗号化されていない接続の設定がリストされていないことに注意してください。
デフォルト以外の値を含む設定を表示します。
# doveconf -n
関連情報
-
firewall-cmd(1)man ページ
9.3. MariaDB SQL 認証を使用した Dovecot サーバーのセットアップ
ユーザーとパスワードを MariaDB SQL サーバーに保存する場合、それをユーザーデータベースと認証バックエンドとして使用するように、Dovecot を設定できます。この設定では、アカウントをデータベースで集中管理するため、ユーザーは Dovecot サーバー上のファイルシステムにローカルアクセスできません。
複数の Dovecot サーバーをレプリケーションでセットアップして、メールボックスを高可用性にする予定がある場合にも、集中管理されたアカウントは利点があります。
9.3.1. Dovecot のインストール
dovecot パッケージは以下を提供します。
-
dovecotサービスとそれを管理するユーティリティー - Dovecot がオンデマンドで開始するサービス (認証など)
- サーバーサイドメールフィルタリングなどのプラグイン
-
/etc/dovecot/ディレクトリーの設定ファイル -
/usr/share/doc/dovecot/ディレクトリーのドキュメント
手順
dovecotパッケージをインストールします。# yum install dovecot注記Dovecot がすでにインストールされていて、クリーンな設定ファイルが必要な場合は、
/etc/dovecot/ディレクトリーを名前変更するか削除してください。その後、パッケージを再インストールします。設定ファイルを削除しないと、yum uninstall dovecotコマンドは/etc/dovecot/内の設定ファイルをリセットしません。
次のステップ
9.3.2. Dovecot サーバーでの TLS 暗号化の設定
Dovecot はセキュアなデフォルト設定を提供します。たとえば、TLS はデフォルトで有効になっており、認証情報と暗号化されたデータをネットワーク経由で送信します。Dovecot サーバーで TLS を設定するには、証明書と秘密鍵ファイルへのパスを設定するだけです。さらに、Diffie-Hellman パラメーターを生成して使用し、Perfect Forward Secrecy (PFS) を提供することで、TLS 接続のセキュリティーを強化できます。
前提条件
- Dovecot がインストールされています。
次のファイルが、サーバー上のリストされた場所にコピーされました。
-
サーバー証明書:
/etc/pki/dovecot/certs/server.example.com.crt -
秘密鍵:
/etc/pki/dovecot/private/server.example.com.key -
認証局 (CA) 証明書:
/etc/pki/dovecot/certs/ca.crt
-
サーバー証明書:
-
サーバー証明書の
Subject DNフィールドのホスト名は、サーバーの完全修飾ドメイン名 (FQDN) と一致します。
手順
秘密鍵ファイルにセキュアな権限を設定します。
# chown root:root /etc/pki/dovecot/private/server.example.com.key # chmod 600 /etc/pki/dovecot/private/server.example.com.key
Diffie-Hellman パラメーターを使用してファイルを生成します。
# openssl dhparam -out /etc/dovecot/dh.pem 4096サーバーのハードウェアとエントロピーによっては、4096 ビットの Diffie-Hellman パラメーターを生成するのに数分かかる場合があります。
/etc/dovecot/conf.d/10-ssl.confファイルで証明書と秘密鍵ファイルへのパスを設定します。ssl_certおよびssl_keyパラメーターを更新し、サーバーの証明書と秘密鍵へのパスを使用するように設定します。ssl_cert = </etc/pki/dovecot/certs/server.example.com.crt ssl_key = </etc/pki/dovecot/private/server.example.com.key
ssl_caパラメーターをコメント解除し、CA 証明書へのパスを使用するように設定します。ssl_ca = </etc/pki/dovecot/certs/ca.crtssl_dhパラメーターをコメント解除し、Diffie-Hellman パラメーターファイルへのパスを使用するように設定します。ssl_dh = </etc/dovecot/dh.pem
重要Dovecot がファイルからパラメーターの値を確実に読み取るようにするには、パスの先頭に
<文字を付ける必要があります。
次のステップ
関連情報
-
/usr/share/doc/dovecot/wiki/SSL.DovecotConfiguration.txt
9.3.3. 仮想ユーザーを使用するための Dovecot の準備
デフォルトでは、Dovecot はサービスを使用するユーザーとして、ファイルシステム上で多くのアクションを実行します。ただし、1 人のローカルユーザーを使用してこれらのアクションを実行するように Dovecot バックエンドを設定すると、複数の利点があります。
- Dovecot は、ユーザーの ID (UID) を使用する代わりに、特定のローカルユーザーとしてファイルシステムアクションを実行します。
- ユーザーは、サーバー上でローカルに利用できる必要はありません。
- すべてのメールボックスとユーザー固有のファイルを 1 つのルートディレクトリーに保存できます。
- ユーザーは UID とグループ ID (GID) を必要としないため、管理作業が軽減されます。
- サーバー上のファイルシステムにアクセスできるユーザーは、これらのファイルにアクセスできないため、メールボックスやインデックスを危険にさらす可能性はありません。
- レプリケーションのセットアップはより簡単です。
前提条件
- Dovecot がインストールされています。
手順
vmailユーザーを作成します。# useradd --home-dir /var/mail/ --shell /usr/sbin/nologin vmailDovecot は後でこのユーザーを使用してメールボックスを管理します。セキュリティー上の理由から、この目的で
dovecotまたはdovenullシステムユーザーを使用しないでください。/var/mail/以外のパスを使用する場合は、それに SELinux コンテキストmail_spool_tを設定します。例:# semanage fcontext -a -t mail_spool_t "<path>(/.*)?" # restorecon -Rv <path>
/var/mail/への書き込み権限をvmailユーザーにのみ付与します。# chown vmail:vmail /var/mail/ # chmod 700 /var/mail/
/etc/dovecot/conf.d/10-mail.confファイルのmail_locationパラメーターをコメント解除し、メールボックスの形式と場所を設定します。mail_location = sdbox:/var/mail/%n/この設定の場合:
-
Dovecot は、
singleモードで高パフォーマンスのdboxメールボックス形式を使用します。このモードでは、サービスは、maildir形式と同様に、各メールを個別のファイルに保存します。 -
Dovecot はパス内の
%n変数をユーザー名に解決します。これは、各ユーザーがメールボックス用に個別のディレクトリーを持つようにするために必要です。
-
Dovecot は、
関連情報
-
/usr/share/doc/dovecot/wiki/VirtualUsers.txt -
/usr/share/doc/dovecot/wiki/MailLocation.txt -
/usr/share/doc/dovecot/wiki/MailboxFormat.dbox.txt -
/usr/share/doc/dovecot/wiki/Variables.txt
9.3.4. Dovecot 認証バックエンドとして MariaDB SQL データベースを使用する
Dovecot は、MariaDB データベースからアカウントとパスワードを読み取り、これを使用して、ユーザーが IMAP または POP3 サービスにログインする場合、ユーザーを認証できます。この認証方法の利点は次のとおりです。
- 管理者は、データベースでユーザーを集中管理できます。
- ユーザーはサーバー上でローカルにアクセスできません。
前提条件
- Dovecot がインストールされています。
- 仮想ユーザー機能が設定されています。
- MariaDB サーバーへの接続では、TLS 暗号化がサポートされます。
-
dovecotDBデータベースは MariaDB に存在し、usersテーブルには、少なくともusernameおよびpassword列が含まれています。 -
password列には、Dovecot がサポートするスキームで暗号化されたパスワードが含まれています。 -
パスワードは、同じスキームを使用するか、
{pw-storage-scheme}接頭辞を使用します。 -
MariaDB ユーザー
dovecotは、dovecotDBデータベースのusersテーブルに対する読み取り権限を持っています。 -
MariaDB サーバーの TLS 証明書を発行した認証局 (CA) の証明書は、Dovecot サーバーの
/etc/pki/tls/certs/ca.crtファイルに保存されます。
手順
dovecot-mysqlパッケージをインストールします。# yum install dovecot-mysql/etc/dovecot/conf.d/10-auth.confファイルで認証バックエンドを設定します。不要な
auth-*.conf.ext認証バックエンド設定ファイルのincludeステートメントをコメントアウトします。次に例を示します。#!include auth-system.conf.ext次の行をコメント解除して、SQL 認証を有効にします。
!include auth-sql.conf.ext
/etc/dovecot/conf.d/auth-sql.conf.extファイルを編集し、override_fieldsパラメーターをuserdbセクションに次のように追加します。userdb { driver = sql args = /etc/dovecot/dovecot-sql.conf.ext override_fields = uid=vmail gid=vmail home=/var/mail/%n/ }固定値のため、Dovecot はこれらの設定を SQL サーバーからクエリーしません。
次の設定で
/etc/dovecot/dovecot-sql.conf.extファイルを作成します。driver = mysql connect = host=mariadb_srv.example.com dbname=dovecotDB user=dovecot password=dovecotPW ssl_ca=/etc/pki/tls/certs/ca.crt default_pass_scheme = SHA512-CRYPT user_query = SELECT username FROM users WHERE username='%u'; password_query = SELECT username AS user, password FROM users WHERE username='%u'; iterate_query = SELECT username FROM users;
データベースサーバーに対して TLS 暗号化を使用するには、
ssl_caオプションに MariaDB サーバー証明書を発行した CA の証明書のパスを設定します。証明書の検証を機能させるには、MariaDB サーバーのホスト名が TLS 証明書で使用されているホスト名と一致する必要があります。データベースのパスワード値に
{pw-storage-scheme}接頭辞が含まれている場合は、default_pass_scheme設定を省略できます。ファイル内のクエリーは、次のように設定する必要があります。
-
user_queryパラメーターの場合、クエリーは Dovecot ユーザーのユーザー名を返す必要があります。また、クエリーは 1 つの結果のみを返す必要があります。 -
password_queryパラメーターの場合、クエリーはユーザー名とパスワードを返す必要があり、Dovecot はuserおよびpassword変数でこれらの値を使用する必要があります。したがって、データベースが異なる列名を使用している場合は、ASSQL コマンドを使用して、結果の列の名前を変更してください。 -
iterate_queryパラメーターの場合、クエリーはすべてのユーザーのリストを返す必要があります。
-
/etc/dovecot/dovecot-sql.conf.extファイルにセキュアな権限を設定します。# chown root:root /etc/dovecot/dovecot-sql.conf.ext # chmod 600 /etc/dovecot/dovecot-sql.conf.ext
次のステップ
関連情報
-
/usr/share/doc/dovecot/example-config/dovecot-sql.conf.ext -
/usr/share/doc/dovecot/wiki/Authentication.PasswordSchemes.txt
9.3.5. Dovecot 設定の完了
Dovecot をインストールして設定したら、firewalld サービスで必要なポートを開き、サービスを有効にして開始します。その後、サーバーをテストできます。
前提条件
以下は Dovecot で設定されています。
- TLS 暗号化
- 認証バックエンド
- クライアントは認証局 (CA) 証明書を信頼します。
手順
IMAP または POP3 サービスのみをユーザーに提供する場合は、
/etc/dovecot/dovecot.confファイルのprotocolパラメーターをコメント解除し、必要なプロトコルに設定します。たとえば、POP3 を必要としない場合は、次のように設定します。protocols = imap lmtpデフォルトでは、
imap、pop3、およびlmtpプロトコルが有効になっています。ローカルファイアウォールでポートを開きます。たとえば、IMAPS、IMAP、POP3S、および POP3 プロトコルのポートを開くには、次のように入力します。
# firewall-cmd --permanent --add-service=imaps --add-service=imap --add-service=pop3s --add-service=pop3 # firewall-cmd --reload
dovecotサービスを有効にして開始します。# systemctl enable --now dovecot
検証
Dovecot に接続して電子メールを読むには、Mozilla Thunderbird などのメールクライアントを使用します。メールクライアントの設定は、使用するプロトコルによって異なります。
表9.3 Dovecot サーバーへの接続設定
デフォルトでは、Dovecot は TLS を使用しない接続ではプレーンテキスト認証を受け入れないため、この表には暗号化されていない接続の設定がリストされていないことに注意してください。
デフォルト以外の値を含む設定を表示します。
# doveconf -n
関連情報
-
firewall-cmd(1)man ページ
9.4. 2 つの Dovecot サーバー間のレプリケーションの設定
双方向のレプリケーションを使用すると、Dovecot サーバーを高可用性にすることができ、IMAP および POP3 クライアントは両方のサーバーのメールボックスにアクセスできます。Dovecot は、各メールボックスのインデックスログの変更を追跡し、競合を安全な方法で解決します。
両方の複製パートナーでこの手順を実行します。
レプリケーションは、サーバーペア間でのみ機能します。したがって、大規模なクラスターでは、複数の独立したバックエンドペアが必要になります。
前提条件
- 両方のサーバーが同じ認証バックエンドを使用します。できれば、LDAP または SQL を使用して、アカウントを集中管理してください。
-
Dovecot ユーザーデータベース設定は、ユーザーリストをサポートします。これを確認するには、
doveadm user '*'コマンドを使用します。 -
Dovecot は、ユーザー ID (UID) ではなく、
vmailユーザーとしてファイルシステム上のメールボックスにアクセスします。
手順
/etc/dovecot/conf.d/10-replication.confファイルを作成し、その中で次の手順を実行します。notifyおよびreplicationプラグインを有効にします。mail_plugins = $mail_plugins notify replicationservice replicatorセクションを追加します。service replicator { process_min_avail = 1 unix_listener replicator-doveadm { mode = 0600 user = vmail } }
これらの設定により、
dovecotサービスの開始時に、Dovecot は 1 つ以上のレプリケータープロセスを開始します。さらに、このセクションはreplicator-doveadmソケットの設定を定義します。service aggregatorセクションを追加して、replication-notify-fifoパイプとreplication-notifyソケットを設定します。service aggregator { fifo_listener replication-notify-fifo { user = vmail } unix_listener replication-notify { user = vmail } }
service doveadmセクションを追加して、レプリケーションサービスのポートを定義します。service doveadm { inet_listener { port = 12345 } }
doveadmレプリケーションサービスのパスワードを設定します。doveadm_password = replication_passwordパスワードは、両方のサーバーで同じにする必要があります。
レプリケーションパートナーを設定します。
plugin { mail_replica = tcp:server2.example.com:12345 }
オプション: 並列
dsyncプロセスの最大数を定義します。replication_max_conns = 20replication_max_connsのデフォルト値は10です。
/etc/dovecot/conf.d/10-replication.confファイルにセキュアな権限を設定します。# chown root:root /etc/dovecot/conf.d/10-replication.conf # chmod 600 /etc/dovecot/conf.d/10-replication.conf
Dovecot が
doveadmレプリケーションポートを開くことができるように、SELinux ブール値nis_enabledを有効にします。setsebool -P nis_enabled onレプリケーションパートナーのみがレプリケーションポートにアクセスできるように、
firewalldルールを設定します。次に例を示します。# firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv4" source address="192.0.2.1/32" port protocol="tcp" port="12345" accept" # firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv6" source address="2001:db8:2::1/128" port protocol="tcp" port="12345" accept" # firewall-cmd --reload
IPv4 アドレスのサブネットマスク
/32と IPv6 アドレスのサブネットマスク/128は、指定されたアドレスへのアクセスを制限します。- この手順は、他のレプリケーションパートナーでも実行します。
Dovecot をリロードします。
# systemctl reload dovecot
検証
- 1 つのサーバーのメールボックスでアクションを実行し、Dovecot が変更を他のサーバーにレプリケートしたかどうかを確認します。
レプリケーターステータスを表示します。
# doveadm replicator status Queued 'sync' requests 0 Queued 'high' requests 0 Queued 'low' requests 0 Queued 'failed' requests 0 Queued 'full resync' requests 30 Waiting 'failed' requests 0 Total number of known users 75特定のユーザーのレプリケーターステータスを表示します。
# doveadm replicator status example_user username priority fast sync full sync success sync failed example_user none 02:05:28 04:19:07 02:05:28 -
関連情報
-
dsync(1)man ページ -
/usr/share/doc/dovecot/wiki/Replication.txt
9.5. ユーザーを IMAP メールボックスに自動的に登録する
通常、IMAP サーバー管理者は、Dovecot が Sent や Trash などの特定のメールボックスを自動的に作成し、ユーザーをそれらに登録することを望んでいます。これは設定ファイルに設定できます。
さらに、特殊用途のメールボックス を定義できます。多くの場合、IMAP クライアントは、メールの送信など、特別な目的のためにメールボックスを定義することをサポートしています。ユーザーが正しいメールボックスを手動で選択して設定する必要がないようにするために、IMAP サーバーは IMAP LIST コマンドで special-use 属性を送信できます。その後、クライアントはこの属性を使用して、送信済みメールのメールボックスなどを識別および設定できます。
前提条件
- Dovecot が設定されている。
手順
/etc/dovecot/conf.d/15-mailboxes.confファイルのinboxnamespace セクションを更新します。auto = subscribe設定を、ユーザーが利用できるようにする必要がある各特殊用途のメールボックスに追加します。次に例を示します。namespace inbox { ... mailbox Drafts { special_use = \Drafts auto = subscribe } mailbox Junk { special_use = \Junk auto = subscribe } mailbox Trash { special_use = \Trash auto = subscribe } mailbox Sent { special_use = \Sent auto = subscribe } ... }メールクライアントがより特殊用途のメールボックスをサポートしている場合は、同様のエントリーを追加できます。
special_useパラメーターは、Dovecot がspecial-use属性でクライアントに送信する値を定義します。オプション: 特別な目的のない他のメールボックスを定義する場合は、ユーザーの受信トレイにそれらの
mailboxセクションを追加します。次に例を示します。namespace inbox { ... mailbox "Important Emails" { auto = <value> } ... }autoパラメーターは、次のいずれかの値に設定できます。-
subscribe: メールボックスを自動的に作成し、ユーザーを登録します。 -
create: ユーザーを登録せずに、メールボックスを自動的に作成します。 -
no(デフォルト): Dovecot はメールボックスを作成することも、ユーザーを登録することもしません。
-
Dovecot をリロードします。
# systemctl reload dovecot
検証
IMAP クライアントを使用してメールボックスにアクセスします。
auto = subscribeが設定されたメールボックスは、自動的に表示されます。クライアントが特殊用途のメールボックスと定義された目的をサポートしている場合、クライアントはそれらを自動的に使用します。
関連情報
- RFC 6154: 特殊用途メールボックスの IMAP LIST 拡張
-
/usr/share/doc/dovecot/wiki/MailboxSettings.txt
9.6. LMTP ソケットと LMTPS リスナーの設定
Postfix などの SMTP サーバーは、Local Mail Transfer Protocol (LMTP) を使用して電子メールを Dovecot に配信します。SMTP サーバーが実行されている場合:
- Dovecot と同じホストで、LMTP ソケットを使用します。
別のホストで、LMTP サービスを使用する
デフォルトでは、LMTP プロトコルは暗号化されていません。ただし、TLS 暗号化を設定した場合、Dovecot は LMTP サービスに同じ設定を自動的に使用します。その後、SMTP サーバーは、LMTPS プロトコルまたは LMTP 上の
STARTTLSコマンドを使用して接続できます。
前提条件
- Dovecot がインストールされています。
- LMTP サービスを設定する場合、Dovecot で TLS 暗号化が設定されます。
手順
LMTP プロトコルが有効になっていることを確認します。
# doveconf -a | egrep "^protocols" protocols = imap pop3 lmtp出力に
lmtpが含まれている場合、プロトコルは有効になっています。lmtpプロトコルが無効になっている場合は、/etc/dovecot/dovecot.confファイルを編集し、protocolsパラメーターの値にlmtpを追加します。protocols = ... lmtpLMTP ソケットまたはサービスが必要かどうかに応じて、
/etc/dovecot/conf.d/10-master.confファイルのservice lmtpセクションで次の変更を行います。LMTP ソケット: デフォルトでは、Dovecot は自動的に
/var/run/dovecot/lmtpソケットを作成します。オプション: 所有権と権限をカスタマイズします。
service lmtp { ... unix_listener lmtp { mode = 0600 user = postfix group = postfix } ... }LMTP サービス:
inet_listenerサブセクションを追加します。service lmtp { ... inet_listener lmtp { port = 24 } ... }
SMTP サーバーのみが LMTP ポートにアクセスできるように、
firewalldルールを設定します。次に例を示します。# firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv4" source address="192.0.2.1/32" port protocol="tcp" port="24" accept" # firewall-cmd --permanent --zone=public --add-rich-rule="rule family="ipv6" source address="2001:db8:2::1/128" port protocol="tcp" port="24" accept" # firewall-cmd --reload
IPv4 アドレスのサブネットマスク
/32と IPv6 アドレスのサブネットマスク/128は、指定されたアドレスへのアクセスを制限します。Dovecot をリロードします。
# systemctl reload dovecot
検証
LMTP ソケットを設定した場合は、Dovecot がソケットを作成したことと、権限が正しいことを確認します。
# ls -l /var/run/dovecot/lmtp srw-------. 1 postfix postfix 0 Nov 22 17:17 /var/run/dovecot/lmtp
LMTP ソケットまたはサービスを使用して、Dovecot に電子メールを送信するように、SMTP サーバーを設定します。
LMTP サービスを使用する場合は、SMTP サーバーが LMTPS プロトコルを使用するか、
STARTTLSコマンドを送信して暗号化された接続を使用するようにしてください。
関連情報
-
/usr/share/doc/dovecot/wiki/LMTP.txt
9.7. Dovecot で IMAP または POP3 サービスを無効にする
デフォルトでは、Dovecot は IMAP および POP3 サービスを提供します。そのうちの 1 つだけが必要な場合は、もう 1 つを無効にして、攻撃サーフェスを減らすことができます。
前提条件
- Dovecot がインストールされています。
手順
/etc/dovecot/dovecot.confファイルのprotocolsパラメーターをコメント解除し、必要なプロトコルを使用するように設定します。たとえば、POP3 を必要としない場合は、次のように設定します。protocols = imap lmtpデフォルトでは、
imap、pop3、およびlmtpプロトコルが有効になっています。Dovecot をリロードします。
# systemctl reload dovecotローカルファイアウォールで不要になったポートを閉じます。たとえば、POP3S および POP3 プロトコルのポートを閉じるには、次のように入力します。
# firewall-cmd --remove-service=pop3s --remove-service=pop3 # firewall-cmd --reload
検証
dovecotプロセスによって開かれたLISTENモードのすべてのポートを表示します。# ss -tulp | grep dovecot tcp LISTEN 0 100 0.0.0.0:993 0.0.0.0:* users:(("dovecot",pid=1405,fd=44)) tcp LISTEN 0 100 0.0.0.0:143 0.0.0.0:* users:(("dovecot",pid=1405,fd=42)) tcp LISTEN 0 100 [::]:993 [::]:* users:(("dovecot",pid=1405,fd=45)) tcp LISTEN 0 100 [::]:143 [::]:* users:(("dovecot",pid=1405,fd=43))
この例では、Dovecot は TCP ポート
993(IMAPS) と143(IMAP) のみをリッスンします。ソケットを使用する代わりにポートをリッスンするようにサービスを設定した場合、Dovecot は LMTP プロトコルのポートのみを開くことに注意してください。
関連情報
-
firewall-cmd(1)man ページ
9.8. Dovecot IMAP サーバーで Sieve を使用してサーバーサイドメールフィルタリングを有効にする
ManageSieve プロトコルを使用して、Sieve スクリプトをサーバーにアップロードできます。Sieve スクリプトは、受信メールに対してサーバーが検証して実行するルールとアクションを定義します。たとえば、ユーザーは Sieve を使用して特定の送信者からの電子メールを転送でき、管理者はグローバルフィルターを作成して、スパムフィルターによってフラグが付けられたメールを別の IMAP フォルダーに移動できます。
ManageSieve プラグインは、Sieve スクリプトと ManageSieve プロトコルのサポートを Dovecot IMAP サーバーに追加します。
TLS 接続を介した ManageSieve プロトコルの使用をサポートするクライアントのみを使用してください。このプロトコルの TLS を無効にすると、クライアントはネットワーク経由で認証情報をプレーンテキストで送信します。
前提条件
- Dovecot が設定され、IMAP メールボックスを提供します。
- TLS 暗号化は Dovecot で設定されます。
- メールクライアントは、TLS 接続を介して ManageSieve プロトコルをサポートします。
手順
dovecot-pigeonholeパッケージをインストールします。# yum install dovecot-pigeonhole/etc/dovecot/conf.d/20-managesieve.confの次の行をコメント解除して、sieveプロトコルを有効にします。protocols = $protocols sieveこの設定により、すでに有効になっている他のプロトコルに加えて、Sieve が有効になります。
firewalldで ManageSieve ポートを開きます。# firewall-cmd --permanent --add-service=managesieve # firewall-cmd --reload
Dovecot をリロードします。
# systemctl reload dovecot
検証
クライアントを使用し、Sieve スクリプトをアップロードします。次の接続設定を使用します。
- ポート: 4190
- 接続セキュリティー: SSL/TLS
- 認証方法: PLAIN
- Sieve スクリプトをアップロードしたユーザーに電子メールを送信します。電子メールがスクリプトのルールと一致する場合は、サーバーが定義されたアクションを実行することを確認します。
関連情報
-
/usr/share/doc/dovecot/wiki/Pigeonhole.Sieve.Plugins.IMAPSieve.txt -
/usr/share/doc/dovecot/wiki/Pigeonhole.Sieve.Troubleshooting.txt -
firewall-cmd(1)man ページ
9.9. Dovecot が設定ファイルを処理する方法
dovecot パッケージは、メインの設定ファイル /etc/dovecot/dovecot.conf、および /etc/dovecot/conf.d/ ディレクトリー内の複数の設定ファイルを提供します。Dovecot は、サービスの開始時にファイルを組み合わせて設定を構築します。
複数の設定ファイルの主な利点は、設定をグループ化し、読みやすくすることです。単一の設定ファイルを使用する場合は、代わりに /etc/dovecot/dovecot.conf ですべての設定を維持し、そのファイルからすべての include および include_try ステートメントを削除できます。
関連情報
-
/usr/share/doc/dovecot/wiki/ConfigFile.txt -
/usr/share/doc/dovecot/wiki/Variables.txt
第10章 印刷の設定
Red Hat Enterprise Linux では、Common UNIX Printing System (CUPS) によって印刷を管理します。ユーザーはホスト上の CUPS でプリンターを設定して印刷します。さらに、CUPS でプリンターを共有し、ホストをプリントサーバーとして使用できます。
CUPS は次のプリンターへの印刷をサポートしています。
- AirPrint™ および IPP Everywhere™ プリンター
- 従来の PostScript Printer description (PPD) ベースのドライバーを備えたネットワークおよびローカル USB プリンター
10.1. CUPS のインストールと設定
CUPS を使用してローカルホストから印刷できます。このホストを使用してネットワーク内でプリンターを共有し、プリントサーバーとして機能させることもできます。
手順
cupsパッケージをインストールします。# yum install cupsCUPS をプリントサーバーとして設定する場合は、
/etc/cups/cupsd.confファイルを編集し、次の変更を加えます。CUPS をリモートで設定する場合、またはこのホストをプリントサーバーとして使用する場合は、CUPS がリッスンする IP アドレスとポートを設定します。
Listen 192.0.2.1:631 Listen [2001:db8:1::1]:631
デフォルトでは、CUPS は
localhostインターフェイス (127.0.0.1および::1) でのみリッスンします。IPv6 アドレスは角括弧で囲んで指定します。重要信頼できないネットワーク (インターネットなど) からのアクセスを許可するインターフェイスをリッスンするように CUPS を設定しないでください。
<Location />ディレクティブでそれぞれの IP 範囲を許可することで、サービスにアクセスできる IP 範囲を設定します。<Location /> Allow from 192.0.2.0/24 Allow from [2001:db8:1::1]/32 Order allow,deny </Location>
<Location /admin>ディレクティブで、CUPS 管理サービスにアクセスできる IP アドレスと範囲を設定します。<Location /admin> Allow from 192.0.2.15/32 Allow from [2001:db8:1::22]/128 Order allow,deny </Location>
この設定では、IP アドレス
192.0.2.15および2001:db8:1::22を持つホストのみが管理サービスにアクセスできます。オプション: Web インターフェイスで設定ファイルとログファイルへのアクセスを許可する IP アドレスと範囲を設定します。
<Location /admin/conf> Allow from 192.0.2.15/32 Allow from [2001:db8:1::22]/128 ... </Location> <Location /admin/log> Allow from 192.0.2.15/32 Allow from [2001:db8:1::22]/128 ... </Location>
firewalldサービスを実行し、CUPS へのリモートアクセスを設定する場合は、firewalldで CUPS ポートを開きます。# firewall-cmd --permanent --add-port=631/tcp # firewall-cmd --reload
複数のインターフェイスを持つホストで CUPS を実行する場合は、必要なネットワークにアクセスを制限することを検討してください。
cupsサービスを有効にして起動します。# systemctl enable --now cups
検証
ブラウザーを使用して、
http://<hostname>:631にアクセスします。Web インターフェイスに接続できれば、CUPS は動作しています。Administrationタブなどの一部の機能では、認証と HTTPS 接続が必要であることに注意してください。デフォルトでは、CUPS は HTTPS アクセスに自己署名証明書を使用するため、認証時の接続はセキュアではありません。
10.2. CUPS サーバーでの TLS 暗号化の設定
CUPS は TLS 暗号化接続をサポートしており、デフォルトでは、サービスは認証を必要とするすべてのリクエストに対して暗号化接続を強制します。証明書が設定されていない場合、CUPS は秘密鍵と自己署名証明書を作成します。これで十分なのは、ローカルホスト自体から CUPS にアクセスする場合だけです。ネットワーク経由でセキュアに接続するには、認証局 (CA) によって署名されたサーバー証明書を使用します。
暗号化を使用しなかった場合、または自己署名証明書を使用した場合、中間者 (MITM) 攻撃により、次のような情報が漏洩する可能性があります。
- Web インターフェイスを使用して CUPS を設定する際の管理者の認証情報
- ネットワーク経由で印刷ジョブを送信する際の機密データ
前提条件
- CUPS が設定されている。
- 秘密鍵の作成 が完了していて、その秘密鍵に対するサーバー証明書が CA から発行されている。
- 中間証明書をサーバー証明書にアタッチしている (サーバー証明書を検証するために中間証明書が必要な場合)。
- CUPS にはサービスが鍵を読み取るときにパスワードを入力するオプションがないため、秘密鍵はパスワードで保護されません。
証明書の正規名 (
CN) またはサブジェクト代替名 (SAN) フィールドが、次のいずれかと一致する。- CUPS サーバーの完全修飾ドメイン名 (FQDN)
- DNS によってサーバーの IP アドレスに解決されるエイリアス
- 秘密鍵とサーバー証明書ファイルが、Privacy Enhanced Mail (PEM) 形式を使用している。
- クライアントが CA 証明書を信頼している。
手順
/etc/cups/cups-files.confファイルを編集し、次の設定を追加して自己署名証明書の自動作成を無効にします。CreateSelfSignedCerts no自己署名証明書と秘密鍵を削除します。
# rm /etc/cups/ssl/<hostname>.crt /etc/cups/ssl/<hostname>.keyオプション: サーバーの FQDN を表示します。
# hostname -f server.example.comオプション: 証明書の
CNフィールドと SAN フィールドを表示します。# openssl x509 -text -in /etc/cups/ssl/server.example.com.crt Certificate: Data: ... Subject: CN = server.example.com ... X509v3 extensions: ... X509v3 Subject Alternative Name: DNS:server.example.com ...サーバー証明書の
CNまたは SAN フィールドにサーバーの FQDN とは異なるエイリアスが含まれている場合は、ServerAliasパラメーターを/etc/cups/cupsd.confファイルに追加します。ServerAlias alternative_name.example.comこの場合、以降の手順で FQDN の代わりに代替名を使用します。
秘密鍵とサーバー証明書を
/etc/cups/ssl/ディレクトリーに保存します。次に例を示します。# mv /root/server.key /etc/cups/ssl/server.example.com.key # mv /root/server.crt /etc/cups/ssl/server.example.com.crt
重要CUPS では、秘密鍵に
<fqdn>.key、サーバー証明書ファイルに<fqdn>.crtという名前を付ける必要があります。エイリアスを使用する場合は、ファイルに<alias>.keyおよび<alias>.crtという名前を付ける必要があります。rootユーザーのみがこのファイルを読み取ることができるように、秘密鍵にセキュアなパーミッションを設定します。# chown root:root /etc/cups/ssl/server.example.com.key # chmod 600 /etc/cups/ssl/server.example.com.key
証明書は、セキュアな接続を確立する前のクライアントとサーバー間の通信の要素であるため、どのクライアントも認証なしで証明書を取得できます。したがって、サーバー証明書ファイルに厳密なパーミッションを設定する必要はありません。
SELinux コンテキストを復元します。
# restorecon -Rv /etc/cups/ssl/デフォルトでは、CUPS は、Web インターフェイスの
/adminページで管理タスクを実行する場合など、タスクで認証が必要な場合にのみ暗号化接続を強制します。CUPS サーバー全体の暗号化を強制するには、
/etc/cups/cupsd.confファイル内のすべての<Location>ディレクティブにEncryption Requiredを追加します。次に例を示します。<Location /> ... Encryption Required </Location>CUPS を再起動します。
# systemctl restart cups
検証
-
ブラウザーを使用して、
https://<hostname>:631/admin/にアクセスします。接続が成功すれば、CUPS で TLS 暗号化が正しく設定されています。 -
サーバー全体の暗号化を必須とするように設定した場合は、
http://<hostname>:631/にアクセスします。この場合、CUPS はUpgrade Requiredというエラーを返します。
トラブルシューティング
cupsサービスのsystemdジャーナルエントリーを表示します。# journalctl -u cupsHTTPS プロトコルを使用した Web インターフェイスへの接続に失敗した後、ジャーナルに
Unable to encrypt connection: Error while reading fileというエラーが含まれている場合は、秘密鍵とサーバー証明書ファイルの名前を確認します。
10.3. Web インターフェイスで CUPS サーバーを管理するための管理権限の付与
デフォルトでは、sys、root、および wheel グループのメンバーは、Web インターフェイスで管理タスクを実行できます。しかし、他の特定のサービスもこれらのグループを使用します。たとえば、wheel グループのメンバーは、デフォルトで、sudo を使用して root 権限でコマンドを実行できます。CUPS 管理者が他のサービスで予期しない権限を取得しないようにするには、CUPS 管理者専用のグループを使用します。
前提条件
- CUPS が設定されている。
- 使用するクライアントの IP アドレスに、Web インターフェイスの管理領域にアクセスする権限がある。
手順
CUPS 管理者用のグループを作成します。
# groupadd cups-adminsWeb インターフェイスでサービスを管理する必要があるユーザーを、
cups-adminsグループに追加します。# usermod -a -G cups-admins <username>/etc/cups/cups-files.confファイルのSystemGroupパラメーターの値を更新し、cups-adminグループを追加します。SystemGroup sys root wheel cups-adminscups-adminグループのみに管理アクセス権を与える必要がある場合は、パラメーターから他のグループ名を削除します。CUPS を再起動します。
# systemctl restart cups
検証
ブラウザーを使用して、
https://<hostname_or_ip_address>:631/admin/にアクセスします。注記ユーザーは HTTPS プロトコルを使用する場合のみ、Web UI の管理領域にアクセスできます。
-
管理タスクの実行を開始します。たとえば、
Add printerをクリックします。 Web インターフェイスで、ユーザー名とパスワードの入力を求められます。続行するには、
cups-adminsグループのメンバーであるユーザーの認証情報を使用して認証します。認証が成功すると、このユーザーは管理タスクを実行できます。
10.4. プリンタードライバーを含むパッケージの概要
Red Hat Enterprise Linux (RHEL) は、CUPS 用のプリンタードライバーを含むさまざまなパッケージを提供しています。これらのパッケージの概要と、パッケージに含まれるドライバーが対応するベンダーを以下に示します。
表10.1 ドライバーパッケージのリスト
| パッケージ名 | プリンター用ドライバー |
|---|---|
|
| Zebra、Dymo |
|
| Kodak |
|
| Brother、Canon、Epson、Gestetner、HP、Infotec、Kyocera、Lanier、Lexmark、NRG、Ricoh、Samsung、Savin、Sharp、Toshiba、Xerox など |
|
| Brother、Canon、Epson、Fujitsu、HP、Infotec、Kyocera、Lanier、NRG、Oki、Minolta、Ricoh、Samsung、Savin、Xerox など |
|
| HP |
|
| HP |
|
| Samsung、Xerox など |
パッケージによっては、同じプリンターベンダーまたはモデル用の、異なる機能を持つドライバーが含まれている場合があることに注意してください。
必要なパッケージをインストールした後、CUPS Web インターフェイスまたは lpinfo -m コマンドを使用してドライバーのリストを表示できます。
10.5. プリンターがドライバーレス印刷をサポートしているかどうかの確認
CUPS はドライバーレス印刷をサポートしています。つまり、ハードウェア固有のソフトウェアをプリンターに提供しなくても印刷できます。ドライバーレス印刷を使用するには、プリンターからクライアントにその機能を通知し、次のいずれかの標準をプリンターで使用する必要があります。
- AirPrint™
- IPP Everywhere™
- Mopria®
- Wi-Fi Direct Print Services
ipptool ユーティリティーを使用すると、プリンターがドライバーレス印刷をサポートしているかどうかを確認できます。
前提条件
- プリンターまたはリモートプリントサーバーが、インターネット印刷プロトコル (IPP) をサポートしている。
- ホストが、プリンターまたはリモートプリントサーバーの IPP ポートに接続できる。デフォルトの IPP ポートは 631 です。
手順
ipp-versions-supported属性とdocument-format-supported属性を照会し、get-printer-attributesテストに合格することを確認します。リモートプリンターの場合は、次のように入力します。
# ipptool -tv ipp://<ip_address_or_hostname>:631/ipp/print get-printer-attributes.test | grep -E "ipp-versions-supported|document-format-supported|get-printer-attributes" Get printer attributes using get-printer-attributes [PASS] ipp-versions-supported (1setOf keyword) = ... document-format-supported (1setOf mimeMediaType) = ...リモートプリントサーバー上のキューの場合は、次のように入力します。
# ipptool -tv ipp://<ip_address_or_hostname>:631/printers/<queue_name> get-printer-attributes.test | grep -E "ipp-versions-supported|document-format-supported|get-printer-attributes" Get printer attributes using get-printer-attributes [PASS] ipp-versions-supported (1setOf keyword) = ... document-format-supported (1setOf mimeMediaType) = ...
ドライバーレス印刷が機能することを確認するには、出力で次のことを確認します。
-
get-printer-attributesテストがPASSを返す。 - プリンターがサポートする IPP バージョンが 2.0 以降である。
形式のリストに次のいずれかが含まれている。
-
application/pdf -
image/urf -
image/pwg-raster
-
-
カラープリンターの場合、前述の形式のいずれかに加えて、
image/jpegが出力に含まれている。
10.6. Web インターフェイスを使用した CUPS へのプリンターの追加
ユーザーが CUPS 経由で印刷できるようにするには、事前にプリンターを追加する必要があります。ネットワークプリンターと、USB 経由などで CUPS ホストに直接接続されているプリンターの両方を使用できます。
CUPS ドライバーレス機能を使用するか、PostScript Printer Description (PPD) ファイルを使用してプリンターを追加できます。
CUPS はドライバーレス印刷を優先しており、ドライバーの使用は非推奨です。
Red Hat Enterprise Linux (RHEL) は、mDNS レスポンダーにクエリーを実行することでリクエストを解決する、Name Service Switch Multicast DNS プラグイン (nss-mdns) を提供しません。そのため、RHEL では、mDNS を使用したローカルドライバーレスプリンターの自動検出とインストールは利用できません。この問題を回避するには、1 台のプリンターを手動でインストールするか、cups-browsed を使用してリモートプリントサーバーで使用可能な多数の印刷キューを自動的にインストールします。
前提条件
- CUPS が設定されている。
- CUPS でプリンターを管理する権限を持っている。
- CUPS をプリントサーバーとして使用する場合は、ネットワーク上でデータをセキュアに送信するために TLS 暗号化を設定 している。
- プリンターがドライバーレス印刷をサポートしている (この機能を使用する場合)。
手順
ブラウザーを使用して、
https://<hostname>:631/admin/にアクセスします。Web インターフェイスには HTTPS プロトコルを使用して接続する必要があります。使用しないと、セキュリティー上の理由から、CUPS が後のステップで認証できなくなります。
- をクリックします。
- ユーザーがまだ認証されていない場合、CUPS は管理ユーザーの認証情報の入力を求めます。許可されたユーザーのユーザー名とパスワードを入力します。
- ドライバーレス印刷を使用せず、追加するプリンターが自動的に検出された場合は、それを選択し、 をクリックします。
プリンターが検出されなかった場合は、以下を実行します。
プリンターがサポートするプロトコルを選択します。
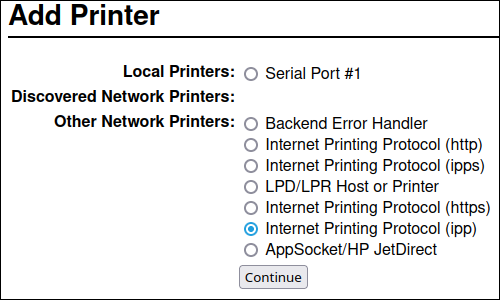
プリンターがドライバーレス印刷をサポートしており、この機能を使用する場合は、
ippまたはippsプロトコルを選択します。- をクリックします。
プリンターまたはリモートプリントサーバー上のキューへの URL を入力します。
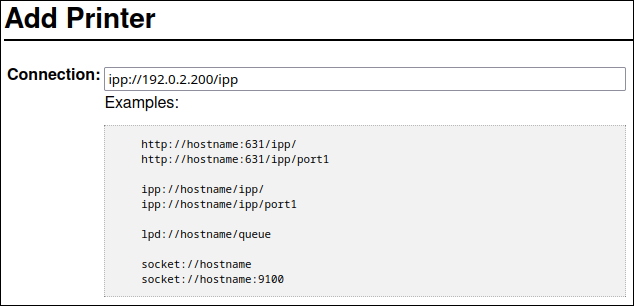
- をクリックします。
名前を入力し、必要に応じて説明と場所を入力します。CUPS をプリントサーバーとして使用し、他のクライアントが CUPS を介してこのプリンターで印刷できるようにする場合は、Share this printer も選択します。

Make リストからプリンターの製造元を選択します。プリンターの製造元がリストにない場合は、Generic を選択するか、プリンターの PPD ファイルをアップロードします。
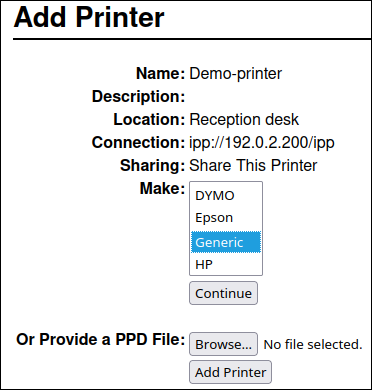
- をクリックします。
プリンターのモデルを選択します。
- プリンターがドライバーレス印刷をサポートしている場合は、IPP Everywhere を選択します。なお、以前にプリンター固有のドライバーをローカルにインストールしていた場合は、リストに <printer_name> - IPP Everywhere などのエントリーも含まれている可能性があります。
- プリンターがドライバーレス印刷をサポートしていない場合は、モデルを選択するか、プリンターの PPD ファイルをアップロードします。
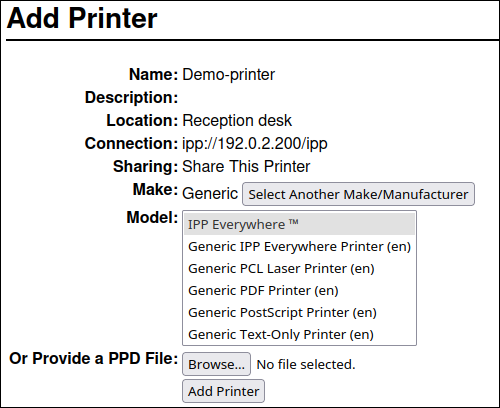
- をクリックします。
Set printer options ページの設定とタブは、ドライバーとプリンターがサポートする機能によって異なります。このページを使用して、用紙サイズなどのデフォルトのオプションを設定します。
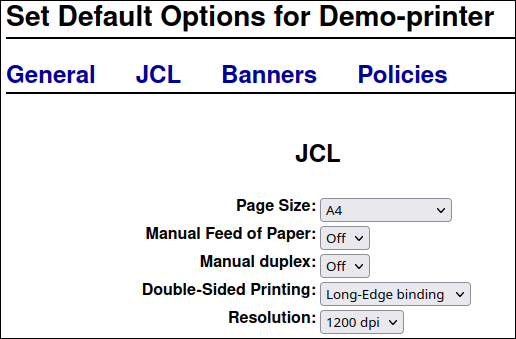
- をクリックします。
検証
- Web インターフェイスで Printers タブを開きます。
- プリンターの名前をクリックします。
Maintenance リストで、Print test page を選択します。
トラブルシューティング
-
ドライバーレス印刷を使用していて印刷がうまくいかない場合は、
lpadminユーティリティーを使用してコマンドラインでプリンターを追加します。詳細は、lpadmin ユーティリティーを使用した CUPS へのプリンターの追加 を参照してください。
10.7. lpadmin ユーティリティーを使用した CUPS へのプリンターの追加
ユーザーが CUPS 経由で印刷できるようにするには、事前にプリンターを追加する必要があります。ネットワークプリンターと、USB 経由などで CUPS ホストに直接接続されているプリンターの両方を使用できます。
CUPS ドライバーレス機能を使用するか、PostScript Printer Description (PPD) ファイルを使用してプリンターを追加できます。
CUPS はドライバーレス印刷を優先しており、ドライバーの使用は非推奨です。
Red Hat Enterprise Linux (RHEL) は、mDNS レスポンダーにクエリーを実行することでリクエストを解決する、Name Service Switch Multicast DNS プラグイン (nss-mdns) を提供しません。そのため、RHEL では、mDNS を使用したローカルドライバーレスプリンターの自動検出とインストールは利用できません。この問題を回避するには、1 台のプリンターを手動でインストールするか、cups-browsed を使用してリモートプリントサーバーで使用可能な多数の印刷キューを自動的にインストールします。
前提条件
- CUPS が設定されている。
- プリンターがドライバーレス印刷をサポートしている (この機能を使用する場合)。
- プリンターが、ポート 631 (IPP)、9100 (ソケット)、または 515 (LPD) でデータを受信する。ポートは、プリンターへの接続に使用する方法によって異なります。
手順
CUPS にプリンターを追加します。
ドライバーレスサポートを使用してプリンターを追加するには、次のように入力します。
# lpadmin -p Demo-printer -E -v ipp://192.0.2.200/ipp/print -m everywhereお使いのプリンターで
-m everythingオプションが機能しない場合は、-m driverless:<uri>を試してください (例:-m driverless:ipp://192.0.2.200/ipp/print)。ドライバーレスサポートを使用してリモートプリントサーバーのキューを追加するには、次のように入力します。
# lpadmin -p Demo-printer -E -v ipp://192.0.2.201/printers/example-queue -m everywhereお使いのプリンターで
-m everythingオプションが機能しない場合は、-m driverless:<uri>を試してください (例:-m driverless:ipp://192.0.2.200/printers/example-queue)。ファイル内のドライバーを使用してプリンターを追加するには、次のように入力します。
# lpadmin -p Demo-printer -E -v socket://192.0.2.200/ -P /root/example.ppdファイル内のドライバーを使用してリモートプリントサーバーのキューを追加するには、次のように入力します。
# lpadmin -p Demo-printer -E -v ipp://192.0.2.201/printers/example-queue -P /root/example.ppdローカルドライバーデータベース内のドライバーを使用してプリンターを追加するには、次の手順を実行します。
データベース内のドライバーをリスト表示します。
# lpinfo -m ... drv:///sample.drv/generpcl.ppd Generic PCL Laser Printer ...データベース内のドライバーへの URI を使用してプリンターを追加します。
# lpadmin -p Demo-printer -E -v socket://192.0.2.200/ -m drv:///sample.drv/generpcl.ppd
これらのコマンドでは、次のオプションを使用します。
-
-p <printer_name>: CUPS 内のプリンターの名前を設定します。 -
-E: プリンターを有効にします。CUPS はそのプリンターのジョブを受け付けます。このオプションは-pの後に指定する必要があることに注意してください。詳細は、man ページのオプションの説明を参照してください。 -
-v <uri>: プリンターまたはリモートプリントサーバーキューへの URI を設定します。 -
-m <driver_uri>: ローカルドライバーデータベースから取得した指定のドライバー URI に基づいて PPD ファイルを設定します。 -
-P <PPD_file>: PPD ファイルへのパスを設定します。
検証
使用可能なプリンターを表示します。
# lpstat -p printer Demo-printer is idle. enabled since Fri 23 Jun 2023 09:36:40 AM CEST
テストページを印刷します。
# lp -d Demo-printer /usr/share/cups/data/default-testpage.pdf
10.8. Web インターフェイスを使用した CUPS プリンターのメンテナンスおよび管理タスクの実行
プリンター管理者は、場合によってはプリントサーバー上でさまざまなタスクを実行する必要があります。以下に例を示します。
- 技術者がプリンターを修理している間のプリンターの一時停止などのメンテナンスタスク
- プリンターのデフォルト設定の変更などの管理タスク
これらのタスクは、CUPS の Web インターフェイスを使用して実行できます。
前提条件
- CUPS が設定されている。
- CUPS でプリンターを管理する権限を持っている。
- CUPS をプリントサーバーとして使用する場合は、ネットワーク上で認証情報をプレーンテキストで送信しないように TLS 暗号化を設定 している。
- プリンターが CUPS にすでに存在する。
手順
ブラウザーを使用して、
https://<hostname>:631/printers/にアクセスします。Web インターフェイスには HTTPS プロトコルを使用して接続する必要があります。使用しないと、セキュリティー上の理由から、CUPS が後のステップで認証できなくなります。
- 設定するプリンターの名前をクリックします。
メンテナンスタスクを実行するか管理タスクを実行するかに応じて、対応するリストから必要なアクションを選択します。
- ユーザーがまだ認証されていない場合、CUPS は管理ユーザーの認証情報の入力を求めます。許可されたユーザーのユーザー名とパスワードを入力します。
- タスクを実行します。
10.9. Samba を使用した Kerberos 認証による Windows プリントサーバーへの印刷
samba-krb5-printing ラッパーを使用すると、Red Hat Enterprise Linux (RHEL) にログインした Active Directory (AD) ユーザーは、Kerberos を使用して Active Directory (AD) に対して認証して、Windows プリントサーバーに印刷ジョブを転送するローカルの CUPS プリントサーバーに印刷を出力できます。
この設定の利点は、RHEL 上の CUPS の管理者が、設定で固定ユーザー名およびパスワードを保存する必要がないことです。CUPS は、印刷ジョブを送信するユーザーの Kerberos チケットで AD に対して認証します。
Red Hat は、ローカルシステムから CUPS への印刷ジョブの送信のみをサポートしています。Samba プリントサーバー上のプリンターの再共有はサポートしていません。
前提条件
- ローカルの CUPS インスタンスに追加するプリンターが、AD プリントサーバーで共有されている。
- AD のメンバーとして RHEL ホストに参加している。
-
CUPS が RHEL にインストールされており、
cupsサービスが実行されている。 -
プリンターの PostScript Printer description (PPD) ファイルが
/usr/share/cups/model/ディレクトリーに保存されている。
手順
samba-krb5-printing、samba-client、およびkrb5-workstationパッケージをインストールします。# yum install samba-krb5-printing samba-client krb5-workstation必要に応じて、ドメイン管理者として認証を行い、Windows プリントサーバーで共有されるプリンターの一覧を表示します。
# smbclient -L win_print_srv.ad.example.com -U administrator@AD_KERBEROS_REALM --use-kerberos=required Sharename Type Comment --------- ---- ------- ... Example Printer Example ...必要に応じて、CUPS モデルのリストを表示して、プリンターの PPD 名を指定します。
lpinfo -m ... samsung.ppd Samsung M267x 287x Series PXL ...
次のステップでプリンターを追加する場合は、PPD ファイルの名前が必要です。
CUPS にプリンターを追加します。
# lpadmin -p "example_printer" -v smb://win_print_srv.ad.example.com/Example -m samsung.ppd -o auth-info-required=negotiate -Eこのコマンドでは次のオプションを使用します。
-
-p printer_nameは、CUPS にプリンターの名前を設定します。 -
-v URI_to_Windows_printerは、Windows プリンターに URI を設定します。smb://host_name/printer_share_nameという形式を使用します。 -
-m PPD_fileは、プリンターが使用する PPD ファイルを設定します。 -
-o auth-info-required=negotiateは、印刷ジョブをリモートサーバーに転送する際に CUPS が Kerberos 認証を使用するように設定します。 -
-Eはプリンターを有効にします。CUPS はそのプリンターのジョブを受け付けます。
-
検証
- AD ドメインユーザーとして RHEL ホストにログインします。
AD ドメインユーザーとして認証します。
# kinit domain_user_name@AD_KERBEROS_REALMローカルの CUPS プリントサーバーに追加したプリンターにファイルを出力します。
# lp -d example_printer file
10.10. cups-browsed を使用してリモートプリントサーバーのプリンターをローカルに統合する
cups-browsed サービスは、DNS サービス検出 (DNS-SD) と CUPS ブラウジングを使用して、共有リモートプリンターのすべて、またはフィルタリング後のサブセットを、ローカルの CUPS サービスで自動的に利用できるようにします。
たとえば、管理者はワークステーションでこの機能を使用して、信頼できるプリントサーバーのプリンターのみをアプリケーションの印刷ダイアログで使用できるようにすることができます。プリントサーバーが多数のプリンターを共有している場合、リストに表示されるプリンターの数を減らすために、参照するプリンターを特定の条件でフィルタリングするように cup-browsed を設定することもできます。
アプリケーションの印刷ダイアログが DNS-SD などの他のメカニズムを使用してリモートプリンターのリストを表示している場合、cups-browsed は影響を及ぼしません。また、cups-browsed サービスは、ユーザーがリストにないプリンターに手動でアクセスすることを妨げるものではありません。
前提条件
- CUPS サービスがローカルホストで設定されている。
リモート CUPS プリントサーバーが存在する。このサーバーには次の条件が適用されます。
- サーバーが、クライアントからアクセス可能なインターフェイスでリッスンしている。
-
/etc/cups/cups.confファイル内のサーバーの<Location />ディレクティブにあるAllow fromパラメーターにより、クライアントの IP アドレスからのアクセスが許可されている。 - サーバーがプリンターを共有している。
- ファイアウォールルールにより、クライアントからサーバーの CUPS ポートへのアクセスが許可されている。
手順
/etc/cups/cups-browsed.confファイルを編集し、次の変更を加えます。ポーリングするリモート CUPS サーバーごとに
BrowsePollパラメーターを追加します。BrowsePoll remote_cups_server.example.com BrowsePoll 192.0.2.100:1631
リモート CUPS サーバーが 631 とは異なるポートでリッスンする場合は、ホスト名または IP アドレスに
<port>を追加します。オプション: フィルターを設定して、ローカル CUPS サービスに表示されるプリンターを制限します。たとえば、名前に
sales_が含まれるキューをフィルタリングするには、次のパラメーターを追加します。BrowseFilter name sales_さまざまなフィールド名でフィルタリングしたり、フィルターを無効にしたり、正確な値を照合したりできます。詳細は、
cups-browsed.conf(5)マニュアルページのパラメーターの説明と例を参照してください。オプション: ポーリング間隔とタイムアウトを変更して、参照サイクルの数を制限します。
BrowseInterval 1200 BrowseTimeout 6000
プリンターが参照リストから消えるのを避けるために、
BrowseIntervalとBrowseTimeoutの両方を同じ比率で増やしてください。つまり、BrowseIntervalの値を 5 以上の整数で乗算し、その計算結果の値をBrowseTimeoutに使用します。デフォルトでは、
cups-browsedは 60 秒ごとにリモートサーバーをポーリングし、タイムアウトは 300 秒です。ただし、キューの数が多いプリントサーバーでこれらのデフォルト値を使用すると、大量のリソースが消費される可能性があります。
cups-browsedサービスを有効にして起動します。# systemctl enable --now cups-browsed
検証
使用可能なプリンターをリスト表示します。
# lpstat -v device for Demo-printer: implicitclass://Demo-printer/ ...
プリンターの出力に
implicitclassが含まれていれば、cups-browsedが CUPS でプリンターを管理しています。
関連情報
-
cups-browsed.conf(5)man ページ
10.11. systemd ジャーナルの CUPS ログへのアクセス
デフォルトでは、CUPS はログメッセージを systemd ジャーナルに保存します。これには、以下のものが含まれます。
- エラーメッセージ
- アクセスログエントリー
- ページログエントリー
前提条件
手順
ログエントリーを表示します。
すべてのログエントリーを表示するには、次のように入力します。
# journalctl -u cups特定の印刷ジョブのログエントリーを表示するには、次のように入力します。
# journalctl -u cups JID=<print_job_id>特定の期間内のログエントリーを表示するには、次のように入力します。
# journalectl -u cups --since=<YYYY-MM-DD> --until=<YYYY-MM-DD>YYYYは年に、MMは月に、DDは日に置き換えます。
関連情報
-
journalctl(1)の man ページ
10.12. systemd ジャーナルではなくファイルにログを保存するように CUPS を設定する
デフォルトでは、CUPS はログメッセージを systemd ジャーナルに保存します。ログメッセージをファイルに保存するように CUPS を設定することもできます。
前提条件
手順
/etc/cups/cups-files.confファイルを編集し、AccessLog、ErrorLog、およびPageLogパラメーターを、これらのログファイルを保存するパスに設定します。AccessLog /var/log/cups/access_log ErrorLog /var/log/cups/error_log PageLog /var/log/cups/page_log
/var/log/cups/以外のディレクトリーにログを保存するように CUPS を設定する場合は、このディレクトリーにcupd_log_tSELinux コンテキストを設定します。たとえば、次のように設定します。# semanage fcontext -a -t cupsd_log_t "/var/log/printing(/.*)?" # restorecon -Rv /var/log/printing/
cupsサービスを再起動します。# systemctl restart cups
検証
ログファイルを表示します。
# cat /var/log/cups/access_log # cat /var/log/cups/error_log # cat /var/log/cups/page_log
/var/log/cups/以外のディレクトリーにログを保存するように CUPS を設定した場合は、ログディレクトリーの SELinux コンテキストがcupd_log_tであることを確認します。# ls -ldZ /var/log/printing/ drwxr-xr-x. 2 lp sys unconfined_u:object_r:cupsd_log_t:s0 6 Jun 20 15:55 /var/log/printing/
10.13. CUPS ドキュメントへのアクセス
CUPS では、CUPS サーバーにインストールされているサービスのドキュメントにブラウザーからアクセスできます。このドキュメントには次のものが含まれます。
- コマンドラインによるプリンターの管理やアカウンティングなどに関する管理ドキュメント
- man ページ
- 管理 API などのプログラミングドキュメント
- 参考資料
- Specifications
前提条件
- CUPS がインストールされ、実行されている。
- 使用するクライアントの IP アドレスに、Web インターフェイスにアクセスする権限がある。
手順
ブラウザーを使用して、
http://<hostname_or_ip_address>:631/help/にアクセスします。
-
Online Help Documentsのエントリーを展開し、参照するドキュメントを選択します。