
管理および設定ガイド
Red Hat JBoss Data Grid 6.3 向け
概要
第1章 Red Hat JBoss Data Grid のセットアップ
1.1. 前提条件
1.2. Red Hat JBoss Data Grid のセットアップ手順
手順1.1 JBoss Data Grid のセットアップ
キャッシュマネージャーのセットアップ
JBoss Data Grid の設定手順は、キャッシュマネージャーから始まります。キャッシュマネージャーは、事前に設定した設定テンプレートを使ってキャッシュインスタンスを素早くかつ簡単に取得し、作成することができます。キャッシュマネージャーのセットアップについてさらに詳しくは、パートI「キャッシュマネージャーのセットアップ」を参照してください。JVM メモリー管理のセットアップ
JBoss Data Grid の設定における重要な手順は、お使いの Java 仮想マシン (JVM) のメモリー管理をセットアップすることです。JBoss Data Grid は、JVM メモリーの管理に役立つ、エビクションおよびエクスパレーションなどの各種機能を提供します。エビクションのセットアップ
エントリーがどの程度頻繁に使用されているかに基づき、インメモリーキャッシュの実装からエントリーを削除するために使用するロジックを指定します。JBoss Data Grid は、データグリッド内のエントリーのエビクションに対するきめ細やかな制御を行うための複数の異なるエビクションストラテジーを提供します。エビクションのストラテジーおよびエビクションを設定する手順については、3章エビクションのセットアップ を参照してください。エクスパレーションのセットアップ
キャッシュにおけるエントリーの時間の上限を設定するために、エクスパレーション情報を各エントリーに添付します。エクスパレーションを使用して、エントリーがキャッシュ内に留まれる最長期間や、取得されたエントリーがキャッシュから削除される前にアイドル状態として有効となる期間をセットアップします。さらに詳しくは、4章エクスパレーションのセットアップ を参照してください。
キャッシュのモニタリング
JBoss Data Grid では、JBoss ロギングによるロギング機能を使用し、ユーザーのキャッシュをモニタリングする支援を行います。ロギングのセットアップ
JBoss Data Grid にロギングをセットアップするのは必須ではありませんが、これを強く推奨します。JBoss Data Grid は、ユーザーがデータグリッド内の各種操作に対する自動化されたロギングを簡単にセットアップすることを可能にする JBoss ロギングを使用します。ログは、その後エラーのトラブルシューティングや予想外の失敗の原因の特定に使用することができます。さらに詳しくは、5章ロギングのセットアップを参照してください。
キャッシュモードのセットアップ
キャッシュモードは、キャッシュがローカル (単純なインメモリーキャッシュ) か、またはクラスター化されたキャッシュ (ノードの小さなサブセット上で状態変更をレプリケートする) のいずれかを指定するために使用されます。さらに、キャッシュがクラスター化されている場合、変更をノードのサブセットにどのように伝搬させるかを定めるために、レプリケーション、ディストリビューションまたはインバリデーションモードのいずれかを適用する必要があります。さらに詳しくは、パートIV「キャッシュモードのセットアップ」を参照してください。キャッシュのロックのセットアップ
レプリケーションまたはディストリビューションが有効な場合、エントリーのコピーは複数のノードでアクセスできます。結果として、データのコピーは、異なる複数のスレッドで同時にアクセスしたり、変更したりすることができます。複数のノード間ですべてのコピーの一貫性を維持するには、ロックを設定します。さらに詳しくは、パートVI「キャッシュのロックのセットアップ」および16章分離レベルのセットアップを参照してください。キャッシュストアのセットアップと設定
JBoss Data Grid は、メモリーから削除されたエントリーを永続外部キャッシュストアに一時的に保存するために、パッシベーション機能 (またはパッシベーションがオフになっている場合はキャッシュ書き込みストラテジー) を提供します。パッシベーションまたはキャッシュ書き込みストラテジーをセットアップするには、まずキャッシュストアをセットアップする必要があります。キャッシュストアのセットアップ
キャッシュストアは永続ストアへの接続として機能します。キャッシュストアは、エントリーを永続ストアから取得し、変更を永続ストアに戻すために主に使用されます。さらに詳しくは、パートVII「キャッシュストアのセットアップと設定」を参照してください。パッシベーションのセットアップ
パッシベーションは、メモリーからエビクトされたエントリーをキャッシュストアに保存します。この機能により、エントリーがメモリー内に存在しないのにもかかわらず使用可能な状態となり、永続キャッシュへの高いコストが発生する可能性のある操作を回避できます。さらに詳しくは、パートVIII「パッシベーションのセットアップ」を参照してください。キャッシュ書き込みストラテジーのセットアップ
パッシベーションが無効な場合、キャッシュへの書き込みが試行されるたびに、キャッシュストアへの書き込みが行なわれます。これは、デフォルトのライトスルーキャッシュ書き込みストラテジーです。これらのキャッシュ書き込みが同期的または非同期的に実行されるかを定めるためにキャッシュライティングストラテジーを設定します。さらに詳しくは、パートIX「キャッシュ書き込みのセットアップ」を参照してください。
キャッシュとキャッシュマネージャーのモニタリング
JBoss Data Grid には、データグリッドが実行中の場合にキャッシュとキャッシュマネージャーをモニタリングするための 2 つの主なツールが含まれます。JMX のセットアップ
JMX は、JBoss Data Grid に使用される標準的な統計および管理ツールです。ユースケースに応じて、JMX はキャッシュまたはキャッシュマネージャー、またはそれら両方のレベルで設定することができます。さらに詳しくは、21章Java Management Extensions (JMX) のセットアップを参照してください。Red Hat JBoss Operations Network (JON) のセットアップ
Red Hat JBoss Operations Network (JON) は、JBoss Data Grid で利用できる 2 番目のモニタリングソリューションです。JBoss Operations Network (JON) は、キャッシュおよびキャッシュマネージャーのランタイムパラメーターおよび統計をモニタリングするためのグラフィカルインターフェースを提供します。さらに詳しくは、22章JBoss Operations Network (JON) のセットアップを参照してください。
トポロジー情報の導入
オプションとして、データグリッド内の特定タイプの情報またはオブジェクトが置かれる場所を指定するために、データグリッドにトポロジー情報を提供します。サーバーヒンティングは、トポロジー情報を JBoss Data Grid に導入する数ある方法の中の 1 つです。サーバーヒンティングのセットアップ
サーバーヒンティングは、セットアップされると、データのオリジナルおよびバックアップコピーが同じ物理サーバー、ラックまたはデータセンターに保存されていないことを確認することにより高可用性を提供します。これは、すべてのデータがすべてのサーバー、ラックおよびデータセンターでバックアップされるレプリケートされたキャッシュなどの場合にはオプションになります。さらに詳しくは、28章サーバーヒンティングを用いた高可用性を参照してください。
パート I. キャッシュマネージャーのセットアップ
第2章 キャッシュマネージャー
- 指定された標準を使用して、複数のインスタンスをオンデマンドで作成します。
- 既存のキャッシュインスタンスを読み出します (すでに作成されたキャッシュ)。
2.1. キャッシュマネージャーの種類
EmbeddedCacheManagerは、クライアントが使用する Java 仮想マシン (JVM) 内で実行されるキャッシュマネージャーです。現在 JBoss Data Grid は、EmbeddedCacheManagerインターフェースのDefaultCacheManager実装のみを提供しています。RemoteCacheManagerは、リモートキャッシュにアクセスするために使用されます。RemoteCacheManagerは、起動時に Hot Rod サーバー (または複数の Hot Rod サーバー) への接続をインスタンス化します。次にRemoteCacheManagerは、それが実行されている間に永続的なTCP接続を管理します。結果的に、RemoteCacheManagerはリソースを集中的に使用します。そのため、それぞれの Java 仮想マシン (JVM) に対して単一のRemoteCacheManagerインスタンスを設定する方法が推奨されます。
2.2. CacheManagers の作成
2.2.1. 新しい RemoteCacheManager の作成
例2.1 新しい RemoteCacheManager の設定
import org.infinispan.client.hotrod.configuration.Configuration;
import org.infinispan.client.hotrod.configuration.ConfigurationBuilder;
Configuration conf = new
ConfigurationBuilder().addServer().host("localhost").port(11222).build();
RemoteCacheManager manager = new RemoteCacheManager(conf);
RemoteCache defaultCache = manager.getCache();指定された設定の各行の説明は以下のとおりです。
ConfigurationBuilder()メソッドを使用して、新しいビルダーを設定します。.addServer()プロパティーは、.host(<hostname|ip>)および.port(<port>)プロパティーで指定されたリモートサーバーを追加します。Configuration conf = new ConfigurationBuilder().addServer().host(<hostname|ip>).port(<port>).build();
- 指定された設定を使用して新しい
RemoteCacheManagerを作成します。RemoteCacheManager manager = new RemoteCacheManager(conf);
- リモートサーバーからデフォルトキャッシュを取得します。
RemoteCache defaultCache = manager.getCache();
2.2.2. 新しい組み込みキャッシュマネージャーの作成
手順2.1 新しい組み込みキャッシュマネージャーの作成
- 設定 XML ファイルを作成します。クラスパス上 (たとえば
resources/内) にmy-config.file.xmlファイルを作成します。このファイルに設定情報を追加します。 - 設定ファイルを使用してキャッシュマネージャーを作成するには、以下のプログラムを使用した設定を使用します。
EmbeddedCacheManager manager = new DefaultCacheManager("my-config-file.xml"); Cache defaultCache = manager.getCache();
2.2.3. CDI の使用による新しい組み込みキャッシュマネージャーの作成
手順2.2 CDI を使用した新規 EmbeddedCacheManager の作成
- 次のようにデフォルト設定を指定します。
public class Config @Produces public EmbeddedCacheManager defaultCacheManager() { Configuration configuration = new ConfigurationBuilder(); builder.eviction().strategy(EvictionStrategy.LRU).maxEntries(100).build(); return new DefaultCacheManager(configuration); } } - デフォルトのキャッシュマネージャーを挿入します。
... @Inject EmbeddedCacheManager cacheManager; ...
2.3. 複数のキャッシュマネージャー
2.3.1. 単一のキャッシュマネージャーを用いた複数キャッシュの作成
2.3.2. 複数のキャッシュマネージャーの使用
TCP プロトコルを使用し、他のキャッシュが UDP プロトコルを使用する場合など、複数のキャッシュに異なるネットワーク特性が必要な場合は、複数のキャッシュマネージャーを使用する必要があります。
2.3.3. 複数のキャッシュマネージャーの作成
infinispan.xml ファイルの内容を新規の設定ファイルにコピーします。新規ファイルで必要な設定についての編集を行ってから、新しいキャッシュマネージャー用にこの新規ファイルを使用します。
パート II. JVM メモリー管理のセットアップ
第3章 エビクションのセットアップ
3.1. エビクションについて
関連トピック:
3.2. エビクションストラテジー
表3.1 エビクションストラテジー
| ストラテジー名 | 操作 | 説明 |
|---|---|---|
EvictionStrategy.NONE | エビクションは一切発生しません。 | - |
EvictionStrategy.LRU | LRU (Least Recently Used) 方式のエビクションストラテジーです。このストラテジーは、最も長い期間にわたって使用されてこなかったエントリーをエビクトします。これにより、定期的に再利用されるエントリーが確実にメモリーに残ります。 | |
EvictionStrategy.UNORDERED | 順序付けのないエビクションストラテジーです。このストラテジーは、順序付けのあるアルゴリズムを使用せずにエントリーをエビクトするため、後で必要になるエントリーをエビクトする可能性があります。しかし、このストラテジーでは、エビクションの前にアルゴリズムに関連する計算が不要であるため、リソースを節約します。 | テストを目的とする場合にはこのストラテジーが推奨されますが、実際の作業の実装にあたっては推奨されません。 |
EvictionStrategy.LIRS | LIRS (Low Inter-Reference Recency Set) 方式のエビクションストラテジーです。 | LIRS は、実稼働での多岐にわたるユースケースに適しているため、Red Hat JBoss Data Grid のデフォルトのエビクションアルゴリズムになっています。 |
3.2.1. LRU エビクションアルゴリズムの制限
- 1 回限りの使用のためにアクセスされるエントリーが時間内に置き換えられない。
- 最初にアクセスされるエントリーが不必要に置き換えられる。
3.3. エビクションの使用
eviction /> 要素を使用して、ストラテジーや最大エントリー数の設定なしにエビクションを有効にすると、次のデフォルト値が自動的に実装されます。
- ストラテジー: 指定されたエビクションストラテジーがない場合、
EvictionStrategy.NONEがデフォルトとみなされます。 - max-entries/maxEntries: 指定された値がない場合、
max-entries/maxEntries の値は無制限のエントリーを許可する-1に設定されます。
3.3.1. エビクションの初期化
max-entries 属性の値をゼロよりも大きい数に設定します。max-entries に設定された値を調整して、使用する設定に最適な値を探します。max-entries に設定する値が大きすぎると、Red Hat JBoss Data Grid のメモリーが不足するため注意してください。
手順3.1 エビクションの初期化
エンビクションタグの追加
<eviction> タグを次のようにプロジェクトの <cache> タグに追加します。<eviction />
エビクションストラテジーの設定
使用するエビクションストラテジーを設定するためにstrategyの値を設定します。使用可能な値は、LRU、UNORDEREDおよびLIRS(またはエビクションが不要な場合はNONE) です。以下は、このステップのサンプルです。<eviction strategy="LRU" />
最大エントリー数の設定
メモリー内で許可されるエントリーの最大数を設定します。無制限のエントリーを許可するためのデフォルト値は-1です。- ライブラリーモードで、
maxEntriesパラメーターを次のように設定します。<eviction strategy="LRU" maxEntries="200" />
- リモートクライアントモードで、
max-entriesを次のように設定します。<eviction strategy="LRU" max-entries="200" />
エンビクションがターゲットキャッシュ用に設定されます。
3.3.2. エビクションの設定例
- ライブラリーモードの XML 設定例は以下のようになります。
<eviction strategy="LRU" maxEntries="2000"/>
- リモートクライアントサーバーモードの XML 設定例は以下のようになります。
<eviction strategy="LRU" max-entries="20"/>
- ライブラリーモードのプログラムを用いた設定例は以下のようになります。
Configuration c = new ConfigurationBuilder().eviction().strategy(EvictionStrategy.LRU) .maxEntries(2000) .build();
注記
maxEntries パラメーター、リモートクライアントサーバーモードは max-entries パラメーターを使用します。
3.3.3. エビクション設定のトラブルシューティング
configuration 要素の max-entries パラメーターに指定された値よりも大きくすることができます。これは、max-entries の値を 2 の累乗以外の値に設定することは可能ですが、基盤のアルゴリズムがこの値を V (max-entries の値に最も近い 2 を累乗した値) に変更するからです。エビクションアルゴリズムは、キャッシュコンテナーのサイズが V の値を超えないようにします。
3.3.4. エビクションとパッシベーション
第4章 エクスパレーションのセットアップ
4.1. エクスパレーションについて
- ライフスパンの値。
- 最大アイドル時間の値。
lifespan または maxIdle 値を明示的に指定しないすべてのエントリーに適用されます。
- エクスパレーションは、エントリーがメモリーに存在していた期間に基づいてエントリーを削除します。エクスパレーションは、ライフスパンの期間が終了するか、またはエントリーが指定したアイドル時間よりも長くアイドル状態になっていた場合のみ、エントリーを削除します。
- エビクションは、エントリーがどの程度最近 (および頻繁) に使用されるかに基づいてエントリーを削除します。エビクションは、メモリーに存在するエントリーが多すぎる場合にエントリーを削除します。キャッシュストアが設定されている場合、エビクトされたエントリーがキャッシュストアで永続化します。
4.2. エクスパレーションの操作
lifespan) または最大アイドル時間 (ライブラリーモードでは maxIdle、リモートクライアントサーバーモードでは max-idle) は、エントリーのキャッシュ全体のデフォルトよりも優先されます。
4.3. エビクションとエクスパレーションの比較
lifespan) とアイドル時間 (ライブラリーモードでは maxIdle、リモートクライアントサーバーモードでは max-idle) の値は、各キャッシュエントリーと一緒にレプリケートされます。
4.4. キャッシュエントリーの期限切れ通知
- エントリーがディスクへパッシベートまたはオーバフローされ、期限切れであることが判明した場合。
- エビクションメンテナンススレッドが見つけたエントリーが期限切れであることが判明した場合。
4.5. エクスパレーションの設定
手順4.1 エクスパレーションの設定
エクスパレーションタグの追加
<expiration> タグを次のようにプロジェクトの <cache> タグに追加します。<expiration />
エクスパレーションのライフスパンの設定
エントリーがメモリーに留まる時間 (ミリ秒単位) を設定するためにlifespanの値を設定します。以下はこのステップの例になります。<expiration lifespan="1000" />
最大アイドル時間の設定
エントリーが削除された後にアイドル (未使用) の状態のままにすることのできる時間 (ミリ秒単位) を設定します。無制限にするためのデフォルト値は-1です。- ライブラリーモードで、
maxIdleパラメーターを次のように設定します。<expiration lifespan="1000" maxIdle="1000" />
- リモートクライアントサーバーモードで、
max-idleを次のように設定します。<expiration lifespan="1000" max-idle="1000" />
キャッシュの実装用にエクスパレーションが設定されます。
4.6. 期限つき (mortal) データと期限なし (immortal) データ
put(key, value) を使用すると、期限なし (immortal) エントリーと呼ばれる永久に期限切れにならないエントリーが作成されます。また、put(key, value, lifespan, timeunit) を使用して作成されるエントリーは、指定の固定ライフスパンを持つ期限つき (mortal) エントリーで、ライフスパンの後に期限が切れます。
lifespan パラメーターの他に、エクスパレーションを判断するために使用される maxIdle パラメーターも提供します。maxIdle パラメーターと lifespan パラメーターをさまざまな組み合わせで使用してエントリーのライフスパンを設定することができます。
4.7. エクスパレーションのトラブルシューティング
put() のような複数キャッシュの操作では、ライフスパン値がパラメーターとして渡されます。この値は間隔を定義し、この間隔の後にエントリーが期限切れになります。エビクションが設定されていない状態でライフスパンが期限切れになると、Red Hat JBoss Data Grid がエントリーを削除しなかったように見えます。例えば、number of entries など JMX の統計を表示する場合、無効の数字が表示されたり、JBoss Data Grid に関連する永続ストアにこのエントリーが依然含まれていることがあります。JBoss Data Grid は背後でこのエントリーを期限切れエントリーとしてマーク付けしても、削除しません。このようなエントリーの削除は、以下のように行われます。
- エビクション機能を有効にすると、エビクションスレッドが期限切れエントリーを定期的に検出し、これらを消去します。
get() または containsKey() の使用を試みると、JBoss Data Grid が null 値を返します。期限切れのエントリーはエビクションスレッドとして後で削除されます。
パート III. キャッシュのモニタリング
第5章 ロギングのセットアップ
5.1. ロギングについて
5.2. サポート対象のアプリケーションロギングフレームワーク
- JBoss ロギングは、Red Hat JBoss Data Grid 6 に含まれています。
5.2.1. JBoss ロギングについて
5.2.2. JBoss ロギングの機能
- 革新的で使いやすい型指定されたロガーを提供します。
- 国際化およびローカリゼーションを完全サポート。翻訳者は properties ファイルのメッセージバンドルを、開発者はインターフェースやアノテーションを使い作業を行います。
- 実稼働用の型指定されたロガーを生成し、開発用の型指定されたロガーをランタイムに生成する build-time ツール。
5.3. ブートロギング
5.3.1. ブートロギングの設定
logging.properties ファイルを編集します。このファイルは標準的な Java プロパティーファイルであるため、テキストエディターで編集することができます。このファイルの各行の形式は property=value になります。
logging.properties ファイルは $JDG_HOME/standalone/configuration フォルダーにあります。
5.3.2. デフォルトのログファイルの場所
表5.1 デフォルトのログファイルの場所
| ログファイル | 場所 | 説明 |
|---|---|---|
boot.log | $JDG_HOME/standalone/log/ | サーバーブートログ。サーバーの起動に関連するログメッセージが含まれます。 |
server.log | $JDG_HOME/standalone/log/ | サーバーログ。サーバー起動後のすべてのログメッセージが含まれます。 |
5.4. ロギング属性
5.4.1. ログレベルについて
TRACEDEBUGINFOWARNERRORFATAL
WARN レベルのログハンドラーは、WARN、ERROR、および FATAL レベルのメッセージのみを記録します。
5.4.2. サポート対象のログレベル
表5.2 サポート対象のログレベル
| ログレベル | 値 | 説明 |
|---|---|---|
| FINEST | 300 | - |
| FINER | 400 | - |
| TRACE | 400 | アプリケーションの実行状態について詳細な情報を提供するメッセージに使用されます。TRACE レベルが有効な状態でサーバーが実行されている時に TRACE レベルのログメッセージがキャプチャーされます。 |
| DEBUG | 500 | 個々の要求の進捗やアプリケーションのアクティビティーを示すメッセージに使用されます。DEBUG レベルが有効な状態でサーバーが実行されている時に DEBUG レベルのログメッセージがキャプチャーされます。 |
| FINE | 500 | - |
| CONFIG | 700 | - |
| INFO | 800 | アプリケーションの全体的な進捗を示すメッセージに使用されます。アプリケーションの起動やシャットダウン、その他の主なライフサイクルイベントに対して使用されます。 |
| WARN | 900 | エラーではないが、理想的とは見なされない状況を示すために使用されます。将来的にエラーをもたらす可能性のある状況を示します。 |
| WARNING | 900 | - |
| ERROR | 1000 | 発生したエラーの中で、現在のアクティビティーや要求の完了を妨げる可能性があるが、アプリケーション実行の妨げにはならないエラーを示すために使用されます。 |
| SEVERE | 1000 | - |
| FATAL | 1100 | 重大なサービス障害やアプリケーションのシャットダウンをもたらしたり、JBoss Data Grid のシャットダウンを引き起こす可能性があるイベントを表示するのに使用されます。 |
5.4.3. ログカテゴリーについて
WARNING ログレベルでは、900、1000、および 1100 のログの値がキャプチャーされます。
5.4.4. ルートロガーについて
server.log ファイルに書き込むように設定されています。このファイルはサーバーログと呼ばれる場合もあります。
5.4.5. ログハンドラーについて
ConsoleFilePeriodicSizeAsyncCustom
5.4.6. ログハンドラーのタイプ
表5.3 ログハンドラーのタイプ
| ログハンドラーのタイプ | 説明 | ユースケース |
|---|---|---|
| コンソール (Console) | コンソールログハンドラーは、ログメッセージをホストオペレーティングシステムの標準出力 (stdout) または標準エラー (stderr) ストリームに書き込みます。これらのメッセージは、JBoss Data Grid がコマンドラインプロンプトから実行される場合に表示されます。 | コンソールログハンドラーは、JBoss Data Grid がコマンドラインを使って管理されている場合に推奨されます。この場合、コンソールログハンドラーからのメッセージは、オペレーティングシステムが標準出力や標準エラーストリームをキャプチャーするように設定されていない限り、保存されません。 |
| ファイル (File) | ファイルログハンドラーは最も単純なログハンドラーです。主に、ログメッセージを指定のファイルへ書き込むために使用されます。 | ファイルログハンドラーは、時間に従ってすべてのログエントリーを 1 つの場所に保存することが要件である場合に最も役に立ちます。 |
| 定期 (Periodic) | 定期ファイルハンドラーは、指定した時間が経過するまで、ログメッセージを指定ファイルに書き込みます。その時間が経過した後は、指定のタイムスタンプがファイル名に追加されます。その後、ハンドラーは元の名前で新たに作成されたログファイルへの書き込みを継続します。 | 定期ファイルハンドラーは、環境の要件に応じて、週ごと、日ごと、時間ごと、またはその他の単位ごとにログメッセージを蓄積するために使用することができます。 |
| サイズ (Size) | サイズログハンドラーは、指定のファイルが指定サイズに到達するまで、そのファイルにログメッセージを書き込みます。ファイルが指定のサイズに到達すると、名前に数値のプレフィックスを追加して名前が変更され、ハンドラーは元の名前で新規に作成されたログファイルに書き込みを継続します。各サイズログハンドラーは、このような方式で保管されるファイルの最大数を指定する必要があります。 | サイズハンドラーは、ログファイルのサイズが一致している必要のある環境に最も適しています。 |
| 非同期 (Async) | 非同期ログハンドラーは、単一または複数の他のログハンドラーを対象とする非同期動作を提供するラッパーログハンドラーです。非同期ログハンドラーは、待ち時間が長かったり、ネットワークファイルシステムへのログファイルの書き込みなどの他のパフォーマンス上の問題があるログハンドラーに対して有用です。 | 非同期ログハンドラーは、待ち時間が長いことが問題になる環境や、ネットワークファイルシステムへログファイルを書き込む際に最も適しています。 |
| カスタム (Custom) | カスタムログハンドラーにより、実装されている新たなタイプのログハンドラーを設定することが可能になります。カスタムハンドラーは、java.util.logging.Handler を拡張する Java クラスとして実装し、モジュール内に格納する必要があります。 | カスタムログハンドラーは、ログハンドラーのカスタマイズしたタイプを作成するもので、高度なユーザー用として推奨されます。 |
5.4.7. ログハンドラーの選択
コンソール (Console)ログハンドラーは、JBoss Data Grid がコマンドラインを使って管理される場合に推奨されます。このような場合、エラーやログメッセージはコンソールウィンドウに表示され、保存されるように別途設定されない限り保存されません。ファイル (File)ログハンドラーは、ログエントリーを指定のファイルに送信するために使用されます。この単純なログハンドラーは、時間に従ってすべてのログエントリーを 1 つの場所に保存することが要件である場合に役に立ちます。定期 (Periodic)ログハンドラーは、ファイル (File)ハンドラーと似ていますが、指定された期間に応じてファイルを作成します。例として、このハンドラーは環境の要件に応じて、週ごと、日ごと、時間ごと、またはその他の単位ごとにログメッセージを蓄積するために使用することができます。サイズ (Size)ログハンドラーも、指定されたファイルにログメッセージを書き込みますが、ログファイルのサイズが指定の制限内にある場合にのみ、これが実行されます。ファイルサイズが指定したサイズまで達すると、ログファイルは新規のログファイルに書き込まれます。このハンドラーは、ログファイルのサイズが一貫している必要のある環境に最も適しています。非同期 (Async)ログハンドラーは、他のログハンドラーが非同期に動作するように強制するラッパーです。このログハンドラーは、待ち時間が長いことが問題となる環境や、ネットワークファイルシステムへの書き込み時に最も適しています。カスタム (Custom)ログハンドラーは、新規の、カスタマイズされたタイプのログハンドラーを作成します。これは、高度なログハンドラーです。
5.4.8. ログフォーマッターについて
java.util.Formatter クラスと同じ構文を使用する文字列です。
5.5. ロギングの設定例
5.5.1. ルートロガーの XML 設定例
手順5.1 ルートロガーの設定
levelプロパティーを設定しますlevelプロパティーは、ルートロガーが記録するログメッセージの最大レベルを設定します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <root-logger> <level name="INFO"/>handlersを一覧表示しますhandlersは、ルートロガーによって使用されるログハンドラーの一覧です。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <root-logger> <level name="INFO"/> <handlers> <handler name="CONSOLE"/> <handler name="FILE"/> </handlers> </root-logger> </subsystem>
5.5.2. ログカテゴリーの XML 設定例
手順5.2 ログカテゴリーの設定
カテゴリーの定義
ログメッセージがキャプチャーされるログカテゴリーを指定するために、categoryプロパティーを使用します。use-parent-handlersはデフォルトで"true"に設定されています。"true"に設定した場合、このカテゴリーは、割り当てられた他のハンドラーだけでなく、ルートロガーのログハンドラーを使用します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <logger category="com.company.accounts.rec" use-parent-handlers="true">
levelプロパティーを設定しますログカテゴリーが記録するログメッセージの最大レベルを設定するために、levelプロパティーを設定します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <logger category="com.company.accounts.rec" use-parent-handlers="true"> <level name="WARN"/>handlersを一覧表示しますhandlersは、ログハンドラーの一覧です。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <logger category="com.company.accounts.rec" use-parent-handlers="true"> <level name="WARN"/> <handlers> <handler name="accounts-rec"/> </handlers> </logger> </subsystem>
5.5.3. コンソールログハンドラーの XML 設定例
手順5.3 コンソールログハンドラーの設定
ログハンドラーの ID 情報を追加します。
nameプロパティーは、このログハンドラーの一意の ID を設定します。autoflushを"true"に設定すると、ログメッセージは要求直後にハンドラーのターゲットに送信されます。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true">
levelプロパティーを設定しますlevelプロパティーは、記録されるログメッセージの最大レベルを設定します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true"> <level name="INFO"/>encoding出力を設定します。出力に使用する文字エンコーディングスキームを設定するには、encodingを使用します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/>target値を定義します。targetプロパティーは、ログハンドラーの出力先となるシステム出力ストリームを定義します。これはシステムエラーストリームの場合はSystem.err、標準出力ストリームの場合はSystem.outとすることができます。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <target value="System.out"/>filter-specプロパティーを定義します。filter-specプロパティーはフィルターを定義する式の値です。以下の例では、not(match("JBAS.*"))はパターンに一致しないフィルターを定義します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <target value="System.out"/> <filter-spec value="not(match("JBAS.*"))"/>formatterを指定します。このログハンドラーで使用するログフォーマッターの一覧を表示するには、formatterを使用します。<subsystem xmlns="urn:jboss:domain:logging:1.2"> <console-handler name="CONSOLE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <target value="System.out"/> <filter-spec value="not(match("JBAS.*"))"/> <formatter> <pattern-formatter pattern="%K{level}%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> </console-handler> </subsystem>
5.5.4. ファイルログハンドラーの XML 設定例
手順5.4 ファイルログハンドラーの設定
ファイルログハンドラーの ID 情報を追加します。
nameプロパティーは、このログハンドラーの一意の ID を設定します。autoflushを"true"に設定すると、ログメッセージは要求直後にハンドラーのターゲットに送信されます。<file-handler name="accounts-rec-trail" autoflush="true">
levelプロパティーを設定しますlevelプロパティーは、ルートロガーが記録するログメッセージの最大レベルを設定します。<file-handler name="accounts-rec-trail" autoflush="true"> <level name="INFO"/>encoding出力を設定します。出力に使用する文字エンコーディングスキームを設定するには、encodingを使用します。<file-handler name="accounts-rec-trail" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/>fileオブジェクトを設定します。fileオブジェクトは、このログハンドラーの出力が書き込まれるファイルを表します。relative-toとpathの 2 つの設定プロパティーが含まれます。relative-toプロパティーは、ログファイルが書き込まれるディレクトリーです。JBoss Enterprise Application Platform 6 のファイルパス変数をここで指定できます。jboss.server.log.dir変数はサーバーのlog/ディレクトリーを指します。pathプロパティーは、ログメッセージが書き込まれるファイルの名前です。これは、完全パスを決定するためにrelative-toプロパティーの値に追加される相対パス名です。<file-handler name="accounts-rec-trail" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-rec-trail.log"/>formatterを指定します。このログハンドラーで使用するログフォーマッターの一覧を表示するには、formatterを使用します。<file-handler name="accounts-rec-trail" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-rec-trail.log"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter>appendプロパティーを設定します。appendプロパティーを"true"に設定した場合、このハンドラーが書き込んだすべてのメッセージが既存のファイルに追加されます。"false"に設定した場合、アプリケーションサーバーが起動するたびに新規ファイルが作成されます。appendへの変更を反映させるには、サーバーの再起動が必要です。<file-handler name="accounts-rec-trail" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-rec-trail.log"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> <append value="true"/> </file-handler>
5.5.5. 定期ログハンドラーの XML 設定例
手順5.5 定期ログハンドラーの設定
定期ログハンドラーの ID 情報を追加します。
nameプロパティーは、このログハンドラーの一意の ID を設定します。autoflushを"true"に設定すると、ログメッセージは要求直後にハンドラーのターゲットに送信されます。<periodic-rotating-file-handler name="FILE" autoflush="true">
levelプロパティーを設定します。levelプロパティーは、ルートロガーが記録するログメッセージの最大レベルを設定します。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/>
encoding出力を設定します。出力に使用する文字エンコーディングスキームを設定するには、encodingを使用します。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/>
formatterを指定します。このログハンドラーで使用するログフォーマッターの一覧を表示するには、formatterを使用します。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter>fileオブジェクトを設定します。fileオブジェクトは、このログハンドラーの出力が書き込まれるファイルを表します。relative-toとpathの 2 つの設定プロパティーが含まれます。relative-toプロパティーは、ログファイルが書き込まれるディレクトリーです。JBoss Enterprise Application Platform 6 のファイルパス変数をここで指定できます。jboss.server.log.dir変数はサーバーのlog/ディレクトリーを指します。pathプロパティーは、ログメッセージが書き込まれるファイルの名前です。これは、完全パスを決定するためにrelative-toプロパティーの値に追加される相対パス名です。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> <file relative-to="jboss.server.log.dir" path="server.log"/>suffix値を設定しますsuffixは、ローテーションされたログのファイル名に追加され、ローテーションの周期を決定するために使用されます。suffixの形式では、ドット (.) の後にjava.text.SimpleDateFormatクラスで解析できる日付文字列が指定されます。ログはsuffixで定義された最小時間単位に基づいてローテーションされます。たとえば、yyyy-MM-ddの場合は、ログが日次でローテーションされます。http://docs.oracle.com/javase/6/docs/api/index.html?java/text/SimpleDateFormat.htmlを参照してください。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> <file relative-to="jboss.server.log.dir" path="server.log"/> <suffix value=".yyyy-MM-dd"/>appendプロパティーを設定します。appendプロパティーを"true"に設定した場合、このハンドラーが書き込んだすべてのメッセージが既存のファイルに追加されます。"false"に設定した場合、アプリケーションサーバーが起動するたびに新規ファイルが作成されます。appendへの変更を反映させるには、サーバーの再起動が必要です。<periodic-rotating-file-handler name="FILE" autoflush="true"> <level name="INFO"/> <encoding value="UTF-8"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> <file relative-to="jboss.server.log.dir" path="server.log"/> <suffix value=".yyyy-MM-dd"/> <append value="true"/> </periodic-rotating-file-handler>
5.5.6. サイズログハンドラーの XML 設定例
手順5.6 サイズログハンドラーの設定
サイズログハンドラーの ID 情報を追加します。
nameプロパティーは、このログハンドラーの一意の ID を設定します。autoflushを"true"に設定すると、ログメッセージは要求直後にハンドラーのターゲットに送信されます。<size-rotating-file-handler name="accounts_debug" autoflush="false">
levelプロパティーを設定しますlevelプロパティーは、ルートロガーが記録するログメッセージの最大レベルを設定します。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/>
encoding出力を設定します。出力に使用する文字エンコーディングスキームを設定するには、encodingを使用します。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/>
fileオブジェクトを設定します。fileオブジェクトは、このログハンドラーの出力が書き込まれるファイルを表します。relative-toとpathの 2 つの設定プロパティーが含まれます。relative-toプロパティーは、ログファイルが書き込まれるディレクトリーです。JBoss Enterprise Application Platform 6 のファイルパス変数をここで指定できます。jboss.server.log.dir変数はサーバーのlog/ディレクトリーを指します。pathプロパティーは、ログメッセージが書き込まれるファイルの名前です。これは、完全パスを決定するためにrelative-toプロパティーの値に追加される相対パス名です。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/>
rotate-size値を指定します。ログファイルがローテーションされる前に到達できる最大サイズです。数字に追加された単一の文字はサイズ単位を示します。バイトの場合はb、キロバイトの場合はk、メガバイトの場合はm、ギガバイトの場合はgになります。たとえば、50 メガバイトの場合は、50mになります。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/>
max-backup-index数を設定します。保持されるローテーションログの最大数です。この数字に達すると、最も古いログが再利用されます。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/> <max-backup-index value="5"/>
formatterを指定します。このログハンドラーで使用するログフォーマッターの一覧を表示するには、formatterを使用します。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/> <max-backup-index value="5"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter>appendプロパティーを設定します。appendプロパティーを"true"に設定した場合、このハンドラーが書き込んだすべてのメッセージが既存のファイルに追加されます。"false"に設定した場合、アプリケーションサーバーが起動するたびに新規ファイルが作成されます。appendへの変更を反映させるには、サーバーの再起動が必要です。<size-rotating-file-handler name="accounts_debug" autoflush="false"> <level name="DEBUG"/> <encoding value="UTF-8"/> <file relative-to="jboss.server.log.dir" path="accounts-debug.log"/> <rotate-size value="500k"/> <max-backup-index value="5"/> <formatter> <pattern-formatter pattern="%d{HH:mm:ss,SSS} %-5p [%c] (%t) %s%E%n"/> </formatter> <append value="true"/> </size-rotating-file-handler>
5.5.7. 非同期ログハンドラーの XML 設定例
手順5.7 非同期ログハンドラーの設定
非同期ログハンドラーの ID 情報を追加します。
nameプロパティーは、このログハンドラーの一意の ID を設定します。<async-handler name="Async_NFS_handlers">
levelプロパティーを設定しますlevelプロパティーは、ルートロガーが記録するログメッセージの最大レベルを設定します。<async-handler name="Async_NFS_handlers"> <level name="INFO"/>
queue-lengthを定義します。queue-lengthは、サブハンドラーの応答を待機する間に、このハンドラーが保持するログメッセージの最大数を定義します。<async-handler name="Async_NFS_handlers"> <level name="INFO"/> <queue-length value="512"/>
オーバーフロー応答を設定します。
overflow-actionは、キューの長さを超えたときにこのハンドラーがどのように応答するかを定義します。これはBLOCKまたはDISCARDに設定できます。BLOCKの場合、キューでスペースが利用可能になるまでロギングアプリケーションが待機します。これは、非同期ではないログハンドラーと同じ動作です。DISCARDの場合、ロギングアプリケーションは動作を続けますが、ログメッセージは削除されます。<async-handler name="Async_NFS_handlers"> <level name="INFO"/> <queue-length value="512"/> <overflow-action value="block"/>
subhandlersの一覧を表示します。subhandlersリストは、この非同期ハンドラーがログメッセージを渡すログハンドラーの一覧です。<async-handler name="Async_NFS_handlers"> <level name="INFO"/> <queue-length value="512"/> <overflow-action value="block"/> <subhandlers> <handler name="FILE"/> <handler name="accounts-record"/> </subhandlers> </async-handler>
パート IV. キャッシュモードのセットアップ
第6章 キャッシュモード
- ローカルモードは、JBoss Data Grid で提供される唯一のクラスターキャッシュモードではないモードです。ローカルモードの JBoss Data Grid は、簡単な単一ノードのインメモリーデータキャッシュとして動作します。ローカルモードは、スケーラビリティーおよびフェイルオーバーが不要な場合に最も効果的であり、クラスターモードに比べてパフォーマンスが高くなります。
- クラスターモードは、状態の変更をノードの小型のサブセットにレプリケートするクラスターモードを提供します。サブセットのサイズは、フォールトトラレンスを実現するには十分なサイズですが、スケーラビリティーを妨げるほど大きくはありません。クラスターモードを使用する前に、クラスター化された設定に対して JGroup を設定することが重要です。JGroups の設定方法についてさらに詳しくは、「JGroups の設定 (ライブラリーモード) 」 を参照してください。
6.1. キャッシュコンテナーについて
cache-container 要素は 1 つ以上の (ローカルまたはクラスター) キャッシュの親として動作します。クラスターキャッシュをコンテナーに追加するには、トランスポートを定義する必要があります。
手順6.1 キャッシュコンテナーの設定方法
キャッシュコンテナーを指定します。
cache-container要素は、次のパラメーターを使用してキャッシュコンテナーに関する情報を指定します。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default">
キャッシュコンテナーの名前を設定します。
nameパラメーターはキャッシュコンテナーの名前を定義します。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" />
デフォルトキャッシュを指定します。
default-cacheパラメーターは、キャッシュコンテナーと共に使用されるデフォルトキャッシュの名前を定義します。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" default-cache="default" />
統計を有効/無効にします。
statistics属性は任意であり、デフォルトはtrueです。統計は、JMX または JBoss Operations Network 経由で JBoss Data Grid を監視する際に役立ちますが、パフォーマンスにはマイナスの影響を与えます。統計が不要な場合は、これをfalseに設定してこの属性を無効にします。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" default-cache="default" statistics="true"/>
リスナーのエグゼキューターを定義します。
listener-executorは非同期キャッシュリスナーの通知に使用されるエグゼキューターを定義します。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" default-cache="default" statistics="true" listener-executor="infinispan-listener" />
キャッシュコンテナーの開始モードを設定します。
startパラメーターはキャッシュコンテナーが起動する時を示します (要求時にレイジーに起動するか、またはサーバー起動時に「イーガーに (eagerly)」起動するかなど)。このパラメーターの有効な値はEAGERとLAZYです。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" default-cache="default" statistics="true" listener-executor="infinispan-listener" start="EAGER">
キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合、statistics属性をfalseに設定することにより、キャッシュごとの統計は、監視を必要としないキャッシュについては選択的に無効にすることができます。<subsystem xmlns="urn:infinispan:server:core:6.0" default-cache-container="default"> <cache-container name="default" default-cache="default" statistics="true" listener-executor="infinispan-listener" start="EAGER"> <local-cache name="default" statistics="true"> ... </local-cache> </cache-container> </subsystem>
6.2. ローカルモード
- データを永続化するライトスルーおよびライトビハインドキャッシュ。
- Java 仮想マシン (JVM) がメモリー不足にならないようにするためのエントリーエビクション。
- 定義された期間後に期限切れになるエントリーのサポート。
ConcurrentMap を拡張するため、マップから JBoss Data Grid への移行プロセスが簡単になります。
6.2.1. ローカルモードの設定 (リモートクライアントサーバーモード)
local-cache 要素を追加する方法について説明しています。
手順6.2 local-cache 要素
local-cache 要素は次のパラメーターを使用して、キャッシュコンテナーと共に使用されるローカルキャッシュに関する情報を指定します。
ローカルキャッシュ名の追加
nameパラメーターは使用するローカルキャッシュの名前を指定します。<cache-container name="local" default-cache="default" statistics="true"> <local-cache name="default" >キャッシュコンテナーの開始モードを設定します。
startパラメーターはキャッシュコンテナーが起動する時を示します (要求時にレイジーに起動するか、またはサーバー起動時に「すぐに (eargerly)」起動するかなど)。このパラメーターの有効な値はEAGERとLAZYです。<cache-container name="local" default-cache="default" statistics="true"> <local-cache name="default" start="EAGER" >バッチ処理の設定
batchingパラメーターは、ローカルキャッシュに対してバッチ処理が有効であるかを指定します。<cache-container name="local" default-cache="default" statistics="true"> <local-cache name="default" start="EAGER" batching="false" >キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合、statistics属性をfalseに設定することにより、キャッシュごとの統計は、モニタリングを必要としないキャッシュについては選択的に無効にすることができます。<cache-container name="local" default-cache="default" statistics="true"> <local-cache name="default" start="EAGER" batching="false" statistics="true">インデックス化のタイプの指定
indexingパラメーターはローカルキャッシュに使用されるインデックス化のタイプを指定します。このパラメーターの有効な値はNONE、LOCAL、およびALLです。<cache-container name="local" default-cache="default" statistics="true"> <local-cache name="default" start="EAGER" batching="false" statistics="true"> <indexing index="NONE"> <property name="default.directory_provider">ram</property> </indexing> </local-cache>
DefaultCacheManager を作成することもできます。どちらの方法でも、ローカルのデフォルトキャッシュが作成されます。
<transport/> がない場合はローカルキャッシュのみ格納できます。例で使用されたコンテナーには <transport/> がないため、ローカルキャッシュのみを格納できます。
ConcurrentMap を拡張し、複数のキャッシュシステムと互換性があります。
6.2.2. ローカルモードの設定 (ライブラリーモード)
mode パラメーターを local に設定することは、クラスタリングモードを指定しないことと等しいということではありません。後者の場合には、キャッシュのキャッシュマネージャーがトランスポートを定義する場合でも、キャッシュはデフォルトでローカルモードに設定されます。
<clustering mode="local" />
6.3. クラスターモード
- レプリケーションモードは、クラスターのすべてのキャッシュインスタンスにわたって追加されたエントリーをレプリケートします。
- インバリデーションモードはデータを共有しませんが、無効なエントリーの削除を開始するようリモートキャッシュに伝えます。
- ディストリビューションモードは、クラスターの全ノード上ではなく、ノードのサブセット上の各エントリーを保管します。
6.3.1. 非同期および同期の操作
6.3.2. キャッシュモードのトラブルシューティング
6.3.2.1. ReadExternal の無効なデータ
Cache.putAsync() を使用する場合、シリアライズを開始するとオブジェクトが変更される可能性があります。それによってデータストリームが破損されると、無効なデータが readExternal に渡されます。このような場合、オブジェクトへのアクセスを同期化すると、この問題を解決することができます。
6.3.2.2. 非同期通信について
local-cache によって表され、ディストリビューションモードは distributed-cache、レプリケーションモードは replicated-cache によって表されます。これらの各要素には、mode プロパティーが含まれ、同期通信の場合は SYNC、非同期通信の場合は SYNC に値を設定することができます。
例6.1 非同期通信の設定例
<replicated-cache name="default"
start="EAGER"
mode="SYNC"
batching="false"
statistics="true">
...
</replicated-cache>注記
6.3.2.3. クラスター物理アドレスの読み出し
インスタンスメソッド呼び出しを使用して物理アドレスを読み出すことができます。たとえば、AdvancedCache.getRpcManager().getTransport().getPhysicalAddresses() のように読み出します。
6.4. 状態の転送 (State Transfer)
- レプリケーションモードでは、クラスターに参加するノードは、現在キャッシュ内の他のノードにあるデータのコピーを受信します。これは、既存のノードが現在のキャッシュの状態の一部を配置するときに発生します。
- ディストリビューションモードでは、一貫性のあるハッシュで決定される、キー領域全体のスライスが含まれます。新規ノードがクラスターに参加すると、それぞれの既存ノードから取られたキー領域のスライスが受信されます。状態の転送により、新規ノードでキー領域のスライスが受信され、既存のノードが以前に対象としていたデータの一部が減少します。
6.4.1. 非ブロッキング状態転送
- 状態の遷移を実行することを可能にします (クラスターのパフォーマンスが低下します)。ただし、状態の遷移時にパフォーマンスが低下すると、例外がスローされず、プロセスを続行できます。
- マージ後のデータ競合を解決するためのメカニズムは追加しませんが、今後これを追加することについては実行可能です。
6.4.2. JMX による状態転送の抑制
getCache() 呼び出しは、再調整が再度有効にされないか、または stateTransfer.awaitInitialTransfer が false に設定されない限り、stateTransfer.timeout が期限切れになった後にタイムアウトになります。
6.4.3. rebalancingEnabled 属性
rebalancingEnabled JMX 属性によってのみトリガーでき、これには特定の設定は不要です。
rebalancingEnabled 属性は、いずれのノードでも LocalTopologyManager JMX Mbean から、クラスター全体に対して変更することができます。この属性はデフォルトではtrue であり、プログラムを使って設定することができます。
<await-initial-transfer="false"/>
第7章 ディストリビューションモードのセットアップ
7.1. ディストリビューションモードについて
7.2. ディストリビューションモードの一貫したハッシュアルゴリズム
7.3. ディストリビューションモードにおけるエントリーの検索
PUT 操作が実行されると、リモート呼び出しが num_copies に指定された回数実行されます。クラスターのいずれかのノードで GET 操作が実行されると、リモート呼び出しが 1 回実行されます。バックグラウンドでは、GET 操作が実行されると PUT 操作と同じ回数 (num_copies パラメーターの値) のリモート呼び出しが行われますが、これらの呼び出しは同時に実行され、返されたエントリーは即座に呼び出し側に渡されます。
7.4. ディストリビューションモードの戻り値
7.5. ディストリビューションモードの設定 (リモートクライアントサーバーモード)
手順7.1 distributed-cache 要素
distributed-cache 要素は、以下のパラメーターを使用して分散キャッシュの設定を行います。
キャッシュ名の追加
nameパラメーターは、キャッシュの一意の ID を提供します。<cache-container name="clustered" default-cache="default" statistics="true"> <transport executor="infinispan-transport" lock-timeout="60000"/> <distributed-cache name="default" />
クラスター化されたキャッシュの開始モードの設定
modeパラメーターは、クラスター化されたキャッシュモードを設定します。有効な値はSYNC(同期) とASYNC(非同期) です。<cache-container name="clustered" default-cache="default" statistics="true"> <transport executor="infinispan-transport" lock-timeout="60000"/> <distributed-cache name="default" mode="SYNC" />
セグメント数の指定
(オプションの)segmentsパラメーターは、クラスターごとのハッシュ領域セグメントの数を指定します。このパラメーターの推奨される値は、クラスターサイズに 10 を乗算した値であり、デフォルト値は20です。<cache-container name="clustered" default-cache="default" statistics="true"> <transport executor="infinispan-transport" lock-timeout="60000"/> <distributed-cache name="default" mode="SYNC" segments="20" />
キャッシュの開始モードの設定
startパラメーターは、サーバーの起動時か、サーバーが要求またはデプロイされるときにキャッシュを起動させるかどうかを指定します。<cache-container name="clustered" default-cache="default" statistics="true"> <transport executor="infinispan-transport" lock-timeout="60000"/> <distributed-cache name="default" mode="SYNC" segments="20" start="EAGER"/>
キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合、statistics属性をfalseに設定することにより、キャッシュごとの統計は、監視を必要としないキャッシュについては選択的に無効にすることができます。<cache-container name="clustered" default-cache="default" statistics="true"> <transport executor="infinispan-transport" lock-timeout="60000"/> <distributed-cache name="default" mode="SYNC" segments="20" start="EAGER" statistics="true"> ... </distributed-cache> </cache-container>
重要
cache-container、locking、および transaction 要素について詳しくは、該当する章を参照してください。
7.6. ディストリビューションモードの設定 (ライブラリーモード)
手順7.2 分散キャッシュの設定
クラスターモードの設定
clustering要素のmodeパラメーター値は、キャッシュに選択されたクラスタリングモードを決定します。<clustering mode="distribution">
リモート呼び出しタイムアウトの指定
sync要素のreplTimeoutパラメーターは、リモート呼び出し後の確認に設定される最大の時間範囲 (ミリ秒単位) を指定します。この時間範囲が確認なしに終了する場合、例外がスローされます。<clustering mode="distribution"> <sync replTimeout="${TIME}" />状態の転送設定の定義
stateTransfer要素は、ノードがクラスターを出るか、またはクラスターに参加する際に状態がどのように転送されるかを指定します。これは以下のパラメーターを使用します。状態転送のバッチサイズの指定
chunkSizeパラメーターは、転送するキャッシュエントリーの状態バッチのサイズを指定します。この値が0より大きい場合、設定される値は送信されるチャンクのサイズになります。値が0より小さい場合、すべての状態は同時に転送されます。<clustering mode="distribution"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" />fetchInMemoryStateパラメーターの設定trueに設定されるfetchInMemoryStateパラメーターは、起動時に隣接したキャッシュから状態についての情報を要求します。これは、キャッシュの起動時間に影響を与えます。<clustering mode="distribution"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" />awaitInitialTransferパラメーターの定義awaitInitialTransferパラメーターにより、joiner ノードでのメソッドCacheManager.getCache()への最初の呼び出しはブロックし、参加が完了し、キャッシュが隣接するキャッシュからの状態の受信を完了するまでブロックします (fetchInMemoryStateが有効な場合)。このオプションは、分散キャッシュとレプリケートされたキャッシュにのみ適用され、デフォルトで有効にされます。<clustering mode="distribution"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" />timeout値の設定timeoutパラメーターは、キャッシュが要求された状態を持つ隣接キャッシュからの応答を待機する最長時間 (ミリ秒単位) を指定します。timeout期間内で応答が受信されない場合、起動プロセスは中止し、例外がスローされます。<clustering mode="distribution"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
トランスポート設定の指定
transport要素は、以下のようにキャッシュコンテナのトランスポート設定を定義します。クラスター名の指定
clusterNameパラメーターはクラスターの名前を指定します。ノードは同じ名前を共有するクラスターのみに接続できます。<global> <transport clusterName="${NAME}" /> </global>distributedSyncTimeout値の設定distributedSyncTimeoutパラメーターは、分散ロック上でロックを取得するために待機する時間を指定します。この分散ロックにより、単一キャッシュは一度に状態を転送するか、または状態をリハッシュすることができます。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" /> </global>ネットワークトランスポートの設定
transportClassパラメーターは、キャッシュコンテナのネットワークトランスポートを表すクラスを指定します。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" transportClass="${CLASS}" /> </global>
7.7. 同期および非同期の分散
例7.1 通信モードの例
A、B、C という 3 つのキャッシュがクラスターにあり、キャッシュ A を B にマップする K というキーがあるとします。戻り値の必要なクラスター C 上で、Cache.remove(K) のような操作を実行するとします。正常に実行するには、操作が最初にキャッシュ A と B の両方に呼び出しを同期転送し、キャッシュ A または B より返される結果を待つ必要があります。非同期通信が使用された場合、操作が想定通り動作しても戻り値の有用性は保証されません。
7.8. ディストリビューションモードにおける GET および PUT の使用
GET コマンドを実行します。これは、java.util.Map コントラクトに従って指定されたキーに関連する以前の値を返すメソッド (Cache.put()) があるからです。これがキーを所有しないインスタンスで実行され、エントリーが 1 次キャッシュで見つからない場合、PUT の前にリモートの GET を実行することが、戻り値を取得するための信頼できる唯一の方法になります。
PUT 操作の前に発生する GET 操作は常に同期になります。
7.8.1. 分散された GET および PUT 操作
PUT 操作を実行する前に、キャッシュが GET 操作を実行することがあります。
GET 操作は同期であるにも関わらず、すべての応答を待たないため、無駄になるリソースが発生します。GET 処理は最初に受信する有効な応答を許可するため、パフォーマンスとクラスターの大きさとの関連性はありません。
Flag.SKIP_REMOTE_LOOKUP フラグを使用します。
java.util.Map インターフェースコントラクトに違反します。これは、信頼できず正確でない戻り値が特定のメソッドに提供されるため、コントラクトに違反することになります。そのため、これらの戻り値が設定上重要な目的に使用されないようにしてください。
第8章 レプリケーションモードのセットアップ
8.1. レプリケーションモードについて
8.2. 最適化されたレプリケーションモードの使用
8.3. レプリケーションモードの設定 (リモートクライアントサーバーモード)
手順8.1 replicated-cache 要素
replicated-cache 要素は、以下のパラメーターを使用して分散キャッシュの設定を行います。
キャッシュ名の追加
nameパラメーターは、キャッシュの一意の ID を提供します。<cache-container name="clustered" default-cache="default" statistics="true"> <replicated-cache name="default">
クラスター化されたキャッシュの開始モードの設定
modeパラメーターは、クラスター化されたキャッシュモードを設定します。有効な値はSYNC(同期) とASYNC(非同期) です。<cache-container name="clustered" default-cache="default" statistics="true"> <replicated-cache name="default" mode="SYNC">
キャッシュの開始モードの設定
startパラメーターは、サーバーの起動時か、サーバーが要求またはデプロイされるときにキャッシュを起動させるかどうかを指定します。<cache-container name="clustered" default-cache="default" statistics="true"> <replicated-cache name="default" mode="SYNC" start="EAGER">
キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合、statistics属性をfalseに設定することにより、キャッシュごとの統計は、監視を必要としないキャッシュについては選択的に無効にすることができます。<cache-container name="clustered" default-cache="default" statistics="true"> <replicated-cache name="default" mode="SYNC" start="EAGER" statistics="true"> ... </replicated-cache> </cache-container>トランザクションのセットアップ
transaction要素は、レプリケートされたキャッシュのトランザクションモードをセットアップします。重要
リモートクライアントサーバーモードでは、JBoss Data Grid が互換モードで使用され、クラスターに JBoss Data Grid サーバーインスタンスとライブラリーインスタンスの両方が含まれない限り、トランザクション要素がNONEに設定されます。このときにトランザクションがライブラリーモードインスタンスで設定される場合は、サーバーインスタンスでもトランザクションを設定する必要があります。<cache-container name="clustered" default-cache="default" statistics="true"> <replicated-cache name="default" mode="SYNC" start="EAGER" statistics="true"> <transaction mode="NONE" /> </replicated-cache> </cache-container>
重要
cache-container および locking の詳細については、該当する章を参照してください。
8.4. レプリケーションモードの設定 (ライブラリーモード)
手順8.2 レプリケーションモードの設定
クラスターモードの設定
clustering要素のmodeパラメーター値は、キャッシュに選択されたクラスタリングモードを決定します。<clustering mode="replication">
リモート呼び出しタイムアウトの指定
sync要素のreplTimeoutパラメーターは、リモート呼び出し後の確認に設定される最大の時間範囲 (ミリ秒単位) を指定します。この時間範囲が確認なしに終了する場合、例外がスローされます。<clustering mode="replication"> <sync replTimeout="${TIME}" />状態の転送設定の定義
stateTransfer要素は、ノードがクラスターを出るか、またはクラスターに参加する際に状態がどのように転送されるかを指定します。これは以下のパラメーターを使用します。状態転送のバッチサイズの指定
chunkSizeパラメーターは、転送するキャッシュエントリーの状態バッチのサイズを指定します。この値が0より大きい場合、設定される値は送信されるチャンクのサイズになります。値が0より小さい場合、すべての状態は同時に転送されます。<clustering mode="replication"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" />fetchInMemoryStateパラメーターの設定trueに設定されるfetchInMemoryStateパラメーターは、起動時に隣接したキャッシュから状態についての情報を要求します。これは、キャッシュの起動時間に影響を与えます。<clustering mode="replication"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" />awaitInitialTransferパラメーターの定義awaitInitialTransferパラメーターにより、joiner ノードでのメソッドCacheManager.getCache()への最初の呼び出しはブロックし、参加が完了し、キャッシュが隣接するキャッシュからの状態の受信を完了するまでブロックします (fetchInMemoryStateが有効な場合)。このオプションは、分散キャッシュとレプリケートされたキャッシュにのみ適用され、デフォルトで有効にされます。<clustering mode="replication"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" />timeout値を設定します。timeoutパラメーターは、キャッシュが要求された状態を持つ隣接キャッシュからの応答を待機する最長時間 (ミリ秒単位) を指定します。timeout期間内で応答が受信されない場合、起動プロセスは中止し、例外がスローされます。<clustering mode="replication"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
トランスポート設定の指定
transport要素は、以下のようにキャッシュコンテナのトランスポート設定を定義します。クラスター名の指定
clusterNameパラメーターはクラスターの名前を指定します。ノードは同じ名前を共有するクラスターのみに接続できます。<global> <transport clusterName="${NAME}" /> </global>distributedSyncTimeout値の設定distributedSyncTimeoutパラメーターは、分散ロック上でロックを取得するために待機する時間を指定します。この分散ロックにより、単一キャッシュは一度に状態を転送するか、または状態をリハッシュすることができます。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" /> </global>ネットワークトランスポートの設定
transportClassパラメーターは、キャッシュコンテナのネットワークトランスポートを表すクラスを指定します。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" transportClass="${CLASS}" /> </global>
8.5. 同期および非同期のレプリケーション
- 同期レプリケーションは、クラスターの全ノードで変更がレプリケートされるまでスレッドや呼び出し側 (
put()操作の場合など) をブロックします。確認応答を待つために、同期レプリケーションでは操作が終了する前にすべてのレプリケーションが正常に適用されます。 - 非同期レプリケーションはノードからの応答を待つ必要がないため、同期レプリケーションよりもかなり高速になります。非同期レプリケーションはバックグラウンドでレプリケーションを実行し、呼び出しは即座に返されます。非同期レプリケーション中に発生したエラーはログに書き込まれます。そのため、クラスターのすべてのキャッシュインスタンスでトランザクションが正常にレプリケートされなくても、トランザクションは正常に終了することが可能です。
8.5.1. 非同期レプリケーションの挙動に対するトラブルシューティング
- 状態転送を無効にし、
ClusteredCacheLoaderを使用して必要な時にリモート状態をレイジーにルックアップします。 - 状態転送と
REPL_SYNCを有効にします。非同期 API (cache.putAsync(k, v)など) を使用して「fire-and-forget」機能をアクティベートします。 - 状態転送と
REPL_ASYNCを有効にします。PRC はすべて同期的になりますが、レプリケーションキューを有効にすると (非同期モードで推奨) クライアントスレッドは中断されません。
8.6. レプリケーションキュー
- 以前に設定された間隔。
- 要素数を超えるキューサイズ。
- 以前に設定された間隔と要素数を超えるキューサイズの組み合わせ。
8.6.1. レプリケーションキューの使用
- 非同期マーシャリングを無効にします。
max-threads数の値を、transport executorに対して1に設定します。transport executorは次のようにstandalone.xmlで定義されます。<transport executor="infinispan-transport"/>
queue-flush-interval、値はミリ秒単位) やキューサイズ (queue-size) と共に次のように設定することができます。
例8.1 非同期モードのレプリケーションキュー
<replicated-cache name="asyncCache"
start="EAGER"
mode="ASYNC"
batching="false"
indexing="NONE"
statistics="true"
queue-size="1000"
queue-flush-interval="500">
...
</replicated-cache>8.7. レプリケーション保証について
8.8. 内部ネットワークのレプリケーショントラフィック
IP アドレスを介したトラフィックにパブリック IP アドレスを介したトラフィックよりも低い課金を行ったり、内部ネットワークトラフィックにまったく課金しないことがあります (GoGrid など)。低料金で利用できるよう、内部ネットワークを使用してレプリケーションのトラフィックを転送するよう Red Hat JBoss Data Grid を設定することが可能です。このような設定では、割り当てられた内部 IP アドレスを調べるのは簡単ではありませんが、JBoss Data Grid は JGroups インターフェースを使用してこの問題を解決します。
第9章 インバリデーションモードのセットアップ
9.1. インバリデーションモードについて
9.2. インバリデーションモードの設定 (リモートクライアントサーバーモード)
手順9.1 invalidation-cache 要素
invalidation-cache 要素は、以下のパラメーターを使用して分散キャッシュの設定を行います。
キャッシュ名の追加
nameパラメーターは、キャッシュの一意の ID を提供します。<cache-container name="local" default-cache="default" statistics="true"> <invalidation-cache name="default">クラスター化されたキャッシュの開始モードの設定
modeパラメーターは、クラスター化されたキャッシュモードを設定します。有効な値はSYNC(同期) とASYNC(非同期) です。<cache-container name="local" default-cache="default" statistics="true"> <invalidation-cache name="default" mode="ASYNC">キャッシュの開始モードの設定
startパラメーターは、サーバーの起動時か、またはサーバーが要求またはデプロイされるときにキャッシュを起動させるかどうかを指定します。<cache-container name="local" default-cache="default" statistics="true"> <invalidation-cache name="default" mode="ASYNC" start="EAGER">キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合、statistics属性をfalseに設定することにより、キャッシュごとの統計は、モニタリングを必要としないキャッシュについては選択的に無効にすることができます。<cache-container name="local" default-cache="default" statistics="true"> <invalidation-cache name="default" mode="ASYNC" start="EAGER" statistics="true"> ... </invalidation-cache> </cache-container>
重要
cache-container、locking、および transaction 要素について詳しくは、該当する章を参照してください。
9.3. インバリデーションモードの設定 (ライブラリーモード)
手順9.2 インバリデーションモードの設定
クラスターモードの設定
clustering要素のmodeパラメーター値は、キャッシュに選択されたクラスタリングモードを決定します。<clustering mode="invalidation">
リモート呼び出しタイムアウトの指定
sync要素のreplTimeoutパラメーターは、リモート呼び出し後の確認に設定される最大の時間範囲 (ミリ秒単位) を指定します。この時間範囲が確認なしに終了する場合、例外がスローされます。<clustering mode="invalidation"> <sync replTimeout="${TIME}" />状態の転送設定の定義
stateTransfer要素は、ノードがクラスターを出るか、またはクラスターに参加する際に状態がどのように転送されるかを指定します。これは以下のパラメーターを使用します。状態転送のバッチサイズの指定
chunkSizeパラメーターは、転送するキャッシュエントリーの状態バッチのサイズを指定します。この値が0より大きい場合、設定される値は送信されるチャンクのサイズになります。値が0より小さい場合、すべての状態は同時に転送されます。<clustering mode="invalidation"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" />fetchInMemoryStateパラメーターの設定trueに設定されるfetchInMemoryStateパラメーターは、起動時に隣接したキャッシュから状態についての情報を要求します。これは、キャッシュの起動時間に影響を与えます。<clustering mode="invalidation"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" />awaitInitialTransferパラメーターの定義awaitInitialTransferパラメーターにより、joiner ノードでのメソッドCacheManager.getCache()への最初の呼び出しはブロックし、参加が完了し、キャッシュが隣接するキャッシュからの状態の受信を完了するまでブロックします (fetchInMemoryStateが有効な場合)。このオプションは、分散キャッシュとレプリケートされたキャッシュにのみ適用され、デフォルトで有効にされます。<clustering mode="invalidation"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" />timeout値の設定timeoutパラメーターは、キャッシュが要求された状態を持つ隣接キャッシュからの応答を待機する最長時間 (ミリ秒単位) を指定します。timeout期間内で応答が受信されない場合、起動プロセスは中止し、例外がスローされます。<clustering mode="invalidation"> <sync replTimeout="${TIME}" /> <stateTransfer chunkSize="${SIZE}" fetchInMemoryState="{true/false}" awaitInitialTransfer="{true/false}" timeout="${TIME}" />
トランスポート設定の指定
transport要素は、以下のようにキャッシュコンテナのトランスポート設定を定義します。クラスター名の指定
clusterNameパラメーターはクラスターの名前を指定します。ノードは同じ名前を共有するクラスターのみに接続できます。<global> <transport clusterName="${NAME}" /> </global>distributedSyncTimeout値の設定distributedSyncTimeoutパラメーターは、分散ロック上でロックを取得するために待機する時間を指定します。この分散ロックにより、単一キャッシュは一度に状態を転送するか、または状態をリハッシュすることができます。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" /> </global>ネットワークトランスポートの設定
transportClassパラメーターは、キャッシュコンテナのネットワークトランスポートを表すクラスを指定します。<global> <transport clusterName="${NAME}" distributedSyncTimeout="${TIME}" transportClass="${CLASS}" /> </global>
9.4. 同期的/非同期の無効化
- 同期的な無効化は、クラスターのすべてのキャッシュが無効化メッセージを受信し、古いデータをエビクトするまでスレッドをブロックします。
- 非同期的な無効化は、応答待ちのスレッドをブロックせずに無効化メッセージがブロードキャストされる fire-and-forget モードで操作します。
9.5. 1 次キャッシュと無効化
パート V. リモートクライアントサーバーモードインターフェース
- 非同期 API (リモートクライアントサーバーモードで Hot Rod クライアントを併用する場合のみ使用可能)
- REST インターフェース
- Memcached インターフェース
- Hot Rod インターフェース
- RemoteCache API
第10章 非同期 API
Async を追加します。非同期メソッドは、操作の結果が含まれる Future を返します。
Cache(String, String) とパラメーター化されたキャッシュでは、Cache.put(String key, String value) は String を返します。また、Cache.putAsync(String key, String value) は Future(String) を返します。
10.1. 非同期 API の利点
- 同期通信が保証される (エラーと例外を処理する機能が追加される)。
- 呼び出しが完了するまでスレッドの操作をブロックする必要がない。
例10.1 非同期 API の使用
Set<Future<?>> futures = new HashSet<Future<?>>();
futures.add(cache.putAsync("key1", "value1"));
futures.add(cache.putAsync("key2", "value2"));
futures.add(cache.putAsync("key3", "value3"));futures.add(cache.putAsync(key1, value1));futures.add(cache.putAsync(key2, value2));futures.add(cache.putAsync(key3, value3));
10.2. 非同期プロセスについて
- ネットワークコール
- マーシャリング
- キャッシュストアへの書き込み (オプション)
- ロック
10.3. 戻り値と非同期 API
Future または NotifyingFuture を返す必要があります。
注記
NotifyingFutures は、JBoss Data Grid ライブラリーモードでのみ利用できます。
Future.get()
第11章 REST インターフェース
11.1. Ruby クライアントコード
例11.1 Ruby での REST API の使用
require 'net/http'
http = Net::HTTP.new('localhost', 8080)
#An example of how to create a new entry
http.post('/rest/MyData/MyKey', 'DATA_HERE', {"Content-Type" => "text/plain"})
#An example of using a GET operation to retrieve the key
puts http.get('/rest/MyData/MyKey').body
#An Example of using a PUT operation to overwrite the key
http.put('/rest/MyData/MyKey', 'MORE DATA', {"Content-Type" => "text/plain"})
#An example of Removing the remote copy of the key
http.delete('/rest/MyData/MyKey')
#An example of creating binary data
http.put('/rest/MyImages/Image.png', File.read('/Users/michaelneale/logo.png'), {"Content-Type" => "image/png"})11.2. Ruby のサンプルで JSON を使用
ruby で JavaScript Object Notation (JSON) を使用して Red Hat JBoss Data Grid の REST インターフェースと対話するために、JSON Ruby をインストールし (プラットフォームのパッケージマネージャーに問い合わせるか、Ruby ドキュメンテーションを参照)、以下のコードを使用して要件を宣言します。
require 'json'
以下のコードは、Ruby で JavaScript Object Notation (JSON) と PUT 関数を使用して特定のデータ (この場合は、個人の名前と年齢) を送信する例です。
data = {:name => "michael", :age => 42 }
http.put('/infinispan/rest/Users/data/0', data.to_json, {"Content-Type" => "application/json"})11.3. Python クライアントコード
例11.2 Python での REST API の使用
import httplib
#How to insert data
conn = httplib.HTTPConnection("localhost:8080")
data = "SOME DATA HERE \!" #could be string, or a file...
conn.request("POST", "/rest/Bucket/0", data, {"Content-Type": "text/plain"})
response = conn.getresponse()
print response.status
#How to retrieve data
import httplib
conn = httplib.HTTPConnection("localhost:8080")
conn.request("GET", "/rest/Bucket/0")
response = conn.getresponse()
print response.status
print response.read()
11.4. Java クライアントコード
例11.3 インポートの定義
import java.io.BufferedReader;import java.io.IOException; import java.io.InputStreamReader;import java.io.OutputStreamWriter; import java.net.HttpURLConnection;import java.net.URL;
例11.4 文字列値をキャッシュに追加
public class RestExample {
/**
* Method that puts a String value in cache.
* @param urlServerAddress
* @param value
* @throws IOException
*/
public void putMethod(String urlServerAddress, String value) throws IOException {
System.out.println("----------------------------------------");
System.out.println("Executing PUT");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
System.out.println("Executing put method of value: " + value);
connection.setRequestMethod("PUT");
connection.setRequestProperty("Content-Type", "text/plain");
connection.setDoOutput(true);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(connection.getOutputStream());
outputStreamWriter.write(value);
connection.connect();
outputStreamWriter.flush();
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
}例11.5 キャッシュから文字列値を取得
/**
* Method that gets an value by a key in url as param value.
* @param urlServerAddress
* @return String value
* @throws IOException
*/
public String getMethod(String urlServerAddress) throws IOException {
String line = new String();
StringBuilder stringBuilder = new StringBuilder();
System.out.println("----------------------------------------");
System.out.println("Executing GET");
System.out.println("----------------------------------------");
URL address = new URL(urlServerAddress);
System.out.println("executing request " + urlServerAddress);
HttpURLConnection connection = (HttpURLConnection) address.openConnection();
connection.setRequestMethod("GET");
connection.setRequestProperty("Content-Type", "text/plain");
connection.setDoOutput(true);
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
connection.connect();
while ((line = bufferedReader.readLine()) != null) {
stringBuilder.append(line + '\n');
}
System.out.println("Executing get method of value: " + stringBuilder.toString());
System.out.println("----------------------------------------");
System.out.println(connection.getResponseCode() + " " + connection.getResponseMessage());
System.out.println("----------------------------------------");
connection.disconnect();
return stringBuilder.toString();
}例11.6 Java Main メソッドの使用
/**
* Main method example.
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
//Note that the cache name is "cacheX"
RestExample restExample = new RestExample();
restExample.putMethod("http://localhost:8080/rest/cacheX/1", "Infinispan REST Test");
restExample.getMethod("http://localhost:8080/rest/cacheX/1");
}
}
}11.5. REST インターフェースコネクター
- Hot Rod ベースコネクターの設定を定義する
hotrod-connector要素。 - memcached ベースコネクターの設定を定義する
memcached-connector要素。 - REST インターフェースベースのコネクターの設定を定義する
rest-connector要素。
<socket-binding-group /> 内で宣言されたソケットバインディングを使用し、local コンテナーで宣言されたキャッシュを公開し、他のすべての設定でデフォルト値を使用して Hot Rod、Memcached、または REST サーバーが有効になります。以下の例は、Hot Rod、Memcached、および REST サーバーに接続する方法を示しています。
<rest-connector virtual-server="default-host" cache-container="local" security-domain="other" auth-method="BASIC"/>
11.5.1. REST コネクターの設定
rest-connector 要素を設定します。
手順11.1 リモートクライアントサーバーモード用 REST コネクターの設定
rest-connector 要素は、REST コネクターの設定情報を指定します。
virtual-serverパラメーターvirtual-serverパラメーターは、REST コネクターで使用される仮想サーバーを指定します。このパラメーターのデフォルト値はdefault-hostです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" /> </subsystem>
cache-containerパラメーターcache-containerパラメーターは、REST コネクターで使用されるキャッシュコンテナーを指定します。これは必須パラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" /> </subsystem>context-pathパラメーターcontext-pathパラメーターは、REST コネクターのコンテキストパスを指定します。このパラメーターのデフォルト値は空の文字列 ("") です。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" context-path="${CONTEXT_PATH}" /> </subsystem>security-domainパラメーターsecurity-domainパラメーターは、REST エンドポイントへのアクセスを認証するためにセキュリティーサブシステムで宣言された指定済みドメインを使用することを指定します。これはオプションパラメーターです。このパラメーターが省略されると、認証は実行されません。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" context-path="${CONTEXT_PATH}" security-domain="${SECURITY_DOMAIN}" /> </subsystem>auth-methodパラメーターauth-methodパラメーターは、エンドポイントのクレデンシャルを取得するために使用するメソッドを指定します。このパラメーターのデフォルト値はBASICです。サポートされる別の値にはBASIC、DIGEST、およびCLIENT-CERTがあります。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" context-path="${CONTEXT_PATH}" security-domain="${SECURITY_DOMAIN}" auth-method="${METHOD}" /> </subsystem>security-modeパラメーターsecurity-modeパラメーターは、書き込み操作 (PUT、POST、DELETE など) または読み取り操作 (GET や HEAD など) に対してのみ認証が必要かどうかを指定します。このパラメーターの有効な値はWRITE(書き込み操作のみを認証する場合) またはREAD_WRITE(読み書き操作を認証する場合) です。このパラメーターのデフォルト値はREAD_WRITEです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" context-path="${CONTEXT_PATH}" security-domain="${SECURITY_DOMAIN}" auth-method="${METHOD}" security-mode="${MODE}" /> </subsystem>
11.6. REST インターフェースの使用
- データの追加
- データの取得
- データの削除
11.6.1. REST を使用したデータの追加
- HTTP
PUTメソッド - HTTP
POSTメソッド
PUT メソッドと POST メソッドが使用される場合、要求の本文には、ユーザーにより追加された情報を含むこのデータが含まれます。
PUT メソッドと POST メソッドの両方には、Content-Type ヘッダーが必要です。
11.6.1.1. PUT /{cacheName}/{cacheKey} について
PUT 要求により、提供されたキーを使用して要求本文からのペイロードがターゲットキャッシュに配置されます。このタスクが正常に完了するには、ターゲットキャッシュがサーバに存在する必要があります。
hr がキャッシュ名であり、payRoll%2F3 がキーです。値 %2F は、/ がキーで使用されたことを示します。
http://someserver/rest/hr/payRoll%2F3
Time-To-Live 値と Last-Modified 値が更新されます。
注記
/ を表す値 %2F を含むキャッシュキー (提供された例を参照) を正常に実行できます。
-Dorg.apache.tomcat.util.buf.UDecoder.ALLOW_ENCODED_SLASH=true
11.6.1.2. POST /{cacheName}/{cacheKey} について
POST メソッドにより、提供されたキーを使用して (要求本文からの) ペイロードがターゲットキャッシュに配置されます。ただし、POST メソッドでは、値がキャッシュ/キーに存在する場合に、HTTP CONFLICT ステータスが返され、内容が更新されません。
11.6.2. REST を使用したデータの取得
- HTTP
GETメソッド。 - HTTP
HEADメソッド。
11.6.2.1. GET /{cacheName}/{cacheKey} について
GET メソッドは、応答の本文として、提供された cacheName に存在し、関連するキーに一致するデータを返します。Content-Type ヘッダーは、データのタイプを提供します。ブラウザーはキャッシュに直接アクセスできます。
11.6.2.2. HEAD /{cacheName}/{cacheKey} について
HEAD メソッドは、GET メソッドと同様に動作しますが、コンテンツを返しません (ヘッダーフィールドが返されます)。
11.6.3. REST を使用したデータの削除
DELETE メソッドを使用してキャッシュからデータを取得します。DELETE メソッドは以下のことを行えます。
- キャッシュエントリー/値を削除します。(
DELETE /{cacheName}/{cacheKey}) - キャッシュからすべてのエントリーを削除します。(
DELETE /{cacheName})
11.6.3.1. DELETE /{cacheName}/{cacheKey} について
DELETE /{cacheName}/{cacheKey}) で使用された場合は、DELETE メソッドは提供されたキーのキャッシュからキー/値を削除します。
11.6.3.2. DELETE /{cacheName} について
DELETE /{cacheName}) では、DELETE メソッドが名前付きキャッシュ内のすべてのエントリーを削除します。正常な DELETE 操作後に、HTTP ステータスコード 200 が返されます。
11.6.3.3. バックグラウンド削除操作
performAsync ヘッダーの値を true に設定して、削除操作がバックグラウンドで続行される状態で値がすぐに返されるようにします。
11.6.4. REST インターフェース操作ヘッダー
表11.1 ヘッダータイプ
| ヘッダー | 必須/オプション | 値 | デフォルト値 | 説明 |
|---|---|---|---|---|
| Content-Type | 必須 | - | - | Content-Type が application/x-java-serialized-object に設定された場合は、Java オブジェクトとして格納されます。 |
| performAsync | 任意 | true/false | - | true に設定された場合は、すぐに返され、独自にクラスターにデータがレプリケートされます。この機能は、大量のデータ挿入と大きいクラスターを取り扱う場合に役に立ちます。 |
| timeToLiveSeconds | 任意 | 数値 (正の値および負の値) | -1 (この値により、timeToLiveSeconds の直接的な結果としてエクスパレーションが回避されます。このデフォルト値よりも、他の場所で設定されたエクスパレーションの値が優先されます。) | 該当するエントリーが自動的に削除されるまでの秒数を反映します。timeToLiveSeconds に負の値を設定すると、デフォルト値と同じ結果が提供されます。 |
| maxIdleTimeSeconds | 任意 | 数値 (正の値および負の値) | -1 (この値により、maxIdleTimeSeconds の直接的な結果としてエクスパレーションが回避されます。このデフォルト値よりも、他の場所で設定されたエクスパレーションの値が優先されます。) | エントリーが自動的に削除される場合の、最後の使用時以降の秒数を含みます。負の値を渡すと、デフォルト値と同じ結果が提供されます。 |
timeToLiveSeconds ヘッダーと maxIdleTimeSeconds ヘッダーには以下の組み合わせを設定できます。
timeToLiveSecondsヘッダーとmaxIdleTimeSecondsヘッダーに値0が割り当てられた場合、キャッシュは、 XML を使用するか、またはプログラミングにより設定されたデフォルトのtimeToLiveSeconds値とmaxIdleTimeSeconds値を使用します。maxIdleTimeSecondsヘッダー値のみが0に設定された場合は、timeToLiveSeconds値をパラメーター (または、デフォルトの-1(パラメーターが存在しない場合)) として渡す必要があります。また、maxIdleTimeSecondsパラメーター値は、 XML を使用するか、プログラミングにより、設定された値にデフォルトで設定されます。timeToLiveSecondsヘッダー値のみが0に設定された場合は、エクスパレーションが即座に発生し、maxIdleTimeSeconds値がパラメーターとして渡された値に設定されます (パラメーターが提供されなかった場合はデフォルトの-1)。
各 REST インターフェースエントリーに対して、提供された URL でデータの状態を示す Last-Modified ヘッダーとともに、ETags (エンティティータグ) が返されます。ETags は、帯域幅を節約するためにデータが変更された場合にのみ、データを要求する HTTP 操作で使用されます。以下のヘッダーは、ETags (エンティティータグ) ベースの楽観的ロックをサポートします。
表11.2 エンティティータグ関連ヘッダー
| Header | アルゴリズム | 例 | 説明 |
|---|---|---|---|
| If-Match | If-Match = "If-Match" ":" ( "*" | 1#entity-tag ) | - | (リソースから以前に取得された) 指定されたエンティティーが最新であることを確認するために、関連するエンティティータグのリストとともに使用されます。 |
| If-None-Match | - | (リソースから以前に取得された) 指定されたエンティティーが最新でないことを確認するために、関連するエンティティータグのリストとともに使用されます。この機能により、必要なときに、最小のトランザクションオーバーヘッドで、キャッシュされた情報が効率的に更新されます。 | |
| If-Modified-Since | If-Modified-Since = "If-Modified-Since" ":" HTTP-date | If-Modified-Since: Sat, 29 Oct 1994 19:43:31 GMT | 要求されたバリアントの最終変更日時と、提供された時間および日付の値とを比較します。指定された日時以降に要求されたバリアントが変更されなかった場合は、エンティティーの代わりに 304 (未変更) 応答がメッセージ本文なしで返されます。 |
| If-Unmodified-Since | If-Unmodified-Since = "If-Unmodified-Since" ":" HTTP-date | If-Unmodified-Since: Sat, 29 Oct 1994 19:43:31 GMT | 要求されたバリアントの最終変更日時と、提供された時間および日付の値とを比較します。指定された日時以降に要求されたリソースが変更されなかった場合は、指定された操作が実行されます。指定された日時以降に要求されたリソースが変更された場合は、操作が実行されず、エンティティーの代わりに 412 (事前条件失敗) 応答が返されます。 |
11.7. REST インターフェースセキュリティー
11.7.1. REST エンドポイントをパブリックインターフェースとして公開
management の socket-binding 要素の interface パラメーターの値を public に変更します。
<socket-binding name="http" interface="public" port="8080"/>
11.7.2. REST エンドポイントのセキュリティーの有効化
注記
手順11.2 REST エンドポイントのセキュリティーの有効化
standalone.xml に以下の変更を行います。
セキュリティーパラメーターの指定
rest エンドポイントでsecurity-domainパラメーターおよびauth-methodパラメーターの有効な値を指定するようにします。これらのパラメーターの推奨設定は以下のとおりです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <rest-connector virtual-server="default-host" cache-container="local" security-domain="other" auth-method="BASIC"/> </subsystem>セキュリティードメイン宣言のチェック
セキュリティーサブシステムに、対応するセキュリティードメイン宣言が含まれるようにします。セキュリティードメイン宣言の設定の詳細については、JBoss Enterprise Application Platform 6 ドキュメンテーションを参照してください。アプリケーションユーザーの追加
該当するスクリプトを実行し、アプリケーションユーザーを追加する設定を入力します。adduser.shスクリプト ($JDG_HOME/binに存在) を実行します。- Windows システムでは、
adduser.batファイル ($JDG_HOME/binに存在) を代わりに実行します。
- 追加するユーザーのタイプについて尋ねられたら、
bを入力してApplication User (application-users.properties)を選択します。 - リターンキーを押して、レルム (
ApplicationRealm) のデフォルト値を使用します。 - ユーザー名とパスワードを指定します。
- 作成されたユーザーのロールを尋ねられたら、
RESTと入力します。 - プロンプトが表示されたら、ユーザー名とアプリケーションレルム情報が正しいことを確認し、"yes" と入力して作業を続行します。
作成されたアプリケーションユーザーの確認
作成されたアプリケーションユーザーが正しく設定されていることを確認します。application-users.propertiesファイル ($JDG_HOME/standalone/configuration/に存在) にリストされた設定を確認します。以下は、このファイルの正しい設定の例です。user1=2dc3eacfed8cf95a4a31159167b936fc
application-roles.propertiesファイル ($JDG_HOME/standalone/configuration/に存在) にリストされた設定を確認します。以下は、このファイルの正しい設定の例です。user1=REST
サーバーのテスト
サーバーを起動し、ブラウザーウィンドウに以下のリンクを入力して REST エンドポイントにアクセスします。http://localhost:8080/rest/namedCache
注記
GET 要求の使用をテストする場合は、405応答コードが期待され、サーバーが正常に認証されたことが示されます。
第12章 Memcached インターフェース
12.1. Memcached サーバーについて
- スタンドアロン。各サーバーは、他の memcached サーバーと通信せずに独立して動作します。
- クラスター。サーバーはデータを他の memcached サーバーにレプリケートおよび分散します。
12.2. memcached 統計
表12.1 memcached 統計
| 統計 | データタイプ | 説明 |
|---|---|---|
| アップタイム | 32 ビット符号なし整数。 | memcached インスタンスが利用可能であり、実行されている時間 (秒数単位) を含みます。 |
| 時間 | 32 ビット符号なし整数。 | 現在の時間を含みます。 |
| version | 文字列 | 現在のバージョンを含みます。 |
| curr_items | 32 ビット符号なし整数。 | インスタンスが現在格納しているアイテムの数を含みます。 |
| total_items | 32 ビット符号なし整数。 | 存続期間中にインスタンスにより格納されたアイテムの合計数を含みます。 |
| cmd_get | 64 ビット符号なし整数 | get 操作要求 (データ取得要求) の合計数を含みます。 |
| cmd_set | 64 ビット符号なし整数 | 設定された操作要求 (データ格納要求) の合計数を含みます。 |
| get_hits | 64 ビット符号なし整数 | 要求されたキーにあるキーの数を含みます。 |
| get_misses | 64 ビット符号なし整数 | 要求されたキーにないキーの数を含みます。 |
| delete_hits | 64 ビット符号なし整数 | 削除するキー (特定され正常に削除されたキー) の数を含みます。 |
| delete_misses | 64 ビット符号なし整数 | 削除するキー (特定されず、削除できなかったキー) の数を含みます。 |
| incr_hits | 64 ビット符号なし整数 | 増分するキー (特定され正常に増分されたキー) の数を含みます。 |
| incr_misses | 64 ビット符号なし整数 | 増分するキー (特定されず、増分できなかったキー) の数を含みます。 |
| decr_hits | 64 ビット符号なし整数 | 減分するキー (特定され正常に減分されたキー) の数を含みます。 |
| decr_misses | 64 ビット符号なし整数 | 減分するキー (特定されず、減分できなかったキー) の数を含みます。 |
| cas_hits | 64 ビット符号なし整数 | 比較し、スワップするキー (特定され正常に比較およびスワップされたキー) の数を含みます。 |
| cas_misses | 64 ビット符号なし整数 | 比較し、スワップするキー (特定されず、比較およびスワップされなかったキー) の数を含みます。 |
| cas_badval | 64 ビット符号なし整数 | 比較およびスワップが行われたが、元の値が提供された値に一致しなかったキーの数を含みます。 |
| evictions | 64 ビット符号なし整数 | 実行されたエビクションコールの数を含みます。 |
| bytes_read | 64 ビット符号なし整数 | ネットワークからサーバーが読み取ったバイトの合計数を含みます。 |
| bytes_written | 64 ビット符号なし整数 | ネットワークからサーバーが書き込んだバイトの合計数を含みます。 |
12.3. Memcached インターフェースコネクター
- Hot Rod ベースコネクターの設定を定義する
hotrod-connector要素。 - memcached ベースコネクターの設定を定義する
memcached-connector要素。 - REST インターフェースベースのコネクターの設定を定義する
rest-connector要素。
<socket-binding-group /> 内で宣言されたソケットバインディングを使用し、local コンテナーで宣言されたキャッシュを公開し、他のすべての設定でデフォルト値を使用して Hot Rod、Memcached、または REST サーバーが有効になります。以下の例は、Hot Rod、Memcached、および REST サーバーに接続する方法を示しています。
memcached ソケットバインディングを使用して Memcached サーバーが有効になり、local コンテナーで宣言された memcachedCache キャッシュが公開され、他のすべての設定にデフォルト値が使用されます。
<memcached-connector socket-binding="memcached" cache-container="local"/>
12.3.1. Memcached コネクターの設定
connectors 要素内にある memcached コネクターを設定するために使用する属性を示しています。
手順12.1 リモートクライアントサーバーモードでの Memcached コネクターの設定
memcached-connector 要素は、memcached で使用する設定要素を定義します。
socket-bindingパラメーターsocket-bindingパラメーターは、memcached コネクターで使用されるソケットバインディングポートを指定します。これは必須パラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" />
cache-containerパラメーターcache-containerパラメーターは、memcached コネクターで使用されるキャッシュコンテナーを指定します。これは必須パラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" />worker-threadsパラメーターworker-threadsパラメーターは、memcached コネクターで利用可能なワーカースレッドの数を指定します。このパラメーターのデフォルト値は、160 です。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" worker-threads="${VALUE}" />idle-timeoutパラメーターidle-timeoutパラメーターは、接続がタイムアウトするまでコネクターがアイドル状態のままになる時間 (ミリ秒単位) を指定します。このパラメーターのデフォルト値は-1です (タイムアウト期間が設定されません)。これは、オプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" />tcp-nodelayパラメーターtcp-no-delayパラメーターは、TCP パケットが遅延され一括して送信されるかを指定します。このパラメーターの有効な値はtrueとfalseになります。このパラメーターのデフォルト値は、trueです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" worker-threads="${VALUE}" idle-timeout="{VALUE}" tcp-nodelay="{TRUE/FALSE}"/>send-buffer-sizeパラメーターsend-buffer-sizeパラメーターは、memcached コネクターの送信バッファーのサイズを指定します。このパラメーターのデフォルト値は TCP スタックバッファーのサイズです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" worker-threads="${VALUE}" idle-timeout="{VALUE}" tcp-nodelay="{TRUE/FALSE}" send-buffer-size="{VALUE}" />receive-buffer-sizeパラメーターreceive-buffer-sizeパラメーターは、memcached コネクターの受信バッファーのサイズを指定します。このパラメーターのデフォルト値は TCP スタックバッファーのサイズです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <memcached-connector socket-binding="memcached" cache-container="local" worker-threads="${VALUE}" idle-timeout="{VALUE}" tcp-nodelay="{TRUE/FALSE}" send-buffer-size="{VALUE}" receive-buffer-size="${VALUE}" /> </subsystem>
12.4. Memcached インターフェースセキュリティー
12.4.1. Memcached エンドポイントをパブリックインターフェースとして公開
management の socket-binding 要素の interface パラメーターの値を public に変更します。
<socket-binding name="memcached" interface="public" port="11211" />
第13章 Hot Rod インターフェース
13.1. Hot Rod について
13.2. Memcached ではなく Hot Rod を使用する利点
- Memcached
- memcached プロコトルでは、サーバーエンドポイントが memcached text wire protocol を使用します。memcached wire protocol の利点は、一般的に使用されていることであり、これはほとんどのプラットフォームで利用できます。memcached を使用する場合は、クラスタリング、スケーラビリティの状態共有、および高可用性を含む JBoss Data Grid のすべての機能を利用できます。ただし、memcached プロトコルには dynamicity がなく、クラスタのいずれかのノードで障害が発生したときにクライアント上のサーバーノードのリストを手動で更新する必要があります。また、memcached クライアントはクラスタのデータの場所を認識しません。つまり、クライアントは非所有者のノードからデータを要求し、データをクライアントに返す前に、そのノードから実際の所有者への追加の要求のペナルティーが発生します。この結果、Hot Rod プロトコルは memcached よりも優れたパフォーマンスを提供できます。
- Hot Rod
- JBoss Data Grid の Hot Rod プロトコルは、memcached のすべての機能を提供するバイナリーワイヤープロトコルであり、優れたスケーリング、持続性、および弾力性を提供します。Hot Rod プロトコルは、リモートキャッシュで各ノードのホスト名とポートを必要としませんが、memcached ではこれらのパラメーターを指定する必要があります。Hot Rod クライアントはクラスタ化された Hot Rod サーバーのトポロジーの変更を自動的に検出します。新しいノードがクラスタに参加したり、クラスタから脱退したりすると、クライアントは Hot Rod サーバートポロジービューを更新します。この結果、Hot Rod では、設定と保守が容易になり、動的なロードバランシングとフェイルオーバーの利点が提供されます。また、Hot Rod ワイヤープロトコルは分散キャッシュに接続するときにスマートルーティングを使用します。この場合に、サーバーノードとクライアント間で一貫したハッシュアルゴリズムが共有され、memcached よりも高速な読み取りおよび書き込み機能が提供されます。
13.3. Hot Rod ハッシュ機能
numSegments を使用して設定でき、クラスターを再起動しても変更されません。キーとセグメントのマッピングも固定されます。クラスターのトポロジーがどのように変更するかに関係なく、キーは同じセグメントに対してマップされます。
13.4. Hot Rod インターフェースコネクター
- Hot Rod ベースコネクターの設定を定義する
hotrod-connector要素。 - memcached ベースコネクターの設定を定義する
memcached-connector要素。 - REST インターフェースベースのコネクターの設定を定義する
rest-connector要素。
<socket-binding-group /> 内で宣言されたソケットバインディングを使用し、local コンテナーで宣言されたキャッシュを公開し、他のすべての設定でデフォルト値を使用して Hot Rod、Memcached、または REST サーバーが有効になります。以下の例は、Hot Rod、Memcached、および REST サーバーに接続する方法を示しています。
hotrod ソケットバインディングを使用して Hot Rod サーバーが有効になります。
<hotrod-connector socket-binding="hotrod" cache-container="local" />
<topology-state-transfer /> 子要素をコネクターに追加することにより、調整できます。
<hotrod-connector socket-binding="hotrod" cache-container="local"> <topology-state-transfer lazy-retrieval="false" lock-timeout="1000" replication-timeout="5000" /> </hotrod-connector>
注記
13.4.1. Hot Rod コネクターの設定
hotrod-connector 要素と topology-state-transfer 要素は、次の手順に基いて設定する必要があります。
手順13.1 リモートクライアントサーバーモード用 Hot Rod コネクターの設定
hotrod-connector要素hotrod-connector要素は、Hot Rod で使用する設定要素を定義します。socket-bindingパラメーターsocket-bindingパラメーターは、Hot Rod コネクターで使用されるソケットバインディングポートを指定します。これは必須パラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" />cache-containerパラメーターcache-containerパラメーターは、Hot Rod コネクターで使用されるキャッシュコンテナーを指定します。これは必須パラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" />worker-threadsパラメーターworker-threadsパラメーターは、Hot Rod コネクターで利用可能なワーカースレッドの数を指定します。このパラメーターのデフォルト値は、160です。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" />idle-timeoutパラメーターidle-timeoutパラメーターは、接続がタイムアウトするまでコネクターがアイドル状態のままになる時間 (ミリ秒単位) を指定します。このパラメーターのデフォルト値は-1です (タイムアウト期間が設定されません)。これは、オプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}"/>tcp-nodelayパラメーターtcp-no-delayパラメーターは、TCP パケットが遅延され一括して送信されるかを指定します。このパラメーターの有効な値はtrueとfalseになります。このパラメーターのデフォルト値は、trueです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" />send-buffer-sizeパラメーターsend-buffer-sizeパラメーターは、Hot Rod コネクターの送信バッファーのサイズを指定します。このパラメーターのデフォルト値は TCP スタックバッファーのサイズです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}"/>receive-buffer-sizeパラメーターreceive-buffer-sizeパラメーターは、Hot Rod コネクターの受信バッファーのサイズを指定します。このパラメーターのデフォルト値は TCP スタックバッファーのサイズです。これはオプションパラメーターです。subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" />
topology-state-transfer要素topology-state-transfer要素は、Hot Rod コネクターのトポロジー状態転送設定を指定します。この要素はhotrod-connector要素内でのみ使用できます。lock-timeoutパラメーターlock-timeoutパラメーターは、ロックを取得しようとする操作がタイムアウトする時間を指定します。このパラメーターのデフォルト値は10秒です。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" />replication-timeoutパラメーターreplication-timeoutパラメーターは、レプリケーション操作がタイムアウトする時間 (ミリ秒単位) を指定します。このパラメーターのデフォルト値は10秒です。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" replication-timeout="${MILLISECONDS}" />external-hostパラメーターexternal-hostパラメーターは、トポロジー情報にリストされたクライアントに Hot Rod サーバーが送信するホスト名を指定します。このパラメーターのデフォルト値は、ホストアドレスです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" replication-timeout="${MILLISECONDS}" external-host="${HOSTNAME}" />external-portパラメーターexternal-portパラメーターは、トポロジー情報にリストされたクライアントに Hot Rod サーバーが送信するポートを指定します。このパラメーターのデフォルト値は、設定されたポートです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" replication-timeout="${MILLISECONDS}" external-host="${HOSTNAME}" external-port="${PORT}" />lazy-retrievalパラメーターlazy-retrievalパラメーターは、Hot Rod コネクターが取得操作をレイジーに実行するかどうかを指定します。このパラメーターのデフォルト値はtrueです。これはオプションパラメーターです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" replication-timeout="${MILLISECONDS}" external-host="${HOSTNAME}" external-port="${PORT}" lazy-retrieval="${TRUE/FALSE}" /> </subsystem>await-initial-transferパラメーターawait-initial-transferパラメーターは、初期状態の取得を起動時にすぐに行うかどうかを指定します。このパラメーターは、lazy-retrievalがfalseに設定されている場合のみ適用されます。このパラメーターのデフォルト値はtrueです。<subsystem xmlns="urn:infinispan:server:endpoint:6.0"> <hotrod-connector socket-binding="hotrod" cache-container="local" worker-threads="${VALUE}" idle-timeout="${VALUE}" tcp-nodelay="${TRUE/FALSE}" send-buffer-size="${VALUE}" receive-buffer-size="${VALUE}" /> <topology-state-transfer lock-timeout"="${MILLISECONDS}" replication-timeout="${MILLISECONDS}" external-host="${HOSTNAME}" external-port="${PORT}" lazy-retrieval="${TRUE/FALSE}" await-initial-transfer="${TRUE/FALSE}" /> </subsystem>
13.5. Hot Rod ヘッダー
13.5.1. Hot Rod ヘッダーデータタイプ
表13.1 ヘッダーデータタイプ
| データタイプ | サイズ | 説明 |
|---|---|---|
| vInt | 1〜5 バイト。 | 符号なし可変長整数値。 |
| vLong | 1〜9 バイト。 | 符号なし可変長ロング値。 |
| 文字列 | - | 文字列は常に UTF-8 エンコーディングを使用して表されます。 |
13.5.2. 要求ヘッダー
表13.2 要求ヘッダーフィールド
| フィールド名 | データタイプ/サイズ | 説明 |
|---|---|---|
| Magic | 1 バイト | ヘッダーが要求ヘッダーまたは応答ヘッダーであるかどうかを示します。 |
| Message ID | vLong | メッセージ ID を含みます。この一意の ID は、要求に応答するときに使用されます。これにより、Hot Rod クライアントは非同期でプロトコルを実装できるようになります。 |
| Version | 1 バイト | Hot Rod サーバーバージョンを含みます。 |
| Opcode | 1 バイト | 関連する操作コードを含みます。要求ヘッダー内でopcode には要求操作コードのみを含めることができます。 |
| Cache Name Length | vInt | キャッシュ名の長さを格納します。キャッシュ名の長さが 0 に設定され、キャッシュ名に値が提供されない場合、操作はデフォルトのキャッシュと対話します。 |
| Cache Name | 文字列 | 指定された操作のターゲットキャッシュの名前を格納します。この名前は、キャッシュ設定ファイルの事前定義済みキャッシュの名前に一致する必要があります。 |
| Flags | vInt | システムに渡されるフラグを表す可変長の数値を含みます。さらに多くのバイトを読み取る必要があるかどうかを決定するために使用される最大ビットを除き、各ビットはフラグを表します。各フラグを表すためにビットを使用すると、フラグの組み合わせが連結された状態で表されます。 |
| Client Intelligence | 1 バイト | サーバーに対するクライアント機能を示す値を含みます。 |
| Topology ID | vInt | クライアントの最後の既知なビュー ID を含みます。基本的なクライアントはこのフィールドに値 0 を提供します。トポロジーまたはハッシュ情報をサポートするクライアントは、サーバーが現在のビュー ID に応答するまで値 0 (新しいビュー ID が現在のビュー ID を置き換えるためにサーバーにより返されるまで使用されます) を提供します。 |
| Transaction Type | 1 バイト | 2 つの既知のトランザクションタイプのいずれかを表す値を含みます。現時点でサポートされている値は 0 のみです。 |
| Transaction ID | バイトアレイ | 呼び出しに関連するトランザクションを一意に識別するバイトアレイを含みます。トランザクションタイプはこのバイトアレイの長さを決定します。Transaction Type の値が 0 に設定された場合、トランザクション ID は存在しません。 |
13.5.3. 応答ヘッダー
表13.3 応答ヘッダーフィールド
| フィールド名 | データタイプ | 説明 |
|---|---|---|
| Magic | 1 バイト | ヘッダーが要求または応答ヘッダーであるかどうかを示します。 |
| Message ID | vLong | メッセージ ID を含みます。この一意の ID は、応答を元の要求とペアにするために使用されます。これにより、Hot Rod クライアントは非同期でプロトコルを実装できるようになります。 |
| Opcode | 1 バイト | 関連する操作コードを含みます。応答ヘッダー内で opcode には応答操作コードのみを含めることができます。 |
| Status | 1 バイト | 応答のステータスを表すコードを含みます。 |
| Topology Change Marker | 1 バイト | 応答がトポロジー変更情報に含まれるかどうかを示すマーカーバイトを含みます。 |
13.5.4. トポロジー変更ヘッダー
topology ID と、クライアントにより送信された topology ID を比較し、2 つの値が異なる場合は、新しい topology ID を返します。
13.5.4.1. トポロジー変更マーカー値
Topology Change Marker フィールドの有効な値のリストです。
表13.4 Topology Change Marker フィールド値
| 値 | 説明 |
|---|---|
| 0 | トポロジーの変更情報は追加されません。 |
| 1 | トポロジーの変更情報が追加されます。 |
13.5.4.2. トポロジー認識クライアントのトポロジー変更ヘッダー
表13.5 トポロジー変更ヘッダーフィールド
| 応答ヘッダーフィールド | データタイプ/サイズ | 説明 |
|---|---|---|
| Response Header with Topology Change Marker | - | - |
| Topology ID | vInt | - |
| Num Servers in Topology | vInt | クラスターで稼働している Hot Rod サーバーの数を含みます。一部のノードのみが Hot Rod サーバーを稼働している場合に、この値は、クラスター全体のサブセットになることがあります。 |
| mX: Host/IP Length | vInt | 個別クラスターメンバーのホスト名または IP アドレスの長さを含みます。可変長により、この要素にはホスト名、IPv4、および IPv6 アドレスを含めることができます。 |
| mX: Host/IP Address | 文字列 | 個別クラスターメンバーのホスト名または IP アドレスを含みます。Hot Rod クライアントはこの情報を使用して個別クラスターメンバーにアクセスします。 |
| mX: Port | 符号なしショート。2 バイト | クラスターメンバーと通信するために Hot Rod クライアントが使用するポートを含みます。 |
mX の 3 つのエントリーが繰り返されます。トポロジーの情報フィールド内の最初のサーバーには接頭辞 m1 が付けられ、X の値が num servers in topology フィールドで指定されたサーバーの数と等しくなるまで、各追加サーバーに対して数値が 1 つずつ増分されます。
13.5.4.3. ハッシュ配布認識クライアントのトポロジー変更ヘッダー
表13.6 トポロジー変更ヘッダーフィールド
| フィールド | データタイプ/サイズ | 説明 |
|---|---|---|
| Response Header with Topology Change Marker | - | - |
| Topology ID | vInt | - |
| Number Key Owners | 符号なしショート、2 バイト | 配布された各キーに対してグローバルに設定されたコピーの数を含みます。配布がキャッシュで設定されていない場合は、値 0 を含みます。 |
| Hash Function Version | 1 バイト | 使用中のハッシュ機能へのポインターを含みます。配布がキャッシュで設定されていない場合は、値 0 を含みます。 |
| Hash Space Size | vInt | ハッシュコード生成に関連するすべてのモジュール計算のために JBoss Data Grid により使用されるモジュールを含みます。クライアントはこの情報を使用して正しいハッシュ計算をキーに適用します。配布がキャッシュで設定されていない場合は、値 0 を含みます。 |
| Number servers in topology | vInt | クラスター内で稼働している Hot Rod サーバーの数を含みます。一部のノードのみが Hot Rod サーバーを稼働している場合に、この値は、クラスター全体のサブセットになることがあります。また、この値はヘッダーに含まれるホストとポートのペアの数を表します。 |
| Number Virtual Nodes Owners | vInt | 設定された仮想ノードの数を含みます。仮想ノードが設定されていない場合、または配布がキャッシュで設定されていない場合は、値 0 を含みます。 |
| mX: Host/IP Length | vInt | 個別クラスターメンバーのホスト名または IP アドレスの長さを含みます。可変長により、この要素にはホスト名、IPv4、および IPv6 アドレスを含めることができます。 |
| mX: Host/IP Address | 文字列 | 個別クラスターメンバーのホスト名または IP アドレスを含みます。Hot Rod クライアントはこの情報を使用して個別クラスターメンバーにアクセスします。 |
| mX: Port | 符号なしショート、2 バイト | クラスターメンバーと通信するために Hot Rod クライアントが使用するポートを含みます。 |
| mX: Hashcode | 4 バイト |
mX の 3 つのエントリーが繰り返されます。トポロジーの情報フィールド内の最初のサーバーには接頭辞 m1 が付けられ、X の値が num servers in topology フィールドで指定されたサーバーの数と等しくなるまで、各追加サーバーに対して数値が 1 つずつ増分されます。
13.6. Hot Rod 操作
13.6.1. Hot Rod 操作
- BulkGetKeys
- BulkGet
- Clear
- ContainsKey
- Get
- GetWithMetadata
- Ping
- PutIfAbsent
- Put
- Query
- RemoveIfUnmodified
- Remove
- ReplaceIfUnmodified
- Replace
- Stats
13.6.2. Hot Rod BulkGetKeys 操作
BulkGetKeys 操作は、以下の要求形式を使用します。
表13.7 BulkGetKeys 操作の要求形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | 変数 | 要求ヘッダー |
| Scope | vInt |
|
表13.8 BulkGetKeys 操作の応答形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | 変数 | 応答ヘッダー |
| Response status | 1 バイト | 0x00 = 成功 (データが続きます)。 |
| More | 1 バイト | ストリームからより多くのキーを読み取る必要があるかを表す 1 つのバイト。1 に設定されている場合はエントリーが続き、0 に設定されている場合はストリームの最後であり、読み取るエントリーが残っていません。 |
| Key 1 Length | vInt | キーの長さ |
| Key 1 | バイトアレイ | 取得されたキー |
| More | 1 バイト | - |
| Key 2 Length | vInt | - |
| Key 2 | バイトアレイ | - |
| ...etc |
13.6.3. Hot Rod BulkGet 操作
BulkGet 操作は、以下の要求形式を使用します。
表13.9 BulkGet 操作要求形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| エントリー数 | vInt | サーバーにより返される Red Hat JBoss Data Grid エントリーの最大数が含まれます。エントリーはキーと値のペアです。 |
表13.10 BulkGet 操作応答形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| 詳細 | vInt | ストリームからエントリーをさらに読み取る必要があるかどうかを示します。More は 1 に設定される一方で、More の値が 0 (ストリームの最後を示します) に設定されるまで追加のエントリーが続きます。 |
| キーサイズ | - | キーのサイズを含みます。 |
| キー | - | キーの値を含みます。 |
| 値サイズ | - | 値のサイズを含みます。 |
| 値 | - | 値を含みます。 |
More、Key Size、Key、Value Size、および Value エントリーが応答に追加されます。
13.6.4. Hot Rod clear 操作
clear 操作形式には、ヘッダーのみ含まれます。
表13.11 clear 操作応答
| 応答ステータス | 説明 |
|---|---|
| 0x00 | Red Hat JBoss Data Grid が正常に消去されました。 |
13.6.5. Hot Rod ContainsKey 操作
ContainsKey 操作は、以下の要求形式を使用します。
表13.12 ContainsKey 操作要求形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| キーの長さ | vInt | キーの長さを含みます。Integer.MAX_VALUE のサイズよりも大きいサイズ (最大 5 バイト) のため、vInt データタイプが使用されます。ただし、Java では、単一アレイサイズを Integer.MAX_VALUE のサイズよりも大きくすることはできません。結果として、この vInt は Integer.MAX_VALUE の最大サイズに限定されます。 |
| キー | バイトアレイ | キーを含みます (このキーの対応する値が要求されます)。 |
表13.13 ContainsKey 操作応答形式
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 操作が成功。 |
| 0x02 | キーが存在しない。 |
13.6.6. Hot Rod Get 操作
Get 操作は、以下の要求形式を使用します。
表13.14 Get 操作要求形式
| フィールド | データタイプ | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。Integer.MAX_VALUE のサイズよりも大きいサイズ (最大 5 バイト) のため、vInt データタイプが使用されます。ただし、Java では、単一アレイサイズを Integer.MAX_VALUE のサイズよりも大きくすることはできません。結果として、この vInt は Integer.MAX_VALUE の最大サイズに限定されます。 |
| Key | バイトアレイ | キーを含みます (このキーの対応する値が要求されます)。 |
表13.15 Get 操作応答形式
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 操作が成功。 |
| 0x02 | キーが存在しない。 |
get 操作の応答の形式は以下のとおりです。
表13.16 Get 操作応答形式
| フィールド | データタイプ | 説明 |
|---|---|---|
| Header | - | - |
| Value Length | vInt | 値の長さを含みます。 |
| Value | バイトアレイ | 要求された値を含みます。 |
13.6.7. Hot Rod GetWithMetadata 操作
GetWithMetadata 操作は以下の要求形式を使用します。
表13.17 GetWithMetadata 操作の要求形式
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | 変数 | 要求ヘッダー。 |
| Key Length | vInt | キーの長さ。vInt のサイズは最大 5 バイトであり、理論的には Integer.MAX_VALUE よりも大きい数を生成できます。ただし、Java では Integer.MAX_VALUE よりも大きい単一アレイを作成できず、プロトコルにより vInt アレイの長さが Integer.MAX_VALUE に制限されます。 |
| Key | バイトアレイ | 値が要求されるキーを含むバイトアレイ。 |
表13.18 GetWithMetadata 操作の応答要求
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | 変数 | 応答ヘッダー。 |
| Response status | 1 バイト | 0x00 = 成功 (キーが取得された場合)。
0x02 = キーが存在しない場合。
|
| Flag | 1 バイト | 応答に失効に関する情報含まれるかどうかを示すフラグ。フラグの値は、 INFINITE_LIFESPAN (0x01) と INFINITE_MAXIDLE (0x02) 間のビットごとの OR 演算として取得されます。 |
| Created | Long | (オプション) サーバーでエントリが作成されたときのタイムスタンプを表すLong。この値は、フラグの INFINITE_LIFESPAN ビットが設定されていない場合にのみ返されます。 |
| Lifespan | vInt | (オプション) エントリのライフスパンを表すvInt (秒単位)。この値は、フラグの INFINITE_LIFESPAN ビットが設定されていない場合にのみ返されます。 |
| LastUsed | Long | (オプション) サーバーでエントリが最後にアクセスされたときのタイムスタンプを表すLong。この値は、フラグの INFINITE_MAXIDLE ビットが設定されていない場合にのみ返されます。 |
| MaxIdle | vInt | (オプション) エントリの maxIdle を表すvInt (秒単位)。この値は、フラグの INFINITE_MAXIDLE ビットが設定されていない場合にのみ返されます。 |
| Entry Version | 8 バイト | 既存のエントリー変更の一意の値。プロトコルでは entry_version の値はシーケンシャルであることが保証されず、キーレベルで更新ごとに一意である必要があります。 |
| Value Length | vInt | 成功した場合は、値の長さ。 |
| Value | バイトアレイ | 成功した場合は、要求された値。 |
13.6.8. Hot Rod ping 操作
ping は、サーバーの可用性を確認するアプリケーションレベルの要求です。
表13.19 ping 操作応答
| 応答ステータス | 説明 |
|---|---|
| 0x00 | エラーなしの正常な ping。 |
13.6.9. Hot Rod PutIfAbsent 操作
putIfAbsent 操作要求形式には、以下のものが含まれます。
表13.20 PutIfAbsent 操作要求フィールド
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。 |
| Key | バイトアレイ | キーの値を含みます。 |
| Lifespan | vInt | エントリーが期限切れになるまでの秒数を含みます。秒数が 30 日を超える場合、その値はエントリーライフスパンの UNIX 時間 (つまり、日付 1/1/1970 以降の秒数) として処理されます。値が 0 に設定された場合、エントリーは期限切れになりません。 |
| Max Idle | vInt | キャッシュからエビクトされるまでエントリーがアイドル状態のままになることが許可される秒数を含みます。このエントリーが 0 に設定された場合、エントリーは無期限でアイドル状態のままになることが許可され、max idle 値のため、エビクトされません。 |
| Value Length | vInt | 値の長さを含みます。 |
| Value | バイトアレイ | 要求された値を含みます。 |
表13.21
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 値が正常に格納されました。 |
| 0x01 | キーが存在しないため、値が格納されませんでした。キーの現在の値が返されました。 |
ForceReturnPreviousValue が渡された場合は、以前の値とキーが返されます。以前のキーと値が存在しない場合は、値の長さに値 0 が含まれます。
13.6.10. Hot Rod Put 操作
put 操作要求形式には、以下のものが含まれます。
表13.22
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | - | キーの長さを含みます。 |
| Key | バイトアレイ | キーの値を含みます。 |
| Lifespan | vInt | エントリーが期限切れになるまでの秒数を含みます。秒数が 30 日を超える場合、その値はエントリーライフスパンの UNIX 時間 (つまり、日付 1/1/1970 以降の秒数) として処理されます。値が 0 に設定された場合、エントリーは期限切れになりません。 |
| Max Idle | vInt | キャッシュからエビクトされるまでエントリーがアイドル状態のままになることが許可される秒数を含みます。このエントリーが 0 に設定された場合、エントリーは無期限でアイドル状態のままになることが許可され、max idle 値のため、エビクトされません。 |
| Value Length | vInt | 値の長さを含みます。 |
| Value | バイトアレイ | 要求された値。 |
表13.23
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 値が正常に格納されました。 |
ForceReturnPreviousValue が渡された場合は、以前の値とキーが返されます。以前のキーと値が存在しない場合は、値の長さに値 0 が含まれます。
13.6.11. Hot Rod クエリー操作
Query 操作要求形式には、以下のものが含まれます。
表13.24 クエリー操作要求フィールド
| フィールド | データ型 | 詳細 |
|---|---|---|
| Header | 変数 | 要求ヘッダー。 |
| Query Length | vInt | Protobuf エンコードされたクエリーオブジェクトの長さ。 |
| Query | バイトアレイ | Protobuf エンコードされたクエリーオブジェクトを含むバイトアレイ。長さは目のフィールドにより指定されます。 |
表13.25 クエリー操作応答
| 応答ステータス | データ | 詳細 |
|---|---|---|
| Header | 変数 | 応答ヘッダー。 |
| Response payload Length | vInt | Protobuf エンコードされた応答オブジェクトの長さ。 |
| Response payload | バイトアレイ | Protobuf エンコードされた応答オブジェクトを含むバイトアレイ。長さは目のフィールドにより指定されます。 |
13.6.12. Hot Rod RemoveIfUnmodified 操作
RemoveIfUnmodified 操作要求形式には、以下のものが含まれます。
表13.26 RemoveIfUnmodified 操作要求フィールド
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。 |
| Key | バイトアレイ | キーの値を含みます。 |
| Entry Version | 8 バイト | エントリーのバージョン番号。 |
表13.27 RemoveIfUnmodified 操作応答
| 応答ステータス | 説明 |
|---|---|
| 0x00 | エントリーが置換または削除された場合に返されたステータス。 |
| 0x01 | キーが変更されたため、エントリーの置換または削除が失敗した場合に、ステータスを返します。 |
| 0x02 | キーが存在しない場合に、ステータスを返します。 |
ForceReturnPreviousValue が渡された場合は、以前の値とキーが返されます。以前のキーと値が存在しない場合は、値の長さに値 0 が含まれます。
13.6.13. Hot Rod Remove 操作
Hot Rod Remove 操作は、以下の要求形式を使用します。
表13.28 Remove 操作要求形式
| フィールド | データタイプ | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。Integer.MAX_VALUE のサイズよりも大きいサイズ (最大 5 バイト) のため、vInt データタイプが使用されます。ただし、Java では、単一アレイサイズを Integer.MAX_VALUE のサイズよりも大きくすることはできません。結果として、この vInt は Integer.MAX_VALUE の最大サイズに限定されます。 |
| Key | バイトアレイ | キーを含みます (このキーの対応する値が要求されます)。 |
表13.29 Remove 操作応答形式
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 操作が成功。 |
| 0x02 | キーが存在しない。 |
ForceReturnPreviousValue が渡された場合は、応答ヘッダーに以下のいずれかが含まれます。
- 以前のキーの値および長さ。
- キーが存在しないことを示す、値の長さ
0と応答ステータス0x02。
ForceReturnPreviousValue が渡された場合)。キーが存在しない場合、または以前の値が null の場合、値の長さは 0 です。
13.6.14. Hot Rod ReplaceIfUnmodified 操作
ReplaceIfUnmodified 操作要求形式には、以下のものが含まれます。
表13.30 ReplaceIfUnmodified 操作要求フィールド
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。 |
| キー | バイトアレイ | キーの値を含みます。 |
| Lifespan | vInt | エントリーが期限切れになるまでの秒数を含みます。秒数が 30 日を超える場合、その値はエントリーライフスパンの UNIX 時間 (つまり、日付 1/1/1970 以降の秒数) として処理されます。値が 0 に設定された場合、エントリーは期限切れになりません。 |
| Max Idle | vInt | キャッシュからエビクトされるまでエントリーがアイドル状態のままになることが許可される秒数を含みます。このエントリーが 0 に設定された場合、エントリーは無期限でアイドル状態のままになることが許可され、max idle 値のため、エビクトされません。 |
| Entry Version | 8 バイト | エントリーのバージョン番号。 |
| Value Length | vInt | 値の長さを含みます。 |
| 値 | バイトアレイ | 要求された値を含みます。 |
表13.31 ReplaceIfUnmodified 操作応答
| 応答ステータス | 説明 |
|---|---|
| 0x00 | エントリーが置換または削除された場合に返されたステータス。 |
| 0x01 | キーが変更されたため、エントリーの置換または削除が失敗した場合に、ステータスを返します。 |
| 0x02 | キーが存在しない場合に、ステータスを返します。 |
ForceReturnPreviousValue が渡された場合は、以前の値とキーが返されます。以前のキーと値が存在しない場合は、値の長さに値 0 が含まれます。
13.6.15. Hot Rod replace 操作
replace 操作要求形式には、以下のものが含まれます。
表13.32 replace 操作要求フィールド
| フィールド | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Key Length | vInt | キーの長さを含みます。 |
| Key | バイトアレイ | キーの値を含みます。 |
| Lifespan | vInt | エントリーが期限切れになるまでの秒数を含みます。秒数が 30 日を超える場合、その値はエントリーライフスパンの UNIX 時間 (つまり、日付 1/1/1970 以降の秒数) として処理されます。値が 0 に設定された場合、エントリーは期限切れになりません。 |
| Max Idle | vInt | キャッシュからエビクトされるまでエントリーがアイドル状態のままになることが許可される秒数を含みます。このエントリーが 0 に設定された場合、エントリーは無期限でアイドル状態のままになることが許可され、max idle 値のため、エビクトされません。 |
| Value Length | vInt | 値の長さを含みます。 |
| Value | バイトアレイ | 要求された値を含みます。 |
表13.33 replace 操作応答
| 応答ステータス | 説明 |
|---|---|
| 0x00 | 値が正常に格納されました。 |
| 0x01 | キーが存在しないため、値が格納されませんでした。 |
ForceReturnPreviousValue が渡された場合は、以前の値とキーが返されます。以前のキーと値が存在しない場合は、値の長さに値 0 が含まれます。
13.6.16. Hot Rod 統計操作
表13.34 統計操作要求フィールド
| 名前 | 説明 |
|---|---|
| timeSinceStart | Hot Rod が起動した以降の秒数を含みます。 |
| currentNumberOfEntries | Hot Rod サーバーに現在存在するエントリーの数を含みます。 |
| totalNumberOfEntries | Hot Rod サーバーに格納されたエントリーの合計数を含みます。 |
| stores | put 操作の試行回数を含みます。 |
| retrievals | get 操作の試行回数を含みます。 |
| hits | get ヒット数を含みます。 |
| misses | get 失敗数を含みます。 |
| removeHits | remove ヒット数を含みます。 |
| removeMisses | removal 失敗数を含みます。 |
表13.35 統計操作応答
| 名前 | データ型 | 説明 |
|---|---|---|
| Header | - | - |
| Number of Stats | vInt | 返された個別統計の数を含みます。 |
| Name Length | vInt | 名前付き統計の長さを含みます。 |
| 名前 | 文字列 | 統計の名前を含みます。 |
| Value Length | vInt | 値の長さを含みます。 |
| 値 | 文字列 | 統計値を含みます。 |
Name Length、Name、Value Length、および Value が繰り返されます。
13.7. Hot Rod 操作の値
opcode 値のリストです。
表13.36 opcode 要求および応答ヘッダー値
| 操作 | 要求操作コード | 応答操作コード |
|---|---|---|
| put | 0x01 | 0x02 |
| get | 0x03 | 0x04 |
| putIfAbsent | 0x05 | 0x06 |
| replace | 0x07 | 0x08 |
| replaceIfUnmodified | 0x09 | 0x0A |
| remove | 0x0B | 0x0C |
| removeIfUnmodified | 0x0D | 0x0E |
| containsKey | 0x0F | 0x10 |
| clear | 0x13 | 0x14 |
| stats | 0x15 | 0x16 |
| ping | 0x17 | 0x18 |
| bulkGet | 0x19 | 0x1A |
| getWithMetadata | 0x1B | 0x1C |
| bulkKeysGet | 0x1D | 0x1E |
| query | 0x1F | 0x20 |
opcode 値が 0x50 の場合は、エラー応答を示します。
13.7.1. Magic 値
Magic フィールドの有効な値のリストです。
表13.37 Magic フィールド値
| 値 | 説明 |
|---|---|
| 0xA0 | キャッシュ要求マーカー。 |
| 0xA1 | キャッシュ応答マーカー。 |
13.7.2. ステータス値
Status フィールドに対するすべての有効な値を含む表です。
表13.38 ステータス値
| 値 | 説明 |
|---|---|
| 0x00 | エラーなし。 |
| 0x01 | 配置、削除、置換なし。 |
| 0x02 | キーは存在しない。 |
| 0x81 | 無効なマジック値またはメッセージ ID。 |
| 0x82 | 不明なコマンド。 |
| 0x83 | 不明なバージョン。 |
| 0x84 | 要求解析エラー。 |
| 0x85 | サーバーエラー。 |
| 0x86 | コマンドタイムアウト。 |
13.7.3. トランザクションタイプ値
Transaction Type の有効な値のリストです。
表13.39 Transaction Type フィールド値
| 値 | 説明 |
|---|---|
| 0 | 非トランザクション呼び出し、またはクライアントがトランザクションをサポートしないことを示します。使用された場合は、TX_ID フィールドが省略されます。 |
| 1 | X/Open XA トランザクション ID (XID) を示します。この値は現在サポートされていません。 |
13.7.4. Client Intelligence 値
Client Intelligence の有効な値のリストです。
表13.40 Client Intelligence フィールド値
| 値 | 説明 |
|---|---|
| 0x01 | クラスターまたはハッシュ情報が必要でない基本的なクライアントを示します。 |
| 0x02 | トポロジーを認識し、クラスター情報が必要なクラスターを示します。 |
| 0x03 | ハッシュと配布を認識し、クラスターおよびハッシュ情報が必要なクライアントを示します。 |
13.7.5. フラグ値
flag 値のリストです。
表13.41 フラグフィールド値
| 値 | 説明 |
|---|---|
| 0x0001 | ForceReturnPreviousValue |
13.7.6. Hot Rod エラー処理
表13.42 応答ヘッダーフィールドを使用した Hot Rod エラー処理
| フィールド | データ型 | 説明 |
|---|---|---|
| Error Opcode | - | エラー操作コードを含みます。 |
| Error Status Number | - | error opcode に対応するステータス番号を含みます。 |
| Error Message Length | vInt | エラーメッセージの長さを含みます。 |
| エラーメッセージ | 文字列 | 実際のエラーメッセージを含みます。要求の解析エラーが存在することを示す 0x84 エラーコードが返された場合、このフィールドには、Hot Rod サーバーでサポートされた最新バージョンが含まれます。 |
13.8. put 要求の例
put 要求例からのコーディングされた要求です。
表13.43 put 要求の例
| バイト | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA0 | 0x09 | 0x41 | 0x01 | 0x07 | 0x4D ('M') | 0x79 ('y') | 0x43 ('C') |
| 16 | 0x61 ('a') | 0x63 ('c') | 0x68 ('h') | 0x65 ('e') | 0x00 | 0x03 | 0x00 | 0x00 |
| 24 | 0x00 | 0x05 | 0x48 ('H') | 0x65 ('e') | 0x6C ('l') | 0x6C ('l') | 0x6F ('o') | 0x00 |
| 32 | 0x00 | 0x05 | 0x57 ('W') | 0x6F ('o') | 0x72 ('r') | 0x6C ('l') | 0x64 ('d') | - |
表13.44 要求例のフィールド名と値
| フィールド名 | バイト | 値 |
|---|---|---|
| Magic | 0 | 0xA0 |
| Version | 2 | 0x41 |
| Cache Name Length | 4 | 0x07 |
| Flag | 12 | 0x00 |
| Topology ID | 14 | 0x00 |
| Transaction ID | 16 | 0x00 |
| Key | 18-22 | 'Hello' |
| Max Idle | 24 | 0x00 |
| 値 | 26-30 | 'World' |
| Message ID | 1 | 0x09 |
| Opcode | 3 | 0x01 |
| Cache Name | 5-11 | 'MyCache' |
| Client Intelligence | 13 | 0x03 |
| Transaction Type | 15 | 0x00 |
| Key Field Length | 17 | 0x05 |
| Lifespan | 23 | 0x00 |
| Value Field Length | 25 | 0x05 |
put 要求の例に対するコーディングされた応答です。
表13.45 put 要求の例のコーディングされた応答
| バイト | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 8 | 0xA1 | 0x09 | 0x01 | 0x00 | 0x00 | - | - | - |
表13.46 応答例のフィールド名および値
| フィールド名 | バイト | 値 |
|---|---|---|
| Magic | 0 | 0xA1 |
| Opcode | 2 | 0x01 |
| Topology Change Marker | 4 | 0x00 |
| Message ID | 1 | 0x09 |
| Status | 3 | 0x00 |
13.9. Hot Rod Java クライアント
13.9.1. Hot Rod Java クライアントのダウンロード
手順13.2 Hot Rod Java クライアントのダウンロード
- カスタマーポータル (https://access.redhat.com) にログインします。
- ページ最上部にある ボタンをクリックします。
- 製品のダウンロード ページで をクリックします。
- バージョン: ドロップダウンメニューから適切な JBoss Data Grid バージョンを選択します。
- Red Hat JBoss Data Grid ${VERSION} Hot Rod Java Client エントリーを探し、対応する リンクをクリックします。
13.9.2. Hot Rod Java クライアントの設定
例13.1 クライアントインスタンスの作成
org.infinispan.client.hotrod.configuration.ConfigurationBuilder cb
= new org.infinispan.client.hotrod.configuration.ConfigurationBuilder();
cb.tcpNoDelay(true)
.connectionPool()
.numTestsPerEvictionRun(3)
.testOnBorrow(false)
.testOnReturn(false)
.testWhileIdle(true)
.addServer()
.host("localhost")
.port(11222);
RemoteCacheManager rmc = new RemoteCacheManager(cb.build());
Hot Rod Java クライアントを設定するには、クラスパス上の hotrod-client.properties ファイルを編集します。
hotrod-client.properties ファイルの内容を示しています。
例13.2 設定
infinispan.client.hotrod.transport_factory = org.infinispan.client.hotrod.impl.transport.tcp.TcpTransportFactory infinispan.client.hotrod.server_list = 127.0.0.1:11222 infinispan.client.hotrod.marshaller = org.infinispan.commons.marshall.jboss.GenericJBossMarshaller infinispan.client.hotrod.async_executor_factory = org.infinispan.client.hotrod.impl.async.DefaultAsyncExecutorFactory infinispan.client.hotrod.default_executor_factory.pool_size = 1 infinispan.client.hotrod.default_executor_factory.queue_size = 10000 infinispan.client.hotrod.hash_function_impl.1 = org.infinispan.client.hotrod.impl.consistenthash.ConsistentHashV1 infinispan.client.hotrod.tcp_no_delay = true infinispan.client.hotrod.ping_on_startup = true infinispan.client.hotrod.request_balancing_strategy = org.infinispan.client.hotrod.impl.transport.tcp.RoundRobinBalancingStrategy infinispan.client.hotrod.key_size_estimate = 64 infinispan.client.hotrod.value_size_estimate = 512 infinispan.client.hotrod.force_return_values = false infinispan.client.hotrod.tcp_keep_alive = true ## below is connection pooling config maxActive=-1 maxTotal = -1 maxIdle = -1 whenExhaustedAction = 1 timeBetweenEvictionRunsMillis=120000 minEvictableIdleTimeMillis=300000 testWhileIdle = true minIdle = 1
注記
TCP KEEPALIVE 設定は、 例で示された設定プロパティー (infinispan.client.hotrod.tcp_keep_alive = true/false) または org.infinispan.client.hotrod.ConfigurationBuilder.tcpKeepAlive() メソッドを使用したプログラムによって Hot Rod Java クライアントで有効/無効になります。
new RemoteCacheManager(boolean start)new RemoteCacheManager()
13.9.3. Hot Rod Java クライアント基本 API
localhost:11222 にバインドするよう起動されていることを前提とします。
例13.3 基本 API
//API entry point, by default it connects to localhost:11222
CacheContainer cacheContainer = new RemoteCacheManager();
//obtain a handle to the remote default cache
Cache<String, String> cache = cacheContainer.getCache();
//now add something to the cache and make sure it is there
cache.put("car", "ferrari");]
assert cache.get("car").equals("ferrari");
//remove the data
cache.remove("car");
assert !cache.containsKey("car") : "Value must have been removed!";RemoteCacheManager は、DefaultCacheManager に対応し、両方とも CacheContainer を実装します。
DefaultCacheManager と RemoteCacheManager を切り替えることによって行うことができ、共通の CacheContainer インターフェースによって単純化されます。
keySet() メソッドを使用してリモートキャッシュから取得できます。リモートキャッシュが分散キャッシュである場合は、サーバーによりマップ/削減ジョブが開始され、クラスタノードからすべてのキーが取得され、すべてのキーがクライアントに返されます。
Set keys = remoteCache.keySet();
13.9.4. Hot Rod Java クライアントバージョン API
getVersioned を使用して、クライアントはキーと現在のバージョンに関連付けられた値を取得できます。
RemoteCacheManager は、リモートクラスタ上の名前付きまたはデフォルトのキャッシュにアクセスする RemoteCache インターフェースのインスタンスを提供します。これにより、バージョン API を含む、新しいメソッドを追加する Cache インターフェースが拡張されます。
例13.4 バージョンメソッドの使用
// To use the versioned API, remote classes are specifically needed
RemoteCacheManager remoteCacheManager = new RemoteCacheManager();
RemoteCache<String, String> cache = remoteCacheManager.getCache();
remoteCache.put("car", "ferrari");
VersionedValue valueBinary = remoteCache.getVersioned("car");
// removal only takes place only if the version has not been changed
// in between. (a new version is associated with 'car' key on each change)
assert remoteCache.remove("car", valueBinary.getVersion());
assert !cache.containsKey("car");例13.5 置換の使用
remoteCache.put("car", "ferrari");
VersionedValue valueBinary = remoteCache.getVersioned("car");
assert remoteCache.replace("car", "lamborghini", valueBinary.getVersion());13.10. Hot Rod C ++ クライアント
13.10.1. Hot Rod C ++ クライアント形式
- 静的ライブラリー
- 共有/動的ライブラリー
静的ライブラリーはアプリケーションに静的にリンクされます。これにより、最終的な実行可能ファイルのサイズは増加します。アプリケーションは自己完結型であり、別のライブラリーを提供する必要はありません。
共有/動的ライブラリーは、実行時にアプリケーションに動的にリンクされます。ライブラリーは別のファイルに格納され、アプリケーションを再コンパイルせずアプリケーションとは別にアップグレードできます。
注記
13.10.2. Hot Rod C ++ クライアントの前提条件
- shared_ptr TR1 (GCC 4.0+、Visual Studio C++ 2010) をサポートする C++ 03 コンパイラー。
- Red Hat JBoss Data Grid Server 6.1.0 以上のバージョン。
13.10.3. Hot Rod C ++ クライアントのダウンロード
jboss-datagrid-<version>-hotrod-cpp-client-<platform>.zip に含まれます。使用しているオペレーティングシステムに適切な Hot Rod C++ クライアントをダウンロードしてください。
13.10.4. Hot Rod C ++ クライアントの設定
- 接続するサーバーの初期セット。
- 接続プール属性。
- 接続/ソケットタイムアウトおよび TCP nodelay。
- Hot Rod プロトコルバージョン。
以下の例は、ConfigurationBuilder を使用して RemoteCacheManager を設定する方法とデフォルトのリモートキャッシュを取得する方法を示しています。
例13.6 SimpleMain.cpp
#include "infinispan/hotrod/ConfigurationBuilder.h"
#include "infinispan/hotrod/RemoteCacheManager.h"
#include "infinispan/hotrod/RemoteCache.h"
#include <stdlib.h>
using namespace infinispan::hotrod;
int main(int argc, char** argv) {
ConfigurationBuilder b;
b.addServer().host("127.0.0.1").port(11222);
RemoteCacheManager cm(builder.build());
RemoteCache<std::string, std::string> cache = cm.getCache<std::string, std::string>();
return 0;
}13.10.5. Hot Rod C ++ クライアント API
例13.7 SimpleMain.cpp
RemoteCache<std::string, std::string> rc = cm.getCache<std::string, std::string>();
std::string k1("key13");
std::string v1("boron");
// put
rc.put(k1, v1);
std::auto_ptr<std::string> rv(rc.get(k1));
rc.putIfAbsent(k1, v1);
std::auto_ptr<std::string> rv2(rc.get(k1));
std::map<HR_SHARED_PTR<std::string>,HR_SHARED_PTR<std::string> > map = rc.getBulk(0);
std::cout << "getBulk size" << map.size() << std::endl;
..
.
cm.stop();13.11. Hot Rod C# クライアント
警告
13.11.1. Hot Rod C# クライアントのダウンロードとインストール
jboss-datagrid-<version>-hotrod-dotnet-client.msi に含まれます。Hot Rod C# クライアントをインストールするには、以下の手順を実行してください。
手順13.3 Hot Rod C# クライアントのインストール
- 管理者として、Hot Rod C# .msi ファイルがダウンロードされた場所に移動します。.msi ファイルを実行してウィンドウインストーラーを起動し、 (次へ) をクリックします。
図13.1 Hot Rod C# クライアントのセットアップの開始
- 使用許諾契約書の内容を確認します。I accept the terms in the License Agreement (使用許諾契約に同意します) チェックボックスを選択し、 (次へ) をクリックします。

図13.2 Hot Rod C# クライアントの使用許諾契約
- デフォルトのディレクトリーを変更するには、 (変更...) または (次へ) をクリックしてデフォルトのディレクトリーにインストールします。
図13.3 Hot Rod C# クライアントの宛先フォルダー
- (完了) をクリックして Hot Rod C# クライアントのインストールを完了します。
図13.4 Hot Rod C# クライアントのセットアップの完了
13.11.2. Hot Rod C# クライアントの設定
以下の例は、ConfigurationBuilder を使用して RemoteCacheManager を設定する方法を示しています。
例13.8 C# の設定
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace simpleapp
{
class Program
{
static void Main(string[] args)
{
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.AddServer()
.Host(args.Length > 1 ? args[0] : "127.0.0.1")
.Port(args.Length > 2 ? int.Parse(args[1]) : 11222);
Configuration config = builder.Build();
RemoteCacheManager cacheManager = new RemoteCacheManager(config);
[...]
}
}
}13.11.3. Hot Rod C# クライアント API
RemoteCacheManager は、RemoteCache への参照を取得する開始点です。
例13.9
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using Infinispan.HotRod;
using Infinispan.HotRod.Config;
namespace simpleapp
{
class Program
{
static void Main(string[] args)
{
ConfigurationBuilder builder = new ConfigurationBuilder();
builder.AddServer()
.Host(args.Length > 1 ? args[0] : "127.0.0.1")
.Port(args.Length > 2 ? int.Parse(args[1]) : 11222);
Configuration config = builder.Build();
RemoteCacheManager cacheManager = new RemoteCacheManager(config);
cacheManager.Start();
// Retrieve a reference to the default cache.
IRemoteCache<String, String> cache = cacheManager.GetCache<String, String>();
// Add entries.
cache.Put("key1", "value1");
cache.PutIfAbsent("key1", "anotherValue1");
cache.PutIfAbsent("key2", "value2");
cache.PutIfAbsent("key3", "value3");
// Retrive entries.
Console.WriteLine("key1 -> " + cache.Get("key1"));
// Bulk retrieve key/value pairs.
int limit = 10;
IDictionary<String, String> result = cache.GetBulk(limit);
foreach (KeyValuePair<String, String> kv in result)
{
Console.WriteLine(kv.Key + " -> " + kv.Value);
}
// Remove entries.
cache.Remove("key2");
Console.WriteLine("key2 -> " + cache.Get("key2"));
cacheManager.Stop();
}
}
}13.12. Hot Rod C++ と Hot Rod Java クライアント間の相互運用性
Person オブジェクトを記述し、Java C++ クライアントが Protobuf として構造化された同じ Person オブジェクトを読み取ることができます。
例13.10 言語間の相互運用性の使用
package sample;
message Person {
required int32 age = 1;
required string name = 2;
}パート VI. キャッシュのロックのセットアップ
第14章 ロック
14.1. ロックの設定 (リモートクライアントサーバーモード)
invalidation-cache、distributed-cache、 replicated-cache または local-cache) 内で locking 要素を使用して設定されます。
注記
READ_COMMITTED です。分離モードを明示的に指定するために isolation 属性が含まれる場合、この属性は無視され、警告がスローされて、デフォルト値が代わりに使用されます。
手順14.1 ロックの設定 (リモートクライアントサーバーモード)
acquire-timeoutパラメーターを設定します。acquire-timeoutパラメーターは、ロックの取得がタイムアウトになった後のミリ秒数を指定します。<distributed-cache> <locking acquire-timeout="30000" />
ロックストライプの数を設定します。
concurrency-levelパラメーターは、LockManager によって使用されるロックストライプの数を定義します。<distributed-cache> <locking acquire-timeout="30000" concurrency-level="1000" />
ロックストライピングを設定します。
stripingパラメーターは、ロックストライピングがローカルキャッシュに使用されるかどうかを指定します。<distributed-cache> <locking acquire-timeout="30000" concurrency-level="1000" striping="false" /> ... </distributed-cache>
14.2. ロックの設定 (ライブラリーモード)
locking 要素とそのパラメーターは、キャッシュごとにオプションの configuration 要素内で設定されます。たとえば、デフォルトのキャッシュの場合、configuration 要素は default 要素内で発生し、それぞれの名前付きキャッシュについては、namedCache 要素内で発生します。以下は、この設定例になります。
手順14.2 ロックの設定 (ライブラリーモード)
平行性レベルを設定します。
concurrencyLevelパラメーターは、ロックコンテナーの平行性レベルを指定します。データグリッドと通信する並行スレッドの数に従ってこの値を設定します。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" />キャッシュの分離レベルを指定します。
isolationLevelパラメーターはキャッシュの分離レベルを指定します。有効な分離レベルは、READ_COMMITTEDおよびREPEATABLE_READです。分離レベルについてさらに詳しくは、「分離レベルについて」を参照してください。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" />ロック取得タイムアウトを設定します。
lockAcquisitionTimeoutパラメーターは、ロック取得の試行がタイムアウトになった後の時間 (ミリ秒単位) を指定します。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}" />ロックストライピングを設定します。
useLockStripingパラメーターは、ロックを必要とするすべてのエントリーに対して、共有ロックのプールを維持するかどうかを指定します。FALSEに設定されると、ロックがキャッシュ内のそれぞれのエントリーに対して作成されます。さらに詳しくは、「ロックストライピングについて」を参照してください。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}" useLockStriping="${TRUE/FALSE}" />writeSkewCheckパラメーターを設定します。writeSkewCheckパラメーターは、isolationLevelがREPEATABLE_READに設定される場合にのみ有効です。このパラメーターがFALSEに設定される場合、書き込み時に動作中のエントリーと基礎となるエントリー間の相違があると、動作中のエントリーが基礎となるエントリーを上書きします。このパラメーターがTRUEに設定されている場合、このような競合 (つまり書き込みスキュー) によって、例外がスローされます。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}" useLockStriping="${TRUE/FALSE}" writeSkewCheck="${TRUE/FALSE}" />
14.3. ロックのタイプ
14.3.1. 楽観的ロックについて
writeSkewCheck が有効になっている場合、トランザクションが終了する前に、競合する変更が 1 つ以上データに加えられると、楽観的ロックモードのトランザクションはロールバックします。
14.3.2. 悲観的ロックについて
14.3.3. 悲観的ロックのタイプ
- 明示的な楽観的ロックは、JBoss Data Grid Lock API を使用してトランザクションの期間にキャッシュユーザーがキャッシュキーを明示的にロックできるようにします。ロック呼び出しは、クラスターの全ノードにおいて、指定されたキャッシュキー上でロックの取得を試みます。ロックはすべてコミットまたはロールバックフェーズ中に開放されます。
- 暗黙的な悲観的ロックは、キャッシュキーが変更操作のためアクセスされる時にキャッシュキーがバックグラウンドでロックされるようにします。暗黙的な悲観的ロックを使用すると、各変更操作に対してキャッシュキーが確実にローカルでロックされるよう JBoss Data Grid がチェックします。ロックされていないキャッシュキーが見つかると、JBoss Data Grid はロックされていないキャッシュキーのロックを取得するため、クラスターワイドのロックを要求します。
14.3.4. 明示的な悲観的ロックの例
手順14.3 明示的な悲観的ロックによるトランザクション
- 行
cache.lock(K)が実行されると、Kでクラスター全体のロックが取得されます。tx.begin() cache.lock(K)
- 行
cache.put(K,V5)が実行されると、取得の成功が保証されます。tx.begin() cache.lock(K) cache.put(K,V5)
- 行
tx.commit()が実行されると、この処理のために保持されたロックが開放されます。tx.begin() cache.lock(K) cache.put(K,V5) tx.commit()
14.3.5. 暗黙的な悲観的ロックの例
手順14.4 暗黙的な悲観的ロックによるトランザクション
- 行
cache.put(K,V)が実行されると、Kでクラスター全体のロックが取得されます。tx.begin() cache.put(K,V)
- 行
cache.put(K2,V2)が実行されると、K2でクラスター全体のロックが取得されます。tx.begin() cache.put(K,V) cache.put(K2,V2)
- 行
cache.put(K,V5)が実行されると、Kのクラスター全体のロックは以前取得されたため、ロックの取得は実行できませんが、put操作は発生します。tx.begin() cache.put(K,V) cache.put(K2,V2) cache.put(K,V5)
- 行
tx.commit()が実行されると、このトランザクションのために保持されたすべてのロックが開放されます。tx.begin() cache.put(K,V) cache.put(K2,V2) cache.put(K,V5) tx.commit()
14.3.6. ロックモードの設定 (リモートクライアントサーバーモード)
transaction 要素を使用します。
<transaction locking="OPTIMISTIC/PESSIMISTIC" />
14.3.7. ロックモードの設定 (ライブラリーモード)
transaction 要素内で設定されます。
<transaction transactionManagerLookupClass="{TransactionManagerLookupClass}"
transactionMode="{TRANSACTIONAL,NON_TRANSACTIONAL}"
lockingMode="{OPTIMISTIC,PESSIMISTIC}"
useSynchronization="true">
</transaction>lockingMode 値を OPTIMISTIC または PESSIMISTIC に設定します。
14.4. ロック操作
14.4.1. LockManager について
LockManager コンポーネントは、書き込み処理が始まる前にエントリーをロックします。LockManager は LockContainer を使用してロックを見つけたり、ロックを保持および作成します。このような実装では、通常 2 つのタイプの LockContainer が使用されます。1 つ目のタイプはロックストライピングのサポート提供し、2 つ目のタイプはエントリーごとに 1 つのロックをサポートします。
関連トピック:
14.4.2. ロックの取得について
14.4.3. 平行性レベルについて
DataContainers 内部のコレクションなど、関連するすべての JDK ConcurrentHashMap ベースのコレクションを調整します。
第15章 ロックストライピングのセットアップ
15.1. ロックストライピングについて
15.2. ロックストライピングの設定 (リモートクライアントサーバーモード)
striping 要素を true に設定して有効になります。
例15.1 ロックストライピング (リモートクライアントサーバーモード)
<locking acquire-timeout="20000" concurrency-level="500" striping="true" />
注記
READ_COMMITTED です。分離モードを明示的に指定するために isolation 属性が含まれる場合、この属性は無視され、警告がスローされて、デフォルト値が代わりに使用されます。
locking 要素は以下の属性を使用します。
acquire-timeout属性は、ロックの取得を試行する最大時間を指定します。この属性のデフォルト値は15000ミリ秒です。concurrencyLevel属性は、ロックコンテナーの同時実行レベルを指定します。JBoss Data Grid と通信する同時スレッドの数に従ってこの値を設定します。この属性のデフォルト値は1000です。striping属性は、ロックを必要とするすべてのエントリーに対してロックの共有プールを維持するかどうかを指定します (true)。falseに設定された場合は、各エントリーに対してロックが作成されます。ロックストライピングによりメモリーフットプリントが制御され、システムでの同時実行性を削減できます。この属性のデフォルト値はfalseです。
15.3. ロックストライピングの設定 (ライブラリーモード)
useLockStriping パラメーターを使用して行います。
手順15.1 ロックストライピングの設定 (ライブラリーモード)
平行性レベルを設定します。
concurrencyLevelは、ロックストライピングが有効な場合に使用される共有ロックコレクションのサイズを指定するために使用されます。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" />分離レベルの設定
isolationLevelパラメーターは、キャッシュの分離レベルを指定します。有効な分離レベルはREAD_COMMITTEDとREPEATABLE_READです。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}"/>ロック取得タイムアウトの指定
lockAcquisitionTimeoutパラメーターは、ロック取得の試行がタイムアウトになった後の時間 (ミリ秒単位) を指定します。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}"/>ロックストライピングを設定します。
useLockStripingパラメーターは、ロックを必要とするすべてのエントリーに対して、共有ロックのプールを維持するかどうかを指定します。FALSEに設定されると、ロックがキャッシュ内のそれぞれのエントリーに対して作成されます。TRUEに設定されると、ロックストライピングは有効にされ、共有ロックは必要に応じてプールから使用されます。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}" useLockStriping="${TRUE/FALSE}"/>書き込みスキューチェックを設定します。
writeSkewCheckは、異なるトランザクションからのエントリーへの変更によりトランザクションがロールバックされるかどうかを判別します。true に設定される書き込みスキューにより、isolation_levelはREPEATABLE_READに設定する必要があります。writeSkewCheckおよびisolation_levelのデフォルト値はそれぞれFALSEとREAD_COMMITTEDです。<infinispan> ... <default> <locking concurrencyLevel="${VALUE}" isolationLevel="${LEVEL}" lockAcquisitionTimeout="${TIME}" useLockStriping="${TRUE/FALSE}" writeSkewCheck="${TRUE/FALSE}" /> ... </default> </infinispan>
第16章 分離レベルのセットアップ
16.1. 分離レベルについて
READ_COMMITTED と REPEATABLE_READ の 2 つです。
READ_COMMITTED。この分離レベルは、さまざまな要件に適用されます。これは、リモートクライアントサーバーおよびライブラリーモードでのデフォルト値です。REPEATABLE_READ。重要
リモートクライアントサーバーモードのロックに有効な唯一の値はデフォルトのREAD_COMMITTED値です。isolation値で明示的に指定された値は無視されます。locking要素が設定に存在しない場合、デフォルトの分離値はREAD_COMMITTEDです。
- リモートクライアントサーバーモードの設定例については、「ロックストライピングの設定 (リモートクライアントサーバーモード)」を参照してください。
- ライブラリーモードの設定例については、「ロックストライピングの設定 (ライブラリーモード)」を参照してください。
16.2. READ_COMMITTED について
READ_COMMITTED は Red Hat JBoss Data Grid で使用できる 2 つの分離モードの 1 つです。
READ_COMMITTED モードでは、書き込み操作はデータ自体ではなくデータのコピーとして作成されます。書き込み操作は他のデータの書き込みをブロックしますが、書き込みは読み出し操作をブロックしません。そのため、READ_COMMITTED と REPEATABLE_READ の両モードは、書き込み操作がいつ発生するかに関係なく、いつでも読み取り操作を許可します。
READ_COMMITTED モードでは、読み取りの合間に書き込み操作によってデータが変更されると、トランザクション内で同じキーが複数読み取りされた場合に結果が異なる可能性があります。 これは、反復不可能読み出しと呼ばれ、REPEATABLE_READ モードでは回避されます。
16.3. REPEATABLE_READ について
REPEATABLE_READ は Red Hat JBoss Data Grid で使用できる 2 つの分離モードの 1 つです。
REPEATABLE_READ は読み取り操作中の書き込み操作や、書き込み操作時の読み取り操作を許可しません。これにより、単一のトランザクションの同じ行に 2 つの読み取り操作があるのに読み出した値が異なる時に発生する「反復不可能読み取り」が起こらないようにします。
REPEATABLE_READ 分離モードは、変更が発生する前にエントリーの値を保存します。これにより、同じエントリーの 2 番目の読み取り操作は変更された新しい値ではなく、保存された値を読み出すため、「反復不可能読み取り」の発生を防ぐことができます。そのため、読み出しの合間に書き込み操作が発生しても、2 つの読み取り操作によって読み出される 2 つの値は常に同じになります。
パート VII. キャッシュストアのセットアップと設定
第17章 キャッシュストア
17.1. キャッシュローダーとキャッシュライター
org.infinispan.persistence.spi にある以下の SPI を介して行われます。
CacheLoaderCacheWriterAdvancedCacheLoaderAdvancedCacheWriter
CacheLoader と CacheWriter は、ストアに対して読み書きを行う基本的なメソッドを提供します。CacheLoader は、必要なデータがキャッシュにない場合にデータストアからデータを取得します。
AdvancedCacheLoader と AdvancedCacheWriter は、基礎となるストレージを一括で処理する並列反復、失効したエントリーの削除、クリア、およびサイズ指定などの操作を提供します。
org.infinispan.persistence.file.SingleFileStore インターフェースは、カスタムストア実装を記述するために利用できます (必要な場合)。
注記
CacheLoader、CacheStore により拡張) が使用されていました (ただし、これは引き続き使用されています)。
17.2. キャッシュストアの設定
17.2.1. キャッシュストアの設定
ignoreModifications 要素が特定のキャッシュストアに対して "true" にされない限り、すべてのキャッシュストアに影響を与えます。
17.2.2. XML を使用したキャッシュストアの設定 (ライブラリーモード)
手順17.1 XML を使用したキャッシュストアの設定
新しいキャッシュストアの作成
passivation、shared、およびpreload設定を指定して、新規のキャッシュストアを作成します。passivationは Red Hat JBoss Data Grid がストアと通信する方法に影響を与えます。パッシベーションは、インメモリーキャッシュからオブジェクトを削除し、システムまたはデータベースなどの 2 次的なデータストアに書き込みます。パッシベーションはデフォルトでfalseです。sharedは、キャッシュストアが異なるキャッシュインスタンスによって共有されていることを示します。例えば、クラスター内のすべてのインスタンスが、同じリモートの共有データベースと通信するために同じ JDBC 設定を使用する場合があります。sharedは、デフォルトでfalseになります。trueに設定すると、異なるキャッシュインスタンスによって重複データがキャッシュストアに書き込まれることが避けられます。preloadはデフォルトではfalseに設定されます。trueに設定されると、キャッシュストアに保存されるデータは、キャッシュが起動するとメモリーにプリロードされます。これにより、キャッシュストアのデータが起動後すぐに利用できるようになり、データのレイジーなロードの結果としてキャッシュ操作の遅れを防ぐことができます。プリロードされたデータは、ノード上でローカルにのみに保存され、プリロードされたデータのレプリケーションや分散はありません。Red Hat JBoss Data Grid は、エビクションのエントリーの最大設定数のみをプリロードします。
<persistence passivation="false" shared="false" preload="true">
永続性とパージのセットアップ
fetchPersistentStateは、キャッシュの永続ステートを取り込むかどうかを決定し、クラスターに参加する際にこれをローカルキャッシュストアに適用します。キャッシュストアが共有される場合、キャッシュが同じキャッシュストアにアクセスする際に、fetch persistent 状態は無視されます。複数のキャッシュストアがこのプロパティーをtrueに設定する場合にキャッシュサービスを起動すると、設定の例外がスローされます。fetchPersistentStateプロパティーはデフォルトではfalseです。purgeSynchronouslyは、エクスパレーションをエビクションスレッドで発生させるかどうかを制御します。trueに設定されると、エビクションスレッドは、返されるものを即時にもたらすのではなく、パージが終了するまでブロックします。purgeSychronouslyプロパティーはデフォルトでfalseに設定されます。キャッシュストアが マルチスレッドパージをサポートする場合、期限の切れたエントリーを削除するためにpurgeThreadsが使用されます。purgeThreadsは、デフォルトで1に設定されます。マルチスレッドパージがサポートされているかを判断するには、キャッシュストアの設定を確認します。ignoreModificationsは、書き込み操作を共有キャッシュストアではなく、ローカルファイルキャッシュストアに許可することで、書き込みメソッドが特定のキャッシュストアにプッシュされるかどうかを決定します。特定の場合に、一時的なアプリケーションデータは、インメモリーキャッシュと同じサーバー上のファイルベースのキャッシュストアにのみ存在します。例えば、これはネットワーク内のすべてのサーバーによって使用される追加の JDBC ベースのキャッシュストアで適用されます。ignoreModificationsはデフォルトではfalseです。
<persistence passivation="false" shared="false" preload="true"> <fileStore fetchPersistentState="true" purgerThreads="3" purgeSynchronously="true" ignoreModifications="false" purgeOnStartup="false" location="${java.io.tmpdir}" />非同期設定
これらの属性は、それぞれのキャッシュストアに固有の側面を設定します。例えば、location属性は、SingleFileStore がデータが含まれるファイルを維持する場所を指します。他のストアには、さらに複雑な設定が必要な場合があります。<persistence passivation="false" shared="false" preload="true"> <fileStore fetchPersistentState="true" purgerThreads="3" purgeSynchronously="true" ignoreModifications="false" purgeOnStartup="false" location="${java.io.tmpdir}" > <async enabled="true" flushLockTimeout="15000" threadPoolSize="5" /> </fileStore>シングルトンと Push 状態の設定
singletonStoreは、クラスター内の 1 つのノードのみによって変更が保存されるのを可能にします。このノードはコーディネーターと呼ばれます。コーディネーターは、インメモリー状態のキャッシュをディスクにプッシュします。この機能は、すべてのノードのenabled属性をtrueに設定することによりアクティベートされます。sharedパラメーターは、singletonStoreを有効にした状態で同時に定義することはできません。enabled属性はデフォルトではfalseです。pushStateWhenCoordinatorはデフォルトではtrueに設定されます。trueの場合、このプロパティーは、コーディネーターになったノードに、インメモリー状態を基礎となるキャッシュストアに転送させます。このパラメーターは、コーディネーターがクラッシュし、新規のコーディネーターが選択される場合に役に立ちます。
<persistence passivation="false" shared="false" preload="true"> <fileStore fetchPersistentState="true" purgerThreads="3" purgeSynchronously="true" ignoreModifications="false" purgeOnStartup="false" location="${java.io.tmpdir}" > <async enabled="true" flushLockTimeout="15000" threadPoolSize="5" /> <singletonStore enabled="true" pushStateWhenCoordinator="true" pushStateTimeout="20000" /> </fileStore> </persistence>
17.2.3. プログラムを使用してキャッシュストアを設定
手順17.2 プログラムを使用してキャッシュストアを設定
新規の設定ビルダーの作成
ConfigurationBuilderを使用して、新規の設定オブジェクトを作成します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence()
パッシベーションの設定
passivationは Red Hat JBoss Data Grid がストアと通信する方法に影響を与えます。パッシベーションは、インメモリーキャッシュからオブジェクトを削除し、システムまたはデータベースなどの 2 次的なデータストアに書き込みます。パッシベーションはデフォルトでfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false)共有のセットアップ
sharedは、キャッシュストアが異なるキャッシュインスタンスによって共有されていることを示します。例えば、クラスター内のすべてのインスタンスが、同じリモートの共有データベースと通信するために同じ JDBC 設定を使用する場合があります。sharedは、デフォルトでfalseになります。trueに設定すると、異なるキャッシュインスタンスによって重複データがキャッシュストアに書き込まれることが避けられます。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false)プリロードのセットアップ
preloadはデフォルトではfalseに設定されます。trueに設定されると、キャッシュストアに保存されるデータは、キャッシュが起動するとメモリーにプリロードされます。これにより、キャッシュストアのデータが起動後すぐに利用できるようになり、データのレイジーなロードの結果としてキャッシュ操作の遅れを防ぐことができます。プリロードされたデータは、ノード上でローカルにのみに保存され、プリロードされたデータのレプリケーションや分散はありません。JBoss Data Grid は、エビクションのエントリーの最大設定数のみをプリロードします。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true)キャッシュストアの設定
addSingleFileStore()は、この設定用のキャッシュストアとして SingleFileStore を追加します。addStoreメソッドを使用して追加できる、JDBC キャッシュストアなどの他のストアを作成することができます。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore()永続性のセットアップ
fetchPersistentStateは、キャッシュの永続ステートを取り込むかどうかを決定し、クラスターに参加する際にこれをローカルキャッシュストアに適用します。キャッシュストアが共有される場合、キャッシュが同じキャッシュストアにアクセスする際に、fetch persistent 状態は無視されます。複数のキャッシュストアがこのプロパティーをtrueに設定する場合にキャッシュサービスを起動すると、設定の例外がスローされます。fetchPersistentStateプロパティーはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true)パージのセットアップ
purgeSynchronouslyは、エクスパレーションをエビクションスレッドで発生させるかどうかを制御します。trueに設定されると、エビクションスレッドは、返されるものを即時にもたらすのではなく、パージが終了するまでブロックします。purgeSychronouslyプロパティーはデフォルトでfalseに設定されます。キャッシュストアが マルチスレッドパージをサポートする場合、期限の切れたエントリーを削除するためにpurgeThreadsが使用されます。purgeThreadsは、デフォルトで1に設定されます。マルチスレッドパージがサポートされているかを判断するには、キャッシュストアの設定を確認します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true) .purgerThreads(3) .purgeSynchronously(true)変更の設定
ignoreModificationsは、書き込み操作を共有キャッシュストアではなく、ローカルファイルキャッシュストアに許可することで、書き込みメソッドが特定のキャッシュストアにプッシュされるかどうかを決定します。特定の場合に、一時的なアプリケーションデータは、インメモリーキャッシュと同じサーバー上のファイルベースのキャッシュストアにのみ存在します。例えば、これはネットワーク内のすべてのサーバーによって使用される追加の JDBC ベースのキャッシュストアで適用されます。ignoreModificationsはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true) .purgerThreads(3) .purgeSynchronously(true) .ignoreModifications(false)非同期設定
これらの属性は、それぞれのキャッシュストアに固有の側面を設定します。例えば、location属性は、SingleFileStore がデータが含まれるファイルを維持する場所を指します。他のストアには、さらに複雑な設定が必要な場合があります。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true) .purgerThreads(3) .purgeSynchronously(true) .ignoreModifications(false) .purgeOnStartup(false) .location(System.getProperty("java.io.tmpdir")) .async() .enabled(true) .flushLockTimeout(15000) .threadPoolSize(5)シングルトンの設定
singletonStoreは、クラスター内の 1 つのノードのみによって変更が保存されるのを可能にします。このノードはコーディネーターと呼ばれます。コーディネーターは、インメモリー状態のキャッシュをディスクにプッシュします。この機能は、すべてのノードのenabled属性をtrueに設定することによりアクティベートされます。sharedパラメーターは、singletonStoreを有効にした状態で同時に定義することはできません。enabled属性はデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true) .purgerThreads(3) .purgeSynchronously(true) .ignoreModifications(false) .purgeOnStartup(false) .location(System.getProperty("java.io.tmpdir")) .async() .enabled(true) .flushLockTimeout(15000) .threadPoolSize(5) .singletonStore() .enabled(true)Push 状態のセットアップ
pushStateWhenCoordinatorはデフォルトではtrueに設定されます。trueの場合、このプロパティーは、コーディネーターになったノードに、インメモリー状態を基礎となるキャッシュストアに転送させます。このパラメーターは、コーディネーターがクラッシュし、新規のコーディネーターが選択される場合に役に立ちます。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .passivation(false) .shared(false) .preload(true) .addSingleFileStore() .fetchPersistentState(true) .purgerThreads(3) .purgeSynchronously(true) .ignoreModifications(false) .purgeOnStartup(false) .location(System.getProperty("java.io.tmpdir")) .async() .enabled(true) .flushLockTimeout(15000) .threadPoolSize(5) .singletonStore() .enabled(true) .pushStateWhenCoordinator(true) .pushStateTimeout(20000);
17.2.4. SKIP_CACHE_LOAD フラグについて
SKIP_CACHE_LOAD フラグを使用します。
17.4. 接続ファクトリー
ConnectionFactory 実装に依存してデータベースへの接続を取得します。このプロセスは接続管理またはプーリングとも呼ばれます。
ConnectionFactoryClass 設定属性を使用して指定することができます。JBoss Data Grid には次の ConnectionFactory 実装が含まれています。
- ManagedConnectionFactory
- SimpleConnectionFactory。
17.4.1. ManagedConnectionFactory について
ManagedConnectionFactory は、アプリケーションサーバーなど管理された環境内での使用に適した接続ファクトリーです。この接続ファクトリーは JNDI ツリー内の設定された場所を探索し、接続管理を DataSource へ委譲できます。 ManagedConnectionFactory は DataSource が含まれる管理された環境内で使用されます。この Datasource は接続プーリングへ委譲されます。
17.4.2. SimpleConnectionFactory について
SimpleConnectionFactory は呼び出しごとにデータベース接続を作成する接続ファクトリーです。この接続ファクトリーは実稼働環境での使用向けには設計されていません。
第18章 キャッシュストアの実装
18.1. キャッシュストアの比較
- 単一ファイルキャッシュストアはローカルのファイルキャッシュストアです。これにより、クラスタ化されたキャッシュの各ノードに対してデータがローカルで永続化されます。単一ファイルキャッシュストアは、優れた読み書きパフォーマンスを提供しますが、キーがメモリーに保持され、各ノードで大きいデータセットを永続化するときに使用が制限されます。詳細については、「単一ファイルキャッシュストア」を参照してください。
- LevelDB ファイルキャッシュストアは、高い読み書きパフォーマンスを提供するローカルのファイルキャッシュストアです。キーがメモリに保持される単一ファイルキャッシュストアの制限はありません。詳細については、「LevelDB キャッシュストア」を参照してください。
- JDBC キャッシュストアは、必要に応じて共有できるキャッシュストアです。使用時に、クラスタ化されたキャッシュのすべてのノードは、クラスターの各ノードに対して単一のデータベースまたはローカルの JDBC データベースに永続化されます。共有キャッシュストアには、LevelDB キャッシュストアなどのローカルキャッシュストアのスケーラビリティーとパフォーマンスがありませんが、永続化データに対して単一の場所が提供されます。JDBC キャッシュストアでは、エントリーがバイナリー blob として永続化され、JBoss Data Grid 外部で読み取ることができません。詳細については、「JDBC ベースのキャッシュストア」を参照してください。
- JPA キャッシュストア (ライブラリーモードでのみサポート) は JDBC キャッシュストアのような要求キャッシュストアですが、データベースに永続化するときにスキーマ情報が保持されます。したがって、永続化されたエントリーは、JBoss Data Grid 外部で読み取ることができます。詳細については、「JPA キャッシュストア」を参照してください。
18.2. 単一ファイルキャッシュストア
SingleFileCacheStore が含まれています。
SingleFileCacheStore は、単純なファイルシステムベースの実装であり、古くなったファイルシステムベースのキャッシュストアである FileCacheStore の代わりになるものです。
SingleFileCacheStore は、単一ファイルに、すべてのキーバリューペアと、それらの対応するメタデータ情報を保存します。データ検索のスピードを速めるために、すべてのキーとそれらの値およびメタデータの位置をメモリーに保存します。そのため、単一ファイルキャッシュストアを使用すると、キーのサイズと保存されるキーの数量に応じて、必要なメモリーが若干増加します。そのため、SingleFileCacheStore は、キーが大きすぎる場合のユースケースでは推奨されません。
SingleFileCacheStore には制限があるため、実稼働環境では制限内での使用が可能です。適切なファイルロックがなく、データが破損する原因となるため、共有ファイルシステム (NFS や Windows の共有など) 上では使用しないでください。また、ファイルシステムは本質的にトランザクションではないため、トランザクションコンテキストでキャッシュが使用されると、コミットフェーズ中にファイルが障害を書き込む原因となります。
18.2.1. 単一ファイルストアの設定 (リモートクライアントサーバーモード)
手順18.1 単一ファイルストアの設定
キャッシュ名の追加
キャッシュの名前を指定するため、local-cache属性のnameパラメーターが使用されます。<local-cache name="default">
キャッシュごとの統計
statisticsがコンテナーレベルで有効にされている場合は、statistics属性をfalseに設定することにより、キャッシュごとに統計を有効または無効にします。<local-cache name="default" statistics="true">
file-store要素の設定file-store要素は、単一ファイルストアの設定情報を指定します。file-store要素のnameパラメーターが、ファイルストアの名前を指定するために使用されます。<local-cache name="default" statistics="true"> <file-store name="myFileStore" />passivation パラメーターの設定
passivationパラメーターは、キャッシュのエントリーがパッシベートされるか (true) またはキャッシュストアが内容のコピーをメモリーに保持するか (false) を決定します。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" />purgeパラメーターの設定purgeパラメーターは、起動時にキャッスストアがパージされるかどうかを指定します。 このパラメーターの有効な値はtrueとfalseです。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" />sharedパラメーターを設定します。sharedパラメーターは、複数のキャッシュストアインスタンスがキャッシュストアを共有する場合に使用されます。複数のキャッシュインスタンスが同じ変更内容を複数回書き込まないようにするため、このパラメーターを設定することができます。このパラメーターに有効な値はtrueとfalseです。ただし、sharedパラメーターはfile-storeには推奨されません。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" />relative-toパラメーター内のディレクトリーパスを指定します。relative-toプロパティーは、file-storeがデータを保存するディレクトリーです。これは名前付きのパスを定義するために使用されます。pathプロパティーは、データが保存されるファイルの名前です。これは、完全パスを決定するためにrelative-toプロパティーの値に追加される相対パス名です。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" relative-to="{PATH}" path="{DIRECTORY}" /> </local-cache>最大エントリー数の設定
maxEntriesパラメーターは、許可されるエントリーの最大数を指定します。無制限のエントリーの場合のデフォルト値は -1 です。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" relative-to="{PATH}" path="{DIRECTORY}" max-entries="10000"/> </local-cache>fetch-state パラメーターの設定
fetch-stateパラメーターは、true に設定されている場合に、クラスターへ参加する際に永続状態を取り込みます。複数のキャッシュストアがチェーン化されている場合、その内の 1 つのみでこのプロパティーを有効にできます。共有キャッシュストアが使用されている場合、永続状態の転送は、データを提供する同じ永続ストアがそれを受信するだけなので意味をなしません。そのため、共有キャッシュストアが使用されている場合、キャッシュストアがこのプロパティーを true に設定している場合であっても、永続状態の転送を許可しません。クラスター化環境でのみこのプロパティーを true に設定することが推奨されます。このパラメーターのデフォルト値は false です。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" relative-to="{PATH}" path="{DIRECTORY}" max-entries="10000" fetch-state="true"/> </local-cache>Preload パラメーターの設定
preloadパラメーターは、true に設定されている場合に、キャッシュの起動時にキャッシュストアに保存されたデータをメモリーにロードします。ただし、このパラメーターを true に設定することにより、起動時間が増加するためパフォーマンスへの影響があります。このパラメーターのデフォルト値は false です。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" relative-to="{PATH}" path="{DIRECTORY}" max-entries="10000" fetch-state="true" preload="false"/> </local-cache>シングルトンパラメーターの設定
singletonパラメーターは、シングルトンストアのキャッシュストアを有効にします。SingletonStore は、クラスター内の唯一のインスタンスが基礎となるストアと通信する場合にのみ使用される委譲するキャッシュストアです。ただし、singletonパラメーターはfile-storeには推奨されません。<local-cache name="default" statistics="true"> <file-store name="myFileStore" passivation="true" purge="true" shared="false" relative-to="{PATH}" path="{DIRECTORY}" max-entries="10000" fetch-state="true" preload="false" singleton="true"/> </local-cache>
18.2.2. 単一ファイルストアの設定 (ライブラリーモード)
手順18.2 ライブラリーモードでの単一ファイルストアの設定
infinispan.xml で以下を設定します。
- 名前の値を
namedCache要素に追加します。以下はこの手順の例になります。<namedCache name="writeThroughToFile">
persistence要素で、passivationパラメーターをfalseに設定します。使用できる値は「true」と「false」です。<namedCache name="writeThroughToFile"> <persistence passivation="false" />singleFile要素を使用して、単一ファイルの設定をセットアップします。fetchPersistentState-trueに設定されると、クラスターへ参加する時に永続状態が取り込まれます。複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアのみがこのプロパティーをtrueに設定できます。この値のデフォルトはfalseです。ignoreModificationsパラメーターは、キャッシュを変更する操作 (例: 配置、削除、消去、格納など) がキャッシュストアに影響を与えるかどうかを決定します。結果として、キャッシュストアは、キャッシュと同期が取れなくなります。purgeOnStartupパラメーターは、初回起動時にキャッシュがパージされるかどうかを指定します。sharedパラメーターは、複数のキャッシュインスタンスがキャッシュストアを共有する場合にtrueに設定されます。これにより、複数のキャッシュインスタンスが同じ変更内容を個別に書き込むことを防ぐことができます。この属性のデフォルトはfalseです。ただし、sharedパラメーターはfile-storeには推奨されません。preloadパラメーターは、キャッシュストアデータがメモリーにプリロードされ、起動後すぐにアクセス可能にするかどうかを設定します。これを true に設定する不利な点には、起動時間が増えることが挙げられます。この属性のデフォルト値はfalseです。locationパラメーターはファイルストアの場所を示します。maxEntriesパラメーターは、許可されるエントリーの最大数を指定します。無制限のエントリーの場合のデフォルト値は -1 です。maxKeysInMemoryパラメーターは、データのルックアップを迅速化を図るために使用されます。単一ファイルストアは、maxKeysInMemoryパラメーターを使用して、キーのインデックスとファイル内のキーの場所を保持します。このパラメーターのデフォルト値は -1 です。
<namedCache name="writeThroughToFile"> <persistence passivation="false"> <singleFile fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false" shared="false" preload="false" location="/tmp/Another-FileCacheStore-Location" maxEntries="100" maxKeysInMemory="100"> </singleFile> </persistence> </namedCache>- 非同期設定を行うには
async要素を追加します。enabledパラメーターは、ファイルストアを非同期にするかどうかを決定します。threadPoolSizeパラメーターは、変更をストアに同時に適用するスレッドの数を指定します。このパラメーターのデフォルト値は5です。flushLockTimeoutパラメーターは、キャッシュストアに定期的にフラッシュする状態を保護するロックを取得するための時間を指定します。このパラメーターのデフォルト値は1です。modificationQueueSizeパラメーターは、非同期ストアの変更キューのサイズを指定します。基礎となるキャッシュストアがこのキューを処理するよりも速く更新される場合に、その期間において非同期ストアは同期ストアのように動作し、キューがさらに多くの要素を許可できるようになるまでブロックします。このパラメーターのデフォルト値は1024要素です。shutdownTimeoutパラメーターは、キャッシュストアを停止する時間を指定します。このパラメーターのデフォルト値は25秒です。
<namedCache name="writeThroughToFile"> <persistence passivation="false"> <singleFile fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false" shared="false" preload="false" location="/tmp/Another-FileCacheStore-Location" maxEntries="100" maxKeysInMemory="100"> <async enabled="true" threadPoolSize="500" flushLockTimeout="1" modificationQueueSize="1024" shutdownTimeout="25000"/> </singleFile> </persistence> </namedCache>
18.2.3. FileCacheStore から SingleFileCacheStore へのデータ移行
18.3. LevelDB キャッシュストア
18.3.1. LevelDB キャッシュストアの設定
手順18.3 LevelDB キャッシュストアの設定
- データベースを設定するには、
standalone.xmlのキャッシュ定義に以下の要素を追加します。<leveldb-store path="/path/to/leveldb/data" passivation="false" purge="false" > <expiration path="/path/to/leveldb/expires/data" /> <implementation type="JNI" /> </leveldb-store>
18.3.2. LevelDB キャッシュストアのプログラムを使用した設定
手順18.4 LevelDB キャッシュストアのプログラムを使用した設定
新規の設定ビルダーの作成
ConfigurationBuilderを使用して、新規の設定オブジェクトを作成します。Configuration cacheConfig = new ConfigurationBuilder().persistence()
LevelDBStoreConfigurationBuilder ストアの追加
ストアをLevelDBCacheStoreConfigurationBuilderインスタンスに追加して、その設定を構築します。Configuration cacheConfig = new ConfigurationBuilder().persistence() .addStore(LevelDBStoreConfigurationBuilder.class)ロケーションのセットアップ
LevelDB キャッシュストアのロケーションパスを設定します。指定したパスは、主なキャッシュストアデータを保存します。ディレクトリーがない場合は自動的に作成されます。Configuration cacheConfig = new ConfigurationBuilder().persistence() .addStore(LevelDBStoreConfigurationBuilder.class) .location("/tmp/leveldb/data")期限切れのロケーションのセットアップ
LevelDB ストアのexpiredLocationパラメーターを使用して、期限切れデータのロケーションを指定します。指定されたパスは、パージされる前に期限切れデータを保存します。ディレクトリーがない場合は自動的に作成されます。Configuration cacheConfig = new ConfigurationBuilder().persistence() .addStore(LevelDBStoreConfigurationBuilder.class) .location("/tmp/leveldb/data") .expiredLocation("/tmp/leveldb/expired").build();
注記
18.3.3. LevelDB キャッシュストアの XML 設定例 (ライブラリーモード)
手順18.5 LevelDB キャッシュストアの XML 設定例
namedCache 要素の追加
以下のようにnamedCache要素のnameパラメーターを使用して LevelDB キャッシュストアの名前を指定します。<namedCache name="vehicleCache">
persistence 要素の追加
以下のようにpersistence要素のpassivationパラメーターの値を指定します。使用できる値は true および false です。<namedCache name="vehicleCache"> <persistence passivation="false">leveldbStore 要素の追加
以下のようにleveldbStore要素のlocationパラメーターを使用して主なキャッシュストア日付を保存するロケーションを指定します。ディレクトリーがない場合は自動的に作成されます。以下はこの手順の例になります。<namedCache name="vehicleCache"> <persistence passivation="false"> <leveldbStore location="/path/to/leveldb/data" />期限切れの値の設定
以下のようにexpiredLocationパラメーターを使用して期限切れデータのロケーションを指定します。ディレクトリーは、パージされる前の期限切れのデータを保存します。ディレクトリーがない場合は自動的に作成されます。<namedCache name="vehicleCache"> <persistence passivation="false"> <leveldbStore location="/path/to/leveldb/data" expiredLocation="/path/to/expired/data" />Shared パラメーターの設定
以下のようにleveldbStore要素のsharedパラメーターの値を指定します。使用できる値は true および false です。<namedCache name="vehicleCache"> <persistence passivation="false"> <leveldbStore location="/path/to/leveldb/data" expiredLocation="/path/to/expired/data" shared="true" />Preload パラメーターの設定
以下のようにleveldbStore要素のpreloadパラメーターの値を指定します。使用できる値は true および false です。<namedCache name="vehicleCache"> <persistence passivation="false"> <leveldbStore location="/path/to/leveldb/data" expiredLocation="/path/to/expired/data" shared="true" preload="true"/> </persistence> </namedCache>
18.3.4. JBoss Operations Network を使用した LevelDB キャッシュストアの設定
手順18.6
- Red Hat JBoss Operations Network 3.2 以上がインストールされ、起動されていることを確認します。
- JBoss Operations Network 3.2.0 用 Red Hat JBoss Data Grid プラグインパックをインストールします。
- JBoss Data Grid がインストールされ、起動されていることを確認します。
- JBoss Data Grid サーバーをインベントリーにインポートします。
- JBoss Data Grid 接続設定を実行します。
- 以下のように新しい LevelDB キャッシュストアを作成します。

図18.1 新しい LevelDB キャッシュストアの作成
defaultキャッシュを右クリックします。- メニューで、 オプションにカーソルを置きます。
- サブメニューで、 をクリックします。
- 以下のように新しい LevelDB キャッシュストアの名前を指定します。
図18.2 新しい LevelDB キャッシュストアの名前指定
- 表示された Resource Create Wizard で、新しい LevelDB キャッシュストアの名前を追加します。
- クリックして作業を継続します。
- 以下のように LevelDB キャッシュストアを設定します。
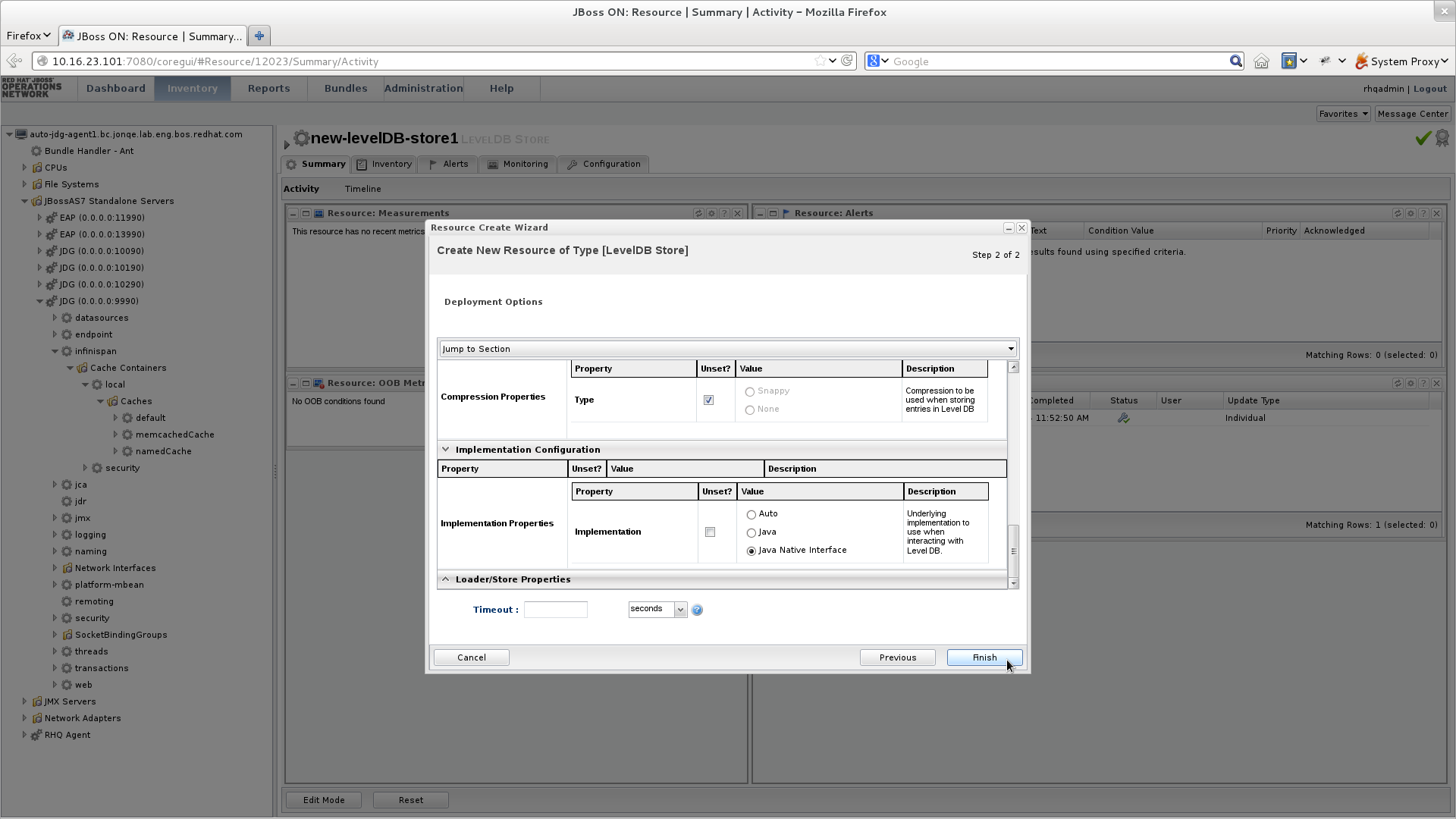
図18.3 LevelDB キャッシュストアの設定
- 設定ウィンドウのオプションを使用して新しい LevelDB キャッシュストアを設定します。
- をクリックして設定を完了します。
- 以下のように再起動操作をスケジュールします。

図18.4 再起動操作のスケジュール
- 画面の左パネルで、JBossAS7 Standalone Servers エントリーを展開します (まだ展開されていない場合)。
- 展開されたメニュー項目から JDG (0.0.0.0:9990) をクリックします。
- 画面の右パネルに、選択されたサーバーの詳細が表示されます。 タブをクリックします。
- Operation ドロップダウンボックスで、Restart 操作を選択します。
- Now エントリーのラジオボタンを選択します。
- をクリックしてサーバーをすぐに再起動します。
- 以下のように新しい LevelDB キャッシュストアを検出します。
図18.5 新しい LevelDB キャッシュストアの検出
- 画面の左パネルで、指定された順序で次の項目を選択して展開します: → → → → → → →
- 新しい LevelDB キャッシュストアの名前をクリックして右パネルの設定情報を表示します。
18.4. JDBC ベースのキャッシュストア
JdbcBinaryStore。JdbcStringBasedStore。JdbcMixedStore。
18.4.1. JdbcBinaryStores
JdbcBinaryStore はすべてのキータイプをサポートします。同じテーブル行/Blob の同じハッシュ値 (キー上の hashCode メソッド) を持つすべてのキーを格納します。組み込まれるキーに共通するハッシュ値が、テーブルの行/Blob の主キーとして設定されます。このハッシュ値により、JdbcBinaryStore は大変優れた柔軟性を提供しますが、これにより平行性とスループットのレベルが下がります。
k1、k2、k3) のハッシュコードが同じである場合、同じテーブル行に格納されます。3 つの異なるスレッドが k1、k2、k3 を同時に更新しようとすると、すべてのキーが同じ行を共有するため同時には更新できないことから、順次更新する必要があります。
18.4.1.1. JdbcBinaryStore の設定 (リモートクライアントサーバーモード)
JdbcBinaryStore の設定です。
手順18.7 リモートクライアントサーバーノード用に JdbcBinaryStore を設定します。
binary-keyed-jdbc-store 要素
binary-keyed-jdbc-store要素は、バイナリのキーボードから情報が入力されたキャッシュの JDBC ストアに対する設定を指定します。datasourceパラメーターはデータソースの JNDI 名を定義します。データソースの詳細については、「JDBC 」を参照してください。passivationパラメーターは、キャッシュのエントリーがパッシベートされるか (true) またはキャッシュストアが内容のコピーをメモリーに保持するか (false) を決定します。preloadパラメーターは、起動中にエントリーをキャッシュにロードするかどうかを指定します。このパラメーターの有効な値はtrueとfalseです。purgeパラメーターは、起動時にキャッスストアがパージされるかどうかを指定します。 このパラメーターの有効な値はtrueとfalseです。
<local-cache> ... <binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="${true/false}" preload="${true/false}" purge="${true/false}">binary-keyed-table 要素
binary-keyed-table要素は、バイナリーのキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<local-cache> ... <binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="${true/false}" preload="${true/false}" purge="${true/false}"> <binary-keyed-table prefix="JDG">id-column 要素
id-column要素は、キャッシュエントリーの ID を保持するデータベース列に関する情報を指定します。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> ... <binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="${true/false}" preload="${true/false}" purge="${true/false}"> <binary-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/>data-column 要素
data-column要素には、キャッシュエントリーデータを保持するデータベース列に関する情報が含まれます。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> ... <binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="${true/false}" preload="${true/false}" purge="${true/false}"> <binary-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/>timestamp-column 要素
timestamp-column要素は、キャッシュエントリーのタイムスタンプを保持するデータベース列に関する情報を指定します。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> ... <binary-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="${true/false}" preload="${true/false}" purge="${true/false}"> <binary-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table> </binary-keyed-jdbc-store> </local-cache>
18.4.1.2. JdbcBinaryStore の設定 (ライブラリーモード)
JdbcBinaryStore の設定例です。
手順18.8 ライブラリーモードの JdbcBinaryStore の設定
binaryKeyedJdbcStore 要素
binaryKeyedJdbcStore要素は、キャッシュストアを設定するための次のパラメーターを使用します。fetchPersistentStateパラメーターは、クラスターへ参加する時に永続状態が取り込まれるかを決定します。クラスター環境でレプリケーションとインバリデーションを使用している場合は、これをtrueに設定します。さらに、複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアのみがこのプロパティーを有効に設定できます。共有キャッシュストアが使用されている場合、キャッシュは、このプロパティーがtrueに設定されているにも関わらず、永続状態の転送を許可しません。fetchPersistentStateパラメーターはデフォルトではfalseに設定されます。ignoreModificationsパラメーターは、キャッシュを変更する操作 (例: 配置、削除、消去、保存など) がキャッシュストアに影響を与えるかどうかを決定します。結果として、キャッシュストアは、キャッシュと同期しなくなります。purgeOnStartupパラメーターは、初回起動時にキャッシュがパージされるかどうかを指定します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false">
connectionPool 要素
connectionPool要素は、次のパラメーターを使用して JDBC ドライバーの接続プールを指定します。connectionUrlパラメーターは、JDBC ドライバー固有の接続 URL を指定します。usernameパラメーターには、connectionUrl経由で接続するために使用されるユーザー名が含まれます。driverClassパラメーターは、データベースに接続するために使用されるドライバーのクラス名を指定します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/>
binaryKeyedTable 要素
binaryKeyedTable要素は、キャッシュエントリーを保存するテーブルを定義します。これは、キャッシュストアを設定するために以下のパラメーターを使用します。dropOnExitパラメーターは、シャットダウン時にデータベーステーブルがドロップされるかどうかを指定します。createOnStartパラメーターは、スタートアップ時にストアによってデータベーステーブルが作成されるかどうかを指定します。prefixパラメーターは、キャッシュバケットテーブルの名前を作成する際に、ターゲットキャッシュの名前に付与される文字列を定義します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE">
idColumn 要素
idColumn要素は、キャッシュキーまたはバケット ID が保存される列を定義します。これは以下のパラメーターを使用します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" />
dataColumn 要素
dataColumn要素は、キャッシュエントリーまたはバケットが保存される列を指定します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" />
timestampColumn 要素
timestampColumn要素は、キャッシュエントリーまたはバケットのタイムスタンプが保存される列を指定します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <binaryKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" /> <timestampColumn name="TIMESTAMP_COLUMN" type="BIGINT" /> </binaryKeyedTable> </binaryKeyedJdbcStore> </persistence>
18.4.1.3. JdbcBinaryStore のプログラムを用いた設定
JdbcBinaryStore の設定例です。
手順18.9 JdbcBinaryStore のプログラムを用いた設定 (ライブラリーモード)
新規の設定ビルダーの作成
ConfigurationBuilderを使用して、新規の設定オブジェクトを作成します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence()
JdbcBinaryStoreConfigurationBuilderの追加このストアに関連する特定の設定を構築するには、JdbcBinaryStore設定ビルダーを追加します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class)永続性のセットアップ
fetchPersistentStateは、キャッシュの永続状態を取り込むかどうかを決定し、クラスターに参加する際にこれをローカルキャッシュストアに適用します。キャッシュストアが共有される場合、キャッシュが同じキャッシュストアにアクセスする際に、永続状態の取り込みは無視されます。複数のキャッシュローダーがこのプロパティーをtrueに設定する場合にキャッシュサービスを起動すると、設定の例外がスローされます。fetchPersistentStateプロパティーはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class) .fetchPersistentState(false)変更の設定
ignoreModificationsは、書き込み操作を共有キャッシュローダーではなく、ローカルファイルキャッシュローダーに許可することで、書き込みメソッドが特定のキャッシュローダーにプッシュされるかどうかを決定します。特定の場合に、一時的なアプリケーションデータは、インメモリーキャッシュと同じサーバー上のファイルベースのキャッシュローダーにのみ存在します。たとえば、これはネットワーク内のすべてのサーバーによって使用される追加の JDBC ベースのキャッシュローダーで適用されます。ignoreModificationsはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false)パージの設定
purgeOnStartupは、初回の起動時にキャッシュがパージされるかどうかを指定します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false)テーブルの設定
Drop Table On Exit メソッドの設定
dropOnExitは、キャッシュストアが停止している際にテーブルを破棄するかどうかを決定します。これは、デフォルトではfalseに設定されます。Create Table On Start メソッドの設定
createOnStartは、現在テーブルが存在しない場合にキャッシュストアを起動すると、テーブルを作成します。このメソッドはデフォルトではtrueです。Table Name Prefix の設定
tableNamePrefixは、データが保存されるテーブルの名前にプレフィックスを設定します。idColumnNameidColumnNameプロパティーは、キャッシュキーまたはバケット ID が保存される列を定義します。dataColumnNamedataColumnNameプロパティーは、キャッシュエントリーまたはバケット ID が保存される列を指定します。timestampColumnNametimestampColumnName要素は、キャッシュエントリーのタイムスタンプまたはバケットが保存される列を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .table() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_BUCKET_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")connectionPool 要素
connectionPool要素は、次のパラメーターを使用して JDBC ドライバーの接続プールを指定します。connectionUrlパラメーターは、JDBC ドライバー固有の接続 URL を指定します。usernameパラメーターには、connectionUrl経由で接続するために使用されるユーザー名が含まれます。driverClassパラメーターは、データベースに接続するために使用されるドライバーのクラス名を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence() .addStore(JdbcBinaryStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .table() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_BUCKET_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT") .connectionPool() .connectionUrl("jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1") .username("sa") .driverClass("org.h2.Driver");
注記
18.4.2. JdbcStringBasedStores
JdbcStringBasedStore は複数のエントリーを各行にグループ化せずに、各エントリーをテーブルの独自の行に格納するため、同時負荷の下でスループットが増加します。また、各キーを String オブジェクトへマッピングする (プラグ可能な) バイジェクション (bijection) も使用します。Key2StringMapper インターフェースはバイジェクションを定義します。
DefaultTwoWayKey2StringMapper と呼ばれるデフォルトの実装が含まれています。
18.4.2.1. JdbcStringBasedStore の設定 (リモートクライアントサーバーモード)
JdbcStringBasedStore のサンプル設定です。
手順18.10 リモートクライアントサーバーモードでの JdbcStringBasedStore の設定
string-keyed-jdbc-store 要素
string-keyed-jdbc-store要素は、文字列ベースのキーボードから情報が入力されたキャッシュの JDBC ストアに対する設定を指定します。datasourceパラメーターはデータソースの JNDI 名を定義します。データソースの詳細については、「JDBC 」を参照してください。passivationパラメーターは、キャッシュのエントリーがパッシベートされるか (true) またはキャッシュストアが内容のコピーをメモリーに保持するか (false) を決定します。preloadパラメーターは、起動中にエントリーをキャッシュにロードするかどうかを指定します。このパラメーターの有効な値はtrueとfalseです。purgeパラメーターは、起動時にキャッスストアがパージされるかどうかを指定します。 このパラメーターの有効な値はtrueとfalseです。sharedパラメーターは、複数のキャッシュストアインスタンスがキャッシュストアを共有する場合に使用されます。複数のキャッシュインスタンスが同じ変更内容を複数回書き込まないようにするため、このパラメーターを設定することができます。このパラメーターに有効な値はtrueとfalseです。singletonパラメーターは、シングルトンストアのキャッシュストアを有効にします。SingletonStore は、クラスター内の唯一のインスタンスが基礎となるストアと通信する場合にのみ使用される委任中のキャッシュストアです。
<local-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false" shared="false" singleton="true">
string-keyed-table 要素
string-keyed-table要素は、文字別ベースのキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<local-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG">id-column 要素
id-column要素は、キャッシュエントリーの ID を保持するデータベース列に関する情報を指定します。nameパラメーターは ID 列の名前を指定します。typeパラメーターは ID 列のタイプを指定します。
<local-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/>data-column 要素
data-column要素には、キャッシュエントリーデータを保持するデータベース列に関する情報が含まれます。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/>timestamp-column 要素
timestamp-column要素は、キャッシュエントリーのタイムスタンプを保持するデータベース列に関する情報を指定します。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </string-keyed-table> </string-keyed-jdbc-store> </local-cache>
18.4.2.2. JdbcStringBasedStore 設定 (ライブラリーモード)
JdbcStringBasedStore の設定例は次の通りです。
手順18.11 ライブラリーモードでの JdbcStringBasedStore の設定
stringKeyedJdbcStore 要素
stringKeyedJdbcStore要素は、キャッシュストアを設定するための次のパラメーターを使用します。fetchPersistentStateパラメーターは、クラスターへ参加する時に永続状態が取り込まれるかを決定します。クラスター環境でレプリケーションとインバリデーションを使用している場合は、これをtrueに設定します。さらに、複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアのみがこのプロパティーを有効に設定できます。共有キャッシュストアが使用されている場合、キャッシュは、このプロパティーがtrueに設定されているにも関わらず、永続状態の転送を許可しません。fetchPersistentStateパラメーターはデフォルトではfalseに設定されます。ignoreModificationsパラメーターは、キャッシュを変更する操作 (例: 配置、削除、消去、保存など) がキャッシュストアに影響を与えるかどうかを決定します。結果として、キャッシュストアは、キャッシュと同期しなくなります。purgeOnStartupパラメーターは、初回起動時にキャッシュがパージされるかどうかを指定します。key2StringMapperパラメーターは、キーをデータベーステーブルの文字列にマップするために使用される Key2StringMapper のクラス名を指定します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper">
connectionPool 要素
connectionPool要素は、次のパラメーターを使用して JDBC ドライバーの接続プールを指定します。connectionUrlパラメーターは、JDBC ドライバー固有の接続 URL を指定します。usernameパラメーターには、connectionUrl経由で接続するために使用されるユーザー名が含まれます。driverClassパラメーターは、データベースに接続するために使用されるドライバーのクラス名を指定します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/>
stringKeyedTable 要素
stringKeyedTable要素を追加すると、キャッシュエントリーを保存するテーブルが定義されます。これは、キャッシュストアを設定するために以下のパラメーターを使用します。dropOnExitパラメーターは、シャットダウン時にデータベーステーブルがドロップされるかどうかを指定します。createOnStartパラメーターは、スタートアップ時にストアによってデータベーステーブルが作成されるかどうかを指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <stringKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_STRING_TABLE">
idColumn 要素
idColumn要素は、キャッシュキーまたはバケット ID が保存される列を定義します。これは以下のパラメーターを使用します。- ID 列の名前を指定するには、
nameパラメーターを指定します。 - ID 列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <stringKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_STRING_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" />
dataColumn 要素
dataColumn要素は、キャッシュエントリーまたはバケットが保存される列を指定します。- データベース列の名前を指定するには、
nameパラメーターを使用します。 - データベース列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <stringKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_STRING_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" />
timestampColumn 要素
timestampColumn要素は、キャッシュエントリーまたはバケットのタイムスタンプが保存される列を指定します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <stringKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.loaders.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <stringKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_STRING_TABLE"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" /> <timestampColumn name="TIMESTAMP_COLUMN" type="BIGINT" /> </stringKeyedTable> </stringKeyedJdbcStore> </persistence>
18.4.2.3. JdbcStringBasedStore の複数ノード設定 (リモートクライアントサーバーモード)
JdbcStringBasedStore の設定になります。この設定は、複数のノードを使用しなければならない場合に使用されます。
手順18.12 リモートクライアントサーバーノード用の JdbcStringBasedStore の複数ノード設定
string-keyed-jdbc-store 要素
string-keyed-jdbc-store要素は、文字列ベースのキーボードから情報が入力されたキャッシュの JDBC ストアに対する設定を指定します。fetch-stateパラメーターは、クラスターへ参加する時にキャッシュの永続状態が取り込まれるかを決定します。複数のキャッシュストアがチェーン化されている場合に、それらの内の 1 つのみでこのプロパティーを有効にすることができます。datasourceパラメーターはデータソースの JNDI 名を定義します。データソースの詳細については、「JDBC 」を参照してください。passivationパラメーターは、キャッシュのエントリーがパッシベートされるか (true) またはキャッシュストアが内容のコピーをメモリーに保持するか (false) を決定します。preloadパラメーターは、起動中にエントリーをキャッシュにロードするかどうかを指定します。このパラメーターの有効な値はtrueとfalseです。purgeパラメーターは、起動時にキャッスストアがパージされるかどうかを指定します。 このパラメーターの有効な値はtrueとfalseです。sharedパラメーターは、複数のキャッシュストアインスタンスがキャッシュストアを共有する場合に使用されます。複数のキャッシュインスタンスが同じ変更内容を複数回書き込まないようにするため、このパラメーターを設定することができます。このパラメーターに有効な値はtrueとfalseです。singletonパラメーターは、シングルトンストアのキャッシュストアを有効にします。SingletonStore は、クラスター内の唯一のインスタンスが基礎となるストアと通信する場合にのみ使用される委譲するキャッシュストアです。
<subsystem xmlns="urn:infinispan:server:core:5.2" default-cache-container="default"> <cache-container ... > ... <replicated-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" fetch-state="true" passivation="false" preload="false" purge="false" shared="false" singleton="true">string-keyed-table 要素
string-keyed-table要素は、文字別ベースのキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<subsystem xmlns="urn:infinispan:server:core:5.2" default-cache-container="default"> <cache-container ... > ... <replicated-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" fetch-state="true" passivation="false" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG">id-column 要素
id-column要素は、キャッシュエントリーの ID を保持するデータベース列に関する情報を指定します。nameパラメーターは ID 列の名前を指定します。typeパラメーターは ID 列のタイプを指定します。
<subsystem xmlns="urn:infinispan:server:core:5.2" default-cache-container="default"> <cache-container ... > ... <replicated-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" fetch-state="true" passivation="false" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/>data-column 要素
data-column要素には、キャッシュエントリーデータを保持するデータベース列に関する情報が含まれます。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<subsystem xmlns="urn:infinispan:server:core:5.2" default-cache-container="default"> <cache-container ... > ... <replicated-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" fetch-state="true" passivation="false" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/>timestamp-column 要素
timestamp-column要素は、キャッシュエントリーのタイムスタンプを保持するデータベース列に関する情報を指定します。nameパラメーターはタイムスタンプ列の名前を指定します。typeパラメーターはタイムスタンプ列のタイプを指定します。
<subsystem xmlns="urn:infinispan:server:core:5.2" default-cache-container="default"> <cache-container ... > ... <replicated-cache> ... <string-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" fetch-state="true" passivation="false" preload="false" purge="false" shared="false" singleton="true"> <string-keyed-table prefix="JDG"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </string-keyed-table> </string-keyed-jdbc-store> </replicated-cache> </cache-container> </subsystem>
18.4.2.4. JdbcStringBasedStore のプログラムを使用した設定
JdbcStringBasedStore の設定例は次の通りです。
手順18.13 プログラムを使用した JdbcStringBasedStore の設定
新規設定ビルダーの作成
ConfigurationBuilderを使用して、新規の設定オブジェクトを作成します。ConfigurationBuilder builder = new ConfigurationBuilder();
JdbcStringBasedStoreConfigurationBuilderの追加このストアに関連する特定の設定を構築するにはJdbcStringBasedStore設定ビルダーを追加します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class)
永続性のセットアップ
fetchPersistentStateは、キャッシュの永続状態を取り込むかどうかを決定し、クラスターに参加する際にこれをローカルキャッシュストアに適用します。キャッシュストアが共有される場合、キャッシュが同じキャッシュストアにアクセスする際に、永続状態の取り込みは無視されます。複数のキャッシュローダーがこのプロパティーをtrueに設定する場合にキャッシュサービスを起動すると、設定の例外がスローされます。fetchPersistentStateプロパティーはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class) .fetchPersistentState(false)変更の設定
ignoreModificationsは、書き込み操作を共有キャッシュローダーではなく、ローカルファイルキャッシュローダーに許可することで、書き込みメソッドが特定のキャッシュローダーにプッシュされるかどうかを決定します。特定の場合に、一時的なアプリケーションデータは、インメモリーキャッシュと同じサーバー上のファイルベースのキャッシュローダーにのみ存在します。たとえば、これはネットワーク内のすべてのサーバーによって使用される追加の JDBC ベースのキャッシュローダーで適用されます。ignoreModificationsはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false)パージの設定
purgeOnStartupは、初回の起動時にキャッシュがパージされるかどうかを指定します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false)テーブルの設定
Drop Table On Exit メソッドの設定
dropOnExitは、キャッシュストアが停止している際にテーブルを破棄するかどうかを決定します。これは、デフォルトではfalseに設定されます。Create Table On Start メソッドの設定
createOnStartは、現在テーブルが存在しない場合にキャッシュストアを起動すると、テーブルを作成します。このメソッドはデフォルトではtrueです。Table Name Prefix の設定
tableNamePrefixは、データが保存されるテーブルの名前にプレフィックスを設定します。idColumnNameidColumnNameプロパティーは、キャッシュキーまたはバケット ID が保存される列を定義します。dataColumnNamedataColumnNameプロパティーは、キャッシュエントリーまたはバケット ID が保存される列を指定します。timestampColumnNametimestampColumnName要素は、キャッシュエントリーのタイムスタンプまたはバケットが保存される列を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .table() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_STRING_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")connectionPool 要素
connectionPool要素は、次のパラメーターを使用して JDBC ドライバーの接続プールを指定します。connectionUrlパラメーターは、JDBC ドライバー固有の接続 URL を指定します。usernameパラメーターには、connectionUrl経由で接続するために使用されるユーザー名が含まれます。driverClassパラメーターは、データベースに接続するために使用されるドライバーのクラス名を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcStringBasedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .table() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_STRING_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT") .connectionPool() .connectionUrl("jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1") .username("sa") .driverClass("org.h2.Driver");
注記
18.4.3. JdbcMixedStores
JdbcMixedStore は、キーのタイプを基にキーを JdbcBinaryStore または JdbcStringBasedStore に委譲するハイブリッド実装です。
18.4.3.1. JdbcMixedStore の設定 (リモートクライアントサーバーモード)
JdbcBinaryStore の設定です。
手順18.14 リモートクライアントサーバーモードでの JdbcMixedStore の設定
mixed-keyed-jdbc-store 要素
mixed-keyed-jdbc-store要素は、混合のキーボードから情報が入力されたキャッシュの JDBC ストアに対する設定を指定します。datasourceパラメーターはデータソースの JNDI 名を定義します。データソースの詳細については、「JDBC 」を参照してください。passivationパラメーターは、キャッシュのエントリーがパッシベートされるか (true) またはキャッシュストアが内容のコピーをメモリーに保持するか (false) を決定します。preloadパラメーターは、起動中にエントリーをキャッシュにロードするかどうかを指定します。このパラメーターの有効な値はtrueとfalseです。purgeパラメーターは、起動時にキャッスストアがパージされるかどうかを指定します。 このパラメーターの有効な値はtrueとfalseです。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false">binary-keyed-table 要素
binary-keyed-table要素は、混合のキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false"> <binary-keyed-table prefix="MIX_BKT2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table>string-keyed-table 要素
string-keyed-table要素は、文字別ベースのキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false"> <binary-keyed-table prefix="MIX_BKT2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table> <string-keyed-table prefix="MIX_STR2">id-column 要素
id-column要素は、キャッシュエントリーの ID を保持するデータベース列に関する情報を指定します。nameパラメーターは ID 列の名前を指定します。typeパラメーターは ID 列のタイプを指定します。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false"> <binary-keyed-table prefix="MIX_BKT2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table> <string-keyed-table prefix="MIX_STR2"> <id-column name="id" type="${id.column.type}"/>data-column 要素
data-column要素には、キャッシュエントリーデータを保持するデータベース列に関する情報が含まれます。nameパラメーターはデータベース列の名前を指定します。typeパラメーターはデータベース列のタイプを指定します。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false"> <binary-keyed-table prefix="MIX_BKT2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table> <string-keyed-table prefix="MIX_STR2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/>timestamp-column 要素
timestamp-column要素は、キャッシュエントリーのタイムスタンプを保持するデータベース列に関する情報を指定します。nameパラメーターはタイムスタンプ列の名前を指定します。typeパラメーターはタイムスタンプ列のタイプを指定します。
<local-cache> <mixed-keyed-jdbc-store datasource="java:jboss/datasources/JdbcDS" passivation="true" preload="false" purge="false"> <binary-keyed-table prefix="MIX_BKT2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </binary-keyed-table> <string-keyed-table prefix="MIX_STR2"> <id-column name="id" type="${id.column.type}"/> <data-column name="datum" type="${data.column.type}"/> <timestamp-column name="version" type="${timestamp.column.type}"/> </string-keyed-table> </mixed-keyed-jdbc-store> </local-cache>
18.4.3.2. JdbcMixedStore の設定 (ライブラリーモード)
mixedKeyedJdbcStore の設定例は次の通りです。
手順18.15 ライブラリーモードでの JdbcMixedStore の設定
mixedKeyedJdbcStore 要素
mixedKeyedJdbcStore要素は、キャッシュストアを設定するための次のパラメーターを使用します。fetchPersistentStateパラメーターは、クラスターへ参加する時に永続状態が取り込まれるかを決定します。クラスター環境でレプリケーションとインバリデーションを使用している場合は、これをtrueに設定します。さらに、複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアのみがこのプロパティーを有効に設定できます。共有キャッシュストアが使用されている場合、キャッシュは、このプロパティーがtrueに設定されているにも関わらず、永続状態の転送を許可しません。fetchPersistentStateパラメーターはデフォルトではfalseに設定されます。ignoreModificationsパラメーターは、キャッシュを変更する操作 (例: 配置、削除、消去、保存など) がキャッシュストアに影響を与えるかどうかを決定します。結果として、キャッシュストアは、キャッシュと同期しなくなります。purgeOnStartupパラメーターは、初回起動時にキャッシュがパージされるかどうかを指定します。key2StringMapperパラメーターは、キーをデータベーステーブルの文字列にマップするために使用される Key2StringMapper のクラス名を指定します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper">
binaryKeyedTable 要素および stringKeyedTable 要素
binaryKeyedTableおよびstringKeyedTable要素は、キャッシュエントリーを保存するテーブルを定義します。それぞれのユーザーは以下のパラメーターを使用してキャッシュストアを設定します。dropOnExitパラメーターは、シャットダウン時にデータベーステーブルがドロップされるかどうかを指定します。createOnStartパラメーターは、スタートアップ時にストアによってデータベーステーブルが作成されるかどうかを指定します。prefixパラメーターは、キャッシュバケットテーブルの名前を作成する際に、ターゲットキャッシュの名前に付与される文字列を定義します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_BINARY">
idColumn 要素
idColumn要素は、キャッシュキーまたはバケット ID が保存される列を定義します。これは以下のパラメーターを使用します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_BINARY"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" />
dataColumn 要素
dataColumn要素は、キャッシュエントリーまたはバケットが保存される列を指定します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_BINARY"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" />
timestampColumn 要素
timestampColumn要素は、キャッシュエントリーまたはバケットのタイムスタンプが保存される列を指定します。- 使用されている列の名前を指定するには、
nameパラメーターを使用します。 - 使用されている列のタイプを指定するには、
typeパラメーターを使用します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_BINARY"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" /> <timestampColumn name="TIMESTAMP_COLUMN" type="BIGINT" /> </binaryKeyedTable>
string-keyed-table 要素
string-keyed-table要素は、文字別ベースのキャッシュエントリーを格納するために使用されるデータベーステーブルに関する情報を指定します。prefixパラメーターはデータベーステーブル名のプレフィックスの文字列を指定します。
<persistence> <mixedKeyedJdbcStore fetchPersistentState="false" ignoreModifications="false" purgeOnStartup="false" key2StringMapper="org.infinispan.persistence.keymappers.DefaultTwoWayKey2StringMapper"> <connectionPool connectionUrl="jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1" username="sa" driverClass="org.h2.Driver"/> <binaryKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_BINARY"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" /> <timestampColumn name="TIMESTAMP_COLUMN" type="BIGINT" /> </binaryKeyedTable> <stringKeyedTable dropOnExit="true" createOnStart="true" prefix="ISPN_BUCKET_TABLE_STRING"> <idColumn name="ID_COLUMN" type="VARCHAR(255)" /> <dataColumn name="DATA_COLUMN" type="BINARY" /> <timestampColumn name="TIMESTAMP_COLUMN" type="BIGINT" /> </stringKeyedTable> </mixedKeyedJdbcStore> </persistence>
18.4.3.3. JdbcMixedStore のプログラムを使用した設定
JdbcMixedStore の設定例です。
手順18.16 プログラムを使用した JdbcMixedStore の設定
新規の設定ビルダーを作成します。
ConfigurationBuilderを使用して、新規の設定オブジェクトを作成します。ConfigurationBuilder builder = new ConfigurationBuilder();
JdbcMixedStoreConfigurationBuilderの追加このストアに関連する特定の設定を構築するには、JdbcMixedStore設定ビルダーを追加します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class)
永続性のセットアップ
fetchPersistentStateは、キャッシュの永続状態を取り込むかどうかを決定し、クラスターに参加する際にこれをローカルキャッシュストアに適用します。キャッシュストアが共有される場合、キャッシュが同じキャッシュストアにアクセスする際に、 は無視されます。複数のキャッシュローダーがこのプロパティーをtrueに設定する場合にキャッシュサービスを起動すると、設定の例外がスローされます。fetchPersistentStateプロパティーはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class) .fetchPersistentState(false)変更の設定
ignoreModificationsは、書き込み操作を共有キャッシュローダーではなく、ローカルファイルキャッシュローダーに許可することで、書き込みメソッドが特定のキャッシュローダーにプッシュされるかどうかを決定します。特定の場合に、一時的なアプリケーションデータは、インメモリーキャッシュと同じサーバー上のファイルベースのキャッシュローダーにのみ存在します。たとえば、これはネットワーク内のすべてのサーバーによって使用される追加の JDBC ベースのキャッシュローダーで適用されます。ignoreModificationsはデフォルトではfalseです。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false)パージの設定
purgeOnStartupは、初回の起動時にキャッシュがパージされるかどうかを指定します。ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false)テーブルの設定
Drop Table On Exit メソッドの設定
dropOnExitは、キャッシュストアが停止している際にテーブルを破棄するかどうかを決定します。これは、デフォルトではfalseに設定されます。Create Table On Start メソッドの設定
createOnStartは、現在テーブルが存在しない場合にキャッシュストアを起動すると、テーブルを作成します。このメソッドはデフォルトではtrueです。Table Name Prefix の設定
tableNamePrefixは、データが保存されるテーブルの名前にプレフィックスを設定します。idColumnNameidColumnNameプロパティーは、キャッシュキーまたはバケット ID が保存される列を定義します。dataColumnNamedataColumnNameプロパティーは、キャッシュエントリーまたはバケット ID が保存される列を指定します。timestampColumnNametimestampColumnName要素は、キャッシュエントリーのタイムスタンプまたはバケットが保存される列を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .stringTable() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_MIXED_STR_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT")connectionPool 要素
connectionPool要素は、次のパラメーターを使用して JDBC ドライバーの接続プールを指定します。connectionUrlパラメーターは、JDBC ドライバー固有の接続 URL を指定します。usernameパラメーターには、connectionUrl経由で接続するために使用されるユーザー名が含まれます。driverClassパラメーターは、データベースに接続するために使用されるドライバーのクラス名を指定します。
ConfigurationBuilder builder = new ConfigurationBuilder(); builder.persistence().addStore(JdbcMixedStoreConfigurationBuilder.class) .fetchPersistentState(false) .ignoreModifications(false) .purgeOnStartup(false) .stringTable() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_MIXED_STR_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT") .binaryTable() .dropOnExit(true) .createOnStart(true) .tableNamePrefix("ISPN_MIXED_BINARY_TABLE") .idColumnName("ID_COLUMN").idColumnType("VARCHAR(255)") .dataColumnName("DATA_COLUMN").dataColumnType("BINARY") .timestampColumnName("TIMESTAMP_COLUMN").timestampColumnType("BIGINT") .connectionPool() .connectionUrl("jdbc:h2:mem:infinispan_binary_based;DB_CLOSE_DELAY=-1") .username("sa") .driverClass("org.h2.Driver");
注記
18.4.4. キャッシュストアのトラブルシューティング
18.4.4.1. JdbcStringBasedStore の IOExceptions
JdbcStringBasedStore を使用している時に IOException Unsupported protocol version 48 エラーが発生した場合、データ列タイプが正しいタイプである BLOB や VARBINARY ではなく、VARCHAR や CLOB などに設定されていることを示しています。JdbcStringBasedStore は文字列であるキーのみを必要とし、値はバイナリー列に保存されるため、すべてのデータタイプを値に使用できます。
18.5. リモートキャッシュストア
RemoteCacheStore は、リモート Red Hat JBoss Data Grid クラスターにデータを保存するキャッシュローダーの実装です。RemoteCacheStore は Hot Rod クライアントサーバーアーキテクチャーを使用してリモートクラスターと通信します。
RemoteCacheStore とクラスター間の接続を細かく調整する機能も提供します。
18.5.1. リモートキャッシュストアの設定 (リモートクライアントサーバーモード)
手順18.17 リモートキャッシュストアの設定
remote-store 要素のパラメーターは次の情報を定義します。
cacheパラメーターは、リモートキャッシュの名前を定義します。定義されない状態のままの場合、デフォルトのキャッシュが代わりに使用されます。<remote-store cache="default">
socket-timeoutパラメーターは、SO_TIMEOUTで定義される値 (ミリ秒単位) が指定されるタイムアウトでリモート Hot Rod サーバーに適用されるかどうかを設定します。タイムアウト値が0の場合は、無限のタイムアウトを示します。<remote-store cache="default" socket-timeout="60000">tcp-no-delayは、TCP_NODELAYがソケット接続でリモートの Hot Rod サーバーに適用されるかどうかを設定します。<remote-store cache="default" socket-timeout="60000" tcp-no-delay="true">hotrod-wrappingは、リモートストア上でラッパーが Hot Rod に必要となるかどうかを設定します。<remote-store cache="default" socket-timeout="60000" tcp-no-delay="true" hotrod-wrapping="true">remote-server要素の単一パラメーターは以下の通りです。outbound-socket-bindingパラメーターは、リモートサーバーのアウトバウンドソケットバインディングを設定します。
<remote-store cache="default" socket-timeout="60000" tcp-no-delay="true" hotrod-wrapping="true"> <remote-server outbound-socket-binding="remote-store-hotrod-server" /> </remote-store>
18.5.2. リモートキャッシュストアの設定 (ライブラリーモード)
手順18.18 リモートキャッシュストアの設定
Persistence 要素の設定
passivationをfalseに設定した状態で、persistence要素を作成します。<persistence passivation="false" />
- リモートキャッシュストアの属性を設定するために、
persistence要素内にremoteStore要素を作成します。<persistence passivation="false"> <remoteStore xmlns="urn:infinispan:config:remote:6.0" remoteCacheName="default" fetchPersistentState="false" shared="true" preload="false" ignoreModifications="false" purgeOnStartup="false" tcpNoDelay="true" pingOnStartup="true" keySizeEstimate="62" valueSizeEstimate="512" forceReturnValues="false"> </remoteStore> </persistence>
remoteCacheName属性を追加します。リモート Infinispan クラスターに接続するリモートキャッシュの名前を指定します。リモートキャッシュの名前が指定されないと、デフォルトのキャッシュが使用されます。fetchPersistentState属性を追加します。trueに設定されると、リモートキャッシュがクラスターに加わる際に永続状態が取り込まれます。複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアでのみこのプロパティーをtrueに設定できます。この値のデフォルトはfalseです。shared属性を追加します。これは、複数のキャッシュインスタンスがキャッシュストアを共有する場合にtrueに設定されます。これにより、複数のキャッシュインスタンスが同じ変更内容を個別に書き込むことを避けられます。この属性のデフォルトはfalseです。preload属性を追加します。trueに設定されている場合、キャッシュストアデータがメモリーに事前にロードされ、起動後すぐにアクセス可能になります。これをtrueに設定する不利な点には、起動時間が増えることが挙げられます。この属性のデフォルト値はfalseです。ignoreModifications属性を追加します。true に設定されると、この属性は、キャッシュを変更する操作 (例: 配置、削除、消去、保存など) がキャッシュストアに影響を与えることを防ぎます。その結果、キャッシュストアは、キャッシュと同期しなくなります。この属性のデフォルト値はfalseです。purgeOnStartup属性を追加します。trueに設定されると、キャッシュストアは起動プロセス時にパージされます。この属性のデフォルト値はfalseです。tcpNoDelay属性を追加します。trueに設定されると、これはTCPNODELAYスタックをトリガーします。この属性のデフォルト値はtrueです。pingOnStartup属性を追加します。trueに設定されると、クラスタートポロジーを取り込むために ping 要求がバックエンドサーバーに送信されます。この属性のデフォルト値はtrueです。keySizeEstimate属性を追加します。この値は、データベースに接続するためのドライバーユーザーのクラス名です。この属性のデフォルト値は64です。valueSizeEstimate属性を追加します。この値は、値をシリアライズおよびデシリアライズする時のバイトバッファーのサイズです。この属性のデフォルト値は512です。forceReturnValues属性を追加します。この属性は、FORCE_RETURN_VALUEをすべての呼び出しに対して有効にするかどうかを設定します。この属性のデフォルト値はfalseです。
- サーバー情報をセットアップするために
remoteStore要素内にservers要素を作成します。情報を単一サーバーに追加するには、一般的なservers要素内にserver要素を追加します。<persistence passivation="false"> <remoteStore xmlns="urn:infinispan:config:remote:6.0" remoteCacheName="default" fetchPersistentState="false" shared="true" preload="false" ignoreModifications="false" purgeOnStartup="false" tcpNoDelay="true" pingOnStartup="true" keySizeEstimate="62" valueSizeEstimate="512" forceReturnValues="false"> <servers> <server host="127.0.0.1" port="19711"/> </servers> </remoteStore> </persistence>
- ホストアドレスを設定するには
host属性を追加します。 - リモートキャッシュストアで使用されるポートを設定するには
port属性を追加します。
connectionPool要素をremoteStore要素に対して作成します。<persistence passivation="false"> <remoteStore xmlns="urn:infinispan:config:remote:6.0" remoteCacheName="default" fetchPersistentState="false" shared="true" preload="false" ignoreModifications="false" purgeOnStartup="false" tcpNoDelay="true" pingOnStartup="true" keySizeEstimate="62" valueSizeEstimate="512" forceReturnValues="false"> <servers> <server host="127.0.0.1" port="19711"/> </servers> <connectionPool maxActive="99" maxIdle="97" maxTotal="98" /> </remoteStore> </persistence>
maxActive属性を追加します。これは、一度に各サーバーに設定できるアクティブな接続の最大数を示します。この属性のデフォルト値は-1であり、これはアクティブな接続の無限な数を示します。maxIdle属性を追加します。これは、一度に各サーバーに設定できるアイドル状態の接続の最大数を示します。この属性のデフォルト値は-1であり、これはアイドル状態の接続の無限な数を示します。maxTotal属性を追加します。これは、組み合わされたサーバーセット内の永続的な接続の最大数を示します。この属性のデフォルト設定は-1であり、これは接続の無限な数を示します。
18.5.3. リモートキャッシュストアのアウトバウンドソケットの定義
standalone.xml ファイルの outbound-socket-binding 要素を使用して定義されます。
standalone.xml ファイルにおけるこの設定の例は次の通りです。
例18.1 アウトバウンドソケットの定義
<server>
...
<socket-binding-group name="standard-sockets"
default-interface="public"
port-offset="${jboss.socket.binding.port-offset:0}">
...
<outbound-socket-binding name="remote-store-hotrod-server">
<remote-destination host="remote-host"
port="11222"/>
</outbound-socket-binding>
</socket-binding-group>
</server>18.6. JPA キャッシュストア
重要
18.6.1. JPA キャッシュストアの XML 設定例 (ライブラリーモード)
persistence.xml ファイルに追加します。
<persistence passivation="false" shared="true" preload="true"> <jpaStore persistenceUnitName="MyPersistenceUnit" entityClassName="org.infinispan.loaders.jpa.entity.User" /> </persistence>
persistenceUnitName属性は、JPA キャッシュストアの名前を指定します。entityClassName属性は、キャッシュエントリー値を格納するために使用する JPA エントリーの完全修飾クラス名を指定します。batchSize(オプション) 属性は、キャッシュストアストリーミングのバッチサイズを指定します。この属性のデフォルト値は100です。storeMetadata(オプション) 属性は、キャッシュストアがメタデータ (失効やバージョンに関する情報など) を保持するかどうかを指定します。この属性のデフォルト値はtrueです。
18.6.2. JPA キャッシュストア例のプログラミングによる設定
Configuration cacheConfig = new ConfigurationBuilder().loaders()
.addLoader(JpaCacheStoreConfigurationBuilder.class)
.persistenceUnitName("org.infinispan.loaders.jpa.configurationTest")
.entityClass(User.class)
.build();persistenceUnitNameパラメーターは、JPA エンティティークラスを含む設定ファイル (persistence.xml) の JPA キャッシュストアの名前を指定します。entityClassパラメーターは、このキャッシュに格納された JPA エンティティークラスを指定します。各設定で指定できるクラスは 1 つだけです。
18.6.3. データベースへのメタデータの格納
storeMetadata が true (デフォルト値) に設定された場合、有効期限、作成および変更タイムスタンプ、バージョンなどのエントリーに関するメタ情報はデータベースに格納されます。エンティティーテーブルのレイアウトは固定され、メタデータを収めることができないため、JBoss Data Grid はメタデータを __ispn_metadata__ という名前の追加テーブルにメタデータを格納します。
手順18.19 persistence.xml でのメタデータエンティティーの設定
- Hibernate を JPA 実装として使用すると、以下のように
persistence.xmlのプロパティーhibernate.hbm2ddl.autoを使用してこれらのテーブルの自動作成を許可できます。<property name="hibernate.hbm2ddl.auto" value="update"/>
- 以下の内容を
persistence.xmlに追加して、JPA プロバイダーに対してメタデータエンティティークラスを宣言します。<class>org.infinispan.persistence.jpa.impl.MetadataEntity</class>
storeMetadata 属性を false に設定します。
18.6.4. さまざまなコンテナーでの JPA キャッシュストアのデプロイ
手順18.20 JBoss EAP での JPA キャッシュストアのデプロイ
- JBoss Data Grid モジュールの依存関係をアプリケーションのクラスパスに追加するには、以下のいずれかの方法で JBoss EAP デプロイヤーに依存関係のリストを提供します。
- 依存関係設定を
MANIFEST.MFファイルに追加します。Manifest-Version: 1.0 Dependencies: org.infinispan:jdg-6.3 services, org.infinispan.persistence.jpa:jdg-6.3 services
- 依存関係設定を
jboss-deployment-structure.xmlファイルに追加します。<jboss-deployment-structure xmlns="urn:jboss:deployment-structure:1.2"> <deployment> <dependencies> <module name="org.infinispan" slot="jdg-6.3" services="export"/> </dependencies> </deployment> </jboss-deployment-structure>
重要
18.7. カスタムキャッシュストア
18.7.1. カスタムキャッシュストアの設定 (リモートクライアントサーバーモード)
<local-cache name="default"
statistics="true">
<store class="my.package.CustomCacheStore">
<properties>
<property name="customStoreProperty" value="10" />
</properties>
</store>
</local-cache>重要
org.jboss.as.clustering.infinispan モジュールの依存関係に追加します。
18.7.2. カスタムキャッシュストアの設定 (ライブラリーモード)
例18.2 カスタムキャッシュストアの設定
<persistence>
<store class="org.infinispan.custom.CustomCacheStore"
preload="true"
shared="true">
<properties>
<property name="customStoreProperty"
value="10" />
</properties>
</store>
</persistence>パート VIII. パッシベーションのセットアップ
第19章 アクティベーションモードとパッシベーションモード
19.1. パッシベーションモードの利点
19.2. パッシベーションの設定
passivation パラメーターをキャッシュストア要素に追加します。
例19.1 リモートクライアントサーバーモードでのパッシベーションの切り替え
<local-cache> ... <file-store passivation="true" ... /> ... </local-cache>
passivation パラメーターを persistence 要素に追加します。
例19.2 ライブラリーモードでのパッシベーションの切り替え
<persistence passivation="true" ... > ... </persistence>
19.3. エビクションとパッシベーション
19.3.1. エビクションとパッシベーションの用途
- パッシベートされたエントリーに関する通知がキャッシュリスナーへ送信されます。
- エビクトされたエントリーが保存されます。
19.3.2. パッシベーションが無効な場合のエビクションの例
表19.1 パッシベーションが無効な場合のエビクション
| 手順 | メモリー内のキー | ディスク上のキー |
|---|---|---|
keyOne の挿入 | メモリー: keyOne | ディスク: keyOne |
keyTwo の挿入 | メモリー: keyOne、 keyTwo | ディスク: keyOne、 keyTwo |
エビクションスレッドが実行され、keyOne をエビクトする | メモリー: keyTwo | ディスク: keyOne、 keyTwo |
keyOne の読み取り | メモリー: keyOne、 keyTwo | ディスク: keyOne、 keyTwo |
エビクションスレッドが実行され、keyTwo をエビクトする | メモリー: keyOne | ディスク: keyOne、 keyTwo |
keyTwo の削除 | メモリー: keyOne | ディスク: keyOne |
19.3.3. パッシベーションが有効な場合のエビクションの例
表19.2 パッシベーションが有効な場合のエビクション
| 手順 | メモリー内のキー | ディスク上のキー |
|---|---|---|
keyOne の挿入 | メモリー: keyOne | ディスク: |
keyTwo の挿入 | メモリー: keyOne、 keyTwo | ディスク: |
エビクションスレッドが実行され、keyOne をエビクトする | メモリー: keyTwo | ディスク: keyOne |
keyOne の読み取り | メモリー: keyOne、 keyTwo | ディスク: |
エビクションスレッドが実行され、keyTwo をエビクトする | メモリー: keyOne | ディスク: keyTwo |
keyTwo の削除 | メモリー: keyOne | ディスク: |
パート IX. キャッシュ書き込みのセットアップ
第20章 キャッシュ書き込みモード
- ライトスルー (同期)
- ライトビハインド (非同期)
20.1. ライトスルーキャッシング
Cache.put() 呼び出しより)、JBoss Data Grid が基盤のキャッシュストアを見つけ、更新するまで呼び出しが返されないようにします。この機能により、キャッシュストアへの更新をクライアントスレッド境界内で終了させることができます。
20.1.1. ライトスルーキャッシングの利点
20.1.2. ライトスルーキャッシングの設定 (ライブラリーモード)
手順20.1 ライトスルーのローカルファイルキャッシュストアの設定
namedCacheを特定します。nameパラメーターは、使用するnamedCacheの名前を指定します。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache">キャッシュローダーの設定
sharedパラメーターは、複数のキャッシュストアインスタンスがキャッシュストアを共有する場合に使用されます。複数のキャッシュインスタンスが同じ変更内容を複数回書き込まないようにするため、このパラメーターを設定することができます。このパラメーターに有効な値はtrueとfalseです。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false">ローダークラスを指定します。
class属性は、キャッシュローダー実装のクラスを定義します。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false"> <store class="org.infinispan.loaders.file.FileCacheStore"fetchPersistentStateパラメーターの設定fetchPersistentStateパラメーターは、クラスターへ参加する時に永続状態が取り込まれるかを決定します。クラスター環境でレプリケーションとインバリデーションを使用している場合は、これをtrueに設定します。さらに、複数のキャッシュストアがチェーンされている場合、1 つのキャッシュストアのみがこのプロパティーを有効に設定できます。共有キャッシュストアが使用されている場合、キャッシュは、このプロパティーがtrueに設定されているにも関わらず、永続状態の転送を許可しません。fetchPersistentStateパラメーターはデフォルトではfalseに設定されます。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false"> <store class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true"ignoreModificationsパラメーターを設定します。ignoreModificationsパラメーターは、キャッシュを変更する操作 (例: 配置、削除、消去、保存など) がキャッシュストアに影響を与えるかどうかを決定します。結果として、キャッシュストアは、キャッシュと同期しなくなります。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false"> <store class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true" ignoreModifications="false"起動時のパージの設定
purgeOnStartupパラメーターは、初回起動時にキャッシュがパージされるかどうかを指定します。<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false"> <store class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false">property要素property要素には、キャッシュストアに関連するプロパティーに関する情報が含まれます。nameパラメーターは、プロパティーの名前を指定します。
<?xml version="1.0" encoding="UTF-8"?> <infinispan xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="urn:infinispan:config:5.0"> <global /> <default /> <namedCache name="persistentCache"> <persistence shared="false"> <store class="org.infinispan.loaders.file.FileCacheStore" fetchPersistentState="true" ignoreModifications="false" purgeOnStartup="false"> <properties> <property name="location" value="${java.io.tmpdir}" /> </properties> </store> </persistence> </namedCache> </infinispan>
20.2. ライトビハインドキャッシング
20.2.1. スケジュール外のライトビハインドストラテジーについて
20.2.2. スケジュール外のライトビハインドストラテジーの設定 (リモートクライアントサーバーモード)
write-behind 要素をターゲットキャッシュストアの設定に追加します。
手順20.2 write-behind 要素
write-behind 要素は次の設定パラメーターを使用します。
modification-queue-sizeパラメーターmodification-queue-sizeパラメーターは、非同期ストアの変更キューサイズを設定します。更新がキャッシュストアがキューを処理するよりも速く行なわれる場合に、非同期ストアは同期ストアのように動作します。ストアの動作は、キューが要素を許可できるようになるまで同期された状態になり、要素をブロックします。その後ストアの動作は再び非同期になります。<file-store passivation="false" path="${PATH}" purge="true" shared="false"> <write-behind modification-queue-size="1024" />shutdown-timeoutパラメーターshutdown-timeoutパラメーターは、キャッシュストアがシャットダウンするまでのミリ秒単位の時間を指定します。ストアが停止している場合でも、いくらかの変更が依然として適用される必要がある場合があります。タイムアウトの値として大きな値を設定すると、データを損失する可能性が低くなります。このパラメーターのデフォルト値は25000です。<file-store passivation="false" path="${PATH}" purge="true" shared="false"> <write-behind modification-queue-size="1024" shutdown-timeout="25000" />flush-lock-timeoutパラメーターflush-lock-timeoutパラメーターは、定期的にフラッシュされる状態を保護するロックを取得するための時間 (ミリ秒単位) を指定します。このパラメーターのデフォルト値は15000です。<file-store passivation="false" path="${PATH}" purge="true" shared="false"> <write-behind modification-queue-size="1024" shutdown-timeout="25000" flush-lock-timeout="15000" />thread-pool-sizeパラメーターthread-pool-sizeパラメーターはスレッドプールのサイズを指定します。このスレッドプール内のスレッドによって、変更がキャッシュストアに適用されます。このパラメーターのデフォルト値は5です。<file-store passivation="false" path="${PATH}" purge="true" shared="false"> <write-behind modification-queue-size="1024" shutdown-timeout="25000" flush-lock-timeout="15000" thread-pool-size="5" /> </file-store>
20.2.3. スケジュール外のライトビハインドストラテジーの設定 (ライブラリーモード)
async 要素をストア設定に追加します。
手順20.3 async 要素
async 要素は次の設定パラメーターを使用します。
modificationQueueSizeパラメーターは、非同期ストアの変更キューサイズを設定します。更新がキャッシュストアがキューを処理するよりも速く行なわれる場合に、非同期ストアは同期ストアのように動作します。ストアの動作は、キューが要素を受け入れるまで同期が取られた状態のままになり、要素をブロックします。その後ストアの動作は再び非同期になります。<persistence> <fileStore location="${LOCATION}"> <async enabled="true" modificationQueueSize="1024" />shutdownTimeoutパラメーターは、キャッシュストアがシャットダウンされた後の時間 (ミリ秒単位) を指定します。これにより、キャッシュがシャットダウンされた際に非同期ライターがデータをストアへフラッシュする時間が提供されます。このパラメーターのデフォルト値は25000です。<persistence> <fileStore location="${LOCATION}"> <async enabled="true" modificationQueueSize="1024" shutdownTimeout="25000" />flushLockTimeoutパラメーターは、定期的にフラッシュする状態を保護するロックを取得するための時間 (ミリ秒単位) を指定します。このパラメーターのデフォルト値は15000です。<persistence> <fileStore location="${LOCATION}"> <async enabled="true" modificationQueueSize="1024" shutdownTimeout="25000" flushLockTimeout="15000" />threadPoolSizeパラメーターは、変更をストアに同時に適用するスレッドの数を指定します。このパラメーターのデフォルト値は5です。<persistence> <fileStore location="${LOCATION}"> <async enabled="true" modificationQueueSize="1024" shutdownTimeout="25000" flushLockTimeout="15000" threadPoolSize="5"/> </fileStore> </persistence>
パート X. キャッシュとキャッシュマネージャーのモニタリング
第21章 Java Management Extensions (JMX) のセットアップ
21.1. Java Management Extensions (JMX) について
MBeans によって管理および監視されます。
21.2. Red Hat JBoss Data Grid における JMX の使用
21.3. JMX 統計レベル
- 個別のキャッシュインスタンスによって管理情報が生成されるキャッシュレベル。
CacheManagerレベル。このレベルでは、CacheManagerエンティティーがCacheManagerより作成されたすべてのキャッシュインスタンスを管理します。そのため、管理情報は個別のキャッシュではなく、これらすべてのキャッシュインスタンスに対して生成されます。
重要
21.4. キャッシュインスタンスに対して JMX を有効にする
デフォルトキャッシュインスタンスに対する <default> 要素内または特定の名前付きキャッシュに対するターゲット <namedCache> 要素の下に、次のスニペットを追加します。
<jmxStatistics enabled="true"/>
プログラムを用いて JMX をキャッシュレベルで有効にするには、以下のコードを追加します。
Configuration configuration = ... configuration.setExposeJmxStatistics(true);
21.5. CacheManagers に対して JMX を有効にする
CacheManager レベルでは、宣言的に、またはプログラムを用いて次のように JMX 統計を有効にすることができます。
次の <global> 要素を追加して、CacheManager レベルで JMX を宣言的に有効にします。
<globalJmxStatistics enabled="true"/>
次のコードを追加して、プログラムを用いて JMX を CacheManager レベルで有効にします。
GlobalConfiguration globalConfiguration = ... globalConfiguration.setExposeGlobalJmxStatistics(true);
21.6. JMX による CacheStore の無効化
RollingUpgradeManager MBean で disconnectSource 操作を呼び出すことで、JMX を使用して CacheStore を無効にすることができます。
関連トピック:
21.7. 複数の JMX ドメイン
CacheManager インスタンスが 1 つの仮想マシンに存在したり、キャッシュインスタンスの名前が CacheManager と異なる場合に、複数の JMX ドメインが使用されます。
CacheManager に付けるようにします。
次のスニペットを関係する CacheManager 設定に追加します。
<globalJmxStatistics enabled="true" cacheManagerName="Hibernate2LC"/>
次のコードを追加し、プログラムを用いて CacheManager の名前を設定します。
GlobalConfiguration globalConfiguration = ...
globalConfiguration.setExposeGlobalJmxStatistics(true);
globalConfiguration.setCacheManagerName("Hibernate2LC");21.8. MBeans
MBean は、サービス、コンポーネント、デバイス、またはアプリケーションなどの管理可能なリソースを表します。
MBeans を提供します。たとえば、トランスポート層で統計を提供する MBeans などが提供されます。JBoss Data Grid サーバーは、JMX 統計で設定されます。JMX 統計はホスト名、ポート、読み取りバイト、書き込みバイト、およびワーカースレッドの数を提供する MBean で、次の場所に存在します。
jboss.infinispan:type=Server,name=<Memcached|Hotrod>,component=Transport
注記
21.8.1. MBean を理解する
MBean を使用できます。
- キャッシュマネージャーレベルの JMX 統計が有効になっている場合、
jboss.infinispan:type=CacheManager,name="DefaultCacheManager"という名前のMBeanが存在し、キャッシュマネージャーMBeanによってプロパティーが指定されます。 - キャッシュレベルの JMX 統計が有効になっている場合、使用される設定に応じて複数の
MBeanが表示されます。たとえば、ライトビハインドキャッシュストアが設定されている場合、キャッシュストアコンポーネントに属するプロパティーを公開するMBeanが表示されます。すべてのキャッシュレベルのMBeansは同じ形式を使用します。jboss.infinispan:type=Cache,name="<name-of-cache>(<cache-mode>)",manager="<name-of-cache-manager>",component=<component-name>
この形式の詳細は次の通りです。cache-container要素のdefault-cache属性を使用してキャッシュのデフォルト名を指定します。cache-modeはキャッシュのキャッシュモードに置き換えられます。可能な列挙値を小文字にしたものがキャッシュモードを表します。component-nameは、 JMX 参考ドキュメントにある JMX コンポーネント名の 1 つに置き換えられます。
MBean の名前は次のようになります。
jboss.infinispan:type=Cache,name="default(dist_sync)", manager="default",component=CacheStore
21.8.2. デフォルトでない MBean サーバーでの MBean の登録
getMBeanServer() メソッドが必要な (デフォルト以外の) MBeanServer を返すようにします。
次のスニペットを追加します。
<globalJmxStatistics enabled="true" mBeanServerLookup="com.acme.MyMBeanServerLookup"/>
次のコードを追加します。
GlobalConfiguration globalConfiguration = ...
globalConfiguration.setExposeGlobalJmxStatistics(true);
globalConfiguration.setMBeanServerLookup("com.acme.MyMBeanServerLookup")第22章 JBoss Operations Network (JON) のセットアップ
22.1. JBoss Operations Network (JON) について
重要
重要
22.2. JBoss Operations Network (JON) のダウンロード
22.2.1. JBoss Operations Network (JON) インストールの前提条件
- Linux、Windows、または Mac OSX オペレーティングシステム、および x86_64、i686、または ia64 プロセッサー。
- JBoss Operations Network サーバーおよび JBoss Operations Network エージェントの両方を実行するには、Java 6 以上が必要です。
- JBoss Operations Network サーバー とエージェントで同期されたクロック。
- 外部データベースをインストールする必要があります。
22.2.2. JBoss Operations Network のダウンロード
手順22.1 JBoss Operations Network のダウンロード
- Red Hat カスタマーポータルにアクセスするには、ブラウザーで https://access.redhat.com/home に移動します。
- をクリックします。
- Red Hat JBoss Middleware というラベルのボックスで、 (ソフトウェアのダウンロード) ボタンをクリックします。
- Red Hat ログイン フィールドと パスワード フィールドに該当するクレデンシャルを入力し、 をクリックします。
- Software Downloads (ソフトウェアのダウンロード) ページで、ドロップダウン値のリストから JBoss Operations Network を選択します。
- Version (バージョン) ドロップダウンメニューリストから適切なバージョンを選択します。
- 必要なダウンロードファイルの横にある (ダウンロード) ボタンをクリックします。
22.2.3. リモート JMX ポートの値
22.2.4. JBoss Operations Network (JON) プラグインのダウンロード
手順22.2 インストールファイルのダウンロード
- Web ブラウザーで http://access.redhat.com を開きます。
- ページ上部にあるメニュー内の をクリックします。
- JBoss Enterprise Middleware 以下のリスト内にある をクリックします。
- ログイン情報を入力します。「Software Downloads」ページに移動します。
JBoss Operations Network プラグインをダウンロードします。
JBoss Data Grid の JBoss Operations Network プラグインを使用する予定であれば、「Software Downloads」ドロップダウンボックスか、または左側のメニューのいずれかからJBoss ON for JDGを選択します。JBoss Operations Network VERSION Base Distributionダウンロードリンクをクリックします。- Base Distribution のダウンロードを開始するには、 リンクをクリックします。
JDG Plugin Pack for JBoss ON VERSIONをダウンロードする手順を繰り返します。
22.3. JBoss Operations Network サーバーのインストール
注記
22.4. JBoss Operations Network エージェント
init.d スクリプトとして実行できます。
注記
22.5. リモートクライアントサーバーモードの JBoss Operations Network
- インストールおよび設定操作の開始および実行。
- リソースおよびメトリックスの監視。
22.5.1. JBoss Operations Network プラグインのインストール (リモートクライアントサーバーモード)
プラグインのインストール
- JBoss Data Grid サーバーの RHQ プラグインを
$JON_SERVER_HOME/pluginsにコピーします。 - JBoss Enterprise Application Platform プラグインを
$JON_SERVER_HOME/pluginsにコピーします。
サーバーはここでプラグインを自動的に検出し、これらをデプロイします。プラグインはデプロイメントが成功すると、プラグインディレクトリーから削除されます。プラグインの取得
JBoss Operations Network サーバーから利用可能なすべてのプラグインを取得します。これを実行するには、以下をエージェントのコンソールに入力します。plugins update
インストール済みプラグインのリスト
以下のコマンドを使用して、JBoss Enterprise Application Platform プラグインと JBoss Data Grid サーバー rhq プラグインが正しくインストールされていることを確認します。plugins info
22.6. ライブラリーモードの JBoss Operations Network
- インストールおよび設定操作の開始および実行。
- リソースおよびメトリックスの監視。
22.6.1. JBoss Operations Network プラグインのインストール (ライブラリーモード)
手順22.3 JBoss Operations Network ライブラリーモードプラグインのインストール
JBoss Operations Network コンソールを開きます。
- JBoss Operations Network コンソールから、 を選択します。
- コンソールの左側にある オプションから を選択します。
図22.1 JBoss Data Grid 用の JBoss Operations Network コンソール
ライブラリーモードプラグインをアップロードします。
- をクリックし、ローカルファイルシステムで
InfinispanPluginを見つけます。 - をクリックして、プラグインを JBoss Operations Network サーバーに追加します。
図22.2
InfinispanPluginのアップロード。更新のためのスキャン
- ファイルが正常にアップロードされたら、画面の下部にある をクリックします。
InfinispanPluginがインストール済みプラグインのリストに表示されます。
図22.3 更新済みプラグインのためのスキャン。
プラットフォームのインポート
- にナビゲートし、コンソールの左側の リストから を選択します。
- アプリケーションが実行されているプラットフォームを選択し、画面の下部で をクリックします。
図22.4 からのプラットフォームのインポート。
プラットフォーム上のサーバーへのアクセス
jdgプラットフォームが Platforms リストに表示されます。- 実行中のサーバーにアクセスするためにプラットフォームをクリックします。
図22.5 サーバーのリストを表示するために
jdgプラットフォームを開く。JMX サーバーのインポート
- タブから、 を選択します。
- 画面の下部で ボタンをクリックし、リストから オプションを選択します。
図22.6 JMX サーバーのインポート
JDK 接続設定を有効にします。
- ウィンドウで、 オプションのリストから を指定します。
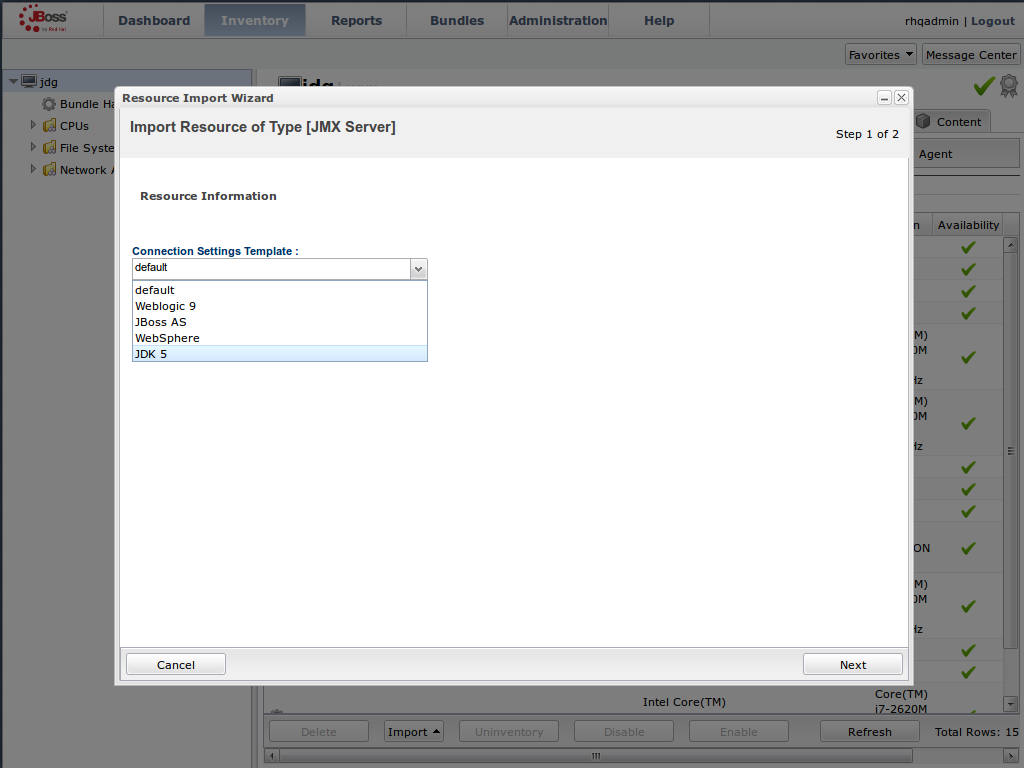
図22.7 JDK 5 テンプレートの選択。
コネクターアドレスを変更します。
- メニューで、指定された を、Infinispan ライブラリーを含むプロセスのホスト名と JMX ポートで修正します。
- 必要な場合は、 および 情報を指定します。
- をクリックします。
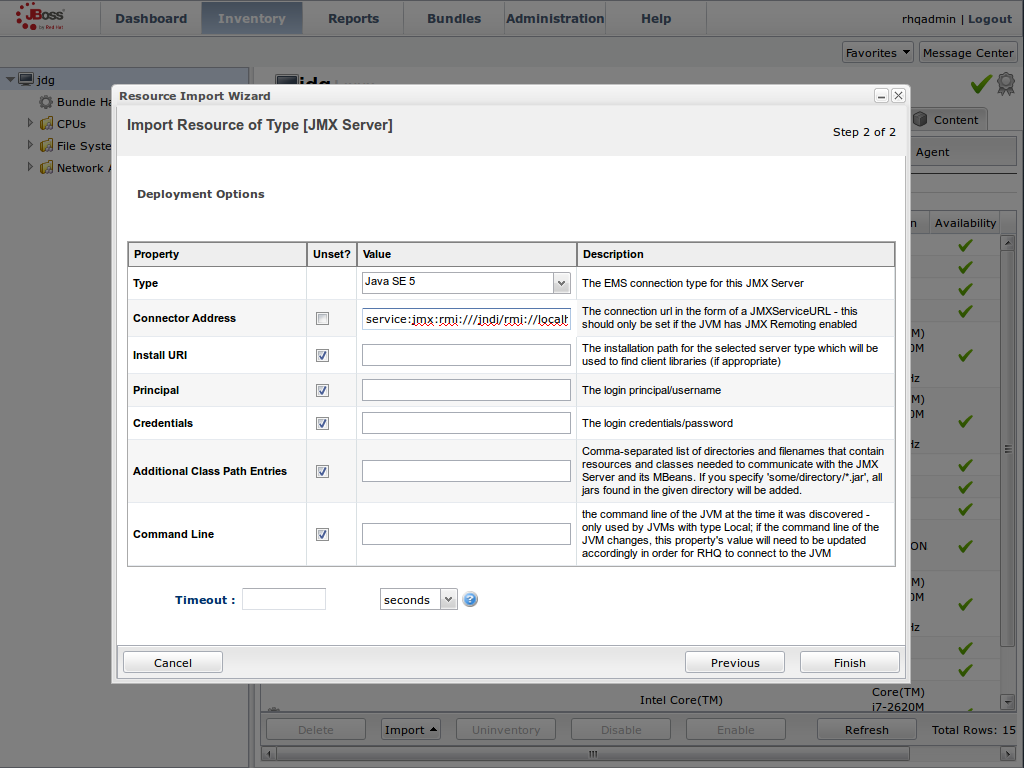
図22.8 Deployment Options 画面での値の修正。
キャッシュ統計および操作を表示します。
- をクリックして、サーバー一覧を最新の情報に更新します。
- 画面の左側のパネルにある ツリーには、 ノードが含まれ、これには利用可能なキャッシュマネージャーが含まれます。利用可能なキャッシュマネージャ−には利用可能なキャッシュが含まれます。
- メトリックスを表示するために利用可能なキャッシュからキャッシュを選択します。
- タブを選択します。
- ビューは、統計およびメトリックスを表示します。
- タブは、サービスで実行できるさまざまな操作へのアクセスを提供します。
図22.9 JMX 経由でリレーされるメトリックスおよび操作データは、JBoss Operations Network コンソールで利用可能。
22.6.2. ライブラリーモードでの JBoss Data Grid インスタンスの手動による追加
- >>> の順に選択します。
- ページの下部にある セクションの横のドロップダウンメニューを開きます。
- を選択し、 をクリックします。
- 次のページの
defaultテンプレートを選択します。 JBoss Data Grid インスタンスの手動による追加
- 監視する新規 JBoss Data Grid インスタンスの JMX コネクターのアドレスとキャッシュマネージャーの Mbean オブジェクト名の両方を入力します。以下が例になります。コネクターアドレス:
service:jmx:rmi://127.0.0.1/jndi/rmi://127.0.0.1:7997/jmxrmi
- オブジェクト名:
org.infinispan:type=CacheManager,name="<name_of_cache_manager>
注記
-Dcom.sun.management.jmxremote.port=7997 -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false
22.7. JBoss Operations Network リモートクライアントサーバーのプラグイン
22.7.1. JBoss Operations Network プラグインのメトリックス
表22.1 キャッシュコンテナーの JBoss Operations Network 特性 (キャッシュマネージャー)
| メトリック名 | 表示名 | 説明 |
|---|---|---|
| cache-manager-status | Cache Container Status | キャッシュコンテナーの現在のランタイム状態です。 |
| cluster-name | Cluster Name | クラスターの名前です。 |
| coordinator-address | Coordinator Address | コーディネーターノードのアドレスです。 |
| local-address | Local Address | ローカルノードのアドレスです。 |
表22.2 キャッシュについての JBoss Operations Network メトリックス
| メトリック名 | 表示名 | 説明 |
|---|---|---|
| cache-status | Cache Status | キャッシュの現在のランタイム状態です。 |
| number-of-locks-available | [LockManager] Number of locks available | 現在利用可能な排他ロックの数です。 |
| concurrency-level | [LockManager] Concurrency level | LockManager の設定済みの平行性レベルです。 |
| average-read-time | [Statistics] Average read time | キャッシュでの読み取り操作が完了するまでに必要な平均のミリ秒数です。 |
| hit-ratio | [Statistics] Hit ratio | ヒット数 (試行が成功した回数) を試行の合計数で割った結果 (パーセント単位) です。 |
| elapsed-time | [Statistics] Seconds since cache started | キャッシュ起動後の秒数です。 |
| read-write-ratio | [Statistics] Read/write ratio | キャッシュの読み取り/書き込み比率 (パーセント単位) です。 |
| average-write-time | [Statistics] Average write time | キャッシュでの書き込み操作の完了に必要な平均のミリ秒数です。 |
| hits | [Statistics] Number of cache hits | キャッシュヒット数です。 |
| evictions | [Statistics] Number of cache evictions | キャッシュエビクション操作の数です。 |
| remove-misses | [Statistics] Number of cache removal misses | キーが見つからなかった場合のキャッシュ除去の回数です。 |
| time-since-reset | [Statistics] Seconds since cache statistics were reset | 最後にキャッシュ統計がリセットされてからの秒数です。 |
| number-of-entries | [Statistics] Number of current cache entries | キャッシュ内の現在のエントリーの数です。 |
| stores | [Statistics] Number of cache puts | キャッシュの put 操作の回数 |
| remove-hits | [Statistics] Number of cache removal hits | キャッシュの remove 操作のヒット数です。 |
| misses | [Statistics] Number of cache misses | キャッシュミスの数です。 |
| success-ratio | [RpcManager] Successful replication ratio | 数値 (double) 形式でのレプリケーションの合計数に対する正常なレプリケーションの比率です。 |
| replication-count | [RpcManager] Number of successful replications | 成功したレプリケーションの数 |
| replication-failures | [RpcManager] Number of failed replications | 失敗したレプリケーションの数 |
| average-replication-time | [RpcManager] Average time spent in the transport layer | トランスポート層で費やされた平均時間 (ミリ秒単位) です。 |
| commits | [Transactions] Commits | 最終リセット時から実行されるトランザクションのコミット数です。 |
| prepares | [Transactions] Prepares | 最終リセット時から実行されるトランザクションの準備回数です。 |
| rollbacks | [Transactions] Rollbacks | 最終リセット時から実行されるトランザクションのロールバック回数です。 |
| invalidations | [Invalidation] Number of invalidations | インバリデーションの数です。 |
| passivations | [Passivation] Number of cache passivations | パッシベーションイベントの数です。 |
| activations | [Activations] Number of cache entries activated | アクティベーションイベントの数です。 |
| cache-loader-loads | [Activation] Number of cache store loads | キャッシュストアから読み込まれるエントリーの数です。 |
| cache-loader-misses | [Activation] Number of cache store misses | キャッシュストアに存在しなかったエントリーの数です。 |
| cache-loader-stores | [CacheStore] Number of cache store stores | キャッシュストアに保存されるエントリーの数です。 |
注記
Red Hat JBoss Data Grid の JBoss Operations Network (JON) プラグインによって提供されるメトリックスは、REST と Hot Rod エンドポイント用のみです。REST プロトコルの場合、データは Web サブシステムのメトリックスから取られる必要があります。これらのエンドポイントのそれぞれについてさらに詳しくは、『スタートガイド』を参照してください。
表22.3 コネクターついての JBoss Operations Network メトリックス
| メトリック名 | 表示名 | 説明 |
|---|---|---|
| bytesRead | Bytes Read | 読み込まれるバイト数です。 |
| bytesWritten | Bytes Written | 書き込まれるバイト数です。 |
注記
22.7.2. JBoss Operations Network プラグイン操作
表22.4 キャッシュについての JBoss ON プラグイン操作
| 操作名 | 説明 |
|---|---|
| Clear Cache | キャッシュ内容をクリアにします。 |
| Reset Statistics | キャッシュによって収集される統計をリセットします。 |
| Reset Activation Statistics | キャッシュによって収集されるアクティベーション統計をリセットします。 |
| Reset Invalidation Statistics | キャッシュによって収集されるインバリデーション統計をリセットします。 |
| Reset Passivation Statistics | キャッシュによって収集されるパッシベーション統計をリセットします。 |
| Reset Rpc Statistics | キャッシュによって収集されるレプリケーション統計をリセットします。 |
| Remove Cache | キャッシュコンテナーから所定のキャッシュを削除します。 |
これらの操作に使用されるキャッシュバックアップは、データセンター間レプリケーションを使用して設定されます。JBoss Operations Network (JON) ユーザーインターフェースでは、それぞれのキャッシュバックアップはキャッシュの子です。データセンター間のレプリケーションについてさらに詳しくは、「データセンター間レプリケーションについて」を参照してください。
表22.5 キャッシュバックアップについての JBoss Operations Network プラグイン操作
| 操作名 | 説明 |
|---|---|
| status | サイトの状態を表示します。 |
| bring-site-online | サイトをオンラインにします。 |
| take-site-offline | サイトをオフラインにします。 |
Red Hat JBoss Data Grid は、リモートクライアントサーバーモードでのトランザクションの使用をサポートしません。結果として、いずれのエンドポイントでもトランザクションを使用することができません。
22.7.3. JBoss Operations Network プラグイン属性
表22.6 キャッシュの JBoss ON プラグイン属性 (トランスポート)
| 属性名 | タイプ | 説明 |
|---|---|---|
| cluster | string | グループ通信クラスターの名前。 |
| executor | string | トランスポートに使用されるエグゼキューター。 |
| lock-timeout | long | トランスポートにおけるロックのタイムアウト期間。デフォルト値は 240000 です。 |
| machine | string | トランスポートのマシン ID。 |
| rack | string | トランスポートのラック ID。 |
| site | string | トランスポートのサイト ID。 |
| stack | string | トランスポートに使用される JGroups スタック。 |
22.8. ライブラリーモードを使用した JBoss Enterprise Application Platform 6 アプリケーションのモニタリング
22.8.1. 前提条件
- JBoss Operations Network (JON) 3.1.x 以上の正しく設定されたインスタンス。
- アプリケーションが実行されるサーバー上での JBoss Operations Network (JON) エージェントの実行中のインスタンスです。さらに詳しくは、「JBoss Operations Network エージェント」を参照してください。
- 完全な JDK を含む RHQ エージェントの操作インスタンス。エージェントには、とくに JDK からの
tools.jarファイルへのアクセスがあることを確認します。JBoss Operations Network (JON) エージェントの環境ファイル (bin/rhq-env.sh) で、RHQ_AGENT_JAVA_HOMEプロパティーの値を完全な JDK に設定します。 - RHQ エージェントは、JBoss Enterprise Application Platform インスタンスと同じユーザーを使用して起動している必要があります。例として、JBoss Operations Network (JON) エージェントを root 権限を持つユーザーとして実行し、JBoss Enterprise Application Platform プロセスを異なるユーザーとして実行しても予想通りには機能しないため、この実行を避ける必要があります。
- ライブラリーモード用にインストールされた JBoss Operations Network (JON) プラグインです。さらに詳しくは、「JBoss Operations Network プラグインのインストール (ライブラリーモード) 」を参照してください。
- Red Hat JBoss Data Grid のライブラリーモードを使用したカスタムアプリケーションです。このアプリケーションでは、
jmxStatisticsを有効にする必要があります (宣言的にか、またはプログラムを使用するかのいずれかによる)。さらに詳しくは、「キャッシュインスタンスに対して JMX を有効にする」を参照してください。 - Java 仮想マシン (JVM) は、JMX MBean Server を公開するために設定する必要があります。Oracle/Sun JDK については、http://docs.oracle.com/javase/1.5.0/docs/guide/management/agent.htmlを参照してください。
- JBoss Enterprise Application Platform の正しく追加され、設定された管理ユーザーです。
22.8.2. スタンドアロンモードでデプロイされたアプリケーションの監視
手順22.4 スタンドアロンモードでデプロイされたアプリケーションの監視
JBoss Enterprise Application Platform インスタンスを起動します。
JBoss Enterprise Application Platform インスタンスを以下のように起動します。- 以下のコマンドをコマンドラインに入力し、新規オプションをスタンドアロン設定ファイル (
/bin/standalone.conf) に追加します。JAVA_OPTS="$JAVA_OPTS -Dorg.rhq.resourceKey=MyEAP"
- JBoss Enterprise Application Platform インスタンスをスタンドアロンモードで以下のように起動します。
$JBOSS_HOME/bin/standalone.sh
JBoss Operations Network (JON) 検出を実行します。
JBoss Operations Network (JON) エージェントでdiscovery --fullコマンドを実行します。アプリケーションサーバープロセスを見つけます。
JBoss Operations Network (JON) web インターフェースに、JBoss Enterprise Application Platform 6 プロセスが JMX サーバーとしてリストされます。プロセスをインベントリーにインポートします。
プロセスを JBoss Operations Network (JON) インベントリーにインポートします。Red Hat JBoss Data Grid アプリケーションをデプロイします。
globalJmxStatisticsおよびjmxStatisticsを有効にした JJBoss Data Grid ライブラリーモードアプリケーションが含まれる WAR ファイルをデプロイします。オプション: 検出を再度実行します。
必要な場合は、discovery --fullコマンドを再び実行し、新規リソースを検出します。
JBoss Data Grid ライブラリーモードアプリケーションが JBoss Enterprise Application Platform のスタンドアロンモードでデプロイされ、JBoss Operations Network (JON) を使用して監視することができるようになります。
22.8.3. ドメインモードでデプロイされたアプリケーションの監視
手順22.5 ドメインモードでデプロイされたアプリケーションの監視
ホスト設定の編集
domain/configuration/host.xmlファイルを編集し、server要素を以下の設定に置き換えます。<servers> <server name="server-one" group="main-server-group"> <jvm name="default"> <jvm-options> <option value="-Dorg.rhq.resourceKey=EAP1"/> </jvm-options> </jvm> </server> <server name="server-two" group="main-server-group" auto-start="true"> <socket-bindings port-offset="150"/> <jvm name="default"> <jvm-options> <option value="-Dorg.rhq.resourceKey=EAP2"/> </jvm-options> </jvm> </server> </servers>
JBoss Enterprise Application Platform の起動
ドメインモードによる JBoss Enterprise Application Platform 6 の起動:$JBOSS_HOME/bin/domain.sh
Red Hat JBoss Data Grid アプリケーションのデプロイ
globalJmxStatisticsおよびjmxStatisticsを有効にした JBoss Data Grid ライブラリーモードアプリケーションが含まれる WAR ファイルをデプロイします。JBoss Operations Network (JON) での検出の実行
必要な場合は、新規リソースを検出するために JBoss Operations Network (JON) エージェントについてdiscovery --fullコマンドを実行します。
JBoss Data Grid ライブラリーモードアプリケーションが、JBoss Enterprise Application Platform のドメインモードでデプロイされ、JBoss Operations Network (JON) を使用して監視することができるようになります。
22.9. JBoss Operations Network のプラグインクイックスタート
パート XI. コマンドラインツール
- JBoss Data Grid Library CLI。詳細については、「Red Hat JBoss Data Grid ライブラリーモード CLI」を参照してください。
- JBoss Data Grid Server CLI。詳細については、「Red Hat Data Grid Server CLI」を参照してください。
第23章 Red Hat JBoss Data Grid CLI
23.1. Red Hat JBoss Data Grid ライブラリーモード CLI
infinispan-cli-server-$VERSION.jar) にはコマンドのインタープリターが含まれており、このモジュールはアプリケーションに組み込まれている必要があります。
23.1.1. ライブラリーモード CLI (サーバー) の起動
standalone および cluster ファイルを使って起動します。Linux の場合、standlaone.sh または clustered.sh スクリプトを使用し、Windows の場合、standalone.bat または clustered.bat ファイルを使用します。
23.1.2. ライブラリーモード CLI (クライアント) の起動
bin ディレクトリーにある cli ファイルを使用して JBoss Data Grid CLI クライアントを起動します。Linux の場合は、bin/cli.sh を実行し、Windows の場合は、bin\cli.bat を実行します。
23.1.3. CLI クライアントのコマンドラインスイッチ
表23.1 CLI クライアントのコマンドラインスイッチ
| 短縮表記 | 全表記 | 説明 |
|---|---|---|
| -c | --connect=${URL} | 実行中の Red Hat JBoss Data Grid インスタンスに接続します。たとえば、JMX over RMI の場合、jmx://[username[:password]]@host:port[/container[/cache]] を使用し、JMX over JBoss Remoting の場合は remoting://[username[:password]]@host:port[/container[/cache]] を使用します。 |
| -f | --file=${FILE} | インタラクティブモードではなく、指定されたファイルからの入力を読み込みます。値が - に設定されると、stdin が入力として使用されます。 |
| -h | --help | ヘルプ情報を表示します。 |
| -v | --version | CLI のバージョン情報を表示します。 |
23.1.4. アプリケーションへの接続
[disconnected//]> connect jmx://localhost:12000 [jmx://localhost:12000/MyCacheManager/>
注記
12000 は、JVM が開始される際の値によって変わります。たとえば、JVM を -Dcom.sun.management.jmxremote.port=12000 コマンドラインパラメーターを使用して開始する場合はこのポートが使用されますが、それ以外の場合はランダムポートが選択されます。リモートプロトコル (remoting://localhost:9999) が使用される場合、Red Hat JBoss Data Grid サーバー管理ポートが使用されます (デフォルトはポート 9999)。
CacheManager を含む、アクティブな接続情報を表示します。
cache コマンドを使用してキャッシュを選択します。CLI はタブ補完をサポートしているため、cache を使用してタブボタンを押すと、アクティブなキャッシュのリストが表示されます。
[[jmx://localhost:12000/MyCacheManager/> cache ___defaultcache namedCache [jmx://localhost:12000/MyCacheManager/]> cache ___defaultcache [jmx://localhost:12000/MyCacheManager/___defaultcache]>
23.1.5. CLI による Red Hat JBoss Data Grid インスタンスの終了
コンテナー内で Red Hat JBoss Data Grid インスタンスをライブラリーモードのデプロイとして実行している場合、JBoss Data Grid のライフサイクルはユーザーデプロイメントのライフサイクルにバインドされます。
リモートクライアントサーバーの JBoss Data Grid インスタンスは、以下のスクリプトを使用して終了することができます。
jboss-datagrid-{VERSION}-server/bin/init.d/jboss-datagrid.sh stopkill コマンドを直接使用することができます。
kill -15 $pid # send the TERM signal
PID が残っている場合、以下を使用してください。
kill -9 $pid
23.2. Red Hat Data Grid Server CLI
- 設定
- 管理
- メトリックスの取得
23.2.1. サーバーモード CLI の起動
$ JDG_HOME/bin/cli.sh
C:\>JDG_HOME\bin\cli.bat
23.3. CLI コマンド
deny (「deny コマンド」を参照)、grant (「grant コマンド」を参照)、およびroles (「roles コマンド」を参照) コマンドは、サーバーモード CLI でのみ利用可能です。
23.3.1. abort コマンド
abort コマンドは、start コマンドを使用して開始された実行中のバッチを中止します。バッチ処理は指定したキャッシュに対して有効にされている必要があります。以下は使用例です。
[jmx://localhost:12000/MyCacheManager/namedCache]> start [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> abort [jmx://localhost:12000/MyCacheManager/namedCache]> get a null
23.3.2. begin コマンド
begin コマンドはトランザクションを開始します。このコマンドでは、対象とするキャッシュに対してトランザクションを有効にする必要があります。このコマンドの使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> begin [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> put b b [jmx://localhost:12000/MyCacheManager/namedCache]> commit
23.3.3. cache コマンド
cache コマンドは、すべての後続の操作に使用されるデフォルトキャッシュを指定します。パラメーターを指定せずに呼び出されると、現在選択されているキャッシュを表示します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> cache ___defaultcache [jmx://localhost:12000/MyCacheManager/___defaultcache]> cache ___defaultcache [jmx://localhost:12000/MyCacheManager/___defaultcache]>
23.3.4. clear コマンド
clear コマンドは、キャッシュからすべてのコンテンツをクリアします。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> clear [jmx://localhost:12000/MyCacheManager/namedCache]> get a null
23.3.5. commit コマンド
commit コマンドは、進行中のトランザクションへの変更をコミットします。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> begin [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> put b b [jmx://localhost:12000/MyCacheManager/namedCache]> commit
23.3.6. container コマンド
container コマンドはデフォルトのキャッシュコンテナー (キャッシュマネージャー) を選択します。パラメーターを指定せずに呼び出されると、利用可能なすべてのコンテナーをリストします。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> container MyCacheManager OtherCacheManager [jmx://localhost:12000/MyCacheManager/namedCache]> container OtherCacheManager [jmx://localhost:12000/OtherCacheManager/]>
23.3.7. create コマンド
create コマンドは、既存のキャッシュ定義に基づいて新規のキャッシュを作成します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> create newCache like namedCache [jmx://localhost:12000/MyCacheManager/namedCache]> cache newCache [jmx://localhost:12000/MyCacheManager/newCache]>
23.3.8. deny コマンド
deny コマンドは、以前にプリンシパルに割り当てられたロールを拒否するために使用できます。
[remoting://localhost:9999]> deny supervisor to user1
注記
deny コマンドは JBoss Data Grid サーバーモード CLI でのみ利用できます。
23.3.9. disconnect コマンド
disconnect コマンドは、現在アクティブな接続を解除します。これにより、CLI は別のインスタンスに接続できます。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> disconnect [disconnected//]
23.3.10. encoding コマンド
encoding コマンドは、キャッシュから/へのエントリーの読み書きを行う際に使用するデフォルトのコーデックを設定します。引数なしで呼び出される場合、現在選択されているコーデックが表示されます。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> encoding none [jmx://localhost:12000/MyCacheManager/namedCache]> encoding --list memcached hotrod none rest [jmx://localhost:12000/MyCacheManager/namedCache]> encoding hotrod
23.3.11. end コマンド
end コマンドは、 start コマンドを使用して開始された実行中のバッチを終了します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> start [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> end [jmx://localhost:12000/MyCacheManager/namedCache]> get a a
23.3.12. evict コマンド
evict コマンドは、キャッシュから特定のキーに関連付けられたエントリーをエビクトします。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> evict a
23.3.13. get コマンド
get コマンドは、指定されたキーと関連付けられている値を表示します。プリミティブ型および 文字列の場合に、get コマンドはデフォルト表現のみを表示します。他のオブジェクトの場合、オブジェクトの JSON 表現が表示されます。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> get a a
23.3.14. grant コマンド
ClusterRoleMapper と設定された場合は、ロールマッピングに対するプリンシパルはクラスターレジストリー (すべてのノードで利用可能なレプリケートされたキャッシュ) 内に格納されます。grant コマンドは、以下のようにプリンシパルに新しいロールを与えるために使用できます。
[remoting://localhost:9999]> grant supervisor to user1
注記
grant コマンドは JBoss Data Grid サーバーモード CLI でのみ利用できます。
23.3.15. info コマンド
info コマンドは選択されたキャッシュまたはコンテナーの設定を表示します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> info
GlobalConfiguration{asyncListenerExecutor=ExecutorFactoryConfiguration{factory=org.infinispan.executors.DefaultExecutorFactory@98add58}, asyncTransportExecutor=ExecutorFactoryConfiguration{factory=org.infinispan.executors.DefaultExecutorFactory@7bc9c14c}, evictionScheduledExecutor=ScheduledExecutorFactoryConfiguration{factory=org.infinispan.executors.DefaultScheduledExecutorFactory@7ab1a411}, replicationQueueScheduledExecutor=ScheduledExecutorFactoryConfiguration{factory=org.infinispan.executors.DefaultScheduledExecutorFactory@248a9705}, globalJmxStatistics=GlobalJmxStatisticsConfiguration{allowDuplicateDomains=true, enabled=true, jmxDomain='jboss.infinispan', mBeanServerLookup=org.jboss.as.clustering.infinispan.MBeanServerProvider@6c0dc01, cacheManagerName='local', properties={}}, transport=TransportConfiguration{clusterName='ISPN', machineId='null', rackId='null', siteId='null', strictPeerToPeer=false, distributedSyncTimeout=240000, transport=null, nodeName='null', properties={}}, serialization=SerializationConfiguration{advancedExternalizers={1100=org.infinispan.server.core.CacheValue$Externalizer@5fabc91d, 1101=org.infinispan.server.memcached.MemcachedValue$Externalizer@720bffd, 1104=org.infinispan.server.hotrod.ServerAddress$Externalizer@771c7eb2}, marshaller=org.infinispan.marshall.VersionAwareMarshaller@6fc21535, version=52, classResolver=org.jboss.marshalling.ModularClassResolver@2efe83e5}, shutdown=ShutdownConfiguration{hookBehavior=DONT_REGISTER}, modules={}, site=SiteConfiguration{localSite='null'}}
23.3.16. locate コマンド
locate コマンドは、分散クラスター内の指定されたエントリーの物理的な場所を表示します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> locate a [host/node1,host/node2]
23.3.17. put コマンド
put コマンドはエントリーをキャッシュに挿入します。キーに対するマッピングが存在する場合、put コマンドは古い値を上書きします。CLI により、キーと値を保存するために使用されるデータのタイプに対して制御が可能になります。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a
[jmx://localhost:12000/MyCacheManager/namedCache]> put b 100
[jmx://localhost:12000/MyCacheManager/namedCache]> put c 4139l
[jmx://localhost:12000/MyCacheManager/namedCache]> put d true
[jmx://localhost:12000/MyCacheManager/namedCache]> put e { "package.MyClass": {"i": 5, "x": null, "b": true } }put は次のようにライフスパンと最大アイドル時間の値を指定することができます。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a expires 10s [jmx://localhost:12000/MyCacheManager/namedCache]> put a a expires 10m maxidle 1m
23.3.18. replace コマンド
replace コマンドはキャッシュ内の既存のエントリーを指定した新しい値に置き換えます。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> replace a b [jmx://localhost:12000/MyCacheManager/namedCache]> get a b [jmx://localhost:12000/MyCacheManager/namedCache]> replace a b c [jmx://localhost:12000/MyCacheManager/namedCache]> get a c [jmx://localhost:12000/MyCacheManager/namedCache]> replace a b d [jmx://localhost:12000/MyCacheManager/namedCache]> get a c
23.3.19. roles コマンド
ClusterRoleMapper と設定された場合は、ロールマッピングに対するプリンシパルはクラスターレジストリー (すべてのノードで利用可能なレプリケートされたキャッシュ) 内に格納されます。roles コマンドは、特定のユーザーまたはすべてのユーザー (ユーザーが指定されていない場合) に関連付けられたロールをリストするために使用できます。
[remoting://localhost:9999]> roles user1 [supervisor, reader]
注記
roles コマンドは JBoss Data Grid サーバーモード CLI でのみ利用できます。
23.3.20. rollback コマンド
rollback コマンドは、進行中のトランザクションによる変更をロールバックします。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> begin [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> put b b [jmx://localhost:12000/MyCacheManager/namedCache]> rollback
23.3.21. site コマンド
site コマンドは、データセンター間レプリケーションに関連する管理タスクを実行します。また、このコマンドはサイトの状態についての情報を取得し、サイトの状態を切り替えます。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> site --status NYC online [jmx://localhost:12000/MyCacheManager/namedCache]> site --offline NYC ok [jmx://localhost:12000/MyCacheManager/namedCache]> site --status NYC offline [jmx://localhost:12000/MyCacheManager/namedCache]> site --online NYC
23.3.22. start コマンド
start コマンドは、操作のバッチを開始します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> start [jmx://localhost:12000/MyCacheManager/namedCache]> put a a [jmx://localhost:12000/MyCacheManager/namedCache]> put b b [jmx://localhost:12000/MyCacheManager/namedCache]> end
23.3.23. stats コマンド
stats コマンドはキャッシュの統計を表示します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> stats
Statistics: {
averageWriteTime: 143
evictions: 10
misses: 5
hitRatio: 1.0
readWriteRatio: 10.0
removeMisses: 0
timeSinceReset: 2123
statisticsEnabled: true
stores: 100
elapsedTime: 93
averageReadTime: 14
removeHits: 0
numberOfEntries: 100
hits: 1000
}
LockManager: {
concurrencyLevel: 1000
numberOfLocksAvailable: 0
numberOfLocksHeld: 0
}23.3.24. upgrade コマンド
upgrade コマンドは、ローリングアップグレードの手順を実装します。ローリングアップグレードの詳細については、『Red Hat JBoss Data Grid 開発者ガイド』の『ローリングアップグレード』の章を参照してください。
upgrade コマンドの使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> upgrade --synchronize=hotrod --all [jmx://localhost:12000/MyCacheManager/namedCache]> upgrade --disconnectsource=hotrod --all
23.3.25. version コマンド
version コマンドは、CLI クライアントおよびサーバーのバージョン情報を表示します。この使用例は次の通りです。
[jmx://localhost:12000/MyCacheManager/namedCache]> version Client Version 5.2.1.Final Server Version 5.2.1.Final
パート XII. 他の Red Hat JBoss Data Grid 機能
第24章 1 次キャッシュのセットアップ
24.1. 1 次キャッシュについて
24.2. 1 次キャッシュの設定
24.2.1. 1 次キャッシュの設定 (ライブラリーモード)
例24.1 ライブラリーモードの L1 キャッシュ設定
<clustering mode="distribution">
<sync/>
<l1 enabled="true"
lifespan="60000" />
</clustering>l1 要素は、分散キャッシュインスタンスにおけるキャッシュの動作を設定します。分散されていないキャッシュと共に使用されている場合、この要素は無視されます。
enabledパラメーターは 1 次キャッシュを有効にします。lifespanパラメーターは、1 次キャッシュに置かれる際に、エントリーの最大ライフスパンを設定します。
24.2.2. 1 次キャッシュの設定 (リモートクライアントサーバーモード)
例24.2 リモートクライアントサーバーモード用 L1 キャッシュの設定
<distributed-cache l1-lifespan="${VALUE}">
...
</distributed-cache>l1-lifespan 要素は、1 次キャッシュを有効にし、キャッシュの 1 次キャッシュエントリーについてのライフスパンを設定するために distributed-cache 要素に追加されます。この要素は、分散キャッシュにのみ有効です。
l1-lifespan が 0 または負の数値 (-1) に設定される場合、1 次キャッシュは無効になります。1 次キャッシュは、l1-lifespan の値が 0 より大きくなる場合に有効になります。
注記
注記
l1-lifespan 属性が設定されていない場合であっても分散キャッシュが使用されたときにデフォルトで有効になります。デフォルトのライフスパン値は 10 分です。JBoss Data Grid 6.3 以降、デフォルトのライフスパンは 0 であり L1 キャッシュが無効になります。l1-lifespan パラメーターにゼロ以外の値を設定して L1 キャッシュを有効にします。
第25章 トランザクションのセットアップ
25.1. トランザクション
25.1.1. トランザクションマネージャーについて
- トランザクションの開始および終了
- 各トランザクションについての情報の管理
- トランザクションが複数リソースにまたがって動作する際のトランザクションの調整
- 変更のロールバックによる、失敗したトランザクションからのリカバリー
25.1.2. XA リソースおよび同期
OK または ABORT のいずれかの投票を返します。トランザクションマネージャーがすべての XA リソースから OK 投票を受信する場合、トランザクションはコミットされ、それ以外の場合にはロールバックされます。
25.1.3. 楽観的トランザクションと悲観的トランザクション
- トランザクションの実行時に送信されるメッセージが少なくなる
- ロックの保持期間が短くなる
- スループットが改善する
注記
FORCE_WRITE_LOCK フラグを使用した場合の悲観的トランザクションでのみ可能になります。
25.1.4. 書き込みスキューのチェック
REPEATABLE_READ の分離レベルが必要です。さらに、クラスターモード (ディストリビューションモードまたはレプリケーションモード) で、エントリーのバージョン管理をセットアップします。ローカルモードの場合、エントリーのバージョン管理は不要です。
重要
25.1.5. 複数のキャッシュインスタンスにわたるトランザクション
25.2. トランザクションの設定
25.2.1. トランザクションの設定 (ライブラリーモード)
手順25.1 ライブラリーモードでのトランザクションの設定 (XML 設定)
トランザクションモードを設定します。
以下のテーブルで、利用可能なルックアップクラスのリストについての手順を確認します。<namedCache ...> <transaction transactionMode="{TRANSACTIONAL,NON_TRANSACTIONAL}"> ... </namedCache>トランザクションマネージャーを設定します。
transactionMode要素は、キャッシュがトランザクションであるかどうかを設定します。<namedCache ...> <transaction transactionMode="TRANSACTIONAL" transactionManagerLookupClass="{TransactionManagerLookupClass}"> </namedCache>ロックモードを設定します。
lockingModeパラメーターは、楽観的ロックまたは悲観的ロックのメソッドが使用されるかどうかを決定します。キャッシュが非トランザクションの場合、ロックモードは無視されます。このパラメーターのデフォルト値はOPTIMISTICです。<namedCache ...> <transaction transactionMode="TRANSACTIONAL" transactionManagerLookupClass="{TransactionManagerLookupClass}" lockingMode="{OPTIMISTIC,PESSIMISTIC}"> </namedCache>同期化を指定します。
useSynchronization要素は、トランザクションマネージャーを使って同期化を登録するようにキャッシュを設定するか、またはキャッシュ自体を XA リソースとして登録するようにキャッシュを設定します。この要素のデフォルト値はtrue(同期化の使用) です。<namedCache ...> <transaction transactionMode="TRANSACTIONAL" transactionManagerLookupClass="{TransactionManagerLookupClass}" lockingMode="{OPTIMISTIC,PESSIMISTIC}" useSynchronization="{true,false}"> </namedCache>リカバリーを設定します。
recovery要素は、trueに設定されるとキャッシュのリカバリーを有効にします。recoveryInfoCacheNameパラメーターは、リカバリー情報が保持されるキャッシュの名前を設定します。キャッシュのデフォルト名は__recoveryInfoCacheName__です。<namedCache ...> <transaction transactionMode="TRANSACTIONAL" transactionManagerLookupClass="{TransactionManagerLookupClass}" lockingMode="{OPTIMISTIC,PESSIMISTIC}" useSynchronization="{true,false}"> <recovery enabled="true" recoveryInfoCacheName="{CacheName}" /> </namedCache>書き込みスキューチェックを設定します。
writeSkewチェックは、異なるトランザクションからのエントリーに対する変更によりトランザクションがロールバックされるべきかどうかを判別します。trueに設定された書き込みスキューにより、isolation_levelをREPEATABLE_READに設定する必要があります。writeSkewおよびisolation_levelのデフォルト値はそれぞれfalseとREAD_COMMITTEDです。<namedCache ...> <transaction ...> <locking isolation_level="{READ_COMMITTED,REPEATABLE_READ}" writeSkew="{true,false}" /> ... </namedCache>エントリーのバージョン管理を設定します。
クラスター化されたキャッシュについては、エントリーのバージョン管理を有効にし、その値をSIMPLEに設定することにより書き込みスキューのチェックを有効にします。<namedCache ...> <transaction ...> <locking ...> <versioning enabled="{true,false}" versioningScheme="{NONE|SIMPLE}"/> ... </namedCache>
手順25.2 ライブラリーモード (プログラムを用いた設定) でトランザクションを設定します。
トランザクションモードを設定します。
以下のようにトランザクションモードを設定します。Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL);トランザクションマネージャーを設定します。
以下のテーブルで、利用可能なルックアップクラスのリストについての手順を確認します。Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL) .transactionManagerLookup(new GenericTransactionManagerLookup());ロックモードを設定します。
lockingMode値は、楽観的または悲観的ロックを使用するかどうかを決定します。キャッシュが非トランザクションの場合、ロックモードは無視されます。デフォルト値はOPTIMISTICです。Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL) .transactionManagerLookup(new GenericTransactionManagerLookup()); .lockingMode(LockingMode.OPTIMISTIC);同期化を指定します。
useSynchronization値は、トランザクションマネージャーを使って同期化を登録するようにキャッシュを設定するか、またはキャッシュ自体を XA リソースとして登録するようにキャッシュを設定します。デフォルト値はtrue(同期の使用) です。Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL) .transactionManagerLookup(new GenericTransactionManagerLookup()); .lockingMode(LockingMode.OPTIMISTIC) .useSynchronization(true);リカバリーを設定します。
recoveryパラメーターは、trueに設定されるとキャッシュのリカバリーを有効にします。recoveryInfoCacheNameは、リカバリー情報が保持されるキャッシュの名前を設定します。キャッシュのデフォルト名はRecoveryConfiguration.DEFAULT_RECOVERY_INFO_CACHEによって指定されます。Configuration config = new ConfigurationBuilder()/* ... */.transaction() .transactionMode(TransactionMode.TRANSACTIONAL) .transactionManagerLookup(new GenericTransactionManagerLookup()); .lockingMode(LockingMode.OPTIMISTIC) .useSynchronization(true) .recovery() .recoveryInfoCacheName("anotherRecoveryCacheName");書き込みスキューチェックを設定します。
writeSkewチェックは、異なるトランザクションからのエントリーに対する変更によりトランザクションがロールバックされるべきかどうかを判別します。trueに設定された書き込みスキューにより、isolation_levelをREPEATABLE_READに設定する必要があります。writeSkewおよびisolation_levelのデフォルト値はそれぞれfalseとREAD_COMMITTEDです。Configuration config = new ConfigurationBuilder()/* ... */.locking() .isolationLevel(IsolationLevel.REPEATABLE_READ).writeSkewCheck(true);エントリーのバージョン管理を設定します。
クラスター化されたキャッシュについては、エントリーのバージョン管理を有効にし、その値をSIMPLEに設定することにより書き込みスキューのチェックを有効にします。Configuration config = new ConfigurationBuilder()/* ... */.versioning() .enable() .scheme(VersioningScheme.SIMPLE);
表25.1 トランザクションマネージャーのルックアップクラス
| クラス名 | 説明 |
|---|---|
| org.infinispan.transaction.lookup.DummyTransactionManagerLookup | テスト環境で主に使用されます。このテスト向けのトランザクションマネージャーは実稼働環境では使用されず、特に並列トランザクションやリカバリーなどの機能は厳しく制限されます。 |
| org.infinispan.transaction.lookup.JBossStandaloneJTAManagerLookup | Red Hat JBoss Data Grid がスタンドアロン環境で実行される場合のデフォルトのトランザクションマネージャーです。これにより、JBoss Transactions ベースの完全に機能するトランザクションマネージャーで、DummyTransactionManager の機能上の制限が解消されます。 |
| org.infinispan.transaction.lookup.GenericTransactionManagerLookup | GenericTransactionManagerLookup は、トランザクションルックアップクラスが指定されていない場合にデフォルトで使用されます。このルックアップクラスは、TransactionManager インターフェースを提供する Java EE 互換環境で JBoss Data Grid を使用する場合に推奨され、ほとんどの Java EE アプリケーションサーバーでトランザクションマネージャーを見つけるために使用できます。トランザクションマネージャーが見つからない場合、デフォルトは DummyTransactionManager になります。 |
| org.infinispan.transaction.lookup.JBossTransactionManagerLookup | JbossTransactionManagerLookup は、アプリケーションサーバーで実行中の標準的なトランザクションマネージャーを見つけます。このルックアップクラスは JNDI を使用して TransactionManager インスタンスを検索します。これは、カスタムキャッシュが JTA トランザクションで使用されている場合に推奨されます。 |
25.2.2. トランザクションの設定 (リモートクライアントサーバーモード)
例25.1 リモートクライアントサーバーモードでのトランザクション設定
<cache> ... <transaction mode="NONE" /> ... </cache>
重要
NONE に設定されます。このときにトランザクションがライブラリーモードインスタンスで設定される場合は、サーバーインスタンスでもトランザクションを設定する必要があります。
25.3. トランザクションリカバリー
25.3.1. トランザクションリカバリーのプロセス
手順25.3 トランザクションリカバリーのプロセス
- トランザクションマネージャーは介入が必要なトランザクションの一覧を作成します。
- 電子メールまたはログを使用して、JMX を使用して JBoss Data Grid に接続するシステム管理者へトランザクション (トランザクション ID を含む) の一覧を提供します。各トランザクションの状態は
COMMITTEDかPREPAREDになります。COMMITTEDとPREPAREDの両方の状態であるトランザクションがある場合、トランザクションがあるノード上でコミットされている一方、他のノードで準備状態のトランザクションがあることを示しています。 - システム管理者は、トランザクションマネージャーより受信した XID を JBoss Data Grid の内部 ID へ視覚的にマッピングします。XID (バイトアレイ) を JMX ツールに渡し、このマッピングがない状態で JBoss Data Grid によって再アセンブルすることはできないため、この手順が必要となります。
- マッピングされた内部 ID を基に、システム管理者はトランザクションに対してコミットまたはロールバックプロセスを強制します。
25.3.2. トランザクションリカバリーの例
例25.2 データベースに格納された口座から JBoss Data Grid 内の口座への送金
- 送信元 (データベース) と送信先 (JBoss Data Grid) リソース間の 2 フェーズコミットプロトコルを実行するために、
TransactionManager.commit()メソッドが呼び出されます。 TransactionManagerが、準備フェーズ (2 フェーズコミットの最初のフェーズ) を開始するようデータベースと JBoss Data Grid に指示します。
注記
25.4. デッドロックの検出
disabled に設定されます。
25.4.1. デッドロック検出を有効にする
disabled に設定されていますが、以下を追加して namedCache 設定要素を使用すると、デッドロック検出を有効にし、各キャッシュに対して設定を行うことが可能です。
<deadlockDetection enabled="true" spinDuration="100"/>
spinDuration 属性は、特定ロックの取得が許可される時間 (ミリ秒単位) 内にロックの取得を試行する頻度を定義します。
第26章 JGroups の設定
26.1. JGroups について
26.2. Red Hat JBoss Data Grid インターフェースバインディングの設定 (リモートクライアントサーバーモード)
26.2.1. インターフェース
link-local:169.x.x.xまたは254.x.x.xアドレスを使用します。これは、1 つのボックス内のトラフィックに適しています。<interfaces> <interface name="link-local"> <link-local-address/> </interface> ... </interfaces>site-local: たとえば192.168.x.xなどのプライベート IP アドレスを使用します。これにより、GoGrid や同様のプロバイダーから追加の帯域幅についてチャージされることを避けられます。<interfaces> <interface name="site-local"> <site-local-address/> </interface> ... </interfaces>global: パブリック IP アドレスを選択します。これは、レプリケーショントラフィックの場合は避ける必要があります。<interfaces> <interface name="global"> <any-address/> </interface> ... </interfaces>non-loopback:127.x.x.xアドレスではないアクティブなインターフェースにある最初のアドレスを使用します。<interfaces> <interface name="non-loopback"> <not> <loopback /> </not> </interface> </interfaces>
26.2.2. ソケットのバインディグ
26.2.2.1. 単一のソケットをバインドする例
socket-binding 要素を用いて個別のソケットをバインドする例を表しています。
例26.1 ソケットバインディング
<socket-binding name="jgroups-udp" ... interface="site-local"/>
26.2.2.2. ソケットのグループをバインドする例
socket-binding-group 要素を用いてグループをバインドする例を表しています。
例26.2 グループのバインド
<socket-binding-group name="ha-sockets" default-interface="global"> ... <socket-binding name="jgroups-tcp" port="7600"/> <socket-binding name="jgroups-tcp-fd" port="57600"/> ... </socket-binding-group>
default-interface (global) にバインドされます。そのため、インターフェース属性を指定する必要はありません。
26.2.3. JGroups ソケットバインディングの設定
例26.3 JGroups ソケットバインディング設定
<subsystem xmlns="urn:jboss:domain:jgroups:1.2" default-stack="udp">
<stack name="udp">
<transport type="UDP" socket-binding="jgroups-udp">
...
</transport>
<!-- rest of protocols -->
</stack>
</subsystem>重要
26.3. JGroups の設定 (ライブラリーモード)
例26.4 JGroups プログラムによる設定
GlobalConfiguration gc = new GlobalConfigurationBuilder()
.transport()
.defaultTransport()
.addProperty("configurationFile","jgroups.xml")
.build();例26.5 JGroups XML 設定
<infinispan>
<global>
<transport>
<properties>
<property name="configurationFile" value="jgroups.xml" />
</properties>
</transport>
</global>
...
</infinispan>jgroups.xml を検索します。
26.3.1. JGroups トランスポートプロトコル
26.3.1.1. UDP トランスポートプロトコル
- クラスターのすべてのメンバーにメッセージを送信する IP マルチキャスト。
- 単一メンバーに送信されるユニキャストメッセージの UDP データグラム。
26.3.1.2. TCP トランスポートプロトコル
- マルチキャストメッセージを送信する場合に、TCP は複数のユニキャストメッセージを送信します。
- TCP を使用する場合に、すべてのクラスターメンバーに対するそれぞれのメッセージが複数のユニキャストメッセージとして送信されるか、または各メンバーに対して 1 つのメッセージが送信されます。
26.3.1.3. TCPPing プロトコルの使用
jgroups-tcp.xml には、検出に UDP マルチキャストを使用する MPING プロトコルが含まれます。UDP マルチキャストが使用できない場合、MPING プロトコルは異なるメカニズムによって置き換えられる必要があります。推奨される代替案は、TCPPING プロトコルの使用です。TCPPING 設定には、ノード検出のために接続される IP アドレスの静的なリストが含まれます。
例26.6 JGroups サブシステムが TCPPING を使用するよう設定する
<TCP bind_port="7800" />
<TCPPING timeout="3000"
initial_hosts="${jgroups.tcpping.initial_hosts:HostA[7800],HostB[7801]}"
port_range="1"
num_initial_members="3"/>26.3.2. 事前設定された JGroups ファイル
infinispan-core.jar にパッケージ化され、デフォルトでクラスパス上にて使用可能です。これらのファイルの 1 つを使用するには、jgroups.xml を使用する代わりに使用するファイルの名前を指定します。
jgroups-udp.xmljgroups-tcp.xmljgroups-ec2.xml
26.3.2.1. jgroups-udp.xml
jgroups-udp.xml は Red Hat JBoss Data Grid の事前設定された JGroups ファイルです。jgroups-udp.xml 設定には次のような特徴があります。
- UDP をトランスポートとして使用し、UDP マルチキャストをディスカバリーに使用します。
- 大型のクラスター (9 以上のノード) に適しています。
- インバリデーションまたはレプリケーションモードを使用する場合に適しています。
表26.1 jgroups-udp.xml システムプロパティー
| システムプロパティー | 説明 | デフォルト | 必要性 |
|---|---|---|---|
| jgroups.udp.mcast_addr | マルチキャスト (通信とディスカバリーの両方) に使用する IP アドレス。IP マルチキャストに適した有効なクラス D IPアドレスでなければなりません。 | 228.6.7.8 | いいえ |
| jgroups.udp.mcast_port | マルチキャストに使用するポート | 46655 | いいえ |
| jgroups.udp.ip_ttl | IP マルチキャストパケットの TTL (有効期間) を指定します。この値は、パケットがドロップされる前に許可されるネットワークホップの数になります。 | 2 | いいえ |
26.3.2.2. jgroups-tcp.xml
jgroups-tcp.xml は Red Hat JBoss Data Grid の事前設定された JGroups ファイルです。jgroups-tcp.xml 設定には次のような特徴があります。
- TCP をトランスポートとして使用し、UDP マルチキャストをディスカバリーに使用します。
- 通常は、マルチキャスト UDP がオプションではない場合にのみ使用されます。
- 8 つ以上のノードから構成されるクラスターの場合、TCP は UDP ほどパフォーマンスがよくありません。4 つ以下のノードで構成されるクラスターの場合、UDP と TCP のパフォーマンスはほとんど同じレベルになります。
表26.2 jgroups-udp.xml システムプロパティー
| システムプロパティー | 説明 | デフォルト | 必要性 |
|---|---|---|---|
| jgroups.tcp.address | TCP トランスポートに使用する IP アドレス | 127.0.0.1 | いいえ |
| jgroups.tcp.port | TCP ソケットに使用するポート | 7800 | いいえ |
| jgroups.udp.mcast_addr | マルチキャスト (ディスカバリー) に使用する IP アドレス。IP マルチキャストに適した有効なクラス D IP アドレスでなければなりません。 | 228.6.7.8 | いいえ |
| jgroups.udp.mcast_port | マルチキャストに使用するポート | 46655 | いいえ |
| jgroups.udp.ip_ttl | IP マルチキャストパケットの TTL (有効期間) を指定します。この値は、パケットがドロップされる前に許可されるネットワークホップの数になります。 | 2 | いいえ |
26.3.2.3. jgroups-ec2.xml
jgroups-ec2.xml は Red Hat JBoss Data Grid の事前設定された JGroups ファイルです。jgroups-ec2.xml 設定には次のような特徴があります。
- TCP をトランスポートとして使用し、ディスカバリーに S3_PING を使用します。
- UDP マルチキャストが使用できない Amazon EC2 ノードに適しています。
表26.3 jgroups-ec2.xml システムプロパティー
| システムプロパティー | 説明 | デフォルト | 必要性 |
|---|---|---|---|
| jgroups.tcp.address | TCP トランスポートに使用する IP アドレス。 | 127.0.0.1 | いいえ |
| jgroups.tcp.port | TCP ソケットに使用するポート。 | 7800 | いいえ |
| jgroups.s3.access_key | S3 バケットのアクセスに使用される Amazon S3 アクセスキー | はい | |
| jgroups.s3.secret_access_key | S3 バケットのアクセスに使用される Amazon S3 の秘密キー。 | はい | |
| jgroups.s3.bucket | 使用する Amazon S3 バケットの名前。一意の名前で、すでに存在している必要があります。 | はい | |
| jgroups.s3.pre_signed_delete_url | DELETE 操作に使用する事前署名付き URL。 | はい | |
| jgroups.s3.pre_signed_put_url | PUT 操作に使用する事前署名付き URL。 | はい | |
| jgroups.s3.prefix | 設定された場合、S3_PING はそのプレフィックス値で始まる名前のバケットを検索します。 | いいえ |
26.4. JGroups を使用したマルチキャストのテスト
26.4.1. 異なる Red Hat JBoss Data Grid バージョンを使用したテスト
表26.4 異なる JBoss Data Grid バージョンを使用したテスト
| バージョン | テストケース | 説明 |
|---|---|---|
| JBoss Data Grid 6.0 | 使用不可 | JBoss Data Grid のこのバージョンには、このテストで使用されるテストクラスが含まれない JBoss Enterprise Application Server 6.0 をベースにしています。 |
| JBoss Data Grid 6.0.1 | 使用不可 | JBoss Data Grid のこのバージョンには、このテストで使用されるテストクラスが含まれない JBoss Enterprise Application Platform 6.0 をベースにしています。 |
| JBoss Data Grid 6.1 | 利用可能 | JBoss Data Grid のこのバージョンは、JBoss Enterprise Application Platform 6.0.1 をベースとしていますが、JBoss Enterprise Application Platform に含まれる JAR ファイルよりも新しいバージョンの JGroups JAR ファイルが含まれます。そのため、このテストに必要なテストクラスは、JBoss Data Grid 6.1 用の $JBOSS_HOME/modules/org/jgroups/main ディレクトリーで入手できます。 |
| JBoss Data Grid 6.2 | 利用可能 | JBoss Data Grid のこのバージョンは、JBoss Enterprise Application Platform 6.1 をベースにしています。JAR ファイルの名前はバージョンに基づいて指定されます。たとえば、jgroups-3.2.7.Final-redhat-1.jar という名前になり、$JBOSS_HOME/modules/system/layers/base/org/jgroups/main ディレクトリーで入手できます。 |
26.4.2. JGroups を使用したマルチキャストのテスト
テストの手順を開始する前に以下の要件を満たしていることを確認してください。
bind_addr値をインスタンスの適切な IP アドレスに設定します。- 精度を高めるために、クラスター通信の値と同じ
mcast_addrとportの値を設定します。 - 2 つのコマンドラインターミナルウィンドウを起動します。最初のターミナルで 2 つのノードの内の 1 つの JGroups JAR ファイルのロケーションと、2 番目のターミナルで 2 つ目のノードの同じロケーションにナビゲートします。
手順26.1 JGroups を使用したマルチキャストのテスト
1 つ目のノードでマルチキャストサーバーを実行します。
最初のノードについて、コマンドラインターミナルで以下のコマンドを実行します。java -cp jgroups.jar org.jgroups.tests.McastReceiverTest -mcast_addr 230.1.2.3 -port 5555 -bind_addr $YOUR_BIND_ADDRESS
2 つ目のノードでマルチキャストサーバーを実行します。
2 つ目のノードについて、コマンドラインターミナルで以下のコマンドを実行します。java -cp jgroups.jar org.jgroups.tests.McastSenderTest -mcast_addr 230.1.2.3 -port 5555 -bind_addr $YOUR_BIND_ADDRESS
情報パケットを送信します。
2 つ目のノード (パケットを送信するノード) のインスタンスに情報を入力し、Enter を押して情報を送信します。受信情報パケットを表示します。
1 番目のノードのインスタンスで受信された情報を表示します。直前の手順で入力した情報がここに表示されます。情報転送を確認します。
パケットがドロップされずに、送信情報がすべて受信されていることを確認するために、手順 3 と 4 を繰り返します。他のインスタンスのテストを繰り返します。
送信者と受信者のそれぞれを確認するために、手順 1 から 4 を繰り返します。テストを繰り返すことにより、誤って設定された他のインスタンスが特定されます。
送信者ノードから送信されるすべての情報パケットは、受信者ノードに表示される必要があります。送信された情報が予想どおりに表示されない場合、マルチキャストがオペレーティングシステムまたはネットワークで誤って設定されていることになります。
第27章 Red Hat Data Grid の Amazon Web サービスとの使用
27.1. S3_PING JGroups 検出プロトコル
MPING が許可されないため、S3_PING は EC2 と一緒に使用するのに最適な検出プロトコルです。
27.2. S3_PING 設定オプション
- ライブラリーモードでは、JGroups の
jgroups-ec2.xmlファイル (さらに詳しくは 「jgroups-ec2.xml」 を参照してください) またはS3_PINGプロトコルを使用します。 - リモートクライアントサーバーモードでは、JGroups の
S3_PINGプロトコルを使用します。
S3_PING プロトコルを設定する方法として 3 つの方法があります。
- プライベート S3 バケットを使用します。これらのバケットは Amazon AWS の認証情報を使用します。
- 事前署名付き URL を使用します。これらの事前に割り当てられる URL は、プライベートの書き込みアクセスとパブリックの読み取りアクセスを持つバケットに割り当てられます。
- パブリック S3 バケットを使用します。これらのバケットには認証情報がありません。
27.2.1. プライベート S3 バケットの使用
- List
- Upload/Delete
- View Permissions
- Edit Permissions
S3_PING 設定には以下のプロパティーが含まれることを確認してください。
- バケットを指定するための
locationまたはprefixプロパティー (両方ではない)。prefixプロパティーが設定されている場合、S3_PINGはプレフィックス値で始まる名前のバケットを検索します。名前の先頭がプレフィックスのバケットが見つかった場合、S3_PINGはそのバケットを使用します。このプレフィックスを持つバケットが見つからない場合、S3_PINGは、AWS クレデンシャルを使用してバケットを作成し、そのプレフィックスと UUID に基いて名前を指定します (名前の形式は {prefix value}-{UUID})。 - AWS ユーザーには
access_keyとsecret_access_keyプロパティー。
注記
403 エラーが表示される場合、プロパティーに正しい値があることを検証してください。問題が存続する場合、EC2 ノードのシステム時間が正しいことを確認してください。Amazon S3 は、セキュリティー上の理由により、サーバーの時間よりも 15 分を超える遅れがあるタイムスタンプを持つ要求を拒否します。
例27.1 プライベートバケットの使用による Red Hat JBoss Data Grid サーバーの起動
bin/clustered.sh -Djboss.bind.address={server_ip_address} -Djboss.bind.address.management={server_ip_address} -Djboss.default.jgroups.stack=s3 -Djgroups.s3.bucket={s3_bucket_name} -Djgroups.s3.access_key={access_key} -Djgroups.s3.secret_access_key={secret_access_key}- {server_ip_address} をサーバーの IP アドレスに置き換えます。
- {s3_bucket_name} を適切なバケット名に置き換えます。
- {access_key} をユーザーのアクセスキーに置き換えます。
- {secret_access_key} をユーザーの秘密アクセスキーに置き換えます。
27.2.2. 事前署名付き URL の使用
S3_PING プロトコルで要求される場合に、put および delete 操作用に事前署名付き URL を生成します。この URL は固有のファイルを参照し、バケット内のフォルダーパスを組み込むことができます。
注記
S3_PING にエラーが発生します。たとえば、my_bucket/DemoCluster/node1 のようなパスは機能しますが、my_bucket/Demo/Cluster/node1 のようにパスが長くなると機能しません。
27.2.2.1. 事前署名付き URL の生成
S3_PING クラスには、事前署名付き URL を生成するためのユーティリティーメソッドが含まれます。このメソッドの最後の引数は、Unix epoch (1970 年 1 月 1 日) からの秒数で表される URL の有効期間です。
String Url = S3_PING.generatePreSignedUrl("{access_key}", "{secret_access_key}", "{operation}", "{bucket_name}", "{path}", {seconds});- {operation} を
PUTまたはDELETEのいずれかに置き換えます。 - {access_key} をユーザーのアクセスキーに置き換えます。
- {secret_access_key} をユーザーの秘密アクセスキーに置き換えます。
- {bucket_name} をバケットの名前に置き換えます。
- {path} をバケット内のファイルへの必要なパスに置き換えます。
- {seconds} を、Unix epoch (1970 年 1 月 1 日) からのパスの有効期間を表す秒数に置き換えます。
例27.2 事前署名付き URL の生成
String putUrl = S3_PING.generatePreSignedUrl("access_key", "secret_access_key", "put", "my_bucket", "DemoCluster/node1", 1234567890);S3_PING 設定に、S3_PING.generatePreSignedUrl() の呼び出しで生成された pre_signed_put_url および pre_signed_delete_url プロパティーが含まれていることを確認してください。この設定の場合、AWS 認証情報がクラスター内の各ノードに保存されないため、プライベート S3 バケットを使用する設定よりも安全度が高くなります。
注記
& 文字をその XML エンティティー (&) に置き換える必要があります。
27.2.2.2. コマンドラインを使用した事前署名付き URL の設定
- URL を二重引用符 (
"") で囲みます。 - URL では、アンパーサンド (
&) 文字の各出現箇所はバックスラッシュ (\) でエスケープする必要があります。
例27.3 事前署名付き URL による JBoss Data Grid サーバーの起動
bin/clustered.sh -Djboss.bind.address={server_ip_address} -Djboss.bind.address.management={server_ip_address} -Djboss.default.jgroups.stack=s3 -Djgroups.s3.pre_signed_put_url="http://{s3_bucket_name}.s3.amazonaws.com/ node1?AWSAccessKeyId={access_key}\&Expires={expiration_time}\&Signature={signature}"-Djgroups.s3.pre_signed_delete_url="http://{s3_bucket_name}.s3.amazonaws.com/ node1?AWSAccessKeyId={access_key}\&Expires={expiration_time}\&Signature={signature}"{signatures} 値は S3_PING.generatePreSignedUrl() メソッドによって生成されます。さらに、{expiration_time} 値は、S3_PING.generatePreSignedUrl() メソッドに渡される URL の有効期間です。
27.2.3. パブリック S3 バケットの使用
location プロパティーは、この設定のバケット名で指定する必要があります。この設定メソッドは、バケットの名前を知っているいずれのユーザーもバケットにデータをアップロードしたり、保存したりでき、バケット作成者のアカウントはこのデータについてチャージされるため、安全度は最も低くなります。
bin/clustered.sh -Djboss.bind.address={server_ip_address} -Djboss.bind.address.management={server_ip_address} -Djboss.default.jgroups.stack=s3 -Djgroups.s3.bucket={s3_bucket_name}27.2.4. S3_PING 警告のトラブルシューティング
S3_PING 設定タイプにより、以下の警告が JBoss Data Grid サーバーの起動時に表示される場合があります。
15:46:03,468 WARN [org.jgroups.conf.ProtocolConfiguration] (MSC service thread 1-7) variable "${jgroups.s3.pre_signed_put_url}" in S3_PING could not be substituted; pre_signed_put_url is removed from properties15:46:03,469 WARN [org.jgroups.conf.ProtocolConfiguration] (MSC service thread 1-7) variable "${jgroups.s3.prefix}" in S3_PING could not be substituted; prefix is removed from properties15:46:03,469 WARN [org.jgroups.conf.ProtocolConfiguration] (MSC service thread 1-7) variable "${jgroups.s3.pre_signed_delete_url}" in S3_PING could not be substituted; pre_signed_delete_url is removed from propertiesS3_PING 設定では不要であることを確認してください。
第28章 サーバーヒンティングを用いた高可用性
machineId、rackId、または siteId を transport 設定に設定することにより、TopologyAwareConsistentHashFactory の使用がトリガーされます。これは、サーバーヒンティングが有効にされた状態の DefaultConsistentHashFactory に相当します。
28.1. JGroups によるサーバーヒンティングの設定
関連トピック:
28.2. サーバーヒンティングの設定 (リモートクライアントサーバーモード)
transport 要素の JGroup サブシステムで設定されます。
手順28.1 リモートクライアントサーバーモードでのサーバーヒンティングの設定
JGroups サブシステム設定を検索します。
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="${jboss.default.jgroups.stack:udp}"> <stack name="udp">transport要素でサーバーヒンティングを有効にします。サイト ID を設定します。
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="${jboss.default.jgroups.stack:udp}"> <stack name="udp"> <transport type="UDP" socket-binding="jgroups-udp" site="${jboss.jgroups.transport.site:s1}">ラック ID を設定します。
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="${jboss.default.jgroups.stack:udp}"> <stack name="udp"> <transport type="UDP" socket-binding="jgroups-udp" site="${jboss.jgroups.transport.site:s1}" rack="${jboss.jgroups.transport.rack:r1}">マシン ID を設定します。
<subsystem xmlns="urn:jboss:domain:jgroups:1.1" default-stack="${jboss.default.jgroups.stack:udp}"> <stack name="udp"> <transport type="UDP" socket-binding="jgroups-udp" site="${jboss.jgroups.transport.site:s1}" rack="${jboss.jgroups.transport.rack:r1}" machine="${jboss.jgroups.transport.machine:m1}"> ... </transport> </stack> </subsystem>
28.3. サーバーヒンティングの設定 (ライブラリーモード)
手順28.2 ライブラリーモードでのサーバーヒンティングの設定
clusterName属性を設定します。clusterName属性はクラスターに割り当てられた名前を指定します。<transport clusterName = "MyCluster" />
machineIdを追加します。machineId属性は、元データを格納する JVM インスタンスを指定します。これは、複数の JVM があるノードや複数の仮想ホストを持つ物理ホストに対して特に有用な属性です。<transport clusterName = "MyCluster" machineId = "LinuxServer01" />rackIdを追加します。rackIdパラメーターは、元データが含まれるラックを指定します。これにより、別のラックがバックアップに使用されるようにします。<transport clusterName = "MyCluster" machineId = "LinuxServer01" rackId = "Rack01" />siteIdを追加します。siteIdパラメーターは、相互にレプリケーションを行っている異なるデータセンターのノードを区別します。<transport clusterName = "MyCluster" machineId = "LinuxServer01" rackId = "Rack01" siteId = "US-WestCoast" />
machineId、rackId、または siteId が設定に含まれている場合、TopologyAwareConsistentHashFactory が自動的に選択され、サーバーヒンティングを有効にします。ただし、サーバーヒンティングが設定されていない場合、JBoss Data Grid の分散アルゴリズムにより元データと同じ物理マシン/ラック/データセンターにレプリケーションを保存することができます。
28.4. ConsistentHashFactories
DefaultConsistentHashFactory- あらゆるノード全体でセグメントの均等な分散を図りますが、キーマッピングは、各キャッシュの履歴に依存するので、複数のキャッシュ間で同じであることは保証されません。SyncConsistentHashFactory- 現在のメンバーシップが同じである場合、キーマッピングが各キャッシュについて同一であることを保証します。ただし、この欠点として、キャッシュに参加するノードが既存ノードによるセグメントの交換を生じさせる可能性があり、その結果、追加の状態転送のトラフィックが発生するか、またはデータ分散が少なくなるかのいずれか、またはそれらの両方が生じる場合があります。TopologyAwareConsistentHashFactory-DefaultConsistentHashFactoryと同等であるが、サーバーヒンティングが有効にされます。TopologyAwareSyncConsistentHashFactory-SyncConsistentHashFactoryと同等であるが、サーバーヒンティングが有効にされます。
<hash consistentHashFactory="org.infinispan.distribution.ch.TopologyAwareSyncConsistentHashFactory"/>
machineId、rackId、または siteId 属性がトランスポート設定で指定される場合、バックアップコピーを複数の物理マシン/ラック/データセンターにまたがって分散させます。
28.4.1. ConsistentHashFactory の実装
ConsistentHashFactory は、以下のメソッド (これらすべては org.infinispan.distribution.ch.ConsistentHash の実装を返します) を使って、org.infinispan.distribution.ch.ConsistenHashFactory インターフェースを実装する必要があります。
例28.1 ConsistentHashFactory メソッド
create(Hash hashFunction, int numOwners, int numSegments, List<Address> members,Map<Address, Float> capacityFactors) updateMembers(ConsistentHash baseCH, List<Address> newMembers, Map<Address, Float> capacityFactors) rebalance(ConsistentHash baseCH) union(ConsistentHash ch1, ConsistentHash ch2)
ConsistentHashFactory 実装に渡すことはできません。
28.5. キーアフィニティーサービス
例28.2 キーアフィニティーサービス
EmbeddedCacheManager cacheManager = getCacheManager();
Cache cache = cacheManager.getCache();
KeyAffinityService keyAffinityService =
KeyAffinityServiceFactory.newLocalKeyAffinityService(
cache,
new RndKeyGenerator(),
Executors.newSingleThreadExecutor(),
100);
Object localKey = keyAffinityService.getKeyForAddress(cacheManager.getAddress());
cache.put(localKey, "yourValue");手順28.3 キーアフィニティーサービスの使用
キャッシュマネージャーおよびキャッシュの参照の取得
EmbeddedCacheManager cacheManager = getCacheManager(); Cache cache = cacheManager.getCache();
アフィニティーサービスの作成
これにより、サービスが起動され、キーを生成し、キューに格納するために、提供されたExecutorが使用されます。KeyAffinityService keyAffinityService = KeyAffinityServiceFactory.newLocalKeyAffinityService( cache, new RndKeyGenerator(), Executors.newSingleThreadExecutor(), 100);特定のアドレスにマップするキーの取得
ローカルノードにマップされるサービスからキーを取得します (cacheManager.getAddress()はローカルアドレスを返します)。Object localKey = keyAffinityService.getKeyForAddress(cacheManager.getAddress());
値をノードに配置
KeyAffinityServiceから取得されたキーを持つエントリーは常に、提供されたアドレスを持つノードに格納されます。この場合は、ローカルノードになります。cache.put(localKey, "yourValue");
28.5.1. ライフサイクル
KeyAffinityService は、 Lifecycle を拡張します。これにより、キーアフィニティーサービスを停止、起動、および再起動することが可能になります。
例28.3 キーアフィニティーサービスライフサイクルパラメーター
public interface Lifecycle {
void start();
void stop();
}
KeyAffinityServiceFactory を介してインスタンス化されます。すべてのファクトリーメソッドは非同期キー生成に使用される Executor を持つため、これは呼び出し元のスレッドで使用されません。ユーザーはこの Executor のシャットダウンを制御します。
KeyAffinityService は、必要なくなったときに明示的に停止する必要があります。これにより、バックグラウンドキー生成が停止され、保持された他のリソースがリリースされます。KeyAffinityServce は、登録したキャッシュマネージャーがシャットダウンされた場合のみ停止します。
28.5.2. トポロジーの変更
KeyAffinityService キーの所有権は、トポロジーが変更されると、変わることがあります。キーアフィニティーサービスは、トポロジーの変更と更新を監視し、古いキーまたは指定されたものと異なるノードにマップされるキーを返さないようにします。ただし、キーが使用されたときにノードアフィニティーが変更されないことは保証されません。以下に例を示します。
- スレッド (
T1) は、ノード (A) にマップされるキー (K1) を読み取ります。 - トポロジーが変更され、
K1がノードBにマップされます。 T1はK1を使用してキャッシュにデータを追加します。この時点でK1は読み取り時に要求されたものと異なるノードであるBにマップされます。
KeyAffinityService は安定したクラスターに対してアクセス近接の最適化を提供します。トポロジーの変更が安定的でないときには適用されません。
第29章 データセンター間のレプリケーションのセットアップ
29.1. データセンター間レプリケーションについて
RELAY2 プロトコルをベースとします。
29.2. データセンター間レプリケーションの操作
例29.1 データセンター間レプリケーションの例
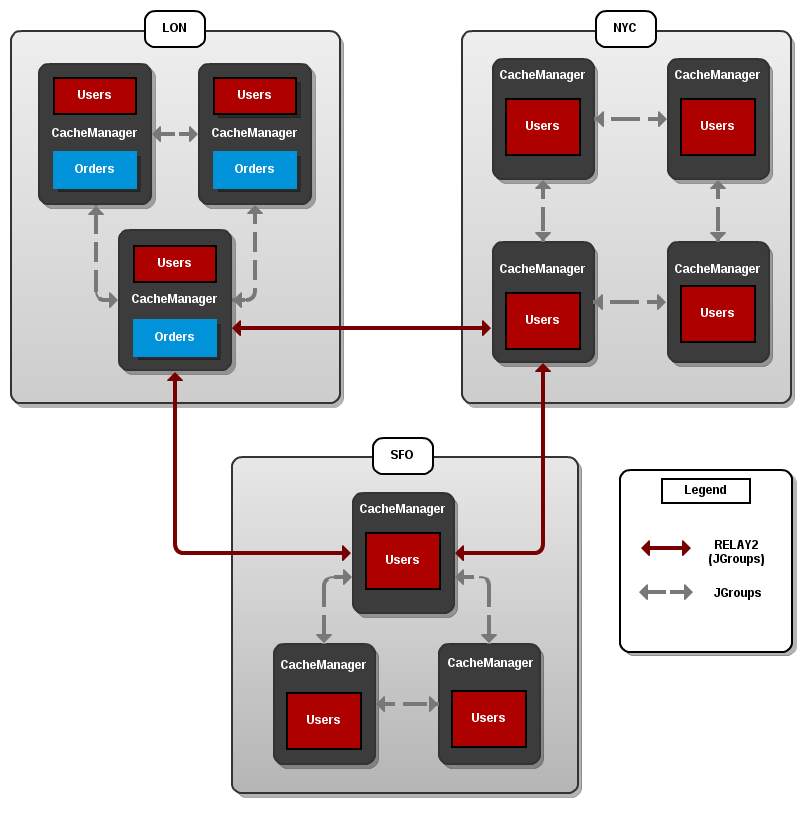
図29.1 データセンター間レプリケーションの例
LON、NYC および SFO の 3 つのサイトが設定されます。それぞれのサイトは、3 つから 4 つの物理ノードから構成される実行中の JBoss Data Grid クラスターをホストします。
Users キャッシュは、3 つのすべてのサイトでアクティブです。LON サイトでの Users キャッシュへの変更は、他の 2 つのサイトでレプリケートされます。ただし、Orders キャッシュは、他のサイトにレプリケートされないので LON サイトのローカルでのみ利用可能です。
Users キャッシュは各サイトで異なるレプリケーションメカニズムを使用できます。たとえば、データのバックアップを SFO に同期的に、NYC と LON に非同期的に行います。
Users キャッシュにはあるサイトから別のサイトへとそれぞれ異なる設定を持たせることもできます。たとえば、これを LON サイトで numOwners を 2 に設定した分散キャッシュとして、NYC サイトではレプリケートされたキャッシュとして、さらに SFO サイトでは numOwners を 1 に設定した分散キャッシュとして設定することができます。
RELAY2 という JGroups プロトコルは、サイト間の通信を容易にします。さらに詳しくは、「RELAY2 について」を参照してください。
29.3. データセンター間レプリケーションの設定
29.3.1. データセンター間レプリケーションの設定 (リモートクライアントサーバーモード)
手順29.1 データセンター間のレプリケーションのセットアップ
RELAY のセットアップ
RELAYをセットアップするには、以下の設定をstandalone.xmlファイルに追加します。<subsystem xmlns="urn:jboss:domain:jgroups:1.2" default-stack="udp"> <stack name="udp"> <transport type="UDP" socket-binding="jgroups-udp"/> ... <relay site="LON"> <remote-site name="NYC" stack="tcp" cluster="global"/> <remote-site name="SFO" stack="tcp" cluster="global"/> <property name="relay_multicasts">false</property> </relay> </stack> </subsystem>
RELAYプロトコルは、リモートサイトと通信するために追加のスタック (既存のTCPスタックと並行して実行される) を作成します。TCPベースのスタックがローカルクラスターに使用される場合、2 つのTCPベースのスタック設定が必要になります。1 つはローカル通信用で、もう 1 つはリモートサイトへの接続用になります。さらに詳しい説明は、「データセンター間レプリケーションの操作」を参照してください。サイトのセットアップ
クラスター内のそれぞれの分散キャッシュに対してサイトをセットアップするには、standalone.xmlファイルで以下の設定を使用します。<distributed-cache> ... <backups> <backup site="{FIRSTSITENAME}" strategy="{SYNC/ASYNC}" /> <backup site="{SECONDSITENAME}" strategy="{SYNC/ASYNC}" /> </backups> </distributed-cache>ローカルサイトトランスポートの設定
トランスポートを設定するには、transport要素にローカルサイトの名前を追加します。<transport executor="infinispan-transport" lock-timeout="60000" cluster="LON" stack="udp"/>
29.3.2. データセンター間レプリケーション (ライブラリーモード) の設定
29.3.2.1. データセンター間レプリケーションを宣言的に設定する
relay.RELAY2 プロトコルは、リモートサイトと通信するために追加のスタック (既存の TCP スタックと並行して実行される) を作成します。TCP ベースのスタックがローカルクラスターに使用される場合、2 つの TCP ベースのスタック設定が必要になります。1 つはローカル通信用で、もう 1 つはリモートサイトへの接続用です。
手順29.2 データセンター間のレプリケーションのセットアップ
ローカルサイトを設定します。
site要素をglobal要素に追加してローカルサイト (この例では、ローカルサイトの名前はLONです) を追加します。<infinispan> <global> ... <site local="LON" /> ... </global> </infinispan>ローカルサイト用に JGroups を設定します。
サイト間のレプリケーションには、デフォルト以外の JGroups 設定が必要です。transport要素を追加し、設定ファイルへのパスをconfigurationFileプロパティーとしてセットアップします。この例では、JGroups 設定ファイルの名前はjgroups-with-relay.xmlです。<infinispan> <global> ... <site local="LON" /> <transport clusterName="default"> <properties> <property name="configurationFile" value="jgroups-with-relay.xml" /> </properties> </transport> ... </global> </infinispan>LON キャッシュを設定します。
NYCおよびSFOサイトにバックアップするには、LONサイトでキャッシュを設定します。<infinispan> <global> <site local="LON" /> ... </global> ... <namedCache name="lon"> <sites> <backups> <backup site="NYC" strategy="SYNC" backupFailurePolicy="WARN" /> <backup site="SFO" strategy="ASYNC" backupFailurePolicy="IGNORE"/> </backups> </sites> </namedCache> </infinispan>バックアップキャッシュを設定します。
LONからバックアップデータを受信するには、NYCサイトでキャッシュを設定します。<infinispan> <global> <site local="NYC" /> ... </global> ... <namedCache name="lonBackup"> <sites> <backupFor remoteSite="LON" remoteCache="lon" /> </sites> </namedCache> </infinispan>LONからバックアップデータを受信するには、SFOサイトでキャッシュを設定します。<infinispan> <global> <site local="SFO" /> ... </global> ... <namedCache name="lonBackup"> <sites> <backupFor remoteSite="LON" remoteCache="lon" /> </sites> </namedCache> </infinispan>
設定ファイルの内容を追加します。
デフォルトでは、Red Hat JBoss Data Grid にはinfinispan-core-{VERSION}.jarパッケージ内のjgroups-tcp.xmlおよびjgroups-udp.xmlなどの JGroups 設定ファイルが含まれます。JGroups 設定を新規ファイル (この例では、ファイル名はjgroups-with-relay.xml) にコピーし、指定される設定情報をこのファイルに追加します。relay.RELAY2プロトコル設定は、設定スタックの最新のプロトコルである必要があります。<config> ... <relay.RELAY2 site="LON" config="relay.xml" relay_multicasts="false" /> </config>relay.xml ファイルを設定します。
relay.xmlファイルでrelay.RELAY2設定をセットアップします。このファイルは、グローバルクラスター設定について説明するものです。<RelayConfiguration> <sites> <site name="LON" id="0"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="NYC" id="1"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="SFO" id="2"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> </sites> </RelayConfiguration>グローバルクラスターを設定します。
relay.xmlで参照されるファイルjgroups-global.xmlには、グローバルクラスター、つまりサイト間の通信で使用される別の JGroups 設定が含まれます。グローバルクラスター設定は、通常はTCPベースであり、TCPPINGプロトコル (PINGまたはMPINGではない) を使用してメンバーを検出します。jgroups-tcp.xmlの内容をjgroups-global.xmlにコピーし、TCPPINGを設定するために次の設定を追加します。<config> <TCP bind_port="7800" ... /> <TCPPING initial_hosts="lon.hostname[7800],nyc.hostname[7800],sfo.hostname[7800]" num_initial_members="3" ergonomics="false" /> <!-- Rest of the protocols --> </config>TCPPING.initial_hostsのホスト名 (または IP アドレス) をサイトマスターに使用されるものに置き換えます。ポート (この場合は7800) はTCP.bind_portに一致している必要があります。TCPPINGプロトコルについてさらに詳しくは、「TCPPing プロトコルの使用」を参照してください。
29.3.2.2. データセンター間レプリケーションをプログラムを用いて設定する
手順29.3 データセンター間レプリケーションをプログラムを用いて設定する
ノードの場所を特定します。
ノードが所属するサイトを宣言します。globalConfiguration.site().localSite("LON");JGroups を設定します。
RELAYプロトコルを使用するように JGroups を設定します。globalConfiguration.transport().addProperty("configurationFile", jgroups-with-relay.xml);リモートサイトをセットアップします。
リモートサイトにレプリケートするために JBoss Data Grid キャッシュをセットアップします。ConfigurationBuilder lon = new ConfigurationBuilder(); lon.sites().addBackup() .site("NYC") .backupFailurePolicy(BackupFailurePolicy.WARN) .strategy(BackupConfiguration.BackupStrategy.SYNC) .replicationTimeout(12000) .sites().addInUseBackupSite("NYC") .sites().addBackup() .site("SFO") .backupFailurePolicy(BackupFailurePolicy.IGNORE) .strategy(BackupConfiguration.BackupStrategy.ASYNC) .sites().addInUseBackupSite("SFO")オプション: バックアップクラッシュを設定します。
JBoss Data Grid は、リモートサイトと同じ名前を使って、データをキャッシュに暗黙的にレプリケートします。リモートサイトのバックアップキャッシュが異なる名前を持つ場合、ユーザーは、データが正しいキャッシュにレプリケートされていることを確認するためにbackupForキャッシュを指定する必要があります。注記
この手順は任意であり、リモートサイトのキャッシュの名前が元のキャッシュとは異なるものに設定される場合にのみ必要になります。LONからのバックアップデータを受信できるようにサイトNYCのキャッシュを設定します。ConfigurationBuilder NYCbackupOfLon = new ConfigurationBuilder(); lonBackup.sites().backupFor().remoteCache("lon").remoteSite("LON");LONからバックアップデータを受信できるようにサイトSFOのキャッシュを設定します。ConfigurationBuilder SFObackupOfLon = new ConfigurationBuilder(); lonBackup.sites().backupFor().remoteCache("lon").remoteSite("LON");
設定ファイルの内容を追加します。
デフォルトでは、Red Hat JBoss Data Grid には、infinispan-core-{VERSION}.jarパッケージ内のjgroups-tcp.xmlおよびjgroups-udp.xmlなどの JGroups 設定ファイルが含まれます。JGroups 設定を新規ファイル (この例では、ファイル名はjgroups-with-relay.xml) にコピーし、指定される設定情報をこのファイルに追加します。relay.RELAY2プロトコル設定は、設定スタックの最新のプロトコルである必要があります。<config> ... <relay.RELAY2 site="LON" config="relay.xml" relay_multicasts="false" /> </config>relay.xml ファイルを設定します。
relay.xmlファイルでrelay.RELAY2設定をセットアップします。このファイルは、グローバルクラスター設定について説明するものです。<RelayConfiguration> <sites> <site name="LON" id="0"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="NYC" id="1"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> <site name="SFO" id="2"> <bridges> <bridge config="jgroups-global.xml" name="global"/> </bridges> </site> </sites> </RelayConfiguration>グローバルクラスターを設定します。
relay.xmlで参照されるファイルjgroups-global.xmlには、グローバルクラスター、つまりサイト間の通信で使用される別の JGroups 設定が含まれます。グローバルクラスター設定は、通常はTCPベースであり、TCPPINGプロトコル (PINGまたはMPINGではない) を使用してメンバーを検出します。jgroups-tcp.xmlの内容をjgroups-global.xmlにコピーし、TCPPINGを設定するために以下の設定を追加します。<config> <TCP bind_port="7800" ... /> <TCPPING initial_hosts="lon.hostname[7800],nyc.hostname[7800],sfo.hostname[7800]" num_initial_members="3" ergonomics="false" /> <!-- Rest of the protocols --> </config>TCPPING.initial_hostsのホスト名 (または IP アドレス) をサイトマスターに使用されるものに置き換えます。ポート (この場合は7800) はTCP.bind_portに一致している必要があります。TCPPINGプロトコルについてさらに詳しくは、「TCPPing プロトコルの使用」を参照してください。
29.4. サイトをオフラインにする
- サイトの自動的なオフライン設定:
- リモートクライアントサーバーモードで宣言的に実行。
- ライブラリーモードで宣言的に実行。
- プログラムを用いたメソッドの使用。
- サイトの手動によるオフライン設定:
- JBoss Operations Network (JON) の使用。
- JBoss Data Grid コマンドラインインターフェース (CLI) の使用。
29.4.1. サイトをオフラインに設定する (リモートクライアントサーバーモード)
take-offline 要素が backup 要素に追加されます。
例29.2 サイトをオフラインに設定する (リモートクライアントサーバーモード)
<backup>
<take-offline after-failures="${NUMBER}"
min-wait="${PERIOD}" />
</backup>take-offline 要素は、いつサイトをオフラインにするかを設定するために以下のパラメーターを使用します。
after-failuresパラメーターは、サイトがオフラインになる前にサイトへの接続の試行を失敗できる回数を指定します。min-waitパラメーターは、応答しないサイトをオフラインとしてマークするために待機する時間 (秒数単位) を指定します。このサイトは、min-wait期間が最初の試行後に経過した時やafter-failuresパラメーターで指定される試行の失敗回数に達した時にオフラインになります。
29.4.2. サイトをオフラインにする (ライブラリーモード)
backups 要素内ですべてのバックアップサイトを定義した後に backupFor 要素を使用します。
例29.3 サイトをオフラインに設定する (ライブラリーモード)
<backup>
<takeOffline afterFailures="${NUM}"
minTimeToWait="${PERIOD}"/>
</backup>takeOffline 要素を backup 要素に追加します。
afterFailuresパラメーターは、サイトがオフラインになる前にサイトへの接続を失敗できる回数を指定します。デフォルト値 (0) は、minTimeToWaitが0より小さい値の場合に失敗の回数を無限にすることを許可します。minTimeToWaitが0より小さい値でない場合、afterFailuresは、その値が負の値であるかのように動作します。つまり、このパラメーターが負の値である場合、minTimeToWaitで指定される時間が経過した後にサイトがオフラインになることを示します。minTimeToWaitパラメーターは、応答しないサイトをオフラインとしてマークするために待機する時間 (秒数単位) を指定します。サイトは、afterFailuresパラメーターで指定される試行回数に達し、最初の失敗後にminTimeToWaitで指定される時間が経過した後にオフラインになります。このパラメーターが0以下の値に設定される場合、このパラメーターは無視され、サイトはafterFailuresパラメーターのみに基づいてオフラインになります。
29.4.3. サイトをオフラインにする (プログラムを用いた場合)
例29.4 サイトをオフラインにする (プログラムを使用)
lon.sites().addBackup()
.site("NYC")
.backupFailurePolicy(BackupFailurePolicy.FAIL)
.strategy(BackupConfiguration.BackupStrategy.SYNC)
.takeOffline()
.afterFailures(500)
.minTimeToWait(10000);29.4.4. JBoss Operations Network (JON) 経由でサイトをオフラインにする
29.4.5. CLI でサイトをオフラインにする
site コマンドを使用して、データセンター間のレプリケーション設定からサイトを手動でシャットダウンします。
site コマンドを使用して、以下のようにサイトの状態を確認することができます。
[jmx://localhost:12000/MyCacheManager/namedCache]> site --status ${SITENAME}online または offline のいずれかになります。
[jmx://localhost:12000/MyCacheManager/namedCache]> site --offline ${SITENAME}[jmx://localhost:12000/MyCacheManager/namedCache]> site --online ${SITENAME}ok の出力がコマンドの後に表示されます。
29.4.6. サイトをオンラインに戻す
XSiteAdmin MBean 上で bringSiteOnline(siteName) 操作を起動することです。この MBean についてさらに詳しくは、「XSiteAdmin」を参照してください。
29.5. 複数サイトマスターの設定
29.5.1. 複数サイトマスターの操作
29.5.2. 複数サイトマスターの設定 (リモートクライアントサーバーモード)
Red Hat JBoss Data Grid のリモートクライアントサーバーモード用にデータセンター間レプリケーションを設定します。
手順29.4 リモートクライアントサーバーモードで複数のサイトマスターを設定します。
ターゲット設定の特定
clustered-xsite.xmlの設定ファイル例でターゲットサイトの設定を見つけます。この設定例は、以下のようになります。<relay site="LON"> <remote-site name="NYC" stack="tcp" cluster="global"/> <remote-site name="SFO" stack="tcp" cluster="global"/> <property name="relay_multicasts">false</property> </relay>
最大サイトの設定
サイト内のマスターノードの最大数を決定するにはmax_site_mastersプロパティーを使用します。すべてのノードをマスターにするために、この値をサイト内のノード数に設定します。<relay site="LON"> <remote-site name="NYC" stack="tcp" cluster="global"/> <remote-site name="SFO" stack="tcp" cluster="global"/> <property name="relay_multicasts">false</property> <property name="max_site_masters">16</property> </relay>
サイトマスターの設定
ノードをサイトマスターにすることを許可するには、can_become_site_masterプロパティーを使用します。このフラグはデフォルトでtrueに設定されます。このフラグをfalseに設定することにより、ノードがサイトマスターになることを防ぐことができます。これは、ノードが外部ネットワークに接続されたネットワークインターフェースを持たない状況で必要になります。<relay site="LON"> <remote-site name="NYC" stack="tcp" cluster="global"/> <remote-site name="SFO" stack="tcp" cluster="global"/> <property name="relay_multicasts">false</property> <property name="max_site_masters">16</property> <property name="can_become_site_master">true</property> </relay>
29.5.3. 複数サイトマスターの設定 (ライブラリーモード)
手順29.5 複数サイトマスターの設定 (ライブラリーモード)
データセンター間レプリケーションを設定します。
JBoss Data Grid でデータセンター間レプリケーションを設定します。XML 設定については 「データセンター間レプリケーションを宣言的に設定する」 の手順を使用し、プログラミングによる設定の場合は 「データセンター間レプリケーションをプログラムを用いて設定する」 の手順を使用します。設定ファイルの内容を追加します。
以下のようにcan_become_site_masterおよびmax_site_mastersパラメーターを設定に追加します。<config> ... <relay.RELAY2 site="LON" config="relay.xml" relay_multicasts="false" can_become_site_master="true" max_site_masters="16"/> </config>すべてのノードをマスターにするために、max_site_masters値をクラスター内のノード数に設定します。
付録A Red Hat JBoss Data Grid における JMX MBeans
A.1. アクティベーション
org.infinispan.eviction.ActivationManagerImpl
表A.1 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| activations | アクティベーションイベントの数です。 | 文字列 | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.2 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.2. キャッシュ
org.infinispan.CacheImpl
表A.3 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| cacheName | キャッシュ名を返します。 | 文字列 | いいえ |
| cacheStatus | キャッシュの状態を返します。 | 文字列 | いいえ |
| configurationAsProperties | プロパティーの形式でキャッシュの設定を返します。 | java.util.Properties | いいえ |
| version | Infinispan のバージョンを返します。 | java.lang.String | いいえ |
表A.4 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| start | キャッシュを起動します。 | void start() |
| stop | キャッシュを停止します。 | void stop() |
| clear | キャッシュをクリアにします。 | void clear() |
A.3. CacheLoader
org.infinispan.interceptors.CacheLoaderInterceptor
表A.5 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| cacheLoaderLoads | キャッシュストアからロードされるエントリーの数です。 | long | いいえ |
| cacheLoaderMisses | キャッシュストアに存在しなかったエントリーの数です。 | long | いいえ |
| stores | 設定済みの有効にされているキャッシュローダーのコレクションを返します。 | コレクション | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.6 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| disableStore | 指定されるタイプのすべてのキャッシュローダーを無効にします。このタイプは、無効にするキャッシュローダーの完全修飾クラス名です。 | void disableStore(String storeType) |
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.4. CacheManager
org.infinispan.manager.DefaultCacheManager
表A.7 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| cacheManagerStatus | キャッシュマネージャーのインスタンスの状態です。 | 文字列 | いいえ |
| clusterMembers | クラスターのメンバーを一覧表示します。 | 文字列 | いいえ |
| clusterName | クラスター名。 | 文字列 | いいえ |
| clusterSize | ノードの数で表されるクラスターのサイズです。 | int | いいえ |
| createdCacheCount | デフォルトキャッシュを含む、作成されたキャッシュの合計数です。 | 文字列 | いいえ |
| definedCacheCount | デフォルトキャッシュを除く、定義されたキャッシュの合計数です。 | 文字列 | いいえ |
| definedCacheNames | 定義されたキャッシュ名とそれらのキャッシュの状態です。デフォルトのキャッシュはこの表示には含まれません。 | 文字列 | いいえ |
| name | このキャッシュマネージャーの名前です。 | 文字列 | いいえ |
| nodeAddress | このインスタンスに関連付けられたネットワークアドレスです。 | 文字列 | いいえ |
| physicalAddresses | このインスタンスに関連付けられた物理ネットワークアドレスです。 | 文字列 | いいえ |
| runningCacheCount | デフォルトキャッシュを含む、実行中のキャッシュの合計数です。 | 文字列 | いいえ |
| version | Infinispan のバージョンです。 | 文字列 | いいえ |
表A.8 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| startCache | キャッシュマネージャーに関連付けられたデフォルトのキャッシュを起動します。 | void startCache() |
| startCache | このキャッシュマネージャーから名前付きキャッシュを起動します。 | void startCache (String p0) |
A.5. CacheStore
org.infinispan.interceptors.CacheWriterInterceptor
表A.9 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| writesToTheStores | ストアへの書き込み回数です。 | long | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.10 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.6. DeadlockDetectingLockManager
org.infinispan.util.concurrent.locks.DeadlockDetectingLockManager
表A.11 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| detectedLocalDeadlocks | デッドロックによりロールバックされたローカルトランザクションの数です。 | long | いいえ |
| detectedRemoteDeadlocks | デッドロックによりロールバックされたリモートトランザクションの数です。 | long | いいえ |
| overlapWithNotDeadlockAwareLockOwners | デッドロックの判別を試行しているが、他のロックを所有するのがトランザクションでは「ない」状況の数です。このシナリオでは、デッドロック検出メカニズムを実行することはできません。 | long | いいえ |
| totalNumberOfDetectedDeadlocks | 検出されたローカルデッドロックの合計数です。 | long | いいえ |
| concurrencyLevel | MVCC ロックマネージャーについて設定された平行性レベルです。 | int | いいえ |
| numberOfLocksAvailable | 利用可能な排他ロックの数です。 | int | いいえ |
| numberOfLocksHeld | 保持されている排他ロックの数です。 | int | いいえ |
表A.12 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.7. DistributionManager
org.infinispan.distribution.DistributionManagerImpl
注記
表A.13 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| isAffectedByRehash | 指定されたキーが進行中のリハッシュによって影響を受けるかどうかを決定します。 | boolean isAffectedByRehash(Object p0) |
| isLocatedLocally | 指定されたキーがキャッシュのこのインスタンスに対してローカルであるかどうかを示します。文字列キーでのみ機能します。 | boolean isLocatedLocally(String p0) |
| locateKey | クラスター内のオブジェクトを見つけます。文字列キーでのみ機能します。 | List locateKey(String p0) |
A.8. インタープリター
org.infinispan.cli.interpreter.Interpreter
表A.14 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| cacheNames | キャッシュマネージャーのキャッシュのリストを取得します。 | String[] | いいえ |
表A.15 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| createSessionId | 新規のインタープリターセッションを作成します。 | String createSessionId(String cacheName) |
| execute | IspnCliQL ステートメントを解析し、実行します。 | String execute(String p0, String p1) |
A.9. インバリデーション
org.infinispan.interceptors.InvalidationInterceptor
表A.16 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| invalidations | インバリデーションの数です。 | long | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.17 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.10. LockManager
org.infinispan.util.concurrent.locks.LockManagerImpl
表A.18 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| concurrencyLevel | MVCC ロックマネージャーが設定される平行性レベル。 | 整数 | いいえ |
| numberOfLocksAvailable | 利用可能な排他ロックの数。 | 整数 | いいえ |
| numberOfLocksHeld | 保留にされている排他ロックの数。 | 整数 | いいえ |
A.11. LocalTopologyManager
org.infinispan.topology.LocalTopologyManagerImpl
注記
表A.19 属性
| 名前 | 説明 | Type | 書き込み可能 |
|---|---|---|---|
| rebalancingEnabled | false の場合、新規に起動したノードは既存のクラスターに参加せず、状態もそれらに転送されません。現在のクラスターメンバーのいずれかが再調整が無効にされている状態で停止した場合、ノードがそのクラスターを離れ、状態の再調整は残りのノード間で行なわれません。これにより、再調整が再び有効にされるまで、コピーの数は numOwners 属性で指定される数よりも少なくなります。 | ブール値 | はい |
A.12. MassIndexer
org.infinispan.query.MassIndexer
表A.20 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| start | インデックスの再構築を開始します。 | void start() |
注記
A.13. パッシベーション
org.infinispan.interceptors.PassivationInterceptor
表A.21 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| passivations | パッシベーションイベントの数です。 | 文字列 | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.22 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.14. RecoveryAdmin
org.infinispan.transaction.xa.recovery.RecoveryAdminOperations
表A.23 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| forceCommit | 不明なトランザクションのコミットを強制します。 | String forceCommit(long p0) |
| forceCommit | 不明なトランザクションのコミットを強制します。 | String forceCommit(int p0, byte[] p1, byte[] p2) |
| forceRollback | 不明なトランザクションのロールバックを強制します。 | String forceRollback(long p0) |
| forceRollback | 不明なトランザクションのロールバックを強制します。 | String forceRollback(int p0, byte[] p1, byte[] p2) |
| forget | 指定されるトランザクションのリカバリー情報を削除します。 | String forget(long p0) |
| forget | 指定されるトランザクションのリカバリー情報を削除します。 | String forget(int p0, byte[] p1, byte[] p2) |
| showInDoubtTransactions | 発進されるノードがクラッシュする準備されたトランザクションをすべて表示します。 | String showInDoubtTransactions() |
A.15. RollingUpgradeManager
org.infinispan.upgrade.RollingUpgradeManager
表A.24 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| disconnectSource | 指定される移行プログラムに従って、ターゲットクラスターをソースクラスターから切り離します。 | void disconnectSource(String p0) |
| recordKnownGlobalKeyset | アップグレードプロセスで取得するために、グローバルな既知のキーセットを既知のキーにダンプします。 | void recordKnownGlobalKeyset() |
| synchronizeData | 指定された移行プログラムを使用して、古いクラスターのデータをこれに同期します。 | long synchronizeData(String p0) |
A.16. RpcManager
org.infinispan.remoting.rpc.RpcManagerImpl
注記
表A.25 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| averageReplicationTime | トランスポート層で費やされた平均時間 (ミリ秒単位) です。 | long | いいえ |
| committedViewAsString | コミット済みのビューを取得します。 | 文字列 | いいえ |
| pendingViewAsString | 保留中のビューを取得します。 | 文字列 | いいえ |
| replicationCount | 正常なレプリケーションの数です。 | long | いいえ |
| replicationFailures | 失敗したレプリケーションの数です。 | long | いいえ |
| successRatio | レプリケーションの合計数に対する正常なレプリケーションの比率です。 | 文字列 | いいえ |
| successRatioFloatingPoint | 数値 (double) 形式でのレプリケーションの合計数に対する正常なレプリケーションの比率です。 | double | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.26 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
| setStatisticsEnabled | 統計を有効または無効にするかを設定します (true/false)。 | void setStatisticsEnabled(boolean enabled) |
A.17. StateTransferManager
org.infinispan.statetransfer.StateTransferManager
注記
表A.27 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| joinComplete | true の場合、ノードはグリッドに正常に加わっており、保留状態であると見なされます。false の場合、join プロセスは依然として進行中です。 | ブール値 | いいえ |
| stateTransferInProgress | このクラスターメンバーに保留中のインバウンドの状態転送があるかどうかをチェックします。 | ブール値 | いいえ |
A.18. 統計
org.infinispan.interceptors.CacheMgmtInterceptor
表A.28 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| averageReadTime | キャッシュの読み取り操作にかかる平均のミリ秒数です。 | long | いいえ |
| averageWriteTime | キャッシュの書き込み操作にかかる平均のミリ秒数です。 | long | いいえ |
| elapsedTime | キャッシュの開始以降の秒数です。 | long | いいえ |
| evictions | キャッシュエビクション操作の数です。 | long | いいえ |
| hitRatio | キャッシュのヒット/(ヒット+ミス) 比率 (パーセンテージ) です。 | double | いいえ |
| hits | キャッシュ属性のヒット数です。 | long | いいえ |
| misses | キャッシュ属性の失敗回数です。 | long | いいえ |
| numberOfEntries | 現在キャッシュにあるエントリーの数です。 | 整数 | いいえ |
| readWriteRatio | キャッシュの読み取り/書き込み比率です。 | double | いいえ |
| removeHits | キャッシュ除去のヒット数です。 | long | いいえ |
| removeMisses | キーが見つからなかった場合のキャッシュ除去の回数です。 | long | いいえ |
| stores | キャッシュ属性 PUT 操作の数です。 | long | いいえ |
| timeSinceReset | キャッシュ統計が最後にリセットされてからの秒数です。 | long | いいえ |
表A.29 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.19. トランザクション
org.infinispan.interceptors.TxInterceptor
表A.30 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| commits | 最終リセット時から実行されるトランザクションのコミット数です。 | long | いいえ |
| prepares | 最終リセット時から実行されるトランザクションの準備回数です。 | long | いいえ |
| rollbacks | 最終リセット時から実行されるトランザクションのロールバック回数です。 | long | いいえ |
| statisticsEnabled | このコンポーネントにより、統計の収集を有効または無効にします。 | ブール値 | はい |
表A.31 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| resetStatistics | このコンポーネントによって収集される統計をリセットします。 | void resetStatistics() |
A.20. トランスポート
org.infinispan.server.core.transport.NettyTransport
表A.32 属性
| 名前 | 説明 | タイプ | 書き込み可能 |
|---|---|---|---|
| hostName | トランスポートがバインドされるホストを戻します。 | 文字列 | いいえ |
| idleTimeout | アイドル状態のタイムアウトを戻します。 | 文字列 | いいえ |
| numberOfGlobalConnections | クラスター内のアクティブな接続の数を戻します。この操作は、結果を集約するためのリモート呼び出しを行うため、待ち時間がこの属性の計算スピードに影響を与える場合があります。 | 整数 | false |
| numberOfLocalConnections | このサーバーのアクティブな接続の数を戻します。 | 整数 | いいえ |
| numberWorkerThreads | ワーカースレッドの数を戻します。 | 文字列 | いいえ |
| port | トランスポートがバインドされるポートを戻します。 | 文字列 | |
| receiveBufferSize | 受信バッファーサイズを戻します。 | 文字列 | いいえ |
| sendBufferSize | 送信バッファーサイズを戻します。 | 文字列 | いいえ |
| totalBytesRead | プロトコルおよびユーザー情報の両方を含む、サーバーがクライアントから読み取るバイト数の合計を戻します。 | 文字列 | いいえ |
| totalBytesWritten | プロトコルおよびユーザー情報の両方を含む、サーバーがクライアントに書き戻すバイト数の合計を戻します。 | 文字列 | いいえ |
| tcpNoDelay | TCP no delay (TCP 遅延なし) が設定されているかどうかの情報を戻します。 | 文字列 | いいえ |
A.21. XSiteAdmin
org.infinispan.xsite.XSiteAdminOperations
表A.33 操作
| 名前 | 説明 | 署名 |
|---|---|---|
| bringSiteOnline | すべてのクラスターで指定されたサイトをオンラインに戻します。 | String bringSiteOnline(String p0) |
| amendTakeOffline | クラスター内のすべてのノードで 'TakeOffline' 機能の値を修正します。 | String amendTakeOffline(String p0, int p1, long p2) |
| getTakeOfflineAfterFailures | 'TakeOffline' 機能に対して 'afterFailures' の値を戻します。 | String getTakeOfflineAfterFailures(String p0) |
| getTakeOfflineMinTimeToWait | 'TakeOffline' 機能に対して 'minTimeToWait' の値を戻します。 | String getTakeOfflineMinTimeToWait(String p0) |
| setTakeOfflineAfterFailures | クラスター内のすべてのノードで 'TakeOffline' 機能について 'afterFailures' の値を修正します。 | String setTakeOfflineAfterFailures(String p0, int p1) |
| setTakeOfflineMinTimeToWait | クラスター内のすべてのノードで 'TakeOffline' 機能について 'minTimeToWait' の値を修正します。 | String setTakeOfflineMinTimeToWait(String p0, long p1) |
| siteStatus | 指定されるバックアップサイトがオフラインかどうかをチェックします。 | String siteStatus(String p0) |
| 状態 | 設定されたすべてのバックアップサイトについて、ステータス (オフライン/オンライン) を戻します。 | String status() |
| takeSiteOffline | クラスター内のすべてのノードでこのノードをオフラインにします。 | String takeSiteOffline(String p0) |
付録B データソース管理
B.1. JDBC
B.2. データソースの型
datasources と XA datasources の 2 つがあります。
B.3. JDBC ドライバーの使用
B.3.1. コアモジュールとしての JDBC ドライバーのインストール
このタスクを実行する前に、以下の前提条件を満たしている必要があります。
- データベースのベンダーから JDBC ドライバーをダウンロードする必要があります。JDBC ドライバーをダウンロードする場所の一覧は「JDBC ドライバーをダウンロードできる場所」を参照してください。
- アーカイブを展開します。
手順B.1 コアモジュールとしての JDBC ドライバーのインストール
EAP_HOME/modules/ディレクトリー下にファイルパス構造を作成します。たとえば、MySQL JDBC ドライバーの場合には、EAP_HOME/modules/com/mysql/main/のようなディレクトリー構造を作成します。- JDBC ドライバー JAR を
main/サブディレクトリーにコピーします。 main/サブディレクトリーに、module.xmlファイルを作成します。以下は、module.xmlファイルの例です。<?xml version="1.0" encoding="UTF-8"?> <module xmlns="urn:jboss:module:1.0" name="com.mysql"> <resources> <resource-root path="mysql-connector-java-5.1.15.jar"/> </resources> <dependencies> <module name="javax.api"/> <module name="javax.transaction.api"/> </dependencies> </module>- サーバーを起動します。
- 管理 CLI を起動します。
- CLI コマンドを実行して JDBC ドライバーモジュールをサーバー設定に追加します。選択するコマンドは、JDBC ドライバー JAR にある
/META-INF/services/java.sql.Driverファイルにリストされたクラスの数によって異なります。たとえば、MySQL 5.1.20 JDBC JAR 内の/META-INF/services/java.sql.Driverファイルは以下の 2 つのクラスをリストします。複数のエントリーがある場合は、ドライバークラスの名前も指定する必要があります。これを行わないと、以下のようなエラーが発生します。com.mysql.jdbc.Drivercom.mysql.fabric.jdbc.FabricMySQLDriver
JBAS014749: Operation handler failed: Service jboss.jdbc-driver.mysql is already registered
- 1 つのクラスエントリーを含む JDBC JAR に対して CLI コマンドを実行します。
/subsystem=datasources/jdbc-driver=DRIVER_NAME:add(driver-name=DRIVER_NAME,driver-module-name=MODULE_NAME,driver-xa-datasource-class-name=XA_DATASOURCE_CLASS_NAME)
例B.1 1 つのドライバークラスを持つ JDBC JAR に対するスタンドアロンモードの CLI コマンドの例
/subsystem=datasources/jdbc-driver=mysql:add(driver-name=mysql,driver-module-name=com.mysql,driver-xa-datasource-class-name=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource)
例B.2 1 つのドライバークラスを持つ JDBC JAR に対するドメインモードの CLI コマンドの例
/profile=ha/subsystem=datasources/jdbc-driver=mysql:add(driver-name=mysql,driver-module-name=com.mysql,driver-xa-datasource-class-name=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource)
- 複数のクラスエントリーを含む JDBC JAR に対して CLI コマンドを実行します。
/subsystem=datasources/jdbc-driver=DRIVER_NAME:add(driver-name=DRIVER_NAME,driver-module-name=MODULE_NAME,driver-xa-datasource-class-name=XA_DATASOURCE_CLASS_NAME, driver-class-name=DRIVER_CLASS_NAME)
例B.3 複数のドライバークラスエントリーを持つ JDBC JAR に対するスタンドアロンモードの CLI コマンドの例
/subsystem=datasources/jdbc-driver=mysql:add(driver-name=mysql,driver-module-name=com.mysql,driver-xa-datasource-class-name=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource, driver-class-name=com.mysql.jdbc.Driver)
例B.4 複数のドライバークラスエントリーを持つ JDBC JAR に対するドメインモードの CLI コマンドの例
/profile=ha/subsystem=datasources/jdbc-driver=mysql:add(driver-name=mysql,driver-module-name=com.mysql,driver-xa-datasource-class-name=com.mysql.jdbc.jdbc2.optional.MysqlXADataSource, driver-class-name=com.mysql.jdbc.Driver)
JDBC ドライバーがインストールされ、コアモジュールとして設定されます。アプリケーションのデータソースが JDBC ドライバーを参照できる状態になります。
B.3.2. JDBC ドライバーをダウンロードできる場所
表B.1 JDBC ドライバーをダウンロードできる場所
| ベンダー | ダウンロード場所 |
|---|---|
| MySQL | |
| PostgreSQL | |
| Oracle | |
| IBM | |
| Sybase | |
| Microsoft |
B.3.3. ベンダー固有クラスへのアクセス
このトピックでは、JDBC 固有クラスを使用するのに必要な手順について説明します。これは、アプリケーションが JDBC API の一部でないベンダー固有の機能を使用する必要がある場合に必要です。
警告
重要
重要
手順B.2 アプリケーションへの依存関係の追加
MANIFEST.MFファイルの設定- テキストエディターでアプリケーションの
META-INF/MANIFEST.MFファイルを開きます。 - JDBC モジュールの依存関係を追加し、ファイルを保存します。
依存関係: MODULE_NAME
例B.5 依存関係の例
依存関係: com.mysql
jboss-deployment-structure.xmlファイルの作成アプリケーションのMETA-INF/またはWEB-INFフォルダーでjboss-deployment-structure.xmlという名前のファイルを作成します。例B.6 サンプル
jboss-deployment-structure.xmlファイル<jboss-deployment-structure> <deployment> <dependencies> <module name="com.mysql" /> </dependencies> </deployment> </jboss-deployment-structure>
例B.7 ベンダー固有 API へのアクセス
import java.sql.Connection; import org.jboss.jca.adapters.jdbc.WrappedConnection; Connection c = ds.getConnection(); WrappedConnection wc = (WrappedConnection)c; com.mysql.jdbc.Connection mc = wc.getUnderlyingConnection();
B.4. データソース設定
B.4.1. データソースのパラメーター
表B.2 非 XA および XA データソースに共通のデータソースパラメーター
| パラメーター | 説明 |
|---|---|
| jndi-name | データソースの一意の JNDI 名。 |
| pool-name | データソースの管理プール名。 |
| enabled | データソースが有効かどうかを指定します。 |
| use-java-context |
データソースをグローバルの JNDI にバインドするかどうかを指定します。
|
| spy |
JDBC レイヤーで
spy 機能を有効にします。この機能は、データソースへの JDBC トラフィックをすべてログに記録します。ロギングカテゴリーの jboss.jdbc.spy もロギングサブシステムのログレベルである DEBUG に設定する必要があることに注意してください。
|
| use-ccm | キャッシュ接続マネージャーを有効にします。 |
| new-connection-sql | 接続プールに接続が追加された時に実行する SQL ステートメント。 |
| transaction-isolation |
次のいずれかになります。
|
| url-selector-strategy-class-name | インターフェース org.jboss.jca.adapters.jdbc.URLSelectorStrategy を実装するクラス。 |
| security |
セキュリティー設定である子要素が含まれます。表B.7「セキュリティーパラメーター」を参照してください。
|
| validation |
検証設定である子要素が含まれます。表B.8「検証パラメーター」を参照してください。
|
| timeout |
タイムアウト設定である子要素が含まれます。表B.9「タイムアウトパラメーター」を参照してください。
|
| statement |
ステートメント設定である子要素が含まれます。表B.10「ステートメントのパラメーター」を参照してください。
|
表B.3 非 XA データソースのパラメーター
| パラメーター | 説明 |
|---|---|
| jta | 非 XA データソースの JTA 統合を有効にします。XA データソースには適用されません。 |
| connection-url | JDBC ドライバーの接続 URL。 |
| driver-class | JDBC ドライバークラスの完全修飾名。 |
| connection-property | Driver.connect(url,props) メソッドに渡される任意の接続プロパティー。各 connection-property は、文字列名と値のペアを指定します。プロパティー名は名前、値は要素の内容に基づいています。
|
| pool |
プーリング設定である子要素が含まれます。表B.5「非 XA および XA データソースに共通のプールパラメーター」を参照してください。
|
表B.4 XA データソースのパラメーター
| パラメーター | 説明 |
|---|---|
| xa-datasource-property |
実装クラス
XADataSource に割り当てるプロパティー。name=value で指定。 setName という形式で setter メソッドが存在する場合、プロパティーは setName(value) という形式の setter メソッドを呼び出すことで設定されます。
|
| xa-datasource-class |
実装クラス
javax.sql.XADataSource の完全修飾名。
|
| driver |
JDBC ドライバーが含まれるクラスローダーモジュールへの一意参照。driverName#majorVersion.minorVersion の形式にのみ対応しています。
|
| xa-pool |
プーリング設定である子要素が含まれます。表B.5「非 XA および XA データソースに共通のプールパラメーター」および表B.6「XA プールパラメーター」を参照してください。
|
| recovery |
リカバリー設定である子要素が含まれます。表B.11「リカバリーパラメーター」を参照してください。
|
表B.5 非 XA および XA データソースに共通のプールパラメーター
| パラメーター | 説明 |
|---|---|
| min-pool-size | プールが保持する最小接続数 |
| max-pool-size | プールが保持可能な最大接続数 |
| prefill | 接続プールのプレフィルを試行するかどうかを指定します。要素が空の場合は true を示します。デフォルトは、false です。 |
| use-strict-min | pool-size が厳密かどうかを指定します。デフォルトは false に設定されています。 |
| flush-strategy |
エラーの場合にプールをフラッシュするかどうかを指定します。有効な値は次の通りです。
デフォルトは
FailingConnectionOnly です。
|
| allow-multiple-users | 複数のユーザーが getConnection(user, password) メソッドを使いデータソースへアクセスするかどうか、また内部プールタイプがこの動作に対応するかを指定します。 |
表B.6 XA プールパラメーター
| パラメーター | 説明 |
|---|---|
| is-same-rm-override | javax.transaction.xa.XAResource.isSameRM(XAResource) クラスが true あるいは false のどちらを返すか。 |
| interleaving | XA 接続ファクトリーのインターリービングを有効にするかどうか。 |
| no-tx-separate-pools |
コンテキスト毎に sub-pool を作成するかどうか。これには Oracle のデータソースが必要ですが、JTA トランザクションの内部と外部の両方で XA 接続が使用できなくなります。
このオプションを使用することにより、2 つの実際のファイルが作成されるため、プールサイズの合計が
max-pool-size の 2 倍になります。
|
| pad-xid | Xid のパディングを行うかどうかを指定します。 |
| wrap-xa-resource |
XAResource を
org.jboss.tm.XAResourceWrapper インスタンスでラップするかどうかを指定します。
|
表B.7 セキュリティーパラメーター
| パラメーター | 説明 |
|---|---|
| user-name | 新規接続の作成に使うユーザー名 |
| password | 新規接続の作成に使うパスワード |
| security-domain | 認証処理を行う JAAS security-manager 名が含まれます。この名前は、JAAS ログイン設定の application-policy/name 属性に相関します。 |
| reauth-plugin | 物理接続の再認証に使う再認証プラグインを定義します。 |
表B.8 検証パラメーター
| パラメーター | 説明 |
|---|---|
| valid-connection-checker | SQLException.isValidConnection(Connection e) メソッドを提供し接続を検証するインターフェース org.jboss.jca.adaptors.jdbc.ValidConnectionChecker の実装。例外が発生すると接続が破棄されます。存在する場合、check-valid-connection-sql パラメーターが上書きされます。
|
| check-valid-connection-sql | プール接続の妥当性を確認する SQL ステートメント。これは、管理接続をプールから取得し利用する場合に呼び出される場合があります。 |
| validate-on-match |
接続ファクトリーが指定のセットに対して管理された接続をマッチしようとした時に接続レベルの検証を実行するかどうかを示します。
通常、
validate-on-match に「true」を指定した時に background-validation を「true」に指定することはありません。クライアントが使用前に接続を検証する必要がある場合に Validate-on-match が必要になります。このパラメーターはデフォルトでは false になっています。
|
| background-validation |
接続がバックグラウンドスレッドで検証されることを指定します。
validate-on-match を使用しない場合、バックグラウンドの検証はパフォーマンスを最適化します。validate-on-match が true の時に background-validation を使用すると、チェックが冗長になることがあります。バックグラウンド検証では、不良の接続がクライアントに提供される可能性があります (検証スキャンと接続がクライアントに提供されるまでの間に接続が悪くなります)。そのため、クライアントアプリケーションはこの接続不良の可能性に対応する必要があります。
|
| background-validation-millis | バックグラウンド検証を実行する期間 (ミリ秒単位)。 |
| use-fast-fail |
true の場合、接続が無効であれば最初に接続を割り当てしようとした時点で失敗します。デフォルトは
false です。
|
| stale-connection-checker |
ブール値の
isStaleConnection(SQLException e) メソッドを提供する org.jboss.jca.adapters.jdbc.StaleConnectionChecker のインスタンス。このメソッドが true を返すと、SQLException のサブクラスである org.jboss.jca.adapters.jdbc.StaleConnectionException に例外がラップされます。
|
| exception-sorter |
ブール値である
isExceptionFatal(SQLException e) メソッドを提供する org.jboss.jca.adapters.jdbc.ExceptionSorter のインスタンス。このメソッドは、例外が connectionErrorOccurred メッセージとして javax.resource.spi.ConnectionEventListener のすべてのインスタンスへブロードキャストされるかどうかを検証します。
|
表B.9 タイムアウトパラメーター
| パラメーター | 説明 |
|---|---|
| use-try-lock | lock() の代わりに tryLock() を使用します。これは、ロックが使用できない場合に即座に失敗するのではなく、設定された秒数間ロックの取得を試みます。デフォルトは 60 秒です。たとえば、タイムアウトを 5 分に設定するには、<use-try-lock>300</use-try-lock> を設定します。 |
| blocking-timeout-millis | 接続待機中にブロックする最大時間 (ミリ秒)。この時間を超過すると、例外がスローされます。これは、接続許可の待機中のみブロックし、新規接続の作成に長時間要している場合は例外をスローしません。デフォルトは 30000 (30 秒) です。 |
| idle-timeout-minutes |
アイドル接続が切断されるまでの最大時間 (分単位)。実際の最大時間は idleRemover のスキャン時間によって異なります。idleRemover のスキャン時間はプールの最小
idle-timeout-minutes の半分になります。
|
| set-tx-query-timeout |
トランザクションがタイムアウトするまでの残り時間を基にクエリーのタイムアウトを設定するかどうかを指定します。トランザクションが存在しない場合は設定済みのクエリーのタイムアウトが使用されます。デフォルトは
false です。
|
| query-timeout | クエリーのタイムアウト (秒)。デフォルトはタイムアウトなしです。 |
| allocation-retry | 例外をスローする前に接続の割り当てを再試行する回数。デフォルトは 0 で、初回の割り当て失敗で例外がスローされます。 |
| allocation-retry-wait-millis |
接続の割り当てを再試行するまで待機する期間 (ミリ秒単位)。デフォルトは 5000 (5 秒) です。
|
| xa-resource-timeout |
ゼロでない場合、この値は
XAResource.setTransactionTimeout メソッドへ渡されます。
|
表B.10 ステートメントのパラメーター
| パラメーター | 説明 |
|---|---|
| track-statements |
接続がプールへ返され、ステートメントが準備済みステートメントキャッシュへ返された時に、閉じられていないステートメントをチェックするかどうかを指定します。false の場合、ステートメントは追跡されません。
有効な値
|
| prepared-statement-cache-size | LRU (Least Recently Used) キャッシュにある接続毎の準備済みステートメントの数。 |
| share-prepared-statements |
閉じずに同じステートメントを 2 回要求した場合に、同じ基盤の準備済みステートメントを使用するかどうかを指定します。デフォルトは
false です。
|
表B.11 リカバリーパラメーター
| パラメーター | 説明 |
|---|---|
| recover-credential | リカバリーに使用するユーザー名とパスワードのペア、あるいはセキュリティドメイン。 |
| recover-plugin |
リカバリーに使用される
org.jboss.jca.core.spi.recoveryRecoveryPlugin クラスの実装。
|
B.4.2. データソース接続 URL
表B.12 データソース接続 URL
| データソース | 接続 URL |
|---|---|
| PostgreSQL | jdbc:postgresql://SERVER_NAME:PORT/DATABASE_NAME |
| MySQL | jdbc:mysql://SERVER_NAME:PORT/DATABASE_NAME |
| Oracle | jdbc:oracle:thin:@ORACLE_HOST:PORT:ORACLE_SID |
| IBM DB2 | jdbc:db2://SERVER_NAME:PORT/DATABASE_NAME |
| Microsoft SQLServer | jdbc:microsoft:sqlserver://SERVER_NAME:PORT;DatabaseName=DATABASE_NAME |
B.4.3. データソースの拡張
表B.13 データソースの拡張
| データソースの拡張 | 設定パラメーター | 説明 |
|---|---|---|
| org.jboss.jca.adapters.jdbc.spi.ExceptionSorter | <exception-sorter> | SQLException が発生した接続にとってこの例外は致命的かどうかを確認します。 |
| org.jboss.jca.adapters.jdbc.spi.StaleConnection | <stale-connection-checker> | org.jboss.jca.adapters.jdbc.StaleConnectionException の古い SQLExceptions をラップします。 |
| org.jboss.jca.adapters.jdbc.spi.ValidConnection | <valid-connection-checker> | アプリケーションによる接続の使用が有効であるかどうかを確認します。 |
拡張の実装
- 汎用
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullStaleConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.NullValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.novendor.JDBC4ValidConnectionChecker
- PostgreSQL
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker
- MySQL
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLReplicationValidConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker
- IBM DB2
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker
- Sybase
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker
- Microsoft SQLServer
- org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker
- Oracle
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleStaleConnectionChecker
- org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker
B.4.4. データソース統計の表示
jdbc および pool の定義済みデータソースより統計を表示できます。
手順B.3
/subsystem=datasources/data-source=ExampleDS/statistics=jdbc:read-resource(include-runtime=true)
/subsystem=datasources/data-source=ExampleDS/statistics=pool:read-resource(include-runtime=true)
注記
false であるため、必ず include-runtime=true 引数を指定するようにしてください。
B.4.5. データソースの統計
サポートされるデータソースの主要統計は以下の表の通りです。
表B.14 主要統計
| 名前 | 説明 |
|---|---|
ActiveCount |
アクティブな接続の数。各接続はアプリケーションによって使用されているか、プールで使用可能な状態であるかのいずれかになります。
|
AvailableCount |
プールの使用可能な接続の数。
|
AverageBlockingTime |
プールの排他ロックの取得をブロックするために費やされた平均時間。値はミリ秒単位です。
|
AverageCreationTime |
接続の作成に費やされた平均時間。値はミリ秒単位です。
|
CreatedCount |
作成された接続の数。
|
DestroyedCount |
破棄された接続の数。
|
InUseCount |
現在使用中の接続の数。
|
MaxCreationTime |
接続の作成にかかった最大時間。値はミリ秒単位です。
|
MaxUsedCount |
使用される接続の最大数。
|
MaxWaitCount |
同時に接続を待機するリクエストの最大数。
|
MaxWaitTime |
プールの排他ロックの待機に費やされた最大時間。
|
TimedOut |
タイムアウトした接続の数。
|
TotalBlockingTime |
プールの排他ロックの待機に費やされた合計時間。値はミリ秒単位です。
|
TotalCreationTime |
接続の作成に費やされた合計時間。値はミリ秒単位です。
|
WaitCount |
接続を待機する必要があるリクエストの数。
|
サポートされるデータソースの JDBC 統計は以下の表の通りです。
表B.15 JDBC の統計
| 名前 | 説明 |
|---|---|
PreparedStatementCacheAccessCount |
ステートメントキャッシュがアクセスされた回数。
|
PreparedStatementCacheAddCount |
ステートメントキャッシュに追加されたステートメントの数。
|
PreparedStatementCacheCurrentSize |
ステートメントキャッシュに現在キャッシュされた準備済みおよび呼び出し可能ステートメントの数。
|
PreparedStatementCacheDeleteCount |
キャッシュから破棄されたステートメントの数。
|
PreparedStatementCacheHitCount |
キャッシュからのステートメントが使用された回数。
|
PreparedStatementCacheMissCount |
ステートメント要求がキャッシュのステートメントと一致しなかった回数。
|
Core と JDBC の統計を有効にできます。
/subsystem=datasources/data-source=ExampleDS/statistics=pool:write-attribute(name=statistics-enabled,value=true)
/subsystem=datasources/data-source=ExampleDS/statistics=jdbc:write-attribute(name=statistics-enabled,value=true)
B.5. データソース例
B.5.1. PostgreSQL のデータソースの例
例B.8
<datasources>
<datasource jndi-name="java:jboss/PostgresDS" pool-name="PostgresDS">
<connection-url>jdbc:postgresql://localhost:5432/postgresdb</connection-url>
<driver>postgresql</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="postgresql" module="org.postgresql">
<xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次のとおりです。
<module xmlns="urn:jboss:module:1.1" name="org.postgresql">
<resources>
<resource-root path="postgresql-9.1-902.jdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.2. PostgreSQL XA のデータソースの例
例B.9
<datasources>
<xa-datasource jndi-name="java:jboss/PostgresXADS" pool-name="PostgresXADS">
<driver>postgresql</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="PortNumber">5432</xa-datasource-property>
<xa-datasource-property name="DatabaseName">postgresdb</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLValidConnectionChecker">
</valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.postgres.PostgreSQLExceptionSorter">
</exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="postgresql" module="org.postgresql">
<xa-datasource-class>org.postgresql.xa.PGXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次のとおりです。
<module xmlns="urn:jboss:module:1.1" name="org.postgresql">
<resources>
<resource-root path="postgresql-9.1-902.jdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.3. MySQL のデータソースの例
例B.10
<datasources>
<datasource jndi-name="java:jboss/MySqlDS" pool-name="MySqlDS">
<connection-url>jdbc:mysql://mysql-localhost:3306/jbossdb</connection-url>
<driver>mysql</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="mysql" module="com.mysql">
<xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次のとおりです。
<module xmlns="urn:jboss:module:1.1" name="com.mysql">
<resources>
<resource-root path="mysql-connector-java-5.0.8-bin.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.4. MySQL XA のデータソースの例
例B.11
<datasources>
<xa-datasource jndi-name="java:jboss/MysqlXADS" pool-name="MysqlXADS">
<driver>mysql</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mysqldb</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.mysql.MySQLExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="mysql" module="com.mysql">
<xa-datasource-class>com.mysql.jdbc.jdbc2.optional.MysqlXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次のとおりです。
<module xmlns="urn:jboss:module:1.1" name="com.mysql">
<resources>
<resource-root path="mysql-connector-java-5.0.8-bin.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.5. Oracle のデータソースの例
注記
例B.12
<datasources>
<datasource jndi-name="java:/OracleDS" pool-name="OracleDS">
<connection-url>jdbc:oracle:thin:@localhost:1521:XE</connection-url>
<driver>oracle</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleStaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="oracle" module="com.oracle">
<xa-datasource-class>oracle.jdbc.xa.client.OracleXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.oracle">
<resources>
<resource-root path="ojdbc6.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.6. Oracle XA データソースの例
注記
重要
user は、JBoss から Oracle に接続するために定義されたユーザーです。
- GRANT SELECT ON sys.dba_pending_transactions TO user;
- GRANT SELECT ON sys.pending_trans$ TO user;
- GRANT SELECT ON sys.dba_2pc_pending TO user;
- GRANT EXECUTE ON sys.dbms_xa TO user; (パッチ済みの Oracle 10g R2、または Oracle 11g を使用する場合)またはGRANT EXECUTE ON sys.dbms_system TO user; (パッチされていない 11g 以前のバージョンの Oracle を使用する場合)
例B.13
<datasources>
<xa-datasource jndi-name="java:/XAOracleDS" pool-name="XAOracleDS">
<driver>oracle</driver>
<xa-datasource-property name="URL">jdbc:oracle:oci8:@tc</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
<no-tx-separate-pools />
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleStaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.oracle.OracleExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="oracle" module="com.oracle">
<xa-datasource-class>oracle.jdbc.xa.client.OracleXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.oracle">
<resources>
<resource-root path="ojdbc6.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.7. Microsoft SQLServer のデータソースの例
例B.14
<datasources>
<datasource jndi-name="java:/MSSQLDS" pool-name="MSSQLDS">
<connection-url>jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=MyDatabase</connection-url>
<driver>sqlserver</driver>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker"></valid-connection-checker>
</validation>
</datasource>
<drivers>
<driver name="sqlserver" module="com.microsoft">
<xa-datasource-class>com.microsoft.sqlserver.jdbc.SQLServerXADataSource</xa-datasource-class>
</driver>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.microsoft">
<resources>
<resource-root path="sqljdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.8. Microsoft SQLServer XA のデータソースの例
例B.15
<datasources>
<xa-datasource jndi-name="java:/MSSQLXADS" pool-name="MSSQLXADS">
<driver>sqlserver</driver>
<xa-datasource-property name="ServerName">localhost</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mssqldb</xa-datasource-property>
<xa-datasource-property name="SelectMethod">cursor</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.mssql.MSSQLValidConnectionChecker"></valid-connection-checker>
</validation>
</xa-datasource>
<drivers>
<driver name="sqlserver" module="com.microsoft">
<xa-datasource-class>com.microsoft.sqlserver.jdbc.SQLServerXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.microsoft">
<resources>
<resource-root path="sqljdbc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.9. IBM DB2 のデータソースの例
例B.16
<datasources>
<datasource jndi-name="java:/DB2DS" pool-name="DB2DS">
<connection-url>jdbc:db2:ibmdb2db</connection-url>
<driver>ibmdb2</driver>
<pool>
<min-pool-size>0</min-pool-size>
<max-pool-size>50</max-pool-size>
</pool>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="ibmdb2" module="com.ibm">
<xa-datasource-class>com.ibm.db2.jdbc.DB2XADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>
module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.ibm">
<resources>
<resource-root path="db2jcc4.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.10. IBM DB2 XA のデータソースの例
例B.17
<datasources>
<xa-datasource jndi-name="java:/DB2XADS" pool-name="DB2XADS">
<driver>ibmdb2</driver>
<xa-datasource-property name="DatabaseName">ibmdb2db</xa-datasource-property>
<xa-datasource-property name="ServerName">hostname</xa-datasource-property>
<xa-datasource-property name="PortNumber">port</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<xa-pool>
<is-same-rm-override>false</is-same-rm-override>
</xa-pool>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ValidConnectionChecker"></valid-connection-checker>
<stale-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2StaleConnectionChecker"></stale-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.db2.DB2ExceptionSorter"></exception-sorter>
</validation>
<recovery>
<recover-plugin class-name="org.jboss.jca.core.recovery.ConfigurableRecoveryPlugin">
<config-property name="EnableIsValid">false</config-property>
<config-property name="IsValidOverride">false</config-property>
<config-property name="EnableClose">false</config-property>
</recover-plugin>
</recovery>
</xa-datasource>
<drivers>
<driver name="ibmdb2" module="com.ibm">
<xa-datasource-class>com.ibm.db2.jcc.DB2XADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.ibm">
<resources>
<resource-root path="db2jcc4.jar"/>
<resource-root path="db2jcc_license_cisuz.jar"/>
<resource-root path="db2jcc_license_cu.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.11. Sybase データソースの例
例B.18
<datasources>
<datasource jndi-name="java:jboss/SybaseDB" pool-name="SybaseDB" enabled="true">
<connection-url>jdbc:sybase:Tds:localhost:5000/DATABASE?JCONNECT_VERSION=6</connection-url>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter"></exception-sorter>
</validation>
</datasource>
<drivers>
<driver name="sybase" module="com.sybase">
<datasource-class>com.sybase.jdbc4.jdbc.SybDataSource</datasource-class>
<xa-datasource-class>com.sybase.jdbc4.jdbc.SybXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.sybase">
<resources>
<resource-root path="jconn2.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>B.5.12. Sybase XA データソースの例
例B.19
<datasources>
<xa-datasource jndi-name="java:jboss/SybaseXADS" pool-name="SybaseXADS" enabled="true">
<xa-datasource-property name="NetworkProtocol">Tds</xa-datasource-property>
<xa-datasource-property name="ServerName">myserver</xa-datasource-property>
<xa-datasource-property name="PortNumber">4100</xa-datasource-property>
<xa-datasource-property name="DatabaseName">mydatabase</xa-datasource-property>
<security>
<user-name>admin</user-name>
<password>admin</password>
</security>
<validation>
<background-validation>true</background-validation>
<valid-connection-checker class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseValidConnectionChecker"></valid-connection-checker>
<exception-sorter class-name="org.jboss.jca.adapters.jdbc.extensions.sybase.SybaseExceptionSorter"></exception-sorter>
</validation>
</xa-datasource>
<drivers>
<driver name="sybase" module="com.sybase">
<datasource-class>com.sybase.jdbc4.jdbc.SybDataSource</datasource-class>
<xa-datasource-class>com.sybase.jdbc4.jdbc.SybXADataSource</xa-datasource-class>
</driver>
</drivers>
</datasources>module.xml ファイルの例は次の通りです。
<module xmlns="urn:jboss:module:1.1" name="com.sybase">
<resources>
<resource-root path="jconn2.jar"/>
</resources>
<dependencies>
<module name="javax.api"/>
<module name="javax.transaction.api"/>
</dependencies>
</module>付録C 参照
C.1. 一貫性について
C.2. 一貫性保証について
- キー
Kはノード{A,B}へハッシュ化されます。トランザクションTX1は、たとえばノードA上のKロックを取得します。 - 他のキャッシュへのアクセスが、ノード
Bまたは他のノードで発生すると、TX2がKをロックしようとしますが、トランザクションTX1がすでにKのロックを保持しているため、タイムアウトが発生してこのアクセスの試行は失敗します。
K のロックはトランザクションの発生元に関係なく、常にクラスターの同じノード上で取得されるため、このロックの取得は常に失敗します。
C.3. JBoss Cache について
C.4. RELAY2 について
RELAY プロトコルは、各サイトの 1 つのノード間の接続を作成することによって 2 つのリモートクラスターをブリッジします。これにより、1 つのサイトに送信されたマルチキャストメッセージが他のサイトにリレーされ、他のサイトからそのサイトにもリレーさせることができます。
RELAY2 プロトコルが含まれます。
RELAY2 プロトコルは RELAY と同様に機能しますが、若干の相違点があります。RELAY とは異なり、RELAY2 プロトコルは以下を実行します。
- 3 つ以上のサイトを接続します。
- 自律的に機能し、相互に認識しないサイトに接続します。
- サイト間のユニキャストとマルチキャストのルーティングの両方を提供します。
C.5. 戻り値について
C.6. 実行可能インターフェースについて
run() メソッドを宣言します。実行可能オブジェクトは、スレッドコンストラクターに渡された後、独自のスレッドでの実行が可能です。
C.7. 2 相コミット (2PC) について
C.8. キーバリューペアについて
- キーは特定のデータエントリーに一意であり、関連する特定エントリーのデータ属性によって構成されます。
- バリュー (値) は、キーによって割り当てられ、キーによって識別されるデータです。
C.9. エクスターナライザー
C.9.1. エクスターナライザーについて
Externalizer クラスは、以下のことを行えるクラスです。
- 該当するオブジェクトタイプをバイトアレイにマーシャリングします。
- バイトアレイの内容をオブジェクトタイプのインスタンスにマーシャリング解除します。
C.9.2. 内部エクスターナライザー実装アクセス
public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
MapExternalizer ma = new MapExternalizer();
ma.writeObject(output, object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
MapExternalizer ma = new MapExternalizer();
hi.setMap((ConcurrentHashMap<Long, Long>) ma.readObject(input));
return hi;
}
...public static class ABCMarshallingExternalizer implements AdvancedExternalizer<ABCMarshalling> {
@Override
public void writeObject(ObjectOutput output, ABCMarshalling object) throws IOException {
output.writeObject(object.getMap());
}
@Override
public ABCMarshalling readObject(ObjectInput input) throws IOException, ClassNotFoundException {
ABCMarshalling hi = new ABCMarshalling();
hi.setMap((ConcurrentHashMap<Long, Long>) input.readObject());
return hi;
}
...
}C.10. ハッシュ領域の割り当て
C.10.1. ハッシュ領域の割り当てについて
C.10.2. ハッシュ領域におけるキーの検索
C.10.3. 完全なバイトアレイの要求
デフォルトでは、必要のない巨大なバイトアレイを出力しないように、JBoss Data Grid はバイトアレイの一部のみをログに出力します。以下の場合にバイトアレイがログに出力されます。
- JBoss Data Grid のキャッシュにレイジーデシリアライゼーションが設定されている場合。レイジーデシリアライゼーションは JBoss Data Grid のリモートクライアントサーバーモードでは使用できません。
MemcachedまたはHot Rodサーバーが実行されている場合。
-Dinfinispan.arrays.debug=true システムプロパティーを渡します。
例C.1 部分的なバイトアレイのログ
2010-04-14 15:46:09,342 TRACE [ReadCommittedEntry] (HotRodWorker-1-1) Updating entry
(key=CacheKey{data=ByteArray{size=19, hashCode=1b3278a,
array=[107, 45, 116, 101, 115, 116, 82, 101, 112, 108, ..]}}
removed=false valid=true changed=true created=true value=CacheValue{data=ByteArray{size=19,
array=[118, 45, 116, 101, 115, 116, 82, 101, 112, 108, ..]},
version=281483566645249}]
And here's a log message where the full byte array is shown:
2010-04-14 15:45:00,723 TRACE [ReadCommittedEntry] (Incoming-2,Infinispan-Cluster,eq-6834) Updating entry
(key=CacheKey{data=ByteArray{size=19, hashCode=6cc2a4,
array=[107, 45, 116, 101, 115, 116, 82, 101, 112, 108, 105, 99, 97, 116, 101, 100, 80, 117, 116]}}
removed=false valid=true changed=true created=true value=CacheValue{data=ByteArray{size=19,
array=[118, 45, 116, 101, 115, 116, 82, 101, 112, 108, 105, 99, 97, 116, 101, 100, 80, 117, 116]},
version=281483566645249}]付録D 改訂履歴
| 改訂履歴 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 改訂 6.3.0-12.1 | Wed Feb 18 2015 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-12 | Tue Jul 15 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-11 | Monday Jul 07 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-10 | Monday Jun 30 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-9 | Tue Jun 24 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-8 | Fri Jun 20 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-7 | Fri Jun 20 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-6 | Tue Jun 03 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-5 | Mon May 26 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-4 | Mon May 19 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-3 | Wed May 07 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-2 | Tue Apr 29 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-1 | Mon Apr 07 2014 | ||||||||||||
| |||||||||||||
| 改訂 6.3.0-0 | Wed Feb 26 2014 | ||||||||||||
| |||||||||||||