
アーキテクチャーガイド
Red Hat Ceph Storage アーキテクチャーガイド
概要
第1章 Ceph アーキテクチャー
Red Hat Ceph Storage クラスターは、優れたパフォーマンス、信頼性、スケーラビリティーを提供するように設計された、分散型のデータオブジェクトストアです。分散オブジェクトストアは、非構造化データに対応し、クライアントが最新のオブジェクトインターフェイスとレガシーのインターフェイスを同時に使用できるため、ストレージの未来と言えます。
以下に例を示します。
- 多くの言語の API (C/C++、Java、Python)
- RESTful インターフェイス (S3/Swift)
- ブロックデバイスインターフェイス
- ファイルシステムインターフェイス
Red Hat Ceph Storage クラスターの電源は、特に Red Hat Enterprise Linux OSP などのクラウドコンピューティングプラットフォーム用に、組織の IT インフラストラクチャーと大量のデータを管理する能力を変革することができます。Red Hat Ceph Storage クラスターは、ペタバイトからエクサバイト以上のデータにアクセスする数千のクライアントという 並外れた スケーラビリティーを提供します。
すべての Ceph デプロイメントの中心となるのは、Red Hat Ceph Storage クラスターです。これは、3 種類のデーモンで設定されます。
- Ceph OSD デーモン: Ceph OSD は、Ceph クライアントの代わりにデータを格納します。また、Ceph OSD は Ceph ノードの CPU、メモリー、ネットワークを使用して、データの複製、イレイジャーコーディング、リバランス、復旧、監視、レポート作成などの機能を実行します。
- Ceph Monitor: Ceph Monitor は、Red Hat Ceph Storage クラスターの現在の状態を備えた Red Hat Ceph Storage クラスターのマッピングのマスターコピーを維持します。監視には高い整合性が必要で、Paxos を使用して Red Hat Ceph Storage クラスターの状態に関する合意を確保します。
- Ceph Manager: Ceph Manager は、Ceph Monitor の代わりに、配置グループ、プロセスメタデータ、ホストメタデータに関する詳細情報を維持します。これにより、スケーリング時にパフォーマンスを大幅に向上させます。Ceph Manager は、配置グループの統計など、読み取り専用の Ceph CLI クエリーの多くの実行を処理します。Ceph Manager は RESTful モニタリング API も提供します。

Ceph クライアントインターフェイスは、Red Hat Ceph Storage クラスターとの間で、データの読み取りと書き込みを行います。クライアントが、Red Hat Ceph Storage クラスターと通信するには、以下のデータが必要です。
-
Ceph 設定ファイル、またはクラスター名 (通常は
ceph) およびモニターアドレス - プール名
- ユーザー名およびシークレットキーへのパス。
Ceph クライアントは、オブジェクト ID とオブジェクトを保存するプール名を維持します。ただし、Object-to-OSD インデックスを維持したり、オブジェクトの位置を検索するために集中化オブジェクトインデックスと通信したりする必要はありません。データを保存および取得するために、Ceph クライアントは Ceph Monitor にアクセスし、Red Hat Ceph Storage クラスターマップの最新コピーを取得します。次に、Ceph クライアントは librados にオブジェクト名とプール名を提供します。これは、CRUSH (Controlled Replication Under Scalable Hashing) アルゴリズムを使用して、オブジェクトの配置グループと、データの保存と取得のための主要な OSD を計算します。Ceph クライアントは、読み取りおよび書き込み操作を実行することができるプライマリー OSD に接続します。クライアントと OSD には、中間サーバー、ブローカー、またはバスがありません。
OSD がデータを保存すると、クライアントが Ceph Block Device、Ceph Object Gateway、Ceph Filesystem または別のインターフェイスであるかどうかに関わらず、Ceph クライアントからデータを受信し、データをオブジェクトとして格納します。
オブジェクト ID は、OSD のストレージメディアだけでなく、クラスター全体で一意です。
Ceph OSD は、すべてのデータをオブジェクトとしてフラットな namespace に格納します。ディレクトリーの階層はありません。オブジェクトには、クラスター全体での一意の ID、バイナリーデータ、および名前/値のペアで設定されるメタデータがあります。
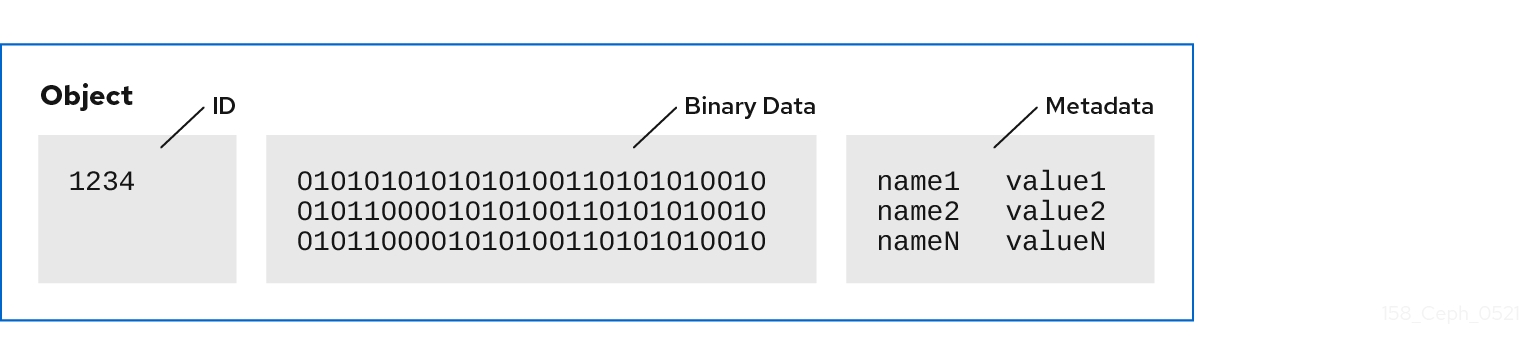
Ceph クライアントは、クライアントのデータフォーマットのセマンティクスを定義します。たとえば、Ceph ブロックデバイスはブロックデバイスイメージを、クラスター全体で保存した一連のオブジェクトにマッピングします。
一意の ID、データ、および名前と値のペアのメタデータで設定されるオブジェクトは、構造化と非構造化のデータの両方だけでなく、レガシーと最新のデータストレージインターフェイスを表すことができます。
第2章 コア Ceph コンポーネント
Red Hat Ceph Storage クラスターは、制限なしのスケーラビリティー、高可用性、およびパフォーマンスのために、多数の Ceph ノードを持つことができます。各ノードは、相互に通信する非独占的なハードウェアとインテリジェントな Ceph デーモンを活用して、以下を行います。
- データの書き込みと読み取り
- データの圧縮
- データの複製またはイレイジャーコーディングによる持続性の確保
- クラスターの健全性の監視およびレポート (別名ハートビート)
- データの動的な再配布 (別名バックフィル)
- データの整合性の確認
- 障害からの回復
データの読み取りおよび書き込みを行う Ceph クライアントインターフェイスに対して、Red Hat Ceph Storage クラスターはデータを格納する単純なプールとして表示されます。ただし、librados およびストレージクラスターは、クライアントインターフェイスから完全に透過的な方法で多くの複雑な操作を実行します。Ceph クライアントおよび Ceph OSD はどちらも CRUSH (Controlled Replication Under Scalable Hashing) アルゴリズムを使用します。以下のセクションでは、CRUSH がこれらの操作をシームレスに実行できるようにする方法について詳しく説明します。
2.1. 前提条件
- 分散ストレージシステムについての基本的な理解
2.2. Ceph プール
Ceph Storage クラスターは、データオブジェクトをプールと呼ばれる論理パーティションに格納します。Ceph 管理者は、ブロックデバイス、オブジェクトゲートウェイなどの特定タイプのデータ用に、または単にあるユーザーのグループを別のグループから分離するために、プールを作成することができます。
Ceph クライアントの視点からは、ストレージクラスターは非常に簡単です。Ceph クライアントが I/O コンテキストを使用してデータの読み取りまたは書き込みを行う場合は、常に Ceph Storage クラスター内のストレージプールに接続します。クライアントはプール名、ユーザーおよびシークレットキーを指定するため、プールはデータオブジェクトへのアクセス制御が設定された論理パーティションとして機能します。
実際に、Ceph プールは、オブジェクトデータを格納するための論理パーティションのみではありません。プールは、Ceph Storage クラスターがデータを分散し、格納する方法において重要なロールを果たします。ただし、これらの複雑な操作は、Ceph クライアントに対して完全に透過的です。
Ceph プールは、以下を定義します。
- プールタイプ: Ceph の初期バージョンでは、1 つのプールがオブジェクトの複数のディープコピーを保持するだけです。現在、Ceph はオブジェクトの複数のコピーを維持することも、イレイジャーコーディングを使用して耐久性を確保することもできます。データの耐久性の方法はプール全体のものであり、プールの作成後も変更されません。プールタイプは、プールの作成時にデータの持続性メソッドを定義します。プールタイプは、クライアントに対して完全に透過的です。
- 配置グループ: エクサバイトスケールストレージクラスターでは、Ceph プールには、数百万以上のデータオブジェクトが格納される可能性があります。Ceph は、レプリカまたはイレイジャーコードチャンクによるデータの耐久性、スクラブまたは CRC チェックによるデータの整合性、レプリケーション、リバランス、リカバリーなど、さまざまな種類の操作を処理する必要があります。そのため、オブジェクトごとにデータを管理することは、スケーラビリティーとパフォーマンスのボトルネックを示します。Ceph は、プールを配置グループにシャーディングして、このボトルネックに対応します。CRUSH アルゴリズムは、オブジェクトを格納するために配置グループを計算し、配置グループに対して OSD の動作セットを計算します。CRUSH は各オブジェクトを配置グループに配置します。次に、CRUSH は各配置グループを OSD のセットに保存します。システム管理者は、プールを作成または変更する際に配置グループ数を設定します。
- CRUSH Ruleset: CRUSH は別の重要なロールを果たします。CRUSH は障害ドメインおよびパフォーマンスドメインを検出できます。CRUSH はストレージメディアタイプで OSD を特定し、OSD をノード、ラック、および行に階層的に編成できます。CRUSH により、Ceph OSD は障害ドメイン全体でオブジェクトのコピーを格納できます。たとえば、オブジェクトのコピーは、異なるサーバールーム、アイル、ラック、およびノードに保存することができます。ラックなど、クラスターの大部分に障害が発生した場合でも、クラスターが回復するまで、クラスターはデグレード状態で動作できます。
さらに、CRUSH を使用すると、クライアントは、SSD、SSD ジャーナルを備えたハードドライブ、またはデータと同じドライブにジャーナルを備えたハードドライブなど、特定のタイプのハードウェアにデータを書き込むことができます。CRUSH ルールセットは、プールの障害ドメインとパフォーマンスドメインを決定します。管理者は、プールの作成時に CRUSH ルールセットを設定します。
管理者は、プールの作成後にプールのルールセットを変更 できません。
耐久性: エクサバイトスケールストレージクラスターでは、ハードウェア障害は予想され、例外ではありません。データオブジェクトを使用して、ブロックデバイスなどの非常に粒度の高いストレージインターフェイスを表す場合に、その非常に粒度の高いインターフェイス用に 1 つ以上のデータオブジェクトが失われると、非常に粒度の高いストレージエンティティーの整合性が損なわれ、使用できなくなる可能性があります。したがって、データの損失は許容できません。Ceph は、以下の 2 つの方法でデータの持続性を提供します。
- レプリカプールは、CRUSH 障害ドメインを使用してオブジェクトの複数のディープコピーを格納し、1 つのデータオブジェクトコピーを別のデータオブジェクトコピーから物理的に分離します。つまり、コピーは別の物理ハードウェアに分散されます。これにより、ハードウェアの障害時の持続性が向上します。
-
イレイジャーコーディングされたプールは各オブジェクトを
K+Mチャンクとして格納します。Kはデータチャンクを表し、Mはコーディングチャンクを表します。合計は、オブジェクトを保存するために使用される OSD 数を表し、Mの値は失敗する可能性がある OSD 数を表します。Mの値は、OSD が失敗するとデータが復元する回数を表します。
クライアントの観点からは、Ceph はエレガントでシンプルです。クライアントは、プールからの読み取りとプールへの書き込みを行うだけです。ただし、プールは、データの耐久性、パフォーマンス、および高可用性において重要なロールを果たします。
2.3. Ceph 認証
ユーザーを特定し、中間者攻撃から保護するために、Ceph は cephx 認証システムを提供し、ユーザーおよびデーモンを認証します。
cephx プロトコルは、ネットワーク経由で転送されるデータや OSD に保存されるデータの暗号化には対応しません。
Cephx は共有シークレットキーを使用して認証を行います。つまり、クライアントとモニタークラスターの両方にはクライアントの秘密鍵のコピーがあります。認証プロトコルにより、両当事者は、実際にキーを公開することなく、キーのコピーを持っていることを互いに証明できます。これは相互認証を提供します。つまり、ユーザーがシークレットキーを所有し、ユーザーにはシークレットキーのコピーがあることを確認します。
Cephx
cephx 認証プロトコルは、Kerberos と同様に動作します。
ユーザー/アクターが Ceph クライアントを呼び出してモニターに接続します。Kerberos とは異なり、各モニターはユーザーを認証して鍵を配布できるため、cephx を使用する際に単一障害点やボトルネックはありません。このモニターは、Ceph サービスの取得に使用するセッションキーが含まれる Kerberos チケットと同様の認証データ構造を返します。このセッションキー自体はユーザーの永続的なシークレットキーで暗号化されるため、ユーザーだけが Ceph モニターからサービスを要求することができます。次に、クライアントはセッションキーを使用してモニターから必要なサービスを要求し、モニターはクライアントに実際にデータを処理する OSD に対してクライアントを認証するチケットと共にクライアントを提供します。Ceph モニターおよび OSD はシークレットを共有しているため、クライアントはモニターが提供するチケットをクラスター内の任意の OSD またはメタデータサーバーと共に使用することができます。攻撃者は、Kerberos のように cephx チケットの有効期限が切れるため、攻撃者は取得した期限切れのチケットまたはセッションキーを誤って使用できません。この形式の認証は、通信媒体にアクセスできる攻撃者が、ユーザーの秘密鍵が期限切れになる前に漏えいしない限り、別のユーザーの ID で偽のメッセージを作成したり、別のユーザーの正当なメッセージを変更したりすることを防ぎます。
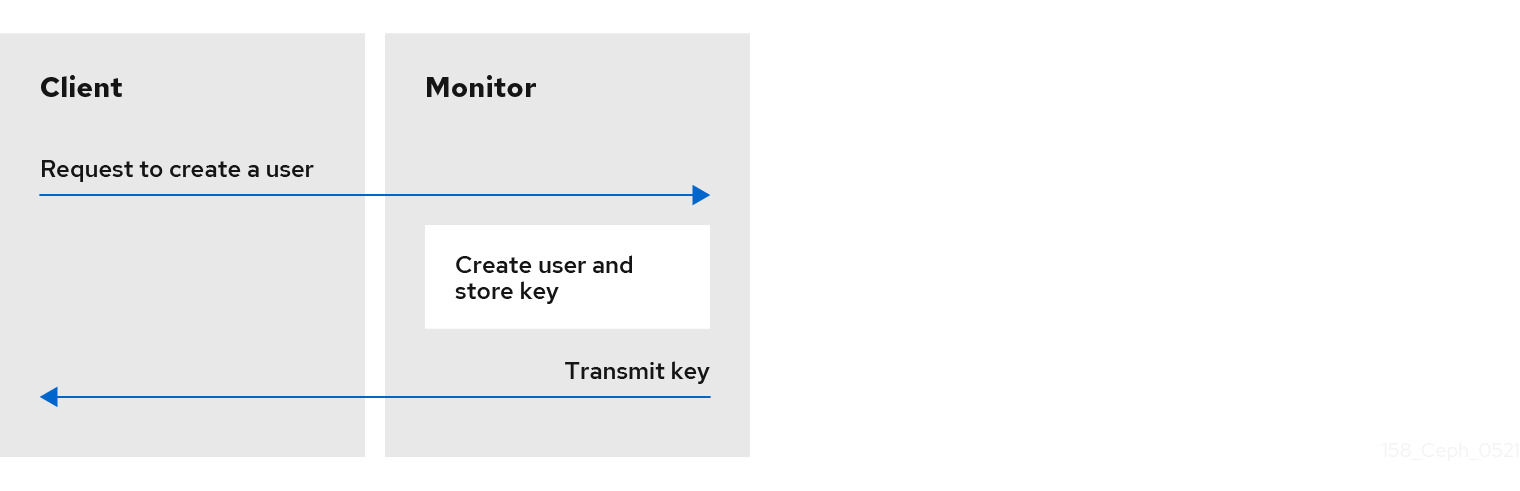
cephx を使用するには、管理者は最初にユーザーを設定する必要があります。以下の図では、client.admin ユーザーはコマンドラインから ceph auth get-or-create-key を呼び出して、ユーザー名およびシークレットキーを生成します。Ceph の auth サブシステムはユーザー名およびキーを生成し、モニターでコピーを保存し、ユーザーのシークレットを client.admin ユーザーに送り返します。つまり、クライアントとモニターが秘密鍵を共有していることを意味します。
client.admin ユーザーは、安全にユーザー ID とシークレットキーを提供する必要があります。
2.4. Ceph の配置グループ
何百万ものオブジェクトをクラスターに格納し、それらを個別に管理することは、リソースを大量に消費します。Ceph は配置グループ (PG) を使用して、大量のオブジェクトをより効率的に管理できるようにします。
PG は、オブジェクトのコレクションを含むために機能するプールのサブセットです。Ceph は、プールを一連の PG にシャードします。次に、CRUSH アルゴリズムはクラスターマップとクラスターのステータスを考慮し、PG をクラスター内の OSD に均等に、かつ疑似ランダムに分散します。
以下は、その仕組みです。
システム管理者はプールを作成すると、CRUSH はプールのユーザー定義の PG を作成します。通常 PG の数は、データの合理的に細分化されたサブセットになります。たとえば、1 プールの 1 OSD あたり 100 PG は、各 PG にプールのデータの約 1% が含まれていることを意味します。
Ceph が PG をある OSD から別の OSD に移動する必要がある場合に、PG の数はパフォーマンスに影響を与えます。プールの PG が少なすぎると、Ceph はデータの大部分を同時に移動し、ネットワークの負荷がクラスターのパフォーマンスに悪影響を及ぼします。プールに PG が多すぎると、Ceph は、データのごく一部を移動する際に CPU および RAM を過剰に使用するので、クラスターのパフォーマンスに悪影響を与えます。パフォーマンスを最適化するために PG 数を計算する方法は、PG Count を参照してください。
Ceph は、オブジェクトのレプリカを保存するか、オブジェクトのイレイジャーコードチャンクを保存することで、データの損失を防ぎます。Ceph は、オブジェクトまたはオブジェクトのイレイジャーコードチャンクを PG 内に格納するため、Ceph は、オブジェクトのコピーごとまたはオブジェクトのイレイジャーコードチャンクごとに、動作セットと呼ばれる OSD のセットに各 PG を複製します。システム管理者は、プール内の PG 数と、レプリカまたは消去コードチャンクの数を判断できます。ただし、CRUSH アルゴリズムは、特定の PG の動作セットに含まれる OSD を計算します。
CRUSH アルゴリズムおよび PGs は Ceph を動的にします。クラスターマップまたはクラスターの状態の変更により、Ceph が PG をある OSD から別の OSD に自動的に移動させる可能性があります。
以下にいくつか例を示します。
- クラスターの拡張: 新規ホストとその OSD をクラスターに追加すると、クラスターマップが変更されます。CRUSH は PG を OSD にクラスター全体に疑似ランダムに分散するため、新規ホストおよびその OSD を追加すると、CRUSH はプールの配置グループの一部をそれらの新規 OSD に再度割り当てます。つまり、システム管理者は、クラスターを手動でリバランスする必要はありません。また、新規の OSD には、他の OSD とほぼ同じ量のデータが含まれていることを意味します。これは、新規の OSD に新規作成の OSD が含まれていないことも意味し、クラスター内のホットスポットを防ぎます。
- OSD 失敗: OSD が失敗すると、クラスターの状態が変わります。Ceph は、レプリカまたはイレイジャーコードのチャンクの 1 つを一時的に失い、別のコピーを作成する必要があります。動作セットのプライマリー OSD が失敗すると、動作セットの次の OSD がプライマリーになり、CRUSH は新規の OSD を計算して、追加のコピーまたはイレイジャーコードチャンクを格納します。
何十万もの PG のコンテキスト内で何百万ものオブジェクトを管理することで、Ceph Storage クラスターは効率的に拡張、縮小、および障害からの回復を行うことができます。
Ceph クライアントの場合は、librados を介した CRUSH アルゴリズムにより、オブジェクトの読み取りおよび書き込みプロセスが非常にシンプルになります。Ceph クライアントは単にオブジェクトをプールに書き込むか、プールからオブジェクトを読み取ります。動作セットのプライマリー OSD は、Ceph クライアントに代わって、オブジェクトのレプリカまたはオブジェクトのイレイジャーコードチャンクを動作セットのセカンダリー OSD に書き込むことができます。
クラスターマップまたはクラスターの状態が変更されると、OSD が PG を格納する CRUSH 計算も変更されます。たとえば、Ceph クライアントはオブジェクト foo をプール bar に書き込むことができます。CRUSH はオブジェクトを PG 1.a に割り当て、これを OSD 5 に保存します。これにより、OSD 10 および OSD 15 のレプリカがそれぞれ作成されます。OSD 5 が失敗すると、クラスターの状態が変わります。Ceph クライアントがプール bar からオブジェクト foo を読み込むと、librados 経由のクライアントは新しいプライマリー OSD として OSD 10 から自動的に取得されます。
librados を使用する Ceph クライアントは、オブジェクトの書き込みおよび読み取り時に、動作セット内でプライマリー OSD に直接接続します。I/O 操作は集中化ブローカーを使用しないため、ネットワークのオーバーサブスクリプションは通常、Ceph の問題ではありません。
以下の図は、CRUSH がオブジェクトを PG に割り当てる方法、および PG を OSD に割り当てる方法を示しています。CRUSH アルゴリズムでは、動作セットの各 OSD が別の障害ドメインに置かれるように PG を OSD に割り当てます。これは通常、OSD が常に別々のサーバーホストに置かれ、別のラックに置かれることを意味します。

2.5. Ceph CRUSH ルールセット
Ceph は CRUSH ルールセットをプールに割り当てます。Ceph クライアントがプールにデータを保存または取得する場合、Ceph は CRUSH ルールセット、ルールセット内のルール、およびデータを保存および取得するためのルールの最上位バケットを特定します。Ceph が CRUSH ルールを処理する際に、オブジェクトの配置グループが含まれるプライマリー OSD を特定します。これにより、クライアントは OSD に直接接続し、配置グループにアクセスして、オブジェクトデータの読み取りまたは書き込みを行うことができます。
配置グループを OSD にマッピングするには、CRUSH マップはバケットタイプの階層リストを定義します。バケットタイプのリストは、生成された CRUSH マップの types の下にあります。バケット階層を作成する目的は、ドライブタイプ、ホスト、シャーシ、ラック、電源分散ユニット、Pod、行、部屋、およびデータセンターなどの障害ドメインやパフォーマンスドメインによって、リーフノードを分離することです。
OSD を表すリーフノードを除き、残りの階層は任意になります。デフォルトのタイプが要件に適さない場合、管理者は独自のニーズに合わせて定義することができます。CRUSH は、通常は階層内の Ceph OSD ノードをモデル化する有向非巡回グラフをサポートします。そのため、Ceph 管理者は、単一の CRUSH マップで複数の root ノードを持つ複数の階層をサポートできます。たとえば、管理者は、高パフォーマンス用に高コストの SSD を表す階層を作成したり、中程度のパフォーマンス用に SSD ジャーナルを備えた低コストのハードドライブの別の階層を作成したりできます。
2.6. Ceph の入出力操作
Ceph クライアントは、Ceph モニターからクラスターマップを取得し、プールにバインドして、プールの配置グループ内にあるオブジェクトに対して入力/出力 (I/O) を実行します。プールの CRUSH ルールセットと配置グループの数は、Ceph がデータを配置する方法を決定する主要な要因です。クラスターマップの最新バージョンでは、クライアントは、クラスター内のすべてのモニターおよび OSD、およびそれらの現在の状態を認識します。ただし、クライアントはオブジェクトの場所について何も知りません。
クライアントが必要とする入力は、オブジェクト ID とプール名のみです。これは単純な方法です。Ceph はデータを名前付きプールに保管します。クライアントがプールに名前付きのオブジェクトを保存する場合は、オブジェクト名、ハッシュコード、プール名の PG 数およびプール名を入力として取り、次に CRUSH (Controlled Replication Under Scalable Hashing) は配置グループの ID および配置グループのプライマリー OSD を計算します。
Ceph クライアントは、以下の手順を使用して PG ID を計算します。
-
クライアントはプール ID とオブジェクト ID を入力します。たとえば、
pool = liverpoolおよびobject-id = johnです。 - CRUSH はオブジェクト ID を取得し、それをハッシュします。
-
CRUSH は PG 数のハッシュモジュロを計算し、PG ID を取得します。たとえば
58です。 - CRUSH は PG ID に対応するプライマリー OSD を計算します。
-
クライアントはプール名が指定されたプール ID を取得します。たとえば、プール
liverpoolはプール番号4です。 -
クライアントはプール ID を PG ID の前に追加します。たとえば
4.58です。 - クライアントは、動作セットのプライマリー OSD と直接通信することにより、書き込み、読み取り、削除などのオブジェクト操作を実行します。
Ceph Storage クラスターのトポロジーおよび状態は、セッション時に比較的安定しています。librados を介して Ceph クライアントにオブジェクトの場所を計算する権限を付与することは、クライアントが読み取り/書き込み操作ごとにチャットセッションを介してストレージクラスターにクエリーを実行することを要求するよりもはるかに高速です。CRUSH アルゴリズムにより、クライアントはオブジェクトが 保存される 場所を計算でき、クライアントが動作セットのプライマリー OSD に直接アクセスできる ようにし、オブジェクト内のデータを保存または取得できるようにします。エクサバイト規模のクラスターには数千もの OSD があるため、クライアントと Ceph OSD 間のネットワークオーバーサブスクリプションは重大な問題ではありません。クラスターの状態が変更された場合は、クライアントは単に Ceph モニターからクラスターマップへ更新をリクエストすることができます。
2.7. Ceph レプリケーション
Ceph クライアントと同様に、Ceph OSD は Ceph モニターに接続してクラスターマップの最新コピーを取得できます。Ceph OSD も CRUSH アルゴリズムを使用しますが、これを使用してオブジェクトのレプリカを保存する場所を計算します。標準的な書き込みシナリオでは、Ceph クライアントは CRUSH アルゴリズムを使用して、オブジェクトの動作セット内の配置グループ ID とプライマリー OSD を計算します。クライアントがプライマリー OSD にオブジェクトを書き込む際に、プライマリー OSD は格納する必要のあるレプリカ数を見つけます。値は osd_pool_default_size 設定にあります。次に、プライマリー OSD は、オブジェクト ID、プール名、およびクラスターマップを取得し、CRUSH アルゴリズムを使用して動作セットのセカンダリー OSD の ID を計算します。プライマリー OSD はオブジェクトをセカンダリー OSD に書き込みます。プライマリー OSD がセカンダリー OSD から確認応答を受信し、プライマリー OSD 自体がその書き込み操作を完了すると、Ceph クライアントへの書き込み操作が成功したことを確認します。

Ceph クライアントの代わりにデータレプリケーションを実行する機能を使用すると、Ceph OSD デーモンは、高いデータ可用性とデータの安全性を確保しながら、Ceph クライアントをその責務から解放します。
プライマリー OSD とセカンダリー OSD は通常、別の障害ドメインに配置するように設定されています。CRUSH は、障害ドメインについて考慮し、セカンダリー OSD の ID を計算します。
データのコピー
複製されたストレージプールでは、Ceph では、パフォーマンスが低下した状態で動作するためにオブジェクトの複数のコピーが必要になります。理想的には、Ceph Storage クラスターは、動作セットの OSD のいずれかが失敗しても、クライアントがデータの読み取りと書き込みを行えるようにします。このため、Ceph はオブジェクトの 3 つのコピーを作成するようにデフォルトで設定されます (書き込み操作用に少なくとも 2 つのコピーがクリーンであること)。Ceph は、2 つの OSD が失敗してもデータを保持します。ただし、書き込み操作が中断されます。
イレイジャーコーディングされたプールでは、Ceph はパフォーマンスが低下した状態で操作できるように、複数の OSD にまたがるオブジェクトのチャンクを格納する必要があります。複製されたプールと同様に、理想としては、レイジャーコーディングされたプールにより、Ceph クライアントはパフォーマンスが低下した状態で読み書きできるようになります。
Red Hat は、k および m に以下の jerasure コーディング値をサポートしています。
- k=8 m=3
- k=8 m=4
- k=4 m=2
2.8. Ceph イレイジャーコーディング
Ceph は、多くのイレイジャーコードアルゴリズムのいずれかを読み込むことができます。Reed-Solomon アルゴリズムが最も早く一般的に使用されるものになります。イレイジャーコードは、実際には前方誤り訂正 (FEC: forward error correction) コードです。FEC コードは、K チャンクのメッセージを、N チャンクのコードワードと呼ばれる長いメッセージに変換し、Ceph が N チャンクのサブセットから元のメッセージを復元できるようにします。
具体的には、変数 K が元のデータチャンク量である N = N = K+M です。変数 M は、余分または冗長なチャンクを表し、イレイジャーコードアルゴリズムが障害から保護します。変数 N は、イレイジャーコーディングプロセス後に作成されたチャンクの合計数です。M の値は N-K です。これは、アルゴリズムが K の元のデータチャンクから N-K 冗長チャンクを計算することを意味します。このアプローチにより、Ceph が元のデータすべてにアクセスできることを保証します。システムが任意の N-K の障害に対して回復性があります。たとえば、16 の N 設定のうち 10 K、またはイレイジャーコーディング 10/16 の場合、イレイジャーコードアルゴリズムは 10 ベースチャンク K に 6 つの追加チャンクを追加します。たとえば、M = K-N または 16-10 = 6 の設定では、Ceph は 16 チャンク N を 16 OSD に分散します。元のファイルは、6 つの OSD に障害が発生した場合でも、検証済みの 10 個の N チャンクから再構築できます。これにより、Red Hat Ceph Storage クラスターがデータを失うことがなくなり、非常に高いレベルのフォールトトレランスが保証されます。
複製されたプールと同様に、イレイジャーコーディングされたプールでは、セットアップ内のプライマリー OSD がすべての書き込み操作を受け取ります。複製されたプールでは、Ceph はセットのセカンダリー OSD 上の配置グループで各オブジェクトのディープコピーを作成します。イレイジャーコーディングの場合、プロセスは少し異なります。コード化されたプールは各オブジェクトを K+M チャンクとして格納します。これは K データチャンクと M コーディングチャンクに分割されます。プールには K+M のサイズが設定され、これにより Ceph が各チャンクを動作セットの OSD に保管することができます。Ceph は、チャンクのランクをオブジェクトの属性として保存します。プライマリー OSD はペイロードを K+M チャンクにエンコードし、それらを他の OSD に送信します。プライマリー OSD は、配置グループログの権威バージョンを維持するロールも果たします。
たとえば、一般的な設定では、システム管理者は 6 つの OSD を使用し、そのうちの 2 つの OSD の損失を維持するために、イレイジャーコード化されたプールを作成します。つまり、(K+M = 6) であり、(M = 2) になります。
Ceph が ABCDEFGHIJKL を含むオブジェクト NYAN をプールに書き込む場合、イレイジャーエンコーディングアルゴリズムは、コンテンツを ABC、DEF、GHI、および JKL の 4 つの部分に分割するだけで、コンテンツを 4 つのデータチャンクに分割します。コンテンツの長さが K の倍数でない場合は、アルゴリズムによりコンテンツをパディングします。この関数は、2 つのコーディングチャンクも作成します。4 つ目は YXY、5 つ目は QGC が付きます。Ceph は、動作セット内の OSD 上にそれぞれのチャンクを保存します。ここで、NYAN の名前を持つオブジェクトにチャンクが保管されますが、異なる OSD にあります。アルゴリズムは、名前に加えて、チャンクをオブジェクト shard_t の属性として作成した順番を保持する必要があります。たとえば、チャンク 1 には ABC が含まれ、Ceph はこれを OSD5 に格納されます。一方、チャンク 5 には YXY が含まれ、OSD4 に格納されます。
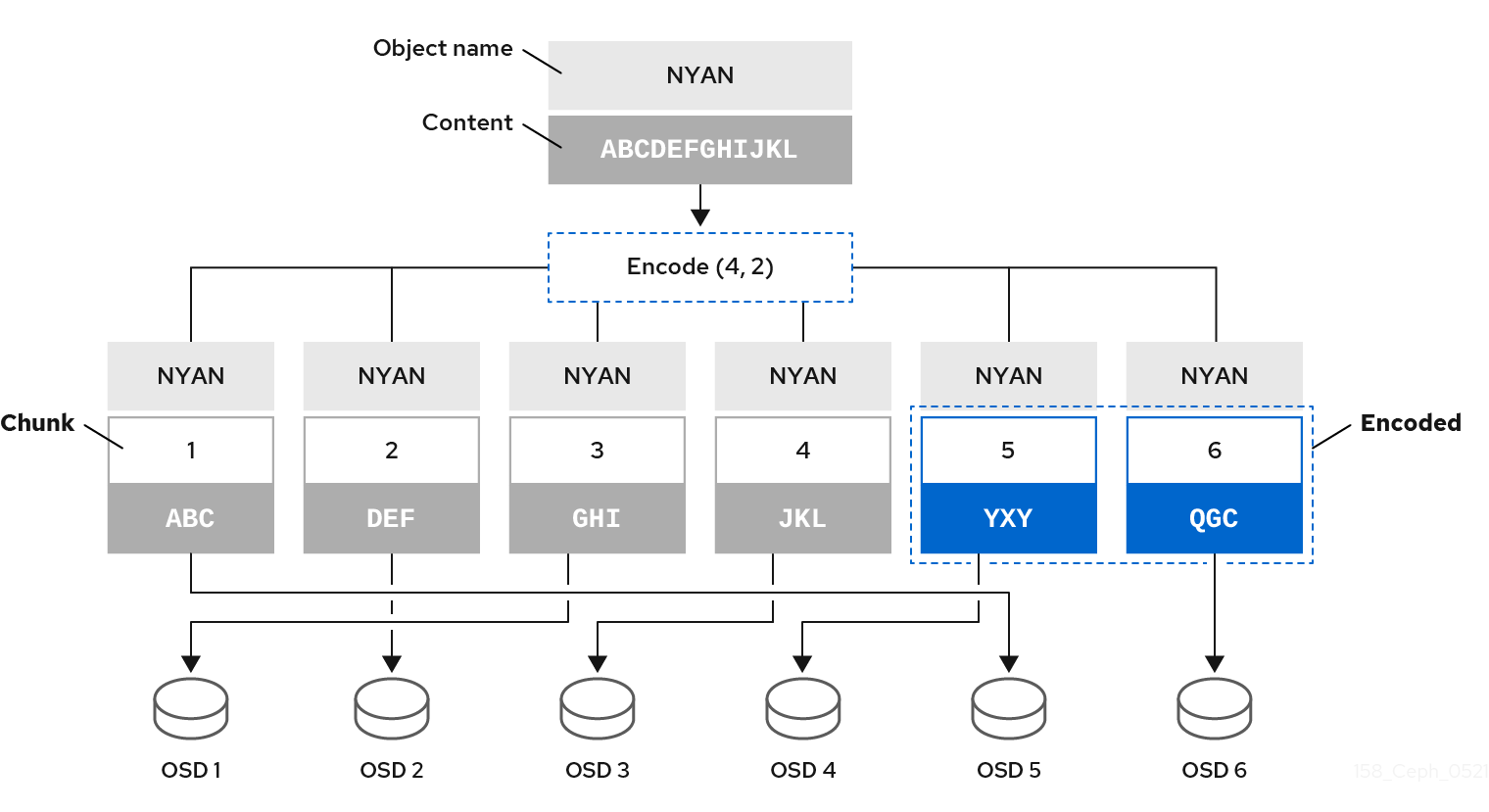
リカバリーのシナリオでは、クライアントはチャンク 1 から 6 を読み取ることで、イレイジャーコーディングされたプールからオブジェクト NYAN を読み込もうとします。OSD は、2 と 6 のチャンクがないことをアルゴリズムに通知します。これらのチャンクはイレイジャーと呼ばれます。たとえば、OSD6 が除外されているため、プライマリー OSD はチャンク 6 を読み取ることができませんでした。また、OSD2 は最も遅く、そのチャンクを考慮していなかったため、チャンク 2 を読み取ることができませんでした。ただし、アルゴリズムに 4 つのチャンクがあるとすぐに、ABC を含むチャンク 1、GHI を含むチャンク 3、JKL を含むチャンク 4、および YXY を含むチャンク 5 の 4 つのチャンクが読み取られます。次に、オブジェクト ABCDEFGHIJKL の元のコンテンツと、QGC を含むチャンク 6 の元のコンテンツを再構築します。
データをチャンクに分割することは、オブジェクトの配置とは無関係です。CRUSH ルールセットとイレイジャーコーディングされたプールプロファイルにより、OSD 上のチャンクの配置が決定されます。たとえば、イレイジャーコードプロファイルで Locally Repairable Code (lrc) プラグインを使用すると、追加のチャンクが作成され、回復に必要な OSD が少なくなります。たとえば、lrc プロファイル設定 K=4 M=2 L=3 では、アルゴリズムは、jerasure プラグインと同じように 6 つのチャンク (K+M) を作成しますが、局所性の値 (L=3) では、アルゴリズムはさらに 2 つのチャンクをローカルに作成する必要があります。アルゴリズムは、(K+M)/L などの追加チャンクを作成します。チャンク 0 を含む OSD が失敗すると、チャンク 1、2、および最初のローカルチャンクを使用してこのチャンクを回復できます。この場合、アルゴリズムは 5 つではなく 3 つのチャンクのみを回復に必要とします。
イレイジャーコーディングされたプールを使用すると、オブジェクトマップが無効になります。
関連情報
- CRUSH、イレイジャーコーディングプロファイル、およびプラグインの詳細は、Red Hat Ceph Storage 5 の ストレージストラテジーガイド を参照してください。
- オブジェクトマップの詳細については、Ceph クライアントオブジェクトマップ のセクションを参照してください。
2.9. Ceph ObjectStore
Objectstore は、OSD の raw ブロックデバイスに低レベルのインターフェイスを提供します。クライアントがデータの読み取りまたは書き込みを行うと、ObjectStore インターフェイスと対話します。Ceph 書き込み操作は、基本的に ACID トランザクションです。つまり、原子性、一貫性、分離、および 耐久性 を提供します。ObjectStore は、トランザクション が 原子性 を提供するために、オールオアナッシングになるようにします。ObjectStore は、オブジェクトセマンティクスも処理します。ストレージクラスターに格納されるオブジェクトには、一意の識別子、オブジェクトデータ、およびメタデータがあります。したがって、ObjectStore は Ceph オブジェクトセマンティクスが正しいことを確認して 整合性 を提供します。ObjectStore は、書き込み操作で Sequencer を呼び出して ACID トランザクションの 分離 部分も提供し、Ceph 書き込み操作が順番に実行されるようにします。対照的に、OSD のレプリケーションまたはイレイジャーコーディング機能は、ACID トランザクションの 耐久性 コンポーネントを提供します。ObjectStore は、ストレージメディアへの低レベルのインターフェイスであるため、パフォーマンスの統計も提供します。
Ceph は、データを保管するための具体的な方法を実装します。
- BlueStore: オブジェクトデータを保存するために raw ブロックデバイスを使用した実稼働クラスの実装。
- Memstore: RAM で読み取り/書き込み操作を直接テストするための開発者の実装。
- K/V Store: Ceph がキー/値データベースを使用する内部実装。
管理者は通常 BlueStore にのみ対応するため、以下のセクションではこれらの実装についてのみ詳しく説明します。
2.10. Ceph BlueStore
BlueStore は Ceph の次世代ストレージ実装です。ストレージデバイスの市場にはソリッドステートドライブ、SSD、PCI Express または NVMe 経由の不揮発性メモリーが含まれるようになったため、Ceph での使用により、FileStore ストレージの実装の制限の一部が示されます。FileStore には、SSD ストレージおよび NVMe ストレージを容易にするために多くの改良がありますが、他の制限は残ります。それらの中で、配置グループの増加は依然として計算コストが高く、二重書き込みペナルティーが残っています。FileStore はブロックデバイスのファイルシステムと対話し、BlueStore はその間接状態をなくし、オブジェクトストレージ用に raw ブロックデバイスを直接使用します。BlueStore は、k/v データベース用に小規模なパーティションで非常に軽量な BlueFS ファイルシステムを使用します。BlueStore では、配置グループを表すディレクトリー (オブジェクトを表すファイルおよびメタデータを表すファイルの) の XATTR がなくなります。BlueStore では FileStore の 2 回の書き込みペナルティーが解消されるため、ほとんどのワークロードで BlueStore を使用する場合に、書き込み操作はほぼ 2 倍速くなります。
BlueStore は以下のようにデータを保存します。
-
オブジェクトデータ:
BlueStoreでは、Ceph はオブジェクトを raw ブロックデバイスに直接ブロックとして保存します。オブジェクトデータを格納する raw ブロックデバイスの部分にはファイルシステムが含まれません。ファイルシステム省略により間接的な層が排除され、パフォーマンスが向上します。ただし、BlueStoreのパフォーマンスのほとんどは、ブロックデータベースと write-ahead ログにより向上されます。 -
ブロックデータベース:
BlueStoreでは、整合性 を保証するために、ブロックデータベースがオブジェクトのセマンティクスを処理します。オブジェクトの一意の ID はブロックデータベースのキーです。ブロックデータベースの値は、格納したオブジェクトデータ、オブジェクトの配置グループ、およびオブジェクトメタデータを参照する一連のブロックアドレスで設定されます。ブロックデータベースは、オブジェクトデータを格納する同じ raw ブロックデバイス上のBlueFSパーティションに存在する場合もあれば、別のブロックデバイスに存在する場合もあります。通常、ハードディスクドライブがプライマリーリブロックデバイスであり、SSD または NVMe によってパフォーマンスが向上します。ブロックデータベースでは、FileStoreに対する多くの改善が行われています。つまり、BlueStoreのキー/値のセマンティクスはファイルシステム XATTR の制限に悪い影響を与えません。BlueStoreは、FileStoreのように、ファイルをディレクトリーから別のディレクトリーに移動するオーバーヘッドなしに、ブロックデータベース内の他の配置グループにオブジェクトをすぐに割り当てることができます。BlueStoreには新機能も導入されています。ブロックデータベースは、保存されたオブジェクトデータとそのメタデータのチェックサムを保存できるため、読み取りごとに完全なデータチェックサム操作が可能になります。これは、ビットロットを検出するための定期的なスクラブよりも効率的です。BlueStoreはオブジェクトを圧縮でき、ブロックデータベースはオブジェクトの圧縮に使用されるアルゴリズムを保存できます。これにより、読み取り操作で解凍に適切なアルゴリズムが選択されます。 -
先行書き込みログ:
BlueStoreでは、FileStoreのジャーナリング機能と同様に、先行書き込みログによって 原子性 が保証されます。FileStoreと同様に、BlueStoreは各トランザクションのすべての要素をログに記録します。ただし、BlueStoreの先行書き込みログまたは WAL は、この機能を同時に実行できるため、FileStoreの二重書き込みペナルティーがなくなります。その結果、BlueStoreは、ほとんどのワークロードの書き込み操作でFileStoreのほぼ 2 倍の速度になります。BlueStore は、オブジェクトデータを保存するために同じデバイスに WAL をデプロイできます。または、通常、プライマリーブロックデバイスがハードディスクドライブである場合や、SSD または NVMe によってパフォーマンスが向上する場合は、WAL を別のデバイスにデプロイできます。
個別のデバイスがプライマリーストレージデバイスよりも高速である場合にのみ、ブロックデータベースまたは先行書き込みログを別のブロックデバイスに保存すると便利です。たとえば、SSD デバイスおよび NVMe デバイスは通常 HDD よりも高速です。ブロックデータベースと WAL を別のデバイスに配置すると、ワークロードの違いにより、パフォーマンス上の利点があります。
2.11. Ceph の自己管理操作
Ceph クラスターは、多くの自己監視および管理操作を自動的に実行します。たとえば、Ceph OSD はクラスターの正常性を確認し、Ceph モニターに報告することができます。CRUSH を使用してオブジェクトを配置グループに割り当て、配置グループを OSD のセットに割り当てることにより、Ceph OSD は CRUSH アルゴリズムを使用して、クラスターのバランスを取り直したり、OSD 障害から動的に回復したりできます。
2.12. Ceph ハートビート
Ceph OSD はクラスターに参加し、そのステータスについて Ceph Monitors に報告します。最下位レベルでは、Ceph OSD ステータスは up または down で、実行中で Ceph クライアント要求を処理できるかどうかを反映しています。Ceph OSD が down で、Ceph Storage クラスターの in (内) にある場合、このステータスは、Ceph OSD の失敗を示す可能性があります。たとえば、Ceph OSD が稼働していない場合に、クラッシュします。Ceph OSD は、down していることを Ceph Monitor に通知できません。Ceph Monitor は Ceph OSD デーモンに定期的に ping して、実行されていることを確認できます。ただし、ハートビートにより、Ceph OSD は、隣接 OSD が down しているかどうかを判断し、クラスターマップを更新して、Ceph モニターに報告することができます。つまり、Ceph Monitor が軽量プロセスを維持できることを意味します。
2.13. Ceph ピアリング
Ceph は、複数の OSD 上の配置グループのコピーを保存します。配置グループのコピーごとにステータスがあります。これらの OSD は相互にピアチェックし、PG の各コピーのステータスに同意していることを確認します。通常、ピアリングの問題は自己解決します。
Ceph モニターが配置グループを保存する OSD の状態に同意する場合、配置グループが最新のコンテンツを持っていることを意味しません。
Ceph が配置グループを有効な OSD セットに保存する場合は、それらを プライマリー、セカンダリー などとして参照します。通常、プライマリー は 動作セット の最初の OSD になります。配置グループの最初のコピーを保存する プライマリー は、その配置グループのピアプロセスを調整するロールを果たします。プライマリー は、指定した配置グループのオブジェクトに対してクライアントが開始する書き込みを許可する 唯一 の OSD で、プライマリー として機能します。
動作セット は、配置グループを格納する一連の OSD です。動作セット は、現在配置グループを担当している Ceph OSD デーモンや、あるエポックの時点で特定の配置グループを担当していた Ceph OSD デーモンを指す場合があります。
動作セット に含まれる Ceph OSD デーモンは常に up であるとは限りません。動作セット の OSD が up であると、これは Up Set の一部になります。OSD に障害が発生した場合に Ceph は PG を他の Ceph OSD に再マッピングできるため、Up Set は重要な違いです。
osd.25、osd.32、および osd.61 を含む PG の Acting Set では、最初の OSD osd.25 は プライマリー です。OSD が失敗すると、セカンダリー では、osd.32 が プライマリー になり、Ceph は Up Set から osd.25 を削除します。
2.14. Ceph のリバランスおよびリカバリー
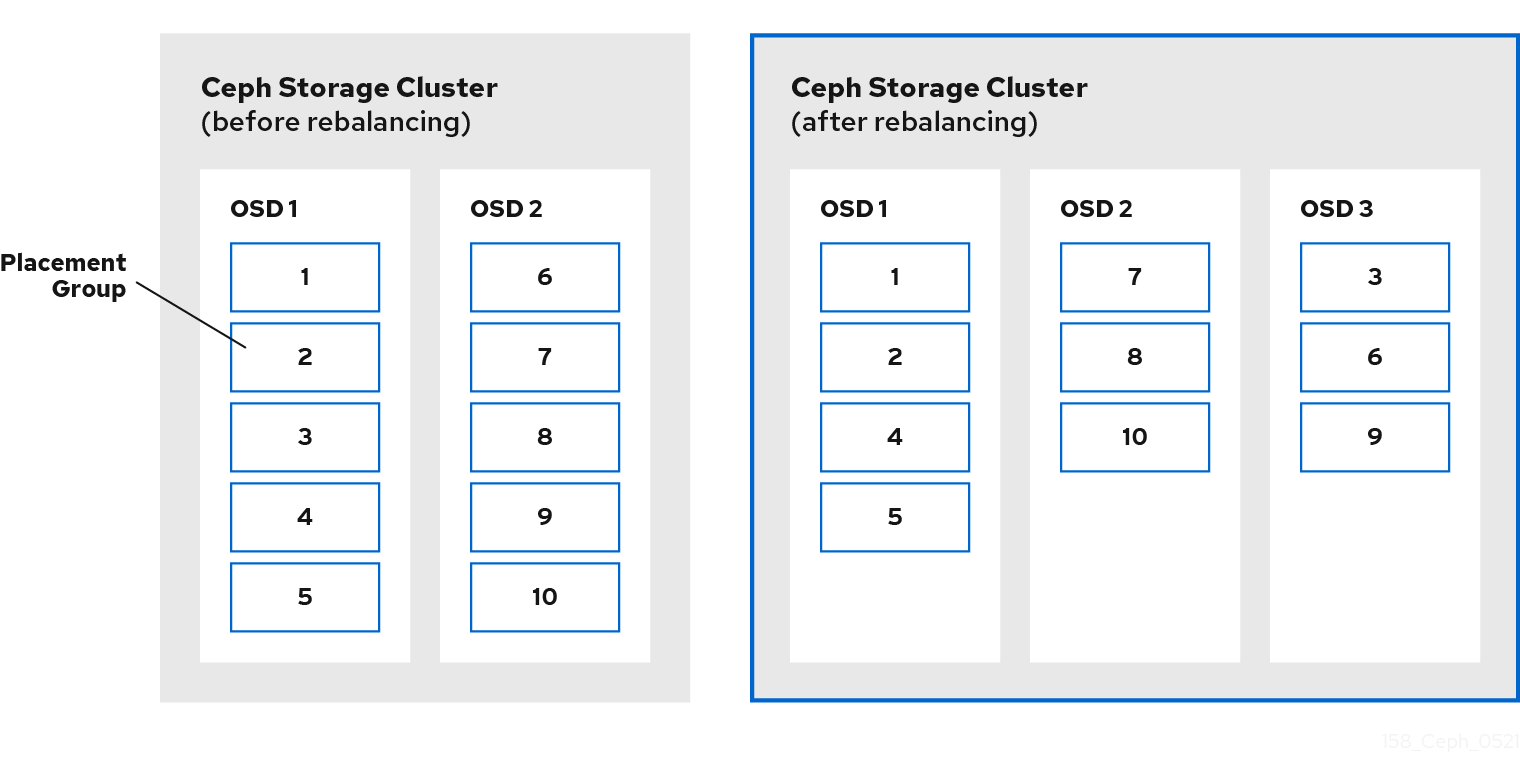
管理者が Ceph OSD を Ceph Storage クラスターに追加する際に、Ceph はクラスターマップを更新します。変更されたクラスターマップは CRUSH 計算の入力を変更するため、クラスターマップへのこの変更は、オブジェクトの配置も変更します。CRUSH はデータを均等に配置しますが、疑似ランダムに配置します。そのため、管理者が新しい OSD を追加すると、移動するデータはごくわずかになります。データの量は通常、新しい OSD の数をクラスター内のデータの合計量で割ったものになります。たとえば、50 個の OSD があるクラスターでは、OSD を追加すると、データの 1/50 または 2% が移動する可能性があります。
次の図は、すべてではなく一部の PG が図にある既存の OSD である OSD 1 および 2 から、新しい OSD である OSD 3 に移行するリバランスプロセスを示しています。リバランスを行う場合でも、CRUSH は安定しています。配置グループの多くは元の設定のままであり、各 OSD には容量が追加されるため、クラスターのリバランス後に新しい OSD に負荷が急増することはありません。
2.15. Ceph データの整合性
データの整合性を維持する一環として、Ceph は、不良ディスクセクターやビットロットを防ぐための多数のメカニズムを提供します。
- スクラブ: Ceph OSD デーモンは配置グループ内のオブジェクトをスクラブすることができます。つまり、Ceph OSD デーモンは、1 つの配置グループのオブジェクトメタデータを、他の OSD に保存されている配置グループのレプリカと比較できます。スクラビング (通常は毎日実行) は、バグやストレージエラーをキャッチします。Ceph OSD デーモンは、オブジェクト内のデータをビットごとに比較することにより、より深いスクラビングも実行します。ディープスクラビング (通常は毎週実行) は、軽量スクラブでは見られなかったドライブ上の不良セクターを見つけます。
-
CRC チェック:
BlueStoreを使用する場合の Red Hat Ceph Storage 5 では、Ceph は書き込み操作で CRC (cyclical redundancy check) を実行することにより、データの整合性を確保できます。次に、CRC 値をブロックデータベースに保存します。読み取り操作では、Ceph はブロックデータベースから CRC 値を取得し、取得したデータの 生成された CRC と比較して、データの整合性を即時に確保できます。
2.16. Ceph の高可用性
CRUSH アルゴリズムで有効化されたスケーラビリティーに加え、Ceph も高可用性を維持する必要があります。つまり、Ceph クライアントは、クラスターのパフォーマンスが低下した状態にある場合や、モニターに障害が発生した場合でも、データの読み取りと書き込みができる必要があります。
2.17. Ceph Monitor のクラスタリング
Ceph クライアントがデータの読み取りまたは書き込みを行う前に、Ceph Monitor に接続して、クラスターマップの最新のコピーを取得する必要があります。Red Hat Ceph Storage クラスターは単一のモニターで動作しますが、これにより単一障害点が発生します。つまり、モニターがダウンした場合、Ceph クライアントはデータの読み取りと書き込みができなくなります。
信頼性とフォールトトレランスを強化するために、Ceph はモニターのクラスターをサポートしています。Ceph Monitor のクラスターでは、レイテンシーやその他の障害により、1 つ以上のモニターがクラスターの現在の状態より遅れる可能性があります。このため、Ceph はストレージクラスターの状態に関して、さまざまなモニターインスタンス間で合意する必要があります。Ceph は、大多数のモニターと Paxos アルゴリズムを常に使用して、ストレージクラスターの現在の状態についてモニター間でコンセンサスを確立します。クロックドリフトを防ぐために Ceph Monitors ノードに NTP が必要です。
ストレージ管理者は通常、奇数のモニターを使用して Ceph をデプロイするため、効率的に過半数を決定することができます。たとえば、過半数は 1、2:3、3:5、4:6 などになります。
第3章 Ceph クライアントコンポーネント
Ceph クライアントは、データストレージインターフェイスの表示方法が大きく異なります。Ceph ブロックデバイスは、物理ストレージドライブと同様にマウントするブロックストレージを表示します。Ceph ゲートウェイは、S3 準拠のオブジェクトストレージサービスと Swift 準拠の RESTful インターフェイスを独自のユーザー管理と共に表示します。ただし、すべての Ceph クライアントは Reliable Autonomic Distributed Object Store (RADOS) プロトコルを使用して Red Hat Ceph Storage クラスターと対話します。
これらはすべて、同じ基本的なニーズを持っています。
- Ceph 設定ファイルおよび Ceph Monitor アドレス。
- プール名
- ユーザー名およびシークレットキーへのパス。
Ceph クライアントは、object-watch-notify や striping などのいくつかの同様のパターンに従う傾向があります。以下のセクションでは、RADOS、librados、および Ceph クライアントで使用される一般的なパターンについて、もう少し説明します。
3.1. 前提条件
- 分散ストレージシステムについての基本的な理解
3.2. Ceph クライアントネイティブプロトコル
最新のアプリケーションには、非同期通信機能を備えた単純なオブジェクトストレージインターフェイスが必要です。Ceph Storage Cluster は、非同期通信機能を備えたシンプルなオブジェクトストレージインターフェイスを提供します。このインターフェイスは、クラスター全体でオブジェクトへの直接並行アクセスを提供します。
- プール操作
- スナップショット
オブジェクトの読み取り/書き込み
- 作成または削除
- オブジェクト全体またはバイト範囲
- 追加または切り捨て
- Create/Set/Get/Remove XATTRs
- Create/Set/Get/Remove Key/Value Pairs
- 複合操作および dual-ack セマンティクス
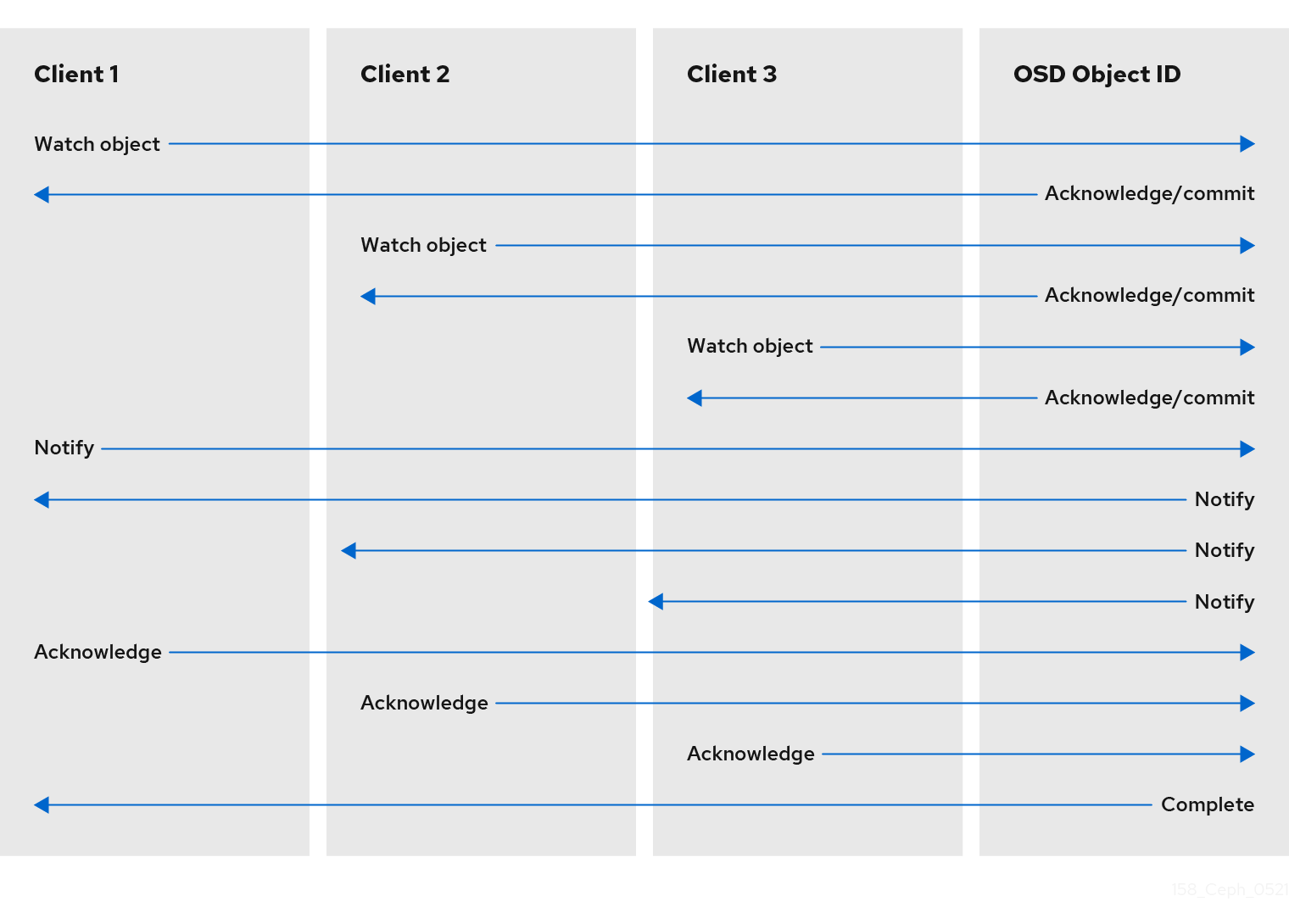
3.3. Ceph クライアントオブジェクトの監視および通知
Ceph クライアントは、永続的な関心をオブジェクトに登録し、プライマリー OSD へのセッションを開いたままにすることができます。クライアントは、通知メッセージおよびペイロードをすべてのウォッチャーに送信し、ウォッチャーが通知を受信したときに通知を受信できます。これにより、クライアントは同期/通信チャネルとして、任意のオブジェクトを使用できます。
3.4. Ceph クライアントの Mandatory Exclusive Locks
必須の排他的ロックは、複数のマウントが設定されている場合に、RBD を単一のクライアントにロックする機能です。これは、マウントされた複数のクライアントが同じオブジェクトに書き込もうとした場合の書き込みの競合状況に対処する上で役立ちます。この機能は、前セクションで説明した object-watch-notify で構築されます。したがって、書き込み時に、あるクライアントがオブジェクトに排他ロックを最初に確立すると、マウントされた別のクライアントは、書き込み前にピアがオブジェクトにロックを設定したかどうかを最初に確認します。
この機能を有効にすると、1 つのクライアントのみが一度に RBD デバイスを変更することができます。特に、スナップショットの作成/削除 などの操作中に内部 RBD 構造を変更する場合などです。また、障害が発生したクライアントをある程度保護します。たとえば、仮想マシンが応答していないように見え、他の場所で同じディスクを使用してそのコピーを開始した場合、最初の仮想マシンは Ceph でブラックリストに登録され、新しい仮想マシンを破損することはできません。
必須の排他ロックはデフォルトでは有効になっていません。イメージの作成時に、--image-feature パラメーターを使用して明示的に有効にする必要があります。
Example
[root@mon ~]# rbd create --size 102400 mypool/myimage --image-feature 5
ここで、数値の 5 は、1 と 4 の合計であり、1 は階層化サポートを有効にし、4 は排他的ロックサポートを有効にします。したがって、上記のコマンドは 100 GB rbd イメージを作成し、階層化および排他的ロックを有効にします。
必須の排他的ロックも object map の前提条件となります。排他的なロックサポートを有効にしないと、オブジェクトマップのサポートを有効にすることはできません。
必須の排他的ロックは、ミラーリングのためのいくつかの基本的な作業も行います。
3.5. Ceph クライアントオブジェクトマップ
オブジェクトマップは、クライアントが rbd イメージに書き込む際にサポートする RADOS オブジェクトの存在を追跡する機能です。書き込みが発生すると、その書き込みはバッキング RADOS オブジェクト内のオフセットに変換されます。オブジェクトマップ機能が有効になっている場合、これらの RADOS オブジェクトの存在が追跡されます。したがって、オブジェクトが実際に存在するかどうかを知ることができます。オブジェクトマップは、librbd クライアントのメモリー内に保持されるため、存在しないことがわかっているオブジェクトを OSD に照会することを回避できます。つまり、オブジェクトマップは実際に存在するオブジェクトのインデックスです。
オブジェクトマップは、以下のような特定の操作に有益です。
- サイズ変更
- エクスポート
- コピー
- フラット化
- 削除
- 読み取り
縮小サイズ変更操作は、末尾のオブジェクトが削除される部分的な削除のようなものです。
エクスポート操作は、RADOS から要求されるオブジェクトを認識します。
コピー操作では、どのオブジェクトが存在し、コピーする必要があるかを認識します。潜在的に数百、数千の可能なオブジェクトを反復する必要はありません。
フラット化操作は、クローンへのすべての親オブジェクトのコピーアップを実行して、クローンを親から切り離すことができるようにします。つまり、子クローンから親スナップショットへの参照を削除できます。したがって、すべての潜在的なオブジェクトの代わりに、コピーアップは存在するオブジェクトに対してのみ行われます。
削除操作は、イメージに存在するオブジェクトのみを削除します。
読み取り操作は、存在しないことがわかっているオブジェクトの読み取りをスキップします。
したがって、サイズ変更、縮小のみ、エクスポート、コピー、フラット化、削除などの操作の場合、これらの操作は、影響を受けた可能性のあるすべての RADOS オブジェクトに対して、存在するかどうかに関係なく操作を実行する必要があります。オブジェクトマップを有効にすると、オブジェクトが存在しない場合は、操作を発行する必要はありません。
たとえば、1 TB のスパース RBD イメージがある場合は、数百、数千というバッキングする RADOS オブジェクトが含まれる可能性があります。オブジェクトマップを有効にしない削除操作では、イメージの潜在的な オブジェクトごとに remove object 操作を実行する必要があります。ただし、オブジェクトマップが有効な場合は、存在するオブジェクトの remove object 操作のみを実行する必要があります。
オブジェクトマップは、実際のオブジェクトを持たないが、親からオブジェクトを取得するクローンに対して価値があります。クローンで作成されたイメージがある場合、クローンには最初にオブジェクトがなく、すべての読み取りは親にリダイレクトされます。したがって、オブジェクトマップは、オブジェクトマップがない場合と同様に読み取りを改善できます。最初に、クローンの OSD に対して読み取り操作を発行する必要があります。それが失敗すると、オブジェクトマップを有効にして、親に対して別の読み取りを発行します。存在しないことがわかっているオブジェクトの読み取りをスキップします。
オブジェクトマップは、デフォルトでは有効になっていません。イメージの作成時に、--image-features パラメーターを使用して明示的に有効にする必要があります。また、Mandatory Exclusive Locks は、object map の前提条件となります。排他的なロックサポートを有効にしないと、オブジェクトマップのサポートを有効にすることはできません。イメージの作成時にオブジェクトマップのサポートを有効にするには、以下を実行します。
[root@mon ~]# rbd -p mypool create myimage --size 102400 --image-features 13
ここで、数値の 13 は、1 と 4、8 の合計であり、1 は階層化サポートを有効にし、4 は排他的ロックサポートを有効にして、8 は、オブジェクトマップサポートを有効にします。したがって、上記のコマンドは 100 GB rbd イメージを作成し、階層化、排他ロックおよびオブジェクトマップを有効にします。
3.6. Ceph クライアントデータのストライピング
ストレージデバイスにはスループットの制限があり、パフォーマンスとスケーラビリティーに影響を及ぼします。そのため、ストレージシステムは多くの場合、スループットとパフォーマンスを向上させるために、ストライピング (複数のストレージデバイス間で連続した情報を保存する) をサポートします。データストライピングの最も一般的な形式は RAID から来ています。Ceph のストライピングに最も類似する RAID タイプは、RAID 0、つまりストライプ化ボリュームです。 Ceph のストライピングでは、RAID 0 ストライピングのスループット、n-way RAID ミラーリングの信頼性、および迅速なリカバリーを提供します。
Ceph には、Ceph Block Device、Ceph Filesystem、および Ceph Object Storage の 3 種類のクライアントがあります。Ceph クライアントは、ブロックデバイスイメージ、RESTful オブジェクト、CephFS ファイルシステムディレクトリーなど、ユーザーに提供する表現形式から、Ceph Storage Cluster に格納するためのオブジェクトにデータを変換します。
Ceph Storage Cluster に Ceph が格納するオブジェクトはストライプ化されていません。Ceph Object Storage、Ceph Block Device、および Ceph Filesystem は、複数の Ceph Storage Cluster オブジェクトにデータのストライプ化を行います。librados を使用して Ceph Storage クラスターに直接書き込む Ceph クライアントは、これらの利点を得るためにストライプ化を実施し、並行 I/O を実行する必要があります。
最も単純な Ceph のストライプ化形式には、1 つのオブジェクトのストライプ数が含まれます。Ceph クライアントは、オブジェクトが最大容量になるまで Ceph Storage Cluster オブジェクトにストライプユニットを書き込みます。その後、データの追加のストライプ用に別のオブジェクトを作成します。ストライプ化の最も単純な形式は、小さなブロックデバイスイメージ、S3 または Swift オブジェクトにとって十分と言えます。ただし、この単純な形式では、配置グループ全体にデータを分散する Ceph の機能をを最大限に活用しないため、パフォーマンスはそれほど向上しません。以下の図は、ストライプ化の最も単純な形式を示しています。
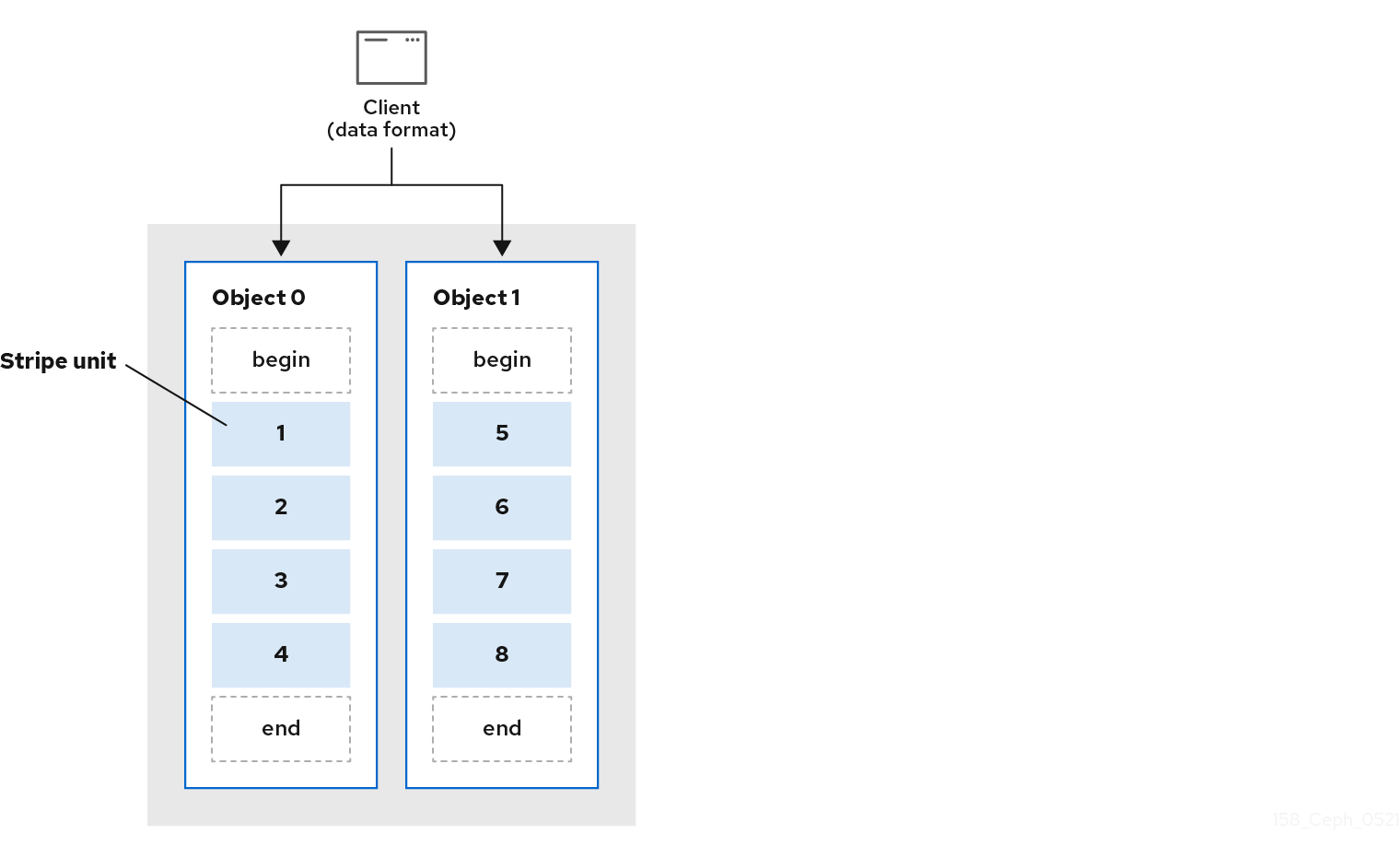
大きなイメージサイズや、たとえばビデオなどの大きな S3 または Swift オブジェクトが予想される場合は、オブジェクトセット内の複数のオブジェクトにクライアントデータをストライプ化することで、読み取り/書き込みのパフォーマンスが大幅に向上する可能性があります。クライアントが対応するオブジェクトに並列にストライプユニットを書き込むと、書き込みパフォーマンスが大幅に向上します。オブジェクトは異なる配置グループにマッピングされ、さらに異なる OSD にマッピングされるため、それぞれの書き込みは最大書き込み速度で並行して行われます。単一のディスクへの書き込みは、ヘッドの動き、たとえばシークあたり 6 ミリ秒、およびその 1 つのデバイスの帯域幅 (たとえば 100MB/秒) によって制限されます。異なる配置グループおよび OSD にマッピングする複数のオブジェクトに書き込みを分散することにより、Ceph はドライブごとのシーク数を減らし、複数のドライブのスループットを組み合わせて、はるかに高速な書き込みまたは読み取り速度を実現できます。
ストライプ化は、オブジェクトレプリカとは独立しています。CRUSH は OSD 間でオブジェクトを複製するため、ストライプは自動的に複製されます。
以下の図では、クライアントデータは、4 つのオブジェクトで設定されるオブジェクトセット (以下の図の object set 1) でストライプ化されます。最初のストライプユニットは、object 0 の stripe unit 0 です。4 番目のストライプユニットは、object 3 の stripe unit 3 です。4 番目のストライプを作成したら、クライアントはオブジェクトセットがいっぱいかどうかを判断します。オブジェクトセットが満杯でない場合は、クライアントが最初のオブジェクトにストライプを書き始め、以下の図の object 0 を参照してください。オブジェクトセットが満杯になると、クライアントは新しいオブジェクトセットを作成し、以下の図の object set 2 を参照し、ストライプユニットが 16 の状態で最初のストライプへの書き込みを開始します。新しいオブジェクトセットの最初のオブジェクトセットでは、以下の図の object 4 を参照してください。

3 つの重要な変数が、Ceph によるデータのストライプ化方法を決定します。
オブジェクトサイズ: Ceph Storage クラスターのオブジェクトには、設定可能な最大サイズ (2 MB または 4 MB) があります。オブジェクトのサイズは、多くのストライプユニットを収容するのに十分な大きさであり、ストライプユニットの倍数である必要があります。
重要Red Hat では、安全な最大値である 16 MB を推奨しています。
- ストライプの幅: ストライプは、64 KB などの設定可能なユニットサイズがあります。Ceph クライアントは、オブジェクトに書き込むデータを、最後のストライプユニットを除いて、同じサイズのストライプユニットに分割します。ストライプ幅は、オブジェクトに多くのストライプユニットが含まれるように、オブジェクトサイズのごく一部にする必要があります。
- ストライプ数: Ceph クライアントは、ストライプ数で決定される一連のオブジェクトに一連のストライプユニットを書き込みます。一連のオブジェクトは、オブジェクトセットと呼ばれます。Ceph クライアントがオブジェクトセットの最後のオブジェクトに書き込みした後に、オブジェクトセットの最初のオブジェクトに戻ります。
クラスターを実稼働環境に移行する前に、ストライプ化設定のパフォーマンスをテストします。データをストライプ化してオブジェクトに書き込んだ後は、これらのストライプ化パラメーターを変更することはできません。
Ceph クライアントがデータをストライプユニットにストライプ化し、ストライプユニットをオブジェクトにマッピングすると、Ceph の CRUSH アルゴリズムは、オブジェクトをストレージディスクにファイルとして保存する前に、オブジェクトを配置グループにマッピングし、配置グループを CephOSD デーモンにマッピングします。
クライアントは単一のプールに書き込むため、オブジェクトにストライプ化されたすべてのデータは、同じプールの配置グループにマッピングされます。したがって、同じ CRUSH マップと同じアクセス制御を使用します。
第4章 Ceph の伝送時暗号化
messenger バージョン 2 プロトコルを使用して、ネットワーク経由ですべての Ceph トラフィックの暗号化を有効にできます。メッセンジャー v2 の secure モード設定は、Ceph デーモンと Ceph クライアント間の通信を暗号化し、エンドツーエンドの暗号化を提供します。
Ceph の有線プロトコルの 2 つ目のバージョンである msgr2 には、以下の新機能が含まれています。
- 安全なモードは、ネットワークを介したすべてのデータの移動を暗号化します。
- 認証ペイロードのカプセル化による改善。
- 機能のアドバタイズおよびネゴシエーションの改善。
Ceph デーモンは、レガシー、v1 互換、および新しい v2 互換の Ceph クライアントを同じストレージクラスターに接続することができるように、複数のポートにバインドします。Ceph Monitor デーモンに接続する Ceph クライアントまたはその他の Ceph デーモンは、まず v2 プロトコルの使用を試みますが、可能でない場合は古い v1 プロトコルが使用されます。デフォルトでは、メッセンジャープロトコル v1 と v2 の両方が有効です。新規の v2 ポートは 3300 で、レガシー v1 ポートはデフォルトで 6789 になります。
messenger v2 プロトコルには、v1 プロトコルまたは v2 プロトコルを使用するかどうかを制御する 2 つの設定オプションがあります。
-
ms_bind_msgr1- このオプションは、デーモンが v1 プロトコルと通信するポートにバインドするかどうかを制御します。デフォルトではtrueです。 -
ms_bind_msgr2- このオプションは、デーモンが v2 プロトコルと通信するポートにバインドするかどうかを制御します。デフォルトではtrueです。
同様に、使用する IPv4 アドレスと IPv6 アドレスに基づいて 2 つのオプションを制御します。
-
ms_bind_ipv4- このオプションは、デーモンが IPv4 アドレスにバインドするかどうかを制御します。デフォルトではtrueです。 -
ms_bind_ipv6- このオプションは、デーモンが IPv6 アドレスにバインドするかどうかを制御します。デフォルトではtrueです。
メッセンジャープロトコル v1 または v2 を使用する Ceph デーモンまたはクライアントは、スロットル、つまりメッセージキューの増大を制限する機能を実装できます。まれに、デーモンまたはクライアントがスロットルを超えて、メッセージ処理に遅延が生じることがあります。スロットル制限に達すると、次の低レベルの警告メッセージが表示されます。
Throttler Limit has been hit. Some message processing may be significantly delayed.
msgr2 プロトコルは、以下の 2 つの接続モードをサポートします。
crc-
cephxで接続を確立すると、強固な初期認証を提供します。 -
ビットフリップから保護する
crc32c整合性チェックを提供します。 - 悪意のある中間者攻撃に対する保護を提供しません。
- 盗聴者がすべての認証後のトラフィックを見るのを妨げません。
-
secure-
cephxで接続を確立すると、強固な初期認証を提供します。 - 認証後トラフィックをすべて完全に暗号化します。
- 暗号化整合性チェックを提供します。
-
デフォルトのモードは crc です。
Red Hat Ceph Storage クラスターを計画するときは、暗号化のオーバーヘッドを含めるために、クラスターの CPU 要件を必ず考慮してください。
現在、secure なモードの使用は、Red Hat Enterprise Linux 上の CephFS や krbd など、Ceph カーネルクライアントでサポートされています。secure モードの使用は、OpenStack Nova、Glance、Cinder などの librbd を使用する Ceph クライアントでサポートされています。
アドレスの変更
メッセンジャープロトコルの両方のバージョンが、同じストレージクラスターに共存するために、アドレスのフォーマットが変更されました。
-
古いアドレスの形式は、
IP_ADDR: PORT / CLIENT_IDです (例:1.2.3.4:5678/91011)。 -
新しいアドレスの形式は、
PROTOCOL_VERSION : IP_ADDR : PORT / CLIENT_IDです (例:v2:1.2.3.4:5678/91011)。たとえば、PROTOCOL_VERSION はv1またはv2のいずれかになります。
Ceph デーモンは複数のポートにバインドするようになったため、デーモンは単一のアドレスではなく複数のアドレスを表示します。モニターマップのダンプの例を以下に示します。
epoch 1 fsid 50fcf227-be32-4bcb-8b41-34ca8370bd17 last_changed 2021-12-12 11:10:46.700821 created 2021-12-12 11:10:46.700821 min_mon_release 14 (nautilus) 0: [v2:10.0.0.10:3300/0,v1:10.0.0.10:6789/0] mon.a 1: [v2:10.0.0.11:3300/0,v1:10.0.0.11:6789/0] mon.b 2: [v2:10.0.0.12:3300/0,v1:10.0.0.12:6789/0] mon.c
また、mon_host 設定オプション、-m を使用してコマンドラインでアドレスを指定することで、新しいアドレス形式がサポートされます。
接続フェーズ
暗号化された接続を確立するには、以下の 4 つのフェーズがあります。
- バナー
-
接続で、クライアントとサーバーの両方がバナーを送信します。現在、Ceph バナーは
ceph 0 0nです。 - 認証エクスチェンジ
- 送信または受信されたすべてのデータは、接続の間、フレームに含まれます。サーバーは、認証が完了したかどうかについて、および接続モードについて決定します。フレームフォーマットは修正され、使用される認証フラグに応じて 3 つの異なる形式にすることができます。
- メッセージフローハンドシェイクエクスチェンジ
- ピアは相互に識別し、セッションを確立します。クライアントは最初のメッセージを送信し、サーバーは同じメッセージで応答します。クライアントが誤ったデーモンと通信すると、サーバーが接続を閉じることがあります。新しいセッションの場合、クライアントとサーバーはメッセージのエクスチェンジに進みます。クライアントのクッキーはセッションを識別するために使用され、既存のセッションに再接続できます。
- メッセージエクスチェンジ
- クライアントおよびサーバーは、接続が閉じられるまで、メッセージのエクスチェンジを開始します。
関連情報
-
msgr2プロトコルの有効化に関する詳細は、Red Hat Ceph Storage データのセキュリティーおよび強化機能ガイド を参照してください。