
Red Hat Training
A Red Hat training course is available for Red Hat Enterprise Linux
電源管理ガイド
RHEL 7 での消費電力の管理と最適化
概要
第1章 概要
1.1. 電源管理の重要性
- 全体的な消費電力を削減してコストを節約
- サーバーやコンピューティングセンターにおける熱の削減
- 冷却、空間、ケーブル、ジェネレーター、無停電電源装置 (UPS) などの二次コストの削減
- ノートパソコンのバッテリー寿命の延長
- 二酸化炭素排出量の削減
- 政府の規制や Green IT (Energy Star など) に関する法的要件に合致する
- 新システムに関する企業ガイドラインの遵守
- 問: 最適化する必要がありますか?
- 問: どのくらい最適化する必要がありますか?
- 問: 最適化によって、システムのパフォーマンスが許容できないレベルまで低下しますか?
- 問: システムを最適化するために費やされる時間とリソースは、得られる利益を上回りますか?
1.2. 電源管理の基本
An idle CPU should only wake up when needed
Red Hat Enterprise Linux 6 以降では、カーネルが tickless を実行しています。つまり、以前の定期的なタイマー割り込みが、オンデマンド割り込みに置き換えられたことを意味します。そのため、新しいタスクが処理のキューに追加されるまで、アイドル状態の CPU はアイドル状態を維持できます。低電力状態にある CPU は、この状態を持続できます。ただし、システムに、不要なタイマーイベントを作成するアプリケーションが存在する場合は、この機能の利点が相殺される可能性があります。ボリュームの変更やマウスの動きの確認などのポーリングイベントは、このようなイベントの例です。
Unused hardware and devices should be disabled completely
これは特に、可動部品 (ハードディスクなど) を持つデバイスに当てはまります。また、一部のアプリケーションでは、使用されていない有効なデバイスが "open" 状態のままにすることがあります。これが発生すると、カーネルは、そのデバイスが使用中であることを想定します。これにより、そのデバイスが省電力状態にならないようにできます。
Low activity should translate to low wattage
ただし、多くの場合は、これは最新のハードウェアと正しい BIOS 設定に依存します。古いシステムコンポーネントは、Red Hat Enterprise Linux 7 で現在サポートできる新機能の一部をサポートしていないことがよくあります。システムに最新の公式ファームウェアを使用していること、および BIOS の電源管理またはデバイス設定セクションで電源管理機能が有効になっていることを確認してください。以下のような機能を確認してください。
- SpeedStep
- PowerNow!
- Cool'n'Quiet
- ACPI (C 状態)
- Smart
Different forms of CPU states and their effects
最新の CPU は、ACPI (Advanced Configuration and Power Interface) とともに、さまざまな電源状態を提供します。3 つの異なる状態は以下のとおりです。
- スリープ (C-state)
- 周波数と電圧 (P-state)P 状態は、プロセッサーの周波数とその電圧動作点を表し、どちらも P 状態が増加するにつれてスケーリングされます。
- 熱の出力 (T-states または「熱状態」)
A turned off machine uses the least amount of power
当たり前のように聞こえるかもしれませんが、実際に電力を節約する最善の方法の 1 つは、システムの電源を切ることです。たとえば、会社では、昼休みや帰宅時にマシンをオフにするガイドラインを使用して、Green IT を意識することに焦点をあてた企業文化を育成できます。また、複数の物理サーバーを 1 つの大きなサーバーに統合し、Red Hat Enterprise Linux 7 に同梱される仮想化技術を使用して仮想化することもできます。
第2章 電源管理の監査と分析
2.1. 監査および分析の概要
2.2. PowerTOP
root として次のコマンドを実行します。
~]# yum install powertoproot として次のコマンドを使用します。
~]# powertoproot として次のコマンドを実行します。
~]# powertop --calibrate~]# systemctl disable servicename.serviceroot として次のコマンドを実行してください。
~]# ps -awux | grep processname ~]# strace -p processid
C4 はC3 よりも高い)。これは、CPU 使用率がどの程度最適化されているかを示す良い指標です。レジデンシーは、システムがアイドル状態の間、最高の C または P 状態で 90% 以上であることが理想的です。
図2.1 稼働中の PowerTOP
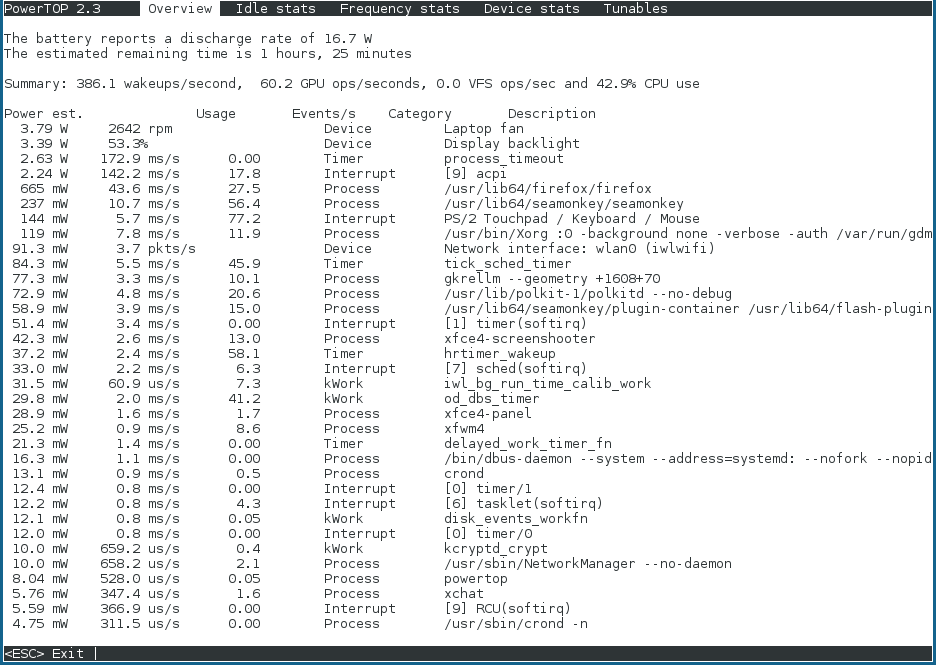
[D]
--html オプションを指定して PowerTOP を実行して、HTML レポートを生成することもできます。htmlfile.html パラメーターを、出力ファイルに必要な名前に置き換えます。
~]# powertop --html=htmlfile.html--time オプションを使用して変更できます。
~]# powertop --html=htmlfile.html --time=seconds2.3. Diskdevstat and netdevstat
root として次のコマンドを使用して、SystemTap でこれらのツールをインストールします。
~]# yum install tuned-utils-systemtap kernel-debuginfo~]# diskdevstat~]# netdevstat- update_interval
- 表示の更新間隔 (秒単位)。デフォルト:
5 - total_duration
- 実行全体の秒単位の時間。デフォルト:
86400(1 日) - display_histogram
- 実行の最後に収集されたすべてのデータのヒストグラムを作成するかどうかをフラグします。
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 5494 0 sda1 0 0.000 0.000 0.000 758 0.000 0.012 0.000 0logwatch 5520 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 5549 0 sda1 0 0.000 0.000 0.000 140 0.000 0.009 0.000 perl 5585 0 sda1 0 0.000 0.000 0.000 108 0.001 0.002 0.000 perl 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 5429 0 sda1 0 0.000 0.000 0.000 62 0.009 0.009 0.000 crond 5379 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5473 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5415 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5433 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5425 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 5375 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5477 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 5469 0 sda1 0 0.000 0.000 0.000 62 0.007 0.007 0.000 crond 5419 0 sda1 0 0.000 0.000 0.000 62 0.008 0.008 0.000 crond 5481 0 sda1 0 0.000 0.000 0.000 61 0.000 0.001 0.000 crond 5355 0 sda1 0 0.000 0.000 0.000 37 0.000 0.014 0.001 laptop_mode 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd 5575 0 sda1 0 0.000 0.000 0.000 16 0.000 0.000 0.000 cat 5581 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 5582 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 5579 0 sda1 0 0.000 0.000 0.000 12 0.000 0.001 0.000 perl 5580 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 5354 0 sda1 0 0.000 0.000 0.000 12 0.000 0.170 0.014 s h 5584 0 sda1 0 0.000 0.000 0.000 12 0.001 0.002 0.000 perl 5548 0 sda1 0 0.000 0.000 0.000 12 0.001 0.014 0.001 perl 5577 0 sda1 0 0.000 0.000 0.000 12 0.001 0.003 0.000 perl 5519 0 sda1 0 0.000 0.000 0.000 12 0.001 0.005 0.000 perl 5578 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 5583 0 sda1 0 0.000 0.000 0.000 12 0.001 0.001 0.000 perl 5547 0 sda1 0 0.000 0.000 0.000 11 0.000 0.002 0.000 perl 5576 0 sda1 0 0.000 0.000 0.000 11 0.001 0.001 0.000 perl 5518 0 sda1 0 0.000 0.000 0.000 11 0.000 0.001 0.000 perl 5354 0 sda1 0 0.000 0.000 0.000 10 0.053 0.053 0.005 lm_lid.sh
- PID
- アプリケーションのプロセス ID
- UID
- アプリケーションが実行しているユーザー ID
- DEV
- I/O が発生したデバイス
- WRITE_CNT
- 書き込み操作の総数
- WRITE_MIN
- 2 つの連続した書き込みにかかった最短時間 (秒単位)
- WRITE_MAX
- 2 つの連続した書き込みにかかった最大時間 (秒単位)
- WRITE_AVG
- 2 つの連続した書き込みにかかった平均時間 (秒単位)
- READ_CNT
- 読み取り操作の総数
- READ_MIN
- 2 つの連続した読み取りにかかった最短時間 (秒単位)
- READ_MAX
- 2 つの連続した読み取りにかかった最大時間 (秒単位)
- READ_AVG
- 2 つの連続した読み取りにかかった平均時間 (秒単位)
- COMMAND
- プロセスの名前
PID UID DEV WRITE_CNT WRITE_MIN WRITE_MAX WRITE_AVG READ_CNT READ_MIN READ_MAX READ_AVG COMMAND 2789 2903 sda1 854 0.000 120.000 39.836 0 0.000 0.000 0.000 plasma 2573 0 sda1 63 0.033 3600.015 515.226 0 0.000 0.000 0.000 auditd 2153 0 sda1 26 0.003 3600.029 1290.730 0 0.000 0.000 0.000 rsyslogd
WRITE_CNT は0 より大きく、これは測定中に何らかの形式の書き込みを実行したことを意味します。それらの中で、プラズマは かなりの程度で最悪の攻撃者でした。プラズマは最も多くの書き込み操作を実行し、当然ながら書き込み間の平均時間は最も短かったのです。したがって、電力効率の悪いアプリケーションが懸念される場合には、プラズマ が調査対象となる最適な候補となります。
~]# strace -p 27892.4. バッテリ寿命ツールキット
-a を指定して起動すると、デスクトップコンピューターのパフォーマンスについても報告できます。
オフィスの ワークロードでは、テキストを作成し、その内容を修正し、スプレッドシートに対しても同じことを行います。BLTK を PowerTOP またはその他の監査または分析ツールと組み合わせて実行すると、実行した最適化が、マシンがアイドリング時だけでなくアクティブに使用されているときに効果があるかどうかをテストできます。異なる設定でまったく同じワークロードを複数回実行できるため、異なる設定の結果を比較できます。
~]# yum install bltk~]$ bltk workload optionsアイドル状態の ワークロードを 120 秒間実行するには、次のようにします。
~]$ bltk -I -T 120-I,--idle- システムがアイドル状態で、他のワークロードと比較するためのベースラインとして使用
-R,--reader- ドキュメントの読み取りをシミュレートします (デフォルトでは Firefox を使用)
-P,--player- CD または DVD ドライブからマルチメディアファイルの視聴をシミュレートします (デフォルトでは mplayer を使用)
-O,--office- OpenOffice.org スイートを使用したドキュメントの編集をシミュレートします
-a,--ac-ignore- AC 電源が利用可能かどうかを無視します (デスクトップでの使用に必要)
-T number_of_seconds,--time number_of_seconds- テストを実行する時間 (秒単位)。
アイドル状態のワークロードにはこのオプションを使用してください -F filename,--file filename- 特定のワークロードで使用されるファイルを指定します。たとえば、CD または DVD ドライブにアクセスする代わりに
プレーヤーのワークロードが再生するファイルです。 -W application,--prog application- 特定のワークロードで使用されるアプリケーションを指定します。たとえば、
リーダーのワークロードには Firefox 以外のブラウザーを使用します。
bltk の マニュアルページを参照してください。
/etc/bltk.conf 設定ファイルで指定されたディレクトリー (デフォルトでは ~/.bltk/workload .results) に保存します。番号/。たとえば、~/.bltk/reader.results.002/ ディレクトリーには、リーダー ワークロードの 3 番目のテストの結果が保持されます (最初のテストには番号が付けられていません)。結果は複数のテキストファイルに分散されます。これらの結果を読みやすい形式に要約するには、次を実行します。
~]$ bltk_report path_to_results_directoryReport という名前のテキストファイルに表示されます。代わりに端末エミュレーターで結果を表示するには、-o オプションを使用します。
~]$ bltk_report -o path_to_results_directory2.5. Tuned
udev デバイスマネージャーを使用して接続されたデバイスを監視し、システム設定の静的および動的チューニングの両方を可能にする、プロファイルベースのシステムチューニングツールです。動的チューニングは実験的な機能であり、Red Hat Enterprise Linux 7 ではデフォルトでオフになっています。
バランスの取れた プロファイルが設定されます。
バランスの取れた プロファイルは、ほとんどのワークロードに適しており、エネルギー消費、パフォーマンス、遅延のバランスが取れています。バランスの取れた プロファイルを使用すると、利用可能な最大のコンピューティング能力でタスクを迅速に完了する方が、通常、より少ないコンピューティング能力で同じタスクを長時間実行するよりも少ないエネルギーで済みます。
省電力 プロファイルを使用すると、バッテリー寿命を延ばすことができます。このような操作では、エネルギー消費を抑える代わりに待ち時間が長くなることは一般的に許容されます。または、IRC を使用したり、単純な Web ページを表示したり、オーディオファイルやビデオファイルを再生したりするなど、操作をすばやく終了する必要はありません。
powertop2tuned の使用
powertop2tuned ユーティリティーを使用すると、PowerTOP の 提案からカスタム Tuned プロファイルを作成できます。PowerTOP については、次を参照してください。「PowerTOP」。
powertop2tuned ユーティリティーをインストールするには、次を使用します。
~]# yum install tuned-utils
~]# powertop2tuned new_profile_namepowertop2tuned は/etc/tuned/ ディレクトリーにプロファイルを作成し、現在選択されている Tuned プロファイルに基づいてカスタムプロファイルを作成します。安全上の理由から、新しいプロファイルでは最初はすべての PowerTOP チューニングが無効になっています。チューニングを有効にするには、/etc/tuned/profile_name/tuned.conf ファイル内のチューニングのコメントを解除します。
--enable または -e オプションを使用すると、PowerTOP が提案するほとんどのチューニングを有効にする新しいプロファイルを生成できます。USB 自動サスペンドなど、既知の問題のある特定のチューニングはデフォルトで無効になっているため、手動でコメントを解除する必要があります。
~]# tuned-adm profile new_profile_namepowertop2tuned が サポートするオプションの完全なリストについては、次を使用してください。
~]$ powertop2tuned --help2.6. UPower
--enumerate,-e- システム上の各電源デバイスのオブジェクトパスを表示します。次に例を示します。
/org/freedesktop/UPower/devices/line_power_AC/org/freedesktop/UPower/devices/battery_BAT0 --dump,-d- システム上のすべての電源装置のパラメーターを表示します。
--wakeups,-w- システムの CPU ウェイクアップを表示します。
--monitor,-m- AC 電源の接続または切断、バッテリーの消耗など、電源装置の変更についてシステムを監視します。Ctrl+C を押してシステムの監視を停止します。
--monitor-detail- AC 電源の接続または切断、バッテリーの消耗など、電源装置の変更についてシステムを監視します。
--monitor-detailオプションは、--monitorオプションよりも詳細を表示します。Ctrl+C を押してシステムの監視を停止します。 --show-info object_path,-i object_path- 特定のオブジェクトパスで利用可能なすべての情報を表示します。たとえば、オブジェクトパス
/org/freedesktop/UPower/devices/battery_BAT0で表されるシステム上のバッテリーに関する情報を取得するには、次を実行します。~]$ upower -i /org/freedesktop/UPower/devices/battery_BAT0
2.7. GNOME Power Manager
2.8. 監査用のその他のツール
- vmstat
- vmstat は、プロセス、メモリー、ページング、ブロック I/O、トラップ、CPU アクティビティーに関する詳細情報を提供します。これを使用して、システム全体が何をしているか、どこがビジーかを詳しく調べます。
- iostat
- iostat は vmstat に似ていますが、ブロックデバイス上の I/O のみを対象としています。また、より詳細な出力と統計も提供します。
- blktrace
- blktrace は、非常に詳細なブロック I/O トレースプログラムです。アプリケーションに関連付けられた単一のブロックに情報を分解します。これは、discdevstat と組み合わせると非常に便利です。
第3章 コアインフラストラクチャーとメカニズム
3.1. CPU アイドル状態
- C0
- 動作中または実行中の状態。この状態では、CPU は動作しており、アイドル状態ではありません。
- C1, Halt
- プロセッサーが命令を実行していないが、通常は低電力状態ではない状態。CPU は事実上遅延なしで処理を継続できます。C-State を提供するすべてのプロセッサーが、この状態に対応する必要があります。Pentium 4 プロセッサーは、C1E と呼ばれる拡張された C1 状態に対応しています。これは、低消費電力を実現する状態です。
- C2, Stop-Clock
- このプロセッサーのクロックが凍結されている状態ですが、レジスターとキャッシュの完全な状態を維持しているため、クロックを再開した後、すぐに処理を再開できます。この状態はオプションになります。
- C3, Sleep
- プロセッサーが実際にスリープ状態になり、キャッシュを最新の状態に保つ必要がない状態。このため、この状態からの起動は C2 からの起動よりかなり時間がかかります。繰り返しますが、これはオプションの状態です。
~]$ cpupower idle-info3.2. CPUfreq
3.2.1. CPUfreq ドライバー
ACPI CPUfreq
Intel P-state
max_perf_pct: ドライバーが要求する最大 P ステートを制限し、利用可能なパフォーマンスのパーセンテージで表します。利用可能な P-state パフォーマンスは、no_turbo 設定により削減できます (以下を参照)。min_perf_pct: min_perf_pct: ドライバーによって要求される最小 P ステートを制限します。最大 (ターボなし) パフォーマンスレベルのパーセンテージで表されます。no_turbo: ドライバーがターボ周波数範囲未満の P ステートを選択するように制限します。turbo_pct: ターボ範囲内のハードウェアによってサポートされる合計パフォーマンスの割合を表示します。この数は、ターボが無効になっているかどうかに関係ありません。num_pstates: ハードウェアによってサポートされている P ステートの数を表示します。この数は、ターボが無効になっているかどうかに関係ありません。
intel_pstate=disable
3.2.2. CPUfreq ガバナー
3.2.2.1. コア CPUfreq ガバナー
cpufreq_performance
パフォーマンスガバナーは、CPU が可能な限り高いクロック周波数を使用するように強制します。この頻度は静的に設定され、変更されません。このため、この特定のガバナーでは 省電力の利点はありません。これは、数時間の負荷の高いワークロードにのみ適しています。その場合でも、CPU がめったに (またはまったく) アイドル状態にならない時間帯にのみ適しています。
cpufreq_powersave
対照的に、Powersave ガバナーは、CPU が可能な限り低いクロック周波数を使用するように強制します。この頻度は静的に設定され、変更されません。そのため、この特定のガバナーは電力を最大限に節約できますが、CPU パフォーマンスが最も低く なります。
cpufreq_ondemand
Ondemand ガバナーは動的なガバナーであり、システム負荷が高いときに CPU が最大クロック周波数を達成し、システムがアイドル状態のときに最小クロック周波数を達成できるようにします。これにより、システムはシステム負荷に応じて消費電力を調整できますが、周波数切り替えの間の待ち時間 はかかります。このため、システムがアイドル状態と高負荷のワークロードを頻繁に切り替える場合、レイテンシーは、Ondemand ガバナーが提供するパフォーマンスや省電力の利点を相殺することができます。
cpufreq_userspace
Userspace ガバナーを使用すると、ユーザー空間プログラム、または root で実行しているプロセスで頻度を設定できます。すべてのガバナーの中で、Userspace は最もカスタマイズ可能で、設定方法に応じて、システムのパフォーマンスと消費の最適なバランスを実現できます。
cpufreq_conservative
Ondemand ガバナーと同様に、Conservative ガバナーも使用状況に応じてクロック周波数を調整します。ただし、Ondemand ガバナーはより早く (つまり、最大から最小へ、またその逆) 切り替えますが、Conservative ガバナーはより時間をかけて周波数を切り替えます。
3.2.2.2. Intel P-state の CPUfreq ガバナー
- ハードウェア管理の P 状態 (HWP) によるアクティブモード
- ハードウェア管理の P 状態 (HWP) を使用しないアクティブモード
- パッシブモード
Active mode with hardware-managed P-states
- パフォーマンス
- Powersave
Active mode without hardware-managed P-states
- パフォーマンス
- Powersave
パッシブモード
3.2.3. CPUfreq セットアップ
~]# cpupower frequency-info --governors~]# cpupower frequency-set --governor [governor]~]# cpupower -c 1-3,5 frequency-set --governor cpufreq_userspace3.2.4. CPUfreq ポリシーと速度の調整
- --freq — CPUfreq コアに応じた CPU の現在の速度を KHz 単位で表示します。
- --hwfreq — ハードウェアに応じた CPU の現在の速度を KHz 単位で表示します (root としてのみ使用可能)。
- --driver — この CPU の周波数を設定するためにどの CPUfreq ドライバーが使用されているかを示します。
- --governors — このカーネルで使用可能な CPUfreq ガバナーを表示します。このファイルにリストされていない CPUfreq ガバナーを使用する場合は、その方法を 「CPUfreq セットアップ」 で参照してください。
- --affected-cpus — 周波数調整ソフトウェアを必要とする CPU をリストします。
- --policy — 現在の CPUfreq ポリシーの範囲 (KHz 単位)、および現在アクティブなガバナーを表示します。
- --hwlimits — CPU で使用可能な周波数を KHz 単位でリストします。
/sys/devices/system/cpu/cpuid/cpufreq/ にある調整パラメーターで CPUfreq 設定を確認できます。設定および値は、この調整可能パラメーターに書き込むことで変更できます。たとえば、最小クロック速度の cpu0 から 360 KHz を設定するには、次のコマンドを使用します。
echo 360000 > /sys/devices/system/cpu/cpu0/cpufreq/scaling_min_freq
3.3. CPU モニター
- -l — システムで利用可能なすべてのモニターをリスト表示します。
- -m <monitor1>、<monitor2> — 特定のモニターを表示します。それらの識別子は、-l を実行すると見つかります。
- コマンド — 特定のコマンドのアイドル統計と CPU 要求を表示します。
3.4. CPU 省電力ポリシー
- --perf-bias <0-15>
- サポートされている Intel プロセッサーのソフトウェアが、最適なパフォーマンスと省電力のバランスを決定するために、より積極的に貢献できるようにします。これは、他の省電力ポリシーを上書きしません。割り当てる値は 0 から 15 まであり、0 はパフォーマンスを最適化し、15 は電力効率を最適化します。デフォルトでは、このオプションはすべてのコアに適用されます。個々のコアにのみ適用するには、--cpu <cpulist> オプションを追加します。
- --sched-mc <0|1|2>
- 他の CPU パッケージが引き出される前に、システムプロセスによる電力の使用を 1 つの CPU パッケージのコアに制限します。0 は制限を設定せず、1 は最初に単一の CPU パッケージのみを採用し、2 はこれを行い、タスクのウェイクアップを処理するためにセミアイドル CPU パッケージを優先します。
- --sched-smt <0|1|2>
- システムプロセスによる電力の使用を、1 つの CPU コアのスレッドシブリングに制限してから、他のコアを使用します。0 は制限を設定せず、1 は最初に単一の CPU パッケージのみを採用し、2 はこれを行い、タスクのウェイクアップを処理するためにセミアイドル CPU パッケージを優先します。
3.5. 一時停止と再開
3.6. ランタイムデバイスの電源管理
、/sys/devices/device/power/ ディレクトリーにあります。ここで、device は 特定のデバイスのディレクトリーへのパスを置き換えます。
/sys/devices/system/cpu/power//sys/devices/device/power ディレクトリーには、次の設定ファイルが含まれています。
control
制御 ファイル内の属性の次の 2 つの値のいずれかが含まれます。
auto- すべてのデバイスのデフォルト。ドライバーによっては、自動 RDPM の対象となる場合があります。
on- ドライバーが実行時にデバイスの電源状態を管理できないようにします
autosuspend_delay_ms
/sys/devices/device/power/control ファイルの属性を on に設定するのと同じ効果になります。1000 を超える値は、最も近い秒に切り上げられます。
3.7. アクティブ状態の電源管理
- default
- システムのファームウェア (BIOS など) によって指定されたデフォルトに従って、PCIe リンクの電源状態を設定します。これは ASPM のデフォルトの状態です。
- powersave
- パフォーマンスへのコストに関係なく、可能な限り電力を節約するように ASPM を設定します。
- performance
- ASPM を無効にして、PCIe リンクが最大のパフォーマンスで動作できるようにします。
pcie_aspm カーネルパラメーターを使用して、ASPM サポートを強制的に有効または無効にできます。
pcie_aspm=offASPM を無効にしますpcie_aspm=force は、ASPM をサポートしていないデバイスでも ASPM を有効にします
~]$ journalctl -b | grep ASPMpcie_aspm=force により、 システムが応答しなくなる可能性がありますpcie_aspm=force を使用して ASPM を強制的に有効にすると、システムが応答しなくなる可能性があります。pcie_aspm=force を設定する前に、システム上のすべての PCIe ハードウェアが ASPM をサポートしていることを確認してください。
/sys/module/pcie_aspm/parameters/policyファイルの設定を変更します。- ブート時に
pcie_aspm.policyカーネルパラメーターを指定しますたとえば、pcie_aspm.policy=performance はASPM パフォーマンスポリシーを設定します。
3.8. アグレッシブリンク電源管理
medium_power
このモードは、ディスクに I/O がない場合に、リンクを 2 番目に低い電力状態 (PARTIAL) に設定します。このモードは、パフォーマンスへの影響を最小限に抑えながら、リンクの電源状態を移行できるように設計されています (たとえば、断続的な重い I/O とアイドル I/O の間)。
/sys/class/scsi_host/host*/link_power_management_policy が存在するかどうかを確認します。設定を変更するには、このセクションで説明されている値をこれらのファイルに書き込むか、ファイルを表示して現在の設定を確認します。
3.9. Relatime ドライブアクセスの最適化
atime と呼ばれ、これを維持するにはストレージへの一定の一連の書き込み操作が必要です。これらの書き込みは、ストレージデバイスとそのリンクをビジー状態に保ち、電源を入れたままにします。atime データを利用するアプリケーションはほとんどないため、このストレージデバイスの動作により電力が無駄になります。重要なのは、ファイルがストレージから読み取られたのではなく、キャッシュから読み取られた場合でも、ストレージへの書き込みが発生することです。しばらくの間、Linux カーネルは マウント の noatime オプションをサポートしていましたが、このオプションでマウントされたファイルシステムには atime データを書き込みませんでした。ただし、一部のアプリケーションは atime データに依存しており、それが利用できない場合は失敗するため、この機能を単にオフにするだけでは問題があります。
relatime をサポートしています。Relatime はatime データを維持しますが、ファイルがアクセスされるたびに維持するわけではありません。このオプションを有効にすると、atime データが最後に更新された (mtime) 以降にファイルが変更された場合、またはファイルが一定期間 (デフォルトでは 1 回) よりも前に最後にアクセスされた場合にのみ、atime データがディスクに書き込まれます。日)。
relatime を有効にしてマウントされるようになりました。オプション noelatime を使用してファイルシステムをマウントすることにより、特定のファイルシステムに対してこれを抑制することができます。
3.10. 電力上限
HP 動的電力上限
動的電力上限は、一部の ProLiant および BladeSystem サーバーで利用できる機能で、システム管理者がサーバーまたはサーバーグループの電力消費を制限できるようにします。上限は、現在のワークロードに関係なく、サーバーが超えない決定的な制限です。サーバーが消費電力の上限に達するまで、上限は効果がありません。その時、管理プロセッサーは CPU の P ステートとクロックスロットリングを調整して、消費電力を制限します。
/dev/hpilo/d X ccb N にある管理プロセッサーにクエリーを実行できます。このカーネルには、電力制限機能をサポートするための hwmon sysfs インターフェイスの拡張機能と、sysfs インターフェイスを使用する ACPI 4.0 パワーメーター用の hwmon ドライバーも含まれています。これらの機能を組み合わせることで、オペレーティングシステムとユーザー空間ツールは、システムの現在の電力使用量と共に、電力上限に設定された値を読み取ることができます。
Intel Node Manager
Intel Node Manager は、プロセッサーの P ステートと T ステートを使用してシステムに電力上限を課し、CPU のパフォーマンスを制限して消費電力を制限します。管理者は、電源管理ポリシーを設定することにより、夜間や週末など、システムの負荷が低い時間帯に消費電力を抑えるようにシステムを設定できます。
3.11. 強化されたグラフィック電源管理
LVDS リクロッキング
LVDS (低電圧差動信号) は、銅線を介して電子信号を伝送するシステムです。このシステムの重要なアプリケーションの 1 つは、ノートブックコンピューターの LCD (liquid crystal display) 画面にピクセル情報を送信することです。すべてのディスプレイには リフレッシュレート があります。これは、グラフィックコントローラーから新しいデータを受け取り、画面にイメージを再描画するレートです。通常、画面は 1 秒間に 60 回 (60 Hz の周波数) 新しいデータを受信します。画面とグラフィックスコントローラーが LVDS によってリンクされている場合、LVDS システムはリフレッシュサイクルごとに電源を使用します。アイドル状態の場合は、多くの LCD 画面のリフレッシュレートを 30 Hz に落としても、目立った影響はありません (リフレッシュレートの低下によって特徴的なちらつきが発生する ブラウン管 (CRT) モニターとは異なります)。Red Hat Enterprise Linux 7 で使用されるカーネルに組み込まれている Intel グラフィックスアダプターのドライバーは、この ダウンクロック を自動的に実行し、画面がアイドル状態のときに約 0.5 W 節約します。
メモリーのセルフリフレッシュを有効にする
同期ダイナミックランダムアクセスメモリー (SDRAM) は、グラフィックスアダプターのビデオメモリーに使用され、1 秒あたり何千回も再充電されるため、個々のメモリーセルはそこに保存されているデータを保持します。メモリーに出入りするデータを管理するという主な機能とは別に、メモリーコントローラーは通常、これらのリフレッシュサイクルを開始します。ただし、SDRAM には低電力の セルフリフレッシュ モードもあります。このモードでは、メモリーは内部タイマーを使用して独自のリフレッシュサイクルを生成します。これにより、現在メモリーに保持されているデータを危険にさらすことなく、システムがメモリーコントローラーをシャットダウンできます。Red Hat Enterprise Linux 7 で使用されるカーネルは、Intel グラフィックスアダプターがアイドル状態のときにメモリーのセルフリフレッシュをトリガーできるため、約 0.8 W 節約できます。
GPU クロックの削減
一般的なGPU (graphical processing units) には、内部回路のさまざまな部分を制御する内部クロックが含まれています。Red Hat Enterprise Linux 7 で使用されるカーネルは、Intel および ATI GPU の一部の内部クロックの周波数を下げることができます。GPU コンポーネントが特定の時間内に実行するサイクル数を減らすと、実行する必要のないサイクルで消費される電力を節約できます。カーネルは、GPU がアイドル状態のときにこれらのクロックの速度を自動的に下げ、GPU のアクティビティーが増加すると速度を上げます。GPU クロックサイクルを減らすと、最大 5 W 節約できます。
GPU パワーダウン
Red Hat Enterprise Linux 7 の Intel および ATI グラフィックスドライバーは、アダプターにモニターが接続されていないことを検出できるため、GPU を完全にシャットダウンします。この機能は、モニターが定期的に接続されていないサーバーにとって特に重要です。
3.12. RFKill
/dev/rfkill にあり、システム上のすべての無線送信機の現在の状態が含まれています。各デバイスの現在の RFKill 状態は sysfs に登録されています。さらに、RFKill は、RFKill 対応デバイスの状態が変化するたびに uevent を発行します。
0 から始まる インデックス番号 が関連付けられています。このインデックス番号を使用して、rfkill にデバイスをブロックまたはブロック解除するように指示できます。次に例を示します。
~]# rfkill block 0~]# rfkill block wifi~]# rfkill block all第4章 ユースケース
4.1. 例 — サーバー
Webserver
Web サーバーには、ネットワークとディスク I/O が必要です。外部接続速度によっては、100 Mbit/s で十分な場合があります。マシンが主に静的ページを提供する場合、CPU パフォーマンスはそれほど重要ではない可能性があります。したがって、電源管理の選択肢には次のようなものがあります。
- tuned 用のディスクまたはネットワークプラグインはありません。
- ALPM がオンになりました。
オンデマンドガバナーがオンになりました。- ネットワークカードは 100 Mbit/s に制限されています。
コンピュートサーバー
コンピュートサーバーは主に CPU を必要とします。電源管理の選択肢には次のものがあります。
- ジョブとデータの保存場所に応じて、ディスクまたはネットワークのプラグインが 調整されます。または、バッチモードシステムの場合は、完全にアクティブな tuned。
- 使用状況によっては、
パフォーマンスガバナーが使用される可能性があります。
メールサーバー
メールサーバーは主にディスク I/O と CPU を必要とします。電源管理の選択肢には次のものがあります。
- CPU パフォーマンスの最後の数パーセントは重要ではないため、
オンデマンドガバナはオンになっています。 - tuned 用のディスクまたはネットワークプラグインはありません。
- メールは内部にあることが多く、1 Gbit/s または 10 Gbit/s リンクの恩恵を受けることができるため、ネットワーク速度は制限されるべきではありません。
ファイルサーバー
ファイルサーバーの要件はメールサーバーの要件と似ていますが、使用するプロトコルによっては、より多くの CPU パフォーマンスが必要になる場合があります。通常、Samba ベースのサーバーは NFS より多くの CPU を必要とし、NFS は通常 iSCSI よりも多くの CPU を必要とします。それでも、オンデマンド ガバナーを使用できるはずです。
Directory server
特に十分な RAM が装備されている場合、通常、Directory Server はディスク I/O の要件が低くなります。ネットワーク I/O はそれほど重要ではありませんが、ネットワーク遅延は重要です。より遅いリンク速度での遅延ネットワークチューニングを検討することもできますが、特定のネットワークについてこれを慎重にテストする必要があります。
4.2. 例 — ラップトップ
- システム BIOS を設定して、使用しないすべてのハードウェアを無効にします。たとえば、パラレルポートまたはシリアルポート、カードリーダー、Web カメラ、WiFi、Bluetooth などは、考えられる候補をいくつか挙げただけです。
- 画面を快適に読むために完全な照明を必要としない暗い環境では、ディスプレイを暗くします。GNOME デスクトップでは + → を使用し、KDE デスクトップでは +++ → 使用します。または、コマンドラインで gnome-power-manager または xbacklight を 使用します。またはラップトップのファンクションキー。
オンデマンドガバナーを使用します (Red Hat Enterprise Linux 7 ではデフォルトで有効になります)- AC97 オーディオ省電力を有効にします (Red Hat Enterprise Linux 7 ではデフォルトで有効になっています):
~]# echo Y > /sys/module/snd_ac97_codec/parameters/power_save - USB 自動サスペンドを有効にします。
~]# for i in /sys/bus/usb/devices/*/power/autosuspend; do echo 1 > $i; doneUSB 自動サスペンドは、すべての USB デバイスで正しく機能しないことに注意してください。 - relatime を使用してファイルシステムをマウントします (Red Hat Enterprise Linux 7 のデフォルト):
~]# mount -o remount,relatime mountpoint - 画面の明るさを
50以下に下げます。例:~]$ xbacklight -set 50 - 画面アイドル状態の DPMS を有効にします。
~]$ xset +dpms; xset dpms 0 0 300 - Wi-Fi を無効にします。
~]# echo 1 > /sys/bus/pci/devices/*/rf_kill
付録A 開発者向けのヒント
- スレッドを使用します。
- 不必要な CPU ウェイクアップが発生し、ウェイクアップを効率的に使用していません。起動しないといけない場合は、(アイドリングに対して) すべてを一度に、できるだけ早く行います。
- を使用して
[f]sync()不必要に。 - 不必要なアクティブポーリングまたは短い定期的なタイムアウトの使用。(代わりにイベントに反応します)。
- ウェイクアップを効率的に使用していません。
- 非効率的なディスクアクセス。頻繁なディスクアクセスを避けるために、大きなバッファーを使用します。一度に 1 つの大きなブロックを書き込みます。
- タイマーの非効率的な使用。可能であれば、アプリケーション全体 (またはシステム全体) でタイマーをグループ化します。
- 過剰な I/O、電力消費、またはメモリー使用量 (メモリーリークを含む)
- 不要な計算を行っています。
A.1. スレッドの使用
Python
Python は Global Lock Interpreter を使用します[1]であるため、スレッド化は大規模な I/O 操作でのみ有効です。Unladen-swallow [2] は、コードを最適化できる Python のより高速な実装です。
Perl
Perl スレッドはもともと、フォークしないシステム (32 ビット Windows オペレーティングシステムのシステムなど) で実行するアプリケーション用に作成されました。Perl スレッドでは、データはスレッドごとにコピーされます (Copy On Write)。ユーザーはデータ共有のレベルを定義できる必要があるため、デフォルトではデータは共有されません。データを共有するには、threads::shared モジュールを含める必要があります。ただし、データがコピーされるだけでなく (Copy On Write)、モジュールはデータに関連付けられた変数も作成します。これにはさらに時間がかかり、さらに遅くなります。[3]
C
C スレッドは同じメモリーを共有し、各スレッドには独自のスタックがあり、カーネルは新しいファイル記述子を作成して新しいメモリー空間を割り当てる必要はありません。C は、より多くのスレッドに対してより多くの CPU のサポートを実際に使用できます。したがって、スレッドのパフォーマンスを最大化するには、C や C++ などの低水準言語を使用してください。スクリプト言語を使用する場合は、C バインディングを作成することを検討してください。プロファイラーを使用して、コードのパフォーマンスが低下している部分を特定します。[4]
A.2. ウェイクアップ
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <sys/types.h>
#include <sys/inotify.h>
#include <unistd.h>
int main(int argc, char *argv[]) {
int fd;
int wd;
int retval;
struct timeval tv;
fd = inotify_init();
/* checking modification of a file - writing into */
wd = inotify_add_watch(fd, "./myConfig", IN_MODIFY);
if (wd < 0) {
printf("inotify cannot be used\n");
/* switch back to previous checking */
}
fd_set rfds;
FD_ZERO(&rfds);
FD_SET(fd, &rfds);
tv.tv_sec = 5;
tv.tv_usec = 0;
retval = select(fd + 1, &rfds, NULL, NULL, &tv);
if (retval == -1)
perror("select()");
else if (retval) {
printf("file was modified\n");
}
else
printf("timeout\n");
return EXIT_SUCCESS;
}
/proc/sys/fs/inotify/max_user_watches から取得でき、変更することもできますが、これは推奨できません。さらに、inotify が 失敗した場合、コードは別のチェックメソッドにフォールバックする必要があります。これは通常、次のような問題が多数発生することを意味します。#if #defineソースコード内で。
A.3. Fsync
Fsync は I/O 負荷の高い操作として知られていますが、これは完全に真実ではありません。
fsyncまた、ファイルシステム設定 (主にデータ順序モードの ext3) が原因で、何も起こらないときに長い遅延が発生しました。別のプロセスが同時に大きなファイルをコピーしていた場合、これには長時間 (最大 30 秒) かかることがあります。
fsyncまったく使用されていなかったため、ext4 ファイルシステムへの切り替えで問題が発生しました。Ext3 はデータ順モードに設定され、数秒ごとにメモリーをフラッシュしてディスクに保存しました。ただし、ext4 と laptop_mode では、保存の間隔が長くなり、システムが予期せずオフになったときにデータが失われる可能性がありました。現在、ext4 にはパッチが適用されていますが、アプリケーションの設計を慎重に検討し、使用する必要があります。fsync適切に。
/* open and read configuration file e.g. ./myconfig */
fd = open("./myconfig", O_RDONLY);
read(fd, myconfig_buf, sizeof(myconfig_buf));
close(fd);
...
fd = open("./myconfig", O_WRONLY | O_TRUNC | O_CREAT, S_IRUSR | S_IWUSR);
write(fd, myconfig_buf, sizeof(myconfig_buf));
close(fd);/* open and read configuration file e.g. ./myconfig */
fd = open("./myconfig", O_RDONLY);
read(fd, myconfig_buf, sizeof(myconfig_buf));
close(fd);
...
fd = open("./myconfig.suffix", O_WRONLY | O_TRUNC | O_CREAT, S_IRUSR | S_IWUSR
write(fd, myconfig_buf, sizeof(myconfig_buf));
fsync(fd); /* paranoia - optional */
...
close(fd);
rename("./myconfig", "./myconfig~"); /* paranoia - optional */
rename("./myconfig.suffix", "./myconfig");付録B 更新履歴
| 改訂履歴 | |||
|---|---|---|---|
| 改訂 2.2-9 | Mon Aug 05 2019 | ||
| |||
| 改訂 2.2-6 | Mon Jul 24 2017 | ||
| |||
| 改訂 2.2-5 | Tue Mar 21 2017 | ||
| |||
| 改訂 2.0-2 | Fri Oct 14 2016 | ||
| |||
| 改訂 2.0-1 | Wed 11 Nov 2015 | ||
| |||
| 改訂 1-3 | Fri 19 Jun 2015 | ||
| |||
| 改訂 1-2 | Wed 18 Feb 2015 | ||
| |||
| 改訂 1-1 | Thu Dec 4 2014 | ||
| |||
| 改訂 1.0-9 | Tue Jun 9 2014 | ||
| |||
| 改訂 0.9-1 | Fri May 9 2014 | ||
| |||
| 改訂 0.9-0 | Wed May 7 2014 | ||
| |||
| 改訂 0.1-1 | Thu Jan 17 2013 | ||
| |||