
Red Hat Training
A Red Hat training course is available for Red Hat Ceph Storage
管理ガイド
Red Hat Ceph Storage の管理
概要
第1章 Ceph 管理の概要
Red Hat Ceph Storage クラスターは、すべての Ceph デプロイメントの基盤です。Red Hat Ceph Storage クラスターをデプロイしたら、Red Hat Ceph Storage クラスターの正常な状態を維持し、最適に実行するための管理操作を実行できます。
『Red Hat Ceph Storage 管理ガイド』は、ストレージ管理者が以下のようなタスクを実行するのに役立ちます。
- Red Hat Ceph Storage クラスターの正常性を確認する方法
- Red Hat Ceph Storage クラスターサービスを起動および停止する方法
- 実行中の Red Hat Ceph Storage クラスターから OSD を追加または削除する方法
- Red Hat Ceph Storage クラスターに保管されたオブジェクトへのユーザー認証およびアクセス制御を管理する方法
- Red Hat Ceph Storage クラスターでオーバーライドを使用する方法
- Red Hat Ceph Storage クラスターのパフォーマンスを監視する方法
基本的な Ceph ストレージクラスターは、2 種類のデーモンで構成されます。
- Ceph Object Storage Device (OSD) は、OSD に割り当てられた配置グループ内にオブジェクトとしてデータを格納します。
- Ceph Monitor はクラスターマップのマスターコピーを維持します。
実稼働システムでは、高可用性を実現する Ceph Monitor が 3 つ以上含まれます。通常、許容可能な負荷分散、データのリバランス、およびデータ復旧に備えて最低 50 OSD が含まれます。
関連情報
Red Hat Ceph Storage インストールガイド
第2章 Ceph のプロセス管理の理解
ストレージ管理者は、Ceph デーモンをさまざまな方法で操作できます。これらのデーモンを操作すると、必要に応じてすべての Ceph サービスを開始、停止、および再起動することができます。
2.1. 前提条件
- 実行中の Red Hat Ceph Storage クラスター
2.2. Ceph のプロセス管理の概要
Red Hat Ceph Storage 3 では、すべてのプロセス管理は Systemd サービスを介して行われます。Ceph デーモンの start、restart、および stop を行う場合には毎回、デーモンの種別またはデーモンインスタンスを指定する必要があります。
関連情報
- Systemd の使用に関する詳細は、Red Hat Enterprise Linux『System Administrator’s Guide』の Chapter 9 を参照してください。
2.3. すべての Ceph デーモンの開始、停止、および再起動
ノード上で実行中のすべての Ceph デーモンを起動、停止、または再起動するには、以下の手順を行います。
前提条件
-
ノードへの
rootアクセスを持つ。
手順
すべての Ceph デーモンを起動します。
[root@admin ~]# systemctl start ceph.target
すべての Ceph デーモンを停止します。
[root@admin ~]# systemctl stop ceph.target
すべての Ceph デーモンを再起動します。
[root@admin ~]# systemctl restart ceph.target
2.4. タイプ別の Ceph デーモンの開始、停止、および再起動
特定の種別のすべての Ceph デーモンを起動、停止、または再起動するには、Ceph デーモンを実行するノードで以下の手順に従います。
前提条件
-
ノードへの
rootアクセスを持つ。
手順
Ceph Monitor ノード上で以下を行います。
起動
[root@mon ~]# systemctl start ceph-mon.target
停止
[root@mon ~]# systemctl stop ceph-mon.target
再起動
[root@mon ~]# systemctl restart ceph-mon.target
Ceph Manager ノードで以下を行います。
起動
[root@mgr ~]# systemctl start ceph-mgr.target
停止
[root@mgr ~]# systemctl stop ceph-mgr.target
再起動
[root@mgr ~]# systemctl restart ceph-mgr.target
Ceph OSD ノード上で以下を行います。
起動
[root@osd ~]# systemctl start ceph-osd.target
停止
[root@osd ~]# systemctl stop ceph-osd.target
再起動
[root@osd ~]# systemctl restart ceph-osd.target
Ceph Object Gateway ノードの場合:
起動
[root@rgw ~]# systemctl start ceph-radosgw.target
停止
[root@rgw ~]# systemctl stop ceph-radosgw.target
再起動
[root@rgw ~]# systemctl restart ceph-radosgw.target
2.5. インスタンス別の Ceph デーモンの開始、停止、および再起動
インスタンスごとに Ceph デーモンを起動、停止、または再起動するには、Ceph デーモンを実行するノードで以下の手順に従います。
前提条件
-
ノードへの
rootアクセスを持つ。
手順
Ceph Monitor ノード上で以下を行います。
起動
[root@mon ~]# systemctl start ceph-mon@$MONITOR_HOST_NAME
停止
[root@mon ~]# systemctl stop ceph-mon@$MONITOR_HOST_NAME
再起動
[root@mon ~]# systemctl restart ceph-mon@$MONITOR_HOST_NAME
置き換え
-
$MONITOR_HOST_NAMEは、Ceph Monitor ノードの名前に置き換えます。
-
Ceph Manager ノードで以下を実行します。
起動
[root@mgr ~]# systemctl start ceph-mgr@MANAGER_HOST_NAME
停止
[root@mgr ~]# systemctl stop ceph-mgr@MANAGER_HOST_NAME
再起動
[root@mgr ~]# systemctl restart ceph-mgr@MANAGER_HOST_NAME
置き換え
-
$MANAGER_HOST_NAMEは、Ceph Manager ノードの名前に置き換えます。
-
Ceph OSD ノード:
起動
[root@osd ~]# systemctl start ceph-osd@$OSD_NUMBER
停止
[root@osd ~]# systemctl stop ceph-osd@$OSD_NUMBER
再起動
[root@osd ~]# systemctl restart ceph-osd@$OSD_NUMBER
置き換え
$OSD_NUMBERを Ceph OSD のID番号に置き換えます。たとえば、
ceph osd ツリーコマンドの出力を確認すると、osd.0のIDは0になります。
Ceph Object Gateway ノードで以下を行います。
起動
[root@rgw ~]# systemctl start ceph-radosgw@rgw.$OBJ_GATEWAY_HOST_NAME
停止
[root@rgw ~]# systemctl stop ceph-radosgw@rgw.$OBJ_GATEWAY_HOST_NAME
再起動
[root@rgw ~]# systemctl restart ceph-radosgw@rgw.$OBJ_GATEWAY_HOST_NAME
置き換え
-
$OBJ_GATEWAY_HOST_NAMEは、Ceph Object Gateway ノードの名前に置き換えます。
-
2.6. Red Hat Ceph Storage クラスターの電源をオフにして再起動
Ceph クラスターの電源をオフにして再起動するには、以下の手順に従います。
前提条件
-
rootアクセスを持つ。
手順
Red Hat Ceph Storage クラスターの電源オフ
クライアントがこのクラスターおよび他のクライアントで RBD イメージ、NFS-Ganesha Gateway、および RADOS Gateway を使用しないようにします。
NFS-Ganesha Gateway ノードで以下を行います。
# systemctl stop nfs-ganesha.service
RADOS Gateway ノードで以下を行います。
# systemctl stop ceph-radosgw.target
-
次のステップに進む前に、クラスターの状態が正常な状態 (
Health_OKおよびすべての PG がactive+clean) である必要があります。Ceph Monitor や OpenStack コントローラーceph statusノードなどのクライアントキーリングを持つノードで実行し、クラスターが正常であることを確認します。 Ceph File System (
CephFS) を使用する場合は、CephFSクラスターを停止する必要があります。CephFSクラスターをダウンさせるには、ランク数を1に減らし、cluster_downフラグを設定して最後のランクを失敗させることで行います。以下に例を示します。#ceph fs set <fs_name> max_mds 1 #ceph mds deactivate <fs_name>:1 # rank 2 of 2 #ceph status # wait for rank 1 to finish stopping #ceph fs set <fs_name> cluster_down true #ceph mds fail <fs_name>:0
cluster_downフラグを設定することで、スタンバイが失敗したランクを引き継ぐことを防ぎます。nooutフラグ、norecoverフラグ、norebalanceフラグ、nobackfillフラグ、nodownフラグ、およびpauseフラグを設定します。Ceph Monitor または OpenStack コントローラーなどのクライアントキーリングを持つノードで以下を実行します。#ceph osd set noout #ceph osd set norecover #ceph osd set norebalance #ceph osd set nobackfill #ceph osd set nodown #ceph osd set pause
OSD ノードを 1 つずつシャットダウンします。
[root@osd ~]# systemctl stop ceph-osd.target
監視ノードを 1 つずつシャットダウンします。
[root@mon ~]# systemctl stop ceph-mon.target
Red Hat Ceph Storage クラスターのリブート
モニターノードの電源をオンにします。
[root@mon ~]# systemctl start ceph-mon.target
OSD ノードの電源をオンにします。
[root@osd ~]# systemctl start ceph-osd.target
- すべてのノードが起動するのを待ちます。すべてのサービスが稼働中であり、ノード間の接続に問題がないことを確認します。
nooutフラグ、norecoverフラグ、norebalanceフラグ、nobackfillフラグ、nodownフラグ、およびpauseフラグの設定を解除します。Ceph Monitor または OpenStack コントローラーなどのクライアントキーリングを持つノードで以下を実行します。#ceph osd unset noout #ceph osd unset norecover #ceph osd unset norebalance #ceph osd unset nobackfill #ceph osd unset nodown #ceph osd unset pause
Ceph File System (
CephFS) を使用する場合は、cluster_downフラグをfalseに設定してCephFSクラスターをバックアップする必要があります。[root@admin~]# ceph fs set <fs_name> cluster_down false
RADOS Gateway および NFS-Ganesha Gateway を起動します。
RADOS Gateway ノードで以下を行います。
# systemctl start ceph-radosgw.target
NFS-Ganesha Gateway ノードで以下を行います。
# systemctl start nfs-ganesha.service
-
クラスターの状態が正常であることを確認します (
Health_OK、およびすべての PG がactive+clean)。Ceph Monitor や OpenStack コントローラーceph statusノードなどのクライアントキーリングを持つノードで実行し、クラスターが正常であることを確認します。
2.7. 関連情報
Red Hat Ceph Storage のインストールに関する詳細は、以下を参照してください。
- Red Hat Enterprise Linux Installation Guide
- Ubuntu Installation Guide
第3章 モニタリング
クラスターを実行したら、ストレージクラスターのモニタリングを開始し、Ceph Monitor および OSD デーモンがハイレベルで実行されるようにします。Ceph ストレージクラスターのクライアントは Ceph モニターに接続し、最新バージョンの Ceph クラスターマップを取得してから、ストレージクラスターの Ceph プールにデータを読み書きできます。そのため、モニタークラスターには、Ceph クライアントがデータの読み取りおよび書き込みが可能になる前に、クラスターの状態に関する合意が必要です。
Ceph OSD は、セカンダリー OSD の配置グループのコピーと、プライマリー OSD 上の配置グループをピアにする必要があります。障害が発生した場合、ピアリングは active + clean 状態以外のものを反映します。
3.1. ハイレベルのモニタリング
ストレージクラスターの高レベルのモニタリングには、通常、Ceph OSD および Monitor デーモンのステータスを確認し、それらが稼働していることを確認します。また、高レベルのモニタリングには、ストレージクラスター容量を確認して、クラスターが完全な比率を超えないようにします。Ansible Tower または Red Hat Storage Console ノードの Calamari インスタンスは、高レベルのモニタリングを実行する最も一般的な方法です。ただし、コマンドライン、管理ソケット、または Ceph API を使用してストレージクラスターを監視することもできます。
3.1.1. インタラクティブモード
インタラクティブモードで ceph ユーティリティーを実行するには、引数なしでコマンドラインに ceph と入力します。以下に例を示します。
# ceph ceph> health ceph> status ceph> quorum_status ceph> mon_status
3.1.2. クラスターのヘルスチェク
Ceph Storage クラスターを起動してからデータの読み書きを開始する前に、ストレージクラスターの健全性を確認します。Ceph Storage クラスターの正常性を確認するには、以下を使用します。
# ceph health
設定またはキーリングにデフォルト以外の場所を指定した場合は、その場所を指定できます。
# ceph -c /path/to/conf -k /path/to/keyring health
Ceph クラスターの起動時に、HEALTH_WARN XXX num placement groups stale などの正常性警告が生じる可能性があります。しばらく待ってから再度確認します。ストレージクラスターの準備が整ったら、ceph health は HEALTH_OK などのメッセージを返すはずです。この時点で、クラスターの使用を問題なく開始することができます。
3.1.3. クラスターの監視
コマンドラインでクラスターの続行中のイベントを監視するには、新しいターミナルを開きます。次に、以下を入力します。
# ceph -w
Ceph は各イベントを出力します。たとえば、1 台のモニターで構成され、2 つの OSD で構成される小さな Ceph クラスターが以下のように出力されます。
cluster b370a29d-9287-4ca3-ab57-3d824f65e339
health HEALTH_OK
monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
osdmap e63: 2 osds: 2 up, 2 in
pgmap v41338: 952 pgs, 20 pools, 17130 MB data, 2199 objects
115 GB used, 167 GB / 297 GB avail
952 active+clean
2014-06-02 15:45:21.655871 osd.0 [INF] 17.71 deep-scrub ok
2014-06-02 15:45:47.880608 osd.1 [INF] 1.0 scrub ok
2014-06-02 15:45:48.865375 osd.1 [INF] 1.3 scrub ok
2014-06-02 15:45:50.866479 osd.1 [INF] 1.4 scrub ok
2014-06-02 15:45:01.345821 mon.0 [INF] pgmap v41339: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:05.718640 mon.0 [INF] pgmap v41340: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:53.997726 osd.1 [INF] 1.5 scrub ok
2014-06-02 15:45:06.734270 mon.0 [INF] pgmap v41341: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:45:15.722456 mon.0 [INF] pgmap v41342: 952 pgs: 952 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail
2014-06-02 15:46:06.836430 osd.0 [INF] 17.75 deep-scrub ok
2014-06-02 15:45:55.720929 mon.0 [INF] pgmap v41343: 952 pgs: 1 active+clean+scrubbing+deep, 951 active+clean; 17130 MB data, 115 GB used, 167 GB / 297 GB avail出力には以下が含まれます。
- クラスター ID
- クラスターの正常性ステータス
- モニターマップエポックおよびモニタークォーラムのステータス
- OSD マップエポックおよび OSD のステータス
- 配置グループマップバージョン
- 配置グループとプールの数
- 保存されるデータの 想定 量および保存されるオブジェクト数
- 保存されるデータの合計量
Ceph によるデータ使用量の計算方法
使用される 値は、使用される生のストレージの 実際 の量を反映します。xxx GB / xxx GB の値は、クラスターの全体的なストレージ容量のうち、2 つの数字の小さい方の利用可能な量を意味します。概念番号は、複製、クローン、またはスナップショットを作成する前に、保存したデータのサイズを反映します。したがって、Ceph はデータのレプリカを作成し、クローン作成やスナップショットのためにストレージ容量を使用することもあるため、実際に保存されるデータの量は、通常、保存された想定される量を上回ります。
3.1.4. クラスターの使用統計の確認
クラスターのデータの使用状況とプール間のデータ分散を確認するには、df オプションを使用します。これは Linux の df に似ています。以下のコマンドを実行します。
# ceph df
出力の GLOBAL セクションは、ストレージクラスターがデータに使用するストレージ容量の概要を示します。
- SIZE: ストレージクラスターの全体的なストレージ容量。
- AVAIL: ストレージクラスターで利用可能な空き容量。
- RAW USED: 使用されている raw ストレージの量。
-
% RAW USED: 使用されている raw ストレージの割合。この数字は、
full ratioとnear full ratioで使用して、ストレージクラスターの容量に達しないようにします。
出力の POOLS セクションは、プールの一覧と、各プールの概念的な使用目的を提供します。このセクションの出力には、レプリカ、クローン、またはスナップショットを反映 しません。たとえば、1MB のデータを持つオブジェクトを保存する場合、概念上の使用量は 1MB ですが、実際の使用量はレプリカの数 (例: size = 3、クローンおよびスナップショット) に応じて 3 MB 以上になる場合があります。
- NAME: プールの名前。
- ID: プール ID。
- USED: メガバイトの場合は M、ギガバイトの場合は G を付加しない限り、キロバイト単位で保存されたデータの想定量。
- %USED: プールごとに使用されるストレージの概念パーセンテージ。
- Objects: プールごとに格納されているオブジェクトの想定数。
POOLS セクションの数字は概念的です。レプリカ、スナップショット、またはクローンの数が含まれません。その結果、USED と %USED の量の合計は、出力の GLOBAL セクションの RAW USED と %RAW USED の量に加算されません。詳しくは、Ceph によるデータ使用量の計算方法 を参照してください。
3.1.5. クラスターステータスの確認
クラスターのステータスを確認するには、以下を実行します。
# ceph status
または以下を実行します。
# ceph -s
インタラクティブモードで、status と入力し、Enter を押します。
ceph> status
Ceph により、クラスターのステータスが出力されます。たとえば、1 つのモニターと 2 つの OSD で構成される小さな Ceph クラスターは以下を出力することがあります。
cluster b370a29d-9287-4ca3-ab57-3d824f65e339
health HEALTH_OK
monmap e1: 1 mons at {ceph1=10.0.0.8:6789/0}, election epoch 2, quorum 0 ceph1
osdmap e63: 2 osds: 2 up, 2 in
pgmap v41332: 952 pgs, 20 pools, 17130 MB data, 2199 objects
115 GB used, 167 GB / 297 GB avail
1 active+clean+scrubbing+deep
951 active+clean3.1.6. モニターステータスの確認
ストレージクラスターに複数のモニターがある場合、これは実稼働用の Ceph ストレージクラスターの高可用性に必要です。Ceph ストレージクラスターの起動後に、データの読み書きの前に Ceph Monitor クォーラムのステータスを確認する必要があります。複数のモニターを実行している場合はクォーラムが存在する必要があります。また、Ceph Monitor ステータスを定期的に確認して、それらが稼働していることを確認する必要があります。ストレージクラスターの状態で合意できないような問題が Monitor で発生した場合、問題によって Ceph クライアントがデータを読み書きできない可能性があります。
監視マップを表示するには、以下を実行します。
# ceph mon stat
または
# ceph mon dump
ストレージクラスターのクォーラムステータスを確認するには、以下を実行します。
# ceph quorum_status -f json-pretty
Ceph はクォーラムのステータスを返します。たとえば、3 つのモニターで構成される Ceph ストレージクラスターは、以下を返す可能性があります。
{ "election_epoch": 10, "quorum": [ 0, 1, 2], "monmap": { "epoch": 1, "fsid": "444b489c-4f16-4b75-83f0-cb8097468898", "modified": "2011-12-12 13:28:27.505520", "created": "2011-12-12 13:28:27.505520", "mons": [ { "rank": 0, "name": "a", "addr": "127.0.0.1:6789\/0"}, { "rank": 1, "name": "b", "addr": "127.0.0.1:6790\/0"}, { "rank": 2, "name": "c", "addr": "127.0.0.1:6791\/0"} ] } }
3.1.7. 管理ソケットの使用
管理ソケットを使用して、UNIX ソケットファイルを使用して、指定したデーモンと直接対話します。たとえば、ソケットを使用すると以下を行うことができます。
- ランタイム時に Ceph 設定を一覧表示します。
-
Monitor にリレーせずに起動時に値を直接設定します。これは、モニターが
ダウンしている場合に便利です。 - ダンプの履歴操作
- 操作優先度キューの状態をダンプします。
- 再起動しないダンプ操作
- パフォーマンスカウンターのダンプ
さらに、Monitor または OSD に関連する問題のトラブルシューティングを行う場合は、ソケットの使用に役立ちます。詳細は、Red Hat Ceph Storage 3『Troubleshooting Guide』を参照してください。
ソケットを使用するには、以下を実行します。
ceph daemon <type>.<id> <command>
以下を置き換えます。
-
<type>は、Ceph デーモンのタイプ (mon、osd、mds) に置き換えます。 -
<id>をデーモン ID に置き換えます。 -
<command>を実行するコマンドに置き換えます。指定のデーモンで利用可能なコマンドを一覧表示するには、helpを使用します。
たとえば、mon.0 という名前の Monitor ステータスを表示するには、以下を実行します。
# ceph daemon mon.0 mon_status
または、ソケットファイルを使用してデーモンを指定します。
ceph daemon /var/run/ceph/<socket-file> <command>
たとえば、osd.2 という名前の OSD のステータスを表示するには、以下を実行します。
# ceph daemon /var/run/ceph/ceph-osd.2.asok status
Ceph プロセスのソケットファイルの一覧を表示するには、以下のコマンドを実行します。
$ ls /var/run/ceph
3.1.8. OSD ステータスの確認
OSD のステータスは、クラスター内の in またはクラスター外の out のいずれかで、稼働中である up または稼働中でない down のいずれかです。OSD が up である場合、データの読み取りが可能なクラスター内の in であるか、クラスター外の out のいずれかになります。クラスター内 (in) にあり、最近クラスターの外 (out) に移動すると、Ceph は配置グループを他の OSD に移行します。OSD がクラスター 外 の場合、CRUSH は配置グループを OSD に割り当てません。OSD が down している場合は、それも out となるはずです。
OSD がdown して in にある場合は問題があり、クラスターは正常な状態になりません。

ceph health、ceph -s、ceph -w などのコマンドを実行すると、クラスターが常に HEALTH OK をエコーバックしないことが分かります。慌てないでください。OSD に関連して、予想される状況でクラスターが HEALTH OK をエコー しない ことが予想されます。
- クラスターを起動していないと、応答しません。
- クラスターを起動または再起動したばかりで、配置グループが作成されつつあり、OSD がピアリング中であるため、準備はできていません。
- OSD を追加または削除したのみです。
- クラスターマップを変更しただけです。
OSD の監視の重要な要素は、クラスターの起動時および稼働時にクラスター 内 のすべての OSD が 稼働 していることを確認することです。すべての OSD が実行中かどうかを確認するには、以下を実行します。
# ceph osd stat
または
# ceph osd dump
結果により、マップのエポック (eNNNN)、OSD の総数 (x)、いくつの y が up で、いくつの z が in であるかが分かります。
eNNNN: x osds: y up, z in
クラスター内である in の OSD の数が up の OSD の数よりも多い場合、以下のコマンドを実行して、稼働していない ceph-osd デーモンを特定します。
# ceph osd tree
出力例:
# id weight type name up/down reweight -1 3 pool default -3 3 rack mainrack -2 3 host osd-host 0 1 osd.0 up 1 1 1 osd.1 up 1 2 1 osd.2 up 1
適切に設計された CRUSH 階層で検索する機能は、物理ロケーションをより迅速に特定してストレージクラスターをトラブルシューティングするのに役立ちます。
OSD がダウンしている (down) 場合は、ノードに接続して開始します。Red Hat Storage Console を使用して OSD ノードを再起動するか、以下のようにコマンドラインを使用できます。
# systemctl start ceph-osd@<osd_id>
3.2. 低レベルのモニタリング
通常、低レベルのモニタリングでは、OSD がピアリングできるようにする必要があります。障害が発生すると、配置グループはデグレード状態で動作します。これには、障害が発生したハードウェア、ハングまたはクラッシュしたデーモン、ネットワークレイテンシーまたは停止などの多くの原因が考えられます。
3.2.1. 配置グループセット
CRUSH が配置グループを OSD に割り当てると、プールのレプリカ数を確認し、配置グループの各レプリカが別の OSD に割り当てられるように配置グループを OSD に割り当てます。たとえば、プールに配置グループの 3 つのレプリカが必要な場合、CRUSH はそれらをそれぞれ osd.1、osd.2、および osd.3 に割り当てることができます。CRUSH は実際には、CRUSH マップで設定した障害ドメインを考慮した擬似ランダムな配置を求めているため、大規模なクラスター内で最も近い OSD に割り当てられた配置グループを目にすることはほとんどありません。特定の配置グループのレプリカを Acting Set として組み込む必要がある OSD のセットを参照します。場合によっては、Acting Set の OSD が down になった場合や、配置グループ内のオブジェクトのリクエストに対応できない場合があります。このような状況になっても、慌てないでください。以下に一般的な例を示します。
- OSD を追加または削除しています。次に、CRUSH は配置グループを他の OSD に再度割り当てます。これにより、動作セットの構成を変更し、「バックフィル」プロセスでデータの移行を生成します。
-
OSD が
downになり、再起動されてリカバリー中 (recovering) となっています。 -
動作セットの OSD は
downとなっているが、要求に対応できず、別の OSD がその役割を一時的に想定しています。
Ceph は Up Set を使用してクライアント要求を処理します。これは、実際に要求を処理する OSD のセットです。ほとんどの場合、Up Set と Acting Set はほぼ同じです。そうでない場合には、Ceph がデータを移行しているか、OSD が復旧するか、または問題がある場合に、通常 Ceph がこのようなシナリオで「stuck stale」メッセージと共に HEALTH WARN 状態を出すことを示しています。
配置グループの一覧を取得するには、次のコマンドを実行します。
# ceph pg dump
Acting Set にどの OSD があるか、または特定の配置グループの Up Set を表示するには、以下を実行します。
# ceph pg map <pg-num>
結果を見ると、osdmap epoch
eNNN、配置グループ番号<pg-num>、up セットの OSDup[]、および acting セットの OSDacting[]であることが分かります。osdmap eNNN pg <pg-num> -> up [0,1,2] acting [0,1,2]
注記Up Set と Acting Set が一致しない場合は、クラスター自体をリバランスするか、クラスターで潜在的な問題があることを示している可能性があります。
3.2.2. ピアリング
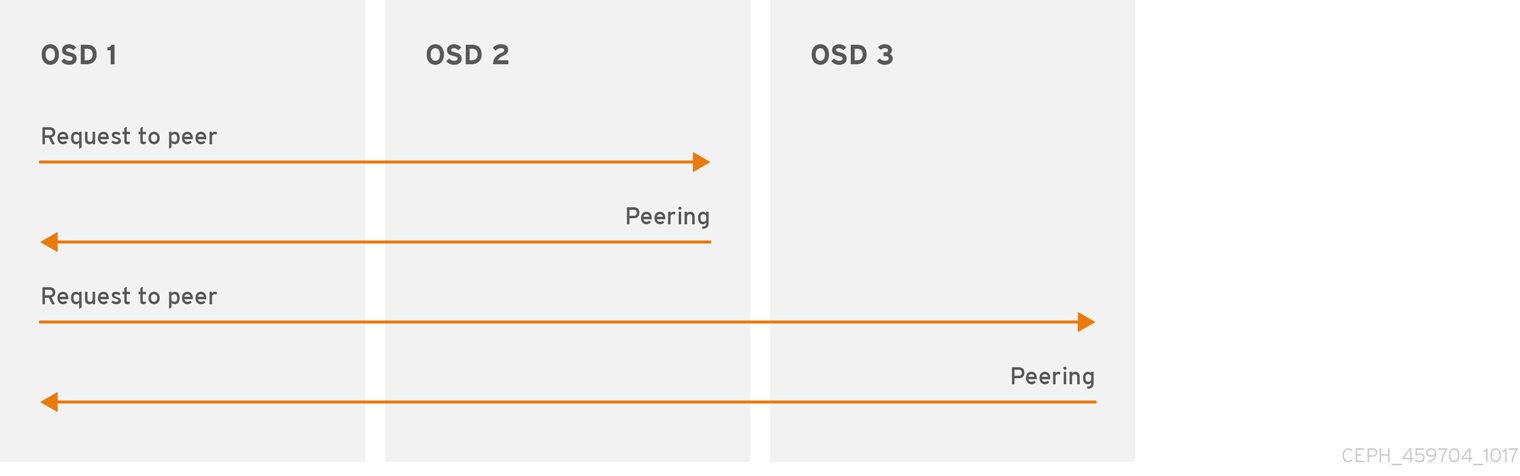
配置グループにデータを書き込む前に、そのデータを active 状態にし、clean な状態で なければなりません。Ceph が配置グループの現在の状態を決定するためには、配置グループの第一 OSD (動作セットの最初の OSD など) が、第二および第三の OSD とピアリングを行い、配置グループの現在の状態についての合意を確立します (PG の 3 つのレプリカを持つプールであることを仮定します)。
3.2.3. 配置グループの状態の監視
ceph health、ceph -s、ceph -w などのコマンドを実行すると、クラスターが常に HEALTH OK をエコーバックしないことが分かります。OSD が実行中であるかを確認したら、配置グループのステータスも確認する必要があります。数多くの配置グループのピア関連状況で、クラスターが HEALTH OK を しない ことが予想されます。
- プールを作成したばかりで、配置グループはまだピアリングしていません。
- 配置グループは復旧しています。
- クラスターに OSD を追加したり、クラスターから OSD を削除したりしたところです。
- CRUSH マップを変更し、配置グループが移行中である必要があります。
- 配置グループの異なるレプリカに一貫性のないデータがあります。
- Ceph は配置グループのレプリカをスクラビングします。
- Ceph には、バックフィルの操作を完了するのに十分なストレージ容量がありません。
前述の状況のいずれかにより Ceph が HEALTH WARN をエコーしても慌てる必要はありません。多くの場合、クラスターは独自にリカバリーします。場合によっては、アクションを実行する必要がある場合があります。配置グループを監視する上で重要なことは、クラスタの起動時にすべての配置グループがactive で、できれば clean な状態であることを確認することです。すべての配置グループのステータスを表示するには、以下を実行します。
# ceph pg stat
その結果、配置グループマップバージョン (vNNNNNN)、配置グループの合計 (x)、および配置グループの数 (y) が、active+clean などの特定の状態にあることを示します。
vNNNNNN: x pgs: y active+clean; z bytes data, aa MB used, bb GB / cc GB avail
Ceph では、配置グループについて複数の状態を報告するのが一般的です。
スナップショットトリミングの PG の状態
スナップショットが存在する場合には、追加の PG ステータスが 2 つ報告されます。
-
snaptrim: PG は現在トリミング中です。 -
snaptrim_wait: PG はトリム処理を待機中です。
出力例:
244 active+clean+snaptrim_wait 32 active+clean+snaptrim
スナップショットのトリミング設定の詳細は、Red Hat Ceph Storage 3『Configuration Guide』のその他の OSD 設定を参照してください。
Cephは、配置グループの状態に加えて、使用データ量 (aa)、ストレージ容量残量 (bb)、配置グループの総ストレージ容量をエコーバックします。いくつかのケースでは、これらの数字が重要になります。
-
near full ratioまたはfull ratioに達しています。 - CRUSH 設定のエラーにより、データがクラスター全体に分散されません。
配置グループ ID
配置グループ ID は、プール名ではなくプール番号で構成され、ピリオド (.) と配置グループ ID が続きます (16 進数)。ceph osd lspools の出力で、プール番号およびその名前を表示することができます。デフォルトのプール名 data、metadata、rbd はそれぞれプール番号 0、1、2 に対応しています。完全修飾配置グループ ID の形式は以下のとおりです。
<pool_num>.<pg_id>
出力例:
0.1f
配置グループの一覧を取得するには、次のコマンドを実行します。
# ceph pg dump
JSON 形式で出力をフォーマットし、ファイルに保存するには、以下を実行します。
# ceph pg dump -o <file_name> --format=json
特定の配置グループをクエリーするには、次のコマンドを実行します。
# ceph pg <pool_num>.<pg_id> query
JSON 形式の出力例:
{ "state": "active+clean", "up": [ 1, 0 ], "acting": [ 1, 0 ], "info": { "pgid": "1.e", "last_update": "4'1", "last_complete": "4'1", "log_tail": "0'0", "last_backfill": "MAX", "purged_snaps": "[]", "history": { "epoch_created": 1, "last_epoch_started": 537, "last_epoch_clean": 537, "last_epoch_split": 534, "same_up_since": 536, "same_interval_since": 536, "same_primary_since": 536, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174" }, "stats": { "version": "4'1", "reported": "536'782", "state": "active+clean", "last_fresh": "2013-01-25 10:12:23.828271", "last_change": "2013-01-25 10:12:23.828271", "last_active": "2013-01-25 10:12:23.828271", "last_clean": "2013-01-25 10:12:23.828271", "last_unstale": "2013-01-25 10:12:23.828271", "mapping_epoch": 535, "log_start": "0'0", "ondisk_log_start": "0'0", "created": 1, "last_epoch_clean": 1, "parent": "0.0", "parent_split_bits": 0, "last_scrub": "4'1", "last_scrub_stamp": "2013-01-25 10:12:23.828174", "log_size": 128, "ondisk_log_size": 128, "stat_sum": { "num_bytes": 205, "num_objects": 1, "num_object_clones": 0, "num_object_copies": 0, "num_objects_missing_on_primary": 0, "num_objects_degraded": 0, "num_objects_unfound": 0, "num_read": 1, "num_read_kb": 0, "num_write": 3, "num_write_kb": 1 }, "stat_cat_sum": { }, "up": [ 1, 0 ], "acting": [ 1, 0 ] }, "empty": 0, "dne": 0, "incomplete": 0 }, "recovery_state": [ { "name": "Started\/Primary\/Active", "enter_time": "2013-01-23 09:35:37.594691", "might_have_unfound": [ ], "scrub": { "scrub_epoch_start": "536", "scrub_active": 0, "scrub_block_writes": 0, "finalizing_scrub": 0, "scrub_waiting_on": 0, "scrub_waiting_on_whom": [ ] } }, { "name": "Started", "enter_time": "2013-01-23 09:35:31.581160" } ] }
以下のサブセクションでは、一般的な状態について詳しく説明します。
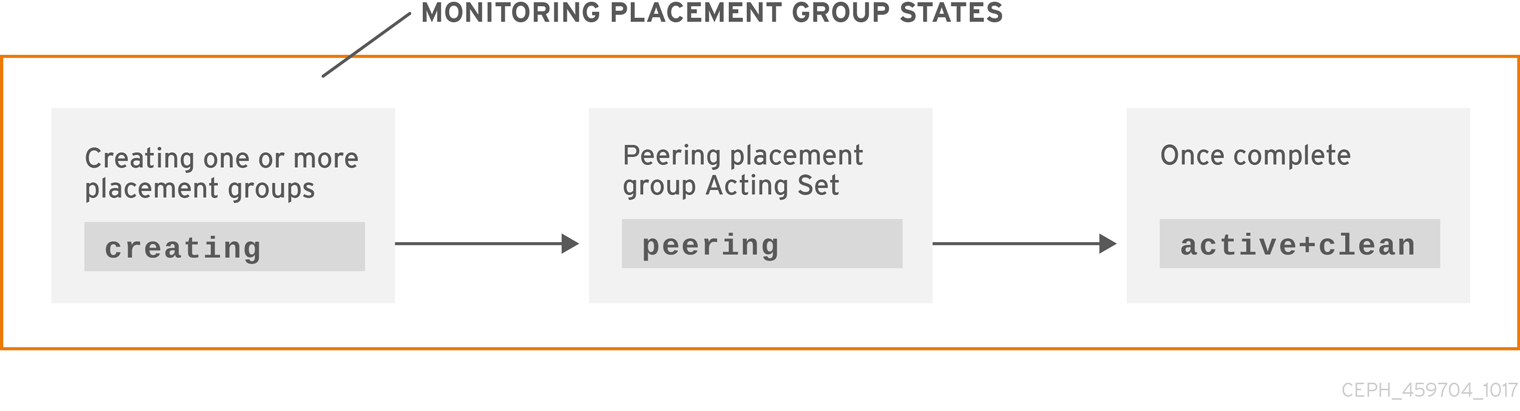
3.2.3.1. 作成
プールを作成すると、指定した数の配置グループが作成されます。Ceph は、1 つ以上の配置グループの 作成 時に作成をエコーします。これが作成されると、配置グループのアクティングセットの一部である OSD がピアリングを行います。ピアリングが完了すると、配置グループのステータスは active+clean になり、Ceph クライアントが配置グループへの書き込みを開始できるようになります。
3.2.3.2. ピアリング
Ceph が配置グループをピアリングする場合、Ceph は配置グループのレプリカを保存する OSD を配置グループ内のオブジェクトおよびメタデータの 状態について合意 に持ち込みます。Ceph がピアリングを完了すると、配置グループを格納する OSD が配置グループの現在の状態について合意することを意味します。ただし、ピアリングプロセスを完了しても、各レプリカに最新のコンテンツがある わけではありません。
権威の履歴
Ceph は、動作セットのすべての OSD が書き込み操作を持続させるまで、クライアントへの書き込み操作を 承認しません。これにより、有効なセットの少なくとも 1 つメンバーが、最後に成功したピア操作以降の確認済みの書き込み操作がすべて記録されるようになります。
確認された各書き込み操作の正確な記録により、Ceph は配置グループの新しい権限履歴を構築および配布することができます。これは、実行された場合に OSD の配置グループのコピーを最新の状態にする、完全な順序付けされた操作のセットです。
3.2.3.3. アクティブ
Ceph がピア処理を完了すると、配置グループが active になる可能性があります。active 状態とは、配置グループのデータがプライマリー配置グループで一般的に利用可能で、読み取り操作および書き込み操作用のレプリカになります。
3.2.3.4. クリーン
配置グループが クリーン な状態にある場合、プライマリー OSD とレプリカ OSD は正常にピアリングを行い、配置グループ用の迷子のレプリカが存在しないことを意味します。Ceph は、配置グループ内のすべてのオブジェクトの複製を適切な回数実行します。
3.2.3.5. デグレード
クライアントがプライマリー OSD にオブジェクトを書き込む際に、プライマリー OSD はレプリカ OSD にレプリカを書き込みます。プライマリー OSD がオブジェクトをストレージに書き込んだ後に、配置グループは、Ceph がレプリカオブジェクトを正しく作成したレプリカ OSD からプライマリー OSD が確認応答を受け取るまで、動作が 低下 した状態になります。
配置グループが active+degraded になる理由は、OSD がまだすべてのオブジェクトを保持していない場合でも active である可能性があることです。OSD が down する場合、Ceph は OSD に割り当てられた各配置グループを degraded としてマークします。OSD がオンラインに戻る際に、OSD を再度ピアする必要があります。ただし、クライアントは、active であれば、degraded である配置グループに新しいオブジェクトを記述できます。
OSD が down していてパフォーマンスの低下 (degraded) が続く場合には、Ceph は down 状態である OSD をクラスターの外 (out) としてマークし、down 状態である OSD から別の OSD にデータを再マッピングする場合があります。down とマークされた時間と out とマークされた時間の間の時間は mon_osd_down_out_interval によって制御され、デフォルトでは 600 に設定されています。
また、配置グループは、Ceph が配置グループにあるべきだと考えるオブジェクトを 1 つ以上見つけることができないため、低下 してしまうこともあります。未検出オブジェクトへの読み取りまたは書き込みはできませんが、動作が低下した (degraded) 配置グループ内の他のすべてのオブジェクトにアクセスできます。
オブジェクトの 3 つのコピーを持つ OSD が 9 個あるとします。OSD の数の 9 がダウンすると、9 の OSD に割り当てられた PG は動作が低下します。OSD 9 がリカバリーされない場合は、クラスターから送信され、クラスターがリバランスします。このシナリオでは、PG のパフォーマンスが低下してから、アクティブな状態に戻ります。
3.2.3.6. リカバリー
Ceph は、ハードウェアやソフトウェアの問題が存在する場合に大規模にフォールトトレランスを実現することを目的として設計されています。OSD がダウンする (down) と、そのコンテンツは配置グループ内の他のレプリカの現在の状態のままになる可能性があります。OSD が up 状態に戻ったら、配置グループの内容を更新して、現在の状態を反映させる必要があります。その間、OSD は リカバリー の状態を反映する場合があります。
ハードウェアの故障は、複数の OSD のカスケード障害を引き起こす可能性があるため、回復は常に些細なことではありません。たとえば、ラックやキャビネット用のネットワークスイッチが故障して、多数のホストマシンの OSD がクラスターの現在の状態から遅れてしまうことがあります。各 OSD は、障害が解決されたら回復しなければなりません。
Ceph は、新しいサービス要求とデータオブジェクトの回復と配置グループを現在の状態に復元するニーズの間でリソース競合のバランスを取るためのいくつかの設定を提供しています。osd recovery delay start 設定により、回復プロセスを開始する前に OSD を再起動し、ピアリングを再度行い、さらにはいくつかの再生要求を処理できます。osd recovery threads 設定により、デフォルトで 1 つのスレッドでリカバリープロセスのスレッド数が制限されます。osd recovery thread timeout は、複数の OSD が驚きの速さで失敗、再起動、再ピアする可能性があるため、スレッドタイムアウトを設定します。osd recovery max active 設定では、OSD が送信に失敗するのを防ぐために OSD が同時に実行するリカバリー要求の数を制限します。osd recovery の max chunk 設定により、復元されたデータチャンクのサイズが制限され、ネットワークの輻輳を防ぐことができます。
3.2.3.7. バックフィル
新規 OSD がクラスターに参加する際に、CRUSH はクラスター内の OSD から新たに追加された OSD に配置グループを再割り当てします。新規 OSD が再割り当てされた配置グループをすぐに許可するように強制すると、新規 OSD に過剰な負荷が生じる可能性があります。OSD を配置グループでバックフィルすると、このプロセスはバックグラウンドで開始できます。バックフィルが完了すると、新しい OSD の準備が整い次第、要求への対応を開始します。
バックフィル操作中は、いくつかの状態のうちの 1 つを確認できます。backfill_wait は、バックフィル操作が保留されているが、まだ進行していないことを示します。backfill は、バックフィル操作が進行中であることを示します。backfill_too_full は、バックフィル操作が要求されたが、ストレージ容量が不足しているために完了できなかったことを示します。配置グループをバックフィルできない場合は、incomplete とみなされることがあります。
Cephは、OSD、特に新しい OSD への配置グループの再割り当てに伴い負荷の急増を管理するいくつかの設定を提供しています。デフォルトでは、osd_max_backfills は、OSD から 10 への同時バックフィルの最大数を設定します。osd backfill full ratio により、OSD は、OSD が完全な比率 (デフォルトでは 85%) に近づけている場合にバックフィル要求を拒否することができます。OSD がバックフィル要求を拒否する場合は、osd backfill retry interval により、OSD はデフォルトで 10 秒後に要求を再試行できます。また、OSD は、スキャン間隔 (デフォルトで 64 および 512) を管理するために、osd backfill scan min および osd backfill scan max を設定することもできます。
ワークロードによっては、通常のリカバリーを完全に回避し、代わりにバックフィルを使用することが推奨されます。バックフィルはバックグラウンドで実行されるため、I/O は OSD のオブジェクトで続行できます。復元せずにバックフィルを強制するには、osd_min_pg_log_entries を 1 に設定し、osd_max_pg_log_entries を 2 に設定します。この状況がご使用のワークロードに適切な場合についての詳細は、Red Hat サポートアカウントチームにお問い合わせください。
3.2.3.8. リカバリーまたはバックフィル操作の優先度の強制
一部の配置グループ (PG) にリカバリーやバックフィルが必要で、一部の配置グループに他のグループよりも重要なデータが含まれているという状況が発生する場合があります。pg force-recovery または pg force-backfill コマンドを使用して、優先度の高いデータを持つ PG が最初にリカバリーまたはバックフィルされるようにします。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- ノードへのルートレベルのアクセス。
手順
pg force-recoveryまたはpg force-backfillコマンドを実行し、優先度の高いデータを持つ PG の優先順位を指定します。構文
# ceph pg force-recovery PG1 [PG2] [PG3 ...] # ceph pg force-backfill PG1 [PG2] [PG3 ...]
例
[root@node]# ceph pg force-recovery group1 group2 [root@node]# ceph pg force-backfill group1 group2
このコマンドにより、Red Hat Ceph Storage は指定された配置グループ (PG) でリカバリーまたはバックフィルを実行してから、他の配置グループを処理します。コマンドを実行しても、現在実行中のバックフィルまたはリカバリー操作は中断されません。現在実行中の操作が終了した後、指定の PG に対してできるだけ早期にリカバリーまたはバックフィルが行われます。
3.2.3.9. リカバリーまたはバックフィル操作の優先順位の変更またはキャンセル
ストレージクラスター内の特定の配置グループ (PG) で優先度の高い force-recovery または force-backfill 操作をキャンセルすると、これらの PG の操作はデフォルトのリカバリー設定またはバックフィル設定に戻ります。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- ノードへのルートレベルのアクセス。
手順
指定の配置グループでリカバリーまたはバックフィルの操作を変更またはキャンセルするには、以下を実行します。
構文
ceph pg cancel-force-recovery PG1 [PG2] [PG3 ...] ceph pg cancel-force-backfill PG1 [PG2] [PG3 ...]
例
[root@node]# ceph pg cancel-force-recovery group1 group2 [root@node]# ceph pg cancel-force-backfill group1 group2
これにより、
forceフラグが取り消され、デフォルトの順序で PG を処理します。指定された PG のリカバリーまたはバックフィル操作が完了したら、処理の順序がデフォルトに戻ります。
3.2.3.10. プールのリカバリーまたはバックフィル操作の優先度の強制
プールのすべての配置グループに優先度の高いリカバリーまたはバックフィルが必要な場合は、force-recovery または force-backfill オプションを使用して操作を開始します。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- ノードへのルートレベルのアクセス。
手順
指定されたプールのすべての配置グループで優先度の高いリカバリーまたはバックフィルを強制するには、以下を実行します。
構文
ceph osd pool force-recovery POOL_NAME ceph osd pool force-backfill POOL_NAME
例
[root@node]# ceph osd pool force-recovery pool1 [root@node]# ceph osd pool force-backfill pool1
注記force-recoveryおよびforce-backfillコマンドの使用には注意が必要です。これらの操作の優先度を変更すると、Ceph の内部優先度計算の順序付けが乱れる可能性があります。
3.2.3.11. プールのリカバリーまたはバックフィル操作の優先度のキャンセル
プールのすべての配置グループで優先度の高い force-recovery または force-backfill 操作をキャンセルすると、そのプールの PG の操作はデフォルトのリカバリーまたはバックフィルの設定に戻ります。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- ノードへのルートレベルのアクセス。
手順
指定されたプールのすべての配置グループで優先度の高いリカバリーまたはバックフィル操作をキャンセルするには、以下を実行します。
構文
ceph osd pool cancel-force-recovery POOL_NAME ceph osd pool cancel-force-backfill POOL_NAME
例
[root@node]# ceph osd pool cancel-force-recovery pool1 [root@node]# ceph osd pool cancel-force-backfill pool1
3.2.3.12. プールのリカバリー操作とバックフィルの操作の優先度の再調整
現在、同じ基礎となる OSD を使用している複数のプールがあり、一部のプールに優先度の高いデータが含まれている場合、操作の実行順序を再調整できます。recovery_priority オプションを使用して、優先度の高いデータのあるプールに優先度の高い値を割り当てます。これらのプールは、優先度の低い値を持つプールやデフォルトの優先度に設定されたプールよりも先に実行されます。
前提条件
- Red Hat Ceph Storage クラスターが実行中である。
- ノードへのルートレベルのアクセス。
手順
プールのリカバリーやバックフィルの優先度を再調整するには、以下を実行します。
構文
ceph osd pool set POOL_NAME recovery_priority VALUE
VALUE は優先順位を設定します。たとえば、プールが 10 個ある場合、優先度の値が 10 のプールは最初に処理され、次に優先順位が 9 のプールが処理されます。一部のプールのみ優先度が高い場合は、そのプールのみにに優先度の値を設定できます。優先度の値が設定されていないプールは、デフォルトの順序で処理されます。
例
ceph osd pool set pool1 recovery_priority 10
3.2.3.13. RADOS における配置グループのリカバリーの優先順位
ここでは、RADOS における配置グループ (PG) のリカバリーおよびバックフィルの相対的な優先度の値について説明します。高い値が先に処理されます。非アクティブな PG の値は、アクティブまたはデグレードの PG よりも優先度が高い値になります。
| 操作 | 値 | 説明 |
|---|---|---|
| OSD_RECOVERY_PRIORITY_MIN | 0 | 最小リカバリー値 |
| OSD_BACKFILL_PRIORITY_BASE | 100 | MBackfillReserve のベースのバックフィル優先度 |
| OSD_BACKFILL_DEGRADED_PRIORITY_BASE | 140 | MBackfillReserve のベースのバックフィル優先度 (デグレード PG) |
| OSD_RECOVERY_PRIORITY_BASE | 180 | MBackfillReserve のベースのリカバリー優先度 |
| OSD_BACKFILL_INACTIVE_PRIORITY_BASE | 220 | MBackfillReserve のベースのバックフィル優先度 (非アクティブ PG) |
| OSD_RECOVERY_INACTIVE_PRIORITY_BASE | 220 | MRecoveryReserve のベースのリカバリー優先度 (非アクティブ) |
| OSD_RECOVERY_PRIORITY_MAX | 253 | MBackfillReserve の手動または自動で設定される最大リカバリー優先度 |
| OSD_BACKFILL_PRIORITY_FORCED | 254 | MBackfillReserve のバックフィル優先度 (手動で強制) |
| OSD_RECOVERY_PRIORITY_FORCED | 255 | MRecoveryReserve のリカバリー優先度 (手動で強制) |
| OSD_DELETE_PRIORITY_NORMAL | 179 | OSD が満杯状態でない場合の PG の削除の優先度 |
| OSD_DELETE_PRIORITY_FULLISH | 219 | OSD がほぼ満杯状態である場合の PG の削除の優先度 |
| OSD_DELETE_PRIORITY_FULL | 255 | OSD が満杯である場合の削除の優先度 |
3.2.3.14. 再マッピング
配置グループにサービスを提供する動作セットが変更すると、古い動作セットから新しい動作セットにデータを移行します。新規プライマリー OSD がリクエストを処理するには、多少時間がかかる場合があります。したがって、配置グループの移行が完了するまで、古いプライマリーに要求への対応を継続するように依頼する場合があります。データの移行が完了すると、マッピングは新しい動作セットのプライマリー OSD を使用します。
3.2.3.15. 陳腐
Ceph はハートビートを使用してホストとデーモンが稼働していることを確認しますが、ceph-osd デーモンも stuck 状態になり、一時的なネットワーク障害などの場合に統計をタイムリーに報告しません。デフォルトでは、OSD デーモンは、配置グループ、アップスルー、ブート、失敗の統計情報を半秒 (0.5) ごとに報告しますが、これはハートビートのしきい値よりも頻度が高くなります。配置グループの動作セットの プライマリー OSD がモニターへの報告に失敗した場合や、他の OSD がプライマリー OSD の down を報告した場合、モニターは配置グループに stale マークを付けます。
ストレージクラスターを起動すると、ピアリング処理が完了するまで stale 状態になるのが一般的です。ストレージクラスタがしばらく稼働している間に、配置グループが stale 状態になっているのが確認された場合は、その配置グループのプライマリー OSD が down になっているか、モニターに配置グループの統計情報を報告していないことを示しています。
3.2.3.16. 誤配置
PG が OSD に一時的にマップされる一時的なバックフィルシナリオが想定されます。一時的 な状況がなくなった場合には、PG は一時的な場所に留まり、適切な場所にない可能性があります。いずれの場合も、それらは 誤って配置 されます。それは、実際には正しい数の追加コピーが存在しているのに、1 つ以上のコピーが正しくない場所にあるためです。
たとえば、0、1、2 の 3 つの OSD およびすべての PG がこれら 3 つの順列にマッピングされるとします。別の OSD (OSD 3) を追加する場合、一部の PG は、他のものではなく OSD 3 にマッピングされるようになりました。しかし、OSD 3 がバックフィルされるまで、PG には一時的なマッピングがあり、古いマッピングからの I/O を提供し続けることができます。その間、PG には一時的な待っピンがありますが、コピーが 3 つあるため degraded はしていないため、間違った場所に置かれます (misplaced)。
例
pg 1.5: up=acting: [0,1,2] <add osd 3> pg 1.5: up: [0,3,1] acting: [0,1,2]
ここで、[0,1,2] は一時的なマッピングであるため、up セットは acting なセットとは等しくならず、[0,1,2] がまだ 3 つのコピーであるため、PG は misplaced ですが、パフォーマンスは degraded ではありません。
例
pg 1.5: up=acting: [0,3,1]
OSD 3 はバックフィルされ、一時的なマッピングは削除され、パフォーマンスは低下せず、誤って配置されなくなりました。
3.2.3.17. 不完全
PG は、不完全なコンテンツがあり、ピアリングが失敗する場合、つまり、現時点でリカバリーを実行するために十分な OSD が十分にない場合に、incomplete 状態になります。
たとえば、OSD 1、2、3 が OSD の動作セットであり、それが OSD 1、4、3 に切り替わる場合、osd.1 が 4 をバックフィルする間に、OSD 1、2、および 3 の一時的な動作セットを要求します。この間、OSD 1、2、および 3 すべてがダウンすると、osd.4 は、すべてのデータが完全にバックフィルされていない可能性がある唯一のものとして残されています。このとき、PG は incomplete となり、リカバリーを実行するのに十分な現在の完全な OSD がないことを示す不完全な状態になります。
別の方法として、osd.4 が使用されておらず、OSD の 1、2、3 がダウンしたときに動作セットが単に OSD 1、2、3 になっている場合、PG はおそらく動作セットが変更されてからその PG で何も通知されていないことを示す stale になります。新規 OSD に通知する OSD が残されない理由。
3.2.4. 問題のある配置グループの特定
前述のように、配置グループは、その状態が active+clean ではないため、必ずしも問題になるとは限りません。一般的に、Ceph の自己修復機能は、配置グループが停止しても機能しない場合があります。スタック状態には、以下が含まれます。
- Unclean: 配置グループには、必要な回数複製しないオブジェクトが含まれます。これらは回復中である必要があります。
-
Inactive: 配置グループは、最新のデータを持つ OSD が
upに戻るのを待っているため、読み取りや書き込みを処理できません。 -
Stale: 配置グループは不明な状態です。配置グループは、これらをホストする OSD がしばらくモニタークラスターに報告されず、
mon osd report timeout設定で設定できるためです。
スタックした配置グループを特定するには、以下のコマンドを実行します。
# ceph pg dump_stuck {inactive|unclean|stale|undersized|degraded [inactive|unclean|stale|undersized|degraded...]} {<int>}3.2.5. オブジェクトの場所の検索
Ceph Object Store にオブジェクトデータを保存するには、Ceph クライアントで以下を行う必要があります。
- オブジェクト名の設定
- プールの指定
Ceph クライアントは最新のクラスターマップを取得し、CRUSH アルゴリズムはオブジェクトを配置グループにマッピングする方法を計算してから、配置グループを OSD に動的に割り当てる方法を計算します。オブジェクトの場所を見つけるのに必要なのはオブジェクト名とプール名だけです。以下に例を示します。
# ceph osd map <pool_name> <object_name>
3.3. Red Hat Ceph Storage Dashboard を使用した Ceph Storage クラスターのモニタリング
Red Hat Ceph Storage Dashboard は、Ceph Storage Cluster の状態を視覚化するためのモニタリングダッシュボードを提供します。また、Red Hat Ceph Storage Dashboard アーキテクチャーは、ストレージクラスターに機能を追加する追加のモジュール用のフレームワークを提供します。
- Dashboard の詳細は、「Red Hat Ceph Storage Dashboard」 を参照してください。
- Dashboard をインストールするには、「Red Hat Ceph Storage Dashboard のインストール」 を参照してください。
- Dashboard にアクセスするには、「Red Hat Ceph Storage Dashboard へのアクセス」 を参照してください。
- Dashboard のインストール後にデフォルトのパスワードを変更するには、「デフォルトの Red Hat Ceph Storage ダッシュボードパスワードの変更」 を参照してください。
- Prometheus プラグインの詳細は、「Red Hat Ceph Storage の Prometheus プラグイン」 を参照してください。
- Red Hat Ceph Storage Dashboard のアラートおよび設定方法について詳しく知るには、「Red Hat Ceph Storage Dashboard アラート」 を参照してください。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
3.3.1. Red Hat Ceph Storage Dashboard
Red Hat Ceph Storage Dashboard は、Ceph クラスターのモニタリングダッシュボードを提供し、ストレージクラスターの状態を可視化します。ダッシュボードは Web ブラウザーからアクセスでき、クラスター、モニター、OSD、プール、またはネットワークの状態に関するメトリックおよびグラフを多数提供します。
Red Hat Ceph Storage のこれまでのリリースでは、監視データは collectd プラグインを介して提供され、これにより、データを Graphite 監視ユーティリティーのインスタンスに送信されました。Red Hat Ceph Storage 3.3 以降、監視データは ceph-mgr Prometheus プラグインを使用して ceph-mgr デーモンから直接取得されます。
監視データソースとして Prometheus が導入されたことで、Red Hat Ceph Storage Dashboard ソリューションのデプロイメントと操作管理が簡素化され、全体的なハードウェア要件も軽減されました。Ceph モニタリングデータを直接適用することで、Red Hat Ceph Storage Dashboard ソリューションはコンテナーにデプロイされる Ceph クラスターをよりよくサポートできるようになりました。
アーキテクチャーにおけるこの変更により、監視データの Red Hat Ceph Storage 2.x および 3.0 から Red Hat Ceph Storage 3.3 への移行パスはありません。
Red Hat Ceph Storage Dashboard は、以下のユーティリティーを使用します。
- デプロイメント用の Ansible 自動化アプリケーション。
-
埋め込み Prometheus
ceph-mgrプラグイン。 -
ストレージクラスターの各ノードで実行される Prometheus
node-exporterデーモン。 - ユーザーインターフェースおよびアラートを提供する Grafana プラットフォーム。
Red Hat Ceph Storage Dashboard は以下の機能をサポートします。
- 一般機能
- Red Hat Ceph Storage 3.1 以降のサポート
- SELinux サポート
- FileStore および BlueStore OSD バックエンドのサポート
- 暗号化された OSD および暗号化されていない OSD のサポート
- Monitor、OSD、Ceph Object Gateway、および iSCSI ロールのサポート
- Metadata Servers (MDS) の初期サポート
- ドリルダウンおよびダッシュボードのリンク
- 15 秒の粒度
- ハードディスクドライブ (HDD)、ソリッドステートドライブ (SSD)、Non-volatile Memory Express (NVMe) インターフェース、Intel® Cache Acceleration Software (Intel® CAS) のサポート
- ノードメトリクス
- CPU および RAM の使用状況
- ネットワーク負荷
- 設定可能なアラート
- OOB (Out-of-Band) アラートおよびトリガー
- インストール時に通知チャネルが自動的に定義される
デフォルトで作成された Ceph Health Summary ダッシュボード
詳細は、「Red Hat Ceph Storage Dashboard Alerts」セクションを参照してください。
- クラスターの概要
- OSD 設定概要
- OSD FileStore および BlueStore の概要
- ロール別のクラスターバージョンの内訳
- ディスクサイズの概要
- 容量およびディスク数によるホストサイズ
- 配置グループ (PG) の状況内訳
- プール数
- HDD vs などのデバイスクラスの概要SSD
- クラスターの詳細
-
クラスターフラグの状況 (
noout、nodownなど) -
OSD または Ceph Object Gateway ホストの
upおよびdownステータス - プールごとの容量使用度
- Raw 容量の使用状況
- アクティブなスクラブおよびリカバリープロセスのインジケーター
- 増加の追跡および予想 (raw 容量)
-
OSD ホストおよびディスクを含む、
downまたはnear fullの OSD に関する情報 - OSD ごとの PG の分散
- 使用過剰または使用不足の OSD を強調するための PG 数別の OSD
-
クラスターフラグの状況 (
- OSD のパフォーマンス
- 1 秒あたりの I/O 操作に関する情報 (IOPS) およびプール別のスループット
- OSD パフォーマンスインジケーター
- OSD ごとのディスク統計
- クラスター全体のディスクスループット
- 読み取り/書き込み比率 (クライアント IOPS)
- ディスク使用率ヒートマップ
- Ceph ロールによるネットワーク負荷
- Ceph Object Gateway の詳細
- 集約された負荷ビュー
- ホストごとのレイテンシーとスループット
- HTTP 操作によるワークロードの内訳
- Ceph iSCSI Gateway の詳細
- 集約ビュー
- 設定
- パフォーマンス
- Gateway ごとのリソース使用度
- クライアントごとの負荷および設定
- Ceph Block Device 別のイメージパフォーマンス
3.3.2. Red Hat Ceph Storage Dashboard のインストール
Red Hat Ceph Storage Dashboard は、実行中の Ceph Storage Cluster のさまざまなメトリックを監視するビジュアルダッシュボードを提供します。
Red Hat Ceph Storage Dashboard のアップグレードに関する情報は、『Installation Guide for Red Hat Enterprise Linux』の「Upgrading Red Hat Ceph Storage Dashboard」を参照してください。
前提条件
- ストレージクラスターノードは Red Hat Enterprise Linux 7 を使用します。
- クラスターノードからデータを受信し、Red Hat Ceph Storage Dashboard を提供する別のノードである Red Hat Ceph Storage Dashboard ノード。
Red Hat Ceph Storage Dashboard ノードを準備します。
すべてのノードで Tools リポジトリーを有効にします。
詳細は、Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling the Red Hat Ceph Storage Repositories」セクションを参照してください。
ファイアウォールを使用している場合は、以下の TCP ポートが開いていることを確認します。
表3.1 TCP ポート要件
ポート 使用方法 場所 3000Grafana
Red Hat Ceph Storage Dashboard ノード。
9090基本的な Prometheus グラフ
Red Hat Ceph Storage Dashboard ノード。
9100Prometheus の
node-exporterデーモンすべてのストレージクラスターノード。
9283Ceph データの収集
すべての
ceph-mgrノード。9287Ceph iSCSI ゲートウェイデータ
すべての Ceph iSCSI ゲートウェイノード。
詳細は、Red Hat Enterprise Linux 7『Security Guide』の「Using Firewalls」の章 を参照してください。
手順
Ansible 管理ノードで root ユーザーとして以下のコマンドを実行します。
cephmetrics-ansibleパッケージをインストールします。[root@admin ~]# yum install cephmetrics-ansible
Ceph Ansible インベントリーをベースとして使用し、デフォルトでは
/etc/ansible/hostsにある Ansible インベントリーファイルの[ceph-grafana]セクションに Red Hat Ceph Storage Dashboard ノードを追加します。[ceph-grafana] $HOST_NAME
以下を置き換えます。
-
$HOST_NAMEは、Red Hat Ceph Storage Dashboard ノードの名前に置き換えます。
以下に例を示します。
[ceph-grafana] node0
-
/usr/share/cephmetrics-ansible/ディレクトリーに移動します。[root@admin ~]# cd /usr/share/cephmetrics-ansible
Ansible Playbook を実行します。
[root@admin cephmetrics-ansible]# ansible-playbook -v playbook.yml
重要MON または OSD ノードを追加するなど、クラスター設定を更新するたびに、
cephmetricsAnsible Playbook を再実行する必要があります。注記cephmetricsAnsible Playbook は以下のアクションを実行します。-
ceph-mgrインスタンスを更新して、prometheus プラグインを有効にし、TCP ポート 9283 を開きます。 Prometheus
node-exporterデーモンをストレージクラスターの各ノードにデプロイします。- TCP ポート 9100 を開きます。
-
node-exporterデーモンを起動します。
Grafana および Prometheus コンテナーを、Red Hat Ceph Storage Dashboard ノードの Docker/systemd 下にデプロイします。
- Prometheus は、ceph-mgr ノードおよび各 ceph ホストで稼働している node-exporters からデータを収集するように設定されます。
- TCP ポート 3000 を開きます。
- ダッシュボード、テーマ、およびユーザーアカウントはすべて Grafana に作成されます。
- 管理者の Grafana の URL を出力します。
-
3.3.3. Red Hat Ceph Storage Dashboard へのアクセス
Red Hat Ceph Storage Dashboard にアクセスすると、Red Hat Ceph Storage クラスターを管理する Web ベースの管理ツールにアクセスできます。
前提条件
- Red Hat Ceph Storage Dashboard のインストール。
- ノードが適切に同期されない場合に Ceph Storage Dashboard ノード、クラスターノード、およびブラウザーとの間でタイムラグが発生する可能性があるため、NTP がクロックを正しく同期していることを確認してください。Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Configuring the Network Time Protocol for Red Hat Ceph Storage」または「Ubuntu」を参照してください。
手順
Web ブラウザーに以下の URL を入力します。
http://$HOST_NAME:3000
以下を置き換えます。
-
$HOST_NAMEは、Red Hat Ceph Storage Dashboard ノードの名前に置き換えます。
以下に例を示します。
http://cephmetrics:3000
-
adminユーザーのパスワードを入力します。インストール時にパスワードを設定しなかった場合は、デフォルトのパスワードであるadminを使用します。ログインすると、Ceph At a Glance ダッシュボードに自動的に配置されます。Ceph At a Glance ダッシュボードは、ハイレベルの容量の概要、パフォーマンス、およびノードレベルのパフォーマンス情報を提供します。
例
関連情報
- 『Red Hat Ceph Storage Administration Guide』の「Changing the Default Red Hat Ceph Storage Dashboard Password」セクションを参照してください。
3.3.4. デフォルトの Red Hat Ceph Storage ダッシュボードパスワードの変更
Red Hat Ceph Storage Dashboard にアクセスするためのデフォルトのユーザー名およびパスワードは admin および admin に設定されます。セキュリティー上の理由から、インストール後にパスワードを変更する必要がある場合があります。
パスワードをデフォルト値にリセットしないようにするには、/usr/share/cephmetrics-ansible/group_vars/all.yml ファイルでカスタムパスワードを更新します。
手順
- 左上隅の Grafana アイコンをクリックします。
-
パスワードを変更するユーザー名の上にカーソルを合わせます。この場合、
adminになります。 -
Profileをクリックします。 -
Change Passwordをクリックします。 -
新しいパスワードを 2 回入力し、
Change Passwordをクリックします。
その他のリソース
- パスワードを忘れた場合は、Grafana Web ページの「Reset admin password」の手順に従います。
3.3.5. Red Hat Ceph Storage の Prometheus プラグイン
ストレージ管理者は、パフォーマンスデータを収集し、Red Hat Ceph Storage Dashboard の Prometheus プラグインモジュールを使用してそのデータをエクスポートしてから、このデータでクエリーを実行できます。Prometheus モジュールにより、ceph-mgr は Ceph 関連の状態およびパフォーマンスデータを Prometheus サーバーに公開することができます。
3.3.5.1. 前提条件
- Red Hat Ceph Storage 3.1 以降を稼働している。
- Red Hat Ceph Storage Dashboard のインストール。
3.3.5.2. Prometheus プラグイン
Prometheus プラグインは、ceph-mgr のコレクションポイントから Ceph パフォーマンスカウンターに渡すためのエクスポーターを提供します。Red Hat Ceph Storage Dashboard は、Ceph Monitors や OSD などのすべての MgrClient プロセスから MMgrReport メッセージを受信します。歳簿のサンプル数の循環バッファーには、パフォーマンスカウンタースキーマデータと実際のカウンターデータが含まれます。このプラグインは HTTP エンドポイントを作成し、ポーリング時にすべてのカウンターの最新サンプルを取得します。HTTP パスおよびクエリーパラメーターは無視され、すべてのレポートエンティティーのすべての現存カウンターはテキスト表示形式で返されます。
関連情報
- テキスト表示形式についての詳細は、Prometheus ドキュメントを参照してください。
3.3.5.3. Prometheus 環境の管理
Prometheus を使用して Ceph ストレージクラスターを監視するには、Prometheus エクスポーターを設定および有効にし、Ceph ストレージクラスターに関するメタデータ情報を収集できるようにします。
前提条件
- 稼働中の Red Hat Ceph Storage 3.1 クラスター
- Red Hat Ceph Storage Dashboard のインストール
手順
rootユーザーとして、/etc/prometheus/prometheus.ymlファイルを開いて編集します。globalセクションで、scrape_intervalおよびevaluation_intervalオプションを 15 秒に設定します。例
global: scrape_interval: 15s evaluation_interval: 15s
scrape_configsセクションの下にhonor_labels: trueオプションを追加し、ceph-mgrノードごとにtargetsオプションおよびinstanceオプションを編集します。例
scrape_configs: - job_name: 'node' honor_labels: true static_configs: - targets: [ 'node1.example.com:9100' ] labels: instance: "node1.example.com" - targets: ['node2.example.com:9100'] labels: instance: "node2.example.com"注記honor_labelsオプションを使用すると、Ceph は Ceph Storage クラスターの任意のノードに関連する適切にラベル付けされたデータを出力できます。これにより、Prometheus が上書きせずに Ceph は適切なinstanceラベルをエクスポートできます。新規ノードを追加するには、以下の形式で
targetsオプションおよびinstanceオプションを追加します。例
- targets: [ 'new-node.example.com:9100' ] labels: instance: "new-node"注記instanceラベルは、Ceph の OSD メタデータのinstanceフィールドに表示されるノードの短いホスト名と一致する必要があります。これにより、Ceph 統計をノードの統計と関連付けるのに役立ちます。
以下の形式で、Ceph ターゲットを
/etc/prometheus/ceph_targets.ymlファイルに追加します。例
[ { "targets": [ "cephnode1.example.com:9283" ], "labels": {} } ]Prometheus モジュールを有効にします。
# ceph mgr module enable prometheus
3.3.5.4. Prometheus expression browser の使用
組み込みの Prometheus expression browser を使用して、収集したデータに対してクエリーを実行します。
前提条件
- 稼働中の Red Hat Ceph Storage 3.1 クラスター
- Red Hat Ceph Storage Dashboard のインストール
手順
Web ブラウザーで Prometheus の URL を入力します。
http://$DASHBOARD_SEVER_NAME:9090/graph
以下を置き換えます。
-
$DASHBOARD_SEVER_NAMEは、Red Hat Ceph Storage Dashboard サーバーの名前に置き換えます。
-
Graph をクリックして、クエリーウィンドウにクエリーを入力または貼り付けし、Execute ボタンを押します。
- コンソールウィンドウの結果を確認します。
- Graph をクリックしてレンダリングされたデータを表示します。
関連情報
- 詳細は、Prometheus Web サイトの Prometheus expression browser ドキュメントを参照してください。
3.3.5.5. Prometheus データおよびクエリーの使用
統計名は Ceph の名前と同じで、無効な文字がアンダースコアに変換され、すべての名前の先頭に ceph_ が付きます。すべての Ceph デーモン統計には、ceph_daemon ラベルがあります。そのラベルからデーモンのタイプと ID を識別します (例:osd.123)。統計情報の中には、異なる種類のデーモンから得られるものもあるため、クエリを実行するときには、Ceph Monitorと RocksDB の統計情報が混ざらないように、osd で始まる Ceph デーモンに絞り込む必要があります。グローバル Ceph ストレージクラスター統計には、レポート対象に応じたラベルが付けられています。たとえば、プールに関連するメトリクスには pool_id ラベルが付けられます。コア Ceph のヒストグラムを表す長期的な平均値は、sum と count のパフォーマンスメトリクスのペアで表されます。
以下のクエリーの例は、Prometheus expression browser で使用できます。
OSD の物理ディスク使用状況を表示
(irate(node_disk_io_time_ms[1m]) /10) and on(device,instance) ceph_disk_occupation{ceph_daemon="osd.1"}
オペレーティングシステムから見た OSD の物理的な IOPS を表示
irate(node_disk_reads_completed[1m]) + irate(node_disk_writes_completed[1m]) and on (device, instance) ceph_disk_occupation{ceph_daemon="osd.1"}
プールおよび OSD メタデータシリーズ
特定のメタデータフィールドの表示とクエリーを可能にするために、特別なデータシリーズが出力されます。プールには、以下の例のような ceph_pool_metadataフィールドがあります。
ceph_pool_metadata{pool_id="2",name="cephfs_metadata_a"} 1.0
OSD には、以下の例のような ceph_osd_metadataフィールドがあります。
ceph_osd_metadata{cluster_addr="172.21.9.34:6802/19096",device_class="ssd",ceph_daemon="osd.0",public_addr="172.21.9.34:6801/19096",weight="1.0"} 1.0node_exporter でのドライブ統計の相関
Ceph からの Prometheus 出力は、Prometheus ノードエクスポーターからの汎用ノードモニタリングと併せて使用するように設計されています。Ceph OSD 統計値と汎用ノード監視ドライブ統計値を相関させると、以下の例のような特別なデータシリーズが出力されます。
ceph_disk_occupation{ceph_daemon="osd.0",device="sdd", exported_instance="node1"}
OSD ID でディスクの統計を取得するには、Prometheus クエリーの and 演算子またはアスタリスク (*) 演算子を使用します。すべてのメタデータメトリクスの値は 1 であるため、アスタリスク演算子で中立になります。アスタリスク演算子を使用すると、group_left および group_right グループ化修飾子を使用することができ、結果として得られるメトリックに、クエリの一方から追加ラベルが付けられます。以下に例を示します。
rate(node_disk_bytes_written[30s]) and on (device,instance) ceph_disk_occupation{ceph_daemon="osd.0"}label_replace の使用
label_replace 関数は、クエリのメトリックにラベルを追加したり、ラベルを変更したりすることができます。OSDとそのディスクの書き込み率を相関させるには、次のようなクエリーを使用できます。
label_replace(rate(node_disk_bytes_written[30s]), "exported_instance", "$1", "instance", "(.*):.*") and on (device,exported_instance) ceph_disk_occupation{ceph_daemon="osd.0"}関連情報
- クエリー作成についての詳細は、Prometheus「querying basics」を参照してください。
-
詳細は、Prometheus の
label_replaceドキュメントを参照してください。
3.3.5.6. 関連情報
3.3.6. Red Hat Ceph Storage Dashboard アラート
本項では、Red Hat Ceph Storage Dashboard でのアラートについて説明します。
- Red Hat Ceph Storage Dashboard のアラートの詳細は、「アラートについて」 を参照してください。
- アラートを表示するには、「Alert Status ダッシュボードへのアクセス」 を参照してください。
- 通知ターゲットを設定するには、「通知ターゲットの設定」 を参照してください。
- デフォルトのアラートを変更したり、新規のアラートを追加するには、「デフォルトアラートの変更および新規アラートの追加」 を参照してください。
3.3.6.1. 前提条件
3.3.6.2. アラートについて
Red Hat Ceph Storage Dashboard は、Grafana プラットフォームで提供されるアラートメカニズムをサポートします。メトリクスが特定の値に到達する際に、ダッシュボードが通知を送信するように設定できます。このようなメトリクスは Alert Status ダッシュボードにあります。
デフォルトでは、Alert Status には、Overall Ceph Health、OSDs Down、または Pool Capacity などの特定のメトリクスがすでに含まれています。このダッシュボードに関心のあるメトリクスを追加したり、トリガーの値を変更したりすることができます。
以下は、Red Hat Ceph Storage Dashboard に含まれる事前に定義されたアラートの一覧です。
- Overall Ceph Health
- Disks Near Full (>85%)
- OSD Down
- OSD Host Down
- PG’s Stuck Inactive
- OSD Host Less - Free Capacity Check
- OSD’s With High Response Times
- Network Errors
- Pool Capacity High
- Monitors Down
- Overall Cluster Capacity Low
- OSDs With High PG Count
3.3.6.3. Alert Status ダッシュボードへのアクセス
Red Hat Ceph Storage Dashboard の特定のアラートは、Alert Status ダッシュボードでデフォルトで設定されます。ここでは、そのアクセス方法を 2 つ紹介します。
手順
ダッシュボードにアクセスするには、以下を行います。
- メインの At the Glance Dashboard で、右上隅の Active Alerts パネルをクリックします。
または以下を行います。
- Grafana アイコンの横にある左上隅のダッシュボードメニューをクリックします。Alert Status を選択します。
3.3.6.4. 通知ターゲットの設定
cephmetrics と呼ばれる通知チャンネルはインストール時に自動的に作成されます。事前設定されているアラートはすべて cephmetrics チャネルを参照しますが、アラートを受け取る前に、必要な通知タイプを選択して通知チャネル定義を完了します。Grafana プラットフォームは、メール、Slack、PagerDuty などのさまざまな通知タイプをサポートします。
手順
- 通知チャネルを設定するには、Grafana Web ページの Alert Notifications セクションの手順に従います。
3.3.6.5. デフォルトアラートの変更および新規アラートの追加
ここでは、すでに設定されているアラートのトリガー値を変更する方法と、Alert Status ダッシュボードに新しいアラートを追加する方法について説明します。
手順
アラートのトリガー値を変更したり、新しいアラートを追加したりするには、Grafana Webページの「Alerting Engine & Rules Guide」に従います。
重要カスタムアラートを上書きしないようにするため、トリガーの値を変更したり、新しいアラートを追加したりするときに、Red Hat Ceph Storage Dashboard パッケージをアップグレードしても、Alert Status ダッシュボードは更新されません。
関連情報
3.4. ceph-medic を使用した Ceph Storage クラスターの診断
ceph-medic ユーティリティーは、実行中の Ceph Storage クラスターに対してチェックを実行し、潜在的な問題を特定します。
ceph-medics ユーティリティー (例: チェック):
- ファイルおよびディレクトリーの正しい所有権
-
ストレージクラスターのすべてのノードで
fsidが同じかどうか - キーリングの秘密鍵がストレージクラスターの他のノードと異なるかどうか
3.4.1. 前提条件
- 稼働中の Red Hat Ceph Storage クラスター
-
ストレージノードへの SSH および
sudoアクセス
3.4.2. ceph-medic ユーティリティーのインストール
前提条件
- Red Hat Ceph Storage 3 ソフトウェアリポジトリーへのアクセス
手順
root ユーザーとして、Ansible 管理ノードで以下の手順を実行します。
ceph-medicパッケージをインストールします。[root@admin ~]# yum install ceph-medic
ceph-medicのインストールを確認します。[root@admin ~]# ceph-medic --help
関連情報
- Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling the Red Hat Ceph Storage Repositories」
3.4.3. 診断チェックの実行
Ceph Storage Cluster の潜在的な問題をチェックする基本的な検査。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
-
ストレージノードへの SSH および
sudoアクセス
手順
通常ユーザーとして、Ansible 管理ノードで以下の手順を実行します。
ceph-medic checkコマンドを使用します。[admin@admin ~]$ ceph-medic check Host: mon0 connection: [connected ] Host: mon1 connection: [connected ] Host: mon2 connection: [connected ] Host: osd0 connection: [connected ] Host: osd1 connection: [connected ] Host: osd2 connection: [connected ] Collection completed! ======================= Starting remote check session ======================== Version: 1.0.2 Cluster Name: "example" Total hosts: [6] OSDs: 3 MONs: 3 Clients: 0 MDSs: 0 RGWs: 0 MGRs: 0 ================================================================================ ------------ osds ------------ osd0 osd1 osd2 ------------ mons ------------ mon0 mon1 mon2 17 passed, 0 errors, on 6 hosts
関連情報
-
付録A
ceph-medicのエラーコード定義 - Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling Passwordless SSH for Ansible」
3.4.4. カスタムインベントリーファイルの使用
ceph-medic ユーティリティーは、ストレージクラスタートポロジーを認識している必要があります。デフォルトでは、ceph-medic は Ansible インベントリーファイル (/etc/ansible/hosts) を使用してノードを検出します。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
-
ストレージノードへの SSH および
sudoアクセス
手順
カスタムのインベントリーファイルを使用するには、Ansible 管理ノードで、ユーザーとして以下の手順を実行します。
カスタム
hostsファイルを作成します。[admin@admin ~]$ touch ~/example/hosts
hostsファイルを開いて編集します。適切なノードグループタイプの下に、ストレージクラスターのノードを追加します。ceph-medicツールは、mons、osds、rgws、mdss、mgrs、およびclientsノードグループタイプをサポートします。以下に例を示します。
[mons] mon0 mon1 mon2 [osds] osd0 osd1 osd2
診断チェックを行う場合は、カスタムインベントリーファイルを指定するには、
--inventoryオプションを使用します。ceph-medic --inventory $PATH_TO_HOSTS_FILE check
- 置き換え
$PATH_TO_HOSTS_FILEをhostsファイルへの完全パスに置き換えます。以下に例を示します。
[admin@admin ~]$ ceph-medic --inventory ~/example/hosts check
関連情報
-
付録A
ceph-medicのエラーコード定義 - Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling Passwordless SSH for Ansible」
3.4.5. カスタムロギングパスの設定
ceph-medic ログファイルには、端末のコマンドの出力よりも多くの詳細が含まれています。ceph-medic ツールはデフォルトで、現在の作業ディレクトリーにログを書き込みます。
前提条件
- 稼働中の Red Hat Ceph Storage クラスター
-
ストレージノードへの SSH および
sudoアクセス
手順
これらのログが書き込まれる場所を変更するには、Ansible 管理ノードで通常のユーザーとして以下の手順を実行します。
-
~/.cephmedic.confファイルを開いて編集します。 --log-pathオプションを、.からカスタムログの場所に変更します。以下に例を示します。
--log-path = /var/log/ceph-medic/
関連情報
-
付録A
ceph-medicのエラーコード定義 - Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』の「Enabling Passwordless SSH for Ansible」
第4章 オーバーライド
デフォルトでは、Ceph は OSD の現在の状態を反映し、リバランス、リカバリ、スクラビングなどの通常の操作を行います。場合によっては、Ceph のデフォルトの動作をオーバーライドすると有益なことがあります。
4.1. オーバーライドの設定と設定解除
Ceph のデフォルトの動作を上書きするには、ceph osd set コマンドおよび上書きする動作を使用します。以下に例を示します。
# ceph osd set <flag>
動作を設定したら、ceph health には、クラスターに設定したオーバーライドが反映されます。
Ceph のデフォルトの動作を上書きするには、ceph osd unset コマンドおよび停止するオーバーライドを使用します。以下に例を示します。
# ceph osd unset <flag>
| フラグ | 詳細 |
|---|---|
|
|
OSD が、クラスター |
|
|
OSD が、クラスター |
|
|
OSD が |
|
|
OSD が |
|
|
クラスターが |
|
|
Ceph は読み取り操作および書き込み操作の処理を停止しますが、ステータスの OSD のステータス |
|
| Ceph により、新しいバックフィルの操作が回避されます。 |
|
| Ceph により、新たなリバランス操作が回避されます。 |
|
| Ceph により、新たなリカバリー操作が回避されます。 |
|
| Ceph は新規スクラビングの操作を回避します。 |
|
| Ceph は、新たな深層スクラブ作業を行いません。 |
|
| Ceph は、フラッシュし、エビクトするコールド/ダーティーオブジェクトを検索するプロセスを無効にします。 |
4.2. 使用例
-
noin: フラッピング OSD に対応するために、多くの場合nooutと一緒に使用されます。 -
noout:mon osd report timeoutを超え、OSD がモニターに報告されていない場合には、OSD はoutとマークされます。誤って発生する場合は、問題のトラブルシューティング中に OSD がoutとマークされないようにnooutを設定できます。 -
noup: 一般的に、nodownで使用され、フラグッピング OSD に対応します。 -
nodown: ネットワークの問題が Ceph の「heartbeat」プロセスが中断する可能性があり、OSD がupにある可能性がありますが、down をマークされる場合もあります。nodownを設定すると、問題のトラブルシューティング中に OSD が down をマークされないようにできます。 -
full: クラスターがfull_ratioに到達する場合は、事前にクラスターをfullに設定し、容量を拡張することができます。注記: クラスターをfullに設定すると書き込み操作ができなくなります。 -
pause: クライアントがデータの読み取りおよび書き込みを行わずに実行中の Ceph クラスターをトラブルシューティングする必要がある場合は、クライアントの操作を防ぐためにクラスターを一時停止するように設定できます。 -
nobackfill: OSD またはノードを一時的にdownする必要がある場合 (デーモンのアップグレードなど)、nobackfillを設定して OSD がdown状態である間は Ceph がバックフィルを行わないようにすることができます。 -
norecover: OSD を置き換える必要がえあり、ディスクをホットスワップする間に PG を別の OSD に復元しないようする場合は、他の OSD のセットが他の OSD に新しいセットをコピーしないように、norecoverも設定できます。 -
noscrubおよびnodeep-scrubb: スクラビングの発生を防ぐには (例: 高負荷、リカバリー、バックフィル、リバランス中にオーバヘッドを軽減する)、noscrubとnodeep-scrubのいずれかまたは両方を設定して、クラスターが OSD をスクラビングしないようにすることができます。 -
notieragent: 階層エージェントプロセスで、バッキングストレージ層にコールドオブジェクトを検索しないようにするには、notieragentを設定する可能性があります。
第5章 ユーザー管理
本項では、Ceph クライアントユーザーと、 Red Hat Ceph Storage クラスターを使用した認証および承認について説明します。ユーザーは、Ceph クライアントを使用して Red Hat Ceph Storage クラスターデーモンと対話する個人またはアプリケーションなどのシステムアクターです。

Ceph が認証および承認が有効な状態 (デフォルトでは有効) で実行された場合には、ユーザー名および指定したユーザーの秘密鍵が含まれるキーリングを指定する必要があります (通常はコマンドラインを使用)。ユーザー名を指定しない場合、Ceph は client.admin 管理ユーザーをデフォルトのユーザー名として使用します。キーリングを指定しない場合には、Ceph 設定の keyring 設定を使用してキーリングを探します。たとえば、ユーザーやキーリングを指定せずに ceph health コマンドを実行する場合は、以下を実行します。
# ceph health
Ceph は以下のようなコマンドを解釈します。
# ceph -n client.admin --keyring=/etc/ceph/ceph.client.admin.keyring health
ユーザー名およびシークレットの再入力を避けるために、CEPH_ARGS 環境変数を使用できます。
Red Hat Ceph Storage クラスターを認証を使用するように設定する方法の詳細は、Red Hat Ceph Storage 3 『Configuration Guide』を参照してください。
5.1. 背景
Ceph クライアントのタイプ (ブロックデバイス、オブジェクトストア、ファイルシステム、ネイティブ API、Ceph コマンドラインなど) に関係なく、Ceph はすべてのデータをプール内のオブジェクトとして保存します。データの読み取りおよび書き込みを行うには、Ceph ユーザーはプールにアクセスできる必要があります。また、管理用 Ceph ユーザーには、Ceph の管理コマンドを実行するパーミッションが必要です。以下の概念は、Ceph ユーザー管理を理解するのに役立ちます。
5.1.1. ユーザー
Red Hat Ceph Storage クラスターのユーザーは、個人またはアプリケーションなどのシステムアクターです。ユーザーを作成すると、ストレージクラスター、そのプール、およびプール内のデータにアクセスできる対象を制御できます。
Ceph の概念にはユーザーの タイプ があります。ユーザー管理の目的で、タイプは常に client になります。Cephは、ピリオド (.) で区切られたユーザータイプとユーザーID で構成される形式でユーザーを識別します (例: TYPE.ID、client.admin、または client.user1)。ユーザーの入力は、Ceph Monitor および OSD も Cephx プロトコルを使用しますが、それらはクライアントではないために必要になります。ユーザータイプの分類することにより、クライアントユーザーと他のユーザーを区別でき、アクセス制御、ユーザーの監視および追跡可能性をさらに単純化します。
Ceph コマンドラインを使用すると、コマンドラインでの使用に応じて、タイプを使用せずにユーザーを指定できるため、Ceph のユーザータイプが混乱する場合があります。--user または --id を指定した場合は、タイプを省略できます。そのため、client.user1 は user1 として簡単に入力できます。--name または -n を指定する場合は、client.user1 などのタイプおよび名前を指定する必要があります。ベストプラクティスとして、可能な限りタイプと名前を使用することが推奨されます。
Red Hat Ceph Storage クラスターのユーザーは、Ceph Object Storage のユーザーとは異なります。オブジェクトゲートウェイは、ゲートウェイデーモンとストレージクラスター間の通信に Red Hat Ceph Storage クラスタユーザーを使用しますが、ゲートウェイにはエンドユーザーのための独自のユーザー管理機能があります。
5.1.2. 承認 (機能)
Ceph では、認証されたユーザーがモニターおよび OSD の機能を実行するために行う承認を「capabilities」(caps) という用語を使用して表現しています。ケイパビリティーは、プール内のデータやプール内の namespace へのアクセスを制限することもできます。ユーザーを作成または更新する際に、Ceph 管理ユーザーはユーザーのケイパビリティーを設定します。
ケイパビリティーの構文は以下の形式に従います。
<daemon_type> 'allow <capability>' [<daemon_type> 'allow <capability>']
Monitor Caps: モニターのケイパビリティーには、
r、w、x、allow profile <cap>、およびprofile rbdがあります。以下に例を示します。mon 'allow rwx` mon 'allow profile osd'
OSD Caps: OSD ケイパビリティーには、
r、w、x、class-read、class-write、profile osd、profile rbd、およびprofile rbd-read-onlyがあります。さらに OSD ケイパビリティーは、プールおよび namespace の設定も許可します。osd 'allow <capability>' [pool=<pool_name>] [namespace=<namespace_name>]
Ceph Object Gateway デーモン (radosgw) は Ceph Storage Cluster のクライアントであるため、Ceph Storage Cluster のデーモンタイプとしては表示されません。
以下のエントリーは、それぞれのケイパビリティーについて説明します。
|
| デーモンのアクセス設定の前に使用してください。 |
|
| ユーザーに読み取り権限を付与します。CRUSH マップを取得するためにモニターで必要です。 |
|
| ユーザーがオブジェクトへの書き込みアクセス権を付与します。 |
|
|
クラスメソッド (読み取りおよび書き込みの両方) をユーザーに呼び出し、モニターで |
|
|
クラスの読み取りメソッドを呼び出すケイパビリティーを提供します。 |
|
|
クラスの書き込みメソッドを呼び出すケイパビリティーを提供します。 |
|
| 特定のデーモンまたはプールに対する読み取り、書き込み、実行のパーミッション、および admin コマンドの実行権限をユーザーに付与します。 |
|
| OSD として他の OSD またはモニターに接続するためのパーミッションをユーザーに付与します。OSD がレプリケーションのハートビートトラフィックおよびステータス報告を処理できるようにするために OSD に付与されました。 |
|
| OSD のブートストラップ時にキーを追加するパーミッションを持つように、OSD をブートストラップするユーザーパーミッションを付与します。 |
|
| ユーザーに、Ceph ブロックデバイスへの読み取り/書き込み権限を付与します。 |
|
| ユーザーに、Ceph ブロックデバイスへの読み取り専用アクセスを付与します。 |
5.1.3. プール
プールは Ceph クライアントのストレージストラテジーを定義し、そのストラテジーの論理パーティションとして機能します。
Ceph デプロイメントでは、さまざまなタイプのユースケース (クラウドボリューム/イメージ、オブジェクトストレージ、ホットストレージ、コールドストレージなど) をサポートするプールを作成するのが一般的です。OpenStack のバックエンドとして Ceph をデプロイする場合、標準的なデプロイメントにはボリューム、イメージ、バックアップと、client.glance、client.cinder などユーザーのプールが含まれます。
5.1.4. 名前空間
プール内のオブジェクトは、プール内のオブジェクトの論理グループである namespace に関連付けることができます。ユーザーのプールへのアクセスは、ユーザーによる読み書きが名前空間内でのみ行われるように、その名前空間と関連付けることができます。プール内の名前空間に書き込まれたオブジェクトには、その名前空間にアクセスできるユーザーのみがアクセスできます。
現在、名前空間は、librados に記述されたアプリケーションにのみ役立ちます。ブロックデバイスやオブジェクトストレージなどの Ceph クライアントでは、この機能は現在サポートされていません。
名前空間の合理的な理由は、各プールが OSD にマッピングされる配置グループのセットを作成するため、プールはユースケース別にデータを分離するために計算量の多い方法になる可能性があるからです。複数のプールが同じ CRUSH 階層とルールセットを使用する場合、OSD のパフォーマンスは負荷の増加に応じて低下する可能性があります。
たとえば、プールには、OSD ごとに約 100 個の配置グループが必要です。そのため、1000 個 の OSD を持つ模範的なクラスタは、1 つのプールに対して 10 万個の配置グループを持つことになります。同じ CRUSH 階層とルールセットにマップされた各プールは、例示的なクラスターにさらに 10 万の配置グループを作成します。一方、namespace にオブジェクトを書き込むと、別のプールの計算オーバーヘッドを排除して、namespace をオブジェクト名に関連付けられます。ユーザーまたはユーザーセットに個別のプールを作成するのではなく、名前空間を使用できます。
現時点では、librados のみを使用できます。
5.2. ユーザーの管理
ユーザー管理機能により、システム管理者は Red Hat Ceph Storage クラスターのユーザーを作成、更新、削除することができます。
Red Hat Ceph Storage クラスターでユーザーを作成または削除する場合、キーをクライアントに配布して、キーリングに追加する必要がある場合があります。詳細は、「Keyring Management」を参照してください。
5.2.1. ユーザーの一覧表示
ストレージクラスターのユーザーを一覧表示するには、以下を実行します。
# ceph auth list
Ceph はストレージクラスター内の全ユーザーを一覧表示します。例えば、2 ノードの例示的なストレージクラスタでは、ceph auth list は以下のようなものを出力します。
installed auth entries:
osd.0
key: AQCvCbtToC6MDhAATtuT70Sl+DymPCfDSsyV4w==
caps: [mon] allow profile osd
caps: [osd] allow *
osd.1
key: AQC4CbtTCFJBChAAVq5spj0ff4eHZICxIOVZeA==
caps: [mon] allow profile osd
caps: [osd] allow *
client.admin
key: AQBHCbtT6APDHhAA5W00cBchwkQjh3dkKsyPjw==
caps: [mds] allow
caps: [mon] allow *
caps: [osd] allow *
client.bootstrap-mds
key: AQBICbtTOK9uGBAAdbe5zcIGHZL3T/u2g6EBww==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-osd
key: AQBHCbtT4GxqORAADE5u7RkpCN/oo4e5W0uBtw==
caps: [mon] allow profile bootstrap-osd
ユーザーの TYPE.ID 記法が適用され、osd.0 は osd 型のユーザーでその ID は 0、client.admin は client 型のユーザーでその ID は admin、つまりデフォルトの client.admin ユーザーとなることに注意してください。また、各エントリーには key: <value> エントリーがあり、1 つ以上の caps: エントリーがあることに注意してください。
ceph auth list で -o <file_name> オプションを使用して、出力をファイルに保存できます。
5.2.2. ユーザーの取得
特定のユーザー、キーおよびケイパビリティーを取得するには、以下を実行します。
構文
# ceph auth get <TYPE.ID>
例
# ceph auth get client.admin
また、ceph auth get に -o <file_name> オプションを使用して、出力をファイルに保存することもできます。開発者は以下を実行することもできます。
構文
# ceph auth export <TYPE.ID>
例
# ceph auth export client.admin
auth export コマンドは、auth get と同じですが、エンドユーザーとは無関係な内部 auid も出力します。
5.2.3. ユーザーの追加
ユーザーを追加すると、ユーザー名 (つまり TYPE.ID)、シークレットキー、およびユーザーの作成に使用するコマンドに含まれるケイパビリティー) が作成されます。
ユーザーのキーにより、ユーザーは Ceph Storage Cluster との認証を行うことができます。ユーザーのケイパビリティーにより、Ceph モニター (mon)、Ceph OSD (osd)、または Ceph Metadata Server (mds) での読み取り、書き込み、実行を承認します。
ユーザーを追加する方法はいくつかあります。
-
ceph auth add: このコマンドは、ユーザーを追加する正規の方法になります。ユーザーを作成し、キーを生成し、指定の機能を追加します。 -
ceph auth get-or-create: ユーザー名 (括弧内) とキーを持つキーファイルの形式を返すため、このコマンドはユーザーを作成する最も便利な方法です。ユーザーがすでに存在する場合、このコマンドは単にキーファイル形式でユーザー名およびキーを返します。-o <file_name>オプションを使用して、出力をファイルに保存できます。 -
ceph auth get-or-create-key: このコマンドはユーザーを作成し、ユーザーのキーのみを返す便利な方法です。これは、鍵のみを必要とするクライアント (例:libvirt) に役立ちます。ユーザーがすでに存在する場合は、このコマンドが単にキーを返します。-o <file_name>オプションを使用して、出力をファイルに保存できます。
クライアントユーザーの作成時に、ケイパビリティーのないユーザーを作成できます。クライアントはモニターからクラスターマップを取得できないため、ケイパビリティーのないユーザーには認証以上のことができません。ただし、後で ceph auth caps コマンドを使用してケイパビリティーを追加する場合には、ケイパビリティーがないユーザーを作成することができます。
通常ユーザーは、Ceph OSD における Ceph モニターおよび読み取り/書き込みケイパビリティーにおいて、少なくとも読み取りケイパビリティーを持ちます。また、ユーザーの OSD パーミッションは、多くの場合、特定のプールへのアクセスに制限されます。
# ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' # ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' # ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring # ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
ユーザーに OSD に対するケイパビリティーを提供する場合に、特定のプールへのアクセスを制限しない場合は、ユーザーはクラスター内のすべてのプールにアクセスできるようになります。
5.2.4. ユーザー機能の変更
ceph auth caps コマンドを使用すると、ユーザーを指定でき、ユーザーの機能を変更することができます。ケイパビリティーを追加するには、以下の形式を使用します。
構文
# ceph auth caps <USERTYPE.USERID> <daemon> 'allow [r|w|x|*|...] [pool=<pool_name>] [namespace=<namespace_name>]'
例
# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool' # ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool' # ceph auth caps client.brian-manager mon 'allow *' osd 'allow *'
ケイパビリティーを削除するには、このケイパビリティーをリセットできます。以前に設定した特定のデーモンにユーザーがアクセスできないようにする場合は、空の文字列を指定します。以下に例を示します。
# ceph auth caps client.ringo mon 'allow r' osd ' '
ケイパビリティーに関する追加情報は、「承認 (機能) 」 を参照してください。
5.2.5. ユーザーを削除します。
ユーザーを削除するには、ceph auth del を使用します。
# ceph auth del {TYPE}.{ID}
ここで、{TYPE} は client、osd、mon、または mds のいずれかで、{ID} はユーザー名またはデーモンの ID になります。
5.2.6. ユーザーのキーの出力
ユーザーの認証キーを標準出力に出力するには、以下を実行します。
# ceph auth print-key <TYPE>.<ID>
ここで、<TYPE> は client、osd、mon、または mds のいずれかで、<ID> はユーザー名またはデーモンの ID になります。
ユーザーのキーを出力すると、クライアントソフトウェアにユーザーのキー (例] libvirt) を設定する必要がある場合に便利です。
# mount -t ceph <hostname>:/<mount_point> -o name=client.user,secret=`ceph auth print-key client.user`
5.2.7. ユーザーのインポート
1 つ以上のユーザーをインポートするには、ceph auth import を使用してキーリングを指定します。
構文
# ceph auth import -i </path/to/keyring>
例
# ceph auth import -i /etc/ceph/ceph.keyring
Ceph Storage クラスターは、新規ユーザー、そのキー、それらのケイパビリティーを追加し、既存のユーザー、それらのキー、およびそのケイパビリティーを更新します。
5.3. キーリング管理
Ceph クライアントを使用して Ceph にアクセスすると、Ceph クライアントはローカルキーリングを検索します。Ceph では、以下の 4 つのキーリング名で keyring 設定がデフォルトで事前設定されるので、デフォルトをオーバーライドしたい場合を除き、Ceph 設定ファイルで設定する必要はなく、これは推奨されません。
-
/etc/ceph/$cluster.$name.keyring -
/etc/ceph/$cluster.keyring -
/etc/ceph/keyring -
/etc/ceph/keyring.bin
$cluster メタ変数は、Ceph 設定ファイルの名前で定義されている Ceph ストレージクラスター名です。つまり、ceph.conf はクラスター名が ceph であることを意味するため ceph.keyring になります。$name メタ変数は、ユーザータイプとユーザー ID (例: client.admin) であるため、ceph.client.admin.keyring になります。
/etc/ceph に読み書きするコマンドを実行する場合は、sudo を使用して root でコマンドを実行する必要がある場合があります。
client.ringo などのユーザーを作成したら、そのユーザーが Ceph Storage Cluster にアクセスできるように、鍵を取得して Ceph クライアントのキーリングに追加する必要があります。
Ceph Storage Cluster で直接ユーザーをリストアップ、取得、追加、変更、削除する方法の詳細については、5章ユーザー管理 を参照してください。ただし、Ceph では、Ceph クライアントからキーリングを管理できるようにするための ceph-authtool ユーティリティーも提供されます。
5.3.1. キーリングの作成
Managing Users_ セクションの手順を使用してユーザーを作成した場合、Ceph クライアントが指定されたユーザのキーを取得して Ceph Storage Cluster で認証できるように、ユーザキーを Ceph クライアントに提供する必要があります。Ceph クライアントはキーリングにアクセスしてユーザー名を検索し、ユーザーのキーを取得します。
ceph-authtool ユーティリティーを使用すると、キーリングを作成できます。空のキーリングを作成するには、--create-keyring または -C を使用します。以下に例を示します。
# ceph-authtool --create-keyring /path/to/keyring
複数のユーザーでキーリングを作成する場合は、クラスター名 (例: キーリングファイル名の $cluster.keyring ) を使用して、/etc/ceph/ ディレクトリーに保存することが推奨されます。これにより、keyring 設定のデフォルト設定が Ceph 設定ファイルのローカルコピーで指定しなくてもファイル名を取得するようにします。たとえば、以下のコマンドを実行して ceph.keyring を作成します。
# ceph-authtool -C /etc/ceph/ceph.keyring
1 人のユーザーでキーリングを作成する場合は、クラスター名、ユーザータイプ、およびユーザー名を使用して、/etc/ceph/ ディレクトリーに保存することが推奨されます。たとえば、client.admin ユーザーの場合は ceph.client.admin.keyring です。
/etc/ceph/ でキーリングを作成するには、root として設定する必要があります。これは、そのファイルには root ユーザのみに rw パーミッションが付与されることを意味し、キーリングに管理者キーが含まれている場合にはこれが適切です。ただし、特定のユーザーまたはユーザーグループにキーリングを使用する場合は、chown または chmod を実行して、適切なキーリングの所有権とアクセスを確立するようにしてください。
5.3.2. キーリングへのユーザーの追加
ユーザーを Ceph Storage クラスターに追加する際に、get 手順を使用してユーザー、キー、およびケイパビリティーを取得し、ユーザーをキーリングファイルに保存します。
キーリングごとにユーザーを 1人のみ使用する場合は、-o オプションを指定した Get a User_ 手順で、出力をキーリングファイル形式に保存します。たとえば、client.admin ユーザーのキーリングを作成するには、以下を実行します。
# ceph auth get client.admin -o /etc/ceph/ceph.client.admin.keyring
個々のユーザーに推奨されるファイル形式を使用することに注意してください。
ユーザーをキーリングにインポートする場合には、ceph-authtool を使用して、宛先キーリングとソースキーリングを指定することができます。以下に例を示します。
# ceph-authtool /etc/ceph/ceph.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring
5.3.3. ユーザーの作成
Ceph は、Ceph Storage Cluster で直接ユーザーを作成するための User_ 関数を提供します。ただし、Ceph クライアントキーリングでユーザー、キー、およびケイパビリティーを直接作成することもできます。次に、ユーザーを Ceph Storage クラスターにインポートできます。以下に例を示します。
# ceph-authtool -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' /etc/ceph/ceph.keyring
ケイパビリティーに関する追加情報は、「承認 (機能) 」 を参照してください。
キーリングを作成し、新規ユーザーをキーリングに同時に追加することもできます。以下に例を示します。
# ceph-authtool -C /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx' --gen-key
前述のシナリオでは、新しいユーザー client.ringo はキーリングにのみ使用されます。新規ユーザーを Ceph Storage クラスターに追加するには、Ceph Storage クラスターに新規ユーザーを追加する必要があります。
# ceph auth add client.ringo -i /etc/ceph/ceph.keyring
5.3.4. ユーザーの変更
キーリングでユーザーレコードのケイパビリティーを変更するには、キーリングを指定し、ユーザーがその後のケイパビリティーを指定します。以下に例を示します。
# ceph-authtool /etc/ceph/ceph.keyring -n client.ringo --cap osd 'allow rwx' --cap mon 'allow rwx'
ユーザーを Ceph Storage クラスターに更新するには、キーリングのユーザーを Ceph Storage クラスターのユーザーエントリーに更新する必要があります。
# ceph auth import -i /etc/ceph/ceph.keyring
キーリングからの Ceph Storage Cluster ユーザーの更新に関する詳細は、「ユーザーのインポート」 を参照してください。
また、ストレージクラスターでユーザー機能を直接変更し、結果をキーリングファイルに保存してから、キーリングをメインの ceph.keyring ファイルにインポートすることもできます。
5.4. コマンドラインの使用
Ceph では、ユーザー名およびシークレットについて、以下の用途がサポートされます。
--id | --user
- 説明
-
Ceph は、タイプと ID (例:
TYPE.IDまたはclient.admin、client.user1) のユーザーを識別します。id、name、および-nオプションを使用すると、ユーザー名の ID 部分を指定できます (例:admin、user1、fooなど) 。--idでユーザーを指定し、タイプを省略できます。たとえば、ユーザーclient.fooを指定するには、以下を入力します。
# ceph --id foo --keyring /path/to/keyring health # ceph --user foo --keyring /path/to/keyring health
--name | -n
- 説明
-
Ceph は、タイプと ID (例:
TYPE.IDまたはclient.admin、client.user1) のユーザーを識別します。--nameオプションおよび-nオプションを使用すると、完全修飾ユーザー名を指定できます。ユーザータイプ(通常はclient) をユーザー ID で指定する必要があります。例:
# ceph --name client.foo --keyring /path/to/keyring health # ceph -n client.foo --keyring /path/to/keyring health
--keyring
- 詳細
-
1 つ以上のユーザー名およびシークレットが含まれるキーリングへのパス。
--secretオプションは、同じ機能を提供しますが、別の目的で--secretを使用する Ceph RADOS Gateway では機能しません。ceph auth get-or-createでキーリングを取得して、ローカルに保存する場合があります。キーリングパスを切り替えなくてもユーザー名を切り替えることができるため、これは優先されます。例:
# rbd map foo --pool rbd myimage --id client.foo --keyring /path/to/keyring
5.5. 制限
cephx プロトコルは、Ceph クライアントとサーバーを相互に認証します。これは、人間のユーザの認証や、ユーザに代わって実行されるアプリケーションプログラムを扱うことを意図したものではありません。アクセス制御のニーズの処理に効果が必要な場合は、Ceph オブジェクトストアへのアクセスに使用されるフロントエンドに固有の別のメカニズムが必要です。この他のメカニズムは、Ceph がオブジェクトストアへのアクセスを許可するマシン上で、許容されるユーザーとプログラムのみが実行できるようにする役割を持っています。
Ceph クライアントおよびサーバーの認証に使用される鍵は、通常信頼できるホストの適切なパーミッションを持つプレーンテキストファイルに保存されます。
プレーンテキストファイルにキーを保存するにはセキュリティー上の欠陥がありますが、Ceph がバックグラウンドで使用する基本的な認証方法により、その回避は困難です。Ceph システムを構築する方は、これらの欠点を認識しておく必要があります。
特に、任意のユーザーマシン (特にポータブルマシン) は Ceph と直接対話するように設定することはできません。これは、このようなモードにはセキュアでないマシンにプレーンテキスト認証キーのストレージが必要になるためです。そのマシンを盗んだ者や秘密のアクセス権を得た者は、自分のマシンを Ceph に認証させる鍵を手に入れることができます。
潜在的にセキュアでないマシンが Ceph オブジェクトストアに直接アクセスできるようにするのではなく、目的のために十分なセキュリティーを提供する方法を使用して、環境内の信頼済みマシンにログインする必要があります。信頼されるマシンには、ユーザー用のプレーンテキストの Ceph キーが保存されます。Ceph の今後のバージョンでは、これらの特定の認証に関する問題に対処する場合があります。
現時点では、Ceph 認証プロトコルのいずれの場合でも、転送中のメッセージの機密性は提供されていません。このように、ネットワーク上の盗聴者は、たとえ作成や変更ができなくても、Ceph 内のクライアントとサーバーとの間で送信されるすべてのデータを聞いて理解することができます。Ceph に機密データを保存する場合には、Ceph システムにデータを提供する前に、データを暗号化する必要があります。
例えば、Ceph Object Gateway は S3 API サーバー側暗号化 を提供しており、Ceph Object Gateway クライアントから受け取った未暗号化のデータを暗号化してから Ceph Storage クラスターに保存し、同様に Ceph Storage クラスターから取得したデータを復号してからクライアントに送信します。クライアントと Ceph Object Gateway 間の移行で暗号化を確実に行うために、Ceph Object Gateway は SSL を使用するように設定する必要があります。
第6章 ceph-volume ユーティリティーを使用した OSD のデプロイ
ceph-volume ユーティリティーは、論理ボリュームを OSD としてデプロイするための単一の目的コマンドラインツールです。プラグインタイプのフレームワークを使用して、異なるデバイス技術を持つ OSD をデプロイします。ceph-volume ユーティリティーは、OSD のデプロイに使用する ceph-disk ユーティリティーと同様のワークフローに従います。これは、OSD の準備、アクティブ化、および起動を可能にする予測可能で堅牢な方法です。現在、ceph-volume ユーティリティーは lvm プラグインのみをサポートします。また、今後、その他のテクノロジーをサポートする予定があります。
ceph-disk コマンドは非推奨となりました。
6.1. ceph-volume LVM プラグインの使用
LVMタ グを利用することで、lvm サブコマンドは OSD に関連付けられたデバイスを照会して保存し、再検出できるため、それらをアクティブにすることができます。これには、dm-cache などの lvm ベースのテクノロジーもサポートします。
ceph-volume を使用する場合は、dm-cache の使用は透過的になり、dm-cache は論理ボリュームのように処理されます。dm-cache を使用した場合のパフォーマンスの損益は、特定のワークロードに依存します。一般的に、ランダムおよび連続読み取りは、ブロックサイズが小さいほどパフォーマンスが向上し、ランダムおよび連続書き込みは、ブロックサイズが大きいほどパフォーマンスが低下します。
LVM プラグインを使用するには、lvm をサブコマンドとして ceph-volume コマンドに追加します。
ceph-volume lvm
以下のように lvm サブコマンドには 3 つのサブコマンドがあります。
create サブコマンドを使用すると、prepare および activate サブコマンドが 1 つのサブコマンドに統合されます。詳細は、create サブコマンドのセクションを参照してください。
6.1.1. OSD の準備
prepare サブコマンドは OSD バックエンドオブジェクトストアを準備し、OSD データとジャーナル両方の論理ボリュームを使用します。デフォルトのオブジェクトストレージタイプはありません。オブジェクトストレージタイプには、準備時に --filestore オプションまたは --bluestore オプションのいずれかを設定する必要があります。Red Hat Ceph Storage 3.2 以降、BlueStore オブジェクトストレージタイプのサポートが利用可能になりました。prepare サブコマンドは、LVM タグを使用して追加のメタデータを追加する以外に、論理ボリュームを作成または変更しません。
LVM タグを使用すると、ボリュームを後で発見しやすくなり、ボリュームが Ceph システムの一部であることや、どのようなロールを持っているかを識別しやすくなります。ceph-volume lvm prepare コマンドは、以下の LVM タグの一覧を追加します。
-
cluster_fsid -
data_device -
journal_device -
encrypted -
osd_fsid -
osd_id -
journal_uuid
prepare プロセスは非常に厳格で、使用可能な論理ボリュームが 2 つ必要であり、OSD データとジャーナルの最小サイズを必要とします。ジャーナルデバイスは、論理ボリュームまたはパーティションのいずれかになります。
以下は、prepare ワークフロープロセスです。
- データおよびジャーナルの論理ボリュームを許可
- OSD の UUID の生成
- 生成された UUID を再利用して OSD 識別子を取得するように Ceph Monitor に依頼
- OSD データディレクトリーが作成され、データボリュームがマウントされる
- ジャーナルは、データボリュームからジャーナルの場所へのシンボリックリンク
-
monmapはアクティベーション用にフェッチされる -
デバイスがマウントされ、データディレクトリーが
ceph-osdにより入力される - LVM タグが OSD データおよびジャーナルボリュームに割り当てられる
LVM を使用して簡単な OSD デプロイメントを準備するには、以下の手順を OSD ノード上で、root ユーザーとして実行します。
ceph-volume lvm prepare --bluestore --data $VG_NAME/$LV_NAME
以下に例を示します。
# ceph-volume lvm prepare --bluestore --data example_vg/data_lv
BlueStore の場合、RocksDB に別のデバイスを使用するには、--block.db および --block.wal オプションを指定することもできます。
以下は、パーティションでジャーナルデバイスとして FileStore を使用する例です。
# ceph-volume lvm prepare --filestore --data example_vg/data_lv --journal /dev/sdc1
パーティションを使用する場合は、blkid コマンドで検出可能な PARTUUID を含める必要があります。これにより、デバイス名またはパスに関係なく正しく特定できます。
ceph-volume LVM プラグインは、raw ディスクデバイスにパーティションを作成しません。OSD ジャーナルデバイスのパーティションを使用する前に、このパーティションを作成する必要があります。
6.1.2. OSD のアクティブ化
prepare プロセスが完了すると、OSD はアクティブになります。アクティベーションプロセスでは、起動時に Systemd ユニットが有効になります。これにより、正しい OSD ID とその UUID を有効化およびマウントできるようになります。
以下は、activate ワークフロープロセスです。
- OSD id と OSD uuid の両方が必要
- 一致する OSD id および OSD uuid で systemd ユニットを有効化
- systemd ユニットによりすべてのデバイスが準備が整い、マウントされる
-
一致する
ceph-osdsystemd ユニットが開始される
OSD を起動するには、OSD ノードで root ユーザーとして以下の手順を実行します。
ceph-volume lvm activate --filestore $OSD_ID $OSD_UUID
以下に例を示します。
# ceph-volume lvm activate --filestore 0 0263644D-0BF1-4D6D-BC34-28BD98AE3BC8
このコマンドを複数回実行しても、それに伴う影響はありません。
6.1.3. OSD の作成
create サブコマンドは 2 段階のプロセスをラップし、prepare サブコマンドを呼び出してから、activate サブコマンドを 1 つのサブコマンドに呼び出し、新しい OSD をデプロイします。prepare と activate を別々に行う理由は、新しい OSD をストレージクラスターに徐々に導入し、大量のデータがリバランスされるのを避けるためです。完成後すぐに OSD が up および in になること以外は、何も違いはありません。
root ユーザーとして、OSD ノードで FileStore に対して以下の手順を実行します。
ceph-volume lvm create --filestore --data $VG_NAME/$LV_NAME --journal $JOURNAL_DEVICE
以下に例を示します。
# ceph-volume lvm create --filestore --data example_vg/data_lv --journal example_vg/journal_lv
root ユーザーとして、OSD ノードで BlueStore に対して以下の手順を実行します。
# ceph-volume lvm create --bluestore --data <device>
以下に例を示します。
# ceph-volume lvm create --bluestore --data /dev/sda
6.1.4. batch モードの使用
batch サブコマンドは、単一デバイスが提供されると複数の OSD の作成を自動化します。 ceph-volume コマンドは、ドライブの種類に応じて最適な OSD の作成方法を決定します。この最適な方法は、オブジェクトストア形式である BlueStore または FileStore によって異なります。
BlueStore は、OSD のデフォルトのオブジェクトストアタイプです。BlueStore を使用する場合、OSD の最適化は、使用されているデバイスに基づいた 3 つの異なるシナリオによります。すべてのデバイスが従来のハードドライブの場合、デバイスごとに OSD が 1 つ作成されます。すべてのデバイスがソリッドステートドライブの場合は、デバイスごとに OSD が 2 つ作成されます。従来のハードドライブとソリッドステートドライブが混在している場合、データは従来のハードドライブに配置され、ソリッドステートドライブには可能な限り大きな block.db が作成されます。
batch サブコマンドは、ログ先行書き込み (block.wal) デバイスの別の論理ボリュームの作成をサポートしません。
BlusStore の例
# ceph-volume lvm batch --bluestore /dev/sda /dev/sdb /dev/nvme0n1
FileStore を使用する場合、OSD の最適化は、使用されているデバイスに基づいた 2 つの異なるシナリオによります。すべてのデバイスが従来のハードドライブであるか、またはソリッドステートドライブである場合、デバイスごとに 1 つの OSD が作成され、同じデバイス上でジャーナルを併置します。従来のハードドライブとソリッドステートドライブが混在している場合、データは従来のハードドライブに置かれ、ジャーナルは Ceph 設定ファイルで指定されたサイジングパラメーター (デフォルトではceph.conf) を使用してソリッドステートドライブに作成されます (デフォルトのジャーナルサイズは 5GB)。
FileStore の例
# ceph-volume lvm batch --filestore /dev/sda /dev/sdb
第7章 ベンチマークのパフォーマンス
本セクションの目的は、Ceph 管理者が Ceph のネイティブベンチマークツールの基本を理解することを目的としています。これらのツールにより、Ceph Storage クラスターの実行方法についての洞察が提供されます。これは、Ceph パフォーマンスベンチマークの最終ガイドではなく、Ceph を適宜調整する方法に関するガイドです。
7.1. パフォーマンスベースライン
OSD (ジャーナルを含む) ディスクとネットワークスループットには、お互いを比較するパフォーマンスベースラインがそれぞれに必要です。ベースラインのパフォーマンスデータと Ceph のネイティブツールのデータを比較することで、潜在的なチューニング効果を特定することができます。Red Hat Enterprise Linux には、これらのタスクを実現するために利用可能なオープンソースコミュニティーツールが複数含まれています。利用可能なツールの詳細は、ナレッジベースアーティクル 「Red Hat Enterprise Linux で利用できるベンチマークツールおよびパフォーマンステストツールはありますか?」を参照してください。
7.2. ストレージクラスター
Ceph には、RADOS ストレージクラスターでパフォーマンスベンチマークを行う rados bench コマンドが含まれます。このコマンドは、書き込みテストと 2 種類の読み取りテストを実行します。--no-cleanup オプションは、読み取りおよび書き込みパフォーマンスの両方をテストする際に使用することが重要です。デフォルトでは、rados bench コマンドは、ストレージプールに書き込まれたオブジェクトを削除します。これらのオブジェクトをそのまま残すと、2 つの読み取りテストで、順次読み取りパフォーマンスとランダムな読み取りパフォーマンスを測定できます。
これらのパフォーマンステストを実行する前に、次のコマンドを実行してファイルシステムのキャッシュをすべて破棄します。
# echo 3 | sudo tee /proc/sys/vm/drop_caches && sudo sync
新しいストレージプールを作成します。
# ceph osd pool create testbench 100 100
新規作成されたストレージプールへの書き込みテストを 10 秒実行します。
# rados bench -p testbench 10 write --no-cleanup
出力例
Maintaining 16 concurrent writes of 4194304 bytes for up to 10 seconds or 0 objects Object prefix: benchmark_data_cephn1.home.network_10510 sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 16 16 0 0 0 - 0 2 16 16 0 0 0 - 0 3 16 16 0 0 0 - 0 4 16 17 1 0.998879 1 3.19824 3.19824 5 16 18 2 1.59849 4 4.56163 3.87993 6 16 18 2 1.33222 0 - 3.87993 7 16 19 3 1.71239 2 6.90712 4.889 8 16 25 9 4.49551 24 7.75362 6.71216 9 16 25 9 3.99636 0 - 6.71216 10 16 27 11 4.39632 4 9.65085 7.18999 11 16 27 11 3.99685 0 - 7.18999 12 16 27 11 3.66397 0 - 7.18999 13 16 28 12 3.68975 1.33333 12.8124 7.65853 14 16 28 12 3.42617 0 - 7.65853 15 16 28 12 3.19785 0 - 7.65853 16 11 28 17 4.24726 6.66667 12.5302 9.27548 17 11 28 17 3.99751 0 - 9.27548 18 11 28 17 3.77546 0 - 9.27548 19 11 28 17 3.57683 0 - 9.27548 Total time run: 19.505620 Total writes made: 28 Write size: 4194304 Bandwidth (MB/sec): 5.742 Stddev Bandwidth: 5.4617 Max bandwidth (MB/sec): 24 Min bandwidth (MB/sec): 0 Average Latency: 10.4064 Stddev Latency: 3.80038 Max latency: 19.503 Min latency: 3.19824ストレージプールへの 10 秒間の順次読み取りテストを実行します。
# rados bench -p testbench 10 seq
出力例
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 Total time run: 0.804869 Total reads made: 28 Read size: 4194304 Bandwidth (MB/sec): 139.153 Average Latency: 0.420841 Max latency: 0.706133 Min latency: 0.0816332
ストレージプールに対して、10 秒間ランダムな読み取りテストを実行します。
# rados bench -p testbench 10 rand
出力例
sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 16 46 30 119.801 120 0.440184 0.388125 2 16 81 65 129.408 140 0.577359 0.417461 3 16 120 104 138.175 156 0.597435 0.409318 4 15 157 142 141.485 152 0.683111 0.419964 5 16 206 190 151.553 192 0.310578 0.408343 6 16 253 237 157.608 188 0.0745175 0.387207 7 16 287 271 154.412 136 0.792774 0.39043 8 16 325 309 154.044 152 0.314254 0.39876 9 16 362 346 153.245 148 0.355576 0.406032 10 16 405 389 155.092 172 0.64734 0.398372 Total time run: 10.302229 Total reads made: 405 Read size: 4194304 Bandwidth (MB/sec): 157.248 Average Latency: 0.405976 Max latency: 1.00869 Min latency: 0.0378431
同時の読み書き数を増やすには、
-tオプションを使用します (デフォルトは 16 スレッド)。また、-bパラメーターは、書き込まれているオブジェクトのサイズを調整することもできます。デフォルトのオブジェクトサイズは 4MB です。安全な最大オブジェクトサイズは 16MB です。Red Hat は、このベンチマークテストの複数のコピーを異なるプールで実行することを推奨します。これにより、複数のクライアントのパフォーマンスが変更になりました。--run-name <label>オプションを追加して、ベンチマークテスト中に作成するオブジェクトの名前を制御します。実行中の各コマンドインスタンスの--run-nameラベルを変更すると、複数のrados benchコマンドを同時に実行できます。これにより、複数のクライアントが同じオブジェクトにアクセスしようとし、異なるクライアントが異なるオブジェクトにアクセスしようとすると発生する可能性のある I/O エラーを防ぐことができます。--run-nameオプションは、実世界のワークロードをシミュレートしようとしているときにも便利です。以下に例を示します。# rados bench -p testbench 10 write -t 4 --run-name client1
出力例
Maintaining 4 concurrent writes of 4194304 bytes for up to 10 seconds or 0 objects Object prefix: benchmark_data_node1_12631 sec Cur ops started finished avg MB/s cur MB/s last lat avg lat 0 0 0 0 0 0 - 0 1 4 4 0 0 0 - 0 2 4 6 2 3.99099 4 1.94755 1.93361 3 4 8 4 5.32498 8 2.978 2.44034 4 4 8 4 3.99504 0 - 2.44034 5 4 10 6 4.79504 4 2.92419 2.4629 6 3 10 7 4.64471 4 3.02498 2.5432 7 4 12 8 4.55287 4 3.12204 2.61555 8 4 14 10 4.9821 8 2.55901 2.68396 9 4 16 12 5.31621 8 2.68769 2.68081 10 4 17 13 5.18488 4 2.11937 2.63763 11 4 17 13 4.71431 0 - 2.63763 12 4 18 14 4.65486 2 2.4836 2.62662 13 4 18 14 4.29757 0 - 2.62662 Total time run: 13.123548 Total writes made: 18 Write size: 4194304 Bandwidth (MB/sec): 5.486 Stddev Bandwidth: 3.0991 Max bandwidth (MB/sec): 8 Min bandwidth (MB/sec): 0 Average Latency: 2.91578 Stddev Latency: 0.956993 Max latency: 5.72685 Min latency: 1.91967rados benchコマンドで作成したデータを削除します。# rados -p testbench cleanup
7.3. ブロックデバイス
Ceph には、ブロックデバイスへの順次書き込みをテストする rbd bench-write コマンドが含まれます。これは、スループットとレイテンシーの測定を行います。デフォルトのバイトサイズは 4096 で、デフォルトの I/O スレッド数は 16 で、書き込みするデフォルトのバイト数は 1 GB です。これらのデフォルトは、それぞれ --io-size オプション、--io-threads オプション、および --io-total オプションで変更できます。rbd コマンドの詳細は、Red Hat Ceph Storage 3『Ceph Block Device Guide』の「Block Device Commands」セクションを参照してください。
Ceph ブロックデバイスの作成
rbdカーネルモジュールをロードしていない場合はrootとしてロードします。# modprobe rbd
rootとしてtestbenchプールに 1 GB のrbdイメージファイルを作成します。# rbd create image01 --size 1024 --pool testbench
注記ブロックデバイスイメージの作成時には、
layering、object-map、deep-flatten、journaling、exclusive-lock、およびfast-diff機能はデフォルトで有効になります。Red Hat Enterprise Linux 7.2 および Ubuntu 16.04 では、カーネル RBD クライアントを使用するユーザーはブロックデバイスイメージをマッピングできなくなります。最初に、
layering以外のこれらの機能をすべて無効にする必要があります。構文
# rbd feature disable <image_name> <feature_name>
例
# rbd feature disable image1 journaling deep-flatten exclusive-lock fast-diff object-map
rbd createコマンドで--image-feature layeringオプションを使用すると 、新規に作成されるブロックデバイスイメージのlayeringのみが有効になります。詳細は Red Hat Ceph Storage 3.3『Release Notes』を参照してください。
これらの機能はすべて、ユーザー空間 RBD クライアントを使用してブロックデバイスイメージにアクセスするユーザーに対して機能します。
rootとして、イメージファイルをデバイスファイルにマッピングします。# rbd map image01 --pool testbench --name client.admin
rootとして、ブロックデバイスにext4ファイルシステムを作成します。# mkfs.ext4 /dev/rbd/testbench/image01
rootとして、新しいディレクトリーを作成します。# mkdir /mnt/ceph-block-device
rootとして、ブロックデバイスを/mnt/ceph-block-device/にマウントします。# mount /dev/rbd/testbench/image01 /mnt/ceph-block-device
ブロックデバイスに対して書き込みパフォーマンスのテストを実行します。
# rbd bench-write image01 --pool=testbench
例
bench-write io_size 4096 io_threads 16 bytes 1073741824 pattern seq
SEC OPS OPS/SEC BYTES/SEC
2 11127 5479.59 22444382.79
3 11692 3901.91 15982220.33
4 12372 2953.34 12096895.42
5 12580 2300.05 9421008.60
6 13141 2101.80 8608975.15
7 13195 356.07 1458459.94
8 13820 390.35 1598876.60
9 14124 325.46 1333066.62
..
第8章 パフォーマンスカウンター
Ceph パフォーマンスカウンターは、内部インフラストラクチャーメトリックのコレクションです。このメトリックデータの収集、集計、およびグラフ化は、さまざまなツールで実行でき、パフォーマンス分析に役立ちます。
8.1. アクセス
パフォーマンスカウンターは、Ceph Monitor および OSD のソケットインターフェースを介して利用できます。各デーモンのソケットファイルは、デフォルトでは /var/run/ceph の下にあります。パフォーマンスカウンターは、コレクション名にグループ化されます。これらのコレクション名はサブシステムまたはサブシステムのインスタンスを表します。
以下は、Monitor および OSD コレクション名のカテゴリーの一覧です。それぞれの簡単な説明を以下に示します。
コレクション名カテゴリーの監視
- Cluster Metrics - ストレージクラスターに関する情報を表示します (モニター、OSD、プール、PG)。
-
Level Database Metrics - バックエンドの
KeyValueStoreデータベースに関する情報を表示します。 - Monitor Metrics - 一般的なモニター情報を表示します。
- Paxos Metrics - クラスタークォーラム管理に関する情報を表示します。
- Throttle Metrics - モニターのスロットリング方法の統計を表示します。
OSD コレクションの名前カテゴリー
- Write Back Throttle Metrics - 書き込みバックスロットルがフラッシュされていない IO を追跡する方法についての統計を表示します。
- FileStore Metrics - 関連するすべての filestore 統計の情報を表示します。
-
Level Database Metrics - バックエンドの
KeyValueStoreデータベースに関する情報を表示します。 - Objecter Metrics - さまざまなオブジェクトベースの操作に関する情報を表示します。
- Read and Write Operations Metrics - さまざまな読み取りおよび書き込み操作に関する情報を表示します。
- Recovery State Metrics - さまざまなリカバリーの状態のレイテンシーを表示します。
- OSD Throttle Metrics - OSD のスロットリング方法の統計の表示
RADOS ゲートウェイコレクションの名前カテゴリー
- Object Gateway Client Metrics - GET 要求および PUT 要求の統計を表示します。
- Objecter Metrics - さまざまなオブジェクトベースの操作に関する情報を表示します。
- Object Gateway Throttle Metrics: OSD のスロットリングに関する統計の表示
8.2. Schema
ceph daemon .. perf schema コマンドは、利用可能なメトリックを出力します。各メトリックには、関連付けられたビットフィールド値タイプがあります。
メトリックのスキーマを表示するには、以下を実行します。
# ceph daemon <daemon_name> perf schema
デーモンを実行するノードから ceph daemon コマンドを実行する必要があります。
Monitor ノードから ceph daemon .. perf schema コマンドを実行するには、以下を実行します。
# ceph daemon mon.`hostname -s` perf schema
例
{
"cluster": {
"num_mon": {
"type": 2
},
"num_mon_quorum": {
"type": 2
},
"num_osd": {
"type": 2
},
"num_osd_up": {
"type": 2
},
"num_osd_in": {
"type": 2
},
...
OSD ノードから ceph daemon .. perf schema コマンドを実行するには、以下を実行します。
# ceph daemon osd.0 perf schema
例
...
"filestore": {
"journal_queue_max_ops": {
"type": 2
},
"journal_queue_ops": {
"type": 2
},
"journal_ops": {
"type": 10
},
"journal_queue_max_bytes": {
"type": 2
},
"journal_queue_bytes": {
"type": 2
},
"journal_bytes": {
"type": 10
},
"journal_latency": {
"type": 5
},
...
表8.1 ビットフィールド値の定義
| ビット | 意味 |
|---|---|
| 1 | 浮動小数点数 |
| 2 | 署名されていない 64 ビットの整数値 |
| 4 | 平均 (合計 + カウント) |
| 8 | カウンター |
各値には、型 (浮動小数点または整数値) を示すビット 1 または 2 が設定されます。ビット 4 が設定されている場合、読み取る値は合計とカウントの 2 つになります。詳細は、「平均数と合計」 を参照してください。ビット 8 が設定されている場合、以前の間隔の平均は、以前の読み取り以降、合計差分になります。これは、カウントデルタで除算されます。値を除算すると、有効期間の平均値が提供されることになります。通常、これらはレイテンシー、リクエスト数、およびリクエストレイテンシーの合計を測定するために使用されます。ビットの値は組み合わせられます (例: 5、6、10)。ビット値 5 は、ビット 1 とビット 4 の組み合わせです。つまり、平均は浮動小数点の値になります。ビット値 6 は、ビット 2 とビット 4 の組み合わせです。これは、平均値が整数になることを意味します。ビット値 10 は、ビット 2 とビット 8 の組み合わせです。これは、カウンター値が整数値であることを意味します。
8.3. ダンプ
ceph daemon .. perf dump コマンドは、現在の値を出力し、各サブシステムのコレクション名でメトリックをグループ化します。
現在のメトリクスデータを表示するには、以下を実行します。
# ceph daemon {daemon_name} perf dump
デーモンを実行するノードから ceph daemon コマンドを実行する必要があります。
Monitor ノードから ceph daemon .. perf dump コマンドを実行するには、以下のコマンドを実行します。
# ceph daemon mon.`hostname -s` perf dump
例
{
"cluster": {
"num_mon": 1,
"num_mon_quorum": 1,
"num_osd": 2,
"num_osd_up": 2,
"num_osd_in": 2,
...
利用可能な Monitor メトリックの簡単な説明を表示するには、以下の表を参照してください。
OSD ノードから ceph daemon .. perf dump コマンドを実行するには、以下のコマンドを実行します。
# ceph daemon osd.0 perf dump
例
...
"filestore": {
"journal_queue_max_ops": 300,
"journal_queue_ops": 0,
"journal_ops": 992,
"journal_queue_max_bytes": 33554432,
"journal_queue_bytes": 0,
"journal_bytes": 934537,
"journal_latency": {
"avgcount": 992,
"sum": 254.975925772
},
...
8.3.1. 平均数と合計
すべてのレイテンシー番号は、ビットフィールドの値は 5 です。このフィールドには、平均数と合計の浮動小数点値が含まれます。avgcount は、この範囲内の操作数で、sum はレイテンシーの合計 (秒単位) です。sum を avgcount で除算すると、操作ごとのレイテンシーを把握することができます。
利用可能な各 OSD メトリックの簡単な説明を表示するには、以下の OSD の表を参照してください。
8.3.2. モニターメトリクス記述テーブル
表8.2 クラスターメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | モニター数 |
|
| 2 | クォーラムのモニター数 | |
|
| 2 | OSD の合計数 | |
|
| 2 | 稼働中の OSD 数 | |
|
| 2 | クラスターにある OSD 数 | |
|
| 2 | OSD マップの現在のエポック | |
|
| 2 | クラスターの合計容量 (バイト単位) | |
|
| 2 | クラスターで使用されているバイト数 | |
|
| 2 | クラスターで利用可能なバイト数 | |
|
| 2 | プールの数 | |
|
| 2 | 配置グループの合計数 | |
|
| 2 | active+clean 状態の配置グループの数 | |
|
| 2 | アクティブな状態の配置グループの数 | |
|
| 2 | ピア状態の配置グループの数 | |
|
| 2 | クラスター上のオブジェクトの合計数 | |
|
| 2 | パフォーマンス低下 (レプリカが欠落している) オブジェクトの数 | |
|
| 2 | 配置が間違っているオブジェクトの数 (クラスター内の間違った場所) | |
|
| 2 | 不明なオブジェクトの数 | |
|
| 2 | すべてのオブジェクトの合計バイト数 | |
|
| 2 | 稼働している MDS の数 | |
|
| 2 | クラスターにある MDS の数 | |
|
| 2 | 失敗した MDS の数 | |
|
| 2 | MDS マップの現在のエポック |
表8.3 レベルのデータベースメトリクステーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 取得 |
|
| 10 | トランザクション | |
|
| 10 | 補完 | |
|
| 10 | 範囲ごとの比較 | |
|
| 10 | 圧縮キューにおける範囲のマージ | |
|
| 2 | 圧縮キューの長さ |
表8.4 一般的なモニターメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | 現在開いているモニターセッションの数 |
|
| 10 | 作成されたモニターセッションの数 | |
|
| 10 | モニターにおける remove_session 呼び出しの数 | |
|
| 10 | トリミングされたモニターセッションの数 | |
|
| 10 | 参加する選択モニターの数 | |
|
| 10 | モニターにより開始した選択の数 | |
|
| 10 | モニターが勝利した選択の数 | |
|
| 10 | モニターにより失われた選択の数 |
表8.5 Paxos Metrics テーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | リーダーロールで始まります。 |
|
| 10 | peon ロールで開始します。 | |
|
| 10 | 再起動 | |
|
| 10 | 更新 | |
|
| 5 | 更新の待ち時間 | |
|
| 10 | 開始および処理開始 | |
|
| 6 | 開始時のトランザクションのキー | |
|
| 6 | トランザクションの開始時にデータ | |
|
| 5 | 開始操作のレイテンシー | |
|
| 10 | コミット | |
|
| 6 | コミット時にトランザクションのキー | |
|
| 6 | コミット時のトランザクションのデータ | |
|
| 5 | コミットレイテンシー | |
|
| 10 | Peon が収集する | |
|
| 6 | peon collect 上のトランザクションのキー | |
|
| 6 | peon collect 上のトランザクションのデータ | |
|
| 5 | Peon がレイテンシーを収集 | |
|
| 10 | 開始および処理された収集のコミットされていない値 | |
|
| 10 | タイムアウトの収集 | |
|
| 10 | タイムアウトの受け入れ | |
|
| 10 | リースの確認タイムアウト | |
|
| 10 | リースタイムアウト | |
|
| 10 | 共有状態をディスクに保存 | |
|
| 6 | 保存された状態のトランザクションのキー | |
|
| 6 | 保存された状態のトランザクションのデータ | |
|
| 5 | 状態レイテンシーの保存 | |
|
| 10 | 状態の共有 | |
|
| 6 | 共有状態のキー | |
|
| 6 | 共有状態のデータ | |
|
| 10 | 新しい提案番号のクエリー | |
|
| 5 | レイテンシーを取得する新しい提案番号 |
表8.6 スロットルメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 現在利用できるスロットル |
|
| 10 | スロットルの最大値 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | get_or_fail 時にブロックされる | |
|
| 10 | get_or_fail 時の get 成功 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | 送る | |
|
| 10 | データを送る | |
|
| 5 | 待機レイテンシー |
8.3.3. OSD メトリクス記述テーブル
表8.7 ライトバックスロットルメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | ダーティーデータ |
|
| 2 | 書き込まれたデータ | |
|
| 2 | ダーティー操作 | |
|
| 2 | 書き込みされた操作 | |
|
| 2 | 書き込みを待っているエントリー | |
|
| 2 | 書き込まれたエントリー |
表8.8 FileStore メトリクステーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | ジャーナルキューの最大操作数 |
|
| 2 | ジャーナルキューの操作数 | |
|
| 10 | 書き込まれたジャーナルエントリーの合計 | |
|
| 2 | ジャーナルキューの最大データ | |
|
| 2 | ジャーナルキューのサイズ | |
|
| 10 | ジャーナルの合計操作サイズ | |
|
| 5 | ジャーナルキューの平均完了レイテンシー | |
|
| 10 | ジャーナル書き込み IO | |
|
| 6 | ジャーナルデータ書き込み | |
|
| 10 | 満杯時のジャーナル書き込み | |
|
| 2 | 現在コミット中 | |
|
| 10 | コミットサイクル | |
|
| 5 | コミットの平均間隔 | |
|
| 5 | コミットの平均レイテンシー | |
|
| 2 | キューの最大操作数 | |
|
| 2 | キュー内の操作数 | |
|
| 10 | 操作 | |
|
| 2 | キューの最大サイズ | |
|
| 2 | キューのサイズ | |
|
| 10 | ストアに書き込まれたデータ | |
|
| 5 | レイテンシーの適用 | |
|
| 5 | 操作キューレイテンシーの格納 |
表8.9 レベルのデータベースメトリクステーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 取得 |
|
| 10 | トランザクション | |
|
| 10 | 補完 | |
|
| 10 | 範囲ごとの比較 | |
|
| 10 | 圧縮キューにおける範囲のマージ | |
|
| 2 | 圧縮キューの長さ |
表8.10 Objecter Metrics テーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | アクティブな操作 |
|
| 2 | 遅延操作 | |
|
| 10 | 送信された操作 | |
|
| 10 | 送信されたデータ | |
|
| 10 | 再送信捜査 | |
|
| 10 | コールバックのコミット | |
|
| 10 | 操作のコミット | |
|
| 10 | 操作 | |
|
| 10 | 読み取り操作 | |
|
| 10 | 書き込み操作 | |
|
| 10 | read-modify-write 操作 | |
|
| 10 | PG 操作 | |
|
| 10 | 統計操作 | |
|
| 10 | オブジェクト操作の作成 | |
|
| 10 | 読み取り操作 | |
|
| 10 | 書き込み操作 | |
|
| 10 | 完全なオブジェクト操作の書き込み | |
|
| 10 | 追加操作 | |
|
| 10 | オブジェクトをゼロ操作に設定 | |
|
| 10 | オブジェクト操作の切り捨て | |
|
| 10 | オブジェクト操作の削除 | |
|
| 10 | エクステント操作のマップ | |
|
| 10 | スパース読み取り操作 | |
|
| 10 | 範囲のクローン操作 | |
|
| 10 | xattr 操作の取得 | |
|
| 10 | xattr 操作の設定 | |
|
| 10 | xattr の比較操作 | |
|
| 10 | xattr 操作の削除 | |
|
| 10 | xattr 操作のリセット | |
|
| 10 | TMAP 更新操作 | |
|
| 10 | TMAP の put 操作 | |
|
| 10 | TMAP の get 操作 | |
|
| 10 | 操作の呼び出し (実行) | |
|
| 10 | オブジェクト操作による監視 | |
|
| 10 | オブジェクト操作に関する通知 | |
|
| 10 | 複数演算における拡張属性比較 | |
|
| 10 | その他の操作 | |
|
| 2 | アクティブな linger 操作 | |
|
| 10 | 送信された linger 操作 | |
|
| 10 | 送信された linger 操作 | |
|
| 10 | linger 操作に ping が送信 | |
|
| 2 | アクティブなプール操作 | |
|
| 10 | 送信したプール操作 | |
|
| 10 | 再送されたプール操作 | |
|
| 2 | アクティブな get pool stat 操作 | |
|
| 10 | 送信されたプール統計操作 | |
|
| 10 | 再送信されたプール統計 | |
|
| 2 | statfs 操作 | |
|
| 10 | 送信された FS 統計 | |
|
| 10 | 再送信された FS 統計 | |
|
| 2 | アクティブなコマンド | |
|
| 10 | 送信されたコマンド | |
|
| 10 | 再送信された コマンド | |
|
| 2 | OSD マップエポック | |
|
| 10 | 受け取った完全な OSD マップ | |
|
| 10 | 受け取った増分 OSD マップ | |
|
| 2 | セッションを開く | |
|
| 10 | 開いたセッション | |
|
| 10 | 閉じたセッション | |
|
| 2 | Laggy OSD セッション |
表8.11 読み出し操作および書き込み操作のメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | 現在処理中のレプリケーション操作 (プライマリー) |
|
| 10 | クライアント操作の合計書き込みサイズ | |
|
| 10 | クライアント操作合計読み取りサイズ | |
|
| 5 | クライアント操作のレイテンシー (キュー時間を含む) | |
|
| 5 | クライアント操作のレイテンシー (キュー時間を除く) | |
|
| 10 | クライアントの読み取り操作 | |
|
| 10 | 読み込まれたクライアントデータ | |
|
| 5 | 読み取り操作のレイテンシー (キュー時間を含む) | |
|
| 5 | 読み取り操作のレイテンシー (キュー時間を除く) | |
|
| 10 | クライアントの書き込み操作 | |
|
| 10 | 書き込まれたクライアントデータ | |
|
| 5 | クライアントの書き込み操作の読み取り可能/適用されるレイテンシー | |
|
| 5 | 書き込み操作のレイテンシー (キュー時間を含む) | |
|
| 5 | 書き込み操作のレイテンシー (キュー時間を除く) | |
|
| 10 | クライアントの read-modify-write 操作 | |
|
| 10 | クライアントの read-modify-write 操作の書き込み | |
|
| 10 | クライアントの read-modify-write 操作の読み出し | |
|
| 5 | クライアントの読み取り/書き込み操作の読み取り/適用のレイテンシー | |
|
| 5 | read-modify-write 操作のレイテンシー (キュー時間を含む) | |
|
| 5 | read-modify-write 操作のレイテンシー (キュー時間を除く) | |
|
| 10 | サブ操作 | |
|
| 10 | サブ操作の合計サイズ | |
|
| 5 | サブ操作レイテンシー | |
|
| 10 | レプリケートされた書き込み | |
|
| 10 | 複製された書き込みデータのサイズ | |
|
| 5 | レプリケートされた書き込みレイテンシー | |
|
| 10 | サブオペレーションのプルリクエスト | |
|
| 5 | サブオペレーションのプルレイテンシー | |
|
| 10 | サブオペレーションのプッシュメッセージ | |
|
| 10 | サブオペレーションのプッシュサイズ | |
|
| 5 | サブオペレーションのプッシュレイテンシー | |
|
| 10 | 送信されたプル要求 | |
|
| 10 | 送信されたメッセージをプッシュ | |
|
| 10 | プッシュされたサイズ | |
|
| 10 | インバウンドプッシュメッセージ | |
|
| 10 | インバウンドプッシュされるサイズ | |
|
| 10 | 開始したリカバリー操作 | |
|
| 2 | CPU 負荷 | |
|
| 2 | 割り当てられたバッファー合計サイズ | |
|
| 2 | 配置グループ | |
|
| 2 | この osd がプライマリーとなる配置グループ | |
|
| 2 | この osd がレプリカである配置グループ | |
|
| 2 | この osd から削除する準備ができている配置グループ | |
|
| 2 | 送信先のハートビート (ping) ピア | |
|
| 2 | 受信元ハートビート (ping) のピア | |
|
| 10 | OSD マップメッセージ | |
|
| 10 | OSD マップエポック | |
|
| 10 | OSD マップの複製 | |
|
| 2 | OSD のサイズ | |
|
| 2 | 使用されている領域 | |
|
| 2 | 利用可能な領域 | |
|
| 10 | RADOS の「copy-from」操作 | |
|
| 10 | 階層の昇格 | |
|
| 10 | 階層フラッシュ | |
|
| 10 | レイヤーフラッシュの失敗 | |
|
| 10 | 階層のフラッシュ試行 | |
|
| 10 | 階層のフラッシュ試行の失敗 | |
|
| 10 | 階層エビクション | |
|
| 10 | 階層のホワイトアウト | |
|
| 10 | ダーティー階層フラグセット | |
|
| 10 | 消去されたダーティー階層フラグ | |
|
| 10 | 階層遅延 (エージェント待機) | |
|
| 10 | 階層プロキシーの読み込み | |
|
| 10 | 階層化エージェントのウェイクアップ | |
|
| 10 | エージェントによりスキップされるオブジェクト | |
|
| 10 | 階層化エージェントのフラッシュ | |
|
| 10 | 階層化エージェントエビクション | |
|
| 10 | オブジェクトコンテキストキャッシュのヒット数 | |
|
| 10 | オブジェクトコンテキストキャッシュの検索 |
表8.12 リカバリー状態のメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 5 | リカバリーの状態の最初のレイテンシー |
|
| 5 | リカバリー状態のレイテンシーを開始 | |
|
| 5 | リカバリー状態レイテンシーのリセット | |
|
| 5 | リカバリー状態レイテンシーの開始 | |
|
| 5 | プライマリーリカバリーの状態のレイテンシー | |
|
| 5 | リカバリー状態のレイテンシーのピア設定 | |
|
| 5 | リカバリー状態レイテンシーのバックフィル | |
|
| 5 | リモートバックフィルの予約されたリカバリー状態レイテンシーを待機する | |
|
| 5 | ローカルバックフィルの予約されたリカバリー状態のレイテンシーを待機する | |
|
| 5 | Notbackfilling のリカバリー状態のレイテンシー | |
|
| 5 | Repnotrecovering リカバリー状態のレイテンシー | |
|
| 5 | repwaitrecovery が予約したリカバリー状態のレイテンシー | |
|
| 5 | repwaitbackfill が予約したリカバリー状態のレイテンシー | |
|
| 5 | repRecovering リカバリー状態のレイテンシー | |
|
| 5 | リカバリー状態のレイテンシーの有効化 | |
|
| 5 | waitlocalrecovery が予約したリカバリー状態のレイテンシー | |
|
| 5 | waitremoterecovery が予約したリカバリー状態のレイテンシー | |
|
| 5 | リカバリー状態のレイテンシーのリカバリー | |
|
| 5 | リカバリーしたリカバリー状態のレイテンシー | |
|
| 5 | リカバリー状態のレイテンシーの削除 | |
|
| 5 | アクティブリカバリーの状態のレイテンシー | |
|
| 5 | replicaactive のリカバリー状態レイテンシー | |
|
| 5 | 迷子のリカバリー状態レイテンシー | |
|
| 5 | getinfo リカバリー状態レイテンシー | |
|
| 5 | getlog リカバリー状態レイテンシー | |
|
| 5 | Waitactingchange リカバリー状態レイテンシー | |
|
| 5 | 不完全なリカバリー状態レイテンシー | |
|
| 5 | 復旧状態のレイテンシーの取得 | |
|
| 5 | waitupthru リカバリー状態のレイテンシー |
表8.13 OSD スロットルのメトリクステーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 現在利用できるスロットル |
|
| 10 | スロットルの最大値 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | get_or_fail 時にブロックされる | |
|
| 10 | get_or_fail 時の get 成功 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | 送る | |
|
| 10 | データを送る | |
|
| 5 | 待機レイテンシー |
8.3.4. Ceph Object Gateway メトリクスの表
表8.14 RADOS クライアントメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 要求 |
|
| 10 | 中止要求 | |
|
| 10 | 取得 | |
|
| 10 | 取得サイズ | |
|
| 5 | レイテンシーの取得 | |
|
| 10 | 送る | |
|
| 10 | 送信サイズ | |
|
| 5 | レイテンシーの送信 | |
|
| 2 | キューの長さ | |
|
| 2 | アクティブなリクエストキュー | |
|
| 10 | キャッシュのヒット数 | |
|
| 10 | キャッシュミス | |
|
| 10 | Keystone トークンキャッシュのヒット数 | |
|
| 10 | Keystone のトークンキャッシュのミス |
表8.15 Objecter Metrics テーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 2 | アクティブな操作 |
|
| 2 | 遅延操作 | |
|
| 10 | 送信された操作 | |
|
| 10 | 送信されたデータ | |
|
| 10 | 再送信捜査 | |
|
| 10 | コールバックのコミット | |
|
| 10 | 操作のコミット | |
|
| 10 | 操作 | |
|
| 10 | 読み取り操作 | |
|
| 10 | 書き込み操作 | |
|
| 10 | read-modify-write 操作 | |
|
| 10 | PG 操作 | |
|
| 10 | 統計操作 | |
|
| 10 | オブジェクト操作の作成 | |
|
| 10 | 読み取り操作 | |
|
| 10 | 書き込み操作 | |
|
| 10 | 完全なオブジェクト操作の書き込み | |
|
| 10 | 追加操作 | |
|
| 10 | オブジェクトをゼロ操作に設定 | |
|
| 10 | オブジェクト操作の切り捨て | |
|
| 10 | オブジェクト操作の削除 | |
|
| 10 | エクステント操作のマップ | |
|
| 10 | スパース読み取り操作 | |
|
| 10 | 範囲のクローン操作 | |
|
| 10 | xattr 操作の取得 | |
|
| 10 | xattr 操作の設定 | |
|
| 10 | xattr の比較操作 | |
|
| 10 | xattr 操作の削除 | |
|
| 10 | xattr 操作のリセット | |
|
| 10 | TMAP 更新操作 | |
|
| 10 | TMAP の put 操作 | |
|
| 10 | TMAP の get 操作 | |
|
| 10 | 操作の呼び出し (実行) | |
|
| 10 | オブジェクト操作による監視 | |
|
| 10 | オブジェクト操作に関する通知 | |
|
| 10 | 複数演算における拡張属性比較 | |
|
| 10 | その他の操作 | |
|
| 2 | アクティブな linger 操作 | |
|
| 10 | 送信された linger 操作 | |
|
| 10 | 送信された linger 操作 | |
|
| 10 | linger 操作に ping が送信 | |
|
| 2 | アクティブなプール操作 | |
|
| 10 | 送信したプール操作 | |
|
| 10 | 再送されたプール操作 | |
|
| 2 | アクティブな get pool stat 操作 | |
|
| 10 | 送信されたプール統計操作 | |
|
| 10 | 再送信されたプール統計 | |
|
| 2 | statfs 操作 | |
|
| 10 | 送信された FS 統計 | |
|
| 10 | 再送信された FS 統計 | |
|
| 2 | アクティブなコマンド | |
|
| 10 | 送信されたコマンド | |
|
| 10 | 再送信された コマンド | |
|
| 2 | OSD マップエポック | |
|
| 10 | 受け取った完全な OSD マップ | |
|
| 10 | 受け取った増分 OSD マップ | |
|
| 2 | セッションを開く | |
|
| 10 | 開いたセッション | |
|
| 10 | 閉じたセッション | |
|
| 2 | Laggy OSD セッション |
表8.16 RADOS ゲートウェイスロットルメトリックテーブル
| コレクション名 | メトリック名 | ビットフィールド値 | 簡単な説明 |
|---|---|---|---|
|
|
| 10 | 現在利用できるスロットル |
|
| 10 | スロットルの最大値 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | get_or_fail 時にブロックされる | |
|
| 10 | get_or_fail 時の get 成功 | |
|
| 10 | 取得 | |
|
| 10 | 取得したデータ | |
|
| 10 | 送る | |
|
| 10 | データを送る | |
|
| 5 | 待機レイテンシー |
第9章 BlueStore
BlueStore は、OSD デーモンの新たなバックエンドオブジェクトストアです。元のオブジェクトストアである FileStore では、raw ブロックデバイス上にファイルシステムを必要とします。オブジェクトはファイルシステムに書き込まれます。BlueStore はブロックデバイスに直接オブジェクトを配置するため、BlueStore は最初のファイルシステムを必要としません。
BlueStore は、本番環境で OSD デーモン向けに高パフォーマンスのバックエンドを提供します。デフォルトでは、BlueStore はセルフチューニングするように設定されています。BlueStore を手動でチューニングした方が環境のパフォーマンスが良いと判断された場合は、Red Hat サポート に連絡して設定の詳細を共有し、自動チューニングのケイパビリティーを改善する支援を受けるようにしてください。Red Hatは、フィードバックをお待ちしており、お客様の提案に感謝いたします。
9.1. About BlueStore
BlueStore は、OSD デーモンの新しいバックエンドです。BlueStoreは、元の FileStore バックエンドとは異なり、ファイルシステムのインターフェースなしでブロックデバイスに直接オブジェクトを格納するため、クラスタのパフォーマンスが向上します。
以下は、BlueStore を使用する主な機能の一部です。
- ストレージデバイスの直接管理
- BlueStore は raw ブロックデバイスまたはパーティションを使用します。これにより、XFS などのローカルファイルシステムなど、抽象化の層が回避され、パフォーマンスの制限や複雑さの増加が発生する可能性があります。
- RocksDB を使用したメタデータ管理
- BlueStore は、ディスク上の場所をブロックするオブジェクト名からのマッピングなど、内部メタデータの管理にデーターベースのキーと値データベースを使用します。
- 完全なデータおよびメタデータのチェックサム
- デフォルトでは、BlueStore に書き込まれたすべてのデータおよびメタデータは、1 つ以上のチェックサムによって保護されます。検証せずにディスクから読み取られたり、ユーザーに返されたデータやメタデータはありません。
- 効率的なコピーオンライト
- Ceph Block Device および Ceph File System のスナップショットは、BlueStore に効率的に実装されるコピーオンライトのクローンメカニズムに依存します。これにより、通常のスナップショットと、効率的な 2 フェーズコミットを実装するためにクローン作成に依存するイレイジャーコーディングプールの両方で効率的な I/O が実現します。
- 大きな二重書き込みなし
- BlueStore は、まずブロックデバイス上の未割り当ての領域に新しいデータを書き込み、次にディスクの新しい領域を参照するためにオブジェクトのメタデータを更新する RocksDB トランザクションをコミットします。書き込み操作が設定可能なサイズのしきい値を下回る場合にのみ、FileStore の操作と同様に、先行書き込みのジャーナリングスキームにフォールバックします。
- マルチデバイスのサポート
BlueStore は、異なるデータを保存するために複数のブロックデバイスを使用できます。たとえば、データにはハードディスクドライブ (HDD)、メタデータにはソリッドステートドライブ (SSD)、RocksDB ログ先行書き込み (WAL) には不揮発性メモリー (NVM) または不揮発性ランダムアクセスメモリー (NVRAM) などです。詳細は 「BlueStore デバイス」 を参照してください。
注記ceph-diskユーティリティーがまだ複数のデバイスをプロビジョニングしません。複数のデバイスを使用するには、OSD を手動で設定する必要があります。- ブロックデバイスの効率的な使用方法
- BlueStore はファイルシステムを使用しないため、ストレージデバイスキャッシュを削除する必要が最小限に抑えられます。
9.2. BlueStore デバイス
本セクションでは、BlueStore バックエンドが使用するブロックデバイスを説明します。
BlueStore は、1 つ、2 つ、または特定のケースで 3 つのストレージデバイスを管理します。
- プライマリー
- WAL
- DB
最も単純なケースでは、BlueStore は単一の (プライマリー) ストレージデバイスを使用します。ストレージデバイスは、以下を含む 2 つの部分に分割されます。
- OSD メタデータ: OSD の基本的なメタデータが含まれる XFS でフォーマットされた小規模なパーティション。このデータディレクトリーには、OSD に関する情報 (所属するクラスター、およびプライベートキーリング) が含まれます。
- データ: BlueStore によって直接管理され、すべての OSD データが含まれる残りのデバイスを占有する大容量パーティション。このプライマリーデバイスは、data ディレクトリーのブロックシンボリックリンクで識別されます。
2 つの追加デバイスを使用することもできます。
-
WAL (write-ahead-log) デバイス: BlueStore 内部ジャーナルまたは write-ahead ログを保存するデバイス。これは、data ディレクトリーの
block.walシンボリックリンクによって識別されます。WAL デバイスは、たとえば WAL デバイスが SSD ディスクを使用し、プライマリーデバイスが HDD ディスクを使用する場合など、WAL デバイスがプライマリーデバイスよりも高速である場合にのみ、WAL デバイスの使用を検討してください。 - DB デバイス: BlueStore 内部メタデータを保存するデバイス。組み込み RocksDB データベースは、できるだけ多くのメタデータをプライマリーデバイス上ではなく、DB デバイスに配置してパフォーマンスを向上させます。DB デバイスが満杯になると、プライマリーデバイスへのメタデータの追加が開始します。デバイスがプライマリーデバイスよりも高速の場合にのみ DB デバイスを使用することを検討してください。
高速デバイスで利用可能なストレージが 1 ギガバイト未満の場合、Red Hat はそれを WAL デバイスとして使用することを推奨します。より高速なデバイスがある場合は、DB デバイスとして使用することを検討してください。BlueStore ジャーナルは、常に最速のデバイスに配置されるため、DB デバイスを使用すると WAL デバイスと同様のメリットが得られると同時に、追加のメタデータを保存することができます。
9.3. BlueStore キャッシュ
BlueStore キャッシュババッファーの集合体で、設定によっては OSD デーモンがディスクからの読み込みや書き込みを行う際に、データで埋められることがあります。Red Hat Ceph Storage のデフォルトでは、BlueStore は読み取り時にキャッシュされますが、書き込みは行いません。これは、キャッシュエビクションに関連するオーバーヘッドを回避するために bluestore_default_buffered_write オプションが false に設定されているためです。
bluestore_default_buffered_write オプションが true に設定されていると、データは最初にバッファーに書き込まれ、その後ディスクにコミットされます。その後、書き込みの確認がクライアントに送信されます。これにより、データがエビクトされるまで、キャッシュ内のデータへの読み取り速度が速くなります。
読み取り量の多いワークロードでは、BlueStore キャッシングからすぐに利益を得ることはできません。より多くの読み取りが行われると、キャッシュは時間の経過とともに増大し、後続の読み取りではパフォーマンスが向上するようになります。キャッシュがどのくらいの速さで生成されるかは、BlueStore のブロックおよびデータベースのディスクタイプ、ならびにクライアントのワークロード要件に依存します。
bluestore_default_buffered_write オプションを有効にする前に、Red Hat サポート にお問い合わせください。
9.4. BlueStore のサイズ関する考慮事項
BlueStore OSD を使用して従来のドライブとソリッドステートドライブを混在させる場合には、JusDB 論理ボリューム (block.db) のサイズを適切に設定することが重要です。Red Hat では、オブジェクト、ファイル、混合ワークロードで RocksDB の論理ボリュームをブロックサイズの 4% 以下にすることを推奨しています。Red Hat は、JlowsDB および OpenStack のブロックワークロードにおいて、BlueStore ブロックサイズの 1% をサポートしています。たとえば、オブジェクトワークロードのブロックサイズが 1 TB の場合は、最低でも 40 GB の RocksDB 論理ボリュームを作成します。
ドライブタイプを混合しない場合は、個別の RocksDB 論理ボリュームを持つ必要はありません。BlueStore は、RocksDB のサイジングを自動的に管理します。
BlueStore のキャッシュメモリーは、RocksDB、BlueStoreのメタデータ、オブジェクトデータのキー/値のペアのメタデータで使用されます。
BlueStore キャッシュのメモリー値は、OSD によってすでに使用されているメモリーフットプリントに追加されます。
9.5. BlueStore を使用する OSD の追加
本項では、BlueStore バックエンドで新しい Ceph OSD ノードをインストールする方法について説明します。
前提条件
- 稼働中の Ceph クラスター。『Installation Guide for Red Hat Enterprise Linux』または『Ubuntu』を参照してください。
手順
Ansible 管理ノードで以下のコマンドを使用します。
デフォルトでは、新しい OSD ノードを、(デフォルトでは
/etc/ansible/hostsにある) Ansible インベントリーファイルの[osds]セクションに追加します。[osds] node1 node2 node3 <hostname>
以下を置き換えます。
-
<hostname>は OSD ノードの名前に置き換えます。
以下に例を示します。
[osds] node1 node2 node3 node4
-
/usr/share/ceph-ansibleディレクトリーに移動します。[user@admin ~]$ cd /usr/share/ceph-ansible
host_varsディレクトリーを作成します。[root@admin ceph-ansible] mkdir host_vars
新規に追加された OSD の設定ファイルを
host_varsに作成します。[root@admin ceph-ansible] touch host_vars/<hostname>.yml
以下を置き換えます。
-
<hostname>は、新たに追加された OSD のホスト名に置き換えます。
以下に例を示します。
[root@admin ceph-ansible] touch host_vars/node4.yml
-
新規作成されたファイルに以下の設定を追加します。
osd_objectstore: bluestore
注記すべての OSD に BlueStore を使用するには、
osd_objectstore:bluestoreをgroup_vars/all.ymlファイルに追加します。任意。
block.walおよびblock.dbパーティションを専用デバイスに保存する場合は、以下のようにhost_vars/<hostname>.ymlファイルを編集します。block.walに専用のデバイスを使用するには、以下を実行します。osd_scenario: non-collocated bluestore_wal_devices: - <device> - <device>
以下を置き換えます。
-
<device>は、デバイスへのパスに置き換えます。
以下に例を示します。
osd_scenario: non-collocated bluestore_wal_devices: - /dev/sdf - /dev/sdg
-
block.dbに専用デバイスを使用するには、以下を実行します。osd_scenario: non-collocated dedicated_devices: - <device> - <device>
以下を置き換えます。
-
<device>は、デバイスへのパスに置き換えます。
以下に例を示します。
osd_scenario: non-collocated dedicated_devices: - /dev/sdh - /dev/sdi
注記osd_scenario: collocatedパラメーターを使用する場合、block.walおよびblock.dbパーティションはdevicesパラメーターで指定されたデバイスと同じものを使用します。詳細は、Red Hat Ceph Storage 3『Installation Guide for Red Hat Enterprise Linux』または『Ubuntu』の「Installing a Red Hat Ceph Storage Cluster」を参照してください。注記すべての OSD に BlueStore を使用するには、前述のパラメーターを
group_vars/osds.ymlファイルに追加します。-
group_vars/all.ymlファイルでblock.dbおよびblock.walのデフォルトサイズを上書きするには、以下を実行します。ceph_conf_overrides: osd: bluestore_block_db_size: <value> bluestore_block_wal_size: <value>以下を置き換えます。
-
<value>はサイズ (バイト単位) に置き換えます。
以下に例を示します。
ceph_conf_overrides: osd: bluestore_block_db_size: 14336000000 bluestore_block_wal_size: 2048000000-
LVM ベースの BlueStore OSD を設定するには
host_vars/<hostname>.ymlでosd_scenario: lvmを使用します。osd_scenario: lvm lvm_volumes: - data: <datalv> data_vg: <datavg>以下を置き換えます。
-
<datalv>をデータ論理ボリューム名に置き換えます。 -
<datavg>をデータ論理ボリュームグループ名に置き換えます。
以下に例を示します。
osd_scenario: lvm lvm_volumes: - data: data-lv1 data_vg: vg1-
任意。
block.walおよびblock.dbを専用の論理ボリュームに保存する場合は、以下のようにhost_vars/<hostname>.ymlファイルを編集します。osd_scenario: lvm lvm_volumes: - data: <datalv> wal: <wallv> wal_vg: <vg> db: <dblv> db_vg: <vg>以下を置き換えます。
- <datalv> をデータが含まれる必要がある論理ボリュームに置き換えます。
- <wallv> をログ先行書き込みが含まれる必要がある論理ボリュームに置き換えます。
- <vg> を WAL や DB デバイス LV があるボリュームグループに置き換えます。
- <dblv> を BlueStore 内部メタデータが含まれる必要がある論理ボリュームに置き換えます。
以下に例を示します。
osd_scenario: lvm lvm_volumes: - data: data-lv3 wal: wal-lv1 wal_vg: vg3 db: db-lv3 db_vg: vg3注記lvm_volumes:をosd_objectstore: bluestoreと一緒に使用する場合は、lvm_volumesの YAML 辞書には少なくともデータが含まれている必要があります。walまたはdbを定義する際には、LV 名と VG 名の両方が必要になります (dbとwalは必要ありません)。これにより、データのみ、データおよび wal、データおよび wal および db、またはデータおよび db の 4 つの組み合わせを使用できます。データは、生のデバイス、論理ボリューム、またはパーティションにすることができます。walおよびdbは、論理ボリュームまたはパーティションにすることができます。生のデバイスまたはパーティションのceph-volumeを指定すると、その上に論理ボリュームが配置されます。注記現在、
ceph-ansibleは、ボリュームグループまたは論理ボリュームを作成しません。Anisble Playbook を実行する前に、これを実行する必要があります。group_vars/all.ymlファイルを開いて編集し、osd_memory_targetオプションのコメント設定を解除します。OSD が消費するメモリー容量に応じて値を調整します。注記osd_memory_targetオプションのデフォルト値は4000000000( 4 GB) です。このオプションは、メモリー内の BlueStore キャッシュをピニングします。重要osd_memory_targetオプションは、BlueStore がサポートする OSD にのみ適用されます。ansible-playbookを使用します。[user@admin ceph-ansible]$ ansible-playbook site.yml
Monitor ノードから、新規 OSD が正常に追加されたことを確認します。
[root@monitor ~]# ceph osd tree
関連情報
9.6. bluestore_min_alloc_size での少量の書き込みに対する BlueStore の調整
BlueStore では、生のパーティションは bluestore_min_alloc_size のブロックで割り当て、管理されます。デフォルトでは、bluestore_min_alloc_size は HDD の場合は 64 KB、SSD では 16 KB になります。各チャンクの未書き込み領域は、生のパーティションに書き込まれる際にゼロで埋められます。これにより、小さいオブジェクトを書き込むなど、ワークロードのサイズが適切に設定されていない場合に未使用領域が無駄になる可能性があります。
書き込み増幅のペナルティーを回避できるように bluestore_min_alloc_size を最小書き込みに一致させることを推奨します。
たとえば、クライアントが 4 KB のオブジェクトを頻繁に書き込みする場合は、ceph-ansible を使用して OSD ノードで以下の設定を設定します。
bluestore_min_alloc_size = 4096
bluestore_min_alloc_size_ssd 設定および bluestore_min_alloc_size_hdd 設定は、それぞれ SSD および HDD に固有のものですが、bluestore_min_alloc_size によりその設定が上書きされるため、設定する必要は必要ありません。
前提条件
- 実行中の {storage-product} クラスター
- OSD ノードとして新規にプロビジョニングできる新規サーバー、または
- 再デプロイできる OSD ノード。
手順
-
任意手順: 既存の OSD ノードを再デプロイする場合は、Ceph Monitor ノードの
/etc/ceph/から、OSD を削除するノードに管理キーリングをコピーします。 必要に応じて、既存の OSD ノードを再デプロイする場合は、Ansible Playbook
shrink-osd.ymlを使用してクラスターから OSD を削除します。ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=OSD_ID例
[admin@admin ceph-ansible]$ ansible-playbook -v infrastructure-playbooks/shrink-osd.yml -e osd_to_kill=1
- 既存の OSD ノードを再デプロイする場合には、OSD ドライブを削除して、OSD を再インストールします。
- Ansible を使用して OSD プロビジョニング用のノードを準備します。たとえば、{storage-product} リポジトリーの有効化、Ansible ユーザーの追加、パスワードなしの SSH ログインの有効化などです。
bluestore_min_alloc_sizeを Ansible Playbookgroup_vars/all.ymlのceph_conf_overridesセクションに追加します。ceph_conf_overrides: osd: bluestore_min_alloc_size: 4096新規ノードをデプロイする場合は、これを Ansible インベントリーファイル (通常は
/etc/ansible/hosts) に追加します。[osds] OSD_NODE_NAME例
[osds] osd1 devices="[ '/dev/sdb' ]"
Ansible を使用して OSD ノードをプロビジョニングします。
ansible-playbook -v site.yml -l OSD_NODE_NAME例
[admin@admin ceph-ansible]$ ansible-playbook -v site.yml -l osd1
Playbook が完了したら、
ceph daemonコマンドを使用して設定を確認します。ceph daemon OSD.ID config get bluestore_min_alloc_size例
[root@osd1 ~]# ceph daemon osd.1 config get bluestore_min_alloc_size { "bluestore_min_alloc_size": "4096" }bluestore_min_alloc_sizeが 4096 バイトに設定されていることを確認できます。これは 4 KB に相当します。
関連情報
- 詳細は、『{storage-product} インストールガイド』を参照してください。
9.7. BlueStore 断片化ツール
ストレージ管理者は、BlueStore OSD の断片化レベルを定期的にチェックする必要があります。オフライン OSD またはオンライン OSD の場合は、簡単な 1 つのコマンドを使用して断片化レベルを確認できます。
9.7.1. 前提条件
- 稼働中の Red Hat Ceph Storage 3.3 以上のストレージクラスター
- BlueStore OSD
9.7.2. BlueStore 断片化ツールとは
BlueStore OSD の場合は、基となるストレージデバイスの時間の経過とともに空き領域が断片化されます。一部の断片化は正常ですが、過剰な断片化が生じると、パフォーマンスが低下します。
BlueStore 断片化ツールは、BlueStore OSD の断片化レベルでスコアを生成します。この断片化スコアは 0 から 1 の範囲として指定されます。スコアが 0 の場合は断片化がなく、1 は深刻な断片化を意味します。
表9.1 断片化スコアの意味
| スコア | 断片化の量 |
|---|---|
| 0.0 - 0.4 | なしから極小の断片化まで。 |
| 0.4 - 0.7 | 小さく、許容される断片化。 |
| 0.7 - 0.9 | 直感的ですが、安全な断片化です。 |
| 0.9 - 1.0 | 深刻な断片化があり、パフォーマンスの問題が発生することになります。 |
深刻な断片化があり、問題の解決にサポートが必要な場合は、Red Hat サポート にお問い合わせください。
9.7.3. 断片化の確認
BlueStore OSD の断片化レベルのチェックは、オンラインまたはオフラインで行うことができます。
前提条件
- 稼働中の Red Hat Ceph Storage 3.3 以上のストレージクラスター
- BlueStore OSD
オンラインの BlueStore 断片化スコア
実行中の BlueStore OSD プロセスを検証します。
簡単なレポート:
構文
ceph daemon OSD_ID bluestore allocator score block例
[root@osd ~]# ceph daemon osd.123 bluestore allocator score block
より詳細なレポート:
構文
ceph daemon OSD_ID bluestore allocator dump block例
[root@osd ~]# ceph daemon osd.123 bluestore allocator dump block
オフラインの BlueStore 断片化スコア
実行していない BlueStore OSD プロセスを検証します。
簡単なレポート:
構文
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-score例
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-score
より詳細なレポート:
構文
ceph-bluestore-tool --path PATH_TO_OSD_DATA_DIRECTORY --allocator block free-dump例
[root@osd ~]# ceph-bluestore-tool --path /var/lib/ceph/osd/ceph-123 --allocator block free-dump
関連情報
- 断片化スコアの詳細は、Red Hat Ceph Storage 3.3「BlueStore Fragment Tool」を参照してください。
付録A ceph-medic のエラーコード定義
ceph-medic ユーティリティーは、失敗したチェックに対してエラーコードとメッセージを表示します。これらのエラーコードは警告またはエラーであり、Ceph デーモンに固有の一般的な問題に適用されます。エラーコードは E および警告コードで始まり、W で始まります。
一般的なエラーメッセージ
ECOM1-
Ceph 設定ファイルが
/etc/ceph/$CLUSTER_NAME.confで見つかりません。 ECOM2-
ceph実行ファイルが見つかりませんでした。 ECOM3-
/var/lib/ceph/ディレクトリーが存在しないか、アクセスできませんでした。 ECOM4-
/var/lib/ceph/ディレクトリーは、cephユーザーが所有しません。 ECOM5-
Ceph 設定の
fsidは、ストレージクラスター内のノード間で異なります。 ECOM6- インストールされた Ceph のバージョンが、ストレージクラスターにあるノードと異なります。
ECOM7- インストールされた Ceph のバージョンが実行中のソケットとは異なります。
ECOM8-
Ceph の設定に
fsidが見つかりません。 ECOM9- 実行中のソケットからのクラスター FSID がストレージクラスターのノードとは異なります。
ECOM10- 稼働しているモニターが複数あります。
エラーメッセージの監視
EMON1- キーリングで使用されるシークレットキーが、ストレージクラスターのノード間で異なります。
警告メッセージの監視
WMON1- 同じノードで複数の Monitor ディレクトリーが見つかりました。
WMON2- Monitor ノードにある併置された OSD。
OSD 警告メッセージ
WOSD1-
/var/lib/ceph/osd/ディレクトリーにある複数のceph_fsid値