
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
ブロックデバイスガイド
Red Hat Ceph Storage ブロックデバイスの管理、作成、設定、および使用
概要
第1章 概要
ブロックは、512 バイトのデータブロックなどの一連のバイトです。以下のような回転メディアを使用してデータを保存する最も一般的な方法として、ブロックベースのストレージインターフェイスが挙げられます。
- <hard_disk>
- cds
- フロッピーディスク
- 従来の 9 トラッキングテープにも関わっています。
ブロックデバイスインターフェイスは偏在するので、Red Hat Ceph Storage などのマーシャルデータストレージシステムの操作には仮想ブロックデバイスが理想的です。
Reliable Autonomic Distributed Object Store(RADOS)ブロックデバイス(RBD)とも呼ばれる Ceph ブロックデバイスは、シンプロビジョニングされ、分散可能で、Ceph Storage クラスターの複数の Object Storage Device(OSD)でデータのストライプ化されて保存されます。Ceph ブロックデバイスは、以下のような RADOS 機能を利用します。
- スナップショットの作成
- レプリケーション
- かつ一貫性を保ちます。
Ceph ブロックデバイスは、librbd ライブラリーを使用して OSD と対話します。
Ceph ブロックデバイスは、libvirt ユーティリティーおよび QEMU ユーティリティーに依存して Ceph ブロックデバイスと統合するために、Quick Emulator (QEMU) などの Kernel Virtual Machines (KVM) や OpenStack などのクラウドベースのコンピューティングシステムに、無限のスケーラビリティーと、高いパフォーマンスをもたらします。同じストレージクラスターを使用して、Ceph Object Gateway および Ceph ブロックデバイスを同時に運用できます。
Ceph ブロックデバイスを使用するには、稼働中の Ceph Storage クラスターにアクセスできる必要があります。Red Hat Ceph Storage のインストールに関する詳細は、『 Installation Guide for Red Hat Enterprise Linux or Installation Guide for Ubuntu 』を参照してください。
第2章 ブロックデバイスコマンド
rbd コマンドを使用すると、ブロックデバイスイメージの作成、一覧表示、イントロスペクション、および削除を行うことができます。また、これを使用してイメージのクローン作成、スナップショットの作成、イメージのスナップショットへのロールバック、スナップショットの表示などを行うこともできます。
2.1. 前提条件
Ceph ブロックデバイスと rbd コマンドを使用するには、2 つの前提条件を満たす必要があります。
- 実行中の Ceph Storage クラスターにアクセスできる必要があります。詳細は、『Red Hat Ceph Storage 3 インストールガイド for Red Hat Enterprise Linux 』または『 Installation Guide for Ubuntu 』を参照してください。
- Ceph Block Device クライアントをインストールする必要があります。詳細は、『Red Hat Ceph Storage 3 インストールガイド for Red Hat Enterprise Linux 』または『 Installation Guide for Ubuntu 』を参照してください。
「 Ceph ブロックデバイスの手動インストール」の 章は、クライアントノードでの Ceph ブロックデバイスのマウントおよび使用についても説明します。Ceph Storage クラスターにブロックデバイスのイメージを作成した後にのみ、クライアントノードでこの手順を実施します。詳細は、 を参照してください。
2.2. ヘルプの表示
rbd help コマンドを使用して、特定の rbd コマンドとそのサブコマンドのヘルプを表示します。
[root@rbd-client ~]# rbd help <command> <subcommand>
例
snap list コマンドのヘルプを表示するには、次のコマンドを実行します。
[root@rbd-client ~]# rbd help snap list
-h オプションは引き続き、使用できるすべてのコマンドのヘルプを表示します。
2.3. ブロックデバイスプールの作成
ブロックデバイスクライアントを使用する前に、rbd のプールが存在し、初期化されていることを確認します。rbd プールを作成するには、以下を実行します。
[root@rbd-client ~]# ceph osd pool create {pool-name} {pg-num} {pgp-num}
[root@rbd-client ~]# ceph osd pool application enable {pool-name} rbd
[root@rbd-client ~]# rbd pool init -p {pool-name}最初にプールを作成してから、これをソースとして指定する必要があります。詳細は、Red Hat Ceph Storage ストラテジーガイド の プール の章を参照してください。
2.4. ブロックデバイスイメージの作成
ブロックデバイスをノードに追加する前に、Ceph Storage クラスターにそのイメージを作成します。ブロックデバイスイメージを作成するには、以下のコマンドを実行します。
[root@rbd-client ~]# rbd create <image-name> --size <megabytes> --pool <pool-name>
たとえば、stack という名前のプールに情報を保存する data という名前の 1 GB のイメージを作成するには、以下を実行します。
[root@rbd-client ~]# rbd create data --size 1024 --pool stack
- 注記
-
イメージを作成する前に
rbdのプールが存在することを確認します。詳細は、「 ブロックデバイスプールの作成 」を参照してください。
2.5. ブロックデバイスイメージの一覧表示
rbd プールのブロックデバイスを一覧表示するには、以下を実行します (rbd はデフォルトのプール名です)。
[root@rbd-client ~]# rbd ls
特定のプールのブロックデバイスを一覧表示するには、以下を実行します。ただし、POOL_NAME はプールの名前に置き換えます。
[root@rbd-client ~]# rbd ls {poolname}以下に例を示します。
[root@rbd-client ~]# rbd ls swimmingpool
2.6. イメージ情報の取得
特定のイメージから情報を取得するには、以下を実行します。ただし、IMAGE_NAME はイメージの名前に置き換えます。
[root@rbd-client ~]# rbd --image {image-name} info以下に例を示します。
[root@rbd-client ~]# rbd --image foo info
プール内のイメージから情報を取得するには、以下を実行します。ただし、IMAGE_NAME
[root@rbd-client ~]# rbd --image {image-name} -p {pool-name} info以下に例を示します。
[root@rbd-client ~]# rbd --image bar -p swimmingpool info
2.7. ブロックデバイスイメージのサイズ変更
Ceph ブロックデバイスイメージはシンプロビジョニングされています。データの保存を開始する前に、実際には物理ストレージを使用しません。ただし、--size オプションでは、設定する最大容量があります。
Ceph ブロックデバイスイメージの最大サイズを増減するには、以下を実行します。
[root@rbd-client ~]# rbd resize --image <image-name> --size <size>
2.8. ブロックデバイスイメージの削除
ブロックデバイスを削除するには以下を実行します。ただし、IMAGE_NAME は削除するイメージの名前に置き換えます。
[root@rbd-client ~]# rbd rm {image-name}以下に例を示します。
[root@rbd-client ~]# rbd rm foo
プールからブロックデバイスを削除するには以下を実行します。ただし、IMAGE_NAME
[root@rbd-client ~]# rbd rm {image-name} -p {pool-name}以下に例を示します。
[root@rbd-client ~]# rbd rm bar -p swimmingpool
2.9. ブロックデバイスイメージのゴミ箱への移動
RADOS Block Device (RBD) イメージは、rbd trash コマンドを使用してゴミ箱に移動できます。このコマンドは、rbd rm コマンドよりも多くのオプションがあります。
イメージをゴミ箱に移動すると、後でゴミ箱から取り除くこともできます。この機能により、誤って削除されるのを回避できます。
イメージをゴミ箱に移動するには、以下のコマンドを実行します。
[root@rbd-client ~]# rbd trash move {image-spec}
イメージがゴミ箱にある場合は、一意のイメージ ID が割り当てられます。ゴミ箱オプションのいずれかを使用する必要がある場合は、後でこのイメージを指定するのにこのイメージ ID が必要です。ゴミ箱にあるイメージ ID の一覧に対して rbd trash list を実行します。このコマンドは、イメージの削除前の名前も返します。
さらに、rbd info および rbd snap コマンドで使用可能な --image-id 引数 (任意) があります。rbd info コマンドに --image-id を使用し、ごみ箱の中にあるイメージのプロパティーを表示し、rbd snap で、イメージのスナップショットをゴミ箱から削除します。
ゴミ箱からのイメージの削除
ゴミ箱からイメージを削除するには、以下のコマンドを実行します。
[root@rbd-client ~]# rbd trash remove [{pool-name}/] {image-id}イメージがゴミ箱から削除されると、そのイメージは復元できません。
delay Trash removal
--delay オプションを使用して、イメージがゴミ箱から削除されるまでの時間を設定します。以下のコマンドを実行します。{time} は、イメージが削除されるまで待機する秒数に置き換えます(デフォルトは 0)。
[root@rbd-client ~]# rbd trash move [--delay {time}] {image-spec}
--delay オプションを有効にすると、強制されない限り、指定した時間枠内でイメージがゴミ箱から削除できません。
ゴミ箱からのイメージの復元
イメージがゴミ箱から削除されていない限り、rbd trash restore コマンドを使用して復元できます。
rbd trash restore コマンドを実行して、イメージを復元します。
[root@rbd-client ~]# rbd trash restore [{pool-name}/] {image-id}2.10. イメージ機能の有効化および無効化
既存のイメージでは、fast-diff、exclusive-lock、object-map または journaling などのイメージ機能を有効または無効にできます。
機能を有効にします。
[root@rbd-client ~]# rbd feature enable <pool-name>/<image-name> <feature-name>
機能を無効にします。
[root@rbd-client ~]# rbd feature disable <pool-name>/<image-name> <feature-name>
例
dataプールのimage1イメージでexclusive-lock機能を有効にするには、以下を実行します。[root@rbd-client ~]# rbd feature enable data/image1 exclusive-lock
dataプールのimage2イメージでfast-diff機能を無効にするには、以下を実行します。[root@rbd-client ~]# rbd feature disable data/image2 fast-diff
fast-diff および object-map 機能を有効にした後に、オブジェクトマップを再構築します。
[root@rbd-client ~]# rbd object-map rebuild <pool-name>/<image-name>
ディープフラット化 機能は、既存のイメージでのみ無効にできますが、有効化できません。ディープフラット化 を使用するには、イメージ作成時に有効化します。
2.11. イメージメタデータの使用
Ceph は、カスタムイメージメタデータをキーと値のペアとして追加することをサポートしています。ペアには厳密な形式がありません。
また、メタデータを使用して、特定のイメージに RBD 設定パラメーターを設定することもできます。詳細は、「 特定のイメージのデフォルト設定の上書き 」を参照してください。
rbd image-meta コマンドを使用して、メタデータと連携します。
イメージメタデータの設定
新しいメタデータのキー/値のペアを設定するには、以下を行います。
[root@rbd-client ~]# rbd image-meta set <pool-name>/<image-name> <key> <value>
例
dataプールのdatasetイメージでlast_updateキーを2016-06-06値に設定するには、以下を実行します。[root@rbd-client ~]# rbd image-meta set data/dataset last_update 2016-06-06
イメージメタデータの削除
メタデータのキー/値のペアを削除するには、以下を実行します。
[root@rbd-client ~]# rbd image-meta remove <pool-name>/<image-name> <key>
例
last_updateのキーと値のペアをデータプールのデータセットイメージから削除するには、以下を実行します。[root@rbd-client ~]# rbd image-meta remove data/dataset last_update
キーの値の取得
キーの値を表示するには、次のコマンドを実行します。
[root@rbd-client ~]# rbd image-meta get <pool-name>/<image-name> <key>
例
last_updateキーの値を表示するには、次のコマンドを実行します。[root@rbd-client ~]# rbd image-meta get data/dataset last_update
イメージメタデータの一覧表示
イメージの全メタデータを表示するには、以下のコマンドを実行します。
[root@rbd-client ~]# rbd image-meta list <pool-name>/<image-name>
例
データプールのデータを一覧表示するには、以下を実行します。セットイメージに設定されているメタデータ[root@rbd-client ~]# rbd data/dataset image-meta list
特定のイメージのデフォルト設定の上書き
特定のイメージについて Ceph 設定ファイルで設定した RBD イメージ設定をオーバーライドするには、conf_ 接頭辞をイメージメタデータとして指定して設定パラメーターを設定します。
[root@rbd-client ~]# rbd image-meta set <pool-name>/<image-name> conf_<parameter> <value>
例
データプール内のデータセットイメージの RBD キャッシュを無効にするには、以下を実行します。[root@rbd-client ~]# rbd image-meta set data/dataset conf_rbd_cache false
可能な設定オプションの一覧は、「 ブロックデバイスの設定リファレンス 」を参照してください。
第3章 スナップショット
スナップショットは、特定の時点におけるイメージの状態の読み取り専用コピーです。Ceph ブロックデバイスの高度な機能の 1 つとして、イメージのスナップショットを作成して、イメージの状態の履歴を保持できることが挙げられます。また、Ceph はスナップショットの階層化もサポートしており、イメージ(VM イメージなど)のクローンを迅速かつ簡単に作成することができます。Ceph は、QEMU、libvirt、OpenStack、および CloudStack など、rbd コマンドと、より上層レベルのインターフェイスを使用するブロックデバイススナップショットをサポートします。
RBD スナップショットを使用するには、Ceph クラスターが稼働中である必要があります。
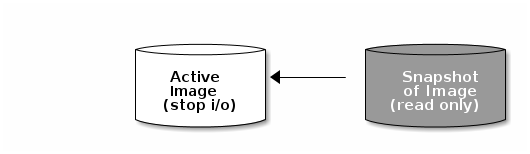
I/O がイメージの進行中にスナップショットを作成する場合は、スナップショットがイメージの正確なデータまたは最新データを取得せず、マウントを可能にするためにスナップショットのクローンを作成する必要がある場合があります。そのため、イメージのスナップショットを作成する前に、I/O を停止することが推奨されます。イメージにファイルシステムが含まれる場合に、ファイルシステムはスナップショットの作成前に整合性のある状態でなければなりません。I/O を停止するには、fsfreeze コマンドを使用します。詳細は、 fsfreeze(8) の man ページを参照してください。仮想マシンの場合には、qemu-guest-agent を使用してスナップショットの作成時にファイルシステムを自動的にフリーズできます。
3.1. cephx に関する注意
cephx が有効な場合には、ユーザー名または ID とユーザーに対応するキーが含まれるキーリングへのパスを指定する必要があります。以下のパラメーターのエントリーを再追加しなくてもいいように、CEPH_ARGS 環境変数を追加することもできます。
[root@rbd-client ~]# rbd --id {user-ID} --keyring=/path/to/secret [commands]
[root@rbd-client ~]# rbd --name {username} --keyring=/path/to/secret [commands]以下に例を示します。
[root@rbd-client ~]# rbd --id admin --keyring=/etc/ceph/ceph.keyring [commands] [root@rbd-client ~]# rbd --name client.admin --keyring=/etc/ceph/ceph.keyring [commands]
ユーザーとシークレットを CEPH_ARGS 環境変数に追加して、毎回入力する必要がないようにします。
3.2. スナップショットの基本
以下の手順では、コマンドラインで rbd コマンドを使用して、スナップショットを作成、一覧表示、および削除する方法を説明します。
3.2.1. スナップショットの作成
rbd でスナップショットを作成するには、snap create オプション、プール名、およびイメージ名を指定します。
[root@rbd-client ~]# rbd --pool {pool-name} snap create --snap {snap-name} {image-name}
[root@rbd-client ~]# rbd snap create {pool-name}/{image-name}@{snap-name}以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap create --snap snapname foo [root@rbd-client ~]# rbd snap create rbd/foo@snapname
3.2.2. スナップショットの一覧表示
イメージのスナップショットを一覧表示するには、プール名とイメージ名を指定します。
[root@rbd-client ~]# rbd --pool {pool-name} snap ls {image-name}
[root@rbd-client ~]# rbd snap ls {pool-name}/{image-name}以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap ls foo [root@rbd-client ~]# rbd snap ls rbd/foo
3.2.3. スナップショットのロールバック
rbd を使用してスナップショットにロールバックするには、snap rollback オプション、プール名、イメージ名、および snap 名を指定します。
rbd --pool {pool-name} snap rollback --snap {snap-name} {image-name}
rbd snap rollback {pool-name}/{image-name}@{snap-name}以下に例を示します。
rbd --pool rbd snap rollback --snap snapname foo rbd snap rollback rbd/foo@snapname
イメージをスナップショットにロールバックすると、イメージの現行バージョンがスナップショットからのデータで上書きされます。ロールバックの実行にかかる時間は、イメージのサイズとともに増加します。スナップショットにイメージを ロールバック するよりも、クローンするほうが短時間ででき、既存の状態戻す方法として推奨の方法です。
3.2.4. スナップショットの削除
rbd でスナップショットを削除するには、snap rm オプション、プール名、イメージ名、およびスナップショット名を指定します。
[root@rbd-client ~]# rbd --pool <pool-name> snap rm --snap <snap-name> <image-name> [root@rbd-client ~]# rbd snap rm <pool-name-/<image-name>@<snap-name>
以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap rm --snap snapname foo [root@rbd-client ~]# rbd snap rm rbd/foo@snapname
イメージにクローンがある場合には、クローン作成されたイメージは、親イメージのスナップショットへの参照を保持します。親イメージのスナップショットを削除するには、最初に子イメージをフラット化する必要があります。詳細は、「クローン作成されたイメージの追加 」を参照してください。
Ceph OSD デーモンはデータを非同期的に削除するため、スナップショットを削除してもディスク領域がすぐに解放されません。
3.2.5. スナップショットのパージ
rbd でイメージのすべてのスナップショットを削除するには、snap purge オプションとイメージ名を指定します。
[root@rbd-client ~]# rbd --pool {pool-name} snap purge {image-name}
[root@rbd-client ~]# rbd snap purge {pool-name}/{image-name}以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap purge foo [root@rbd-client ~]# rbd snap purge rbd/foo
3.2.6. スナップショットの名前変更
スナップショットの名前を変更するには、以下のコマンドを実行します。
[root@rbd-client ~]# rbd snap rename <pool-name>/<image-name>@<original-snapshot-name> <pool-name>/<image-name>@<new-snapshot-name>
例
データ プールの dataset イメージの snap1 スナップショットの名前を snap2 に変更するには、以下を実行します。
[root@rbd-client ~]# rbd snap rename data/dataset@snap1 data/dataset@snap2
rbd help snap rename コマンドを実行して、スナップショットの名前変更に関する追加情報を表示します。
3.3. layering
Ceph は、ブロックデバイススナップショットの多数のコピーオンライト (COW) またはコピーオンリード (COR) のクローンを作成する機能をサポートしています。スナップショットの階層化により、Ceph ブロックデバイスクライアントはイメージを非常に迅速に作成できます。たとえば、Linux 仮想マシンに書き込まれた Linux 仮想マシンを使用してブロックデバイスイメージを作成し、そのイメージをスナップショットを作成してスナップショットを保護し、必要に応じてクローンを作成します。スナップショットは読み取り専用であるため、スナップショットのクローンを作成するとセマンティクスが簡素化され、クローンの作成時間を短縮できます。
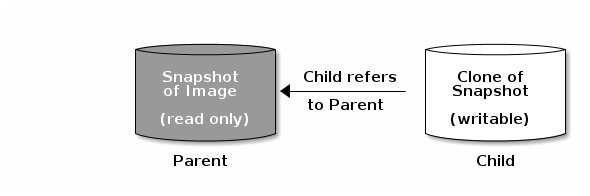
親 および 子 という用語は、Ceph ブロックデバイスのスナップショット (親)、およびスナップショットからクローン作成された対応のイメージ (子) を意味します。以下のコマンドラインを使用する場合に、これらの用語が重要です。
クローン作成された各イメージ (子) は、親イメージへの参照を保存し、クローン作成されたイメージで親スナップショットを開き、読み取ることができるようになります。この参照は、クローンが フラット化 (スナップショットからの情報が完全にクローンにコピー) されると、削除されます。フラット化の詳細は、「クローンしたイメージのフラット化」 を 参照 してください。
スナップショットのクローン作成は、他の Ceph ブロックデバイスイメージのように動作します。クローン作成されたイメージを読み取り、書き込み、クローンし、サイズを変更できます。クローン作成されたイメージには、特別な制限はありません。ただし、スナップショットのクローンはスナップショットを参照するので、クローンを作成する前にスナップショットを保護する 必要があります。
スナップショットのクローンは、コピーオンライト (COW) またはコピーオンリード (COR) のいずれかです。クローンではコピーオンライト (COW) は常に有効で、コピーオンリード (COR) は明示的に有効化する必要があります。コピーオンライト (COW) は、クローン内の未割り当てのオブジェクトへの書き込み時に、親からクローンにデータをコピーします。コピーオンリード (COR) は、クローン内の未割り当てのオブジェクトから読み取る時に、親からクローンにデータをコピーします。クローンからデータの読み取りは、オブジェクトがクローンに存在しない場合、親からのデータのみを読み取ります。RADOS ブロックデバイスでは、大規模なイメージを複数のオブジェクトに分割し(デフォルトは 4 MB)、すべてのコピーオンライト(COW)および Copy-on-read(COR)操作が完全なオブジェクト(つまり 1 バイトをクローンに書き込む)で行われます(つまり、クローンに 1 バイトを書き込む)、宛先オブジェクトが親から読み取られ、以前の COW/COR 操作からクローンに存在しない場合は、クローンに書き込まれます。
コピーオンリード (COR) が有効になっているかどうか。クローンから下層にあるオブジェクトを読み取ることができない場合には、親に再ルーティングされます。実質的に親の数に制限が特にないため、クローンのクローンを作成できます。これは、オブジェクトが見つかるまで、またはベースの親イメージに到達するまで、この再ルーティングが続行されます。コピーオンリード (COR) が有効になっている場合には、クローンから直接読み取ることができない場合には、親からすべてのオブジェクトを読み取り、そのデータをクローンに書き込むことで、今後、親から読み取る必要なく、同じエクステントの読み取りがクローン自体で行われるようにします。
これは基本的に、オンデマンドのオブジェクトごとのフラット化操作です。これは、クローンが親から離れた高遅延接続の場所 (別の地理的場所の別のプールにある親など) にある場合に特に便利です。コピーオンリード (COR) では、読み取りのならし遅延が短縮されます。最初の数回読み取りは、親から追加のデータが読み取られるため、レイテンシーが高くなっています。たとえば、クローンから 1 バイトを読み取る場合に、4 MB を親から読み取り、クローンに書き込みする必要がありますが、それ以降はクローン自体からすべての読み取りが行われます。
スナップショットからコピーオンリード (COR) のクローンを作成するには、ceph.conf ファイルの [global] セクションまたは [client] セクションに rbd_clone_copy_on_read = true を追加してこの機能を明示的に有効にする必要があります。
3.3.1. レイヤーの使用開始
Ceph ブロックデバイスの階層化は単純なプロセスです。イメージが必要です。イメージのスナップショットを作成する必要があります。スナップショットを保護する必要があります。これらの手順を実行すると、スナップショットのクローン作成を開始できます。
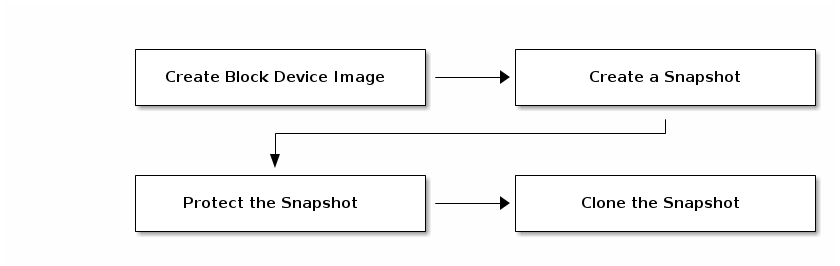
クローン作成されたイメージには、親スナップショットへの参照があり、プール ID、イメージ ID、およびスナップショット ID が含まれます。プール ID が含まれると、あるプールから別のプールにスナップショットのクローンを作成できます。
-
イメージテンプレート: ブロックデバイスの階層化における一般的なユースケースとして、マスターイメージと、クローンのテンプレートとして機能するスナップショットが作成されます。たとえば、RHEL7 ディストリビューションのイメージを作成して、そのスナップショットを作成できます。定期的に、ユーザーはイメージを更新して新規スナップショットを作成することができます(
yum update、yum upgrade、rbd snap createなど)。イメージが成熟すると、ユーザーはスナップショットのいずれかのクローンを作成できます。 - 拡張テンプレート: より高度なユースケースには、ベースイメージよりも多くの情報を提供するテンプレートイメージの拡張が含まれます。たとえば、ユーザーはイメージのクローンを作成し(仮想マシンテンプレートなど)、他のソフトウェア(データベース、コンテンツ管理システム、解析システムなど)をインストールし、ベースイメージと同様に更新できる拡張イメージをスナップショットできます。
- テンプレートプール: ブロックデバイスの階層化を使用する方法は、テンプレートとして機能するマスターイメージを含むプールと、それらのテンプレートのスナップショットを作成することです。その後、ユーザーに読み取り専用の権限を拡張して、プール内で読み書きや実行を実行せずにスナップショットのクローンを作成できます。
- イメージの移行/リカバリー: ブロックデバイスの階層化を使用する方法は、あるプールから別のプールにデータを移行または復元することです。
3.3.2. スナップショットの保護
親スナップショットのクローン作成は、親スナップショットにアクセスします。ユーザーが親のスナップショットを誤って削除した場合に、クローンはすべて破損します。データの損失を防ぐには、クローンを作成する前にスナップショットを保護する 必要 があります。これには以下のコマンドを実行します。
[root@rbd-client ~]# rbd --pool {pool-name} snap protect --image {image-name} --snap {snapshot-name}
[root@rbd-client ~]# rbd snap protect {pool-name}/{image-name}@{snapshot-name}以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap protect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap protect rbd/my-image@my-snapshot
保護されたスナップショットは削除できません。
3.3.3. スナップショットのクローン作成
スナップショットのクローンを作成するには、親プール、イメージ、スナップショット、および子プールおよびイメージ名を指定する必要があります。スナップショットのクローンを作成する前に、スナップショットを保護する必要があります。これには以下のコマンドを実行します。
[root@rbd-client ~]# rbd --pool {pool-name} --image {parent-image} --snap {snap-name} --dest-pool {pool-name} --dest {child-image}
[root@rbd-client ~]# rbd clone {pool-name}/{parent-image}@{snap-name} {pool-name}/{child-image-name}以下に例を示します。
[root@rbd-client ~]# rbd clone rbd/my-image@my-snapshot rbd/new-image
スナップショットは、あるプールから別のプールのイメージにクローンできます。たとえば、読み取り専用のイメージやスナップショットを 1 つのプール内のテンプレートとして維持し、別のプール内の書き込み可能なクローンとして維持することができます。
3.3.4. スナップショットの保護解除
スナップショットを削除する前に、そのスナップショットを保護解除する必要があります。さらに、クローンからの参照があるスナップショットは、削除できません。スナップショットを削除する前に、スナップショットの各クローンをフラット化する必要があります。これには以下のコマンドを実行します。
[root@rbd-client ~]#rbd --pool {pool-name} snap unprotect --image {image-name} --snap {snapshot-name}
[root@rbd-client ~]# rbd snap unprotect {pool-name}/{image-name}@{snapshot-name}以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd snap unprotect --image my-image --snap my-snapshot [root@rbd-client ~]# rbd snap unprotect rbd/my-image@my-snapshot
3.3.5. スナップショットの子の一覧表示
スナップショットの子を一覧表示するには、以下のコマンドを実行します。
rbd --pool {pool-name} children --image {image-name} --snap {snap-name}
rbd children {pool-name}/{image-name}@{snapshot-name}以下に例を示します。
rbd --pool rbd children --image my-image --snap my-snapshot rbd children rbd/my-image@my-snapshot
3.3.6. クローンしたイメージのフラット化
クローン作成されたイメージは、親スナップショットへの参照を保持します。子クローンから親スナップショットに参照を削除すると、スナップショットからクローンに情報をコピーして、イメージを効果的に「フラット化」します。スナップショットのサイズでクローンのフラット化にかかる時間が増加します。
子イメージに関連付けられた親イメージのスナップショットを削除するには、最初に子イメージをフラット化する必要があります。
[root@rbd-client ~]# rbd --pool <pool-name> flatten --image <image-name> [root@rbd-client ~]# rbd flatten <pool-name>/<image-name>
以下に例を示します。
[root@rbd-client ~]# rbd --pool rbd flatten --image my-image [root@rbd-client ~]# rbd flatten rbd/my-image
フラット化イメージにはスナップショットからのすべての情報が含まれるため、フラット化されるイメージは階層化されたクローンよりも多くのストレージ領域を使用します。
イメージで ディープフラット 機能が有効になっている場合には、イメージのクローンは、デフォルトで親から分離されます。
第4章 ブロックデバイスのミラーリング
RADOS Block Device (RBD) ミラーリングとは、2 つ以上の Ceph Storage クラスター間で Ceph ブロックデバイスイメージを非同期にレプリケーションするプロセスのことです。ミラーリングには次の利点があります。* 読み取りと書き込み、ブロックデバイスのサイズ変更、スナップショット、クローン、およびフラット化を含む、イメージに対するすべての変更のポイントインタイムの一貫したレプリカを確保します。
ミラーリングは、必須の排他的ロックと RBD ジャーナリング機能を使用して、すべての変更をイメージに対して発生する順序で記録します。これにより、イメージのクラッシュ整合性のあるミラーが利用できるようになりました。イメージをピアクラスターにミラーリングする前に、ジャーナリングを有効にする必要があります。詳細は、「ジャーナルの有効化」 を参照してください。
これはミラーリングされるブロックデバイスに関連付けられたプライマリーおよびセカンダリープールに保存されるイメージであるため、プライマリープールおよびセカンダリープールの CRUSH 階層には、同じストレージ容量とパフォーマンスの特性が必要です。さらに、プライマリーサイトとセカンダリーサイト間のネットワーク接続には、十分な帯域幅を確保して、ミラーリングがレイテンシーが大きくなりすぎないようにする必要があります。
ブロックデバイスイメージをミラーリングするプライマリーおよびセカンダリープールに対応する CRUSH 階層には、容量とパフォーマンスの特性が同じである必要があり、また、追加のレイテンシーなしにミラーリングを行うために十分な帯域幅が必要になります。たとえば、プライマリークラスター内のイメージへの平均書き込みスループットが X MiB/s である場合に、ネットワークはセカンダリーサイトへのネットワーク接続で N * X スループットと、N イメージをミラーリングする安全係数 Y% に対応している必要があります。
ミラーリングは、主に障害からのリカバリーに対応します。使用しているミラーリングのタイプに応じて、一方向ミラーリングを使用した障害からの復旧 または 双方向ミラーリングを使用した障害からの復旧 を参照してください。
rbd-mirror デーモン
rbd-mirror デーモンは、ある Ceph クラスターから別のクラスターへのイメージの同期を担当します。
レプリケーションのタイプに応じて、rbd-mirror は単一のクラスターまたはミラーリングに参加するすべてのクラスターで実行されます。
一方向レプリケーション
-
データがプライマリークラスターからバックアップとして機能するセカンダリークラスターにミラーリングされる場合、
rbd-mirrorはバックアップクラスターでのみ実行されます。RBD ミラーリングには複数のセカンダリーサイトがある場合があります。
-
データがプライマリークラスターからバックアップとして機能するセカンダリークラスターにミラーリングされる場合、
双方向レプリケーション
-
双方向レプリケーションは、プライマリークラスターに
rbd-mirrorデーモンを追加して、そのクラスターでイメージをデモートし、セカンダリークラスターでプロモートできるようにします。その後、セカンダリークラスターのイメージに対して変更が行われ、セカンダリーからプライマリーに逆方向にレプリケートされます。どちらかのクラスターでのイメージのプロモートとデモートを可能にするには、両方のクラスターでrbd-mirrorが実行されている必要があります。現在、双方向レプリケーションは 2 つのサイトの間でのみサポートされています。
-
双方向レプリケーションは、プライマリークラスターに
rbd-mirror パッケージは、rbd-mirror を提供します。
双方向レプリケーションでは、rbd-mirror の各インスタンスが同時に他の Ceph クラスターに接続できる必要があります。また、ミラーリングを処理するために、ネットワークには 2 つのデータセンターサイトの間で十分な帯域幅が必要です。
Ceph クラスターごとに単一の rbd-mirror デーモンのみを実行します。
ミラーリングモード
ミラーリングは、ピアクラスター内のプールごとに設定されます。Ceph は、プールのミラーリングするイメージに応じて、2 つのモードをサポートします。
- プールモード
- ジャーナリング機能が有効になっているプール内のイメージはすべてミラーリングされます。詳細は、プールミラーリングの設定 を参照してください。
- イメージモード
- プール内のイメージの特定のサブセットのみがミラーリングされるため、イメージごとにミラーリングを個別に有効にする必要があります。詳細は、イメージのミラーリングの設定 を参照してください。
イメージの状態
イメージの変更が可能かどうかは、その状態により異なります。
- プライマリー状態のイメージを変更できます。
- プライマリー状態以外のイメージは変更できません。
イメージでミラーリングが最初に有効化された時点で、イメージはプライマリーに自動的にプロモートされます。以下でプロモートが可能です。
- プールモードでミラーリングを暗黙的に有効にする。
- 特定のイメージのミラーリングを明示的に有効にする。
プライマリーイメージをデモートし、プライマリー以外のイメージをプロモートすることができます。詳細は、「イメージ設定」 を参照してください。
4.1. ジャーナルの有効化
RBD ジャーナリング機能を有効にできます。
- イメージが作成されたとき
- 既存のイメージに対して動的に。
ジャーナリングは、有効にする必要がある exclusive-lock 機能に依存します。以下の手順を参照してください。
イメージの作成時にジャーナリングを有効にするには、--image-feature オプションを使用します。
rbd create <image-name> --size <megabytes> --pool <pool-name> --image-feature <feature>
以下に例を示します。
# rbd create image1 --size 1024 --pool data --image-feature exclusive-lock,journaling
以前に作成したイメージでジャーナリングを有効にするには、rbd feature enable コマンドを使用します。
rbd feature enable <pool-name>/<image-name> <feature-name>
以下に例を示します。
# rbd feature enable data/image1 exclusive-lock # rbd feature enable data/image1 journaling
デフォルトですべての新規イメージのジャーナリングを有効にするには、以下の設定を Ceph 設定ファイルに追加します。
rbd default features = 125
4.2. プール設定
本章では、以下のタスクを実行する方法を説明します。
- プールでのミラーリングの有効化
- プールでのミラーリングの無効化
- クラスターピアの追加
- ピアに関する情報の表示
- クラスターピアの削除
- プールのミラーリングステータスの取得
両方のピアクラスターで以下のコマンドを実行します。
プールでのミラーリングの有効化
プールのミラーリングを有効にするには、以下を実行します。
rbd mirror pool enable <pool-name> <mode>
例
data という名前のプール全体のミラーリングを有効にするには、以下を実行します。
# rbd mirror pool enable data pool
data という名前のプールでイメージモードのミラーリングを有効にするには、以下を実行します。
# rbd mirror pool enable data image
詳細は、「 Mirroring Modes 」を参照してください。
プールでのミラーリングの無効化
プールのミラーリングを無効にするには、以下を実行します。
rbd mirror pool disable <pool-name>
例
data という名前のプールのミラーリングを無効にするには、以下を実行します。
# rbd mirror pool disable data
ミラーリングを無効にする前に、ピアクラスターを削除します。詳細は、「プール設定」 を参照してください。
プールのミラーリングを無効にすると、ミラーリングを別に有効化していたプール内にあるイメージに対するミラーリングも無効化されます。詳細は イメージ設定 を参照してください。
クラスターピアの追加
rbd-mirror デーモンがそのピアクラスターを検出するには、ピアをプールに登録する必要があります。
rbd --cluster <cluster-name> mirror pool peer add <pool-name> <peer-client-name>@<peer-cluster-name> -n <client-name>
例
site-a クラスターをピアとして site-b クラスターに追加するには、site-b クラスターのクライアントノードから以下のコマンドを実行します。
# rbd --cluster site-b mirror pool peer add data client.site-a@site-a -n client.site-b
ピアに関する情報の表示
ピアの情報を表示するには、以下を実行します。
rbd mirror pool info <pool-name>
例
# rbd mirror pool info data Mode: pool Peers: UUID NAME CLIENT 7e90b4ce-e36d-4f07-8cbc-42050896825d site-a client.site-a
クラスターピアの削除
ミラーリングピアクラスターを削除するには、以下を実行します。
rbd mirror pool peer remove <pool-name> <peer-uuid>
プール名とピア一意識別子 (UUID) を指定します。ピア UUID を表示するには、rbd mirror pool info コマンドを使用します。
例
# rbd mirror pool peer remove data 7e90b4ce-e36d-4f07-8cbc-42050896825d
プールのミラーリングステータスの取得
ミラーリングプールの概要を取得するには、以下を実行します。
rbd mirror pool status <pool-name>
例
データ プールのステータスを取得するには、以下を実行します。
# rbd mirror pool status data health: OK images: 1 total
プールのすべてのミラーリングイメージのステータス詳細を出力するには、--verbose オプションを使用します。
4.3. イメージ設定
本章では、以下のタスクを実行する方法を説明します。
- イメージミラーリングの有効化
- イメージミラーリングの無効化
- イメージのプロモートおよびデモート
- イメージの再同期
- 単一イメージのミラーリングステータスの取得
単一クラスターでのみ以下のコマンドを実行します。
イメージミラーリングの有効化
特定のイメージのミラーリングを有効にするには、以下を実行します。
- 両方のピアクラスターでプール全体のミラーリングを有効にします。詳細は、「プール設定」 を参照してください。
次に、プール内の特定イメージのミラーリングを明示的に有効にします。
rbd mirror image enable <pool-name>/<image-name>
例
データ プールの image 2 イメージ のミラーリングを有効にするには、以下を実行します。
# rbd mirror image enable data/image2
イメージミラーリングの無効化
特定のイメージのミラーリングを無効にするには、以下を実行します。
rbd mirror image disable <pool-name>/<image-name>
例
データ プールの image 2 イメージ のミラーリングを無効にするには、以下を実行します。
# rbd mirror image disable data/image2
イメージのプロモートおよびデモート
プライマリー以外にイメージをデモートするには、以下のコマンドを実行します。
rbd mirror image demote <pool-name>/<image-name>
例
データ プールの image 2 イメージ を降格するには、以下を実行します。
# rbd mirror image demote data/image2
イメージをプライマリーにプロモートするには、以下のコマンドを実行します。
rbd mirror image promote <pool-name>/<image-name>
例
データ プールの image 2 イメージ をプロモートするには、以下を実行します。
# rbd mirror image promote data/image2
使用しているミラーリングのタイプに応じて、一方向ミラーリングを使用した障害からの復旧 または 双方向ミラーリングを使用した障害からの復旧 を参照してください。
--force オプションを使用して、プライマリー以外のイメージを強制的にプロモートします。
# rbd mirror image promote --force data/image2
クラスターの障害や通信の停止などの理由により、降格がピア Ceph クラスターに伝播できない場合、強制的なプロモートを使用します。詳細は、正常にシャットダウンされなかった場合のフェイルオーバー を参照してください。
プロモート後にイメージは有効にならないので、プライマリー以外の同期中のイメージを強制的にプロモートしないでください。
イメージの再同期
プライマリーイメージに再同期を要求するには、以下を実行します。
rbd mirror image resync <pool-name>/<image-name>
例
データ プール内の image 2 イメージ の再同期を要求するには、以下を実行します。
# rbd mirror image resync data/image2
2 つのピアクラスターの間で整合性がない状態の場合に、rbd-mirror デーモンは、不整合の原因となるイメージのミラーリングは試行しません。この問題を修正する方法は、「障害からの復旧」セクションを参照してください。使用しているミラーリングのタイプに応じて、一方向ミラーリングを使用した障害からの復旧 または 双方向ミラーリングを使用した障害からの復旧 を参照してください。
単一イメージのミラーリングステータスの取得
ミラーリングされたイメージのステータスを取得するには、以下を実行します。
rbd mirror image status <pool-name>/<image-name>
例
データ プールの image 2 イメージ のステータスを取得するには、以下を実行します。
# rbd mirror image status data/image2 image2: global_id: 703c4082-100d-44be-a54a-52e6052435a5 state: up+replaying description: replaying, master_position=[object_number=0, tag_tid=3, entry_tid=0], mirror_position=[object_number=0, tag_tid=3, entry_tid=0], entries_behind_master=0 last_update: 2019-04-23 13:39:15
4.4. 1-Way ミラーリングの設定
一方向ミラーリングは、1 つのクラスターのプライマリーイメージがセカンダリークラスターに複製されることを意味します。セカンダリークラスターでは、複製されたイメージはプライマリーではありません。つまり、ブロックデバイスクライアントはイメージに書き込みできません。
一方向ミラーリングは、複数のセカンダリーサイトをサポートします。複数のセカンダリーサイトで一方向ミラーリングを設定するには、各セカンダリークラスターで以下の手順を繰り返します。
一方向ミラーリングは、イメージのクラッシュコンバーストコピーを維持するのに適しています。一方向ミラーリングは、一方向ミラーリングの使用時にクラスターがフェイルバックできないため、OpenStack でセカンダリーイメージを使用し、OpenStack でフェイルバックするなど、すべての状況には適さない場合があります。このようなシナリオでは、双方向ミラーリングを使用します。詳細は、「2 つのWay Mirroring の設定」 を参照してください。
以下の手順では、以下を前提としています。
-
2 つのクラスターがあり、プライマリークラスターからセカンダリークラスターにイメージを複製する必要があります。この手順では、プライマリーイメージを
site-aクラスター、およびイメージをsite-bクラスターとして複製するクラスターを参照して、2 つのクラスターを区別します。Ceph Storage クラスターのインストールに関する情報は、『 Installation Guide for Red Hat Enterprise Linux 』または『 Installation Guide for Ubuntu 』を参照してください。 -
site-bクラスターには、rbd-mirrorデーモンが実行されるクライアントノードが割り当てられます。このデーモンはsite-aクラスターに接続し、イメージをsite-bクラスターに同期します。Ceph クライアントのインストールに関する情報は、『 Installation Guide for Red Hat Enterprise Linux 』または「 Installation Guide for Ubuntu」を参照してください。 -
両方のクラスターに同じ名前を持つプールが作成されます。以下の例では、プールの名前は
dataです。詳細は、『 Storage Strategies Guide 』の「 Pools 」または「Red Hat Ceph Storage 3」の章を参照してください。 -
プールにはミラーリングするイメージが含まれ、ジャーナリングを有効にしておく。以下の例では、イメージの名前は
image1およびimage2です。詳細は、「 ジャーナルの有効化 」を参照してください。
ブロックデバイスのミラーリングを設定する方法は 2 つあります。
- プール のミラー リング: プール内のすべてのイメージをミラーリングするには、「プールミラーリング の設定」の手順を使用します。
- イメージ のミラー リング: プール内のイメージを反映させるには、「イメージミラーリング の設定」の手順を使用します。
プールミラーリングの設定
-
データプール内のすべてのイメージが排他的ロックを持ち、ジャーナリングが有効になっていることを確認します。詳細は、 を参照してください。 site-bクラスターのクライアントノードで、rbd-mirrorパッケージをインストールします。パッケージは Red Hat Ceph Storage Tools リポジトリーによって提供されます。Red Hat Enterprise Linux
# yum install rbd-mirror
Ubuntu
$ sudo apt-get install rbd-mirror
site-bクラスターのクライアントノードで、CLUSTERオプションを適切なファイルに追加してクラスター名を指定します。Red Hat Enterprise Linux で、/etc/sysconfig/cephファイルを更新し、Ubuntu で、それに応じて/etc/default/cephファイルを更新します。CLUSTER=site-b
両方のクラスターで、
データプールにアクセスしてキーリングを <cluster-name>.client.<user-name>.keyring ファイルに出力するパーミッションを持つユーザーを作成します。site-aクラスターのモニターホストで、client.site-aユーザーを作成し、キーリングをsite-a.client.site-a.keyringファイルに出力します。# ceph auth get-or-create client.site-a mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-a.client.site-a.keyring
site-bクラスターのモニターホストで、client.site-bユーザーを作成し、キーリングをsite-b.client.site-b.keyringファイルに出力します。# ceph auth get-or-create client.site-b mon 'profile rbd' osd 'profile rbd pool=data' -o /etc/ceph/site-b.client.site-b.keyring
Ceph 設定ファイルおよび新たに作成された鍵ファイルを
site-aのモニターノードからsite-bのモニターおよびクライアントノードにコピーします。# scp /etc/ceph/ceph.conf <user>@<site-b_mon-host-name>:/etc/ceph/site-a.conf # scp /etc/ceph/site-a.client.site-a.keyring <user>@<site-b_mon-host-name>:/etc/ceph/ # scp /etc/ceph/ceph.conf <user>@<site-b_client-host-name>:/etc/ceph/site-a.conf # scp /etc/ceph/site-a.client.site-a.keyring <user>@<site-b_client-host-name>:/etc/ceph/
注記Ceph 設定ファイルを
site-bCeph Monitor ノードからsite-aの Ceph Monitor およびクライアントノードに転送するscpコマンドをし用すると、ファイルの名前がsite-a.confに変更されます。キーリングファイル名は同じままです。site-bクラスタークライアントノードのceph.confをポイントするsite-b.confという名前のシンボリックリンクを作成します。# cd /etc/ceph # ln -s ceph.conf site-b.conf
site-aクライアントノードでrbd-mirrorデーモンを有効にして起動します。systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@<client-id> systemctl start ceph-rbd-mirror@<client-id>
CLIENT_IDcephxアクセスが必要です。詳細は、Red Hat Ceph Storage 管理ガイド の ユーザー管理 の章を参照してください。site-bを使用した前述の例に基づいて、以下のコマンドを実行します。# systemctl enable ceph-rbd-mirror.target # systemctl enable ceph-rbd-mirror@site-b # systemctl start ceph-rbd-mirror@site-b
site-aクラスターのモニターノードで以下のコマンドを実行して、site-aクラスターにあるデータプールのプールミラーリングを有効にします。# rbd mirror pool enable data pool
また、ミラーリングが正常に有効化されていることを確認します。
# rbd mirror pool info data Mode: pool Peers: none
site-bクラスターのクライアントノードから以下のコマンドを実行して、site-aクラスターをsite-bクラスターのピアとして追加します。# rbd --cluster site-b mirror pool peer add data client.site-a@site-a -n client.site-b
また、ピアが正常に追加されたことを確認します。
# rbd mirror pool info data Mode: pool Peers: UUID NAME CLIENT 7e90b4ce-e36d-4f07-8cbc-42050896825d site-a client.site-a
しばらく後に、
image1イメージおよび image2 イメージのステータスを確認します。それらがup+replaying状態の場合には、ミラーリングが適切に機能します。site-bクラスターの監視ノードから以下のコマンドを実行します。# rbd mirror image status data/image1 image1: global_id: 7d486c3f-d5a1-4bee-ae53-6c4f1e0c8eac state: up+replaying description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2019-04-22 13:19:27
# rbd mirror image status data/image2 image2: global_id: 703c4082-100d-44be-a54a-52e6052435a5 state: up+replaying description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[], entries_behind_master=3 last_update: 2019-04-22 13:19:19
イメージのミラーリングの設定
-
データプール内のミラーリングに使用する選択したイメージの排他ロックとジャーナリングが有効になっていることを確認します。詳細は、 を参照してください。 - プールミラーリングの設定 の手順 2 - 7 に従ってください。
site-aクラスターのモニターノードから、データプールのイメージのミラーリングを有効にします。# rbd mirror pool enable data image
また、ミラーリングが正常に有効化されていることを確認します。
# rbd mirror pool info data Mode: image Peers: none
site-aクラスターのクライアントノードから、site-bクラスターをピアとして追加します。# rbd --cluster site-b mirror pool peer add data client.site-a@site-a -n client.site-b
また、ピアが正常に追加されたことを確認します。
# rbd mirror pool info data Mode: image Peers: UUID NAME CLIENT 9c1da891-b9f4-4644-adee-6268fe398bf1 site-a client.site-a
site-aクラスターのモニターノードから、image1およびimage2イメージのイメージのミラーリングを明示的に有効にします。# rbd mirror image enable data/image1 Mirroring enabled # rbd mirror image enable data/image2 Mirroring enabled
しばらく後に、
image1イメージおよび image2 イメージのステータスを確認します。それらがup+replaying状態の場合には、ミラーリングが適切に機能します。site-bクラスターの監視ノードから以下のコマンドを実行します。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+replaying description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2019-04-12 17:24:04
# rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+replaying description: replaying, master_position=[object_number=3, tag_tid=1, entry_tid=3], mirror_position=[object_number=3, tag_tid=1, entry_tid=3], entries_behind_master=0 last_update: 2019-04-12 17:23:51
4.5. 2 つのWay Mirroring の設定
双方向のミラーリングにより、2 つのクラスター間でいずれかの方向でイメージを複製できます。いずれかのクラスターから同じイメージへの変更を書き込むことはできず、変更が伝播され、変更が反映されます。イメージがクラスターからプロモートまたは降格され、読み取り元および同期する場所が変更されます。
以下の手順では、以下を前提としています。
-
ストレージクラスターが 2 台あり、それらのクラスター間でイメージをどちらの方向にでも複製できる。以下の例では、クラスターは
site-aおよびsite-bクラスターと呼ばれます。Ceph Storage クラスターのインストールに関する情報は、『 Installation Guide for Red Hat Enterprise Linux 』または『 Installation Guide for Ubuntu 』を参照してください。 -
両方のクラスターには、
rbd-mirrorデーモンが実行されるクラスターノードが割り当てられます。site-bクラスターのデーモンはsite-aクラスターに接続してイメージをsite-bsite-aクラスターのデーモンは site-b クラスターに接続し、イメージをsite-aに同期します。Ceph クライアントのインストールに関する情報は、『 Installation Guide for Red Hat Enterprise Linux 』または「 Installation Guide for Ubuntu 」を参照してください。 -
両方のクラスターに同じ名前を持つプールが作成されます。以下の例では、プールの名前は
dataです。詳細は、『 Storage Strategies Guide 』の「 Pools 」または「Red Hat Ceph Storage 3」の章を参照してください。 -
プールにはミラーリングするイメージが含まれ、ジャーナリングを有効にしておく。以下の例では、イメージの名前は
image1およびimage2です。詳細は、「 ジャーナルの有効化 」を参照してください。
ブロックデバイスのミラーリングを設定する方法は 2 つあります。
- プール のミラーリング: プール内のすべてのイメージをミラーリングするには、以下の「プールミラー リングの設定 」に従ってください。
- イメージ のミラー リング: プール内のイメージを反映させるには、以下の「イメージのミラーリングの設定」 に従ってください。
プールミラーリングの設定
-
データプール内のすべてのイメージが排他的ロックを持ち、ジャーナリングが有効になっていることを確認します。詳細は、 を参照してください。 - 「 1-Way Mirroring の設定」の「プールミラーリングの設定」 セクションの手順 2 - 7 に従って 1 方向ミラーリングを設定します。
site-aクラスターのクライアントノードで、rbd-mirrorパッケージをインストールします。パッケージは Red Hat Ceph Storage Tools リポジトリーによって提供されます。Red Hat Enterprise Linux
# yum install rbd-mirror
Ubuntu
$ sudo apt-get install rbd-mirror
site-aクラスターのクライアントノードで、CLUSTERオプションを適切なファイルに追加してクラスター名を指定します。Red Hat Enterprise Linux で、/etc/sysconfig/cephファイルを更新し、Ubuntu で、それに応じて/etc/default/cephファイルを更新します。CLUSTER=site-a
site-bCeph 設定ファイルおよび RBD キーリングファイルをsite-bmonitor からsite-amonitor およびクライアントノードにコピーします。# scp /etc/ceph/ceph.conf <user>@<site-a_mon-host-name>:/etc/ceph/site-b.conf # scp /etc/ceph/site-b.client.site-b.keyring root@<site-a_mon-host-name>:/etc/ceph/ # scp /etc/ceph/ceph.conf user@<site-a_client-host-name>:/etc/ceph/site-b.conf # scp /etc/ceph/site-b.client.site-b.keyring user@<site-a_client-host-name>:/etc/ceph/
注記Ceph 設定ファイルを
site-bmonitor ノードから site-a モニターノードからsite-a監視ノードに転送するscpコマンドおよびクライアントノードの名前変更をsite-b.confに変更します。キーリングファイル名は同じままです。site-aキーリングファイルをsite-aCeph Monitor ノードからsite-aクライアントノード にコピーします。# scp /etc/ceph/site-a.client.site-a.keyring <user>@<site-a_client-host-name>:/etc/ceph/
site-aクラスタークライアントノードのceph.confをポイントするsite-a.confという名前のシンボリックリンクを作成します。# cd /etc/ceph # ln -s ceph.conf site-a.conf
site-aクライアントノードでrbd-mirrorデーモンを有効にして起動します。systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@<client-id> systemctl start ceph-rbd-mirror@<client-id>
$CLIENT_IDは、rbd-mirrorデーモンが使用する Ceph Storage クラスターユーザーです。ユーザーに、クラスターへの適切なcephxアクセスが必要です。詳細は、Red Hat Ceph Storage 管理ガイド の ユーザー管理 の章を参照してください。site-aを使用した前述の例に基づいて、以下のコマンドを実行します。# systemctl enable ceph-rbd-mirror.target # systemctl enable ceph-rbd-mirror@site-a # systemctl start ceph-rbd-mirror@site-a
site-bクラスターのモニターノードで以下のコマンドを実行して、site-bクラスターにあるデータプールのプールミラーリングを有効にします。# rbd mirror pool enable data pool
また、ミラーリングが正常に有効化されていることを確認します。
# rbd mirror pool info data Mode: pool Peers: none
site-aクラスターのクライアントノードから以下のコマンドを実行して、site-bクラスターをsite-aクラスターのピアとして追加します。# rbd --cluster site-a mirror pool peer add data client.site-b@site-b -n client.site-a
また、ピアが正常に追加されたことを確認します。
# rbd mirror pool info data Mode: pool Peers: UUID NAME CLIENT dc97bd3f-869f-48a5-9f21-ff31aafba733 site-b client.site-b
site-aクラスターのクライアントノードからミラーリングのステータスを確認します。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-16 15:45:31
# rbd mirror image status data/image2 image1: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-16 15:55:33
イメージは
up+stopped状態である必要があります。ここでは、upはrbd-mirrorデーモンが実行中で、stoppedは、イメージが別のクラスターからのレプリケーション先ではないことを意味します。これは、イメージがこのクラスターのプライマリーであるためです。注記以前のバージョンでは、一方向ミラーリングを設定する場合は、イメージを
site-bに複製するように設定されていました。これにより、site-bクライアントノードにrbd-mirrorをインストールして、site-aからsite-bに更新を「プル」できるようになりました。この時点で、site-aクラスターはミラーリングすることができますが、イメージはこれを必要とする状態ではありません。他の方向のミラーリングは、site-aのイメージが降格され、site-bのイメージがプロモートされる場合に起動します。イメージのプロモートおよび降格方法に関する情報は、「イメージの 設定」を参照し てください。
イメージのミラーリングの設定
ミラーリングがまだ設定されていない場合に 1 方向のミラーリングを設定します。
- 1-Way Mirroring の設定 の「プールミラーリングの設定」 セクションの手順 2 -7 に従ってください。
- 「 1-Way Mirroring の設定」 セクションの手順 3 - 5 に従ってください。
- 2- Way Mirroring の設定 の「プールミラーリングの設定」 セクションの手順 3 - 7 に従います。このセクションは直前です。
site-aクラスターのクライアントノードから以下のコマンドを実行して、site-bクラスターをsite-aクラスターのピアとして追加します。# rbd --cluster site-a mirror pool peer add data client.site-b@site-b -n client.site-a
また、ピアが正常に追加されたことを確認します。
# rbd mirror pool info data Mode: pool Peers: UUID NAME CLIENT dc97bd3f-869f-48a5-9f21-ff31aafba733 site-b client.site-b
site-aクラスターのクライアントノードからミラーリングのステータスを確認します。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-16 15:45:31
# rbd mirror image status data/image2 image1: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-16 15:55:33
イメージは
up+stopped状態である必要があります。ここでは、upはrbd-mirrorデーモンが実行中で、stoppedは、イメージが別のクラスターからのレプリケーション先ではないことを意味します。これは、イメージがこのクラスターのプライマリーであるためです。注記以前のバージョンでは、一方向ミラーリングを設定する場合は、イメージを
site-bに複製するように設定されていました。これにより、site-bクライアントノードにrbd-mirrorをインストールして、site-aからsite-bに更新を「プル」できるようになりました。この時点で、site-aクラスターはミラーリングすることができますが、イメージはこれを必要とする状態ではありません。他の方向のミラーリングは、site-aのイメージが降格され、site-bのイメージがプロモートされる場合に起動します。イメージのプロモートおよび降格方法に関する情報は、「イメージの 設定」を参照し てください。
4.6. 遅延レプリケーション
一方向レプリケーションを使用する場合でも、RADOS Block Device (RBD) ミラーリングイメージ間でレプリケーションを遅延させることができます。セカンダリーイメージにレプリケーションされる前に、プライマリーイメージへの不要な変更を元に戻せるように、猶予の期間が必要な場合には、遅延レプリケーションを実装することができます。
遅延レプリケーションを実装するには、宛先ストレージクラスター内の rbd-mirror デーモンで rbd_mirroring_replay_delay = MINIMUM_DELAY_IN_SECONDS 設定オプションを指定する必要があります。この設定は、rbd-mirror デーモンが使用する ceph.conf ファイル内でグローバルに適用することも、個別のイメージベースで適用することも可能です。
特定のイメージで遅延レプリケーションを使用するには、プライマリーイメージで以下の rbd CLI コマンドを実行します。
rbd image-meta set <image-spec> conf_rbd_mirroring_replay_delay <minimum delay in seconds>
たとえば、プール vms のイメージ vm-1 に最小レプリケーション遅延を 10 分設定するには、以下を実行します。
rbd image-meta set vms/vm-1 conf_rbd_mirroring_replay_delay 600
4.7. 一方向ミラーリングを使用した障害からの復旧
一方向のミラーリングで障害から回復するには、以下の手順を使用します。以下で、プライマリークラスターを終了してからセカンダリークラスターにフェイルオーバーする方法、およびフェイルバックする方法が紹介します。シャットダウンは、正常でもそうでなくても構いません。
以下の例では、プライマリークラスターは site-a クラスターと呼ばれ、セカンダリークラスターは site-b クラスターと呼ばれます。また、ストレージクラスターにはどちらも image1 と image2 の 2 つのイメージが含まれる data プールがあります。
一方向ミラーリングは、複数のセカンダリーサイトをサポートします。追加のセカンダリークラスターを使用している場合は、セカンダリークラスターの中から 1 つ選択してフェイルオーバーします。フェイルバック中に同じクラスターから同期します。
前提条件
- 2 つ以上の実行中のクラスター。
- 一方向ミラーリングを使用して設定されるプールのミラーリングまたはイメージミラーリング。
正常なシャットダウン後のフェイルオーバー
- プライマリーイメージを使用するクライアントをすべて停止します。この手順は、どのクライアントがイメージを使用するかにより異なります。たとえば、イメージを使用する OpenStack インスタンスからボリュームの割り当てを解除します。Red Hat OpenStack Platform ストレージガイドの ブロックストレージおよびボリューム の章を参照してください。
site-aクラスターのモニターノードで以下のコマンドを実行して、site-aクラスターにあるプライマリーイメージをデモートします。# rbd mirror image demote data/image1 # rbd mirror image demote data/image2
site-bクラスターにあるプライマリー以外のイメージをプロモートするには、site-bクラスターのモニターノードで以下のコマンドを実行します。# rbd mirror image promote data/image1 # rbd mirror image promote data/image2
しばらくすると、
site-bクラスターのモニターノードからイメージのステータスを確認します。up+stoppedの状態が表示されるはずです。また、説明にはprimaryが表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-17 13:18:36 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-17 13:18:36
正常にシャットダウンされなかった場合のフェイルオーバー
- プライマリークラスターが停止していることを確認します。
- プライマリーイメージを使用するクライアントをすべて停止します。この手順は、どのクライアントがイメージを使用するかにより異なります。たとえば、イメージを使用する OpenStack インスタンスからボリュームの割り当てを解除します。Red Hat OpenStack Platform ストレージガイドの ブロックストレージおよびボリューム の章を参照してください。
site-bクラスターの監視ノードから、プライマリー以外のイメージをプロモートします。site-aストレージクラスターにデモートが伝播されないので、--force オプションを使用します。# rbd mirror image promote --force data/image1 # rbd mirror image promote --force data/image2
もう一度、
site-bクラスターのモニターノードからイメージのステータスを確認します。状態として、up+stopping_replayが、説明にforce promotedと表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06
フェイルバックの準備
以前のプライマリークラスターが回復すると、フェイルバックを行います。
2 つのクラスターが最初に一方向ミラーリング用にのみ設定されている場合、フェイルバックを行うためにプライマリークラスターもミラーリング用に設定され、逆方向でイメージを複製する必要があります。
site-aクラスターのクライアントノードで、rbd-mirrorパッケージをインストールします。パッケージは Red Hat Ceph Storage Tools リポジトリーによって提供されます。Red Hat Enterprise Linux
# yum install rbd-mirror
Ubuntu
$ sudo apt-get install rbd-mirror
site-aクラスターのクライアントノードで、CLUSTERオプションを適切なファイルに追加してクラスター名を指定します。Red Hat Enterprise Linux で、/etc/sysconfig/cephファイルを更新し、Ubuntu で、それに応じて/etc/default/cephファイルを更新します。CLUSTER=site-b
site-bCeph 設定ファイルおよび RBD キーリングファイルをsite-bmonitor からsite-amonitor およびクライアントノードにコピーします。# scp /etc/ceph/ceph.conf <user>@<site-a_mon-host-name>:/etc/ceph/site-b.conf # scp /etc/ceph/site-b.client.site-b.keyring root@<site-a_mon-host-name>:/etc/ceph/ # scp /etc/ceph/ceph.conf user@<site-a_client-host-name>:/etc/ceph/site-b.conf # scp /etc/ceph/site-b.client.site-b.keyring user@<site-a_client-host-name>:/etc/ceph/
注記Ceph 設定ファイルを
site-bCeph Monitor ノードからsite-aの Ceph Monitor およびクライアントノードに転送するscpコマンドをし用すると、ファイルの名前がsite-a.confに変更されます。キーリングファイル名は同じままです。site-aキーリングファイルをsite-aCeph Monitor ノードからsite-aクライアントノード にコピーします。# scp /etc/ceph/site-a.client.site-a.keyring <user>@<site-a_client-host-name>:/etc/ceph/
site-aクライアントノードでrbd-mirrorデーモンを有効にして起動します。systemctl enable ceph-rbd-mirror.target systemctl enable ceph-rbd-mirror@<client-id> systemctl start ceph-rbd-mirror@<client-id>
CLIENT_IDcephxアクセスが必要です。詳細は、Red Hat Ceph Storage 管理ガイド の ユーザー管理 の章を参照してください。site-aを使用した前述の例に基づいて、コマンドは以下のようになります。# systemctl enable ceph-rbd-mirror.target # systemctl enable ceph-rbd-mirror@site-a # systemctl start ceph-rbd-mirror@site-a
site-aクラスターのクライアントノードから、site-bクラスターをピアとして追加します。# rbd --cluster site-a mirror pool peer add data client.site-b@site-b -n client.site-a
複数のセカンダリークラスターを使用している場合は、フェイルオーバー先に選択したセカンダリークラスターのみを追加し、フェイルバックから追加する必要があります。
site-aクラスターのモニターノードから、site-bクラスターが正常にピアとして追加されたことを確認します。# rbd mirror pool info -p data Mode: image Peers: UUID NAME CLIENT d2ae0594-a43b-4c67-a167-a36c646e8643 site-b client.site-b
failback
以前のプライマリークラスターが回復すると、フェイルバックを行います。
site-aクラスターのモニターノードから、イメージがプライマリーかどうかを判別します。# rbd info data/image1 # rbd info data/image2
コマンドの出力で、
mirroring primary: trueまたはmirroring primary: falseを検索し、状態を判断します。site-aクラスターのモニターノードから以下のようなコマンドを実行して、プライマリーとして一覧表示されるイメージを降格します。# rbd mirror image demote data/image1
正常にシャットダウンされなかった場合にのみ、イメージをもう一度同期します。
site-aストレージクラスターのモニターノードで以下のコマンドを実行し、イメージをsite-bからsite-aに再同期します。# rbd mirror image resync data/image1 Flagged image for resync from primary # rbd mirror image resync data/image2 Flagged image for resync from primary
しばらくしたら、状態が
up+replayingかをチェックして、イメージの最同期が完了していることを確認します。site-a ストレージクラスターのモニターノードで以下のコマンドを実行して、イメージの状態を確認します。# rbd mirror image status data/image1 # rbd mirror image status data/image2
site-bクラスターのモニターノードで以下のコマンドを実行して、site-bクラスターのイメージを降格します。# rbd mirror image demote data/image1 # rbd mirror image demote data/image2
注記複数のセカンダリークラスターがある場合、これは昇格されたセカンダリークラスターからのみ実行する必要があります。
site-aクラスターのモニターノードで以下のコマンドを実行して、site-aクラスターにあるプライマリーイメージをデモートします。# rbd mirror image promote data/image1 # rbd mirror image promote data/image2
site-aクラスターの監視ノードからイメージのステータスを確認します。状態としてup+stopped、説明としてlocal image is primaryと表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51
双方向ミラーリングの削除
上記の Prepare for failback セクションで、双方向ミラーリングの機能は site-b クラスターから site-a クラスターへの同期を有効にするように設定されています。フェイルバックが完了すると、これらの関数を無効にすることができます。
site-aクラスターからピアとしてsite-bクラスターを削除します。$ rbd mirror pool peer remove data client.remote@remote --cluster local # rbd --cluster site-a mirror pool peer remove data client.site-b@site-b -n client.site-a
site-aクライアントでrbd-mirrorデーモンを停止して無効にします。systemctl stop ceph-rbd-mirror@<client-id> systemctl disable ceph-rbd-mirror@<client-id> systemctl disable ceph-rbd-mirror.target
以下に例を示します。
# systemctl stop ceph-rbd-mirror@site-a # systemctl disable ceph-rbd-mirror@site-a # systemctl disable ceph-rbd-mirror.target
関連情報
- イメージの降格、プロモート、再同期に関する詳細は、『 ブロックデバイスガイド』 の 「イメージの設定 」を参照してください。
4.8. 双方向ミラーリングを使用した障害からの復旧
双方向ミラーリングで障害から回復するには、以下の手順を使用します。以下で、プライマリークラスターを終了してからセカンダリークラスターのミラーリングデータにフェイルオーバーする方法、およびフェイルバックする方法が紹介します。シャットダウンは、正常でもそうでなくても構いません。
以下の例では、プライマリークラスターは site-a クラスターと呼ばれ、セカンダリークラスターは site-b クラスターと呼ばれます。また、ストレージクラスターにはどちらも image1 と image2 の 2 つのイメージが含まれる data プールがあります。
前提条件
- 2 つ以上の実行中のクラスター。
- 一方向ミラーリングを使用して設定されるプールのミラーリングまたはイメージミラーリング。
正常なシャットダウン後のフェイルオーバー
- プライマリーイメージを使用するクライアントをすべて停止します。この手順は、どのクライアントがイメージを使用するかにより異なります。たとえば、イメージを使用する OpenStack インスタンスからボリュームの割り当てを解除します。Red Hat OpenStack Platform ストレージガイドの ブロックストレージおよびボリューム の章を参照してください。
site-aクラスターのモニターノードで以下のコマンドを実行して、site-aクラスターにあるプライマリーイメージをデモートします。# rbd mirror image demote data/image1 # rbd mirror image demote data/image2
site-bクラスターにあるプライマリー以外のイメージをプロモートするには、site-bクラスターのモニターノードで以下のコマンドを実行します。# rbd mirror image promote data/image1 # rbd mirror image promote data/image2
しばらくすると、
site-bクラスターのモニターノードからイメージのステータスを確認します。イメージのステータスは、up+stoppedの状態を表示し、プライマリーとしてリストされているはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-17 16:04:37
- イメージへのアクセスを再開します。この手順は、どのクライアントがイメージを使用するかにより異なります。
正常にシャットダウンされなかった場合のフェイルオーバー
- プライマリークラスターが停止していることを確認します。
- プライマリーイメージを使用するクライアントをすべて停止します。この手順は、どのクライアントがイメージを使用するかにより異なります。たとえば、イメージを使用する OpenStack インスタンスからボリュームの割り当てを解除します。Red Hat OpenStack Platform ストレージガイドの ブロックストレージおよびボリューム の章を参照してください。
site-bクラスターの監視ノードから、プライマリー以外のイメージをプロモートします。site-aストレージクラスターにデモートが伝播されないので、--force オプションを使用します。# rbd mirror image promote --force data/image1 # rbd mirror image promote --force data/image2
もう一度、
site-bクラスターのモニターノードからイメージのステータスを確認します。状態として、up+stopping_replayが、説明にforce promotedと表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopping_replay description: force promoted last_update: 2019-04-17 13:25:06
failback
以前のプライマリークラスターが回復すると、フェイルバックを行います。
もう一度、
site-bクラスターのモニターノードからイメージのステータスを確認します。状態としてup-stopped、説明としてlocal image is primaryと表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:37:48 # rbd mirror image status data/image2 image2: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 17:38:18
site-aクラスターのモニターノードから、イメージがプライマリーかどうかを判別します。# rbd info data/image1 # rbd info data/image2
コマンドの出力で、
mirroring primary: trueまたはmirroring primary: falseを検索し、状態を判断します。site-aクラスターのモニターノードから以下のようなコマンドを実行して、プライマリーとして一覧表示されるイメージを降格します。# rbd mirror image demote data/image1
正常にシャットダウンされなかった場合にのみ、イメージをもう一度同期します。
site-aストレージクラスターのモニターノードで以下のコマンドを実行し、イメージをsite-bからsite-aに再同期します。# rbd mirror image resync data/image1 Flagged image for resync from primary # rbd mirror image resync data/image2 Flagged image for resync from primary
しばらくしたら、状態が
up+replayingかをチェックして、イメージの最同期が完了していることを確認します。site-a ストレージクラスターのモニターノードで以下のコマンドを実行して、イメージの状態を確認します。# rbd mirror image status data/image1 # rbd mirror image status data/image2
site-bクラスターのモニターノードで以下のコマンドを実行して、site-bクラスターのイメージを降格します。# rbd mirror image demote data/image1 # rbd mirror image demote data/image2
注記複数のセカンダリークラスターがある場合、これは昇格されたセカンダリークラスターからのみ実行する必要があります。
site-aクラスターのモニターノードで以下のコマンドを実行して、site-aクラスターにあるプライマリーイメージをデモートします。# rbd mirror image promote data/image1 # rbd mirror image promote data/image2
site-aクラスターの監視ノードからイメージのステータスを確認します。状態としてup+stopped、説明としてlocal image is primaryと表示されるはずです。# rbd mirror image status data/image1 image1: global_id: 08027096-d267-47f8-b52e-59de1353a034 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51 # rbd mirror image status data/image2 image2: global_id: 596f41bc-874b-4cd4-aefe-4929578cc834 state: up+stopped description: local image is primary last_update: 2019-04-22 11:14:51
関連情報
- イメージの降格、プロモート、再同期に関する詳細は、『 ブロックデバイスガイド』 の 「イメージの設定 」を参照してください。
4.9. ミラーリングを使用したインスタンスの更新
非同期更新で Ceph Block Device ミラーリングを使用してクラスターを更新する場合は、インストールの指示に従って更新してください。次に、Ceph ブロックデバイスインスタンスを再起動します。
規定されているインスタンスの再起動の順番はありません。Red Hat では、プライマリーイメージで、プールを参照するインスタンスを再起動して、その後にミラーリングされたプールを参照するインスタンスを再起動することを推奨します。
第5章 librbd(Python)
rbd python モジュールは、RBD イメージへのファイルのようなアクセスを提供します。この組み込みツールを使用するには、rbd モジュールおよび rados モジュールをインポートする必要があります。
イメージの作成および書き込み
RADOS に接続し、IO コンテキストを開きます。
cluster = rados.Rados(conffile='my_ceph.conf') cluster.connect() ioctx = cluster.open_ioctx('mypool')イメージの作成に使用する
:class:rbd.RBDオブジェクトをインスタンス化します。rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size)
イメージで I/O を実行するには、
:class:rbd.Imageオブジェクトをインスタンス化します。image = rbd.Image(ioctx, 'myimage') data = 'foo' * 200 image.write(data, 0)
これにより、イメージの最初の 600 バイトに foo が書き込まれます。データは
:type:unicodeに指定できない点に注意してください。librbdは:c:type:charよりも幅の広い文字の処理方法を認識していません。イメージ、IO コンテキスト、および RADOS への接続を終了します。
image.close() ioctx.close() cluster.shutdown()
念のために、これらの呼び出しごとに、個別の
:finallyブロックを割り当てる必要があります。import rados import rbd cluster = rados.Rados(conffile='my_ceph_conf') try: ioctx = cluster.open_ioctx('my_pool') try: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) image = rbd.Image(ioctx, 'myimage') try: data = 'foo' * 200 image.write(data, 0) finally: image.close() finally: ioctx.close() finally: cluster.shutdown()これは面倒な場合があるので、自動的に終了またはシャットダウンするコンテキストマネージャーとしてRados、Ioctx および Image クラスを使用できます。これらのクラスをコンテキストマネージャーとして使用すると、上記の例は以下のようになります。
with rados.Rados(conffile='my_ceph.conf') as cluster: with cluster.open_ioctx('mypool') as ioctx: rbd_inst = rbd.RBD() size = 4 * 1024**3 # 4 GiB rbd_inst.create(ioctx, 'myimage', size) with rbd.Image(ioctx, 'myimage') as image: data = 'foo' * 200 image.write(data, 0)
第6章 カーネルモジュールの操作
カーネルモジュールの操作を使用するには、Ceph クラスターが稼働中である必要があります。
Red Hat Enterprise Linux(RHEL)以外の Linux ディストリビューション上のクライアントは許可されますが、サポートされていません。これらのクライアントを使用する際にクラスターで見つかった問題(MDS など)がある場合、Red Hat はそれらに対応しますが、原因がクライアント側にある場合は、カーネルのベンダーが問題に対処する必要があります。
6.1. イメージ一覧の取得
ブロックデバイスイメージをマウントするには、まずイメージの一覧を返します。
これを行うには、以下を実行します。
[root@rbd-client ~]# rbd list
6.2. ブロックデバイスのマッピング
rbd を使用して、イメージ名をカーネルモジュールにマッピングします。イメージ名、プール名、およびユーザー名を指定する必要があります。rbd がまだロードされていない場合は、RBD カーネルモジュールを読み込みます。
これを行うには、以下を実行します。
[root@rbd-client ~]# rbd map {image-name} --pool {pool-name} --id {user-name}以下に例を示します。
[root@rbd-client ~]# rbd map --pool rbd myimage --id admin
cephx 認証を使用する場合は、シークレットも指定する必要があります。これはキーリングまたはシークレットを含むファイルからのものである可能性があります。
これを行うには、以下を実行します。
[root@rbd-client ~]# rbd map --pool rbd myimage --id admin --keyring /path/to/keyring [root@rbd-client ~]# rbd map --pool rbd myimage --id admin --keyfile /path/to/file
6.3. マップブロックデバイスの表示
rbd コマンドでカーネルモジュールにマッピングされたブロックデバイスイメージを表示するには、showmapped オプションを指定します。
これを行うには、以下を実行します。
[root@rbd-client ~]# rbd showmapped
6.4. ブロックデバイスのマッピング解除
rbd コマンドでブロックデバイスイメージをマッピング解除するには、unmap オプションとデバイス名を指定します(規則によりブロックデバイスのイメージ名と同じです)。
これを行うには、以下を実行します。
[root@rbd-client ~]# rbd unmap /dev/rbd/{poolname}/{imagename}以下に例を示します。
[root@rbd-client ~]# rbd unmap /dev/rbd/rbd/foo
第7章 Ceph ブロックデバイス設定の参照
7.1. 一般設定
- rbd_op_threads
- 詳細
- ブロックデバイス操作スレッドの数。
- 型
- 整数
- デフォルト
-
1
rbd_op_threads のデフォルト値を変更しないでください。これは、1 を超える値に設定するとデータが破損する可能性があるためです。
- rbd_op_thread_timeout
- 詳細
- ブロックデバイス操作スレッドのタイムアウト (秒単位)。
- 型
- 整数
- デフォルト
-
60
- rbd_non_blocking_aio
- 詳細
-
trueの場合、Ceph はブロックを防ぐためにワーカースレッドからブロックデバイスの非同期 I/O 操作を処理します。 - 型
- ブール値
- デフォルト
-
true
- rbd_concurrent_management_ops
- 詳細
- フライトでの同時管理操作の最大数 (イメージの削除またはサイズ変更など)。
- 型
- 整数
- デフォルト
-
10
- rbd_request_timed_out_seconds
- 詳細
- メンテナンス要求がタイムアウトするまでの秒数。
- 型
- 整数
- デフォルト
-
30
- rbd_clone_copy_on_read
- 詳細
-
trueに設定すると、コピーオン読み取りのクローン作成が有効になります。 - 型
- ブール値
- デフォルト
-
false
- rbd_enable_alloc_hint
- 詳細
-
trueの場合、割り当てヒントは有効にされ、ブロックデバイスは OSD バックエンドにヒントを発行し、予想されるサイズオブジェクトを示します。 - 型
- ブール値
- デフォルト
-
true
- rbd_skip_partial_discard
- 詳細
-
trueの場合、オブジェクト内で範囲を破棄しようとすると、ブロックデバイスは範囲のゼロを省略します。 - 型
- ブール値
- デフォルト
-
false
- rbd_tracing
- 詳細
-
Linux Trace Toolkit Next Generation User Space Tracer (LTTng-UST) トレースポイントを有効にするには、このオプションを
trueに設定します。詳細は、RBD Replay 機能を使用した RADOS Block Device (RBD) ワークロードのトレース を参照してください。 - 型
- ブール値
- デフォルト
-
false
- rbd_validate_pool
- 詳細
-
RBD の互換性について空のプールを検証するには、このオプションを
trueに設定します。 - 型
- ブール値
- デフォルト
-
true
- rbd_validate_names
- 詳細
-
イメージの仕様を検証するには、このオプションを
trueに設定します。 - 型
- ブール値
- デフォルト
-
true
7.2. デフォルトの設定
イメージを作成するデフォルト設定を上書きできます。Ceph は、2 のフォーマットでイメージを作成し、ストライピングを行わずにイメージを作成します。
- rbd_default_format
- 詳細
-
その他の形式が指定されていない場合のデフォルト形式 (
2)。フォーマット1は、librbdおよび カーネルモジュールの全バージョンと互換性がある新しいイメージの元の形式ですが、クローンなどの新しい機能をサポートしません。2形式は、librbdおよびカーネルモジュールバージョン 3.11 以降でサポートされます (ストライピングを除く)。フォーマット2により、クローン作成のサポートが追加され、今後より簡単に機能性を持たせることができます。 - 型
- 整数
- デフォルト
-
2
- rbd_default_order
- 詳細
- 他の順序が指定されていない場合のデフォルトの順番です。
- 型
- 整数
- デフォルト
-
22
- rbd_default_stripe_count
- 詳細
- 他のストライプ数が指定されていない場合、デフォルトのストライプ数。デフォルト値を変更するには、v2 機能の削除が必要です。
- 型
- 64 ビット未署名の整数
- デフォルト
-
0
- rbd_default_stripe_unit
- 詳細
-
他のストライプユニットが指定されていない場合は、デフォルトのストライプユニットです。単位を
0(オブジェクトサイズ) から変更するには、v2 ストライピング機能が必要です。 - 型
- 64 ビット未署名の整数
- デフォルト
-
0
- rbd_default_features
- 詳細
ブロックデバイスイメージの作成時にデフォルトの機能が有効になります。この設定は、2 つのイメージのみに適用されます。設定は以下のとおりです。
1: レイヤーサポート。レイヤー化により、クローンを使用できます。
2: v2 サポートのストライピング。ストライピングは、データを複数のオブジェクト全体に分散します。ストライピングは、連続の読み取り/書き込みワークロードの並行処理に役立ちます。
4: 排他的ロックのサポート。有効にすると、書き込みを行う前にクライアントがオブジェクトのロックを取得する必要があります。
8: オブジェクトマップのサポート。ブロックデバイスはシンプロビジョニングされており、実際に存在するデータのみを保存します。オブジェクトマップのサポートは、実際に存在するオブジェクト (ドライブに格納されているデータ) を追跡するのに役立ちます。オブジェクトマップを有効にすると、クローン作成用の I/O 操作が高速化され、スパースに設定されたイメージのインポートおよびエクスポートが実行されます。
16: fast-diff サポート。fast-diff サポートは、オブジェクトマップのサポートと排他的ロックのサポートに依存します。別の属性をオブジェクトマップに追加して、イメージのスナップショット間の差異の生成と、スナップショットの実際のデータ使用量がはるかに速くなります。
32: deep-flatten サポート。deep-flatten を使用すると、イメージ自体に加えて、
rbd flattenがイメージのすべてのスナップショットで機能します。これを使用しないと、イメージのスナップショットは親に依存するため、スナップショットが削除されるまで親は削除できません。deep-flatten は、スナップショットがある場合でも、クローンから親を切り離します。64: ジャーナリングサポート。ジャーナリングは、イメージの実行順にイメージへの変更をすべて記録します。これにより、リモートイメージのクラッシュ調整ミラーがローカルで使用できるようになります。
有効な機能は、数値設定の合計です。
- 型
- 整数
- デフォルト
61: レイヤー化、exclusive-lock、object-map、fast-diff、および deep-flatten が有効にされます。重要現在のデフォルト設定は RBD カーネルドライバーや古い RBD クライアントと互換性がありません。
- rbd_default_map_options
- 詳細
-
ほとんどのオプションは、主にデバッグおよびベンチマークに役立ちます。詳細は、
Map Optionsのman rbdを参照してください。 - 型
- 文字列
- デフォルト
-
""
7.3. cache_settings
Ceph ブロックデバイスのユーザー空間実装 (librbd) は Linux ページキャッシュを利用できないため、RBD キャッシュ と呼ばれる独自のインメモリーキャッシュが含まれます。RBD キャッシュは、適切に動作するハードディスクキャッシュのように動作します。OS がバリアまたはフラッシュ要求を送信すると、ダーティーデータはすべて OSD に書き込まれます。つまり、ライトバックキャッシングを使用することは、フラッシュを適切に送信する仮想マシン(つまり Linux kernel >= 2.6.32)で適切に機能する物理ハードディスクを使用するだけで安全です。キャッシュは Least Recently Used (LRU) アルゴリズムを使用し、ライトバックモードでは、スループット向上のために連続したリクエストを結合できます。
Ceph は RBD のライトバックキャッシュをサポートします。これを有効にするには、ceph.conf ファイルの [client] セクションに rbd cache = true を追加します。デフォルトでは、librbd はキャッシュを実行しません。書き込みおよび読み取りはストレージクラスターに直接移動し、データがすべてのレプリカのディスクにある場合にのみ書き込みに戻ります。キャッシュを有効にすると、rbd_cache_max_dirty の非フラッシュバイト数を超えない限り、書き込みは即座に返します。この場合、書き込みによって、十分なバイト数がフラッシュされるまでライトバックおよびブロックがトリガーされます。
Ceph は RBD のライトスルーキャッシュをサポートします。キャッシュのサイズを設定し、ターゲットと制限を設定して、ライトバックキャッシュから write-through キャッシュに切り替えることができます。write-through モードを有効にするには、rbd_cache_max_dirty を 0 に設定します。つまり、書き込みは、データがすべてのレプリカのディスクにある場合にのみ返されますが、読み取りはキャッシュから送られる可能性があります。キャッシュはクライアントのメモリーにあり、各 RBD イメージには独自のイメージがあります。キャッシュはクライアントのローカルなので、イメージにアクセスする他の条件がある場合は、一貫性がありません。RBD 上で GFS または OCFS を実行しても、キャッシュが有効になっています。
RBD の ceph.conf ファイル設定は、設定ファイルの [client] セクションで設定する必要があります。設定には以下が含まれます。
- rbd_cache
- 説明
- RADOS Block Device (RBD) のキャッシュを有効にします。
- 型
- ブール値
- 必須
- いいえ
- デフォルト
-
true
- rbd_cache_size
- 説明
- RBD キャッシュサイズ (バイト単位)。
- 型
- 64 ビット整数
- 必須
- いいえ
- デフォルト
-
32 MiB
- rbd_cache_max_dirty
- 説明
-
キャッシュがライトバックをトリガーする
ダーティー制限 (バイト単位)。0の場合、ライトスルー (ライトスルー) キャッシュを使用します。 - 型
- 64 ビット整数
- 必須
- いいえ
- 制約
-
rbd cache sizeより小さくなければなりません。 - デフォルト
-
24 MiB
- rbd_cache_target_dirty
- 説明
-
キャッシュがデータストレージにデータを書き込む前に
dirty target。キャッシュへの書き込みをブロックしません。 - 型
- 64 ビット整数
- 必須
- いいえ
- 制約
-
rbd cache max dirty未満である必要があります。 - デフォルト
-
16 MiB
- rbd_cache_max_dirty_age
- 説明
- ライトバックの開始前にダーティーデータがキャッシュ内にある秒数。
- 型
- 浮動小数点 (Float)
- 必須
- いいえ
- デフォルト
-
1.0
- rbd_cache_max_dirty_object
- 詳細
-
オブジェクトのダーティー制限:
rbd_cache_sizeからの自動計算の場合は0に設定します。 - 型
- 整数
- デフォルト
-
0
- rbd_cache_block_writes_upfront
- 詳細
-
trueの場合、aio_write呼び出しが完了するまでキャッシュへの書き込みをブロックします。falseの場合、aio_completionが呼び出される前にブロックされます。 - 型
- ブール値
- デフォルト
-
false
- rbd_cache_writethrough_until_flush
- 説明
- write-through モードで起動し、最初のフラッシュ要求が受信後に write-back に切り替えます。この有効化は Conservative ですが、rbd で実行している仮想マシンが、2.6.32 以前の Linux における virtio ドライバーと同様にフラッシュを送信することが古い場合は安全な設定です。
- 型
- ブール値
- 必須
- いいえ
- デフォルト
-
true
7.4. 親/子読み取りの設定
- rbd_balance_snap_reads
- 詳細
- Ceph は通常、プライマリー OSD からオブジェクトを読み取ります。読み取りは不変であるため、この機能を使用すると、プライマリー OSD とレプリカとの間で snap の読み取りのバランスを取ることができます。
- 型
- ブール値
- デフォルト
-
false
- rbd_localize_snap_reads
- 説明
-
rbd_balance_snap_readsはスナップショットを読み取るためにレプリカをランダム化しますが、rbd_localize_snap_readsを有効にすると、ブロックデバイスは CRUSH マップを検索し、スナップショットを読み取るために最も近い(ローカル)OSD を検索します。 - タイプ
- ブール値
- デフォルト
-
false
- rbd_balance_parent_reads
- 詳細
- Ceph は通常、プライマリー OSD からオブジェクトを読み取ります。読み取りは不変であるため、この機能を使用すると、プライマリー OSD とレプリカとの間で親読み取りのバランスを取ることができます。
- 型
- ブール値
- デフォルト
-
false
- rbd_localize_parent_reads
- 説明
-
rbd_balance_parent_readsは親を読み取るためにレプリカをランダム化しますが、rbd_localize_parent_readsを有効にすると、ブロックデバイスは CRUSH マップを検索し、親を読み取るために最も近い(ローカル)OSD を検索します。 - タイプ
- ブール値
- デフォルト
-
true
7.5. read-ahead 設定
RBD は、小規模な連続読み取りを最適化するために read-ahead/prefetching をサポートします。これは通常、仮想マシンではゲスト OS で処理する必要がありますが、ブートローダーは効率的な読み取りでは機能しない場合があります。キャッシュが無効になっている場合、先読み (read-ahead) は自動的に無効になります。
- rbd_readahead_trigger_requests
- 説明
- read-ahead をトリガーするために必要な順次読み取り要求の数。
- 型
- 整数
- 必須
- いいえ
- デフォルト
-
10
- rbd_readahead_max_bytes
- 説明
- read-ahead リクエストの最大サイズ。ゼロの場合は、read-ahead が無効になります。
- 型
- 64 ビット整数
- 必須
- いいえ
- デフォルト
-
512 KiB
- rbd_readahead_disable_after_bytes
- 説明
- この多数のバイトが RBD イメージから読み取られると、閉じられるまでそのイメージの読み取りは無効にされます。これにより、ゲスト OS が起動したら、事前に読み取れることができます。ゼロの場合は、読み取り先は有効のままになります。
- 型
- 64 ビット整数
- 必須
- いいえ
- デフォルト
-
50 MiB
7.6. ブラックリストの設定
- rbd_blacklist_on_break_lock
- 詳細
- ロックが破損しているクライアントをブラックリストに登録するかどうか。
- 型
- ブール値
- デフォルト
-
true
- rbd_blacklist_expire_seconds
- 詳細
- ブラックリストする秒数 (OSD のデフォルトの場合は 0 に設定)。
- 型
- 整数
- デフォルト
-
0
7.7. ジャーナル設定
- rbd_journal_order
- 詳細
-
ジャーナルオブジェクトの最大サイズを計算するための移動ビット数。この値は、
12から64までになります。 - 型
- 32 ビット未署名の整数
- デフォルト
-
24
- rbd_journal_splay_width
- 詳細
- アクティブなジャーナルオブジェクトの数。
- 型
- 32 ビット未署名の整数
- デフォルト
-
4
- rbd_journal_commit_age
- 詳細
- コミットの間隔 (秒単位)。
- 型
- 倍精度浮動小数点数型
- デフォルト
-
5
- rbd_journal_object_flush_interval
- 詳細
- ジャーナルオブジェクトごとの保留中のコミットの最大数。
- 型
- 整数
- デフォルト
-
0
- rbd_journal_object_flush_bytes
- 詳細
- ジャーナルオブジェクトあたりの保留中の最大バイト数。
- 型
- 整数
- デフォルト
-
0
- rbd_journal_object_flush_age
- 詳細
- 保留中のコミットの最大間隔 (秒単位)。
- 型
- 倍精度浮動小数点数型
- デフォルト
-
0
- rbd_journal_pool
- 詳細
- ジャーナルオブジェクトのプールを指定します。
- 型
- 文字列
- デフォルト
-
""
第8章 iSCSI ゲートウェイの使用
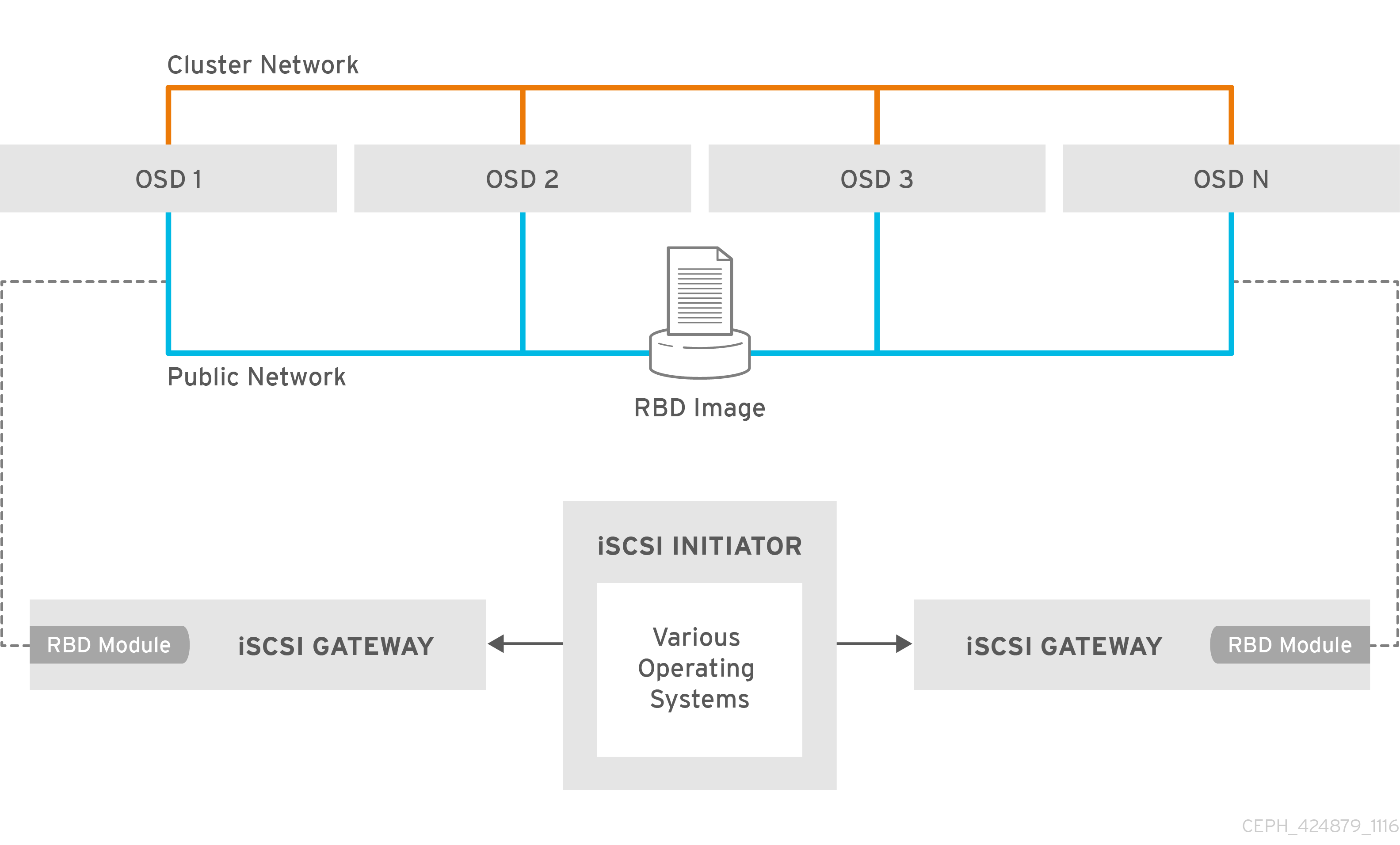
iSCSI ゲートウェイは Red Hat Ceph Storage と iSCSI 標準を統合し、RADOS Block Device (RBD) イメージを SCSI ディスクとしてエクスポートする可用性の高い (HA) iSCSI ターゲットを提供します。iSCSI プロトコルを使用すると、クライアント(initiator)は TCP/IP ネットワーク上で SCSI ストレージデバイス(ターゲット)に SCSI コマンドを送信できます。これにより、Microsoft Windows などの異種クライアントが Red Hat Ceph Storage クラスターにアクセスできるようになります。
各 iSCSI ゲートウェイは、Linux I/O ターゲットカーネルサブシステム (LIO) を実行して、iSCSI プロトコルをサポートします。LIO はユーザー空間パススルー (TCMU) を使用して Ceph librbd ライブラリーと対話し、RBD イメージを iSCSI クライアントに公開します。Ceph の iSCSI ゲートウェイの場合には、従来のストレージエリアネットワーク (SAN) のすべての機能および利点を使用して、完全に統合されたブロックストレージインフラストラクチャーを効率的に実行できます。
図8.1 Ceph iSCSI Gateway HA 設計
8.1. iSCSI ターゲットの要件
Red Hat Ceph Storage の高可用性 (HA) iSCSI ゲートウェイソリューションには、ゲートウェイノード数、メモリー容量、ダウンしている OSD を検出するタイマー設定の要件があります。
必要なノード数
最低でも 2 つの iSCSI ゲートウェイノードをインストールします。レジリエンスおよび I/O 処理を向上するには、最大 4 つの iSCSI ゲートウェイノードをインストールします。
メモリーの要件
RBD イメージのメモリーフットプリントのサイズが大きくなる可能性があります。iSCSI ゲートウェイノードにマッピングされる各 RBD イメージは、約 90 MB のメモリーを使用します。マッピングされた各 RBD イメージをサポートするのに十分なメモリーが、iSCSI ゲートウェイノードにあることを確認します。
ダウンした OSD の検出
Ceph Monitor または OSD には特定の iSCSI ゲートウェイオプションはありませんが、OSD を検出するためのデフォルトのタイマーの時間を減らし、イニシエーターがタイムアウトする可能性を少なくすることが重要です。ダウンした OSD を検出するためにタイマー設定の数値を下げる 手順に従って、イニシエーターのタイムアウトの可能性を低減します。
関連情報
- 詳細は、Red Hat Ceph Storage ハードウェアの選択ガイド を参照してください。
- 詳細は、『 ブロックデバイスガイド』 の「OSD を検出するためのタイマー設定の低い 設定」を参照してください。
8.2. ダウンしている OSD を検出するためのタイマー設定の低減
ダウンしている OSD を検出するためにタイマー設定の時間を減らす必要がある場合があります。たとえば、Red Hat Ceph Storage を iSCSI ゲートウェイとして使用する場合に、ダウンしている OSD を検出するためにタイマー設定の時間を減らすことで、イニシエーターがタイムアウトする可能性を軽減できます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
新しいタイマー設定を使用するように Ansible を設定します。
以下のような
group_vars/all.ymlファイルにceph_conf_overridesセクションを追加するか、既存のceph_conf_overridesセクションを編集して、osdで始まるすべての行を含めます。ceph_conf_overrides: osd: osd_client_watch_timeout: 15 osd_heartbeat_grace: 20 osd_heartbeat_interval: 5Ansible Playbook の
site.ymlが OSD ノードに対して実行すると、上記の設定がceph.conf設定ファイルに追加されます。Ansible を使用して
ceph.confファイルを更新し、すべての OSD ノードで OSD デーモンを再起動します。Ansible 管理ノードで、以下のコマンドを実行します。[user@admin ceph-ansible]$ ansible-playbook --limit osds site.yml
タイマー設定が
ceph_conf_overridesで設定されている値と同じであることを確認します。1 つ以上の OSD では、
ceph daemonコマンドを使用して設定を表示します。# ceph daemon osd.OSD_ID config get osd_client_watch_timeout # ceph daemon osd.OSD_ID config get osd_heartbeat_grace # ceph daemon osd.OSD_ID config get osd_heartbeat_interval
例:
[root@osd1 ~]# ceph daemon osd.0 config get osd_client_watch_timeout { "osd_client_watch_timeout": "15" } [root@osd1 ~]# ceph daemon osd.0 config get osd_heartbeat_grace { "osd_heartbeat_grace": "20" } [root@osd1 ~]# ceph daemon osd.0 config get osd_heartbeat_interval { "osd_heartbeat_interval": "5" }オプション: OSD デーモンをすぐに再起動できない場合は、Ceph Monitor ノードからオンライン更新を実行します。または、すべての OSD ノードで直接更新を実行します。OSD デーモンの再起動ができたら、上記のように Ansible を使用して新しいタイマー設定を
ceph.confに追加し、設定が再起動後も維持されるようにします。Ceph Monitor ノードから OSD タイマー設定のオンライン更新を実行するには、以下を実行します。
# ceph tell osd.OSD_ID injectargs '--osd_client_watch_timeout 15' # ceph tell osd.OSD_ID injectargs '--osd_heartbeat_grace 20' # ceph tell osd.OSD_ID injectargs '--osd_heartbeat_interval 5'
例:
[root@mon ~]# ceph tell osd.0 injectargs '--osd_client_watch_timeout 15' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_grace 20' [root@mon ~]# ceph tell osd.0 injectargs '--osd_heartbeat_interval 5'
Ceph OSD ノードから OSD タイマー設定のオンライン更新を実行するには、以下を実行します。
# ceph daemon osd.OSD_ID config set osd_client_watch_timeout 15 # ceph daemon osd.OSD_ID config set osd_heartbeat_grace 20 # ceph daemon osd.OSD_ID config set osd_heartbeat_interval 5
例:
[root@osd1 ~]# ceph daemon osd.0 config set osd_client_watch_timeout 15 [root@osd1 ~]# ceph daemon osd.0 config set osd_heartbeat_grace 20 [root@osd1 ~]# ceph daemon osd.0 config set osd_heartbeat_interval 5
関連情報
- Red Hat Ceph Storage を iSCSI ゲートウェイとして使用 する方法は、『 ブロックデバイスガイド』 の「Ceph iSCSI ゲートウェイの概要 」を参照してください。
8.3. iSCSI ターゲットの設定
従来は、Ceph ストレージクラスターへのブロックレベルのアクセスは QEMU および librbd に制限されていました。これは、OpenStack 環境で採用するための主要なイネーブラーです。Ceph Storage クラスターにブロックレベルでアクセスできると、iSCSI 標準を活用してデータストレージを提供できます。
前提条件:
- Red Hat Enterprise Linux 7.5 以降。
- 稼働中の Red Hat Ceph Storage クラスター (バージョン 5.0 以降)。
- iSCSI ゲートウェイノード。OSD ノードまたは専用ノードと同じ場所に配置できます。
- iSCSI ゲートウェイノードで有効な Red Hat Enterprise Linux 7 および Red Hat Ceph Storage 3.3 のエンタイトルメント/サブスクリプション。
- iSCSI フロントエンドトラフィックと Ceph バックエンドトラフィック用のネットワークサブネットを分離します。
Ceph iSCSI ゲートウェイのデプロイは、Ansible またはコマンドラインインターフェースを使用して実行できます。
- Ansible
- コマンドラインインターフェイス
8.3.1. Ansible を使用した iSCSI ターゲットの設定
要件
- Red Hat Enterprise Linux 7.5 以降。
- 稼働中の Red Hat Ceph Storage 3 以降
インストール
iSCSI ゲートウェイノードで、Red Hat Ceph Storage 4 Tools リポジトリーを有効にします。Installation Guide for Red Hat Enterprise Linux または Ubuntu のEnabling the Red Hat Ceph Storage Repositoriesセクションを参照してください。
ceph-iscsi-configパッケージをインストールします。# yum install ceph-iscsi-config
rootユーザーとして、Ansible 管理ノードで以下の手順を実行します。- Red Hat Ceph Storage 6 Tools リポジトリーを有効にします。Installation Guide for Red Hat Enterprise Linux または Ubuntu のEnabling the Red Hat Ceph Storage Repositoriesセクションを参照してください。
ceph-ansibleパッケージをインストールします。# yum install ceph-ansible
ゲートウェイグループの
/etc/ansible/hostsファイルにエントリーを追加します。[iscsigws] ceph-igw-1 ceph-igw-2
注記OSD ノードと iSCSI ゲートウェイを共存させる場合は、OSD ノードを
[iscsigws]セクションに追加します。
設定
ceph-ansible パッケージは、iscsigws.yml.sample と呼ばれる /usr/share/ceph-ansible/group_vars/ ディレクトリーにファイルを配置します。
iscsigws.yml.sampleファイルのコピーを作成し、iscsigws.ymlという名前を付けます。重要新しいファイル名 (
iscsigws.yml) と新しいセクション見出し (iscsigws) は、Red Hat Ceph Storage 3.1 以降にのみ適用されます。以前のバージョンの Red Hat Ceph Storage から 3.1 にアップグレードすると、古いファイル名 (iscsi-gws.yml) と古いセクション見出し (iscsi-gws) が引き続き使用されます。-
iscsigws.ymlファイルを開いて編集します。 trusted_ip_listオプションのコメントを解除し、IPv4 アドレスまたは IPv6 アドレスを使用して値を適宜更新します。たとえば、IPv4 アドレスが 10.172.19.21 および 10.172.19.22 のゲートウェイを 2 つ追加し、
gateway_ip_listを設定します。gateway_ip_list: 10.172.19.21,10.172.19.22
重要gateway_ip_listオプションに IP アドレスを指定する必要があります。IPv4 アドレスと IPv6 アドレスを混在させることはできません。rbd_devices変数のコメントを解除して、適宜値を更新します。以下に例を示します。rbd_devices: - { pool: 'rbd', image: 'ansible1', size: '30G', host: 'ceph-1', state: 'present' } - { pool: 'rbd', image: 'ansible2', size: '15G', host: 'ceph-1', state: 'present' } - { pool: 'rbd', image: 'ansible3', size: '30G', host: 'ceph-1', state: 'present' } - { pool: 'rbd', image: 'ansible4', size: '50G', host: 'ceph-1', state: 'present' }client_connections変数のコメントを解除し、適宜値を更新します。以下に例を示します。CHAP 認証の有効化例
client_connections: - { client: 'iqn.1994-05.com.redhat:rh7-iscsi-client', image_list: 'rbd.ansible1,rbd.ansible2', chap: 'rh7-iscsi-client/redhat', status: 'present' } - { client: 'iqn.1991-05.com.microsoft:w2k12r2', image_list: 'rbd.ansible4', chap: 'w2k12r2/microsoft_w2k12', status: 'absent' }CHAP 認証を無効にする例
client_connections: - { client: 'iqn.1991-05.com.microsoft:w2k12r2', image_list: 'rbd.ansible4', chap: '', status: 'present' } - { client: 'iqn.1991-05.com.microsoft:w2k16r2', image_list: 'rbd.ansible2', chap: '', status: 'present' }重要CHAP の無効化は、Red Hat Ceph Storage 3.1 以降でのみサポートされています。Red Hat は、CHAP が有効になっているクライアントと CHAP が無効になっているクライアントの混在をサポートしていません。
presentとマークされているクライアントはすべて CHAP を有効にするか、CHAP を無効にする必要があります。以下の Ansible 変数と説明を確認し、必要に応じて随時更新してください。
表8.1 iSCSI ゲートウェイの一般変数
変数 means/Purpose seed_monitorEach gateway needs access to the ceph cluster for rados and rbd calls. This means the iSCSI gateway must have an appropriate
/etc/ceph/directory defined. Theseed_monitorhost is used to populate the iSCSI gateway’s/etc/ceph/directory.cluster_nameDefine a custom storage cluster name.
gateway_keyringDefine a custom keyring name.
deploy_settingsIf set to
true, then deploy the settings when the playbook is ran.perform_system_checksThis is a boolean value that checks for multipath and lvm configuration settings on each gateway. It must be set to true for at least the first run to ensure multipathd and lvm are configured properly.
gateway_iqnThis is the iSCSI IQN that all the gateways will expose to clients. This means each client will see the gateway group as a single subsystem.
gateway_ip_listThe comma separated ip list defines the IPv4 or IPv6 addresses that will be used on the front end network for iSCSI traffic. This IP will be bound to the active target portal group on each node, and is the access point for iSCSI traffic. Each IP should correspond to an IP available on the hosts defined in the
iscsigws.ymlhost group in/etc/ansible/hosts.rbd_devicesThis section defines the RBD images that will be controlled and managed within the iSCSI gateway configuration. Parameters like
poolandimageare self explanatory. Here are the other parameters:
size= This defines the size of the RBD. You may increase the size later, by simply changing this value, but shrinking the size of an RBD is not supported and is ignored.
host= This is the iSCSI gateway host name that will be responsible for the rbd allocation/resize. Every definedrbd_deviceentry must have a host assigned.
state= This is typical Ansible syntax for whether the resource should be defined or removed. A request with a state of absent will first be checked to ensure the rbd is not mapped to any client. If the RBD is unallocated, it will be removed from the iSCSI gateway and deleted from the configuration.クライアント接続
This section defines the iSCSI client connection details together with the LUN (RBD image) masking. Currently only CHAP is supported as an authentication mechanism. Each connection defines an
image_listwhich is a comma separated list of the formpool.rbd_image[,pool.rbd_image,…]. RBD images can be added and removed from this list, to change the client masking. Note, that there are no checks done to limit RBD sharing across client connections.表8.2 iSCSI ゲートウェイ
RBD-TARGET-API変数変数 means/Purpose api_user
API のユーザー名。デフォルトは
adminです。api_password
API を使用するためのパスワード。デフォルトは
adminです。api_port
API を使用する TCP ポート番号。デフォルトは
5000です。api_secure
値は
trueまたはfalseです。デフォルトはfalseです。loop_delay
iSCSI 管理オブジェクトをポーリングする時のスリープの間隔を秒単位で制御します。デフォルト値は
1です。trusted_ip_list
API にアクセスできる IPv4 アドレスまたは IPv6 アドレスの一覧。デフォルトでは、iSCSI ゲートウェイノードだけがアクセスできます。
重要rbd_devicesの場合、プール名またはイメージ名にピリオド(.)を使用することはできません。警告ゲートウェイ設定の変更は、一度に 1 つのゲートウェイからのみサポートされます。複数のゲートウェイで同時に変更を実行しようとすると、設定が不安定になり、不整合が発生する可能性があります。
警告Ansible は、
ansible-playbookコマンドの実行時にgroup_vars/iscsigws.ymlファイルの設定に基づいてceph-iscsi-cliパッケージをインストールしてから、/etc/ceph/iscsi-gateway.cfgファイルを更新します。コマンドラインインストール手順を使用してceph-iscsi-cliパッケージをインストール している場合は、iscsi-gateway.cfgファイルの既存の設定をgroup_vars/iscsigws.ymlファイルにコピーする必要があります。完全な
iscsigws.yml.sampleファイルを表示するには、付録Aiscsigws.ymlファイルのサンプル を参照してください。
デプロイ
root ユーザーとして、Ansible 管理ノードで以下の手順を実行します。
Ansible Playbook を実行します。
# cd /usr/share/ceph-ansible # ansible-playbook site.yml
注記Ansible Playbook は、RPM の依存関係、RBD 作成、および Linux iSCSI ターゲット設定を処理します。
警告スタンドアロン iSCSI ゲートウェイノードで、正しい Red Hat Ceph Storage 4 ソフトウェアリポジトリーが有効であることを確認します。利用できない場合は、誤ったパッケージがインストールされます。
以下のコマンドを実行して設定を確認します。
# gwcli ls
重要targetcliユーティリティーを使用して設定を変更しないでください。これにより、ALUA のご設定とパスのフェイルオーバーという問題が発生します。データが破損して iSCSI ゲートウェイ間で設定が一致しない場合や、WWN 情報が一致しなくなる可能性があり、クライアントのパスに問題が生じます。
サービス管理
ceph-iscsi-config パッケージは、設定管理ロジックと rbd-target-gw と呼ばれる Systemd サービスをインストールします。Systemd サービスを有効にすると、システムの起動時に rbd-target-gw が起動し、Linux iSCSI ターゲットの状態が復元されます。Ansible Playbook で iSCSI ゲートウェイをデプロイすると、ターゲットサービスが無効になります。
# systemctl start rbd-target-gw
以下は、rbd-target-gw Systemd サービスとの対話の結果です。
# systemctl <start|stop|restart|reload> rbd-target-gw
reload-
リロード要求により、
rbd-target-gwに設定が再読み取られ、現在の実行環境に適用されます。Ansible からすべての iSCSI ゲートウェイノードに変更が並行してデプロイされるため、これは通常は不要です。 stop- stop リクエストはゲートウェイのポータルインターフェイスを閉じ、クライアントへの接続をドロップし、カーネルから現在の Linux iSCSI ターゲット設定を消去します。これにより、iSCSI ゲートウェイがクリーンな状態に戻ります。クライアントが切断されると、アクティブな I/O はクライアント側マルチパス層によって他の iSCSI ゲートウェイに再スケジュールされます。
administration
/usr/share/ceph-ansible/group_vars/iscsigws.yml ファイルには、Ansible Playbook がサポートする操作ワークフローが多数あります。
Red Hat は、gwcli や ceph-ansible などの Ceph iSCSI ゲートウェイツールでエクスポートされる RBD イメージの管理をサポートしません。また、rbd コマンドを使用して Ceph iSCSI ゲートウェイでエクスポートされた RBD イメージの名前を変更または削除すると、ストレージクラスターが不安定になる可能性があります。
iSCSI ゲートウェイ設定から RBD イメージを削除する前に、オペレーティングシステムからストレージデバイスを削除する標準的な手順に従います。
Red Hat Enterprise Linux 7 を使用するクライアントおよびシステムの場合は、『Red Hat Enterprise Linux 7 ストレージ管理ガイド』 でデバイスの削除に関する詳細を参照してください。
表8.3 運用ワークフロー
| I want to… | iscsigws.yml ファイルを... |
|---|---|
| RBD イメージの追加 |
新しいイメージを使用して |
| 既存の RBD イメージのサイズ変更 |
|
| クライアントの追加 |
|
| 別の RBD のクライアントへの追加 |
関連する RBD |
| クライアントからの RBD の削除 |
クライアント |
| システムから RBD を削除 |
RBD エントリー状態変数を |
| クライアント CHAP 認証情報の変更 |
|
| クライアントの削除 |
関連する |
変更が完了したら、Ansible Playbook を再実行して、iSCSI ゲートウェイノード全体で変更を適用します。
# ansible-playbook site.yml
設定の削除:
iSCSI ゲートウェイ設定をパージする前に、すべての iSCSI イニシエーターを切断します。適切なオペレーティングシステムについては、以下の手順に従います。
Red Hat Enterprise Linux イニシエーター:
Syntax
iscsiadm -m node -T $TARGET_NAME --logout
TARGET_NAMEは、設定した iSCSI ターゲット名に置き換えます。例
# iscsiadm -m node -T iqn.2003-01.com.redhat.iscsi-gw:ceph-igw --logout Logging out of session [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] Logging out of session [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] Logout of [sid: 1, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.21,3260] successful. Logout of [sid: 2, target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw, portal: 10.172.19.22,3260] successful.
Windows イニシエーター:
詳細は、Microsoft のドキュメント を参照してください。
VMware ESXi イニシエーター:
詳細は、VMware のドキュメント を参照してください。
Ansible 管理ノードで、Ansbile ユーザーとして
/usr/share/ceph-ansible/ディレクトリーに移動します。[user@admin ~]$ cd /usr/share/ceph-ansible/
Ansible Playbook を実行して、iSCSI ゲートウェイ設定を削除します。
[user@admin ceph-ansible]$ ansible-playbook purge-cluster.yml --limit iscsigws
Ceph Monitor または Client ノードで、
rootユーザーとして、iSCSI ゲートウェイ設定オブジェクト (gateway.conf) を削除します。[root@mon ~]# rados rm -p pool gateway.conf
オプション。
オプションで、エクスポートされた Ceph RADOS Block Device (RBD) が不要になった場合は、RBD イメージを削除します。
rootユーザーとして、Ceph Monitor またはクライアントノードで以下のコマンドを実行します。Syntax
rbd rm $IMAGE_NAME
$IMAGE_NAMEを RBD イメージの名前に置き換えます。例
[root@mon ~]# rbd rm rbd01
8.3.2. コマンドラインインターフェイスを使用した iSCSI ターゲットの設定
Ceph iSCSI ゲートウェイは、iSCSI ターゲットノードおよび Ceph クライアントノードです。Ceph iSCSI ゲートウェイはスタンドアロンノードにすることも、Ceph Object Store Disk (OSD) ノードと同じ場所に配置することもできます。以下の手順を実行し、基本的な操作用に Ceph iSCSI ゲートウェイをインストールし、設定します。
要件
- Red Hat Enterprise Linux 7.5 以降
- 稼働中の Red Hat Ceph Storage 3.3 クラスターまたはそれ以降
以下のパッケージをインストールする必要があります。
-
targetcli-2.1.fb47-0.1.20170815.git5bf3517.el7cpor newer package -
python-rtslib-2.1.fb64-0.1.20170815.gitec364f3.el7cpor newer package -
tcmu-runner-1.4.0-0.2.el7cpor newer package openssl-1.0.2k-8.el7以降のパッケージ重要これらのパッケージの以前のバージョンが存在する場合は、新しいバージョンをインストールする前に最初に削除する必要があります。これらの新しいバージョンは、Red Hat Ceph Storage リポジトリーからインストールする必要があります。
-
gwcli ユーティリティーを使用する前に、ストレージクラスター内のすべての Ceph Monitor ノードで以下の手順を実施します。
rootユーザーとしてceph-monサービスを再起動します。# systemctl restart ceph-mon@$MONITOR_HOST_NAME
以下に例を示します。
# systemctl restart ceph-mon@monitor1
「 インストール 」セクションに進む前に、root ユーザーとして Ceph iSCSI ゲートウェイノードで以下の手順を実施します。
-
Ceph iSCSI ゲートウェイが OSD ノードに共存していない場合は、
/etc/ceph/にある Ceph 設定ファイルをストレージクラスターの実行中の Ceph ノードから iSCSI ゲートウェイノードにコピーします。Ceph 設定ファイルは、/etc/ceph/ の iSCSI ゲートウェイノードに存在している必要があります。 - Ceph コマンドラインインターフェースをインストールして設定します。詳細は、Red Hat Enterprise Linux の 『Red Hat Ceph Storage 3 インストールガイド』の「Ceph コマンドライン インターフェースのインストール」の 章を参照してください。
ceph-tools リポジトリーを有効にします。
# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-rpms
- 必要な場合は、ファイアウォールで TCP ポート 3260 および 5000 を開きます。
新規を作成するか、既存の RADOS ブロックデバイス (RBD) を使用します。
- (詳細は、「前提条件」 を参照してください。)
Ansible を使用して Ceph iSCSI ゲートウェイをすでにインストールしている場合は、この手順は使用しないでください。
Ansible は、ansible-playbook コマンドの実行時に group_vars/iscsigws.yml ファイルの設定に基づいて ceph-iscsi-cli パッケージをインストールしてから、/etc/ceph/iscsi-gateway.cfg ファイルを更新します。詳細は、 を参照してください。
インストール
特に記述がない限り、すべての iSCSI ゲートウェイノードで root ユーザーとして以下の手順を実行します。
ceph-iscsi-cliパッケージをインストールします。# yum install ceph-iscsi-cli
tcmu-runnerパッケージをインストールします。# yum install tcmu-runner
必要に応じて、
opensslパッケージをインストールします。# yum install openssl
プライマリー iSCSI ゲートウェイノードで、SSL キーを保存するディレクトリーを作成します。
# mkdir ~/ssl-keys # cd ~/ssl-keys
プライマリー iSCSI ゲートウェイノードで、証明書およびキーファイルを作成します。
# openssl req -newkey rsa:2048 -nodes -keyout iscsi-gateway.key -x509 -days 365 -out iscsi-gateway.crt
注記環境情報を入力するよう求められます。
プライマリー iSCSI ゲートウェイノードで、PEM ファイルを作成します。
# cat iscsi-gateway.crt iscsi-gateway.key > iscsi-gateway.pem
プライマリー iSCSI ゲートウェイノードで、公開鍵を作成します。
# openssl x509 -inform pem -in iscsi-gateway.pem -pubkey -noout > iscsi-gateway-pub.key
-
プライマリー iSCSI ゲートウェイノードから、
iscsi-gateway.crt、iscsi-gateway.pem、iscsi-gateway-pub.keyおよびiscsi-gateway.keyファイルを、他の iSCSI ゲートウェイノードの/etc/ceph/ディレクトリーにコピーします。
/etc/ceph/ディレクトリーにiscsi-gateway.cfgという名前のファイルを作成します。# touch /etc/ceph/iscsi-gateway.cfg
iscsi-gateway.cfgファイルを編集し、以下の行を追加します。Syntax
[config] cluster_name = <ceph_cluster_name> gateway_keyring = <ceph_client_keyring> api_secure = true trusted_ip_list = <ip_addr>,<ip_addr>
例
[config] cluster_name = ceph gateway_keyring = ceph.client.admin.keyring api_secure = true trusted_ip_list = 192.168.0.10,192.168.0.11
これらのオプションの詳細については、要件 の Tables 8.1 および 8.2 を参照してください。
重要iscsi-gateway.cfgファイルは、すべての iSCSI ゲートウェイノードで同一でなければなりません。-
iscsi-gateway.cfgファイルをすべての iSCSI ゲートウェイノードにコピーします。
API サービスを有効にして起動します。
# systemctl enable rbd-target-api # systemctl start rbd-target-api
設定
iSCSI ゲートウェイのコマンドラインインターフェイスを起動します。
# gwcli
IPv4 アドレスまたは IPv6 アドレスのいずれかを使用して iSCSI ゲートウェイを作成します。
構文
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:<target_name> > goto gateways > create <iscsi_gw_name> <IP_addr_of_gw> > create <iscsi_gw_name> <IP_addr_of_gw>
例
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-1 10.172.19.21 > create ceph-gw-2 10.172.19.22
重要IPv4 アドレスと IPv6 アドレスを混在させることはできません。
RADOS ブロックデバイス(RBD)の追加:
構文
> cd /disks >/disks/ create <pool_name> image=<image_name> size=<image_size>m|g|t max_data_area_mb=<buffer_size>
例
> cd /disks >/disks/ create rbd image=disk_1 size=50g max_data_area_mb=32
重要プール名またはイメージ名にピリオド (.) を含めることはできません。
警告max_data_area_mbオプションは、iSCSI ターゲットと Ceph クラスターの間で SCSI コマンドデータを渡す時に各イメージが使用できるメモリー量をメガバイト単位で制御します。この値が小さすぎると、パフォーマンスに影響を与える過剰なキューのフル再試行が発生する可能性があります。値が大きすぎると、1 つのディスクがシステムのメモリーを過剰に使用する結果になり、他のサブシステムの割り当てエラーを引き起こす可能性があります。デフォルト値は 8 です。この値は、
gwcli reconfigureサブコマンドを使用して変更できます。このコマンドを有効にするには、イメージが iSCSI イニシエーターでは使用できません。本書に規定されているか、Red Hat サポートからの指示がない限り、gwcli reconfigureサブコマンドを使用して他のオプションを調整しないようにしてください。構文
>/disks/ reconfigure max_data_area_mb <new_buffer_size>
例
>/disks/ reconfigure max_data_area_mb 64
クライアントの作成
構文
> goto hosts > create iqn.1994-05.com.redhat:<client_name> > auth chap=<user_name>/<password>
例
> goto hosts > create iqn.1994-05.com.redhat:rh7-client > auth chap=iscsiuser1/temp12345678
重要CHAP の無効化は、Red Hat Ceph Storage 3.1 以降でのみサポートされています。Red Hat は、CHAP が有効になっているクライアントと CHAP が無効になっているクライアントの混在をサポートしていません。すべてのクライアントの CHAP を有効にするか、無効にする必要があります。デフォルトの動作としては、イニシエーター名でイニシエーターを認証するだけです。
イニシエーターがターゲットへのログインに失敗している場合、一部のイニシエーターで CHAP 認証が正しく設定されていない可能性があります。
例
o- hosts ................................ [Hosts: 2: Auth: MISCONFIG]
hostsレベルで次のコマンドを実行して、すべての CHAP 認証をリセットします。/> goto hosts /iscsi-target...csi-igw/hosts> auth nochap ok ok /iscsi-target...csi-igw/hosts> ls o- hosts ................................ [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ........... [Auth: None, Disks: 4(310G)] o- iqn.1994-05.com.redhat:rh7-client .. [Auth: None, Disks: 0(0.00Y)]
クライアントへのディスクの追加
構文
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:<client_name> > disk add <pool_name>.<image_name>
例
>/iscsi-target..eph-igw/hosts> cd iqn.1994-05.com.redhat:rh7-client > disk add rbd.disk_1
必要に応じて、API が SSL を正しく使用していることを確認し、
/var/log/rbd-target-api.logファイルでhttpsを調べます。次に例を示します。Aug 01 17:27:42 test-node.example.com python[1879]: * Running on https://0.0.0.0:5000/
- 次のステップは、iSCSI イニシエーターを設定することです。iSCSI イニシエーターの設定に関する詳細は、「iSCSI イニシエーターの設定」 を参照してください。
検証
iSCSI ゲートウェイが機能しているかどうかを確認するには、次のコマンドを実行します。
例
/> goto gateways /iscsi-target...-igw/gateways> ls o- gateways ............................ [Up: 2/2, Portals: 2] o- ceph-gw-1 ........................ [ 10.172.19.21 (UP)] o- ceph-gw-2 ........................ [ 10.172.19.22 (UP)]
注記ステータスが
UNKNOWNの場合は、ネットワークの問題と設定ミスがないか確認します。ファイアウォールを使用している場合は、適切な TCP ポートが開いているかどうかを確認します。iSCSI ゲートウェイがtrusted_ip_listオプションに一覧表示されているかどうかを確認します。rbd-target-apiサービスが iSCSI ゲートウェイノードで実行されていることを確認します。イニシエーターが iSCSI ターゲットに接続されているかどうかを確認するには、イニシエーター
LOGGED-INを確認します。例
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts .............................. [Hosts: 1: Auth: None] o- iqn.1994-05.com.redhat:rh7-client [LOGGED-IN, Auth: None, Disks: 0(0.00Y)]
iSCSI ゲートウェイ全体で LUN が分散されているかどうかを確認するには、次のコマンドを実行します。
/> goto hosts /iscsi-target...csi-igw/hosts> ls o- hosts ................................. [Hosts: 2: Auth: None] o- iqn.2005-03.com.ceph:esx ............ [Auth: None, Disks: 4(310G)] | o- lun 0 ............................. [rbd.disk_1(100G), Owner: ceph-gw-1] | o- lun 1 ............................. [rbd.disk_2(10G), Owner: ceph-gw-2]
ディスクを作成すると、ディスクには、イニシエーターのマルチパスレイヤーに基づいて、iSCSI ゲートウェイが
Ownerとして割り当てられます。イニシエーターのマルチパス層は、ALUA Active-Optimized(AO)状態であると報告されます。他のパスは、ALUA Active-non-Optimized(ANO)状態にあると報告されます。AO パスに障害が発生した場合、他の iSCSI ゲートウェイのいずれかが使用されます。フェイルオーバーゲートウェイの順序は、イニシエーターの multipath レイヤーによって異なります。通常、この順序は最初に検出したパスに基づきます。
現在、LUN のバランスは動的ではありません。独自の iSCSI ゲートウェイはディスク作成時に選択され、変更することはできません。
8.3.3. iSCSI ターゲットのパフォーマンスの最適化
ネットワーク上で iSCSI ターゲット転送データを送信する方法を制御する設定は多数あります。これらの設定を使用して、iSCSI ゲートウェイのパフォーマンスを最適化できます。
Red Hat サポートの指示または本書の記載がない限り、この設定は変更しないでください。
gwcli reconfigure サブコマンド
gwcli reconfigure サブコマンドは、iSCSI ゲートウェイのパフォーマンスの最適化に使用される設定を制御します。
iSCSI ターゲットのパフォーマンスに影響する設定
- max_data_area_mb
- cmdsn_depth
- immediate_data
- initial_r2t
- max_outstanding_r2t
- first_burst_length
- max_burst_length
- max_recv_data_segment_length
- max_xmit_data_segment_length
関連情報
-
max_data_area_mbに関する情報 (gwcli reconfigureを使用して調整する方法を示す例を含む) は、ブロックデバイスガイドのコマンドラインインターフェイスを使用した iSCSI ターゲットの設定 セクションと、コンテナーガイド のコンテナー での Ceph iSCSI ゲートウェイの設定セクションに あります。
8.3.4. iSCSI ゲートウェイの追加
ストレージ管理者は、Ansible または gwcli コマンドラインツールを使用して、最初の 2 つの iSCSI ゲートウェイを 4 つの iSCSI ゲートウェイに拡張できます。iSCSI ゲートウェイを追加すると、負荷分散とフェイルオーバーオプションを使用したときに、より多くの冗長性とともに、さらなる柔軟性が確立されます。
8.3.4.1. 前提条件
- Red Hat Ceph Storage 6 クラスターが実行されている。
- iSCSI ゲートウェイソフトウェアのインストール。
- スペアノードまたは既存の OSD ノード
8.3.4.2. Ansible を使用した iSCSI ゲートウェイの追加
Ansible 自動化ユーティリティーを使用して、iSCSI ゲートウェイを追加できます。この手順では、2 つの iSCSI ゲートウェイのデフォルトインストールを 4 つの iSCSI ゲートウェイに拡張します。スタンドアロンのノードで iSCSI ゲートウェイを設定するか、または既存の OSD ノードと共存させることができます。
前提条件
- Red Hat Ceph Storage 6 クラスターが実行されている。
- iSCSI ゲートウェイソフトウェアのインストール。
-
Ansible 管理ノードで
rootユーザーアクセスがある。 -
新規ノードでの
rootユーザーアクセスがあること。
手順
新しい iSCSI ゲートウェイノードで、Red Hat Ceph Storage Tools リポジトリーを有効にします。
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpms
Installation Guide for Red Hat Enterprise Linux または Ubuntu のEnabling the Red Hat Ceph Storage Repositoriesセクションを参照してください。
ceph-iscsi-configパッケージをインストールします。[root@iscsigw ~]# yum install ceph-iscsi-config
ゲートウェイグループの
/etc/ansible/hostsファイルの一覧に追加します。例
[iscsigws] ... ceph-igw-3 ceph-igw-4
注記OSD ノードと iSCSI ゲートウェイを共存させる場合は、OSD ノードを
[iscsigws]セクションに追加します。/usr/share/ceph-ansible/group_vars/iscsigws.ymlファイルを開いて編集し、IPv4 アドレスを持つ 2 つの iSCSI ゲートウェイをgateway_ip_listオプションに追加します。例
gateway_ip_list: 10.172.19.21,10.172.19.22,10.172.19.23,10.172.19.24
重要gateway_ip_listオプションに IP アドレスを指定する必要があります。IPv4 アドレスと IPv6 アドレスを混在させることはできません。Ansible 管理ノードで、
rootユーザーとして Ansible Playbook を実行します。# cd /usr/share/ceph-ansible # ansible-playbook site.yml
- iSCSI イニシエーターから再ログインして、新たに追加された iSCSI ゲートウェイを使用します。
関連情報
- iSCSI イニシエーターの使用に関する詳細は、iSCSI イニシエーターの設定 を参照してください。
8.3.4.3. gwcli を使用した iSCSI ゲートウェイの追加
gwcli コマンドラインツールを使用して、iSCSI ゲートウェイを追加できます。この手順では、2 つの iSCSI ゲートウェイのデフォルトを 4 つの iSCSI ゲートウェイに拡張します。
前提条件
- Red Hat Ceph Storage 6 クラスターが実行されている。
- iSCSI ゲートウェイソフトウェアのインストール。
-
新規ノードまたは OSD ノードへの
rootユーザーアクセスがあること。
手順
-
Ceph iSCSI ゲートウェイが OSD ノードと同じ場所に配置されていない場合には、
/etc/ceph/ディレクトリーにある Ceph 設定ファイルを、ストレージクラスターにある実行中の Ceph ノードから新しい iSCSI ゲートウェイノードにコピーしてください。Ceph 設定ファイルは、/etc/ceph/ディレクトリーにある iSCSI ゲートウェイノードに存在している必要があります。 - Ceph コマンドラインインターフェイスをインストールおよび設定します。詳細は、Red Hat Enterprise Linux の 『Red Hat Ceph Storage 3 インストールガイド』の「Ceph コマンドラインインターフェース のインストール」の 章を参照してください。
新しい iSCSI ゲートウェイノードで、Red Hat Ceph Storage Tools リポジトリーを有効にします。
[root@iscsigw ~]# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-els-rpms
Installation Guide for Red Hat Enterprise Linux または Ubuntu のEnabling the Red Hat Ceph Storage Repositoriesセクションを参照してください。
ceph-iscsiパッケージおよびtcmu-runnerパッケージをインストールします。[root@iscsigw ~]# yum install ceph-iscsi-cli tcmu-runner
必要に応じて、
opensslパッケージをインストールします。[root@iscsigw ~]# yum install openssl
既存の iSCSI ゲートウェイノードの 1 つで、
/etc/ceph/iscsi-gateway.cfgファイルを編集し、trusted _ip_listオプションを新しい iSCSI ゲートウェイノードの新しい IP アドレスに追加します。例
[config] ... trusted_ip_list = 10.172.19.21,10.172.19.22,10.172.19.23,10.172.19.24
これらのオプション の詳細については、「Ansible テーブルを使用した iSCSI ターゲット の設定」を参照してください。
更新された
/etc/ceph/iscsi-gateway.cfgファイルを、すべての iSCSI ゲートウェイノードにコピーします。重要iscsi-gateway.cfgファイルは、すべての iSCSI ゲートウェイノードで同一でなければなりません。-
必要に応じて、SSL を使用する場合は、既存の iSCSI ゲートウェイノードの 1 つから
~/ssl-keys/iscsi- gateway.crt、~/ssl-keys/iscsi-gateway.pem、~/ssl-keys/iscsi-gateway-pub.keyファイル、および~/ssl -keys /iscsi-gateway.keyファイルも SiSCI ゲートウェイノードの/etc/ceph/ディレクトリーにコピーします。 新しい iSCSI ゲートウェイノードで API サービスを有効にして起動します。
[root@iscsigw ~]# systemctl enable rbd-target-api [root@iscsigw ~]# systemctl start rbd-target-api
iSCSI ゲートウェイのコマンドラインインターフェイスを起動します。
[root@iscsigw ~]# gwcli
IPv4 アドレスまたは IPv6 アドレスのいずれかを使用して iSCSI ゲートウェイを作成します。
構文
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:_TARGET_NAME_ > goto gateways > create ISCSI_GW_NAME IP_ADDR_OF_GW > create ISCSI_GW_NAME IP_ADDR_OF_GW
例
>/iscsi-target create iqn.2003-01.com.redhat.iscsi-gw:ceph-igw > goto gateways > create ceph-gw-3 10.172.19.23 > create ceph-gw-4 10.172.19.24
重要IPv4 アドレスと IPv6 アドレスを混在させることはできません。
- iSCSI イニシエーターから再ログインして、新たに追加された iSCSI ゲートウェイを使用します。
関連情報
- iSCSI イニシエーターの使用に関する詳細は、iSCSI イニシエーターの設定 を参照してください。
8.4. iSCSI イニシエーターの設定
Red Hat Ceph Storage は、Ceph iSCSI ゲートウェイに接続するために、3 つのオペレーティングシステムで iSCSI イニシエーターをサポートします。
8.4.1. Red Hat Enterprise Linux の iSCSI イニシエーター
前提条件:
-
パッケージ
iscsi-initiator-utils-6.2.0.873-35以降がインストールされている。 -
パッケージ
device-mapper-multipath-0.4.9-99以降がインストールされている。
ソフトウェアのインストール
iSCSI イニシエーターおよびマルチパスツールをインストールします。
# yum install iscsi-initiator-utils # yum install device-mapper-multipath
イニシエーター名の設定
/etc/iscsi/initiatorname.iscsiファイルを編集します。注記イニシエーター名は、Ansible
client_connectionsオプションで使用したイニシエーター名、またはgwcliを使用した初期設定時に使用したものと一致する必要があります。
Multipath IO の設定:
デフォルトの
/etc/multipath.confファイルを作成し、multipathdサービスを有効にします。# mpathconf --enable --with_multipathd y
以下を
/etc/multipath.confファイルに追加します。devices { device { vendor "LIO-ORG" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }multipathdサービスを再起動します。# systemctl reload multipathd
CHAP 設定および iSCSI の検出/ログイン:
それぞれ
/etc/iscsi/iscsid.confファイルを更新して CHAP のユーザー名とパスワードを指定します。例
node.session.auth.authmethod = CHAP node.session.auth.username = user node.session.auth.password = password
注記これらのオプションを更新する場合は、
iscsiadm discoveryコマンドを再実行する必要があります。ターゲットポータルを検出します。
# iscsiadm -m discovery -t st -p 192.168.56.101 192.168.56.101:3260,1 iqn.2003-01.org.linux-iscsi.rheln1 192.168.56.102:3260,2 iqn.2003-01.org.linux-iscsi.rheln1
target にログインします。
# iscsiadm -m node -T iqn.2003-01.org.linux-iscsi.rheln1 -l
Multipath IO 設定の表示
マルチパスデーモン(multipathd)は、multipath.conf 設定に基づいてデバイスを自動的に設定します。multipath コマンドを使用して、パスごとに優先度の高いグループが含まれるフェイルオーバー設定でのデバイス設定を表示します。
# multipath -ll mpathbt (360014059ca317516a69465c883a29603) dm-1 LIO-ORG ,IBLOCK size=1.0G features='0' hwhandler='1 alua' wp=rw |-+- policy='queue-length 0' prio=50 status=active | `- 28:0:0:1 sde 8:64 active ready running `-+- policy='queue-length 0' prio=10 status=enabled `- 29:0:0:1 sdc 8:32 active ready running
multipath -ll 出力の prio 値は ALUA の状態を示します。ここでは、prio=50 は、ALUA Active-Optimized の状態の独自の iSCSI ゲートウェイへのパスであり、prio=10 は Active-non-Optimized パスであることを示します。status フィールドは、使用されているパスを示します。こででは、active は現在使用されているパス、enabled は active なパスに問題が発生した場合にフェイルオーバーパスが有効になります 。multipath -ll 出力でデバイス名( sde など)を iSCSI ゲートウェイに一致させるには、以下のコマンドを実行します。
# iscsiadm -m session -P 3
Persistent Portal の値は、gwcli に一覧表示されている iSCSI ゲートウェイに割り当てられた IP アドレス、または gateway_ip_list に記載されている iSCSI ゲートウェイの IP アドレス(Ansible を使用している場合は)です。
8.4.2. Red Hat Virtualization の iSCSI イニシエーター
前提条件:
- Red Hat Virtualization 4.1
- すべての Red Hat Virtualization ノードでの MPIO デバイスの設定
-
パッケージ
iscsi-initiator-utils-6.2.0.873-35以降がインストールされている。 -
パッケージ
device-mapper-multipath-0.4.9-99以降がインストールされている。
Multipath IO の設定:
以下のように
/etc/multipath/conf.d/DEVICE_NAME.confファイルを更新します。devices { device { vendor "LIO-ORG" hardware_handler "1 alua" path_grouping_policy "failover" path_selector "queue-length 0" failback 60 path_checker tur prio alua prio_args exclusive_pref_bit fast_io_fail_tmo 25 no_path_retry queue } }multipathdサービスを再起動します。# systemctl reload multipathd
iSCSI ストレージの追加
- Storage resource タブをクリックして既存のストレージドメインを一覧表示します。
- 新規ドメイン ボタンをクリックして、新規ドメイン ウィンドウを開きます。
- 新規ストレージドメインの 名前 を入力します。
- データセンター ドロップダウンメニューを使用してデータセンターを選択します。
- ドロップダウンメニューを使用して、Domain Function および Storage Type を選択します。選択したドメイン機能との互換性がないストレージドメインタイプは利用できません。
- Use Host フィールドでアクティブなホストを選択します。データセンターの最初のデータドメインではない場合は、データセンターの SPM ホストを選択する必要があります。
新規ドメイン ウィンドウで、iSCSI がストレージタイプとして選択されている場合に、未使用の LUN が割り当てられた既知のターゲットが自動的に表示されます。ストレージを追加するターゲットが一覧にない場合には、ターゲット検出を使用して検索できます。それ以外の場合は、次のステップに進みます。
ターゲットを検出 をクリックし、ターゲットの検出オプションを有効にします。ターゲットが検出され、ログインすると、新規ドメイン ウィンドウに、その環境で未使用の LUN が割り当てられたターゲットが自動的に表示されます。
注記環境外の LUN も表示されます。
ターゲットを検出 のオプションを使用すると、多くのターゲットに LUN を追加したり、同じ LUN に複数のパスを追加したりすることができます。
- Address フィールドに、iSCSI ホストの完全修飾ドメイン名または IP アドレスを入力します。
-
ポートフィールドでのターゲットの参照時に、ホストに接続する ポート を入力します。デフォルトは
3260です。 - ストレージのセキュリティー保護にチャレンジハンドシェイク認証プロトコル (CHAP) を使用している場合は、ユーザー認証のチェックボックスを選択します。CHAP のユーザー名 と CHAP のパスワード を入力します。
- 検出 ボタンをクリックします。
検出結果から使用するターゲットを選択し、ログイン ボタンをクリックします。または、Login All をクリックし、検出されたすべてのターゲットにログインします。
重要複数のパスのアクセスが必要な場合には、すべての必要なパスでターゲットを検出してログインするようにしてください。ストレージドメインを変更してパスを追加する方法は、現在サポートされていません。
- 対象のターゲットの横にある + ボタンをクリックします。これにより、エントリーを展開し、ターゲットにアタッチされている未使用の LUN をすべて表示します。
- ストレージドメインの作成に使用する各 LUN のチェックボックスを選択します。
オプションで、詳細パラメーターを設定することが可能です。
- 詳細パラメーター をクリックします。
- 容量不足の警告 のフィールドに、パーセンテージ値を入力します。ストレージドメインの空き容量がこの値を下回ると、ユーザーに警告メッセージが表示され、ログに記録されます。
- アクションをブロックする 深刻な容量不足 のフィールドに GB 単位で値を入力します。ストレージドメインの空き容量がこの値を下回ると、ユーザーにエラーメッセージが表示され、ログに記録されます。容量を消費する新規アクションは、一時的であってもすべてブロックされます。
- 削除後にワイプするオプションを有効にするには、Wipe After Delete チェックボックスを選択します。このオプションは、ドメインの作成後に編集できますが、その場合はすでに存在している wipe after delete プロパティーは変更されません。
- 削除後に破棄 チェックボックスを選択して、削除後に破棄のオプションを有効化します。このオプションは、ドメインの作成後に編集できます。このオプションは、ブロックストレージドメインでのみ使用できます。
- OK をクリックしてストレージドメインを作成し、ウィンドウを閉じます。
8.4.3. Microsoft Windows の iSCSI イニシエーター
前提条件:
- Microsoft Windows Server 2016
iSCSI イニシエーター、検出、およびセットアップ:
- iSCSI イニシエータードライバーおよび MPIO ツールをインストールします。
- MPIO プログラムを起動し、Discover Multi-Paths タブをクリックし、iSCSI デバイスのサポートの追加 チェックボックスにチェックを入れ、Add をクリックします。この変更には再起動が必要になります。
iSCSI Initiator プロパティーウィンドウの Discovery タブ
 で、ターゲットポータルを追加します。Ceph iSCSI ゲートウェイの IP アドレスまたは DNS 名
で、ターゲットポータルを追加します。Ceph iSCSI ゲートウェイの IP アドレスまたは DNS 名
 および ポート
および ポート
 を入力します。
を入力します。
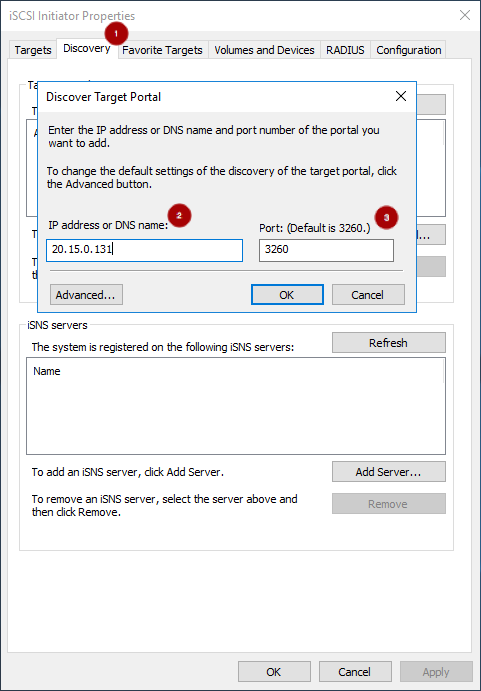
Targets タブ
でターゲットを選択し、Connect
をクリックします。

Connect To Target ウィンドウで Enable multi-path オプション
を選択し、Advanced ボタン
をクリックします。
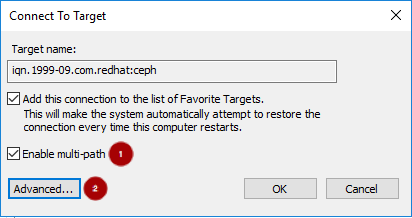
Connect using セクションで、Target portal IP
を選択します。
で CHAP ログインを有効 にし、Ceph iSCSI Ansible クライアント認証情報セクションから Name および Target secret values
を入力して、OK  をクリックします。
をクリックします。
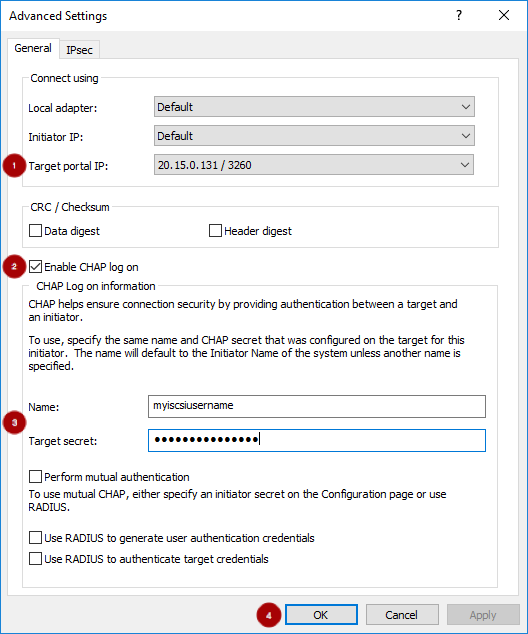 重要
重要Windows Server 2016 は 12 バイト未満の CHAP シークレットを受け入れません。
- iSCSI ゲートウェイの設定時に定義される各ターゲットポータルに対して、ステップ 5 と 6 を繰り返します。
イニシエーター名が初期設定中に使用されるイニシエーター名と異なる場合は、イニシエーター名を変更します。iSCSI Initiator Properties ウィンドウの Configuration タブ
で Change button
をクリックしてイニシエーター名を変更します。
マルチパス IO 設定:
MPIO 負荷分散ポリシーの設定。タイムアウトオプションおよび再試行オプションの設定は、mpclaim コマンドで PowerShell を使用します。iSCSI Initiator Tool は、残りのオプションを設定します。
Red Hat は、PDORemovePeriod オプションを PowerShell から 120 秒に増やすことを推奨します。この値はアプリケーションに基づいて調整する必要がある場合があります。すべてのパスがダウンし、120 秒の有効期限が切れると、オペレーティングシステムは失敗した IO 要求を開始します。
Set-MPIOSetting -NewPDORemovePeriod 120
- フェイルオーバーポリシーの設定
mpclaim.exe -l -m 1
- フェイルオーバーポリシーの確認
mpclaim -s -m MSDSM-wide Load Balance Policy: Fail Over Only
iSCSI Initiator ツールを使用して、Targets タブ
から Devices… ボタン
をクリックします。
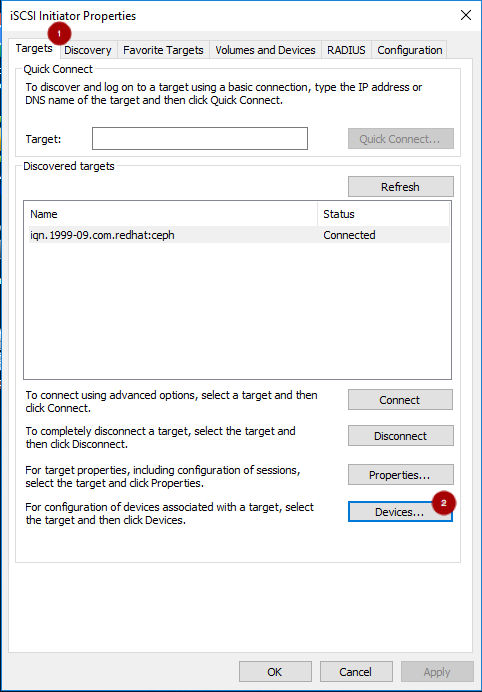
Devices ウィンドウでディスク
を選択し、MPIO… ボタン
をクリックします。
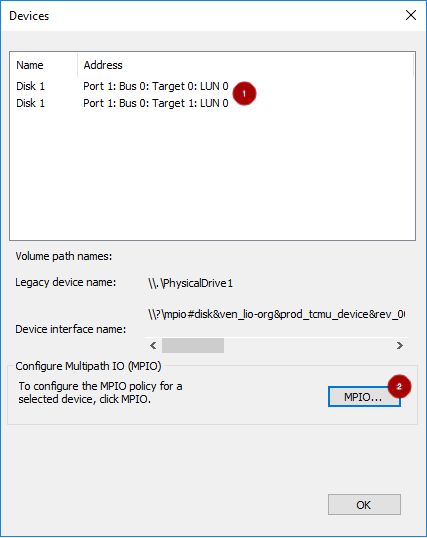
デバイスの 詳細 ウィンドウ で、各ターゲットポータルへのパスが表示されます。
ceph-ansibleセットアップ方法を使用する場合、iSCSI ゲートウェイは ALUA を使用して、iSCSI イニシエーターに、プライマリーパスとして使用する必要があるパスと iSCSI ゲートウェイを通知します。Load Balancing Policy Fail Over Only を選択する必要があります。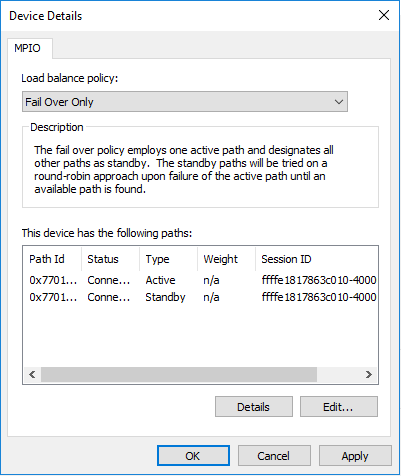
- PowerShell からマルチパス設定を表示する
mpclaim -s -d $MPIO_DISK_ID
MPIO_DISK_ID を適切なディスク識別子に置き換えます。
LUN を所有する iSCSI ゲートウェイノードへのパスである Active/Optimized パスが 1 つあります。他の iSCSI ゲートウェイノードごとに Active/optimized パスがあります。
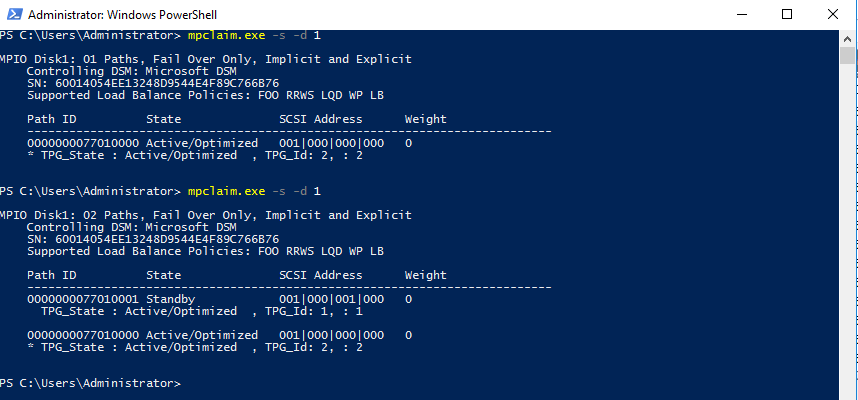
チューニング
以下のレジストリー設定の使用を検討してください。
Windows ディスクのタイムアウト
キー
HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Disk
値
TimeOutValue = 65
Microsoft iSCSI イニシエータードライバー
キー
HKEY_LOCAL_MACHINE\\SYSTEM\CurrentControlSet\Control\Class\{4D36E97B-E325-11CE-BFC1-08002BE10318}\<Instance_Number>\Parameters値
LinkDownTime = 25 SRBTimeoutDelta = 15
8.4.4. VMware ESX vSphere Web クライアント用の iSCSI イニシエーター
前提条件:
- 仮想マシンの互換 6.5 と VMFS 6 を使用した VMware ESX 6.5 以降
- vSphere Web クライアントへのアクセス
-
esxcliコマンドを実行する VMware ESXi ホストへの root アクセス
iSCSI 検出およびマルチパスデバイスの設定:
HardwareAcceleratedMoveを無効にします。# esxcli system settings advanced set --int-value 0 --option /DataMover/HardwareAcceleratedMove
iSCSI ソフトウェアを有効にします。Navigator ペインから、Storage
をクリックします。Adapters タブ
を選択します。Confgure iSCSI
をクリックします。

名前 & エイリアス のセクション
でイニシエーター名を確認します。
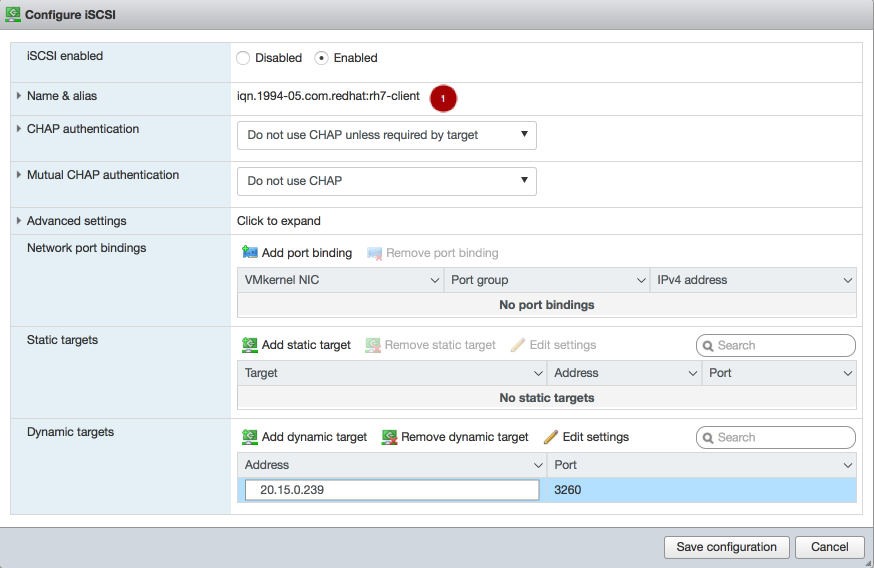 注記
注記gwcliを使用して初期設定時にクライアントを作成する際に使用されるイニシエーター名とは異なる場合や、Ansibleclient_connections:client変数で使用されるイニシエーター名が異なる場合は、以下の手順に従ってイニシエーター名を変更します。VMware ESX ホストから、esxcliコマンドを実行します。iSCSI ソフトウェアのアダプター名を取得します。
> esxcli iscsi adapter list > Adapter Driver State UID Description > ------- --------- ------ ------------- ---------------------- > vmhba64 iscsi_vmk online iscsi.vmhba64 iSCSI Software Adapter
イニシエーター名を設定します。
構文
> esxcli iscsi adapter set -A <adaptor_name> -n <initiator_name>
例
> esxcli iscsi adapter set -A vmhba64 -n iqn.1994-05.com.redhat:rh7-client
CHAP を設定します。CHAP 認証 セクション
を展開します。"Do not use CHAP unless unless required by target" (ターゲットによって必要な場合を除き、CHAP は使用しないでください)
を選択してください。gwcli authコマンドまたは Ansibleclient_connections:credentials変数を使用しているかどうかに関係なく、初期設定で使用された CHAP Name および Secret
認証情報を入力します。Mutual CHAP 認証 セクション
で "Do not use CHAP" (CHAP は使用しないでください) が選択されていることを確認します。
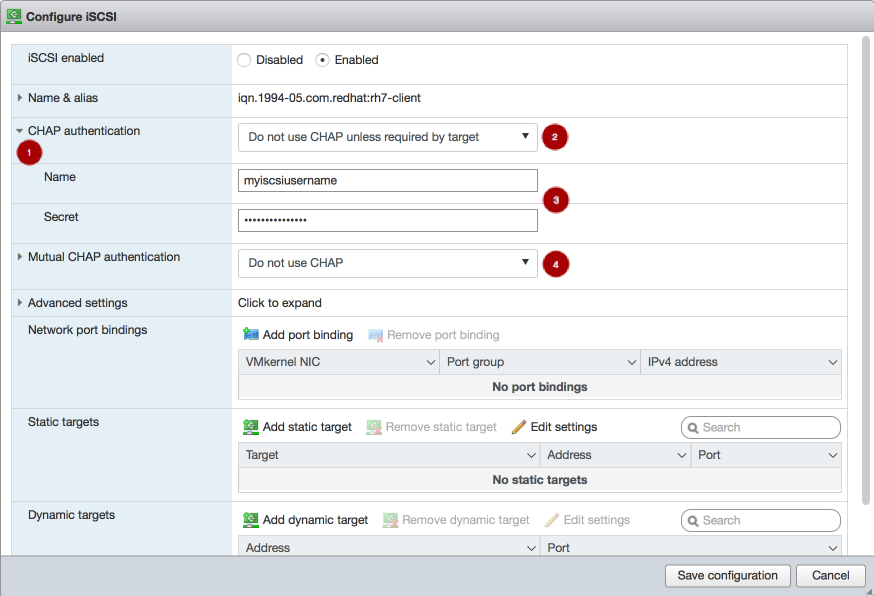 警告
警告vSphere Web クライアントには、CHAP 設定が最初に使用されていないバグがあります。Ceph iSCSI ゲートウェイノードでは、カーネルログに以下のエラーがバグを示しています。
> kernel: CHAP user or password not set for Initiator ACL > kernel: Security negotiation failed. > kernel: iSCSI Login negotiation failed.
このバグを回避するには、
esxcliコマンドを使用して CHAP を設定します。authname引数は vSphere Web クライアントの Name です。> esxcli iscsi adapter auth chap set --direction=uni --authname=myiscsiusername --secret=myiscsipassword --level=discouraged -A vmhba64
iSCSI 設定を設定します。Advanced settings
を展開します。RecoveryTimeout の値を 25
に設定します。
検出アドレスを設定します。Dynamic targets セクション
で、Add dynamic target
をクリックします。Address
の下に、Ceph iSCSI ゲートウェイの 1 つに IP アドレスを追加します。1 つの IP アドレスのみを追加する必要があります。最後に、Save configuration ボタン
をクリックします。Devices タブのメインインターフェイスから RBD イメージが表示されます。
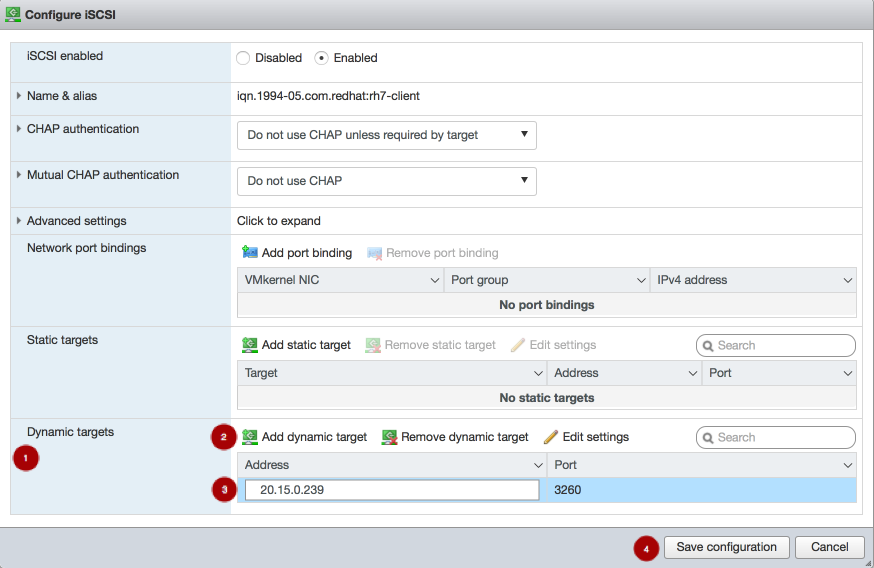 注記
注記LUN の設定は、ALUA SATP および MRU PSP を使用して自動的に行われます。他の SATP および PSP は使用できません。これは、
esxcliコマンドで検証できます。esxcli storage nmp path list -d eui.$DEVICE_ID
DEVICE_IDを適切なデバイス識別子に置き換えます。マルチパスが正しく設定されていることを確認します。
デバイスを一覧表示します。
例
# esxcli storage nmp device list | grep iSCSI Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Device Display Name: LIO-ORG iSCSI Disk (naa.6001405057360ba9b4c434daa3c6770c)
直前の手順で Ceph iSCSI ディスクのマルチパス情報を取得します。
例
# esxcli storage nmp path list -d naa.6001405f8d087846e7b4f0e9e3acd44b iqn.2005-03.com.ceph:esx1-00023d000001,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,1-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C0:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active Array Priority: 0 Storage Array Type Path Config: {TPG_id=1,TPG_state=AO,RTP_id=1,RTP_health=UP} Path Selection Policy Path Config: {current path; rank: 0} iqn.2005-03.com.ceph:esx1-00023d000002,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,t,2-naa.6001405f8d087846e7b4f0e9e3acd44b Runtime Name: vmhba64:C1:T0:L0 Device: naa.6001405f8d087846e7b4f0e9e3acd44b Device Display Name: LIO-ORG iSCSI Disk (naa.6001405f8d087846e7b4f0e9e3acd44b) Group State: active unoptimized Array Priority: 0 Storage Array Type Path Config: {TPG_id=2,TPG_state=ANO,RTP_id=2,RTP_health=UP} Path Selection Policy Path Config: {non-current path; rank: 0}この出力例から、各パスには iSCSI または SCSI 名があり、以下の部分があります。
Initiator name =
iqn.2005-03.com.ceph:esx1ISID =00023d000002Target name =iqn.2003-01.com.redhat.iscsi-gw:iscsi-igwTarget port group =2Device id =naa.6001405f8d087846e7b4f0e9e3acd44bGroup Stateの値がactiveの場合は、これが iSCSI ゲートウェイへの Active-Optimized パスであることを示します。gwcliコマンドは、iSCSI ゲートウェイ所有者としてactiveを一覧表示します。パスの残りの部分には、unoptimized の Group State の値があり、active パスが dead 状態になる場合にフェイルオーバーパスになります。
対応する iSCSI ゲートウェイへのパスをすべて照合するには、次のコマンドを実行します。
# esxcli iscsi session connection list
出力例
vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000001,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000001 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.21 RemoteAddress: 10.172.19.21 LocalAddress: 10.172.19.11 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:45 State: logged_in vmhba64,iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw,00023d000002,0 Adapter: vmhba64 Target: iqn.2003-01.com.redhat.iscsi-gw:iscsi-igw ISID: 00023d000002 CID: 0 DataDigest: NONE HeaderDigest: NONE IFMarker: false IFMarkerInterval: 0 MaxRecvDataSegmentLength: 131072 MaxTransmitDataSegmentLength: 262144 OFMarker: false OFMarkerInterval: 0 ConnectionAddress: 10.172.19.22 RemoteAddress: 10.172.19.22 LocalAddress: 10.172.19.12 SessionCreateTime: 08/16/18 04:20:06 ConnectionCreateTime: 08/16/18 04:20:06 ConnectionStartTime: 08/16/18 04:30:41 State: logged_in
パス名を
ISID値と照合し、RemoteAddress値は独自の iSCSI ゲートウェイの IP アドレスです。
8.5. Ansible を使用した Ceph iSCSI ゲートウェイのアップグレード
Red Hat Ceph Storage iSCSI ゲートウェイのアップグレードは、ローリングアップグレード用に設計された Ansible Playbook を使用して実行できます。
前提条件
- 実行中の Ceph iSCSI ゲートウェイがある。
- 稼働中の Red Hat Ceph Storage クラスターがある。
手順
-
正しい iSCSI ゲートウェイノードが Ansible インベントリーファイル (
/etc/ansible/hosts) に一覧表示されていることを確認します。 ローリングアップグレード Playbook を実行します。
[admin@ansible ~]$ ansible-playbook rolling_update.yml
サイト Playbook を実行してアップグレードを終了します。
[admin@ansible ~]$ ansible-playbook site.yml --limit iscsigws
8.6. コマンドラインインターフェイスを使用した Ceph iSCSI ゲートウェイのアップグレード
Red Hat Ceph Storage iSCSI ゲートウェイは、一度に 1 つのベアメタル iSCSI ゲートウェイノードをアップグレードすることでローリング方式で実行できます。
Ceph OSD のアップグレードおよび再起動中の iSCSI ゲートウェイをアップグレードしないでください。OSD のアップグレードが完了し、ストレージクラスターが active+clean の状態になる まで待ちます。
前提条件
- 実行中の Ceph iSCSI ゲートウェイがある。
- 稼働中の Red Hat Ceph Storage クラスターがある。
-
iSCSI ゲートウェイノードへの
rootアクセスがある。
手順
iSCSI ゲートウェイパッケージを更新します。
[root@igw ~]# yum update ceph-iscsi-config ceph-iscsi-cli
iSCSI ゲートウェイデーモンを停止します。
[root@igw ~]# systemctl stop rbd-target-api [root@igw ~]# systemctl stop rbd-target-gw
iSCSI ゲートウェイデーモンが正常に停止したことを確認します。
[root@igw ~]# systemctl status rbd-target-gw
-
rbd-target-gwサービスが正常に停止している場合は、手順 4 に進みます。 rbd-target-gwサービスを停止できない場合は、以下の手順を実行します。targetcliパッケージがインストールされていない場合は、targetcliパッケージをインストールします。[root@igw ~]# yum install targetcli
既存のターゲットオブジェクトを確認します。
[root@igw ~]# targetlci ls
出力例
o- / ............................................................. [...] o- backstores .................................................... [...] | o- user:rbd ..................................... [Storage Objects: 0] o- iscsi .................................................. [Targets: 0]
backstoresおよびStorage Objectが空の場合は、iSCSI ターゲットが正常にシャットダウンされ、ステップ 4 に進むことができ ます。ターゲットオブジェクトがまだある場合には、以下のコマンドを使用して、すべてのターゲットオブジェクトを強制的に削除します。
[root@igw ~]# targetlci clearconfig confirm=True
警告複数のサービスが iSCSI ターゲットを使用している場合は、インタラクティブモードで
targetcliを使用して、これらの特定のオブジェクトを削除します。
-
tcmu-runnerパッケージを更新します。[root@igw ~]# yum update tcmu-runner
tcmu-runnerサービスを停止します。[root@igw ~]# systemctl stop tcmu-runner
以下の順序ですべての iSCSI ゲートウェイサービスを再起動します。
[root@igw ~]# systemctl start tcmu-runner [root@igw ~]# systemctl start rbd-target-gw [root@igw ~]# systemctl start rbd-target-api
8.7. iSCSI ゲートウェイの監視
Red Hat は、エクスポートした Ceph ブロックデバイス (RBD) イメージのパフォーマンスを監視する Ceph iSCSI ゲートウェイ環境の追加ツールを提供します。
gwtop ツールは、iSCSI 経由でクライアントにエクスポートされる RBD イメージの集約されたパフォーマンスメトリックを表示する top のようなツールです。メトリクスは Performance Metrics Domain Agent (PMDA) から取得されます。Linux-IO ターゲット (LIO) PMDA からの情報を使用して、接続されたクライアントおよび関連する I/O メトリックと共にエクスポートされる各 RBD イメージを一覧表示します。
要件
- 実行中の Ceph iSCSI ゲートウェイがある。
インストール
iSCSI ゲートウェイノードで root ユーザーとして以下の手順を実施します。
ceph-tools リポジトリーを有効にします。
# subscription-manager repos --enable=rhel-7-server-rhceph-3-tools-rpms
ceph-iscsi-toolsパッケージをインストールします。# yum install ceph-iscsi-tools
パフォーマンス co-pilot パッケージをインストールします。
# yum install pcp
注記Performance co-pilot の詳細は、『Red Hat Enterprise Linux パフォーマンス チューニングガイド』 を参照してください。
LIO PMDA パッケージをインストールします。
# yum install pcp-pmda-lio
パフォーマンス co-pilot サービスを有効にして起動します。
# systemctl enable pmcd # systemctl start pmcd
pcp-pmda-lioエージェントを登録します。cd /var/lib/pcp/pmdas/lio ./Install
デフォルトでは、gwtop は、iSCSI ゲートウェイ設定オブジェクトが rbd プールの gateway.conf という RADOS オブジェクトに保存されていることを前提としています。この設定では、パフォーマンス統計情報を収集する iSCSI ゲートウェイを定義します。これは、-g フラグまたは -c フラグを使用して上書きできます。詳細は gwtop --help を参照してください。
LIO 設定は、パフォーマンス co-pilot から抽出するパフォーマンス統計の種類を決定します。gwtop がこれを LIO 設定を確認し、ユーザー空間ディスクを見つけると、gwtop は自動的に LIO コレクターを選択します。
gwtop 出力の例:
ユーザーでサポートされるストレージ (TCMU) デバイスの場合:
gwtop 2/2 Gateways CPU% MIN: 4 MAX: 5 Network Total In: 2M Out: 3M 10:20:00 Capacity: 8G Disks: 8 IOPS: 503 Clients: 1 Ceph: HEALTH_OK OSDs: 3 Pool.Image Src Size iops rMB/s wMB/s Client iscsi.t1703 500M 0 0.00 0.00 iscsi.testme1 500M 0 0.00 0.00 iscsi.testme2 500M 0 0.00 0.00 iscsi.testme3 500M 0 0.00 0.00 iscsi.testme5 500M 0 0.00 0.00 rbd.myhost_1 T 4G 504 1.95 0.00 rh460p(CON) rbd.test_2 1G 0 0.00 0.00 rbd.testme 500M 0 0.00 0.00
クライアント 列の (CON) は、iSCSI イニシエーター (クライアント) が現在 iSCSI ゲートウェイにログインしていることを意味します。-multi- が表示される場合、複数のクライアントが単一の RBD イメージにマッピングされます。
SCSI の永続的な予約はサポートされていません。SCSI の永続的な予約に依存しないクラスター対応ファイルシステムまたはクラスターリングソフトウェアを使用している場合、複数の iSCSI イニシエーターを RBD イメージへのマッピングに対応しています。たとえば、ATS を使用する VMware vSphere 環境はサポートされますが、Microsoft のクラスターリングサーバー (MSCS) の使用はサポートされていません。
付録A iscsigws.yml ファイルのサンプル
# Variables here are applicable to all host groups NOT roles
# This sample file generated by generate_group_vars_sample.sh
# Dummy variable to avoid error because ansible does not recognize the
# file as a good configuration file when no variable in it.
dummy:
# You can override vars by using host or group vars
###########
# GENERAL #
###########
# Specify the iqn for ALL gateways. This iqn is shared across the gateways, so an iscsi
# client sees the gateway group as a single storage subsystem.
#gateway_iqn: "iqn.2003-01.com.redhat.iscsi-gw:ceph-igw"
# gateway_ip_list provides a list of the IP Addrresses - one per gateway - that will be used
# as an iscsi target portal ip. The list must be comma separated - and the order determines
# the sequence of TPG's within the iscsi target across each gateway. Once set, additional
# gateways can be added, but the order must *not* be changed.
#gateway_ip_list: 0.0.0.0
# rbd_devices defines the images that should be created and exported from the iscsi gateways.
# If the rbd does not exist, it will be created for you. In addition you may increase the
# size of rbd's by changing the size parameter and rerunning the playbook. A size value lower
# than the current size of the rbd is ignored.
#
# the 'host' parameter defines which of the gateway nodes should handle the physical
# allocation/expansion or removal of the rbd
# to remove an image, simply use a state of 'absent'. This will first check the rbd is not allocated
# to any client, and the remove it from LIO and then delete the rbd image
#
# NB. this variable definition can be commented out to bypass LUN management
#
# Example:
#
#rbd_devices:
# - { pool: 'rbd', image: 'ansible1', size: '30G', host: 'ceph-1', state: 'present' }
# - { pool: 'rbd', image: 'ansible2', size: '15G', host: 'ceph-1', state: 'present' }
# - { pool: 'rbd', image: 'ansible3', size: '30G', host: 'ceph-1', state: 'present' }
# - { pool: 'rbd', image: 'ansible4', size: '50G', host: 'ceph-1', state: 'present' }
#rbd_devices: {}
# client_connections defines the client ACL's to restrict client access to specific LUNs
# The settings are as follows;
# - image_list is a comma separated list of rbd images of the form <pool name>.<rbd_image_name>
# - chap supplies the user and password the client will use for authentication of the
# form <user>/<password>
# - status shows the intended state of this client definition - 'present' or 'absent'
#
# NB. this definition can be commented out to skip client (nodeACL) management
#
# Example:
#
#client_connections:
# - { client: 'iqn.1994-05.com.redhat:rh7-iscsi-client', image_list: 'rbd.ansible1,rbd.ansible2', chap: 'rh7-iscsi-client/redhat', status: 'present' }
# - { client: 'iqn.1991-05.com.microsoft:w2k12r2', image_list: 'rbd.ansible4', chap: 'w2k12r2/microsoft_w2k12', status: 'absent' }
#client_connections: {}
# Whether or not to generate secure certificate to iSCSI gateway nodes
#generate_crt: False
##################
# RBD-TARGET-API #
##################
# Optional settings related to the CLI/API service
#api_user: admin
#api_password: admin
#api_port: 5000
#api_secure: false
#loop_delay: 1
#trusted_ip_list: 192.168.122.1
##########
# DOCKER #
##########
# Resource limitation
# For the whole list of limits you can apply see: docs.docker.com/engine/admin/resource_constraints
# Default values are based from: https://access.redhat.com/documentation/ja-jp/red_hat_ceph_storage/2/html/red_hat_ceph_storage_hardware_guide/minimum_recommendations
# These options can be passed using the 'ceph_mds_docker_extra_env' variable.
# TCMU_RUNNER resource limitation
#ceph_tcmu_runner_docker_memory_limit: 1g
#ceph_tcmu_runner_docker_cpu_limit: 1
# RBD_TARGET_GW resource limitation
#ceph_rbd_target_gw_docker_memory_limit: 1g
#ceph_rbd_target_gw_docker_cpu_limit: 1
# RBD_TARGET_API resource limitation
#ceph_rbd_target_api_docker_memory_limit: 1g
#ceph_rbd_target_api_docker_cpu_limit: 1