
導入ガイド
効果的なディレクトリーサービスを計画するための概念と設定オプション
概要
多様性を受け入れるオープンソースの強化
はじめに
1. Directory Server の概要
- マルチサプライヤーレプリケーション: 読み取りおよび書き込み両方の操作に高可用性のディレクトリーサービスを提供します。マルチサプライヤーレプリケーションは、簡単なレプリケーションシナリオおよびカスケードレプリケーションシナリオと組み合わせることで、柔軟性が高く、スケーラブルなレプリケーション環境を提供できます。
- チェーンおよび参照: 多数の Directory Server のデータをユーザーに透過的に維持しながら、ディレクトリーの完全な論理ビューを 1 台のサーバーに保存することで、ディレクトリーの能力を向上させます。
- ロールおよびサービスクラス: エントリー間で属性を動的にグループ化および共有するための柔軟なメカニズムを提供します。
- 効率的なアクセス制御メカニズム: ディレクトリーで使用されるアクセス制御ステートメントの数を大幅に削減し、アクセス制御評価のスケーラビリティーを高めるマクロに対応します。
- バインド DN によるリソース制限: クライアントのバインド DN に基づいて検索操作に割り当てられるサーバーリソースの量を制御する権限を付与します。
- 複数のデータベース: ディレクトリーサービスにおけるレプリケーションとチェーンの実装を簡素化するために、ディレクトリーデータをブレークダウンする簡単な方法を提供します。
- パスワードポリシーおよびアカウントのロックアウト: パスワードおよびユーザーアカウントを Directory Server で管理する方法を制御する一連のルールを定義します。
- TLS は、暗号化用の Mozilla Network Security Services (NSS) ライブラリーを使用して、ネットワーク上でのセキュアな認証と通信を提供します。
- LDAP サーバー: LDAP v3 準拠のネットワークデーモン
- Web コンソール: ディレクトリーサービスのセットアップと保守の作業を軽減するグラフィカル管理コンソール
- SNMP エージェント: Simple Network Management Protocol (SNMP) を使用して Directory Server を監視できます。
第1章 ディレクトリーサービスの概要
1.1. ディレクトリーサービスについて
- 場所、カラーまたは白黒、メーカー、購入日、シリアル番号など、組織内のプリンターのデータ等の物理デバイスの情報
- 名前、メールアドレス、部門などの公開されている従業員情報
- 給与、マイナンバー、自宅住所、電話番号、給与水準など、非公開の従業員情報
- クライアントの名前、最終納期、見積もり情報、契約番号、プロジェクト期日などの契約またはアカウント情報
1.1.1. グローバルディレクトリーサービスについて
1.1.2. LDAP について
1.2. Directory Server の概要
- コア Directory Server LDAP サーバー、LDAP v3 準拠のネットワークデーモン(ns-slapd)と、サーバーとそのデータベースを管理するための関連プラグイン、コマンドラインツール、その設定およびスキーマファイル。コマンドラインツールの詳細は、『Red Hat Directory Server 設定、コマンド、およびファイルリファレンス』を参照してください。
- Administration Server (LDAP サーバーにアクセスする異なるポータルを制御する Web サーバー)。Administration Server についての詳細は、『Red Hat Directory Server 管理ガイド』を参照してください。
- Web コンソール (ディレクトリーサービスのセットアップと保守の作業を軽減するグラフィカル管理コンソール)Web コンソールについての詳細は、『Red Hat Directory Server 管理ガイド』を参照してください。
- Simple Network Management Protocol (SNMP) を使用して Directory Server を監視する SNMP エージェント。SNMP による監視についての詳細は、『Red Hat Directory Server 管理ガイド』を参照してください。
1.2.1. サーバーフロントエンドの概要
1.2.2. サーバープラグインの概要
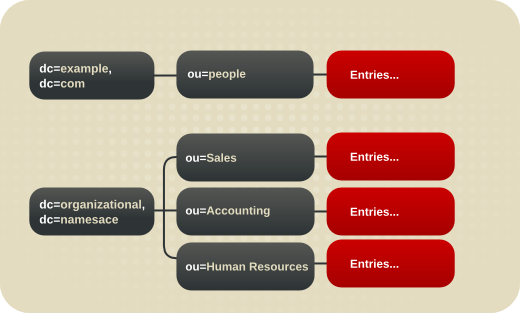
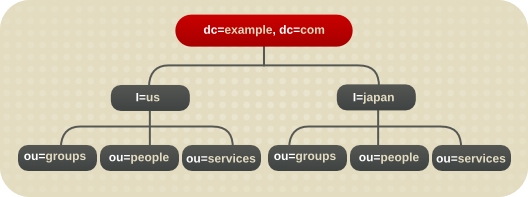
1.2.3. 基本的なディレクトリーツリーの概要
図1.1 デフォルトの Directory Server ディレクトリーツリーのレイアウト
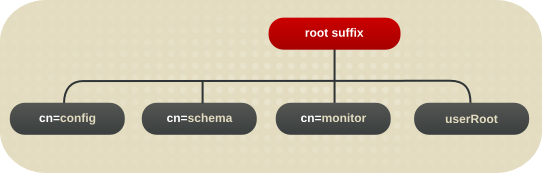
- cn=config: サーバーの内部設定に関する情報が含まれるサブツリー
- cn=monitor: Directory Server サーバーおよびデータベース監視統計が含まれるサブツリー
- cn=schema: 現在サーバーに読み込まれているスキーマ要素が含まれるサブツリー
- user_suffix: Directory Server の設定時に作成されるデフォルトのユーザーデータベースの接尾辞接尾辞の名前は、サーバーの作成時にユーザーが定義します。関連付けられたデータベースの名前は userRoot です。データベースには、セットアップ時に LDIF ファイルをインポートしてエントリーを投入することも、後でエントリーを追加することもできます。user_suffix 接尾辞には、頻繁に
dcの命名規則があります(例: dc=example,dc=com )。もう 1 つの一般的な命名属性はo属性で、組織全体に使用されます(例: o=example.com )。
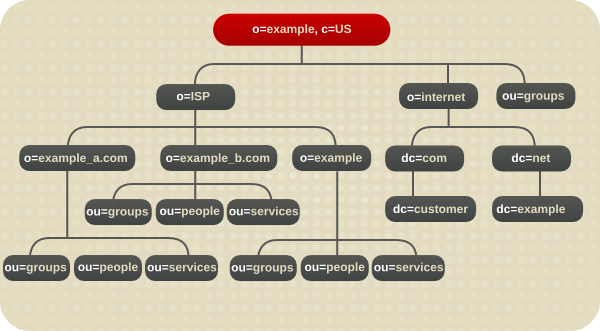
図1.2 Example Corp 用の拡張されたディレクトリーツリー
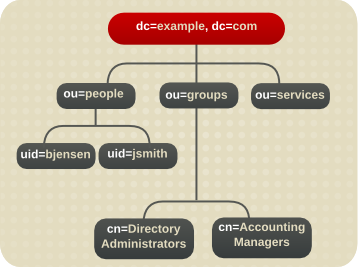
1.3. Directory Server のデータストレージ
1.3.1. ディレクトリーエントリーについて
givenname および telephoneNumber 属性をサポートします。これらの属性に割り当てられている値は、エントリーによって表される人員の名前と電話番号を提供します。
1.3.1.1. ディレクトリーエントリーでのクエリーの実行
1.3.2. ディレクトリーデータの分散
1.4. ディレクトリー設計の概要
1.4.1. 設計プロセスの概要
- ディレクトリーには、ユーザー名、電話番号、グループの詳細などのデータが含まれます。本章では、組織内のさまざまなデータソースを分析し、相互関係を理解します。これは、ディレクトリーに格納できるデータのタイプと、Directory Server の内容を設計するための他のタスクを説明します。
- ディレクトリーは、1 つ以上のディレクトリー対応アプリケーションをサポートするように設計されています。これらのアプリケーションには、ファイル形式などのディレクトリーに保存されているデータに対する要件があります。ディレクトリースキーマは、ディレクトリーに格納されているデータの特性を決定します。本章では、Directory Server に同梱される標準スキーマに加えて、スキーマをカスタマイズする方法および一貫性のあるスキーマを維持するためのヒントも紹介します。
- Directory Server に どのような 情報を含めるかを決定すると共に、その情報を どのように 整理して参照するかを決定することが重要です。本章では、ディレクトリーツリーを紹介し、データ階層の設計の概要を説明します。サンプルディレクトリーツリー設計も提供されます。
- トポロジー設計とは、ディレクトリーツリーを複数の物理 Directory Server に分割する方法、およびこれらのサーバーが相互に通信する方法を決定することを指します。設計の前提となる一般原則、複数のデータベースの使用、分散データの統合に使用できるメカニズム、およびディレクトリー自体が分散データを追跡する方法を、すべて本章で説明します。
- レプリケーションを使用すると、複数の Directory Server が同じディレクトリーデータを維持し、パフォーマンスが向上し、耐障害性が提供されます。本章では、レプリケーションの仕組み、レプリケーションできるデータタイプ、一般的なレプリケーションシナリオ、および高可用性ディレクトリーサービスを構築するためのヒントを紹介します。
- Red Hat Directory Server に保存されている情報は、Microsoft Active Directory データベースに保存されている情報と同期でき、複合プラットフォームインフラストラクチャーとの統合を向上させることができます。本章では、同期の仕組み、どのデータの種類を同期できるか、また同期に最適な情報のタイプおよびディレクトリーツリー内の場所についての考慮事項を説明します。
- 最後に、ユーザーおよびアプリケーションのセキュリティー要件を満たすために、ディレクトリー内のデータを保護する方法や、サービスの他の側面を計画します。本章では、一般的なセキュリティーの脅威、セキュリティーメソッドの概要、セキュリティーニーズの分析に関する手順、ならびにアクセス制御の設計およびディレクトリーデータの整合性の保護に関するヒントについて説明します。
1.4.2. ディレクトリーのデプロイ
- 必須リソースの推定
- 達成すべき事項および時期に関するスケジュール
- 導入の成功を測定するための基準セット
1.5. その他の一般的なディレクトリーリソース
- RFC 2849: The LDAP Data Interchange Format (LDIF) Technical Specification, http://www.ietf.org/rfc/rfc2849.txt
- RFC 2251: Lightweight Directory Access Protocol (v3) (http://www.ietf.org/rfc/rfc2251.txt)
- 『Understanding and Deploying LDAP Directory Services』T. Howes, M. Smith, G. Good, Macmillan Technical Publishing, 1999.
第2章 ディレクトリーデータのプランニング
2.1. ディレクトリーデータの概要
- 書き込みよりも読み取りが頻繁である。
- 複数の人やグループがそのデータに関心を持っている。たとえば、従業員の名前またはプリンターの場所には、多くの人やアプリケーションが関心を持ちます。
- 複数の物理的な場所からアクセスされる。
2.1.1. ディレクトリーに含める情報
- 電話番号、物理アドレス、メールアドレスなどの連絡先情報
- 従業員番号、ジョブタイトル、マネージャーまたは管理者 ID 、仕事に関する興味などの説明情報
- 組織の連絡先情報 (電話番号、物理アドレス、管理者 ID、ビジネスの説明など)
- プリンターの物理的な場所、プリンターの種類、プリンターが作成できる 1 分あたりのページ数などのデバイス情報
- 企業の取引パートナー、取引先、および顧客に関する連絡先および請求情報
- 顧客の名前、納期、ジョブの説明、課金情報などのコントラクト情報
- 個別のソフトウェア設定またはソフトウェア設定情報
- Web サーバーへのポインター、または特定のファイルまたはアプリケーションのファイルシステムなどのリソースサイト
- コントラクトまたはクライアントアカウントの詳細
- 給与データ
- 物理デバイス情報
- 自宅連絡先情報
- エンタープライズ内のさまざまなサイトに関するオフィスの連絡先情報
2.1.2. ディレクトリーから除外する情報
2.2. ディレクトリーニーズの定義
- 今ディレクトリーに何を格納すべきか
- ディレクトリーを導入するすることで、どんな直近の問題が解決されるか
- 使用中のディレクトリー対応アプリケーションの直近のニーズは何か
- 近日中にディレクトリーに追加される情報は何か。たとえば、ある企業では、現在 LDAP をサポートしていない会計パッケージを使用しているが、これが数ヶ月後に LDAP 対応になる可能性があります。LDAP 対応アプリケーションで使用されるデータを特定し、技術が利用可能になった時点でデータをディレクトリーに移行する計画を作成します。
- 今後、ディレクトリーに格納されている可能性のある情報は何か。たとえば、ホスト企業は、イメージやメディアファイルを格納する必要があるなど、現行の顧客とは異なるデータ要件を持つ顧客を持つ可能性があります。これは予測が困難な回答ですが、予期せぬ成果を生む場合があります。この種の計画は、少なくとも、考慮されなかった可能性のあるデータソースの特定に役立ちます。
2.3. サイト調査の実行
- ディレクトリーを使用するアプリケーションを特定する。エンタープライズ全体にデプロイされるディレクトリー対応アプリケーションとそのデータのニーズを判断する。
- データソースを特定する。企業の調査を行い、Active Directory、その他の LDAP サーバー、PBX システム、人材データベース、電子メールシステムなどのデータソースを特定する。
- ディレクトリーに含まれる必要のあるデータを特徴付ける。ディレクトリーに存在すべきオブジェクト (例: 人またはグループ) と、ディレクトリーで維持すべきオブジェクトの属性 (ユーザー名とパスワードなど) を決定します。
- 提供するサービスレベルを決定する。ディレクトリーデータをクライアントアプリケーションに提供する際の可用性を決定し、それに応じてアーキテクチャーを設計します。ディレクトリーに要求される可用性が、データのレプリケート方法およびリモートサーバーに保存されたデータを接続するためのチェーンポリシーの設定方法に影響を及ぼします。レプリケーションについての詳細は7章レプリケーションプロセスの設計を、チェーンの詳細についての詳細は「トポロジーの概要」を、それぞれ参照してください。
- データサプライヤーを特定する。データサプライヤーには、ディレクトリーデータのプライマリーソースが含まれます。このデータは、負荷分散および復元の目的で、他のサーバーにミラーリングされる可能性があります。各データで、データサプライヤーを決定します。
- データの所有者を決定する。各データについて、データが最新の状態であることを確認する担当者を決定します。
- データアクセスを決定する。データを他のソースからインポートする場合には、一括インポートと増分更新の両方のストラテジーを作成します。このストラテジーの一部として、データを 1 カ所で管理し、データを変更できるアプリケーションの数を制限するようにします。また、任意のデータに書き込みするユーザーの数を制限します。小規模なグループにより、管理のオーバーヘッドを削減しつつ、データの整合性が確保されます。
- サイト調査を文書化します。
2.3.1. ディレクトリーを使用するアプリケーションの特定
- オンライン電話帳などのディレクトリーブラウザーアプリケーション。ユーザーが必要な情報 (メールアドレス、電話番号、従業員名など) を決定し、ディレクトリーに追加します。
- 電子メールアプリケーション (特に電子メールサーバー)すべての電子メールサーバーには、ディレクトリーで利用可能なメールアドレス、ユーザー名、および一部のルーティング情報が必要です。ただし、ユーザーのメールボックスが格納されているディスク上の場所や、不在時の自動返信情報、プロトコル情報 (たとえば、IMAP と POP) など、より高度な情報が必要です。
- ディレクトリー対応人事アプリケーション。これには、マイナンバー、自宅住所、自宅電話番号、生年月日、所得、およびジョブタイトルなど、より個人的な情報が必要です。
- Microsoft Active Directory.Windows User Sync により、Windows ディレクトリーサービスを統合して、Directory Server と連動できます。どちらのディレクトリーでも、ユーザー情報 (ユーザー名とパスワード、メールアドレス、電話番号など) およびグループ情報 (メンバー) を保存できます。ユーザー、グループ、その他のディレクトリーデータがスムーズに同期できるように、既存の Windows サーバー導入の後に Directory Server の導入をスタイルします (またはその逆)。
表2.1 アプリケーションデータニーズの例
| アプリケーション | データのクラス | データ |
|---|---|---|
| 電話帳 | 人 | 名前、メールアドレス、電話番号、ユーザー ID、パスワード、部署番号、マネージャー、メール停止 |
| Web サーバー | 人、グループ | ユーザー ID、パスワード、グループ名、グループメンバー、グループ所有者 |
| カレンダーサーバー | 人、会議室 | 名前、ユーザー ID、立方数、会議室名 |
- さまざまなレガシーアプリケーションとユーザーが必要とするデータ
- レガシーアプリケーションの LDAP ディレクトリーと通信する能力
2.3.2. データソースの特定
- 情報を提供する組織を特定する。エンタープライズにとって必要とされる情報を管理するすべての組織を見つけます。通常、これには情報サービス、人事、支払い部門、経理部門が含まれます。
- 情報ソースであるツールおよびプロセスを特定する。情報の一般的なソースには、ネットワークオペレーティングシステム (Windows、Willell Netware、UNIX NIS)、電子メールシステム、セキュリティーシステム、PBX (電話交換) システム、および人事アプリケーションなどがあります。
- 各データを一元化する方法を判断することが、データの管理に影響を及ぼします。集中データ管理では、新しいツールおよび新しいプロセスが必要になる場合があります。集中化により、一部の組織でスタッフを増やす必要があり、他の組織のスタッフが減少する必要があることがあります。
表2.2 情報ソースの例
| データソース | データのクラス | データ |
|---|---|---|
| 人事データベース | 人 | 名前、住所、電話番号、部署番号、マネージャー |
| E メールシステム | 人、グループ | 名前、メールアドレス、ユーザー ID、パスワード、電子メール設定 |
| ファシリティーシステム | ファシリティー | ビル名、フロア名、立方数、アクセスコード |
2.3.3. ディレクトリーデータの特徴付け
- 形式
- サイズ
- 各種アプリケーションで発生回数
- データの所有者
- 他のディレクトリーデータとの関係
表2.3 ディレクトリーデータの特徴付け
| データ | 形式 | サイズ | 所有者 | 関連 |
|---|---|---|---|---|
| 従業員名 | テキスト文字列 | 128 文字 | 人事 | ユーザーエントリー |
| Fax 番号 | 電話番号 | 14 桁の数字 | ファシリティー | ユーザーエントリー |
| メールアドレス | テキスト | 多くの文字 | 情報システム部門 | ユーザーエントリー |
2.3.4. サービスレベルの決定
2.3.5. データサプライヤーの検討
- Directory Server 間でのレプリケーション
- Directory Server と Active Directory との間の同期
- Directory Server データにアクセスする独立したクライアントアプリケーション
- ディレクトリーと、ディレクトリーを使用しないすべてのアプリケーションの両方でデータを管理する。複数のデータサプライヤーを維持する場合、ディレクトリーおよびその他のアプリケーションにデータを出し入れするのにカスタムスクリプトは必要ありません。ただし、データが 1 カ所で変更された場合は、他のすべてのサイトでデータを変更する必要があります。ディレクトリーおよびディレクトリーを使用しないすべてのアプリケーションでサプライヤーデータを維持すると、データが企業全体で同期されないことになります (ディレクトリーはこれを防ぐことが期待されます)。
- ディレクトリー以外の一部のアプリケーションでデータを管理し、スクリプト、プログラム、またはゲートウェイを作成し、そのデータをディレクトリーにインポートする。データを管理するのにすでに使用されているアプリケーションが 1 つまたは 2 つある場合には、ディレクトリーを使用しないアプリケーションでデータを管理するのが最も妥当です。ディレクトリーは検索にのみ使用されます (例: オンラインの企業電話帳)。
2.3.6. データオーナーの決定
- ディレクトリーコンテンツマネージャーの小さなグループ以外のすべてのユーザーに対して、ディレクトリーへの読み取り専用アクセスを許可します。
- 個々のユーザーが、自分に関する情報の戦略的サブセットを管理できるようにします。この情報のサブセットには、パスワード、自身の説明情報、組織内のロールり、ナンバープレートの番号、電話番号やオフィス番号などの連絡先情報が含まれる可能性があります。
- ユーザーのマネージャーに、連絡先情報やジョブタイトルなど、そのユーザーの情報の戦略的サブセットへの書き込みを可能にします。
- 組織の管理者が、その組織のエントリーを作成して管理できるようにします。この方法では、組織の管理者がディレクトリーコンテンツマネージャーとして機能します。
- 読み取りまたは書き込みアクセス権限を持つユーザーグループのロールを作成します。たとえば、人事、会計、またはアカウンティング向けに作成されたロールがあります。これらの各ロールに、そのグループが必要とするデータへの読み取りアクセス、書き込みアクセス、またはその両方を許可します。これには、給与情報、マイナンバー、および自宅電話番号および住所が含まれる可能性があります。ロールおよびエントリーのグループ化の詳細は、「ディレクトリーエントリーのグループ化」を参照してください。
2.3.7. データアクセスの決定
- データは匿名で読み取りできるかLDAP プロトコルは匿名アクセスをサポートし、オフィスサイト、メールアドレス、ビジネス電話番号などの情報を簡単に検索することができます。ただし、匿名アクセスにより、誰でも共通情報へのディレクトリーアクセスが可能になります。したがって、匿名アクセスの使用は限定的にします。
- データは企業全体で読み取りできるかアクセス制御は、クライアントが特定の情報を読み取るためにディレクトリーへのログイン (またはバインド) する必要があるように設定できます。匿名アクセスとは異なり、この形式のアクセス制御により、組織のメンバーのみがディレクトリー情報を表示できます。また、ディレクトリーのアクセスログにログイン情報を取得するので、誰が情報にアクセスしたかが記録に残ります。アクセス制御の詳細は、「アクセス制御の設計」を参照してください。
- データの読み取りが必要な人やアプリケーションの特定可能なグループはあるかデータへの書き込み権限があるユーザーは、通常 (パスワードへの書き込みアクセスを除き) 読み取りアクセスが必要です。特定の組織またはプロジェクトグループに固有のデータがある場合もあります。これらのアクセスのニーズを特定することは、ディレクトリーが必要とするグループ、ロール、およびアクセス制御を把握するのに役立ちます。グループおよびロールの詳細は、4章ディレクトリーツリーの設計を参照してください。アクセス制御の詳細は、「アクセス制御の設計」を参照してください。
2.4. サイト調査の文書化
表2.4 例: データ所有者およびアクセスのリスト
| データ名 | 所有者 | サプライヤーサーバー/アプリケーション | 自己読み取り/書き込み | グローバルな読み取り | 人事部門による書き込み | 情報システム部門による書き込み |
|---|---|---|---|---|---|---|
| 従業員名 | HR | PeopleSoft | 読み取り専用 | ◯ (匿名) | はい | はい |
| ユーザーパスワード | IS | Directory US-1 | 読み取り/書き込み | ✕ | ✕ | ○ |
| 自宅電話番号 | HR | PeopleSoft | 読み取り/書き込み | ✕ | ○ | ✕ |
| 従業員のロケーション | IS | Directory US-1 | 読み取り専用 | ○ (ログインが必要) | ✕ | ○ |
| オフィスの電話番号 | ファシリティー | Phone switch | 読み取り専用 | ◯ (匿名) | ✕ | ✕ |
- 所有者:人事部門はこの情報を所有しているため、更新や変更を行います。
- サプライヤーサーバー/アプリケーション:PeopleSoft アプリケーションは従業員名の情報を管理します。
- 自己読み取り/書き込み:ユーザーは自分の名前を読み取ることができますが、書き込み (または変更) することはできません。
- グローバルな読み取り:従業員名は、ディレクトリーへのアクセスがあるすべてのユーザーが匿名で読み取ることができます。
- 人事部門による書き込み:人事グループのメンバーは、ディレクトリー内の従業員名を変更、追加、および削除できます。
- 情報システム部門による書き込み:情報サービスグループのメンバーは、ディレクトリー内の従業員名を変更、追加、および削除できます。
2.5. サイト調査の繰り返し
第3章 ディレクトリースキーマの設計
3.1. スキーマ設計プロセスの概要
- 可能な限り多くのデータニーズに合わせて事前定義されたスキーマ要素を選択する。
- 標準の Directory Server スキーマを拡張して、その他の残りのニーズを満たす新しい要素を定義する。
- スキーマメンテナンスをプランニングする。
3.2. 標準スキーマ
3.2.1. スキーマの形式
objectclasses: ( 2.5.6.6 NAME 'person' DESC 'Standard Person Object Class' SUP top
MUST (objectclass $ sn $ cn) MAY (description $ seeAlso $ telephoneNumber $ userPassword)
X-ORIGIN 'RFC 2252' )objectclass、sn、および cn)、および許可される属性(description、seeAlso、telephoneNumber、および userPassword)を記載します。
3.2.2. 標準属性
commonName (cn))。そのため、Babs Jensen という名前のユーザーのエントリーには、属性データペア cn: Babs Jensen があります。
dn: uid=bjensen,ou=people,dc=example,dc=com objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson cn: Babs Jensen sn: Jensen givenName: Babs givenName: Barbara mail: bjensen@example.com
givenName 属性は、それぞれ一意の値で 2 回表示されます。
- 一意な名前
- 属性のオブジェクト識別子 (OID)
- 属性のテキストでの説明
- 属性構文の OID
- 属性が単一値か複数値かどうか、属性がディレクトリー専用かどうか、属性の元、および属性に関連付けられた追加のマッチングルールを示します。
cn 属性定義は以下のようにスキーマに表示されます。
attributetypes: ( 2.5.4.3 NAME 'cn' DESC 'commonName Standard Attribute'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 )3.2.3. 標準のオブジェクトクラス
- 一意な名前
- オブジェクトの名前である オブジェクト識別子 (OID)
- 必須属性のセット
- 可能な (または任意の) 属性のセット
objectclasses: ( 2.5.6.6 NAME 'person' DESC 'Standard Person Object Class' SUP top
MUST (objectclass $ sn $ cn) MAY (description $ seeAlso $ telephoneNumber $ userPassword)
X-ORIGIN 'RFC 2252' )3.3. データのデフォルトスキーマへのマッピング
3.3.1. デフォルトのディレクトリースキーマの表示
/usr/share/dirsrv/schema/ ディレクトリーに保存されます。
00core.ldif ファイルにあります。以前のバージョンのディレクトリーで使用される設定スキーマは 50ns-directory.ldif ファイルにあります。
3.3.2. スキーマ要素へのデータのマッチング
- データが記述するオブジェクトのタイプを特定する。サイト調査で説明されるデータに最もマッチするオブジェクトを選択します。データは、複数のオブジェクトを記述できる場合があります。ディレクトリースキーマで違い記述する必要があるかどうかを判断します。たとえば、電話番号は、従業員の電話番号と会議部屋の電話番号を記述できます。ディレクトリースキーマで、これらの異なるデータを異なるオブジェクトとして見なす必要があるかどうかを判断します。
- デフォルトスキーマから類似のオブジェクトクラスを選択する。グループ、ユーザー、組織など、共通のオブジェクトクラスを使用すると良いでしょう。
- マッチするオブジェクトクラスから類似の属性を選択する。マッチするオブジェクトクラスから、サイト調査で特定されたデータと最もマッチする属性を選択します。
- サイト調査からマッチしないデータを特定する。デフォルトのディレクトリースキーマで定義されたオブジェクトクラスおよび属性とマッチしないデータがある場合には、スキーマをカスタマイズします。詳細は、「スキーマのカスタマイズ」を参照してください。
表3.1 デフォルトのディレクトリースキーマにマッピングされるデータ
| データ | 所有者 | オブジェクトクラス | 属性 |
|---|---|---|---|
| 従業員名 | HR | person | cn (commonName) |
| ユーザーパスワード | IS | person | userPassword |
| 自宅電話番号 | HR | inetOrgPerson | homePhone |
| 従業員のロケーション | IS | inetOrgPerson | localityName |
| オフィスの電話番号 | ファシリティー | person | telephoneNumber |
cn または commonName 属性)がユーザーのフルネームを記述することを許可します。この属性は、従業員名データを含めるのに最もマッチします。
userPassword 属性は person オブジェクトクラスの許可される属性に一覧表示されます。
homePhone 属性があります。
3.4. スキーマのカスタマイズ
- スキーマはできるだけシンプルに保ちます。
- 可能であれば、既存のスキーマ要素を再利用します。
- 各オブジェクトクラスに定義される必須属性の数を最小限に抑える。
- 複数のオブジェクトクラスまたは属性を同じ目的 (データ) に定義しないでください。
- 属性またはオブジェクトクラスの既存の定義は変更しないでください。
99user.ldif ファイルで定義されます。個々のインスタンスは、/etc/dirsrv/slapd-instance_name/schema/ ディレクトリーに独自の 99user.ldif ファイルを維持します。カスタムスキーマファイルを作成し、スキーマを動的にサーバーにリロードすることもできます。
3.4.1. スキーマを拡張するケース
3.4.2. オブジェクト識別子の取得と割り当て
- Internet Assigned Numbers Authority (IANA) または国際的な組織から OID を取得します。国によっては、企業に OID がすでに割り当てられています。組織に OID がない場合は、IANA から取得できます。詳細は、IANA の Web サイト (http://www.iana.org/cgi-bin/enterprise.pl) にアクセスしてください。
- OID 割り当てを追跡する OID レジストリーを作成します。OID レジストリーは、OID と、ディレクトリースキーマで使用される OID の説明のリストです。これにより、OID が複数の目的に使用されないようにします。次に、スキーマに OID レジストリーをパブリッシュします。
- スキーマ要素に対応するために OID ツリーでブランチを作成します。属性に OID.1 を、オブジェクトクラスに OID.2 を使用して、OIDブランチまたはディレクトリースキーマに少なくとも 2 つのブランチを作成します。カスタムマッチングルールまたは制御を定義するには、必要に応じて新規ブランチを追加します(例:OID.3 )。
3.4.3. 命名属性およびオブジェクトクラス
3.4.4. 新規オブジェクトクラスを定義するストラテジー
- 属性を追加する各オブジェクトクラス構造に対して、多くの新規オブジェクトクラスを作成します。
- ディレクトリーに作成されるすべてのカスタム属性をサポートする単一のオブジェクトクラスを作成します。この種類のオブジェクトクラスは、補助オブジェクトクラスとして定義して作成します。
exampleDateOfBirth、examplePreferredOS、exampleBuildingFloor、および exampleVicePresident を作成するとします。簡単なソリューションは、これらの属性のサブセットを許可する複数のオブジェクトクラスを作成することです。
- 1 つのオブジェクトクラス examplePerson が作成され、
exampleDateOfBirthおよびexamplePreferredOSを許可します。examplePerson の親は inetOrgPerson です。 - 2 つ目のオブジェクトクラス exampleOrganization は、
exampleBuildingFloorおよびexampleVicePresidentを許可します。exampleOrganization の親は、organization オブジェクトクラスです。
objectclasses: ( 2.16.840.1.117370.999.1.2.3 NAME 'examplePerson' DESC 'Example Person Object Class'
SUP inetorgPerson MAY (exampleDateOfBirth $ examplePreferredOS) )
objectclasses: ( 2.16.840.1.117370.999.1.2.4 NAME 'exampleOrganization' DESC 'Organization Object Class'
SUP organization MAY (exampleBuildingFloor $ exampleVicePresident) )objectclasses: (2.16.840.1.117370.999.1.2.5 NAME 'exampleEntry' DESC 'Standard Entry Object Class' SUP top
AUXILIARY MAY (exampleDateOfBirth $ examplePreferredOS $ exampleBuildingFloor $ exampleVicePresident) )- 複数のオブジェクトクラスによって、作成および維持するスキーマ要素がより多くなります。通常、要素の数が小さいため、メンテナンスはほとんど必要ありません。ただし、スキーマに 2 つ以上のオブジェクトクラスが追加されている場合は、単一のオブジェクトクラスを使用するのがより簡単です。
- 複数のオブジェクトクラスの場合には、より注意深い厳密なデータ設計が必要です。厳密なデータ設計により、すべてのデータが置かれるオブジェクトクラス構造に注意を払うことが強制されます。これには、便利な面と面倒な面があります。
- 人とアセットエントリーの両方など、複数のタイプのオブジェクトクラスに適用できるデータがある場合に、単一のオブジェクトクラスはデータ設計を簡素化します。たとえば、カスタムの
preferredOS属性は、ユーザーエントリーとグループエントリーの両方に設定できます。単一のオブジェクトクラスは両方のタイプのエントリーでこの属性を許可できます。 - 新規オブジェクトクラスには、必要な属性は使用しないでください。新規オブジェクトクラスの属性に
許可ではなく必要を指定すると、スキーマが柔軟ではなくなります。新規オブジェクトクラスを作成する場合には、できるだけ必要でなく許可を使用します。新しいオブジェクトクラスを定義したら、許可および必要な属性、ならびに属性を継承するオブジェクトクラスを決定します。
3.4.5. 新規属性を定義する際のストラテジー
dateOfBirth を作成し、新しい補助オブジェクトクラス examplePerson 内で許可される属性として設定できます。
attributetypes: ( dateofbirth-oid NAME 'dateofbirth' DESC 'For employee birthdays'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 X-ORIGIN 'Example defined')
objectclasses: ( 2.16.840.1.117370.999.1.2.3 NAME 'examplePerson' DESC 'Example Person Object Class'
SUP inetorgPerson MAY (exampleDateOfBirth $ cn) X-ORIGIN 'Example defined')3.4.6. スキーマ要素の削除
3.4.7. カスタムスキーマファイルの作成
99user.ldif ファイルに加えて、Directory Server が使用するカスタムスキーマファイルを作成できます。これらのスキーマファイルは、組織に固有の新しいカスタム属性とオブジェクトクラスを保持します。新しいスキーマファイルは、スキーマディレクトリー /etc/dirsrv/slapd-instance_name/schema/ に配置する必要があります。
99user.ldif より数字またはアルファベット順で高くしないでください。そうしないと、サーバーで問題が発生する可能性があります。
- このカスタムスキーマファイルをインスタンスのスキーマディレクトリー
/etc/dirsrv/slapd-instance/schemaに手動でコピーします。スキーマをロードするには、サーバーを再起動するか、schema-reload.pl スクリプトを実行してスキーマを動的にリロードします。 - Web コンソールまたは ldapmodify などの LDAP クライアントでサーバーのスキーマを変更します。
- サーバーがレプリケートされたら、レプリケーションプロセスがスキーマ情報を各コンシューマーサーバーにコピーするのを許可します。レプリケーションでは、レプリケートされたスキーマ要素はすべてコンシューマーサーバーの
99user.ldifファイルにコピーされます。90example_schema.ldifなどのカスタムスキーマファイルにスキーマを保持するには、ファイルを手動でコンシューマーサーバーにコピーする必要があります。レプリケーションは、スキーマファイルをコピーしません。
99user.ldif ファイルに保存されます。このディレクトリーは、スキーマ定義の保存場所を追跡しません。コンシューマーの 99user.ldif ファイルにスキーマ要素を保存しても、スキーマがサプライヤーサーバーでのみ維持されている限り、問題はありません。
99user.ldif ファイルに複製され保存される可能性があります。99user.ldif ファイルに変更を加えると、スキーマ管理が困難になる可能性があります。これは、一部の属性がコンシューマー上の 2 つの別個のスキーマファイルに表示されるためです。1 度は、サプライヤーからコピーされた元のカスタムスキーマファイルで、レプリケーション後に 99user.ldif ファイルに再度表示されるためです。
3.4.8. カスタムスキーマのベストプラクティス
3.4.8.1. スキーマファイルの命名
[00-99]yourName.ldif
99user.ldif よりも低いもの(数字とアルファベット順)のカスタムスキーマファイルに名前を付けます。これにより、LDAP ツールと Web コンソールの両方で、Directory Server が 99user.ldif への書き込みが可能になります。
99user.ldif ファイルには、X-ORIGIN 値が 'user defined' の属性が含まれます。ただし、Directory Server は、すべての ユーザー定義のスキーマ要素を、数値順でアルファベット順に名前の高いファイルに書き込みます。99zzz.ldif という名前のスキーマファイルがある場合、次にスキーマが更新されるとき(LDAP コマンドラインツールまたは Web コンソールを使用)、'user defined' の値を持つ X-ORIGIN 属性はすべて 99zzz.ldif に書き込まれます。結果は、重複情報が含まれる 2 つの LDIF ファイルであり、99zzz.ldif ファイルの一部の情報が消去される可能性があります。
3.4.8.2. Origin として 'user defined' の使用
60example.ldif)の X-ORIGIN フィールドに 'user defined' を使用し ない でください。カスタムスキーマファイルで、'Example Corp. defined' などの説明的なものを使用します。
99user.ldif に直接追加する場合は、'user defined' を X-ORIGIN の値として使用します。別の X-ORIGIN 値を設定すると、サーバーはそれを上書きする可能性があります。
99user.ldif ファイルのスキーマ定義が Directory Server によってファイルから削除されないようにします。Directory Server は、'user defined' の値の X-ORIGIN を使用して、99user.ldif ファイルに存在する必要がある要素を指示するため、これらを削除しません。
attributetypes: ( exampleContact-oid NAME 'exampleContact' DESC 'Example Corporate contact' SYNTAX 1.3.6.1.4.1.1466.115.121.1.15 X-ORIGIN 'Example defined')
attributetypes: ( exampleContact-oid NAME 'exampleContact'
DESC 'Example Corporate contact'
SYNTAX 1.3.6.1.4.1.1466.115.121.1.15
X-ORIGIN ('Example defined' 'user defined') )3.4.8.3. オブジェクトクラスの前の属性の定義
3.4.8.4. 単一ファイルでのスキーマの定義
- 各スキーマファイルにどのスキーマ要素が含まれているかに注意してください。
- スキーマファイルの命名および更新には注意が必要です。スキーマ要素が LDAP ツールを使用して編集されると、変更が自動的に最後のファイル (アルファベット順) に書き込まれます。ほとんどのスキーマの変更は、デフォルトのファイル
99user.ldifに書き込みます。これは、60example.ldifなどのカスタムスキーマファイルではありません。また、99user.ldifのスキーマ要素は、他のスキーマファイルの重複要素を上書きします。 - すべてのスキーマ定義を
99user.ldifファイルに追加します。これは、Web コンソールからスキーマを管理している場合に便利です。
3.5. 一貫性のあるスキーマの維持
- スキーマチェックを使用して、属性とオブジェクトクラスがスキーマルールに準拠していることを確認します。
- 構文検証を使用して、属性値が必要な属性構文と一致するようにします。
- 一貫性のあるデータ形式を選択して適用します。
3.5.1. スキーマチェック
cn)および姓(sn)属性が必要です。つまり、エントリーの作成時にこれらの属性の値を設定する必要があります。さらに、telephoneNumber、uid、streetAddress、および userPassword などの説明的な属性など、エントリーでオプションで使用できる属性のリストがあります。
3.5.2. 構文の検証
telephoneNumber 属性に、実際にその値に有効な電話番号が指定されていることを確認します。
3.5.2.1. 構文の検証の概要
3.5.2.2. 構文の検証およびその他の Directory Server 操作
データベース暗号化
通常の LDAP 操作では、値がデータベースに書き込まれる直前に属性は暗号化されます。これは、属性構文の検証 後に 暗号化が実行されることを意味します。
-E フラグを使用して行うことが強く推奨されます。これにより、インポート操作で構文の検証が問題になる可能性もあります。ただし、-E フラグを使用せずに暗号化されたデータベースをエクスポートする場合は (サポートされていない)、暗号化された値で LDIF が作成されます。この LDIF をインポートすると、暗号化された属性を検証できず、警告がログに記録され、インポートされたエントリーで属性検証はスキップされます。
同期
Windows Active Directory エントリーと Red Hat Directory Server エントリーでは、属性の許容構文または強制構文に違いがある場合があります。この場合、構文の検証により Directory Server エントリーの RFC 標準が強制されるため、Active Directory の値を適切に同期できませんでした。
レプリケーション
Directory Server 11.0 インスタンスがコンシューマーに変更を複製するサプライヤーである場合は、構文検証の使用に問題はありません。ただし、レプリケーションのサプライヤーが古いバージョンの Directory Server であったり、構文の検証が無効になっていたりする場合は、Directory Server 11.0 コンシューマーは、サプライヤーが許可する属性値を拒否する可能性があるため、構文の検証を 11.0 コンシューマーで使用しないでください。
3.5.3. 一貫性のあるデータフォーマットの選択
- ITU-T Recommendation E.123:国内およびおよび国際電話番号の記法
- ITU-T Recommendation E.163:国際的な電話サービスの番号付けプランたとえば、米国の電話番号は +1 555 222 1717 としてフォーマットされます。
postalAddress 属性は、ドル記号($)を行区切り文字として使用する複数行の文字列の形式の属性値を想定します。適切にフォーマットされたディレクトリーエントリーは以下のように表示されます。
postalAddress: 1206 Directory Drive$Pleasant View, MN$34200
3.5.4. 複製されたスキーマでの一貫性の維持
- 読み取り専用レプリカでスキーマを変更しないでください。読み取り専用レプリカでスキーマを変更すると、スキーマで不整合が生じ、レプリケーションが失敗します。
- 異なる構文を使用する同じ名前の属性を 2 つ作成しないでください。読み取り/書き込みレプリカで作成された属性がサプライヤーレプリカ上の属性と同じ名前を持ち、サプライヤー上の属性とは異なる構文を持つ場合、レプリケーションは失敗します。
3.6. その他のスキーマリソース
- RFC 2251: Lightweight Directory Access Protocol (v3) (http://www.ietf.org/rfc/rfc2251.txt)
- RFC 2252: LDAPv3 Attribute Syntax Definitions (http://www.ietf.org/rfc/rfc2252.txt)
- RFC 2256: Summary of the X.500 User Schema for Use with LDAPv3 (http://www.ietf.org/rfc/rfc2256.txt)
- Internet Engineering Task Force (IETF) (http://www.ietf.org/)
- 『Understanding and Deploying LDAP Directory Services』T. Howes, M. Smith, G. Good, Macmillan Technical Publishing, 1999.
第4章 ディレクトリーツリーの設計
4.1. ディレクトリーツリーの概要
- ディレクトリーデータのメンテナンスの簡素化
- レプリケーションポリシーおよびアクセス制御の作成の柔軟性
- ディレクトリーサービスを使用するアプリケーションのサポート
- ディレクトリーユーザーの簡素化されたディレクトリーナビゲーション
4.2. ディレクトリーツリーの設計
- データを含めるための接尾辞を選択する。
- データエントリー間での階層関係を決定する。
- ディレクトリーツリー階層のエントリーに名前を付ける。
4.2.1. 接尾辞の選択
4.2.1.1. 接尾辞の命名規則
- グローバルに一意であること
- 静的であること、したがって、ほとんど変更されないこと。
- ルートディレクトリーの下にあるエントリーが画面で読みやすいように、短いこと
- 入力と覚えておくのが簡単なこと
dc 属性は、ドメイン名をコンポーネント部分に分割することで接尾辞を表します。
dcドメイン名のコンポーネントを定義します。cISO で定義されている国名を表す 2 桁のコードが含まれます。lエントリーが配置されている、またはエントリーに関連付けられている国、都市、またはその他の地理的エリアを識別します。stエントリーが存在する州または地区を識別します。oエントリーが属する組織の名前を識別します。
4.2.1.2. 複数接尾辞の命名
図4.1 データベースへの複数のディレクトリーツリーの追加
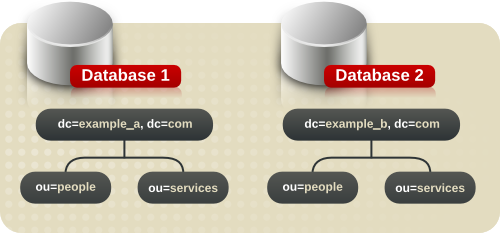
4.2.2. ディレクトリーツリー構造の作成
4.2.2.1. ディレクトリーの分岐
- 企業内の最大下部組織を表すツリーだけを分岐します。このような分岐点は、法務サービス、カスタマーサポート、セールス、エンジニアリングなどの部門に制限する必要があります。ディレクトリーツリーの分岐に使用される部門を一定にいます。企業が頻繁に再編成する場合は、このような分岐は実行しないでください。
- 分岐点には、実際の組織名ではなく、機能または汎用名を使用します。名前の変更サブツリーの名前を変更できますが、多くの子エントリーを持つ大きな接尾辞では、長くリソースを必要とするプロセスになります。組織の機能を表す汎用名(例: Widget Research and Developmentの代わりに Engineering を使用)を使用すると、組織またはプロジェクトの変更後にサブツリーの名前を変更する必要がはるかに低くなります。
- 同様の機能を実行する組織が複数になる場合は、部門をベースに分岐するのではなく、その機能に対して分岐点を 1 つ作成してみてください。たとえば、特定の製品ラインを担当するマーケティング組織が複数存在する場合でも、ou=Marketing サブツリーを 1 つ作成します。すべてのマーケティングエントリーはそのツリーに属します。
エンタープライズ環境における分岐
ディレクトリーツリー構造が変更されない情報に基づいている場合、名前の変更は回避できます。たとえば、組織ではなくツリー内のオブジェクトのタイプを構造のベースとします。これは、組織ユニット間でエントリーをシャッフルするのを回避するのに役立ちます。シャッフルする場合、コストのかかる操作である識別名 (DN) の変更が必要になります。
- ou=people
- ou=groups
- ou=services
図4.2 環境ディレクトリーツリーの例
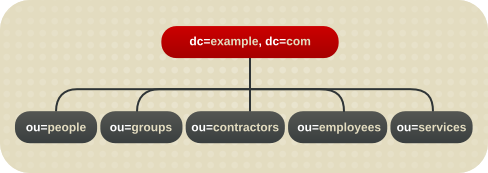
ホスト環境でのブランチング
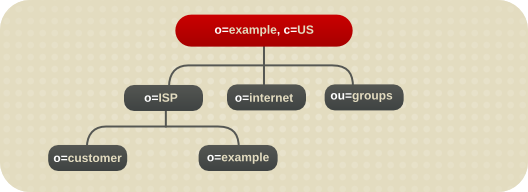
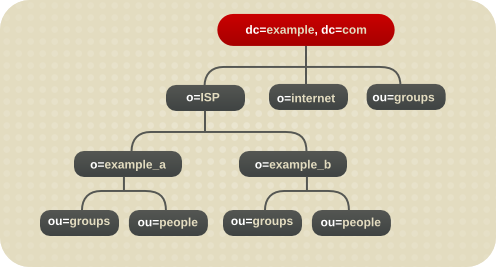
ホスト環境の場合は、ルート接尾辞の下に、オブジェクトクラス organization oの 2 つのエントリーとオブジェクトクラスの 1 つのエントリーを含むツリーを作成します。organizationalUnit ouたとえば、Example ISP は、ディレクトリーを以下のように分岐します。
図4.3 ホストディレクトリーツリーの例
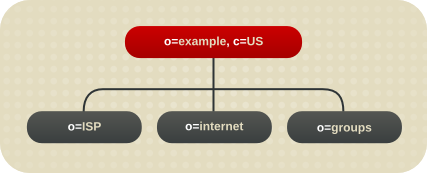
4.2.2.2. 分岐点の特定
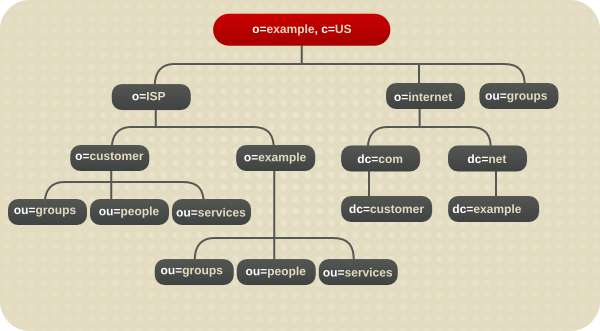
図4.4 Example Corp のディレクトリーツリー
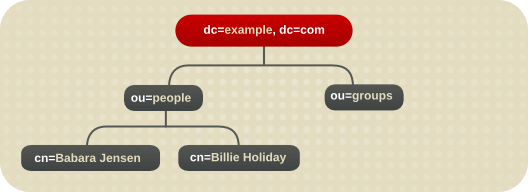
図4.5 Example ISP のディレクトリーツリー
- 一貫性を持たせる必要があります。ディレクトリーツリー全体で識別名 (DN) 形式に一貫性がない場合、一部の LDAP クライアントアプリケーションは混同する可能性があります。つまり、ディレクトリーツリーの 1 つで
lがouに従属する場合、ディレクトリーサービスの他の部分でlがouに従属するようにします。 - 従来の属性 (「分岐点の特定」に示す) のみの使用を試みます。従来の属性を使用すると、サードパーティーの LDAP クライアントアプリケーションとの互換性を維持する可能性が高まります。従来の属性を使用すれば、デフォルトのディレクトリースキーマに認識されるため、ブランチ DN のエントリーの構築が容易になります。
表4.1 従来の DN 分岐点属性
| 属性 | 定義 |
|---|---|
dc | dc=example などのドメイン名の要素。これは、dc=example,dc=com や dc= mtv, dc=example,dc=com など、ドメインに応じてペアまたはそれ以上で指定されます。 |
c | 国名。 |
o | 組織名。この属性は、通常、「接尾辞の命名規則」のように、企業の部門、学問 (人間、サイエンス)、子会社、または企業内のその他の主要なブランチなど、大規模な部門の分岐を表すために使用されます。 |
ou | 組織単位。この属性は、通常、組織よりも小さな企業部門のブランチを表すために使用されます。通常、組織単位は前述の組織に従属します。 |
st | 州または地区名。 |
l または、以下を実行します。 locality | 都市、国、オフィス、またはファシリティー名などのローカリティー。 |
4.2.2.3. レプリケーションに関する考慮事項
図4.6 Example Corp. のディレクトリーツリーの初期分岐
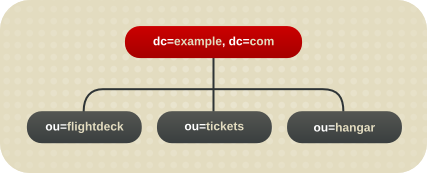
図4.7 Example Corp. の拡張ブランチ
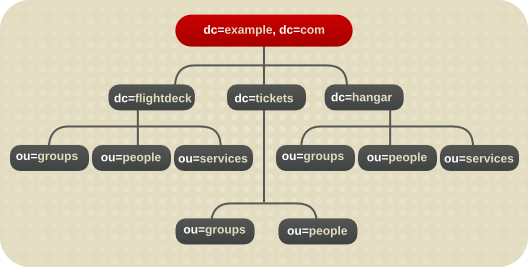
図4.8 Example ISP のディレクトリーの分岐
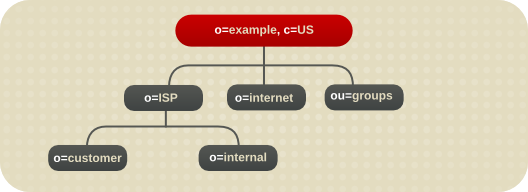
図4.9 Example ISP の拡張ブランチ
4.2.2.4. アクセス制御に関する考慮事項
4.2.3. エントリーの命名
- 命名用に選択される属性は、変更されてないけません。
- この名前は、ディレクトリー全体で一意でなければなりません。一意の名前により、DN は最大でも 1 つのディレクトリー内のエントリーを確認できるようになります。
l を使用しないでください。また、組織単位を表すのに c を使用しないでください。
4.2.3.1. 人物エントリーの命名
commonName または cn 属性を使用して人物エントリーに名前を付けます。つまり、Babs Jensen という名前のユーザーのエントリーは、cn=Babs Jensen,dc=example,dc=com の識別名になります。
cn 以外の属性を持つ個人のエントリーを特定することです。以下の属性のいずれかを使用することを検討してください。
uiduid属性を使用して、個人の一意の値を指定します。可能性としては、ユーザーログイン ID または従業員番号が含まれます。ホスト環境のサブスクライバーは、uid属性で識別する必要があります。mailmail属性には、常に一意のユーザーのメールアドレスが含まれます。このオプションを使用すると、重複した属性値(例: mail=bjensen@example.com,dc=example,dc=com)を含む awkward DN が発生する可能性があるため、uid属性で使用する他の一意の値がない場合に限りこのオプションを使用します。たとえば、企業が一時的または契約社員に従業員番号やユーザー ID を割り当てない場合は、mail属性の代わりにuid属性を使用します。employeeNumberinetOrgPerson オブジェクトクラスの従業員の場合は、employeeNumberなどの勤務担当者が割り当てた属性値を使用することを検討してください。
uid および cn 属性に人間が判読できる名前が使用されることを想定しています。
ホストされる環境の人物エントリーに関する考慮事項
人物がサービスへのサブスクライバーである場合、エントリーはオブジェクトクラス inetUser になり、エントリーに uid 属性が含まれている必要があります。属性は、顧客サブツリー内で一意である必要があります。
DIT への人物エントリーの配置
以下は、ディレクトリーツリーに人物エントリーを配置するためのガイドラインです。
- エンタープライズ内のユーザーは、組織のエントリー下のディレクトリーツリーに置く必要があります。
- ホスティング組織をお持ちのお客様は、ホストされた組織の ou=people ブランチの下になければなりません。
4.2.3.2. グループエントリーの命名
- 静的グループ は、明示的にメンバーを定義します。groupOfNames または groupOfUniqueNames オブジェクトクラスには、グループのメンバーに名前を付ける値が含まれます。静的グループは、ディレクトリー管理者のグループなど、メンバーの少ないグループに適しています。静的グループは、数千のメンバーを持つグループには適していません。uniqueMember は groupOfUniqueNames オブジェクトの必須の属性であるため、静的グループエントリーには uniqueMember 属性値が含まれている必要があります。このオブジェクトクラスは、グループエントリーの DN を形成するために使用できる
cn属性を必要とします。 - 動的グループ は、検索フィルターとサブツリーを含むグループを表すエントリーを使用します。フィルターにマッチするエントリーはグループのメンバーです。
- ロール は、静的グループおよび動的グループの概念を統一します。詳細は、「ディレクトリーエントリーのグループ化」を参照してください。
4.2.3.3. 組織エントリーの命名
organization (o)属性を命名属性として使用します。
4.2.3.4. その他の種類のエントリーの命名
cn 属性を使用します。次に、グループエントリーに名前を付けるために、cn=administrators,dc=example,dc=com のように名前を付けます。
commonName 属性をサポートしない場合があります。代わりに、エントリーのオブジェクトクラスがサポートする属性を使用します。
4.2.4. エントリーおよびサブツリーの名前変更
例4.1 エントリー DN のビルド
dc=example,dc=com => root suffix
ou=People,dc=example,dc=com => org unit
st=California,ou=People,dc=example,dc=com => state/province
l=Mountain View,st=California,ou=People,dc=example,dc=com => city
ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => org unit
uid=jsmith,ou=Engineering,l=Mountain View,st=California,ou=People,dc=example,dc=com => leaf entry図4.10 リーフエントリーに対する modrdn 操作

図4.11 サブツリーエントリーに対する modrdn 操作

newsuperior 属性を設定して、エントリーを別の親に移動します。
図4.12 新しい親エントリーに対する modrdn 操作

entryrdn.db インデックスに保存される方法が原因で、新しい上位操作とサブツリーの名前変更操作の両方が可能です。各エントリーは、独自のキー (自己リンク) で、続いてその親 (親リンク) と子を特定するサブキーで識別されます。これには、親と子をエントリーに対する属性として処理することでディレクトリーツリー階層を配置する形式があり、すべてのエントリーが完全な DN ではなく一意の ID とその RDN によって記述されます。
numeric_id:RDN => self link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
P#:RDN => parent link
ID: #; RDN: "rdn"; NRDN: normalized_rdn
C#:RDN => child link
ID: #; RDN: "rdn"; NRDN: normalized_rdn4:ou=people ID: 4; RDN: "ou=People"; NRDN: "ou=people" P4:ou=people ID: 1; RDN: "dc=example,dc=com"; NRDN: "dc=example,dc=com" C4:ou=people ID: 10; RDN: "uid=jsmith"; NRDN: "uid=jsmith"
- root 接尾辞の名前を変更することはできません。
- サブツリー名前変更操作によるレプリケーションへの影響は最小限に抑えられます。レプリカ合意は、データベースのサブツリーではなく、データベース全体に適用されます。したがって、サブツリーの名前変更操作ではレプリカ合意の再設定は必要ありません。サブツリーの名前変更操作後のすべての名前の変更は、通常どおり複製されます。
- サブツリーの名前を変更し、同期合意を再設定する必要がある 場合があります。同期合意は、接尾辞またはサブツリーレベルで設定されるため、サブツリーの名前を変更すると、同期が破損してしまう可能性があります。
- サブツリーの名前を変更するには、サブツリーに設定されたサブツリーレベルの ACI を手動で再設定し、サブツリーの子エントリーに設定されたエントリーレベルの ACI (エントリーレベルの ACI) を手動で再設定する 必要があります。
- 子を持つサブツリーの名前を変更できますが、子を持つサブツリーを削除できません。
ouからdcへの移行など、サブツリーのコンポーネントを変更しようとすると、スキーマ違反で失敗する可能性があります。たとえば、organizationalUnit オブジェクトクラスにはou属性が必要です。サブツリーの名前変更の一部としてその属性を削除すると、操作は失敗します。
4.3. ディレクトリーエントリーのグループ化
- グループの使用
- ロールの使用
4.3.1. グループについて
- 静的グループ には、グループエントリーに手動で追加されるメンバーの、有限な定義済みのリストがあります。
- 動的グループ は、フィルターを使用してグループのメンバーであるエントリーを認識します。したがって、グループメンバーシップはグループフィルターに一致するエントリーが変わるにつれて絶えず変更されます。
4.3.1.1. ユーザーエントリーにおけるグループメンバーシップのリスト表示
memberOf 属性を作成します。
memberOf 属性のユーザーのエントリーに 反映され ます。ユーザーが属するすべてのグループの名前は、memberOf 属性として一覧表示されます。これらの memberOf 属性の値は、Directory Server によって管理されます。
memberOf 属性で更新されません。
memberOfAllBackends 属性を有効にすると、設定されたすべてのデータベースを検索するように MemberOf プラグインを設定できます。
memberofgroupattr を設定することで、複数のメンバー属性を識別するように MemberOf プラグインの 1 つのインスタンスを設定できます。これにより、MemberOf プラグインは複数のグループタイプを管理できます。
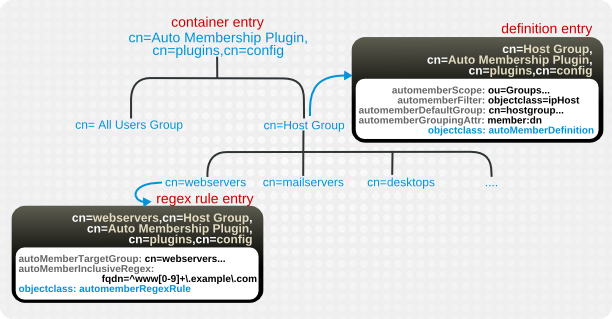
4.3.1.2. グループへの新規エントリーの自動追加
図4.13 正規表現の条件
4.3.2. ロールの概要
- ロールメンバーを明示的にリスト表示します。ロールを表示すると、そのロールのメンバーの完全なリストが表示されます。ロール自体にクエリーを実行してメンバーシップを確認することができます (動的グループでは不可能です)。
- エントリーが属するロールの表示します。ロールのメンバーシップはエントリーの属性によって決定されます。エントリーを表示するだけで、所属するロールがすべて表示されます。これはグループの memberOf 属性と似ていますが、この機能が機能するためにプラグインインスタンスを有効化または設定する必要がないだけです。これは自動的です。
- 適切なロールを割り当てます。ロールのメンバーシップは、ロールからではなく、エントリー から割り当てられます。そのため、ユーザーが所属するロールは、1 つの手順でエントリーを編集して簡単に割り当てられ、削除することができます。
- マネージドロール には、メンバーの明示的な列挙リストがあります。
- フィルターされたロール には、LDAP フィルターで指定される各エントリーに含まれる属性に応じて、エントリーがロールに割り当てられます。フィルターに一致するエントリーはロールを持ちます。
- ネストされたロール は、他のロールが含まれるロールです。
nsAccountLock 属性が true に設定されます。
nsAccountLock が true に設定されています。何層にもなったネスティングロールが可能です。ネスティング内のどのネスティングされたロールを非アクティブにしても、その下にあるすべてのロールとユーザーが非アクティブになります。
4.3.3. ロールとグループの使い分け
nsRole 操作属性を検索して、ロールのメンバーシップを確認できます。この多値属性は、エントリーが属するすべてのロールを識別します。クライアントアプリケーションの観点からは、メンバーシップを確認する方法は統一されており、サーバー側で実行されます。
memberOf を使用すると、クライアントにとっての使いやすさと、サーバーによる計算効率の良さのバランスがとります。
memberOf 属性を動的に作成します。クライアントは、グループエントリーを 1 回検索することで、そのグループのすべてのメンバーのリストを取得できます。ユーザーエントリーを 1 回検索することで、そのユーザーが属するすべてのグループの完全なリストを取得できます。
memberOf (ユーザー)属性の両方がデータベースに格納されるため、検索に必要な追加の処理がないため、クライアントからの検索は非常に効率的になります。
4.4. 仮想ディレクトリー情報ツリービュー
4.4.1. 仮想 DIT ビューについて
- 階層構造のディレクトリー情報ツリー。
- フラットなディレクトリー情報ツリー。
図4.14 フラットな DIT と組織ベースの DIT の例
nsviewfilter)を作成します。追加属性の追加後、ビューフィルターにマッチするエントリーが即座にビューを反映させます。対象となるエントリーは、ビューの中に存在している ように見える だけで、実際の場所は変わりません。仮想 DIT ビューは、サブツリーまたは 1 レベルの検索が、想定された結果で返されることで、通常の DIT と同様に動作します。
図4.15 ビューを使用した DIT の組み合わせ
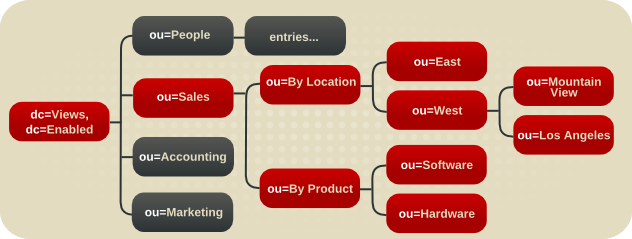
図4.16 仮想 DIT ビュー階層を含む DIT
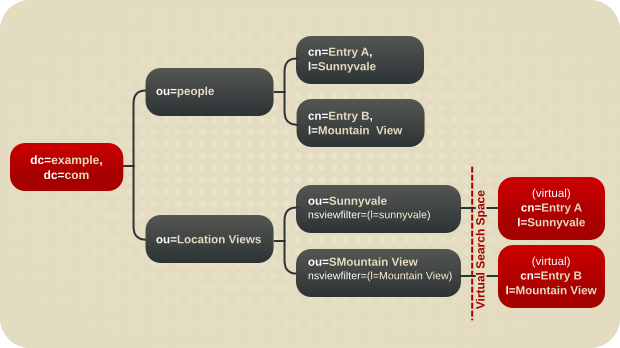
- サブツリー ou=People には、実際の エントリー A および エントリー B エントリーが含まれています。
- サブツリー ou=Location Views は、ビュー階層です。
- リーフノード ou=Sunnyvale および ou=Mountain View には、ビューを記述する属性
nsviewfilterが含まれています。実際のエントリーを含まないため、これらはリーフノードです。ただし、クライアントアプリケーションがこれらのビューを検索すると、ou=Mountain View の下で ou=Sunnyvale および Entry B の下にエントリー A が見つかります。この仮想検索領域は、すべての上位ビューのnsviewfilter属性によって記述されます。ビューからの検索では、仮想検索空間からのエントリーと実際の検索空間からのエントリーの両方が返されます。これにより、ビュー階層を従来の DIT として機能させたり、従来の DIT をビュー階層に変更したりすることができます。
4.4.2. 仮想 DIT ビュー活用のメリット
- 仮想 DIT ビューは、従来の階層構造が提供するのと同様のナビゲーションと管理のサポートを提供するため、ビューではエントリーにフラットな名前空間を使用することができます。また、DIT に変更があった場合でも、エントリーを移動する必要はなく、仮想 DIT ビュー階層のみが変更されます。これらの階層は実際のエントリーを含まないため、シンプルで素早く変更することができます。
- 導入計画中の見落としは、仮想 DIT ビューを使用することで、壊滅的ではなくなります。最初の段階で階層が正しく開発されていなくても、サービスに支障をきたすことなく、簡単かつ迅速に変更することができます。
- ビュー階層を数分で完全に修正し、その結果を即座に実現できるため、ディレクトリーのメンテナンスコストを大幅に削減できます。仮想 DIT 階層の変更は瞬時に実現されます。組織変更があっても、新しい仮想 DIT ビューを迅速に作成することができます。新しい仮想 DIT ビューは古いビューと同時に存在できるので、エントリー自体およびそれらを使用するアプリケーション向けに、より段階的な変更が可能です。ディレクトリーの組織の変更は、1 か 0 かの操作ではないため、一定期間サービスを中断せずに実行できます。
- ナビゲーションと管理に複数の仮想 DIT ビューを使用すると、ディレクトリーサービスをより柔軟に利用することができます。仮想 DIT ビューで提供される機能により、組織は古いメソッドと新しいメソッドの両方を使用して、DIT の特定のポイントにエントリーを配置する必要なしにディレクトリーデータを編成できます。
- 仮想 DIT ビュー階層は、共通的に必要とされる情報の取得を容易にするために、レディーメイドのクエリーとして作成できます。
- ビューは、作業の柔軟性を高め、ディレクトリーユーザーが通常は知る必要のない属性名や値を使用して複雑な検索フィルターを作成する必要性を軽減します。ディレクトリー情報を表示およびクエリーする手段が複数ある柔軟性により、エンドユーザーとアプリケーションは階層ナビゲーションを通じて必要とされるものを直感的に把握できます。
4.4.3. 仮想 DIT ビューの例
dn: ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Location Views description: views categorized by location dn: ou=Sunnyvale,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Sunnyvale nsViewFilter: (l=Sunnyvale) description: views categorized by location dn: ou=Santa Clara,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Santa Clara nsViewFilter: (l=Santa Clara) description: views categorized by location dn: ou=Cupertino,ou=Location Views,dc=example,dc=com objectclass: top objectclass: organizationalUnit objectclass: nsView ou: Cupertino nsViewFilter: (l=Cupertino) description: views categorized by location
nsfilter 属性を追加します。
4.4.4. 表示およびその他のディレクトリー機能
4.4.5. パフォーマンスに対する仮想ビューの影響
4.4.6. 既存のアプリケーションとの互換性
- ターゲットエントリーの DN を使用して DIT をナビゲートするアプリケーション。このタイプのアプリケーションは、エントリーが見つかったビュー階層ではなく、エントリーが物理的に存在する階層をナビゲートしていることを把握します。その理由は、ビューは、ビューの階層に合わせてエントリーの DN を変更することで、エントリーの本当の位置を隠そうとはしないからです。これは意図的なものです。エントリーの真の位置が偽装されていると、多くのアプリケーションが機能しなくなります。例えば、一意のエントリーを識別するために DN に依存するアプリケーションなどです。このように DN を分解して上方向にナビゲートするのは、クライアントアプリケーションとしては珍しい手法ですが、それにもかかわらず、これを行うクライアントは意図した通りに機能しない可能性があります。
numSubordinates操作属性を使用して、ノードの下に存在するエントリーの数を決定するアプリケーション。ビュー内のノードについては、現在、仮想検索空間を無視して、実際の検索空間に存在するエントリーのみをカウントしています。そのため、アプリケーションでは検索を使用してビューを評価できない場合があります。
4.5. ディレクトリーツリーの設計例
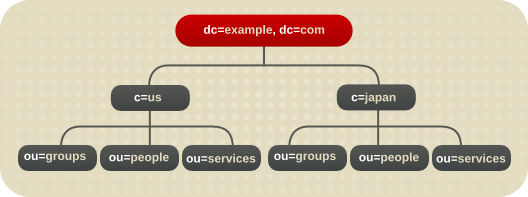
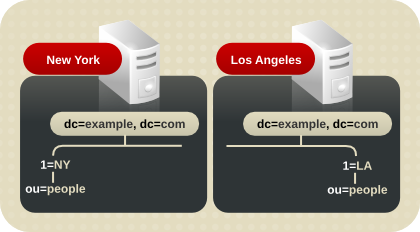
4.5.1. グローバル企業のディレクトリーツリー
c 属性は各国のブランチを表すことができます。
図4.17 c 属性を使用した様々な国を表現
l 属性を使用してさまざまな国を表します。
図4.18 l 属性を使用した様々な国を表現
4.5.2. ISP のディレクトリーツリー
図4.19 Example ISP のディレクトリーツリー
4.6. その他のディレクトリーツリーリソース
第5章 動的属性値の定義
5.1. 管理属性の概要
- 属性の一意性 は、サブツリーまたはデータベース内の特定の属性のすべてのインスタンスが一意の値を持つことを必要とします。これは、エントリーが作成されるか、属性が変更されるたびに実施されます。
- サービスクラス では、1 つのエントリーをテンプレートとして使用します。その属性値が変更されるたびに、CoS の範囲内の他のすべてのエントリーは、エントリーの同じ属性を自動的に変更します。(CoS の影響を受けるエントリーは、定義エントリーによって特定されます)
- 管理エントリー は、定義された範囲内の別のエントリーが作成されるたびに、定義されたテンプレートに従って 1 つのエントリーを作成します。特に外部クライアントとの統合では、エントリーペアを自動的に作成し、管理する必要がある場合があります。管理エントリーは、2 番目のエントリーのテンプレートを定義し、自動的に更新するメカニズムを提供します。
- リンク先属性 は、あるエントリーの属性の DN 値に従い、参照されるエントリーに (元のエントリーを参照する値を持つ) 所定の属性を自動的に追加します。したがって、エントリー A が直接レポートとしてエントリー B を一覧表示した場合、エントリー B が自動的に更新されて、指定されたマネージャーとしてエントリー A を持つ
manager属性を指定できます。 - 分散数値の割り当て では、固有の識別番号をエントリーに自動的に割り当てます。これは、組織全体で一意でなければならない GID または UID 番号の割り当てに役立ちます。
- エントリー間の関係はどのようなものですか ?エントリー間で共有される共通の属性はありますか ?エントリー間のつながりを表す必要がある属性はありますか ?
- データの元のソースは、どのように、どこで (どのエントリーで) 維持される可能性がありますか ?この情報はどのくらいの頻度で更新され、データが変更された場合、どれくらいのエントリーが影響を受けるのでしょうか ?
- このエントリーではどのようなスキーマ要素が使用されていますか ? また、それらの属性の構文は何ですか ?
- プラグインは、レプリケーションや同期などの分散ディレクトリー設定をどのように処理しますか ?
5.2. 属性の一意性について
- 指定されたサブツリーのすべてのエントリーを確認できます。たとえば、会社 example.com が example_a.com および example_b.com のディレクトリーをホストしている場合、uid=jdoe,ou=people,o=example_a,dc=example,dc=com などのエントリーが追加された場合、o=example_a,dc=example,dc=com サブツリーでのみ一意性を適用する必要があります。これは、Attribute Uniqueness プラグイン設定にサブツリーの DN を明示的にリスト表示することで実施されます。
- 更新されたエントリーの DN のエントリーに関連するオブジェクトクラスを指定し、その下のすべてのエントリーで一意性チェックを実行します。このオプションはホスト環境で役に立ちます。たとえば、uid=jdoe,ou=people,o=example_a,dc=example,dc=com などのエントリーを追加する場合、o=example_a,dc=example,dc=com サブツリーの下で一意性を強制しますが、このサブツリーを明示的に設定内に一覧表示するのではなく、marker オブジェクトクラス を示します。マーカーオブジェクトクラスが organization に設定されている場合、一意性チェックアルゴリズムは、このオブジェクトクラス(o=example_a)を持つ DN のエントリーを見つけ、その下のすべてのエントリーでチェックを実行します。また、更新されたエントリーに指定のオブジェクトクラスが含まれる場合に限り、一意性を確認することもできます。たとえば、更新されたエントリーに objectclass=inetorgperson が含まれている場合にのみ、チェックを実行できます。
uid 属性の Attribute Uniqueness プラグインのデフォルトインスタンスを提供します。このプラグインインスタンスは、uid 属性に指定された値がルート接尾辞( userRoot データベースに対応する接尾辞)で一意になるようにします。
- 一意性のチェックが行われる属性は、ネーミング属性です。
- Attribute Uniqueness プラグインは、両方のサプライヤーサーバーで有効化されます。
5.3. サービスクラスについて
facsimileTelephoneNumber を共有する数千ものエントリーが含まれています。従来は、FAX 番号を変更するためには、各エントリーを個別に更新する必要があり、管理者にとっては大きな負担となり、すべてのエントリーが更新されないリスクがありました。CoS を使用すると、属性値を動的に生成できます。facsimileTelephoneNumber 属性は 1 つのロケーションに保存され、各エントリーはその場所から fax number 属性を取得します。アプリケーションの場合、これらの属性は、実際にはエントリー自体に保存されていないにもかかわらず、他のすべての属性と同じように表示されます。
- エントリーの DN (ディレクトリーツリーの異なる部分に異なる CoS が含まれる場合があります)。
- エントリーで保存されるサービスクラスの属性値。サービスクラス属性がない場合、特定のデフォルト CoS を意味することがあります。
- CoS テンプレートエントリーに保存される属性値。各 CoS テンプレートエントリーは、特定の CoS の属性値を提供します。
- エントリーのオブジェクトクラス。COS の属性値は、スキーマチェックが有効な場合、エントリーに属性を許可するオブジェクトクラスが含まれている場合にのみ生成され、そうでない場合は、すべての属性値が生成されます。
- ディレクトリーツリーの特定エントリーの一部に保存される属性。
cosAttribute パラメーター)。
5.3.1. Pointer CoS について
図5.1 Pointer CoS のサンプル
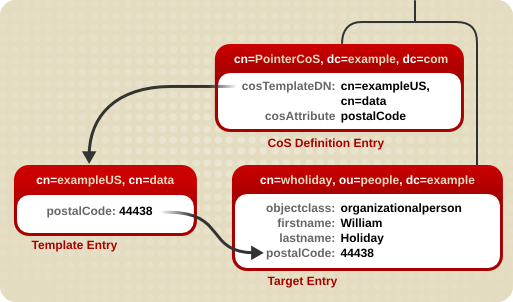
postalCode 属性がエントリー cn=wholiday,ou=people,dc=example,dc=com に対してクエリーされるたびに、Directory Server は、テンプレートエントリー cn=exampleUS,cn=data で使用可能な値を返します。
5.3.2. 間接的な CoS について
図5.2 間接的な CoS の例
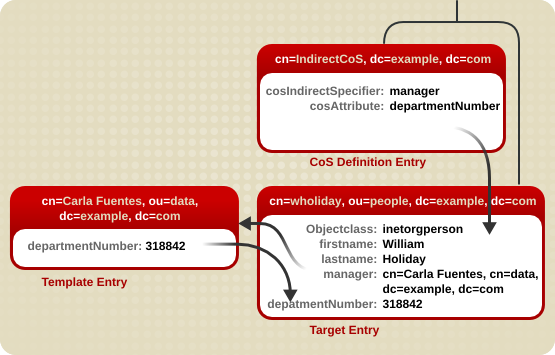
manager 属性) が含まれます。William のマネージャーは Carla Fuentes であるため、manager 属性にはテンプレートエントリーの DN へのポインター cn=Carla Fuentes,ou=people,dc=example,dc=com が含まれます。テンプレートエントリーは次に、318842 の departmentNumber 属性値を提供します。
5.3.3. Classic CoS について
図5.3 Classic CoS のサンプル
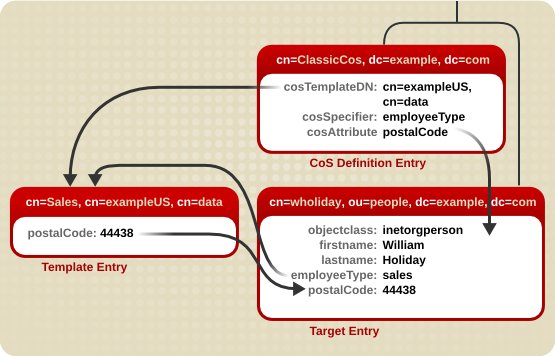
cosSpecifier 属性は、employeeType 属性を指定しています。この属性は、テンプレート DN と組み合わせて、テンプレートエントリーを cn=sales,cn=exampleUS,cn=data として特定します。その後、テンプレートエントリーは、postalCode 属性値をターゲットエントリーに提供します。
5.4. 管理エントリーについて
- (検索範囲と検索フィルターを使用する) 作成元のエントリーを識別する検索基準
- 管理エントリーを作成するサブツリー (新しいエントリーの場所)
- 管理エントリーに使用するテンプレートエントリー
図5.4 管理エントリーの定義
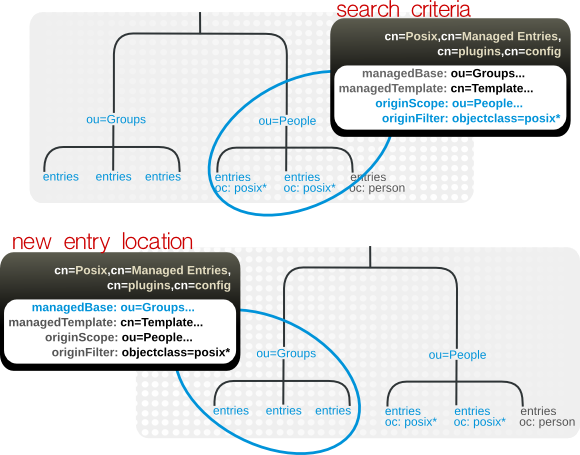
dn: cn=Posix User-Group,cn=Managed Entries,cn=plugins,cn=config objectclass: extensibleObject cn: Posix User-Group originScope: ou=people,dc=example,dc=com originFilter: objectclass=posixAccount managedBase: ou=groups,dc=example,dc=com managedTemplate: cn=Posix User-Group Template,ou=Templates,dc=example,dc=com
5.4.1. 管理エントリーのテンプレートの定義
dn: cn=Posix User-Group Template,ou=Templates,dc=example,dc=com objectclass: mepTemplateEntry cn: Posix User-Group Template mepRDNAttr: cn mepStaticAttr: objectclass: posixGroup mepMappedAttr: cn: $uid Group mepMappedAttr: gidNumber: $gidNumber mepMappedAttr: memberUid: $uid
図5.5 管理エントリー、テンプレート、および作成元のエントリー
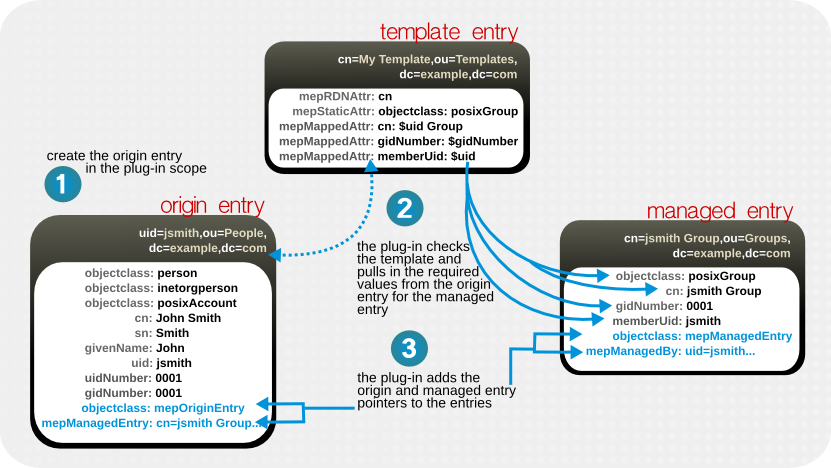
5.4.2. 管理エントリープラグインにより書き込まれるエントリー属性
dn: uid=jsmith,ou=people,dc=example,dc=com objectclass: mepOriginEntry objectclass: posixAccount ... sn: Smith mail: jsmith@example.com mepManagedEntry: cn=jsmith Posix Group,ou=groups,dc=example,dc=com
dn: cn=jsmith Posix Group,ou=groups,dc=example,dc=com objectclass: mepManagedEntry objectclass: posixGroup ... mepManagedBy: uid=jsmith,ou=people,dc=example,dc=com
5.4.3. 管理エントリープラグインおよび Directory Server 操作
- 追加。すべての追加操作では、サーバーは新しいエントリーが管理エントリープラグインインスタンスの範囲内にあるかどうかを確認します。作成元エントリーの基準を満たすと、管理エントリーが作成され、管理エントリー関連の属性が元のエントリーと管理エントリーの両方に追加されます。
- 修正。作成元のエントリーが変更されると、プラグインをトリガーして管理エントリーを更新します。ただし、テンプレート エントリーを変更しても、自動的に管理エントリーを更新しません。テンプレートエントリーへの変更は、次に作成元エントリーが変更するまで、管理エントリーに反映されません。管理エントリー 内 でマップされた管理属性は、管理エントリープラグインでのみ手動で変更することができません。マネージドエントリーの他の属性 (管理エントリープラグインによって追加された静的属性を含む) は手動で変更できます。
- 削除。作成元のエントリーが削除されると、管理エントリープラグインもそのエントリーに関連付けられた管理エントリーを削除します。削除できるエントリーにはいくつかの制限があります。
- テンプレートエントリーは、プラグインインスタンス定義で現在参照されている場合は削除できません。
- 管理エントリーは、管理エントリープラグイン以外では削除できません。
- 名前の変更。元のエントリーの名前を変更した場合は、プラグインは対応する管理エントリーを更新します。エントリーがプラグインスコープの 外 に移動すると、管理エントリーが削除されますが、エントリーがプラグインスコープの 中 に移動した場合は、追加操作のように処理され、新しい管理エントリーが作成されます。削除操作と同様に、名前変更または移動できるエントリーに制限があります。
- 設定定義エントリーは、コンテナーエントリーの管理エントリープラグインを外に移動できません。エントリーが削除されると、そのプラグインインスタンスが非アクティブになります。
- エントリーが管理エントリープラグインのコンテナーエントリー 内 に移動する場合、これは検証され、アクティブな設定定義として処理されます。
- テンプレートエントリーの名前を変更したり、プラグインインスタンス定義で現在参照している場合は移動したりすることはできません。
- 管理エントリープラグイン以外が、管理エントリーの名前を変更したり、移動したりできません。
- レプリケーション。管理エントリープラグイン操作は、レプリケーションの更新によって開始しません。プラグインスコープのエントリーの追加または修正操作が別のレプリカに複製される場合、その操作はレプリカで管理エントリープラグインインスタンスを発生させず、エントリーを作成または更新しません。管理エントリーの更新を複製する唯一の方法は、最終管理エントリーをレプリカに複製することです。
5.5. リンク属性の概要
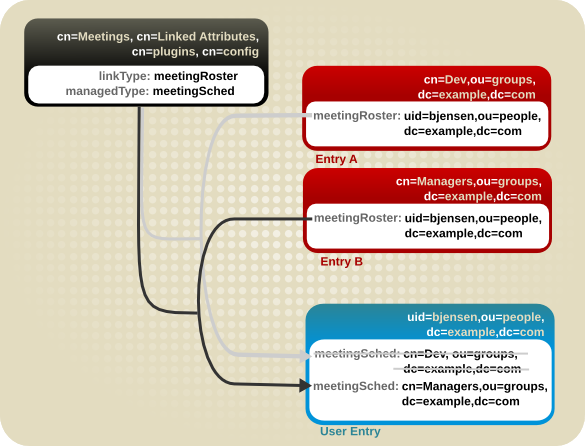
member などの属性のメンバーを一覧表示します。ユーザーがどのグループに所属するかをユーザーエントリーに表示することは自然です。これは memberOf 属性で設定されます。memberOf 属性は、MemberOf プラグインによる 管理 属性です。プラグインは、それぞれのメンバー属性の変更についてすべてのグループエントリーをポーリングします。グループメンバーがグループから追加または削除されるたびに、対応するユーザーエントリーが memberOf 属性を変更して更新されます。これにより、member (およびその他のメンバー属性)および memberOf 属性が リンクされ ます。
linkType) およびプラグインによって自動的に維持される 1 つの属性 (managedType) を設定します。
図5.6 リンク先属性の基本設定
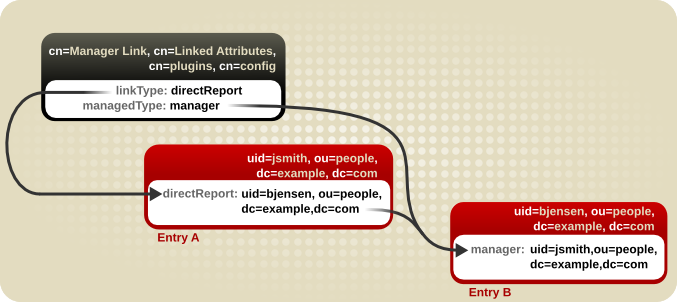
図5.7 リンク先属性プラグインを特定のサブツリーに制限
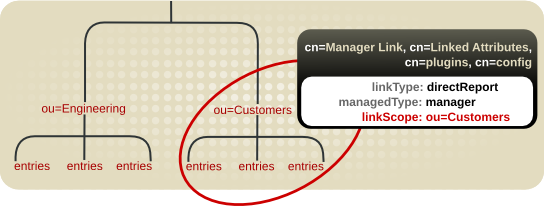
5.5.1. リンク属性のスキーマ要件
図5.8 誤った使用方法: 単一値のリンク先属性の使用
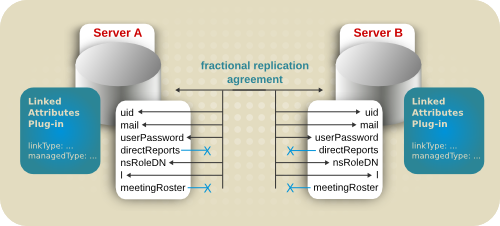
5.5.2. レプリケーションでのリンク先属性の使用
図5.9 リンク先属性とレプリケーション
5.6. 一意の数値を動的に割り当てる方法について
uidNumber や gidNumber などの一意の番号が必要です。Directory Server は、DNA (Distributed Numeric Assignment) プラグインを使用して、指定された属性に一意の番号を自動的に生成して提供できます。
5.6.1. Directory Server の一意の番号の管理方法
- 一意の番号の 1 つの範囲から、1 つの属性タイプに割り当てられた 1 つの番号。
- 1 つのエントリーの 2 つの属性に割り当てられた同じ一意の番号。
- 2 つの異なる属性は、同じ範囲の一意の数字から 2 つの異なる数字を割り当てていました。
employeeID を割り当てる際には、各従業員エントリーに一意の employeeID が割り当てられます。
uidNumber と gidNumber を posixAccount エントリーに割り当てる場合、両方の属性に同じ数を割り当てるように DNA プラグインを設定できます。
5.6.2. DNA を使用した値の属性への割り当て
uidNumber 属性が必要です。uidNumber 属性が DNA プラグインで管理されており、フィルターの範囲内で uidNumber 属性なしでユーザーエントリーが追加されると、サーバーは新しいエントリーをチェックし、マネージドの uidNumber 属性が必要であることを確認し、自動的に割り当てられた値で属性を追加します。
ldapmodify-a-D "cn=Directory Manager" -W -p 389 -h server.example.com -x dn: uid=jsmith,ou=people,dc=example,dc=com objectClass: top objectClass: personobjectClass: posixAccountuid: jsmith cn: John Smith ....
uidNumber と gidNumber の両方に同じ一意の番号を posixAccount エントリーに割り当てるように設定されていると、DNA プラグインは同じ番号を両方の属性に割り当てます。これを行うには、マジック番号を指定して、変更操作に両方の管理属性を渡します。以下に例を示します。
ldapmodify-a-D "cn=Directory Manager" -W -p 389 -h server.example.com -x dn: uid=jsmith,ou=people,dc=example,dc=com objectClass: top objectClass: person objectClass: posixAccount uid: jsmith cn: John SmithuidNumber: magicgidNumber: magic....
5.6.3. レプリケーションでの DNA プラグインの使用
- DNA プラグインのマネージド範囲
- サーバーで利用可能な範囲に関する情報を保存する共有設定エントリー
dn: dnaHostname=ldap1.example.com+dnaPortNum=389,cn=Account UIDs,ou=Ranges,dc=example,dc=com objectClass: extensibleObject objectClass: top dnahostname: ldap1.example.com dnaPortNum: 389 dnaSecurePortNum: 636 dnaRemainingValues: 1000
第6章 ディレクトリートポロジーの設計
6.1. トポロジーの概要
- ディレクトリー対応アプリケーション向けに最適なパフォーマンスを実現します。
- ディレクトリーサービスの可用性を増やします。
- ディレクトリーサービスの管理を改善します。
6.2. ディレクトリーデータの配布
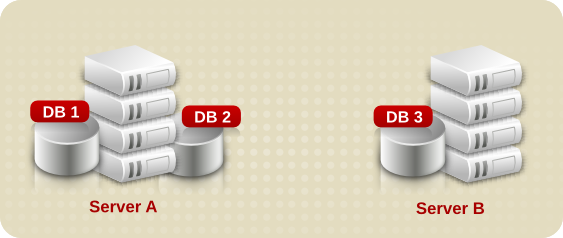
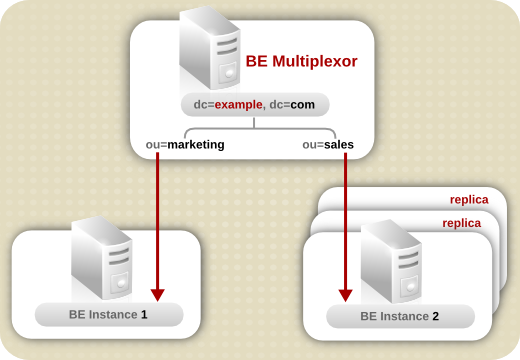
6.2.1. 複数のデータベースの使用について

図6.1 別のデータベースでの接尾辞データの保存

図6.2 個別のサーバー間での接尾辞データベースの分割
6.2.2. 接尾辞について
図6.3 Example Corp. のディレクトリーツリー
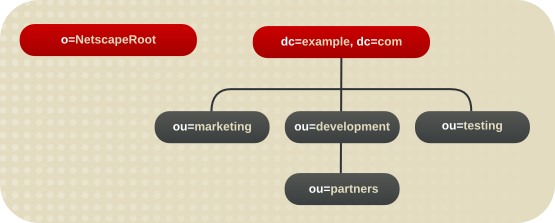
図6.4 複数のデータベースにまたがるディレクトリーツリー
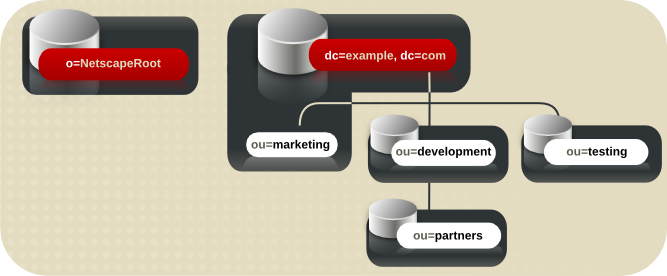
図6.5 分散ディレクトリーツリーの接尾辞

複数の root 接尾辞の使用
ディレクトリーサービスには複数の root 接尾辞が含まれる場合があります。たとえば、Example と呼ばれる ISP は、example_a.com 用と example_b.com 用など、複数の Web サイトをホストする可能性があります。ISP は、o=example_a.com 命名コンテキストに対応するものと、o=example_b.com 命名コンテキストに対応するものの 2 つのルート接尾辞を作成します。
図6.6 複数の root 接尾辞を含むディレクトリーツリー
6.3. ナレッジ参照について
- 参照: サーバーは、クライアントアプリケーションが要求を満たすために別のサーバーに問い合わせる必要があることを示す情報をクライアントアプリケーションに返します。
- チェーン: サーバーは、クライアントアプリケーションの代わりに他のサーバーに問い合わせ、操作の完了時にクライアントアプリケーションに結果をまとめて返します。
6.3.1. 参照の使用
- デフォルトの参照: サーバーが一致する接尾辞を持たない DN をクライアントのアプリケーションが提示した場合、ディレクトリーはデフォルトの参照を返します。デフォルトの参照は、サーバーの設定ファイルに保存されます。Directory Server にはデフォルトの参照 1 つを設定し、各データベースには個別のデフォルト参照を設定できます。各データベースのデフォルトの参照は、接尾辞の設定情報により行われます。データベースの接尾辞が無効になっている場合は、その接尾辞に対して行われたクライアントの要求に対してデフォルトの参照を返すようにディレクトリーサービスを設定します。接尾辞の詳細は、「接尾辞について」 を参照してください。接尾辞の設定に関する詳細は、『Red Hat Directory Server Administration Guide』を参照してください。
- スマート参照: スマート参照は、ディレクトリーサービス自体のエントリーに保存されます。スマート参照は、スマート参照を含むエントリーの DN に一致する DN を持つサブツリーの知識を有する Directory Server を指します。
6.3.1.1. LDAP 参照の構造
- 問い合わせるサーバーのホスト名。
- LDAP 要求をリッスンするように設定されたサーバーのポート番号。
- ベース DN (検索操作用) またはターゲット DN (操作の追加、削除、および変更用)。
ldap://europe.example.com:389/ou=people, l=europe,dc=example,dc=com
6.3.1.2. デフォルトの参照について
uid=bjensen,ou=people,dc=example,dc=com
nsslapd-referral 属性で設定します。ディレクトリーインストールの各データベースのデフォルトの参照は、設定のデータベースエントリーの nsslapd-referral 属性で設定されます。これらの属性値は、dse.ldif ファイルに保存されます。
6.3.1.3. スマート参照
- 別のサーバーに含まれる同じ namespace。
- ローカルサーバー上の異なる namespace。
- 同じサーバー上の異なる namespace。
図6.7 スマート参照を使用したリクエストのリダイレクト
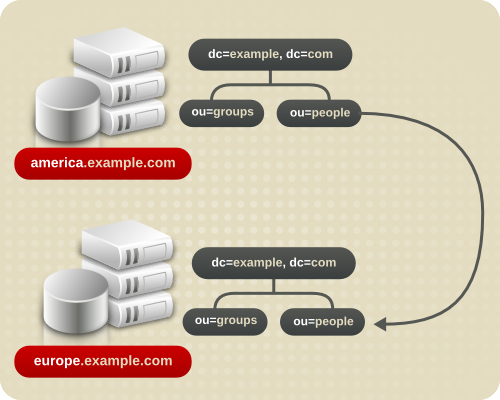
図6.8 異なるサーバーと namespace へのクエリーのリダイレクト
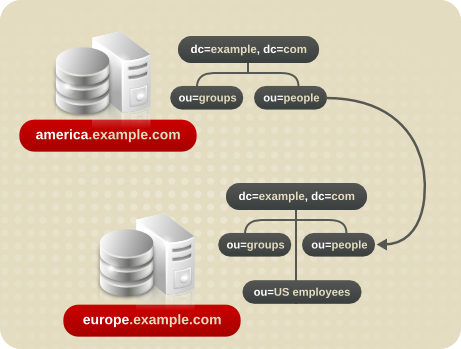
図6.9 同一サーバー上のある namespace から別の namespace へのクエリーのリダイレクト
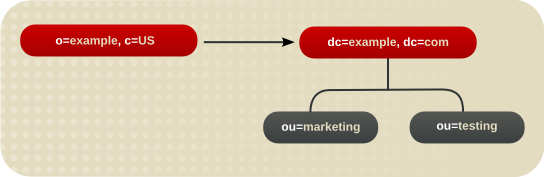
6.3.1.4. スマート参照の設計に関するヒント
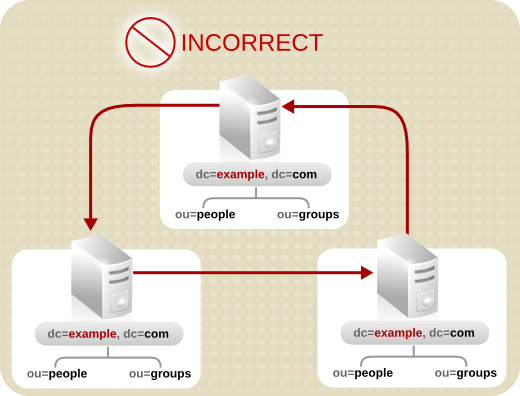
- 設計はシンプルにします。複雑な参照の Web を使用してディレクトリーサービスをデプロイすると、管理が困難になります。スマート参照を使いすぎると、循環参照パターンが発生する可能性もあります。たとえば、参照が LDAP URL を指し、その URL がまた別の LDAP URL を指し、といった具合に、チェーンのどこかの参照が元のサーバーを指すまで続きます。以下で説明します。
図6.10 循環参照パターン
- メジャーなブランチポイントでリダイレクトします。ディレクトリーツリーの接尾辞レベルでリダイレクトを処理する参照の使用を制限します。スマート参照は、リーフ (ブランチ以外) エントリーに対するルックアップ要求を、異なるサーバーおよび DN にリダイレクトします。その結果、スマート参照をエイリアスメカニズムとして使用したくなるため、ディレクトリー構造のセキュア化は複雑で困難な方法になります。ディレクトリーツリーの接尾辞またはメジャーブランチポイントに対する参照を制限すると、管理する必要のある参照数が制限され、その後ディレクトリーの管理オーバーヘッドが削減されます。
- セキュリティーへの影響を考慮します。アクセス制御は参照の境界を越えません。リクエストを発信したサーバーがエントリーへのアクセスを許可していても、スマート参照が別のサーバーにクライアントリクエストを送信すると、クライアントアプリケーションのアクセスが許可されない場合があります。さらに、クライアントの認証が行われるためにクライアントが参照されるサーバー上でクライアントの認証情報が利用可能である必要があります。
6.3.2. チェーンの使用

- リモートデータへの非表示のアクセス。データベースリンクはクライアントのリクエストを解決するため、データ配布はクライアントから完全に非表示になります。
- 動的管理。システム全体をクライアントアプリケーションで利用できる状態で、ディレクトリーサービスの一部をシステムに追加したり、システムから削除したりできます。データベースリンクは、ディレクトリーサービス全体にエントリーが再分散されるまで、アプリケーションに参照を一時的に返すことができます。これは、クライアントアプリケーションをデータベースに転送するのではなく、参照を返すことができる接尾辞自体で実施することも可能です。
- アクセス制御。データベースリンクは、クライアントアプリケーションになりすまし、適切な認証 ID をリモートサーバーに提供します。アクセス制御の評価が必要ない場合は、リモートサーバーでユーザーのなりすましを無効にすることができます。データベースリンクの設定に関する詳細は、『Red Hat Directory Server Administration Guide』を参照してください。
6.3.3. 参照とチェーンのどちらかを選択する
6.3.3.1. 使用に関する相違点
6.3.3.2. アクセス制御の評価
参照を使用した検索リクエストの実行
以下の図は、参照を使用したクライアントからサーバーへの要求を示しています。
図6.11 参照を使用したクライアント要求のサーバーへの送信
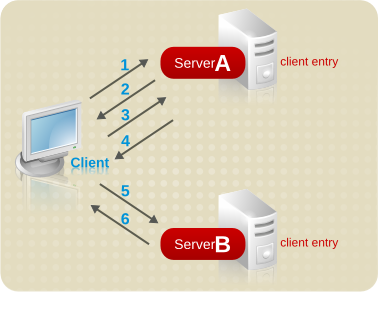
- クライアントアプリケーションは、最初にサーバー A にバインドします。
- サーバー A にはユーザー名とパスワードを提供するクライアントのエントリーが含まれるため、バインドの受け入れメッセージを返します。参照を機能させるためには、クライアントエントリーがサーバー A に存在する必要があります。
- クライアントアプリケーションは操作リクエストをサーバー A に送信します。
- ただし、サーバー A には要求された情報が含まれていません。代わりに、サーバー A は、サーバー B に連絡するよう指示するクライアントアプリケーションへの参照を返します。
- その後、クライアントアプリケーションはサーバー B にバインドリクエストを送信します。正常にバインドするには、サーバー B にクライアントアプリケーションのエントリーも含まれている必要があります。
- バインドに成功し、クライアントアプリケーションは検索操作をサーバー B に再送信できるようになりました。
チェーンを使用した検索リクエストの実行
サーバー間でクライアントエントリーを複製する問題は、チェーンを使用して解決されます。チェーンシステムでは、検索リクエストは応答があるまで複数回転送されます。
図6.12 チェーンを使用したクライアント要求のサーバーへの送信
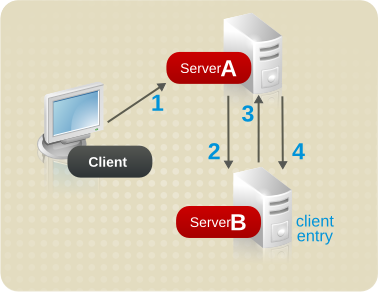
- クライアントアプリケーションがサーバー A にバインドすると、サーバー A はユーザー名とパスワードが正しいかどうかを確認しようとします。
- サーバー A にはクライアントアプリケーションに対応するエントリーが含まれません。代わりに、クライアントの実際のエントリーが含まれるサーバー B へのデータベースリンクが含まれます。サーバー A はバインドリクエストをサーバー B に送信します。
- サーバー B はサーバー A に受け入れ応答を送信します。
- 次に、サーバー A はクライアントアプリケーションのリクエストをデータベースリンクを使用して処理します。データベースリンクは、サーバー B にあるリモートデータストアに問い合わせ、検索操作を処理します。
図6.13 異なるサーバーを使用したクライアントの認証およびデータの取得
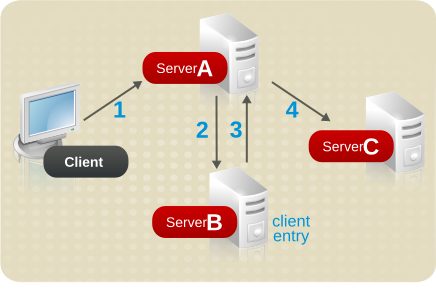
- クライアントアプリケーションがサーバー A にバインドすると、サーバー A はユーザー名とパスワードが正しいかどうかを確認しようとします。
- サーバー A にはクライアントアプリケーションに対応するエントリーが含まれません。代わりに、クライアントの実際のエントリーが含まれるサーバー B へのデータベースリンクが含まれます。サーバー A はバインドリクエストをサーバー B に送信します。
- サーバー B はサーバー A に受け入れ応答を送信します。
- サーバー A は次に別のデータベースリンクを使用して、クライアントアプリケーションのリクエストを処理します。データベースリンクは、サーバー C にあるリモートデータストアに問い合わせ、検索操作を処理します。
サポートされないアクセス制御
データベースリンクは、以下のアクセス制御をサポートしません。
- ユーザーエントリーが別のサーバーにある場合、ユーザーエントリーのコンテンツにアクセスする必要のあるコントロールはサポートされません。これには、グループ、フィルター、およびロールに基づくアクセス制御が含まれます。
- クライアント IP アドレスまたは DNS ドメインに基づいた制御は拒否される可能性があります。これは、データベースリンクがリモートサーバーに問い合わせする際に、クライアントになりすますためです。リモートデータベースに IP ベースのアクセス制御が含まれている場合は、元のクライアントドメインではなく、データベースリンクのドメインを使用して評価されます。
6.4. データベースパフォーマンスを改善するためのインデックスの使用
cn.db というファイルには、共通名属性のすべてのインデックスが含まれます。
6.4.1. ディレクトリーインデックスタイプの概要
- インデックスの存在:
uidなどの特定の属性を持つエントリーを一覧表示します。 - Equality index: cn=Babs Jensen など、特定の属性値を含むエントリーを一覧表示します。
- 概算インデックス: 概算 (または sounds-like) 検索を可能にします。たとえば、エントリーには cn=Babs L. Jensen の属性値が含まれる場合があります。概算検索では、cn~=Babs Jensen、cn~=Babs、および cn~=Jensen に対する検索に対してこの値を返します。注記概算インデックスでは、ASCII 文字を使用して、英語で名前を表記する必要があります。
- 部分文字列インデックス: エントリー内の部分文字列に対する検索を許可します。たとえば、cn=*derson の検索は、この文字列を含む共通名と一致します(Bill Anderson、Norma Henderson、Steve Sanderson など)。
- 国際インデックス: 国際ディレクトリーでの情報検索のパフォーマンスが向上します。ロケール (国際化 OID) をインデックス化する属性に関連付けることにより、一致するルールを適用するインデックスを設定します。
- 参照インデックスまたは仮想リストビュー (VLV) インデックス: Web コンソールのエントリーの表示パフォーマンスを向上させます。参照インデックス をディレクトリーツリーの任意のブランチに作成して、表示パフォーマンスを向上させることができます。
6.4.2. インデックス化のコストの評価
- インデックスを使用すると、エントリーの修正にかかる時間が長くなります。維持されるインデックスが増えれば増えるほど、ディレクトリーサービスがデータベースを更新するのに時間がかかります。
- インデックスファイルはディスク領域を使用します。インデックス化される属性が多ければ多いほど、多くのファイルが作成されます。長い文字列を含む属性に概算インデックスおよび部分文字列インデックスがある場合、これらのファイルは急速に大きくなる可能性があります。
- インデックスファイルはメモリーを使用します。さらに効率的に実行するには、ディレクトリーサービスは可能な限り多くのインデックスファイルをメモリーに配置します。インデックスファイルは、データベースキャッシュのサイズに応じて利用可能なプールのメモリーを使用します。インデックスファイルの数が多いと、データベースキャッシュも大きくなります。
- インデックスファイルの作成には時間がかかります。インデックスファイルは検索時の時間を短縮しますが、不要なインデックスを維持することは時間の浪費につながります。ディレクトリーサービスを利用するクライアントアプリケーションが必要とするファイルのみを維持するようにしてください。
第7章 レプリケーションプロセスの設計
7.1. レプリケーションの概要
- フォールトトレランスおよびフェイルオーバー - ディレクトリーツリーを複数のサーバーに複製することで、ハードウェア、ソフトウェア、ネットワークの問題により、ディレクトリークライアントアプリケーションが特定のディレクトリーサーバーにアクセスできない場合でも、ディレクトリーサービスを利用できます。クライアントは、読み取りと書き込み操作のために、別の Directory Server を参照します。注記書き込みフェイルオーバーは、マルチサプライヤーのレプリケーションでのみ可能です。
- 負荷分散: サーバー全体でディレクトリーツリーを複製すると、指定したマシンのアクセス負荷が減り、サーバーの応答時間が改善します。
- パフォーマンスの向上とレスポンスタイムの短縮 - ディレクトリーエントリーをユーザーに近い場所に複製することで、ディレクトリーのレスポンスタイムが大幅に向上します。
- ローカルデータ管理: レプリケーションにより、企業全体で他の Directory Server と情報を共有しながら、ローカルで情報を所有および管理することができます。
7.1.1. レプリケーションの概念
- 複製する情報。
- その情報のメインコピー (読み取り/書き込みレプリカ) を保持するサーバー。
- その情報の読み取り専用コピー (読み取り専用レプリカ) を保持するサーバー。
- 読み取り専用のレプリカが更新要求を受け取ったときに何をすべきか、つまり、どのサーバーにその要求を参照すべきか。
7.1.1.1. レプリケーションのユニット
7.1.1.2. 読み取り/書き込みレプリカおよび読み取り専用レプリカ
7.1.1.3. サプライヤーとコンシューマー
- マルチサプライヤーのレプリケーション の場合、サプライヤーは、同じ読み取り/書き込みレプリカのサプライヤーとコンシューマーの両方として機能します。詳細は、「マルチサプライヤーのレプリケーション」 を参照してください。
サプライヤー
特定のレプリカの場合は、サプライヤーサーバーでは以下を行う必要があります。
- ディレクトリークライアントからの読み取りリクエストや更新リクエストへの対応。
- レプリカの状態情報と changelog を維持します。
- コンシューマーサーバーへのレプリケーションを開始します。
コンシューマー
コンシューマーサーバーは、以下を行う必要があります。
- 読み取りのリクエストに応える。
- レプリカのサプライヤーサーバーへの更新リクエストを参照する。
ハブサプライヤー
レプリケーションをカスケードする特殊なケースでは、ハブサプライヤーは以下を行う必要があります。
- 読み取りのリクエストに応える。
- レプリカのサプライヤーサーバーへの更新リクエストを参照する。
- コンシューマーサーバーへのレプリケーションを開始します。
7.1.1.4. レプリケーションとチェンジログ
nsslapd-changelogmaxage または nsslapd-changelogmaxentries の 2 つの属性で維持されます。これらの属性は古い changelog をトリミングして、changelog サイズを妥当な状態に維持します。
7.1.1.5. レプリカ合意
- 複製するデータベース。
- データがプッシュされるコンシューマーサーバー。
- レプリケーションが実行される時間。
- サプライヤーサーバーがバインドする際に使用しなければならない DN (サプライヤーバインド DN と呼びます)。
- 接続のセキュリティーを確保する方法 (TLS、Start TLS、クライアント認証、SASL、または簡易認証)。
- レプリケートされない属性 (「一部レプリケーションで選択された属性を複製する」 を参照)
7.1.2. データの整合性
- サーバー間に、信頼できる高速接続があります。
- ディレクトリーサービスが提供するクライアント要求は主に検索、読み取り、および比較操作でであり、更新操作は比較的少ないです。
- 信頼できないネットワーク接続、または断続的に利用可能なネットワーク接続があります。
- ディレクトリーサービスが提供するクライアントリクエストは主に更新操作です。
- 通信コストを低くする必要があります。
- サプライヤー間の更新操作の伝播にはレイテンシーがあります。
- 更新操作を処理したサプライヤーは、2 番目のサプライヤーが更新操作を検証するのを待たずに、operation successful というメッセージをクライアントに返します。
7.2. 一般的なレプリケーションシナリオ
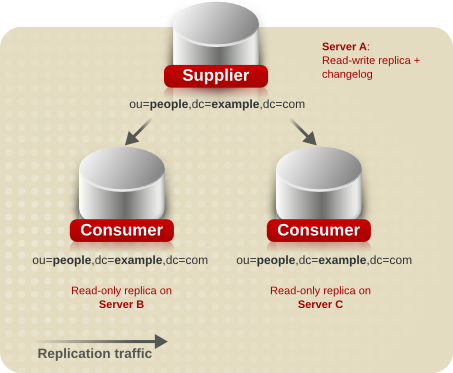
7.2.1. 単一サプライヤーレプリケーション
図7.1 単一サプライヤーレプリケーション
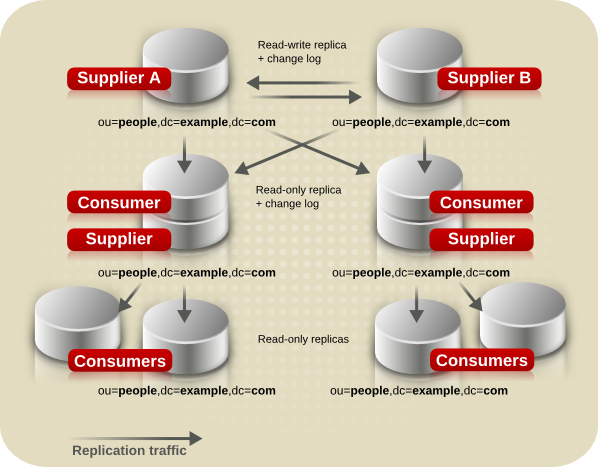
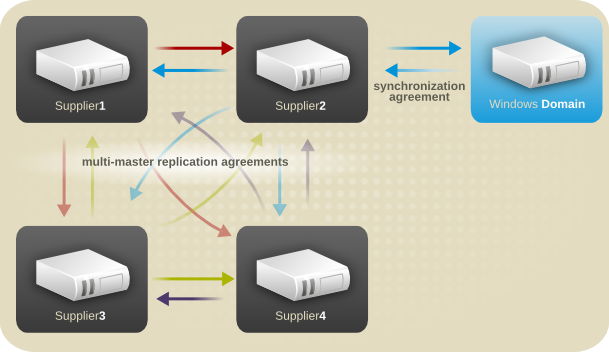
7.2.2. マルチサプライヤーのレプリケーション
図7.2 簡素化されたマルチサプライヤーレプリケーション設定
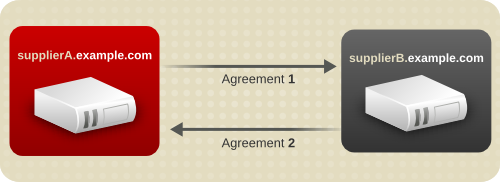
図7.3 簡素なマルチサプライヤー環境でのレプリケーショントラフィック
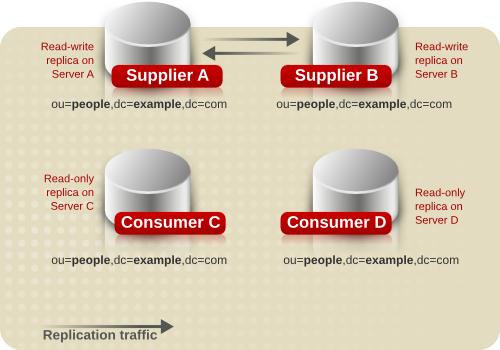
図7.4 マルチサプライヤーのレプリケーション設定 A
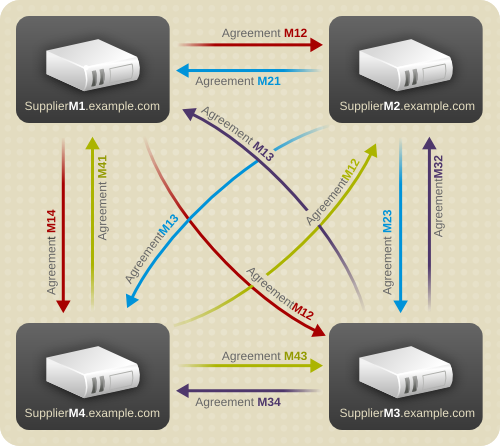
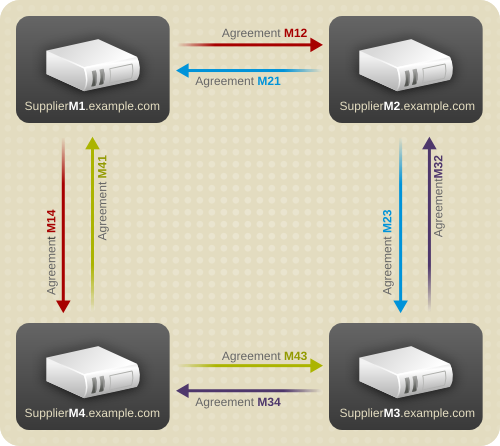
図7.5 マルチサイトのレプリケーション設定 B
- サプライヤーの数
- 地理的な場所
- サプライヤーが他の場所にあるサーバーを更新するために使用するパス
- 異なるサプライヤーのトポロジー、ディレクトリーツリー、およびスキーマ
- ネットワークの品質
- サーバーの負荷およびパフォーマンス
- ディレクトリーデータに必要な更新間隔
7.2.3. カスケードレプリケーション
図7.6 カスケードレプリケーションのシナリオ
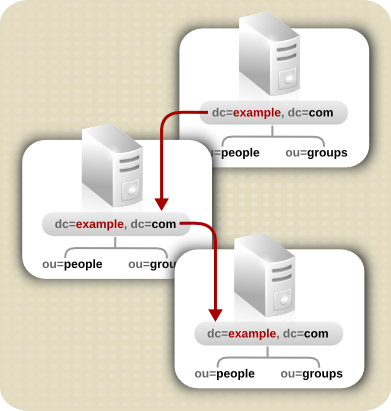
図7.7 カスケードレプリケーションにおけるレプリケーショントラフィックと changelog
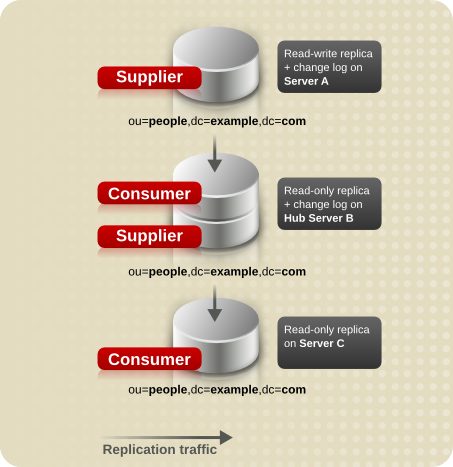
7.2.4. 混合環境
図7.8 マルチサプライヤーとカスケードレプリケーションの組み合わせ
7.3. レプリケーションストラテジーの定義
- ネットワーク内のリソース、トラフィックの負荷、ディレクトリーサービスのリソース要件を評価します。
- 会社の場所やセクションごとに複数のコンシューマーがいる場合や、一部のサーバーがセキュアでない場合は、一部レプリケーション を使用して、機密情報やめったに変更されない情報を除外することで、機密情報を損なうことなくデータの整合性を保つことができます。詳細は、「一部レプリケーションで選択された属性を複製する」 を参照してください。
- ネットワークが地理的に広い地域に広がっている場合、複数のサイトに複数の Directory Server があり、ローカルのデータサプライヤーはマルチサプライヤーレプリケーションで接続されています。詳細は、「ワイドエリアネットワーク全体でのレプリケーション」 を参照してください。
- 高可用性が主な懸念である場合は、1 つのサイトに複数の Directory Server を持つデータセンターを作成します。単一サプライヤーレプリケーションは、read-failover を提供しますが、マルチサプライヤーレプリケーションは write-failover を提供します。詳細は、「高可用性でのレプリケーションの使用」 を参照してください。
- ローカル可用性が主要な懸念事項である場合は、レプリケーションを使用して、世界中の現地事務所の Directory Server にデータを地理的に分散します。すべての情報のメインコピーは、本社などの 1 つの場所に保持することも、現地事務所 で DIT の関連する部分を管理することもできます。詳細は、「ローカル可用性でのレプリケーションの使用」 を参照してください。
- いずれの場合も、Directory Server によって処理される要求の負荷を分散し、ネットワークの輻輳を回避します。詳細は、「ロードバランシングでのレプリケーションの使用」 を参照してください。
7.3.1. レプリケーションサーベイの実施
- さまざまな建物やリモートサイトを接続する LAN と WAN の品質、および使用可能な帯域幅の量。
- ユーザーの物理的な場所、各サイトのユーザー数、使用状況パターン。これがディレクトリーサービスの使用目的になります。
- ディレクトリーサービスにアクセスするアプリケーションの数。読み取り、検索、および比較操作と書き込み操作の相対的な割合。
- メッセージングサーバーがディレクトリーを使用する場合は、処理する電子メールメッセージごと実行する操作の数を調べます。ディレクトリーサービスに依存するその他の製品は、通常、認証アプリケーションやメタディレクトリーアプリケーションなどの製品です。それぞれについて、ディレクトリーサービスで実行される操作の種類および頻度を決定します。
- ディレクトリーサービスに保存されているエントリーの数およびサイズ。
7.3.2. 一部レプリケーションで選択された属性を複製する
- コンシューマーサーバーが低速なネットワークを使用して接続されている場合、頻繁に変更されていない属性や
jpegPhotoなどの大きな属性により、ネットワークトラフィックが少なくなります。 - コンシューマーサーバーがパブリックインターネットなどの信頼できないネットワーク上に配置されている場合、電話番号などの機密属性を除外すると、サーバーのアクセス制御手段が無効になったり、マシンが攻撃者によって悪用されても、これらの属性にアクセスしないことを保証する追加レベルの保護が提供されます。
7.3.3. レプリケーションリソース要件
- ディスク使用量 - サプライヤーサーバーでは、変更ログは各更新操作の後に書き込まれます。多数の更新操作を受信するサプライヤーサーバーでは、ディスク使用量が増える可能性があります。注記各サプライヤーサーバーは 1 つの changelog を使用します。サプライヤーに複数の複製されたデータベースが含まれる場合、changelog はより頻繁に使用され、ディスク使用量がさらに高くなります。
- サーバースレッド - 各レプリケーションアグリーメントは 1 つのサーバースレッドを消費します。そのため、クライアントアプリケーションが使用できるスレッドの数が減少し、クライアントアプリケーションのサーバーパフォーマンスに影響を与える可能性があります。
- ファイル記述子 - サーバーで利用可能なファイル記述子の数は、変更ログ (1 つのファイル記述子) および各レプリケーションアグリーメント (アグリーメントごとに 1 つのファイル記述子) によって削減されます。
7.3.4. マルチサプライヤーレプリケーションに必要なディスク領域の管理
nsslapd-changelogmaxagechangelog のエントリーの最大期間を設定します。エントリーがその制限より古い場合は、削除されます。これにより、変更ログが無期限に大きくなるのを防ぎます。nsslapd-changelogmaxentrieschangelog で許可されるエントリーの最大数を設定します。nsslapd-changelogmaxageと同様に、changelog もトリミングされますが、設定に注意してください。これは、ディレクトリー情報の完全なセットを許可するのに十分な大きさである必要があります。そうしないと、マルチサプライヤーのレプリケーションが正しく機能しない可能性があります。
nsDS5ReplicaPurgeDelaytombstone (削除済み)エントリーおよび状態情報が changelog に設定可能な最大期間を設定します。tombstone または状態情報エントリーがその時間よりも古くなると、削除されます。nsslapd-changelogmaxageの値は、tombstone および状態情報エントリーにのみ適用される点でnsDS5ReplicaPurgeDelay属性とは異なります。nsslapd-changelogmaxageは、ディレクトリーの変更など、変更ログ内のすべてのエントリーに適用されます。nsDS5ReplicaTombstonePurgeIntervalサーバーがパージ操作を実行する頻度を設定します。この間隔で、Directory Server は内部操作を実行して、tombstone および状態のエントリーを削除します。最大経過時間が最長のレプリケーション更新スケジュールよりも長いことを確認してください。そうしないと、マルチサプライヤーレプリケーションがレプリカを適切に更新できない場合があります。
7.3.5. ワイドエリアネットワーク全体でのレプリケーション
- インターネットなどのパブリックネットワークを介してレプリケーションを実行する場合は、TLS を使用することが強く推奨されます。これにより、レプリケーショントラフィックの盗聴が防止されます。
- ネットワークには T-1 以上のインターネット接続を使用してください。
- ワイドエリアネットワークを介したレプリケーションアグリーメントを作成するときは、サーバー間を持続的に同期しないでください。レプリケーショントラフィックは帯域幅を大量に消費し、ネットワークとインターネット接続全体の速度を低下させる可能性があります。
- コンシューマーを初期化するときは、コンシューマーをすぐに初期化しないでください。代わりに、ファイルシステムレプリカの初期化を利用します。これは、オンライン初期化やファイルからの初期化よりもはるかに高速です。ファイルシステムレプリカの初期化の使用方法については、『Red Hat Directory Server Administration Guide』を参照してください。
7.3.6. 高可用性でのレプリケーションの使用
7.3.7. ローカル可用性でのレプリケーションの使用
- データのローカルメインコピーを保持する。これは、特定の国の社員のみに関連するディレクトリー情報を維持する必要がある大規模な多国籍企業にとって重要なストラテジーです。データのローカルメインコピーを保持することは、データを部門または組織レベルで管理する企業においても重要です。
- 信頼できないネットワーク接続または断続的に利用可能なネットワーク接続への対策。国際ネットワークで頻繁に発生しますが、信頼性の低い WAN がある場合は、ネットワーク接続が断続的になる可能性があります。
- ディレクトリーサービスのパフォーマンスを大幅に低下させる可能性のある、定期的で非常に重いネットワーク負荷を補正。ネットワークが古い企業でもパフォーマンスに影響が出る可能性があり、通常の営業時間中にこのような状態が発生する可能性があります。
7.3.8. ロードバランシングでのレプリケーションの使用
- 複数のサーバーにユーザーの検索アクティビティーを分散させます。
- サーバーを読み取り専用にします (書き込みはサプライヤーサーバーでのみ行われます)。
- メールサーバーのアクティビティーのサポートなど、特定のタスク専用の特別なサーバーを提供します。
表7.1 ネットワークにおけるレプリケーションおよびリモートルックアップの影響
| 負荷タイプ | オブジェクト[a] | アクセス/日[b] | 平均エントリーサイズ | 負荷 |
|---|---|---|---|---|
| レプリケーション | 100 万 | 100,000 | 1KB | 100Mb/日 |
| リモートルックアップ | 100 | 1,000 | 1KB | 1Mb/日 |
[a]
レプリケーションの場合、オブジェクト はデータベースのエントリー数を参照します。リモートルックアップの場合、データベースにアクセスするユーザーの数を参照します。
[b]
レプリケーションの場合、Accesses/Day は、レプリケートする必要があるデータベースの変更率を 10% としています。リモートルックアップの場合、各リモートユーザーの 1 日あたり 10 ルックアップに基づきます。
| ||||
7.3.8.1. ネットワーク負荷分散の例
図7.9 リモートオフィスでのエンタープライズサブツリーの管理
- ローカルで管理されているデータのサプライヤーサーバーとして、各オフィスで 1 台ずつサーバーを選択します。
- ローカルに管理されているデータを、そのサーバーからリモートオフィスの対応するサプライヤーサーバーに複製します。
- 各サプライヤーサーバーのディレクトリーツリー (リモートオフィスから提供されるデータを含む) を少なくとも 1 つのローカルの Directory Server に複製して、ディレクトリーデータの可用性を確保します。ローカルで管理される接尾辞にマルチサプライヤーレプリケーションを使用し、リモートサーバーからデータのメインコピーを受け取る接尾辞にはカスケードレプリケーションを使用します。

7.3.8.2. パフォーマンス向上のための負荷分散の例
- 100 万人のユーザーをサポートする 150 万エントリーの Directory Server を使用しています。
- 各ユーザーは、1 日あたり 10 個のディレクトリールックアップを実行します。
- 1 日あたり 2,500 万通のメールを処理するメッセージングサーバーを使用します。
- メッセージングサーバーは、処理するメールごとに 5 つのディレクトリールックアップを行います。
表7.2 Directory Server の読み込みの計算
| アクセスタイプ | タイプ数 | 1 日あたりのアクセス数 | 合計アクセス数 |
|---|---|---|---|
| ユーザー検索 | 100 万 | 10 | 1,000 万 |
| メールルックアップ | 2,500 万 | 5 | 1.25 億 |
| アクセスの合計 | 1.35 億 | ||
| 合計 | 1.35 億 (3,125/秒) |
- すべての書き込みトラフィックを処理するために、1 つの都市のマルチサプライヤー設定に 2 つの Directory Server を配置します。この設定は、すべてのディレクトリーデータに単一の制御ポイントがあることを前提としています。
- これらのサプライヤーサーバーを使用して、1 つ以上のハブサプライヤーを複製します。ディレクトリーサービスによって処理される読み取り、検索、および比較の要求は、コンシューマーサーバーを対象にする必要があります。これにより、サプライヤーサーバーは書き込み要求を処理できるようになります。
- ハブサプライヤーを使用して、企業全体のローカルサイトに複製します。ローカルサイトに複製することで、サーバーおよび WAN のワークロードのバランスを取ることや、ディレクトリーデータを高可用性を確保するのに役立ちます。
- 各サイトで、少なくとも読み取り操作のために、最低 1 回複製して高可用性を確保します。
- DNS ソートを使用して、ローカルユーザーがディレクトリールックアップに使用できるローカルディレクトリーサーバーを常に見つけられるようにします。
7.3.8.3. 小規模サイトのレプリケーションストラテジーの例
- 企業全体が 1 つのビルに入っています。
- ビルには、非常に高速 (毎秒 100 Mb) で、使用量の少ないネットワークがあります。
- ネットワークは非常に安定しており、サーバーハードウェアと OS プラットフォームは信頼できます。
- 単一のサーバーでサイトの負荷を簡単に処理できます。
7.3.8.4. 大規模サイトのレプリケーションストラテジーの例
- 会社は 2 つビルに分かれています。
- ビル間の接続は遅く、これらの接続は通常の営業時間中は非常に混雑しています。
- 2 つのビルのいずれかで、ディレクトリーデータのメインコピーを格納する単一のサーバーを選択します。このサーバーは、ディレクトリーデータのメインコピーを担当するユーザーが最も多いビルに配置する必要があります。このビルを Buidling A とします。
- ディレクトリーデータの高可用性のために、Buidling A 内で最低 1 回複製を行います。マルチサプライヤーレプリケーション設定を使用して、書き込みフェイルオーバーを確実に実行します。
- 別のビル (Building B) に 2 つのレプリカを作成します。
- サプライヤーサーバーとコンシューマーサーバーの間で厳密な一貫性を保つ必要がない場合は、オフピーク時にのみ実行されるようにレプリケーションをスケジュールします。
7.4. 他の Directory Server 機能でのレプリケーションの使用
7.4.1. レプリケーションおよびアクセス制御
7.4.2. レプリケーションおよび Directory Server プラグイン
- Attribute Uniqueness プラグインAttribute Uniqueness プラグインは、ローカルエントリーに追加された属性値を検証し、すべての値が一意であることを確認します。ただし、このチェックはサーバー上で直接行われ、他のサプライヤーから複製されることはありません。たとえば、Example Corp. では、
mail属性が一意でなければなりませんが、同じmail属性を持つ 2 人のユーザーが 2 つの異なるサプライヤーサーバーに同時に追加されます。命名の競合がない限り、レプリケーションの競合はありませんが、mail属性は一意ではありません。 - 参照整合性プラグイン参照整合性は、このプラグインがマルチサプライヤーセットの 1 つのサプライヤーでのみ有効になっている場合に、マルチサプライヤーレプリケーションで機能します。これにより、参照整合性の更新が 1 つのサプライヤーサーバーのみで行われ、他のサーバーに伝播されます。
7.4.3. レプリケーションおよびデータベースのリンク
図7.10 チェーンされたデータベースの複製
7.4.4. スキーマレプリケーション
- サプライヤーとコンシューマーの両方のスキーマエントリーが同じである場合、レプリケーション操作が続行されます。
- サプライヤーサーバー上のスキーマのバージョンがコンシューマーに保存されているバージョンより新しい場合、サプライヤーサーバーはそのスキーマをコンシューマーに複製してからデータの複製を続行します。
- サプライヤーサーバーのスキーマがコンシューマーに保存されているバージョンよりも古い場合、コンシューマーのスキーマが新しいデータをサポートできないため、サーバーはレプリケーション中に多くのエラーを返すことがあります。
99user.ldif ファイルに直接行われた変更が含まれます。カスタムスキーマファイル、およびカスタムスキーマファイルに追加された変更は複製されません。
カスタムスキーマ
標準の 99user.ldif ファイルがカスタムスキーマに使用される場合、これらの変更はすべてのコンシューマーに複製されます。
7.4.5. レプリケーションおよび同期
第8章 同期の設計
8.1. Windows 同期の概要
- ユーザーおよびグループの同期マルチサプライヤーレプリケーションと同様に、ユーザーとグループのエントリーは、デフォルトで有効になっているプラグインを介して同期されます。マルチサプライヤーレプリケーションに使用されるものと同じ changelog は、LDAP 操作として Directory Server から Windows 同期ピアサーバーに更新を送信するためにも使用されます。サーバーは、Windows サーバーに対して LDAP 検索操作を実行し、Windows エントリーに加えた変更を対応する Directory Server エントリーと同期します。
- Password Sync.このアプリケーションは、Windows ユーザーのパスワードの変更をキャプチャーし、これらの変更を LDAPS 経由で Directory Server に中継します。Active Directory マシンにインストールする必要があります。
図8.1 同期プロセス

8.1.1. 同期合意
8.1.2. changelog
8.2. サポート対象の Active Directory のバージョン
8.3. Windows 同期の計画
8.3.1. リソース要件
- ディスク使用量 - changelog は各更新操作の後に書き込まれます。多数の更新操作を受信するサーバーでは、ディスク使用量が増える可能性があります。さらに、すべてのレプリケーションデータベースと同期データベースに対して単一の changelog が維持されます。サプライヤーに複数の複製および同期されたデータベースが含まれる場合、changelog はより頻繁に使用され、ディスク使用量がさらに高くなります。
- サーバースレッド - 同期アグリーメントは 1 つのサーバースレッドを使用します。
- ファイル記述子 - サーバーで利用可能なファイル記述子の数は、変更ログ (1 つのファイル記述子) および各レプリケーションおよび同期アグリーメント (アグリーメントごとに 1 つのファイル記述子) によって削減されます。
- さまざまな建物やリモートサイトを接続する LAN と WAN の品質、および使用可能な帯域幅の量。
- ディレクトリーに保存されたエントリーの数およびサイズ。
8.3.2. changelog のディスク領域の管理
nsslapd-changelogmaxagechangelog のエントリーの最大期間を設定します。エントリーがその制限より古い場合は、削除されます。これにより、変更ログが無期限に大きくなるのを防ぎます。nsslapd-changelogmaxentrieschangelog で許可されるエントリーの最大数を設定します。nsslapd-changelogmaxageと同様に、changelog もトリミングされますが、設定に注意してください。これは、ディレクトリー情報の完全なセットを許可するのに十分な大きさである必要があります。そうしないと、同期が正しく機能しない可能性があります。
nsDS5ReplicaPurgeDelaytombstone (削除済み)エントリーおよび状態情報が changelog に設定可能な最大期間を設定します。tombstone または状態情報エントリーがその時間よりも古くなると、削除されます。nsslapd-changelogmaxageの値は、tombstone および状態情報エントリーにのみ適用される点でnsDS5ReplicaPurgeDelay属性とは異なります。nsslapd-changelogmaxageは、ディレクトリーの変更など、変更ログ内のすべてのエントリーに適用されます。nsDS5ReplicaTombstonePurgeIntervalサーバーがパージ操作を実行する頻度を設定します。この間隔で、Directory Server は内部操作を実行して、tombstone および状態のエントリーを削除します。最大経過時間が最長のレプリケーション更新スケジュールよりも長いことを確認してください。そうしないと、マルチサプライヤーレプリケーションがレプリカを適切に更新できない場合があります。
8.3.3. 接続型の定義
8.3.4. データサプライヤーの検討
8.3.5. 同期するサブツリーの決定
samAccount と Directory Server の uid 属性に基づいて相関します。Synchronization プラグインは、( samAccount/uid 関係に基づいて)エントリーが削除または移動されたために同期されたサブツリーから削除された場合、その旨を通知します。これは、そのエントリーがもう同期されないことを同期プラグインに示すためのものです。この問題は、同期プロセスで、移動したエントリーの処理方法を決定するための設定が必要となることです。同期アグリーメントでは、3 つのオプションを設定できます (適切な Directory Server エントリーの削除、変更の無視 (デフォルト)、またはエントリーを同期せずに現状を維持)。
8.3.6. 複製された環境との連携
ou=People,dc=example,dc=com)を対応する Windows ドメインとサブツリー(cn=Users,dc=test,dc=com)にリンクします。各サブツリーは、命名の競合や変更の競合を回避するために、他の 1 つのサブツリーにのみ同期させることができます。
図8.2 マルチサプライヤーディレクトリーサーバー - Windows ドメインの同期
8.3.7. 同期方向の制御
oneWaySync パラメーターを同期合意に追加することで、一方向 同期 を作成できます。この属性は、変更を送信する方向を定義します。
fromWindows になります。この場合、定期的な同期の更新間隔で、Directory Server が Active Directory Server に接続し、DirSync コントロールを送信して更新を要求します。ただし、Directory Server は、その側から変更やエントリーは送信されません。つまり、同期更新は、Active Directory の変更内容が Directory Server のエントリーに送信され、更新されることで設定されています。
toWindows になります。Directory Server は通常の更新で Active Directory サーバーにエントリー変更を送信しますが、Active Directory 側から更新を要求しないように DirSync 制御は含まれません。
8.3.8. 同期されるエントリーの制御
- Windows サブツリー内では、ユーザーおよびグループのエントリーのみを Directory Server に同期できます。同期アグリーメントを作成するとき、新しい Windows ユーザーおよびグループエントリーを作成時に同期するオプションがあります。これらの属性が on に設定されている場合は、既存の Windows エントリーが Directory Server に同期され、Windows サーバーで作成されるエントリーが Directory Server と同期されます。
- Active Directory エントリーと同様に、Directory Server のユーザーおよびグループエントリーのみを同期できます。同期されるエントリーには、ntUser または ntGroup オブジェクトクラスと必須の属性が必要で、その他のエントリーはすべて無視されます。
8.3.9. 同期するディレクトリーデータの特定
- 電話番号、自宅住所、会社の住所、電子メールアドレスなどのディレクトリーユーザーおよび従業員の連絡先情報。
- 取引先、取引先、および顧客の連絡先情報。
- ユーザーのソフトウェア設定またはソフトウェア設定情報。
- グループ情報とグループメンバーシップ。グループメンバーは、同期済みの接尾辞内である場合のみ同期されます。アグリーメントの範囲外のグループメンバーは、両側で変更されません。つまり、それらは適切なディレクトリーサービスのグループのメンバーとして一覧表示されますが、グループエントリーの
member属性は同期ピアと同期されません。
8.3.10. ユーザーとグループの POSIX 属性の同期
ntUser 属性および ntGroup 属性が自動的に追加されますが、POSIX 属性は同期されず(Active Directory エントリーに存在していても)、Directory Server 側では POSIX 属性は追加されません。
uidNumber、gidNumber、および homeDirectory)は、Active Directory エントリーと Directory Server エントリー間で同期されます。ただし、新しい POSIX エントリーまたは POSIX 属性が Directory Server の既存のエントリーに追加されると、POSIX 属性のみが Active Directory に対応するエントリーと同期します。POSIX オブジェクトクラス (ユーザーの場合は posixAccount、グループの場合は posixGroup) は Active Directory エントリーに追加されません。
8.3.11. パスワードの同期およびパスワードサービスのインストール
userPassword 属性の同期)は有効になりません。つまり、Directory Server ユーザーエントリーが Windows サーバーに同期されていても、ユーザーエントリーは Windows ドメインでアクティブではありません (つまり、同期されたユーザーはパスワードがないため、ドメインにログインできません)。
passwordTrackUpdateTime というパスワードポリシー属性があります。これにより、Active Directory と Directory Server 間または他のクライアントとのパスワード変更を同期することが簡単になります。
8.3.12. 更新ストラテジーの定義
winSyncInterval)を変更するか、別の更新スケジュール(nsDS5ReplicaUpdateSchedule)を設定して変更できます。
8.3.13. 同期アグリーメントの編集
8.4. Active Directory と Directory Server 間で同期されるスキーマ要素
ntUniqueId対応する Windows エントリーのobjectGUID属性の値が含まれます。この属性は同期プロセスで設定され、手動で設定または変更しないでください。ntUserDeleteAccountWindows エントリーが同期されても、Directory Server エントリーに対して手動で設定する必要がある場合に自動的に設定されます。ntUserDeleteAccountの値が true であれば、Directory Server エントリーが削除されると、対応する Windows エントリーが削除されます。ntDomainUserActive Directory エントリーのsamAccountName属性に対応します。ユーザーエントリーのみ。ntGroupType同期される Windows グループには自動的に設定されますが、同期する前に Directory Server エントリーに手動で設定する必要があります。グループエントリーのみ。
givenName 属性と Active Directory の givenName 属性が一致するように、これらの属性の一部は同じです。Active Directory と Red Hat Directory Server で定義されたスキーマは若干異なるため、Active Directory と Red Hat Directory Server との間で他の属性はマッピングされます。これらのほとんどは、Directory Server の Windows 固有の属性です。
8.4.1. Directory Server と Active Directory 間で同期されるユーザー属性
表8.1 Directory Server と Active Directory との間でマッピングされるユーザースキーマ
| Directory Server | Active Directory |
|---|---|
| cn | name |
| ntUserDomainId | sAMAccountName |
| ntUserHomeDir | homeDirectory |
| ntUserScriptPath | scriptPath |
| ntUserLastLogon | lastLogon |
| ntUserLastLogoff | lastLogoff |
| ntUserAcctExpires | accountExpires |
| ntUserCodePage | codePage |
| ntUserLogonHours | logonHours |
| ntUserMaxStorage | maxStorage |
| ntUserProfile | profilePath |
| ntUserParms | userParameters |
| ntUserWorkstations | userWorkstations |
表8.2 Directory Server および Windows サーバーで同一のユーザースキーマ
| cn | physicalDeliveryOfficeName |
| description | postOfficeBox |
| destinationIndicator | postalAddress |
| facsimileTelephoneNumber | postalCode |
| givenName | registeredAddress |
| homePhone | sn |
| homePostalAddress | st |
| initials | street |
| l | telephoneNumber |
| teletexTerminalIdentifier | |
| manager | telexNumber |
| mobile | title |
| o | userCertificate |
| ou | x121Address |
| pager |
8.4.2. Red Hat Directory Server と Active Directory との間のユーザースキーマの相違点
8.4.2.1. cn 属性の値
cn 属性に複数の値を指定できますが、Active Directory ではこの属性に単一の値しか持たせません。Directory Server の cn 属性が同期されると、単一の値のみが Active Directory ピアに送信されます。
cn の値が Active Directory エントリーに追加され、その値が Directory Server の cn の値のいずれでもない場合、Directory Server の cn 値がすべて単一の Active Directory 値で上書きされます。
cn 属性をその命名属性として使用するのに対し、Directory Server では uid を使用する点があります。つまり、Directory Server で cn 属性が編集されると、エントリーの名前が完全に変更になる可能性があります。この cn の変更が Active Directory エントリーに書き込まれると、エントリーの名前が変更になり、新しい名前付きエントリーが Directory Server に書き込まれます。ただし、cn 属性が同期されている場合のみ発生します。変更が同期されていない場合、エントリーの名前は変更されません。
8.4.2.2. パスワードポリシー
8.4.2.3. street および streetAddress の値
streetAddress 属性を使用します。これは、Directory Server が street 属性を使用する方法です。Active Directory および Directory Server が streetAddress 属性および street 属性を使用する方法には 2 つの重要な相違点があります。
- Directory Server では、
streetAddressはstreetのエイリアスです。Active Directory にもstreet属性がありますが、streetAddressのエイリアスではなく、別の属性で個別の値を保持することができます。 - Active Directory は
streetAddressとstreetを単一値の属性として定義しますが、Directory Server は RFC 4519 で指定されるようにstreetを多値属性として定義します。
streetAddress および street 属性を処理する方法が異なるため、Active Directory および Directory Server で address 属性を設定する際に従う 2 つのルールがあります。
- Windows Sync は、Windows エントリーの
streetAddressを Directory Server のstreetにマッピングします。競合を避けるために、street属性は Active Directory では使用しないようにしてください。 - Directory Server の
street属性値は 1 つだけ Active Directory に同期されます。streetAddress属性が Active Directory で変更され、新しい値が Directory Server に存在しない場合は、Directory Server のすべてのstreet属性値が新しい Active Directory 値に置き換えられます。
8.4.2.4. initials 属性の制約
initials 属性では、Active Directory は最大長 6 文字の制限を課しますが、Directory Server には長さ制限がありません。6 文字を超える initials 属性が Directory Server に追加されると、その値は Active Directory エントリーと同期したときにトリミングされます。
8.4.3. Directory Server と Active Directory 間で同期されたグループ属性
表8.3 Directory Server と Active Directory との間のグループエントリー属性のマッピング
| Directory Server | Active Directory | |||
|---|---|---|---|---|
| cn | name | |||
| ntGroupAttributes | groupAttributes | |||
| ntGroupId |
| |||
| ntGroupType | groupType |
表8.4 Directory Server と Active Directory との間のグループエントリー属性
| cn | member |
| description | ou |
| l | seeAlso |
8.4.4. Red Hat Directory Server と Active Directory のグループスキーマの相違点
第9章 セキュアなディレクトリーの設計
9.1. セキュリティーの脅威
- 不正アクセス
- 不正な改ざん
- サービス拒否
9.1.1. 不正アクセス
9.1.2. 不正な改ざん
9.1.3. サービス拒否
9.2. セキュリティーニーズの分析
- ユーザーおよびアプリケーションに、ジョブの実行に必要な情報へのアクセスを提供する方法。
- 社員またはビジネスに関する機密データを一般アクセスから保護する方法。
- 顧客にプライバシーの保証を提供する方法。
- 情報の整合性を保証する方法。
9.2.1. アクセス権限の決定
- 機密データを保護しながら、すべてのカテゴリーのユーザーにできるだけ多くの権限を付与します。オープンな方法では、どのデータがビジネスにとって機密または重要であるかを正確に判断する必要があります。
- 各カテゴリーのユーザーに、業務の遂行に必要な最小限のアクセス権を付与します。制限的な方法では、組織の内部、場合によっては外部のユーザーの各カテゴリーの情報ニーズを詳細に理解する必要があります。
9.2.2. データのプライバシーおよび整合性の確保
- データ転送を暗号化する。
- 証明書を使用してデータ転送に署名する。
9.2.3. 定期的な監査の実施
9.2.4. セキュリティーニーズ分析の例
- example.com の内部情報
- 法人のお客様の情報
- 個人加入者に関する情報
- ホストしている会社 (example_a および example_b) のディレクトリー管理者に独自のディレクトリー情報へのアクセスを提供します。
- ホストしている会社のディレクトリー情報にアクセス制御ポリシーを実装します。
- 自宅からのインターネットアクセスに example.com を使用するすべての個人顧客に標準のアクセス制御ポリシーを実装します。
- example.com の企業ディレクトリーへのアクセスをすべての部外者に拒否します。
- example.com の加入者名簿への読み取りアクセスを全員に付与します。
9.3. セキュリティーメソッドの概要
表9.1 Directory Server で利用可能なセキュリティーメソッド
| セキュリティーメソッド | 説明 |
|---|---|
| 認証 | ある当事者が別の当事者のアイデンティティーを検証する手段です。たとえば、クライアントは LDAP バインド操作時に Directory Server にパスワードを提供します。 |
| パスワードポリシー | パスワードが有効であると見なされるために満たさなければならない基準を定義します (期限、長さ、構文など)。 |
| 暗号化 | 情報のプライバシーを保護します。データを暗号化する際には、受信者だけが理解できるようにスクランブルをかけます。 |
| アクセス制御 | 異なるディレクトリーユーザーに付与されたアクセス権を調整し、必要な認証情報またはバインド属性を指定する方法を提供します。 |
| アカウントの非アクティブ化 | すべての認証の試行が自動的に拒否されるよう、ユーザーアカウント、アカウントグループ、またはドメイン全体を無効にします。 |
| セキュアな接続 | TLS、Start TLS、または SASL での接続を暗号化することで、情報の整合性を維持します。送信中に情報が暗号化されていれば、受信者は送信中に情報が変更されていないと判断できます。最小限のセキュリティー強度係数を設定することにより、セキュアな接続が必要になる場合があります。 |
| 監査 | ディレクトリーのセキュリティーが侵害されたかどうかを判断します。簡単な監査方法の 1 つは、ディレクトリーが維持するログファイルを確認することです。 |
| SELinux | Red Hat Enterprise Linux マシンでセキュリティーポリシーを使用して、Directory Server ファイルとプロセスへのアクセスを制限して制御します。 |
9.4. 適切な認証方法の選択
9.4.1. 匿名および認証されていないアクセス
ldapsearch -x -D "cn=jsmith,ou=people,dc=example,dc=com" -b "dc=example,dc=com" "(cn=joe)"
9.4.2. シンプルバインドとセキュアなバインド
userPassword 属性を許可するオブジェクトクラスである必要があります。これにより、ディレクトリーはバインド DN およびパスワードを確実に認識します。
- ユーザーは、ユーザー ID ( fchenなど)などの一意の識別子を入力します。
- LDAP クライアントアプリケーションは、ディレクトリーでその識別子を検索し、関連付けられた識別名(例: uid=fchen,ou=people,dc=example,dc=com)を返します。
- LDAP クライアントアプリケーションは、取得した識別名と、ユーザーが指定したパスワードを使用してディレクトリーにバインドします。
nsslapd-require-secure-binds 設定属性では、TLS または Start TLS を使用してセキュアな接続で簡単なパスワード認証を行う必要があります。これにより、プレーンテキストのパスワードが実質的に暗号化されるため、ハッカーが盗み見ることができなくなります。
nsslapd-require-secure-binds 設定属性には、TLS または Start TLS などのセキュアな接続でシンプルなパスワード認証が必要です。この設定により、SASL 認証や証明書ベースの認証などの他のセキュアな接続も使用できます。
9.4.3. 証明書ベースの認証
9.4.4. プロキシー認証
ldapmodify -D "cn=Directory Manager" -W -x -D "cn=directory manager" -W -p 389 -h server.example.com -x -Y "cn=joe,dc=example,dc=com" -f mods.ldif
mods.ldif ファイルに変更を適用します。マネージャーは、この変更を加えるためにジョーのパスワードを提供する必要はありません。
9.4.5. パススルー認証
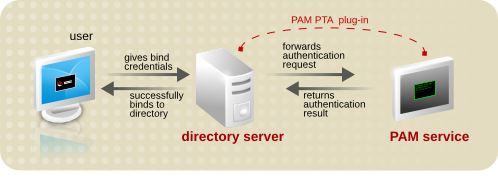
図9.1 簡単なパススルー認証プロセス
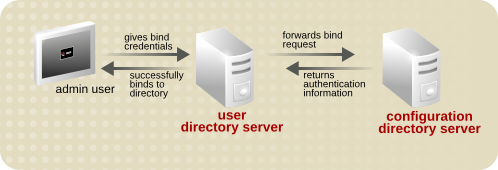
図9.2 PAM パススルー認証プロセス
/etc/pam.d/system-auth )を指すようにします。
9.4.6. パスワードなしの認証
9.5. アカウントロックアウトポリシーの設計
nsAccountLock で実装されます。値が true の nsAccountLock 属性がエントリーに含まれる場合、サーバーはそのアカウントによるバインドの試行を拒否します。
- アカウントロックアウトポリシーをパスワードポリシー (「パスワードポリシーの設計」) に関連付けることができます。ユーザーが一定回数以上、適切な認証情報でログインできない場合、管理者が手動でロックを解除するまでアカウントがロックされます。これにより、ユーザーのパスワードを繰り返し推測してディレクトリーに侵入しようとするクラッカーから守ることができます。
- 一定の時間が経過すると、アカウントをロックすることができます。これは、アカウントが作成された時間に基づいて、時間制限のあるアクセス権を持つ、インターン、学生、季節労働者などの一時的なユーザーのアクセスを制御するために使用できます。または、アカウントが最後のログイン時刻から一定期間非アクティブの場合に、ユーザーアカウントを非アクティブにするアカウントポリシーを作成することもできます。タイムベースのアカウントロックアウトポリシーは、ディレクトリーのグローバル設定を行う Account Policy プラグインによって定義されます。複数のアカウントポリシーサブエントリーを作成して、異なる有効期限やタイプを設定し、サービスクラスを通じてエントリーに適用することができます。
9.6. パスワードポリシーの設計
9.6.1. パスワードポリシーの仕組み
- ディレクトリー全体。このようなポリシーは グローバル パスワードポリシーと呼ばれます。ポリシーは設定および有効化されると、ディレクトリー内のすべてのユーザーに適用されます。ただし、Directory Manager エントリーと、ローカルのパスワードポリシーが有効になっているユーザーエントリーは適用から除外されます。これにより、すべてのディレクトリーユーザーに共通の単一のパスワードポリシーを定義することができます。
- ディレクトリーの特定のサブツリー。このようなポリシーは サブツリーレベル または ローカル パスワードポリシーと呼ばれます。設定および有効化されると、ポリシーは指定されたサブツリー配下のすべてのユーザーに適用されます。これは、すべてのホストされた会社に単一のポリシーを適用するのではなく、ホストされた会社ごとに異なるパスワードポリシーをサポートするホスティング環境に適しています。
- ディレクトリーの特定のユーザー。このようなポリシーは ユーザーレベル または ローカル パスワードポリシーと呼ばれます。設定および有効化されると、ポリシーは指定されたユーザーのみに適用されます。これにより、ディレクトリーユーザーごとに異なるパスワードポリシーを定義できます。たとえば、一部のユーザーがパスワードを毎日変更し、一部のユーザーが毎月パスワードを変更し、他のすべてのユーザーが 6 か月ごとにパスワードを変更するように指定します。
nsslapd-pwpolicy-local 属性を有効にします。この属性はスイッチとして機能し、粒度の細かいパスワードポリシーをオンおよびオフに切り替えます。
ns-newpwpolicy.pl スクリプトが非推奨になりました。ただし、このスクリプトは 389-ds-base-legacy-tools パッケージで使用できます。
- 詳細なパスワードポリシーが有効になっているかどうかを判断するために、サーバーは cn=config エントリーの
nsslapd-pwpolicy-local属性に割り当てられた値(on または off)をチェックします。値が off の場合、サーバーはサブツリーおよびユーザーレベルで定義されたポリシーを無視し、グローバルパスワードポリシーを適用します。 - ローカルポリシーがサブツリーまたはユーザーに定義されているかどうかを判断するために、サーバーは対応するユーザーエントリーの
pwdPolicysubentry属性をチェックします。属性が存在する場合は、サーバーは、ユーザーに設定されたローカルパスワードポリシーを適用します。属性が存在しない場合、サーバーはエラーメッセージをログに記録し、グローバルパスワードポリシーを強制します。
図9.3 パスワードポリシーの確認プロセス
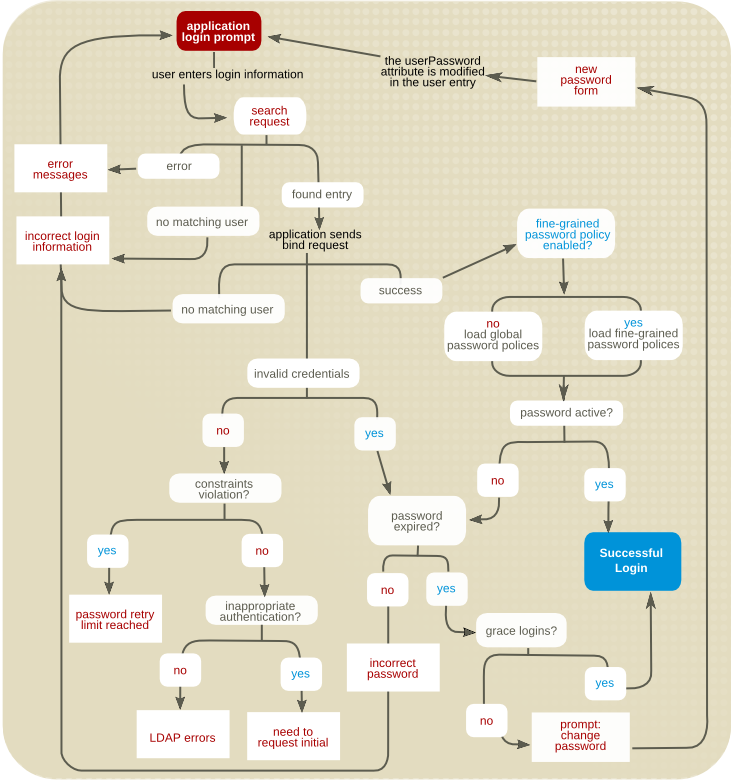
userPassword 属性(以下のセクションを参照)が要求に存在する場合、パスワードポリシーチェックは追加および変更操作中にも行われます。
userPassword の値を変更すると、以下の 2 つのパスワードポリシー設定が確認されます。
- パスワードの最低期間ポリシーがアクティブになります。最低期間要件が満たされないと、サーバーは constraintViolation エラーを返します。パスワード更新操作は失敗します。
- パスワード履歴ポリシーがアクティブになります。
userPasswordの新しい値がパスワード履歴にある場合、または現在のパスワードと同じ場合は、サーバーは constraintViolation エラーを返します。パスワード更新操作は失敗します。
userPassword の値を追加および変更すると、パスワードポリシーでパスワード構文がチェックされます。
- パスワードの最小長ポリシーがアクティブになります。
userPasswordの新しい値が必要な最小長未満の場合、サーバーは constraintViolation エラーを返します。パスワード更新操作は失敗します。 - パスワード構文の確認ポリシーがアクティブになります。
userPasswordの新しい値がエントリーの別の属性と同じ場合、サーバーは constraintViolation エラーを返します。パスワード更新操作は失敗します。
9.6.2. パスワードポリシーの属性
9.6.2.1. 失敗の最大回数
passwordMaxFailure パラメーターで設定されます。
passwordLegacyPolicy パラメーターでレガシー動作を有効にできます。
9.6.2.2. リセット後のパスワード変更
9.6.2.3. ユーザー定義のパスワード
- 管理者の時間がかなり必要です。
- 管理者が指定したパスワードは通常、覚えるのが難しいため、ユーザーはパスワードを書き留める可能性が高く、発見されるリスクが高くなります。
9.6.2.4. パスワードの有効期限
9.6.2.5. 有効期限の警告
9.6.2.6. 猶予ログイン制限
9.6.2.7. パスワードの構文チェック
passwordCheckSyntax 属性で設定されます。
uid、cn、sn、givenName、ou、または mail属性に保存されている値です。
- パスワードに必要な最小文字数(
passwordMinLength) - 桁の最小数。ゼロから 9 の間の数字を意味します(
passwordMinDigits) - ASCII アルファベットの最小数(大文字と小文字の両方)(
passwordMinAlphas) - 大文字の ASCII アルファベットの最小数(
passwordMinUppers) - 小文字の ASCII アルファベットの最小数(
passwordMinLowers) - !@#$ などの特殊 ASCII 文字の最小数(
passwordMinSpecials) - 8 ビット文字の最小数(
passwordMin8bit) - aaabbb (
passwordMaxRepeats)など、同じ文字をすぐに繰り返すことができる最大回数() - パスワードごとに必要な文字カテゴリーの最小数。カテゴリーは大文字、小文字、特殊文字、数字、または 8 ビット文字(
passwordMinCategories) - Directory Server は
CrackLibディクショナリーに対してパスワードをチェックします(passwordDictCheck)。 - Directory Server はパスワードに回文が含まれているかどうかを確認します(
passwordPalindrome) - Directory Server は、同じカテゴリーの文字を連続して持つパスワードを設定できなくなります(
passwordMaxClassChars) - Directory Server が特定の文字列を含むパスワードが設定されないようにする(
passwordBadWords) - Directory Server は管理者定義属性に設定された文字列を含むパスワードが設定されないようにする(
passwordUserAttributes)
9.6.2.8. パスワードの長さ
9.6.2.9. パスワードの最小期間
passwordHistory 属性とともに使用すると、古いパスワードの再使用は推奨されません。
passwordMinAge)属性が 2 日である場合、ユーザーは 1 つのセッション中にパスワードを繰り返し変更できません。これにより、パスワード履歴を循環して、古いパスワードを再利用できるようになります。
9.6.2.10. パスワード履歴
9.6.2.11. パスワードストレージスキーム
- CLEAR、暗号化がないことを意味します。これは SASL Digest-MD5 と併用できる唯一のオプションであるため、SASL を使用するには CLEAR パスワードストレージスキームが必要です。ディレクトリーに保存されているパスワードは、アクセス制御情報 (ACI) 命令を使用して保護できますが、プレーンテキストのパスワードをディレクトリーに保存することは適切とはいえません。
- Secure Hash Algorithm (SHA、SHA-256、SHA-384、および SHA-512).これは SSHA よりも安全性が低いです。
- UNIX CRYPT アルゴリズム。このアルゴリズムは、UNIX パスワードとの互換性を提供します。
- MD5。このストレージスキームは SSHA よりも安全性が低くなりますが、MD5 を必要とするレガシーアプリケーション用に含まれています。
- Salted MD5。このストレージスキームは、プレーンな MD5 ハッシュよりも安全ですが、SSHA よりも安全性が低くなります。このストレージスキームは、新しいパスワードと併用するために含まれていませんが、salted MD5 に対応するディレクトリーからのユーザーアカウントを移行するのに役立ちます。
9.6.2.12. パスワードの最終変更時刻
passwordTrackUpdateTime 属性は、エントリーのパスワードが最後に更新されたときのタイムスタンプを記録するようにサーバーに指示します。パスワードの変更時間はユーザーエントリーで pwdUpdateTime 操作属性 (modifyTimestamp または lastModified 操作属性とは別) として保存されます。
9.6.3. レプリケートされた環境でのパスワードポリシーの設計
- パスワードポリシーはデータサプライヤーで実施されます。
- アカウントのロックアウトは、レプリケーション設定のすべてのサーバーに適用されます。
- すべてのレプリカは、パスワードの期限切れが近いことを警告します。この情報は各サーバーでローカルに保存されるため、ユーザーが複数のレプリカに順番にバインドすると、ユーザーは同じ警告を複数回受け取ります。さらに、ユーザーがパスワードを変更すると、この情報がレプリカにフィルターされるまで時間がかかる場合があります。ユーザーがパスワードを変更してからすぐに再バインドすると、レプリカが変更を登録するまでバインドに失敗する可能性があります。
- サプライヤーやレプリカなど、すべてのサーバーで同じバインド動作が発生する必要があります。各サーバーに常に同じパスワードポリシー設定情報を作成します。
- アカウントロックアウトカウンターは、マルチサプライヤー環境で想定どおりに機能しない場合があります。
9.7. アクセス制御の設計
- ディレクトリー全体。
- ディレクトリーの特定のサブツリー。
- ディレクトリーの特定のエントリー。
- エントリー属性の特定セット。
- 指定の LDAP 検索フィルターと一致するエントリー。
9.7.1. ACI 形式
- targetACI が対象とするエントリー (通常はサブツリー)、対象とする属性、またはその両方を指定します。ターゲットは ACI が適用されるディレクトリー要素を識別します。ACI はエントリーを 1 つだけターゲットにできますが、複数の属性をターゲットにできます。さらに、ターゲットには LDAP 検索フィルターを含めることができます。パーミッションは、共通の属性値を含む、広範囲に散在するエントリーにパーミッションを設定することができます。
- パーミッション.この ACI によって設定される実際のパーミッションを特定します。permission 変数は、ACI が指定されたターゲットへの特定タイプのディレクトリーアクセス (読み取りや検索など) を許可または拒否していることを示します。
- bind ruleパーミッションが適用されるバインド DN またはネットワークの場所を特定します。バインドルールは LDAP フィルターを指定する場合もあり、そのフィルターがバインドクライアントアプリケーションに対して true であると評価された場合、ACI はクライアントアプリケーションに適用されます。
target (permission bind_rule)(permission bind_rule)...
9.7.1.1. ターゲット
targetattr パラメーターを設定して、1 つ以上の属性をターゲットにします。targetattr パラメーターが設定されていない場合、ターゲットになる属性はありません。詳細は、『Red Hat Directory Server Administration Guide』の該当セクションを参照してください。
9.7.1.2. パーミッション
| パーミッション | 説明 |
|---|---|
| Read | ディレクトリーデータを読み取ることができるかどうかを示します。 |
| Write | ディレクトリーデータを変更または作成できるかどうかを示します。このパーミッションは、ディレクトリーデータの削除を許可しますが、エントリー自体は削除できません。エントリー全体を削除するには、ユーザーに delete パーミッションが必要です。 |
| Search |
ディレクトリーデータを検索できるかどうかを示します。これは、検索操作の一部として返される場合にディレクトリーデータを表示できる点で、read パーミッションとは異なります。
たとえば、共通名の検索と、人の部屋番号の読み取りが許可された場合は、共通名の検索の一部として部屋番号を返すことができますが、部屋番号自体は検索の対象として使用できません。この組み合わせを使用して、ディレクトリーを検索してどの部屋に誰がいるかを検索できないようにします。
|
| Compare | 比較操作でデータを使用できるかどうかを示します。compare パーミッションは検索可能であることを意味しますが、検索の結果として実際のディレクトリー情報は返されません。代わりに、比較した値と一致するかどうかを示す簡単なブール値が返されます。これは、ディレクトリー認証中に userPassword 属性値を照合するために使用されます。 |
| Self-write | グループ管理にのみ使用されます。このパーミッションにより、ユーザーはグループに自身を追加したり、グループから削除したりできます。 |
| 追加 | 子エントリーを作成できるかどうかを示します。このパーミッションにより、ユーザーはターゲットとなるエントリーの下に子エントリーを作成できます。 |
| 削除 | エントリーを削除できるかどうかを示します。このパーミッションにより、ユーザーはターゲットとなるエントリーを削除できます。 |
| Proxy | ユーザーがディレクトリーマネージャー以外の他の DN を使用して、この DN の権限でディレクトリーにアクセスできることを示します。 |
9.7.1.3. バインドルール
- バインド操作が特定の IP アドレス (IPv4 または I Pv6) または DNS ホスト名から送信される場合のみ。これは、特定のマシンまたはネットワークドメインからすべてのディレクトリー更新を強制的に実行するためによく使用されます。
- ユーザーが匿名でバインドする場合。匿名バインドのパーミッションを設定すると、ディレクトリーにバインドするすべてのユーザーにもパーミッションが適用されます。
- ディレクトリーに正常にバインドされるユーザーの場合。これにより、匿名アクセスを阻止する一方で、一般的なアクセスが可能になります。
- クライアントがエントリーの直接の親としてバインドされている場合のみ。
- ユーザーがバインドしたエントリーが特定の LDAP 検索条件を満たしている場合のみ。
- Parentバインド DN が直接の親エントリーである場合、バインドルールは true になります。これは、ディレクトリー分岐点がその直接の子エントリーを管理できるようにする特定のパーミッションを付与できることを意味します。
- Selfバインド DN がアクセスを要求するエントリーと同じである場合、バインドルールは true になります。個人が独自のエントリーを更新できるように特定のパーミッションを付与できます。
- Allディレクトリーに正常にバインドされたユーザーは、バインドルールは true になります。
- Anyonebind ルールは、すべてのユーザーで true になります。このキーワードは、匿名アクセスを許可または拒否するために使用されます。
9.7.2. パーミッションの設定
9.7.2.1. 優先度ルール
9.7.2.2. アクセスの許可または不許可
uid 属性に書き込む権限を拒否します。または、以下の方法で書き込みアクセスを許可する 2 つのアクセス制御ルールを作成します。
uid属性以外のすべての属性への書き込み権限を許可するルールを 1 つ作成します。このルールはすべてのユーザーに適用される必要があります。uid属性への書き込み権限を許可するルールを 1 つ作成します。このルールは、Directory Administrators グループのメンバーにのみ適用する必要があります。
9.7.2.3. アクセスを拒否する場合
- 複雑な ACL が分散している大きなディレクトリーツリーがある。セキュリティー上の理由から、特定のユーザー、グループ、または物理的な場所へのアクセスを突然拒否しなければならない場合があります。時間をかけて既存の ACL を注意深く調べて、許可パーミッションを適切に制限する方法を理解するのではなく、分析を行う時間ができるまで、明示的な拒否特権を一時的に設定します。ACL がこのように複雑になった場合、長期的には、拒否 ACI は管理オーバーヘッドを増やすだけです。できるだけ早く ACL を作り直して、明示的な拒否特権を回避し、アクセス制御スキーム全体を簡素化します。
- アクセス制御は、曜日または 1 日の時間を基にする必要があります。たとえば、すべての書き込みアクティビティーは日曜日の午後 11 時から拒否できます。(2300) to Monday at 1:00 a.m.(0100).管理の観点からは、すべての allow-for-write ACI のディレクトリーを検索し、この期間でスコープを制限するよりも、このタイプの時間ベースのアクセスを明示的に制限する ACI を管理する方が簡単かもしれません。
- ディレクトリー管理者権限を複数のユーザーに委譲する場合は、特権を制限する必要があります。個人またはユーザーのグループに、ツリーの一部を変更を許可せずに、ディレクトリーツリーの一部の管理を許可するには、明示的な拒否特権を使用します。たとえば、メール管理者が共通名属性への書き込みアクセスを許可しないようにするには、共通名属性への書き込みアクセスを明示的に拒否する ACI を設定します。
9.7.2.4. アクセス制御ルールの配置場所
9.7.2.5. フィルターされたアクセス制御ルールの使用
organizationalUnit 属性が含まれるエントリーの読み取りアクセスを許可します。
publishHomeContactInfoという属性をすべてのユーザーのディレクトリーエントリーに作成します。homePhone属性が true (有効)に設定されているエントリーに対してのみ、homePostalAddress属性およびpublishHomeContactInfo属性への読み取りアクセスを許可するアクセス制御ルールを設定します。LDAP 検索フィルターを使用して、このルールのターゲットを表します。- ディレクトリーユーザーが、独自の
publishHomeContactInfo属性の値を true または false に変更できるようにします。これにより、ディレクトリーユーザーは、この情報が公開されているかどうかを判断できます。
9.7.3. ACI の表示: Get Effective Rights
- 管理者は、get effective rights コマンドを使用して、特定のグループまたはユーザーのエントリーへのアクセスを許可し、他のユーザーを制限するなど、細かなアクセス制御を行うことができます。たとえば、QA Managers グループのメンバーには、
titleやsalaryなどの属性を検索および読み取る権限がありますが、HR Group メンバーのみが変更または削除する権限を持ちます。 - ユーザーは、有効な権限を取得するオプションを使用して、個人エントリーで表示または変更できる属性を決定できます。たとえば、ユーザーは
homePostalAddressおよびcnなどの属性にアクセスできますが、titleおよびsalaryへの読み取りアクセスのみが許可されます。
-E スイッチを使用して実行される ldapsearch は、通常の検索結果の一部として、特定のエントリーのアクセス制御を返します。次の検索は、ユーザー Ted Morris が個人エントリーに対して持っている権限を示しています。
ldapsearch -x -p 389 -h server.example.com -D "uid=tmorris,ou=people,dc=example,dc=com" -W -b "uid=tmorris,ou=people,dc=example,dc=com" -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=tmorris,ou=people,dc=example,dc=com "(objectClass=*)"
version: 1
dn: uid=tmorris,ou=People,dc=example,dc=com
givenName: Ted
sn: Morris
ou: Accounting
ou: People
l: Santa Clara
manager: uid=dmiller,ou=People,dc=example,dc=com
roomNumber: 4117
mail: tmorris@example.com
facsimileTelephoneNumber: +1 408 555 5409
objectClass: top
objectClass: person
objectClass: organizationalPerson
objectClass: inetOrgPerson
uid: tmorris
cn: Ted Morris
userPassword: {SSHA}bz0uCmHZM5b357zwrCUCJs1IOHtMD6yqPyhxBA==
entryLevelRights: vadn
attributeLevelRights: givenName:rsc, sn:rsc, ou:rsc, l:rscow, manager:rsc, roomNumber:rscwo, mail:rscwo, facsimileTelephoneNumber:rscwo, objectClass:rsc, uid:rsc, cn:rsc, userPassword:woentryLevelRights の結果が示すように、Ted Morris には自分のエントリーの DN を追加、表示、削除、または名前変更する権限があります。lの結果に示されるように、場所の読み取り、検索、比較、自己変更、または自己削除を行えますが、パスワードに対する自己書き込みおよび自己削除の権限のみになります。attributeLevelRights
userPassword の値が削除されると、自己書き込みおよび自己削除の権限が許可されていても、将来的に上記のエントリーで有効な権限を検索しても、userPassword の有効な権限は返されません。同様に、street 属性に読み取り、比較、および検索の権限が追加されると、street: rsc は attributeLevelRights の結果に表示されます。
ldapsearch -x -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=scarter,ou=people,dc=example,dc=com "(objectclass=*)" "*"ldapsearch -x -E !1.3.6.1.4.1.42.2.27.9.5.2:dn:uid=scarter,ou=people,dc=example,dc=com "(objectclass=*)" "+"9.7.4. ACI の使用: いくつかのヒントとコツ
- ディレクトリー内の ACI の数を最小限に抑えます。Directory Server は 50,000 を超える ACI を評価できますが、多数の ACI ステートメントを管理するのは困難です。ACI の数が多いと、人間の管理者が特定のクライアントが使用できるディレクトリーオブジェクトをすぐに判断することが難しくなります。Directory Server は、マクロを使用してディレクトリー内の ACI の数を最小限に抑えます。マクロは、ACI の DN または DN の一部を表すために使用されるプレースホルダーです。マクロを使用して、ACI のターゲット部分、バインドルール部分、またはその両方で DN を表現することができます。マクロ ACI の詳細は、『Red Hat Directory Server Administration Guide』の Managing Access Control の章を参照してください。
- アクセス許可の許可と拒否のバランスを取ります。デフォルトのルールでは、特にアクセスを許可されていないユーザーへのアクセスは拒否されますが、1 つの ACI を使用してツリーのルートに近いアクセスを許可し、少数の拒否を許可することで、ACI の数を減らす方がよい場合があります。リーフエントリーに近い ACI。このシナリオでは、リーフエントリーの近くで複数の許可 ACI を使用することを回避できます。
- 特定の ACI で最小の属性セットを特定します。オブジェクトの属性のサブセットへのアクセスを許可または拒否する場合、最小のリストが、許可される属性のセットであるか、拒否される属性のセットであるかを決定します。次に、最小のリストのみを管理する必要があるように ACI を表現します。たとえば、person オブジェクトクラスには多数の属性が含まれます。ユーザーがこれらの属性の 1 つまたは 2 つだけを更新できるようにするには、それらのいくつかの属性のみに書き込みアクセスを許可するように ACI を記述します。ただし、1 つまたは 2 つの属性を除くすべての属性をユーザーが更新できるようにするには、いくつかの名前付き属性を除くすべての属性に対して書き込みアクセスを許可するように ACI を作成します。
- LDAP 検索フィルターの使用には注意が必要です。検索フィルターは、アクセスを管理しているオブジェクトに直接名前を付けません。したがって、それらを使用すると、予期しない結果が生じる可能性があります。これは、ディレクトリーがより複雑になるにつれて特に当てはまります。ACI で検索フィルターを使用する前に、同じフィルターを使用して ldapsearch 操作を実行し、変更の結果がディレクトリーにとって何を意味するかを明確にします。
- ディレクトリーツリーの異なる部分で ACI を複製しないでください。ACI の重複を防ぎます。たとえば、
commonName属性およびgivenName属性へのグループの書き込みアクセスを許可する ACI と、同じグループの書き込みアクセスを許可する別の ACI がディレクトリールートポイントにある場合は、1 つの制御のみがグループに書き込みアクセスを付与するように ACI を再起動することを検討してください。commonNameディレクトリーが複雑になるにつれて、誤って ACI が重複するリスクが急速に高まります。ACI の重複を避けることで、セキュリティー管理が容易になり、ディレクトリーに含まれる ACI の総数が減る可能性があります。 - ACI に名前を付けます。ACI の命名は任意ですが、各 ACI に短くて意味のある名前を付けることは、セキュリティーモデルの管理に役立ちます。
- ディレクトリー内で ACI をできるだけ密接にグループ化します。ACI の配置をディレクトリールートポイントと主要なディレクトリーブランチポイントに制限するようにしてください。ACI をグループ化すると、ディレクトリー内の ACI の総数を最小限に抑えるだけでなく、ACI の合計リストを管理するのにも役立ちます。
- バインド DN が cn=Joe と等しくない場合に書き込みを拒否する など、二重否定を使用しないでください。この構文はサーバーには完全に受け入れられますが、人間の管理者にとっては混乱を招きます。
9.7.5. ルート DN への ACI の適用 (Directory Manager)
dse.ldif ファイルで定義されているため、ACI ターゲットにはそのユーザーが含まれません。
- 8 a.m. から 5 p.m.までのような時間的な範囲での時間ベースのアクセス制御(0800 - 1700)。
- 曜日のアクセス制御により、アクセスは明示的に定義された日数でのみ許可されます。
- 指定した IP アドレス、ドメイン、またはサブネットのみが明示的に許可または拒否される IP アドレスルールです。
- ホストアクセスルール。指定されたホスト名、ドメイン名、またはサブドメインのみが明示的に許可または拒否されます。
9.8. データベースの暗号化
9.9. サーバー接続の保護
- Transport Layer Security (TLS)ネットワーク上で安全な通信を提供するために、Directory Server は Transport Layer Security (TLS) で LDAP を使用できます。TLS は、RSA の暗号化アルゴリズムと組み合わせて使用できます。特定の接続に対して選択される暗号化方式は、クライアントアプリケーションと Directory Server 間のネゴシエーションの結果です。
- Start TLSDirectory Server は、通常の暗号化されていない LDAP ポートを介して Transport Layer Security (TLS) 接続を開始する方法である Start TLS もサポートしています。
- Simple Authentication and Security Layer (SASL)SASL はセキュリティーフレームワークです。つまり、クライアントアプリケーションとサーバーアプリケーションの両方で有効になっているメカニズムに応じて、サーバーに対してユーザーを認証するさまざまなメカニズムを許可するシステムをセットアップします。また、クライアントとサーバー間で暗号化されたセッションを確立することもできます。Directory Server では、SASL を GSS-API とともに使用して Kerberos ログインを有効にし、レプリケーション、連鎖、パススルー認証など、ほぼすべてのサーバー間接続に使用できます。(SASL は Windows Sync では使用できません。)
9.10. SELinux ポリシーの使用
- Directory Server の dirsrv_t
- SNMP の場合は dirsrv_snmp_t
図9.4 Directory Server のファイルラベリングの編集
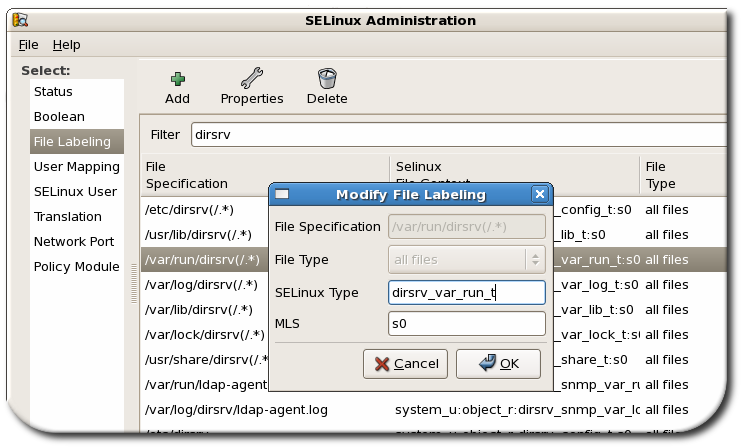
- 各インスタンスのファイルとディレクトリーは、特定の SELinux コンテキストでラベル付けされています。(Directory Server が使用するメインディレクトリーのほとんどには、ローカルインスタンスの数に関係なく、すべてのローカルインスタンス用のサブディレクトリーがあるため、1 つのポリシーを新しいインスタンスに簡単に適用できます。)
- 各インスタンスのポートは、特定の SELinux コンテキストでラベル付けされています。
- すべての Directory Server プロセスは、適切なドメイン内に制限されます。
- 各ドメインには、ドメインに承認されたアクションを定義する特定のルールがあります。
- SELinux ポリシーで指定されていないアクセスは、インスタンスに対して拒否されます。
9.11. その他のセキュリティーリソース
- 『Understanding and Deploying LDAP Directory Services.』T. Howes, M. Smith, G. Good, Macmillan Technical Publishing, 1999.
- SecurityFocus.com http://www.securityfocus.com
- Computer Emergency Response Team (CERT) Coordination Center http://www.cert.org
第10章 ディレクトリー設計の例
10.1. 設計例: ローカル企業
10.1.1. ローカルエンタープライズデータの設計
- Example Corp. のディレクトリーは、メッセージングサーバー、Web サーバー、カレンダーサーバー、人事アプリケーション、およびホワイトページアプリケーションによって使用されます。
- メッセージングサーバーは、
uid、mailServerName、mailAddressなどの属性に対して正確な検索を実行します。データベースのパフォーマンスを向上させるために、Example Corp. はこれらの属性のインデックスを維持して、メッセージングサーバーによる検索をサポートします。インデックスの使用に関する詳細は、「データベースパフォーマンスを改善するためのインデックスの使用」 を参照してください。 - ホワイトページアプリケーションは、ユーザー名と電話番号を頻繁に検索します。したがって、ディレクトリーは、大量の結果を返す部分文字列、ワイルドカード、およびあいまい検索を頻繁に実行できる必要があります。Example Corp. は、
cn属性、sn属性、およびgivenName属性の存在、等価、近似、および部分文字列インデックスと、telephoneNumber属性の存在、等価、および部分文字列インデックスを維持することを決定します。 - Example Corp. のディレクトリーは、組織全体にデプロイメントされた LDAP サーバーベースのイントラネットをサポートするために、ユーザーとグループの情報を保持しています。Example Corp. のユーザーおよびグループ情報のほとんどは、ディレクトリー管理者のグループによって集中管理されます。ただし、Example Corp. は、メール情報を別のメール管理者グループで管理することも望んでいます。
- Example Corp. は、S/MIME メールなどの公開鍵基盤 (PKI) アプリケーションを将来的にサポートする予定であるため、ユーザーの公開鍵証明書をディレクトリーに格納する準備を整える必要があります。
10.1.2. ローカルエンタープライズスキーマの設計
userCertificate と uid (userID)属性を許可します。これらは、Example Corp. のディレクトリーがサポートするアプリケーションに必要です。
exampleID 属性)を許可します。この属性には、Example Corp. の各従業員に割り当てられた特別な従業員番号が含まれています。
10.1.3. ローカルエンタープライズのディレクトリーツリー設計
- ディレクトリーツリーのルートは、Example Corp. のインターネットドメイン名である
dc=example,dc=comです。 - ディレクトリーツリーには、
ou=people、ou=groupsou=roles、および,のブランチポイントが 4 つあります。ou=resources - Example Corp. の人のエントリーはすべて
ou=peopleブランチの下に作成されます。人のエントリーはすべてperson、organizationalPerson、、inetOrgPerson、および examplePerson オブジェクトクラスのメンバーになります。uid属性は、各エントリーの DN を一意に識別します。たとえば、Example Corp. には、Babs Jensen (uid=bjensen))および Emily Stanton (uid=estanton)のエントリーが含まれます。 - これらは、Example Corp. の営業、マーケティング、会計の各部門に 1 つずつ、3 つのロールを作成します。人のエントリーにはそれぞれ、その人が所属する部門を識別するロール属性が含まれます。Example Corp. は、これらのロールに基づいて、ACI を作成できるようになりました。ロールの詳細は、「ロールの概要」 を参照してください。
ou=groupsブランチに 2 つのグループブランチを作成します。最初のグループcn=administratorsには、ディレクトリーの内容を管理するディレクトリー管理者のエントリーが含まれます。2 つ目のグループcn=messaging adminには、メールアカウントを管理するメール管理者のエントリーが含まれています。このグループは、メッセージングサーバーによって使用される管理者グループに対応します。Example Corp. は、メッセージングサーバーに設定するグループが、Directory Server 用に作成するグループとは異なるようにします。- これらは、
ou=resourcesブランチの下に、2 つのブランチを作成します。1 つは会議部屋(ou=conference rooms)用で、もう 1 つはオフィスが 1 つです。ou=offices - これらは、エントリーが管理グループに属するかどうかに応じて
mailquota属性 の値を提供するサービスクラス(CoS) を作成します。この CoS では、管理者には 100GB のメールクォータが与えられ、一般の Example Corp. の従業員には 5GB のメールクォータが与えられます。サービスクラスの詳細は、「サービスクラスについて」 を参照してください。
図10.1 Example Corp. のディレクトリーツリー
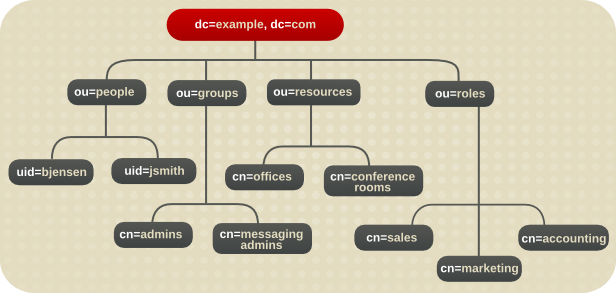
10.1.4. ローカルエンタープライズのトポロジー設計
10.1.4.1. データベーストポロジー
root suffix の情報は 3 番目のデータベース(DB3)に格納されます。これは 図10.2「Example Corp. のデータベーストポロジー」 で説明されています。
図10.2 Example Corp. のデータベーストポロジー
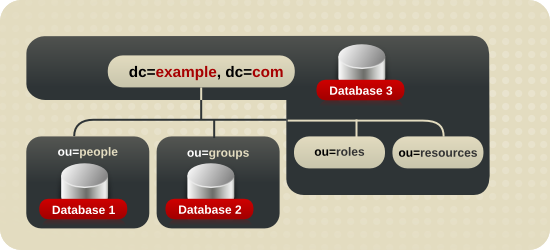
図10.3 Example Corp. のサーバートポロジー
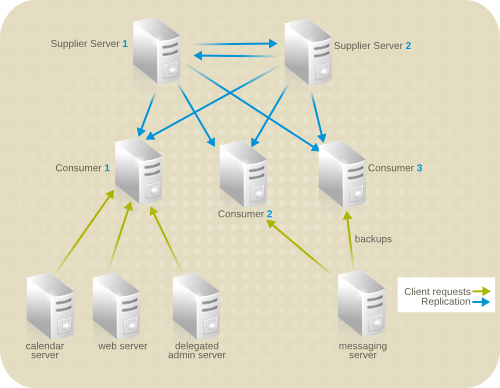
10.1.5. ローカルエンタープライズレプリケーション設計
10.1.5.1. サプライヤーアーキテクチャー
図10.4 Example Corp. のサプライヤーアーキテクチャー
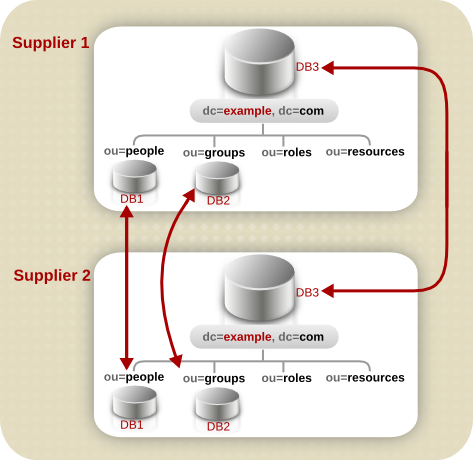
10.1.5.2. サプライヤーコンシューマーアーキテクチャー
図10.5 Example Corp. のサプライヤーとコンシューマーアーキテクチャー
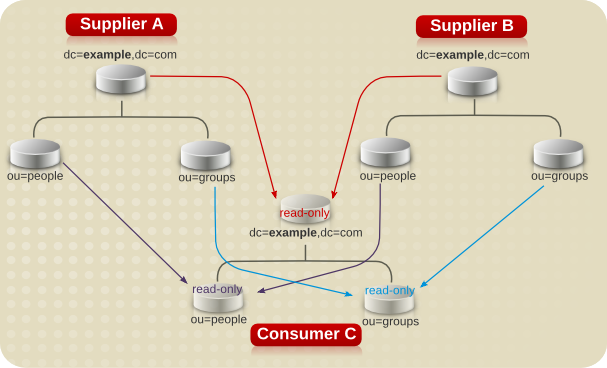
10.1.6. ローカルの企業セキュリティー設計
- 従業員が独自のエントリーを変更できるようにする ACI を作成します。ユーザーは、
uid属性、manager属性、およびdepartment属性以外のすべての属性を変更できます。 - 従業員データのプライバシーを保護するために、従業員とそのマネージャーのみが従業員の自宅住所と電話番号を閲覧できる ACI を作成します。
- 2 つの管理者グループに適切なディレクトリー権限を与える ACI をディレクトリーツリーの root に作成します。ディレクトリー管理者グループは、ディレクトリーへのフルアクセスが必要です。メッセージング管理者グループは、mailRecipient および mailGroup オブジェクトクラス、およびそれらのオブジェクトクラスに含まれる属性、および
mail属性への書き込みおよび削除アクセスが必要です。Example Corp. は、メッセージング管理者グループwrite、delete、およびaddに、メールグループを作成するためのグループサブディレクトリーへのパーミッションも付与します。 - ディレクトリーツリーのルートに一般的な ACI を作成し、読み取り、検索、および比較アクセスの匿名アクセスを許可します。この ACI は、パスワード情報への匿名書き込みアクセスを拒否します。
- サービス拒否攻撃や不適切な使用からサーバーを保護するために、ディレクトリークライアントがバインドするために使用する
DNに基づいてリソース制限を設定しました。Example Corp. では、匿名ユーザーが検索要求に応じて一度に 100 エントリーを受信できるようにし、管理ユーザーにメッセージを送信して 1,000 エントリーを受信し、ディレクトリー管理者が無制限の数のエントリーを受信できるようにしています。バインド DN に基づいてリソース制限を設定する方法の詳細は、『Red Hat Directory Server Administrator's Guide』の User Account Management の章を参照してください。 - 彼らは、パスワードの長さが 8 文字以上で、90 日後に有効期限が切れる必要があることを指定するパスワードポリシーを作成します。パスワードポリシーの詳細は、「パスワードポリシーの設計」 を参照してください。
- 彼らは、会計ロールのメンバーがすべての給与情報にアクセスできるようにする ACI を作成します。
10.1.7. ローカルエンタープライズ操作の決定
- 毎晩、データベースをバックアップします。
- SNMP を使用してサーバーの状態を監視します。SNMP の詳細は、『Red Hat Directory Server Administrator's Guide』を参照してください。
- アクセスログとエラーログを自動でローテーションします。
- エラーログを監視し、サーバーが想定どおりに実行されていることを確認します。
- アクセスログを監視して、インデックスを作成すべき検索を選別します。
10.2. 設計の例: 多国籍企業とそのエクストラネット
10.2.1. 多国籍企業のデータ設計
- メッセージングサーバーは、ほとんどの Example Corp. のサイト向けに、電子メールルーティング、配信、および読み取りサービスを提供するために使用されます。企業サーバーは、ドキュメント公開サービスを提供します。すべてのサーバーは Red Hat Enterprise Linux 7 で実行されます。
- Example Corp. は、データをローカルで管理できるようにする必要があります。たとえば、ヨーロッパのサイトは、ディレクトリーのヨーロッパのブランチを管理します。これは、ヨーロッパが自身のデータのメインコピーに責任を持つということでもあります。
- Example Corp. のオフィスは地理的に分散しているため、ユーザーやアプリケーションが 24 時間ディレクトリーを利用できるようにする必要があります。
- データ要素の多くは、複数の異なる言語のデータ値に対応している必要があります。注記すべてのデータは UTF-8 文字セットを使用しています。他の文字セットは LDAP 標準に違反しています。
- パーツのサプライヤーは、Example Corp. のディレクトリーにログインして、Example Corp との契約を管理する必要があります。パーツのサプライヤーは、名前やユーザーパスワードなどの、認証に使用するデータ要素に依存します。
- Example Corp. のパートナーは、ディレクトリーを使用して、パートナーネットワーク内の人々の連絡先情報 (メールアドレスや電話番号など) を検索します。
10.2.2. 多国籍企業のスキーマ設計
exampleSupplierID 属性)が許可されます。この属性には、Example Corp. によって割り当てられた一意の ID が含まれます。国際から、提携している各自動車部品サプライヤーへ。
examplePartnerID 属性)が許可されます。この属性には、Example Corp. によって割り当てられた一意の ID が含まれます。各トレードパートナーへの International。
10.2.3. 多国籍企業のディレクトリーツリー設計
- ディレクトリーツリーの root は、
dc=com接尾辞です。この接尾辞の下に、Example Corp. は 2 つのブランチを作成します。1 つのブランチdc=exampleCorp,dc=comには、Example Corp の内部のデータが含まれます。国際。他のブランチdc=exampleNet,dc=comには、エクストラネットのデータが含まれます。 - イントラネットのディレクトリーツリー(
dc=exampleCorp,dc=com)下)には、Example Corp. がオフィスを持つリージョンの 1 つに対応する 3 つの主要なブランチがあります。これらのブランチは、l(ローカリティー)属性を使用して識別されます。 dc=exampleCorp,dc=com下の各メインブランチは、Example Corp の元のディレクトリーツリー設計に似ています。各ローカリティーの下に、Example Corp. はou=people、ou=groups、ou=roles、およびou=resourcesブランチを作成します。このディレクトリーツリーの設計の詳細は、図10.1「Example Corp. のディレクトリーツリー」 を参照してください。dc=exampleNet,dc=comブランチの下に、Example Corp. は 3 つのブランチを作成します。サプライヤー用に 1 つのブランチ(o=suppliers)、Partner (Partner) (o=partners)用ブランチを 1 つ、および groups]-[ 用にブランチを 1 つ、および 1 つのブランチです。ou=groups- エクストラネットの
ou=groupsブランチには、エクストラネットの管理者のエントリーと、パートナーが自動検出したパーツの製造に関する最新情報をサブスクライブするメーリングリストのエントリーが含まれています。
図10.6 Example Corp. の基本的なディレクトリーツリーインド在外のお客様:
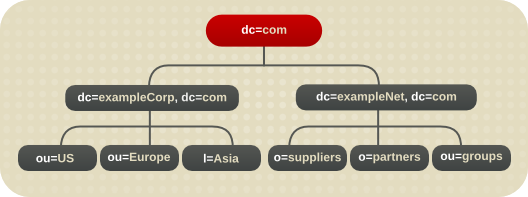
図10.7 Example Corp. のディレクトリーツリーInternational のイントラネット
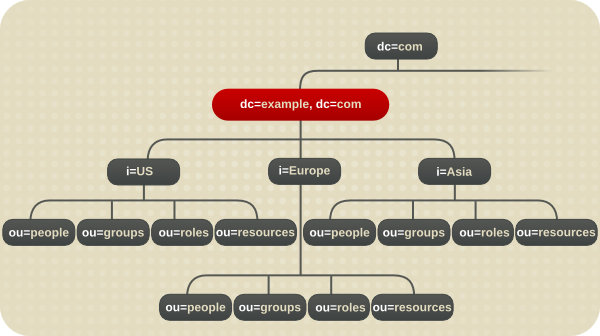
l=Asia エントリーのエントリーは、以下のように LDIF に表示されます。
dn: l=Asia,dc=exampleCorp,dc=com objectclass: top objectclass: locality l: Asia description: includes all sites in Asia
図10.8 Example Corp. のディレクトリーツリーInternational のエクストラネット
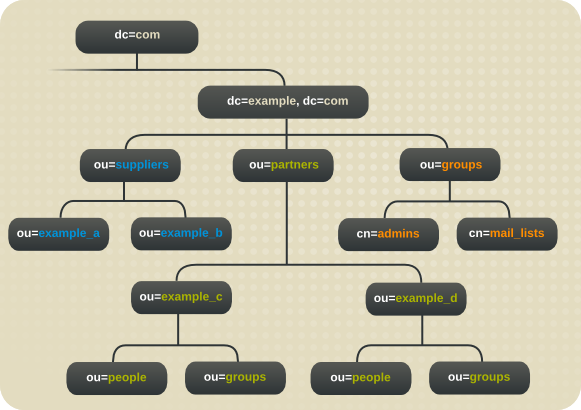
10.2.4. 多国籍企業のトポロジー設計
10.2.4.1. データベーストポロジー
図10.9 Example Corp. のデータベーストポロジーヨーロッパ
l=US ブランチ下のデータのヨーロッパサーバーは、オーストイン Texas 内のサーバー上のデータベースへのデータベースリンクによってチェーンされます。データベースリンクおよびチェーンの詳細は、「チェーンの使用」 を参照してください。
dc=exampleCorp,dc=com およびルートエントリーである dc=com のデータのメインコピーは、l=Europe データベースに保存されます。
o=suppliers のデータのメインコピーは 1 つ(DB1)に保存され、o=partners 用の ou=groups はデータベース 2 (DB2)に保存され、の場合はデータベース 3 (DB3)に保存されます。
図10.10 Example Corp. のデータベーストポロジーInternational のエクストラネット
10.2.4.2. サーバートポロジー
図10.11 Example Corp. のサーバートポロジーヨーロッパ
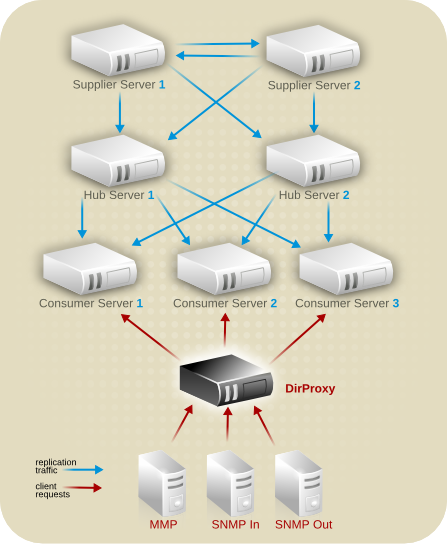
図10.12 Example Corp. のサーバートポロジーInternational のエクストラネット
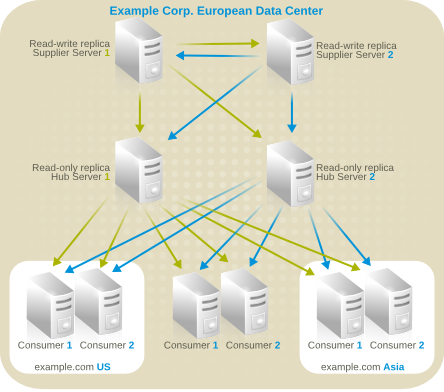
10.2.5. 多国籍企業のレプリケーション設計
- データはローカルで管理されます。
- ネットワーク接続の品質は、サイトごとに異なります。
- データベースリンクは、リモートサーバー上のデータを接続するために使用されます。
- データの読み取り専用コピーを含むハブサーバーは、コンシューマーサーバーにデータを複製するために使用されます。
10.2.5.1. サプライヤーアーキテクチャー
dc=exampleCorp,dc=com および dc=com の情報が含まれます。
図10.13 Example Corp. のサプライヤーアーキテクチャーヨーロッパ
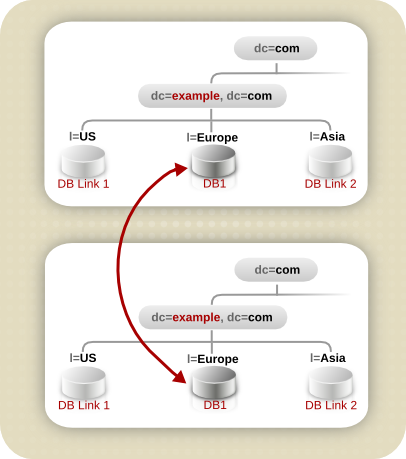
図10.14 Example Corp. のマルチサプライヤーレプリケーション設計ヨーロッパと Example Corp.US
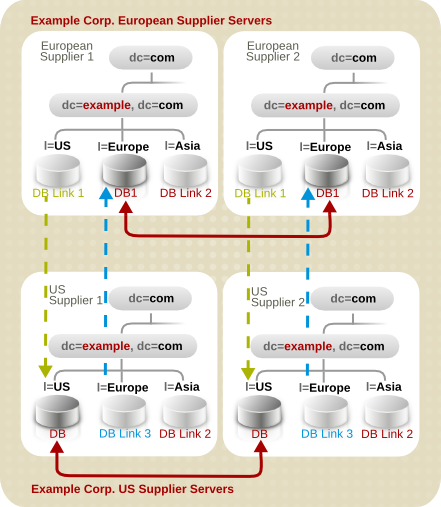
10.2.6. 多国籍企業のセキュリティー設計
- Example Corp. は、一般的な ACI をイントラネットのルートに追加し、各国および各国の下の支社により制限の厳しい ACI を作成します。
- Example Corp. は、マクロ ACI を使用して、ディレクトリー内の ACI の数を最小限に抑えることにしました。Example Corp. はマクロを使用して、ACI のターゲットまたはバインドルール部分で DN を表します。ディレクトリーが着信 LDAP 操作を取得すると、ACI マクロは LDAP 操作の対象となるリソースと照合されます。一致する場合、マクロはターゲットリソースの DN の値に置き換えられます。マクロ ACI の詳細は、『Red Hat Directory Server Administrator's Guide』を参照してください。
- Example Corp. は、すべてのエクストラネットアクティビティーに証明書ベースの認証を使用するかどうかを決定します。ユーザーがエクストラネットにログインする際には、デジタル証明書が必要となります。ディレクトリーは証明書を保存するために使用されます。ディレクトリーは証明書を保存するため、ディレクトリーに保存された公開鍵を検索することで、暗号化されたメールを送信することができます。
- Example Corp. は、エクストラネットへの匿名アクセスを禁止する ACI を作成します。これにより、サービス拒否攻撃からエクストラネットを守ることができます。
- Example Corp. は、Example Corp.がホストするアプリケーションのみから、ディレクトリーデータの更新を行うようにしています。つまり、エクストラネットを利用するパートナーやサプライヤーは、Example Corp. が提供するツールのみを利用できることを意味します。エクストラネットのネットユーザーを Example Corp. の推奨するツールに制限することで、Example Corp. の管理者は監査ログを使用してディレクトリーの使用状況を追跡することができ、Example Corp. 以外のエクストラネットのユーザーがもたらす可能性のある問題の種類を制限することができます。国際。
付録A Directory Server の RFC サポート
A.1. LDAPv3 の機能
- Technical Specification Road Map (RFC 4510)
- これは追跡ドキュメントであり、要件は含まれていません。
- Protocol (RFC 4511)
- サポート対象例外:
- RFC 4511 Section 4.4.1.Notice of Disconnection: この場合、Directory Server は接続を終了します。
- RFC 4511 Section 4.5.1.3.SearchRequest.derefAliases: LDAP エイリアスはサポートされません。
- Directory Information Models (RFC 4512)
- サポート対象例外:
- RFC 4512 Section 2.4.2.Structural Object Classes: Directory Server は、複数の構造オブジェクトクラスを持つエントリーをサポートします。
- RFC 4512 Section 4.1.2.Attribute Types: 属性タイプ
COLLECTIVEはサポートされていません。
RFC 4512 により、LDAP サーバーが前述の例外に対応できないことに注意してください。詳細は、RFC 4512 Section 7.1. を参照してください。サーバーのガイドライン. - Authentication Methods and Security Mechanisms (RFC 4513)
- サポート対象
- String Representation of Distinguished Names (RFC 4514)
- サポート対象
- String Representation of Search Filters (RFC 4515)
- サポート対象
- Uniform Resource Locator (RFC 4516)
- サポート対象ただし、この RFC は主に LDAP クライアントに焦点を当てています。
- Syntaxes and Matching Rules (RFC 4517)
- サポート対象例外:
directoryStringFirstComponentMatchintegerFirstComponentMatchobjectIdentifierFirstComponentMatchobjectIdentifierFirstComponentMatchkeywordMatchwordMatch
- Internationalized String Preparation (RFC 4518)
- サポート対象
- Schema for User Applications (RFC 4519)
- サポート対象
A.2. 認証方法
- Anonymous SASL Mechanism (RFC 4505)
- サポート対象外。RFC 4512 は、
ANONYMOUSSASL メカニズムを必要としない点に留意してください。ただし、Directory Server は LDAP 匿名バインドをサポートします。 - External SASL Mechanism (RFC 4422)
- サポート対象
- Plain SASL Mechanism (RFC 4616)
- サポート対象外。RFC 4512 は、
PLAINSASL メカニズムを必要としない点に留意してください。ただし、Directory Server は LDAP 匿名バインドをサポートします。 - SecurID SASL Mechanism (RFC 2808)
- サポート対象外。ただし、Cyrus SASL プラグインが存在する場合は、Directory Server はそれを使用することができます。
- Kerberos V5 (GSSAPI) SASL Mechanism (RFC 4752)
- サポート対象
- CRAM-MD5 SASL Mechanism (RFC 2195)
- サポート対象
- Digest-MD5 SASL Mechanism (RFC 2831)
- サポート対象
- One-time Password SASL Mechanism (RFC 2444)
- サポート対象外。ただし、Cyrus SASL プラグインが存在する場合は、Directory Server はそれを使用することができます。
A.3. X.509 証明書のスキーマおよび属性サポート
- X.509 証明書の LDAP スキーマ定義 (RFC 4523)
- 属性タイプとオブジェクトクラス: サポート対象
- 構文: サポート対象外(Directory Server はバイナリーおよび octet 構文を使用)
- 一致規則: サポートされていません。
付録B 改訂履歴
| 改訂履歴 | |||
|---|---|---|---|
| 改訂 11.5-1 | Tue May 10 2022 | ||
| |||
| 改訂 11.4-1 | Tue Nov 09 2021 | ||
| |||
| 改訂 11.3-1 | Tue May 11 2021 | ||
| |||
| 改訂 11.2-1 | Tue Nov 03 2020 | ||
| |||
| 改訂 11.1-1 | Tue Apr 28 2020 | ||
| |||
| 改訂履歴 | |||
|---|---|---|---|
| 改訂 11.0-1 | Thu Nov 21 2019 | ||
| |||