
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
2.5. I/O 操作
Ceph クライアントは、Ceph モニターから「クラスターマップ」を取得し、プールにバインドし、プール内の配置グループ内のオブジェクトで i/o を実行します。プールの CRUSH ルールセットと配置グループの数は、Ceph がデータを配置する方法を決定する主要な要因です。クラスターマップの最新バージョンでは、クライアントは、クラスター内のすべてのモニターおよび OSD、およびそれらの現在の状態を認識します。ただし、クライアントはオブジェクトの場所について何も知りません。
クライアントが必要とする入力は、オブジェクト ID とプール名のみです。これは単純な方法です。Ceph はデータを名前付きプールに保管します。クライアントがプールに名前付きのオブジェクトを保存する場合は、オブジェクト名、ハッシュコード、プール名の PG 数およびプール名を入力として取り、次に CRUSH (Controlled Replication Under Scalable Hashing) は配置グループの ID および配置グループのプライマリー OSD を計算します。
Ceph クライアントは、以下の手順を使用して PG ID を計算します。
-
クライアントはプール ID とオブジェクト ID を入力します。たとえば、
pool = liverpoolおよびobject-id = johnです。 - CRUSH はオブジェクト ID を取得し、それをハッシュします。
-
CRUSH は PG 数のハッシュモジュロを計算し、PG ID を取得します。たとえば
58です。 - CRUSH は PG ID に対応するプライマリー OSD を計算します。
-
クライアントはプール名が指定されたプール ID を取得します。たとえば、プール「liverpool」はプール番号
4です。 -
クライアントはプール ID を PG ID の前に追加します。たとえば
4.58です。 - クライアントは、動作セットのプライマリー OSD と直接通信することにより、書き込み、読み取り、削除などのオブジェクト操作を実行します。
Ceph Storage クラスターのトポロジーおよび状態は、セッション時に比較的安定しています。librados を介して Ceph クライアントにオブジェクトの場所を計算する権限を付与することは、クライアントが読み取り/書き込み操作ごとにチャットセッションを介してストレージクラスターにクエリーを実行することを要求するよりもはるかに高速です。CRUSH アルゴリズムにより、クライアントはオブジェクトが 保存される 場所を計算でき、クライアントが動作セットのプライマリー OSD に直接アクセスできる ようにし、オブジェクト内のデータを保存または取得できるようにします。エクサバイト規模のクラスターには数千もの OSD があるため、クライアントと Ceph OSD 間のネットワークオーバーサブスクリプションは重大な問題ではありません。クラスターの状態が変更された場合は、クライアントは単に Ceph モニターからクラスターマップへ更新をリクエストすることができます。
RHCS 2 以前のリリースでは、非常に大規模なクラスターのデーモンは、クラスターマップのサイズが大きすぎるとパフォーマンスが遅くなる可能性があります。たとえば、OSD が 10k のクラスターには OSD ごとに 100 PG がある場合があり、これにより、データを効率的に分散するために ~1M PG が使用され、クラスターマップ用に多数のエポックが分散されます。そのため、デーモンは、非常に大きなクラスターを持つ RHCS 2 でより多くの CPU および RAM を使用します。RHCS 3 以降のリリースでは、デーモンは RHCS 2 以前のリリースのようにクラスターの現在の状態を受け取ります。ただし、Ceph Manager (ceph-mgr) デーモンは PG のクエリーを処理するようになり、大規模でパフォーマンスが大幅に改善されました。Red Hat は、数千の OSD を持つ非常に大規模なクラスターに RHCS 3 以降のリリースを使用することを推奨します。
2.5.1. レプリケートされた I/O
Ceph クライアントと同様に、Ceph OSD は Ceph モニターに接続してクラスターマップの最新コピーを取得できます。Ceph OSD も CRUSH アルゴリズムを使用しますが、これを使用してオブジェクトのレプリカを保存する場所を計算します。標準的な書き込みシナリオでは、Ceph クライアントは CRUSH アルゴリズムを使用して、オブジェクトの動作セット内の配置グループ ID とプライマリー OSD を計算します。クライアントがプライマリー OSD にオブジェクトを書き込む際に、プライマリー OSD は格納する必要のあるレプリカ数を見つけます。値は osd_pool_default_size 設定にあります。次に、プライマリー OSD は、オブジェクト ID、プール名、およびクラスターマップを取得し、CRUSH アルゴリズムを使用して動作セットのセカンダリー OSD の ID を計算します。プライマリー OSD はオブジェクトをセカンダリー OSD に書き込みます。プライマリー OSD がセカンダリー OSD から確認応答を受信し、プライマリー OSD 自体がその書き込み操作を完了すると、Ceph クライアントへの書き込み操作が成功したことを確認します。
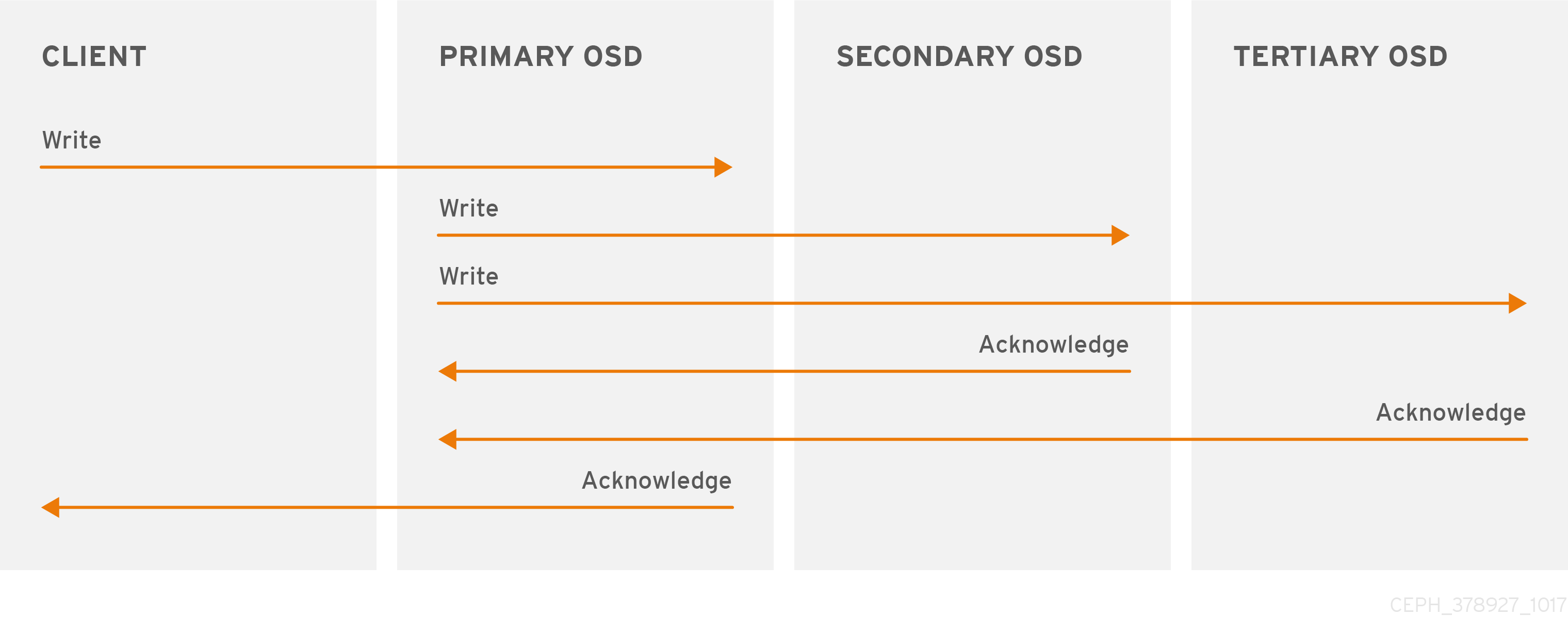
Ceph クライアントの代わりにデータレプリケーションを実行する機能を使用すると、Ceph OSD デーモンは、高いデータ可用性とデータの安全性を確保しながら、Ceph クライアントをその責務から解放します。
プライマリー OSD とセカンダリー OSD は通常、別の障害ドメインに配置するように設定されています。CRUSH は、障害ドメインについて考慮し、セカンダリー OSD の ID を計算します。