
インストールガイド
Red Hat Enterprise Linux への Red Hat Ceph Storage のインストール
概要
第1章 Red Hat Ceph Storage とは
Red Hat Ceph Storage は、スケーラブルでオープンなソフトウェア定義のストレージプラットフォームであり、エンタープライズ向けバージョンの Ceph ストレージシステムと Ceph 管理プラットフォーム、デプロイメントユーティリティー、およびサポートサービスを組み合わせたものです。Red Hat Ceph Storage は、クラウドインフラストラクチャーおよび Web スケールオブジェクトストレージ用に設計されています。Red Hat Ceph Storage クラスターは、以下のタイプのノードで設定されます。
Red Hat Ceph Storage Ansible 管理
Ansible 管理ノードは、以前のバージョンの Red Hat Ceph Storage で使用されていた従来の Ceph 管理ノードとして機能します。Ansible の管理ノードには、以下の機能があります。
- 集中ストレージクラスター管理。
- Ceph 設定ファイルおよびキー。
- 必要に応じて、セキュリティー上の理由からインターネットにアクセスできないノードに Ceph をインストールするためのローカルリポジトリー。
Ceph Monitor
各 Ceph Monitor ノードは ceph-mon デーモンを実行し、ストレージクラスターマップのマスターコピーを維持します。ストレージクラスターマップには、ストレージクラスタートポロジーが含まれます。Ceph ストレージクラスターに接続するクライアントは、Ceph Monitor からストレージクラスターマッピングの現在のコピーを取得します。これにより、クライアントはストレージクラスターからデータの読み取りおよび書き込みが可能になります。
ストレージクラスターは、1 つの Ceph Monitor でのみ実行できます。ただし、実稼働環境のストレージクラスターで高可用性を確保するために、RedHat は少なくとも 3 つの Ceph Monitor ノードを使用したデプロイメントのみをサポートします。Red Hat は、750 Ceph OSD を超えるストレージクラスター用に合計 5 つの Ceph Monitor をデプロイすることを推奨します。
Ceph OSD
各 Ceph Object Storage Device(OSD) ノードは ceph-osd デーモンを実行し、ノードに接続されている論理ディスクと対話します。ストレージクラスターは、データをこれらの Ceph OSD ノードに保存します。
Ceph は、OSD ノードを非常に少ない状態で実行できます (デフォルトは 3 つですが、実稼働ストレージクラスターは適度な規模から初めてより良いパフォーマンスが向上します)。たとえば、ストレージクラスター内の 50 の Ceph OSD など。理想的には、Ceph Storage クラスターには複数の OSD ノードがあり、CRUSH マップを適宜設定して障害のドメインを分離できることが望ましいと言えます。
Ceph MDS
各 Ceph Metadata Server (MDS) ノードは ceph-mds デーモンを実行し、Ceph File System (CephFS) に保管されたファイルに関するメタデータを管理します。Ceph MDS デーモンは、共有ストレージクラスターへのアクセスも調整します。
Ceph Object Gateway
Ceph Object Gateway ノードは ceph-radosgw デーモンを実行し、librados 上に構築されたオブジェクトストレージインターフェイスで、アプリケーションに Ceph ストレージクラスターへの RESTful アクセスポイントを提供します。Ceph Object Gateway は以下の 2 つのインターフェイスをサポートします。
S3
Amazon S3 RESTful API の大規模なサブセットと互換性のあるインターフェイスでオブジェクトストレージ機能を提供します。
Swift
OpenStack Swift API の大規模なサブセットと互換性のあるインターフェイスでオブジェクトストレージ機能を提供します。
関連情報
- Ceph アーキテクチャーの詳細は、Red Hat Ceph ストレージ管理ガイド を参照してください。
- ハードウェアの最小推奨事項は、Red Hat Ceph Storage ハードウェア選択ガイド を参照してください。
第2章 Red Hat Ceph Storage に関する考慮事項および推奨事項
ストレージ管理者は、Red Hat Ceph Storage クラスターを実行する前に考慮すべき内容を基本的に理解しておくようにしてください。ハードウェアおよびネットワークの要件、Red Hat Ceph Storage クラスターと適切に機能するワークロードのタイプや Red Hat の推奨事項を確認してください。Red Hat Ceph Storage は、特定のビジネスニーズまたは要件に基づいて異なるワークロードに使用できます。Red Hat Ceph Storage をインストールする前に、Ceph ストレージクラスターを効率的に実行するには、ビジネス要件を達成するのに必要な計画を立てます。
特定のユースケースで Red Hat Ceph Storage クラスターの使用計画にサポートが必要ですか ?レッドハットの担当者にご相談ください。
2.1. 前提条件
- ストレージソリューションを理解、検討、計画する時間を確保する。
2.2. Red Hat Ceph Storage の基本的な考慮事項
Red Hat Ceph Storage を使用するための最初の考慮事項は、データのストレージストラテジーの開発についてです。ストレージストラテジーとは、特定のユースケースに対応するためのデータを保管する手法を指します。OpenStack などのクラウドプラットフォームのボリュームおよびイメージを保存する必要がある場合は、ジャーナル用に Solid State Drives(SSD) を使用する高速な Serial Attached SCSI(SAS) ドライブにデータを保存することができます。一方、S3 または Swift 準拠のゲートウェイのオブジェクトデータを保存する必要がある場合は、従来の Serial Advanced Technology Attachment(SATA) ドライブなど、より経済的な方法を使用できます。Red Hat Ceph Storage は、同じストレージクラスターの両方のシナリオに対応しますが、クラウドプラットフォーム用に高速ストレージストラテジーと、オブジェクトストア用に従来のストレージを提供する手段が必要です。
Ceph のデプロイメントを正常に実行するための最も重要な手順の 1 つとして、クラスターのユースケースとワークロードに適した価格性能比のプロファイルを特定します。ユースケースに適したハードウェアを選択することが重要です。たとえば、コールドストレージアプリケーション用に IOPS が最適化されたハードウェアを選択すると、ハードウェアのコストが必要以上に増加します。また、IOPS が重視されるワークロードにおいて、より魅力的な価格帯に対して容量が最適化されたハードウェアを選択すると、パフォーマンスの低下に不満を持つユーザーが出てくる可能性が高くなります。
Red Hat Ceph Storage は、複数のストレージストラテジーをサポートできます。健全なストレージ戦略を策定するには、ユースケース、費用対効果、パフォーマンスのトレードオフ、データの耐久性などを考慮する必要があります。
ユースケース
Ceph は大容量のストレージを提供し、多くのユースケースをサポートします。
- Ceph Block Device クライアントは、クラウドプラットフォーム向けの代表的なストレージバックエンドで、ボリュームやイメージに対して制限なくストレージを提供し、コピーオンライトクローニングなど、高パフォーマンス機能を備えています。
- Ceph Object Gateway クライアントは、音声、ビットマップ、ビデオなどのオブジェクト向けの RESTful S3 準拠のオブジェクトおよび Swift 準拠のオブジェクトストレージを提供するクラウドプラットフォームの主要なストレージバックエンドです。
- 従来のファイルストレージである Ceph ファイルシステム。
コスト vs.パフォーマンス
速度、サイズ、耐久性など高いほうが優れています。ただし、優れた品質にはそれぞれコストがかかるので、費用対効果の面でトレードオフがあります。パフォーマンスの観点からでは、以下のユースケースを考慮してください。SSD は、比較的小規模なデータおよびジャーナリングのために非常に高速ストレージを提供できます。データベースやオブジェクトインデックスの保存には、非常に高速な SSD のプールが有効ですが、他のデータの保存にはコストがかかりすぎてしまいます。SSD ジャーナリングのある SAS ドライブは、ボリュームやイメージを安価かつ高速なパフォーマンスで提供できます。SSD ジャーナリングのない SATA ドライブは、全体的なパフォーマンスは低くなりますが、ストレージの価格を安価に抑えることができます。OSD の CRUSH 階層を作成する場合は、ユースケースと許容コスト/パフォーマンスのトレードオフを考慮する必要があります。
データの持続性
大規模なクラスターでは、ハードウェア障害は想定されており、例外ではありません。ただし依然として、データの損失および中断は受け入れられません。そのため、データの持続性は非常に重要になります。Ceph は、オブジェクトの複数のレプリカコピー、またはイレイジャーコーディングおよび複数のコーディングのチャンクでデータの持続性に対応します。複数のコピーまたはコーディングチャンクにより、さらに費用対効果の面でのトレードオフが分かります。コピーやコーディングのチャンクが少ない場合にはコストがかかりませんが、パフォーマンスが低下した状態で、書き込み要求に対応できなくなる可能性があります。通常、追加のコピーまたはコーディングチャンクが 2 つあるオブジェクトを使用すると、ストレージクラスターが復旧する間に、パフォーマンスが低下した状態でクラスターの書き込みを行うことができます。
レプリケーションでは、ハードウェア障害に備えて、障害ドメインをまたいで 1 つ以上のデータの冗長コピーを保存します。しかし、データの冗長コピーは、規模が大きくなるとコスト高になります。たとえば、1 ペタバイトのデータを 3 つのレプリケーションで保存するには、少なくとも容量が 3 ペタバイトあるストレージクラスターが必要になります。
イレイジャーコーディングでは、データをデータチャンクとコーディングチャンクに分けて保存します。データチャンクが失われた場合には、イレイジャーコーディングにより、残りのデータチャンクとコーディングチャンクで失われたデータチャンクを回復できます。イレイジャーコーディングはレプリケーションに比べて大幅に経済的です。たとえば、データチャンク 8 つとコーディングチャンク 3 つのイレイジャーコーディングを使用すると、データのコピーが 3 つある状態と同じ冗長性が得られます。ただし、このようなエンコーディングスキームでは、初期のデータ保存量が約 1.5 倍になるのに対し、レプリケーションでは 3 倍になります。
CRUSH アルゴリズムは、Ceph が、ストレージクラスター内の異なる場所に追加のコピーまたはコーディングチャンクを保存して、このプロセスをサポートします。これにより、1 つのストレージデバイスまたはノードに障害が発生しても、データ損失を回避するために必要なコピーやコーディングチャンクがすべて失われないようにします。費用対効果の面でのトレードオフやデータの耐性を考慮してストレージ戦略を計画し、ストレージプールとして Ceph クライアントに提示します。
データストレージプールのみがイレイジャーコーディングを使用できます。サービスデータやバケットインデックスを格納するプールはレプリケーションを使用します。
Ceph のオブジェクトコピーやコーディングチャンクを使用すると、RAID ソリューションが古く感じられます。Ceph はすでにデータの持続性に対応しており、質の低い RAID ではパフォーマンスに悪影響があり、RAID を使用してデータを復元すると、ディープコピーや消失訂正を使用するよりもはるかにスピードが遅くなるので、RAID は使用しないでください。
関連情報
- 詳細は、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage の最小ハードウェア考慮事項 のセクションを参照してください。
2.3. Red Hat Ceph Storage ワークロードに関する考慮事項
Ceph Storage クラスターの主な利点の 1 つとして、パフォーマンスドメインを使用して、同じストレージクラスター内のさまざまなタイプのワークロードをサポートする機能があります。各パフォーマンスドメインには、異なるハードウェア設定を関連付けることができます。ストレージ管理者は、ストレージプールを適切なパフォーマンスドメインに配置し、特定のパフォーマンスとコストプロファイルに合わせたストレージをアプリケーションに提供できます。これらのパフォーマンスドメインに適切なサイズ設定と最適化されたサーバーを選択することは、Red Hat Ceph Storage クラスターを設計するのに不可欠な要素です。
データの読み取りおよび書き込みを行う Ceph クライアントインターフェイスに対して、Ceph Storage クラスターはクライアントがデータを格納する単純なプールとして表示されます。ただし、ストレージクラスターは、クライアントインターフェイスから完全に透過的な方法で多くの複雑な操作を実行します。Ceph クライアントおよび Ceph オブジェクトストレージデーモン (Ceph OSD または単に OSD) はいずれも、オブジェクトのストレージおよび取得にスケーラブルなハッシュ (CRUSH) アルゴリズムで制御されたレプリケーションを使用します。Ceph OSD は、コンテナーまたは RPM ベースのデプロイメントを使用して、ストレージクラスター内のベアメタルサーバーまたは仮想マシンで実行できます。
CRUSH マップはクラスターリソースのトポロジーを表し、マップは、クラスター内のクライアントノードと Ceph Monitor ノードの両方に存在します。Ceph クライアントおよび Ceph OSD はどちらも CRUSH マップと CRUSH アルゴリズムを使用します。Ceph クライアントは OSD と直接通信することで、オブジェクト検索の集中化とパフォーマンスのボトルネックとなる可能性を排除します。CRUSH マップとピアとの通信を認識することで、OSD は動的障害復旧のレプリケーション、バックフィル、およびリカバリーを処理できます。
Ceph は CRUSH マップを使用して障害ドメインを実装します。Ceph は CRUSH マップを使用してパフォーマンスドメインの実装も行います。パフォーマンスドメインは、基礎となるハードウェアのパフォーマンスプロファイルを反映させます。CRUSH マップは Ceph のデータの格納方法を記述し、これは単純な階層 (例: 非周期グラフ) およびルールセットとして実装されます。CRUSH マップは複数の階層をサポートし、ハードウェアパフォーマンスプロファイルのタイプを別のタイプから分離できます。Ceph では、デバイスの classes でパフォーマンスドメインを実装しています。
たとえば、これらのパフォーマンスドメインを同じ Red Hat Ceph Storage クラスター内に共存させることができます。
- ハードディスクドライブ (HDD) は、一般的にコストと容量を重視したワークロードに適しています。
- スループットを区別するワークロードは通常、ソリッドステートドライブ (SSD) の Ceph 書き込みジャーナルで HDD を使用します。
- MySQL や MariaDB のような IOPS を多用するワークロードでは、SSD を使用することが多いです。
ワークロード
Red Hat Ceph Storage は、3 つの主要なワークロードに最適化されています。
IOPS を最適化: IOPS (Input, Output per Second) が最適化されたデプロイメントは、MYSQL や MariaDB インスタンスを OpenStack 上の仮想マシンとして稼働させるなど、クラウドコンピューティングの操作に適しています。IOPS が最適化された導入では、15k RPM の SAS ドライブや、頻繁な書き込み操作を処理するための個別の SSD ジャーナルなど、より高性能なストレージが必要となります。一部の IOPS のシナリオでは、すべてのフラッシュストレージを使用して IOPS と総スループットが向上します。
IOPS が最適化されたストレージクラスターには、以下のプロパティーがあります。
- IOPS あたり最小コスト
- 1 GB あたりの最大 IOPS。
- 99 パーセンタイルのレイテンシーの一貫性。
IOPS に最適化されたストレージクラスターの用途は以下のとおりです。
- 典型的なブロックストレージ。
- ハードドライブ (HDD) の 3x レプリケーションまたはソリッドステートドライブ (SSD) の 2x レプリケーション。
- OpenStack クラウド上の MySQL
最適化されたスループット: スループットが最適化されたデプロイメントは、グラフィック、音声、ビデオコンテンツなどの大量のデータを提供するのに適しています。スループットが最適化されたデプロイメントには、高帯域幅のネットワークハードウェア、コントローラー、高速シーケンシャル読み取り/書き込み機能のあるハードディスクドライブが必要です。高速なデータアクセスが必要な場合は、スループットを最適化したストレージ戦略を使用します。また、高速な書き込み性能が必要な場合は、ジャーナルに SSD (Solid State Disks) を使用すると、書き込み性能が大幅に向上します。
スループットが最適化されたストレージクラスターには、以下のような特性があります。
- MBps あたりの最小コスト (スループット)。
- TB あたり最も高い MBps。
- BTU あたりの最大 MBps
- Watt あたりの MBps の最大数。
- 97 パーセンタイルのレイテンシーの一貫性。
スループットを最適化したストレージクラスターの用途は以下のとおりです。
- ブロックまたはオブジェクトストレージ。
- 3x レプリケーション。
- ビデオ、音声、およびイメージのアクティブなパフォーマンスストレージ。
- 4K 映像などのストリーミングメディア
最適化された容量: 容量が最適化されたデプロイメントは、大量のデータを可能な限り安価に保存するのに適しています。容量が最適化されたデプロイメントは通常、パフォーマンスがより魅力的な価格と引き換えになります。たとえば、容量を最適化したデプロイメントでは、ジャーナリングに SSD を使用するのではなく、より低速で安価な SATA ドライブを使用し、ジャーナルを同じ場所に配置することがよくあります。
コストと容量が最適化されたストレージクラスターには、次のような特性があります。
- TB あたり最小コスト
- TB あたり最小の BTU 数。
- TB あたりに必要な最小 Watt。
コストと容量が最適化されたストレージクラスターの用途は以下のとおりです。
- 典型的なオブジェクトストレージ。
- 使用可能な容量を最大化するイレイジャーコーディング
- オブジェクトアーカイブ。
- ビデオ、音声、およびイメージオブジェクトのリポジトリー。
ストレージクラスターの価格とパフォーマンスに大きな影響を与えるので、どのハードウェアを購入するかを検討する前に、Red Hat Ceph Storage クラスターで実行するワークロードを慎重に検討してください。たとえば、ワークロードの容量が最適化されいるにも拘らず、スループットが最適化されたワークロードに、対象のハードウェアがより適している場合に、ハードウェアが必要以上に高価になってしまいます。逆に、ワークロードのスループットが最適化されていて、容量が最適化されたワークロードに、対象のハードウェアが適している場合は、ストレージクラスターのパフォーマンスが低下します。
2.4. Red Hat Ceph Storage のネットワークに関する考察
クラウドストレージソリューションの重要な点は、ネットワークのレイテンシーなどの要因により、ストレージクラスターが IOPS 不足になることです。また、ストレージクラスターがストレージ容量を使い果たす、はるか前に、帯域幅の制約が原因でスループットが不足することがあります。つまり、価格対性能の要求を満たすには、ネットワークのハードウェア設定が選択されたワークロードをサポートする必要があります。
ストレージ管理者は、ストレージクラスターをできるだけ早く復旧することを望みます。ストレージクラスターネットワークの帯域幅要件を慎重に検討し、ネットワークリンクのオーバーサブスクリプションに注意してください。また、クライアント間のトラフィックからクラスター内のトラフィックを分離します。また、SSD (Solid State Disk) やフラッシュ、NVMe などの高性能なストレージデバイスの使用を検討する場合には、ネットワークパフォーマンスの重要性が増していることも考慮してください。
Ceph はパブリックネットワークとストレージクラスターネットワークをサポートしています。パブリックネットワークは、クライアントのトラフィックと Ceph Monitor との通信を処理します。ストレージクラスターネットワークは、Ceph OSD のハートビート、レプリケーション、バックフィル、リカバリーのトラフィックを処理します。ストレージハードウェアには、最低でも 10GB のイーサネットリンクを 1 つ使用し、接続性とスループット向けにさらに 10GB イーサネットリンクを追加できます。
Red Hat では、レプリケートされたプールをもとに osd_pool_default_size を使用してパブリックネットワークの倍数となるように、ストレージクラスターネットワークに帯域幅を割り当てることを推奨しています。また、Red Hat はパブリックネットワークとストレージクラスターネットワークを別々のネットワークカードで実行することを推奨しています。
Red Hat では、実稼働環境での Red Hat Ceph Storage のデプロイメントに 10GB のイーサネットを使用することを推奨しています。1GB のイーサネットネットワークは、実稼働環境のストレージクラスターには適していません。
ドライブに障害が発生した場合、1 GB イーサネットネットワーク全体で 1 TB のデータをレプリケートするには 3 時間かかります。3 TB には 9 時間かかります。3TB を使用するのが一般的なドライブ設定です。一方、10GB のイーサネットネットワークの場合、レプリケーションにかかる時間はそれぞれ 20 分、1 時間となります。Ceph OSD に障害が発生した場合には、ストレージクラスターは、含まれるデータをプール内の他の Ceph OSD にレプリケートして復元することに注意してください。
ラックなどの大規模なドメインに障害が発生した場合は、ストレージクラスターが帯域幅を大幅に消費することになります。複数のラックで設定されるストレージクラスター (大規模なストレージ実装では一般的) を構築する際には、最適なパフォーマンスを得るために、ファットツリー設計でスイッチ間のネットワーク帯域幅をできるだけ多く利用することを検討してください。一般的な 10 GB のイーサネットスイッチには、48 個の 10 GB ポートと 4 個の 40 GB のポートがあります。スループットを最大にするには、Spine (背骨) で 40 GB ポートを使用します。または、QSFP+ および SFP+ ケーブルを使用する未使用の 10 GB ポートを別のラックおよびスパインルーターに接続するために、さらに 40 GB のポートに集計することを検討します。また、LACP モード 4 でネットワークインターフェイスを結合することも検討してください。また、特にバックエンドやクラスターのネットワークでは、ジャンボフレーム、最大伝送単位 (MTU) 9000 を使用してください。
Red Hat Ceph Storage クラスターをインストールしてテストする前に、ネットワークのスループットを確認します。Ceph のパフォーマンスに関する問題のほとんどは、ネットワークの問題から始まります。Cat-6 ケーブルのねじれや曲がりといった単純なネットワークの問題は、帯域幅の低下につながります。フロント側のネットワークには、最低でも 10 GB のイーサネットを使用してください。大規模なクラスターの場合には、バックエンドやクラスターのネットワークに 40GB のイーサネットを使用することを検討してください。
ネットワークの最適化には、CPU/帯域幅の比率を高めるためにジャンボフレームを使用し、非ブロックのネットワークスイッチのバックプレーンを使用することを Red Hat は推奨します。Red Hat Ceph Storage では、パブリックネットワークとクラスターネットワークの両方で、通信パスにあるすべてのネットワークデバイスに同じ MTU 値がエンドツーエンドで必要となります。Red Hat Ceph Storage クラスターを実稼働環境で使用する前に、環境内のすべてのノードとネットワーク機器で MTU 値が同じであることを確認します。
関連情報
- 詳細は Red Hat Ceph Storage Configuration Guide の MTU 値の確認と設定 のセクションを参照してください。
2.5. Ceph 実行時の Linux カーネルのチューニングに関する考察
実稼働環境用の Red Hat Ceph Storage クラスターでは、一般的にオペレーティングシステムのチューニング (特に制限とメモリー割り当て) が有効です。ストレージクラスター内の全ノードに調整が設定されていることを確認します。また、Red Hat サポートでケースを開き、追加でアドバイスを求めることもできます。
Ceph OSD 用の空きメモリーの確保
Ceph OSD のメモリー割り当て要求時にメモリー不足関連のエラーが発生しないように、予備として確保する物理メモリーの量を具体的に設定します。Red Hat では、システムメモリーの量に応じて以下の設定を推奨しています。
64 GB の場合は 1 GB を確保する。
vm.min_free_kbytes = 1048576
128 GB の場合は 2 GB を確保する。
vm.min_free_kbytes = 2097152
256 GB の場合は 3 GB を確保する。
vm.min_free_kbytes = 3145728
ファイル記述子の増加
Ceph Object Gateway は、ファイル記述子が不足すると停止することがあります。Ceph Object Gateway ノードの /etc/security/limits.conf ファイルを変更して、Ceph Object Gateway のファイル記述子を増やすことができます。
ceph soft nofile unlimited
大規模ストレージクラスターの ulimit 値の調整
Ceph OSD が 1024 個以上あるなど、大規模なストレージクラスターで Ceph の管理コマンドを実行する場合は、管理コマンドを実行する各ノードに、次の内容の /etc/security/limits.d/50-ceph.conf ファイルを作成します。
USER_NAME soft nproc unlimitedUSER_NAME は、Ceph の管理コマンドを実行する root 以外のユーザーのアカウント名に置き換えます。
Red Hat Enterprise Linux では、root ユーザーの ulimit 値はすでにデフォルトで unlimited に設定されています。
2.6. OSD ノードで RAID コントローラーを使用する際の考慮事項
必要に応じて、OSD ノードで RAID コントローラーを使用することを検討してください。考慮すべき事項を以下に示します。
- OSD ノードに 1 ~ 2 GB のキャッシュがインストールされている RAID コントローラーがある場合は、ライトバックキャッシュを有効にすると、I/O 書き込みスループットが向上する可能性があります。ただし、キャッシュは不揮発性である必要があります。
- 最新の RAID コントローラーにはスーパーキャパシエーターがあり、電力損失イベント中に不揮発性 NAND メモリーに揮発性メモリーを流すのに十分な電力が提供されます。電源の復旧後に、特定のコントローラーとそのファームウェアがどのように動作するかを理解することが重要です。
- RAID コントローラーによっては、手動の介入が必要になります。ハードドライブは、ディスクキャッシュをデフォルトで有効または無効にすべきかどうかに関わらず、オペレーティングシステムにアドバタイズします。ただし、特定の RAID コントローラーとファームウェアは、このような情報を提供しません。ファイルシステムが破損しないように、ディスクレベルのキャッシュが無効になっていることを確認します。
- ライトバックキャッシュを有効にして、各 Ceph OSD データドライブにライトバックを設定して、単一の RAID 0 ボリュームを作成します。
- Serial Attached SCSI (SAS) または SATA 接続の Solid-state Drive (SSD) ディスクも RAID コントローラーに存在する場合は、コントローラーとファームウェアが pass-through モードをサポートしているかどうかを確認します。pass-through モードを有効にすると、キャッシュロジックが回避され、通常は高速メディアの待ち時間が大幅に低くなります。
2.7. Object Gateway で NVMe を使用する際の考慮事項
必要に応じて、Ceph Object Gateway に NVMe を使用することを検討してください。
Red Hat Ceph Storage のObject Gateway 機能を使用する予定で、OSD ノードが NVMe ベースの SSD を使用している場合は、実稼働向け Ceph Object Gateway の LVM での NVMe の最適な使用 に記載される手順に従ってください。これらの手順では、ジャーナルとバケットインデックスを SSD に一緒に配置する特別に設計された Ansible Playbook の使用方法を説明します。これにより、すべてのジャーナルを 1 つのデバイスに配置する場合に比べてパフォーマンスを向上させることができます。
2.8. Red Hat Ceph Storage の最小ハードウェア要件
Red Hat Ceph Storage は、プロプライエタリーではない、商用ハードウェアでも動作します。小規模な実稼働クラスターや開発クラスターは、適度なハードウェアで性能を最適化せずに動作させることができます。
Red Hat Ceph Storage は、デプロイメントがベアメタルであるか、コンテナー化されているかによって、要件が若干異なります。
ディスク領域の要件は、/var/lib/ceph/ ディレクトリー下の Ceph デーモンのデフォルトパスに基づいています。
表2.1 ベアメタル
| Process | 条件 | 最小推奨 |
|---|---|---|
|
| プロセッサー | 1x AMD64 または Intel 64 |
| RAM |
| |
| OS ディスク | ホストごとに 1x OS ディスク | |
| ボリュームストレージ | デーモンごとに 1x ストレージドライブ | |
|
|
任意ですが、Red Hat は、デーモンごとに 1x SSD、NVMe または Optane パーティション、または論理ボリューム 1 つを推奨します。サイズ設定は、オブジェクト、ファイルおよび混合ワークロード用に BlueStore に | |
|
|
任意、1x SSD、NVMe または Optane パーティション、またはデーモンごとに論理ボリューム。サイズが小さい (10 GB など) を使用し、 | |
| ネットワーク | 2x 10GB イーサネット NIC | |
|
| プロセッサー | 1x AMD64 または Intel 64 |
| RAM | デーモンごとに 1 GB | |
| ディスク容量 | デーモンごとに 15 GB | |
| 監視ディスク |
任意で、 | |
| ネットワーク | 2x 1 GB のイーサネット NIC | |
|
| プロセッサー | 1x AMD64 または Intel 64 |
| RAM | デーモンごとに 1 GB | |
| ネットワーク | 2x 1 GB のイーサネット NIC | |
|
| プロセッサー | 1x AMD64 または Intel 64 |
| RAM | デーモンごとに 1 GB | |
| ディスク容量 | デーモンごとに 5 GB | |
| ネットワーク | 1x 1 GB のイーサネット NIC | |
|
| プロセッサー | 1x AMD64 または Intel 64 |
| RAM | デーモンごとに 2 GB
この数は、設定可能な MDS キャッシュサイズに大きく依存します。通常、RAM 要件は、 | |
| ディスク容量 | デーモンごとに 2 MB、さらにロギングに必要な領域があり、設定されたログレベルに応じて異なる場合があります。 | |
| ネットワーク | 2x 1 GB のイーサネット NIC これは OSD と同じネットワークであることに注意してください。OSD で 10GB のネットワークを使用している場合は、MDS でも同じものを使用することで、レイテンシーの面で MDS が不利にならないようにする必要があります。 |
表2.2 コンテナー
| Process | 条件 | 最小推奨 |
|---|---|---|
|
| プロセッサー | OSD コンテナーごとに 1x AMD64 または Intel 64 CPU CORE |
| RAM | 1 OSD コンテナーごとに最小 5 GB の RAM | |
| OS ディスク | ホストごとに 1x OS ディスク | |
| OSD ストレージ | OSD コンテナーごとに 1x ストレージドライブ。OS ディスクと共有できません。 | |
|
|
任意ですが、Red Hat は、デーモンごとに SSD、NVMe または Optane パーティション、または lvm を 1 つ推奨します。サイズ設定は、オブジェクト、ファイルおよび混合ワークロード用に BlueStore に | |
|
|
任意ですが、デーモンごとに 1x SSD、NVMe または Optane パーティション、または論理ボリューム。サイズが小さい (10 GB など) を使用し、 | |
| ネットワーク | 2x 10 GB のイーサネット NIC (10 GB の推奨) | |
|
| プロセッサー | mon-container ごとに 1x AMD64 または Intel 64 CPU CORE |
| RAM |
| |
| ディスク容量 |
| |
| 監視ディスク |
任意で、 | |
| ネットワーク | 2x 1 GB のイーサネット NIC (10 GB の推奨) | |
|
| プロセッサー |
|
| RAM |
| |
| ネットワーク | 2x 1 GB のイーサネット NIC (10 GB の推奨) | |
|
| プロセッサー | radosgw-container ごとに 1x AMD64 または Intel 64 CPU CORE |
| RAM | デーモンごとに 1 GB | |
| ディスク容量 | デーモンごとに 5 GB | |
| ネットワーク | 1x 1 GB のイーサネット NIC | |
|
| プロセッサー | mds-container ごとに 1x AMD64 または Intel 64 CPU CORE |
| RAM |
この数は、設定可能な MDS キャッシュサイズに大きく依存します。通常、RAM 要件は、 | |
| ディスク容量 |
| |
| ネットワーク | 2x 1 GB のイーサネット NIC (10 GB の推奨) これは、OSD コンテナーと同じネットワークであることに注意してください。OSD で 10GB のネットワークを使用している場合は、MDS でも同じものを使用することで、レイテンシーの面で MDS が不利にならないようにする必要があります。 |
2.9. 関連情報
- Ceph のさまざまな内部コンポーネントと、それらのコンポーネントにまつわる戦略をより深く理解するには、Red Hat Ceph Storage ストレージ戦略ガイド を参照してください。
第3章 Red Hat Ceph Storage のインストール要件
図3.1 前提条件のワークフロー
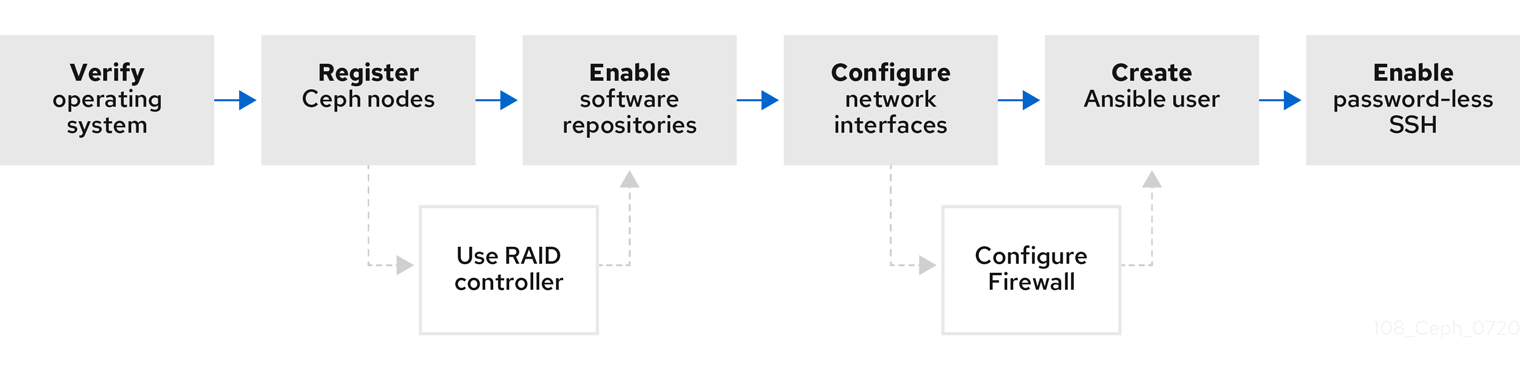
Red Hat Ceph Storage をインストールする前に、以下の要件をチェックして、各 Monitor、OSD、メタデータサーバー、およびクライアントノードを適宜準備します。
Red Hat Ceph Storage のリリースおよび対応する Red Hat Ceph Storage パッケージのバージョンは、Red Hat カスタマーポータルの What are the Red Hat Ceph Storage releases and corresponding Ceph package versions? を参照してください。
3.1. 前提条件
- ハードウェア が Red Hat Ceph Storage 4 の最小要件を満たしていることを確認します。
3.2. Red Hat Ceph Storage のインストールに関する要件チェックリスト
| タスク | 必須 | セクション | 推奨事項 |
|---|---|---|---|
| オペレーティングシステムのバージョンの確認 | はい | ||
| Ceph ノードの登録 | はい | ||
| Ceph ソフトウェアリポジトリーの有効化 | はい | ||
| OSD ノードでの RAID コントローラーの使用 | いいえ | RAID コントローラーでライトバックキャッシュを有効にすると、OSD ノードの小規模な I/O 書き込みスループットが増大する場合があります。 | |
| ネットワークの設定 | はい | 少なくとも、パブリックネットワークが必要です。ただし、クラスター通信用のプライベートネットワークが推奨されます。 | |
| ファイアウォールの設定 | いいえ | ファイアウォールは、ネットワークの信頼レベルを大きくすることができます。 | |
| Ansible ユーザーの作成 | はい | すべての Ceph ノードで Ansible ユーザーを作成する必要があります。 | |
| パスワードを使用しない SSH の有効化 | はい | Ansible で必須。 |
デフォルトでは、ceph-ansible は、NTP/chronyd を要件としてインストールします。NTP/chronyd がカスタマイズされている場合は、Red Hat Ceph Storage の手動インストール セクションのRed Hat Ceph Storage のネットワークタイムプロトコルの設定を参照して、Ceph で正しく機能するように NTP/chronyd を設定する方法を理解してください。
3.3. Red Hat Ceph Storage のオペレーティングシステム要件
Red Hat Enterprise Linux のエンタイトルメントは、Red Hat Ceph Storage のサブスクリプションに含まれます。
Red Hat Ceph Storage 4 の初期リリースは、Red Hat Enterprise Linux 7.7 または Red Hat Enterprise Linux 8.1 でサポートされています。現行バージョンの Red Hat Ceph Storage 4.3 は、Red Hat Enterprise Linux 7.9、8.4 EUS、8.5、および 8.6 でサポートされています。
Red Hat Ceph Storage 4 は、RPM ベースのデプロイメントまたはコンテナーベースのデプロイメントでサポートされます。
Red Hat Ceph Storage 4 を Red Hat Enterprise Linux 7 上に実行中のコンテナーにデプロイすると、Red Hat Enterprise Linux 8 コンテナーイメージで実行している Red Hat Ceph Storage 4 がデプロイされます。
すべてのノードで、同じオペレーティングシステムバージョン、アーキテクチャー、およびデプロイメントタイプを使用します。たとえば、AMD64 アーキテクチャーと Intel 64 アーキテクチャーの両方を備えたノードの混合、Red Hat Enterprise Linux 7 と Red Hat Enterprise Linux 8 オペレーティングシステムの両方を備えたノードの混合、RPM ベースのデプロイメントとコンテナーベースのデプロイメントの両方を備えたノードの混合は使用しないでください。
Red Hat は、異種アーキテクチャー、オペレーティングシステムバージョン、またはデプロイメントタイプを持つクラスターをサポートしません。
SELinux
デフォルトでは、SELinux は Enforcing モードに設定され、ceph-selinux パッケージがインストールされます。SELinux の詳細は、データのセキュリティーおよび強化機能ガイド、Red Hat Enterprise Linux 7 SELinux ユーザーおよび管理者のガイド、および Red Hat Enterprise Linux 8 SELinux の使用ガイド を参照してください。
関連情報
- Red Hat Enterprise Linux 8 用ドキュメントは、https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/8/ から入手できます。
- Red Hat Enterprise Linux 7 用ドキュメントは、https://access.redhat.com/documentation/ja-jp/red_hat_enterprise_linux/7/ から入手できます。
3.4. Red Hat Ceph Storage ノードの CDN への登録およびサブスクリプションの割り当て
各 Red Hat Ceph Storage ノードをコンテンツ配信ネットワーク (CDN) に登録し、ノードがソフトウェアリポジトリーにアクセスできるように適切なサブスクリプションを割り当てます。各 Red Hat Ceph Storage ノードは、完全な Red Hat Enterprise Linux 8 ベースコンテンツおよび extras リポジトリーコンテンツにアクセスできる必要があります。特に記述がない限り、ストレージクラスター内のベアメタルおよびコンテナーノードで以下の手順を実行します。
インストール時にインターネットにアクセスできないベアメタルの Red Hat Ceph Storage ノードの場合は、Red Hat Satellite サーバーを使用してソフトウェアコンテンツを提供します。ローカルの Red Hat Enterprise Linux 8 Server ISO イメージをマウントし、Red Hat Ceph Storage ノードを ISO イメージに指定します。詳細は、Red Hat サポート にお問い合わせください。
Red Hat Satellite サーバーに Ceph ノードの登録に関する詳細は、Red Hat カスタマーポータルの記事 How to Register Ceph with Satellite 6 および How to Register Ceph with Satellite 5 を参照してください。
前提条件
- 有効な Red Hat サブスクリプション
- Red Hat Ceph Storage ノードはインターネットに接続できるようにする必要があります。
- Red Hat Ceph Storage ノードへの root レベルのアクセス。
手順
コンテナー デプロイメントの場合には、Red Hat Ceph Storage ノードがデプロイ中にインターネットにアクセス できない 場合に限ります。最初に、インターネットアクセスのあるノードで、以下の手順を実行する必要があります。
ローカルのコンテナーレジストリーを起動します。
Red Hat Enterprise Linux 7
# docker run -d -p 5000:5000 --restart=always --name registry registry:2
Red Hat Enterprise Linux 8
# podman run -d -p 5000:5000 --restart=always --name registry registry:2
registry.redhat.ioがコンテナーレジストリーの検索パスにあることを確認します。編集するために、
/etc/containers/registries.confファイルを開きます。[registries.search] registries = [ 'registry.access.redhat.com', 'registry.fedoraproject.org', 'registry.centos.org', 'docker.io']
registry.redhat.ioがファイルに含まれていない場合は、これを追加します。[registries.search] registries = ['registry.redhat.io', 'registry.access.redhat.com', 'registry.fedoraproject.org', 'registry.centos.org', 'docker.io']
Red Hat カスタマーポータルから Red Hat Ceph Storage 4 イメージ、Prometheus イメージ、およびダッシュボードイメージをプルします。
Red Hat Enterprise Linux 7
# docker pull registry.redhat.io/rhceph/rhceph-4-rhel8:latest # docker pull registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 # docker pull registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8:latest # docker pull registry.redhat.io/openshift4/ose-prometheus:v4.6 # docker pull registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6
Red Hat Enterprise Linux 8
# podman pull registry.redhat.io/rhceph/rhceph-4-rhel8:latest # podman pull registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 # podman pull registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8:latest # podman pull registry.redhat.io/openshift4/ose-prometheus:v4.6 # podman pull registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6
注記Red Hat Enterprise Linux 7 および 8 はいずれも、Red Hat Enterprise Linux 8 をベースとした同じコンテナーイメージを使用します。
イメージにタグを付けます。
Prometheus のイメージタグのバージョンは、Red Hat Ceph Storage 4.2 の場合は v4.6 です。
Red Hat Enterprise Linux 7
# docker tag registry.redhat.io/rhceph/rhceph-4-rhel8:latest LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-rhel8:latest # docker tag registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-node-exporter:v4.6 # docker tag registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8:latest LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-dashboard-rhel8:latest # docker tag registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-alertmanager:v4.6 # docker tag registry.redhat.io/openshift4/ose-prometheus:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus:v4.6
- 置き換え
- LOCAL_NODE_FQDN を、ローカルホストの FQDN に置き換えます。
Red Hat Enterprise Linux 8
# podman tag registry.redhat.io/rhceph/rhceph-4-rhel8:latest LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-rhel8:latest # podman tag registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-node-exporter:v4.6 # podman tag registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8:latest LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-dashboard-rhel8:latest # podman tag registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-alertmanager:v4.6 # podman tag registry.redhat.io/openshift4/ose-prometheus:v4.6 LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus:v4.6
- 置き換え
- LOCAL_NODE_FQDN を、ローカルホストの FQDN に置き換えます。
etc/containers/registries.confファイルを編集し、ファイルに、ノードの FQDN とポートを追加し、保存します。[registries.insecure] registries = ['LOCAL_NODE_FQDN:5000']注記この手順は、ローカルの Docker レジストリーにアクセスするすべてのストレージクラスターノードで行う必要があります。
イメージを、起動したローカルの Docker レジストリーにプッシュします。
Red Hat Enterprise Linux 7
# docker push --remove-signatures LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-rhel8 # docker push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-node-exporter:v4.6 # docker push --remove-signatures LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-dashboard-rhel8 # docker push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-alertmanager:v4.6 # docker push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus:v4.6
- 置き換え
- LOCAL_NODE_FQDN を、ローカルホストの FQDN に置き換えます。
Red Hat Enterprise Linux 8
# podman push --remove-signatures LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-rhel8 # podman push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-node-exporter:v4.6 # podman push --remove-signatures LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-dashboard-rhel8 # podman push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-alertmanager:v4.6 # podman push --remove-signatures LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus:v4.6
- 置き換え
- LOCAL_NODE_FQDN を、ローカルホストの FQDN に置き換えます。
Red Hat Enterprise Linux 7 では、
dockerサービスを再起動します。# systemctl restart docker
注記デプロイメント中に RedHat Ceph Storage ノードがインターネットにアクセスできない場合の
all.ymlファイルの例は、Red Hat Ceph Storage クラスターのインストール インストールを参照してください。
すべてのデプロイメントで、ベアメタル または コンテナー の場合:
ノードを登録します。プロンプトが表示されたら、適切な Red Hat カスタマーポータルの認証情報を入力します。
# subscription-manager register
CDN から最新のサブスクリプションデータをプルします。
# subscription-manager refresh
Red Hat Ceph Storage で利用可能なサブスクリプションのリストを表示します。
# subscription-manager list --available --all --matches="*Ceph*"
Red Hat Ceph Storage の利用可能なサブスクリプションのリストから Pool ID をコピーします。
サブスクリプションを割り当てます。
# subscription-manager attach --pool=POOL_ID- 置き換え
- POOL_ID を、直前の手順で特定したプール ID に置き換えます。
デフォルトのソフトウェアリポジトリーを無効にし、各バージョンの Red Hat Enterprise Linux でサーバーおよび追加のリポジトリーを有効にします。
Red Hat Enterprise Linux 7
# subscription-manager repos --disable=* # subscription-manager repos --enable=rhel-7-server-rpms # subscription-manager repos --enable=rhel-7-server-extras-rpms
Red Hat Enterprise Linux 8
# subscription-manager repos --disable=* # subscription-manager repos --enable=rhel-8-for-x86_64-baseos-rpms # subscription-manager repos --enable=rhel-8-for-x86_64-appstream-rpms
システムを更新して、最新のパッケージを受け取ります。
Red Hat Enterprise Linux 7 の場合:
# yum update
Red Hat Enterprise Linux 8 の場合:
# dnf update
関連情報
- Red Hat Subscription Management の Subscription Manager の使用および設定 を参照してください。
- Red Hat Ceph Storage リポジトリーの有効化 を参照してください。
3.5. Red Hat Ceph Storage リポジトリーの有効化
Red Hat Ceph Storage をインストールする前に、インストール方法を選択する必要があります。Red Hat Ceph Storage では、以下の 2 つのインストール方法がサポートされます。
コンテンツ配信ネットワーク (CDN)
インターネットに直接接続可能な Ceph ノードを持つ Ceph Storage クラスターの場合は、Red Hat Subscription Manager を使用して必要な Ceph リポジトリーを有効にします。
ローカルリポジトリー
セキュリティー対策がインターネットにアクセスできない Ceph Storage クラスターでは、ISO イメージとして配信される単一のソフトウェアビルドから Red Hat Ceph Storage 4 をインストールします。これにより、ローカルリポジトリーをインストールできます。
前提条件
- 有効なカスタマーサブスクリプション
CDN インストールの場合:
- Red Hat Ceph Storage ノードはインターネットに接続できるようにする必要があります。
- クラスターノードを CDN に登録 します。
有効にする場合は、Exttra Packages for Enterprise Linux (EPEL) ソフトウェアリポジトリーを無効にします。
[root@monitor ~]# yum install yum-utils vim -y [root@monitor ~]# yum-config-manager --disable epel
手順
CDN インストールの場合:
Ansible 管理ノード で、Red Hat Ceph Storage 4 Tools リポジトリーおよび Ansible リポジトリーを有効にします。
Red Hat Enterprise Linux 7
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms --enable=rhel-7-server-ansible-2.9-rpms
Red Hat Enterprise Linux 8
[root@admin ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms --enable=ansible-2.9-for-rhel-8-x86_64-rpms
デフォルトでは、Red Hat Ceph Storage リポジトリーは対応するノードの
ceph-ansibleにより有効になります。リポジトリーを手動で有効にするには、以下を実行します。注記これらのリポジトリーは不要なため、コンテナー化されたデプロイメントでは有効にしないでください。
Ceph Monitor ノード で、Red Hat Ceph Storage 4 Monitor リポジトリーを有効にします。
Red Hat Enterprise Linux 7
[root@monitor ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-mon-rpms
Red Hat Enterprise Linux 8
[root@monitor ~]# subscription-manager repos --enable=rhceph-4-mon-for-rhel-8-x86_64-rpms
Ceph OSD ノード で、Red Hat Ceph Storage 4 OSD リポジトリーを有効にします。
Red Hat Enterprise Linux 7
[root@osd ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-osd-rpms
Red Hat Enterprise Linux 8
[root@osd ~]# subscription-manager repos --enable=rhceph-4-osd-for-rhel-8-x86_64-rpms
RBD ミラーリング、Ceph クライアント、Ceph Object Gateways、Metadata Servers、NFS、iSCSI ゲートウェイ、Dashboard サーバー などのノード種別で Red Hat Ceph Storage 4 Tools リポジトリーを有効にします。
Red Hat Enterprise Linux 7
[root@client ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
Red Hat Enterprise Linux 8
[root@client ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ISO インストールの場合:
- Red Hat カスタマーポータルにログインします。
- Downloads をクリックして、Software & Download センターに移動します。
- Red Hat Ceph Storage エリアで Download Software をクリックして、最新バージョンのソフトウェアをダウンロードします。
関連情報
- Red Hat Subscription Management 1 の Red Hat Subscription Manager の使用および設定 ガイド
3.6. Red Hat Ceph Storage のネットワーク設定の確認
すべての Red Hat Ceph Storage ノードにはパブリックネットワークが必要です。Ceph クライアントが Ceph monitor ノードおよび Ceph OSD ノードに到達できるパブリックネットワークにネットワークインターフェイスカードが設定されている必要があります。
Ceph がパブリックネットワークとは別のネットワークでハートビート、ピアリング、レプリケーション、および復元を実行できるように、クラスターネットワーク用のネットワークインターフェイスカードがある場合があります。
ネットワークインターフェイスを設定し、変更を永続化します。
Red Hat では、パブリックネットワークとプライベートネットワークの両方に単一のネットワークインターフェイスカードを使用することは推奨していません。
前提条件
- ネットワークに接続されたネットワークインターフェイスカード。
手順
ストレージクラスター内のすべての Red Hat Ceph Storage ノードで、root ユーザーとして以下の手順を実施します。
以下の設定が、公開されているネットワークインターフェイスカードに対応する
/etc/sysconfig/network-scripts/ifcfg-*ファイルにあることを確認します。-
静的 IP アドレスについて
BOOTPROTOパラメーターはnoneに設定されます。 ONBOOTパラメーターはyesに設定する必要があります。これが
noに設定されていると、Ceph ストレージクラスターがリブート時にピアに機能しなくなる可能性があります。IPv6 アドレス指定を使用する場合には、
IPV6_FAILURE_FATALパラメーターを除き、IPV6INITなどの IPV6 パラメーターをyesに設定する必要があります。また、Ceph 設定ファイル
/etc/ceph/ceph.confを編集して Ceph に IPv6 を使用するように指示します。指定しないと、Ceph は IPv4 を使用します。
-
静的 IP アドレスについて
関連情報
- Red Hat Enterprise Linux 8 用のネットワークインターフェイススクリプトの設定の詳細は、Red Hat Enterprise Linux 8 の ネットワークの設定および管理の ifcfg ファイルで IP ネットワークの設定 を参照してください。
- ネットワーク設定の詳細については、Red Hat Ceph Storage4 の 設定ガイド の Ceph ネットワーク設定 のセクションを参照してください。
3.7. Red Hat Ceph Storage のファイアウォールの設定
Red Hat CephStorage は、firewalld サービスを使用します。Firewalld サービスには、各デーモンのポートのリストが含まれています。
Ceph Monitor デーモンは、Ceph ストレージクラスター内の通信にポート 3300 および 6789 を使用します。
各 Ceph OSD ノードで、OSD デーモンは範囲 6800-7300 内の複数のポートを使用します。
- パブリックネットワークを介してクライアントおよびモニターと通信するための 1 つ
- クラスターネットワーク上で他の OSD にデータを送信する 1 つ (利用可能な場合)。それ以外の場合は、パブリックネットワーク経由でデータを送信します。
- 可能な場合は、クラスターネットワークを介してハートビートパケットを交換するための 1 つ。それ以外の場合は、パブリックネットワーク経由
Ceph Manager (ceph-mgr) デーモンは、6800-7300 範囲内のポートを使用します。同じノード上で Ceph Monitor と ceph-mgr デーモンを共存させることを検討してください。
Ceph Metadata Server ノード (ceph-mds) はポート範囲 6800-7300 を使用します。
Ceph Object Gateway ノードは、デフォルトで 8080 を使用するように Ansible によって設定されます。ただし、デフォルトのポート (例: ポート 80) を変更できます。
SSL/TLS サービスを使用するには、ポート 443 を開きます。
firewalld が有効な場合には、以下の手順は任意です。デフォルトでは、ceph-ansible には group_vars/all.yml に以下の設定が含まれ、これにより適切なポートが自動的に開きます。
configure_firewall: True
前提条件
- ネットワークハードウェアが接続されている。
-
ストレージクラスター内のすべてのノードへの
rootまたはsudoアクセスがある。
手順
ストレージクラスター内のすべてのノードで
firewalldサービスを起動します。これを有効にして、システムの起動時に実行し、実行していることを確認します。# systemctl enable firewalld # systemctl start firewalld # systemctl status firewalld
すべての Monitor ノードで、パブリックネットワークの
3300および6789ポートを開く。[root@monitor ~]# firewall-cmd --zone=public --add-port=3300/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=3300/tcp --permanent [root@monitor ~]# firewall-cmd --zone=public --add-port=6789/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6789/tcp --permanent [root@monitor ~]# firewall-cmd --permanent --add-service=ceph-mon [root@monitor ~]# firewall-cmd --add-service=ceph-mon
ソースアドレスに基づいてアクセスを制限するには、以下を実行します。
firewall-cmd --zone=public --add-rich-rule='rule family=ipv4 \ source address=IP_ADDRESS/NETMASK_PREFIX port protocol=tcp \ port=6789 accept' --permanent
- 置き換え
- IP_ADDRESS は、Monitor ノードのネットワークアドレスに置き換えます。
NETMASK_PREFIX は、CIDR 表記のネットマスクに置き換えます。
例
[root@monitor ~]# firewall-cmd --zone=public --add-rich-rule='rule family=ipv4 \ source address=192.168.0.11/24 port protocol=tcp \ port=6789 accept' --permanent
すべての OSD ノードで、パブリックネットワークでポート
6800-7300を開きます。[root@osd ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp [root@osd ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent [root@osd ~]# firewall-cmd --permanent --add-service=ceph [root@osd ~]# firewall-cmd --add-service=ceph
別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Manager (
ceph-mgr) ノードで、パブリックネットワークでポート6800-7300を開きます。[root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Metadata Server (
ceph-mds) ノードにおいて、パブリックネットワークでポート6800-7300を開きます。[root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp [root@monitor ~]# firewall-cmd --zone=public --add-port=6800-7300/tcp --permanent
別のクラスターネットワークがある場合には、適切なゾーンでコマンドを繰り返します。
すべての Ceph Object Gateway ノードで、パブリックネットワーク上の関連するポートを開きます。
デフォルトの Ansible が設定されたポート
8080を開くには、以下のコマンドを実行します。[root@gateway ~]# firewall-cmd --zone=public --add-port=8080/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=8080/tcp --permanent
ソースアドレスに基づいてアクセスを制限するには、以下を実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="8080" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="8080" accept" --permanent
- 置き換え
- IP_ADDRESS は、Monitor ノードのネットワークアドレスに置き換えます。
NETMASK_PREFIX は、CIDR 表記のネットマスクに置き換えます。
例
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept"
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="8080" accept" --permanent
必要に応じて、Ansible を使用して Ceph Object Gateway をインストールし、使用する Ceph Object Gateway を Ansible が設定するデフォルトのポートを
8080からポート80に変更した場合は、次のポートを開きます。[root@gateway ~]# firewall-cmd --zone=public --add-port=80/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=80/tcp --permanent
ソースアドレスに基づいてアクセスを制限するには、以下のコマンドを実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="80" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="80" accept" --permanent
- 置き換え
- IP_ADDRESS は、Monitor ノードのネットワークアドレスに置き換えます。
- NETMASK_PREFIX は、CIDR 表記のネットマスクに置き換えます。
例
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept"
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="80" accept" --permanent
オプション: SSL/TLS を使用するには、
443ポートを開きます。[root@gateway ~]# firewall-cmd --zone=public --add-port=443/tcp [root@gateway ~]# firewall-cmd --zone=public --add-port=443/tcp --permanent
ソースアドレスに基づいてアクセスを制限するには、以下のコマンドを実行します。
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="443" accept"
firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="IP_ADDRESS/NETMASK_PREFIX" port protocol="tcp" \ port="443" accept" --permanent
- 置き換え
- IP_ADDRESS は、Monitor ノードのネットワークアドレスに置き換えます。
- NETMASK_PREFIX は、CIDR 表記のネットマスクに置き換えます。
例
[root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="443" accept" [root@gateway ~]# firewall-cmd --zone=public --add-rich-rule="rule family="ipv4" \ source address="192.168.0.31/24" port protocol="tcp" \ port="443" accept" --permanent
関連情報
- パブリックネットワークおよびクラスターネットワークの詳細は、Red Hat Ceph Storage のネットワーク設定の確認 を参照してください。
-
firewalldの詳細は、Red Hat Enterprise Linux 8 のネットワークのセキュリティー保護の firewalld の使用および設定 の章を参照してください。
3.8. sudo アクセスのある Ansible ユーザーの作成
Ansible は、ソフトウェアをインストールし、パスワードを要求せずに設定ファイルを作成するための root 権限を持つユーザーとして、すべての Red Hat Ceph Storage (RHCS) ノードにログインできる必要があります。Ansible を使用して Red Hat Ceph Storage クラスターをデプロイおよび設定する際に、ストレージクラスター内のすべてのノードにパスワードなしの root アクセスで Ansible ユーザーを作成する必要があります。
前提条件
-
ストレージクラスター内のすべてのノードへの
rootまたはsudoアクセスがある。
手順
rootユーザーとしてノードにログインします。ssh root@HOST_NAME- 置き換え
HOST_NAME は、Ceph ノードのホスト名に置き換えます。
例
# ssh root@mon01
プロンプトに従い
rootパスワードを入力します。
新しい Ansible ユーザーを作成します。
adduser USER_NAME- 置き換え
USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
例
# adduser admin
重要cephをユーザー名として使用しないでください。cephユーザー名は、Ceph デーモン用に予約されます。クラスター全体で統一されたユーザー名を使用すると、使いやすさが向上しますが、侵入者は通常、そのユーザー名をブルートフォース攻撃に使用するため、明白なユーザー名の使用は避けてください。
このユーザーに新しいパスワードを設定します。
# passwd USER_NAME- 置き換え
USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
例
# passwd admin
プロンプトが表示されたら、新しいパスワードを 2 回入力します。
新規に作成されたユーザーの
sudoアクセスを設定します。cat << EOF >/etc/sudoers.d/USER_NAME $USER_NAME ALL = (root) NOPASSWD:ALL EOF- 置き換え
USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
例
# cat << EOF >/etc/sudoers.d/admin admin ALL = (root) NOPASSWD:ALL EOF
正しいファイル権限を新しいファイルに割り当てます。
chmod 0440 /etc/sudoers.d/USER_NAME- 置き換え
USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
例
# chmod 0440 /etc/sudoers.d/admin
関連情報
- Red Hat Enterprise Linux 8 の基本的なシステム設定の設定の ユーザーアカウントの管理 セクション
3.9. Ansible のパスワードなし SSH の有効化
Ansible 管理ノードで SSH キーペアを生成し、ストレージクラスター内の各ノードに公開キーを配布して、Ansible がパスワードの入力を求められることなくノードにアクセスできるようにします。
Cockpit の Web ベースのインターフェイスを使用して Red Hat Ceph Storage をインストールする場合は、この手順は必要ありません。これは、Cockpit Ceph Installer により独自の SSH キーが生成されるためです。クラスターのすべてのノードに Cockpit SSH キーをコピー の手順は、Cockpit Web インターフェイスを使用した Red Hat Ceph Storage のインストール の章になります。
前提条件
- Ansible 管理ノードへのアクセス
-
sudoアクセスのある Ansible ユーザーの作成
手順
SSH キーペアを生成し、デフォルトのファイル名を受け入れ、パスフレーズを空のままにします。
[ansible@admin ~]$ ssh-keygen
公開鍵をストレージクラスター内のすべてのノードにコピーします。
ssh-copy-id USER_NAME@HOST_NAME
- 置き換え
- USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
HOST_NAME は、Ceph ノードのホスト名に置き換えます。
例
[ansible@admin ~]$ ssh-copy-id ceph-admin@ceph-mon01
ユーザーの SSH の
configファイルを作成します。[ansible@admin ~]$ touch ~/.ssh/config
configファイルを編集するために開きます。ストレージクラスター内の各ノードのHostnameおよびUserオプションの値を設定します。Host node1 Hostname HOST_NAME User USER_NAME Host node2 Hostname HOST_NAME User USER_NAME ...
- 置き換え
- HOST_NAME は、Ceph ノードのホスト名に置き換えます。
USER_NAME は、Ansible ユーザーの新しいユーザー名に置き換えます。
例
Host node1 Hostname monitor User admin Host node2 Hostname osd User admin Host node3 Hostname gateway User admin
重要~/.ssh/configファイルを設定すると、ansible-playbookコマンドを実行するたびに-u USER_NAMEオプションを指定する必要がありません。
~/.ssh/configファイルに正しいファイルパーミッションを設定します。[admin@admin ~]$ chmod 600 ~/.ssh/config
関連情報
-
ssh_config(5)の man ページ。 - Red Hat Enterprise Linux 8 のネットワークのセキュリティー保護の章の 2 台のシステム間で OpenSSH を使用した安全な通信の使用 の章を参照してください。
第4章 Cockpit Web インターフェイスを使用した Red Hat Ceph Storage のインストール
本章では、Cockpit Web ベースのインターフェイスを使用して、Red Hat Ceph Storage クラスターおよびその他のコンポーネント (メタデータサーバー、Ceph クライアント、Ceph Object Gateway など) をインストールする方法を説明します。
このプロセスは、Cockpit Ceph インストーラーのインストール、Cockpit へのログイン、およびインストーラー内の異なるページを使用してクラスターのインストールの設定と開始で設定されます。
Cockpit Ceph Installer は、実際のインストールを実行するために、ceph-ansible RPM によって提供される Ansible および Ansible Playbook を使用します。これらの Playbook を使用して、Cockpit を使用せずに Ceph をインストールすることは引き続き可能です。このプロセスは本章に関連し、直接の Ansible インストール t または Ansible Playbook を直接使用 と呼ばれています。
Cockpit Ceph インストーラーは、現在 IPv6 ネットワークをサポートしていません。IPv6 ネットワークが必要な場合は、Ansible Playbook を使用して Ceph を直接 インストールします。
Ceph の管理と監視に使用されるダッシュボード Web インターフェイスは、Cockpit がバックエンドで使用する ceph-ansible RPM の Ansible Playbook によってデフォルトでインストールされます。したがって、Ansible Playbook を直接使用する場合や、Cockpit を使用して Ceph をインストールしたりしても、Dashboard の Web インターフェイスもインストールされます。
4.1. 前提条件
- Ansible Red Hat Ceph Storage の直接インストールに必要な 一般的な前提条件 を完了してください。
- Firefox または Chrome の最新バージョン。
- 複数のネットワークを使用してクラスター内トラフィック、クライアントからクラスターへのトラフィック、RADOS ゲートウェイトラフィック、または iSCSI トラフィックをセグメント化する場合は、関連するネットワークがホスト上ですでに設定されていることを確認してください。詳細は、ハードウェアガイド の ネットワークの留意事項 と、Cockpit Ceph Installer のネットワークページの完了 のこの章のこのセクションを参照してください。
-
Cockpit Web ベースのインターフェイスのデフォルトポート
9090にアクセスできることを確認します。
4.2. インストール要件
- Ansible 管理ノードとして機能する 1 つのノード。
- パフォーマンスメトリックおよびアラートプラットフォームを提供するノード。これは、Ansible 管理ノードと同じ場所に配置することができます。
- Ceph クラスターを設定する 1 つ以上のノード。インストーラーは、Development/POC と呼ばれるオールインワンインストールをサポートします。このモードでは、全 Ceph サービスを同じノードから実行でき、データレプリケーションはデフォルトでホストレベルの保護ではなく、ディスクにデフォルト設定されます。
4.3. Cockpit Ceph Installer のインストールおよび設定
Cockpit Ceph Installer を使用して Red Hat Ceph Storage クラスターをインストールする前に、Cockpit Ceph Installer を Ansible 管理ノードにインストールする必要があります。
前提条件
- Ansible 管理ノードへのルートレベルのアクセス。
-
Ansible アプリケーションで使用する
ansibleユーザーアカウント。
手順
Cockpit がインストールされていることを確認します。
$ rpm -q cockpit
以下に例を示します。
[admin@jb-ceph4-admin ~]$ rpm -q cockpit cockpit-196.3-1.el8.x86_64
上記の例と同様の出力が表示された場合は、確認用 Cockpit が実行している ステップに進みます。出力が
package cockpit is not installedされていない場合は、Install Cockpit のステップに進みます。必要に応じて Cockpit をインストールします。
Red Hat Enterprise Linux 8 の場合:
# dnf install cockpit
Red Hat Enterprise Linux 7 の場合:
# yum install cockpit
Cockpit が実行中であることを確認します。
# systemctl status cockpit.socket
出力に
Active: active (listening)が表示されている場合は、Red Hat Ceph Storage 用の Cockpit プラグインのインストール 手順に進みます。代わりにActive: inactive(dead)と表示される場合には、Cockpit の有効化 手順に進んでください。必要に応じて、Cockpit を有効にします。
systemctlコマンドを使用して、Cockpit を有効にします。# systemctl enable --now cockpit.socket
以下のような行が表示されます。
Created symlink /etc/systemd/system/sockets.target.wants/cockpit.socket → /usr/lib/systemd/system/cockpit.socket.
Cockpit が実行中であることを確認します。
# systemctl status cockpit.socket
以下のような行が表示されます。
Active: active (listening) since Tue 2020-01-07 18:49:07 EST; 7min ago
Red Hat Ceph Storage 用の Cockpit Ceph Installer をインストールします。
Red Hat Enterprise Linux 8 の場合:
# dnf install cockpit-ceph-installer
Red Hat Enterprise Linux 7 の場合:
# yum install cockpit-ceph-installer
Ansible ユーザーとして、sudo を使用してコンテナーカタログにログインします。
注記デフォルトでは、Cockpit Ceph Installer は
rootユーザーを使用して Ceph をインストールします。Ceph をインストールするための前提条件の一部として作成した Ansible ユーザーを使用するには、この手順の残りのコマンドを実行し、sudoを Ansible ユーザーとして実行します。Red Hat Enterprise Linux 7
$ sudo docker login -u CUSTOMER_PORTAL_USERNAME https://registry.redhat.io例
[admin@jb-ceph4-admin ~]$ sudo docker login -u myusername https://registry.redhat.io Password: Login Succeeded!
Red Hat Enterprise Linux 8
$ sudo podman login -u CUSTOMER_PORTAL_USERNAME https://registry.redhat.io例
[admin@jb-ceph4-admin ~]$ sudo podman login -u myusername https://registry.redhat.io Password: Login Succeeded!
registry.redhat.ioがコンテナーレジストリーの検索パスにあることを確認します。編集するために、
/etc/containers/registries.confファイルを開きます。[registries.search] registries = [ 'registry.access.redhat.com', 'registry.fedoraproject.org', 'registry.centos.org', 'docker.io']
registry.redhat.ioがファイルに含まれていない場合は、これを追加します。[registries.search] registries = ['registry.redhat.io', 'registry.access.redhat.com', 'registry.fedoraproject.org', 'registry.centos.org', 'docker.io']
Ansible ユーザーとして、sudo を使用して
ansible-runner-serviceを起動します。$ sudo ansible-runner-service.sh -s
例
[admin@jb-ceph4-admin ~]$ sudo ansible-runner-service.sh -s Checking environment is ready Checking/creating directories Checking SSL certificate configuration Generating RSA private key, 4096 bit long modulus (2 primes) ..................................................................................................................................................................................................................................++++ ......................................................++++ e is 65537 (0x010001) Generating RSA private key, 4096 bit long modulus (2 primes) ........................................++++ ..............................................................................................................................................................................++++ e is 65537 (0x010001) writing RSA key Signature ok subject=C = US, ST = North Carolina, L = Raleigh, O = Red Hat, OU = RunnerServer, CN = jb-ceph4-admin Getting CA Private Key Generating RSA private key, 4096 bit long modulus (2 primes) .....................................................................................................++++ ..++++ e is 65537 (0x010001) writing RSA key Signature ok subject=C = US, ST = North Carolina, L = Raleigh, O = Red Hat, OU = RunnerClient, CN = jb-ceph4-admin Getting CA Private Key Setting ownership of the certs to your user account(admin) Setting target user for ansible connections to admin Applying SELINUX container_file_t context to '/etc/ansible-runner-service' Applying SELINUX container_file_t context to '/usr/share/ceph-ansible' Ansible API (runner-service) container set to rhceph/ansible-runner-rhel8:latest Fetching Ansible API container (runner-service). Please wait... Trying to pull registry.redhat.io/rhceph/ansible-runner-rhel8:latest...Getting image source signatures Copying blob c585fd5093c6 done Copying blob 217d30c36265 done Copying blob e61d8721e62e done Copying config b96067ea93 done Writing manifest to image destination Storing signatures b96067ea93c8d6769eaea86854617c63c61ea10c4ff01ecf71d488d5727cb577 Starting Ansible API container (runner-service) Started runner-service container Waiting for Ansible API container (runner-service) to respond The Ansible API container (runner-service) is available and responding to requests Login to the cockpit UI at https://jb-ceph4-admin:9090/cockpit-ceph-installer to start the install
出力の最後の行には、Cockpit Ceph Installer の URL が含まれます。上記の例では、URL は
https://jb-ceph4-admin:9090/cockpit-ceph-installerです。お使いの環境で出力される URL を書き留めておきます。
4.4. Cockpit Ceph Installer SSH 鍵をクラスター内のすべてのノードにコピーします。
Cockpit Ceph Installer は、SSH を使用してクラスター内のノードに接続し、設定します。これを実行するために、インストーラーは SSH キーペアを生成し、パスワードを求められることなくノードにアクセスできるようにします。SSH 公開鍵はクラスター内のすべてのノードに転送される必要があります。
前提条件
- sudo アクセスを持つ Ansible ユーザー が作成されました。
- Cockpit Ceph Installer が インストールされ、設定されている。
手順
Ansible 管理ノードに Ansible ユーザーとしてログインします。
ssh ANSIBLE_USER@HOST_NAME
以下に例を示します。
$ ssh admin@jb-ceph4-admin
SSH 公開鍵を最初のノードにコピーします。
sudo ssh-copy-id -f -i /usr/share/ansible-runner-service/env/ssh_key.pub _ANSIBLE_USER_@_HOST_NAME_
以下に例を示します。
$ sudo ssh-copy-id -f -i /usr/share/ansible-runner-service/env/ssh_key.pub admin@jb-ceph4-mon /bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/usr/share/ansible-runner-service/env/ssh_key.pub" admin@192.168.122.182's password: Number of key(s) added: 1 Now try logging into the machine, with: "ssh 'admin@jb-ceph4-mon'" and check to make sure that only the key(s) you wanted were added.
クラスターのすべてのノードに対してこの手順を繰り返します。
4.5. Cockpit へのログイン
Cockpit Ceph Installer の Web インターフェイスは、Cockpit にログインして確認することができます。
前提条件
- Cockpit Ceph Installer が インストールされ、設定されている。
- Cockpit Ceph Installer の設定の一部として URL が出力されていること。
手順
Web ブラウザーで URL を開きます。
Ansible ユーザー名およびそのパスワードを入力します。
特権タスクにパスワードを再使用 するラジオボタンをクリックします。
Log In をクリックします。
Welcome ページをチェックして、インストーラーの動作方法とインストールプロセスの全体的なフローを確認します。

Welcome ページで情報を確認したら、Web ページの右下隅にある Environment ボタンをクリックします。
4.6. Cockpit Ceph インストーラーの環境ページの完了
Environment ページでは、使用するインストールソースや、ストレージにハードディスクドライブ (HDD) とソリッドステートドライブ (SSD) を使用する方法など、クラスターの全体的な側面を設定できます。
前提条件
- Cockpit Ceph Installer が インストールされ、設定されている。
- Cockpit Ceph Installer の設定の一部として URL が出力されている必要があります。
- レジストリーサービスアカウント を作成している。
続いて表示されるダイアログには、一部の設定の右側にあるツールチップがあります。これを表示するには、そのあたりに i のようなアイコンにマウスカーソルを合わせたカーソルをかざすようにカーソルを合わせます。
手順
インストールソース を選択します。Red Hat カスタマーポータルからダウンロードした CD イメージを使用するには、Red Hat Subscription Manager からリポジトリーを使用するか、ISO を選択します。

Red Hat を選択した場合は、他のオプションを指定せずに Target Version が RHCS 4 に設定されます。ISO を選択すると、Target Version が ISO イメージファイルに設定されます。
重要ISO を選択する場合、イメージファイルは
/usr/share/ansible-runner-service/isoディレクトリーにあり、その SELinux コンテキストはcontainer_file_tに設定する必要があります。重要インストールソース の コミュニティー オプションおよび ディストリビューション オプションには対応していません。
Cluster Type を選択します。実稼働 の選択では、CPU 番号やメモリーサイズなどの特定のリソース要件を満たしていないと、インストールが続行できなくなります。リソース要件を満たしている場合でもクラスターのインストールを続行できるようにするには、Development/POC を選択します。
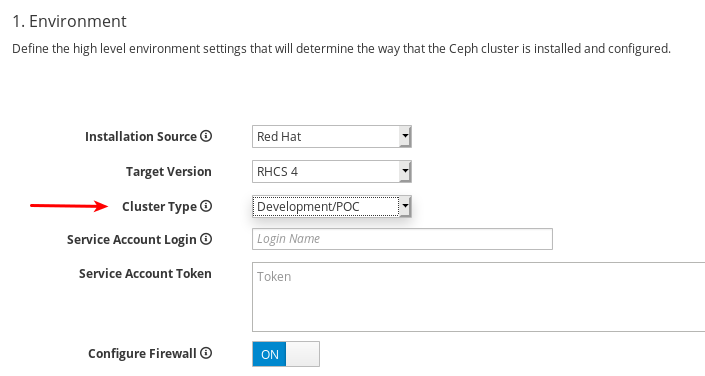 重要
重要Development/POC モードは、実稼働環境で使用する Ceph クラスターをインストールしないでください。
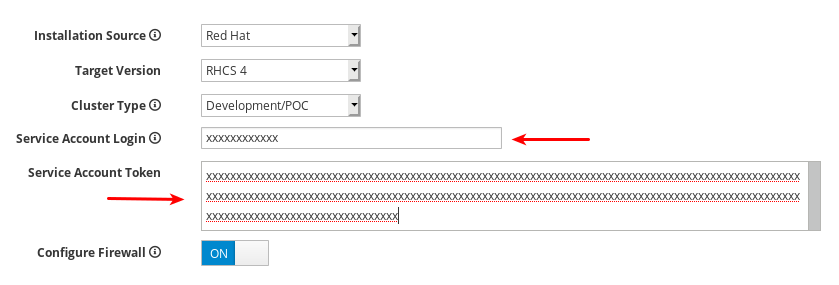
Service Account Login および Service Account Token を設定します。Red Hat レジストリーサービスアカウントがない場合は、レジストリーサービスアカウントの Web ページ を使用して作成します。
Configure Firewall を ON に設定して、Ceph サービスのポートを開くルールを
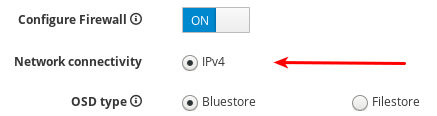
firewalldに適用します。firewalldを使用していない場合は、OFF 設定を使用します。
現在、Cockpit Ceph Installer は IPv4 のみをサポートしています。IPv6 サポートが必要な場合は、Cockpit Ceph Installer を使用を停止し、Ansible スクリプトを直接 使用して Ceph のインストールに進む必要があります。
OSD Type を BlueStore または FileStore に設定します。
 重要
重要BlueStore はデフォルトの OSD タイプです。以前のバージョンでは、Ceph は FileStore をオブジェクトストアとして使用していました。BlueStore はより多くの機能を提供し、パフォーマンスを向上させるため、この形式は Red Hat Ceph Storage 4.0 で非推奨になっています。FileStore は依然として使用できますが、サポート例外が必要です。BlueStore の詳細は、アーキテクチャーガイド の Ceph BlueStore を参照してください。
Flash Configuration を Journal/Logs または OSD データ に設定します。ソリッドステートドライブ (SSD) を使用している場合は、NVMe または従来の SATA/SAS インターフェイスのどちらを使用する場合でも、実際のデータがハードディスクドライブ (HDD) に保存されている間、ジャーナルとログの書き込みにのみ使用することを選択できます。ジャーナリング、ログ、およびデータに SSD を使用し、CephOSD 機能に HDD を使用しないでください。

Encryption を None または Encrypted に設定します。これは、LUKS1 形式を使用したストレージデバイスの残り暗号化を指します。

インストールタイプ を Container または RPM に設定します。従来は、Red Hat Enterprise Linux にソフトウェアをインストールするのに Red Hat Package Manager (RPM) が使用されていました。これで、RPM またはコンテナーを使用して Ceph をインストールできます。コンテナーを使用して Ceph をインストールすると、サービスを分離して共存させることができるため、ハードウェアの使用率が向上します。

すべての環境設定を確認し、Web ページの右下隅にある Hosts ボタンをクリックします。
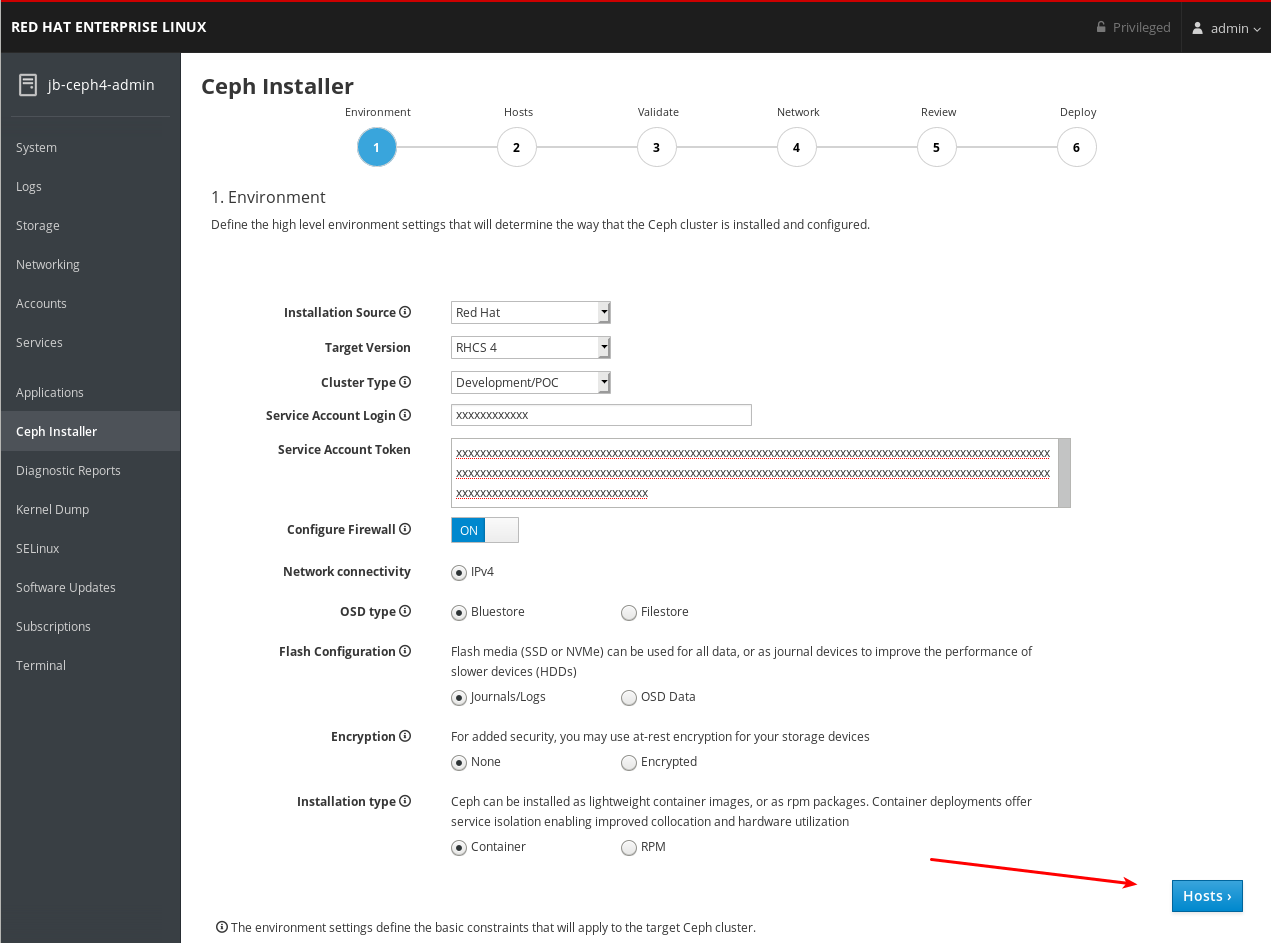
4.7. Cockpit Ceph インストーラーの Hosts ページの完了
Hosts のページでは、Ceph をインストールするホストと各ホストが使用するロールについて Cockpit Ceph Installer に通知することができます。ホストを追加すると、インストーラーは SSH と DNS 接続の有無をチェックします。
前提条件
- Cockpit Ceph Installer の環境ページ が完了している。
- Cockpit Ceph Installer SSH キーが クラスター内のすべてのノードにコピー されている。
手順
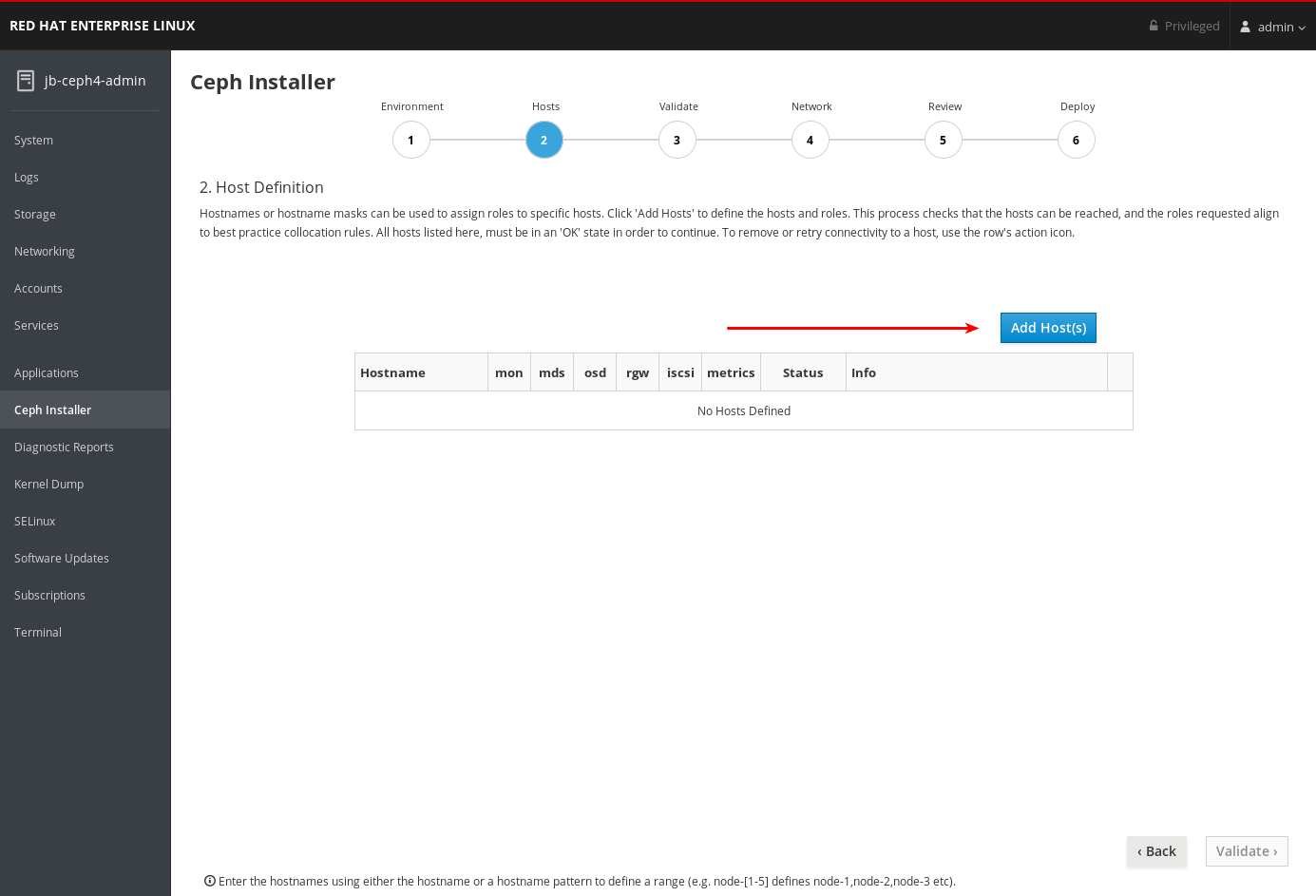
Add Host(s) ボタンをクリックします。
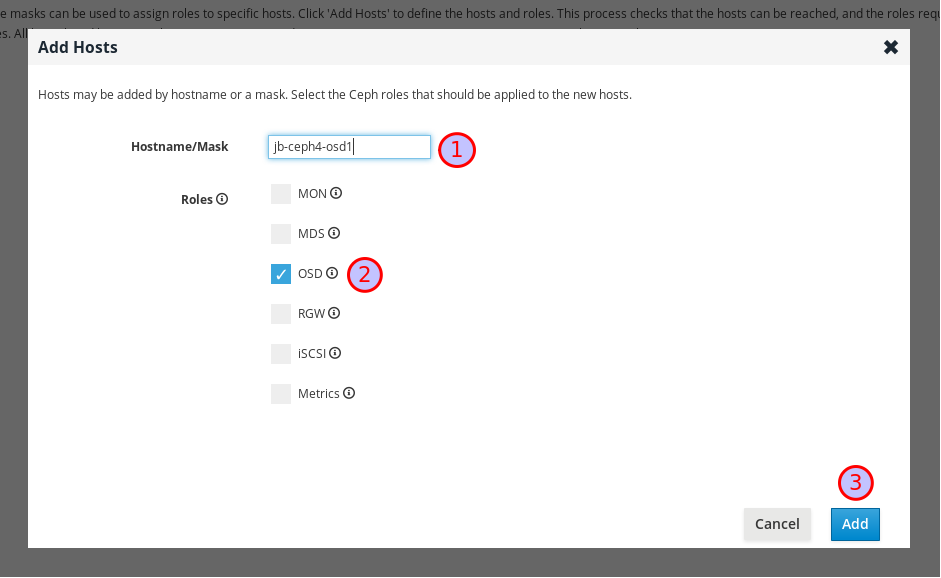
Ceph OSD ノードのホスト名を入力し、OSD のチェックボックスを選択して 追加 ボタンをクリックします。
最初の Ceph OSD ノードが追加されます。

実稼働クラスターの場合、少なくとも 3 つの Ceph OSD ノードを追加するまで、この手順を繰り返します。
必要に応じて、ホスト名のパターンを使用してノードの範囲を定義します。たとえば、
jb-ceph4-osd2とjb-ceph4-osd3を同時に追加するには、jb-ceph4-osd[2-3]を入力します。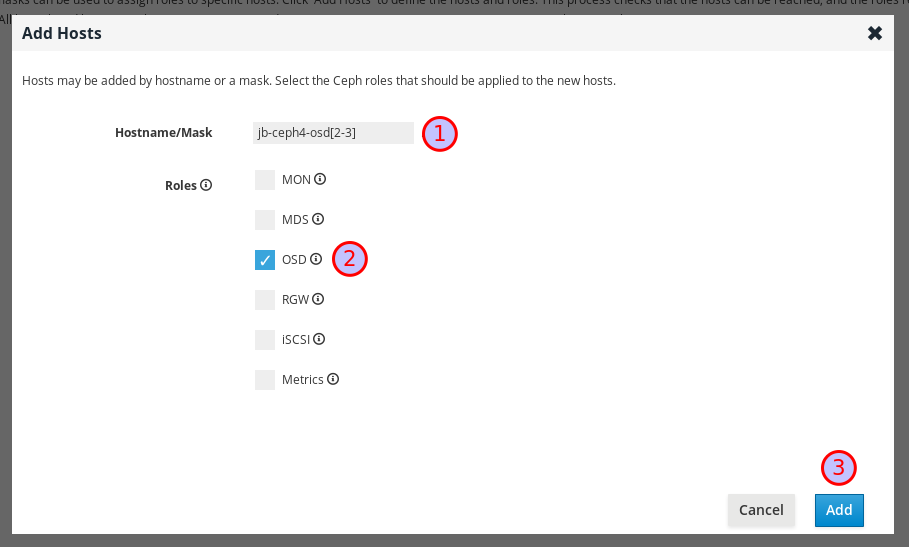
jb-ceph4-osd2とjb-ceph4-ods3の両方が追加されます。
クラスター内の他のノードについて上記の手順を繰り返します。
-
実稼働クラスターの場合は、少なくとも 3 つの Ceph Monitor ノードを追加します。ダイアログでは、ロールは
MONとしてリスト表示されます。 -
Metricsのロールを持つノードを追加します。Metricsロールは Grafana および Prometheus をインストールし、Ceph クラスターのパフォーマンスに関するリアルタイムの洞察を提供します。これらのメトリックは Ceph Dashboard に提示されています。これにより、クラスターの監視および管理が可能になります。Dashboard、Grafana、および Prometheus のインストールが必要です。Ansible Administration ノードでメトリック関数を同じ場所に配置できます。これを実行する場合は、ノードのシステムリソースが スタンドアロンのメトリックノードに必要とされるもの よりも大きいことを確認します。 -
必要に応じて
MDSロールを持つノードを追加します。MDSロールは Ceph Metadata Server (MDS) をインストールします。Ceph File System をデプロイするには、メタデータサーバーデーモンが必要です。 -
必要に応じて
RGWロールを持つノードを追加します。RGWロールは、Ceph Object Gateway もインストールします。RADOS ゲートウェイは、librados API 上に構築されたオブジェクトストレージインターフェイスで、Ceph ストレージクラスターに RESTful ゲートウェイを提供するアプリケーションを提供します。Amazon S3 および OpenStack Swift API をサポートします。 -
必要に応じて
iSCSIロールを持つノードを追加します。iSCSIロールは iSCSI ゲートウェイをインストールするため、iSCSI で Ceph ブロックデバイスを共有することができます。Ceph で iSCSI を使用するには、マルチパス I/O 用に iSCSI ゲートウェイを少なくとも 2 つのノードにインストールする必要があります。
-
実稼働クラスターの場合は、少なくとも 3 つの Ceph Monitor ノードを追加します。ダイアログでは、ロールは
必要に応じて、ノードを追加する際に複数のロールを選択して、同じノードに複数のサービスを割り当てます。

デーモンを同じ場所に配置するデーモンの詳細は、インストールガイド の コンテナー化された Ceph デーモンのコロケーション を参照してください。
必要に応じて、テーブルのロールをオンまたはオフにして、ノードに割り当てられたロールを変更します。

必要に応じて、ノードを削除するには、削除するノードの行の右端にあるケバブアイコンをクリックし、Delete をクリックします。

クラスター内のすべてのノードを追加したら、ページの右下隅にある Validate ボタンをクリックして、必要なロールをすべて設定します。

実稼働クラスターの場合は、3 つまたは 5 台のモニターがない場合に Cockpit Ceph インストーラーは続行されません。この例では、Cluster Type は Development/POC に設定されているため、インストールは 1 つのモニターのみを続行できます。
4.8. Cockpit Ceph インストーラーの Validate ページの完了
Validate ページでは、Hosts ページで指定したノードをプローブし、使用するロールのハードウェア要件を満たしていることを確認してください。
前提条件
- Cockpit Ceph インストーラーのホストページ が完了している。
手順
Probe Hosts ボタンをクリックします。

続行するには、OK ステータス を持つホストを少なくとも 3 台選択する必要があります。
必要に応じて、ホストについて警告またはエラーが生成された場合は、ホストのチェックマークの左側にある矢印をクリックして、問題を表示します。

 重要
重要Cluster Type を Production に設定すると、生成されたエラーによって Status が NOTOK となり、インストール用に選択できなくなります。エラーを解決する方法は、次の手順を参照してください。
重要Cluster Type を Development/POC に設定すると、生成されたエラーは警告としてリスト表示されるため、Status は常に OK になります。これにより、ホストが要件や提案を満たしているかどうかに関係なく、ホストを選択して Ceph をインストールできます。必要に応じて警告を解決できます。警告を解決する方法については、次の手順を参照してください。
必要に応じて、エラーと警告を解決するには、以下のメソッドを 1 つ以上使用します。
エラーや警告を解決する最も簡単な方法は、特定のロールを完全に無効にしたり、1 台のホストでロールを無効にして、必要なリソースがある別のホストで有効にすることです。
Development/POC クラスターをインストールしている場合は、警告が残っていても安心して進めることができ、実稼働 クラスターをインストールする場合は、少なくとも 3 台のホストに割り当てられたロールに必要なリソースがすべて揃っていて、警告が残っていても安心して進めることができる組み合わせが見つかるまで、ロールの有効化と無効化を試してみてください。
必要なロールの要件を満たす新規ホストを使用することもできます。まず、ホスト ページに戻り、問題のあるホストを削除します。

次に、新規ホストを追加 します。
- ホストのハードウェアをアップグレードするか、何らかの方法で要件または提案を満たすには、最初にホストに変更を加えてから、再度 ホストのプローブ をクリックします。オペレーティングシステムを再インストールする必要がある場合は、再度 SSH キーをコピーする 必要があります。
ホストの横にあるチェックボックスを選択して、Red Hat Ceph Storage をインストールするホストを選択します。
 重要
重要実稼働クラスターをインストールする場合は、インストール用にエラーを選択する前にエラーを解決する必要があります。
ページの右下隅の Network ボタンをクリックして、クラスターのネットワークを確認し、設定します。

4.9. Cockpit Ceph インストーラーのネットワークページの完了
Network ページでは、特定のクラスター通信タイプを特定のネットワークに分離することができます。これには、クラスターのホスト全体に複数の異なるネットワークを設定する必要があります。
Network ページは、Validate ページで実行されたプローブから収集された情報を使用して、ホストがアクセスできるネットワークを表示します。現在、Network ページにすでに進む場合は、新規ネットワークをホストに追加したり、Validate ページに戻り、ホストを再プローブしてから、再度 Network ページに移動して新しいネットワークを使用することができません。選択のためには表示されません。Network ページに移動してからホストに追加したネットワークを使用するには、Web ページを完全に更新し、最初からインストールを再起動する必要があります。
実稼働クラスターの場合は、クラスター内トラフィックをクライアントからクラスターへのトラフィックから別々の NIC に分離する必要があります。クラスタートラフィックの種別を分離する他に、Ceph クラスターの設定時に、ネットワークについて考慮すべき他の考慮点があります。詳細は、ハードウェアガイド の ネットワークの考慮事項 を参照してください。
前提条件
- Cockpit Ceph インストーラーの Validate ページ が完了しました。
手順
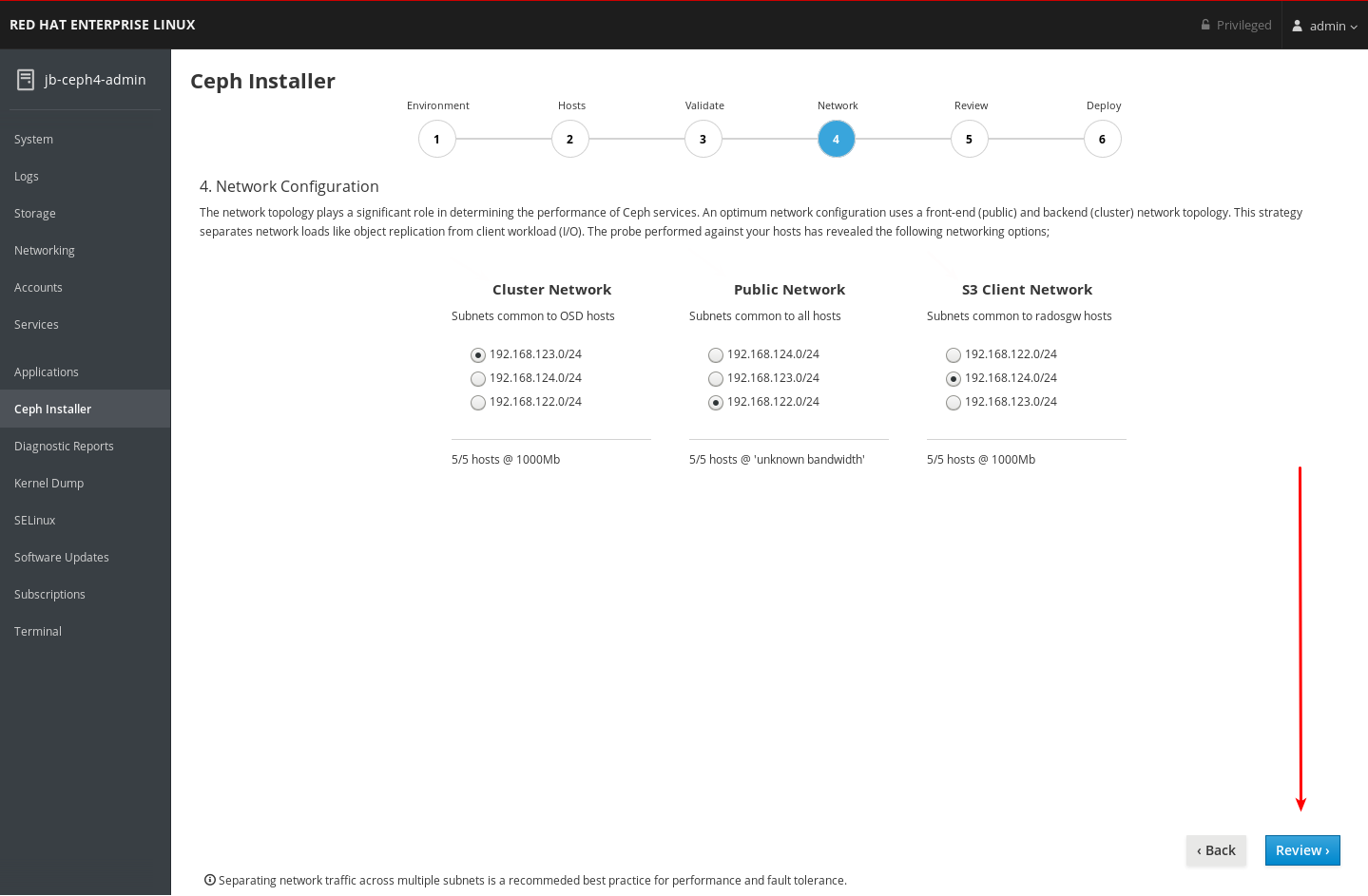
ネットワークページで設定できるネットワーク種別を書き留めておきます。各タイプには独自の列があります。クラスターネットワーク および パブリックネットワーク の列は常に表示されます。RADOS Gateway ロールでホストをインストールする場合は、S3 Network 列が表示されます。iSCSI ロールでホストをインストールする場合は、iSCSI ネットワーク の列が表示されます。以下の例では、Cluster Network、Public Network、および S3 Network の列が表示されます。
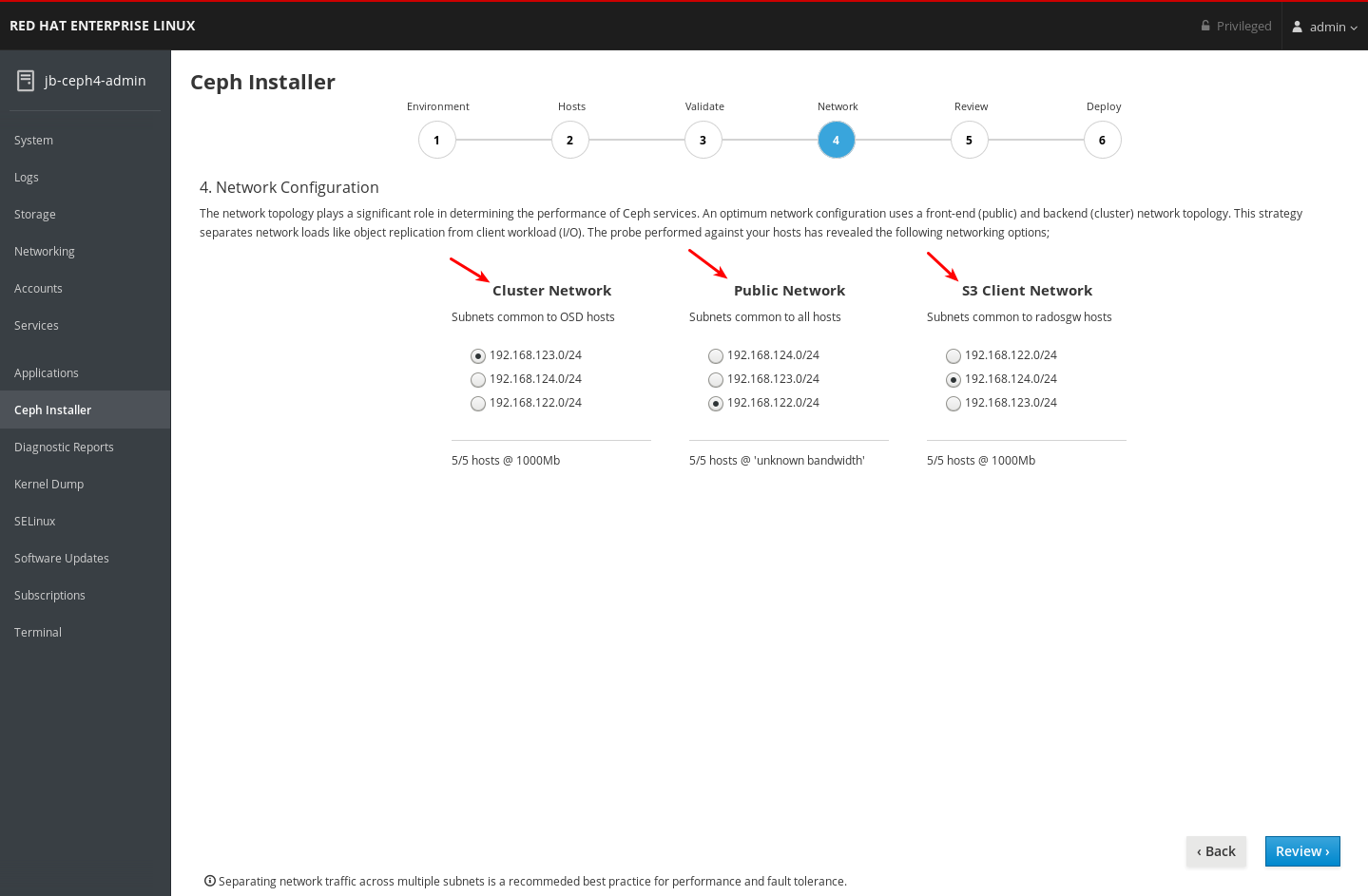
各ネットワーク種別に選択できるネットワークを書き留めておきます。特定のネットワーク種別を設定する全ホストで利用可能なネットワークのみが表示されます。以下の例では、クラスター内の全ホストで利用可能なネットワークが 3 つあります。3 つのネットワークはすべて、ネットワーク種別を設定する全ホストセットで利用可能であるため、各ネットワーク種別には同じ 3 つのネットワークがリスト表示されます。
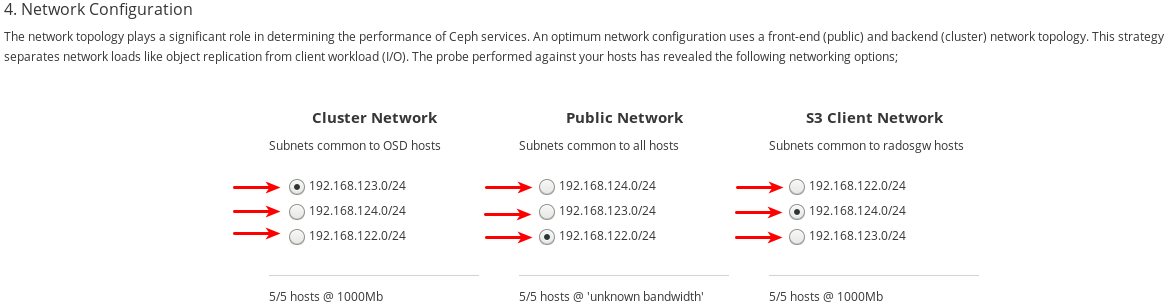
利用可能な 3 つのネットワークは、
192.168.122.0/24、192.168.123.0/24、および192.168.124.0/24です。各ネットワークが操作する速度を書き留めておきます。これは、特定のネットワークに使用される NIC の速度です。以下の例では、
192.168.123.0/24および192.168.124.0/24は 1,000 mbps になります。Cockpit Ceph Installer は192.168.122.0/24ネットワークの速度を把握できませんでした。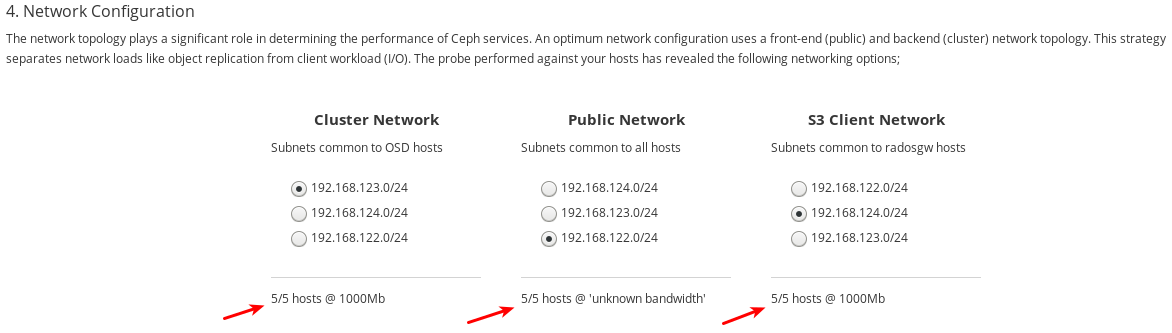
各ネットワークタイプに使用するネットワークを選択します。実稼働クラスターの場合は、Cluster Network および Public Network 用に別個のネットワークを選択する必要があります。Development/POC クラスターでは、両方のタイプに同じネットワークを選択するか、すべてのホストにネットワークが 1 つのみ設定されている場合は、そのネットワークのみが表示され、他のネットワークを選択できなくなります。
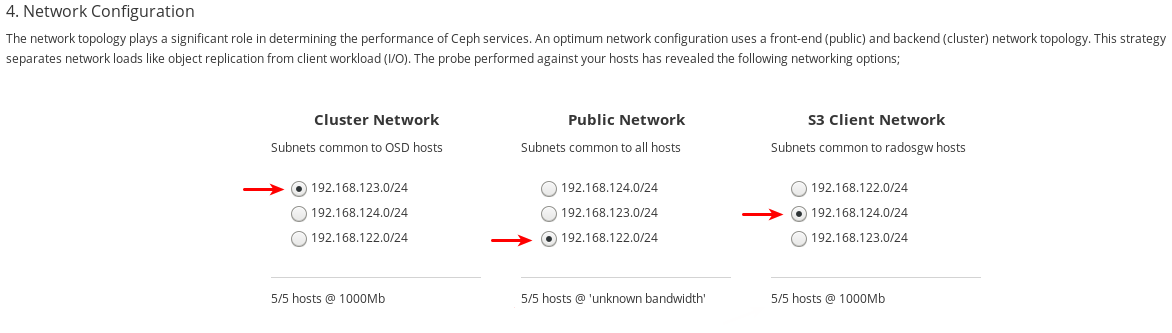
192.168.122.0/24ネットワークは パブリックネットワーク に使用され、192.168.123.0/24ネットワークが クラスターネットワーク に使用されます。また、192.168.124.0/24ネットワークは S3 ネットワーク に使用されます。ページの右下隅にある Review ボタンをクリックして、インストール前にクラスター設定全体を確認します。
4.10. インストール設定の確認
Review ページを使用すると、前のページで設定した Ceph クラスターのインストール設定の詳細と、以前のページに含まれていなかったホストに関する詳細を表示できます。
前提条件
- Cockpit Ceph Installer のネットワークページ が完了している。
手順
レビューページを表示します。

Review ページに表示されるように、各ページの情報が予想どおりに表示されていることを確認します。Environment ページの情報の概要が 1、Hosts ページが 2、Validate ページが 3、Network ページが 4、ホストの詳細 (前のページには含まれていなかったいくつかの追加の詳細を含む) が 5 にあります。

ページの右下隅にある Deploy ボタンをクリックして、実際のインストールプロセスを確定および開始できる Deploy ページに移動します。

4.11. Ceph クラスターのデプロイ
Deploy ページを使用すると、インストール設定をネイティブの Ansible 形式で保存し、必要に応じてそれらの設定の確認または変更、インストールの開始、その進捗の監視、インストールが正常に完了した後にクラスターのステータスを表示することができます。
前提条件
- Review ページ でのインストール設定が検証済みである。
手順
ページの右下隅にある Save ボタンをクリックして、実際にインストールを実行するために Ansible が使用する Ansible Playbook にインストール設定を保存します。

-
必要に応じて、Ansible 管理ノードにある Ansible Playbook の設定を表示するか、カスタマイズします。Playbook は
/usr/share/ceph-ansibleにあります。Ansible Playbook の詳細と、これらを使用してインストールをカスタマイズする方法については、Red Hat Ceph Storage クラスターのインストール を参照してください。 -
Grafana およびダッシュボードのデフォルトユーザー名およびパスワードを保護します。Red Hat Ceph Storage 4.1 以降、
/usr/share/ceph-ansible/group_vars/all.ymlのdashboard_admin_passwordおよびgrafana_admin_passwordをコメント解除するか設定する必要があります。それぞれに安全なパスワードを設定します。dashboard_admin_userおよびgrafana_admin_userのカスタムユーザー名も設定します。 ページの右下隅にある Deploy ボタンをクリックして、インストールを開始します。
実行中のインストールの進捗を確認します。
1 にある情報は、インストールが実行しているかどうか、開始時間、および経過時間を示します。2 にある情報は、試行された Ansible タスクの概要を示しています。3 にある情報は、インストールされているロールまたはインストールしているロールを示しています。緑色は、そのロールに割り当てられたすべてのホストにそのロールがインストールされているロールを表します。青色は、ロールが割り当てられているホストが依然としてインストールされているロールを表します。4 の場合は、現在のタスクの詳細を表示したり、失敗したタスクを表示できます。Filter by メニューを使用して、現在のタスクと失敗したタスクを切り換えます。
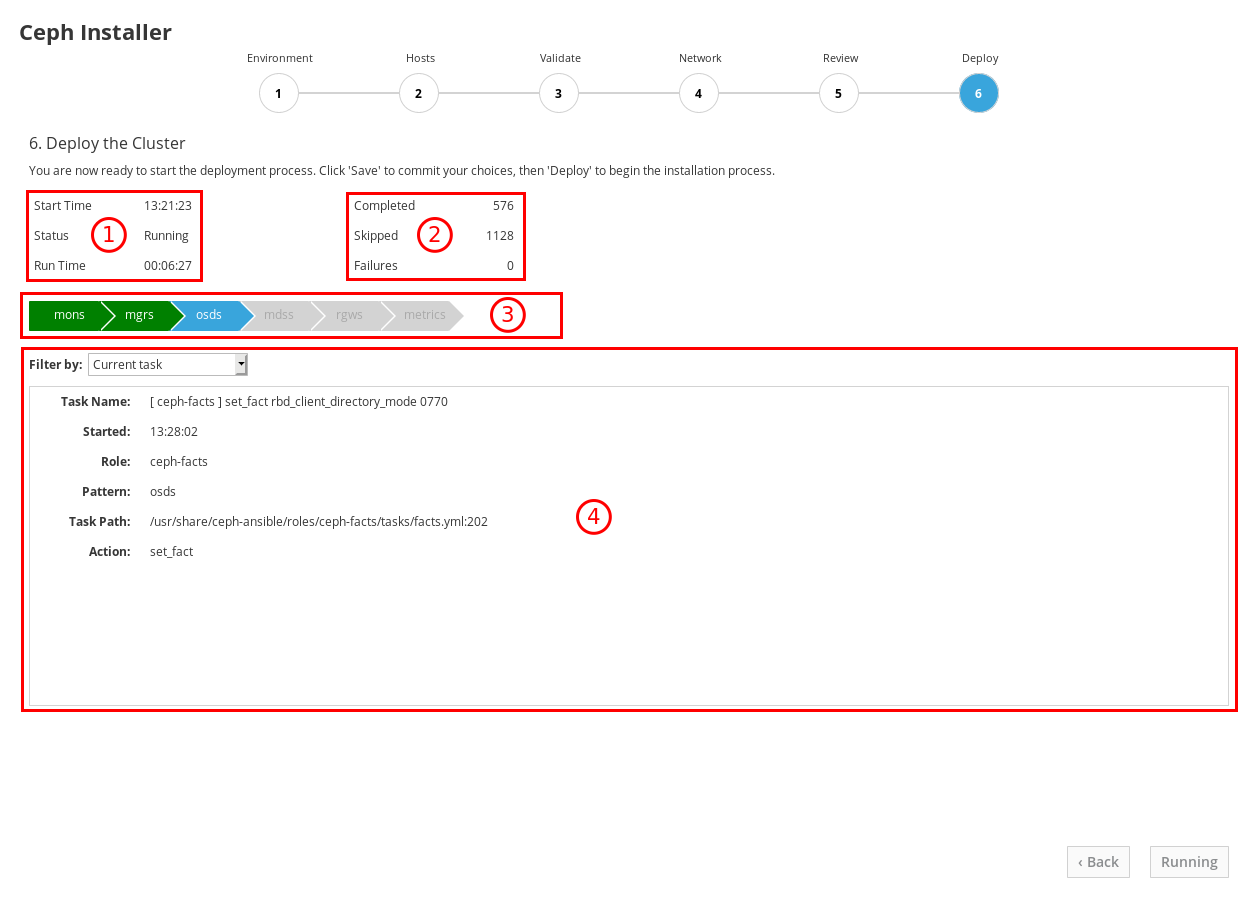
ロール名は、Ansible インベントリーファイルから取得されます。
monsは Monitors で、mgrsは Managers で、osdは Object Storage Devices で、mdssはメタデータサーバーで、rgwsは RADOS ゲートウェイで、metricsはダッシュボードメトリックの Grafana および Prometheus サービスです。スクリーンショットの例には表示されません。iscsigwsは iSCSI ゲートウェイです。インストールが完了したら、ページの右下隅にある Complete ボタンをクリックします。これにより、
ceph statusコマンドの出力と Dashboard のアクセス情報を表示するウィンドウが開きます。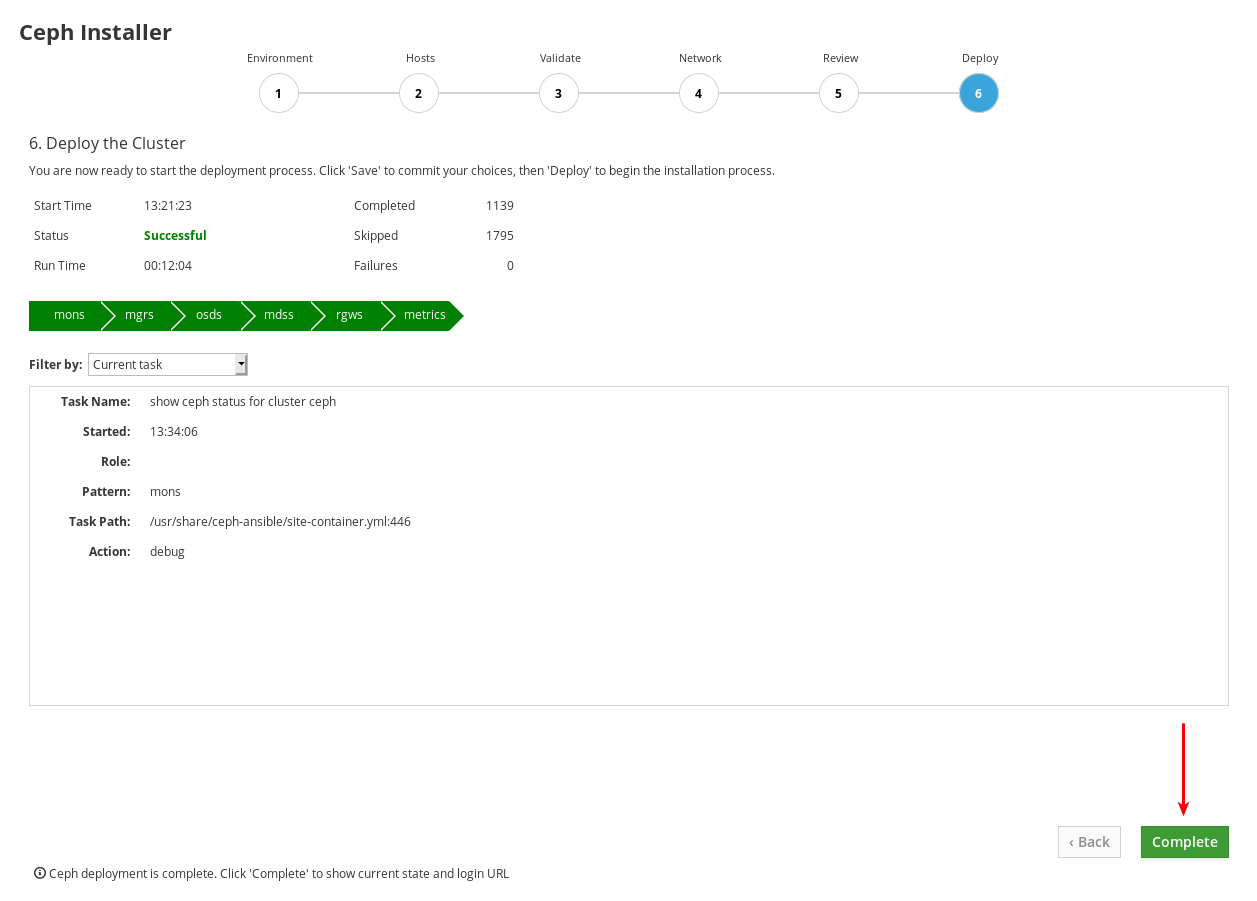
以下の例のクラスターステータス情報を、クラスターのクラスターステータス情報と比較します。この例では、すべての OSD が稼働中、およびすべてのサービスがアクティブな正常なクラスターを示しています。PG は、
active+clean状態です。クラスターの一部の要素が同一ではない場合は、トラブルシューティングガイド で問題の解決方法に関する情報を参照してください。
Ceph Cluster Status ウィンドウ下部に、URL、ユーザー名、パスワードなど、Dashboard のアクセス情報が表示されます。この情報を書き留めておいてください。

ダッシュボードにアクセス するには、ダッシュボードガイド と共に前のステップの情報を使用します。

ダッシュボードは Web インターフェイスを提供するので、Red Hat Ceph Storage クラスターを管理および監視することができます。詳細は、ダッシュボードガイド を参照してください。
-
オプション:
cockpit-ceph-installer.logファイルを表示します。このファイルは、作成された選択のログを記録し、生成されたプローブプロセスに関連する警告を記録します。これは、インストーラースクリプトを実行したユーザーのホームディレクトリーansible-runner-service.shにあります。
第5章 Ansible を使用した Red Hat Ceph Storage のインストール
本章では、Ansible アプリケーションを使用して Red Hat Ceph Storage クラスターおよびその他のコンポーネントをデプロイする方法を説明します (メタデータサーバーや Ceph Object Gateway など)。
- Red Hat Ceph Storage クラスターをインストールするには、「Red Hat Ceph Storage クラスターのインストール」 を参照してください。
- メタデータサーバーをインストールするには、「メタデータサーバーのインストール」 を参照してください。
-
ceph-clientロールをインストールするには、「Ceph クライアントロールのインストール」 を参照してください。 - Ceph Object Gateway をインストールするには、「Ceph Object Gateway のインストール」 を参照してください。
- マルチサイトの Ceph Object Gateway を設定するには、「マルチサイト Ceph Object Gateway の設定」 を参照してください。
-
Ansible の
--limitオプションについては、「limitオプションについて」 を参照してください。
5.1. 前提条件
- 有効なカスタマーサブスクリプションを取得します。
各ノードで以下の手順を実行してクラスターノードを準備します。
5.2. Red Hat Ceph Storage クラスターのインストール
Playbook ceph-ansible で Ansible アプリケーションを使用して、ベアメタルまたはコンテナーに Red Hat Ceph Storage をインストールします。実稼働環境で Ceph ストレージクラスターを使用するには、最小で 3 つの監視ノードと、複数の OSD デーモンが含まれる OSD ノードが必要です。通常、実稼働環境で実行されている一般的な Ceph ストレージクラスターは、10 台以上のノードで設定されます。
以下の手順では、特に指示しない限り、Ansible 管理ノードからコマンドを実行します。この手順は、指定しない限り、ベアメタルおよびコンテナーのデプロイメントの両方に適用されます。
Ceph はモニター 1 つで実行できますが、実稼働クラスターで高可用性を確保するためには、Red Hat は少なくとも 3 つのモニターノードを持つデプロイメントのみをサポートします。
Red Hat Ceph Storage 4 を Red Hat Enterprise Linux 7.7 のコンテナーにデプロイすると、Red Hat Ceph Storage 4 が Red Hat Enterprise Linux 8 コンテナーイメージにデプロイされます。
前提条件
- 有効なカスタマーサブスクリプションです。
- Ansible 管理ノードへのルートレベルのアクセス。
-
Ansible アプリケーションで使用する
ansibleユーザーアカウント。 - Red Hat Ceph Storage Tools および Ansible リポジトリーの有効化
- ISO インストールの場合は、Ansible ノードに最新の ISO イメージをダウンロードします。Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage リポジトリーの有効化 の章の ISO のインストールセクションを参照してください。
手順
-
Ansible 管理ノードで
rootユーザーアカウントとしてログインします。 すべてのデプロイメント (ベアメタル または コンテナー 内) については、
ceph-ansibleパッケージをインストールします。Red Hat Enterprise Linux 7
[root@admin ~]# yum install ceph-ansible
Red Hat Enterprise Linux 8
[root@admin ~]# dnf install ceph-ansible
/usr/share/ceph-ansibleディレクトリーに移動します。[root@admin ~]# cd /usr/share/ceph-ansible
新しい
ymlファイルを作成します。[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml
ベアメタル デプロイメント:
[root@admin ceph-ansible]# cp site.yml.sample site.yml
コンテナー デプロイメント:
[root@admin ceph-ansible]# cp site-container.yml.sample site-container.yml
新しいファイルを編集します。
group_vars/all.ymlファイルを編集するために開きます。重要カスタムストレージクラスター名の使用はサポートされていません。
clusterパラメーターにはceph以外の値を設定しないでください。カスタムストレージクラスター名は、librados、Ceph Object Gateway、RADOS ブロックデバイスミラーリングなどの Ceph クライアントでのみサポートされます。警告デフォルトでは、Ansible はインストール済みの再起動を試みますが、マスクされた
firewalldサービスにより、Red Hat Ceph Storage デプロイメントが失敗する可能性があります。この問題を回避するには、all.ymlファイルでconfigure_firewallオプションをfalseに設定します。firewalldサービスを実行している場合は、all.ymlファイルでconfigure_firewallオプションを使用する必要はありません。注記ceph_rhcs_versionオプションを4に設定すると、最新バージョンの Red Hat Ceph Storage 4 がプルされます。注記Red Hat は、
group_vars/all.ymlファイルでdashboard_enabledオプションをTrueに設定し、これをFalseに変更しないことを推奨します。Dashboard を無効にする場合には、Disabling the Ceph Dashboard を参照してください。注記Dashboard 関連のコンポーネントはコンテナー化されています。したがって、ベアメタル または コンテナー のデプロイメントでは、
ceph_docker_registry_usernameおよびceph_docker_registry_passwordのパラメーターを追加して、ceph-ansible が、ダッシュボードに必要なコンテナーイメージを取得できるようにする必要があります。注記Red Hat レジストリーサービスアカウントがない場合は、レジストリーサービスアカウントの Web ページ を使用して作成します。トークンの作成および管理方法に関する詳細は、ナレッジベースアーティクル Red Hat Container Registry Authentication を参照してください。
注記ceph_docker_registry_usernameおよびceph_docker_registry_passwordパラメーターにサービスアカウントを使用するだけでなく、カスタマーポータルの認証情報を使用することもできますが、ceph_docker_registry_passwordパラメーターを暗号化してセキュリティーを確保してください。詳細は、ansible-vault で Ansible のパスワード変数を暗号化する を参照してください。CDN インストール用の
all.ymlファイルの ベアメタル の例:fetch_directory: ~/ceph-ansible-keys ceph_origin: repository ceph_repository: rhcs ceph_repository_type: cdn ceph_rhcs_version: 4 monitor_interface: eth0 1 public_network: 192.168.0.0/24 ceph_docker_registry: registry.redhat.io ceph_docker_registry_auth: true ceph_docker_registry_username: SERVICE_ACCOUNT_USER_NAME ceph_docker_registry_password: TOKEN dashboard_admin_user: dashboard_admin_password: node_exporter_container_image: registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 grafana_admin_user: grafana_admin_password: grafana_container_image: registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8 prometheus_container_image: registry.redhat.io/openshift4/ose-prometheus:v4.6 alertmanager_container_image: registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6
- 1
- これは、パブリックネットワーク上のインターフェイスです。
重要Red Hat Ceph Storage 4.1 以降、
/usr/share/ceph-ansible/group_vars/all.ymlのdashboard_admin_passwordおよびgrafana_admin_passwordをコメント解除するか設定する必要があります。それぞれに安全なパスワードを設定します。dashboard_admin_userおよびgrafana_admin_userのカスタムユーザー名も設定します。注記Red Hat Ceph Storage 4.2 で、インストールにローカルレジストリーを使用している場合は、Prometheus のイメージタグとして 4.6 を使用します。
ISO インストール
all.ymlファイルの ベアメタル の例:fetch_directory: ~/ceph-ansible-keys ceph_origin: repository ceph_repository: rhcs ceph_repository_type: iso ceph_rhcs_iso_path: /home/rhceph-4-rhel-8-x86_64.iso ceph_rhcs_version: 4 monitor_interface: eth0 1 public_network: 192.168.0.0/24 ceph_docker_registry: registry.redhat.io ceph_docker_registry_auth: true ceph_docker_registry_username: SERVICE_ACCOUNT_USER_NAME ceph_docker_registry_password: TOKEN dashboard_admin_user: dashboard_admin_password: node_exporter_container_image: registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 grafana_admin_user: grafana_admin_password: grafana_container_image: registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8 prometheus_container_image: registry.redhat.io/openshift4/ose-prometheus:v4.6 alertmanager_container_image: registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6
- 1
- これは、パブリックネットワーク上のインターフェイスです。
all.ymlファイルの Containers の例:fetch_directory: ~/ceph-ansible-keys monitor_interface: eth0 1 public_network: 192.168.0.0/24 ceph_docker_image: rhceph/rhceph-4-rhel8 ceph_docker_image_tag: latest containerized_deployment: true ceph_docker_registry: registry.redhat.io ceph_docker_registry_auth: true ceph_docker_registry_username: SERVICE_ACCOUNT_USER_NAME ceph_docker_registry_password: TOKEN ceph_origin: repository ceph_repository: rhcs ceph_repository_type: cdn ceph_rhcs_version: 4 dashboard_admin_user: dashboard_admin_password: node_exporter_container_image: registry.redhat.io/openshift4/ose-prometheus-node-exporter:v4.6 grafana_admin_user: grafana_admin_password: grafana_container_image: registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8 prometheus_container_image: registry.redhat.io/openshift4/ose-prometheus:v4.6 alertmanager_container_image: registry.redhat.io/openshift4/ose-prometheus-alertmanager:v4.6
- 1
- これは、パブリックネットワーク上のインターフェイスです。
重要Red Hat Ecosystem Catalog で最新のコンテナーイメージタグを検索し、最新のパッチが適用された最新のコンテナーイメージをインストールします。
デプロイメント中に Red Hat Ceph Storage ノードがインターネットにアクセスできない場合の、
all.ymlファイルの Containers の例:fetch_directory: ~/ceph-ansible-keys monitor_interface: eth0 1 public_network: 192.168.0.0/24 ceph_docker_image: rhceph/rhceph-4-rhel8 ceph_docker_image_tag: latest containerized_deployment: true ceph_docker_registry: LOCAL_NODE_FQDN:5000 ceph_docker_registry_auth: false ceph_origin: repository ceph_repository: rhcs ceph_repository_type: cdn ceph_rhcs_version: 4 dashboard_admin_user: dashboard_admin_password: node_exporter_container_image: LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-node-exporter:v4.6 grafana_admin_user: grafana_admin_password: grafana_container_image: LOCAL_NODE_FQDN:5000/rhceph/rhceph-4-dashboard-rhel8 prometheus_container_image: LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus:4.6 alertmanager_container_image: LOCAL_NODE_FQDN:5000/openshift4/ose-prometheus-alertmanager:4.6
- 1
- これは、パブリックネットワーク上のインターフェイスです。
- 置き換え
- LOCAL_NODE_FQDN を、ローカルホストの FQDN に置き換えます。
Red Hat Ceph Storage 4.2 からは、
dashboard_protocolはhttpsに設定されており、Ansible でダッシュボードと grafana の鍵と証明書が生成されます。ベアメタル または コンテナー デプロイメントでカスタム証明書の場合には、all.ymlファイルで、dashboard_crt、dashboard_key、grafana_crt、grafana_keyの Ansible インストーラーホストのパスを更新します。構文
dashboard_protocol: https dashboard_port: 8443 dashboard_crt: 'DASHBOARD_CERTIFICATE_PATH' dashboard_key: 'DASHBOARD_KEY_PATH' dashboard_tls_external: false dashboard_grafana_api_no_ssl_verify: "{{ True if dashboard_protocol == 'https' and not grafana_crt and not grafana_key else False }}" grafana_crt: 'GRAFANA_CERTIFICATE_PATH' grafana_key: 'GRAFANA_KEY_PATH'
http または https プロキシーで到達可能なコンテナーレジストリーを使用して Red Hat Ceph Storage をインストールするには、
group_vars/all.ymlファイルのceph_docker_http_proxyまたはceph_docker_https_proxy変数を設定します。例
ceph_docker_http_proxy: http://192.168.42.100:8080 ceph_docker_https_proxy: https://192.168.42.100:8080
プロキシー設定で一部のホストを除外する必要がある場合は、
group_vars/all.ymlファイルでceph_docker_no_proxy変数を使用できます。例
ceph_docker_no_proxy: "localhost,127.0.0.1"
Red Hat Ceph Storage のプロキシーインストール用に
all.ymlファイルを編集する他に、/etc/environmentファイルを編集します。例
HTTP_PROXY: http://192.168.42.100:8080 HTTPS_PROXY: https://192.168.42.100:8080 NO_PROXY: "localhost,127.0.0.1"
これにより、podman がトリガーされ、prometheus、grafana-server、alertmanager、node-exporter などのコンテナー化されたサービスを起動し、必要なイメージをダウンロードします。
全デプロイメントの場合には (ベアメタル または コンテナー)、
group_vars/osds.ymlファイルを編集します。重要オペレーティングシステムがインストールされているデバイスに OSD をインストールしないでください。オペレーティングシステムと OSD 間で同じデバイスを共有すると、パフォーマンスの問題が発生することになります。
ceph-ansible は
ceph-volumeツールを使用して、Ceph の使用に向けてストレージデバイスを準備します。ストレージデバイスを使用するようにosds.ymlを設定し、特定のワークロードのパフォーマンスを最適化することができます。重要以下の例では、BlueStore オブジェクトストアを使用します。これは、Ceph がデバイスにデータを保存するのに使用する形式です。以前のバージョンでは、Ceph は FileStore をオブジェクトストアとして使用していました。BlueStore はより多くの機能を提供し、パフォーマンスを向上させるため、この形式は Red Hat Ceph Storage 4.0 で非推奨になっています。FileStore は依然として使用できますが、Red Hat サポート例外が必要です。BlueStore の詳細は、Red Hat Ceph Storage アーキテクチャーガイド の Ceph BlueStore を参照してください。
自動検出
osd_auto_discovery: true
上記の例では、システム上の空のストレージデバイスをすべて使用して OSD を作成するため、明示的に指定する必要はありません。この
ceph-volumeツールは、空のデバイスを確認するため、空ではないデバイスは使用されません。注記後で
purge-docker-cluster.ymlまたはpurge-cluster.ymlを使用してクラスターを削除する場合は、osd_auto_discoveryをコメントアウトし、osds.ymlファイルで OSD デバイスを宣言する必要があります。詳細については、Ansible によってデプロイされたストレージクラスターのパージ を参照してください。簡易設定
初回のシナリオ
devices: - /dev/sda - /dev/sdb
または、以下を実行します。
2 つ目のシナリオ
devices: - /dev/sda - /dev/sdb - /dev/nvme0n1 - /dev/sdc - /dev/sdd - /dev/nvme1n1
または、以下を実行します。
3 つ目のシナリオ
lvm_volumes: - data: /dev/sdb - data: /dev/sdc
または、以下を実行します。
4 つ目のシナリオ
lvm_volumes: - data: /dev/sdb - data:/dev/nvme0n1devicesオプションのみを使用する場合には、ceph-volume lvm batchモードは OSD 設定を自動的に最適化します。最初のシナリオでは、
devicesを従来のハードドライブまたは SSD の場合には、デバイスごとに OSD が 1 つ作成されます。2 つ目のシナリオでは、従来のハードドライブと SSD が混在している場合、データは従来のハードドライブ (
sda、sdb) に配置され、BlueStore データベースは SSD (nvme0n1) にできる限り大きく作成されます。同様に、データは従来のハードドライブ (sdc、sdd) に配置され、デバイスの順序に関係なく、SSDnvme1n1に BlueStore データベースが作成されます。注記デフォルトでは、
ceph-ansibleではbluestore_block_db_sizeおよびbluestore_block_wal_sizeのデフォルト値は上書きされません。group_vars/all.ymlファイルのceph_conf_overridesを使用してbluestore_block_db_sizeを設定できます。bluestore_block_db_sizeの値は 2 GB より大きくする必要があります。3 つ目のシナリオでは、データは従来のハードドライブ (
sdb、sdc) に置かれ、BlueStore データベースは同じデバイスに置かれます。4 番目のシナリオでは、従来のハードドライブ (
sdb) および SSD (nvme1n1) にデータが配置され、BlueStore データベースが同じデバイスに配置されます。これは、BlueStore データベースが SSD に配置されるdevicesディレクティブの使用とは異なります。重要ceph-volume lvm batch modeコマンドは、従来のハードドライブおよび BlueStore データベースに SSD にデータを配置することで、OSD 最適化設定を作成します。使用する論理ボリュームとボリュームグループを指定する場合は、以下の 高度な設定 シナリオに従って、論理ボリュームとボリュームグループを直接作成できます。高度な設定
初回のシナリオ
devices: - /dev/sda - /dev/sdb dedicated_devices: - /dev/sdx - /dev/sdy
または、以下を実行します。
2 つ目のシナリオ
devices: - /dev/sda - /dev/sdb dedicated_devices: - /dev/sdx - /dev/sdy bluestore_wal_devices: - /dev/nvme0n1 - /dev/nvme0n2
最初のシナリオでは、OSD が 2 つあります。
sdaデバイスおよびsdbデバイスには、独自のデータセグメントと先行書き込みログがあります。追加のディクショナリーdedicated_devicesを使用して、sdxとsdyのデータベース (block.dbとも呼ばれる) を分離します。2 つ目のシナリオでは、別のディクショナリー
bluestore_wal_devicesを使用して、NVMe デバイスnvme0n1およびnvme0n2のログ先行書き込みを分離します。devicesオプション、dedicated_devicesオプション、bluestore_wal_devices,オプションを一緒に使用すると、OSD のすべてのコンポーネントを別々のデバイスに分離できます。このように OSD を配置すると、全体的なパフォーマンスが向上する場合があります。事前作成された論理ボリューム
初回のシナリオ
lvm_volumes: - data: data-lv1 data_vg: data-vg1 db: db-lv1 db_vg: db-vg1 wal: wal-lv1 wal_vg: wal-vg1 - data: data-lv2 data_vg: data-vg2 db: db-lv2 db_vg: db-vg2 wal: wal-lv2 wal_vg: wal-vg2または、以下を実行します。
2 つ目のシナリオ
lvm_volumes: - data: /dev/sdb db: db-lv1 db_vg: db-vg1 wal: wal-lv1 wal_vg: wal-vg1デフォルトでは、Ceph は論理ボリュームマネージャーを使用して OSD デバイスに論理ボリュームを作成します。上記の 単純な設定 および 高度な設定 例では、Ceph はデバイス上に論理ボリュームを自動的に作成します。
lvm_volumesディクショナリーを指定すると、Ceph で以前に作成した論理ボリュームを使用できます。最初のシナリオでは、データは専用の論理ボリューム、データベース、および WAL に置かれます。データ、データおよび WAL、またはデータおよびデータベースのみを指定することもできます。
data:行は、データの保存先の論理ボリューム名を指定し、data_vg:データの論理ボリュームが含まれるボリュームグループの名前を指定する必要があります。同様に、db:は、データベースが保存されている論理ボリュームを指定するために使用されます。db_vg:は、論理ボリュームが存在するボリュームグループを指定するために使用されます。wal:行は、WAL が格納する論理ボリュームを指定し、wal_vg:行は、それを含むボリュームグループを指定します。2 つ目のシナリオでは、実際のデバイス名が
data:オプションに設定されているため、data_vg:オプションを指定する必要はありません。BlueStore データベースおよび WAL デバイスに、論理ボリューム名とボリュームグループの詳細を指定する必要があります。重要lvm_volumes:では、ボリュームグループと論理ボリュームを、事前に作成する必要があります。ボリュームグループと論理ボリュームは、ceph-ansibleでは作成されません。注記すべての NVMe SSD を使用する場合は、
osds_per_device: 2を設定します。詳細は、Red Hat Ceph Storage インストールガイドの すべての NVMe ストレージに OSD Ansible 設定の設定 を参照してください。注記Ceph OSD ノードのリブート後には、ブロックデバイスの割り当てが変更される可能性があります。たとえば、
sdcは、sddになる場合があります。従来のブロックデバイス名ではなく、/dev/disk/by-path/デバイスパスなどの永続的な命名デバイスを使用できます。
すべてのデプロイメント (ベアメタル または コンテナー) について、Ansible インベントリーファイルを作成してから、そのファイルを開いて編集します。
[root@admin ~]# cd /usr/share/ceph-ansible/ [root@admin ceph-ansible]# touch hosts
それに応じて
hostsファイルを編集します。注記Ansible インベントリーの場所の編集に関する詳細は、Ansible インベントリーの場所の設定 を参照してください。
[grafana-server]の下にノードを追加します。このロールは Grafana および Prometheus をインストールし、Ceph クラスターのパフォーマンスに関するリアルタイムの洞察を提供します。これらのメトリックは Ceph Dashboard に提示されています。これにより、クラスターの監視および管理が可能になります。Dashboard、Grafana、および Prometheus のインストールが必要です。Ansible Administration ノードでメトリック関数を同じ場所に配置できます。これを実行する場合は、ノードのシステムリソースが スタンドアロンのメトリックノードに必要とされるもの よりも大きいことを確認します。[grafana-server] GRAFANA-SERVER_NODE_NAME[mons]セクションに monitor ノードを追加します。[mons] MONITOR_NODE_NAME_1 MONITOR_NODE_NAME_2 MONITOR_NODE_NAME_3
[osds]セクションに OSD ノードを追加します。[osds] OSD_NODE_NAME_1 OSD_NODE_NAME_2 OSD_NODE_NAME_3
注記ノード名が数値的に連続している場合は、ノード名の末尾に範囲指定子 (
[1:10]) を追加できます。以下に例を示します。[osds] example-node[1:10]
注記新規インストールの OSD の場合、デフォルトのオブジェクトストア形式は BlueStore です。
-
必要に応じて、コンテナー デプロイメントで、
[mon]セクションおよび[osd]セクションに同じノードを追加して、Ceph Monitor デーモンを 1 つのノードの Ceph OSD デーモンと同じ場所に配置します。詳細は、Additional Resources セクションで、Ceph デーモンの配置に関するリンクを参照してください。 [mgrs]セクションに Ceph Manager (ceph-mgr) ノードを追加します。これは、Ceph Manager デーモンと Ceph Monitor デーモンを共存させます。[mgrs] MONITOR_NODE_NAME_1 MONITOR_NODE_NAME_2 MONITOR_NODE_NAME_3
必要に応じて、すべてのデプロイメント (ベアメタル または コンテナー 内) ホスト固有のパラメーターを使用する場合は、ホストに固有のパラメーターが含まれるホストファイルで
host_varsディレクトリーを作成します。host_varsディレクトリーを作成します。[ansible@admin ~]$ mkdir /usr/share/ceph-ansible/host_vars
host_varsディレクトリーに変更します。[ansible@admin ~]$ cd /usr/share/ceph-ansible/host_vars
ホストファイルを作成します。ファイル名に、host-name-short-name 形式を使用します。以下に例を示します。
[ansible@admin host_vars]$ touch tower-osd6
以下のように、ホスト固有のパラメーターでファイルを更新します。
bare-metal デプロイメントでは、
devicesパラメーターを使用して OSD ノードが使用するデバイスを指定します。OSD が異なる名前のデバイスを使用する場合や、いずれかの OSD でデバイスのいずれかに障害が発生した場合にdevicesの使用が役に立ちます。devices: DEVICE_1 DEVICE_2例
devices: /dev/sdb /dev/sdc注記デバイスを指定しない場合は、
group_vars/osds.ymlファイルでosd_auto_discoveryパラメーターをtrueに設定します。
オプションで、ベアメタルまたはコンテナー内のすべてのデプロイメントで、Ceph Ansible を使用してカスタム CRUSH 階層を作成できます。
Ansible のインベントリーファイルを設定します。
osd_crush_locationパラメーターを使用して、OSD ホストを CRUSH マップの階層内のどこに配置するかを指定します。OSD の場所を指定するために、2 つ以上の CRUSH バケットタイプを指定し、1 つのバケットのtypeをホストに指定する必要があります。デフォルトでは、これには、root、datacenter、room、row、pod、pdu、rack、chassisおよびhostが含まれます。構文
[osds] CEPH_OSD_NAME osd_crush_location="{ 'root': ROOT_BUCKET_', 'rack': 'RACK_BUCKET', 'pod': 'POD_BUCKET', 'host': 'CEPH_HOST_NAME' }"
例
[osds] ceph-osd-01 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'pod': 'monpod', 'host': 'ceph-osd-01' }"group_vars/osds.ymlファイルを編集し、crush_rule_configパラメーターとcreate_crush_treeパラメーターをTrueに設定します。デフォルトの CRUSH ルールを使用しない場合は、少なくとも 1 つの CRUSH ルールを作成します。次に例を示します。crush_rule_config: True crush_rule_hdd: name: replicated_hdd_rule root: root-hdd type: host class: hdd default: True crush_rules: - "{{ crush_rule_hdd }}" create_crush_tree: Trueより高速な SSD デバイスを使用している場合は、次のようにパラメーターを編集します。
crush_rule_config: True crush_rule_ssd: name: replicated_ssd_rule root: root-ssd type: host class: ssd default: True crush_rules: - "{{ crush_rule_ssd }}" create_crush_tree: True注記ssdとhddの両方の OSD がデプロイされていない場合、デフォルトの CRUSH ルールは失敗します。これは、デフォルトのルールに、定義する必要のあるclassパラメーターが含まれているためです。group_vars/clients.ymlファイルで作成したcrush_rulesを使用してpoolsを作成します。例
copy_admin_key: True user_config: True pool1: name: "pool1" pg_num: 128 pgp_num: 128 rule_name: "HDD" type: "replicated" device_class: "hdd" pools: - "{{ pool1 }}"ツリーを表示します。
[root@mon ~]# ceph osd tree
プールを検証します。
[root@mon ~]# for i in $(rados lspools); do echo "pool: $i"; ceph osd pool get $i crush_rule; done pool: pool1 crush_rule: HDD
すべてのデプロイメント (ベアメタル または コンテナー 内) では、ログインするか、
ansibleユーザーに切り替えます。Ansible が
ceph-ansiblePlaybook で生成される一時的な値を保存するceph-ansible-keysディレクトリーを作成します。[ansible@admin ~]$ mkdir ~/ceph-ansible-keys
/usr/share/ceph-ansible/ディレクトリーに移動します。[ansible@admin ~]$ cd /usr/share/ceph-ansible/
Ansible が Ceph ノードに到達できることを確認します。
[ansible@admin ceph-ansible]$ ansible all -m ping -i hosts
ceph-ansiblePlaybook を実行します。ベアメタル デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml -i hosts
注記Red Hat Ceph Storage を Red Hat Enterprise Linux Atomic Host ホストにデプロイする場合は、
--skip-tags=with_pkgオプションを使用します。[user@admin ceph-ansible]$ ansible-playbook site-container.yml --skip-tags=with_pkg -i hosts
注記デプロイメントの速度を増やすには、
--forksオプションをansible-playbookに指定します。デフォルトでは、ceph-ansibleはフォークを20に設定します。この設定では、ノードを同時にインストールします。一度に最大 30 台までインストールするには、ansible-playbook --forks 30 PLAYBOOK FILE -i hostsを実行します。管理ノードのリソースが過剰に使用されていないことを確認するために、監視する必要があります。そうである場合は、--forksに渡される数を減らします。
Ceph デプロイメントが完了するまで待ちます。
出力例
INSTALLER STATUS ******************************* Install Ceph Monitor : Complete (0:00:30) Install Ceph Manager : Complete (0:00:47) Install Ceph OSD : Complete (0:00:58) Install Ceph RGW : Complete (0:00:34) Install Ceph Dashboard : Complete (0:00:58) Install Ceph Grafana : Complete (0:00:50) Install Ceph Node Exporter : Complete (0:01:14)
Ceph Storage クラスターのステータスを確認します。
ベアメタル デプロイメント:
[root@mon ~]# ceph health HEALTH_OK
コンテナー デプロイメント:
Red Hat Enterprise Linux 7
[root@mon ~]# docker exec ceph-mon-ID ceph healthRed Hat Enterprise Linux 8
[root@mon ~]# podman exec ceph-mon-ID ceph health- 置き換え
IDは、Ceph Monitor ノードのホスト名に置き換えます。例
[root@mon ~]# podman exec ceph-mon-mon0 ceph health HEALTH_OK
ベアメタル または コンテナー 内のすべてのデプロイメントについて、ストレージクラスターが
radosを使用して機能していることを確認します。Ceph Monitor ノードから、8 つの配置グループ (PG) でテストプールを作成します。
構文
[root@mon ~]# ceph osd pool create POOL_NAME PG_NUMBER
例
[root@mon ~]# ceph osd pool create test 8
hello-world.txtというファイルを作成します。構文
[root@mon ~]# vim FILE_NAME例
[root@mon ~]# vim hello-world.txt
オブジェクト名
hello-worldを使用して、hello-world.txtをテストプールにアップロードします。構文
[root@mon ~]# rados --pool POOL_NAME put OBJECT_NAME OBJECT_FILE_NAME
例
[root@mon ~]# rados --pool test put hello-world hello-world.txt
テストプールからファイル名
fetch.txtとしてhello-worldをダウンロードします。構文
[root@mon ~]# rados --pool POOL_NAME get OBJECT_NAME OBJECT_FILE_NAME
例
[root@mon ~]# rados --pool test get hello-world fetch.txt
fetch.txtの内容を確認してください。[root@mon ~]# cat fetch.txt "Hello World!"
注記ストレージクラスターのステータスを確認する他に、
ceph-medicユーティリティーを使用して Ceph Storage クラスター全体の診断を行うことができます。Red Hat Ceph Storage 4 のトラブルシューティングガイドのceph-medicをインストールおよび使用して Ceph Storage クラスターの検証 の章を参照してください。
関連情報
- 一般的な Ansible 設定 のリスト。
- 一般的な OSD 設定 のリスト。
- 詳細は、コンテナー化された Ceph デーモンのコロケーション を参照してください。
5.3. すべての NVMe ストレージに OSD Ansible 設定の設定
全体的なパフォーマンスを向上させるには、Ansible がストレージ用に不揮発性メモリー表現 (NVMe) デバイスのみを使用するように設定することができます。通常、デバイスごとに 1 つの OSD のみが設定されているため、NVMe デバイスの潜在的なスループットが十分に活用されていません。
SSD と HDD を混在する場合、SSD は OSD のデータに使用されず、データベース (block.db) に使用されます。
テストでは、各 NVMe デバイスに 2 つの OSD を設定すると、最適なパフォーマンスが得られます。Red Hat は、osds_per_device オプションを 2 に設定することを推奨しますが、必須ではありません。その他の値により、お使いの環境でパフォーマンスが向上します。
前提条件
- Ansible 管理ノードへのアクセス
-
ceph-ansibleパッケージのインストール。
手順
group_vars/osds.ymlにosds_per_device: 2を設定します。osds_per_device: 2
devicesの下に NVMe デバイスをリスト表示します。devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1
group_vars/osds.ymlの設定は以下のようになります。osds_per_device: 2 devices: - /dev/nvme0n1 - /dev/nvme1n1 - /dev/nvme2n1 - /dev/nvme3n1
lvm_volumes ではなく、この設定で devices を使用する必要があります。これは、lvm_volumes が、通常、作成済みの論理ボリュームで使用され、osds_per_device は Ceph による論理ボリュームの自動作成を意味するためです。
関連情報
- 詳細は、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage Cluster のインストール を参照してください。
5.4. メタデータサーバーのインストール
Ansible 自動化アプリケーションを使用して Ceph Metadata Server (MDS) をインストールします。Ceph File System をデプロイするには、メタデータサーバーデーモンが必要です。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
- パスワードなしの SSH アクセスを有効にします。
手順
Ansible 管理ノードで以下の手順を実行します。
新しいセクション
[mdss]を/etc/ansible/hostsファイルに追加します。[mdss] MDS_NODE_NAME1 MDS_NODE_NAME2 MDS_NODE_NAME3
MDS_NODE_NAME は、Ceph Metadata サーバーをインストールするノードのホスト名に置き換えます。
[osds]セクションおよび[mdss]セクションに同じノードを追加して、1 つのノードにメタデータサーバーと OSD デーモンを同じ場所に置く事ができます。/usr/share/ceph-ansibleディレクトリーに移動します。[root@admin ~]# cd /usr/share/ceph-ansible
必要に応じて、デフォルトの変数を変更できます。
mdss.ymlという名前のgroup_vars/mdss.yml.sampleファイルのコピーを作成します。[root@admin ceph-ansible]# cp group_vars/mdss.yml.sample group_vars/mdss.yml
-
必要に応じて、
mdss.ymlのパラメーターを編集します。詳細は、mdss.ymlを参照してください。
ansibleユーザーとして、Ansible Playbook を実行します。ベアメタル デプロイメント:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit mdss -i hosts
コンテナー デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml --limit mdss -i hosts
- メタデータサーバーをインストールした後に、それらを設定できるようになりました。詳細は、Red Hat Ceph Storage ファイルシステムガイドの Ceph File System Metadata Server の章を参照してください。
関連情報
- Red Hat Ceph Storage 4 の Ceph ファイルシステムガイド を参照してください。
- 詳細は、コンテナー化された Ceph デーモンのコロケーション を参照してください。
-
詳細は、
limitオプションの理解 を参照してください。
5.5. Ceph クライアントロールのインストール
ceph-ansible ユーティリティーは、Ceph 設定ファイルと管理キーリングをノードにコピーする ceph-client ロールを提供します。さらに、このロールを使用してカスタムプールおよびクライアントを作成することができます。
前提条件
-
稼働中の Ceph ストレージクラスター (
active + cleanの状態が望ましい)。 - 要件 に記載されているタスクを実行します。
- パスワードなしの SSH アクセスを有効にします。
手順
Ansible 管理ノードで以下のタスクを実行します。
新しいセクション
[clients]を/etc/ansible/hostsファイルに追加します。[clients] CLIENT_NODE_NAMECLIENT_NODE_NAME は、
ceph-clientロールをインストールするノードのホスト名に置き換えます。/usr/share/ceph-ansibleディレクトリーに移動します。[root@admin ~]# cd /usr/share/ceph-ansible
clients.ymlという名前のclients.yml.sampleファイルの新しいコピーを作成します。[root@admin ceph-ansible ~]# cp group_vars/clients.yml.sample group_vars/clients.yml
group_vars/clients.ymlファイルを開き、以下の行をコメント解除します。keys: - { name: client.test, caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }client.testを実際のクライアント名に置き換え、クライアントキーをクライアント定義の行に追加します。以下に例を示します。key: "ADD-KEYRING-HERE=="
これで、行全体の例は次のようになります。
- { name: client.test, key: "AQAin8tUMICVFBAALRHNrV0Z4MXupRw4v9JQ6Q==", caps: { mon: "allow r", osd: "allow class-read object_prefix rbd_children, allow rwx pool=test" }, mode: "{{ ceph_keyring_permissions }}" }注記ceph-authtool --gen-print-keyコマンドは、新しいクライアントキーを生成することができます。
必要に応じて、プールおよびクライアントを作成するように
ceph-clientに指示します。clients.ymlを更新します。-
user_config設定のコメントを解除して、trueに設定します。 -
poolsセクションおよびkeysセクションのコメントを解除し、必要に応じて更新します。cephx機能を使用して、カスタムプールとクライアント名をまとめて定義できます。
-
osd_pool_default_pg_num設定をall.ymlファイルのceph_conf_overridesセクションに追加します。ceph_conf_overrides: global: osd_pool_default_pg_num: NUMBERNUMBER は、デフォルトの配置グループ数に置き換えます。
ansibleユーザーとして、Ansible Playbook を実行します。ベアメタル デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site.yml --limit clients -i hosts
コンテナー デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml --limit clients -i hosts
関連情報
-
詳細は、
limitオプションの理解 を参照してください。
5.6. Ceph Object Gateway のインストール
Ceph Object Gateway は、RADOS ゲートウェイとも呼ばれ、librados API 上に構築されたオブジェクトストレージインターフェイスであり、アプリケーションに Ceph ストレージクラスターへの RESTful ゲートウェイを提供します。
前提条件
-
稼働中の Red Hat Ceph Storage クラスター (
active + clean状態が望ましい) - パスワードなしの SSH アクセスを有効にします。
- Ceph Object Gateway ノードで、3章Red Hat Ceph Storage のインストール要件 に記載されているタスクを実行します。
Ceph Object Gateway をマルチサイト設定で使用する場合は、ステップ 1 から 6 のみを完了します。マルチサイトを設定する前に Ansible Playbook を実行しないでください。単一のサイト設定で Object Gateway が起動します。Ansible は、ゲートウェイがシングルサイト設定で開始した後に、マルチサイトセットアップにゲートウェイを再設定することはできません。ステップ 1 ~ 6 を完了したら、マルチサイト Ceph Object Gateways の設定 セクションに進み、マルチサイトを設定します。
手順
Ansible 管理ノードで以下のタスクを実行します。
[rgws]セクションの下の/etc/ansible/hostsファイルにゲートウェイホストを追加して、それらのロールを Ansible に識別します。ホストに連続する命名がある場合は、以下のように範囲を使用します。[rgws] <rgw_host_name_1> <rgw_host_name_2> <rgw_host_name[3..10]>
Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
サンプルファイルから
rgws.ymlファイルを作成します。[root@ansible ~]# cp group_vars/rgws.yml.sample group_vars/rgws.yml
group_vars/rgws.ymlファイルを開いて編集します。管理者キーを Ceph Object Gateway ノードにコピーするには、copy_admin_keyオプションのコメントを解除します。copy_admin_key: true
all.ymlファイルで、radosgw_interfaceを指定する 必要 があります。radosgw_interface: <interface>
以下を置き換えます。
-
Ceph Object Gateway がリッスンするインターフェイスを使用する
<interface>
以下に例を示します。
radosgw_interface: eth0
インターフェイスを指定すると、同じホストで複数のインスタンスを実行している場合に、Civetweb が別の Civetweb インスタンスと同じ IP アドレスにバインドされないようにします。
詳細は、
all.ymlファイルを参照してください。-
Ceph Object Gateway がリッスンするインターフェイスを使用する
通常、デフォルト設定を変更するには、
rgws.ymlファイルの設定をコメント解除し、それに応じて変更を加えます。rgws.ymlファイルに含まれていない設定に追加の変更を行うには、all.ymlファイルでceph_conf_overrides:を使用します。ceph_conf_overrides: client.rgw.rgw1: rgw_override_bucket_index_max_shards: 16 rgw_bucket_default_quota_max_objects: 1638400詳細な設定の詳細は、Red Hat Ceph Storage 4 の 実稼働環境への Ceph Object Gateway ガイド を参照してください。高度なトピックには以下が含まれます。
- Ansible グループの設定
ストレージストラテジーの開発プールの作成方法および設定方法の詳細は、ルートプールの作成、システムプールの作成、およびデータ配置戦略の作成セクションを参照してください。
バケットのシャード化の詳細は、バケットのシャード化 を参照してください。
Ansible Playbook を実行します。
警告マルチサイトを設定する場合には、Ansible Playbook を実行しないでください。マルチサイト Ceph Object Gateways の設定 セクションに進み、マルチサイトを設定します。
ベアメタル デプロイメント:
[user@admin ceph-ansible]$ ansible-playbook site.yml --limit rgws -i hosts
コンテナー デプロイメント:
[user@admin ceph-ansible]$ ansible-playbook site-container.yml --limit rgws -i hosts
Ansible は、各 Ceph Object Gateway が確実に実行されていることを確認します。
単一サイトの設定の場合は、Ceph ObjectGateway を Ansible 設定に追加します。
マルチサイトデプロイメントでは、各ゾーンの Ansible 設定を行う必要があります。つまり、Ansible によって、そのゾーン用に Ceph Storage クラスターおよびゲートウェイインスタンスが作成されます。
マルチサイトクラスターのインストールが完了したら、マルチサイト用のクラスターの設定方法は、Red Hat Ceph Storage 4 のObject Gateway ガイドの マルチサイト の章に進んでください。
関連情報
-
詳細は、
limitオプションの理解 を参照してください。 - Red Hat Ceph Storage 4 の オブジェクトゲートウェアガイド
5.7. マルチサイト Ceph Object Gateway の設定
システム管理者は、障害復旧目的で、マルチサイト Ceph Object Gateways をクラスター間でデータのミラーリングを実行するように設定できます。
1 つ以上の RGW レルムを使用してマルチサイトを設定できます。レルムは、その内部の RGW を独立した状態にし、レルム外の RGW から分離できるようにします。これにより、あるレルムの RGW に書き込まれたデータは、別のレルムの RGW からはアクセスできません。
Ceph-Ansible は、ゲートウェイがシングルサイト設定で開始した後に、マルチサイトセットアップにゲートウェイを再設定することはできません。この設定は手動でデプロイできます。レッドハットサポート にお問い合わせください。
Red Hat Ceph Storage 4.1 から、group_vars/all.yml ファイルで rgw_multisite_endpoints_list の値を設定する必要はありません。
詳細については、Red Hat Ceph Storage Object Gateway の設定および管理ガイド の マルチサイト セクションを参照してください。
5.7.1. 前提条件
- 2 つの Red Hat Ceph Storage クラスター
- Ceph Object Gateway ノード上で、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage のインストール要件 セクションに記載のタスクを実行します。
- 各 Object Gateway ノードについて、Red Hat Ceph Storage インストールガイドの Ceph Object Gateway のインストール セクションに記載のステップ 1 から 6 を実施します。
5.7.2. 1 つのレルムのあるマルチサイト Ceph Object Gateway の設定
Ceph-Ansible は、複数の Ceph Object Gateway インスタンスが含まれる、複数のストレージクラスター全体で 1 つのレルムのデータをミラーリングするように Ceph Object Gateway を設定します。
Ceph-Ansible は、ゲートウェイがシングルサイト設定で開始した後に、マルチサイトセットアップにゲートウェイを再設定することはできません。この設定は手動でデプロイできます。レッドハットサポート にお問い合わせください。
前提条件
- Red Hat Ceph Storage クラスターを実行する 2 つ。
- Ceph Object Gateway ノード上で、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage のインストール要件 セクションに記載のタスクを実行します。
- 各 Object Gateway ノードについて、Red Hat Ceph Storage インストールガイドの Ceph Object Gateway のインストール セクションに記載のステップ 1 から 6 を実施します。
手順
システムキーを生成し、
multi-site-keys.txtファイルで出力を取得します。[root@ansible ~]# echo system_access_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 20 | head -n 1) > multi-site-keys.txt [root@ansible ~]# echo system_secret_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 40 | head -n 1) >> multi-site-keys.txt
プライマリーストレージクラスター
Ceph-Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.ymlファイルを開いて編集します。rgw_multisite行のコメントを解除して、trueに設定します。rgw_multisite_protoパラメーターのコメントを解除します。rgw_multisite: true rgw_multisite_proto: "http"
usr/share/ceph-ansibleにhost_varsディレクトリーを作成します。[root@ansible ceph-ansible]# mkdir host_vars
プライマリーストレージクラスター上の各 Object Gateway ノードの
host_varsにファイルを作成します。ファイル名は、Ansible インベントリーファイルで使用される名前と同じである必要があります。たとえば、Object Gateway ノードの名前がrgw-primaryの場合は、host_vars/rgw-primaryファイルを作成します。構文
touch host_vars/NODE_NAME例
[root@ansible ceph-ansible]# touch host_vars/rgw-primary
注記マルチサイト設定で使用するクラスター内に複数の Ceph Object Gateway ノードがある場合は、ノードごとにファイルを作成します。
ファイルを編集して、各 Object Gateway ノードにある全インスタンスに対して設定詳細を追加します。それぞれ、ZONE_NAME、ZONE_GROUP_NAME、ZONE_USER_NAME、ZONE_DISPLAY_NAME、および REALM_NAME の更新と共に以下の設定を行います。ACCESS_KEY および SECRET_KEY の
multi-site-keys.txtファイルに保存されるランダムな文字列を使用します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: RGW_PRIMARY_PORT_NUMBER_1
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080オプション: 複数のインスタンスを作成する場合は、ファイルを編集して、各 Object Gateway ノードにある全インスタンスに対して設定詳細を追加します。
rgw_instancesの下にある項目を更新するとともに、以下の設定を行います。ACCESS_KEY_1 および SECRET_KEY_1 のmulti-site-keys-realm-1.txtファイルに保存されるランダムな文字列を使用します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 - instance_name: 'INSTANCE_NAME_2' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_2
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8081
セカンダリーストレージクラスター
Ceph-Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.ymlファイルを開いて編集します。rgw_multisite行のコメントを解除して、trueに設定します。rgw_multisite_protoパラメーターのコメントを解除します。rgw_multisite: true rgw_multisite_proto: "http"
usr/share/ceph-ansibleにhost_varsディレクトリーを作成します。[root@ansible ceph-ansible]# mkdir host_vars
セカンダリーストレージクラスター上の各 Object Gateway ノードの
host_varsにファイルを作成します。ファイル名は、Ansible インベントリーファイルで使用される名前と同じである必要があります。たとえば、Object Gateway のノード名がrgw-secondaryの場合は、host_vars/rgw-secondaryというファイルを作成します。構文
touch host_vars/NODE_NAME例
[root@ansible ceph-ansible]# touch host_vars/rgw-secondary
注記マルチサイト設定で使用するクラスター内に複数の Ceph Object Gateway ノードがある場合は、ノードごとにファイルを作成します。
以下の設定を設定します。ZONE_USER_NAME、ZONE_DISPLAY_NAME、ACCESS_KEY、SECRET_KEY、REALM_NAME、および ZONE_GROUP_NAME の最初のクラスターで使用するものと同じ値を指定します。ZONE_NAME には、プライマリーストレージクラスターとは異なる値を使用します。マスターゾーンの Ceph Object Gateway ノードに MASTER_RGW_NODE_NAME を設定します。なお、プライマリーストレージクラスターと比較して、
rgw_zonemaster、rgw_zonesecondary、rgw_zonegroupmasterの設定が逆にることに注意してください。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_PRIMARY_HOSTNAME_ENDPOINT:RGW_PRIMARY_PORT_NUMBER_1
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: lyon rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 endpoint: http://rgw-primary:8081オプション: 複数のインスタンスを作成する場合は、ファイルを編集して、各 Object Gateway ノードにある全インスタンスに対して設定詳細を追加します。
rgw_instancesの下にある項目を更新するとともに、以下の設定を行います。ACCESS_KEY_1 および SECRET_KEY_1 のmulti-site-keys-realm-1.txtファイルに保存されるランダムな文字列を使用します。RGW_PRIMARY_HOSTNAME をプライマリーストレージクラスターの Object Gateway ノードに設定します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_1 - instance_name: '_INSTANCE_NAME_2_' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_PRIMARY_HOSTNAME:RGW_PRIMARY_PORT_NUMBER_2
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: lyon rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 endpoint: http://rgw-primary:8080 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: lyon rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8081 endpoint: http://rgw-primary:8081
両方のサイトで以下の手順を実行します。
プライマリーストレージクラスターで Ansible Playbook を実行します。
ベアメタル デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
セカンダリーのストレジクラスターがプライマリーのストレージクラスターの API にアクセスできることを確認します。
セカンダリーのストレージクラスターの Object Gateway ノードから、
curlまたは別の HTTP クライアントを使用して、プライマリークラスターの API に接続します。all.ymlでrgw_pull_proto、rgw_pullhost、およびrgw_pull_portの設定に使用する情報を使用して URL を作成します。上記の例では、URL はhttp://cluster0-rgw-000:8080です。API にアクセスできない場合は、URL が正しいことを確認し、必要な場合はall.ymlを更新します。URL が有効になり、ネットワークの問題が解決したら、次の手順に進み、セカンダリーのストレージクラスターで Ansible Playbook を実行します。セカンダリーのストレージクラスターで Ansible Playbook を実行します。
注記クラスターがデプロイされていて、Ceph Object Gateway に変更を加える場合は、
--limit rgwsオプションを使用します。ベアメタル デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
プライマリーストレージクラスターおよびセカンダリーストレージクラスターで Ansible Playbook を実行した後に、Ceph Object Gateway はアクティブ/アクティブ状態で実行されます。
両方のサイトでマルチサイト Ceph Object Gateway の設定を確認します。
構文
radosgw-admin sync status
5.7.3. 複数のレルムと複数のインスタンスのあるマルチサイト Ceph Object Gateway の設定
Ceph-Ansible は、複数の Ceph Object Gateway インスタンスが含まれる、複数のストレージクラスター全体で複数のレルムのデータをミラーリングするように Ceph Object Gateway を設定します。
ゲートウェイがシングルサイト設定ですでに使用されていると、Ceph-Ansible はゲートウェイをマルチサイト設定に再設定することはできません。この設定は手動でデプロイできます。レッドハットサポート にお問い合わせください。
前提条件
- Red Hat Ceph Storage クラスターを実行する 2 つ。
- 各ストレージクラスター内に少なくとも 2 つの Object Gateway ノードがある。
- Ceph Object Gateway ノード上で、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage のインストール要件 セクションに記載のタスクを実行します。
- 各 Object Gateway ノードについて、Red Hat Ceph Storage インストールガイドの Ceph Object Gateway のインストール セクションに記載のステップ 1 から 6 を実施します。
手順
いずれのノードでも、レルム 1 と 2 のシステムアクセスキーとシークレットキーを生成し、それぞれ
multi-site-keys-realm-1.txtおよびmulti-site-keys-realm-2.txtという名前のファイルに保存します。# echo system_access_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 20 | head -n 1) > multi-site-keys-realm-1.txt [root@ansible ~]# echo system_secret_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 40 | head -n 1) >> multi-site-keys-realm-1.txt # echo system_access_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 20 | head -n 1) > multi-site-keys-realm-2.txt [root@ansible ~]# echo system_secret_key: $(cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w 40 | head -n 1) >> multi-site-keys-realm-2.txt
サイト A ストレージクラスター
Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.ymlファイルを開いて編集します。rgw_multisite行のコメントを解除して、trueに設定します。rgw_multisite_protoパラメーターのコメントを解除します。rgw_multisite: true rgw_multisite_proto: "http"
usr/share/ceph-ansibleにhost_varsディレクトリーを作成します。[root@ansible ceph-ansible]# mkdir host_vars
サイト A ストレージクラスター上の各 Object Gateway ノードの
host_varsにファイルを作成します。ファイル名は、Ansible インベントリーファイルで使用される名前と同じである必要があります。たとえば、Object Gateway ノードの名前がrgw-site-aの場合は、host_vars/rgw-site-aファイルを作成します。構文
touch host_vars/NODE_NAME例
[root@ansible ceph-ansible]# touch host_vars/rgw-site-a
注記マルチサイト設定で使用するクラスター内に複数の Ceph Object Gateway ノードがある場合は、ノードごとにファイルを作成します。
最初のレルムに複数のインスタンスを作成するために、ファイルを編集して、各 Object Gateway ノードにある全インスタンスに対して設定詳細を追加します。最初のレルムの
rgw_instancesの下にある項目を更新するとともに、以下の設定を行います。ACCESS_KEY_1 および SECRET_KEY_1 のmulti-site-keys-realm-1.txtファイルに保存されるランダムな文字列を使用します。構文
rgw_instances: - instance_name: '_INSTANCE_NAME_1_' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 - instance_name: '_INSTANCE_NAME_2_' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080注記サイト A はサイト B のレルムに対してセカンダリであるため、サイト B のすべてのレルムを設定した後に、次のステップにスキップして実行し、その後に Ansible Playbook を実行します。
他のレルムに複数のインスタンスを作成するために、
rgw_instancesの下の項目の更新するとともに、以下の設定を行います。ACCESS_KEY_2 および SECRET_KEY_2 のmulti-site-keys-realm-2.txtファイルに保存されるランダムな文字列を使用します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_2 rgw_realm: REALM_NAME_2 rgw_zone_user: ZONE_USER_NAME_2 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_2" system_access_key: ACCESS_KEY_2 system_secret_key: SECRET_KEY_2 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_SITE_B_PRIMARY_HOSTNAME_ENDPOINT:RGW_SITE_B_PORT_NUMBER_1 - instance_name: 'INSTANCE_NAME_2' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_2 rgw_realm: REALM_NAME_2 rgw_zone_user: ZONE_USER_NAME_2 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_2" system_access_key: ACCESS_KEY_2 system_secret_key: SECRET_KEY_2 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_SITE_B_PRIMARY_HOSTNAME_ENDPOINT:RGW_SITE_B_PORT_NUMBER_1
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: fairbanks rgw_zonegroup: alaska rgw_realm: usa rgw_zone_user: edward.lewis rgw_zone_user_display_name: "Edward Lewis" system_access_key: yu17wkvAx3B8Wyn08XoF system_secret_key: 5YZfaSUPqxSNIkZQQA3lBZ495hnIV6k2HAz710BY radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 endpoint: http://rgw-site-b:8081 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: fairbanks rgw_zonegroup: alaska rgw_realm: usa rgw_zone_user: edward.lewis rgw_zone_user_display_name: "Edward Lewis" system_access_key: yu17wkvAx3B8Wyn08XoF system_secret_key: 5YZfaSUPqxSNIkZQQA3lBZ495hnIV6k2HAz710BY radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8081 endpoint: http://rgw-site-b:8081サイト A ストレージクラスターで Ansible Playbook を実行します。
ベアメタル デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
サイト B ストレージクラスター
Ceph-Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
group_vars/all.ymlファイルを開いて編集します。rgw_multisite行のコメントを解除して、trueに設定します。rgw_multisite_protoパラメーターのコメントを解除します。rgw_multisite: true rgw_multisite_proto: "http"
usr/share/ceph-ansibleにhost_varsディレクトリーを作成します。[root@ansible ceph-ansible]# mkdir host_vars
サイト B ストレージクラスター上の各 Object Gateway ノードの
host_varsにファイルを作成します。ファイル名は、Ansible インベントリーファイルで使用される名前と同じである必要があります。たとえば、Object Gateway ノードの名前がrgw-site-bの場合は、host_vars/rgw-site-bファイルを作成します。構文
touch host_vars/NODE_NAME例
[root@ansible ceph-ansible]# touch host_vars/rgw-site-b
注記マルチサイト設定で使用するクラスター内に複数の Ceph Object Gateway ノードがある場合は、ノードごとにファイルを作成します。
最初のレルムに複数のインスタンスを作成するために、ファイルを編集して、各 Object Gateway ノードにある全インスタンスに対して設定詳細を追加します。最初のレルムの
rgw_instancesの下にある項目を更新するとともに、以下の設定を行います。ACCESS_KEY_1 および SECRET_KEY_1 のmulti-site-keys-realm-1.txtファイルに保存されるランダムな文字列を使用します。RGW_SITE_A_PRIMARY_HOSTNAME_ENDPOINT をサイト A ストレージクラスターの Object Gateway ノードに設定します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_SITE_A_HOSTNAME_ENDPOINT:RGW_SITE_A_PORT_NUMBER_1 - instance_name: '_INSTANCE_NAME_2_' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: ZONE_NAME_1 rgw_zonegroup: ZONE_GROUP_NAME_1 rgw_realm: REALM_NAME_1 rgw_zone_user: ZONE_USER_NAME_1 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_1" system_access_key: ACCESS_KEY_1 system_secret_key: SECRET_KEY_1 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 endpoint: RGW_SITE_A_PRIMARY_HOSTNAME_ENDPOINT:RGW_SITE_A_PORT_NUMBER_1
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 endpoint: http://rgw-site-a:8080 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: false rgw_zonesecondary: true rgw_zonegroupmaster: false rgw_zone: paris rgw_zonegroup: idf rgw_realm: france rgw_zone_user: jacques.chirac rgw_zone_user_display_name: "Jacques Chirac" system_access_key: P9Eb6S8XNyo4dtZZUUMy system_secret_key: qqHCUtfdNnpHq3PZRHW5un9l0bEBM812Uhow0XfB radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8081 endpoint: http://rgw-site-a:8081他のレルムに複数のインスタンスを作成するために、
rgw_instancesの下の項目の更新するとともに、以下の設定を行います。ACCESS_KEY_2 および SECRET_KEY_2 のmulti-site-keys-realm-2.txtファイルに保存されるランダムな文字列を使用します。RGW_SITE_A_PRIMARY_HOSTNAME_ENDPOINT をサイト A ストレージクラスターの Object Gateway ノードに設定します。構文
rgw_instances: - instance_name: 'INSTANCE_NAME_1' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_2 rgw_realm: REALM_NAME_2 rgw_zone_user: ZONE_USER_NAME_2 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_2" system_access_key: ACCESS_KEY_2 system_secret_key: SECRET_KEY_2 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1 - instance_name: '_INSTANCE_NAME_2_' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: ZONE_NAME_2 rgw_zonegroup: ZONE_GROUP_NAME_2 rgw_realm: REALM_NAME_2 rgw_zone_user: ZONE_USER_NAME_2 rgw_zone_user_display_name: "ZONE_DISPLAY_NAME_2" system_access_key: ACCESS_KEY_2 system_secret_key: SECRET_KEY_2 radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: PORT_NUMBER_1
例
rgw_instances: - instance_name: 'rgw0' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: fairbanks rgw_zonegroup: alaska rgw_realm: usa rgw_zone_user: edward.lewis rgw_zone_user_display_name: "Edward Lewis" system_access_key: yu17wkvAx3B8Wyn08XoF system_secret_key: 5YZfaSUPqxSNIkZQQA3lBZ495hnIV6k2HAz710BY radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8080 - instance_name: 'rgw1' rgw_multisite: true rgw_zonemaster: true rgw_zonesecondary: false rgw_zonegroupmaster: true rgw_zone: fairbanks rgw_zonegroup: alaska rgw_realm: usa rgw_zone_user: edward.lewis rgw_zone_user_display_name: "Edward Lewis" system_access_key: yu17wkvAx3B8Wyn08XoF system_secret_key: 5YZfaSUPqxSNIkZQQA3lBZ495hnIV6k2HAz710BY radosgw_address: "{{ _radosgw_address }}" radosgw_frontend_port: 8081サイト B ストレージクラスターで Ansible Playbook を実行します。
ベアメタル デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント:
[user@ansible ceph-ansible]$ ansible-playbook site-container.yml -i hosts
サイト A の 他 のレルム用の サイト A ストレージクラスターで Ansible Playbook を再度実行します。
サイト A および サイト B ストレージクラスターで Ansible Playbook を実行した後、Ceph Object Gateway はアクティブ/アクティブ状態で実行されます。
検証
マルチサイト Ceph Object Gateway の設定を確認します。
-
各サイト (サイト A およびサイト B) の Ceph Monitor ノードおよび Object Gateway ノードから、
curlまたは別の HTTP クライアントを使用して、API が他のサイトからアクセスできることを確認します。 両方のサイトで
radosgw-admin sync statusコマンドを実行します。構文
radosgw-admin sync status radosgw-admin sync status --rgw -realm REALM_NAME 1
- 1
- このオプションは、ストレージクラスターの各ノードで複数のレルムを使用する場合に使用します。
例
[user@ansible ceph-ansible]$ radosgw-admin sync status [user@ansible ceph-ansible]$ radosgw-admin sync status --rgw -realm usa
-
各サイト (サイト A およびサイト B) の Ceph Monitor ノードおよび Object Gateway ノードから、
5.8. 同じホストに異なるハードウェアを持つ OSD のデプロイメント
Ansible の device_class 機能を使用して、同じホストに HDD や SSD などの複数の OSD をデプロイすることができます。
前提条件
- 有効なカスタマーサブスクリプションです。
- Ansible 管理ノードへのルートレベルのアクセス。
- Red Hat Ceph Storage Tools および Ansible リポジトリーを有効にします。
- Ansible アプリケーションで使用する Ansible ユーザーアカウント。
- OSD がデプロイされている。
手順
group_vars/mons.ymlファイルにcrush_rulesを作成します。例
crush_rule_config: true crush_rule_hdd: name: HDD root: default type: host class: hdd default: true crush_rule_ssd: name: SSD root: default type: host class: ssd default: true crush_rules: - "{{ crush_rule_hdd }}" - "{{ crush_rule_ssd }}" create_crush_tree: true注記クラスターで SSD デバイスまたは HDD デバイスを使用していない場合は、そのデバイスの
crush_rulesを定義しないでください。group_vars/clients.ymlファイルで作成したcrush_rulesを使用してpoolsを作成します。例
copy_admin_key: True user_config: True pool1: name: "pool1" pg_num: 128 pgp_num: 128 rule_name: "HDD" type: "replicated" device_class: "hdd" pools: - "{{ pool1 }}"ルートを OSD に割り当てるためのインベントリーファイルをサンプリングします。
例
[mons] mon1 [osds] osd1 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'host': 'osd1' }" osd2 osd_crush_location="{ 'root': 'default', 'rack': 'rack1', 'host': 'osd2' }" osd3 osd_crush_location="{ 'root': 'default', 'rack': 'rack2', 'host': 'osd3' }" osd4 osd_crush_location="{ 'root': 'default', 'rack': 'rack2', 'host': 'osd4' }" osd5 devices="['/dev/sda', '/dev/sdb']" osd_crush_location="{ 'root': 'default', 'rack': 'rack3', 'host': 'osd5' }" osd6 devices="['/dev/sda', '/dev/sdb']" osd_crush_location="{ 'root': 'default', 'rack': 'rack3', 'host': 'osd6' }" [mgrs] mgr1 [clients] client1ツリーを表示します。
構文
[root@mon ~]# ceph osd tree
例
TYPE NAME root default rack rack1 host osd1 osd.0 osd.10 host osd2 osd.3 osd.7 osd.12 rack rack2 host osd3 osd.1 osd.6 osd.11 host osd4 osd.4 osd.9 osd.13 rack rack3 host osd5 osd.2 osd.8 host osd6 osd.14 osd.15プールを検証します。
例
# for i in $(rados lspools);do echo "pool: $i"; ceph osd pool get $i crush_rule;done pool: pool1 crush_rule: HDD
関連情報
- 詳細は、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage Cluster のインストール を参照してください。
- 詳細は、Red Hat Ceph Storage ストレージ戦略ガイドの デバイスクラス を参照してください。
5.9. NFS-Ganesha ゲートウェイのインストール
Ceph NFS Ganesha ゲートウェイは、Ceph Object Gateway 上に構築される NFS インターフェイスで、ファイルシステム内のファイルを Ceph Object Storage に移行するために POSIX ファイルシステムインターフェイスを使用するアプリケーションを Ceph Object Gateway に提供します。
前提条件
-
稼働中の Ceph ストレージクラスター (
active + cleanの状態が望ましい)。 - Ceph Object Gateway を実行するノードを少なくとも 1 つ。
- NFS-Ganesha を実行する前に、NFS-Ganesha を実行するホストで実行中のカーネル NFS サービスインスタンスをすべて無効にします。NFS-Ganesha は、別の NFS インスタンスが実行している場合は起動しません。
rpcbind サービスが実行していることを確認します。
# systemctl start rpcbind
注記rpcbind を提供する rpcbind パッケージは通常、デフォルトでインストールされます。そうでない場合は、最初にパッケージをインストールします。
nfs-service サービスが実行中である場合は、これを停止して無効にします。
# systemctl stop nfs-server.service # systemctl disable nfs-server.service
手順
Ansible 管理ノードで以下のタスクを実行します。
サンプルファイルから
nfss.ymlファイルを作成します。[root@ansible ~]# cd /usr/share/ceph-ansible/group_vars [root@ansible ~]# cp nfss.yml.sample nfss.yml
[nfss]グループの下にゲートウェイホストを/etc/ansible/hostsファイルに追加して、Ansible へのグループメンバーシップを特定します。[nfss] NFS_HOST_NAME_1 NFS_HOST_NAME_2 NFS_HOST_NAME[3..10]
ホストに連続する命名がある場合は、
[3..10]のように範囲指定子を使用できます。Ansible 設定ディレクトリーに移動します。
[root@ansible ~]# cd /usr/share/ceph-ansible
管理者キーを Ceph Object Gateway ノードにコピーするには、
/usr/share/ceph-ansible/group_vars/nfss.ymlファイルのcopy_admin_key設定をコメント解除します。copy_admin_key: true
/usr/share/ceph-ansible/group_vars/nfss.ymlファイルの FSAL (File System Abstraction Layer) セクションを設定します。エクスポート ID (NUMERIC_EXPORT_ID)、S3 ユーザー ID (S3_USER)、S3 アクセスキー (ACCESS_KEY)、およびシークレットキー (SECRET_KEY) を提供します。# FSAL RGW Config # ceph_nfs_rgw_export_id: NUMERIC_EXPORT_ID #ceph_nfs_rgw_pseudo_path: "/" #ceph_nfs_rgw_protocols: "3,4" #ceph_nfs_rgw_access_type: "RW" ceph_nfs_rgw_user: "S3_USER" ceph_nfs_rgw_access_key: "ACCESS_KEY" ceph_nfs_rgw_secret_key: "SECRET_KEY"
警告アクセスおよびシークレットキーは任意で、生成できます。
Ansible Playbook を実行します。
ベアメタル デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site.yml --limit nfss -i hosts
コンテナー デプロイメント:
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml --limit nfss -i hosts
5.10. limit オプションについて
本セクションでは、Ansible の --limit オプションを説明します。
Ansible は --limit オプションをサポートし、インベントリーファイルの特定のロールに Ansible Playbook site および site-container を使用できます。
ansible-playbook site.yml|site-container.yml --limit osds|rgws|clients|mdss|nfss|iscsigws -i hosts
ベアメタル
たとえば、ベアメタルに OSD のみを再デプロイするには、Ansible ユーザーとして以下のコマンドを実行します。
[ansible@ansible ceph-ansible]$ ansible-playbook site.yml --limit osds -i hosts
コンテナー
たとえば、コンテナーに OSD のみを再デプロイするには、Ansible ユーザーとして以下のコマンドを実行します。
[ansible@ansible ceph-ansible]$ ansible-playbook site-container.yml --limit osds -i hosts
5.11. 配置グループ autoscaler
配置グループ (PG) チューニングでは、PG の計算ツールを使用して、pg_num の数字のプラグを手動で処理します。Red Hat Ceph Storage 4.1 以降では、Ceph Manager モジュール pg_autoscaler を有効にすると、PG のチューニングを自動的に実行できます。PG autoscaler はプールごとに設定され、pg_num を 2 の累乗でスケーリングします。PG Autoscaler は、推奨される値が実際の値が 3 倍を超える場合に、pg_num への変更のみを提案します。
PG autoscaler には 3 つのモードがあります。
warn-
新しいプールおよび既存のプールのデフォルトモード。推奨される
pg_numの値が現在のpg_num値と大きく異なる場合に、ヘルス警告が生成されます。 on-
プールの
pg_numは、自動的に調整されます。 off-
プールでは Autoscaler をオフにすることができますが、ストレージ管理者はプールの
pg_num値を手動で設定する必要があります。
プールに対して PG autoscaler が有効になったら、ceph osd pool autoscale-status コマンドを実行して値の調整を表示できます。この autoscale-status コマンドは、プールの現在の状態を示します。autoscale-status 列の説明は次のとおりです。
SIZE- プールに保存されているデータの合計量をバイト単位で報告します。このサイズには、オブジェクトデータと OMAP データが含まれます。
TARGET SIZE- ストレージ管理者が提供するプールの予想されるサイズを報告します。この値は、プールの理想的な PG 数を計算するために使用されます。
RATE- レプリケートされたバケットのレプリケーション係数、またはイレイジャーコーディングされたプールの比率。
RAW CAPACITY- プールが CRUSH に基づいてマップされるストレージデバイスの raw ストレージ容量。
RATIO- プールによって消費されるストレージの合計比率。
TARGET RATIO- ストレージ管理者によって提供された、ストレージクラスター全体のスペースのどの部分がプールによって消費されるかを指定する比率。
PG_NUM- プールの現在の配置グループ数。
NEW PG_NUM- 提案される値。この値は設定できません。
AUTOSCALE- プールに設定された PG Autoscaler モード。
関連情報
5.11.1. 配置グループ autoscaler の設定
Ceph Ansible を設定して、Red Hat Ceph Storage クラスターの新規プールの PG Autoscaler を有効および設定することができます。デフォルトでは、配置グループ (PG) はオフになっています。
現在、新しい Red Hat Ceph Storage デプロイメントでのみ配置グループ Autoscaler を設定でき、既存の Red Hat Ceph Storage インストールには設定できません。
前提条件
- Ansible 管理ノードへのアクセス
- Ceph Monitor ノードへのアクセス
手順
-
Ansible 管理ノードで、編集のために
group_vars/all.ymlファイルを開きます。 pg_autoscale_modeオプションをTrueに設定し、新規または既存のプールのtarget_size_ratioの値を設定します。例
openstack_pools: - {"name": backups, "target_size_ratio": 0.1, "pg_autoscale_mode": True, "application": rbd} - {"name": volumes, "target_size_ratio": 0.5, "pg_autoscale_mode": True, "application": rbd} - {"name": vms, "target_size_ratio": 0.2, "pg_autoscale_mode": True, "application": rbd} - {"name": images, "target_size_ratio": 0.2, "pg_autoscale_mode": True, "application": rbd}注記target_size_ratio値は、ストレージクラスター内の他のプールとの対比で、重みの値になります。-
group_vars/all.ymlファイルへの変更を保存します。 適切な Ansible Playbook を実行します。
ベアメタル デプロイメント
[ansible@admin ceph-ansible]$ ansible-playbook site.yml -i hosts
コンテナー デプロイメント
[ansible@admin ceph-ansible]$ ansible-playbook site-container.yml -i hosts
Ansible Playbook が完了したら、Ceph Monitor ノードから Autoscaler のステータスを確認します。
[user@mon ~]$ ceph osd pool autoscale-status
5.12. 関連情報
第6章 コンテナー化された Ceph デーモンのコロケーション
本セクションでは、以下を説明します。
6.1. コロケーションの仕組みとその利点
コンテナー化された Ceph デーモンを同じノードの同じ場所に配置できます。Ceph のサービスの一部を共存する利点を以下に示します。
- 小規模での総所有コスト (TCO) の大幅な改善
- 最小設定の場合は、6 ノードから 3 ノードまで削減
- より簡単なアップグレード
- リソース分離の改善
Red Hat Ceph Storage クラスターのデーモンのコロケーションに関する詳細は、ナレッジベースの記事 Red Hat Ceph Storage: Supported Configurations を参照してください。
コロケーションの仕組み
Ansible インベントリーファイルの適切なセクションに同じノードを追加することで、次のリストから 1 つのデーモンを OSD デーモン (ceph-osd) と同じ場所に配置できます。
-
Ceph メタデータサーバー (
ceph-mds) -
Ceph Monitor (
ceph-mon) および Ceph Manager (ceph-mgr) デーモン -
NFS Ganesha (
nfs-ganesha) -
RBD ミラー (
rbd-mirror) -
iSCSI Gateway (
iscsigw)
Red Hat Ceph Storage 4.2 以降、Metadata Server (MDS) を 1 つの追加のスケールアウトデーモンと同じ場所に配置できます。
さらに、Ceph Object Gateway (radosgw) または Grafana の場合、RBD mirror.z を除く、OSD デーモンと上記のリストのデーモンのいずれかを共存させることができます。たとえば、以下は有効な 5 ノードの共存設定です。
| ノード | デーモン | デーモン | デーモン |
|---|---|---|---|
| node1 | OSD | Monitor | Grafana |
| node2 | OSD | Monitor | RADOS Gateway |
| node3 | OSD | Monitor | RADOS Gateway |
| node4 | OSD | メタデータサーバー | |
| node5 | OSD | メタデータサーバー |
上記の設定のように 5 つのノードクラスターをデプロイするには、以下のように Ansible インベントリーファイルを設定します。
同じ場所に配置されたデーモンを含む Ansible インベントリーファイル
[grafana-server] node1 [mons] node[1:3] [mgrs] node[1:3] [osds] node[1:5] [rgws] node[2:3] [mdss] node[4:5]
ceph-mon と ceph-mgr は密接に連携するため、コロケーションのために、2 つの別のデーモンとしてカウントしません。
Grafana と他のデーモンのコロケーションは、Cockpit ベースのインストールではサポートされません。ceph-ansible を使用してストレージクラスターを設定します。
Red Hat は、Ceph Object Gateway を OSD コンテナーと併置してパフォーマンスを向上することを推奨します。追加コストを発生せずに最高のパフォーマンスを実現するには、group_vars/all.yml で radosgw_num_instances: 2 に設定して、2 つのゲートウェイを使用します。詳細は、Red Hat Ceph Storage RGW deployment strategies and sizing guidance を参照してください。
Grafana を他の 2 つのコンテナーと同じ場所に配置するには、適切な CPU とネットワークリソースが必要です。リソースの枯渇が発生した場合は、Grafana と Monitor のみを同じ場所に配置し、それでもリソースの枯渇が発生した場合は、専用ノードで Grafana を実行します。
図6.1「同じ場所に配置されたデーモン」 イメージおよび 図6.2「同じ場所に配置されていないデーモン」 イメージは、同じ場所に置かれたデーモンと、同じ場所に置かれていないデーモンの相違点を示しています。
図6.1 同じ場所に配置されたデーモン

図6.2 同じ場所に配置されていないデーモン

複数のコンテナー化された Ceph デーモンを同じノードにコロケートする場合、Playbook ceph-ansible は専用の CPU および RAM リソースをそれぞれに予約します。デフォルトでは、ceph-ansible は、Red Hat Ceph Storage ハードウェアガイドの 推奨される最小ハードウェア の章に記載される値を使用します。デフォルト値の変更方法は、同じ場所に配置されたデーモンの専用リソースの設定 セクションを参照してください。
6.2. 同じ場所に配置されたデーモンの専用リソースの設定
同じノードで 2 つの Ceph デーモンを共存させる場合には、Playbook ceph-ansible は各デーモンに CPU および RAM リソースを予約します。ceph-ansible が使用するデフォルト値は、Red Hat Ceph Storage ハードウェア選択ガイドの 推奨される最小ハードウェア の章に記載されています。デフォルト値を変更するには、Ceph デーモンのデプロイ時に必要なパラメーターを設定します。
手順
デーモンのデフォルト CPU 制限を変更するには、デーモンのデプロイ時に、適切な
.yml設定ファイルにceph_daemon-type_docker_cpu_limitパラメーターを設定します。詳細は以下の表を参照してください。デーモン パラメーター 設定ファイル OSD
ceph_osd_docker_cpu_limitosds.ymlMDS
ceph_mds_docker_cpu_limitmdss.ymlRGW
ceph_rgw_docker_cpu_limitrgws.ymlたとえば、Ceph Object Gateway のデフォルトの CPU 制限を 2 に変更するには、以下のように
/usr/share/ceph-ansible/group_vars/rgws.ymlファイルを編集します。ceph_rgw_docker_cpu_limit: 2
OSD デーモンのデフォルト RAM を変更するには、デーモンのデプロイ時に
/usr/share/ceph-ansible/group_vars/all.ymlファイルにosd_memory_targetを設定します。たとえば、OSD RAM を 6 GB に制限するには、以下を実行します。ceph_conf_overrides: osd: osd_memory_target=6000000000重要ハイパーコンバージドインフラストラクチャー (HCI) 設定では、
osds.yml設定ファイルのceph_osd_docker_memory_limitパラメーターを使用して Docker メモリー CGroup 制限を変更することもできます。この場合、ceph_osd_docker_memory_limitをosd_memory_targetよりも 50% 高く設定し、CGroup の制限は、HCI 設定の場合のデフォルトよりも制限が高くなります。たとえば、osd_memory_targetが 6 GB に設定されている場合は、ceph_osd_docker_memory_limitを 9 GB に設定します。ceph_osd_docker_memory_limit: 9g
関連情報
-
/usr/share/ceph-ansible/group_vars/ディレクトリーにある設定ファイルのサンプル
6.3. 関連情報
第7章 Red Hat Ceph Storage クラスターのアップグレード
ストレージ管理者は、Red Hat Ceph Storage クラスターを新しいメジャーバージョンまたは新しいマイナーバージョンにアップグレードしたり、現行バージョンに非同期更新を適用するだけで済みます。Ansible Playbook rolling_update.yml は、Red Hat Ceph Storage のベアメタルまたはコンテナー化されたデプロイメントのアップグレードを実行します。Ansible は Ceph ノードを以下の順序でアップグレードします。
- ノードの監視
- MGR ノード
- OSD ノード
- MDS ノード
- Ceph Object Gateway ノード
- その他すべての Ceph クライアントノード
Red Hat Ceph Storage 3.1 以降、Object Gateway および高速 NVMe ベースの SSD (および SATA SSD) を使用する場合のパフォーマンスのためにストレージを最適化するために、新しい Ansible Playbook が追加されました。Playbook は、ジャーナルとバケットインデックスを SSD にまとめて配置してこれを行います。これにより、1 つのデバイスにすべてのジャーナルがある場合よりもパフォーマンスが向上します。これらの Playbook は、Ceph のインストール時に使用されます。既存の OSD は動作し続け、アップグレード中に追加のステップは必要ありません。このようにストレージを最適化するために OSD を同時に再設定する際に、Ceph クラスターをアップグレードする方法はありません。ジャーナルまたはバケットインデックスに異なるデバイスを使用するには、OSD を再プロビジョニングする必要があります。実稼働向け Ceph Object Gateway ガイド の LVM での NVMe の最適な使用 を参照してください。
Red Hat Ceph Storage クラスターを以前のサポートされているバージョンからバージョン 4.2z2 にアップグレードすると、モニターがセキュアでない global_id の再要求を許可していると記載の HEALTH_WARN 状態のままアップグレードが完了します。これは、CVE のパッチ適用が原因で、詳細は CVE-2021-20288 を確認してください。この問題は Red Hat Ceph Storage 4.2z2 の CVE で修正されています。
ヘルスに関する警告をオフにすることを推奨します。
-
AUTH_INSECURE_GLOBAL_ID_RECLAIMの警告のceph ヘルス詳細の出力を確認して、更新されていないクライアントを特定します。 - すべてのクライアントを Red Hat Ceph Storage 4.2z2 リリースにアップグレードします。
すべてのクライアントが更新され、AUTH_INSECURE_GLOBAL_ID_RECLAIM 警告がクライアントに表示されなくなったことを確認してから、
auth_allow_insecure_global_id_reclaimをfalseに設定します。このオプションがfalseに設定されている場合には、パッチを適用していないクライアントは、ネットワークの断続的な障害によりモニターへの接続が切断された後にストレージクラスターに再接続できず、タイムアウト (デフォルトでは 72 時間) 時に認証チケットを更新できません。構文
ceph config set mon auth_allow_insecure_global_id_reclaim false
-
AUTH_INSECURE_GLOBAL_ID_RECLAIMの警告が表示されているクライアントがないことを確認してください。
Playbook rolling_update.yml には、同時に更新するノード数を調整する シリアル 変数が含まれます。Red Hat では、デフォルト値 (1) を使用することを強く推奨します。これにより、Ansible がクラスターノードを 1 つずつアップグレードします。
いずれかの時点でアップグレードが失敗した場合は、ceph status コマンドでクラスターの状態を確認して、アップグレードの失敗理由を把握します。不具合の原因や解決方法がわからない場合は、Red Hat サポート にお問い合わせください。
マルチサイト設定を RedHat Ceph Storage 3 から RedHat Ceph Storage 4 にアップグレードする場合は、以下の推奨事項に注意してください。そうしないと、レプリケーションが破損する可能性があります。rolling_update.yml を実行する前に、all.yml に rgw_multisite: false を設定します。アップグレード後に rgw_multisite を再度有効にしないでください。アップグレード後に新しいゲートウェイを追加する必要がある場合にのみ使用してください。バージョン 3.3z5 以降の Red Hat Ceph Storage 3 クラスターのみを Red Hat Ceph Storage 4 にアップグレードします。3.3z5 以降に更新できない場合は、クラスターをアップグレードする前にサイト間の同期を無効にします。同期を無効にするには、rgw_run_sync_thread = false を設定して、RADOS Gateway デーモンを再起動します。最初にプライマリークラスターをアップグレードします。Red Hat Ceph Storage 4.1 以降にアップグレードします。3.3z5 に関連するパッケージバージョンを確認するには、What are the Red Hat Ceph Storage releases and corresponding Ceph package versions? を参照してください。同期を無効にする方法については、RGW Multisite の同期を一時的に無効にする方法 を参照してください。
Ceph Object Gateway を使用して Red Hat Ceph Storage 3.x から Red Hat Ceph Storage 4.x にアップグレードする場合、フロントエンドは自動的に CivetWeb から Beast (新しいデフォルト) に変更されます。詳細は、オブジェクトのゲートウェイ設定および管理ガイド の 設定 を参照してください。
RADOS Gateway を使用している場合には、Ansible はフロントエンドを CivetWeb から Beast に切り替えます。この過程で、RGW のインスタンス名が rgw.HOSTNAME から rgw.HOSTNAME.rgw0 に変更されます。名前が変更されたため、Ansible は ceph.conf 内の既存の RGW 設定を更新せず、代わりにデフォルトの設定を追加して、以前の CivetWeb ベースの RGW 設定はそのままですが、これは使用されません。そうすると、RGW のカスタム設定の変更が失われ、RGW のサービスが中断される可能性があります。これを回避するには、アップグレードの前に、all.yml の ceph_conf_overrides セクションに既存の RGW 設定を追加します。ただし、.rgw0 を追加して RGW インスタンス名を変更し、RGW サービスを再起動します。これにより、アップグレード後もデフォルトではない RGW の設定変更が保持されます。ceph_conf_overrides の詳細は、Ceph のデフォルト設定の上書き を参照してください。
7.1. サポート対象の Red Hat Ceph Storage アップグレードシナリオ
Red Hat は、以下のアップグレードシナリオをサポートします。
ベアメタル、コンテナー化された の表を読み、特定のアップグレード後の状態に移行するためにクラスターがログインする必要のある状態を確認します。
ceph-ansible を使用して、ベアメタルまたはコンテナー化アップグレードを行います。この場合、ベアメタまたはホストのオペレーティングシステムのメジャーバージョンは変わりません。Red Hat Enterprise Linux 7 から RedHat Enterprise Linux 8 へのアップグレードは、ceph-ansible ではサポートされていません。Red Hat Ceph Storage のアップグレードの一環としてベアメタルオペレーティングシステムを Red Hat Enterprise Linux 7.9 から Red Hat Enterprise Linux 8.4 にアップグレードするには、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage クラスターおよびオペレーティングシステムの手動アップグレード のセクションを参照してください。
Red Hat は、クラスターを Red Hat Ceph Storage 4 にアップグレードする場合に、クラスターが最新バージョンの Red Hat Ceph Storage 3 を使用していることを推奨しています。Red Hat Ceph Storage の最新バージョンを知るには、What are the Red Hat Ceph Storage releases? を参照してください。詳細は、ナレッジベースの記事を参照してください。
表7.1 ベアメタルデプロイメントでサポートされるアップグレードシナリオ
| アップグレード前の状態 | アップグレード後の状態 | ||
|---|---|---|---|
| Red Hat Enterprise Linux のバージョン | Red Hat Ceph Storage のバージョン | Red Hat Enterprise Linux のバージョン | Red Hat Ceph Storage のバージョン |
| 7.6 | 3.3 | 7.9 | 4.2 |
| 7.6 | 3.3 | 8.4 | 4.2 |
| 7.7 | 3.3 | 7.9 | 4.2 |
| 7.7 | 4.0 | 7.9 | 4.2 |
| 7.8 | 3.3 | 7.9 | 4.2 |
| 7.8 | 3.3 | 8.4 | 4.2 |
| 7.9 | 3.3 | 8.4 | 4.2 |
| 8.1 | 4.0 | 8.4 | 4.2 |
| 8.2 | 4.1 | 8.4 | 4.2 |
| 8.2 | 4.1 | 8.4 | 4.2 |
| 8.3 | 4.1 | 8.4 | 4.2 |
表7.2 コンテナー化されたデプロイメントでサポートされるアップグレードシナリオ
| アップグレード前の状態 | アップグレード後の状態 | ||||
|---|---|---|---|---|---|
| ホストの Red Hat Enterprise Linux のバージョン | コンテナーの Red Hat Enterprise Linux バージョン | Red Hat Ceph Storage のバージョン | ホストの Red Hat Enterprise Linux のバージョン | コンテナーの Red Hat Enterprise Linux バージョン | Red Hat Ceph Storage のバージョン |
| 7.6 | 7.8 | 3.3 | 7.9 | 8.4 | 4.2 |
| 7.7 | 7.8 | 3.3 | 7.9 | 8.4 | 4.2 |
| 7.7 | 8.1 | 4.0 | 7.9 | 8.4 | 4.2 |
| 7.8 | 7.8 | 3.3 | 7.9 | 8.4 | 4.2 |
| 8.1 | 8.1 | 4.0 | 8.4 | 8.4 | 4.2 |
| 8.2 | 8.2 | 4.1 | 8.4 | 8.4 | 4.2 |
| 8.3 | 8.3 | 4.1 | 8.4 | 8.4 | 4.2 |
7.2. アップグレードの準備
Red Hat Ceph Storage クラスターのアップグレードを開始する前に、いくつかの操作を完了する必要があります。これらのステップは、Red Hat Ceph Storage クラスターのベアメタルおよびコンテナーデプロイメントの両方に適用されます (指定がある場合)。
Red Hat Ceph Storage 4 の最新バージョンにのみアップグレードできます。たとえば、バージョン 4.1 が利用可能な場合、3 から 4.0 にアップグレードすることはできません。4.1 に直接移行する必要があります。
FileStore オブジェクトストアを使用する場合は、Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードした後に BlueStore に移行する必要があります。
Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード中に、ceph-ansible を使用して Red Hat Ceph Storage をアップグレードすることはできません。Red Hat Enterprise Linux 7 を使用する必要があります。オペレーティングシステムもアップグレードするには、Red Hat Ceph Storage クラスターとオペレーティングシステムの手動アップグレード を参照してください。
Red Hat Ceph Storage 4.2z2 以降のバージョンでは、オプション bluefs_buffered_io がデフォルトで True に設定されています。このオプションは、場合によって BlueFS でバッファー読み取りができるようにし、カーネルページキャッシュが RocksDB ブロック読み取りのような読み取りの二次キャッシュとして機能できるようにします。たとえば、 OMAP の反復時にすべてのブロックを保持ほど、RocksDB のブロックキャッシュが十分にない場合には、ディスクの代わりにページキャッシュから読み出すことが可能な場合があります。これにより、osd_memory_target が小さすぎてブロックキャッシュのすべてのエントリーを保持できない場合に、パフォーマンスが劇的に向上します。現在、bluefs_buffered_io を有効にし、システムレベルのスワップを無効にすることで、パフォーマンスの低下を防いでいます。
前提条件
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
- ストレージクラスター内のすべてのノードのシステムクロックが同期されます。Monitor ノードが同期していない場合、アップグレードプロセスが適切に完了していない可能性があります。
- バージョン 3 からアップグレードする場合、バージョン 3 クラスターが Red Hat Ceph Storage 3 の最新バージョンにアップグレード されている。
バージョン 4 にアップグレードする前に、Prometheus ノードエクスポーターサービスが動作している場合は、サービスを停止する。
例
[root@mon ~]# systemctl stop prometheus-node-exporter.service
重要これは既知の問題で、今後の Red Hat Ceph Storage のリリースで修正される予定です。この問題の詳細は、Red Hat ナレッジベースの 記事 を参照してください。
注記アップグレード中にインターネットにアクセスできないベアメタル または コンテナー の Red Hat Ceph Storage クラスターノードの場合は、Red Hat Ceph Storage Installation Guideの Registering Red Hat Ceph Storage nodes to the CDN and attaching subscriptions のセクションに記載の手順に従います。
手順
-
ストレージクラスター内のすべてのノードで
rootユーザーとしてログインします。 - Ceph ノードが Red Hat コンテンツ配信ネットワーク (CDN) に接続されていない場合は、ISO イメージを使用して Red Hat Ceph Storage の最新バージョンでローカルリポジトリーを更新することで、Red Hat Ceph Storage をアップグレードできます。
Red Hat Ceph Storage をバージョン 3 からバージョン 4 にアップグレードする場合は、既存の Ceph ダッシュボードのインストールを削除します。
Ansible 管理ノードで、
cephmetrics-ansibleディレクトリーに移動します。[root@admin ~]# cd /usr/share/cephmetrics-ansible
purge.ymlPlaybook を実行して、既存の Ceph ダッシュボードのインストールを削除します。[root@admin cephmetrics-ansible]# ansible-playbook -v purge.yml
Red Hat Ceph Storage をバージョン 3 からバージョン 4 にアップグレードする場合は、Ansible 管理ノードで Ceph リポジトリーおよび Ansible リポジトリーを有効にします。
Red Hat Enterprise Linux 7
[root@admin ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms --enable=rhel-7-server-ansible-2.9-rpms
Red Hat Enterprise Linux 8
[root@admin ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms --enable=ansible-2.9-for-rhel-8-x86_64-rpms
Ansible 管理ノードで、
ansibleパッケージおよびceph-ansibleパッケージの最新バージョンがインストールされていることを確認します。Red Hat Enterprise Linux 7
[root@admin ~]# yum update ansible ceph-ansible
Red Hat Enterprise Linux 8
[root@admin ~]# dnf update ansible ceph-ansible
Playbook
infrastructure-playbooks/rolling_update.yml編集し、health_osd_check_retriesおよびhealth_osd_check_delayの値をそれぞれ50および30に変更します。health_osd_check_retries: 50 health_osd_check_delay: 30
各 OSD ノードについて、この値により Ansible は最大 25 分待機し、アップグレードプロセスを続行する前に 30 秒ごとにストレージクラスターの正常性をチェックします。
注記ストレージクラスターで使用されているストレージ容量に基づいて、
health_osd_check_retriesオプションの値をスケールアップまたはダウンします。たとえば、436 TB 未満の 218 TB (ストレージ容量の 50%) を使用している場合は、health_osd_check_retriesオプションを50に設定します。アップグレードするストレージクラスターに
exclusive-lock機能を使用する Ceph Block Device イメージが含まれている場合には、全 Ceph Block Device ユーザーにクライアントをブラックリストに登録するパーミッションがあるようにしてください。ceph auth caps client.ID mon 'allow r, allow command "osd blacklist"' osd 'EXISTING_OSD_USER_CAPS'
ストレージクラスターが Cockpit を使用して最初にインストールされている場合は、
/usr/share/ceph-ansibleディレクトリーに、Cockpit が作成したインベントリーファイルへのシンボリックリンクを/usr/share/ansible-runner-service/inventory/hostsに作成します。/usr/share/ceph-ansibleディレクトリーに移動します。# cd /usr/share/ceph-ansible
シンボリックリンクを作成します。
# ln -s /usr/share/ansible-runner-service/inventory/hosts hosts
ceph-ansibleを使用してクラスターをアップグレードするには、hostsインベントリーファイルのシンボリックリンクをetc/ansible/hostsディレクトリーに作成します。# ln -s /etc/ansible/hosts hosts
ストレージクラスターが Cockpit を使用して最初にインストールされている場合は、Cockpit で生成された SSH 鍵を Ansible ユーザーの
~/.sshディレクトリーにコピーします。鍵をコピーします。
# cp /usr/share/ansible-runner-service/env/ssh_key.pub /home/ANSIBLE_USERNAME/.ssh/id_rsa.pub # cp /usr/share/ansible-runner-service/env/ssh_key /home/ANSIBLE_USERNAME/.ssh/id_rsa
ANSIBLE_USERNAME は、Ansible のユーザー名に置き換えます (通常は
admin)。例
# cp /usr/share/ansible-runner-service/env/ssh_key.pub /home/admin/.ssh/id_rsa.pub # cp /usr/share/ansible-runner-service/env/ssh_key /home/admin/.ssh/id_rsa
キーファイルに適切な所有者、グループ、およびパーミッションを設定します。
# chown ANSIBLE_USERNAME:_ANSIBLE_USERNAME_ /home/ANSIBLE_USERNAME/.ssh/id_rsa.pub # chown ANSIBLE_USERNAME:_ANSIBLE_USERNAME_ /home/ANSIBLE_USERNAME/.ssh/id_rsa # chmod 644 /home/ANSIBLE_USERNAME/.ssh/id_rsa.pub # chmod 600 /home/ANSIBLE_USERNAME/.ssh/id_rsa
ANSIBLE_USERNAME は、Ansible のユーザー名に置き換えます (通常は
admin)。例
# chown admin:admin /home/admin/.ssh/id_rsa.pub # chown admin:admin /home/admin/.ssh/id_rsa # chmod 644 /home/admin/.ssh/id_rsa.pub # chmod 600 /home/admin/.ssh/id_rsa
関連情報
- 詳細は、Red Hat Ceph Storage リポジトリーの有効化 を参照してください。
- クロックの同期およびクロックスキューの詳細は、Red Hat Ceph Storage トラブルシューティングガイド の クロックスキュー セクションを参照してください。
7.3. Ansible を使用したストレージクラスターのアップグレード
Ansible デプロイメントツールを使用して、ローリングアップグレードを実行して Red Hat Ceph Storage クラスターをアップグレードできます。これらのステップは、特に特に記載がない限り、ベアメタルおよびコンテナーのデプロイメントの両方に適用されます。
前提条件
- Ansible 管理ノードへのルートレベルのアクセス。
-
ansibleユーザーアカウント。
手順
/usr/share/ceph-ansibleディレクトリーに移動します。例
[root@admin ~]# cd /usr/share/ceph-ansible/
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードする場合は、
group_vars/all.ymlファイル、group_vars/osds.ymlファイル、およびgroup_vars/clients.ymlファイルのバックアップコピーを作成します。[root@admin ceph-ansible]# cp group_vars/all.yml group_vars/all_old.yml [root@admin ceph-ansible]# cp group_vars/osds.yml group_vars/osds_old.yml [root@admin ceph-ansible]# cp group_vars/clients.yml group_vars/clients_old.yml
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードする場合は、
group_vars/all.yml.sample、group_vars/osds.yml.sample、およびgroup_vars/clients.yml.sampleファイルの新しいコピーを作成し、名前をgroup_vars/all.yml、group_vars/osds.yml、およびgroup_vars/clients.ymlに変更します。以前にバックアップしたコピーに基づいて変更を開き、編集します。[root@admin ceph-ansible]# cp group_vars/all.yml.sample group_vars/all.yml [root@admin ceph-ansible]# cp group_vars/osds.yml.sample group_vars/osds.yml [root@admin ceph-ansible]# cp group_vars/clients.yml.sample group_vars/clients.yml
group_vars/osds.ymlファイルを編集します。以下のオプションを追加して設定します。nb_retry_wait_osd_up: 60 delay_wait_osd_up: 10
注記これらはデフォルトの値であり、ユーザーの使用目的に応じて値を変更できます。
Red Hat Ceph Storage 4 の新規マイナーバージョンにアップグレードする場合は、
group_vars/all.ymlのgrafana_container_imageの値がgroup_vars/all.yml.sampleの値と同じであることを確認します。同じでない場合は、同じになるように編集します。例
grafana_container_image: registry.redhat.io/rhceph/rhceph-4-dashboard-rhel8:4
注記以下に示すイメージパスは、
ceph-ansibleバージョン 4.0.23-1 に含まれています。サンプルファイルから最新の
site.ymlファイルまたはsite-container.ymlファイルをコピーします。ベアメタル デプロイメントの場合:
[root@admin ceph-ansible]# cp site.yml.sample site.yml
コンテナー デプロイメントの場合:
[root@admin ceph-ansible]# cp site-container.yml.sample site-container.yml
group_vars/all.ymlファイルを開き、以下のオプションを編集します。fetch_directoryオプションを追加します。fetch_directory: FULL_DIRECTORY_PATH- 置き換え
- FULL_DIRECTORY_PATH を、書き込み可能な場所 (Ansible ユーザーのホームディレクトリーなど) に置き換えます。
アップグレードするクラスターに Ceph Object Gateway ノードが含まれている場合には、
radosgw_interfaceオプションを追加します。radosgw_interface: INTERFACE- 置き換え
- Ceph Object Gateway がリッスンするインターフェイスを使用する INTERFACE
現在の設定で SSL 証明書が設定されている場合は、以下を編集する必要があります。
radosgw_frontend_ssl_certificate: /etc/pki/ca-trust/extracted/CERTIFICATE_NAME radosgw_frontend_port: 443デフォルトの OSD オブジェクトストアは BlueStore です。従来の OSD オブジェクトストアを維持するには、
osd_objectstoreオプションを明示的にfilestoreに設定する必要があります。osd_objectstore: filestore
注記osd_objectstoreオプションをfilestoreに設定し、OSD を置き換えると BlueStore ではなく FileStore が使用されます。重要Red Hat Ceph Storage 4 以降、FileStore は非推奨の機能になりました。Red Hat は、FileStore OSD を BlueStore OSD に移行することを推奨します。
-
Red Hat Ceph Storage 4.1 以降、
/usr/share/ceph-ansible/group_vars/all.ymlのdashboard_admin_passwordおよびgrafana_admin_passwordをコメント解除するか設定する必要があります。それぞれに安全なパスワードを設定します。dashboard_admin_userおよびgrafana_admin_userのカスタムユーザー名も設定します。 ベアメタル および コンテナー の両方のデプロイメントの場合:
upgrade_ceph_packagesオプションをコメント解除して、Trueに設定します。upgrade_ceph_packages: True
ceph_rhcs_versionオプションを4に設定します。ceph_rhcs_version: 4
注記ceph_rhcs_versionオプションを4に設定すると、最新バージョンの Red Hat Ceph Storage 4 がプルされます。ceph_docker_registry情報をall.ymlに追加します。構文
ceph_docker_registry: registry.redhat.io ceph_docker_registry_username: SERVICE_ACCOUNT_USER_NAME ceph_docker_registry_password: TOKEN
注記Red Hat レジストリーサービスアカウントがない場合は、レジストリーサービスアカウントの Web ページ を使用して作成します。詳細は、Red Hat Container Registry Authentication のナレッジベース記事を参照してください。
注記ceph_docker_registry_usernameおよびceph_docker_registry_passwordパラメーターにサービスアカウントを使用するだけでなく、カスタマーポータルの認証情報を使用することもできますが、ceph_docker_registry_passwordパラメーターを暗号化してセキュリティーを確保してください。詳細は、ansible-vault で Ansible のパスワード変数を暗号化する を参照してください。
コンテナー のデプロイメントの場合:
ceph_docker_imageオプションを変更して、Ceph 4 コンテナーバージョンを指定します。ceph_docker_image: rhceph/rhceph-4-rhel8
ceph_docker_image_tagオプションを変更して、rhceph/rhceph-4-rhel8の最新バージョンを参照します。ceph_docker_image_tag: latest
-
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードする場合は、Ansible インベントリーファイルでデフォルトで
/etc/ansible/hostsを開き、[grafana-server]セクションに Ceph ダッシュボードのノード名または IP アドレスを追加します。このセクションが存在しない場合は、ノード名または IP アドレスとともにこのセクションも追加します。 Ansible ユーザーに切り替えるかログインしてから、
rolling_update.ymlPlaybook を実行します。[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/rolling_update.yml -i hosts
重要rolling_update.ymlPlaybook で--limitAnsible オプションを使用することはサポートされていません。RBD ミラーリングデーモンノードの
rootユーザーとして、rbd-mirrorパッケージを手動でアップグレードします。[root@rbd ~]# yum upgrade rbd-mirror
rbd-mirrorデーモンを再起動します。systemctl restart ceph-rbd-mirror@CLIENT_IDストレージクラスターのヘルスステータスを確認します。
ベアメタル デプロイメントの場合は、
rootユーザーとして monitor ノードにログインし、Ceph status コマンドを実行します。[root@mon ~]# ceph -s
container デプロイメントの場合は、Ceph Monitor ノードに
rootユーザーとしてログインします。実行中のコンテナーのリストを表示します。
Red Hat Enterprise Linux 7
[root@mon ~]# docker ps
Red Hat Enterprise Linux 8
[root@mon ~]# podman ps
ヘルスステータスを確認します。
Red Hat Enterprise Linux 7
[root@mon ~]# docker exec ceph-mon-MONITOR_NAME ceph -sRed Hat Enterprise Linux 8
[root@mon ~]# podman exec ceph-mon-MONITOR_NAME ceph -s- 置き換え
MONITOR_NAME は、前のステップで見つかった Ceph Monitor コンテナーの名前にします。
例
[root@mon ~]# podman exec ceph-mon-mon01 ceph -s
オプション: Red Hat Ceph Storage 3.x から Red Hat Ceph Storage 4.x にアップグレードした場合に、Legacy BlueStore stats reporting detected on 336 OSD(s). というヘルスに関する警告が表示される場合があります。これは、新しいコードではプール統計の計算方法が異なることが原因です。これは、
bluestore_fsck_quick_fix_on_mountパラメーターを設定することで解決できます。bluestore_fsck_quick_fix_on_mountはtrueに設定します。例
[root@mon ~]# ceph config set osd bluestore_fsck_quick_fix_on_mount true
nooutフラグとnorebalanceフラグを設定して、OSD がダウンしている間のデータ移動を防止します。例
[root@mon ~]# ceph osd set noout [root@mon ~]# ceph osd set norebalance
ベアメタル デプロイメントの場合は、ストレージクラスターのすべての OSD ノードで
ceph-osd.targetを再起動します。例
[root@osd ~]# systemctl restart ceph-osd.target
コンテナー化された デプロイメントの場合は、個々の OSD を順次再起動し、すべての配置グループが
active+clean状態になるまで待機します。構文
systemctl restart ceph-osd@OSD_ID.service例
[root@osd ~]# systemctl restart ceph-osd@0.service
すべての OSD が修復されたら、
noutフラグおよびnorebalanceフラグの設定を解除します。例
[root@mon ~]# ceph osd unset noout [root@mon ~]# ceph osd unset norebalance
すべての OSD が修復されたら、
bluestore_fsck_quick_fix_on_mountをfalseに設定します。例
[root@mon ~]# ceph config set osd bluestore_fsck_quick_fix_on_mount false
オプション: ベアメタル デプロイメントの代替方法として、OSD サービスを停止し、
ceph-bluestore-toolコマンドを使用して OSD で修復機能を実行してから、OSD サービスを起動します。OSD サービスを停止します。
[root@osd ~]# systemctl stop ceph-osd.target
実際の OSD ID を指定して、OSD の修復機能を実行します。
構文
ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-OSDID repair例
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-2 repair
OSD サービスを起動します。
[root@osd ~]# systemctl start ceph-osd.target
アップグレードが終了したら、Ansible の Playbook を実行して、FileStore OSD を BlueStore OSD に移行します。
構文
ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit OSD_NODE_TO_MIGRATE例
[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/filestore-to-bluestore.yml --limit osd01
移行が完了したら、以下のサブ手順を実行します。
group_vars/osds.ymlファイルを編集するために開き、osd_objectstoreオプションをbluestoreに設定します。以下に例を示します。osd_objectstore: bluestore
lvm_volumes変数を使用している場合は、journalオプションおよびjournal_vgオプションをそれぞれdbおよびdb_vgに変更します。以下に例を示します。前
lvm_volumes: - data: /dev/sdb journal: /dev/sdc1 - data: /dev/sdd journal: journal1 journal_vg: journalsBluestore への変換後
lvm_volumes: - data: /dev/sdb db: /dev/sdc1 - data: /dev/sdd db: journal1 db_vg: journals
OpenStack 環境で動作する場合には、すべての
cephxユーザーがプールに RBD プロファイルを使用するように更新します。以下のコマンドはrootユーザーとして実行する必要があります。Glance ユーザー:
構文
ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=GLANCE_POOL_NAME'例
[root@mon ~]# ceph auth caps client.glance mon 'profile rbd' osd 'profile rbd pool=images'
Cinder ユーザー:
構文
ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=CINDER_VOLUME_POOL_NAME, profile rbd pool=NOVA_POOL_NAME, profile rbd-read-only pool=GLANCE_POOL_NAME'
例
[root@mon ~]# ceph auth caps client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
OpenStack の一般ユーザーは、以下のようになります。
構文
ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=CINDER_VOLUME_POOL_NAME, profile rbd pool=NOVA_POOL_NAME, profile rbd-read-only pool=GLANCE_POOL_NAME'
例
[root@mon ~]# ceph auth caps client.openstack mon 'profile rbd' osd 'profile rbd-read-only pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images'
重要ライブクライアントの移行を実行する前に、これらの CAPS 更新を行います。これにより、クライアントがメモリーで実行している新しいライブラリーを使用でき、古い CAPS 設定がキャッシュから破棄され、新しい RBD プロファイル設定が適用されるようになります。
必要に応じて、クライアントノードで、Ceph クライアント側ライブラリーに依存するアプリケーションを再起動します。
注記QEMU または KVM インスタンスを実行している OpenStack Nova コンピュートノードをアップグレードする場合や、専用の QEMU または KVM クライアントを使用する場合には、インスタンスを再起動しても機能しないため、QEMU または KVM インスタンスを停止して起動してください。
関連情報
- 詳細は、limit オプションの理解 を参照してください。
- 詳細は、Red Hat Ceph Storage 管理ガイドの オブジェクトストアを FileStore から BlueStore に移行する方法 を参照してください。
- 詳細は、ナレッジベースの記事 After a ceph-upgrade the cluster status reports 'Legacy BlueStore stats reporting detected' を参照してください。
7.4. コマンドラインインターフェイスを使用したストレージクラスターのアップグレード
ストレージクラスターの実行中に、Red Hat Ceph Storage 3.3 から Red Hat Ceph Storage 4 にアップグレードできます。これらのバージョンの重要な違いは、Red Hat Ceph Storage4 がデフォルトで msgr2 プロトコルを使用することです。これはポート 3300 を使用します。開いていない場合、クラスターは HEALTH_WARN エラーを発行します。
ストレージクラスターのアップグレード時に考慮すべき制約を以下に示します。
-
Red Hat Ceph Storage 4 では、デフォルトで
msgr2プロトコルが使用されます。Ceph Monitor ノードでポート3300が開いていることを確認します。 -
ceph-monitorデーモンを Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードしたら、Red Hat Ceph Storage 3 のceph-osdデーモンは、Red Hat Ceph Storage 4 にアップグレードするまで、新しい OSD を作成 できません。 - アップグレードの進行中はプールを 作成しないでください。
前提条件
- Ceph Monitor ノード、OSD ノード、および Object Gateway ノードへのルートレベルのアクセス。
手順
Red Hat Ceph Storage 3 の実行中に、クラスターがすべての PG の完全スクラブを 1 つ以上完了していることを確認します。これを実行しないと、モニターデーモンは起動時にクォーラムへの参加を拒否し、機能しなくなる可能性があります。クラスターがすべての PG の完全スクラブを 1 つ以上完了していることを確認するには、以下を実行します。
# ceph osd dump | grep ^flags
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 へのアップグレードを続行するには、OSD マップに
recovery_deletesフラグおよびpurged_snapdirsフラグが含まれている必要があります。クラスターが正常な状態でクリーンな状態であることを確認します。
ceph health HEALTH_OK
ceph-monおよびceph-managerを実行しているノードの場合は、以下のコマンドを実行します。# subscription-manager repos --enable=rhel-7-server-rhceph-4-mon-rpms
Red Hat Ceph Storage 4 パッケージを有効にしたら、それぞれの
ceph-monノードおよびceph- managerノードで以下のコマンドを実行します。# firewall-cmd --add-port=3300/tcp # firewall-cmd --add-port=3300/tcp --permanent # yum update -y # systemctl restart ceph-mon@<mon-hostname> # systemctl restart ceph-mgr@<mgr-hostname>
<mon-hostname>および<mgr-hostname>をターゲットホストのホスト名に置き換えます。OSD をアップグレードする前に、Ceph Monitor ノードで
nooutフラグおよびnodeep-scrubフラグを設定して、アップグレード中に OSD がリバランスされないようにします。# ceph osd set noout # ceph osd det nodeep-scrub
各 OSD ノードで、以下を実行します。
# subscription-manager repos --enable=rhel-7-server-rhceph-4-osd-rpms
Red Hat Ceph Storage 4 パッケージを有効にしたら、OSD ノードを更新します。
# yum update -y
ノードで実行している各 OSD デーモンについて、以下のコマンドを実行します。
# systemctl restart ceph-osd@<osd-num>
<osd-num>を、再起動する osd 番号に置き換えてください。次の OSD ノードに進む前に、ノード上の全 OSD が再起動したことを確認します。ceph-diskを使用してデプロイされたストレージクラスターに OSD がある場合には、ceph-volumeにデーモンを起動するように指示します。# ceph-volume simple scan # ceph-volume simple activate --all
Nautilus の機能のみを有効にします。
# ceph osd require-osd-release nautilus
重要このステップの実行に失敗すると、
msgr2が有効になってから OSD が通信できなくなります。すべての OSD ノードをアップグレードしたら、Ceph Monitor ノードで
nooutフラグおよびnodeep-scrubフラグの設定を解除します。# ceph osd unset noout # ceph osd unset nodeep-scrub
既存の CRUSH バケットを、最新のバケットタイプ
straw2に切り替えます。# ceph osd getcrushmap -o backup-crushmap # ceph osd crush set-all-straw-buckets-to-straw2
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードした後、すべてのデーモンが更新されたら、以下のステップを実行します。
Specify v2 プロトコル
msgr2を有効にします。ceph mon enable-msgr2
これにより、古いデフォルトポート 6789 にバインドされるすべての Ceph Monitor が新しいポート 3300 にバインドされるように指示します。
monitor のステータスを確認します。
ceph mon dump
注記nautilus OSD を実行しても、v2 アドレスに自動的にバインドされません。再起動する必要があります。
-
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードされたホストごとに、
ceph.confファイルを更新して、モニターポートを指定しないか、v2 と v1 の両方のアドレスとポートを参照します。 ceph.confファイルの設定オプションをストレージクラスターの設定データベースにインポートします。例
[root@mon ~]# ceph config assimilate-conf -i /etc/ceph/ceph.conf
ストレージクラスターの設定データベースを確認してください。
例
[root@mon ~]# ceph config dump
オプション: Red Hat Ceph Storage 4 にアップグレードした後、ホストごとに最小限の
ceph.confファイルを作成します。例
[root@mon ~]# ceph config generate-minimal-conf > /etc/ceph/ceph.conf.new [root@mon ~]# mv /etc/ceph/ceph.conf.new /etc/ceph/ceph.conf
Ceph Object Gateway ノードで、以下を実行します。
# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
Red Hat Ceph Storage 4 パッケージを有効にしたら、ノードを更新して、
ceph-rgwデーモンを再起動します。# yum update -y # systemctl restart ceph-rgw@<rgw-target>
<rgw-target>を、再起動する rgw ターゲットに置き換えてください。管理ノードの場合には、以下のコマンドを実行します。
# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms # yum update -y
クラスターが正常な状態でクリーンな状態であることを確認します。
# ceph health HEALTH_OK
必要に応じて、クライアントノードで、Ceph クライアント側ライブラリーに依存するアプリケーションを再起動します。
注記QEMU または KVM インスタンスを実行している OpenStack Nova コンピュートノードをアップグレードする場合や、専用の QEMU または KVM クライアントを使用する場合には、インスタンスを再起動しても機能しないため、QEMU または KVM インスタンスを停止して起動してください。
7.5. Ceph File System Metadata Serve r ノードの手動アップグレード
Red Hat Enterprise Linux 7 または 8 を実行している Red Hat Ceph Storage クラスターで、Ceph File System (CephFS) Metadata Server (MDS) ソフトウェアを手動でアップグレードできます。
ストレージクラスターをアップグレードする前に、アクティブな MDS ランクの数を減らし、ファイルシステムごとに 1 つにします。これにより、複数の MDS 間でバージョンの競合が発生しなくなります。また、アップグレードを行う前に、すべてのスタンバイノードをオフラインにしてください。
これは、MDS クラスターにはバージョニングやファイルシステムフラグが組み込まれていないためです。これらの機能がないと、複数の MDS が異なるバージョンの MDS ソフトウェアを使用して通信することになり、アサーションやその他の不具合が発生する可能性があります。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- ノードは Red Hat Ceph Storage バージョン 3.3z64 または 4.1 を使用している。
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
基盤となる XFS ファイルシステムが ftype=1 でフォーマットされているか、d_type をサポートしている。xfs_info /var コマンドを実行し、ftype が 1 になっていることを確認します。ftype の値が 1 でない場合は、新しいディスクをアタッチするか、ボリュームを作成します。この新しいデバイスの上に、新しい XFS ファイルシステムを作成し、/var/lib/containers にマウントします。
Red Hat Enterprise Linux 8.0 以降、mkfs.xfs はデフォルトで ftype=1 を有効にします。
手順
アクティブな MDS ランクを 1 にします。
構文
ceph fs set FILE_SYSTEM_NAME max_mds 1例
[root@mds ~]# ceph fs set fs1 max_mds 1
クラスターがすべての MDS ランクを停止するのを待ちます。すべての MDS が停止したら、ランク 0 だけがアクティブになるはずです。残りはスタンバイモードにしておきます。ファイルシステムの状態を確認します。
[root@mds ~]# ceph status
systemctlを使用して、スタンバイしているすべての MDS をオフラインにします。[root@mds ~]# systemctl stop ceph-mds.target
MDS が 1 つだけオンラインになっており、ファイルシステムのランクが 0 であることを確認します。
[root@mds ~]# ceph status
RHEL 7 で Red Hat Ceph Storage 3 からアップグレードする場合は、Red Hat Ceph Storage 3 のツールリポジトリーを無効にして、Red Hat Ceph Storage 4 のツールリポジトリーを有効にします。
[root@mds ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms [root@mds ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms
ノードを更新し、ceph-mds デーモンを再起動します。
[root@mds ~]# yum update -y [root@mds ~]# systemctl restart ceph-mds.target
スタンバイ中のデーモンについても同じプロセスを実行します。ツールリポジトリーを無効にして、有効にしてから、各スタンバイ中の MDS をアップグレードし、再起動します。
[root@mds ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms [root@mds ~]# subscription-manager repos --enable=rhel-7-server-rhceph-4-tools-rpms [root@mds ~]# yum update -y [root@mds ~]# systemctl restart ceph-mds.target
スタンバイ中のすべての MDS の再起動が完了したら、ストレージクラスターの
max_mdsの値を以前の値に戻します。構文
ceph fs set FILE_SYSTEM_NAME max_mds ORIGINAL_VALUE
例
[root@mds ~]# ceph fs set fs1 max_mds 5
7.6. 関連情報
- 3.3z5 に関連するパッケージバージョンを確認するには、What are the Red Hat Ceph Storage releases and corresponding Ceph package versions? を参照してください。
第8章 Red Hat Ceph Storage クラスターおよびオペレーティングシステムの手動によるアップグレード
通常、ceph-ansible を使用する場合には、Red Hat Ceph Storage および Red Hat Enterprise Linux を同時に新しいメジャーリリースにアップグレードすることはできません。たとえば、Red Hat Enterprise Linux 7 を使用し、ceph-ansible を使用している場合は、そのバージョンを使用する必要があります。ただし、システム管理者は手動で実行できます。
本章では、Red Hat Enterprise Linux 7.9 で実行しているバージョン 4.1 または 3.3z6 の Red Hat Ceph Storage クラスターを、Red Hat Enterprise Linux 8.4 で実行するバージョン 4.2 の Red Hat Ceph Storage クラスターに手動でアップグレードします。
コンテナー化された Red Hat Ceph Storage クラスターをバージョン 3.x または 4.x からバージョン 4.2 にアップグレードする場合は、Red Hat Ceph Storage インストールガイドの サポートされている Red Hat Ceph Storage のアップグレードシナリオ、アップグレードの準備 および Ansible を使用したストレージクラスターのアップグレード の 3 つのセクションを参照してください。
既存の systemd テンプレートを移行するには、docker-to-podman Playbook を実行します。
[user@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/docker-to-podman.yml -i hosts
user は Ansible のユーザーに置き換えます。
1 つのノードに複数のデーモンが配置されている場合には、そのノードに配置されているデーモンに関する、本章の特定のセクションに従ってください。たとえば、Ceph Monitor デーモンや OSD デーモンが配置されているノードなどです。
Ceph Monitor ノードとそのオペレーティングシステムを手動でアップグレード および Ceph OSD ノードとそのオペレーティングシステムの手動によるアップグレード を参照してください。
Leapp アップグレードユーティリティーは OSD 暗号化によるアップグレードをサポートしないため、Ceph OSD ノードとオペレーティングシステムの手動アップグレードは、暗号化された OSD パーティションでは機能しません。
8.1. 前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- 各ノード で Red Hat Enterprise Linux 7.9 を使用している。
- ノードは Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を使用している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
8.2. Ceph Monitor ノードとそのオペレーティングシステムを手動でアップグレード
システム管理者は、Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph Monitor ソフトウェアを、同時に新しいメジャーリリースに手動でアップグレードできます。
一度に 1 つのモニターノードのみで手順を実施します。クラスターアクセスの問題を防ぐために、次のノードに進む 前 に、現在のアップグレードされた Monitor ノードが通常の操作に返されていることを確認してください。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- 各ノード で Red Hat Enterprise Linux 7.9 を使用している。
- ノードは Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を使用している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
手順
monitor サービスを停止します。
構文
systemctl stop ceph-mon@MONITOR_IDMONITOR_ID を Monitor の ID 番号に置き換えます。
Red Hat Ceph Storage 3 を使用している場合は、Red Hat Ceph Storage 3 リポジトリーを無効にします。
tools リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms
mon リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-mon-rpms
Red Hat Ceph Storage 4 を使用している場合は、Red Hat Ceph Storage 4 リポジトリーを無効にします。
tools リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-4-tools-rpms
mon リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-4-mon-rpms
-
leappユーティリティーをインストールします。Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード を参照してください。 - leapp のアップグレード前チェックを実行します。コマンドラインからのアップグレード可能性の評価 を参照してください。
-
/etc/ssh/sshd_configにPermitRootLogin yesを設定します。 OpenSSH SSH デーモンを再起動します。
[root@mon ~]# systemctl restart sshd.service
Linux カーネルから iSCSI モジュールを削除します。
[root@mon ~]# modprobe -r iscsi
- RHEL 7 から RHEL 8 へのアップグレードの実行 に従って、アップグレードを実行します。
- ノードを再起動します。
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のリポジトリーを有効にします。
tools リポジトリーを有効にします。
[root@mon ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
mon リポジトリーを有効にします。
[root@mon ~]# subscription-manager repos --enable=rhceph-4-mon-for-rhel-8-x86_64-rpms
ceph-monパッケージをインストールします。[root@mon ~]# dnf install ceph-mon
マネージャーサービスが monitor サービスと同じ場所にある場合は、
ceph-mgrパッケージをインストールします。[root@mon ~]# dnf install ceph-mgr
-
アップグレードされていない、またはそれらのファイルをすでに復元しているノードから、
ceph-client-admin.keyringファイルおよびceph.confファイルを復元します。 既存の CRUSH バケットを、最新のバケットタイプ
straw2に切り替えます。# ceph osd getcrushmap -o backup-crushmap # ceph osd crush set-all-straw-buckets-to-straw2
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードした後、すべてのデーモンが更新されたら、以下のステップを実行します。
Specify v2 プロトコル
msgr2を有効にします。ceph mon enable-msgr2
これにより、古いデフォルトポート 6789 にバインドされるすべての Ceph Monitor が新しいポート 3300 にバインドされるように指示します。
重要さらに Ceph Monitor 設定を実行する前に、すべての Ceph Monitor が Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードされていることを確認してください。
monitor のステータスを確認します。
ceph mon dump
注記nautilus OSD を実行しても、v2 アドレスに自動的にバインドされません。再起動する必要があります。
Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードされたホストごとに、
ceph.confファイルを更新して、モニターポートを指定しないか、v2 と v1 の両方のアドレスとポートを参照します。ceph.confファイルの設定オプションをストレージクラスターの設定データベースにインポートします。例
[root@mon ~]# ceph config assimilate-conf -i /etc/ceph/ceph.conf
ストレージクラスターの設定データベースを確認してください。
例
[root@mon ~]# ceph config dump
オプション: Red Hat Ceph Storage 4 にアップグレードした後、ホストごとに最小限の
ceph.confファイルを作成します。例
[root@mon ~]# ceph config generate-minimal-conf > /etc/ceph/ceph.conf.new [root@mon ~]# mv /etc/ceph/ceph.conf.new /etc/ceph/ceph.conf
leveldbパッケージをインストールします。[root@mon ~]# dnf install leveldb
monitor サービスを起動します。
[root@mon ~]# systemctl start ceph-mon.target
マネージャーサービスが monitor サービスと同じ場所にある場合は、マネージャーサービスも起動します。
[root@mon ~]# systemctl start ceph-mgr.target
モニターサービスが復旧し、クォーラムになっていることを確認します。
[root@mon ~]# ceph -s
services: の mon: 行で、ノードが 定足数 の外ではなく 定足数 内にリスト表示されていることを確認します。
例
mon: 3 daemons, quorum ceph4-mon,ceph4-mon2,ceph4-mon3 (age 2h)
マネージャーサービスが monitor サービスと同じ場所にある場合は、それも稼働していることを確認します。
[root@mon ~]# ceph -s
services の下にある mgr: 行でマネージャーのノード名を検索します。
例
mgr: ceph4-mon(active, since 2h), standbys: ceph4-mon3, ceph4-mon2
- すべてのアップグレードが完了するまで、すべての監視ノードで上記の手順を繰り返します。
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
8.3. Ceph OSD ノードとそのオペレーティングシステムの手動によるアップグレード
システム管理者は、Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph OSD ソフトウェアを、同時に新しいメジャーリリースに手動でアップグレードできます。
この手順は、Ceph クラスターの各 OSD ノードに対して実行する必要がありますが、通常は一度に 1 つの OSD ノードに対してのみ実行してください。OSD ノードに相当する最大 1 つ障害ドメインを並行して実行することが可能です。たとえば、ラックごとのレプリケーションが使用されている場合は、ラックの OSD ノード全体を並行してアップグレードできます。データへのアクセスの問題を防ぐには、現在の OSD ノードの OSD が正常な動作に戻り、クラスターの PG が すべて次の OSD に進む 前 に active+clean 状態にあることを確認します。
Leapp アップグレードユーティリティーは OSD 暗号化によるアップグレードをサポートしないため、この手順は暗号化された OSD パーティションでは機能しません。
OSD が ceph-disk を使用して作成されていて、ceph-disk が管理している場合には、ceph-volume を使用してそれらの管理を引き継ぐ必要があります。これは、以下の任意の手順で説明されています。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- 各ノード で Red Hat Enterprise Linux 7.9 を使用している。
- ノードは Red Hat Ceph Storage バージョン 3.3z6 または 4.0 を使用している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
手順
OSD の
nooutフラグを設定して、移行中に OSD がダウンとマークされないようにします。ceph osd set noout
クラスター上で不要な負荷を回避するには、OSD
nobackfillフラグ、norecoverフラグ、norrebalanceフラグ、noscrubフラグ、およびnodeep-scrubフラグを設定し、ノードが移行のためにダウンした場合にデータの再起動を回避します。ceph osd set nobackfill ceph osd set norecover ceph osd set norebalance ceph osd set noscrub ceph osd set nodeep-scrub
ノード上のすべての OSD プロセスを正常にシャットダウンします。
[root@mon ~]# systemctl stop ceph-osd.target
Red Hat Ceph Storage 3 を使用している場合は、Red Hat Ceph Storage 3 リポジトリーを無効にします。
tools リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms
osd リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-osd-rpms
Red Hat Ceph Storage 4 を使用している場合は、Red Hat Ceph Storage 4 リポジトリーを無効にします。
tools リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-4-tools-rpms
osd リポジトリーを無効にします。
[root@mon ~]# subscription-manager repos --disable=rhel-7-server-rhceph-4-osd-rpms
-
leappユーティリティーをインストールします。Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード を参照してください。 - leapp のアップグレード前チェックを実行します。コマンドラインからのアップグレード可能性の評価 を参照してください。
-
/etc/ssh/sshd_configにPermitRootLogin yesを設定します。 OpenSSH SSH デーモンを再起動します。
[root@mon ~]# systemctl restart sshd.service
Linux カーネルから iSCSI モジュールを削除します。
[root@mon ~]# modprobe -r iscsi
- RHEL 7 から RHEL 8 へのアップグレードの実行 に従って、アップグレードを実行します。
- ノードを再起動します。
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のリポジトリーを有効にします。
tools リポジトリーを有効にします。
[root@mon ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
osd リポジトリーを有効にします。
[root@mon ~]# subscription-manager repos --enable=rhceph-4-osd-for-rhel-8-x86_64-rpms
ceph-osdパッケージをインストールします。[root@mon ~]# dnf install ceph-osd
leveldbパッケージをインストールします。[root@mon ~]# dnf install leveldb
-
まだアップグレードされていないノードから、またはそれらのファイルがすでに復元されているノードから、
ceph.confファイルを復元します。 noout、nobackfill、norecover、norrebalance、noscrub、およびnodeep-scrubフラグの設定を解除します。# ceph osd unset noout # ceph osd unset nobackfill # ceph osd unset norecover # ceph osd unset norebalance # ceph osd unset noscrub # ceph osd unset nodeep-scrub
既存の CRUSH バケットを、最新のバケットタイプ
straw2に切り替えます。# ceph osd getcrushmap -o backup-crushmap # ceph osd crush set-all-straw-buckets-to-straw2
必要に応じて、OSD が
ceph-diskを使用して作成されていて、ceph-diskで引き続き管理されている場合には、ceph-volumeを使用してそれらの管理を引き継ぐ必要があります。各オブジェクトのストレージデバイスをマウントします。
構文
/dev/DRIVE /var/lib/ceph/osd/ceph-OSD_ID
DRIVE は、ストレージデバイス名とパーティション番号に置き換えます。
OSD_ID を OSD ID に置き換えます。
例
[root@mon ~]# mount /dev/sdb1 /var/lib/ceph/osd/ceph-0
ID_NUMBER が正しいことを確認します。
構文
cat /var/lib/ceph/osd/ceph-OSD_ID/whoamiOSD_ID を OSD ID に置き換えます。
例
[root@mon ~]# cat /var/lib/ceph/osd/ceph-0/whoami 0
追加のオブジェクトストアデバイスに対して上記の手順を繰り返します。
新たにマウントしたデバイスをスキャンします。
構文
ceph-volume simple scan /var/lib/ceph/osd/ceph-OSD_IDOSD_ID を OSD ID に置き換えます。
例
[root@mon ~]# ceph-volume simple scan /var/lib/ceph/osd/ceph-0 stderr: lsblk: /var/lib/ceph/osd/ceph-0: not a block device stderr: lsblk: /var/lib/ceph/osd/ceph-0: not a block device stderr: Unknown device, --name=, --path=, or absolute path in /dev/ or /sys expected. Running command: /usr/sbin/cryptsetup status /dev/sdb1 --> OSD 0 got scanned and metadata persisted to file: /etc/ceph/osd/0-0c9917f7-fce8-42aa-bdec-8c2cf2d536ba.json --> To take over management of this scanned OSD, and disable ceph-disk and udev, run: --> ceph-volume simple activate 0 0c9917f7-fce8-42aa-bdec-8c2cf2d536ba
追加のオブジェクトストアデバイスに対して上記の手順を繰り返します。
デバイスをアクティベートします。
構文
ceph-volume simple activate OSD_ID UUID
OSD_ID を OSD ID に置き換え、UUID を、以前のスキャン出力で出力される UUID に置き換えます。
例
[root@mon ~]# ceph-volume simple activate 0 0c9917f7-fce8-42aa-bdec-8c2cf2d536ba Running command: /usr/bin/ln -snf /dev/sdb2 /var/lib/ceph/osd/ceph-0/journal Running command: /usr/bin/chown -R ceph:ceph /dev/sdb2 Running command: /usr/bin/systemctl enable ceph-volume@simple-0-0c9917f7-fce8-42aa-bdec-8c2cf2d536ba stderr: Created symlink /etc/systemd/system/multi-user.target.wants/ceph-volume@simple-0-0c9917f7-fce8-42aa-bdec-8c2cf2d536ba.service → /usr/lib/systemd/system/ceph-volume@.service. Running command: /usr/bin/ln -sf /dev/null /etc/systemd/system/ceph-disk@.service --> All ceph-disk systemd units have been disabled to prevent OSDs getting triggered by UDEV events Running command: /usr/bin/systemctl enable --runtime ceph-osd@0 stderr: Created symlink /run/systemd/system/ceph-osd.target.wants/ceph-osd@0.service → /usr/lib/systemd/system/ceph-osd@.service. Running command: /usr/bin/systemctl start ceph-osd@0 --> Successfully activated OSD 0 with FSID 0c9917f7-fce8-42aa-bdec-8c2cf2d536ba
追加のオブジェクトストアデバイスに対して上記の手順を繰り返します。
必要に応じて、OSD が
ceph-volumeで作成され、直前の手順を完了していない場合は、ここで OSD サービスを起動します。[root@mon ~]# systemctl start ceph-osd.target
OSD をアクティベートします。
BlueStore
[root@mon ~]# ceph-volume lvm activate --all
OSD が
upおよびinになっていること、ならびに、active+clean状態にあることを確認します。[root@mon ~]# ceph -s
services: サービス下の osd: 行で、すべての OSD が
upおよびinであることを確認します。例
osd: 3 osds: 3 up (since 8s), 3 in (since 3M)
- すべての OSD ノードがアップグレードされるまで、上記の手順をすべての OSD ノードで繰り返します。
Red Hat Ceph Storage 3 からアップグレードする場合は、pre-Nautilus OSD は使用できず、Nautilus 専用機能を有効にします。
[root@mon ~]# ceph osd require-osd-release nautilus
注記このステップの実行に失敗すると、
msgrv2が有効になってからは OSD の通信ができなくなります。Red Hat Ceph Storage 3 から Red Hat Ceph Storage 4 にアップグレードした後、すべてのデーモンが更新されたら、以下のステップを実行します。
Specify v2 プロトコル
msgr2を有効にします。[root@mon ~]# ceph mon enable-msgr2
これにより、古いデフォルトポート 6789 にバインドされるすべての Ceph Monitor が新しいポート 3300 にバインドされるように指示します。
すべてのノードで、
ceph.confファイルの設定オプションをストレージクラスターの設定データベースにインポートします。例
[root@mon ~]# ceph config assimilate-conf -i /etc/ceph/ceph.conf
注記同じオプションセットに異なる設定値が設定されている場合など、モニターに設定をシミュレーションする場合、最終的な結果は、ファイルがシミュレートされる順序によって異なります。
ストレージクラスターの設定データベースを確認します。
例
[root@mon ~]# ceph config dump
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
8.4. Ceph Object Gateway ノードとそのオペレーティングシステムの手動によるアップグレード
システム管理者は、Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph Object Gateway (RGW) ソフトウェアを、同時に新しいメジャーリリースに手動でアップグレードできます。
この手順は、Ceph クラスターの各 RGW ノードに対して実行する必要がありますが、一度に 1 つの RGW ノードに対してのみ実行してください。現在アップグレードした RGW が通常操作に戻るには、クライアントアクセスの問題を防ぐために、次のノードに進む 前 に、通常の操作に戻ります。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- 各ノード で Red Hat Enterprise Linux 7.9 を使用している。
- ノードは Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を使用している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
手順
Ceph Object Gateway サービスを停止します。
# systemctl stop ceph-radosgw.target
Red Hat Ceph Storage 3 を使用している場合は、Red Hat Ceph Storage 3 ツールリポジトリーを無効にします。
# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms
Red Hat Ceph Storage 4 を使用している場合は、Red Hat Ceph Storage 4 ツールリポジトリーを無効にします。
# subscription-manager repos --disable=rhel-7-server-rhceph-4-tools-rpms
-
leappユーティリティーをインストールします。Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード を参照してください。 - leapp のアップグレード前チェックを実行します。コマンドラインからのアップグレード可能性の評価 を参照してください。
-
/etc/ssh/sshd_configにPermitRootLogin yesを設定します。 OpenSSH SSH デーモンを再起動します。
# systemctl restart sshd.service
Linux カーネルから iSCSI モジュールを削除します。
# modprobe -r iscsi
- RHEL 7 から RHEL 8 へのアップグレードの実行 に従って、アップグレードを実行します。
- ノードを再起動します。
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のツールリポジトリーを有効にします。
# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ceph-radosgwパッケージをインストールします。# dnf install ceph-radosgw
- 必要に応じて、このノードにコロケーションされる Ceph サービスのパッケージをインストールします。必要に応じて追加の Ceph リポジトリーを有効にします。
必要に応じて、他の Ceph サービスに必要な
leveldbパッケージをインストールします。# dnf install leveldb
-
アップグレードされていないノードまたはそれらのファイルを復元しているノードから
ceph-client-admin.keyringファイルおよびceph.confファイルを復元します。 RGW サービスを起動します。
# systemctl start ceph-radosgw.target
既存の CRUSH バケットを、最新のバケットタイプ
straw2に切り替えます。# ceph osd getcrushmap -o backup-crushmap # ceph osd crush set-all-straw-buckets-to-straw2
デーモンがアクティブであることを確認します。
# ceph -s
services: の下に rgw: 行があります。
例
rgw: 1 daemon active (jb-ceph4-rgw.rgw0)
- すべてがアップグレードされるまで、すべての Ceph ObjectGateway ノードで上記の手順を繰り返します。
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
8.5. Ceph Dashboard ノードとそのオペレーティングシステムを手動でアップグレード
システム管理者は、Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph Dashboard ソフトウェアを同時に新しいメジャーリリースにアップグレードできます。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- ノードで Red Hat Enterprise Linux 7.9 を実行している。
- ノードが Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を実行している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
手順
クラスターから既存のダッシュボードをアンインストールします。
/usr/share/cephmetrics-ansibleディレクトリーに移動します。# cd /usr/share/cephmetrics-ansible
Ansible Playbook の
purge.ymlを実行します。# ansible-playbook -v purge.yml
Red Hat Ceph Storage 3 を使用している場合は、Red Hat Ceph Storage 3 ツールリポジトリーを無効にします。
# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms
Red Hat Ceph Storage 4 を使用している場合は、Red Hat Ceph Storage 4 ツールリポジトリーを無効にします。
# subscription-manager repos --disable=rhel-7-server-rhceph-4-tools-rpms
-
leappユーティリティーをインストールします。Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード を参照してください。 -
leappのアップグレード前のチェックを行います。コマンドラインからのアップグレード可能性の評価 を参照してください。 -
/etc/ssh/sshd_configにPermitRootLogin yesを設定します。 OpenSSH SSH デーモンを再起動します。
# systemctl restart sshd.service
Linux カーネルから iSCSI モジュールを削除します。
# modprobe -r iscsi
- RHEL 7 から RHEL 8 へのアップグレードの実行 に従って、アップグレードを実行します。
- ノードを再起動します。
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のツールリポジトリーを有効にします。
# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
Ansible リポジトリーを有効にします。
# subscription-manager repos --enable=ansible-2.9-for-rhel-8-x86_64-rpms
-
クラスターを管理するために
ceph-ansibleを設定します。ダッシュボードがインストールされます。Ansible を使用した Red Hat Ceph Storage のインストール (前提条件を含む) の手順に従ってください。 -
上記の手順の一部として
ansible-playbook site.ymlを実行すると、ダッシュボードの URL が出力されます。URL の場所とダッシュボードへのアクセスに関する詳細は、ダッシュボード の Ansible を使用したダッシュボードのインストール を参照してください。
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
- 詳細は、ダッシュボード の Ansible を使用したダッシュボードのインストール 参照してください。
8.6. Ceph Ansible ノードの手動でのアップグレードと再設定
Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph Ansible ソフトウェアを、同時に新しいメジャーリリースに手動でアップグレードできます。この手順は、指定しない限り、ベアメタルおよびコンテナーのデプロイメントの両方に適用されます。
Ceph Ansible ノードの hostOS をアップグレードする前に、group_vars と hosts ファイルのバックアップを取ります。Ceph Ansible ノードを再設定する前に、作成したバックアップを使用します。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- ノードで Red Hat Enterprise Linux 7.9 を実行している。
- ノードが Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を実行している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
手順
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のツールリポジトリーを有効にします。
[root@dashboard ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
Ansible リポジトリーを有効にします。
[root@dashboard ~]# subscription-manager repos --enable=ansible-2.9-for-rhel-8-x86_64-rpms
-
ceph-ansibleを設定して、ストレージクラスターを管理します。ダッシュボードがインストールされます。Ansible を使用した Red Hat Ceph Storage のインストール (前提条件を含む) の手順に従ってください。 -
上記の手順の一部として
ansible-playbook site.ymlを実行すると、ダッシュボードの URL が出力されます。URL の場所とダッシュボードへのアクセスに関する詳細は、ダッシュボード の Ansible を使用したダッシュボードのインストール を参照してください。
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
- 詳細は、ダッシュボード の Ansible を使用したダッシュボードのインストール 参照してください。
8.7. Ceph File System Metadata Server ノードとそのオペレーティングシステムを手動でアップグレードします。
Red Hat Ceph Storage クラスターノードおよび Red Hat Enterprise Linux オペレーティングシステム上の Ceph File System (CephFS) Metadata Server (MDS) ソフトウェアを、同時に新しいメジャーリリースに手動でアップグレードできます。
ストレージクラスターをアップグレードする前に、アクティブな MDS ランクの数を減らし、ファイルシステムごとに 1 つにします。これにより、複数の MDS 間でバージョンの競合が発生しなくなります。また、アップグレードを行う前に、すべてのスタンバイノードをオフラインにしてください。
これは、MDS クラスターにはバージョニングやファイルシステムフラグが組み込まれていないためです。これらの機能がないと、複数の MDS が異なるバージョンの MDS ソフトウェアを使用して通信することになり、アサーションやその他の不具合が発生する可能性があります。
前提条件
- Red Hat Ceph Storage クラスターが実行されている。
- 各ノード で Red Hat Enterprise Linux 7.9 を使用している。
- ノードは Red Hat Ceph Storage バージョン 3.3z6 または 4.1 を使用している。
- Red Hat Enterprise Linux 8.3 のインストールソースにアクセスできる。
- ストレージクラスター内のすべてのノードへの root レベルのアクセス。
基盤となる XFS ファイルシステムが ftype=1 でフォーマットされているか、d_type をサポートしている。xfs_info /var コマンドを実行し、ftype が 1 になっていることを確認します。ftype の値が 1 でない場合は、新しいディスクをアタッチするか、ボリュームを作成します。この新しいデバイスの上に、新しい XFS ファイルシステムを作成し、/var/lib/containers にマウントします。
Red Hat Enterprise Linux 8 以降、mkfs.xfs はデフォルトで ftype=1 を有効にします。
手順
アクティブな MDS ランクを 1 にします。
構文
ceph fs set FILE_SYSTEM_NAME max_mds 1例
[root@mds ~]# ceph fs set fs1 max_mds 1
クラスターがすべての MDS ランクを停止するのを待ちます。すべての MDS が停止したら、ランク 0 だけがアクティブになるはずです。残りはスタンバイモードにしておきます。ファイルシステムの状態を確認します。
[root@mds ~]# ceph status
systemctlを使用して、スタンバイしているすべての MDS をオフラインにします。[root@mds ~]# systemctl stop ceph-mds.target
MDS が 1 つだけオンラインになっており、ファイルシステムのランクが 0 であることを確認します。
[root@mds ~]# ceph status
OS のバージョンに合わせて、ツールのリポジトリーを無効にします。
RHEL 7 で Red Hat Ceph Storage 3 からアップグレードする場合は、Red Hat Ceph Storage 3 のツールリポジトリーを無効にします。
[root@mds ~]# subscription-manager repos --disable=rhel-7-server-rhceph-3-tools-rpms
Red Hat Ceph Storage 4 を使用している場合は、Red Hat Ceph Storage 4 のツールリポジトリーを無効にします。
[root@mds ~]# subscription-manager repos --disable=rhel-7-server-rhceph-4-tools-rpms
-
leappユーティリティーをインストールします。leappの詳細については、Red Hat Enterprise Linux 7 から Red Hat Enterprise Linux 8 へのアップグレード を参照してください。 -
leappのアップグレード前のチェックを行います。詳細は、コマンドラインからのアップグレード可能性の評価 を参照してください。 -
etc/ssh/sshd_configを編集し、PermitRootLoginをyesに設定します。 OpenSSH SSH デーモンを再起動します。
[root@mds ~]# systemctl restart sshd.service
Linux カーネルから iSCSI モジュールを削除します。
[root@mds ~]# modprobe -r iscsi
- アップグレードを行います。RHEL 7 から RHEL 8 へのアップグレードの実行 を参照してください。
- MDS ノードを再起動します。
Red Hat Ceph Storage 4 for Red Hat Enterprise Linux 8 のツールリポジトリーを有効にします。
[root@mds ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
ceph-mdsパッケージをインストールします。[root@mds ~]# dnf install ceph-mds -y
- 必要に応じて、このノードにコロケーションされる Ceph サービスのパッケージをインストールします。必要に応じて、追加の Ceph リポジトリーを有効にします。
必要に応じて、他の Ceph サービスに必要な
leveldbパッケージをインストールします。[root@mds ~]# dnf install leveldb
-
アップグレードされていないノードまたはそれらのファイルを復元しているノードから
ceph-client-admin.keyringファイルおよびceph.confファイルを復元します。 既存の CRUSH バケットを、最新のバケットタイプ
straw2に切り替えます。# ceph osd getcrushmap -o backup-crushmap # ceph osd crush set-all-straw-buckets-to-straw2
MDS サービスを開始します。
[root@mds ~]# systemctl restart ceph-mds.target
デーモンが有効であることを確認します。
[root@mds ~]# ceph -s
- スタンバイ中のデーモンについても同じプロセスを実行します。
スタンバイ中のすべての MDS の再起動が完了したら、クラスターの
max_mdsの値を以前の値に戻します。構文
ceph fs set FILE_SYSTEM_NAME max_mds ORIGINAL_VALUE
例
[root@mds ~]# ceph fs set fs1 max_mds 5
8.8. OSD ノードでのオペレーティングシステムのアップグレード失敗からの復旧
システム管理者は、手動で Ceph OSD ノードとそのオペレーティングシステムをアップグレード する手順に障害が発生した場合に、以下の手順に従って障害から回復することができます。この手順では、ノードに Red Hat Enterprise Linux 8.4 を新規インストールし、OSD が停止している間にダウンしていた書き込み以外に、データを大幅に埋め戻すことなく OSD を回復できます。
OSD をサポートするメディアや、それぞれの wal.db データベースまたは block.db データベースには影響を及ぼさないようにしてください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- アップグレードに失敗した OSD ノード。
- Red Hat Enterprise Linux 8.4 のインストールソースにアクセスできる。
手順
障害のあるノードで Red Hat Enterprise Linux 8.4 の標準的なインストールを実行し、Red Hat Enterprise Linux リポジトリーを有効にします。
Red Hat Enterprise Linux 8 用の Red Hat Ceph Storage 4 用のリポジトリーを有効にします。
tools リポジトリーを有効にします。
# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
osd リポジトリーを有効にします。
# subscription-manager repos --enable=rhceph-4-osd-for-rhel-8-x86_64-rpms
ceph-osdパッケージをインストールします。# dnf install ceph-osd
-
アップグレードされていないノードから、またはそれらのファイルがすでに復元されているノードから、
ceph.confファイルを/etc/cephに復元します。 OSD サービスを起動します。
# systemctl start ceph-osd.target
オブジェクトストアデバイスをアクティブにします。
ceph-volume lvm activate --all
OSD のリカバリーおよびクラスターのバックフィルが、復旧した OSD への書き込みを確認します。
# ceph -w
すべての PG が
active+cleanの状態になるまで、出力を監視します。
関連情報
- 詳細は、インストールガイド の Red Hat Ceph Storage クラスターおよびオペレーティングシステムを手動でアップグレード を参照してください。
- 詳細は、RHEL 7 から RHEL 8 へのアップグレード を参照してください。
8.9. 関連情報
- オペレーティングシステムを新しいメジャーリリースにアップグレードする必要がない場合は、Red Hat Ceph Storage クラスターのアップグレード を参照してください。
第9章 次のステップ
これは、最新のデータセンターの困難なストレージ要求を満たすために Red Hat Ceph Storage が実行できることの開始点にすぎません。以下は、さまざまなトピックの情報へのリンクになります。
- パフォーマンスのベンチマークとパフォーマンスカウンターへのアクセスは、Red Hat Ceph Storage 4 の管理ガイドの パフォーマンスのベンチマーク の章を参照してください。
- スナップショットの作成および管理。Red Hat Ceph Storage 4 の ブロックデバイスガイド のスナップショットの章を参照してください。
- Red Hat Ceph Storage クラスターの拡張については Red Hat Ceph Storage 4 のオペレーションガイドの ストレージクラスターサイズの管理 の章を参照してください。
- Ceph Block Device のミラーリングは、Red Hat Ceph Storage 4 のブロックデバイスガイドの ブロックデバイスのミラーリング の章を参照してください。
- プロセス管理。Red Hat Ceph Storage 4 の管理ガイドの プロセスの管理 の章を参照してください。
- 調整可能なパラメーター。Red Hat Ceph Storage 4 の 設定ガイド を参照してください。
- OpenStack のバックエンドストレージとして Ceph を使用する場合には、Red Hat OpenStack Platform の ストレージガイドの バックエンド セクションを参照してください。
- Ceph Dashboard を使用して、Red Hat Ceph Storage クラスターの正常性および容量を監視します。詳細は、ダッシュボードガイド を参照してください。
付録A トラブルシューティング
A.1. 予想したデバイスよりも少ないため、Ansible がインストールを停止します。
Ansible 自動化アプリケーションはインストールプロセスを停止し、以下のエラーを返します。
- name: fix partitions gpt header or labels of the osd disks (autodiscover disks)
shell: "sgdisk --zap-all --clear --mbrtogpt -- '/dev/{{ item.0.item.key }}' || sgdisk --zap-all --clear --mbrtogpt -- '/dev/{{ item.0.item.key }}'"
with_together:
- "{{ osd_partition_status_results.results }}"
- "{{ ansible_devices }}"
changed_when: false
when:
- ansible_devices is defined
- item.0.item.value.removable == "0"
- item.0.item.value.partitions|count == 0
- item.0.rc != 0エラー内容:
/usr/share/ceph-ansible/group_vars/osds.yml ファイルで osd_auto_discovery パラメーターが true に設定されている場合、Ansible は利用可能なすべてのデバイスを自動的に検出して設定します。このプロセス中、Ansible はすべての OSD が同じデバイスを使用することを想定します。デバイスは、Ansible が名前を検出するのと同じ順序で名前を取得します。いずれかの OSD でデバイスのいずれかが失敗すると、Ansible は障害が発生したデバイスの検出に失敗し、インストールプロセス全体を停止します。
状況例:
-
3 つの OSD ノード (
host1、host2、host3) は、/dev/sdbディスク、/dev/sdcディスク、およびdev/sddディスクを使用します。 -
host2では、/dev/sdcディスクに障害が発生し、削除されます。 -
次回の再起動時に、Ansible は削除した
/dev/sdcディスクの検出に失敗し、host2、/dev/sdbおよび/dev/sdc(以前は/dev/sdd) には 2 つのディスクのみが使用されることを想定します。 - Ansible はインストールプロセスを停止し、上記のエラーメッセージを返します。
この問題を修正するには、以下を実行します。
/etc/ansible/hosts ファイルで、障害が発生したディスクを持つ OSD ノードが使用するデバイスを指定します (上記の例の host2 )。
[osds] host1 host2 devices="[ '/dev/sdb', '/dev/sdc' ]" host3
詳細は5章Ansible を使用した Red Hat Ceph Storage のインストール をご覧ください。
付録B コマンドラインインターフェイスを使用した Ceph ソフトウェアのインストール
ストレージ管理者は、Red Hat Ceph Storage ソフトウェアのさまざまなコンポーネントを手動でインストールすることを選択できます。
B.1. Ceph コマンドラインインターフェイスのインストール
Ceph コマンドラインインターフェイス (CLI) により、管理者は Ceph 管理コマンドを実行できます。CLI は ceph-common パッケージにより提供され、以下のユーティリティーが含まれます。
-
ceph -
ceph-authtool -
ceph-dencoder -
rados
前提条件
-
稼働中の Ceph ストレージクラスター (
active + cleanの状態が望ましい)。
手順
クライアントノードで、Red Hat Ceph Storage 4 Tools リポジトリーを有効にします。
[root@gateway ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-rpms
クライアントノードで、
ceph-commonパッケージをインストールします。# yum install ceph-common
最初の監視ノードから、Ceph 設定ファイル (ここでは
ceph.conf) と管理キーリングをクライアントノードにコピーします。構文
# scp /etc/ceph/ceph.conf <user_name>@<client_host_name>:/etc/ceph/ # scp /etc/ceph/ceph.client.admin.keyring <user_name>@<client_host_name:/etc/ceph/
例
# scp /etc/ceph/ceph.conf root@node1:/etc/ceph/ # scp /etc/ceph/ceph.client.admin.keyring root@node1:/etc/ceph/
<client_host_name>を、クライアントノードのホスト名に置き換えてください。
B.2. Red Hat Ceph Storage の手動インストール
Red Hat は、手動でデプロイしたクラスターのアップグレードをサポートしたり、テストしたりしません。したがって、Red Hat は、Ansible を使用して Red Hat Ceph Storage 4 で新規クラスターをデプロイすることを推奨します。詳細は5章Ansible を使用した Red Hat Ceph Storage のインストール をご覧ください。
Yum などのコマンドラインユーティリティーを使用して、手動でデプロイされたクラスターをアップグレードすることができますが、Red Hat ではこのアプローチのサポートまたはテストを行いません。
すべての Ceph クラスターにはモニターが少なくとも 1 つ、最低でも OSD がクラスターに保存されているオブジェクトのコピーとして必要になります。Red Hat は、実稼働環境に 3 台のモニターを使用し、少なくとも 3 つのオブジェクトストレージデバイス (OSD) を使用することを推奨します。
初期モニターのブートストラップは、Ceph ストレージクラスターをデプロイする最初のステップです。Ceph monitor デプロイメントは、以下のようなクラスター全体の重要な基準も設定します。
- プールのレプリカ数
- OSD ごとの配置グループ数
- ハートビートの間隔
- 認証要件
これらの値の多くはデフォルトで設定されるため、実稼働環境用のクラスターを設定する際に便利です。
コマンドラインインターフェイスを使用して Ceph Storage クラスターをインストールするには、以下の手順を行います。
ブートストラップの監視
Monitor のブートストラップおよび Ceph Storage クラスターの拡張には、以下のデータが必要です。
- 一意識別子
-
ファイルシステム識別子 (
fsid) はクラスターの一意の識別子です。fsidは、Ceph ストレージクラスターが Ceph ファイルシステムに主に使用する場合に使用されていました。Ceph はネイティブのインターフェイス、ブロックデバイス、およびオブジェクトストレージゲートウェイのインターフェイスもサポートするようになり、fsidは一部の誤検出になります。 - 監視名
-
クラスター内の各 Monitor インスタンスには一意の名前があります。一般的には、Ceph Monitor 名はノード名です。Red Hat では、ノードごとに Ceph Monitor を 1 つ推奨していますが、Ceph OSD デーモンを Ceph Monitor デーモンと同じ場所に配置しないことを推奨します。短いノード名を取得するには、
hostname -sコマンドを使用します。 - マップの監視
初期モニターのブートストラップでは、モニターマップを生成する必要があります。Monitor マップには以下が必要です。
-
ファイルシステム識別子 (
fsid) -
クラスター名、または
cephのデフォルトのクラスター名が使用されます。 - 1 つ以上のホスト名とその IP アドレス
-
ファイルシステム識別子 (
- キーリングの監視
- モニターは、秘密鍵を使用して相互に通信します。Monitor 秘密鍵でキーリングを生成し、初期 Monitor のブートストラップ時にこれを提供する必要があります。
- 管理者キーリング
-
cephコマンドラインインターフェイスユーティリティーを使用するには、client.adminユーザーを作成し、そのキーリングを生成します。また、client.adminユーザーを Monitor キーリングに追加する必要があります。
前述の要件は、Ceph 設定ファイルの作成を意味するものではありません。ただし、Red Hat では、Ceph 設定ファイルを作成し、少なくとも fsid、mon initial members、および mon host の設定で設定することを推奨します。
実行時にすべての Monitor 設定を取得および設定できます。ただし、Ceph 設定ファイルには、デフォルト値を上書きする設定のみが含まれる場合があります。Ceph 設定ファイルに設定を追加すると、デフォルト設定が上書きされます。Ceph 設定ファイルでこれらの設定を維持すると、クラスターを簡単に維持できます。
初期モニターをブートストラップするには、以下の手順を実行します。
Red Hat Ceph Storage 4 Monitor リポジトリーを有効にします。
[root@monitor ~]# subscription-manager repos --enable=rhceph-4-mon-for-rhel-8-x86_64-rpms
初期 Monitor ノードで、
rootでceph-monパッケージをインストールします。# yum install ceph-mon
rootで、/etc/ceph/ディレクトリーに Ceph 設定ファイルを作成します。# touch /etc/ceph/ceph.conf
rootでクラスターの一意の識別子を生成し、一意の ID を Ceph 設定ファイルの[global]セクションに追加します。# echo "[global]" > /etc/ceph/ceph.conf # echo "fsid = `uuidgen`" >> /etc/ceph/ceph.conf
現在の Ceph 設定ファイルを表示します。
$ cat /etc/ceph/ceph.conf [global] fsid = a7f64266-0894-4f1e-a635-d0aeaca0e993
rootとして、最初の Monitor を Ceph 設定ファイルに追加します。構文
# echo "mon initial members = <monitor_host_name>[,<monitor_host_name>]" >> /etc/ceph/ceph.conf
例
# echo "mon initial members = node1" >> /etc/ceph/ceph.conf
rootとして、初期 Monitor の IP アドレスを Ceph 設定ファイルに追加します。構文
# echo "mon host = <ip-address>[,<ip-address>]" >> /etc/ceph/ceph.conf
例
# echo "mon host = 192.168.0.120" >> /etc/ceph/ceph.conf
注記IPv6 アドレスを使用するには、
ms bind ipv6オプションをtrueに設定します。詳細は、Red Hat Ceph Storage 4 の設定ガイドの バインド セクションを参照してください。rootとして、クラスターのキーリングを作成し、Monitor シークレットキーを生成します。# ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' creating /tmp/ceph.mon.keyring
rootで管理者キーリングを生成し、ceph.client.admin.keyringユーザーを生成し、ユーザーをキーリングに追加します。構文
# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon '<capabilites>' --cap osd '<capabilites>' --cap mds '<capabilites>'
例
# ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --set-uid=0 --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow' creating /etc/ceph/ceph.client.admin.keyring
rootでceph.client.admin.keyringキーをceph.mon.keyringに追加します。# ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring importing contents of /etc/ceph/ceph.client.admin.keyring into /tmp/ceph.mon.keyring
Monitor マップを生成します。初期 Monitor のノード名、IP アドレス、および
fsidを使用して指定し、/tmp/monmapとして保存します。構文
$ monmaptool --create --add <monitor_host_name> <ip-address> --fsid <uuid> /tmp/monmap
例
$ monmaptool --create --add node1 192.168.0.120 --fsid a7f64266-0894-4f1e-a635-d0aeaca0e993 /tmp/monmap monmaptool: monmap file /tmp/monmap monmaptool: set fsid to a7f64266-0894-4f1e-a635-d0aeaca0e993 monmaptool: writing epoch 0 to /tmp/monmap (1 monitors)
初期モニターノードで、
rootとしてデフォルトのデータディレクトリーを作成します。構文
# mkdir /var/lib/ceph/mon/ceph-<monitor_host_name>
例
# mkdir /var/lib/ceph/mon/ceph-node1
rootとして、最初の Monitor デーモンに Monitor マップとキーリングを設定します。構文
# ceph-mon --mkfs -i <monitor_host_name> --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring
例
# ceph-mon --mkfs -i node1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring ceph-mon: set fsid to a7f64266-0894-4f1e-a635-d0aeaca0e993 ceph-mon: created monfs at /var/lib/ceph/mon/ceph-node1 for mon.node1
現在の Ceph 設定ファイルを表示します。
# cat /etc/ceph/ceph.conf [global] fsid = a7f64266-0894-4f1e-a635-d0aeaca0e993 mon_initial_members = node1 mon_host = 192.168.0.120
さまざまな Ceph 設定に関する詳細は、Red Hat Ceph Storage 4 の 設定ガイド を参照してください。Ceph 設定ファイルの例では、最も一般的な設定の一部を示しています。
例
[global] fsid = <cluster-id> mon initial members = <monitor_host_name>[, <monitor_host_name>] mon host = <ip-address>[, <ip-address>] public network = <network>[, <network>] cluster network = <network>[, <network>] auth cluster required = cephx auth service required = cephx auth client required = cephx osd journal size = <n> osd pool default size = <n> # Write an object n times. osd pool default min size = <n> # Allow writing n copy in a degraded state. osd pool default pg num = <n> osd pool default pgp num = <n> osd crush chooseleaf type = <n>
rootとして、doneファイルを作成します。構文
# touch /var/lib/ceph/mon/ceph-<monitor_host_name>/done
例
# touch /var/lib/ceph/mon/ceph-node1/done
rootとして、新しく作成されたディレクトリーおよびファイルで所有者とグループのアクセス権を更新します。構文
# chown -R <owner>:<group> <path_to_directory>
例
# chown -R ceph:ceph /var/lib/ceph/mon # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown ceph:ceph /etc/ceph/ceph.client.admin.keyring # chown ceph:ceph /etc/ceph/ceph.conf # chown ceph:ceph /etc/ceph/rbdmap
注記Ceph Monitor ノードが OpenStack Controller ノードと同じ場所にある場合、Glance および Cinder キーリングファイルは、それぞれ
glanceおよびcinderによって所有されている必要があります。以下に例を示します。# ls -l /etc/ceph/ ... -rw-------. 1 glance glance 64 <date> ceph.client.glance.keyring -rw-------. 1 cinder cinder 64 <date> ceph.client.cinder.keyring ...
rootとして、初期モニターノードでceph-monプロセスを開始して有効にします。構文
# systemctl enable ceph-mon.target # systemctl enable ceph-mon@<monitor_host_name> # systemctl start ceph-mon@<monitor_host_name>
例
# systemctl enable ceph-mon.target # systemctl enable ceph-mon@node1 # systemctl start ceph-mon@node1
rootとして、monitor デーモンが実行していることを確認します。構文
# systemctl status ceph-mon@<monitor_host_name>
例
# systemctl status ceph-mon@node1 ● ceph-mon@node1.service - Ceph cluster monitor daemon Loaded: loaded (/usr/lib/systemd/system/ceph-mon@.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2018-06-27 11:31:30 PDT; 5min ago Main PID: 1017 (ceph-mon) CGroup: /system.slice/system-ceph\x2dmon.slice/ceph-mon@node1.service └─1017 /usr/bin/ceph-mon -f --cluster ceph --id node1 --setuser ceph --setgroup ceph Jun 27 11:31:30 node1 systemd[1]: Started Ceph cluster monitor daemon. Jun 27 11:31:30 node1 systemd[1]: Starting Ceph cluster monitor daemon...
Red Hat Ceph Storage Monitor をストレージクラスターに追加するには、Red Hat Ceph Storage 4 の管理ガイドの モニターの追加 セクションを参照してください。
OSD ブート制約
モニターを最初に実行したら、オブジェクトストレージデバイス (OSD) の追加を開始できます。オブジェクトのコピー数を処理するのに十分な OSD があるまで、クラスターは active + clean 状態に到達できません。
オブジェクトのデフォルトのコピー数は 3 です。少なくとも 3 つの OSD ノードが必要です。ただし、オブジェクトのコピーを 2 つだけ使用する場合には、OSD ノードを 2 つだけ追加してから、Ceph 設定ファイルの osd pool default size および osd pool default min size 設定を更新します。
詳細は、Red Hat Ceph Storage 4 の設定の OSD 設定参照 セクションを参照してください。
初期モニターのブートストラップ後に、クラスターにはデフォルトの CRUSH マップがあります。ただし、CRUSH マップには Ceph ノードにマッピングされた Ceph OSD デーモンがありません。
OSD をクラスターに追加し、デフォルトの CRUSH マップを更新するには、各 OSD ノードで以下のコマンドを実行します。
Red Hat Ceph Storage 4 OSD リポジトリーを有効にします。
[root@osd ~]# subscription-manager repos --enable=rhceph-4-osd-for-rhel-8-x86_64-rpms
rootで Ceph OSD ノードにceph-osdパッケージをインストールします。# yum install ceph-osd
Ceph 設定ファイルと管理キーリングファイルを初期 Monitor ノードから OSD ノードにコピーします。
構文
# scp <user_name>@<monitor_host_name>:<path_on_remote_system> <path_to_local_file>
例
# scp root@node1:/etc/ceph/ceph.conf /etc/ceph # scp root@node1:/etc/ceph/ceph.client.admin.keyring /etc/ceph
OSD 用の Universally Unique Identifier (UUID) を生成します。
$ uuidgen b367c360-b364-4b1d-8fc6-09408a9cda7a
rootとして、OSD インスタンスを作成します。構文
# ceph osd create <uuid> [<osd_id>]
例
# ceph osd create b367c360-b364-4b1d-8fc6-09408a9cda7a 0
注記このコマンドは、後続のステップに必要な OSD 番号識別子を出力します。
rootとして、新規 OSD のデフォルトディレクトリーを作成します。構文
# mkdir /var/lib/ceph/osd/ceph-<osd_id>
例
# mkdir /var/lib/ceph/osd/ceph-0
rootとして、OSD として使用するドライブを準備し、作成したディレクトリーにマウントします。Ceph データおよびジャーナル用にパーティションを作成します。ジャーナルとデータパーティションは同じディスクに配置できます。以下の例では、15 GB のディスクを使用しています。構文
# parted <path_to_disk> mklabel gpt # parted <path_to_disk> mkpart primary 1 10000 # mkfs -t <fstype> <path_to_partition> # mount -o noatime <path_to_partition> /var/lib/ceph/osd/ceph-<osd_id> # echo "<path_to_partition> /var/lib/ceph/osd/ceph-<osd_id> xfs defaults,noatime 1 2" >> /etc/fstab
例
# parted /dev/sdb mklabel gpt # parted /dev/sdb mkpart primary 1 10000 # parted /dev/sdb mkpart primary 10001 15000 # mkfs -t xfs /dev/sdb1 # mount -o noatime /dev/sdb1 /var/lib/ceph/osd/ceph-0 # echo "/dev/sdb1 /var/lib/ceph/osd/ceph-0 xfs defaults,noatime 1 2" >> /etc/fstab
rootとして、OSD データディレクトリーを初期化します。構文
# ceph-osd -i <osd_id> --mkfs --mkkey --osd-uuid <uuid>
例
# ceph-osd -i 0 --mkfs --mkkey --osd-uuid b367c360-b364-4b1d-8fc6-09408a9cda7a ... auth: error reading file: /var/lib/ceph/osd/ceph-0/keyring: can't open /var/lib/ceph/osd/ceph-0/keyring: (2) No such file or directory ... created new key in keyring /var/lib/ceph/osd/ceph-0/keyring
rootとして、OSD 認証キーを登録します。構文
# ceph auth add osd.<osd_id> osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-<osd_id>/keyring
例
# ceph auth add osd.0 osd 'allow *' mon 'allow profile osd' -i /var/lib/ceph/osd/ceph-0/keyring added key for osd.0
rootとして、OSD ノードを CRUSH マップに追加します。構文
# ceph osd crush add-bucket <host_name> host
例
# ceph osd crush add-bucket node2 host
rootで OSD ノードをdefaultの CRUSH ツリーに配置します。構文
# ceph osd crush move <host_name> root=default
例
# ceph osd crush move node2 root=default
rootとして、OSD ディスクを CRUSH マップに追加します。構文
# ceph osd crush add osd.<osd_id> <weight> [<bucket_type>=<bucket-name> ...]
例
# ceph osd crush add osd.0 1.0 host=node2 add item id 0 name 'osd.0' weight 1 at location {host=node2} to crush map注記CRUSH マップを逆コンパイルし、OSD をデバイスリストに追加することもできます。OSD ノードをバケットとして追加してから、デバイスを OSD ノードの項目として追加し、OSD に重みを割り当て、CRUSH マップを再コンパイルし、CRUSH マップを設定します。詳細は、Red Hat Ceph Storage 4 のストレージ戦略ガイドのセクション CRUSH マップの編集 を参照してください。
rootとして、新しく作成されたディレクトリーおよびファイルで所有者とグループのアクセス権を更新します。構文
# chown -R <owner>:<group> <path_to_directory>
例
# chown -R ceph:ceph /var/lib/ceph/osd # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown -R ceph:ceph /etc/ceph
OSD ノードは Ceph Storage クラスターの設定にあります。ただし、OSD デーモンは
downおよびinです。新しい OSD は、データの受信開始前にupである必要があります。rootとして、OSD プロセスを有効にして開始します。構文
# systemctl enable ceph-osd.target # systemctl enable ceph-osd@<osd_id> # systemctl start ceph-osd@<osd_id>
例
# systemctl enable ceph-osd.target # systemctl enable ceph-osd@0 # systemctl start ceph-osd@0
OSD デーモンを起動すると、これが
upおよびinになります。
モニターと一部の OSD が稼働しています。以下のコマンドを実行して、配置グループピアを監視できます。
$ ceph -w
OSD ツリーを表示するには、以下のコマンドを実行します。
$ ceph osd tree
例
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY -1 2 root default -2 2 host node2 0 1 osd.0 up 1 1 -3 1 host node3 1 1 osd.1 up 1 1
OSD をストレージクラスターに追加してストレージ容量を拡張するには、Red Hat Ceph Storage 4 管理ガイドの OSD の追加 セクションを参照してください。
B.3. Ceph Manager の手動インストール
通常、Ansible 自動化ユーティリティーは、Red Hat Ceph Storage クラスターをデプロイする際に Ceph Manager デーモン (ceph-mgr) をインストールします。ただし、Ansible を使用して Red Hat Ceph Storage を管理しない場合は、Ceph Manager を手動でインストールすることができます。Red Hat は、Ceph Manager デーモンと Ceph Monitor デーモンを同じノードに配置することを推奨します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
-
rootまたはsudoアクセス -
rhceph-4-mon-for-rhel-8-x86_64-rpmsリポジトリーが有効になっている -
ファイアウォールを使用している場合は、パブリックネットワーク上でポート
6800-7300を開く
手順
ceph-mgr がデプロイされるノードで、root ユーザーまたは sudo ユーティリティーで以下のコマンドを使用します。
ceph-mgrパッケージをインストールします。[root@node1 ~]# yum install ceph-mgr
/var/lib/ceph/mgr/ceph-hostname/ディレクトリーを作成します。mkdir /var/lib/ceph/mgr/ceph-hostnamehostname を、
ceph-mgrデーモンがデプロイされるノードのホスト名に置き換えます。以下に例を示します。[root@node1 ~]# mkdir /var/lib/ceph/mgr/ceph-node1
新しく作成されたディレクトリーで、
ceph-mgrデーモンの認証キーを作成します。[root@node1 ~]# ceph auth get-or-create mgr.`hostname -s` mon 'allow profile mgr' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mgr/ceph-node1/keyring
/var/lib/ceph/mgr/ディレクトリーの所有者とグループをceph:cephに変更します。[root@node1 ~]# chown -R ceph:ceph /var/lib/ceph/mgr
ceph-mgrターゲットを有効にします。[root@node1 ~]# systemctl enable ceph-mgr.target
ceph-mgrインスタンスを有効にして開始します。systemctl enable ceph-mgr@hostname systemctl start ceph-mgr@hostname
hostname を、
ceph-mgrをデプロイするノードのホスト名に置き換えます。以下に例を示します。[root@node1 ~]# systemctl enable ceph-mgr@node1 [root@node1 ~]# systemctl start ceph-mgr@node1
ceph-mgrデーモンが正常に起動していることを確認します。ceph -s
出力には、
services:セクションの下に以下の行と同様の行が含まれます。mgr: node1(active)
-
追加の
ceph-mgrデーモンをインストールして、現在のアクティブなデーモンに障害が発生した場合にアクティブになるスタンバイデーモンとして機能します。
B.4. Ceph ブロックデバイスの手動インストール
以下の手順では、シンプロビジョニングされ、サイズが変更可能な Ceph ブロックデバイスをインストールおよびマウントする方法を説明します。
Ceph ブロックデバイスは、Ceph Monitor ノードと OSD ノードとは別のノードにデプロイする必要があります。同じノードでカーネルクライアントとカーネルサーバーデーモンを実行すると、カーネルのデッドロックが発生する可能性があります。
前提条件
- 「Ceph コマンドラインインターフェイスのインストール」 セクションに記載されているタスクを実施するしておく。
- QEMU を使用する仮想マシンのバックエンドとして Ceph ブロックデバイスを使用する場合は、デフォルトのファイル記述子を増やします。詳細は、ナレッジベースの記事 Ceph - VM hangs when transferring large amounts of data to RBD disk を参照してください。
手順
OSD ノード (
osd 'allow rwx') 上のファイルへの完全なパーミッションを持つclient.rbdという名前の Ceph Block Device ユーザーを作成し、結果をキーリングファイルに出力します。ceph auth get-or-create client.rbd mon 'profile rbd' osd 'profile rbd pool=<pool_name>' \ -o /etc/ceph/rbd.keyring
<pool_name>を、client.rbdによるアクセスを許可するプールの名前 (例:rbd) に置き換えます。# ceph auth get-or-create \ client.rbd mon 'allow r' osd 'allow rwx pool=rbd' \ -o /etc/ceph/rbd.keyring
ユーザーの作成に関する詳細は、Red Hat Ceph Storage 4 管理ガイドの ユーザー管理 セクションを参照してください。
ブロックデバイスイメージを作成します。
rbd create <image_name> --size <image_size> --pool <pool_name> \ --name client.rbd --keyring /etc/ceph/rbd.keyring
<image_name>、<image_size>、および<pool_name>を指定します。以下に例を示します。$ rbd create image1 --size 4G --pool rbd \ --name client.rbd --keyring /etc/ceph/rbd.keyring
警告デフォルトの Ceph 設定には、以下の Ceph ブロックデバイス機能が含まれます。
-
layering -
exclusive-lock -
object-map -
deep-flatten -
fast-diff
カーネル RBD (
krbd) クライアントを使用する場合は、ブロックデバイスイメージをマッピングできない可能性があります。この問題を回避するには、サポートされていない機能を無効にします。これを行うには、以下のいずれかのオプションを使用します。
サポートされていない機能を動的に無効にします。
rbd feature disable <image_name> <feature_name>
以下に例を示します。
# rbd feature disable image1 object-map deep-flatten fast-diff
-
rbd createコマンドで--image-feature layeringオプションを使用して、新たに作成されたブロックデバイスイメージで階層化のみを有効にします。 Ceph 設定ファイルで機能のデフォルトを無効にします。
rbd_default_features = 1
これは既知の問題です。詳細は、Red Hat Ceph Storage 4 のリリースノートの 既知の問題 の章を参照してください。
これらの機能はすべて、ユーザー空間の RBD クライアントを使用してブロックデバイスイメージにアクセスするユーザーに機能します。
-
新規に作成されたイメージをブロックデバイスにマッピングします。
rbd map <image_name> --pool <pool_name>\ --name client.rbd --keyring /etc/ceph/rbd.keyring
以下に例を示します。
# rbd map image1 --pool rbd --name client.rbd \ --keyring /etc/ceph/rbd.keyring
ファイルシステムを作成してブロックデバイスを使用します。
mkfs.ext4 /dev/rbd/<pool_name>/<image_name>
以下のように、プール名とイメージ名を指定します。
# mkfs.ext4 /dev/rbd/rbd/image1
このアクションには少し時間がかかる場合があります。
新しく作成されたファイルシステムをマウントします。
mkdir <mount_directory> mount /dev/rbd/<pool_name>/<image_name> <mount_directory>
以下に例を示します。
# mkdir /mnt/ceph-block-device # mount /dev/rbd/rbd/image1 /mnt/ceph-block-device
関連情報
- Red Hat Ceph Storage 4 の ブロックデバイスガイド
B.5. Ceph Object Gateway の手動インストール
Ceph Object Gateway は RADOS ゲートウェイとしても知られている librados API 上に構築されたオブジェクトストレージインターフェイスで、RESTful ゲートウェイを Ceph ストレージクラスターに提供します。
前提条件
-
稼働中の Ceph ストレージクラスター (
active + cleanの状態が望ましい)。 - 3章Red Hat Ceph Storage のインストール要件 に記載されているタスクを実行します。
手順
Red Hat Ceph Storage 4 Tools リポジトリーを有効にします。
[root@gateway ~]# subscription-manager repos --enable=rhceph-4-tools-for-rhel-8-x86_64-debug-rpms
Object Gateway ノードで、
ceph-radosgwパッケージをインストールします。# yum install ceph-radosgw
初期モニターノードで、以下の手順を実施します。
以下のように Ceph 設定ファイルを更新します。
[client.rgw.<obj_gw_hostname>] host = <obj_gw_hostname> rgw frontends = "civetweb port=80" rgw dns name = <obj_gw_hostname>.example.com
ここで、
<obj_gw_hostname>はゲートウェイノードの短縮ホスト名です。短縮ホスト名を表示するには、hostname -sコマンドを使用します。更新された設定ファイルを新しい Object Gateway ノードおよび Ceph Storage クラスターのその他のノードにコピーします。
構文
# scp /etc/ceph/ceph.conf <user_name>@<target_host_name>:/etc/ceph
例
# scp /etc/ceph/ceph.conf root@node1:/etc/ceph/
ceph.client.admin.keyringファイルを新しい Object Gateway ノードにコピーします。構文
# scp /etc/ceph/ceph.client.admin.keyring <user_name>@<target_host_name>:/etc/ceph/
例
# scp /etc/ceph/ceph.client.admin.keyring root@node1:/etc/ceph/
Object Gateway ノードで、データディレクトリーを作成します。
# mkdir -p /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`
Object Gateway ノードで、ユーザーとキーリングを追加して、Object Gateway をブートストラップします。
構文
# ceph auth get-or-create client.rgw.`hostname -s` osd 'allow rwx' mon 'allow rw' -o /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`/keyring
例
# ceph auth get-or-create client.rgw.`hostname -s` osd 'allow rwx' mon 'allow rw' -o /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`/keyring
重要ゲートウェイキーの機能を提供する場合は、読み取り機能を指定する必要があります。ただし、Monitor 書き込み機能を提供することはオプションです。指定した場合、Ceph Object Gateway はプールを自動的に作成できます。
このような場合は、プール内の配置グループの数に適切な数を指定してください。そうでない場合には、ゲートウェイはデフォルトの番号を使用しますが、これはニーズに適しているとは 限りません。詳細は、Ceph Placement Groups (PGs) per Pool Calculator を参照してください。
Object Gateway ノードで、
doneファイルを作成します。# touch /var/lib/ceph/radosgw/ceph-rgw.`hostname -s`/done
Object Gateway ノードで、所有者およびグループのパーミッションを変更します。
# chown -R ceph:ceph /var/lib/ceph/radosgw # chown -R ceph:ceph /var/log/ceph # chown -R ceph:ceph /var/run/ceph # chown -R ceph:ceph /etc/ceph
Object Gateway ノードで、TCP ポート 8080 を開きます。
# firewall-cmd --zone=public --add-port=8080/tcp # firewall-cmd --zone=public --add-port=8080/tcp --permanent
Object Gateway ノードで、
ceph-radosgwプロセスを開始して有効にします。構文
# systemctl enable ceph-radosgw.target # systemctl enable ceph-radosgw@rgw.<rgw_hostname> # systemctl start ceph-radosgw@rgw.<rgw_hostname>
例
# systemctl enable ceph-radosgw.target # systemctl enable ceph-radosgw@rgw.node1 # systemctl start ceph-radosgw@rgw.node1
インストールが完了すると、書き込み機能が Monitor に設定されると、Ceph Object Gateway はプールを自動的に作成します。プールの手動作成に関する詳細は、ストラテジー戦略ガイドの プール の章を参照してください。
関連情報
- Red Hat Ceph Storage 4 の Object Gateway Configuration and Administration Guide を参照してください。
付録C Ansible インベントリー場所の設定
オプションとして、ceph-ansible ステージング環境および実稼働環境用のインベントリーの場所ファイルを設定することができます。
前提条件
- Ansible 管理ノード。
- Ansible 管理ノードへの root レベルのアクセス。
-
ceph-ansibleパッケージがノードにインストールされている。
手順
/usr/share/ceph-ansibleディレクトリーに移動します。[ansible@admin ~]# cd /usr/share/ceph-ansible
ステージングおよび実稼働環境用のサブディレクトリーを作成します。
[ansible@admin ceph-ansible]$ mkdir -p inventory/staging inventory/production
ansible.cfgファイルを編集し、以下の行を追加します。[defaults] inventory = ./inventory/staging # Assign a default inventory directory
各環境用にインベントリーの hosts ファイルを作成します。
[ansible@admin ceph-ansible]$ touch inventory/staging/hosts [ansible@admin ceph-ansible]$ touch inventory/production/hosts
各
hostsファイルを開いて編集し、[mons]セクションの下に Ceph Monitor ノードを追加します。[mons] MONITOR_NODE_NAME_1 MONITOR_NODE_NAME_1 MONITOR_NODE_NAME_1
例
[mons] mon-stage-node1 mon-stage-node2 mon-stage-node3
注記デフォルトでは、Playbook はステージング環境で実行されます。実稼働環境で Playbook を実行するには、以下を実行します。
[ansible@admin ceph-ansible]$ ansible-playbook -i inventory/production playbook.yml
関連情報
-
ceph-ansibleパッケージのインストールに関する詳細は、Red Hat Storage Cluster のインストール を参照してください。
付録D Ceph のデフォルト設定の上書き
Ansible 設定ファイルに特に指定しない限り、Ceph はデフォルト設定を使用します。
Ansible は Ceph 設定ファイルを管理するため、/usr/share/ceph-ansible/group_vars/all.yml ファイルを編集して Ceph の設定を変更します。ceph_conf_overrides の設定を使用して、デフォルトの Ceph 設定を上書きします。
Ansible は、Ceph 設定ファイル ([global]、[mon]、[osd]、[mds]、[rgw] など) と同じセクションをサポートします。特定の Ceph Object Gateway インスタンスなどの特定のインスタンスをオーバーライドすることもできます。以下に例を示します。
###################
# CONFIG OVERRIDE #
###################
ceph_conf_overrides:
client.rgw.server601.rgw1:
rgw_enable_ops_log: true
log_file: /var/log/ceph/ceph-rgw-rgw1.log
変数は、ceph_conf_overrides 設定のキーとして使用しないでください。特定の設定値をオーバーライドするセクションに、ホストの絶対ラベルを渡す必要があります。
Ansible には、Ceph 設定ファイルの特定セクションを参照する際に中かっこが含まれません。セクション名および設定名はコロンで終了します。
CONFIG OVERRIDE セクションの cluster_network パラメーターを使用してクラスターネットワークを設定しないでください。競合する 2 つのクラスターネットワークが Ceph 設定ファイルに設定されている可能性があるためです。
クラスターネットワークを設定するには、CEPH CONFIGURATION セクションで cluster_network パラメーターを使用します。詳細は、Red Hat Ceph Storage インストールガイドの Red Hat Ceph Storage クラスターのインストール を参照してください。
付録E 既存の Ceph クラスターの Ansible へのインポート
Ansible が Ansible なしでデプロイされたクラスターを使用するように設定することができます。たとえば、Red Hat Ceph Storage 1.3 クラスターを手動でバージョン 2 にアップグレードした場合は、以下の手順により Ansible を使用するように設定してください。
- バージョン 1.3 からバージョン 2 に手動でアップグレードした後、管理ノードに Ansible をインストールおよび設定します。
-
Ansible 管理ノードに、クラスター内の全 Ceph ノードにパスワードレスの
sshアクセスがあることを確認します。詳細は、「Ansible のパスワードなし SSH の有効化」 を参照してください。 rootで、/etc/ansible/ディレクトリーに Ansible のgroup_varsディレクトリーへのシンボリックリンクを作成します。# ln -s /usr/share/ceph-ansible/group_vars /etc/ansible/group_vars
rootでall.yml.sampleファイルからall.ymlファイルを作成し、編集用に開きます。# cd /etc/ansible/group_vars # cp all.yml.sample all.yml # vim all.yml
-
group_vars/all.ymlでgenerate_fsid設定をfalseに設定します。 -
ceph fsidを実行して、現在のクラスターfsidを取得します。 -
取得した
fsidをgroup_vars/all.ymlに設定します。 -
Ceph ホストが含まれるように、
/etc/ansible/hostsの Ansible インベントリーを変更します。[mons]セクションの下にモニター、[osds]セクションの下に OSD、および[rgws]セクションのゲートウェイを追加して、それらのロールを Ansible に特定します。 ceph_conf_overridesセクションが、all.ymlファイルの[global]セクション、[osd]セクション、[mon]セクション、および[client]セクションに使用される元のceph.confオプションで更新されていることを確認します。osd ジャーナル、public_network、cluster_networkなどのオプションはすでにall.ymlに含まれているため、ceph_conf_overridesには追加しないでください。all.ymlに含まれず、元のceph.confにあるオプションのみをceph_conf_overridesに追加する必要があります。/usr/share/ceph-ansible/ディレクトリーから Playbook を実行します。# cd /usr/share/ceph-ansible/ # ansible-playbook infrastructure-playbooks/take-over-existing-cluster.yml -u <username> -i hosts
付録F Ansible によってデプロイされたストレージクラスターのパージ
Ceph ストレージクラスターを使用しない場合には、Playbook purge-docker-cluster.yml を使用してクラスターを削除します。ストレージクラスターのパージは、インストールプロセスが失敗し、最初からやり直したい場合にも役立ちます。
Ceph ストレージクラスターをパージすると、OSD のデータはすべて永続的に失われます。
前提条件
- Ansible 管理ノードへのルートレベルのアクセス。
-
ansibleユーザーアカウントへのアクセス。 ベアメタル デプロイメントの場合:
-
/usr/share/ceph-ansible/group-vars/osds.ymlファイルのosd_auto_discoveryオプションがtrueに設定されている場合、Ansible はストレージクラスターのパージに失敗します。したがって、osd_auto_discoveryをコメントアウトし、osds.ymlファイルで OSD デバイスを宣言します。
-
-
/var/log/ansible/ansible.logファイルがansibleユーザーアカウントで書き込み可能であることを確認してください。
手順
/usr/share/ceph-ansibleディレクトリーに移動します。[root@admin ~]# cd /usr/share/ceph-ansible
ansibleユーザーとして、purge Playbook を実行します。ベアメタル デプロイメントの場合は、
purge-cluster.ymlPlaybook を使用して Ceph ストレージクラスターをパージします。[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/purge-cluster.yml
コンテナー デプロイメントの場合:
Playbook
purge-docker-cluster.ymlを使用して Ceph ストレージクラスターをパージします。[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/purge-docker-cluster.yml
注記この Playbook により、パッケージ、コンテナー、設定ファイル、および Ceph Ansible Playbook により作成されたすべてのデータが削除されます。
デフォルトの (
/etc/ansible/hosts) 以外のインベントリーファイルを指定するには、-iパラメーターを使用します。構文
[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/purge-docker-cluster.yml -i INVENTORY_FILE- 置き換え
INVENTORY_FILE は、インベントリーファイルへのパスに置き換えます。
例
[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/purge-docker-cluster.yml -i ~/ansible/hosts
Ceph コンテナーイメージの削除を省略するには、
--skip-tags="remove_img"オプションを使用します。[ansible@admin ceph-ansible]$ ansible-playbook --skip-tags="remove_img" infrastructure-playbooks/purge-docker-cluster.yml
インストール時にインストールしたパッケージの削除を省略するには、
--skip-tags="with_pkg"オプションを使用します。[ansible@admin ceph-ansible]$ ansible-playbook --skip-tags="with_pkg" infrastructure-playbooks/purge-docker-cluster.yml
関連情報
- 詳細は、OSD Ansible の設定 を参照してください。
付録G Ansible を使用した Ceph Dashboard のパージ
ダッシュボードをインストールする必要がなくなった場合は、purge-dashboard.yml Playbook を使用してダッシュボードを削除します。ダッシュボードまたはそのコンポーネントに関する問題をトラブルシューティングするときに、ダッシュボードをパージすることもできます。
前提条件
- Red Hat Ceph Storage 4.3 以降
- Ceph-ansible には、最新バージョンの Red Hat Ceph Storage が同梱されている
- ストレージクラスター内すべてのノードへの sudo レベルのアクセス。
手順
- Ansible 管理ノードにログインします。
/usr/share/ceph-ansibleディレクトリーに移動します。例
[ansible@admin ~]$ cd /usr/share/ceph-ansible/
Ansible
purge-dashboard.ymlPlaybook を実行し、プロンプトが表示されたら、yesと入力してダッシュボードのパージを確認します。例
[ansible@admin ceph-ansible]$ ansible-playbook infrastructure-playbooks/purge-dashboard.yml -i hosts -vvvv
検証
ceph mgr servicesコマンドを実行して、ダッシュボードが実行されていないことを確認します。構文
ceph mgr services
ダッシュボードの URL は表示されません。
関連情報
- ダッシュボードをインストールするには、Red Hat Ceph Storage ダッシュボードガイド の Ansbile を使用したダッシュボードのインストール を参照してください。
付録H ansible-vault を使用した Ansible パスワード変数の暗号化
パスワードの格納に使用する Ansible 変数を暗号化するには ansible-vault を使用し、プレーンテキストとして読み込めないようにします。たとえば、group_vars/all.yml で、ceph_docker_registry_username および ceph_docker_registry_password 変数をサービスアカウントの認証情報またはカスタマーポータルの認証情報に設定できます。サービスアカウントは共有されるように作られていますが、カスタマーポータルのパスワードのセキュリティーを確保する必要があります。ceph_docker_registry_password の暗号化に加えて dashboard_admin_password と grafana_admin_password も暗号化することを推奨します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
- Ansible 管理ノードへのアクセス
手順
- Ansible 管理ノードにログインします。
/usr/share/ceph-ansible/ディレクトリーに移動します。[admin@admin ~]$ cd /usr/share/ceph-ansible/
ansible-vaultを実行して、新しい vault パスワードを作成します。例
[admin@admin ceph-ansible]$ ansible-vault encrypt_string --stdin-name 'ceph_docker_registry_password_vault' New Vault password:
vault パスワードを再入力して確定します。
例
[admin@admin ceph-ansible]$ ansible-vault encrypt_string --stdin-name 'ceph_docker_registry_password_vault' New Vault password: Confirm New Vault password:
暗号化するパスワードを入力し、CTRL+D を 2 回入力してエントリーを完了します。
構文
ansible-vault encrypt_string --stdin-name 'ceph_docker_registry_password_vault' New Vault password: Confirm New Vault password: Reading plaintext input from stdin. (ctrl-d to end input) PASSWORDPASSWORD はパスワードに置き換えます。
例
[admin@admin ceph-ansible]$ ansible-vault encrypt_string --stdin-name 'ceph_docker_registry_password_vault' New Vault password: Confirm New Vault password: Reading plaintext input from stdin. (ctrl-d to end input) SecurePassword
パスワードの入力後に Enter は押さないようにしてください。暗号化文字列のパスワードの一部として、改行が追加されてしまいます。
ceph_docker_registry_password_vault: !vault |で開始し、数字の行 2-3 行で終了する出力をメモし、次の手順で使用します。例
[admin@admin ceph-ansible]$ ansible-vault encrypt_string --stdin-name 'ceph_docker_registry_password_vault' New Vault password: Confirm New Vault password: Reading plaintext input from stdin. (ctrl-d to end input) SecurePasswordceph_docker_registry_password_vault: !vault | $ANSIBLE_VAULT;1.1;AES256 38383639646166656130326666633262643836343930373836376331326437353032376165306234 3161386334616632653530383231316631636462363761660a373338373334663434363865356633 66383963323033303662333765383938353630623433346565363534636434643634336430643438 6134306662646365370a343135316633303830653565633736303466636261326361333766613462 39353365343137323163343937636464663534383234326531666139376561663532 Encryption successfulスペースや改行なしで、パスワード直後に開始される出力が必要となります。
group_vars/all.ymlを編集し、上記からの出力をファイルに貼り付けます。例
ceph_docker_registry_password_vault: !vault | $ANSIBLE_VAULT;1.1;AES256 38383639646166656130326666633262643836343930373836376331326437353032376165306234 3161386334616632653530383231316631636462363761660a373338373334663434363865356633 66383963323033303662333765383938353630623433346565363534636434643634336430643438 6134306662646365370a343135316633303830653565633736303466636261326361333766613462 39353365343137323163343937636464663534383234326531666139376561663532以下を使用して、暗号化されたパスワードの下に行を追加します。
例
ceph_docker_registry_password: "{{ ceph_docker_registry_password_vault }}"注記上記のように 2 つの変数を使用する必要があります。これは、Ansible のバグ が原因で、vault 値を直接 Ansible 変数に割り当てる時に、文字列のタイプが破損するためです。
ansible-playbookの実行時に vault パスワードを要求するように Ansible を設定します。/usr/share/ceph-ansible/ansible.cfgを開いて編集し、[defaults]セクションに以下の行を追加します。ask_vault_pass = True
必要に応じて、ansible-playbook を実行するたびに
--ask-vault-passを渡すことができます。例
[admin@admin ceph-ansible]$ ansible-playbook -v site.yml --ask-vault-pass
site.ymlまたはsite-container.ymlを再実行して、暗号化されたパスワードに関連するエラーがないことを確認します。例
[admin@admin ceph-ansible]$ ansible-playbook -v site.yml -i hosts --ask-vault-pass
-i hostsオプションは、/etc/ansible/hostsのデフォルトの Ansible インベントリーの場所を使用していない場合にのみ必要です。
関連情報
- サービスアカウントの情報については、Red Hat コンテナーレジストリーの認証 を参照してください。
付録I Ansible の全般的な設定
これは最も一般的な設定可能な Ansible パラメーターです。ベアメタルまたはコンテナーのデプロイメント方法に応じて、2 つのパラメーターセットを使用できます。
これは、利用可能なすべての Ansible パラメーターの完全なリストではありません。
ベアメタル および コンテナー の設定
monitor_interfaceCeph Monitor ノードがリッスンするインターフェイス。
- 値
- ユーザー定義
- 必須
- はい
- 注記
-
1 つ以上の
monitor_*パラメーターに値を割り当てる必要があります。
monitor_addressCeph Monitor ノードもリッスンするアドレス。
- 値
- ユーザー定義
- 必須
- はい
- 注記
-
1 つ以上の
monitor_*パラメーターに値を割り当てる必要があります。
monitor_address_blockCeph パブリックネットワークのサブネット。
- 値
- ユーザー定義
- 必須
- はい
- 注記
-
ノードの IP アドレスが不明ではあるが、サブネットが既知である場合に使用します。1 つ以上の
monitor_*パラメーターに値を割り当てる必要があります。
ip_version- 値
-
ipv6 - 必須
- IPv6 アドレス指定を使用している場合は必須です。
public_networkIPv6 を使用する場合には、Ceph パブリックネットワークの IP アドレスとネットマスク、または対応する IPv6 アドレス。
- 値
- ユーザー定義
- 必須
- はい
- 注記
- 詳細は、Red Hat Ceph Storage のネットワーク設定の確認 を参照してください。
cluster_networkIPv6 を使用する場合には、Ceph クラスターネットワークの IP アドレスとネットマスク、または対応する IPv6 アドレス。
- 値
- ユーザー定義
- 必須
- いいえ
- 注記
- 詳細は、Red Hat Ceph Storage のネットワーク設定の確認 を参照してください。
configure_firewallAnsible は適切なファイアウォールルールの設定を試みます。
- 値
-
trueまたはfalse - 必須
- いいえ
ベアメタル 固有の設定
ceph_origin- 値
-
repositoryまたはdistroまたはlocal - 必須
- はい
- 注記
-
repository値は、新しいリポジトリーで Ceph をインストールすることを意味します。distroの値は、個別のリポジトリーファイルが追加されず、Linux ディストリビューションに含まれる Ceph のバージョンをすべて取得することを意味します。localの値は、Ceph バイナリーがローカルマシンからコピーされることを意味します。
ceph_repository_type- 値
-
cdnまたはiso - 必須
- はい
ceph_rhcs_version- 値
-
4 - 必須
- はい
ceph_rhcs_iso_pathISO イメージの完全パス。
- 値
- ユーザー定義
- 必須
-
はい (
ceph_repository_typeがiso設定されている場合)
コンテナー 固有の設定
ceph_docker_image- 値
-
ローカルの Docker レジストリーを使用している場合には
rhceph/rhceph-4-rhel8またはcephimageinlocalreg。 - 必須
- はい
ceph_docker_image_tag- 値
-
ローカルレジストリーの設定中に提供された
rhceph/rhceph-4-rhel8またはcustomtagのlatestバージョン。 - 必須
- はい
containerized_deployment- 値
-
true - 必須
- はい
ceph_docker_registry- 値
-
ローカルの Docker レジストリーを使用している場合は、
registry.redhat.io、またはLOCAL_FQDN_NODE_NAME。 - 必須
- はい
付録J OSD Ansible の設定
これらは、設定可能な OSD Ansible パラメーターの最も一般的なものです。
osd_auto_discoveryOSD として使用する空のデバイスを自動的に検索します。
- 値
-
false - 必須
- いいえ
- 備考
-
devicesでは使用できません。purge-docker-cluster.ymlまたはpurge-cluster.ymlと一緒に使用することはできません。これらの Playbook を使用するには、osd_auto_discoveryをコメントアウトし、devicesを使用して OSD デバイスを宣言します。
devicesCeph のデータが保存されるデバイスのリスト。
- 値
- ユーザー定義
- 必須
- デバイスのリストを指定する場合は、はい。
- 注記
-
osd_auto_discovery設定を使用する場合は使用できません。devicesオプションを使用する場合は、ceph-volume lvm batchモードにより、最適化 OSD 設定が作成されます。
dmcryptOSD を暗号化するには。
- 値
-
true - 必須
- いいえ
- 注記
-
デフォルト値は
falseです。
lvm_volumesFileStore または BlueStore ディクショナリーのリスト。
- 値
- ユーザー定義
- 必須
-
はい (ストレージデバイスが
devicesパラメーターで定義されていない場合)。 - 注記
-
各ディクショナリーには、
dataキー、journalキー、およびdata_vgキーが含まれている必要があります。論理ボリュームまたはボリュームグループはすべて、完全パスではなく、名前にする必要があります。dataキーおよびjournalキーは論理ボリューム (LV) またはパーティションにすることができますが、複数のdata論理ボリュームに 1 つのジャーナルを使用しないでください。data_vgキーは、data論理ボリューム含むボリュームグループである必要があります。必要に応じて、journal_vgキーを使用して、ジャーナル LV を含むボリュームグループを指定できます (該当する場合)。
osds_per_deviceデバイスごとに作成する OSD 数。
- 値
- ユーザー定義
- 必須
- いいえ
- 注記
-
デフォルト値は
1です。
osd_objectstoreOSD の Ceph オブジェクトストアタイプ。
- 値
-
BlueStoreまたはfilestore - 必須
- いいえ
- 注記
-
デフォルト値は
bluestoreです。アップグレードに必要です。